
Pruebas Hipotesis Andres
39
2. Diga las siguientes hipótesis a que prueba corresponden y cuál es la escala de medición de las variables. La hipótesis a contrastar es: A. Ho: μ1 = μ2 = μ3 =. . . μk Ha: μ1 = μ2 = μ3 =. . . μk Para este caso las hipótesis no corresponden a ninguna prueba debido a que la hipótesis nula y la hipótesis alterna son iguales. B) Ho: No existe correlación entre las dos variables. Ha: Existe una relación o asociación entre las dos variables. En este caso la prueba a la que corresponde es una prueba de hipótesis para dos muestras en las cuales se busca probar el grado de asociación entre las variables, y las variables se miden de acuerdo a una escala de razón. C) Ho: Los datos se distribuyen binomial. Ha: Los datos no se distribuyen binomial.
-
Upload
yilber-rojas -
Category
Documents
-
view
408 -
download
10
description
Definición de pruebas de hipotesis
Transcript of Pruebas Hipotesis Andres

2. Diga las siguientes hipótesis a que prueba corresponden y cuál es la escala de medición de las variables.
La hipótesis a contrastar es:
A.
Ho: μ1 = μ2 = μ3 =. . . μk
Ha: μ1 = μ2 = μ3 =. . . μk
Para este caso las hipótesis no corresponden a ninguna prueba debido a que la hipótesis nula y la hipótesis alterna son iguales.
B)
Ho: No existe correlación entre las dos variables.
Ha: Existe una relación o asociación entre las dos variables.
En este caso la prueba a la que corresponde es una prueba de hipótesis para dos muestras en las cuales se busca probar el grado de asociación entre las variables, y las variables se miden de acuerdo a una escala de razón.
C)
Ho: Los datos se distribuyen binomial.
Ha: Los datos no se distribuyen binomial.
En este caso la prueba a la que corresponde es una prueba de hipótesis para proporciones y los datos se miden de acuerdo a una escala de intervalo.

3. Consultar y consignar ecuaciones sobre intervalos de confianza para la media y pruebas de hipótesis, sus ecuaciones, algoritmos con ejemplo para una, dos y más poblaciones en cada una de los siguientes casos:
a. Prueba de una cola y de dos colas (unilateral y bilateral)b. Prueba sobre una sola media, varianza conocida.c. Prueba de una sola media, varianza desconocida d. Prueba sobre dos medias, varianza conocida.e. Prueba de dos medias, varianza desconocida.f. Pruebas sobre proporciones.g. Pruebas sobre varianzas.h. ANOVA (ANAVA o ANDEVA)
Solución
a. Para prueba de una cola y de dos colas (unilateral y bilateral)
Al calcular pruebas de hipótesis, las hay dos métodos para hacerlo, prueba de una cola y de dos colas, para saber cuál usar hay que tener en la Hipótesis Alterna (H ao H1 ), al conocer esta podemos saber qué tipo de prueba usar, si la hipótesis alterna indica una dirección usamos una prueba de una cola, si por el contrario, la Hipótesis alterna no indica dirección alguna nos remitimos a usar una prueba de dos colas.
Prueba de una cola Prueba de dos colasH 0 : μ≤200H 1: μ>200
H 0 : μ=200H 1: μ≠200
Para calcular las zonas de rechazo y de aceptación se determina bajo distribución normal Z, para lo cual se tiene en cuanta en nivel de significancia α, para el caso de una cola se calcula Z de la tabla según 1-α, si se desea calcular en dos colas se estima con 1-(α/2).
Para el cálculo de los intervalos de confianza de la madia y el determinar prueba de hipótesis nos remitimos a las siguientes formulas, dado el caso:
Prueba de una cola Prueba de dos colas
IC=μ∓σ Zα√n
IC=μ∓σ Zα /2
√n
b. Para prueba sobre una sola media, varianza conocida.
Ejemplo:

Jamestown Steel Company fabrica y arma escritorios y otros muebles para oficina en diferentes plantas en el oeste del estado de Nueva York. La producción semanal del escritorio modelo A325 en la planta de Fredonia tiene una distribución normal, con una media de 200 y una desviación estándar de 16. Hace poco, con motivo de la expansión del mercado, se introdujeron nuevos métodos de producción y se contrató a más empleados. El vicepresidente de fabricación pretende investigar si hubo algún cambio en la producción semanal del escritorio modelo A325. En otras palabras, ¿la cantidad media de escritorios producidos en la planta de Fredonia es diferente de 200 escritorios semanales con un nivel de significancia de 0.01? Aplique el procedimiento de prueba de hipótesis estadística para investigar si cambió el índice de producción de 200 escritorios semanales.
Paso 1: Se establecen las hipótesis nula y alternativa. La hipótesis nula es: “la media de la población es de 200”. La hipótesis alternativa es: “la media es diferente de 200” o “la media no es de 200”. Estas dos hipótesis se expresan de la siguiente manera:
H0: μ = 200H1: μ ≠ 200
Ésta es una prueba con dos colas, pues la hipótesis alternativa no indica dirección alguna. En otras palabras, no establece si la producción media es mayor que 200 o menor que 200. El vicepresidente sólo desea saber si la tasa de producción es distinta de 200.
Paso 2: Se selecciona el nivel de significancia. Como ya se indicó, se utiliza el nivel de significancia de 0.01. Éste es α, la probabilidad de cometer un error tipo I, que es la probabilidad de rechazar una hipótesis nula verdadera.
Paso 3: Se selecciona el estadístico de prueba. El estadístico de prueba para una muestra grande es z. La transformación de los datos de producción en unidades estándares (valores z) permite que se les utilice no sólo en este problema, sino en otros relacionados con la prueba de hipótesis.
Z= X−μσ /√n
Paso 4: Se formula la regla de decisión. La regla de decisión se formula al encontrar los valores críticos de z con ayuda de la tabla de las distribuciones de la normal Z. Como se trata de una prueba de dos colas, la mitad de 0.01, o 0.005, se localiza en cada cola. Por consiguiente, el área en la que no se rechaza H0, localizada entre las dos colas, es 0.99. La tabla de las distribuciones de la normal Z, se basa en la mitad del área bajo la curva, o 0.5000. Entonces, 0.5000 – 0.0050 es 0.4950, por lo que 0.4950 es el área entre 1 y el valor crítico. Se localiza 0.4950 en el cuerpo de la tabla. El valor

más cercano a 0.4950 es 0.4951. Enseguida se lee el valor crítico en el renglón y columna correspondientes a 0.4951. Éste es de 2.58. Todas las facetas de este problema aparecen en el siguiente diagrama:
Por tanto, la regla de decisión es: rechazar la hipótesis nula y aceptar la hipótesis alternativa (que indica que la media de la población no es 200) si el valor z calculado no se encuentra entre –2.58 y +2.58. La hipótesis nula no se rechaza si z se ubica entre –2.58 y +2.58.
Paso 5: Se toma una decisión y se interpreta el resultado. Se toma una muestra de la población (producción semanal), se calcula z, se aplica la regla de decisión y se llega a la decisión de rechazar o no H0. La cantidad media de escritorios producidos el año pasado (50 semanas, pues la planta cerró 2 semanas por vacaciones) es de 203.5. La desviación estándar de la población es de 16 escritorios semanales. Al calcular el valor z a partir de la fórmula (10.1), se obtiene:
Z= X−μσ /√n
=203.5−20016 /√50
=1.55
Como 1.55 no cae en la región de rechazo, H0 no se rechaza. La conclusión es: la media de la población no es distinta de 200. Así, se informa al vicepresidente de fabricación que la evidencia de la muestra no indica que la tasa de producción en la planta de Fredonia haya cambiado de 200 semanales. La diferencia de 3.5 unidades entre la producción semanal histórica y la del año pasado puede atribuirse razonablemente al error de muestreo. Esta información se resume en el siguiente diagrama:

