
Corso di Laurea in Informatica A.A. 2015/2016 · genericamente con θ) generata dall’analizzatore...
54
LFC Parsing Generalità sul parsing Parser a discesa ricorsiva Linguaggi formali e compilazione Corso di Laurea in Informatica A.A. 2015/2016
Transcript of Corso di Laurea in Informatica A.A. 2015/2016 · genericamente con θ) generata dall’analizzatore...

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Linguaggi formali e compilazioneCorso di Laurea in Informatica
A.A. 2015/2016

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
L’input per il parser
◮ Nel contesto della compilazione l’input per il parser ècostituito da una stringa di token (che indicheremogenericamente con θ) generata dall’analizzatorelessicale.
◮ Per semplicità di linguaggio ignoreremo la presenzadello scanner e supporremo che il parser leggadirettamente θ dallo stream di input.
◮ Per individuare la “fine” della stringa di input, neglialgoritmi di parsing supporremo che la stringa stessasia terminata da uno speciale simbolo, non presentefra i token del linguaggio, ad esempio $.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
L’input per il parser
◮ Se S è l’assioma iniziale della grammatica, pertenere conto del simbolo di terminazioneintroduciamo “formalmente” un nuovo assioma S ′,con la sola produzione S ′ → S$.
◮ In questo modo, S ⇒∗ θ se e solo se S ′ ⇒∗ θ$.◮ Nel seguito lasceremo implicita questa “aggiunta”
alla grammatica, a meno che non risulti importanteconsiderarla per comprendere meglio qualche altroconcetto.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Tipi di parser
◮ Una prima classificazione suddivide il parsing inaccordo all’ordine di costruzione del parse tree per θ.
◮ Nel parsing top-down l’albero viene costruito apartire dalla radice, corrispondente all’assiomainiziale.
◮ Equivalentemente, possiamo dire che nel parsingtop-down si cerca una derivazione canonica sinistraper θ$ partendo da S ′.
◮ Si noti che la costruzione top-down dell’albero diderivazione corrisponde in modo naturale alriconoscimento di categorie sintattiche (es, uncomando o una espressione) in termini delle particostituenti.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Tipi di parser (continua)
◮ Nel parsing bottom-up il parse tree per θ vienecostruito procedendo dalle foglie verso la radice.
◮ Equivalentemente, possiamo dire che nel parsingbottom-up si cerca una derivazione canonica (destra)per la stringa θ$ applicando riduzioni successive.
◮ Una riduzione non è nient’altro che l’applicazione “insenso opposto” di una produzione della grammatica.
◮ Si noti che la costruzione bottom-up dell’albero diderivazione corrisponde in modo naturale alriconoscimento di singole porzioni di un programmae alla loro composizione in parti più complesse.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Tipi di parser (continua)
◮ I tipi di parser più diffusi includono:◮ parser a discesa ricorsiva con backtracking,◮ parser a discesa ricorsiva senza backtracking
(parsing predittivi),◮ parser di tipo shift-reduce.
◮ I parser a discesa ricorsiva sono di tipo top-down,mentre i parser shift-reduce sono di tipo bottom-up.
◮ Considereremo sottoinsiemi di grammatiche libereper cui si possono costruire parser efficienti adiscesa ricorsiva (grammatiche LL(1)) o di tiposhift-reduce (grammatiche LR(1))

