







γλώσσες
Σελίδες
Νομικός


Methodes de statistique inferentielle.
A. Philippe
Laboratoire de mathematiques Jean LerayUniversite de Nantes
Version modifiee le 19 mai 2016
http://www.math.sciences.univ-nantes.fr/~philippe/
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 1 / 166
Plan du cours
1 Introduction
2 Probabilites : Variables Aleatoires Continues
3 Estimation
4 Tests
5 Regression
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 2 / 166
Introduction
Plan de la section
1 Introduction
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 3 / 166
Introduction
Quelques problemes
1 Un fabricant souhaite verifier la qualite des ampoules electriquesproduites par une nouvelle chaıne de production.Il faut donc evaluer la duree moyenne de fonctionnement desampoules.
Comment evaluer cette duree moyenne ?
On ne peut pas tester toutes les ampoules !
2 Le responsable d’un parti politique souhaite estimer la proportiondes militants favorables a la candidature de Mr X pour laprochaine election presidentielle.
Comment calculer la popularite d’un candidat au sein d’unepopulation ?
Interroger tous les militants est trop couteux.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 4 / 166
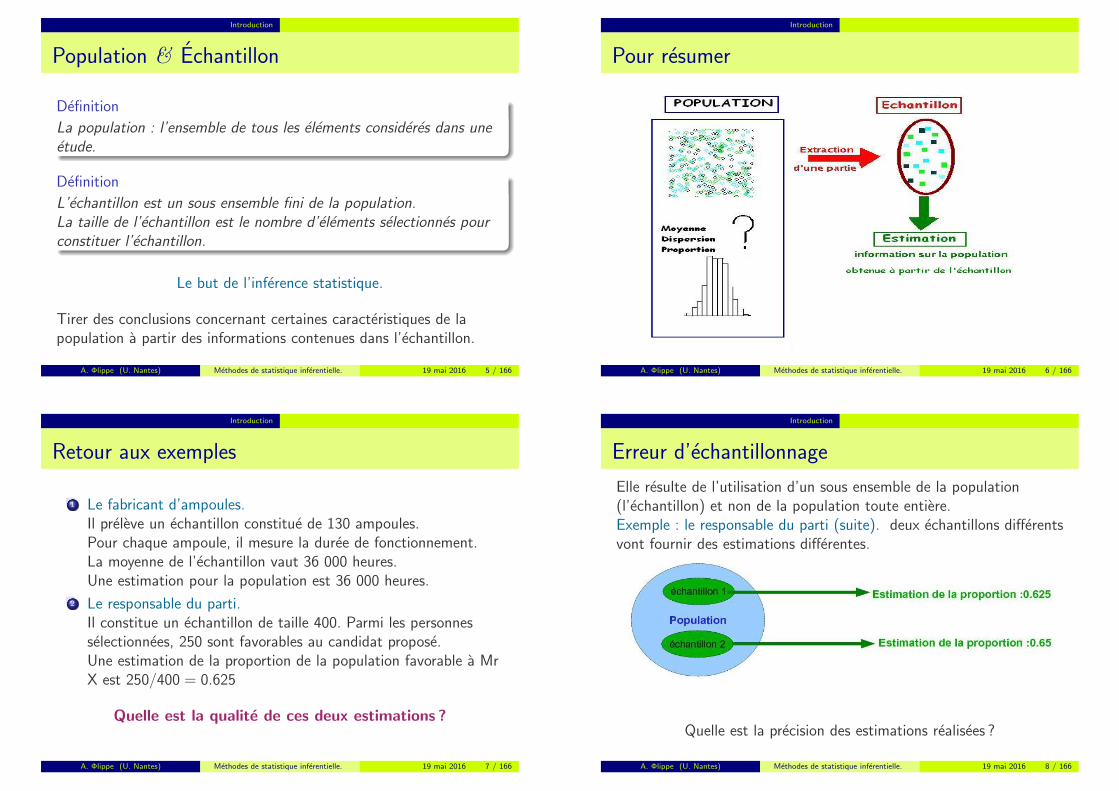
Introduction
Population & Echantillon
Definition
La population : l’ensemble de tous les elements consideres dans uneetude.
Definition
L’echantillon est un sous ensemble fini de la population.La taille de l’echantillon est le nombre d’elements selectionnes pourconstituer l’echantillon.
Le but de l’inference statistique.
Tirer des conclusions concernant certaines caracteristiques de lapopulation a partir des informations contenues dans l’echantillon.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 5 / 166
Introduction
Pour resumer
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 6 / 166
Introduction
Retour aux exemples
1 Le fabricant d’ampoules.Il preleve un echantillon constitue de 130 ampoules.Pour chaque ampoule, il mesure la duree de fonctionnement.La moyenne de l’echantillon vaut 36 000 heures.Une estimation pour la population est 36 000 heures.
2 Le responsable du parti.Il constitue un echantillon de taille 400. Parmi les personnesselectionnees, 250 sont favorables au candidat propose.Une estimation de la proportion de la population favorable a MrX est 250/400 = 0.625
Quelle est la qualite de ces deux estimations ?
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 7 / 166
Introduction
Erreur d’echantillonnage
Elle resulte de l’utilisation d’un sous ensemble de la population(l’echantillon) et non de la population toute entiere.Exemple : le responsable du parti (suite). deux echantillons differentsvont fournir des estimations differentes.
Quelle est la precision des estimations realisees ?
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 8 / 166

Probabilites : Variables Aleatoires Continues
Plan de la section
2 Probabilites : Variables Aleatoires ContinuesGeneralitesLoi gaussienne/normale
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 9 / 166
Probabilites : Variables Aleatoires Continues Generalites
2 Probabilites : Variables Aleatoires ContinuesGeneralitesLoi gaussienne/normale
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 10 / 166
Probabilites : Variables Aleatoires Continues Generalites
Un exemple de loi discrete : la loi Binomiale
Un hotel possede 50 chambres. Au printemps le taux de remplissageest de 75%.On note X le nombre de chambres occupees un jour donne. C’est unevariable aleatoire.X ∈ {0, . . . , 50} prend un nombre fini de valeurs,
c’est une variable aleatoire discrete.La loi de X est la loi binomiale de parametre n = 50 et p = 0.75.c’est a dire, pour tout k ∈ {0, . . . , 50}, on a
P(X = k) = C k50pk(1− p)50−k
La probabilite que l’hotel soit complet vaut
P(X = 50) = C 5050 0.7550(1− 0.75)0 = 0.7550
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 11 / 166
Probabilites : Variables Aleatoires Continues Generalites
Plus generalement
Une variable aleatoire discrete prend un nombre au plusdenombrable de valeurs. L’ensemble des valeurs prises par Xpeut donc s’ecrire de la forme {xi , i ∈ E} ou E est un sousensemble de NLa loi de la variable aleatoire X est la suite des probabilitespk = P(X = xk) pour tout k ∈ E
L’esperance (moyenne) de X :
E(X ) =∑k∈E
pkxk
La variance de X :
var(X ) =∑k∈E
pkx2k −
(∑k∈E
pkxk
)2
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 12 / 166
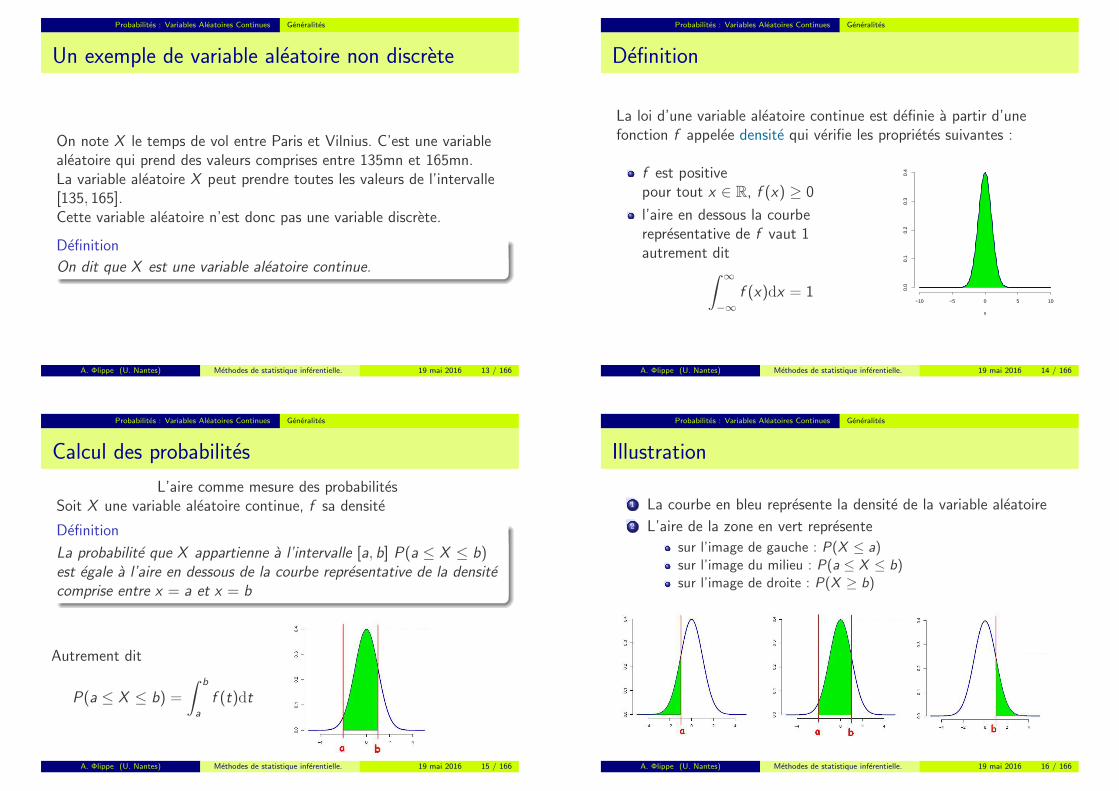
Probabilites : Variables Aleatoires Continues Generalites
Un exemple de variable aleatoire non discrete
On note X le temps de vol entre Paris et Vilnius. C’est une variablealeatoire qui prend des valeurs comprises entre 135mn et 165mn.La variable aleatoire X peut prendre toutes les valeurs de l’intervalle[135, 165].Cette variable aleatoire n’est donc pas une variable discrete.
