« Amidon: du modèle biologique au modèle acellulaire · réverse et la biochimie • Le choix du...
51
« Amidon: du modèle biologique au modèle acellulaire"
Transcript of « Amidon: du modèle biologique au modèle acellulaire · réverse et la biochimie • Le choix du...

« Amidon: du modèle biologique aumodèle acellulaire"
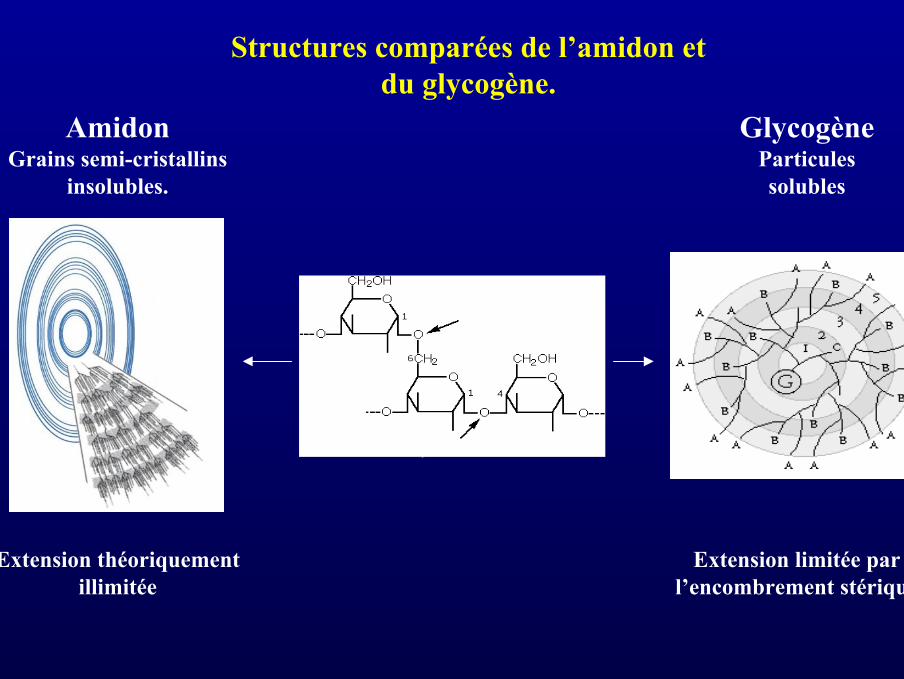
Structures comparées de l’amidon etdu glycogène.
AmidonGrains semi-cristallins
insolubles.
GlycogèneParticulessolubles
Extension limitée parl’encombrement stérique
Extension théoriquementillimitée
Liaison α,1-6
Liaison α,1-4
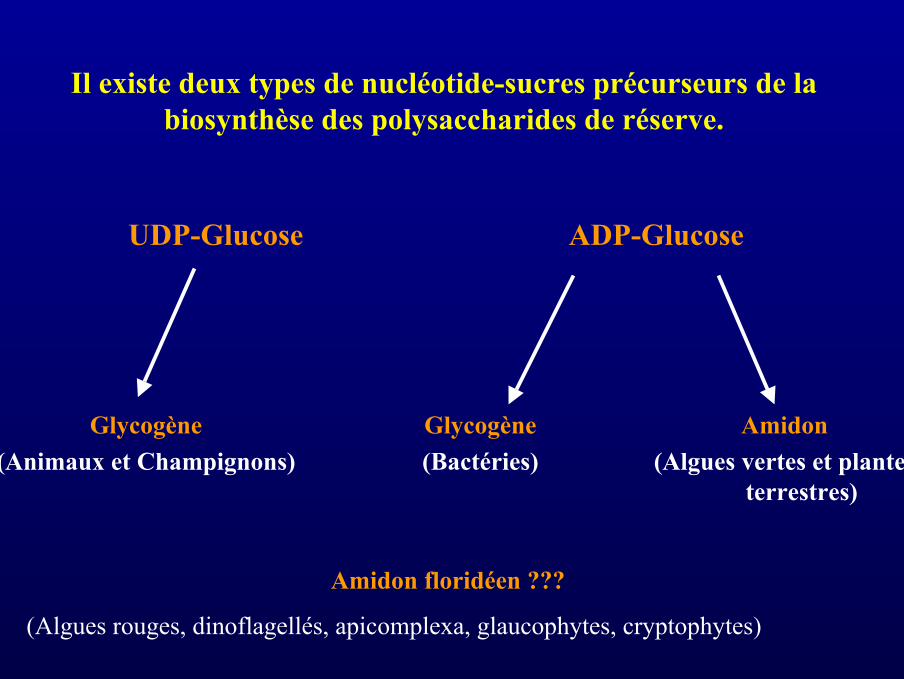
Il existe deux types de nucléotide-sucres précurseurs de labiosynthèse des polysaccharides de réserve.
UDP-Glucose ADP-Glucose
Glycogène(Animaux et Champignons)
Glycogène(Bactéries)
Amidon(Algues vertes et plantes
terrestres)
Amidon floridéen ???
(Algues rouges, dinoflagellés, apicomplexa, glaucophytes, cryptophytes)
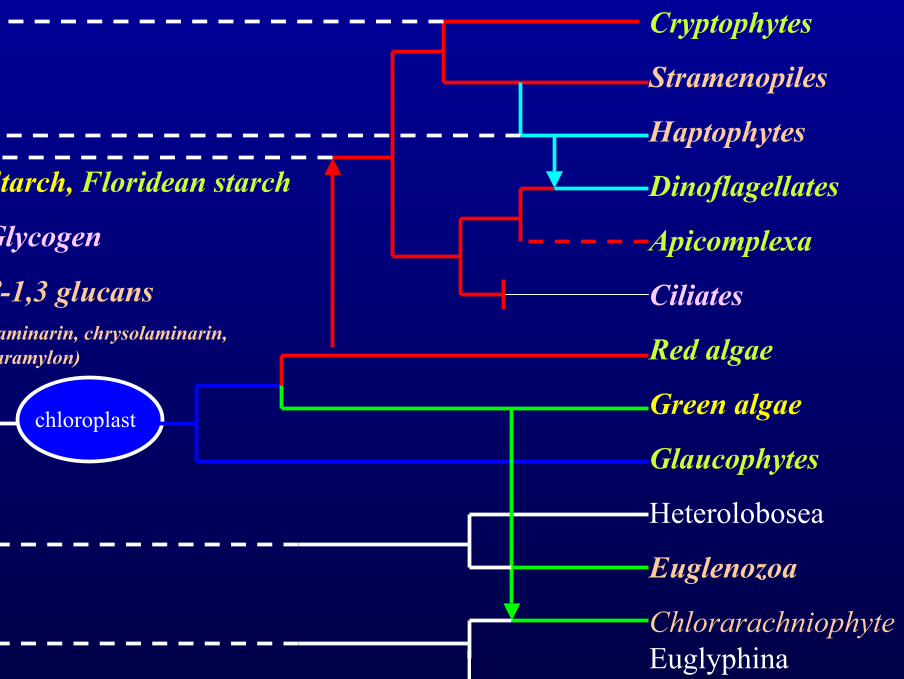
Cryptophytes
Stramenopiles
Haptophytes
Dinoflagellates
Apicomplexa
Ciliates
Red algae
Green algae
Glaucophytes
Heterolobosea
Euglenozoa
ChlorarachniophyteEuglyphina
Chromaleolate
PlantaeCabozoa
chloroplast
Starch, Floridean starch
Glycogen
β-1,3 glucans(laminarin, chrysolaminarin,paramylon)
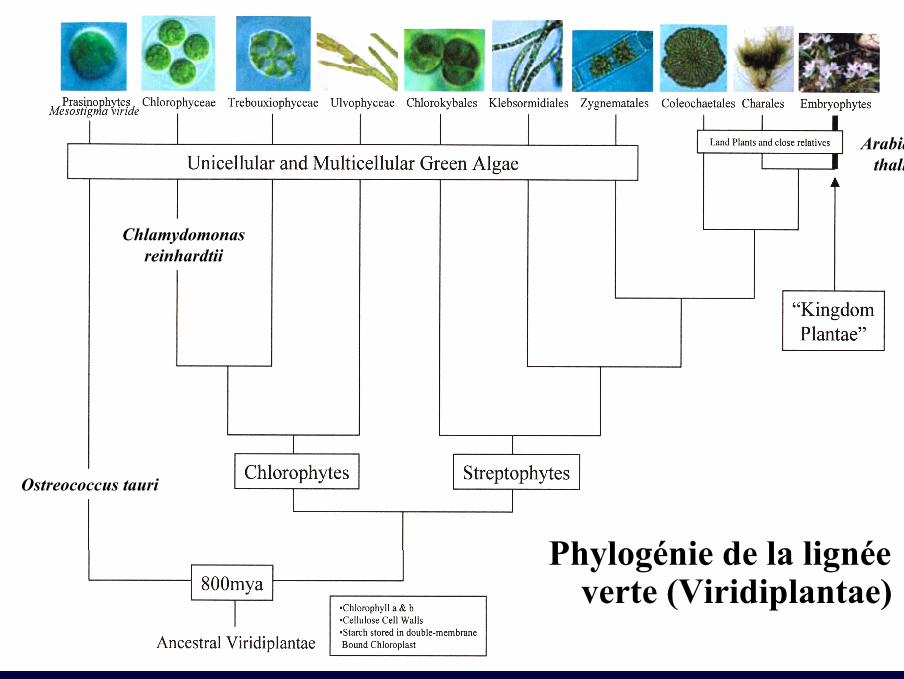
Ostreococcus tauri
Chlamydomonasreinhardtii
Arabidopsisthaliana
Phylogénie de la lignéeverte (Viridiplantae)

