Internet Monetization - Reinforcement · PDF fileReinforcement Learning Temporal Difference...
253
Web and Internet Economics Reinforcement Learning Andrea Tirinzoni Matteo Papini May, 2018
Transcript of Internet Monetization - Reinforcement · PDF fileReinforcement Learning Temporal Difference...
Web and Internet EconomicsReinforcement Learning
Andrea TirinzoniMatteo Papini
May, 2018

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
RL techniques
Model–free vs Model–basedOn–policy vs Off–policyOnline vs OfflineTabular vs Function ApproximationValue–based vs Policy–based vs Actor–Critic

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
RL techniques
Model–free vs Model–basedOn–policy vs Off–policyOnline vs OfflineTabular vs Function ApproximationValue–based vs Policy–based vs Actor–Critic

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
RL techniques
Model–free vs Model–basedOn–policy vs Off–policyOnline vs OfflineTabular vs Function ApproximationValue–based vs Policy–based vs Actor–Critic

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
RL techniques
Model–free vs Model–basedOn–policy vs Off–policyOnline vs OfflineTabular vs Function ApproximationValue–based vs Policy–based vs Actor–Critic

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
RL techniques
Model–free vs Model–basedOn–policy vs Off–policyOnline vs OfflineTabular vs Function ApproximationValue–based vs Policy–based vs Actor–Critic

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
RL problems
Model–free Prediction: Estimate the value function ofan unknown MRP (MDP + policy)Model-free Control: Optimize the value function of anunknown MDP

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
RL problems
Model–free Prediction: Estimate the value function ofan unknown MRP (MDP + policy)Model-free Control: Optimize the value function of anunknown MDP

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Outline
1 Model–free PredictionMonte–Carlo Reinforcement LearningTemporal Difference Reinforcement LearningComparison between MC and TDTD(λ)
2 Model–free ControlOn–Policy Monte–Carlo ControlOn–Policy Temporal–Difference LearningOff–Policy Learning

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Outline
1 Model–free PredictionMonte–Carlo Reinforcement LearningTemporal Difference Reinforcement LearningComparison between MC and TDTD(λ)
2 Model–free ControlOn–Policy Monte–Carlo ControlOn–Policy Temporal–Difference LearningOff–Policy Learning

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Monte–Carlo Reinforcement Learning
MC methods learn directly from episodes ofexperienceMC is model–free: no knowledge of MDPtransitions/rewardsMC learns from complete episodes: no bootstrappingMC uses the simplest possible idea: value = meanreturnCaveat: can only apply MC to episodic MDPs
All episodes must terminate

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Monte–Carlo Reinforcement Learning
MC methods learn directly from episodes ofexperienceMC is model–free: no knowledge of MDPtransitions/rewardsMC learns from complete episodes: no bootstrappingMC uses the simplest possible idea: value = meanreturnCaveat: can only apply MC to episodic MDPs
All episodes must terminate

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Monte–Carlo Reinforcement Learning
MC methods learn directly from episodes ofexperienceMC is model–free: no knowledge of MDPtransitions/rewardsMC learns from complete episodes: no bootstrappingMC uses the simplest possible idea: value = meanreturnCaveat: can only apply MC to episodic MDPs
All episodes must terminate

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Monte–Carlo Reinforcement Learning
MC methods learn directly from episodes ofexperienceMC is model–free: no knowledge of MDPtransitions/rewardsMC learns from complete episodes: no bootstrappingMC uses the simplest possible idea: value = meanreturnCaveat: can only apply MC to episodic MDPs
All episodes must terminate

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Monte–Carlo Reinforcement Learning
MC methods learn directly from episodes ofexperienceMC is model–free: no knowledge of MDPtransitions/rewardsMC learns from complete episodes: no bootstrappingMC uses the simplest possible idea: value = meanreturnCaveat: can only apply MC to episodic MDPs
All episodes must terminate

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Monte–Carlo Reinforcement Learning
MC methods learn directly from episodes ofexperienceMC is model–free: no knowledge of MDPtransitions/rewardsMC learns from complete episodes: no bootstrappingMC uses the simplest possible idea: value = meanreturnCaveat: can only apply MC to episodic MDPs
All episodes must terminate

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Monte Carlo for Prediction and Control
MC can be used for prediction:Input: Episodes of experience {s1,a1, r2, . . . , sT}generated by following policy π in given MDPor: Episodes of experience {s1,a1, r2, . . . , sT}generated by MRPOutput: Value function Vπ
Or for control:Input: Episodes of experience {s1,a1, r2, . . . , sT} ingiven MDPOutput: Optimal value function V ∗
Output: Optimal policy π∗

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Monte Carlo for Prediction and Control
MC can be used for prediction:Input: Episodes of experience {s1,a1, r2, . . . , sT}generated by following policy π in given MDPor: Episodes of experience {s1,a1, r2, . . . , sT}generated by MRPOutput: Value function Vπ
Or for control:Input: Episodes of experience {s1,a1, r2, . . . , sT} ingiven MDPOutput: Optimal value function V ∗
Output: Optimal policy π∗

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Monte Carlo for Prediction and Control
MC can be used for prediction:Input: Episodes of experience {s1,a1, r2, . . . , sT}generated by following policy π in given MDPor: Episodes of experience {s1,a1, r2, . . . , sT}generated by MRPOutput: Value function Vπ
Or for control:Input: Episodes of experience {s1,a1, r2, . . . , sT} ingiven MDPOutput: Optimal value function V ∗
Output: Optimal policy π∗

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Monte Carlo for Prediction and Control
MC can be used for prediction:Input: Episodes of experience {s1,a1, r2, . . . , sT}generated by following policy π in given MDPor: Episodes of experience {s1,a1, r2, . . . , sT}generated by MRPOutput: Value function Vπ
Or for control:Input: Episodes of experience {s1,a1, r2, . . . , sT} ingiven MDPOutput: Optimal value function V ∗
Output: Optimal policy π∗

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Monte Carlo for Prediction and Control
MC can be used for prediction:Input: Episodes of experience {s1,a1, r2, . . . , sT}generated by following policy π in given MDPor: Episodes of experience {s1,a1, r2, . . . , sT}generated by MRPOutput: Value function Vπ
Or for control:Input: Episodes of experience {s1,a1, r2, . . . , sT} ingiven MDPOutput: Optimal value function V ∗
Output: Optimal policy π∗

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Monte Carlo for Prediction and Control
MC can be used for prediction:Input: Episodes of experience {s1,a1, r2, . . . , sT}generated by following policy π in given MDPor: Episodes of experience {s1,a1, r2, . . . , sT}generated by MRPOutput: Value function Vπ
Or for control:Input: Episodes of experience {s1,a1, r2, . . . , sT} ingiven MDPOutput: Optimal value function V ∗
Output: Optimal policy π∗

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Monte Carlo for Prediction and Control
MC can be used for prediction:Input: Episodes of experience {s1,a1, r2, . . . , sT}generated by following policy π in given MDPor: Episodes of experience {s1,a1, r2, . . . , sT}generated by MRPOutput: Value function Vπ
Or for control:Input: Episodes of experience {s1,a1, r2, . . . , sT} ingiven MDPOutput: Optimal value function V ∗
Output: Optimal policy π∗

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Monte Carlo for Prediction and Control
MC can be used for prediction:Input: Episodes of experience {s1,a1, r2, . . . , sT}generated by following policy π in given MDPor: Episodes of experience {s1,a1, r2, . . . , sT}generated by MRPOutput: Value function Vπ
Or for control:Input: Episodes of experience {s1,a1, r2, . . . , sT} ingiven MDPOutput: Optimal value function V ∗
Output: Optimal policy π∗

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Estimation of Mean: Monte Carlo
Let X be a random variable with mean µ = E[x ] andvariance σ2 = Var [X ]. Let xi ∼ X , i = 1, . . . ,n be n i.i.d.realizations of X .Empirical mean of X :
µ̂n =1n
n∑i=1
xi
We have E[µ̂n] = µ, Var[µ̂n] = Var[X ]n
Weak law of large numbers: µ̂nP−→ µ
limn→∞ P(|µ̂n − µ| > ε) = 0Strong law of large numbers: µ̂n
a.s.−−→ µP((limn→∞ µ̂n = µ) = 1)Central limit theorem:
√n(µ̂n − µ)
D−→ N (0,Var[x ])

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Estimation of Mean: Monte Carlo
Let X be a random variable with mean µ = E[x ] andvariance σ2 = Var [X ]. Let xi ∼ X , i = 1, . . . ,n be n i.i.d.realizations of X .Empirical mean of X :
µ̂n =1n
n∑i=1
xi
We have E[µ̂n] = µ, Var[µ̂n] = Var[X ]n
Weak law of large numbers: µ̂nP−→ µ
limn→∞ P(|µ̂n − µ| > ε) = 0Strong law of large numbers: µ̂n
a.s.−−→ µP((limn→∞ µ̂n = µ) = 1)Central limit theorem:
√n(µ̂n − µ)
D−→ N (0,Var[x ])

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Estimation of Mean: Monte Carlo
Let X be a random variable with mean µ = E[x ] andvariance σ2 = Var [X ]. Let xi ∼ X , i = 1, . . . ,n be n i.i.d.realizations of X .Empirical mean of X :
µ̂n =1n
n∑i=1
xi
We have E[µ̂n] = µ, Var[µ̂n] = Var[X ]n
Weak law of large numbers: µ̂nP−→ µ
limn→∞ P(|µ̂n − µ| > ε) = 0Strong law of large numbers: µ̂n
a.s.−−→ µP((limn→∞ µ̂n = µ) = 1)Central limit theorem:
√n(µ̂n − µ)
D−→ N (0,Var[x ])

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Estimation of Mean: Monte Carlo
Let X be a random variable with mean µ = E[x ] andvariance σ2 = Var [X ]. Let xi ∼ X , i = 1, . . . ,n be n i.i.d.realizations of X .Empirical mean of X :
µ̂n =1n
n∑i=1
xi
We have E[µ̂n] = µ, Var[µ̂n] = Var[X ]n
Weak law of large numbers: µ̂nP−→ µ
limn→∞ P(|µ̂n − µ| > ε) = 0Strong law of large numbers: µ̂n
a.s.−−→ µP((limn→∞ µ̂n = µ) = 1)Central limit theorem:
√n(µ̂n − µ)
D−→ N (0,Var[x ])

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Estimation of Mean: Monte Carlo
Let X be a random variable with mean µ = E[x ] andvariance σ2 = Var [X ]. Let xi ∼ X , i = 1, . . . ,n be n i.i.d.realizations of X .Empirical mean of X :
µ̂n =1n
n∑i=1
xi
We have E[µ̂n] = µ, Var[µ̂n] = Var[X ]n
Weak law of large numbers: µ̂nP−→ µ
limn→∞ P(|µ̂n − µ| > ε) = 0Strong law of large numbers: µ̂n
a.s.−−→ µP((limn→∞ µ̂n = µ) = 1)Central limit theorem:
√n(µ̂n − µ)
D−→ N (0,Var[x ])

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Estimation of Mean: Monte Carlo
Let X be a random variable with mean µ = E[x ] andvariance σ2 = Var [X ]. Let xi ∼ X , i = 1, . . . ,n be n i.i.d.realizations of X .Empirical mean of X :
µ̂n =1n
n∑i=1
xi
We have E[µ̂n] = µ, Var[µ̂n] = Var[X ]n
Weak law of large numbers: µ̂nP−→ µ
limn→∞ P(|µ̂n − µ| > ε) = 0Strong law of large numbers: µ̂n
a.s.−−→ µP((limn→∞ µ̂n = µ) = 1)Central limit theorem:
√n(µ̂n − µ)
D−→ N (0,Var[x ])

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Monte–Carlo Policy Evaluation
Goal: learn Vπ from experience under policy π
s1,a1, r2, . . . , sT ∼ π
Recall that the return is the total discounted reward:
vt = rt+1 + γrt+2 + · · ·+ γT−1rt+T
Recall that the value function is the expected return:
Vπ(s) = E[vt |st = s]
Monte Carlo policy evaluation uses empirical meanreturn instead of expected return
first visit: average returns only for the first time s isvisited (unbiased estimator)every visit: average returns for every time s is visited(biased but consistent estimator)

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Monte–Carlo Policy Evaluation
Goal: learn Vπ from experience under policy π
s1,a1, r2, . . . , sT ∼ π
Recall that the return is the total discounted reward:
vt = rt+1 + γrt+2 + · · ·+ γT−1rt+T
Recall that the value function is the expected return:
Vπ(s) = E[vt |st = s]
Monte Carlo policy evaluation uses empirical meanreturn instead of expected return
first visit: average returns only for the first time s isvisited (unbiased estimator)every visit: average returns for every time s is visited(biased but consistent estimator)

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Monte–Carlo Policy Evaluation
Goal: learn Vπ from experience under policy π
s1,a1, r2, . . . , sT ∼ π
Recall that the return is the total discounted reward:
vt = rt+1 + γrt+2 + · · ·+ γT−1rt+T
Recall that the value function is the expected return:
Vπ(s) = E[vt |st = s]
Monte Carlo policy evaluation uses empirical meanreturn instead of expected return
first visit: average returns only for the first time s isvisited (unbiased estimator)every visit: average returns for every time s is visited(biased but consistent estimator)

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Monte–Carlo Policy Evaluation
Goal: learn Vπ from experience under policy π
s1,a1, r2, . . . , sT ∼ π
Recall that the return is the total discounted reward:
vt = rt+1 + γrt+2 + · · ·+ γT−1rt+T
Recall that the value function is the expected return:
Vπ(s) = E[vt |st = s]
Monte Carlo policy evaluation uses empirical meanreturn instead of expected return
first visit: average returns only for the first time s isvisited (unbiased estimator)every visit: average returns for every time s is visited(biased but consistent estimator)

