Genes & Developmentgenesdev.cshlp.org/content/suppl/2013/12/02/27.23.2590... · Web view2013/12/02...
28
Figure S1. (A) Detection of the hyper-osmotic stress-induced interaction between Hog1 and Rgc2 using the M-track assay. Left: An rgc1∆ rgc2∆ strain (DL3188) co-expressing Rgc2-H3-HA and Hog1-HKMT from centromeric plasmids was treated with 0.5M NaCl for 60min or left untreated. Total cell extracts were separated by SDS-PAGE and subjected to immunoblot analysis using α-me3K9H3 antibodies to detect the trimethylation signal (Zuzuarregui et al., 2012) or α-HA antibodies (Roche Applied Science) to detect Rgc2 expression levels. A strain expressing Rgc2-H3HA only was used as control. Right: Similar 1
Transcript of Genes & Developmentgenesdev.cshlp.org/content/suppl/2013/12/02/27.23.2590... · Web view2013/12/02...
Figure S1. (A) Detection of the hyper-osmotic stress-induced interaction between Hog1 and Rgc2 using the M-track assay. Left: An rgc1∆ rgc2∆ strain (DL3188) co-expressing Rgc2-H3-HA and Hog1-HKMT from centromeric plasmids was treated with 0.5M NaCl for 60min or left untreated. Total cell extracts were separated by SDS-PAGE and subjected to immunoblot analysis using α-me3K9H3 antibodies to detect the trimethylation signal (Zuzuarregui et al., 2012) or α-HA antibodies (Roche Applied Science) to detect Rgc2 expression levels. A strain expressing Rgc2-H3HA only was used as control. Right: Similar to left except that Rgc1-H3-HA was expressed. (B) and (C) Phosphorylation sites on Rgc1. Markings as in Figure 1 C and D. Asterisks: phosphorylated S/T-P motifs, red: confirmed Hog1 phosphorylation sites.
A. The Rgc2 Tripartite PH domain
PH1 482-CIKAGYFLKKSELLPTYHQGYFVLTSNYIHEFQSSDF-518
PH2 584-KSYLAPIMSIPLNDCTLKDASSTKF-608
PH3 682-QKESNNYVTWTFKIVSPEPSEEELKHFKRWVQDLKNLTS-720
B. Sequence alignment of composite Rgc2 PH domain with a consensus PH domain
Rgc2 PH1+2+3
CIKAGYFLKKSELLPTYHQGYFVLTSNYIHEFQSSDFKSYLAPIMSIPLNDCTLKDASSTKFQKESNNYVTWTFKIVSPEPSEEELKHFKRWVQDLKNLTS
PH consensus vikeGyllkksellktwkkryfvLtsnyLlyfksskkksykapkasiplndctvkkasst Rgc2 PH CIKAGYFLKKSELLPTYHQGYFVLTSNYIHEFQSSDFKSYLAPIMSIPLNDCTLKDASST ** **:******* *::: ********: *:**. *** ** ********:*.****
PH consensus kfalqkesnnyfeitfkdvesyllsaeseeerkrWvqalknlls Rgc2 PH KF--QKESNNYVTWTFK-IVSPEPSEEELKHFKRWVQDLKNLTS ** *******. *** : * * *. :. ***** **** *
Figure S2. Identification of the tripartite PH domain of Rgc2. The pfam Sanger domain search algorithm was used to identify the PH domain of Rgc2. http://pfam.sanger.ac.uk/search?tab=searchSequenceBlock
(A) The three regions of the Rgc2 PH domain are shown in different colors. The bold and underlined residues (G486, L505, I510, and W711) were chosen for mutation to Ala based on their identification by the pfam Sanger program as highly conserved among PH domains. (B) alignment of a consensus PH domain from pfam Sanger with the composite Rgc2 PH domain. Upper case residues are highly conserved among PH domains and the corresponding residues in Rgc2 (underlined) were chosen for mutation.
