![Estadística mci - distribucion normal [Modo de compatibilidad]](https://static.fdocument.org/doc/165x107/55cf9cff550346d033abd4d9/estadistica-mci-distribucion-normal-modo-de-compatibilidad.jpg)
Estadística mci - distribucion normal [Modo de compatibilidad]
Upload
universidad-santo-tomasCategory
view
234download
8description

τττFACULTAD DE ESTADÍSTICA
Editorial
JORGE IVÁN VÉLEZ & JUAN CARLOS CORREAUna prueba de independencia completa basada en la FDR
CRISTIAN FERNANDO TÉLLEZ & VÍCTOR IGNACIO LÓPEZ RÍOSPropuesta para aumentar los puntos experimentales en diseños D-óptimos bayesianos
DANNA LESLEY CRUZ REYESCópulas en geoestadística o lo que se puede hacer con coordenadas y estructuras de dependencia
LILIANA VANESSA PACHECO & JUAN CARLOS CORREAComparación de intervalos de confianza para el coeficiente de correlación
JUAN FELIPE DÍAZ & JUAN CARLOS CORREAComparación entre árboles de regresión CART y regresión lineal
LUIS CARLOS SILVAEn defensa de la racionalidad bayesiana: a propósito de Mario Bunge y su “Filosofía para médicos”
Comentarios sobre el artículo de Luis Carlos Silva
ANDRÉS GUTIÉRREZ ROJAS Acerca de la defensa de la racionalidad bayesiana y la obra de Mario Bunge
JAIRO FÚQUENE El caso de la estadística bayesiana objetiva como una posibilidad en ensayos clínicos
JORGE ORTIZ PINILLA Mario Bunge y la estadística bayesiana
Réplica de Luis Carlos Silva
LUIS CARLOS SILVA La larga vida científica que le espera a Thomas Bayes
Vol.
6, N
.o 2,
julio
-dic
iem
bre
de
201
3
Certificado SC 4289-1
Comunicaciones en
Estadística
Bogotá, D. C.Colombia
Vol. 6, N.o 2 pp. 99-242ISSN:
2027-3335Julio-diciembre 2013

Universidad Santo Tomás Facultad de Estadística
Centro de Investigaciones y Estudios Estadísticos (CIEES)
Revista Comunicaciones en Estadística
ISSN: 2027-3335 (impresa)
ISSN: 2339-3076 (online)
Julio-diciembre 2013
Vol. 6, N.° 2
Bogotá, D. C., Colombia
Indexada en IBN Publindex (categoría C)

REVISTA COMUNICACIONES EN ESTADÍSTICA
Directora Hanwen Zhang, M. Sc.
COMITÉ EDITORIAL
Jorge Eduardo Ortiz, Ph. D. Universidad Santo Tomás
Elkin Castaño, M. Sc. Universidad Nacional de Colombia
Andrés Gutiérrez, M. Sc. Universidad Santo Tomás
Liliam Cardeño Acero, Ph. D. Universidad de Antioquia
Heivar Yesid Rodríguez, M. Sc. Universidad Santo Tomás
Cristiano Ferraz, Ph. D. Universidad Federal de Pernambuco
Amparo Vallejo Arboleda, Ph. D. Universidad de Antioquia
Sander Rangel, M. Sc. Universidad Santo Tomás
COMITÉ CIENTÍFICO
Juan Carlos Salazar, Ph. D. Universidad Nacional de Colombia
Luis Francisco Rincón Suárez, M. Sc. Universidad Santo Tomás
Brenda Betancourt, M. Sc. University of California, Santa Cruz
José Domingo Restrepo, Ph. D. Universidad de Antioquia
Daniel Andrés Díaz Pachón, Ph. D. University of Miami
Isabel García Arboleda, M. Sc. CIMAT, México
CONSEJO EDITORIAL PARTICULAR
Fr. Carlos Mario Alzate Montes, O. P. Rector General
Fr. Eduardo González Gil, O. P. Vicerrector Académico General
Fr. Jaime Monsalve Trujillo, O. P. Vicerrector Administrativo y Financiero General
Eduardo Franco Martínez Coordinador editorial
Dr. Henry Borja Orozco Director Unidad de Investigación
Fr. Javier Antonio Hincapié Ardila Director Ediciones USTA
Fr. Érico Juan Macchi Céspedes, O. P. Vicerrector General de Universidad Abierta y a Distancia
(VUAD)
Hecho el depósito que establece la ley ISSN: 2027-3335 (impresa) ISSN: 2339-3076 (online) © Derechos reservados Universidad Santo Tomás Bogotá, D. C., Colombia
UNIVERSIDAD SANTO TOMÁS Ediciones USTA Carrera 13 No. 54-39, Bogotá, Colombia Teléfonos: 235 1975-249 71 21 http://www.usta.edu.co [email protected]
Publicación del Centro de Investigaciones y Estudios Estadísticos (CIEES)

Revista Comunicaciones en Estadıstica
Contenido
Editorial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105-108
JORGE IVAN VELEZ & JUAN CARLOS CORREA
Una prueba de independencia completa basada en la FDR . . . . . . . . . . . . . . 109-120
CRISTIAN FERNANDO TELLEZ PINEREZ & VICTOR IGNACIO
LOPEZ RIOS
Propuesta para aumentar los puntos experimentales en disenos D-optimos
bayesianos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .121-137
DANNA LESLEY CRUZ REYES
Copulas en geoestadıstica o lo que se puede hacer con coordenadas y estructuras
de dependencia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139-156
LILIANA VANESSA PACHECO & JUAN CARLOS CORREA
Comparacion de intervalos de confianza para el coeficiente de correlacion
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 157-174
JUAN FELIPE DIAZ & JUAN CARLOS CORREA
Comparacion entre arboles de regresion CART y regresion lineal . . . . . . . . 175-195
LUIS CARLOS SILVA
En defensa de la racionalidad bayesiana: a proposito de Mario Bunge y su
“Filosofıa para medicos” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 197-212
Comentarios sobre el artıculo de Luis Carlos Silva
ANDRES GUTIERREZ ROJAS
Acerca de la defensa de la racionalidad bayesiana y la obra de Mario Bunge
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 213-220
JAIRO FUQUENE
El caso de la estadıstica bayesiana objetiva como una posibilidad en ensayos
clınicos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .221-224
JORGE ORTIZ PINILLA
Mario Bunge y la estadıstica bayesiana . . . . . . . . . . . . . . . . . . . . . . . . . . . 225-229
Replica de Luis Carlos Silva
LUIS CARLOS SILVA
La larga vida cientıfica que le espera a Thomas Bayes . . . . . . . . . . . . 231-235


Revista Comunicaciones en Estadıstica
Content
Editorial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105-108
JORGE IVAN VELEZ & JUAN CARLOS CORREA
A test for complete Independence based on FDR . . . . . . . . . . . . . . . . . . . . . . . 109-120
CRISTIAN FERNANDO TELLEZ PINEREZ & VICTOR IGNACIO
LOPEZ RIOS
Proposal to increase experimental points in Bayesian D-optimal design
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121-137
DANNA LESLEY CRUZ REYES
Copulas in geostatistic or what can be done with coordinates and dependency
structures . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139-156
LILIANA VANESSA PACHECO & JUAN CARLOS CORREA
Comparison of confidence intervals for the correlation coefficient . . . . . . . . . 157-174
JUAN FELIPE DIAZ & JUAN CARLOS CORREA
Comparison between CART regression trees and linear regression . . . . . . . 175-195
LUIS CARLOS SILVA
In defense of Bayesian rationality: about Mario Bunge and his “Philosophy for
physicians” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 197-212
Comments on article by Luis Carlos Silva
ANDRES GUTIERREZ ROJAS
About the defense of Bayesian rationality and work of Mario Bunge
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 213-220
JAIRO FUQUENE
The case for objective Bayesian statistics as a possibility in clinical trials
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 221-224
JORGE ORTIZ PINILLA
Mario Bunge and the bayesian statistics . . . . . . . . . . . . . . . . . . . . . . . . . .225-229
Rejoinder by Luis Carlos Silva
LUIS CARLOS SILVA
The long scientific life that waits for Thomas Bayes . . . . . . . . . . . . . 231-235


Comunicaciones en Estadıstica
Diciembre 2013, Vol. 6, No. 2, pp. 105–108
Editorial
Hanwen Zhanga
En el numero 11 de la revista Comunicaciones en Estadıstica queremos, por medio
de esta editorial, compartir con nuestros lectores la buena noticia de la categori-
zacion de la Revista en la II actualizacion Publindex de Colciencias del 2012, la
categorıa otorgada por Colciencias es C, y esperamos mantenernos en esta cate-
gorıa en la I actualizacion Publindex del 2013, que se encuentra en proceso en este
momento, en busca de mejorar la categorıa en futuras actualizaciones de Colcien-
cias. Queremos expresar nuestros mas sinceros agradecimientos a los miembros
del Comite Editorial y Cientıfico, los autores que nos confiaron sus resultados de
investigacion, los arbitros que nos ayudaron a mantener la calidad de la Revista, y
obviamente a los lectores que son nuestra motivacion; por otro lado, queremos re-
conocer el apoyo que hemos recibido en el proceso editorial por parte de Ediciones
USTA, la Unidad de Investigacion y la decanatura de la Facultad de Estadıstica
de la Universidad Santo Tomas.
En el primer artıculo de este numero los profesores Velez y Correa nos traen una
nueva prueba de independencia completa en el contexto del analisis multivariado,
la cual esta basada en la tasa de falsos descubrimientos. Los estudios de simulacion
muestran que esta nueva prueba tiene mayor robustez frente al numero de variables
y al tamano muestral, comparado con otras pruebas existentes en la literatura.
Los profesores Tellez y Lopez nos comparten su propuesta para mejorar los disenos
D-optimos bayesianos, aumentando el numero de puntos de soporte tal que la
aplicacion de las pruebas de bondad de ajuste resulten factibles.
En el campo de la geoestadıstica, Cruz nos presenta el uso de las funciones copula
mostrando tres metodos: el indicador y el kriging disyuntivo, el kriging simple y
la generalizacion del kriging trans-gaussiano.
El cuarto artıculo de este numero lo traen Pacheco y Correa desde Medellın, y
nos presentan una revision de diferentes intervalos existentes para el coeficiente de
correlacion en una distribucion normal bivariada. Adicionalmente, en un estudio
de simulacion, los autores comparan estos intervalos en terminos de la probabilidad
de cobertura y la longitud, proporcionando conclusiones que pueden ser utiles para
la comunidad.
aEditora. Revista Comunicaciones en Estadıstica. Universidad Santo Tomas.
105

106 Hanwen Zhang
El quinto artıculo nos ilustra el uso de los arboles de regresion CART, los autores
Dıaz y Correa consideran la comparacion en el nivel predictivo de estos modelos
frente a los conocidos modelos de regresion lineal, y encontraron que en el momento
en que se dispone de una muestra grande de datos, los arboles de regresion arrojan
un menor error de prediccion cuando el modelo ajustado es erroneo.
Este numero de la Revista finaliza con cinco artıculos de discusion acerca de la
filosofıa de la estadıstica bayesiana. La iniciativa la dio el renombrado investigador
Luis Carlos Silva desde Cuba, a raız de la reciente publicacion del libro Filosofıa
para medicos del ilustre filosofo argentino Mario Bunge. Silva hace reflexiones sobre
las fuertes crıticas de Bunge hacia la estadıstica bayesiana y revela las falencias del
razonamiento de Bunge. Posteriormente, Gutierrez, Fuquene y Ortiz responden a
la discusion de Silva desde diferentes puntos de vista, y, finalmente, Silva concluye
el foro de discusion replicando estas reflexiones.
Esperamos que este numero sea de utilidad para nuestros lectores, y poder contar
con sus valiosos comentarios y crıticas constructivas.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Editorial 107
Comunicaciones en Estadıstica
Diciembre 2013, Vol. 6, No. 2, pp. 105–108
Editorial
In issue 11 of the journal Communications in Statistics we wish, through this
Editorial, to share with our readers the good news of the categorization of the
Journal in the II update of Publindex Colciencias 2012, the category granted by
Colciencias is C, and we expect to maintain this category in the I update of
Publindex 2013, currently in process, in search of improving the category in future
Colciencias updates.
We want to express out most sincere thanks to the members of the Editorial
and Scientific Committee, the authors who trusted their research results, the peer
reviewers who helped us keep the Journal’s quality, and of course our readers who
are our motivation; also, we want to acknowledge the support we have received in
the editorial process by USTA Editions, the Research Unit and dean’s office of the
Faculty of Statistics of Universidad Santo Tomas.
In the first article of this issue professors Velez and Correa bring us new evidence
of complete independence in the context of multivariate analysis which is based on
the false discovery rates. Simulation studies show that this new evidence is more
robust with regards to the number of variables and sample size, compared with
other existing evidence in literature.
Professors Tellez and Lopez share their proposal to improve the Bayesian D-
optimal designs, increasing the number of support points so that the application
of the goodness of fit tests results feasible.
In the geostatistics field, Cruz presents us the use of copula functions showing three
methods: indicator and disjunctive kriging, simple kriging and generalization of the
trans-Gaussian kriging.
The fourth article of this issue is brought by Pacheco and Correa from Medellin,
and presents us a review of various existing intervals for the correlation coefficient
in a bivariate normal distribution. Additionally, in a simulation study, authors
compare these intervals in terms of coverage and longitude probability, providing
conclusions that might be useful for the community.
The fifth article illustrated us the use of CART regression trees, authors Diaz and
Correa consider the comparison at predictive level of these models with regards to
known models of linear regression, and found that when there is a large sample of
data, the regression trees show a lower prediction error when the adjusted model
is erroneous.
This issue of the Journal ends with five articles of discussion on the philosophy of
Bayesian statistics. The initiative was given by renowned researcher Luis Carlos
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

108 Hanwen Zhang
Silva from Cuba, following recent publication of the book Philosophy for physi-
cians by illustrious Argentinean philosopher Mario Bunge. Silva reflects on Bunge’s
strong criticism towards Bayesian statistics and reveals the flaws of Bunge’s reaso-
ning. Afterwards, Gutierrez, Fuquene and Ortiz reply to Silva’s discussion from
several points of view, and, finally, Silva concludes the discussion forum replying
to these reflections.
We hope this issue is useful to our readers, and to have their valuable comments
and constructive criticism.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Comunicaciones en EstadısticaDiciembre 2013, Vol. 6, No. 2, pp. 109–120
Una prueba de independencia completa basada
en la FDR
A test for complete Independence based on FDR
Jorge Ivan Veleza
[email protected] Carlos Correab
Resumen
El analisis e interpretacion de datos multivariados se facilita enormemente si las
variables son independientes. En la practica, este supuesto se verifica a traves de
una prueba de independencia completa. Proponemos una nueva prueba de inde-
pendencia completa basada en la tasa de falsos descubrimientos (FDR, en ingles),
y reportamos los resultados de un estudio de simulacion en el que se comparan los
niveles de significancia real de esta propuesta y otras pruebas comunmente utiliza-
das. Encontramos que el nivel de significancia real solo se mantiene por debajo del
teorico para la prueba basada en la FDR, y que este es independiente del tamano
de muestra y el numero de variables. Finalmente, ilustramos nuestra propuesta
con dos ejemplos.
Palabras clave: independencia completa, tasa de falsos descubrimientos, matriz
de correlacion.
Abstract
Analysis and interpretation of multivariate data is largely facilitated if the variables
are independent. In the practice, this supposition is verified through a test for
complete independence. We propose a new test for complete independence based
on the false discovery rate (FDR), and report the results of a simulation study
which compares the real significance levels of this proposal and other tests generally
used. We found that the real significance level only remains under the theoretical
one for the test based on FDR, and that this is regardless the size of the sample
and number of variables. Finally, we illustrate our proposal with two examples.
Keywords: complete independence, false discovery rate, correlation matrix.
aTranslational Genomics Group, Genome Biology Department, John Curtin School of MedicalResearch, The Australian National University, Canberra, ACT, Australia. Grupo de Neurocien-cias de Antioquia, Universidad de Antioquia, Colombia. Grupo de Investigacion en Estadıstica,Universidad Nacional de Colombia, sede Medellın, Colombia.
bGrupo de Investigacion en Estadıstica, Universidad Nacional de Colombia, sede Medellın,Colombia. Profesor asociado, Escuela de Estadıstica, Universidad Nacional de Colombia, sedeMedellın, Colombia.
109

110 Jorge Ivan Velez & Juan Carlos Correa
1. Introduccion
Desarrollos relativamente recientes en genetica y procesamiento de imagenes han
dado lugar a experimentos y aplicaciones cuyos resultados corresponden a grandes
conjuntos de datos. En la actualidad, una de las areas mas importantes en el
campo de la investigacion medica es el estudio de niveles de expresion de m genes
en n1 casos y n2 controles utilizando microarreglos (Nguyen et al. 2002, Dudoit
et al. 2002).
Por lo general, en este tipo de estudios el interes se centra en determinar aquellos
genes para los que sus niveles de expresion difieren significativamente entre ambos
grupos, o aquellos pares de genes para los cuales su correlacion es estadısticamente
significativa para alguna probabilidad de error tipo I α predeterminada. En el
primer caso, la deteccion de diferencias significativas permite determinar que genes
se encuentran alterados en los casos y no en los controles (Dudoit et al. 2002),
mientras en el segundo el coeficiente de correlacion corresponde a un proxy que
cuantifica una potencial interaccion entre un par de genes.
Dado un conjunto de datos con p variables numericas, independencia completa se
refiere a probar
H0: Σ = D(σ2
1, σ2
2, . . . , σ2
p) (1)
donde Σ es la matriz de varianzas-covarianzas, D(·) corresponde a una matriz
diagonal cuyas componentes son σ2
1, σ2
2, . . . , σ2
p, con σ2
i la varianza de la i-esima
variable, i = 1, 2, . . . , p. Si P es la matriz de correlacion, lo anterior se reduce a
probar H0: P = Ip, con Ip una matriz diagonal de orden p. Si se rechaza H0 para
algun nivel de significancia α, esto indica que por lo menos una de las correlaciones
entre pares de variables es estadısticamente diferente de cero. En el caso de estudios
con microarreglos, rechazar la hipotesis de independencia completa indicarıa que
existe al menos un par de genes que interactuan.
En la literatura, se encuentran disponibles la prueba basada en la razon de verosi-
militud (LRT, en ingles) (Wilks 1935, Morrison 2005), y las aproximaciones segun
Box (1949), Bartlett (1954) y Schott (2005) para probar H0. El rechazo o no de
H0 en (1) puede contextualizarse de diferentes maneras, por ejemplo, en regresion
lineal, es deseable que las covariables del modelo sean ortogonales, i.e., no exista
multicolinealidad (no se rechace H0). Sin embargo, la existencia de correlacion es
deseable en analisis de componentes principales y analisis factorial. En el primer
caso, permite reducir la dimensionalidad del problema; en el segundo, las pruebas
de independencia completa se utilizan para determinar si es recomendable realizar
este tipo de analisis.
En este trabajo proponemos una metodologıa basada en la tasa de falsos descubri-
mientos (FDR, en ingles) y comparamos su desempeno con los metodos mencio-
nados previamente. Finalmente, ilustramos nuestra propuesta con dos conjuntos
de datos, uno relacionado con un experimento taxonomico (Anderson 1935) y otro
sobre medidas de los pies (Correa 2006).
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Una prueba de independencia completa basada en la FDR 111
2. Pruebas de independencia completa
Supongamos que se tiene una matriz de datos (continuos)Xn×p donde n correspon-
de al numero de observaciones y p al numero de variables. La matriz de correlacion
muestral R esta dada por
R =
1 r12 · · · r1pr21 1 · · · r2p...
.... . .
...
rp1 rp2 · · · 1
(2)
donde rij = sij (siisjj)−1/2, sij = (n − 1)−1
nk=1
(xki − xi)(xkj − xj) y sii =
var(xi), i, j = 1, 2, . . . , p.
Bajo normalidad multivariada, esto es, si X ∼ Np(µ,Σp), Wilks (1935) mostro que
para probar (1) el estadıstico de prueba es
Λ = |R|n/2 (3)
La distribucion de Λ es aun motivo de extensa investigacion (Mudholkar et al.
1982).
2.1. Razon de verosimilitud (LRT)
La prueba LRT (Morrison 2005, Seccion 1.9) considera el estadıstico de prueba
G = −[n− (2p+ 5)/6] log |R| (4)
Bajo H0, G tiene una distribucion χ2 con p(p − 1)/2 grados de libertad. Schott
(2005) mostro que G tiene un pobre desempeno cuando p → ∞ debido a que
|R| → 0.
2.2. Aproximacion de Box
De acuerdo con Box (1949), la distribucion de Λ en (3) puede aproximarse como:
P [C ≤ z] ≈ Pχ2
w ≤ z
+γ2m2
Pχ2
w+4≤ z − Pχ2
w ≤ z+O(m−3) (5)
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

112 Jorge Ivan Velez & Juan Carlos Correa
con C = −n log |R|, γ2 = p(p − 1)(2p2 − 2p − 13)/288, m = n − (2p + 11)/6,w = p(p− 1)/2 y χ2
w una variable χ2 con w grados de libertad.
2.3. Aproximacion de Bartlett
Morrison (1976) menciona que Bartlett (1954) propuso aproximar el estadıstico
Q = −[n− (2p+ 11)/6] log |R| (6)
utilizando una χ2
p(p−1)/2. El estadıstico Q, ademas de ser mucho mas simple de
calcular que la aproximacion de Box, no utiliza la expansion de Taylor de tercer
orden, lo cual garantiza esta converja mucho mas rapido a la distribucion lımite.
Mudholkar et al. (1982) mostraron que el estadıstico Q tiene un mejor desempeno
que la aproximacion en (5).
2.4. Aproximacion de Schott
Schott (2005) propone una prueba de independencia completa basada en probar
las hipotesis
H0: ρi,j = 0 vs. H1: ρi,j = 0 i > j (7)
donde ρi,j es el (i, j)-esimo elemento de la matriz de correlacion P . El estadıstico
de prueba esta dado por
Z = tn,p/σtn,p(8)
donde
tn,p =
p∑
i=2
i−1∑
j=1
r2i,j − 2p(p− 1)/n,
σtn,p= n−2(n+2)−1p(p−1)(n−1) y ri,j es el estimador de ρi,j . Bajo independencia
completa, Z ∼ N(0, 1). Para p > n, esta prueba mostro tener un mejor desempeno
que la prueba LRT (Schott 2005).
2.5. Propuesta basada en FDR
La tasa de falsos descubrimientos (FDR, en ingles) esta definida como la propor-
cion de hipotesis nulas verdaderas que resultan ser rechazadas dentro del total de
hipotesis rechazadas (Benjamini & Hochberg 1995). Para una revision sobre este
y otros metodos, ver Schaffer (1995) y Correa (2011).
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Una prueba de independencia completa basada en la FDR 113
Tabla 1: Posibles resultados cuando se prueban m hipotesis. T : cierto; F : falso,D: descubrimiento (rechazo de H0); N : no descubrimiento. Fuente: modificado deBenjamini & Hochberg (1995)
Acepto H0 Rechazo H0 Total
H0 Verdadera NT DF m0
H0 Falsa NF DT m1
Total N D m
En la Tabla 1 presentamos los posibles resultados cuando se realizan m prue-
bas de hipotesis independientes. A partir de esta informacion, la FDR se define
formalmente como (Benjamini & Hochberg 1995)
FDR = E
(DF
D
∣∣∣∣D > 0
)P (D > 0) (9)
y el procedimiento FDR (Benjamini & Hochberg 1995) se reduce a:
1. Probar m hipotesis independientes H0,1, H0,2, . . . , H0,m a partir de las cua-
les se obtienen los estadısticos de prueba T0,1, T0,2, . . . , T0,m y los valores pp0,1, . . . , p0,m, respectivamente.
2. Calcular κ como
κ = max
i : p
(i) ≤i
mα
(10)
para algun nivel de significancia α ∈ (0, 1).
3. Rechazar H0,1, H0,2, . . . , H0,κ. Si no existe tal κ, ninguna hipotesis nula
podra ser rechazada.
Nuestra propuesta para realizar la prueba de independencia completa implica pro-
bar (7) para la l-esima componente de la matriz de correlacion R en (2) y aplicar
el procedimiento FDR descrito anteriormente, de tal manera que para una matriz
de datos (continuos) Xn×p deben calcularse p(p− 1)/2 coeficientes de correlacion,
estadısticos de prueba y valores p. Una vez calculado el l-esimo coeficiente de co-
rrelacion muestral rl, el estadıstico de prueba es tl = rl(n− 2)1/2(1− r2l )−1/2 y el
valor−p puede calcularse como pl = P (tl > tn−2), l = 1, 2, . . . , p(p− 1)/2. Recha-zaremos H0 en (1) si κ ≥ 1. En el Apendice A presentamos una implementacion
de nuestra propuesta en R (R Core Team 2013).
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

114 Jorge Ivan Velez & Juan Carlos Correa
3. Estudio de simulacion y resultados
3.1. Estudio de simulacion
El desempeno de nuestra propuesta y las aproximaciones antes mencionadas se
evaluo a traves de un estudio de simulacion. Para ello, implementamos un algorıtmo
en R que funciona de la siguiente manera1:
1. Generacion de datos. Defina la tripleta (n, p, ρ) y genere una muestra alea-
toria de tamano n de una distribucion normal p-variada con matriz de
correlacion P = (1 − ρ) Ip + ρ1p1′
p. Se utilizaron 10 ≤ n ≤ 200, p =
2, 5, 10, 30, 50, 100.
2. Aproximaciones LRT, Box, Bartlett y Schott. Estime la matriz de correlacion
muestral R y determine si se rechaza H0 en (1) con las aproximaciones LRT,
Bartlett, Box y Schott.
3. Prueba basada en la FDR. A partir de la matriz de correlacion R, determine
el valor de κ como se describe en la seccion 2.5. Rechace H0 en (1) si κ ≥ 1.
4. Tasa de rechazos. Repita los pasos 1–3, B veces. Calcule la tasa de rechazos
(TdRs) para cada metodo como la proporcion de veces que se rechaza H0 en
las B muestras.
Con el proposito de estimar el de cada una de las pruebas, se determino su desem-
peno bajo H0, es decir, con P = Ip (equivalente a ρ = 0). En total se evaluaron
240 escenarios de simulacion. En todos ellos, la probabilidad de error tipo I fue
α = 0.05 y B = 10000.
3.2. Resultados
Los resultados obtenidos se presentan en la Figura 1. A diferencia de las demas
pruebas para independencia completa, nuestra propuesta basada en la FDR man-
tiene niveles de significancia reales cercanos al 5% independiente del tamano de
muestra n y el numero de variables p. Las pruebas tradicionales presentan TdRs
cercanos al 5% solo para n > 100 y p ≤ 10 (panel superior, Figura 1). Sin embargo,
la prueba de Schott para p = 2 y la de Box para p = 5 y p = 10, son claras excep-
ciones. Para p > 2, la prueba LRT presenta las TdRs mas altas independiente del
tamano de muestra.
1El programa en R se encuentra disponible a peticion del lector.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2
Una prueba de independencia completa basada en la FDR 115
45678910
2050
80110
140
170
200
(a)
200
51015202530
2050
80110
140
170
200
(b)
200
010203040
2050
80110
140
170
200
(c)
020406080100
2050
80110
140
170
200
(d)
200
020406080100
2050
80110
140
170
200
(e)
200
020406080100
2050
80110
140
170
200
(f)
Tam
año
de m
uest
ra (n
)
Tasa de Rechazos (%)
FDR
BoxBartlett
Schott
LRT
p=2
p=5
p=10
p=30
p=
50
p=10
0
Figura
1:Nivel
design
ificanciarealdelasaproximaciones
LRT,Box,
Bartlett,Schott
ynuestrapropuesta
basadaen
laFDR
comofunciondel
taman
odemuestranyel
numerodevariables
p.Fuen
te:elaboracionpropia.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Una prueba de independencia completa basada en la FDR 115
45678910
2050
80110
140
170
200
(a)
200
51015202530
2050
80110
140
170
200
(b)
200
010203040
2050
80110
140
170
200
(c)
020406080100
2050
80110
140
170
200
(d)
200
020406080100
2050
80110
140
170
200
(e)
200
020406080100
2050
80110
140
170
200
(f)
Tam
año
de m
uest
ra (n
)
Tasa de Rechazos (%)
FDR
BoxBartlett
Schott
LRT
p=2
p=5
p=10
p=30
p=
50
p=10
0
Figura
1:Nivel
design
ificanciarealdelasaproximaciones
LRT,Box,
Bartlett,Schott
ynuestrapropuesta
basadaen
laFDR
comofunciondel
taman
odemuestranyel
numerodevariables
p.Fuen
te:elaboracionpropia.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

116 Jorge Ivan Velez & Juan Carlos Correa
Cuando p ≥ 30, las TdRs de las pruebas clasicas son superiores al nivel de signifi-
cancia nominal del 5% en muchos ordenes de magnitud. A excepcion de la prueba
de Box, las TdRs son cercanas al nivel nominal cuando p = 30 y n > 120. Sin
embargo, para p = 50 y p = 100 este comportamiento es menos evidente y las
TdRs varıan considerablemente. Para p ≥ 30 (panel inferior, Figura 1) las unicas
pruebas evaluadas con resultados consistentes, i.e., que igualan o tienden rapida-
mente al nivel nominal cuando n aumenta, son nuestra propuesta y la prueba de
Schott.
4. Ejemplos
4.1. Datos taxonomicos
Anderson (1935) presenta un conjunto de datos, ahora clasicos, correspondiente a
medidas (en centımetros) del ancho y la longitud del sepalo y los petalos en 150
flores iris de tres especies diferentes (setosa, versicolor y virginica, Figura 2)2. Los
datos, disponibles en R, corresponden a mediciones de estas cuatro caracterısticas
en 50 flores de cada especie.
Setosa Versicolor Virginica
Figura 2: Especies setosa, versicolor y virginica de la variedad de flores iris. Fuente:ver nota de pie.
Para ilustrar el uso de nuestra propuesta se hicieron dos tipos de analisis. En el
primero, se analizo el conjunto de datos sin dividir por especie; en el segundo,
se realizo dicha division. En el primer caso, todas las pruebas de independencia
rechazaron H0 en (1), excepto la prueba de Box (LRT: G = 711.77, p = 1.75 ×10−150; Bartlett: Q = 706.96, p = 1.92× 10−149; Schott: Z = 115.79, p < 10−150).
Resultados similares se obtienen al realizar el analisis de independencia completa
por especie.
2Imagenes tomadas de www.alaska-in-pictures.com/data/media/10/wild-iris_8865.jpg,http://goo.gl/nEGwEr y http://goo.gl/7PRWSf
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Una prueba de independencia completa basada en la FDR 117
4.2. Medidas de pies
Correa (2006) presenta datos3 correspondientes a mediciones de la longitud (x1) y
la amplitud (x2) maxima del pie, la amplitud maxima del talon (x3), la longitud
maxima del dedo grande (x4) y la amplitud maxima del dedo grande (x5) en
n = 10 personas.
La matriz de correlacion muestral (diagonal inferior) y los respectivos valores p(diagonal superior) al probar (7) son
D =
x1 x2 x3 x4 x5
x1 − 0.0018 0.5881 0.1413 0.0107x2 0.8507 − 0.7924 0.3767 0.1589x3 0.1956 −0.0958 − 0.9448 0.1963x4 0.4998 0.3141 0.0253 − 0.1989x5 0.7600 0.4814 0.4461 0.4438 −
,
de tal manera que rx1,x2= 0.8507 y el correspondiente valor p es 0.0018.
La hipotesis de independencia completa es rechazada al utilizar nuestra propuesta
basada en la FDR. Este resultado es equivalente al obtenido con cualquiera de
las aproximaciones clasicas (LRT: G = 24.45, p = 6.48 × 10−3; Box: C = 32.61,p = 4.48 × 10−4; Bartlett: Q = 21.19, p = 1.97 × 10−2; Schott: Z = 3.42, p =
3.10× 10−4).
5. Discusion
El analisis multivariado de datos se simplifica en gran medida si se asume que
las p variables disponibles son independientes. La principal ventaja de tener datos
con estas caracterısticas radica en que cada una de las variables podrıa analizarse
utilizando metodos univariados. Ahora, si el supuesto de independencia completa
no se cumple y aun ası este se asume, podrıan obtenerse resultados alejados de la
realidad, especialmente cuando el estudio de relaciones entre variables, como en
experimentos con microarreglos, es de gran importancia.
En este artıculo hemos presentado una nueva prueba de independencia completa,
basada en la FDR, que consiste en realizar p(p−1)/2 pruebas de hipotesis indepen-dientes sobre igual numero de coeficientes de correlacion de una matriz de datos
(continuos) Xn×p, y que ofrece una alternativa facil de implementar en cualquier
programa de analisis estadıstico (ver Apendice A para nuestra implementacion en
R). A diferencia de otras pruebas de independencia completa tambien evaluadas,
el nivel de significancia real de esta nueva alternativa es comparable con el nivel
teorico nominal (en este caso del 5%) y no depende del numero de variables p ni
del tamano de muestra n. En la practica, estas tres propiedades son deseables. Por
3Disponibles bajo solicitud expresa del lector.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

118 Jorge Ivan Velez & Juan Carlos Correa
otro lado, la potencia de nuestra propuesta basada en la FDR es comparable o su-
perior a las obtenidas con las demas aquı mencionadas4. Este resultado garantiza,
en cierta medida, que nuestra propuesta representa una mejor alternativa a las ya
existentes.
Tabla 2: Tiempos de ejecucion (en segundos) de la prueba de independencia com-pleta basada en la FDR para combinaciones de n y p. Fuente: elaboracion propia
n|p 100 200 500 1000 1500 2000 3000 5000
500 0.007 0.029 0.199 0.960 2.549 5.219 13.256 42.116
1000 0.011 0.043 0.283 1.239 3.298 6.572 16.253 50.630
2000 0.017 0.071 0.456 1.919 4.787 9.017 22.076 67.222
3000 0.024 0.097 0.643 2.688 6.321 11.701 28.206 84.214
5000 0.038 0.158 0.960 3.930 9.424 17.226 39.996 117.902
Uno de los problemas que podrıan presentarse en la implementacion y aplicacion
de esta prueba es el costo computacional (e.g., tiempo de ejecucion). Por ejem-
plo, para p = 5000 e independiente del tamano de muestra, es necesario calcular
12,497,500 coeficientes de correlacion, probar igual numero de hipotesis y compu-
tar los respectivos valores−p. Sin embargo, los tiempos de ejecucion en R (ver
Tabla 2) son relativamente cortos; el procedimiento tarda menos de 120 segundos5
para p = n = 5000.
Posibles direcciones de investigacion podrıan estar enfocadas a la evaluacion de
nuestra propuesta en presencia de datos faltantes. Puesto que la prueba FDR
se basa en el calculo de coeficientes de correlacion y la determinacion de si al
menos uno es significativo, el problema se reduce a escoger diferentes metodos
para el calculo de estos (e.g., usando toda la informacion, solo la informacion
completa, o solo la informacion completa por pares de variables) y calcular el nivel
de significancia real de la prueba.
Agradecimientos
Los autores agradecen los comentarios y sugerencias de un revisor anonimo, quien
ayudo a mejorar sustancialmente la version previa de este documento. El trabajo
de JIV fue financiado parcialmente por The Eccles Scholarship in Medical Sciences,
The Fenner Merit Scholarship y The Australian National University (ANU) High
Degree Research Scholarship. JIV agradece el apoyo del dr. Mauricio Arcos-Burgos
de ANU.
Recibido: 10 de abril de 2013
Aceptado: 14 de mayo de 2013
4Los resultados se encuentran disponibles a peticion del lector.5Se utilizo R version 3.0.0 Patched (2013-04-08 r62531) en un MacBook Pro con 8GB de RAM
y procesador 2.3 GHz Intel Core i7.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Una prueba de independencia completa basada en la FDR 119
Referencias
Anderson, E. (1935), ‘The irises of the Gaspe peninsula’, Bulletin of the AmericanIris Society 59, 2–5.
Bartlett, M. (1954), ‘A note on multiplying factors for various χ2 approximations’,
Journal of the Royal Statistical Society, Ser. B (Methodological) 16, 296–298.
Benjamini, Y. & Hochberg, Y. (1995), ‘Controlling the false discovery rate: A
practical and powerful approach to multiple testing’, Journal of the RoyalStatistial Society, Series B (Methodological) 57(1), 389–400.
Box, G. (1949), ‘A general distribution theory for a class of likelihood criteria’,
Biometrika 36, 317–346.
Correa, J. C. (2006), Control de la proporcion de hipotesis rechazadas equivocada-mente, Curso de Estadıstica Genetica, Universidad de Antioquia.
Correa, J. C. (2011), ‘Diagnosticos de regresion usando la FDR (Tasa de Descu-
brimientos Falsos)’, Comunicaciones en Estadıstica 3(2), 109–118.
Dudoit, S., Yang, Y.-H., Callow, M. J. & Speed, T. P. (2002), ‘Statistical methods
for identifying differentially expressed genes in replicated cDNA experiments’,
Statistica Sinica 12, 111–139.
Morrison, D. F. (1976), Multivariate statistical methods, 2 edn, New York:
McGraw-Hill.
Morrison, D. F. (2005), Multivariate statistical methods, 4 edn, Belmont, CA:
Brooks/Cole.
Mudholkar, G. S., Trivedi, M. C. & Lin, T. (1982), ‘An approximation to the dis-
tribution of the likelihood ratio statistic for testing complete independence’,
Technometrics 24(2), 139–143.
Nguyen, D. V., Bulak Apart, A., Wang, N. & Carrol, R. J. (2002), ‘DNAmicroarray
experiments: biological and technological aspects’, Biometrics 58, 701–717.
R Core Team (2013), R: A language and environment for statistical computing, RFoundation for Statistical Computing, Vienna, Austria. ISBN 3-900051-07-0.
*http://www.R-project.org/
Schaffer, J. P. (1995), ‘Multiple hypothesis testing: A review’, Annu. Rev. Psychol.46, 561–84.
Schott, J. R. (2005), ‘Testing for complete independence in high dimensions’, Bio-metrika 92(4), 951–956.
Wilks, S. S. (1935), ‘On the independence of k sets of normally distributed statis-
tical variables’, Econometrika 3, 309–26.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

120 Jorge Ivan Velez & Juan Carlos Correa
A. Apendice. Programa en R para la prueba deindependencia completa basada en la FDR
## Calculo del valor p para los coef. de correlacion de una matriz X
cor.pvalue <- function(X, method = "pearson", use = "complete") dfr <- nrow(X) - 2
R <- cor(X, method = method, use = use)
above <- row(R) < col(R)
r2 <- R[above]^2
Fstat <- r2 * dfr/(1 - r2)
R[above] <- 1 - pf(Fstat, 1, dfr)
R[above]
## Prueba de independencia completa basada en la FDR
fdrci <- function(x, alpha = 0.05) p <- cor.pvalue(x)
p <- p.adjust(p, method = "fdr")
ifelse(any(p <= alpha), "Rechace H0", "No rechace H0")
## Ejemplo con una normal 5-variada independiente, n = 100
set.seed(1)
X <- matrix(rnorm(100 * 5), ncol = 5)
fdrci(X)
## [1] "No rechace H0"
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Comunicaciones en Estadıstica
Diciembre 2013, Vol. 6, No. 2, pp. 121–137
Propuesta para aumentar los puntosexperimentales en disenos D-optimos bayesianos
Proposal to increase experimental points in Bayesian
D-optimal design
Cristian Fernando Tellez Pinereza
Vıctor Ignacio Lopez Rıosb
Resumen
Uno de los criterios de uso mas frecuente para la obtencion de disenos optimos
es el D-optimalidad, el cual proporciona los puntos experimentales donde se mi-
nimiza el volumen del elipsoide de confianza asociado al vector de parametros en
el modelo propuesto. A diferencia del diseno D-optimo clasico, el diseno D-opti-
mo bayesiano no necesariamente tiene tantos puntos de soporte como parametros
tiene el modelo. En este artıculo se considera el caso en donde el diseno D-opti-
mo promediado por una a priori particular tiene tantos puntos de soporte como
el numero de parametros del modelo. Esta situacion puede no ser tan favorable
cuando el modelo no se tiene especificado con total certeza, dado que no serıa posi-
ble realizar pruebas de falta de ajuste para el modelo. En este artıculo se propone
una metodologıa que permite aumentar el numero de puntos de soporte del diseno
con el fin de que, con el diseno resultante, se pueda aplicar la prueba de bondad
de ajuste. Finalmente, se ejemplifica la metodologıa con un modelo exponencial.
Palabras clave: D-optimalidad bayesiano, bondad de ajuste, D-eficiencia, incre-
mento puntos experimentales, disenos optimos.
Abstract
One of the most frequent used criteria to obtain optimal designs is D-optimality
designs, which provides experimental points where the volume of confidence ellip-
soid associated to the vector of parameters in the proposed model is minimized.
Unlike the classical D-optimal design, the Bayesian D-optimal design does not
necessarily have as many support points as the model parameters. This article
considers the case where D-optimal design averaged by a specific a priori has as
many support points as the number of parameters of the model. This situation
aDocente tiempo completo. Fundacion Universitaria Los Libertadores, Colombia.bProfesor Asociado. Universidad Nacional de Colombia, sede Medellın, Colombia.
121

