
CAE Model Interrogation & Data Mining - BETA CAE Systems S.A
Upload
ilya-kavalerovCategory
view
218download
2
Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 1
Data Mining

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 2
Introduction
Finding interesting trends or pattern in large datasets
Statistics: exploratory data analysis
Artificial intelligence: knowledge discovery and machine learning
Scalability with respect to data size
An algorithm is scalable if the running time grows (linearly) in proportion to the dataset size, given the available system resources
Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 3
Introduction
Finding interesting trends or pattern in large datasets
SQL queries (based on the relational algebra) OLAP queries (higher-level query constructs – multidimensional data model) Data mining techniques
Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 4
Knowledge Discovery (KDD)
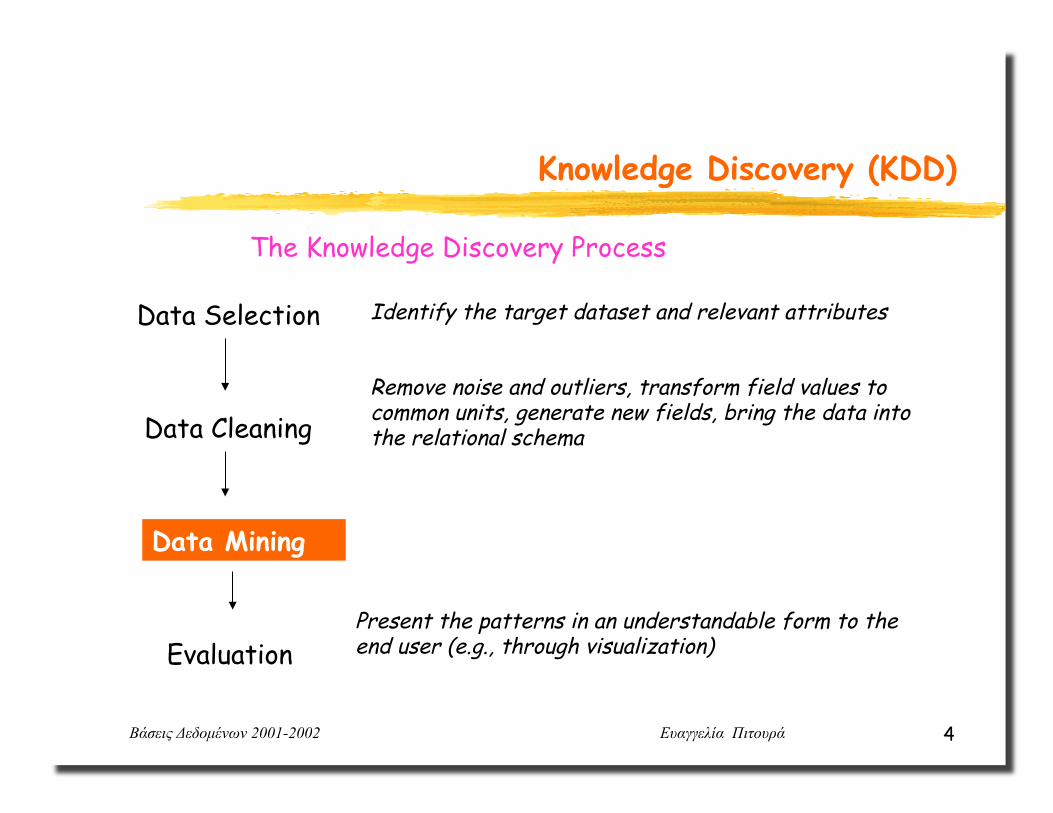
Data Selection
Data Cleaning
Data Mining
Evaluation
The Knowledge Discovery Process
Identify the target dataset and relevant attributes
Remove noise and outliers, transform field values to common units, generate new fields, bring the data into the relational schema
Present the patterns in an understandable form to the end user (e.g., through visualization)

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 5
Overview
Counting Co-occurrences
Frequent Itemsets
Iceberg Queries
Mining for Rules
Association Rules
Sequential Rules
Classification and Regression
Tree-Structures Rules
Clustering
Similarity Search over Sequences

