
Introduzione ai Minimi Quadrati - laboratorio di...
51
Introduzione ai Minimi Quadrati Misure ripetute della medesima grandezza, eseguite al limite della precisione possibile con il metodo e gli strumenti utilizzati, forniscono sempre risultati diversi per la presenza degli errori casuali; tali errori, non noti, non possono essere eliminati. Come si può stimare il valore “vero” di una grandezza se non si conoscono gli errori in ciascuna osservazione? Si associa alle misure una modellizzazione statistica e matematica: l’osservazione (misura) y O è la somma di due componenti: il valore vero della grandezza y (osservabile) e l’errore di misura incognito ν. ν + = y y O Rapidi cenni ai differenti tipi di errori Errori casuali, a media nulla e di entità dipendente dalle precisioni strumentale e di lettura: ineliminabili ma facilmente modellizzabili statisticamente (vedi subito sotto). Errori sistematici o di modello, dovuti a sistematismi strumentali e/o errata modellizzazione delle osservazioni o delle relazioni fra osservazioni e incognite; in alcuni casi identificabili e eliminabili ma non modellizzabili in senso generale vanno trattati caso per caso (vedi la verifica di ipotesi). Modellizzazione dei puri errori casuali
Transcript of Introduzione ai Minimi Quadrati - laboratorio di...

Introduzione ai Minimi Quadrati
Misure ripetute della medesima grandezza, eseguite al limite della precisione possibile con il metodo e gli
strumenti utilizzati, forniscono sempre risultati diversi per la presenza degli errori casuali; tali errori, non noti, non
possono essere eliminati.
Come si può stimare il valore “vero” di una grandezza se non si conoscono gli errori in ciascuna osservazione? Si associa alle misure una modellizzazione statistica e
matematica: l’osservazione (misura) yO è la somma di due componenti: il valore vero della grandezza y (osservabile)
e l’errore di misura incognito ν.
ν+= yyO
Rapidi cenni ai differenti tipi di errori
Errori casuali, a media nulla e di entità dipendente dalle precisioni strumentale e di lettura: ineliminabili ma facilmente
modellizzabili statisticamente (vedi subito sotto).
Errori sistematici o di modello, dovuti a sistematismi strumentali e/o errata modellizzazione delle osservazioni o delle relazioni fra osservazioni e incognite; in alcuni casi identificabili e eliminabili ma non modellizzabili in senso
generale vanno trattati caso per caso (vedi la verifica di ipotesi).
Modellizzazione dei puri errori casuali

Un buon modello formale per descrivere
le osservazioni di precisione è quello di considerarle come estrazioni di variabili casuali gaussiane o normali,
definite da media y e varianza σ2;
2)(22
1
2/12 )2(1)(
yOy
O eyf−
σ−
πσ=
ove
f(yO): distribuzione di densità di probabilità
y: valore vero, incognito, dell’osservazione (osservabile) σ2: parametro di dispersione o varianza.
Nota
Indichiamo con )( MOm yyyP ≤≤ la probabilità di ottenere una misura che cada nell’intervallo di valori
compresi tra ym e yM; tale probabilità è data da
∫=≤≤My
myOOMOm dyyfyyyP )()(

Indicativamente il risultato di una misura cade con il
99.9% di probabilità nell’intervallo y-3σ e y+3σ; inoltre, formalmente si ha probabilità nulla di ottenere da un’osservazione il valore dell’osservabile: infatti
∫ =y
yOO dyyf 0)(
Caso Rm
Se supponiamo di avere m osservabili, cioè di
osservare m grandezze diverse, possiamo utilizzare lo stesso modello visto precedentemente e scrivere in modo compatto, utilizzando la notazione vettoriale:
νyy +=O
con
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=
mmOm
O
O
O
y
yy
y
yy
ν
νν
νyy...
;...
;...2
1
2
1
2
1
)(1)(
21
2/2/ )(det)2(1)(
yyCyy
Cy
−−−−
π=
OyyT
Om
yymO ef
ove m è la dimensione di y.

Cyy è la matrice di covarianza delle osservazioni.
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
σσσ
σσσ
σσσ
=
221
22221
11221
...............
...
...
mmm
m
m
yyC
contiene:
in diagonale le varianze delle singole osservazioni, fuori diagonale le covarianze fra coppie di osservazioni; la
matrice è simmetrica e definita positiva, quindi invertibile.
Nota
Se yO segue una distribuzione normale con media y e covarianza Cyy si indica
[ ]yyO N Cyy ,~

Terminologia
Campione bernoulliano Un campione bernoulliano è un insieme di elementi
estratti indipendentemente da una Variabile Casuale (VC). Esempio:
più ripetizioni indipendenti della stessa osservazione
Statistiche campionarie Variabili casuali funzioni della VC
dalla quale il campione è stato estratto:
media campionaria: ∑ == Ni OiyN
y ,...,11ˆ ;
varianza campionaria corretta: 2
,...,12 )ˆ(
11ˆ ∑ = −−
=σ Ni Oi yyN
Stima dei parametri statistici di una VC
Calcolo dei valori dei parametri caratteristici di una VC (ad esempio media e varianza,…) a partire da
un campione bernoulliano per mezzo di opportuni stimatori, definiti in base a determinati
criteri statistici.
Correttezza Uno stimatore è corretto se la sua media
coincide con la media della VC.
Consistenza Uno stimatore è consistente se,
al tendere a infinito della numerosità del campione, la sua media tende alla media della VC in probabilità

e la sua varianza tende a 0 in probabilità.
Minima varianza Uno stimatore è di minima varianza se
la sua varianza è la minore tra quelle degli stimatori dello stesso parametro statistico della VC.
Robustezza
Uno stimatore è robusto se non viene significativamente influenzato da
pochi elementi del campione non appartenenti alla VC considerata.
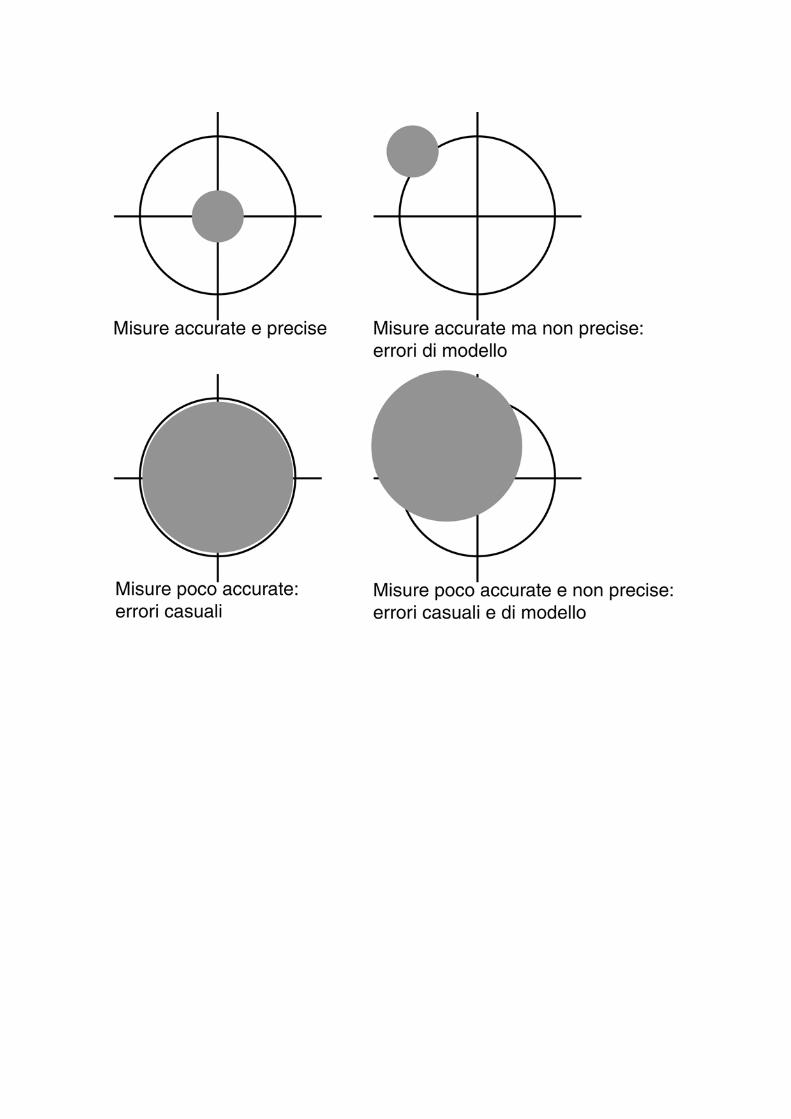
Accuratezza
Definisce la dispersione dei valori campionari intorno alla media campionaria;
la varianza campionaria è un indice di accuratezza.
Precisione Definisce la dispersione dei valori campionari
intorno alla media teorica della VC dalla quale si ritiene estratto il campione;
Misure molto accurate (σ2 piccolo) risultano poco precise se si hanno errori di modello.