122 Cristian Fernando Tellez Pinerez & Vıctor Ignacio Lopez Rıos
may not be as favorable when the model is not specified with complete certainty,
since it would not be possible to conduct tests due to lack of fitness for the model.
This article proposes a methodology that allows increasing the number of support
points of the design in order that, with the resulting design, goodness of fitness
test can be applied. Finally, the methodology is exemplified with an exponential
model.
Keywords: Bayesian D-optimality, goodness of fit, D-efficiency, increase in expe-
rimental points, optimal designs.
1. Introduccion
En trabajos de investigacion, usualmente se tiene el interes de modelar el com-
portamiento de una variable de interes Y a traves de un conjunto de k−variables
explicativas x =(x1, x2, ..., xk), por medio de un modelo estadıstico que describa
esta posible relacion. Este modelo puede tener la forma:
Y (x) = η(x; θ) + ǫ, (1)
donde η(x; θ) es una funcion del vector de parametros desconocido θ ∈ Rp, x toma
valores en un espacio de diseno χ y ǫ, el error aleatorio, se asume que tiene media
cero y varianza constante σ2.
En este artıculo se analizara un modelo no lineal, en donde la matriz de informacion
depende de θ.
La teorıa de los disenos optimos en el contexto de la estadıstica bayesiana presen-
ta algunos resultados o criterios de optimalidad, que son utiles para determinar
las condiciones experimentales o niveles de las covariables donde se debe expe-
rimentar para obtener estimaciones optimas de los parametros del modelo bajo
estudio. Por ejemplo, Argumedo-Galvan & Lopez (2011) realizan una generaliza-
cion de la metodologıa propuesta por O’Brien (1995) para el aumento del numero
de puntos de soporte en un diseno D-optimo local. Cardona et al. (2012) realizaron
una caracterizacion de los disenos optimos obtenidos a traves de dos funciones de
utilidad asociados al D-optimalidad bayesiano para estimar en forma optima los
parametros de dos modelos no lineales, entre otras.
Este artıculo propone e implementa una estrategia que busca el aumento del nume-
ro de puntos experimentales del diseno D-optimo obtenido a partir de una distri-
bucion apriori. Para ello se adapta la propuesta de O’Brien (1995) y de Cardona
et al. (2012). Se deduce explıcitamente la expresion para la funcion de sensibilidad
asociada al criterio en terminos de una constante de ponderacion (δ), la eficiencia
que se quiere alcanzar con el nuevo diseno y el numero de parametros del mode-
lo. Se determina la mejor eleccion para δ, al maximizar la potencia de la prueba
de falta de ajuste del modelo en estudio. Finalmente, se evalua la bondad de la
metodologıa en el modelo exponencial, vıa simulacion.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Propuesta para aumentar los puntos experimentales 123
2. Diseno optimo bayesiano
A continuacion se ilustran algunos conceptos basicos de la teorıa clasica de disenos
optimos para modelos no lineales, y se dan resultados importantes del enfoque
bayesiano asociados con algunos criterios de optimalidad.
2.1. Diseno exacto
Sean x1, ..., xd una sucesion de d puntos distintos, y ri el numero de repeticiones
del punto xi, entonces se define un diseno exacto como una medida de probabilidad
discreta ξN , en el espacio de diseno χ, representado por:
ξ =
[x1 · · · xdr1N · · · rd
N
], (2)
donde∑d
i=1 ri = N , siendo N el numero total de corridas experimentales. La
primera fila denota los puntos del espacio de diseno, χ, donde toman las mediciones
de la variable respuesta y la segunda fila contiene los pesos wi = ξ(xi) = riN ,
indicando la proporcion de mediciones para ser tomadas en cada punto.
2.2. Diseno continuo
A diferencia del diseno exacto, los pesos wi pueden ser cualquier numero entre cero
y uno, no se exige que sean numeros racionales. Aunque en la practica todos los
disenos son exactos, desde el punto de vista de la obtencion de estos es recomen-
dable usar los disenos aproximados por las ventajas que ofrece el usar el analisis
convexo.
2.3. Matriz de informacion
Para cada diseno ξ se define la matriz de informacion:
M(ξ; θ) =
∫
χ
f(x; θ)fT (x; θ)dξ(x), (3)
y como el diseno es una medida discreta con soporte finito, entonces (3) es equi-
valente a:
M(ξ; θ) =d∑
i=1
f(xi; θ)fT (xi; θ)wi, (4)
donde f(x; θ) = ∂η(x;θ)∂θ . En este caso la matriz de informacion depende del vector
de parametros, θ.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

124 Cristian Fernando Tellez Pinerez & Vıctor Ignacio Lopez Rıos
2.4. Criterios de optimalidad
La teorıa de disenos optimos, Kiefer (1959), esta relacionada con la seleccion de
un diseno ξ que maximiza algun funcional de la matriz de informacion. Ası, los
criterios de optimalidad (Lopez & Ramos 2007) son definidos como juicios que
maximizan algun funcional real (con un significado estadıstico) de la matriz de
informacion sobre la clase de todos los disenos aproximados definidos en χ.
El criterio D-optimalidad se define como el siguiente funcional:
ψ (ξ) := ψ (M (ξ))
= |M−1 (ξ; θ) |. (5)
Busca aquel diseno que minimiza un funcional escalar de la varianza gene-
ralizada asintotica asociada a los estimadores de maxima verosimilitud del
vector de parametros dada por:
det(M−1 (ξ)
),
donde det(A) denota la funcion determinante de la matriz A. Segun lo ex-
puesto en Atkinson et al. (2007), es mas conveniente el uso de una funcion
convexa dada por el logaritmo natural, puesto que se facilitan los calculos
y ademas la funcion logaritmo natural del determinante es convexa, ası un
diseno ξD se dice que es D-optimo si minimiza − log(|M(ξ)|) o equivalente-
mente maximiza log(|M(ξ)|).
El criterio G-optimalidad, propuesto por Kiefer (1959), consiste en encontrar
el diseno que minimiza la varianza de la respuesta predicha mas grande. Es
decir, un diseno ξ∗ es G-optimo si minimiza el maximo de la funcion d (x; ξ, θ)sobre todo los x ∈ χ. Es decir,
mınξ
maxx∈χ
d (x; ξ, θ) = maxx∈χ
d (x; ξ∗, θ) (6)
donde d(x; ξ, θ) = fT (x; θ)M−1(ξ; θ)f(x; θ) representa la funcion de varianza
de la respuesta predicha estandarizada.
Existen otros criterios de optimalidad que no se exploran en este artıculo, pa-
ra ello se pueden consultar los trabajos de Lopez & Ramos (2007), Atkinson
et al. (2007).
2.5. Teorema de equivalencia para un diseno D-optimo
Kiefer &Wolfowitz (1959) mostraron la equivalencia entre el criterio D-optimalidad
y G-optimalidad, el cual se puede enunciar de la siguiente manera:
Un diseno ξ∗ con matriz de momentos M(ξ∗), definida positiva, es D-optimo sı y
solo si es G-optimo sı y solo si:
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Propuesta para aumentar los puntos experimentales 125
maxxǫχ
d(x; ξ∗) = p.
Donde p es el numero de parametros del modelo.
El maximo de la funcion de varianza de la respuesta predicha se obtiene en los
puntos de soporte del diseno D-optimo y es igual al numero de parametros del mo-
delo, en caso de D-optimalidad, el peso de cada punto de soporte es inversamente
proporcional a p, ωi =1p .
2.6. Eficiencia de un diseno
Una forma de medir la eficiencia de un diseno, ξ, con respecto al diseno Dπ(ξ)-optimo, ξ∗, es a partir del cociente del criterio de optimalidad evaluado tanto en
ξ, como ξ∗, es decir,
efDπ(ξ) =
Dπ (ξ)
Dπ (ξ∗), (7)
de donde 0 < efDπ(ξ) ≤ 1. Un diseno ξ es comparable con un diseno Dπ−optimo
en la medida que su eficiencia sea cercana a uno, (ver Lopez (2008)).
efD(ξ) =
[|M(ξ; θ)|
|M(ξ∗; θ)|
]1/p. (8)
Al tomar la p-esima raız cuadrada se obtiene una medida de eficiencia que tiene
las dimensiones de una razon de varianza. La efD(ξ) permite determinar la ca-
pacidad del diseno ξ para estimar de manera eficiente los parametros del modelo
en comparacion con el diseno D-optimo, ξ∗D. La D-eficiencia se puede interpretar
como el numero de replicas requeridas del diseno para que sea tan eficiente como
el diseno D-optimo (Atkinson et al. 2007).
2.7. Criterio D-optimalidad bayesiano
Los disenos D-optimos locales maximizan log|M (ξ; θ0) |, donde θ0 representa un
valor apriori de θ. Si ademas es posible tener una distribucion apriori π(θ) para el
vector de parametros θ, el diseno D-optimo promediado π(θ) puede ser obtenido
al maximizar:
Dπ(ξ) =
∫
Θ
log|M(ξ; θ)|π(θ)dθ, (9)
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

126 Cristian Fernando Tellez Pinerez & Vıctor Ignacio Lopez Rıos
donde Θ es el soporte de la distribucion π(θ). Para este criterio, se define la funcion
de sensibilidad para un diseno ξ, d(x; ξ), como:
d(x; ξ) =
∫
Θ
d(x; ξ, θ)π(θ)dθ, (10)
donde d(x; ξ, θ) = fT (x; θ)M−1(ξ; θ)f(x; θ). Un diseno que maximice la funcion
dada en (9) se denomina diseno Ψπ-optimo.
La matriz de informacion para un diseno D-optimo bayesiano, la cual depende de
un vector de parametros θ. esta dada por:
M (ξ; θ) =
∫
χ
f (x; θ) fT (x; θ) ξ (dx) ,
= =∑
x∈Soporte(ξ)
f(x; θ)fT (x; θ)ξ(x), (11)
Para este caso el teorema de equivalencia asociado es: un diseno ξ∗ es Dπ- optimo
si φ(x; ξ) = p−∫Θtr[fT (x; θ)M−1(ξ∗ : θ)f(x; θ)]π(θ) ≤ 0 y la igualdad se cumple
en los puntos de soporte del diseno.
La funcion φ(x; ξ) se conoce como la derivada direccional asociada al criterio de
optimalidad y varıa dependiendo del criterio utilizado (Atkinson et al. 2007).
En la Tabla 1 se muestra la derivada direccional asociada a diferentes versiones
del criterio de optimalidad bayesiano.
Tabla 1: Versiones del criterio de optimalidad bayesianos junto con su respectivaderivada direccional asociada. Fuente: elaboracion propia.
Criterio Ψ M (ξ; θ) Derivada direccional φ (x; ξ)
I Eθlog[|M−1|
]p− Eθ
trM−1M (ξx; θ)
II log[Eθ
(|M−1|
)]p− Eθ
|M−1|trM−1M (ξx; θ) /Eθ|M
−1|
III log[|Eθ
(M−1
)|]
p− Eθ
trM−1Eθ
(M−1
)M−1M (ξx; θ)
IV log[Eθ (|M |)]−1
p− Eθ
|M |trM−1M
(ξ; θ
)/Eθ|M |
V log[|Eθ (M) |]−1
p− tr (Eθ (M))−1
M (ξx; θ)
donde M−1 = M−1 (ξ; θ) . En este artıculo se utiliza la version I.
3. El problema de la falta de ajuste en el disenoD-optimo
La estrategia para obtener disenos con puntos extras ha sido trabajada por O’Brien
(1992), O’Brien (1995), Chaloner & Larntz (1989), entre otros. O’Brien (1995)
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Propuesta para aumentar los puntos experimentales 127
recomienda la siguiente estrategia para obtener disenos con puntos de soporte
extras:
3.1. Algoritmo
1. Encontrar el diseno D-optimo local, ξD. Este diseno tendra p puntos de
soporte (Gaffke 1987).
2. Construir el diseno:
ξN =p
p+ 1ξD +
1
p+ 1ξx, (12)
donde ξD es el diseno D-optimo local encontrado (1) y ξx es un diseno con
un solo punto, es decir, tiene concentrado todo su peso en el punto x.
3. Fijar un valor mınimo para la eficiencia que se desea alcanzar con el nuevo
diseno, denotado por de, valor entre 0 y 1, y encontrar los t valores de x tal
que:
d(x; ξD, θ0
)= p
[(p+ 1
pde
)p
− 1
]. (13)
4. Por ultimo, tomar como diseno seudo-optimo aquel diseno que tenga r1 repli-cas en los p puntos de soporte del diseno D-optimo ξD, y r2 replicas en los tpuntos de soporte obtenidos en el paso anterior.
La propuesta de O’Brien (1995) da igual peso a cada punto de soporte del nuevo
diseno, ξN , con lo cual surgen los siguientes interrogantes: ¿Que ocurre si la pon-
deracion dada a los nuevos puntos es δ y a los puntos del diseno Ψπ-optimo es
1− δ? ¿Que estrategias se pueden proponer para la escogencia del valor de δ?
La respuesta a ambos interrogantes sera el objetivo de las siguientes secciones.
4. Generalizacion
Se propone construir el nuevo diseno a partir de:
ξN = (1− δ)ξD + δξx, (14)
o de forma explıcita
ξN =
x1 · · · xp x1−δp · · · 1−δ
p δ
. (15)
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

128 Cristian Fernando Tellez Pinerez & Vıctor Ignacio Lopez Rıos
Donde ξD es el diseno Dπ-optimo asumiendo que este tiene p puntos de soporte, la
constante δ determina el peso en el diseno ξx, diseno que tiene su peso concentrado
en el punto x.
Una expresion equivalente para la funcion de sensibilidad del diseno Dπ usando el
nuevo diseno ξN = (1− δ) ξD + δξx y asumiendo la D-eficiencia del diseno ξN fija
se puede escribir como:
d(x; ξD) =
∫(|M (ξD; θ) |m − 1)
1− δ
δπ(θ)dθ. (16)
con m = εpfξD(ξN )− 1, εfξD (ξN ) la Dπ eficiencia del diseno ξN y p el numero de
parametros del modelo.
Con los x’s que satisfacen la ecuacion (16) y los puntos de soporte del diseno Dπ-
optimo, se forma el nuevo diseno ξN el cual tendra los p puntos del diseno Dπ y
los s nuevos puntos adicionales, es decir, tendra p+ s puntos de soporte.
A continuacion se muestra un algoritmo para la escogencia del δ.
4.1. Escogencia del δ
A partir del diseno Dπ-optimo, el numero de corridas experimentales (N), la efi-
ciencia del diseno ξN y una rejilla fija para δ, se encuentra el diseno ξiN dado por
(1− δi) ξD + δiξx para un δi fijo en la rejilla. El diseno ξN es transformado a un
diseno exacto de tamano N mediante la metodologıa de Fedorov & Hackl (1997).
Dado los disenos exactos asociados a cada δ en la rejilla, se define una estrategia
para determinar el peso δ (lo cual implica escoger uno o varios disenos) de tal forma
que el diseno resultante maximice la potencia de la prueba de falta de ajuste del
modelo propuesto. El algoritmo para calcular la potencia de la prueba de falta de
ajuste se desarrolla en dos pasos. En el primer paso se encuentra una distribucion
empırica para el estadıstico −2log (Λ) para muestras pequenas, donde Λ es la
razon de verosimilitud entre el modelo que se asume es correcto (modelo bajo
H0) y un modelo distinto al considerado, en el cual el conjunto de parametros sea
subconjunto del modelo anterior (modelo bajo H1). En el segundo paso se calcula
la potencia de la prueba. Es decir,
I. Distribucion del estadıstico −2log (Λ) en muestras pequenas
1. Fijar un numero de simulaciones Nsim.
2. Para el diseno exacto se calculan las medias; estas se calculan evaluando
los puntos de soporte del diseno exacto y usando como estimacion de θsu valor local, es decir,
µi = η (xi, θ0) , (17)
donde xi son los puntos de soporte del diseno.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Propuesta para aumentar los puntos experimentales 129
3. Para el diseno exacto, se simulan observaciones de la variable respuesta
segun el modelo para trabajar (Modelo bajo H0 cierta en la prueba de
falta de ajuste), para el que se asume que el termino del error es normal
con media cero, varianza constante e independientes y tomando como
varianza para el error la obtenida en un estudio previo.
4. Para las observaciones de la variable respuesta generada en el paso 3
y los puntos de soporte del diseno exacto, se hace el ajuste del mo-
delo propuesto mediante mınimos cuadrados no lineales (ajuste bajo
H0 cierta).
5. Para el ajuste en el paso 4, se calcula el estadıstico:
χo = −2log (Λ) , (18)
donde Λ es la razon de verosimilitudes entre el modelo bajo H0 (modelo
propuesto) y el modelo bajo H1(modelo general) en la prueba de falta
de ajuste.
6. Para el numero de simulaciones fijo Nsim se computa un vector de
cuantiles al 1, 5 y 10% de la distribucion empırica −2log (Λ) (QempA),
luego se incrementa ese numero de simulaciones, por ejemplo el doble
y se computa otro vector de cuantiles al 1,5 y 10% (QempB) y fijando
un error se calcula la norma euclidiana:
||QempA −QempB|| < ǫ, (19)
Si la diferencia en la ecuacion (19) es pequena, el numero de simulacio-
nes Nsim para la distribucion empırica de −2log (Λ) es aquella con la
que se obtuvo QempA, de lo contrario se incrementa y ası sucesivamente
hasta que se cumpla la ecuacion (19).
7. Se repiten los pasos 5 y 6 un numero Nsim de veces y se encuentra la
distribucion empırica del estadıstico −2log (Λ) para muestras pequenas.
II. Calculo de la potencia de la prueba de falta de ajuste del modelo
1. Se perturban las medias obtenidas en el paso 2 de la estimacion de la
distribucion empırica con un γ fijo; siendo γ el factor de perturbacion de
las medias; adicionalmente, se toma el cuadrado medio del error (MSE)
obtenido en un estudio previo como varianza para el error. Para el diseno
exacto, se simulan observaciones de la variable respuesta conforme el
modelo para trabajar, donde se asume que el termino del error es normal
con media cero, varianza constante y ademas independiente (modelo
bajo H1 cierto), es decir,
Yip = µip + ǫi, (20)
donde µip = µi ± γj , con γj una perturbacion fija. Las medias per-
turbadas para el diseno exacto, ǫi ∼ N (0,MSE) y Yip las respuestas
simuladas bajo H1 para el diseno.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

130 Cristian Fernando Tellez Pinerez & Vıctor Ignacio Lopez Rıos
2. Para el diseno exacto, con cada perturbacion de las medias, se hace el
ajuste del modelo propuesto mediante mınimos cuadrados no lineales
(ajuste bajo H0 falsa), es decir, se tienen tantos ajustes como pertur-
baciones hayan considerado.
3. Para cada ajuste en el paso 2, se calcula el estadıstico χ0 dado en la
ecuacion (18).
4. Se repiten los pasos del 1 al 3 Nsim veces y a partir de esto se obtiene la
potencia de la prueba de falta de ajuste para los niveles de significancia
del 1, 5 y 10% para el diseno exacto mediante:
Potencia de la prueba = P (rechazar H0|H0 falsa)
= P (χ0 > QEmpi)
=# de rechazos de la prueba
Nsim
Donde QEmpi es el vector de cuantiles calculado de la distribucion
empırica al 1, 5 y 10%. Se tendra por cada nivel de significancia tantas
potencias como perturbaciones haya.
5. Se promedian las potencias obtenidas en el paso 2 por cada nivel de
significancia y se toman estas como valor representativo.
Los procedimientos I y II deben ser repetidos para cada uno de los δ’s de
la rejilla.
5. Aplicacion de la metodologıa
Como una aplicacion para evidenciar los resultados obtenidos en este artıculo,
se utiliza un modelo de decrecimiento exponencial en un estudio que investiga la
accion conjunta de mezclas de acidos fenolicos en la inhibicion del crecimiento de
las raıces del tipo de hierba perennial ryegrass (Lolium perenne L.) y su significado
en investigacion alelopatica, datos tomados de Inderjit & Olofsdotter (2002). El
termino alelopatica se refiere a los efectos perjudiciales o beneficos que son directa
o indirectamente el resultado de la accion de compuestos quımicos que, liberados
por una planta, ejercen su accion en otra.
La idea es entonces, obtener disenos que maximicen la prueba de falta de ajus-
te para el modelo de decrecimiento exponencial. Para obtener estos disenos se
tomo como distribucion apriori, una distribucion uniforme discreta alrededor de
los valores locales ΘT = [θ0, θ1], con el fin de incorporar informacion asociada al
desconocimiento de estos parametros. A continuacion se muestra el procedimiento
para encontrar dichos disenos.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2
Propuesta para aumentar los puntos experimentales 131
5.1. Modelo y estimacion del modelo
Los datos correspondientes al estudio de la toxicidad del acido ferulico son presen-
tados en la Figura 1, donde se observa la tendencia exponencial de la longitud de
la raız en funcion de la concentracion.
Figura 1: Dispersion de los datos de longitud de la raız en terminos de la concen-tracion de acido ferulico. Fuente: elaboracion propia.
La parte determinıstica del modelo propuesto para explicar la relacion entre estas
dos variables es la siguiente:
η (x, θ0, θ1) = θ0exp
(−
x
θ1
), (21)
donde x es la concentracion de acido en la planta y la respuesta del modelo es
la longitud de la raız. En el modelo anterior la funcion que relaciona la variable
explicativa con la variable respuesta es no lineal en los parametros, los valores
ajustados de θ0 y θ1 se obtuvieron con la funcion nls de la librerıa nlstools del
paquete R, estos se muestran en la Tabla 2 y el modelo ajustado se muestra en la
Figura 2.
Tabla 2: Parametros estimados por mınimos cuadrados no lineales para el modelode decrecimiento exponencial. Fuente: elaboracion propia.
Estimacion Error estandar Valor t Pr(> |t|)θ0 9.2 0.65 13.98 0.00
θ1 4.1 0.58 7.03 0.00
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Propuesta para aumentar los puntos experimentales 131
5.1. Modelo y estimacion del modelo
Los datos correspondientes al estudio de la toxicidad del acido ferulico son presen-
tados en la Figura 1, donde se observa la tendencia exponencial de la longitud de
la raız en funcion de la concentracion.
Figura 1: Dispersion de los datos de longitud de la raız en terminos de la concen-tracion de acido ferulico. Fuente: elaboracion propia.
La parte determinıstica del modelo propuesto para explicar la relacion entre estas
dos variables es la siguiente:
η (x, θ0, θ1) = θ0exp
(−
x
θ1
), (21)
donde x es la concentracion de acido en la planta y la respuesta del modelo es
la longitud de la raız. En el modelo anterior la funcion que relaciona la variable
explicativa con la variable respuesta es no lineal en los parametros, los valores
ajustados de θ0 y θ1 se obtuvieron con la funcion nls de la librerıa nlstools del
paquete R, estos se muestran en la Tabla 2 y el modelo ajustado se muestra en la
Figura 2.
Tabla 2: Parametros estimados por mınimos cuadrados no lineales para el modelode decrecimiento exponencial. Fuente: elaboracion propia.
Estimacion Error estandar Valor t Pr(> |t|)θ0 9.2 0.65 13.98 0.00
θ1 4.1 0.58 7.03 0.00
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

132 Cristian Fernando Tellez Pinerez & Vıctor Ignacio Lopez Rıos
0 5 10 15 20 25 300
24
68
Concentración
Cre
cim
ient
o
Figura 2: Curva ajustada para modelo de decrecimiento exponencial. Fuente: ela-boracion propia.
5.2. Diseno Dπ-optimo para el modelo de decrecimiento
exponencial
A continuacion se mostrara el procedimiento para hallar un diseno Dπ-optimo
cuando la distribucion π es una distribucion uniforme discreta. En este caso el
diseno Dπ-optimo sera aquel que minimice la siguiente funcion:
ψ (ξ) =
∫
Θ
− log |M(ξ, θ)|dπ(θ) =d∑
i=1
− log |M(ξ, θi)|1
d, (22)
donde d es el numero de puntos de la distribucion uniforme considerada. Los datos
de la distribucion uniforme considerada son mostrados en la Tabla 3:
Tabla 3: Observaciones de la distribucion uniforme. Fuente: elaboracion propia
θ0 θ19.44667 3.6234
10.49630 3.6234
13.64519 3.6234
9.44667 3.2940
10.49630 3.2940
13.64519 3.2940
9.44667 2.3058
10.49630 2.3058
13.64519 2.3058
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2
Propuesta para aumentar los puntos experimentales 133
Para obtener la matriz de informacion se requiere calcular las derivadas de la
funcion η con respecto a cada parametro, dichas derivadas son mostradas en el
siguiente vector:
f(x; θ0, θ1) =
exp
−
x
θ1
,θ0xexp
− x
θ1
θ21
T
. (23)
Para minimizar la funcion dada en la ecuacion (22), se utilizo la funcion nlminbde la librerıa DEoptim del paquete estadıstico R Development Core Team. Se
verifico que la funcion de sensibilidad asociada alcanzaba su maximo en p = 2,
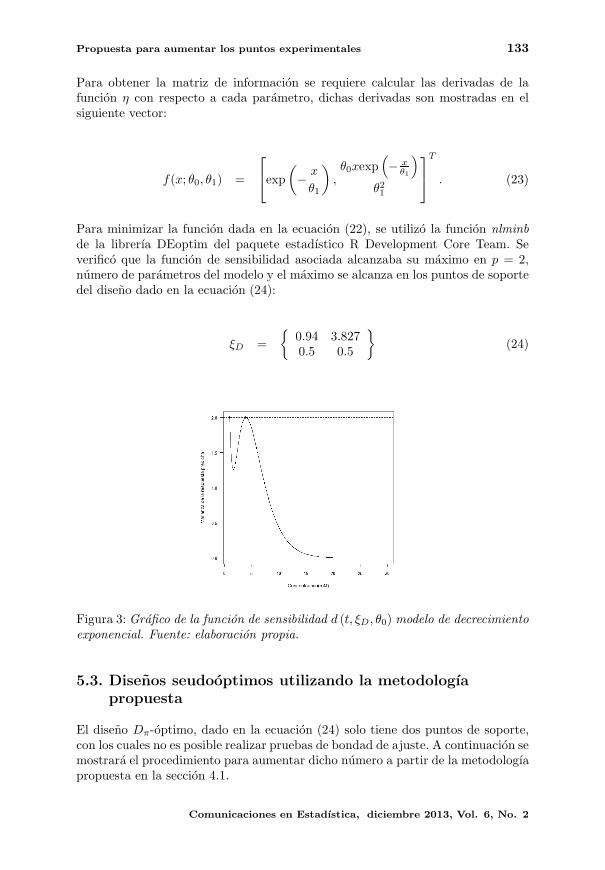
numero de parametros del modelo y el maximo se alcanza en los puntos de soporte
del diseno dado en la ecuacion (24):
ξD =
0.94 3.8270.5 0.5
(24)
Figura 3: Grafico de la funcion de sensibilidad d (t, ξD, θ0) modelo de decrecimientoexponencial. Fuente: elaboracion propia.
5.3. Disenos seudooptimos utilizando la metodologıapropuesta
El diseno Dπ-optimo, dado en la ecuacion (24) solo tiene dos puntos de soporte,
con los cuales no es posible realizar pruebas de bondad de ajuste. A continuacion se
mostrara el procedimiento para aumentar dicho numero a partir de la metodologıa
propuesta en la seccion 4.1.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

134 Cristian Fernando Tellez Pinerez & Vıctor Ignacio Lopez Rıos
En la Tabla 4 se muestran los disenos seudo-optimos donde se incorpora el nuevo
punto que satisface la ecuacion (16) donde δ ∈ (0.285, 0.5) con incrementos de 0.05,N = 20 corridas experimentales y EfξDπ
(ξN ) = 0.95. Los lımites del intervalo para
δ se escogieron de tal forma que existiera solucion para la ecuacion (16) y con la
condicion de que el nuevo diseno otorgara al menos el 50% al diseno D-optimo.
Tabla 4: Disenos seudo-optimos con tres puntos de soporte. Fuente: elaboracionpropia
δ ξN
0.285 ξN1=
0.94 3.827 6.8220.35 0.35 0.3
0.335 ξN2=
0.94 3.827 7.630.35 0.35 0.3
0.385 ξN3=
0.94 3.827 8.3140.3 0.3 0.4
0.435 ξN4=
0.94 3.827 8.930.27 0.27 0.46
0.485 ξN5=
0.94 3.827 9.500.25 0.25 0.5
5.4. Distribucion empırica del estadıstico −2Log(Λ) y calculode potencia de los disenos seudooptimos
La metodologıa consiste en escoger los disenos que maximicen la prueba de falta
de ajuste del modelo. Siguiendo el algoritmo mostrado en la seccion 4.1. En la
Tabla 5 se muestra el numero de simulaciones y la diferencia, en norma, de los
cuantiles calculados con las distribuciones empıricas.
De acuerdo con los resultados de la Tabla 5 y con un ǫ = 0.05, el numero de
simulaciones apropiado para encontrar la distribucion empırica del estadıstico
−2Log(Λ) es Nsim = 10000 para los disenos ξN1hasta ξN4
y para el diseno ξN5es
de Nsim = 5000.
Tabla 5: Normas de las diferencias de los cuantiles para distintos Nempi. Fuente:elaboracion propia
Nempi ||QempA,(1−α) −QempD,(1−α)||ξN1
ξN2ξN3
ξN4ξN5
500 0.26 0.36 0.231 0.31 0.16
1000 0.20 0.27 0.20 0.24 0.09
2000 0.11 0.14 0.128 0.16 0.07
5000 0.08 0.09 0.11 0.07 0.028
10000 0.03 0.012 0.02 0.019 0.0152
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Propuesta para aumentar los puntos experimentales 135
Para determinar la mejor eleccion de la constante de ponderacion δ, se realiza un
estudio de simulacion descrito en la seccion 4.1, de tal forma que el diseno para
escoger sera aquel que maximice la potencia de la prueba de falta de ajuste.
Despues de realizar el proceso de simulacion propuesto se halla el grafico de las
potencias para los cinco disenos seudo-optimos con diferentes valores de α, verFigura 4. Se observa que el diseno seudo-optimo que presenta la mayor potencia
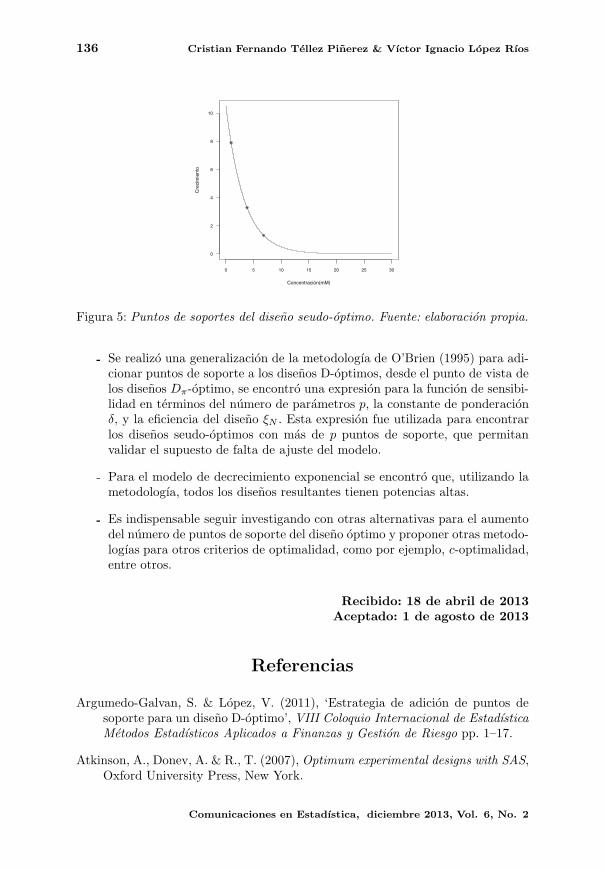
de la prueba de falta de ajuste es el diseno ξN1el cual es:
ξN1=
0.94 3.827 6.8220.35 0.35 0.3
, (25)
Figura 4: Potencia de la prueba de falta de ajuste con N = 20. Fuente: elaboracionpropia.
Este diseno permite validar el supuesto de falta de ajuste del modelo, lo cual como
ya se menciono, es muy util cuando no se tiene certeza del modelo. Tambien, se
interpreta de la siguiente manera: de las 20 corridas experimentales, siete se deben
realizar con una concentracion de 0.94 mM, otras siete con una concentracion de
3.827 mM y las 6 restantes se haran con una concentracion 6.822 mM.
En la Figura 5 se muestra el grafico de dispersion con los puntos de soporte del
diseno (25).
6. Conclusion y discusion
A partir del estudio realizado en este artıculo, con el fin de aumentar el numero
de puntos de soporte en un diseno Dπ-optimo se puede concluir lo siguiente:
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2
136 Cristian Fernando Tellez Pinerez & Vıctor Ignacio Lopez Rıos
0 5 10 15 20 25 30
0
2
4
6
8
10
Concentración(mM)
Cre
cim
ient
o
Figura 5: Puntos de soportes del diseno seudo-optimo. Fuente: elaboracion propia.
Se realizo una generalizacion de la metodologıa de O’Brien (1995) para adi-
cionar puntos de soporte a los disenos D-optimos, desde el punto de vista de
los disenos Dπ-optimo, se encontro una expresion para la funcion de sensibi-
lidad en terminos del numero de parametros p, la constante de ponderacion
δ, y la eficiencia del diseno ξN . Esta expresion fue utilizada para encontrar
los disenos seudo-optimos con mas de p puntos de soporte, que permitan
validar el supuesto de falta de ajuste del modelo.
Para el modelo de decrecimiento exponencial se encontro que, utilizando la
metodologıa, todos los disenos resultantes tienen potencias altas.
Es indispensable seguir investigando con otras alternativas para el aumento
del numero de puntos de soporte del diseno optimo y proponer otras metodo-
logıas para otros criterios de optimalidad, como por ejemplo, c-optimalidad,
entre otros.
Recibido: 18 de abril de 2013
Aceptado: 1 de agosto de 2013
Referencias
Argumedo-Galvan, S. & Lopez, V. (2011), ‘Estrategia de adicion de puntos de
soporte para un diseno D-optimo’, VIII Coloquio Internacional de EstadısticaMetodos Estadısticos Aplicados a Finanzas y Gestion de Riesgo pp. 1–17.
Atkinson, A., Donev, A. & R., T. (2007), Optimum experimental designs with SAS,Oxford University Press, New York.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Propuesta para aumentar los puntos experimentales 137
Cardona, J., Lopez, V. I. & Correa, J. C. (2012), ‘Disenos optimos bayesianos para
estimacion de parametros en farmacocinetica’, Comunicaciones en Estadıstica5(1), 97–112.
Chaloner, K. & Larntz (1989), ‘Optimal bayesian design applied to logistic regres-
sion experiments’, Journal of Statistical 1, 191–208.
Fedorov, V. & Hackl, P. (1997), ‘Model oriented design of experiments.’, LectureNotes in Statistics .
Gaffke, N. (1987), ‘On D-optimality of exact linear regression designs with mini-
mum support’, Journal of Statistical Planning and Inference 15, 189–204.
Inderjit, J. C. & Olofsdotter, M. (2002), ‘Joint action of phenolic acid mixtures and
its significance in allelopathy research’, Physiologia Plantarum 114, 422–428.
Kiefer, J. (1959), ‘Optimum experimental designs’, Journal of the Royal StatisticalSociety 21, 272–319.
Kiefer, J. & Wolfowitz, J. (1959), ‘Optimum designs in regression problems’, An-nals of Mathematical Statistics 30(2), 271–294.
Lopez, V. I. (2008), Disenos optimos para discriminacion y estimacion en mode-
los no lineales, PhD thesis, Centro de Investigacion en Matematicas, A.C,
Guanajuato, Mexico.
Lopez, V. I. & Ramos, R. (2007), ‘Una introduccion a los disenos optimos’, RevistaColombiana de Estadıstica 30(1), 37–51.
O’Brien, T. (1992), ‘A note on quadratic designs for nonlinear regression models’,
Biometrika 79, 847–859.
O’Brien, T. (1995), ‘Optimal design and lack of fit in nonlinear regression models’,
Statistical modelling, Lecture Notes in Statistics 104, 201–206.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2


Comunicaciones en EstadısticaDiciembre 2013, Vol. 6, No. 2, pp. 139–156
Copulas en geoestadıstica o lo que se puede hacer
con coordenadas y estructuras de dependencia
Copulas in geostatistic or what can be done with coordinates and
dependency structures
Danna Lesley Cruz Reyesa
Resumen
Es comun en geoestadıstica utilizar metodos como el variograma o el coeficiente
de correlacion para describir la dependencia espacial, y kriging para realizar inter-
polacion y prediccion, pero estos metodos son sensibles a valores extremos y estan
fuertemente influenciados por la distribucion marginal del campo aleatorio. Por
tanto, pueden conducir a resultados poco fiables. Como alternativa a los mode-
los tradicionales de geoestadıstica se considera el uso de las funciones copula. La
copula es ampliamente usada en el campo de las finanzas y ciencias actuariales y
debido a sus resultados satisfactorios empezaron a ser consideradas en otras areas
de aplicacion de las ciencias estadısticas. En este trabajo se muestra el efecto de
las copulas como una herramienta que presenta un analisis geoestadıstico bajo to-
do el rango de cuantiles y una estructura de dependencia completa, considerando
modelos de tendencia espacial, distribuciones marginales continuas y discretas y
funciones de covarianza. Se presentan tres metodos de interpolacion espacial: el
primero corresponde al indicador kriging y kriging disyuntivo, el segundo metodo
se conoce como el kriging simple y el tercer metodo es una prediccion plug-in y la
generalizacion del kriging trans-gaussiano. Estos metodos son utilizados con base
en la funcion copula debido a la relacion que existe entre las copulas bivariadas y
los indicadores de covarianzas. Se presentan resultados obtenidos para un conjunto
de datos reales de la ciudad de Gomel que contiene mediciones de isotopos radio-
activos, consecuencia del accidente nuclear de Chernobil. Finalmente, se estudian
las copulas discretas y se aplican a un conjunto de datos simulados, esto permite
realizar una extension a los trabajos usuales de copulas en geoestadıstica.
Palabras clave: copulas, geoestadıstica, estadıstica espacial, estadıstica compu-
tacional, tendencia.
aInvestigadora Semillero IPREA. Departamento de Matematicas. Universidad Distrital Fran-cisco Jose de Caldas. Colombia
139

140 Danna Lesley Cruz Reyes
Abstract
It is common in geostatistics to use methods such as the variogram or the correla-
tion coefficient to describe spatial dependence, and kriging to make interpolation
and predictions, but these methods are sensitive to extreme values and are strongly
influenced by marginal distribution of the random field. Hence they can lead to
unreliable results. As an alternative to traditional models in geostatistics are con-
sidered the use of the copula functions. Copula is widely used in the finance and
actuary fields and due to satisfactory results they started to be considered in other
areas of application of statistical sciences. This work shows the effect of copulas
as a tool that presents a geostatistical analysis under the range of quantiles and
a dependence structure, considering models of spatial tendency, continuous and
discrete marginal distributions and covariance functions. Three interpolation met-
hods are shown: the first is the kriging indicator and disjunctive kriging, the second
method is known as the simple kriging and the third method is a plug-in prediction
and the generalization of the trans-Gaussian kriging, these methods are used based
on the copula function due to the existing relationship between bivariate copulas
and covariance indicators. Results are presented for a set of actual data in the city
of Gomel that contains measurements of radioactive isotopes, consequence of the
Chernobyl nuclear accident. Finally, discrete copulas are studied and applied to
a set of simulated data, this allows an extension of the usual works of copulas in
Geostatistics.
Keywords: copulas, geostatistics, spatial statistics, computational statistics, trend.
1. Introduccion
Las copulas describen la estructura de dependencia entre variables aleatorias, no es
extrano que la palabra copula insinua vınculo o union, proviene del latın y su signi-
ficado es conexion o lazo que une dos cosas distintas, fue utilizada por primera vez
por Sklar en su celebre teorema en 1959, para describir funciones de distribucion
multivariadas definidas sobre el cubo unidad [0, 1]n enlazando variables aleatorias
con funciones de distribucion de una sola dimension (Ayyad et al. 2008).
En geoestadıstica se analizan las realizaciones de un campo aleatorio Z(s) : s ∈D donde D ⊂ R
n, cuya realizacion, z(s) representa el valor de interes registrado
en la medicion con respecto a cierto sistema de referencia s.
En la actualidad existen herramientas para modelar la variabilidad espacial. La
primera fue usada en principios de los cincuenta por Danie G. Krige, en Sudafrica,
para ampliar tecnicas estadısticas para la estimacion de las reservas de minerales
(Bardossy & Li 2008). En los anos sesenta el trabajo de Krige fue formalizado por
el matematico Georges Matheron, desde entonces ha sido ampliamente utilizado
en areas como la minerıa, la industria petrolera, hidrologıa, meteorologıa, ocea-
nografıa, el control del medio ambiente, la ecologıa del paisaje y la agricultura.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Copulas en geoestadıstica 141
A pesar de estos desarrollos, el modelado espacial a menudo se basa en hipotesis
gaussianas, que muchas veces no se consideran realistas para los tipos de datos y
se reportan datos atıpicos que causan problemas en las investigaciones (Bardossy
& Li 2008).
Bardossy en el ano 2006 fue el pionero en proponer el uso de copulas para des-
cribir variabilidad espacial, Bardossy & Li (2008) realizan modelacion de campos
aleatorios continuos, Kazianka & Pilz (2010) adoptan la metodologıa de Bardossy
y realiza una extension considerando modelos de tendencia y campos aleatorios
discretos, Kazianka & Pilz (2011) muestran como se incorporan en un marco ba-
yesiano mediante la asignacion de probabilidades apriori de todos los parametros
del modelo, en este trabajo se propone una extension a estos modelos incluyendo
las copulas radialmente asimetricas que resultan mas eficientes que las hasta ahora
usadas.
Con el fin de describir la estructura de dependencia en un campo aleatorio en el
area de geoestadıstica, se enfoca en los metodos clasicos como propiedades de sua-
vizamiento de los campos aleatorios, la funcion de autocorrelacion, variogramas y
tecnicas para la interpolacion espacial, kriging simple, kriging universal, cokriging,kriging disyuntivo, kriging bayesiano entre otros (Diggle & Ribeiro 2007). En este
trabajo se presenta el analisis de estructura de dependencia a traves de copulas
proponiendo una familia de copulas radialmente asimetricas.
Bardossy & Li (2008) proponen una familia de distribuciones que se obtienen a
traves de una transformacion no-monotonica de la copula gaussiana multivariante,
llamada copula V−transformada. En este trabajo se proponen dos extensiones
de esta metodologıa: la primera es la inclusion de tendencia y la segunda es el
metodo de indicador kriging e interpolacion usando copulas que se presentaran
mas adelante.
El trabajo se organiza de la siguiente manera. La seccion 2, describe como las
copulas seran implementas en los campos aleatorios, en la seccion 3, se presenta
un metodo de exploracion de datos utilizando las funciones copula. La seccion 4 se
refiere a la copula gaussiana mientras que la Seccion 5 se presenta la familia de las
copulas no gaussianas. Los resultados de la estimacion y la copula son presentados
en la Seccion 6, para analizar el conjunto de datos llamados Gomel, en la Seccion
7 se presentan copulas discretas y finalmente, en la ultima seccion se presentan las
conclusiones.
2. Descripcion del campo aleatorio usando copulas
Bardossy (Bardossy & Li 2008) presento un metodo diferente a los metodos clasi-
cos mencionados en la introduccion para el modelado de dependencia espacial
por medio de copulas, se pretende describir todas las distribuciones multivariadas
necesarias del campo aleatorio por medio de copulas.
Se asume un campo aleatorio estacionario Z(x)|x ∈ D, donde D ∈ R2 es el
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

