
1 Semantic Web & Peer-To-Peer HY566 Semantic Web Instructor Grigoris Antoniou Πετράκη...
50
1 Semantic Web & Peer-To-Peer HY566 Semantic Web Instructor Grigoris Antoniou Πετράκη Μερόπη Σκυλογιάννης Θωμάς Ιούνιος 2003
-
date post
22-Dec-2015 -
Category
Documents
-
view
220 -
download
0
Transcript of 1 Semantic Web & Peer-To-Peer HY566 Semantic Web Instructor Grigoris Antoniou Πετράκη...

1
Semantic Web & Peer-To-Peer
HY566 Semantic WebInstructor Grigoris Antoniou
Πετράκη ΜερόπηΣκυλογιάννης Θωμάς
Ιούνιος 2003

2
Issues of Research Work Semantic Web Vision Peer to Peer technologies
The JXTA framework 2 Main directions: Combining SW and P2P Projects overview
InfoQuilt Edutella Elena project Neurogrid Swap Discovery Service based on Edutella infrastructure
Hypercubes, Ontologies and efficient search on P2P networks

3
Peer-To-Peer overview (Napster - Gnutella)
Peer to peer systems have similar goals: to facilitate the location and exchange of files (typically images ,audio, or video) among a large group of independent users connected through the Internet.
In these systems, files are stored on the computers of the individual users or peers, and exchanged through a direct connection between the downloading and uploading peers, over an HTTP-style protocol.
All peers in this system are symmetric: they all have the ability to function both as a client and a server.
This symmetry distinguishes peerto-peer systems from many conventional distributed system architectures.
Though the process of exchanging files is similar in both systems, Napster and Gnutella differ substantially in how peers locate files

4
Napster In Napster, a large cluster of dedicated central servers
maintain an index of the files that are currently being shared by active peers.
Each peer maintains a connection to one of the central servers, through which the file location queries are sent. The servers then cooperate to process the query and return a list of matching files and locations.
On receiving the results, the peer may choose to initiate a file exchange directly from another peer.
In addition to maintaining an index of shared files, the centralized servers also monitor the state of each peer
in the system, keeping track of metadata such as the peers’ reported connection bandwidth and the duration that the peer has remained connected to the system.
This metadata is returned with the results of a query, so that the initiating peer has some information to distinguish possible download sites.

5
Gnutella There are no centralized servers in Gnutella, however.
Instead, Gnutella peers form an overlay network by forging point-to-point connections with a set of neighbors.
To locate a file, a peer initiates a controlled flood of the network by sending a query packet to all of its neighbors.
Upon receiving a query packet, a peer checks if any locally stored files match the query.
If so, the peer sends a query response packet back towards the query
originator. Whether or not a file match is found, the peer continues to
flood the query through the overlay. To help maintain the overlay as the users enter and leave
the system, the Gnutella protocol includes ping and pong messages that help peers to discover other nodes.
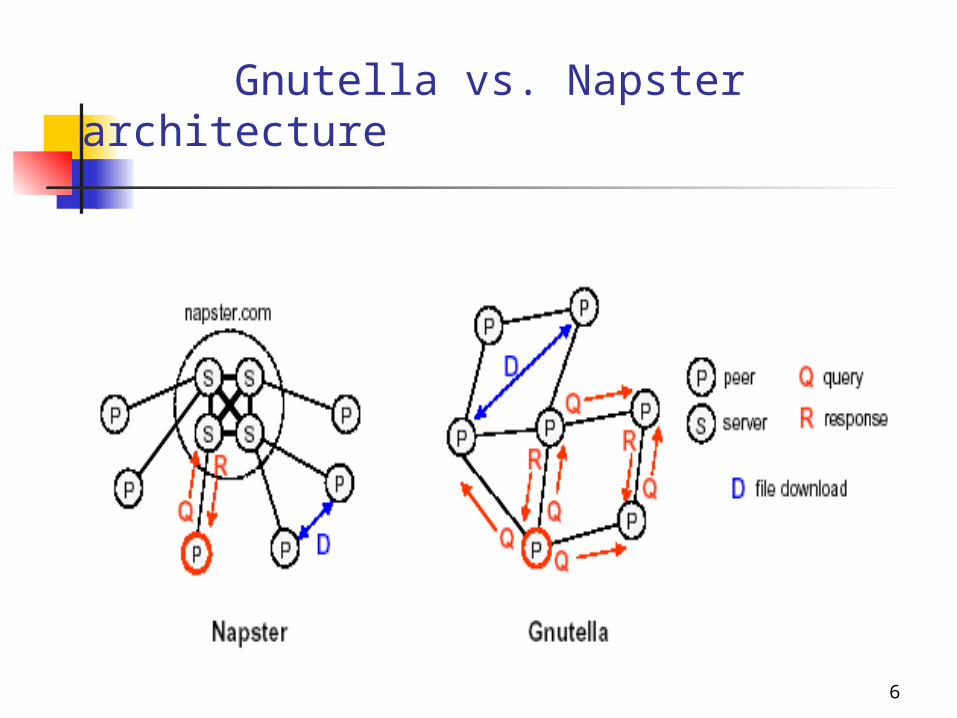
6
Gnutella vs. Napster architecture

