INTEGRACIÓN DE LÓGICA LINEAL TEMPORAL A MODELOS...
126
INTEGRACI ´ ON DE L ´ OGICA LINEAL TEMPORAL A MODELOS DE ARQUITECTURAS DE SOFTWARE BASADAS EN COMPONENTES ESPECIFICADAS A TRAV ´ ES DEL C ´ ALCULO ρ arq OSCAR JAVIER PUENTES PUENTES
Transcript of INTEGRACIÓN DE LÓGICA LINEAL TEMPORAL A MODELOS...

INTEGRACION DE LOGICA LINEAL TEMPORAL A
MODELOS DE ARQUITECTURAS DE SOFTWARE
BASADAS EN COMPONENTES ESPECIFICADAS A
TRAVES DEL CALCULO ρarq
OSCAR JAVIER PUENTES PUENTES

INTEGRACION DE LOGICA LINEAL TEMPORAL SOBRE MODELOS DEARQUITECTURAS DE SOFTWARE BASADAS EN COMPONENTES ESPECIFICADAS
A TRAVES DEL CALCULO ρarq
OSCAR JAVIER PUENTES PUENTES
UNIVERSIDAD DISTRITAL FRANCISCO JOSE DE CALDASFACULTAD DE INGENIERIA
MAESTRIA EN CIENCIAS DE LA INFORMACION Y LAS COMUNICACIONESBOGOTA D.C.
2017

INTEGRACION DE LOGICA LINEAL TEMPORAL A MODELOS DEARQUITECTURAS DE SOFTWARE BASADAS EN COMPONENTES ESPECIFICADAS
A TRAVES DEL CALCULO ρarq
OSCAR JAVIER PUENTES PUENTES
PROYECTO DE GRADO
MAESTRIA EN CIENCIAS DE LA INFORMACION Y LAS COMUNICACIONES
Director:Ing. Ph.D. HENRY ALBERTO DIOSA
UNIVERSIDAD DISTRITAL FRANCISCO JOSE DE CALDASFACULTAD DE INGENIERIA
MAESTRIA EN CIENCIAS DE LA INFORMACION Y LAS COMUNICACIONESBOGOTA D. C.
2017

CONTENIDO
1. DESCRIPCION Y PLANTEAMIENTO DEL PROYECTO 101.1. Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101.2. Formulacion del problema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111.3. Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
1.3.1. General . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121.3.2. Especıficos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
1.4. Justificacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121.5. Metodologıa utilizada . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2. MARCO REFERENCIAL Y ESTADO DEL ARTE 152.1. Modelos y metodos formales en la Ingenierıa de Software . . . . . . . . . . . . 15
2.1.1. Chequeo de modelos de software . . . . . . . . . . . . . . . . . . . . . 162.1.2. Verificacion de sistemas . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.2. Chequeo de modelos y arquitecturas de software . . . . . . . . . . . . . . . . . 182.2.1. Chequeo de arquitecturas de software . . . . . . . . . . . . . . . . . . 182.2.2. Arquitecturas de software y Lenguaje de Modelado Unificado (UML) . 18
2.3. Logicas Temporales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202.3.1. Modelado de sistemas y logicas temporales . . . . . . . . . . . . . . . . 202.3.2. Generalidades de las logicas temporales . . . . . . . . . . . . . . . . . . 212.3.3. Clasificacion de las logicas temporales . . . . . . . . . . . . . . . . . . . 212.3.4. Logica de Arboles de Computo Cerradura (CTL*) . . . . . . . . . . . . 232.3.5. Logica de Arboles de Computo Simple (CTL) . . . . . . . . . . . . . . 272.3.6. Logica Lineal Temporal (LTL) . . . . . . . . . . . . . . . . . . . . . . . 29
2.4. Chequeo de modelos y logicas temporales . . . . . . . . . . . . . . . . . . . . . 322.4.1. Generalidades . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 322.4.2. Chequeo de modelos CTL . . . . . . . . . . . . . . . . . . . . . . . . . 33
2.5. Calculo ρarq . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 462.5.1. Sintaxis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 462.5.2. Especificacion formal de una arquitectura . . . . . . . . . . . . . . . . . 482.5.3. Semantica Operacional y Ejecucion de una arquitectura . . . . . . . . . 492.5.4. Sistemas de Transicion Rotulados Condicionados . . . . . . . . . . . . 52
2.6. Lenguajes de Descripcion Arquitectural y Logicas Temporales . . . . . . . . . 542.7. Tecnologıas para el chequeo de modelos . . . . . . . . . . . . . . . . . . . . . . 58
2.7.1. SPIN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
4

CONTENIDO 5
3. DESARROLLO DE LA SOLUCION 633.1. Sintaxis y semantica de los operadores temporales . . . . . . . . . . . . . . . . 63
3.1.1. Reglas de equivalencia logica . . . . . . . . . . . . . . . . . . . . . . . . 643.1.2. Definiciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 643.1.3. Reglas de verificacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
3.2. Especificacion de una propiedad temporal . . . . . . . . . . . . . . . . . . . . 673.3. Verificacion de una propiedad temporal . . . . . . . . . . . . . . . . . . . . . . 763.4. Implementacion del mecanismo en PintArq . . . . . . . . . . . . . . . . . . . . 81
3.4.1. Modelo funcional de PintArq extendido . . . . . . . . . . . . . . . . . . 813.4.2. Arquitectura prescriptiva extendida . . . . . . . . . . . . . . . . . . . . 893.4.3. Breve descripcion de interfaz grafica de usuario . . . . . . . . . . . . . 963.4.4. Aspecto tecnologico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
4. CONCLUSIONES Y TRABAJO FUTURO 1144.1. Trabajo futuro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
A. Manual de usuario 116A.1. Requerimientos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116A.2. Operacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
A.2.1. Cargar una especificacion de arquitectura . . . . . . . . . . . . . . . . . 117A.2.2. Verificar una propiedad temporal . . . . . . . . . . . . . . . . . . . . . 118
B. Manual de instalacion 121B.1. Requerimientos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121B.2. Instalacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
B.2.1. Wildfly . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121B.2.2. Graphviz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122B.2.3. Spin . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122B.2.4. PintArq . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
BIBLIOGRAFIA 123

INDICE DE FIGURAS
1.1. Actividades relevantes para el desarrollo del proyecto . . . . . . . . . . . . . . 14
2.1. Ciclo de vida del software y costos asociados a los errores . . . . . . . . . . . . 172.2. Las cuatro capas de la Arquitectura de Metamodelamiento de UML . . . . . . 192.3. Relacion entre las logicas temporales . . . . . . . . . . . . . . . . . . . . . . . 272.4. Representacion grafica de algunos operadores CTL . . . . . . . . . . . . . . . . 292.5. Representacion grafica de los operadores LTL . . . . . . . . . . . . . . . . . . 302.6. Ejemplo funcion de etiquetado EX f . Estado inicial del sistema. Parte 1 de 2 . 372.7. Ejemplo funcion de etiquetado EX f . Estado final del sistema. Parte 2 de 2 . . 382.8. Algoritmo EX f. Desarrollo del arbol del sistema. . . . . . . . . . . . . . . . . 382.9. Ejemplo para la funcion de etiquetado AF f . . . . . . . . . . . . . . . . . . . 402.10. Ejemplo funcion de etiquetado E(f1 U f2). Estado inicial del sistema. Parte 1 de 4 412.11. Ejemplo funcion de etiquetado E(f1 U f2). Estado intermedio 1. Parte 2 de 4 . 422.12. Ejemplo funcion de etiquetado E(f1 U f2). Estado intermedio 2. Parte 3 de 4 . 422.13. Ejemplo funcion de etiquetado E(f1 U f2). Estado final del sistema. Parte 4 de 4 432.14. Representacion grafica del algoritmo para EG alternativo . . . . . . . . . . . 452.15. Sintaxis del calculo ρarq . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 462.16. Representacion grafica de un componente . . . . . . . . . . . . . . . . . . . . . 492.17. Axiomas del calculo ρarq . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 492.18. Reglas de reduccion del ρArq . . . . . . . . . . . . . . . . . . . . . . . . . . . . 502.19. Notacion grafica del ensamble de componentes . . . . . . . . . . . . . . . . . 512.20. Reglas de transicion del ρArq . . . . . . . . . . . . . . . . . . . . . . . . . . . 532.21. Representacion grafica de un Sistema Productor-Consumidor en SAM . . . . . 552.22. Representacion grafica de un Sistema Productor-Consumidor en CBabel . . . . 562.23. Descripcion textual de una arquitectura en Æmilia . . . . . . . . . . . . . . . 572.24. Transformacion de diagrama de estados CHARMY a especificacion en Promela 572.25. Estructura de una simulacion y verificacion en SPIN . . . . . . . . . . . . . . 592.26. Ejemplo de la especificacion de un modelo a traves del lenguaje Promela . . . 602.27. Construccion gramatica de una formula en LLT en Promela para SPIN. . . . . 62
3.1. Ensamble complejo de componentes . . . . . . . . . . . . . . . . . . . . . . . 683.2. Vista parcial del STR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 693.3. STPA del Ensamble complejo de componentes . . . . . . . . . . . . . . . . . . 713.4. Ejemplo de representacion de la ejecucion de un componente en el STPA . . . 723.5. Ejemplo de representacion del STPA completo . . . . . . . . . . . . . . . . . 73
6

INDICE DE FIGURAS 7
3.6. Configuracion con componentes alternativos para proveer servicios . . . . . . 743.7. STPA para una Configuracion con componentes alternativos . . . . . . . . . . 753.8. Relacion entre Traces(TS) y Words(ϕ) . . . . . . . . . . . . . . . . . . . . . 783.9. Modelo funcional de PintArq extendido. . . . . . . . . . . . . . . . . . . . . . 823.10. Casos de uso Crear STPA y Graficar STPA. . . . . . . . . . . . . . . . . . . . 833.11. Fragmento - Diagrama de secuencia caso de uso Crear STPA. . . . . . . . . . . 843.12. Fragmento - Diagrama de secuencia caso de uso Graficar STPA. . . . . . . . . 853.13. Casos de uso Verificar propiedad y Mostrar contraejemplo . . . . . . . . . . . 863.14. Fragmento - Diagrama de secuencia caso de uso Verificar propiedad. . . . . . . 873.15. Fragmento - Diagrama de secuencia caso de uso Mostrar contraejemplo. . . . . 883.16. Arquitectura prescriptiva con los componentes adicionales. . . . . . . . . . . . 903.17. Modelo estructural para el Generador STPA. . . . . . . . . . . . . . . . . . . . 923.18. Ejemplo de representacion de la ejecucion de un componente en el STPA . . . 933.19. Modelo estructural para el Visor de chequeo del modelo . . . . . . . . . . . . 943.20. Ejemplo de un grafo generado para un STPA a traves del graficador . . . . . 953.21. Modelo estructural para el Verificador de propiedad . . . . . . . . . . . . . . . 963.22. Prototipo de Interfaz Grafica de Usuario. . . . . . . . . . . . . . . . . . . . . . 973.23. Fragmento Documento LaTeX con reglas de observacion OSO . . . . . . . . . 983.24. Visualizacion de la configuracion arquitectural y el STPA en la extension . . . 993.25. Verificacion de una propiedad temporal. El modelo satisface la propiedad . . . 1003.26. Verificacion de una propiedad temporal. El modelo no satisface la propiedad . 1023.27. Ejemplo del lenguaje DOT y su representacion grafica . . . . . . . . . . . . . 1033.28. Representacion de un STPA en lenguaje DOT . . . . . . . . . . . . . . . . . . 1043.29. Representacion grafica de un STPA posterior a la transformacion del lenguaje DOT 1053.30. Ejemplo de un programa y una propiedad escritos en Promela . . . . . . . . . 1063.31. Representacion en Promela de un STPA. Parte 1 de 4 . . . . . . . . . . . . . . 1083.32. Representacion en Promela de un STPA. Parte 2 de 4 . . . . . . . . . . . . . . 1093.33. Representacion en Promela de un STPA. Parte 3 de 4 . . . . . . . . . . . . . . 1103.34. Representacion en Promela de un STPA. Parte 4 de 4 . . . . . . . . . . . . . . 111
A.1. Pantalla inicial PintArq . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117A.2. Representacion grafica de la Arquitectura y el STPA en el aplicativo . . . . . 117A.3. Verificacion de la propiedad con resultado satisfactorio . . . . . . . . . . . . . 119A.4. Verificacion de la propiedad con resultado no satisfactorio . . . . . . . . . . . 120

Algoritmos
2.1. Algoritmo sat(f) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 342.2. Algoritmo satEX(f) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 352.3. Algoritmo satAF (f) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 352.4. Algoritmo satEU(f1 , f2) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 362.5. Algoritmo alterno para el operador EG . . . . . . . . . . . . . . . . . . . . . . 44
8

RESUMEN
El presente trabajo de investigacion establece un mecanismo para incorporar logica linealtemporal a una configuracion arquitectural especificada a traves del calculo ρarq. Este proceso serealiza interpretando los componentes y la definicion del sistema (estructura y comportamiento)de una configuracion arquitectural y la generacion de un procedimiento para construir unSistema de Transicion de Proposiciones Atomicas (STPA) sobre el cual se realiza la verificacionde propiedades temporales. La visualizacion de este proceso se realiza a traves de una extensionde la aplicacion PintArq.
9

Capıtulo 1
DESCRIPCION YPLANTEAMIENTO DELPROBLEMA
1.1. Introduccion
La construccion y evolucion de los sistemas de software tiene grandes retos en la actualidad.El tamano de estos retos es proporcional con la cantidad de informacion que se produce yconsume diariamente. Dicha informacion puede estar distribuida geograficamente, puede serconsultada de forma concurrente y las operaciones sobre esta informacion pueden ser simples ocomplejas de acuerdo al dominio en el que se desarrolla. Para hacer frente a los problemas queesto conlleva, se deben disenar y construir grandes sistemas de informacion, que no solo brindenla informacion correcta sino tambien de forma oportuna, eficiente y segura, entre otros muchosatributos de calidad. Hay desafıos que exigen este tipo de sistemas en los que su desarrollo yoperacion tienen gran complejidad, no solo por la cantidad de elementos, sino por las relacionese interaccion que existe entre ellos.
Durante un tiempo, la Ingenierıa de Software no conto con herramientas matematicas quele permitieran desarrollarse con mas seguridad y alcance a pesar de los grandes desarrollosteoricos y tecnologicos, no solo por su reciente aparicion sino tambien porque dichas herra-mientas fueron consideradas muy complejas de aprender y como ejercicios teoricos. A raız deesto, y en la busqueda de un desarrollo mucho mas riguroso y fuerte en terminos matematicos,se ha investigado sobre herramientas que contribuyan a su desarrollo formal. Siguiendo estalınea, dentro del tema de arquitecturas de software se busca definir herramientas matematicasque permitan chequear las propiedades y aspectos de calidad deben satisfacer; se busca de-finir metodos formales que permitan evaluar los modelos de manera precisa y confiable. Lospropositos de los metodos formales en la Ingenierıa de Software son entre otros, sistematizar
10

1.2. FORMULACION DEL PROBLEMA 11
todas las fases del proceso y hacer mas riguroso su desarrollo[1].
Como antecedentes importantes, cabe destacar el desarrollo de metodos para especificarprocesos y sus interacciones como el calculo λ para procesos secuenciales, el calculo π paraprocesos concurrentes y mas recientemente, el calculo ρ para paradigmas orientados a objetos[2]. El calculo ρ ha proporcionado un excelente fundamento para modelar soluciones recientes,debido a la gran extension del paradigma orientado a objetos y el uso del Lenguaje de ModeladoUnificado (UML). Con base en estos, se han desarrollado varias herramientas que se podrıandenominar mixtas, debido a que UML no es un lenguaje formal estricto. El calculo ρarq espropuesto para especificar aspectos estructurales y dinamicos de las arquitecturas de softwarebasadas en componentes; ası como tambien una herramienta para evaluar las propiedadesdeseables de arquitecturas como la correccion [3, 4].
Adicionalmente, dentro de los metodos formales que han entrado a ser parte de la Inge-nierıa de Software se encuentran las logicas temporales, que se utilizan para describir sistemasconcurrentes y reactivos. Es utilizada para especificar propiedades y verificar que modelos desoftware las satisfacen[5]. Su utilizacion usualmente se incorpora en la ejecucion de programasconcurrentes y tienen una sintaxis y semantica especıficas [6].
En el contexto de sistemas reactivos y concurrentes se encuentran las arquitecturas desoftware basadas en componentes y el chequeo de modelos conformes a este estilo arquitectonicoes una necesidad evidente en la actualidad.
Es por estas razones que se busca contribuir en la aplicacion de tecnicas formales al desa-rrollo de software basado en componentes con el objeto de que desde el punto de vista formalpueda ser mas confiable.
1.2. Formulacion del problema
El calculo ρarq es una notacion formal para especificar arquitecturas de software basadasen componentes desde el punto de vista estructural y dinamico [3]. Su definicion se estructuraen las algebras de procesos, las cuales permiten modelar sistemas de software concurrentes,que proveen el mecanismo para describir interacciones, comunicacion y sincronizacion de suselementos a alto nivel. Una de sus principales caracterısticas es que permite realizar razona-miento formal sobre su estructura y comportamiento. Adicionalmente, la posibilidad de utilizarUML como Lenguaje de Descripcion Arquitectural que permitirıa no solo la formalidad de laespecificacion sino tambien la posibilidad de ser usado no solo en el ambito academico sino enel ambiente industrial.
Actualmente con el calculo ρarq no es posible especificar propiedades temporales, relaciona-das con el orden logico de ejecucion de una arquitectura; es decir, determinar en un momentodado si una arquitectura llega a cierto estado deseado que depende de la ejecucion correcta y

12 CAPITULO 1. DESCRIPCION Y PLANTEAMIENTO DEL PROYECTO
en cierto orden de sus componentes. Serıa util establecer los mecanismos que permitieran espe-cificar y validar estas propiedades. En este sentido, se propone integrarlo con la Logica LinealTemporal para determinar y especificar un mecanismo mediante el cual se pueda modelar laejecucion de una arquitectura de software especificada en calculo ρarq con esta logica modal.
El problema planteado en el presente trabajo es el siguiente ¿Que caracterısticas debecontener un mecanismo que permita especificar y verificar propiedades temporales para modelosde arquitecturas de software basadas en componentes modelados a traves del calculo ρarq?
1.3. Objetivos
1.3.1. General
Establecer el mecanismo para incorporar Logica Lineal Temporal sobre arquitecturas desoftware basadas en componentes modeladas a traves del calculo ρarq.
1.3.2. Especıficos
Establecer la sintaxis y semantica de los operadores temporales.
Determinar los pasos para especificar una propiedad temporal para arquitecturas desoftware basada en componentes especificadas a traves del calculo.
Aplicar y validar la propiedad de vivacidad en un modelo arquitectonico basado en com-ponentes especificado a traves del calculo.
Implementar el mecanismo de integracion de analisis de propiedades usando Logica LinealTemporal a la herramienta PintArq.
1.4. Justificacion
El desarrollo del presente proyecto pretende contribuir en el area de la Ingenierıa de Softwareen la medida que se pueda aplicar y extender el paradigma del desarrollo de software basado encomponentes, especialmente en el campo de la Arquitectura de Software. De igual forma aportaren la utilizacion de metodos formales sobre los productos de software, para que esto puedaayudar a mejorar la calidad de los mismos, ası como reducir riesgos inherentes al desarrollo desoftware en donde ciertos aspectos son todavıa subjetivos y algunos de los metodos formalesutilizados no han tenido la expansion suficiente.

1.5. METODOLOGIA UTILIZADA 13
Desde el punto de vista academico, se propende por la investigacion de temas que contribu-yan al desarrollo de una Ingenierıa de Software mucho mas estable y con bases formales muchomas fuertes.
1.5. Metodologıa utilizada
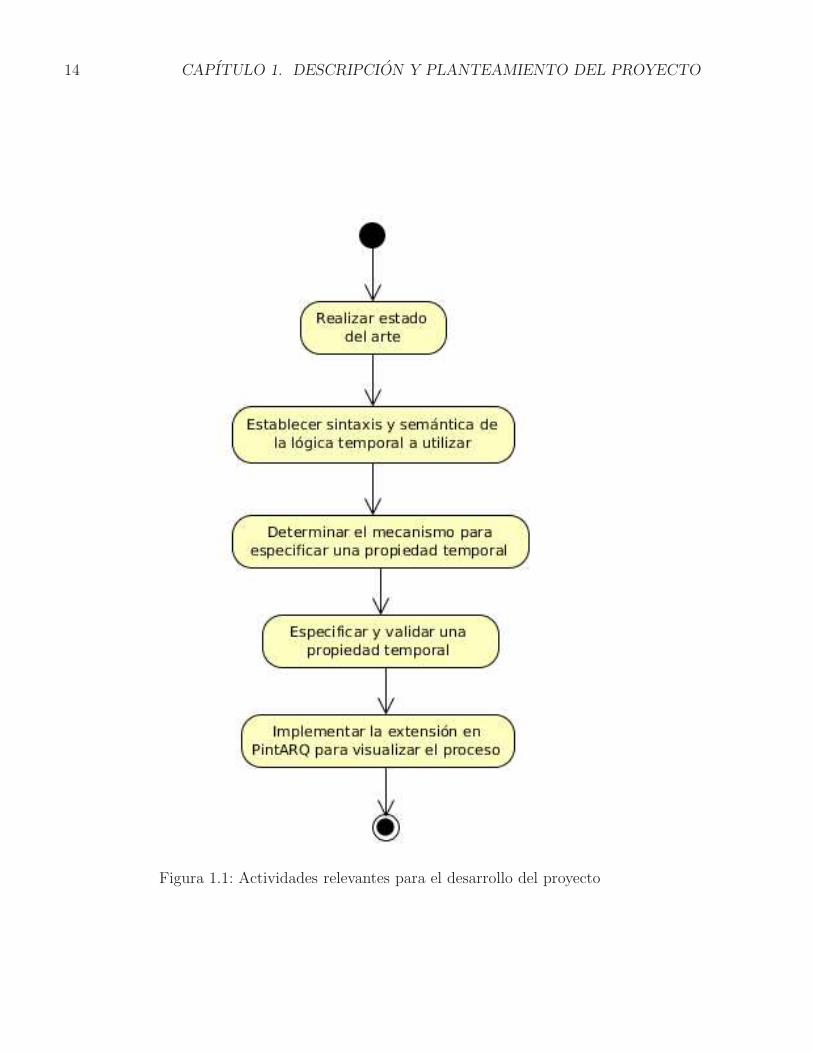
Como primera parte del desarrollo del proyecto se investigaron los procedimientos me-diante los cuales se especifican las propiedades temporales en otros sistemas concurrentes,posteriormente se establecio la sintaxis y semantica de los elementos que fueron utilizados pa-ra especificar los estados y propiedades para un modelo arquitectonico basado en componentesen el calculo ρarq. Con los elementos propuestos se procedio a definir la propiedad que serıaverificada. El proceso se documento en cada etapa, paso por paso para permitir que sea repro-ducido posteriormente para verificar una nueva propiedad. La metodologıa se presenta en laFigura 1.1. Se desarrollo un mecanismo que incorporo la Logica Lineal Temporal para especi-ficar propiedades temporales a modelos de arquitecturas de software basadas en componentesespecificadas a traves del calculo ρarq y se integro a la herramienta PintArq.
14 CAPITULO 1. DESCRIPCION Y PLANTEAMIENTO DEL PROYECTO
Figura 1.1: Actividades relevantes para el desarrollo del proyecto

Capıtulo 2
MARCO REFERENCIAL Y ESTADODEL ARTE
2.1. Modelos y metodos formales en la Ingenierıa de
Software
El termino “metodo formal” es ampliamente usado sin existir una definicion unica. Usual-mente es utilizado para hacer referencia a la utilizacion de un lenguaje de especificacion formalpero no se describe el alcance que este tiene. En lineas generales entre mas abstracto sea ellenguaje en el que se describa un sistema, este lenguaje se denomina formal. En muchas oca-siones no existe un unico lenguaje para describir un sistema y se pueden utilizar lenguajes endiferentes grados de formalidad para describir diferentes partes del sistema; sin embargo, unlenguaje con fundamentacion matematica es considerado un lenguaje completamente formal[7]. Algunos de los enfoques desarrollados alrededor de estos lenguajes son:
Algebras de procesos : Son metodos utilizados para modelar concurrencia y comunicacionentre procesos. Unos de los metodos mas conocidos son CSP (Communication Sequential Pro-cesses) de Hoare[8] y CCS (Calculus of Communicating Systems) de Milner [9].
Tecnicas algebraicas: Son metodos basados en el algebra, como por ejemplo el uso deEspecificacion Algebraica para Tipos Abstractos de Datos en donde el comportamiento de lasoperaciones sobre los Tipos Abstractos de Datos se expresan a traves de ecuaciones.
15