142 Danna Lesley Cruz Reyes
area de interes. Se nota h el vector de separacion entre dos puntos. Sea FZ la
distribucion univariante del proceso espacial, debido a que el campo aleatorio es
estacionario FZ es la misma para cada localizacion x ∈ D.
Con el teorema de Sklar, se puede establecer un modelo multivariante del campo
tomando FZ = F1 = F2 = · · · = Fn tal que, su destitucion conjunta H(x1, . . . , xn)
de las variables x1, . . . , xn,
H(x1, . . . , xn) = C(F1, F2, . . . , Fn), (1)
Entonces, la relacion entre dos localizaciones separadas por el vector h esta carac-
terizada por la distribucion bivariante:
P (Z(x) ≤ z1, Z(x+ h) ≤ z2) = Ch(FZ(z1), FZ(z2)),
Por tanto, la estructura de dependencia quedarıa descrita por la funcion copula
Ch en funcion del vector h, esto implica que la copula podrıa describir la estruc-
tura completa de dependencia a diferencia de los variogramas que solo describen
con respecto a la media. Por otro lado, la eleccion de la copula C sera determi-
nada aplicando varias familias de copulas al modelo y comparando los diferentes
resultados.
Es de esperarse que no todas las familias de copulas continuas sean apropiadas para
este modelo, de manera natural se puede suponer una copula simetrica, debido a
que la dependencia entre dos localizaciones x1 y x2 es la misma que x2 y x1, de
manera general se tiene que:
Ch(u1, . . . , un) = Ch(uπ(1), . . . , uπ(1)), (2)
para una permutacion arbitraria π.
Ademas, se deben anadir las siguientes restricciones:
Cuando h → ∞ entonces, Ch(u) → Πn(x), ya que se quiere independencia
sobre localizaciones muy alejadas entre sı,
Cuando h → 0 entonces, Ch(u) → Mn(x) o equivalentemente, en localiza-
ciones muy proximas entre sı, se quiere dependencia muy fuerte.
Donde, la Πn(x) representa la copula de independencia y Mn(x) la copula mınima.
Estas condiciones son fundamentales para la construccion de la copula, permite
realizar un filtro de las copulas que se podrıan proponer, por ejemplo, la familia
Farlie-Gumbel-Morgenstern, no son utiles.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2
Copulas en geoestadıstica 143
3. Copulas empıricas bivariadas
Las copulas empıricas son usadas por primera vez en el area de geoestadıstica,
por Haussler quien implemento las copulas bivariadas empıricas, describiendo la
estructura de dependencia entre variables aleatorias. En este artıculo se consideran
este tipo de copulas como una metodologıa de exploracion de datos, de tal forma
que se pueda considerar la forma de la distribucion que puedan tener, para esto
el campo aleatorio debe cumplir la condicion de estacionariedad fuerte y como
consecuencia se pueden obtener las siguientes ventajas (Haslauer et al. 2010):
La distribucion marginal, que podrıa distorsionar la estructura de depen-
dencia, se filtra usando copulas. Ası, quedarıa definida unicamente por los
datos.
La copula permiten una mejora en la cuantificacion de la incertidumbre en
la interpolacion.
Un modelo estocastico completo es la columna vertebral para el analisis
geoestadıstico.
3.1. Algoritmo para la aplicacion de las copulas empıricasbivariadas
Las copulas son usadas para explorar la estructura de dependencia entre dos va-
riables aleatorias sin considerar las distribuciones marginales de cada variable. Las
copulas empıricas son el caso mas simple de construccion, pero no es computacio-
nalmente optimo, aun ası, estas copulas se pueden evaluar en diferentes direcciones
y angulos para cada par de puntos y generar una idea de la forma de la estructura
de dependencia del campo aleatorio.
Segun Haslauer (Haslauer et al. 2010) se debe considerar el campo aleatorio es-
tacionario, la construccion de la copula correspondiente se puede realizar con el
siguiente algoritmo:
1. Se calcula la copula empırica marginal FZ(z) de las observaciones.
2. Para algun vector h dado, se calcula el conjunto S(h):
S(h) = (FZ(z(si)), FZ(z(sj)))||si − sj | ≈ h (3)
3. Debido a que S(h) es un conjunto de pares de puntos definidos en el cuadrado
unidad, se puede calcular la funcion de densidad de la copula empırica dado
un vector h usando la siguiente ecuacion:
gi,j = c∗(2i− 1
2k,2j − 1
2k
)
=k2
|S(h)|; (u, v) ∈ S(h)|
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Copulas en geoestadıstica 143
3. Copulas empıricas bivariadas
Las copulas empıricas son usadas por primera vez en el area de geoestadıstica,
por Haussler quien implemento las copulas bivariadas empıricas, describiendo la
estructura de dependencia entre variables aleatorias. En este artıculo se consideran
este tipo de copulas como una metodologıa de exploracion de datos, de tal forma
que se pueda considerar la forma de la distribucion que puedan tener, para esto
el campo aleatorio debe cumplir la condicion de estacionariedad fuerte y como
consecuencia se pueden obtener las siguientes ventajas (Haslauer et al. 2010):
La distribucion marginal, que podrıa distorsionar la estructura de depen-
dencia, se filtra usando copulas. Ası, quedarıa definida unicamente por los
datos.
La copula permiten una mejora en la cuantificacion de la incertidumbre en
la interpolacion.
Un modelo estocastico completo es la columna vertebral para el analisis
geoestadıstico.
3.1. Algoritmo para la aplicacion de las copulas empıricasbivariadas
Las copulas son usadas para explorar la estructura de dependencia entre dos va-
riables aleatorias sin considerar las distribuciones marginales de cada variable. Las
copulas empıricas son el caso mas simple de construccion, pero no es computacio-
nalmente optimo, aun ası, estas copulas se pueden evaluar en diferentes direcciones
y angulos para cada par de puntos y generar una idea de la forma de la estructura
de dependencia del campo aleatorio.
Segun Haslauer (Haslauer et al. 2010) se debe considerar el campo aleatorio es-
tacionario, la construccion de la copula correspondiente se puede realizar con el
siguiente algoritmo:
1. Se calcula la copula empırica marginal FZ(z) de las observaciones.
2. Para algun vector h dado, se calcula el conjunto S(h):
S(h) = (FZ(z(si)), FZ(z(sj)))||si − sj | ≈ h (3)
3. Debido a que S(h) es un conjunto de pares de puntos definidos en el cuadrado
unidad, se puede calcular la funcion de densidad de la copula empırica dado
un vector h usando la siguiente ecuacion:
gi,j = c∗(2i− 1
2k,2j − 1
2k
)
=k2
|S(h)|; (u, v) ∈ S(h)|
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

144 Danna Lesley Cruz Reyes
donde i−1k < u < i
k ,j−1k < v < j
k , y |S(h)| denota el numero de parejas que
tienen como vector de separacion h.
4. Copula gaussiana
Debido a que los campos aleatorios mas importantes son los gaussianos, es de espe-
rarse que las copulas tambien lo sean, la copula gaussiana definida en la ecuacion 4
con marginal FZ = Φµ,σ2 , donde µ y σ denota la media y varianza respectivamente,
es muy utilizada en campos aleatorios,
CGΣ = Φ0,Σ(Φ
−1(u1), . . . ,Φ−1(un)). (4)
Las ventajas de trabajar con estas copulas es que son invariantes bajo transforma-
ciones estrictamente crecientes de las variables aleatorias, ademas de cumplir con
las condiciones anteriormente dadas para campos aleatorios. La copula gaussiana
se convierte en una funcion de h, suponiendo que la funcion de correlacion sigue
uno de los modelos parametricos conocidos, por ejemplo, el modelo Matern.
La copula gaussiana toma la forma:
C(u1, u2; θ) = ΦG(Φ−1(u1),Φ
−1(u2)),
donde Φ es la funcion de distribucion normal estandar y ΦG(u1, u2) es la distri-
bucion normal bivariada con parametro de correlacion θ restringido al intervalo
(−1, 1).
La copula normal permite por igual, grados de dependencia positiva o negativa,
y por esto que es una de las mas utilizadas. Pero a pesar de esto, esta copula
es simetrica y en muchos casos, los datos reales no cumplen esta propiedad; para
solucionar este problema se utiliza una nueva familia de copulas que permiten
asimetrıa en los datos y se presenta en la siguiente seccion.
5. Familia de copulas no gaussianas
En este capıtulo se presenta una familia de copulas asimetricas multivariadas no
gaussianas, debido a la necesidad que surge en geoestadıstica para solucionar la
asimetrıa por naturaleza de este tipo de datos, la copula gaussiana no solo expresa
simetrıa, sino tambien dependencia de simetrıa radial, tal que los cuantiles altos y
bajos de la distribucion tienen propiedades iguales de dependencia. Este supuesto
pocas veces se cumple con datos reales.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Copulas en geoestadıstica 145
La construccion de una familia de copulas no es trivial, actualmente existen nu-
merosas copulas, pero no cumplen las condiciones necesarias para ser utilizadas
en geoestadıstica, y en otros casos la construccion es imposible debido a pro-
blemas computacionales. Por tanto, se presenta la siguiente definicion de copula
V-transformada:
Sea Y ∼ N(0,Γ) una variable aleatoria n− dimensional con media 0T = (0, . . . , 0)y matriz de correlacion Γ. Todas las marginales se suponen con varianza unitaria.
Sea X definida para cada coordenada j = 1, . . . , n de tal forma:
Xj =
k(Yj −m)α Yj ≥ m,
m− Yj Yj < m,
donde k es una constante positiva y α y m numeros reales arbitrarios, a manera de
ejemplo, en la Figura 1, se presentan algunas transformaciones, se puede observar
que la copula recibe este nombre debido a la forma de V en la grafica.
−2.5 −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 2.50
0.5
1
1.5
2
2.5
3
3.5
Variable Normal
Nor
mal
tran
form
ada
m=0, k=1, alpha=1m=0.5, k=2.5, alpha =0.5m=0.5, k=2, alpha =0.5
Figura 1: Transformaciones V -normal. Fuente: elaboracion propia.
La funcion de distribucion marginal de X es:
H(x) = P (X ≤ x)
= P (Y <(xk
) 1
α
+m) + P (Y > x−m)
= Φ((xk
) 1
α
+m)− Φ(−x+m)
y la funcion de densidad:
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

146 Danna Lesley Cruz Reyes
h(x) =1
kα
(xk
) 1
α−1
φ((xk
) 1
α
+m) + φ(−x+m)
tal que Φ(.) y φ(.) son las funciones de distribucion y densidad de la normal
estandar, respectivamente.
La consecuencia mas importante es que para valores menores que m, los cuales
son los valores menores en el espacio original, se convierten, en el nuevo espacio en
los valores mayores; tal que el valor m se convierte en el valor mas pequeno para
el nuevo espacio, en cuanto a los valores mayores que m en el espacio original,
la transformacion produce un concentramiento o una division dependiendo de la
configuracion de k y α. Este efecto produce que la dependencia asociada con los
valores cercanos o iguales a m influya en la dependencia de los valores bajos en el
nuevo espacio (Jing 2010).
El efecto de la transformacion tambien puede explicarse por el cambio en la distri-
bucion marginal. La Figura 2 muestra como la densidad en la distribucion cambia
despues de la transformacion. Se pueden notar las siguientes caracterısticas:
Por lo general, los datos se dispersan despues de la transformacion.
Si los valores de k y α son invariables, pero el valor de m incrementa, la den-
sidad esta mas concentrada a la mediana y la distribucion es mas simetrica.
Si k = 1, α = 1 la transformada V−normal se aproxima a la distribucion χ2
con un grado de libertad.
La Figura 3 muestra la densidad de algunas copulas bivariadas, en todos los casos
ρ = 0.8 pero m va aumentando, tal que m = 0, 1.3, 15 y 50. Se puede notar que
las copulas son asimetricas y similares a los resultados de la distribucion empırica.
Ademas, cada vez que incrementa m la distribucion es mas simetrica, ası que se
puede concluir que si m → ∞ la copula converge a la copula gaussiana (Jing 2010).
Para m = 0, k = 1 y α = 1 la copula que se genera es la copula χ2, en la figura se
ubica en la esquina superior derecha.
6. Catastrofe en Chernobil
En abril de 1986, ocurrio el peor accidente nuclear en Chernobil en la antigua
Union Sovietica (ahora Ucrania). La central nuclear de Chernobil, situada a 100
kilometros al norte de Kiev, tenıa 4 reactores. En un dıa de abril a las 1:23 a.m.
la reaccion en cadena en un reactor perdio el control, la creacion de explosiones
y una bola de fuego volo el acero pesado del reactor y la tapa de concreto. El
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Copulas en geoestadıstica 147
Figura 2: Transformaciones V -Normal con parametros: m = 0, k = 1 y α = 1
(esquina superior izquierda), m = 0, k = 3 y α = 1 (esquina superior derecha),m = 0, k = 2.5 y α = 0.5 (esquina inferior izquierda) y m = 1, k = 2.5 y α = 0.5(esquina inferior izquierda). Fuente: elaboracion propia.
Figura 3: Copula V−transformada normal. Fuente: elaboracion propia.
desastre destruyo el reactor Chernobil-4 y mato a 30 personas, entre ellas 28 por
exposicion a la radiacion, 209 mas fueron tratadas por envenenamiento agudo por
radiacion y entre estos, 134 casos fueron confirmados. Grandes areas de Bielorrusia,
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2
148 Danna Lesley Cruz Reyes
Ucrania, Rusia y mas alla estaban contaminadas en diversos grados. El desastre
de Chernobil fue un evento unico y el unico accidente en la historia de la energıa
nuclear comercial. Ahora, 26 anos despues del accidente todavıa mas de 3 millones
de ninos sufren de estos efectos, la zona alrededor del reactor todavıa esta muy
contaminada, la naturaleza esta muerta y no hay vida silvestre. En la region de
Gomel el gobierno ruso construyo una red donde se estudia la concentracion de la
cantidad de radiactividad. El conjunto de datos que se utiliza son mediciones de
Cs137, un isotopo radiactivo.
Se analiza el conjunto de datos que corresponde a 148 localizaciones xi = (x1i, x2i)T ,
i = 1, . . . , 148 en la region de Gomel. Los datos son observados diez anos despues
del accidente de Chernobil. En la Figura 4 se muestran las realizaciones donde se
encontro el isotopo radiactivo (cruces rojas), se puede ver que la mayorıa de los
valores son pequenos, sin embargo, en la parte noreste, noroeste y sur de la region
algunos valores relativamente grandes se producen.
El analisis de datos en copulas bivariadas permite la prediccion, en la Figura 4
se muestran las localizaciones observadas marcadas con una x roja, y los puntos
azules la grilla de interpolacion, donde se realizaran las respectivas predicciones.
−150 −100 −50 0 50 100 150−150
−100
−50
0
50
100
150
Figura 4: Observaciones y datos interpolados de los datos de Gomel. Fuente: ela-boracion propia.
Para encontrar una marginal univariada apropiada, se prueban las distribuciones
univariadas normal, gamma, transformacion box-cox, el valor generalizado extremo
(GEV) y la distribucion de log-normal, para todas ellas se calculan las estimaciones
de maxima verosimilitud, asumiendo que las observaciones son independientes. De
esta forma, la eleccion que se toma sera de la distribucion marginal box-cox con
parametro γ = 0.0032.
La seleccion de una copula gaussiana se puede justificar por medio del ajuste de
bondad que se presenta en Genest (Genest & Remillard 2008), es recomendable
realizar un numero grande de simulaciones, pero en este caso es casi imposible, ya
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Copulas en geoestadıstica 149
que la complejidad computacional es muy alta, por tanto, segun Genest (Genest
& Remillard 2008) se pueden realizar 150 simulaciones, los resultados de la prueba
muestran que:
Tabla 1: Valor p para el estadıstico de eleccion de la copula gaussiana. Fuente:elaboracion propia
Resultado p−valor con 95%
h 0− 10 10− 20 90− 100
Tn 0.33 0.999 0.99Sn 0.99 0.99 0.999
Los valores de la prueba de Kolmogorov−Smirnovparecen ser menores que los valo-
res de p para el de Cramer−vonMises prueba puesto que la prueba de Kolmogorov−Smirnov es insensible a valores extremos. Ademas, no existe un p− valor signifi-
cantemente pequeno, por tanto, se puede asumir que el modelo propuesto se ajusta
a los datos. A pesar de esto, se puede comparar en la Figura 5 la copula empırica
con la teorica, mostrando de manera grafica que el modelo no puede ser simetrico.
0 0.2 0.4 0.6 0.8 10
0.5
1
lag=
10
0 0.2 0.4 0.6 0.8 10
0.5
1
lag=
20
0 0.2 0.4 0.6 0.8 10
0.5
1
lag=
40
0 0.2 0.4 0.6 0.8 10
0.5
1
lag=
60
0 0.5 10
0.5
1
0
10
20
30
0 0.5 10
0.5
1
5
10
15
20
0 0.5 10
0.5
1
2468101214
0 0.5 10
0.5
1
246810
Figura 5: Grafico de dispersion de los pares de datos de rango transformados, esdecir, densidad de la copula empırica bivariado (columna de la izquierda), copulateorica bivariada gaussiana (columna de la derecha). Fuente: elaboracion propia.
Aun ası, se realiza la estimacion de los parametros, se utiliza el modelo de correla-
cion Matern incluyendo un termino efecto de pepita, con los valores de ν1 ∈ [0,∞]
que corresponde al parametro de rango, ν2 ∈ [0, 1] el parametro del efecto pepita y
κ es el parametro de suavizamiento. Entonces, se deben calcular cinco parametros,
los parametros correspondientes a la transformacion Box−cox, γ, y los parame-
tros de la funcion de correlacion θ = (ν1, ν2, κ). Los resultados son: γ = 0, 090,ν1 = 61.92, ν2 = 0.0539 y κ = 0.8650.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

150 Danna Lesley Cruz Reyes
Para la copula no gaussiana se estudiara la copula V−transformada, se selecciona
la distribucion marginal log Normal, con esto se pretende tomar en cuenta la
propiedad fundamental de las copula que permite a la estructura de dependencia
no ser influenciada con las distribuciones marginales. De la misma forma que en
la anterior seccion, la seleccion de la copula V se puede justificar por medio del
ajuste de bondad de Genest (Genest & Remillard 2008), los resultados de la prueba
muestran que:
Tabla 2: Valor p para el estadıstico de eleccion de la copula V - Normal. Fuente:elaboracion propia
h 0− 10 10− 20 90− 100
Tn 0.99 0.999 0.99Sn 0.99 0.99 0.99
Al realizar una comparacion con los valores p de la copula gaussiana, se puede
notar que son mas bajos que los de la copula V− transformada. Por tanto, se
puede asumir que el modelo propuesto se ajusta a los datos. Se puede comparar
en las Figura 7) y 8 la copula empırica con la teorica, mostrando un mejor ajuste
que la copula gaussiana de la 5.
0 0.2 0.4 0.6 0.8 10
0.5
1
lag=
20
0 0.2 0.4 0.6 0.8 10
0.5
1
lag=
40
0 0.2 0.4 0.6 0.8 10
0.5
1
lag=
60
0 0.5 10
0.5
1
5
10
15
20
25
0 0.5 10
0.5
1
5
10
15
0 0.5 10
0.5
1
2
4
6
Figura 6: Grafico de dispersion de los pares de datos de rango transformados, esdecir, densidad de la copula empırica bivariado (columna de la izquierda), copulateorica bivariada χ2-copula (columna de la derecha). Fuente: elaboracion propia.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2
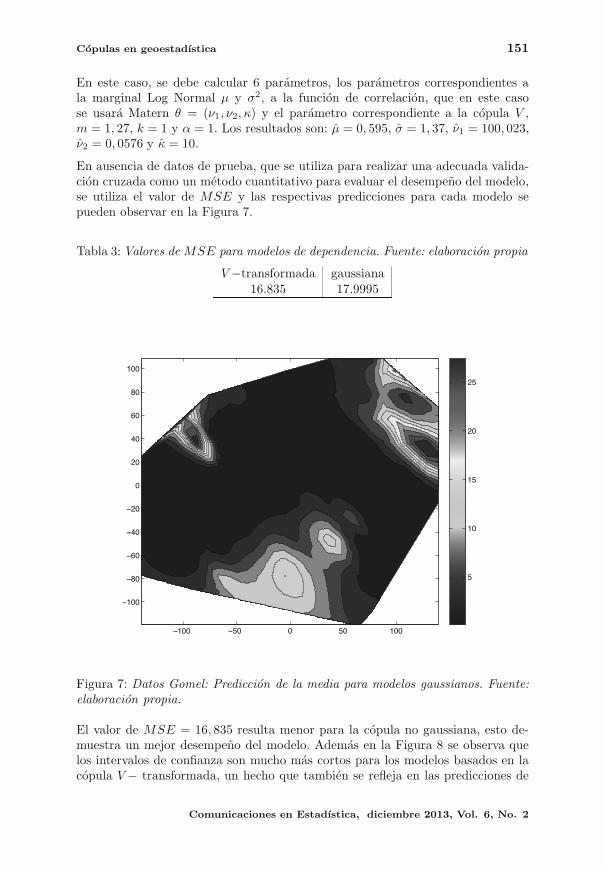
Copulas en geoestadıstica 151
En este caso, se debe calcular 6 parametros, los parametros correspondientes a
la marginal Log Normal µ y σ2, a la funcion de correlacion, que en este caso
se usara Matern θ = (ν1, ν2, κ) y el parametro correspondiente a la copula V ,
m = 1, 27, k = 1 y α = 1. Los resultados son: µ = 0, 595, σ = 1, 37, ν1 = 100, 023,ν2 = 0, 0576 y κ = 10.
En ausencia de datos de prueba, que se utiliza para realizar una adecuada valida-
cion cruzada como un metodo cuantitativo para evaluar el desempeno del modelo,
se utiliza el valor de MSE y las respectivas predicciones para cada modelo se
pueden observar en la Figura 7.
Tabla 3: Valores de MSE para modelos de dependencia. Fuente: elaboracion propia
V−transformada gaussiana
16.835 17.9995
−100 −50 0 50 100
−100
−80
−60
−40
−20
0
20
40
60
80
100
5
10
15
20
25
Figura 7: Datos Gomel: Prediccion de la media para modelos gaussianos. Fuente:elaboracion propia.
El valor de MSE = 16, 835 resulta menor para la copula no gaussiana, esto de-
muestra un mejor desempeno del modelo. Ademas en la Figura 8 se observa que
los intervalos de confianza son mucho mas cortos para los modelos basados en la
copula V− transformada, un hecho que tambien se refleja en las predicciones de
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

152 Danna Lesley Cruz Reyes
−100 −50 0 50 100
−100
−80
−60
−40
−20
0
20
40
60
80
100
2
4
6
8
10
12
14
16
18
20
Figura 8: Datos Gomel: Prediccion de la desviacion estandar para modelos gaus-sianos. Fuente: elaboracion propia.
las desviaciones estandar.
7. Copula discreta
En las secciones anteriores se ha descrito la forma como se utilizan las copulas
para construir estructuras de dependencia, pero unicamente se consideran variables
aleatorias con distribuciones marginales continuas y en algunos casos se puede
presentar la necesidad de implementar otro tipo de copulas.
En algunos casos geoestadısticos, se pueden tener variables aleatorias cuyas rea-
lizaciones pertenezcan al conjunto de los numeros naturales, de tal forma que, lo
mas conveniente es utilizar distribuciones discretas. En el marco de este artıculo,
donde el principal objetivo es utilizar copulas para datos geoestadısticos y siguien-
do el teorema de Sklar (1) el cual garantiza la existencia de la copula para una
funcion de distribucion conjunta H(X,Y ) de las variables aleatorias X e Y , se
propone una extension a este teorema considerando X y Y variables aleatorias
discretas. Kazianka (Kazianka & Pilz 2010) introduce copulas en geoestadıstica
para marginales discretas, con base en este ultimo artıculo se realiza este capıtulo,
sin embargo, se considera por una metodologıa diferente para realizar la inferencia
y estimacion de parametros, ya que la complejidad computacional de Kazianka es
alta.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Copulas en geoestadıstica 153
7.1. Inferencia para copulas con marginales discretasen geoestadıstica
Las copulas con marginales discretas no difieren demasiado para el caso continuo,
se deben tener en cuenta los anteriores resultados, pero se aplican de la misma
forma.
La estructura de dependencia esta caracterizada por las familias de copulas pa-
rametricas, por ejemplo, la copula gaussiana definida como:
Cµ,Σ(u, v) = ΦΣ(φ−1(u), φ−1(v)) (5)
Por tanto, es posible realizar una estimacion de maxima verosimilitud, consideran-
do un modelo generativo donde los marginales uniformes se generan a partir de la
densidad de la copula, y a su vez, se utilizan para generar las variables discretas
con el uso de la distribucion inversa de la marginal de las funciones de distribu-
cion. Esta marginal puede ser de cualquier familia parametrizada de distribuciones
univariantes discretas.
A manera de ejemplo, se utiliza la simulacion realizada por Diggle (Diggle &
Ribeiro 2007) con respuestas Poisson y un proceso gaussiano en el programa R.
Se considero un proceso gaussiano para simular las localizaciones con µ = 0.5mσ2 = 3 y funcion de correlacion Matern con κ = 1.5 y φ = 0.2. Las realizaciones sonexponenciales con media Poisson, µi = exp(0.5+z(xi)). EL resultado y el computo
de la copula se realiza en MATLAB. En la Figura 9 se muestra la simulacion
realizada.
De la misma forma que procedio anteriormente, se realiza una exploracion de datos
de la estructura de dependencia utilizando la copula empırica, en la Figura 10 se
muestra la estructura de dependencia para lags = 0.15, 0.19, 0.198, 0.21, se puede
notar una clara simetrıa en los puntos lo que puede indicar una copula gaussiana.
Esta copula se presenta en la Figura 11.
Los resultados muestran que es posible construir una estructura de dependencia
para copulas con marginales discretas, para el caso bivariado y que ademas re-
sulta flexible para la estructura de dependencia, sin embargo, matematicamente,
la generalizacion de este metodo no es una tarea trivial debido a la complejidad
computacional que se puede presentar para un caso multivariado (n > 2).
8. Conclusion
Si la estructura de dependencia entre una poblacion es relativamente homogenea,
entonces, las copulas pueden ser utiles, en el sentido de que se puede estimar a
partir de una muestra mucho menor que la necesaria, por ejemplo, para una ma-
triz de covarianza completa. Por otra parte, si las dependencias dentro de una
poblacion varıan notablemente para diferentes pares de datos, la copula gaussiana
carece de la flexibilidad para capturar las dependencias extremas. En tales casos,
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2
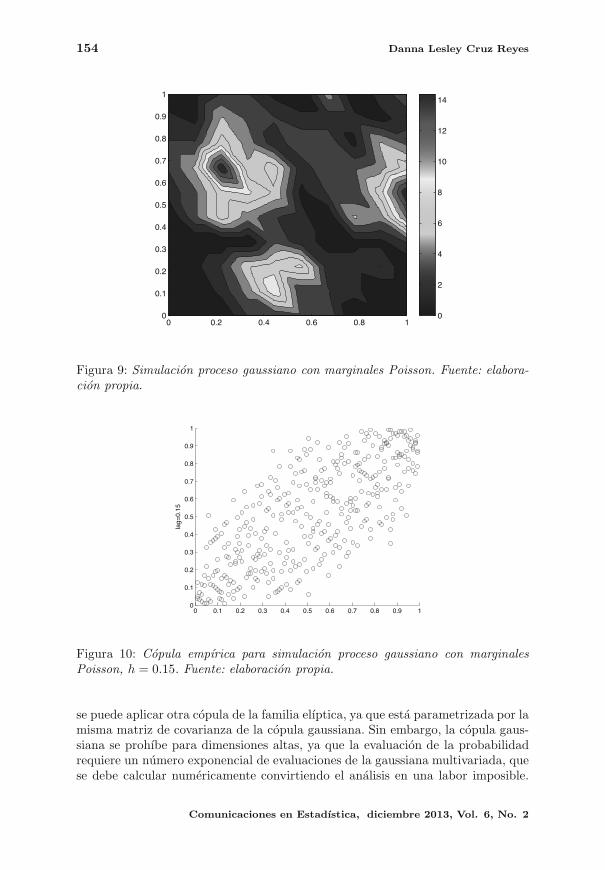
154 Danna Lesley Cruz Reyes
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0
2
4
6
8
10
12
14
Figura 9: Simulacion proceso gaussiano con marginales Poisson. Fuente: elabora-cion propia.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
lag=
0.15
Figura 10: Copula empırica para simulacion proceso gaussiano con marginalesPoisson, h = 0.15. Fuente: elaboracion propia.
se puede aplicar otra copula de la familia elıptica, ya que esta parametrizada por la
misma matriz de covarianza de la copula gaussiana. Sin embargo, la copula gaus-
siana se prohıbe para dimensiones altas, ya que la evaluacion de la probabilidad
requiere un numero exponencial de evaluaciones de la gaussiana multivariada, que
se debe calcular numericamente convirtiendo el analisis en una labor imposible.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Copulas en geoestadıstica 155
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
lag=
0.2
0 0.5 10
0.5
1
0
20
40
60
80
100
Figura 11: Copula gaussiana con marginales Poisson. Fuente: elaboracion propia.
Este artıculo es producto de la tesis de maestrıa dirigida por el profesor Edilberto
Cepeda de la Universidad Nacional de Colombia.
Recibido: 04 de junio de 2013
Aceptado: 20 de septiembre de 2013
Referencias
Ayyad, C., Mateu, J. & Porcu, E. (2008), Inferencia y modelizacion mediantecopulas, Universidad Jaume.
Bardossy, A. & Li, J. (2008), ‘Geostatistical interpolation using copulas’, WaterResources Research 44(7).
Diggle, P. & Ribeiro, P. (2007), Model-based Geostatistics, Springer Series in Sta-
tistics, Springer.
Genest, C. & Remillard, B. (2008), ‘Validity of the parametric bootstrap for
goodness-of-fit testing in semiparametric models’, Annales de I’institut HenriPoincare (B) Probabilites et Statistiques 44(6), 1096–1127.
Haslauer, C., Li, J. & Bardossy, A. (2010), ‘Application of copulas in geostatis-
tics’, geoENV VII Geostatistics for Environmental Applications. QuantitativeGeology and Geostatistics 16, 395–404.
Jing, L. (2010), Application of copulas as a new geostatistical tool, PhD thesis,
Universitat Stuttgart, Holzgartenstr. 16, 70174 Stuttgart.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

156 Danna Lesley Cruz Reyes
Kazianka, H. & Pilz, J. (2010), ‘Copula based geostatistical modeling of continuous
and discrete data including covariates’, Stochastic environmental research andrisk assessment 24(5), 661–673.
Kazianka, H. & Pilz, J. (2011), ‘Bayesian spatial modeling and interpolation using
copulas’, Computers & Geosciences 37(3), 310–319.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Comunicaciones en Estadıstica
Diciembre 2013, Vol. 6, No. 2, pp. 157–174
Comparacion de intervalos de confianza parael coeficiente de correlacion
Comparison of confidence intervals for the correlation coefficient
Liliana Vanessa Pachecoa
[email protected] Carlos Correab
Resumen
La construccion de intervalos de confianza para la estimacion de la correlacion en
la distribucion normal bivariable y multivariable, ρ, es un problema importante
en el trabajo estadıstico aplicado. Uno de los propositos principales de este tra-
bajo es hacer una revision de los diferentes procedimientos para su construccion.
Se realizo ademas, un estudio de simulacion para analizar el comportamiento de
los niveles de confianza reales y compararlos con los teoricos, analizar el compor-
tamiento de las longitudes de los intervalos de confianza logrados por los nueve
metodos considerados y determinar cual metodologıa provee los intervalos mas
cortos. Ası como tambien se obtuvo un indicador que resume de manera mas efec-
tiva la calidad del intervalo analizado.
Palabras clave: coeficiente de correlacion, estimacion, intervalo de confianza.
Abstract
The construction of confidence intervals to estimate the correlation in the normal
bivariate and multivariate distribution, ρ, is an important problem in applied sta-
tistical work. One of the main purposes of this work is to make a review of the
different procedures for their construction. In addition, a simulation study was
conducted to analyze the behavior of real confidence levels and compare them to
theoretical ones, analyze the behavior of the lengths of the confidence intervals
achieved by the nine methods considered and determine which methodology pro-
vides the shortest intervals. Likewise an indicator that summarizes more effectively
the quality of the analyzed interval was also obtained.
Keywords: correlation coefficient, estimation, confidence interval.
aUniversidad Nacional de Colombia, sede Medellın. Escuela de Estadıstica. Colombia.bUniversidad Nacional de Colombia, sede Medellın. Escuela de Estadıstica. Colombia.
157

158 Liliana Vanessa Pacheco & Juan Carlos Correa
1. Introduccion
El coeficiente de correlacion es una de las medidas estadısticas mas usadas dentro
del trabajo aplicado. Algunas de sus propiedades fueron estudiadas por Zheng &
Matis (1994), donde presentan y demuestran las que consideron las mas destacadas:
1. |R| ≤ 1.
2. Si |R| = 1 entonces los pares (x1, y1), (x2, y2), . . . , (xn, yn) yacen en una lınea
recta.
3. Recıprocamente, si los (x1, y1), (x2, y2), . . . , (xn, yn) yacen en una lınea recta,
entonces |R| = 1.
Debido a su amplia utilizacion, varias son sus interpretaciones. Falk & Well (1997)
sustentan que el coeficiente de correlacion de Pearson, ρ, es ampliamente usado en
campos como la educacion, psicologıa, y todas las ciencias sociales, y el concepto
es empleado en diversas metodologıas de tipo estadıstico.
La estimacion del coeficiente de correlacion por medio de intervalos es importante,
y para ello se disponen de diversos metodos. La metodologıa quiza mas conocida es
la propuesta originalmente por Fisher en la cual se realiza una transformacion del
coeficiente de correlacion muestral, r, y asumiendo normalidad asintotica, se desa-
rrolla un intervalo para el coeficiente de correlacion poblacional ρ (Krishnamoorthy
& Xia 2007). Tambien se conocen transformaciones adicionales hechas por Hote-
lling (1953) a la propuesta inicial de Fisher.
El problema para el analista es la carencia de reglas sobre cual formula es preferi-
ble. Para esto se pretende realizar un estudio de simulacion que permita analizar
el comportamiento de los niveles de confianza reales y compararlos con los teoricos
para los diversos intervalos disponibles. Ası como tambien, hacer una comparacion
de las longitudes del intervalo obtenido por las diferentes metodologıas y la imple-
mentacion de un indicador que permita relacionar los dos criterios de evaluacion
anteriormente mencionados.
Algunas de las metodologıas empleadas para la construccion de los intervalos de
confianza pueden encontrarse en Fisher (1921), Hotelling (1953), Pawitan (2001),
Efron (1979) y Krishnamoorthy & Xia (2007).
Ademas, en Krishnamoorthy & Xia (2007) se pueden encontrar los resultados de
estudios comparativos realizados previamente para tres metodos de construccion
de intervalos, en los cuales la metodologıa consistio en la obtencion de lımites
superiores para ρ bajo diferentes escenarios: Tamanos de muestra pequenos (n=5,
n=10, n=20 y n=30) y valores de r positivos; y el calculo de la probabilidad
P (R ≤ r|n, ρU ). Estos estudios mostraron que, en particular, el mejor metodo
para construir intervalos unilaterales para ρ en muestras pequenas es el de pivote
generalizado.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Comparacion de intervalos de confianza para el coeficiente de correlacion 159
2. Intervalos de confianza
2.1. Metodo I: basado en la transformacion Arcotangente
Este intervalo puede considerarse el intervalo clasico para este parametro y fue
propuesto por Fisher (1921). Debido a que la distribucion del coeficiente de corre-
lacion muestral no es centrada y/o simetrica, el calculo de intervalos de confianza
a partir de los cuantiles de la distribucion no se hace sencillo. Por tanto, Fisher
propone la transformacion arcotangente hiperbolico:
r = tanh(z) ⇔ z =1
2log
1 + r
1− r(1)
y demostro que z tiene una distribucion aproximadamente normal cuando el ta-
mano muestral es grande. Dicha distribucion normal se caracteriza por una media
ξ = 1
2log
(1+ρ1−ρ
)y varianza 1
n−3. El intervalo hallado a partir de la transformacion
Arcotangente hiperbolico tiene la siguiente forma:
(tanh
(arctanh(r) −
zα/2√n− 3
), tanh
(arctanh(r) +
zα/2√n− 3
))(2)
donde zα2es el percentil superior α/2 de la distribucion normal estandar.
2.1.1. Modificaciones a la transformacion Arcotangente
Teniendo en cuenta el hecho de que la transformacion propuesta por Fisher fun-
ciona adecuadamente siempre y cuando los tamanos muestrales sean grandes, se
hizo necesario encontrar la manera de reducir el error al trabajar esta transfor-
macion en muestras pequenas. Hotelling (1953) estudio esta situacion y propuso 4
transformaciones zi con i = 1, . . . , 4, para la transformacion z original de Fisher,
las cuales tambien, asintoticamente tienen una distribucion Normal con media ξiy varianza 1
n−1:
z1 = z −7z + r
8(n− 1)ξ1 = ξ −
7ξ + ρ
8(n− 1)(3)
z2 = z −7z + r
8(n− 1)−
119z + 57r + 3r2
384(n− 1)2ξ2 = ξ −
7ξ + ρ
8(n− 1)−
119ξ + 57ρ+ 3ρ2
384(n− 1)2
(4)
z3 = z −3z + r
4(n− 1)ξ3 = ξ −
3ξ + ρ
4(n− 1)(5)
z4 = z−3z + r
4(n− 1)−
23z + 33r − 5r2
96(n− 1)2ξ4 = ξ−
3ξ + ρ
4(n− 1)−23ξ + 33ρ− 5ρ2
96(n− 1)2(6)
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

160 Liliana Vanessa Pacheco & Juan Carlos Correa
2.2. Metodo II: Intervalo de la razon de verosimilitud
Kalbfleish (1985) y Pawitan (2001) presentan la metodologıa para construir inter-
valos de verosimilitud. Un intervalo de la razon de verosimilitud para θ es definido
como el conjunto de valores parametrales con valores altamente verosımiles:θ,
L(θ)
L(θ)> c
(7)
para un valor c ∈ (0, 1) y donde θ es el estimador muestral del parametro θ
Sabiendo que 2 logL(θ)
L(θ)
d→ χ2
1, la probabilidad de cubrimiento aproximada para
este tipo de intervalos esta dada por:
P
(L(θ)
L(θ)> c
)= P
(2 log
L(θ)
L(θ)< −2 log c
)(8)
≈ P(χ2
1< −2 log c
). (9)
Luego, para cualquier valor 0 < α < 1 el punto de corte c es:
c = exp
[−1
2χ2
1,1−α
](10)
donde χ2
1,1−α es el 100(1− α) percentil de una χ2
1. Por tanto:
P
(L(θ)
L(θ)> c
)= P
(χ2
1< χ2
1,1−α
)= 1− α. (11)
Si L(ρ) es la funcion de verosimilitud, se define la funcion de verosimilitud relativacomo:
R(ρ) =L(ρ)
L(r)(12)
El conjunto de valores de ρ para los cuales R(ρ) > c es llamado intervalo de100× c% de verosimilitud para ρ. Los intervalos del 14.7% y del 3.6% de verosi-
militud corresponden a intervalos de confianza de niveles del 95% y 99% aproxi-
madamente.
Lo que se debe hacer entonces es hallar las raıces que nos dan los lımites del
intervalo. Para el caso del parametro ρ tenemos que un intervalo de confianza del
95% se halla encontrando el par de raıces tal que
R(ρ) =L(ρ)
L(r)(13)
=
(1− ρ2
1− r2
) (n−1)
2
∫∞
0
(coshw − ρr)−(n−1) dw∫
∞
0
(coshw − r2)−(n−1) dw
≥ K(k, α) (14)
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2
Comparacion de intervalos de confianza para el coeficiente de correlacion 161
donde K(k, α) es el valor crıtico mınimo con el cual aseguramos una confianza
deseada, ya sea del 95% o 99%, por ejemplo.
2.3. Metodo III: Bootstrap
La primera aplicacion del metodo bootstrap fue en la determinacion del intervalo
de confianza del coeficiente de correlacion en el artıculo seminal de Efron (1979).
A partir de la muestra (x1, y1), (x2, y2), . . . , (xn, yn) se calculan las estimacio-
nes de maxima verosimilitud del vector de medias y de la matriz de varianzas
y covarianzas de la distribucion normal bivariable.
Se generan M muestras de tamano n de una distribucion normal bivariable
con parametros µ y Σ. Y para cada una de estas muestras se estima el
parametro ρ, por ejemplo, para la muestra j el valor del estimador para el
coeficiente de correlacion es rj .
Para los rj , j = 1, . . . ,M , se construye un histograma y se calculan los
percentiles 0.025 y 0.975 los cuales se denotaran: r0.025i y r
0.975i .
Y el intervalo de Bootstrap para ρ esta dado por r0.025i y r
0.975i como lımite
inferior y superior respectivamente.
2.4. Metodo IV: Intervalo de Jeyaratnam
Jeyaratnam propone un intervalo para el coeficiente de correlacion de la distribu-
cion normal bivariada y este tiene la siguiente forma (Krishnamoorthy & Xia 2007):
(r − w
1− rw,r + w
1 + rw
)(15)
donde
w =
tn−2,1−α/2√
n−2√1 +
(tn−2,1−α/2)2
n−2
(16)
y tm,p denota el p-esimo cuantil de la distribucion t-Student con m grados de
libertad.
2.5. Metodo V: Test generalizado para ρ
Segun el artıculo publicado por Krishnamoorthy & Xia (2007), los autores citados
proponen un algoritmo para construir un intervalo de confianza para ρ a partir de
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Comparacion de intervalos de confianza para el coeficiente de correlacion 161
donde K(k, α) es el valor crıtico mınimo con el cual aseguramos una confianza
deseada, ya sea del 95% o 99%, por ejemplo.
2.3. Metodo III: Bootstrap
La primera aplicacion del metodo bootstrap fue en la determinacion del intervalo
de confianza del coeficiente de correlacion en el artıculo seminal de Efron (1979).
A partir de la muestra (x1, y1), (x2, y2), . . . , (xn, yn) se calculan las estimacio-
nes de maxima verosimilitud del vector de medias y de la matriz de varianzas
y covarianzas de la distribucion normal bivariable.
Se generan M muestras de tamano n de una distribucion normal bivariable
con parametros µ y Σ. Y para cada una de estas muestras se estima el
parametro ρ, por ejemplo, para la muestra j el valor del estimador para el
coeficiente de correlacion es rj .
Para los rj , j = 1, . . . ,M , se construye un histograma y se calculan los
percentiles 0.025 y 0.975 los cuales se denotaran: r0.025i y r
0.975i .
Y el intervalo de Bootstrap para ρ esta dado por r0.025i y r
0.975i como lımite
inferior y superior respectivamente.
2.4. Metodo IV: Intervalo de Jeyaratnam
Jeyaratnam propone un intervalo para el coeficiente de correlacion de la distribu-
cion normal bivariada y este tiene la siguiente forma (Krishnamoorthy & Xia 2007):
(r − w
1− rw,r + w
1 + rw
)(15)
donde
w =
tn−2,1−α/2√
n−2√1 +
(tn−2,1−α/2)2
n−2
(16)
y tm,p denota el p-esimo cuantil de la distribucion t-Student con m grados de
libertad.
2.5. Metodo V: Test generalizado para ρ
Segun el artıculo publicado por Krishnamoorthy & Xia (2007), los autores citados
proponen un algoritmo para construir un intervalo de confianza para ρ a partir de
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

