
Mathematical Foundation of Statistical Learningwatanabe- · Statistical Learning Theory Part I –...
32
Statistical Learning Theory Part I – 5. Deep Learning Sumio Watanabe Tokyo Institute of Technology
-
Upload
duongquynh -
Category
Documents
-
view
225 -
download
0
Transcript of Mathematical Foundation of Statistical Learningwatanabe- · Statistical Learning Theory Part I –...

Statistical Learning Theory
Part I – 5.
Deep Learning
Sumio WatanabeTokyo Institute of Technology
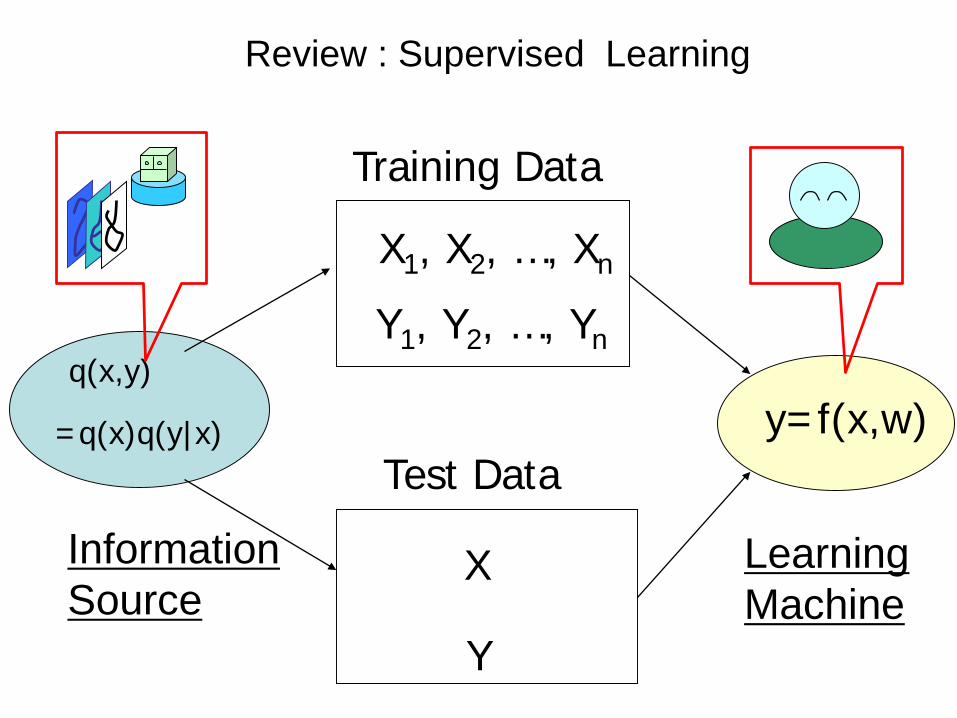
Review : Supervised Learning
Training Data
X1, X2, …, Xn
Y1, Y2, …, Yn
Test Data
X
Y
InformationSource
q(x,y)
=q(x)q(y|x) y=f(x,w)
LearningMachine

Review : Training and Generalization
E(w) = (1/n) Σ (Yi-f(Xi,w))2n
i=1
TrainingError
GeneralizationError F(w) = (1/m) Σ (Y’i-f(X’i,w))2
m
i=1
Stochastic gradient descent: In each t, (Xi,Yi) is randomly chosen,
w(t+1) - w(t) = - η(t) grad (Yi-f(Xi,w(t)))2

2017/10/5
We are going into Deep Learning.

Deep Network
H1
k=1oi =σ( ∑wij σ( ∑ wjk σ( ∑ wkmxm+ θk) + θj) + θi)
H2
j=1
M
m=1
x1 x2 xM
o1 o2 oN
We learned three layer network. It is easy to define a network which has deeper layers.
Note: wij, wjk, and wkm are different parameters.
x1 xm xM
o1 oi oN
oj
ok
H2
H1
N
M

Error Backropagation (1)
Network’s output o = (oi), desired output y= (yi) .
Square Error E(w) = ― ∑(oi -yi )2N
i=1
12
(N = Output dimension)
∂E∂ wij
= (oi -yi ) oi (1- oi ) oj
= (oi -yi ) ∂ oi∂ wij
(1) Hidden 2 -- Output
= δi
oj=σ(∑wjkok+θj)H1
k=1
oi =σ(∑wijoj+θi)H2
j=1
Hidden 2 -- Output
Hidden 1 – Hidden 2
ok=σ(∑wkmxm+θk)M
m=1
Input - Hidden 1
It is easy to generalize the training algorithm for deeper network.

