







γλώσσες
Σελίδες
Νομικός


UQ for high dimensional problems
with a view towards hyperbolic conservation laws
Kjetil Olsen Lye
ETH Zurich

Recap from last time

Convergence of Monte Carlo
E((E(X )− 1
M
M∑k=1
Xk)2)1/2 =Var(X )1/2
M1/2.
New notation for today:
‖f ‖L2(Ω) := E(f 2)1/2 for f ∈ L2(Ω).
∥∥∥∥∥E(X )− 1
M
M∑k=1
Xk
∥∥∥∥∥L2(Ω)
=Var(X )1/2
M1/2
1

Convergence of Monte Carlo
E((E(X )− 1
M
M∑k=1
Xk)2)1/2 =Var(X )1/2
M1/2.
New notation for today:
‖f ‖L2(Ω) := E(f 2)1/2 for f ∈ L2(Ω).
∥∥∥∥∥E(X )− 1
M
M∑k=1
Xk
∥∥∥∥∥L2(Ω)
=Var(X )1/2
M1/2
1

Convergence of Monte Carlo
E((E(X )− 1
M
M∑k=1
Xk)2)1/2 =Var(X )1/2
M1/2.
New notation for today:
‖f ‖L2(Ω) := E(f 2)1/2 for f ∈ L2(Ω).
∥∥∥∥∥E(X )− 1
M
M∑k=1
Xk
∥∥∥∥∥L2(Ω)
=Var(X )1/2
M1/2
1

Model problem
d
dtu(ω; t) = F (u(ω; t))
u(ω; 0) = u0(ω)
u10 , . . . , u
M0 i.i.d. samples of u0.
Let u∆t,Tk (ω) = F∆t,T (uk0 ), where F is some numerical scheme
Approximate:
E(u(·;T )) ≈ 1
M
M∑k=1
u∆t,Tk (ω)
2

Model problem
d
dtu(ω; t) = F (u(ω; t))
u(ω; 0) = u0(ω)
u10 , . . . , u
M0 i.i.d. samples of u0.
Let u∆t,Tk (ω) = F∆t,T (uk0 ), where F is some numerical scheme
Approximate:
E(u(·;T )) ≈ 1
M
M∑k=1
u∆t,Tk (ω)
2

Model problem
d
dtu(ω; t) = F (u(ω; t))
u(ω; 0) = u0(ω)
u10 , . . . , u
M0 i.i.d. samples of u0.
Let u∆t,Tk (ω) = F∆t,T (uk0 ), where F is some numerical scheme
Approximate:
E(u(·;T )) ≈ 1
M
M∑k=1
u∆t,Tk (ω)
2

Model problem
d
dtu(ω; t) = F (u(ω; t))
u(ω; 0) = u0(ω)
u10 , . . . , u
M0 i.i.d. samples of u0.
Let u∆t,Tk (ω) = F∆t,T (uk0 ), where F is some numerical scheme
Approximate:
E(u(·;T )) ≈ 1
M
M∑k=1
u∆t,Tk (ω)
2

Error estimation

Error estimation
Triangle inequality
∥∥∥∥∥E(u(·;T ))− 1
M
M∑k=1
u∆t,Tk
∥∥∥∥∥L2(Ω)
6
=:ε1︷ ︸︸ ︷∥∥∥E(u(·;T ))− E(u∆t,Tk
)∥∥∥L2(Ω)
+
∥∥∥∥∥E(u∆t,Tk )− 1
M
M∑k=1
u∆t,Tk
∥∥∥∥∥L2(Ω)︸ ︷︷ ︸
=:ε2
3

