
Robust Submodular Maximization: A Non-Uniform Partitioning ...
Upload
cigdem-aslayCategory
view
297download
0
Online Topic-aware Influence Maximization Queries
Cigdem Aslay
Nicola Barbieri
Francesco Bonchi
Ricardo Baeza-Yates
n
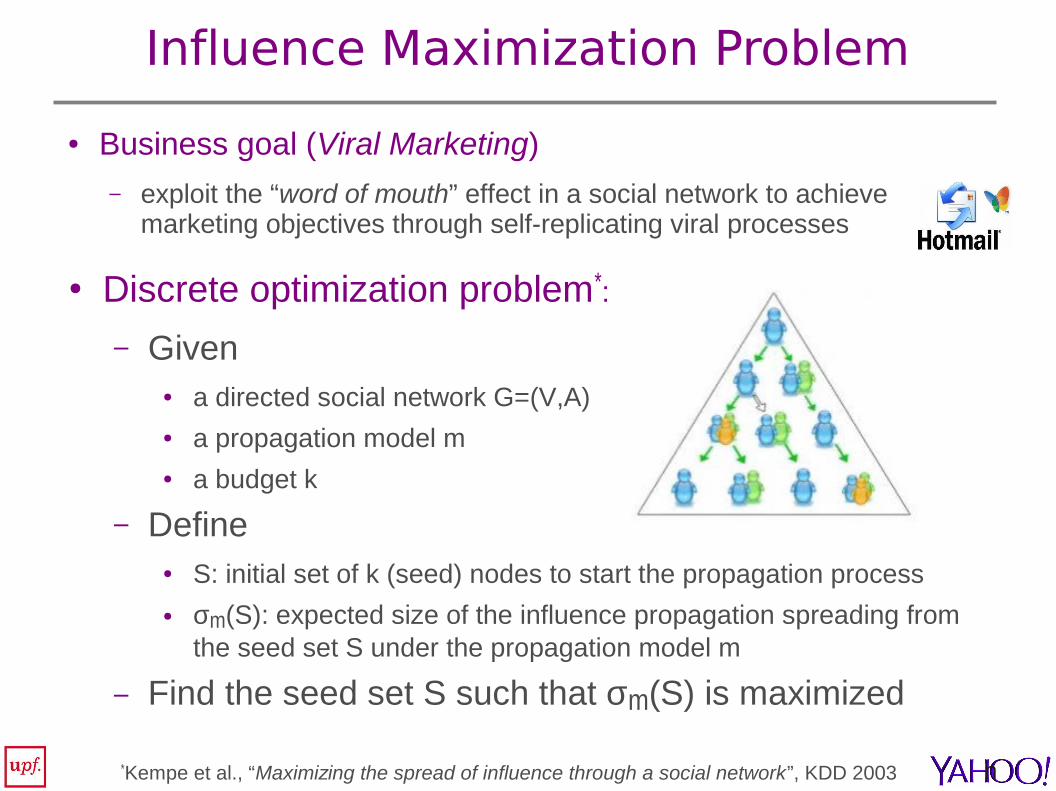
Influence Maximization Problem
● Discrete optimization problem*:
– Given ● a directed social network G=(V,A)● a propagation model m● a budget k
– Define● S: initial set of k (seed) nodes to start the propagation process● σm(S): expected size of the influence propagation spreading from
the seed set S under the propagation model m
– Find the seed set S such that σm(S) is maximized
*Kempe et al., “Maximizing the spread of influence through a social network”, KDD 2003
● Business goal (Viral Marketing)
– exploit the “word of mouth” effect in a social network to achieve marketing objectives through self-replicating viral processes
n
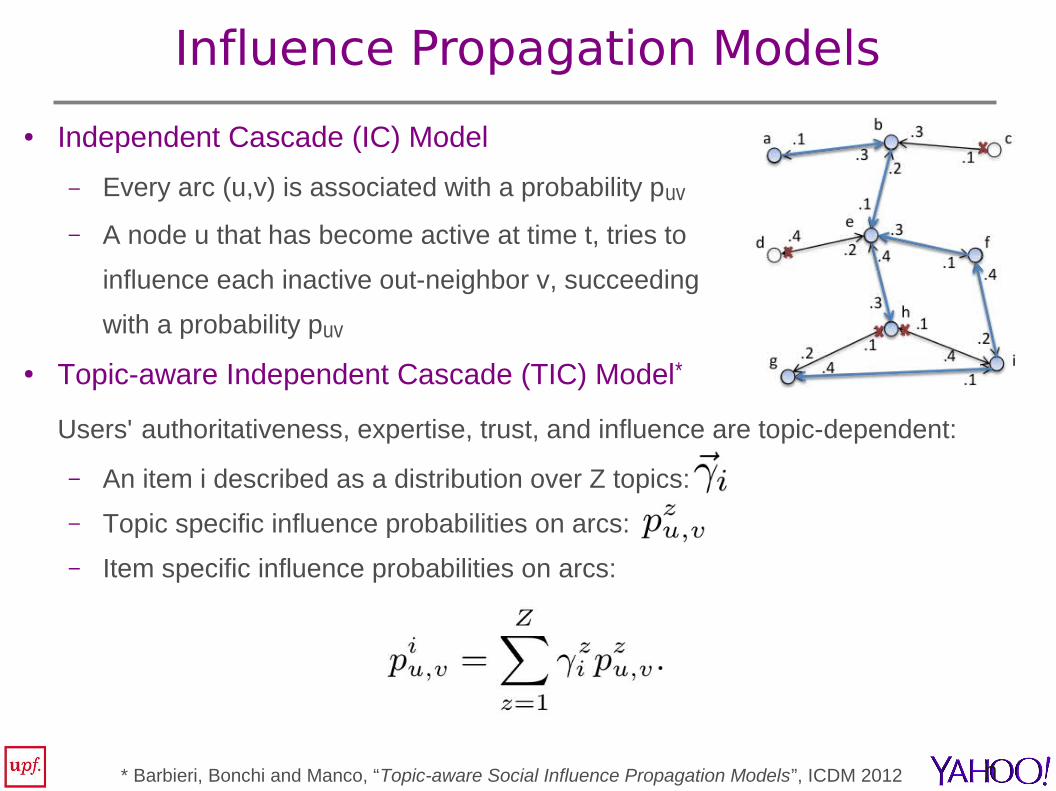
Influence Propagation Models
● Independent Cascade (IC) Model
– Every arc (u,v) is associated with a probability puv
– A node u that has become active at time t, tries to
influence each inactive out-neighbor v, succeeding
with a probability puv
● Topic-aware Independent Cascade (TIC) Model*
Users' authoritativeness, expertise, trust, and influence are topic-dependent:
– An item i described as a distribution over Z topics:
– Topic specific influence probabilities on arcs:
– Item specific influence probabilities on arcs:
* Barbieri, Bonchi and Manco, “Topic-aware Social Influence Propagation Models”, ICDM 2012

n
● Given
– a space of Z topics
– a directed social network G=(V,A)
– topic specific influence probabilities on arcs,
– a query item q,
– a budget k
● TIM query finds a seed set S of k nodes that maximizes the expected number of nodes adopting item q in the network
Topic-aware Influence Maximization Queries

n
Complexity and Approximation
● Influence Maximization is NP-Hard under both IC and TIC models– TIC model boils down to IC model on the probabilistic graph Gq = (V,A,pq)
– Reduction from set cover
● Greedy algorithm by Kempe et al.