E(w) = ― ∑(oi -yi )2N
i=1
12
∂E∂wjk
= ∑ (oi -yi ) N
i=1
∂oi∂oj
∂oj
∂wjk
∂oi
∂oj= oi(1-oi)wij
∂ oj
∂wjk= oj(1-oj)xk
(2) Hidden 1 -- Hidden 2
= oi(1-oi)wij oj(1-oj)ok
oj=σ(∑wjkok+θj)H1
k=1
oi =σ(∑wijoj+θi)H2
j=1
Hidden 2 -- Output
Hidden 1 – Hidden 2
ok=σ(∑wkmxm+θk)M
m=1
Input - Hidden 1N
i=1∑ (oi -yi )
= δj = Σi δi wijoj(1-oj)
Error Backpropagation (2)

E(w) = ― ∑(oi -yi )2N
i=1
12
∂oi∂oj
∂oj
∂ok
oi(1-oi)wij oj(1-oj)wjkok(1-ok)xm
∂ok∂wkm
(3) Input – Hidden 1
∂E∂wkm
= ∑ ∑ (oi -yi ) H2
j=1
N
i=1
H2
j=1
N
i=1∑ ∑ (oi -yi ) =
= δk = Σj δj wjkok(1-ok)
Error Backpropagation (3)
oj=σ(∑wjkok+θj)H1
k=1
oi =σ(∑wijoj+θi)H2
j=1
Hidden 2 -- Output
Hidden 1 – Hidden 2
ok=σ(∑wkmxm+θk)M
m=1
Input - Hidden 1