A. Rgc2 PH2 + PH3
KSYLAPIMSIPLNDCTLKDASSTKFQKESNNYVTWTFKIVSPEPSEEELKHFKRWVQDLKNLTS
B. Fps1 C-terminal domain (residues 535 – 649)
HESPVNWSLPVYKEMIMRAWFRRPGWKKRNRARRTSDLSDFSYNNDDDEEFGERMALQKTKTKSSISDNENEAGEKKVQFKSVQRGKRTFGGIPTILEEEDSIETASLGATTTDS
C. Optimized placement of Rgc2 PH2 + PH3 within Fps1 to create a recognizable PH domain
HESPVNWSLPVYKEMIMRAWFRRPGWKKRNRARRTSDLSDFSYNNKSYLAPIMSIPLNDCTLKDASSTKFQKESNNYVTWTFKIVSPEPSEEELKHFKRWVQDLKNLTSDDDEEFGERMALQKTKTKSSISDNENEAGEKKVQFKSVQRGGKRTFGGIPTILEEEDSIETASLGATTTDS
D.
Figure S3. Conceptual fusion of Rgc2 and Fps1 sequences to create a chimeric PH domain. (A) The second and third regions of the Rgc2 tripartite PH domain (PH2 + PH3) were conceptually fused to each other and inserted into each position within the Fps1 C-terminal domain (B). The resultant chimeras were subjected to domain search using the conserved domain search algorithm (http://www.ncbi.nlm.nih.gov/Structure/cdd/wrpsb.cgi).
The optimal placement of Rgc2 sequences within the Fps1 domain (C) to identify a chimeric PH domain (D) is shown. Fps1 residues in green were identified by deletion mapping as important for Rgc2 interaction.
A
30oC
30oC + 3mM As
FPS1
fps1-∆PHD
39oC
Vector
fps1∆ +
B
Intracellular Glycerol (µg/ODU)
5
10
15
20
25
30
0
35
FPS1
fps1-∆PHD
Vector
fps1∆ +
Figure S4. The fps1-∆PHD mutant displays defects in channel activity. (A) Arsenite resistance and temperature sensitivity (due to cell lysis) of the fps1-∆PHD mutant. Equivalent numbers of cells in 10-fold serial dilutions of each strain were spotted onto YEPD plates with or without 3mM arsenite and incubated for three days at the indicated temperature. Yeast strains were: fps1∆ (DL3226) expressing FPS1, fps1-∆PHD, or bearing centromeric vector only. (B) Intracellular glycerol accumulation of the fps1-∆PHD mutant. The same yeast strains were used for measurements of basal intracellular glycerol content. Values are the mean and standard deviation from three independent transformants.
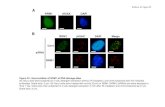
Figure S5. Bimolecular Fluorescence Complementation between Hog1 and Fps1. Cells were assessed for visibly detectable fluorescence from CFP in control (n=758) and sorbitol-treated (n=605) cultures. Fluorescence signals were quantified in cells with fluorescence detectably above background in the control sample (209 cells; 27.6%) and sorbitol-stressed sample (341 cells; 56.4%) using Zen pro 2012 software. The area of each cell with detectable fluorescence was isolated by contour drawing to yield the fluorescence signal of that area. Background fluorescence from a comparable area in the same image was subtracted from each value prior to the determination of mean and standard deviation.
Control
Sorbitol
2000
4000
6000
8000
10000
12000
14000
16000
18000
20000
11253 ± 7230
6391 ± 4871
CFP Fluorescence Intensity
0
Strain
Relevant genotype
Source or Reference
DL3158
MATa S288c hog1∆::KanMX
Research Genetics
DL3187
MATa S288c (BY4741) his3∆ leu2∆ ura3∆ lys2∆
Research Genetics
DL3186
MATα S288c rgc1∆::KanMX
Research Genetics
DL3188
MATα S288c rgc1∆::KanMX rgc2∆::KanMX
Beese et al., 2009
DL3207
MATa S288c rgc1∆::KanMX rgc2∆::KanMX
Beese et al., 2009
DL3226
MATa S288c fps1∆::KanMX
Research Genetics
DL4046
MATα S288c rgc1∆::KanMX rgc2::URA3
This study
DL4062
MATα S288c rgc1::KanMX rgc2::RGC2-S344A, T808A, S948A, S75A ,S827A, S1021A, S1035A-HPH (RGC2-7A)
This study
DL4066
MATα S288c rgc1∆::KanMX rgc2::RGC2-S75A, S344A, S948-HPH (RGC2-3A)
This study
DL4070
MATα S288c rgc1∆::KanMX rgc2::RGC2-HPH
This study
DL4120
MATα S288c rgc1∆::KanMX rgc2::rgc2-G486A, L505A, I510A, W711-HPH (rgc2-4PHA)
This study
DL4136
MATα S288c rgc1∆::KanMX rgc2::rgc2-PHD123∆-HPH
This study
WR467
MATa S288c (BY4741) SILAC, RGC1-HTBeaq::HphMX, lys1::KanMX, arg4::KanMX
This study
WR500
MATα S288c (BY4742) SILAC, RGC2-HTBeaq::HphMX, lys1::KanMX, arg4::KanMX
This study
Table S1. S. cerevisiae strains used in this study. All strains were derived from the S288c genetic background from Research Genetics.