• Comment se réalise la biosynthèse de l’amylopectine• Comment se réalise la biosynthèse de l’amylose• Comment le grain est il initié ?• Comment les métabolisme du glycogène des
cyanobactéries a-t-il pu évoluer vers l’édification destructures cristallines complexes ?
• Comment le métabolisme est-il régulé ?• Quel est le métabolisme de l’amidon floridéen ?

La relation gène enzyme permet de décrire laphysico-chimie de l’assemblage du grain
• L’ensemble des réactions chimiques dans la cellulenécessite la présence de catalyseurs
• Tous les catalyseurs cellulaires sont des protéines• Chaque protéine est codée par un gène• La séquence en nucléotides d’un gène permet de déduire
la séquence en acides aminés de la protéine produit dugène
• La séquence en acides aminés permet quelques fois dedéduire la nature de la fonction enzymatique

La connaissance de la séquence des génomes permetd’avoir une idée de la complexité de l’assemblage du
grain d’amidon• En théorie la connaissance de la séquence du génome
devrait permettre de déduire le nombre et la fonction detoutes les réactions impliquées
• En pratique on ne peut souvent pas prédire la fonctiond’une enzyme avec sa séquence en acides aminés
• La recherche biologique s’applique à établir la nature etla fonction des enzymes impliquées
• Des banques de données de plus en plus exhaustivespermettent de déduire la fonction supposée de certainesprotéines
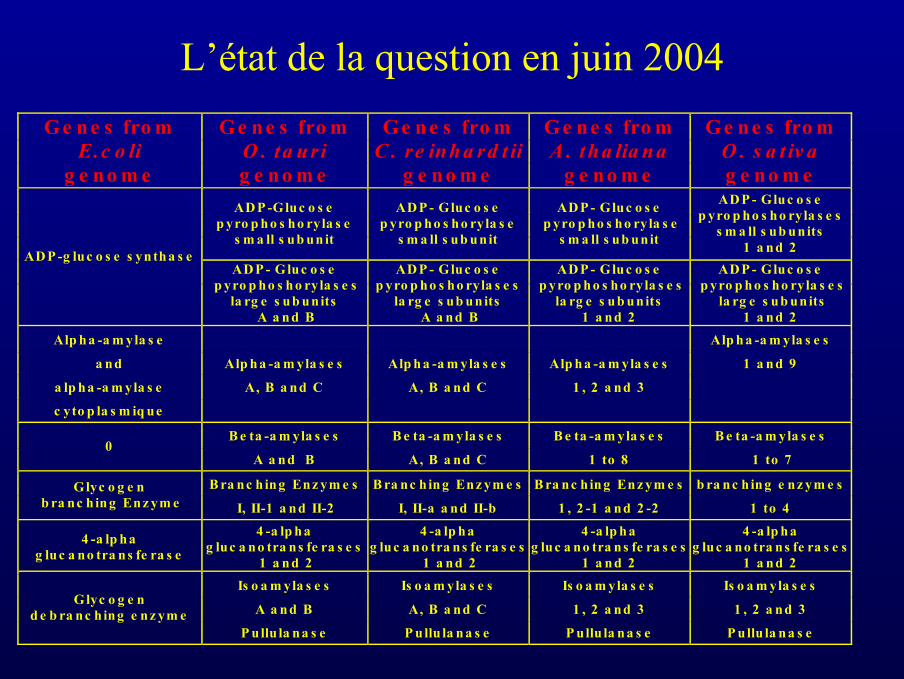
Ge n e s fro m E.c o li
g e no m e
Ge ne s fro m O . ta ur i g e no m e
Ge ne s fro m C . re inha rd t ii
g e no m e
Ge ne s fro m A . tha lia n a
g e no m e
Ge ne s fro mO . s a t iv a g e no m e
AD P -Gluc o s e p yro p ho s ho ryla s e
s m a ll s ub un it
AD P - Gluc o s e p yro p ho s ho ryla s e
s m a ll s ub unit
AD P - Gluc o s e p yro p ho s ho ryla s e
s m a ll s ub unit
AD P - Gluc o s e p yro p ho s ho ryla s e s
s m a ll s ub units 1 a nd 2 AD P -g luc o s e s yn tha s e
AD P - Gluc o s e p yro p ho s ho ryla s e s
la rg e s ub units A a nd B
AD P - Gluc o s e p yro p ho s ho ryla s e s
la rg e s ub un its A a nd B
AD P - Gluc o s e p yro p ho s ho ryla s e s
la rg e s ub units 1 a nd 2
AD P - Gluc o s e p yro p ho s ho ryla s e s
la rg e s ub un its 1 a nd 2
Alp ha -a m yla s e Alp ha -a m yla s e s
a nd Alp ha -a m yla s e s Alp ha -a m yla s e s Alp ha -a m yla s e s 1 a nd 9
a lp ha -a m yla s e A, B a nd C A, B a nd C 1 , 2 a nd 3 c yto p la s m iq ue
B e ta -a m yla s e s B e ta -a m yla s e s B e ta -a m yla s e s B e ta -a m yla s e s 0
A a nd B A, B a nd C 1 to 8 1 to 7
B ra nc hing Enz ym e s B ra nc hing Enz ym e s B ra nc hing Enz ym e s b ra nc hing e nz ym e sGlyc o g e n b ra nc hing Enz ym e I, II-1 a nd II-2 I, II-a a nd II-b 1 , 2 -1 a nd 2 -2 1 to 4
4 -a lp ha g luc a no tra ns fe ra s e
4 -a lp ha g luc a no tra ns fe ra s e s
1 a nd 2
4 -a lp ha g luc a no tra ns fe ra s e s
1 a nd 2
4 -a lp ha g luc a no tra ns fe ra s e s
1 a nd 2
4 -a lp ha g luc a no tra ns fe ra s e s
1 a nd 2 Is o a m yla s e s Is o a m yla s e s Is o a m yla s e s Is o a m yla s e s
A a nd B A, B a nd C 1 , 2 a nd 3 1 , 2 a nd 3 Glyc o g e n
d e b ra nc hing e nz ym e P u llu la na s e P ullu la na s e P ullu la na s e P ullu la na s e
L’état de la question en juin 2004
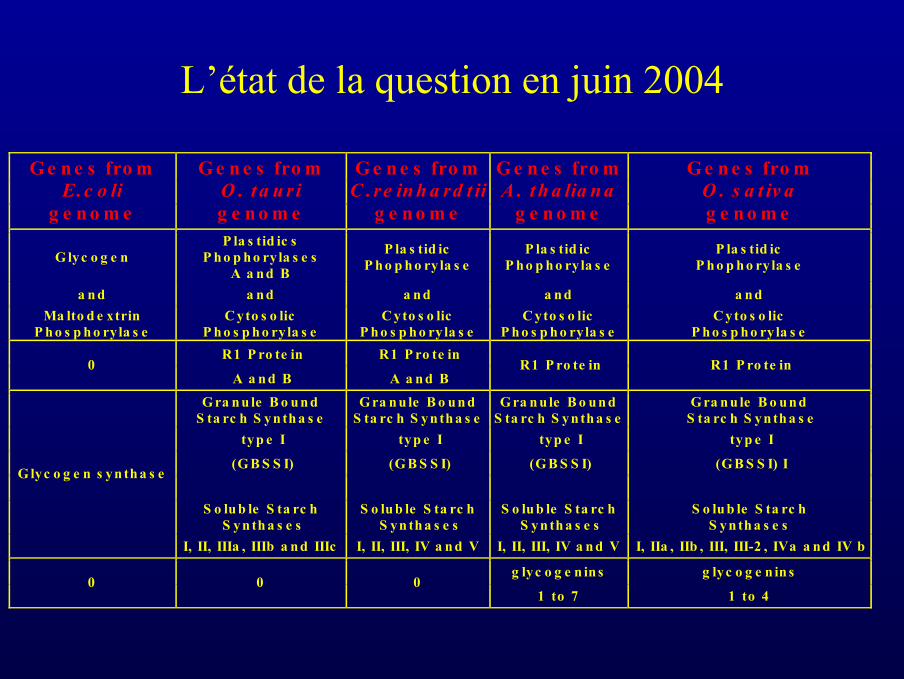
G e n e s fro m E.c o li
g e n o m e
G e n e s fro m O . t a u r i g e n o m e
G e n e s fro mC .re in h a rd t ii
g e n o m e
G e n e s fro m A . t h a lia n a
g e n o m e
G e n e s fro m O . s a t iv a g e n o m e
G lyc o g e n P la s tid ic s
P h o p h o ry la s e s A a n d B
P la s tid ic P h o p h o ryla s e
P la s tid ic P h o p h o ryla s e
P la s tid ic P h o p h o ry la s e
a n d a n d a n d a n d a n d Ma lto d e xtrin
P h o s p h o ryla s e C yto s o lic
P h o s p h o ryla s e C yto s o lic
P h o s p h o ry la s e C yto s o lic
P h o s p h o ryla s e C yto s o lic
P h o s p h o ry la s e R1 P ro te in R1 P ro te in
0 A a n d B A a n d B
R1 P ro te in R1 P ro te in
G ra n u le B o u n d S ta rc h S yn th a s e
G ra n u le B o u n dS ta rc h S yn th a s e
G ra n u le B o u n d S ta rc h S yn th a s e
G ra n u le B o u n d S ta rc h S yn th a s e
typ e I typ e I typ e I typ e I
(G B S S I) (G B S S I) (G B S S I) (G B S S I) I
S o lu b le S ta rc h
S yn th a s e s S o lu b le S ta rc h
S yn th a s e s S o lu b le S ta rc h
S yn th a s e s S o lu b le S ta rc h
S yn th a s e s
G lyc o g e n s yn th a s e
I, II, IIIa , IIIb a n d IIIc I, II, III, IV a n d V I, II, III, IV a n d V I, IIa , IIb , III, III-2 , IVa a n d IV b
g lyc o g e n in s g lyc o g e n in s 0 0 0
1 to 7 1 to 4
L’état de la question en juin 2004

