
Variab. discrete: funzione di P o distribuzione di Pciullo/MOM/2018_MOM_lez_10_11_Gauss.pdf · ......
24
Variab . discrete: funzione di P o distribuzione di P Una funzione casuale può essere, p.e., la probabilità, che associ ad ogni valore della variabile casuale – o aleatoria X la probabilità P f(x)= P(X=x) La funzione probabilità deve soddisfare le seguen< relazioni P(x) > 0 (*) Σ x P(x)=1 (**) dove per Σ x si intende sommatoria su tutti i valori x, che può acquisire la variabile X. 1 La (**) è nota anche come normalizzazione. Lezione 10
-
Upload
truongdang -
Category
Documents
-
view
221 -
download
0
Transcript of Variab. discrete: funzione di P o distribuzione di Pciullo/MOM/2018_MOM_lez_10_11_Gauss.pdf · ......

Variab.discrete:funzionediPodistribuzionediP
Unafunzionecasualepuòessere,p.e.,laprobabilità,cheassociadognivaloredella
variabilecasuale–oaleatoriaXlaprobabilitàP f(x)= P(X=x)
Lafunzioneprobabilitàdevesoddisfareleseguen<relazioni
P(x)>0(*)ΣxP(x)=1 (**)
dove per Σx si intende sommatoria su tutti i valori x, che può acquisire la variabile X.
1La(**) è nota anche come normalizzazione.
Lezio
ne10