Table S2. Plasmids used in this study.
Plasmid
Description
Source or Reference
p115
pRS316
Sikorski & Hieter, 1989
p117
pRS313
Sikorski & Hieter, 1989
p119
pRS315
Sikorski & Hieter, 1989
p904
pLG178 CYC1-lacZ
Guarente and Mason, 1983
p1105
pRS425
Sikorski & Hieter, 1989
p1106
pRS426
Sikorski & Hieter, 1989
p2098
pAK3; pRS316-RGC2-3HA-ADH1T
Cohen et al., 2003
p2156
pLG178-GPD1 (-1000 to +1)-lacZ
This study
p2501
pUT36-MET25P-RGC2-HIS6
Beese et al., 2009
p2809
pUT36-MET25P-rgc2 (1-720)-HIS6
Beese et al., 2009
p2833
pRS316-FPS1
Beese et al., 2009
p3064
pAG32-RGC2
This study
p3090
plac111-HOG1
F. Posas
p3121
pYEP181-MET25P-FPS1-Myc
Beese-Sims et al., 2011
p3132
pAG32-RGC2-S75A, S344A,T808A, S827A, S948A, S1021A, S1035A (RGC2-7A)
This study
p3133
pAG32-RGC2-S75A, S344A, S948A (RGC2-3A)
This study
p3147
pRS315-3HA-ADH1T
This study
p3148
pRS316-3HA-ADH1T
This study
p3149
pRS425-3HA-ADH1T
This study
p3150
pRS426-3HA-ADH1T
This study
p3151
pRS316-MET25P-RGC2-3HA
This study
p3152
pRS316-MET25P-RGC2-S75A, S344A, S948A-3HA (3A)
This study
p3155
pRS316-MET25P-RGC2-S75A,S344A,T808A, S827A, S948A, S1021A, S1035A-3HA (7A)
This study
p3182
pRS316-RGC2-3HA
This study
p3183
pRS316-RGC2-S75A, S344A, S948A-3HA
This study
p3185
pRS316-RGC2-S75A, S344A, T808A, S827A, S948A, S1021A, S1035A-3HA
This study
p3186
pRS316-MET25P-rgc2-G486A-3HA
This study
p3187
pRS316-MET25P-rgc2-L505A-3HA
This study
p3188
pRS316-MET25P-rgc2-I510A-3HA
This study
p3189
pRS316-MET25P-rgc2-W711A-3HA
This study
p3188
pRS316-MET25P-rgc2-G486A, L505A, I510A, W711A-3HA (rgc2-4PHA)
This study
p3196
pYEP181-MET25P-FPS1-∆1-Myc
This study
p3197
pYEP181-MET25P-FPS1C1-Myc
This study
p3209
pYEP181-MET25P-FPS1C1+1-Myc
This study
p3210
pYEP181-MET25P-FPS1C1+2-Myc
This study
p3211
pYEP181-MET25P-FPS1C1+3-Myc
This study
p3212
pYEP181-MET25P-FPS1C1+4-Myc
This study
p3213
pYEP181-MET25P-FPS1C1+5-Myc
This study
p3214
pYEP181-MET25P-fps1∆KQVF-Myc
This study
p3215
pYEP181-MET25P-fps1-F614A, K615A, S616A, V617A-Myc (FKSV)
This study
p3216
pRS413-CFPC-FPS1 (BiFC)
This study
p3217
pRS413-CFPC-HOG1 (BiFC)
This study
p3218
pRS415-FPS1-CFPN (BiFC)
This study
p3219
pRS415-HOG1-CFPN (BiFC)
This study
p3223
pAG32-rgc2-G486A, L505A, I510A, W711A (4PHA)
This study
p3224
pAG32-rgc2-PHD123∆
This study
p3225
pRS426-HOG1-3HA
This study
p3227
pRS316-MET25P-rgc2-PHD1∆-3HA
This study
p3228
pRS316-MET25P-rgc2-PHD2∆-3HA
This study
p3229
pRS316-MET25P-rgc2-PHD3∆-3HA
This study
p3230
pRS316-MET25P-rgc2-PHD123∆-3HA
This study
p3259
pYEP181-MET25P-fps1-∆PHD-Myc