7
2 Main directions: Combining SW and P2P
The first research direction uses peer-to-peer networks as a basis infrastructure for the exchange of semantic information. The peers can create and maintain their own ontologies and definitions. In addition, they can create their own relationships between their ontologies, or use the ontologies of other peers to create inter relationships.
The second research direction combines semantic web and peer-to-peer technology in order to support schema-based P2P networks. Τhe general objective here is to extend conventional peer-to-peer networks by allowing different and extensible schemas to describe the peer content

8
1st Direction: InfoQuilt Overview
Challenges we need to address in order to realize SW vision
Info Quilt system Why are P2P desirable to be an infrastructure for
knowledge sharing System’s Architecture - A multi agent information brokering
system Knowledge space construction and navigation Semantic Search

9
Semantic web vision
The usage of programs that can “understand” the semantics of the data.
Use of ontologies in order to: Provide the context for capturing the meaning of data Capture the user’s intention in a query

10
Challenges we need to address in order to realize SW vision
A way to advertise knowledge and ontologies of different information domains, which are maintained by different persons, groups and organizations on the Web.
A semantic search mechanism is needed to find most relevant set ontologies using users’ context for information request and his profile.
Once the ontologies are located there is a need for introducing some relationships across ontologies and supporting techniques for ontology interoperation
users need tools that would allow them to define information requests

11
Peer to peer Semantic Web (PSW)
Consists of two basic components
DAML+OIL provides a specification framework for independently
creating maintaining and interoperating
ontologies while preserving their semantics
Peer To Peer (P2P) systems are used to provide a distributed architecture which can support sharing of independently created and maintained ontologies

12
Info Quilt system
A system developed at the university of Georgia which facilitates:
Distributed and autonomous creation and maintenance of local ontologies,
Advertisement (i.e., registry) and search of (local) ontologies,
Introducing inter-ontological relationships between relevant ontologies as-needed basis once they are located,
Controlled sharing of knowledge base components among users in the network,
Ontology-driven semantic search of concepts and services, Knowledge discovery and exploration of inter-ontological
relationships.

13
Why are P2P desirable to be an infrastructure for knowledge sharing
It encourages distributed architecture, and supports decentralization of control and access to information and services A way to harness the computing power and knowledge of millions of computers in the web.
It provides access to semantic information published by several independent content providers,and enables creation of personalized semantic relationships.
It supports for publishing peer definitions and relationships to other peers and software agents.
It offers user-centered, data-centered and computing centered models, which provide suitable architectures for distributed content management.

14
Knowledge Discovery
system includes:
(a) language and tools to specify IScapes (i.e., semantic information requests), and
(b) tools and algorithms to perform what-if analyses to search the information space of semantically related data.
IScapes allow parameterized specification of information requests and correlation that utilizes the domain ontologies, inter-ontological relationships and user defined functions to accurately describe a user’s information need.
IScapes are more than a traditional query in that they can understand user’s request by embedding semantic information
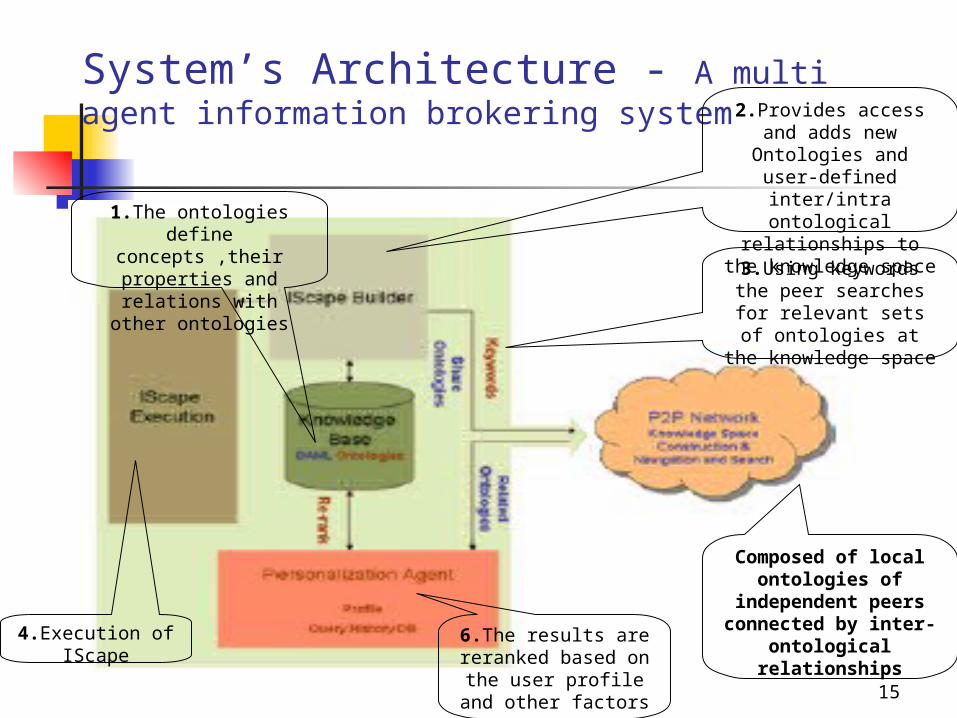
15
System’s Architecture - A multi agent information brokering system 2.Provides access and
adds new Ontologies and user-defined
inter/intra ontological relationships to the knowledge space
Composed of local ontologies of
independent peers connected by inter-
ontological relationships
1.The ontologies define concepts ,their
properties and relations with other
ontologies
3.Using keywords the peer searches for relevant sets of
ontologies at the knowledge space
4.Execution of IScape
6.The results are reranked based on the user profile and
other factors

