Performance Characterization of a 10-Gigabit Ethernet TOE W. Feng ¥ P. Balaji α C. Baron £ L. N....
21
Performance Characterization of a 10-Gigabit Ethernet TOE W. Feng ¥ P. Balaji α C. Baron £ L. N. Bhuyan £ D. K. Panda α ¥ Advanced Computing Lab, Los Alamos National Lab α Network Based Computing Lab, Ohio State University £ CARES Group, U. C. Riverside
-
Upload
suzanna-collins -
Category
Documents
-
view
221 -
download
1
Transcript of Performance Characterization of a 10-Gigabit Ethernet TOE W. Feng ¥ P. Balaji α C. Baron £ L. N....

Performance Characterization of a
10-Gigabit Ethernet TOE
W. Feng¥ P. Balajiα C. Baron£
L. N. Bhuyan£ D. K. Pandaα
¥Advanced Computing Lab,
Los Alamos National Lab
αNetwork Based Computing Lab,
Ohio State University
£CARES Group,
U. C. Riverside

Ethernet Overview
• Ethernet is the most widely used network infrastructure today
• Traditionally Ethernet has been notorious for performance issues
– Near an order-of-magnitude performance gap compared to IBA, Myrinet, etc.
• Cost conscious architecture
• Most Ethernet adapters were regular (layer 2) adapters
• Relied on host-based TCP/IP for network and transport layer support
• Compatibility with existing infrastructure (switch buffering, MTU)
– Used by 42.4% of the Top500 supercomputers
– Key: Reasonable performance at low cost
• TCP/IP over Gigabit Ethernet (GigE) can nearly saturate the link for current systems
• Several local stores give out GigE cards free of cost !
• 10-Gigabit Ethernet (10GigE) recently introduced
– 10-fold (theoretical) increase in performance while retaining existing features

10GigE: Technology Trends• Broken into three levels of technologies
– Regular 10GigE adapters
• Layer-2 adapters
• Rely on host-based TCP/IP to provide network/transport functionality
• Could achieve a high performance with optimizations
– TCP Offload Engines (TOEs)
• Layer-4 adapters
• Have the entire TCP/IP stack offloaded on to hardware
• Sockets layer retained in the host space
– RDDP-aware adapters
• Layer-4 adapters
• Entire TCP/IP stack offloaded on to hardware
• Support more features than TCP Offload Engines
– No sockets ! Richer RDDP interface !
– E.g., Out-of-order placement of data, RDMA semantics
[feng03:hoti, feng03:sc]
[Evaluation based on the Chelsio T110 TOE adapters]

Presentation Overview
• Introduction and Motivation
• TCP Offload Engines Overview
• Experimental Evaluation
• Conclusions and Future Work
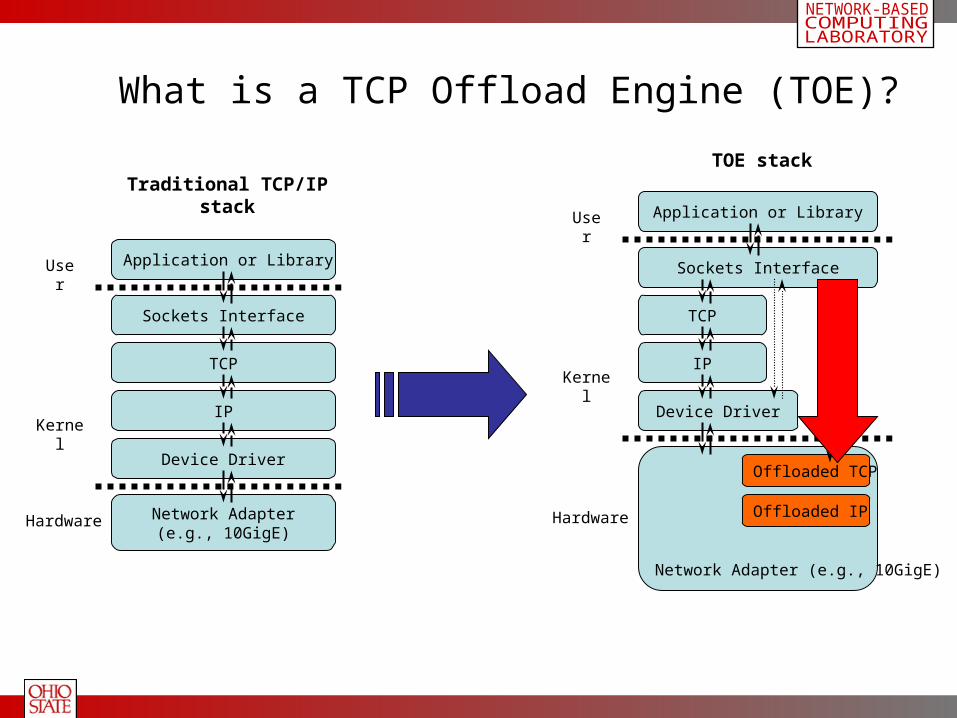
Sockets Interface
Application or Library
What is a TCP Offload Engine (TOE)?