162 Liliana Vanessa Pacheco & Juan Carlos Correa
la distribucion del pivote generalizado para el coeficiente de correlacion:
Gρij=
j∑
k=1
bikbjk
√∑ik=1
b2ik
√∑jk=1
b2jk
(17)
para i > j. Que en el caso bivariado lo anterior se expresa de la siguiente forma:
Gρ21=
b21√b221
+ b222
(18)
Y simplificando la expresion anterior, se tiene:
Gρ21=
r∗V22 − V21√(r∗V22 − V21)2 + V 2
11
(19)
Donde r∗ =r
√1− r2
y V es una matriz triangular inferior, las Vij ’s son indepen-
dientes con V 2
ii ∼ χ2
n−i para i = 1, . . . , p y Vij ∼ N(0, 1) para i < j. Para mayor
detalle, se sugiere remitirse al desarrollo completo para la obtencion de los Gρijy
la matriz V , que se encuentra en Krishnamoorthy & Xia (2007).
Entonces, segun los autores, para un r dado la distribucion de Gρ no depende
de algun parametro que sea desconocido, y el intervalo se calcula empleando el
siguiente algoritmo:
Algoritmo 1 Generar valores del pivote Gρij
Requiere Un n y ρ fijo
Calcular: r∗ = ρ/√1− ρ2
Para: i = 1 hasta m Haga
Generar: Z0 ∼ N(0, 1).Generar: U1 ∼ χ2
n−1.
Generar: U2 ∼ χ2
n−2.
Calcular: Qi =r∗√U2− Z0√
(r∗√U2− Z0)2 + U1
Fin del ciclo.
Luego, los percentiles α2y (1 − α
2) de los valores calculados para el pivote Gρij
mediante el mencionado algoritmo conforman los lımites del intervalo de confianza
al 100(1− α)% para ρ.
3. Resultados de la simulacion
Para comparar los nueve metodos de construccion de intervalos de confianza en
este caso se realizo una simulacion en R en la cual se consideraron combinaciones
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Comparacion de intervalos de confianza para el coeficiente de correlacion 163
de (ρ, n) con valores de ρ = 0.0, 0.1, 0.2, . . . , 0.9 y de n = 5, 10, 20, 50, 100; un
vector de medias µ =
[1
1
]y∑
=
(1 ρρ 1
).
Para cada pareja se realizaron 1000 replicas y se calcularon las formulas previas a
un nivel de confianza del 95% (Este es conocido como el nivel nominal). Para cada
metodo y combinacion se calculo la mediana de la longitud de los 1000 intervalos
calculados y la proporcion de intervalos que cubren el verdadero valor de ρ, estoes lo que se llama el nivel de confianza real. Los resultados se encuentran en las
tablas 1 al 5 y en las Figuras 1 y 2.
De las graficas y las tablas observamos que las longitudes mas amplias en los
intervalos se encuentran en los tamanos de muestra mas pequenos, siendo el caso
de n = 5 donde los nueve tipos de intervalo alcanzan las mayores longitudes para
el respectivo valor de ρ. Ademas, vemos que a medida que se amplıa el valor de
ρ para un tamano de muestra particular, las longitudes son cada vez menores, lo
que sugiere que los intervalos de confianza alcanzan menores longitudes cuando el
valor verdadero de ρ se va acercando a 1.
Con respecto al nivel real alcanzado por cada intervalo se observa que cada uno
de los metodos cuando el tamano muestral es bastante pequeno, por ejemplo,
n = 5, tienen una probabilidad de cobertura diferente a la deseada 95%, y no
es homogenea en cada valor de ρ, es decir, que en cada metodo se observa que
algunas veces el nivel real supera al nominal y a veces es al contrario, conforme
se varıa el valor de ρ. Los mas cercanos a 95% de nivel real, cuando n = 5 son
ArcTanh, Jeyaratnam y P.G; y el que se comporta peor es Bootstrap. A medida
que aumenta el tamano de muestra se nota una tendencia en todos los intervalos
a estar cerca del nivel nominal deseado, 95%.
3.1. Indice de resumenes
A manera de resumen se presenta un ındice que senala la calidad de las metodo-
logıas anteriormente mencionadas. Este ındice busca favorecer a aquellos metodos
que presenten longitudes de intervalo pequenos y niveles reales de confianza cer-
canos o mayores al 95%:
I = (2− LI)NR
NN(20)
donde:
LI: Mediana de la longitud del intervalo.
NR: Promedio del nivel real del intervalo.
NN: Nivel nominal de los intervalos, que en este caso es 0.95.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

164 Liliana Vanessa Pacheco & Juan Carlos Correa
Tabla
1:Longitudynivel
deconfianza
delosintervalos.
Taman
odemuestra5.Fuen
te:elaboracionpropia
n=
5
ρBootstrap
Arctanh
L.R
Jeyaratnam
Z1
Z2
Z3
Z4
P.G
0.0
Longitud
1.6233
1.6864
1.4864
1.6766
1.6056
1.6267
1.5718
1.5880
1.5498
Nivel
0.9010
0.9530
0.9270
0.9500
0.9290
0.9360
0.9190
0.9240
0.9430
0.1
Longitud
1.6392
1.6903
1.4905
1.6806
1.6102
1.6311
1.5770
1.5928
1.5346
Nivel
0.9130
0.9470
0.9330
0.9460
0.9340
0.9380
0.9260
0.9310
0.9440
0.2
Longitud
1.6221
1.6848
1.4848
1.6750
1.6038
1.6249
1.5699
1.5861
1.5360
Nivel
0.9120
0.9610
0.9440
0.9590
0.9490
0.9520
0.9380
0.9450
0.9490
0.3
Longitud
1.6003
1.6678
1.4671
1.6576
1.5837
1.6056
1.5487
1.5654
1.5235
Nivel
0.8920
0.9390
0.9140
0.9340
0.9120
0.9220
0.9040
0.9080
0.9420
0.4
Longitud
1.5846
1.6597
1.4588
1.6492
1.5741
1.5964
1.5386
1.5556
1.4994
Nivel
0.9130
0.9470
0.9360
0.9450
0.9370
0.9400
0.9280
0.9310
0.9600
0.5
Longitud
1.5141
1.6095
1.4081
1.5979
1.5157
1.5399
1.4772
1.4955
1.4397
Nivel
0.8940
0.9550
0.9290
0.9540
0.9290
0.9370
0.9180
0.9240
0.9420
0.6
Longitud
1.2966
1.4664
1.2712
1.4522
1.3534
1.3821
1.3086
1.3298
1.3934
Nivel
0.9170
0.9590
0.9410
0.9570
0.9390
0.9450
0.9330
0.9340
0.9540
0.7
Longitud
1.1093
1.3313
1.1492
1.3153
1.2061
1.2374
1.1578
1.1806
1.2438
Nivel
0.8760
0.9350
0.9140
0.9330
0.9170
0.9200
0.9010
0.9130
0.9590
0.8
Longitud
0.8765
1.1527
0.9949
1.1353
1.0195
1.0521
0.9698
0.9931
1.0838
Nivel
0.8970
0.9510
0.9270
0.9490
0.9360
0.9410
0.9250
0.9310
0.9520
0.9
Longitud
0.4787
0.7521
0.6612
0.7355
0.6314
0.6598
0.5896
0.6090
0.7449
Nivel
0.8960
0.9550
0.9170
0.9510
0.9330
0.9390
0.9240
0.9290
0.9460
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

164 Liliana Vanessa Pacheco & Juan Carlos Correa
Tabla
1:Longitudynivel
deconfianza
delosintervalos.
Taman
odemuestra5.Fuen
te:elaboracionpropia
n=
5
ρBootstrap
Arctanh
L.R
Jeyaratnam
Z1
Z2
Z3
Z4
P.G
0.0
Longitud
1.6233
1.6864
1.4864
1.6766
1.6056
1.6267
1.5718
1.5880
1.5498
Nivel
0.9010
0.9530
0.9270
0.9500
0.9290
0.9360
0.9190
0.9240
0.9430
0.1
Longitud
1.6392
1.6903
1.4905
1.6806
1.6102
1.6311
1.5770
1.5928
1.5346
Nivel
0.9130
0.9470
0.9330
0.9460
0.9340
0.9380
0.9260
0.9310
0.9440
0.2
Longitud
1.6221
1.6848
1.4848
1.6750
1.6038
1.6249
1.5699
1.5861
1.5360
Nivel
0.9120
0.9610
0.9440
0.9590
0.9490
0.9520
0.9380
0.9450
0.9490
0.3
Longitud
1.6003
1.6678
1.4671
1.6576
1.5837
1.6056
1.5487
1.5654
1.5235
Nivel
0.8920
0.9390
0.9140
0.9340
0.9120
0.9220
0.9040
0.9080
0.9420
0.4
Longitud
1.5846
1.6597
1.4588
1.6492
1.5741
1.5964
1.5386
1.5556
1.4994
Nivel
0.9130
0.9470
0.9360
0.9450
0.9370
0.9400
0.9280
0.9310
0.9600
0.5
Longitud
1.5141
1.6095
1.4081
1.5979
1.5157
1.5399
1.4772
1.4955
1.4397
Nivel
0.8940
0.9550
0.9290
0.9540
0.9290
0.9370
0.9180
0.9240
0.9420
0.6
Longitud
1.2966
1.4664
1.2712
1.4522
1.3534
1.3821
1.3086
1.3298
1.3934
Nivel
0.9170
0.9590
0.9410
0.9570
0.9390
0.9450
0.9330
0.9340
0.9540
0.7
Longitud
1.1093
1.3313
1.1492
1.3153
1.2061
1.2374
1.1578
1.1806
1.2438
Nivel
0.8760
0.9350
0.9140
0.9330
0.9170
0.9200
0.9010
0.9130
0.9590
0.8
Longitud
0.8765
1.1527
0.9949
1.1353
1.0195
1.0521
0.9698
0.9931
1.0838
Nivel
0.8970
0.9510
0.9270
0.9490
0.9360
0.9410
0.9250
0.9310
0.9520
0.9
Longitud
0.4787
0.7521
0.6612
0.7355
0.6314
0.6598
0.5896
0.6090
0.7449
Nivel
0.8960
0.9550
0.9170
0.9510
0.9330
0.9390
0.9240
0.9290
0.9460
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2
Comparacion de intervalos de confianza para el coeficiente de correlacion 165
Tabla
2:Longitudynivel
deconfianza
delosintervalos.
Taman
odemuestra10.Fuen
te:elaboracionpropia
n=
10
ρBootstrap
Arctanh
L.R
Jeyaratnam
Z1
Z2
Z3
Z4
P.G
0.0
Longitud
1.1964
1.2101
1.1349
1.2146
1.1890
1.1928
1.1753
1.1782
1.1521
Nivel
0.9460
0.9560
0.9510
0.9570
0.9510
0.9520
0.9490
0.9500
0.9570
0.1
Longitud
1.1960
1.2102
1.1350
1.2147
1.1891
1.1930
1.1754
1.1783
1.1456
Nivel
0.9360
0.9470
0.9410
0.9490
0.9430
0.9440
0.9390
0.9400
0.9470
0.2
Longitud
1.1841
1.1956
1.1220
1.2002
1.1745
1.1784
1.1608
1.1637
1.1393
Nivel
0.9270
0.9500
0.9410
0.9500
0.9430
0.9440
0.9390
0.9400
0.9460
0.3
Longitud
1.1494
1.1667
1.0968
1.1713
1.1460
1.1494
1.1318
1.1347
1.1105
Nivel
0.9160
0.9310
0.9250
0.9340
0.9260
0.9260
0.9210
0.9220
0.9570
0.4
Longitud
1.0879
1.1161
1.0523
1.1207
1.0949
1.0988
1.0812
1.0841
1.0698
Nivel
0.9460
0.9660
0.9600
0.9660
0.9630
0.9630
0.9580
0.9590
0.9520
0.5
Longitud
0.9960
1.0308
0.9770
1.0354
1.0097
1.0135
0.9961
0.9990
0.9997
Nivel
0.9350
0.9550
0.9460
0.9560
0.9450
0.9450
0.9440
0.9440
0.9590
0.6
Longitud
0.8717
0.9138
0.8731
0.9183
0.8934
0.8971
0.8802
0.8830
0.8713
Nivel
0.9300
0.9460
0.9370
0.9480
0.9370
0.9380
0.9340
0.9340
0.9620
0.7
Longitud
0.7072
0.7581
0.7331
0.7623
0.7392
0.7426
0.7271
0.7296
0.7578
Nivel
0.9280
0.9460
0.9420
0.9470
0.9410
0.9420
0.9390
0.9400
0.9440
0.8
Longitud
0.4859
0.5427
0.5349
0.5461
0.5272
0.5299
0.5173
0.5194
0.5887
Nivel
0.9250
0.9420
0.9390
0.9430
0.9410
0.9410
0.9390
0.9390
0.9580
0.9
Longitud
0.2707
0.3157
0.3186
0.3180
0.3055
0.3073
0.2991
0.3004
0.3340
Nivel
0.9420
0.9600
0.9480
0.9600
0.9570
0.9570
0.9510
0.9530
0.9450
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2
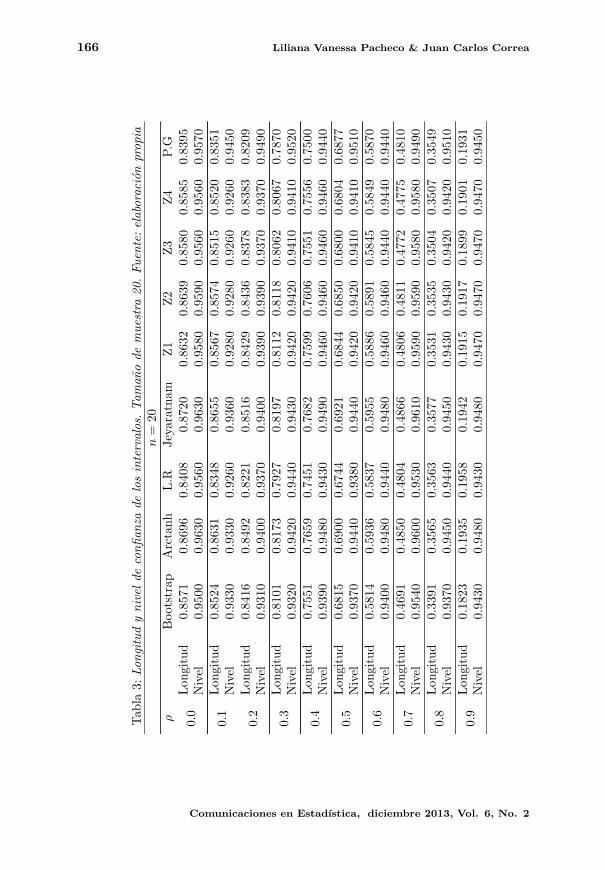
166 Liliana Vanessa Pacheco & Juan Carlos Correa
Tabla
3:Longitudynivel
deconfianza
delosintervalos.
Taman
odemuestra20.Fuen
te:elaboracionpropia
n=
20
ρBootstrap
Arctanh
L.R
Jeyaratnam
Z1
Z2
Z3
Z4
P.G
0.0
Longitud
0.8571
0.8696
0.8408
0.8720
0.8632
0.8639
0.8580
0.8585
0.8395
Nivel
0.9500
0.9630
0.9560
0.9630
0.9580
0.9590
0.9560
0.9560
0.9570
0.1
Longitud
0.8524
0.8631
0.8348
0.8655
0.8567
0.8574
0.8515
0.8520
0.8351
Nivel
0.9330
0.9330
0.9260
0.9360
0.9280
0.9280
0.9260
0.9260
0.9450
0.2
Longitud
0.8416
0.8492
0.8221
0.8516
0.8429
0.8436
0.8378
0.8383
0.8209
Nivel
0.9310
0.9400
0.9370
0.9400
0.9390
0.9390
0.9370
0.9370
0.9490
0.3
Longitud
0.8101
0.8173
0.7927
0.8197
0.8112
0.8118
0.8062
0.8067
0.7870
Nivel
0.9320
0.9420
0.9440
0.9430
0.9420
0.9420
0.9410
0.9410
0.9520
0.4
Longitud
0.7551
0.7659
0.7451
0.7682
0.7599
0.7606
0.7551
0.7556
0.7500
Nivel
0.9390
0.9480
0.9430
0.9490
0.9460
0.9460
0.9460
0.9460
0.9440
0.5
Longitud
0.6815
0.6900
0.6744
0.6921
0.6844
0.6850
0.6800
0.6804
0.6877
Nivel
0.9370
0.9440
0.9380
0.9440
0.9420
0.9420
0.9410
0.9410
0.9510
0.6
Longitud
0.5814
0.5936
0.5837
0.5955
0.5886
0.5891
0.5845
0.5849
0.5870
Nivel
0.9400
0.9480
0.9440
0.9480
0.9460
0.9460
0.9440
0.9440
0.9440
0.7
Longitud
0.4691
0.4850
0.4804
0.4866
0.4806
0.4811
0.4772
0.4775
0.4810
Nivel
0.9540
0.9600
0.9530
0.9610
0.9590
0.9590
0.9580
0.9580
0.9490
0.8
Longitud
0.3391
0.3565
0.3563
0.3577
0.3531
0.3535
0.3504
0.3507
0.3549
Nivel
0.9370
0.9450
0.9440
0.9450
0.9430
0.9430
0.9420
0.9420
0.9510
0.9
Longitud
0.1823
0.1935
0.1958
0.1942
0.1915
0.1917
0.1899
0.1901
0.1931
Nivel
0.9430
0.9480
0.9430
0.9480
0.9470
0.9470
0.9470
0.9470
0.9450
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

166 Liliana Vanessa Pacheco & Juan Carlos Correa
Tabla
3:Longitudynivel
deconfianza
delosintervalos.
Taman
odemuestra20.Fuen
te:elaboracionpropia
n=
20
ρBootstrap
Arctanh
L.R
Jeyaratnam
Z1
Z2
Z3
Z4
P.G
0.0
Longitud
0.8571
0.8696
0.8408
0.8720
0.8632
0.8639
0.8580
0.8585
0.8395
Nivel
0.9500
0.9630
0.9560
0.9630
0.9580
0.9590
0.9560
0.9560
0.9570
0.1
Longitud
0.8524
0.8631
0.8348
0.8655
0.8567
0.8574
0.8515
0.8520
0.8351
Nivel
0.9330
0.9330
0.9260
0.9360
0.9280
0.9280
0.9260
0.9260
0.9450
0.2
Longitud
0.8416
0.8492
0.8221
0.8516
0.8429
0.8436
0.8378
0.8383
0.8209
Nivel
0.9310
0.9400
0.9370
0.9400
0.9390
0.9390
0.9370
0.9370
0.9490
0.3
Longitud
0.8101
0.8173
0.7927
0.8197
0.8112
0.8118
0.8062
0.8067
0.7870
Nivel
0.9320
0.9420
0.9440
0.9430
0.9420
0.9420
0.9410
0.9410
0.9520
0.4
Longitud
0.7551
0.7659
0.7451
0.7682
0.7599
0.7606
0.7551
0.7556
0.7500
Nivel
0.9390
0.9480
0.9430
0.9490
0.9460
0.9460
0.9460
0.9460
0.9440
0.5
Longitud
0.6815
0.6900
0.6744
0.6921
0.6844
0.6850
0.6800
0.6804
0.6877
Nivel
0.9370
0.9440
0.9380
0.9440
0.9420
0.9420
0.9410
0.9410
0.9510
0.6
Longitud
0.5814
0.5936
0.5837
0.5955
0.5886
0.5891
0.5845
0.5849
0.5870
Nivel
0.9400
0.9480
0.9440
0.9480
0.9460
0.9460
0.9440
0.9440
0.9440
0.7
Longitud
0.4691
0.4850
0.4804
0.4866
0.4806
0.4811
0.4772
0.4775
0.4810
Nivel
0.9540
0.9600
0.9530
0.9610
0.9590
0.9590
0.9580
0.9580
0.9490
0.8
Longitud
0.3391
0.3565
0.3563
0.3577
0.3531
0.3535
0.3504
0.3507
0.3549
Nivel
0.9370
0.9450
0.9440
0.9450
0.9430
0.9430
0.9420
0.9420
0.9510
0.9
Longitud
0.1823
0.1935
0.1958
0.1942
0.1915
0.1917
0.1899
0.1901
0.1931
Nivel
0.9430
0.9480
0.9430
0.9480
0.9470
0.9470
0.9470
0.9470
0.9450
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2
Comparacion de intervalos de confianza para el coeficiente de correlacion 167
Tabla
4:Longitudynivel
deconfianza
delosintervalos.
Taman
odemuestra50.Fuen
te:elaboracionpropia
n=
50
ρBootstrap
Arctanh
L.R
Jeyaratnam
Z1
Z2
Z3
Z4
P.G
0.0
Longitud
0.5461
0.5519
0.5441
0.5526
0.5504
0.5505
0.5491
0.5491
0.5408
Nivel
0.9530
0.9530
0.9510
0.9530
0.9520
0.9520
0.9510
0.9510
0.9480
0.1
Longitud
0.5421
0.5483
0.5406
0.5490
0.5468
0.5469
0.5455
0.5455
0.5389
Nivel
0.9470
0.9540
0.9540
0.9540
0.9540
0.9540
0.9540
0.9540
0.9530
0.2
Longitud
0.5295
0.5343
0.5272
0.5350
0.5329
0.5330
0.5316
0.5316
0.5271
Nivel
0.9570
0.9580
0.9580
0.9580
0.9580
0.9580
0.9570
0.9570
0.9370
0.3
Longitud
0.5075
0.5114
0.5050
0.5120
0.5100
0.5100
0.5087
0.5087
0.5010
Nivel
0.9420
0.9490
0.9490
0.9500
0.9490
0.9490
0.9490
0.9490
0.9340
0.4
Longitud
0.4660
0.4696
0.4646
0.4702
0.4683
0.4683
0.4671
0.4672
0.4686
Nivel
0.9400
0.9410
0.9380
0.9410
0.9390
0.9390
0.9390
0.9390
0.9390
0.5
Longitud
0.4211
0.4240
0.4203
0.4245
0.4228
0.4229
0.4217
0.4218
0.4187
Nivel
0.9370
0.9430
0.9430
0.9430
0.9420
0.9420
0.9410
0.9410
0.9350
0.6
Longitud
0.3576
0.3623
0.3601
0.3627
0.3612
0.3613
0.3603
0.3603
0.3594
Nivel
0.9510
0.9570
0.9580
0.9570
0.9560
0.9560
0.9560
0.9560
0.9530
0.7
Longitud
0.2819
0.2869
0.2862
0.2873
0.2861
0.2861
0.2853
0.2854
0.2942
Nivel
0.9370
0.9500
0.9500
0.9500
0.9500
0.9500
0.9490
0.9500
0.9550
0.8
Longitud
0.2046
0.2096
0.2098
0.2099
0.2090
0.2090
0.2084
0.2085
0.2076
Nivel
0.9420
0.9470
0.9430
0.9470
0.9470
0.9470
0.9460
0.9460
0.9400
0.9
Longitud
0.1095
0.1126
0.1132
0.1127
0.1122
0.1123
0.1119
0.1119
0.1126
Nivel
0.9520
0.9550
0.9530
0.9550
0.9550
0.9550
0.9530
0.9530
0.9500
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

168 Liliana Vanessa Pacheco & Juan Carlos Correa
Tabla
5:Longitudynivel
deconfianza
delosintervalos.
Taman
odemuestra100.Fuen
te:elaboracionpropia
n=
100
ρBootstrap
Arctanh
L.R
Jeyaratnam
Z1
Z2
Z3
Z4
P.G
0.0
Longitud
0.3874
0.3912
0.3882
0.3914
0.3907
0.3907
0.3902
0.3902
0.3858
Nivel
0.9470
0.9530
0.9510
0.9530
0.9530
0.9530
0.9520
0.9520
0.9330
0.1
Longitud
0.3846
0.3887
0.3858
0.3890
0.3882
0.3882
0.3877
0.3877
0.3824
Nivel
0.9510
0.9530
0.9510
0.9530
0.9520
0.9520
0.9520
0.9520
0.9460
0.2
Longitud
0.3763
0.3788
0.3760
0.3790
0.3783
0.3783
0.3778
0.3778
0.3735
Nivel
0.9470
0.9510
0.9500
0.9510
0.9500
0.9500
0.9490
0.9500
0.9320
0.3
Longitud
0.3558
0.3595
0.3571
0.3597
0.3590
0.3590
0.3586
0.3586
0.3554
Nivel
0.9420
0.9450
0.9440
0.9450
0.9430
0.9430
0.9430
0.9430
0.9430
0.4
Longitud
0.3297
0.3314
0.3295
0.3316
0.3309
0.3310
0.3305
0.3305
0.3291
Nivel
0.9490
0.9490
0.9480
0.9490
0.9490
0.9490
0.9490
0.9490
0.9450
0.5
Longitud
0.2952
0.2970
0.2956
0.2972
0.2966
0.2966
0.2962
0.2962
0.2943
Nivel
0.9500
0.9560
0.9540
0.9560
0.9560
0.9560
0.9560
0.9560
0.9560
0.6
Longitud
0.2530
0.2552
0.2544
0.2554
0.2549
0.2549
0.2546
0.2546
0.2518
Nivel
0.9480
0.9530
0.9530
0.9530
0.9510
0.9510
0.9510
0.9510
0.9500
0.7
Longitud
0.2018
0.2041
0.2037
0.2042
0.2038
0.2038
0.2036
0.2036
0.2023
Nivel
0.9420
0.9510
0.9490
0.9510
0.9510
0.9510
0.9510
0.9510
0.95500
0.8
Longitud
0.1420
0.1440
0.1441
0.1441
0.1438
0.1438
0.1436
0.1436
0.1441
Nivel
0.9350
0.9380
0.9410
0.9390
0.9380
0.9380
0.9380
0.9380
0.9530
0.9
Longitud
0.0750
0.0761
0.0763
0.0762
0.0760
0.0760
0.0759
0.0759
0.0772
Nivel
0.9380
0.9420
0.9420
0.9420
0.9410
0.9410
0.9410
0.9410
0.9460
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

168 Liliana Vanessa Pacheco & Juan Carlos Correa
Tabla
5:Longitudynivel
deconfianza
delosintervalos.
Taman
odemuestra100.Fuen
te:elaboracionpropia
n=
100
ρBootstrap
Arctanh
L.R
Jeyaratnam
Z1
Z2
Z3
Z4
P.G
0.0
Longitud
0.3874
0.3912
0.3882
0.3914
0.3907
0.3907
0.3902
0.3902
0.3858
Nivel
0.9470
0.9530
0.9510
0.9530
0.9530
0.9530
0.9520
0.9520
0.9330
0.1
Longitud
0.3846
0.3887
0.3858
0.3890
0.3882
0.3882
0.3877
0.3877
0.3824
Nivel
0.9510
0.9530
0.9510
0.9530
0.9520
0.9520
0.9520
0.9520
0.9460
0.2
Longitud
0.3763
0.3788
0.3760
0.3790
0.3783
0.3783
0.3778
0.3778
0.3735
Nivel
0.9470
0.9510
0.9500
0.9510
0.9500
0.9500
0.9490
0.9500
0.9320
0.3
Longitud
0.3558
0.3595
0.3571
0.3597
0.3590
0.3590
0.3586
0.3586
0.3554
Nivel
0.9420
0.9450
0.9440
0.9450
0.9430
0.9430
0.9430
0.9430
0.9430
0.4
Longitud
0.3297
0.3314
0.3295
0.3316
0.3309
0.3310
0.3305
0.3305
0.3291
Nivel
0.9490
0.9490
0.9480
0.9490
0.9490
0.9490
0.9490
0.9490
0.9450
0.5
Longitud
0.2952
0.2970
0.2956
0.2972
0.2966
0.2966
0.2962
0.2962
0.2943
Nivel
0.9500
0.9560
0.9540
0.9560
0.9560
0.9560
0.9560
0.9560
0.9560
0.6
Longitud
0.2530
0.2552
0.2544
0.2554
0.2549
0.2549
0.2546
0.2546
0.2518
Nivel
0.9480
0.9530
0.9530
0.9530
0.9510
0.9510
0.9510
0.9510
0.9500
0.7
Longitud
0.2018
0.2041
0.2037
0.2042
0.2038
0.2038
0.2036
0.2036
0.2023
Nivel
0.9420
0.9510
0.9490
0.9510
0.9510
0.9510
0.9510
0.9510
0.95500
0.8
Longitud
0.1420
0.1440
0.1441
0.1441
0.1438
0.1438
0.1436
0.1436
0.1441
Nivel
0.9350
0.9380
0.9410
0.9390
0.9380
0.9380
0.9380
0.9380
0.9530
0.9
Longitud
0.0750
0.0761
0.0763
0.0762
0.0760
0.0760
0.0759
0.0759
0.0772
Nivel
0.9380
0.9420
0.9420
0.9420
0.9410
0.9410
0.9410
0.9410
0.9460
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2
Comparacion de intervalos de confianza para el coeficiente de correlacion 169
Figura
1:Amplitudporcadaintervalo.Fuen
te:elaboracionpropia.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2
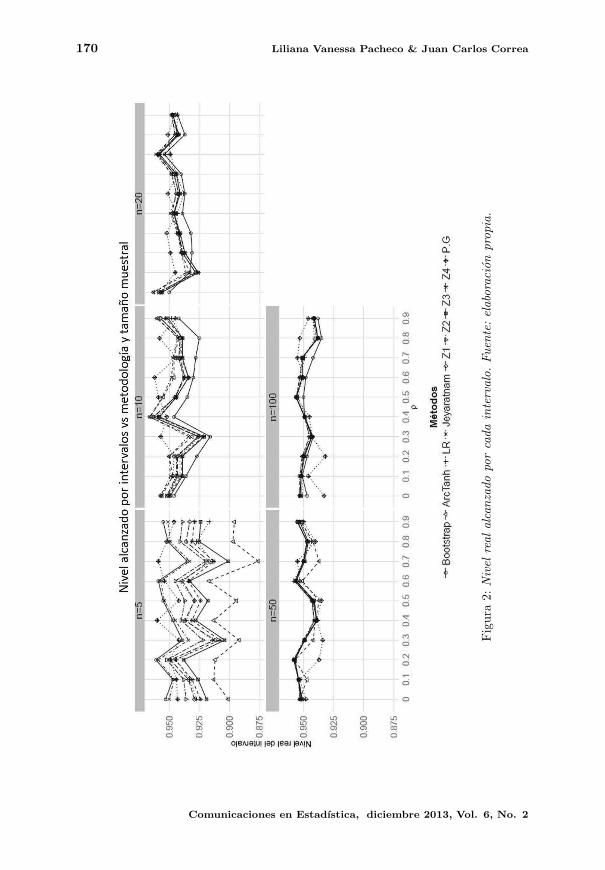
170 Liliana Vanessa Pacheco & Juan Carlos Correa
Figura
2:Nivel
realalcanzadoporcadaintervalo.Fuen
te:elaboracionpropia.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2
Comparacion de intervalos de confianza para el coeficiente de correlacion 171
Y ademas, cabe aclarar que el ındice esta limitado a 2 porque el rango parametral
de ρ es desde -1 hasta 1, es decir, una longitud equivalente a dos unidades. Y por
lo anterior el codigo de la simulacion que se empleo en este estudio esta restringido
para no tener en cuenta posibles resultados para ρ mayores que 1, o en su defecto,
menores que -1.
El rango de este ındice corresponde a (0, 2.1052) dado que si el nivel real, NR,
se acerca al 100% y/o la longitud maxima es lo mas pequena posible, entonces
I sera cercano a 2.1052; o si la longitud o el nivel real del intervalo es cercana a
cero entonces el I = 0. Luego, a valores mayores del ındice propuesto, mejor el
intervalo obtenido. Las siguientes tablas muestran los resultados a partir del ındice
propuesto, donde se resalta por cada valor de ρ el mejor metodo:
Tabla 6: Indice de resumen: Tamano de muestra 5. Fuente: elaboracion propian = 5
ρ Bootstrap ArcTanh LR Jayaratnam Z1 Z2 Z3 Z4 P.G
0 0.3572 0.3145 0.5011 0.3234 0.3856 0.3677 0.4142 0.4007 0.4468
0.1 0.3467 0.3087 0.5003 0.3180 0.3832 0.3642 0.4123 0.3990 0.4624
0.2 0.3626 0.3187 0.5119 0.3280 0.3957 0.3758 0.4246 0.4117 0.4635
0.3 0.3752 0.3282 0.5126 0.3366 0.3996 0.3827 0.4294 0.4153 0.4724
0.4 0.3991 0.3391 0.5332 0.3488 0.4199 0.3993 0.4506 0.4355 0.5058
0.5 0.4572 0.3925 0.5787 0.4037 0.4735 0.4537 0.5051 0.4906 0.5555
0.6 0.6789 0.5386 0.7218 0.5517 0.6390 0.6146 0.6790 0.6588 0.6091
0.7 0.8212 0.6580 0.8185 0.6723 0.7662 0.7384 0.7987 0.7874 0.7632
0.8 1.0607 0.8481 0.9807 0.8637 0.9660 0.9388 1.0030 0.9866 0.9180
0.9 1.4347 1.2544 1.2922 1.2657 1.3440 1.3246 1.3717 1.3601 1.2497
Tabla 7: Indice de resumen: Tamano de muestra 10. Fuente: elaboracion propian = 10
ρ Bootstrap ArcTanh LR Jayaratnam Z1 Z2 Z3 Z4 P.G
0 0.8002 0.7948 0.8660 0.7911 0.8118 0.8088 0.8238 0.8218 0.8541
0.1 0.7921 0.7873 0.8568 0.7844 0.8049 0.8019 0.8150 0.8130 0.8517
0.2 0.7961 0.8044 0.8696 0.7998 0.8194 0.8164 0.8294 0.8274 0.8570
0.3 0.8201 0.8166 0.8794 0.8147 0.8324 0.8291 0.8416 0.8397 0.8960
0.4 0.9082 0.8987 0.9576 0.8941 0.9174 0.9135 0.9265 0.9245 0.9321
0.5 0.9881 0.9743 1.0186 0.9706 0.9850 0.9813 0.9975 0.9946 1.0097
0.6 1.1045 1.0816 1.1114 1.0794 1.0914 1.0889 1.1009 1.0981 1.1429
0.7 1.2628 1.2366 1.2562 1.2337 1.2488 1.2467 1.2581 1.2569 1.2342
0.8 1.4741 1.4450 1.4480 1.4431 1.4588 1.4560 1.4654 1.4634 1.4231
0.9 1.7147 1.7019 1.6778 1.6996 1.7069 1.7050 1.7026 1.7048 1.6571
De las anteriores tablas se observa que, segun el criterio establecido para con-
cluir con el ındice de resumen propuesto, en tamanos de muestra pequenos y para
correlaciones menores que 0.7 (dentro de las empleadas en este estudio), el me-
jor metodo para la construccion de intervalos de confianza para el coeficiente de
correlacion agrupando las caracterısticas deseadas (longitud del intervalo corta y
mayor porcentaje de cobertura) es el de la razon de verosimilitud. Le sigue el
metodo Bootstrap en calidad. El metodo menos eficiente es el de la Trasforma-
cion de Fisher. Esto es apenas logico de esperar ya que establece que z tiene una
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2
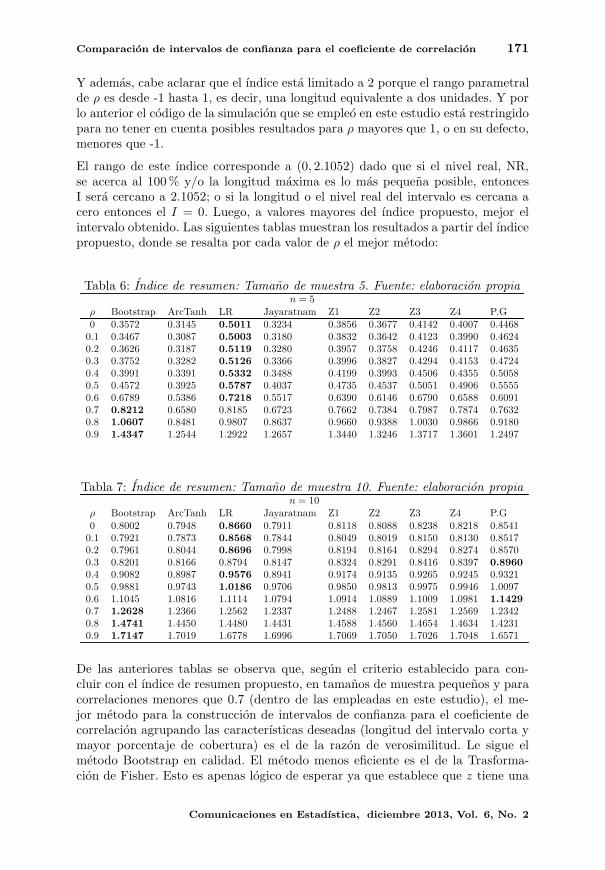
Comparacion de intervalos de confianza para el coeficiente de correlacion 171
Y ademas, cabe aclarar que el ındice esta limitado a 2 porque el rango parametral
de ρ es desde -1 hasta 1, es decir, una longitud equivalente a dos unidades. Y por
lo anterior el codigo de la simulacion que se empleo en este estudio esta restringido
para no tener en cuenta posibles resultados para ρ mayores que 1, o en su defecto,
menores que -1.
El rango de este ındice corresponde a (0, 2.1052) dado que si el nivel real, NR,
se acerca al 100% y/o la longitud maxima es lo mas pequena posible, entonces
I sera cercano a 2.1052; o si la longitud o el nivel real del intervalo es cercana a
cero entonces el I = 0. Luego, a valores mayores del ındice propuesto, mejor el
intervalo obtenido. Las siguientes tablas muestran los resultados a partir del ındice
propuesto, donde se resalta por cada valor de ρ el mejor metodo:
Tabla 6: Indice de resumen: Tamano de muestra 5. Fuente: elaboracion propian = 5
ρ Bootstrap ArcTanh LR Jayaratnam Z1 Z2 Z3 Z4 P.G
0 0.3572 0.3145 0.5011 0.3234 0.3856 0.3677 0.4142 0.4007 0.4468
0.1 0.3467 0.3087 0.5003 0.3180 0.3832 0.3642 0.4123 0.3990 0.4624
0.2 0.3626 0.3187 0.5119 0.3280 0.3957 0.3758 0.4246 0.4117 0.4635
0.3 0.3752 0.3282 0.5126 0.3366 0.3996 0.3827 0.4294 0.4153 0.4724
0.4 0.3991 0.3391 0.5332 0.3488 0.4199 0.3993 0.4506 0.4355 0.5058
0.5 0.4572 0.3925 0.5787 0.4037 0.4735 0.4537 0.5051 0.4906 0.5555
0.6 0.6789 0.5386 0.7218 0.5517 0.6390 0.6146 0.6790 0.6588 0.6091
0.7 0.8212 0.6580 0.8185 0.6723 0.7662 0.7384 0.7987 0.7874 0.7632
0.8 1.0607 0.8481 0.9807 0.8637 0.9660 0.9388 1.0030 0.9866 0.9180
0.9 1.4347 1.2544 1.2922 1.2657 1.3440 1.3246 1.3717 1.3601 1.2497
Tabla 7: Indice de resumen: Tamano de muestra 10. Fuente: elaboracion propian = 10
ρ Bootstrap ArcTanh LR Jayaratnam Z1 Z2 Z3 Z4 P.G
0 0.8002 0.7948 0.8660 0.7911 0.8118 0.8088 0.8238 0.8218 0.8541
0.1 0.7921 0.7873 0.8568 0.7844 0.8049 0.8019 0.8150 0.8130 0.8517
0.2 0.7961 0.8044 0.8696 0.7998 0.8194 0.8164 0.8294 0.8274 0.8570
0.3 0.8201 0.8166 0.8794 0.8147 0.8324 0.8291 0.8416 0.8397 0.8960
0.4 0.9082 0.8987 0.9576 0.8941 0.9174 0.9135 0.9265 0.9245 0.9321
0.5 0.9881 0.9743 1.0186 0.9706 0.9850 0.9813 0.9975 0.9946 1.0097
0.6 1.1045 1.0816 1.1114 1.0794 1.0914 1.0889 1.1009 1.0981 1.1429
0.7 1.2628 1.2366 1.2562 1.2337 1.2488 1.2467 1.2581 1.2569 1.2342
0.8 1.4741 1.4450 1.4480 1.4431 1.4588 1.4560 1.4654 1.4634 1.4231
0.9 1.7147 1.7019 1.6778 1.6996 1.7069 1.7050 1.7026 1.7048 1.6571
De las anteriores tablas se observa que, segun el criterio establecido para con-
cluir con el ındice de resumen propuesto, en tamanos de muestra pequenos y para
correlaciones menores que 0.7 (dentro de las empleadas en este estudio), el me-
jor metodo para la construccion de intervalos de confianza para el coeficiente de
correlacion agrupando las caracterısticas deseadas (longitud del intervalo corta y
mayor porcentaje de cobertura) es el de la razon de verosimilitud. Le sigue el
metodo Bootstrap en calidad. El metodo menos eficiente es el de la Trasforma-
cion de Fisher. Esto es apenas logico de esperar ya que establece que z tiene una
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2
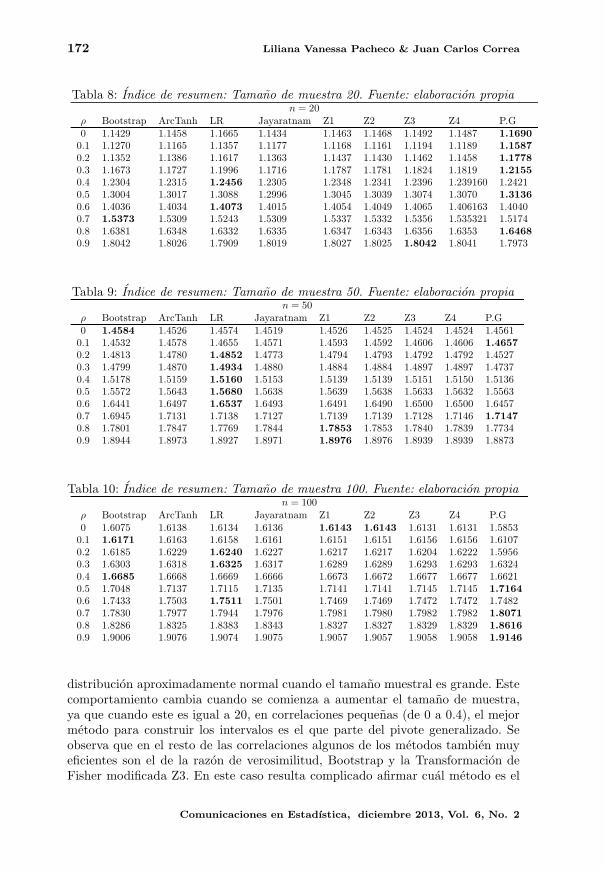
172 Liliana Vanessa Pacheco & Juan Carlos Correa
Tabla 8: Indice de resumen: Tamano de muestra 20. Fuente: elaboracion propian = 20
ρ Bootstrap ArcTanh LR Jayaratnam Z1 Z2 Z3 Z4 P.G
0 1.1429 1.1458 1.1665 1.1434 1.1463 1.1468 1.1492 1.1487 1.1690
0.1 1.1270 1.1165 1.1357 1.1177 1.1168 1.1161 1.1194 1.1189 1.1587
0.2 1.1352 1.1386 1.1617 1.1363 1.1437 1.1430 1.1462 1.1458 1.1778
0.3 1.1673 1.1727 1.1996 1.1716 1.1787 1.1781 1.1824 1.1819 1.2155
0.4 1.2304 1.2315 1.2456 1.2305 1.2348 1.2341 1.2396 1.239160 1.2421
0.5 1.3004 1.3017 1.3088 1.2996 1.3045 1.3039 1.3074 1.3070 1.3136
0.6 1.4036 1.4034 1.4073 1.4015 1.4054 1.4049 1.4065 1.406163 1.4040
0.7 1.5373 1.5309 1.5243 1.5309 1.5337 1.5332 1.5356 1.535321 1.5174
0.8 1.6381 1.6348 1.6332 1.6335 1.6347 1.6343 1.6356 1.6353 1.6468
0.9 1.8042 1.8026 1.7909 1.8019 1.8027 1.8025 1.8042 1.8041 1.7973
Tabla 9: Indice de resumen: Tamano de muestra 50. Fuente: elaboracion propian = 50
ρ Bootstrap ArcTanh LR Jayaratnam Z1 Z2 Z3 Z4 P.G
0 1.4584 1.4526 1.4574 1.4519 1.4526 1.4525 1.4524 1.4524 1.4561
0.1 1.4532 1.4578 1.4655 1.4571 1.4593 1.4592 1.4606 1.4606 1.4657
0.2 1.4813 1.4780 1.4852 1.4773 1.4794 1.4793 1.4792 1.4792 1.4527
0.3 1.4799 1.4870 1.4934 1.4880 1.4884 1.4884 1.4897 1.4897 1.4737
0.4 1.5178 1.5159 1.5160 1.5153 1.5139 1.5139 1.5151 1.5150 1.5136
0.5 1.5572 1.5643 1.5680 1.5638 1.5639 1.5638 1.5633 1.5632 1.5563
0.6 1.6441 1.6497 1.6537 1.6493 1.6491 1.6490 1.6500 1.6500 1.6457
0.7 1.6945 1.7131 1.7138 1.7127 1.7139 1.7139 1.7128 1.7146 1.7147
0.8 1.7801 1.7847 1.7769 1.7844 1.7853 1.7853 1.7840 1.7839 1.7734
0.9 1.8944 1.8973 1.8927 1.8971 1.8976 1.8976 1.8939 1.8939 1.8873
Tabla 10: Indice de resumen: Tamano de muestra 100. Fuente: elaboracion propian = 100
ρ Bootstrap ArcTanh LR Jayaratnam Z1 Z2 Z3 Z4 P.G
0 1.6075 1.6138 1.6134 1.6136 1.6143 1.6143 1.6131 1.6131 1.5853
0.1 1.6171 1.6163 1.6158 1.6161 1.6151 1.6151 1.6156 1.6156 1.6107
0.2 1.6185 1.6229 1.6240 1.6227 1.6217 1.6217 1.6204 1.6222 1.5956
0.3 1.6303 1.6318 1.6325 1.6317 1.6289 1.6289 1.6293 1.6293 1.6324
0.4 1.6685 1.6668 1.6669 1.6666 1.6673 1.6672 1.6677 1.6677 1.6621
0.5 1.7048 1.7137 1.7115 1.7135 1.7141 1.7141 1.7145 1.7145 1.7164
0.6 1.7433 1.7503 1.7511 1.7501 1.7469 1.7469 1.7472 1.7472 1.7482
0.7 1.7830 1.7977 1.7944 1.7976 1.7981 1.7980 1.7982 1.7982 1.8071
0.8 1.8286 1.8325 1.8383 1.8343 1.8327 1.8327 1.8329 1.8329 1.8616
0.9 1.9006 1.9076 1.9074 1.9075 1.9057 1.9057 1.9058 1.9058 1.9146
distribucion aproximadamente normal cuando el tamano muestral es grande. Este
comportamiento cambia cuando se comienza a aumentar el tamano de muestra,
ya que cuando este es igual a 20, en correlaciones pequenas (de 0 a 0.4), el mejor
metodo para construir los intervalos es el que parte del pivote generalizado. Se
observa que en el resto de las correlaciones algunos de los metodos tambien muy
eficientes son el de la razon de verosimilitud, Bootstrap y la Transformacion de
Fisher modificada Z3. En este caso resulta complicado afirmar cual metodo es el
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Comparacion de intervalos de confianza para el coeficiente de correlacion 173
menos efectivo, ya que las diferencias en el ındice de resumen para el resto de los
metodos son mınimas, y por tanto no muy significativas.
El metodo de la razon de verosimilitud en tamanos de muestra iguales a 50 dan
los mejores resultados para estos intervalos de confianza y en menor medida el
del pivote generalizado y la transformacion de Fisher modificada Z1. Cabe aclarar
que, las diferencias que hicieron que cada uno de estos metodos sobresaliese en el
respectivo caso, fueron mınimas, es decir, con tamanos de muestra grandes, todos
los metodos ofrecen ındices de resumen casi iguales y por tanto, decidir cual es
mejor se hace indiferente.
4. Conclusiones
Los procedimientos que se tuvieron en cuenta para la construccion de intervalos de
confianza para el coeficiente de correlacion en una distribucion normal bivariada,
ρ, difieren en calidad dependiendo del tamano de muestra empleado para ello. Se
pudo observar que, en el caso de muestras pequenas (n = 5 y n = 10), los que mejor
desempeno tuvieron fueron los de razon de verosimilitud y Bootstrap. El metodo
de razon de verosimilitud ofrece longitudes cortas de intervalo y nivel de confianza
real mas cercano al nivel nominal establecido en este estudio de simulacion, 95%
para correlaciones desde 0 hasta 0.7. En los casos restantes, es decir, correlaciones
de 0.8 y 0.9, el metodo Bootstrap supera al anterior.
Cuando n = 20, el metodo que se comporta mejor en la gran mayorıa de las
correlaciones consideradas es el de pivote generalizado. Le sigue en orden de calidad
de intervalo obtenido por el metodo de razon de verosimilitud. Cuando n = 50 y
n = 100, todos los metodos tienen un comportamiento casi igual. Las longitudes
de intervalo para cada uno de estos dos casos (n = 50 y n = 100) disminuyen
considerablemente a lo observado en el caso anterior, es decir, en comparacion con
n = 20, como se puede evidenciar en las tablas.
En la mayorıa de los casos, el metodo de Bootstrap ofrece niveles de confianza
reales menores que los de los demas metodos. Se observa un detalle muy particu-
lar con respecto a esta caracterıstica y todos los metodos a excepcion del pivote
generalizado: los niveles de confianza reales son muy parecidos entre sı cuando el
tamano de muestra es muy grande (n=100).
Recibido: 5 de mayo de 2013
Aceptado: 14 de agosto de 2013
Referencias
Efron, B. (1979), ‘Computers and theory of statistics: Thinking the unthinkable’,
SIAM Review 21(4), 460–480.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

