
TUGboat, Volume 34 (2013), No. 1 47 - LaTeX · 48 TUGboat, Volume 34 (2013), No. 1 Figure 1:...
17
TUGboat, Volume 34 (2013), No. 1 47 E-T E X: Guidelines for Future T E X Extensions — revisited Frank Mittelbach Contents 1 Introduction 47 2 A short history of “Extended”-T E X engines 48 2.1 pT E X .................. 48 2.2 ML-T E X ................ 48 2.3 N T S /ε X T E X .............. 49 2.4 ε-T E X ................. 49 2.5 Omega/Aleph ............. 49 2.6 pdfT E X ................ 49 2.7 X E T E X ................. 49 2.8 LuaT E X ................ 50 2.9 iT E X .................. 50 3 Review of the issues raised in 1990 50 3.1 Line breaking ............. 50 3.1.1 Line-breaking parameters .. 51 3.2 Spacing ................ 51 3.3 Page breaking ............. 52 3.4 Page layout .............. 54 3.5 Penalties — measurement for decisions 55 3.6 Hyphenation ............. 55 3.7 Box rotation ............. 56 3.8 Fonts .................. 56 3.9 Tables ................. 57 3.10 Math .................. 57 3.11 T E X’s language ............ 58 4 Overcoming the mouth/stomach separation 59 4.1 A standard T E X solution ....... 60 4.2 A LuaT E X solution .......... 61 5 Conclusions 61 List of Figures 1 T E X-like engines evolution ...... 48 2 Areas of concern in original article . 50 3 Interword spacing ........... 52 4 T E X’s box/glue/penalty model ... 53 5 Baseline to baseline spacing ..... 55 6 The expl3 logo ............ 58 Abstract Shortly after Don Knuth announced T E X 3.0 I gave a paper analyzing T E X’s abilities as a typesetting engine. The abstract back then said: Now it is time, after ten years’ experience, to step back and consider whether or not T E X 3.0 is an adequate answer to the typesetting re- quirements of the nineties. Output produced by T E X has higher stan- dards than output generated automatically by most other typesetting systems. Therefore, in this paper we will focus on the quality stan- dards set by typographers for hand-typeset documents and ask to what extent they are achieved by T E X. Limitations of T E X’s algo- rithms are analyzed; and missing features as well as new concepts are outlined. Now — two decades later — it is time to take another look and see what has been achieved since then, and perhaps more importantly, what can be achieved now with computer power having multiplied by a huge factor and, last but not least, by the arrival of a number of successors to T E X that have lifted some of the limitations identified back then. 1 Introduction When I was asked by the organizers of the TUG 2012 conference to give a talk, I asked myself What am I currently working on that could be of interest? The answer I gave myself was: I’m working on ideas to resolve or at least lessen the issues around complex page layout; in particular mechanisms to re-break textual material in different ways so that you can, for example, evaluate different float placements in conjunction with different caption formats, or to float galley text in different ways around floats protruding into the galley. All that goes way back in time: the issues were formulated more than 20 years ago in a paper I gave in 1990 in Texas: “E-T E X: Guidelines for future T E X extensions” [26]. Back then there were no answers to the issues raised. However, that was a long time ago; computers got faster and people invented various T E X extensions since then — and once in a while there are even new ideas. So when I reread my paper from that time I thought that it would be a good idea to analyze the issues listed from the 1990 paper again and see what has been achieved since then. This paper starts with a short overview of the history of T E X’s successor engines and the capabili- ties they added or improved. We will then re-analyze issues discussed two decades ago and evaluate their status. We conclude with a summary of the findings and a suggestion for a way forward. E-T E X: Guidelines for Future T E X Extensions — revisited
Transcript of TUGboat, Volume 34 (2013), No. 1 47 - LaTeX · 48 TUGboat, Volume 34 (2013), No. 1 Figure 1:...

TUGboat, Volume 34 (2013), No. 1 47
E-TEX: Guidelines for Future TEXExtensions—revisited
Frank Mittelbach
Contents
1 Introduction 47
2 A short history of “Extended”-TEX engines 482.1 pTEX . . . . . . . . . . . . . . . . . . 482.2 ML-TEX . . . . . . . . . . . . . . . . 482.3 NTS/εXTEX . . . . . . . . . . . . . . 492.4 ε-TEX . . . . . . . . . . . . . . . . . 492.5 Omega/Aleph . . . . . . . . . . . . . 492.6 pdfTEX . . . . . . . . . . . . . . . . 492.7 X ETEX . . . . . . . . . . . . . . . . . 492.8 LuaTEX . . . . . . . . . . . . . . . . 502.9 iTEX . . . . . . . . . . . . . . . . . . 50
3 Review of the issues raised in 1990 503.1 Line breaking . . . . . . . . . . . . . 50
3.1.1 Line-breaking parameters . . 513.2 Spacing . . . . . . . . . . . . . . . . 513.3 Page breaking . . . . . . . . . . . . . 523.4 Page layout . . . . . . . . . . . . . . 543.5 Penalties — measurement for decisions 553.6 Hyphenation . . . . . . . . . . . . . 553.7 Box rotation . . . . . . . . . . . . . 563.8 Fonts . . . . . . . . . . . . . . . . . . 563.9 Tables . . . . . . . . . . . . . . . . . 573.10 Math . . . . . . . . . . . . . . . . . . 573.11 TEX’s language . . . . . . . . . . . . 58
4 Overcoming the mouth/stomach separation 594.1 A standard TEX solution . . . . . . . 604.2 A LuaTEX solution . . . . . . . . . . 61
5 Conclusions 61
List of Figures
1 TEX-like engines evolution . . . . . . 482 Areas of concern in original article . 503 Interword spacing . . . . . . . . . . . 524 TEX’s box/glue/penalty model . . . 535 Baseline to baseline spacing . . . . . 556 The expl3 logo . . . . . . . . . . . . 58
Abstract
Shortly after Don Knuth announced TEX 3.0 I gavea paper analyzing TEX’s abilities as a typesettingengine. The abstract back then said:
Now it is time, after ten years’ experience, tostep back and consider whether or not TEX 3.0
is an adequate answer to the typesetting re-quirements of the nineties.
Output produced by TEX has higher stan-dards than output generated automatically bymost other typesetting systems. Therefore, inthis paper we will focus on the quality stan-dards set by typographers for hand-typesetdocuments and ask to what extent they areachieved by TEX. Limitations of TEX’s algo-rithms are analyzed; and missing features aswell as new concepts are outlined.
Now — two decades later — it is time to take anotherlook and see what has been achieved since then, andperhaps more importantly, what can be achievednow with computer power having multiplied by ahuge factor and, last but not least, by the arrival ofa number of successors to TEX that have lifted someof the limitations identified back then.
1 Introduction
When I was asked by the organizers of the TUG 2012conference to give a talk, I asked myself
What am I currently working on that couldbe of interest?
The answer I gave myself was: I’m working on ideasto resolve or at least lessen the issues around complexpage layout; in particular mechanisms to re-breaktextual material in different ways so that you can,for example, evaluate different float placements inconjunction with different caption formats, or to floatgalley text in different ways around floats protrudinginto the galley.
All that goes way back in time: the issues wereformulated more than 20 years ago in a paper I gavein 1990 in Texas: “E-TEX: Guidelines for future TEXextensions” [26]. Back then there were no answers tothe issues raised. However, that was a long time ago;computers got faster and people invented variousTEX extensions since then — and once in a whilethere are even new ideas.
So when I reread my paper from that time Ithought that it would be a good idea to analyze theissues listed from the 1990 paper again and see whathas been achieved since then.
This paper starts with a short overview of thehistory of TEX’s successor engines and the capabili-ties they added or improved. We will then re-analyzeissues discussed two decades ago and evaluate theirstatus.
We conclude with a summary of the findingsand a suggestion for a way forward.
E-TEX: Guidelines for Future TEX Extensions — revisited