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Scelta della produzione da usare al genericopasso
◮ In entrambi i tipi di parser (top-down o bottom-up) lascelta della produzione da utilizzare (rispettivamenti,in avanti o all’indietro) viene effettuata in funzionedello stato interno del parser e della prossimaporzione di input (1 o più caratteri).
◮ Come vedremo, lo stato interno del parser saràtipicamente espresso dall’informazione memorizzatanella cima di una struttura dati stack.
◮ Il numero di caratteri di input considerati perprendere la decisione è noto invece comelookahead.
◮ Noi saremo interessati di norma ad un lookahead diun carattere.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Algoritmo generale
◮ Un parser a discesa ricorsiva (d.r.) costruisce ilparse tree (eventualmente non in modo esplicito) apartire dall’assioma ed esaminandoprogressivamente l’input.
◮ Al generico passo, l’algoritmo è idealmente“posizionato” su un nodo x dell’albero.
◮ Se il nodo è una foglia etichettata con un simboloterminale a, l’algoritmo controlla se il prossimosimbolo in input coincide con a.
◮ In caso affermativo fa avanzare il puntatore di input,altrimenti (nel caso più semplice) dichiara errore.
◮ Se invece il nodo è un simbolo non terminale A,sceglie una produzione A→ X1X2 . . .Xk , crea i nodi(figli di A) etichettandoli con X1,X2, . . . ,Xk , e passaricorsivamente ad esaminare tali nodi, da sinistraverso destra.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Algoritmo generale (continua)
◮ Da un punto di vista implementativo, un parser a d.r.può essere realizzato come una collezione diprocedure mutuamente ricorsive, una per ognisimbolo non terminale della grammatica.
◮ Il problema fondamentale consiste nella “scelta” dellaproduzione da applicare, nel caso in cui (per un datonon terminale) ne esista più d’una.
◮ Lo pseudocodice nella diapositiva seguente lasciaaperto questo problema, che andremosuccessivamente a risolvere in almeno due modidiversi.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Procedura per il generico non terminale A
1: Scegli “opportunamente” una produzioneA→ X1X2 . . .Xk (Xj ∈ V)
2: for j = 1, . . . , k do
3: if Xj ∈ N then
4: Xj()5: else
6: x ← READ()7: if Xj 6= x then
8: ERROR() {Include il caso x = EOF}
LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
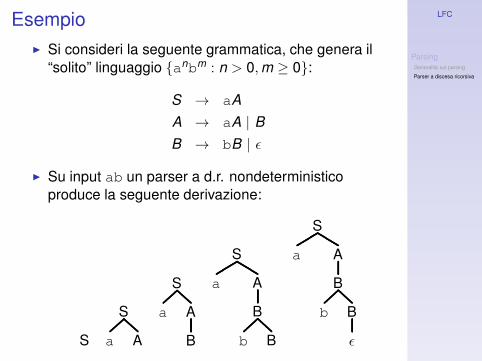
Esempio◮ Si consideri la seguente grammatica, che genera il
“solito” linguaggio {anb
m : n > 0,m ≥ 0}:
S → aA
A → aA | B
B → bB | ǫ
◮ Su input ab un parser a d.r. nondeterministicoproduce la seguente derivazione:
S
S
Aa
S
A
B
a
S
A
B
Bb
a
S
A
B
B
ǫ
b
a

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Implementazione concreta
◮ Per eliminare il non determinismo insito nel codiceprecedente, una prima soluzione consistenell’esplorare tutte le possibili produzioni relative algenerico non terminale A prima eventualmente didichiarare errore.
◮ Se una particolare produzione fallisce, ma prima delfallimento sono stati letti simboli di input, ènecessario operare un backtracking sull’input stesso.
◮ Per i parser a discesa ricorsiva ciò può esseresufficientemente agevole (dal punto di vistadell’implementatore), anche se computazionalmentepesante.
◮ Questa prima variante è mostrata nella diapositivasuccessiva.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Procedura con backtracking per A
1: SAVEINPUTPOINTER()2: for all produzione A→ X1X2 . . .Xk (Xj ∈ V) do
3: fail ← False
4: for j ← 1 . . . k do
5: if Xj ∈ N and Xj() then
6: continue
7: if Xj ∈ T then
8: x ← READ()9: if Xj = x then
10: continue
11: RESTOREINPUTPOINTER()12: fail ← True
13: break
14: if not fail then
15: return True
16: return False