16
Knowledge space construction and navigation (1/3)
When a person defines his own concept or notion based on a predefined or agreed upon concepts, it is marked up in the knowledge space by these references.
One concept (ontology)that survives is the one that is most referenced, other definitions go by unnoticed.
In using DAML+OIL, the only concepts everybody agrees upon are the basic classes like Thing
When a new ontology is created, it is already hooked up in the knowledge space because of the use of imports and namespaces
In order for the programs to access this knowledge space programmatically, a data structure is used

17
Knowledge space construction and navigation (2/3)
RDF statement in an ontology can define a class, its properties and its relationships with other classes. For example a statement would look like
<#boy> <#drinks> <#coffee>. Now all of the triples, boy, drinks and coffee are qualified by
use of URIs. The data structure stores subject (boy), the object (coffee) and
the verb (drinks) that relates them. So the core components of the data structure are
Concepts: Concepts or KObjects contains information about each class. In the example, boy and coffee qualify to be KObjects.
Links: Links or relationships contain information about the predicate and the KObjects it relates.
In our example drinks qualifies as a Link.

18
Knowledge space construction and navigation (2/3)
For each KObject, the pointers to the Links that has this KObject as a subject or object and the ontology it is defined along with the user information are maintained.
In creation of the knowledge space the following steps are involved:1. Retrieve every RDF triple (subject, predicate, and object) from
each source ontology,2. For every assertion of a fact or a definition made in the ontology,
recursively trace its link to the most general class of the knowledge space (#Thing),
3. Repeat 1 and 2 untill all the ontologies are hooked into the knowledge space.
For knowledge space navigation, we can start with the KObject Thing and then traverse through the Links in the KObject.

19
Ontology registration The peers can create and maintain their own ontologies
conforming to DAML + OIL formalisms They have control as whether or not to share an ontology A peer who decides to share an ontology must upload it to the
knowledge space (registration). New concepts (Kobjects) and relationships (Links) are created
appropriately Once an ontology is uploaded, other peers can refer to its
definitions In case a peer removes his ontology, all definitions and
assertions that refer to these definitions become invalid in the knowledge space
Tools like DAML validator can check for obsolete definitions and stale links

20
Semantic Search (1/3)
One of the key advantages of constructing a knowledge space is semantic search. In the IScape Builder, the user specifies the keywords (usually common nouns) used in the information request.
The data structure representing the knowledge space is a collection of KObjects and Links.
The input is a set of keywords and the output is a list of ontologies. The process of searching involves the following steps…

21
Semantic Search (2/3)
1. Take each keyword and run a basic keyword match on the subject, object and the predicate (in that particular order) in the entire knowledge space,
2. Retrieve the name of the ontologies that satisfy the above match along with the ownership details,
3. If the keywords result in a number of ontologies, compare the ontologies for common parents and eliminate the ontologies without any common links,
4. If there is more than one ontology describing the same keyword, perform search with more keywords or compare the resulting ontologies to help user select the ontology.

22
Semantic Search (3/3)
One other utility awhich uses the knowledge space is the ability to compare two ontologies. This involves the following steps:
1. Identify the KObjects (concepts) used in each ontology in the knowledge space,
2. Find a common parent KObject that links two Objects that are defined in each of the compared ontologies;
in other words, find a connecting link (relationship) between the two ontologies and trace it for the user.