174 Liliana Vanessa Pacheco & Juan Carlos Correa
Falk, R. & Well, A. (1997), ‘Many faces of the correlation coefficient’, Journal ofStatistics Education 5(3).
Fisher, R. (1921), ‘On the “probable error” of a coefficient of correlation deduced
from a small sample’, Metron 1, 3–32.
Hotelling, H. (1953), ‘New light on the correlation coefficient and its transforms’,
Journal of the Royal Statistical Society 15(2), 193–232.
Kalbfleish, J. (1985), Probability and statistical inference, Springer-Verlag: NewYork.
Krishnamoorthy, I. & Xia, Y. (2007), ‘Inferences on correlation coefficients: One-
sample, independent and correlated cases’, Journal of Statistical Planningand Inference 137(7), 2362–2379.
Pawitan, Y. (2001), In all likelihood, Clarendon Press: Oxford.
Zheng, Q. & Matis, J. (1994), ‘Correlation coefficient revisited’, The AmericanStatistician 48(3), 240–241.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Comunicaciones en Estadıstica
Diciembre 2013, Vol. 6, No. 2, pp. 175–195
Comparacion entre arboles de regresion CARTy regresion lineal
Comparison between CART regression trees and linear regression
Juan Felipe Dıaza
[email protected] Carlos Correab
Resumen
La regresion lineal es el metodo mas usado en estadıstica para predecir valores de
variables continuas debido a su facil interpretacion, pero en muchas situaciones
los supuestos para aplicar el modelo no se cumplen y algunos usuarios tienden a
forzarlos llevando a conclusiones erroneas. Los arboles de regresion CART son una
alternativa de regresion que no requiere supuestos sobre los datos por analizar y es
un metodo de facil interpretacion de los resultados. En este trabajo se comparan a
nivel predictivo la regresion lineal con CART mediante simulacion. En general, se
encontro que cuando se ajusta el modelo de regresion lineal correcto a los datos, el
error de prediccion de regresion lineal siempre es menor que el de CART. Tambien
se encontro que cuando se ajusta erroneamente un modelo de regresion lineal a
los datos, el error de prediccion de CART es menor que el de regresion lineal solo
cuando se tiene una cantidad de datos suficientemente grande.
Palabras clave: simulacion, error de prediccion, regresion lineal, arboles de cla-
sificacion y regresion CART.
Abstract
Linear regression is the most widely used method in statistics to predict values
of continuous variables due to its easy interpretation, but in many situations the
suppositions to apply the model are not met and some users tend to force them
leading them to erroneous conclusions. CART regression trees is a regression al-
ternative that does not require suppositions on the data to be analyzed and is
a method of easy interpretation of results. This work compares predictive levels
of linear regression with CART through simulation. In general, it was found that
when the correct linear regression model is adjusted to the data, the prediction
aMaestrıa en Ciencias - Estadıstica. Universidad Nacional de Colombia, sede Medellın,
Colombia.bProfesor Asociado. Universidad Nacional de Colombia, sede Medellın, Colombia.
175

176 Juan Felipe Dıaz & Juan Carlos Correa
error of linear regression is always lower than that of CART. It was also found that
when linear regression model is erroneously adjusted to the data, the prediction
error of CART is lower than that of linear regression only when it has a sufficiently
large amount of data.
Keywords: simulation, prediction error, linear regression, CART classification
and regression trees.
1. Introduccion
El modelo lineal clasico ha sido utilizado extensivamente y con mucho exito en
multiples situaciones. Tiene ventajas que lo hacen muy util para el usuario, de-
bido a que es facil de interpretar, facil de estimar y poco costoso. La facilidad
de interpretacion de este modelo lo ha popularizado bastante y no es raro ver su
ajuste en situaciones inapropiadas, por ejemplo, en respuestas que son discretas
o sesgadas; y el desespero por parte de los usuarios por aproximarse a el, por
ejemplo, mediante transformaciones de los datos, sin considerar los cambios en la
estructura del error. Por lo anterior, es necesario un modelo que tenga similares
ventajas y que no sea tan rıgido con los supuestos, para que el usuario final lo
pueda aplicar tranquilamente.
Los arboles de clasificacion y regresion (CART) es un metodo que utiliza datos
historicos para construir arboles de clasificacion o de regresion, los cuales son usa-
dos para clasificar o predecir nuevos datos. Estos arboles CART pueden manipular
facilmente variables numericas y categoricas. Entre otras ventajas esta su robus-
tez a outliers, la invarianza en la estructura de sus arboles de clasificacion o de
regresion a transformaciones monotonas de las variables independientes, y sobre
todo, su interpretabilidad.
Desde el planteamiento de los arboles de clasificacion y regresion CART por Leo
Breiman y otros en 1984 (Breiman et al. 1984), se presento gran interes en la
utilizacion de esta metodologıa por parte de la comunidad cientıfica debido a su
facil implementacion en todo tipo de problemas y su clara interpretacion de los
resultados.
Muchos investigadores despues de la publicacion del libro de Breiman (Breiman
et al. 1984) han planteado variaciones del metodo en sus distintas etapas, pero
en muchos casos la idea inicial del particionamiento recursivo es la misma, otros
han aplicado CART y sus variaciones en distintos campos como la medicina, la
biologıa y el aprendizaje de maquinas. Algunos investigadores han comparado es-
ta metodologıa con otras tecnicas de modelamiento como Tamminen, Laurinen y
Roning (Tamminen et al. 1999) quienes en 1999, debido a que el sistema fısico de
los humanos es altamente no lineal y la regresion lineal tradicional no puede ser
usada como modelo de aproximacion, compararon los arboles de regresion con las
redes neuronales en un conjunto de datos obtenidos por un metodo de medicion
de aptitud aerobica, concluyendo que las redes neuronales son una potente herra-
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Comparacion entre arboles de regresion CART y regresion lineal 177
mienta de aproximacion, pero se dificulta la interpretacion del modelo, mientras
que los arboles de regresion son faciles de visualizar y su estructura es mas com-
prensible. Ankarali, Canan, Akkus, Bugdayci y Ali Sungur (Ankarali et al. 2007)
en 2007 compararon los metodos de arboles de clasificacion y regresion logıstica en
la determinacion de factores de riesgo sociodemograficos que influyen en el estado
de depresion de 1447 mujeres en periodos separados de posparto, y concluyeron
que los arboles de clasificacion dan informacion mas detallada sobre el diagnostico
mediante la evaluacion conjunta de una gran cantidad de factores de riesgo que el
modelo de regresion logıstica.
El problema central es comparar por medio de un estudio de simulacion, a nivel
predictivo, el metodo no parametrico CART con el metodo parametrico Regresion
lineal, dos tecnicas que tienen similares ventajas en cuanto a la simplicidad de sus
modelos y su facil interpretacion de los resultados. En la seccion 2 se presenta
el metodo CART: particionamiento recursivo, arboles de clasificacion y arboles de
regresion. En la seccion 3 se describe el estudio de simulacion: errores de prediccion
y pasos. En las secciones 4 y 5 se simulan conjuntos de datos cuyo verdadero modelo
es un modelo de regresion lineal y se ajusta a estos datos tanto los modelos de
regresion correctos como modelos de regresion incorrectos, para comparar luego
sus errores de prediccion con los errores de prediccion de arboles de regresion
ajustados a los mismos datos. En las secciones 6 y 7 se dan las conclusiones y
agradecimientos.
2. CART
2.1. Particionamiento recursivo
El algoritmo conocido como particionamiento recursivo es el proceso paso a paso
para construir un arbol de decision y es la clave para el metodo estadıstico no
parametrico CART (Izenman 2008).
Sea Y una variable respuesta y sean p variables predictoras x1, x2, . . . , xp, donde
las x´s son tomadas fijas y Y es una variable aleatoria. El problema estadıstico
es establecer una relacion entre Y y las x´s de tal forma que sea posible prede-
cir Y basado en los valores de las x´s. Matematicamente, se quiere estimar la
probabilidad condicional de la variable aleatoria Y ,
P [Y = y|x1, x2, . . . , xp]
cuando la variable Y es discreta, o un funcional de su probabilidad tal como la
esperanza condicional
E[Y |x1, x2, . . . , xp].
cuando la variable Y es continua.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

178 Juan Felipe Dıaz & Juan Carlos Correa
2.1.1. Elementos de la construccion del arbol
Segun Zhang & Singer (2010) para ilustrar las ideas basicas considere el diagrama
de la Figura 1.
Figura 1: Ejemplo arbol. Fuente: modificado de Zhang & Singer 2010.
El arbol tiene tres niveles de nodos. El primer nivel tiene un unico nodo en la cima
(el cırculo) llamado nodo raız. Un nodo interno (el cırculo) en el segundo nivel, y
tres nodos terminales (las cajas) que estan respectivamente en el segundo y tercer
nivel. El nodo raız y el nodo interno son particionados cada uno en dos nodos en
el siguiente nivel, los cuales son llamados nodos hijos izquierdo y derecho.
El nodo raız contiene una muestra de sujetos desde la cual se aumenta el arbol,
es decir, desde donde se desprenden los demas nodos. Estos sujetos constituyen
lo que se llama una muestra de aprendizaje, la cual puede ser la muestra total en
estudio o una parte de esta.
El objetivo del particionamiento recursivo es acabar en nodos terminales que sean
homogeneos en el sentido de que ellos contengan solo puntos o cırculos Figura 1b.
Una medida cuantitativa de la homogeneidad de un nodo es la nocion de impureza,
para la cual se define el siguiente indicador:
Impureza del nodo =# sujetos que cumplen la caracterıstica en el nodo
# total de sujetos en el nodo. (1)
En la Figura 1, si la caracterıstica es ser cırculo, el nodo hijo izquierdo del nodo
raız tiene impureza igual a 1, debido a que en este nodo solo hay cırculos, pero,
si la caracterıstica es ser punto, la impureza es igual a 0, debido a que no hay
ningun punto en este nodo. Notese que en el nodo hijo derecho del nodo raız el
numero de cırculos es aproximadamente igual al numero de puntos, teniendo este
nodo una medida de la impureza de aproximadamente 0.5 independientemente de
si la caracterıstica sea ser cırculo o punto. Mientras mas homogeneo sea el nodo el
lımite del cociente en la ecuacion (1) es 0 o 1.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Comparacion entre arboles de regresion CART y regresion lineal 179
2.1.2. Division de un nodo
Para dividir el nodo raız en dos nodos homogeneos, se debe seleccionar entre los
rangos de todas las variables predictoras el valor de la division que mas lleve al
lımite de 0 o 1 el cociente en la ecuacion (1) para cada nodo hijo. En la Figura
1 a) se selecciono como division el valor c2 entre el rango de la variable x3. El
proceso continua para los dos nodos hijos, teniendo en cuenta para cada nodo el
rango resultante de la variable con la que se dividio el nodo padre y el rango de
las demas variables involucradas.
Antes de seleccionar la mejor division, se debe definir la bondad de una division.
Se busca una division que resulte en dos nodos hijos puros (u homogeneos). Sin
embargo, en la realidad los nodos hijos son usual y parcialmente puros. Ademas,
la bondad de una division debe poner en una balanza la homogeneidad (o la
impureza) de los dos nodos hijos simultaneamente.
2.1.3. Nodos terminales
El proceso de particionamiento recursivo continua hasta que el arbol sea saturado
en el sentido de que los sujetos en los nodos descendientes no se pueden partir en
una division adicional. Esto sucede, por ejemplo, cuando en un nodo queda solo un
sujeto. El numero total de divisiones permitidas para un nodo disminuye cuando
aumentan los niveles del arbol. Cualquier nodo que no pueda o no sea dividido es un
nodo terminal. El arbol saturado generalmente es bastante grande para utilizarse,
porque los nodos terminales son tan pequenos que no se puede hacer inferencia
estadıstica razonable, debido a que los datos quedan ”sobre-ajustados”, es decir,
el arbol alcanza un ajuste tan fiel a la muestra de aprendizaje que cuando en la
practica se aplique el modelo obtenido a nuevos datos los resultados pueden ser
muy malos, y por tanto, no es necesario esperar hasta que el arbol sea saturado.
En lugar de esto, se escoge un tamano mınimo de nodo apriori. Se detiene la
division cuando el tamano del nodo es menor que el mınimo. La escogencia del
tamano mınimo depende del tamano de muestra (uno por ciento) o se puede tomar
simplemente como cinco sujetos (los resultados generalmente no son significativos
con menos de cinco sujetos).
Breiman et al. (1984) argumentan que dependiendo del lımite de parada, el par-
ticionamiento tiende a terminar muy pronto o muy tarde. En consecuencia, ellos
hacen un cambio fundamental introduciendo un segundo paso llamado “poda”.
La poda consiste en encontrar un subarbol del arbol saturado que sea el mas “pre-
dictivo” de los resultados y menos vulnerable al ruido en los datos. Los subarboles
se obtienen podando el arbol saturado desde el ultimo nivel hacia arriba. Por
ejemplo, el arbol de la Figura 2a es un subarbol del arbol de la Figura 2b.
Los pasos de particionamiento y poda se pueden ver como variantes de los procesos
paso a paso forward y backward en regresion lineal.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

180 Juan Felipe Dıaz & Juan Carlos Correa
Figura 2: El nodo 1 se divide en los nodos 2 y 3, luego, el nodo 2 se divide en los
nodos 3 y 4. Fuente: modificado de Zhang & Singer 2010.
2.2. Arboles de clasificacion
Los arboles de clasificacion y regresion (CART) fueron desarrollados en los anos
ochenta por Breiman, Freidman, Olshen y Stone en el libro Classification and
regression trees (Breiman et al. 1984).
La metodologıa CART utiliza datos historicos para construir arboles de clasifica-
cion o de regresion, los cuales son usados para clasificar o predecir nuevos datos.
Estos arboles CART pueden manipular facilmente como variable respuesta varia-
bles numericas y categoricas. Entre otras ventajas esta su robustez a outliers, la
invarianza en la estructura de sus arboles de clasificacion o de regresion a trans-
formaciones monotonas de las variables independientes, y sobre todo, su interpre-
tabilidad.
Esta metodologıa consiste de tres pasos:
Construccion del arbol saturado.
Escogencia del tamano correcto del arbol.
Clasificacion de nuevos datos usando el arbol construido.
La construccion del arbol saturado se hace con particionamiento recursivo. La
diferencia en la construccion de los arboles de clasificacion y los arboles de regresion
es el criterio de division de los nodos, es decir, la medida de impureza y la bondad
de una division es diferente para los arboles de clasificacion y de regresion. En esta
seccion se considera primero la construccion de arboles de clasificacion.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Comparacion entre arboles de regresion CART y regresion lineal 181
2.2.1. Determinacion de la division de un nodo
Sea Y una variable dicotomica con valores 0 y 1, y sea τ un nodo. Para construir
el arbol saturado, en el proceso de particionamiento recursivo se tiene que, si τes el nodo menos impuro la impureza es 0 y debe tener como resultado P [Y =
1|τ ] = 0 o P [Y = 1|τ ] = 1. El nodo τ es mas impuro cuando su impureza es 1
con P [Y = 1|τ ] = 1
2. Por tanto, la funcion impureza tiene una forma concava y se
puede definir formalmente como
i(τ) = φ(P [Y = 1|τ ]), (2)
donde φ tiene las siguientes propiedades,
(i) φ ≥ 0 y
(ii) para cualquier p ∈ (0, 1), φ(p) = φ(1 − p) y φ(0) = φ(1) < φ(p).
Las escogencias mas comunes de funciones de impureza para la construccion de
arboles de clasificacion son:
φ(p) = min(p, 1− p), (mınimo error o error de Bayes)
φ(p) = −p log(p)− (1 − p) log(1− p), (entropıa)
φ(p) = p(1− p), (ındice Gini)
donde, se define 0 log(0) := 0.
Ademas, se define la bondad de una division s como
∆I(τ) = i(τ)− P [τL]i(τL)− P [τR]i(τR), (3)
donde τ es el nodo padre del nodo izquierdo τL y del nodo derecho τR, y P [τL] yP [τR] son respectivamente las probabilidades de que un sujeto caiga dentro de los
nodos τL y τR.
La ecuacion (3) mide el grado de reduccion de la impureza cuando se pasa del
nodo padre a los nodos hijos. Se selecciona s tal que ∆I(τ) sea maxima.
2.2.2. Determinacion de los nodos terminales
Una vez se tiene construido el arbol saturado se inicia la etapa de poda. La po-
da consiste en encontrar el subarbol del arbol saturado con la mejor calidad en
cuanto a que sea lo mas predictivo posible y lo menos sensible al ruido de los
datos. Es decir, se debe definir una medida de calidad de un arbol. Para esto se
debe recordar que el objetivo de los arboles de clasificacion es el mismo que el
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

182 Juan Felipe Dıaz & Juan Carlos Correa
del particionamiento recursivo: extraer subgrupos homogeneos de la poblacion o
muestra en estudio. Para alcanzar este objetivo se debe tener certeza de que los
nodos terminales son homogeneos, es decir, la calidad de un arbol es simplemente
la calidad de sus nodos terminales. Por tanto, para un arbol T se define
R(T ) =∑
τ∈ ˜T
P[τ ]r(τ), (4)
donde T es el conjunto de nodos terminales de T , P[τ ] es la probabilidad de que
un sujeto pertenezca al nodo τ y r(τ), es una medida de calidad del nodo τ la cual
es similar a la suma de cuadrados de los residuales en regresion lineal.
El proposito de la poda es seleccionar el mejor subarbol, T ∗, de un arbol saturado
inicialmente, T0, tal que R(T ∗) sea mınimo.
Una escogencia obvia para r(τ) es la medida de impureza del nodo τ , aunque en ge-
neral se toma como el costo de mala clasificacion, es decir, r(τ) =∑l
i=1c(j|i)P[Y =
i|τ ], donde c(i|j) es el costo de mala clasificacion de que un sujeto de la clase j seaclasificado en la clase i, con i, j = 1, . . . , l. Cuando i = j, se tiene la clasificacion
correcta y el costo deberıa ser cero, es decir, c(i|i) = 0.
Generalmente, es difıcil en la practica medir el costo relativo c(j|i) para i = j, ypor tanto, no se puede asignar el costo de mala clasificacion de cada nodo antes
de aumentar cualquier arbol, incluso cuando se conoce el perfil del arbol. Por otra
parte, existe suficiente evidencia empırica en la literatura que demuestra que el
uso de una funcion de impureza como la entropıa usualmente lleva a arboles utiles
con tamanos de muestra razonables.
Estimacion del costo de mala clasificacion
Sea Rs(τ) la proporcion de elementos mal clasificados del nodo τ , tambien conocida
como estimacion por resustitucion del costo de mala clasificacion para el nodo τ .Se define la estimacion por resustitucion del costo de mala clasificacion para el
arbol T como,
Rs(T ) =∑
τ∈ ˜T
Rs(τ). (5)
Zhang & Singer (2010) afirman que esta estimacion por resustitucion generalmente
subestima el costo. Ademas, Breiman et al. (1984) prueban que a medida que
aumentan los nodos en el arbol disminuye la estimacion por resustitucion (5), y
como consecuencia, este estimador tiene el problema de seleccionar arboles sobre-
ajustados.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Comparacion entre arboles de regresion CART y regresion lineal 183
2.2.3. Costo-complejidad
El tamano del arbol es importante a la hora de dar conclusiones sobre la muestra
o poblacion en estudio, debido a que un arbol con una gran cantidad de nodos
puede tener problemas de sobreajuste. Una medida de la calidad de un arbol debe
tener en cuenta tanto la calidad de los nodos terminales como el tamano del arbol
(numero de nodos del arbol), y tener en cuenta solo el costo de mala clasificacion
puede llevar a arboles muy grandes.
Se define el costo-complejidad del arbol T como
Rα(T ) = R(T ) + α|T |, (6)
donde α (≥ 0) es el parametro de complejidad y |T | es el numero de nodos termi-
nales en T llamado complejidad del arbol T . La diferencia entre R(T ) y Rα(T )
como una medida de la calidad del arbol reside en que Rα(T ) penaliza un gran
arbol.
Aunque se dijo anteriormente que la aproximacion por resustitucion tiene sus
problemas al estimar el costo de mala clasificacion para un nodo, es muy util al
estimar el costo-complejidad.
El uso del costo-complejidad permite construir una secuencia de subarboles opti-
mos anidados (ver Zhang & Singer 2010) desde cualquier arbol T dado. La idea
es construir una secuencia de subarboles anidados para un arbol saturado T , mi-
nimizando el costo-complejidad Rα(T ), y seleccionar como subarbol final el que
tenga el mas pequeno costo de mala clasificacion de estos subarboles.
Cuando se tiene una muestra de prueba, estimar R(T ) es sencillo para cualquier
subarbol T , porque solo se necesita aplicar los subarboles a la muestra de prueba
y luego se escoge el mejor valor de α, pero, si no se tiene una muestra de prueba,
se pueden crear muestras artificiales utilizando el proceso de validacion cruzada
(ver Zhang & Singer 2010) para estimar R(T ) y ası escoger el mejor valor de α.
2.3. Arboles de regresion
En la construccion de arboles de clasificacion se indico que es necesario una medida
de impureza dentro de un nodo, es decir, un criterio de division de nodo para
construir un gran arbol y luego un criterio de costo-complejidad para podarlo.
Estas directrices generales se aplican cada vez que se intenta desarrollar metodos
basados en arboles. Para la construccion de arboles de clasificacion la variable
respuesta debe ser categorica, mientras que para la construccion de arboles de
regresion la variable respuesta debe ser continua. En general, la metodologıa para
construir arboles de clasificacion y arboles de regresion es la misma, por tanto, los
pasos vistos anteriormente para construir arboles de clasificacion son aplicables en
la construccion de arboles de regresion. La diferencia radica en la escogencia de la
funcion impureza para dividir un nodo y en la estimacion del costo-complejidad
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

184 Juan Felipe Dıaz & Juan Carlos Correa
para podar el arbol. Para una respuesta continua, una escogencia natural de la
impureza para un nodo τ es la varianza de la respuesta dentro del nodo:
i(τ) =∑
sujeto i∈τ
(Yi − Y (τ))2, (7)
donde Y (τ) es el promedio de Yi´s dentro del nodo τ . Para dividir un nodo τ en
dos nodos hijos, τL y τR, se define la bondad de una division s como
∆I(τ) = i(τ)− i(τL)− i(τR). (8)
A diferencia de la ecuacion (3), la ecuacion (8) no necesita pesos. Ademas, se puede
hacer uso de i(τ) para definir el costo del arbol como
R(T ) =∑
τ∈ ˜T
i(τ), (9)
y luego sustituirlo en la ecuacion (6) para formar el costo-complejidad.
3. Descripcion del estudio de simulacion
3.1. Medidas del error de prediccion
Suponga que se tiene un conjunto de datos (x1, y1), (x2, y2), . . . , (xn, yn) que sigueun modelo de regresion lineal:
yi = β0 + β1xi1 + . . .+ βpxip + εi, donde εi ∼ N(0, σ2), i = 1, . . . , n. (10)
De lo anterior se sabe que
yverdi = E(yi) = β0 + β1xi1 + . . .+ βpxip, i = 1, . . . , n.
Se ajusta un modelo de regresion lineal a los datos (x1, y1), (x2, y2), . . . , (xn, yn),luego, los valores predichos son de la forma:
yregi = β0 + β1xi1 + . . .+ βpxip, i = 1, . . . , n,
donde, β0, β1, . . . , βp son las estimaciones por mınimos cuadrados de los parametros
β0, β1, . . . , βp.
Por tanto, el error de prediccion por regresion lineal se calcula como
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Comparacion entre arboles de regresion CART y regresion lineal 185
EPRL =
ni=1
(yregi − yverdi)2
n. (11)
Ademas, se ajusta un arbol de regresion a los datos (x1, y1), (x2, y2), . . . , (xn, yn),obteniendo un arbol de l nodos terminales. Sean C1, C2, . . . , Cl las clases corres-
pondientes a los l nodos terminales, luego, los valores predichos por el arbol de
regresion son de la forma:
ycarti =
rk si xi ∈ Ck ; k = 1, . . . , l
0 si en otro caso
donde,
rk =
yi|xi ∈ Ck, i = 1, . . . , n
#(yi|xi ∈ Ck, i = 1, . . . , n); k = 1, . . . , l.
Por tanto, el error de prediccion por CART se calcula como
EPCART =
ni=1
(ycarti − yverdi)2
n. (12)
3.2. Pasos del estudio de simulacion
Los conjuntos de datos simulados en este trabajo se generan de modelos de regre-
sion lineal de la forma:
Yi = F (xi1, xi2, . . . , xip) + εi, donde εi ∼ N(0, σ2), i = 1, . . . , n (13)
donde
E[Yi] = F (xi1, xi2, . . . , xip) = β0+
p
j=1
βjxij = β0+
p
j=1
βjgj(xi) = f(xi), i = 1, . . . , n
(14)
mediante los siguientes pasos:
1. Se especifican las funciones g1(x), . . . , gp(x) y valores de los parametros
β0, β1, . . . , βp en la ecuacion (14).
2. Se genera una secuencia de n numeros x1, x2, . . . , xn igualmente espaciados
del conjunto (soporte) X = [1, 100].
3. Se generan aleatoriamente n numeros ε1, ε2, . . . , εn de la distribucionN(0, σ2).
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

186 Juan Felipe Dıaz & Juan Carlos Correa
4. Se calculan los valores yi = f(xi) + εi para todo i = 1, . . . , n.
5. Se estandarizan los datos y1, y2, . . . , yn obteniendo y∗1, y∗
2, . . . , y∗n, donde,
y∗i =yi − y
sy(15)
6. Se toma como muestra de aprendizaje L = (x1, y∗
1), (x2, y
∗
2), . . . , (xn, y
∗
n)la cual sigue el modelo de regresion lineal descrito por la ecuacion (13).
7. Para la muestra de aprendizaje L se ajusta un modelo de regresion lineal
utilizando la librerıa MASS y se ajusta un arbol de regresion utilizando la
librerıa rpart del paquete estadıstico R.
8. Se estiman los errores de prediccion para el modelo de regresion lineal ajusta-
do y para el arbol de regresion ajustado, los cuales se definen respectivamente
en las ecuaciones (11) y (12).
9. Se repiten los pasos 3 a 8 para obtener 1000 errores de prediccion por regre-
sion lineal EPRL1, EPRL2,..., EPRL1000 y 1000 errores de prediccion por
arboles de clasificacion EPCART1, EPCART2,..., EPCART1000.
10. Se calcula el promedio de los 1000 errores de prediccion para regresion li-
neal y el promedio de los 1000 errores de prediccion para arboles de regre-
sion, los cuales son respectivamente EPRL =∑
1000
k=1EPRLk
1000y EPCART =
∑1000
k=1EPCARTk
1000.
11. Se calcula la diferencia de logaritmos de los errores de prediccion,DIFLOG =
Log(EPCART )−Log(EPRL), la cual es una medida de proximidad de los
dos errores. A medida que DIFLOG → 0, los dos errores de prediccion se
van acercando entre ellos. Si DIFLOG > 0 entonces EPCART > EPRL y
la regresion lineal predice mejor los datos que los arboles de regresion, pero,
si DIFLOG < 0 entonces EPCART < EPRL y los arboles de regresion
predicen mejor los datos que la regresion lineal. Si DIFLOG = 0 entonces
EPCART = EPRL y ambos modelos predicen igual.
4. Comparacion de las predicciones cuando elmodelo lineal ajustado es el correcto
En esta seccion se supone que los datos siguen un modelo de regresion lineal
especıfico. Se ajusta un arbol de regresion CART y el modelo correcto a los datos
para predecir la respuesta. El objetivo es comparar las magnitudes de los errores
de prediccion de CART y de regresion lineal, cambiando el tamano y la varianza
de los errores de los datos. A continuacion, se simularan conjuntos de datos para
cinco modelos de regresion lineal, dos modelos cuadraticos y tres trigonometricos,
variando el numero de datos y la desviacion estandar de los errores.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2
Comparacion entre arboles de regresion CART y regresion lineal 187
4.1. Prediccion de modelos de regresion lineal cuadraticos
Suponga que se tiene un conjunto de datos (x1, y1), (x2, y2), . . . , (xn, yn) que sigueun modelo de regresion cuadratico de la forma:
yi = β0 + β1xi + β2x2
i + εi, donde εi ∼ N(0, σ2), i = 1, . . . , n. (16)
De lo anterior, se sabe que
yverdi = E(yi) = β0 + β1xi + β2x2
i , i = 1, . . . , n. (17)
Para simular los conjuntos de datos se siguen los pasos descritos en la seccion 1.5.
En el paso 1, se toma p = 2 y se especifican las funciones
g1(x) = x, g2(x) = x2. (18)
El primer modelo por analizar se obtiene al sustituir β0 = 1, β1 = 2, β2 = 3 en la
ecuacion (16) y se llamara modelo cuadratico 1. El segundo modelo por analizar
se obtiene al sustituir β0 = 680, β1 = −22, β2 = 0.25 en la ecuacion (16) y se
llamara modelo cuadratico 2.
En la Tabla 1 se puede observar para los modelos cuadraticos 1 y 2, que para
cualquier valor de n fijo, al aumentar la desviacion estandar σ, los errores de
prediccion de la regresion lineal y de CART se aproximan entre sı, siendo en todos
los casos menor el error de prediccion de la regresion lineal.
En los graficos de los modelos cuadraticos de la Tabla 2, se puede ver como las pre-
dicciones de CART describen la forma del verdadero modelo de los datos simulados
para n = 100 y n = 1000.
4.2. Prediccion de modelos de regresion linealtrigonometricos
Suponga que se tiene un conjunto de datos (x1, y1), (x2, y2), . . . , (xn, yn) que sigueun modelo trigonometrico de la forma:
yi = a sin(bxi + c) + d+ εi, donde εi ∼ N(0, σ2), i = 1, . . . , n (19)
donde el valor de b es conocido. De lo anterior se tiene que
yverdi = E(yi) = a sin(bxi + c) + d, i = 1, . . . , n. (20)
El modelo (19) se puede reescribir como
a sin(bxi+c)+d+εi = a sin(c) cos(bxi)+a cos(c) sin(bxi)+d+εi, i = 1, . . . , n. (21)
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Comparacion entre arboles de regresion CART y regresion lineal 187
4.1. Prediccion de modelos de regresion lineal cuadraticos
Suponga que se tiene un conjunto de datos (x1, y1), (x2, y2), . . . , (xn, yn) que sigueun modelo de regresion cuadratico de la forma:
yi = β0 + β1xi + β2x2
i + εi, donde εi ∼ N(0, σ2), i = 1, . . . , n. (16)
De lo anterior, se sabe que
yverdi = E(yi) = β0 + β1xi + β2x2
i , i = 1, . . . , n. (17)
Para simular los conjuntos de datos se siguen los pasos descritos en la seccion 1.5.
En el paso 1, se toma p = 2 y se especifican las funciones
g1(x) = x, g2(x) = x2. (18)
El primer modelo por analizar se obtiene al sustituir β0 = 1, β1 = 2, β2 = 3 en la
ecuacion (16) y se llamara modelo cuadratico 1. El segundo modelo por analizar
se obtiene al sustituir β0 = 680, β1 = −22, β2 = 0.25 en la ecuacion (16) y se
llamara modelo cuadratico 2.
En la Tabla 1 se puede observar para los modelos cuadraticos 1 y 2, que para
cualquier valor de n fijo, al aumentar la desviacion estandar σ, los errores de
prediccion de la regresion lineal y de CART se aproximan entre sı, siendo en todos
los casos menor el error de prediccion de la regresion lineal.
En los graficos de los modelos cuadraticos de la Tabla 2, se puede ver como las pre-
dicciones de CART describen la forma del verdadero modelo de los datos simulados
para n = 100 y n = 1000.
4.2. Prediccion de modelos de regresion linealtrigonometricos
Suponga que se tiene un conjunto de datos (x1, y1), (x2, y2), . . . , (xn, yn) que sigueun modelo trigonometrico de la forma:
yi = a sin(bxi + c) + d+ εi, donde εi ∼ N(0, σ2), i = 1, . . . , n (19)
donde el valor de b es conocido. De lo anterior se tiene que
yverdi = E(yi) = a sin(bxi + c) + d, i = 1, . . . , n. (20)
El modelo (19) se puede reescribir como
a sin(bxi+c)+d+εi = a sin(c) cos(bxi)+a cos(c) sin(bxi)+d+εi, i = 1, . . . , n. (21)
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2
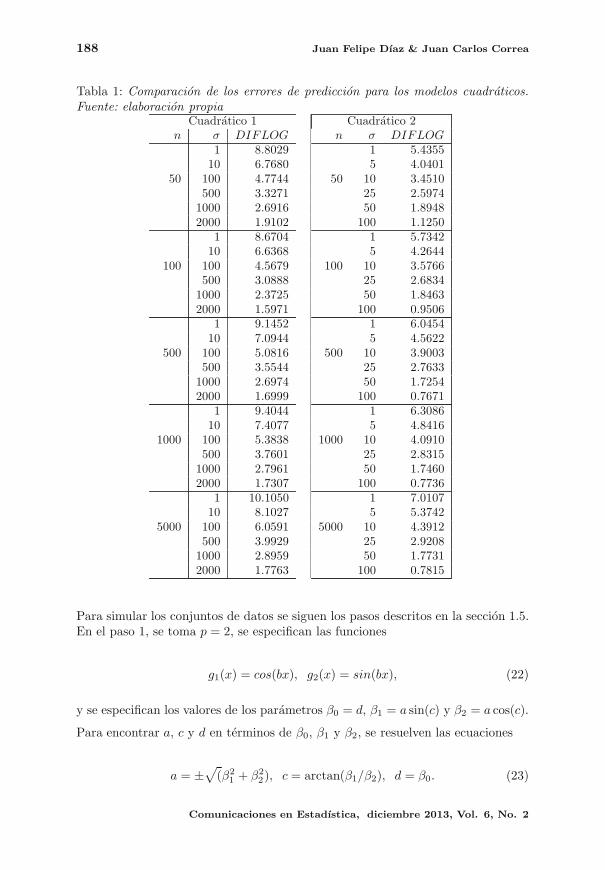
188 Juan Felipe Dıaz & Juan Carlos Correa
Tabla 1: Comparacion de los errores de prediccion para los modelos cuadraticos.
Fuente: elaboracion propiaCuadratico 1 Cuadratico 2
n σ DIFLOG n σ DIFLOG1 8.8029 1 5.4355
10 6.7680 5 4.0401
50 100 4.7744 50 10 3.4510
500 3.3271 25 2.5974
1000 2.6916 50 1.8948
2000 1.9102 100 1.1250
1 8.6704 1 5.7342
10 6.6368 5 4.2644
100 100 4.5679 100 10 3.5766
500 3.0888 25 2.6834
1000 2.3725 50 1.8463
2000 1.5971 100 0.9506
1 9.1452 1 6.0454
10 7.0944 5 4.5622
500 100 5.0816 500 10 3.9003
500 3.5544 25 2.7633
1000 2.6974 50 1.7254
2000 1.6999 100 0.7671
1 9.4044 1 6.3086
10 7.4077 5 4.8416
1000 100 5.3838 1000 10 4.0910
500 3.7601 25 2.8315
1000 2.7961 50 1.7460
2000 1.7307 100 0.7736
1 10.1050 1 7.0107
10 8.1027 5 5.3742
5000 100 6.0591 5000 10 4.3912
500 3.9929 25 2.9208
1000 2.8959 50 1.7731
2000 1.7763 100 0.7815
Para simular los conjuntos de datos se siguen los pasos descritos en la seccion 1.5.
En el paso 1, se toma p = 2, se especifican las funciones
g1(x) = cos(bx), g2(x) = sin(bx), (22)
y se especifican los valores de los parametros β0 = d, β1 = a sin(c) y β2 = a cos(c).
Para encontrar a, c y d en terminos de β0, β1 y β2, se resuelven las ecuaciones
a = ±√(β2
1+ β2
2), c = arctan(β1/β2), d = β0. (23)
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2
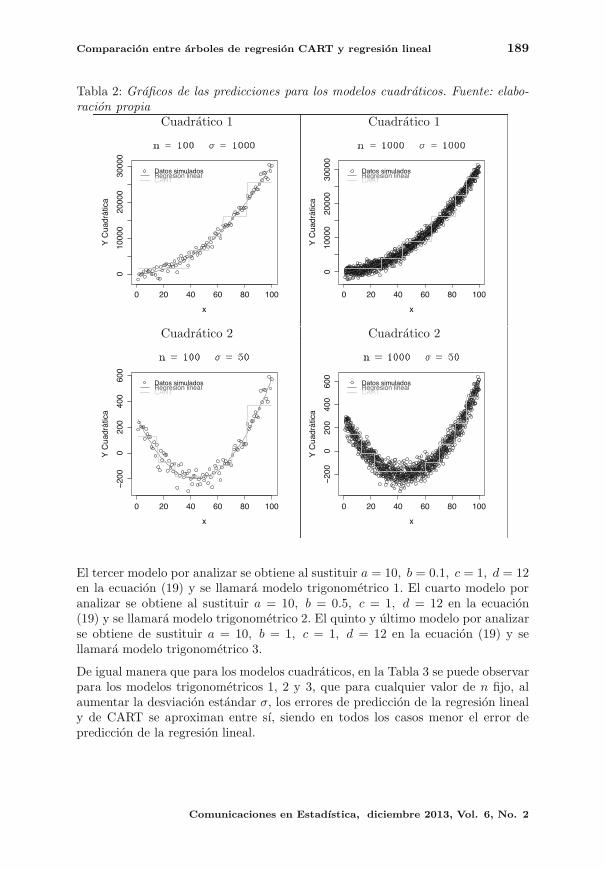
Comparacion entre arboles de regresion CART y regresion lineal 189
Tabla 2: Graficos de las predicciones para los modelos cuadraticos. Fuente: elabo-
racion propia
Cuadratico 1 Cuadratico 1
0 20 40 60 80 100
010
000
2000
030
000
x
Y C
uadr
átic
a
Datos simuladosRegresión linealCART
0 20 40 60 80 100
010
000
2000
030
000
xY
Cua
drát
ica
Datos simuladosRegresión linealCART
Cuadratico 2 Cuadratico 2
0 20 40 60 80 100
−200
020
040
060
0
x
Y C
uadr
átic
a
Datos simuladosRegresión linealCART
0 20 40 60 80 100
−200
020
040
060
0
x
Y C
uadr
átic
a
Datos simuladosRegresión linealCART
El tercer modelo por analizar se obtiene al sustituir a = 10, b = 0.1, c = 1, d = 12
en la ecuacion (19) y se llamara modelo trigonometrico 1. El cuarto modelo por
analizar se obtiene al sustituir a = 10, b = 0.5, c = 1, d = 12 en la ecuacion
(19) y se llamara modelo trigonometrico 2. El quinto y ultimo modelo por analizar
se obtiene de sustituir a = 10, b = 1, c = 1, d = 12 en la ecuacion (19) y se
llamara modelo trigonometrico 3.
De igual manera que para los modelos cuadraticos, en la Tabla 3 se puede observar
para los modelos trigonometricos 1, 2 y 3, que para cualquier valor de n fijo, al
aumentar la desviacion estandar σ, los errores de prediccion de la regresion lineal
y de CART se aproximan entre sı, siendo en todos los casos menor el error de
prediccion de la regresion lineal.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2
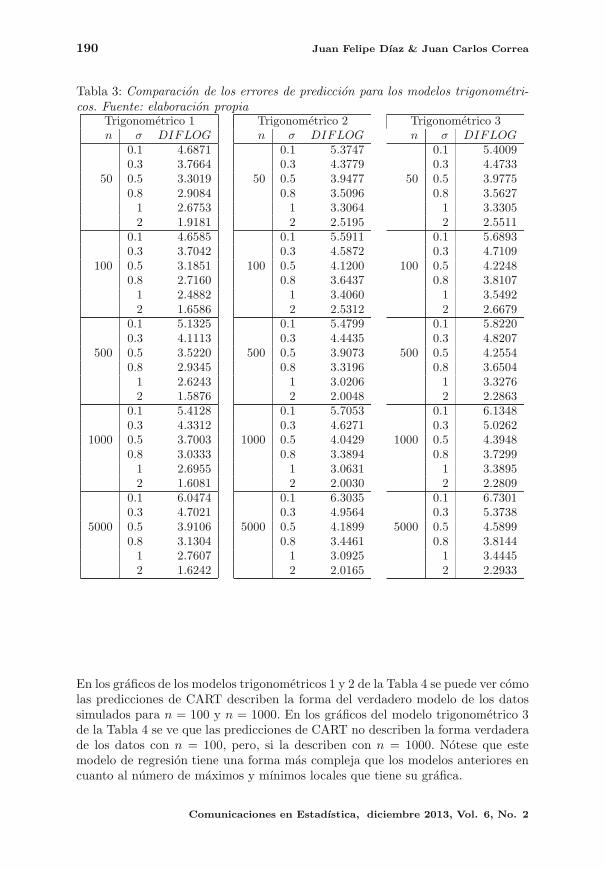
190 Juan Felipe Dıaz & Juan Carlos Correa
Tabla 3: Comparacion de los errores de prediccion para los modelos trigonometri-
cos. Fuente: elaboracion propiaTrigonometrico 1 Trigonometrico 2 Trigonometrico 3
n σ DIFLOG n σ DIFLOG n σ DIFLOG0.1 4.6871 0.1 5.3747 0.1 5.4009
0.3 3.7664 0.3 4.3779 0.3 4.4733
50 0.5 3.3019 50 0.5 3.9477 50 0.5 3.9775
0.8 2.9084 0.8 3.5096 0.8 3.5627
1 2.6753 1 3.3064 1 3.3305
2 1.9181 2 2.5195 2 2.5511
0.1 4.6585 0.1 5.5911 0.1 5.6893
0.3 3.7042 0.3 4.5872 0.3 4.7109
100 0.5 3.1851 100 0.5 4.1200 100 0.5 4.2248
0.8 2.7160 0.8 3.6437 0.8 3.8107
1 2.4882 1 3.4060 1 3.5492
2 1.6586 2 2.5312 2 2.6679
0.1 5.1325 0.1 5.4799 0.1 5.8220
0.3 4.1113 0.3 4.4435 0.3 4.8207
500 0.5 3.5220 500 0.5 3.9073 500 0.5 4.2554
0.8 2.9345 0.8 3.3196 0.8 3.6504
1 2.6243 1 3.0206 1 3.3276
2 1.5876 2 2.0048 2 2.2863
0.1 5.4128 0.1 5.7053 0.1 6.1348
0.3 4.3312 0.3 4.6271 0.3 5.0262
1000 0.5 3.7003 1000 0.5 4.0429 1000 0.5 4.3948
0.8 3.0333 0.8 3.3894 0.8 3.7299
1 2.6955 1 3.0631 1 3.3895
2 1.6081 2 2.0030 2 2.2809
0.1 6.0474 0.1 6.3035 0.1 6.7301
0.3 4.7021 0.3 4.9564 0.3 5.3738
5000 0.5 3.9106 5000 0.5 4.1899 5000 0.5 4.5899
0.8 3.1304 0.8 3.4461 0.8 3.8144
1 2.7607 1 3.0925 1 3.4445
2 1.6242 2 2.0165 2 2.2933
En los graficos de los modelos trigonometricos 1 y 2 de la Tabla 4 se puede ver como
las predicciones de CART describen la forma del verdadero modelo de los datos
simulados para n = 100 y n = 1000. En los graficos del modelo trigonometrico 3
de la Tabla 4 se ve que las predicciones de CART no describen la forma verdadera
de los datos con n = 100, pero, si la describen con n = 1000. Notese que este
modelo de regresion tiene una forma mas compleja que los modelos anteriores en
cuanto al numero de maximos y mınimos locales que tiene su grafica.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Comparacion entre arboles de regresion CART y regresion lineal 191
Tabla 4: Graficos de las predicciones para los modelos trigonometricos. Fuente:
elaboracion propia
Trigonometrico 1 Trigonometrico 1
0 20 40 60 80 100
05
1015
2025
x
Y Tr
igon
omét
rica
Datos simuladosRegresión linealCART
0 20 40 60 80 100
05
1015
2025
xY
Trig
onom
étric
a
Datos simuladosRegresión linealCART
Trigonometrico 2 Trigonometrico 2
0 20 40 60 80 100
05
1015
2025
x
Y Tr
igon
omét
rica
Datos simuladosRegresión linealCART
0 20 40 60 80 100
05
1015
2025
30
x
Y Tr
igon
omét
rica
Datos simuladosRegresión linealCART
Trigonometrico 3 Trigonometrico 3
0 20 40 60 80 100
05
1015
2025
x
Y Tr
igon
omét
rica
Datos simuladosRegresión linealCART
0 20 40 60 80 100
05
1015
2025
30
x
Y Tr
igon
omét
rica
Datos simuladosRegresión linealCART
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