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 6
Counting Co-Occurrences
A market basket is a collection of items purchased by a customer in a single customer transaction
Identify items that are purchased together
Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 7
Example
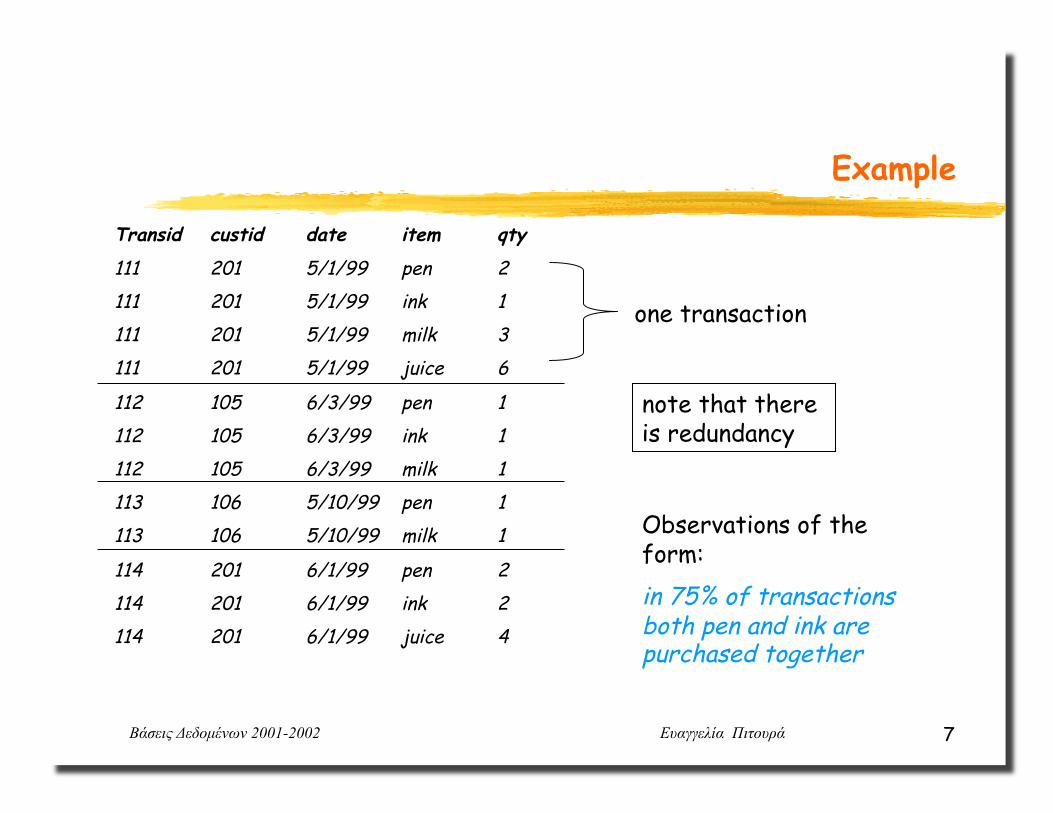
Transid custid date item qty
111 201 5/1/99 pen 2 111 201 5/1/99 ink 1 111 201 5/1/99 milk 3 111 201 5/1/99 juice 6
112 105 6/3/99 pen 1 112 105 6/3/99 ink 1 112 105 6/3/99 milk 1 113 106 5/10/99 pen 1 113 106 5/10/99 milk 1
114 201 6/1/99 pen 2 114 201 6/1/99 ink 2 114 201 6/1/99 juice 4
one transaction
note that there is redundancy
Observations of the form: in 75% of transactions both pen and ink are purchased together

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 8
Frequent Itemsets
Itemset: a set of items
Support of an itemset: the fraction of transactions in the database that contain all items in the itemset
Example:
Itemset {pen, ink} Support 75%
Itemset {milk, juice} Support 25%

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 9
Frequent Itemsets
Example:
If minsup = 70%,
Frequent Itemsets
{pen}, {ink}, {milk}, {pen, ink}, {pen, milk}
Frequent Itemsets: itemsets whose support is higher than a user specified minimum support called minsup

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 10
Frequent Itemsets
An algorithm for identify (all) frequent itemsets?
The a priory property:
Every subset of a frequent itemset must also be a frequent itemset

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 11
Frequent Itemsets
For each item,
check if it is a frequent itemset
k = 1
repeat
for each new frequent itemset Ik with k items Generate all itemsets Ik+1 with k+1 items, Ik ⊂ Ik+1
Scan all transactions once and check if the generated k+1 itemsets are frequent
k = k + 1
Until no new frequent itemsets are identified
An algorithm for identifying frequent itemsets

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 12
Frequent Itemsets
For each item,
check if it is a frequent itemset
k = 1
repeat
for each new frequent itemset Ik with k items Generate all itemsets Ik+1 with k+1 items, Ik ⊂ Ik+1 whose subsets are ferquent itemsets
Scan all transactions once and check if the generated k+1 itemsets are frequent
k = k + 1
Until no new frequent itemsets are identified
A refinement of the algorithm for identifying frequent itemsets

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 13
Iceberg Queries
Assume we want to find pairs of customers and items such that the customer has purchased the item at least 5 times
select P.custid, P. item, sum(P.qty)
from Purchases P
group by P.custid, P.item
having sum (P.qty) > 5
Execution plan for the query?
The number of groups is very large but the answer to the query (the tip of the iceberg) is usually very small

