
STAT 200C: High-dimensional Statisticsarash.amini/teaching/stat200c/notes/200C_slides.pdf · STAT...
130
STAT 200C: High-dimensional Statistics Arash A. Amini June 4, 2019 1 / 124
Transcript of STAT 200C: High-dimensional Statisticsarash.amini/teaching/stat200c/notes/200C_slides.pdf · STAT...

STAT 200C: High-dimensional Statistics
Arash A. Amini
June 4, 2019
1 / 124

• Classical case:
• n� d .
• Asymptotic assumption: d is fixed and n→∞.
• Basic tools: LLN and CLT.
• High-dimensional setting:
• n ∼ d , e.g. n/d → γ or
• d � n, e.g. d ∼ en
• e.g. 104 genes with only 50 samples.
• Classical methods fail. E.g.,
• Linear regression y = Xβ + ε, where ε ∼ N(0, σ2In).
βOLS = argminβ∈Rd
‖y − Xβ‖22
We have MSE(βOLS) = O(σ2dn ).
• Solution: Assume some underlying low-dimensional structure (e.g. sparsity).
• Basic tools: Concentration inequalities.
2 / 124

Table of Contents I1 Concentration inequalities
Sub-Gaussian concentration (Hoeffding inequality)Sub-exponential concentration (Bernstein inequality)Applications of Bernstein inequalityχ2 ConcentrationJohnson-Lindenstrauss embedding`2 norm concentration`∞ norm
Bounded difference inequality (Azuma–Hoeffding)Detour: MartingalesAzuma–HoeffdingBounded difference inequalityConcentration of (bounded) U-statisticsConcentration of clique numbers
Gaussian concentrationχ2 concentration revisitedOrder statistics and singular values
Gaussian chaos (Hanson–Wright inequality)
2 Sparse linear modelsBasis Pursuit
Restricted null space property (RNS)3 / 124

Table of Contents IISufficient conditions for RNS
Pairwise incoherenceRestricted isometry property (RIP)
Noisy sparse regressionRestricted eigenvalue conditionDeviation bounds under RERE for anisotropic designOracle inequality (and `q sparsity)
3 Metric entropyPacking and coveringVolume ratio estimates
4 Random matrices and covariance estimationOp-norm concentration: sub-Gaussian matrices, independent entriesOp-norm concentration: Gaussian caseSub-Gaussian random vectorsOp-norm concentration: sample covariance
5 Structured covariance matricesHard thresholding estimatorApproximate sparsity (`q balls)
6 Matrix concentration inequalities4 / 124

Concentration inequalities
• Main tools in dealing with high-dimensional randomness.
• Non-asymptotic versions of the CLT.
• General form: P(|X − EX | > t) < something small.
• Classical examples: Markov and Chebyshev inequalities:
• Markov: Assume X ≥ 0, then
P(X ≥ t) ≤ EXt.
• Chebyshev: Assume EX 2 <∞, and let µ = EX . Then,
P(|X − µ| ≥ t) ≤ var(X )
t2.
• Stronger assumption: E|X |k <∞. Then,
P(|X − µ| ≥ t) ≤ E|X − µ|ktk
.
5 / 124

Concentration inequalities
Example 1
• X1, . . . ,Xn ∼ Ber(1/2) and Sn =∑n
i=1 Xi . Then, by CLT
Zn :=Sn − n/2√
n/4
d→ N(0, 1).
• Letting g ∼ N(0, 1),
P(Sn ≥
n
2+
√n
4t
)≈ P(g ≥ t) ≤ 1
2e−t
2/2.
• Letting t = α√n,
P(Sn ≥
n
2(1 + α)
)/
1
2e−nα
2/2.
• Problem: Approximation is not tight in general.
6 / 124

Theorem 1 (Berry–Esseen CLT)
Under the assumption of CLT, with ρ = E|X1 − µ|3/σ3,∣∣P(Zn ≥ t)− P(g ≥ t)∣∣ ≤ ρ√
n.
• Bound is tight since P(Sn = n/2) = 12n
(n
n/2
)∼ 1√
n, for Bernoulli exa.
• Conclusion, the approximation error is O(n−1/2) which is a lot larger than
the exponential bound O(e−nα2/2) that we want to establish.
• Solution: Directly obtain the concentration inequalities,
• often using Chernoff bounding technique: for any λ > 0,
P(Zn ≥ t) = P(eλZn ≥ eλt) ≤ EeλZn
eλt, t ∈ R.
• Leads to the study of the MGF of random variables.
7 / 124

Sub-Gaussian concentration
Definition 1A zero-mean random variable X is sub-Gaussian if for some σ > 0.
EeλX ≤ eσ2λ2/2, for all λ ∈ R. (1)
A general random variable is sub-Gaussian if X − EX is sub-Gaussian.
• X ∼ N(0, σ2) satisfies (1) with equality.
• A Rademacher variable, also called symmetric Bernoulli P(X = ±1) = 12 is
sub-Gaussian,
EeλX = cosh(λ) ≤ eλ2/2.
• Any bounded RV is sub-Gaussian: X ∈ [a, b] a.s., then (1) with σ = b−a2 .
8 / 124

Proposition 1
Assume that X is zero-mean sub-Gaussian satisfying (1). Then,
P(X ≥ t) ≤ exp(− t2
2σ2
), for all t ≥ 0.
Same bound holds with X replaced with −X .
• Proof: Chernoff bound
P(X ≥ t) ≤ infλ>0
[e−λtEeλX
]= infλ>0
exp(−λt +
λ2σ2
2
).
• Union bound gives two-sided bound: P(|X | ≥ t) ≤ 2 exp(− t2
2σ2 ).
• What if µ := EX 6= 0? Apply to X − µ,
P(|X − µ| ≥ t) ≤ 2 exp(− t2
2σ2
).
9 / 124

Proposition 2
Assume that {Xi} are
• independent, zero-mean sub-Gaussian with parameters {σi}.Then, Sn =
∑i Xi is sub-Gaussian with parameter σ :=
√∑i σ
2i .
• Sub-Gaussian parameter squared behaves like the variance.
• Proof: EeλSn =∏
i EeλXi .
10 / 124

Theorem 2 (Hoeffding)
Assume that {Xi} are
• independent, zero-mean sub-Gaussian with parameters {σi}.Then, letting σ2 :=
∑i σ
2i ,
P(∑
i
Xi ≥ t)≤ exp
(− t2
2σ2
), t ≥ 0.
Same bound holds with Xi replaced with −Xi .
• Alternative form, assume there are n variables, and
• let σ2 := 1n
∑ni=1 σ
2i , and Xn := 1
n
∑ni=1 Xi . Then,
P(Xn ≥ t
)≤ exp
(− nt2
2σ2
), t ≥ 0.
• Example: Xiiid∼Rad so that σ = σi = 1.
11 / 124

Equivalent characterizations of sub-Gaussianity
For a RV X , the following are equivalent: (HDP, Prop. 2.5.2)
1. The tails of X satisfy
P(|X | ≥ t) ≤ 2 exp(−t2/K 21 ), for all t ≥ 0.
2. The moments of X satisfy
‖X‖p = (E|X |p)1/p ≤ K2√p, for all p ≥ 1.
3. The MGF of X 2 satisfies
E exp(λX 2) ≤ exp(K 23λ
2), for all |λ| ≤ 1
K3
4. The MGF of X 2 is bounded at some point,
E exp(X 2/K 24 ) ≤ 2.
Assuming EX = 0, the above are equivalent to: 5. The MGF of X satisfies
E exp(λX ) ≤ exp(K 25λ
2), for all λ ∈ R.
12 / 124

Sub-Gaussian norm
• The sub-Gaussian norm is the smallest K4 in property 4, i.e.,
‖X‖ψ2 = inf{t > 0 : E exp(X 2/t2) ≤ 2
}.
• X is sub-Gaussian iff ‖X‖ψ2 <∞.
• ‖ · ‖ψ2 is a proper norm on the space of sub-Gaussian RVs.
• Every sub-Gaussian variable satisfies the following bounds:
P(|X | ≥ t) ≤ 2 exp(−ct2/‖X‖2ψ2
), for all t ≥ 0.
‖X‖p ≤ C‖X‖ψ2
√p, for all p ≥ 1.
E exp(X 2/‖X‖2ψ2
) ≤ 2
When EX = 0, E exp(λX ) ≤ exp(Cλ2‖X‖2ψ2
) for all λ ∈ R.
for some universal constant C , c > 0.
13 / 124

Some consequences
• Recall what a universal/numerical/absolute constant means.
• Sub-Gaussian norm is within a constant factor of the sub-Gaussianparameter σ: for numerical constant c1, c2 > 0,
c1‖X‖ψ2 ≤ σ(X ) ≤ c2‖X‖ψ2 .
• Easy to see that ‖X‖ψ2 . ‖X‖∞. (Bounded variables are sub-Gaussian)
• a . b means a ≤ Cb for some universal constant C .
Lemma 1 (Centering)
If X is sub-Gaussian, then X − EX is sub-Gaussian too and
‖X − EX‖ψ2 ≤ C‖X‖ψ2
where C is a universal constant.
• Proof: ‖EX‖ψ2 . |EX | ≤ E|X | = ‖X‖1 . ‖X‖ψ2 .
• Note: ‖X − EX‖ψ2 could be much smaller than ‖X‖ψ2 .
14 / 124

Alternative forms
• Alternative form of Proposition 2:
Proposition 3 (HDP 2.6.1)
Assume that {Xi} are
• independent, zero-mean sub-Gaussian RVs.
Then∑
i Xi is also sub-Gaussian and
‖∑i
Xi‖2ψ2≤ C
∑i
‖Xi‖2ψ2
where C is an absolute constant.
15 / 124

• Alternative form of Theorem 2:
Theorem 3 (Hoeffding)
Assume that {Xi} are independent, zero-mean sub-Gaussian RVs. Then,
P(∣∣∣∑
i
Xi
∣∣∣ ≥ t)≤ 2 exp
(− c t2∑
i ‖Xi‖ψ2
), t ≥ 0.
• c > 0 is some universal constant.
16 / 124

Sub-exponential concentration
Definition 2A zero-mean random variable X is sub-exponential if for some ν, α > 0.
EeλX ≤ eν2λ2/2, for all |λ| < 1
α. (2)
A general random variable is sub-exponential if X − EX is sub-exponential.
• If Z ∼ N(0, 1), then Z 2 is sub-exponential.
Eeλ(Z 2−1) =
{e−λ√
1−2λλ < 1/2
∞ λ > 1/2.
• We have Eeλ(Z 2−1) ≤ e4λ2/2, |λ| < 1/4.
• hence sub-exponential with parameters (2, 4).
• Tails of Z 2 − 1 are heavier than a Gaussian.
17 / 124

Proposition 4
Assume that X is zero-mean sub-exponential satisfying (2). Then,
P(X ≥ t) ≤ exp(−1
2min
{ t2
ν2,t
α
}), for all t ≥ 0.
Same bound holds with X replaced with −X .
• Proof: Chernoff bound
P(X ≥ t) ≤ infλ≥0
[e−λtEeλX
]≤ inf
0≤λ< 1α
exp(−λt +
λ2ν2
2
).
• Let f (λ) = −λt + λ2ν2/2.
• Minimizer of f over R is λ = t/ν2.
18 / 124