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Procedura con backtracking per S)
◮ La procedura precedente va modificata nel casodell’assioma S che deve dichiarare il successocomplessivo o il fallimento
◮ Per questo è sufficiente rimpiazzare la riga 16 con ilseguente codice:
16: if not EOF() then
17: FAIL()18: else
19: SUCCESS()
dove FAIL() e SUCCESS() sono due opportuneprocedure che “informano” il main program sull’esitodel parsing
LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
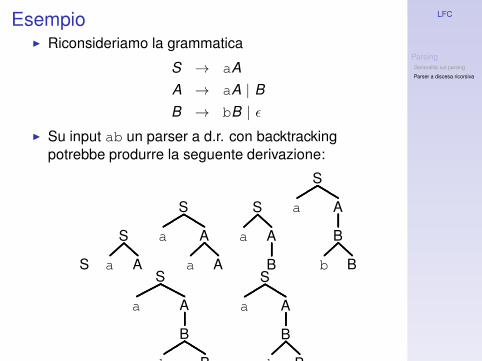
Esempio◮ Riconsideriamo la grammatica
S → aA
A → aA | B
B → bB | ǫ
◮ Su input ab un parser a d.r. con backtrackingpotrebbe produrre la seguente derivazione:
S
S
Aa
S
A
Aa
a
S
A
B
a
S
A
B
Bb
a
S
A
B
Bb
a
S
A
B
Bb
a

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Parsing a discesa ricorsiva (continua)◮ Se analizziamo attentamente il codice del parser a
d.r., comprendiamo perché una grammatica conricorsioni a sinistra sia inadatta al parsing a discesaricorsiva.
◮ Supponiamo, infatti, che ad un determinato passo ilparser sia “posizionato” su un nodo (etichettato con ilnon terminale) A dell’albero.
◮ Supponiamo inoltre che la prima produzione cheviene (tentativamente) applicata abbia una ricorsionea sinistra, sia cioè del tipo A→ Aα (dove α è unaqualunque stringa di terminali e/o non terminali).
◮ Accade allora che il codice relativo al non terminaleA:
◮ consideri il primo simbolo della parte sinistra dellaproduzione, che è ancora A;
◮ chiami ricorsivamente la procedura per A,innescando così un ciclo infinito.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Esempio
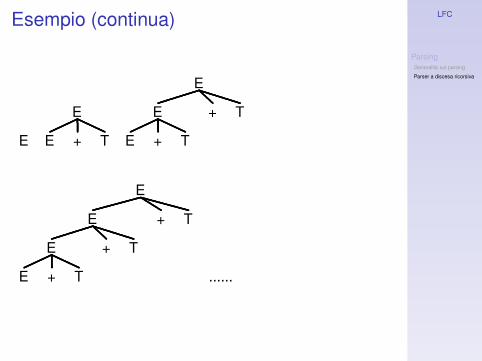
◮ Per la grammatica con precedenza di operatori (cheabbiamo già incontrato):
E → E + T | T
T → T × F | F
F → number | (E)
le procedure per i non terminali E e T innescanopotenzialmente un ciclo infinito.
◮ Ad esempio, su input number + number, laproduzione corretta da applicare inizialmente èE → E + E (se si applica E → number laderivazione fallisce e bisogna operare backtrackingsull’input), ma questa innesca un ciclo infinito.
LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Esempio (continua)
E
E
T+E
E
T+E
T+E
E
T+E
T+E
T+E ......

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Parsing a discesa ricorsiva (continua)◮ Una soluzione migliore rispetto all’esplorazione
esaustiva delle possibili derivazioni consistenell’usare un certo numero di caratteri di lookaheadper decidere la prossima produzione da utilizzare.
◮ Naturalmente, se questa strada possa esserepercorsa con successo dipende dalla grammatica.
◮ Consideriamo la semplice grammatica:
A → aA | bB
B → ǫ | bB
◮ Per entrambi i non terminali, la scelta dellaproduzione da usare può essere fatta guardandosolo il prossimo simbolo x in input.
◮ Per A: se x = a, usa la produzione A→ aA; sex = b, usa la produzione A→ bB.
◮ Per B. se x = $ (end of input), usa la produzioneB → ǫ; se x = b, usa la produzione B → bB;