Hardware
User
Kernel
TCP
IP
Device Driver
Network Adapter(e.g., 10GigE)
Sockets Interface
Application or Library
Hardware
User
Kernel
TCP
IP
Device Driver
Network Adapter (e.g., 10GigE)
Offloaded TCP
Offloaded IP
Traditional TCP/IP stack
TOE stack
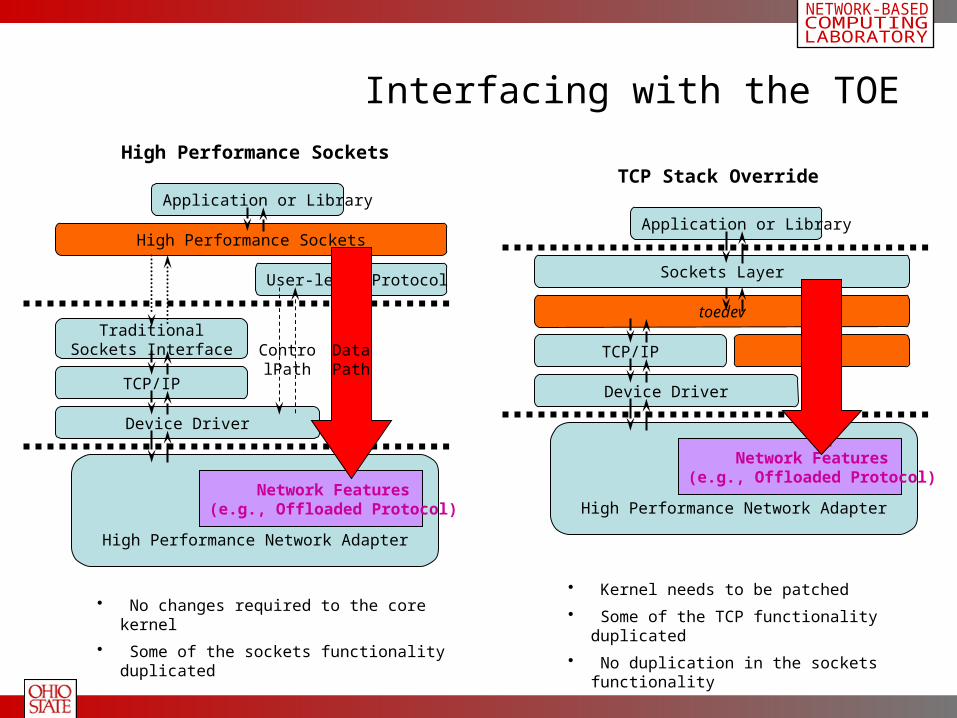
Sockets Layer
Interfacing with the TOE
Application or Library
TraditionalSockets Interface
High Performance Sockets
User-level Protocol
TCP/IP
Device Driver
High Performance Network Adapter
Network Features(e.g., Offloaded Protocol)
TOM
Application or Library
toedev
TCP/IP
Device Driver
High Performance Network Adapter
Network Features(e.g., Offloaded Protocol)
High Performance SocketsTCP Stack Override
• No changes required to the core kernel
• Some of the sockets functionality duplicated
• Kernel needs to be patched
• Some of the TCP functionality duplicated
• No duplication in the sockets functionality
ControlPath
Data Path
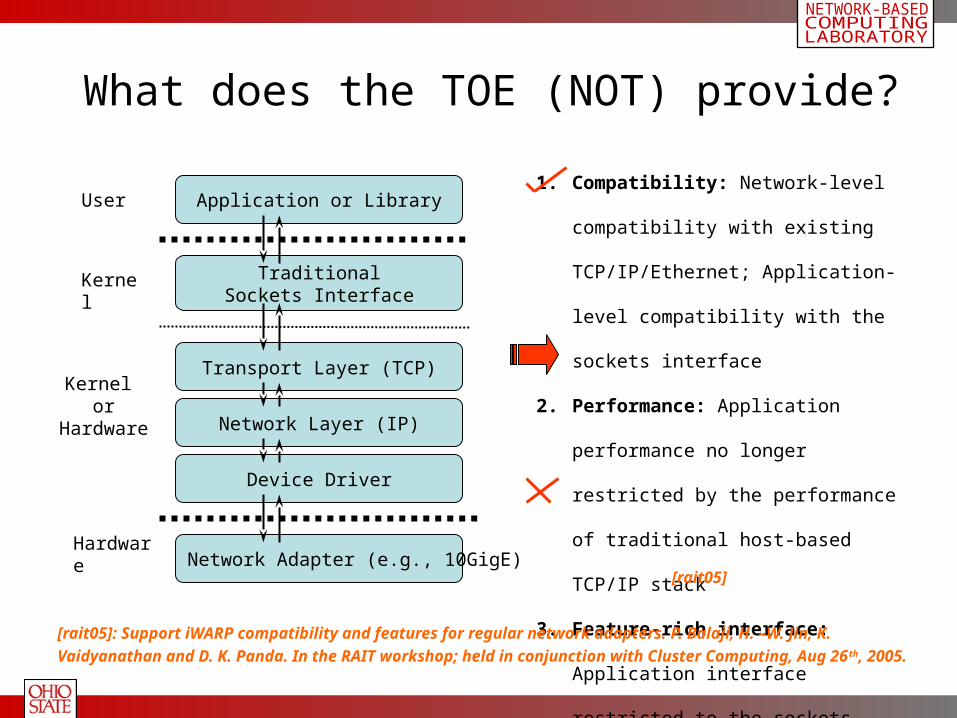
1. Compatibility: Network-level
compatibility with existing