– Achieves an approximation guarantee of (1 – 1/e) ≈ 0.63 using monotonicity1 and submodularity2 of the spread function
#P-hard

n
Offline TIM Query Processing
● TIM query can be processed by standard influence maximization algorithms– Takes days to find 50 seed nodes on a graph with 30K nodes when
using 5000 Monte Carlo iterations
– Enjoys usual approximation guarantees but neither efficient nor interactive
● Indexing necessary to answer TIM queries in an online fashion– Milliseconds response time to enable online analytics for viral
marketing
● Challenges
– Enormous number of potential queries● any point lying on the probability simplex ● any potential query corresponding to a different probabilistic graph
n
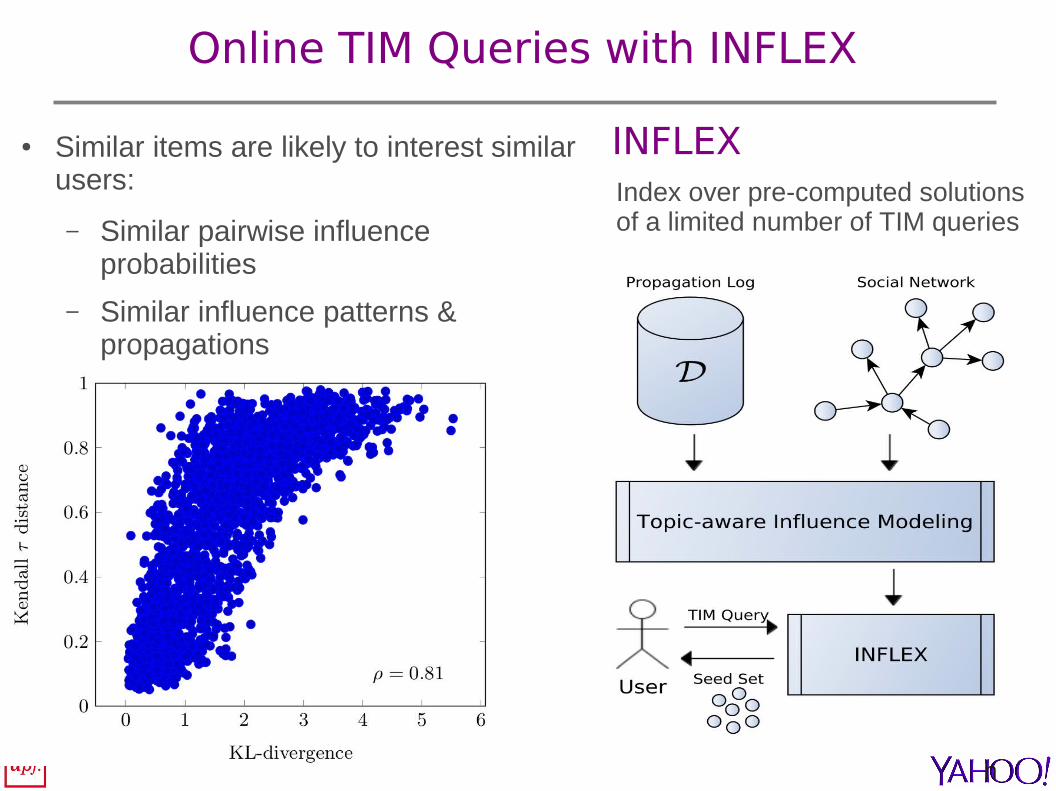
Online TIM Queries with INFLEX
● Similar items are likely to interest similar users:
– Similar pairwise influence probabilities
– Similar influence patterns & propagations
