
lim - ip.ase.roip.ase.ro/AD2.pdf · lim! x n x x e p x p x n x n n O O o f. Proprietăți ale...
6
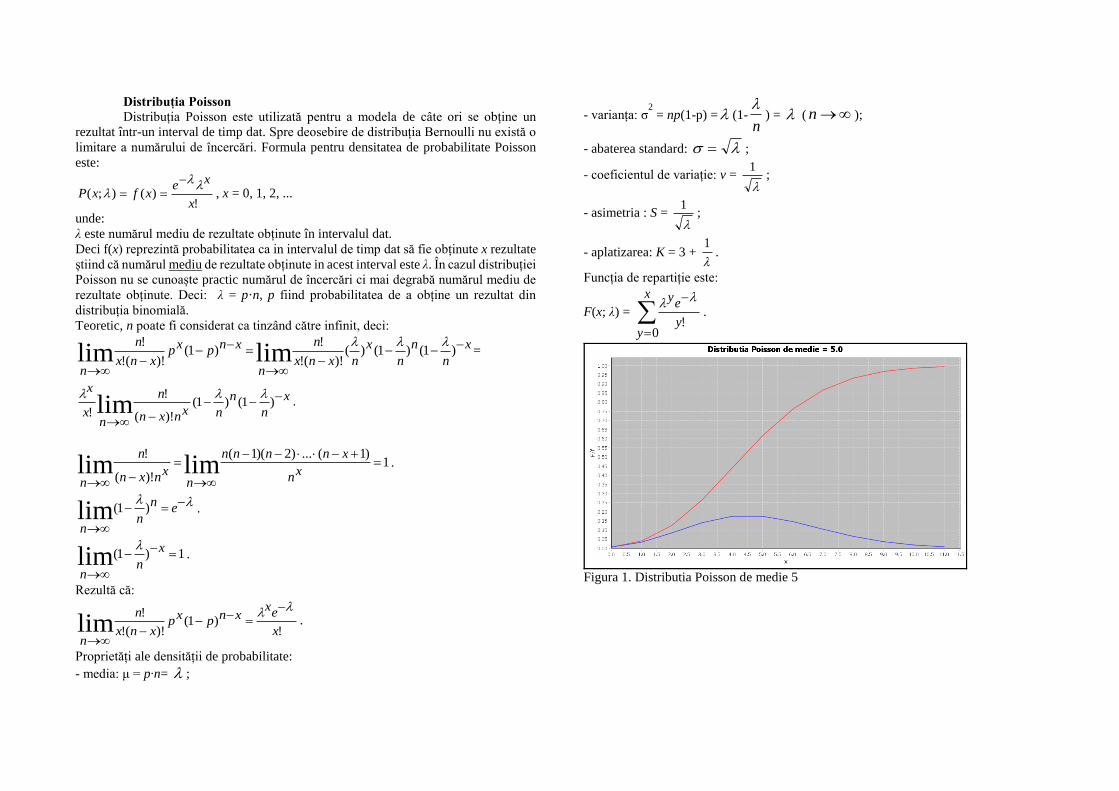
Distribuția Poisson Distribuția Poisson este utilizată pentru a modela de câte ori se obține un rezultat într-un interval de timp dat. Spre deosebire de distribuția Bernoulli nu există o limitare a numărului de încercări. Formula pentru densitatea de probabilitate Poisson este: ! ) ( ) ; ( x x e x f x P , x = 0, 1, 2, ... unde: λ este numărul mediu de rezultate obținute în intervalul dat. Deci f(x) reprezintă probabilitatea ca in intervalul de timp dat să fie obținute x rezultate știind că numărul mediu de rezultate obținute in acest interval este λ. În cazul distribuției Poisson nu se cunoaște practic numărul de încercări ci mai degrabă numărul mediu de rezultate obținute. Deci: λ = p·n, p fiind probabilitatea de a obține un rezultat din distribuția binomială. Teoretic, n poate fi considerat ca tinzând către infinit, deci: x n n n x n x n x n n x n p x p x n x n n ) 1 ( ) 1 ( ) ( )! ( ! ! ) 1 ( )! ( ! ! lim lim = x n n n x n x n n n x x ) 1 ( ) 1 ( )! ( ! ! lim . 1 ) 1 ( ... ) 2 )( 1 ( )! ( ! lim lim x n x n n n n n x n x n n n . e n n n ) 1 ( lim . 1 ) 1 ( lim x n n . Rezultă că: ! ) 1 ( )! ( ! ! lim x e x x n p x p x n x n n . Proprietăți ale densității de probabilitate: - media: μ = p‧n= ; - varianța: σ 2 = np(1-p) = (1- n ) = ( n ); - abaterea standard: ; - coeficientul de variație: v = 1 ; - asimetria : S = 1 ; - aplatizarea: K = 3 + 1 . Funcția de repartiție este: F(x; λ) = x y y e y 0 ! . Figura 1. Distributia Poisson de medie 5
Transcript of lim - ip.ase.roip.ase.ro/AD2.pdf · lim! x n x x e p x p x n x n n O O o f. Proprietăți ale...