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 14
Iceberg Queries
select R.A1, R.A2, …, R.Ak, agr(R.B)
from Relation R
group by R.A1, R.A2, …, R.Ak
having agr(R.B) > = constant
Iceberg query
A priory property similar to the a priori property for the frequent itemsets?
Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 15
Iceberg Queries
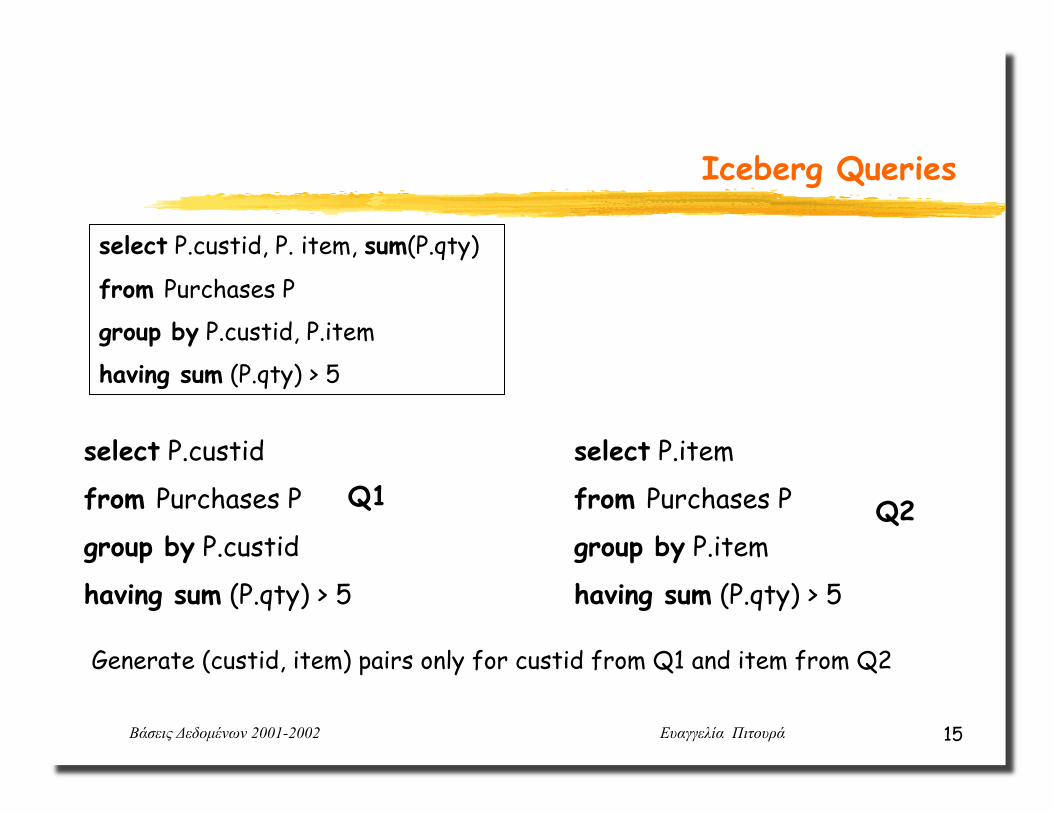
select P.custid, P. item, sum(P.qty)
from Purchases P
group by P.custid, P.item
having sum (P.qty) > 5
select P.custid
from Purchases P
group by P.custid
having sum (P.qty) > 5
select P.item
from Purchases P
group by P.item
having sum (P.qty) > 5
Generate (custid, item) pairs only for custid from Q1 and item from Q2
Q1 Q2

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 16
Overview
Counting Co-occurences
Frequent Itemsets
Iceberg Queries
Mining for Rules
Association Rules
Sequential Rules
Classification and Regression
Tree-Structures Rules
Clustering
Similarity Search over Sequences