48 TUGboat, Volume 34 (2013), No. 1
Figure 1: TEX-like engines evolution
2 A short history of “Extended”-TEXengines
Professor Donald Knuth developed the first versionof the TEX program in 1978–79 [16, 17]. (The firstspecifications in writing date back to 1977; see [21].)Over the course of the next two years he improvedand changed the program further and it then becameknown as TEX 82. This was the first widespreadversion of TEX, with documented source code [19]and a published manual [18], and people all over theworld started using it.
Back then TEX used 7-bit fonts and typeset-ting in languages that required diacritics (as mostEuropean languages do) was difficult because, forexample, hyphenation didn’t work properly in thatcase. Also, mixing of several languages in one docu-ment was impossible, at least if one wanted them tobe hyphenated automatically.
Therefore, in 1989 a delegation of TEX usersfrom Europe came to the Stanford meeting and pre-sented Don with a proposal to extend TEX in sev-eral ways [31]. After several meetings and publicdiscussions, Don recognized that he did not origi-nally foresee a need for 8-bit input, and he agreedto extend TEX slightly to account for the needs of
the extended user base [20]. However, he only ac-cepted those proposals that could be achieved withminimal adjustments to the existing program. Ifyou compare The TEXbook before and after, youwill have difficulty spotting the differences, becauseapart from the introduction of language support,nothing much changed. For example, my requestfor \holdinginserts was added because that wastrivial to implement, but the suggestion for provid-ing \reconsiderparagraph (to allow undoing theparagraph breaking to re-typeset it under differentconditions) was rejected, as it would have meant moredrastic updates to the paragraph-breaking algorithm.
This new version of TEX was called TEX 3.0,and shortly afterwards Don publicly announced thatthere would be no further version of TEX (except forbug fixes) and that his involvement in any futuredevelopment of typesetting engines has ended withthat version [20]. That announcement prompted meto analyze TEX’s abilities compared to high qualityhand-typeset documents resulting in the paper givenat the conference in Texas.
While TEX was thus officially frozen with ver-sion 3.0, other people started to build TEX enginevariants to resolve one or another issue. The mostinfluential ones are briefly outlined below; a nice over-view of the more complete picture is given in [40],from which Figure 1 was taken with kind permission.
In the following we only discuss the major de-velopments that contributed in one way or the otherto an enriched feature set of the engine or have beeninfluential in other ways.
2.1 pTEX
Typesetting in Japanese requires support of a hugecharacter set and the ability to handle different type-setting directions. Thus early on developers in Japancreated an extension to TEX that supports both Kanji(two-byte fonts) and proper vertical typesetting, inaddition to TEX’s horizontally oriented approach.Early versions of pTEX predate TEX 3.0 [11,32].
2.2 ML-TEX
One of the earliest attempts to modify TEX itselfto handle the problem of multilingual typesettingwas Michael Ferguson’s work on ML-TEX. Amongstother things it added a \charsubdef primitive thatprovided substitutions for accented characters. Thisway TEX’s hyphenation algorithm would be ableto correctly hyphenate words with diacritics, evenif the fonts used did not contain the characters asindividual glyphs.
With the availability of T1-encoded fonts (con-taining most of the accented characters used in
Frank Mittelbach

TUGboat, Volume 34 (2013), No. 1 49
“Western” languages as individual glyphs) ML-TEXwas no longer necessary for these languages. Never-theless, it is still available in most engines, but needsto be explicitly enabled on the command line.
2.3 NTS/εXTEX
The NTS project (New Typesetting System) wasinaugurated by DANTE (the German TEX UsersGroup) in 1992. Its objective was to re-implementTEX in a 100% compatible way in Java. While TEXwas frozen, NTS was to remain flexible and exten-sible. The project completed successfully in 2000,passing the trip test, and thus proving that a reim-plementation of TEX in a different language waspossible. As it turned out though, full compatibilitywith TEX resulted in code that was less modular thaninitially hoped for, so that adding any extensionsor providing modifications of algorithms turned outto be far more difficult than initially anticipated.For this and a number of other reasons, NTS itselfwasn’t developed any further.
εXTEX is a spin-off started around 2003 withthe intention of developing a new Java-based sys-tem incorporating the experiences from NTS, ε-TEX,pdfTEX and Omega. The project is represented onthe web [1], but as of today it hasn’t left alpha stage.
2.4 ε-TEX
ε-TEX started out in 1992 as a project by PeterBreitenlohner reimplementing ideas by Knuth [15] fora bi-directional extension but avoiding the need forspecial DVI drivers. Ideas for additional extensionsthen were added, and in 1994 the first version ofε-TEX was published.
Around that time members from the NTS teamjoined the effort and during 1994–98 ε-TEX was run asan NTS-project in order to provide a small numberof useful extensions to TEX to fill the gap whileNTS was still under development. As it turned out,however, this set of extensions took on a life of itsown and over time was incorporated into all majorTEX-based engines. As a result, nowadays one canassume that all engines support the original TEXprimitives plus the extensions offered by ε-TEX.
The new features offered by ε-TEX are a num-ber of additional programming primitives and bettertracing facilities, support for mixed-direction typeset-ting, and an increase in the number of most registertypes. In the area of micro-typography enhance-ments, it offers a generalization of \orphanpenaltyand \widowpenalty by supporting special penaltyvalues for the first or last n lines. It also added amethod to adjust the spacing in the last line of a para-
graph to be close to that of the preceding line (insteadof being set tight as standard TEX normally does).
2.5 Omega/Aleph
Omega, developed by John Plaice with Yannis Hara-lambous contributing ideas and developing fonts,was the first extension of the TEX program that sup-ported Unicode instead of 8-bit input encodings. Thedriving force behind its development was to enhanceTEX’s multilingual typesetting abilities and bettersupport for complex scripts.
Aleph is a spin-off of Omega that was startedto include ε-TEX capabilities and stabilize the codebase. Neither project is being developed any more,but most of Aleph’s and thus Omega’s functionalityhas been integrated into LuaTEX.
2.6 pdfTEX
The pdfTEX engine started as a Master’s thesis byHan The Thanh in the mid-nineties and initiallyoffered PDF output, support for embedded Type 1fonts, virtual fonts, hyper-links, and compression.
For his PhD thesis [37], Han The Thanh exper-imented with various micro-typography algorithmsincluding the hz approach [42] and several of themwere implemented in pdfTEX [38,39].
Today, pdfTEX (with the ε-TEX extensions in-cluded) is the dominant TEX-based engine in practi-cal use, i.e., all major distributions use this programas the default TEX engine.
2.7 X ETEX
X ETEX is one of the more recent additions to the TEXengine successors [6]. It was created by JonathanKew and provides as one of its major distinguishingfeatures extensive support for modern font technolo-gies such as OpenType, Graphite and Apple Ad-vanced Typography (AAT). It can make direct useof the advanced typographic features offered by thesefont technologies, such as alternative glyphs, swashes,optional ligatures, variant weights, etc. These fontscan be used without the need for configuring TEXfont metrics for them.1
X ETEX natively supports Unicode both for input(UTF-8 encoding) as well as for accessing font glyphs.It can also typeset mathematics using Unicode fontssuch as Cambria Math or Asana Math [3], providedthey contain special mathematical features.
1. The downside of this is that it can’t be guaranteed thatthe formatting of a source document does not change overtime (when libraries are updated on the host system) andthere is no way to freeze all components of a document, as ispossible with traditional TEX.
E-TEX: Guidelines for Future TEX Extensions — revisited

50 TUGboat, Volume 34 (2013), No. 1
Figure 2: Areas of concern in original article
2.8 LuaTEX
LuaTEX made its first public appearance in 2005at the TUG conference in China, as a version ofpdfTEX with an embedded Lua scripting engine. Thefirst public beta was presented in 2007. It is beingdeveloped by a core team of Hans Hagen, HartmutHenkel and Taco Hoekwater [4].
Important project objectives are merging of en-gines (combining ideas from Aleph and pdfTEX),support for OpenType fonts, and access to all TEXinternals from Lua. Through various callbacks it ispossible to hook into TEX’s typesetting algorithmsand adjust or even replace them.
2.9 iTEX
Finally, as the ultimate successor engine we have orwill have iTEX, a fictitious XML-based successor toTEX announced by Donald Knuth at the TUG 2010conference in San Francisco [14]. According to itsauthor this program will resolve all issues related tohigh quality typesetting, including those that aren’tyet discovered — we can only hope that it doesn’ttake Don too much time to finish it.
3 Review of the issues raised in 1990
With the knowledge of what today’s successors ofthe TEX engine are capable of, we are now ready tore-analyze the issues discussed two decades ago andevaluate which of them are nowadays:
1. resolved (best case, denoted byU below), or
2. could now be resolved using the improvedfeatures of modern engines (hopeful case,denoted byR), or
3. is still out there waiting for a resolution(bad case, denoted byD).
We follow the order of the original paper (see Fig-ure 2) to help people looking up additional detailson the problems outlined. It is available in facsimileon the web [26].
3.1 Line breaking
TEX’s line-breaking algorithm is clearly a central partof the TEX system. Instead of finding breaks lineby line, the algorithm regards paragraphs as a unitand searches for an ‘optimal solution’ based on thecurrent values of several parameters. Consequently,a comparison of results produced by TEX and othersystems will normally favor TEX’s methods.
Such an approach, however, has its drawbacks,especially in situations requiring more than block-style text with a fixed width.
R Issue: No post-processing of final lines based ontheir content
The final line breaks are determined at a time wheninformation about the content of the current line hasbeen lost (at least for the eyes of TEX, i.e., its ownmacro language), so that TEX provides no supportfor post-processing of the final lines based on theircontent.
For example, the last line of a paragraph isusually typeset using normal spacing between words,even if the previous line has been set loosely or tightly.(ε-TEX can now handle this to some extent, with its\lastlinefit primitive.)
Another example is that the tallest object in aline determines its height or depth so that lines might
Frank Mittelbach

