
Metodo dei minimi quadratipeople.na.infn.it/~chiefari/didattica/LabFis1/aa2013...Metodo dei minimi...
47
Metodo dei minimi quadrati Viene usato quando si vuole trovare la migliore curva che, tenendo conto degli errori, passa il più possibile vicino ai dati sperimentali ( best fit ). Siano x 1 , x 2 ,…x N N punti in cui si effettuano N misurazioni indipendenti y 1 ,y 2 ,…y N . I valori veri η 1 , η 2 , … η N delle osservabili non sono noti ma supponiamo che esista un modello teorico che predica i valori η i associati a ciascun x i attraverso una dipendenza funzionale f, tale che η i = f i ( θ 1 , … θ L; x i ) con θ i parametri incogniti e L ≤ N.
Transcript of Metodo dei minimi quadratipeople.na.infn.it/~chiefari/didattica/LabFis1/aa2013...Metodo dei minimi...

Metodo dei minimi quadrati
Viene usato quando si vuole trovare la
migliore curva che, tenendo conto degli
errori, passa il più possibile vicino ai dati
sperimentali ( best fit ).
Siano x1, x2,…xN N punti in cui si
effettuano N misurazioni indipendenti
y1,y2,…yN.
I valori veri η1, η2, … ηN delle osservabili
non sono noti ma supponiamo che esista
un modello teorico che predica i valori ηi
associati a ciascun xi attraverso una
dipendenza funzionale f, tale che
ηi = fi ( θ1 , … θL; xi )
con θi parametri incogniti e L ≤ N.

Il Principio dei Minimi Quadrati afferma
che i valori migliori dei parametri incogniti
sono quelli per cui
X2 = ∑
sia minimo, dove è il peso dell’i-ma
osservazione.
Si può dimostrare che se il modello
teorico prevede una dipendenza lineare
dai parametri, la minimizzazione di
X2 = ∑
porta ad un sistema di equazioni lineare,
non omogeneo, che ammette una ed una
sola soluzione esatta e non approssimata.
Da notare che ad esempio un modello
polinomiale del tipo f = a0 +a1x +a2x2… è
lineare nei parametri a0, a1 a2…

Se le misure si distribuiscono secondo
una gaussiana N( fi,
) e =
allora X2min è una variabile χ² con N-L gradi
di libertà.
Il metodo dei minimi quadrati porta in
questo caso alla cosiddetta
minimizzazione del χ² e alla sua
equivalenza col principio di massima
verosimiglianza : infatti
L =∏
√
exp[ -
(
)² ]
è proporzionale a
exp[ -
∑
(
)² ] per cui L massima
corrisponde a ∑ (
)² minimo ,

come si ottiene col metodo dei minimi
quadrati.
C’è da notare comunque che entrambi i
metodi fanno l’ipotesi che le xi siano
prive di errori, cosa del tutto ideale. Come
comportarsi nei casi reali ?
Non esiste una ricetta magica valida per
tutti i casi che si possono incontrare
quando di elaborano i dati di un
esperimento. In tal senso è significativa
l’introduzione ad un libro della nostra
biblioteca :

Tuttavia se anche le xi si distribuiscono
come una gaussiana N( , ) il χ² da
minimizzare diventa
χ² = ∑ (
)² + ∑ (
)²
in cui adesso fi = fi ( θ1 , … θL; ).
Quindi le incognite non sono solo i
parametri θi ma anche le .

La minimizzazione analitica
conduce ad un sistema di equazioni non
lineare nelle incognite θi e , che non è
semplice risolvere. Si preferisce in tal caso
ricorrere a metodi numerici : un
programma come MINUIT della CERN
LIBRARY è in grado di minimizzare una
funzione contenente 50 parametri
incogniti ed è largamente adottato dalla
comunità dei fisici. Tuttavia, ai fini degli
scopi del corso di laboratorio del primo
anno si possono trarre delle utili
conclusioni, anche senza ricorrere ad un
programma di calcolo così potente.
Senza entrare nei dettagli dei calcoli, si
può trovare che, definendo
=
+ (
∙

