
RAMP Gold RAMPants {rimas,waterman,yunsup}@cs Parallel Computing Laboratory University of...
19
RAMP Gold RAMPants {rimas,waterman,yunsup}@cs Parallel Computing Laboratory University of California, Berkeley
-
date post
21-Dec-2015 -
Category
Documents
-
view
213 -
download
0
Transcript of RAMP Gold RAMPants {rimas,waterman,yunsup}@cs Parallel Computing Laboratory University of...

RAMP Gold
RAMPants{rimas,waterman,yunsup}@cs
Parallel Computing LaboratoryUniversity of California, Berkeley
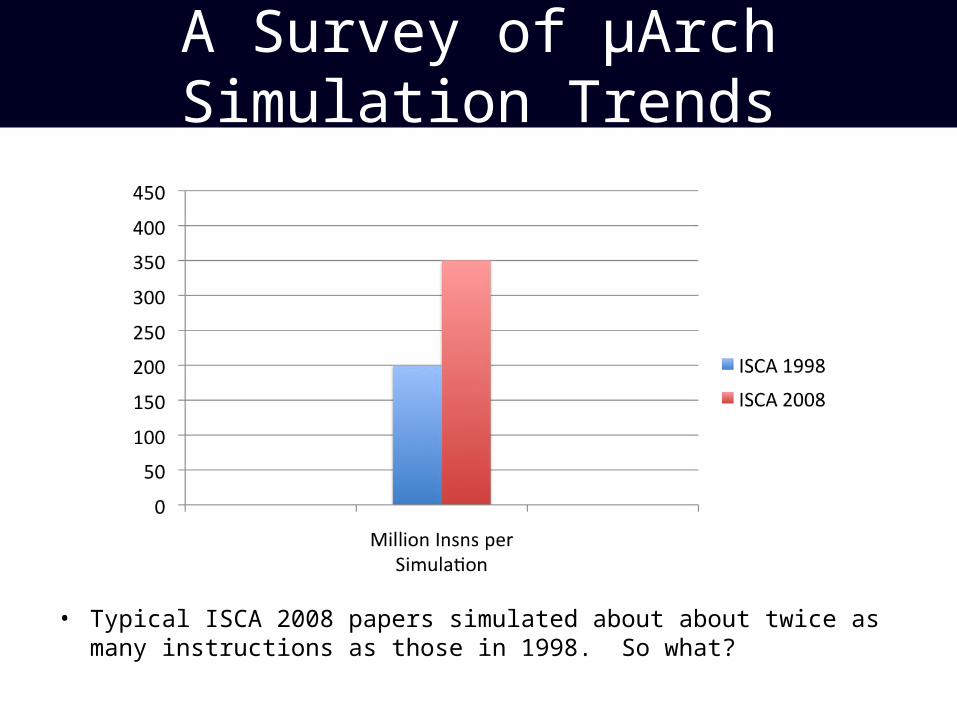
A Survey of μArch Simulation Trends
• Typical ISCA 2008 papers simulated about about twice as many instructions as those in 1998. So what?