Definition
On dit que X est une variable aleatoire continue.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 13 / 166
Probabilites : Variables Aleatoires Continues Generalites
Definition
La loi d’une variable aleatoire continue est definie a partir d’unefonction f appelee densite qui verifie les proprietes suivantes :
f est positivepour tout x ∈ R, f (x) ≥ 0
l’aire en dessous la courberepresentative de f vaut 1autrement dit∫ ∞
−∞f (x)dx = 1
−10 −5 0 5 10
0.0
0.1
0.2
0.3
0.4
x
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 14 / 166
Probabilites : Variables Aleatoires Continues Generalites
Calcul des probabilites
L’aire comme mesure des probabilitesSoit X une variable aleatoire continue, f sa densite
Definition
La probabilite que X appartienne a l’intervalle [a, b] P(a ≤ X ≤ b)est egale a l’aire en dessous de la courbe representative de la densitecomprise entre x = a et x = b
Autrement dit
P(a ≤ X ≤ b) =
∫ b
a
f (t)dt
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 15 / 166
Probabilites : Variables Aleatoires Continues Generalites
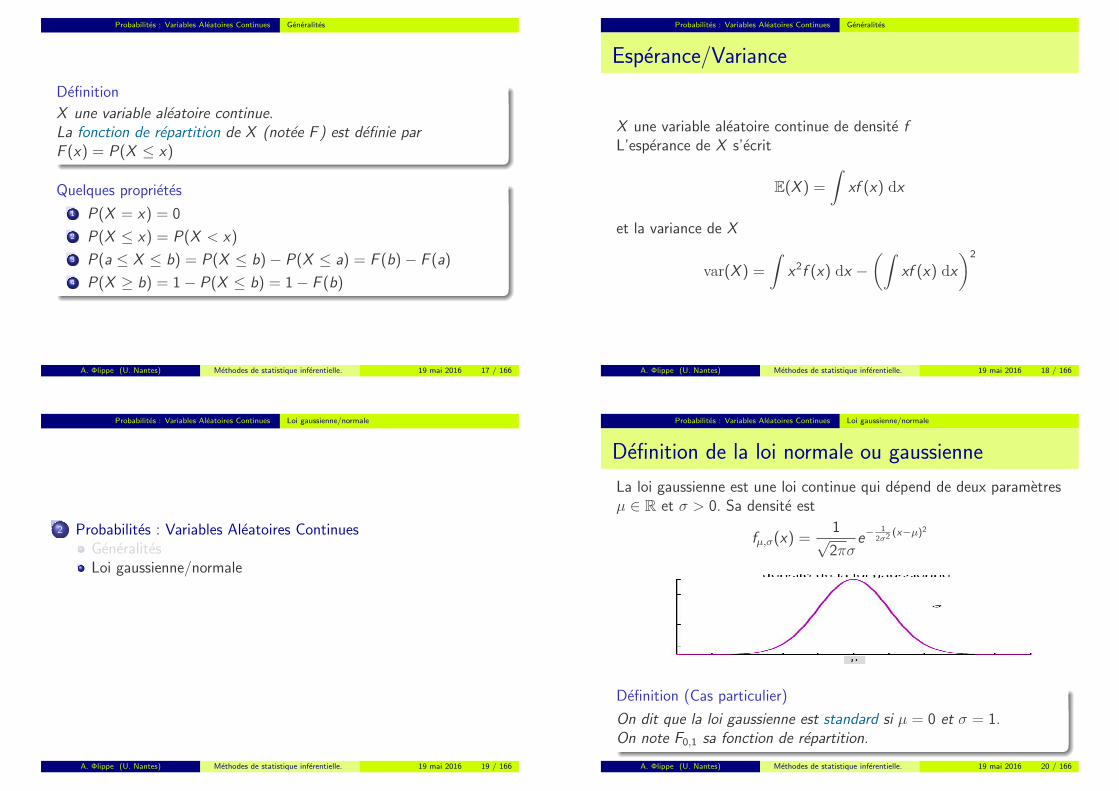
Illustration
1 La courbe en bleu represente la densite de la variable aleatoire2 L’aire de la zone en vert represente
sur l’image de gauche : P(X ≤ a)sur l’image du milieu : P(a ≤ X ≤ b)sur l’image de droite : P(X ≥ b)
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 16 / 166
Probabilites : Variables Aleatoires Continues Generalites
Definition
X une variable aleatoire continue.La fonction de repartition de X (notee F ) est definie parF (x) = P(X ≤ x)
Quelques proprietes
1 P(X = x) = 0
2 P(X ≤ x) = P(X < x)
3 P(a ≤ X ≤ b) = P(X ≤ b)− P(X ≤ a) = F (b)− F (a)
4 P(X ≥ b) = 1− P(X ≤ b) = 1− F (b)
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 17 / 166
Probabilites : Variables Aleatoires Continues Generalites
Esperance/Variance
X une variable aleatoire continue de densite fL’esperance de X s’ecrit
E(X ) =
∫xf (x) dx
et la variance de X
var(X ) =
∫x2f (x) dx −
(∫xf (x) dx
)2
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 18 / 166
Probabilites : Variables Aleatoires Continues Loi gaussienne/normale
2 Probabilites : Variables Aleatoires ContinuesGeneralitesLoi gaussienne/normale
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 19 / 166
Probabilites : Variables Aleatoires Continues Loi gaussienne/normale
Definition de la loi normale ou gaussienne
La loi gaussienne est une loi continue qui depend de deux parametresµ ∈ R et σ > 0. Sa densite est
fµ,σ(x) =1√2πσ
e−1
2σ2 (x−µ)2
Definition (Cas particulier)
On dit que la loi gaussienne est standard si µ = 0 et σ = 1.On note F0,1 sa fonction de repartition.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 20 / 166
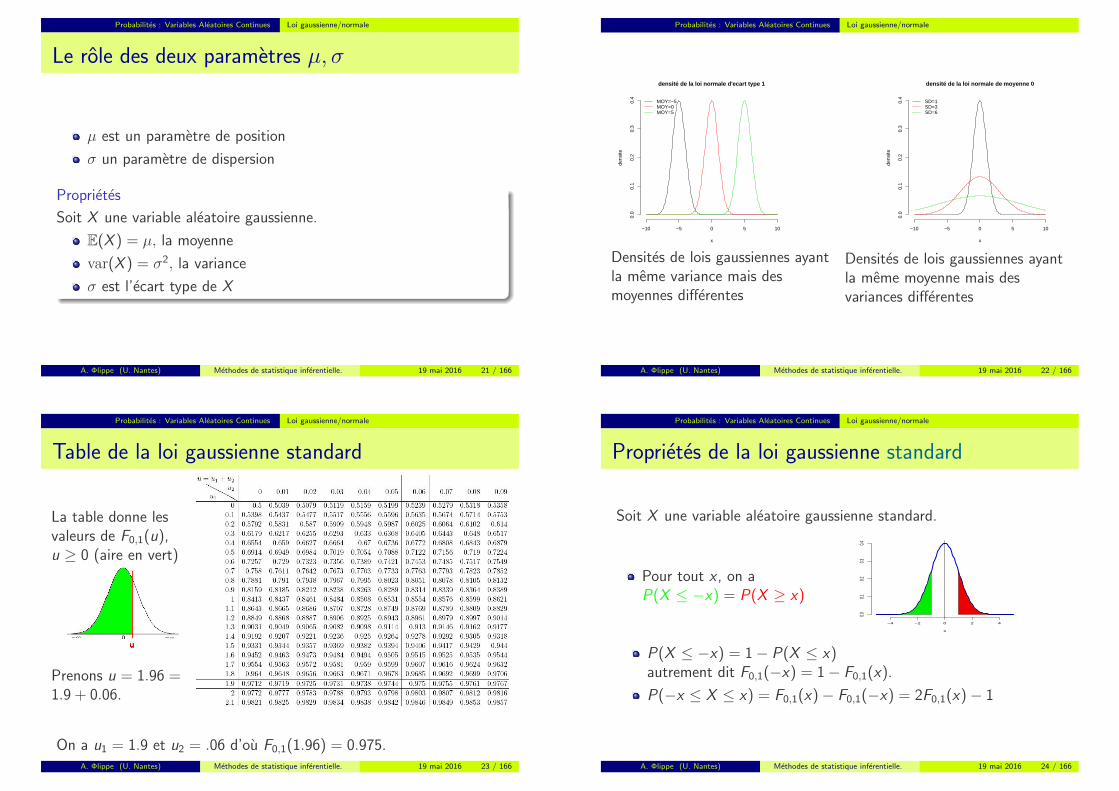
Probabilites : Variables Aleatoires Continues Loi gaussienne/normale
Le role des deux parametres µ, σ
µ est un parametre de position
σ un parametre de dispersion
Proprietes
Soit X une variable aleatoire gaussienne.