Error estimation
Triangle inequality
∥∥∥∥∥E(u(·;T ))− 1
M
M∑k=1
u∆t,Tk
∥∥∥∥∥L2(Ω)
6
=:ε1︷ ︸︸ ︷∥∥∥E(u(·;T ))− E(u∆t,Tk
)∥∥∥L2(Ω)
+
∥∥∥∥∥E(u∆t,Tk )− 1
M
M∑k=1
u∆t,Tk
∥∥∥∥∥L2(Ω)︸ ︷︷ ︸
=:ε2
Assume∗ |u(ω;T )− u∆t,Tk (ω)| 6 C∆ts for all ω, then:
ε1 =∥∥∥E(u(·;T )− u∆t,T
k (·))∥∥∥
L2(Ω)6 ‖u(·;T )− u∆t,T
k ‖L2(Ω) 6 C∆ts .
∗Can be replaced by L2 assumption, can be shown for a large class of
schemes/ODEs/RFs
3

Error estimation
Triangle inequality
∥∥∥∥∥E(u(·;T ))− 1
M
M∑k=1
u∆t,Tk
∥∥∥∥∥L2(Ω)
6
=:ε16C∆ts︷ ︸︸ ︷∥∥∥E(u(·;T ))− E(u∆t,Tk
)∥∥∥L2(Ω)
+
∥∥∥∥∥E(u∆t,Tk )− 1
M
M∑k=1
u∆t,Tk
∥∥∥∥∥L2(Ω)︸ ︷︷ ︸
=:ε2
Assume∗ |u(ω;T )− u∆t,Tk (ω)| 6 C∆ts for all ω, then:
ε1 =∥∥∥E(u(·;T )− u∆t,T
k (·))∥∥∥
L2(Ω)6 ‖u(·;T )− u∆t,T
k ‖L2(Ω) 6 C∆ts .
∗Can be replaced by L2 assumption, can be shown for a large class of
schemes/ODEs/RFs
3

Error estimation
Triangle inequality
∥∥∥∥∥E(u(·;T ))− 1
M
M∑k=1
u∆t,Tk
∥∥∥∥∥L2(Ω)
6
=:ε16C∆ts︷ ︸︸ ︷∥∥∥E(u(·;T ))− E(u∆t,Tk
)∥∥∥L2(Ω)
+
∥∥∥∥∥E(u∆t,Tk )− 1
M
M∑k=1
u∆t,Tk
∥∥∥∥∥L2(Ω)︸ ︷︷ ︸
=:ε26Var(u∆t,T ))1/2
M1/2
ε2 6Var(u∆t,T )1/2
M1/2.
3

Error estimation
Triangle inequality
∥∥∥∥∥E(u(·;T ))− 1
M
M∑k=1
u∆t,Tk
∥∥∥∥∥L2(Ω)
6
=:ε16C∆ts︷ ︸︸ ︷∥∥∥E(u(·;T ))− E(u∆t,Tk
)∥∥∥L2(Ω)
+
∥∥∥∥∥E(u∆t,Tk )− 1
M
M∑k=1
u∆t,Tk
∥∥∥∥∥L2(Ω)︸ ︷︷ ︸
=:ε26Var(u∆t,T ))1/2
M1/2
Hence,∥∥∥∥∥E(u(·;T ))− 1
M
M∑k=1
u∆t,Tk
∥∥∥∥∥L2(Ω)
6 C∆ts +Var(u∆t,T )1/2
M1/2.
3

Equilibrating the error
∥∥∥∥∥E(u(·;T ))− 1
M
M∑k=1
u∆t,Tk
∥∥∥∥∥L2(Ω)
6 C∆ts +Var(u∆t,T )1/2
M1/2.
Want
C∆ts ≈ Var(u∆t,T )1/2
M1/2.
So choose
M = O(∆t−2s).
4

Equilibrating the error
∥∥∥∥∥E(u(·;T ))− 1
M
M∑k=1
u∆t,Tk
∥∥∥∥∥L2(Ω)
6 C∆ts +Var(u∆t,T )1/2
M1/2.
Want
C∆ts ≈ Var(u∆t,T )1/2
M1/2.
So choose
M = O(∆t−2s).
4