( somma in quadratura di un errore su yi
intrinseco e di un errore su yi derivato
dall'errore su xi ), il χ² da minimizzare
diventa
χ² = ∑ (
)²
che appare identico al χ² che abbiamo
scritto per il caso in cui l’errore su xi è
uguale a zero. Da questo consegue che le

formule ricavate per il fit dei minimi
quadrati, quando l’errore su xi è uguale a
zero, sono ancora valide purché si tenga
conto del nuovo significato di .
Il problema è ora che, per determinare ,
bisogna conoscere la derivata di f rispetto
ad x, ossia anche la funzione f stessa,
prima ancora di averla determinata con i
minimi quadrati. Bisogna allora usare un
metodo ricorsivo.
Supponiamo per esempio che
per cui
b.
Si può allora determinare con le rette di
massima e minima pendenza un valore b0
approssimato di b, si determina
=
+ b ∙
,

si inserisce nell'espressione del χ², si
determina un nuovo valore di b, diciamo
b1, si inserisce b1 in e si continua
finché il χ² non è sufficientemente
minimo.
In generale si preferisce una situazione in
cui si possa trascurare l'effetto dell'errore
su x.
Quanto detto finora consente di stabilire
un criterio generale per la scelta della
variabile indipendente, ossia della
variabile che va graficata sull'asse delle
ascisse. La scelta corretta è quella per cui
b ∙ <<
e quindi è circa
uguale a
.

Nel caso di una retta passante per
l'origine b è circa uguale a (
) e la
condizione b ∙ <<
è equivalente
a (
) << (
)
per cui la variabile
indipendente è quella che ha l’errore
relativo minore.
In un esperimento ben progettato si
usano strumenti tali che gli errori di
sensibilità non coprano le fluttuazioni
statistiche.
Nella pratica di laboratorio ( a causa della
limitatezza della strumentazione usata,
della scarsità di tempo che si può
dedicare alle misure, ... ) accade spesso di
conoscere una grandezza con un errore di
tipo massimo.

Il problema è come regolarsi quando si
vuole studiare, mediante un best fit, una
relazione fra questa grandezza ed un'altra
( che può essere eventualmente anche
essa affetta da errore massimo ).
Ipotesi 1:
Supponiamo di conoscere di una
grandezza l'errore massimo e dell'altra
l'errore statistico.
Caso a) :
Quando possiamo riportare sull'asse x la
variabile con errore massimo e
trascurarne nel best fit l'errore ? Se

accade che b ∙ <<
, allora è
anche verificato che b ∙ <<
( essendo sempre ≤
)
Caso b) :
Quando possiamo riportare sull'asse x la
variabile con errore statistico e
trascurarne nel best l'errore ? Se accade
che b ∙ <<
, possiamo ritenere (
con una certa dose di prudenza però )
che, essendo minore o circa uguale a
, valga ancora b ∙ <<
. In
questo caso si avrebbe una situazione in
cui si potrebbe considerare la x priva di
errore ma l’errore sulla y è di tipo
massimo: vedremo in seguito come
procedere.

Caso c) :
Nei casi intermedi, non c' è soluzione
generale. Ritornando al caso a), è
sbagliato dire che =
ed è di
nessuna utilità ricavarsi una specie di
errore massimo = 3
+ |b |
perché non si sa come metterlo in
relazione con = √
Ipotesi 2:
Supponiamo che entrambe le grandezze
siano affette da errore massimo.
In questo caso la grandezza da porre
sull'asse x deve essere tale che

|b | <<
sicché, se
≤
e
≤
, accada che |b |
<<
e si possa trascurare l'errore sulla x. Nei
casi intermedi non c'è soluzione
generale.
Best fit di una retta per n coppie
di punti sperimentali (xi, yi )
Supponiamo che le xi siano prive di errore
e che l’equazione della retta sia y= a +b x,
con a e b parametri da determinare.
La minimizzazione del χ² porta alle
seguenti espressioni per le stime dei