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Monte–Carlo Policy Evaluation
Goal: learn Vπ from experience under policy π
s1,a1, r2, . . . , sT ∼ π
Recall that the return is the total discounted reward:
vt = rt+1 + γrt+2 + · · ·+ γT−1rt+T
Recall that the value function is the expected return:
Vπ(s) = E[vt |st = s]
Monte Carlo policy evaluation uses empirical meanreturn instead of expected return
first visit: average returns only for the first time s isvisited (unbiased estimator)every visit: average returns for every time s is visited(biased but consistent estimator)

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Monte–Carlo Policy Evaluation
Goal: learn Vπ from experience under policy π
s1,a1, r2, . . . , sT ∼ π
Recall that the return is the total discounted reward:
vt = rt+1 + γrt+2 + · · ·+ γT−1rt+T
Recall that the value function is the expected return:
Vπ(s) = E[vt |st = s]
Monte Carlo policy evaluation uses empirical meanreturn instead of expected return
first visit: average returns only for the first time s isvisited (unbiased estimator)every visit: average returns for every time s is visited(biased but consistent estimator)

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
First–Visit Monte–Carlo Policy Evaluation
Initialize:π ← policy to be evaluatedV ← an arbitrary state–value functionReturns(s)← an empty list, for all s ∈ S
loopGenerate an episode using πfor each state s in the episode do
R ← return following the first occurrence of sAppend R to Returns(s)V (s)← average(Returns(s))
end forend loop

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Every–Visit Monte–Carlo Policy Evaluation
Initialize:π ← policy to be evaluatedV ← an arbitrary state–value functionReturns(s)← an empty list, for all s ∈ S
loopGenerate an episode using πfor each state s in the episode do
for each occurrence of state s in the episode doR ← return following this occurrence of sAppend R to Returns(s)V (s)← average(Returns(s))
end forend for
end loop
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
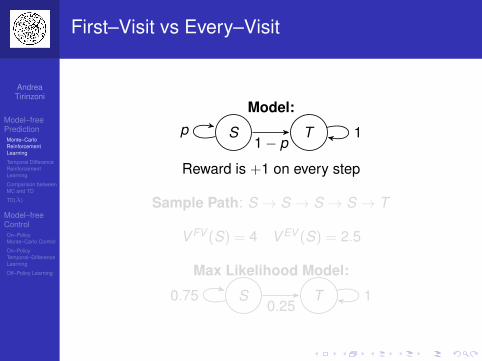
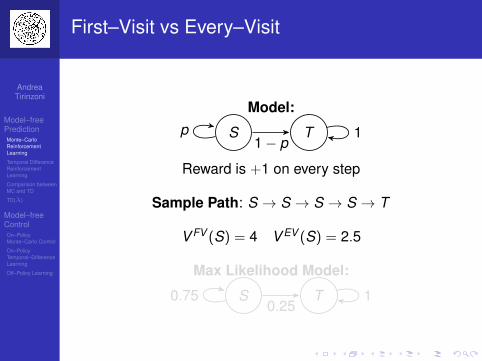
First–Visit vs Every–Visit
Model:
S Tp1− p
1
Reward is +1 on every step
Sample Path: S → S → S → S → T
V FV (S) = 4 V EV (S) = 2.5
Max Likelihood Model:
S T0.750.25
1
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
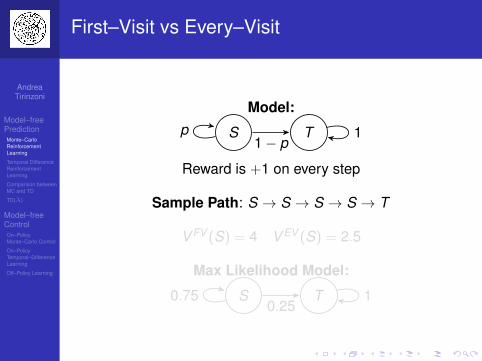
First–Visit vs Every–Visit
Model:
S Tp1− p
1
Reward is +1 on every step
Sample Path: S → S → S → S → T
V FV (S) = 4 V EV (S) = 2.5
Max Likelihood Model:
S T0.750.25
1
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
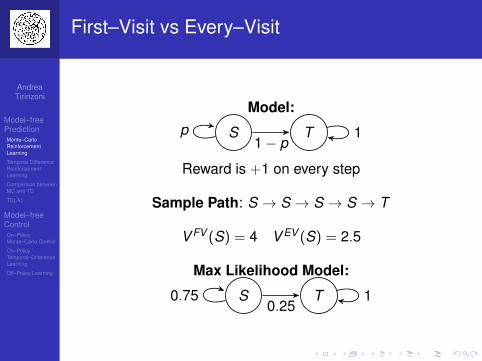
First–Visit vs Every–Visit
Model:
S Tp1− p
1
Reward is +1 on every step
Sample Path: S → S → S → S → T
V FV (S) = 4 V EV (S) = 2.5
Max Likelihood Model:
S T0.750.25
1
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
First–Visit vs Every–Visit
Model:
S Tp1− p
1
Reward is +1 on every step
Sample Path: S → S → S → S → T
V FV (S) = 4 V EV (S) = 2.5
Max Likelihood Model:
S T0.750.25
1
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
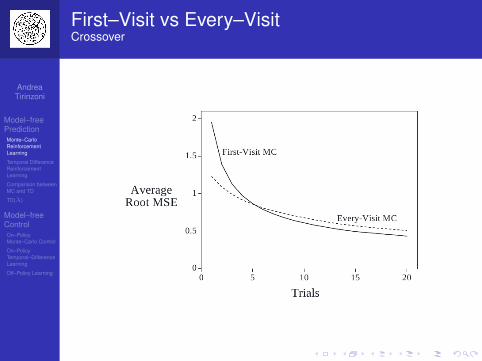
First–Visit vs Every–VisitCrossover

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
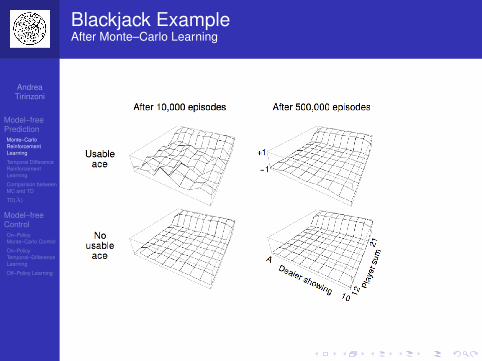
Blackjack Example
Goal: Have your card sum be greater than the dealerswithout exceeding 21States (200 of them):
current sum (12–21)dealer’s showing card (ace–10)do I have a usable ace?
Reward: +1 for winning, 0 for a draw, -1 for losingActions: stand (stop receiving cards), hit (receiveanother card)Policy: Stand if my sum is 20 or 21, else hit
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Blackjack ExampleAfter Monte–Carlo Learning

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Incremental Mean
The mean µ̂1, µ̂2, . . . of a sequence x1, x2, . . . can becomputed incrementally
µ̂k =1k
k∑j=1
xj
=1k
xk +k−1∑j=1
xj
=
1k
(xk + (k − 1)µ̂k−1)
= µ̂k−1 +1k
(xk − µ̂k−1)

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Incremental Monte–Carlo Updates
Update V (s) incrementally after episodes1,a1, r2, . . . , sT
For each state st with return vt
N(st )← N(st ) + 1
V (st )← V (st ) +1
N(st )(vt − V (st ))
In non–stationary problems, it is useful to track arunning mean, i.e., forget old episodes
V (st )← V (st ) + α(vt − V (st ))

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Incremental Monte–Carlo Updates
Update V (s) incrementally after episodes1,a1, r2, . . . , sT
For each state st with return vt
N(st )← N(st ) + 1
V (st )← V (st ) +1
N(st )(vt − V (st ))
In non–stationary problems, it is useful to track arunning mean, i.e., forget old episodes
V (st )← V (st ) + α(vt − V (st ))

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Incremental Monte–Carlo Updates
Update V (s) incrementally after episodes1,a1, r2, . . . , sT
For each state st with return vt
N(st )← N(st ) + 1
V (st )← V (st ) +1
N(st )(vt − V (st ))
In non–stationary problems, it is useful to track arunning mean, i.e., forget old episodes
V (st )← V (st ) + α(vt − V (st ))

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Stochastic ApproximationEstimation of Mean
Let X be a random variable in [0,1] with mean µ = E[X ]. Letxi ∼ X , i = 1, . . . ,n be n i.i.d. realizations of X .Consider the estimator (exponential average)
µi = (1− αi)µi−1 + αixi ,
with µ1 = x1 and αi ’s are step–size parameters orlearning rates
Proposition
If∑
i≥0 αi =∞ and∑
i≥0 α2i <∞, then µ̂n
P−→ µ, i.e., theestimator µ̂n is consistent
Note: The step sizes αi = 1i satisfy the above conditions. In
this case, the exponential average gives us the empiricalmean µ̂n = 1
n∑n
i=1 xi , which is consistent according to theweak law of large numbers

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Monte–Carlo Backups
Entire episode includedOnly one choice at each state (unlike DP)MC does not bootstrapTime required to estimate one state does not dependon the total number of states

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Monte–Carlo Backups
Entire episode includedOnly one choice at each state (unlike DP)MC does not bootstrapTime required to estimate one state does not dependon the total number of states

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Monte–Carlo Backups
Entire episode includedOnly one choice at each state (unlike DP)MC does not bootstrapTime required to estimate one state does not dependon the total number of states

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Monte–Carlo Backups
Entire episode includedOnly one choice at each state (unlike DP)MC does not bootstrapTime required to estimate one state does not dependon the total number of states
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
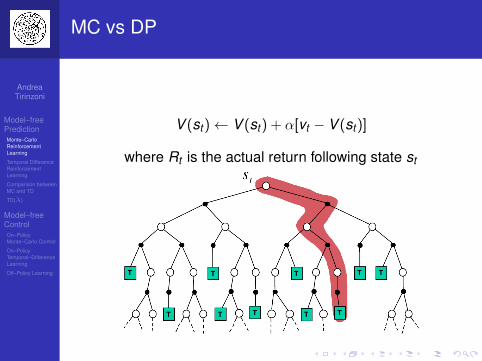
MC vs DP
V (st )← V (st ) + α[vt − V (st )]
where Rt is the actual return following state st
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
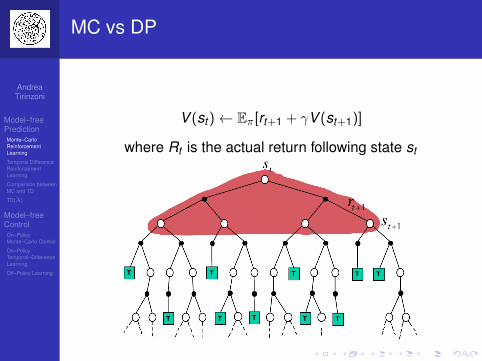
MC vs DP
V (st )← Eπ[rt+1 + γV (st+1)]
where Rt is the actual return following state st

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Outline
1 Model–free PredictionMonte–Carlo Reinforcement LearningTemporal Difference Reinforcement LearningComparison between MC and TDTD(λ)
2 Model–free ControlOn–Policy Monte–Carlo ControlOn–Policy Temporal–Difference LearningOff–Policy Learning

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Temporal Difference Learning
TD methods learn directly from episodes ofexperienceTD is model–free: no knowledge of MDPtransitions/rewardsTD learns from incomplete episodes: bootstrappingTD updates a guess towards a guess

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Temporal Difference Learning
TD methods learn directly from episodes ofexperienceTD is model–free: no knowledge of MDPtransitions/rewardsTD learns from incomplete episodes: bootstrappingTD updates a guess towards a guess

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Temporal Difference Learning
TD methods learn directly from episodes ofexperienceTD is model–free: no knowledge of MDPtransitions/rewardsTD learns from incomplete episodes: bootstrappingTD updates a guess towards a guess

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Temporal Difference Learning
TD methods learn directly from episodes ofexperienceTD is model–free: no knowledge of MDPtransitions/rewardsTD learns from incomplete episodes: bootstrappingTD updates a guess towards a guess

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
TD Prediction
Goal: learn Vπ online from experience under policy πRecall: incremental every–visit Monte Carlo
V (st )← V (st ) + α(vt − V (st ))
Simplest temporal–difference learning algorithm:TD(0)
Update value V (st ) towards estimated returnrt+1 + γV (st+1)
V (st )← V (st ) + α(rt+1 + γV (st+1)− V (st ))
rt+1 + γV (st+1) is called the TD targetδt = rt+1 + γV (st+1)− V (st ) is called the TD error

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
TD Prediction
Goal: learn Vπ online from experience under policy πRecall: incremental every–visit Monte Carlo
V (st )← V (st ) + α(vt − V (st ))
Simplest temporal–difference learning algorithm:TD(0)
Update value V (st ) towards estimated returnrt+1 + γV (st+1)
V (st )← V (st ) + α(rt+1 + γV (st+1)− V (st ))
rt+1 + γV (st+1) is called the TD targetδt = rt+1 + γV (st+1)− V (st ) is called the TD error

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
TD Prediction
Goal: learn Vπ online from experience under policy πRecall: incremental every–visit Monte Carlo
V (st )← V (st ) + α(vt − V (st ))
Simplest temporal–difference learning algorithm:TD(0)
Update value V (st ) towards estimated returnrt+1 + γV (st+1)
V (st )← V (st ) + α(rt+1 + γV (st+1)− V (st ))
rt+1 + γV (st+1) is called the TD targetδt = rt+1 + γV (st+1)− V (st ) is called the TD error