I Minimi Quadrati Formalizzazione del problema e degli obiettivi
Non è sempre possibile osservare direttamente grandezze
alle quali siamo interessati. Se ad esempio vogliamo determinare coordinate di punti sulla superficie terrestre, non è possibile eseguire la loro misura diretta; possiamo però fare misure di angoli e distanze o di basi, e costruire un modello fisico e geometrico che leghi tali osservabili
alle coordinate dei punti. In questo caso quindi le osservabili y (angoli, distanze e
basi) possono essere descritte funzionalmente a partire da parametri incogniti x (le coordinate dei punti).
Ovvero
Siano date m osservazioni
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
=
om
o
o
o
y
yy
...2
1
y
per ogni osservazione i-esima valga
iioi yy ν+=
[ ] 0;0 =ν≠ν ii E
ovvero

νyy +=o [ ] yy =oE
y: vettore delle osservabili, incognite;
oy : vettore delle osservazioni, note; ν: vettore degli errori di osservazione, incogniti.
Sia noto il modello stocastico delle osservazioni,
ovvero la loro matrice di covarianza:
QCC 20σ== ννyy
ove rappresenta un fattore di precisione “comune”; 2
0σQ è detta matrice dei cofattori ed esprime in diagonale le
precisioni relative delle diverse osservazioni, fuori diagonale le correlazioni fra le diverse osservazioni.
Sia x un vettore contenente n parametri incogniti:
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=
nx
xx
...2
1
x
con mn ≤
Sia noto il modello deterministico del problema,
ovvero la relazione funzionale fra x e y

)(xfy =
con f funzione nota.
Il sistema in x sarebbe risolvibile supponendo di conoscere le osservabili y;
in tal caso infatti si avrebbe
)(1 yfx −=
Però il sistema non è risolvibile utilizzando direttamente le osservazioni,
perché queste sono affette da errori incogniti; non è cioè possibile in alcun modo risolvere la
)(1
oyfx −=
poiché, a causa degli errori, si ha
)()( xfνxfνyy ≠+=+=o
Si pone il problema di trovare un metodo che, sfruttando le informazioni disponibili, permetta la miglior stima possibile (in senso statistico) dei parametri incogniti
x ( ) e delle osservabili y (y ); x ˆ
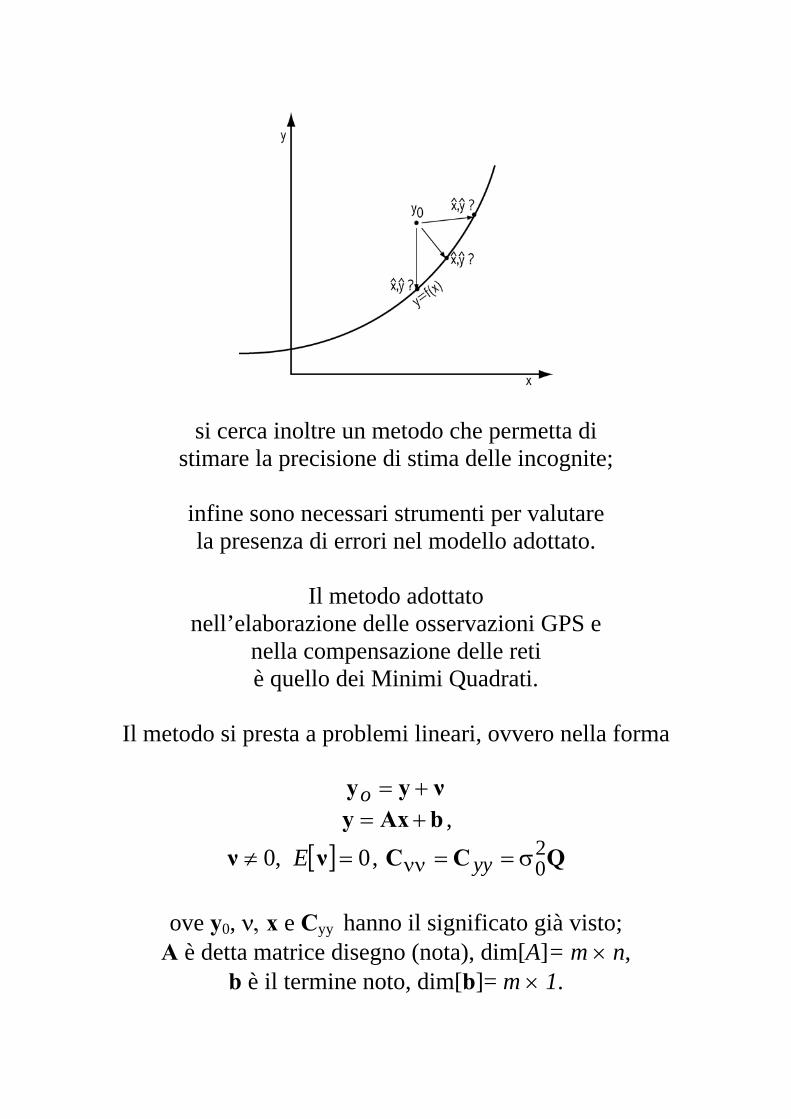
si cerca inoltre un metodo che permetta di stimare la precisione di stima delle incognite;
infine sono necessari strumenti per valutare la presenza di errori nel modello adottato.
Il metodo adottato
nell’elaborazione delle osservazioni GPS e nella compensazione delle reti è quello dei Minimi Quadrati.
Il metodo si presta a problemi lineari, ovvero nella forma
νyy +=o bAxy += ,
[ ] 0,0 =≠ νν E , QCC 20σ==νν yy
ove y0, ν, x e Cyy hanno il significato già visto;
A è detta matrice disegno (nota), dim[A]= m × n, b è il termine noto, dim[b]= m × 1.
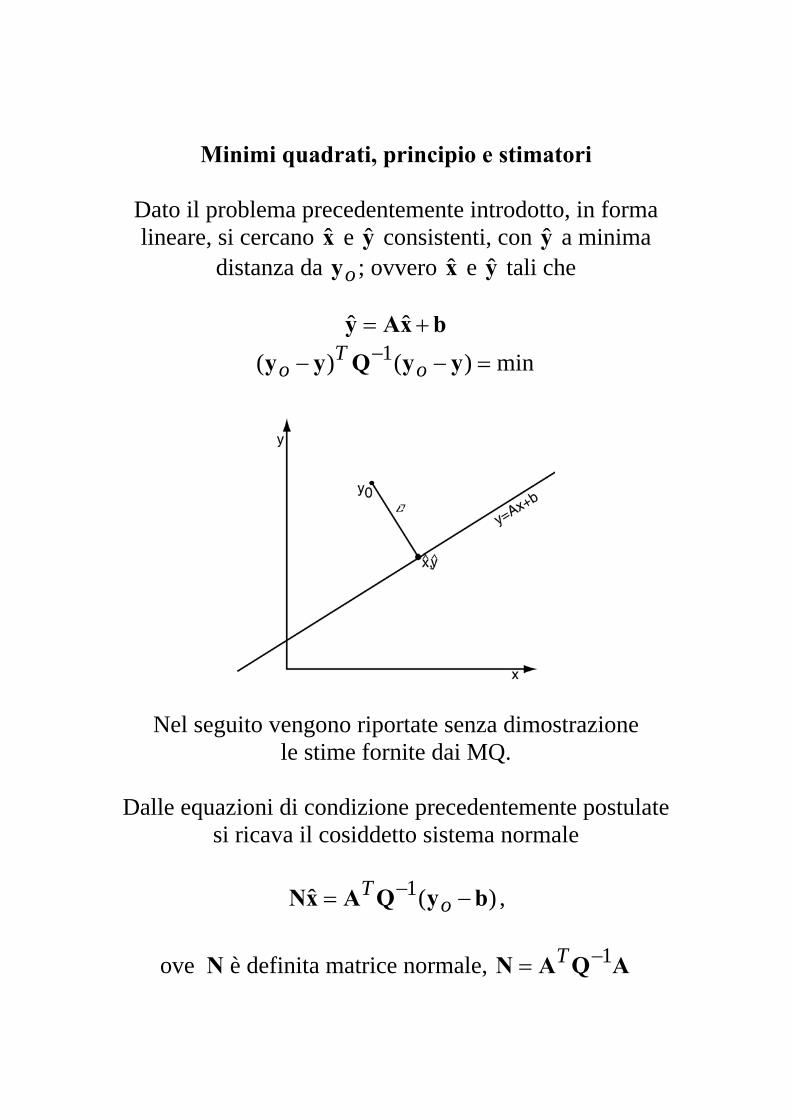
Minimi quadrati, principio e stimatori
Dato il problema precedentemente introdotto, in forma lineare, si cercano e consistenti, con a minima
distanza da ; ovvero x e y tali che x y y
oy ˆ ˆ
bxAy += ˆˆ min)()( 1 =−− − yyQyy o
To
Nel seguito vengono riportate senza dimostrazione le stime fornite dai MQ.
Dalle equazioni di condizione precedentemente postulate
si ricava il cosiddetto sistema normale
)(ˆ 1 byQAxN −= −o
T ,
ove N è definita matrice normale, AQAN 1−= T

