







γλώσσες
Σελίδες
Νομικός


Fast Big Data Analytics with Spark on Tachyon
Shaoshan Liu
1
http://www.meetup.com/Tachyon/

Fun Facts – Tachyon
A tachyon is a particle that always moves faster than light. The word comes from the Greek: ταχύς or tachys, meaning "swift, quick, fast, rapid", and was coined in 1967 by Gerald Feinberg. The complementary particle types are called luxon (always moving at the speed of light) and bradyon (always moving slower than light), which both exist. In the movie, “K-PAX”, Kevin Spacey's character claims to have traveled to Earth at Tachyon speeds
2

Fun Facts – Baidu
One of the top tech companies in the World, and we have an office here!
3

Serious Fact – When Tachyon Meets Baidu
~ 100 nodes in deployment, > 1 PB storage space 4
30X Acceleration of our Big Data Analytics Workload

Agenda
• Motivation: Why Tachyon? • Tachyon Production Usage at Baidu
• Problems Encountered in Practice • Advanced Features
• Performance Deep Dive • Future Works
5

Motivation: Why Tachyon?
6

Interactive Query System
7
• Example: – John is a PM and he needs to keep track of the top queries submitted to
Baidu everyday – Based on the top queries of the day, he will perform additional analysis – But John is very frustrated that each query takes tens of minutes to finish
• Requirements: – Manages PBs of data – Able to finish 95% of queries within 30 seconds
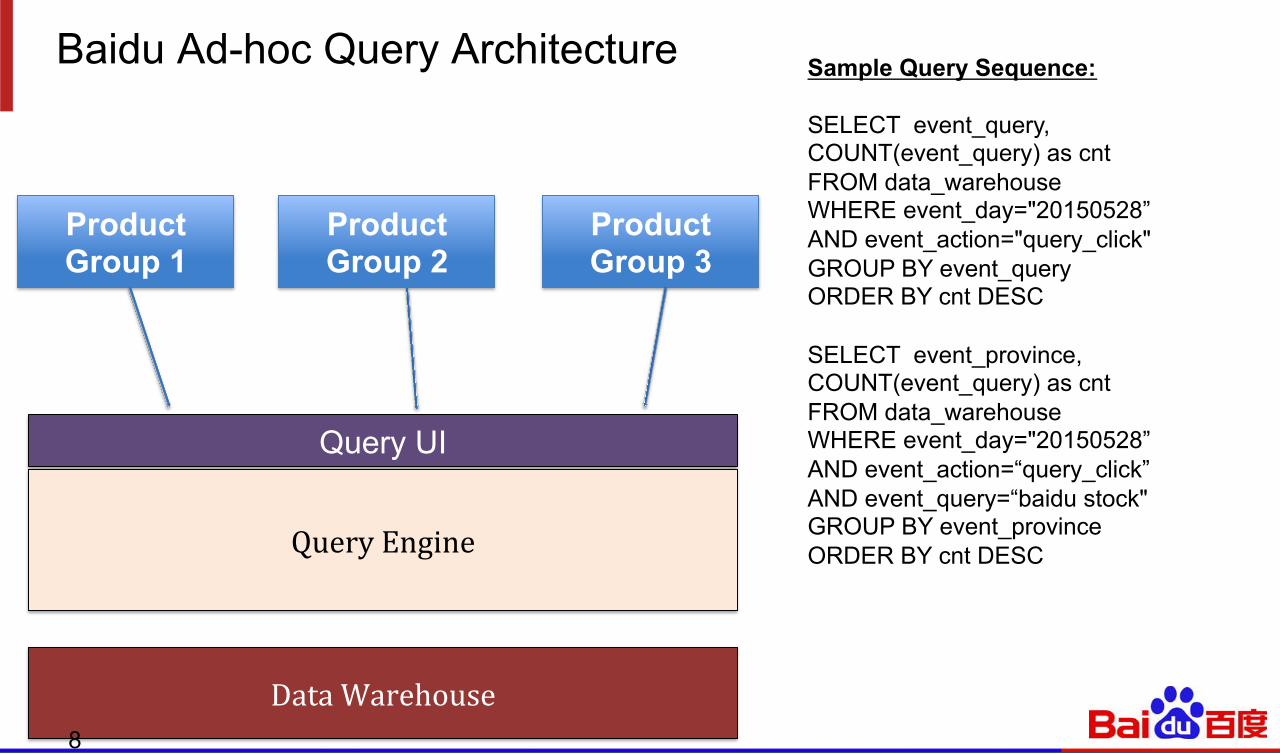
Baidu Ad-hoc Query Architecture
Product Group 1
Query UI
Query Engine
Data Warehouse
Product Group 2
Product Group 3
Sample Query Sequence: SELECT event_query, COUNT(event_query) as cnt FROM data_warehouse WHERE event_day="20150528” AND event_action="query_click" GROUP BY event_query ORDER BY cnt DESC SELECT event_province, COUNT(event_query) as cnt FROM data_warehouse WHERE event_day="20150528” AND event_action=“query_click” AND event_query=“baidu stock" GROUP BY event_province ORDER BY cnt DESC
8

Baidu Ad-hoc Query Architecture
Data Warehouse
BFS
Spark SQL Hive on MR
Hive
Map Reduce
4X Improvement but not good enough!
Compute Center
Data Center
9