16 CAPITULO 2. MARCO REFERENCIAL Y ESTADO DEL ARTE
2.1.1. Chequeo de modelos de software
El chequeo de modelos es una tecnica de verificacion formal para la evaluacion de propie-dades formales de sistemas de informacion y comunicacion. El chequeo de modelos requiere unmodelo del sistema que se va a analizar, una propiedad deseada y un metodo para verificarsistematicamente si el modelo satisface o no la propiedad (por ejemplo, si es libre de inter-bloqueos, invariabilidad o propiedades de solicitud-respuesta). El chequeo de modelos es unatecnica automatizada para verificar la ausencia de errores y considerada como una tecnica dedepuracion efectiva e inteligente. Sus fundamentos formales se encuentran en la logica propo-sicional, teorıa de automatas, lenguajes formales, estructuras de datos y algoritmos de grafos.[10, 5]
2.1.2. Verificacion de sistemas
La verificacion de sistemas es utilizada para establecer que el diseno o producto a consi-deracion posee ciertas propiedades. Las propiedades a ser verificadas pueden ser elementalescomo que un sistema nunca debe caer en un estado de interbloqueo, esto puede obtenerse dela especificacion del sistema, la cual establece lo que el sistema tiene o no tiene que hacer, locual es la base para la actividad de la verificacion. De esta forma, si el sistema no cumple conuna propiedad que ha sido especificada se ha encontrado un defecto, asimismo si un sistemacumple con todas las propiedades es considerado correcto. [10, 11]
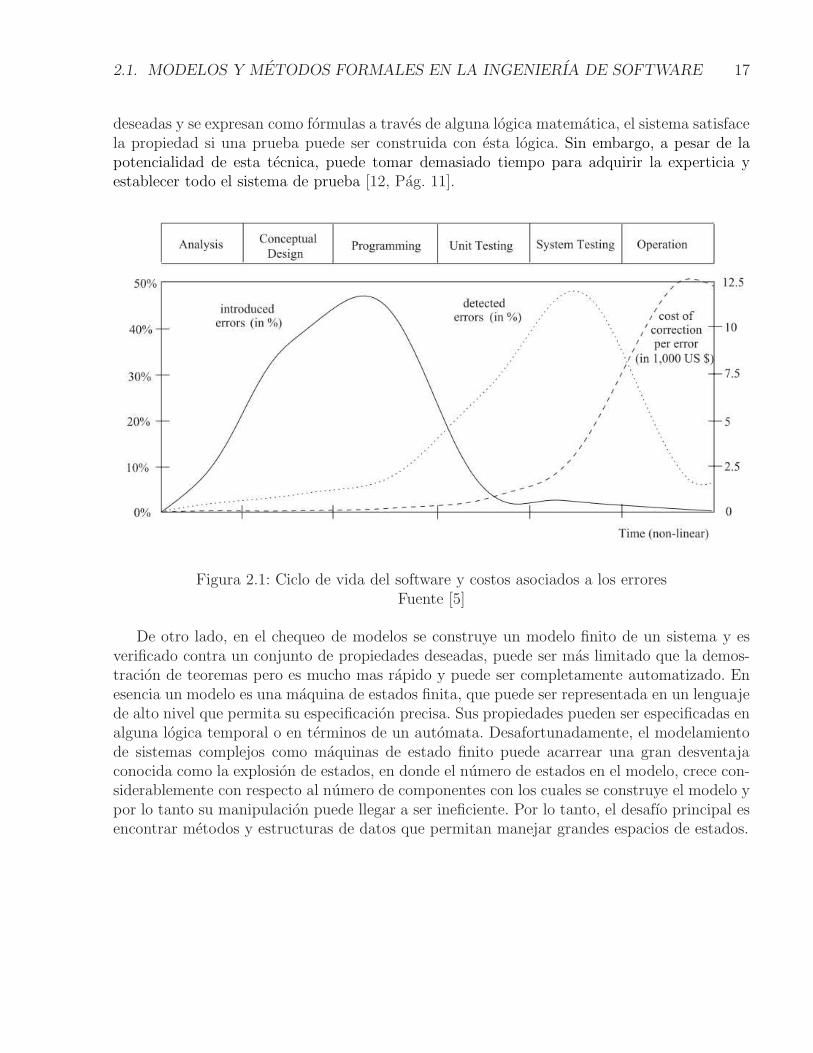
En la actualidad, las tecnicas para realizar verificacion a sistemas de informacion y comu-nicaciones se realizan de una forma mas confiable pero no de forma completa. Para realizarla verificacion del software usualmente se utilizan dos tecnicas que pueden combinarse paraobtener mejores resultados, una corresponde a la revision por pares y la otra consiste en laspruebas de software. En la primera el codigo es analizado antes de su compilacion y ejecucionpor una persona diferente a quien lo codifico pero conoce el objetivo del software; sin embargo,y a pesar de los grandes esfuerzos, sus resultados obtienen en promedio el 60% de los errores [5,pag. 4]. Por otro lado, las pruebas de software se realizan a traves de la ejecucion del software,en donde se compara la salida del software frente al valor esperado de la especificacion. Laspruebas de software consumen entre el 30 y 50% de los costos de un proyecto y sin embargo nodan confiabilidad de que el software no tenga errores [5, pag. 4]. Asimismo, la importancia deencontrar errores en las etapas iniciales del ciclo de desarrollo de software es imperativa puesel costo de corregirlos es considerablemente menor, la Figura 2.1 ilustra este comportamiento.
La verificacion formal significa la creacion de un modelo matematico de un sistema, usandoun lenguaje para especificar las propiedades deseadas en una forma concisa y sin ambiguedad,y usando un metodo de prueba para verificar las propiedades que satisfacen el modelo. Cuandoel metodo de prueba es llevado a cabo por una maquina se denomina verificacion automatica.Dentro de las tecnicas utilizadas para realizar esta verificacion encontramos la demostracionde teoremas y el chequeo de modelos. En el primero, se toma el sistema y las propiedades
2.1. MODELOS Y METODOS FORMALES EN LA INGENIERIA DE SOFTWARE 17
deseadas y se expresan como formulas a traves de alguna logica matematica, el sistema satisfacela propiedad si una prueba puede ser construida con esta logica. Sin embargo, a pesar de lapotencialidad de esta tecnica, puede tomar demasiado tiempo para adquirir la experticia yestablecer todo el sistema de prueba [12, Pag. 11].
Figura 2.1: Ciclo de vida del software y costos asociados a los erroresFuente [5]
De otro lado, en el chequeo de modelos se construye un modelo finito de un sistema y esverificado contra un conjunto de propiedades deseadas, puede ser mas limitado que la demos-tracion de teoremas pero es mucho mas rapido y puede ser completamente automatizado. Enesencia un modelo es una maquina de estados finita, que puede ser representada en un lenguajede alto nivel que permita su especificacion precisa. Sus propiedades pueden ser especificadas enalguna logica temporal o en terminos de un automata. Desafortunadamente, el modelamientode sistemas complejos como maquinas de estado finito puede acarrear una gran desventajaconocida como la explosion de estados, en donde el numero de estados en el modelo, crece con-siderablemente con respecto al numero de componentes con los cuales se construye el modelo ypor lo tanto su manipulacion puede llegar a ser ineficiente. Por lo tanto, el desafıo principal esencontrar metodos y estructuras de datos que permitan manejar grandes espacios de estados.

18 CAPITULO 2. MARCO REFERENCIAL Y ESTADO DEL ARTE
2.2. Chequeo de modelos y arquitecturas de software
2.2.1. Chequeo de arquitecturas de software
Con el objetivo de encontrar errores en el software en las etapas iniciales del ciclo de vidadel software, y con el fin de que los costos de su reparacion tiendan a disminuir, se establecenherramientas para realizar verificacion de software en la etapa de diseno, especıficamente en laespecificacion de una arquitectura. Uno de los enfoques para realizar pruebas de software en laetapa de diseno es denominado Pruebas basadas en Arquitecturas de Software [13], en dondese utilizan la parte dinamica de la arquitectura para identificar esquemas utiles de interaccionentre los componentes de software y realizar una seleccion de clases de prueba que correspondana comportamientos relevantes de la arquitectura.
Este enfoque recae entonces en la utilizacion de metodos formales para la descripcion dela arquitectura, entre ellos encontramos los Sistemas de Transicion Rotulados que menciona-remos mas adelante [10]. De manera general, un Sistema de Transicion Rotulado provee unadescripcion global y monolıtica del conjunto de todos los posibles comportamientos del sistema,aunque muchas veces este modelo genera demasiada informacion que no puede ser analizada,pues la cantidad de estados del sistema puede crecer considerablemente.
Muchos de los enfoques utilizados para describir y realizar pruebas de software basadas enarquitecturas hacen uso del Lenguaje de Modelado Unificado. Esto debido a la gran versatilidaddel lenguaje, a su amplia y extendida utilizacion en la industria; por lo tanto, muchos de losmecanismos analizados se soportan sobre esta base [5].
2.2.2. Arquitecturas de software y Lenguaje de Modelado Unificado(UML)
Para realizar el modelamiento de arquitecturas de software, es necesario establecer lenguajescon los cuales se pueda describir la parte estatica y dinamica de una arquitectura. Con esteproposito se han creado varios Lenguajes de Descripcion Arquitecturales para proveer estetipo de abstracciones para sistemas grandes y complejos; sin embargo, se han desarrolladobastantes tipos de lenguajes y no se ve muy claro un horizonte de convergencia. Para resolveresto, varias propuestas se han dado a la tarea de basarse en uno de los lenguajes mayormenteutilizados en la industria; es decir, el Lenguaje de Modelado Unificado (UML por sus siglas eningles, www.uml.org) , al ser un lenguaje semiformal, debe ser utilizado con otras herramientasformales que le permitan desarrollar una semantica completa.
Existen en esencia tres enfoques que utilizan UML para realizar el modelamiento de Ar-quitecturas de Software: 1. El lenguaje en sı, 2. El lenguaje junto con restricciones a traves demecanismos de extension (como estereotipos) y 3. Extender el metamodelo UML para soportar

2.2. CHEQUEO DE MODELOS Y ARQUITECTURAS DE SOFTWARE 19
directamente los conceptos arquitecturales necesarios [14]; este esquema puede visualizarse enla Figura 2.2.
La primera opcion presentada presenta como una de sus mayores ventajas la posibilidad demanipulacion rapida y facil de los modelos a traves de las variadas herramientas existentes; sinembargo, no provee los mecanismos para representar caracterısticas y relaciones intrınsecamen-te arquitecturales, dejando por fuera aspectos importantes de una arquitectura de software.
La segunda opcion aprovecha uno de los conceptos fundamentales inherentes a UML queconsiste en la posibilidad de incorporar nuevas capacidades y conceptos sin cambiar el sentidode la semantica o sintaxis original del lenguaje. Esto se realiza utilizando Restricciones, Este-reotipos, Valores etiquetados y Perfiles. Una de las desventajas importantes es que no permitela definicion clara de las fronteras del espacio de modelado.
La tercera opcion, la cual consiste en aumentar el metamodelo, podrıa incorporar todos losconceptos que el diseno de una arquitectura de software pueda necesitar prestando el soportesuficiente. A pesar de esto, no esta considerada como una de las estrategias mas fuertes puessu estandarizacion para este proposito serıa bastante engorrosa abriendo la posibilidad de queno cumpla con la notacion original y no llegue a ser compatible con el desarrollo actual dellenguaje y sus herramientas.
En algunos casos, como se presenta en el caso del calculo ρarq [3], se utiliza el segundoenfoque complementandolo con herramientas formales que brinden una herramienta completapara el modelamiento y chequeo de las propiedades de una arquitectura.
Figura 2.2: Las cuatro capas de la Arquitectura de Metamodelamiento de UMLTomado de: [14]. Pagina 7

20 CAPITULO 2. MARCO REFERENCIAL Y ESTADO DEL ARTE
2.3. Logicas Temporales
2.3.1. Modelado de sistemas y logicas temporales
La correccion funcional es la propiedad de un sistema de computo que permite determinarsi este hace aquello para lo cual ha sido desarrollado.
Para realizar chequeo de correccion funcional de un sistema, es necesario en primer lu-gar, establecer las propiedades que deberıa tener o aquellas consideradas importantes para elanalisis. Posteriormente se debe construir un modelo formal que lo represente y que capturelas propiedades que se desean verificar. De igual forma, se debe establecer un nivel adecuadode abstraccion que permita identificar y modelar estas caracterısticas sin necesidad de incluirdetalles que no sean relevantes para el analisis. Por ejemplo, si se desea modelar un circuitodigital, puede que no sea necesario pensarlo en terminos de voltajes y corrientes sino por el con-trario usar compuertas logicas booleanas. Usualmente los sistemas pueden ser modelados comosistemas transformacionales o sistemas reactivos, pero los procesos concurrentes se modelan atraves de los sistemas reactivos [15].
Conceptualmente los sistemas de computo o programas se dividen en dos, los sistemastransformacionales, que son los mas comunes, cuyo objetivo principal es producir una salidacon su ejecucion y finalmente terminar. De esta forma, estos sistemas pueden verse comofunciones que reciben parametros, los transforman y ofrecen una salida, es decir, tienen unestado inicial y un estado final [12, Pag. 47]. Usualmente se describen a traves de logica deprimer orden. Por otro lado, los sistemas reactivos, no presentan necesariamente un resultadofinal sino que por el contrario, mantienen una interaccion constante con su entorno y algunos deellos podrıan no terminar su ejecucion. No se definen en terminos de estados iniciales y finales,sino en terminos de la evolucion del sistema a traves de diferentes estados, usualmente se usaun modelo basado en logica lineal temporal para describir y especificar su comportamiento[16].
Una de las caracterısticas que se desea capturar de un sistema reactivo, es el estado actual,que es una “instantanea” de los valores de las variables en un momento determinado. De igualforma, cuando se ejecuta una accion que hace evolucionar el sistema de un estado a otro, sepuede definir una transicion, esta transicion se puede describir como el par de estados quedescriben al sistema antes y despues de la accion. Otra caracterıstica que se define es unacomputacion, que corresponde a una secuencia infinita de estados que describe la evolucion delsistema de un estado a otro a traves de varias transiciones.
Asimismo, pueden identificarse los sistemas concurrentes, los cuales se conforman de unconjunto de componentes que pueden ejecutarse juntos y tienen algun mecanismo para co-municarse. Estos mecanismos pueden variar de un sistema a otro pero se pueden considerarprincipalmente dos mecanismos de ejecucion:
Asıncrono o intercalado: Dos o mas componentes ejecutan un paso en un momento de-

2.3. LOGICAS TEMPORALES 21
terminado.
Sincronico: Solamente un componente ejecuta un paso en un momento determinado.
De igual forma, existen dos mecanismos de comunicacion [15, Pag. 17]:
Estado compartido: los componentes se comunican intercambiando valores a traves devariables compartidas.
Intercambio de mensajes: los componentes usan una cola de mensajes o algun tipo deprotocolo de sincronizacion (handshaking).
2.3.2. Generalidades de las logicas temporales
Las logicas temporales se extienden de la logica proposicional y de predicados a travesde modos que hacen referencia al comportamiento infinito de un sistema reactivo, es unaespecializacion de las logicas modales que incluyen terminos y caracterısticas para identificary especificar propiedades relacionadas con estados de un sistema en diferentes instantes detiempo. Es un metodo formal utilizado para describir secuencias de transiciones entre estadosde un sistema reactivo en el sentido de la descripcion del comportamiento deseado u operaciondel sistema, mientras evita mencionar detalles de implementacion. El calificativo de temporal,no hace alusion a “tiempo real” sino a una abstraccion del tiempo que permite la especificacionde un relativo orden de eventos, se puede decir que se trata de una interpretacion discreta deltiempo. Una transicion corresponde al avance de una unidad de tiempo simple, el sistema esobservable en los puntos 0,1,2,..., etc. La aplicacion de este modelo a sistemas computacionalescomplejos es propuesto inicialmente por Pnueli en los anos 70 del siglo veinte[17].
2.3.3. Clasificacion de las logicas temporales
Las logicas lineales temporales pueden dividirse en: proposicionales o de primer orden, glo-bales o composicionales, lineales o ramificadas, basadas en puntos en el tiempo o en intervalosy en tiempo pasado o futuro. A continuacion se describen de manera general cada uno de estosaspectos [18].
2.3.3.1. Proposicional / De primer orden
Proposicional hace referencia a logica clasica, la cual se construye a partir de proposicio-nes atomicas, las cuales expresan hechos subyacentes al estado del sistema, usa tambien los

22 CAPITULO 2. MARCO REFERENCIAL Y ESTADO DEL ARTE
conectores logicos clasicos y adicionalmente los temporales. Sobre estos conceptos se construyela logica de primer orden que incluye variables, constantes, funciones, predicados y cuanti-ficadores. Se pueden distinguir tambien variables locales que pueden tener diferentes valoresen diferentes estados o globales que mantienen su valor independiente del estado en el que seencuentren. Pueden imponerse tambien ciertas restricciones sintacticas sobre los operadorestemporales o los cuantificadores.
2.3.3.2. Global / Composicional
Usar una logica global hace referencia cuando se puede razonar sobre un programa porcompleto, es decir, se puede ver el sistema como un unico programa, tambien denominadocomo endogeno. Si por el contrario, los operadores plantean el analisis sobre distintas partes deun programa, de tal forma que este se puede descomponer y estudiar en partes independientespero posteriormente se puede sacar conclusiones del sistema completo, se dice que es una logicacomposicional o exogena.
2.3.3.3. Lineal / Ramificada
Estas dos visiones consideran la naturaleza del tiempo. Por un lado, lineal quiere decir queen un momento especıfico solo existe un unico momento futuro posible y por lo tanto describeneventos a lo largo de un solo camino y, por otro lado, en la ramificada se entiende que enun momento dado, el tiempo puede dividirse en varios caminos alternativos que representandiferentes posibles futuros.
2.3.3.4. Basadas en puntos en el tiempo / Intervalos
Esta caracterıstica hace referencia a que pueden analizarse en un momento especıfico deltiempo o por el contrario se pueden determinar espacios de tiempo sobre los cuales se puederazonar un programa.
2.3.3.5. Discreta / Continua
El concepto de discreto hace referencia al momento presente que corresponde al estadoactual del sistema y el momento futuro al estado sucesor inmediato. De otro lado, el terminocontinuo, describe una estructura de tiempo real en donde algunos sistemas tienen requeri-mientos mas estrictos de rendimiento.

2.3. LOGICAS TEMPORALES 23
2.3.3.6. De tiempo pasado / De tiempo futuro
Esta caracterıstica esta definida por los operadores que la logica, en su mayorıa se utilizanen tiempo futuro en donde se establece un punto inicial y se evalua el comportamiento haciaadelante y la inclusion de operadores en tiempo pasado no agregan ningun valor adicional; sinembargo, cualquiera de los dos tipos de operadores puede ser utilizado.
La mayorıa de las investigaciones se centran en la utilizacion de logicas, en tiempo futu-ro, discretas, basadas en puntos y combinan la logica de primer orden que incluye la logicaproposicional.
2.3.4. Logica de Arboles de Computo Cerradura (CTL*)
Logica de Arboles de Computo Cerradura (del ingles Computation Tree Logic * - CTL*)es una logica temporal que describe el comportamiento de un sistema a traves de arboles decomputaciones (o computo). La estructura subyacente es un arbol ramificado infinito, el cualdetermina, que un momento especıfico (o nodo dentro del arbol) puede tener varios momentossucesores y un cada uno debe tener al menos un predecesor. Para representar estos sistemasse utilizan estructuras Kripke [15, Pag. 27]. Una estructura Kripke se puede definir como unmodelo formal que representa el comportamiento de un sistema de computo a traves de unconjunto de estados, un conjunto de transiciones entre los estados y una funcion que etiqueta acada estado con un conjunto de propiedades que son ciertas en ese estado. Las rutas o caminosen una estructura modelan una computacion o camino de estados. El modelo tiene la suficientesimpleza para no agregar complejidades innecesarias y la suficiente expresividad para capturaraspectos relacionados con el tiempo, con lo cual, permite razonar sobre los sistemas reactivos.
2.3.4.1. Sintaxis y Semantica
Una formula es un representacion formal a traves de proposiciones y sımbolos definidos porel lenguaje. Las formulas en esta logica pueden clasificarse en dos:
Formulas de estado: aquellas que son ciertas en un estado o momento especıfico y abrenvarios caminos posibles.
Formulas de ruta: aquellas que son ciertas a lo largo de una unica ruta o camino de estados.
Los elementos sintacticos basicos de una formula son:
AP : conjunto de proposiciones atomicas. (a ∈ AP )

24 CAPITULO 2. MARCO REFERENCIAL Y ESTADO DEL ARTE
∧,∨,¬: conectores booleanos. (AND, OR, NOT)
©,⋃: modalidades temporales basicas. (NEXT, UNTIL)
∃, ∀: cuantificadores.
Las proposiciones atomicas son afirmaciones sobre valores de variables de control o valoresde variables de programa. Los conectores logicos son usados de la misma forma que en lalogica proposicional y pueden derivar conectores mas complejos a traves de la definicion deestos primeros, tales como la implicacion o la doble implicacion.
Una formula se representa con la letra ϕ y se define ası:
ϕ ::= true | a | ϕ1 ∧ ϕ2 | ¬ϕ | ©ϕ | ϕ1
⋃ϕ2
donde (a ∈ AP )
De otro lado, las modalidades temporales basicas se describen intuitivamente de la siguienteforma:
©: es un operador prefijo unario que requiere una formula como argumento, en donde©ϕes cierta si ϕ es cierta en el siguiente momento. Puede leerse como “siguiente” del ingles “next”,el sımbolo X tambien puede ser usado para representarlo (Xϕ).
⋃: es un operador infijo binario que requiere dos formulas como argumentos. ϕ1
⋃ϕ2 es
cierta en este momento si existe un paso en el futuro en el que ϕ2 sea cierta y ϕ1 sea cierta entodos los momentos desde el presente hasta que llegue este ultimo. Puede leerse como “hasta”del ingles “until”, el sımbolo U tambien puede ser usado para representarlo (ϕ1Uϕ2).
A partir de las modalidades temporales basicas pueden derivarse las siguientes modalidadesmas complejas:
♦ϕdef= true
⋃ϕ
♦: Es un operador prefijo unario que requiere una formula como argumento, en donde♦ϕ es cierta si existe un momento en el futuro en el que ϕ sea cierta. Puede leerse como“eventualmente”, “en el futuro” o “es posible que”, del ingles “eventually” y tambien se puedeusar el sımbolo F para representarlo (Fϕ).
�ϕdef= ¬♦¬ϕ
�: Es un operador prefijo unario que requiere una formula como argumento, en donde �ϕes cierta si ϕ es cierta en este y todos los momentos futuros. Puede leerse como “siempre”,

2.3. LOGICAS TEMPORALES 25
“globalmente” o “es necesario que” del ingles “globally” y tambien se puede usar el sımbolo Gpara representarlo (Gϕ).
Adicionalmente, existe el operador R denominado “hasta que libera” del ingles “release” yse considera como el dual del operador
⋃.
R: es un operador infijo binario que requiere dos formulas como argumentos. ϕ1Rϕ2escierta si ϕ2 es cierta en el presente y hasta que ϕ1 sea cierta junto con ϕ2. Si ϕ1no llega a serverdadera, quiere decir que ϕ2 sera siempre verdadera y la formula tambien sera cierta.
A traves de la combinacion de los operadores ♦ y �, “eventualmente” y “globalmente”respectivamente, se generan los siguiente operadores compuestos:
�♦ϕ: “infinitamente con frecuencia”, describe la existencia de un momento j en el cual enun momento i > j, la formula ϕ es cierta y esto ocurre periodicamente en el futuro.
♦�ϕ: “eventualmente y para siempre”, desde un momento j la formula ϕ sera cierta desdeese momento en adelante.
Los cuantificadores son utilizados en estados determinados para especificar que las rutasque inician en ese estado, tienen una formula que es cierta.
∃: se lee “para algunas” o “existe al menos una” ruta. Puede usarse tambien el sımbolo E.
∀: se lee “para todas” las rutas. Puede usarse tambien el sımbolo A.
La sintaxis de las formulas esta determinada por las siguientes reglas:
Si p ∈ AP entonces p es una formula de estado.
Si f y g son formulas de estado, entonces ¬f , f ∧ g, f ∨ g son formulas de estado.
Si f es una formula de ruta, entonces E f y Af son formulas de ruta.
Si f es una formula de estado, entonces f es una formula de ruta.
Si f y g son formulas de ruta, entonces ¬f , f ∧ g, f ∨ g, X f , F f , Gf , f⋃g y f R g
son formulas de ruta.
2.3.4.2. Estructuras Kripke
Una estructura Kripke se define de la siguiente manera:

26 CAPITULO 2. MARCO REFERENCIAL Y ESTADO DEL ARTE
Se tiene AP como el conjunto de proposiciones atomicas. Una estructura Kripke M sobreAP es una tupla de 4 elementos
M = (S, S0, R, L)
donde:
S: es el conjunto de estados finitos
S0 : es el conjunto de estados iniciales. S0 ⊆ S
R: es una relacion de transiciones entre estados que debe ser total. Esto quiere decir quepara cada estado s ∈ S hay un estado s′ ∈ S, tal que R(s, s′) y R ⊆ S × S.
L: es una funcion que etiqueta cada estado con el conjunto de proposiciones atomicasverdaderas en ese estado S → 2AP .
Una ruta en M desde un estado s, es una secuencia infinita de estados π = s0s1s2... tal quepara cada i ≥ 0 existe un (si, si+1) ∈ R.
Se usa la notacion πi para denotar que el camino π inicia en el estado si.
Si f es una formula de estado, la notacionM, s |= f significa que f es cierta en el estados en la estructura M .
Si f es una formula de ruta, la notacion M,π |= f es cierta a lo largo del camino π enla estructura M .
Asumiendo que f1, f2 son formulas de estado y, g1, g2 son formulas de ruta:
• M, s |= p ⇐⇒ p ∈ L(s)
• M, s |= ¬f1 ⇐⇒ M, s 2 f1
• M, s |= f1 ∨ f2 ⇐⇒ M, s |= f1 o M, s |= f2
• M, s |= f1 ∧ f2 ⇐⇒ M, s |= f1 y M, s |= f2
• M, s |= E g1 ⇐⇒ hay una ruta π desde s tal que M,π |= g1
• M, s |= Ag1 ⇐⇒ para cada ruta π desde s tal que M,π |= g1
• M,π |= f1 ⇐⇒ s es el primer estado de π y M,π |= f1
• M,π |= ¬g1 ⇐⇒ M,π 2 g1
• M,π |= g1 ∨ g2 ⇐⇒ M,π |= g1o M,π |= g2
• M,π |= g1 ∧ g2 ⇐⇒ M,π |= g1y M,π |= g2

2.3. LOGICAS TEMPORALES 27
• M,π |= X g1 ⇐⇒ M,π1 |= g1
• M,π |= F g1 ⇐⇒ existe un k ≥ 0 tal que M,πk |= g1
• M,π |= Gg1 ⇐⇒ para todos los i ≥ 0 tal que M,πi |= g1
• M,π |= g1⋃
g2 ⇐⇒ existe un k ≥ 0 tal que M,πk |= g2 y para todos los0 ≤ j ≤ k tal queM,πj |= g2
• M,π |= g1Rg2 ⇐⇒ para todos los j ≥ 0, si para cada i < j , M,πi2 g1
entonces M,πj |= g2
La Logica de Arboles de Computo * (CTL*) se divide a su vez en Logica de Arboles deComputo simple (Computation Tree Logic - CTL) y Logica Lineal Temporal (Lineal TemporalLogic - LTL), a continuacion se describen las caracterısticas de cada una.
Las relaciones entre las diferentes logicas se pueden ver clasificadas en el esquema de laFigura 2.3.
Figura 2.3: Relacion entre las logicas temporalesTomado de [19]
2.3.5. Logica de Arboles de Computo Simple (CTL)
Esta logica es un subconjunto de CTL* con la restriccion de que sus formulas deben utili-zar siempre los cuantificadores. Utiliza unicamente formulas de ruta. Existen diez operadoresbasicos:
AX y EX
AF y EF
AG y EG

28 CAPITULO 2. MARCO REFERENCIAL Y ESTADO DEL ARTE
A⋃
y E⋃
AR y ER
Cada uno de estos operadores puede ser expresado en terminos de tres operadores solamente,EX , EG y E
⋃:
AX f = ¬EX(¬f)
EF f = E(True⋃f)
AGf = ¬EF (¬f)
AF f = ¬EG(¬f)
A(f⋃g) ≡ ¬E[¬g
⋃(¬f ∧ ¬g)] ∧ ¬EG¬g
A(f R g) ≡ ¬E(¬f⋃
¬g)]
E(f R g) ≡ ¬A(¬f⋃
¬g)]
Una representacion grafica de algunos de los operadores puede verse en la Figura 2.4. Cadauna de los arboles tiene como nodo inicial el estado s0 .
De igual forma cabe recordar que los operadores logicos implicacion (→) y doble implicacion(↔) se pueden representar a traves de composicion de los otros operadores mas basicos y losoperadores (and) y (or) pueden expresarse en sus opuestos:
p ∧ q = ¬(¬p ∨ ¬q)
p ∨ q = ¬(¬p ∧ ¬q)
p→ q = ¬p ∨ q
p↔ q = (p→ q) ∧ (q → p)

2.3. LOGICAS TEMPORALES 29
Figura 2.4: Representacion grafica de algunos operadores CTLTomado de [15]
2.3.6. Logica Lineal Temporal (LTL)
La Logica Lineal Temporal se construye a partir de la sintaxis y semantica descritas enCTL* con la restriccion que no utiliza cuantificadores, por lo tanto, sus formulas son unicamentede ruta, su representacion no genera una estructura de arbol sino un unico camino. Desde estepunto de vista, un momento en el tiempo tiene un unico sucesor y un unico predecesor.
Esta logica, es utilizada para modelar sistemas sincronicos en los cuales cada componenteactua en un paso a la vez. Esto quiere decir que una transicion corresponde con el avance deuna unidad de tiempo, haciendo referencia a la naturaleza discreta del tiempo; el momentopresente se define como el estado actual y el momento siguiente como al estado sucesor. Sepuede decir que el sistema es observable en los momentos 0,1,2...
Una representacion grafica de algunos estos operadores de la Logica Lineal Temporal sepueden apreciar en la Figura 2.5.