E(X ) = µ, la moyenne
var(X ) = σ2, la variance
σ est l’ecart type de X
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 21 / 166
Probabilites : Variables Aleatoires Continues Loi gaussienne/normale
−10 −5 0 5 10
0.0
0.1
0.2
0.3
0.4
x
dens
ite
densité de la loi normale d'ecart type 1
MOY=−5MOY=0MOY=5
−10 −5 0 5 10
0.0
0.1
0.2
0.3
0.4
x
dens
ite
densité de la loi normale de moyenne 0
SD=1SD=3SD=6
Densites de lois gaussiennes ayantla meme variance mais desmoyennes differentes
Densites de lois gaussiennes ayantla meme moyenne mais desvariances differentes
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 22 / 166
Probabilites : Variables Aleatoires Continues Loi gaussienne/normale
Table de la loi gaussienne standard
La table donne lesvaleurs de F0,1(u),u ≥ 0 (aire en vert)
Prenons u = 1.96 =1.9 + 0.06.
On a u1 = 1.9 et u2 = .06 d’ou F0,1(1.96) = 0.975.A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 23 / 166
Probabilites : Variables Aleatoires Continues Loi gaussienne/normale
Proprietes de la loi gaussienne standard
Soit X une variable aleatoire gaussienne standard.
Pour tout x , on aP(X ≤ −x) = P(X ≥ x)
−4 −2 0 2 4
0.00.1
0.20.3
0.4
x
P(X ≤ −x) = 1− P(X ≤ x)autrement dit F0,1(−x) = 1− F0,1(x).
P(−x ≤ X ≤ x) = F0,1(x)− F0,1(−x) = 2F0,1(x)− 1
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 24 / 166

Probabilites : Variables Aleatoires Continues Loi gaussienne/normale
Applications
Soit X une variable aleatoire gaussienne standard.1 En utilisant la table : P(X ≤ 1.96) = F0,1(1.96) = 0.9752 Calcul de P(X ≤ −1.96). Cette valeur n’est pas dans la table.
P(X ≤ −1.96) = F0,1(−1.96) = 1− F0,1(1.96)
= 1− 0.975 = 0.025
3 Calcul de P(−x ≤ X ≤ x) pour x = 1, 2, 3
P(−x ≤ X ≤ x) = F0,1(x)− F0,1(−x)
= 2F0,1(x)− 1
=
0.68 x = 1
0.95 x = 2
0.99 x = 3
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 25 / 166
Probabilites : Variables Aleatoires Continues Loi gaussienne/normale
Lien entre les lois gaussiennes
1 Si la loi de X est la loi gaussienne de moyenne µ et d’ecart typeσ alors la loi de Y = X−µ
σest la loi gaussienne de moyenne 0 et
d’ecart type 1
2 Si la loi de Y est la loi gaussienne de moyenne 0 et d’ecart type1 alors la loi de X = σY + µ est la loi gaussienne de moyenne µet d’ecart type σ
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 26 / 166
Probabilites : Variables Aleatoires Continues Loi gaussienne/normale
Calcul pour la loi gaussienne (µ, σ)
Soit X est une variable gaussienne de moyenne µ et d’ecart type σ.Pour calculer P(X ≤ x), on se ramene a une loi gaussienne standard.On pose
Y =X − µσ
⇔ X = σY + µ
P(X ≤ x) = P(σY + µ ≤ x)
= P(Y ≤ x − µσ
)
Comme la loi de Y est la loi gaussienne standard, le dernier terme estdonne par la table de la loi gaussienne.
P(X ≤ x) = F0,1
(x − µσ
)A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 27 / 166
Probabilites : Variables Aleatoires Continues Loi gaussienne/normale
Exemple
Si la loi de X est gaussienne de moyenne 4 et d’ecart type 2. On poseY = X−4
2
P(X ≤ 6.5) = P(2Y + 4 ≤ 6.5)
= P(Y ≤ 6.5− 4
2)
= P(Y ≤ 1.25) = 0.8943
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 28 / 166

Estimation
Plan de la section
3 EstimationExemple introductifEchantillonnageEstimation ponctuelle d’une moyenneTheoreme central limiteErreur d’estimation : Conclusions probabilistesEstimation par intervalle de la moyenneEstimation ponctuelle d’une varianceEstimation ponctuelle d’une proportionConclusion
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 29 / 166
Estimation Exemple introductif
3 EstimationExemple introductifEchantillonnageEstimation ponctuelle d’une moyenneTheoreme central limiteErreur d’estimation : Conclusions probabilistesEstimation par intervalle de la moyenneEstimation ponctuelle d’une varianceEstimation ponctuelle d’une proportionConclusion
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 30 / 166
Estimation Exemple introductif
La situation
Le directeur du personnel du groupe αβ a ete charge de developper leprofil de 2500 responsables de societes appartenant au groupe αβ.Les caracteristiques a etudier sont
le salaire moyen annuel et sa dispersion
la participation au programme de formation en gestion mis enplace par la societe.
On a donc trois parametres a calculer
la moyenne µ et l’ecart type σ du salaire annuel pour lapopulation
la proportion p de la population ayant suivi la formation
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 31 / 166
Estimation Exemple introductif
Deux methodes
Le recensement. On doit interroger 2500 personnes. Le cout dela collecte est tres eleve, il necessite un entretien avec chaqueresponsable.
L’estimation. On estime les trois parametres a partir d’unechantillon de taille n << 2500. Il faut alors
1 Construire un echantillon de taille n2 Calculer des estimateurs des trois parametres3 Evaluer la qualite des estimateurs.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 32 / 166

Estimation Exemple introductif
On construit un echantillon constitue de 30 responsables de societesdu groupe.Pour chaque personne de l’echantillon, on collecte deux informations
son salaire. On note S1, . . . , S30 les salaires
s’il a participe au programme de formation que l’on code par 1pour oui et 0 pour non. On note F1, . . . ,F30 les reponses
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 33 / 166
Estimation Exemple introductif
les donnees collectees
S F S F S F
1 50427.82 1 11 53714.13 1 21 54276.3 1
2 47770.71 1 12 56641.81 1 22 58389.2 1
3 51686.39 1 13 45535.32 0 23 48762.44 0
4 44520.07 1 14 55626.63 1 24 48916.25 0
5 47976.9 0 15 54898.44 0 25 51026.77 1
6 59979.41 1 16 49246.59 0 26 50999.26 1
7 47022.2 1 17 57261.6 1 27 55811.3 1
8 44252.88 1 18 52876.62 0 28 48622.47 1
9 51641.93 1 19 49841.11 1 29 47226.59 0
10 51206.19 1 20 54256.2 0 30 53419.27 1S = salaireF = formation (0 :non, 1 :oui)
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 34 / 166
Estimation Exemple introductif
Caracteristiques de l’echantillon
1 moyenne de l’echantillon : x = 51461.09
2 ecart type de l’echantillon : S = 4091.18
3 proportion de l’echantillon ayant suivi le programme deformation : p = .7
x1, . . . , xn un echantillon de taille n.
sa moyenne : x = 1n
∑ni=1 xi
sa variance : S2 = 1n
∑ni=1(xi − x)2
son ecart type S =√
1n
∑ni=1(xi − x)2
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 35 / 166
Estimation Exemple introductif
Recensement
Apres un recensement de la population entiere, on obtient
1 moyenne de la population µ = 51800 x = 51461.09
2 ecart type de la population σ = 4000 S = 4091.18
3 proportion de la population ayant suivi le programme deformation p = .67 p = .7
Les valeurs calculees sur l’echantillon ne correspondent pasexactement aux valeurs de la population.