Possiamoestendereglis9matorista9s9ciintrodo:perlemisureripetuteaqualsiasi9podivariabilecasualeefunzionediprobabilità
F(E) P(E)
Valorimedieaspe=a9ve.
2
media
x = Fkxkk=1
nclassi∑Valore di aspettazione E[X]
E[X]= Pkxkk=1
nclassi∑ = µX
Varianza della popolazione
σ 2x = Fk xk − x( )2
k=1
nclassi∑varianza della distribuzione di probabilità
V[X]= Pk xk −E[X]( )2
k=1
nclassi∑ =
= x2kPk −µX
2
k=1
nclassi∑
Richiamiallalavagnadelladerivazionedelleformule
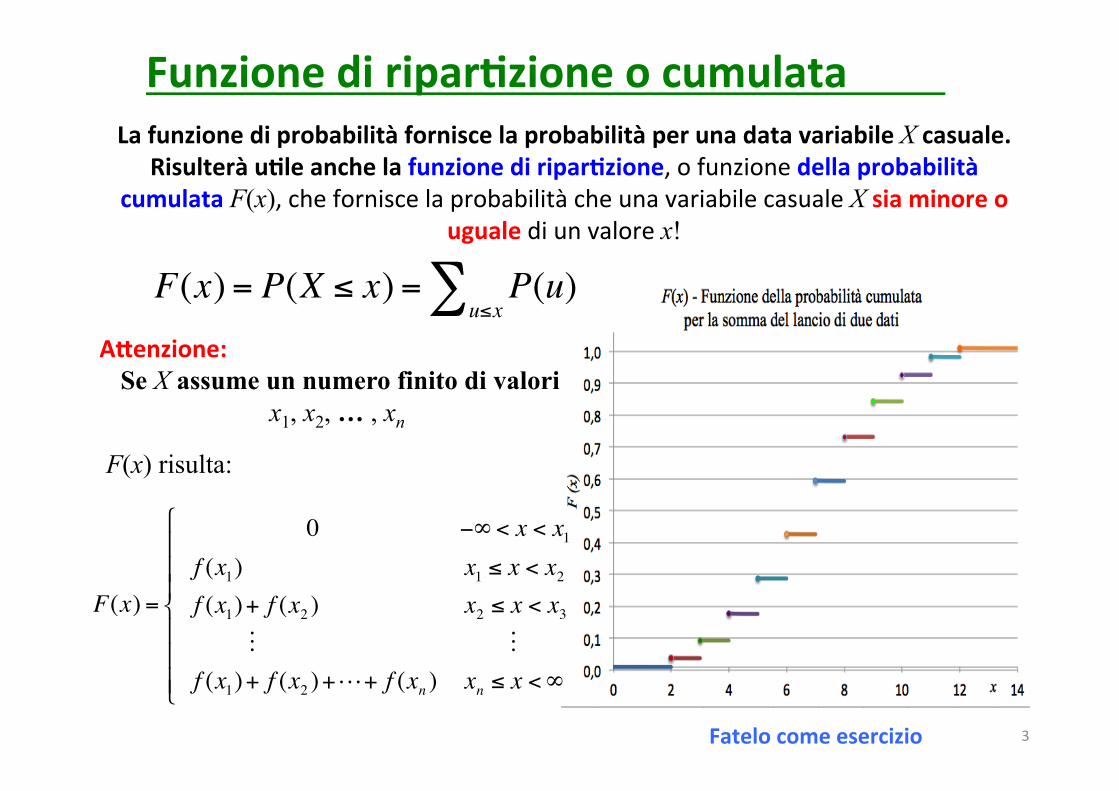
LafunzionediprobabilitàforniscelaprobabilitàperunadatavariabileXcasuale.Risulteràu9leanchelafunzionediripar9zione,ofunzionedellaprobabilità
cumulataF(x),cheforniscelaprobabilitàcheunavariabilecasualeXsiaminoreougualediunvalorex!
F(x) = P(X ≤ x) = P(u)u≤x∑
Funzionediripar9zioneocumulata
3
F(x) =
0 −∞ < x < x1
f (x1)f (x1)+ f (x2 ) !f (x1)+ f (x2 )+"+ f (xn )
x1 ≤ x < x2
x2 ≤ x < x3
!xn ≤ x <∞
⎧
⎨
⎪⎪⎪
⎩
⎪⎪⎪
A=enzione:Se X assume un numero finito di valori
x1, x2, … , xn
F(x) risulta:
Fatelocomeesercizio
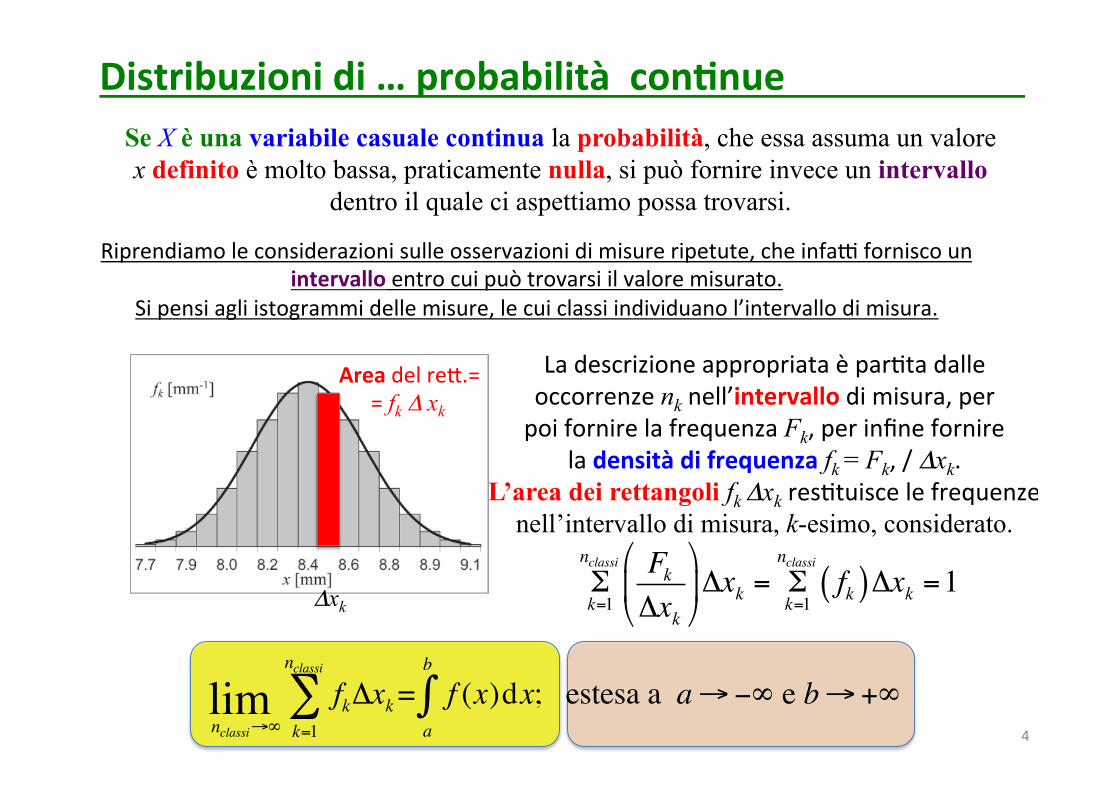
Distribuzionidi…probabilitàcon9nue
4
Se X è una variabile casuale continua la probabilità, che essa assuma un valore x definito è molto bassa, praticamente nulla, si può fornire invece un intervallo
dentro il quale ci aspettiamo possa trovarsi.
Riprendiamoleconsiderazionisulleosservazionidimisureripetute,cheinfaHforniscounintervalloentrocuipuòtrovarsiilvaloremisurato.
Sipensiagliistogrammidellemisure,lecuiclassiindividuanol’intervallodimisura.
Σk=1
nclassi FkΔxk
⎛
⎝⎜
⎞
⎠⎟Δxk = Σ
k=1
nclassifk( )Δxk =1
nclassi→∞lim fk
k=1
nclassi
∑ Δxk= f (x)dxa
b
∫ ; estesa a a→−∞ e b→+∞
Ladescrizioneappropriataèpar<tadalleoccorrenzenknell’intervallodimisura,perpoifornirelafrequenzaFk,perinfinefornire
ladensitàdifrequenzafk = Fk,/Δxk.L’area dei rettangoli fk Δxkres<tuiscelefrequenze
nell’intervallo di misura, k-esimo, considerato.
Δxk
AreadelreO.==fkΔxk