(5) Hidden 1 -- Hidden 2
Δwjk = -η(t) δj ok
δj = Σi δi wijoj(1-oj)
Δθj = -η(t) δj
δi = (oi -yi ) oi (1- oi )Δwij = -η(t) δi oj
(4) Hidden 2 -- Output
Δθi = -η(t) δi
(6) Input -- Hidden 1δk = Σj δj wjkok(1-ok)
Δwkm = -η(t) δkxm
Δθk = -η(t) δk
Deep Training Algorithm
oi =σ(∑wijoj+θi)H2
j=1
(3) Hidden 2 -- Output
oj=σ(∑wjkok+θj)H1
k=1
(2) Hidden 1 -- Hidden 2
ok=σ(∑wkmxm+θk)M
m=1
(1) Input -- Hidden 1

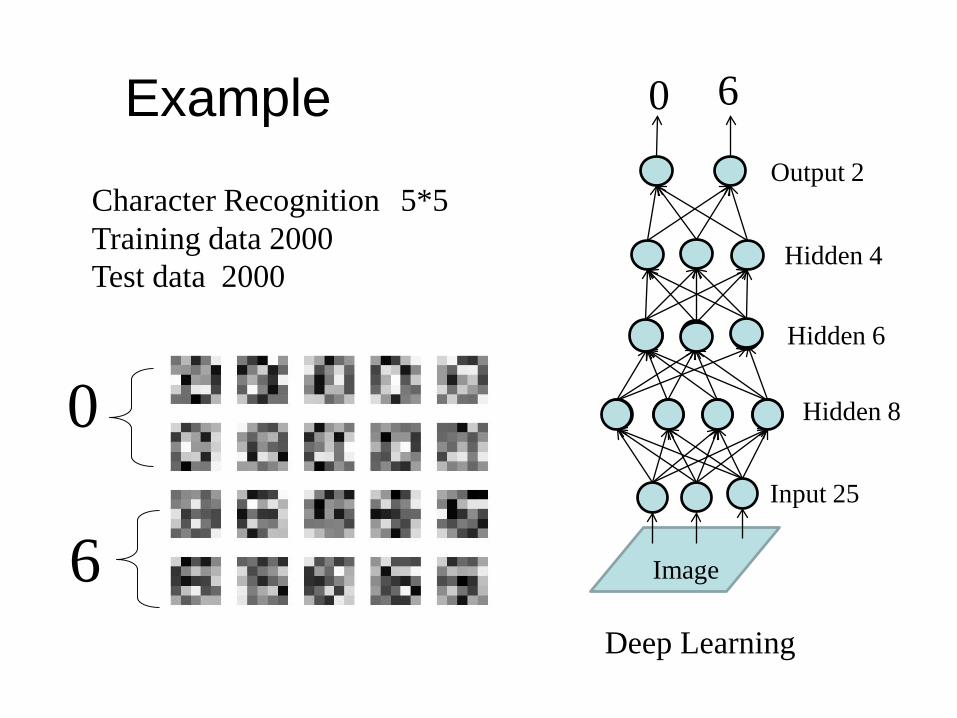
Example
Character 5*5Training data 400Test data 400
0
6Image
25
Deep Learning
8
2
4
0 6A four layer network for character recognition is devised.
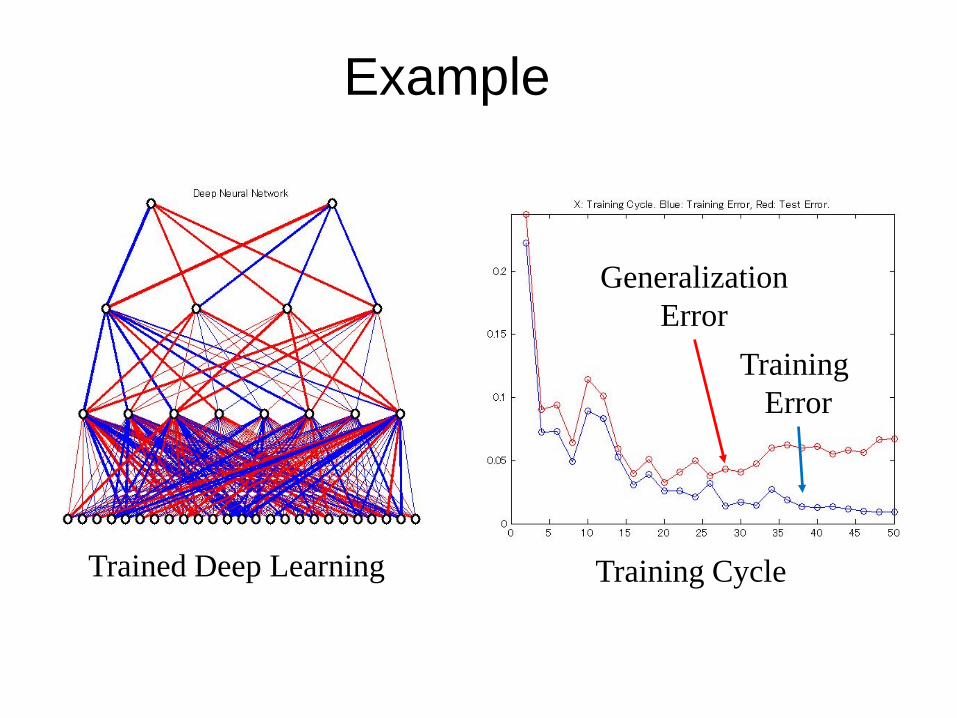
Example
Trained Deep Learning Training Cycle
TrainingError
GeneralizationError

