
CS 387: GAME AI - Drexel Universitysanti/teaching/2016/CS... · • Compare Go and Chess: ... a...
47
CS 387: GAME AI BOARD GAMES 6/24/2016 Instructor: Santiago Ontañón [email protected] Class website: https://www.cs.drexel.edu/~santi/teaching/2016/CS387/intro.html
Transcript of CS 387: GAME AI - Drexel Universitysanti/teaching/2016/CS... · • Compare Go and Chess: ... a...

CS 387: GAME AI BOARD GAMES
6/24/2016 Instructor: Santiago Ontañón
[email protected] Class website:
https://www.cs.drexel.edu/~santi/teaching/2016/CS387/intro.html
Reminders • Check BBVista site for the course regularly • Also: https://www.cs.drexel.edu/~santi/teaching/2016/CS387/intro.html
• Thursday, project 4 submission deadline

Outline • Board Games • Game Tree Search • Portfolio Search • Monte Carlo Methods • UCT

Outline • Board Games • Game Tree Search • Portfolio Search • Monte Carlo Methods • UCT

Go • Board is 19x19 • Branching factor:
• Starts at 361 • Decreases (more or less) in 1 after every move
• Compare Go and Chess: • Chess, assume a branching factor of 35:
• Search at depth 4: 1,500,625 nodes • Go, assume a branching factor of 300:
• Search at depth 4: 8,100,000,000 nodes
• What can we do?
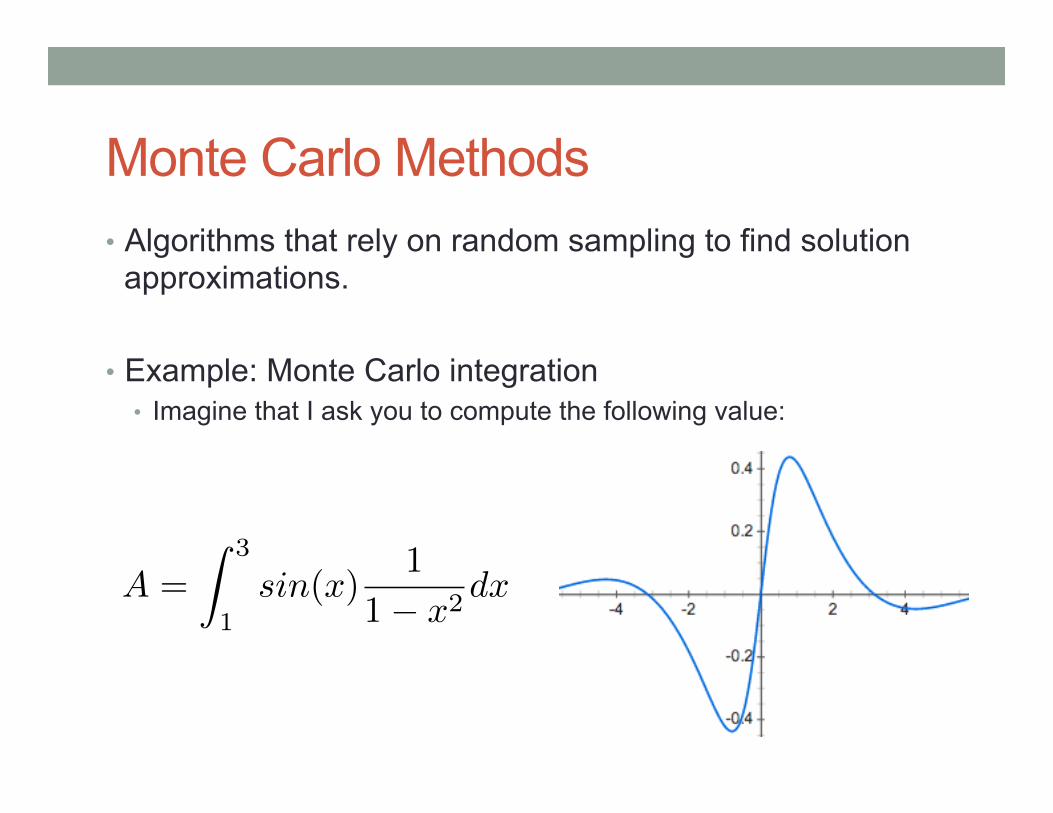
Monte Carlo Methods • Algorithms that rely on random sampling to find solution
approximations.
• Example: Monte Carlo integration • Imagine that I ask you to compute the following value:
A =
Z 3
1sin(x)
1
1� x
2dx

Monte Carlo Methods • Method 1: Symbolic integration
• You could fetch your calculus book, integrate the function, etc. • But this method you’ll have to do by hand (did you know that
automatic symbolic integration is still a hard problem?)
• Method 2: Numerical computations • Simpson method, etc. (recall from calculus?)
• Method 3: Monte Carlo

Monte Carlo Methods • Method 3: Monte Carlo
• Repeat N times: • Pick a random x between 1 and 3 • Evaluate f(x)
• Now do the average and multiply by 2 (3 – 1) • Voilà!
• The larger N, the better the approximation
f(x) = sin(x)1
1� x
2dx

Monte Carlo Methods • Idea:
• Use random sampling to approximate the solution to complex problems
• How can we apply this idea to adversarial search? • The answer to this question is the responsible for having computer
programs that can play Go at master level.

