t ∇Φ ∫∫δ = Φ ∇Φ dxdy - CVIP Lab REPORT 2005.pdf · The Health Science Center is...
55
∫∫ Φ ∇ Φ = dxdy ) ( δ L 0 . | | | | = Φ ∇ Φ ∇ Φ ∇ + ∂ Φ ∂ v t CVIP Laboratory University of Louisville, KY Phone: (502) 852-7510, (502) 852-2789, (502) 852-6130 Fax: (502) 852-1580 Email: [email protected] http://www.cvip.louisville.edu
Transcript of t ∇Φ ∫∫δ = Φ ∇Φ dxdy - CVIP Lab REPORT 2005.pdf · The Health Science Center is...

∫∫ Φ∇Φ= dxdy)(δL
0.||
|| =Φ∇Φ∇
Φ∇+∂Φ∂ vt
CVIP Laboratory
University of Louisville, KY Phone: (502) 852-7510,
(502) 852-2789, (502) 852-6130 Fax: (502) 852-1580
Email: [email protected] http://www.cvip.louisville.edu

About CVIP…
Our Vision:
Providing a Better Understanding of the Human and Computer Vision Systems
Our Mission: The Computer Vision and Image Processing (CVIP) Laboratory was established in 1994 at the University of Louisville and is committed to excellence in research and teaching of computer vision and its application. The CVIP has two broad focus areas: computer vision and medical imaging. The laboratory is housed in a modern state-of-the-art research building and is linked, via a high-speed network, to the university’s medical center. The laboratory hosts unique and modern hardware for imaging, computing and visualization. Among the active research projects at the laboratory are the following:
1. Trinocular active vision, which aims at creating accurate 3-D model of indoor environments. This research is leading to creation of the UofL CardEye active vision system, which is our research platform in advanced manufacturing and robotics.
2. Multimodality image fusion, which aims at creating robust target models using multisensory information.
3. Building a functional model of human brain based on integration of structural information (from CT and MRI) and functional information (from EEG signals and functional-MRI scans). The functional brain model is our platform for our brain research in learning, aging, and dysfunctions.
4. Image-guided minimally invasive endoscopic surgery which aims at creating a system to assist the surgeons locate and visualize, in real-time, the endoscope’s tip and field of view during surgery.
5. Large-scale visualization for modeling and simulations of physical systems, and applications in visual reality.
6. Building a computer vision-based system for reconstruction of human jaw using intra oral video images. This research will create the UofL Dental Station, which will have various capabilities for dental research and practice.
7. Vision-based system for autonomous vehicle navigation. 8. Image modeling, segmentation, registration and pattern recognition.

Network Facilities:
Fast Internet and Internet2 connection
Local Gigabit Ethernet connection to Medical School
Local OC3 ATM
Two Supercomputers
3D Scanner
ImmersaDesk Display
ATRV-Mini &
ATRV2 robots
Card Eye Robotic Arm
FACILITIES IN CVIP

About The University of Louisville The University of Louisville is a state supported urban university located in Kentucky’s largest metropolitan area. It was a municipally supported public institution for many decades prior to joining the university system in 1970. The university has three campuses. The 177-acre Belknap Campus is three miles from downtown Louisville and houses seven of the universities eleven colleges and schools. The Health Science Center is situated in downtown Louisville’s medical complex and houses the university’s health related programs and the University of Louisville Hospital. On 243-acre Shelby Campus located in eastern Jefferson County are the National Crime Prevention Institute and the University Center for Continuing and Professional Education. In recent years, the university has also offered expanded campus courses at Fort Knox, Kentucky. About The J. B. Speed School of Engineering Founded in 1924, the University of Louisville Speed Scientific School (recently re-named The J.B. Speed School of Engineering) is the University’s college of engineering and applied sciences. Endowments from the James Breckinridge Speed Foundation, named after an influential Louisville industrialist (1844-1912), started and have continually supported the Speed School. The School consists of Chemical Engineering, Civil & Environmental Engineering, Computer Engineering and Computer Science, Electrical and Computer Engineering, Industrial Engineering and Mechanical Engineering programs.
CVIP Laboratory/Lutz Hall, University of Louisville
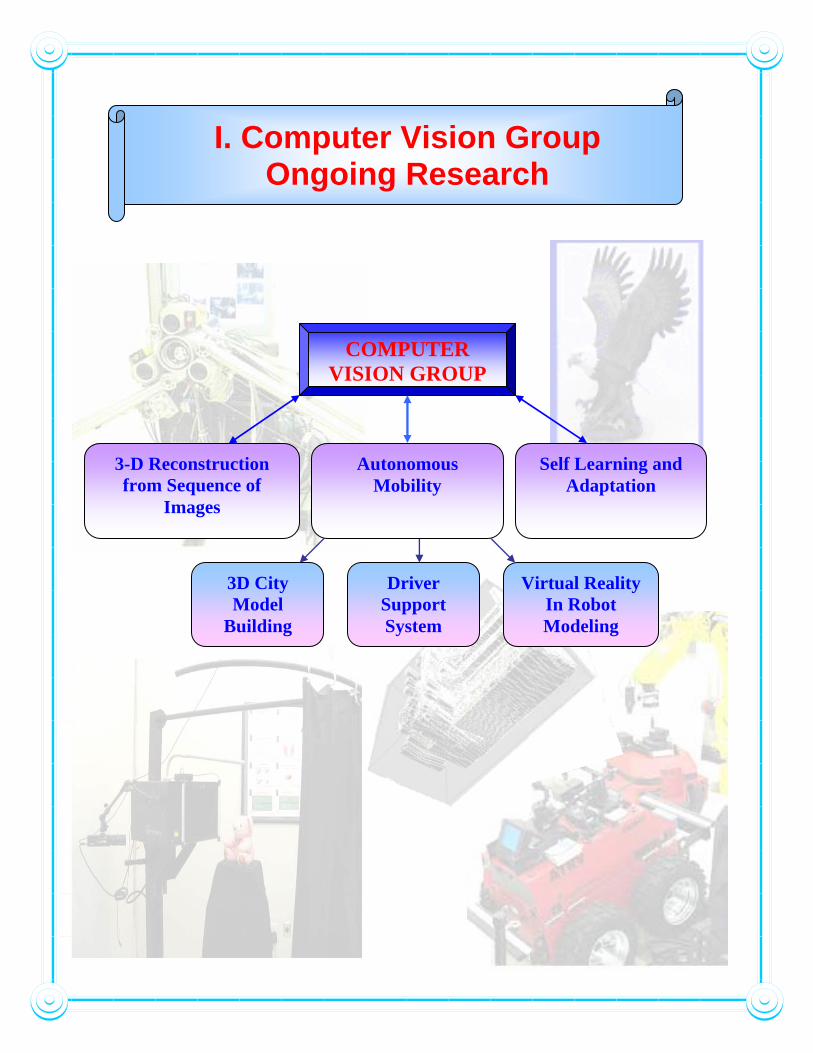
I. Computer Vision Group Ongoing Research
COMPUTER VISION GROUP
3-D Reconstruction from Sequence of
Images
3D City Model
Building
Driver Support System
Virtual Reality In Robot Modeling
Self Learning and Adaptation
Autonomous Mobility

1. Novel Approaches in Perception for Autonomous Mobility (Sponsored by the US Army) Research Team: Alaa El-Din Aly, Emir Dizdarevic, Asem Ali, Aly A. Farag
Goal: Robotics, in general, has its impact on the society in all venues, industrial, defense, medical and the environment. The purpose of the project is to create software and algorithms to autonomously move a robot from one location to another without human interaction, avoiding static and dynamic obstacles and relying on sensors attached to the
Equipments: The equipments used for this project are ATRV-Mini and ATRV2 robots with many navigational sensors and instruments (Differential GPS, odometers, compass, inclinometer, and inertial sensor). The ATRV2 robot is equipped with excellent vision systems (color cameras on pan-tilt units), obstacle detection sensors (laser scanner and sonar), and adequate on-board computing power. It carries many sensors that go along with the biological principle of sensing redundancy. Some of the sensors sort of mimic their natural counterparts. Stereo pair of cameras rigged on a pan-tilt unit allows the robot to look around, and have depth perception. The inertial sensor has its counterpart in the most biological entities. The network connecting the on board computers, all sensors and hardware components, in a way emulates the nervous system. Wireless Ethernet enables the robots to communicate with each other, and to the external world. The other instruments, namely the Differential GPS (DGPS), full orientation sensor, sonar array, and laser line scanner, do not have direct biological counterparts in physical sense. They are more of a compensation for the many perceptual and navigational capabilities that come natural to humans and animals. The software running the bots is based on the CORBA architecture, which is designed to ease the development of very modular and distributed, large scale programs, such as the ones used to run teams of robots. The actual control program would ideally consist of many client/server type programs, running on board or over the net.
The themes involved in this research include real time processing of localization, mapping, navigation, obstacle avoidance, computer vision, and other behavioral algorithms. The application areas of this autonomous navigation are various such as 3D city building, driver support systems and virtual reality in robot modeling. We are also working on these areas to use the autonomous mobility system with.
CVIP Research Robots

1.1 3D City Model Building Research Team: Refaat Mohamed, Alaa El-Din Aly and Aly Farag
Goal: The goal of this project is a fast and automated generation of photo realistic 3D models of city environments. This project involves the combination of various research areas including ground based data acquisition and processing, airborne data processing, 3D model building and texture processing.
Equipments: The equipment used in the experiment consists of the ATRV2 mobile robot with some Add-ups. The Add-up consists of two fast 2D laser scanners and a digital camera mounted on a rack which is fixed to the robot. The The data is acquired continuously while the robot is moving at normal speeds rather than in a slow stop-and-go fashion. One 2D scanner is mounted vertically and scans the buildings and street scenery as the truck drives by. The other one is mounted horizontally and is used to scan the scene in a plane parallel to the ground. The consecutive horizontal scans determine the vehicle’s pose via scan-to-scan matching which is used for position estimation to construct the moving path.
The software used in this experiment consists of service modules created to accomplish the tasks of the project in addition to the software used for the navigation and path planning project. These services consist of Scan-to-Scan matching module which registers two horizontal scans to each other in order estimate the relative displacement between them which can be used later to estimate the traveling path. This module is built using the Iterative Closest Point (ICP) registration algorithm. Using this scan-to-scan matching, we obtain a series of relative position estimates to be concatenated to an "initial path". The second module reconstructs the facades by imposing the vertical scanner data (depth and height) to the estimated pat. At every step of the estimated path, there is a vertical scan which contains the depth and height data.
The ATRV-Robot with the Add-up

Two scans taken in the same coordinate
system at two time steps
Optimal displacement parameters are
estimated by ICP algorithm.
Snapshots of the reconstructed 3D model of the hallway.

1.2 Driver Support System Research Team: Alaa El-Din Aly and Aly Farag
Goal: The main objective of this work is to develop a smart autonomous vehicle that can navigate through an environment and, through a sensor suite, collect data about the environment which feeds into an on board intelligent system for understanding the environment and providing a Driver Support System (DSS) that will be employed in a pedestrians aiding system. In such applications, road sign detection and recognition (RSR) is very important, since the road signs carry much information necessary for successful, safe and easy driving and navigation. Therefore, the first stage of this work is to design a robust RSR system.
Equipments: The equipments used in this work is the ATRV2 robot with it vision module. Toward our goal, we developed a RSR approach using a Bayes classifier to detect the road signs in the captured image based on its color content. The Bayes classifier does not just label the captured image only, but it categorizes the labels to the appropriate category of the road sings as well. Based on the results obtained by the Bayes classifier, an invariant feature transform, namely the Scale Invariant Feature Transform (SIFT) is used to match the detected labels with the correspondent road sign. The contribution in this work is using an invariant feature approach (SIFT) for the RSR problem. Using the SIFT transform for the matching process achieves several advantages over the previous work in RSR. For example, it overcomes some difficulties with previous algorithms such as the slowness of template matching based techniques, the need for a large number of various real images of signs for training like the neural-based approaches, or the need for need a priori knowledge of the physical characteristics of the lighting illumination of the signs like in. As another advantage of using the Bayes classifier is the acceleration of features extraction and matching operations of the SIFT transform by shrinking the matching area to the labels only. Also, it limits the search subspace of the SIFT transform by determining the color category of the detected sign. Reference: A. A. Farag and A. E. Abdel-Hakim, “Detection, Categorization and Recognition of Road Signs for
Autonomous Navigation,” Advanced Concepts for Intelligent Vision Systems (ACIVS 2004), Brussels, Belgium, September 2004.
Road signs detection and recognition sample results

1.3. Sensor Planning in Smart Vision Systems Research Team: Alaa El-Din Aly and Aly Farag
Goal: Plan the cameras of the vision system by assigning the proper camera parameters in order to get an object of interest to the most suitable area in the field of view. Camera planning can be viewed as the problem of assigning proper values for camera parameters to achieve some visual requirements. The number of the camera parameters, that can be generated using a planning algorithm, depends on the number of the degrees of freedom of the vision system. For example, position and orientation parameters are the degrees of freedom of vision systems with passive lenses. They can be extended to include zoom and focus settings in vision systems with active lenses. The visual requirements vary according to the application; e.g., in visual tracking applications, the visual requirement is to keep a target object in the field of view of the camera. In 3D modeling applications using stereo or multi-camera acquisition systems, the camera planning process aims to maximize the overlap of the relevant object(s) in the acquired images. We have developed a sensor planning approach for a mobile trinocular active vision system [1-2]. At the stationary state (i.e., no motion) the sensor planning system calculates the generalized cameras' parameters (i.e., translational distance from the center, zoom, focus and vergence) using deterministic geometric specifications of both the sensors and the objects in their field of view. Some of these geometric parameters are difficult to be predetermined for the mobile system operation. Therefore, we have developed a new sensor planning approach based on processing the content of the captured images. The approach uses a combination of a closed-form solution for the translation between the three cameras, the vergence angle of the cameras as well as zoom and focus setting with the results of the correspondences between the acquired images and a predefined target object(s) obtained using the SIFT algorithm The work we have developed in [1] was restricted to the design of the CardEye. As a generalization, we have presented a novel and robust model for camera planning in any smart vision systems [3]. This approach uses virtual forces to adjust camera parameters (pan and tilt) to the most proper values with respect to the application. The proposed model employs the information in the acquired image and some of the intrinsic camera parameters to estimate pan and tilt displacements required to bring a target object into a specific location of interest in the image. This model is a general framework and any vision system can be easily modeled to use it. This approach has several advantages over previous work in camera planning. It is portable, expandable, robust, and flexible. Also, there is no need for complicated calibration for the cameras or their pan-tilt heads. The results show that our approach is efficient even with poor system initialization and it is robust against possible weakness in the auxiliary algorithms used.