limn→∞
F(E) = P(E)
5
fkΔxK =k=1
nclassi∑ 1
sx2 = (xk − x )
2
k
nclassi∑ fkΔxk
f (x)dx−∞
+∞
∫ =1
x = Σxk fkΔxk
V[X]= (x −E[X])2 f (x)dx−∞
+∞
∫
E[X]= x f (x)dx−∞
+∞
∫
DalledensitàdiFalle⇒densitàdiP
⇒
⇒
⇒
Derivazionedelleformuleperledensitàdifrequenza.
Valoremedio ValorediaspeOazione
Varianzadella“popolazione”*
ValorediaspeOazione
perlaVarianza
Nelpassaggiodallevariabilidiscreteallecon<nuedovremmousarelaformulaperlavarianzadella“popolazione” s2
x,perconsiderazionista<s<chelamigliores<maèσ 2x = s2x[n/(n-1)]

CalcolodelleprobabilitàconledensitàdiP
Data X una variabile casuale continua con densità di probabilità f(x) e dati a e b due valori di x con a < b, per le proprietà degli integrali definiti si ha :
P(a < x < b) =P(a < x < b) = P(a < x < b) = P(a < x < b)
Nel caso di variabili casuali continue la probabilità è data dall’area sottesa dalla curva densità di probabilità.
P(X ≤ a) = P(X < a) = f (x)dx−∞
a
∫
= f (x)dxa
b
∫
P(X ≥ a) = P(X > a) = f (x)dxa
+∞
∫
1° criterio: f (x) ≥ 0 per qualsiasi x,
Dato che f(x) è una densità di probabilità la funzione deve anche soddisfare i seguenti criteri:
2° criterio: f (x)dx−∞
+∞
∫ =1 assioma della certezzanormalizzazione della densità di P
⎧⎨⎩
Si ha ovviamente anche:
6

Lafunzionedidistribuzionecumulata(var.con9nue)La funzione di distribuzione cumulata, o funzione di ripartizione è sempre data da
F(x) = P(X < x), pertanto per una variabile continua risulta:
F(x) = P(X ≤ x) = f (t)dt−∞
x
∫RelazionetraF(x) ef(x)
7
Derivando rispetto ad x la funzione di ripartizione si ottiene per le proprietà del calcolo differenziale e integrale che
ddxF(x) = d
dxP(X ≤ x) = f (x)
Cosaindica f(x)
P(x − ε2≤ t ≤ x + ε
2) = f (t)dt
x−ε /2
x+ε /2
∫ ≈ ε f (x)
La probabilità che X stia in un intorno di x di ampiezza ε è proporzionale a εf(x), quindi f(x) dà un’indicazione di quanto sia probabile che i valori di X cadano vicino ad x.