Deeper network
M
k=1fi =σ( ∑uij σ( ∑ wjk(・・・) k + θj) + φi)
H
j=1
x1 x2 xM
f1 f2 fN
f1 f2 fN
x1 x2 xM
It is easy to define any deepernetwork.
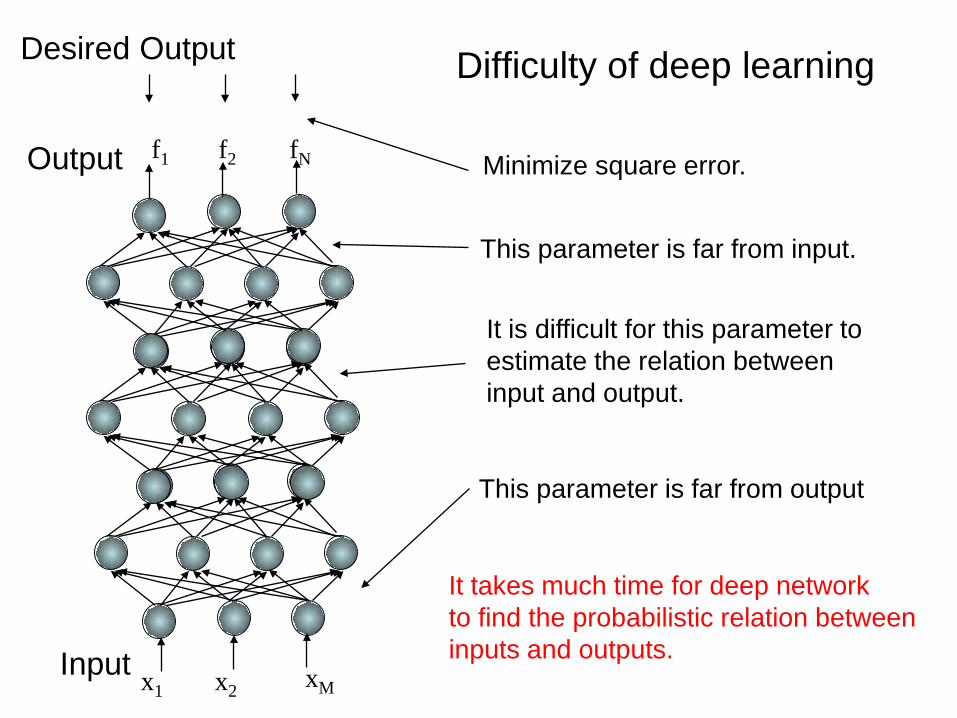
Difficulty of deep learning
f1 f2 fN
x1 x2 xM
This parameter is far from input.
Minimize square error.
Desired Output
This parameter is far from output
It takes much time for deep networkto find the probabilistic relation betweeninputs and outputs.Input
Output
It is difficult for this parameter toestimate the relation between input and output.
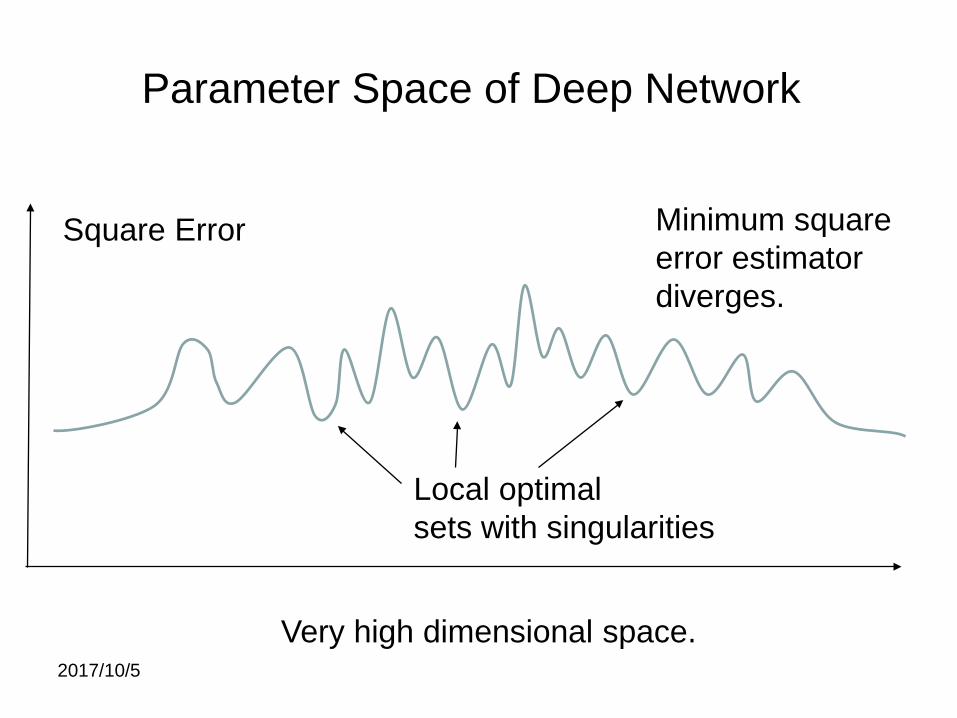
2017/10/5
Parameter Space of Deep Network
Square Error Minimum squareerror estimatordiverges.
Very high dimensional space.
Local optimalsets with singularities