TUGboat, Volume 34 (2013), No. 1 51
get spread apart, even if they would fit perfectly.In theory these issues could now be catered
to with the LuaTEX program, because it offers theability to post-process the lines and modify the finalappearance.
DR Issue: No way to influence the paragraphshape with regard to the current position on the page
TEX and all its successors break paragraph text intolines at a time where they do not know where thistext will eventually appear on a page. Consequently,there is no possibility within the model of cateringto special paragraph shape requirements based onthat position.
The only way to work around this is a complexfeedback loop, using placement information from aprevious run to calculate the necessary \parshape.Because this requires multi-pass formatting (withmany passes), it is impractical. A simpler, thoughstill complicated, approach is to assume a strict linearformatting, in which case one can build the para-graph shapes one after the other.
A new approach, that we are currently exploringfor LATEX3, involves storing paragraph data in a datastructure that allows re-breaking the material fortrial typesetting. This is outlined in Section 4.
3.1.1 Line-breaking parameters
While the algorithm provides a wide variety of pa-rameters to influence layout, some important onesfor high-quality typesetting are missing. To resolvesome of these issues, we need only (slightly) modifyor extend the current algorithm. For others, seri-ous research is required just to understand how asolution might be approached.
None of the engines has modified the TEX al-gorithm, so all of the problems are still unsolved.LuaTEX offers a way to replace the whole algo-rithm, but for most of these problems, that wouldbe overkill, because it would require reprogrammingeverything from scratch in Lua.
R Issue: Zero-width indentation box
When TEX breaks text into individual lines it dis-cards whitespace and kerns at both sides of eachline except for the first. On the left side of the firstline (in left-to-right formatting) the existence of theparagraph indentation box prevents this from hap-pening. Normally this is not noticeable, but in thecase of layouts without paragraph indentation it canlead to problems, e.g., when \mathsurround has apositive value.
In LuaTEX this could now be resolved by defin-ing code that preprocesses the paragraph material
and removes discardable items following the inden-tation box.
D Issue: Managing consecutive hyphens in ageneral way
In TEX it is possible to discourage two consecutivehyphens, but there is no way to prohibit or stronglydiscourage three or more. Technically, this wouldmean a slight extension of the current algorithm bykeeping track of the number of hyphens in a row.None of today’s engines supports that concept.
R Issue: Only four types of line quality
To implement good-looking paragraphs, TEX classi-fies each line into one of four categories based on theline’s glue setting (tight, decent, loose, very loose). Itthen uses that classification to avoid abrupt changesin spacing (if possible). However, the small numberof classes results in grouping of fairly incompatiblesettings in a single class (especially, loose and veryloose are affected). Technically, it would be simpleto extend the number of classes to support bettergranularity.
D Issue: Rivers and identical words across lines
If interword spaces from different lines happen tofall close to each other, they form noticeable stripes(rivers) through the paragraph that can be quitedisconcerting. TEX’s line-breaking algorithm is un-able to detect such situations. Resolving this wouldrequire serious research into the question on howto detect rivers and how to classify the “badness”of different scenarios in order to programmaticallyhandle it through an algorithm.
A somewhat related issue (but rather easier toresolve) is the placement of the same word at thesame position in consecutive lines, especially at thebeginnings of lines, which is likely to disrupt thereading flow.
3.2 Spacing
Micro-typography deals with methods for improv-ing the readability and appearance of text; see forexample [5]. While TEX already does a great job inthis area, some of the finer controls and methods arenot available in the original program.
However, most of them have been implementedin some of the successor engines and an interface forLATEX to these micro-typography features is providedthrough the package microtype [33].
R Issue: No flexible interword spacing
In order to produce justified text, a line-breakingalgorithm has to stretch or shrink the interword
E-TEX: Guidelines for Future TEX Extensions — revisited

52 TUGboat, Volume 34 (2013), No. 1
Das
2
Aus
6
kam
7
in
5
der
3
letzten
4
Runde,
1
wobei
Das Aus kam in der letzten Runde, wobei
Das Aus kam in der letzten Runde, wobei
Das Aus kam in der letzten Runde,wobei
DasAus kam in der letzten Runde,wobei
DasAus kam in der letztenRunde,wobei
Das Aus kam in der letzten Runde, wobei
Figure 3: Interword spacing
The interword spaces are numbered in a way sothat higher numbers denote spaces which shouldshrink less using the rules given by Siemoneit [34].The last line shows the resulting overfull boxwhich would be produced by standard TEX inthis situation.
space starting from some optimal value (e.g., givenby the font designer) until the final word positionsare determined. TEX has a well-designed algorithmto take such stretchability into account. It can alsoalter spacing depending on the character in front ofthe space to change the behavior after punctuation,for example.
There is no provision, however, for influencingthe interword spaces in relation to the current char-acters on both word boundaries. Ideally, shrinkingor stretching should depend on the character shapeson both sides of the space as exemplified in Figure 3.
None of the TEX successors provides any ad-ditional support for controlling the interword spac-ing above and beyond TEX’s capabilities. But withLuaTEX’s callback interfaces it is possible to analyzeand modify textual material just before it is passedto the line-breaking algorithm. This allows for waysto resolve this issue either as a table-based solution(one size fits all), or on a more granular level wherethe chosen adjustments are tied to the current font.
U Issue: No flexible intercharacter spacing
Instead of, or in addition to, stretching or shrinkingthe interword spaces to produce justified text, thereare also the methods of tracking (increasing or de-creasing inter-letter spaces) and expansion (changingthe width of glyphs). There are debates by designerswhether such distortions are acceptable approaches,but there is not much doubt that, if used with careand not excessively, they can help to successfullyresolve difficult typesetting scenarios.2
pdfTEX provides both methods, the latter byimplementing a version of the hz algorithm originallydeveloped by Hermann Zapf and Peter Karow [42].
U Issue: No native support for hanging punctuation
Don Knuth [18, pp. 394–395] gave an example of howto achieve hanging punctuation but it required the
use of specially adjusted fonts and it also interferedwith the ligature mechanism. In other words, it isonly a partial solution for restricted scenarios.
Fortunately, a fully general solution was im-plemented in pdfTEX and later also incorporatedinto LuaTEX, so nowadays this can be considered re-solved. The remainder of the article is typeset usinghanging punctuation to allow for a comparison.
3.3 Page breaking
In 1990 I wrote “The main contribution of TEX 82to computer-based typesetting was the step takenfrom a line-by-line paragraph-breaking algorithm toa global optimizing algorithm. The main goal fora future system should be to solve the similar, butmore complex, problem of global page breaking”.Unfortunately in the TEX world no serious attemptwas made since then to address the fundamentallimitation in TEX’s algorithm, let alone designing andimplementing a globally optimizing page-breakingalgorithm.3
D Issue: TEX generates pages based onprecompiled paragraph data
This issue describes the fundamental problem inTEX’s approach: the program builds optimized para-graph shapes without any knowledge about their finalplacement on a page. The result is a “galley” fromwhich columns are cut to a specified vertical size. Aconsequence of this is that one can’t have the shapeof a paragraph depend on its final position on thepage when using TEX’s page builder algorithm.
To some extent, it is possible to program aroundthis limitation, e.g., by measuring the remainingspace on a page and explicitly changing paragraphshapes after determining where the current textualmaterial will finally appear. However, besides beingcomplicated to implement, it requires accounting forall kinds of special situations that normally wouldbe automatically managed by TEX, and providing“programmed” solutions for them.
As a result, all attempts so far to provide suchfunctionality had to impose strong limitations onthe allowed input material, i.e., they worked onlyin restricted setups and even then, the results wereoften not satisfactory.
2. On page 54 one paragraph was typeset with a negativeexpansion of 3% to avoid an overfull line. See if you can spotit without peeking at the end of the article where we revealwhich it was.
3. In the wider document engineering research communitysome research was carried out in the last thirty years, e.g.,[7, 9, 22,41], but so far none has led to a production system.
Frank Mittelbach
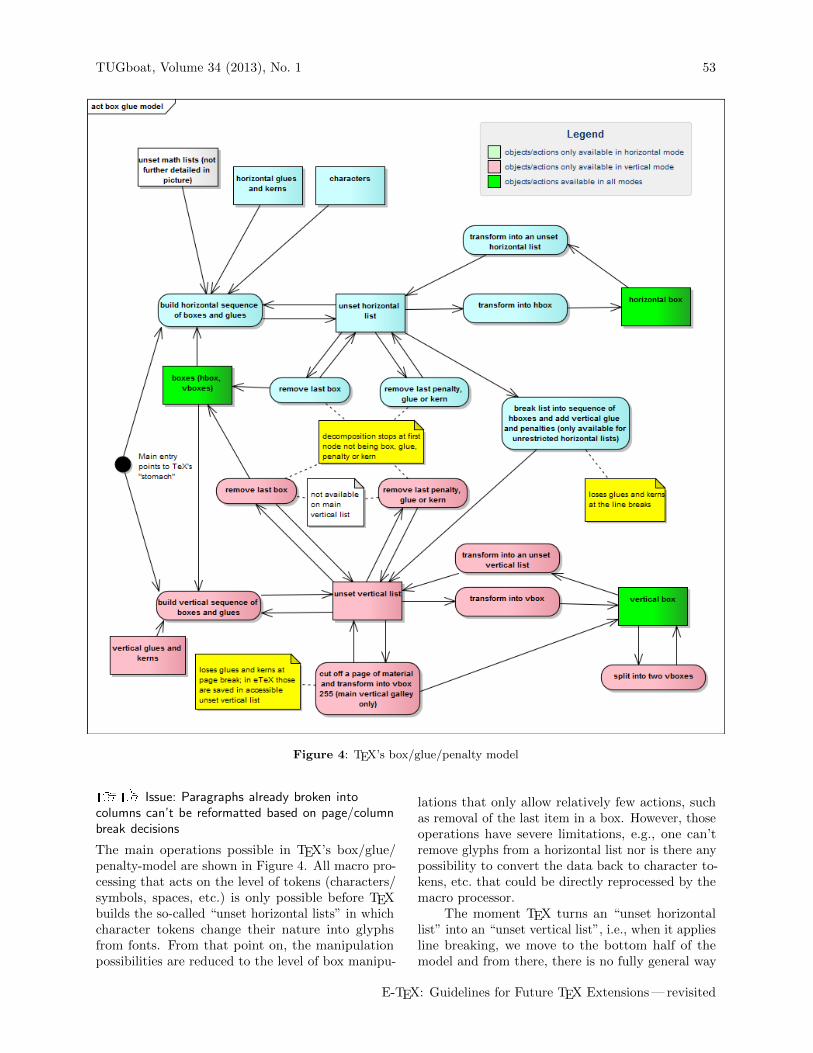
TUGboat, Volume 34 (2013), No. 1 53
Figure 4: TEX’s box/glue/penalty model
RU Issue: Paragraphs already broken intocolumns can’t be reformatted based on page/columnbreak decisions
The main operations possible in TEX’s box/glue/penalty-model are shown in Figure 4. All macro pro-cessing that acts on the level of tokens (characters/symbols, spaces, etc.) is only possible before TEXbuilds the so-called “unset horizontal lists” in whichcharacter tokens change their nature into glyphsfrom fonts. From that point on, the manipulationpossibilities are reduced to the level of box manipu-
lations that only allow relatively few actions, suchas removal of the last item in a box. However, thoseoperations have severe limitations, e.g., one can’tremove glyphs from a horizontal list nor is there anypossibility to convert the data back to character to-kens, etc. that could be directly reprocessed by themacro processor.
The moment TEX turns an “unset horizontallist” into an “unset vertical list”, i.e., when it appliesline breaking, we move to the bottom half of themodel and from there, there is no fully general way
E-TEX: Guidelines for Future TEX Extensions — revisited