A Cache Layer Is Needed !!
10
• Three Requirements: – High Performance – Reliable – Provides Enough Capacity

Transparent Cache Layer
• Problem: – Data nodes and compute nodes do not reside in the same data center, and
thus data access latency may be too high – Specifically, this could be a major performance problem for ad-hoc query
workloads
• Solution: – Use Tachyon as a transparent cache layer – Cold query: read from remote storage node – Warm\hot query: read from Tachyon directly – Initially at Baidu, 50 machines deployed with Spark and Tachyon
• Mostly serving Spark SQL ad-hoc queries • Tachyon as transparent cache layer
11
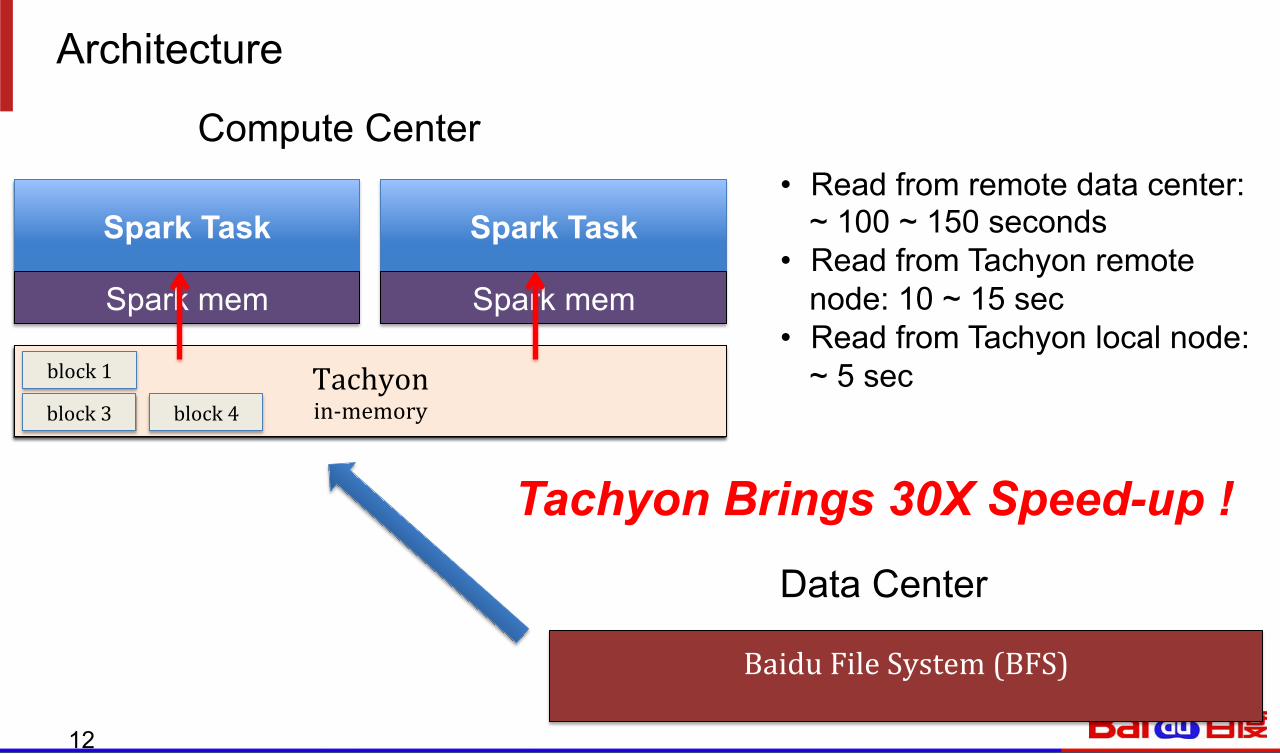
Architecture
Spark Task
Spark mem
Spark Task
Spark mem
HDFS disk
block 1
block 3
block 2
block 4 Tachyon in-‐memory
block 1
block 3 block 4
Compute Center
Baidu File System (BFS)
Data Center
• Read from remote data center: ~ 100 ~ 150 seconds
• Read from Tachyon remote node: 10 ~ 15 sec
• Read from Tachyon local node: ~ 5 sec
Tachyon Brings 30X Speed-up !
12

Tachyon Production Usage at Baidu
13

Architecture: Interactive Query Engine
Spark
Tachyon Data Warehouse
Operation Manager
Query UI
View Manager Cache Meta
14

Architecture: Interactive Query Engine
• Operation Manager: – Accepts queries from query UI – Query parsing and optimization using Spark SQL – Checks whether the requested data is already cache: if so, read from Tachyon – Otherwise, initiate a spark job to read from Data warehouse
• View Manager: – Manages view meta data – Handles requests from operation manager: if cache miss, then build new views by reading
from data warehouse and then writing to Tachyon
• Tachyon: – View cache: instead of caching raw blocks, we cache views – View: <table name, partition key, attributes, data>
• Data Warehouse: – HDFS-based data warehouse that stores all raw data
15