LamediadiXcondensitàdiprobabilitàf (x)
E[X]= x f (x)dx−∞
+∞
∫il valore medio della variabile, detto valore di aspettazione , E[X], aspettativa, speranza
matematica, o valore atteso, è indicato anche come E{x}, µX o semplicemente µ.
LavarianzadiXcondensitàdiprobabilitàf (x)
V[X]= (x −E[X])2 f (x)dx−∞
+∞
∫ oppure x2 f (x)dx−∞
+∞
∫ − (E[X])2
la varianza della variabile, è indicata anche come Var{x}, con σX2 o semplicemente σ 2.
La sua radice quadrata è detta deviazione standard della popolazione, Viene riportata anche come σX o semplicemente σ.
8

terminologia
• Vistochenelcasodivariabilicon<nuesièdeOa f(x) funzione densitàdiprobabilità,ècomuneperlevariabilidiscretechiamare
P(x)=P(X=x)funzionedimassadiprobabilità.SichiamanorispeHvamenteanche
semplicementefunzionedidensitàosolodensità,efunzionedimassaomassa.
9

LamedianadiXcondensitàdiprobabilitàf (x)La mediana di un campione è stata definita come il valore che occupa la posizione centrale, una volta ordinati i valori in modo crescente, o la
media dei due numeri centrali. Similmente la mediana di una variabile casuale continua, che segue una
densità di probabilità f(x) è quel valore xm, tale che:
la mediana è quindi il 50-esimo percentile.
P(X ≤ xm ) = f (x)dx−∞
xm
∫ = 0.5
Percen9li
Dato un numero 0 < p < 100, il p-esimo percentile di una popolazione è quel valore xp, tale che il p % dei valori della popolazione sono
inferiori o uguali a xp.
P(X ≤ xp ) = f (x)dx−∞
xp
∫ = p /100
10

Esercizi.
Si dimostri che , utile nei casi pratici per i calcoli, equivale a che presenta in modo più evidente il suo significato.
Densità di probabilità costantePer la misura di un singolo valore letto (xl), si può considerare la densità di probabilità costante in tutto l’intervallo individuato dagli estremi x=xl + εx e si pone f(x) = c, si
dimostri che il valore di aspettazione E[X]= xl e la varianza V[X] = ε2x/3
Densità di probabilità Gaussiana .
Equivalenza delle formule per V[X]
Gauss dall’assunzione per una variabile aleatoria, che se compare un’incertezza rispetto ad un valore atteso X, questa ha la stessa probabilità di comparire sia con il
segno più, che con il segno meno, ne ricavò che la densità di probabilità come:
Fare lo studio di funzione per descriverne le proprietà, poi applicare le regole delle funzioni di densità di probabilità ed infine ricavare che E[X] = X e V[X]=σ 2.
Fornire anche il valore più probabile e la mediana.
f (x) =C e−
(x−X )2
2σ 2 .
11
V[X]= (x −E[X])2 f (x)dx−∞
+∞
∫
V[X]= x2 f (x)dx−∞
+∞
∫ − (E[X])2
Svolgimentoinclassealla.
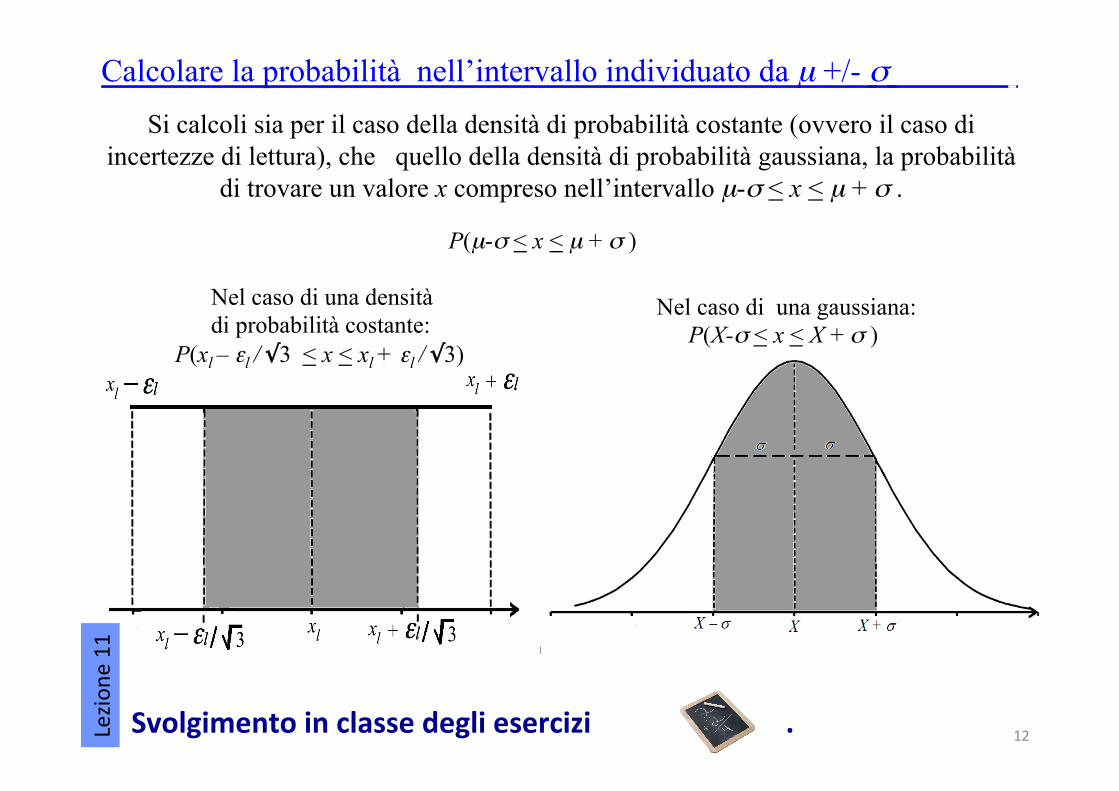
Si calcoli sia per il caso della densità di probabilità costante (ovvero il caso di incertezze di lettura), che quello della densità di probabilità gaussiana, la probabilità
di trovare un valore x compreso nell’intervallo µ-σ < x < µ + σ .
Calcolare la probabilità nell’intervallo individuato da µ +/- σ .
P(µ-σ < x < µ + σ )
Svolgimentoinclassedegliesercizi. 12
Nel caso di una densità di probabilità costante:
P(xl – εl / √3 < x < xl + εl / √3)
Nel caso di una gaussiana: P(X-σ < x < X + σ )
Lezio
ne11