54 TUGboat, Volume 34 (2013), No. 1
to get back to the upper half. At the line breaks, wepotentially lose spaces that can’t be recovered. Thus,it is not possible to reconstruct the original “unsethorizontal list” even if we would recursively take offitems from the end of the “unset vertical list” in theattempt to reassemble it.
As a consequence it is not possible to safely reusetextual material once it has been manipulated byTEX’s paragraph builder. Instead one needs to find away to record the “unset horizontal list”. That this iseasily possible in LuaTEX (but also in standard TEXwith somewhat more effort) will be demonstrated inSection 4 on page 59, which is the reason why wegive this issue a combinedRU rating.
3.4 Page layout
For the tasks of page makeup, TEX provides theconcept of output routines together with insertionsand marks. The concepts of insertions and marks aretailored to the needs of a relatively simple page layoutmodel involving only one column output, footnotes,and at the most, simple figures once in a while.4
The mark mechanism provides information aboutcertain objects and their relative order on the cur-rent page, or more specifically, information about thefirst and last of these objects on the current pageand about the last of these objects on any of thepreceding pages. However, being a global conceptonly one class of objects can take advantage of thewhole mechanism.5
DU Issue: Only a single type of marks isfully supported
In the original paper, I suggested extending this tosupport multiple independent mark registers; thatidea was later implemented in the ε-TEX program.As it turned out, however, this did not really solvethe issue. Whenever the page layout gets more com-plicated and output routines are used to inspect thecurrent state without actually shipping out pagesin a linear fashion, the information maintained in\topmark is always lost.
In the end, we abandoned the whole mechanismfor LATEX3 and used only TEX’s \botmark registerto put marks on the page and kept track of all otherinformation (class of mark and content of the mark)externally [27]. This solves the issue, but at a fairlyhigh programming cost with complex data manage-ment.
D Issue: Missing built-in support for complexfloat management
Float placement across different types of publicationsis governed by rules of high complexity: placement
options may depend on aesthetic requirements, cap-tions and legends might require different formattingdepending on placement, positioning of floats mayinfluence options available for other floats, etc.
Unfortunately, out of the box, TEX offers only asimplistic mechanism derived as an extension to thefootnote concept. LATEX extended this to a slightlymore flexible algorithm but only with respect tosupporting different classes of floats (where the floatsof one class have to stay in sequence) and by addinga few parameters to add limits for the number offloats in a float area or the maximum size of an area.More complex rules or arrangements with varyingformatting depending on placements, support forfloats across multiple columns (other than a simpletwo-column mode) are not supported.
To some extent, this is not that surprising, be-cause codification of placement rules and effectivealgorithms for computing complex layouts is an areathat is not well understood, and at the same timehasn’t attracted much attention by the research com-munity. Only a handful of publications in threedecades approach one or another aspect of this topic[7, 12, 25, 27, 30]. For the same reason, none of thenewer engines offers any additional built-in supportthat would ease the implementation of more com-plex algorithms. Using an early version of expl3, anattempt was made [27] to design and implement acustomizable float algorithm that supports a richerset of rules. Unfortunately this has not yet gonebeyond a proof-of-concept implementation.6
D Issue: No conceptual support for baseline tobaseline spacing
For designers, TEX’s way of specifying interline glue isa rather foreign concept; they typically use baseline-to-baseline spacing instructions in their specifications.Unfortunately, those prescriptions are not directlypossible in TEX because of the way TEX determinesthe “current” \baselineskip value: see Figure 5 onthe next page. Only with rigorous control on the
4. The term ‘one column output’ means that all text isassembled using the same line width. Problems with variableline width are discussed in Section 3.3. Of course, this alreadycovers a wide range of possible multi-column layouts, e.g.,the footnote handling in this article. But a similar range ofinteresting layouts is not definable in TEX’s box-glue-penaltymodel.
5. The LATEX implementation provides an extended markmechanism with two kinds of independent marks with theresult that one always behaves like a \firstmark and the otherlike a \botmark. The information contained in the primitive\topmark is lost.
6. A new implementation of these ideas using the currentexpl3 language is high on the current LATEX3 road map.
Frank Mittelbach

