
Deteção de Valores Influentes e Outliers em Modelos de ...ehlers/finance/hotta.pdf · log(1+...
51
Deteção de Valores Influentes e Outliers em Modelos de Volatilidade Estocástica Luiz Koodi Hotta Anderson Carlos O. Motta Departamento de Estatística IMECC - UNICAMP [email protected] I Workshop de Métodos Estatísticos Aplicados à Finanças 27-28 de novembro de 2006 – p. 1/46
Transcript of Deteção de Valores Influentes e Outliers em Modelos de ...ehlers/finance/hotta.pdf · log(1+...

Deteção de Valores Influentes eOutliers em Modelos de Volatilidade
Estocástica
Luiz Koodi Hotta
Anderson Carlos O. Motta
Departamento de EstatísticaIMECC - UNICAMP
I Workshop de Métodos Estatísticos Aplicados à Finanças27-28 de novembro de 2006
– p. 1/46

Plano
1. Introdução2. Modelo de Volatilidade Estocástica.
2.1. Modelo clássico
2.2. Modelo bayesiano
2.3. Séries exemplos
3. Detecção de Blocos de Outliers.3.1. Passos para detecção dos blocos de outliers
3.2. Aplicações
3.3. Conclusões
– p. 2/46

4. Detecção de Observações Influentes.4.1. Introdução
4.2. Distribuição empírica dos máximos
4.3. Aplicações
4.4. Conclusões
5. Conclusões Finais6. Referências
– p. 3/46

1. Introdução
Relevância: Detecção de outliers e valores influentes são
importantes no conhecimento do objeto em estudo e na
estimação de modelos. Estes valores ocorrem com frequência
na prática.
Problema: Dificuldade de detectar outliers em blocos e critério
útil para detectar valores influentes.
Metodologia utilizada: Estimação bayesiana através de método
MCMC com amostragem conjunta em blocos e adaptaçãodo
método de Peña (Technometrics, 2005) proposto inicialmente
para modelos de regressão.
– p. 4/46

2. Modelo de Volatilidade Estocástica
2.1. Modelo Clássico:
yt = βeh′t/2ǫt, t ≧ 1,
h′t+1 = µ+ φ(h′t − µ) + σηηt,
h′t ∼ N
(
µ,σ2
η
(1 − φ2)
)
,
onde φ é invariante no tempo e ηt é um processo estacionário com
média zero e variância unitária.
– p. 5/46

2.2 Modelo bayesiano:
Sem a acomodação de outlier é dado por:
yt = βeht2 ǫt
ht = µ+ φ(ht−1 − µ) + σηηt
Prioris: µ ∼ N(0, 10) (priori difusa),
σ2η|φ, µ ∼ IG(σr/2, Sσ/2) onde σr = 5 e Sσ = 0.01 × σr.
π(φ) ∝
{
(1 + φ)
2
}φ(1)−1{(1 − φ)
2
}φ(2)−1
, φ(1), φ(2) >1
2,
– p. 6/46

O modelo considerando outliers do tipo aditivo será dado por
yt = δtβt + eht2 ǫt
ht = µ+ φ(ht−1 − µ) + σηηt
δt ∼ Ber(k) onde k ∼ Beta(u0, n0).
log(1 + βt) ∼ N(−0.5ν2, ν2), onde βt é o tamanho do outlier
com ν ∼ LN(ν0, V0).
ση ∼ LN(σ0,Σ0).
– p. 7/46