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Grammatiche LL(1)
◮ Un parser predittivo può essere realizzatoagevolmente nel caso di grammatiche cosiddetteLL(1).
◮ La doppia L sta per Left-Left, ad indicare che l’input èletto da sinistra verso destra e che la derivazioneprodotta è canonica sinistra.
◮ Il “parametro” 1 indica che un carattere di lookaheadè sufficiente per decidere correttamente laproduzione da utilizzare.
◮ Più in generale, si possono considerare grammaticheLL(k), dove sono sufficienti (e, in generale,necessari) k caratteri di lookahead.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Grammatiche “non” LL(k)
◮ Nessuna grammatica con ricorsioni a sinistra puòessere LL(k), per nessun k .
◮ Anche nel caso in cui esistano produzioni conprefissi comuni la quantità di lookahead necessarianon è limitabile a priori.
◮ Un esempio grammatica con prefissi comuni è datadal più volte esaminato caso del “dangling else”.
S → I | A
I → if B then S | if B then S else S
A → a, B → b
◮ Infatti, la quantità di codice che può essere presentefra le keyword then e else non è limitabile a priori.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Grammatiche “non” LL(k) (continua)
◮ Un altro esempio è dato dalla grammatica:
A → aB | aC
B → aB | b
C → aC | c
◮ Su input anb è necessario un lookahead di n + 1
caratteri per decidere inizialmente che la produzionecorretta è A→ aB.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Grammatiche LL(1)
◮ Analizziamo ora in dettaglio le caratteristiche chedeve avere una grammatica G per potersi qualificareLL(1).
◮ Consideriamo un generico non terminale per il qualeesistano almeno due produzioni, poniamo
A → α | β
◮ Se vale simultaneamente che α∗
⇒ aα′ e β∗
⇒ aβ′,cioè se da α e da β si possono derivare stringhe cheiniziano con lo stesso simbolo non terminale, alloraG non è LL(1).

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Esempi◮ Il caso più semplice è quando α e β iniziano con lo
stesso simbolo terminale.◮ Ad esempio, se la grammatica contiene le produzioni
S → aA | aB non può essere LL(1).◮ Tuttavia il problema può non essere di così
immediata evidenza.◮ Ad esempio, la grammatica
S → aA | B
A → aA | ǫ
B → b | C
C → aB | c
non è LL(1) perché B ⇒ C ⇒ aB e dunque laprocedura per il non terminale S, su input a . . . nonpuò decidere quale produzione usare (S → aA
oppure S → B) guardando solo il primo simbolo diinput.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Grammatiche LL(1) (continua)
◮ La situazione appena descritta non è l’unica chedeve essere evitata affinché la grammatica sia LL(1).
◮ Un secondo vincolo è che, sempre considerandouna coppia di produzioni A→ α | β, se risulta α
∗
⇒ ǫ
allora non può accadere che β∗
⇒ ǫ (e viceversa).◮ Infatti, in caso contrario, qualunque sia il prossimo
simbolo di input entrambe le produzioni potrebberoteoricamente essere valide.
◮ Anche questo non basta ancora; è infatti necessarioche sia verificata un’ultima condizione.
◮ Se α∗
⇒ ǫ e β∗
⇒ aβ′, allora non deve accadere cheS
∗
⇒ γ1Aaγ2, dove β′, γ1, γ2 ∈ V∗.
◮ In altri termini a non deve apparire subito dopo A inalcuna forma di frase.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Esempio◮ Si consideri la grammatica
S → A | B
A → aA | ǫ
B → Aab
◮ Su input la stringa “a” la procedura per il nonterminale S non può decidere correttamente laproduzione da usare.
◮ Risulta infatti:
S ⇒ A⇒ aA⇒ a
S ⇒ A⇒ aA⇒ a
e
S ⇒ B ⇒ Aab⇒ ab