Before Planning After Planning
References
[1] Aly A. Farag and Alaa E. Abdel-Hakim, "Image Content-Based Active Sensor Planning for a Mobile Trinocular Active Vision System,” Proc. IEEE International Conference on Image Processing (ICIP’2004), Singapore, October 2004, Vol. II, pp. 193-196.
[2] Aly A. Farag and Alaa E. Abdel-Hakim, " Scale Invariant Features for Camera Planning in a Mobile Trinocular Active Vision System,” Proc. Advanced Concepts in Intelligent Vision Systems (ACIVS’2004), Brussel, Belgium, August-September 2004, pp. 169-176.
[3] Aly A. Farag and Alaa E. Abdel-Hakim, “Virtual Forces for Camera Planning in Smart Vision Systems,” Proceedings IEEE Workshop on Applications of Computer Vision (WACV 2005), Breckenridge CO, January 2005.

1.4. Applications of Virtual Reality in Robot Modeling Research Team: Alaa El-Din Aly, Asem Ali, Aly A. Farag In today’s life, due to technological breakthroughs and economic factors, human operators have been replaced with intelligent robots. Decisions made by live beings are now left to be made by machines. In order to allow robots to make critical and right decisions, large and complex algorithms were developed, and still have to be improved. Testing of the algorithm functionality is the only way of finding bugs and fixing them, but testing can sometimes tend to be very expensive. The cost of equipment and time to set up testing equipment and procedures is sometimes not adequate to requirements set in the project. Therefore, we propose a virtual reality application which will serve as testing bed for Artificial Intelligence algorithms. Project involves the creation of the virtual world to test and evaluate different AI Algorithms for our Autonomous Mobility Project. It consists of virtual terrain, a robot, static and dynamic obstacles represented as different objects like signs, trees bushes and ditches, as well as a range of software-based sensors which interact with the artificial environment. In order to present accurate results and interpret them correctly, each part of the virtual world has to be modeled according to the real world. Different facts have to be considered and simulated, like visibility of satellites for GPS Sensors, different wheel slipping factors based on terrain the robot is on, as well as uneven grass and ditches for laser based obstacle detection and avoidance. By creating an environment which can be modeled with least effort, we are able to change conditions like terrain, vehicle physics, weather and other facts. This way, we can observe the performance of algorithms in degraded as well as optimal conditions, and make comparisons of obtained results. We also propose a method to load different terrains from Digital Elevation Maps, mirroring real world conditions in virtual reality, and observing robot behavior. This gives us an ability to detect anomalies in AI algorithms used in sensor data fusion and interpretation, and modify them to correspond to specific terrains.

2. Self Learning and Adaptation
Research Team: Refaat M Mohamed, Ayman S El-Baz and Aly A Farag
The goal of this project is to develop algorithms which have the ability for self learning and adaptation from the training data.
This project includes various research areas including mathematical theory, pattern recognition and random processes. Applications of this project include density estimation, image segmentation and classification. The algorithms developed within this research are can be summarized as follows:
1. Learning of Support Vector Machines using Mean Field theory for Density Estimation in high dimensional data sets.
2. Bayesian classification based on the estimation of the probability density function using SVM.
3. Analytical approach for the estimating the clique coefficients of Gibbs Markov Random Fields.
4. Map refinement using Iterative Conditional Modes (ICM) algorithm and the analytical estimation of the clique coefficients of the GMRF.
RGB from a 34-band hyperspectral data set
Segmentation results using MF-based SVM algorithm
Segmentation refinement using MRF modeling
References:
[1] Aly A Farag, Refaat M. Mohamed and Ayman S El-Baz, “A Unified Framework for MAP Estimation in Remote Sensing Image Segmentation,” IEEE Transactions on Geoscience and Remote Sensing
[2] Ayman S El-Baz, Refaat M. Mohamed, and Aly A Farag, “Advanced Support Vector Machines for Image Modeling Using Gibbs-Markov Random Field,” International Journal of Computational Intelligence,
[3] Refaat M. Mohamed, Ayman S El-Baz, and Aly A Farag, “Probability Density Estimation Using Advanced Support Vector Machines and the Expectation Maximization Algorithm,” International Journal Of Signal Processing Vol. 1, No. 4, pp. 260-264, 2004.
[4] Aly A. Farag, Ayman S El-Baz, and Refaat M. Mohamed, “Density Estimation using Generalized Linear Model and a Linear Combination of Gaussians,” International Journal Of Signal Processing Vol. 1, No. 4, pp. 265-268, 2004.
[5] R. M. Mohamed and A. A Farag, "Mean Field Theory for Density Estimation Using Support Vector Machines, "Seventh International Conference on Information Fusion, Stockholm, July, 2004, pp. 495-501.
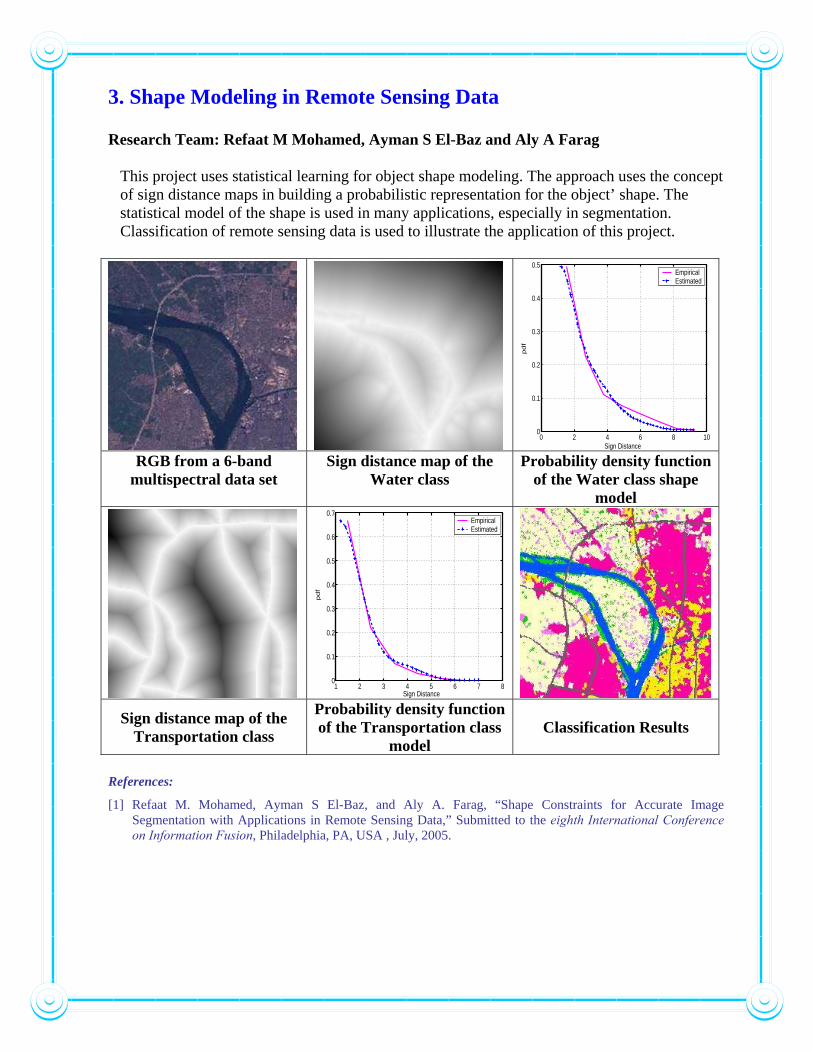
3. Shape Modeling in Remote Sensing Data Research Team: Refaat M Mohamed, Ayman S El-Baz and Aly A Farag
This project uses statistical learning for object shape modeling. The approach uses the concept of sign distance maps in building a probabilistic representation for the object’ shape. The statistical model of the shape is used in many applications, especially in segmentation. Classification of remote sensing data is used to illustrate the application of this project.
0 2 4 6 8 10
0
0.1
0.2
0.3
0.4
0.5
Sign Distance
pd
f
EmpiricalEstimated
RGB from a 6-band multispectral data set
Sign distance map of the Water class
Probability density function of the Water class shape
model
1 2 3 4 5 6 7 80
0.1
0.2
0.3
0.4
0.5
0.6
0.7
Sign Distance
EmpiricalEstimated
Sign distance map of the Transportation class
Probability density function of the Transportation class
model Classification Results
References:
[1] Refaat M. Mohamed, Ayman S El-Baz, and Aly A. Farag, “Shape Constraints for Accurate Image Segmentation with Applications in Remote Sensing Data,” Submitted to the eighth International Conference on Information Fusion, Philadelphia, PA, USA , July, 2005.

4. 3-D Reconstruction from Sequence of Images Research Team: Ahmed Eid, Aly A. Farag The goal is guiding the research of 3-D reconstruction from sequence of images to achieve
high quality reconstructions The 3-D reconstruction from sequence of images finds many applications in modern computer vision systems such as virtual reality, vision-guided surgeries, autonomous navigation, medical studies and simulations, reverse engineering, and architectural design. The very basic requirement of these applications is to find accurate and realistic reconstructions. In fact, the 3-D scene reconstruction from multiple images is a challenging and interesting problem to tackle. It is interesting because humans naturally solve this problem in an easy and efficient way. However, it is a challenge because there is no single solution of many different solutions proposed to solve the problem has the completeness of the human's solution. Of course, there are good solutions and there may be others in the future. This project has an ultimate goal of guiding the research of 3-D model building towards better performance of image-based 3-D reconstruction techniques. To achieve this goal we introduce a unified framework for performance evaluation of 3-D reconstruction techniques from sequence of images. This framework provides designs and developments of the following building blocks: 1- Experimental Setup (test-bed): To provide the input sequence of images to the vision technique under-test and the ground truth data necessary to examine the performance of the given vision technique. With this setup we are able to build database of ground truth data, using 3-D laser scanner, and intensity data, using CCD camera, as well to be ready for use by the vision community for further studies of performance tracking and analysis of different 3-D reconstruction techniques [1].
Support
β Rotating screen
Scanner head
CCD camera Scanner base
Support
β
Top view Diagram System Setup
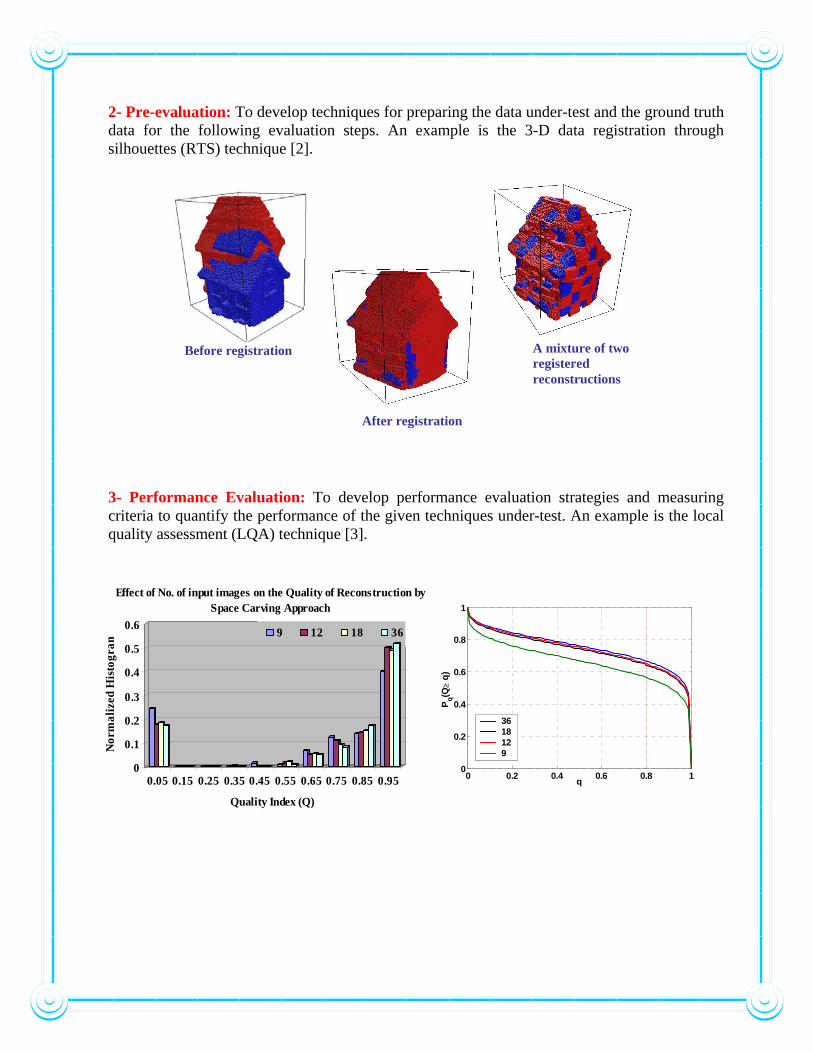
2- Pre-evaluation: To develop techniques for preparing the data under-test and the ground truth data for the following evaluation steps. An example is the 3-D data registration through silhouettes (RTS) technique [2]. 3- Performance Evaluation: To develop performance evaluation strategies and measuring criteria to quantify the performance of the given techniques under-test. An example is the local quality assessment (LQA) technique [3].
0
0.1
0.2
0.3
0.4
0.5
0.6
Nor
mal
ized
His
togr
am
0.05 0.15 0.25 0.35 0.45 0.55 0.65 0.75 0.85 0.95
Quality Index (Q)
Effect of No. of input images on the Quality of Reconstruction by
Space Carving Approach 9 12 18 36
Before registration
After registration
A mixture of two registered reconstructions
0 0.2 0.4 0.6 0.8 10
0.2
0.4
0.6
0.8
1
q
P q(Q≥
q)
3618129