23
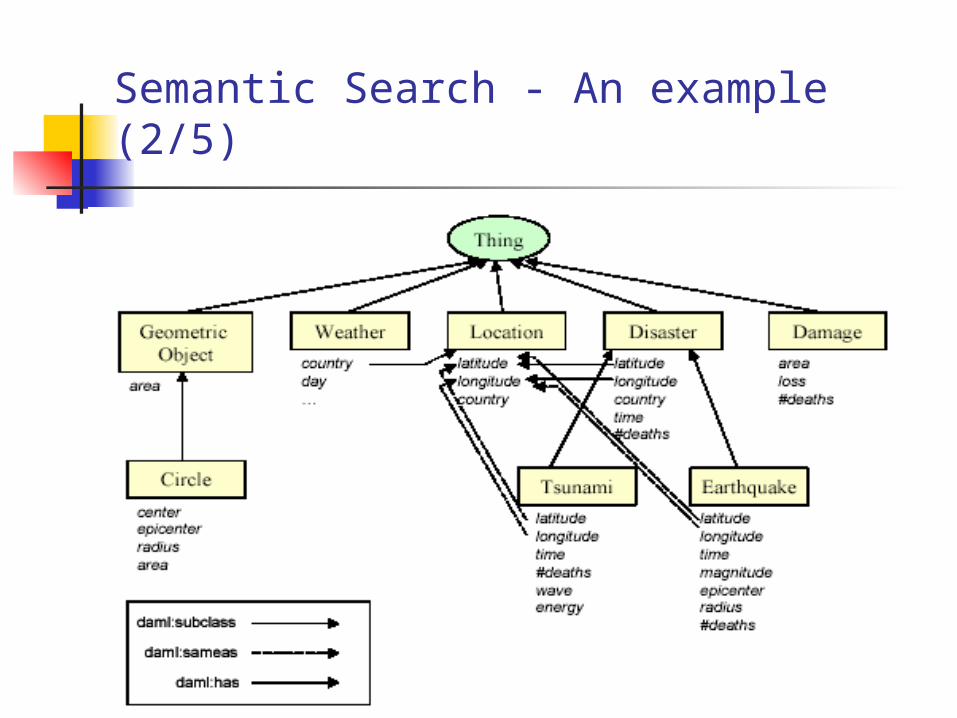
Semantic Search - An example (1/5)
“Find all earthquakes with epicenter in a 5000 mile radius of the location at latitude 60.790 North and longitude 97.570 East and find all tsunamis that they might have caused.”
The keywords in the above information request are earthquake, epicenter, radius, location, latitude, longitude, and tsunamis.
Let assume the following results for the keyword matches on the subject, object and the predicate of all the triples in the DAML+OIL ontologies:
24
Semantic Search - An example (2/5)

25
Semantic Search - An example (3/5)
After the above results are obtained, we have to arrive at the semantically relevant set of ontologies.
This is done by comparing every KObject in the ontology with every other KObject in the other ontologies.
If they have acommon KObject linked by both the KObjects, they are related (e.g., tsunamis and earthquakes are related because they have a common parent, i.e., a KObject, namely disaster).

26
Semantic Search - An example (4/5)
In addition, of these ontologies earthquake.daml, location.daml andtsunami.daml, are linked with KObjects latitude, longitude. So the relevant set of ontologies will be
earthquake.daml location.daml tsunami.daml
…discarding damage.daml, weather.daml and circle.daml.
The ontology weather.daml is discarded even though it has a reference to the definition of location because, although the definition of weather involves country, which is a sub-class of location it is not related in the sense it does not have a common parent with earthquake and tsunami.

27
Semantic Search - An example (5/5)
Thus, the system considers earthquake, tsunami, and location ontologies as relevant because this is the minimal set of ontologies with all keyword matches and has at least one common KObject linked.

28
2nd Direction : Οverview
Introduction to the second main research area Problems of current P2P implementations Project Edutella JXTA Framework Overview: Edutella Services Edutella Query Service Example: O-Telos provider peer

29
The 2nd research area: Semantic Web & Peer-to-Peer
Combines semantic web and peer-to-peer technology in order to support schema-based P2P networks
Aims to extend conventional peer-to-peer networks by allowing different and extensible schemas to describe the peer content
“Metadata for the WWW are important, but metadata for Peer-to-Peer networks are absolutely crucial”

30
Problems of P2P applications
Information Resources in P2P networks are no longer organized in hypertext like structures
Information resources are stored on numerous peer waiting to be queried
If we know what we want to retrieve Which peer is able to provide that information
Querying peers requires metadata describing the resources Easy for specialized cases: like exchanging music files Non trivial for general applications: like exchanging
educational material