Query: Check Cache
Spark
Tachyon Data Warehouse
Operation Manager
Query UI
View Manager Cache Meta
16
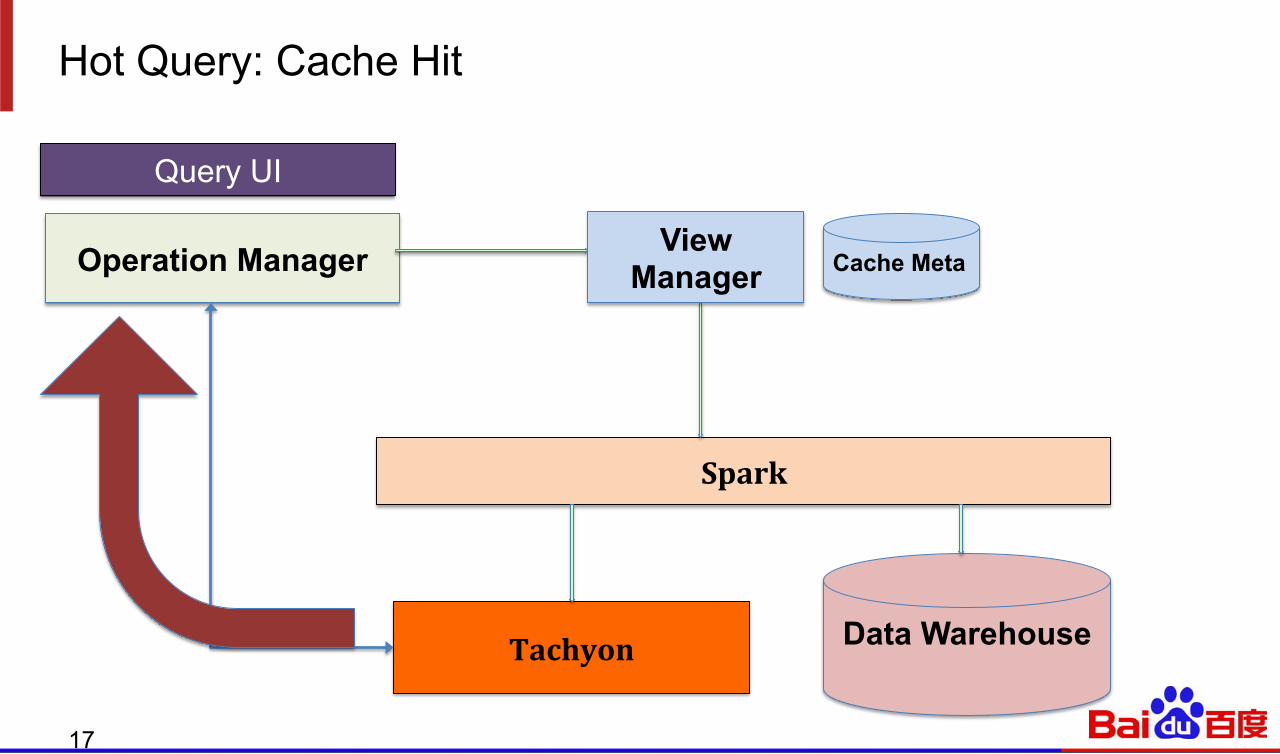
Hot Query: Cache Hit
Spark
Tachyon Data Warehouse
Operation Manager
Query UI
View Manager Cache Meta
17
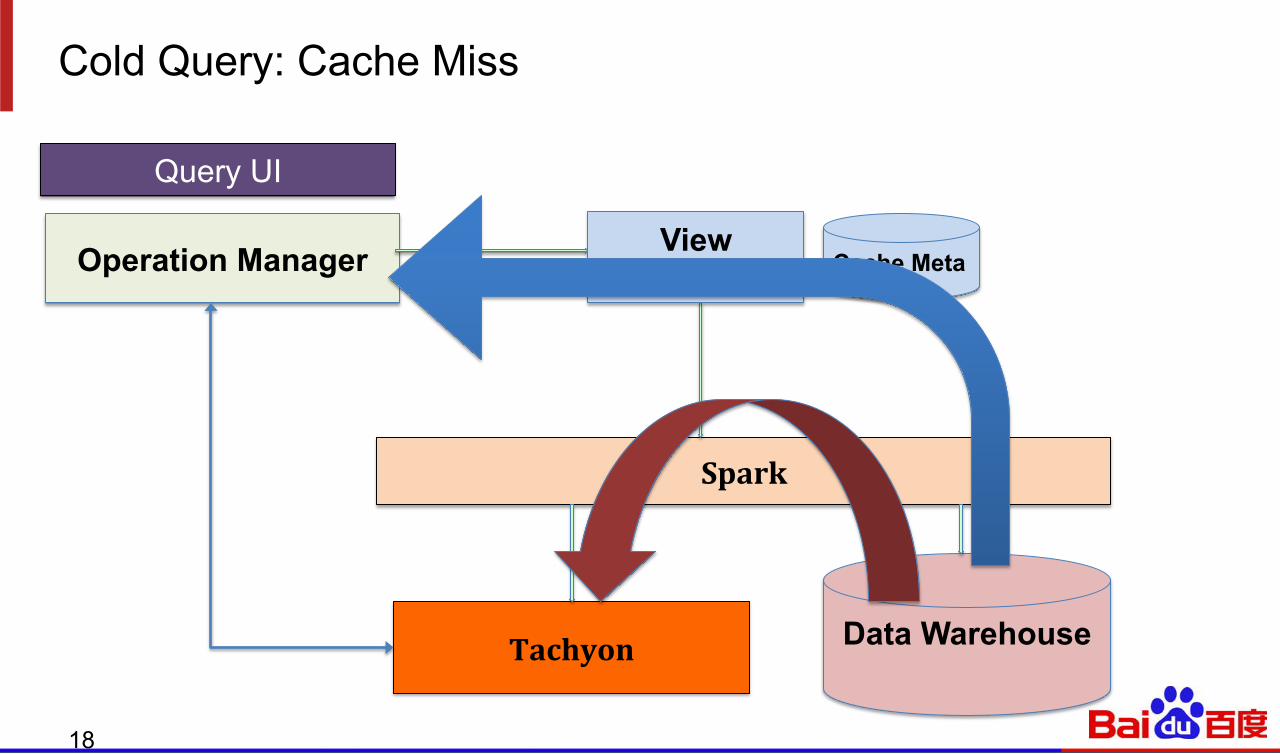
Cold Query: Cache Miss
Spark
Tachyon Data Warehouse
Operation Manager
Query UI
View Manager Cache Meta
18