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
FIRST e FOLLOW◮ Per esprimere in modo compatto le condizioni che
qualificano come LL(1) una data grammatica,introduciamo le funzioni FIRST e FOLLOW .
◮ Data G = (N ,T ,P,S) e data una stringaα ∈ (N ∪ T )∗, si definisce FIRST (α) l’insieme deisimboli terminali con cui può iniziare una frasederivabile da α, più eventualmente ǫ se α⇒∗ ǫ:
FIRST (α) = {x ∈ T |α⇒∗ xβ, β ∈ T ∗}
∪ {ǫ} , se α⇒∗ ǫ.
◮ Per ogni non terminale A ∈ N , FOLLOW (A) èl’insieme dei terminali che si possono trovareimmediatamente alla destra di A in una forma difrase di una qualche derivazione canonica (destra osinistra):x ∈ FOLLOW (A) se S ⇒∗ αAxβ, con α, β ∈ V∗.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Calcolo di FIRST (α)
◮ Definiamo innanzitutto come si calcola FIRST (α) nelcaso in cui α sia un singolo simbolo dellagrammatica, cioè α = X con X ∈ N ∪ T .
◮ Se X è un terminale, si pone naturalmenteFIRST (X) = {X};
◮ se X è un non terminale il calcolo procede per passi,con l’inizializzazione FIRST (X) = {}.
◮ Se esiste la produzione X → X1 . . .Xn, e risultaǫ ∈ FIRST (Xj), j = 1, . . . , k − 1, poniamoFIRST (X ) = FIRST (X ) ∪ {x} per ogni simbolox ∈ FIRST (Xk).
◮ Infine, se esiste la produzione X → ǫ oppureǫ ∈ FIRST (Xj), j = 1, . . . , k , poniamoFIRST (X ) = FIRST (X ) ∪ {ǫ}.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Esempi
◮ Si riconsideri la grammatica per le espressioni che“forza” la precedenza di operatori:
E → E + T | T
T → T × F | F
F → number | (E)
◮ Per questa grammatica risulta◮ FIRST (F ) = {( ,number};◮ FIRST (T ) = FIRST (F );◮ FIRST (E) = FIRST (T ).

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Esempi◮ La seguente grammatica genera lo stesso linguaggio
della precedente
E → (E)E ′ | number E ′
E ′ → +E E ′ | × E E ′ | ǫ
◮ Risulta◮ FIRST (E) = {( ,number}◮ FIRST (E ′) = {+,×, ǫ}
◮ Si consideri ora la grammatica per anb
mc
k
A → aA | BC
B → bB | ǫ
C → cC | ǫ
◮ Per questa grammatica risulta◮ FIRST (C) = {c, ǫ}◮ FIRST (B) = {b, ǫ}◮ FIRST (A) = {a,b,c, ǫ}

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Calcolo di FIRST (α) (continua)
◮ Il calcolo di FIRST (α), dove α = X1 . . .Xn è unagenerica stringa di terminali e nonterminali, può oraessere svolto nel modo seguente
◮ a ∈ FIRST (α) se e solo se, per qualche indicek ∈ 1, . . . n, risulta a ∈ FIRST (Xk) e ǫ ∈ FIRST (Xj),j = 1, . . . , k − 1 (si suppone sempre ǫ ∈ FIRST (X0)).
◮ Se ǫ ∈ FIRST (Xj), j = 1, . . . ,n, allora ǫ ∈ FIRST (α).◮ Ad esempio, nel caso della seconda grammatica del
lucido precedente
A → aA | BC
B → bB | ǫ
C → cC | ǫ
risulta: FIRST (aA) = {a} e FIRST (BC) = {b,c, ǫ}.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Calcolo di FOLLOW (A)
◮ Il calcolo di FOLLOW (A), per un generico nonterminale A, può essere svolto in questo modo.
◮ Se esiste la produzione B → αAβ, tutti i terminali inFIRST (β) si inseriscono in FOLLOW (A).
◮ In particolare, poiché (almeno implicitamente) esistesempre la produzione S ′ → S$, il simbolo speciale $sta sempre nel FOLLOW (S).

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Calcolo di FOLLOW (A)
◮ Se esiste la produzione B → αA, tutti i terminali chestanno in FOLLOW (B) si inseriscono inFOLLOW (A).
◮ Infatti, se esiste una derivazione S ⇒∗ βBγ, allorausando la produzione B → αA abbiamo anche:
S ⇒∗ βBγ ⇒ βαAγ
◮ Dunque ciò che segue B in una forma di frase (cioè ilFIRST (γ)) può anche seguire A.
◮ Si arriva alla stessa conclusione anche nel caso incui B → αAδ e ǫ ∈ FIRST (δ).
◮ Infatti:
S ⇒∗ βBγ ⇒ βαAδγ ⇒∗ βαAγ