parametri, della matrice di covarianza V e
del χ² stesso.
=
=
(
) =
= (
)
dove
∑
∑
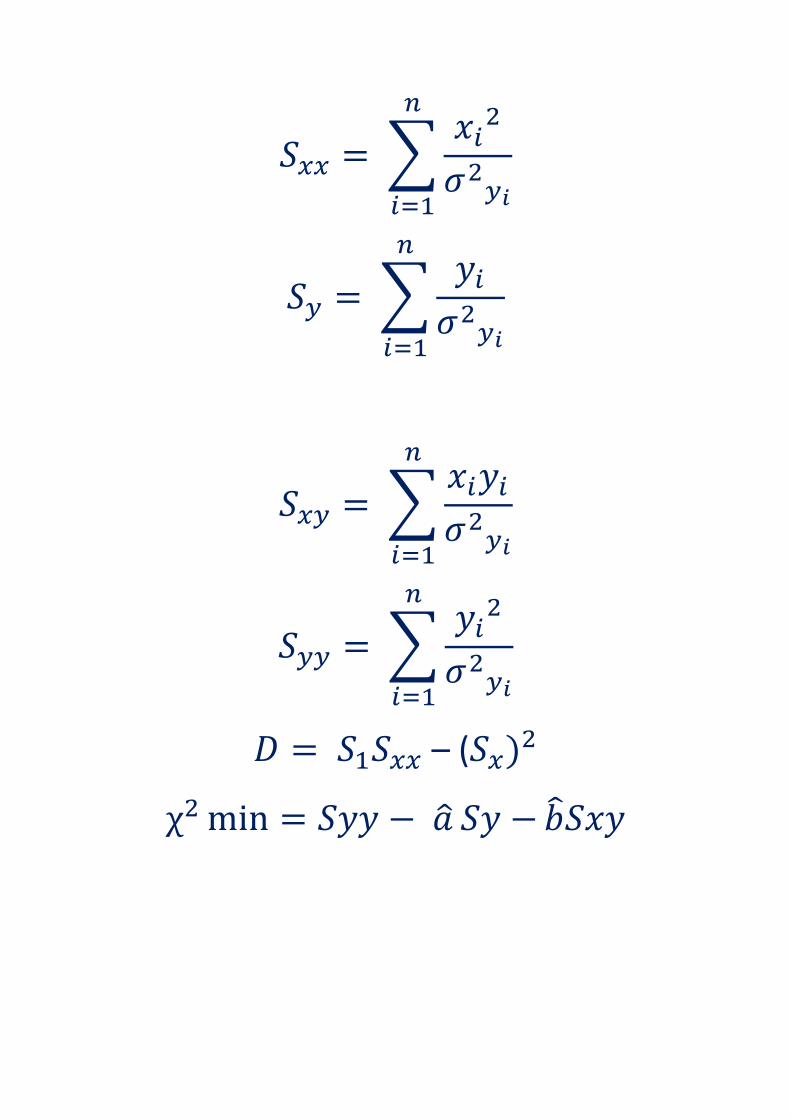
∑
∑
∑
∑
– (

NOTA 1 : usando un foglio di calcolo del
tipo EXCEL o CALC, è agevole determinare
dapprima le sei quantità
, , , , e poi tutte le
altre grandezze di interesse.
NOTA 2 :
Usare la formula
rende più agevole la determinazione del
χ² minimo, anche se occorre fare il calcolo
con tutte le cifre disponibili sulla
calcolatrice ) o sul calcolatore ) per evitare
che, a causa degli arrotondamenti, possa
risultare alla fine un χ²min negativo.

La covarianza dei parametri.
Cosa rappresentano gli elementi fuori
diagonale nella matrice di covarianza ?
Sono la stima della covarianza fra i
parametri e danno una misura del grado
di dipendenza statistica dei parametri,
ossia del fatto che la stima di un
parametro influenza la stima dell’altro
parametro, anche se i punti sperimentali
(xi,yi ) sono indipendenti fra di loro.
NB : Date due grandezze casuali z e w si
chiama covarianza di z e w e si indica con
cov (z,w ) ( talora viene usato il simbolo
σzw )il valore atteso di (z-µz)(w-µw) , dove
µz e µw sono i valori attesi della
popolazione di z e w.