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
TD Prediction
Goal: learn Vπ online from experience under policy πRecall: incremental every–visit Monte Carlo
V (st )← V (st ) + α(vt − V (st ))
Simplest temporal–difference learning algorithm:TD(0)
Update value V (st ) towards estimated returnrt+1 + γV (st+1)
V (st )← V (st ) + α(rt+1 + γV (st+1)− V (st ))
rt+1 + γV (st+1) is called the TD targetδt = rt+1 + γV (st+1)− V (st ) is called the TD error

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
TD Prediction
Goal: learn Vπ online from experience under policy πRecall: incremental every–visit Monte Carlo
V (st )← V (st ) + α(vt − V (st ))
Simplest temporal–difference learning algorithm:TD(0)
Update value V (st ) towards estimated returnrt+1 + γV (st+1)
V (st )← V (st ) + α(rt+1 + γV (st+1)− V (st ))
rt+1 + γV (st+1) is called the TD targetδt = rt+1 + γV (st+1)− V (st ) is called the TD error

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
TD Prediction
Goal: learn Vπ online from experience under policy πRecall: incremental every–visit Monte Carlo
V (st )← V (st ) + α(vt − V (st ))
Simplest temporal–difference learning algorithm:TD(0)
Update value V (st ) towards estimated returnrt+1 + γV (st+1)
V (st )← V (st ) + α(rt+1 + γV (st+1)− V (st ))
rt+1 + γV (st+1) is called the TD targetδt = rt+1 + γV (st+1)− V (st ) is called the TD error
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Outline
1 Model–free PredictionMonte–Carlo Reinforcement LearningTemporal Difference Reinforcement LearningComparison between MC and TDTD(λ)
2 Model–free ControlOn–Policy Monte–Carlo ControlOn–Policy Temporal–Difference LearningOff–Policy Learning
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
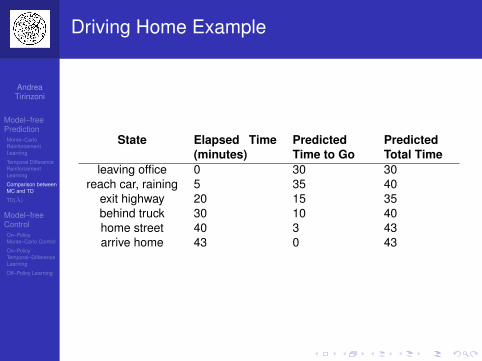
Driving Home Example
State Elapsed Time(minutes)
PredictedTime to Go
PredictedTotal Time
leaving office 0 30 30reach car, raining 5 35 40
exit highway 20 15 35behind truck 30 10 40home street 40 3 43arrive home 43 0 43
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
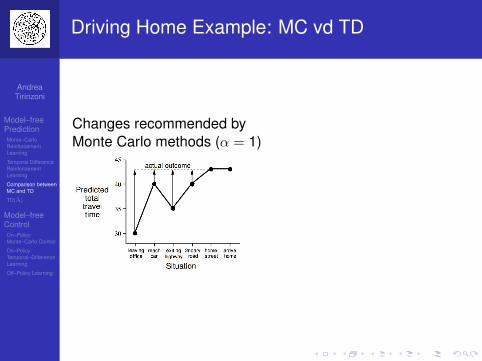
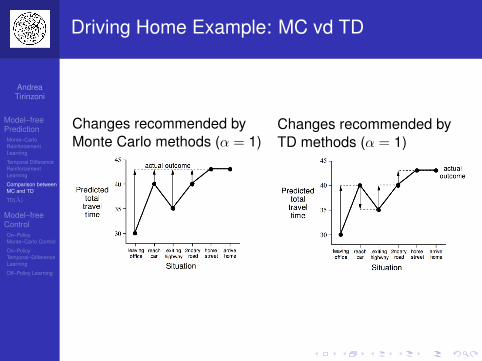
Driving Home Example: MC vd TD
Changes recommended byMonte Carlo methods (α = 1)
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Driving Home Example: MC vd TD
Changes recommended byMonte Carlo methods (α = 1)
Changes recommended byTD methods (α = 1)

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Comparison between MC and TD
TD can learn before knowing the final outcomeTD can learn online after every stepMC must wait until end of episode before return isknown
TD can learn without the final outcomeTD can learn from incomplete sequencesMC can only learn form complete sequencesTD works in continuing (non–terminating)environmentsMC only works for episodic (terminating) environments

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Comparison between MC and TD
TD can learn before knowing the final outcomeTD can learn online after every stepMC must wait until end of episode before return isknown
TD can learn without the final outcomeTD can learn from incomplete sequencesMC can only learn form complete sequencesTD works in continuing (non–terminating)environmentsMC only works for episodic (terminating) environments

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Comparison between MC and TD
TD can learn before knowing the final outcomeTD can learn online after every stepMC must wait until end of episode before return isknown
TD can learn without the final outcomeTD can learn from incomplete sequencesMC can only learn form complete sequencesTD works in continuing (non–terminating)environmentsMC only works for episodic (terminating) environments

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Comparison between MC and TD
TD can learn before knowing the final outcomeTD can learn online after every stepMC must wait until end of episode before return isknown
TD can learn without the final outcomeTD can learn from incomplete sequencesMC can only learn form complete sequencesTD works in continuing (non–terminating)environmentsMC only works for episodic (terminating) environments

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Comparison between MC and TD
TD can learn before knowing the final outcomeTD can learn online after every stepMC must wait until end of episode before return isknown
TD can learn without the final outcomeTD can learn from incomplete sequencesMC can only learn form complete sequencesTD works in continuing (non–terminating)environmentsMC only works for episodic (terminating) environments

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Comparison between MC and TD
TD can learn before knowing the final outcomeTD can learn online after every stepMC must wait until end of episode before return isknown
TD can learn without the final outcomeTD can learn from incomplete sequencesMC can only learn form complete sequencesTD works in continuing (non–terminating)environmentsMC only works for episodic (terminating) environments

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Comparison between MC and TD
TD can learn before knowing the final outcomeTD can learn online after every stepMC must wait until end of episode before return isknown
TD can learn without the final outcomeTD can learn from incomplete sequencesMC can only learn form complete sequencesTD works in continuing (non–terminating)environmentsMC only works for episodic (terminating) environments

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Comparison between MC and TD
TD can learn before knowing the final outcomeTD can learn online after every stepMC must wait until end of episode before return isknown
TD can learn without the final outcomeTD can learn from incomplete sequencesMC can only learn form complete sequencesTD works in continuing (non–terminating)environmentsMC only works for episodic (terminating) environments

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
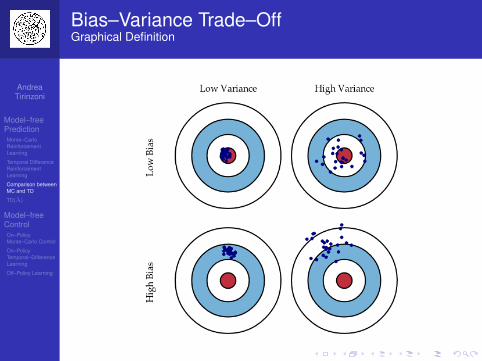
Bias–Variance Trade–OffConceptual Definition
Error due to bias: is the difference between theexpected prediction of our model and the actual valuewe want to predictError due to variance: is the variability of a modelprediction for a given data point

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Bias–Variance Trade–OffConceptual Definition
Error due to bias: is the difference between theexpected prediction of our model and the actual valuewe want to predictError due to variance: is the variability of a modelprediction for a given data point
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Bias–Variance Trade–OffGraphical Definition
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
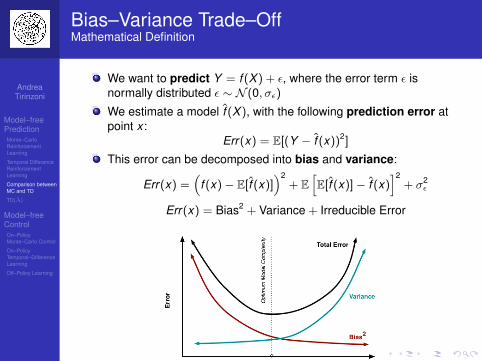
Bias–Variance Trade–OffMathematical Definition
We want to predict Y = f (X ) + ε, where the error term ε isnormally distributed ε ∼ N (0, σε)
We estimate a model f̂ (X ), with the following prediction error atpoint x :
Err(x) = E[(Y − f̂ (x))2]
This error can be decomposed into bias and variance:
Err(x) =(
f (x)− E[̂f (x)])2
+ E[E[̂f (x)]− f̂ (x)
]2+ σ2
ε
Err(x) = Bias2 + Variance + Irreducible Error

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Bias–Variance Trade–OffMC vs TD
Return vt = rt+1 + γrt+2 + · · ·+ γT−1rt+T is anunbiased esitmate of Vπ(st )
TD target rt+1 + γV (st+1) is a biased estimate ofVπ(st )
Unless V (st+1) = Vπ(st+1)
But the TD target is much lower variance:Return depends on many random actions, transitions,rewardsTD target depends on one random action, transition,reward

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Bias–Variance Trade–OffMC vs TD
Return vt = rt+1 + γrt+2 + · · ·+ γT−1rt+T is anunbiased esitmate of Vπ(st )
TD target rt+1 + γV (st+1) is a biased estimate ofVπ(st )
Unless V (st+1) = Vπ(st+1)
But the TD target is much lower variance:Return depends on many random actions, transitions,rewardsTD target depends on one random action, transition,reward

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Bias–Variance Trade–OffMC vs TD
Return vt = rt+1 + γrt+2 + · · ·+ γT−1rt+T is anunbiased esitmate of Vπ(st )
TD target rt+1 + γV (st+1) is a biased estimate ofVπ(st )
Unless V (st+1) = Vπ(st+1)
But the TD target is much lower variance:Return depends on many random actions, transitions,rewardsTD target depends on one random action, transition,reward

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Bias–Variance Trade–OffMC vs TD
Return vt = rt+1 + γrt+2 + · · ·+ γT−1rt+T is anunbiased esitmate of Vπ(st )
TD target rt+1 + γV (st+1) is a biased estimate ofVπ(st )
Unless V (st+1) = Vπ(st+1)
But the TD target is much lower variance:Return depends on many random actions, transitions,rewardsTD target depends on one random action, transition,reward

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Bias–Variance Trade–OffMC vs TD
Return vt = rt+1 + γrt+2 + · · ·+ γT−1rt+T is anunbiased esitmate of Vπ(st )
TD target rt+1 + γV (st+1) is a biased estimate ofVπ(st )
Unless V (st+1) = Vπ(st+1)
But the TD target is much lower variance:Return depends on many random actions, transitions,rewardsTD target depends on one random action, transition,reward

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Bias–Variance Trade–OffMC vs TD
Return vt = rt+1 + γrt+2 + · · ·+ γT−1rt+T is anunbiased esitmate of Vπ(st )
TD target rt+1 + γV (st+1) is a biased estimate ofVπ(st )
Unless V (st+1) = Vπ(st+1)
But the TD target is much lower variance:Return depends on many random actions, transitions,rewardsTD target depends on one random action, transition,reward

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Bias–Variance comparison between MC andTD
MC has high variance, zero biasGood convergence propertiesWorks well with function approximationNot very sensitive to initial valueVery simple to understand and use
TD has low variance, some biasUsually more efficient than MCTD(0) converges to Vπ(s)Problem with function approximationMore sensitive to initial values

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Bias–Variance comparison between MC andTD
MC has high variance, zero biasGood convergence propertiesWorks well with function approximationNot very sensitive to initial valueVery simple to understand and use
TD has low variance, some biasUsually more efficient than MCTD(0) converges to Vπ(s)Problem with function approximationMore sensitive to initial values

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Bias–Variance comparison between MC andTD
MC has high variance, zero biasGood convergence propertiesWorks well with function approximationNot very sensitive to initial valueVery simple to understand and use
TD has low variance, some biasUsually more efficient than MCTD(0) converges to Vπ(s)Problem with function approximationMore sensitive to initial values

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Bias–Variance comparison between MC andTD
MC has high variance, zero biasGood convergence propertiesWorks well with function approximationNot very sensitive to initial valueVery simple to understand and use
TD has low variance, some biasUsually more efficient than MCTD(0) converges to Vπ(s)Problem with function approximationMore sensitive to initial values

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Bias–Variance comparison between MC andTD
MC has high variance, zero biasGood convergence propertiesWorks well with function approximationNot very sensitive to initial valueVery simple to understand and use
TD has low variance, some biasUsually more efficient than MCTD(0) converges to Vπ(s)Problem with function approximationMore sensitive to initial values

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Bias–Variance comparison between MC andTD
MC has high variance, zero biasGood convergence propertiesWorks well with function approximationNot very sensitive to initial valueVery simple to understand and use
TD has low variance, some biasUsually more efficient than MCTD(0) converges to Vπ(s)Problem with function approximationMore sensitive to initial values

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Bias–Variance comparison between MC andTD
MC has high variance, zero biasGood convergence propertiesWorks well with function approximationNot very sensitive to initial valueVery simple to understand and use
TD has low variance, some biasUsually more efficient than MCTD(0) converges to Vπ(s)Problem with function approximationMore sensitive to initial values

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Bias–Variance comparison between MC andTD
MC has high variance, zero biasGood convergence propertiesWorks well with function approximationNot very sensitive to initial valueVery simple to understand and use
TD has low variance, some biasUsually more efficient than MCTD(0) converges to Vπ(s)Problem with function approximationMore sensitive to initial values