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Esempio
◮ Consideriamo ancora la grammatica
E → (E)E ′ | number E ′
E ′ → +E E ′ | × E E ′ | ǫ
◮ Possiamo subito stabilire che FOLLOW (E) include ilsimbolo $ e il simbolo ); inoltre contiene i simboli inFIRST (E ′) (eccetto ǫ) e cioè + e ×.
◮ FOLLOW (E ′) include FOLLOW (E), a causa (adesempio) della produzione E → numberE ′.
◮ La produzione E ′ → +EE ′, unitamente a E ′ → ǫ,stabilisce che vale anche il contrario, e cioè cheFOLLOW (E) include FOLLOW (E ′).
◮ Mettendo tutto insieme si ottieneFOLLOW (E) = FOLLOW (E ′) = {$, ) ,+,×}.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Esempio
◮ Per la grammatica
A → aA | BC | ǫ
B → bB | ǫ
C → cC | ǫ
risulta FOLLOW (A) = FOLLOW (C) = {$} eFOLLOW (B) = {c, $}.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Esempio
◮ Per la grammatica con precedenza di operatori:
E → E + T | T
T → T × F | F
F → number | (E)
risulta:◮ FOLLOW (E) = {$,+, )};◮ FOLLOW (T ) = FOLLOW (E) ∪ {×};◮ FOLLOW (F ) = FOLLOW (T ).

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Grammatiche LL(1) (continua)
◮ Possiamo ora rivedere in modo più compatto lanozione di grammatica LL(1).
◮ Una grammatica è LL(1) se, qualora esistano dueproduzioni A→ α e A→ β, risulta:
FIRST (α) ∩ FIRST (β) = {} ,
◮ Inoltre, se α∗
⇒ ǫ, deve valereFOLLOW (A) ∩ FIRST (β) = {}.
◮ Analogamente, se β∗
⇒ ǫ, deve valereFOLLOW (A) ∩ FIRST (α) = {}.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Esempio◮ Si consideri la grammatica
A → B E
B → C | D
C → ǫ | cc
D → ǫ | dd
E → c | d
◮ Poiché risulta FIRST (C) ∩ FIRST (D) = {ǫ}, lagrammatica non è LL(1).
◮ Infatti, supponiamo che la stringa in input inizi con c.Dopo la riscrittura dell’assioma il parser verrebbe atrovarsi con la forma di frase BE e il carattere c ininput.
◮ A questo punto potrebbe essere corretto derivaretanto CE (se l’input fosse, ad esempio, ccd) quantoDE (se l’input fosse c).

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Esempio◮ Si modifichi la precedente grammatica nel modo
seguente
A → B E
B → C | D
C → ǫ | cc
D → dd
E → c | d
(cancellando cioè la produzione D → ǫ).◮ Poiché risulta FIRST (D)∩ FOLLOW (B) = {d}, la
grammatica non è LL(1).◮ Il problema si verifica con input che inizia con d,
perché potrebbe essere corretto (dopo la derivazioneiniziale) derivare tanto CE (se l’input fosse d) quantoDE (se l’input fosse, ad esempio ddc).

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Esempio
◮ Consideriamo ancora la grammatica con precedenzadi operatori:
E → E + T | T
T → T × F | F
F → number | (E)
◮ Sappiamo già che tale grammatica non è LL(1)perché contiene ricorsioni a sinistra.
◮ Possiamo anche verificare, ad esempio, cheFIRST (E)∩ FIRST (T ) k {number}.
◮ Eliminando la left-recursion si può però ottenere unagrammatica equivalente che è LL(1)

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Esempio (continua)◮ Per la grammatica modificata
E → TE ′
E ′ → +TE ′ | ǫ
T → FT ′
T ′ → ×FT ′ | ǫ
F → number | (E)
dobbiamo solo verificare che FOLLOW (E ′) noncontenga il simbolo + e che FOLLOW (T ′) noncontenga il simbolo ×.
◮ È facile verificare che risulta:◮ FOLLOW (E) = FOLLOW (E ′) = {$, )};◮ FIRST (E ′) = {+, ǫ};◮ FOLLOW (T ) = (FIRST (E ′)\ {ǫ}) ∪ FOLLOW (E ′) ={+, $, )};
◮ FOLLOW (T ′) = FOLLOW (T ) = {+, $, )};

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Tabella di parsing LL(1)
◮ Per una grammatica LL(1) è possibile costruire(utilizzando le funzioni FIRST e FOLLOW ) unatabella, detta tabella di parsing, che, per ogni nonterminale A e ogni terminale x , prescrive ilcomportamento del parser.
◮ Indicheremo con MG la tabella di parsing relativa allagrammatica G (o semplicemente con M, se lagrammatica è evidente).
◮ La generica entry MG[A, x ] della tabella puòcontenere una produzione A→ α di G, oppureessere vuota, ad indicare che si è verificato unerrore.
◮ Disponendo di MG, la prima riga dell’algoritmo adiscesa ricorsiva (cioè la scelta della produzione)viene sostituita da un lookup alla tabella MG[A, x ].