Naturalmente la covarianza di una
grandezza con se stessa è uguale alla sua
varianza.
Nel caso specifico, se non ci fosse una
formula a dirci quanto vale la covarianza
fra i parametri, dovremmo immaginare di
fare un numero elevato di esperimenti, in
ognuno dei quali ricavare una stima di
, ottenere la media aritmetica di
ed applicare la formula della
covarianza del campione
∑
Si può facilmente vedere che la retta di
best fit passa sempre per il centro di

gravità dei punti sperimentali , avente
come coordinate
=
e =
: infatti = .
La retta di best fit quindi può solo ruotare
intorno al punto ( , e quindi, se la
pendenza aumenta, diminuisce
l’intercetta e viceversa dando origine alla
covarianza fra pendenza e intercetta.

Quando serve le covarianza ?
Supponiamo di avere una grandezza fisica
derivata z , che sia funzione f delle stime
dei parametri : ( ) . Quanto vale
? Per effetto della covarianza fra i
parametri
=
+
+ 2
cov( ,
)
Caso A ):
Supponiamo ora di voler conoscere
l’errore su un valore di y corrispondente
ad un fissato valore ξ di x, nel caso in cui si
abbia una retta di calibrazione y =
( interpolazione o
estrapolazione ). La migliore stima di y è
= e

=
+
+ 2 (1)(ξ)
cov( , )=
=
+
(
)
e quindi
è minimo quando
.
Caso B ):
Supponiamo di voler trovare la coordinata
x0 dell’intersezione della retta di best fit
con l’asse y e il suo errore.

Da = , si ricava che =
mentre
=
+
+ 2
(
) (
)cov( , )
Caso C ) :

Supponiamo di avere z = x+y. Se x e y
sono indipendenti =
. Ma
se x =y, sembrerebbe che sia uguale a
2 , mentre da z =2x si ottiene
. Il motivo risiede nel fatto
che =
+ 2 cov ( x,y ), che,
se x=y, cov( x,x ) = e quindi ancora
una volta
.
Alcuni esempi di propagazione
degli errori.


Quando non si conosce la
varianza della popolazione.
Per minimizzare il χ², è necessario
conoscere che rappresenta la

varianza della popolazione della variabile
gaussiana yi.
Questo significa che in effetti
non è
mai nota : infatti dai dati sperimentali si
può solo avere la migliore stima di
.
Può accadere inoltre che l'errore di
sensibilità sommerga le fluttuazioni
statistiche e che yi sia nota solo con un
errore Δyi di tipo massimo.
E allora ? Non c'è nulla da fare ?
Fortunatamente, no !
Il best fit non pesato ( quando le
sono tutte uguali ad una
certa
)

