
YV - Relational DB Design and Normalization 236 Κεφάλαιο 6 ΣΧΕΔΙΑΣΜΟΣ ΒΑΣΕΩΝ...
38
- Relational DB Design and Normalization Κεφάλαιο 6 ΣΧΕΔΙΑΣΜΟΣ ΒΑΣΕΩΝ ΔΕΔΟΜΕΝΩΝ ΚΑΙ ΚΑΝΟΝΙΚΟΠΟΙΗΣΗ (Normalization)
-
date post
19-Dec-2015 -
Category
Documents
-
view
226 -
download
1
Transcript of YV - Relational DB Design and Normalization 236 Κεφάλαιο 6 ΣΧΕΔΙΑΣΜΟΣ ΒΑΣΕΩΝ...

YV - Relational DB Design and Normalization 1
Κεφάλαιο 6 Κεφάλαιο 6
ΣΧΕΔΙΑΣΜΟΣ ΒΑΣΕΩΝ ΔΕΔΟΜΕΝΩΝ ΚΑΙ ΚΑΝΟΝΙΚΟΠΟΙΗΣΗ (Normalization)
YV - Relational DB Design and Normalization 2
OutlineOutline
Relational Database Design and Normalization– Relational Database Design - Objectives– Criteria / Guidelines for a good design– Functional Dependencies - The Normal Forms– Decompositions– Dependency Preservation and Lossless-joins– More Dependencies (Multivalued, Join)

YV - Relational DB Design and Normalization 3
Relational Database DesignRelational Database Design
RELATIONAL DESIGN: Grouping the attributes to form “good” relation schemes (for base relations)
INFORMAL CRITERIA:– Aim for Semantic Clarity– Avoid Redundancy for space efficiency– Avoid Update Anomalies (integrity)– Avoid the need for NULL values in tuples– Aim for Linguistic Efficiency– Aim for Performance

YV - Relational DB Design and Normalization 4
Design Criteria (1)Design Criteria (1)
Aim for Semantic Clarity– Informally (and ideally), each tuple should represent exactly
one entity or relationship instance– In other words, relation tuple should not be overloaded with
semantic information (e.g., represent more than one facts)– Different entities should not be mixed -- only way for inter-
reference between relations should be the “foreign key”
Avoid Redundancy for space efficiency– Redundant storage implies wasting storage– Redundancy may cause inconsistencies
(also called, update anomalies)

YV - Relational DB Design and Normalization 5
Design Criteria (2)Design Criteria (2)
Avoid Update Anomalies– The integrity of the database is damaged when insertion,
deletion and modification anomalies occur.– An update in one place may cause an unpredictable number
of updates in other places.
Avoid Null Values in Tuples– Null values imply “lack of knowledge” or “inapplicability” and
frequently cause processing problems (correct execution of queries requires the use of a different logic (higher level) than the two-valued logic we use in traditional systems)

YV - Relational DB Design and Normalization 6
Design Criteria (3)Design Criteria (3)
Aim for Linguistic Efficiency– The simpler the queries in the applications the better for the
application programmer and (usually) for the query optimizer– Queries are often simpler when they are executed on relations
that have a lot of information (e.g., no need to do many joins for getting the result)
Aim for Performance– As in the previous case, when the relations have very few
attributes (e.g., they are binary), a large number of joins is necessary for processing the queries.
MANY OF THE CRITERIA ARE CONTRADICTORY

YV - Relational DB Design and Normalization 7
Example of a Bad DesignExample of a Bad Design
Assume a database with one relation scheme:ED(SSN, EName, Salary, DNumber, DName, Location, MgrSSN)
Q1: Find all employees that make more than their manager
select e.EName from ED e, ED m
where e.MgrSSN = m.SSN and e.Salary > m.Salary
Q2: For each department, find the maximum salary
select DName, max(Salary) from ED group by DNumber