31
Problems of P2P applications
Current P2P implementations: Concentrate on domain specific formats: appear to be
fragmenting into niche markets No unifying mechanisms for future P2P applications
There is indeed a great danger that unifying interfaces and protocols introduced by the WWW get lost in the P2P arena

32
Project Edutella Edutella Project: addresses shortcomings of current P2P
applications by building on W3C metadata standard RDF Edutella is a metadata-based P2P system
Integrate heterogeneous peers (Different repositories, Query languages, Functionality)
Different kinds of metadata schemas Common ground is an essential assumption
All resources (metadata) maintained in the Edutella network can be described in RDF
First application:a P2P network for the exchange of education resources
33
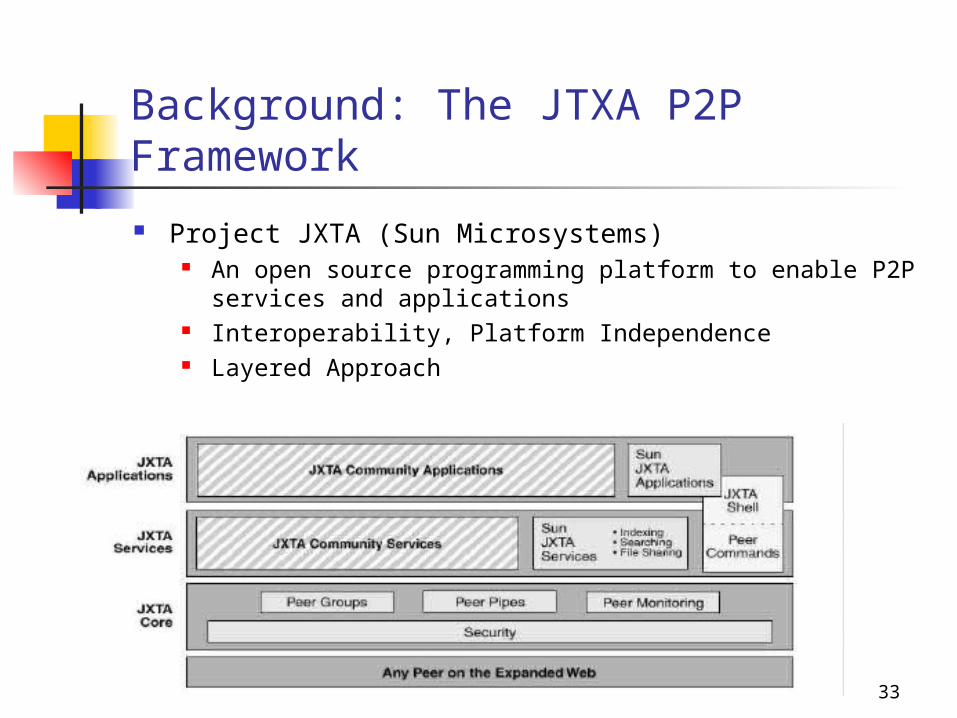
Background: The JTXA P2P Framework
Project JXTA (Sun Microsystems) An open source programming platform to enable P2P
services and applications Interoperability, Platform Independence Layered Approach

34
JXTA & Edutella
Edutella Services Complements the JXTA Service Layer Build upon the JXTA Core Layer Described in web service language like DAML-S, WSDL
Edutella Peers Live on the JXTA Application layer Are using the functionality provided by the Edutella
Services

35
Edutella Services
Query Services Standardized query and retrieval of RDF metadata
Replication Services Providing data persistence/availability and workload
balancing Mapping Service
Translate between different metadata vocabularies to enable interoperability between different peers.
Annotation Service Annotate materials stored anywhere in the Edutella
Network.