In questo caso χ² = ∑ (
)² =
∑ (
)² =
∑
2 da cui si ricava che
=
∑
.
Se è incognita, il suo valore atteso è
dato sostituendo nella precedente
espressione al il valore atteso del ,
ossia ν, il numero dei gradi di libertà.
Quindi
∑ (
)
2
Tuttavia questo ragionamento porta ad
una incertezza nella stima non solo di σ²
ma anche degli errori dei parametri.
Infatti non sono accettabili valori di χ² né
troppo bassi ( possibile sovrastima degli
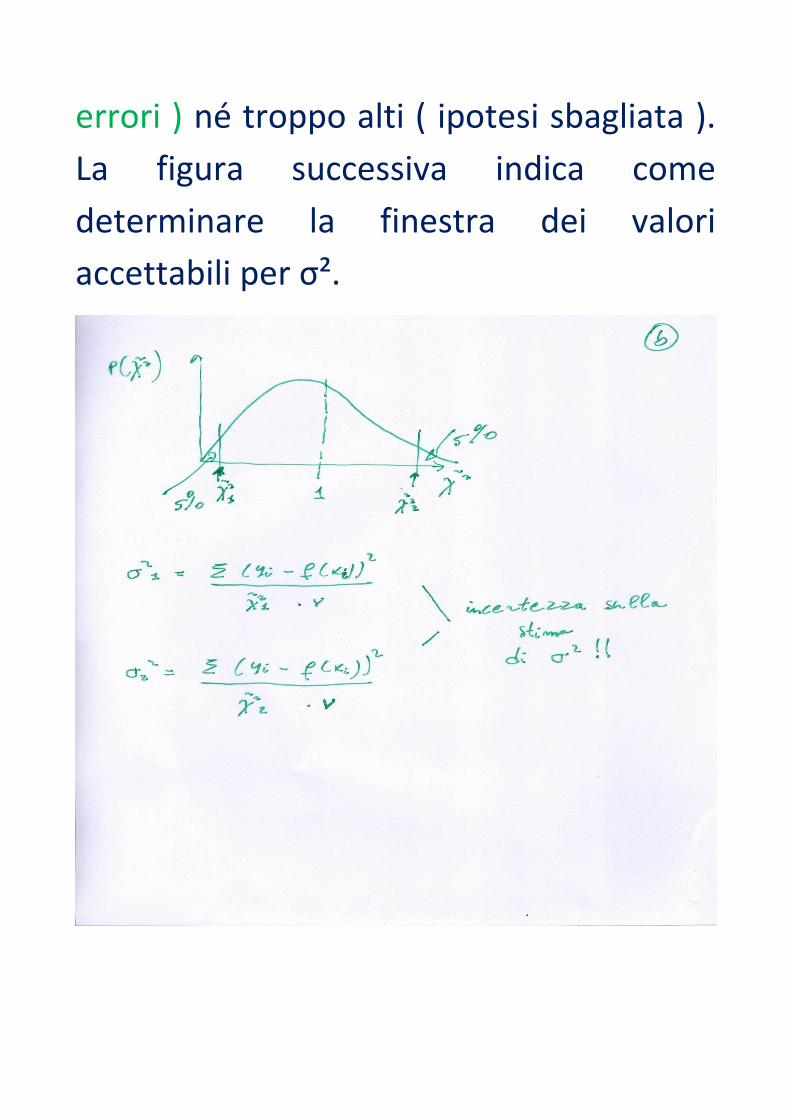
errori ) né troppo alti ( ipotesi sbagliata ).
La figura successiva indica come
determinare la finestra dei valori
accettabili per σ².

Ma quando si può assumere che le
incognite siano uguali fra di loro per tutti i
punti sperimentali ?
Se
1. Lo strumento è sempre lo
stesso
2. L’operatore è sempre lo
stesso
3. Le condizioni ambientali
restano costanti durante
l’esperimento
è ragionevole ipotizzare che le σ delle
fluttuazioni statistiche introdotte da 1), 2)
e 3) siano costanti e che possano essere
sommate in quadratura per dare una σ
finale costante. Tuttavia “ragionevole”
non vuol dire “sicuro”.

Best fit non pesato di una retta
Per ottenere i parametri di una retta con i
relativi errori si possono usare le formule
del best fit pesato scrivendo
esplicitamente che gli errori sono uguali
fra di loro.
In tal caso si ottiene :

dove 2 ha lo stesso significato del
quadrato di σy dato dalla formula 8.15 del
Taylor.
Stimare “ a posteriori” 2 però comporta
la rinuncia al test del χ² per verificare
l’attendibilità di un’ipotesi.
NB : Se si usa EXCEL o CALC per fare un
grafico e si traccia la linea di tendenza,
bisogna fare attenzione al fatto che viene
sottinteso un fit non pesato. La stessa
cosa accade se si stampa la matrice di
RegrLin: in particolare la grandezza che
appare nella seconda colonna, terza riga è
proprio la stima della radice quadrata di
∑ (
)
2

Ci sono casi in cui , nonostante che il
modello teorico sia corretto, accade di
ottenere un valore di χ² o troppo alto o
troppo basso. Questo accade quando gli
errori statistici stimati si sono più bassi o
più alti delle corrispondenti σi .
Se supponiamo che
=
con un
fattore costante, allora il chi quadro
sperimentale sarà dato da
χ²sper = ∑ (
)² = ∑
(
)²
= χ²
Quindi il valore atteso di sarà dato da
=
=
dove ν è il numero dei
gradi di libertà.