Conclusions
• L’édification du grain d’amidon est beaucoupplus compliquée qu’on ne le croit et requiert unminimum de 30 réactions enzymatiquesdifférentes
• Le métabolisme de l’amidon est unecaractéristique « ancestrale » de la lignée verte.Elle peut donc être étudiée dans n’importe quelorganisme de cette lignée

Comment la recherche biologique permet-ellede démasquer la fonction et la nature des
enzymes impliquées ?
• La biochimie s’emploie à purifier et caractériserles enzymes. Cette démarche nécessite que l’onaie déjà une idée de la nature de cette enzyme
• La génétique s’emploie à démasquer le nombre etla nature des enzymes impliquées en les rendantsélectivement inactives.

Comment les généticiens rendent ils lesenzymes impliquées sélectivement inactives
• Soit ils engendrent des mutations aux hasard etsélectionnent dans une population de mutants ceux dontla biosynthèse de l’amidon est perturbée: c’est lagénétique classique encore appelée inférence génétique
• Soit ils engendrent dans un gène particulier, qu’ilssoupçonnent impliqué, une mutation et examine l’effet del’absence de l’enzyme codée par le gène déficient dans lemétabolisme de l’amidon: c’est la génétique inverse
• Seule la génétique classique ne requiert aucuneconnaissance préalable des fonctions impliquées

Un exemple idéalisé d’inférence génétique: lasynthèse du tryptophane (I)
• Le généticien commence par engendrer des mutations auhasard sur un modèle biologique pertinent (la levure):c’est la mutagénèse
• Ils sélectionnent les mutants devenus incapables depousser en absence de tryptophane (par ex 37 sur un totalde 100000 colonies de levure): c’est le criblagephénotypique
• Ils croisent les mutants entre eux pour dénombrer lenombre de gènes mutants: c’est l’analyse decomplémentation

Un exemple idéalisé d’inférence génétique: lasynthèse du tryptophane (II)
• Les 37 mutants se répartissent en 5 gènes différents (encoreappelés groupes de complémentation). Il n’existe jamais decertitude de toucher tous les gènes possibles au moins une fois
• Chaque mutant renferme une mutation différente conduisant àun allèle déficient du gène qui annule l’activité enzymatiquecorrespondante
• Le blocage de l’étape enzymatique concernée aboutit àl’accumulation du précurseur de la réaction

Un exemple idéalisé d’inférence génétique: lasynthèse du tryptophane (III)
• Tous les mutants atteints dans le même gène accumuleront lemême précurseur
• Les niveaux d’accumulation sont tels qu’il devient possiblepour le chimiste de déterminer la structure de cette molécule
• 5 précurseurs ont été identifiés de cette manière: l’acidechorismique, anthranilique, phosphoribosylanthranilique, le 1-O- carboxyphenylamino-1-deoxyribulose-5-P, l’indole-3-glycerol-P: c’est la caractérisation biochimique du phénotypemutant
• Comment établir la séquence de la synthèse ?

• Pour déterminer la séquence de la synthèse, on croise deux souchesportant deux blocages différents dans la voie de synthèse ex: un mutantaccumulant de l’indole-3-glycerol-P et un mutant accumulant del’anthranilate. On isole une souche portant les 2 mutations simultanément:c’est l’analyse d’épistasie
• Possibilité 1: l’indole-3-glycerol-P est synthétisé avant l’anthranilate:l’I3P s’accumulera
• Possibilité 2: l’indole-3-glycerol-P est synthétisé après l’anthranilate:l’anthranilate s’accumulera
Un exemple idéalisé d’inférence génétique: lasynthèse du tryptophane (IV)
indole3P anthranilate tryptophane
anthranilate indole3P tryptophane
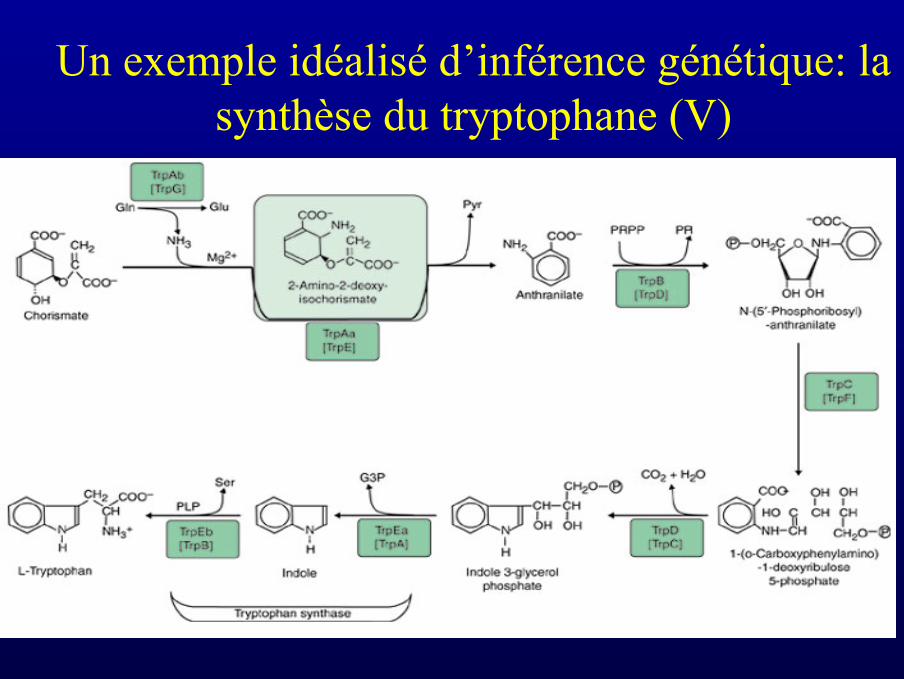
Un exemple idéalisé d’inférence génétique: lasynthèse du tryptophane (V)