30 CAPITULO 2. MARCO REFERENCIAL Y ESTADO DEL ARTE
Figura 2.5: Representacion grafica de los operadores LTLAdaptada de [15] y [5]
2.3.6.1. Ejemplo: Para ilustrar como se construyen las formulas para una Logica LinealTemporal, se presenta un ejemplo que muestra como se representan algunas propie-dades para un problema de exclusion mutua entre procesos:
Se consideran dos procesos concurrentes P1 y P2. Cada proceso Pi puede estar en una detres fases:
1. En su seccion no crıtica.
2. En espera de entrar a su seccion crıtica.
3. En su seccion crıtica.

2.3. LOGICAS TEMPORALES 31
Primero se definen las proposiciones atomicas que representan las fases de estar o no en laseccion crıtica y estar en estado de espera: criti (proceso i que ejecuta su seccion crıtica) seutilizara para las fases 1 y 3 y waiti(proceso i que espera para la ejecucion de su seccion crıtica)para la fase 2.
Posteriormente se definen cuales son las condiciones que se deben cumplir para que se cum-pla que existe exclusion mutua entre los procesos. Para esto se definen las siguientes propiedadesy se expresan a traves de formulas:
Certeza: Describe que ninguno de los dos procesos entrara en su seccion crıtica.
�[¬crit1 ∨ ¬crit2] = �[¬(crit1 ∧ crit2)]
La formula asegura que “siempre”, al menos uno de sus procesos no esta en la seccioncrıtica, o lo que es lo mismo, que “siempre” ambos procesos no estaran en su seccion crıtica.
Vivacidad: Describe que cada uno de los procesos debe entrar en algun momento y confrecuencia en su seccion crıtica.
�♦(crit1) ∧ �♦(crit2)
En este caso la formula, determina que es obligatorio que cada uno de los procesos ejecutesu seccion crıtica siempre y con cierta regularidad.
Libre de inanicion: Describe que si un proceso entra en su fase de espera en algun momentoposterior debe entrar a su seccion crıtica.
(�♦wait1 → �♦crit1) ∧ (�♦wait2 → �♦crit2)
Tambien se podrıa usar una variable adicional (variable del programa) que represente unsemaforo para describir la exclusion mutua:
�((y = 0) → crit1 ∨ crit2)
La formula indicarıa que si el semaforo y tiene el valor 0, uno de los procesos entrara en suseccion crıtica.

32 CAPITULO 2. MARCO REFERENCIAL Y ESTADO DEL ARTE
2.4. Chequeo de modelos y logicas temporales
2.4.1. Generalidades
Es una tecnica de verificacion de sistemas concurrentes, en el que teniendo un modelodel sistema y la especificacion de una propiedad determinada, se desea evaluar exhaustiva yautomaticamente si el modelo cumple con la propiedad bajo verificacion. El proceso del chequeode modelos se compone de los siguientes elementos[20]:
Modelo: Corresponde al modelo del sistema, es una abstraccion de la estructura y com-portamiento de este.
Especificacion: Corresponde a la caracterizacion formal de la propiedad que se ha de-terminado que debe satisfacer el sistema.
Metodo de verificacion: Corresponde a un algoritmo que define los pasos mediante loscuales se va a establecer si la especificacion de la propiedad es satisfecha por el modelodel sistema.
Estos elementos deben estar representados a traves de un lenguaje o metodo formal que permitacumplir el objetivo.
El problema del chequeo de modelos puede describirse formalmente de la siguiente manera[15]:
Se tienen dos elementos, una estructura KripkeM = (S, R, L) (en algunos casos los estadosiniciales no son de particular interes y pueden ser omitidos de la definicion) que representa elsistema concurrente de estados finitos y una formula en logica temporal f que especifica ciertapropiedad. A partir de estos, se establece que debe encontrarse el conjunto de estados en Sque satisface f , esto se representa de la siguiente forma:
{s ∈ S |M, s |= f}
Los primeros algoritmos para resolver problemas de chequeo de modelos usaban represen-tacion explıcita del modelo a traves de un grafo dirigido en donde los nodos corresponden alos estados en S, los arcos estan dados por la relacion R y las etiquetas asociadas a los nodoscorresponden a la funcion L. Esta representacion es util para entender el problema pero puedellegar a ser compleja de manejar para modelos grandes. Por lo tanto, se han establecido otrosmecanismos para llevar a cabo la verificacion.

2.4. CHEQUEO DE MODELOS Y LOGICAS TEMPORALES 33
2.4.2. Chequeo de modelos CTL
Para realizar el chequeo de modelos de un sistema representado a traves de la logica CTL,se parte de una estructura Kriple M = (S,R, L) y se desea determinar los estados en S quesatisfacen la formula CTL f .
El algoritmo para realizar el chequeo tiene en cuenta lo siguiente:
Se etiqueta cada estado s con el conjunto label(s) de subformulas de f que son ciertas ens. Las subformulas de f son todas aquellas en las que se puede descomponer, por ejemplo: sif = ¬(EF (p ∧EG¬q)) el conjunto completo de las subformulas de f son {p, q,¬q, EG¬q, p ∧EG¬q, EF (p∧EG¬q),¬(EF (p∧EG¬q))}, que como puede notarse incluye a f misma; cuandoel conjunto contiene todas las subformulas de f , esto se conoce como el conjunto potencia.
Inicialmente label(s) y L(s) son iguales (contienen las subformulas atomicas que son ciertasen el estado) y el proceso ocurre a traves de varias etapas, en las que se van agregando lassubformulas al conjunto label(s).
La etapa i = 0, consiste en etiquetar cada estado con las subformulas atomicas que sonciertas en cada estado. En cada i-esima etapa, se procesan los operadores de la subformula dela etapa i− 1. Si esta subformula es verdadera en el estado se agrega al conjunto label(s) delestado.
Cuando el algoritmo termina, se tiene que M, s |= f si y solo sif ∈ label(s).
Previamente se mostro que cualquier formula CTL puede expresarse en terminos de ¬, ∨y los tres operadores temporales EX, EU y EG, por lo tanto, para cada etapa intermedia soloes necesario manejar seis casos dependiendo si la subformula es atomica o tiene una de lassiguientes formas: ¬f1, f1 ∨ f2,EXf1,E[f1Uf2] o EGf1.
2.4.2.1. Algoritmos para Chequeo de modelos
Como se puede ver, el modelo esta representado por el grafo dirigido o segun la estructu-ra Kripke M , la especificacion esta representada por la formula CTL f y el algoritmo paradeterminar si el modelo satisface la especificacion se puede describir de la siguiente forma, lacual es adaptada de[20]. Se tiene S, el conjunto de estados del modelo M y f la propiedad quedebe ser satisfecha, entonces sat(f) es la funcion que determina el conjunto de estados de Mque satisfacen f . Este algoritmo etiqueta cada estado iterativamente hasta encontrar todoslos estados que satisfacen la formula. Se cuenta tambien con L(s) que corresponde al conjuntode subformulas que son verdaderas en el estado s (esto es llamado tambien la etiqueta de s).Los pasos del algoritmo se pueden ver en el Algoritmo 2.1:
El algoritmo 2.1 describe todos los posibles casos que pueden presentarse en un sistema.

34 CAPITULO 2. MARCO REFERENCIAL Y ESTADO DEL ARTE
Algoritmo 2.1 Algoritmo sat(f)
Funcion sat(f)
Inicio Segun sea 1. g es true: retornar S
2. g es false: retornar Ø
3. g es atomica: retornar {s ∈ S | g ∈ L(s)}
4. g es ¬f1 : retornar S − sat(f1)
5. g es f1 ∧ f2 : retornar sat(f1) ∩ sat(f2)
6. g es f1 ∨ f2 : retornar sat(f1) ∪ sat(f2)
7. g es f1 → f2 : retornar sat(¬f1 ∨ f2)
8. g es AX f1 : retornar sat(¬EX ¬f1)
9. g es EX f1 : retornar satEX(f1)
10. g es A(f1 U f2) : retornar sat(¬(E [f2 U (¬f1 ∧ ¬f2)] ∨ EG¬f2))
11. g es E(f1 U f2) : retornar satEU(f1 , f2)
12. g es EF f1 : retornar sat(E (trueU f1))
13. g es EGf1 : retornar sat(¬AF ¬f1))
14. g es AF f1 : retornar satAF (f1)
15. g es AGf1 : retornar sat(¬EF ¬f1)
Fin Segun sea
FinFuente: Adaptado de [20]
Debido que algunas de las verificaciones son mas complejas, se establecen tres funcionesadicionales que se presentan para los operadores EX, EU y AF que corresponden a satEX(f1),satEU(f1 , f2) y satAF (f1) respectivamente, cada uno de estos algoritmos se describe mas ade-lante y se muestran ejemplos para cada uno de ellos.
Para el proceso de etiquetado, se establece que si la formula f es cierta en el estado s, dichaformula es agregada al conjunto de etiquetas representado por label(s). Para algunos casos sedefine un esquema particular para realizar el etiquetado:
Para el caso 3, g es atomica, se etiqueta el estado con cada una de las formulas que seanciertas en dicho estado.
Para el caso 5, g es f1 ∧ f2, se etiqueta el estado con f1 ∧ f2, si f1 y f2 ya estan dentrodel conjunto, de igual forma con el caso 6 el estado es etiquetado con f1 ∨ f2 si cualquiera delos dos estados se encuentra en el conjunto.
Para el caso 9, g es EX f1 algoritmo 2.2, se etiquetan los estados con la formula si uno desus sucesores esta etiquetado con f1; de igual forma para el caso 8, AX f1, se etiquetan losestados con la formula, si todos los sucesores estan etiquetados con f1.

2.4. CHEQUEO DE MODELOS Y LOGICAS TEMPORALES 35
Algoritmo 2.2 Algoritmo satEX(f)
Funcion satEX(f)
local var X , Y
Inicio X := sat(f)
Y := {s ∈ S | s → s′ para algun s′ ∈ X}
retornar Y
FinFuente: Adaptado de [20]
Algoritmo 2.3 Algoritmo satAF (f)
Funcion satAF (f)
local var X,Y
Inicio X := S
Y := sat(f)
Repetir hasta X = Y
X := Y
Y := Y ∪ {s | para todos los s′ con s→ s′ }
Fin Repetir hasta
retornar Y
FinFuente: Adaptado de [20]
Para el caso 14, g es AF f1 algoritmo 2.3, el proceso de etiquetado consiste en dos grandespasos:
1. Si cualquier estado s esta etiquetado con f1, entonces etiquetar el estado tambien conAF f1.
2. Repetir: etiquetar cada estado s con AF f1si todos sus sucesores estan etiquetados conAF f1hasta que ya no haya ningun cambio.
Este procedimiento proviene de la siguiente regla:
AF f1 ≡ f1 ∨ AX AFf1
Para el caso 11, E(f1 U f2) algoritmo 2.4, el proceso de etiquetado tambien es compuesto

36 CAPITULO 2. MARCO REFERENCIAL Y ESTADO DEL ARTE
Algoritmo 2.4 Algoritmo satEU(f1 , f2)
Funcion satEU(f1 , f2)
local var W, X, Y
Inicio W := sat(f1)
X := S
Y := sat(f2)
Repetir hasta X = Y
X := Y
Y := Y ∪ [W ∩ {s | existe s′ tal que s→ s′ y s′ ∈ Y }]
Fin Repetir hasta
retornar Y
Fin
Fuente: Adaptado de [20]
de la siguiente forma:
1. Si cualquier estado s esta etiquetado con f2 entonces etiquetarlo tambien con E(f1 U f2).
2. Repetir: etiquetar cada estado s con E(f1 U f2) si el estado esta etiquetado con f1 y almenos uno de sus sucesores esta etiquetado con E(f1 U f2). Realizar esto hasta que nohayan mas cambios.
Este procedimiento proviene de la siguiente regla:
E(f1 U f2) ≡ f2 ∨ (f1 ∧ EX E(f1 U f2))
Los algoritmos para etiquetar los demas pueden establecerse a partir de los anteriormenteexplicados, pues se componen de elementos ya mencionados.
Despues de realizar el etiquetado para todas las subformulas de g, incluyendo g misma,tenemos como salida los estados en los cuales g se satisface.
La complejidad del algoritmo es lineal y esta dada por:
O(|f |.(|S|+ |R|))
en donde:

2.4. CHEQUEO DE MODELOS Y LOGICAS TEMPORALES 37
|f |: es el numero de conectores en la formula.
|S|: es el numero de estados del modelo
|R|: es el numero de transiciones del modelo
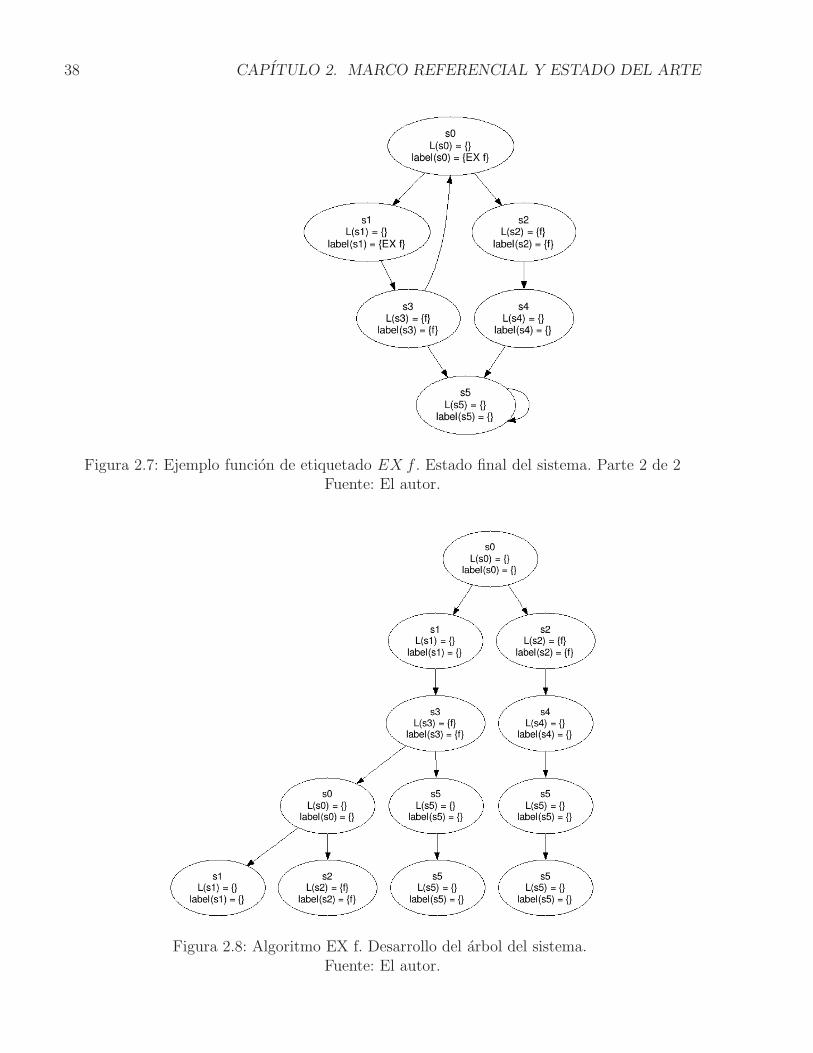
2.4.2.1.1. Ejecucion aplicada de los algoritmos Un ejemplo del procedimiento para laformula EX f se puede ver en las Figura 2.6 y 2.7. En el estado inicial se establece arbitraria-mente que la formula f es verdadera en s2 y s3. Por definicion, los conjuntos label(s) y L(s)son iguales. Posteriormente a la ejecucion del procedimiento de etiquetado, el conjunto label(s)contiene las formulas que son verdaderas en cada estado. Para este ejemplo, los estados quesatisfacen la formula EX f (que corresponde a la que deseamos evaluar), son s0 y s1, es decir,que en estos estados f es cierta en alguno de sus sucesores. Tambien puede verse el desarrollodel arbol que se despliega a partir del estado inicial del sistema en la Figura 2.8.
Figura 2.6: Ejemplo funcion de etiquetado EX f . Estado inicial del sistema. Parte 1 de 2Fuente: El autor.
38 CAPITULO 2. MARCO REFERENCIAL Y ESTADO DEL ARTE
Figura 2.7: Ejemplo funcion de etiquetado EX f . Estado final del sistema. Parte 2 de 2Fuente: El autor.
Figura 2.8: Algoritmo EX f. Desarrollo del arbol del sistema.Fuente: El autor.

2.4. CHEQUEO DE MODELOS Y LOGICAS TEMPORALES 39
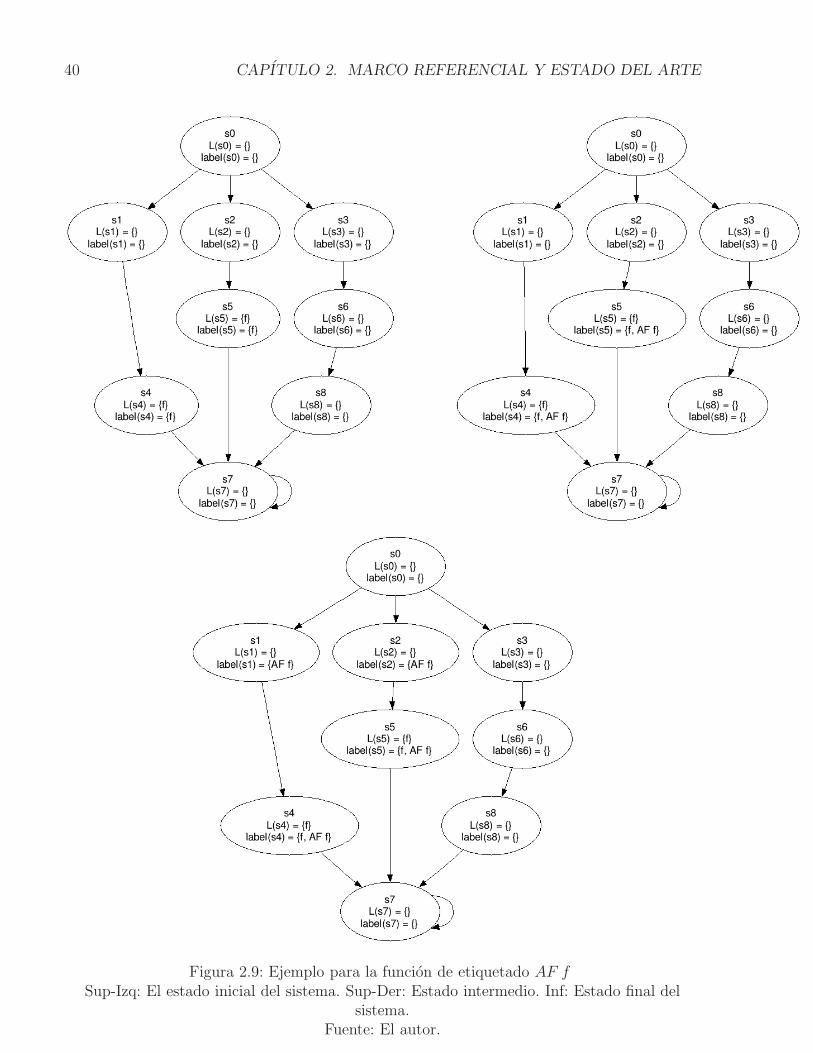
El ejemplo del procedimiento para la formula AF f , se representa a traves de la Figura2.9. Nuevamente, en el estado inicial se establecen arbitrariamente los estados en los que laformula f es verdadera: s4 y s5. En el estado intermedio, segun el algoritmo, se etiquetan conAF f , los estados que tienen f , es decir, s4 y s5 inicialmente. Por ultimo, se evalua en cadauno de los predecesores de estos estados si todos sus sucesores contienen la etiqueta AF f sies cierto, se etiquetan con esta; los nuevos estados que cumplen con la formula son s1 y s2.Despues de esta iteracion, no hay mas predecesores en donde todos sus sucesores contengan laetiqueta AF f , pues en el estado s0 no es posible afirmar esto ya que s3 no esta etiquetado yel algoritmo termina. Finalmente, los estados que satisfacen la formula AF f desde el estados0, son s1,s2,s4,s5, lo cual quiere decir que para todos esos estados en todos los caminos que sedesprenden desde s0, eventualmente f es verdadera.
40 CAPITULO 2. MARCO REFERENCIAL Y ESTADO DEL ARTE
Figura 2.9: Ejemplo para la funcion de etiquetado AF fSup-Izq: El estado inicial del sistema. Sup-Der: Estado intermedio. Inf: Estado final del
sistema.Fuente: El autor.

2.4. CHEQUEO DE MODELOS Y LOGICAS TEMPORALES 41
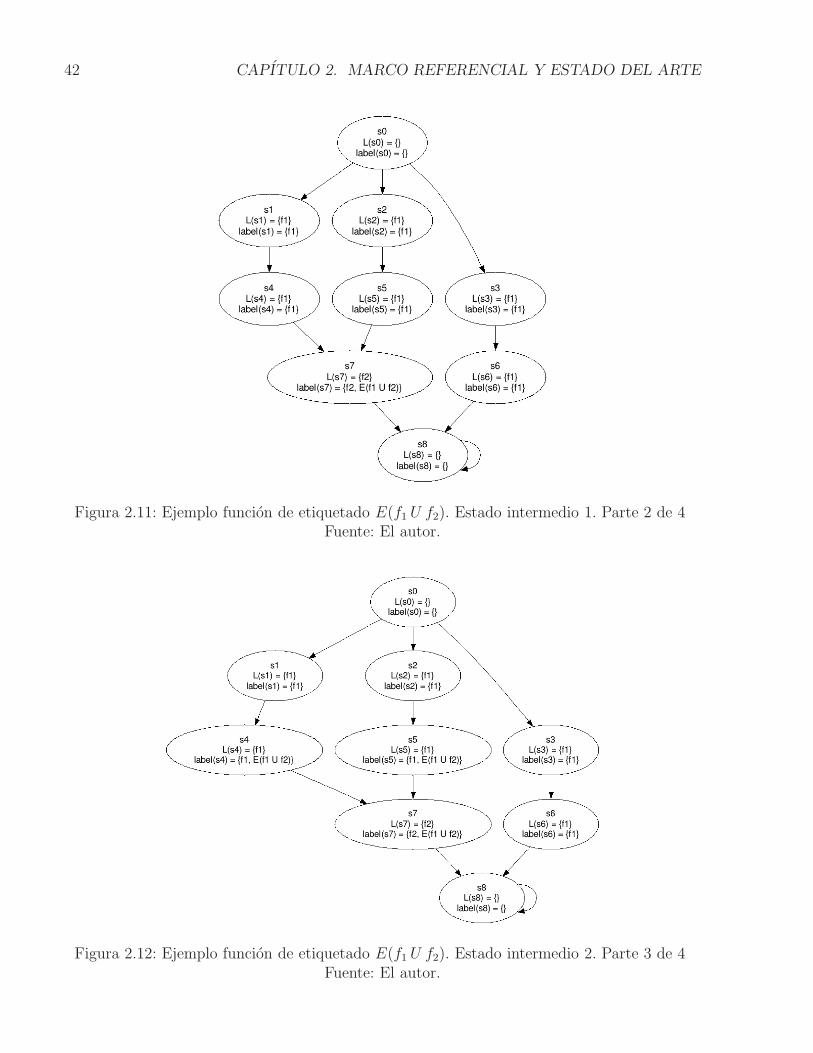
El ejemplo del procedimiento para la formula E(f1 U f2) se puede ver representado en laFiguras 2.10, 2.11, 2.12 y 2.13. Inicialmente se ha establecido que la formula f1 es verdaderaen s1, s2, s3, s4, s5 y s6. De igual forma, la formula f2 es verdadera en s7. De acuerdo con elalgoritmo, si un estado es etiquetado con f2, debe etiquetarse con E(f1 U f2), por lo tanto elestado s7 es etiquetado con esta formula como puede verse en el paso intermedio 1. Posterior-mente, se inicia un ciclo en el que se indica que si un estado esta etiquetado con f1 y al menosuno de sus sucesores con E(f1 U f2), dicho estado debe etiquetarse con la misma formula; en elpaso intermedio 2 puede verse este proceso, en donde, los estados s4 y s5 son etiquetados, esteproceso continua hasta que ya no se cumpla la condicion. En este ejemplo, el proceso terminacuando se llega a los estados s1y s2 que son los ultimos estados que pueden ser etiquetados.Finalmente, los estados que satisfacen la formula E(f1 U f2) son s1, s2, s4, s5 y s7. La formulaindica que f1 sera cierta a traves de las rutas que inician en s1 y s2 y hasta que f2 sea ciertaen s7.
Figura 2.10: Ejemplo funcion de etiquetado E(f1 U f2). Estado inicial del sistema. Parte 1 de4
Fuente: El autor.
42 CAPITULO 2. MARCO REFERENCIAL Y ESTADO DEL ARTE
Figura 2.11: Ejemplo funcion de etiquetado E(f1 U f2). Estado intermedio 1. Parte 2 de 4Fuente: El autor.
Figura 2.12: Ejemplo funcion de etiquetado E(f1 U f2). Estado intermedio 2. Parte 3 de 4Fuente: El autor.

2.4. CHEQUEO DE MODELOS Y LOGICAS TEMPORALES 43
Figura 2.13: Ejemplo funcion de etiquetado E(f1 U f2). Estado final del sistema. Parte 4 de 4Fuente: El autor.
2.4.2.2. Algoritmos alternos para Chequeo de modelos
Los algoritmos alternos para el chequeo de modelos hacen referencia a opciones alterna-tivas para resolver la cuestion de satisfactibilidad de la propiedad en el modelo para algunosoperadores, tales como EG y AG.
Operador EG - Algoritmo alterno 1
En el algoritmo 2.5 aparece un nuevo concepto relacionado con los grafos: ComponenteFuertemente Conectado no trivial (non-trivial Strongly Connected Component (SCC)), estoscomponentes son subgrafos en los cuales desde cualquiera de los nodos que lo componen sepuede llegar a cualquiera de los demas nodos que hacen parte del subgrafo (esencialmentegeneran un ciclo entre ellos mismos), un grafo C es no trivial si y solo si tiene mas de un nodoo contiene un nodo con una transicion a si mismo. Se tiene que S ′, es el conjunto de estadosque estan etiquetados con f , se seleccionan los nodos que hacen parte de los SCC del modeloy se almacenan en T . El procedimiento de etiquetado consiste en marcar los nodos de los SCCya que estan conectados, y por lo tanto existira al menos un camino en el que se podra llegara otro de los estados con la formula EGf . Despues, se ira recorriendo desde cada uno de losnodos de S ′ revisando si tiene como sucesores a alguno de los estados que pertenecen a T (losnodos conectados). Al final se tendran etiquetados los estados que satisfacen la formula EGf .

44 CAPITULO 2. MARCO REFERENCIAL Y ESTADO DEL ARTE
Algoritmo 2.5 Algoritmo alterno para el operador EG
Procedimiento checkEG(f)
Inicio S ′ := {s | f ∈ label(s)}
SCC := {C |C es un SCC de S ′}
T :=⋃
C∈SCC{s | s ∈ C}
Para todo s ∈ T hacer label(s) ∪ {EGf}
Mientras T 6= Ø hacer
seleccionar s ∈ T
T := T − {s}
Para todo t ∈ S ′ y R(t, s) hacer
Si EGf /∈ label(t) entonces
label(t) := label(t) ∪ {EGf}
T := T ∪ {t}
Fin Si
Fin Para
Fin Mientras
Fin Para
Fin
Fuente: Adaptado de [15]
Operador EG - Algoritmo alterno 2
Otra alternativa para el operador EG , es la siguiente:
1. Etiquetar todos los estados con EGf en donde f sea verdadera.
2. Repetir: En los nodos restantes, borrar la etiqueta si ninguno de los sucesores de unestado esta etiquetado con EGf . Terminar cuando no haya ningun cambio.
Puede verse graficamente la ejecucion de un ejemplo en la Figura 2.14. En el estado inicialdel sistema, los estados en los que f es verdadera son s1, s2, s4, s6, s7 y s8. En el siguientepaso, a los nodos que no tienen al menos un sucesor etiquetado con la formula se les remuevela etiqueta, en este caso s2.