4- Post-evaluation: To develop methods for analyzing the evaluation results for diagnosis purposes. Further steps include data fusion in competitive-cooperative fashion. An example is the closest contour (CC) 3-D data fusion technique [4]. Reconstruction Reconstruction By Laser Scanner
Fused Reconstruction References: [1] A. A. Eid and A. H. Farag, “Design of an Experimental Setup for Performance Evaluation of 3-D Reconstruction Techniques from Sequence of Images,” Eighth European Conference on Computer Vision, ECCV-04, Workshop on Applications of Computer Vision, Prague, Czech Republic, May 11-14, 2004, pp. 69-77. [2] A. H. Eid and A. A. Farag, “A Unified Framework for Performance Evaluation of 3-D Reconstruction Techniques,” IEEE Conference on Computer Vision and Pattern Recognition, CVPR-04, Workshop on Real-time 3-D Sensors and their Use, Washington DC, June 27-July 2, 2004. [3] A. A. Farag and A. H. Eid, “Local Quality Assessment of 3-D Reconstructions from Sequence of Images: A Quantitative Approach,” Advanced Concepts for Intelligent Vision Systems, ACIVS-04, Brussels, Belgium, August 31-September 3, 2004. [4] A. H. Eid and A. A. Farag, “On the Fusion of 3-D Reconstruction Techniques," Seventh International Conference on Information Fusion, IF-04, Stockholm, Sweden, June 28-July 1, 2004, pp. 856-861.
By Space Carving

5. Biometrics Research team: Aly Farag, Sergey Checkmenev, Wael Emara, Ham Rara 5.1 Smart Multi-sensor System for Threats Identification The goal of this research is to approach the problem of biometrics from a different
perspective, that is, instead of focusing only on the question “who are you”, we address additional questions such as “what are you about to do”, “do you carry concealed weapons”, and “do you have access to an area/site”.
Project Description: The smart multi-sensor system would be capable of identifying most of the threats by human subjects involved in terrorist or illegal activities in public areas like court houses, airports, schools, libraries, shopping malls, bus and railroad stops, and other high-risk installations. The main idea is to integrate multi-sensor data for successful threat identification. The main features of the system include person identification/verification, identification of person’s intent, and identification of infectious diseases. The sensors involved are passive (no energy of any kind is projected to the scene) and there is continuous monitoring of human subjects at stand-off distance. The figure below illustrates the overall setup of the system.
Multi-Sensor Data
SubjectCovert, Passive, Multi-Sensor Set-UpControl Server
PTZ Video PTZ Long IRPTZ MMW
Static Video
Static Video

Preliminary Results: 1. Face Recognition is integral to any intelligent surveillance system. The classical approaches
to the recognition problem include the eigenface and fisherface methods.
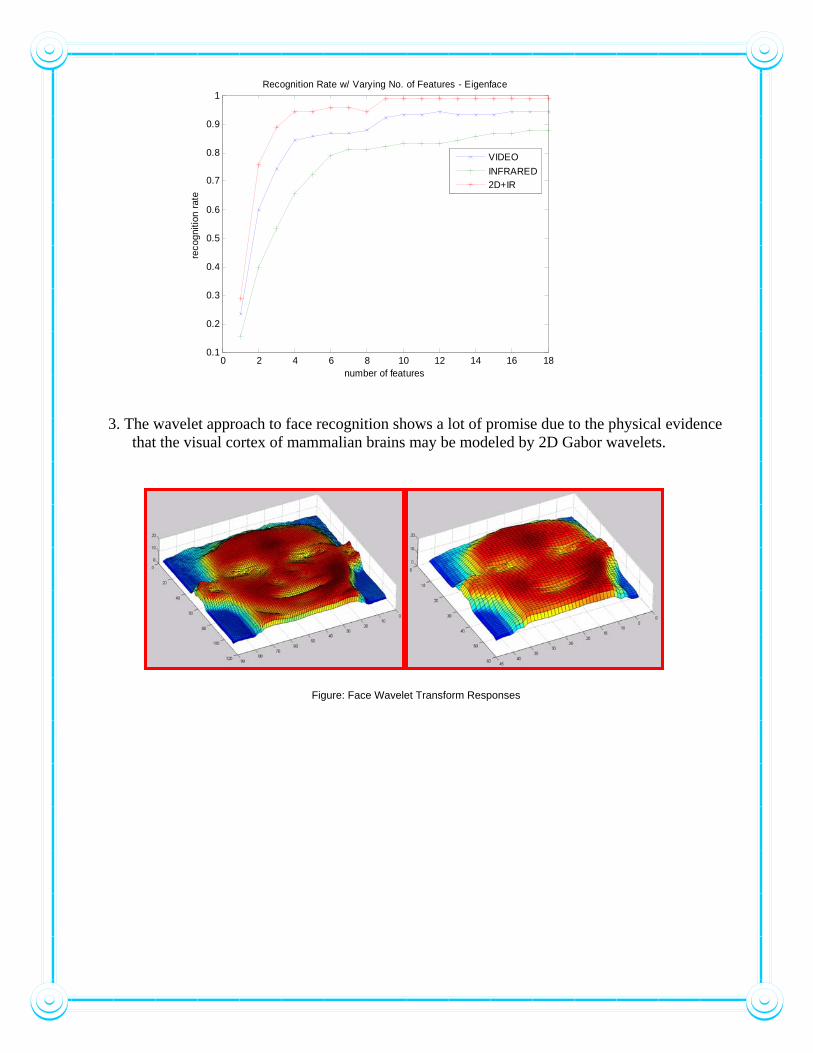
2. Face recognition using video and infrared (IR) can significantly improve the recognition rate. The CVIP Lab assembled a database of its own members composed of video and infrared modalities. Each subject is made to do different facial expressions to add challenges to the recognition problem.
Figure: Face Database using Video and Infrared Modalities
3. The wavelet approach to face recognition shows a lot of promise due to the physical evidence
that the visual cortex of mammalian brains may be modeled by 2D Gabor wavelets.
Figure: Face Wavelet Transform Responses
0 2 4 6 8 10 12 14 16 180.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
number of features
reco
gniti
on ra
te
Recognition Rate w/ Varying No. of Features - Eigenface
VIDEOINFRARED2D+IR

5.2 Human Identification Using Gait Signature Recognition
The goal of this study is to develop automated simple and efficient algorithms to identify humans at distance using their gait signature.
Human identification at a distance is currently considered one of the most attractive points for computer vision researchers. This is due to the increased need for automated visual surveillance and monitoring systems for security sensitive environments such as airports and nuclear facilities. Gait is basically defined as the manner of walking. That each person has an idiosyncratic way of walking has been proved through medical studies which proved the proposition that if all gait movements are considered then the gait is unique. Also Psychological research shows that humans have the ability to identify other humans by just observing the moving light displays attached to the body parts of the observed objects. The increased interest in gait as a biometric is due to its non-invasive non-concealable nature in addition to its collectability at great distances; features that other biometrics don not have. Approach The aim of this study is to develop automatic gait recognition algorithm that is based on spatiotemporal analysis of the walking silhouettes of the observed subject. The first stage of the algorithm consists of human detection and tracking which is performed by a background subtraction procedure. The second stage is concerned with extracting the binary silhouette of the walking subject in each frame and map the 2D silhouette image into a 1D normalized distance signal by contour unwrapping with respect to the silhouette centroid. Accordingly, the shape changes of the silhouettes over time are transformed into a sequence of 1D distance signals to approximate temporal changes of gait pattern. In the third stage eigenspace transformations based on Principal Component Analysis (PCA) and Kernel based PCA (KPCA) are used to reduce the dimensionality of the input feature space and to find the predominant components of gait signatures.
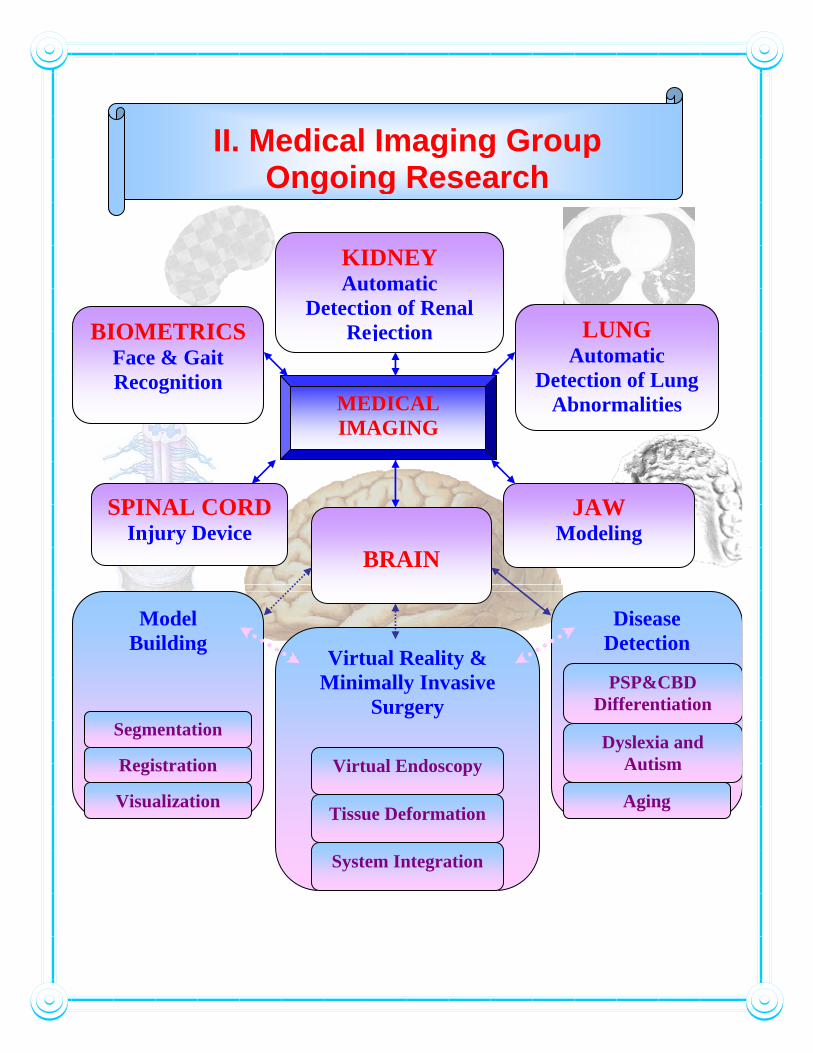
II. Medical Imaging Group Ongoing Research
BRAIN
Model Building
Virtual Reality & Minimally Invasive
Surgery
LUNG Automatic
Detection of Lung Abnormalities
BIOMETRICS Face & Gait Recognition
MEDICAL IMAGING
SPINAL CORD Injury Device
JAW Modeling
KIDNEY Automatic
Detection of Renal Rejection
Disease Detection
PSP&CBD
Differentiation Segmentation
Dyslexia and Autism Registration Virtual Endoscopy
Visualization Aging Tissue Deformation
System Integration

1. Tissue Deformation Research Team: Hongjian Shi, M. Sabry Hassouna, Hossam Hassan, Rachid Fahmi, Ayman El-baz, Mike Miller, Chuck Sites, Aly A. Farag
Accurate knowledge of biomechanical characteristics of soft tissues is essential for developing realistic computer-based surgical simulators incorporating haptic feedback. The goal of this project is to provide a new method for quantifying soft tissue deformation using MicroCT scanner. Then the brain deformation caused by the moving endoscope or brain shift will be modeled using finite elements methods.
Image-guided minimally invasive surgery (MIS) is a very active field of research in medical imaging. The technology involves both virtual and augmented reality tools to facilitate a surgeon’s task before and during surgery. A team of clinicians, researchers, and computer scientists at the University of Louisville has been developing a minimally invasive image guided neurosurgery system based on state-of-the-art techniques in computer technology that will help surgeons localizing targeted tissue with high precision and minimal damage. The main components of the system are (1) Building a faithful 3D model of the brain from preoperative multimodal scans, which requires segmentation of the soft tissue from MRI, blood vessels from MRA, and CT from bones then align them altogether using fusion and multimodal registration. (2) Modeling the brain deformation caused by the moving endoscope or brain shift using finite elements methods. (3) Tracking the patient head movement and surgical instruments and update their locations within the 3D model. (4) Registering the 2D image seen by a flexible endoscope to its corresponding location in the 3D model. In this research, we are interested in modeling the soft tissue deformation caused by an external force that simulates a moving endoscope. Fig. 1 shows our image-guided neuroendoscopic surgical system.
Fig. 1: Neuroendoscopic surgical system