Outline • Board Games • Game Tree Search • Monte Carlo Methods • UCT

Monte-Carlo Tree Search • Upper Confidence Tree (UCT) is a state of the art, simple
variant of Monte-Carlo Tree Search, responsible for the recent success of many Computer Go programs
• Ideas: • Sampling smartly (UCB) • Instead of opening the whole Minimax tree or play N random
games open only the upper part of the tree, and play random games from there
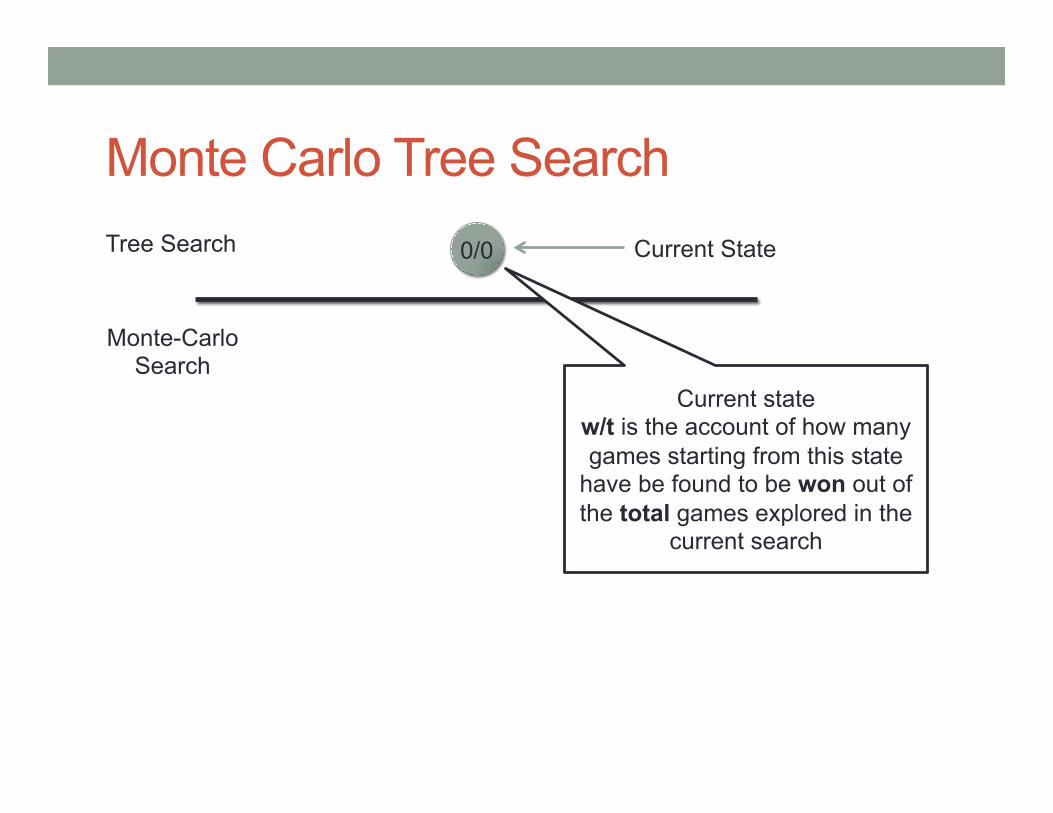
Monte Carlo Tree Search 0/0 Tree Search
Monte-Carlo Search
Current state w/t is the account of how many games starting from this state
have be found to be won out of the total games explored in the
current search
Current State
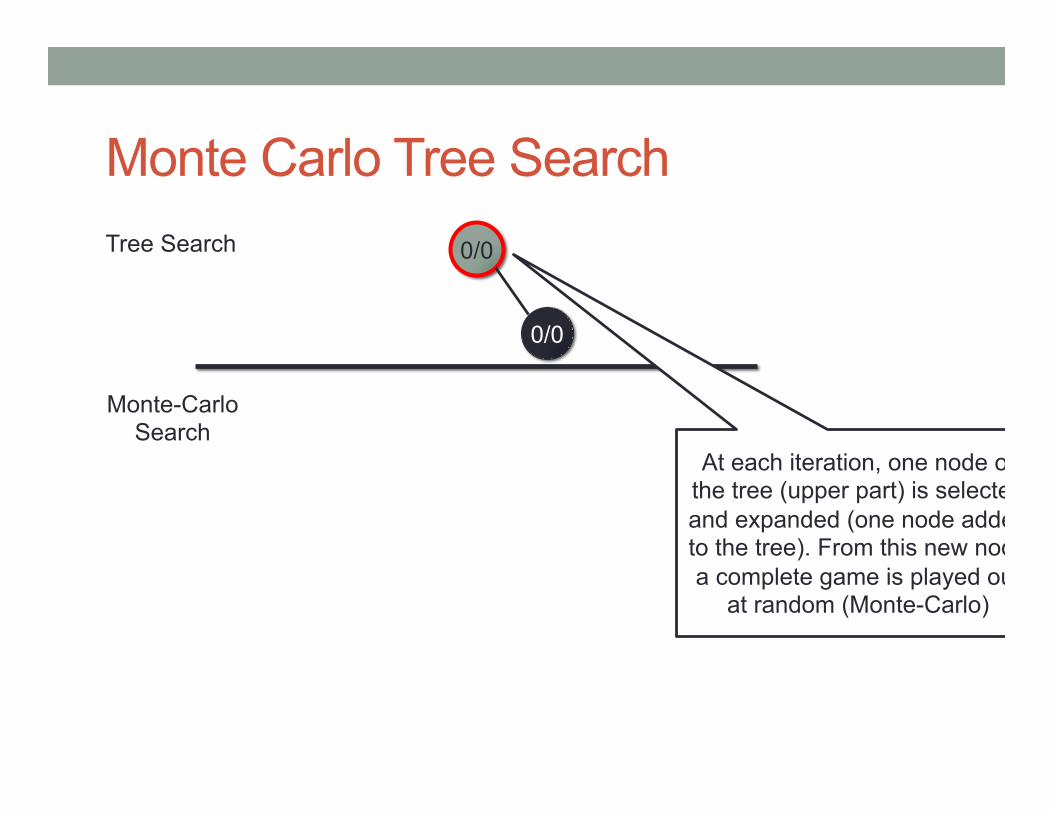
Monte Carlo Tree Search 0/0 Tree Search
Monte-Carlo Search
0/0
At each iteration, one node of the tree (upper part) is selected and expanded (one node added to the tree). From this new node a complete game is played out