Un exemple idéalisé d’inférence génétique: lasynthèse du tryptophane (VI)
• Pour connaître la séquence de l’enzyme impliquée à chaque étape, legénéticien purifiera (on dit qu’il clone) le gène normal correspondant
• L’enzyme dont le gène est désormais « cloné » pourra être produite engrandes quantités et étudiée en détail
• Le généticien ne se bornera pas à décrypter les voies métaboliques. Il seraattentif à analyser les effets secondaires des mutations sur d’autres voiesmétaboliques : c’est l’analyse de pleiotropie (ex aa aromatiques)
• Pour analyser la régulation métabolique des mutants seront soumis à uneseconde mutagénèse en vue de restaurer le phénotype normal: c’estl’analyse de suppression

Les limites de l’inférence génétique (I)
• La présence d’une enzyme active domine sur son absence dans unecellule renfermant une copie d’un gène actif et une mutation de cemême gène (dans le cas des génomes diploides). On dit que l’allèlemutant est récessif et l’allèle normal dominant
• De la même manière dans un génome simple (haploide) l’existencede deux copies d’un même gène nécessite l’extinction des deux parmutation pour visualiser un phénotype défectueux
• La probalité de toucher lors d’une mutagénèse aléatoire deux gènesdupliqués simultanément est proche de 0.

Les limites de l’inférence génétique (II)
• L’efficacité de l’inférence génétique dépend de l’efficacitédu crible permettant de repérer les mutants
• L’efficacité de l’inférence génétique dépend de l’absencede gènes redondants ou dupliqués
• L’analyse d’épistasie ne peut s’appliquer aisément que siles voies métaboliques sont séquentielles et simples

La génétique réverse peut pallier les limitesde l’inférence génétique
• Si plusieurs activités enzymatiques sontsoupçonnées impliquées dans une voiemétabolique, il reste possible de les inactiver parmutations ciblées et de combiner les mutationspar de simples croisement
• La génétique réverse impose que l’on aie déjà uneidée de ce que l’on veut inhiber

L’assemblage du grain d’amidon est difficile àappréhender par l’inférence génétique
• Pratiquement toutes les enzymes sont présentes sousforme multiple et partiellement redondante
• La synthèse est typiquement « non linéaire ». En effet desenzymes d’élongation synthétisent des produits utiliséscomme substrat par des enzymes de ramification quiforment des produits utilisables à nouveau par lesenzymes de ramification…
• Les outils de biochimie structurale ne permettent pasd’apprécier la structure des intermédiaires

Conclusions
• La complexité de l’assemblage du grain d’amidonrequiert une démarche de recherche utilisantsimultanément l’inférence génétique, la génétiqueréverse et la biochimie
• Le choix du ou des modèles d’étude se fera enfonction des outils disponibles relativement à cestrois approches

• Comment se réalise la biosynthèse de l’amylopectine• Comment se réalise la biosynthèse de l’amylose• Comment le grain est il initié ?• Comment les métabolisme du glycogène des
cyanobactéries a-t-il pu évoluer vers l’édification destructures cristallines complexes ?
• Comment le métabolisme est-il régulé ?• Quel est le métabolisme de l’amidon floridéen ?
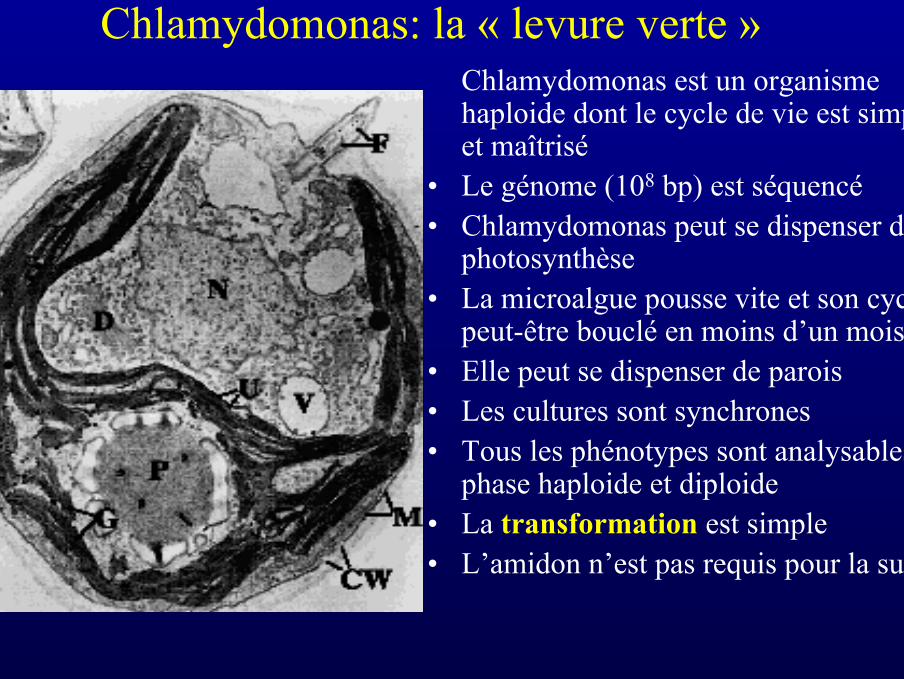
Chlamydomonas: la « levure verte »Chlamydomonas est un organismehaploide dont le cycle de vie est simpleet maîtrisé
• Le génome (108 bp) est séquencé• Chlamydomonas peut se dispenser de la
photosynthèse• La microalgue pousse vite et son cycle
peut-être bouclé en moins d’un mois• Elle peut se dispenser de parois• Les cultures sont synchrones• Tous les phénotypes sont analysables en
phase haploide et diploide• La transformation est simple• L’amidon n’est pas requis pour la survie
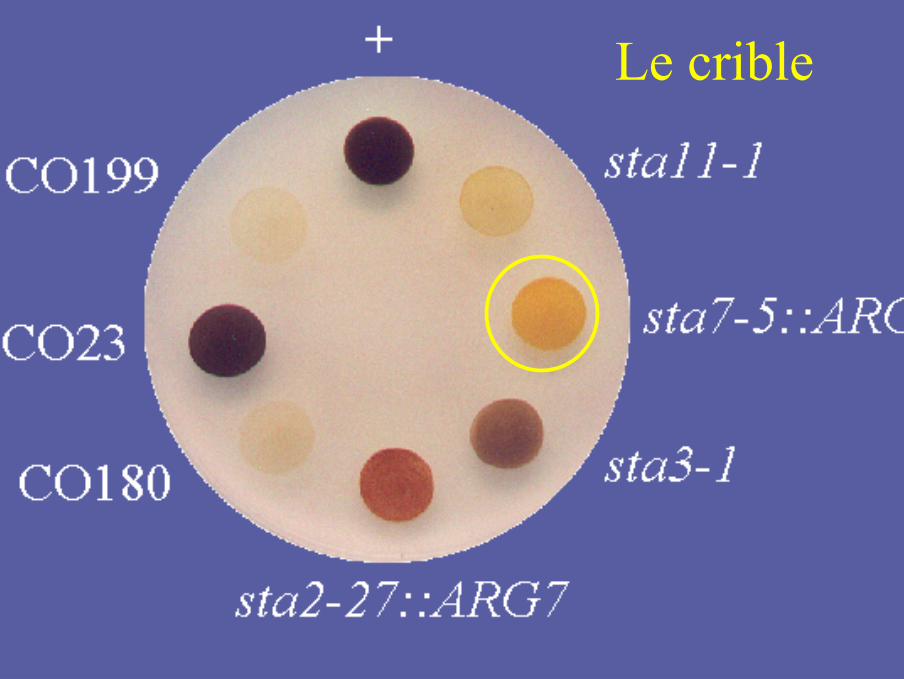
Le crible