Si hanno due casi:
A è di rango pieno, ovvero le sue colonne sono
linearmente indipendenti:
0x0Ax =⇒=
in questo caso il problema non presenta deficienza di rango;
A non è di rango pieno, ovvero alcune sue colonne sono
linearmente dipendenti dalle altre:
0x0Ax ≠= qualcheper
in questo caso il problema presenta deficienza di rango.
Soluzione del problema senza deficienza di rango
Se A è di rango pieno lo è anche N, che è dunque invertibile. Si hanno dunque le seguenti stime.
Stima dei parametri incogniti:
)(ˆ 11 byQANx −= −−
oT ;
stima delle osservabili e degli scarti:
bxAy += ˆˆ yyν ˆˆˆ −= o ;

La ridondanza e le stime di covarianza
Ridondanza: differenza fra numero di osservazioni
e numero di parametri incogniti, detta anche numero di gradi di libertà:
nmR −=
Si può dimostrare che 0ˆ yy =⇒= nm ,
ovvero quando la ridondanza è nulla non è possibile ristimare le osservazioni e quindi gli scarti di osservazione
Si può inoltre dimostrare che yx yx ==
∞→∞→ˆlimˆlim ;
RR
ovvero: al tendere all’infinito del numero di osservazioni, gli errori di osservazione si scaricano solo sulle stime degli
errori e non sulle stime dei parametri incogniti e delle osservabili.
Quindi una ridondanza elevata consente:
la validazione reciproca delle osservazioni; una stima più precisa dei parametri incogniti;
una stima delle loro precisioni di stima.
stima del : 20σ
nm
T
−=σ
− νQν ˆˆˆ1
20 ;
stima della matrice di covarianza dei parametri:

12
0ˆˆ ˆ −σ= NC xx ;
stima della matrice di covarianza delle osservabili:
Tyy AANC 12
0ˆˆ ˆ −σ= ;
stima della matrice di covarianza degli scarti
)(ˆ 120ˆˆ
TAANQC νν−−σ=
Note
Il metodo dei minimi quadrati fornisce stime corrette e di
minima varianza per i parametri incogniti.
Le stime sono indipendenti dal valore di : 20σ
quindi non è necessario conoscere tale valore a priori; dipendono però da Q, A e b
(modelli stocastico e deterministico).

Esempio di applicazione dei MQ
Siano A, B e C tre punti; sia HA la quota nota di A;
Siano stati misurati i dislivelli da A a B ( oABDH ), da B a C ( oBCDH ) e da C a A ( oCADH ).
Evidentemente vale la
ABAB DHHH =− CACA DHHH =− BCBC DHHH =−
Soluzione mediante MQ
Si scrive il modello deterministico del problema:
ABABOAB HHDH ν+−= CACAOCA HHDH ν+−=
BCBCOBC HHDH ν+−=
ovvero

νyy +=O bAxy +=
ove
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡−=⎥
⎦
⎤⎢⎣
⎡=
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−=
0,,
110110
A
A
B
C HH
HH
x bA
Modello stocastico
Nel presente esempio si considerano le misure di uguale precisione (che indichiamo con σ2)
e scorrelate:
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
σσ
σ=
2
2
2
000000
yyC
ovvero
IC 2σ=yy
Una volta calcolate la matrice normale e la sua inversa,
⎥⎦
⎤⎢⎣
⎡−
−==== −−
211211 AAAIAAQAN TTT
⎥⎦
⎤⎢⎣
⎡=−
2112
311N

le soluzioni fornite dai MQ sono le seguenti.
Parametri incogniti
⎥⎦
⎤⎢⎣
⎡−−
−++⎥
⎦
⎤⎢⎣
⎡=
=⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−+
⎥⎦
⎤⎢⎣
⎡−
−⎥⎦
⎤⎢⎣
⎡=
=−=⎥⎦
⎤⎢⎣
⎡= −−
OBCOCAOABOCAOBCOAB
A
A
OBC
AOCA
AOAB
T
B
C
DHDHDHDHDHDH
HH
DHHDHHDH
HH
22
31
101110
2112
31
)(ˆˆ
ˆ 011 byQANx
Osservabili
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
ννν
−⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
=⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡−+⎥
⎦
⎤⎢⎣
⎡
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−=
=+=⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
=
ˆˆˆ
31
0ˆˆ
110110
ˆˆˆˆ
ˆ
OBCOCAOAB
A
A
B
C
BC
CA
AB
DHDHDH
HH
HH
HDHDHD
bxAy
Scarti
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=−=
ννν
ˆˆˆ
31ˆˆ yyν O