TCP/IP/Ethernet; Application-level
compatibility with the sockets interface
2. Performance: Application performance
no longer restricted by the performance
of traditional host-based TCP/IP stack
3. Feature-rich interface: Application
interface restricted to the sockets
interface !
What does the TOE (NOT) provide?
Hardware
Kernel or Hardware
User Application or Library
TraditionalSockets Interface
Transport Layer (TCP)
Network Layer (IP)
Device Driver
Network Adapter (e.g., 10GigE)
Kernel
[rait05]: Support iWARP compatibility and features for regular network adapters. P. Balaji, H. –W. Jin, K.
Vaidyanathan and D. K. Panda. In the RAIT workshop; held in conjunction with Cluster Computing, Aug 26 th, 2005.
[rait05]

Presentation Overview
• Introduction and Motivation
• TCP Offload Engines Overview
• Experimental Evaluation
• Conclusions and Future Work

Experimental Test-bed and the Experiments
• Two test-beds used for the evaluation
– Two 2.2GHz Opteron machines with 1GB of 400MHz DDR SDRAM
• Nodes connected back-to-back
– Four 2.0GHz quad-Opteron machines with 4GB of 333MHz DDR SDRAM
• Nodes connected with a Fujitsu XG1200 switch (450ns flow-through latency)
• Evaluations in three categories
– Sockets-level evaluation
• Single-connection Micro-benchmarks
• Multi-connection Micro-benchmarks
– MPI-level Micro-benchmark evaluation
– Application-level evaluation with the Apache Web-server
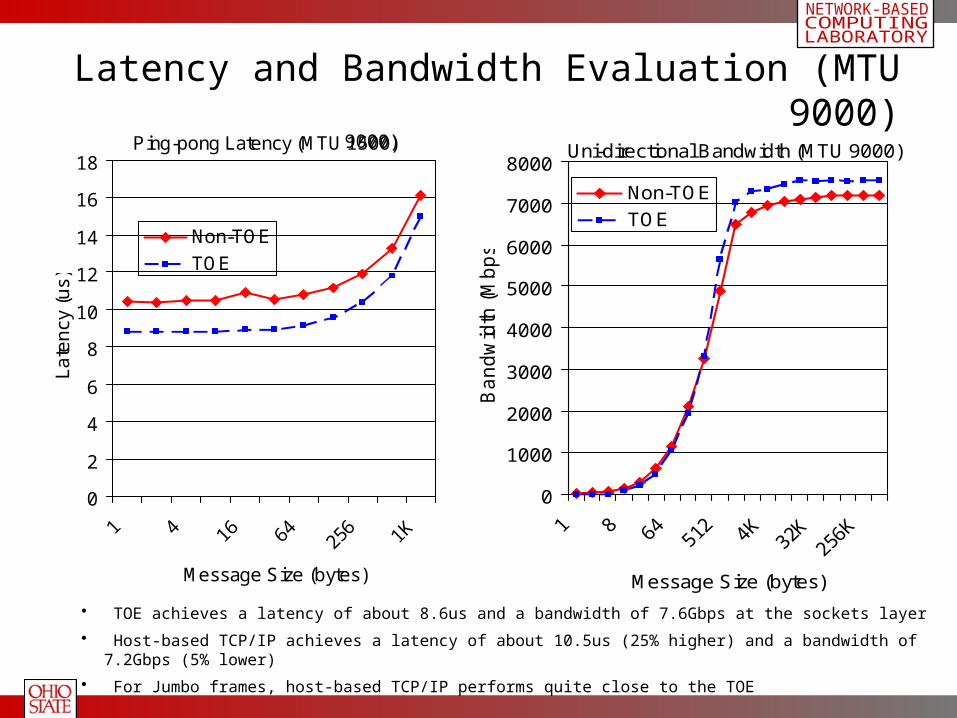
Latency and Bandwidth Evaluation (MTU 9000)Ping-pong Latency (MTU 1500)
0
2
4
6
8
10
12
14
16
18
1 4 16 64 256 1K
Message Size (bytes)
La
ten
cy (
us)
Non-TOE
TOE
Uni-directional Bandwidth (MTU 9000)
0
1000
2000
3000
4000
5000
6000
7000
8000
Message Size (bytes)
Ba
nd
wid
th (
Mb
ps)
Non-TOE
TOE
• TOE achieves a latency of about 8.6us and a bandwidth of 7.6Gbps at the sockets layer
• Host-based TCP/IP achieves a latency of about 10.5us (25% higher) and a bandwidth of 7.2Gbps (5% lower)
• For Jumbo frames, host-based TCP/IP performs quite close to the TOE
9000)