Approach : One of the important factors in image-guided minimally invasive surgery is to quantify the deformation induced by surgical tools. The traditional approach uses the finite element method (FEM) to solve the partial differential equation which governing the tissue deformation during or after surgical operation. However, the traditional FEM is applied over the entire volume despite the fact the surgical tool is applied only over a small and well specified region of the soft tissue. In this respect, the traditional FEM is quite computationally costly, and may not be suitable for real-time analysis of the soft tissue deformation induced during surgery. Also, the traditional FEM assumes the tissue is linear elastic and isotropic, which is not the fact that most tissues are anisotropic, nonlinear and even several kinds of materials are complicatedly distributed such as brain tissue. In our research, we developed intensity and region-of-interest based finite element modeling of brain deformation. The modeling is based on the intensities of voxels within each element. We comprehensively employed the local elasticity of brain tissue. The brain tissue is assumed isotropic only locally. We propose to configure a region of interest (ROI) at the tip of surgical tools in stead of the whole brain so that the maximum nodal displacement outside the ROI is small and in control. In this way, large computation can be saved to satisfy real time finite element analysis. Because of the employment of local elasticity, the deformed MR image using the proposed finite element modeling shows better proportional to the original structure in elasticity. Our ongoing research is to develop more accurate finite element modeling technique. We will improve the modeling in several aspects: efficient implementation of FEM, replacement of local isotropic condition by specific material property such as anisotropic property, and consideration of the viscosity and plasticity of the modeling tissues. Subtle combination or employment of all tissue properties will be a great challenge for soft tissue modeling with the coexistence of complicated distributed different types of materials such as brain tissue. Experimental Setup for Quantifying Soft Tissue Deformation Our new experimental setup will induce load automatically to the soft tissue under the MicroCT scanner, which will acquire different scans under different loads. The mesh of the undeformed tissue will be deformed using both linear elastic and non linear finite element models (FEM). The resultant deformed model will be registered to the deformed tissue acquired by the MicroCT. The accurate FEM model must lead to very small error between the deformed model and deformed tissue.
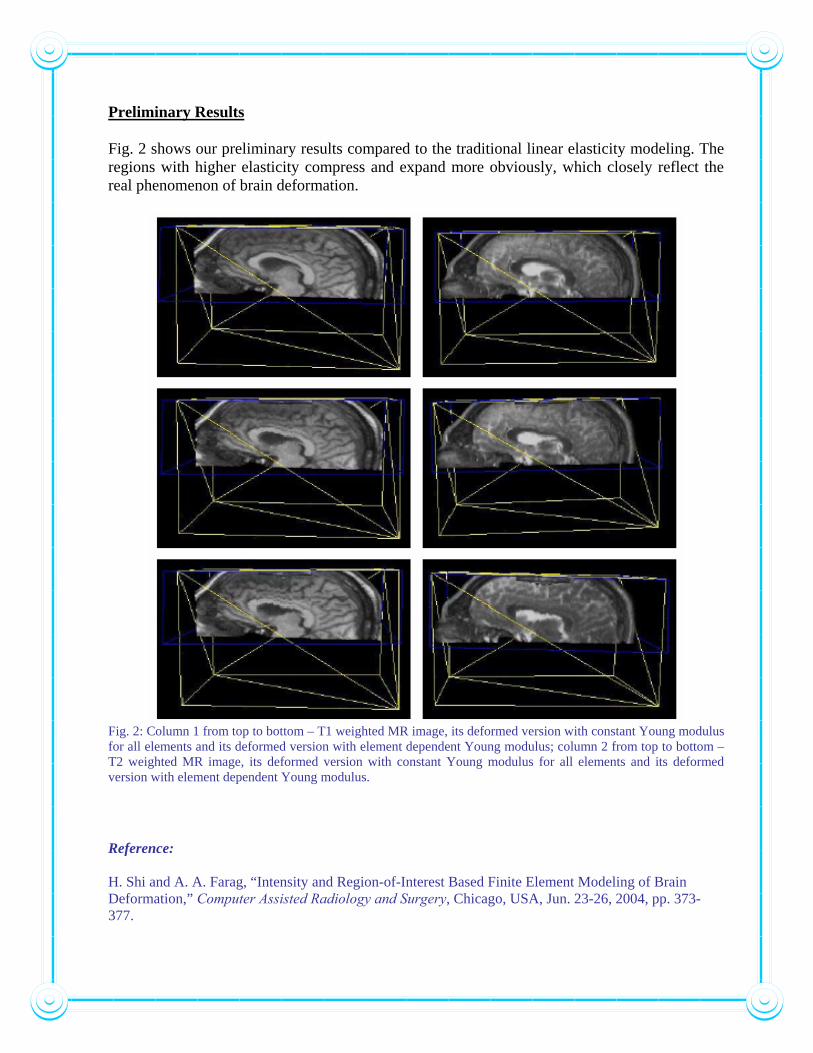
Preliminary Results Fig. 2 shows our preliminary results compared to the traditional linear elasticity modeling. The regions with higher elasticity compress and expand more obviously, which closely reflect the real phenomenon of brain deformation.
Fig. 2: Column 1 from top to bottom – T1 weighted MR image, its deformed version with constant Young modulus for all elements and its deformed version with element dependent Young modulus; column 2 from top to bottom – T2 weighted MR image, its deformed version with constant Young modulus for all elements and its deformed version with element dependent Young modulus. Reference: H. Shi and A. A. Farag, “Intensity and Region-of-Interest Based Finite Element Modeling of Brain Deformation,” Computer Assisted Radiology and Surgery, Chicago, USA, Jun. 23-26, 2004, pp. 373-377.

2. Real Time Vision-Based Image Guided Neurosurgery
Research Team: Aly Farag, M. Sabry Hassouna, and Ayman El-Baz
The goal of this project is to build an image guided neurosurgery system (IGNS) that tracks a hand held probe used by surgeons during the surgical planning or the surgical procedure to display the anatomy beneath its tip as three orthogonal image slices on a workstation-based 3D imaging system. Existing IGNS systems use different tracking techniques including mechanical, optical, ultrasonic, and electromagnetic systems. In this work, we present a new computational vision-based probe tracking technique, which provides both position and orientation. We also propose another new computational vision-based technique to track the patient head and thus compensate for its movement during probing procedure. The proposed system is completely passive, works in real time, and has been validated using a skull phantom and a hand made probe.
Research Description Our optical system consists of two tracking modules; one for tracking the surgical probe, and the other for tracking the patient head movement. The tracking modules are based on stereo vision, which requires an accurate camera calibration for reconstructing 3D points from 2D scenes captured by a video stream. The probe can enters and exit the scene as many times before and during the operation. Also, the patient can move his head without any restriction; hence our system employs fast but accurate two modes of operations; searching and tracking. In the searching mode, the system searches for the probe and/or the patient head in each video frame until it is found by tracking a special markers glued on the probe surface (at least three) or the patient head (at least four). In the tracking mode, the system tracks the probe and/or the patient head movement from one frame to another and thus reducing the search space greatly. If the probe exits the scene, the system goes back into the searching mode. The depth of the probe inside the patient head is computed from the detected markers. Validation
We validated our system using a hand held probe, a skull phantom, and a rotating table driven by a stepper motor to simulate the motion of a patient. In the first experiment, we rotated and translated the skull, while the probe is fixed and recorded the new location of the head markers, which are then compared with the tracked ones. In the second experiment, we fixed the head, while moving the probe freely. The new location of the probe is compared with the tracked one. Validation results against ground truth values of the markers showed high accuracy of the proposed system.

Results
Fig.1: The components of the proposed IGNS system
In Fig. 1, we show the components of our system. The tracked tip of the probe as well as its orientation is rendered in 3D using VTK as shown in Fig. 2. The anatomy of the brain at the tip is visualized in the form of three orthogonal slices as shown in the same figure.
Fig.2: The components of the proposed IGNS system
References: A. A. Farag, M. S. Hassouna, and A. El-Baz, “Real Time Vision-Based Image Guided Neurosurgery,” Computer Assisted Radiology and Surgery, Chicago, USA, Jun. 23-26, 2004, pp. 230-238.

3. Automatic Detection of Lung Abnormalities in CT Scans
Research Team: Ayman El-Baz, Aly Farag
This research aims at developing a fully automatic Computer-Assisted Diagnosis (CAD) system for lung cancer screening using chest spiral CT scans.
Lung Cancer remains the leading cause of mortality cancer. In 1999, there were approximately 170,000 new cases of lung cancer, one in every 18 women and every 12 men develop lung cancer. Early detection of lung tumors (visible on chest film as nodules) may increase the patient’s chance of survival. But detecting nodules is a complicated task. Nodules show up as relatively low-contrast white circular objects within the lung fields. The difficulty for CAD schemes is distinguishing true nodules from (overlapping) shadows, vessels and ribs. The research team in University of Louisville, Louisville, KY proposed a novel approach for isolating lung abnormalities (nodules) from low dose spiral chest CT scans. The proposed approach consists of the following main steps: 1) Accurate statistical model describing the distribution of gray level for each CT slice; 2) Lung extraction; 3) Arteries, veins, bronchi, bronchioles, and abnormalities extraction (if it exists); 4) Detection of lung abnormalities; and 5) Reduction of false positive nodules. Figure1 shows a block diagram of the proposed approach.
3D CT Image Data
Fig. 1: The Lung Abnormality Detection System.
In this project we classify the lung nodules to four classes depending on their shapes. These four types are: 1) Small calcified and non-calcified lung nodules which appear in a CT like small circles; 2) Large calcified and non-calcified lung nodules which appear in a CT like solid spheres; 3) Cavity lung nodules which appear in a CT like hollow spheres; and 4) Lung wall nodules which appear in a CT like semicircles at the intersection between lung and chest tissues.

The CT slices in our study have in-plane spatial resolution of 0.4 mm per pixel so that the radius range for all lung nodules is 305 −=R pixels. The third spatial axis has lower resolution, for large solid and hollow lung nodules we use the 3-layer template. Thin lung nodules appearing only in a single slice have the circular templates. The lung wall nodules are semicircular shapes. Examples of the deformed templates are presented in Fig. 2.
(a) Solid spherical models (b) Hollow spherical models
(c) Solid circular models (d) Semicircular models
Fig. 2: Examples of deformable models
The radii and the gray level distribution of these templates are selected in a way to maximize the normalized cross correlation between the template and the true nodule as shown in Fig 3.
Fig. 3: Template matching process
RR
(a) Example of 2D deformable
template (b) Normalize cross correlation between the true nodules
and the deformable templates
The template radius and the gray level distribution are selected in a way that maximize the normalized cross correlation
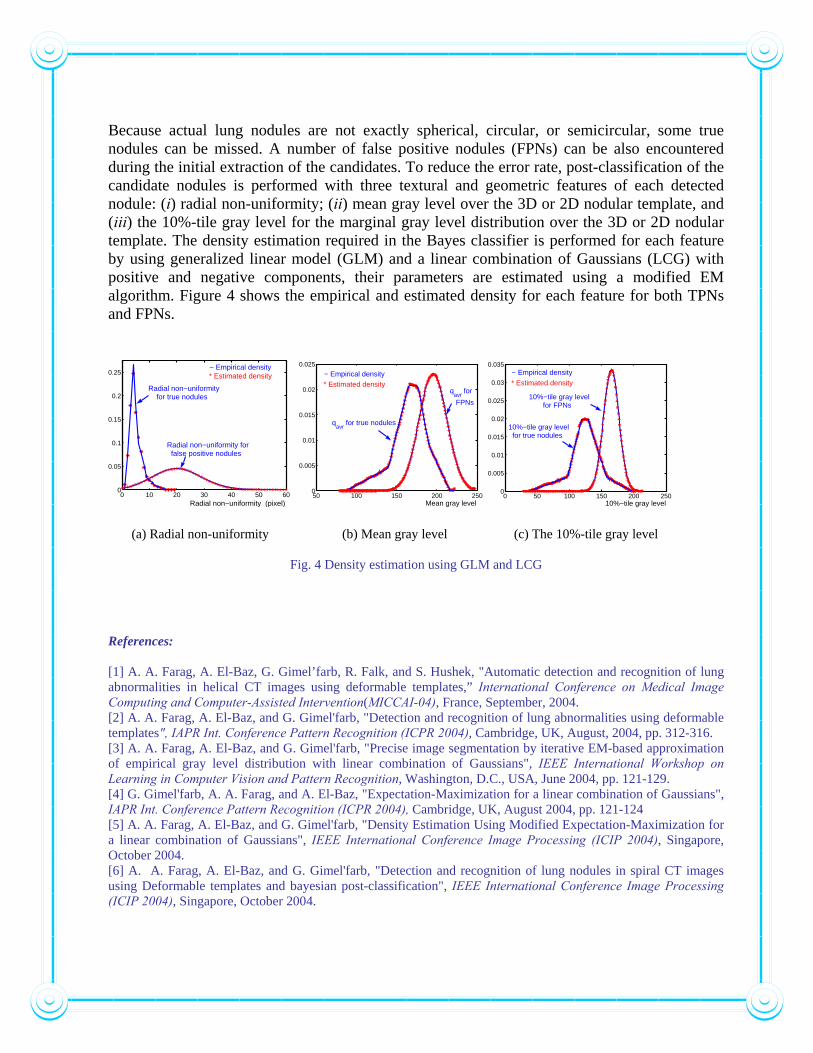
Because actual lung nodules are not exactly spherical, circular, or semicircular, some true nodules can be missed. A number of false positive nodules (FPNs) can be also encountered during the initial extraction of the candidates. To reduce the error rate, post-classification of the candidate nodules is performed with three textural and geometric features of each detected nodule: (i) radial non-uniformity; (ii) mean gray level over the 3D or 2D nodular template, and (iii) the 10%-tile gray level for the marginal gray level distribution over the 3D or 2D nodular template. The density estimation required in the Bayes classifier is performed for each feature by using generalized linear model (GLM) and a linear combination of Gaussians (LCG) with positive and negative components, their parameters are estimated using a modified EM algorithm. Figure 4 shows the empirical and estimated density for each feature for both TPNs and FPNs.
(a) Radial non-uniformity (b) Mean gray level (c) The 10%-tile gray level
Fig. 4 Density estimation using GLM and LCG References: [1] A. A. Farag, A. El-Baz, G. Gimel’farb, R. Falk, and S. Hushek, "Automatic detection and recognition of lung abnormalities in helical CT images using deformable templates,” International Conference on Medical Image Computing and Computer-Assisted Intervention(MICCAI-04), France, September, 2004. [2] A. A. Farag, A. El-Baz, and G. Gimel'farb, "Detection and recognition of lung abnormalities using deformable templates", IAPR Int. Conference Pattern Recognition (ICPR 2004), Cambridge, UK, August, 2004, pp. 312-316. [3] A. A. Farag, A. El-Baz, and G. Gimel'farb, "Precise image segmentation by iterative EM-based approximation of empirical gray level distribution with linear combination of Gaussians", IEEE International Workshop on Learning in Computer Vision and Pattern Recognition, Washington, D.C., USA, June 2004, pp. 121-129. [4] G. Gimel'farb, A. A. Farag, and A. El-Baz, "Expectation-Maximization for a linear combination of Gaussians", IAPR Int. Conference Pattern Recognition (ICPR 2004), Cambridge, UK, August 2004, pp. 121-124 [5] A. A. Farag, A. El-Baz, and G. Gimel'farb, "Density Estimation Using Modified Expectation-Maximization for a linear combination of Gaussians", IEEE International Conference Image Processing (ICIP 2004), Singapore, October 2004. [6] A. A. Farag, A. El-Baz, and G. Gimel'farb, "Detection and recognition of lung nodules in spiral CT images using Deformable templates and bayesian post-classification", IEEE International Conference Image Processing (ICIP 2004), Singapore, October 2004.
0 50 100 150 200 2500
0.005
0.01
0.015
0.02
0.025
0.03
0.035
10%−tile gray level for true nodules
10%−tile gray level
10%−tile gray level for FPNs
− Empirical density
* Estimated density
50 100 150 200 2500
0.005
0.01
0.015
0.02
0.025
Mean gray level
qavr
for true nodules
qavr
for
FPNs
− Empirical density* Estimated density
0 10 20 30 40 50 600
0.05
0.1
0.15
0.2
0.25
Radial non−uniformity for true nodules
Radial non−uniformity for false positive nodules
− Empirical density* Estimated density
Radial non−uniformity (pixel)