Examples
SELECT a.key * (2 + 3), b.value FROM T a JOIN T b ON a.key=b.key AND a.key>3
== Physical Plan == Project [(CAST(key#27, DoubleType) * 5.0) AS c_0#24,value#30] BroadcastHashJoin [key#27], [key#29], BuildLeft Filter (CAST(key#27, DoubleType) > 3.0) HiveTableScan [key#27], (MetastoreRelation default, T, Some(a)), None HiveTableScan [key#29,value#30], (MetastoreRelation default, T, Some(b)), None
Once we have the Spark SQL physical plan, we parse the HiveTableScan part and then determines whether the requested view is in Cache
Cache Hit: directly pull data from Tachyon Cache Miss: get data from remote data storage
19

Caching Strategies
• On-Demand (default): – Triggered by cold cache – Query parsing and optimization using Spark SQL – Checks whether the requested data is already cache: if so, read from Tachyon – Otherwise, initiate a spark job to read from Data warehouse
• Prefetch: (new feature for Tachyon?) – Current Strategy: analyze prefetch patterns of the past month, and then use a static strategy – Based on user behavior, prefetch data before users actually access the data – Finer details:
• Which storage tier should we put the data into? • Do we actively delete obsolete blocks or just let it phase out?
20

Problems Encountered in Practice
21

Problem 1: Failed to Cache Blocks Problem
In our experiments, we observe that blocks can not be cached by Tachyon, the same query would keep going to fetch blocks from the storage node instead of from Tachyon
22

Problem 1: Failed to Cache Blocks Problem
23
Root Problem: Tachyon would only cache the block if the whole block has been read Solution: read the whole block if you want to cache it

Problem 2: Locality Problem
• DAGScheduler:
– When DAGScheduler schedules tasks, it schedules tasks on the workers that have the data to make sure there is no network traffic, and thus high performance
• Also, the master thinks that it is local (no remote fetch needed)
24

Problem 2: Reality
• However, we do observe heavy network traffic:
• Impact:
– We expect the Tachyon cache hit rate is 100% – We end up with 33% cache hit rate
25
Root Problem: we were using a very old InputFormat Solution: update your InputFormat

Problem 3: SIGBUS
26

Problem 3: SIGBUS
27
Root Problem: bug in Java 1.6 CompressedOops feature Solution: disable CompressedOops or update your Java version
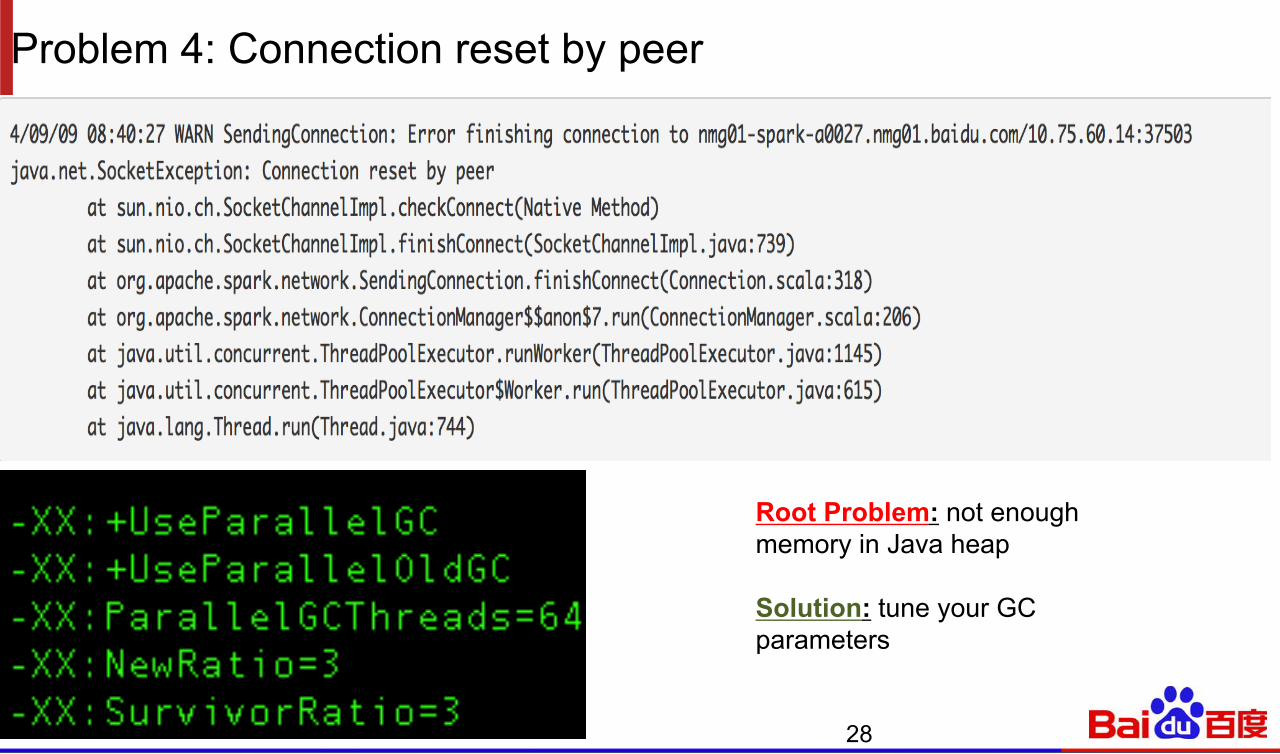
Problem 4: Connection reset by peer
28
Root Problem: not enough memory in Java heap Solution: tune your GC parameters