TUGboat, Volume 34 (2013), No. 1 55
\baselineskip 1?6
\baselineskip 1?6
?
6 \parskip?
?
6
?6 \baselineskip 2
?6 \baselineskip 2
Figure 5: Baseline to baseline spacing
To implement a baseline to baseline dimension,for example between a paragraph and a heading(denoted by the question mark), the value for\parskip has to be determined depending on the\baselineskip of the second paragraph. Unfor-tunately, the value of \baselineskip used willbe the one current at the end of the second para-graph while the \parskip has to be computed atits beginning.
programming level (i.e., by preventing the users andpackage writer from accessing the full power of TEX)can one provide an interface supporting baseline-to-baseline spacing specification.
Because the interline glue concept is deeplyburied in TEX algorithms, it is not surprising thatnone of today’s engines (including LuaTEX) addressesthis area.
D Issue: No built-in support for grid-based design
TEX’s concepts that conflict with baseline to base-line spacing also make grid-based design difficult, asthis strongly depends on text baselines appearing inpredictable positions.
Nevertheless, over the last three decades therehave been a number of attempts to provide supportfor grid based-design on top of standard LATEX. Noneof them has been particularly successful — due to themissing support from the engine, all of them workedonly with subsets of the many LATEX packages. Tomake things work, it is necessary to adjust behaviorof various commands, and thus any package notexplicitly considered is a likely candidate for disaster.
The xor package for LATEX3 offers a structuredinterface on the code level for grid-design. Unfortu-nately, it isn’t production ready and awaits a ma-jor refactoring based on the new expl3 language forLATEX3. But even then it would suffer from the lim-itations listed above as long as it is used togetherwith LATEX 2ε packages that do not interface with itsgrid support.
From an engine perspective, LuaTEX is the onlyengine that offers some additional possibilities thatmay help with grid design, through additional hooksprovided, and through access to the internal TEX
data structures. If and how this could be usefullydeployed remains to be seen. To my knowledge, noLuaTEX-specific code for grid design yet exists.
3.5 Penalties—measurement for decisions
Line and page breaks in TEX are determined chieflyby weighing the “badness” of the resulting output7
and the penalty for breaking at the current point.This works very well in most situations but there isone severe problem with the concept of penalties.
D Issue: Consecutive penalties behaveas min(p1, p2)
The problem is that an implicit penalty (e.g., fordiscouraging but not prohibiting orphans or widows)will always allow a break at this particular point evenif an explicit penalty by the user attempts to disal-low a break there. Changing the algorithm to usemax(p1, p2) instead would resolve the problem. Withthis approach an explicit breakpoint could still beinserted by interrupting the sequence of consecutivepenalties, e.g., through \kern0pt.
With LuaTEX this could probably be imple-mented, but would most likely require very com-plicated parsing and manipulation of internal TEXdata structures, unless LuaTEX itself gets extended,i.e., by making the code that handles consecutivepenalties directly accessible.
3.6 Hyphenation
When typesetting text, especially innarrow columns, hyphenation is ofteninevitable in order to avoid unreadable,spaced out lines.TEX’s pattern-based hyphenation algorithm [23] isquite good at identifying correct hyphenation pointsto avoid such situations.
However, hyphenation is a second-best solutionand, if applied, there are a number of guidelines thatan algorithm should follow to improve the overallresult. Several of them cannot be specified withTEX’s algorithm. In fact, all of the ones below areunresolved with today’s engines, if we disregard thatin LuaTEX one could in principle replace the fullparagraph-breaking algorithm with a new routine.
D Issue: Prevent more than two consecutivehyphens
Hyphenation of two consecutive lines is con-trolled by the algorithm (\doublehyphendemerits),
7. The badness is a function of the white space used in aline in comparison to the optimal amount, e.g., if the spacebetween words needs to stretch or shrink, the badness of thesolution increases.
E-TEX: Guidelines for Future TEX Extensions — revisited

56 TUGboat, Volume 34 (2013), No. 1
but there is no possibility of avoiding para-graphs like the current one, in certain circum-stances. As one can easily observe, the number of hy-phens in this paragraph has been artificially in-creased by setting relevant line-breaking parame-ters to unusual values. In languages that havelonger average word lengths than English, such situ-ations present real-life problems.
D Issue: Assigning weights to hyphenation points
TEX’s hyphenation algorithm knows only two states:a place in a word can or cannot act as a hyphen-ation point. However, in real life certain hyphenationpoints are preferable over others. For example, “Non-nenkloster” (abbey of nuns) should preferably notbe hyphenated as “Nonnenklo-ster” (as that wouldleave the word “nun’s toilet” on the first line).
D Issue: More generally, support other approachesto hyphenation
Liang’s pattern-based approach works very well forlanguages for which the hyphenation rules can beexpressed as patterns of adjacent characters next tohyphenation points. Such patterns may not be easyto detect but once determined they will hyphenatereasonably well. For the approach to be usable, thenecessary set of patterns should be be reasonablysmall, as each discrepancy needs one or more excep-tion patterns with the result that the pattern setwould either become very large or the hyphenationresults would have many errors.
To improve the situation for the latter type oflanguages one would need to implement and poten-tially first develop other types of approaches. Fornow Liang’s algorithm is hardwired in all engines,though in theory LuaTEX offers possibilities of drop-ping in some replacement.
3.7 Box rotation
TEX’s concept of document representation is strictlyhorizontal and left-to-right oriented. Any furthermanipulation is left to the capabilities of the outputdevice using \special commands in the language ofthe device.
U Issue: No built-in support for rotation
Because of the lack of a common interface for suchoperations, any document making use of \specialcommands is processable only in a specific environ-ment, so that exchange of such documents is onlypossible in a limited fashion.
With the event of LATEX 2ε the LATEX projectteam resolved this issue by providing an abstractinterface layer that (in the form of the graphics and
color packages) hides the device peculiarities inter-nally so that documents using these interfaces be-came portable again.
3.8 Fonts
R Issue: Available font information (non-issue)
In the Texas paper, I suggested that additional fontcharacteristics should be made available as font pa-rameters to enable smarter layout algorithms. Look-ing at this from today’s perspective I think it waslargely a misguided idea, at least until recently. Manyof the fonts that have been made accessible to theTEX engines in the last decades (mainly PostScriptType 1 fonts) do indeed have various additional at-tributes defined by their designers but alas withlargely non-comparable values between different fontsmaking any interpretation difficult if not impossible.
With OpenType fonts, this may change again,and engines like X ETEX or LuaTEX allow access tosuch additional attributes.
UR Issue: Encoding standardization
By default, TEX translates the input encoding (rep-resentation of characters in the document) one toone into the output encoding (glyph positions inthe current font). E.g., if you put a “b” into yourdocument then this is understood as “typeset thecharacter in position 96 (ascii code for “b”) in thecurrent font”. This tight coupling between encodingof data in different places required that fonts usedby TEX always stored the glyphs in the same posi-tion (which they did only partially) or that the userunderstood the subtle differences and adjusted thedocument input accordingly. For example, in plainTEX the command \$ produces a $-sign — unless youare typesetting in Computer Modern Text Italic, inwhich case your output suddenly shows £-signs.
With more and more fonts (with different fontencodings) becoming available and TEX entering the8-bit world (with numerous input encodings inter-preting the document source differently), such issuesgot worse.
These problems were resolved for LATEX throughthree developments. Don Knuth developed the ideaof virtual fonts [13] and that concept was quicklyadopted by nearly all major output-device drivers, sothat it became usable in practical terms.8 With thisconcept available the TEX community agreed in Corkon a special virtual font encoding [2]. Finally wedesigned and implemented the LATEX Internal Char-
8. In 1990 I expressed my hope that these ideas would helpto simplify matters [26, p. 342] and as it turned out, that wasindeed the case.
Frank Mittelbach