c. Para una prueba de una sola media, varianza desconocida
En la mayoría de los casos, la desviación estándar de la población es desconocida. Por consiguiente, σ debe basarse en estudios previos o calcularse por medio de la desviación estándar de la muestra, s. La desviación estándar poblacional en el siguiente ejemplo no se conoce, por lo que se emplea la desviación estándar muestral para estimar σ.
Ejemplo:
El departamento de quejas de McFarland Insurance Company informa que el costo medio para tramitar una queja es de $60. Una comparación industrial mostró que esta cantidad es mayor que en las demás compañías de seguros, así que la compañía tomó medidas para reducir gastos. Para evaluar el efecto de las medidas de reducción de gastos, el supervisor del departamento de quejas seleccionó una muestra aleatoria de 26 quejas atendidas el mes pasado. La información de la muestra aparece a continuación.
¿Es razonable concluir que el costo medio de atención de una queja ahora es menor que $60 con un nivel de significancia de 0.01?
Aplique la prueba de hipótesis con el procedimiento de los cinco pasos.
Paso 1: Se establecen las hipótesis nula y alternativa. La hipótesis nula consiste en que la media poblacional es de por lo menos $60. La hipótesis alternativa consiste en que la media poblacional es menor que $60. Se expresan las hipótesis nula y alternativa de la siguiente manera:
H0: μ ≥ $60H1: μ < $60

La prueba es de una cola, pues desea determinar si hubo una reducción en el costo. La desigualdad en la hipótesis alternativa señala la región de rechazo en la cola izquierda de la distribución.
Paso 2: Se selecciona un nivel de significancia. El nivel de significancia es 0.01.
Paso 3: se identifica el estadístico de la prueba. El estadístico de la prueba en este caso es la distribución t. ¿Por qué? Primero, porque resulta razonable concluir que la distribución del costo por queja sigue la distribución normal.
No se conoce la desviación estándar de la población, así que se sustituye ésta por la desviación estándar de la muestra. El valor del estadístico de la prueba se calcula por medio de la fórmula:
t= X−μs/√n
Paso 4: Se formula una regla para tomar decisiones. Los valores críticos de t aparecen en la tabla de distribuciones de la t-Student. El número de observaciones en la muestra es de 26, y se muestrea una población, así que hay 26 – 1 = 25 grados de libertad. Determine, según la tabal de distribución t-Student, el valor crítico t. Enseguida determine si la prueba es de una o de dos colas. En este caso, es una prueba de una cola, así que busque la sección de la tabla una cola. Localice la columna con el nivel de significancia elegido. En este ejemplo, el nivel de significancia es de 0.01. Desplácese hacia abajo por la columna rotulada 0.01 hasta intersecar el renglón con 25 grados de libertad. El valor es de 2.485. Como se trata de una prueba de una cola y la región de rechazo se localiza en la cola izquierda, el valor crítico es negativo. La regla de decisión consiste en rechazar H0 si el valor de t es menor que –2.485.
Paso 5: Se toma una decisión y se interpreta el resultado. Al aplicar las medidas de resumen a la muestra, se determina que el costo medio por queja para la muestra de 26 observaciones es de $56.42. La desviación estándar de esta muestra es de $10.04. Al sustituir estos valores en la fórmula anterior y calcular el valor de t:
t= X−μs/√n
= $56.42−$60$10 /√26
=−1.818
Como –1.818 se localiza en la región ubicada a la derecha del valor crítico de –2.485, la hipótesis nula no se rechaza con el nivel de significancia de 0.01. No se demostró que las medidas de reducción de costos hayan bajado el costo medio por queja a menos de $60. En otras palabras, la diferencia de $3.58 ($56.52 – $60) entre la media muestral y la media poblacional puede deberse al error de muestreo. El valor calculado de t aparece en la gráfica 10.6. Éste se encuentra en la región en que la hipótesis nula no se rechaza.

d. Para prueba sobre dos medias, varianza conocida.
EjemploLos clientes de los supermercados FoodTown tienen una opción a pagar por sus compras. Pueden pagar en una caja registradora normal operada por un cajero, o emplear el nuevo procedimiento: U-Scan. En el procedimiento tradicional en FoodTown, un empleado registra cada artículo, lo pone en una banda transportadora pequeña de donde otro empleado lo toma y lo pone en una bolsa, y después en el carrito de víveres. En el procedimiento U-Scan, el cliente registra cada artículo, lo pone en una bolsa y coloca las bolsas en el carrito. Este procedimiento está diseñado para reducir el tiempo que un cliente pasa en la fila de la caja.El aparato de U-Scan se acaba de instalar en la sucursal de la calle Byrne de FoodTown. La gerente de la tienda desea saber si el tiempo medio de pago con el método tradicional es mayor que con U-Scan, para lo cual reunió la información siguiente sobre la muestra. El tiempo se mide desde el momento en que el cliente ingresa a la fila hasta que sus bolsas están en el carrito. De aquí que el tiempo incluye tanto la espera en la fila como el registro. ¿Cuál es el valor p?
Para responder la pregunta anterior emplee el procedimiento de prueba de cinco pasos.
Paso 1: Formule las hipótesis nula y alternativa. La hipótesis nula es que no hay diferencia entre los tiempos medios de pago para los dos grupos.

En otras palabras, la diferencia de 0.20 minutos entre el tiempo medio de pago para e método tradicional y el tiempo medio de pago para U-Scan se debe a la casualidad. La hipótesis alternativa es que el tiempo medio de pago es mayor para quienes utilizan el método tradicional. Si μs se refiere al tiempo medio de pago para la población de clientes tradicionales y μu al tiempo medio de pago para los clientes que emplean U-Scan, las hipótesis nula y alternativa son:
H0: μs ≤ μuH1: μs > μu
Paso 2: Seleccione el nivel de significancia. Éste es la probabilidad de que rechace la hipótesis nula cuando en realidad sea verdadera. Esta posibilidad se determina antes de seleccionar la muestra o de realizar algún cálculo. Los niveles de significancia 0.05 y 0.01 son los más comunes, pero otros valores, como 0.02 y 0.10, también se emplean. En teoría, se puede seleccionar cualquier valor entre 0 y 1 para el nivel de significancia.En este caso se seleccionó el nivel de significancia 0.01.
Paso 3: Determine el estadístico de prueba. En el capítulo 10 empleó la distribución normal estándar (es decir, z) y t como estadísticos de prueba. En este caso se usa la distribución z como el estadístico de prueba debido a que conoce las desviaciones estándares de las dos poblaciones.
Paso 4: Formule una regla de decisión. Esta regla se basa en las hipótesis nula y alternativa (es decir, prueba de una o dos colas), en el nivel de significancia y en el estadístico de prueba empleado. Seleccionó el nivel de significancia 0.01 y la distribución z como el estadístico de prueba, y desea determinar si el tiempo medio de pago es mayor con el método tradicional. Se formula la hipótesis alternativa para indicar que el tiempo medio de pago es mayor para quienes emplean el método tradicional que el método U-Scan. De aquí, la región de rechazo se encuentra en la cola superior de la distribución normal (una prueba de una cola). Para determinar el valor crítico, coloque 0.01 del área total en la cola superior. Esto significa que 0.4900 (0.5000 – 0.0100) del área se ubica entre el valor z de 0 y el valor crítico. Después, busque en el cuerpo de la tabla de la normal Z un valor ubicado cerca de 0.4900. Éste es 2.33, por tanto, su regla de decisión es rechazar H0 si el valor calculado a partir del estadístico de prueba es mayor que 2.33. En la siguiente grafica aparece la regla de decisión.