2.4. CHEQUEO DE MODELOS Y LOGICAS TEMPORALES 45
Figura 2.14: Representacion grafica del algoritmo para EG alternativoIzq: El estado inicial del sistema. Der: Estado final del sistema.
Fuente: El autor.
Operador AG - Algoritmo alterno 1
Otra alternativa para el operador AG , es la siguiente:
1. Etiquetar todos los estados con AGf en donde f sea verdadera.
2. Repetir: En los nodos restantes, borrar la etiqueta si todos los sucesores de un estado noestan etiquetados con AGf . Terminar cuando no haya ningun cambio.
Puede verse que para el operador AG la formula f debe ser verdadera en todos los estados delmodelo.

46 CAPITULO 2. MARCO REFERENCIAL Y ESTADO DEL ARTE
2.5. Calculo ρarq
El calculoρarq , un lenguaje de descripcion arquitectural con notacion formal para especificarlos aspectos estructurales y dinamicos de arquitecturas de software basadas en componentes[4]. Posee una semantica operacional que le permite representar el cambio de estado de unaarquitectura pasando de una configuracion estatica a una nueva configuracion a traves de lasreglas definidas por el lenguaje. De igual forma, posee una notacion grafica basada en UML 2.xa traves de una extension estereotipada que puede ser traducida al calculo. Basado en el calculoρ, es especificado a traves de tres elementos: expresiones, congruencia estructural y reduccion.En la actualidad se ha desarrollado una aplicacion que permite visualizar la ejecucion de unaarquitectura especificada a traves del calculo. La aplicacion desarrollada recibe un conjunto deformulas especificadas en el calculo y se encarga de la visualizacion de cada una de las etapasde la ejecucion [21].
2.5.1. Sintaxis
El lenguaje se compone de un conjunto de sımbolos y expresiones basadas en las entidadesdel calculo ρ original y adaptando algunas al contexto de las arquitecturas de software [22].
Figura 2.15: Sintaxis del calculo ρarqFuente: [4]

2.5. CALCULO ρARQ 47
Sımbolos y Expresiones
El lenguaje define como sımbolos a las referencias, estas pueden ser variables o nombres.Los nombres (a, b, c) son elementos que pueden ser cargados dentro de las variables (x, y, z). Elsımbolo x define una secuencia de finita de variables (x1, x2, ..., xn). Las variables ligadas deE se representan por BV(E) y las variables libres FV(E). Las primeras representan aquellasvariables que son solo validas en el contexto de E y no pueden ser reemplazadas (o que ya hansido reemplazadas en su contexto y no pueden ser de nuevo reemplazadas), por el contrario laslibres pueden ser sustituidas desde una invocacion externa.
Las expresiones son elementos definidos por el calculo que representan componentes y con-figuraciones arquitecturales que a su vez pueden ser consideradas componentes en si mismas.Se describen algunas de ellas:
Nulo(⊤): es un componente nulo que no ejecuta ninguna accion.
Composicion(E ∧ F ): expresa composicion concurrente entre dos componentes.
Parte interna de E (Eint): representa la parte interna de E, permite establecer la dife-rencia entre E el cual puede conectarse con otros componentes a traves de sus interfacesy Eint que ayuda a determinar si su parte interna fue ejecutada con exito.
Combinador de seleccion condicionada (if (C1)...(Cn) elseG): es la generalizacion de unaexpresion condicional en donde cada elemento (Ck) tiene una condicion de guarda re-presentada por Ck = ∃ ¯x(φk thenEk), si la clausula se cumple, se libera el cuerpo deexpresion definida por Ek, si por el contrario ninguna de las clausulas se cumple, se libe-ra G, que puede ser usado en el calculo para el manejo de fallas. Esta expresion introduceno-determinismo si mas de una clausula es cierta y se libera mas de una expresion.
Abstraccion (x :: y/E): se lee, el componente E con entrada y a lo largo de x. Suinterpretacion establece que el componente recibe una variable x, que reemplaza a y enel componente. Esto es posible solo si x, es libre en E.
Aplicacion (xy/E): se lee, enviar y a lo largo de x y continuar con la ejecucion de E. Seasocia con el envıo de un mensaje a lo largo de un canal asociado a un componente, enel caso que el componente sea nulo (xy/⊤), se puede abreviar con (xy).
Reaccion interna (τ/E): Se lee como la reaccion interna de E cuyo estado observable noes de interes y permite reducir el numero de estados a analizar en la ejecucion de unaconfiguracion.
Declaracion (∃wE): se lee, se introduce una referencia w con alcance E.
Replicacion de abstraccion (x : y/E): se lee, se genera una nueva abstraccion listapara reaccionar y se queda listo para replicar. Esta expresion permite representar laejemplificacion de los componentes. Puede ser expresada tambien de la siguiente formax : y/E ≡ x :: y/E ∧ x : y/E.

48 CAPITULO 2. MARCO REFERENCIAL Y ESTADO DEL ARTE
Ejecucion exitosa / fallida del componente (E⊤, E⊥): representan respectivamente laejecucion exitosa o fallida del componente E.
Observacion de ejecucion (OSO(E) do F elseG): representa la observacion sobre la eje-cucion del componente E, si su ejecucion es exitosa se libera F de lo contrario se liberaG.
2.5.2. Especificacion formal de una arquitectura
La especificacion formal de cada componente se realiza a traves de la descripcion de cadauna de sus interfaces. Se especificara el componente E ilustrado en la Figura 2.16. Esta repre-sentacion se basa en dos fuentes, por un lado, la notacion visual del lenguaje de configuracionDarwin al calculo π y por otro, la notacion grafica de componentes propuesta por UML 2.0. Uncomponente se representa por un rectangulo con el estereotipo <<component>> y el nombredel componente en el centro. Si se desea puede agregarse el ıcono de componente en la margensuperior derecha. Los puertos publicos, son representados a traves de cuadrados que sobresa-len del componente; estos tienen un nombre que usualmente contiene una referencia al tipo deservicio que ofrece y un subındice al componente al que pertenece (p, representa que provee, yr, que requiere).
Las interfaces, se representan con una lınea continua saliendo de un puerto, las que son desalida tienen un circulo cerrado no relleno, se denomina de provision de servicio. Este serviciotiene un nombre identificado con la letra (s) y un subındice asociado al componente al quepertenece, su especificacion formal en el calculo es:
PROVE(p, s)def= pE : x/xsE ≡ pE :: x/xsE ∧ pE : x/xsE
Las interfaces de entrada terminan en un semicırculo abierto y se denominan lugar requi-sitor de servicio o de entrada, en donde la pareja (lE , iE) se interpreta como una ubicacionlE que espera recibir un valor que pueda reemplazar el parametro iE en el componente. Suespecificacion formal es:
REQE(r, l, i)def= ∃lE [(rE :: y/ylE ∧ lE :: iE/E
(int))]
De esta forma, un componente es representado por las interfaces publicas de salida y entradaque lo configuran actuando de forma concurrente, su especificacion es:
Edef= PROVE(p, s) ∧ REQE(r, l, i)

2.5. CALCULO ρARQ 49
Figura 2.16: Representacion grafica de un componenteFuente: [4]
De esta forma, se especifica y representa graficamente un componente y una configuracionarquitectural.
2.5.3. Semantica Operacional y Ejecucion de una arquitectura
El calculo permite modelar el comportamiento de arquitecturas basadas en componentes atraves de su semantica operacional. Por un lado, se utiliza la congruencia estructural (≡) delcalculo ρ, que corresponde a la menor congruencia (menor relacion logica de equivalencia) delos axiomas del calculo y reglas de reduccion que representan esta semantica. Por otro lado,utiliza los sistemas de transicion rotulados para representar la evolucion en la ejecucion de laarquitectura a traves de semantica operacional definida para este fin.
Con respecto a los axiomas que se muestran en la Figura 2.17, se encuentran: Replicacionde observacion, que permite hacer vistas sucesivas de la ejecucion de un componente y, Exi-to/Fracaso Observacional que permite realizar reemplazos en las entradas de un componentey ejecutarlo. Una ejecucion exitosa o no-exitosa puede representarse con (E⊤, E⊥) respectiva-mente.
Figura 2.17: Axiomas del calculo ρarqFuente: [4]

50 CAPITULO 2. MARCO REFERENCIAL Y ESTADO DEL ARTE
Del conjunto de reglas de reduccion, que se muestran en la Figura 2.18, se encuentran:
Aρarq(aplicacion), que ejecuta una combinacion de forma concurrente de una abstrac-cion con una replicacion que ejemplifica una aplicacion. Esta regla modela llamadas deprocedimientos pasando parametros dentro de un componente.
Cρarq(combinacion de restricciones), permite combinar restricciones con el proposito deampliar o simplificar el conjunto de estas restricciones del repositorio.
Comb ρarq , dispara la ejecucion de un Ek si la restriccion de contexto es suficientementefuerte y permite deducir desde φ la guarda ψk del condicional respectivo. Esta regla per-mite escoger un componente Ek dentro de un grupo, siempre y cuando cumpla la guardadefinida. De otro lado, si la restriccion de contexto arquitectural no es lo suficientementefuerte para deducir desde esta alguna de las guardas de las clausulas, se generarıa elcomportamiento alterno del componente F , que podrıa corresponder al manejo de fallaso errores en el sistema.
Ejecτ , esta regla permite establecer la ejecucion de exito o fracaso observacional de uncomponente. Esto se realiza con el proposito de representar un componente como unacaja negra, en donde lo relevante es el comportamiento final de su ejecucion y no elprocesamiento interno del mismo, que no es visible para un observador externo.
Estas reglas, permiten especificar formalmente el avance de la ejecucion de una arquitectura.
Figura 2.18: Reglas de reduccion del ρArq
Fuente: [4]
Una vez se realiza la especificacion de los componentes de una arquitectura, puede esta-blecerse una interaccion entre los mismos, esta interaccion se realiza a traves del ensamblajede las interfaces de entrada y de salida en donde puede ocurrir una ejecucion, un ejemplo deeste ensamblaje puede observarse en la Figura 2.19 y cuya especificacion en el calculo es lasiguiente:

2.5. CALCULO ρARQ 51
Edef= [(pE : x/xsE)] ∧ ∃lE [(rE :: y/ylE) ∧ (lE :: iE/E
(int))]
Fdef= (pF : z/zsF )
El ensamblaje se realiza a traves de un conector, este conector se denomina C y estaidentificado por los componentes que ensambla, es decir:
CEFdef= rEpF
Figura 2.19: Notacion grafica del ensamble de componentesFuente: [4]
La ejecucion concurrente de los componentes con el conector hace que se inicie la ejecucionde la arquitectura y queda especificada de la siguiente forma:
S1 = E ∧ F ∧ CEF = {(pE : x/xsE)] ∧ ∃lE [(rE :: y/ylE) ∧ (lE :: iE/E(int))} ∧ {pF :
z/zsF } ∧ {rEpF}
Esta especificacion junto con las reglas de transicion y el repositorio de restricciones per-miten que la configuracion de la arquitectura avance hacia una nueva configuracion en dondesus componentes interactuan mostrando su evolucion.
Este comportamiento viene especificado por:
S1Aρarq=⇒ (pE : x/xsE) ∧ [sF/iE ]E
(int))
En donde se indica que la ejecucion que lleva el servicio sF a la ubicacion lE que le requiere.

52 CAPITULO 2. MARCO REFERENCIAL Y ESTADO DEL ARTE
La representacion grafica de la ejecucion es simbolizada por un token (punto negro en la Figura2.19).
2.5.4. Sistemas de Transicion Rotulados Condicionados
Otro de los conceptos utilizados en el calculo, son sistemas de transicion rotulados, quese usan para representar la evolucion comportamental del sistema especificado. Este conceptopermite verificar la propiedad de correccion entre una especificacion de un conjunto de arqui-tecturas comunes de comportamiento (modelo de referencia) y una arquitectura de referenciaparticular. El calculo permite la utilizacion de variables logicas en las restricciones de las ar-quitecturas basadas en componentes, esto permite incorporar un modelo de computacion porrestricciones que posee un repositorio (store) que son utilizadas para controlar el flujo de eje-cucion de la arquitectura. Este esquema permite establecer un sistema de transicion rotuladocondicionado con el fin de representar la evolucion en el comportamiento de la arquitectura.Las reglas previamente definidas son las que determinan el momento en el que una nuevaconfiguracion evoluciona hacia una siguiente configuracion.
El sistema de transicion rotulado (STR), establece un elemento basico denominado accion,el cual permite fluir de un estado a otro. Un STR sobre un conjunto de acciones Act, es unpar (Q, T ) se define de la siguiente forma[4]:
Conjunto de estados (Q)
Relacion de Transicion: relacion ternaria T ⊆ (Q × Act×Q)
De igual forma, un STR Condicionado es aquel en el que una accion α ∈ Act, puede ser unarestriccion o guarda booleano y acciones que no sean restricciones pueden estar condicionadasa estos mismo elementos.
Adicionalmente, el calculo establece varias definiciones sobre la relacion entre el calculoρArq y los STR Condicionados con el fin de estructurar el modelo que representara la evolucionen la configuracion de la arquitectura a traves de las reglas. Esta correspondencia se definea traves de los estados en el sistema, en donde estos estados son expresiones arquitecturalesque se reducen de manera concurrente. De esta manera, cuando las expresiones se reducen,la arquitectura pasa de una configuracion a otra a traves de las acciones observables y noobservables. La regla Ejecτ permite modelar en los casos de exito o fracaso observacional en laejecucion de un componente. De igual forma, la expresion OSO (On Success Of) en composicioncon un componente que se ejecuta de forma exitosa se reduce a una expresion arquitectural Fo G que representan los caso de exito o fracaso respectivamente; a traves de este esquema, seespecifica formalmente el avance en la ejecucion de la arquitectura.
Las reglas de transicion del calculo se definen en la Figura 2.20, estas reglas determinan lasacciones posibles en una configuracion, representan el envıo o recepcion de mensajes, activar

2.5. CALCULO ρARQ 53
un conjunto de componentes de acuerdo a las restricciones, ejecucion de los componentes yobservabilidad de la misma de acuerdo a la granularidad necesaria.
Figura 2.20: Reglas de transicion del ρArq
Fuente: [4]
Adicionalmente, el calculo ρArq, define tambien un modelo de congruencia estructural y bi-similaridad con el cual se puede realizar chequeo de correccion. Este modelo permite establecersi una arquitectura de referencia es “correcta” con respecto a su especificacion de alto niveldefinida por un modelo de referencia.

54 CAPITULO 2. MARCO REFERENCIAL Y ESTADO DEL ARTE
2.6. Lenguajes de Descripcion Arquitectural y Logicas
Temporales
Con el proposito de desarrollar grandes sistemas de software que necesita la sociedad ac-tual, se han establecido tambien diversos modelos, tecnicas, metodologıas y tecnologıas, queprocuren desarrollar software complejo y de calidad. Dentro de estas posibilidades se encuentrael desarrollo de software basado en componentes y por supuesto la concepcion de arquitecturasde software basadas en este paradigma[23]. Igualmente, se han desarrollado metodologıas paraarquitecturas basadas en componentes que buscan la reutilizacion de software previamenteconstruido o que pueda servir para este proposito y por lo tanto, reducir el tiempo y/o costosde implementacion de un nuevo sistema, estas metodologıas buscan incorporar de la forma maselegante, software previamente desarrollado con el que esta por construirse[24]. Es por estasrazones que se busca contribuir en el desarrollo de software basado en componentes que puedaser confiable desde el punto de vista formal incluyendo modelos y mecanismos que permitanestablecer y evaluar propiedades que mejoren la calidad de software que se desarrolla.
Las arquitecturas de software emergieron con el proposito de establecer un mecanismo paraentender y caracterizar los sistemas de software a gran escala; de esta forma, se establecıa undiseno de alto nivel del sistema que podıa ser utilizado como base para la implementacion yposterior mantenimiento del sistema, ası como un elemento para la reutilizacion del softwarea grandes niveles[25]. En este sentido, se han desarrollado diferentes tecnicas para describiruna arquitectura de software en diferentes niveles y con diferentes caracterısticas, pero en elpresente trabajo se analizaran aquellas que permitan no solo una descripcion sino tambienpermitan especificar y chequear propiedades temporales.
Los lenguajes de descripcion arquitectural (ADL) utilizan diversos mecanismos para espe-cificar propiedades temporales dentro de los que se identifican LTL (Lineal Temporal Logic),CTL (Computation Tree Logic) y CTL* (Computation Tree Logic star), los lenguajes que per-miten especificar propiedades a traves de LTL son: SAM, CBabel, Æmilia, CHARMY, Bose,Arcade, LfP, Garlan y AutoFOCUS [25].
Uno de estos metodos es Modelo de Arquitectura de Software (Software Architecture Model(SAM)) definido como un marco de trabajo para visualizar, especificar y analizar arquitecturasde software. Este metodo permite modelar una arquitectura de forma jerarquica con lo quepermite modularizar el analisis, esta jerarquıa se conforma de componentes y conectores endonde estos pueden estar constituidos a su vez de otros componentes y conectores, creandode esta forma subarquitecturas, la ejecucion de sus partes se representa a traves de una redde Petri. De otro lado, se establecen las restricciones que debe satisfacer la arquitectura, estasrestricciones se definen basicamente a traves de la logica proposicional y si es necesario utilizala logica temporal para complementarse. Estas restricciones deben ser consistentes en cadauno de los niveles que constituye la arquitectura y subarquitecturas. Adicionalmente, cada uno

2.6. LENGUAJES DE DESCRIPCION ARQUITECTURAL Y LOGICAS TEMPORALES55
de los componentes se puede especificar a traves de una formula temporal que describe sucomportamiento interno, de esta forma, la logica no solo se utiliza para las propiedades quedebe cumplir el sistema sino tambien para representar el comportamiento de un componenteo conector [26, 27]. A traves de este ADL, se especifican los componentes y los conectoresde manera independiente y se permite especificar el comportamiento de cada uno a travesde formulas. La Figura 2.21 muestra la estructura de un sistema Productor-Consumidor y suespecificacion.
../../2015II/Tesis_I/SAMArquitectura.png
Figura 2.21: Representacion grafica de un Sistema Productor-Consumidor en SAMFuente: [28]
El componente Productor se especifica de la siguiente forma:
AG (¬ready − to− produce ∨ AF produced)
El componente Consumidor se especifica de la siguiente forma:
AG (¬ready − to− consume ∨ AF consumed)
El conector (tipo Buffer) se especifica de la siguiente manera:
AG ((empty ∨ full) ∧ (¬(empty ∧ full))
AG (¬produced ∨ AF ready − to− consume)
Adicionalmente, se especifican restricciones globales
AG (¬ready − to− produce ∨ AF consumed)
Primero se verifica cada uno de los componentes y por ultimo la configuracion completa[28].
Por otro lado CBabel es un ADL que provee las primitivas arquitecturales basicas comocomponentes y puertos , adicionalmente provee el concepto de contratos como elementos prin-cipales. Otro aspecto constitutivo de este lenguaje es la logica de reescritura, que es un marcode trabajo que permite la reescritura o reduccion de terminos dentro de una formula para

56 CAPITULO 2. MARCO REFERENCIAL Y ESTADO DEL ARTE
reducir la complejidad en su ejecucion. De manera general, los componentes son representadospor clases, las ejemplificaciones de componentes por objetos, las declaraciones de puertos pormensajes y el estımulo entre puestos por paso de mensajes entre los objetos. Un componentepuede puede ser un modulo o un conector, un modulo es un objeto que envuelve una entidadque realiza una computacion; un conector es un elemento que media la comunicacion entremodulos a traves de un puerto, en donde son solicitados o aprovisionados los servicios. Lacomunicacion se realiza a traves de paso de mensajes. La representacion de una arquitecturabasica Productor-Consumidor se puede visualizar en la Figura 2.22 [29].
../../2015II/Tesis_I/CBABELArq.png
Figura 2.22: Representacion grafica de un Sistema Productor-Consumidor en CBabelFuente: [29]
Los contratos de coordinacion definen la forma mediante la cual un grupo de puertos debeinteractuar: secuencialmente, mutuamente excluyente o a traves de una condicion o guarda.Una aplicacion es un modulo especial que define como se deben ejemplificar los componentes,como deben ser enlazados y las variables de estado que van a compartir. Una vez definidoslos elementos de la arquitectura, son reescritos al sistema Maude que permite su ejecucion atraves de una herramienta computacional orientada a objetos en donde se puede simular sucomportamiento; una vez reescritas se pueden especificar propiedades temporales y validarlasa traves de una de las herramientas implementadas para este fin [30].
En comparacion con SAM, CBabel ofrece un esquema de especificacion y validacion muchomas intuitivo para un disenador pues su estructura se basa en la programacion orientada a ob-jetos, CBabel ofrece un nivel de abstraccion por encima de Maude el cual permite trabajar conun lenguaje que contiene los conceptos y relaciones definidos dentro del area de la arquitecturade software pero que posteriormente a traves de la traduccion verifica propiedades temporalescon una herramienta que soporta estos elementos. Esto puede verse como una facilidad parasu incorporacion en la industria.
Æmilia es un ADL basado en algebras estocasticas de procesos que surge con el proposito deespecificar y verificar propiedades no funcionales de una arquitectura de software, tales como, elrendimiento. Una descripcion en este lenguaje representa un Tipo Arquitectural (ArchitecturalType - AT). Cada AT define un conjunto de Tipos de Elementos Arquitecturales (ArchitecturalElement Types- AET) que permiten modelar los componentes y conectores para estableceruna topologıa o configuracion, una descripcion textual de una arquitectura en este lenguajese puede ver en la Figura 2.23. Toda esta informacion puede ser representada a traves de una

2.6. LENGUAJES DE DESCRIPCION ARQUITECTURAL Y LOGICAS TEMPORALES57
notacion grafica incorporada en su especificacion. Debido que Æmilia esta basado en un algebraestocastica de procesos, sus modelos pueden incorporar logicas modales, en este caso de tipotemporal; de este modo, una arquitectura descrita a traves de este lenguaje puede incluir laespecificacion de propiedades temporales que posteriormente pueden ser verificadas a travesde la herramienta tecnologica desarrollada para este proposito llamada TwoTowers [31, 32].
../../2015II/Tesis_I/AEmilia.png
Figura 2.23: Descripcion textual de una arquitectura en ÆmiliaFuente: [33]
Este lenguaje puede especificar propiedades con los operadores temporales pasados e im-plementa tambien una serie de “constantes” para determinar por ejemplo si la ejecucion deuna arquitectura cae en un abrazo mortal, o un conjunto de funciones con las cuales se puedenconstruir propiedades mas complejas para determinar por ejemplo si la ejecucion es “libre deinanicion” (es decir, todos sus componentes se ejecutan al menos una vez consumiendo losrecursos que necesitan para su correcto funcionamiento). A pesar de que fue disenado paraespecificar propiedades temporales a traves de CTL, tambien permite especificar en LTL.
Otro de los lenguajes es CHARMY, que ha sido desarrollado como un marco de trabajopara ayudar a automatizar el diseno y validacion de una arquitectura de software. Se componede una herramienta grafica basada en UML para realizar el diseno de la arquitectura que pos-teriormente es traducida para validar propiedades que sean especificadas. El comportamientode los componentes de la arquitectura se describen a traves de diagramas de estado que soninterpretados para producir un prototipo expresado en el lenguaje Promela y que podra serejecutado a traves de la herramienta SPIN [34, 35]. Un ejemplo de la transformacion de undiagrama de estados basico a lenguaje Promela puede verse en la Figura 2.24.
../../2015II/Tesis_I/charmy.png
Figura 2.24: Transformacion de diagrama de estados CHARMY a especificacion en PromelaFuente: [34]
La escritura de propiedades temporales a traves de Promela, le permite al lenguaje no solo

58 CAPITULO 2. MARCO REFERENCIAL Y ESTADO DEL ARTE
especificarlas sino tambien prepararlas para ser ejecutadas en la herramienta. Con respectoa los otros lenguajes, CHARMY provee un aspecto importante para la industria y es que,por un lado, utiliza modelos basados en UML para describir la estructura y comportamientode la arquitectura y por otro lado, la traduccion en la que finalmente pueden validarse laspropiedades temporales a traves de SPIN que es una de las herramientas de chequeo de modelosmas utilizadas, por lo que le confiere unas caracterısticas bastante llamativas para disenadoresy arquitectos.
2.7. Tecnologıas para el chequeo de modelos
2.7.1. SPIN
SPIN es el acronimo de Simple Promela Interpreter. Es un verificador de modelos orienta-do a procesos distribuidos, asıncronos y/o concurrentes. La herramienta provee: Una notacionintuitiva basada en esquema de programacion para especificar decisiones de diseno sin am-biguedades y sin necesidad de entrar en detalles de implementacion, esta notacion tambien,posibilita expresar requerimientos generales de “correccion”, ası como una metodologıa paraestablecer la consistencia de los disenos y los requerimientos de correccion. La herramientaposee su propio lenguaje para realizar la especificacion denominado Promela (Process MetaLanguage), el cual permite especificar propiedades en sintaxis de la Logica Lineal Temporal[35][6].
La estructura basica de la ejecucion de una simulacion y verificacion en la herramienta,se ilustra en la Figura 2.25. En primera medida, se escribe la especificacion del sistema enun modelo de alto nivel, para esto se puede utilizar una herramienta grafica (como XSPINo JSPIN); posteriormente, un analizador sintactico verifica que dicha especificacion cumplecon la estructura del lenguaje y las propiedades temporales si las posee (el sistema muestra unreporte con los errores de sintaxis encontrados). Si la especificacion es sintacticamente correcta,se realiza una simulacion para proveer cierta confianza de que la salida corresponde con loesperado por el disenador. Luego, se genera un programa en C, que representa la especificacionde alto nivel, este programa es compilado y ejecutado, si se encuentra algun contra-ejemploa las propiedades especificadas se debe volver a la simulacion con el proposito de encontrar yremover la causa que disparo el contraejemplo[36].
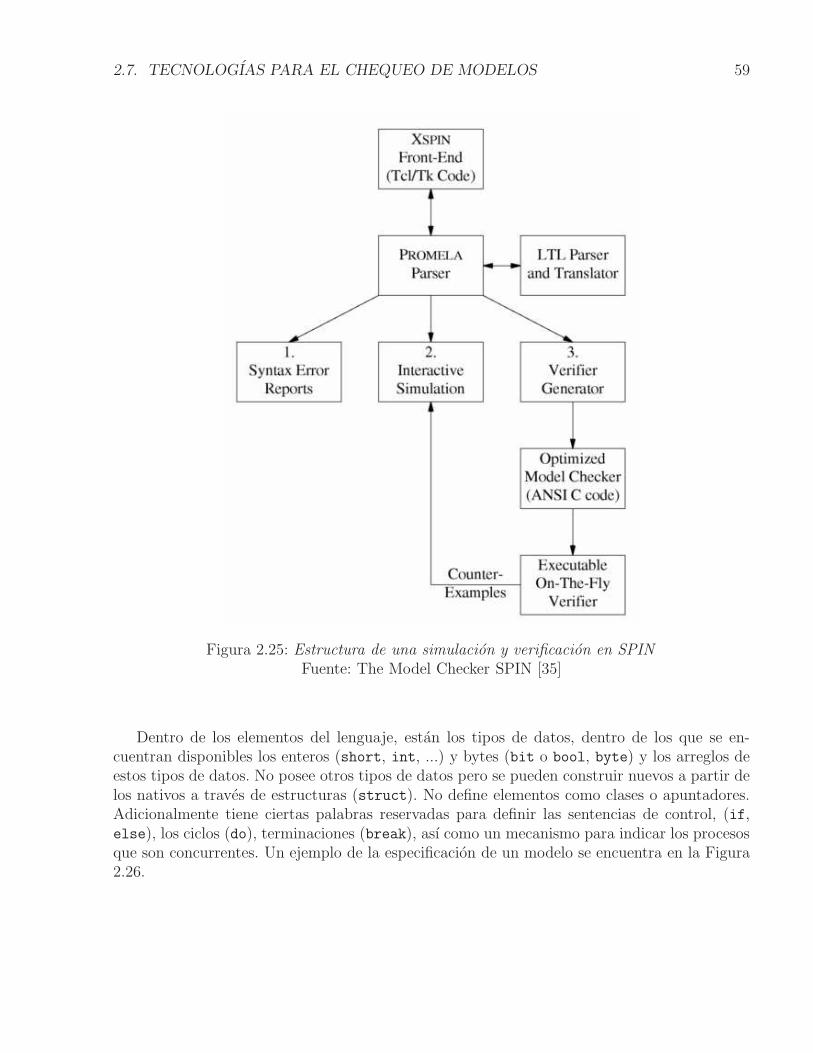
2.7. TECNOLOGIAS PARA EL CHEQUEO DE MODELOS 59
Figura 2.25: Estructura de una simulacion y verificacion en SPINFuente: The Model Checker SPIN [35]
Dentro de los elementos del lenguaje, estan los tipos de datos, dentro de los que se en-cuentran disponibles los enteros (short, int, ...) y bytes (bit o bool, byte) y los arreglos deestos tipos de datos. No posee otros tipos de datos pero se pueden construir nuevos a partir delos nativos a traves de estructuras (struct). No define elementos como clases o apuntadores.Adicionalmente tiene ciertas palabras reservadas para definir las sentencias de control, (if,else), los ciclos (do), terminaciones (break), ası como un mecanismo para indicar los procesosque son concurrentes. Un ejemplo de la especificacion de un modelo se encuentra en la Figura2.26.