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Costruzione della tabella di parsing
◮ L’algoritmo di costruzione della parsing table è moltosemplice ed è formato da un ciclo principale nelquale si prendono in considerazione tutte leproduzioni.
◮ Per ogni produzione A→ α:◮ per ogni simbolo x in FIRST (α) si pone
M[A, x ]=‘A→ α’;◮ se ǫ ∈ FIRST (α), per ogni simbolo y in FOLLOW (A)
si pone M[A, y ]=‘A→ α’.
◮ Tutte le altre entry della tabella vengono lasciatevuote (ad indicare l’occorrenza di un errore).
◮ Se la grammatica è LL(1), nessuna entry dellatabella viene riempita con più di una produzione.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Esempio◮ Consideriamo ancora la grammatica
E → TE ′
E ′ → +TE ′ | ǫ
T → FT ′
T ′ → ×FT ′ | ǫ
F → number | (E)
◮ Il calcolo completo degli insiemi FIRST e FOLLOWproduce:
◮ FIRST (F ) = FIRST (T ) = FIRST (E) ={number, (};
◮ FIRST (E ′) = {+, ǫ}, FIRST (T ′) = {×, ǫ};◮ FOLLOW (E) = FOLLOW (E ′) = {$, )};◮ FOLLOW (T ) = (FIRST (E ′)\ {ǫ}) ∪ FOLLOW (E ′) ={+, $, )};
◮ FOLLOW (T ′) = FOLLOW (T ) = {+, $, )};◮ FOLLOW (F ) = (FIRST (T ′)\ {ǫ}) ∪ FOLLOW (T ′) ={×,+, $, )}.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Esempio (continua)
◮ L’algoritmo prima delineato produce quindi laseguente tabella di parsing
N.T.Simbolo di input
number ( ) + × $E E→TE′ E→TE′
E′ E′→ǫ E′
→+TE′ E′→ǫ
T T→FT ′ T→FT ′
T ′ T ′→ǫ T ′
→ǫ T ′→×FT ′ T ′
→ǫ
F F→number F→(E)
in cui le entry vuote corrispondono ad una situazionedi errore.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Esempio
◮ Se tentassimo di produrre la tabella di parsing per lagrammatica
E → (E)E ′ | number E ′
E ′ → +E E ′ | × E E ′ | ǫ
otterremmo
N.T.Simbolo di input
number ( ) + × $E E→numberE′ E→(E)E′
E′ E′→ǫ
E′→+EE′ E′
→×EE′
E′→ǫ
E′→ǫ E′
→ǫ
◮ Con in input il carattere + o il carattere ×, il parsernon saprebbe quindi come procedere.
◮ Il non soddisfacimento delle proprietà LL(1) è inquesto caso una conseguenza dell’ambiguità dellagrammatica.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Esempio (continua)◮ A volte è possibile risolvere il conflitto presente in
una entry della tabella scegliendo opportunamente laproduzione da applicare (fra quelle in conflitto).
◮ Naturalmente la scelta non deve compromettere lacapacità di riconoscere il linguaggio generato dallagrammatica.
◮ Nel caso dell’esempio, si deve optare in favore delleproduzioni E ′ → +EE ′ e E ′ → ×EE ′, anziché E ′ → ǫ
(si provi, ad esempio, a riconoscere la stringanumber + number).
◮ Si noti tuttavia che, pur avendo risolto l’ambiguità,l’interpretazione delle espressioni che derivadall’albero di parsing non è quella “naturale” (nonviene soddisfatta la precedenza naturale deglioperatori).
◮ Al riguardo, si provi a costruire l’albero di parsing perla stringa number× number + number.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Esempio◮ Consideriamo la seguente grammatica (che esprime,
usando simbologia diversa, il problema del dangling
else che abbiamo già esaminato in precedenza):
S → i E t S e S | i E t S | a
E → b
◮ Tale grammatica presenta produzioni con prefissocomune e dunque non è idonea al parsing a d.r.
◮ È possibile eliminare i prefissi comuni, ottenendo:
S → i E t S S′ | a
S′ → e S | ǫ
E → b
e risulta◮ FIRST (S) = {i, a}; FIRST (S′) = {e, ǫ};
FIRST (E) = {b};◮ FOLLOW (S) = FOLLOW (S′) = {$, e}.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Esempio (continua)
◮ La grammatica modificata non è ancora LL(1) inquanto FIRST (eS) ∩ FOLLOW (S′) = {e}.
◮ Ciò si riflette in una definizione multipla per una entrydella tabella di parsing:
N.T.Simbolo di input
i t e a b $S S→iE tSS′ S→a
S′ S′→eS
S′→ǫ
S′→ǫ
E E→b
◮ Tuttavia se, con in input il carattere e, il parservenisse “istruito” a scegliere sempre la produzioneS′ → eS, l’ambiguità si risolverebbe (e pure conl’intepretazione “naturale”, che associa ogni else althen più vicino).