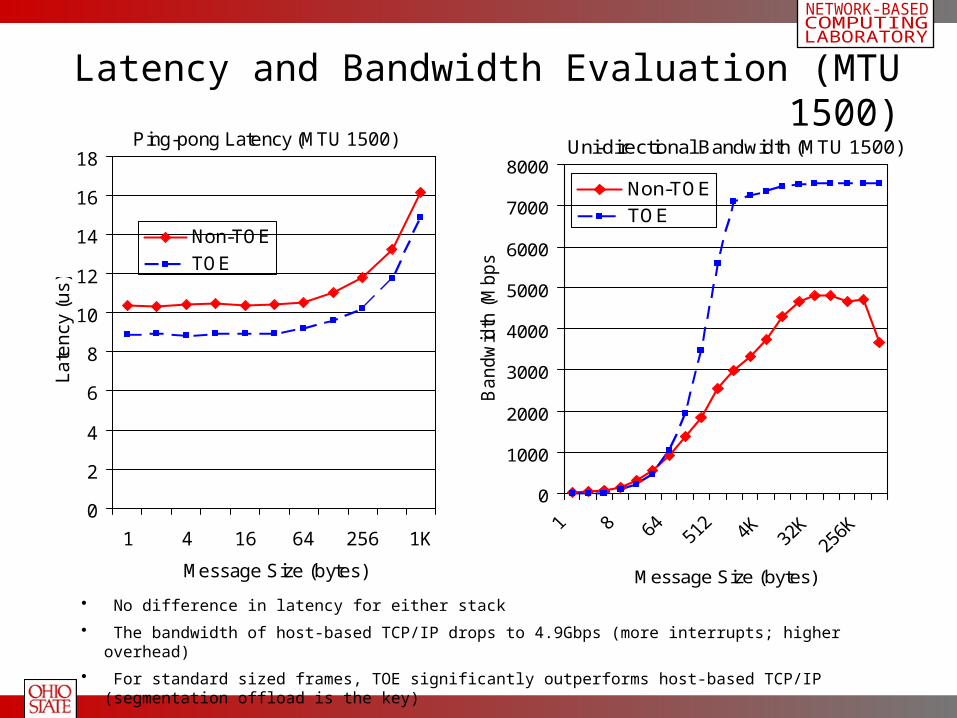
Latency and Bandwidth Evaluation (MTU 1500)Ping-pong Latency (MTU 1500)
0
2
4
6
8
10
12
14
16
18
1 4 16 64 256 1K
Message Size (bytes)
La
ten
cy (
us)
Non-TOE
TOE
Uni-directional Bandwidth (MTU 1500)
0
1000
2000
3000
4000
5000
6000
7000
8000
Message Size (bytes)
Ba
nd
wid
th (
Mb
ps)
Non-TOE
TOE
• No difference in latency for either stack
• The bandwidth of host-based TCP/IP drops to 4.9Gbps (more interrupts; higher overhead)
• For standard sized frames, TOE significantly outperforms host-based TCP/IP (segmentation offload is the key)
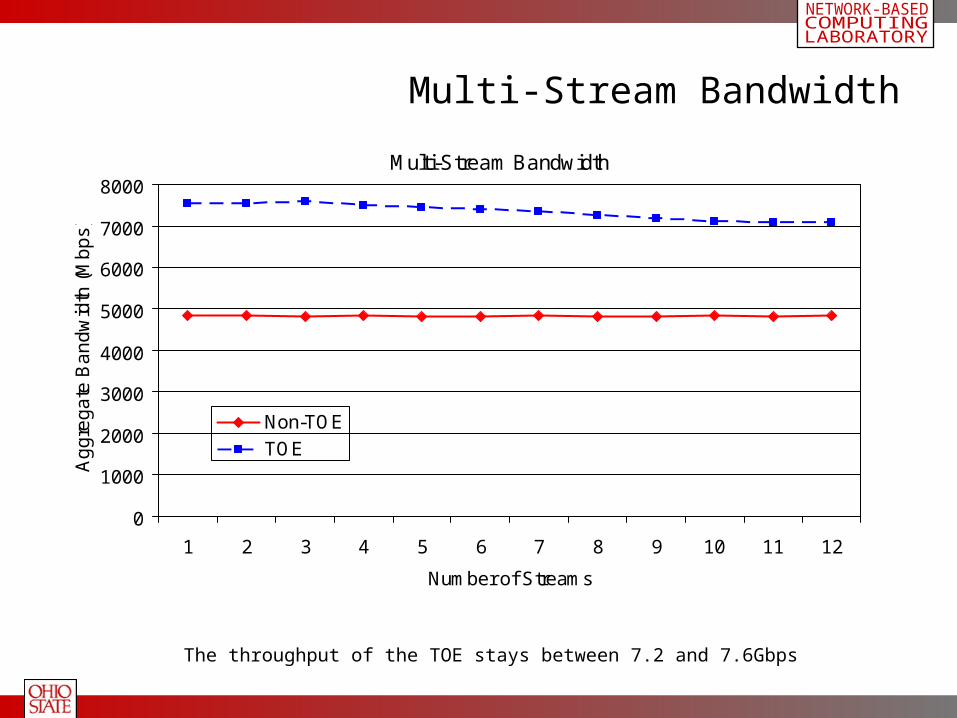
Multi-Stream Bandwidth
Multi-Stream Bandwidth
0
1000
2000
3000
4000
5000
6000
7000
8000
1 2 3 4 5 6 7 8 9 10 11 12
Number of Streams
Ag
gre
ga
te B
an
dw
idth
(M
bp
s)
Non-TOE
TOE
The throughput of the TOE stays between 7.2 and 7.6Gbps
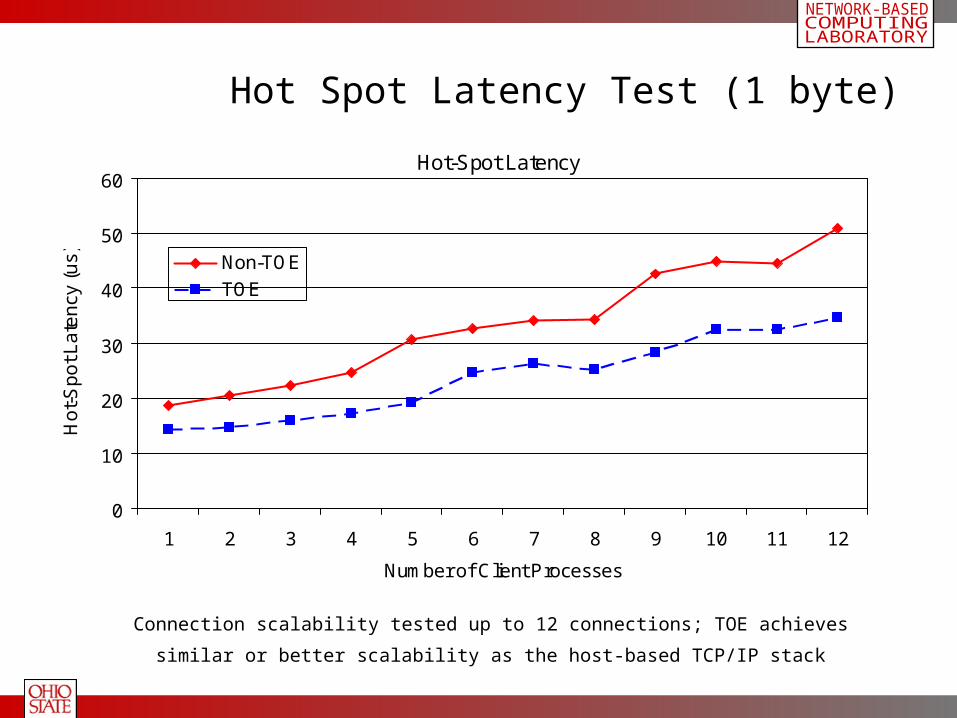
Hot Spot Latency Test (1 byte)
Hot-Spot Latency
0
10
20
30
40
50
60
1 2 3 4 5 6 7 8 9 10 11 12
Number of Client Processes
Ho
t-S
po