at random (Monte-Carlo)
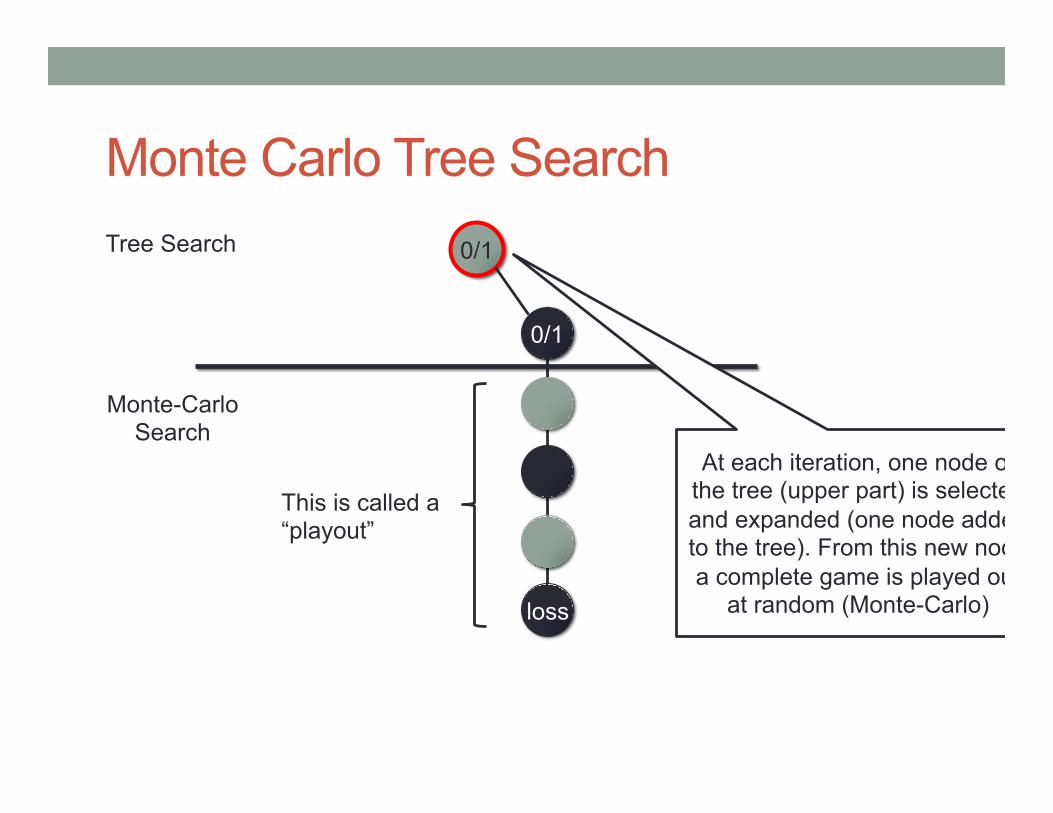
Monte Carlo Tree Search 0/1 Tree Search
Monte-Carlo Search
0/1
loss
At each iteration, one node of the tree (upper part) is selected and expanded (one node added to the tree). From this new node a complete game is played out
at random (Monte-Carlo)
This is called a “playout”
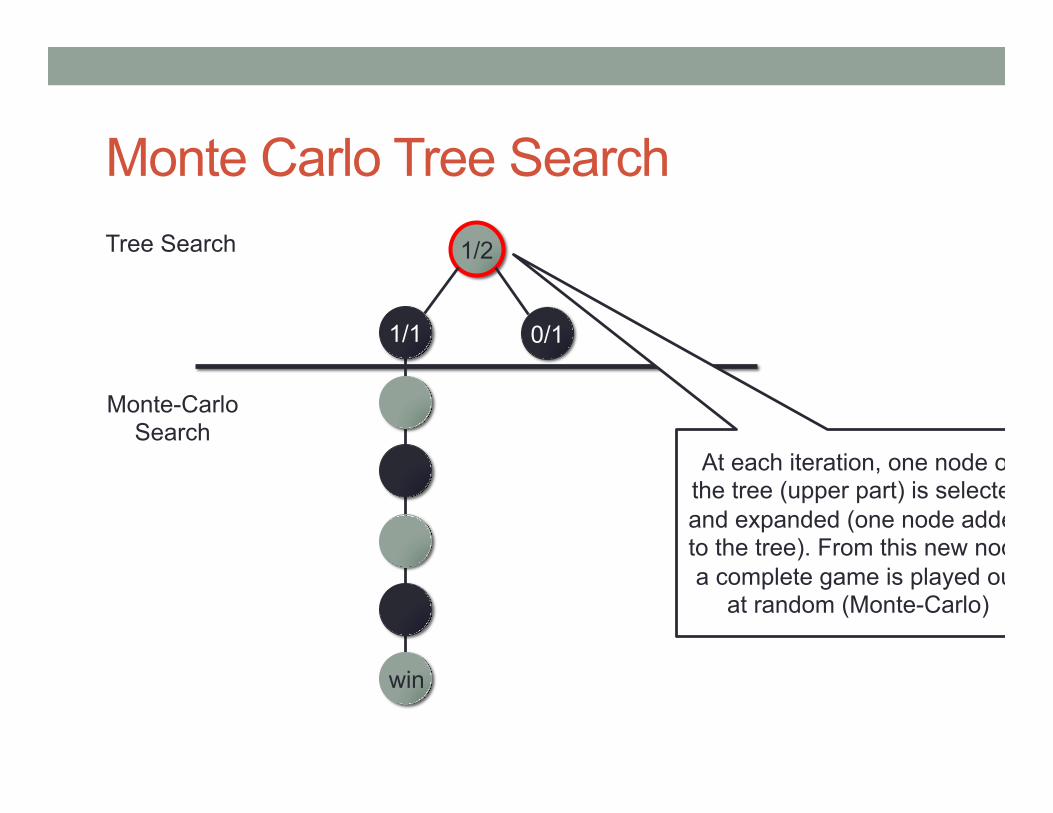
Monte Carlo Tree Search 1/2 Tree Search
Monte-Carlo Search
0/1
At each iteration, one node of the tree (upper part) is selected and expanded (one node added to the tree). From this new node a complete game is played out
at random (Monte-Carlo)
1/1
win
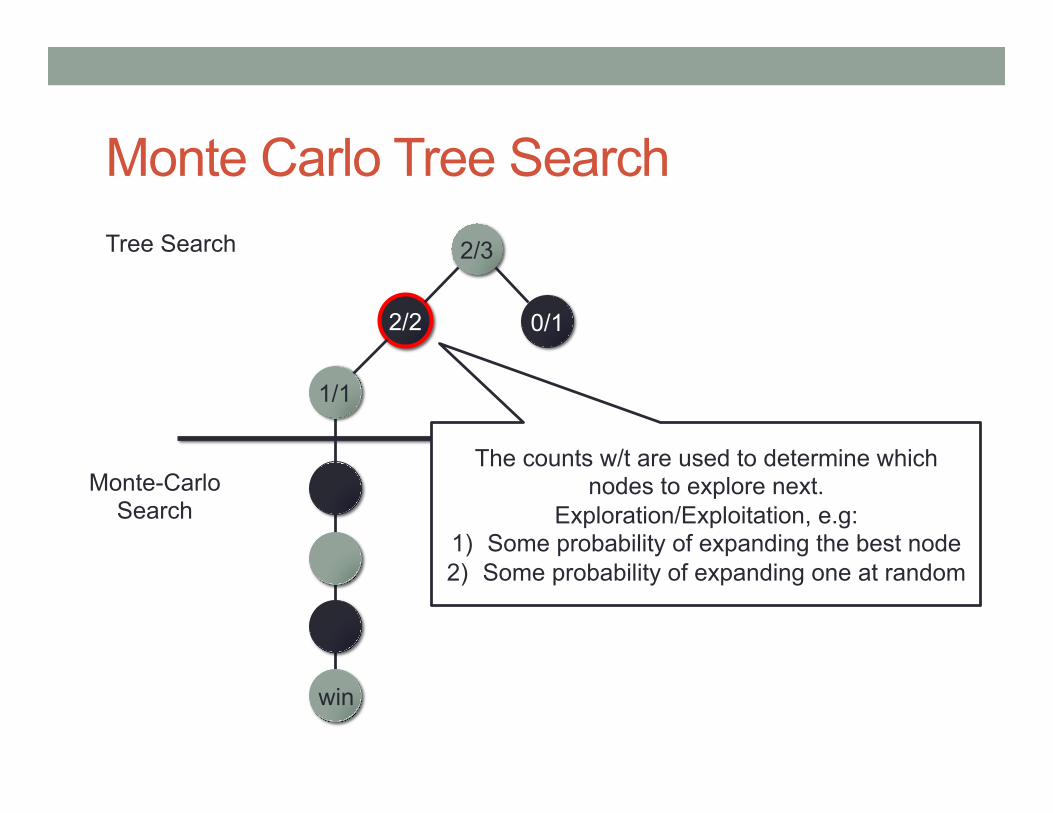
Monte Carlo Tree Search 2/3 Tree Search
Monte-Carlo Search
0/1 2/2
1/1
win
The counts w/t are used to determine which nodes to explore next.
Exploration/Exploitation, e.g: 1) Some probability of expanding the best node 2) Some probability of expanding one at random