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Bias–Variance comparison between MC andTD
MC has high variance, zero biasGood convergence propertiesWorks well with function approximationNot very sensitive to initial valueVery simple to understand and use
TD has low variance, some biasUsually more efficient than MCTD(0) converges to Vπ(s)Problem with function approximationMore sensitive to initial values

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Bias–Variance comparison between MC andTD
MC has high variance, zero biasGood convergence propertiesWorks well with function approximationNot very sensitive to initial valueVery simple to understand and use
TD has low variance, some biasUsually more efficient than MCTD(0) converges to Vπ(s)Problem with function approximationMore sensitive to initial values

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Random Walk Example
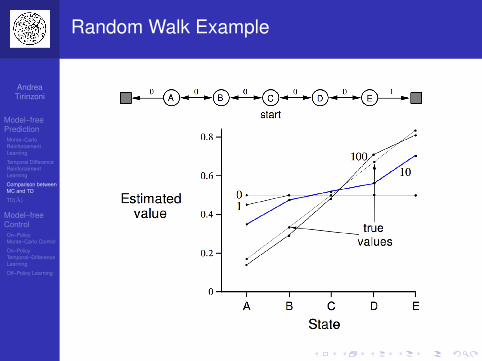
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Random Walk Example
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
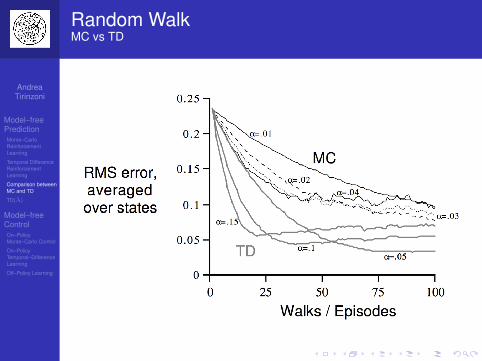
Random WalkMC vs TD

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Comparison between MC and TDMarkov Property
TD exploits Markov propertyUsually more efficient in Markov environments
MC does not exploit Markov propertyUsually more efficient in non–Markov environments

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Comparison between MC and TDMarkov Property
TD exploits Markov propertyUsually more efficient in Markov environments
MC does not exploit Markov propertyUsually more efficient in non–Markov environments

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Comparison between MC and TDMarkov Property
TD exploits Markov propertyUsually more efficient in Markov environments
MC does not exploit Markov propertyUsually more efficient in non–Markov environments

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Comparison between MC and TDMarkov Property
TD exploits Markov propertyUsually more efficient in Markov environments
MC does not exploit Markov propertyUsually more efficient in non–Markov environments
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
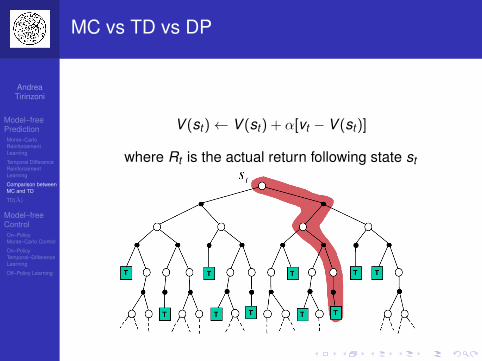
MC vs TD vs DP
V (st )← V (st ) + α[vt − V (st )]
where Rt is the actual return following state st
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
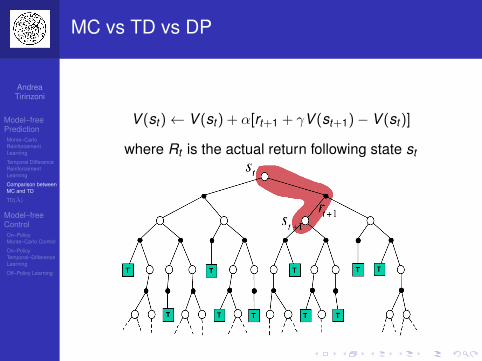
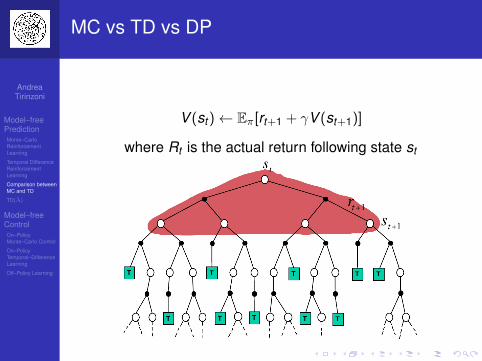
MC vs TD vs DP
V (st )← V (st ) + α[rt+1 + γV (st+1)− V (st )]
where Rt is the actual return following state st
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
MC vs TD vs DP
V (st )← Eπ[rt+1 + γV (st+1)]
where Rt is the actual return following state st
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
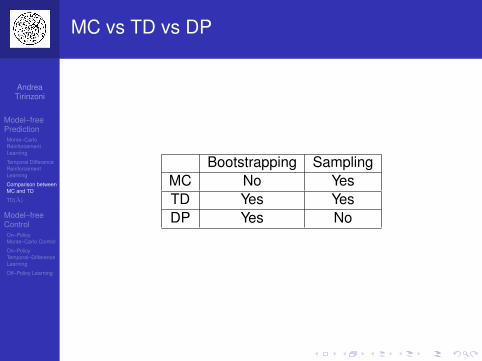
MC vs TD vs DP
Bootstrapping SamplingMC No YesTD Yes YesDP Yes No
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
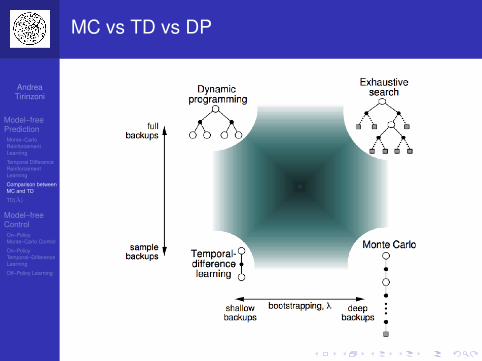
MC vs TD vs DP
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Outline
1 Model–free PredictionMonte–Carlo Reinforcement LearningTemporal Difference Reinforcement LearningComparison between MC and TDTD(λ)
2 Model–free ControlOn–Policy Monte–Carlo ControlOn–Policy Temporal–Difference LearningOff–Policy Learning
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
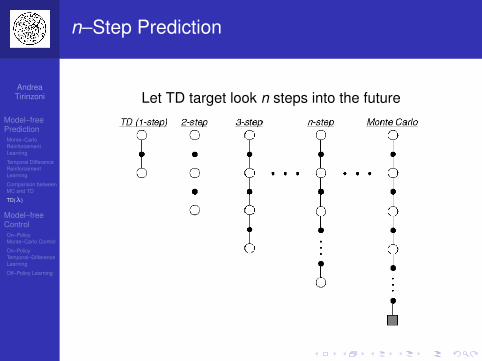
n–Step Prediction
Let TD target look n steps into the future

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
n–Step Return
Consider the following n–step returns forn = 1,2, . . . ,∞:
n = 1 (TD) v (1)t = rt+1 + γV (st+1)
n = 2 v (2)t = rt+1 + γrt+2 + γ2V (st+2)
......
n =∞ (MC) v (∞)t = rt+1 + γrt+2 + · · ·+ γT−1rT
Define the n–step return
v (n)t = rt+1 + γrt+2 + · · ·+ γn−1rt+n + γnV (st+n)
n–step temporal–difference learning
V (st )← V (st ) + α(v (n)t − V (st ))

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
n–Step Return
Consider the following n–step returns forn = 1,2, . . . ,∞:
n = 1 (TD) v (1)t = rt+1 + γV (st+1)
n = 2 v (2)t = rt+1 + γrt+2 + γ2V (st+2)
......
n =∞ (MC) v (∞)t = rt+1 + γrt+2 + · · ·+ γT−1rT
Define the n–step return
v (n)t = rt+1 + γrt+2 + · · ·+ γn−1rt+n + γnV (st+n)
n–step temporal–difference learning
V (st )← V (st ) + α(v (n)t − V (st ))

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
n–Step Return
Consider the following n–step returns forn = 1,2, . . . ,∞:
n = 1 (TD) v (1)t = rt+1 + γV (st+1)
n = 2 v (2)t = rt+1 + γrt+2 + γ2V (st+2)
......
n =∞ (MC) v (∞)t = rt+1 + γrt+2 + · · ·+ γT−1rT
Define the n–step return
v (n)t = rt+1 + γrt+2 + · · ·+ γn−1rt+n + γnV (st+n)
n–step temporal–difference learning
V (st )← V (st ) + α(v (n)t − V (st ))
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
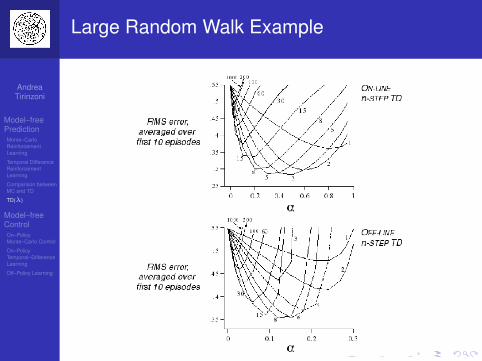
Large Random Walk Example

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Averaging n–step Returns
We can average n–step returns over different ne.g., average the 2–step and 4–step returns
12
v (2) +12
v (4)
Combines information from two different time–stepsCan we efficiently combine information from alltime–steps?
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Averaging n–step Returns
We can average n–step returns over different ne.g., average the 2–step and 4–step returns
12
v (2) +12
v (4)
Combines information from two different time–stepsCan we efficiently combine information from alltime–steps?

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Averaging n–step Returns
We can average n–step returns over different ne.g., average the 2–step and 4–step returns
12
v (2) +12
v (4)
Combines information from two different time–stepsCan we efficiently combine information from alltime–steps?

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Averaging n–step Returns
We can average n–step returns over different ne.g., average the 2–step and 4–step returns
12
v (2) +12
v (4)
Combines information from two different time–stepsCan we efficiently combine information from alltime–steps?
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
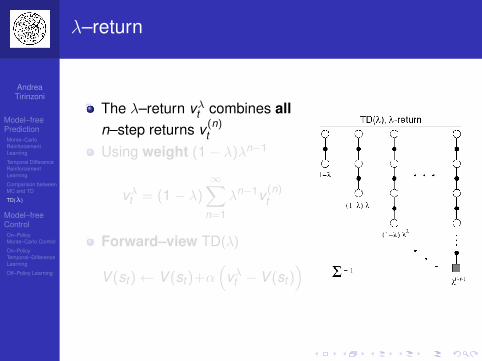
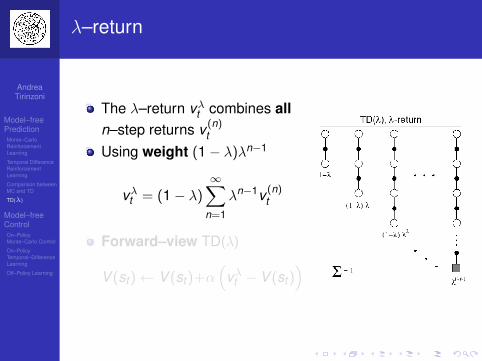
λ–return
The λ–return vλt combines alln–step returns v (n)
t
Using weight (1− λ)λn−1
vλt = (1− λ)∞∑
n=1
λn−1v (n)t
Forward–view TD(λ)
V (st )← V (st )+α(
vλt − V (st ))
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
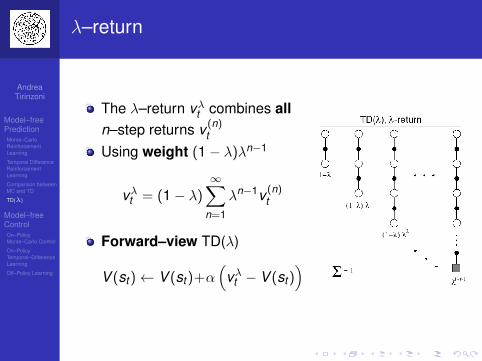
λ–return
The λ–return vλt combines alln–step returns v (n)
t
Using weight (1− λ)λn−1
vλt = (1− λ)∞∑
n=1
λn−1v (n)t
Forward–view TD(λ)
V (st )← V (st )+α(
vλt − V (st ))
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
λ–return
The λ–return vλt combines alln–step returns v (n)
t
Using weight (1− λ)λn−1
vλt = (1− λ)∞∑
n=1
λn−1v (n)t
Forward–view TD(λ)
V (st )← V (st )+α(
vλt − V (st ))
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
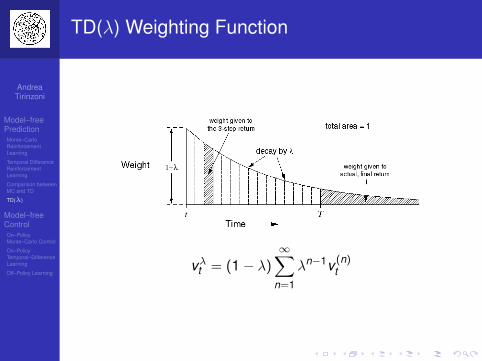
TD(λ) Weighting Function
vλt = (1− λ)∞∑
n=1
λn−1v (n)t
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
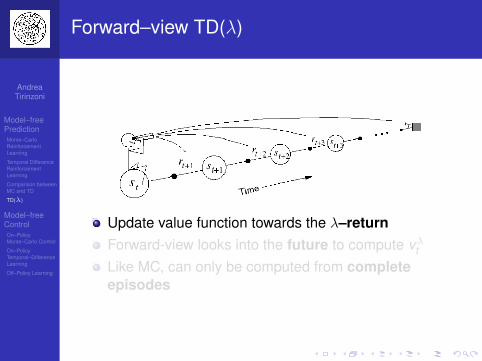
Forward–view TD(λ)
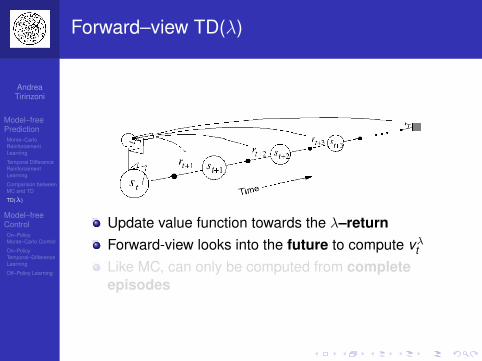
Update value function towards the λ–returnForward-view looks into the future to compute vλtLike MC, can only be computed from completeepisodes
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Forward–view TD(λ)
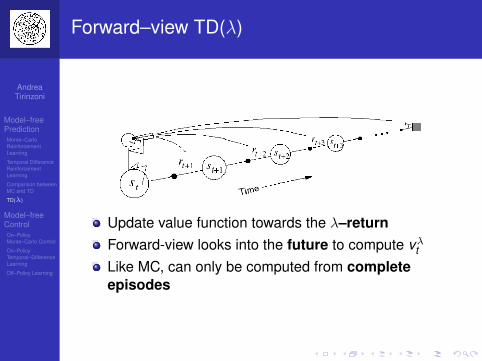
Update value function towards the λ–returnForward-view looks into the future to compute vλtLike MC, can only be computed from completeepisodes
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Forward–view TD(λ)
Update value function towards the λ–returnForward-view looks into the future to compute vλtLike MC, can only be computed from completeepisodes
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
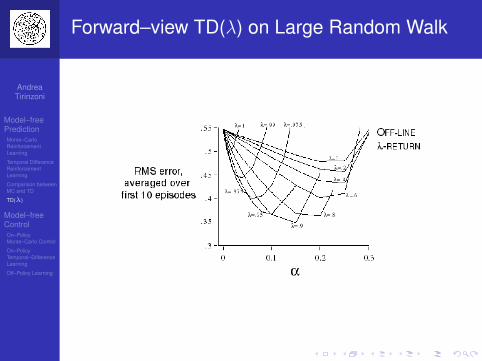
Forward–view TD(λ) on Large Random Walk