2.3. Séries Simuladas
Tabela 1: Conjunto de Parâmetros para o Processo Gerador de Da-dos: ∆(t,κ) é o tamanho dos outliers do tempo t até o tempo t+ κ.
Modelos φ ση β ∆(50,0) ∆(250,5) ∆(500,0) Λ700
Ψ1 0.98 0.12 1.0 - - - -
Ψ2 0.95 0.20 1.0 - - - -
Ψ3 0.98 0.12 1.0 8 4 5 5
Ψ4 0.95 0.20 1.0 8 4 5 5
– p. 8/46
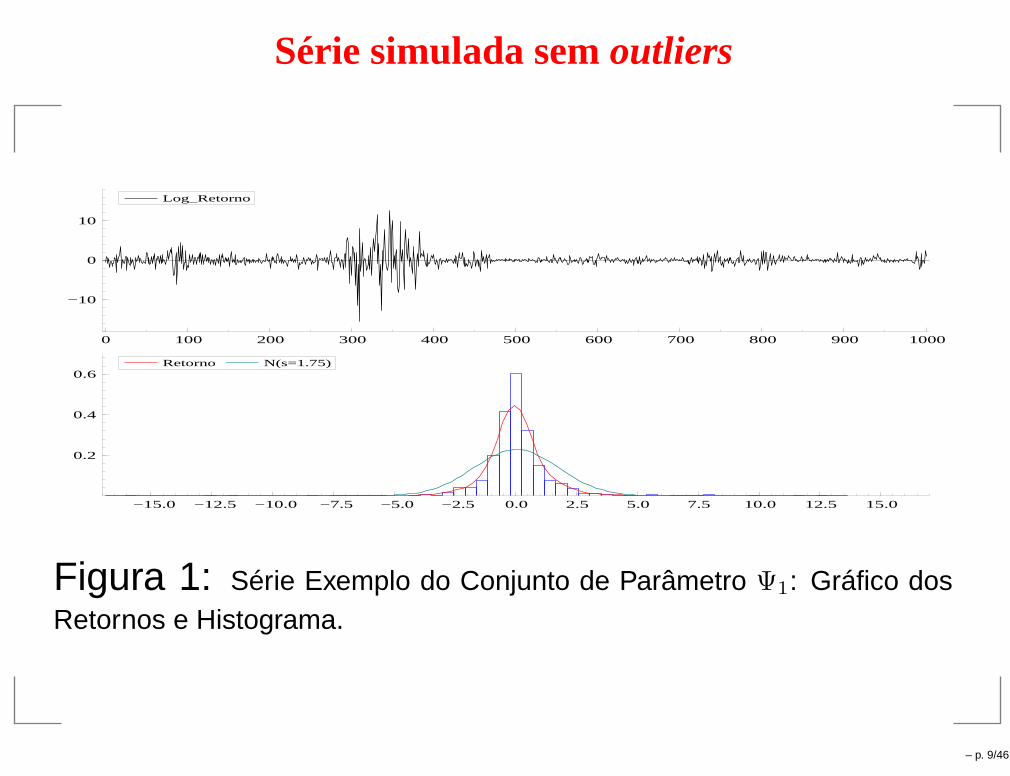
Série simulada semoutliers
0 100 200 300 400 500 600 700 800 900 1000
−10
0
10
Log_Retorno
−15.0 −12.5 −10.0 −7.5 −5.0 −2.5 0.0 2.5 5.0 7.5 10.0 12.5 15.0
0.2
0.4
0.6Retorno N(s=1.75)
Figura 1: Série Exemplo do Conjunto de Parâmetro Ψ1: Gráfico dosRetornos e Histograma.
– p. 9/46
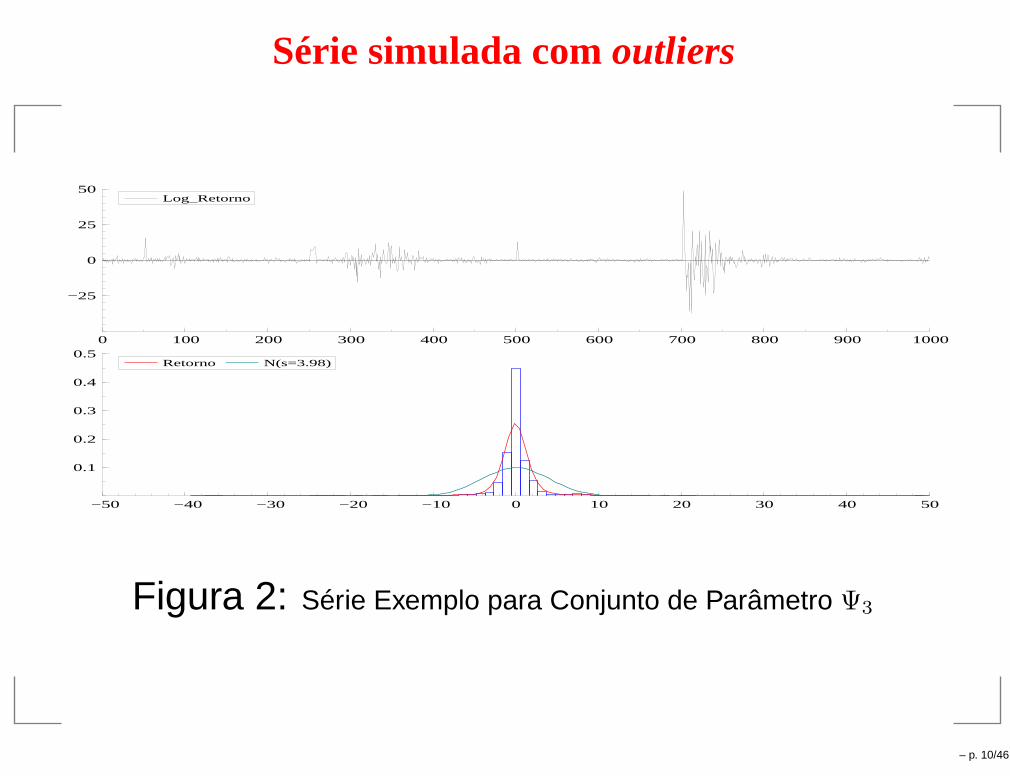
Série simulada comoutliers
0 100 200 300 400 500 600 700 800 900 1000
−25
0
25
50Log_Retorno
−50 −40 −30 −20 −10 0 10 20 30 40 50
0.1
0.2
0.3
0.4
0.5Retorno N(s=3.98)
Figura 2: Série Exemplo para Conjunto de Parâmetro Ψ3
– p. 10/46
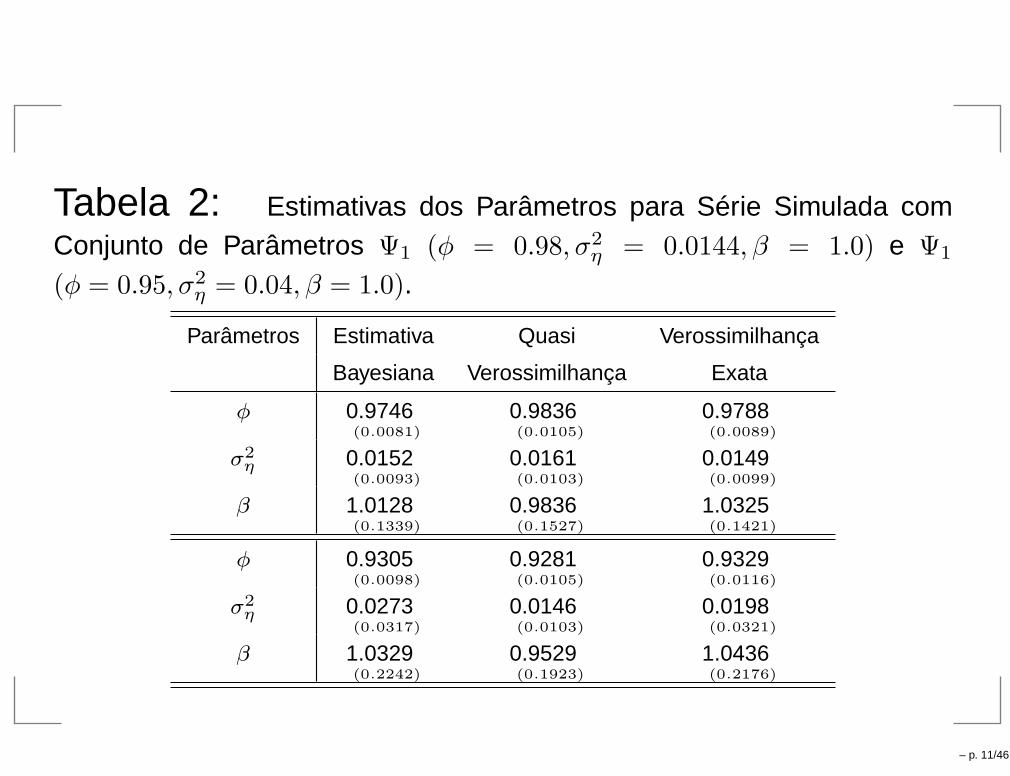
Tabela 2: Estimativas dos Parâmetros para Série Simulada comConjunto de Parâmetros Ψ1 (φ = 0.98, σ2
η = 0.0144, β = 1.0) e Ψ1
(φ = 0.95, σ2η = 0.04, β = 1.0).
Parâmetros Estimativa Quasi Verossimilhança
Bayesiana Verossimilhança Exata
φ 0.9746(0.0081)
0.9836(0.0105)
0.9788(0.0089)
σ2η 0.0152
(0.0093)
0.0161(0.0103)
0.0149(0.0099)
β 1.0128(0.1339)
0.9836(0.1527)
1.0325(0.1421)
φ 0.9305(0.0098)
0.9281(0.0105)
0.9329(0.0116)
σ2η 0.0273
(0.0317)
0.0146(0.0103)
0.0198(0.0321)
β 1.0329(0.2242)
0.9529(0.1923)
1.0436(0.2176)
– p. 11/46
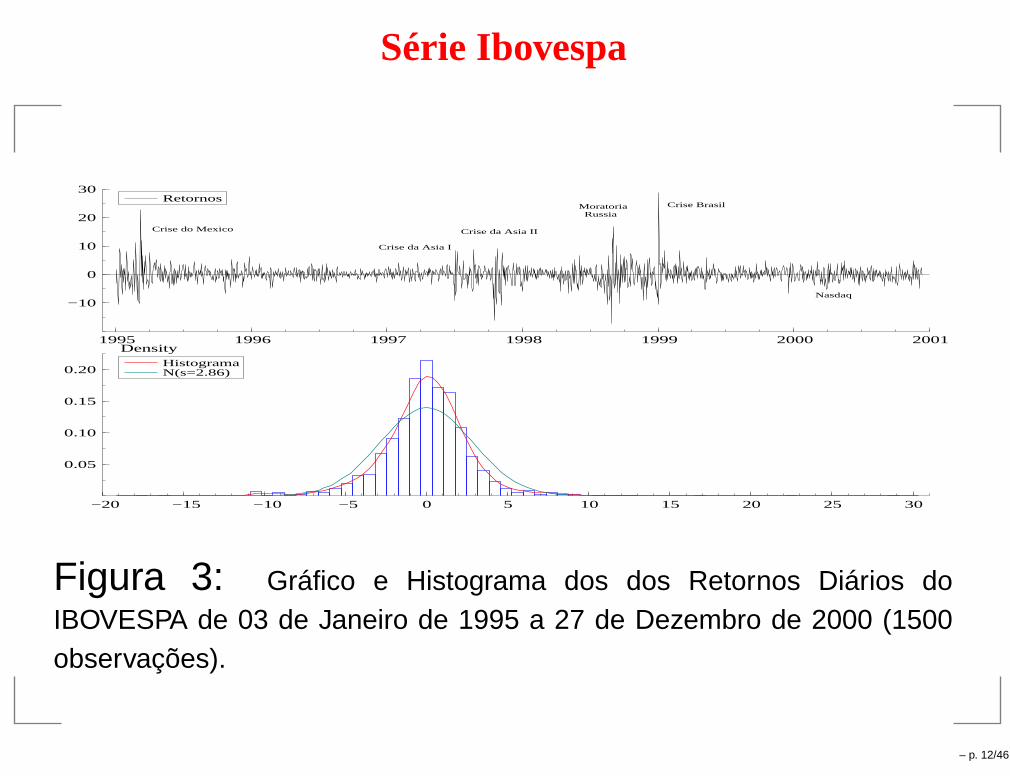
Série Ibovespa
1995 1996 1997 1998 1999 2000 2001
−10
0
10
20
30
Crise do Mexico
Crise da Asia I
Crise da Asia II
MoratoriaRussia
Crise Brasil
Nasdaq
Retornos
−20 −15 −10 −5 0 5 10 15 20 25 30
0.05
0.10
0.15
0.20
DensityHistograma N(s=2.86)
Figura 3: Gráfico e Histograma dos dos Retornos Diários doIBOVESPA de 03 de Janeiro de 1995 a 27 de Dezembro de 2000 (1500observações).
– p. 12/46
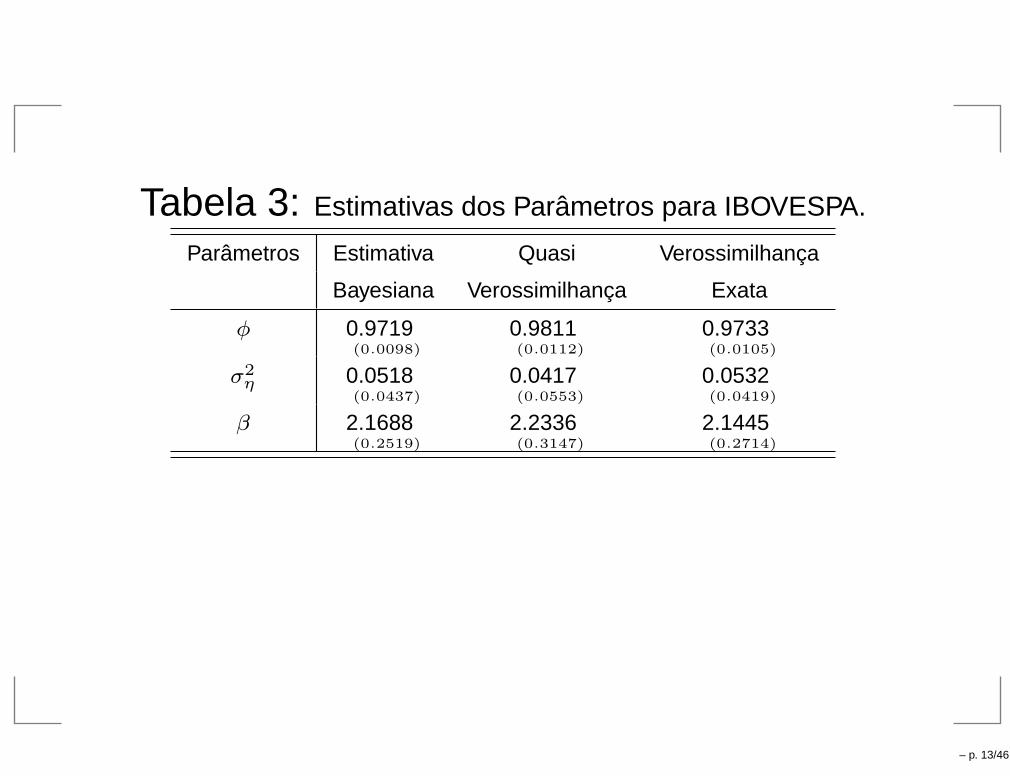
Tabela 3: Estimativas dos Parâmetros para IBOVESPA.
Parâmetros Estimativa Quasi Verossimilhança
Bayesiana Verossimilhança Exata
φ 0.9719(0.0098)
0.9811(0.0112)
0.9733(0.0105)
σ2η 0.0518
(0.0437)
0.0417(0.0553)
0.0532(0.0419)
β 2.1688(0.2519)
2.2336(0.3147)
2.1445(0.2714)
– p. 13/46
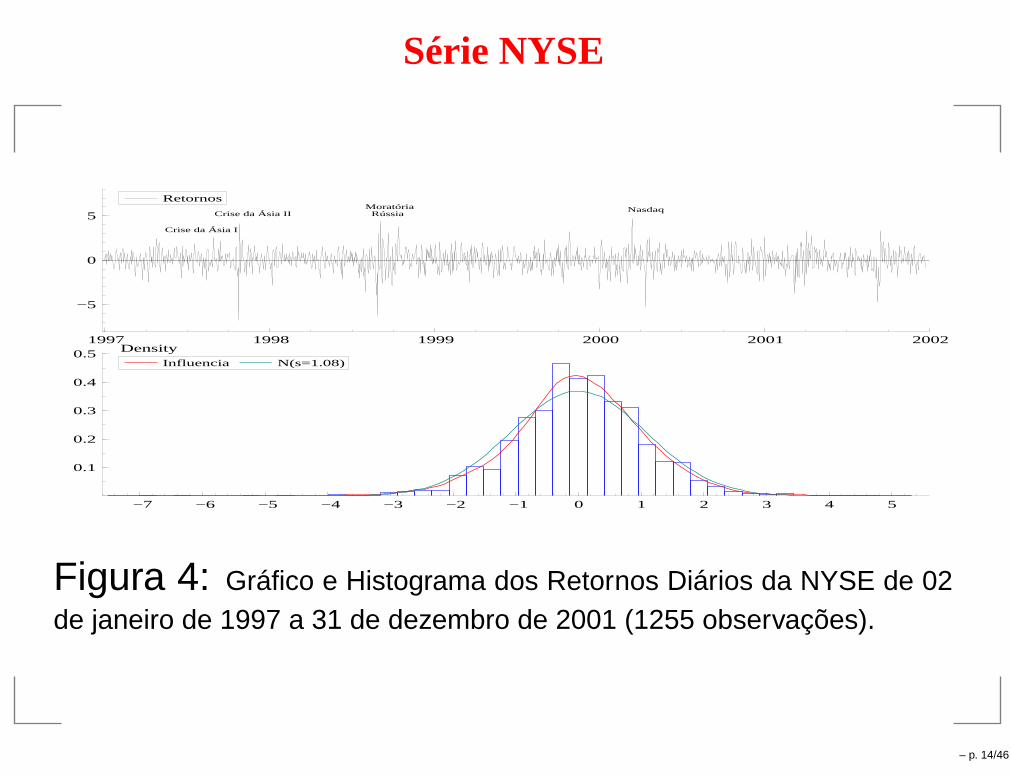
Série NYSE
1997 1998 1999 2000 2001 2002
−5
0
5 Crise da Ásia II
Crise da Ásia I
Moratória Rússia
Nasdaq
Retornos
−7 −6 −5 −4 −3 −2 −1 0 1 2 3 4 5
0.1
0.2
0.3
0.4
0.5 DensityInfluencia N(s=1.08)
Figura 4: Gráfico e Histograma dos Retornos Diários da NYSE de 02de janeiro de 1997 a 31 de dezembro de 2001 (1255 observações).
– p. 14/46
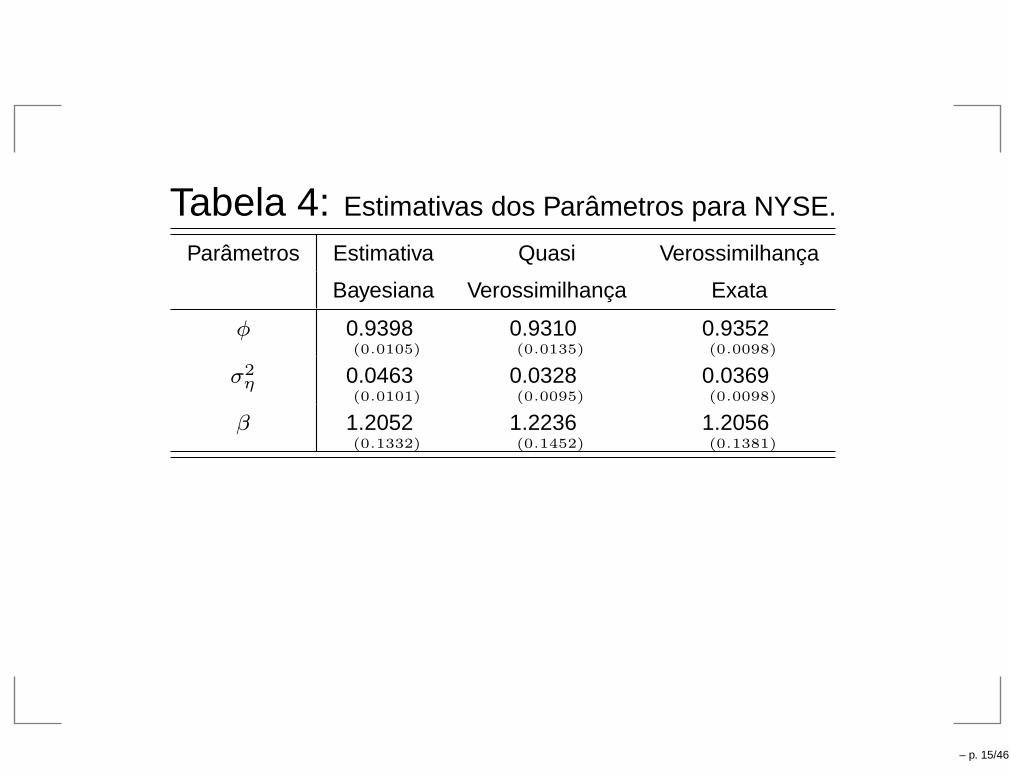
Tabela 4: Estimativas dos Parâmetros para NYSE.
Parâmetros Estimativa Quasi Verossimilhança
Bayesiana Verossimilhança Exata
φ 0.9398(0.0105)
0.9310(0.0135)
0.9352(0.0098)
σ2η 0.0463
(0.0101)
0.0328(0.0095)
0.0369(0.0098)
β 1.2052(0.1332)
1.2236(0.1452)
1.2056(0.1381)
– p. 15/46