4. Segmentation of Vascular Trees Research Team: M. Sabry Hassouna, Hossam Hassan, Ayman El-baz, Aly A. Farag, Chuck Sites, Stephen Hushek, and T. Moriarty Large numbers of people suffer a major cerebrovascular event, usually a stroke, each year.
Serious types of vascular diseases such as carotid stenosis, aneurysms, and arterio-venous malformations (AVM) may lead to brain stroke unless they are detected at early stages. Stenosis is a narrowing of the artery which results in a partial or complete blockage of blood supply. Aneurysm is a balloon of blood that occurs due to weakness in the arterial wall. The rupture of an aneurysm can cause severe headaches or even a life-threatening coma. AVM’s are abnormal connections of an artery, vein, or both, which deprive the tissue of its normal blood supply. Therefore, accurate cerebrovascular segmentation is the key to accurate diagnoses as well as endovascular treatment. The goal of this project is to accurately extract the blood vessels that have been acquired using different magnetic resonance angiography (MRA) modalities.
MRA Modalities MRA is a non-invasive MRI-based flow imaging technique. Its wide variety of acquisition sequences and techniques, beside its ability to provide detailed images of blood vessels, enabled its use in the diagnosis and surgical planning of the aforementioned diseases. There are four techniques commonly used in performing MRA; TOF angiography, phase contrast angiography (PCA), computer tomography angiography (CTA), and contrast enhanced MRA (CE-MRA). Both TOF and PCA utilize the flowing blood as an inherent contrast medium, and as such, can be considered non invasive techniques, while CTA and CE-MRA requires the injection of a paramagnetic substance (commonly gadolinium), which provides contrast upon the introduction into the circulatory system. We have developed at the CVIP Lab two different approaches to tackle this problem. Our first approach is purely statistical and is modal specific, while the second approach is hybrid, where it combines both the statistical and geometrical methods and can be applied to any modality.