INFLEX Index over pre-computed solutionsof a limited number of TIM queries
n
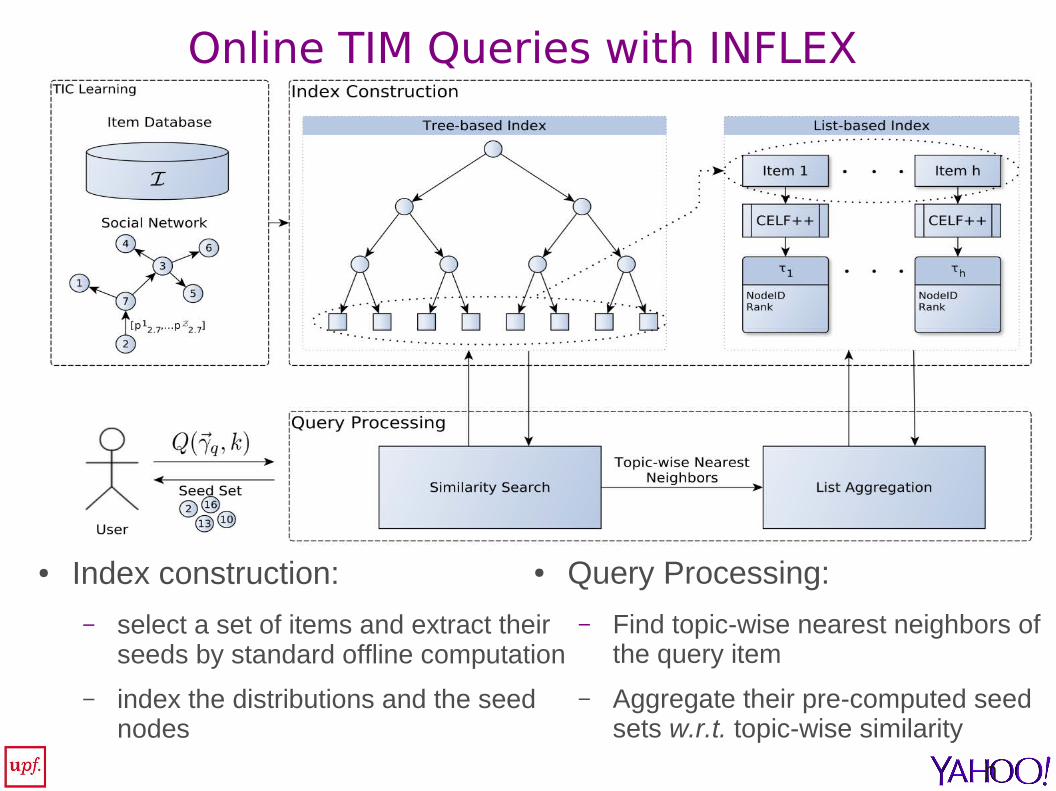
Online TIM Queries with INFLEX
● Index construction:
– select a set of items and extract their seeds by standard offline computation
– index the distributions and the seed nodes
● Query Processing:
– Find topic-wise nearest neighbors of the query item
– Aggregate their pre-computed seed sets w.r.t. topic-wise similarity

n
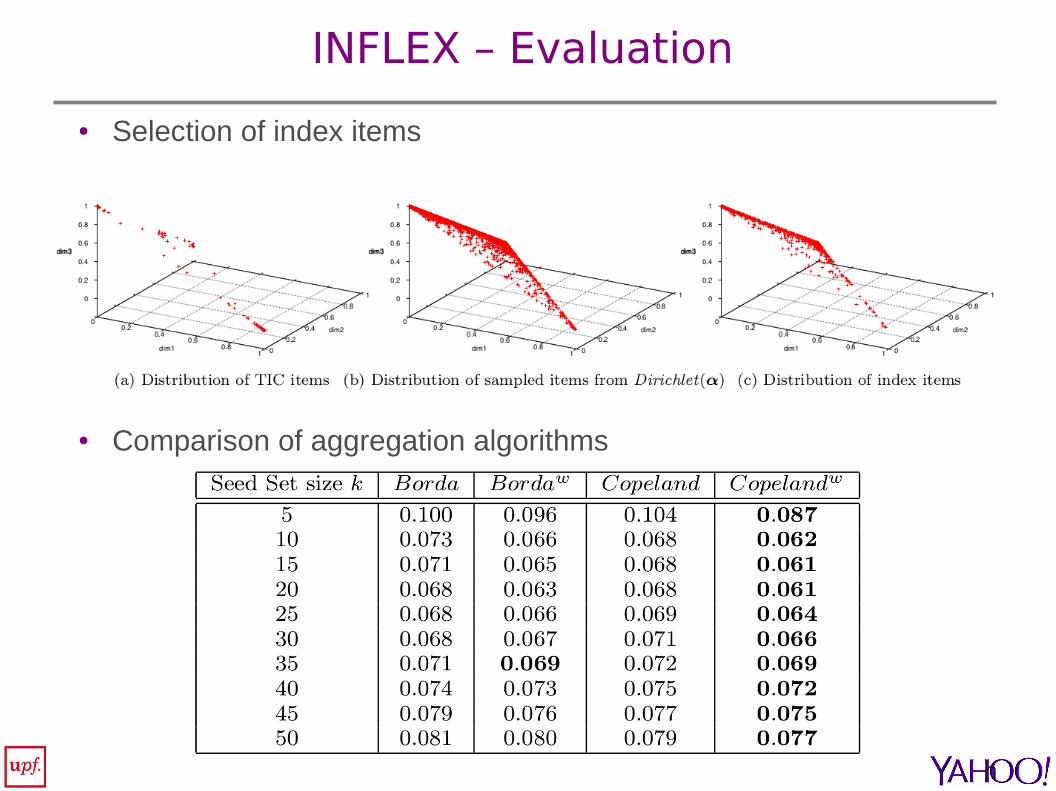
INFLEX – Selection of Index Items
● The number of items needed to build the index
– trade off between accuracy and space-time efficiency
● Space-based selection: equi-distantly positioned topic distributions on the simplex
● (+) Fair coverage of the simplex● (-) Disregards the available workload
● Data-driven selection: items catalog learned from log of past propagations
● (+) Queried items likely to follow the distributions learned from the past data● (-) Sparsity problems for skewed topic distributions in the catalog