Paso 5: Tome la decisión respecto de H0 e interprete el resultado. Emplee la siguiente fórmula para calcular el valor del estadístico de prueba.
Z=X s−Xu
√ σ s2ns + σu2
nu
= 5.5−5.3
√ 0.40250+ 0.30
2
100
=3.13
El valor calculado, 3.13, es mayor que el valor crítico 2.33; entonces rechace la hipótesis nula y acepte la hipótesis alternativa. La diferencia de 0.20 minutos entre el tiempo medio de pago con el método tradicional es demasiado grande para deberse a la casualidad. En otras palabras, la conclusión es que el método U-Scan es más rápido. ¿Cuál es el valor p para el estadístico de prueba? Recuerde que el valor p es la probabilidad de determinar un valor del estadístico de prueba así de excepcional cuando la hipótesis nula es verdadera. Para calcular el valor p es necesaria la probabilidad de un valor z mayor que 3.13. En el apéndice B.1 no aparece la probabilidad asociada con 3.13. El mayor valor disponible es 3.09. El área que corresponde a 3.09 es 0.4990. En este caso, el valor p es menor que 0.0010, calculado mediante 0.5000 – 0.4900. La conclusión es que hay muy pocas probabilidades de que la hipótesis nula sea verdadera.
e. Prueba de dos medias, varianza desconocida.
Ejemplo:Owens Lawn Care, Inc., fabrica y ensambla podadoras de césped que envía a distribuidores en Estados Unidos y Canadá. Se han propuesto dos procedimientos distintos para el montaje del motor al chasis de la podadora. La pregunta es: ¿existe una diferencia en el tiempo medio para montar los motores al chasis de las podadoras? El primer procedimiento lo desarrolló Herb Welles, un empleado desde hace mucho tiempo de Owens (designado como procedimiento 1), y el otro lo desarrolló William Atkins, vicepresidente de ingeniería de Owens (designado como procedimiento 2). Para evaluar los dos

métodos, se decidió realizar un estudio de tiempos y movimientos. Se midió el tiempo de montaje en una muestra de cinco empleados según el método de Welles y seis con el método de Atkins. Los resultados, en minutos, aparecen a continuación. ¿Hay alguna diferencia en los tiempos medios de montaje? Utilice un nivel de significancia de 0.10.
Al seguir el procedimiento de los cinco pasos, la hipótesis nula establece que no hay diferencia en los tiempos medios de montaje entre ambos procedimientos. La hipótesis alternativa indica que sí existe una diferencia.
H0: μ1 = μ2H1: μ1 ≠ μ2
Las suposiciones requeridas son:1. Las observaciones en la muestra de Welles son independientes de las observaciones de la muestra de Atkins.2. Las dos poblaciones siguen la distribución normal.3. Las dos poblaciones tienen desviaciones estándares iguales.
¿Hay alguna diferencia entre los tiempos medios de ensamblado con los métodos de Welles y Atkins? Los grados de libertad son iguales al número total de elementos muestreados menos el número de muestras, en este caso, n1 + n2 – 2. Cinco trabajadores utilizaron el método de Welles y seis el de Atkins. Por tanto, hay 9 grados de libertad, calculados así: 5+6–2. Los valores críticos de t, de la tabla t-Student para gl = 9, una prueba de dos colas y el nivel de significancia de 0.10, son –1.833 y 1.833. La regla de decisión se ilustra en la gráfica 11.3. No se rechaza la hipótesis nula si el valor calculado de t se encuentra entre –1.833 y 1.833.

Se emplean tres pasos para calcular el valor de t.Paso 1: Calcule las desviaciones estándar de las muestras. Vea los detalles a continuación.

X1=∑ X1n1
=205
=4 X2=∑ X2n2
=306
=5
s1=√∑ (X1−X ¿¿1)2
n1−1=√ 345−1
=2.9155¿ s2=√∑ (X2−X ¿¿2)2
n2−1=√ 226−1
=2.0976 ¿
Paso 2: Agrupe las varianzas de las muestras. Emplee la fórmula (11.5) para agrupar las varianzas de las muestras (desviaciones estándares al cuadrado).
sp2=
(n1−1 ) s12+(n2−1)s22
n1+n2−2=
(5−1 ) (2.9155 )2+ (6−1 )(2.0976)2
5+6−2=6.2222
Paso 3: Determine el valor de t. El tiempo medio de montaje para el método de Welles es 4.00 minutos, determinado mediante X1=20/5. El tiempo medio de montaje para el método de Atkins es 5.00 minutos, determinado mediante X2=30/6. Se utiliza la siguiente fórmula para calcular el valor de t.
t=X1X 2
√s p2 ( 1n1+ 1n2 )= 4.00−5.00
√6.2222(15 + 16 )
=−0.662
La decisión es no rechazar la hipótesis nula, porque –0.662 se encuentra en la región entre –1.833 y 1.833. Se concluye que no existe diferencia en los tiempos medios para montar el motor en el chasis con los dos métodos.
También estima el valor p con la t-Student. Localice la fila con 9 grados de libertad y utilice la columna de prueba de dos colas. Encuentre el valor t, sin considerar el signo, el cual está más cercano al valor calculado de 0.662. Es 1.383, que corresponde a un nivel de significancia de 0.20. Así, aunque se hubiera utilizado el nivel de significancia de 20%, no habría rechazado la hipótesis nula de medias iguales. El valor p es mayor que 0.20.
f. Pruebas relacionadas con proporciones
Se deben hacer algunas suposiciones antes de probar una proporción de población. Para probar una hipótesis en cuanto a una proporción de población, se elige una muestra aleatoria de la población:
a. Los datos de la muestra que se recogen son resultado de conteos