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 17
Association Rules
Example
{pen} ⇒ {ink} If a pen is purchased in a transaction, it is likely that ink will also be purchased in the transaction
In general:
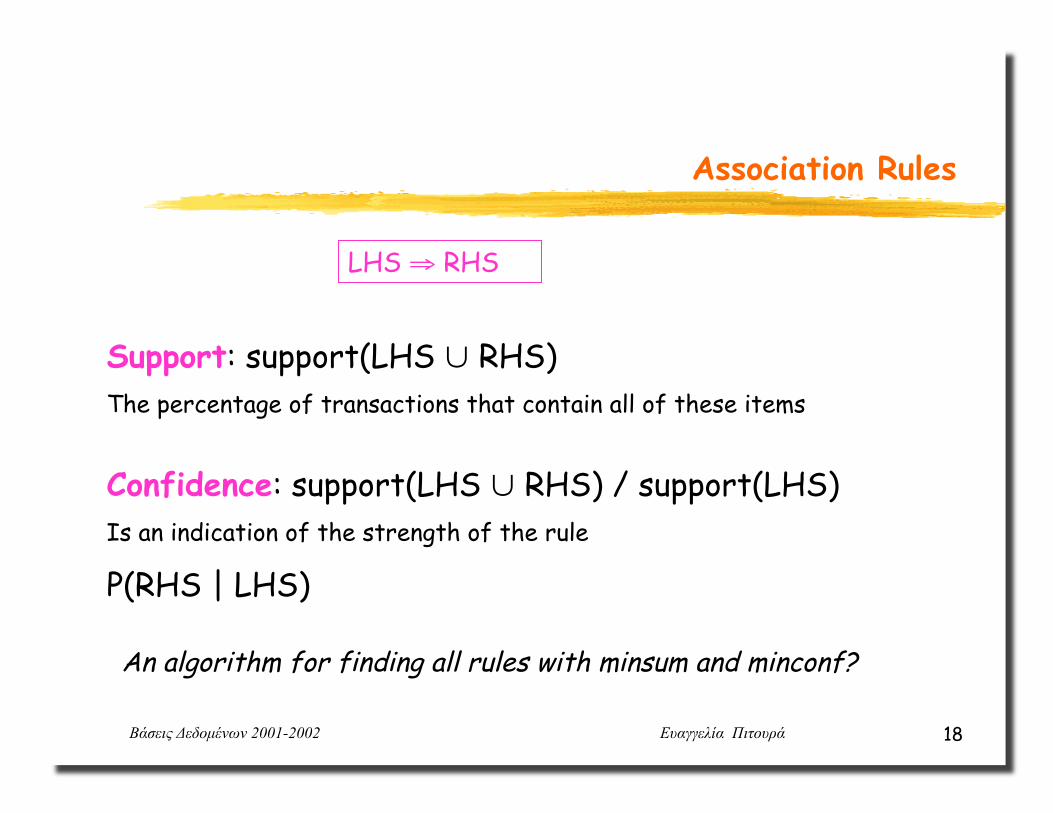
LHS ⇒ RHS
Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 18
Association Rules
LHS ⇒ RHS
Support: support(LHS ∪ RHS) The percentage of transactions that contain all of these items
Confidence: support(LHS ∪ RHS) / support(LHS) Is an indication of the strength of the rule
P(RHS | LHS)
An algorithm for finding all rules with minsum and minconf?
Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 19
Association Rules
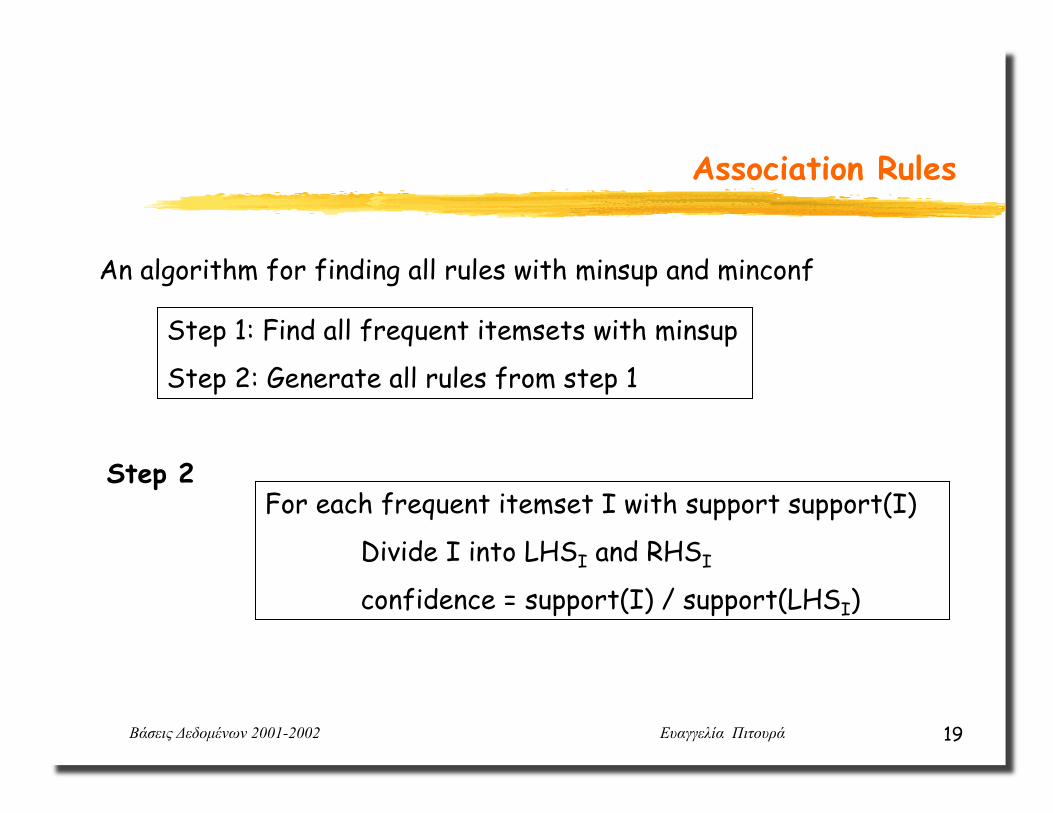
An algorithm for finding all rules with minsup and minconf
Step 1: Find all frequent itemsets with minsup
Step 2: Generate all rules from step 1
For each frequent itemset I with support support(I)
Divide I into LHSI and RHSI
confidence = support(I) / support(LHSI)
Step 2

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 20
Association Rules and ISA Hierarchies
An ISA hierarchy or category hierarchy upon the set of items: a transaction implicitly contains for each of its items all of the item’s ancestors
Beverage
Milk Juice
Stationery
Pen Ink
! Detect relationships between items at different levels of the hierarchy
! In general, the support of an itemset can only increase if an item is replaced by its ancestor