4.1 Statistical-Based Approach for Extracting 3D Blood Vessels from TOF-MRA Data Aly A. Farag, M. Sabry Hassouna, S. Hushek, and T. Moriarty The TOF technique is widely used clinically because it is fast, shows small blood vessels, requires no contrast agents, and provides high contrast images, which is the main motivation behind our work. A variety of techniques have been proposed for segmenting blood vessels from MRA. Most of the 2D approaches are not applicable to 3D images. 3D techniques can be classified under the following categories; scale space analysis, deformable models, statistical models, and Hybrid methods. In this research, we present an automatic statistical approach for extracting 3D blood vessels from time-of-flight (TOF) magnetic resonance angiography (MRA) data. The voxels of the dataset are classified as either background signal, which are modeled by a finite mixture of one Rayleigh and two normal distributions, or blood vessels, which are modeled by one normal distribution. We estimated the parameters of each distribution using the expectation maximization (EM) algorithm. Since the convergence of the EM is sensitive to the initial estimate of the parameters, a novel method for parameter initialization, based on residual histogram analysis, is provided. A new geometrical phantom motivated by a statistical analysis was designed to validate the accuracy of our method. The results showed that the proposed approach provides accurate fit to the clinical data and hence results in fewer misclassified voxels. 4.1.1 Validation
We may find ground truth segmentation for carotid, aneurysm, or both but not for a complete vasculature because of its complexity and the more levels of details it involves. Therefore, in order to validate our method, we CT scanned a wooden tree phantom and considered it as our ground truth. Our proposed noise model is added to the ground truth images to simulate noisy images acquired by the MRI scanner during the MRA acquisition. We first estimated the parameters of our model from the noisy images and then extract the blood vessels using the proposed technique. In Fig. 1 (a), we show the ground truth of the wooden tree, while in Fig. 1(b), we show the segmentation results of the proposed method. Voxels marked with dark grey colors represent those ones which are not detected by our method. The error was 3%.
Fig. 1. (a) Ground truth (b) Segmentation by the proposed algorithm. Undetected voxels are marked by dark color.
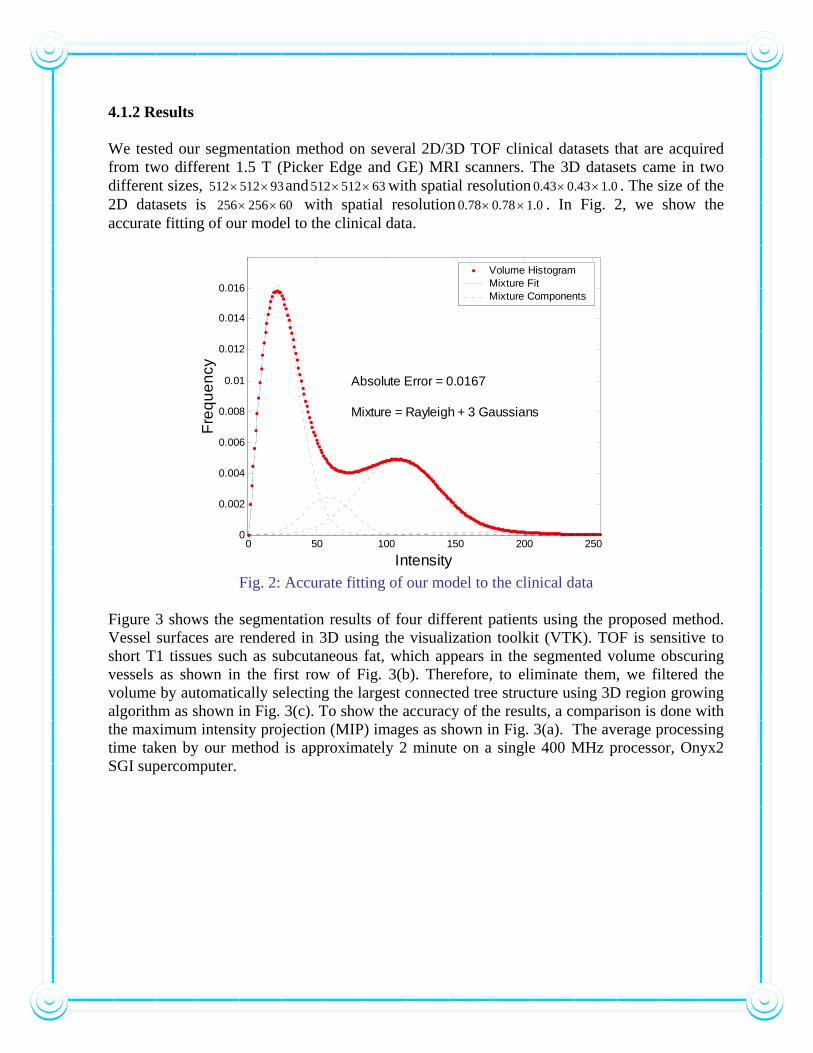
4.1.2 Results We tested our segmentation method on several 2D/3D TOF clinical datasets that are acquired from two different 1.5 T (Picker Edge and GE) MRI scanners. The 3D datasets came in two different sizes, and93 512 512 ×× 63 512 512 ×× with spatial resolution 0.10.43 0.43 ×× . The size of the 2D datasets is with spatial resolution60 256 256 ×× 0.10.78 0.78 ×× . In Fig. 2, we show the accurate fitting of our model to the clinical data.
0 50 100 150 200 2500
0.002
0.004
0.006
0.008
0.01
0.012
0.014
0.016
Intensity
Freq
uenc
y
Absolute Error = 0.0167
Mixture = Rayleigh + 3 Gaussians
Volume HistogramMixture FitMixture Components
Fig. 2: Accurate fitting of our model to the clinical data
Figure 3 shows the segmentation results of four different patients using the proposed method. Vessel surfaces are rendered in 3D using the visualization toolkit (VTK). TOF is sensitive to short T1 tissues such as subcutaneous fat, which appears in the segmented volume obscuring vessels as shown in the first row of Fig. 3(b). Therefore, to eliminate them, we filtered the volume by automatically selecting the largest connected tree structure using 3D region growing algorithm as shown in Fig. 3(c). To show the accuracy of the results, a comparison is done with the maximum intensity projection (MIP) images as shown in Fig. 3(a). The average processing time taken by our method is approximately 2 minute on a single 400 MHz processor, Onyx2 SGI supercomputer.
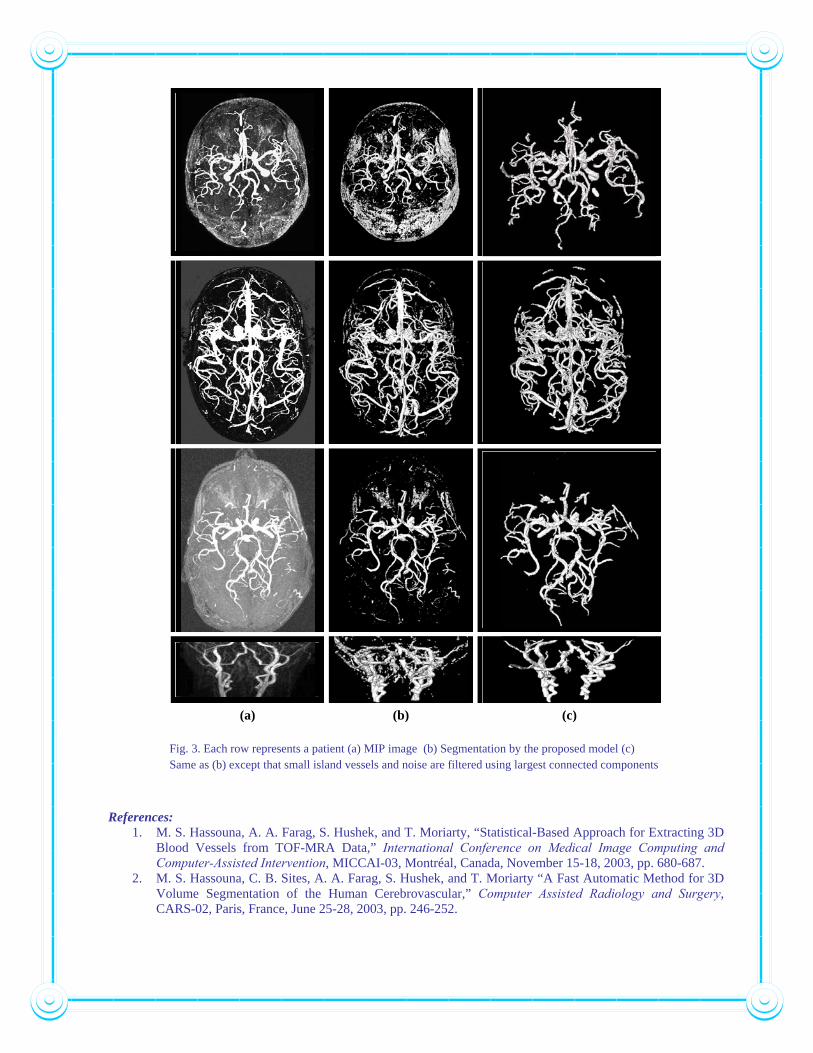
(a) (b) (c)
Fig. 3. Each row represents a patient (a) MIP image (b) Segmentation by the proposed model (c) Same as (b) except that small island vessels and noise are filtered using largest connected components
References:
1. M. S. Hassouna, A. A. Farag, S. Hushek, and T. Moriarty, “Statistical-Based Approach for Extracting 3D Blood Vessels from TOF-MRA Data,” International Conference on Medical Image Computing and Computer-Assisted Intervention, MICCAI-03, Montréal, Canada, November 15-18, 2003, pp. 680-687.
2. M. S. Hassouna, C. B. Sites, A. A. Farag, S. Hushek, and T. Moriarty “A Fast Automatic Method for 3D Volume Segmentation of the Human Cerebrovascular,” Computer Assisted Radiology and Surgery, CARS-02, Paris, France, June 25-28, 2003, pp. 246-252.
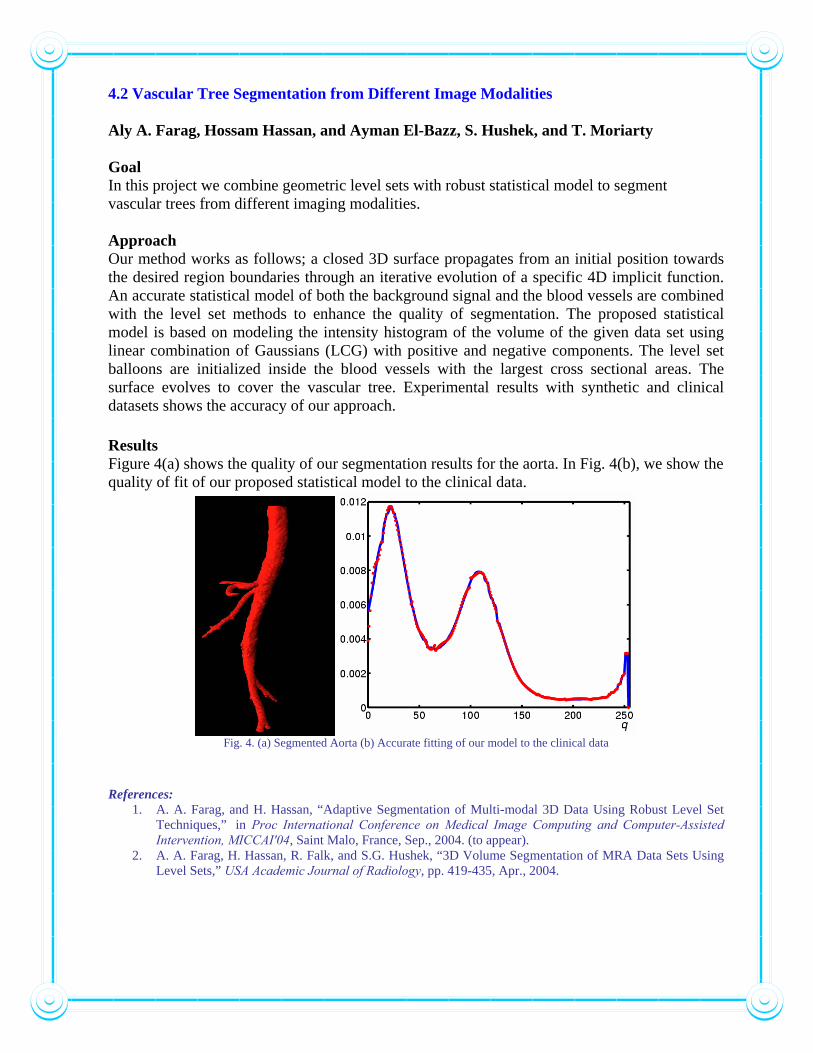
4.2 Vascular Tree Segmentation from Different Image Modalities Aly A. Farag, Hossam Hassan, and Ayman El-Bazz, S. Hushek, and T. Moriarty Goal In this project we combine geometric level sets with robust statistical model to segment vascular trees from different imaging modalities. Approach Our method works as follows; a closed 3D surface propagates from an initial position towards the desired region boundaries through an iterative evolution of a specific 4D implicit function. An accurate statistical model of both the background signal and the blood vessels are combined with the level set methods to enhance the quality of segmentation. The proposed statistical model is based on modeling the intensity histogram of the volume of the given data set using linear combination of Gaussians (LCG) with positive and negative components. The level set balloons are initialized inside the blood vessels with the largest cross sectional areas. The surface evolves to cover the vascular tree. Experimental results with synthetic and clinical datasets shows the accuracy of our approach. Results Figure 4(a) shows the quality of our segmentation results for the aorta. In Fig. 4(b), we show the quality of fit of our proposed statistical model to the clinical data.
Fig. 4. (a) Segmented Aorta (b) Accurate fitting of our model to the clinical data
References:
1. A. A. Farag, and H. Hassan, “Adaptive Segmentation of Multi-modal 3D Data Using Robust Level Set Techniques,” in Proc International Conference on Medical Image Computing and Computer-Assisted Intervention, MICCAI'04, Saint Malo, France, Sep., 2004. (to appear).
2. A. A. Farag, H. Hassan, R. Falk, and S.G. Hushek, “3D Volume Segmentation of MRA Data Sets Using Level Sets,” USA Academic Journal of Radiology, pp. 419-435, Apr., 2004.
5. Reliable Fly-Through of Vascular Trees
Research Team: Aly A. Farag, M. Sabry Hassouna, Stephen Hushek, Thomas Moriarty
Our goal is to generate reliable fly paths suitable for virtual endoscopy applications. To generate reliable fly paths for virtual endoscopy applications, we proposed a completely automated and computationally feasible method. Our proposed method works as follows, potential centerline voxels with maximal balls inscribed in the object are extracted and stored in a priori guidance map. Centerlines are initially extracted as trajectories inside the object, and then centered using a new mechanism that exploits the valuable information contained in the guidance map. A new thinning method is introduced to guarantee one voxel wide centerlines with no 2D manifolds or 3D self intersect. Finally, we build a tree graph of centerlines that provides useful information during navigation, especially, when it is required to find the shortest centerline path between two user defined points inside the object. The proposed algorithm is completely automated, computationally feasible and generates centerlines that are centered, connected, one voxel wide, smooth, and less sensitive to noise. Experimental results on different clinical data sets show the efficiency and robustness of the proposed method.
Experimental Results
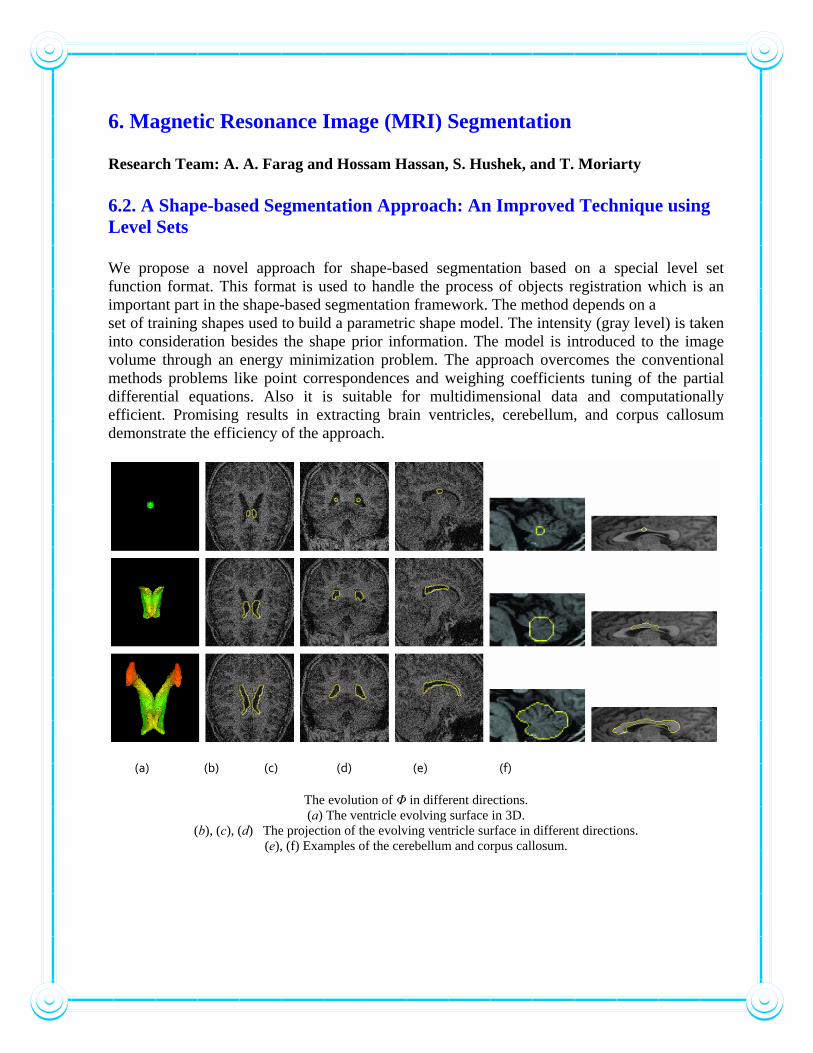
6. Magnetic Resonance Image (MRI) Segmentation Research Team: A. A. Farag and Hossam Hassan, S. Hushek, and T. Moriarty 6.2. A Shape-based Segmentation Approach: An Improved Technique using Level Sets We propose a novel approach for shape-based segmentation based on a special level set function format. This format is used to handle the process of objects registration which is an important part in the shape-based segmentation framework. The method depends on a set of training shapes used to build a parametric shape model. The intensity (gray level) is taken into consideration besides the shape prior information. The model is introduced to the image volume through an energy minimization problem. The approach overcomes the conventional methods problems like point correspondences and weighing coefficients tuning of the partial differential equations. Also it is suitable for multidimensional data and computationally efficient. Promising results in extracting brain ventricles, cerebellum, and corpus callosum demonstrate the efficiency of the approach.
(a) (b) (c) (d) (e) (f)
The evolution of Φ in different directions. (a) The ventricle evolving surface in 3D.
(b), (c), (d) The projection of the evolving ventricle surface in different directions. (e), (f) Examples of the cerebellum and corpus callosum.

6. Robust Computation of Curve Skeleton Using Level Set Methods Research Team: M. Sabry Hassouna and Aly A. Farag Goal: Automatic generation of curve skeleton for both 3D tubular and articulated objects. Understanding shape is of great importance in pattern analysis and machine intelligence. The medial axis (MA) or skeleton has been introduced as a generic and compact representation of a shape while maintaining its topology. Skeletonization aims at reducing the dimensionality of a shape such that it can be represented with less information than the original one. For example, the skeleton of a 2D shape is a set of medial curves or centerlines, while that of a 3D object is a set of medial surfaces. It has been found that reducing the dimensionality of the skeleton describing general shapes from medial surfaces to a set of medial curves or curve skeletons (CS) is of utmost importance in several applications such as 3D path planning, character animation, object recognition, shape matching, shape retrieval, and 3D gait analysis. In this project, we present an original framework for inferring stable discrete curve skeletons for elongated and articulated objects using partial differential equation (PDE). The proposed method works as follows: a curve skeleton point is selected automatically as the point of global maximum Euclidean distance from the boundary, and is considered a point source (PS) that transmits two wave fronts of different speeds that evolve over time and traverse the object domain. The motion of the front is governed by a nonlinear PDE whose solution is computed efficiently using the higher accuracy fast marching methods (HAFMM). Initially, the (PS) transmits a moderate speed wave to explore the object domain and to extract its topological information. Then, it transmits a new front whose speed is proportional to a nonlinear function of the minimum Euclidean distance field of the object. As a consequence, the CS of the object intersects the propagating fronts at those points of maximum positive curvature, which are identified by solving an ordinary differential equation using an efficient numerical scheme. The proposed method is robust, fully automatic, computationally efficient, and computes CS that are centered, connected, one voxel width, and less sensitive to boundary noise.

References [1] M. Sabry Hassouna and A.A. Farag, "Robust Centerline Extraction Framework Using Level Sets," Proc. of IEEE Conference on Computer Vision and Pattern Recognition (CVPR'05), San Diego, CA, USA June 20-26, 2005, to appear.

7. PDE-Based Three Dimensional Path Planning For Virtual Endoscopy Research Team: M. Sabry Hassouna and Aly A. Farag Goal: Automatic generation of flight paths for virtual endoscopy applications, where a
virtual camera navigates the virtual organ and renders its interior views. Virtual endoscopy (VE) is an integration of medical imaging and virtual reality. VE gives a computer-based alternative to standard radiological image viewing and to traditional fiber optic endoscopy for examining the interior structures of human organs. Unlike traditional fiber optic endoscopy, which is confined to the interior of a hollow organ, VE enables navigation between the inner and outer mucosal layers. VE has many advantages, such as being less invasive, cost-effective, and free of risks and side effects. VE is ideal for screening purposes and surgical planning. VE involves three major steps: (1) organ segmentation, (2) flight path generation, and (3) rendering of the organ internal views. The extraction of 3D flight paths of volumetric objects is still a challenging process due to the complex nature of the anatomical structures. In this work, we propose a robust method for computing flight paths for any anatomical structure regardless of its complexity. The computed paths are centered, connected, smooth, and less sensitive to boundary noise. The method is validated against several synthetic phantoms that mimic the topological and geometrical properties of the anatomical organs such as high curvature, high torsion, and several branching and merging nodes. The average and maximum error between the ground truth flight paths and the computed ones never exceed in the worst case 0.5 and 2.0 mm, respectively. In this project, we present a new partial differential equation based flight path generation framework. The key idea is to propagate from a medial curve point wave fronts of different speeds. The first front propagates with a moderate speed to capture the organ topology, while the second one propagates much faster at medial points such that the flight paths intersect the propagating fronts at those points of maximum positive curvature, which are easily identified by solving an ordinary differential equation.
References [1] M. Sabry Hassouna and A.A. Farag, "PDE-Based Three Dimensional Path Planning For Virtual Endoscopy," Proc. of Information Processing in Medical Imaging 2005 (IPMI'05), Glenwood springs, Colorado, USA, July 2005. To appear. [2] M. Sabry Hassouna, A.A. Farag, "3D path planning for virtual endoscopy," Proc. of Computer Assisted Radiology and Surgery (CARS'05), Berlin, Germany, June 22-25, 2005, To appear.