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Backward–view TD(λ)
Forward view provides theoryBackward view provides mechanismUpdate online, every step, from incompletesequences

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Backward–view TD(λ)
Forward view provides theoryBackward view provides mechanismUpdate online, every step, from incompletesequences

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Backward–view TD(λ)
Forward view provides theoryBackward view provides mechanismUpdate online, every step, from incompletesequences

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Eligibility Traces
Credit assignment problem: did bell or light cause shock?
Frequency heuristic: assign credit to the most frequent states
Recency heuristics: assign credit to the most recent states
Eligibility traces combine both heuristics
et+1(s) = γλet(s) + 1(s = st)

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Eligibility Traces
Credit assignment problem: did bell or light cause shock?
Frequency heuristic: assign credit to the most frequent states
Recency heuristics: assign credit to the most recent states
Eligibility traces combine both heuristics
et+1(s) = γλet(s) + 1(s = st)

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Eligibility Traces
Credit assignment problem: did bell or light cause shock?
Frequency heuristic: assign credit to the most frequent states
Recency heuristics: assign credit to the most recent states
Eligibility traces combine both heuristics
et+1(s) = γλet(s) + 1(s = st)

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Eligibility Traces
Credit assignment problem: did bell or light cause shock?
Frequency heuristic: assign credit to the most frequent states
Recency heuristics: assign credit to the most recent states
Eligibility traces combine both heuristics
et+1(s) = γλet(s) + 1(s = st)
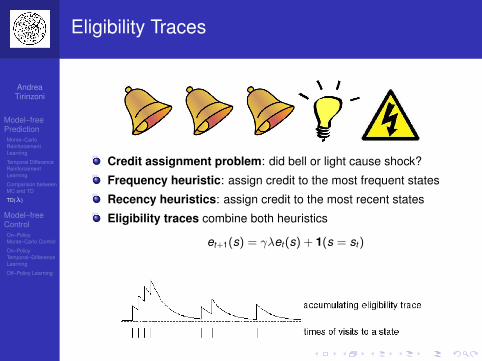
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Eligibility Traces
Credit assignment problem: did bell or light cause shock?
Frequency heuristic: assign credit to the most frequent states
Recency heuristics: assign credit to the most recent states
Eligibility traces combine both heuristics
et+1(s) = γλet(s) + 1(s = st)
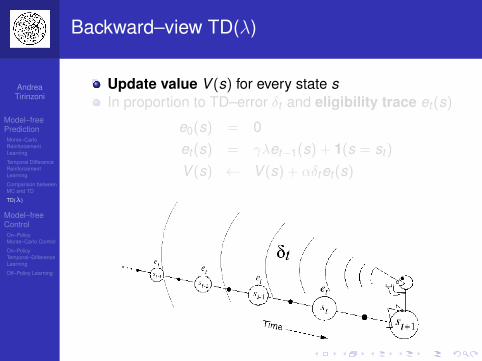
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Backward–view TD(λ)
Update value V (s) for every state sIn proportion to TD–error δt and eligibility trace et (s)
e0(s) = 0et (s) = γλet−1(s) + 1(s = st )
V (s) ← V (s) + αδtet (s)
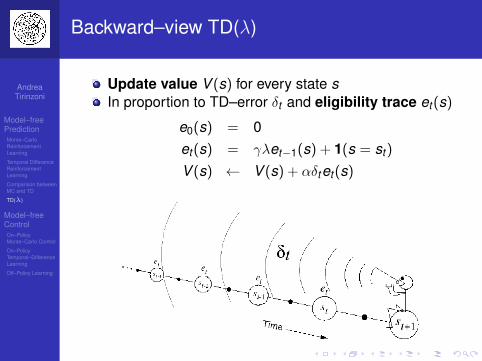
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Backward–view TD(λ)
Update value V (s) for every state sIn proportion to TD–error δt and eligibility trace et (s)
e0(s) = 0et (s) = γλet−1(s) + 1(s = st )
V (s) ← V (s) + αδtet (s)

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Backward–view TD(λ) Algorithm
Initialize V (s) arbitrarilyfor all episodes do
e(s) = 0, ∀s ∈ SInitialize srepeat
a← action given by π for sTake action a, observe reward r , and next state s′
δ ← r + γV (s′)− V (s)e(s)← e(s) + 1for all s ∈ S do
V (s)← V (s) + αδe(s)e(s)← γλe(s)
end fors ← s′
until s is terminalend for

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
TD(λ) and TD(0)
When λ = 0, only current state is updated
et (s) = 1(s = st )
V (s) ← V (s) + αδtet (s)
This is exactly equivalent to TD(0) update
V (st )← V (st ) + αδt

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
TD(λ) and TD(0)
When λ = 0, only current state is updated
et (s) = 1(s = st )
V (s) ← V (s) + αδtet (s)
This is exactly equivalent to TD(0) update
V (st )← V (st ) + αδt

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Telescoping in TD(1)
When λ = 1, sum of TD errors telescopes into MC error
δt + γδt+1 + γ2δt+2 + · · ·+ γT−tδT−1
= rt+1 + γV (st+1)− V (st )
+ γrt+2 + γ2V (st+2)− γV (st+1)
+ γ2rt+3 + γ3V (st+3)− γ2V (st+2)
...+ γT−1rt+T + γT V (st+T )− γT−1V (st+T−1)
= rt+1 + γrt+2 + γ2rt+3 + · · ·+ γT−1rt+T − V (st )
= vt − V (st )

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
TD(λ) and TD(1)
TD(1) is roughly equivalent to every–visitMonte–CarloError is accumulated online, step–by–stepIf value function is only updated offline at end ofepisode, then the total update is exactly the same asMCIf value function is updated online after every step,then TD(1) may have different total update to MC

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
TD(λ) and TD(1)
TD(1) is roughly equivalent to every–visitMonte–CarloError is accumulated online, step–by–stepIf value function is only updated offline at end ofepisode, then the total update is exactly the same asMCIf value function is updated online after every step,then TD(1) may have different total update to MC

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
TD(λ) and TD(1)
TD(1) is roughly equivalent to every–visitMonte–CarloError is accumulated online, step–by–stepIf value function is only updated offline at end ofepisode, then the total update is exactly the same asMCIf value function is updated online after every step,then TD(1) may have different total update to MC

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
TD(λ) and TD(1)
TD(1) is roughly equivalent to every–visitMonte–CarloError is accumulated online, step–by–stepIf value function is only updated offline at end ofepisode, then the total update is exactly the same asMCIf value function is updated online after every step,then TD(1) may have different total update to MC

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Telescoping in TD(λ)
For general λ, TD errors also telescope to λ–error,vλt − V (st )
vλt − V (st ) = −V (st ) + (1− λ)λ0(rt+1 + γV (st+1))+ (1− λ)λ1(rt+1 + γrt+2 + γ2V (st+2))+ (1− λ)λ2(rt+1 + γrt+2 + γ2rt+3 + γ3V (st+3))+ . . .
= −V (st ) + (γλ)0(rt+1 + γV (st+1)− γλV (st+1))+ (γλ)1(rt+2 + γV (st+2)− γλV (st+2))+ (γλ)2(rt+3 + γV (st+3)− γλV (st+3))+ . . .
= (γλ)0(rt+1 + γV (st+1)− V (st+1))+ (γλ)1(rt+2 + γV (st+2)− V (st+2))+ (γλ)2(rt+3 + γV (st+3)− V (st+3))+ . . .
= δt + γλδt+1 + (γλ)2δt+2 + . . .

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Forwards and Backwards TD(λ)
Consider an episode where s is visited once attime–step kTD(λ) eligibility trace discounts time since visit
et (s) = γλet−1(s) + 1(st = s)
=
{0 if t < k(γλ)t−k if t ≥ k
Backward TD(λ) updates accumulate error online
T∑t=1
αδtet (s) = α
T∑t=k
(γλ)t−kδt = α(vk − V (sk ))
By end of episode it accumulates total error forλ–returnFor multiple visits to s, et (s) accumulates many errors

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Forwards and Backwards TD(λ)
Consider an episode where s is visited once attime–step kTD(λ) eligibility trace discounts time since visit
et (s) = γλet−1(s) + 1(st = s)
=
{0 if t < k(γλ)t−k if t ≥ k
Backward TD(λ) updates accumulate error online
T∑t=1
αδtet (s) = α
T∑t=k
(γλ)t−kδt = α(vk − V (sk ))
By end of episode it accumulates total error forλ–returnFor multiple visits to s, et (s) accumulates many errors

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Forwards and Backwards TD(λ)
Consider an episode where s is visited once attime–step kTD(λ) eligibility trace discounts time since visit
et (s) = γλet−1(s) + 1(st = s)
=
{0 if t < k(γλ)t−k if t ≥ k
Backward TD(λ) updates accumulate error online
T∑t=1
αδtet (s) = α
T∑t=k
(γλ)t−kδt = α(vk − V (sk ))
By end of episode it accumulates total error forλ–returnFor multiple visits to s, et (s) accumulates many errors

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Forwards and Backwards TD(λ)
Consider an episode where s is visited once attime–step kTD(λ) eligibility trace discounts time since visit
et (s) = γλet−1(s) + 1(st = s)
=
{0 if t < k(γλ)t−k if t ≥ k
Backward TD(λ) updates accumulate error online
T∑t=1
αδtet (s) = α
T∑t=k
(γλ)t−kδt = α(vk − V (sk ))
By end of episode it accumulates total error forλ–returnFor multiple visits to s, et (s) accumulates many errors

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Forwards and Backwards TD(λ)
Consider an episode where s is visited once attime–step kTD(λ) eligibility trace discounts time since visit
et (s) = γλet−1(s) + 1(st = s)
=
{0 if t < k(γλ)t−k if t ≥ k
Backward TD(λ) updates accumulate error online
T∑t=1
αδtet (s) = α
T∑t=k
(γλ)t−kδt = α(vk − V (sk ))
By end of episode it accumulates total error forλ–returnFor multiple visits to s, et (s) accumulates many errors

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Equivalence of Forward and Backward TD
TheoremThe sum of offline updates is identical for forward–view andbackward–view TD(λ)
T∑t=1
αδtet (s) =T∑
t=1
α(vλt − V (st ))1(st = s)
In practice, value function is updated online by TD(λ)But if α is small then equivalence is almost exact

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Equivalence of Forward and Backward TD
TheoremThe sum of offline updates is identical for forward–view andbackward–view TD(λ)
T∑t=1
αδtet (s) =T∑
t=1
α(vλt − V (st ))1(st = s)
In practice, value function is updated online by TD(λ)But if α is small then equivalence is almost exact

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Replacing Traces
Using accumulating traces, frequently visited statescan have eligibilities greater than 1
This can be a problem for convergence
Replacing traces: Instead of adding 1 when you visit astate, set that trace to 1
et (s) =
{γλet−1(s) if s 6= st
1 if s = st

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Replacing Traces
Using accumulating traces, frequently visited statescan have eligibilities greater than 1
This can be a problem for convergence
Replacing traces: Instead of adding 1 when you visit astate, set that trace to 1
et (s) =
{γλet−1(s) if s 6= st
1 if s = st