Distribuția Poisson
Distribuția Poisson este utilizată pentru a modela de câte ori se obține un
rezultat într-un interval de timp dat. Spre deosebire de distribuția Bernoulli nu există o
limitare a numărului de încercări. Formula pentru densitatea de probabilitate Poisson
este:
!)();(
x
xexfxP
, x = 0, 1, 2, ...
unde:
λ este numărul mediu de rezultate obținute în intervalul dat.
Deci f(x) reprezintă probabilitatea ca in intervalul de timp dat să fie obținute x rezultate
știind că numărul mediu de rezultate obținute in acest interval este λ. În cazul distribuției
Poisson nu se cunoaște practic numărul de încercări ci mai degrabă numărul mediu de
rezultate obținute. Deci: λ = p·n, p fiind probabilitatea de a obține un rezultat din
distribuția binomială.
Teoretic, n poate fi considerat ca tinzând către infinit, deci:
x
n
n
n
x
nxnx
n
n
xnpxpxnx
n
n
)1()1()()!(!
!)1(
)!(!
!
limlim
=
x
n
n
nxnxn
n
nx
x
)1()1()!(
!
! lim
.
1)1(...)2)(1(
)!(
!
limlim
xn
xnnnn
nxnxn
n
n
.
en
nn
)1(lim .
1)1(lim
x
nn
.
Rezultă că:
!)1(
)!(!
!
lim x
exxnpxp
xnx
n
n
.
Proprietăți ale densității de probabilitate:
- media: μ = p‧n= ;
- varianța: σ2 = np(1-p) = (1-
n
) = ( n );
- abaterea standard: ;
- coeficientul de variație: v =
1;
- asimetria : S =
1;
- aplatizarea: K = 3 +
1.
Funcția de repartiție este:
F(x; λ) =
x
yy
ey
0!
.
Figura 1. Distributia Poisson de medie 5
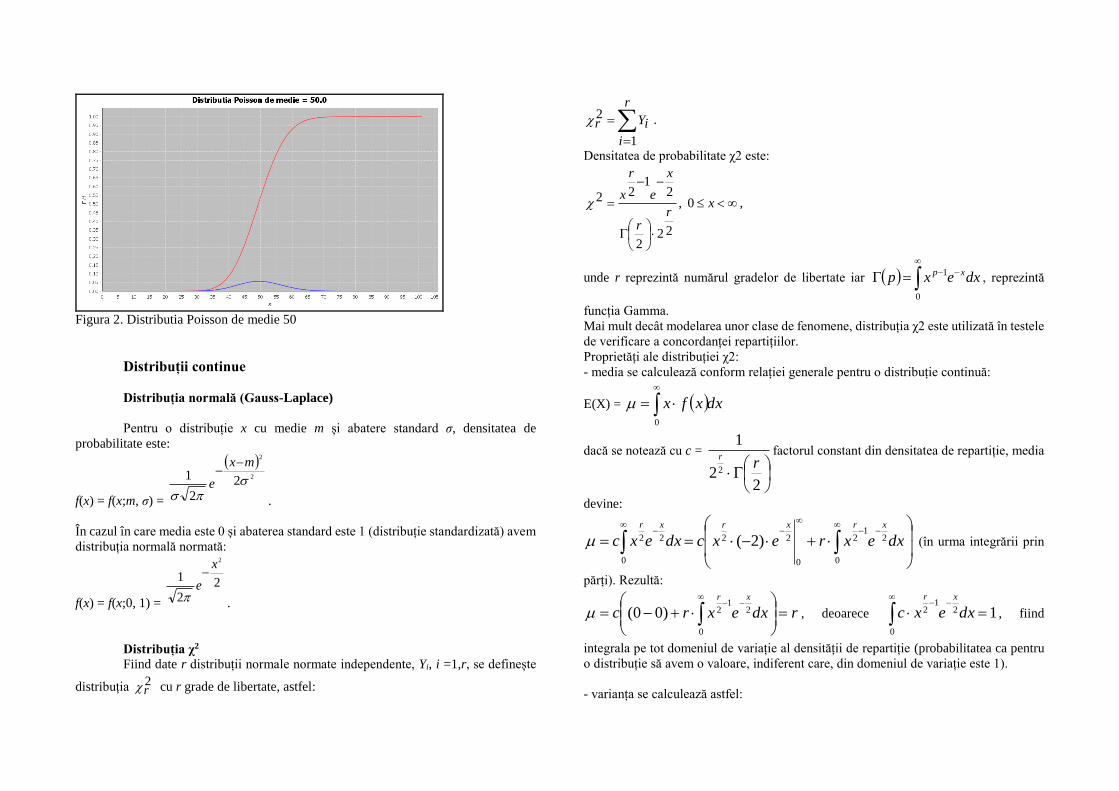
Figura 2. Distributia Poisson de medie 50
Distribuții continue
Distribuția normală (Gauss-Laplace)
Pentru o distribuție x cu medie m și abatere standard σ, densitatea de
probabilitate este:
f(x) = f(x;m, σ) =
2
2
2
2
1
mx
e
.
În cazul în care media este 0 și abaterea standard este 1 (distribuție standardizată) avem