ove si è posto
OCAOBCOAB DHDHDH ++=ν
Precisione delle stime
221
20 ˆ
31
23
ˆ391
ˆˆˆ ν=−
ν=
−=σ
−
nm
T νQν
⎥⎦
⎤⎢⎣
⎡ν=σ= −
2112
ˆ91ˆ 212
0ˆˆ NC xx
BHxxxxCH ˆˆ )2,2(ˆ32)1,1( σ==ν==σ CC
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−−−−−
ν=σ= −
211121112
ˆ91ˆ 212
0ˆˆT
yy AANC
BCHDCAHDyyABHD ˆˆˆˆˆ ˆ32)1,1( σ=σ=ν==σ C
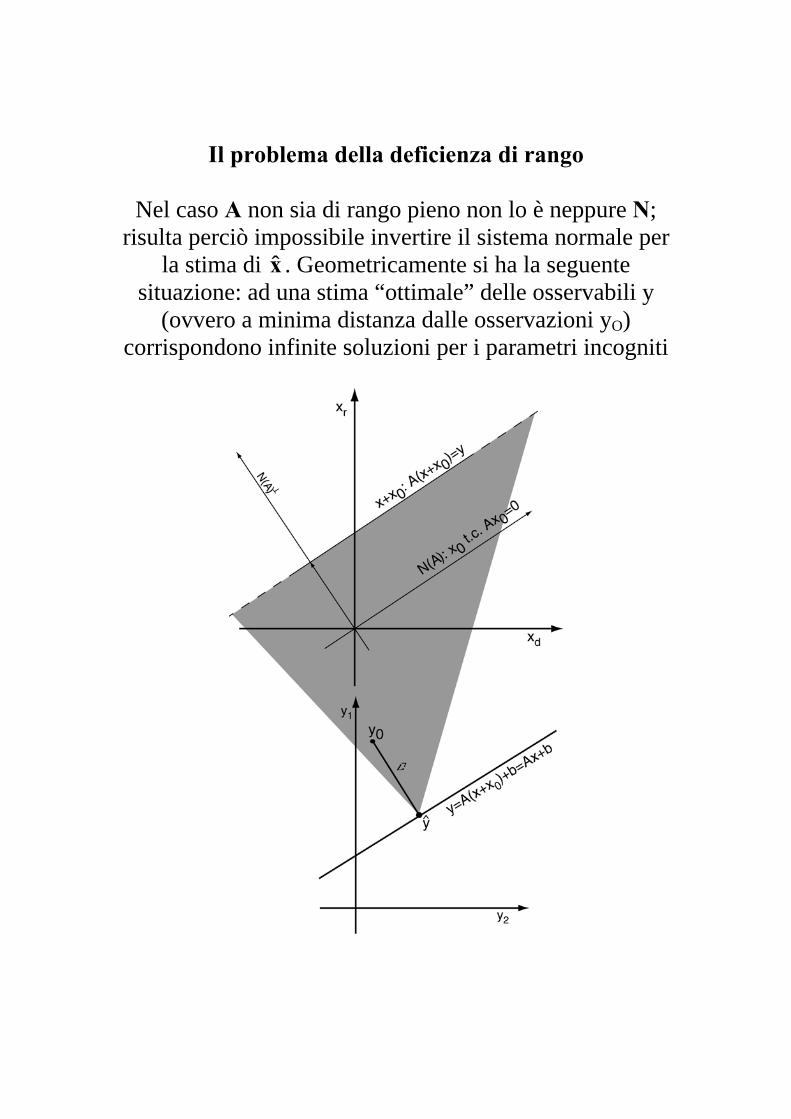
Il problema della deficienza di rango
Nel caso A non sia di rango pieno non lo è neppure N;
risulta perciò impossibile invertire il sistema normale per la stima di x . Geometricamente si ha la seguente
situazione: ad una stima “ottimale” delle osservabili y (ovvero a minima distanza dalle osservazioni y
ˆ
O) corrispondono infinite soluzioni per i parametri incogniti

Definiamo il nucleo N di A come: { }0AxxA == 00 |)(N ; supponiamo di conoscere il valore vero delle osservabili, y; evidentemente se è soluzione di x ybxA =+ˆ , anche
0ˆ xx + lo è; infatti
y0yAxbxAbxxA ˆˆˆ)ˆ( 00 =+=++=++
in sostanza le osservazioni non contengono abbastanza informazione per stimare tutti i parametri desiderati; tale
caratteristica non dipende dalla ridondanza ma dal disegno del problema.
Ad esempio si consideri l’anello di livellazione iniziale e si supponga di voler stimare tutte le quote dalle misure di
dislivello:
νyy +=O bAxy +=
v+⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−
−=
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
C
B
A
OCAOBCOAB
HHH
DHDHDH
101110011
è facile verificare che A non è di rango pieno e che, in
particolare,
⎪⎭
⎪⎬
⎫
⎪⎩
⎪⎨
⎧∈∀
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡= RttN ,
111
)(A

in effetti, pensando al problema dal punto di vista fisico, è evidente che i valori delle osservabili di dislivello del
triangolo non vengono modificati aggiungendo un valore H comune alle 3 quote supposte incognite:
)()()()()()(
HHHHHHDHHHHHHHDHHHHHHHDH
CACACA
BCBCBC
ABABAB
+−+=−=+−+=−=+−+=−=
ovvero le quote dei punti (parametri incogniti), presentano
1 grado di libertà, rispetto ai dislivelli (osservabili); la situazione non cambia aggiungendo una o più
osservazioni di dislivello (a titolo di esercizio lo si verifichi aggiungendo ad esempio ACDH ).
La rimozione della deficienza di rango
Per rimuovere la deficienza di rango in un problema ai MQ si deve innanzitutto identificare preventivamente quali siano i parametri non stimabili del problema: ad
esempio in una rete di livellazione, con sole osservazioni

di dislivelli, sono stimabili le quote di tutti i punti della rete meno uno.
A tale punto sono possibili (e necessari) due approcci alternativi.
1. Si vincolano i parametri non stimabili del problema: ciò
equivale a fissare un Sistema di Riferimento in cui verranno fornite le soluzioni per i restanti parametri
realmente stimabili. Nel problema della rete di livellazione questo equivale ad attribuire la quota “zero” ad uno dei
punti della rete stessa. Tale approccio è quello seguito, appunto, nella definizione
dei Sistemi di Riferimento, globali o nazionali.
2. Si riformula il problema aggiungendo nuove osservazioni sui parametri non stimabili; ad esempio, nella rete di livellazione, misurando direttamente la quota di uno
o più punti ed inserendo le relative equazioni di osservazione nel sistema. Tipicamente, nell’ambito delle reti geodetiche, tali osservazioni aggiuntive, dette anche
pseudoosservazioni, non sono (non possono essere) ottenute direttamente, ma derivano da fonti esterne, che
abbiano risolto a monte il problema di definire un Sistema di Riferimento. Ad esempio, in Italia, è prassi inquadrare
le reti locali di livellazione ai caposaldi IGMI (Istituto Geografico Militare Italiano), utilizzando per questi le
quote trascritte nelle monografie dei punti.
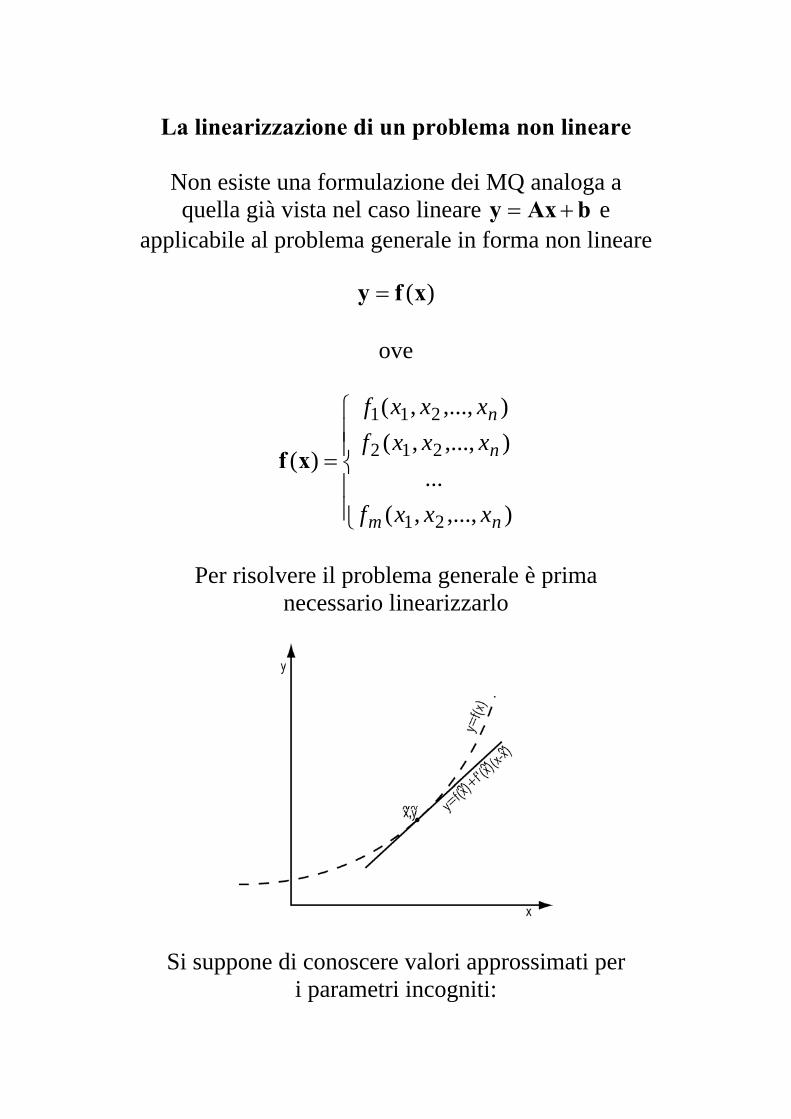
La linearizzazione di un problema non lineare
Non esiste una formulazione dei MQ analoga a quella già vista nel caso lineare bAxy += e
applicabile al problema generale in forma non lineare
)(xfy =
ove
⎪⎪⎩
⎪⎪⎨
⎧
=
),...,,(...
),...,,(),...,,(
)(
21
212
211
nm
n
n
xxxf
xxxfxxxf
xf
Per risolvere il problema generale è prima
necessario linearizzarlo
Si suppone di conoscere valori approssimati per i parametri incogniti:

[ ] nn
Tn
T xxxxxx ≅≅≅= ~,...,~:~,...,~~111 xx ;
è allora possibile linearizzare la relazione )(xfy =
mediante uno sviluppo di Taylor arrestato al primo ordine nell’intorno di x~ :
)~()~(...)~()~()~( 111
1
111 nn
nxx
xfxx
xffy −⋅
∂∂
++−⋅∂∂
+≅ xxx
)~()~(...)~()~()~( 211
1
222 nn
nxx
xfxx
xffy −⋅
∂∂
++−⋅∂∂
+≅ xxx
…
)~()~(...)~()~()~( 111
nnn
mmmm xx
xfxx
xffy −⋅
∂∂
++−⋅∂∂
+≅ xxx
ovvero
)~)(~()~( xxxJxfy −+=
o anche
Aξη =
ove
)~(),...,~(:)~( 111 xxxfyη mmm fyfy −=−=−= ηη nnn xxxx ~,...,~:~
111 −=−=−= ξξxxξ
[ ] )~(;dim xAj
iij x
fAnm∂∂
=×=

Nella prassi operativa si svolgono dunque le seguenti operazioni:
si forniscono i valori approssimati x~ ;
si calcolano i corrispondenti y~ ; si calcolano le derivate e quindi gli elementi Aij ;
si calcola il vettore yyη ~−= OO .
Si ottiene dunque il problema lineare
νηη +=O [ ] ξηη AE O ==
con dim[ηΟ, η , ν]=m; dim[ξ]=n; dim[A]= m × n.
Mediante MQ si risolve il problema lineare rispetto
al vettore dei parametri incogniti ξ;
si calcolano i parametri finali mediante la
ξxx ˆ~ˆ += ηyy ˆ~ˆ +=
Nota
il metodo da adottarsi per ricavare i valori approssimati dipende da caso a caso e non viene
considerato in questa esposizione generale.

Gli effetti della linearizzazione
A causa delle approssimazioni introdotte dalla linearizzazione y=Ax+b per il problema y=f(x)
le prime stime fornite dai MQ non possono essere considerate definitive.
11 ˆ,ˆ yx
In particolare gli divengono nuovi valori approssimati 1x
1~x a partire dai quali si effettua una nuova stima.
Il processo iterativo termina quando due stime successive differiscono in modo non significativo, ovvero quando
ε<− nn xx ~ˆ
con ε assegnato.

Un esempio di linearizzazione per un problema non lineare
Sia P un punto di posizione incognita in R3:
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
P
P
P
ZYX
P
siano invece P1, P2, P3 e P4 quattro punti di posizione nota:
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
=1
1
1
1
ZYX
P ⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
=2
2
2
2
ZYX
P … ⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
=4
4
4
4
ZYX
P
Da P sono state misurate le distanze ai quattro punti,
ottenendo i valori ; si indichi con il vettore delle osservazioni di distanza.
OPOPOPOP4321 ;;; ρρρρ Oρ
E’ noto un valore approssimato della posizione di P

⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
P
P
P
ZYX
P~~~
~
si vuole stimare la posizione di P.
Procedimento
La generica equazione di osservazione da P a Pi è
222 )()()( i
Pi
Pi
PiP ZZYYXX −+−+−=ρ
iiPO
iP νρρ +=
la relazione che lega le distanze (osservate a meno degli errori) alle incognite (la posizione di P) è non lineare;
il sistema è ridondante: 4 osservazioni per 3 incognite;
è possibile risolverlo mediante MQ ma deve
prima essere linearizzato.
Linearizzazione della generica distanza da P a Pi:

)~()~()~()~(
)~(
)~()~()~()~(
)~(
)~()~()~()~(
)~(
)~()~()~(
)()()(
222
222
222
222
222
PPiP
iP
iP
iP
PPiP
iP
iP
iP
PPiP
iP
iP
iP
iP
iP
iP
iP
iP
iP
iP
ZZZZYYXX
ZZ
YYZZYYXX
YY
XXZZYYXX
XX
ZZYYXX
ZZYYXX
−−+−+−
−+
+−−+−+−
−+
+−−+−+−
−+
+−+−+−≅
−+−+−=ρ
ovvero
ξe ⋅+≅ i
PiP
iP
~~ρρ
ove
222 )~()~()~(~ iP
iP
iP
iP ZZYYXX −+−+−=ρ
(distanza calcolata nei valori approssimati)
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−−
=i
P
iP
iP
iP
iP
ZZYYXX
~~~
~1~
ρe
(versore approssimato da Pi a P)

⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−−
=
PP
PP
PP
ZZYYXX
~~~
ξ
(correzioni da apportare alle coordinate approssimate)
Il problema assume dunque la forma
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
ξξξ
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
+
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
ρρρρ
=
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
ρ
ρ
ρ
ρ
Z
Y
X
ZYX
ZYX
ZYX
ZYX
P
P
P
P
OP
OP
OP
OP
eeeeeeeeeeee
444
333
222
111
4
3
2
1
4
3
2
1
~~~~~~~~~~~~
~~~~
ovvero
Aξηνη
νρρρρη
=+=
+−=−= ~~OO
ora risolvibile mediante MQ.

Errori di modello: introduzione alla verifica statistica di ipotesi
Errori di modello deterministico:
errata costruzione delle e.o. fra osservazioni e incognite, ovvero di A e b. In generale si ha
modello deterministico adottato
νbAxy ++=O
modello deterministico corretto
νbbxAAy +δ++δ+= )(O
Ad esempio,
misuro (yO) una lunghezza in pollici e stimo il risultato (x) in centimetri, senza convertire:
relazione adottata 1, =ν+= aaxyO
relazione corretta inccmaaxyO /54.2, =ν+=
Possono essere su tutto il modello
ma tipicamente su singole osservazioni, ovvero: iiiiOi bby δδ +++= xaa )(
solo per l’osservazione i-esima. Sono eliminabili a priori mediante
corretta costruzione delle e.o. (non sempre possibile);

identificabili a posteriori solo (ma non sempre) se non compaiono sistematicamente in tutte le osservazioni.
Comportano stime errate principalmente dei parametri incogniti.
Errori di modello stocastico:
errata ipotesi sulla struttura della matrice Cyy di covarianza delle osservazioni; tipicamente
sovrastima della precisione di alcune osservazioni: relativi sottostimati ("piccoli");
iiyyC=σ2
sottostima delle correlazioni fra coppie di osservazioni: relativi sottostimati (o posti a zero).
ijyyC
Ovvero: modello stocastico adottato per l’osservazione i-esima
mjijijii ,...,1; 0
20
2 =∀== σσσσ
modello stocastico corretto
mjijijijiii ,...,1; 022
02 =∀δσ+σ=σδσ+σ=σ
Eliminabili a priori mediante
corretta costruzione di Cyy (non sempre possibile); identificabili a posteriori solo (ma non sempre) se
si dispone di osservazioni ridondanti. Comportano stime errate
principalmente della matrice di covarianza dei parametri incogniti.
Il metodo dei MQ non è uno stimatore robusto: errori di modello deterministico o stocastico,