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 21
Generalized Association Rules
More general: not just customer transactions
e.g., Group tuples by custid
Rule {pen} ⇒ {milk}: if a pen is purchased by a customer, it likely that milk will also be purchased by the customer
Transid custid date item qty 111 201 5/1/99 pen 2
111 201 5/1/99 ink 1
111 201 5/1/99 milk 3 111 201 5/1/99 juice 6
112 105 6/3/99 pen 1 112 105 6/3/99 ink 1
112 105 6/3/99 milk 1
113 106 5/10/99 pen 1 113 106 5/10/99 milk 1
114 201 6/1/99 pen 2 114 201 6/1/99 ink 2
114 201 6/1/99 juice 4
Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 22
Generalized Association Rules
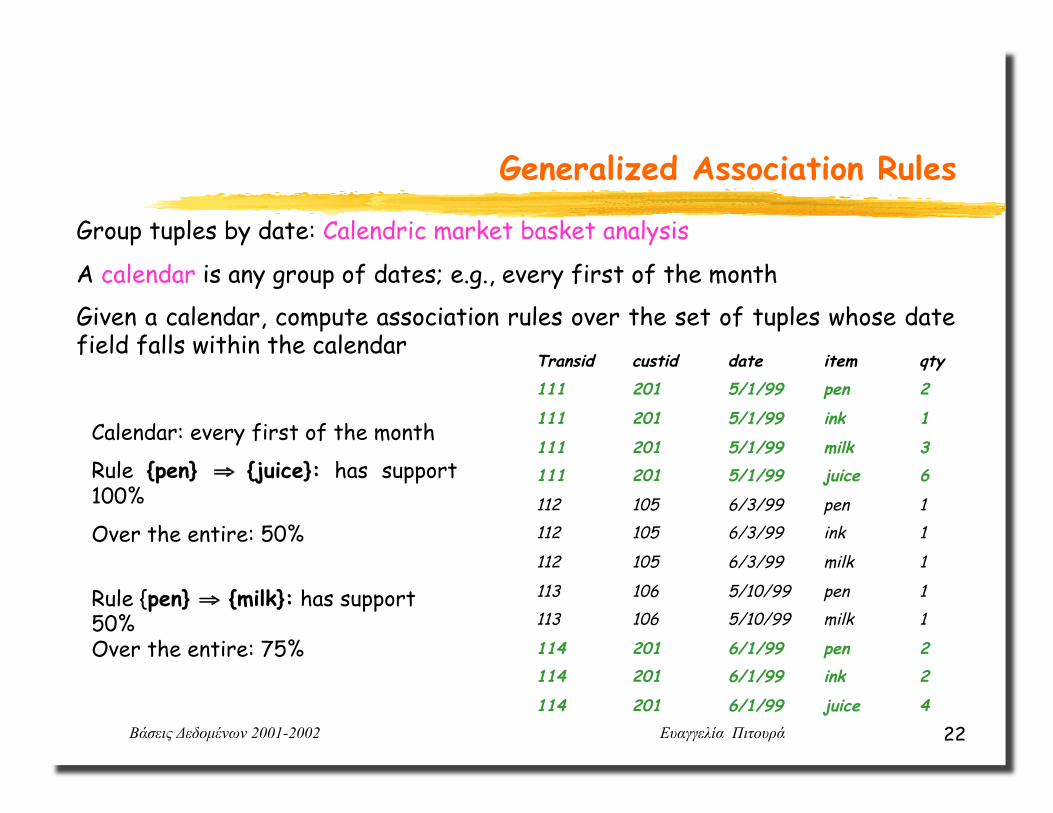
Group tuples by date: Calendric market basket analysis
A calendar is any group of dates; e.g., every first of the month
Given a calendar, compute association rules over the set of tuples whose date field falls within the calendar
Transid custid date item qty 111 201 5/1/99 pen 2
111 201 5/1/99 ink 1
111 201 5/1/99 milk 3 111 201 5/1/99 juice 6
112 105 6/3/99 pen 1 112 105 6/3/99 ink 1
112 105 6/3/99 milk 1
113 106 5/10/99 pen 1 113 106 5/10/99 milk 1
114 201 6/1/99 pen 2 114 201 6/1/99 ink 2
114 201 6/1/99 juice 4
Calendar: every first of the month
Rule {pen} ⇒ {juice}: has support 100%
Over the entire: 50%
Rule {pen} ⇒ {milk}: has support 50% Over the entire: 75%

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 23
Sequential Patterns
Sequence of Itemsets:
The sequence of itemsets purchased by the customer:
Example custid 201: {pen, ink, milk, juice}, {pen, ink, juice}
(ordered by date)
A subsequence of a sequence of itemsets is obtained by deleting one or more itemsets and is also a sequence of itemsets

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 24
Sequential Patterns
A sequence {a1, a2, .., an} is contained in sequence S if S has a subsequence {bq, .., bm} such that ai ⊆ bi for 1 ≤ i ≤ m
Example
{pen}, {ink, milk}, {pen, juice} is contained in {pen, ink}, {shirt}, {juice, ink, milk}, {juice, pen, milk}
The order of items within each itemset does not matter but the order of itemsets does matter {pen}, {ink, milk}, {pen, juice} is not conatined in {pen, ink}, {shirt}, {juice, pen, milk}, {juice, milk, ink}

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 25
Sequential Patterns
The support for a sequence S of itemsets is the percentage of customer sequences of which S is a subsequence
Identify all sequences that have a minimum support

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 26
Overview
Counting Co-occurences
Frequent Itemsets
Iceberg Queries
Mining for Rules
Association Rules
Sequential Rules
Classification and Regression
Tree-Structures Rules
Clustering
Similarity Search over Sequences

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 27
Classification and Regression Rules
InsuranceInfo(age: integer, cartype: string, highrisk: boolean)
There is one attribute (highrisk) whose value we would like to predict: dependent attribute
The other attributes are called the predictors
General form of the types of rules we want to discover:
P1(X1) ∧ P2(X2) ∧ … ∧ Pk(Xk) ⇒ Y = c

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 28
Classification and Regression Rules
P1(X1) ∧ P2(X2) ∧ … ∧ Pk(Xk) ⇒ Y = c Pi(Xi) are predicates
Two types:
! numerical Pi(Xi) : li ≤ Xi ≤ hi
! categorical Pi(Xi) : Xi ∈ {v1, …, vj}
! numerical dependent attribute regression rule
! categorical dependent attribute classification rule
(16 ≤ age ≤ 25) ∧ (cartype ∈ {Sports, Truck}) ⇒ highrisk = true

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 29
Classification and Regression Rules
P1(X1) ∧ P2(X2) ∧ … ∧ Pk(Xk) ⇒ Y = c
Support:
The support for a condition C is the percentage of tuples that satisfy C.
The support for a rule C1 ⇒ C2 is the support of the condition C1 ∧ C2
Confidence
Consider the tuples that satisfy condition C1. The confidence for a rule C1 ⇒ C2 is the percentage of such tuples that also satisfy condition C2