• Hence minimizer of f over [0, 1/α] is
λ∗ =
{t/ν2 t/ν2 < 1/α
1/α t/ν2 ≥ 1/α.
and the minimum is
f (λ∗) =
− t2
2ν2t < ν2/α
− t
α+
ν2
2α2≤ − t
2αt ≥ ν2/α
.
• Thus,
f (λ∗) ≤ max{− t2
2ν2,− t
2α
}= −1
2min
{ t2
ν2,t
α
}.
19 / 124

Bernstein inequality for sub-exponential RVs
Theorem 4 (Bernstein)
Assume that {Xi} are independent, zero-mean sub-exponential RVs with
parameters (νi , αi ). Let ν :=(∑
i ν2i
)1/2and α := maxi αi .
Then∑
i Xi is sub-exponential with parameters (ν, α), and
P(∑
i
Xi ≥ t)≤ exp
(−1
2min
{ t2
ν2,t
α
}).
• Proof: We have
EeλXi ≤ eλ2ν2
i /2, for all |λ| < 1
maxi αi.
• Let Sn =∑
i Xi . By independence
EeλSn =∏i
EeλXi ≤ eλ2 ∑
i ν2i /2, for all |λ| < 1
maxi αi.
• The tail bound follows from Proposition 4.20 / 124

Equivalent characterizations of sub-exponential RVs
For a RV X , the following are equivalent: (HDP, Prop. 2.7.1)
1. The tails of X satisfy
P(|X | ≥ t) ≤ 2 exp(−t/K1), for all t ≥ 0.
2. The moments of X satisfy
‖X‖p = (E|X |p)1/p ≤ K2p, for all p ≥ 1.
3. The MGF of |X | satisfies
E exp(λ|X |) ≤ exp(K3λ), for all 0 ≤ λ ≤ 1
K3
4. The MGF of |X | is bounded at some point,
E exp(|X |/K4) ≤ 2.
Assuming EX = 0, the above are equivalent to: 5. The MGF of X satisfies
E exp(λX ) ≤ exp(K 25λ
2), for all |λ| ≤ 1
K5.
21 / 124

Equivalent characterizations of sub-Gaussianity
For a RV X , the following are equivalent: (HDP, Prop. 2.5.2)
1. The tails of X satisfy
P(|X | ≥ t) ≤ 2 exp(−t2/K 21 ), for all t ≥ 0.
2. The moments of X satisfy
‖X‖p = (E|X |p)1/p ≤ K2√p, for all p ≥ 1.
3. The MGF of X 2 satisfies
E exp(λX 2) ≤ exp(K 23λ
2), for all |λ| ≤ 1
K3
4. The MGF of X 2 is bounded at some point,
E exp(X 2/K 24 ) ≤ 2.
Assuming EX = 0, the above are equivalent to: 5. The MGF of X satisfies
E exp(λX ) ≤ exp(K 25λ
2), for all λ ∈ R.
22 / 124

Sub-exponential norm
• The sub-exponential norm is the smallest K4 in property 4, i.e.,
‖X‖ψ1 = inf{t > 0 : E exp(|X |/t) ≤ 2
}.
• X is sub-exponential iff ‖X‖ψ1 <∞.
• ‖ · ‖ψ1 is a proper norm on the space of sub-exponential RVs.
• Every sub-exponential variable satisfies the following bounds:
P(|X | ≥ t) ≤ 2 exp(−ct/‖X‖ψ1 ), for all t ≥ 0.
‖X‖p ≤ C‖X‖ψ1p, for all p ≥ 1.
E exp(|X |/‖X‖ψ1 ) ≤ 2
When EX = 0, E exp(λX ) ≤ exp(Cλ2‖X‖ψ1 ) for all |λ| ≤ 1/‖X‖ψ1 .
for some universal constant C , c > 0.
23 / 124

Lemma 2
A random variable X is sub-Gaussian if and only if X 2 is sub-exponential, in fact
‖X 2‖ψ1 = ‖X‖2ψ2.
• Proof: Immediate from definition.
Lemma 3If X and Y are sub-Gaussian, then XY is sub-exponential, and
‖XY ‖ψ1 ≤ ‖X‖ψ2‖Y ‖ψ2
• Proof: Assume ‖X‖ψ2 = ‖Y ‖ψ2 = 1, WLOG.
• Apply Young’s inequality ab ≤ (a2 + b2)/2 for all a, b ∈ R, twice
Ee|XY | ≤ Ee(X 2+Y 2)/2 = E[eX2/2eY
2/2] ≤ 1
2E[eX
2
+ eY2] ≤ 2.
24 / 124

• Alternative form of Proposition 4:
Theorem 5 (Bernstein)
Assume that {Xi} are independent, zero-mean sub-exponential RVs. Then,
P(∣∣∣∑
i
Xi
∣∣∣ ≥ t)≤ 2 exp
[−c min
( t2∑i ‖Xi‖2
ψ1
,t
maxi ‖Xi‖ψ1
)], t ≥ 0.
• c > 0 is some universal constant.
Corollary 1 (Bernstein)
Assume that {Xi} are independent, zero-mean sub-exponential RVs with‖Xi‖ψ1 ≤ K for all i . Then,
P(∣∣∣1
n
n∑i=1
Xi
∣∣∣ ≥ t)≤ 2 exp
[−c n ·min
( t2
K 2,t
K
)], t ≥ 0.
25 / 124

Concentration of χ2 RVs I
Example 2
Let Y ∼ χ2n, i.e., Y =
∑ni=1 Z
2i where Zi
iid∼N(0, 1).
• Z 2i are sub-exponential with parameters (2, 4).
• Then, Y is sub-exponential with parameters (2√n, 4) and we obtain
P(|Y − EY |) ≤ 2 exp[−1
2min
( t2
4n,t
4
)]or replacing t with nt
P(∣∣∣1
n
n∑i=1
Z 2i − 1
∣∣∣ ≥ t)≤ 2 exp
[−1
8nmin(t2, t)
], t ≥ 0.
26 / 124

Concentration of χ2 RVs II
• In particular,
P(∣∣∣1
n
n∑i=1
Z 2i − 1
∣∣∣ ≥ t)≤ 2e−nt
2/8, t ∈ [0, 1].
• Second approach ignoring constants:
• We have ‖Z 2i − 1‖ψ1 ≤ C ′‖Z 2
i ‖ψ1 = C ′‖Zi‖2ψ2
= C .
• Applying Corollary 1 with K = C ′
P(∣∣∣1
n
n∑i=1
Z 2i − 1
∣∣∣ ≥ t)≤ 2 exp
[−c n min
( t2
C 2,t
C
)],
≤ 2 exp[−c2n min(t2, t)
], t ≥ 0
where c2 = c min(1/C 2, 1/C ).
27 / 124

Random projection for dimension reduction
• Suppose that we have data points {u1, . . . , uN} ⊆ Rd .
• Want to project them down to a lower-dimensional space Rm (m� d)
• such that pairwise distances ‖ui − uj‖ are approximately preserved.
• Can be done by a linear random projection X : Rd → Rm,
• which can be viewed as a random matrix X ∈ Rm×d .
Lemma 4 (Johnson-Lindenstrauss embedding)
Let X := 1√mZ ∈ Rm×d where Z has iid N(0, 1) entries. Consider any collection
of points {u1, . . . , uN} ⊆ Rd . Take ε, δ ∈ (0, 1) and assume that
m ≥ 16
δ2log( N√
ε
).
Then with probability at least 1− ε,
(1− δ)‖ui − uj‖22 ≤ ‖Xui − Xuj‖2
2 ≤ (1 + δ)‖ui − uj‖22, ∀i 6= j
28 / 124

Proof
• Fix u ∈ Rd and let
Y :=‖Zu‖2
2
‖u‖22
=m∑i=1
〈zi ,u
‖u‖2〉2
where zTi is the ith row of Z .
• Then, Y ∼ χ2m.
• Recalling X = Z/√m, for all δ ∈ (0, 1),
P(∣∣∣‖Xu‖2
2
‖u‖22
− 1∣∣∣ ≥ δ) = P
(∣∣∣Ym− 1∣∣∣ ≥ δ) ≤ 2e−mδ
2/8
• Applying to u = ui − uj , for any fixed pair (i , j), we have
P(∣∣∣‖X (ui − uj)‖2
2
‖ui − uj‖22
− 1∣∣∣ ≥ δ) ≤ 2e−mδ
2/8
29 / 124

• Apply a further union bound for all pairs i 6= j
P(∣∣∣‖X (ui − uj)‖2
2
‖ui − uj‖22
− 1∣∣∣ ≥ δ, for some i 6= j
)≤ 2
(N
2
)e−mδ
2/8
• Since 2(N2
)≤ N2, the result follows by solving the following for m
N2e−mδ2/8 ≤ ε.
30 / 124

`2 norm of sub-Gaussian vectors• Here ‖X‖2 =
√∑ni=1 X
2i .
Proposition 5 (Concenration of norm, HDP 3.1.1)
Let X = (X1, . . . ,Xn) ∈ Rn be a random vector with independent, sub-Gaussiancoordinates Xi that satisfy EX 2
i = 1. Then,
‖ ‖X‖2 −√n ‖ψ2 ≤ CK 2
where K = maxi ‖Xi‖ψ2 and C is an absolute constant.
• The result says that the norm is highly concentration around√n:
‖X‖2 ≈√n
in high dimensions (n large).
• Assuming K = O(1), it shows that w.h.p. ‖X‖2 =√n + O(1).
• More precisely, w.p. ≥ 1− e−c1t2
, we have√n − K 2t ≤ ‖X‖2 ≤
√n + K 2t
31 / 124

• Simple argument:
E‖X‖22 = n
var(‖X‖22) = n var(X 2
1 )
sd(‖X‖22) =
√n sd(X 2
1 )
• Assuming sd(X 21 ) = O(1),
‖X‖2 ≈√n ± O(
√n) =
√n ± O(1).
• The last equality can be shown by Taylor expansion:
•√
1 + t = 1 + O(t), as t → 0. hence√
1 + 1√n
= 1 + O( 1√n
).
• Side note: Better than√a + b ≤ √a +
√b which holds for any a, b ≥ 0.
• That is, when b = o(a), we have√a + b ≤ √a + O( b√
a).
32 / 124

• Proof of Proposition 5: Argue that we can take K ≥ 1.
• Since Xi is sub-Gaussian, X 2i is sub-exponential and
‖X 2i − 1‖ψ1 ≤ C‖X 2
i ‖ψ1 = C‖Xi‖2ψ2≤ CK 2.
• Applying Bernstein’s inequality (Corollary 1), for any u ≥ 0,
P(∣∣∣‖X‖2
2
n− 1∣∣∣ ≥ u
)≤ 2 exp
(−c1n
K 4min(u2, u)
),
where we used K 4 ≥ K 2 and absorbed C into c1.
• Using the inequality |z − 1| ≥ δ =⇒ |z2 − 1| ≥ max(δ, δ2), ∀z ,
P(∣∣∣‖X‖2√
n− 1∣∣∣ ≥ δ) ≤ P
(∣∣∣‖X‖22
n− 1∣∣∣ ≥ max(δ, δ2)
)≤ 2 exp
(−c1n
K 4δ2).
• f (u) = min(u2, u) and g(δ) = max(δ, δ2), then f (g(δ)) = δ2 for all δ ≥ 0.
• Change of variable δ = t/√n gives the result.
33 / 124