TUGboat, Volume 34 (2013), No. 1 57
acter Encoding for LATEX 2ε (LICR) [29, chap. 7] thattransparently maps between different input encod-ings and arbitrary font encodings. This is perhapsnot a perfect solution, but for the 8-bit world iteffectively resolved the issues.
Unicode support was also addressed (throughthe inputenc package) but here better support fromthe engines is required to come to a fully satisfac-tory solution. As mentioned above, explicit Unicodesupport was first added by Omega, and from theremade its way into Aleph and LuaTEX. X ETEX alsonatively supports Unicode.
R Issue: Ligature and kerning table manipulation
In TEX, ligatures and kerns are properties of fonts,i.e., they apply to all text in a document. However,different languages use different rules about what toapply or not to apply in this case. Thus to modelthis in TEX, one would need to define private fontsper language, each differing only in their ligature andkerning tables. While this would be a theoreticalpossibility, in practical terms it would be a logisticalnightmare and so nobody has ever tried to implementsuch fine points of micro-typography.
With pdfTEX this situation changed somewhatas pdfTEX supports suppressing all ligatures or allligatures that start with a certain character. Thisalone does not help much though, as it does notallow, for example, prohibiting the “ffl” ligature (notused in the German language) while allowing for theother ligatures starting with “f”, nor does it supportimplementing new ligatures, such as “ft” or “ck”,through negative kerning.
LuaTEX takes this a huge step forward and pro-vides the necessary controls to improve the situa-tion considerably. While I was writing this article(and asking around), the first experimental packagesstarted to appear, e.g., selnolig [24] by Mico Loretan,so it will be interesting to see what happens in thenear future.
3.9 Tables
D Issue: Combining horizontally- andvertically-spanned columns is impossible
TEX’s input format is inherently linear, and so it isnot surprising that any TEX interface to inherentlytwo-dimensional table data is somewhat limited. Outof the box TEX supports column formatting, e.g., itcan calculate the necessary column width and ap-ply a default formatting per column. It also allowsfor horizontally-spanned cells with their own format-ting. However, there is no provision for providingcells whose content is able to reflow depending onthe available space nor is there any mechanism to
provide vertically-spanned cells. Both are essentialformatting requirements.
LATEX offers a higher-level document syntax tothe low-level capabilities that TEX provides, and overtime, many packages appeared that enhanced thesolution in one way or the other. However, withoutany underlying direct support for the more complexconcepts all these efforts show limitations and areoften difficult to use. So far none of the existingengines addresses this area.
3.10 Math
Mathematical typesetting is one of TEX’s major do-mains where — even today after thirty years — noother automatic typesetting system has been ablefully to catch up. But even in this area several thingscould be improved.
DU Issue: Some mathematical constructs arenot naturally available in TEX, e.g., double accents,under-accents, equation number placement, . . .
For many of these problems workarounds have beenimplemented as (fairly complex) plain TEX macrosby Michael Spivak in the AMS-TEX format [35,36].Most of this code plus further extensions were portedto LATEX and are nowadays available as the LATEXpackage amsmath.
For this reason this issue can be largely regardedas solved, even though native support for most ofthese constructs would improve the situation further.
U Issue: Spacing rules and parameters are allhardwired in the engine or the math fonts
TEX’s spacing rules for math are quite good, but incases where they needed adjustments, it was eitherimpossible or quite difficult to do. This restrictionhas been finally lifted with LuaTEX, because thatengine offers access to all internal parameters of TEX.
D Issue: Sub-formulas are always typeset at theirnatural width
No engine so far provided any alteration to the corealgorithms of TEX that format a formula. Thus sub-formulas (for example from \left . . . \right) arestill boxed at natural width even if the top levelmath-list is subject to stretching or shrinking. Thisalso means that there is no way to automaticallybreak such constructs across lines.
R Issue: Line breaking in formulas (not listed inoriginal paper)
Don declared line breaking in math too hard forTEX to do automatically and as a result countlessusers struggled with manually formatting displayed
E-TEX: Guidelines for Future TEX Extensions — revisited

58 TUGboat, Volume 34 (2013), No. 1
equations to fit a given measure. For a long time itlooked as if that problem was indeed too difficult totackle within the constraints of a formatting engine.However, in the late nineties Michael Downes provedeverybody wrong by designing and implementing afirst version of the breqn package for LATEX.
This package — further improved by MortenHøgholm after Michael’s untimely death — gets usalready quite a way toward the goal of high-qualityautomatic line breaking in formulas [10]. However,with the increased processing power now availableand with LuaTEX’s access to TEX internals, it shouldbe possible to solve most or all of the remaining prob-lems identified.
3.11 TEX’s language
In 1990 I made the bold statement: “TEX’s languageis suitable for simple programming jobs. It is likethe step taken from machine language to assembler”.Since then the new engines added one or the otherprimitive, but with the exception of LuaTEX, whichadded an interface to Lua as an additional program-ming language, the situation hasn’t improved withrespect to core engine support.
U Issue: Incompleteness with respect to standardprogramming constructs
While this statement is still true with respect to mostengines, the situation has nevertheless improved.With expl3 the LATEX Project team has provideda programming layer that offers a large set of datatypes and programming constructs. The develop-ment of expl3 started in fact long ago: initial im-plementations date back to 1992. However, backthen, the processing power of machines was not goodenough to allow executing code written in expl3 ata reasonable speed. For that reason, the ideas andconcepts were put on the shelf, and the project teaminstead concentrated on providing, and later on main-taining, LATEX 2ε.
Since then processor speed has increased tremen-dously, and as a result it became feasible to finallyuse the ideas that had been initially developed nearlytwo decades ago. The core of expl3 has been reimple-mented (again) and its stable release is now gainingmore and more friends — it even got its own logodesigned as shown in Figure 6.
U Issue: A macro language . . . good or bad? /Difficulty of managing expansion-based code
Since the first implementation of TEX people havevoiced their concern about the fact that the TEX lan-guage is a macro language that works by expansionand not a “proper” programming language. However,
Figure 6: The expl3 logo (courtesy of Paulo Cereda)
despite this grumbling, nobody came up with a work-able alternative model that successfully combinesneed for simple and easy input of document material(which makes up the bulk of a TEX document) andthe special needs of a programming environment thatavoids the complexity of programming by macro ex-pansion (which indeed becomes complex and difficultto understand if used for non-trivial tasks).
That the TEX language can be used to producetruly obfuscated code was nicely demonstrated byDavid Carlisle’s seasonal puzzle [8] which is worthtaking a look at, but even normal coding practice willeasily lead to code that is difficult to understand (andto maintain) as demonstrated by many of today’spackages. Part of the reason for this is that allcoding practice around LATEX 2ε (and other macroformats) is based on concepts and ideas originated inplain TEX, with more and more complexity layeredon top but without fundamentally questioning thecore approach which was never intended for complexprogramming tasks.
So whyU? Largely because with expl3 we nowhave a foundation layer available, that — while stillbased on macro expansion — provides a comfortableprogramming environment. From the engine sideLuaTEX nicely sidesteps the question by providing aseparate programming language in addition.
U Issue: Inability to access and manipulate certaininternal TEX data structures
Many of TEX’s internal data structures are inaccessi-ble to the programmer or only observable indirectly.9
Thus, whenever an adjustment to one of TEX’s in-ternal algorithms is needed it becomes necessary tobypass the algorithm completely and reimplementit on the macro level. This means accepting hugeinefficiencies and in many cases makes such imple-mentations unusable in real-life applications.
9. In the 1990 paper I gave the example of measuring thelength of the last line in a paragraph by artificially following itby an invisible displayed formula as only within such a displayis the desired information made available.
Frank Mittelbach

TUGboat, Volume 34 (2013), No. 1 59
For more than two decades this was the situ-ation with all engines. Finally LuaTEX broke thisrestriction by offering access to all (or nearly all)internals including the ability to modify them (withthe danger of breaking the system in unforeseen ways,but that comes with the territory).
UR Issue: The problem of mouth andstomach separation
This is perhaps one of most fundamental issues: notso much with the language but with the underlyingdata structure. A special case of this issue — andperhaps the most important one — was already dis-cussed in Section 3.3 on page 53: the inability toreformat paragraph data that is already broken intoindividual lines.
TEX divides its internal processing into twoparts: the token parsing and manipulation whereexpansion happens (termed the “mouth”) and thebox generation and manipulation processes that buildup the elements on the page (called the “stomach”).Figure 4 on page 53 depicts the operations availablein the “stomach” with the two main entry pointsfrom the “mouth”on the far left. And, as in reallife, this is largely a one-way street, i.e., once tokenshave been transformed into boxes and glue there isno way of getting back to tokens. Furthermore, ma-nipulation possibilities of already-processed materialare limited and usually result in loss of information,so that one has to ensure staying at the token leveluntil the very last moment.
Unfortunately there are also issues with stayingat the token level. For one, only the typesetting stagewill provide the necessary information to successfullyposition material on the page, e.g., to find out howmuch space some text will occupy or where and onwhich page a reference to a float will fall. Thustrial typesetting is necessary and the source materialwould need to be stored on the token level.
However, reprocessing token material meansthat the same macro processing happens severaltimes when you are doing the trial typesetting. Ifthis processing has side effects, such as incrementinga counter, one needs to keep track of all such changesand undo them before restarting a trial.
From the engine perspective the best approachwould be to either
• provide access and manipulation possibilitiesfrom the “mouth” to an intermediate data struc-ture that holds character data plus attributesbefore they are turned into glyphs, or
• provide additional manipulation possibilities of“stomach” material, or
• offer conversion of typeset material back to tokendata similar to what \showbox offers as symbolicinformation in the transcript file.
Sadly, none of the engines offers any direct supportin this area. However, we will see that, with today’sincrease in processing power, it becomes feasible toimplement a strictly TEX-based solution. This solu-tion has some (acceptable) limitations for boundarycases, but a variant implementation using LuaTEX’scallback interface can even get rid of those, as we’llsee in the next section. For this reason we give thisissue aUR rating today.
4 Overcoming the mouth/stomachseparation
If we look back to Figure 4 on page 53 we can see thatthe best data structure available for use in trial type-setting is the “unset horizontal list”. The momentwe apply line breaking we would lose informationand if we store the information at an earlier stage(i.e., as token data) we would have to deal with theside effects of repetitive token processing.
Unfortunately, the “unset horizontal list” is nota data structure made available by TEX. What ispossible though (looking at the right side of thediagram), is to store it in a horizontal box. At alater stage this box can then be transformed backinto an “unset horizontal list” and that could thenbe typeset into a “trial” paragraph shape.
However, simply storing the content of one ormore paragraphs into an \hbox for later processingis not a workable option either, because:
• TEX applies some “optimizations” in restrictedhorizontal mode to save some processing time.10
Under the assumption that text in an \hbox
cannot be broken into several lines, it dropsall break penalties from in-line formulas (i.e.,those normally added after binaries and rela-tional symbols) and also doesn’t add any im-plicit \discretionary hyphens in place of “-”.For the same reason it also ignores changes to\language.• If we save each paragraph into one \hbox then
we effectively surround each paragraph by a TEXgroup. Thus local changes, such as modificationsto fonts or language would suddenly end at theparagraph boundary.
While these restrictions can be overcome, it means afar more elaborate approach needs to be taken.
10. While such optimizations have been important at thetime TEX was originally developed, the speed gain they offernowadays is negligible. What remains are inconsistencies inprocessing that should get removed in today’s engines such aspdfTEX and LuaTEX.
E-TEX: Guidelines for Future TEX Extensions — revisited