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 30
Classification and Regression Rules
Differ from association rules by considering continuous and categorical attributes, rather than one field that is set-valued

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 31
Overview
Counting Co-occurences
Frequent Itemsets
Iceberg Queries
Mining for Rules
Association Rules
Sequential Rules
Classification and Regression
Tree-Structures Rules
Clustering
Similarity Search over Sequences

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 32
Tree-Structured Rules
Classification or decision trees
Regression trees
Typically the tree itself is the output of data mining
Easy to understand
Efficient algorithms to construct them

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 33
Decision Trees
A graphical representation of a collection of classification rules. Given a data record, the tree directs the record from the root to a leaf.
• Internal nodes: labeled with a predictor attribute (called a splitting attribute)
• Outgoing edges: labeled with predicates that involve the splitting attribute of the node (splitting criterion)
• Leaf nodes: labeled with a value of a dependent attribute
Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 34
Decision Trees
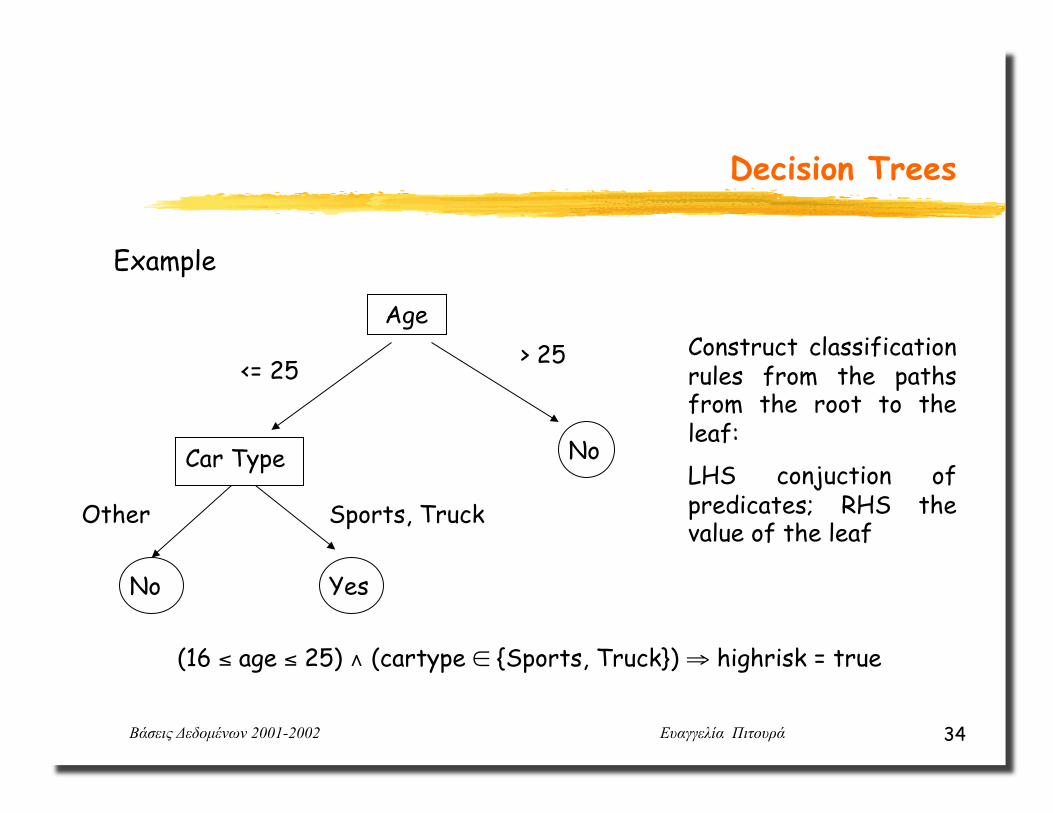
Example
Age
Car Type
> 25
No
<= 25
Sports, Truck Other
Yes No
(16 ≤ age ≤ 25) ∧ (cartype ∈ {Sports, Truck}) ⇒ highrisk = true
Construct classification rules from the paths from the root to the leaf: LHS conjuction of predicates; RHS the value of the leaf

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 35
Decision Trees
Constructed into two phases
Phase 1: growth phase
construct a vary large tree (e.g., leaf nodes for individual records in the database
Phase 2: pruning phase
Build the tree greedily top down:
At the root node, examine the database and compute the locally best splitting criterion
Partition the database into two parts
Recurse on each child

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 36
Decision Trees
Input: node n partition D split selection method S
Output: decision tree for D rooted at node n
Top down Decision Tree Induction Schema
BuildTree(node n, partition D, method S)
Apply S to D to find the splitting criterion
If (a good splitting criterion is found)
create two children nodes n1 and n2 of n
partition D into D1 and D2
BuildTree(n1, D1, S)
Build Tree(n2, D2, S)

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 37
Decision Trees
Split selection method
An algorithm that takes as input (part of) a relation and outputs the locally best spliting criterion
Example: examine the attributes cartype and age, select one of them as a splitting attribute and then select the splitting predicates