13
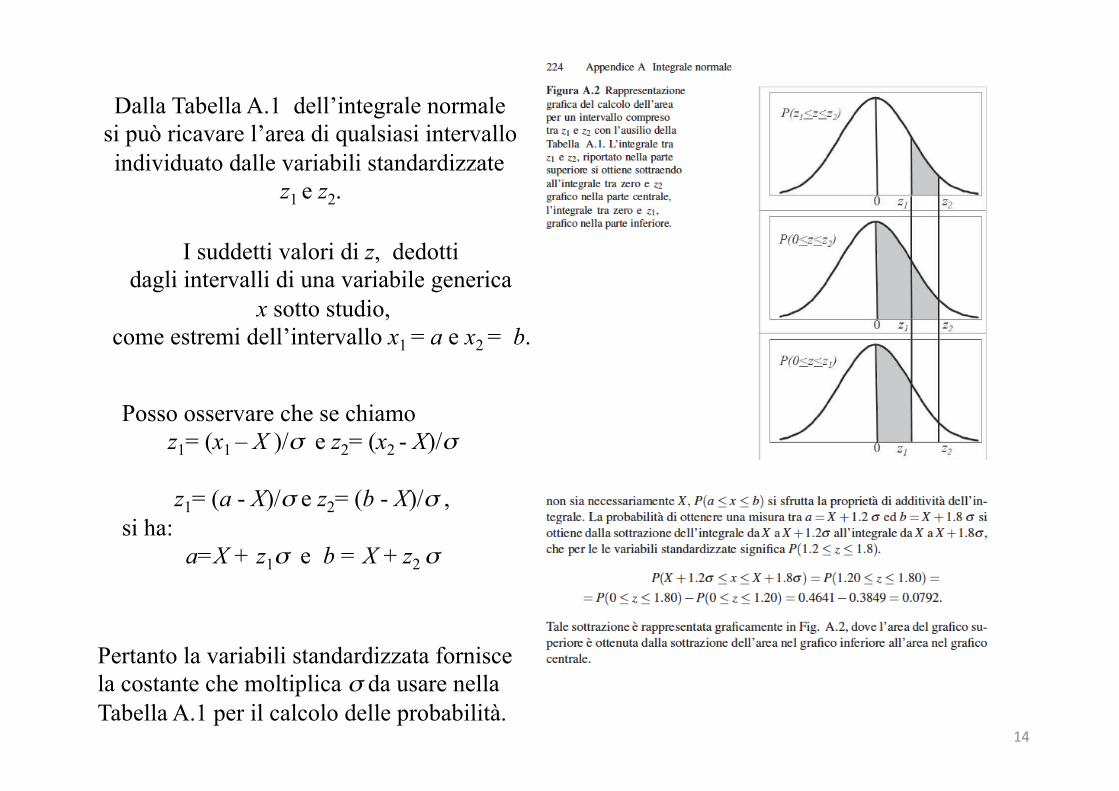
Perilcalcolodelleprobabilitàtraduevaloridiunavariabilegaussianasiu<lizzalaTabellaA.1,spiegatainappendiceA,equiriportata.
14
Dalla Tabella A.1 dell’integrale normale si può ricavare l’area di qualsiasi intervallo individuato dalle variabili standardizzate
z1 e z2.
I suddetti valori di z, dedotti dagli intervalli di una variabile generica
x sotto studio, come estremi dell’intervallo x1 = a e x2 = b.
Posso osservare che se chiamo z1= (x1 – X )/σ e z2= (x2 - X)/σ
z1= (a - X)/σ e z2= (b - X)/σ ,
si ha: a=X + z1σ e b = X + z2 σ
Pertanto la variabili standardizzata fornisce la costante che moltiplica σ da usare nella Tabella A.1 per il calcolo delle probabilità.