2017/10/5
Parameter Space in Deep Learning
(2) The minimum square error estimator diverges.
(1) The parameter space has very high dimension.
(3) The square error can not be approximated by any quadratic form.
(4) There are many local optimal parameter subsetswhich has singularities.
Still there is not any mathematical foundation by which such statistical model can be analyzed.
(5) Thermo-dynamical limit does not exit.

2017/10/5
How to educate deep network.

2017/10/5 Mathematical Learning Theory
Two Basic Methods for Deep Learning
(3) Employing autoencoder.
(2) Successive learning,
How to improve learning process.
In a deep network, learning process becomes slowor inappropriate.
(1) Lasso or Ridge,
(1) was already introduced. Today we learn (2) and (3).

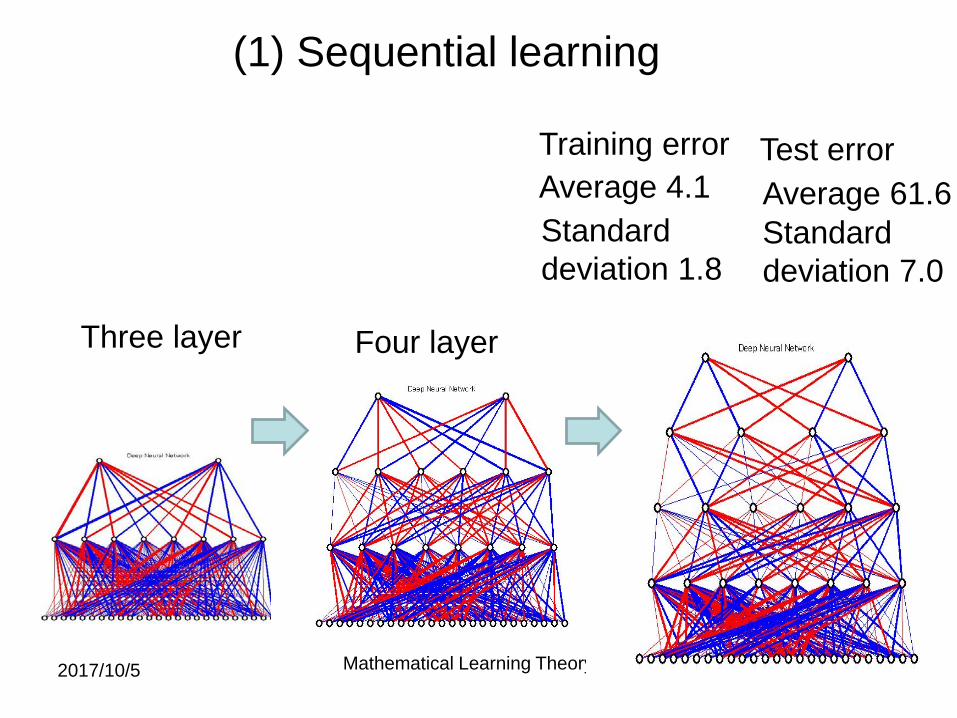
(1) Sequential Learning
x1 x2 xM
f1 f2 fN
x1 x2 xM
f1 f2 fN
x1 x2 xM
f1 f2 fN
Firstly, a shallow network is trained, then the deeper onesare applied sequentially.
Copy Copy
Desired OutputDesired Output
Desired Output
2017/10/5 Mathematical Learning Theory
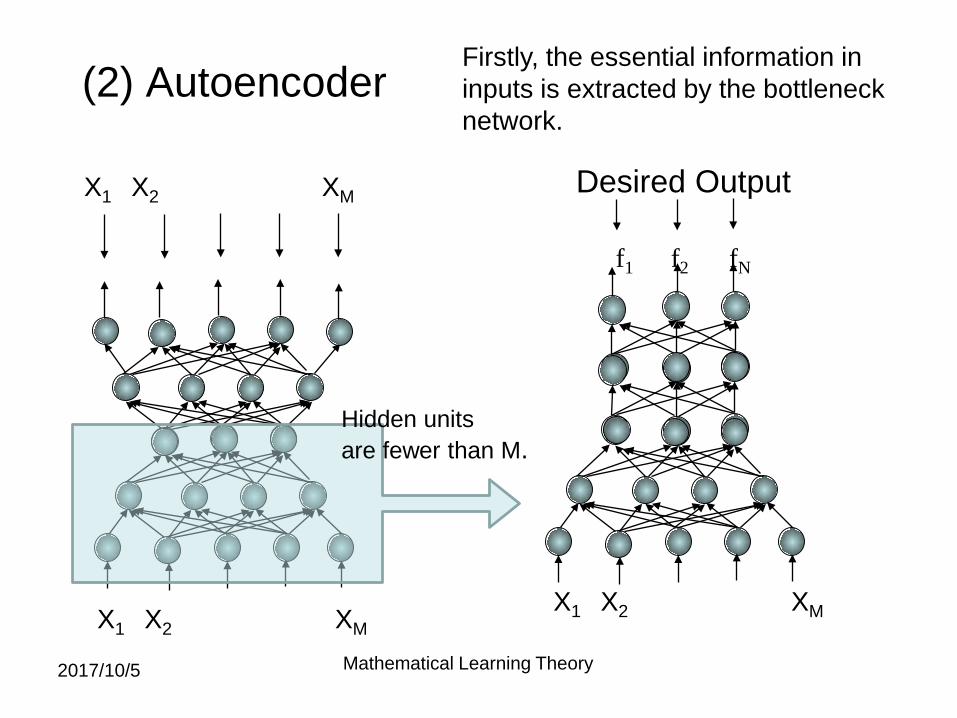
(2) Autoencoder
X1 X2 XM
f1 f2 fN
Firstly, the essential information ininputs is extracted by the bottlenecknetwork.
Hidden units are fewer than M.
X1 X2 XM
X1 X2 XM
Desired Output