`∞ norm of sub-Gaussian vectors
• For any vector X ∈ Rn, the `∞ norm is:
‖X‖∞ = maxi=1,...,n
|Xi |.
Lemma 5
Let X = (X1, . . . ,Xn) ∈ Rn be a random vector with zero-mean, sub-Gaussiancoordinates Xi with parameter σi . Then, for any γ ≥ 0,
P(‖X‖∞ ≥ σ
√2(1 + γ) log n
)≤ 2n−γ
where σ = maxi σi .
• Proof: We have P(|Xi | ≥ t) ≤ 2 exp(−t2/2σ2), hence
P(maxi|Xi | ≥ t) ≤ 2n exp
(− t2
2σ2
)= 2n−γ
taking t =√
2σ2(1 + γ) log n.
34 / 124

Theorem 6
Assume {Xi}ni=1 are zero-mean RVs, sub-Gaussian with parameter σ. Then,
E[ maxi=1,...,n
Xi ] ≤√
2σ2 log n, ∀n ≥ 1.
• Proof of Theorem 6:
• Apply Jensen’s inequality to eλZ where Z = maxi Xi .
• Note that we always have (for any λ ∈ R)
eλmaxi Xi ≤∑i
eλXi .
• Exercise: complete the proof (by optimizing over λ).
35 / 124

Detour: Martingales
• A filteration {Fk}k≥1 is a nested sequence of σ-fields: F1 ⊂ F2 ⊂ · · · .• A sequence of random variables Y1,Y2, . . . .
• The pair ({Yk}, {Fk}) is a martingale if
• {Yk}k≥1 is adapted to {Fk}k≥1, i.e., Yk ∈ Fk for all k ≥ 1,
• E|Yk | <∞,
• E[Yk+1 | Fk ] = Yk . for all k ≥ 1.
• Often Fk = σ(X1,X2, . . . ), in which case we say {Yk} is a martingale, w.r.t.{Xk}. The key condition in this case is
E[Yk+1 | Xk , . . . ,X1] = Yk .
• One of the most general dependence structures in probability.
• Allow relaxing independence assumptions in classical limit theorems.
• {Yk} could be a martingale w.r.t. itself; then it is just called a martingale.
• We have a supermartingle if Yk ≥ E[Yk+1 | Fk ].
• An L1 bounded supermartingle (supk E[Y−k ] <∞) converges almost surely.
36 / 124

Detour: Martingale Examples
• Partial sums Sk :=∑k
j=1 Xj of an iid zero-mean sequence {Xi}.• Partial products Lk :=
∏kj=1 Xj of an iid sequence with E[X1] = 1.
• Likelhood ratio process is an example of the above exponential martingale.
• Doob’s martingale: For any integrable Z (i.e., E|Z | <∞) the following isalways a martingale:
Yk := E[Z | X1, . . . ,Xk ]
• Exercise: verify the martingale property.
37 / 124

Theorem 7 (Azuma–Hoeffding)
Let X = (X1, . . . ,Xn) be a random vector and Z = f (X ). Consider the Doob’smartingale
Yi := Ei [Z ] := E[Z | X1, . . . ,Xi ]
and let ∆i := Yi − Yi−1. Assume that
Ei−1[eλ∆i ] ≤ eσ2i λ
2/2, ∀λ ∈ R (3)
almost surely, for all i = 1, . . . , n.
Then, Z − EZ is sub-Gaussian with parameter σ =√∑n
i=1 σ2i .
• In particular, we have the tail bound
P(|Z − EZ | ≥ t) ≤ 2 exp(− t2
2σ2
).
• {∆i} is a martingale difference sequence, i.e., Ei−1[∆i ] = 0.
38 / 124

Proof• Let Sj :=
∑ji=1 ∆i which is only a function of Xi , i ≤ j .
• Noting that E0[Z ] = E[Z ] and En[Z ] = Z ,
Sn =n∑
i=1
∆i = Z − EZ .
• By properties of conditional expectation, and assumption (3),
En−1[eλSn ] = eλSn−1En−1[eλ∆n ] ≤ eλSn−1eσ2nλ
2/2.
• Taking En−2 of both sides:
En−2[eλSn ] ≤ eσ2nλ
2/2En−2[eλSn−1 ] ≤ eλSn−2e(σ2n+σ2
n−1)λ2/2.
• Repeating the process, we get
E0[eλSn ] ≤ exp(
(n∑
i=1
σ2i )λ2/2
).
39 / 124

Bounded difference inequality
• Conditional sub-G. assump. holds under bounded difference property:∣∣f (x1, . . . , xi−1, xi , xi+1, . . . , xn)− f (x1, . . . , xi−1, x′i , xi+1, . . . , xn)
∣∣ ≤ Li(4)
for all x1, . . . , xn, x′i ∈ X , and all i ∈ [n], for some constants (L1, . . . , Ln).
Theorem 8 (Bounded difference)
Assume that X = (X1, . . . ,Xn) has independent coordinates, andassume that f : X n 7→ R satisfies the bounded difference property (4). Then,
P(∣∣f (X )− Ef (X )
∣∣ ≥ t)≤ 2 exp
(− 2t2∑n
i=1 L2i
), t ≥ 0.
40 / 124

Proof (Naive bound)
• Let gi (X1, . . . ,Xi ) := Ei [Z ] and show that gi also has bounded diff.property.
∆i = Ei [Z ]− Ei−1[Ei [Z ]] = gi (X1, . . . ,Xi )− Ei−1[gi (X1, . . . ,Xi )]
• Let X ′i be an independent copy of Xi .
• Conditioned on X1, . . . ,Xi−1, we are effectively looking at
gi (x1, . . . , xi−1,Xi )− E[gi (x1, . . . , xi−1,X′i )]
due to independence of {X1, . . . ,Xi ,X′i }.
• Thus, |∆i | ≤ Li condition on X1, . . . ,Xi−1.
• That is, Ei−1[eλ∆i ] ≤ eσ2i λ
2/2 where σ2i = (2Li )
2/4 = L2i .
41 / 124

Proof (Better bound)
• Can show that |∆i | ∈ Ii where |Ii | ≤ Li , improving the constant by 4.
• Conditioned on X1, . . . ,Xi , we are effectively looking at
∆i = gi (x1, . . . , xi−1,Xi )− µi
where µi is a constant (only a function of x1, . . . , xi−1).
• Then, ∆i + µi ∈ [ai , bi ] where
ai = infxgi (x1, . . . , xi−1, x), bi = sup
xgi (x1, . . . , xi−1, x).
• We have (need to argue that gi satisfies bounded difference)
bi − ai = supx,y
[gi (x1, . . . , xi−1, x)− gi (x1, . . . , xi−1, y)
]≤ Li .
• Thus Ei−1[eλ∆i ] ≤ eσ2λ2/2 where σ2
i = (bi − ai )2/4 ≤ L2
i /4.
42 / 124

• The role of independence in the second argument is subtle.
• The only place we used independence is to argue that Ei [Z ] satisfiesbounded difference for all i .
• We argue that Ei [Z ] = gi (X1, . . . ,Xi ), which is where we use independence.
• Then, gi by definition and Jensen satisfies bounded difference.
43 / 124

Example: (Bounded) U-statistics
• g : R2 → R a symmetric function,
• X1, . . . ,Xn and iid sequence,
U :=1(n2
) ∑i<j
g(Xi ,Xj)
is called a U-statistic (of order 2).
• U is not a sum of independent variables, e.g. n = 3 gives
U =1
3
(g(X1,X2) + g(X1,X3) + g(X2,X3)
),
but the dependence between terms is relatively weak (made precise shortly).
• For example, g(x , y) = 12 (x − y)2 gives an unbiased estimator of the
variance. (Exercise)
44 / 124

• Assume that g is bounded, i.e. ‖g‖∞ ≤ b, meaning
‖g‖∞ := supx,y|g(x , y)| ≤ b
i.e., |g(x , y)| ≤ b for all x , y ∈ R.
• Writing U = f (X1, . . . ,Xn), we observe that (for fixed k)
|f (x)− f (x\k)| ≤ 1(n2
) ∑i 6=k
|g(xi , xk)− g(xi , x′k)|
≤ (n − 1)2b
n(n − 1)/2=
4b
n
thus f has bounded differences with parameters Lk = 4b/n.
• Applying Theorem 8
P(|U − EU| ≥ t
)≤ 2e−nt
2/8b2
, t ≥ 0.
45 / 124

Clique number of Erdos-Renyi
• Let G be an undirected graph.on n nodes.
• A clique in G is a complete (induced) sub-graph.
• Clique number of G—denoted as ω(G )—is the size of the largest clique(s).
• For two graphs G and G ′ that differ in at most 1 edge,
|ω(G )− ω(G ′)| ≤ 1.
• Thus E (G ) 7→ ω(G ) has bounded difference property with L = 1.
• Let G be an Erdos-Renyi random graph: Edges are independently drawnwith probability p. Then, with m =
(n2
),
P(|ω(G )− Eω(G )| ≥ δ
)≤ 2e−2δ2/m
or setting ω(G ) = ω(G )/m,
P(|ω(G )− E ω(G )| ≥ δ
)≤ 2e−2mδ2
46 / 124

Lipschitz functions of standard Gaussian vector
• A function f : Rn → R is L-Lipschitz w.r.t. ‖ · ‖2 if
|f (x)− f (y)| ≤ L‖x − y‖2, x , y ∈ Rn
Theorem 9 (Gaussian concentration)
Let X ∼ N(0, In) be a standard Gaussian vector and assume that f : Rn → R isL-Lipschitz w.r.t. the Euclidean norm. Then,
P(∣∣f (X )− E[f (X )]
∣∣ ≥ t)≤ 2 exp
(− t2
2L2
), t ≥ 0. (5)
• In other words, f (X ) is sub-Gaussian with parameter L.
• Deep result, no easy proof!
• Has far-reaching consequences.
• One-sided bounds holds with prefactor 2 removed.
47 / 124

Example: χ2 and norm concentrations revisited• Let X ∼ N(0, In) and condition the function f (x) = ‖x‖2/
√n.
• f is L-Lipschitz with L = 1/√n. Hence,
P(‖X‖2√
n− E‖X‖2√
n≥ t)≤ e−nt
2/2, t ≥ 0
• Since E‖X‖2 ≤√n (why?), we have
P(‖X‖2√
n− 1 ≥ t
)≤ e−n t2/2, t ≥ 0.
• For t ∈ [0, 1], (1 + t)2 ≤ 1 + 3t, hence
P(‖X‖2
2
n− 1 ≥ 3t
)≤ e−n t2/2, t ∈ [0, 1].
or setting 3t = δ,
P(‖X‖2
2
n− 1 ≥ δ
)≤ e−n δ
2/18, δ ∈ [0, 3].
48 / 124

Example: order statistics
• Let X ∼ N(0, In), and
• let f (x) = x(k) be the kth order statistic: For x ∈ Rn,
x(1) ≤ x(2) ≤ · · · ≤ x(n)
• For any x , y ∈ Rn, we have
|x(k) − y(k)| ≤ ‖x − y‖2
hence f is 1-Lipschitz. (Exercise)
• It follows that
P(|X(k) − EX(k)| ≥ t
)≤ 2e−t
2/2, t ≥ 0
• In particular, if Xiiid∼N(0, 1), i = 1, . . . , n, then
P(∣∣∣ max
i=1,...,nXn − E[ max
i=1,...,nXn]∣∣∣ ≥ t
)≤ 2e−t
2/2, t ≥ 0
49 / 124