None of the Problems is a Tachyon Problem !
• Problem 1: need to understand the design of Tachyon first • Problem 2: HDFS Input Format Problem
• Problem 3: Java Version Problem
• Problem 4: Memory Budget \ GC Problem
29

Advanced Features
30

Not Enough Cache Space?
• Problem: – Not enough cache space if we cache everything in memory – E.g. a machine with 60 GB of memory, 30 GB given to Spark, and 20 GB
given to Tachyon, 10 such machines would only give us 200 GB of cache space.
• Solution: – What if we extend Tachyon to expand to other storage medium in addition to
memory – Tiered Storage:
• Level 1: Memory • Level 2: SSD • Level 3: HDD
31

Tiered Storage Design
Write Path
32
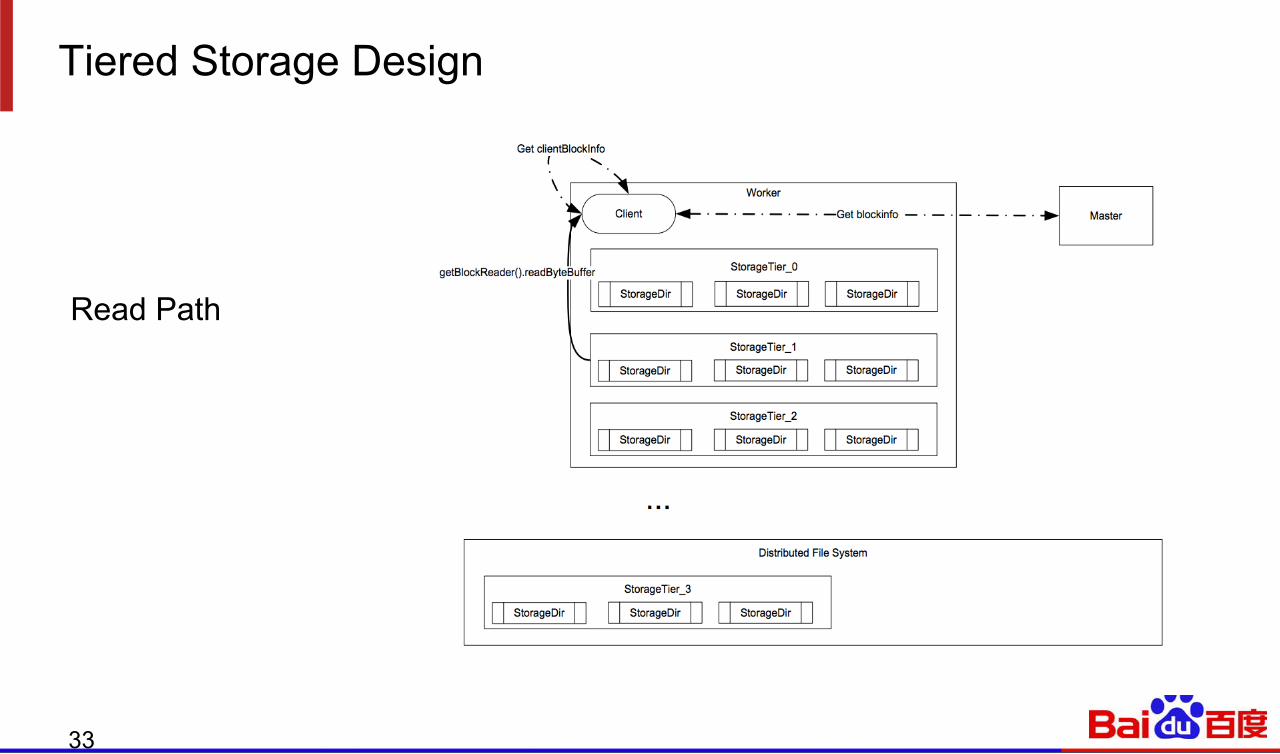
Tiered Storage Design
Read Path
33