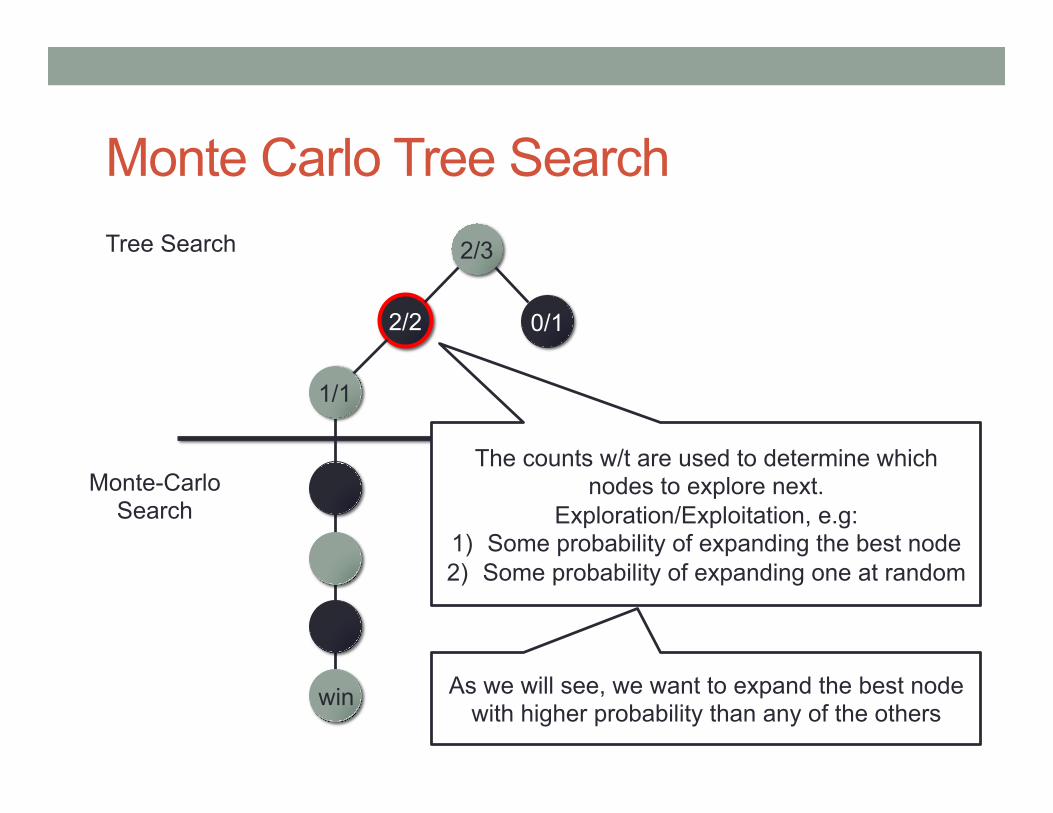
Monte Carlo Tree Search 2/3 Tree Search
Monte-Carlo Search
0/1 2/2
1/1
win
The counts w/t are used to determine which nodes to explore next.
Exploration/Exploitation, e.g: 1) Some probability of expanding the best node 2) Some probability of expanding one at random
As we will see, we want to expand the best node with higher probability than any of the others
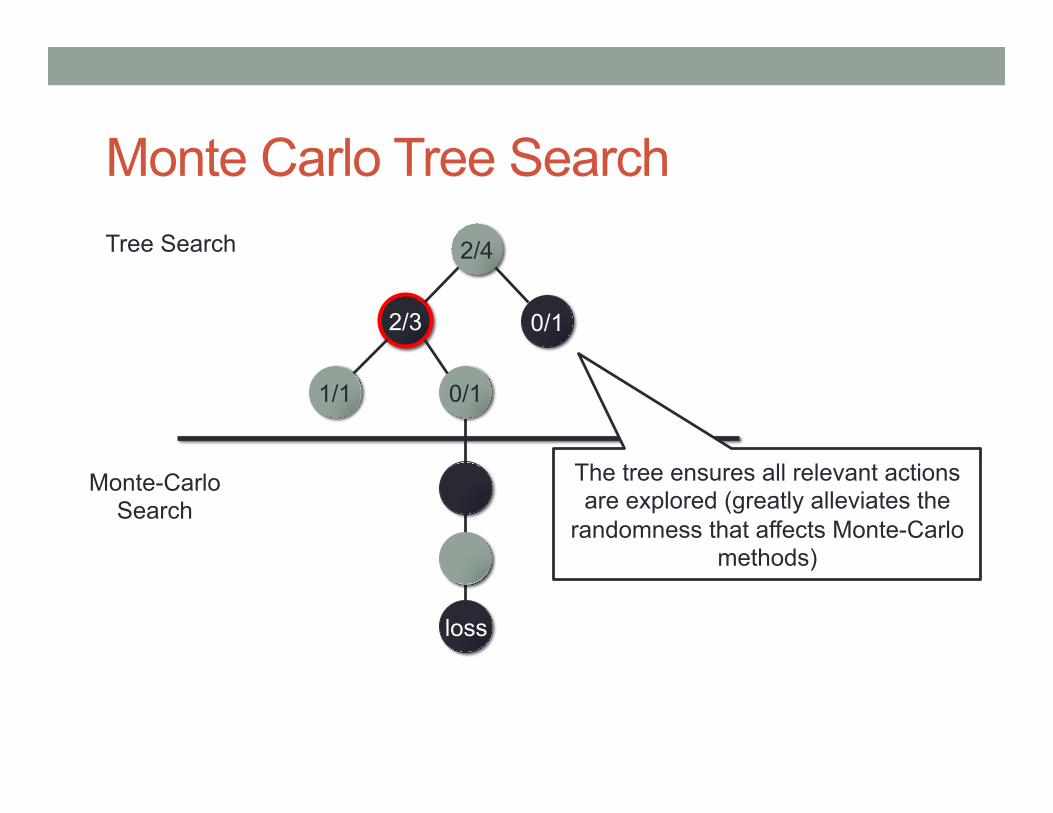
Monte Carlo Tree Search 2/4 Tree Search
Monte-Carlo Search
0/1 2/3
1/1 0/1
loss
The tree ensures all relevant actions are explored (greatly alleviates the
randomness that affects Monte-Carlo methods)
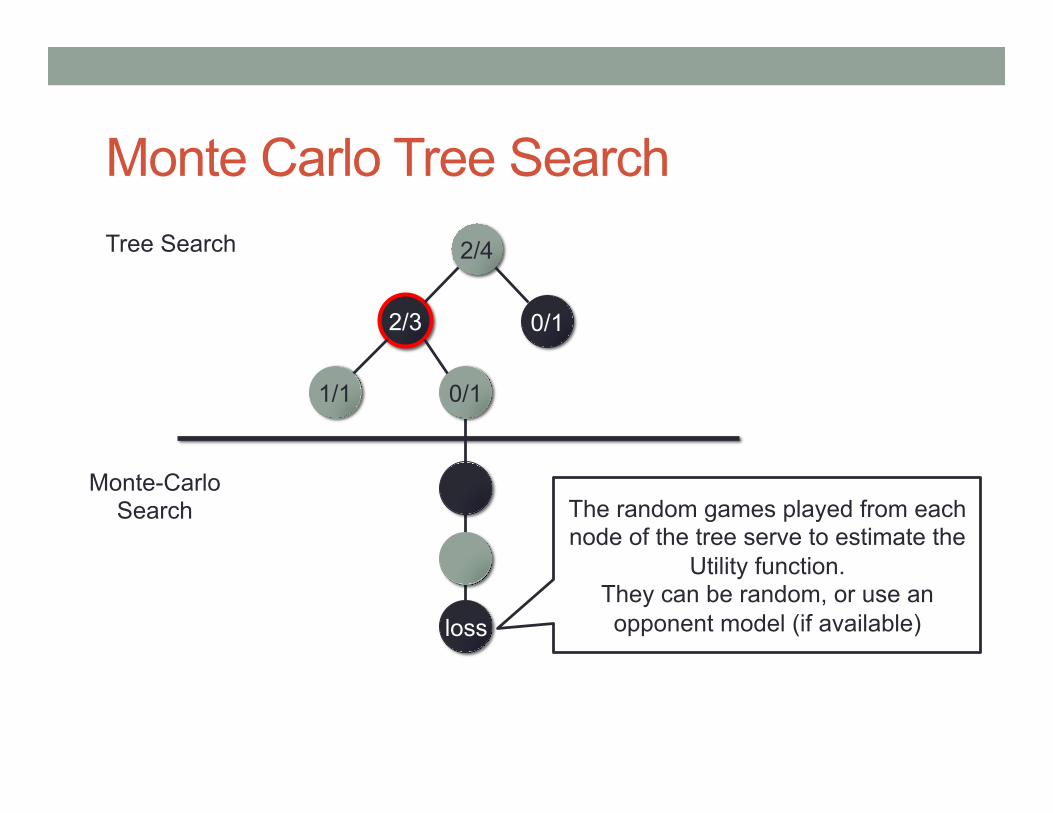
Monte Carlo Tree Search 2/4 Tree Search
Monte-Carlo Search
0/1 2/3
1/1 0/1
loss
The random games played from each node of the tree serve to estimate the
Utility function. They can be random, or use an opponent model (if available)