Example: Singular values
• Consider a matrix X ∈ Rn×d where n > d .
• Let σ1(X ) ≥ σ2(X ) ≥ · · · ≥ σk(X ) be (ordered) singular values of X .
• By Weyl’s theorem, for any X ,Y ∈ Rn×d :
|σk(X )− σk(Y )| ≤ |||X − Y |||op ≤ |||X − Y |||F
(Note that this is a generalization of order-statistics inequality.)
• Thus, X 7→ σk(X ) is 1-Lipschitz:
Proposition 6
Let X ∈ Rn×d be a random matrix with iid N(0, 1) entries. Then,
P(∣∣σk(X )− E[σk(X )]
∣∣ ≥ δ) ≤ 2e−δ2/2, δ ≥ 0
• It remains to characterize E[σk(X )].
• For an overview of matrix norms, see matrix norms.pdf
50 / 124

Table of Contents I1 Concentration inequalities
Sub-Gaussian concentration (Hoeffding inequality)Sub-exponential concentration (Bernstein inequality)Applications of Bernstein inequalityχ2 ConcentrationJohnson-Lindenstrauss embedding`2 norm concentration`∞ norm
Bounded difference inequality (Azuma–Hoeffding)Detour: MartingalesAzuma–HoeffdingBounded difference inequalityConcentration of (bounded) U-statisticsConcentration of clique numbers
Gaussian concentrationχ2 concentration revisitedOrder statistics and singular values
Gaussian chaos (Hanson–Wright inequality)
2 Sparse linear modelsBasis Pursuit
Restricted null space property (RNS)51 / 124

Table of Contents IISufficient conditions for RNS
Pairwise incoherenceRestricted isometry property (RIP)
Noisy sparse regressionRestricted eigenvalue conditionDeviation bounds under RERE for anisotropic designOracle inequality (and `q sparsity)
3 Metric entropyPacking and coveringVolume ratio estimates
4 Random matrices and covariance estimationOp-norm concentration: sub-Gaussian matrices, independent entriesOp-norm concentration: Gaussian caseSub-Gaussian random vectorsOp-norm concentration: sample covariance
5 Structured covariance matricesHard thresholding estimatorApproximate sparsity (`q balls)
6 Matrix concentration inequalities52 / 124

Linear regression setup
• The data is (y ,X ) where y ∈ Rn and X ∈ Rn×d , and the model
y = Xθ∗ + w .
• θ∗ ∈ Rd is an unknown parameter.
• w ∈ Rn is the vector of noise variables.
• Equivalently,yi = 〈θ∗, xi 〉+ wi , i = 1, . . . , n
where xi ∈ Rd is the nth row of X :
X =
− xT
1 −− xT
2 −...
− xTn −
︸ ︷︷ ︸
d
• Recall 〈θ∗, xi 〉 =∑d
j=1 θ∗j xij .
53 / 124

Sparsity models
• When n < d , no hope of estimating θ∗,
• unless we impose some sort of of low-dimensional model on θ∗.
• Support of θ∗ (recall [d ] = {1, . . . , d}):
supp(θ∗) := S(θ∗) ={j ∈ [d ] : θ∗j 6= 0
}.
• Hard sparsity assumption: s = |S(θ∗)| � d .
• Weaker sparsity assumption via `q balls for q ∈ [0, 1]
Bq(Rq) ={θ ∈ Rd :
d∑j=1
|θj |q ≤ Rq
}.
• q = gives `1 ball.
• q = 0 the `0 ball, same as hard sparsity:
‖θ∗‖0 := |S(θ∗)| = #{j ; θ∗j 6= 0
}54 / 124
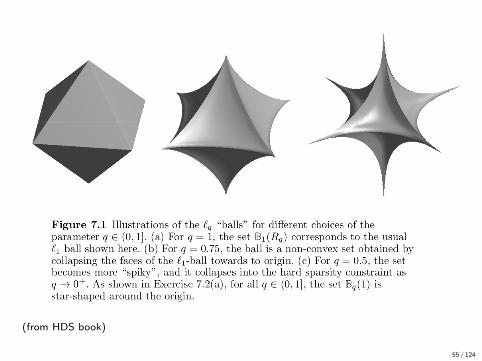
(from HDS book)
55 / 124

Basis pursuit
• Consider the noiseless case y = Xθ∗.
• We assume that ‖θ∗‖0 is small.
• Ideal program to solve:
minθ∈Rd
‖θ‖0 subject to y = Xθ
• ‖ · ‖0 is highly non-convex, relax to ‖ · ‖1:
minθ∈Rd
‖θ‖1 subject to y = Xθ (6)
This is called basis pursuit (regression).
• (6) is a convex program.
• In fact, can be written as a linear program1.
• Global solutions can be obtained very efficiently.
1Exercise: Introduce auxiliary variables sj ∈ R and note that minimizing∑
j sj subject to
|θj | ≤ sj gives the `1 norm of θ.56 / 124

Restricted null space property (RNS)
• Define
C(S) = {∆ ∈ Rd : ‖∆Sc‖1 ≤ ‖∆S‖1}. (7)
Theorem 10The following two are equivalent:
• For any θ∗ ∈ Rd with support ⊆ S , the basis pursuit program (6) applied to
the data (y = Xθ∗,X ) has unique solution θ = θ∗.
• The restricted null space (RNS) property holds, i.e.,
C(S) ∩ ker(X ) = {0}. (8)
57 / 124

Proof
• Consider the tangent cone to the `1 ball (of radius ‖θ∗‖1) at θ∗:
T(θ∗) = {∆ ∈ Rd : ‖θ∗ + t∆‖1 ≤ ‖θ∗‖1, for some t > 0.}
i.e., the set of descent directions for `1 norm at point θ∗.
• Feasible set is θ∗ + ker(X ), i.e.
• ker(X ) is the set of feasible directions ∆ = θ − θ∗.• Hence, there is a minimizer other than θ∗ if and only if
T(θ∗) ∩ ker(X ) 6= {0} (9)
• It is enough to show that
C(S) =⋃
θ∗∈Rd : supp(θ∗)⊆ST(θ∗).
58 / 124
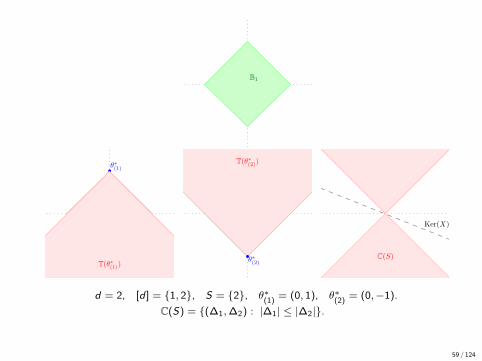
B1
•θ∗(1)
T(θ∗(1))•θ∗(2)
T(θ∗(2))
Ker(X)
C(S)
d = 2, [d ] = {1, 2}, S = {2}, θ∗(1)
= (0, 1), θ∗(2)
= (0,−1).
C(S) = {(∆1,∆2) : |∆1| ≤ |∆2|}.
59 / 124

• It is enough to show that
C(S) =⋃
θ∗∈Rd : supp(θ∗)⊆ST(θ∗) (10)
• We have ∆ ∈ T1(θ∗) iff2
‖∆Sc‖1 ≤ ‖θ∗S‖1 − ‖θ∗S + ∆S‖1
• We have ∆ ∈ T1(θ∗) for some θ∗ ∈ Rd s.t. supp(θ∗) ⊂ S iff
‖∆Sc‖1 ≤ supθ∗S∈Rd
[‖θ∗S‖1 − ‖θ∗S + ∆S‖1
]= ‖∆S‖1
2Let T1(θ∗) be the subset of T(θ∗) where t = 1, and argue that w.l.o.g. we can work thissubset.
60 / 124

Sufficient conditions for restricted nullspace• [d ] := {1, . . . , d}• For a matrix X ∈ Rd , let Xj be its jth column (for j ∈ [d ]).
• The pairwise incoherence of X is defined as
δPW(X ) := maxi, j∈[d ]
∣∣∣ 〈Xi ,Xj〉n
− 1{i = j}∣∣∣
• Alternative form: XTX is the Gram matrix of X ,
• (XTX )ij = 〈Xi ,Xj〉.
δPW(X ) := ‖XTX
n− Ip‖∞
where ‖ · ‖∞ is the vector `∞ norm of the matrix.
Proposition 7 (HDS Prop. 7.1)
(Uniform) restricted nullspace holds for all S with |S | ≤ s if
δPW(X ) ≤ 1
3s
• Proof: Exercise 7.3.61 / 124

Restricted isometry property (RIP)
• A more relaxed condition:
Definition 3 (RIP)
X ∈ Rn×d satisfies a restricted isometry property (RIP) of order s with constantδs(X ) > 0 if
|||XTS XS
n− I |||op ≤ δs(X ), for all S with |S | ≤ s
• PW incoherence is close to RIP with s = 2;
• for example, when ‖Xj/√n‖2 = 1 for all j , we have
δ2(X ) = δPW(X ).
• In general, for any s ≥ 2, (Exercise 7.4)
δPW(X ) ≤ δs(X ) ≤ s δPW(X ).
62 / 124

Definition (RIP)
X ∈ Rn×d satisfies a restricted isometry property (RIP) of order s with constantδs(X ) > 0 if
|||XTS XS
n− I |||op ≤ δs(X ), for all S with |S | ≤ s
• Let xTi be the i th row of X . Consider the sample covariance matrix:
Σ :=1
nXTX =
1
n
n∑i=1
xixTi ∈ Rd×d .
• Then ΣSS = 1nX
TS XS , hence, RIP is
|||ΣSS − I |||op ≤ δ < 1
i.e., ΣSS ≈ Is . More precisely,
(1− δ)‖u‖2 ≤ ‖ΣSSu‖2 ≤ (1 + δ)‖u‖2, ∀u ∈ Rs
63 / 124

• RIP gives sufficient conditions:
Proposition 8 (HDS Prop. 7.2)
(Uniform) restricted null space holds for all S with |S | ≤ s if
δ2s(X ) ≤ 1
3
• Consider a sub-Gaussian matrix X with i.i.d. entries and EXij = 0 andEX 2
ij = 1 (Exercise 7.7):
• We have
n & s2 log d =⇒ δPW(X ) <1
3s, w.h.p.
n & s log(eds
)=⇒ δ2s <
1
3, w.h.p.
• Sample complexity requirement for RIP is milder.
64 / 124

Neither RIP or PWI is necessary
• For more general covariance Σ, it is harder to satisfy either PWI or RIP.
• Consider X ∈ Rn×d with i.i.d. rows Xi ∼ N(0,Σ).
• Letting 1 ∈ Rd be the all-ones vector, and
Σ := (1− µ)Id + µ11T
for µ ∈ [0, 1). (A spiked covariance matrix.)
• We have γmax(ΣSS) = 1 + µ(s − 1)→∞ as s →∞.
• Exercise 7.8,
(a) PW is violated w.h.p. unless µ� 1/s.
(b) RIP is violated w.h.p. unless µ� 1/√s.
In fact δ2s grows like µ√s for any fixed µ ∈ (0, 1).
• However, for any µ ∈ [0, 1), basis pursuit succeeds w.h.p. if
n & s log(eds
).
(A later result shows this.)
65 / 124

Noisy sparse regression
• A very popular estimator is the `1-regularized least-squares:
θ ∈ argminθ∈Rd
[ 1
2n‖y − Xθ‖2
2 + λ‖θ‖1
](11)
• The idea: minimizing `1 norm leads to sparse solutions.
• (11) is a convex program; global solution can be obtained efficiently.
• Other options: constrained form of lasso
min‖θ‖1≤R
1
2n‖y − Xθ‖2
2. (12)
66 / 124