2017/10/5
Bottleneck Neural Network
X1 X2 XM
It is expected that an essential informationis represented on hidden units. This is a generalized version of the principal component analysis.
There are several kinds of autoencoder.For example, Boltzmann machine is employed.
X1 X2 XM
A fewer dimensional manifold in the M dimensional space is extracted.
Example
Image
Input 25
Deep Learning
Hidden 8
0
Output 2
Hidden 6
Hidden 4
6
Character Recognition 5*5Training data 2000Test data 2000
0
6
2017/10/5 Mathematical Learning Theory
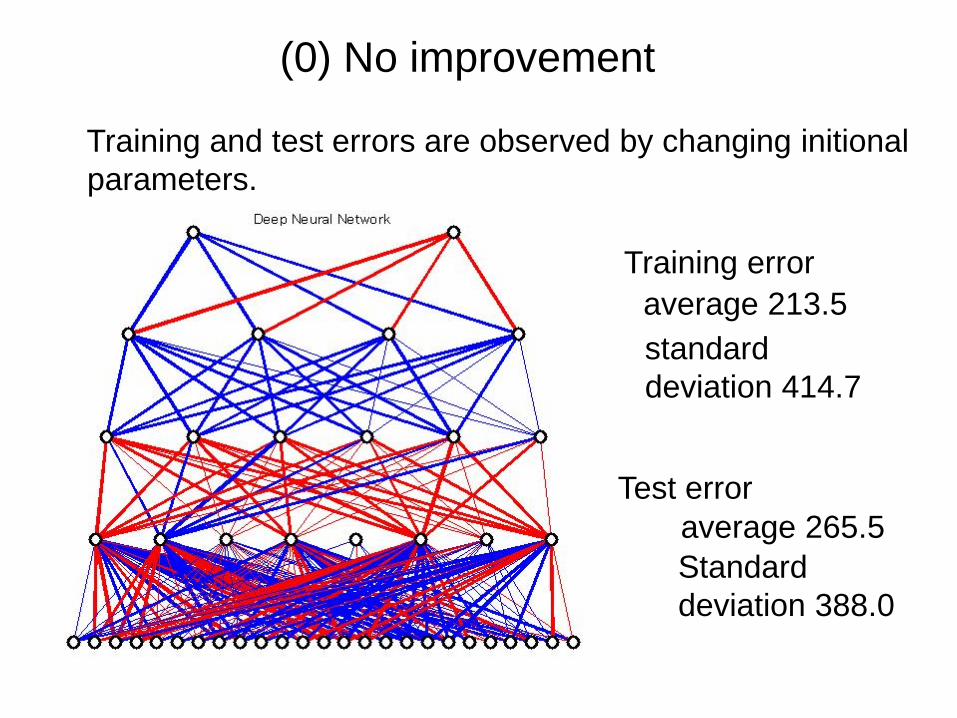
(0) No improvement
average 213.5
average 265.5
standard deviation 414.7
Standarddeviation 388.0
Training error
Test error
Training and test errors are observed by changing initional parameters.
2017/10/5 Mathematical Learning Theory
(1) Sequential learning
Three layer
Test error Average 4.1Standarddeviation 1.8
Average 61.6Standarddeviation 7.0
Training error
Four layer
2017/10/5 Mathematical Learning Theory
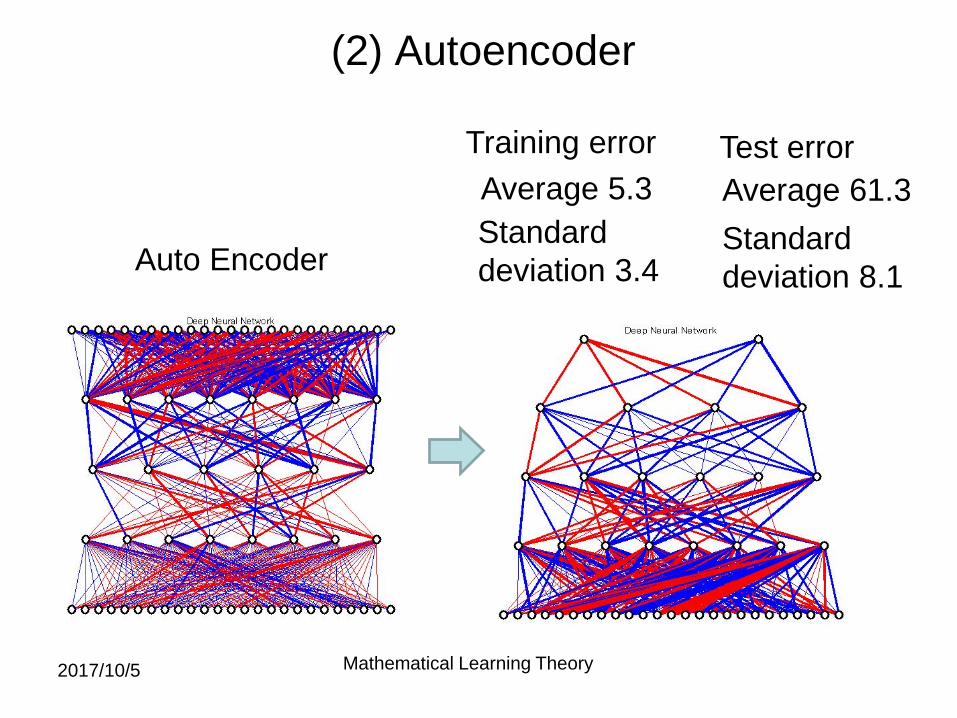
(2) Autoencoder
Standarddeviation 3.4
Average 61.3Standarddeviation 8.1
Average 5.3Training error Test error
Auto Encoder
2017/10/5
Structure originates from nature.