GuidaalpercorsodelcorsoMolti testi affrontano per settori gli argomenti, quindi tutta una serie di informazioni, che riguardano la teoria delle probabilità, con varie distribuzioni, teoremi, e operazioni su variabili casuali, poi la statistica, e ancora una serie di … Noi puntiamo a obiettivi di utilizzo pratico e ingegneristico immediato,
e affrontiamo gli argomenti teorici al fine della comprensione del loro utilizzo pratico.
Affronteremo ora la gaussiana per avere il quadro degli argomenti, sia relativi alla probabilità, che alla statistica, dopodiché, una volta che lo studente si è fatto le ossa sulla gaussiana, che è la distribuzione principe per le discipline scientifiche, sarà utile affrontare la regressione e la verifica di una legge fisica, che ci introdurrà in modo più immediato alla verifica di ipotesi, poi riprenderemo ad affrontare altre distribuzioni, nonché i supporti teorici essenziali.
Questa parte è quanto presentato nel cap. 8 del libro di G. Ciullo, fornito dal docente.
15

La densità di probabilità di Gauss, detta anche normale, risulta normalizzata, se espressa come:
16
ProprietàdellaGaussiana
GX, σ (x) = 1σ 2π
e−
(x−X )2
2σ 2 .
E[X]= xf (x)dx−∞
+∞
∫ = xGX, σ (x)dx−∞
+∞
∫ = X
La speranza matematica E[X]:
Attenzione: X in E[X] indica la variabile casuale X, che può assumere valori x ∈]-∞, +∞[, mentre in GX, σ (x)X è la centralità della curva. Inoltre la speranza matematica E[X] per la
variabile X che segue una gaussiana, frutto della definizione e del calcolo, risulta uguale alla centralità X della curva.
V[X]= (x − X)2 f (x)dx−∞
+∞
∫ = (x − X)2GX, σ (x)dx−∞
+∞
∫ =σ 2
La varianza di una variabile che segue una gaussiana:
risulta il quadrato del parametro σ, che individua la distanza da X dei due punti di flesso, pertanto la sua radice è utilizzata come dist. stand.: deviazione standard della popolazione.