b. El resultado de un experimento se clasifica en una de dos categorías mutuamente excluyentes —“éxito” o “fracaso”—c. La probabilidad de un éxito es la misma para cada pruebad. Las pruebas son independientes, lo cual significa que el resultado de una prueba no influye en el resultado de las demás. La prueba que realizara en breve es adecuada cuando nπ y n (1 – π) son de al menos 5. El tamaño de la muestra es n, y p, la proporción poblacional. Se tiene la ventaja de que una distribución binomial puede aproximarse por medio de la distribución normal.
Paso 1: Se establecen las hipótesis nula y alternativa. La hipótesis nula, H0, consiste en que la proporción de la población π es 0.80. Desde un punto de vista práctico, al gobernador en turno solo le interesa cuando la proporción es menor de 0.80. Si es igual o mayor que 0.80, no pondrá objeción; es decir, los datos de la muestra indicarían que probablemente se le reelija. Estas hipótesis se escriben simbólicamente de la siguiente manera:
H0: π ≥ $0.80H1: π < $0.80
H1 establece una dirección. Por consiguiente, como se hizo notar antes, la prueba es de una cola, en la que el signo de desigualdad apunta a la cola de la distribución que contiene la región de rechazo.
Paso 2: Se selecciona el nivel de significancia. El nivel de significancia es 0.05. Ésta es la probabilidad de rechazar una hipótesis verdadera.
Paso 3: Seleccione el estadístico de prueba. El estadístico adecuado es z, que se determina de la siguiente manera:
z= z−π
√ π (1−π )n
Dónde:π es la proporción poblacionalp es la proporción de la muestran es el tamaño de la muestra
Paso 4: Se formula la regla de decisión. El valor o los valores críticos de z forman el punto o puntos de división entre las regiones en las que se rechaza H0 y en la que no se rechaza. Como la hipótesis alternativa indica una dirección, se trata de una prueba de una cola. El signo de la desigualdad apunta a la izquierda, así que sólo se utiliza el lado izquierdo de la curva. (Véase la gráfica 10.8.) El nivel de significancia del paso 2 fue de 0.05. Esta probabilidad se encuentra en la cola izquierda y determina la región de rechazo. El área entre cero y el valor crítico es de 0.4500, que se calcula

mediante 0.5000 – 0.0500. En el apéndice B.1 y al buscar 0.4500, se halla que el valor crítico de z es 1.65. La regla de decisión es, por tanto: se rechaza la hipótesis nula y se acepta la hipótesis alternativa si el valor calculado de z cae a la izquierda de –1.65; de otra forma no se rechaza H0.
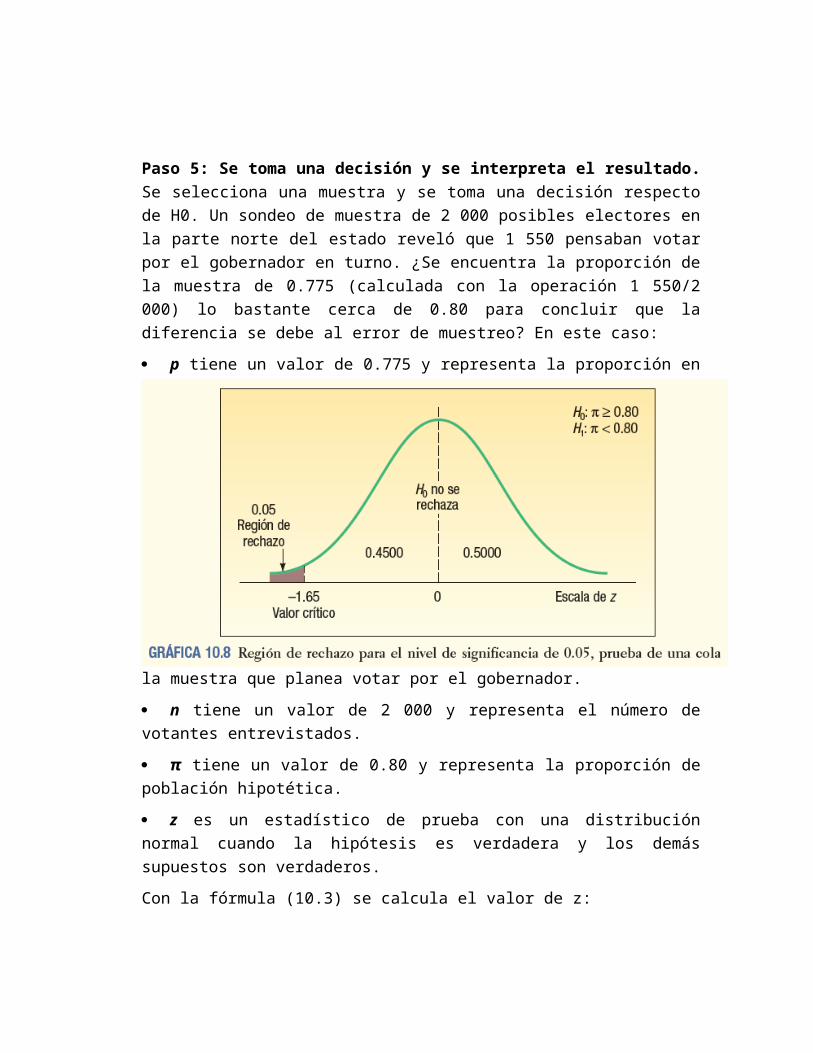
Paso 5: Se toma una decisión y se interpreta el resultado. Se selecciona una muestra y se toma una decisión respecto de H0. Un sondeo de muestra de 2 000 posibles electores en la parte norte del estado reveló que 1 550 pensaban votar por el gobernador en turno. ¿Se encuentra la proporción de la muestra de 0.775 (calculada con la operación 1 550/2 000) lo bastante cerca de 0.80 para concluir que la diferencia se debe al error de muestreo? En este caso:
p tiene un valor de 0.775 y representa la proporción en la muestra que planea votar por el gobernador.
n tiene un valor de 2 000 y representa el número de votantes entrevistados.
π tiene un valor de 0.80 y representa la proporción de población hipotética.
z es un estadístico de prueba con una distribución normal cuando la hipótesis es verdadera y los demás supuestos son verdaderos.
Con la fórmula (10.3) se calcula el valor de z:

z=z−π
√ π (1−π )n
=
15002000
−0.80
√ 0.80(1−0.80)2000
=0.775−0.80√0.00008
=−2.80
El valor calculado de z (–2.80) se encuentra en la región de rechazo, así que la hipótesis nula se rechaza en el nivel 0.05. La diferencia de 2.5 puntos porcentuales entre el porcentaje de la muestra (77.5%) y el porcentaje de la población hipotética en la parte norte del estado que se requiere para ganar las elecciones estatales (80%) resulta estadísticamente significativa. Quizá no se deba a la variación muestral. En otras palabras, le evidencia no apoya la afirmación de que el gobernador en turno vuelva a su mansión otros cuatro años.
El valor p es la probabilidad de hallar un valor z inferior a –2.80. De acuerdo con el apéndice B.1, la probabilidad de un valor de z entre cero y –2.80 es de 0.4974. Así, el valor p es 0.0026, que se determina con el cálculo de 0.5000 – 0.4974. El gobernador no puede confiar en la reelección porque el valor p es inferior al nivel de significancia.
Pruebas relacionadas sobre varianzas
Antes de ingresar a temas de mayor alcance, debemos hablar sobre la distribución F esta distribución de probabilidad sirve como la distribución del estadístico de prueba para varias situaciones. Con ella se pone a prueba si dos muestras provienen de poblaciones que tienen varianzas iguales, y también se aplica cuando se desean comparar varias medias poblacionales en forma simultánea. La comparación simultánea de varias medias poblacionales se denomina análisis de la varianza (ANOVA). En las dos situaciones, las poblaciones deben seguir una distribución normal, y los datos deben ser al menos de escala de intervalos.
¿Cuáles son las características de la distribución F?
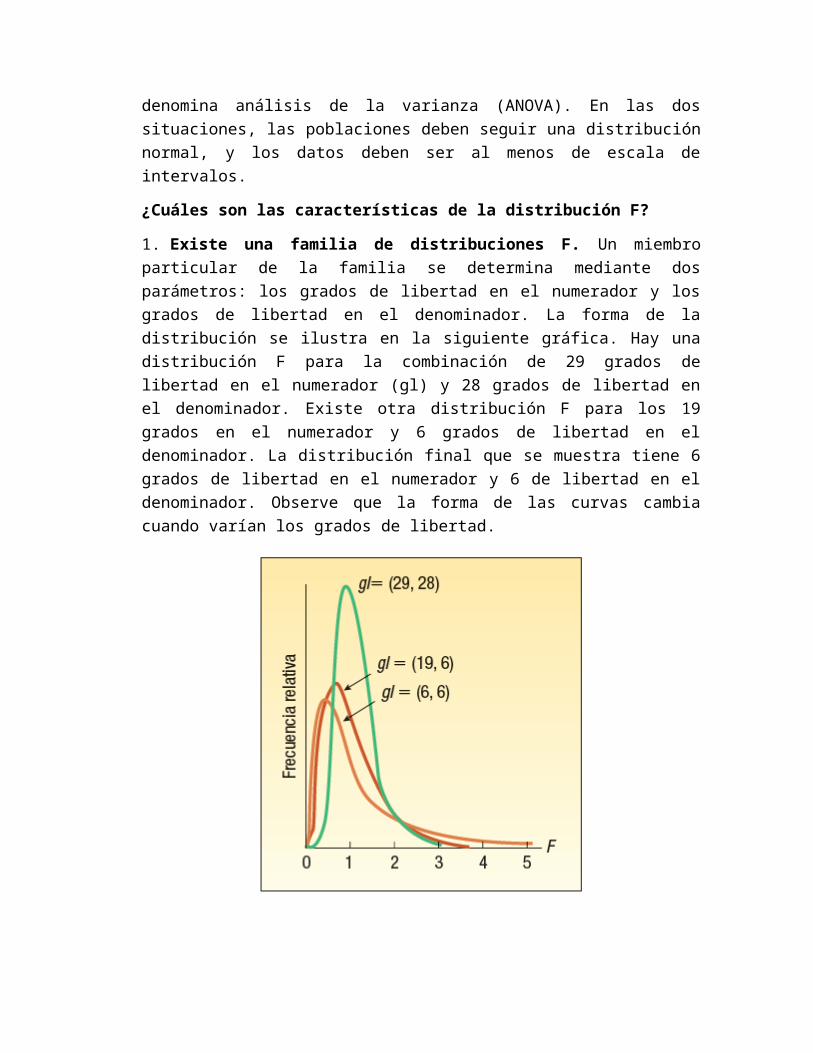
1. Existe una familia de distribuciones F. Un miembro particular de la familia se determina mediante dos parámetros: los grados de libertad en el numerador y los grados de libertad en el denominador. La forma de la distribución se ilustra en la siguiente gráfica. Hay una distribución F para la combinación de 29 grados de libertad en el numerador (gl) y 28 grados de libertad en el denominador. Existe otra distribución F para los 19 grados en el numerador y 6 grados de libertad en el denominador. La distribución final que

se muestra tiene 6 grados de libertad en el numerador y 6 de libertad en el denominador. Observe que la forma de las curvas cambia cuando varían los grados de libertad.
2. La distribución F es continua. Esto significa que se supone un número infinito de valores entre cero y el infinito positivo. 3. La distribución F no puede ser negativa. El valor menor que F puede tomar es 0.4. Tiene sesgo positivo. La cola larga de la distribución es hacia el lado derecho. Cuando el número de grados de libertad aumenta, tanto en el numerador como en el denominador, la distribución se aproxima a ser normal. 5. Es asintótica. Cuando los valores de X aumentan, la curva F se aproxima al eje X pero nunca lo toca. Esto es similar al comportamiento de la distribución de probabilidad normal.
g. Comparación de dos varianzas poblacionales

Con la distribución F se pone a prueba la hipótesis de que la varianza de una población normal es igual a la varianza de otra población normal. La distribución F también sirve para probar suposiciones de algunas pruebas estadísticas. La distribución F proporciona un medio para realizar una prueba considerando las varianzas de dos poblaciones normales.
Sin importar si se desea determinar si una población tiene más variación que otra o validar una suposición para una prueba estadística, primero se formula la hipótesis nula. La hipótesis nula es que la varianza de una población normal,σ 2
2 es igual a la varianza de otra población normal,σ 22. La hipótesis
alternativa podría ser que las varianzas difieran. En este caso, la hipótesis nula y la hipótesis alternativa son:
H o :σ12=σ2
2
H o :σ12≠σ2
2Para realizar la prueba, se selecciona una muestra aleatoria de n1
observaciones de una población y una muestra aleatoria de n2 observaciones de la segunda población. El estadístico de prueba se define como sigue.
F=S12
S22
Los términos S12 y S2
2 son las varianzas muéstrales respectivas. Si la hipótesis nula es verdadera, el estadístico de prueba sigue la distribución F con (n1−1¿ y (n2−1¿grados de libertad. A fin de reducir el tamaño de la tabla de valores críticos, la varianza más grande de la muestra se coloca en el numerador; de aquí, la razón F que se indica en la tabla siempre es mayor que 1.00. Así, el valor crítico de la cola derecha es el único que se requiere. El valor crítico de F para una prueba de dos colas se determina dividiendo el nivel de significancia entre dos (α/2) y después se consultan los grados de libertad apropiados.
Ejemplo
Lammers Limos ofrece servicio de transporte en limusina del ayuntamiento de Toledo, Ohio, al aeropuerto metropolitano de Detroit. Sean Lammers, presidente de la compañía, considera dos rutas. Una por la carretera 25 y la otra por la autopista I-75. Lammers desea estudiar el tiempo que tardaría en conducir al aeropuerto por cada ruta y luego comparar los resultados. Recopiló los siguientes datos muestrales, reportados en minutos. Mediante el nivel de significancia 0.10, ¿hay alguna diferencia en la variación en los tiempos de manejo para las dos rutas?
Los tiempos de manejo medios por las dos rutas son casi iguales. El tiempo medio es de 58.29 minutos para la carretera 25 y de 59.0 minutos por la autopista I-75. Sin embargo, al evaluar los tiempos del recorrido, Lammers también está interesado en la variación en los tiempos de recorrido. El primer paso es calcular las dos varianzas muestrales. Se empleará la fórmula de las desviaciones estándar de las muestras; para obtener las varianzas muestrales se elevan al cuadrado las desviaciones estándar.
Carretera 25
X=∑ X
n=4087
=58.29 s=√∑( x−x �̅ )2
n−1=√ 485.437−1
=8.9947
Autopista I-75
X=∑ X
n=4728
=59.00 s=√∑( x−x �̅ )2
n−1=√ 1348−1
=4.3753
Hay más variación en la carretera 25 que en la autopista I-75 según la medición de la desviación estándar. Esto coincide con su conocimiento de las dos rutas; la ruta por la carretera 25 tiene más semáforos, en tanto que la autopista I-75 es de acceso limitado. Sin embargo, la ruta por la autopista I-75 es varias millas más larga. Es importante que el servicio ofrecido sea tanto puntual como consistente, por lo que decide realizar una prueba estadística para determinar si en realidad existe una diferencia en la variación de las dos rutas.
Seguimos los 5 pasos para prueba de la hipótesis:
Paso 1: Inicia por formular las hipótesis nula y alternativa. La prueba es de dos colas debido a que se busca una diferencia en la variación de las dos rutas. No se trata de demostrar que una ruta tiene más variación que la otra.
H o :σ12=σ2
2 H o :σ12=σ2
2