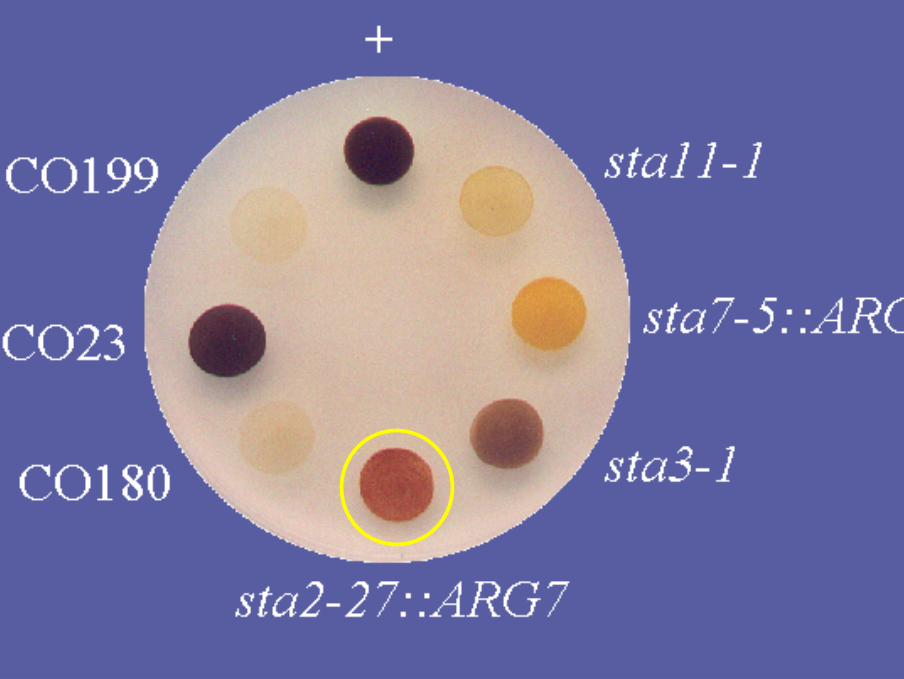
Caractérisation des mutants sta7
• Ces mutants ont été sélectionnés par leurphénotype « brun-orange » de coloration iode
• Ils ne contiennent plus d’amidon et renfermenttoutes les enzymes de synthèse
• Ils subtituent la synthèse d’amidon par celle d’unepetite quantité de glycogène
Découverte de la défectuosité enzymatique
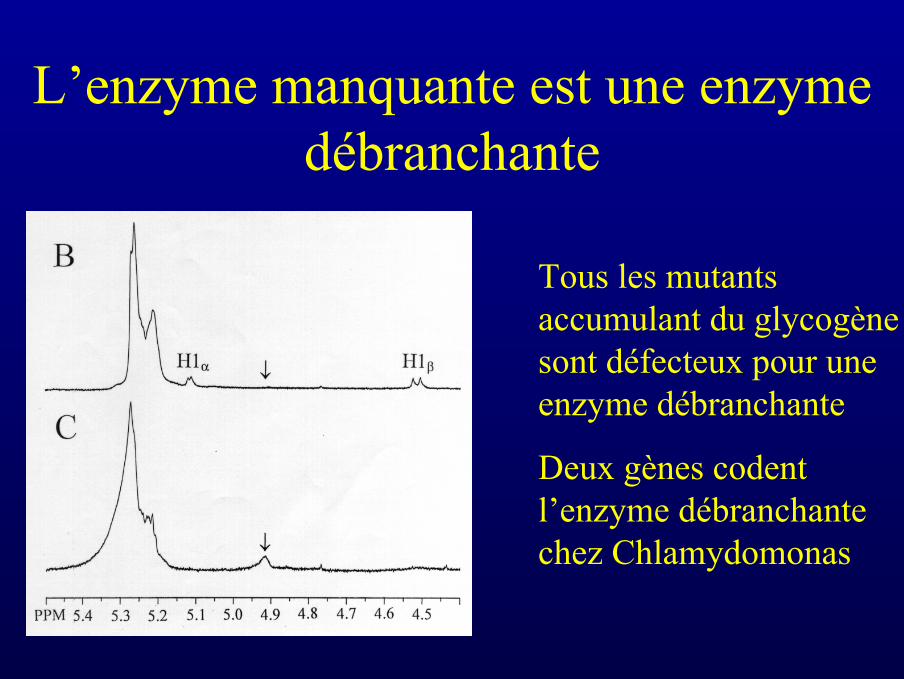
L’enzyme manquante est une enzymedébranchante
Tous les mutantsaccumulant du glycogènesont défecteux pour uneenzyme débranchante
Deux gènes codentl’enzyme débranchantechez Chlamydomonas

L’interprétation du phénotype mutant• L’épissage de glucanes est un concept expliquant la
différence entre la synthèse de glycogène des bactéries etd’amylopectine chez les plantes
• Au cours de la synthèse du glycogène la position desbranches est assurée par l’interaction unique de l’enzymede branchement et de la glycogène synthétase (enzymed’élongation)
• Au cours de la synthèse d’amylopectine, la structureramifiée synthétisée par l’enzyme de branchement etl’amidon synthétase est appelée pre-amylopectine
• Au cours de l’épissage l’isoamylase débranche leschaînes qui préviennent la cristallisation dupolysaccharide