Erreur d’echantillonnage
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 36 / 166

Estimation Exemple introductif
Evaluation des erreurs
Erreur absolue : EA = |estimation− vraie valeur|
Erreur relative : ER =EA
vraie valeur
ici
1 sur la moyenne : EA = |x − µ| = 338.90 et
ER =|x − µ|µ
< 0.01%
2 Sur l’ecart type : EA = 91.18 et ER = 2.2%
3 sur la proportion : EA = .03 et ER = 5%
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 37 / 166
Estimation Echantillonnage
3 EstimationExemple introductifEchantillonnageEstimation ponctuelle d’une moyenneTheoreme central limiteErreur d’estimation : Conclusions probabilistesEstimation par intervalle de la moyenneEstimation ponctuelle d’une varianceEstimation ponctuelle d’une proportionConclusion
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 38 / 166
Estimation Echantillonnage
Definition d’un echantillon
On suppose que l’on dispose d’un echantillon aleatoire de taille n issud’une population.
L’echantillon satisfait les conditions suivantes1 Tous les individus sont selectionnes dans la meme population
2 Les individus sont selectionnes de facon independante.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 39 / 166
Estimation Estimation ponctuelle d’une moyenne
3 EstimationExemple introductifEchantillonnageEstimation ponctuelle d’une moyenneTheoreme central limiteErreur d’estimation : Conclusions probabilistesEstimation par intervalle de la moyenneEstimation ponctuelle d’une varianceEstimation ponctuelle d’une proportionConclusion
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 40 / 166
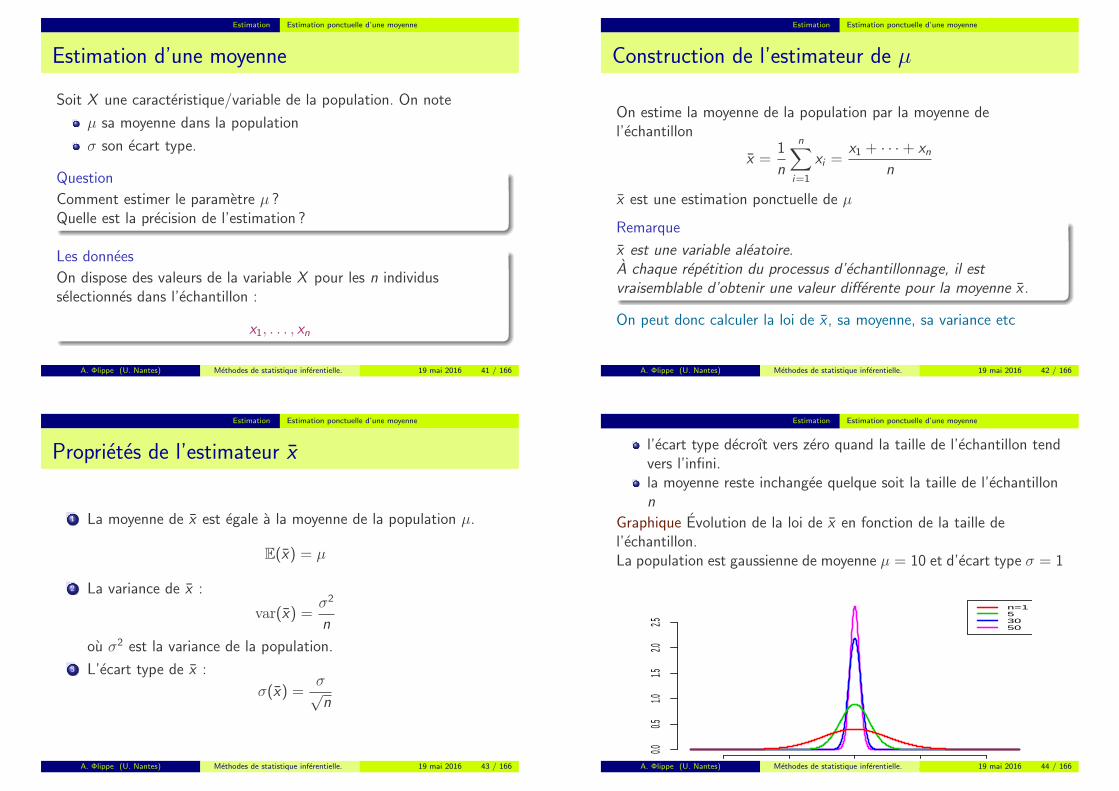
Estimation Estimation ponctuelle d’une moyenne
Estimation d’une moyenne
Soit X une caracteristique/variable de la population. On note
µ sa moyenne dans la population
σ son ecart type.
Question
Comment estimer le parametre µ ?Quelle est la precision de l’estimation ?
Les donnees
On dispose des valeurs de la variable X pour les n individusselectionnes dans l’echantillon :
x1, . . . , xn
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 41 / 166
Estimation Estimation ponctuelle d’une moyenne
Construction de l’estimateur de µ
On estime la moyenne de la population par la moyenne del’echantillon
x =1
n
n∑i=1
xi =x1 + · · ·+ xn
n
x est une estimation ponctuelle de µ
Remarque
x est une variable aleatoire.A chaque repetition du processus d’echantillonnage, il estvraisemblable d’obtenir une valeur differente pour la moyenne x.
On peut donc calculer la loi de x , sa moyenne, sa variance etc
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 42 / 166
Estimation Estimation ponctuelle d’une moyenne
Proprietes de l’estimateur x
1 La moyenne de x est egale a la moyenne de la population µ.
E(x) = µ
2 La variance de x :
var(x) =σ2
n
ou σ2 est la variance de la population.
3 L’ecart type de x :
σ(x) =σ√n
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 43 / 166
Estimation Estimation ponctuelle d’une moyenne
l’ecart type decroıt vers zero quand la taille de l’echantillon tendvers l’infini.la moyenne reste inchangee quelque soit la taille de l’echantillonn
Graphique Evolution de la loi de x en fonction de la taille del’echantillon.La population est gaussienne de moyenne µ = 10 et d’ecart type σ = 1
6 8 10 12 14
0.00.5
1.01.5
2.02.5
n=153050
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 44 / 166
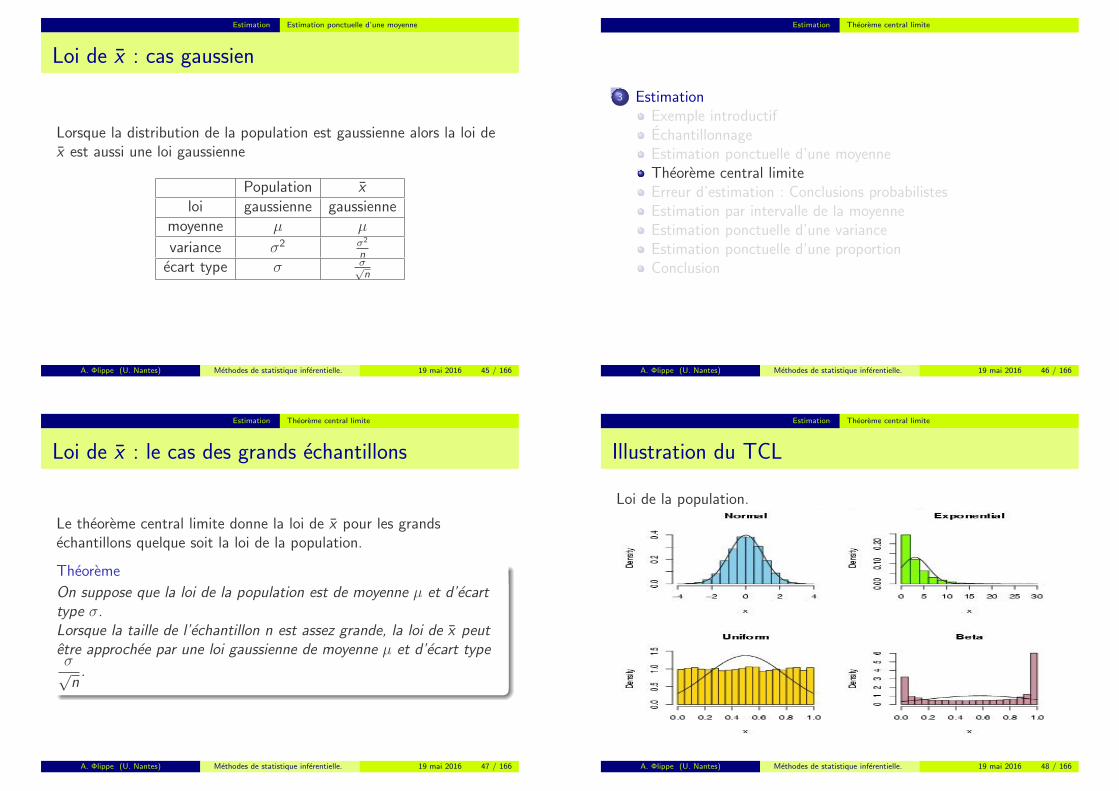
Estimation Estimation ponctuelle d’une moyenne
Loi de x : cas gaussien
Lorsque la distribution de la population est gaussienne alors la loi dex est aussi une loi gaussienne
Population xloi gaussienne gaussienne
moyenne µ µ
variance σ2 σ2
n
ecart type σ σ√n
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 45 / 166
Estimation Theoreme central limite
3 EstimationExemple introductifEchantillonnageEstimation ponctuelle d’une moyenneTheoreme central limiteErreur d’estimation : Conclusions probabilistesEstimation par intervalle de la moyenneEstimation ponctuelle d’une varianceEstimation ponctuelle d’une proportionConclusion
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 46 / 166
Estimation Theoreme central limite
Loi de x : le cas des grands echantillons
Le theoreme central limite donne la loi de x pour les grandsechantillons quelque soit la loi de la population.