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 38
Decision Trees
How can we construct decision trees when the input database is larger than main memory?
Provide the split selection method with aggregated information about the database instead of loading the complete database into main memory
We need aggregated information for each predictor attribute
AVC set of the predictor attribute X at node n is the projection of n’s database partition onto X and the dependent attribute where counts of the individual values in the domain of the dependent attribute are aggregated
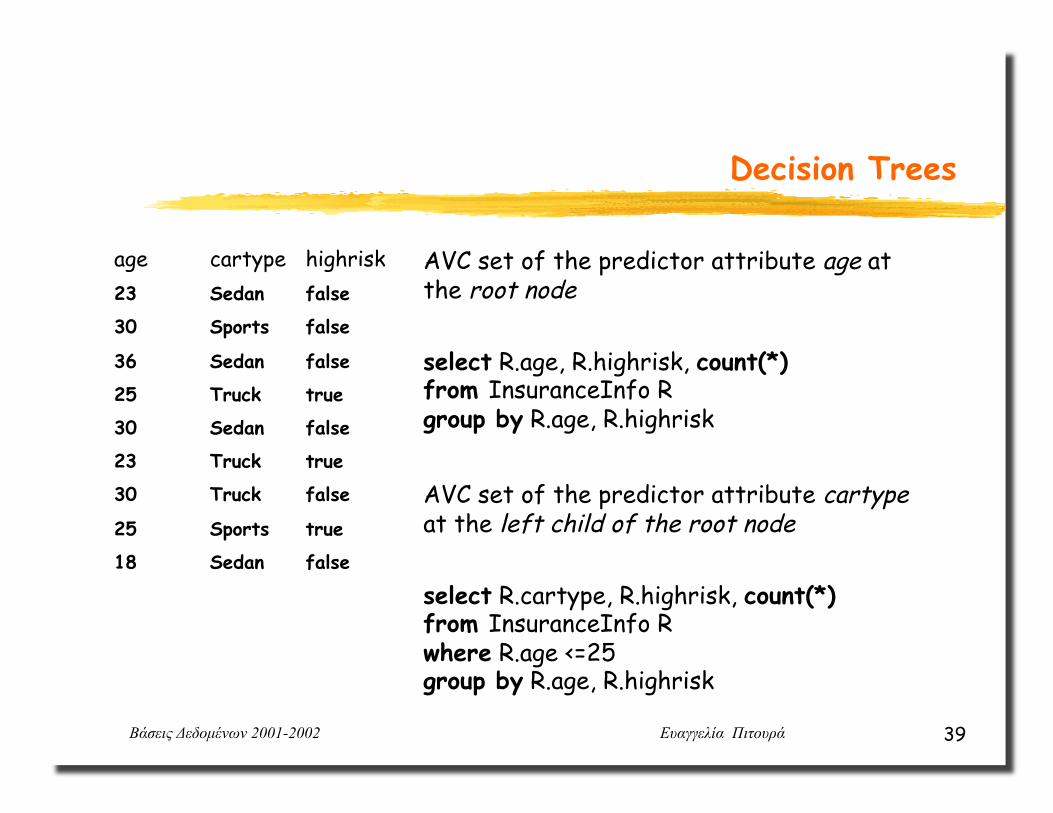
Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 39
Decision Trees
age cartype highrisk 23 Sedan false
30 Sports false
36 Sedan false
25 Truck true
30 Sedan false
23 Truck true
30 Truck false
25 Sports true
18 Sedan false
AVC set of the predictor attribute age at the root node
select R.age, R.highrisk, count(*) from InsuranceInfo R group by R.age, R.highrisk
AVC set of the predictor attribute cartype at the left child of the root node
select R.cartype, R.highrisk, count(*) from InsuranceInfo R where R.age <=25 group by R.age, R.highrisk

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 40
Decision Trees
age cartype highrisk 23 Sedan false
30 Sports false
36 Sedan false
25 Truck true
30 Sedan false
23 Truck true
30 Truck false
25 Sports true
18 Sedan false
AVC set of the predictor attribute age at the root node
select R.age, R.highrisk, count(*) from InsuranceInfo R group by R.age, R.highrisk
True False Sedan 0 4 Sports 1 1 Truck 2 1

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 41
Decision Trees
Size of the AVC set?
AVC group of a node n: the set of the AVC sets of all predictors attributes at node n

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 42
Decision Trees
Input: node n partition D split selection method S
Output: decision tree for D rooted at node n
Top down Decision Tree Induction Schema
BuildTree(node n, partition D, method S)
Make a scan over D and construct the AVC group of node n in memory
Apply S to AVC group to find the splitting criterion
If (a good splitting criterion is found)
create two children nodes n1 and n2 of n
partition D into D1 and D2
BuildTree(n1, D1, S)
Build Tree(n2, D2, S)

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 43
Overview
Counting Co-occurences
Frequent Itemsets
Iceberg Queries
Mining for Rules
Association Rules
Sequential Rules
Classification and Regression
Tree-Structures Rules
Clustering
Similarity Search over Sequences