192 Juan Felipe Dıaz & Juan Carlos Correa
5. Comparacion de las predicciones cuando elmodelo lineal ajustado es incorrecto
A continuacion se tomaran tres modelos de regresion lineal de los descritos en la
seccion 3 para generar conjuntos de datos, a los cuales se ajustan rectas de regresion
lineal como modelo equivocado para comparar estas predicciones con las de CART.
Se escogieron estos modelos porque hay casos en el estudio de simulacion en que
la recta de regresion predice mejor los datos que los arboles de regresion cuando
el tamano muestral es pequeno. El objetivo es ver como CART toma ventaja
del aumento del tamano muestral para predecir mejor los datos que la recta de
regresion en estos modelos.
En la Tabla 5 se puede observar para el modelo cuadratico 1, que en general CART
predice mejor la respuesta que la recta de regresion, exceptuando para n = 50,
donde los errores de prediccion de la recta de regresion son mas pequenos que los
de CART. En los graficos del modelo cuadratico 1 de la Tabla 6, se puede ver
como las predicciones de CART se adaptan a la forma del verdadero modelo de
los datos simulados.
En la Tabla 5 se observa para el modelo trigonometrico 2, que CART es mas preciso
que la recta de regresion, es decir, el error de prediccion de CART es menor que el
error de la recta de regresion para cualquier valor de n y cualquier valor de σ. Enlos graficos de la Tabla 6 para el modelo trigonometrico 2, se puede observar como
las predicciones de CART con n = 50 descubren patrones en los datos que pueden
no notarse a simple vista. Aunque se puede decir para n = 50 y n = 100 que las
predicciones de CART se adaptan a la forma del verdadero modelo de los datos
simulados, es claro que con n = 50 es mas difıcil describir la verdadera forma del
modelo por su cantidad de maximos y mınimos relativos. Para n = 100 es mas
clara la verdadera forma del modelo debido a que se tienen mas cantidad de datos
para describirlo.
En la Tabla 5 se observa para el modelo trigonometrico 3, que el error de prediccion
de CART es mayor que el de la recta de regresion para n = 50 cuando σ =
0.1, 0.3, 0.5, 0.8, y para n = 100 cuando σ = 0.1, 0.3, 0.5, pero, en los otros casos,
el error de prediccion de CART es menor. En los graficos de la Tabla 6 para el
modelo trigonometrico 3, se observa que las predicciones de CART aparentemente
forman una recta, es decir, CART carece de capacidad de captar la verdadera
forma del modelo con n = 100 datos, al igual que con n = 50. Se puede decir,
para este modelo, que con n = 50 y n = 100 es mas difıcil describir la verdadera
forma del modelo por su cantidad de maximos y mınimos relativos. Se observa
que con n = 500 las predicciones de CART se adaptan a la verdadera forma del
modelo debido a que se tiene mas cantidad de datos para describirlo. Si bien no
existe evidencia para todos los modelos que el aumento de n implica un aumento
en la precision de las predicciones de CART con respecto a la recta de regresion
(disminucion de la diferencia de logaritmos de los errores en la tabla), se puede
observar globalmente que esta precision para n = 50 y n = 100 es notablemente
menor que para n = 500, n = 1000 y n = 5000.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2
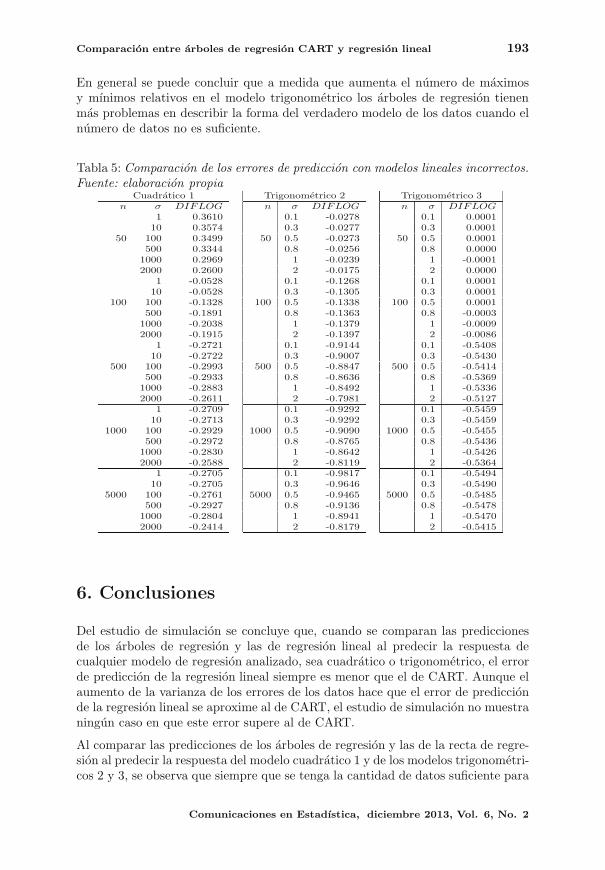
Comparacion entre arboles de regresion CART y regresion lineal 193
En general se puede concluir que a medida que aumenta el numero de maximos
y mınimos relativos en el modelo trigonometrico los arboles de regresion tienen
mas problemas en describir la forma del verdadero modelo de los datos cuando el
numero de datos no es suficiente.
Tabla 5: Comparacion de los errores de prediccion con modelos lineales incorrectos.
Fuente: elaboracion propiaCuadratico 1 Trigonometrico 2 Trigonometrico 3
n σ DIFLOG n σ DIFLOG n σ DIFLOG1 0.3610 0.1 -0.0278 0.1 0.0001
10 0.3574 0.3 -0.0277 0.3 0.0001
50 100 0.3499 50 0.5 -0.0273 50 0.5 0.0001
500 0.3344 0.8 -0.0256 0.8 0.0000
1000 0.2969 1 -0.0239 1 -0.0001
2000 0.2600 2 -0.0175 2 0.0000
1 -0.0528 0.1 -0.1268 0.1 0.0001
10 -0.0528 0.3 -0.1305 0.3 0.0001
100 100 -0.1328 100 0.5 -0.1338 100 0.5 0.0001
500 -0.1891 0.8 -0.1363 0.8 -0.0003
1000 -0.2038 1 -0.1379 1 -0.0009
2000 -0.1915 2 -0.1397 2 -0.0086
1 -0.2721 0.1 -0.9144 0.1 -0.5408
10 -0.2722 0.3 -0.9007 0.3 -0.5430
500 100 -0.2993 500 0.5 -0.8847 500 0.5 -0.5414
500 -0.2933 0.8 -0.8636 0.8 -0.5369
1000 -0.2883 1 -0.8492 1 -0.5336
2000 -0.2611 2 -0.7981 2 -0.5127
1 -0.2709 0.1 -0.9292 0.1 -0.5459
10 -0.2713 0.3 -0.9292 0.3 -0.5459
1000 100 -0.2929 1000 0.5 -0.9090 1000 0.5 -0.5455
500 -0.2972 0.8 -0.8765 0.8 -0.5436
1000 -0.2830 1 -0.8642 1 -0.5426
2000 -0.2588 2 -0.8119 2 -0.5364
1 -0.2705 0.1 -0.9817 0.1 -0.5494
10 -0.2705 0.3 -0.9646 0.3 -0.5490
5000 100 -0.2761 5000 0.5 -0.9465 5000 0.5 -0.5485
500 -0.2927 0.8 -0.9136 0.8 -0.5478
1000 -0.2804 1 -0.8941 1 -0.5470
2000 -0.2414 2 -0.8179 2 -0.5415
6. Conclusiones
Del estudio de simulacion se concluye que, cuando se comparan las predicciones
de los arboles de regresion y las de regresion lineal al predecir la respuesta de
cualquier modelo de regresion analizado, sea cuadratico o trigonometrico, el error
de prediccion de la regresion lineal siempre es menor que el de CART. Aunque el
aumento de la varianza de los errores de los datos hace que el error de prediccion
de la regresion lineal se aproxime al de CART, el estudio de simulacion no muestra
ningun caso en que este error supere al de CART.
Al comparar las predicciones de los arboles de regresion y las de la recta de regre-
sion al predecir la respuesta del modelo cuadratico 1 y de los modelos trigonometri-
cos 2 y 3, se observa que siempre que se tenga la cantidad de datos suficiente para
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

194 Juan Felipe Dıaz & Juan Carlos Correa
Tabla 6: Graficos de los modelos lineales ajustados incorrectamente. Fuente: ela-
boracion propia
Cuadratico 1 Cuadratico 1
0 20 40 60 80 100−500
050
0015
000
2500
0
x
Y C
uadr
átic
a
Datos simuladosRecta de regresiónCART
0 20 40 60 80 100−500
050
0015
000
2500
0
xY
Cua
drát
ica
Datos simuladosRecta de regresiónCART
Trigonometrico 2 Trigonometrico 2
0 20 40 60 80 100
05
1015
2025
x
Y Tr
igon
omét
rica
Datos simuladosRecta de regresiónCART
0 20 40 60 80 100
05
1015
2025
x
Y Tr
igon
omét
rica
Datos simuladosRecta de regresiónCART
Trigonometrico 3 Trigonometrico 3
0 20 40 60 80 100
05
1015
2025
x
Y Tr
igon
omét
rica
Datos simuladosRecta de regresiónCART
0 20 40 60 80 100
05
1015
2025
x
Y Tr
igon
omét
rica
Datos simuladosRecta de regresiónCART
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Comparacion entre arboles de regresion CART y regresion lineal 195
describir la forma funcional de la media de los datos, el error de prediccion de
CART es menor que el de la recta de regresion.
De lo anterior se puede concluir que, el modelo CART es una alternativa que prueba
ser una buena opcion cuando el usuario desconoce la forma funcional verdadera
del modelo, lo cual es comun en investigaciones reales, y puede utilizarse como una
primera etapa en la parte exploratoria en modelacion. Si el usuario esta seguro de
cual es la forma funcional de su modelo, entonces CART no es una opcion viable.
7. Agradecimientos
A los profesores Vıctor Ignacio Lopez Rıos y Rene Iral Palomino por sus invaluables
comentarios y sugerencias. A Diana Guzman Aguilar, Jorge Ivan Velez y en general
a la Escuela de Estadıstica y la Facultad de Ciencias de la Universidad Nacional
de Colombia, sede Medellın por haber propiciado un ambiente idoneo para la
realizacion de este trabajo.
Recibido: 27 de mayo de 2013
Aceptado: 20 de septiembre de 2013
Referencias
Ankarali, H., Canan, A., Akkus, Z., Bugdayci, R. & Ali Sungur, M. (2007), ‘Com-
parison of logistic regression model and classification tree: An application to
postpartum depression data’, Expert Systems with Applications 32, 987–994.
Breiman, L., Friedman, J., Olshen, R. & Stone, C. (1984), Classification And
Regression Trees, CHAPMAN & HALL/CRC, Boca Raton.
Izenman, A. (2008), Modern Multivariate Statistical Techniques, Springer, New
York.
Tamminen, S., Laurinen, P. & Roning, J. (1999), ‘Comparing regression trees with
neural networks in aerobic fitness approximation’.
Zhang, H. & Singer, B. (2010), Recursive Partitioning and Applications, Springer,
New York.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2


Comunicaciones en EstadısticaDiciembre 2013, Vol. 6, No. 2, pp. 197–212
En defensa de la racionalidad bayesiana:
a proposito de Mario Bunge y su “Filosofıapara medicos”
In defense of bayesian rationality: about Mario Bunge and his
“Philosophy for physicians”
Luis Carlos Silvaa
Resumen
Se valoran crıticamente los juicios generales que se hacen sobre la teorıa de proba-
bilidades y su aplicacion en el campo de la salud en el libro Filosofıa para medicos,del fısico y epistemologo argentino Mario Bunge. La obra contiene varias impreci-
siones y desaciertos en esta materia, los cuales son objeto de analisis en el presente
artıculo. Al manejar los conceptos propios de la inferencia bayesiana, en particu-
lar en relacion con la aplicacion del teorema de Bayes, el libro incluye errores y
falacias que tambien se discuten e ilustran pormenorizadamente.
Palabras clave: inferencia, probabilidades subjetivas, frecuentismo, estadıstica
bayesiana, medicina.
Abstract
General judgments on the probability theory and its application on the field of
health are critically assessed in the book Philosophy for physicians, by the Ar-
gentinean physicist and epistemologist Mario Bunge. The work contains several
inaccuracies and mistakes in this subject, which are analyzed in this article. When
handling concepts of Bayesian inference, particularly in relation to the application
of Bayes’ theorem, the book includes errors and fallacies that are also discussed
and illustrated in detail.
Keywords: inference, subjective probabilities, frecuentist, Bayesian statistics, me-
dicine.
aInvestigador titular de la Escuela Nacional de Salud Publica. La Habana, Cuba.
197

198 Luis Carlos Silva
1. Introduccion
El fısico y filosofo de la ciencia, argentino, Mario Bunge publico recientemente el li-
bro Filosofıa para medicos (2012) dedicado a examinar problemas relacionados con
la practica medica desde una perspectiva filosofica y epistemologica. Se abordan
en el temas de muy diversa ındole, lo cual ha motivado un artıculo (Silva 2013),
que intenta repasar crıticamente su contenido en terminos generales. El material
de Bunge incluye algunos asuntos estadısticos, y muy en particular, varias ideas re-
lacionadas con el pensamiento bayesiano, que merecen a mi juicio un tratamiento
especıfico, motivo de la presente contribucion. En esta area, el texto tiene va-
rias imprecisiones, frases difusas o sin sentido, premisas equivocadas y respuestas
erroneas.
La presente nota procura discutir y fundamentar con cierto detalle estos puntos de
vista. Me detendre en diversas cuestiones terminologicas, conceptuales y practicas
ubicadas en el entorno del Teorema de Bayes, con especial enfasis en el desmontaje
de un ejemplo, donde el autor “demuestra”que, segun los bayesianos, tener el VIH
no incrementa la probabilidad de padecer sida y explica que, para ser consecuentes,
los bayesianos han de creer en la resurreccion.
2. Subjetividad y arbitrariedad
El error fundamental de Bunge –que atraviesa toda su predica antibayesiana– resi-
de en no comprender que arbitrariedad y subjetividad son dos conceptos totalmente
diferentes. “Por ser subjetivas, las probabilidades bayesianas son arbitrarias”afirma
textualmente (pagina 99). Si bien la arbitrariedad y el capricho distorsionan cual-
quier discurso cientıfico, la subjetividad es inevitable en la ciencia, como ha sido
de sobra constatado (Press & Tanur 2001, Silva & Benavıdes 2003). A partir de
ese equıvoco, atribuye a los estadısticos bayesianos una conducta antojadiza:
El bayesiano asigna las probabilidades que se le antoje y no le moles-
ta el que otros asignen valores diferentes: las probabilidades son tan
subjetivas como las preferencias esteticas . . . Los conceptos de azar (o
desorden) objetivo y de verdad objetiva o impersonal no intervienen
en la interpretacion bayesiana (p. 99).
Poco mas abajo (p. 100), reafirma la idea:
Contrariamente a lo que suponen los bayesianos (y los partidarios de las
teorıas de la eleccion racional), no es legıtimo asignar una probabilidad
a todo hecho. Solo los hechos al azar y los escogidos al azar tienen
probabilidades.
Y un par de paginas mas adelante, Bunge va mas lejos y asevera que no cabe
siquiera “hablar de probabilidades en medicina”; estas solo podrıan ser aplicadas
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

En defensa de la racionalidad bayesiana 199
en procesos intrınsecamente aleatorios, tales como cuando se lanza un dado o
cuando nos ocupamos de la meiosis que, segun comunica (p. 102), es “el unico
proceso biotico autenticamente aleatorio”.
La idea presente en la interpretacion de la probabilidad como un atributo subjetivo
es que, ante un fenomeno aleatorio o concebido como tal para resolver determinado
problema (en el sentido de que puede verificarse o no y que resulta imposible
conocer de antemano cual de esos desenlaces se producira), se asigna, de forma
implıcita o explıcita, una probabilidad que representa el grado de confianza o
creencia que se tiene en la ocurrencia de ese hecho. Da igual si se trata de que
“salga cara cuando se lance una moneda ligeramente doblada con un alicate”, de
que “obtenga Obama la reeleccion” o de que “Brasil empate con Corea del Norte
en un partido proximo a celebrarse en el mundial de futbol”.
Las diferencias esenciales con la interpretacion frecuentista radican en que la asig-
nacion de valores, aunque condicionada por la informacion de que se disponga,
es propia de cada observador particular, sin que las opiniones de varios analistas
tengan que coincidir y en que estos valores pueden atribuirse tambien a hechos
singulares o irrepetibles. En la concepcion frecuentista, sin embargo, la probabi-
lidad de cierto suceso es un numero unico e ideal (concretamente, el lımite de la
razon entre el numero de veces que dicho suceso ocurre y el numero de veces en
que se lleva adelante el proceso que pudiera producirlo, cuando este ultimo numero
tiende a infinito), y lo que puede variar son las estimaciones que hacemos de ella.
Cuando se dice que la probabilidad de que Brasil gane a Corea del Norte en un
partido que disputaran en el campeonato mundial es 0.95, la de que empate 0.04 y
la de que pierda es 0.01, no se han elegido esos numeros de una tabla de numeros
aleatorios ni a raız de preferencias esteticas. Se han fijado sobre una base subjetiva
–el desempeno de sus delanteros en partidos recientes, el numero de jugadores que
ya tienen una tarjeta amarilla, el valor de los porteros en el mercado, los resultados
obtenidos en partidos recientes y la calidad de los contrincantes en dichos partidos,
etc.–, pero no arbitraria1.
Obviamente, para que esta interpretacion pueda ser aplicada con exito en un mar-
co operativo, es menester que quienes se acogen a ella mantengan un cierto grado
de racionalidad en la asignacion de probabilidades. Si se quiere hacer inferencias
validas, los valores que se determinen no pueden ser fruto del capricho o del “an-
tojo”de quien los fija. Una vez asignados por esa vıa los grados de confianza que
se tengan en la ocurrencia de los sucesos, si los valores correspondientes satisfacen
los axiomas de Kolmogorov (ver Anexo), ya se opera con esas probabilidades como
con cualquier otra manera de definirlas que tambien cumpla aquellos axiomas.
“Solo los hechos al azar y los escogidos al azar tienen probabilidades”, sostiene
Bunge. Sin embargo, es difıcil o imposible interpretar el concepto de que un hecho
“tenga”probabilidades. Los eventos no tienen probabilidades; se les atribuyen pro-
babilidades de ocurrencia, sea subjetivamente o a partir de informacion empırica,
1Dicho sea de paso, esos dos equipos no se habıan enfrentado jamas antes, de modo que serıaimposible realizar una estimacion frecuentista.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

200 Luis Carlos Silva
si se considera que ello puede ser fructuoso. No es un detalle baladı sino medular:
mientras lo primero apunta a un rasgo que serıa presuntamente intrınseco a deter-
minados “hechos”, lo segundo es una convencion que por lo general se adopta con
fines operativos.
Finalmente, llamo la atencion sobre la afirmacion de Bunge (p. 101) de que la
interpretacion bayesiana no se adecua a las ciencias de la salud, ya que en ellas no
prima la diversidad de opiniones. Los pacientes y los medicos, segun el, afortuna-
damente saben que
si hay diferencias de opinion acerca de un tratamiento o una diagnosis,
suele recabarse la opinion de un tercero o de un panel de expertos, de
quienes se espera no solo opinion sino tambien argumentos fundados
en las ciencias biomedicas.
Lo que no capta Bunge es que, en cualquier caso, hablamos de una opinion, en la
cual participara inexorablemente cierto grado de subjetividad, a veces muy grande,
a veces menor. No puede ser de otro modo debido a que las ciencias biomedicas
estan plagadas no solo de incertidumbres, verdades provisionales, controversias
y dudas, sino que con mucha frecuencia, como demuestra Ioannidis (2005), dan
por cierto aquello que no lo es. Y finalmente, los “argumentos fundados”no son
privativos de las ciencias biomedicas; tambien comparecen en la asignacion de
probabilidades, y tal asignacion puede adoptarse asimismo tras la consulta con
otro especialista o con un panel de expertos.
3. Causalidad y casualidad
El autor objeta que “se ha supuesto que tanto el tener VIH como el tener sida
son hechos al azar”, cuando en realidad estos dos acontecimientos, afirma, “no son
casuales sino causales”. Establece ası una falsa dicotomıa.
Aparentemente, Bunge quiere decir con ello que se trata de un hecho cuya ocurren-
cia obedece a una causa, a diferencia de los sucesos a los que el llama “casuales”,
los cuales estarıan exclusivamente determinados por el azar. Sin embargo, nada
prohıbe que, aunque un acontecimiento tenga una causa, cuando aun no conocemos
el desenlace del proceso que podrıa producirlo, le atribuyamos una probabilidad de
ocurrencia, incluso si conocieramos cabalmente el mecanismo causal que subyace
(algo que suele no ocurrir). En el sentido que lo maneja Bunge, la muerte de un
individuo es “causal”, ya que siempre hay una causa para la muerte; pero es evi-
dente que tambien es “casual”, en el sentido de que es imposible saber ni cuando
ni donde ocurrira, de modo que es completamente natural que se maneje la proba-
bilidad de que tal hecho se consume antes de que transcurra cierto lapso prefijado.
La unica regla que hay que cumplir es que tales asignaciones no transgredan los
axiomas de Kolmogorov.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

En defensa de la racionalidad bayesiana 201
Ahora bien, el meollo de este debate reside en lo siguiente: ¿sobre que bases se
puede aceptar o no un enfoque metodologico dado en el contexto de la solucion
de un problema? En el marco que nos ocupa, esto se traduce en la pregunta ¿cual
pudiera ser el arbitro que concede o no validez a la asignacion de probabilidades
a los eventos no aleatorios en el sentido objetivo de la probabilidad?, lo cual se
discute en la siguiente seccion.
4. La legitimidad de los modelos probabilısticos
Examinemos mas detenidamente la afirmacion segun la cual “No es legıtimo asig-
nar una probabilidad a todo hecho. Solo los hechos al azar y los escogidos al azar
tienen probabilidades”.
Mas alla de que no se sabe que es que un hecho “tenga”probabilidad, la pregunta
cuya repuesta tiene interes aquı es esta: ¿que rasgos otorgan o quitan “legitimidad”
a un modelo probabilıstico, entendido como una idealizacion o representacion de
la realidad que procura simplificarla para poder examinarla mejor y para luego
aplicar sus derivaciones con vistas a resolver cualquier otro problema practico
concreto en el contexto del marco de incertidumbre que le dio vida? Un modelo
en general –pero especialmente, estadıstico o predictivo– solo puede deslegitimarse
(al igual que ocurre con un modo de conducirse con vistas a resolver un problema,
siempre que no incorporemos la dimension etica en su valoracion) es que dicho
modelo (o dicha conducta) no contribuya a resolver el problema que ha llevado a
concebirlo (o a desplegar esa conducta).
Como se explica en el Anexo, una probabilidad es una funcion que otorga un valor
entre 0 y 1 a cualquier suceso (subconjunto) de un conjunto universo (un espacio
muestral) a la que se exige el cumplimiento de ciertos axiomas.
¿Como se define la funcion P sobre dicho espacio? Obviamente, dependera del
empleo que uno quiera hacer de ella en terminos reales o practicos. Es importante
recordar que “los numeros no saben de donde vienen”(Lord 1953, Silva 1997). De
modo que, ante un espacio muestral concreto, el analista puede en principio definir
dicha funcion como crea mas oportuno y, si cumple los axiomas mencionados,
estaremos ante una funcion de probabilidad.
Son esas probabilidades subjetivamente determinadas las que, por ejemplo, em-
plean las casas de apuestas para fijar, mediante sus inversos, los odds que a su
vez sirven para establecer cuanto se paga por un acierto. Si fueran “arbitrarias”,
tales empresas quebrarıan, como veremos mas abajo. Sin embargo, lo que hacen es
ganar sumas millonarias. Acaso no haya mejor ejemplo del absurdo de decir que
no se pueden manejar probabilidades en relacion con eventos que son “causales”.
Obviamente, si Brasil vence es por una causa (porque hace mas goles que Corea
del Norte); y si Obama gana las elecciones sera por una causa evidente: porque
obtiene mas votos que su contrincante. El desenlace es debido a una causa; pero el
proceso que lo determina permite manejar dicho desenlace como un suceso aleato-
rio debido a que no existe manera alguna de identificarlo con certeza de antemano,
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

202 Luis Carlos Silva
aunque conozcamos el valor de muchas de las variables que pudieran influir en el.
Y por si fuera poco, en procesos totalmente determinısticos, gobernados por reglas
precisas, el manejo de probabilidades para hacer el ejercicio de ingenierıa inversa
que conduzca a desentranarlas, a partir de los datos, puede ser extraordinaria-
mente fructuoso. El ejemplo mas elocuente, desde mi punto de vista, es el del gran
matematico britanico Alan Turing quien, empleando recursos bayesianos, consi-
guio desencriptar el llamado codigo generado por la maquina Enigma usado por
los alemanes durante la Segunda Guerra Mundial (el cual no solo era “causal”, sino
algorıtmico), conquista que resulto esencial para acelerar la victoria de los aliados
en esa contienda (ver Good (1979) y http://blogs.elpais.com/turing/2012/12/alan-
turing-y-la-estadistica-bayesiana.html).
En terminos generales, si el manejo que se haga de un espacio de probabilidad
bien definido es fructuoso o no, tal y como ocurre con cualquier modelo, es harina
de otro costal. Pudiera no serlo, pero con muchısima frecuencia lo es, como en
los ejemplos arriba mencionados. Por poner otro mas, facilmente comprensible,
consideremos el siguiente.
A las casas de apuestas tal proceder les resulta obviamente redituable. No es una
casualidad, por cierto, que todas ellas otorguen mas o menos los mismos premios.
Si sus decisiones fueran “arbitrarias”, una casa pagarıa, por ejemplo, 3.70 euros a
quien haya apostado un euro por la victoria de Brasil en caso de que esta se pro-
duzca, otra desembolsarıa 212.51 euros y otra pagarıa 1.03 euros. Pero como no son
arbitrarias, y como todas las empresas usan los mismos metodos para determinar
racionalmente esas probabilidades (la llamada “elicitation”de las probabilidades
(ver Garthwaite et al. (2005)), el monto de los premios es similar entre una empre-
sa y otra (por ejemplo, 1.31, 1.29, 1.35....), como puede comprobarse facilmente
consultando varios sitios web dedicados a manejar apuestas en la vıspera de un
partido crucial.
Para que se comprenda esto mas claramente, imaginemos que antes de un partido
se puede apostar por el desenlace “el numero de goles sera par”, o su complementa-
rio, “el numero de goles sera impar”. Cuando se ofrece esa posibilidad, las casas de
apuestas pagan 1.95 euros a quien haya apostado un euro y haya acertado. Puesto
que evidentemente (considerando que un empate a cero arroja un resultado par)
se trata de dos desenlaces que pueden considerarse equiprobables, lo “justo”serıa
pagar 2 euros, en caso de acierto, en lugar de 1.95 (que es el 97.5% de 2) por
cada euro apostado. La disminucion la establecen los organizadores de la apuesta,
en lo sucesivo “la banca”, para garantizarse una ganancia (de lo contrario, ella
solo servirıa como intermediaria para que el dinero pasara de unos apostadores
a otros). Bunge afirmarıa que el caracter par o impar del numero de goles no es
aleatorio sino causal (ya que depende de como se hayan desempenado los equipos
y no responde a un experimento o una seleccion regidos por el azar) y que por
tanto los usuarios de las probabilidades subjetivas actuan a su antojo.
Imaginemos que la banca, en efecto, se conduce tal y como lo harıa un individuo
cuando emite juicios esteticos sobre un poema o elige el color de su ropa. Supon-
gamos que otorgan una probabilidad a priori de 0.2 a que el numero de goles sea
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

En defensa de la racionalidad bayesiana 203
par y 0.8 a que sea impar. Eso les obligarıa a pagar el 97.5% de 5 euros (inverso
de 0.2) por cada euro apostado a esta posibilidad en caso de que se produzca, y el
97.5% de 1.25 euros (inverso de 0.8) en el otro caso2 (es decir, 4.88 y 1.22 euros,
respectivamente). Puesto que cualquier apostador racional intuye que un numero
par de goles es tan probable como uno impar, la inmensa mayorıa aprovecharıa el
caracter irracional de esta oferta y apostarıa por la opcion de que dicho numero
sea par, con la consiguiente ruina para la banca. Obviamente, la banca no elige
probabilidades arbitrariamente, unica explicacion para que, en lugar de ser un
estruendoso fracaso, su negocio sea extraordinariamente prospero.
El proceso, en suma, para atribuir probabilidades a sucesos no intrınsecamente
aleatorios, dista de ser “arbitrario”. Puede ser parcial o totalmente subjetivo, pero
es racional; y puede ser, desde luego, muy util.
Bunge reniega del empleo de la teorıa de probabilidades incluso en situaciones
donde ni siquiera interviene la subjetividad para su definicion. Llega a decir que
llamar “probabilidades”a las frecuencias relativas que manejan los epidemiologos
“es doblemente errado (p. 102): porque las frecuencias son propiedades colectivas
y porque el uso de probabilidades solo se justifica con referencia a procesos alea-
torios”, dado que los procesos subyacentes tienen raıces causales. Y en la pagina
143 vuelve sobre el tema al considerar que:
Es verdad que se habla a menudo de la probabilidad de que tal
tratamiento cure tal mal, pero este uso del concepto de probabilidad
es incorrecto, porque el concepto en cuestion es teorico, no empırico.
Las probabilidades de que se habla en medicina y en epidemiologıa
son en realidad frecuencias relativas, y estas no estan necesariamente
(logicamente) relacionadas con el azar.
De aquı concluye que “los medicos ... haran bien en limitarse a manejar frecuencias
estadısticas”sin considerarlas probabilidades.
La esperanza de vida, que es un parametro capital de la salud publica contem-
poranea, se estima, sin embargo, a traves de la teorıa de probabilidades. Las com-
panıas de seguro, por poner otro ejemplo, ganan sumas enormes aplicando una
teorıa que, segun Bunge, no es legıtimo emplear. Nuevamente: para estas, lo me-
todologicamente legıtimo es un modelo que sirva a sus intereses. Puesto que solo
extienden polizas a sujetos que estan vivos, se manejan con las probabilidades de
que mueran dentro de lapsos especıficos. Ningun ucase metodologico los persua-
dira de no usar probabilidades. Lo que saben es, por ejemplo, que la misma poliza
no debe costar igual (ni dar las mismas recompensas) en Baltimore que en Nairobi,
simplemente porque las probabilidades de morir antes de cumplir N + 1 anos no
son iguales para sujetos de edad N en uno y otro enclave.
Analogamente, los modelos empleados para los vaticinios electorales suelen ser
2 El 97.5% se debe a que las casas pagan siempre un porcentaje inferior a 100 para garantizaruna ganancia. Tıpicamente, en situaciones menos obvias, el porcentaje es bastante menor (entreun 90 y un 92%)
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

204 Luis Carlos Silva
fallidos en Espana (Mora 2012) y otros sitios (donde usan recursos frecuentistas
clasicos), pero pueden ser virtualmente perfectos, como ocurrio en las dos ultimas
elecciones presidenciales en Estados Unidos con los realizados por Nate Silver
con el auxilio de tecnicas bayesianas (Garicano 2012, Silver 2012). Sus resultados
han sido tan notables que en varios foros de internet se ha considerado que el
verdadero ganador de las ultimas elecciones fue el reverendo Thomas Bayes, y no
Barak Obama.
En el campo propiamente de la toma de decisiones medicas, como demuestra el
profesor de la Oregon Health and Science University, Denis Mazur, el recorrido
historico de recursos empleados conduce al punto actual en que los procedimientos
bayesianos –empleando probabilidades provenientes tanto del marco frecuentista
como del subjetivo– ocupan ya un lugar irreversible (Mazur 2012).
Si se quieren ver algunas decenas de ejemplos adicionales, se pueden hallar en el
apasionante y aclamado libro de McGrayne (2011), que versa sobre la extraordi-
naria historia de las aplicaciones bayesianas.
5. Examinando el ejemplo central de Bunge
5.1. Portar el VIH no incrementa la probabilidad de padecersida
La transcripcion textual del ejemplo central de Bunge (p. 100) es la siguiente:
Es sabido que el virus VIH es una causa necesaria del sida. O sea,
el estar sidado implica el tener VIH, aunque no a la inversa. Supon-
gamos que se haya probado que cierto individuo tiene el virus VIH.
Un bayesiano preguntara cual es la probabilidad de que, ademas, el
individuo tenga o pronto adquiera el sida. Para contestar la pregunta
empezara por suponer que se le aplica el teorema de Bayes, que en este
caso reza
P (sida|V IH) =P (V IH |sida)P (sida)
P (V IH)
donde la expresion P (A) significa la probabilidad absoluta (o antece-
dente) de A, mientras que P (A|B) se lee la probabilidad condicional
de A dado (o suponiendo) que B.
Puesto que el analisis de laboratorio muestra que el individuo en cues-
tion lleva el virus, el bayesiano pondra P (V IH) = 1. Ahora, puesto
que todos llevan el virus, tambien se pondra P (V IH |sida) = 1. Re-
emplazando estos valores en la formula de Bayes, esta se reduce a
P (sida|V IH) = P (sida). Pero esto es falso: hay personas con VIH que
no han desarrollado sida.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

En defensa de la racionalidad bayesiana 205
5.2. Algunas precisiones terminologicas y conceptuales
Salta a la vista que, en rigor, no es lo mismo la probabilidad de que “cierto indivi-
duo tenga sida”, a la de que “adquiera sida en el futuro”. Lo primero es algo que
se puede valorar mediante la determinacion del nivel de linfocitos y la presencia de
determinadas dolencias (tales como sarcoma de Kaposi o neumonıas recurrentes).
Lo segundo, sin embargo, es algo que puede o no ocurrir dentro de cierto lapso, y
que, mientras este no transcurra, se halla en una zona de incertidumbre, circuns-
tancia que permite hablar de la probabilidad de que ese desenlace acaezca, como
se hace a diario con los posibles resultados de muchos procesos morbosos.
La argumentacion falaz comienza cuando Bunge, enredado en la naturaleza difusa
de las categorıas que emplea, habla de que “se le aplica el teorema de Bayes”a
“cierto individuo”. Eso no tiene sentido alguno. Si alguien quiere saber si Juan
Perez tiene sida, lo que hace no es aplicar el teorema al sujeto –lo cual en sı mismo
no tiene sentido– sino aplicar las tecnicas de diagnostico de dicha enfermedad a
Juan.
Se atribuye al bayesiano algo que no hace. Bayesiano o no, nadie aplica la teorıa
de probabilidades cuando el desenlace ya se ha consumado y puede conocerse por
alguna vıa cual fue. El teorema de Bayes es un recurso para calcular la probabilidad
de las causas –que ya pasaron o que ya ejercieron su efecto– a partir de ciertos
indicios. Lo que hace el bayesiano, o cualquiera que opere con probabilidades, es
aplicar estos recursos en el contexto de un “espacio de probabilidad”.
Por ejemplo, los trascendentes trabajos de Cornfield (1962), a partir del celebre
estudio de Framingham (O’Donnell & Elosua 2008), permitieron construir tablas
mediante la aplicacion de la regresion logıstica (cuya finalidad es justamente es-
timar probabilidades en funcion de diversas variables) combinada con la teorıa
bayesiana, en las que se consignan las probabilidades de enfermedad cardiovascu-
lar y muerte dentro de cierto lapso que tienen sujetos genericos con determinada
edad y sexo, con cierto grado de tabaquismo, de colesterolemia, etcetera). Luego,
para un sujeto concreto, puede conocerse la probabilidad que le asigna el modelo
de morir antes de que transcurra el susodicho lapso (Wilson 2010). Y al aplicar
tales recursos en el ambito de la salud publica, se consiguio lo que ha sido calificado
como “uno de los mas notables resultados en materia de salud publica del Siglo
XX”debido a que en las tres decadas siguientes “las tasas de mortalidad por enfer-
medades cardiovasculares se redujeron en un 60%, con lo cual pudieron prevenirse
621 mil muertes”(Mazur, 2012).
Obviamente, no se aplica la regresion logıstica a un individuo, ni a nadie se le ocurre
hacerlo (caso de que fuera posible) para saber si esta muerto o no. Se construye
un modelo usando una muestra en el contexto de un espacio de probabilidad, y se
aplica luego, si se desea, a un sujeto que pudiera o no morir antes, por ejemplo, de
que pasen diez anos. La diferencia es crucial, porque lo primero carece de sentido
y lo segundo es una practica habitual y sumamente util para la clınica, la salud
publica y la prevencion.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