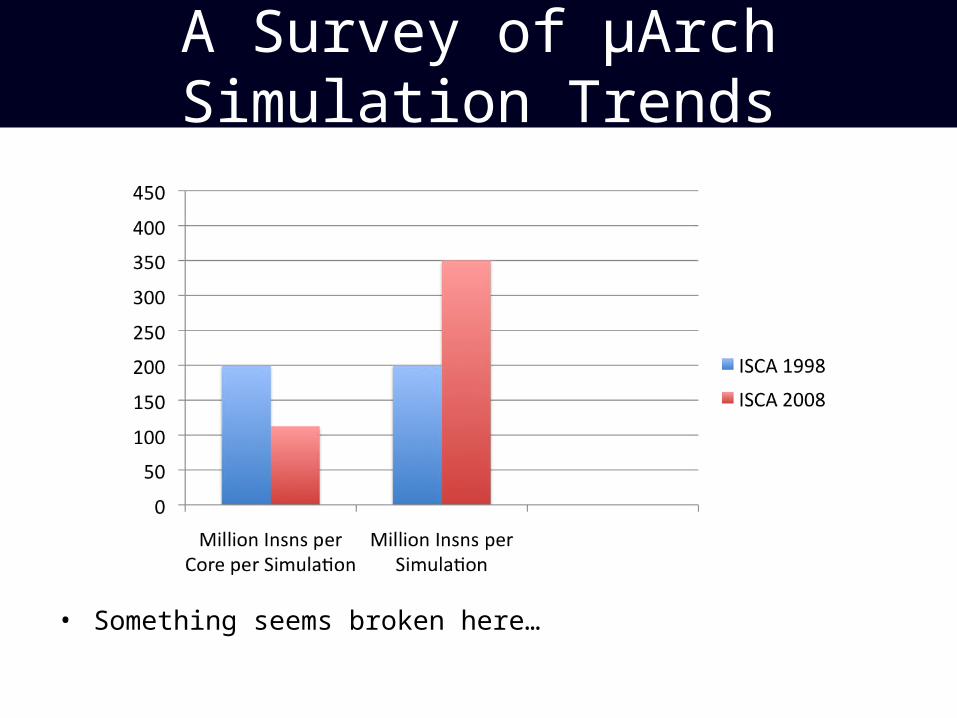
A Survey of μArch Simulation Trends
• Something seems broken here…
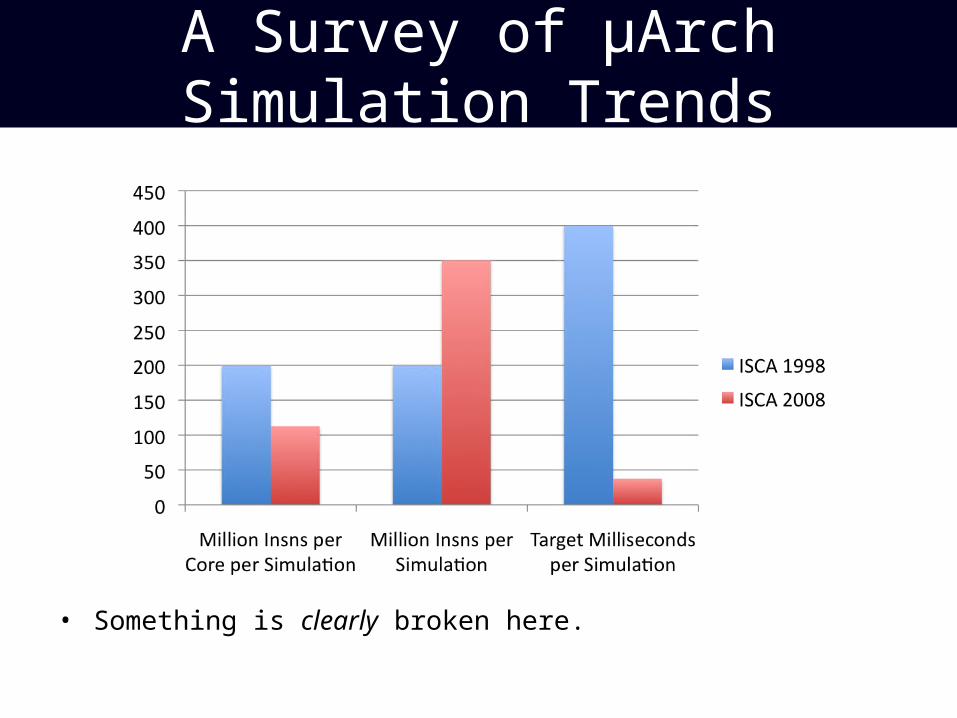
A Survey of μArch Simulation Trends
• Something is clearly broken here.

Something is Rotten in theState of California
• A median ISCA ‘08 paper’s simulations run for fewer than four OS scheduling quanta!– We run yesterday’s apps at yesteryear’s
timescales– And attempt to model N communicating cores
with O(1/N) instructions per core?!