MCTS Algorithm MCTS(state, player) tree = new Node(state, player) Repeat until computation budget is exhausted node = treePolicy(tree) if (node.isTerminal) child = node else child = node.nextChild(); R = playout(child) child.propagateReward(R) Return tree.bestChild();

Tree Policy: ε-greedy • Given a list of children, which one do we explore in a
given iteration of MCTS?
• Ideally, we want: • To spend more time exploring good children (no point wasting time
on bad children) • But spend some time exploring bad children, just in case they are
actually good (since evaluation is stochastic, it might happen that we were just unlucky, and a child we thought was bad is actually good).
• Simplest idea: ε-greedy • With probability 1-ε: choose the current best • With probability ε: choose one at random

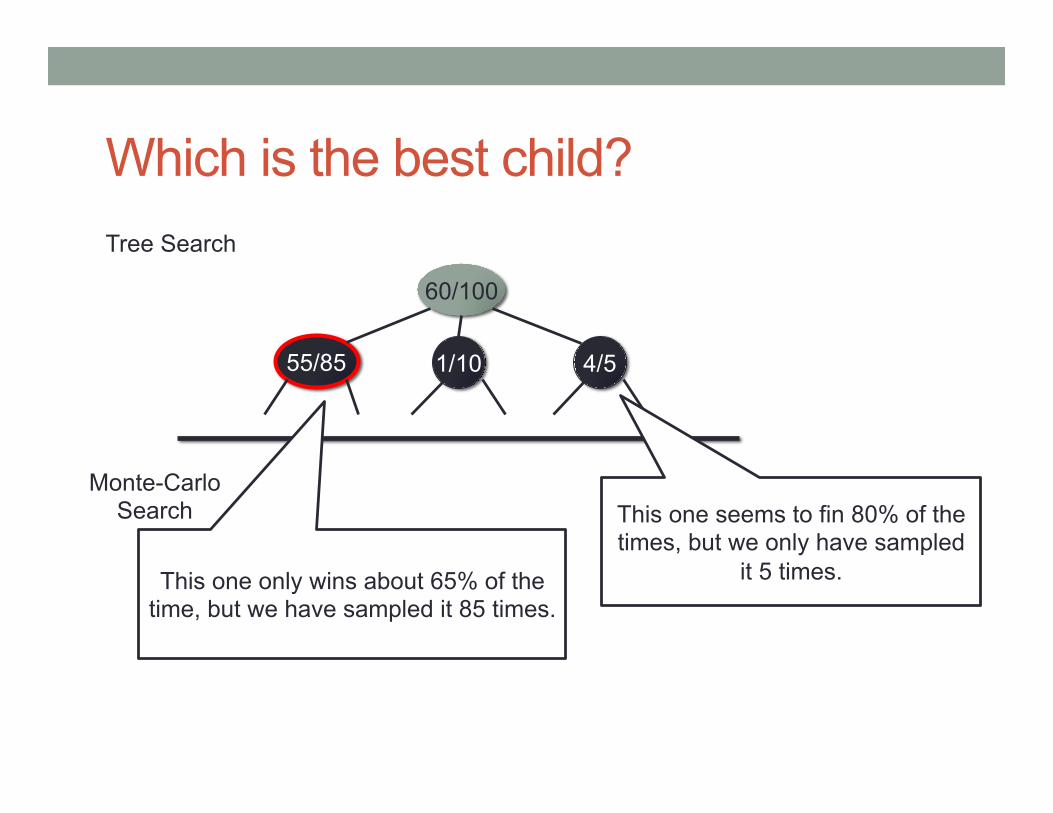
Which is the best child?
60/100
Tree Search
Monte-Carlo Search
1/10 55/85 4/5
Which is the best child?
60/100
Tree Search
Monte-Carlo Search
1/10 55/85 4/5
This one seems to fin 80% of the times, but we only have sampled
it 5 times. This one only wins about 65% of the time, but we have sampled it 85 times.
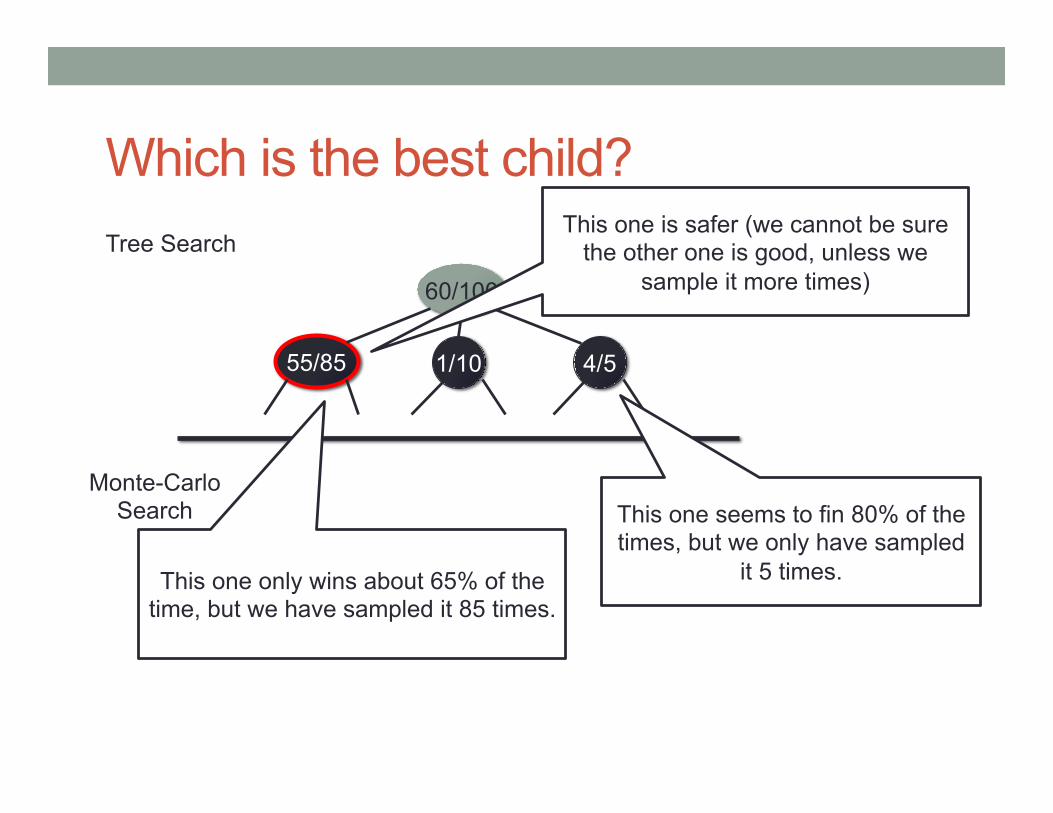
Which is the best child?
60/100
Tree Search
Monte-Carlo Search
1/10 55/85 4/5
This one seems to fin 80% of the times, but we only have sampled
it 5 times. This one only wins about 65% of the time, but we have sampled it 85 times.
This one is safer (we cannot be sure the other one is good, unless we
sample it more times)

Monte Carlo Tree Search • After a fixed number of iterations K (or after the assigned time
is over), MCTS analyzes the resulting tree, and the selected action is that with the highest win ratio (or that with the highest visit count).
• MCTS algorithms do not explore the whole game tree: • They sample the game tree • They spend more time in those moves that are more promising • Any-time algorithms (they can be stopped at any time)
• It can be shown theoretically that when K goes to infinity, the values assigned to each action in the MCTS tree converge to those computed by minimax.
• MCTS algorithms are the standard algorithms for modern Go playing programs

Tree Policy: Can we do Better? • We just learned the ε-greedy policy, but is there a way to
do better?
• ε-greedy is robust, but, for example: • If there are 3 children:
• A: 40/100 • B: 39/100 • C: 2/100

Tree Policy: Can we do Better? • We just learned the ε-greedy policy, but is there a way to
do better?
• ε-greedy is robust, but, for example: • If there are 3 children:
• A: 40/100 • B: 39/100 • C: 2/100
• B and C have the same probability of being chosen, while B is clearly better!
• After lots of iterations, when one child is already clearly better, ε-greedy still keeps sampling bad children with probability ε.
• So can we do better?

Multi-Armed Bandit (MAB) • Imagine you go to Vegas, and you see a row of “bandits”:
• You have no idea which machine gives you the best chance of winning.
• You have 100 tokens to use.
• How can you maximize your expected winnings?

Multi-Armed Bandit (MAB) • Imagine you go to Vegas, and you see a row of “bandits”:
• You have no idea which machine gives you the best chance of winning.
• You have 100 tokens to use.
• How can you maximize your expected winnings?
In terms of game-tree search: - You have a collection of moves
- You only have CPU time to sample them a few times
How do you spread your CPU resources as for figuring out which is
the best one?

MAB: ε-greedy • ε-greedy is the simplest strategy:
• Input: ε (number between 0 and 1, usually small: e.g., 0.1)
• For each “arm”: • Keep track of the average earnings so far: earnings/(coins spent)
• Before spending the next coin: • Figure out which is the best “arm” • With probability 1 – ε: put the coin in the best arm • With probability ε: choose one at random