Tiered Storage Deployment
• Currently use two layers: MEM and HDD • MEM: 16GB per machine (will expand when we get more memory) • HDD: 10 disks with 2TB each (currently use 6 of them, can expand) • > 100 machines: over 2 PB storage space
34
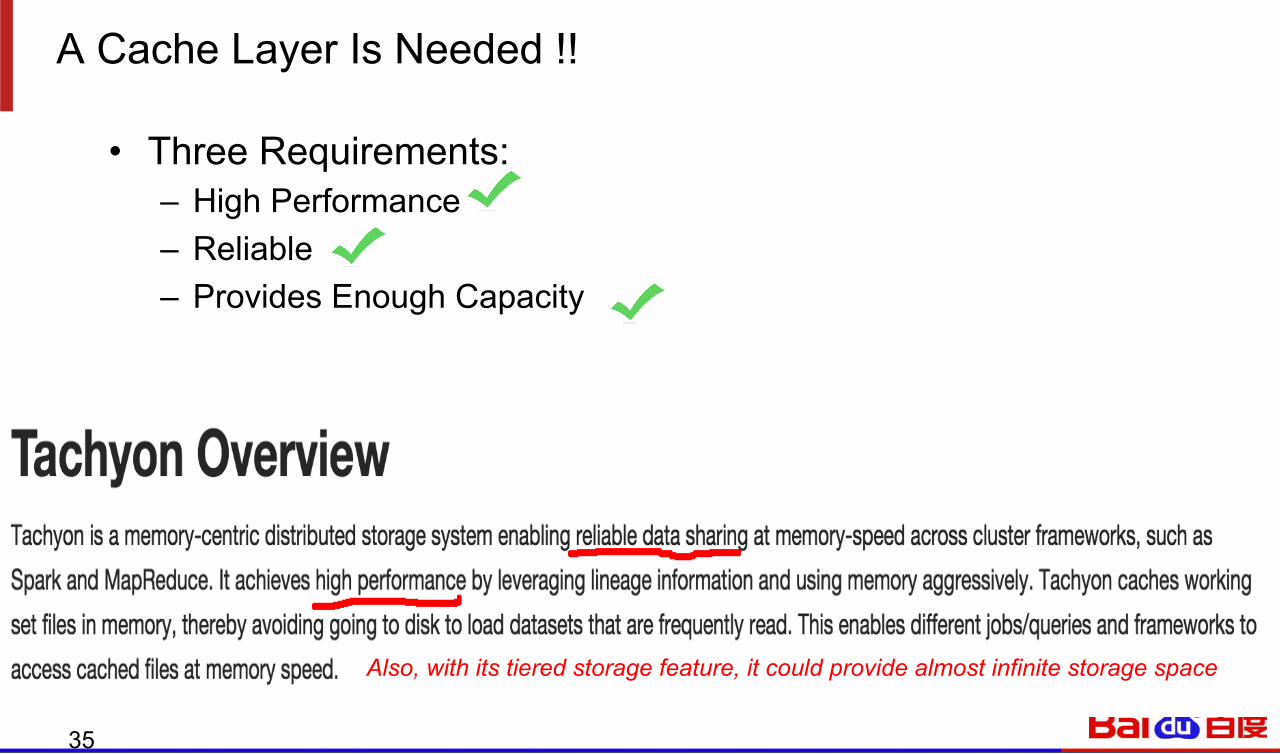
A Cache Layer Is Needed !!
35
• Three Requirements: – High Performance – Reliable – Provides Enough Capacity
Also, with its tiered storage feature, it could provide almost infinite storage space