Conclusions
• Une approche de type inférence génétique démontreque le débranchement par l’isoamylase distingue lasynthèse de polymères cristallins de celle duglycogène
• La démonstration de la validité du modèle del’épissage passe par sa validation dans un systèmeacellulaire de synthèse d’amylopectine
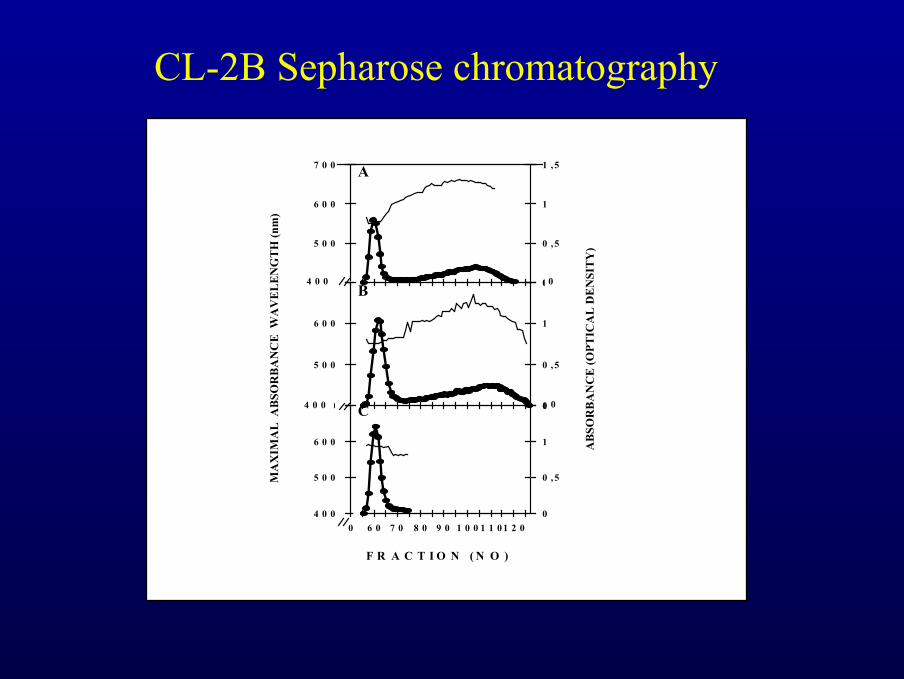
CL-2B Sepharose chromatography
4 0 0
5 0 0
6 0 0
7 0 0
0
0 ,5
1
1 ,5A
4 0 0
5 0 0
6 0 0
7 0 0
0
0 ,5
1
1 ,5BM
AX
IMA
L A
BSO
RB
AN
CE
WA
VE
LE
NG
TH
(nm
)
AB
SOR
BA
NC
E (O
PTIC
AL
DE
NSI
TY
)
4 0 0 0
F R A C T I O N ( N O )
4 0 0
5 0 0
6 0 0
7 0 0
0 6 0 7 0 8 0 9 0 1 0 0 1 1 01 2 00
0 ,5
1
1 ,5C4 0 0 0
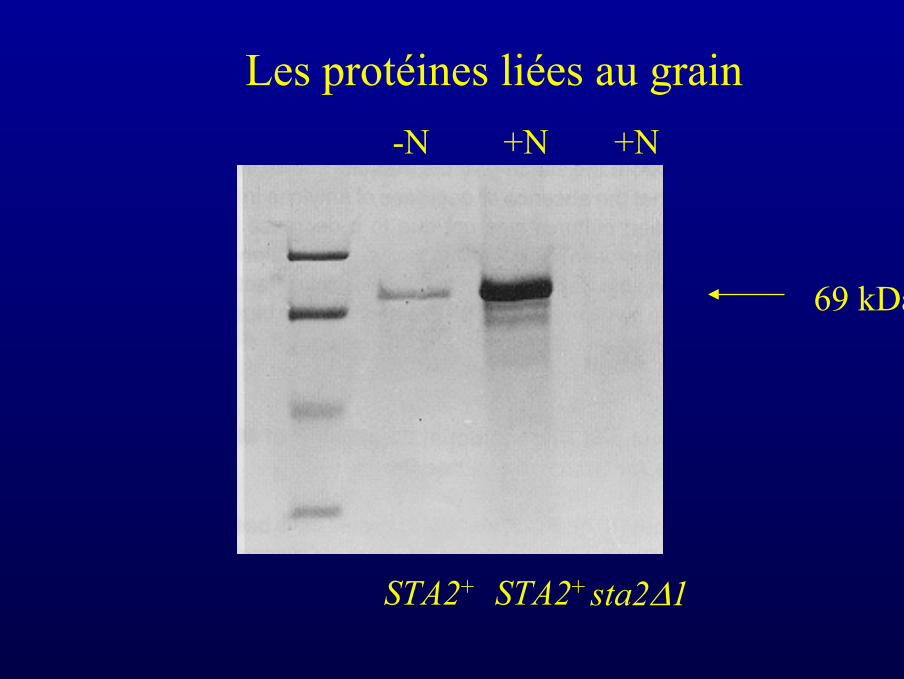
STA2+STA2+ sta2∆1
69 kDa
Les protéines liées au grain-N +N +N
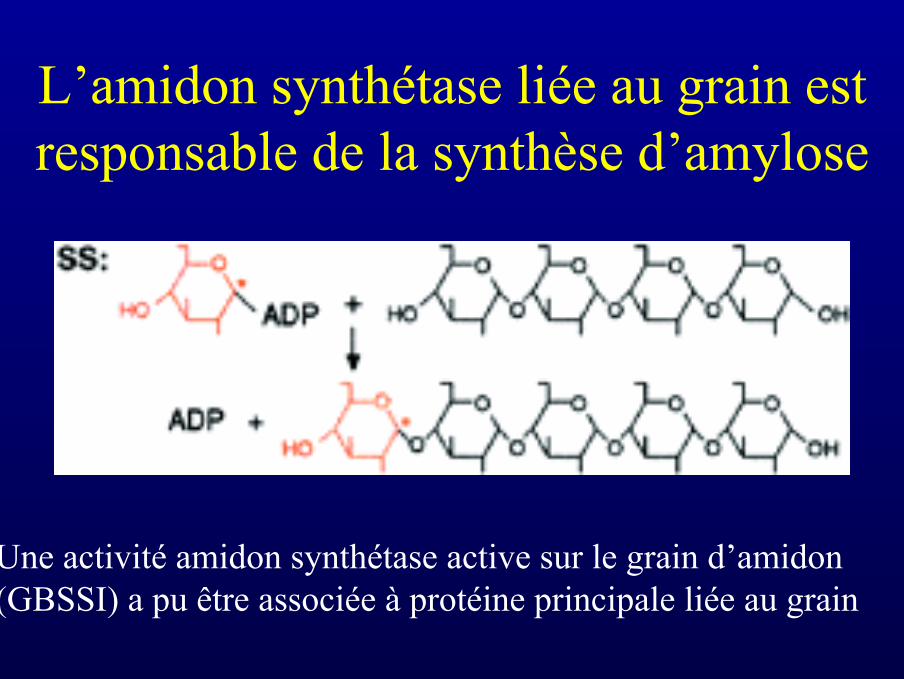
L’amidon synthétase liée au grain estresponsable de la synthèse d’amylose
Une activité amidon synthétase active sur le grain d’amidon(GBSSI) a pu être associée à protéine principale liée au grain