• The problem is that simulators are too slow– Irony: since performance scales as
sqrt(complexity), simulated instructions per wall-clock second falls as processors get faster

RAMP Gold: Our Solution
• RAMP Gold is an FPGA-based, 100 MIPS manycore simulator– Only 100x slower than real-time– Economical: RTL is BSD-licensed;
commodity HW
Cost Performance(MIPS) Simulations per day
SoftwareSimulator $2,000 0.1 - 1 1
RAMP Gold $2,000 + $750 50 - 100 100
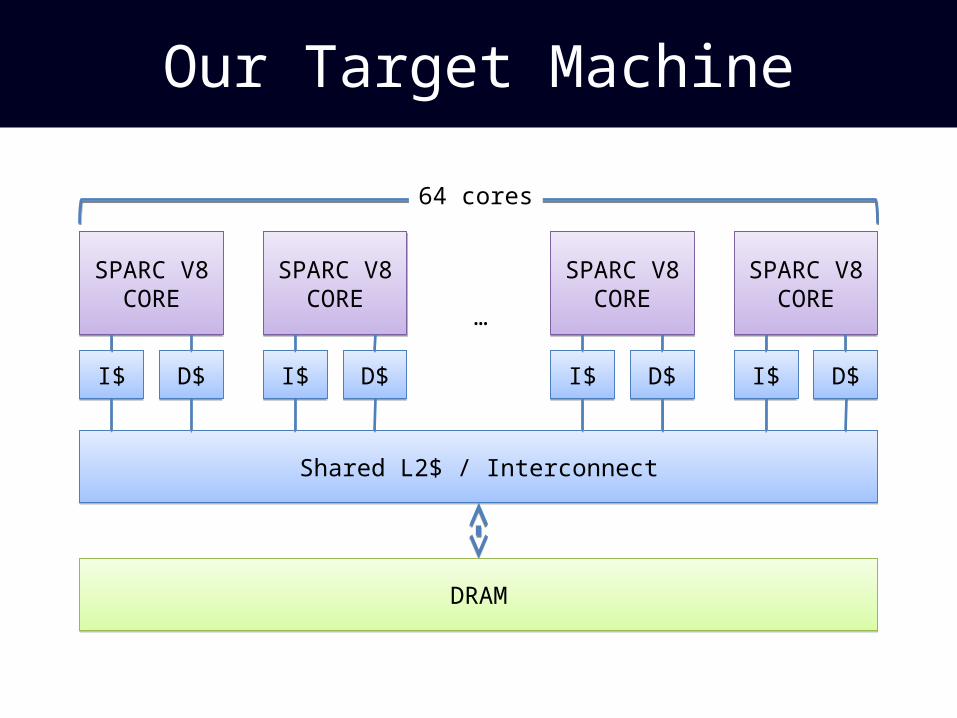
Our Target Machine
SPARC V8CORE
SPARC V8CORE
I$I$ D$D$
DRAMDRAM
Shared L2$ / InterconnectShared L2$ / Interconnect
SPARC V8CORE
SPARC V8CORE
I$I$ D$D$
SPARC V8CORE
SPARC V8CORE
I$I$ D$D$
SPARC V8CORE
SPARC V8CORE
I$I$ D$D$
…
64 cores

RAMP Gold Architecture
• Mapping the target machine directly to an FPGA is inefficient
• Solution: split timing and functionality– The timing logic decides how many target
cycles an instruction sequence should take– Simulating the functionality of an
instruction might take multiple host cycles– Target time and host time are orthogonal