3. Detecção de Blocos deOutliers
Séries Temporais, especialmente de finanças, sãoprones a outliers.
Detectar outliers e valores influentes são úteis naanálise e estimação de modelos.
Métodos existentes tem baixo poder quando outliersaparecem em blocos (próximos).
Blocos de outliers aditivos podem aparecer em umsérie temporal por vários motivos, como intervençõescom efeito temporário. Tsay, Peña e Pankratz (1998)mostraram também que um valor aberrante deinovação multivariado pode gerar um bloco de outlieraditivos em uma série temporal marginal univariada.
– p. 16/46

3.1. Modelo:
yt = δtβt + eht2 ǫt
ht = µ+ φ(ht−1 − µ) + σηηt,
δt ∼ Ber(κ) indicadora de posição do valor aberrante com
κ ∼ Beta(u0, n0).
βt é o tamanho do outlier detectado por δt com distribuição a
priori:
ψt = log(1 + βt) ∼ N(−0.5ν2, ν2) (1)
ν ∼ LN(ν0, N0).
– p. 17/46

A distribuição a posteriori marginal de elementos de δ é dada por:
pt = P(δt = 1|y) =∑
P(δrt |y) t = 2, . . . , n.
=∑
∫
P(δrt |y,Ψ)P(Ψ|y) dΨ
∝∑
∫
P(y|δrt ,Ψ)P(δrt)P(Ψ|y) dΨ,
A posteriori do tamanho do valor espúrio é dada por:
P(βt|y) =∑
P(δr|y)P(βt|y, δr) t = 2, . . . , n.
– p. 18/46

3.2. Passos para Detecção de Blocos deOutliers
1. Estime o modelo e denote por pt a média da distribuição a
posteriori de δt|y .
2. A ti-observação, yti é considerada suspeita de ser outlier se
pt > c1. Seja T ∗ = {t1, · · · , tm} o conjunto detectado
inicialmente como possíveis outliers.
3. Considere o segundo ponto crítico c2 ≤ c1 para testar as 2h
observações em torno de cada uma das m observações
encontradas anteriormente. Teste se pt > c2;
4. 4. Em cada janela, seleciona-se a observação mais distante e
anterior a yti com pt > c2 como sendo o ponto inicial do
conjunto de outlier (yti−ki). O ponto mais distante e posterior a
yti com pt > c2 é considerado o ponto final do conjunto (yti+vi).
– p. 19/46

5. Conjuntos consecutivos ou sobrepostos são concatenados.
6. Se o total de observações dentro dos blocos for maior que n/2
aumenta-se o valor de c2 e volta a (1). Se isso não for
suficiente tomamos h menor do que especificado inicialmente.
7. Após a identificação dos blocos re-estima-se as distribuições a
posteriori dentro de cada bloco.
– p. 20/46

Distribuições posteriori para blocos deoutliers
A distribuição a posteriori de π(h, {δt}, {ψt}, ψ, k, ν|y) é
proporcional ao produto das prioris dos parâmetros π(ψ)π(k)π(ν) e
Πnt=1P(yt|{ht}, {δt}, {ψt}, ψ, k, ν)P(ht|{δt}, {ψt}, ψ, k, ν)P(δt|{ψt}, ψ, k, ν)P(ψt|ψ, k, ν).
Marginais completas são dadas por:
P(δj = 1|y, {ht}, {ψt}, ψ, k, δ(j)) =kfN (yt|βt, e
ht )
kfN (yt|βt, eht ) + (1 − k)fN (yt|0, e
ht ),
Para tamanho do outlier temosψt|y, ψ, δ, ψ(j), ht ∼ N(ψ∗
j ,Ψ−1) onde
Ψ =σ2
η + δ2t
ν2σ2η
e ψ∗
t =−0.5σ2
η + δtyt
Ψσ2η
.
– p. 21/46

Considere partição do vetor de parâmetros
θB = (ψ, {ht}, δ2, . . . , δ′
j,k, δj+k, . . . , δn, β2, . . . , β′
j,k, βj+k, . . . , βn, )′.
Para o cálculo da verossimilhança, temos
f(y‖θδj,k; δj,k) = f(y
j−12 ‖θδj,k
) · f(yTj,kj
‖yj−12 ; θδj,k
; δj,k) · f(ynTj,k+1
‖yTj,k2 ; θδj,k
),
onde ykj = (yj , . . . , yk)
′ e Tj,k = min{n, j + k}, e
f(yTj,kj
‖yj−12 ; θδj,k
; δj,k) ∝ ΠTj,kt=j
fN (yt‖ht, ψ|δtψt; eht )fN (ht‖h(t), ψ|µ + φ(ht−1 − µ);ση).
– p. 22/46

A posteriori de δj,k e βj,k será:
P(δj,k‖y, θδj,k) ∝ f(y‖θδj,k
; δj,k) · κsj,k(1 − κ)k−sj,k ,
onde sj,k =∑j+k−1
t=j δt.
Assim, a posteriori condicional de βj,k será
P(βj,k‖y, θδj,k) ∝ f(y‖θβj,k ;βj,k) · P(βj,k).
– p. 23/46

3.3. Aplicações
Prioris: µ ∼ N(0; 100), φ∗ ∼ Beta(20; 15), κ ∼ Beta(2; 100),
ση ∼ IG(2, 5; 0, 05/2) e log(δ) ∼ N(−3; 0, 15).
média das prioris para φ(0, 86), para δ(0, 05), para κ(0, 020).
Número de interações na parte inicial do amostrador de Gibbs:
150.000.
c1 = 0, 5 no passo 1, c2 = 0, 3 no passo 2 e h = 2 ( largura
inicial dos blocos no máximo igual a 5)
– p. 24/46

Séries simuladas
Serie sem Outlier
0 100 200 300 400 500 600 700 800 900 1000
−10
0
10Simulação Ψ1
0 100 200 300 400 500 600 700 800 900 1000
0.25
0.50
0.75
1.00P{ δt |y}
Figura 5: a) Retornos. b) Média da distribuição posteriori marginal doPasso 1 para Detecção de Outliers da Série Simulada Ψ1
– p. 25/46