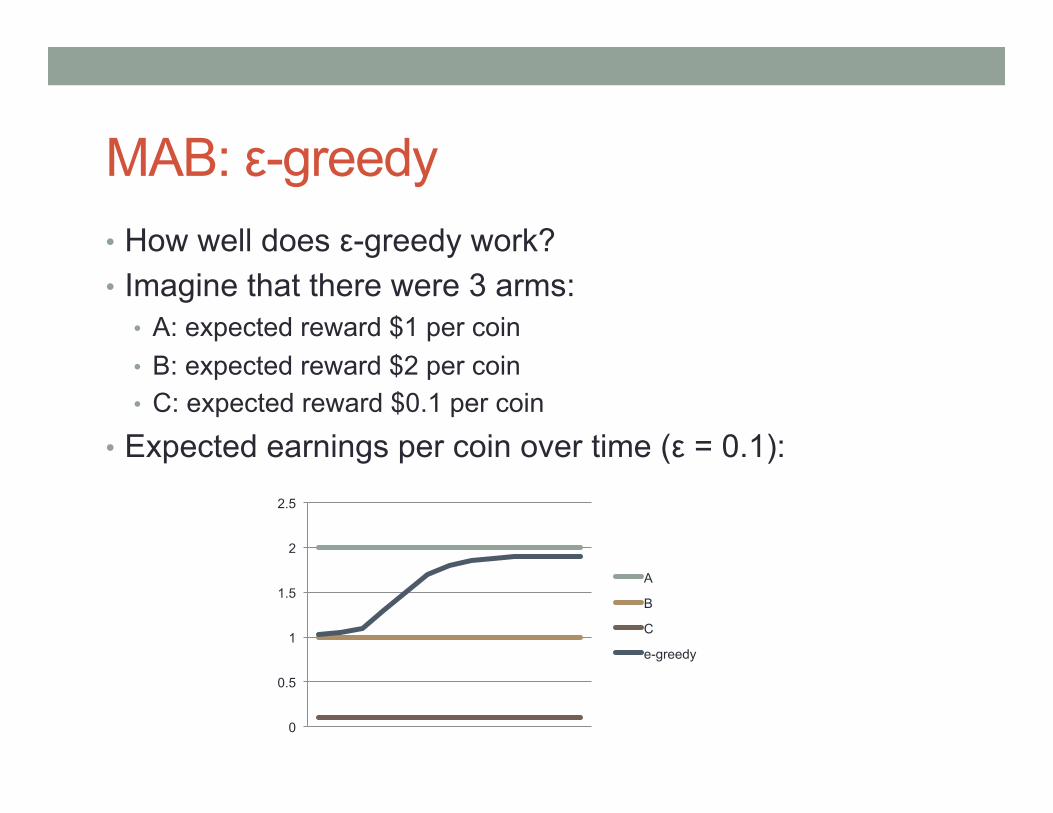
MAB: ε-greedy • How well does ε-greedy work? • Imagine that there were 3 arms:
• A: expected reward $1 per coin • B: expected reward $2 per coin • C: expected reward $0.1 per coin
• Expected earnings per coin over time (ε = 0.1):
MAB: ε-greedy • How well does ε-greedy work? • Imagine that there were 3 arms:
• A: expected reward $1 per coin • B: expected reward $2 per coin • C: expected reward $0.1 per coin
• Expected earnings per coin over time (ε = 0.1):
0
0.5
1
1.5
2
2.5
A
B
C
e-greedy
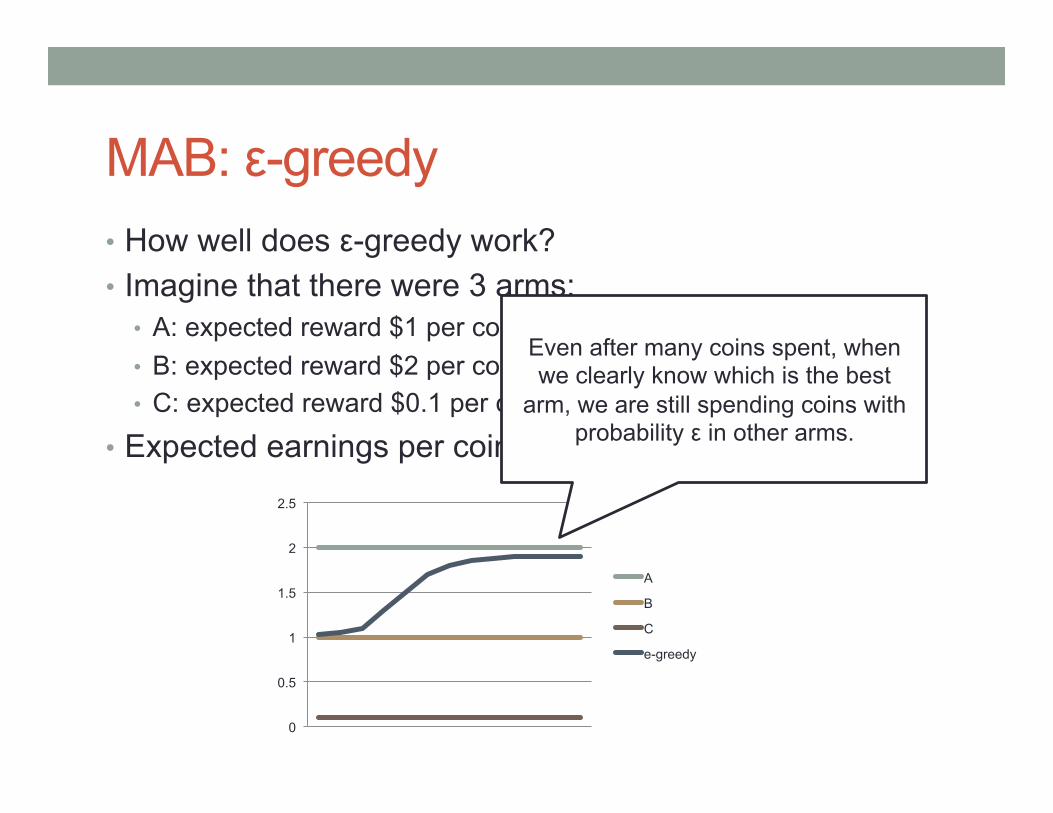
MAB: ε-greedy • How well does ε-greedy work? • Imagine that there were 3 arms:
• A: expected reward $1 per coin • B: expected reward $2 per coin • C: expected reward $0.1 per coin
• Expected earnings per coin over time (ε = 0.1):
0
0.5
1
1.5
2
2.5
A
B
C
e-greedy
Even after many coins spent, when we clearly know which is the best
arm, we are still spending coins with probability ε in other arms.