60 CAPITULO 2. MARCO REFERENCIAL Y ESTADO DEL ARTE
Figura 2.26: Ejemplo de la especificacion de un modelo a traves del lenguaje PromelaFuente: The Model Checker SPIN [35]
La lınea active [2] proctype P() crea dos procesos, esto permite dinamicamente mode-lar multiples procesos sin necesidad de replicar codigo. El comando do-od representa un cicloy puede tener varias alternativas (en el ejemplo aparecen dos) representadas por los cuatropuntos (::), que son evaluadas de forma excluyente, en donde la ultima de ellas else, es eva-luada si todas las demas son falsas. Cuando se llega a la condicion de salida representada porcounter = 10, la expresion break termina el ciclo.
Por otro lado, en la definicion del proceso WaitForFinish(), la expresion finish == 2;,determina una sentencia de posible bloqueo de la ejecucion, pues determina que hasta que nose cumpla la condicion, el proceso no continuara, esto es conveniente en el programa pues losdos procesos concurrentes pueden modificar el valor de la variable global finish. El propositoen el programa es imprimir el valor de la variable n, solo cuando los dos procesos terminen.
SPIN puede ejecutarse en uno de cuatro modos:
Modo de simulacion aleatoria: Utiliza un generador de numeros aleatorios para resol-ver el no-determinismo asociado a la ejecucion de sistemas concurrentes, especıficamentepara escoger la instruccion debe ser ejecutada y de cual proceso.
Modo de simulacion interactiva: Permite que el usuario seleccione la siguiente ins-truccion que debe ser ejecutada.

2.7. TECNOLOGIAS PARA EL CHEQUEO DE MODELOS 61
Modo de verificacion: El sistema recorre sistematicamente el espacio de estados enbusca de un contraejemplo que no cumpla con la propiedad especificada.
Modo de simulacion guiada: Permite establecer y recrear el camino mediante el cualse encontro un contraejemplo a una propiedad especificada que no fue satisfecha.
Un ejemplo de una propiedad no temporal que puede definirse para el programa puede ser lasiguiente: assert (n >= 10). El sistema se ejecutara y en el momento que encuentre un casoen el que no se cumpla la propiedad indicara al usuario que el modelo no cumple con esta.
2.7.1.1. Logica Temporal en SPIN
La herramienta permite especificar propiedades a traves de formulas de Logica Lineal Tem-poral. Estas formulas son transformadas en automatas de Buchi los cuales son ejecutados enel sistema y se aceptan aquellas ejecuciones que satisfacen la formula especificada.
Una formula f , puede contener un sımbolo proposicional p en conjunto con un operadorunario o binario, booleano o temporal. La construccion gramatical de estas formulas puedeverse en la Figura 2.27. Por ejemplo, la expresion [] (pU q) expresa una propiedad deseada, lacual representa el operador globalmente” o “siempre” de la logica temporal, el cual estableceque p es verdadero hasta que q sea verdadero (indicando que p puede ser o no verdaderodespues de la aparicion de q, pero antes es siempre verdadero) y esto es cierto en todos losestados posibles del sistema.
SPIN usa el metodo de Reduccion de Orden Parcial, para disminuir el numero de estadosalcanzables que deben ser explorados con el fin de completar la verificacion de una propiedad.Este metodo utilizado se basa en la observacion de que la validez de una formula de LogicaLineal Temporal no es sensible al orden en el cual los eventos ejecutados concurrente e indepen-dientemente son intercalados en una busqueda en profundidad. En vez de generar un espaciode estados exhaustivo, que incluye todos los caminos de ejecucion, se genera uno reducidoque contiene clases de secuencias de ejecucion representativas que no son distinguibles de lapropiedad especificada.[? ]

62 CAPITULO 2. MARCO REFERENCIAL Y ESTADO DEL ARTE
Figura 2.27: Construccion gramatica de una formula en LLT en Promela para SPIN.Fuente: [6]

Capıtulo 3
DESARROLLO DE LA SOLUCION
La incorporacion de mecanismos para chequear propiedades temporales al calculo ρarq, tienecomo proposito establecer el proceso mediante el cual se definen y validan las propiedades deun modelo arquitectural especificado a traves del calculo. El proceso del chequeo de modelosse divide en tres etapas [15, 10]: 1) la creacion de un modelo de estados finito del sistema, 2)la definicion de las propiedades y 3) la verificacion del modelo frente a las propiedades. Esteproceso implica que se realice una evaluacion exhaustiva de todos los estados alcanzables delsistema.
Para el proposito arriba enunciado, en este trabajo se define inicialmente la sintaxis ysemantica de los operadores temporales que seran utilizados para la especificacion de las pro-piedades, posteriormente se define el mecanismo mediante el cual se describe una propiedadpara una arquitectura de software especificada a traves del calculo. Mas adelante se toma unconjunto de sistemas de ejemplo que incluyen todos los elementos que provee el calculo y serealiza la validacion de la propiedad conocida como “Vivacidad” (Liveness) a traves de estos.Por ultimo, se implementa este mecanismo en la herramienta PintArq[21].
3.1. Sintaxis y semantica de los operadores temporales
Esta seccion define la sintaxis y semantica que se utilizara para especificar las propiedadestemporales que seran incorporadas a un modelo arquitectural descrito a traves del calculo yesta basado en el trabajo de [20] para especificar las propiedades de un sistema reactivo. Paraespecificar las propiedades en Logica Lineal Temporal (LLT) se debe construir una formulaLLT, estas formulas se componen de proposiciones atomicas representadas como ai ∈ AP endonde se establece ai como una etiqueta de estado (o una letra del alfabeto) en el sistema, losconectores booleanos basicos ∧,∨,¬ (and/y, or/o, not/negacion) y las modalidades temporalesbasicas ©,
⋃(next/siguiente, until/hasta) y ϕ, ϕ1 y ϕ2 que son formulas LLT.
63

64 CAPITULO 3. DESARROLLO DE LA SOLUCION
De esta forma, una formula LLT se puede expresar a traves de la notacion Backus-Naurası:
ϕ ::= true | ai |ϕ1 ∧ ϕ2 | ¬ϕ | © ϕ |ϕ1
⋃ϕ2
3.1.1. Reglas de equivalencia logica
Los conectores logicos compuestos como la implicacion y doble implicacion se puedenexpresar a traves de los operadores basicos (∧, ∨). Asimismo las modalidades temporalescompuestas como ♦(eventually/eventualmente), �(globally/globalmente), ♦�(eventually fo-rever/eventualmente para siempre) y �♦ (infinitely often/infinitamente con frecuencia) sepueden reescribir a traves de los operadores basicos. Estas equivalencias son:
ϕ1 ∨ ϕ2 = ¬(¬ϕ1 ∧ ¬ϕ2) (3.1)
ϕ1 → ϕ2 = ¬ϕ1 ∨ ϕ2 (3.2)
ϕ1 ↔ ϕ2 = (ϕ1 → ϕ2) ∧ (ϕ2 → ϕ1) (3.3)
♦ϕ = true⋃
ϕ (3.4)
�ϕ = ¬♦¬ϕ (3.5)
�♦ϕ = �(true⋃
ϕ) (3.6)
♦�ϕ = true⋃
(�ϕ) (3.7)
3.1.2. Definiciones
Se tienen las siguientes definiciones [20][5]:
AP es el conjunto de proposiciones atomicas del sistema, es decir: AP = {a0, a1, a2, ..., an}

3.1. SINTAXIS Y SEMANTICA DE LOS OPERADORES TEMPORALES 65
P(AP ): Es el conjunto potencia sobre AP (conjunto formado por todos los subconjuntosde AP ), es decir:
P(AP ) = {{}, {a0}, {a1}, {a2}, ..., {an}, ..., {a0, a1}, {a0, a2}, ..., {a0, .., an}...{a1, a2}...}
Una palabra es una secuencia de elementos sobre un conjunto. Por ejemplo: una palabrasobre el conjunto AP serıa: a0a2 o sobre el conjunto P(AP ) serıa: {a0}{a1}{a0, a1}{a2}
APINF : es el conjunto infinito de palabras sobre el conjunto potencia P(AP ). Por ejem-plo:
APINF = {{a0}, {a0}{a1}, {a0}{a1}{a0}, {a0}{a1}{a0, a1}, {a0}{a1}{a0, a1}{a0}{a2}{a0, a2}...}
Una propiedad definida sobre AP es un subconjunto de APINF .
Traces(ai): Es el conjunto de caminos cuyo estado inicial es ai. Traces(ai) ⊆ APINF
Traces(ST ): Es el conjunto de caminos desde los estados iniciales del sistema de transicionSTPA. Traces(ST ) ⊆ APINF
Teniendo en cuenta estas definiciones, un ejemplo especificacion de una propiedad sobre unmodelo puede ser:
a1 es verdadera siempre
Esta propiedad se puede representar a traves de: {A0A1A2...An ∈ APINF | cada Ai contiene{a1}, para este caso, un conjunto de palabras de ejemplo que satisface la propiedad, consisteen: {{a1}, {a1}{a0, a1}, {a1}{a1}{a1, a2}, {a1}{a0, a1, a2}, ...}.
En este sentido, una formula especificada en logica lineal temporal (LLT) describe subcon-juntos de APINF , es decir, dada una formula LLT ϕ, se puede asociar a ella un conjunto depalabras que pueden identificarse con la expresion Words(ϕ) en donde sus elementos corres-ponden a la secuencia de estados alcanzados en cada transicion:
Si ϕ es una formula LLT: ϕ −→Words(ϕ) ⊆ APINF
En donde Words(ϕ) es el conjunto de palabras que satisfacen la formula ϕ: Words(ϕ) ={σ ∈ APINF | σ satisface ϕ}
3.1.3. Reglas de verificacion
Para determinar si una palabra satisface una formula se aplican las siguientes reglas:
Se tiene la palabra σ : Word σ : A0A1A2...An ∈ APINF

66 CAPITULO 3. DESARROLLO DE LA SOLUCION
Toda palabra en APINF satisface true.
Words(true) = APINF (3.8)
σ satisface ai, si ai ∈ A0.
Words(ai) = {A0A1A2... | ai ∈ A0} (3.9)
σ satisface ϕ1 ∧ ϕ2, si σ satisface ϕ1 y σ satisface ϕ2.
Words(ϕ1 ∧ ϕ2) = Words(ϕ1) ∩ Words(ϕ2) (3.10)
σ satisface ϕ1 ∨ ϕ2, si σ satisface ϕ1 o σ satisface ϕ2.
Words(ϕ1 ∨ ϕ2) = Words(ϕ1) ∪ Words(ϕ2) (3.11)
σ satisface ¬ϕ, si σ no satisface ϕ.
Words(¬ϕ) = Words(ϕ)′ (3.12)
σ satisface ©ϕ, si A1A2... satisface ϕ.
Words(©ϕ) = {A0A1A2... |A1, A2 ∈ Words(ϕ)} (3.13)
σ satisface ϕ1
⋃ϕ2, si existe un j tal que AjAj+1... satisfacen ϕ2 y para todos los 0 ≤
i < j AiAi+1... satisfacen ϕ1.
Words(ϕ1
⋃ϕ2) = {A0A1A2... | ∃ j.AjAj+1... ∈ Words(ϕ2) (3.14)
y ∀ 0 ≤ i < j, AiAi+1... ∈ Words(ϕ1)}
σ satisface ♦ϕ = true⋃ϕ, si existe un j tal que AjAj+1... satisface ϕ y para todos los
0 ≤ i < j AiAi+1... satisface true.
Words(♦ϕ) = {A0A1A2... | ∃ j.AjAj+1... ∈ Words(ϕ) (3.15)
para∀ 0 ≤ i < j.AiAi+1... ∈ Words(ϕ)
σ satisface �ϕ = ¬♦¬ϕ, para este caso se descompone en:
1. σ satisface ♦¬ϕ, si existe un j tal que AjAj+1... satisface ¬ϕ
2. σ satisface ¬♦¬ϕ, si σ no satisface ♦¬ϕ.
3. σ satisface ¬♦¬ϕ, si para todos j tal que AjAj+1... satisface ϕ
Words(�ϕ) = {A0A1A2... | ∀ j.AjAj+1... ∈ Words(ϕ) (3.16)
En esta seccion se establecen la sintaxis y semantica de los operadores y reglas que rigen laestructura y el comportamiento de la solucion, esta declaracion permite establecer las basespara especificar una propiedad temporal y su posterior validacion.

3.2. ESPECIFICACION DE UNA PROPIEDAD TEMPORAL 67
3.2. Especificacion de una propiedad temporal
El primer paso es construir un Sistema de Transicion de Proposiciones Atomicas (STPA) querepresenta los estados del sistema. Para esto se debe encontrar la mejor forma para construirel STPA. Para realizar esta actividad se revisaron varios enfoques. Inicialmente se observoque la reduccion de una formula del calculo, en donde se representa el flujo de ejecucion dela arquitectura se realiza a traves de un Sistema de Transicion Rotulado STR (del inglesLabeled Transition System - LTS ) y este modelo podrıa ser utilizado como un insumo para laespecificacion.
Por definicion, una configuracion arquitectural se puede expresar a traves de un conjuntode formulas del calculo y, si existen reglas de reduccion que se cumplan, se inicia la ejecucionde la arquitectura. A medida que el proceso avanza y si aparecen nuevas reglas, el sistema lasva evaluando.
Un ejemplo de la configuracion o ensamblaje de componentes de una arquitectura repre-sentada a traves de UML se ve en la Figura 3.1 y el conjunto de formulas que especifican laarquitectura se define de la siguiente forma:
Edef= [(pE : x/xsE)] ∧ ∃lE [(rE :: y/ylE) ∧ (lE :: iE/E
(int))]
Fdef= (pF : z/zsF ) ∧ (pFe : w/wsFe)
Mdef= ∃lM [(rM :: y/ylM) ∧ (lM :: iM/M
(int))]
Tdef= [(pTe : n/nsTe)] ∧ ∃lT [(rT :: q/qlT ) ∧ (lT :: iT /T
(int))]
CFE = rEpF
CFM = rMpF e
CET = rTpE
CEM = rMpEe
CTM = rMpT e

68 CAPITULO 3. DESARROLLO DE LA SOLUCION
S = [F ∧ OSO(F )doCFE ∧ Eelse ∧ CFM ∧M ] ∧ [OSO(E)doCET ∧ TelseCEM ∧M ] ∧[OSO(T )doTelseCTM ∧M ]
Figura 3.1: Ensamble complejo de componentesFuente: Tomado de [3]
Adicionalmente el STR generado a traves de las reglas de reduccion que representa elflujo de ejecucion se ve en la Figura 3.2. Este flujo de “tokens” o servicios en la arquitectura,representa la dinamica en tiempo de ejecucion de dicha arquitectura. Por ejemplo, al ejecutarseel componente F se provee un servicio que es requerido por el componente E, si a su vez Eesta conectado a otros componentes, el “token” pasa de un componente a otro a medida queinteractuan.
Para especificar una propiedad del sistema a traves de formulas LLT el primer paso esdefinir el conjunto de proposiciones atomicas AP con las que se puede construir una formula.La definicion de estas proposiciones y formulas esta dado por:
1. La regla de ejecucion de un componente (Ejecτ ) que genera los posibles estados: fracasoo exito en la ejecucion de un componente (E⊤ y E⊥ respectivamente).

3.2. ESPECIFICACION DE UNA PROPIEDAD TEMPORAL 69
2. La ejecucion de la regla de aplicacion (Aρarq) que corresponde a la interaccion entre doscomponentes (que se encuentran en posicion de enviar y recibir mensajes - un componenterequiere un servicio que otro puede proveer).
3. La ejecucion de la regla de seleccion (Combρarq) que corresponde a la seleccion de unaejecucion de acuerdo a una condicion global de la arquitectura.
Figura 3.2: Vista parcial del STRFuente: Tomado de [4]

70 CAPITULO 3. DESARROLLO DE LA SOLUCION
De esta manera, el conjunto de proposiciones atomicas se enmarcan dentro de las reglasde reduccion propuestas por el calculo y a partir de estas, se pueden definir las formulas quedescriben las propiedades de una arquitectura de software a traves de LLT.
Para la arquitectura anterior se establece el siguiente STPA sobre el cual se pueden definirlas propiedades; este modelo representa las proposiciones atomicas que se satisfacen durantela ejecucion de la arquitectura (STPA). Una representacion grafica del STPA se representa enla Figura 3.3.
Este ejemplo muestra la ejecucion secuencial del proceso cuyos componentes no realizanejecuciones adicionales, en este sentido los estados finales son: 1) la ejecucion exitosa de T(T⊤), 2) la ejecucion exitosa de M (M⊤) y 3) la ejecucion no exitosa de M (M⊥).
Este primer enfoque establece algunas de las caracterısticas para definir el STPA pero tieneuna desventaja y es que depende de la ejecucion de la arquitectura para capturar los estados.Esto tiene dos inconvenientes, por un lado, se tendrıan que evaluar todos los caminos paratener el conjunto completo de estados y por otro lado, el STR es un grafo infinito, y por lotanto evaluar todos los posibles caminos serıa muy costoso. Por otro lado, si el estado inicialdel sistema no conlleva a desarrollar todos los posibles caminos, existe la posibilidad de nocapturar todos los estados posibles del STPA.
Otro de los enfoques analizados consiste en construir el STPA a traves de la definicion dela arquitectura, es decir, que se construya a partir de la especificacion de los componentes, lasconexiones y las reglas de ejecucion de la formula provista por el calculo ρarq. Este enfoquepermite establecer desde la definicion de la arquitectura todos los posibles estados y las posiblestransiciones entre ellos sin depender de la ejecucion de la misma ni de las condiciones inicia-les. Adicionalmente, tambien se pueden simplificar las interacciones reduciendo los nodos querepresentan la comunicacion entre los componentes y por tanto reducir el numero de estadosposible por evaluar.
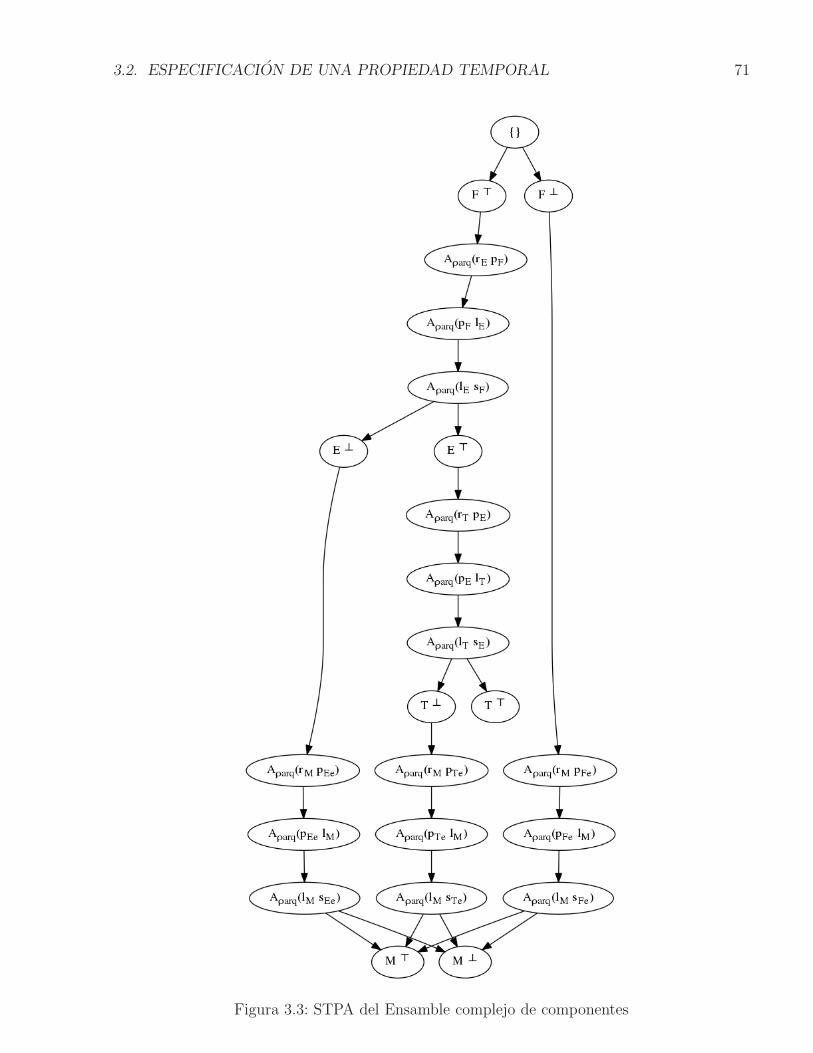
3.2. ESPECIFICACION DE UNA PROPIEDAD TEMPORAL 71
Figura 3.3: STPA del Ensamble complejo de componentes

72 CAPITULO 3. DESARROLLO DE LA SOLUCION
El primer paso es identificar los componentes fuente, pues estos son los unicos que puedeniniciar la ejecucion. Cada componente dentro del modelo representa un estado: su ejecucion(por ejemplo E); las transiciones que puede tomar representan su ejecucion exitosa o ejecucionde fracaso (por ejemplo, E⊤ y E⊥ respectivamente), este comportamiento se ilustra en laFigura 3.4.
Figura 3.4: Ejemplo de representacion de la ejecucion de un componente en el STPA
El segundo paso consiste en obtener las transiciones entre estados, es decir, capturar elcomportamiento del sistema a traves de la evaluacion de las reglas de observacion dispuestasen la formula; una regla de observacion se escribe de la siguiente forma OSO(F ) do [CFE ∧E] else [CFM ∧M ]. A partir de esta regla se pueden construir los enlaces entre los estados, eneste caso si F se ejecuta correctamente se comunica con E de lo contrario se conecta con M .Con la aparicion de nuevos componentes se realiza con ellos el primer paso y se va desarrollandoel STPA hasta que ya no hayan mas componentes por analizar.
Por ultimo, cuando se llega a los estados finales (componentes sumidero) en los que se indicaun estado global del sistema, se procede a establecer si el sistema en su conjunto se ejecutoo no exitosamente. Este estado solo se puede obtener de los nodos terminales cuya ejecucionrepresenta uno de los dos estados finales de exito o fracaso global (exito o fracaso). Al llegar auno de estos estados se conecta nuevamente con los nodos que representan a los componentesfuente para que se pueda evaluar nuevamente otra ejecucion. (Figura 3.5).
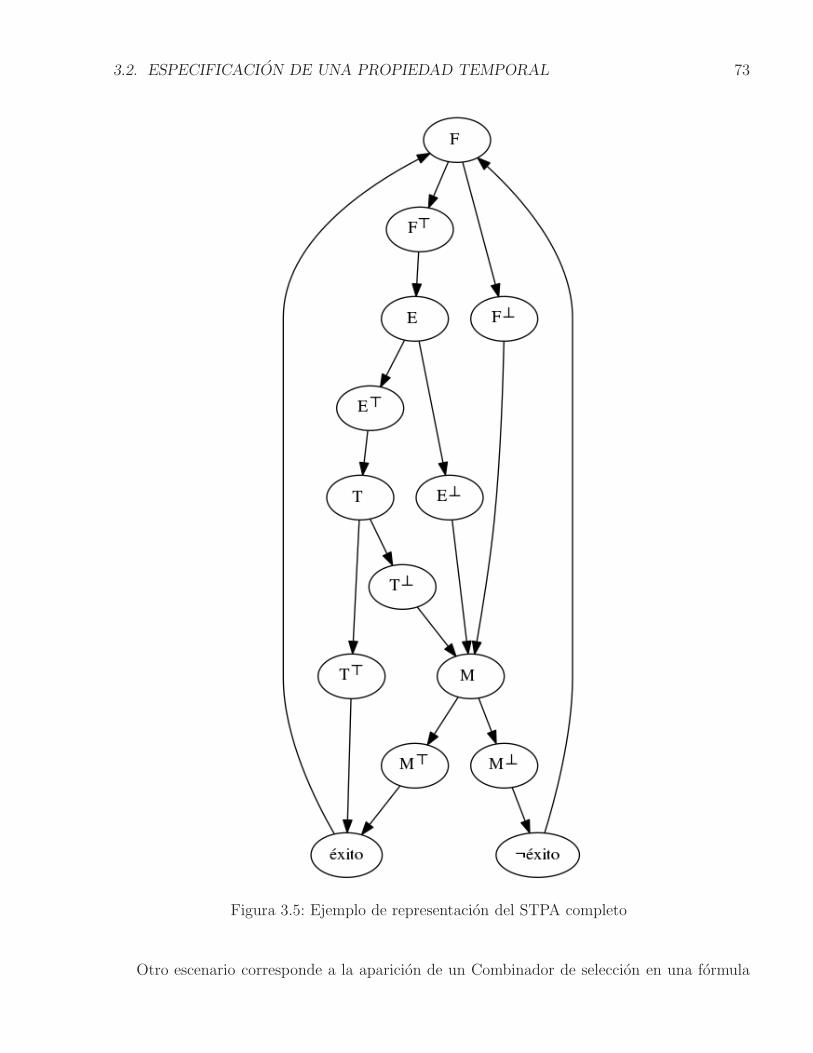
3.2. ESPECIFICACION DE UNA PROPIEDAD TEMPORAL 73
Figura 3.5: Ejemplo de representacion del STPA completo
Otro escenario corresponde a la aparicion de un Combinador de seleccion en una formula

74 CAPITULO 3. DESARROLLO DE LA SOLUCION
del calculo que corresponde a una configuracion con componentes alternativos para proveerservicios (Figura 3.6).
Figura 3.6: Configuracion con componentes alternativos para proveer serviciosFuente: Tomado de [4]
Este sistema se representa en el calculo a traves de las siguientes expresiones:
Sdef= (pS : z/zsS)
Ndef= (pN : x/xsN)
Mdef= ∃lM [(rM :: y/ylM) ∧ (lM :: iM/M
(int))]
Adef= [(pAe : n/nsAe)] ∧ ∃lT [(rA :: q/qlA) ∧ (lA :: iA/A
(int))]
CAM = rMpAe
CNA = rApN
CSA = rApS

3.2. ESPECIFICACION DE UNA PROPIEDAD TEMPORAL 75
En este mismo sentido, la expresion en el calculo que muestra que A sea un componentefuente que reemplaza el parametro de entrada i por d y que cada componente alternativo sepuede ejecutar exitosamente, es:
Sdef= [d/i]A ∧OSO(A) do{if ∃X((X = pS) then {S
⊤ ∧OSO(S)do[rApS ∧ S]
else [ManejarErrorDeS]}), ...,
(X = pN) then {N⊤ ∧ OSO(N) do [rApN ∧N ] else [ManejarErrorDeN ]})
else [rMpAe ∧M ] ∧ A}
Para obtener el STPA de esta configuracion y siguiendo el procedimiento establecido pre-viamente, se obtiene el modelo de la Figura 3.7.
Figura 3.7: STPA para una Configuracion con componentes alternativos
Esta configuracion puede causar no determinismo si la condicion X puede evaluarse ver-dadera para la ejecucion de varios componentes concurrentemente. Para evitar este compor-tamiento, puede establecerse una polıtica de ejecucion que lo elimine, para este proyecto, lapolıtica es ejecutar el componente que satisfaga la primera condicion en ser evaluada comoverdadera).
Este STPA se enmarca dentro del enfoque denominado “sistema basado en estados” quetiene dos caracterısticas: no se utilizan nombres en las transiciones (para el modelamiento delsistema no son necesarias) y se centra en las proposiciones atomicas que se satisfacen en cada

76 CAPITULO 3. DESARROLLO DE LA SOLUCION
estado. De esta forma, las etiquetas que marcan cada estado (L(s)) se elaboran a partir de APhaciendo (L(s) = {s} ∩ AP ) en donde s es cada uno de los estados del sistema [5, pags. 22 y24].
A partir del STPA definido se pueden especificar propiedades temporales. Las propiedadesatomicas se conforman por los estados del sistema y se utilizan los operadores definidos paraeste fin. Para ilustrar este procedimiento y teniendo en cuenta el STPA del primer ejemplo, sepuede especificar una propiedad con la cual se pretende verificar si es satisfecha por el sistema.Por ejemplo:
ϕ = F → ♦(T⊤ ∨M⊤)
Esta propiedad define que si F se ejecuta, eventualmente en el futuro M o T se ejecutarancorrectamente .
En esta seccion se determino la forma mediante el cual se especifica una propiedad temporalpara una arquitectura de software representada a traves del calculo ρarq, en la siguiente seccionse describe el mecanismo mediante el cual se valida una propiedad (la propiedad de vivacidad)para una arquitectura.
3.3. Verificacion de una propiedad temporal
Una propiedad temporal especifica los caminos (o secuencias de estados) que un sistemade transicion deberıa exponer (estados que sean observables); estas propiedades especifican elcomportamiento deseado o admisible que se espera de un sistema.
Formalmente, una propiedad P es un subconjunto de APINF donde AP es el conjunto deproposiciones atomicas y APINF (o tambien conocido con la notacion P(AP )ω) representa elconjunto de palabras que provienen de la concatenacion infinita de palabras en P(AP ) (elconjunto potencia de AP ). Por lo tanto, una propiedad es un conjunto infinito de palabrassobre P(AP ) [5] o visto de otra forma, si la ejecucion de un programa es una secuencia infinitade estados σ, se dice que la propiedad P es cierta en σ si el conjunto de secuencias definidopor el programa esta contenido en la propiedad P [37].
Una de es estas propiedades es la vivacidad (liveness). Esta propiedad intuitivamente afirmaque “algo bueno” eventualmente ocurrira o tambien que un programa eventualmente llegara aun estado deseado [38, 39, 40]. Especıficamente, la propiedad de vivacidad se ve reflejada enuno de los siguientes comportamientos:
Libre de inanicion (Starvation freedom): Un proceso “progresa” con cierta regularidad, seejecuta infinitamente con determinada frecuencia (avanza en su ejecucion).