Dato che la gaussiana è una densità di probabilità, possiamo ricavare la probabilità di ottenere un risultato compreso tra x1 e x2 da: se espressa come:
17
Gauss:probabilitàdio=enereunrisultato
P(x1 ≤ x ≤ x2 ) = GX, σ (x)dxx1
x2
∫ .
Operativamente: troviamo le corrispondenti variabili standardizzate, z1 e z2, successivamente dalla tabella dell’integrale normale A.1, possiamo ottenere l’area sottesa dalla curva per
qualsiasi intervallo.
Vediamotaliprobabilitàperintervallidelimita<propriodalparametroσ, p.e. per gli intervalli, x ∈ [X-σ, X+σ], x ∈ [X-2σ, X+2σ], x ∈ [X-3σ, X+3σ], che per la variabile standardizzata z diventano z ∈ [-1, +1], z ∈ [-2, +2], z ∈ [-3, +3].
P(entro ±σ ) = e−z2 2
−1
1
∫ dz = 2 e−z2 2 dz
0
1
∫ =0.6826
P(entro ± 2σ ) = e−z2 2
−2
2
∫ dz = 2 e−z2 2 dz
0
2
∫ =0.9544
P(entro ±3σ ) = e−z2 2
−3
3
∫ dz = 2 e−z2 2 dz
0
3
∫ =0.9974
Comeesercizio,forniteleprobabilitàalatou<lizzandolatabellaA.1

18
Gauss:probabilitàeconnessioneconida9Attenzione
Adesso affrontiamo la connessione di questa funzione ideale, la gaussiana, con i dati osservati sperimentalmente.
Probabilità Dato che la gaussiana è una densità di probabilità, abbiamo parlato di probabilità, a priori, ovvero un modello teorico, e abbiamo quindi dedotto che l’aspettativa matematica e la varianza per una gaussiana risultato pari rispettivamente a X e σ 2 . X pertanto, essendo il valore per cui si ha un massimo della densità di probabilità, è anche il valore più probabile ovvero la moda, inoltre dato che è anche il 50-percentile è anche la mediana.
Analisi matematica Finora abbiamo parlato delle peculiarità analitiche della curva di Gauss: centralità X, nonché massimo relativo, simmetria, punti di flesso σ.

19
Principiodimassimaverosimiglianza La densità di probabilità di Gauss è quanto ci aspettiamo per n →∞ ( la popolazione), ma noi abbiamo un campione di dati rilevati, che è finito. Abbiamo anticipato, che nel caso di misure ripetute, la migliore stima della misura di una grandezza è la media aritmetica, ora possiamo giustificare tale affermazione. Abbiamo visto che la probabilità di ottenere un dato risultato x1 che segue una densità di probabilità f(x), prendendo un intervallo infinitesimo di larghezza ε è prop. a ε f(x), proporzionale alla larghezza stessa dell’intervallo e alla densità di probabilità (facendo appello al calcolo differenziale potremmo dire equivalentemente che il differenziale della probabilità è proporzionale alla densità di probabilità per il differenziale dx: dP=f(x) dx).
Quindi la probabilità di ottenere un determinato xi è proporzionale a f(xi), nel caso di una gaussiana si avrà: P(xi) ~ GX, σ(xi)
Supponiamo di avere una serie di osservazioni xi per i =1, …, n quale sarà la probabilità P(x1, x2, …,xn) di osservarle tutte?
Se ogni osservazione è stocasticamente indipendente da qualsiasi altra, la probabilità di ottenerle tutte sarà data dal prodotto delle probabilità di ottenere ogni singola misura P(xi) :
P(x1, x2, …,xn) =P(x1) P(x2) …P (xn).

20
TrovareXeσpiùverosimiliperlenosservazioni Il problema è quindi trovare i parametri X e σ più “verosimili” per i dati sperimentali. Ci aspettiamo che questi valori forniscano la probabilità massima di ottenere i risultati osservati sperimentalmente, questa premessa prende il nome di principio di massima
verosimiglianza. Per trovare il parametro X più verosimile, proviamo a cambiarlo fino a ottenerne uno che dia il massimo della probabilità, espressa dal prodotto delle probabilità. Per rendere evidente che
è X che varia, riscrivo P come funzione di X, cioè P(X) ed esplicito la funzione gaussiana: P(X)= P(x1, x2, …,xn) =P(x1) P(x2) …P (xn) ~
~ 1σ
e−(x1−X )2 2σ 2 1σ
e−(x2−X )2 2σ 2
! 1σ
e−(xn−X )2 2σ 2
=1σ n e
− (xi−X )2 2σ 2
i=1
n
∑
QuindirisultachelaprobabilitàdioOeneretuOelenosservazioni,espressainfunzionedelparametroX,dellacurvaidealeG X, σ(x)chedobbiamodeterminarerisulta:perilprincipiodimassimaverosimiglianzaP(X)deveesseremassima,ovverobisognatrovareilmassimodellafunzioneP(X),funzionediX.ilparametrodellacurva.
P(X) ~ 1σ n e
− (xi−X )2 2σ 2
i=1
n
∑
Studiodellaprobabilitàmassimaalla.