t La
ten
cy (
us) Non-TOE
TOE
Connection scalability tested up to 12 connections; TOE achieves similar or better
scalability as the host-based TCP/IP stack
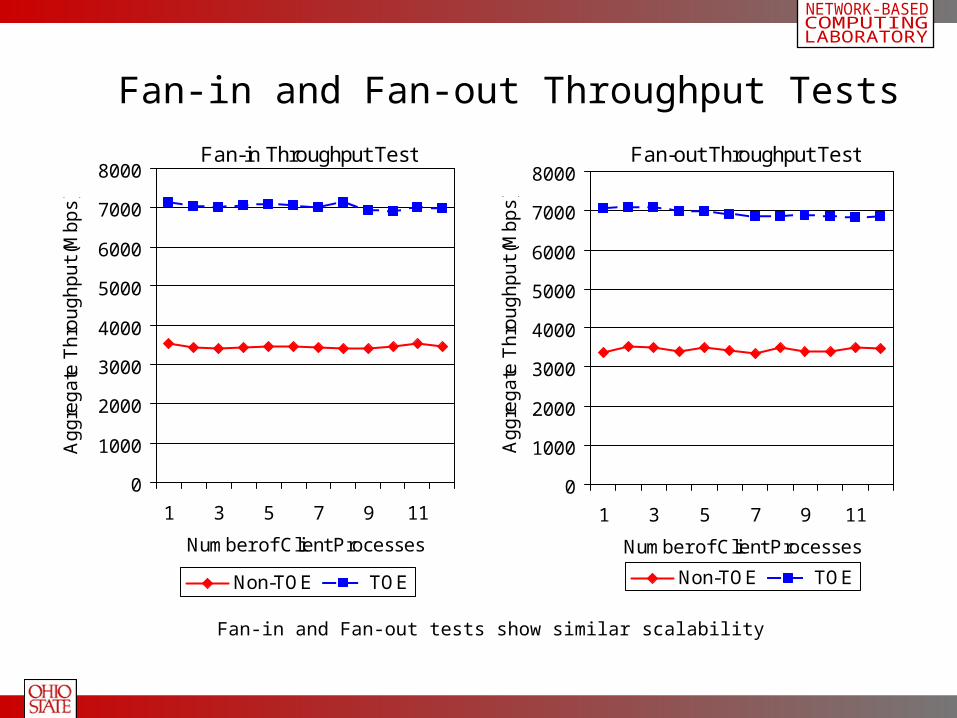
Fan-in and Fan-out Throughput Tests
Fan-in Throughput Test
0
1000
2000
3000
4000
5000
6000
7000
8000
1 3 5 7 9 11
Number of Client Processes
Ag
gre
ga
te T
hro
ug
hp
ut (
Mb
ps)
Non-TOE TOE
Fan-out Throughput Test
0
1000
2000
3000
4000
5000
6000
7000
8000
1 3 5 7 9 11
Number of Client Processes
Ag
gre
ga
te T
hro
ug
hp
ut (
Mb
ps)
Non-TOE TOE
Fan-in and Fan-out tests show similar scalability
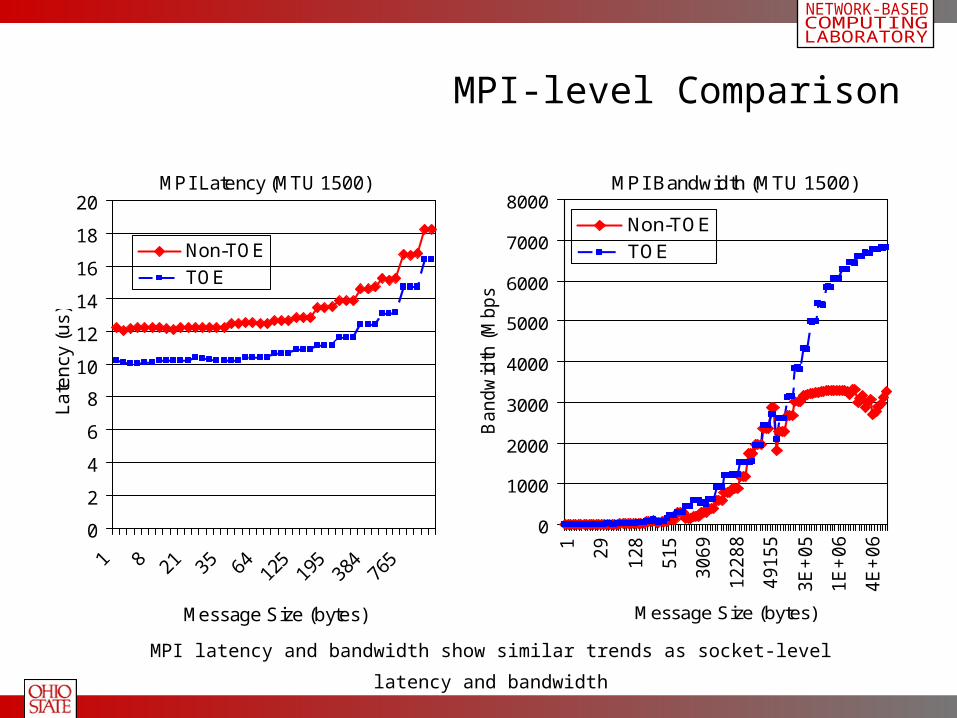
MPI-level Comparison
MPI Latency (MTU 1500)
0
2
4
6
8
10
12
14
16
18
20
1 8 21 35 64 125
195
384
765
Message Size (bytes)
La
ten
cy (
us)
Non-TOE
TOE
MPI Bandwidth (MTU 1500)
0
1000
2000
3000
4000
5000
6000
7000
8000
1 29
12
8
51
5
30
69
12
28
8
49
15
5
3E
+0
5
1E
+0
6
4E
+0
6
Message Size (bytes)
Ba
nd
wid
th (
Mb
ps)
Non-TOE
TOE
MPI latency and bandwidth show similar trends as socket-level latency and bandwidth