This study
p3260
pYEP181-MET25P-FPS1-I218A,V220A-Myc (IV/AA)
This study
p3273
pRS313-FPS1
This study
p3274
pRS313-fps1-F614A, K615A, S616A, V617A (FKSV)
This study
p3301
pRS316-MET25P-rgc2-N∆-3HA
This study
p3302
pRS316-MET25P-rgc2-C∆-3HA
This study
PC8
YCp111-HOG1-HKMT
Zuzuarregui
et al., 2012
pCGS65
YCp33-RGC2-4H3-3HA
This study
pCGS66
Yep195-RGC1-4H3-3HA
This study
Legends to MS data tables
Table S3. SILAC quantifications of phosphorylation at S/T-P sites in Rgc2 and Rgc1. Summarized search results from two experiments are listed. (i) Rgc2-HTBeaq or Rgc1-HTBeaq expressing cells were grown in 12C lysine/arginine (light [L]) SILAC medium to mid log phase and treated with 0.5M NaCl (hyper-osmotic stress). Cells were mixed with an equal amount of cells grown on 13C lysine/arginine (heavy [H]) SILAC medium, serving as unstressed control. (ii) In a further set of experiments Hog1 dependent phosphorylation sites of Rgc2 and Rgc1 were identified. To shut down Hog1 activity a novel Hog1 inhibitor (Diner et al., 2011) was added five minutes before hyperosmotic stress treatment in a final concentration of 5µM to the culture growing on light [L] SILAC medium. Cells were mixed with an equal amount of cells grown on heavy SILAC medium that were treated with hyperosmotic stress. Shown are the averages of normalized stress induction (L/H) ratios of regulated phosphopeptides that harbor an S/T-P motif and the corresponding unphosphorylated peptides.
Table S4. Confirmed phosphorylation sites of Rgc2 and Rgc1. Phosphopeptides from all experiments are listed. Phosphopeptides were assigned with a phosphorylation site probability of >75% according to PhosphoRS 2.0 except for phosphopeptide EFILPETDERSPYFINVPIPK (harboring phosphoserine 75 of Rgc2) for which the phosphorylation site was assigned manually.
Table S5. Ambiguous phosphorylation sites of Rgc2 and Rgc1. Phosphopeptides from all experiments with a phosphorylation site probability of <75% are listed.
Table S6. SILAC quantification of Rgc2 and Rgc1 peptides – complete list. Experiments were performed as described in Table S3. For hypo-osmotic stress (light [L]) cells were washed with and resuspended in H2O for 2 minutes and mixed with an equal amount of unstressed cells grown on heavy (H) SILAC medium. Shown are the averages of normalized stress induction (L/H) ratios of all identified regulated peptides, including unphosphorylated peptides without corresponding phosphopeptide.
Extended Experimental Procedures
Plasmid Construction.