YV - Relational DB Design and Normalization 8
Example of a Bad Design (2)Example of a Bad Design (2)
COMMENTS– The queries are not very complicated (linguistic efficiency)
BUT, we get UPDATE ANOMALIES:
(a) Redundancy: For every employee, the department information is repeated
(b) Modification Anomalies: For a simple change, like changing the manager of a Department, an
unpredictable number of tuples must be changed
(c) Insertion Anomalies: A new department cannot be entered in the database, unless we have an
employee working in this new department
(d) Deletion Anomalies: When the last employee in a department is deleted, we lose all
information for the department (also called: no independent existence)

YV - Relational DB Design and Normalization 9
Example of a Better Design Example of a Better Design
We can choose the equivalent design with two relation schemes:
EMPLOYEE(SSN, EName, Salary, DNumber)
DEPARTMENT(DNumber, DName, Location, MgrSSN)
Q1: Find all employees that make more than their manager
select e.EName from EMPLOYEE e, EMPLOYEE m, DEPARTMENT d where e.DNumber = d.DNumber and e.MgrSSN = m.SSN
and e.Salary > m.Salary

YV - Relational DB Design and Normalization 10
Example of a Better Design (2)Example of a Better Design (2)
Q2: For each department, find the maximum salary
select d.DName, max(e.Salary) from EMPLOYEE e, DEPARTMENT d
where d.DNumber = e.DNumbergroup by d.DNumber
The queries are more complex (linguistic inefficiency) and require more joins (performance), BUT AVOID ALL update anomalies
OUR OBJECTIVE IN THE SEQUEL IS TO EXAMINE HOW THIS SCHEMA CAN BE CHOSEN FORMALLY AND SYSTEMATICALLY

YV - Relational DB Design and Normalization 11
Functional DependenciesFunctional Dependencies
Functional Dependencies are the most common formal measure of “goodness” for relational database designs
They are used to define the normal forms for relations A Functional Dependency specifies a constraint on all
relation instances r(R), but is a property of the attributes in the schema R
DEFINITION: Let X, Y be set of attributes of relation scheme R. We say that the functional dependency (FD): X Y holds if the X-value uniquely determines the Y-value.

YV - Relational DB Design and Normalization 12
FD Definition - continuedFD Definition - continued
ALTERNATIVE DEFINITION: Let X, Y be set of attributes of relation scheme R. We say that the (FD): X Y holds if whenever two tuples in an instance r(R) have the same value for X, then they must have the same value for Y
This is written as:
for any two tuples t1 , t2 in any relation instance r(R):
If t1 [X] = t2 [X] then t1 [Y] = t2 [Y]
If K is a key in R, then K functionally determines ALL attributes in R (since we can never have two distinct tuples t1, t2 with t1 [K] = t2 [K] )

YV - Relational DB Design and Normalization 13
Properties of FDsProperties of FDs
TRIVIAL DEPENDENCY:
Whenever Y X, then X Y
Example: SSN, Salary Salary
FULL FUNCTIONAL DEPENDENCY:
We say that a set of attributes Y is fully functionally dependent on a set of attributes X, if it is FD on X and not FD on any subset of X, i.e., Y is fully functionally dependent on X, if X Y and there exists no W such that W X and W Y
Example: SSN, PNumber HrsPW (HrsPW is fully functionally dependent on both SSN and PNumber)

YV - Relational DB Design and Normalization 14
Properties of FDs - continuedProperties of FDs - continued
PARTIAL DEPENDENCY: As a consequence of the above definition, we say that Y is partially dependent on X, if X Y and there exists a W such that W X and W Y
Example: SSN,Salary Address (but also, SSN Address)
TRANSITIVE DEPENDENCY: A functional dependency X Z is transitive if it can be derived from two other FDs through transitivity (X Y and Y Z )
Example: SSN DNumber and
DNumber MgrSSN, imply: SSN MgrSSN
PRIME ATTRIBUTE: One that is not in a candidate key