Performance Deep Dive
36
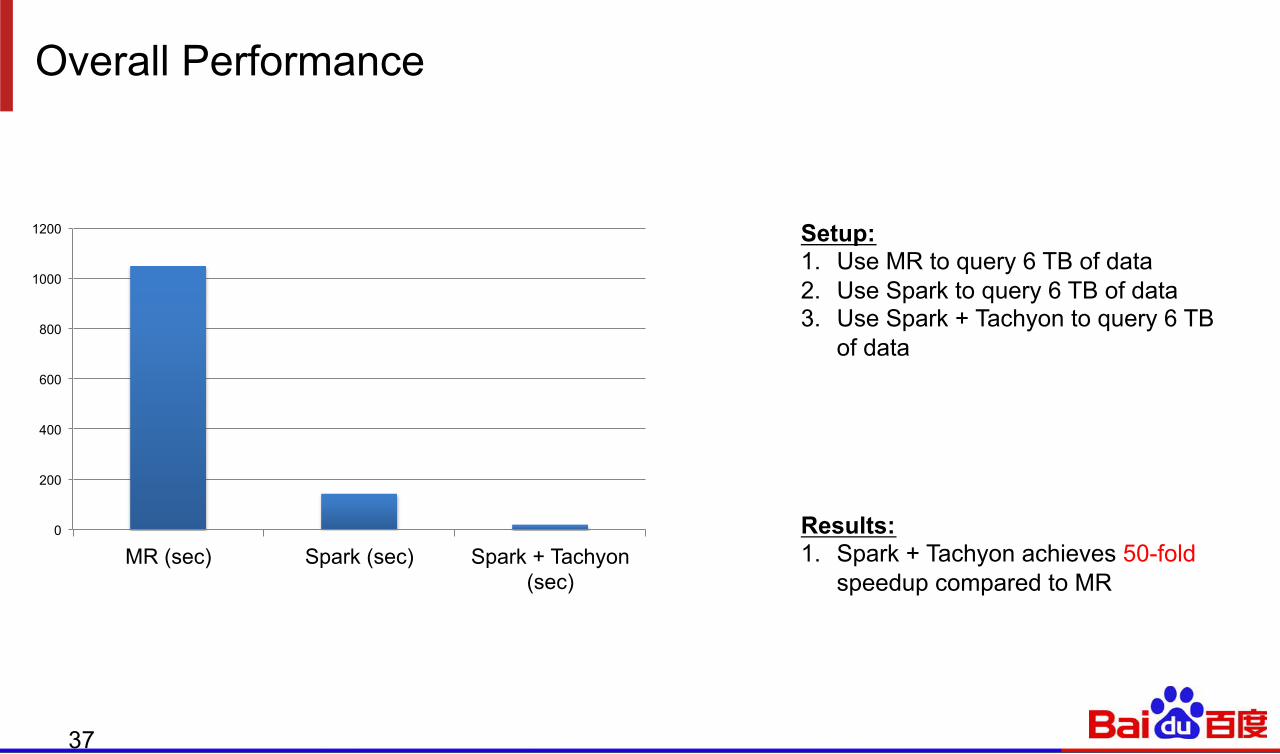
Overall Performance
0
200
400
600
800
1000
1200
MR (sec) Spark (sec) Spark + Tachyon (sec)
Setup: 1. Use MR to query 6 TB of data 2. Use Spark to query 6 TB of data 3. Use Spark + Tachyon to query 6 TB
of data
Results: 1. Spark + Tachyon achieves 50-fold
speedup compared to MR
37
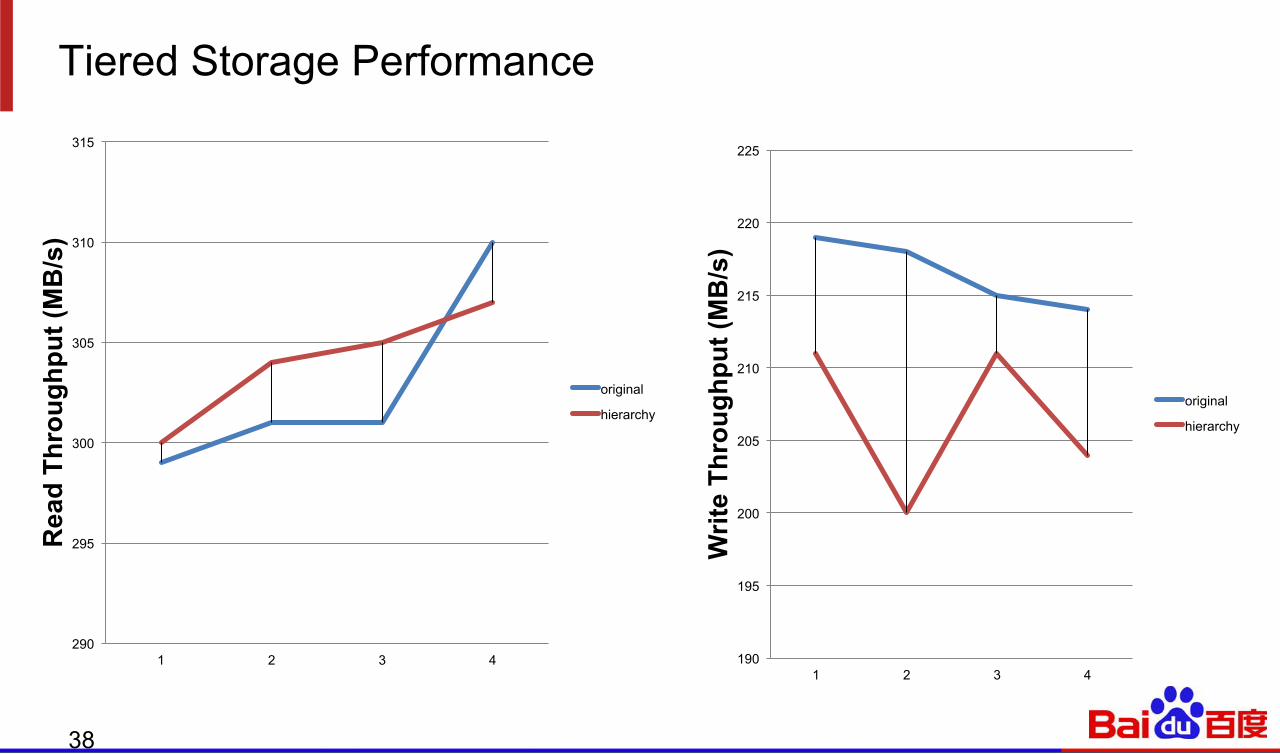
Tiered Storage Performance
190
195
200
205
210
215
220
225
1 2 3 4
Writ
e Th
roug
hput
(MB
/s)
original
hierarchy
290
295
300
305
310
315
1 2 3 4
Rea
d Th
roug
hput
(MB
/s)
original
hierarchy
38
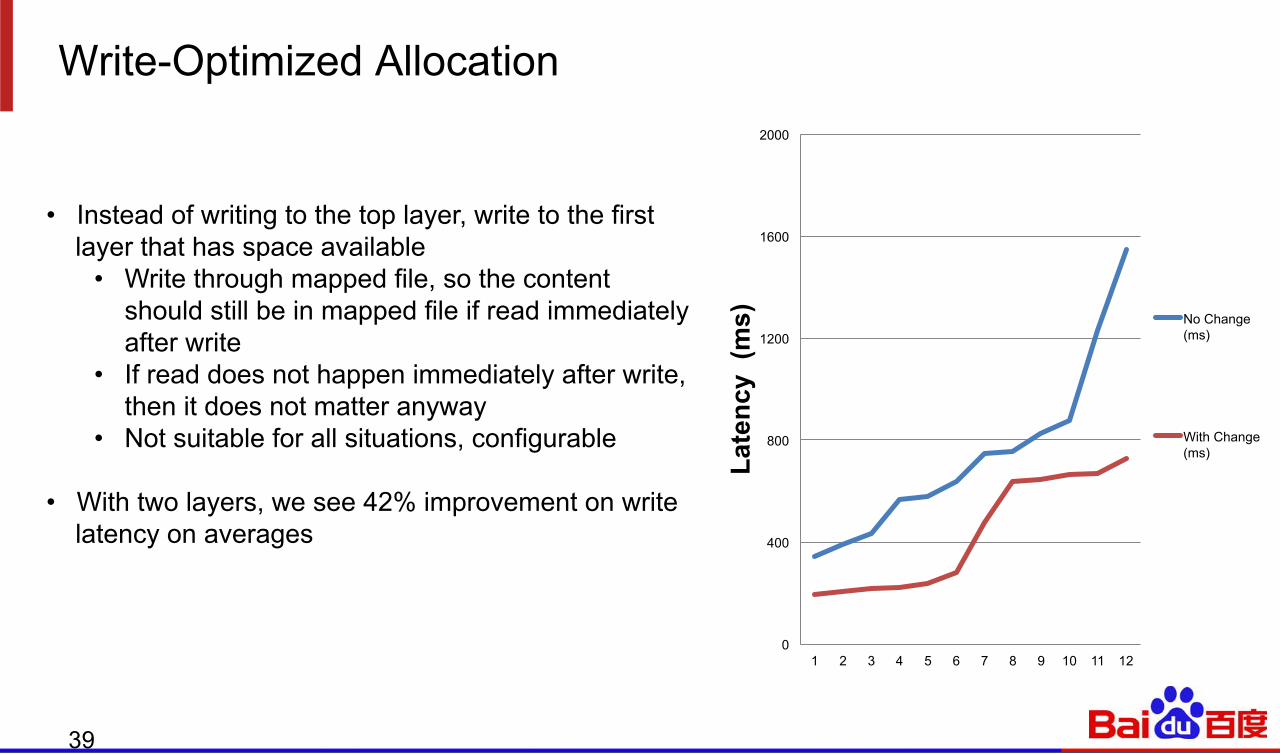
Write-Optimized Allocation
0
400
800
1200
1600
2000
1 2 3 4 5 6 7 8 9 10 11 12
Late
ncy
(ms)
No Change (ms)
With Change (ms)
• Instead of writing to the top layer, write to the first layer that has space available
• Write through mapped file, so the content should still be in mapped file if read immediately after write
• If read does not happen immediately after write, then it does not matter anyway
• Not suitable for all situations, configurable
• With two layers, we see 42% improvement on write latency on averages
39