3.3. VERIFICACION DE UNA PROPIEDAD TEMPORAL 77
Terminacion (Termination): Un programa nunca se ejecuta para siempre, llega a un estadodenominado final (inicia y eventualmente termina).
Servicio garantizado / Capacidad de respuesta (Guaranteed service / Responsiveness): Si serealiza una solicitud de servicio, eventualmente el servicio sera ejecutado; un mensaje eventual-mente llegara a su destino, o tambien un proceso eventualmente ejecutara su seccion crıtica.
La propiedad de vivacidad determina que un proceso siempre avanza pero se denominaque tiene una ejecucion parcial pues no puede asegurar que “algo malo” no ocurra, de esto seencarga la propiedad de fiabilidad (safety).
Formalmente la propiedad de vivacidad de describe ası [37]:
∀α : α ∈ S∗ : (∃β : β ∈ Sω : αβ |= P )
Una ejecucion parcial α “esta viva” para una propiedad P si y solo si existe una secuenciaβ tal que αβ |= P .
En donde S, es el conjunto de estados, Sω es el conjunto infinito de secuencias de estados yS∗ el conjunto finito de secuencias de estados. La ejecucion de un programa se puede modelarcomo un miembro de Sω y una ejecucion parcial es un elemento de S∗.
Para la verificacion de propiedades temporales se propone la propiedad de vivacidad es-pecıficamente para el aspecto de “Capacidad de respuesta”. Para llegar a la validacion de estapropiedad se procede a verificar desde el caso mas simple hasta llegar al caso mas complejo.
Para el caso de ϕ = F⊤ → ♦M⊤
Se tienen por definicion los siguientes conjuntos
AP = {F, F⊤, F⊥, E, E⊤, E⊥, T, T⊤, T⊥,M,M⊤,M⊥, exito, fracaso}
APINF = {{}, {F}, {F⊤}, {F⊥}, {E}, {E⊤}, {E⊥}, {T}, {T⊤}, {T⊥},
{M}, {M⊤}, {M⊥}, {F}{F⊤}, {F}{F⊥}, {F}{F⊤}{E}, ...}
Para que el sistema cumpla la formula debe suceder que:
Words(ϕ) = Words(F⊤ → ♦M⊤) y que Traces(TS) ∩ Words(ϕ)
Se va a analizar la primera parte:
Aplicando las reglas de composicion, la formula se puede expresar en subformulas quepueden ser evaluadas en la siguiente secuencia:

78 CAPITULO 3. DESARROLLO DE LA SOLUCION
Words(ϕ) = Words(F⊤ → ♦M⊤) se aplica 3.2
Words(ϕ) = Words(¬F⊤ ∨ ♦M⊤) se aplica 3.11
Words(ϕ) = Words(¬F⊤) ∪ Words(♦M⊤) se aplica 3.12
Words(ϕ) = Words(F⊤)′ ∪ Words(♦M⊤) se aplica 3.4
Words(ϕ) = Words(F⊤)′ ∪ Words(true⋃M⊤) se describe por extension el conjunto del
primer termino
Words(ϕ) = {{F}, {F}{F⊥}, {F}{F⊥}{M}, {F}{F⊥}{M}{M⊤},
{F}{F⊥}{M}{M⊤}{exito}, {F}{F⊥}{M}{M⊥},
{F}{F⊥}{M}{M⊥}{¬exito}} ∪ Words(true⋃M⊤) se aplica 3.14
...
El proceso continua recursivamente hasta que se encuentran los conjuntos de secuencias deestados (palabras) que satisfacen la propiedad especificada.
Asimismo se deben filtrar las secuencias que deben estar enmarcadas dentro del conjunto deposibles caminos que ofrece el STPA, por tanto se debe satisfacer que Traces(TS) ∩Words(ϕ),en donde Traces(TS) es el conjunto de posibles caminos del sistema de transicion (que estadeterminados por los estados iniciales del sistema); de esta forma solo se filtran los caminosque hacen cierta la propiedad temporal para el STPA con las rutas que comienzan con losestados iniciales establecidos. La Figura 3.8 ilustra la relacion entre estos elementos a travesde un diagrama de Venn; la interserccion representa los elementos que satisfacen la propiedad.
Figura 3.8: Relacion entre Traces(TS) y Words(ϕ)Fuente [20]

3.3. VERIFICACION DE UNA PROPIEDAD TEMPORAL 79
En este sistema, intuitivamente se puede ver que hay caminos que conllevan a la ejecucioncorrecta deM (M⊤) como la secuencia: {F}{F⊤}{E}{E⊤}{T}{T⊥}{M}{M⊤} y por lo tantola propiedad es satisfecha por el sistema.
Por otro lado, una propiedad que el sistema no satisface es la siguiente
ϕ =!(F → ♦no− exito)
pues como puede identificarse en el grafo no todos los caminos conducen a la ejecucioncorrecta de del sistema y existe al menos un camino que fluye hacia un estado no deseado defracaso.
Otra propiedad que el sistema satisface es la siguiente: ϕ = F → ♦(M⊤ ∨ M⊥ ∨ T⊤),una propiedad de este tipo quiere asegurar que eventualmente el sistema da una respuesta alusuario independiente del camino que tome.
El desarrollo completo es el siguiente:
Words(ϕ) =Words(F → ♦[M⊤ ∨M⊥ ∨ T⊤]) se aplica 3.2
Words(ϕ) =Words(¬F ∨ ♦[M⊤ ∨M⊥ ∨ T⊤]) se aplica 3.11
Words(ϕ) =Words(¬F ) ∪ Words(♦[M⊤ ∨M⊥ ∨ T⊤]) se aplica 3.12
Words(ϕ) =Words(F )′ ∪ Words(♦[M⊤ ∨M⊥ ∨ T⊤]) se aplica 3.4
Words(ϕ) =Words(F )′ ∪ Words(true⋃[M⊤ ∨M⊥ ∨ T⊤]) se aplica 3.14
Words(ϕ) =Words(F )′ ∪ Words(M⊤ ∨M⊥ ∨ T⊤) se aplica 3.11
Words(ϕ) =Words(F )′∪Words(M⊤)∪Words(M⊥) ∪ Words(T⊤) se describe por ex-tension el conjunto del termino Words(F )′
Words(ϕ) = {{F}, {F}{F⊥}, {F}{F⊥}{M}, {F}{F⊥}{M}{M⊤},
{F}{F⊥}{M}{M⊤}{exito}, {F}{F⊥}{M}{M⊥},
{F}{F⊥}{M}{M⊥}{¬exito}, {E}, {E}{E⊥}, {E}{E⊥}{M},
{E}{E⊥}{M}{M⊤}, {E}{E⊥}{M}{M⊤}{exito}, {E}{E⊥}{M}{M⊥}
{E}{E⊥}{M}{M⊥}{¬exito}, {E}{E⊤}, {E}{E⊤}{T},
{E}{E⊤}{T}{T⊤}, {E}{E⊤}{T}{T⊤}{exito}, {E}{E⊤}{T}{T⊥},
{E}{E⊤}{T}{T⊥}{M}, {E}{E⊤}{T}{T⊥}{M}{M⊤},
{E}{E⊤}{T}{T⊥}{M}{M⊤}{exito}, {E}{E⊤}{T}{T⊥}{M}{M⊥},
{E}{E⊤}{T}{T⊥}{M}{M⊥}{¬exito}}∪Words(M⊤) ∪ Words(M⊥) ∪ Words(T⊤)
se describe por extension el conjunto del termino Words(M⊤)

80 CAPITULO 3. DESARROLLO DE LA SOLUCION
Words(ϕ) = {{F}, {F}{F⊥}, {F}{F⊥}{M}, {F}{F⊥}{M}{M⊤},
{F}{F⊥}{M}{M⊤}{exito}, {F}{F⊥}{M}{M⊥},
{F}{F⊥}{M}{M⊥}{¬exito}, {E}, {E}{E⊥}, {E}{E⊥}{M},
{E}{E⊥}{M}{M⊤}, {E}{E⊥}{M}{M⊤}{exito}, {E}{E⊥}{M}{M⊥}
{E}{E⊥}{M}{M⊥}{¬exito}, {E}{E⊤}, {E}{E⊤}{T},
{E}{E⊤}{T}{T⊤}, {E}{E⊤}{T}{T⊤}{exito}, {E}{E⊤}{T}{T⊥},
{E}{E⊤}{T}{T⊥}{M}, {E}{E⊤}{T}{T⊥}{M}{M⊤},
{E}{E⊤}{T}{T⊥}{M}{M⊤}{exito}, {E}{E⊤}{T}{T⊥}{M}{M⊥},
{E}{E⊤}{T}{T⊥}{M}{M⊥}{¬exito}} ∪ {{M⊤}, {M⊤}{exito}}
∪Words(M⊥)∪Words(T⊤) se describe por extension el conjunto del terminoWords(M⊥)
Words(ϕ) = {{F}, {F}{F⊥}, {F}{F⊥}{M}, {F}{F⊥}{M}{M⊤},
{F}{F⊥}{M}{M⊤}{exito}, {F}{F⊥}{M}{M⊥},
{F}{F⊥}{M}{M⊥}{¬exito}, {E}, {E}{E⊥}, {E}{E⊥}{M},
{E}{E⊥}{M}{M⊤}, {E}{E⊥}{M}{M⊤}{exito}, {E}{E⊥}{M}{M⊥}
{E}{E⊥}{M}{M⊥}{¬exito}, {E}{E⊤}, {E}{E⊤}{T},
{E}{E⊤}{T}{T⊤}, {E}{E⊤}{T}{T⊤}{exito}, {E}{E⊤}{T}{T⊥},
{E}{E⊤}{T}{T⊥}{M}, {E}{E⊤}{T}{T⊥}{M}{M⊤},
{E}{E⊤}{T}{T⊥}{M}{M⊤}{exito}, {E}{E⊤}{T}{T⊥}{M}{M⊥},
{E}{E⊤}{T}{T⊥}{M}{M⊥}{¬exito}, {M⊤}, {M⊤}{exito}}
∪ {{M⊥}, {M⊥}{¬exito}}∪Words(T⊤) se describe por extension el conjunto del terminoWords(T⊤)
Words(F⊤ → ♦(M⊤ ∨M⊥ ∨ T⊤)) = {{F}, {F}{F⊥}, {F}{F⊥}{M},
{F}{F⊥}{M}{M⊤}, {F}{F⊥}{M}{M⊤}{exito}, {F}{F⊥}{M}{M⊥},
{F}{F⊥}{M}{M⊥}{¬exito}, {E}, {E}{E⊥}, {E}{E⊥}{M},
{E}{E⊥}{M}{M⊤}, {E}{E⊥}{M}{M⊤}{exito}, {E}{E⊥}{M}{M⊥}
{E}{E⊥}{M}{M⊥}{¬exito}, {E}{E⊤}, {E}{E⊤}{T},
{E}{E⊤}{T}{T⊤}, {E}{E⊤}{T}{T⊤}{exito}, {E}{E⊤}{T}{T⊥},
{E}{E⊤}{T}{T⊥}{M}, {E}{E⊤}{T}{T⊥}{M}{M⊤},
{E}{E⊤}{T}{T⊥}{M}{M⊤}{exito}, {E}{E⊤}{T}{T⊥}{M}{M⊥},
{E}{E⊤}{T}{T⊥}{M}{M⊥}{¬exito}, {M⊤}, {M⊤}{exito},
{M⊥}, {M⊥}{¬exito}, {T⊤}, {T⊤}{exito}}
Finalmente, se debe asegurar que Traces(TS) ∩ Words(ϕ), esto quiere que las secuencias quesatisfacen la propiedad deben pertenecer al conjunto de secuencias que tienen estados inicialesen STPA y en este sentido el conjunto final es:

3.4. IMPLEMENTACION DEL MECANISMO EN PINTARQ 81
{{F}, {F}{F⊥}, {F}{F⊥}{M},
{F}{F⊥}{M}{M⊤}, {F}{F⊥}{M}{M⊤}{exito}, {F}{F⊥}{M}{M⊥},
{F}{F⊥}{M}{M⊥}{¬exito}}
En esta seccion se establecio el mecanismo mediante el cual se valida una propiedad temporalpara una arquitectura de software especificada a traves del calculo ρarq, en la siguiente seccionse describe el funcionamiento del modulo que se implemento dentro de la aplicacion PintArq[21]para mostrar este mecanismo de chequeo de propiedades temporales.
3.4. Implementacion del mecanismo en PintArq
En la seccion anterior se presento el formalismo mediante el cual se valida una propiedadtemporal sobre una arquitectura de software especificada a traves del calculo ρarq. En estaseccion se muestra una implementacion de este mecanismo formal como una extension de laherramienta de software PintArq [21].
3.4.1. Modelo funcional de PintArq extendido
En primera medida se establece el modelo funcional a traves de los casos de uso que vaa proveer el sistema. La Figura 3.9 ilustra el modelo funcional de la aplicacion; y en tonomas oscuro los casos de uso que implementan el mecanismo formal de chequeo de propiedadtemporal que aporta este trabajo.
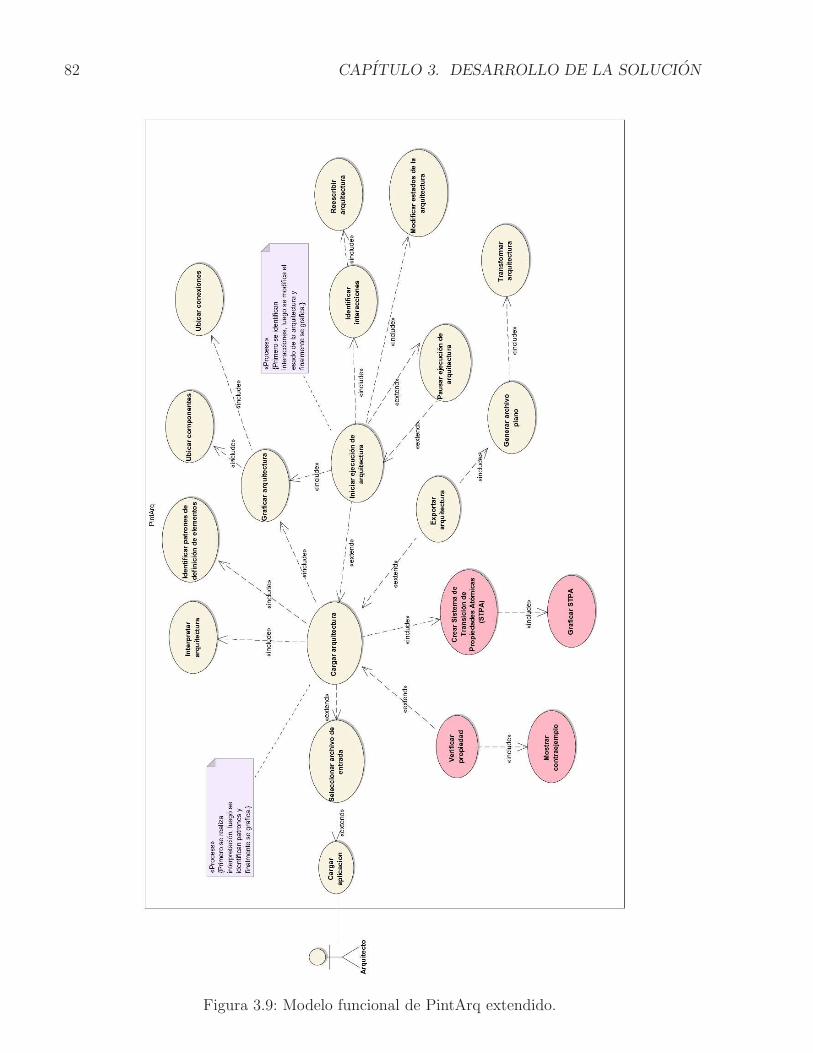
82 CAPITULO 3. DESARROLLO DE LA SOLUCION
Figura 3.9: Modelo funcional de PintArq extendido.

3.4. IMPLEMENTACION DEL MECANISMO EN PINTARQ 83
3.4.1.1. Caso de uso Crear STPA
Este caso de uso, ilustrado en la Figura 3.10 representa la funcionalidad que permite alusuario cargar el archivo en LaTex (que contiene la ecuacion en ρarq) y generar el STPA. Estesistema de transiciones se construye a partir de la arquitectura que provee el modulo Arquitectoy la definicion del sistema que es interpretada por el Reescritor. Para esto se utiliza nuevamenteel patron de diseno visitador que usa ANTLR.
3.4.1.2. Caso de uso Graficar STPA
Esta funcionalidad permite visualizar el STPA ilustrado en la Figura 3.10. El STPA setraduce a lenguaje dot que corresponde al lenguaje que interpreta la herramienta Graphvizy se encarga de dibujar el sistema representandolo a traves de un grafo dirigido compuestode estados y transiciones [41]. Este grafo se convierte a SVG y es presentado al usuario en lainterfaz grafica.
Figura 3.10: Casos de uso Crear STPA y Graficar STPA.
Un fragmento del diagrama de secuencia para estos casos de uso se ilustran en las Figuras3.11 y 3.12. Los diagramas completos se encuentran en los anexos digitales de este trabajo.
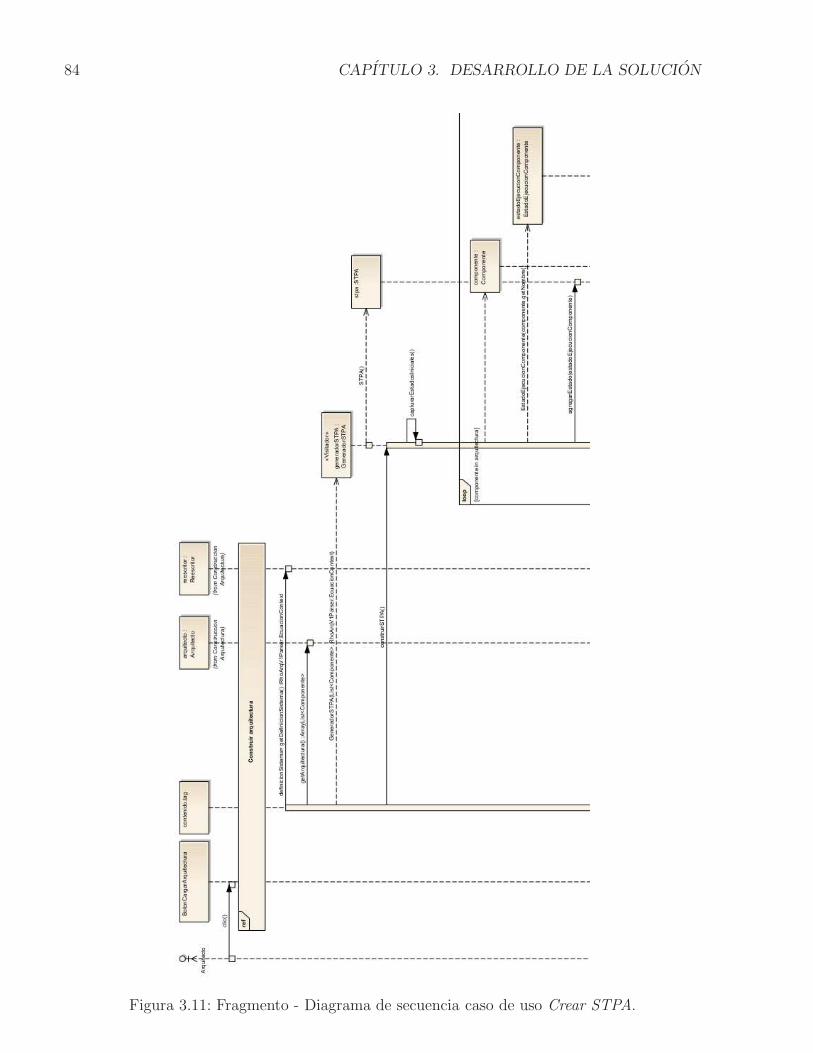
84 CAPITULO 3. DESARROLLO DE LA SOLUCION
Figura 3.11: Fragmento - Diagrama de secuencia caso de uso Crear STPA.
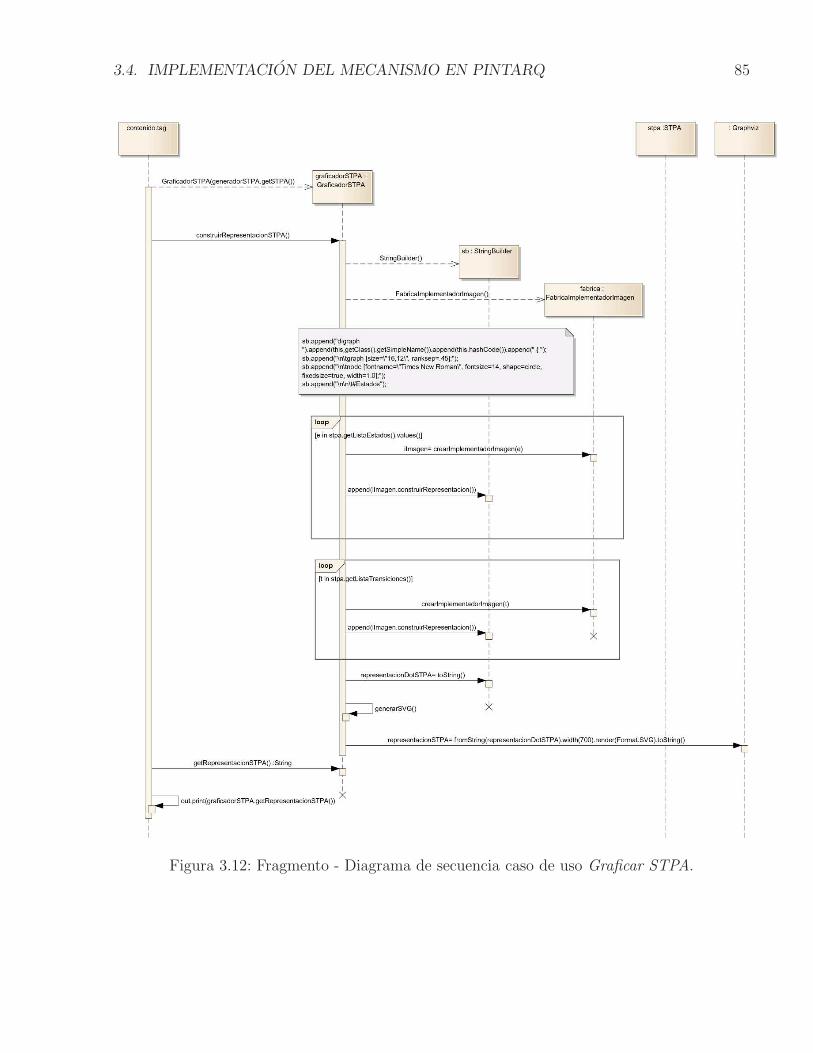
3.4. IMPLEMENTACION DEL MECANISMO EN PINTARQ 85
Figura 3.12: Fragmento - Diagrama de secuencia caso de uso Graficar STPA.