Multilevel Monte Carlo

Multilevel telescoping sum
Numerical approximation u∆
5

Multilevel telescoping sum
t0 t1 t2 t3 t4 t5 t6 t7 t8
t0 t1 t2 t3 t4
t0 t1 t2
Numerical approximation u∆
5
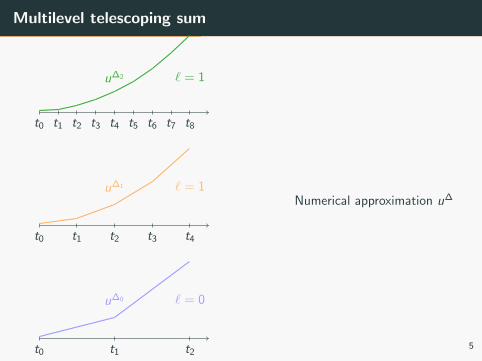
Multilevel telescoping sum
t0 t1 t2 t3 t4 t5 t6 t7 t8
u∆2 ` = 1
t0 t1 t2 t3 t4
u∆1 ` = 1
t0 t1 t2
u∆0 ` = 0
Numerical approximation u∆
5
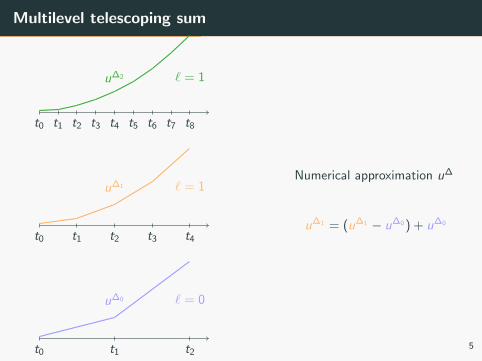
Multilevel telescoping sum
t0 t1 t2 t3 t4 t5 t6 t7 t8
u∆2 ` = 1
t0 t1 t2 t3 t4
u∆1 ` = 1
t0 t1 t2
u∆0 ` = 0
Numerical approximation u∆
u∆1 = (u∆1 − u∆0 ) + u∆0
5
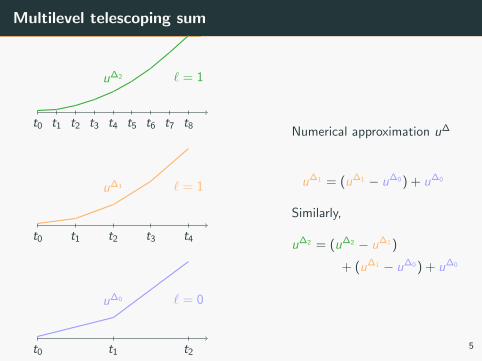
Multilevel telescoping sum
t0 t1 t2 t3 t4 t5 t6 t7 t8
u∆2 ` = 1
t0 t1 t2 t3 t4
u∆1 ` = 1
t0 t1 t2
u∆0 ` = 0
Numerical approximation u∆
u∆1 = (u∆1 − u∆0 ) + u∆0
Similarly,
u∆2 = (u∆2 − u∆1 )
+ (u∆1 − u∆0 ) + u∆0
5
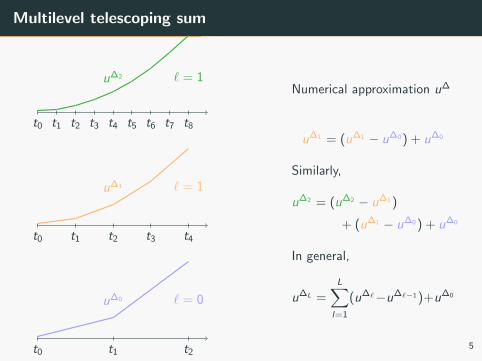
Multilevel telescoping sum
t0 t1 t2 t3 t4 t5 t6 t7 t8
u∆2 ` = 1
t0 t1 t2 t3 t4
u∆1 ` = 1
t0 t1 t2
u∆0 ` = 0
Numerical approximation u∆
u∆1 = (u∆1 − u∆0 ) + u∆0
Similarly,
u∆2 = (u∆2 − u∆1 )
+ (u∆1 − u∆0 ) + u∆0
In general,