2017/10/5 Mathematical Learning Theory
Data Structure
In several data, its structures are known before learning.
Image: each pixel has almost same value as its neighbor except boundary.
Speech: nonlinear expansion and contraction are contained.
Object recognition: same object can be observed from another angle.
By using data structure, an appropriate network can be devised.
Weather: prefectures in the same region have almost sameweather.

2017/10/5 Mathematical Learning Theory
Image analysis and convolution network
In image analysis,convolution networkare often employedsuccessfully.
Localanalysis
Globalinformation

2017/10/5 Mathematical Learning Theory
Multi-resolution analysis
In multi-resolution analysis,the local analyses aresuccessively integrated toglobal information.
Convolution network canbe understood as a kindof multi-resolution analysis.
2017/10/5
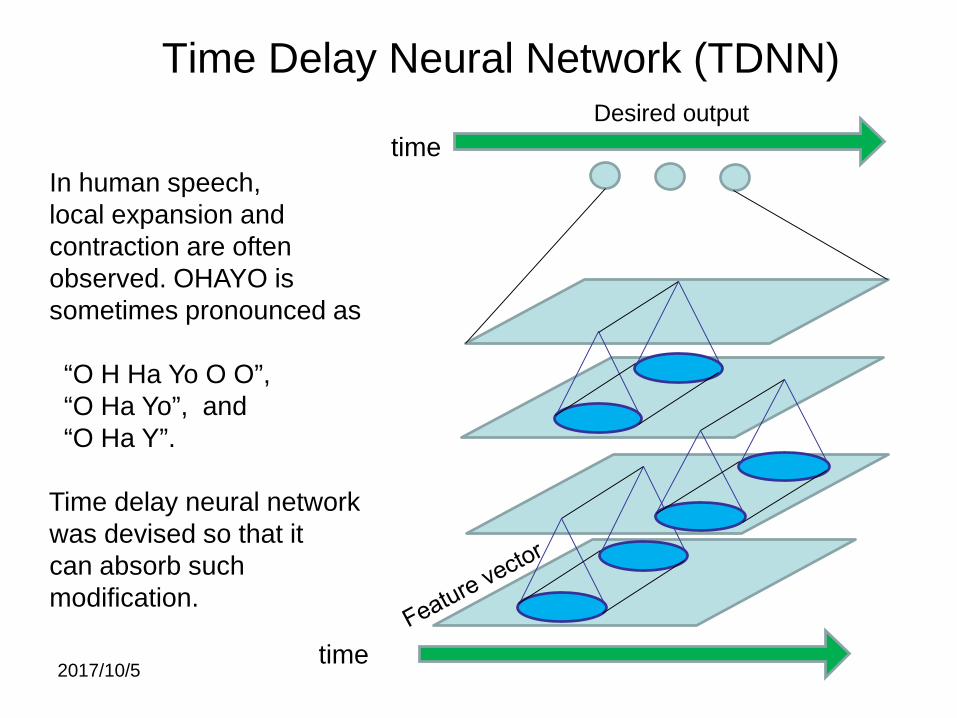
Time Delay Neural Network (TDNN)
In human speech,local expansion and contraction are often observed. OHAYO issometimes pronounced as
“O H Ha Yo O O”,“O Ha Yo”, and“O Ha Y”.
Time delay neural networkwas devised so that it can absorb such modification.
time
timeDesired output

