Human-level Control Through Deep Reinforcement Learning€¦ · 1 Mnih, V. et al. Human-level...
13
Human-level Control Through Deep Reinforcement Learning Google DeepMind: Mnih et al. 2015 CSC2541 Nov. 4th, 2016 Dayeol Choi Deep RL Nov. 4th 2016 1 / 13
Transcript of Human-level Control Through Deep Reinforcement Learning€¦ · 1 Mnih, V. et al. Human-level...

Human-level ControlThrough Deep Reinforcement Learning
Google DeepMind: Mnih et al. 2015
CSC2541Nov. 4th, 2016
Dayeol Choi Deep RL Nov. 4th 2016 1 / 13

Intro
Policy π maps states (observation) to actions: π(s) = a
Action-Value Function Q gives expected total reward from a stateand action from some policy
Qπ(s, a) = E[rt+1 + γrt+2 + γ2rt+3 + ...|st = s, at = a] (1)
Optimal Action-Value Function Q∗ gives best value possible from anypolicy
Q∗(s, a) = maxπ
E[rt+1 + γrt+2 + γ2rt+3 + ...|st = s, at = a, π] (2)
= Es′ [r + γmaxa′
Q∗(s ′, a′)|s, a] (3)
Dayeol Choi Deep RL Nov. 4th 2016 2 / 13

Deep Q Networks (DQN)
Idea: want to replicate successes of Supervised Learning inReinforcement Learning.
Q∗ is a function, so we can approximate with a Deep Network.
Loss Function for Q-learning updates (MSE)
L(w) = E
[(r + γmax
a′Q(s ′, a′,w)− Q(s, a,w)
)2]
Loss is difference between target value (fixed) and current estimate ofQ.
Gradient of Loss
∇wL(w) = E[(
r + γmaxa′
Q(s ′, a′,w)− Q(s, a,w)
)∇wQ(s, a,w)
]
Dayeol Choi Deep RL Nov. 4th 2016 3 / 13
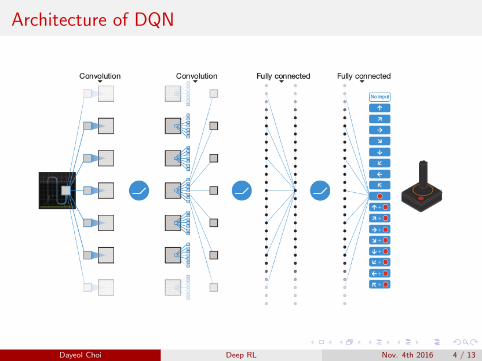
Architecture of DQN
Dayeol Choi Deep RL Nov. 4th 2016 4 / 13
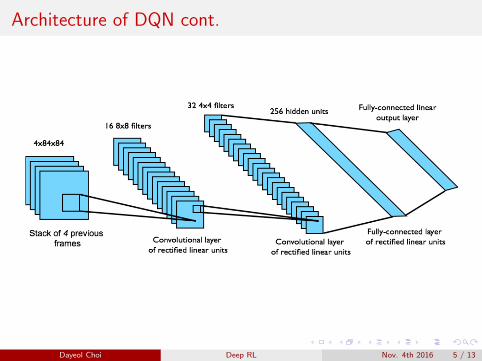
Architecture of DQN cont.
Dayeol Choi Deep RL Nov. 4th 2016 5 / 13

Architecture of DQN cont..
Dayeol Choi Deep RL Nov. 4th 2016 6 / 13

Issues
1 Observations are sequential and correlated (non iid).
How about destroying the temporal structure?
2 Data distribution depends on policy (action), which may changedrastically with small changes in Q.
Good policy at some situations will be irrelevant at other situations.
3 Gradients are sensitive to scale of Rewards
Gradient Clipping, restrict reward e.g. r ∈ [−1, 1], batch normalization
Dayeol Choi Deep RL Nov. 4th 2016 7 / 13

Experience Replay [Lin 1993]
Helps with the first two issues (correlated observations, non-stationarydata distribution).
First, choose action from ε-greedy policy, then store (st , at , rt , st+1)to memory D.
Sample a mini-batch of (s, a, r , s ′) ∼ D and use that to optimize loss.
L(w) = Es,a,r ,s′∼D
[(r + γmax
a′Q(s ′, a′,w)− Q(s, a,w)
)2]
By doing batch learning, we gained some protection from correlatedobservations and non-stationary data distribution.
However, we have lost the temporal structure of the data.
Instead of looking at individual experience samples, we could replaysequences of experiences (lessons).
Dayeol Choi Deep RL Nov. 4th 2016 8 / 13

Fixed Target Q Network
Often, whenever we update Q(st , at) by increasing it, Q(st+1, at) isincreased for all actions.
This means our target r + γmaxa Q(s, a,w) is also increased.
Our updates to Q and our targets are correlated.
To fix this correlation, we add a delay between updates to Q andcomputation of targets.
This is done by computing targets using older sets of parameters, notthe most recent.
Dayeol Choi Deep RL Nov. 4th 2016 9 / 13
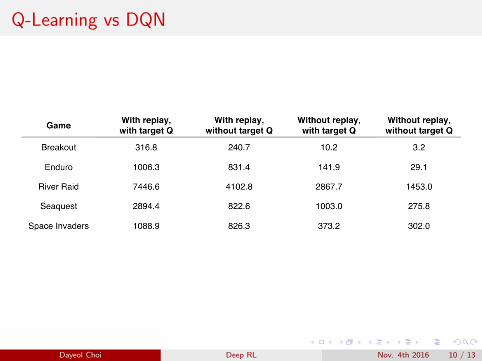
Q-Learning vs DQN
Dayeol Choi Deep RL Nov. 4th 2016 10 / 13

Linear vs. Nonlinear Function Approximator
Effect of replacing a Deep Network with a shallow network with one linearhidden layer.Note: Previous work using linear function approximation will sometimesperform better than shallow network e.g. 129.1 in Enduro.
Dayeol Choi Deep RL Nov. 4th 2016 11 / 13

The learning algorithm
Dayeol Choi Deep RL Nov. 4th 2016 12 / 13

References
1 Mnih, V. et al. Human-level control through deep reinforcementlearning. Nature 518, 529–533 (2015)
2 Lin, L.-J. Reinforcement learning for robots using neural networks.Technical Report, DTIC Document (1993)
Dayeol Choi Deep RL Nov. 4th 2016 13 / 13