● Sampling distributions from the simplex
– Estimate the Dirichlet distribution that maximizes the log-likelihood of the available workload
– Generate a large sample
– Apply Bregman K-means++ on the sample
– Take distributions on the centroids from Bregman K-means++

n
INFLEX - Tree Construction
● Bregman Ball Trees1,2
– Efficient similarity search with Kullback-Leibler divergence
– Hierarchical space partition based on convex Bregman Balls
– Bregman K-means++ to create child nodes from the parent
– Gaussian clustering to find optimal number of child nodes
1 Cayton, “Fast Nearest Neighbor Retrieval for Bregman Divergences”, ICML 2008
2 Nielsen, Piro, and Barlaud, “Tailored Bregman Ball Trees for Effective Nearest Neighbors”, EuroCG 2009

n
INFLEX - Similarity Search
early stopping based on Anderson-Darling Test
ϵ-exact match

n
INFLEX – Rank Aggregation
● Combine the rankings of topic-wise nearest neighbors into one “consensus” ranking based on their similarity to the query item
● Kemeny-Optimal Rank Aggregation
– Produce a ranking that has the minimum Kendall-Tau distance to all the input lists
● NP-Hard even for 4 input permutations

n
INFLEX – Rank Aggregation
● Weighted versions of classical techniques from Social Choice Theory for efficiency, followed by Local Kemenization*
– Weighted Borda Aggregation:
– Weighted Copeland Aggregation:
– Aggregation weights: non-linear transformation of KL-Divergence with automatic marginal list trimming
* Dwork, Kumar, Naor, and Sivakumar “Rank Aggregation Methods for the Web”, WWW 2001
n
INFLEX – Evaluation
● Selection of index items
● Comparison of aggregation algorithms
n
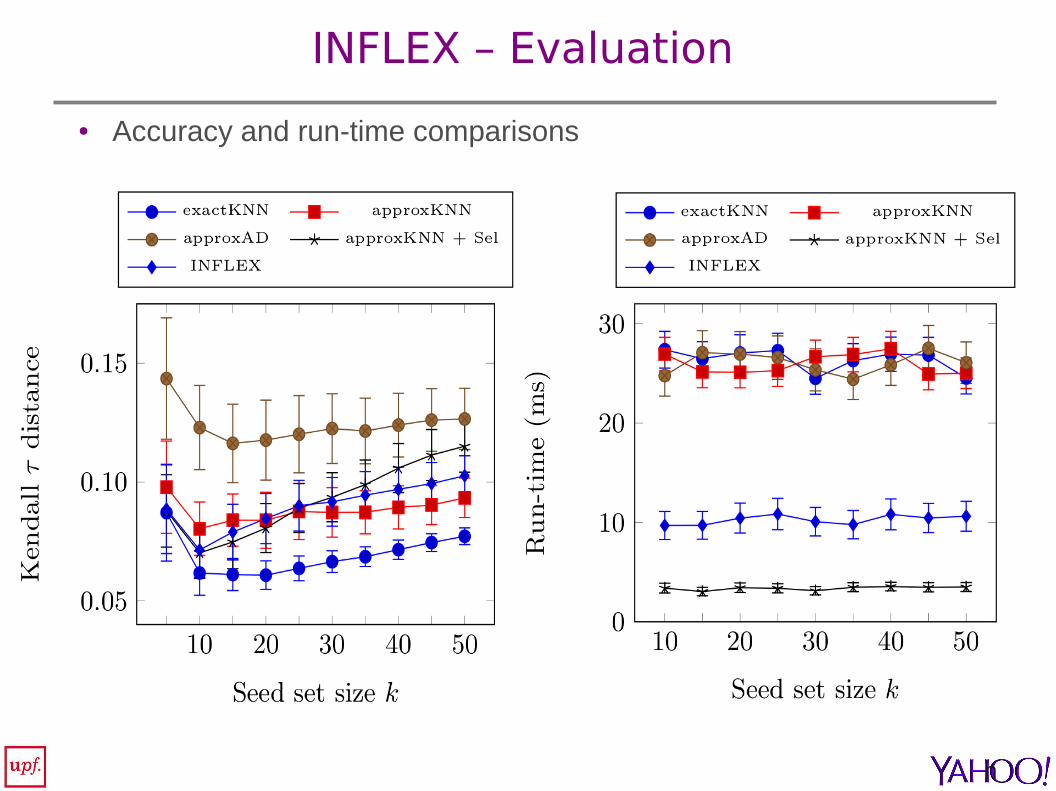
INFLEX – Evaluation
● Accuracy and run-time comparisons
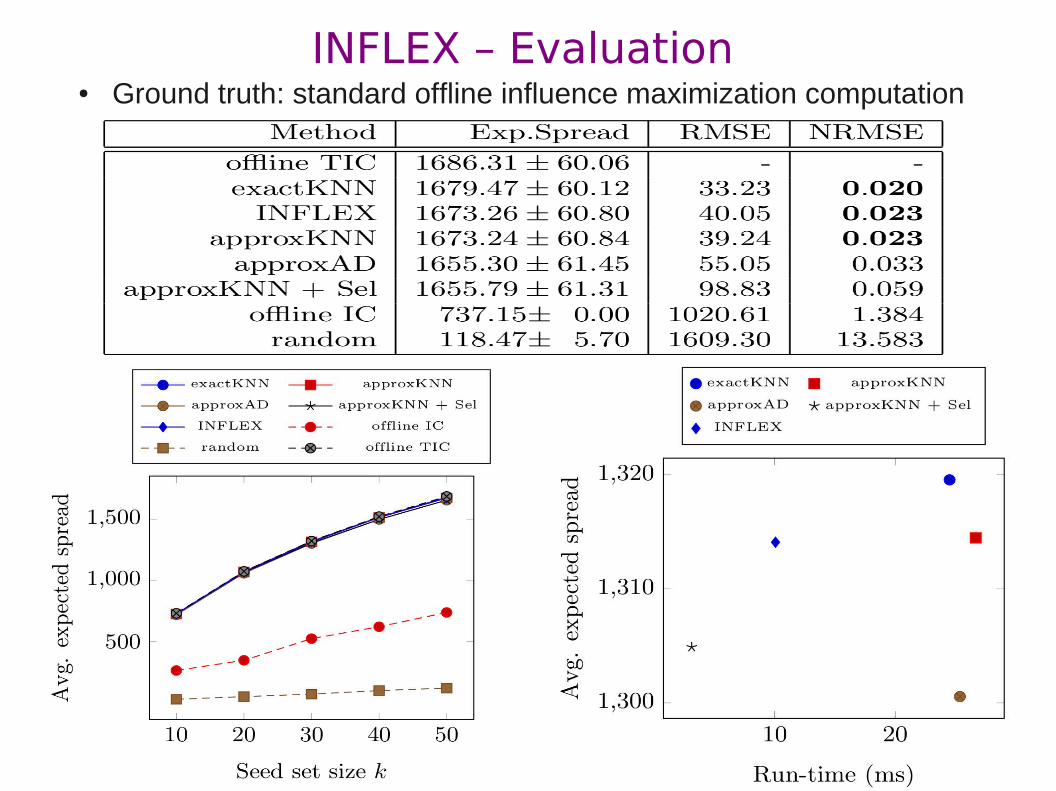
● Ground truth: standard offline influence maximization computationINFLEX – Evaluation

n
Thank you!


