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Replacing Traces
Using accumulating traces, frequently visited statescan have eligibilities greater than 1
This can be a problem for convergence
Replacing traces: Instead of adding 1 when you visit astate, set that trace to 1
et (s) =
{γλet−1(s) if s 6= st
1 if s = st
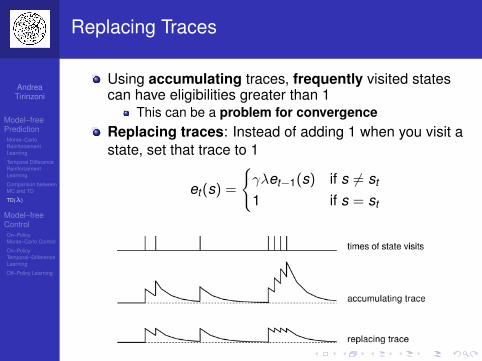
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Replacing Traces
Using accumulating traces, frequently visited statescan have eligibilities greater than 1
This can be a problem for convergenceReplacing traces: Instead of adding 1 when you visit astate, set that trace to 1
et (s) =
{γλet−1(s) if s 6= st
1 if s = st

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Outline
1 Model–free PredictionMonte–Carlo Reinforcement LearningTemporal Difference Reinforcement LearningComparison between MC and TDTD(λ)
2 Model–free ControlOn–Policy Monte–Carlo ControlOn–Policy Temporal–Difference LearningOff–Policy Learning

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Use of Model–Free Control
Some example problems that can be modeled as MDPs:
ElevatorParallel ParkingShip SteeringBioreactorHelicopterAirplane Logistics
Robocup SoccerQuakePortfolio managementProtein foldingRobot walkingGame of Go
For most of these problems, either:MDP model is unknown, but experience can besampledMDP model is known, but is too big to use, except bysamples
Model–free control can solve these problems

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Use of Model–Free Control
Some example problems that can be modeled as MDPs:
ElevatorParallel ParkingShip SteeringBioreactorHelicopterAirplane Logistics
Robocup SoccerQuakePortfolio managementProtein foldingRobot walkingGame of Go
For most of these problems, either:MDP model is unknown, but experience can besampledMDP model is known, but is too big to use, except bysamples
Model–free control can solve these problems

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Use of Model–Free Control
Some example problems that can be modeled as MDPs:
ElevatorParallel ParkingShip SteeringBioreactorHelicopterAirplane Logistics
Robocup SoccerQuakePortfolio managementProtein foldingRobot walkingGame of Go
For most of these problems, either:MDP model is unknown, but experience can besampledMDP model is known, but is too big to use, except bysamples
Model–free control can solve these problems

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
On and Off–Policy Learning
On–policy learning“Learn on the job”Learn about policy π from experience sampled from π
Off–policy learning“Learn over someone’s shoulder”Learn about policy π from experience sampled from π

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
On and Off–Policy Learning
On–policy learning“Learn on the job”Learn about policy π from experience sampled from π
Off–policy learning“Learn over someone’s shoulder”Learn about policy π from experience sampled from π

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
On and Off–Policy Learning
On–policy learning“Learn on the job”Learn about policy π from experience sampled from π
Off–policy learning“Learn over someone’s shoulder”Learn about policy π from experience sampled from π

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
On and Off–Policy Learning
On–policy learning“Learn on the job”Learn about policy π from experience sampled from π
Off–policy learning“Learn over someone’s shoulder”Learn about policy π from experience sampled from π

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
On and Off–Policy Learning
On–policy learning“Learn on the job”Learn about policy π from experience sampled from π
Off–policy learning“Learn over someone’s shoulder”Learn about policy π from experience sampled from π

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
On and Off–Policy Learning
On–policy learning“Learn on the job”Learn about policy π from experience sampled from π
Off–policy learning“Learn over someone’s shoulder”Learn about policy π from experience sampled from π

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Outline
1 Model–free PredictionMonte–Carlo Reinforcement LearningTemporal Difference Reinforcement LearningComparison between MC and TDTD(λ)
2 Model–free ControlOn–Policy Monte–Carlo ControlOn–Policy Temporal–Difference LearningOff–Policy Learning
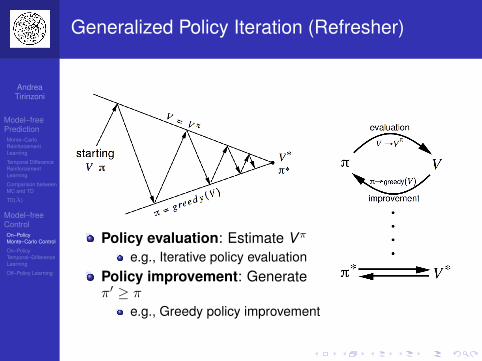
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Generalized Policy Iteration (Refresher)
Policy evaluation: Estimate Vπ
e.g., Iterative policy evaluationPolicy improvement: Generateπ′ ≥ π
e.g., Greedy policy improvement
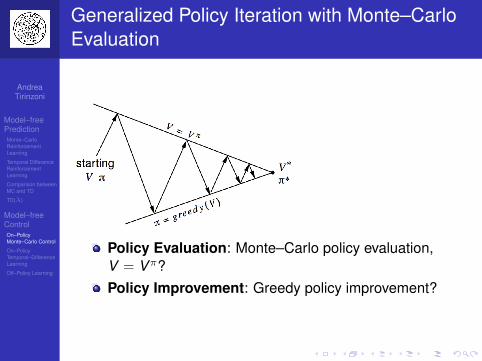
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Generalized Policy Iteration with Monte–CarloEvaluation
Policy Evaluation: Monte–Carlo policy evaluation,V = Vπ?Policy Improvement: Greedy policy improvement?

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Model–Free Policy Iteration Using Action–ValueFunction
Greedy policy improvement over V (s) requires modelof MDP
π′(s) = arg maxa∈A
{R(s,a) + P(s′|s,a)V (s′)
}Greedy policy improvement over Q(s,a) is model–free
π′(s) = arg maxa∈A
Q(s,a)

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Model–Free Policy Iteration Using Action–ValueFunction
Greedy policy improvement over V (s) requires modelof MDP
π′(s) = arg maxa∈A
{R(s,a) + P(s′|s,a)V (s′)
}Greedy policy improvement over Q(s,a) is model–free
π′(s) = arg maxa∈A
Q(s,a)
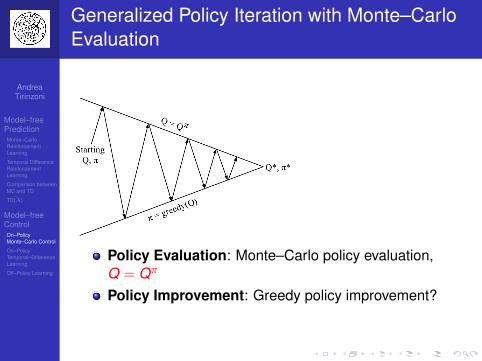
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Generalized Policy Iteration with Monte–CarloEvaluation
Policy Evaluation: Monte–Carlo policy evaluation,Q = Qπ
Policy Improvement: Greedy policy improvement?

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
On–Policy Exploration
There are two doors in front of you
You open the left door and getreward 0, V (left) = 0
You open the right door and getreward +1, V (right) = +1
You open the right door and getreward +3, V (right) = +2
You open the right door and getreward +2, V (right) = +2
...
Are you sure you’ve chosen thebest door?

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
On–Policy Exploration
There are two doors in front of you
You open the left door and getreward 0, V (left) = 0
You open the right door and getreward +1, V (right) = +1
You open the right door and getreward +3, V (right) = +2
You open the right door and getreward +2, V (right) = +2
...
Are you sure you’ve chosen thebest door?

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
On–Policy Exploration
There are two doors in front of you
You open the left door and getreward 0, V (left) = 0
You open the right door and getreward +1, V (right) = +1
You open the right door and getreward +3, V (right) = +2
You open the right door and getreward +2, V (right) = +2
...
Are you sure you’ve chosen thebest door?

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
On–Policy Exploration
There are two doors in front of you
You open the left door and getreward 0, V (left) = 0
You open the right door and getreward +1, V (right) = +1
You open the right door and getreward +3, V (right) = +2
You open the right door and getreward +2, V (right) = +2
...
Are you sure you’ve chosen thebest door?

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
On–Policy Exploration
There are two doors in front of you
You open the left door and getreward 0, V (left) = 0
You open the right door and getreward +1, V (right) = +1
You open the right door and getreward +3, V (right) = +2
You open the right door and getreward +2, V (right) = +2
...
Are you sure you’ve chosen thebest door?

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
On–Policy Exploration
There are two doors in front of you
You open the left door and getreward 0, V (left) = 0
You open the right door and getreward +1, V (right) = +1
You open the right door and getreward +3, V (right) = +2
You open the right door and getreward +2, V (right) = +2
...
Are you sure you’ve chosen thebest door?

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
On–Policy Exploration
There are two doors in front of you
You open the left door and getreward 0, V (left) = 0
You open the right door and getreward +1, V (right) = +1
You open the right door and getreward +3, V (right) = +2
You open the right door and getreward +2, V (right) = +2
...
Are you sure you’ve chosen thebest door?

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
ε–Greedy Exploration
Simplest idea for ensuring continual explorationAll m actions are tried with non–zero probabilityWith probability 1− ε choose the greedy actionWith probability ε choose an action at random
π(s,a) =
{εm + 1− ε if a∗ = arg maxa∈AQ(s,a)εm otherwise

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
ε–Greedy Exploration
Simplest idea for ensuring continual explorationAll m actions are tried with non–zero probabilityWith probability 1− ε choose the greedy actionWith probability ε choose an action at random
π(s,a) =
{εm + 1− ε if a∗ = arg maxa∈AQ(s,a)εm otherwise

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
ε–Greedy Exploration
Simplest idea for ensuring continual explorationAll m actions are tried with non–zero probabilityWith probability 1− ε choose the greedy actionWith probability ε choose an action at random
π(s,a) =
{εm + 1− ε if a∗ = arg maxa∈AQ(s,a)εm otherwise

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
ε–Greedy Exploration
Simplest idea for ensuring continual explorationAll m actions are tried with non–zero probabilityWith probability 1− ε choose the greedy actionWith probability ε choose an action at random
π(s,a) =
{εm + 1− ε if a∗ = arg maxa∈AQ(s,a)εm otherwise

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
ε–Greedy Policy Improvement
Theorem
For any ε–greedy policy π, the ε–greedy policy π′ with respect to Qπ is animprovement
Qπ(s, π′(s)) =∑a∈A
π′(a|s)Qπ(s, a)
=ε
m
∑a∈A
Qπ(s, a) + (1− ε)maxa∈A
Qπ(s, a)
≥ ε
m
∑a∈A
Qπ(s, a) + (1− ε)∑a∈A
π(a|s)− εm
1− ε Qπ(s, a)
=∑a∈A
π(a|s)Qπ(s, a) = Vπ(s)
Therefore from policy improvement theorem, Vπ′(s) ≥ Vπ(s)
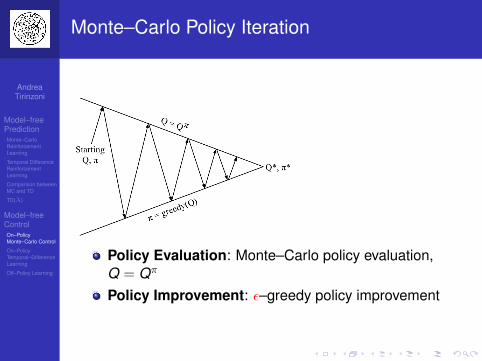
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Monte–Carlo Policy Iteration
Policy Evaluation: Monte–Carlo policy evaluation,Q = Qπ
Policy Improvement: ε–greedy policy improvement
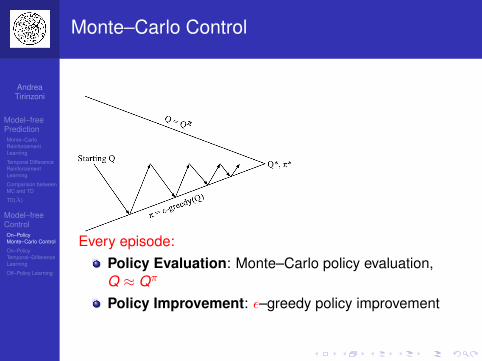
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Monte–Carlo Control
Every episode:Policy Evaluation: Monte–Carlo policy evaluation,Q ≈ Qπ
Policy Improvement: ε–greedy policy improvement

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
GLIE
DefinitionGreedy in the Limit of Infinite Exploration (GLIE)
All state–action pairs are explored infinitely manytimes
limt→∞
Nk (s,a) =∞
The policy converges on a greedy policy
limt→∞
πk (a|s) = 1(a = arg maxa′∈A
Qk (s′,a′))

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
GLIE Monte–Carlo Control
Sample k–th episode using π: {s1,a1, r2, . . . , sT} ∼ πFor each state st and action at in the episode,
N(st ,at )← N(st ,at ) + 1
Q(st ,at )← Q(st ,at ) +1
N(st ,at )(vt −Q(st ,at ))
Improve policy based on new action–value function
ε← 1k
π ← ε–greedy(Q)
TheoremGLIE Monte–Carlo control converges to the optimalaction–value function, Q(s,a)→ Q∗(s,a)

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
GLIE Monte–Carlo Control
Sample k–th episode using π: {s1,a1, r2, . . . , sT} ∼ πFor each state st and action at in the episode,
N(st ,at )← N(st ,at ) + 1
Q(st ,at )← Q(st ,at ) +1
N(st ,at )(vt −Q(st ,at ))
Improve policy based on new action–value function
ε← 1k
π ← ε–greedy(Q)
TheoremGLIE Monte–Carlo control converges to the optimalaction–value function, Q(s,a)→ Q∗(s,a)