Vers un système de synthèseacellulaire d’amylose
• La GBSSI (amidon synthétase liée au grain) est la seuleenzyme de biosynthèse que l’on sait active au sein dugrain d’amidon (elle n’est d’ailleurs pas retrouvée enphase soluble)
• L’isolement dans le grain de la GBSSI explique en partiela nature non ramifiée de l’amylose
• Puisque les grains d’amidon sont faciles à purifier, onpeut espérer qu’ils contiennent tout l’équipementenzymatique pour faire de l’amylose authentique « invitro »
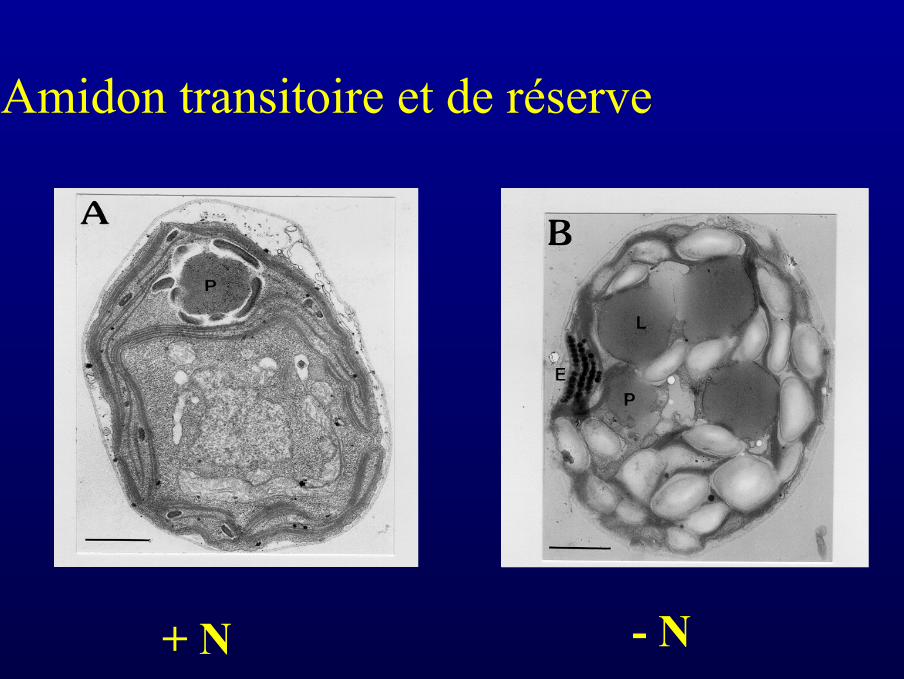
Amidon transitoire et de réserve
+ N - N
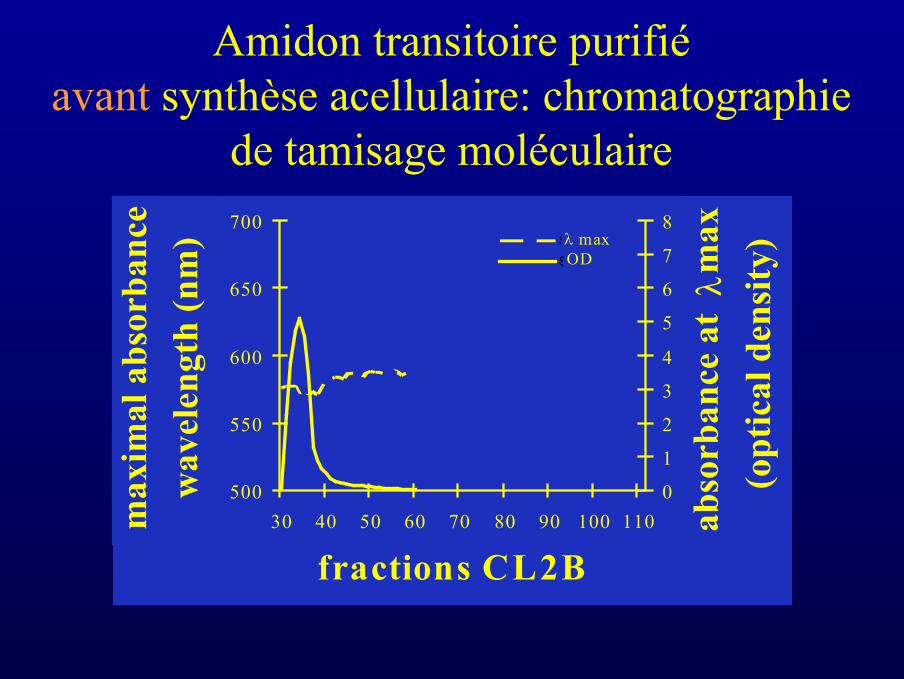
Amidon transitoire purifiéavant synthèse acellulaire: chromatographie
de tamisage moléculaire
500
550
600
650
700
30 40 50 60 70 80 90 100 1100
1
2
3
4
5
6
7
8Series2Series1
max
imal
abs
orba
nce
wav
elen
gth
(nm
)
abso
rban
ce a
t λm
ax (o
ptic
al d
ensi
ty)
ODλ max
fractions CL2B
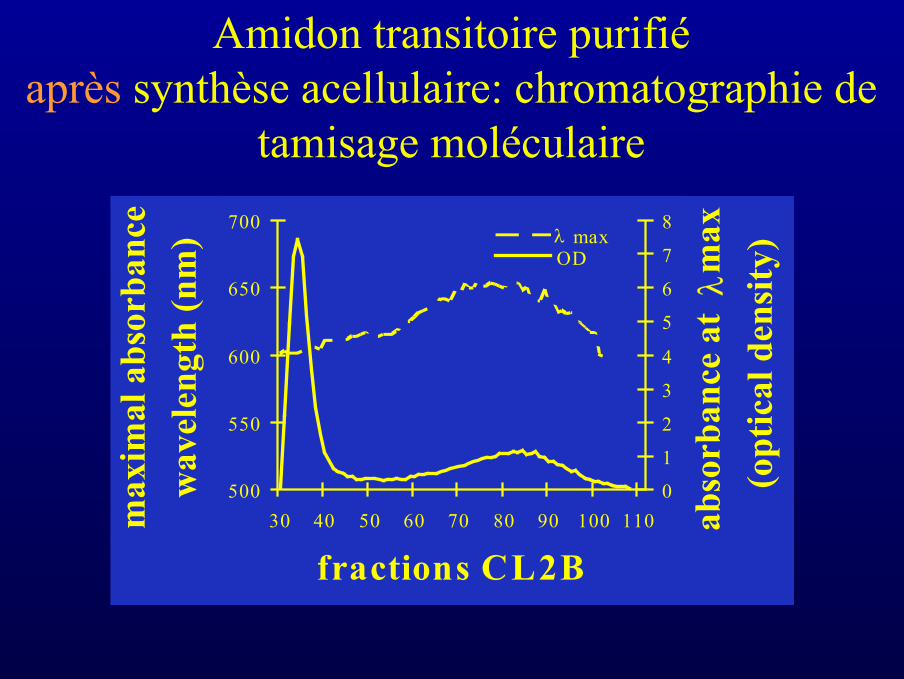
Amidon transitoire purifiéaprès synthèse acellulaire: chromatographie de
tamisage moléculaire
500
550
600
650
700
30 40 50 60 70 80 90 100 1100
1
2
3
4
5
6
7
8Series2Series1
max
imal
abs
orba
nce
wav
elen
gth
(nm
)
abso
rban
ce a
t λm
ax (o
ptic
al d
ensi
ty)
ODλ max
fractions CL2B

Conclusions
• La GBSSI étant le seul déterminant de la synthèsed’amylose, nous avons pu bâtir un système de synthèseacellulaire d’amylose
• Ce système de synthèse acellulaire a permis de déterminerplus précisément les modalités de synthèse de l’amylose parextension de l’amylopectine
• Ce système devrait autoriser à l’avenir d’autrescaractérisations physiocochimiques permettant de mieuxappréhender cette synthèse

Quelles fonctions pour les amidon synthétasessolubles?
SSIVb OryzaSSIVa Oryza
SSIII Oryza SSIII ZeaSSIII Solanum
SSIII Arath
SSV Arath
GBSSI Oryza GBSSI Zea
SSIII CreinSSIII OsttaSSIIIb Ostta
SSIIIc Ostta
SSIV Crein
GBSSI ArathGBSSI Solanum
SSI OryzaSSI Zea
GBSSI CreinGBSSI Ostta
Gls
SSI ArathSSI Solanum
SSI Ostta
SSIIb ZeaSSIIb OryzaSSIIa Zea SSIIa OryzaSSII Solanum
SSII Arath
SSII Ostta SSII Crein
Dendogramme des amidonssynthétases de plantes etmicroalgues
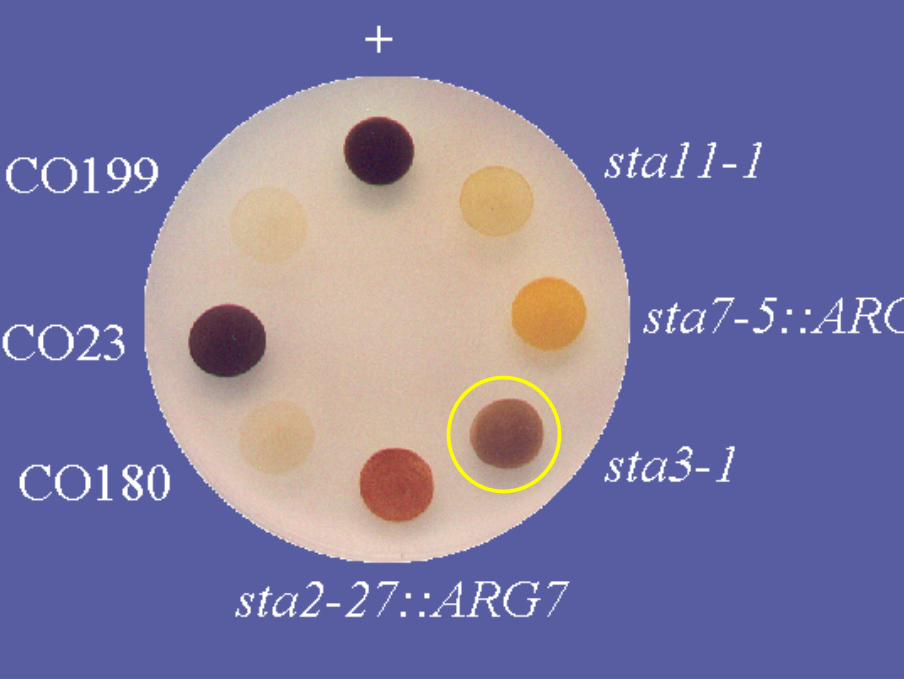

Les mutants sta3 sont déficients pour une formeparticulière d’amidon synthétase soluble: la SSIII

Analyse structurale des répartitions de longueurs de chaînes de l’amylopectine
0
4
8
1 2
1 6
2 0A
0
4
8
1 2
1 6
2 0
0
4
8
1 2
1 6
2 0
2 4 6 8 1 0 1 2 1 4
B
C
0
0
D
3
8
5 . 0p p m

Conclusions
• La SSIII est un déterminant important de la synthèse del ’amylopectine
• Les mutants SSIII ont été rapportés dans d’autres systèmes• La SSII constitue la seule autre amidon synthétase soluble
pour laquelle des mutants sont disponibles• Aucun mutant de la SSI, SSIV et SSV n’a été rapporté pour
aucune espèce• Une vue claire de l’implication des SS dans la biosynthèse
de l’amylopectine ne pourra être obtenue que par génétiqueréverse