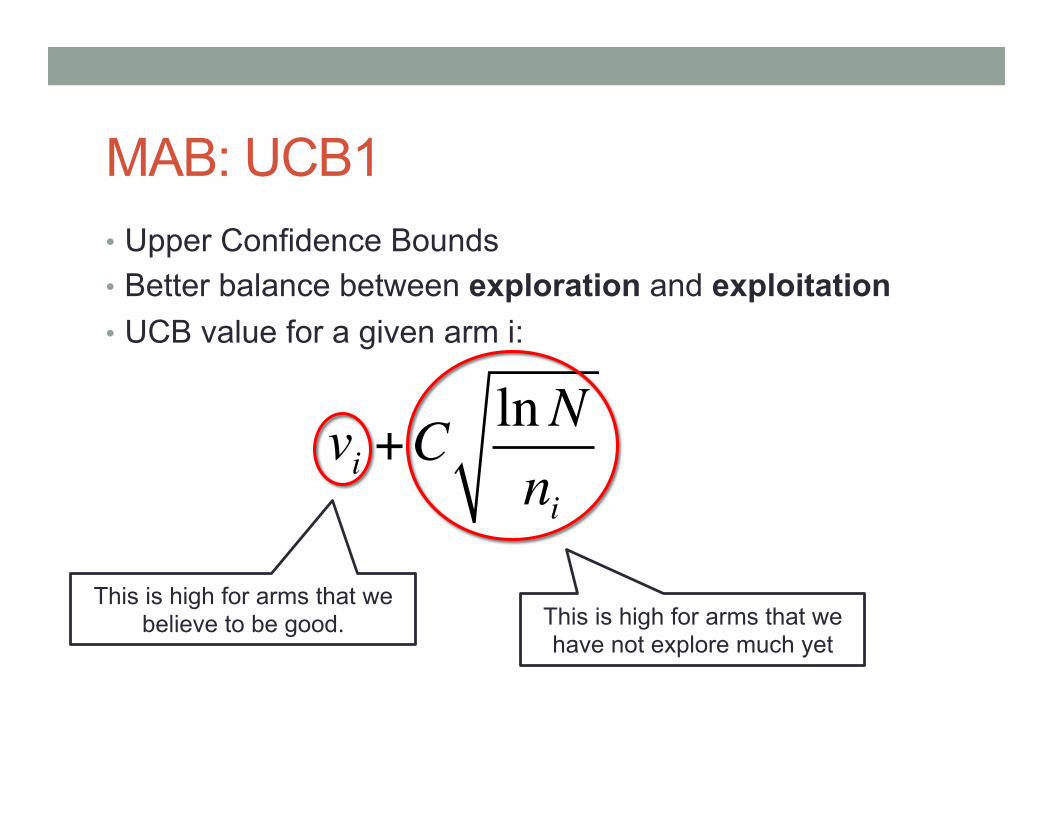
MAB: UCB1 • Upper Confidence Bounds • Better balance between exploration and exploitation • UCB value for a given arm i:
vi +ClnNni
Expected reward so far Number of coins used in this arm so far
Number of coins used so far in total
MAB: UCB1 • Upper Confidence Bounds • Better balance between exploration and exploitation • UCB value for a given arm i:
vi +ClnNni
This is high for arms that we believe to be good. This is high for arms that we
have not explore much yet
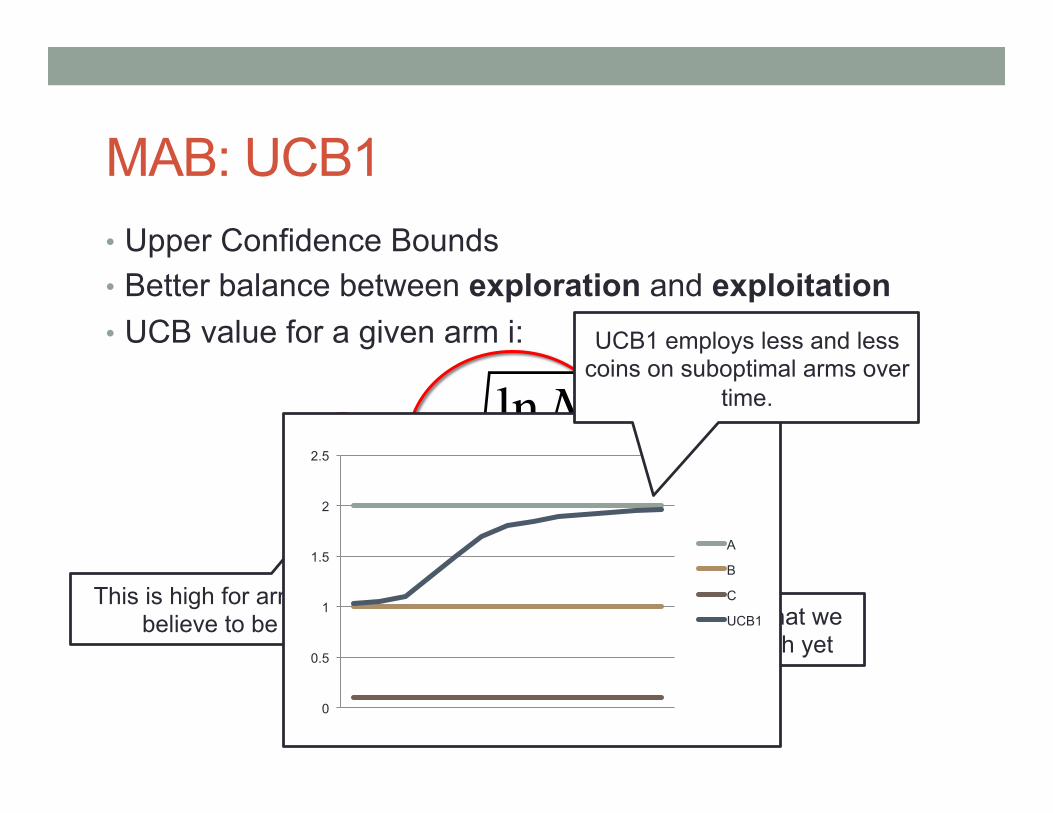
MAB: UCB1 • Upper Confidence Bounds • Better balance between exploration and exploitation • UCB value for a given arm i:
vi +ClnNni
This is high for arms that we believe to be good. This is high for arms that we
have not explore much yet
0
0.5
1
1.5
2
2.5
A
B
C
UCB1
UCB1 employs less and less coins on suboptimal arms over
time.

UCT UCT(state, player) tree = new Node(state, player) Repeat until computation budget is exhausted node = selectNodeViaUCB1(tree) if (node.isTerminal) child = node else child = node.nextChild(); R = playout(child) child.propagateReward(R) Return tree.bestChild();
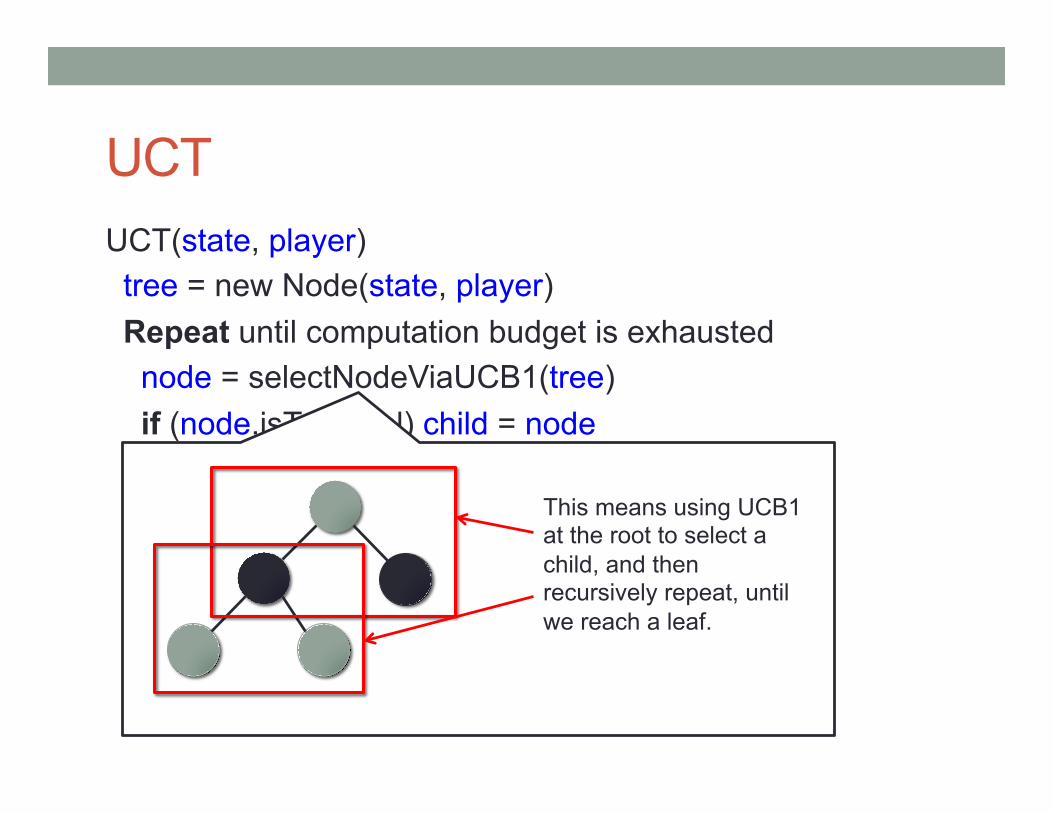
UCT UCT(state, player) tree = new Node(state, player) Repeat until computation budget is exhausted node = selectNodeViaUCB1(tree) if (node.isTerminal) child = node else child = node.nextChild(); R = playout(child) child.propagateReward(R) Return tree.bestChild();
This means using UCB1 at the root to select a child, and then recursively repeat, until we reach a leaf.