globali o su osservazioni isolate (outlier), possono distorcere le stime.
Esistono algoritmi per:
verificare a posteriori la correttezza globale dei modelli adottati (test del χ2);
identificare eventuali errori di modello
su singole osservazioni (identificazione degli outlier e data snooping).
La verifica statistica di ipotesi
E' un’operazione che consente di stabilire se,
statisticamente, ovvero con una certa probabilità di errore, due valori sono uguali o diversi.
Tipicamente: si pone l’ipotesi H0 che le grandezze oggetto di verifica siano uguali; si costruisce una statistica
campionaria che, sotto l’ipotesi H0, debba seguire una distribuzione nota;
che viceversa, qualora H0 sia sbagliata, vada ad assumere valori “grandi”,
ovvero non accettabili statisticamente; si confronta quindi la statistica campionaria con

i valori limite ammessi dalla sua distribuzione teorica. Nelle nostre applicazioni la verifica viene finalizzata
al controllo di presenza di errori di modello.
Livello di significatività α del test: probabilità di errore che si accetta nell’eseguire il test,
tipicamente 0.01, 0.05, 0.10.
Esempio: test del χ2 per il controllo di accuratezza.
Uno strumento di misura deve essere caratterizzato da accuratezza σ.
Viene effettuata una serie di osservazioni e Oiy
viene calcolata la varianza campionaria ; 2σsi vuole verificare se 2σ sia statisticamente uguale a 2σ
a un certo livello di significatività α:
220 ˆ: σ=σH
Teoria (non dimostrata):
se fosse vera l’ipotesi H0 dovrebbe valere la
2)1(
222
1~)ˆ(
11ˆ −χ
−σ
−−
=σ ∑ Ni
Oi Nyy
N
ove
2nχ è la V.C. chiquadro a n gradi di libertà,
],[~1ˆ2
NyNy
Ny
iOi
σ= ∑
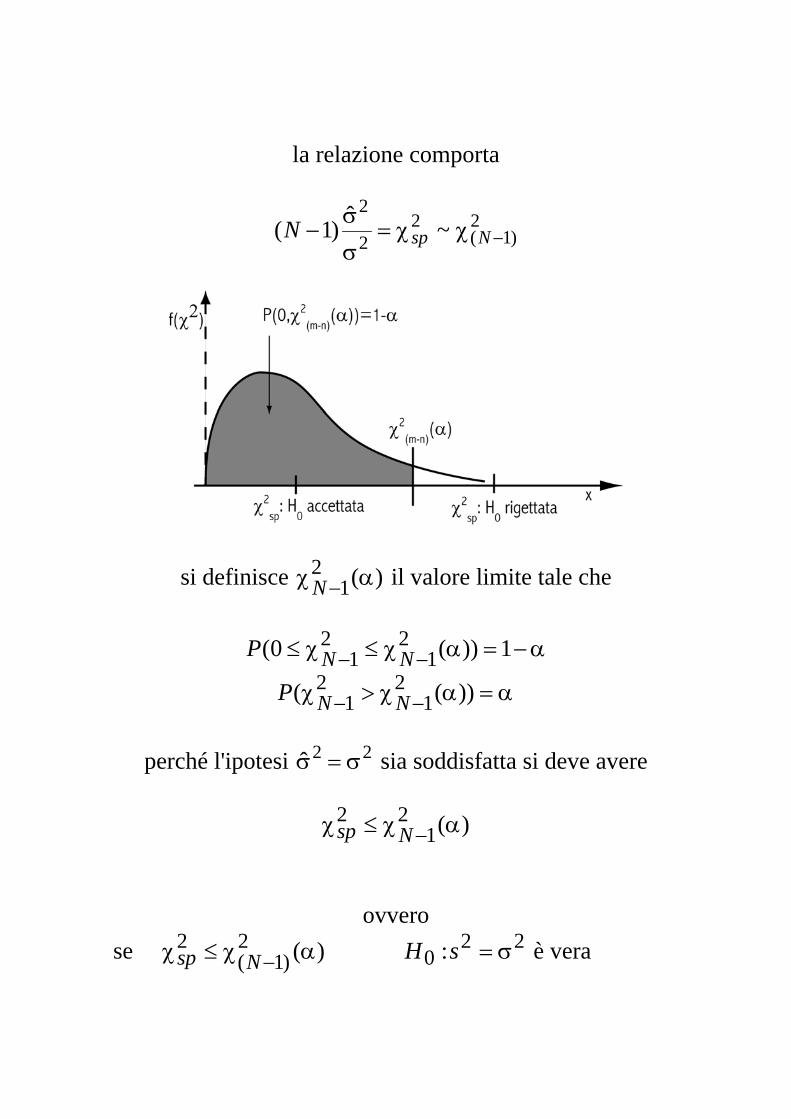
la relazione comporta
2
)1(2
2
2~ˆ)1( −χχ=
σ
σ− NspN
si definisce )(21 αχ −N il valore limite tale che
α−=αχ≤χ≤ −− 1))(0( 2
12
1 NNP
α=αχ>χ −− ))(( 21
21 NNP
perché l'ipotesi 22ˆ σ=σ sia soddisfatta si deve avere
)(2
12 αχ≤χ −Nsp
ovvero se è vera 22
02
)1(2 :)( σ=αχ≤χ − sHNsp

se è falsa 220
2)1(
2 :)( σ=αχ>χ − sHNsp
La verifica di ipotesi per i dati e le reti GPS
Nell’elaborazione dei dati GPS e
nella compensazione di reti rilevate mediante GPS tipicamente vi sono outlier dovuti
sia all’approssimata conoscenza del modello stocastico (le osservazioni vengono ipotizzate più accurate e meno
correlate di quanto non siano in realtà); sia alla presenza di isolati errori di modello deterministico (alcune osservazioni possono contenere termini di disturbo
di entità significativa e non modellizzabili: ad es. il multipath o uno stazionamento fuori centro).
Pertanto, in genere,
prima si verifica la correttezza del modello globale, poi si individuano eventuali outlier,
infine si corregge il modello stocastico.
Il test del χ2 o test globale sul modello
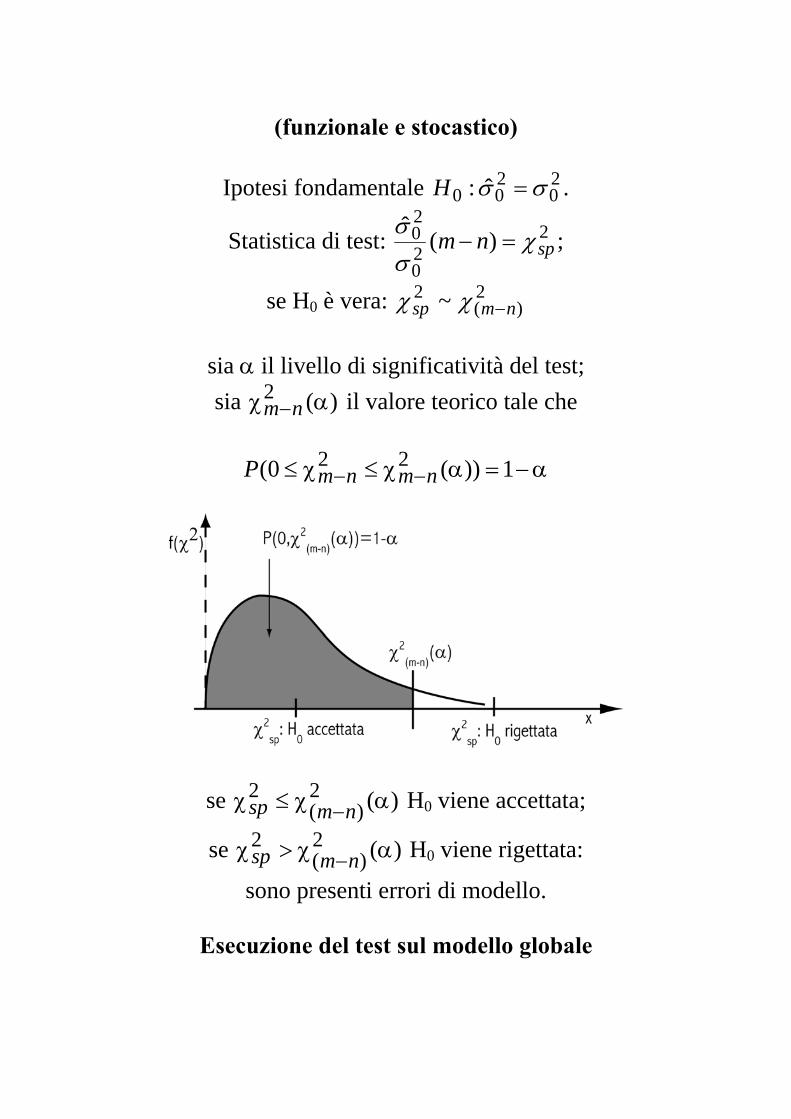
(funzionale e stocastico)
Ipotesi fondamentale . 20
200 ˆ: σσ =H
Statistica di test: 220
20 )(ˆ
spnm χσσ
=− ;
se H0 è vera: 2)(
2 ~ nmsp −χχ
sia α il livello di significatività del test; sia il valore teorico tale che )(2 αχ −nm
α−=αχ≤χ≤ −− 1))(0( 22
nmnmP
se H)(2)(
2 αχ≤χ −nmsp 0 viene accettata;
se H)(2)(
2 αχ>χ −nmsp 0 viene rigettata:
sono presenti errori di modello.
Esecuzione del test sul modello globale