RGC2 Plasmids. We first created a general tool for C-terminal epitope tagging with the HA epitope. The triple hemaglutinin (3HA) epitope fused to the ADH1 terminator was amplified from p2098 (pAK3; gift of Randy Strich: Cohen et al., 2003) by PCR using the primers 5’ gatcCCCGGGgcggccgcaTTAATTAACATCTTTTAC 3’ with SmaI, NotI and PacI sites (upstream) and primer 5’ gatcgagctcTGCCGGTAGAGGTGTGGT 3’ with a SacI site (downstream). The 3HA-ADH1T was cloned by SmaI and SacI into pRS315, pRS316, pRS425 and pRS426 (Sikorski and Heiter, 1989), to yield pRS315-3HA-ADH1T (p3147), pRS316-3HA-ADH1T (p3148), pRS425-3HA-ADH1T (p3149), and pRS426-3HA-ADH1T (p3150). This arrangement allows the in-frame fusion of the epitope tag sequence to the 3’ end of a gene at SmaI, NotI, or PacI sites by the addition of any of those sites to the last nucleotide of the coding sequence.
Next, the RGC2 gene was fused in-frame to a C-terminal 3HA epitope for expression from the RGC2 promoter. The promoter (from -863 relative to the ATG) and coding region of RGC2 gene was amplified from pRS316-RGC2 (p2098) by high-fidelity PCR (Phusion DNA polymerase; New England Biolabs). Primers were designed with an XhoI site (upstream) and a NotI site (downstream) for subcloning into pRS316-3HA-ADH1T (p3148) to yield pRS316-RGC2-3HA (p3182).
For Rgc2 co-immunoprecipitation experiments, Rgc2 tagged at its C-terminus with a 3HA epitope was expressed under the control of the MET25 promoter. The MET25P and the RGC2 coding region was amplified from pUT36-MET25P-RGC2 (p2501; Beese et al., 2009) by PCR using primers with an XhoI site (upstream) and a NotI site (downstream) and cloned into pRS316-3HA-ADH1T (p3148) to yield pRS316-MET25P-RGC2-3HA (p3151).
Mutant forms of Rgc2-3HA were also expressed either from the RGC2 promoter or the MET25 promoter. Point mutations at Rgc2 phosphorylation sites, as well as within the PH domain, were generated using templates, pRS316-RGC2-3HA and pRS316-MET25P-RGC2-3HA, by Quick Change mutagenesis (Agilent Technologies). Multiple mutations within an allele were generated sequentially by the same method. Double-overlap PCR mutagenesis (Ho et al., 1989) was used to generate deletions of the tripartite PH domain of Rgc2 using primers that include an XhoI site (upstream) and a NotI site (downstream), which were cloned into pRS316-3HA-ADH1T (p3148). Similarly, double-overlap PCR was used to create the N-terminal deletion construct of RGC2 (p3301), which retained the first seven amino acids of Rgc2 fused to residue 361 in p3148. The C-terminal deletion construct of RGC2 was subcloned by PCR into p3148 from pUT36-MET25P-rgc2(1-720)-HIS6 (p2809; Beese et al., 2009). The DNA sequences of all mutant alleles were confirmed.
Mutant alleles of RGC2 used for genomic integration were generated with pAG32-RGC2 (p3064) by Quick Change mutagenesis. RGC2 PH domain mutant alleles were amplified from pRS316-MET25P-rgc2 -G486A, L505A, I510A, W711A (4PHA) and pRS31-MET25P-rgc2-PHD123∆ using an upstream primer that includes a HindIII site and a downstream primer that includes a Flag epitope followed by a stop codon and a PacI site. These were cloned into pAG32 to yield pAG32-rgc2-G486A, L505A, I510A, W711A (p3223) and pAG32-rgc2-PHD123∆ (p3224), respectively.
FPS1 plasmids. For Fps1 co-immunoprecipitation experiments, Fps1 was tagged at its C-terminus with a Myc epitope and expressed under the control of the MET25 promoter (YEp181- MET25P-FPS1-Myc, p3121). To generate mutant FPS1 alleles (C1+1, +2, +3, +4, +5, ∆KVQF, ∆PHD, FKSV, IV/AA), double-overlap PCR was used with primers that include a Sal1 (upstream) and a BamH1 (downstream) site. The PCR products were cloned with SalI and BamH1 into p3121 to yield Yep181-MET25P-FPS1C1+1, +2, +3, +4, +5, ∆KVQF, ∆PHD, FKSV, and IV/AA. For expression of FPS1 from centromeric plasmid pRS313, the FPS1 gene was amplified from pRS316-FPS1 (p2833) using primers with SacI and SalI sites and cloned into pRS313 (Sikorski and Heiter, 1989; p117) to yield pRS313-FPS1 (p3273). Double-overlap PCR was used to generate pRS313-FPS1-FKSV (p3274).