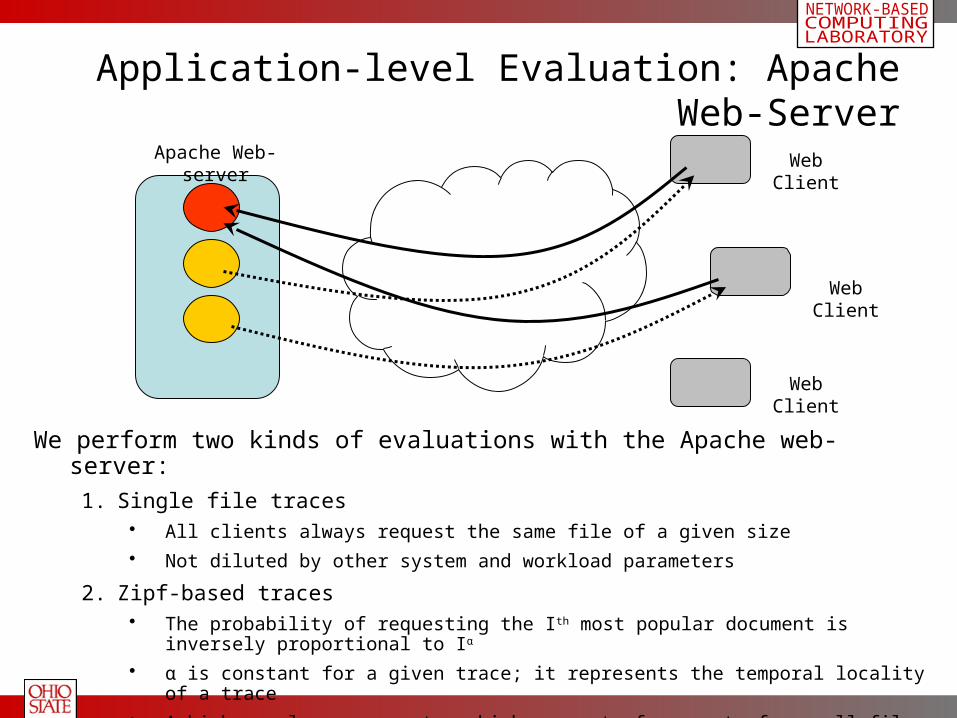
Application-level Evaluation: Apache Web-Server
Apache Web-server
Web Client
Web Client
Web Client
We perform two kinds of evaluations with the Apache web-server:
1. Single file traces• All clients always request the same file of a given size
• Not diluted by other system and workload parameters
2. Zipf-based traces• The probability of requesting the Ith most popular document is inversely proportional to Iα
• α is constant for a given trace; it represents the temporal locality of a trace
• A high α value represents a high percent of requests for small files
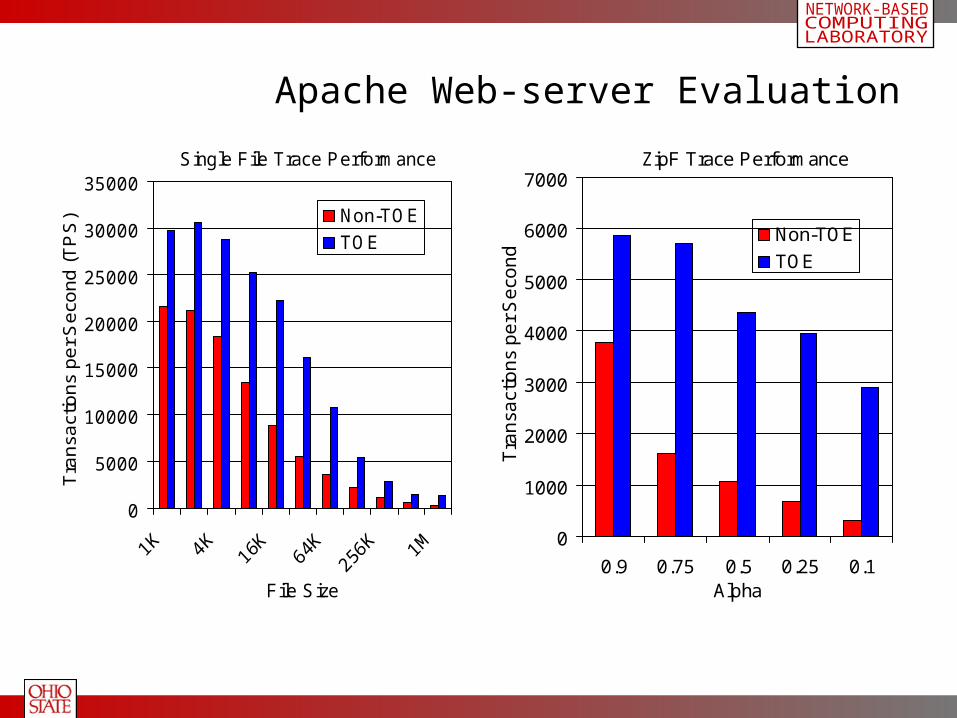
Apache Web-server Evaluation
Single File Trace Performance
0
5000
10000
15000
20000
25000
30000
35000
File Size
Tra
nsa
ctio
ns
pe
r S
eco
nd
(T
PS
) Non-TOE
TOE
ZipF Trace Performance
0
1000
2000
3000
4000
5000
6000
7000
0.9 0.75 0.5 0.25 0.1Alpha
Tra
nsa
ctio
ns
pe
r S
eco
nd
Non-TOE
TOE

Presentation Overview
• Introduction and Motivation
• TCP Offload Engines Overview
• Experimental Evaluation
• Conclusions and Future Work

Conclusions
• For a wide-spread acceptance of 10-GigE in clusters– Compatibility
– Performance
– Feature-rich interface
• Network as well as Application-level compatibility is available– On-the-wire protocol is still TCP/IP/Ethernet
– Application interface is still the sockets interface
• Performance Capabilities– Significant performance improvements compared to the host-stack
• Close to 65% improvement in bandwidth for standard sized (1500byte) frames
• Feature-rich interface: Not quite there yet !– Extended Sockets Interface
– iWARP offload

Continuing and Future Work
• Comparing 10GigE TOEs to other interconnects
– Sockets Interface [cluster05]
– MPI Interface
– File and I/O sub-systems
• Extending the sockets interface to support iWARP capabilities
[rait05]
• Extending the TOE stack to allow protocol offload for UDP sockets

Web Pointers
http://public.lanl.gov/radiant
http://nowlab.cse.ohio-state.edu
NOWLAB