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 44
Clustering
Partition a set of records into groups (clusters) such that all records within a group are similar to each other and records that belong to two different groups are disimilar.
Similarity between records measured computationally by a distance function.
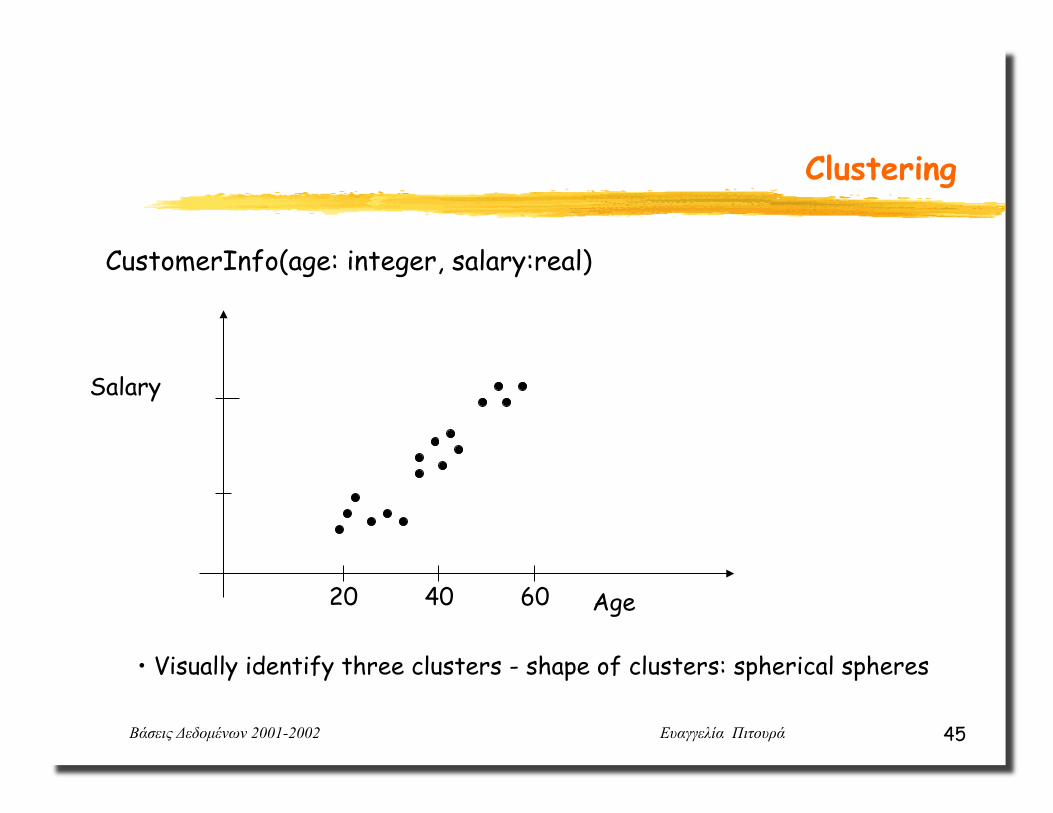
Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 45
Clustering
CustomerInfo(age: integer, salary:real)
Age
Salary
20 40 60
• Visually identify three clusters - shape of clusters: spherical spheres

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 46
Clustering
The output of a clustering algorithm consists of a summarized representation of each cluster.
Type of output depends on type and shape of clusters.
For example if spherical clusters: center C (mean) and radius R:
given a collection of records r1, r2, .., rn
C = ∑ ri R = ∑ (ri - C)
n

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 47
Clustering
Two types of clustering algorithms:
• Partitional clustering: partitions the data into k groups such that some criterion that evaluates the clustering quality is optimized
• Hierarchical clustering generates a sequence of partitions of the records. Starting with a partition in which each cluster consists of a single record, merges two partitions in each step

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 48
Clustering
Assumptions
• Large number of records, just one scan of them
• A limited amount of main memory
The BIRCH algorithm:
Two parameters
• k: main memory threshold: maximum number of clusters that can be maintained in memory
• e: initial threshold of the radius of each cluster. A cluster is compact if its radius is smaller than e.
Always maintain in main memory k or fewer compact cluster summaries (Ci, Ri)
(If this is no possible adjust e)

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 49
Clustering
Read a record r from the database
Compute the distance of r and each of the existing cluster centers
Let i be the cluster (index) such that the distance between r and Ci is the smallest
Compute R’i assuming r is inserted in the ith cluster
If R’i ≤ e,
insert r in the ith cluster recompute Ri and Ci
else
start a new cluster containing only r
The BIRCH algorithm:

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 50
Overview
Counting Co-occurences
Frequent Itemsets
Iceberg Queries
Mining for Rules
Association Rules
Sequential Rules
Classification and Regression
Tree-Structures Rules
Clustering
Similarity Search over Sequences

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 51
Similarity Search over Sequences
A user specifies a query sequence and wants to retrieve all data sequences that are similar to the query sequence
Not exact matches
A data sequence X is a sequence of numbers X = <x1, x2, .., xk>
Also called a time series
k length of the sequence
A subsequence Z = <z1, z2, …, zj> is deleting from another sequence by deleting numbers from the front and back of the sequence

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 52
Similarity Search over Sequences
Given two sequences X and Y we can define the distance of the two sequences as the Euclidean norm
Given a user-specified query sequence and a threshold parameter e, retrieve all data sequences within e-distance to the query sequence
! Complete sequence matching (the query sequence and the sequence in the database have the same length)
! Subsequence matching (the query is shorter)

Βάσεις Δεδοµένων 2001-2002 Ευαγγελία Πιτουρά 53
Similarity Search over Sequences
Given a user-specified query sequence and a threshold parameter e, retrieve all data sequences within e-distance to the query sequence
Brute-force method?
Each data sequence and the query sequence of length k may be represented as a point in a k-dimensional space Construct a multidimensional index
Non-exact matches? Query the index with a hyper-rectangle with side length 2-e and the query sentence as the center


