86 CAPITULO 3. DESARROLLO DE LA SOLUCION
3.4.1.3. Caso de uso Verificar propiedad
El caso de uso “Verificar propiedad” captura la especificacion de la propiedad temporal,cuya sintaxis debe tener en cuenta dos aspectos, por un lado, los estados del sistema corres-ponden a elementos descritos en ecuaciones LaTex y por otro lado, los elementos de promelapara describir una formula LLT que puede verse en la Figura 2.27.
El resultado de la verificacion se presenta en pantalla, ya sea que el modelo cumpla ono con la propiedad. Adicionalmente, si no satisface la propiedad, el caso de uso “Mostrarcontraejemplo” se encarga de mostrar un contraejemplo con la ruta que representa el caminoseguido por el STPA.
Figura 3.13: Casos de uso Verificar propiedad y Mostrar contraejemplo
Un fragmento del diagrama de secuencia para estos casos de uso se ilustra en la Figuras3.13 y 3.15. Los diagramas completos se encuentran en los anexos digitales de este trabajo.
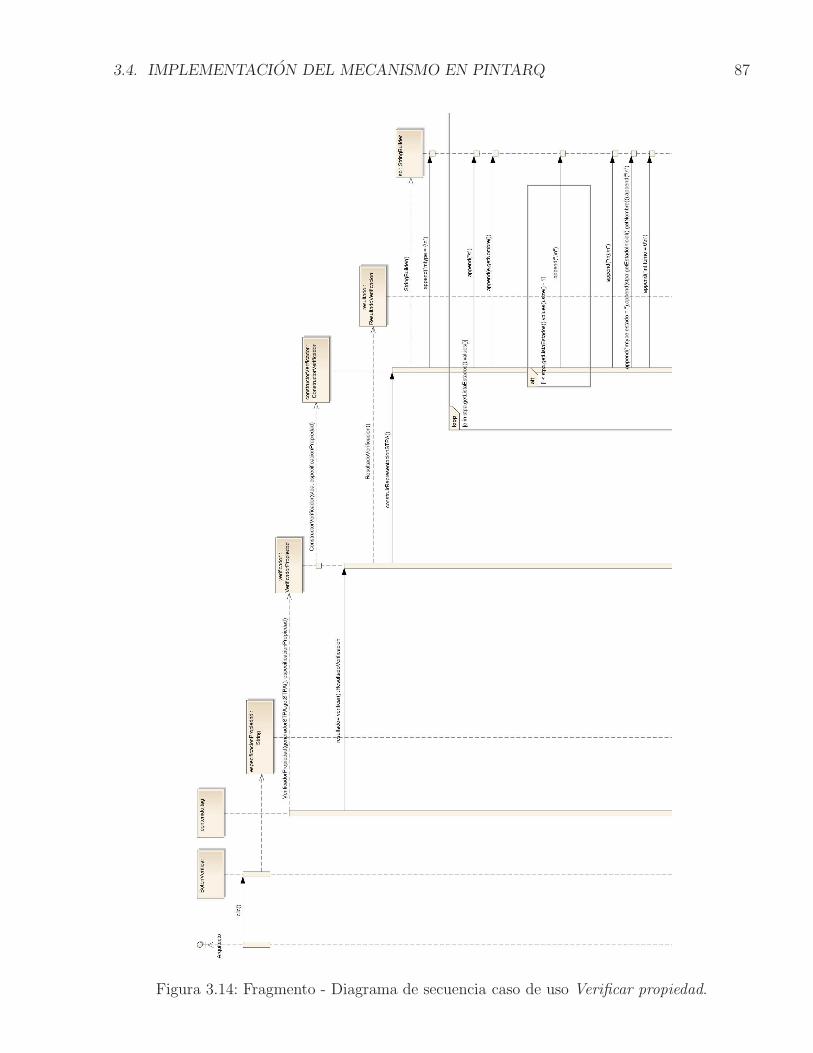
3.4. IMPLEMENTACION DEL MECANISMO EN PINTARQ 87
Figura 3.14: Fragmento - Diagrama de secuencia caso de uso Verificar propiedad.
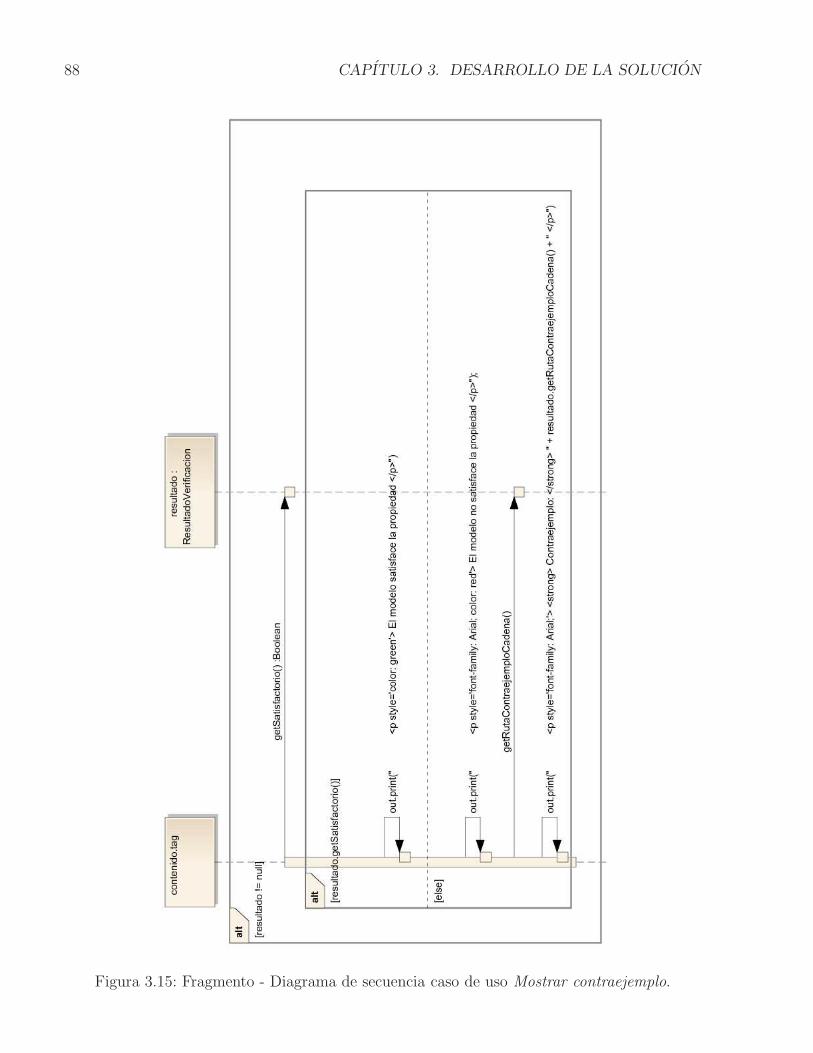
88 CAPITULO 3. DESARROLLO DE LA SOLUCION
Figura 3.15: Fragmento - Diagrama de secuencia caso de uso Mostrar contraejemplo.

3.4. IMPLEMENTACION DEL MECANISMO EN PINTARQ 89
3.4.2. Arquitectura prescriptiva extendida
En la Figura 3.16 se muestra la arquitectura prescriptiva de la solucion, los componentesclaros hacen parte de la implementacion y los componentes mas oscuros hacen parte de lapresente implementacion. Estos componentes realizan las tareas de generar el STPA, verificarla propiedad temporal, representar graficamente el STPA y el resultado de la verificacion.
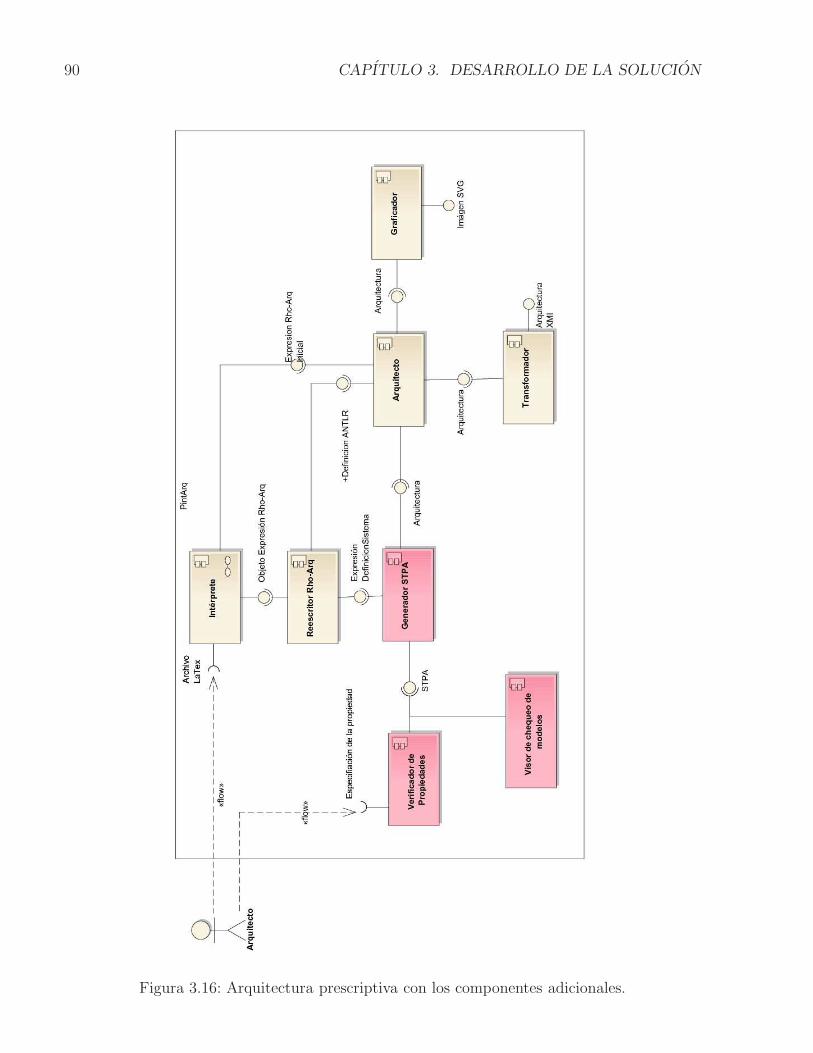
90 CAPITULO 3. DESARROLLO DE LA SOLUCION
Figura 3.16: Arquitectura prescriptiva con los componentes adicionales.

3.4. IMPLEMENTACION DEL MECANISMO EN PINTARQ 91
3.4.2.1. Modelo estructural del Generador STPA
Este componente se encarga de traducir la ecuacion en ρarq a elementos del STPA que serautilizado para validar la propiedad definida por el usuario. En el modelo estructural de estecomponente que puede verse en la Figura 3.17 se identifica la clase GeneradorSTPA, encargadade construir el STPA. Por un lado recibe la especificacion de la arquitectura de componentesque ha construido previamente el modulo Arquitecto y por otro recibe la definicion del sistemaque ha sido provista por el Reescritor.
A partir de la arquitectura se construyen los primeros estados y transiciones del sistemabasados en la existencia de los componentes: Estado de ejecucion del componente, Estado deejecucion exitosa y Estado de Ejecucion no exitosa como se muestra en la Figura 3.18
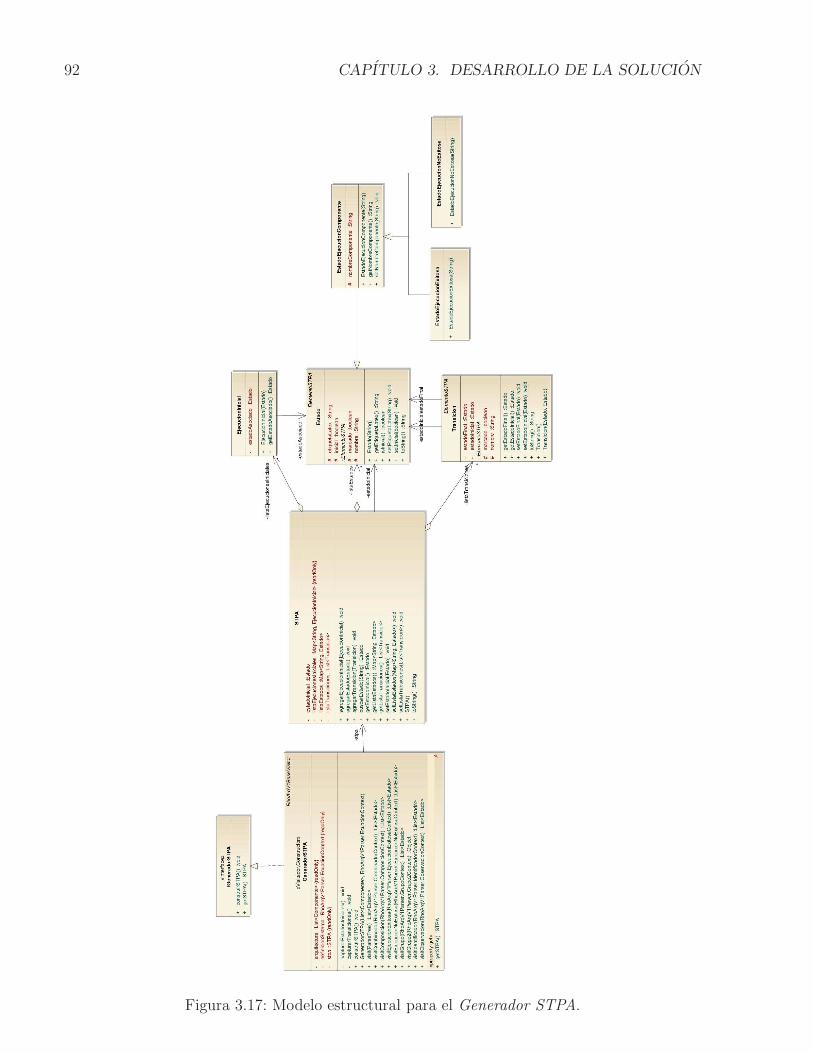
92 CAPITULO 3. DESARROLLO DE LA SOLUCION
Figura 3.17: Modelo estructural para el Generador STPA.

3.4. IMPLEMENTACION DEL MECANISMO EN PINTARQ 93
Figura 3.18: Ejemplo de representacion de la ejecucion de un componente en el STPA
Posteriormente, esta clase, que extiende del visitador que provee ANTLR construye lasdemas transiciones a partir de la definicion del sistema a traves de las expresiones “On SuccessOf” (OSO) encontradas en la ecuacion y que ayudan a determinar hacia donde fluye la ejecucionde la arquitectura. El grafo que representa el STPA es visualizado en la interfaz grafica por elmodulo “Visor de chequeo del modelo”.
3.4.2.2. Modelo estructural Visor de chequeo del modelo
Este componente se encarga de graficar el STPA construido a partir de la especificacion dela arquitectura y la definicion del sistema.
El modelo estructural de este modulo se ilustra en la Figura 3.19. La clase GraficadorSTPAes la encargada de tomar cada uno de los elementos del sistema y transformarlos a traves de susimplementadores con el fin de generar en un primer paso la representacion en formato “dot” yposteriormente en imagen formato svg.
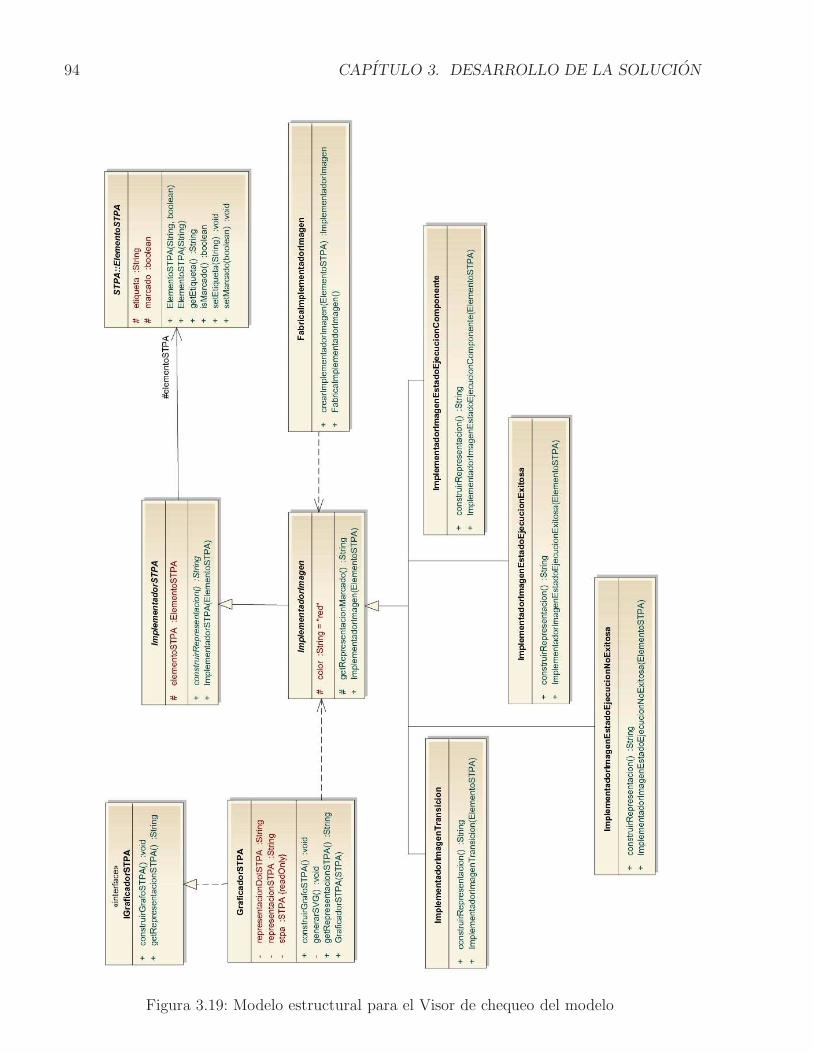
94 CAPITULO 3. DESARROLLO DE LA SOLUCION
Figura 3.19: Modelo estructural para el Visor de chequeo del modelo

3.4. IMPLEMENTACION DEL MECANISMO EN PINTARQ 95
Un ejemplo del grafo generado para una ecuacion se puede ver en la Figura 3.20.
Figura 3.20: Ejemplo de un grafo generado para un STPA a traves del graficador
3.4.2.3. Modelo estructural modulo Verificador de la propiedad
Este componente se encarga de generar el codigo en Promela a partir del STPA y conectarsecon Spin para la ejecucion del proceso de verificacion. El resultado de este proceso es presentadoen pantalla; adicionalmente si el modelo no satisface la propiedad, se muestra un contraejemploque ilustra un camino que no satisface la propiedad. El modelo estructural de este componentese muestra en la Figura 3.21. La Clase VerificadorPropiedad inicia el proceso obteniendo unarepresentacion del STPA de la clase ConstructorVerificador. Este constructor es un traductordel STPA a codigo fuente en Promela.
Posteriormente, el verificador invoca un objeto del tipo ProcesoSPIN que es el encargado dechequear que la propiedad especificada por el usuario es satisfecha por el modelo representadoen el STPA. El resultado del proceso se almacena en un objeto del tipo ResultadoVerificacion

96 CAPITULO 3. DESARROLLO DE LA SOLUCION
que sera enviado a la interfaz grafica para su presentacion. Este objeto contiene la informaciondel resultado final, es decir, si el modelo satisface la propiedad (atributo satisfactorio) y si nola cumple la ruta que muestra por donde no se cumple (atributo rutaContraejemplo).
Figura 3.21: Modelo estructural para el Verificador de propiedad
3.4.3. Breve descripcion de interfaz grafica de usuario
En este mismo sentido, un “layout” de interfaz grafica de usuario se ilustra en la Figura3.22.

3.4. IMPLEMENTACION DEL MECANISMO EN PINTARQ 97
Figura 3.22: Prototipo de Interfaz Grafica de Usuario.
La informacion para probar la aplicacion puede ser consultada a traves del portal del grupode investigacion Arquisoft http://arquisoft.udistrital.edu.co, menu Proyectos > Finalizados yen la tabla de proyecto ubicar Integracion de logica lineal temporal sobre modelos de Arqui-tecturas de Software basadas en componentes especificadas a traves del calculo ρarq. En esaseccion se encuentra el enlace para acceder a la aplicacion, el manual de usuario y los archivosLaTex para efectuar las pruebas.
Funcionalmente, el arquitecto selecciona el archivo LaTex y carga la arquitectura; el sistemamuestra la Arquitectura a lado izquierdo y el Sistema de Transicion de Propiedades Atomicas(STPA) al lado derecho. En este mismo panel se carga tambien como archivo LaTex la propie-dad temporal que se desea verificar y se pulsa en el boton “Verificar” para iniciar el procesode chequeo.
Una vez el proceso termina, el sistema muestra una respuesta indicando si el sistema sa-tisface la propiedad o si por el contrario no es posible y muestra un camino que representa uncontraejemplo.
A partir de estos casos de uso se propone la arquitectura de la Figura 3.16 con sus respectivoscomponentes. De igual forma, los componentes de color oscuro son los propuestos para eldesarrollo de la implementacion.

98 CAPITULO 3. DESARROLLO DE LA SOLUCION
Para verificar el correcto funcionamiento de la extension se realizan pruebas a los siguientesaspectos:
Creacion y visualizacion del STPA a partir de un archivo LaTex que contiene un conjuntode expresiones del calculo ρarq.
Verificacion de una propiedad temporal con resultado en el que el modelo satisface lapropiedad.
Verificacion de una propiedad temporal con resultado en el que el modelo no satisface lapropiedad y visualizacion del contraejemplo.
3.4.3.1. Creacion y visualizacion del STPA
Para esta prueba se utiliza uno de los archivos que contiene expresiones calculo ρarq.
El primer archivo utilizado corresponde a una arquitectura que contiene varios componentesenlazados y ademas tiene expresiones OSO que permiten determinar las proposiciones atomicasdel flujo de ejecucion. El fragmento del documento LaTex que representa la definicion delsistema se muestra en la Figura 3.23.
Figura 3.23: Fragmento Documento LaTeX con reglas de observacion OSO
En esta implementacion se ha realizado una modificacion a la interfaz grafica; el panel devisualizacion se ha dividido en dos partes, al lado izquierdo se sigue mostrando la configuracionarquitectural implementada en el trabajo [21] y en el lado derecho se ilustra el STPA construidoa partir de la configuracion arquitectural y la definicion del sistema. La visualizacion de estecomportamiento se muestra en la Figura 3.24, a la izquierda se ve la configuracion arquitecturalgenerada y a la derecha el STPA generado para esta configuracion.

3.4. IMPLEMENTACION DEL MECANISMO EN PINTARQ 99
Figura 3.24: Visualizacion de la configuracion arquitectural y el STPA en la extension
3.4.3.2. Verificacion de propiedades
Para la prueba de verificacion de la propiedad se utiliza el texto ubicado en la seccionsuperior del marco izquierdo en donde se escribe la propiedad que se desea determinar si elmodelo satisface. En la prueba registrada en las Figura 3.25 se presenta el caso en el cual elmodelo satisface la propiedad. En este caso la propiedad que se desea verificar es ϕ = F →♦M⊤. La propiedad es escrita en el texto en la forma nativa de LaTex: F -> <>Mˆ{\top}.Esta propiedad quiere validar que si se ejecuta el componente F eventualmente se ejecutaraM de forma satisfactoria.

100 CAPITULO 3. DESARROLLO DE LA SOLUCION
Figura 3.25: Verificacion de una propiedad temporal. El modelo satisface la propiedad

3.4. IMPLEMENTACION DEL MECANISMO EN PINTARQ 101
Por otro lado, una propiedad que no es satisfecha por el modelo es ϕ =!(F → ♦fracaso).Descrita en el formato nativo de LaTex es: ! ( F -> <>fracaso ) y la respuesta del sistemase ilustra en la Figura 3.26. Esta propiedad desea verificar que en algun momento el sistemano llegue a un estado de fracaso. En ese caso el modelo no satisface la propiedad debido queexiste al menos un camino desde F que conlleva a un estado de fracaso (estado no deseado)del sistema.
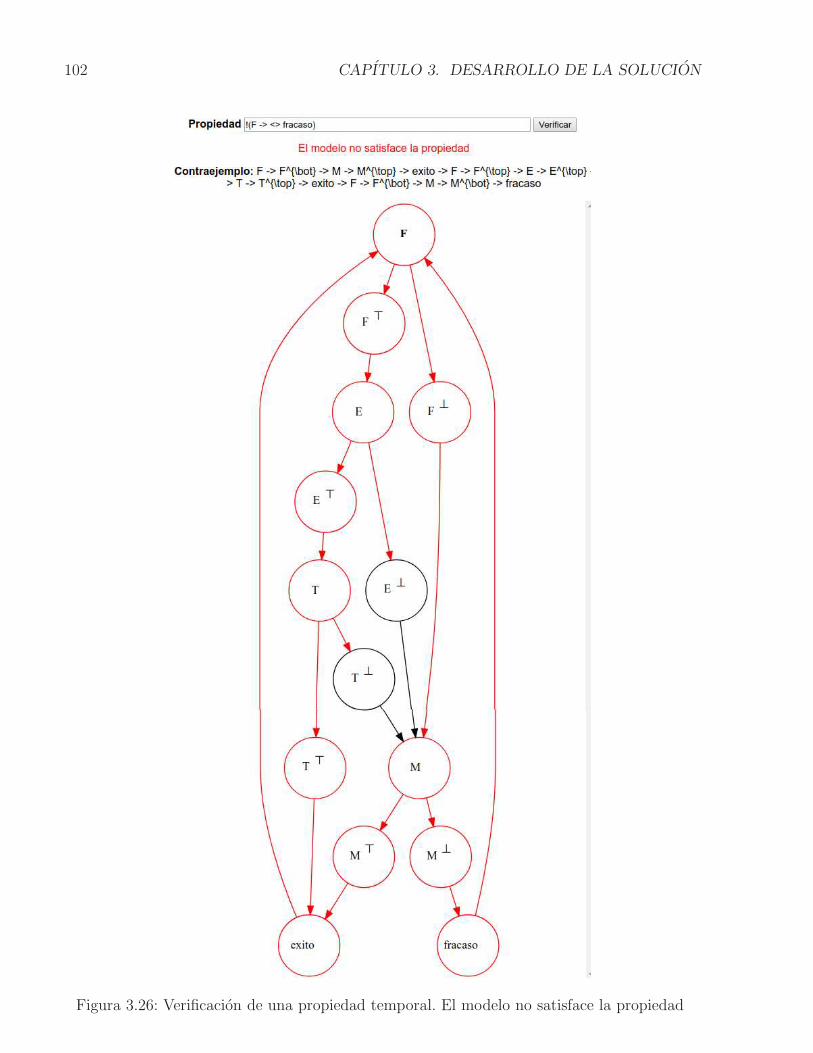
102 CAPITULO 3. DESARROLLO DE LA SOLUCION
Figura 3.26: Verificacion de una propiedad temporal. El modelo no satisface la propiedad

3.4. IMPLEMENTACION DEL MECANISMO EN PINTARQ 103
3.4.4. Aspecto tecnologico
En esta seccion se describen algunas herramientas adicionales utilizadas como apoyo parala implementacion.
3.4.4.1. Graphviz
Es una herramienta de software de codigo abierto utilizada para temas de visualizacion [41].Esta solucion permite representar informacion a traves de diagramas y redes. Los programasde la herramienta toma descripciones de grafos en texto plano y los transforma en diagramas,estos diagramas pueden ser exportados en diferentes formatos (PNG, SVG, PDF, etc.)
Uno de los programas contenidos en la herramienta es “dot” que dibuja grafos dirigidos[42].Incluye algoritmos de para ubicar nodos y aristas sin traslaparse y cruzarse si es posible, definirformatos de fuentes, etiquetas, colores y formas adicionales.
dot recibe como entrada informacion en lenguaje DOT. Este lenguaje define tres tipos deobjetos: grafos, nodos y aristas. Un ejemplo sencillo del lenguaje y su representacion graficapueden verse en la Figura 3.27.
Figura 3.27: Ejemplo del lenguaje DOT y su representacion graficaTomado de [42]

104 CAPITULO 3. DESARROLLO DE LA SOLUCION
Para la implementacion se utilizo el programa dot para generar el grafo que representa elSTPA. Cada elemento del STPA representado por las clases Transicion, Estado y sus subcla-ses, tienen asociado una subclase de ImplementadorImagen, que genera la representacion enlenguaje DOT de cada elemento. La clase GraficadorSTPA, recibe un objeto de tipo STPA yla fabrica FabricaImplementadorImagen crea el implementador correspondiente. En las Figu-ras 3.28 y 3.29 se visualiza la representacion de un STPA en en lenguaje DOT y la imagengenerada.
Figura 3.28: Representacion de un STPA en lenguaje DOT

3.4. IMPLEMENTACION DEL MECANISMO EN PINTARQ 105
E
E⊤
E⊥
F
F⊤
F⊥
T⊤
éxito
M
M⊤ M⊥
T⊥
T
no_éxito
Figura 3.29: Representacion grafica de un STPA posterior a la transformacion del lenguajeDOT
De la representacion en lenguaje DOT se pueden identificar varios elementos:
La definicion del grafo (lınea 1) a traves de la palabra digraph y un nombre (en laimplementacion se genera dinamicamente).
Caracterısticas generales del grafo (lıneas 3 y 4) que establecen aspectos como la formade los nodos (circle), el tipo y tamano de la fuente (Arial 14), la el tamano del grafoen pulgadas por si se excede debido al numero de elementos y sea escalado a 14x12(size), la separacion vertical entre nodos (ranksep), por defecto es de 1 pulgada, en estecaso se establece en 0.25 para contraerlo un poco, hacer los nodos del mismo tamanoindependiente del tamano de la etiqueta (fixedsize).
La definicion de los estados, en este ejemplo se pueden identificar varios tipos de estados:(1) ejecucion de un componente, (2) ejecucion exitosa de un componente, (3) ejecucionno exitosa de un componente y (4) ejecuciones finales del sistema. Adicionalmente, elestado identificado como estado inicial del sistema esta en negrilla y se le asigna el valor“source” al atributo rank que lo establece en la parte superior de la pantalla.