Restricted eigenvalue condition
• For a constant α ≥ 1,
Cα(S) :={
∆ ∈ Rd | ‖∆Sc‖1 ≤ α‖∆S‖1
}.
• A strengthening of RNS is:
Definition 4 (RE condition)
A matrix X satisfies the restricted eigenvalue (RE) condition over S withparameters (κ, α) if
1
n‖X∆‖2
2 ≥ κ‖∆‖22 for all ∆ ∈ Cα(S).
• RNS corresponds to
1
n‖X∆‖2
2 > 0 for all ∆ ∈ C1(S) \ {0}.
67 / 124

Deviation bounds under RE
Theorem 11 (Deterministic deviations)
Assume that y = Xθ∗ + w , where X ∈ Rn×d and θ∗ ∈ Rd , and
• θ∗ is supported on S ⊂ [d ] with |S | ≤ s
• X satisfies RE(κ, 3) over S .
Let us define z = XTwn . Then, we have the following:
(a) Any solution of Lasso (11) with λ ≥ 2‖z‖∞ satisfies
‖θ − θ∗‖2 ≤3
κ
√s λ
(b) Any solution of constrained Lasso (12) with R = ‖θ∗‖1 satisfies
‖θ − θ∗‖2 ≤4
κ
√s‖z‖∞
68 / 124

Example (fixed design regression)• Assume y = Xθ∗ + w where w ∼ N(0, σ2In), and
• X ∈ Rn×d fixed and satisfying RE condition and normalization
maxj=1,...,d
‖Xj‖√n≤ C .
where Xj is the jth column of X .
• Recall z = XTw/n.
• It is easy to show that w.p. ≥ 1− 2e−nδ2/2,
‖z‖∞ ≤ Cσ(√2 log d
n+ δ)
• Thus, setting λ = 2Cσ(√
2 log dn + δ
), Lasso solution satisfies
‖θ − θ∗‖2 ≤6Cσ
κ
√s(√2 log d
n+ δ)
w.p. at least 1− 2e−nδ2/2.
69 / 124

• Taking δ =√
2 log /n, we have
‖θ − θ∗‖2 . σ
√s log d
n
w.h.p. (i.e., ≥ 1− 2d−1).
• This is the typical high-dimensional scaling in sparse problems.
• Had we known the support S in advance, our rate would be (w.h.p.)
‖θ − θ∗‖2 . σ
√s
n.
• The log d factor is the price for not knowing the support;
• roughly the price for searching over(ds
)≤ d s collection of candidate
supports.
70 / 124

Proof of Theorem 11• Let us simplify the loss L(θ) := 1
2n‖Xθ − y‖2.
• Setting ∆ = θ − θ∗,
L(θ) =1
2n‖X (θ − θ∗)− w‖2
=1
2n‖X∆− w‖2
=1
2n‖X∆‖2 − 1
n〈X∆,w〉+ const.
=1
2n‖X∆‖2 − 1
n〈∆,XTw〉+ const.
=1
2n‖X∆‖2 − 〈∆, z〉+ const.
where z = XTw/n. Hence,
L(θ)− L(θ∗) =1
2n‖X∆‖2 − 〈∆, z〉. (13)
• Exercise: Show that (13) is the Taylor expansion of L around θ∗.
71 / 124

Proof (constrained version)• By optimality of θ and feasibility of θ∗:
L(θ) ≤ L(θ∗)
• Error vector ∆ := θ − θ∗ satisfies basic inequality
1
2n‖X ∆‖2
2 ≤ 〈z , ∆〉.
• Using Holder inequality
1
2n‖X ∆‖2
2 ≤ ‖z‖∞‖∆‖1.
• Since ‖θ‖1 ≤ ‖θ∗‖1, we have ∆ = θ − θ∗ ∈ C1(S), hence
‖∆‖1 = ‖∆S‖1 + ‖∆Sc‖1 ≤ 2‖∆S‖1 ≤ 2√s‖∆‖2.
• Combined with RE condition (∆ ∈ C3(S) as well)
1
2κ‖∆‖2
2 ≤ 2√s‖z‖∞‖∆‖2.
which gives the desired result.72 / 124

Proof (Lagrangian version)• Let L(θ) := L(θ) + λ‖θ‖1 be the regularized loss.
• Basic inequality is
L(θ) + λ‖θ‖1 ≤ L(θ∗) + λ‖θ∗‖1
• Rearranging1
2n‖X ∆‖2
2 ≤ 〈z , ∆〉+ λ(‖θ∗‖1 − ‖θ‖1)
• We have
‖θ∗‖1 − ‖θ‖1 = ‖θ∗S‖1 − ‖θ∗S + ∆S‖1 − ‖∆Sc‖1
≤ ‖∆S‖1 − ‖∆Sc‖1
• Since λ ≥ 2‖z‖∞,
1
n‖X ∆‖2
2 ≤ λ‖∆‖1 + 2λ(‖∆S‖1 − ‖∆Sc‖1)
≤ λ( 3‖∆S‖1 − ‖∆Sc‖1 )
• It follows that ∆ ∈ C3(S) and the rest of the proof follows.73 / 124

RE condition for anisotropic design• For a PSD matrix Σ, let
ρ2(Σ) = maxi
Σii .
Theorem 12
Let X ∈ Rn×d with rows i.i.d. from N(0,Σ). Then, there exist universalconstants c1 < 1 < c2 such that
‖Xθ‖22
n≥ c1‖
√Σθ‖2
2 − c2 ρ2(Σ)
log d
n‖θ‖2
1, for all θ ∈ Rd (14)
withe probability at least 1− e−n/32/(1− e−n/32).
• Exercise 7.11: (14) implies RE condition over C3(S) uniformly over allsubsets of cardinality
|S | ≤ c1
32c2
γmin(Σ)
ρ2(Σ)
n
log d
• In other words, n & s log d =⇒ RE condition over C3(S) for all |S | ≤ s.74 / 124

Comments
• Note that E‖Xθ‖22
n = ‖√
Σθ‖22.
• Bound (14) says that ‖Xθ‖22/n is lower-bounded by a multiple of its
expectation minus a slack ∝ ‖θ‖21.
• Why the slack is needed?
• In the high-dimensional setting ‖Xθ‖2 = 0 for any θ ∈ ker(X ), while‖√
Σθ‖2 > 0 for any θ 6= 0 assuming Σ is non-singular.
• In fact, ‖√
Σθ‖2 is uniformly bounded below in that case:
‖√
Σθ‖22 ≥ γmin(Σ)‖θ‖2
2,
showing that the population level version of X/n, that is,√
Σ, satisfies RE,and in fact global eigenvalue condition.
• (14) gives a nontrivial/good lower bound for θ for which ‖θ‖1 is smallcompared to ‖θ‖2, i.e., sparse vectors.
• Recall that if θ is s-sparse, then ‖θ‖1 ≤√s‖θ‖2,
• while for general θ ∈ Rd , we have ‖θ‖1 ≤√d‖θ‖2.
75 / 124

Examples
• Toeplitz family: Σij = ν|i−j|,
ρ2(Σ) = 1, γmin(Σ) ≥ (1− ν)2 > 0
• Spiked model: Σ := (1− µ)Id + µ11T ,
ρ2(Σ) = 1, γmin(Σ) = 1− µ
• For future applications, note that (14) implies
‖Xθ‖22
n≥ α1‖θ‖2
2 − α2‖θ‖21, ∀θ ∈ Rd .
where α1 = c1γmin(Σ) and α2 = c2ρ2(Σ)
log d
n.
76 / 124

Lasso oracle inequality
• For simplicity, let κ = γmin(Σ) and ρ2 = ρ2(Σ) = maxi Σii
Theorem 13
Under condition (14), consider the Lagrangian Lasso with regularizationparameter λ ≥ 2‖z‖∞ where z = XTw/n. For any θ∗ ∈ Rd , any optimal
solution θ satisfies the bound
‖θ − θ∗‖22 ≤
144
c21
λ2
κ2|S |︸ ︷︷ ︸
Estimation error
+16
c1
λ
κ‖θ∗Sc‖1 +
32c2
c1
ρ2
κ
log d
n‖θ∗Sc‖2
1︸ ︷︷ ︸ApproximationError
(15)
valid for any subset S with cardinality
|S | ≤ c1
64c2
κ
ρ2
n
log d.
77 / 124

• Simplifying the bound
‖θ − θ∗‖22 ≤ κ1 λ
2|S |+ κ2 λ‖θ∗Sc‖1 + κ3log d
n‖θ∗Sc‖2
1
where κ1, κ2, κ3 are constant dependent on Σ.
• Assume σ = 1 (noise variance) for simplicity.
• Since we ‖z‖∞ .√
log d/n w.h.p., we can take λ of this order:
‖θ − θ∗‖22 .
log d
n|S |+
√log d
n‖θ∗Sc‖1 +
log d
n‖θ∗Sc‖2
1
• Optimizing the bound
‖θ − θ∗‖22 . inf
|S|. nlog d
[log d
n|S |+
√log d
n‖θ∗Sc‖1 +
log d
n‖θ∗Sc‖2
1
]
• An oracle that knows θ∗ can choose the optimal S .
78 / 124

Example: `q-ball sparsity
• Assume that θ∗ ∈ Bq, i.e.,∑d
j=1 |θ∗j |q ≤ 1, for some q ∈ [0, 1].
• Then, assuming σ2 = 1, we have the rate (Exercise 7.12)
‖θ − θ∗‖22 .
( log d
n
)1−q/2
.
Sketch:
• Trick: take S = {i : |θ∗i | > τ} and find a good threshold τ later.
• Show that ‖θ∗Sc‖1 ≤ τ 1−q and |S | ≤ τ−q.
• The bound would be of the form (ε :=√
log d/n)
ε2τ−q + ετ 1−q + (ετ 1−q)2.
• Ignore the last term (assuming ετ 1−q ≤ 1, it is not dominant),
79 / 124

Proof of Theorem 13 (Compact)• Basic inequality argument and assumption λ ≥ 2‖z‖∞ gives
1
n‖X ∆‖2
2 ≤ λ(3‖∆S‖1 − ‖∆Sc‖1 + b).
where b := 2‖θ∗Sc‖1.
• The error satisfies ‖∆Sc‖1 ≤ 3‖∆S‖1 + b,
• ‖∆‖21 ≤ 32 s ‖∆‖2
2 + 2b2 (∆ behaves almost like an s-sparse vector.)
• Bound (14) can be written as (α1, α2 > 0)
1
n‖X∆‖2
2 ≥ α1‖∆‖22 − α2‖∆‖2
1, ∀∆ ∈ Rd .
• Combining, rearranging, dropping, etc., we get
(α1 − 32α2)‖∆‖22 ≤ λ(3
√s‖∆‖2 + b) + 2α2b
2
• Assume α1 − 32α2s ≥ α1/2 > 0 so that the quadratic inequality enforces an
upper bound on ∆.
• Hint: ax2 ≤ bx + c , x ≥ 0 =⇒ x ≤ ba +
√ca =⇒ x2 ≤ 2b2
a2 + 2ca .
80 / 124