Games using MCTS Variants • Go playing programs:
• AlphaGo • MoGo • CrazyStone • Valkyria • Pachi • Fuego • The Many Faces of Go • Zen • …

Games using MCTS Variants • Card Games:
• Prismata

Games using MCTS Variants • Strategy Games:
• TOTAL WAR: ROME II: • http://aigamedev.com/open/coverage/mcts-rome-ii/

AlphaGo • Google’s AlphaGo defeated Lee Sedol in a best of 5
match in 2016 (a few months ago!) • How?
• Integrating MCTS with deep convolutional neural networks. • Data set of 30 million position from the KGS Go Server • Train a collection of neural networks to predict the probability of
each move in the dataset and the expected value of a given board. • Use the neural networks to inform the MCTS search.
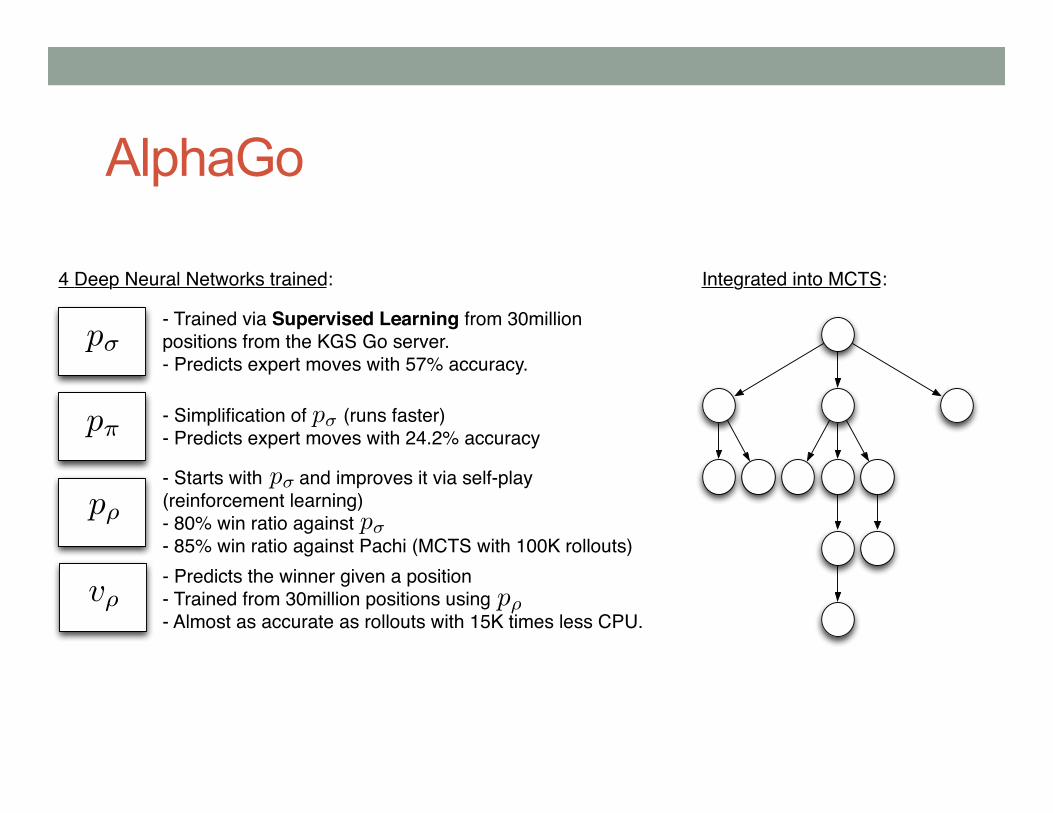
AlphaGo
p�
4 Deep Neural Networks trained:
- Trained via Supervised Learning from 30millionpositions from the KGS Go server.- Predicts expert moves with 57% accuracy.
- Simplification of (runs faster)- Predicts expert moves with 24.2% accuracy
p⇡
- Starts with and improves it via self-play (reinforcement learning)- 80% win ratio against- 85% win ratio against Pachi (MCTS with 100K rollouts)
p�
p�
p�
p⇢
v⇢- Predicts the winner given a position- Trained from 30million positions using- Almost as accurate as rollouts with 15K times less CPU.
p⇢
Integrated into MCTS:
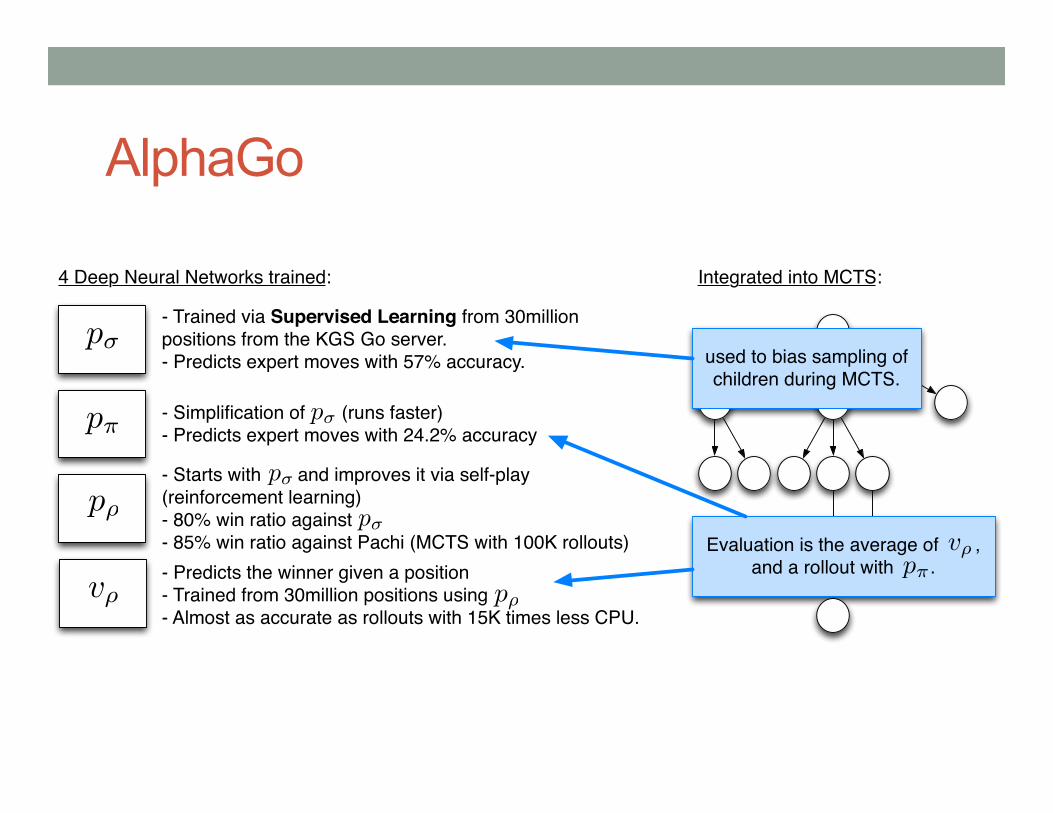
AlphaGo
p�
4 Deep Neural Networks trained:
- Trained via Supervised Learning from 30millionpositions from the KGS Go server.- Predicts expert moves with 57% accuracy.
- Simplification of (runs faster)- Predicts expert moves with 24.2% accuracy
p⇡
- Starts with and improves it via self-play (reinforcement learning)- 80% win ratio against- 85% win ratio against Pachi (MCTS with 100K rollouts)
p�
p�
p�
p⇢
v⇢- Predicts the winner given a position- Trained from 30million positions using- Almost as accurate as rollouts with 15K times less CPU.
p⇢
Integrated into MCTS:
Evaluation is the average of , and a rollout with .
used to bias sampling of children during MCTS.
v⇢p⇡

Extensions • What happens to Game Tree Search when a game has
an element of chance? • E.g., rolling a dice?
• What happens to Game Tree Search when the state is not fully observable? • (this is more complex)

Extensions • What happens to Game Tree Search when a game has
an element of chance? • E.g., rolling a dice? • Add additional “average” layers on the tree
• What happens to Game Tree Search when the state is not fully observable? • (this is more complex) • One possibility: sample the possible states, and then do game tree
search as if it was fully observable.

Summary • Minimax (+ alpha-beta):
• For perfect information, deterministic games • Low branching factor
• When game is too complex (large branching factor): • Portfolio Search • Monte Carlo Tree Search
• Extensions for: • Stochastic games (e.g., dice rolling) • Partial information (e.g., players cannot see the cards of others)














![Introduction to Artificial Intelligence Game Playingbeckert/teaching/... · Minimax Algorithm function MINIMAX-DECISION(game) returns an operator for each op in OPERATORS[game] do](https://static.fdocument.org/doc/165x107/5fcac810217fca008d2a9652/introduction-to-artiicial-intelligence-game-playing-beckertteaching-minimax.jpg)