YV - Relational DB Design and Normalization 15
NORMALIZATIONNORMALIZATION
Normalization is concerned with incorporating the semantic notions of FDs into the relation schemes themselves.
There are several Normal Forms, where the following has been proven:
All Relations 1NF2NF
3NFBCNF
4NF5NF

YV - Relational DB Design and Normalization 16
Normal Forms (1)Normal Forms (1)
FIRST NORMAL FORM (1NF): R is in 1NF if every attribute has an atomic value. We assume that ALL the relations we work with are at least in 1NF.
Example: R(ENumber, ChildrenNames) is not in 1NF
SECOND NORMAL FORM (2NF): R is in 2NF if it is in 1NF and no non-prime attribute is partially dependent on a candidate key.
Example: SUPPLIER(SNumber, SName, ItemNumber, Price) is not in 2NF, since the combination SNumber, ItemNumber is a candidate key, but also SNumber SName holds

YV - Relational DB Design and Normalization 17
Normal Forms (2)Normal Forms (2)
THIRD NORMAL FORM (3NF): R is in 3NF if it is in 2NF and no non-prime attribute is transitively dependent on a candidate key
Example: The relation:ED(SSN, EName, Salary, DNumber, DName, Location, MgrSSN)
is in 2NF BUT NOT in 3NF, since
SSN is the (only) candidate key and we have: SSN Dnumber and DNumber MgrSSN
(i.e., MgrSSN is transitively dependent on SSN)

YV - Relational DB Design and Normalization 18
Normal Forms (3)Normal Forms (3)
Equivalent definition of THIRD NORMAL FORM (3NF): R is in 3NF if and only if for every FD X A, where X is a set of attributes in R and A is a single attribute, at least one of the following is true:
1.- A X (the FD is trivial)
2.- K X (with K being a candidate key of R)
3.- A K (with K being a candidate key of R)

YV - Relational DB Design and Normalization 19
Normal Forms (4)Normal Forms (4)
BOYCE-CODD NORMAL FORM (BCNF): R is in BCNF if and only if when an FD X Y holds then X is a candidate key (where X, Y are sets of attributes in R)
Equivalent definition of BOYCE-CODD NORMAL FORM (BCNF): R is in BCNF if and only if for every FD X A, where X is a set of attributes in R and A is a single attribute, at least one of the following is true:
1.- A X (the FD is trivial)
2.- K X (with K being a candidate key of R)
Note: this is exactly like 3NF without option no.3, which shows directly that BCNF implies 3NF

YV - Relational DB Design and Normalization 20
Normal Forms (5)Normal Forms (5)
Example: The relation:RESTAURANT(Client, Food, ReceiptNumber)
is in 3NF BUT NOT in BCNF, since we have:
Client, Food ReceiptNumber, and
ReceiptNumber Food (this is not a key dependency)
Any relation can be transformed to equivalent relations in 3NF (with the use of well-known algorithms) The process is called decomposition or 3NF normalization.
Unfortunately, there are some 3NF relations that cannot be transformed to BCNF (as the characteristic example above)

YV - Relational DB Design and Normalization 21
Normalization TheoryNormalization Theory
Given a set of FDs F we can determine additional FDs that hold whenever the FDs in F hold - to determine such FDs we need inference rules.
A1. if Y X then X Y (Reflexivity)
A2. if X Y then XZ YZ (Augmentation)
A3. if X Y and Y Z then X Z (Transitivity)
Armstrong proved that: {A1, A2, A3) is a sound and complete set of inference rules
i.e., the rules generate only valid FDs and all FDs that can be inferred will be generated by the above rules

YV - Relational DB Design and Normalization 22
Inference RulesInference Rules
Other inference rules also hold (but can deduced from Armstrong’s rules {A1, A2, A3) above)
A4. if X YZ then X Y and X Z (Decomposition)
A5. if X Y and X Z then X YZ (Union)
A6. if X Y and WY Z then WX Z (Pseudotransitivity)
The closure F+ of a set of FDs F is the set of all FDs that can be inferred from F (by applying the Armstrong rules)
The closure X+ of a set of attributes X with respect to a set FDs F is the set of all attributes that are functionally determined by X (by applying the Armstrong rules in F)