Si effettua la stima ai MQ dei parametri incogniti e delle osservabili;
si stimano gli scarti di osservazione e quindi il ; ν 20σ
si fissa il livello di significatività α per il test; si ricava il valore di da apposite tabelle; )(2
)( αχ −nm
si calcola il e lo si confronta con il valore teorico. 2spχ
Nota: il valore )(2 αχ −nm viene riportato in tabella
come a ν gradi di libertà, 2)1( α−χ nm −=ν
ad esempio:
sia stata effettuata una compensazione di 10 osservazioni in 2 incognite;
a fronte di un dichiarato a priori 220 1cm=σ
si sia ottenuto un . 220 375.2ˆ cm=σ
Sia fissato %5=α : 95.0%951 ==−α ; dai dati precedenti si ricava 8)( =− nm ;
dalla tabella si estrae il valore corrispondente alla colonna e alla riga 2
95.0χ 8=v , ovvero
5.15)05.0(28 =χ
5.15191375.28
ˆ)(
20
202 >==−=
σ
σχ nmsp

Il test non è superato: quindi vi è, a un livello di probabilità del 95%, un errore di modello.
Se si fosse fissato %1=α , si sarebbe ottenuto
(colonna della tabella ) 299.0χ
22
8 1.20)01.0( spχ>=χ
ovvero vi sono errori di modello a livello di significatività 5%,
ma non a livello di significatività 1%.

Il test locale sulla singola osservazione (ipotesi di osservazioni indipendenti)
Serve per identificare errori di modello deterministico o
stocastico su una singola osservazione : Oiy
Ipotesi fondamentale di assenza di errori di modello: ovvero 0ˆ:0 =iH ν
Statistica di test: spi
i τ=σν
νˆˆ
;
se H0 è vera: )(~ nmsp −ττ
ove )( nm−τ è la distribuzione di Thomson a ( m – n ) gradi di libertà;
α livello di significatività del test.
Nota Il test è a due code, ovvero: si devono valutare sia
scarti negativi sia scarti positivi, in modulo “troppo grandi”
Quindi, definito )2/(ατ nm− il valore teorico tale che

ααττ −=≤≤ −− 1))2/(0( nmnmP
α=ατ>τ≤ −− ))2/(0( nmnmP
se )2/()( αττ nmsp −≤ H0 viene accettata;
se )2/()( αττ nmsp −> H0 viene rigettata: l’osservazione i-esima è un sospetto outlier.
Esecuzione del test locale
La non robustezza dei MQ rende complicata
l’identificazione degli outlier poiché un outlier modifica anche
gli scarti delle altre osservazioni; quindi è necessario un procedimento iterativo per
identificare gli outlier (Data snooping).
A ogni iterazione si individua l’osservazione k per la quale:
⎪⎩
⎪⎨⎧
=
> −
spksp
nmksp
ττ
αττ
max
)2/()(
per gestire il sospetto outlier vi sono due approcci:
1) il sospetto outlier viene eliminato dall’insieme delle
osservazioni (tipicamente quando la spτ è significativamente superiore al valore limite);

2) il sospetto outlier viene conservato nell’insieme di osservazioni, diminuendone però il peso di
compensazione (ovvero aumentandone la varianza): empiricamente si può adottare
[ ] 22 ),( iNewyyNewi iiC νσ == (approccio adottabile solo se l’osservazione è indipendente
dalle altre e la spτ è superiore ma confrontabile con il valore limite);
quindi viene ripetuta la stima ai MQ e il test globale;
ci si arresta quando non vi sono più osservazioni sospette.
Si devono poi controllare le osservazioni eliminate (calcolando i loro scarti)
per eliminarle definitivamente o reintrodurle.
Qualora il test sul modello globale non venga superato ma non vi siano sospetti outlier (scarti normalizzati
omogenei) vi è tipicamente un problema di sottostima generale degli elementi della matrice di covarianza delle
osservazioni (sovrastima delle precisioni).

Accuratezza dei parametri stimati
Sono stati eseguiti il test globale sul modello e il data snooping con esiti positivi. Si considera dunque riuscita la
stima dei parametri, ; la loro accuratezza è data dalla relativa matrice di covarianza (nel caso senza deficienza di
rango
x
120ˆˆ ˆ −σ= NC xx ).
Ci si chiede quale sia la regione di confidenza per il valore
vero dei parametri incogniti, ovvero la regione dello spazio n-dimensionale alla quale il vettore x appartiene
con livello di probabilità assegnata.
La regione di confidenza per il vettore dei parametri incogniti ad un certo livello di probabilità 1-α è data dalla
)()ˆ()ˆ( )(,
1ˆˆ α≤−− −
−nmnxx
T FC xxxx
ove Fn, (m - n)(α) è il valore della funzione F di Fisher a (n, (m - n)) gradi di libertà, corrispondente alla probabilità
(1 - α); α: in genere si scelgono i valori 0.01, 0.05, 0.10,
ovvero (1-α)=99%, 95%, 90%.
Nota
Tipicamente si è interessati alla regione di confidenza per un sottoinsieme di parametri incogniti, ξ, dim[ξ]=r × 1.
Per analizzare la regione di confidenza di ξ:

si estrae dal vettore il sottovettore corrispondente ai parametri ξ di interesse; quindi si estrae dalla matrice di covarianza totale
x ξ
xxˆˆC la matrice di covarianza del vettore , ; ξ ξξˆˆC
sia
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
σσσ
σσσ
σσσ
=
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=
221
22221
11221
ˆˆ2
1
...............
...
...
,...
nnn
n
n
xx
nx
xx
Cx
se ad esempio ⎥⎦
⎤⎢⎣
⎡=
j
ixx
ξ si ha ⎥⎥⎦
⎤
⎢⎢⎣
⎡
σσ
σσ=ξξ 2
2
ˆˆjji
ijiC
la regione di confidenza con probabilità 1-α per il vettore
è data dalla ξ
)()ˆ()()ˆ( )(,1
ˆˆ α≤−− −−
nmrT FC ξξξξ
ξξ
Ad esempio, nel caso di una compensazione di rete
geodetica, tipicamente si vuole conoscere per ogni punto la regione tridimensionale di confidenza delle coordinate [XP, YP, ZP] del punto stesso. La regione di confidenza in
questo caso è data da un ellissoide centrato in ]ˆ,ˆ,ˆ[ PPP ZYX , i cui parametri (semiassi e relative
direzioni) dipendono dalla matrice di covarianza delle stime delle coordinate del punto.
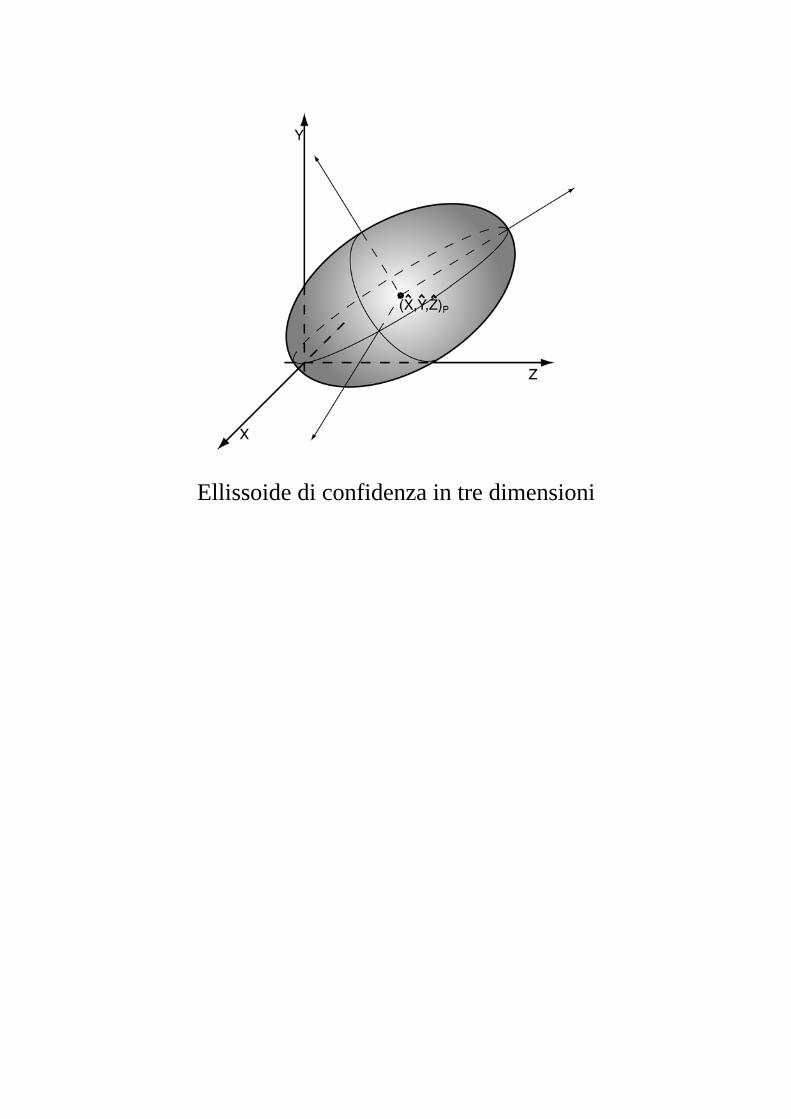
Ellissoide di confidenza in tre dimensioni

Tabella della F di Fisher

Applicazioni dei MQ rilevanti al corso
Elaborazione delle osservazioni GPS
Le relazioni che legano le osservazioni GPS (fasi e codici) alle incognite (posizione del ricevitore o componenti della base) sono simili alle equazioni di distanza; in generale le
osservazioni sono ridondanti, anzi, tipicamente m>>n. Nella maggior parte dei programmi per l’elaborazione dei dati GPS il problema di stima viene linearizzato e quindi
risolto mediante MQ.
I programmi in genere applicano ai dati il test del χ2 per fornire a posteriori un indicatore di qualità dei risultati; viene inoltre effettuato un data snooping delle singole
osservazioni, per la rimozione di eventuali outlier.
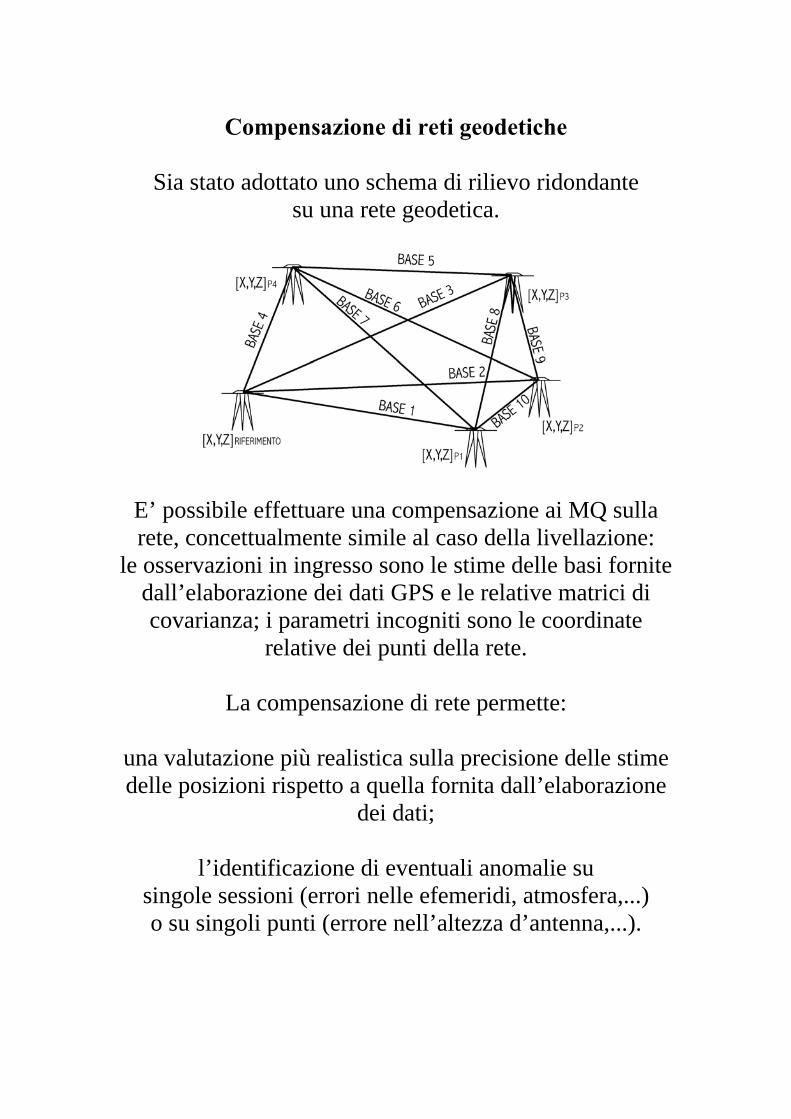
Compensazione di reti geodetiche
Sia stato adottato uno schema di rilievo ridondante su una rete geodetica.
E’ possibile effettuare una compensazione ai MQ sulla rete, concettualmente simile al caso della livellazione:
le osservazioni in ingresso sono le stime delle basi fornite dall’elaborazione dei dati GPS e le relative matrici di covarianza; i parametri incogniti sono le coordinate
relative dei punti della rete.
La compensazione di rete permette:
una valutazione più realistica sulla precisione delle stime delle posizioni rispetto a quella fornita dall’elaborazione
dei dati;
l’identificazione di eventuali anomalie su singole sessioni (errori nelle efemeridi, atmosfera,...) o su singoli punti (errore nell’altezza d’antenna,...).

Autovalutazione sui Minimi Quadrati: argomenti e quesiti di importanza fondamentale
Fornisci una definizione per errori casuali,
di modello deterministico e di modello stocastico.
Descrivi il principio di stima dei MQ e scrivi gli stimatori per x, y, ν, , C2
0σ xx e Cyy forniti dal metodo in assenza di deficienza di rango.
Descrivi il problema della deficienza di rango e di come possa operativamente essere risolto nella compensazione
di reti geodetiche.
Spiega il metodo di linearizzazione per un problema non lineare e applicalo all’esempio delle osservazioni di
distanza.
Descrivi il test del χ2: le finalità, la statistica di test e la sua esecuzione.
Descrivi il test sulla singola osservazione:
le finalità, la statistica di test e la sua esecuzione.
La definizione di regione di confidenza per i parametri stimati e per un loro sottoinsieme.



![Capitolo 3 Massimi e minimi di funzionifabio/didattica/2mat/3esercizi.pdf · c aronetto 1.Ad esempio f: [0;1] !R, f(x) = x, ha derivata sempre non nulla all’interno di [0;1] e comunque](https://static.fdocument.org/doc/165x107/5f8ab5ecf3742a6ae50e497d/capitolo-3-massimi-e-minimi-di-funzioni-fabiodidattica2mat-c-aronetto-1ad.jpg)