Table of Contents I1 Concentration inequalities
Sub-Gaussian concentration (Hoeffding inequality)Sub-exponential concentration (Bernstein inequality)Applications of Bernstein inequalityχ2 ConcentrationJohnson-Lindenstrauss embedding`2 norm concentration`∞ norm
Bounded difference inequality (Azuma–Hoeffding)Detour: MartingalesAzuma–HoeffdingBounded difference inequalityConcentration of (bounded) U-statisticsConcentration of clique numbers
Gaussian concentrationχ2 concentration revisitedOrder statistics and singular values
Gaussian chaos (Hanson–Wright inequality)
2 Sparse linear modelsBasis Pursuit
Restricted null space property (RNS)81 / 124

Table of Contents IISufficient conditions for RNS
Pairwise incoherenceRestricted isometry property (RIP)
Noisy sparse regressionRestricted eigenvalue conditionDeviation bounds under RERE for anisotropic designOracle inequality (and `q sparsity)
3 Metric entropyPacking and coveringVolume ratio estimates
4 Random matrices and covariance estimationOp-norm concentration: sub-Gaussian matrices, independent entriesOp-norm concentration: Gaussian caseSub-Gaussian random vectorsOp-norm concentration: sample covariance
5 Structured covariance matricesHard thresholding estimatorApproximate sparsity (`q balls)
6 Matrix concentration inequalities82 / 124

Metric entropy and related ideas
• Metric entropy ideas allow us to reduce considerations over massive(uncountable) sets, to finite subsets.
• It is a measure of the size of a set; a measure of quantitative measure ofcompactness.
• Totally bounded set in a metric space = can be covered with “finite”number of ε-balls for any ε > 0.
83 / 124

Covering and metric entropy
• How to measure the sizes of sets in metric spaces?
• One idea is based on measures of sets, assuming that there is a suitablemeasure on the space (say Lebesgue measure in Rd).
• A more topological idea: Covering one set with copies of another set.
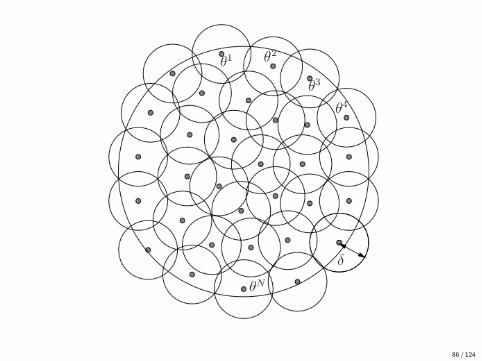
Definition 5 (Covering number)
An ε-cover or ε-net of a set T w.r.t. a metric ρ is a set
N := {θ1, . . . , θN} ⊂ T
such that∀t ∈ T , ∃θi ∈ N such that ρ(θ, θi ) ≤ ε.
The ε-covering number N(ε;T , ρ) is cardinality of the smallest ε-cover.
• logN(ε;T , ρ) is called the metric entropy of the (metric) space (T , ρ) .
84 / 124

• In normed vector spaces, ρ(x , y) = ‖x − y‖.• Notation B := {θ : ‖θ‖ ≤ 1}.• Ball of radius ε centered at θj is θj + εB.
• N := {θ1, . . . , θN} ⊂ T is an ε-covering iff
T ⊂N⋃j=1
(θj + εB)
i.e., covering T with shifted copies of εB.
85 / 124
86 / 124

Packing
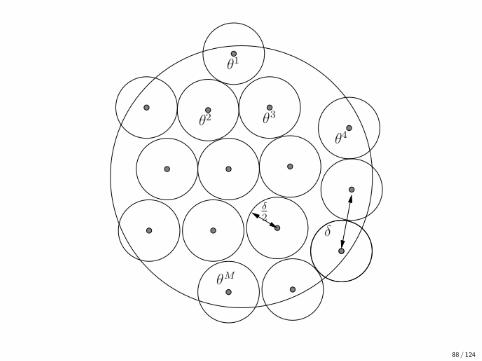
Definition 6A ε-packing of a set T w.r.t. a metric ρ is a set
M := {θ1, . . . , θN} ⊂ T
such thatρ(θi , θj) > ε, ∀i 6= j .
The ε-packing number M(ε;T , ρ) is the cardinality of the largest ε-packing.
87 / 124
88 / 124

Example
Example 3 (Covering `∞)
• Take T = [−1, 1] and ρ(θ, θ′) = |θ − θ′|.• Divide [−1, 1] into L = b1/εc+ 1 sub-intervals,
• centered at the points θi = −1 + (2i − 1)ε for i ∈ [L] = {1, . . . , L}.• Easy to verify that θ1, θ2, . . . , θL forms an ε-net of [−1, 1], hence
N(ε; [−1, 1], | · |) ≤ 1
ε+ 1.
• Exercise: Show that this analysis can be extended to coveringB∞ = [−1, 1]d in the `∞ metric
N(ε; [−1, 1]d , ‖ · ‖∞) ≤(
1 +1
ε
)d.
89 / 124

Relation between packing and covering
Lemma 6For all ε > 0, the packing and covering numbers are related as follows:
M(2ε;T , ρ) ≤ N(ε;T , ρ) ≤ M(ε;T , ρ).
• Proof: Exercise.(Hint: any maximal packing is automatically a covering of suitable radius.)
90 / 124

Volume ratio estimates
Lemma 7
• Let ‖ · ‖ and ‖ · ‖′ be two norms on Rd with respective unit balls B and B′.• That is, B = {θ ∈ Rd | ‖θ‖ ≤ 1}, and similarly for B′.
Then, ε-covering of B in ‖ · ‖′ satisfies(1
ε
)d vol(B)
vol(B′)≤ N(ε;B, ‖ · ‖′) ≤ M(ε;B, ‖ · ‖′) ≤ vol( 2
ε B+B′)vol(B′)
.
• Important special case: Covering balls in their own metric: B = B′
d log(1
ε
)≤ logN(ε;B, ‖ · ‖) ≤ d log
(1 +
2
ε
).
• Recovers N(ε,Bd∞, ‖ · ‖∞) � d log(1/ε) from Example 3.
• Often care about ε→ 0. N(ε,Bd2 , ‖ · ‖2) ≤ (3/ε)d for ε ≤ 1.
• We also write N2(ε,Bd2 ) := N(ε,Bd
2 , ‖ · ‖2)
91 / 124

Proof of Lemma 7
• Let {θ1, . . . , θN} be an ε-covering of B in ‖ · ‖′. Then
B ⊆N⋃j=1
(θj + εB′)
which gives (by union bound)
vol(B) ≤ N vol(εB′) = Nεd vol(B′)
using translation invariance of the Lebesgue measure.
92 / 124

• For the other direction, let {θ1, . . . , θM} be a maximal ε-packing.
• By maximality, it should also be an ε-covering.
• The balls θi + ε2 B′, i = 1, . . . ,M are disjoint and contained in B+ ε
2 B′.
Hence
M vol(ε
2B′)
=M∑i=1
vol(θi +
ε
2B′)≤ vol
(B+
ε
2B′).
• Pulling ε/2 out from both sides completes the proof.
93 / 124

Table of Contents I1 Concentration inequalities
Sub-Gaussian concentration (Hoeffding inequality)Sub-exponential concentration (Bernstein inequality)Applications of Bernstein inequalityχ2 ConcentrationJohnson-Lindenstrauss embedding`2 norm concentration`∞ norm
Bounded difference inequality (Azuma–Hoeffding)Detour: MartingalesAzuma–HoeffdingBounded difference inequalityConcentration of (bounded) U-statisticsConcentration of clique numbers
Gaussian concentrationχ2 concentration revisitedOrder statistics and singular values
Gaussian chaos (Hanson–Wright inequality)
2 Sparse linear modelsBasis Pursuit
Restricted null space property (RNS)94 / 124

Table of Contents IISufficient conditions for RNS
Pairwise incoherenceRestricted isometry property (RIP)
Noisy sparse regressionRestricted eigenvalue conditionDeviation bounds under RERE for anisotropic designOracle inequality (and `q sparsity)
3 Metric entropyPacking and coveringVolume ratio estimates
4 Random matrices and covariance estimationOp-norm concentration: sub-Gaussian matrices, independent entriesOp-norm concentration: Gaussian caseSub-Gaussian random vectorsOp-norm concentration: sample covariance
5 Structured covariance matricesHard thresholding estimatorApproximate sparsity (`q balls)
6 Matrix concentration inequalities95 / 124

Operator norm of sub-G matrices
• Now show that A ∈ Rm×n with independent sub-Gaussian entries withmaxij ‖Aij‖ψ2 = O(1) has operator norm |||A|||op .
√m +
√n.
• An application of metric entropy ideas via discretization arguments.
Theorem 14 (HDP 4.4.5, p. 85)
• A = (Aij) an m × n matrix
• Aij : independent, zero mean, sub-Gaussian
• maxij ‖Aij‖ψ2 ≤ K .
Then, with prob. ≥ 1− exp(−t2).
|||A|||op ≤ C K (√m +
√n + t)
• Will use a discretization argument, using ε-nets (metric entropy ideas).
• For a deterministic matrix with Aij ∈ [−K ,K ], |||A|||op can be as large asK√mn. Consider A = K1m1T
n where 1m is the all-ones vector in Rm.
96 / 124

Discretization argument
• Recall that the operator norm of A ∈ Rm,n is
|||A|||op = supx ∈Bn
2
‖Ax‖2 = supx ∈ Sn−1
‖Ax‖2 = supx,y∈Sn−1
〈Ax , y〉
where Bn2 = {x ∈ Rn : ‖x‖2 ≤ 1} and Sn−1 = {x ∈ Rn : ‖x‖2 = 1}.
• Let N be any ε-net of Bn2 (or Sn−1). Then:
supx ∈N
‖Ax‖2 ≤ |||A|||op ≤1
1− ε supx ∈N
‖Ax‖2 (16)
• Let N and M be any ε-nets of Bn2 and Bm
2 .
supx ∈N , y∈M
〈Ax , y〉 ≤ |||A|||op ≤1
1− 2εsup
x ∈N , y∈M〈Ax , y〉. (17)
97 / 124

Proof
• Discretize the spheres. Recall N2(ε,Bd2 ) ≤ (1 + 2/ε)d .
• Take ε = 1/4 nets M⊂ Sm−1 and N ⊂ Sn−1:
|M| ≤ 9m, |N | ≤ 9n.
• Hence, (1− 2ε)−1 = 2,
|||A|||op ≤ 2 supx ∈N , y∈M
〈Ax , y〉
• Fix x ∈ N and y ∈M, then
‖〈Ax , y〉‖2ψ2≤ C
∑i,j
‖Aijxiyi‖2ψ2
= C∑i,j
x2i y
2i ‖Aij‖2
ψ2≤ CK 2
hence, P(〈Ax , y〉 ≥ Ku) ≤ exp(−cu2) for u ≥ 0.
98 / 124

• Applying union bound, |N ||M| = 9n+m,
P( max(x,y) ∈ N×M
〈Ax , y〉 ≥ Ku) ≤ 9n+m · exp(−cu2)
• Taking c u2 ≥ C (n + m) + t2 for large C we can cancel 9n+m.
• For example, take c u2 = 3(n + m) + t2, then
9n+m · exp(−cu2) ≤ exp(−t2)
and√cu ≤
√3(m + n) + t2 ≤
√3(√m +
√n) + t.
99 / 124