Série comoutliers
0 50 100 150 200 250 300 350 400 450 500
−25
0
25
50Simulação Ψ3
0 50 100 150 200 250 300 350 400 450 500
0.25
0.50
0.75
1.00P{ δt |y}
550 600 650 700 750 800 850 900 950 1000
−25
0
25
50Simulação Ψ3
550 600 650 700 750 800 850 900 950 1000
0.25
0.50
0.75
1.00P{ δt |y}
Figura 6: Detecção de Blocos de Outliers da Série Simulada Ψ3 comoutliers. Retornos e Média da distribuição posteriori marginal.
– p. 26/46
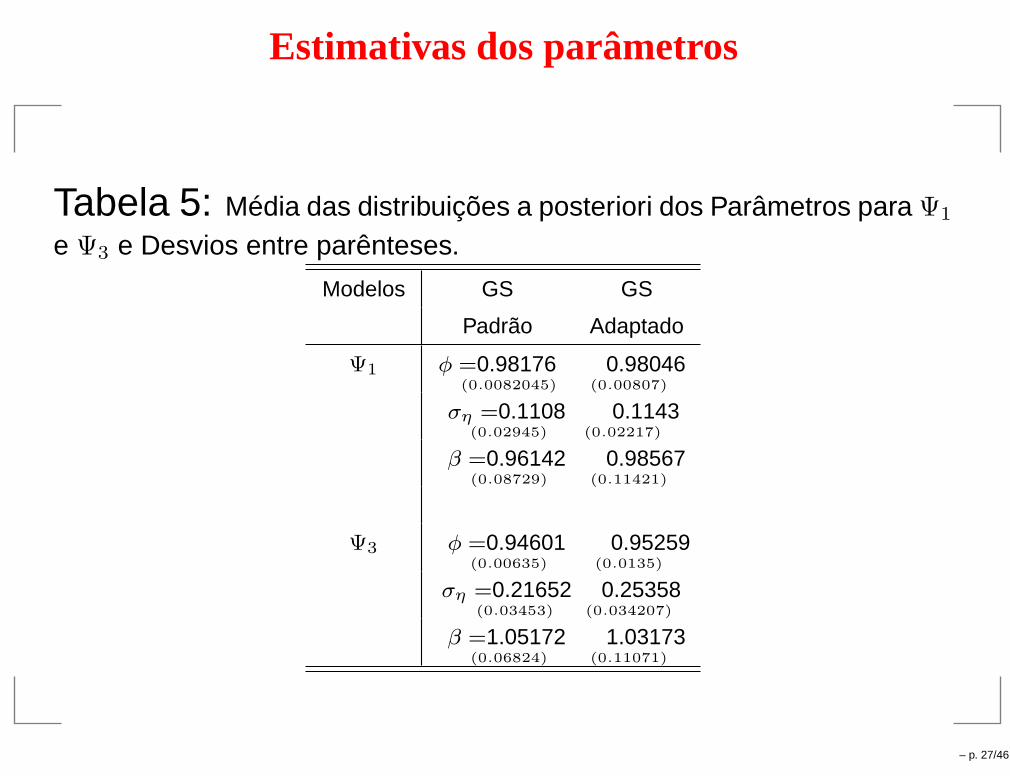
Estimativas dos parâmetros
Tabela 5: Média das distribuições a posteriori dos Parâmetros para Ψ1
e Ψ3 e Desvios entre parênteses.
Modelos GS GS
Padrão Adaptado
Ψ1 φ =0.98176(0.0082045)
0.98046(0.00807)
ση =0.1108(0.02945)
0.1143(0.02217)
β =0.96142(0.08729)
0.98567(0.11421)
Ψ3 φ =0.94601(0.00635)
0.95259(0.0135)
ση =0.21652(0.03453)
0.25358(0.034207)
β =1.05172(0.06824)
1.03173(0.11071)
– p. 27/46
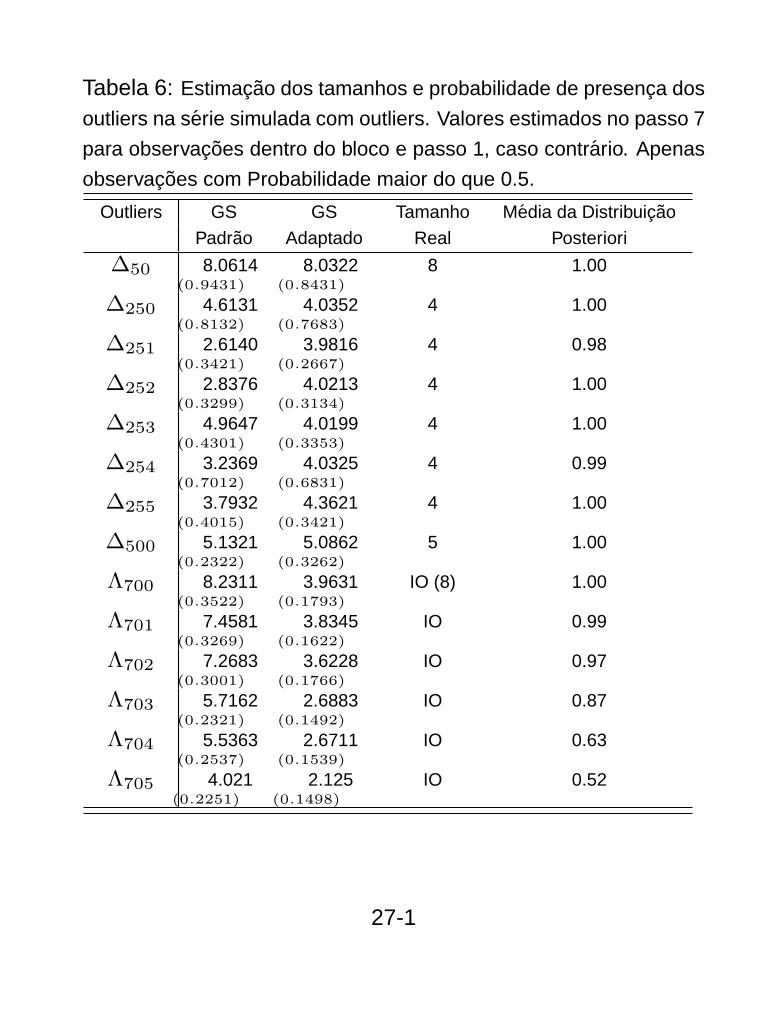
Tabela 6: Estimacao dos tamanhos e probabilidade de presenca dos
outliers na serie simulada com outliers. Valores estimados no passo 7
para observacoes dentro do bloco e passo 1, caso contrario. Apenas
observacoes com Probabilidade maior do que 0.5.
Outliers GS GS Tamanho Media da Distribuicao
Padrao Adaptado Real Posteriori
∆50 8.0614(0.9431)
8.0322(0.8431)
8 1.00
∆250 4.6131(0.8132)
4.0352(0.7683)
4 1.00
∆251 2.6140(0.3421)
3.9816(0.2667)
4 0.98
∆252 2.8376(0.3299)
4.0213(0.3134)
4 1.00
∆253 4.9647(0.4301)
4.0199(0.3353)
4 1.00
∆254 3.2369(0.7012)
4.0325(0.6831)
4 0.99
∆255 3.7932(0.4015)
4.3621(0.3421)
4 1.00
∆500 5.1321(0.2322)
5.0862(0.3262)
5 1.00
Λ700 8.2311(0.3522)
3.9631(0.1793)
IO (8) 1.00
Λ701 7.4581(0.3269)
3.8345(0.1622)
IO 0.99
Λ702 7.2683(0.3001)
3.6228(0.1766)
IO 0.97
Λ703 5.7162(0.2321)
2.6883(0.1492)
IO 0.87
Λ704 5.5363(0.2537)
2.6711(0.1539)
IO 0.63
Λ705 4.021(0.2251)
2.125(0.1498)
IO 0.52
27-1
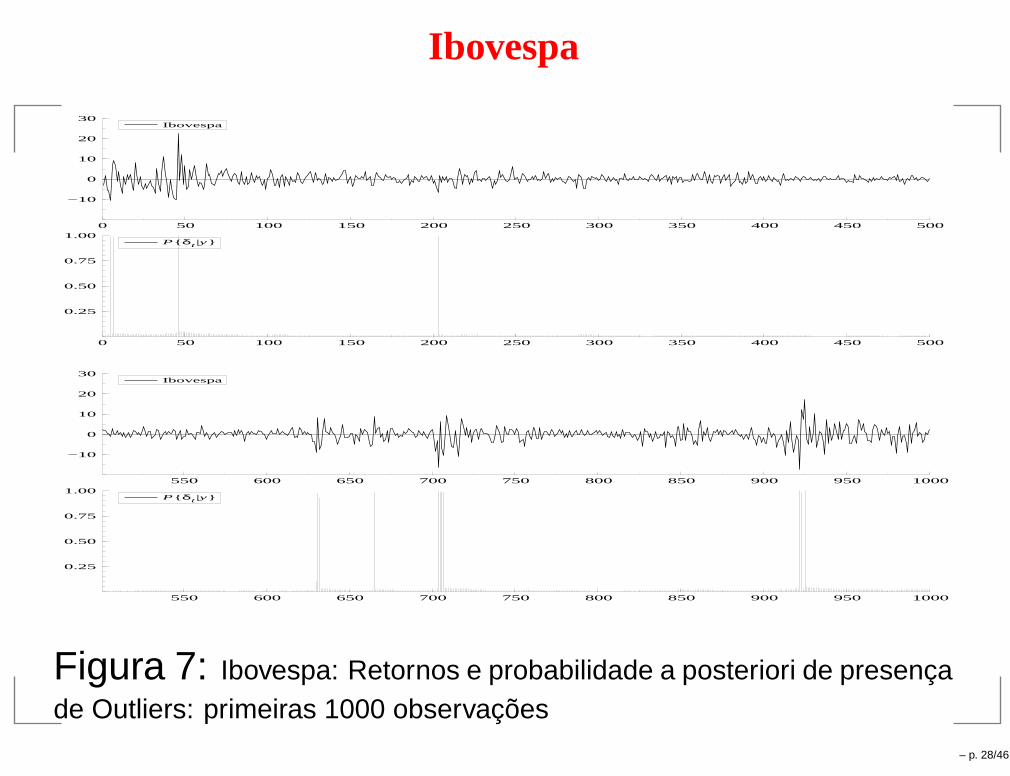
Ibovespa
0 50 100 150 200 250 300 350 400 450 500
−10
0
10
20
30Ibovespa
0 50 100 150 200 250 300 350 400 450 500
0.25
0.50
0.75
1.00P{ δt |y}
550 600 650 700 750 800 850 900 950 1000
−10
0
10
20
30Ibovespa
550 600 650 700 750 800 850 900 950 1000
0.25
0.50
0.75
1.00P{ δt |y}
Figura 7: Ibovespa: Retornos e probabilidade a posteriori de presençade Outliers: primeiras 1000 observações
– p. 28/46
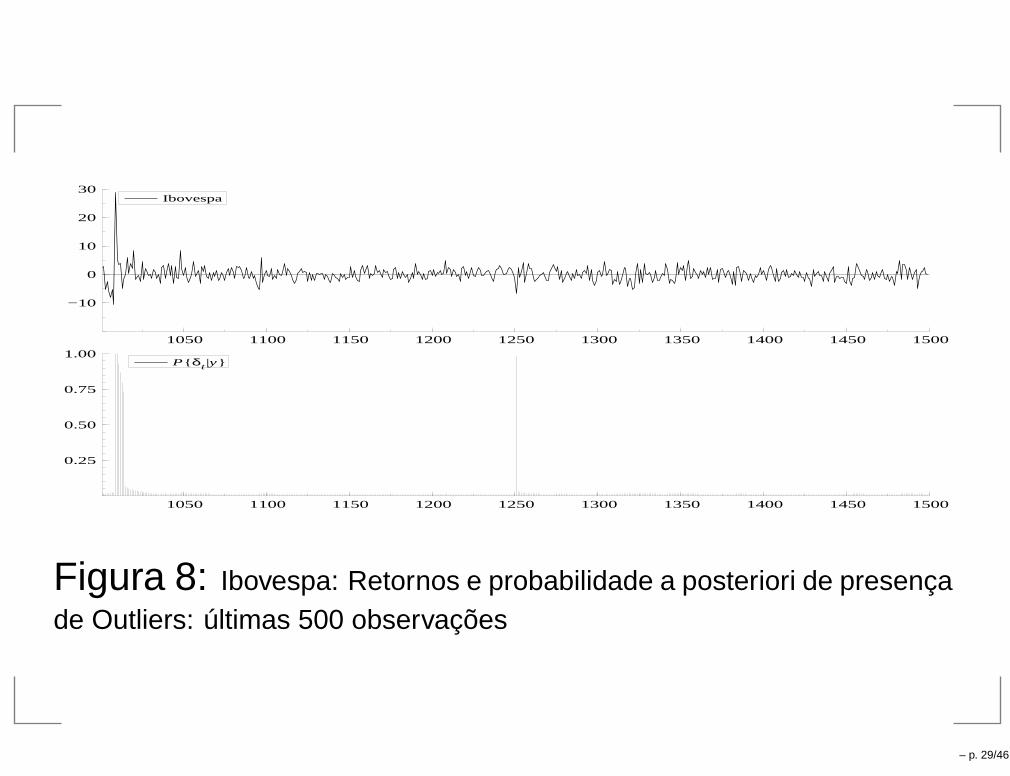
1050 1100 1150 1200 1250 1300 1350 1400 1450 1500
−10
0
10
20
30Ibovespa
1050 1100 1150 1200 1250 1300 1350 1400 1450 1500
0.25
0.50
0.75
1.00P{ δt |y}