Paso 2: Selecciona el nivel de significancia de 0.10.
Paso 3: El estadístico de prueba apropiado sigue la distribución F.
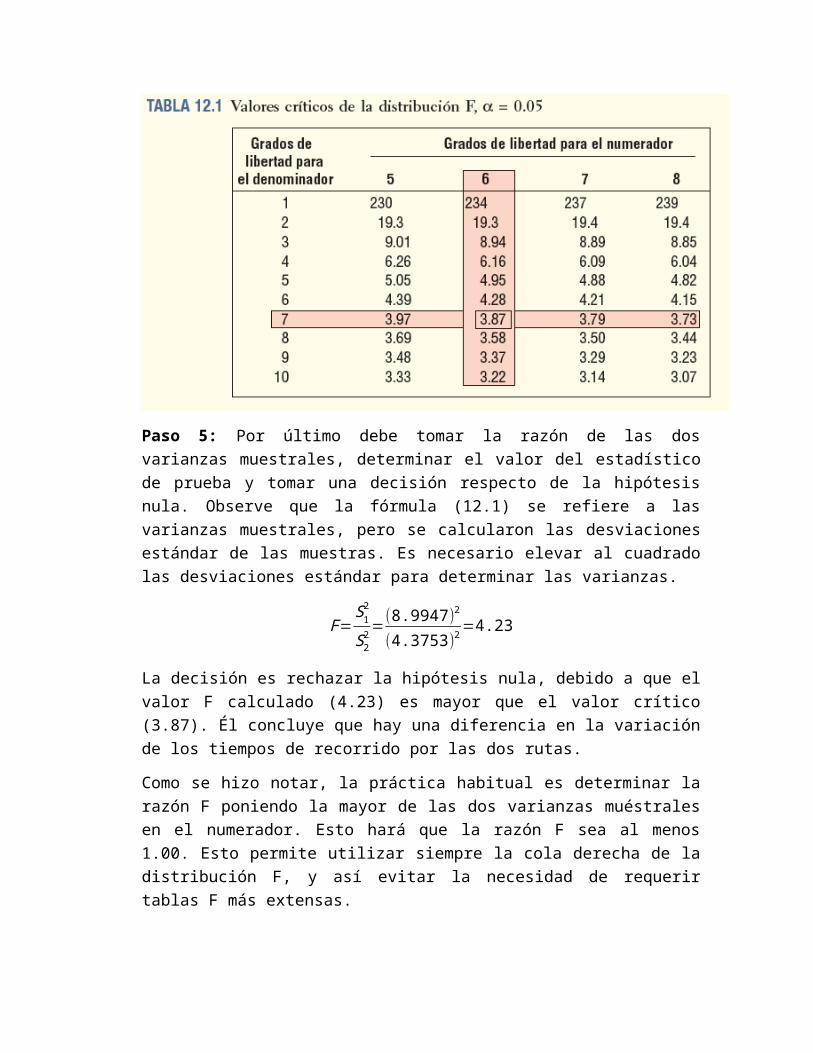
Paso 4: El valor crítico del cual se reproduce una parte como la tabla 12.1. Puesto que conduce una prueba de dos colas, el nivel de significancia en la tabla es 0.05, determinado mediante α/2 = 0.10/2 = 0.05. Hay (n¿¿1−1)=7−1=6¿ grados de libertad en el numerador, y (n¿¿2−1)=8−1=7¿ grados de libertad en el denominador. Para encontrar el valor crítico, recorre en forma horizontal la parte superior de la tabla F (tabla 12.1) para el nivel de significancia 0.05 para 6 grados de libertad en el numerador. Después va hacia abajo por esa columna hasta el valor crítico opuesto a 7 grados de libertad en el denominador. El valor crítico es 3.87. Por tanto, la regla de decisión es: rechazar la hipótesis si la razón de las varianzas muestrales es mayor que 3.87.
Paso 5: Por último debe tomar la razón de las dos varianzas muestrales, determinar el valor del estadístico de prueba y tomar una decisión respecto de la hipótesis nula. Observe que la fórmula (12.1) se refiere a las varianzas muestrales, pero se calcularon las desviaciones estándar de las muestras. Es necesario elevar al cuadrado las desviaciones estándar para determinar las varianzas.
F=S12
S22=
(8.9947)2
(4.3753)2=4.23
La decisión es rechazar la hipótesis nula, debido a que el valor F calculado (4.23) es mayor que el valor crítico (3.87). Él concluye que hay una diferencia en la variación de los tiempos de recorrido por las dos rutas.
Como se hizo notar, la práctica habitual es determinar la razón F poniendo la mayor de las dos varianzas muéstrales en el numerador. Esto hará que la razón F sea al menos 1.00. Esto permite utilizar siempre la cola derecha de la distribución F, y así evitar la necesidad de requerir tablas F más extensas.
Respecto de las pruebas de una cola surge una duda lógica. Por ejemplo, suponga que en el ejemplo anterior sospecha que la varianza de los tiempos en la carretera 25 es mayor que la varianza de los tiempos por la autopista I-75. Las hipótesis nula y alternativa se formularían de la siguiente forma:
H o :σ12≤σ2
2
H o :σ12>σ2
2
El estadístico de prueba se calcula comoS12/ S2
2. Observe que se designó
población 1 a la que se sospecha que tiene la varianza mayor. Por tanto,S12
aparece en el numerador. La razón F será mayor que 1.00, por lo que se puede utilizar la cola superior de la distribución F. Con estas condiciones, no es necesario dividir el nivel de significancia a la mitad.
h. Suposiciones en el análisis de la varianza (ANOVA)
Otro uso de la distribución F es el análisis de la técnica de la varianza (ANOVA), en la cual se comparan tres o más medias poblacionales para determinar si pueden ser iguales. Para emplear ANOVA, se supone lo siguiente:
1. Las poblaciones siguen la distribución normal. 2. Las poblaciones tienen desviaciones estándar iguales (σ).3. Las poblaciones son independientes.
Cuando se cumplen estas condiciones, F se emplea como la distribución del estadístico de prueba.
¿Por qué es necesario estudiar ANOVA? ¿Por qué no sólo se emplea la prueba de las diferencias en medias poblacionales, como se analizó en el capítulo anterior? Se puede comparar dos medias poblacionales a la vez. La razón más importante es la acumulación indeseable del error tipo I. Para ampliar la explicación, suponga cuatro métodos distintos (A, B, C y D) para capacitar personal para ser bomberos. La asignación de cada uno de los 40 prospectos en el grupo de este año es aleatoria para cada uno de los cuatro