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
GLIE Monte–Carlo Control
Sample k–th episode using π: {s1,a1, r2, . . . , sT} ∼ πFor each state st and action at in the episode,
N(st ,at )← N(st ,at ) + 1
Q(st ,at )← Q(st ,at ) +1
N(st ,at )(vt −Q(st ,at ))
Improve policy based on new action–value function
ε← 1k
π ← ε–greedy(Q)
TheoremGLIE Monte–Carlo control converges to the optimalaction–value function, Q(s,a)→ Q∗(s,a)

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
GLIE Monte–Carlo Control
Sample k–th episode using π: {s1,a1, r2, . . . , sT} ∼ πFor each state st and action at in the episode,
N(st ,at )← N(st ,at ) + 1
Q(st ,at )← Q(st ,at ) +1
N(st ,at )(vt −Q(st ,at ))
Improve policy based on new action–value function
ε← 1k
π ← ε–greedy(Q)
TheoremGLIE Monte–Carlo control converges to the optimalaction–value function, Q(s,a)→ Q∗(s,a)

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Relevant Time Scales
There are three main time scales1 Behavioral time scale 1
1−γ (discount factor)2 Sampling in the estimation of the Q–function α
(learning rate)3 Exploration ε (e.g., for ε–greedy strategy)
1− γ � α� ε
Initially 1− γ ≈ α ≈ ε is possibleThen decrease ε faster than αPractically, you can choose number of trials M <∞and set α ∼ 1− m
M and ε ∼(1− m
M
)2, m = 1, . . . ,M
In some cases, γ should be initialized to low valuesand then gradually moved towards its correct value

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Relevant Time Scales
There are three main time scales1 Behavioral time scale 1
1−γ (discount factor)2 Sampling in the estimation of the Q–function α
(learning rate)3 Exploration ε (e.g., for ε–greedy strategy)
1− γ � α� ε
Initially 1− γ ≈ α ≈ ε is possibleThen decrease ε faster than αPractically, you can choose number of trials M <∞and set α ∼ 1− m
M and ε ∼(1− m
M
)2, m = 1, . . . ,M
In some cases, γ should be initialized to low valuesand then gradually moved towards its correct value

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Relevant Time Scales
There are three main time scales1 Behavioral time scale 1
1−γ (discount factor)2 Sampling in the estimation of the Q–function α
(learning rate)3 Exploration ε (e.g., for ε–greedy strategy)
1− γ � α� ε
Initially 1− γ ≈ α ≈ ε is possibleThen decrease ε faster than αPractically, you can choose number of trials M <∞and set α ∼ 1− m
M and ε ∼(1− m
M
)2, m = 1, . . . ,M
In some cases, γ should be initialized to low valuesand then gradually moved towards its correct value

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Relevant Time Scales
There are three main time scales1 Behavioral time scale 1
1−γ (discount factor)2 Sampling in the estimation of the Q–function α
(learning rate)3 Exploration ε (e.g., for ε–greedy strategy)
1− γ � α� ε
Initially 1− γ ≈ α ≈ ε is possibleThen decrease ε faster than αPractically, you can choose number of trials M <∞and set α ∼ 1− m
M and ε ∼(1− m
M
)2, m = 1, . . . ,M
In some cases, γ should be initialized to low valuesand then gradually moved towards its correct value

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Relevant Time Scales
There are three main time scales1 Behavioral time scale 1
1−γ (discount factor)2 Sampling in the estimation of the Q–function α
(learning rate)3 Exploration ε (e.g., for ε–greedy strategy)
1− γ � α� ε
Initially 1− γ ≈ α ≈ ε is possibleThen decrease ε faster than αPractically, you can choose number of trials M <∞and set α ∼ 1− m
M and ε ∼(1− m
M
)2, m = 1, . . . ,M
In some cases, γ should be initialized to low valuesand then gradually moved towards its correct value

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Relevant Time Scales
There are three main time scales1 Behavioral time scale 1
1−γ (discount factor)2 Sampling in the estimation of the Q–function α
(learning rate)3 Exploration ε (e.g., for ε–greedy strategy)
1− γ � α� ε
Initially 1− γ ≈ α ≈ ε is possibleThen decrease ε faster than αPractically, you can choose number of trials M <∞and set α ∼ 1− m
M and ε ∼(1− m
M
)2, m = 1, . . . ,M
In some cases, γ should be initialized to low valuesand then gradually moved towards its correct value

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Relevant Time Scales
There are three main time scales1 Behavioral time scale 1
1−γ (discount factor)2 Sampling in the estimation of the Q–function α
(learning rate)3 Exploration ε (e.g., for ε–greedy strategy)
1− γ � α� ε
Initially 1− γ ≈ α ≈ ε is possibleThen decrease ε faster than αPractically, you can choose number of trials M <∞and set α ∼ 1− m
M and ε ∼(1− m
M
)2, m = 1, . . . ,M
In some cases, γ should be initialized to low valuesand then gradually moved towards its correct value

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Relevant Time Scales
There are three main time scales1 Behavioral time scale 1
1−γ (discount factor)2 Sampling in the estimation of the Q–function α
(learning rate)3 Exploration ε (e.g., for ε–greedy strategy)
1− γ � α� ε
Initially 1− γ ≈ α ≈ ε is possibleThen decrease ε faster than αPractically, you can choose number of trials M <∞and set α ∼ 1− m
M and ε ∼(1− m
M
)2, m = 1, . . . ,M
In some cases, γ should be initialized to low valuesand then gradually moved towards its correct value

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Relevant Time Scales
There are three main time scales1 Behavioral time scale 1
1−γ (discount factor)2 Sampling in the estimation of the Q–function α
(learning rate)3 Exploration ε (e.g., for ε–greedy strategy)
1− γ � α� ε
Initially 1− γ ≈ α ≈ ε is possibleThen decrease ε faster than αPractically, you can choose number of trials M <∞and set α ∼ 1− m
M and ε ∼(1− m
M
)2, m = 1, . . . ,M
In some cases, γ should be initialized to low valuesand then gradually moved towards its correct value

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Outline
1 Model–free PredictionMonte–Carlo Reinforcement LearningTemporal Difference Reinforcement LearningComparison between MC and TDTD(λ)
2 Model–free ControlOn–Policy Monte–Carlo ControlOn–Policy Temporal–Difference LearningOff–Policy Learning

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
MC vs TD Control
Temporal–Difference (TD) learning has severaladvantages over Monte–Carlo (MC)
Lower VarianceOnlineIncomplete sequences
Natural idea: use TD instead of MC in our control loopApply TD to Q(s,a)Use ε–greedy policy improvementUpdate every time–step

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
MC vs TD Control
Temporal–Difference (TD) learning has severaladvantages over Monte–Carlo (MC)
Lower VarianceOnlineIncomplete sequences
Natural idea: use TD instead of MC in our control loopApply TD to Q(s,a)Use ε–greedy policy improvementUpdate every time–step

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
MC vs TD Control
Temporal–Difference (TD) learning has severaladvantages over Monte–Carlo (MC)
Lower VarianceOnlineIncomplete sequences
Natural idea: use TD instead of MC in our control loopApply TD to Q(s,a)Use ε–greedy policy improvementUpdate every time–step

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
MC vs TD Control
Temporal–Difference (TD) learning has severaladvantages over Monte–Carlo (MC)
Lower VarianceOnlineIncomplete sequences
Natural idea: use TD instead of MC in our control loopApply TD to Q(s,a)Use ε–greedy policy improvementUpdate every time–step

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
MC vs TD Control
Temporal–Difference (TD) learning has severaladvantages over Monte–Carlo (MC)
Lower VarianceOnlineIncomplete sequences
Natural idea: use TD instead of MC in our control loopApply TD to Q(s,a)Use ε–greedy policy improvementUpdate every time–step

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
MC vs TD Control
Temporal–Difference (TD) learning has severaladvantages over Monte–Carlo (MC)
Lower VarianceOnlineIncomplete sequences
Natural idea: use TD instead of MC in our control loopApply TD to Q(s,a)Use ε–greedy policy improvementUpdate every time–step

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
MC vs TD Control
Temporal–Difference (TD) learning has severaladvantages over Monte–Carlo (MC)
Lower VarianceOnlineIncomplete sequences
Natural idea: use TD instead of MC in our control loopApply TD to Q(s,a)Use ε–greedy policy improvementUpdate every time–step

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
MC vs TD Control
Temporal–Difference (TD) learning has severaladvantages over Monte–Carlo (MC)
Lower VarianceOnlineIncomplete sequences
Natural idea: use TD instead of MC in our control loopApply TD to Q(s,a)Use ε–greedy policy improvementUpdate every time–step
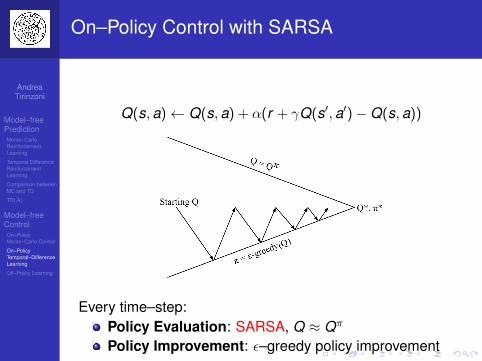
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
On–Policy Control with SARSA
Q(s,a)← Q(s,a) + α(r + γQ(s′,a′)−Q(s,a))
Every time–step:Policy Evaluation: SARSA, Q ≈ Qπ
Policy Improvement: ε–greedy policy improvement

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
SARSA Algorithm for On–Policy Control
Initialize Q(s,a) arbitrarilyloop
Initialize sChoose a from s using policy derived from Q (e.g.,ε–greedy)repeat
Take action a, observe r , s′
Choose a′ from s′ using policy derived from Q (e.g.,ε–greedy)Q(s,a)← Q(s,a) + α[r + γQ(s′,a′)−Q(s,a)]s ← s′; a← a′;
until s is terminalend loop

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Convergence of SARSA
TheoremSARSA converges to the optimal action–value function,Q(s,a)→ Q∗(s,a), under the following conditions:
GLIE sequence of policies πt (s,a)
Robbins–Monro sequence of step–sizes αt
∞∑t=1
αt =∞
∞∑t=1
α2t <∞
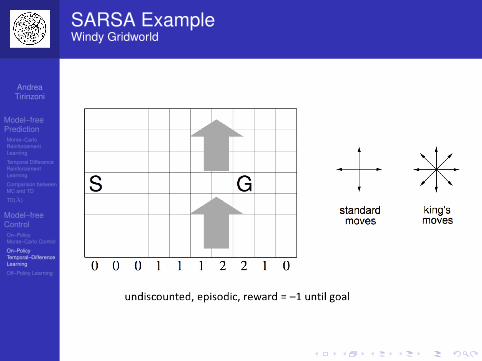
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
SARSA ExampleWindy Gridworld
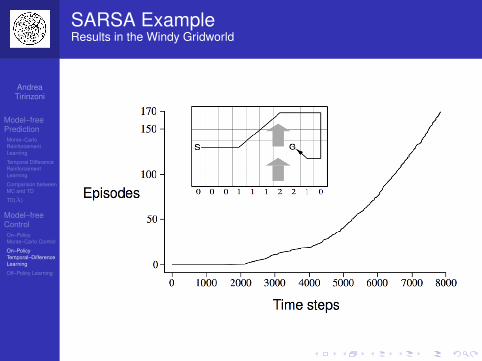
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
SARSA ExampleResults in the Windy Gridworld
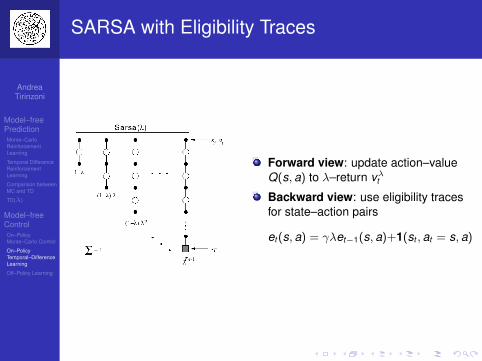
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
SARSA with Eligibility Traces
Forward view: update action–valueQ(s, a) to λ–return vλtBackward view: use eligibility tracesfor state–action pairs
et(s, a) = γλet−1(s, a)+1(st , at = s, a)

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
SARSA(λ) Algorithm
Initialize Q(s, a) arbitrarilyloop
e(s, a) = 0, for all s, aInitialize s, arepeat
Take action a, observe r , s′
Choose a′ from s′ using policy derived from Q (e.g., ε–greedy)δ ← r + γQ(s′, a′)−Q(s, a)e(s, a)← e(s, a) + 1for all s, a do
Q(s, a)← Q(s, a) + αδe(s, a)e(s, a)← γλe(s, a)
end fors ← s′; a← a′;
until s is terminalend loop

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
SARSA(λ) Gridworld Example

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Outline
1 Model–free PredictionMonte–Carlo Reinforcement LearningTemporal Difference Reinforcement LearningComparison between MC and TDTD(λ)
2 Model–free ControlOn–Policy Monte–Carlo ControlOn–Policy Temporal–Difference LearningOff–Policy Learning

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Off–Policy Learning
Learn about target policy π(a|s)
While following behavior policy π(a|s)
Why is this important?Learn from observing humans or other agentsRe–use experience generated from old policiesπ1, π2, . . . , πt−1Learn about optimal policy while following exploratorypolicyLearn about multiple policies while following one policy