Theoreme
On suppose que la loi de la population est de moyenne µ et d’ecarttype σ.Lorsque la taille de l’echantillon n est assez grande, la loi de x peutetre approchee par une loi gaussienne de moyenne µ et d’ecart typeσ√n
.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 47 / 166
Estimation Theoreme central limite
Illustration du TCL
Loi de la population.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 48 / 166
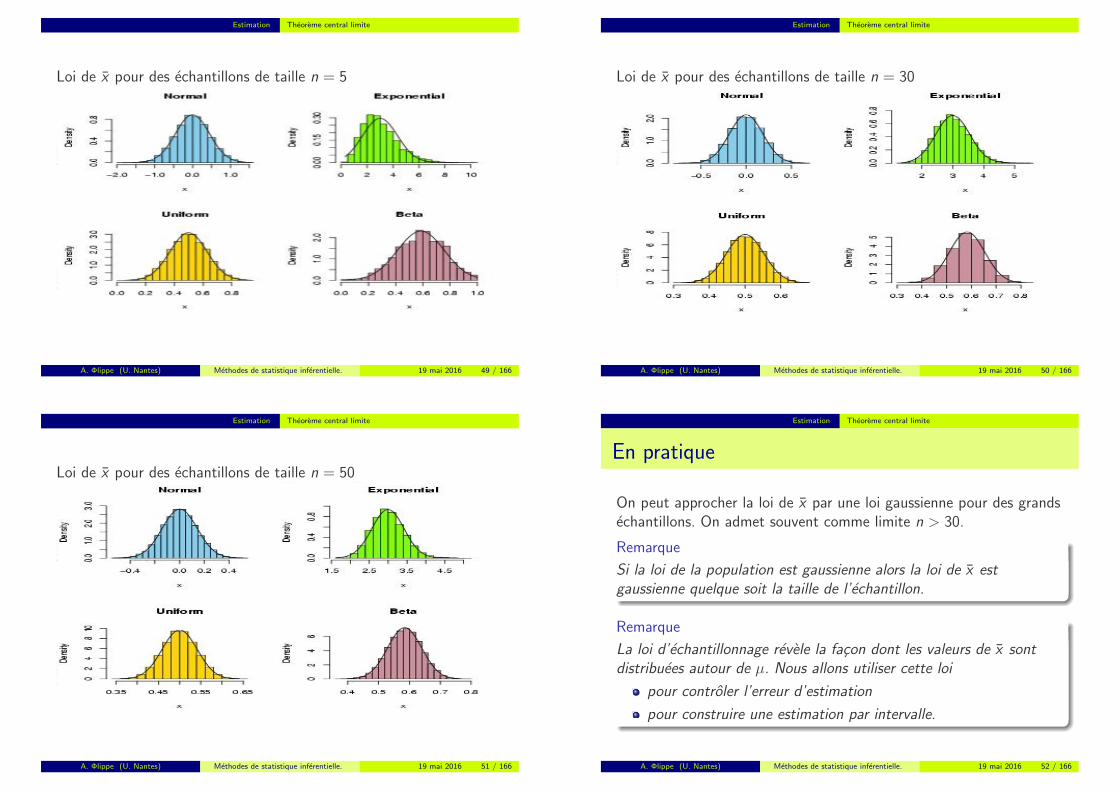
Estimation Theoreme central limite
Loi de x pour des echantillons de taille n = 5
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 49 / 166
Estimation Theoreme central limite
Loi de x pour des echantillons de taille n = 30
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 50 / 166
Estimation Theoreme central limite
Loi de x pour des echantillons de taille n = 50
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 51 / 166
Estimation Theoreme central limite
En pratique
On peut approcher la loi de x par une loi gaussienne pour des grandsechantillons. On admet souvent comme limite n > 30.
Remarque
Si la loi de la population est gaussienne alors la loi de x estgaussienne quelque soit la taille de l’echantillon.
Remarque
La loi d’echantillonnage revele la facon dont les valeurs de x sontdistribuees autour de µ. Nous allons utiliser cette loi
pour controler l’erreur d’estimation
pour construire une estimation par intervalle.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 52 / 166

Estimation Erreur d’estimation : Conclusions probabilistes
3 EstimationExemple introductifEchantillonnageEstimation ponctuelle d’une moyenneTheoreme central limiteErreur d’estimation : Conclusions probabilistesEstimation par intervalle de la moyenneEstimation ponctuelle d’une varianceEstimation ponctuelle d’une proportionConclusion
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 53 / 166
Estimation Erreur d’estimation : Conclusions probabilistes
Erreur d’estimation : conclusions probabilistes
La connaissance de la loi de x permet de tirer des conclusionsprobabilistes sur l’erreur |x − µ| (meme si µ est inconnu)Les situations etudiees sont les suivantes
les grands echantillons
σ connuσ inconnu
les petits echantillons pour des populations gaussiennes
σ connuσ inconnu
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 54 / 166
Estimation Erreur d’estimation : Conclusions probabilistes
Cas des grands echantillons n > 30
D’apres le theoreme central limite la loi de x peut etre approchee parune loi gaussienne de moyenne µ et d’ecart type σ/
√n.
⇒ la loi de√
nx − µσ
peut etre approchee par une loi gaussienne
standard.