HOG1 plasmid. For Hog1 co-immunoprecipitation experiments, Hog1 was tagged at its C-terminus with 3HA epitope and expressed under the control of the HOG1 promoter from a high-copy plasmid. The HOG1 gene with its promoter was amplified from YCplacIII-HOG1 (p3090, Gift of Francesc Posas). The PCR product was cloned with XhoI and NotI into p3150 to yield pRS426-HOG1-3HA (p3225).
BiFC plasmids. To visualize the recruitment of Hog1 to Fps1, Bimolecular Fluorescence Complementation (BiFC) was employed using a split CFP fluorophore. We generated an N-terminal fusion of Fps1 to CFPC and a C-terminal fusion of Hog1 to CFPN. Plasmids pRS413-CFPC (155-238AA yECFP) and pRS415-CFPN (1-172AA cerulean) were the gift of Nava Segev of the University of Illinois (Lipatova et al, 2012). For these fusions, the FPS1 coding sequence and HOG1 gene with its promoter were amplified by PCR using primers with BspE1 (upstream) and Xho1 (downstream) sites for pRS413-CFPC, or XbaI (upstream) and BspE1 (downstream) sites for pRS415-CFPN vector, respectively. The PCR products were cloned into the above vectors, yielding pRS413-CFPC-FPS1 (p3216) and pRS415-HOG1-CFPN (p3219). The HOG1 and FPS1 genes were also cloned as the opposite fusions to yield pRS413-CFPC-HOG1 (p3217) and pRS415-FPS1-CFPN (p3218).
GPD1-lacZ reporter plasmid. GPD1 (-1000 to +1)-lacZ (p2156), was constructed by PCR amplification of the 5’ promoter region of GPD1 using primers with Xho1 (upstream) and BamH1 (downstream) sites for cloning into pLG178 (p904; Guarente and Mason, 1983). This fused the regulatory sequences for GPD1 to lacZ.
M-Track plasmids. A centromeric plasmid expressing Rgc2-4H3-3HA (pCGS65) was derived from plasmid PI225 (Zuzuarregui et al., 2012), but with the SHO1 coding region replaced with the RGC2 coding region using conventional cloning techniques. An episomal plasmid expressing Rgc1-4H3-3HA (pCGS66) was similarly derived from plasmid PI228 (Zuzuarregui et al., 2012). The following primers were used for the amplification of the RGC1 and RGC2 ORFs. Rgc1-s-univ: ACA GCT ATG ACC ATG ATT ACG CCA AGC TTG CAT GCC GCC CCA GTG TTC TTG ATG TTC G; H3-Rgc1-as: ACG ACG CGA ATT CGG GAT CCC CGG GGA TCC TCT AGA CTT ACT TGA CGC GGA TGT AGC AG; Rgc2-s-univ: ACA GCT ATG ACC ATG ATT ACG CCA AGC TTG CAT GCG AGG AAT CTC GTT GCT AGC GAT CT; H3-Rgc2-as: ACG AGC CGA ATT CGG GAT CCC CGG GGA TCC TCT AGA AGA ATA AAT CGA CTG GTT TAG CT. A centromeric plasmid expressing Hog1-HKMT (PC8) was also described previously (Zuzuarregui et al., 2012).