A questo punto non è necessario rifare il
fit : si può dimostrare che i parametri del
fit restano inalterati, mentre bisogna
moltiplicare per la matrice delle
covarianze.
Scelta di modelli diversi
Può accadere che ci siano due o più
modelli teorici che diano origine a χ²
accettabili. In tal caso quale di questi
modelli è preferibile rispetto agli altri ?
In fisica si ritiene che un modello teorico
debba contenere il numero minimo di
parametri incogniti : fissato il numero di
punti sperimentali, questo vuol dire che

deve essere il più alto il numero di gradi di
libertà ν.
Sarà quindi scelto il modello teorico che
comporti il pià alto valore del chi quadro
ridotto,
.
Conclusioni
Al di là dell'aspetto formale, che tuttavia
è importante, bisogna tener conto di
quello sostanziale. Di grande aiuto è
l'esperienza, anzi la ``sensata esperienza''
di Galileo nel giudicare la bontà dei
risultati.
Ad es. una stima di a non compatibile con
zero entro gli errori, nei casi in cui invece
si aspetta che =0, rivela la presenza di

un errore sistematico, che bisogna
rintracciare ed eliminare. Bisogna
controllare se i punti sperimentali sono
coerenti con l'ipotesi fatta : se non è
possibile effettuare il test del χ² perché
non si conoscono le , allora bisogna
ricorrere ad altri test, come l'F-test, che
verrà studiato nel laboratorio del primo
anno della laurea magistrale, oppure
ricorrere al “buon senso”.
Se ad es. stiamo utilizzando il metodo
statico per le molle ed otteniamo come
grafico dell'allungamento in funzione
della massa un grafico del tipo illustrato in
figura, è evidente che non possiamo fare
un best fit lineare su tutti i punti. Infatti gli
ultimi tre punti non sono allineati con i
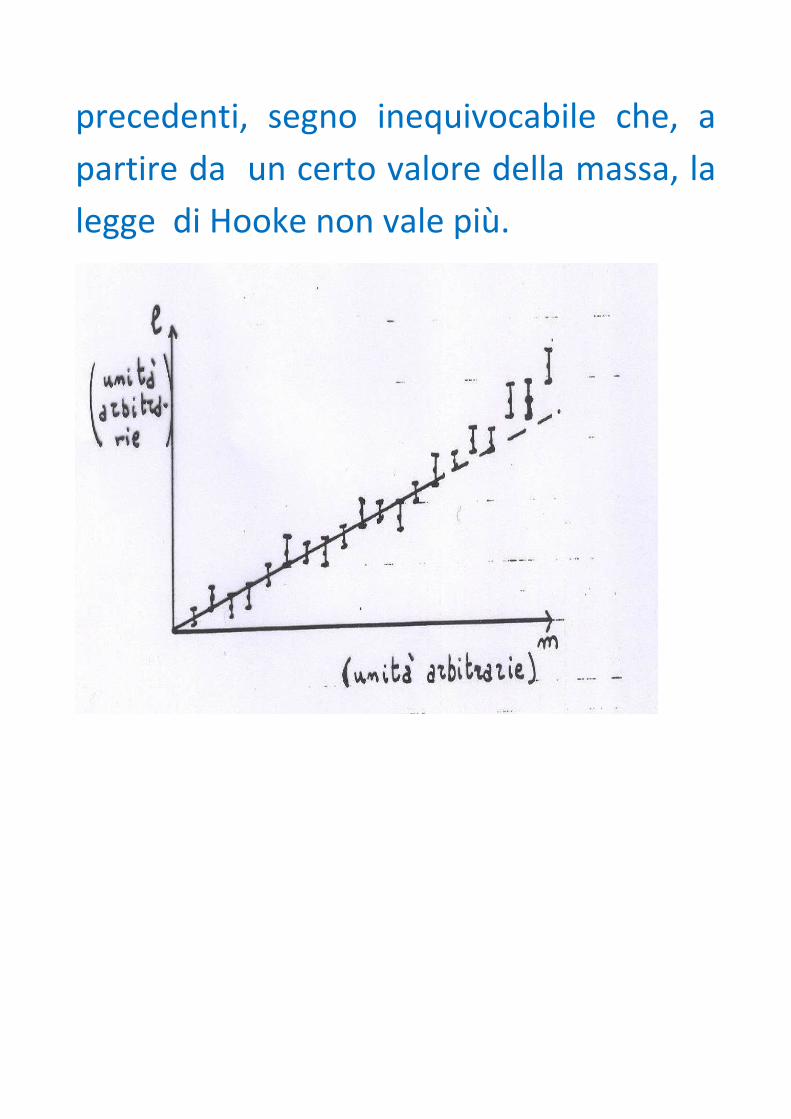
precedenti, segno inequivocabile che, a
partire da un certo valore della massa, la
legge di Hooke non vale più.