Soit Z une variable gaussienne standard. D’apres la table de la loigaussienne, on sait que P(Z ∈ [−1, 96 ; 1.96]) = 0.95
En effetP(Z ∈ [−a ; a]) = 2F0,1(a)− 1 = 0.95 et F0,1(1.96) = 0.975
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 55 / 166
Estimation Erreur d’estimation : Conclusions probabilistes
Par consequent
P
(√n
x − µσ∈ [−1, 96 ; 1.96]
)= 0.95
c’est a dire
P
(x − µ ∈
[−1, 96
σ√n
; 1.96σ√n
])= 0.95
Conclusion probabiliste sur l’erreur
95% des valeurs de x generent une erreur absolue inferieure a
1, 96σ√n
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 56 / 166
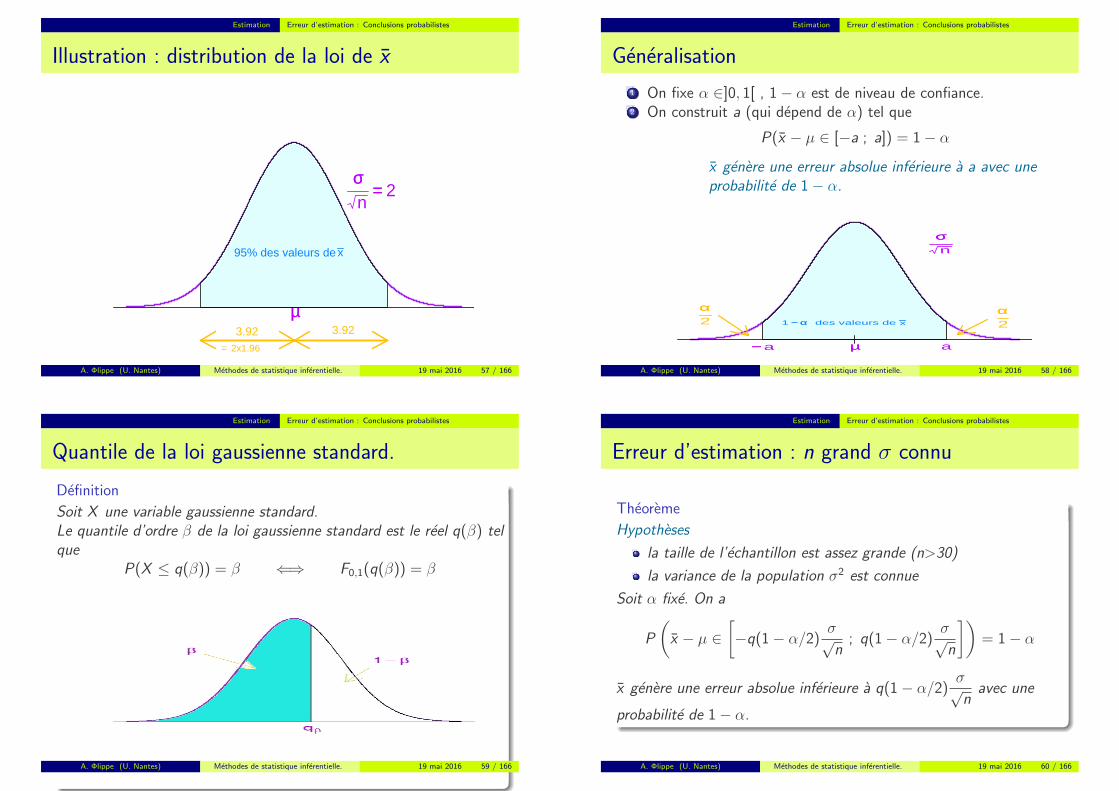
Estimation Erreur d’estimation : Conclusions probabilistes
Illustration : distribution de la loi de x
µµ
95% des valeurs de x
σσn
== 2
3.92 3.92
2x1.96=
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 57 / 166
Estimation Erreur d’estimation : Conclusions probabilistes
Generalisation
1 On fixe α ∈]0, 1[ , 1− α est de niveau de confiance.2 On construit a (qui depend de α) tel que
P(x − µ ∈ [−a ; a]) = 1− α
x genere une erreur absolue inferieure a a avec uneprobabilite de 1− α.
µµ
des valeurs de1 −− αα x
σσn
αα2
αα2
a−− a
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 58 / 166
Estimation Erreur d’estimation : Conclusions probabilistes
Quantile de la loi gaussienne standard.
Definition
Soit X une variable gaussienne standard.Le quantile d’ordre β de la loi gaussienne standard est le reel q(β) telque
P(X ≤ q(β)) = β ⇐⇒ F0,1(q(β)) = β
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 59 / 166
Estimation Erreur d’estimation : Conclusions probabilistes
Erreur d’estimation : n grand σ connu
Theoreme
Hypotheses
la taille de l’echantillon est assez grande (n>30)
la variance de la population σ2 est connue
Soit α fixe. On a
P
(x − µ ∈
[−q(1− α/2)
σ√n
; q(1− α/2)σ√n
])= 1− α
x genere une erreur absolue inferieure a q(1− α/2)σ√n
avec une
probabilite de 1− α.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 60 / 166

Estimation Erreur d’estimation : Conclusions probabilistes
le calcul ...
On remarque que
x − µ ∈[−q(1− α/2)
σ√n
; q(1− α/2)σ√n
]m
√n
σ(x − µ) ∈ [−q(1− α/2) ; q(1− α/2)]
Comme la loi de
√n
σ(x − µ) peut etre approchee par la loi gaussienne
standard, on a
P = P
(x − µ ∈
[−q(1− α/2)
σ√n
; q(1− α/2)σ√n
])= F0,1(q(1− α/2))− F0,1(−q(1− α/2))
= 2F0,1(q(1− α/2))− 1 = 2(1− α/2)− 1 = 1− αA. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 61 / 166
Estimation Erreur d’estimation : Conclusions probabilistes
Grands echantillons, σ est inconnu
Les intervalles dependent de l’ecart type de la population σ quigeneralement est inconnu.On estime l’ecart type de la population par celui de l’echantillon
S =
√√√√1
n
n∑i=1
(xi − x)2
Remarque
S2 est un estimateur ponctuel de la variance de la population σ2
Theoreme
Quand n est assez grand, la loi de
√n
S(x − µ) peut etre approchee
par la loi gaussienne standard.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 62 / 166
Estimation Erreur d’estimation : Conclusions probabilistes
Erreur d’estimation : n grand σ inconnu
Theoreme
Hypotheses
la taille de l’echantillon est assez grande (n>30)
la variance de la population σ2 est inconnue
Soit α fixe. On a
P
(x − µ ∈
[−q(1− α/2)
S√n
; q(1− α/2)S√
n
])= 1− α
x genere une erreur absolue inferieure a q(1− α/2)S√
navec une
probabilite de 1− α.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 63 / 166
Estimation Erreur d’estimation : Conclusions probabilistes
Cas des petits echantillons gaussiens
Si la loi de la population est gaussienne alors la loi de
√n
σ(x − µ) est
la loi gaussienne standard
Theoreme
Hypotheses
la population est gaussienne
la variance de la population σ2 est connue
Soit α fixe. On a
P
(x − µ ∈
[−q(1− α/2)
σ√n
; q(1− α/2)σ√n
])= 1− α
x genere une erreur absolue inferieure a q(1− α/2)σ√n
avec une
probabilite de 1− α.A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 64 / 166
Estimation Erreur d’estimation : Conclusions probabilistes
Loi de Student
Soit ν ∈ R+. La loi de Student a ν degres de liberte est une loicontinue dont la densite est de la forme
Proposition
Quand le degre de liberte ν est grand, on peut approcher la loi deStudent par une loi gaussienne standard
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 65 / 166
Estimation Erreur d’estimation : Conclusions probabilistes
Fonction de repartition des lois de Student
Soit X une variabledistribuee suivant laloi de Student a νdegres de liberte.P = P(X ≤ u) (aireen vert)
si ν = 8 alorsP(X < 1.859) =0.95.
e
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 66 / 166
Estimation Erreur d’estimation : Conclusions probabilistes
Quantiles de la loi de Student
On note t(ν, β) le quantile d’ordreβ de la loi de Student a ν degresde liberte.
P(X ≤ t(ν, β)) = β
Fixons β = 0.975
ν 1 2 3 20 30 40 500t(ν, 0.975) 12.706 4.302 3.182 2.085 2.041 2.022 1.960
Pour la loi gaussienne standard, on a q(0.975) = 1.96.A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 67 / 166
Estimation Erreur d’estimation : Conclusions probabilistes
Petits echantillons gaussiens, σ inconnu
Important : On commence par corriger l’estimateur de la varianceOn pose
S2c =
1
n − 1
n∑i=1
(xi − x)2 =n
n − 1S2
Definition
S2c est la variance modifiee/corrigee de l’echantillon. C’est un
estimateur ponctuel de la variance de la population
Theoreme
La loi de
√n
Sc(x − µ) est une loi de Student a n − 1 degres de liberte.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 68 / 166

Estimation Erreur d’estimation : Conclusions probabilistes
Erreur d’estimation : population gaussienne, σ
inconnu
Theoreme
Hypotheses
la population est gaussienne
la variance de la population σ2 est inconnue
Soit α fixe. On a
P
(x − µ ∈
[−t(n − 1, 1− α/2)
Sc√n
; t(n − 1, 1− α/2)Sc√
n
])= 1− α
x genere une erreur absolue inferieure a t(n − 1, 1− α/2)Sc√
navec
une probabilite de 1− α.A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 69 / 166
Estimation Estimation par intervalle de la moyenne
3 EstimationExemple introductifEchantillonnageEstimation ponctuelle d’une moyenneTheoreme central limiteErreur d’estimation : Conclusions probabilistesEstimation par intervalle de la moyenneEstimation ponctuelle d’une varianceEstimation ponctuelle d’une proportionConclusion
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 70 / 166
Estimation Estimation par intervalle de la moyenne
Estimation par intervalle
A partir de l’echantillon, on souhaite construire un intervalle quiverifie la propriete suivante :
il y a une probabilite 1− α que l’intervalle contienne lamoyenne de la population.