distribuția normală normată:
f(x) = f(x;0, 1) =
22
1
2x
e
.
Distribuția χ2
Fiind date r distribuții normale normate independente, Yi, i =1,r, se definește
distribuția 2r cu r grade de libertate, astfel:
r
i
iYr
1
2 .
Densitatea de probabilitate χ2 este:
xr
r
x
e
r
x0 ,
222
21
22 ,
unde r reprezintă numărul gradelor de libertate iar
0
1 dxexp xp, reprezintă
funcția Gamma.
Mai mult decât modelarea unor clase de fenomene, distribuția χ2 este utilizată în testele
de verificare a concordanței repartițiilor.
Proprietăți ale distribuției χ2:
- media se calculează conform relației generale pentru o distribuție continuă:
E(X) = dxxfx
0
dacă se notează cu c =
22
1
2r
rfactorul constant din densitatea de repartiție, media
devine:
0
21
2
0
22
0
22 )2( dxexrexcdxexcxrxrxr
(în urma integrării prin
părți). Rezultă:
rdxexrcxr
0
21
2)00( , deoarece 10
21
2
dxexc
xr
, fiind
integrala pe tot domeniul de variație al densității de repartiție (probabilitatea ca pentru
o distribuție să avem o valoare, indiferent care, din domeniul de variație este 1).
- varianța se calculează astfel:
2222 XEXE = 22 rXE , unde E(X2) se calculează
conform relației generale pentru medie:
0
21
2
0
21
222 dxexcdxexxcXE
xrxr
0
22
0
21
2 )12
(2)2( dxexr
excxrxr
=
)2(2)2()00(0
22
0
22
rrdxexcrdxexrcxrxr
unde
dxexcxr
0
22 este media calculată mai înainte.
Rezultă: rrrrrXE 22 2222
- abaterea standard: r2 ;
- modulul: r-2;
Funcția de repartiție χ2 este:
2
2,
2
2
22
1
2
22
1
22
2
22
22
22
2/
0
12
0
2
12
0
2
12
0 2
2
12
0 2
21
2
r
xr
dtetr
dyey
rdy
r
ey
dyr
ey
dyr
eyxF
x
t
rx yr
x
yr
x
r
yr
x
r
yr
Funcția dxexap p
a
p
0
1, se numește funcția gamma inferior incompletă.