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Implementazione non ricorsiva
◮ È possibile dare un’implementazione non ricorsiva diun parser predittivo (cioè che non richiedebacktracking) utilizzando esplicitamente una pila.
◮ La pila serve per memorizzare i simboli della partedestra della produzione scelta ad ogni passo.
◮ Tali simboli verranno poi “confrontati” con l’input (seterminali) o ulteriormente riscritti (se non terminali).
◮ Il comportamento del parser è illustrato nellaseguente diapositiva.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Implementazione non ricorsiva (continua)
◮ Inizialmente, sullo stack sono contenuti (partendo dalfondo) i simboli $ ed S, mentre la variabile z punta alprimo carattere di input.
◮ Al generico passo, il parser controlla il simbolo Xsulla testa dello stack;
◮ se X è un non terminale e M[X , z] = ‘X → X1 . . .Xk ‘,esegue una pop dallo stack (rimuove cioè X ) seguitada k push dei simboli Xk , . . . ,X1, nell’ordine;
◮ se X è un non terminale e M[X , z] = ‘error ‘, segnalauna condizione di errore;
◮ se X è un terminale e X = z, esegue una pop e faavanzare z;
◮ se X è un terminale e X 6= z, segnala unacondizione di errore.
◮ Le operazioni terminano quando X = $ e la stringa èaccettata se z = $.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Esempio
◮ Consideriamo nuovamente la grammatica delleespressioni con precedenza di operatore, della qualericordiamo la tabella di parsing:
N.T.Simbolo di input
number ( ) + × $E E→TE′ E→TE′
E′ E′→ǫ E′
→+TE′ E′→ǫ
T T→FT ′ T→FT ′
T ′ T ′→ǫ T ′
→ǫ T ′→×FT ′ T ′
→ǫ
F F→number F→(E)
◮ Supponendo di avere la stringa number+ number
in input, la seguente tabella illustra il progressivocontenuto dello stack e dell’input.

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Esempio (continua)
Stack Input$E number+ number$$E ′T number+ number$$E ′T ′F number+ number$$E ′T ′number number+ number$$E ′T ′ +number$$E ′ +number$$E ′T+ +number$$E ′T number$$E ′T ′F number$$E ′T ′number number$$E ′T ′ $$E ′ $$ $

LFC
ParsingGeneralità sul parsing
Parser a discesa ricorsiva
Esercizi proposti
◮ Si calcolini gli insiemi FIRST e FOLLOW per laseguente grammatica:
S → c | AS | BS
A → aB | ǫ
B → bA | ǫ
e si costruisca la relativa tabella di parsing per unparser a discesa ricorsiva.
◮ Si calcolino gli insiemi FIRST e FOLLOW per lagrammatica G2, che descrive le espressioni regolarisu {0,1}, dopo averla modificata in modo daeliminare i prefissi comuni. Se ne costruisca quindi latabella di parsing per un parser a discesa ricorsiva.


