Figura 8: Ibovespa: Retornos e probabilidade a posteriori de presençade Outliers: últimas 500 observações
– p. 29/46
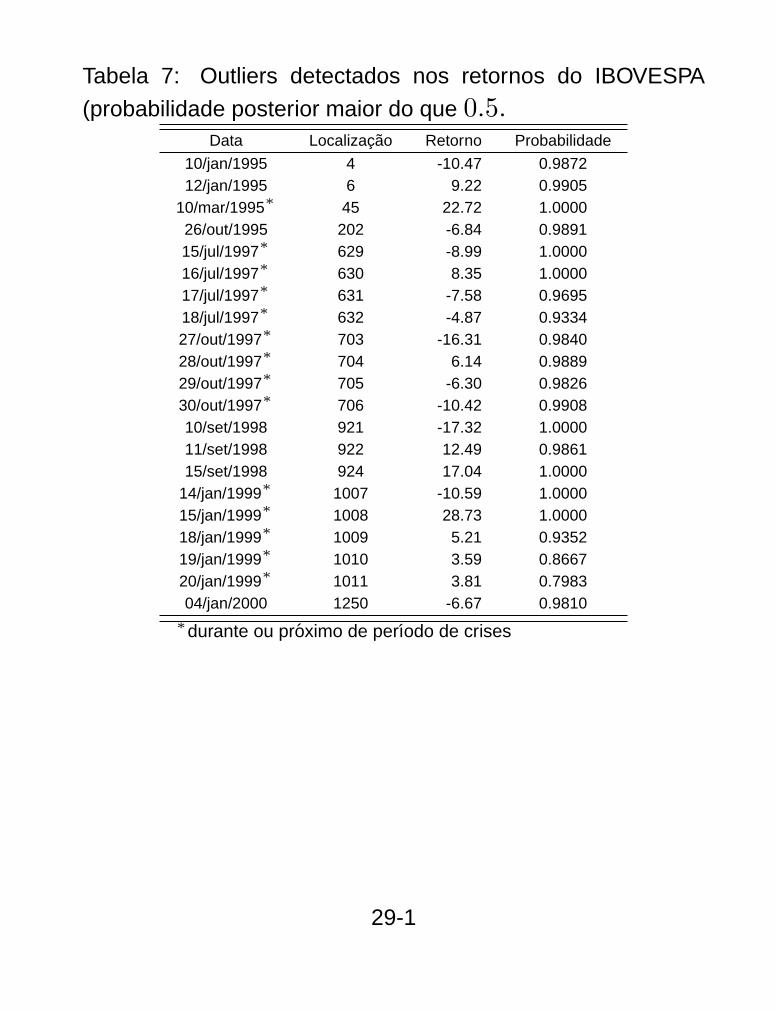
Tabela 7: Outliers detectados nos retornos do IBOVESPA
(probabilidade posterior maior do que 0.5.Data Localizacao Retorno Probabilidade
10/jan/1995 4 -10.47 0.987212/jan/1995 6 9.22 0.9905
10/mar/1995∗ 45 22.72 1.000026/out/1995 202 -6.84 0.989115/jul/1997∗ 629 -8.99 1.000016/jul/1997∗ 630 8.35 1.000017/jul/1997∗ 631 -7.58 0.969518/jul/1997∗ 632 -4.87 0.933427/out/1997∗ 703 -16.31 0.984028/out/1997∗ 704 6.14 0.988929/out/1997∗ 705 -6.30 0.982630/out/1997∗ 706 -10.42 0.990810/set/1998 921 -17.32 1.000011/set/1998 922 12.49 0.986115/set/1998 924 17.04 1.0000
14/jan/1999∗ 1007 -10.59 1.000015/jan/1999∗ 1008 28.73 1.000018/jan/1999∗ 1009 5.21 0.935219/jan/1999∗ 1010 3.59 0.866720/jan/1999∗ 1011 3.81 0.798304/jan/2000 1250 -6.67 0.9810
∗durante ou proximo de perıodo de crises
29-1
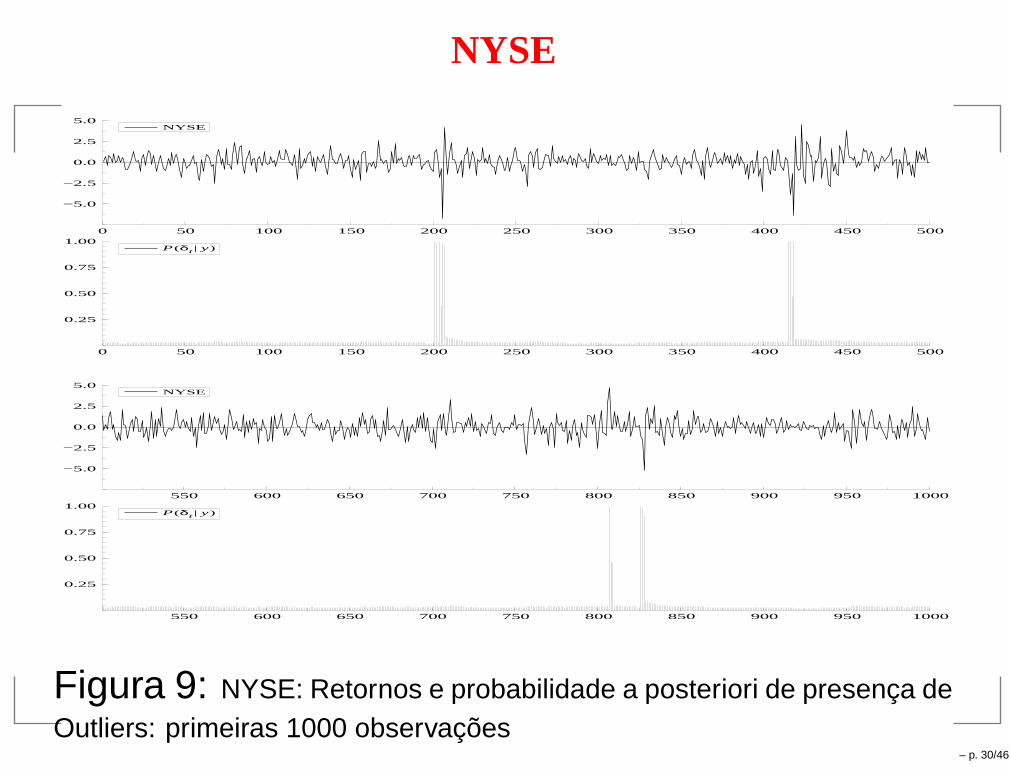
NYSE
0 50 100 150 200 250 300 350 400 450 500
−5.0
−2.5
0.0
2.5
5.0NYSE
0 50 100 150 200 250 300 350 400 450 500
0.25
0.50
0.75
1.00P(δt | y)
550 600 650 700 750 800 850 900 950 1000
−5.0
−2.5
0.0
2.5
5.0NYSE
550 600 650 700 750 800 850 900 950 1000
0.25
0.50
0.75
1.00P(δt | y)
Figura 9: NYSE: Retornos e probabilidade a posteriori de presença deOutliers: primeiras 1000 observações
– p. 30/46
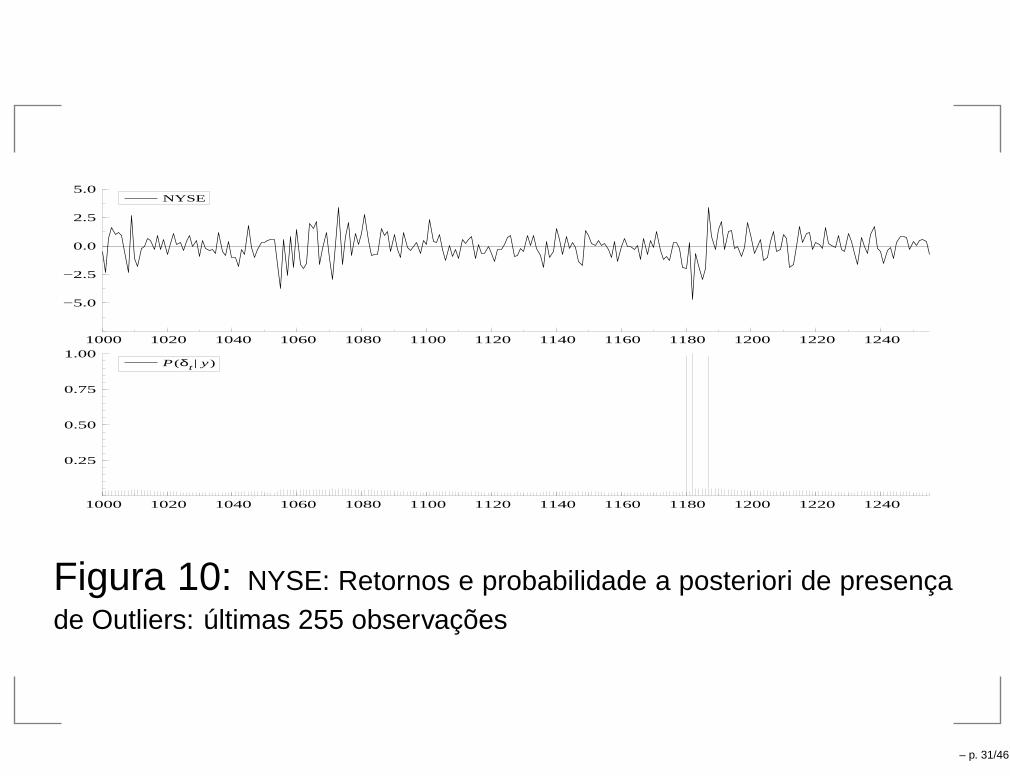
1000 1020 1040 1060 1080 1100 1120 1140 1160 1180 1200 1220 1240
−5.0
−2.5
0.0
2.5
5.0NYSE
1000 1020 1040 1060 1080 1100 1120 1140 1160 1180 1200 1220 1240
0.25
0.50
0.75
1.00P(δt | y)
Figura 10: NYSE: Retornos e probabilidade a posteriori de presençade Outliers: últimas 255 observações
– p. 31/46
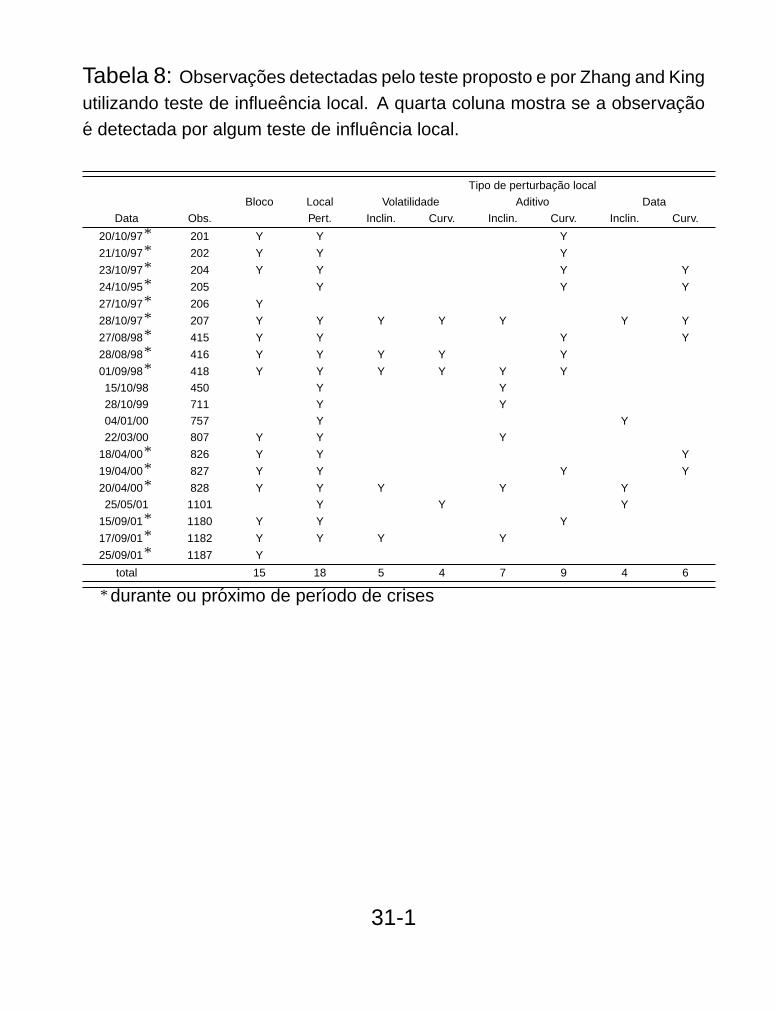
Tabela 8: Observacoes detectadas pelo teste proposto e por Zhang and King
utilizando teste de influeencia local. A quarta coluna mostra se a observacao
e detectada por algum teste de influencia local.
Tipo de perturbacao local
Bloco Local Volatilidade Aditivo Data
Data Obs. Pert. Inclin. Curv. Inclin. Curv. Inclin. Curv.
20/10/97∗ 201 Y Y Y
21/10/97∗ 202 Y Y Y
23/10/97∗ 204 Y Y Y Y
24/10/95∗ 205 Y Y Y
27/10/97∗ 206 Y
28/10/97∗ 207 Y Y Y Y Y Y Y
27/08/98∗ 415 Y Y Y Y
28/08/98∗ 416 Y Y Y Y Y
01/09/98∗ 418 Y Y Y Y Y Y
15/10/98 450 Y Y
28/10/99 711 Y Y
04/01/00 757 Y Y
22/03/00 807 Y Y Y
18/04/00∗ 826 Y Y Y
19/04/00∗ 827 Y Y Y Y
20/04/00∗ 828 Y Y Y Y Y
25/05/01 1101 Y Y Y
15/09/01∗ 1180 Y Y Y
17/09/01∗ 1182 Y Y Y Y
25/09/01∗ 1187 Y
total 15 18 5 4 7 9 4 6
∗durante ou proximo de perıodo de crises
31-1