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Off–Policy Learning
Learn about target policy π(a|s)
While following behavior policy π(a|s)
Why is this important?Learn from observing humans or other agentsRe–use experience generated from old policiesπ1, π2, . . . , πt−1Learn about optimal policy while following exploratorypolicyLearn about multiple policies while following one policy

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Off–Policy Learning
Learn about target policy π(a|s)
While following behavior policy π(a|s)
Why is this important?Learn from observing humans or other agentsRe–use experience generated from old policiesπ1, π2, . . . , πt−1Learn about optimal policy while following exploratorypolicyLearn about multiple policies while following one policy

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Off–Policy Learning
Learn about target policy π(a|s)
While following behavior policy π(a|s)
Why is this important?Learn from observing humans or other agentsRe–use experience generated from old policiesπ1, π2, . . . , πt−1Learn about optimal policy while following exploratorypolicyLearn about multiple policies while following one policy

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Off–Policy Learning
Learn about target policy π(a|s)
While following behavior policy π(a|s)
Why is this important?Learn from observing humans or other agentsRe–use experience generated from old policiesπ1, π2, . . . , πt−1Learn about optimal policy while following exploratorypolicyLearn about multiple policies while following one policy

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Off–Policy Learning
Learn about target policy π(a|s)
While following behavior policy π(a|s)
Why is this important?Learn from observing humans or other agentsRe–use experience generated from old policiesπ1, π2, . . . , πt−1Learn about optimal policy while following exploratorypolicyLearn about multiple policies while following one policy

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Off–Policy Learning
Learn about target policy π(a|s)
While following behavior policy π(a|s)
Why is this important?Learn from observing humans or other agentsRe–use experience generated from old policiesπ1, π2, . . . , πt−1Learn about optimal policy while following exploratorypolicyLearn about multiple policies while following one policy

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Importance Sampling
Estimate the expectation of a different distribution w.r.t. thedistribution used to draw samples
Ex∼P [f (x)] =∑
P(x)f (x)
=∑
Q(x)P(x)
Q(x)f (x)
= Ex∼Q
[P(x)
Q(x)f (x)
]

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Importance Sampling
Estimate the expectation of a different distribution w.r.t. thedistribution used to draw samples
Ex∼P [f (x)] =∑
P(x)f (x)
=∑
Q(x)P(x)
Q(x)f (x)
= Ex∼Q
[P(x)
Q(x)f (x)
]

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Importance Sampling for Off–PolicyMonte–Carlo
Use returns generated from π to evaluate πWeight return vt according to similarity betweenpoliciesMultiply importance sampling corrections alongwhole episode
vµt =π(at |st )
π(at |st )
π(at+1|st+1)
π(at+1|st+1). . .
π(aT |sT )
π(aT |sT )vt
Update value towards corrected return
Q(st ,at )← Q(st ,at ) + α(vt −Q(st ,at ))
Cannot use if π is zero where π is non–zeroImportance sampling can dramatically increasevariance

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Importance Sampling for Off–PolicyMonte–Carlo
Use returns generated from π to evaluate πWeight return vt according to similarity betweenpoliciesMultiply importance sampling corrections alongwhole episode
vµt =π(at |st )
π(at |st )
π(at+1|st+1)
π(at+1|st+1). . .
π(aT |sT )
π(aT |sT )vt
Update value towards corrected return
Q(st ,at )← Q(st ,at ) + α(vt −Q(st ,at ))
Cannot use if π is zero where π is non–zeroImportance sampling can dramatically increasevariance

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Importance Sampling for Off–PolicyMonte–Carlo
Use returns generated from π to evaluate πWeight return vt according to similarity betweenpoliciesMultiply importance sampling corrections alongwhole episode
vµt =π(at |st )
π(at |st )
π(at+1|st+1)
π(at+1|st+1). . .
π(aT |sT )
π(aT |sT )vt
Update value towards corrected return
Q(st ,at )← Q(st ,at ) + α(vt −Q(st ,at ))
Cannot use if π is zero where π is non–zeroImportance sampling can dramatically increasevariance

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Importance Sampling for Off–PolicyMonte–Carlo
Use returns generated from π to evaluate πWeight return vt according to similarity betweenpoliciesMultiply importance sampling corrections alongwhole episode
vµt =π(at |st )
π(at |st )
π(at+1|st+1)
π(at+1|st+1). . .
π(aT |sT )
π(aT |sT )vt
Update value towards corrected return
Q(st ,at )← Q(st ,at ) + α(vt −Q(st ,at ))
Cannot use if π is zero where π is non–zeroImportance sampling can dramatically increasevariance

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Importance Sampling for Off–PolicyMonte–Carlo
Use returns generated from π to evaluate πWeight return vt according to similarity betweenpoliciesMultiply importance sampling corrections alongwhole episode
vµt =π(at |st )
π(at |st )
π(at+1|st+1)
π(at+1|st+1). . .
π(aT |sT )
π(aT |sT )vt
Update value towards corrected return
Q(st ,at )← Q(st ,at ) + α(vt −Q(st ,at ))
Cannot use if π is zero where π is non–zeroImportance sampling can dramatically increasevariance

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Importance Sampling for Off–PolicyMonte–Carlo
Use returns generated from π to evaluate πWeight return vt according to similarity betweenpoliciesMultiply importance sampling corrections alongwhole episode
vµt =π(at |st )
π(at |st )
π(at+1|st+1)
π(at+1|st+1). . .
π(aT |sT )
π(aT |sT )vt
Update value towards corrected return
Q(st ,at )← Q(st ,at ) + α(vt −Q(st ,at ))
Cannot use if π is zero where π is non–zeroImportance sampling can dramatically increasevariance

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Importance Sampling for Off–PolicyMonte–CarloDerivation
Off–policy MC is derived from expected return:
Qπ(s,a) = Eπ[vt |st = s,at = a]
=∑
P[s1,a1, r2, . . . , sT ]vt
=∑
P[s1]
(ΠT
t=1π(st ,at )P(st |st−1,at−1)π(st |at )
π(st ,at )
)vt
= Eπ[
ΠTt=1
π(st ,at )
π(st ,at )vt |st = s,at = a
]

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Off–Policy MC Control
Initialize, for all s ∈ S, a ∈ A:Q(s, a)← arbitraryN(s, a)← 0D(s, a)← 0π ← an arbitrary deterministic policyloop
Using a policy π, generate an episodes0, a0, r1, s1, a1, r2, . . . , sT−1, aT−1, rT , sTτ ← latest time at which aτ 6= π(sτ )for all pair s, a appearing in the episode after τ do
t ← the time of first occurence (after τ ) of s, a
w ← ΠT−1k=t+1
1π(sk , ak )
N(s, a)← N(s, a) + wRtD(s, a)← D(s, a) + wQ(s, a)← N(s,a)
D(s,a)
end forfor all s ∈ S do
π(s)← arg maxa∈A Q(s, a)end for
end loop

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Importance Sampling for Off–Policy SARSA
Use TD targets generated from π to evaluate πWeight TD target r + γQ(s′,a′) according to similaritybetween policiesOnly need a single importance sampling correction
Q(st , at)← Q(st , at) + α
(rt+1 + γ
π(a|s)π(a|s)Q(st+1, at+1)−Q(st , at)
)Much lower variance than Monte–Carlo importancesamplingPolicies only need to be similar over a single step

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Importance Sampling for Off–Policy SARSA
Use TD targets generated from π to evaluate πWeight TD target r + γQ(s′,a′) according to similaritybetween policiesOnly need a single importance sampling correction
Q(st , at)← Q(st , at) + α
(rt+1 + γ
π(a|s)π(a|s)Q(st+1, at+1)−Q(st , at)
)Much lower variance than Monte–Carlo importancesamplingPolicies only need to be similar over a single step

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Importance Sampling for Off–Policy SARSA
Use TD targets generated from π to evaluate πWeight TD target r + γQ(s′,a′) according to similaritybetween policiesOnly need a single importance sampling correction
Q(st , at)← Q(st , at) + α
(rt+1 + γ
π(a|s)π(a|s)Q(st+1, at+1)−Q(st , at)
)Much lower variance than Monte–Carlo importancesamplingPolicies only need to be similar over a single step

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Importance Sampling for Off–Policy SARSA
Use TD targets generated from π to evaluate πWeight TD target r + γQ(s′,a′) according to similaritybetween policiesOnly need a single importance sampling correction
Q(st , at)← Q(st , at) + α
(rt+1 + γ
π(a|s)π(a|s)Q(st+1, at+1)−Q(st , at)
)Much lower variance than Monte–Carlo importancesamplingPolicies only need to be similar over a single step

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Importance Sampling for Off–Policy SARSA
Use TD targets generated from π to evaluate πWeight TD target r + γQ(s′,a′) according to similaritybetween policiesOnly need a single importance sampling correction
Q(st , at)← Q(st , at) + α
(rt+1 + γ
π(a|s)π(a|s)Q(st+1, at+1)−Q(st , at)
)Much lower variance than Monte–Carlo importancesamplingPolicies only need to be similar over a single step

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Importance Sampling for Off–Policy SARSABellman expectation equation
Off–Policy SARSA comes from Bellman expectation equation for Qπ(s, a)
Qπ(s, a) = Eπ [rt+1 + γQπ(st+1, at+1)|st = s, at = a]
= R(s, a) + γ∑s′∈S
P(s′|s, a)∑
a′∈A
π(a′|s′)Qπ(s′, a′)
= R(s, a) + γ∑s′∈S
P(s′|s, a)∑
a′∈A
π(a′|s′)π(a′|s′)
π(a′|s′)Qπ(s′, a′)
= Eµ[rt+1 + γ
π(a|s)π(a|s)Qπ(st+1, at+1)|st = s, at = a
]

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Off–Policy Control with Q–learning
Learn about optimal policy π = π∗
From experience sampled from behavior policy πEstimate Q(s,a) ≈ Q∗(s,a)
Behavior policy can depend on Q(s,a)
e.g., π could be ε–greedy with respect to Q(s,a)As Q(s,a)→ Q∗(s,a), behavior policy π improves

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Off–Policy Control with Q–learning
Learn about optimal policy π = π∗
From experience sampled from behavior policy πEstimate Q(s,a) ≈ Q∗(s,a)
Behavior policy can depend on Q(s,a)
e.g., π could be ε–greedy with respect to Q(s,a)As Q(s,a)→ Q∗(s,a), behavior policy π improves

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Off–Policy Control with Q–learning
Learn about optimal policy π = π∗
From experience sampled from behavior policy πEstimate Q(s,a) ≈ Q∗(s,a)
Behavior policy can depend on Q(s,a)
e.g., π could be ε–greedy with respect to Q(s,a)As Q(s,a)→ Q∗(s,a), behavior policy π improves

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Off–Policy Control with Q–learning
Learn about optimal policy π = π∗
From experience sampled from behavior policy πEstimate Q(s,a) ≈ Q∗(s,a)
Behavior policy can depend on Q(s,a)
e.g., π could be ε–greedy with respect to Q(s,a)As Q(s,a)→ Q∗(s,a), behavior policy π improves

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Off–Policy Control with Q–learning
Learn about optimal policy π = π∗
From experience sampled from behavior policy πEstimate Q(s,a) ≈ Q∗(s,a)
Behavior policy can depend on Q(s,a)
e.g., π could be ε–greedy with respect to Q(s,a)As Q(s,a)→ Q∗(s,a), behavior policy π improves

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Off–Policy Control with Q–learning
Learn about optimal policy π = π∗
From experience sampled from behavior policy πEstimate Q(s,a) ≈ Q∗(s,a)
Behavior policy can depend on Q(s,a)
e.g., π could be ε–greedy with respect to Q(s,a)As Q(s,a)→ Q∗(s,a), behavior policy π improves

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Q–learning Algorithm
Q(s,a)← Q(s,a) + α(r + γmaxa′∈A
Q(s′,a′)−Q(s,a))
Initialize Q(s,a) arbitrarilyloop
Initialize srepeat
Choose a from s using policy derived from Q (e.g.,ε–greedy)Take action a, observe r , s′
Q(s,a)← Q(s,a) +α[r +γmaxa′ Q(s′,a′)−Q(s,a)]s ← s′;
until s is terminalend loop
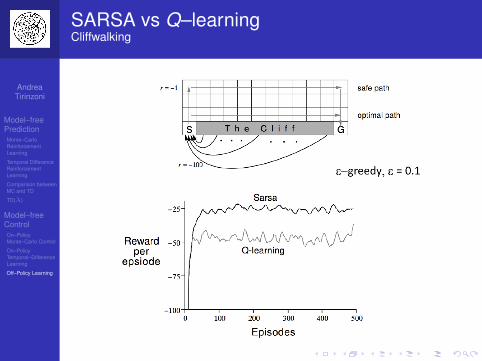
AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
SARSA vs Q–learningCliffwalking

AndreaTirinzoni
Model–freePredictionMonte–CarloReinforcementLearning
Temporal DifferenceReinforcementLearning
Comparison betweenMC and TD
TD(λ)
Model–freeControlOn–PolicyMonte–Carlo Control
On–PolicyTemporal–DifferenceLearning
Off–Policy Learning
Q–learning vs SARSA
SARSA: Q(s,a)← Q(s,a) + α[r + γQ(s′,a′)−Q(s,a)]on–policyQ–learning:Q(s,a)← Q(s,a) + α[r + γmaxa′ Q(s′,a′)−Q(s,a)]off–policyIn the cliff–walking task:
Q–learning: learns optimal policy along edgeSARSA: learns a safe non–optimal policy away fromedge
ε–greedy algorithmFor ε 6= 0 SARSA performs better onlineFor ε→ 0 gradually, both converge to optimal