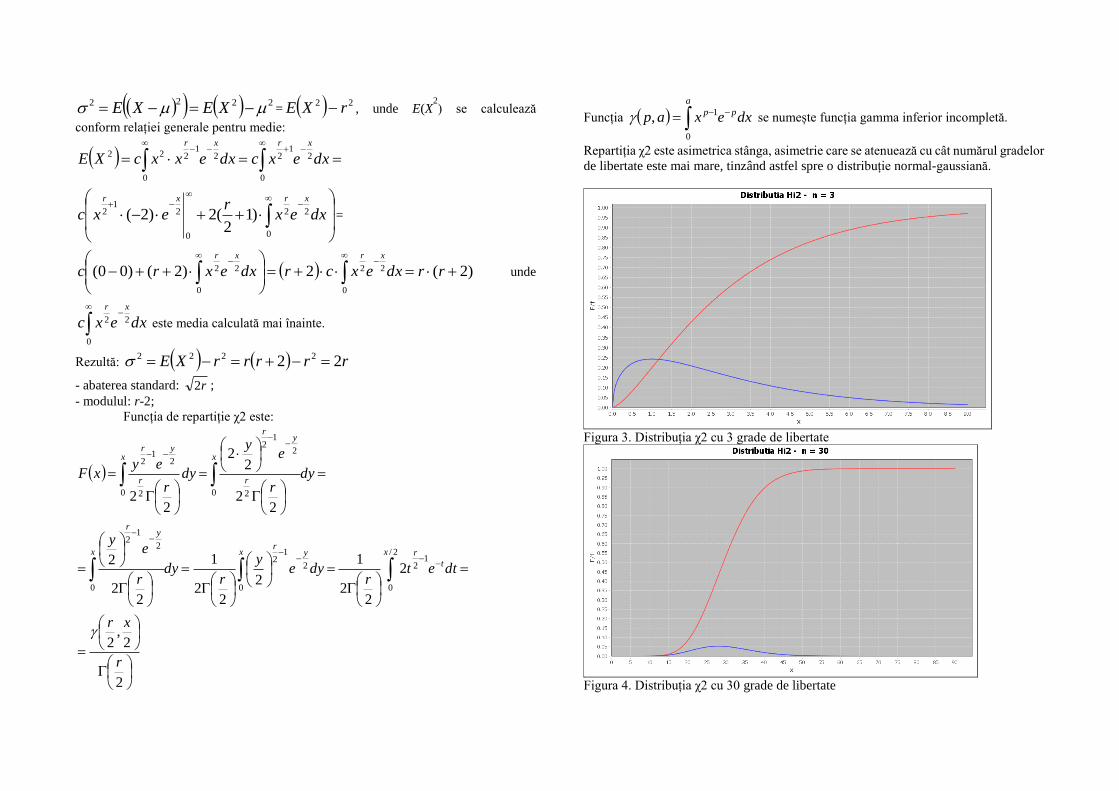
Repartiția χ2 este asimetrica stânga, asimetrie care se atenuează cu cât numărul gradelor
de libertate este mai mare, tinzând astfel spre o distribuție normal-gaussiană.
Figura 3. Distribuția χ2 cu 3 grade de libertate
Figura 4. Distribuția χ2 cu 30 grade de libertate

Teste de concordanță
Un test de concordanță este o ipoteză statistică, o presupunere cu privire la
caracteristicile unei repartiții, existența unei legi de repartiție. Ca în orice test statistic
sunt definite două alternative:
- ipoteza nulă sau H0 constând în afirmația făcută;
- ipoteza alternativă sau H1 care constă în non-afirmație.
Un test statistic este o procedură specifică în urma căreia se trage o concluzie logică
privind afirmația din ipoteza nulă: este adevărată sau falsă. Această procedură este una
probabilistică. Testul are asociat un grad de încredere. În cazul testelor de concordanță
este verificată ipoteza că o distribuție empirică este distribuită după o lege de
probabilitate specificată, sau că două distribuții empirice urmăresc aceeași lege.
Utilizarea clasică este cea legată de “concordanţa” dintre modelul empiric şi modelul
teoretic considerat adecvat pentru populația din care provin datele statistice. În orice
test sunt calculate două mărimi:
- valoarea calculată a testului sau valoarea critică,
- valoarea efectivă a testului sau statistica testului.