3.4 Conclusões
Nas séries simuladas não foi detectada nenhuma observação nasérie sem outlier. Na série com outlier todos os outliers AO foramdetectados. Seis observações consecutivas foram detectadas nocaso do VO, com tamanhos e probabilidades decrescentes. Com oefeito de um IO vai desaparecendo isto era esperado e devecaracterizar um VO. O resultado pode ser considerado como muitobom.
NYSE:Das 15 observações detectadas como outliers apenas doisnão foram detectadas por nenhum teste de influência local de Zhange King(2005) (ZK).
Estas duas observações estão no meio de blocos e próximos acrises. A não detecção pelos testes de influência local pode serdevido ao problema de mascaramento. Não seria falsa deteção.
Por outro lado, das 18 observações detectados por ZK somentecinco não foram detectadas, nenhuma próxima ou durante crises.
– p. 32/46

Das 6 observações detectadas por perturbação local na volatilidadeapenas um não foi detectada pelo nosso teste. Entre 15 detectadaspelas perturbação aditiva 3 não foram detectadas pelo nosso teste, eentre as 9 das perturbação nos dados três não foram detectadas.Isto significa que o teste tem poder para detectar qualquer tipo deperturbação.
As crises da Ásia em Octubro 1997, da Rússia em Agosto de 1998,da Nasdaq em Abril de 2000 e do ataque terrorista de Setembro de2001 foram detectadas, mas a crise cambial do Brasil em Janeiro de1999 não.
IBOVESPA: O método detectou 24 observações como influentes,sendo que 17 estão relacionados à crises que impactaramdiretamente o mercado financeiro, inclusive a crise cambial.
– p. 33/46

4. Deteção de Outliers e Valores Influentes
Peña (2005) Ele sugeriu olhar como cada observação é
influenciada pelos outras observações. Para cada observação
ele observou a modificação da predição deste ponto quando
os outros pontos são deixados fora da amostra
individualmente. Por exemplo, para a i-ésima observação a
estatística é defininida como a norma padronizada do vetor
si = (yi − yi(1), . . . , yi − yi(n))′, onde
yi é o valor predito de yi utilizando todas as outras
observações e
yi(k) é o valor predito de yi utilizando todas as outras
observações exceto yk, i.e
Si =s′isi
ˆV ar(yi)(2)
– p. 34/46

Modificações
Consideramos observações faltantes.
Estimamos estimativas da volatilidade.
Por questão de tempo computacional utilizamos a
quase-verossimilhança.
São utilizados apenas os valores máximos da estatística e não
os mínimos.
É mais adequado para outliers.
– p. 35/46