206 Luis Carlos Silva
5.3. La aplicacion correcta del teorema de Bayes
Es bien conocida la maxima que advierte que
establecer claramente el espacio de probabilidad sera el primer paso
imprescindible para estudiar una experiencia o situacion en terminos
probabilısticos. Muchas de las dificultades que surgen en la practica
y en el analisis estadıstico de investigaciones clınicas, tienen que ver
con el establecimiento implıcito y defectuoso de este espacio (enfasis
anadido por el autor, LCSA).
como puede leerse, por ejemplo, en el sitio Web del Hospital Ramon y Cajal de Ma-
drid (http://www.hrc.es/bioest/Probabilidad_13.html). De la inobservancia
de esta sutil premisa, nace la falacia en que incurre el sr. Bunge. Veamos.
La regla de Bayes establece que para cualquier par de sucesos A y B, se cumple
que
P (A|B) =P (B|A)P (A)
P (B)
Traducido a los terminos de su ejemplo, se trata de la relacion:
P (sida|V IH) =P (V IH |sida)P (sida)
P (V IH)
Sin embargo, el calculo de sus componentes no se puede realizar mientras no se
fije un espacio de probabilidad (Ω, P ). Si fijamos que Ω es el conjunto de todas las
personas que tienen VIH (supongamos que tiene tamano V ) y consideramos que
A es el conjunto de quienes tienen sida (de tamano S), graficamente, la situacion
es la que se registra en la Figura 1.
Figura 1: Representacion del espacio muestral conformado por todos los que portanel VIH (tamano V ) y subconjunto de aquellos que padecen sida (tamano S). Fuente:elaboracion propia.
Esto equivale a asumir que solo interesa ahora el conjunto de aquellos sujetos que
tienen VIH. Si definimos ahora como B al propio conjunto de quienes tienen VIH,
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

En defensa de la racionalidad bayesiana 207
pueden calcularse los componentes de la parte derecha de la ecuacion:
P (sida) =S
V, P (V IH) =
V
V, y P (V IH |sida) =
S
S
de modo que, haciendo las sustituciones correspondientes, se tendra que:
P (V IH |sida)P (sida)
P (V IH)=
SS
SV
VV
=S
V
Si bien hemos llegado a que la probabilidad de tener sida dado que se porta el
virus (parte izquierda de la ecuacion) es S/V , y por ende igual a la probabilidad
incondicional de tener sida, no hay ninguna contradiccion, ya que, bajo la restric-
cion que se ha impuesto (en ese espacio muestral donde no hay sujetos sin el VIH),
la probabilidad de tener sida es necesariamente igual a la de tenerlo supuesto que
se trata de un sujeto de tal espacio, un sujeto que tiene VIH . Dicho de otro mo-
do: la probabilidad de A condicionada a que este sea un subconjunto de Ω es lo
mismo que no condicionarla; estamos hablando, simplemente, de la probabilidad
de A. Esto pasa siempre que el espacio muestral sea una condicion necesaria para
que se produzca A (por ejemplo, la probabilidad de que, tras una relacion sexual,
una mujer quede embarazada es igual a la probabilidad de que quede embarazada
supuesto que es una mujer).
Ahora bien, si el espacio muestral es, por ejemplo, el de todos los seres humanos
en una poblacion de referencia dada, tenemos graficamente la situacion que se
muestra en la Figura 2.
Llamando NV al tamano del conjunto de sujetos sin VIH, definamos N = V +NVy consideremos la relacion
P (sida|V IH) =P (V IH |sida)P (sida)
P (V IH)
El termino de la derecha sera:
P (V IH |sida)P (sida)
P (V IH)=
SS
SNVN
=S
V
coherentemente con lo que nos darıa si sustituimos en el termino izquierdo los
tamanos debidos. Es decir, ya no se cumple que la probabilidad de tener sida
(S/N) sea igual a la de tenerlo dado que se tiene VIH (S/V ).
Bunge incurre en el dislate de atribuir al bayesiano la absurda conducta de aplicar
el Teorema de Bayes a “cierto sujeto”, de quien sabemos que porta el VIH. A
partir de ello, lo que hace es cenirse al espacio muestral Ω = V IH , en el cual,
obviamente, P (V IH) = P (V IH |sida) = 1. Pero estas relaciones no se cumplen
cuando queremos conocer genericamente (no para un sujeto especıfico) el valor de
P (sida|V IH). Habiendolo hecho, ya podemos aplicar el resultado para un portador
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

208 Luis Carlos Silva
Figura 2: Representacion del espacio muestral conformado por todos los seres hu-manos de una poblacion de referencia (tamano N), los subconjuntos de aquellosque portan y no portan el VIH (V y NV respectivamente) y el subconjunto, entrelos primeros, que padecen sida (tamano S). Fuente: elaboracion propia.
del VIH. lo cual exige que operemos en el espacio Ω conformado por una poblacion
de referencia, que contiene individuos tanto con VIH como sin el.
Por ejemplo, si suponemos que en cierto espacio la tasa de prevalencia de sida
asciende al 3% mientras que los portadores del VIH constituyen el 2% entre
aquellos que no tienen sida, se tendra que:
P (sida|V IH) =P (V IH |sida)P (sida)
P (V IH)
=P (V IH |sida)P (sida)
P (V IH |sida)P (sida) + P (V IH |sidac)P (sidac)
=(1)(0.03)
(1)(0.03) + (0.02)(0.97)= 0.61
Es decir, la probabilidad inicial de 0.03 pasa a ser 20 veces mayor (0.61) cuando
se condiciona a que el sujeto tenga VIH.
6. Bunge riza el rizo
El grado en que Bunge sacrifica el rigor con tal de ridiculizar al pensamiento baye-
siano se pone de manifiesto en el segmento donde afirma que, para ser consecuentes,
tendrıamos que creer en la resurreccion. Textualmente, escribe (p. 101):
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2
En defensa de la racionalidad bayesiana 209
Y si los medicos fuesen consecuentes al aceptar la formula de Bayes,
tendrıan que admitir la posibilidad de la resurreccion, ya que dicha
formula permite calcular la probabilidad de P (V |M) de estar vivo ha-
biendo muerto, a partir de la probabilidad inversa de P (M |V ) y de las
probabilidades absolutas de estar vivo y de estar muerto.
Su razonamiento tiene como base de que, como –segun el– podemos calcular las
probabilidades incondicionales de “estar vivo”, la de “estar muerto”, y la de “estar
muerto dado que se esta vivo”, entonces se podrıa calcular, por medio del teorema,
la de estar vivo dado que se esta muerto. Este galimatıas solo puede producirse
porque se habla de las tres probabilidades iniciales sin especificar los espacios de
probabilidad correspondientes. Si se introduce un conjunto de terminos sin sentido
alguno (o, como mınimo, sin sentido claro) en una ecuacion, se obtendra inexora-
blemente algo sin sentido alguno (o sin sentido claro).
En este caso, por ejemplo, Bunge afirma que se podrıan calcular las probabilidades
de estar vivo y la de estar muerto; la pregunta es, ¿respecto de que conjunto de
personas se calcularıan estas probabilidades complementarias? La primera, por
ejemplo, serıa 1 si hablamos de los obreros que laboran una fabrica, serıa 0 si el
espacio muestral es el de quienes yacen en el cementerio, ascenderıa a 0.8 cuando
dicho espacio es el de todos los seres humanos que se encuentran hoy en la morgue
de la ciudad, y serıa 1 entre miles de millones si fuera el conjunto de todos los
humanos que han existido. Y para rematar, hace olımpicamente una afirmacion
descabellada: que se puede calcular la probabilidad de que alguien este muerto
dado que esta vivo. Siendo ası, segun el, el dislate reside en aplicar el Teorema de
Bayes, no en la pretension de que este se pueda aplicar usando un componente que
no tiene el menor sentido. En fin, todo esto no es mas que un amasijo de vaguedades
y contrasentidos, que parecen surgir mas como producto de una emocion que de
un pensamiento medianamente racional.
7. Consideraciones finales
Ya en su libro Capsulas, Bunge (2003) venıa insistiendo en consideraciones desa-
tinadas en relacion con estos temas. Por poner un solo ejemplo, allı afirma lo
siguiente:
Tambien es falsa la opinion de que tenemos derecho a atribuirle una
probabilidad a todo acontecimiento. En efecto, solo podemos adjudicar
probabilidades a acontecimientos aleatorios. Este es el caso del resul-
tado de revolear una moneda honesta. En cambio, si la moneda ha
sido fabricada por un tahur, no corresponde hablar de probabilidades.
En un libro destinado a discutir diversos problemas que aquejan a la investigacion
biomedica (Silva 2009), discutı varias ideas de las expresadas por Bunge en este
material, en particular la que he acabo de citar. Allı escribı:
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

En defensa de la racionalidad bayesiana 209
Y si los medicos fuesen consecuentes al aceptar la formula de Bayes,
tendrıan que admitir la posibilidad de la resurreccion, ya que dicha
formula permite calcular la probabilidad de P (V |M) de estar vivo ha-
biendo muerto, a partir de la probabilidad inversa de P (M |V ) y de las
probabilidades absolutas de estar vivo y de estar muerto.
Su razonamiento tiene como base de que, como –segun el– podemos calcular las
probabilidades incondicionales de “estar vivo”, la de “estar muerto”, y la de “estar
muerto dado que se esta vivo”, entonces se podrıa calcular, por medio del teorema,
la de estar vivo dado que se esta muerto. Este galimatıas solo puede producirse
porque se habla de las tres probabilidades iniciales sin especificar los espacios de
probabilidad correspondientes. Si se introduce un conjunto de terminos sin sentido
alguno (o, como mınimo, sin sentido claro) en una ecuacion, se obtendra inexora-
blemente algo sin sentido alguno (o sin sentido claro).
En este caso, por ejemplo, Bunge afirma que se podrıan calcular las probabilidades
de estar vivo y la de estar muerto; la pregunta es, ¿respecto de que conjunto de
personas se calcularıan estas probabilidades complementarias? La primera, por
ejemplo, serıa 1 si hablamos de los obreros que laboran una fabrica, serıa 0 si el
espacio muestral es el de quienes yacen en el cementerio, ascenderıa a 0.8 cuando
dicho espacio es el de todos los seres humanos que se encuentran hoy en la morgue
de la ciudad, y serıa 1 entre miles de millones si fuera el conjunto de todos los
humanos que han existido. Y para rematar, hace olımpicamente una afirmacion
descabellada: que se puede calcular la probabilidad de que alguien este muerto
dado que esta vivo. Siendo ası, segun el, el dislate reside en aplicar el Teorema de
Bayes, no en la pretension de que este se pueda aplicar usando un componente que
no tiene el menor sentido. En fin, todo esto no es mas que un amasijo de vaguedades
y contrasentidos, que parecen surgir mas como producto de una emocion que de
un pensamiento medianamente racional.
7. Consideraciones finales
Ya en su libro Capsulas, Bunge (2003) venıa insistiendo en consideraciones desa-
tinadas en relacion con estos temas. Por poner un solo ejemplo, allı afirma lo
siguiente:
Tambien es falsa la opinion de que tenemos derecho a atribuirle una
probabilidad a todo acontecimiento. En efecto, solo podemos adjudicar
probabilidades a acontecimientos aleatorios. Este es el caso del resul-
tado de revolear una moneda honesta. En cambio, si la moneda ha
sido fabricada por un tahur, no corresponde hablar de probabilidades.
En un libro destinado a discutir diversos problemas que aquejan a la investigacion
biomedica (Silva 2009), discutı varias ideas de las expresadas por Bunge en este
material, en particular la que he acabo de citar. Allı escribı:
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

210 Luis Carlos Silva
Me resulta curioso que el gran epistemologo argentino no capte que
la situacion es exactamente la opuesta: decir de antemano que una
moneda es honesta equivale a atribuirle (subjetivamente) una pro-
babilidad de 0.5 a cada lado. Por otra parte, si se parte de calificarla
como honesta, entonces ponerse a revolearla ya carece de senti-
do. Finalmente, si hubiera sido fabricada por un tahur, esa serıa
exactamente la situacion en que mas claramente procederıa hablar de
probabilidad, ya sea con vistas a estimar la que corresponda a cada
posible desenlace bajo la definicion frecuentista, ya sea subjetivamen-
te –usando nuestro conocimiento, si lo tuvieramos, sobre las manas
habituales del tahur– o incluso combinando ambos enfoques mediante
el teorema de Bayes.
En sıntesis, la vision que transmite Bunge en su obra sobre las probabilidades y
en especial sobre el teorema de Bayes, especialmente en la que motiva la presente
nota, no solo es poco rigurosa y a la postre equivocada, sino que es tendenciosa
y no parece responder a reflexiones racionales susceptibles de ser desarrolladas
tanto desde el conocimiento de la teorıa de probabilidades como a partir de la
experiencia empırica al respecto.
Recibido: 9 de abril de 2013
Aceptado: 9 de mayo de 2013
Referencias
Bunge, M. (2003), Capsulas, Gedisa, Barcelona.
Cornfield, G. (1962), ‘Joint dependence of risk of coronary heart disease on se-
rum cholesterol and systolic bold pressure: A discriminant function analysis’,
Federation Proceedings 21(4), 58–61.
Garicano, L. (2012), Son las matematicas, estupido. El Paıs (Espana), noviembre
13.
Garthwaite, P., Kadane, J. & O’Hagan, A. (2005), ‘Statistical methods for eliciting
probability distributions’, Journal of the American Statisticians Associaton100, 680–701.
Good, I. J. (1979), ‘Studies in the history of probability and statistics. XXXVII A.
M. Turing’s statistical work in the World War II’, Biometrika 66(2), 393–396.
Ioannidis, J. (2005), ‘Why most published research findings are false?’, PLoS Me-dicine 2(8), e124. doi:10.1371/journal.pmed.0020124.
Lord, F. M. (1953), ‘On the statistical treatment of football numbers.’, AmericanPsychologist 8, 750–751.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

En defensa de la racionalidad bayesiana 211
Mazur, D. J. (2012), ‘A history of evidence in medical decisions from the diagnostic
sign to bayesian inference.’, Medical Decision Making 32, 227–231.
McGrayne, S. B. (2011), The theory that would not die: how bayes rule crackedthe enigma code, hunted down Russian submarines, and emerged triumphantfrom two centuries of controversy, New Haven: Yale University Press.
Mora, J. G. (2012), Elecciones catalanas 2012: Todas las encuestas fallan. ABC,
noviembre 26, (Espana).
O’Donnell, C. J. & Elosua, R. (2008), ‘Cardiovascular risk factors. insights from
framingham heart study’, Revista Espanola de Cardiologıa 61(3), 299–310.
Press, S. J. & Tanur, J. M. (2001), The subjectivity of scientists and the Bayesianapproach, Wiley and Sons, New York.
Silva, L. C. (1997), Cultura estadıstica e investigacion cientıfica en el campo de lasalud: Una mirada crıtica, Dıaz de Santos, Madrid.
Silva, L. C. (2009), Los laberintos de la investigacion biomedica. En defensa de laracionalidad para la ciencia del Siglo XXI, Dıaz de Santos, Madrid.
Silva, L. C. (2013), ‘Reflexiones a raız de Filosofıa para medicos, un texto de Mario
Bunge’, Salud Colectiva 9(1), 115–128.
Silva, L. C. & Benavıdes, A. (2003), ‘Apuntes sobre subjetividad y estadıstica en
la investigacion’, Revista Cubana de Salud Publica 29(2), 170–173.
Silver, N. (2012), The signal and the noise why so many predictions fail - but somedon’t, The Penguin Press, New York.
Wilson, P. W. F. (2010), ‘Estimation of cardiovascular risk in an individual patient
without known cardiovascular disease. UpToDate. Basow, DS (Ed).’, Massa-chusetts Medical Society and Wolters Kluwer publishers. The Netherlands .
A. Definicion axiomatica de probabilidadesde Kolmogorov
Sea Ω un conjunto que se denomina espacio muestral y S el conjunto de todos los
subconjuntos de Ω, a los que se denomina sucesos.
Consideremos una funcion P cuyo dominio sea S y su codominio el conjunto de
los numeros reales (P : S −→ R). Es decir, P es una regla bien definida por la
que se asigna a cada suceso un, y un solo un, numero real). Se le llama funcion deprobabilidad a dicha aplicacion si cumple los tres axiomas siguientes:
(1) P (A) ≥ 0 cualquiera sea A tal que A ∈ S
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

212 Luis Carlos Silva
(2) P (⋃k
i=1Ai) =
∑ki=1
P (Ai) siempre que Ai ∩Aj = ∅ para i = j
(3) P (Ω) = 1
A la estructura (Ω, S, P ) se le denomina espacio de probabilidad.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Comunicaciones en Estadıstica
Diciembre 2013, Vol. 6, No. 2, pp. 213–220
Acerca de la defensa de la racionalidad bayesiana
y la obra de Mario Bunge
About the defense of bayesian rationality and the work of Mario
Bunge
Andres Gutierrez Rojasa
La crıtica de Silva a la obra de Mario Bunge esta sustentada en la ligereza de Bunge
al momento de utilizar el teorema de Bayes, con el cual descalifica abiertamente
el uso del paradigma bayesiano en las ciencias. En este documento se comenta la
definicion correcta de los espacios muestrales al usar probabilidades y se recalca
que el uso de los metodos bayesianos y de la estadıstica en general, no deben estar
supeditados a un razonamiento puramente filosofico.
1. Sobre la probabilidad condicional y los espacios
muestrales
Al leer la introduccion que Mario Bunge hace al problema de calcular la proba-
bilidad de que una persona con VIH tenga sida, es posible advertir que el autor
hace una escala por un problema de probabilidad aplicada en donde se dice que
un evento causa a otro. En estos terminos, el autor concluye que ‘si C y E son
dos suceso aleatorios y C causa a E, entonces P (E|C) ≤ P (E)”. Es aquı en donde
creo que el susodicho autor deberıa haber razonado un poco mas acerca de cuando
se tiene la igualdad en esta regla de probabilidades, puesto que en el ejemplo que
suscita esta discusion, en el que el suceso tener V IH causa al suceso desarrollar
sida, Bunge concluye que P (sida|V IH) = P (sida) y sin ninguna precaucion con-
cluye que las probabilidades bayesianas son arbitrarias y no tienen cabida en la
ciencia autentica.
Desarrollando el anterior planteamiento, al suponer que C causa a E, notese que
P (E|C) =P (E ∩C)
P (C)=
P (E)
P (C)≥ P (E) (1)
con igualdad si y solamente si P (C) = 1. En el ejemplo que nos atane sobre el
hallazgo de Bunge, lo anterior redundarıa en que P (V IH) = 1, que significarıa
aDecano, Facultad de Estadıstica, Universidad Santo Tomas (Colombia). Colombia.
213

214 Andres Gutierrez Rojas
que la probabilidad de que ese cierto individuo, seleccionado al azar, tenga VIH
es la unidad y eso solo serıa posible si, como Silva muy bien lo explica, el espacio
muestral estuviese definido por las personas que tienen V IH , puesto que en este
ejemplo el evento VIH causa al evento sida. No quiero desarrollar mas este punto,
pues el autor del artıculo hace muy bien en develar estos detalles, pero sı quiero
recurrir al siguiente teorema que examina las implicaciones de la igualdad en la
expresion (1).
Teorema 1. Siendo (Ω,F, P ) un espacio de probabilidad en donde los elementosde la sigma-algebra F se denotan como A1, A2, . . . y son tales que P (Ai) = 0 paratodo Ai = ∅, entonces
P (Ak) = 1, para algun Ak ∈ F, si y solo si Ak = Ω.
Demostracion. La implicacion se prueba por contradiccion al asumir que P (Ak) =
1. Al suponer que Ak = Ω, entonces naturalmente Ac
k= ∅. Por tanto, acudiendo
al enunciado del teorema, se tendrıa que P (Ac
k) > 0, y si tenemos en cuenta que
Ak ∪Ac
k= Ω, entonces
P (Ω) = P (Ac
k) + P (Ak) > 1
Lo cual implica una contradiccion a los axiomas basicos de probabilidad. Por otra
parte, la demostracion de la conversa es trivial.
El anterior teorema se puede aplicar al ejemplo de Bunge en donde solo hay dos
eventos de interes V IH y sida, cada uno con probabilidad no nula, y ademas,
P (V IH) = 1, por tanto, el espacio muestral al cual Bunge se refiere en su ejemplo
es sin duda el condicionado a V IH .
2. Razonamiento antibayesiano
En terminos pragmaticos, y teniendo en cuenta los grandes avances que han surgi-
do de la estadıstica bayesiana, ningun cientıfico contemporaneo deberıa negar las
bondades de este tipo de pensamiento. Desde las ciencias de la administracion y el
mercadeo, pasando por la teorıa actuarial y ensayos clınicos, hasta las ciencias de
la computacion y la epidemiologıa, la estadıstica bayesiana ha jugado y jugara un
papel fundamental en el intento humano de extraccion de informacion con base en
un conjunto de datos. Sin embargo, como se evidencia en la obra de Bunge, hay
todavıa pensadores que van en contra del paradigma bayesiano.
Entre los argumento de Bunge, se encuentran frases como las siguientes
Por ser subjetivas las probabilidades bayesianas son arbitrarias y no
deberıan ser usadas en la ciencia...
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Acerca de la defensa de la racionalidad bayesiana y la obra de Mario Bunge 215
Basado en lo anterior, cabrıa recordar que, todas las ciencias, y en particular la
estadıstica, estan compuestas de procedimientos subjetivos que guıan a resulta-
dos medibles objetivamente (Bernardo 2008, Kadane 2008). Sin embargo, el uso
del teorema de Bayes, que afirma que la distribucion posterior de los parametros
condicionada a los datos observados es proporcional al producto de la verosimili-
tud con la distribucion previa de los parametros de interes, no debe ser usado a
la ligera como una formula automatica que brinda inferencias rapidas. En estos
terminos, la asignacion de las probabilidades previas no puede ser arbitraria. La
anterior afirmacion parecerıa un punto a favor de los argumentos de Bunge, pero
cualquier estadıstico, clasico o bayesiano, con experiencia en la creacion de mo-
delos estocasticos sabra que la realidad de la profesion consiste en la asignacion
de diferentes modelos de probabilidad a los datos observados y en la respectiva
escogencia del mejor modelo. Esta tarea debe ser concienzuda y responsable.
Ya sea que el estadıstico opte por un enfoque clasico o bayesiano, se debe notar que
la asignacion o la escogencia de las probabilidades (o distribuciones de probabili-
dad) no esta sujeta a ningun principio objetivo: desde el punto de vista bayesiano,
es menester asignar una distribucion de probabilidad previa a los parametros de
interes y esta tarea es exactamente la misma que el estadıstico clasico enfrenta al
asignar una verosimilitud a sus datos. En la estadıstica aplicada, la asignacion de
verosimilitudes y distribuciones previas esta determinada por la escogencia de un
modelo que represente bien la realidad de los datos observados. En estos termi-
nos, el estadıstico clasico podra optar por un modelo o por otro y, de la misma
manera, el estadıstico bayesiano podra seleccionar una distribucion previa u otra.
Esta libertad de escogencia, que ocurre bajo los dos paradigamas, no induce nin-
guna arbitrariedad. De hecho, como lo mencionan Andrews & Baguley (2013), las
distribuciones previas son supuestos en el modelo bayesiano y como todos los su-
puestos, pueden ser buenos o malos, pueden extenderse, revisarse o posiblemente
abandonarse al no ser idoneos con los datos observados.
Con base en lo anteriormente mencionado, el estadıstico clasico podra escoger un
nuevo modelo a medida que tenga un conocimiento mas profundo de la realidad
a la cual intenta acercarse. De hecho, desde mi punto de vista, considero que
esa escogencia ha definido la historia de la estadıstica hasta hoy. Por ejemplo, es
posible desviarse de un modelo parametrico Gausiano y preferir un modelo no pa-
rametrico, el cual si bien podrıa ser mas complejo en su formulacion matematica,
tiene mejores propiedades en algunos contextos. De la misma manera, el estadısti-
co bayesiano debera escoger distribuciones previas plausibles. Esto, en terminos
practicos, implica que si la distribucion posterior se desvıa significativamente de la
distribucion previa, entonces el estadıstico debera reconsiderar y revaluar la esco-
gencia de la distribucion previa. De esta forma, es posible afirmar que la escogencia
de distribuciones previas es tan objetiva como la escogencia de verosimilitudes en
la estadıstica clasica.
En esta discusion es posible que afloren otro tipo de razonamientos filosoficos;
por ejemplo que los parametros de una distribucion de probabilidad son fijos y no
aleatorios. Salsburg (2001) afirma que, tal como lo mostro Pearson, el proposito de
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

216 Andres Gutierrez Rojas
la investigacion estadıstica es estimar los parametros (fijos pero desconocidos) de
las distribuciones de probabilidad cuyos valores definen dicha distribucion. Por lo
anterior, si los parametros se consideraran aleatorios, el enfoque de la investigacion
cientıfica se desviarıa de su proposito. Sin embargo, muchos autores bayesianos han
fallado en argumentar que, lo que se considera aleatorio no es el parametro en sı,
sino la incertidumbre que se genera ante el desconocimiento del parametro y es eso
exactamente lo que deberıa ser modelado, por medio de una distribucion previa.
3. Argumentos de ambas partes
A simple vista, es posible evidenciar que Bunge y Silva, y los comentaristas invi-
tados en este numero de esta Revista hacemos parte de las animadas, pero intere-
santes y necesarias, discusiones que durante siglos han caracterizado el desarrollo
de la estadıstica y sus diferentes paradigmas, entre ellos el bayesiano y el clasico.
Los estadısticos bayesianos acuden a una vieja contradiccion, basada en el principio
de verosimilitud, para impulsar el abandono de los metodos clasicos en pro del
paradigma bayesiano y, a su vez, los estadısticos clasicos han utilizado un problema
atribuido a Laplace para ridiculizar el punto de vista bayesiano. Detengamonos en
estos ejemplos por un instante.
El ejemplo del principio de verosimilitud sugerido por Lindley & Philips (1976)
reza de la siguiente forma:
Suponga que se realizan 12 lanzamientos independientes de una mone-
da y se observan 9 caras y 3 sellos. Ademas, se desea cotejar el siguiente
conjunto de hipotesis
H0 : θ = 0.5 vs. Ha : θ > 0.5
En donde θ representa la probabilidad de obtener una cara. Si sola-
mente tuviesemos acceso a esta informacion, surgirıan dos opciones de
verosimilitud que podrıan ser candidatas para realizar el cotejo de las
hipotesis de interes. En primer lugar la distribucion binomial, que asu-
me que X es la variable aleatoria que determina el numero de caras en
los 12 lanzamientos, se tiene que
α1 = PH0(X ≥ 9) =
12∑
x=9
(12
x
)θx(1− θ)12−x = 0.075
Y la otra verosimilitud candidata serıa la distribucion Binomial Nega-
tiva, que supone que X representa el numero de caras necesarias para
lograr 3 sellos, para lo cual se tiene que
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Acerca de la defensa de la racionalidad bayesiana y la obra de Mario Bunge 217
α2 = PH0(X ≥ 9) =
∞∑
x=9
(2 + x
x
)θx(1 − θ)3 = 0.0325
De esta forma, asumiendo un nivel de significacion del 5%, el estadısti-
co rechazara la hipotesis nula si la variable aleatoria X tuviese distri-
bucion binomial negativa y no la rechazarıa si X tuviese distribucion
Binomial. Lo anterior constituye una violacion al principio de verosimi-
litud (Birnbaum 1962) que afirma que, si los datos han sido observados,
la funcion de verosimilitud debe contener toda la informacion experi-
mental relevante acerca de los parametros de interes. Notese que estas
dos verosimilitudes son proporcionales entre sı como funciones de θ,pero aunque guıan al mismo estimador de maxima verosimilitud, esta
equivalencia lleva a dos conclusiones diferentes en terminos del sistema
de hipotesis de interes.
El segundo ejemplo, atribuido a Laplace y con el cual los estadısticos clasicos se
mofan de los bayesianos es el siguiente:
Teniendo en cuenta que el sol ha salido n veces consecutivas en los pa-
sados n dıas. Cabe cuestionarse acerca de ¿cual es la probabilidad de
que el sol salga manana, dado que ha salido en los pasados n dıas?
Para resolver esta pregunta, Laplace utilizo la regla de la sucesion
(Wikipedia 2013) para demostrar que, siendo p la probabilidad de que
el sol salga manana, la esperanza posterior de p esn+ 1
n+ 2. Esta con-
jetura se logra al asumir que la distribucion previa de p es uniforme
continua, como una opcion probabilista de la total incertidumbre sobre
este parametro, y una verosimilitud binomial, describiendo el numero
de exitos en n ensayos. Lo anterior, siguiendo la regla de Bayes, re-
dunda en una distribucion posterior con kernel Beta de parametros
(α = n+ 1, β = 1).
Algunos autores (Popper 1957, Schay 2007, Gorroochurn 2011) han
ridiculizado la escogencia de la distribucion previa en el anterior pro-
blema, utilizando sus argumentos para desvirtuar el uso de la estadısti-
ca bayesiana. En particular cabrıa preguntarse ¿por que se justifica la
asignacion de una distribucion uniforme continua a la probabilidad pre-
via de que el sol salga? Esta escogencia implica que el conocimiento
previo de que se tiene del problema le otorga la misma densidad a cual-
quier valor en el intervalo (0, 1) y este supuesto no es cientıficamente
razonable.
Los anteriores dos ejemplos son una muestra de una gran cantidad de argumen-
taciones que intentan desvirtuar los enfoques clasico y bayesiano y que, en mi
apreciacion, alimentan el desarrollo mismo de la estadıstica.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

218 Andres Gutierrez Rojas
Sin embargo, en defensa del estadıstico clasico se puede afirmar que el diseno
del experimento deberıa ser incluido en el contraste de las hipotesis, porque en
terminos experimentales, no es lo mismo lanzar una moneda hasta obtener cierto
numero de caras, que lanzarla un numero predefinido de veces y, por consiguiente,
la manera como se llevo a cabo el experimento1 es informacion relevante (Carlin &
Louis 2009). Por otro lado, en defensa del estadıstico bayesiano, podrıa argumen-
tarse que el ejemplo esta desenfocado y que el problema de Laplace no consiste
en la asignacion de la distribucion previa sino en la asignacion de la verosimili-
tud como una distribucion binomial, que considera eventos independientes, a un
problema que, a todas luces, no deberıa asumir una probabilidad de exito cons-
tante cada dıa, ni tampoco que los dıas en los cuales el sol ha salido son eventos
independientes unos de otros (Gelman & Robert 2013).
Por ultimo, en mi interpretacion de la practica estadıstica y del ejercicio de mode-
lacion que se realiza en esta profesion, suscribo completamente la frase de Gelman
& Cosma (2013) cuando afirman que un metodo estadıstico puede ser util aun
cuando sea filosoficamente errado.
4. Conclusion
A pesar de que en esta discusion se ha demostrado que las conclusiones de Bunge
son, por lo menos, desviadas de las reglas de probabilidad y por tanto no cientıfi-
cas, es de suponer que sin importar la falsedad de sus argumentos, el potencial de
malinterpretacion en una obra escrita difundida de forma masiva es grande. Maxi-
me cuando un gremio, como el de los medicos, no tiene porque conocer los axiomas
fundamentales de la probabilidad. Por tanto, creo yo que este tipo de literatura
desvirtua el quehacer del estadıstico, clasico o bayesiano, y crea en el profesional
de la medicina una gran barrera hacia el uso de nuevas tecnicas estadısticas.
Como bien lo afirman Cox & Donnelly (2011), no todos los analisis estadısticos
que utilicen la regla de Bayes deberıan ser llamados bayesianos. En este sentido
se deberıa garantizar por lo menos que: 1) la distribucion previa represente una
evidencia del conocimiento previo del problema; 2) esta evidencia debe ser con-
sistente con los datos observados; 3) realizar un analisis de sensibilidad2 sobre las
distribuciones previas candidatas cuando hay total incertidumbre del problema
(Gustafson et al. 2010).
Con estas indicaciones en mente, es posible concluir que el ejercicio de probabi-
lidades de Bunge, solamente constituye un esfuerzo filosofico mal planteado en
contra de una corriente de analisis estadıstico posicionada en el mundo cientıfico,
en donde mas de la mitad de los artıculos cientıficos publicados en las mas impor-
1El diseno en la recoleccion de los datos es informativo (y no ignorable), no solo en diseno
experimental, sino en el analisis de encuestas probabilısticas, para las cuales las propiedades de
los estimadores estan supeditadas a la medida de probabilidad discreta inducida por el diseno
muestral (Gutierrez 2009).2En el planteamiento de ensayos clınicos, este enfoque ha sido estudiado por Carlin & Louis
(1996) y recientemente por Fuquene et al. (2009) y Cook et al. (2011).
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Acerca de la defensa de la racionalidad bayesiana y la obra de Mario Bunge 219
tantes revistas estadısticas utilizan metodos bayesianos (Andrews & Baguley 2013,
Figura 1).
Parafraseando a Gelman (2008) mi conclusion final sobre esta interesante discusion
redunda en que hoy en dıa es posible ser no bayesiano –al utilizar en la practica
metodologıas clasicas– pero ser antibayesiano –al desconocer el desarrollo cientıfico
que la estadıstica bayesiana ha traıdo consigo– ya no es una opcion.
Recibido: 23 de julio de 2013
Aceptado: 14 de agosto de 2013
Referencias
Andrews, M. & Baguley, T. (2013), ‘Prior approval: the growth of Bayesian met-
hods in psychology’, British Journal of Mathematical and Statistical Psycho-logy 66, 1–7.
Bernardo, J. M. (2008), ‘Comment on article by gelman’, Bayesian Analysis3(3), 443–658.
Birnbaum, A. (1962), ‘On the foundations of statistical inference’, Journal of Ame-rican Statististical Association 57, 269–326.
Carlin, B. P. & Louis, T. (1996), Identifying prior distributions that produce spe-cific decisions, with application to monitoring clinical trials, Wiley, chapter
Bayesian Analisys in Statistics and Econometrics: Essays in Honor of Arnold
Zellner.
Carlin, B. P. & Louis, T. A. (2009), Bayesian methods for data analysis, 3 edn,
CRC.
Cook, J., Fuquene, J. & Pericchi, L. (2011), ‘Skeptical and optimistic robust priors
for clinical trials’, Revista Colombiana de Estadıstica 34, 333–345.
Cox, D. & Donnelly, C. (2011), Principles of applied statistics, Cambridge Univer-
sity Press.
Fuquene, J., Cook, J. & Pericchi, L. (2009), ‘A case for robust bayesian priors with
applications to clinical trials’, Bayesian Analysis 4, 817–846.
Gelman, A. (2008), ‘Objections to bayesian statistics’, Bayesian Analysis3(3), 445–450.
Gelman, A. & Cosma, R. (2013), ‘Philosophy and the practice of bayesian statis-
tics’, British Journal of Mathematical and Statistical Psychology 66, 8–38.
Gelman, A. & Robert, C. P. (2013), ‘Not only defended but also applied”: The
perceived absurdity of bayesian inference’, The American Statistician 67, 1–5.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

220 Andres Gutierrez Rojas
Gorroochurn, P. (2011), ‘Errors of probability in historical context’, AmericanStatistician 65, 246–254.
Gustafson, P., McCandless, L., Levy, A. & Richardson, S. (2010), ‘Simplified baye-
sian sensitivity analysis for mismeasured and unobserved confounders’, Bio-metrics 66, 1129–1137.
Gutierrez, A. (2009), Estrategias de muestreo: diseno de encuestas y estimacionde parametros, Editorial de la Universidad Santo Tomas.
Kadane, J. (2008), ‘Comment on article by Gelman’, Bayesian Analysis 3(3), 455–458.
Lindley, D. & Philips, L. (1976), ‘Inference from a Bernoulli process (a bayesian
view)’, Journal of American Statististical Association 30, 112–119.
Popper, K. (1957), ‘Probability magic or knowledge out of ignorance’, Dialectica11(354 - 374).
Salsburg, D. (2001), The lady tasting tea, Henry Hold and Company.
Schay, G. (2007), Introduction to probability with statistical applications, Birkhau-ser.
Wikipedia (2013), ‘Rule of succession’. Fecha de acceso: 17 de julio de 2013.
*http://en.wikipedia.org/wiki/Rule of succession
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Comunicaciones en Estadıstica
Diciembre 2013, Vol. 6, No. 2, pp. 221–224
El caso de la estadıstica bayesiana objetiva comouna posibilidad en ensayos clınicos
The case of objective bayesian statistics as a possibility
in clinical trials
Jairo Fuquenea
1. Introduccion
En primer lugar, el autor de esta discusion agradece al Comite Editorial por in-vitarlo a realizar una discusion del artıculo de Silva (2013), el cual presenta unaperspectiva muy interesante con ejemplos bastante claros sobre el uso del teoremade Bayes. Al ser este el ano internacional de la estadıstica y tambien el aniversario250 del teorema de Bayes la discusion resulta aun mas interesante. En particu-lar, la defensa que el autor hace sobre la subjetividad en la informacion previaha sido tema de discusion por los bayesianos en anos recientes. Por tanto, conel objetivo de complementar algunas de las discusiones de Silva (2013), en esteartıculo se presenta una discusion corta de los metodos bayesianos objetivos comouna alternativa a los metodos bayesianos subjetivos en ensayos clınicos.
2. Una aplicacion de los metodos bayesianosobjetivos en ensayos clınicos
Los metodos bayesianos objetivos (ver Berger (2012)) en ensayos clınicos nacenentre otras cosas como una alternativa a la crıtica de los frecuentistas a los baye-sianos que afirman lo siguiente: “Cambiando la distribucion previa en un analisisbayesiano dos medicos pueden obtener resultados diferentes” por esta razon tantoprevias por “default” ası como previas robustas han sido propuestas en el analisisbayesiano de ensayos clınicos. Entre los trabajos mas recientes podemos encontrarFuquene et al. (2009) y Hobbs et al. (2011). Sin llegar a terminos teoricos y con elobjetivo de ejemplificar el uso de previas robustas se presenta el siguiente ejemplo.
aUniversity of Warwick. Department of Statistics. Reino Unido.
221

222 Jairo Fuquene
2.1. Ejemplo
Supongamos que se realiza un ensayo clınico en donde el 80% de 20 pacientestienen VIH dado que tienen sida y de acuerdo con informacion previa entre el0% y 40% de los pacientes en la poblacion de estudio tienen sida. El objetivo esdeterminar la distribucion posterior de pacientes que tienen sida dado que tienenVIH. La informacion previa en este caso nos indica que probablemente el 20%de la poblacion de estudio podrıa tener sida dado que tiene VIH. Sin embargo,es importante resaltar que la discrepancia entre los datos previos y actuales esconsiderable. Varias preguntas naturales surgen en este ensayo clınico: 1) Es racio-nal utilizar una metodologıa bayesiana para obtener conclusiones finales? 2) Sı esracional utilizar dicha metodologıa, ¿resulta adecuado utilizar distribuciones deprobabilidad “conjugadas” para modelar los datos previos? 3) ¿Cual es la mejorescogencia para modelar los datos previos?
Todas estas preguntas son relevantes para la escogencia de la distribucion que mo-dela los datos previos. En el analisis bayesiano es comun utilizar distribucionesprevias conjugadas debido a que en la practica son relativamente faciles de apli-car, ver Spiegelhalter et al. (2004). Sin embargo, dichas distribuciones conjugadasinfluyen en los resultados, dando mucho peso a la informacion previa, cuando da-tos previos y actuales difieren considerablemente. Como una alternativa se puedenutilizar en la fase II del ensayo clınico distribuciones previas robustas. Continuan-do con el ejemplo, la informacion previa se puede elicitar de tal manera que lasprevias conduzcan a un analisis conjugado, donde los datos previos se modelanutilizando una distribucion Beta y los datos actuales utilizando una verosimilitudBinomial. El modelo beta/binomial es uno de los mas populares en ensayos clıni-cos bayesianos. Sin embargo, nace otra alternativa practica y robusta, el modeloCauchy/Binomial en la escala del Log-Odds (ver Fuquene et al. (2009)). Los resul-tados de los dos analisis utilizando el paquete en R (ver Fuquene (2009)) llamadoClinical Robust Priors se muestran en la Figura 1. Como se puede observar en laFigura 1, el modelo Cauchy/Binomial es mucho mas similar a la distribucion delos datos en comparacion con el modelo beta/binomial. En otras palabras, la in-formacion previa es descontada cuando datos previos y actuales son relativamentediferentes conduciendo a resultados practicos mucho mas coherentes. En conclu-sion, en promedio utilizando una distribucion previa robusta como la distribucionCauchy, el 77% de los pacientes tienen sida dado que tienen VIH. Los resultadosson coherentes y similares al caso frecuentista el cual solo considera la distribucionBinomial para modelar los datos.
La objetividad en este analisis se basa en la escogencia de las previas y no en laprobabilidad de tener los datos previos o actuales. Tambien dicha objetividad des-carta la aseveracion que algunos estadısticos hacen: “Cambiando la informacionprevia el bayesiano puede obtener los resultados que desea”. Las previas robustasdescuentan el peso de la informacion previa cuando la informacion previa y losdatos en la muestra o actuales estan en conflicto o en otras palabras son muy di-ferentes. Por tanto esta propuesta se presenta como una opcion por “default”paralos practicantes o expertos en el area de ensayos clınicos que deseen utilizar meto-
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2
El caso de la estadıstica bayesiana objetiva como una posibilidad en ensayos clınicos223
Figura 1: Resultados del ejemplo modelos: beta/binomial y cauchy/binomial en la
escala del Log-Odds. Fuente: elaboracion propia.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

El caso de la estadıstica bayesiana objetiva como una posibilidad en ensayos clınicos223
Figura 1: Resultados del ejemplo modelos: beta/binomial y cauchy/binomial en la
escala del Log-Odds. Fuente: elaboracion propia.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

224 Jairo Fuquene
dos bayesianos. Tambien el escepticismo de utilizar metodos bayesianos queda aun lado debido a que si dos medicos utilizan dichas previas por “default”, inde-pendiente de la informacion previa, ambos podrıan llegar a resultados similaressiempre y cuando los resultados en la muestra tambien sean iguales.
3. Conclusion
Finalmente, esta discusion ratifica no en terminos teoricos pero sı practicos lomostrado por Silva (2013) en su crıtica al ejemplo de Bunge (2012), y tambien sirvecomo una contradiccion al punto de vista Frecuentista. Por tanto, desde el puntode vista del autor de este artıculo, la discusion de Silva (2013) es supremamentecoherente y ratifica lo que ha sucedido en los ultimos anos con el impacto que hatenido el uso de la estadıstica bayesiana en campos como bioestadıstica, medicina,bioinformatica, neurologıa y genetica.
Recibido: 9 de julio de 2013
Aceptado: 23 de julio de 2013
Referencias
Berger, J. O. (2012), ‘The case for objective bayesian analysis’, Bayesian Analysis
1(3), 385–402.
Fuquene, J. (2009), ‘Robust bayesian priors in clinical trials: an R package forpractititoners’, Biometric Brazilian Journal 27(4), 637–643.
Fuquene, J., Cook, J. & L.R., P. (2009), ‘A case for robust bayesian priors withapplications to clinical trials’, Bayesian Analysis 4(4), 817–846.
Hobbs, B. P., Carlin, B. P., Mandrekar, S. J. & Sargent, D. J. (2011), ‘Hierar-quical commensurate and power prior models for adaptative incorporation ofhistorical information in clinical trials’, Biometrics 67(3), 1047–1056.
Spiegelhalter, D. J., Abrams, K. R. & Myles, J. P. (2004), Bayesian approaches to
clinical trials and health-care evaluation, Wiley, London.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Comunicaciones en Estadıstica
Diciembre 2013, Vol. 6, No. 2, pp. 225–229
Mario Bunge y la estadıstica bayesiana
Mario Bunge and Bayesian statistics
Jorge Ortiz Pinillaa
1. Introduccion
Despues de leer el artıculo de Silva (2013), no quedan dudas sobre los errorestecnicos y teoricos de Bunge (2003) cuando “demuestra” las contradicciones a lasque se llega mediante el uso del teorema de Bayes. Tal vez, por su preparacionmatematica como fısico, el filosofo no vio la necesidad de acudir a la revision porparte de un probabilista o de un estadıstico. La ingenuidad de sus errores y sulenguaje casi pasional deslucen la obra de un autor que se declara enemigo de lasubjetividad.
Por otra parte, no se necesitan grandes teorıas para deducir que es mejor saberalgo que nada y que, cuando se conoce algo, es mejor aprovecharlo que no hacerlo.La formula de Bayes y todo lo que ha llevado a los desarrollos actuales de la es-tadıstica bayesiana simplemente ofrecen metodos para aprovechar el conocimientoadquirido. La sola presentacion de los metodos deberıa bastar para convencer quelo hace bien; ademas, se dispone de una enorme y creciente cantidad de ejemplosde aplicaciones exitosas.
En lo que sigue, prefiero leer y tratar de interpretar al filosofo, sin la pretension (apriori) de encontrar con ello motivacion por el estudio de la estadıstica bayesiana.
2. Probabilidades y proporciones
El manejo y la interpretacion de las probabilidades son realmente muy complejos.En eventos o experiencias repetibles, hace mas de 300 anos, Jacob Bernoulli en-contro que la relacion de la cantidad de exitos sobre la de experiencias tiende a unvalor igual al de la relacion de casos favorables sobre casos posibles. La repetibili-dad (en condiciones identicas) abre un camino para acercarse al conocimiento deuna relacion p inicialmente desconocida, pero fija.
aFacultad de Estadıstica, Universidad Santo Tomas (Colombia).
225