60 TUGboat, Volume 34 (2013), No. 1
4.1 A standard TEX solution
If storing the “unset horizontal list” directly in an\hbox is not an option, what alternative is availableaccording to our Figure 4? The only other path thatresults in an \hbox is to transform the list into an“unset vertical list” and then remove the last box fromthat list (i.e., a circular path in clockwise directionaround the center of the diagram). To make thiswork we have to overcome the limitations listed atvarious places along the path:
1. Transforming an “unset horizontal list” into an“unset vertical list” loses glues and penalties atline breaks.
2. Decomposition of the “unset vertical list” is notpossible on the main galley.
3. Decomposition of the “unset vertical list” stopsat the first node that is not a box, glue, penalty,or kern item.
To alleviate issue 1 we will build our “unset verticallist” using the largest possible \hsize available inTEX. We remove the indentation box whenever westart a paragraph. In addition, we trap any forcedbreak penalty, record it, and prematurely end theparagraph at this point to stay in control. As aresult each \hbox in the resulting “unset vertical list”will contain exactly the paragraph material from oneforced break to the next (considering the paragraphboundaries as forced breaks).
What happens if the paragraph material exceedsthe largest possible dimension available in TEX? Inthat case (which means that the paragraph is no-ticeably longer than a page) we will end up withuncontrolled line breaks. In TEX it is impossibleto prevent this from happening, but at least it ispossible to detect that it happened. One can thenwarn the user and request that the paragraph beartificially split somewhere in the middle using aspecial command.
Issue 2 is easily resolved: as we initially wantto store the data, we can simply scan the materialwithin a \vbox. This box, which is later thrownaway, will form a boundary for local changes, butthis is okay, as we can scan as many paragraphs asnecessary in one go.11 This would solve the problemif only portions of a document (e.g., float captions)are subject to trial typesetting. If the intention isto process the whole document in this manner thena slightly different approach is needed. In that casewe would use the main vertical list for collection anddevise a special output routine that is triggered atthe end of each paragraph. The \hboxes holding theparagraph fragments would then be retrieved withinthe output routine. Once everything is collected as
far as necessary, the output routine could then bechanged to do trial typesetting.
To avoid issue 3 it is necessary to ensure thatmaterial from \insert and \vadjust is not migratedout of the horizontal material. If they were, theywould appear after our “paragraph line”. On the onehand, this is the wrong place if we later rebreak thematerial into several lines, and on the other handit would prevent us from disassembling the materialand storing it away. Therefore the solution is to endthe paragraph (generating one line for the currentfragment that we can save away), then start an \hbox
into which we scan the \insert or \vadjust andthen restart the scanning for the remainder of the“real” paragraph.
With these preparations, the algorithm thenworks as follows:
• When we start (or restart) scanning paragraphmaterial we ensure that there is no indentationbox at the beginning.
• When we reach the end of the paragraph (or aparagraph fragment where we have artificiallyforced a paragraph end) TEX will typeset thematerial and because of the large line lengthit will (normally) result in a single-line para-graph. We then pick up this line via \lastbox
and repackage it by removing the glue (from\parfillskip) and penalty at its end. Then wesave this box and an accessing function away insome data structure and restart scanning untilwe reach the end.
• If we see an \insert or \vadjust we interruptand add the scanned material to the data struc-ture. Then scan and store the vertical materialas outlined above.
• If we see a forced penalty we interrupt andsave the scanned material and then also recordthe value of the penalty in the data structure.Note that any non-forcing penalty could just bescanned as normal paragraph material becauseof the large \hsize.
• Once we are finished parsing we end up with adata structure that looks conceptually as follows:
\dobox box1 \dopenalty {10000}
\dobox box2 \doinsert boxx
\dobox box3 \dovadjust boxy . . .
box1 to box3 are \hboxes holding paragraph textfragments; boxx and boxy are also \hboxes con-taining just an \insert or \vadjust, respec-tively, i.e., they are generated basically by:
\setbox boxx =\hbox{\insert{...}}
11. The limit is available memory, which is huge these days.
Frank Mittelbach

TUGboat, Volume 34 (2013), No. 1 61
With the right definitions for \dobox and friends(e.g., \unhcopy, etc.) this data structure can then beused to “pour” the saved paragraph(s) into variousmolds for trial typesetting.
This algorithm works with any TEX engine andits only restriction is the maximum allowed size of asingle paragraph. This is acceptable, as it normallywould not happen unless somebody is typesettinga document in James Joyce style. If it does, it willbe detected and the user can be asked to artificiallysplit the paragraph at a suitable point.
4.2 A LuaTEX solution
Using the LuaTEX engine, it is possible to simplifythe algorithm considerably. LuaTEX offers the possi-bility of replacing the line breaking algorithm witharbitrary Lua code and we can use this fact to tem-porarily replace it with a very trivial function: onethat simply packages the “unset horizontal list” intoan \hbox and returns that. This would look as fol-lows:
function hpack_paragraph (head)
local h = node.hpack(head)
return h
end
callback.register("linebreak_filter",
hpack_paragraph)
The beauty of this is that it automatically resolvesissues 1 and 3 listed above. Issue 1 is fully resolved,because node.hpack is able to build \hboxes of anysize, even wider than \maxdimen (as long as you donot try to access the \wd of the resulting box). Soeven Joycean paragraphs are no longer any problem.Issue 3 is gone because we do not need to decomposematerial. With the simple code above any penalties,\inserts, or \vadjusts simply end up within thebox; in contrast to the normal line breaking algo-rithm, the hpack_paragraph code does not touchthem. For the same reason, we do not have to takeoff any \parfillskip from the end, as it isn’t addedin the first place.
The only problem found so far is a bug in thecurrent implementation of the linebreak_filter
callback rendering \lastbox (which is needed byour algorithm) unusable the moment the callback isinstalled. This is due to some missing settings inthe semantic nest of TEX that are not fully carriedout. Eventually this will most certainly get correctedin a future LuaTEX version. For now it is possibleto implement the correction ourselves in a secondcallback:
function fix_nest_tail (head)
tex.nest[tex.nest.ptr].tail = node.tail(head)
tex.nest[tex.nest.ptr].prevgraf = 1
tex.nest[tex.nest.ptr].prevdepth = head.depth
return true
end
callback.register("post_linebreak_filter",
fix_nest_tail)
That is enough for our use case to work. For some-body interested in implementing a real replacementfor the line breaking algorithm, additional adjust-ments are necessary; see the discussion in [28].
5 Conclusions
In 1990 the author attested that “the current” TEXsystem is not powerful enough to meet all the chal-lenges of high quality (hand) typesetting.U Two decades later the successors offer signif-
icant improvements in that they provide machineryto resolve most of the issues identified.R However, having the tools does not mean
having the solutions and on the algorithmic levelmost questions are still unsolved.
So if they haven’t been solved for so long, aresolutions truly needed?
In the author’s opinion, the answer is clearly yes.The fact that for nearly all issues people struggledagain and again with inadequate ad hoc solutionsshows that there is interest in better and easier waysto achieve the desired results. Or, to paraphraseFrank Zappa, “High-quality typography is not dead,it just smells funny”.RRR The task now is to put the new
possibilities to use and work on solving the openquestions with their help.
∗ ∗ ∗The author wants to thank Nelson Beebe, Karl
Berry, and Barbara Beeton for their invaluable helpin improving the paper through thorough copy-editingand numerous suggestions.
References
[1] Anonymous. εXTEX. Website.http://www.extex.org.
[2] Anonymous. Extended TEX font encodingscheme — Latin, Cork, September 12,1990. TUGboat, 11(4):516–516, November1990. http://tug.org/TUGboat/tb11-4/
tb30ferguson.pdf.[3] Anonymous. Cambria (typeface). Wikipedia,
2012. http://en.wikipedia.org/wiki/
Cambria_(typeface).[4] Anonymous. LuaTEX on the Web. Website,
2012. http://luatex.org.[5] Anonymous. Microtypography. Wikipedia,
2012. http://en.wikipedia.org/wiki/
Microtypography.
E-TEX: Guidelines for Future TEX Extensions — revisited