Op-norm: Gaussian case, sharper constants
• For the Gaussian case Aij ∼ N(0, 1), one can get the sharp version
|||A|||op ≤√m +
√n + t, w.p. ≥ 1− exp(−t2/2).
using concentration of Lipschitz functions of Gaussian vectors
P(|||A|||op − E|||A|||op ≥ t) ≤ exp(−t2/2)
combined with sharp bound E|||A|||op ≤√m +
√n, obtained by
Sudakov-Fernique (an example of Gaussian comparison inequalities).
• This proof is very different than the ε-net argument.
100 / 124

Sub-Gaussian vectors
• A random vector x ∈ Rd has sub-Gaussian distribution if (HDP §3.4)
〈u, x〉 is sub-Gaussian for all u ∈ Sd−1,
in which case the sub-Gaussian norm of x is defined to be
‖x‖ψ2 = supu∈Sd−1
‖〈u, x〉‖ψ2
• Any vector x = (x1, . . . , xd) with independent sub-Gaussian coordinates issub-Gaussian, and (HDP Lemma 3.4.2)
‖x‖ψ2 ≤ C max1≤i≤d
‖xi‖ψ2 .
• The definition includes examples where the coordinates are not independent:
• x ∼ Unif(√dSd−1) =⇒ ‖x‖ψ2 ≤ C . (Uniform distribution on sphere)
• x ∼ N(0, In) =⇒ ‖x‖ψ2 ≤ C .
• x ∼ N(0,Σ) =⇒ ‖x‖ψ2 ≤ C |||√
Σ|||op.
• If x ∼ N(0,Σ) then x =√
Σz for z ∈ N(0, In). Apply Lemma 8.
101 / 124

Lemma 8
Let x ∈ Rd be a sub-Gaussian vector, and A ∈ Rn×d a deterministic matrix.Then, Ax is a sub-Gaussian vector and
‖Ax‖ψ2 ≤ |||A|||op‖x‖ψ2
• Let u ∈ Sn−1. Then 〈u,Ax〉 = 〈ATu, x〉 sub-Gaussian by the definition ofsub-Gaussianity for x .
• Let v = ATu. Then,
‖〈u,Ax〉‖ψ2 = ‖〈v , x〉‖ψ2 = ‖v‖2‖〈v
‖v‖2, x〉‖ψ2 ≤ ‖v‖2‖x‖ψ2 .
• Thus,
supu∈Sn−1
‖〈u,Ax〉‖ψ2 ≤ ‖x‖ψ2 supu∈Sn−1
= ‖x‖ψ2 |||AT |||op
• But |||AT |||op = |||A|||op (Show it!) finishing the proof.
• Lemma 8 parallels similar property for Gaussians.
102 / 124

Concentration of sample covariance matrix• A discretization argument can prove concentration of covariance matrices.
Theorem 15 (≈ HDS Theorem 6.2)
Let X ∈ Rn×d have
• independent sub-Gaussian rows xi ∈ Rd
• with E[xixTi ] = Σ, and
• let σ be a bound on the sub-Gaussian norm of xi for all i .
Let Σ = 1nX
TX = 1n
∑ni=1 xixT
i . Then, for all δ ≥ 0,
P[ |||Σ− Σ|||op
σ2≥ c1
(√d
n+
d
n
)+ δ]≤ c2 exp[−c3n ·min(δ, δ2)].
• For the Gaussian case σ2 . |||Σ|||op, hence w.h.p.
|||Σ− Σ|||op .(√d
n+
d
n
)|||Σ|||op.
• That is, n & ε−2d is enough to get |||Σ− Σ|||op . ε|||Σ|||op.• Significance: Don’t need ∼ d2 samples, just ∼ d , to approximate in operator norm.
103 / 124

Proof sketch
• Again we reduce to an 14 -net N of Sd−1 with |N | ≤ 9d .
• Then for any fixed u ∈ Sd−1, we have
〈u, (Σ− Σ)u〉 =1
n
n∑i=1
[〈xi , u〉2 − E〈xi , u〉2
].
• and by the centering lemma,
‖〈xi , u〉2 − E〈xi , u〉2‖ψ1 . ‖〈xi , u〉2‖ψ1 .
= ‖〈xi , u〉‖2ψ2
. σ2
• Bernstein inequality for sub-exponential variables (Corollary 1):
P(∣∣〈u, (Σ− Σ)u〉
∣∣ ≥ t)≤ 2 exp
[−c n ·min
( t2
σ4,t
σ2
)]
104 / 124

• Replace t with σ2t, take union bound over N ; recall |N | ≤ 9d ,
P(
maxu ∈N
∣∣〈u, (Σ− Σ)u〉∣∣ ≥ σ2t
)≤ 2 · 9d exp
[−c n min(t2, t)
]• Take t = max(ε2, ε). Then,
P(
maxu ∈N
∣∣〈u, (Σ− Σ)u〉∣∣ ≥ σ2 max(ε2, ε)
)≤ 2 · 9d exp
[−c n ε2
]• Taking ε =
√Cd/n + δ for sufficiently large C , we have
9d exp(−cnε2) = 9d exp[−cn
(Cd
n+ δ2
)]= 9de−cCde−cnδ
2 ≤ e−cnδ2
assuming that C is large enough so that 9de−cCd ≤ 1.
105 / 124

• On the other hand
max(ε2, ε) ≤ max(
2Cd
n+ 2δ2,
√Cd
n+ δ)
≤ 2Cd
n+
√Cd
n+ δ2 + 2δ.
• Recalling that |||Σ− Σ|||op ≤ 2 maxu ∈N
∣∣〈u, (Σ− Σ)u〉∣∣, we have proven the
following result
P[ |||Σ− Σ|||op
σ2≥ c1
(dn
+
√d
n+ δ2 + δ
)]≤ 2e−cnδ
2
.
• Alternative form in the statement of the theorem can be obtained as follows:
• First, δ2 + δ ≤ 2 max(δ2, δ).
• Now take δ2 = min(t, t2) for t ≥ 0. By Lemma 9, max(δ2, δ) = t.
106 / 124
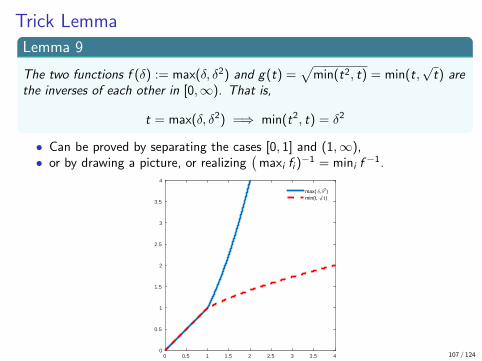
Trick Lemma
Lemma 9
The two functions f (δ) := max(δ, δ2) and g(t) =√
min(t2, t) = min(t,√t) are
the inverses of each other in [0,∞). That is,
t = max(δ, δ2) =⇒ min(t2, t) = δ2
• Can be proved by separating the cases [0, 1] and (1,∞),• or by drawing a picture, or realizing
(maxi fi )
−1 = mini f−1.
0 0.5 1 1.5 2 2.5 3 3.5 40
0.5
1
1.5
2
2.5
3
3.5
4
max( /,/2)min(t, t )
107 / 124

Table of Contents I1 Concentration inequalities
Sub-Gaussian concentration (Hoeffding inequality)Sub-exponential concentration (Bernstein inequality)Applications of Bernstein inequalityχ2 ConcentrationJohnson-Lindenstrauss embedding`2 norm concentration`∞ norm
Bounded difference inequality (Azuma–Hoeffding)Detour: MartingalesAzuma–HoeffdingBounded difference inequalityConcentration of (bounded) U-statisticsConcentration of clique numbers
Gaussian concentrationχ2 concentration revisitedOrder statistics and singular values
Gaussian chaos (Hanson–Wright inequality)
2 Sparse linear modelsBasis Pursuit
Restricted null space property (RNS)108 / 124

Table of Contents IISufficient conditions for RNS
Pairwise incoherenceRestricted isometry property (RIP)
Noisy sparse regressionRestricted eigenvalue conditionDeviation bounds under RERE for anisotropic designOracle inequality (and `q sparsity)
3 Metric entropyPacking and coveringVolume ratio estimates
4 Random matrices and covariance estimationOp-norm concentration: sub-Gaussian matrices, independent entriesOp-norm concentration: Gaussian caseSub-Gaussian random vectorsOp-norm concentration: sample covariance
5 Structured covariance matricesHard thresholding estimatorApproximate sparsity (`q balls)
6 Matrix concentration inequalities109 / 124

Structured covariance matrices
• Assuming that the covariance matrix is simpler leads to faster rates.
• For diagonal matrices, we can achieve
|||Σ− Σ|||op = O(√
log d/n)
w.h.p. as opposed to√d/n. (Exercise 6.15)
• More generally, we work under a sparsity model.
• The sparsity of Σ is the same as that of its adjacency matrix:
A = AΣ = (Aij), Aij = 1{Σij 6= 0}.
• Sparsity of Σ can be effectively measured by |||AΣ|||op.
• Σ has s-sparse rows ≡ AΣ has maximum degree s − 1, hence
|||AΣ|||op ≤ s
using |||AΣ|||op ≤ |||AΣ|||∞ = maxi∑
j |Aij |.
110 / 124

Thresholded covariance estimator
• Consider the hard-thresholding operator
Tλ(u) = u 1{|u| ≥ λ} =
{u |u| > λ
0 otherwise.
Theorem 16 (Covariance thresholding; HDS Theorem 6.23, p.181)
Assume that x1, . . . , xn ∈ Rd are i.i.d. zero mean with covariance matrix Σ and‖xij‖ψ2 ≤ σ for all i , j where xij is the jth element of xi . Assume that
n > log d , λ = σ2(
8
√log d
n+ δ).
Then the thresholded estimator Tλ(Σ) satisfies
P(|||Tλ(Σ)− Σ|||op ≥ 2λ|||AΣ|||op
)≤ 8 exp
(− n
16min(δ, δ2)
)111 / 124

• If Σ has s-sparse rows, the error bound is
O(λs) = O(s
√log d
n
).
• |||AΣ|||op could be as large as s in this case: (HDS Ex.6.16)
Example: a graph with maximum degree s − 1 that contains a s-clique.
• |||AΣ|||op could be smaller:
Example: hub-and-spoke, the hub is connected to s of d − 1 spokes;
|||AΣ|||op = 1 +√s − 1, the bound is then O(
√s log d
n ).
112 / 124

Proof of Theorem 16
• The result follows easily from the following deterministic lemma:
Lemma 10
Assume that ‖Σ− Σ‖∞ ≤ λ. Then, |||Tλ(Σ)− Σ|||op ≤ 2λ|||AΣ|||op.
• If Σij = 0, then |Σij | ≤ λ, hence Tλ(Σij) = 0. Thus, |Tλ(Σij)− Σij | = 0.
• If Σij 6= 0, then
|Tλ(Σij)− Σij | ≤ |Tλ(Σij)− Σij |+ |Σij − Σij | ≤ 2λ
• It follows that |Tλ(Σij)− Σij | ≤ 2λ[AΣ]ij . The lemma follows using:
Lemma 11 (Exercise 6.3)
Assume that A,B,C be symmetric matrices.
(a) If 0 ≤ A ≤ B elementwise, then |||A|||op ≤ |||B|||op.
(b) Let |C | be elementwise absolute value of C . Then, |||C |||op ≤ ||||C ||||op.
113 / 124
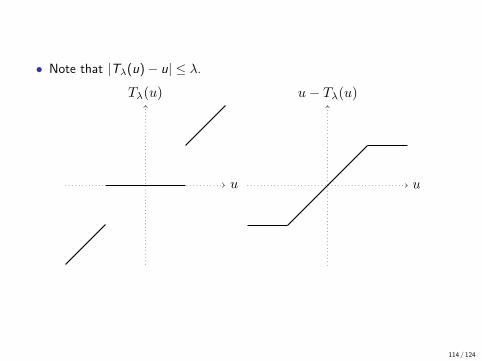
• Note that |Tλ(u)− u| ≤ λ.
u
Tλ(u)
u
u− Tλ(u)
114 / 124