Function/Timing Split Advantages
• Flexibility– Can configure target at runtime– Synthesize design once, change target
model parameters at will
• Efficient FPGA resource usage– Example 1: model a 2-cycle FPU in 10
host cycles– Example 2: model a 16MB L2$ using
only 256KB host BRAM to store tags/metadata
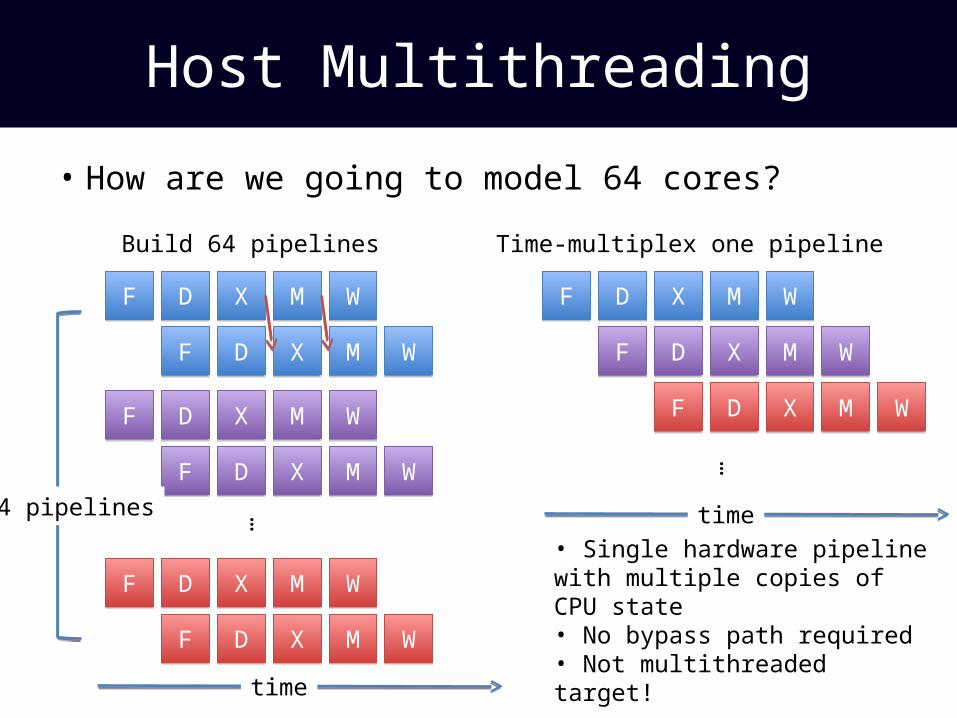
Host Multithreading
• How are we going to model 64 cores?
FF DD XX MM WW
FF DD XX MM WW
FF DD XX MM WW
FF DD XX MM WW
…64 pipelines
time
FF DD XX MM WW
FF DD XX MM WW
FF DD XX MM WW
time
Build 64 pipelines Time-multiplex one pipeline
• Single hardware pipeline with multiple copies of CPU state• No bypass path required• Not multithreaded target!
…
FF DD XX MM WW
FF DD XX MM WW
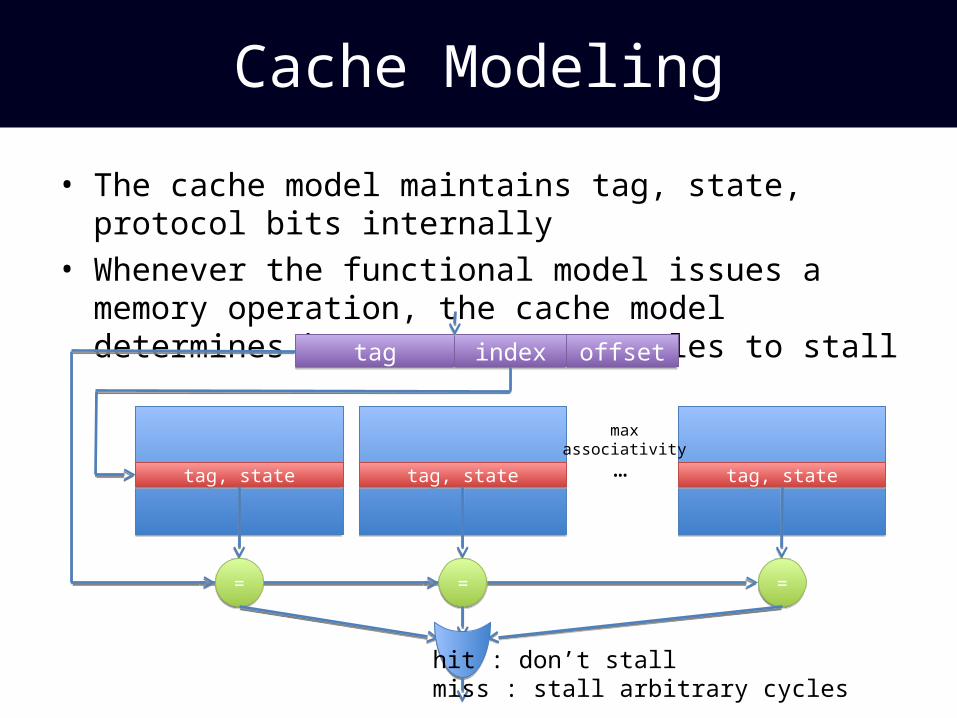
Cache Modeling
• The cache model maintains tag, state, protocol bits internally
• Whenever the functional model issues a memory operation, the cache model determines how many target cycles to stall
…
tagtag indexindex offsetoffset