Mass spectrometric methods
Yeast strain construction. The BY-SILAC Rgc2-HTBeaq (MATa) strain was obtained as follows: lys1 and arg4 deficient BY 4741 SILAC (Gruhler et al., 2005) was transformed with a HTBeaq tagging cassette obtained by PCR amplification of the Rgc2 coding sequence using primers Rgc2_t_fw: ATG GTG ATT CAA CTA ATA ATG ATA CTA TAA AGC TAA ACC AGT CGA TTT ATT CTT CCG GTT CTG CTG CTA G and Rgc2_t_re: CGG TGC TTA GAA AAT AAA CGG CGA ACC ATA CAG GCT GTT TCT CAA AAG AGA ACC CTC GAG GCC AGA AGA C and plasmid pHTBeaq (Reiter et al., 2012) as template. BY-SILAC Rgc2-HTBeaq (MATα) was obtained by backcrossing. The BY-SILAC Rgc1-HTBeaq (MATa) strain was constructed similarly by PCR amplification Rgc1 using primers Rgc1_t_fw: CGC GCA AGG AGG GAA GTA CTA ATA CTG TAC CTG CTA CAT CCG CGT CAA GTA AGT CCG GTT CTG CTG CTA G
Rgc1_t_re: GGT AGT TAA TGG GTT TGT ATT TTC AGC AGG AAC ATG ACC CAG GAC TTT CTT GTC CTC GAG GCC AGA AGA C.
SILAC labeling. SILAC labeling is based on methods described elsewhere (Gruhler et al, 2005) with the following modifications: A BY-SILAC yeast strain expressing endogenously tagged Rgc2-HTBeaq (or Rgc1-HTBeaq) was grown in SILAC medium containing 12C lysine and arginine to mid log phase (OD600=1) and treated with 0.5M NaCl (hyper-osmotic stress) for 10 minutes. Cells were mixed with an equal amount of cells grown on 13C lysine/arginine SILAC medium, serving as unstressed control, prior to cell lysis. To shut down Hog1 activity a novel Hog1 inhibitor (Diner et al., 2011) was added 5 minutes before stress treatment in a final concentration of 5µM. Uninhibited cells were treated with an equal volume of DMSO.
Tandem affinity purification. HB purification is based on methods described elsewhere (Reiter et al., 2012) with modifications: Cells were harvested by filtration and immediately deep frozen in liquid N2. The frozen cell pellet was grinded using a SPEX Freezer Mill 6870 (7 x 3mins breakage, 15 CPS) and immediately resuspended in denaturing buffer conditions (6M Guanidine-HCl, 50mM Tris, 5mM NaF, 1mM PMSF, 0.1% Tween, protease inhibitor cocktail (Roche), pH 8). Extracts were cleared of cell debris and incubated for 4 hours with Ni-Sepharose beads (GE Healthcare), washed twice with urea buffer (8M urea, 50mM Na-PO4, 300mM NaCl, 0.01% Tween, pH 8) and three times with urea buffer pH 6.3. Protein elution was performed with urea buffer pH 4.3 containing 10mM EDTA and the eluate was buffered to pH 8 and incubated overnight with STRP-Agarose beads (Thermo Fisher Scientific) followed by washing three times with urea wash buffer (8M Urea, 100mM Tris, 200mM NaCl) containing 1% SDS. SDS was removed by three washing steps with pure urea wash buffer.
Mass spectrometric analysis. Mass spectrometric analysis is based on methods described elsewhere (Reiter et al., 2012) with modifications: STRP-Agarose beads (Thermo Fisher Scientific) were washed 5 times with 50 mM ammoniumbicarbonate (ABC) buffer. Disulfide bonds were reduced with dithiothreitol (DTT, 5% w/w of the estimated protein amount) for 30 min at 56°C and alkylated with iodoacetamide (IAA, 25% w/w of the estimated protein amount) for 30 min in the dark. The reaction was stopped by addition of DTT (25% w/w of the estimated protein amount). Proteins were digested using different proteases (5% w/w of the estimated protein amount). Trypsin (recombinant, proteomics grade, Roche) digest was performed overnight at 37°C, chymotrypsin digest (both sequencing grade, Roche) was performed overnight at 25°C. Digests were stopped by addition of trifluoroacetic acid (TFA) to approximately pH 3. Phosphopeptide enrichment was performed using titanium dioxide tips from Glygen as described by Mazanek et al. (2010). The peptide mixture was separated on a reversed phase nano-HPLC (Ultimate 3000, Dionex, Sunnyvale CA, USA). Peptides were concentrated and washed with 0.1% TFA on a trapping column (PepMap C18, 300µm×5mm, 3µm, 100Å) for 30min at a flow rate of 25µl/min. Bound peptides were eluted and separated on an analytical column (PepMap C18, 75µm×150mm, 3µm, 100Å) using a linear gradient from 2.5% to 40% acetonitrile (ACN) with 0.1% formic acid in 60 min at a flow rate of 300nl/min. The HPLC was directly coupled to an LTQ, LTQ-FT or an LTQ Orbitrap Velos mass spectrometer (all Thermo Fisher Scientific) via a nanoelectrospray ion source (Proxeon). A full scan was followed by MS2 and neutral loss dependent MS3 analysis of the four (LTQ, LTQ-FT) or ten (Orbitrap; Velos) most intense precursors in the linear iontrap.