métodos. Al final del programa de capacitación, a los cuatro grupos se les administra una prueba común para medir la comprensión de las técnicas contra incendios. La pregunta es: ¿existe una diferencia en las calificaciones medias del examen entre los cuatro grupos? La respuesta a esta pregunta permitirá comparar los cuatro métodos de capacitación.
Si emplea la distribución t para comparar las cuatro medias poblacionales, tendría que efectuar seis pruebas t distinta. Es decir, necesitaría comparar las calificaciones medias de los cuatro métodos como sigue: A contra B, A contra C, A contra D, B contra C, B contra D y C contra D. Si determina el nivel de significancia en 0.05, la probabilidad de una decisión estadística correcta es de 0.95, calculada de 1 – 0.05. Como se realizaron seis pruebas separadas (independientes), la probabilidad de que no se tome una decisión incorrecta debido al error de muestreo en cualquiera de las seis pruebas independientes es:
P (Todas correctas )=(0.95 ) (0.95 ) (0.95 ) (0.95 ) (0.95 ) (0.95 )=0.735
Para encontrar la probabilidad que al menos tenga un error debido al muestreo, reste este resultado a 1. Por tanto, la probabilidad de al menos una decisión incorrecta debida al muestreo es de 1 – 0.735 = 0.265. En resumen, si realiza seis pruebas independientes con la distribución t, la posibilidad de rechazar una hipótesis nula verdadera debido al error de muestreo se incrementa de 0.05 a un nivel insatisfactorio de 0.265. Es obvio que necesita un mejor método que realizar seis pruebas t. ANOVA permitirá comparar las medias de tratamiento de forma simultánea y evitar la acumulación del error de Tipo I. ANOVA se desarrolló para aplicaciones en agricultura, y aún se emplean muchos de los términos relacionados con ese contexto. En particular, con el término tratamiento se identifican las poblaciones diferentes que se examinan. Por ejemplo, el tratamiento se refiere a cómo una extensión de terreno se trató con un tipo particular de fertilizante. La siguiente ilustración aclarará el término tratamiento y mostrará la aplicación de ANOVA.
La Prueba ANOVA
¿Cómo funciona la prueba ANOVA? Recuerde que se desea determinar si varias medias muestrales provienen de una sola población o de poblaciones con medias diferentes. En realidad, estas medias muestrales se comparan mediante sus varianzas. Para explicar esto, recuerde que en la página 412 se listaron las suposiciones requeridas para ANOVA. Una de estas suposiciones fue que las desviaciones estándar de las diversas poblaciones normales tenían que ser las mismas. Se aprovecha este requisito en la prueba ANOVA. La estrategia es estimar la varianza de la población (desviación estándar al cuadrado) de dos formas y después determinar la razón de dichos estimados. Si esta razón es aproximadamente 1, entonces por lógica los dos estimados

son iguales, y se concluye que las medias poblacionales no son iguales. La distribución F sirve como un árbitro al indicar en qué instancia la razón de las varianzas muestrales es mucho mayor que 1 para haber ocurrido por casualidad.
Consulte el ejemplo del centro financiero en la sección anterior. El gerente desea determinar si hay una diferencia en el número medio de clientes atendidos. Para iniciar, determine la media global de las 12 observaciones. Ésta es de 58, calculada de (55 + 54 + … + 48)/12. Después, para cada una de las 12 observaciones encuentre la diferencia entre el valor particular y la media global. Cada una de estas diferencias se eleva al cuadrado y estos cuadrados se suman. Este término se denomina variación total.
En nuestro ejemplo, la variación total es de 1 082, determinada por (55 – 58)2 + (54 – 58)2 + … + (48 – 58)2.
Luego se divide esta variación total en dos componentes: la que se debe a los tratamientos y la que es aleatoria. Para encontrar estas dos componentes, se determina la media de cada tratamiento. La primera fuente de variación se debe a los tratamientos.
En el ejemplo, la variación debida a los tratamientos es la suma de las diferencias al cuadrado entre la media de cada empleado y la media global. Este término es 992. Para calcularlo, primero se encuentra la media de cada uno de los tres tratamientos. La media de Wolfe es 56, determinada por (55 + 54 + 59 + 56)/4. Las otras medias son 70 y 48, respectivamente. La suma de los cuadrados debida a los tratamientos es:
(56−58)2+(56−58)2+…+ (48−58 )2=4 (56−58 )2+4 (70−58 )2+4 (48−58 )2
¿992
Si existe una variación considerable entre las medias de los tratamientos, es lógico que este término sea grande. Si las medias de los tratamientos son similares, este término será un valor bajo. El valor más bajo posible es cero. Esto ocurrirá cuando todas las medias de los tratamientos sean iguales.
A la otra fuente de variación se le conoce como componente aleatoria, o componente de error.
En el ejemplo, este término es la suma de las diferencias al cuadrado entre cada valor y la media para ese empleado en particular. La variación de error es 90.
(55−56)2+(54−56)2+…+(48−48 )2=90
El estadístico de prueba, que es la razón de los dos estimados de la varianza poblacional, se determina a partir de la siguiente ecuación:

F= Estimadode la varianza poblacionalbasado en las diferenciasentre lasmedias muestralesEstimado de la varianza poblacional basadoen la variacióndentro de lamuestra
El primer estimado de la varianza poblacional parte de los tratamientos, es decir, de la diferencia entre las medias. Éste es 992/2. ¿Por qué se dividió entre 2? Recuerde del capítulo 3 que, para encontrar una varianza muestral [véase la fórmula (3.11)], se divide entre el número de observaciones menos uno. En este caso hay tres tratamientos, por lo que se divide entre 2. El primer estimado de la varianza poblacional es 992/2.
El estimado de la varianza dentro de los tratamientos es la variación aleatoria divida entre el número total de observaciones menos el número de tratamiento. Es decir 90/(12 – 3). De aquí, el segundo estimado de la varianza poblacional es 90/9. En realidad es una generalización de la fórmula (11.5), en la cual se agruparon las varianzas muestrales de dos poblaciones.
El paso final es tomar la razón de estos dos estimados.
F=
9922902
=49.6
Como esta razón es muy distinta a 1, se concluye que las medias de los tratamientos no son iguales. Hay una diferencia en el número medio de clientes atendidos por los tres empleados.
Ejemplo
Desde hace algún tiempo las aerolíneas han reducido sus servicios, como alimentos y bocadillos durante sus vuelos, y empezaron a cobrar un precio adicional por algunos servicios, como llevar sobrepeso de equipaje, cambios de vuelo de último momento y por mascotas que viajan en la cabina. Sin embargo, aún están muy preocupadas por el servicio que ofrecen. Hace poco un grupo de cuatro aerolíneas (se emplean nombres históricos por motivos confidenciales) contrató a Brunner Marketing Research, Inc., para encuestar a sus pasajeros sobre la adquisición de boletos, abordaje, servicio durante el vuelo, manejo del equipaje, comunicación del piloto, etc. Hicieron 25 preguntas con diversas respuestas posibles: excelente, bueno, regular o deficiente. Una respuesta de excelente tiene una calificación de 4, bueno 3, regular 2 y deficiente 1. Estas respuestas se sumaron, de modo que la calificación final fue una indicación de la satisfacción con el vuelo. Entre mayor la calificación, mayor el nivel de satisfacción con el servicio. La calificación mayor posible fue 100. Brunner seleccionó y estudió al azar pasajeros de las cuatro aerolíneas. A continuación se muestra la información. ¿Hay alguna