YV - Relational DB Design and Normalization 23
Equivalence of FD SetsEquivalence of FD Sets
Two sets of FDs F and G are equivalent if every FD in F can be inferred from G and every FD in G can be inferred from F (i.e., F and G are equivalent if F+ = G+ )
F covers G if every FD in G can be inferred from F (i.e., G+ F+ )
A set of FDs is minimal if it satisfies the following:(1) Every dependency in F is of the form: X A, where A is
a single attribute
(2) We cannot remove any dependency from F and still have a set of dependencies which is equivalent to F
(3) We cannot replace any dependency X A in F with a dependency Y A, where Y X and still have a set of dependencies which is equivalent to F

YV - Relational DB Design and Normalization 24
Results from FD TheoryResults from FD Theory
There is a simple algorithm for checking equivalence between two sets of FDs
Every set of FDs has an equivalent minimal set There is no simple (efficient) algorithm for computing a
minimal set of FDs that is equivalent to a set F of FDs Having a minimal set is important for several relational
design algorithms
To ensure a good relational design we need to establish additional criteria (lossless join property, dependency preserving property) and algorithms that preserve them.

YV - Relational DB Design and Normalization 25
Relational DecompositionRelational Decomposition
STARING POINT of all algorithms is a universal relation scheme R containing all the database attributes
OBJECTIVE of the design is a decomposition D of R into m relation schemas R1, R2, R3, ... Rm where each Ri contains a subset of the attributes of R and every attribute in R should appear in at least one relation scheme Ri
Intuitively, decomposing R means we will store instances of the relation schemes produced by the decomposition, instead of instances of R.

YV - Relational DB Design and Normalization 26
Problems with DecompositionsProblems with Decompositions
There are three potential problems to consider: Some queries become more expensive.
» e.g., Queries may now require many JOINS
Given instances of the decomposed relations, we may not be able to reconstruct the corresponding instance of the original relation!
» The case of the spurious tuples
Checking some dependencies may require joining the instances of the decomposed relations.
» Attributes in dependencies now are in more than one relations
Tradeoff: Must consider these issues vs. redundancy

YV - Relational DB Design and Normalization 27
Dependency PreservationDependency Preservation
DEPENDENCY PRESERVATION PROPERTY: The decomposition D should preserve the dependencies; that is, the collection of all dependencies that hold on relations Ri should be equivalent to F (the FDs that hold on R)
Formally:
Definition: The projection of F on Ri , denoted by F(Ri), is the set of FDs X Y in F+ such that (X Y) Ri
A decomposition D is dependency preserving if:
( F(R1) F(R2) ... F(Rm) )+ = F+
There is an algorithm, called the relational synthesis algorithm, that decomposes R into a dependency preserving decomposition D = {R1, R2, R3, ... Rm} with respect to F, such that each Ri is in 3NF
The algorithm is based on minimal covers and as we said earlier, there are no efficient algorithms to find such covers

YV - Relational DB Design and Normalization 28
Lossless Join PropertyLossless Join Property
LOSSLESS JOIN PROPERTY: This property ensures that no new (spurious) tuples appear when relations in the decomposition are joined
Formally, A decomposition D = {R1, R2, R3, ... Rm} of R has the lossless join property with respect to a set of FDs F, if for every relation instance r(R) whose tuples satisfy all the FDs in F, we have:
( R1(r(R)) R2(r(R)) ... Rm(r(R)) ) = r(R)
This is a very important condition for a decomposition, since it directly impacts how meaningful the queries will be in the decomposed relations.