226 Jorge Ortiz Pinilla
¿Que pasa si, como plantea Bunge (2012, p. 100), ya se ha probado que un cier-to individuo e tiene VIH y se pregunta por la probabilidad de que tenga sida?Para manejar el tema en un contexto de probabilidad, se necesita admitir que elindividuo ya ha sido seleccionado de alguna manera que posibilita el uso de lasprobabilidades. Admitamos entonces que el espacio de probabilidad para la se-leccion de los individuos esta bien definido, que el evento e forma parte de laσ-algebra respectiva y que su probabilidad es un valor entre 0 y 1. Supongamosahora que el evento e ha ocurrido y ademas ya se sabe que e tiene VIH.
Llamemos SEL al conjunto de seleccionados que, en este caso, consta de unasola persona. Como e ya ha sido seleccionado y tiene V IH , entonces el eventoSEL ∩ V IH = e ya ha sido observado. No hay riesgo de que su probabilidadsea cero. Entonces, la pregunta de Bunge se traduce en buscar P (e ∈ sida | e).Por la definicion de probabilidad condicional,
Pr(e ∈ sida | e) =P (e ∈ sida ∩ e)
P (e)(1)
Si e tiene sida, el numerador en (1) es igual al denominador y la probabilidad bus-cada sera igual a 1; en caso contrario, sera cero. Como puede verse, este resultadoes inutil, pues exige el conocimiento de la condicion que precisamente se descono-ce. El calculo de probabilidades no da respuestas utiles para casos individuales yadeterminados. Sin embargo, para el individuo e del ejemplo, puede ser util saberque de las personas que estan en las mismas condiciones (los que tienen VIH),una proporcion de 0.61 (61%) han desarrollado el sida. Para el especıficamente,no corresponde a una probabilidad formal sino a una frecuencia relativa calculadacon datos de otras personas. Para su caso, nadie esta interesado en extraer alea-toriamente una persona con VIH para ver si tiene sida. Pero la frecuencia relativaresume el aprendizaje a partir de experiencias ajenas, que tambien es valioso.
Un ejemplo famoso es el de la tragedia del Challenger. Los documentos historicosmuestran que al menos uno de los investigadores tenıa conciencia de que el riesgoera real, que dio a conocer su preocupacion, pero que la interpretacion que se dioa los estudios de probabilidad determino que los resultados no eran concluyentesy que, por votacion, se autorizo el lanzamiento. Si la tragedia no hubiera ocurrido,seguramente le hubieran dicho que sus dudas eran infundadas y los ejemplos dehoy dirıan que el lanzamiento fue exitoso a pesar de los altos riesgos senaladospor las probabilidades que ahora se calculan. Realmente, lo mas probable es que elpublico ni siquiera tendrıa ni el problema ni los datos para “resolver” la tragediaa posteriori.
Este ejemplo es muy interesante, porque para su analisis siempre se han considera-do factores que tenıan relaciones causales directas con el desenlace y no con infor-macion de experiencias ajenas al caso estudiado. Se trataba de una probabilidadpropia (objetiva) de un evento irrepetible. En el momento se hicieron calculos quefueron considerados por unos como suficientemente preocupantes, pero no conclu-yentes por la mayorıa. Posteriormente se hicieron otros calculos mediante modeloslineales generalizados que no dejarıan dudas al respecto. Tambien se hicieron otros
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Mario Bunge y la estadıstica bayesiana 227
calculos basados en modelos bayesianos que dejarıan en ridıculo a quien quisieramanifestar alguna duda. Sin embargo, los calculos posteriores a la tragedia sonpuramente academicos o, si se quiere, especulativos, porque en el momento real,cuando se tomaron las decisiones, no se tenıa esa informacion sobre la mesa. Lounico que nos dicen realmente, es que hoy disponemos de mejores herramientas deanalisis.
En el momento historico, lo disponible era un resultado que dejaba un margendemasiado grande para la subjetividad. Uno de los ingenieros prefirio advertir,por su experiencia y conocimiento personales, es decir, subjetivamente, que elriesgo era suficientemente grande como para aplazar el lanzamiento. Los demasconsideraron, tambien subjetivamente, que los resultados no eran concluyentes yvotaron por el lanzamiento. Fue una lucha entre subjetividades donde gano laequivocada.
A la luz de los resultados, hoy podemos decir que la mejor herramienta para elcaso es la bayesiana. Pero, ¿que nos garantiza que la probabilidad calculada es lacorrecta? Como el resultado se conoce, entonces podrıamos decir que el metodoque arroje el resultado mas cercano de 1 es el mejor. Pero si la tragedia no hubieraocurrido ¿habrıa sido considerado como el peor?
Para los eventos irrepetibles, es posible que los mejores calculos sean los mas extre-mos, es decir, los mas cercanos de 0 o de 1, pues ası nos dejan con menor margen deincertidumbre. Es claro que no determinan el resultado, pero es ahı donde adquie-ren el significado de probabilidades. El concepto de entropıa permitirıa generalizarel criterio cuando los resultados no sean dicotomicos.
Una experiencia familiar ayuda a ilustrar algo mas nuestro tema: un pequeno so-brino, gravemente desnutrido y desidratado, fue diagnosticado de estenosis pilorica.El medico advirtio la necesidad urgente de una cirugıa. Al preguntarle por los ries-gos de muerte durante la operacion, respondio que en la clınica habıan practicadono menos de 10000 cirugıas de este tipo y que no mas de 5 ninos habıan falleci-do. Formalmente, la proporcion 0.0005 no era una probabilidad de muerte para elnino; pero para el equipo medico sı era un indicador de que sabıan hacer las cosasbien. Igual que la probabilidad, este indicador fue un factor determinante paratomar la decision de autorizar la cirugıa. Mi sobrino sobrevivio y hoy ya tiene masde 22 anos. ¿Fue la probabilidad la que lo salvo? ¿Como estarıa interpretando lascosas si hubiera muerto? ¿Cual decision hubiera tomado si alguien se me acerca yme dice “cuidado, este medico solo ha practicado 5 cirugıas y todos los ninos se lehan muerto”?
Personalmente, no tengo el afan de interpretar cada fraccion entre 0 y 1 como unaprobabilidad, a menos que tenga los contextos que me convenzan de hacerlo. Enmuchos casos se dispone de datos acerca de proporciones que se pueden tomar comoindicadores de algun tipo de riesgo, pero que en esencia no son probabilidades. Enparticular, los hechos cumplidos tienen probabilidad 1 de haber ocurrido. Todocalculo que de otro valor solo tiene validez en un mundo especulativo.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

228 Jorge Ortiz Pinilla
3. Bunge y la subjetividad
Bunge (2012) destaca que, a lo largo de la historia, el estancamiento de la medicinase ha relacionado con el dominio de criterios atribuidos a dones o a poderes per-sonales adquiridos por artes magicas o directamente de divinidades. Su desarrolloautentico solo se ha dado cuando se han logrado identificar relaciones de las enfer-medades con alteraciones fısicas en determinadas partes del cuerpo. Los avancesse aceleraron cuando se logro entender que las actividades fısicas, emocionales ointelectuales del hombre estaban estrechamente relacionadas con uno o varios desus organos. En la medida en que estas relaciones se han podido comprobar, hamejorado la capacidad de diagnostico y se han promovido mejores opciones detratamientos y de cuidados preventivos.
La medicina ha avanzado en la medida en que se ha dejado de lado el uso decriterios subjetivos y se lo ha reemplazado por el del conocimiento de relacionesobjetivas y comprobables. Podrıamos agregar que estos progresos tambien se handado en la medida en que los conocimientos adquiridos se han podido ensenar ycompartir con un espıritu abierto a la crıtica.
Del escrito de Bunge entiendo lo importante que es distinguir el uso del conoci-miento previo objetivo del manejo de supuestos caprichosos e infundados y de loselaborados a conveniencia de resultados intencionales. Caer en estos ultimos equi-vale a regresar a los dictamenes de “neochamanes” con toda la credibilidad queles darıa la utilizacion ingenua o incluso complice de procedimientos estadısticosde cualquier ındole.
No siempre el respaldo de datos como fuente de informacion previa es sinonimode objetividad. La misma relacion con los datos es fragil, tal como lo muestracon el ejemplo de Durkheim (p. 96) sobre las menores tasas de suicidio en loscatolicos. El investigador debe analizar cuidadosamente la calidad de los datos ylos entornos que rodearon su creacion antes de utilizarlos como base o respaldopara sus estudios. Desgraciadamente, muchas veces se descubren sus problemassolo cuando han generado controversia.
Bunge ataca decididamente la subjetividad y arremete furiosamente contra losbayesianos cuando observa que le abren la puerta. Ve inminente el regreso a lasdecisiones fuertemente influenciadas por opiniones no comprobables de personasque han ganado algun reconocimiento, pero que no corresponden a la realidad. Love como una amenaza al progreso de la ciencia y especialmente de la medicina.Ademas, agravada por el respaldo de una disciplina que gana vertiginosamentecredibilidad en la sociedad cientıfica.
¿Quien de nosotros no ha visto publicaciones o al menos comunicados de prensadonde se anuncia el exito de una dieta o de un tratamiento para combatir unaenfermedad, descalificado pocos meses despues porque se encuentra que el unicorespaldo del estudio eran unos resultados estadısticos donde el 80% de las personasque manifestaban haberse recuperado recordaban haber consumido alguna fruta?Ningun estudio sobre la relacion entre los componentes de la fruta y la enfermedad.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2
Mario Bunge y la estadıstica bayesiana 229
Ningun estudio realmente medico. Solo una intuicion personal “respaldada” porunos resultados numericos obtenidos con metodos estadısticos tambien oscuros oprovenientes de una “minerıa de datos” mal entendida.
El teorico demuestra que los metodos estan bien disenados y desarrollados y en suataque se equivoca Bunge. Pero es en las aplicaciones en las que la condicion hu-mana le da la razon al filosofo. Ya el ejemplo del Challenger pone en evidencia quehasta en esferas de alta calidad cientıfica la subjetividad o incluso determinadosintereses pueden cegar la razon.
4. Interpretacion de un mensaje filosofico
A mi modo de ver, el clamor de Mario Bunge es por la responsabilidad social delmedico. Seguramente en la atencion particular a sus pacientes se vera con frecuen-cia en la necesidad de acudir a su experiencia personal o a la de sus colegas paraproponer diagnosticos o soluciones. Pero para generar y divulgar conocimiento,debera desterrar la subjetividad y buscar explicaciones objetivas que lo acerquena la realidad de la naturaleza de las enfermedades, de su diagnostico, de su trata-miento, de sus causas y de su posible prevencion. Estoy de acuerdo con Bunge enque “la estadıstica es indispensable para estudiar y manipular poblaciones de todotipo [...]. Pero no suministra conocimiento sustantivo. Ni puede hacerlo, porque nose ocupa de las cosas mismas sino de datos acerca de ellas”.
Tambien es un llamado a la responsabilidad social del estadıstico, cualquiera seasu orientacion metodologica. Todos sabemos de la importancia de la estadısticapara la toma de decisiones y para el desarrollo de casi todas las disciplinas; quesu aplicacion cuidadosa ofrece una ventana de transparencia y de rigor cientıficodifıcil de reemplazar. En medio del ataque de Bunge, percibo una defensa demayor dimension: proteger a la estadıstica, bayesiana o no, del uso irracional ointencionado de la subjetividad.
Recibido: 17 de agosto de 2013
Aceptado: 30 de agosto de 2013
Referencias
Bunge, M. (2003), Capsulas, Gedisa, Barcelona.
Bunge, M. (2012), Filosofıa para medicos, Gedisa, Barcelona.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Mario Bunge y la estadıstica bayesiana 229
Ningun estudio realmente medico. Solo una intuicion personal “respaldada” porunos resultados numericos obtenidos con metodos estadısticos tambien oscuros oprovenientes de una “minerıa de datos” mal entendida.
El teorico demuestra que los metodos estan bien disenados y desarrollados y en suataque se equivoca Bunge. Pero es en las aplicaciones en las que la condicion hu-mana le da la razon al filosofo. Ya el ejemplo del Challenger pone en evidencia quehasta en esferas de alta calidad cientıfica la subjetividad o incluso determinadosintereses pueden cegar la razon.
4. Interpretacion de un mensaje filosofico
A mi modo de ver, el clamor de Mario Bunge es por la responsabilidad social delmedico. Seguramente en la atencion particular a sus pacientes se vera con frecuen-cia en la necesidad de acudir a su experiencia personal o a la de sus colegas paraproponer diagnosticos o soluciones. Pero para generar y divulgar conocimiento,debera desterrar la subjetividad y buscar explicaciones objetivas que lo acerquena la realidad de la naturaleza de las enfermedades, de su diagnostico, de su trata-miento, de sus causas y de su posible prevencion. Estoy de acuerdo con Bunge enque “la estadıstica es indispensable para estudiar y manipular poblaciones de todotipo [...]. Pero no suministra conocimiento sustantivo. Ni puede hacerlo, porque nose ocupa de las cosas mismas sino de datos acerca de ellas”.
Tambien es un llamado a la responsabilidad social del estadıstico, cualquiera seasu orientacion metodologica. Todos sabemos de la importancia de la estadısticapara la toma de decisiones y para el desarrollo de casi todas las disciplinas; quesu aplicacion cuidadosa ofrece una ventana de transparencia y de rigor cientıficodifıcil de reemplazar. En medio del ataque de Bunge, percibo una defensa demayor dimension: proteger a la estadıstica, bayesiana o no, del uso irracional ointencionado de la subjetividad.
Recibido: 17 de agosto de 2013
Aceptado: 30 de agosto de 2013
Referencias
Bunge, M. (2003), Capsulas, Gedisa, Barcelona.
Bunge, M. (2012), Filosofıa para medicos, Gedisa, Barcelona.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2


Comunicaciones en EstadısticaDiciembre 2013, Vol. 6, No. 2, pp. 231–235
Replica: La larga vida cientıfica que le espera a
Thomas Bayes
Rejoinder: The long scientific life that awaits Thomas Bayes
Luis Carlos Silvaa
En primer lugar, me corresponde agradecer a Comunicaciones en Estadıstica ladeferencia de someter mi trabajo en defensa del pensamiento bayesiano al juiciocrıtico no solo de sus lectores, sino tambien de tres destacados colegas.
Sus criterios coinciden en respaldar mi conviccion de que el razonamiento queconduce al profesor Bunge a descalificar en bloque el enfoque bayesiano resultainaceptable. Los ejemplos creados por el afamado filosofo y que le autorizarıan atal descalificacion, no es que tengan dudosa validez, sino que contienen, simple-mente, gruesos errores. Sigo convencido, por tanto, de que no hay que admitir laabsurda conclusion de que la probabilidad de padecer sida es igual a la de padecer-lo supuesto que se es portador de VIH, ni mucho menos creer en la resurreccion,para mantener en alta estima a la inferencia bayesiana. No seran enemigos comoBunge quienes pongan en peligro la larga vida cientıfica que le espera a ThomasBayes.
Sin embargo, el artıculo que motivo estos generosos comentarios va mas alla quela simple denuncia de los sofismas puntuales en que incurre Bunge en los ejem-plos de su libro “Filosofıa para medicos”. Se orientaba tambien a subrayar otrasaseveraciones, acaso menos burdas, pero sumamente controvertibles, en especialaquellas relacionadas con el papel de la subjetividad. Estos desaciertos se inscribenen un estilo de corte doctrinal, presente en buena parte del libro, que los propiciay que en parte los explica. Un juicio mas global sobre este problema fue desarro-llado en un artıculo independiente, publicado en una revista de aliento salubristay no de estadıstica (Silva 2013), como corresponde al hecho de que tal estilo no serelacionaba exclusivamente con esta ultima disciplina.
Poco tengo para discrepar con los tres comentaristas. Me cenire por tanto a resal-tar, y ocasionalmente complementar brevemente, algunas de sus observaciones entorno a la problematica general en que se inscribe la inferencia bayesiana, alentadaspor las ideas de Bunge, pero que entranan aportes relativamente independientesde ellas. Seran simples pinceladas relacionadas con asuntos que me llamaron laatencion.
aInvestigador titular. Escuela Nacional de Salud Publica. La Habana, Cuba.
231

232 Luis Carlos Silva
La lucida contribucion del profesor Andres Gutierrez, enfatiza que “la asignacionde las probabilidades previas no puede ser arbitraria” y agrega que “esta tarea debeser concienzuda y responsable”. Desde luego, comparto el espıritu de esta opinion;pero me gustarıa insertar una matizacion. Desde una perspectiva estricta, yo dirıaque sı “puede” ser arbitraria (siempre que cumpla con los axiomas de Kolmogorov).Lo que ocurre, y creo que es lo que en esencia quiere senalar mi colega, es que en talcaso se corre un riesgo nada desdenable de que dicha asignacion no sea fructıfera. Espor ello que ha de ser concienzuda. Asumo el riesgo de parecer descontextualizadoy pongo un ejemplo, en apariencia totalmente ajeno a las probabilidades, peroharto elocuente.
A mediados de la decada de los sesenta del siglo pasado surgio un atleta del saltoalto que empleaba un estilo totalmente heterodoxo. Dick Fosbury no acometıa elliston corriendo de manera oblicua a el y colocando el cuerpo bocabajo tras lacarrera, tal y como hacıan todos. Ası habıa conseguido, por ejemplo, el sovieticoValery Brumel la marca mundial entonces vigente de 228 cm. Fosbury corrıa haciael liston siguiendo una trayectoria curva; una vez frente a la varilla, giraba y seelevaba de espaldas a ella con el brazo mas proximo extendido. Con esa tecni-ca Fosbury obtuvo una plaza para representar a Estados Unidos en los JuegosOlımpicos de Mexico, en 1968. Antes del certamen, su metodo fue objeto de crıti-cas y hasta de burlas, por ser considerado esnobista, rocambolesco y poco natural.Sin embargo, no solo gano la medalla dorada en Mexico con la mejor marca dela historia de dichos juegos (225 cm) sino que su procedimiento, desde entoncesconocido como el “estilo Fosbury”, ha sido el empleado por todos los saltadoresposteriores. Resulta expresivo que Dick Fosbury jamas pudo superar la marca deBrumel pero, usando su invencion, esta no demoro en caer una y otra vez hastallegar a la plusmarca mundial vigente, que ostenta el cubano Javier Sotomayor(245 cm)1. Es decir, el exito del norteamericano no se debio a que fuera un atletasuperior al resto, sino a que usaba un metodo mas eficiente.
La moraleja es muy clara: a la hora de valorar un metodo, ninguna consideracionteorica, ninguna tradicion, ningun presupuesto filosofico puede ser mas persuasivoque las corroboraciones practicas de que por su conducto se consigue aquello quese quiere alcanzar. Llevado a nuestro debate, si el manejo de la teorıa bayesia-na –empleada de una manera sensata y racional– produce resultados palmarios,como efectivamente ocurre, queda poco margen para las objeciones doctrinarias.El profesor Gutierrez introduce e ilustra la violacion del “principio de verosimili-tud” en la que se incurren las tecnicas inferenciales clasicas. Expresado de maneralaxa (para profundizar en el tema, vease Royall (1997)) dicho principio estable-ce que las inferencias estadısticas deberıan realizarse a partir y solo a partir delos datos observados. Siendo, como es, una regla difıcilmente objetable, siempreme ha resultado fascinante que hayamos convivido durante casi un siglo con talviolacion, presente en el nucleo de los ubicuos “valores p”. Quizas la exposicionmas facilmente comprensible de esta inconsecuencia es la debida Berger & Berry(1988). Gutierrez adiciona que: El diseno en la recoleccion de los datos es in-
1Al final, permıtaseme este guino, los saltadores optaron por el estilo Fosbury no porque lesgarantizarıa el exito, sino porque aumentarıa la probabilidad de tenerlo.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2
Replica: La larga vida cientıfica que le espera a Thomas Bayes 233
formativo (y no ignorable), no solo en diseno experimental, sino en el analisis deencuestas probabilısticas, para las cuales las propiedades de los estimadores estansupeditadas a la medida de probabilidad discreta inducida por el diseno muestral.Dicho en terminos algo mas simples, se resalta un hecho real: cuando se realizauna inferencia, por ejemplo al calcular un intervalo de confianza a partir de datosobtenidos a traves de una muestra probabilıstica, las formulas correctas no solohan de contemplar los datos propiamente dichos, sino tambien el diseno muestralempleado. Sin embargo, estimo que hay un matiz que distingue ambas situacionesy que merece ser tenido en cuenta: en el calculo de un “valor p” interviene, pordefinicion, el diseno del estudio, pues dicho calculo exige tener en cuenta lo que“podrıa” haberse observado y no solo lo que objetivamente se observo. Siendo ası,dos analistas podrıan llegar a diferentes valores p en virtud del plan segun el cualcada uno se condujo, no obstante haber obtenido los mismos resultados con el mis-mo modus operandi. Sin embargo, para el computo del intervalo de confianza condatos procedentes de una muestra probabilıstica, si bien se tiene en cuenta algomas que los meros datos, ese algo no depende de lo que el investigador tenıa enmente realizar sino de lo que objetivamente hizo. Dos analistas diferentes que co-nozcan lo que se hizo (el diseno muestral aplicado, en este caso) llegaran al mismoresultado2.
Aparte de resaltar el vuelo de su discurso, vertebrado en torno a muy actualiza-das referencias bibliograficas, destaco la idea final de Gutierrez (desconocer eldesarrollo cientıfico que la estadıstica bayesiana ha traıdo consigo, ya no es unaopcion), tan lapidaria como atinada.
El profesor Jairo Fuquene ofrece un ejemplo complementario para desembocar en laconstatacion, acaso mas persuasiva que cualquier disquisicion teorica, del impactoque ha tenido el uso de la estadıstica bayesiana en diversos terrenos (bioestadıstica,medicina, bioinformatica, neurologıa y genetica, para citar solo las disciplinas queel menciona). Me permito volver a sugerir en este contexto la lectura de un libroexcepcional, que ya mencione en mi contribucion inicial, pero que en el ınterinha sido traducido y publicado en castellano con el tıtulo La teorıa que nuncamurio (McGrayne 2012).
No siempre el respaldo de datos como fuente de informacion previa es sinonimo deobjetividad nos dice el profesor Jorge Ortiz. Excelente acotacion. Y luego sintetizaelegantemente la predica bungeana cuando recuerda que el filosofo ataca decidi-damente la subjetividad y arremete furiosamente contra los bayesianos cuandoobserva que le abren la puerta?. Bunge aprecia el impetuoso desarrollo del pen-samiento bayesiano, senala Ortiz, como una amenaza al progreso de la ciencia yespecialmente de la medicina.
La objetividad es una aspiracion legıtima del pensamiento cientıfico, pero conse-
2El asunto es sutil, y no es facil de exponer en pocas lıneas. En otro sitio (Silva 2009) desa-rrollo un sencillo ejemplo que muestra que una persona que este al tanto de lo que un investigadorhizo –desde el comienzo hasta el final de su experimento– ası como de los datos obtenidos, nosabrıa como calcular el valor p hasta que dicho investigador no le comunique cual era el planexperimental al que respondıa eso que hizo, el cual solo se halla en su cabeza.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Replica: La larga vida cientıfica que le espera a Thomas Bayes 233
formativo (y no ignorable), no solo en diseno experimental, sino en el analisis deencuestas probabilısticas, para las cuales las propiedades de los estimadores estansupeditadas a la medida de probabilidad discreta inducida por el diseno muestral.Dicho en terminos algo mas simples, se resalta un hecho real: cuando se realizauna inferencia, por ejemplo al calcular un intervalo de confianza a partir de datosobtenidos a traves de una muestra probabilıstica, las formulas correctas no solohan de contemplar los datos propiamente dichos, sino tambien el diseno muestralempleado. Sin embargo, estimo que hay un matiz que distingue ambas situacionesy que merece ser tenido en cuenta: en el calculo de un “valor p” interviene, pordefinicion, el diseno del estudio, pues dicho calculo exige tener en cuenta lo que“podrıa” haberse observado y no solo lo que objetivamente se observo. Siendo ası,dos analistas podrıan llegar a diferentes valores p en virtud del plan segun el cualcada uno se condujo, no obstante haber obtenido los mismos resultados con el mis-mo modus operandi. Sin embargo, para el computo del intervalo de confianza condatos procedentes de una muestra probabilıstica, si bien se tiene en cuenta algomas que los meros datos, ese algo no depende de lo que el investigador tenıa enmente realizar sino de lo que objetivamente hizo. Dos analistas diferentes que co-nozcan lo que se hizo (el diseno muestral aplicado, en este caso) llegaran al mismoresultado2.
Aparte de resaltar el vuelo de su discurso, vertebrado en torno a muy actualiza-das referencias bibliograficas, destaco la idea final de Gutierrez (desconocer eldesarrollo cientıfico que la estadıstica bayesiana ha traıdo consigo, ya no es unaopcion), tan lapidaria como atinada.
El profesor Jairo Fuquene ofrece un ejemplo complementario para desembocar en laconstatacion, acaso mas persuasiva que cualquier disquisicion teorica, del impactoque ha tenido el uso de la estadıstica bayesiana en diversos terrenos (bioestadıstica,medicina, bioinformatica, neurologıa y genetica, para citar solo las disciplinas queel menciona). Me permito volver a sugerir en este contexto la lectura de un libroexcepcional, que ya mencione en mi contribucion inicial, pero que en el ınterinha sido traducido y publicado en castellano con el tıtulo La teorıa que nuncamurio (McGrayne 2012).
No siempre el respaldo de datos como fuente de informacion previa es sinonimo deobjetividad nos dice el profesor Jorge Ortiz. Excelente acotacion. Y luego sintetizaelegantemente la predica bungeana cuando recuerda que el filosofo ataca decidi-damente la subjetividad y arremete furiosamente contra los bayesianos cuandoobserva que le abren la puerta?. Bunge aprecia el impetuoso desarrollo del pen-samiento bayesiano, senala Ortiz, como una amenaza al progreso de la ciencia yespecialmente de la medicina.
La objetividad es una aspiracion legıtima del pensamiento cientıfico, pero conse-
2El asunto es sutil, y no es facil de exponer en pocas lıneas. En otro sitio (Silva 2009) desa-rrollo un sencillo ejemplo que muestra que una persona que este al tanto de lo que un investigadorhizo –desde el comienzo hasta el final de su experimento– ası como de los datos obtenidos, nosabrıa como calcular el valor p hasta que dicho investigador no le comunique cual era el planexperimental al que respondıa eso que hizo, el cual solo se halla en su cabeza.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

234 Luis Carlos Silva
guirla en estado puro es una quimera. Contribuir a alcanzarla es (casi) la razon deser de la estadıstica. Pero garantizarla por su conducto es imposible. Consecuente-mente, desde una optica fundamentalista, toda la estadıstica inferencial, y no solola bayesiana, deberıa ser erradicada, ya que lo que pudieramos llamar la estadısticaclasica” esta plagada de subjetivismo. El ejemplo mas inmediato es el umbral em-pleado en las pruebas de hipotesis para declarar “significacion”: el ubicuo α = 0.05es intrınsecamente subjetivo. Las propias pruebas de significacion utilizadas pue-den ser parametricas o no parametricas, de una o de dos colas, desarrollarse con osin correcciones (de Yates o de Bonferroni, por ejemplo), sin que exista un criterioindiscutible para elegir unas u otras. La eleccion del tamano muestral adecuadopara un estudio inexorablemente demanda del concurso de la subjetividad; unadetallada demostracion del caracter hondamente subjetivo de tal determinacionpuede hallarse en Silva (2000) o en Schulz & Grimes (2005). Igualmente subjetivaes la decision de cuales son las variables iniciales de un modelo de regresion multi-ple antes de aplicar una seleccion “paso a paso”, o la de aplicar dicha seleccionhacia adelante o hacia atras. Otro tanto ocurre con la valoracion de si cierto valorse debe o no considerar “aberrante” (un outlier), o con la decision de cuales tra-bajos han de incluirse en un metanalisis. La lista podrıa continuarse, pero se tratade una verdad tan obvia que no vale la pena extenderse. No casualmente, Berger& Berry (1988) en el contexto de la contribucion ya citada, escribıan hace 25 anos:el uso comun de la estadıstica parece haberse fosilizado, principalmente debido ala vision de que la estadıstica clasica es la forma objetiva de analizar datos.
El profesor Ortiz resume su intervencion diciendo que En medio del ataque deBunge, percibo una defensa de mayor dimension: proteger a la estadıstica, baye-siana o no, del uso irracional o intencionado de la subjetividad. Puede ser que tanloable proposito haya estado en el animo de Bunge. Me parece generosa la buenavoluntad del profesor Ortiz al hacer esa lectura; pero me resulta difıcil admitir quese quiera proteger a la estadıstica bayesiana del uso irracional de la subjetividadmediante el recurso de embestir contra ella usando argumentos irracionales.
Recibido: 1 de septiembre de 2013
Aceptado: 7 de octubre de 2013
Referencias
Berger, J. O. & Berry, D. A. (1988), ‘Statistical analysis and the illusion of objec-tivity’, The American Scientist 76, 159–165.
McGrayne, S. B. (2012), La teorıa que nunca murio: de como la Regla de Bayespermitio descifrar el codigo Enigma, perseguir los submarinos rusos y emergertriunfante de dos siglos de controversia, Grupo Planeta.
Royall, R. M. (1997), Statistical evidence: a likelihood paradigm, Chapman &Hall/CRC, Boca Raton.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2

Replica: La larga vida cientıfica que le espera a Thomas Bayes 235
Schulz, K. F. & Grimes, D. A. (2005), ‘Sample size calculations in randomisedtrials: mandatory and mystical’, The Lancet 365, 1348–1353.
Silva, L. C. (2000), Diseno razonado de muestras y captacion de datos para lainvestigacion sanitaria, Dıaz de Santos, Madrid.
Silva, L. C. (2009), Los laberintos de la investigacion biomedica. En defensa de laracionalidad para la ciencia del Siglo XXI, Dıaz de Santos, Madrid.
Silva, L. C. (2013), ‘Reflexiones a raız de Filosofıa para medicos, un texto de MarioBunge’, Salud Colectiva 9(1), 115–128.
Comunicaciones en Estadıstica, diciembre 2013, Vol. 6, No. 2


Revista Comunicaciones en Estadıstica
Informacion para los autores
La revista Comunicaciones en Estadıstica es una publicacion del Centro de Inves-
tigaciones y Estudios Estadısticos (CIEES) adscrito a la Facultad de Estadıstica
de la Universidad Santo Tomas. La periodicidad de esta revista es semestral, el
primer numero se publica en junio y el segundo en diciembre, de cada ano. El
objetivo de esta publicacion es divulgar artıculos originales e ineditos en cualquier
tematica de la estadıstica teorica y aplicada. La finalidad de esta revista es mo-
tivar la cultura de la investigacion estadıstica, y por ende, su publico objetivo
esta en todos aquellos investigadores que utilicen cualquier metodo estadıstico en
el desarrollo de sus proyectos.
La revista Comunicaciones en Estadıstica publica artıculos originales teoricos,
aplicaciones de tecnicas estadısticas en cualquier rama del saber que conlleven a
publicaciones ineditas ası como tambien, cartas al editor surgidas de la discusion
de artıculos ya publicados en esta Revista. A continuacion se presentan algunas
de las caracterısticas principales del proceso editorial en esta publicacion.
Sumision de artıculos
El Comite Editorial de la revista Comunicaciones en Estadıstica sugiere que el for-
mato de los artıculos sometidos sea PDF y preferiblemente en tamano carta. Los
autores deben enviar una version ciega del manuscrito, sin ninguna informacion
de la identidad o afiliacion de estos, usando la plantilla disponible en la pagi-
na webhttp://comunicacionesenestadistica.usta.edu.co/ de la revista. Los
artıculos deberan ser adjuntados y enviados a la direccion de correo electronico1
oficial de la revista y seran socializados por el Editor en el Comite Editorial.
Contenido
La revista Comunicaciones en Estadıstica publica la siguiente clase de artıculos:
Aplicaciones y estudios de caso que presenten analisis estadısticos innovado-
res o implementen ejercicios empıricos para evaluar tecnicas estadısticas en
situaciones particulares reales o simuladas.
Nuevas contribuciones teoricas o metodologicas que conlleven al desarrollo
de procedimientos, algoritmos y metodologıas ineditas desde el punto de
vista teorico. Tambien se incluyen procedimientos computacionales y graficos
ilustrados mediante una aplicacion practica en el caso en que hubiese lugar
para tal implementacion.

Revision exhaustiva de tematicas estadısticas en areas de aplicacion practica
o en campos especıficos de metodos y teorıa estadıstica.
Cartas al editor y correcciones mediante escritos directos y concisos acerca
de la discusion o correccion de algun artıculo publicado con antelacion en
esta revista.
Tıtulo y resumen
El tıtulo del artıculo debe ser especıfico, asimismo, cada artıculo sometido debe
contener un resumen de no mas de 400 palabras y no se deben citar ninguna clase
de referencias bibliograficas en el resumen. Inmediatamente despues del resumen
deben aparecer las palabras clave del artıculo, que deberan describir el contenido
de este.
Por polıticas de la revista Comunicaciones en Estadıstica, el idioma principal de
esta publicacion es el espanol, aunque tambien se publicaran artıculos en el idioma
ingles. Cada artıculo sometido debera contar con el tıtulo en el idioma principal
del artıculo y con su respectiva traduccion al idioma secundario. Lo mismo se debe
hace con el resumen y con las palabras clave. Por ejemplo, si el idioma principal
del artıculo es el espanol, este debera contener el tıtulo principal en espanol y su
respectiva traduccion al ingles. Ademas, el resumen principal debera estar escrito
en espanol y tambien debera ser traducido al ingles junto con las palabras clave.
Figuras y tablas
Al igual que las figuras, las tablas deben ser rotuladas con numeros arabigos.
Cada uno de estos objetos debe contener un tıtulo que lo describa con detalle y
tienen que ser citados dentro del texto del artıculo. Se sugiere a los autores que
las imagenes sean enviadas por aparte en cualquier formato grafico (eps, ps, tif,
jpg o bmp) de alta resolucion, en color y en escala de grises. La version impresa
de la revista contendra solo imagenes en escala de grises; sin embargo, la edicion
virtual de la revista contendra las imagenes a color.
Apendices y referencias bibliograficas
Los apendices del manuscrito deben estar ubicados al final de artıculo, despues de
las referencias bibliograficas. Se sugiere que los apendices correspondan a desarro-
llos teoricos extensos, material suplementario y algoritmos computacionales. Por
otro lado, el sistema de referencia bibliografica que se utiliza en esta publicacion
es el formato autor-ano conocido tambien como formato Harvard. Todas las refe-
rencias bibliograficas que aparezcan en el artıculo deben estar contenidas y citadas
en el texto general o cuerpo del manuscrito. De esta manera, si la referencia forma
parte de una frase, se deben citar los apellidos, colocando en un parentesis el ano
de la publicacion; si la referencia no forma parte de una frase, se deben citar entre
parentesis los apellidos seguidos del ano de publicacion.
Responsabilidad legal
El Comite Editorial de la revista Comunicaciones en Estadıstica asume que los
artıculos sometidos no estan publicados por ningun otro medio impreso o virtual.

Asimismo, se asume que el artıculo es inedito, original y que no se encuentra
en proceso de revision, arbitraje o publicacion en alguna otra revista, magazın o
cualquier sitio virtual. Al momento de recibir un artıculo para revision, los autores
adquieren toda responsabilidad legal acerca de graficas, tablas, datos y texto. De
la misma manera, los autores liberan a la revista Comunicaciones en Estadıstica
de cualquier accion penal emprendida por un tercero por delitos a derechos de
autor o cualquier otra afrenta. Por otro lado, si el Comite Editorial decide a favor
la publicacion de un artıculo, los autores deberan firmar y aceptar el traspaso
de los derechos de autor del artıculo a la revista. Sin embargo, los autores podran
adjuntar a su sitio web una version del documento final. La revista Comunicaciones
en Estadıstica se reserva los derechos de autor o difusion de los contenidos.
Proceso de arbitraje
Los artıculos sometidos a la revista Comunicaciones en Estadıstica seran evalua-
dos en un primer dictamen por el Comite Editorial y luego seran sometidos a
arbitraje tecnico por profesionales especializados en la tematica del manuscrito.
El proceso de arbitraje sera doblemente ciego; es decir, los autores no conoceran
la identidad ni afiliacion de los arbitros y a su vez, los arbitros no conoceran la
identidad ni afiliacion de los autores. De otro lado, la identidad del editor en curso
sera conocida tanto por los autores como por los arbitros. Para facilitar el proce-
so de revision, se les pide a los autores someter dos versiones del manuscrito; la
primera omitiendo las identidades y afiliaciones de los autores y la segunda con-
teniendo tanto las identificaciones como las afiliaciones institucionales. Se asignan
dos arbitros por cada manuscrito y los posibles dictamenes son: aceptar, rechazar o
solicitar modificaciones para una nueva revision. En caso de presentar dictamenes
opuestos por parte de los arbitros se asignara un tercero.

Information for authors
The journal Communications in Statistics is published by the Center for Research
and Statistical Studies (CIEES acronym in Spanish) assigned to the Faculty of
Statistics of Universidad Santo Tomas. The periodicity of this Journal is biannual,
the first issue is published in June and the second in December, of every year. The
intention of this publication is to disseminate original and unpublished articles
on any topic of theoretical and applied statistics. The purpose of this Journal is
to promote a culture of statistical research, and hence, its target audience is in
all those researchers who use any statistical method in the development of their
projects.
The journal Communications in Statistics is publishes original theoretical articles,
applications of statistical techniques in any branch of knowledge that lead to un-
published articles as well as, letters to the editor that arise from the discussion of
articles already published by this Journal. Following are some key features of the
editorial process of this publication.
Submission of articles
The Editorial Committee of the journal Communications in Statistics suggests the
articles be submitted in PDF format and preferably in letter size. Authors must
send a blind copy of the manuscript, without any information of their identity or
affiliation, using the format available in the Journal’s web page2. The articles must
be attached and sent to the Journal’s official e-mail address3 and will be socialized
by the Editor in the Editorial Committee.
Content
The Journal Communications in Statistics publishes the following types of articles:
Applications and case studies that present innovative statistical analysis or
implement empirical exercises to assess statistic techniques in real or simu-
lated specific situations.
New theoretical or methodological contributions that lead to the develop-
ment of procedures, algorithms and unpublished methodologies from the
theoretical point of view. It also includes computational procedures and illus-
trated graphs by a practical application in the event there is space for such
implementation.
Exhaustive review of statistical topics in areas of practical application or
specific fields of statistic methods and theory.
Letters to the editor and corrections through direct and concise writings
2http://comunicacionesenestadistica.usta.edu.co/[email protected]

about the discussion or correction of any article previously published in this
Journal.
Title and abstract
The title of the article must be specific, likewise, each article submitted must
have an abstract of no more than 400 words and no type of type of bibliographic
references should be cited in the abstract. Immediately after the abstract must
appear the article’s keywords, which should describe its content.
By policies of the journal Communications in Statistics, the main language of this
publication is Spanish, although some articles will also be published in English.
Each article submitted shall also have a title in the article’s main language with its
translation to the secondary language. The same must be done with the abstract
and keywords. For instance, if the main language of the article is Spanish, it should
have the main title in Spanish with its translation into English. Moreover, the main
abstract should be written in Spanish and must also be translated into English
along with the keywords.
Figures and charts
Like the figures, charts should be labeled in Arabic numerals. Each one of these
objects must have a title that describes it in detail and have to be cited inside the
text of the article. It is suggested to authors they send images separately in any
graphic format (eps, ps, tif, jpg or bmp), with high resolution, color and gray scale.
The Journal’s printed version will only contain images in grey scale; however, the
virtual edition of the Journal will have color images.
Appendix and bibliographic references
Appendixes of the manuscript must be located at the end of the article, after
the bibliographic references. It is suggested that appendixes refer to extensive
theoretical developments, supplement material and computational algorithms. On
the other hand, the bibliographic reference system used in this publication is the
author-year format also known as the Harvard format. All bibliographic references
that appear in the article should be contained and cited in the general text or body
of the manuscript. Thus, if the reference is part of a phrase, surnames should be
cited, with the year of publication between brackets; if the reference is not part of
a phrase, the surnames followed by the year of publication must be cited between
brackets.
Legal liability
The Editorial Committee of the journal Communications in Statistics assumes
that the articles submitted are not published by any other printed or virtual me-
dia. Likewise, it is assumed that the article is unpublished, original and is not
under review, peer review or publication in any other journal, magazine or any
virtual site. Upon receipt of an article for review, authors acquire all legal liability
on graphs, charts, data and texts. Likewise, authors release from liability the jour-
nal Communications in Statistics in any criminal action brought by a third party,

for crimes related with copyrights or any other offense. On the other hand, if the
Editorial Committee decides in favor of publishing an article, authors must sign
and accept to transfer copyrights of the article to the Journal. However, authors
may attach to their website a version of the final document. The journal Commu-
nications in Statistics reserves copyrights or rights to circulate the contents.
Peer review proceeding
Articles submitted to the journal Communications in Statistics will be assessed on
a first opinion by the Editorial Committee and will then be subject to a technical
peer review by professionals specialized on the topic of the manuscript. The peer
review proceeding will be doubly blind, that is, authors will not know the identity
nor affiliation of peer reviewers and in turn, peer reviewers will not know the
identity nor affiliation of the authors. On the other hand, the identity of the current
editor will be known by both authors and peer reviewers. To facilitate the review
process, authors are requested to present two versions of the manuscript: the first
one omitting the identities and affiliations of the author and the second containing
the identity and as well as institutional affiliations. Two peer reviewers are assigned
for each manuscript and the possible opinions are: accept, reject or request changes
for a new review. In the event of opposite opinions by peer reviewers a third one
will be designated.


