Peptide identification and SILAC quantification were performed using the SEQUEST algorithm in the Proteome Discoverer 1.3.0.339 software package (Thermo Fisher Scientific Fisher Scientific). Carbamidomethylation of Cys was set as static modifications. Phosphorylation of Ser/Thr/Tyr, neutral loss of water from Ser/Thr, oxidation of Met and 13C6 Lys/Arg were set as variable modifications. Spectra were searched against the SGD database (6717 entries, 03-Feb-2011) plus contaminants with tryptic specificity allowing 3 missed cleavages, a peptide tolerance of 3 ppm, a fragment ions tolerance of 0.8 Da. Quantitation settings were the default values for precursor ions quantifier, the event detector was set to 4 ppm. The results were filtered at the XCorr values to an FDR of 1% on the peptide level. The result lists were combined in MS Excel and subjected to further data processing: for each SILAC experiment the mixing ratio was determined on the basis of the quantified unique peptides which contained no phosphorylation and no proline. Due to the metabolic Arg-Pro conversion the impact of heavy proline on the H:L ratios was determined: the divergence from a 1:1 ratio of unphosphorylated peptides containing 1 proline reflected the extent of 13C5-Pro incorporation and was extrapolated for peptides containing more than 1 proline. The probability of phosphosite localization was calculated using the phosphoRS 2.0 software (Taus et al., 2011) implemented into Proteome Discoverer. A phosphosite probability of 75% or higher was considered as confidently localized. Results were divided into lists of highly confident localized (Table S4) and non-localized (< 75% probability) phosphosites (Table S5). Additionally, results were also filtered at the XCorr values to an FDR of 5% on the peptide level. These data were similarly processed as described above, except that all phosphopeptide assignments were also validated manually and SILAC quantification was performed (Tables S3 and S6) by manual peak integration of extracted ion chromatograms (LTQ-FT data). Annotated MS/MS spectra were exported for all peptide-spectrum matches that mapped to Rgc2 or Rgc1. All data are available upon request.
Supplemental References
Diner P, Veide Vilg J, Kjellen J, Migdal I, Andersson T, Gebbia M, Giaever G, Nislow C, Hohmann S, Wysocki R, et al. 2011. Design, synthesis, and characterization of a highly effective Hog1 inhibitor: a powerful tool for analyzing MAP kinase signaling in yeast. PLoS One 6: e20012.
Gruhler A, Olsen JV, Mohammed S, Mortensen P, Faergeman NJ, Mann M, Jensen ON. 2005. Quantitative phosphoproteomics applied to the yeast pheromone signaling pathway. Mol. Cell Proteomics 4: 310-327.
Mazanek M, Roitinger E, Hudecz O, Hutchins JR, Hegemann B, Mitulovic G, Taus T, Stingl C, Peters JM, Mechtler K. 2010. A new acid mix enhances phosphopeptide enrichment on titanium- and zirconium dioxide for mapping of phosphorylation sites on protein complexes. J. Chromatogr. B Analyt. Technol. Biomed. Life Sci. 878: 515-522.
Reiter W, Anrather D, Dohnal I, Pichler P, Veis J, Grotli M, Posas F, Ammerer G. 2012. Validation of regulated protein phosphorylation events in yeast by quantitative mass spectrometry analysis of purified proteins. Proteomics 12: 3030-3043.
Taus T, Kocher T, Pichler P, Paschke C, Schmidt A, Henrich C, Mechtler K. 2011. Universal and confident phosphorylation site localization using phosphoRS. J. Proteome Res 10: 5354-62.
6