8. Automatic Detection of Renal Rejection after Kidney Transplantation Research Team: Ayman El-Baz, Seniha Esen Yuksel, Aly A Farag, Mohamed A. Ghoneim, Taek A. El-Diasty
Our goal is to automatically detect renal rejection after kidney transplantation using Contrast Enhanced Dynamic Magnetic Resonance Imaging and Color Doppler Ultrasonography. Currently, the diagnosis of renal rejection is done via biopsy, which subjects the patients to risks like bleeding and infections and it can lead to over or underestimation of the inflammation. Use of MR and Ultrasonography images will replace these risky procedures and give quantifiable results about the kidney for early detection of rejection.
Renal transplantation is a well-accepted method in the treatment of end-stage renal diseases. In the United States, approximately 12000 renal transplants are performed annually and acute rejection is the most important cause of graft failure after renal transplantation. However, diagnosis of acute transplant dysfunction remains a difficult clinical problem. Currently, the diagnosis of rejection is done via biopsy, but biopsy has the downside effect of subjecting patients to risks like bleeding and infections. Moreover, the relatively small needle biopsies may lead to over or underestimation of the extent of inflammation in the entire graft. Therefore, a noninvasive and repeatable technique is not only helpful but also needed in diagnosis of acute renal rejection. We are trying to combine Color Doppler Ultrasonography and Dynamic Magnetic Resonance Imaging (dMRI) methodologies to detect the size increase and the abnormal flow patterns that develop non-uniformly throughout the whole kidney. Methods: Our image analysis approach consists of three major steps as shown in Fig. 1:
• Segmentation of DMRI scans in order to extract the kidney; • Motion compensation using free form non rigid registration; • Generation of the kidney functionality curve during the DMRI scanning cycle; • Generation of the daily progress metric based on color Doppler US.
US
Fig. 1: The complete system to follow the progress of kidney transplantation using either DMRI or US.
Kidney Segmentation
Compensation of Motion Artifacts
Generation of the Functionality
Curve
DMRI Daily Progress Metric from
Color Doppler
Overall Kidney Functionality
Measure +

Results: Our current efforts are concentrated on the use of Contrast Enhanced Dynamic Magnetic Resonance Imaging (dMRI) technology. dMRI is a powerful imaging technique since it provides both functional and anatomical information and it overcomes the temporal resolution problems with conventional MRI by special encoding techniques. However, in dMRI, the abdomen is scanned repeatedly and rapidly after the injection of the contrast agent; therefore, (i) the spatial resolution of the dynamic MR images is low, (ii) the images suffer from the motion induced by the breathing patient which necessitates advanced registration techniques, (iii) the intensity of the kidney changes non-uniformly as the contrast agent perfuse into the cortex which complicates the segmentation procedures. In our research, we are trying to find automated techniques (i) to segment the kidney, (ii) to correct for the motion artifacts, (iii) to get kidney functionality curve, and (iv) to detect the rejection by comparing the kidney functionality curves for rejected and non-rejected kidneys. Our current approaches can be summarized into 4 steps:
1) Finding a shape model for the kidney using sign distance functions and gray level probability densities,
2) Using this shape model in deformable models to segment the kidney. Three of the original images and their segmentation results are shown in Fig 2.
3) Application of free form non-rigid registration using B-splines to register every image onto the first image of the original sequence. Our registration results are shown in Fig 3.
4) Forming the kidney functionality curve by tracing the gray level changes at particular locations in the kidney as shown in Fig.4.
Fig 2: A typical DMRI sequence of a kidney and its segmentation results
0 4 8 121
1.2
1.4
1.6
1.8
DMRI sequence
Sig
nal m
easu
red
from
DM
RI
The last figure gives the pattern of signals collected from the cortex. Rejected kidneys develop delayed perfusion patterns compared to normal kidneys because of the graft enlargement. Our future work will concentrate on combining ultrasound and dMRI measurements and on detecting the changes in these patterns automatically.
Fig. 4: Average signal measured in the cortex tissues after non rigid registration.
Fig. 3: Results of non rigid registration of DMRI sequence shown in Fig. 2 with the first image of the sequence.

9. Structural MRI analysis of the brains of patients with dyslexia and autism Research Team: Noha El-Zehiry, Manuel Casanova, Hossam Hassan and Aly Farag The major objective of this study is to investigate the anatomical changes in dyslexic and
autistic brains based on two different aspects; the neuropathological aspect and the functional imaging aspect. And find out how the neuropathological findings are correlated to the MRI findings and how the development of the brain is affected by each of these disorders.
Brain learning disorders represent an important category of brain disorders in the neuroscience research. Dyslexia is one of the most common learning disorders; it is defined as an inherited condition that makes it extremely difficult to read, write, and spell in your native language. However, autism is a more complex disease that affects the person’s ability to communicate or respond appropriately to the environment. The main concern of this study is to use Magnetic Resonance Imaging (MRI) to quantify the effect of each disease on the development of the brain through some volumetric measures and to find how the growth of the minicolumns is correlated to these volumetric measures. The image analysis approach used in this study is divided into four major steps;
• Skull Stripping: A skull stripping method will be applied on the slices to remove the noise artifacts represented by the non brain tissue such as eyes, skin and fats. Background removal will also be performed as a preprocessing step.
• Segmentation: Segmentation of the MRI will be performed to segment the white matter and gray matter. Several segmentation approaches, developed by the CVIP lab, such as level sets segmentation and statistical segmentation approaches will be used for this issue.
• White Matter Parcellation: The white matter will be subdivided into inner and outer compartments. The idea of dividing the white matter in this way is inspired by neuroscientists according to the functionality of the minicolumns.
• Volumetric measures and tests of hypotheses: Volumes of inner and outer compartments in patients and normal controls will be calculated and tests of hypotheses will be performed at different confidence levels.
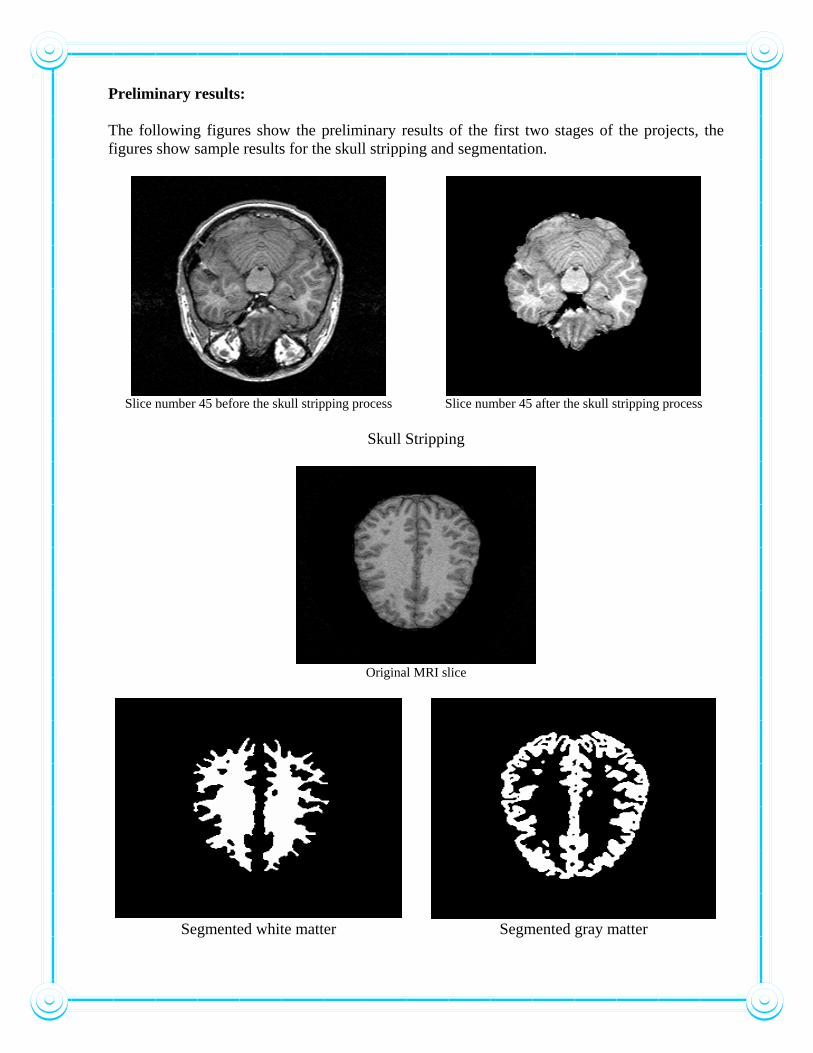
Preliminary results: The following figures show the preliminary results of the first two stages of the projects, the figures show sample results for the skull stripping and segmentation.
Slice number 45 before the skull stripping process Slice number 45 after the skull stripping process
Skull Stripping
Original MRI slice
Segmented white matter Segmented gray matter

10. University of Louisville Spinal Cord Injury Device (Funded by the Department of Neurosurgery, Univ. of Louisville) Research Team: Dongqing Chen, Sergey Y. Chekmenev, Prof. Aly Farag, Ph.D, YiPing Zhang, M.D., Prof. Christopher Shields, M.D.
Our goal is to build a Louisville Spinal Cord Injury Device to model the spinal cord injury in animals. This device will help to understand the efficiency of medical therapy for spinal cord injuries.
Several teams have developed animal models of mechanical spinal cord injury in an attempt to reproduce various aspects of the biomedical responses, neurological syndromes and pathology observed in human spinal cord injury. Such models are necessary in order to determine spinal cord injury mechanisms and to develop and test potential modes of therapy. Spinal cord injury devices have been designed for rat or mice animal experiments before. However, they have some disadvantages, such as: the slow response velocity, the less sensitive feedback system not to stop the plunger quickly enough due to the mechanical inertia, the less stable forceps used for stabilize the experimental animals. Our group is building a Louisville Version Spinal Cord Injury Device to overcome the disadvantages of the existing SCI devices, and also to design clinical animal model to test the efficiency of medical therapy with the following features: simple, accurate and reproducible. The entire system consists of six components, which includes Laceration and Contusion Parts, LVDT - Linear Variable Differential Transformer (Linear Position Sensor), Compact Industrial LVDT Signal Conditioner, USB A/D Converter Board, Data Acquisition Software for PC/Laptop and Data Analysis Software.
Experimental Setup of the Spinal Cord Injury Device

11. Jaw Modeling Project Research Team: Aly A Farag, Abdelrehim Ahmed, Hossam Hassan and Mike Miller Our goal is to create a 3D prototype of the jaw impression. The current research is directed
towards improving the data acquisition system and using finite element models for the 3D reconstruction of the jaw.
The overall aim of this research is to apply model-based computer vision methodology to develop a system for dentistry that goes beyond the traditional approaches in diagnosis, treatment planning, surgical simulation and prosthetic replacements. This computer vision methodology should obsolete the use and avoid the discomfort of the mold process used today as well as substantially improve the data accuracy available to the oral surgeon and dental care personnel. Our main objectives are as follows: (i) to design a flexible data acquisition system to capture high quality calibrated intra-oral images of the jaw, teeth, and gums (ii) to develop methods for accurate 3-D reconstruction from the acquired sequence of intra-oral images using state-of-the-art approaches in 3D reconstruction, including shape from shading, and space carving techniques; (iii) to develop and automate a robust algorithm for fusion of data acquired with accurate and fast 3D data registration; (iv) to develop a specific object segmentation and recognition system to separate and recognize individual 3D tooth information for further analysis and simulations; (v) to develop algorithms for the simulation of tooth movement based on the finite element method and deformable model approaches; (vi) to develop a database software with a user friendly GUI interface which stores the acquired digital models in a database that can be retrieved on demand and shared over computer networks for further assistance in diagnosis and treatment planning; and (vii) to enable the use of haptic feedback interfaces on our 3D jaw models in future work.