4.2 Algoritmo
1. Estime os parâmetros, Ψ, do modelo de Volatilidade.
2. Faça i = 1, . . . , n
[i.]Considere a estimativa, hi considerando Ψ . Faça
j = 1, . . . , n
(a)(b) Trate a j-ésima observação como valor faltante, obtendo
y(j)
Reestime o modelo obtendo-se Ψ(j)
Encontre hi(j), a estimativa de hi baseada em y(j)
3. Calcule a Estatística Si.
4. Calcule a Estatística S∗ = maxTi=1 Si
– p. 36/46
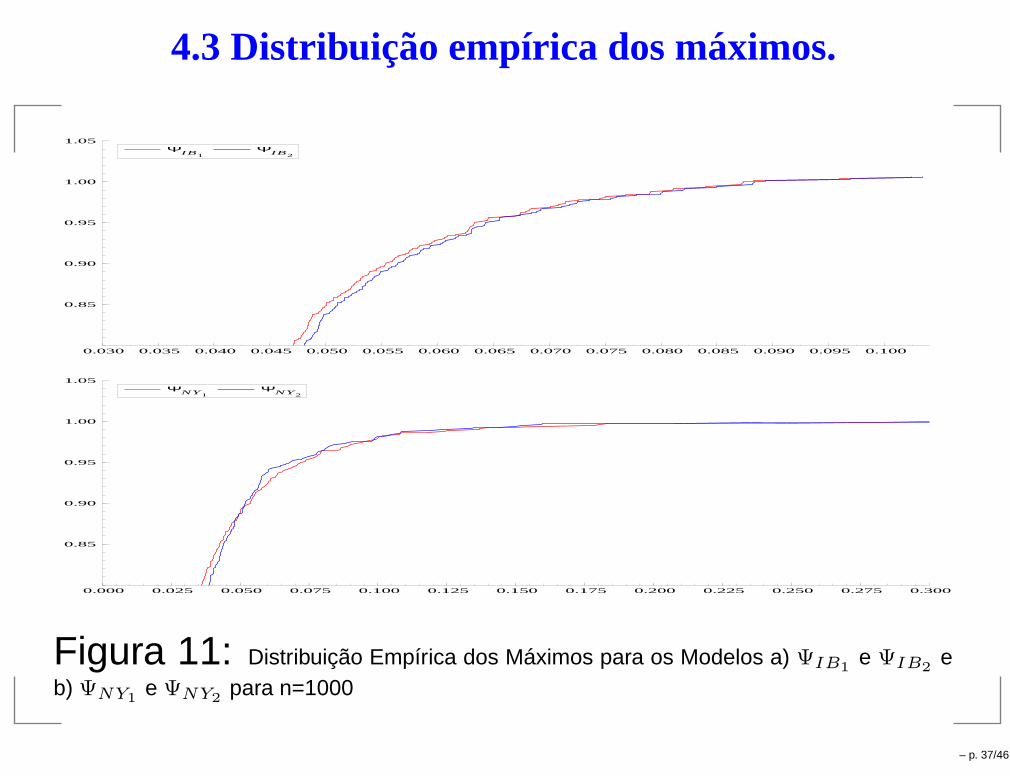
4.3 Distribuição empírica dos máximos.
0.030 0.035 0.040 0.045 0.050 0.055 0.060 0.065 0.070 0.075 0.080 0.085 0.090 0.095 0.100
0.85
0.90
0.95
1.00
1.05ΨIB1
ΨIB2
0.000 0.025 0.050 0.075 0.100 0.125 0.150 0.175 0.200 0.225 0.250 0.275 0.300
0.85
0.90
0.95
1.00
1.05ΨNY1
ΨNY2
Figura 11: Distribuição Empírica dos Máximos para os Modelos a) ΨIB1e ΨIB2
eb) ΨNY1
e ΨNY2para n=1000
– p. 37/46
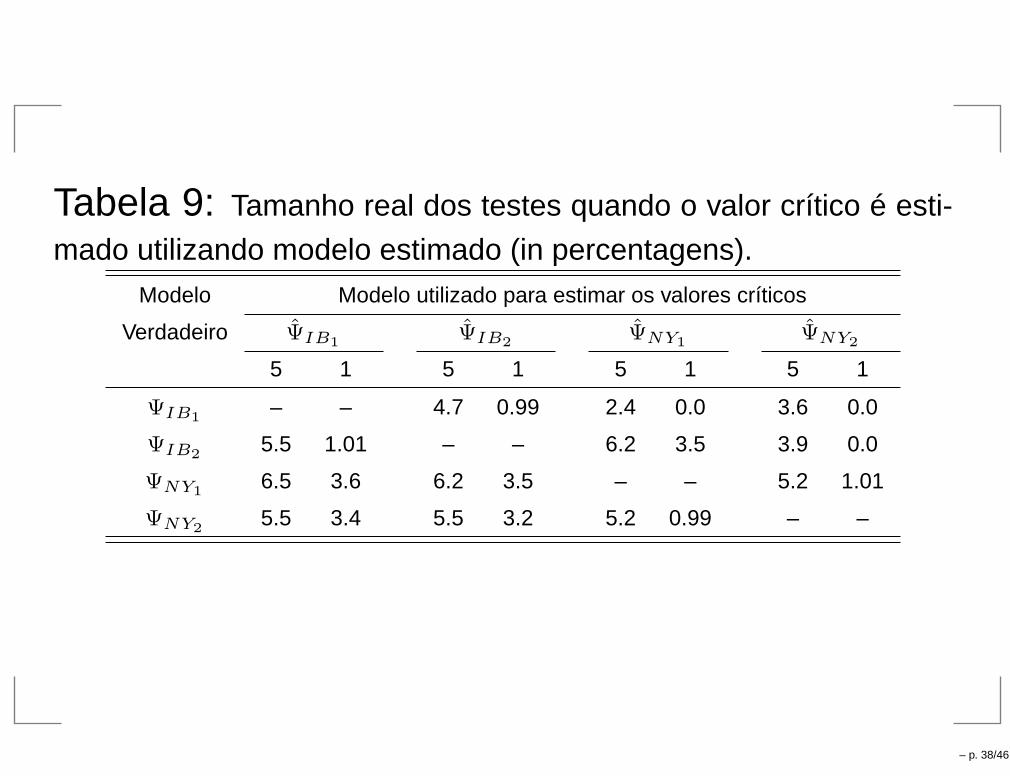
Tabela 9: Tamanho real dos testes quando o valor crítico é esti-
mado utilizando modelo estimado (in percentagens).Modelo Modelo utilizado para estimar os valores críticos
Verdadeiro ΨIB1 ΨIB2 ΨNY1 ΨNY2
5 1 5 1 5 1 5 1
ΨIB1– – 4.7 0.99 2.4 0.0 3.6 0.0
ΨIB25.5 1.01 – – 6.2 3.5 3.9 0.0
ΨNY16.5 3.6 6.2 3.5 – – 5.2 1.01
ΨNY25.5 3.4 5.5 3.2 5.2 0.99 – –
– p. 38/46
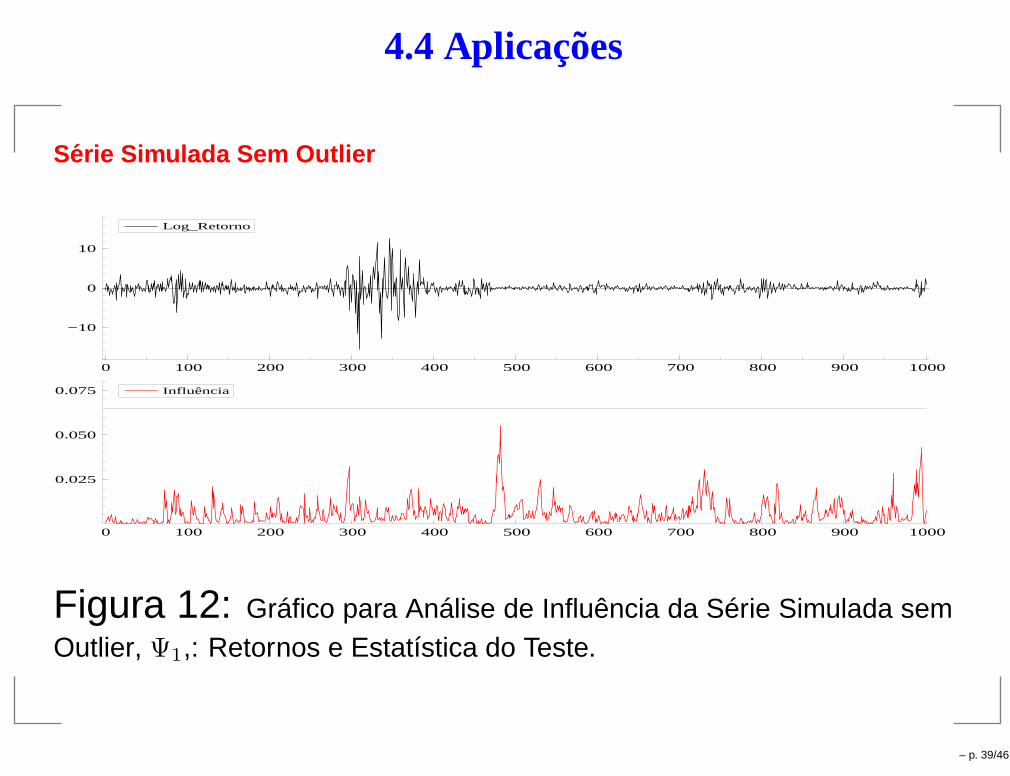
4.4 Aplicações
Serie Simulada Sem Outlier
0 100 200 300 400 500 600 700 800 900 1000
−10
0
10
Log_Retorno
0 100 200 300 400 500 600 700 800 900 1000
0.025
0.050
0.075 Influência
Figura 12: Gráfico para Análise de Influência da Série Simulada semOutlier, Ψ1,: Retornos e Estatística do Teste.
– p. 39/46
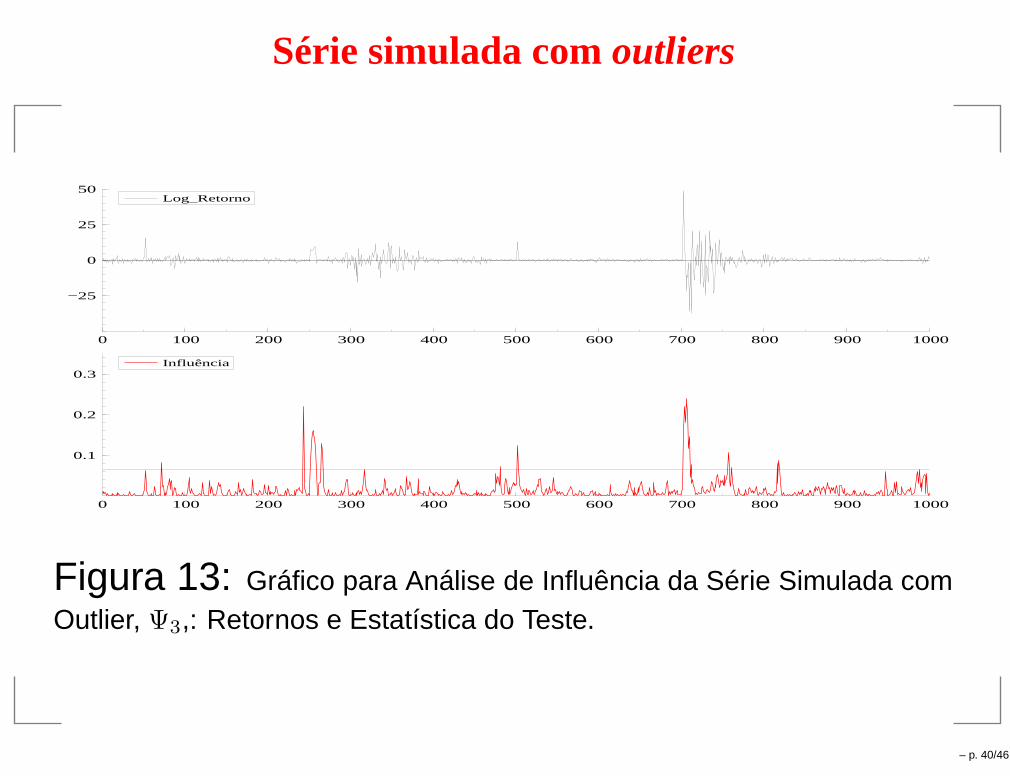
Série simulada comoutliers
0 100 200 300 400 500 600 700 800 900 1000
−25
0
25
50Log_Retorno
0 100 200 300 400 500 600 700 800 900 1000
0.1
0.2
0.3Influência
Figura 13: Gráfico para Análise de Influência da Série Simulada comOutlier, Ψ3,: Retornos e Estatística do Teste.
– p. 40/46
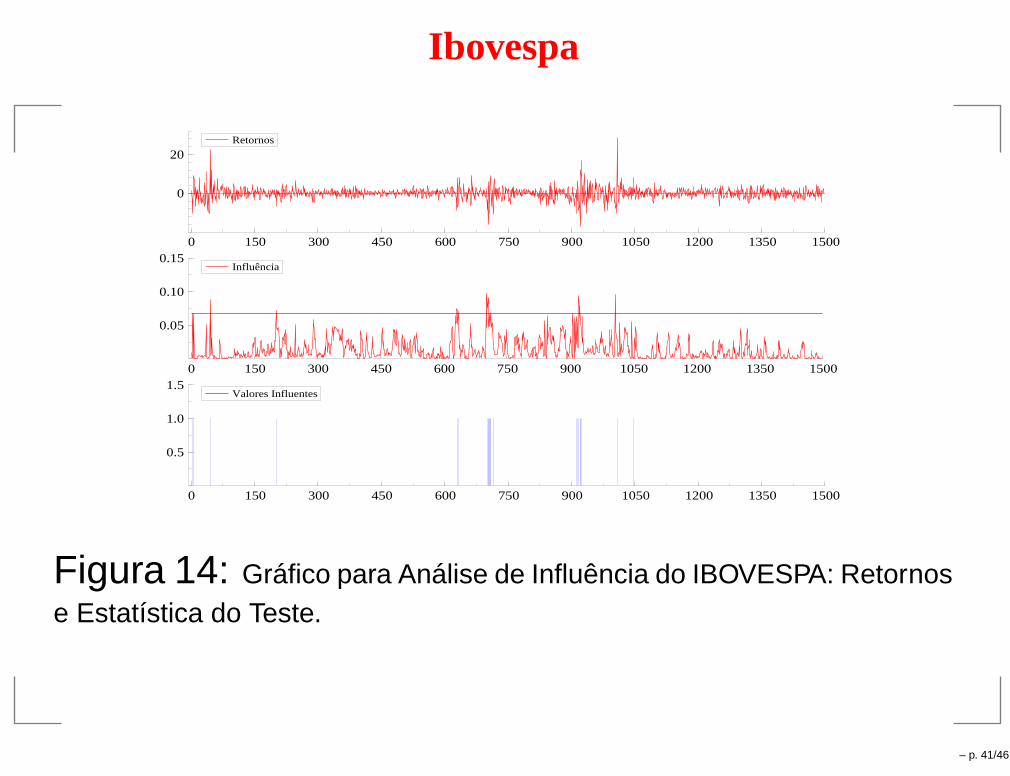
Ibovespa
0 150 300 450 600 750 900 1050 1200 1350 1500
0
20Retornos
0 150 300 450 600 750 900 1050 1200 1350 1500
0.05
0.10
0.15Influência
0 150 300 450 600 750 900 1050 1200 1350 1500
0.5
1.0
1.5Valores Influentes
Figura 14: Gráfico para Análise de Influência do IBOVESPA: Retornose Estatística do Teste.
– p. 41/46
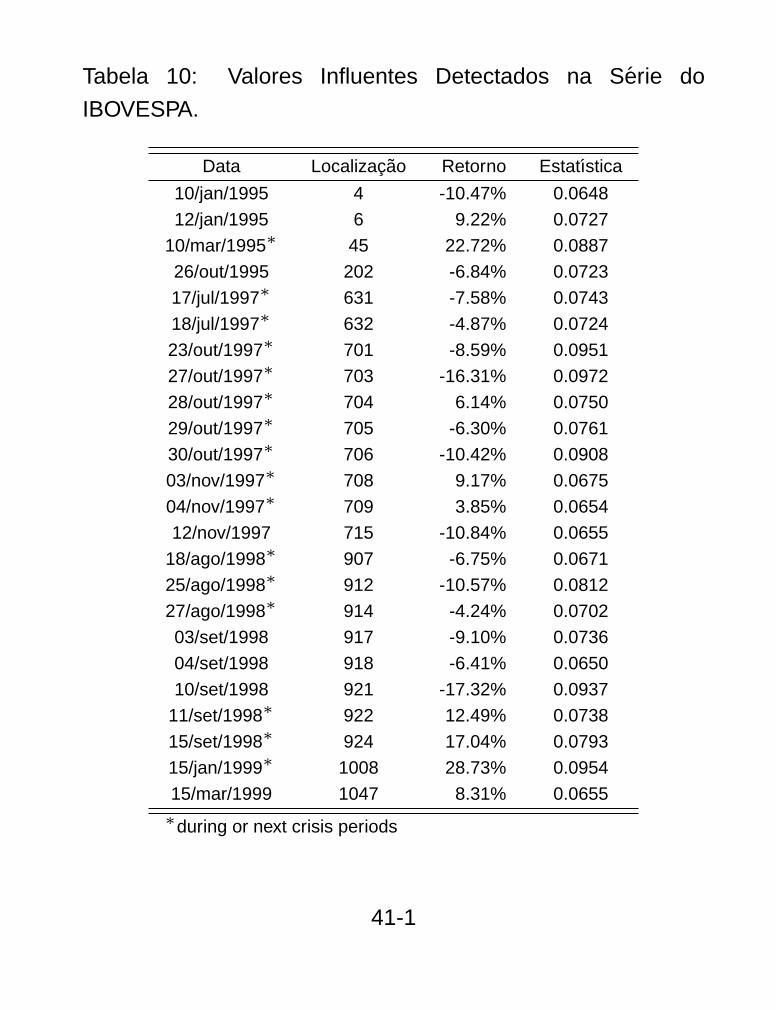
Tabela 10: Valores Influentes Detectados na Serie do
IBOVESPA.
Data Localizacao Retorno Estatıstica
10/jan/1995 4 -10.47% 0.0648
12/jan/1995 6 9.22% 0.0727
10/mar/1995∗ 45 22.72% 0.0887
26/out/1995 202 -6.84% 0.0723
17/jul/1997∗ 631 -7.58% 0.0743
18/jul/1997∗ 632 -4.87% 0.0724
23/out/1997∗ 701 -8.59% 0.0951
27/out/1997∗ 703 -16.31% 0.0972
28/out/1997∗ 704 6.14% 0.0750
29/out/1997∗ 705 -6.30% 0.0761
30/out/1997∗ 706 -10.42% 0.0908
03/nov/1997∗ 708 9.17% 0.0675
04/nov/1997∗ 709 3.85% 0.0654
12/nov/1997 715 -10.84% 0.0655
18/ago/1998∗ 907 -6.75% 0.0671
25/ago/1998∗ 912 -10.57% 0.0812
27/ago/1998∗ 914 -4.24% 0.0702
03/set/1998 917 -9.10% 0.0736
04/set/1998 918 -6.41% 0.0650
10/set/1998 921 -17.32% 0.0937
11/set/1998∗ 922 12.49% 0.0738
15/set/1998∗ 924 17.04% 0.0793
15/jan/1999∗ 1008 28.73% 0.0954
15/mar/1999 1047 8.31% 0.0655∗during or next crisis periods
41-1
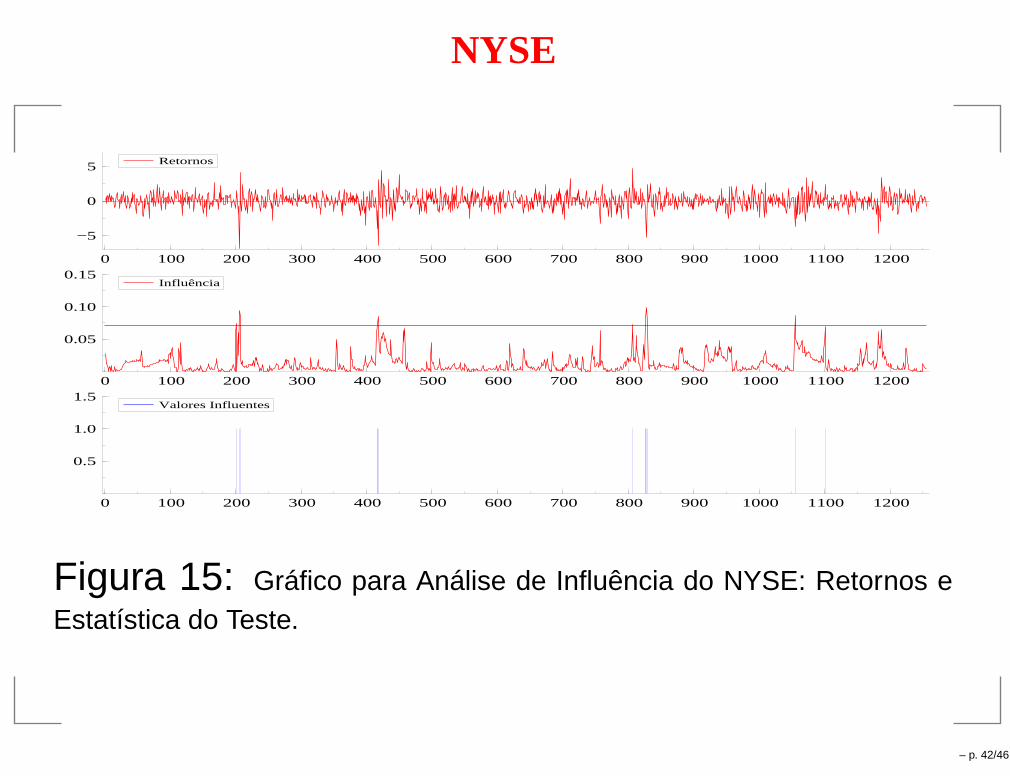
NYSE
0 100 200 300 400 500 600 700 800 900 1000 1100 1200
−5
0
5 Retornos
0 100 200 300 400 500 600 700 800 900 1000 1100 1200
0.05
0.10
0.15Influência
0 100 200 300 400 500 600 700 800 900 1000 1100 1200
0.5
1.0
1.5Valores Influentes
Figura 15: Gráfico para Análise de Influência do NYSE: Retornos eEstatística do Teste.
– p. 42/46
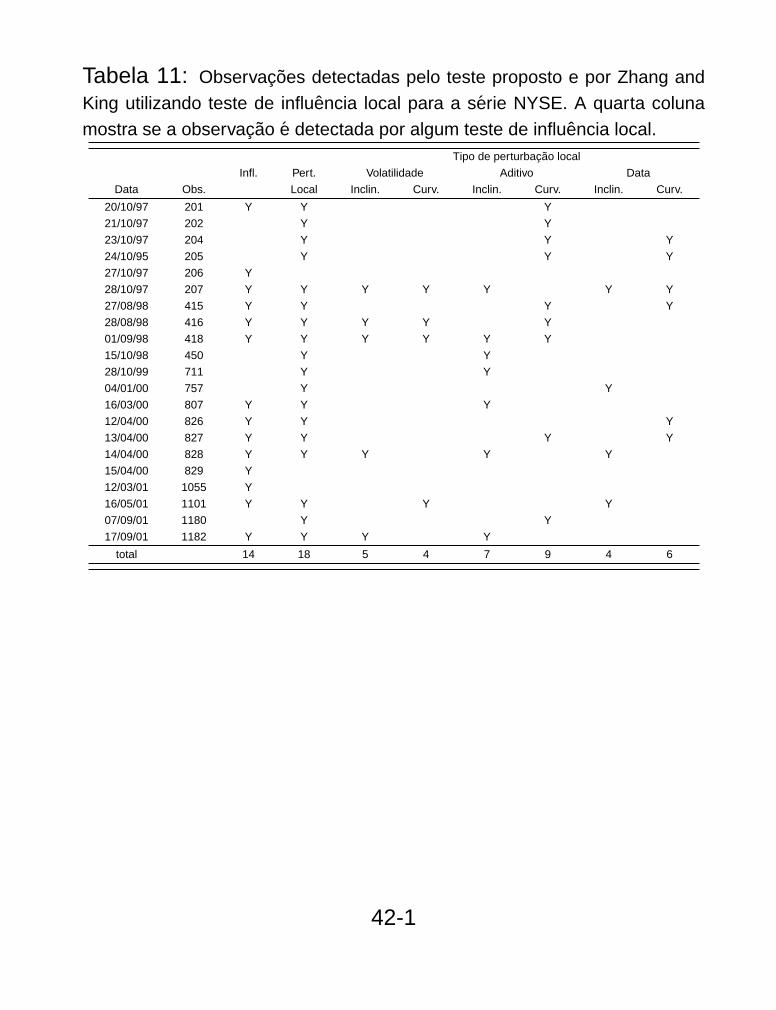
Tabela 11: Observacoes detectadas pelo teste proposto e por Zhang and
King utilizando teste de influencia local para a serie NYSE. A quarta coluna
mostra se a observacao e detectada por algum teste de influencia local.Tipo de perturbacao local
Infl. Pert. Volatilidade Aditivo Data
Data Obs. Local Inclin. Curv. Inclin. Curv. Inclin. Curv.
20/10/97 201 Y Y Y
21/10/97 202 Y Y
23/10/97 204 Y Y Y
24/10/95 205 Y Y Y
27/10/97 206 Y
28/10/97 207 Y Y Y Y Y Y Y
27/08/98 415 Y Y Y Y
28/08/98 416 Y Y Y Y Y
01/09/98 418 Y Y Y Y Y Y
15/10/98 450 Y Y
28/10/99 711 Y Y
04/01/00 757 Y Y
16/03/00 807 Y Y Y
12/04/00 826 Y Y Y
13/04/00 827 Y Y Y Y
14/04/00 828 Y Y Y Y Y
15/04/00 829 Y
12/03/01 1055 Y
16/05/01 1101 Y Y Y Y
07/09/01 1180 Y Y
17/09/01 1182 Y Y Y Y
total 14 18 5 4 7 9 4 6
42-1