PourquoiArabidopsis thaliana ?
• Génétique inverse possible• Génome nucléaire totalement décodé (125 Mb
organisés en 5 chromosomes; environ 27 000 gènes)• Vastes collections de mutants étiquetés par
insertion d’un dérivé de l’ADN-T• Larges collections de FSTs ( > 150 000 juin 2003)
• Croissance rapide, croisements facilementréalisables, infrastructures légères (pièces de cultureconfinées et/ou serres)
• Étude possible du métabolisme de l’amidon(principalement au niveau des feuilles)
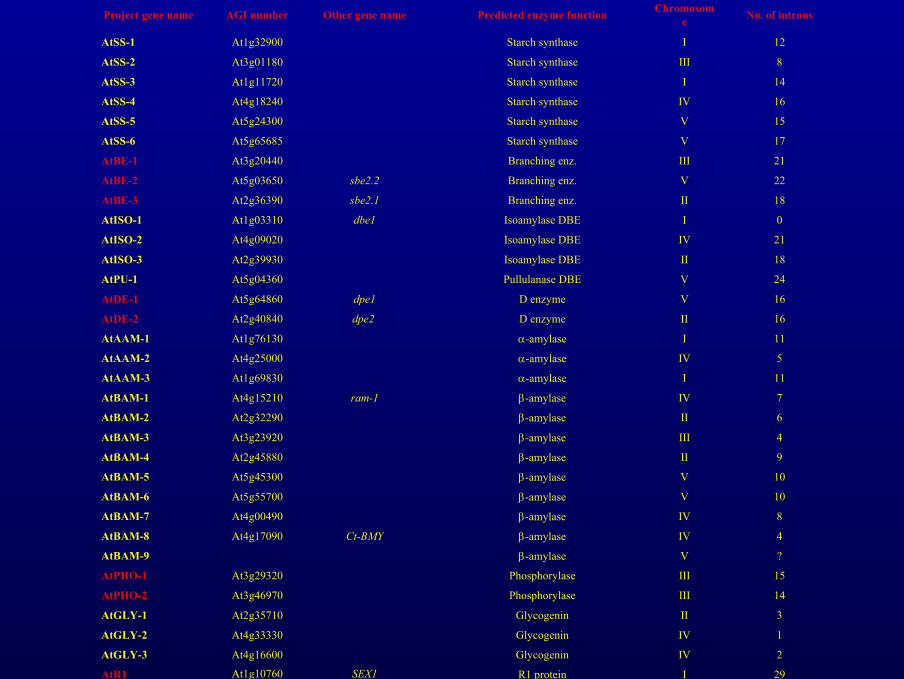
Project gene name AGI number Other gene name Predicted enzyme function Chromosome No. of introns
AtSS-1 At1g32900 Starch synthase I 12
AtSS-2 At3g01180 Starch synthase III 8
AtSS-3 At1g11720 Starch synthase I 14
AtSS-4 At4g18240 Starch synthase IV 16
AtSS-5 At5g24300 Starch synthase V 15
AtSS-6 At5g65685 Starch synthase V 17
AtBE-1 At3g20440 Branching enz. III 21
AtBE-2 At5g03650 sbe2.2 Branching enz. V 22
AtBE-3 At2g36390 sbe2.1 Branching enz. II 18
AtISO-1 At1g03310 dbe1 Isoamylase DBE I 0
AtISO-2 At4g09020 Isoamylase DBE IV 21
AtISO-3 At2g39930 Isoamylase DBE II 18
AtPU-1 At5g04360 Pullulanase DBE V 24
AtDE-1 At5g64860 dpe1 D enzyme V 16
AtDE-2 At2g40840 dpe2 D enzyme II 16
AtAAM-1 At1g76130 α-amylase I 11
AtAAM-2 At4g25000 α-amylase IV 5
AtAAM-3 At1g69830 α-amylase I 11
AtBAM-1 At4g15210 ram-1 β-amylase IV 7
AtBAM-2 At2g32290 β-amylase II 6
AtBAM-3 At3g23920 β-amylase III 4
AtBAM-4 At2g45880 β-amylase II 9
AtBAM-5 At5g45300 β-amylase V 10
AtBAM-6 At5g55700 β-amylase V 10
AtBAM-7 At4g00490 β-amylase IV 8
AtBAM-8 At4g17090 Ct-BMY β-amylase IV 4
AtBAM-9 β-amylase V ?
AtPHO-1 At3g29320 Phosphorylase III 15
AtPHO-2 At3g46970 Phosphorylase III 14
AtGLY-1 At2g35710 Glycogenin II 3
AtGLY-2 At4g33330 Glycogenin IV 1
AtGLY-3 At4g16600 Glycogenin IV 2
AtR1 At1g10760 SEX1 R1 protein I 29
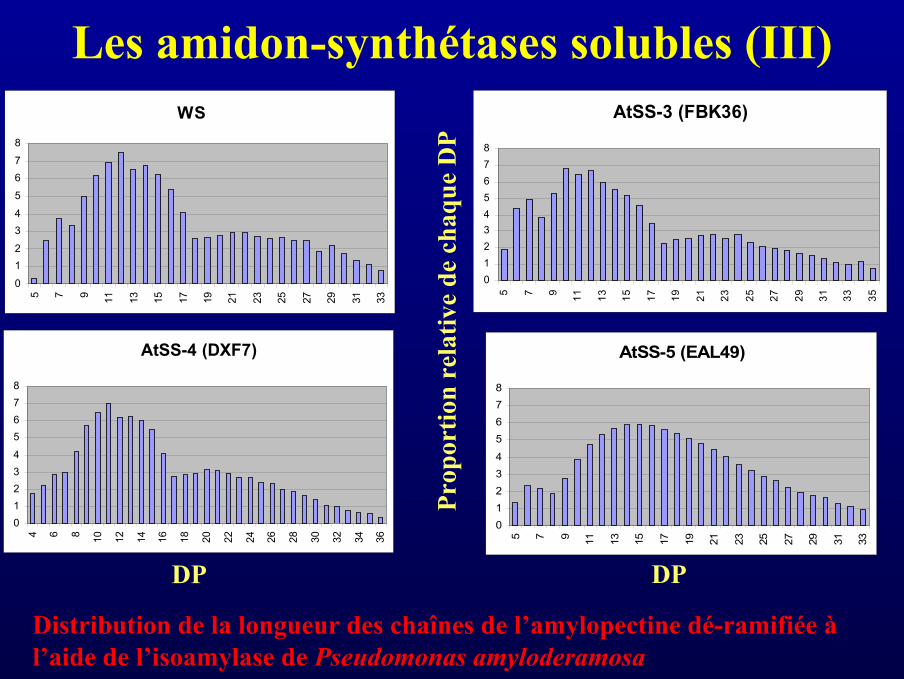
Les amidon-synthétases solubles (III)WS
0
12
34
5
67
8
5 7 9 11 13 15 17 19 21 23 25 27 29 31 33
AtSS-4 (DXF7)
01234
5678
4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36
AtSS-5 (EAL49)
01234
5678
5 7 9 11 13 15 17 19 21 23 25 27 29 31 33
Distribution de la longueur des chaînes de l’amylopectine dé-ramifiée àl’aide de l’isoamylase de Pseudomonas amyloderamosa
Prop
ortio
n re
lativ
e de
cha
que
DP
Prop
ortio
n re
lativ
e de
cha
que
DP
DP DP
AtSS-3 (FBK36)
012345678
5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35

Conclusions (I)
• La SSI, la SSII et la SSIII ont toutes les trois desfonctions importantes dans la biosynthèse del’amylopectine
• Chez les différentes espèces les phénotypes des amidonsrésiduels de chaque classe de mutants ne sont pasidentiques
• Les combinaisons de mutations de différentes classesaboutissent soit à des effets additifs (SSI et SSIII) soit àdes effets mixtes (non additifs et non épistatiques)

Conclusions (II)
• La génétique ne nous pas apporté une visionclaire de la fonction des enzymes d’élongation
• Il devient urgent de bâtir des systèmes acellulairespermettant de définir l’action de chaque enzyme
• Aucun système acellulaire de synthèsed’amylopectine satisfaisant n’ a été décrit






![Les Articles partitifs [μεριστικά άρθρα] du de la de l des de.](https://static.fdocument.org/doc/165x107/551d9d9f497959293b8cd879/les-articles-partitifs-du-de-la-de-l-des-de.jpg)