tag, statetag, state tag, statetag, state tag, statetag, state
==== ==
hit : don’t stallmiss : stall arbitrary cycles
maxassociativity
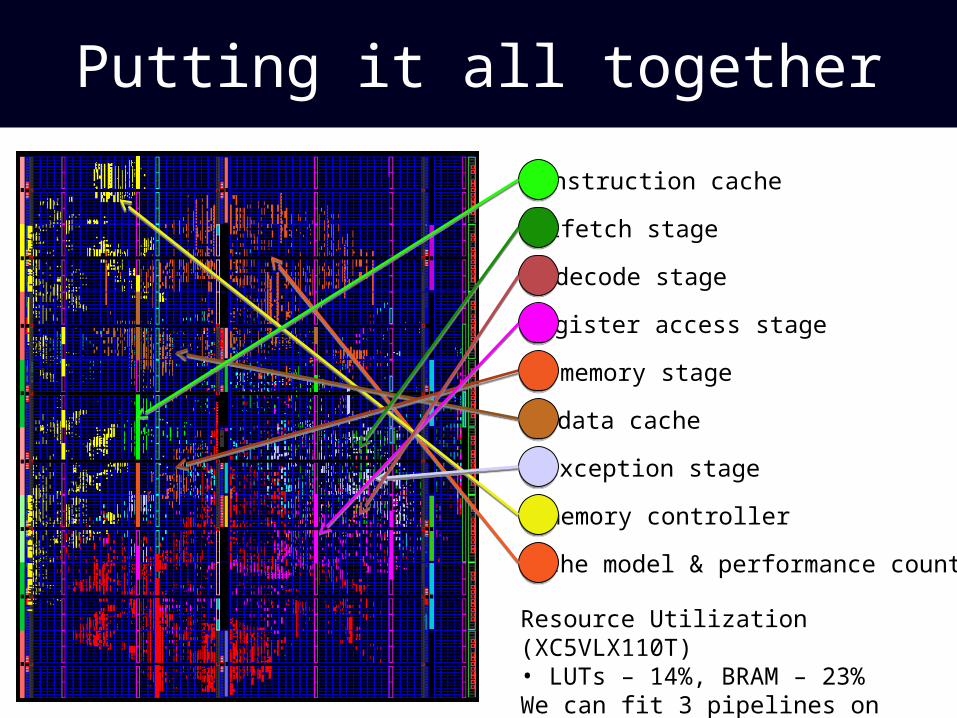
Putting it all together
instruction cache
ifetch stage
decode stage
register access stage
memory stage
data cache
exception stage
memory controller
cache model & performance counters
Resource Utilization (XC5VLX110T)• LUTs – 14%, BRAM – 23%We can fit 3 pipelines on one FPGA!
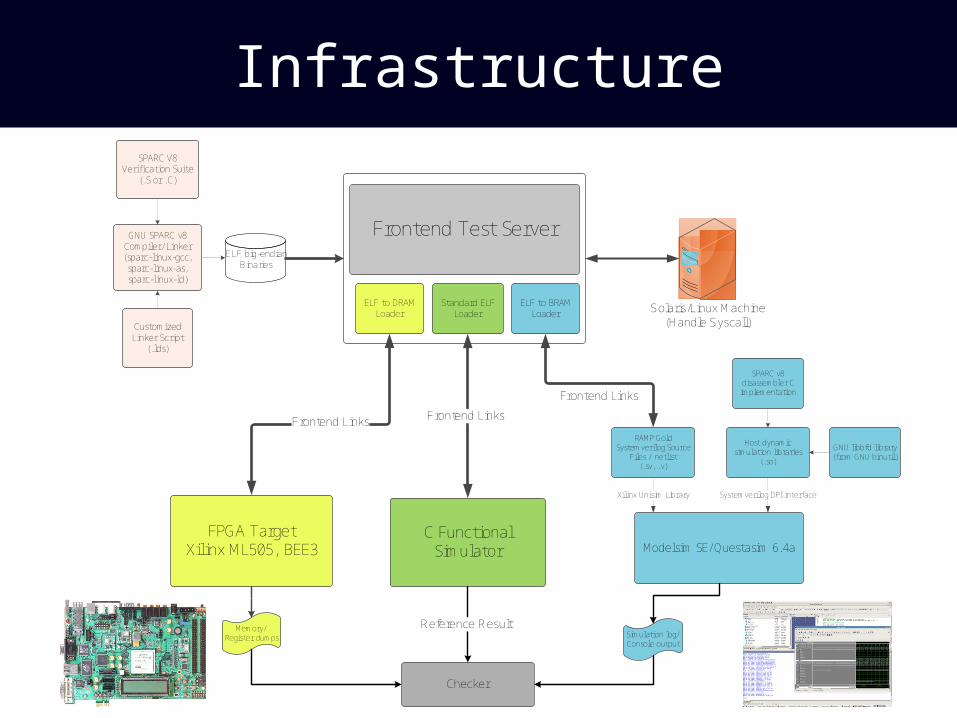
Infrastructure
ELF to BRAM Loader
Standard ELF Loader
Frontend Test Server
ELF to DRAM Loader
SPARC V8 Verification Suite
(.S or .C)
GNU SPARC v8 Compiler/ Linker(sparc-linux-gcc, sparc-linux-as, sparc-linux-ld)
Customized Linker Script
(.lds)
RAMP Gold Systemverilog Source
Files / netlist(.sv, .v)
ELF big-endian Binaries
Modelsim SE/ Questasim 6.4a
Host dynamic simulation libraries
(.so)
GNU libbfd library(from GNU binutil)
SPARC v8 disassembler C implementationFrontend Links
Xilinx Unisim Library Systemverilog DPI interface