36
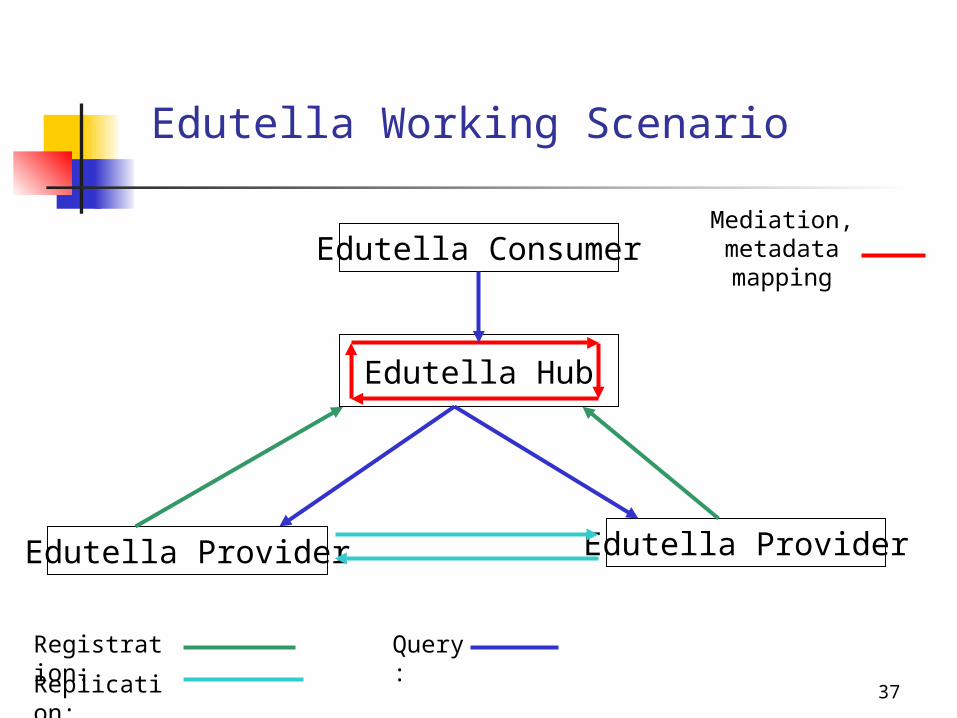
Edutella Query Services
Peer register the queries they may be asked through the query service
Specifying the supported metadata schema Peer provide metadata according to DCMI standards
Specifying the individual properties Peer provides metadata of the form dc_title(X,Y)
Queries are sent through the Edutella network to the subset of peers who have registered to be interested in this kind of query
37
Edutella Working Scenario
Edutella Consumer
Edutella Provider Edutella Provider
Registration:Replication:
Edutella Hub
Mediation, metadata mapping
Query:

38
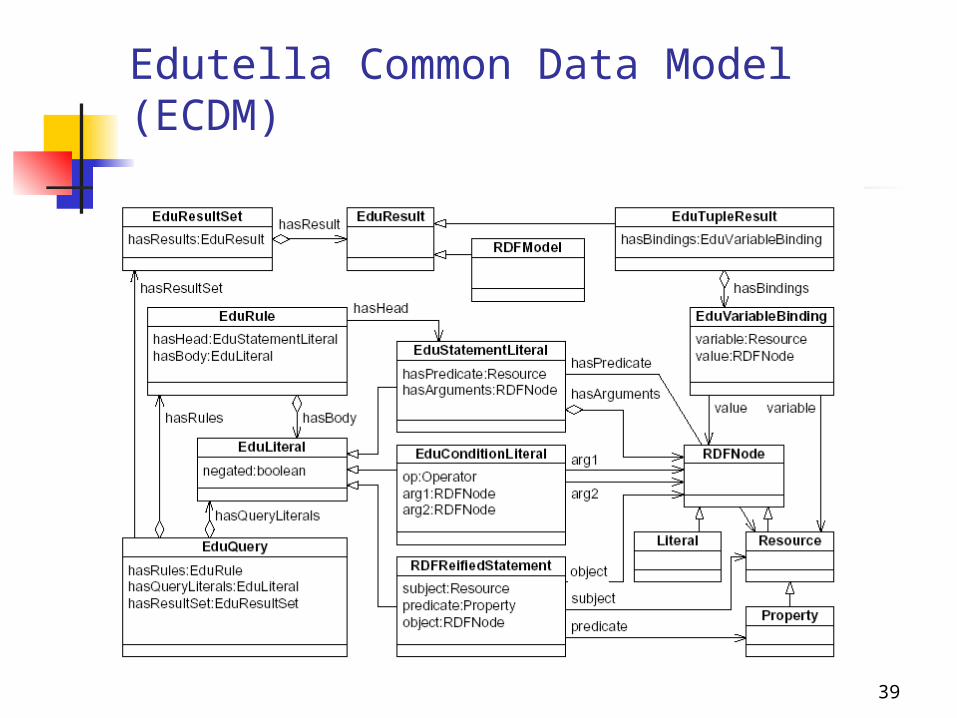
Query Exchange Architecture
Edutella Common Data Model (ECDM) Provides the syntax and semantics for an overall standard
query interface Edutella network uses the query language family RDF-
QEL as a standardized query language format How to enable the peer to participate in the Edutella
network? Edutella wrappers are used to translate queries and results
from the Edutella query and result exchange format (ECDM) to the local format and vice versa
There are several RDF-QEL-i exchange language levels describing which kind of queries a peer can handle
39
Edutella Common Data Model (ECDM)

40
RDF-QEL-i Language Levels
RDF-QEL-1 Simple and readable syntax following the QBE paradigm Query graph has exact the same structure as the answer
graph Logical conjunctive formula
RDF-QEL-2 Extends the 1-level with disjunction Reified RDF statements are building blocks for each query Linked together by an AND-OR tree