u∆L =L∑
l=1
(u∆`−u∆`−1 )+u∆0
5
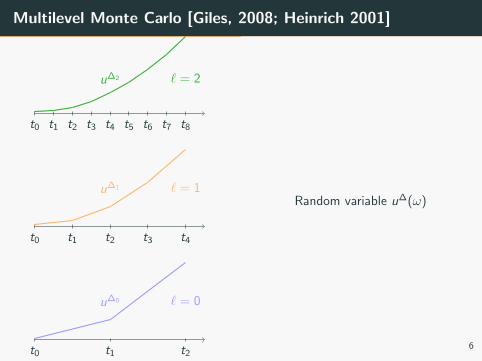
Multilevel Monte Carlo [Giles, 2008; Heinrich 2001]
t0 t1 t2 t3 t4 t5 t6 t7 t8
u∆2 ` = 2
t0 t1 t2 t3 t4
u∆1 ` = 1
t0 t1 t2
u∆0 ` = 0
Random variable u∆(ω)
6
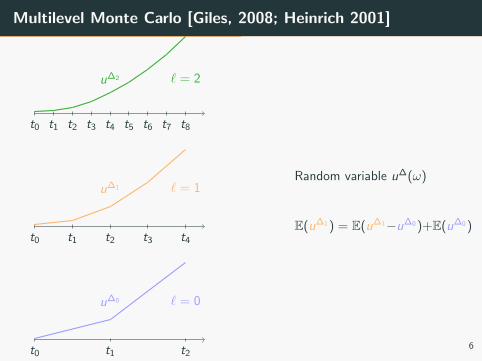
Multilevel Monte Carlo [Giles, 2008; Heinrich 2001]
t0 t1 t2 t3 t4 t5 t6 t7 t8
u∆2 ` = 2
t0 t1 t2 t3 t4
u∆1 ` = 1
t0 t1 t2
u∆0 ` = 0
Random variable u∆(ω)
E(u∆1 ) = E(u∆1−u∆0 )+E(u∆0 )
6
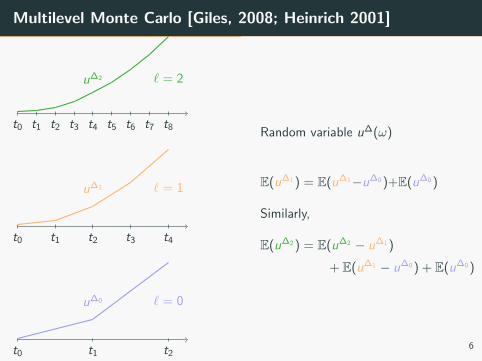
Multilevel Monte Carlo [Giles, 2008; Heinrich 2001]
t0 t1 t2 t3 t4 t5 t6 t7 t8
u∆2 ` = 2
t0 t1 t2 t3 t4
u∆1 ` = 1
t0 t1 t2
u∆0 ` = 0
Random variable u∆(ω)
E(u∆1 ) = E(u∆1−u∆0 )+E(u∆0 )
Similarly,
E(u∆2 ) = E(u∆2 − u∆1 )
+ E(u∆1 − u∆0 ) + E(u∆0 )
6
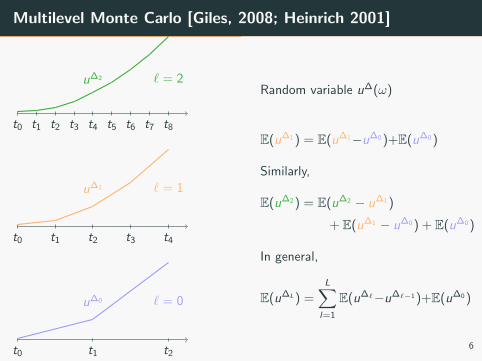
Multilevel Monte Carlo [Giles, 2008; Heinrich 2001]
t0 t1 t2 t3 t4 t5 t6 t7 t8
u∆2 ` = 2
t0 t1 t2 t3 t4
u∆1 ` = 1
t0 t1 t2
u∆0 ` = 0
Random variable u∆(ω)
E(u∆1 ) = E(u∆1−u∆0 )+E(u∆0 )
Similarly,
E(u∆2 ) = E(u∆2 − u∆1 )
+ E(u∆1 − u∆0 ) + E(u∆0 )
In general,
E(u∆L) =L∑
l=1
E(u∆`−u∆`−1 )+E(u∆0 )
6