2017/10/5 Mathematical Learning Theory
Deep Learning and Feature extraction
(1) Automatic feature extraction
(2) Preprocessing using feature vector
In deep learning, feature vectors are automatically generatedat hidden variables. If you are lucky, you can find unknownappropriate feature vector for a set of training data.
If your want to make parallel translation or rotation invariant recognition system, you had better use such invariant featurevectors which are made preprocessing.
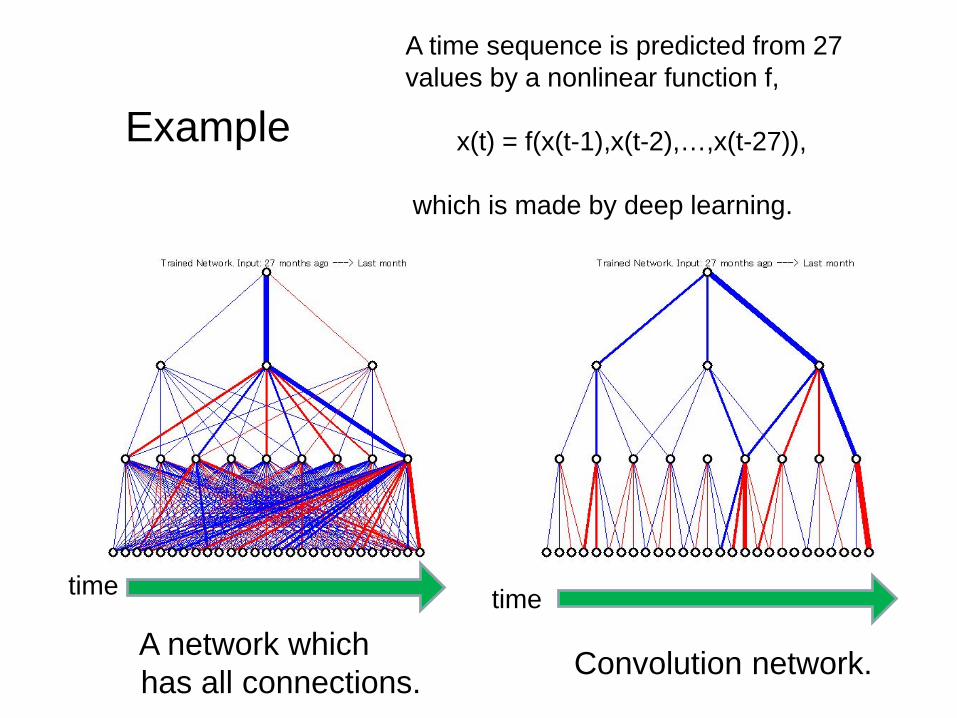
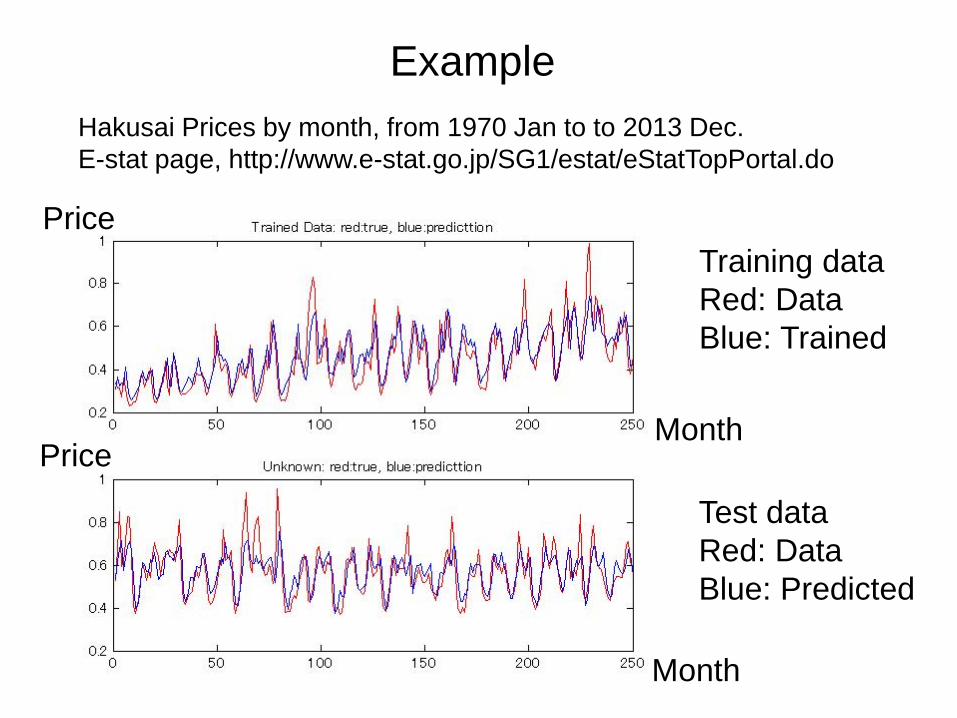
Example
A time sequence is predicted from 27 values by a nonlinear function f,
x(t) = f(x(t-1),x(t-2),…,x(t-27)),
which is made by deep learning.
A network whichhas all connections.
timetime
Convolution network.
2017/10/5 Mathematical Learning Theory
Example
Month
Month
Price
Price
Training dataRed: DataBlue: Trained
Hakusai Prices by month, from 1970 Jan to to 2013 Dec. E-stat page, http://www.e-stat.go.jp/SG1/estat/eStatTopPortal.do
Test dataRed: DataBlue: Predicted


