21
Lamigliors9madiXèlamediaper… Per variabili-grandezze che seguono la distribuzione di Gauss la migliore stima del
parametro X, ovvero la centralità della gaussiana è data dalla media aritmetica.
Studiodellaprobabilitàmassimarispe=oaσalla.
Possiamo allo stesso modo ottenere la migliore stima della varianza.
…σpiùverosimiliperlenosservazioni
P(σ ) ~ 1σ n e
− (xi−X )2 2σ 2
i=1
n
∑
In questo caso vogliamo trovare la σ per la quale si ha il massimo di probabilità di ottenere tutti gli n dati, per cui guarderemo la proporzionalità della probabilità come funzione di σ.
Lamigliors9madiσ è…
σ ms (ideale) =Σ(xi − X)
2
nla migliore stima della deviazione standard è la deviazione standard della popolazione.

22
ManonconosciamoX… Nella formula della migliore stima del parametro σ dai dati (campione) è presente X,
che non conosciamo, del parametro abbiamo una stima utilizzando i dati:
σ ms (statistica) =Σ(xi − x )
2
n−1Xms = x =
Σxin:
Cisonotreargomen<chesupportanotalescelta
deviazione standard del campione.
Ø sostituendo a X con la sua stima che è la media, si ha che σ 2 sarà sottostimato, per cui gli scarti quadratici vanno moltiplicati per una costante maggiore di uno, n/n-1 è maggiore di uno.
Ø Abbiamo già visto che nel caso di un solo dato sx=0/1 che è assurdo, mentre σx =0/0, che quindi risulta indeterminata con un solo dato!
Ø Nel calcolare uno stimatore statistico, come valore medio, si deve dividere per i gradi di libertà statistici d (da “degree of freedom”), in questo caso n il numero di dati meno i vincoli c (da “constrains”) – vincoli statistici.
Σ(xi − x )2 ≤ Σ(xi − X)
2
I vincoli statistici sono quei parametri, utilizzati nello stimatore, ottenuti dai dati sperimentali, in questa caso la media, perché X è stimato con la media dei dati.
Dimostrazionedelladisuguaglianzanelprimoargomentoalla.

23
Densitàtriangolare… Si dimostra che in presenza di una grandezza X dedotta dalla combinazione di due
grandezze a densità costanti si ottiene una densità di probabilità triangolare.
Cambiamo variabile z= x-X, in modo da avere una semplificazione nei calcoli e otteniamole relative speranza matematica e varianza.
È facile calcolare (si faccia come esercizio) le probabilità negli intervalli delimitati dalla
deviazione standard (ottenuta dalla radice quadrata della varianza) che qui etichettiamo σf (vedi dopo).
SioHeneperleprobabilità
tra + 1 σf 0.650 tra + 2 σf 0.966 tra + 3 σf 1.00 { Gauss}tra + 1 σ 0.6826
tra + 2 σ 0.9574 tra + 3 σ 0.9974 ~
=σf 2

24
Leprobabilitàperunadensitàtriangolare,sonomoltosimilialleprobabilità della gaussiana,neglistessiintervalliindividua<dallerispeHveσ.
Questoargomentoèdinotevoleimportanza,unavoltacheverràintrodoOoilteoremadellimitecentrale.
[16]A.Rotondi,P.Pedroni,A.Pievatolo-ProbabilitàSta,s,caeSimulazione(SpringerVerlag,2012,Milano).

















![Cenni di Fonetica e Fonologia - lingue.uniurb.it · non avere la stessa funzione in un’altra lingua. ... Ricostruire la [FONETICA] di una lingua morta è impossibile, perciò sarà](https://static.fdocument.org/doc/165x107/5c6609c809d3f2c14e8b7c77/cenni-di-fonetica-e-fonologia-non-avere-la-stessa-funzione-in-unaltra-lingua.jpg)