Micro-Benchmark Setup: 1. Tiered storage with 1 disk in HDD
layer 2. Tiered storage with 6 disks in HDD
layer 3. Tiered storage with 6 disks in HDD
layer, and with write-optimization 4. OS Paging/Swapping On
Conclusions: 1. Current tiered storage
implementation cant beat OS paging 2. Need better write mechanism, a
garbage collection mechanism would be even better
40
0 20 40 60 80
100 120 140 160 180
tiered storage 1 disk
tiered storage 6 disks
tiered storage 6 disks write
optimization
OS paging
elapsed time (Sec)

About Debugging: You are as good as your tools! new feature for Tachyon?
41
Debugging: Master
• Three logs generated on the Master Side
• Master.log • Normal logging info
• Master.out • Mostly GC / JVM info
• User.log • Rarely used
42
Debugging: Worker
• Three logs generated on the Worker Side
• Worker.log • Normal logging info
• Worker.out • Mostly GC / JVM info
• User.log • Rarely used
43

Debugging: Client
• Client is built into Spark Executor • Just check Spark App stdout log
for more information
44

Future Works
45

Welcome to Contribute • Use of Tachyon as a parameter Server (Machine Learning)
• Restful API support for Tachyon
• Garbage Collection Feature
• Cache Replacement policy
– Currently on LRU by default – Better policies may improve hit rate in different scenarios
• And More……
46

Make your system fly at tachyon speed
http://tachyon-project.org/
Top Related