Valoarea critică depinde de gradul în care sunt acceptate valori marginale, caracterizate
prin densități mici de probabilitate. Acesta este pragul de semnificație și reflectă zona
de respingere a ipotezei nule. Complementar, gradul de încredere reflectă zona de
acceptare. Dacă valoarea efectivă este mai mică sau egală decât valoarea critică, ipoteza
H0 este acceptată, altfel este respinsă.
Metodele de analiză a datelor adeseori fac presupuneri cu privire la distribuții, prepuneri
care trebuie verificate. Din multitudinea de teste de concordanță, două se detașează ca
frecvență de utilizare: testul χ2 și testul Smirnov-Kolmogorov.
Testul χ2
Testul χ2 este un test general, care poate fi aplicat oricărei distribuții empirice
căreia putem sa îi calculăm funcția de repartiție. Testul χ2 se aplică datelor grupate (sau
datelor de frecvență). Algoritmic, testul se aplică astfel:
1. Fie distribuția empirică X = {x1, x2, ..., xT}. Vor fi împărțite observațiile în m grupe și
se vor determina frecvențele absolute ale grupelor:
fai, i = 1,m
2. Se calculează frecvențele medii estimate prin funcția de repartiție testată:
fei = T·(F(li+1)-F(li)), i = 1, m,
unde F este funcția de repartiție testată iar li, i =1,m+1 sunt limitele grupelor
3. Se calculează valoarea efectivă a testului sau statistica testului:
m
iife
ifeifa
Calculat1
22
4. Se determină valoarea critică a testului 2Critic
(α ;m − c +1)
unde:
- α este nivelul (pragul) de semnificație al testului;
- c este numărul de parametri ai distribuției F (distribuția normală-gaussiană are doi
parametrii, media și abaterea standard);
- m−c+1 numărul de grade de libertate ale distribuției χ2.
Această valoare se calculează aplicând funcția de repartiție a distribuției χ2 pentru
parametrii specificați.
5. Decizia asupra acceptării sau respingerii ipotezei H0 se ia astfel:
dacă 22CriticCalculat
atunci se acceptă ipoteza nulă, respectiv datele provin din
distribuția testată
altfel se respinge ipoteza nulă, respectiv datele nu provin din distribuția testată.
Testul Smirnov-Kolmogorov
Este utilizat pentru testarea ipotezei de normalitate. Etapele algoritmului:
1. Fie distribuția empirică X = {x1, x2, ..., xT}. Se calculează media distribuției și abaterea
standard, μ și σ.
2. Se ordonează crescător valorile eșantionului şi se obţine eşantionul ordonat:
x(1), x(2), ..., x(T)
3. Se calculează funcția de repartiție normală pentru valorile ordonate:
F(x(1)), F(x(2)), ... , F(x(T))
4. Se calculează funcția de repartiție empirică:
Fe(x(j)) = T
j, j=1,T, deoarece densitatea de probabilitate pentru repartiția empirică este
T
1
4. Se calculează valoarea efectivă a testului sau statistica testului:
D = )()( jxFjxFe
jMax
5. Se determină valoarea critică a testului, d1-α,T, unde 1-α este gradul de încredere
6. Se ia decizia astfel:
-dacă D≤ d1-α,T se acceptă ipoteza normalității cu un grad de încredere 1-α
- dacă D> d1-α,T se respinge ipoteza normalității cu un grad de încredere 1-α
Relația dintre două variabile cantitative. Legătura liniară simplă

Dacă se notează cu X şi cu Y două variabile cantitative şi cu xi şi y
i valorile
luate de variabile pentru individul i, legătura liniară simplă dintre cele două variabile
este dată de relaţia:
yi = ax
i +b + e
i, i =1,n
unde ei este un termen rezidual.
Problema care se pune este de a măsura intensitatea legăturii dintre cele două
variabile deoarece legătura nu este de regulă absolută. De exemplu, dacă urmărim
variabilele greutate şi talie la un grup de persoane vom observa că ele variază în general
împreună şi în același sens. Există însă situații în care indivizi cu talie mai mică pot
avea greutăți mai mari decât indivizi cu talie mai mare.