YV - Relational DB Design and Normalization 29
Spurious Tuples - ExampleSpurious Tuples - Example
Consider the COMPANY database and a relation E_P(SSN, PNumber, HoursPW, EName, PName, Location) which is generated by taking the natural joins between EMPLOYEE, PROJECT and WORKS_ON (on instances) and then projecting on the above attributes
Convince yourself that the decomposition of E_P into:
R1 (EName, Location)
R2 (SSN, PNumber, HoursPW, PName, Location)
does not have the lossless-join property
HINT: Make projections on the instance of E_P (for R1, R2) and then join these projections. You will not get back E_P !

YV - Relational DB Design and Normalization 30
More on Lossless Join
The decomposition of R into
X and Y is lossless-join wrt F if and only if the closure of F contains:– X Y X, or– X Y Y
In particular, the decomposition of R into UV and R - V is lossless-join if U V holds over R.
A B C1 2 34 5 67 2 81 2 87 2 3
A B C1 2 34 5 67 2 8
A B1 24 57 2
B C2 35 62 8

YV - Relational DB Design and Normalization 31
Results for DecompositionsResults for Decompositions
There is a simple algorithm for testing whether a decomposition D satisfies the lossless join property with respect to a set F of FDs
There is a simple algorithm for decomposing R into BCNF relations such that the decomposition D satisfies the lossless join property with respect to a set F of FDs on R
There is no algorithm for decomposition into BCNF relations that is dependency preserving
There is an algorithm (modification of the synthesis one) for decompositions into 3NF (not BCNF) relations which guarantees both dependency preservation and lossless join

YV - Relational DB Design and Normalization 32
Decomposition into 3NFDecomposition into 3NF
ALGORITHM:
1.- Find a minimal set of FDs G equivalent to F
2.- For each X of an FD X Y in G
Create a relation schema Ri in D with the attributes
{ X A1 A2 ..., Ak} , where each Aj is an attribute appearing in an FD in G with X as left
hand side
3.- If any attributes in R are not placed in any Ri then create another relation in D for these attributes
4.- If none of the relations in D contain a key of R, create a relation that contains a key of R and add it to D
The algorithm above is guaranteed to generate relations in 3NF that preserve both properties
YV - Relational DB Design and Normalization 33
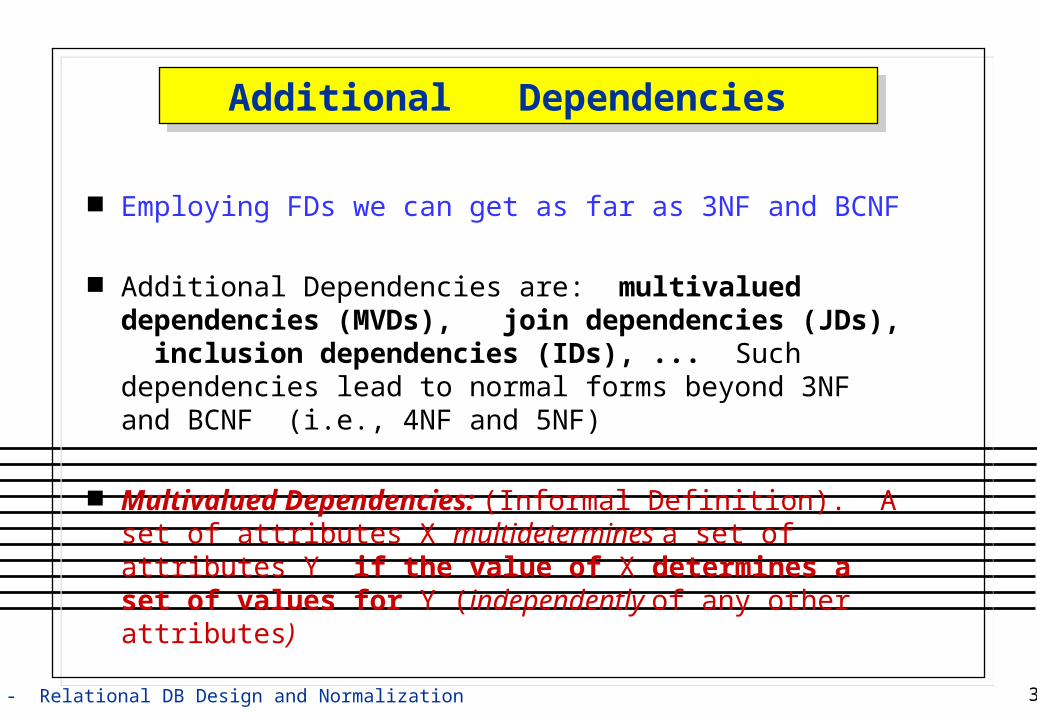
Additional Dependencies Additional Dependencies
Employing FDs we can get as far as 3NF and BCNF
Additional Dependencies are: multivalued dependencies (MVDs), join dependencies (JDs), inclusion dependencies (IDs), ... Such dependencies lead to normal forms beyond 3NF and BCNF (i.e., 4NF and 5NF)
Multivalued Dependencies: (Informal Definition). A set of attributes X multidetermines a set of attributes Y if the value of X determines a set of values for Y (independently of any other attributes)