Variance reduction
E(u∆1 ) = E(u∆1 − u∆0 ) + E(u∆0 )
7

Variance reduction
E(u∆1 ) = E(u∆1 − u∆0 ) + E(u∆0 )
≈ 1
M1
M1∑k=1
(u∆1
k − u∆0
k
)︸ ︷︷ ︸
≈E(u∆1−u∆0 )
+1
M0
M0∑k=1
u∆0
k︸ ︷︷ ︸≈E(u∆0 )
7

Variance reduction
E(u∆1 ) = E(u∆1 − u∆0 ) + E(u∆0 )
≈ 1
M1
M1∑k=1
(u∆1
k − u∆0
k
)︸ ︷︷ ︸
≈E(u∆1−u∆0 )
+1
M0
M0∑k=1
u∆0
k︸ ︷︷ ︸≈E(u∆0 )
=: E2(u)
Error
‖E2(u)− E(u)‖L2(Ω) 6 ‖E(u)− E(u∆1 )‖L2(Ω) +∥∥E2(u)− E(u∆1 )
∥∥L2(Ω)
.
7

Error analysis continued
So
∥∥E2(u)− E(u∆1 )∥∥L2(Ω)
6
∥∥∥∥∥ 1
M1
M1∑k=1
(u∆1
k − u∆0
k
)− E(u∆1 − u∆0 )
∥∥∥∥∥L2(Ω)
+
∥∥∥∥∥E(u∆0 )− 1
M0
M0∑k=1
u∆0
k
∥∥∥∥∥L2(Ω)
8

Error analysis continued
So
∥∥E2(u)− E(u∆1 )∥∥L2(Ω)
6
∥∥∥∥∥ 1
M1
M1∑k=1
(u∆1
k − u∆0
k
)− E(u∆1 − u∆0 )
∥∥∥∥∥L2(Ω)
+
∥∥∥∥∥E(u∆0 )− 1
M0
M0∑k=1
u∆0
k
∥∥∥∥∥L2(Ω)
6Var(u∆1 − u∆0 )1/2
M1/21
+Var(u∆0 )1/2
M1/20
8

Choosing the number of samples
Assume:
• Convergence
|u∆1 (ω)− u(ω)| 6 C∆s for all ω ∈ Ω
• Mesh refinement
∆` = 2`∆0 for all ` > 0.
• Computational work per sample:
Work(∆) = O(∆−1).
then:
Var(u∆1 − u∆0 ) 6 C∆2s0
hence ∥∥E2(u)− E(u∆1 )∥∥L2(Ω)
6C∆s
0
M1/21
+Var(u∆0 )1/2
M1/20
9

Choosing the number of samples
Assume:
• Convergence
|u∆1 (ω)− u(ω)| 6 C∆s for all ω ∈ Ω
• Mesh refinement
∆` = 2`∆0 for all ` > 0.
• Computational work per sample:
Work(∆) = O(∆−1).
then:
Var(u∆1 − u∆0 ) 6 C∆2s0
hence ∥∥E2(u)− E(u∆1 )∥∥L2(Ω)
6C∆s
0
M1/21
+Var(u∆0 )1/2
M1/20
9