11.1. A Complete Volumetric 3D Model of the Human Jaw Research team: Hossam Hassan , Ayman El-Baz, Aly Farag, A. G. Farman, and Mike Miller. The purpose of this work is to introduce a detailed approach for constructing a complete model of the human jaw. Our previous work developed an accurate model of the human jaw surface. Unfortunately this surface is not enough for the analysis purpose which requires a detailed model of the teeth and their roots. A database of volumetric 3D models of teeth is constructed. The upper part of the tooth coming from the shape from shading algorithm provided in our previous work is matched with one of the database teeth. A non-rigid registration technique is used to deform the matched tooth with the given partial-model. Combining this information with the jaw details, we have now a complete volumetric 3D model of the human jaw. This model is suitable for the analysis process which will include Finite Element work to analyze the stress and strains of different simulations. The simulation processes will include tooth-implanting and alignment.
Registration steps of different 3D models

1. M. Sabry. Hassouna, A.A. Farag, S. Hushek, and T. Moriarty, "Cerebrovascular Segmentation from TOF Using Stochastic Models," Medical Image Analysis Journal (MEDIMA), 2005, to appear.
2. M. Sabry Hassouna and A.A. Farag, "Robust Centerline Extraction Framework Using Level Sets," Proc. of IEEE Conference on Computer Vision and Pattern Recognition (CVPR'05), San Diego, CA, USA June 20-26, 2005, to appear.
3. Aly A Farag, Refaat M. Mohamed and Ayman S El-Baz, “A Unified Framework for MAP Estimation in Remote Sensing Image Segmentation,” IEEE Transactions on Geoscience and Remote Sensing, Under print.
4. Ayman S El-Baz, Refaat M. Mohamed, and Aly A Farag, “Advanced Support Vector Machines for Image Modeling Using Gibbs-Markov Random Field,” International Journal of Computational Intelligence, Under print.
5. M. Sabry Hassouna and A.A. Farag, "PDE-Based Three Dimensional Path Planning For Virtual Endoscopy," Proc. of Information Processing in Medical Imaging 2005 (IPMI'05), Glenwood springs, Colorado, USA, July 2005. to appear.
6. M. Sabry Hassouna, A.A. Farag, and Alaa E. Abdel-Hakim, "PDE-Based Robust Robotic Navigation," Proc. of Second Canadian Conference on Computer and Robot Vision (CRV'05), British Columbia, Canada, May 9-11, 2005, (to appear).
7. M. Sabry Hassouna, A.A. Farag, "3D Path Planning for Virtual Endoscopy," Proc. of Computer Assisted Radiology and Surgery (CARS'05), Berlin, Germany, June 22-25, 2005, to appear.
8. Refaat M. Mohamed, Ayman S El-Baz, and Aly A Farag, “Probability Density Estimation Using Advanced Support Vector Machines and the Expectation Maximization Algorithm,” International Journal Of Signal Processing Vol. 1, No. 4, pp. 260-264, 2004.
9. Aly A. Farag, Ayman S El-Baz, and Refaat M. Mohamed, “Density Estimation using Generalized Linear Model and a Linear Combination of Gaussians,” International Journal Of Signal Processing Vol. 1, No. 4, pp. 265-268, 2004.
10. A. A. Farag and A. E. Abdel-Hakim, “Detection, Categorization and Recognition of Road Signs for Autonomous Navigation,” Advanced Concepts for Intelligent Vision Systems, ACIVS 2004, Brussels, Belgium, September 2004.
11. R. M. Mohamed and A. A. Farag, "Mean Field Theory for Density Estimation Using Support Vector Machines," Seventh International Conference on Information Fusion, Stockholm, July, 2004.
12. A. A. Eid and A. H. Farag, “Design of an Experimental Setup for Performance Evaluation of 3-D Reconstruction Techniques from Sequence of Images,” Eighth European Conference on Computer Vision, ECCV-04, Workshop on Applications of Computer Vision, Prague, Czech Republic, May 11-14, 2004, pp. 69-77.
13. A. H. Eid and A. A. Farag, “A Unified Framework for Performance Evaluation of 3-D Reconstruction Techniques,” IEEE Conference on Computer Vision and Pattern Recognition, CVPR-04, Workshop on Real-time 3-D Sensors and their Use, Washington DC, June 27-July 2, 2004.
14. A. A. Farag and A. H. Eid, “Local Quality Assessment of 3-D Reconstructions from Sequence of Images: A Quantitative Approach,” Advanced Concepts for Intelligent Vision Systems, ACIVS-04, Brussels, Belgium, August 31-September 3, 2004.
15. A. H. Eid and A. A. Farag, “On the Fusion of 3-D Reconstruction Techniques," Seventh International Conference on Information Fusion, IF-04, Stockholm, Sweden, June 28-July 1, 2004, pp. 856-861.
16. H. Shi and A. A. Farag, “Intensity and Region-of-Interest Based Finite Element Modeling of Brain Deformation,” Computer Assisted Radiology and Surgery, Chicago, USA, Jun. 23-26, 2004, pp. 373-377.
IV. 2004-2005 Publications

17. A. A. Farag, M. S. Hassouna, and A. El-Baz, “Real Time Vision-Based Image Guided Neurosurgery,” Computer Assisted Radiology and Surgery, Chicago, USA, Jun. 23-26, 2004, pp. 230-238.
18. A. A. Farag, A. El-Baz, G. Gimel’farb, R. Falk, and S. Hushek, "Automatic detection and recognition of lung abnormalities in helical CT images using deformable templates,” International Conference on Medical Image Computing and Computer-Assisted Intervention(MICCAI-04), France, September, 2004.
19. A. A. Farag, A. El-Baz, and G. Gimel'farb, "Detection and recognition of lung abnormalities using deformable templates", IAPR Int. Conference Pattern Recognition (ICPR 2004), Cambridge, UK, August, 2004, pp. 312-316.
20. A. A. Farag, A. El-Baz, and G. Gimel'farb, "Precise image segmentation by iterative EM-based approximation of empirical gray level distribution with linear combination of Gaussians", IEEE International Workshop on Learning in Computer Vision and Pattern Recognition, Washington, D.C., USA, June 2004, pp. 121-129.
21. G. Gimel'farb, A. A. Farag, and A. El-Baz, "Expectation-Maximization for a linear combination of Gaussians", IAPR Int. Conference Pattern Recognition (ICPR 2004), Cambridge, UK, August 2004, pp. 121-124
22. A. A. Farag, A. El-Baz, and G. Gimel'farb, "Density Estimation Using Modified Expectation-Maximization for a linear combination of Gaussians", IEEE International Conference Image Processing (ICIP 2004), Singapore, October 2004.
23. A. Farag, A. El-Baz, and G. Gimel'farb, "Detection and recognition of lung nodules in spiral CT images using Deformable templates and bayesian post-classification", IEEE International Conference Image Processing (ICIP 2004), Singapore, October 2004.
24. A. A. Farag, and H. Hassan, “Adaptive Segmentation of Multi-modal 3D Data Using Robust Level Set Techniques,” in Proc International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI'04), Saint Malo, France, September, 2004.
25. A. A. Farag, H. Hassan, R. Falk, and S.G. Hushek, “3D Volume Segmentation of MRA Data Sets Using Level Sets,” USA Academic Journal of Radiology, pp. 419-435, April, 2004.
26. H. Hassan and A. A. Farag, “Shape Based MRI Data Segmentation in Presence of Intensity In-homogeneities Using Level Sets,” Computer Assisted Radiology and Surgery, Chicago, USA, Jun. 23-26, 2004, pp. 346-352.
27. A. A. Farag, R. M. Mohamed and A. S. El-Baz, “A Unified Framework for MAP Estimation in Remote Sensing Image Segmentation,” IEEE Transactions on Geoscience and Remote Sensing (to appear).
28. R. M. Mohamed, A. S. El-Baz, and A. A. Farag, “Probability Density Estimation Using Advanced Support Vector Machines and the Expectation Maximization Algorithm”, International Journal of Signal Processing (to appear).
29. A. S El-Baz, R. M. Mohamed, and A. A. Farag, “Advanced Support Vector Machines for Image Modeling Using Gibbs-Markov Random Field”, International Journal of Computational Intelligence (to appear).
30. A. A. Farag, A. S. El-Baz, and R. M. Mohamed, “Density Estimation using Generalized Linear Model and a Linear Combination of Gaussians”, International Journal Signal Processing (to appear).

The CVIP Lab Acknowledges the following funding sources:
• The US Army • National Science Foundation • National Cancer Institute • Kentucky Lung Cancer Program • Office of Naval Research • Air Force Office of Scientific Research • Norton Healthcare System • Jewish Hospital Foundation • The Whitaker Foundation • Silicon Graphics Incorporated
V. Acknowledgments

Aly A. Farag was educated at Cairo University (B.S. in Electrical Engineering), Ohio State University (M.S. in Biomedical Engineering), University of Michigan (M.S. in Bioengineering), and Purdue University (Ph.D. in Electrical Engineering). Dr. Farag joined the University of Louisville in August 1990, where he is currently a Professor of Electrical and Computer Engineering. His research interests are concentrated in the fields of Computer Vision and Medical Imaging. Dr. Farag is the founder and director
of the Computer Vision and Image Processing Laboratory (CVIP Lab) at the University of Louisville, which supports a group of over 20 graduate students and postdocs. Dr. Farag's contribution has been mainly in the areas of active vision system design, volume registration, segmentation and visualization, where he has authored or co-authored over 80 technical articles in leading journals and international meetings in the fields of computer vision and medical imaging. Dr. Farag is an associate editor of IEEE Transactions on Image Processing. He is a regular reviewer for a number of technical journals and to national agencies including the NSF and the NIH. He is a Senior Member of the IEEE and SME, and a member of Sigma Xi and Phi Kappa Phi. Dr. Farag was awarded a "University Scholar" in 2002.
Darrel L. Chenoweth is a Professor of Electrical and Computer Engineering and Associate Vice President for research at the University of Louisville. He joined the University of Louisville in 1970 after completing his Ph.D. at Auburn University. He was the chairman of the ECE department from 1992 to 2004. He has been involved in image processing and pattern recognition research since 1981, which is sponsored by the Naval Air Warfare Center and the Office of Naval Research. He's a Fellow of IEE.
Chuck Sites is a University of Louisville staff member for the Electrical and Computer Engineering Department. He received a Bachelor degree in Physics from the University of Louisville in 1990. He has over fifteen years of experience in the computer and electronics industry. He manages the computer systems and networks of the Electrical and Computer Engineering Department and is the System Administrator and Technical Advisor for the CVIP Laboratory.
Mike Miller is a University of Louisville Staff member for the CVIP Lab. He received his Masters Degree in Electrical Engineering in 1979 from the University of Louisville, and brings twenty years of industry experience in design of computer products for Texas Instruments and VeriFone Inc. Mike's experience includes Vision Aided testing design and algorithms, ASIC design, Notebook Computer Design, and Printer Design technology. He also worked in Design of Secure Banking terminals. His focus in the lab is
assisting Grad Students in Design in both the visual and robotic fields.
VI. Staff

VII. Students
Ayman El-Baz received his B.S. in Electrical Engineering with honors from MansouraUniversity, Egypt in 1997, and M.S. from same university in 2000. He joined the Ph.D. Program in the ECE Department in
Summer 2001. Mr. Elbaz is a research assitant at the CVIP Lab working on medical imaging analysis of lung cancer. His interests include statistical modeling, genetic algorithms.
Mohamed Sabry joined the lab as a Ph.D. student in the Fall of 2001. Currently, he is working on 3D volume cerebrovascular segmentation from MRA modality. His research interests include medical imaging, visualization of large-scale medical data sets, pattern recognition, and image
processing. He won in 2002, the "Excellence in Visualization Award" from Silicon Graphics.
Refaat Mohamed received his B.S. in Electrical Engineering with honors from Assiut University, Egypt in 1995, and M.S. from the same university in 2001. He joined the Ph.D. Program in the ECE Department in Fall 2001.
Mr. Mohamed is a research assistant at the CVIP Lab working on Remote Sensing data analysis. His interests include statistical learning systems and multidimensional classification algorithms.
Alaa El-Din Aly received his B.S. in Electrical Engineering with honors from Assiut University, Egypt in 1996, and M.S. from the same university in 2000. He joined the ECE for his Ph.D. in Summer 2002. His research interests include
image processing, computer vision and robotics.
Hossam Hassan joined the lab as a Ph.D. student in the summer of 2002. His research interests include level sets segmentation, image processing and computer vision.
Emir Dizdarevic is studying for his masters. His research interests include robotics and artificial intelligence.
Hongjian Shi holds a Ph.D. in mathematics from Univ. of British Columbia, Canada, and has joined the lab as a Ph.D. student in the fall of 2002. His research interests include application of finite element methods for studying brain deformation.
Seniha Esen Yuksel is working on her MSc degree. She received her BSEE from Middle East Technical University, Turkey in 2003 and she joined the lab in the fall of 2003. Her research interests include medical imaging and visualization.

Rachid Fahmi holds a Ph.D. in mathematics from France and has joined the lab as a PhD student in the fall of 2003. His research interests include application of finite element methods for brain deformation.
Dongqing Chen joined the lab as a Ph.D. student in the summer of 2003. His research interests include medical imaging.
Sergey Checkmenev has joined the lab as a Ph.D student in the fall of 2003. His research interests include medical imaging.
Abdelraheem Ahmed joined the lab as a Ph.D student in the spring of 2004. His research interests include medical imaging.
Asem Ali has joined the lab as a Ph.D. student in the spring of 2004. His research interests include computer vision and robotics
Noha El-Zehiry has joined the lab as a Ph.D. student in the spring of 2004. Her research interests include medical imaging
Ham Rara is working on his Master of Science. He got his BS EE from The University of Philippines
Wael Emara joined the lab as a PhD student in the fall of 2004. His research interests include medical imaging.

Ahmed Eid was educated at Mansoura University, B.Sc. in Electronics Engineering with honor, Mansoura University and M.Sc. in Elect. Comm. Engineering from the same university. He is enrolled in the ECE Ph.D program at UofL since Aug. 2000. His research interests are camera calibration, performance characterization of 3-D reconstructions, and 3-D sensors.
IX. Postdoctoral Fellows
IX. Visiting Scholars

Sensor Planning for a Mobile Trinocular Active Vision System
Computer Vision and Image Processing Laboratory (CVIP Lab) University of Louisville, Louisville, KY 40292
Phone: (502) 852-7510, 2789, 6130 Fax: (502) 852-1580
Email: [email protected] http://www.cvip.uofl.edu