diferencia en el nivel de satisfacción medio entre las cuatro aerolíneas? Use el nivel de significancia 0.01.
Utilice el procedimiento de prueba de hipótesis de cinco pasos.
Paso 1: Formule las hipótesis nula y alternativa. La hipótesis nula es que las calificaciones medias son iguales para las cuatro aerolíneas.
H o : μ1=μ2=μ3=μ4
La hipótesis alternativa es que no todas las calificaciones medias son iguales para las cuatro aerolíneas.
H 1:No todas las calificacionesmediassoniguales .
La hipótesis alternativa también se considera como “al menos dos calificaciones medias no son iguales”.Si no se rechaza la hipótesis nula, se concluye que no hay una diferencia en las calificaciones medias para las cuatro aerolíneas. Si rechaza H o, concluye que hay una diferencia en al menos un par de calificaciones medias, pero en este punto no se sabe cuál par o cuántos pares difieren.
Paso 2: Seleccione el nivel de significancia. Seleccionó el nivel de significancia0.01.Paso 3: Determine el estadístico de prueba. El estadístico de prueba sigue la distribución F.
Paso 4: Formule la regla de decisión. Para determinar la regla de decisión, necesita el valor crítico. El valor crítico para el estadístico F aparece en el apéndice B.4. Los valores críticos para el nivel de significancia 0.05 se encuentran en la primera página, y el nivel de significancia 0.01, en la segunda. Para utilizar esta tabla necesita conocer los grados de libertad en el numerador y el denominador. Los grados de libertad en el numerador son iguales al número de tratamientos, designado k, menos 1. Los grados de libertad en el denominador son el número total de observaciones, n, menos el número de tratamientos. Para este ejemplo hay cuatro tratamientos y un total de 22 observaciones.
Grados de libertad en el numerador = k – 1 = 4 – 1 = 3 Grados de libertad en el denominador = n – k = 22 – 4 = 18
Consulte el apéndice B.4 y el nivel de significancia 0.01. Muévase horizontalmente por la parte superior de la página a tres grados de libertad en el numerador. Después vaya hacia abajo por esa columna hasta la fila con 18 grados de libertad. El valor en esta intersección es 5.09. Por tanto, la regla de decisión es rechazar H0 si el valor calculado de F es mayor que 5.09.
Paso 5: Seleccione la muestra, realice los cálculos y tome una decisión. Es conveniente resumir los cálculos del estadístico F en una tabla ANOVA. El formato para una tabla ANOVA es como sigue. En los paquetes de software estadístico también se emplea este formato.
Hay tres valores, o suma de cuadrados, para calcular el estadístico de prueba F. Estos valores se determinan al obtener SS total y SSE, después SST mediante una resta. El término SS total es la variación total, SST es la variación debida a los tratamientos, y SSE es la variación dentro de los tratamientos o el error aleatorio.En general, el proceso se inicia al determinar SST total: la suma de las diferencias elevadas al cuadrado entre cada observación y la media global. La fórmula para determinar SS total es:
SS total=∑ ( X−X G )2
DondeX es cada observación de la muestra.XG es la media global o total.
Enseguida se determina SSE o la suma de los errores elevados al cuadrado: la suma de las diferencias elevadas al cuadrado entre cada observación y su respectiva media de tratamiento. La fórmula para encontrar SSE es:
SSE=∑ ( X−XC )2
DondeXC Es la media muestral para el tratamiento C
A continuación se presentan los cálculos detallados de SS total y SSE para este ejemplo. Para determinar los valores de SS total y SSE se comienza por calcular la media global o total. Hay 22 observaciones y el total es 1 664, por tanto, la media total es 75.64.

XG=166422
=75.61
Luego se encuentra la desviación de cada observación a la media total: se elevan al cuadrado estas desviaciones y se suma este resultado para las 22 observaciones.Por ejemplo, el primer pasajero encuestado tenía una calificación de 94, y la media global o total es 75.64. Por tanto,(X−XG )=94−75.65=18.36. Para el último pasajero,(X−XG )=65−75.64=−10.64. Los cálculos para los otros pasajeros son:
Después se eleva al cuadrado cada una de estas diferencias y se suman todos los valores. Así, para el primer pasajero:
(X−XG )2=(94−75.65)2=(18.36)2=337.09

El valor SS total es 1 485.09
Para calcular el término SSE se encuentra la desviación entre cada observación y su media de tratamiento. En el ejemplo, la media del primer tratamiento (es decir, los pasajeros en Eastern Airlines) es 87.25, determinada mediante X E=349/4 .El subíndice E se refiere a Eastern Airlines.El primer pasajero calificó a Eastern con 94, por tanto,(X−X E )=(94−87.25 )=6.75El primer pasajero en el grupo de TWA respondió con una calificación total de 75, por tanto,(X−XTWA )=(75−78.20 )=−3.2 El detalle de todos los pasajeros es:
Por tanto, el valor SSE es 594.41. Es decir, ∑ ( X−XC )2=594.41Por último, se determina SST, la suma de los cuadrados debida a los tratamientos, con la resta:
SST=SS total−SSEPor ejemplo:
SST=SS total−SSE=1485.10−594.41=890.69

Para determinar el valor calculado de F, consulte la tabla ANOVA. Los grados de libertad para el numerador y el denominador son los mismos que en el paso 4 en la página 416, donde se determinó el valor crítico de F. El término media cuadrática es otra expresión para un estimado de la varianza. La media cuadrática para tratamientos es SST dividido entre sus grados de libertad. El resultado es la media cuadrática para tratamientos, y se escribe MST. Calcule el error medio cuadrático de una manera similar. Para ser precisos, divida SSE entre sus grados de libertad. Para completar el proceso y obtener F, divida MST entre MSE.Sustituya los valores particulares de F en una tabla ANOVA y calcule el valor deF, como se muestra a continuación.
El valor calculado de F es 8.99, el cual es mayor que el valor crítico de 5.09, por tanto, la hipótesis nula se rechaza. La conclusión es que no todas las medias poblacionales son iguales. Las calificaciones medias no son iguales para las cuatro aerolíneas. Es probable que las calificaciones de los pasajeros se relacionen con una aerolínea particular. En este punto sólo es posible concluir que hay una diferencia en las medias del tratamiento. No se puede determinar cuáles ni cuántos grupos de tratamientos difieren.

Taller No. 2 – Prueba de Hipótesis
Andrés Ávila MottaJulián Torres Mendoza
Yilber Rojas Oviedo
Miguel Armando Rodríguez
Estadística II
EconomíaFacultad de Ciencias Económicas y Administrativas
Universidad del Tolima Ibagué

2015

