106 CAPITULO 3. DESARROLLO DE LA SOLUCION
La definicion de las transiciones que se realiza a cuya sintaxis es “estado inicial” ->“estado final”, en donde “estado inicial“ y “estado final” corresponde a uno de los estadosdefinidos previamente.
Estos elementos son construidos por el GraficadorSTPA y los correspondientes implementado-res de cada elemento en el STPA.
Despues de generar el texto plano en lenguaje DOT, se utiliza una librerıa implementadaen Java [43] que sirve como envoltura del programa dot y genera la imagen en SVG que serapresentada al usuario.
3.4.4.2. Spin
Es una herramienta de software de codigo abierto desarrollado para realizar chequeo depropiedades sobre programas concurrentes. Tiene un modulo para verificar propiedades tem-porales y funciona como simulador y motor de verificacion[44]. Spin utiliza el lenguaje Promelapara modelar el comportamiento del programa. Un ejemplo de un programa escrito en Promelajunto con una propiedad temporal que desea verificarse se ilustra en la Figura 3.30.
Figura 3.30: Ejemplo de un programa y una propiedad escritos en PromelaTomado de [45]
Para la implementacion en este proyecto se utilizo Promela como lenguaje para representarel STPA en un programa que posteriormente sera verificado con Spin.

3.4. IMPLEMENTACION DEL MECANISMO EN PINTARQ 107
Cuando se invoca a un objeto de tipo VerificadorPropiedad, primero se crea un Constructor-Verificador que es el encargado de escribir el programa en Promela de acuerdo a la estructuradel STPA y la propiedad especificada. Posteriormente el VerificadorPropiedad crea una ejem-plificacion de la clase ProcesoSPIN que es la encargada de llamar a los procesos del sistemapara generar el verificador, ejecutarlo y capturar su resultado.
El ConstructorVerificador recorre cada elemento del STPA y genera una representacion entexto plano que cumple con la sintaxis de Promela y contiene los estados y transiciones delmodelo. El codigo en lenguaje Promela para el STPA de la Figura 3.28 se ilustra en las Figuras3.31, 3.32 , 3.33 y 3.34.

108 CAPITULO 3. DESARROLLO DE LA SOLUCION
Figura 3.31: Representacion en Promela de un STPA. Parte 1 de 4

3.4. IMPLEMENTACION DEL MECANISMO EN PINTARQ 109
Figura 3.32: Representacion en Promela de un STPA. Parte 2 de 4

110 CAPITULO 3. DESARROLLO DE LA SOLUCION
Figura 3.33: Representacion en Promela de un STPA. Parte 3 de 4

3.4. IMPLEMENTACION DEL MECANISMO EN PINTARQ 111
Figura 3.34: Representacion en Promela de un STPA. Parte 4 de 4
En terminos generales este codigo define la estructura del STPA a traves de los tipos mtypey el comportamiento a traves de procesos. Cada programa se compone de dos procesos quese ejecutan de forma concurrente pero por turnos. El proceso STPA() es que representa lastransiciones entre los estados y lleva la ejecucion de un estado a otro, por lado el procesoevaluar transicion(), se encarga de resolver la siguiente transicion cuando el primer procesoentra en una instruccion de seleccion de transicion del primer proceso. Cada evaluacion conllevaa la transicion de un estado a otro intercalando cada una de las posibilidades, por ejemplo, siel sistema se encuentra en el estado de ejecucion del componente F , en la primera iteracionevaluara tomar la ejecucion exitosa (F⊤) y en la siguiente iteracion evaluara tomar por laiteracion no exitosa (F⊥), y ası para cada estado que tenga mas de una transicion.
La logica del programa es la siguiente:

112 CAPITULO 3. DESARROLLO DE LA SOLUCION
1. En la primera seccion (lıneas 1 a 16) se definen arreglos de los posibles siguientes estadospara cada estado del sistema. Se define el estado inicial (lınea 17).
2. Se inicia la variable que va a llevar los turnos (lınea 18). El turno 0 e spara la ejecucionde STPA() y turno 1 para la ejecucion de evaluar transicion().
3. Se define el numero maximo de transiciones para cada estado segun el STPA y se inicializacada uno de los indices que navegara por cada transicion, por ejemplo para el caso delestado F , el numero maximo de transiciones es dos (transicion al estado de ejecucionexitosa y transicion al estado de ejecucion no exitosa). Y el indice marca la posicion cero,es decir la posicion exitosa. (lineas 19 a 30).
4. Se define la propiedad temporal y las proposiciones que la componen (lıneas 33 a 37).
5. Se definen los estados para cada posicion en los arreglos de posibles siguientes estados(lıneas 40 a 47).
6. Se inician los procesos del sistema (lıneas 50 y 52).
7. Se define la ejecucion del proceso STPA() (lıneas 58 a 166). Este proceso inicia con elestado definido como inicial (en esta caso la ejecucion de F ).
8. Debido que la ejecucion de F tiene dos posibles transiciones, se establece el turno en 1para que el proceso evaluar transicion() determine el siguiente paso.
9. En este punto el control pasa al proceso evaluar transicion() (lıneas 169 a 211). Primeroevalua si tiene el turno (valor 1) y empieza a evaluar si el estado es uno de los que estaactualmente, si encuentra uno de ellos ejecuta las instrucciones asociadas a la seleccion deun estado. Siguiendo el ejemplo de la ejecucion de F (lınea 183), en este caso la primeraopcion es seleccionar la opcion con ındice cero, es decir la ejecucion exitosa y adelantarlapara la siguiente vez que el sistema llegue a ese estado en donde seleccionara la siguiente.Se aplica la operacion modulo para que reinicie en cero una vez llegue al ultimo indice(lınea 188).
10. Cuando cambia el estado, define el turno en cero para que el proceso STPA() continuecon su ejecucion (lınea 208 y posteriormente lınea 68).
11. Debido que se selecciono el primer ındice el sistema transita hacia la ejecucion exitosade F (lınea 70). Esto mueve el control a la etiqueta que define esta secuencia (lınea 99).Debido que este estado solo tiene una transicion, lo envıa a la ejecucion de E (lınea 102y posteriormente lınea 81). El proceso continua ası sucesivamente hasta que visita cadaestado representado por el STPA.
El procedimiento anterior explica como se implemento la estructura y comportamiento delSTPA a traves de un programa definido en Promela. Para la verificacion de la propiedad, seutiliza el metodo “ejecutar()” de la clase ProcesoSPIN, que se compone de tres metodos quemapean a tres instrucciones de spin:

3.4. IMPLEMENTACION DEL MECANISMO EN PINTARQ 113
1. run(): ejecuta spin para generacion del verificador exhaustivo (spin -a archivoPromela.pml).Esta instruccion genera un codigo fuente en c (pan.c) que contiene las reglas que deter-minan la ejecucion del programa original y que se encarga de verificar la propiedad.
2. compilePan(): ejecuta la instruccion encargada de compilar el codigo generado en c(pan.c) para la validacion exhaustiva (gcc -o pan pan.c). Esto genera un ejecutable(pan) que es propiamente el verificador.
3. pan(): ejecuta la instruccion que se encarga de verificar el modelo y determinar si sa-tisface o no la propiedad. Si satisace la propiedad no genera errores, si por el contrariono se satisface, su salida indica que hay errores y crea un archivo con el nombre delarchivoPromela original con extension .trail. En donde se encuentra la ruta seguida porel verificador en donde se indica el contraejemplo que no satisface la propiedad (pan -a).
4. obtenerRuta(): ejecuta la instruccion para determinar la ruta del contraejemplo (spin-t archivoPromela.pml.trail).
Despues de la ejecucion de esta secuencia se muestra la salida al usuario a traves de la aplica-cion.

Capıtulo 4
CONCLUSIONES Y TRABAJOFUTURO
1. El mayor esfuerzo del proyecto estuvo en la abstraccion de la ejecucion de la arquitecturaa traves del Sistema de Transicion de Proposiciones Atomicas (STPA) que es sobre elcual se puede razonar sobre el comportamiento de la arquitectura.
2. Se logro implementar una extension de la aplicacion PintArq para la visualizacion delmodelo que representa el comportamiento de la arquitectura y sobre el que se puedehacer su analisis a traves de logicas temporales.
3. Contar con la herramienta PintArq y su documentacion y modelos fue de vital importan-cia para implementar de forma mas rapida y precisa el mecanismo formal de especificacionde propiedades temporales.
4. Las herramientas de software libre y abierto bien documentadas y modulares permitenincorporar y expandir proyectos sin necesidad de construir todos sus elementos desdecero.
5. La carga conceptual que conlleva investigar temas relacionados con metodos formales eningenierıa de software es insuficiente en la Maestrıa, especialmente para comprender conmayor rapidez temas como las logicas temporales pues no son temas de estudio regularen las asignaturas del proyecto curricular.
4.1. Trabajo futuro
A traves del proceso de investigacion se identificaron varios escenarios sobre los que sepueden iniciar o continuar trabajos relacionados:
114

4.1. TRABAJO FUTURO 115
1. Implementar una herramienta de software propia de verificacion de propiedades tempo-rales para el calculo ρarq.
2. Ampliar el alcance del mecanismo para verificar propiedades temporales como Fiabilidad(Safety), Deteccion de abrazos mortales o aseguramiento de libertad de inanicion.
3. Optimizar la implementacion para encontrar el camino mas corto que ilustra el contra-ejemplo cuando el modelo no satisface la propiedad especificada.
4. Mejorar la implementacion de la extension en PintArq para visualizar el contraejemploen la sintaxis del calculo formal y no en formato LaTeX.

Apendice A
Manual de usuario
En este capıtulo se presentan las funcionalidades para la correcta operacion de la herra-mienta con el fin de observar los resultados obtenidos.
A.1. Requerimientos
1. Navegador web con soporte para HTML 5 y Javascript. Se sugiere Google Chrome (v50o superior) o Mozilla Firefox (v56 o superior).
2. Archivos de especificacion de arquitecturas en el calculo ρarq. Estos archivos se pueden ob-tener a traves del portal del grupo de investigacion Arquisoft http://arquisoft.udistrital.edu.co,menu Proyectos > Finalizados y en la tabla de proyecto ubicar Integracion de logica linealtemporal sobre modelos de Arquitecturas de Software basadas en componentes especifica-das a traves del calculo ρarq.
A.2. Operacion
La pantalla de inicio de la aplicacion que se ilustra en la Figura A.1 esta dividida en tressecciones. Al inicio se identifica la seccion superior donde se muestran los controles de operaciony en la seccion inferior en donde se visualizaran los diagramas.
116

A.2. OPERACION 117
Figura A.1: Pantalla inicial PintArq
A.2.1. Cargar una especificacion de arquitectura
Para cargar una especificacion de arquitectura se pulsa en el boton ✭✭Seleccionar archivo✮✮se ubica un archivo con extension .tex que contiene la descripcion, se pulsa en ✭✭Abrir✮✮ yposteriormente en el boton ✭✭Cargar Arquitectura✮✮. La aplicacion divide la seccion inferior endos partes, al lado izquierdo se visualiza la representacion en UML de la arquitectura y allado derecho se visualiza el Sistema de Transicion de Proposiciones Atomicas (STPA) quecaptura el modelo obtenido a partir de las ecuaciones del calculo ρarq. La Figura A.2 ilustraeste comportamiento.
Figura A.2: Representacion grafica de la Arquitectura y el STPA en el aplicativo
El funcionamiento de la seccion derecha en donde se muestra la ejecucion de la arquitectura

118 APENDICE A. MANUAL DE USUARIO
(seccion izquierda de la Figura A.2) se puede consultar en el documento Representacion visualde la ejecucion de una arquitectura de software basada en componentes con especificacion formalen calculo ρarq.
A.2.2. Verificar una propiedad temporal
Una vez cargada la arquitectura, se puede proceder a verificar una propiedad temporal.Para el el caso de analisis se ha seleccionado la propiedad de vivacidad. Para la arquitecturacargada, se podrıa desear que llegue a un estado particular iniciando con la ejecucion de F quees el componente fuente del sistema.
Para este caso se podrıa definir que se desea que si se inicia en F eventualmente se llegaraa la ejecucion exitosa de cualquiera de sus componentes finales M o T . La propiedad se definede la siguiente manera:
F −→ ♦(M⊤ ∨ T⊤)
que en lenguaje Promela y teniendo en cuenta la sintaxis de LaTex para la representacionde los estados se escribe:
F -> <>(Mˆ{\top} || Tˆ{\top})
Al introducir esta propiedad y pulsar en ✭✭Verificar✮✮ se puede evidenciar que el sistemasatisface la propiedad:

A.2. OPERACION 119
Figura A.3: Verificacion de la propiedad con resultado satisfactorio
Por otro lado, si se quisiera verificar que el sistema no ingrese en un estado deseado, porejemplo verificar que desde el componente F no se llega al estado de fracaso, la propiedad sedefine de la siguiente forma:
¬(F −→ ♦(fracaso))
nuevamente en lenguaje Promela y teniendo en cuenta la sintaxis de LaTex para la repre-sentacion de los estados se escribe:
!(F -> <>(fracaso))
En este caso el sistema no satisface la propiedad y muestra un contraejemplo indicando elcamino seguido por el verificador:
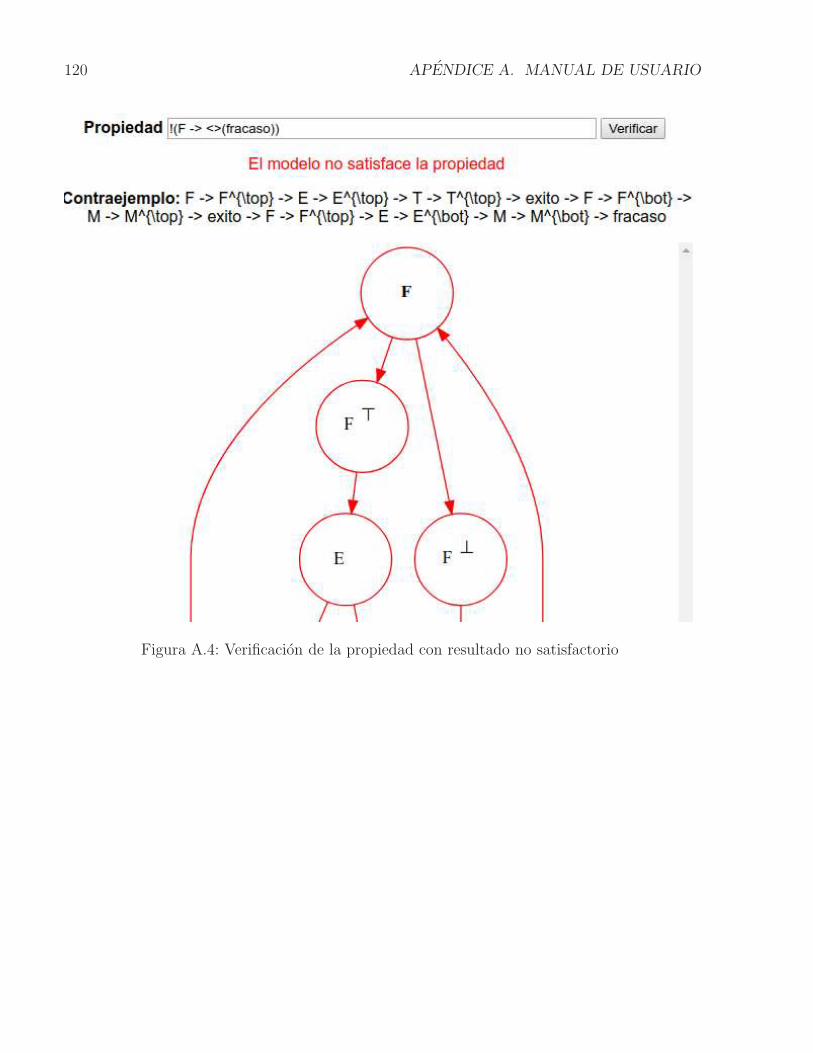
120 APENDICE A. MANUAL DE USUARIO
Figura A.4: Verificacion de la propiedad con resultado no satisfactorio

Apendice B
Manual de instalacion
En este capıtulo se presentan las instrucciones para la instalacion de la herramienta. Elmanual se realiza sobre un sistema operativo GNU/Linux (Ubuntu 16.04.3 - 64 Bits).
B.1. Requerimientos
Oracle JDK 8 o superior.
Compilador de codigo C - (gcc preferiblemente, version 5.4.0)
Usuario con permisos de administracion sobre el sistema operativo.
B.2. Instalacion
B.2.1. Wildfly
1. Descargar los ejecutables del sitio oficial de RedHat (http://wildfly.org). Version 10.1.0.Fi-nal.
2. Descomprimir los ejecutables y copiarlos en un directorio del sistema (se sugiere /opt/wildfly/).
3. Crear un usuario de administracion del servidor de aplicaciones:
a) Ubicarse en el directorio bin dentro del servidor de aplicaciones. En este caso/opt/wildfly/bin
b) Ejecutar el comando ./add-user.sh y seguir las instrucciones hasta asignar unnombre de usuario y contrasena para el rol de administracion.
121

122 APENDICE B. MANUAL DE INSTALACION
4. Editar el archivo de configuracion para permitir el acceso fuera del entorno local:
a) Abrir el archivo /opt/wildfly/standalone/configuration/standalone.xml
b) Ubicar la seccion ✭✭<interface>✮✮ y editar las interfaces con nombre ✭✭management✮✮y ✭✭public✮✮ asignando el valor: ✭✭${jboss.bind.address:0.0.0.0}✮✮
5. Iniciar el servidor de aplicaciones con la instruccion: /opt/wildfly/bin/standalone.sh
B.2.2. Graphviz
1. Ejecutar la instruccion de instalacion de aplicaciones para los repositorios del sistemaoperativo: apt-get install graphviz (Version 2.3.8)
2. Para verificar su instalacion se ejecuta la instruccion: dot -V y debe aparecer la versioninstalada
B.2.3. Spin
1. Descargar el ejecutable de acuerdo a la distribucion de la pagina de la herramienta:http://spinroot.com (Version 6.4.7)
2. Descomprimir el contenido y cambiar el nombre del ejecutable a ✭✭spin✮✮. En este caso seejecuta la instruccion: mv spin647 linux64 spin
3. Copiar el archivo a uno de los directorios de los ejecutables del sistema. En este caso seejecuta la siguiente instruccion: cp spin /usr/bin/
4. Para verificar su funcionamiento se ejecuta la instruccion spin -V y debe mostrar laversion en ejecucion.
B.2.4. PintArq
1. Ingresar a la interfaz grafica de administracion del servidor de aplicaciones a traves de laurl dispuesta para este proposito: En este caso http://xxx.xxx.xxx.xxx:9990/console/App.html.
2. Seleccionar la opcion ✭✭Start✮✮ de la seccion ✭✭Deployments✮✮.
3. En la nueva pagina que aparece pulsar el boton ✭✭Add✮✮ del panel izquierdo, seleccionarla opcion ✭✭Upload new deployment✮✮ y pulsar en ✭✭Next✮✮.
4. Seleccionar el ejecutable .war de la aplicacion y pulsar en ✭✭Next✮✮.
5. Establecer el nombre con el que sera publicada la aplicacion y si va a quedar habilitada(en este caso se dejan los valores por defecto) y se pulsa en ✭✭Finish✮✮.

B.2. INSTALACION 123
6. La aplicacion queda publicada y se puede acceder a traves de la url: http://xxx.xxx.xxx.xxx:8080/Pin

BIBLIOGRAFIA
[1] E. Montoya Serna, “Metodos formales e Ingenierıa de Software,” Revista Virtual Univer-sidad Catolica . . . , no. 30, pp. 1–26, 2011.
[2] J. M. Wing, “FAQ on π-Calculus,” no. December, pp. 1–8, 2002.
[3] H. Diosa, J. F. Dıaz Frıas, and C. M. Gaona, “Calculo para el modelado formal de arqui-tecturas de software basadas en componentes: calculo r-Arq,” 2009.
[4] H. Diosa, J. F. Dıaz Frıas, and C. M. Gaona, “Especificacion formal de arquitecturasde software basadas en componentes: chequeo de correccion con calculo rho-arq,” no. 12,2010.
[5] C. Baier and J.-P. Katoen, Principles of Model Checking. 2008.
[6] M. M. Ben-Ari, “A primer on model checking,” ACM Inroads, vol. 1, no. 1, p. 40, 2010.
[7] C. J. Burguess, “The Role of Formal Methods in Software Engineering Education andIndustry,” Proceedings of the 4th Software Quality Conference, p. 8, 1995.
[8] C. A. R. Hoare, “Communicating Sequential Processes,” vol. 21, no. 8, 2004.
[9] R. Milner, “A Calculus of Communicating Systems,” 1986.
[10] D. Giannakopoulou, Model Checking for Concurrent Software Architectures. PhD thesis,1999.
[11] R. Jhala and R. Majumdar, “Software model checking,” ACM Computing Surveys, vol. 41,pp. 1–54, oct 2009.
[12] J. Katoen, “Concepts, algorithms, and tools for model checking,” Arbeitsberichte des,vol. 2501, no. 32, p. 1, 1999.
[13] A. Bertolino, P. Inverardi, and H. Muccini, “Formal Methods in Testing Software Archi-tectures,” pp. 122—-147, 2003.
[14] N. Medvidovic, D. S. Rosenblum, D. F. Redmiles, and J. E. Robbins, “Modeling SoftwareArchitectures in the Unified Modeling Language,” vol. 11, no. 1, pp. 2–57, 2002.
[15] E. Clarke, “Model Checking,” 2000.
124

BIBLIOGRAFIA 125
[16] J.-P. Katoen, “Concepts, Algorithms and Tools for Model Checking,” 1991.
[17] A. Pnueli, “The Temporal Logic of Programs,” 1977.
[18] J. van Leeuwen, Handbook of Theoretical Computer Science. Volume B. Formal Modelsand Semantics. 1994.
[19] M. Kim, “Slides Temporal Logic - LTL, CTL, and CTL*,” pp. 1–7, 2007.
[20] S. Biswas and J. K. Deka, “NPTEL :: Computer Science and Engineering - Design Veri-fication and Test of Digital VLSI Circuits,” 2014.
[21] J. A. Rico, Representacion visual de la ejecucion de una arquitectura de software basadaen componentes con especificacion formal en calculo ρarq. 2015.
[22] J. Niehren and G. Smolka, “A Confluent Relational Calculus for Higher-Order Program-ming with Constraints,” 2010.
[23] I. Crnkovic and M. Larsson, “Component-based software engineering-new paradigm ofsoftware development,” Invited talk and report, MIPRO, 2001.
[24] J. Cheesman and J. Daniels, UML Components A Simple Process for SpecifyingComponent-Based Software. 2000.
[25] P. Zhang, H. Muccini, and B. Li, “A classification and comparison of model checkingsoftware architecture techniques,” Journal of Systems and Software, vol. 83, pp. 723–744,may 2010.
[26] X. He, H. Yu, T. Shi, J. Ding, and Y. Deng, “Formally analyzing software architecturalspecifications using SAM,” Journal of Systems and Software, vol. 71, pp. 11–29, apr 2004.
[27] J. Wang, X. He, and Y. Deng, “Introducing software architecture specification and analysisin SAM through an example,” Information and Software Technology, vol. 41, pp. 451–467,may 1999.
[28] X. He, J. Ding, and Y. Deng, “Model checking software architecture specifications inSAM,” SEKE ’02 Proceedings of the 14th international conference on Software engineeringand knowledge engineering, p. 4, 2002.
[29] A. Rademaker, C. Braga, and A. Sztajnberg, “A Rewriting Semantics for a SoftwareArchitecture Description Language,” Electronic Notes in Theoretical Computer Science,vol. 130, pp. 345–377, may 2005.
[30] S. Eker, J. Meseguer, and A. Sridharanarayanan, “The Maude LTL Model Checker,”Electronic Notes in Theoretical Computer Science, vol. 71, pp. 162–187, apr 2004.
[31] D. Compare, A. D’Onofrio, A. Di Marco, and P. Inverardi, “Automated performancevalidation of software design: an industrial experience,” Proceedings. 19th InternationalConference on Automated Software Engineering, 2004., pp. 298–301, 2004.

126 BIBLIOGRAFIA
[32] M. Bernardo, “TwoTowers 5.1 User Manual,” no. January, 2006.
[33] L. Donatiello, P. Ciancarini, M. Bernardo, and M. Simeoni, “ADL aspects of AEmilia.Slides.,” 2003.
[34] P. Pelliccione, CHARMY: A framework for Software Architecture. PhD thesis, 2005.
[35] G. J. Holzmann, “The Model Checker SPIN,” vol. 23, no. 5, pp. 279–295, 1997.
[36] M. Ben-Ari, Principles of the SPIN Model Checker. 2008.
[37] B. Alpern and F. B. Schneider, “Defining liveness,” Information Processing Letters, vol. 21,no. 4, pp. 181–185, 1985.
[38] S. Owicki and L. Lamport, “Proving liveness properties of concurrent programs,” ACMTransactions on Programming Languages and Systems, vol. 4, no. 3, pp. 455–495, 1982.
[39] B. Alpern and F. B. Schneider, “Recognizing safety and liveness,” Distributed Computing,vol. 2, no. 3, pp. 117–126, 1987.
[40] S. C. Cheungt, D. Giannakopoulou, and J. Kramer, “Verification of liveness propertiesusing compositional reachability analysis,” Lecture Notes in Computer Science (includingsubseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics),vol. 1301, pp. 227–243, 1997.
[41] A. Bilgin, J. Ellson, E. Gansner, Y. Hu, and S. North, “Graphviz - Graph VisualizationSoftware,” 2017.
[42] E. Gansner, E. Koutsofios, and S. North, “Drawing graphs with dot,” North, pp. 1–40,2006.
[43] S. Niederhauser, “Graphviz Java.” https://github.com/nidi3/graphviz-java, 2017.
[44] H. H. Løvengreen, “Introduction to Spin,” no. Iii, 2016.
[45] M. M. Ben-ari, “Principles of the Spin Model Checker Supplementary Material on SpinVersion 6,” pp. 0–6, 2010.