Prima di ritornare in laboratorio
….
Misura indiretta di una grandezza fisica, a partire da una relazione nota fra due altre
grandezze fisiche.
Accade spesso in laboratorio di poter effettuare una misura indiretta di una grandezza fisica, quando si conosce una relazione fra due ( e talora più di due ) grandezze fisiche, misurabili direttamente. Vediamo adesso come evitare tutta una serie di errori di procedimento, che possono portare a stime per nulla attendibili. Per rendere più concreto il discorso, faremo riferimento alla misura indiretta dell’accelerazione di gravità g, ottenuta misurando la lunghezza l e il

periodo di oscillazione T di un pendolo semplice e sfruttando la relazione
T=2 (l/g) 1) Supponiamo di avere misurato l (
magari anche 30 o più volte per avere una media aritmetica e un errore della media). Supponiamo di avere misurato T ( misurando la durata di 20 o 30 oscillazioni consecutive ) per 30 o più volte per avere una media aritmetica ed un errore della media. A questo punto sembrerebbe plausibile ricavare g dalla formula
g = 4 (l/T2)
e ricavare il suo errore dalla propagazione dell’errore su l e T.
Dove sta il problema ?

Innanzitutto in generale non si sa mai se il modello teorico descrive bene i dati sperimentali : nel caso specifico, non sappiamo “a priori” quanto il nostro apparato sperimentale possa essere considerato la realizzazione di un pendolo semplice.
Per questo motivo non possiamo ad occhi chiusi utilizzare una formula, che è stata ricavata nell’ambito di certe approssimazioni. Tuttavia, se abbiamo misurato diverse coppie di valori di l e T e se notiamo su un grafico che c’ è una relazione lineare fra l e T2, siamo più confidenti che abbiamo realizzato in laboratorio una buona approssimazione del pendolo semplice, che ci consentirà di ottenere g con buona accuratezza.

2) Un altro errore che si può commettere a questo punto è quello di ricavare g per ogni coppia di valori di l e T2, effettuarne la media aritmetica e ricavarne la sigma della media. A parte il fatto che eventualmente andrebbe effettuata la media pesata dei vari valori di g, questo metodo non va bene, perché non tiene in conto che ad esempio l potrebbe essere diversa da zero anche quando T è uguale a zero, a causa di un errore sistematico l0 nello “zero” dello strumento di lunghezze usato. Questo comporta che ci sia una relazione lineare non più fra l e T2, ma fra l-l0 e T2, sicché
g = 4 (l/T2) - 4 (l0/T2) Non tener conto del secondo termine comporta una sovrastima di g di una

quantità, non costante, pari a 4
(l0/T2) . 3) La cosa più opportuna da fare è allora
trovare una relazione lineare fra grandezze misurate, controllare che i punti sperimentali sul grafico suggeriscano un reale andamento lineare, effettuare un best-fit lineare del tipo y= a +bx e dai valori di a e b ottenuti ricavare alla fine la grandezza desiderata. Nel caso in esame, se l=y e x= T2, l’intercetta a dovrebbe essere compatibile con zero, entro gli errori, e in ogni caso rappresenta l0 , mentre
b=g/( 4 2). 4) Prima di effettuare i calcoli del best-fit,
bisogna prima scegliere correttamente la variabile indipendente ( ossia la grandezza da porre sull’asse delle x ). Si
è visto che, chiamando y ex gli