62 TUGboat, Volume 34 (2013), No. 1
[6] Anonymous. X ETEX on the Web. Website,2012. http://tug.org/xetex.
[7] Anne Bruggeman-Klein, Rolf Klein, andStefan Wohlfeil. Pagination reconsidered.Electronic Publishing, 8(2&3):139–152,September 1995. http://cajun.cs.nott.ac.
uk/compsci/epo/papers/volume8/issue2/
2point9.pdf.
[8] David Carlisle. A seasonal puzzle: XII.TUGboat, 19(4):348–348, December 1998. http://tug.org/TUGboat/tb19-4/tb61carl.pdf.
[9] Paolo Ciancarini, Angelo Di Iorio, LucaFurini, and Fabio Vitali. High-qualitypagination for publishing. Software—Practiceand Experience, 42(6):733–751, June 2012.
[10] Michael Downes and Morten Høgholm.The breqn package. CTAN, 2008. http:
//www.ctan.org/pkg/breqn.
[11] Hisato Hamano. Vertical typesetting withTEX. TUGboat, 11(3):346–352, September1990. http://tug.org/TUGboat/tb11-3/
tb29hamano.pdf.
[12] Charles Jacobs, Wilmot Li, Evan Schrier,David Bargeron, and David Salesin. Adaptivegrid-based document layout. In ACMSIGGRAPH 2003 Papers, SIGGRAPH’03,pages 838–847, New York, NY, USA, 2003.ACM. http://grail.cs.washington.edu/
pub/papers/Jacobs2003.pdf.
[13] Donald Knuth. Virtual Fonts: More Fun forGrand Wizards. TUGboat, 11(1):13–23, April1990. http://tug.org/TUGboat/tb11-1/
tb27knut.pdf.
[14] Donald Knuth. An earthshakingannouncement. TUGboat, 31(2):121–124,2010. http://tug.org/TUGboat/tb31-2/
tb98knut.pdf. Also available as videoat http://river-valley.tv/tug-2010/
an-earthshaking-announcement.
[15] Donald Knuth and Pierre MacKay. Mixingright-to-left texts with left-to-right texts.TUGboat, 8(1):14–25, April 1987. http://tug.org/TUGboat/tb08-1/tb17knutmix.pdf.
[16] Donald E. Knuth. TAU EPSILON CHI.A system for technical text. ReportSTAN-CS-78-675, Stanford University,Department of Computer Science, Stanford,CA, USA, 1978.
[17] Donald E. Knuth. TEX and METAFONT—NewDirections in Typesetting. Digital Press,12 Crosby Drive, Bedford, MA 01730, USA,1979.
[18] Donald E. Knuth. The TEXbook.Addison-Wesley, Reading, MA, USA,1984.
[19] Donald E. Knuth. TEX: The Program,volume B of Computers and Typesetting.Addison-Wesley, Reading, MA, USA, 1986.
[20] Donald E. Knuth. The new versionsof TEX and METAFONT. TUGboat,10(3):325–328, November 1989. http:
//tug.org/TUGboat/tb10-3/tb25knut.pdf.
[21] Donald E. Knuth. Digital Typography. CSLIPublications, Stanford, CA, USA, 1999.
[22] Krista Lagus. Automated pagination ofthe generalized newspaper using simulatedannealing. Master’s thesis, Helsinki Universityof Technology, Helsinki, Finland, 1995.http://users.ics.aalto.fi/krista/
personal/dippa/DITYO.ps.gz.
[23] Franklin Mark Liang. Word Hy-phen-a-tionby Com-pu-ter. Ph.D. dissertation,Computer Science Department, StanfordUniversity, Stanford, CA, USA, March 1984.http://tug.org/docs/liang.
[24] Mico Loretan. The selnolig package: Selectivesuppression of typographic ligatures. Website,2012. http://meta.tex.stackexchange.com/questions/2884.
[25] Kim Marriott, Peter Moulder, and NathanHurst. Automatic float placement inmulti-column documents. In Proceedingsof the 2007 ACM symposium on Documentengineering, DocEng’07, pages 125–134,New York, NY, USA, 2007. ACM. http:
//bowman.infotech.monash.edu.au/
~pmoulder/examples/float-placement.pdf.
[26] Frank Mittelbach. E-TEX: Guidelinesfor future TEX extensions. TUGboat,11(3):337–345, September 1990. http:
//tug.org/TUGboat/tb11-3/tb29mitt.pdf.
[27] Frank Mittelbach. Formatting documentswith floats: A new algorithm for LATEX 2ε.TUGboat, 21(3):278–290, September2000. http://tug.org/TUGboat/tb21-3/
tb68mittel.pdf.
[28] Frank Mittelbach. \lastnodetype not workingas expected in LuaTEX. Website, 2012.http://tex.stackexchange.com/questions/
59176.
[29] Frank Mittelbach, Michel Goossens, JohannesBraams, David Carlisle, Chris Rowley,Christine Detig, and Joachim Schrod. TheLATEX Companion. Tools and Techniques
Frank Mittelbach

TUGboat, Volume 34 (2013), No. 1 63
for Computer Typesetting. Addison-Wesley,Reading, MA, USA, second edition, 2004.
[30] Michael F. Plass. Optimal paginationtechniques for automatic typesetting systems.Ph.D. dissertation, Computer ScienceDepartment, Stanford University, Stanford,CA, USA, 1981.
[31] Jan Michael Rynning. Proposal to the TUGmeeting at Stanford. TEXline, 10:10–13, May1990. Reprint of the paper that triggeredTEX 3.0.
[32] Yasuki Saito. Report on JTEX: A JapaneseTEX. TUGboat, 8(2):103–116, July 1987. http://tug.org/TUGboat/tb08-2/tb18saito.pdf.
[33] Robert Schlicht. Microtype; an interface to themicro-typographic extensions of pdfTEX, 2010.http://ctan.org/pkg/microtype.
[34] Manfred Siemoneit. Typographisches Gestalten.Polygraph-Verlag, Frankfurt am Main,Germany, second edition, 1989.
[35] Michael Spivak. amstex.doc, 1990. Commentsto [36].
[36] Michael Spivak. amstex.tex, 1990.
[37] Han The Thanh. Microtypographicextensions to the TeX typesetting system.(Dissertation an der Fakultat Informatik,Masaryk University, Brno, Oktober 2000).TUGboat, 21(4):317–434, 2000. http:
//tug.org/TUGboat/tb21-4/tb69thanh.pdf.
[38] Han The Thanh. Margin kerning andfont expansion with pdfTEX. TUGboat,22(3):146–148, September 2001. http:
//tug.org/TUGboat/tb22-3/tb72thanh.pdf.
[39] Han The Thanh. Micro-typographic extensionsof pdfTEX in practice. TUGboat, 25(1):35–38,2004. http://tug.org/TUGboat/tb25-1/
thanh.pdf.
[40] Arno Trautmann. An overview of TEX, itschildren and their friends. Website, 2012.http://github.com/alt/tex-overview.
[41] Stefan Wohlfeil. On the Pagination of Complex,Book-Like Documents. Shaker Verlag, Aachenand Maastricht, The Netherlands, 1998.
[42] Hermann Zapf. About micro-typographyand the hz-program. Electronic Publishing,6(3):283–288, September 1993. http:
//cajun.cs.nott.ac.uk/compsci/epo/
papers/volume6/issue3/zapf.pdf.
* * *Finally, to answer the question posed in footnote 2:The paragraph typeset with negative expansion wasthe second one in Section 3.4. Without it, it wouldhave looked like this:
The mark mechanism provides information aboutcertain objects and their relative order on the cur-rent page, or more specifically, information aboutthe first and last of these objects on the current pageand about the last of these objects on any of thepreceding pages. However, being a global conceptonly one class of objects can take advantage of thewhole mechanism.
� Frank MittelbachMainz, Germanyfrank.mittelbach (at)
latex-project dot org
http://www.latex-project.org/
latex3.html
E-TEX: Guidelines for Future TEX Extensions — revisited


