Definitions1 1− α est le coefficient de confiance.
2 L’intervalle obtenu est appele intervalle de confiance de niveau1− α.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 71 / 166
Estimation Estimation par intervalle de la moyenne
Cas des grands echantillons
Estimation par intervalle de la moyenne d’une population
Hypotheses
la taille de l’echantillon est assez grande (n>30)
la variance de la population σ2 est connue[x − σ√
nq(1− α/2) ; x +
σ√n
q(1− α/2)
]est un intervalle de confiance de niveau 1− α pour la moyenne µ
il y a une probabilite 1− α que l’intervalle deconfiance contienne la moyenne de la population.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 72 / 166
Estimation Estimation par intervalle de la moyenne
le calcul
Il y a une probabilite 1− α que la valeur de x genere une erreur
inferieure aσ√n
q(1− α/2) d’ou
P(|x − µ| ≤ σ√n
q(1− α/2)) = 1− α
Ensuite, il suffit de remarquer que
|x − µ| ≤ σ√n
q(1− α/2)
m
µ ∈[
x − σ√n
q(1− α/2) ; x +σ√n
q(1− α/2)
]A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 73 / 166
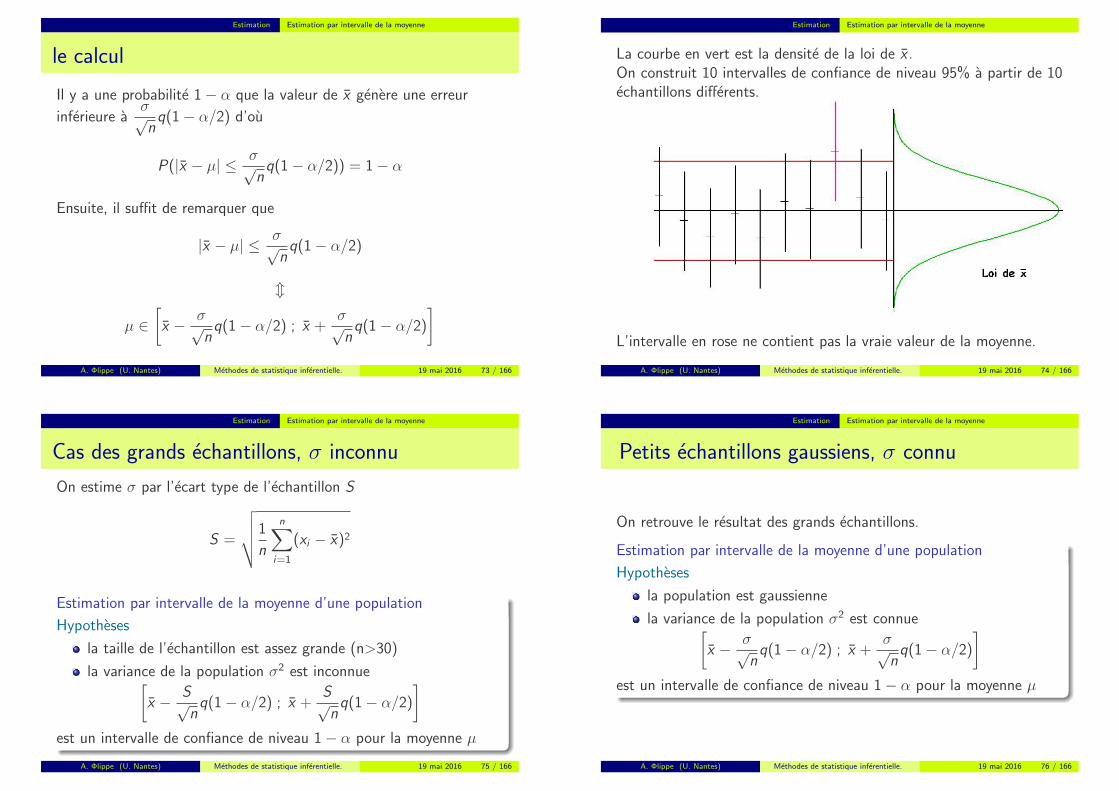
Estimation Estimation par intervalle de la moyenne
La courbe en vert est la densite de la loi de x .On construit 10 intervalles de confiance de niveau 95% a partir de 10echantillons differents.
L’intervalle en rose ne contient pas la vraie valeur de la moyenne.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 74 / 166
Estimation Estimation par intervalle de la moyenne
Cas des grands echantillons, σ inconnu
On estime σ par l’ecart type de l’echantillon S
S =
√√√√1
n
n∑i=1
(xi − x)2
Estimation par intervalle de la moyenne d’une population
Hypotheses
la taille de l’echantillon est assez grande (n>30)
la variance de la population σ2 est inconnue[x − S√
nq(1− α/2) ; x +
S√n
q(1− α/2)
]est un intervalle de confiance de niveau 1− α pour la moyenne µ
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 75 / 166
Estimation Estimation par intervalle de la moyenne
Petits echantillons gaussiens, σ connu
On retrouve le resultat des grands echantillons.
Estimation par intervalle de la moyenne d’une population
Hypotheses
la population est gaussienne
la variance de la population σ2 est connue[x − σ√
nq(1− α/2) ; x +
σ√n
q(1− α/2)
]est un intervalle de confiance de niveau 1− α pour la moyenne µ
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 76 / 166

Estimation Estimation par intervalle de la moyenne
Petits echantillons gaussiens, σ inconnu
On utilise l’ecart type corrige de l’echantillon Sc pour estimer σ
Sc =
√√√√ 1
n − 1
n∑i=1
(xi − x)2
Estimation par intervalle de la moyenne d’une population
Hypotheses
la population est gaussienne
la variance de la population σ2 est inconnue[x − Sc√
nt(n − 1, 1− α/2) ; x +
Sc√n
t(n − 1, 1− α/2)
]est un intervalle de confiance de niveau 1− α pour la moyenne µ.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 77 / 166
Estimation Estimation par intervalle de la moyenne
Retour a l’exemple du groupe αβ
On suppose que la population est gaussienne.Situation 1 On dispose d’un echantillon de taille 30 et la variance dela population est connue.Avec une probabilite de 95%, l’erreur est inferieure a
1.96σ1√n
= 1.96 ∗ 4000/√
30 = 1431.382
L’intervalle de confiance au niveau 95% est[51461.09− 1431.38 ; 51461.09 + 1431.38] = [50029.7 ; 52892.4]
Remarque
Sur l’echantillon selectionne, nous avions EA = |x − µ| = 338.90apres recensement. Le cas observe appartient aux 95% des casfavorables.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 78 / 166
Estimation Estimation par intervalle de la moyenne
Situation 2 On suppose que la loi des salaires est gaussienne. Lavariance de la population est inconnue.
Calcul de la variance modifiee S2c = S230/29. D’ou
Sc =√
S230/29 = 4161.12
Dans la table de la loi de Student , on trouve t(29, 0.975) = 2.04
Avec une probabilite de 95%, l’erreur est inferieure a2.04 ∗ 4161.1/
√30 = 1553.78
L’intervalle de confiance au niveau 95% est
[51461.09− 1553.78 ; 51461.09 + 1553.78] = [49907.31 ; 53014.87]
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 79 / 166
Estimation Estimation par intervalle de la moyenne
Pour resumerLes intervalles de confiance sur la moyenne de la population
petits echantillons grands echantillonsloi gaussienne quelle que soit la loi
σ connu
[x ± σ√
nq(1− α/2)
] [x ± σ√
nq(1− α/2)
]σ inconnu
[x ± Sc√
nt(n − 1, 1− α/2)
] [x ± S√
nq(1− α/2)
]Notations :
[a ± b] est l’intervalle [a − b; a + b]
S =√
1n
∑ni=1(xi − x)2 et Sc =
√1
n−1
∑ni=1(xi − x)2
q(β) est le quantile d’ordre β de la loi gaussienne standard ett(ν, β) celui de la loi de Student a ν degres de liberte
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 80 / 166
Estimation Estimation ponctuelle d’une variance
3 EstimationExemple introductifEchantillonnageEstimation ponctuelle d’une moyenneTheoreme central limiteErreur d’estimation : Conclusions probabilistesEstimation par intervalle de la moyenneEstimation ponctuelle d’une varianceEstimation ponctuelle d’une proportionConclusion
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 81 / 166
Estimation Estimation ponctuelle d’une variance
Construction de l’estimateur
On souhaite estimer la variance de la population.1er estimateur : On estime la variance de la population par lavariance de l’echantillon
S2 =1
n
n∑i=1
(xi − x)2
Remarque (estimation biaisee)
E(S2) = n−1nσ2 6= σ2 on dit que l’estimateur a un biais.