Simulation log/Console output
Checker
C Functional Simulator
Frontend Links
Reference Result
FPGA TargetXilinx ML505, BEE3
Frontend Links
Memory/Register dumps
Solaris/Linux Machine(Handle Syscall)
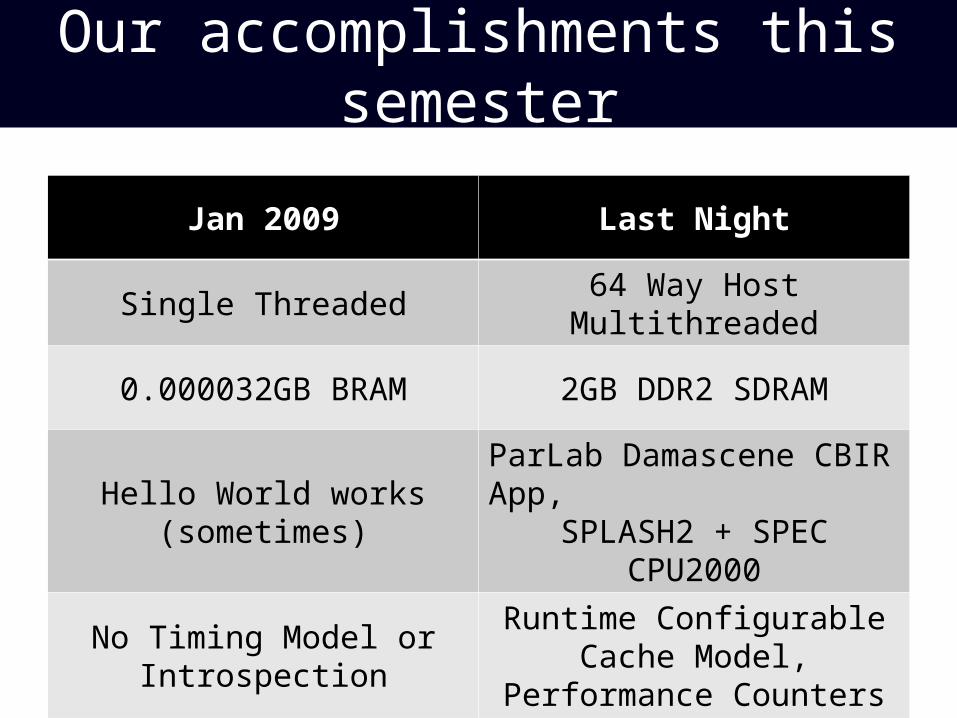
Our accomplishments this semester
Jan 2009 Last Night
Single Threaded 64 Way Host Multithreaded
0.000032GB BRAM 2GB DDR2 SDRAM
Hello World works (sometimes) ParLab Damascene CBIR App,SPLASH2 + SPEC CPU2000
No Timing Model or Introspection
Runtime Configurable Cache Model, Performance Counters
No Floating Point Hardware FPU Multiply/Add + Software Emulation

HARDware ain’t no joke
500+ Man Hours DDR2 Memory Controller Debugging
100+ Man Hours DMA Engine/Pipeline Issues
150+ Man Hours CAD Tool Issues
0 Pipeline Corner Cases

Sample Use Case: L1 D$ Tradeoffs
• Assume we have a 64-core CMP with private 16KB direct-mapped L1 D$
• In the next tech gen, we can fit either of these improved configurations in a clock cycle:– 32KB direct-mapped L1– 16KB 4-way set-associative L1
• Which should we choose?