errori ( statistici o massimi a seconda dei casi ) sulla y e sulla x, se accade che
y |b|x , le cose vanno come se l’errore sulla x sia uguale a zero e quindi è corretta la scelta della variabile indipendente. Solo nel caso di una retta passante per lo zero questo criterio si riduce al confronto fra gli errori relativi e
deve valere che y/y >>|x/x. Nel caso dell’esempio del pendolo semplice ci aspettiamo che la relazione fra l e T2
sia descritta da una retta passante per l’origine e pertanto confrontiamo i loro errori relativi per decidere alla fine che T2 è la giusta variabile indipendente.
5) Bisogna capire a questo punto se effettuare un fit pesato oppure non pesato. Se si conoscono gli errori statistici sulle y, bisogna effettuare sempre un fit

pesato, controllare il valore del chi quadro ottenuto, capire l’origine di un eventuale elevato valore ( dovuto ad esempio ad un singolo punto fortemente disallineato oppure ad una sottostima degli errori oppure è sbagliata di molto l’ipotesi di partenza), porre un certo rimedio, dove possibile e solo a questo punto accettare le stime dei parametri e dei loro errori. Nel caso in cui gli errori statistici noti dovessero risultare fra di loro uguali, non bisogna essere così ingenui nell’affermare che bisogna effettuare un fit non pesato. Infatti bisogna sempre effettuare un fit pesato, che consente un test del chi quadro : accade però che per stimare i parametri ( ma non gli errori dei parametri ) si possano usare le

formule del fit non pesato ed è proprio questo ad ingenerare la confusione. Nel caso in cui non si conoscono gli errori statistici sulle y (è proprio il caso delle l nel pendolo semplice ), si può vedere se essi, sia pure incogniti, possano essere considerati uguali fra di loro. In generale le fluttuazioni statistiche, che portano ad una certa distribuzione gaussiana, possono essere raggruppate in quattro famiglie le cui sigma si sommano in quadratura fra di loro, a causa del Teorema del Limite Centrale. La prima ( che non si incontra nei problemi di Laboratorio di Fisica 1 ) è dovuta a fluttuazioni intrinseche del fenomeno ( del tipo conteggi di radioattività, conteggi di raggi cosmici…). La seconda è dovuta alla precisione dello strumento usato, la

terza all’interazione fra strumento e operatore e la quarta alle condizioni ambientali. In pratica si può affermare che , se nel corso delle misure restano costanti strumento, operatore e condizioni ambientali, la sigma delle misure effettuate resta costante. Da notare che questo non è più vero per misure indirette : per esempio potremmo affermare che le sigma dei
periodi T potrebbero essere considerate costanti, ma non la sigma
dei quadrati dei periodi, visto che T =
2 T T e non è costante al variare di T. Nel caso del pendolo semplice la variabile dipendente è l : siccome lo strumento per misurare le lunghezze resta lo stesso per l’intera esperienza, siccome si suppone che l’operatore resti lo stesso ( sia nel senso che non viene

sostituito da altro componente del gruppo sia nel senso che egli non perda nel tempo le sue capacità reattive ), siccome si suppone che le condizioni ambientali non cambino in maniera apprezzabile ( ci sarà ad esempio un incremento della temperatura ambiente ma in misura tale da non turbare la taratura degli strumenti ), alla fine possiamo supporre che le sigma delle lunghezze siano uguali fra di loro e la loro stima è ottenibile, imponendo che il valore del chi quadro ridotto sia uguale ad uno. Il non poter effettuare più il test del chi quadro è il pegno che si paga per non conoscere gli errori statistici. Si noterà che in questo discorso non sono entrati per nulla gli errori massimi sulle lunghezze, che naturalmente conosciamo in virtù delle nostre misure.


