41
RDF-QEL-i Language Levels
RDF-QEL-3 Allows conjunction, disjunction and negation of literals RDF-QEL is essentially Datalog
RDF-QEL-4 Allows recursion to express transitive closure Compatible with SQL3 Relational query engine with full conformance to the SQL3
standard will be able to support RDF-QEL-4
42
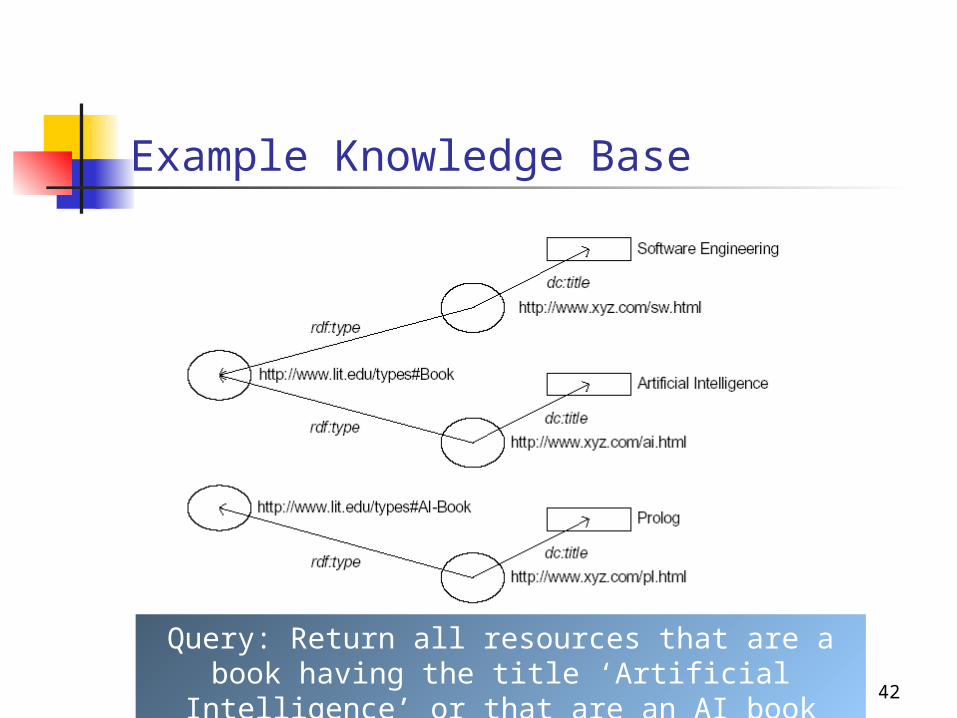
Example Knowledge Base
Query: Return all resources that are a book having the title ‘Artificial Intelligence’ or that
are an AI book
43
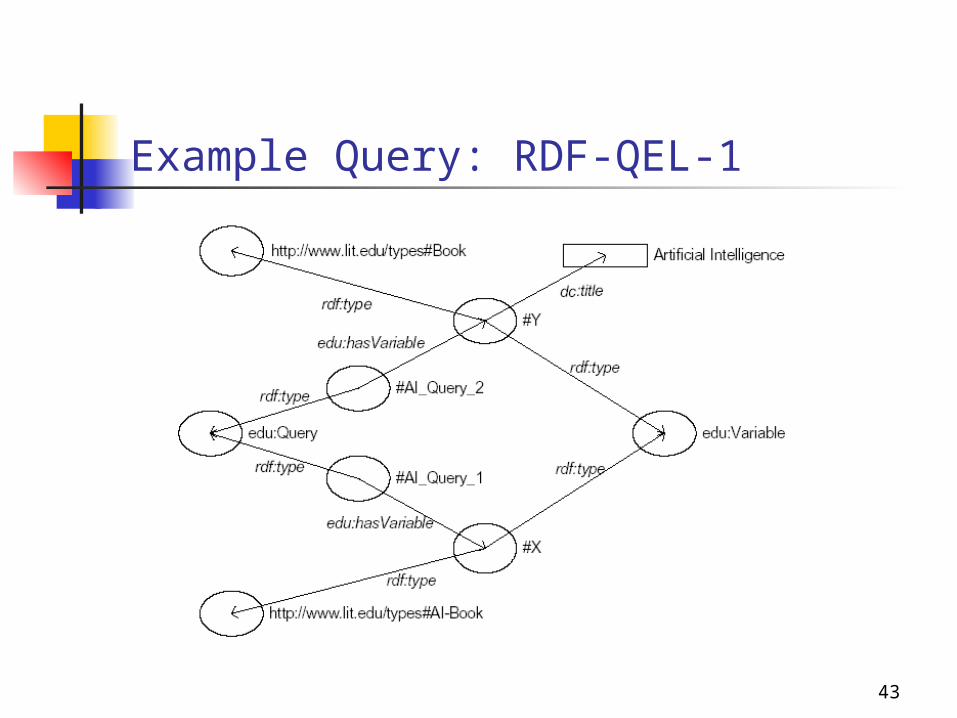
Example Query: RDF-QEL-1