4.5 Conclusões
Nas séries simuladas não foi detectada nenhuma observação nasérie sem outlier. Na série com outlier todos os outliers foramdetectados. Nove observações sem outliers foram detectadas, mas 4foram depois do outlier de volatilidade. O resultado pode serconsiderado como razoável.
NYSE: Das 14 observações detectadas como influentes 11 foramdetectadas por pelo menos um teste de influência local de (ZK).
Todos os pontos detectados por nosso teste e que não foramdetectados por ZK estão no meio de blocos de valores influentes.Isto pode ser devido ao fato do teste de influência local sofrer doproblema de mascaramento. Não seria falsa deteção.
Por outro lado, das 18 observações detectados por ZK 7 não foramdetectadas pelo nosso teste, mas 5 foram detectadas apenas portestes de curvatura e 3 por apenas um dos testes.
– p. 43/46

Das 6 observações detectadas por perturbação local na volatilidadetodas foram detectadas pelo nosso teste. Entre 15 detectadas pelasperturbação aditiva seis não foram detectadas, e entre as nove dasperturbação nos dados três não foram detectadas. Isto significa queo teste tem mais poder para detectar pertubações na volatilidade.
As crises da Ásia em Octubro 1997, da Rússia em Agosto de 1998,da Nasdaq em Abril de 2000 e do ataque terrorista de Setembro de2001 foram detectadas, mas a crise cambial do Brasil em Janeiro de1999 não.
IBOVESPA: O método detectou 24 observações como influentes,sendo que 17 estão relacionados à crises que impactaramdiretamente o mercado financeiro, inclusive a crise cambial.
– p. 44/46

5. Conclusões FinaisSimulações: Na série sem outlier não tivemis falsa detecção. Nasérie com outliers os dois testes detectaram todos os outliers etivemos mais falsa detecção no teste de influência.
IBOVESPA: Entre as 21 observações detectadas pelo teste deblocos sete não foram detectadas pelo teste de influência.
Entre as 25 observações detectadas pelo teste de influência 11 nãoforam detectadas pelo teste de blocos.
NYSE: Entre as 15 observações detectadas pelo teste de blocosapenas quatro não foram detectadas pelo teste de influência.
Entre as 14 observações detectadas pelo teste de influência apenastrês não foram detectadas pelo teste de blocos.
Podemos considerar como boas as performances dos dois testescom indicações de que temos mais falsa detecção no teste deinfluência.
– p. 45/46

6. Referências
Justel, A., Peña, D., and Tsay, R. S. (2001). Detection of outliers patchesin autoregressive time series. Statistics Sinica 11, 651-673.
Hotta, L. K. and Zevallos, M.H. (2006) Comments on Zhang and King’sLocal Influence Test Statistics. Documento de Trabalho, UniversidadeEstadual de Campinas, Campinas, Brazil.
Peña, D. (2005). A new statistic for influence in linear regression.Technometrics, 47:1-12.
Zhang, X. and King, M. L. (2005). Influence diagnostic in GARCHprocesses. Journal of Business and Economic Statistics, 23:118-129.
– p. 46/46