YV - Relational DB Design and Normalization 34
Multivalued DependenciesMultivalued Dependencies
An MVD is written as X Y There are sound and complete inference rules for MVDs Every MVD is also an FD (special case)
A relation schema R is in fourth normal form (4NF) with respect to a set of functional and multivalued dependencies F if for any non-trivial multivalued dependency X Y in F+ then X is a candidate key of R
There is an efficient algorithm for decomposing R into 4NF relations such that the decomposition has the lossless join property with respect to a set F of FDs and MVDs on R

YV - Relational DB Design and Normalization 35
Join DependenciesJoin Dependencies
A join dependency JD(R1, R2, R3, ... Rm) is a constraint on R specifying that every legal instance r(R) should have a lossless join decomposition into R1, R2, R3, ... Rm
An MVD is a special case of a JD (where m=2)
A relation schema R is in fifth normal form (5NF) with respect to a set of functional, multivalued and join dependencies F if for any non-trivial JD(R1, R2, ... Rm) in F+ then each Ri is a super key of R
5NF is sometimes called PJNF

YV - Relational DB Design and Normalization 36
Inclusion DependenciesInclusion Dependencies
FDs, MVDs and JDs are defined within the same relation scheme R (they do not relate attributes from different relation schemes)
There are other constraints, like the inclusion dependencies, that are used to specify referential integrity and class/subclass hierarchies between two relations R and S
An inclusion dependency R.X < S.Y specifies that at any point in time, if r(R) and s(S) are relation instances of R and S, then X(r(R)) Y(s(S))
Until now, there are no proposals for normal forms based on the concept of inclusion dependencies

YV - Relational DB Design and Normalization 37
Practical Issues with NormalizationPractical Issues with Normalization
There is a large number of commercial database tools that, given a set of relation schemes and a set of dependencies (usually FDs), automatically generate relation schemes in 3NF (rarely they go for BCNF, 4NF and 5NF)
Another use of such tools is to check a given relation’s level of normalization and as a heuristic for selecting one design instead of another
There are also some practical theory results that let the designer evaluate the design in a very simple manner, like:– If a relation is in 3NF and every candidate key consists of exactly
one attribute, then it is also in 5NF (Fagin, 1991)

YV - Relational DB Design and Normalization 38
Comments on NormalizationComments on Normalization
The Normalization Process has several drawbacks:– It is not constructive -- there is no provision for getting a
“good” design (with the criteria listed before)– It is usually applied after we have a schema (to tell us
whether this is a good or bad one)– It provides no conceptual design (it focuses on and deals
with relations and attributes)
On the other hand, it is a good attempt to formalize some of the things with which we usually work by intuition


