Relația dintre variabilele X şi Y va fi cu atât mai intensă cu cât valorile
reziduale ei vor fi mai mici. Din punct de vedere matematic vom determina parametrii
a şi b astfel încât
n
i
ie
1
2să fie minimă.
Soluţia acestei probleme obţinută aplicând regula celor mai mici pătrate este:
)(
))((1
1
xayb
XVar
yyxxn
a
n
i
ii
Dacă se notează covarianţa dintre cele două variabile cu Cov(X,Y) =
n
i
ii yyxxn
1
))((1
rezultă:
xayb
XVar
YXCova
)(
),(
.
Fluctuațiile variabilei Y măsurate prin varianţă, Var(y) reprezintă varianţa
totală. Fluctuaţiile valorilor calculate pentru Y, care depind de X, sunt masurate prin
varianţa Var(ax+b) şi reprezintă varianţa explicată. Fluctuaţiile valorilor reziduale ,
Var(e), reprezintă varianţa reziduală. Relaţia dintre cele trei varianţe este următoarea:
Varianţa totală = Varianţa explicată + Varianţa reziduală
Var(y) = Var(ax+b) + Var(e)
Var(y) =
n
i
i yyn
1
2)(1
Deoarece, yi = ax
i +b +e
i si b = xay , rezultă: iii exxayy )( .
Înlocuind în relaţia varianţei se obţine:
Var(y) =
n
i
iiii
n
i
ii eexxaxxan
exxan
1
222
1
2 ))(2)((1
))((1
)()()()( 22
1
2
baxVaraxVarxVaraxxn
ai
n
i
)),(),((2
),(2),(2
1
)(2
baxxCovyxCova
baxyxaCovexaCov
n
i
iexixn
a
=2a(Cov(x,y) – a Cov(x,x)) = 2a ( Cov(x, y) - ))()(
),(xVar
xVar
yxCov= 0.
)(1
1
2 eVaren
n
i
i
Se măsoară intensitatea legăturii dintre X şi Y prin raportul dintre varianţa
explicată şi varianţa totală. Acest raport , numit raport de corelaţie (sau coeficient de
determinare) este notat R2(x,y):
)()(
),(
)(
)(
)(
)(),(
222
yVarxVar
yxCov
yVar
xVara
yVar
baxVaryxR
.
Rădăcina din R2 este numit coeficient de corelaţie liniară şi este:
R = yx
yxCov
),(.
Interpretarea geometrică a coeficientului de corelaţie
O variabilă X luând n valori poate fi reprezentată printr-un vector în spaţiul Rn,
numit şi spaţiul variabilelor. În spaţiul Rn produsul scalar simplu dintre doi vectori X şi
Y de coordonate (x1,...,x
n) şi (y
1,...,y
n) este:
<x,y> =
n
i
ii yx
1
iar normele celor doi vectori sunt :
n
i
ixxxx1
2, .
n
i
iyy1
2.
Cosinusul unghiului dintre cei doi vectori este :
yx
yxyxCos
,),( =
n
i
i
n
i
i
n
i
ii
yx
yx
1
2
1
2
1=
n
i
i
n
i
i
n
i
ii
yn
xn
yxn
1
2
1
2
1
11
1
.
Dacă se consideră vectorii X şi Y două variabile centrate, din relaţia
anterioară obţinem:
Cos(X,Y ) =
YX
YXCov
),(= R(X,Y )
Unghiul G
X
Y
Cos(G) = R(X,Y)
Când coeficientul de corelaţie este egal cu 1 cei doi vectori sunt coliniari, adică
valorile xi şi y
i sunt proporţionale. Absenţa corelaţiei se traduce printr-o valoare nulă
pentru R, deci între cei doi vectori este un unghi de 90 de grade.





![The z Transform - UTKweb.eecs.utk.edu/~hli31/ECE316_2015_files/Chapter9.pdf · Existence of the z Transform! The z transform of x[n]=αnun−n [0], α∈ is X(z)=αnun−n [0]z−n](https://static.fdocument.org/doc/165x107/5e6f952567c1d8438c5967ae/the-z-transform-hli31ece3162015fileschapter9pdf-existence-of-the-z-transform.jpg)