Choosing the number of samples
Assume:
• Convergence
|u∆1 (ω)− u(ω)| 6 C∆s for all ω ∈ Ω
• Mesh refinement
∆` = 2`∆0 for all ` > 0.
• Computational work per sample:
Work(∆) = O(∆−1).
then:
Var(u∆1 − u∆0 ) 6 C∆2s0
hence ∥∥E2(u)− E(u∆1 )∥∥L2(Ω)
6C∆s
0
M1/21
+Var(u∆0 )1/2
M1/20
9

Choosing the number of samples: Part II
∥∥E2(u)− E(u∆1 )∥∥L2(Ω)
6C∆s
0
M1/21
+Var(u∆0 )1/2
M1/20
equilibrate the error
C∆s0
M1/21
≈ Var(u∆0 )1/2
M1/20
≈ C 2s∆2s0
That is
M1 = 4
and
M0 =4
∆2s1
.
10

Choosing the number of samples: Part II
∥∥E2(u)− E(u∆1 )∥∥L2(Ω)
6C∆s
0
M1/21
+Var(u∆0 )1/2
M1/20
equilibrate the error
C∆s0
M1/21
≈ Var(u∆0 )1/2
M1/20
≈ C 2s∆2s0
That is
M1 = 4
and
M0 =4
∆2s1
.
10

Work estimate for the new samples
Work(M0,M1) = M0Work(∆0) + M1Work(∆1)
= M0∆−10 + M1∆−1
1
=4
∆2s0
∆−10 + 4∆−1
1
= 4∆−1−2s0 + 8∆−1
0
Meanwhile, with Monte Carlo:
Work(M) =
=M︷ ︸︸ ︷∆−2s
1 ∆−11 = 22s+1∆−2s−1
0
for small ∆0:
Work(M0,M1) < Work(M).
11

Work estimate for the new samples
Work(M0,M1) = M0Work(∆0) + M1Work(∆1)
= M0∆−10 + M1∆−1
1
=4
∆2s0
∆−10 + 4∆−1
1
= 4∆−1−2s0 + 8∆−1
0
Meanwhile, with Monte Carlo:
Work(M) =
=M︷ ︸︸ ︷∆−2s
1 ∆−11 = 22s+1∆−2s−1
0
for small ∆0:
Work(M0,M1) < Work(M).
11

Work estimate for the new samples
Work(M0,M1) = M0Work(∆0) + M1Work(∆1)
= M0∆−10 + M1∆−1
1
=4
∆2s0
∆−10 + 4∆−1
1
= 4∆−1−2s0 + 8∆−1
0
Meanwhile, with Monte Carlo:
Work(M) =
=M︷ ︸︸ ︷∆−2s
1 ∆−11 = 22s+1∆−2s−1
0
for small ∆0:
Work(M0,M1) < Work(M).
11
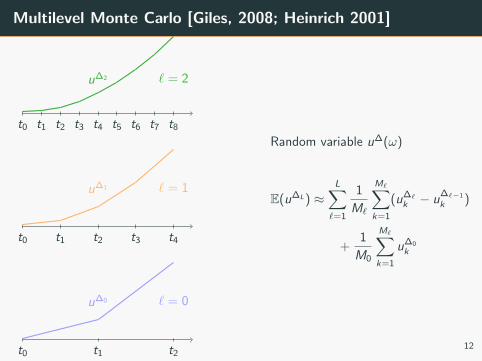
Multilevel Monte Carlo [Giles, 2008; Heinrich 2001]
t0 t1 t2 t3 t4 t5 t6 t7 t8
u∆2 ` = 2
t0 t1 t2 t3 t4
u∆1 ` = 1
t0 t1 t2
u∆0 ` = 0
Random variable u∆(ω)
E(u∆L) ≈L∑
`=1
1
M`
M∑k=1
(u∆`
k − u∆`−1
k )
+1
M0
M∑k=1
u∆0
k
12
Top Related