44
Example Query: RDF/XML serialization
<edu:QEL1Query rdf:ID="AI_Query_1"> <edu:hasVariable rdf:resource="#X"/></edu:QEL1Query>
<edu:Variable rdf:ID="X" rdfs:label="X"> <rdf:type rdf:resource="http://www.lit.edu/types#AIBook"/></edu:Variable>
<edu:QEL1Query rdf:ID="AI_Query_2"><edu:hasVariable rdf:resource="#Y"/></edu:QEL1Query>
<edu:Variable rdf:ID="Y" rdfs:label="X"> <rdf:type rdf:resource="http://www.lit.edu/types#Book"/> <dc:title>Artificial Intelligence</dc:title></edu:Variable>

45
Standard Result Set Query results are represented as as set of tuples of variables and
their bindings<edu:ResultSet rdf:ID="AI_Results"> <edu:hasResult rdf:parseType="Resource"> <rdf:type rdf:resource="edu:TupleResult"/> <edu:hasVariable rdf:parseType="Resource">
<rdf:type rdf:resource="edu:VariableBinding"/><edu:bindsVariable rdf:resource="#X"/><rdf:value rdf:resource="http://www.xyz.com/ai.html"/></edu:hasVariable>
</edu:hasResult></edu:ResultSet>

46
An O-Telos provider peer for the RDF-based Edutella P2P network

47
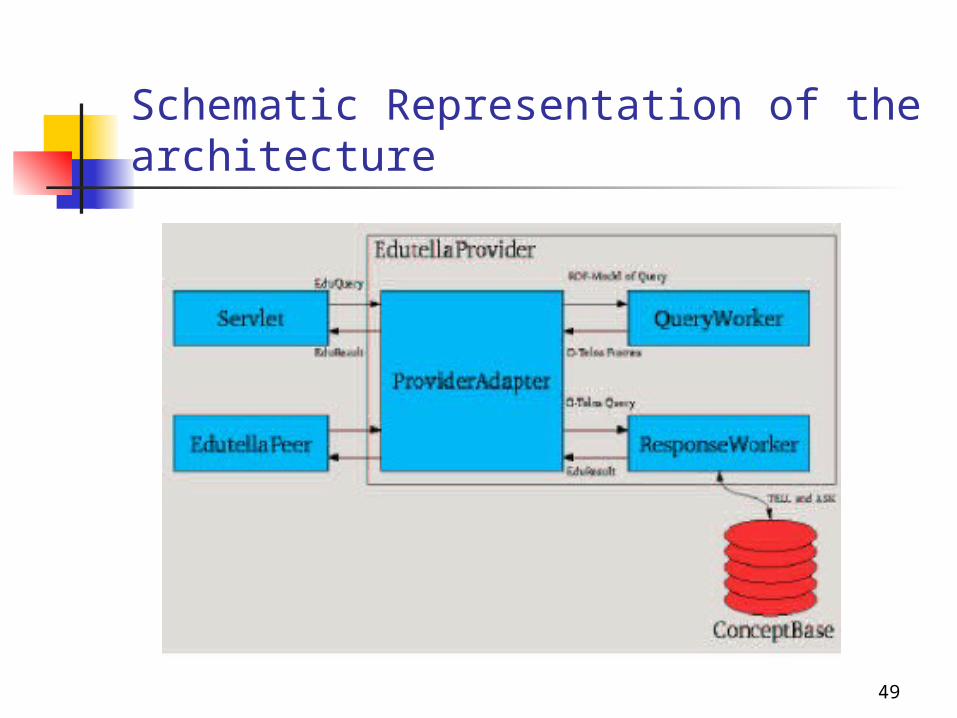
O-Telos Provider
Describes a provider peer and its services for the Edutella network
Provider-peer uses the ConceptBase as a repository for storing meta-data
ConceptBase: implements a meta language representation language O-Telos

48
Provider Peer: Two basic services
Storage service: designed to store RDF(S) data in the ConceptBase repository
The data represented in RDF(S) are translated to O-Telos Query service: the provider-peer serves as query
interface to the RDF data stored in the ConceptBase Queries are formulated in RDF-QEL The peer translates the them into O-Telos queries O-Telos queries are answered by the ConceptBase The peer translates answers from O-Telos into RDF
49
Schematic Representation of the architecture

50
End!
Questions ???


