• It remains to show that
Lemma 12
Under the assumptions of Theorem 16, w.p. ≥ 1− 8 exp(− n
16 min(δ, δ2)),
‖Σ− Σ‖∞ ≤ λ := σ2(
8
√log d
n+ δ)
• Let us establish a tail bound for fixed coordinates (k, `),
Σk` − Σk` =1
n
n∑i=1
(xikxi` − E[xikxi`]
)• We have, by the centering lemma,
‖xikxi` − E[xikxi`]‖ψ1 . ‖xikxi`‖ψ1
≤ ‖xik‖ψ2‖xi`‖ψ2 . σ2
• The second step follows from ‖XY ‖ψ1 ≤ ‖X‖ψ2‖Y ‖ψ2 when k 6= ` and from‖X 2‖ψ1 = ‖X‖2
ψ2when k = `.
115 / 124
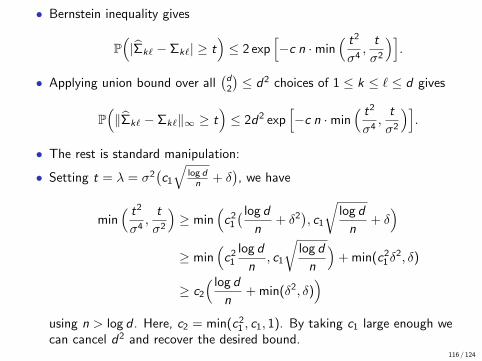
• Bernstein inequality gives
P(|Σk` − Σk`| ≥ t
)≤ 2 exp
[−c n ·min
( t2
σ4,t
σ2
)].
• Applying union bound over all(d2
)≤ d2 choices of 1 ≤ k ≤ ` ≤ d gives
P(‖Σk` − Σk`‖∞ ≥ t
)≤ 2d2 exp
[−c n ·min
( t2
σ4,t
σ2
)].
• The rest is standard manipulation:
• Setting t = λ = σ2(c1
√log dn + δ
), we have
min( t2
σ4,t
σ2
)≥ min
(c2
1
( log d
n+ δ2
), c1
√log d
n+ δ)
≥ min(c2
1
log d
n, c1
√log d
n
)+ min(c2
1δ2, δ)
≥ c2
( log d
n+ min(δ2, δ)
)using n > log d . Here, c2 = min(c2
1 , c1, 1). By taking c1 large enough wecan cancel d2 and recover the desired bound.
116 / 124

Approximate sparsity
• For a completely dense Σ, the bound is very poor:
AΣ = 11T hence |||AΣ|||op = d .
• A milder constraint is approximate row sparsity in the `q sense, for q ∈ [0, 1],
maxi=1,...,d
d∑j=1
|Σij |q ≤ Rq. (18)
117 / 124

Thresholded estimator; `q bound
Theorem 17 (Covariance thresholding; HDS Theorem 6.27, p.)
Suppose that Σ satisfies `q sparsity (18). Then for any λ such that
|||Σ− Σ|||op ≤ λ/2, we have
|||Tλ(Σ)− Σ|||op ≤ 3Rqλ1−q.
Consequently, if x1, . . . , xn ∈ Rd are i.i.d. zero mean with covariance matrix Σand ‖xij‖ψ2 ≤ σ for all i , j where xij is the jth element of xi , and
n > log d , λ = σ2(
8
√log d
n+ δ),
Then the thresholded estimator Tλ(Σ) satisfies
P(|||Tλ(Σ)− Σ|||op ≥ 2Rqλ
1−q)≤ 8 exp
(− n
16min(δ, δ2)
), δ ≥ 0.
• Note that error rate is O(( log d
n )1−q
2
)118 / 124

Proof of Theorem 17
• Stochastic part already proven.
• Only need to prove the deterministic part which follows since
|||Tλ(Σ)− Σ|||op ≤ maxi=1,...,d
‖[Tλ(Σ)− Σ]i∗‖1
followed by the application of the next lemma on each row.
119 / 124

Lemma 13
Assume that ‖θ − θ∗‖∞ ≤ λ/2. Let Sλ = {i : |θ∗i | > λ/2}. Then,
‖Tλ(θ)− θ∗‖1 ≤ |Sλ| · λ+ ‖θ∗Scλ‖1. (19)
In particular, if θ∗ satisfies the `q ball constraint∑
i |θ∗i |q ≤ R, then
‖Tλ(θ)− θ∗‖1 ≤ 3Rλ1−q (20)
• Proof: Recalling that |Tλ(u)− u| ≤ λ for all u ∈ R. We have∑i∈Sλ
|Tλ(θi )− θ∗i | ≤ |Sλ| · λ.
• For i /∈ Sλ, |θ∗i | ≤ λ/2, hence by triangle inequality |θi | ≤ λ.
• It follows that Tλ(θi ) = 0 for i ∈ Sλ, thus,∑i /∈Sλ
|Tλ(θi )− θ∗i | ≤∑i /∈Sλ
|θ∗i | = ‖θ∗Scλ‖1
• This proves the first assertion, (19).120 / 124

• For the second assertion, we apply the next lemma.
• We have |Sλ| ≤ (λ/2)−qR and ‖θ∗Scλ‖1 ≤ (λ/2)1−qR. Hence,
‖Tλ(θ)− θ∗‖1 ≤ (λ/2)−qR · λ+ (λ/2)1−qR
= 3(λ/2)1−qR
which is further bounded by 3λ1−qR.
121 / 124

Lemma 14
Assume that∑
j |θj |q ≤ R for some q ≥ 0. Let S = {i : |θi | > τ}. Then,
(a) |S | ≤ R τ−q.
(b) ‖θSc‖pp ≤ R τp−q for any p ≥ q.
• Proof: Exercise. Note that |x | ≤ 1 implies |x |p ≤ |x |q for p ≥ q.
122 / 124

Table of Contents I1 Concentration inequalities
Sub-Gaussian concentration (Hoeffding inequality)Sub-exponential concentration (Bernstein inequality)Applications of Bernstein inequalityχ2 ConcentrationJohnson-Lindenstrauss embedding`2 norm concentration`∞ norm
Bounded difference inequality (Azuma–Hoeffding)Detour: MartingalesAzuma–HoeffdingBounded difference inequalityConcentration of (bounded) U-statisticsConcentration of clique numbers
Gaussian concentrationχ2 concentration revisitedOrder statistics and singular values
Gaussian chaos (Hanson–Wright inequality)
2 Sparse linear modelsBasis Pursuit
Restricted null space property (RNS)123 / 124

Table of Contents IISufficient conditions for RNS
Pairwise incoherenceRestricted isometry property (RIP)
Noisy sparse regressionRestricted eigenvalue conditionDeviation bounds under RERE for anisotropic designOracle inequality (and `q sparsity)
3 Metric entropyPacking and coveringVolume ratio estimates
4 Random matrices and covariance estimationOp-norm concentration: sub-Gaussian matrices, independent entriesOp-norm concentration: Gaussian caseSub-Gaussian random vectorsOp-norm concentration: sample covariance
5 Structured covariance matricesHard thresholding estimatorApproximate sparsity (`q balls)
6 Matrix concentration inequalities124 / 124

Matrix Bernstein inequality
Theorem 18 (Matrix Bernstein inequality)
Let X1, . . . ,Xn be independent zero-mean d × d symmetric random matricessuch that |||Xi |||op ≤ K a.s. for all i . Then, for all t ≥ 0,
P(|||
n∑i=1
Xi |||op ≥ t)≤ 2d exp
(− t2/2
σ2 + Kt/3
).
Here, σ2 = |||∑ni=1 EX 2
i |||op.
• Since EXi = 0, the matrix variance of Xi is var(Xi ) = EX 2i .
• Note that X 2i , hence EX 2
i is positive semi-definite (why?).
• An alternative form of the bound is
P(|||
n∑i=1
Xi |||op ≥ t)≤ 2d exp
(−c min
( t2
σ2,t
K
)).
125 / 124

Matrix Bernstein: expectation
Corollary 2
Let X1, . . . ,Xn be independent zero-mean d × d symmetric random matricessuch that |||Xi |||op ≤ K a.s. for all i . Then,
E|||n∑
i=1
Xi |||op . σ√
log d + K log d
where σ2 = |||∑ni=1 EX 2
i |||op.
126 / 124

Semidefinite (or Loewner) order
Definition 7For symmetric n × n matrices, we write X � Y or Y � X whenever
X − Y � 0
• |||X |||op ≤ t if and only if −tI � X � tI .
• 0 � X � Y implies |||X |||op ≤ |||Y |||op.
• X � Y implies tr(X ) ≤ tr(Y ).
127 / 124

Estimating a general covariance matrix
Theorem 19 (General covariance, HDP 5.6.1, p. 122)
Let x be a random vector in Rd . Assume that for some K ≥ 1,
‖x‖2 ≤ K (E‖x‖22)1/2, almost surely
Let x1, . . . , xniid∼ x and Σn = 1
n
∑ni=1 xixT
i . Then, for all n ≥ 1,
E‖Σn − Σ‖ ≤ C(√K 2r log d
n+
K 2r log d
n
)‖Σ‖
where Σ = ExxT and r is the stable rank of Σ,
r :=tr(Σ)
|||Σ|||op
• Note that r ≤ d , hence replacing r with d we get a further upper bound.
• We only pay a “log d” price for removing sub-Gaussianity.
• To estimate up to relative error ε, need n & ε−2r log d .
128 / 124

• Let Yi := xixTi − Σ so that EYi = 0.
• Also write Y := xxT − Σ for the generic version.
• We will apply the expectation form of matrix Bernstein.
• E‖x‖22 = tr(Σ), hence by assumption ‖x‖2
2 ≤ K 2 tr(Σ) a.s., giving
|||Y |||op ≤ |||xxT |||op + |||Σ|||op
= ‖x‖22 + |||Σ|||op
≤ K 2 tr(Σ) + |||Σ|||op ≤ 2K 2 tr(Σ) ≤ 2K 2r |||Σ|||op =: M
using K ≥ 1 and r := tr(Σ)/|||Σ|||op. We also have
0 � EY 2 = E(xxT − Σ)2 = E(xxT )2 − Σ2
� E(xxT )2
� (K 2 tr Σ)Σ
using (xxT )2 = ‖x‖22xxT � (K 2 tr Σ)xxT
• We get |||EY 2|||op ≤ (K 2 tr Σ)|||Σ|||op.
129 / 124

• We conclude that
σ2 := |||n∑
i=1
EY 2i |||op = n|||EY 2|||op
≤ n(K 2 tr Σ)|||Σ|||op ≤ nrK 2|||Σ|||2op.
• Applying matrix Bernstein in expectation, we have
E|||Σn − Σ|||op = E|||1n
n∑i=1
Yi |||op
.1
n
(σ√
log d + M log d)
≤ 1
n
(√nrK 2|||Σ|||2op
√log d + 2K 2r |||Σ|||op log d
).(√K 2r log d
n+
K 2r log d
n
)|||Σ|||op
130 / 124


