Sample Use Case: L1 D$ Tradeoffs
• Evidently, the associative cache is superior• It took longer to make these slides than to
run these 10+ billion instruction simulations

Future Directions
• RAMP Gold closes two critical feedback loops– Expedient HW/SW co-tuning is within our
grasp– Simulations can now be run on a
thermal timescale, enabling the exploration of temperature-aware scheduling policies
• We intend to explore both avenues!
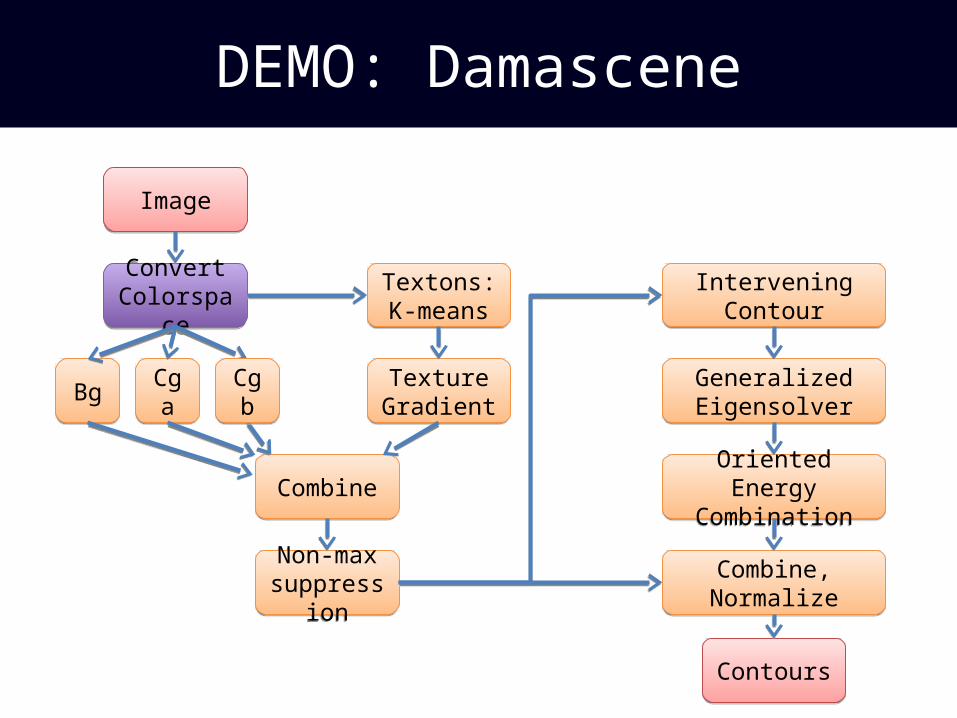
DEMO: Damascene
ImageImage
Convert Colorspace
Convert Colorspace
Textons:K-meansTextons:K-means
Texture GradientTexture Gradient
CombineCombine
Non-maxsuppression
Non-maxsuppression
Intervening ContourIntervening Contour
Generalized EigensolverGeneralized Eigensolver
Oriented Energy Combination
Oriented Energy Combination
Combine, NormalizeCombine, Normalize
ContoursContours
BgBg CgaCga CgbCgb


