2eme estimateur : On ameliore l’estimateur S2 en prenant lavariance modifiee
S2c =
1
n − 1
n∑i=1
(xi − x)2
Le biais est corrige, on a E(S2c ) = σ2
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 82 / 166
Estimation Estimation ponctuelle d’une variance
Proprietes de S2c
La moyenne de S2c est egale a la variance de la population µ
E(S2c ) = σ2
La variance de S2c converge vers zero pour des variables L4. De
plus si l’echantillon est gaussien, on a
var(S2c ) = σ4 2
n − 1
Comparaison des deux estimateurs
Quand la taille de l’echantillon est grande, les deux estimateurs sontequivalents.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 83 / 166
Estimation Estimation ponctuelle d’une variance
Loi du χ2
Soit ν ∈ R+. La loi du χ2 a ν degres de liberte est une loi continue.La densite est de la forme
Remarque
La densite est nulle sur R− donc P(X < 0) = 0 et P(X ≥ 0) = 1
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 84 / 166
Estimation Estimation ponctuelle d’une variance
Proposition
Quand le degre de liberte ν est grand, on peut approcher la loi du χ2
par la loi gaussienne de moyenne ν et d’ecart type√
2ν
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 85 / 166
Estimation Estimation ponctuelle d’une variance
Fonction de repartition des lois du χ2
Soit X une variabledistribuee suivant laloi du χ2 a ν degresde liberte.P = P(X ≤ u)
si ν = 5 alorsP(X < 11.07) =0.95.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 86 / 166
Estimation Estimation ponctuelle d’une variance
Quantiles de la loi du χ2
On note k(ν, β) le quantile d’ordreβ de la loi du χ2 a ν degres deliberte.
P(X ≤ k(ν, β)) = β
Fixons β = 0.975ν 1 3 5 10 20 500
k(ν, 0.975) 5.02 9.35 12.83 20.48 34.17 563.85
Pour la loi gaussienne de moyenne 500 et d’ecart type√
1000, lequantile superieur d’ordre β = 0.975 vaut 561.97
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 87 / 166
Estimation Estimation ponctuelle d’une variance
Loi de l’estimateur S2c
Theoreme
Si la population est gaussienne alors la loi den − 1
σ2S2c est la loi du χ2
a n − 1 degres de liberte.
Grands echantillons gaussien
Quand la taille de la population est assez grande (n > 30), on peut
approcher la loi den − 1
σ2S2c par la loi gaussienne de moyenne n− 1 et
d’ecart type√
2n − 2.
Autrement dit on peut approcher la loi de
(S2c
σ2− 1
) √n − 1√
2par la
loi gaussienne standard
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 88 / 166

Estimation Estimation ponctuelle d’une variance
Intervalle de confiance pour la variance
Estimation par intervalle de la variance d’une population
Hypotheses
la population est gaussienne[(n − 1)S2
c
k(n − 1, 1− α/2);
(n − 1)S2c
k(n − 1, α/2)
]est un intervalle de confiance de niveau 1− α pour la variance σ2
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 89 / 166
Estimation Estimation ponctuelle d’une variance
Approximation gaussienne
Estimation par intervalle de la variance d’une population gaussienne
Quand la taille de l’echantillon est assez grande n > 30, S2c
1 +q(1− α/2)
√2√
n − 1
;S2c
1− q(1− α/2)√
2√n − 1
est un intervalle de confiance de niveau 1− α pour la variance σ2
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 90 / 166
Estimation Estimation ponctuelle d’une proportion
3 EstimationExemple introductifEchantillonnageEstimation ponctuelle d’une moyenneTheoreme central limiteErreur d’estimation : Conclusions probabilistesEstimation par intervalle de la moyenneEstimation ponctuelle d’une varianceEstimation ponctuelle d’une proportionConclusion
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 91 / 166
Estimation Estimation ponctuelle d’une proportion
Construction de l’estimateur
On etudie une caracteristique X qui prend deux modalites {0, 1}.Soit p la proportion de la population qui possede la modalite 1On veut estimer p a partir de notre echantillon.
Construction de l’estimateur
On note p la proportion de l’echantillon qui possede la modalite 1.C’est un estimateur ponctuel de p
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 92 / 166
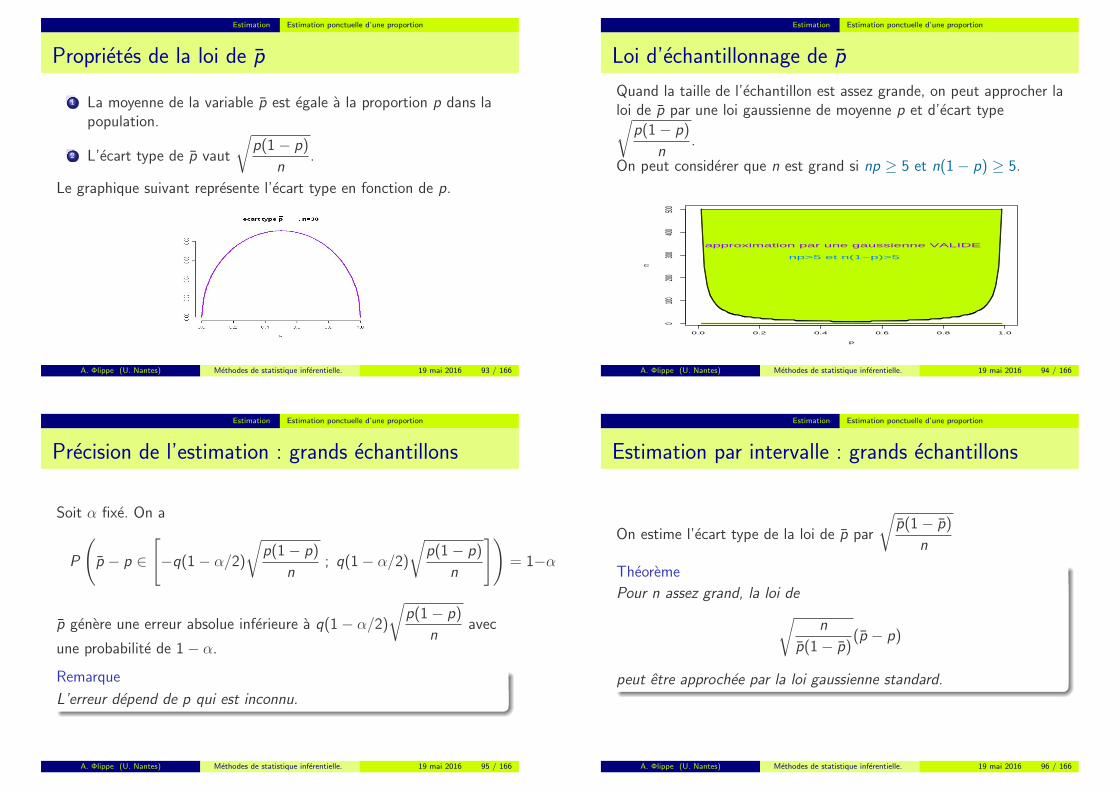
Estimation Estimation ponctuelle d’une proportion
Proprietes de la loi de p
1 La moyenne de la variable p est egale a la proportion p dans lapopulation.
2 L’ecart type de p vaut
√p(1− p)
n.
Le graphique suivant represente l’ecart type en fonction de p.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 93 / 166
Estimation Estimation ponctuelle d’une proportion
Loi d’echantillonnage de p
Quand la taille de l’echantillon est assez grande, on peut approcher laloi de p par une loi gaussienne de moyenne p et d’ecart type√
p(1− p)
n.
On peut considerer que n est grand si np ≥ 5 et n(1− p) ≥ 5.
0.0 0.2 0.4 0.6 0.8 1.0
0100
200300
400500
p
n
approximation par une gaussienne VALIDE
np>5 et n(1−p)>5
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 94 / 166
Estimation Estimation ponctuelle d’une proportion
Precision de l’estimation : grands echantillons
Soit α fixe. On a
P
(p − p ∈
[−q(1− α/2)
√p(1− p)
n; q(1− α/2)
√p(1− p)
n
])= 1−α
p genere une erreur absolue inferieure a q(1− α/2)
√p(1− p)
navec
une probabilite de 1− α.
Remarque
L’erreur depend de p qui est inconnu.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 95 / 166
Estimation Estimation ponctuelle d’une proportion
Estimation par intervalle : grands echantillons
On estime l’ecart type de la loi de p par
√p(1− p)
n
Theoreme
Pour n assez grand, la loi de√n
p(1− p)(p − p)
peut etre approchee par la loi gaussienne standard.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 96 / 166
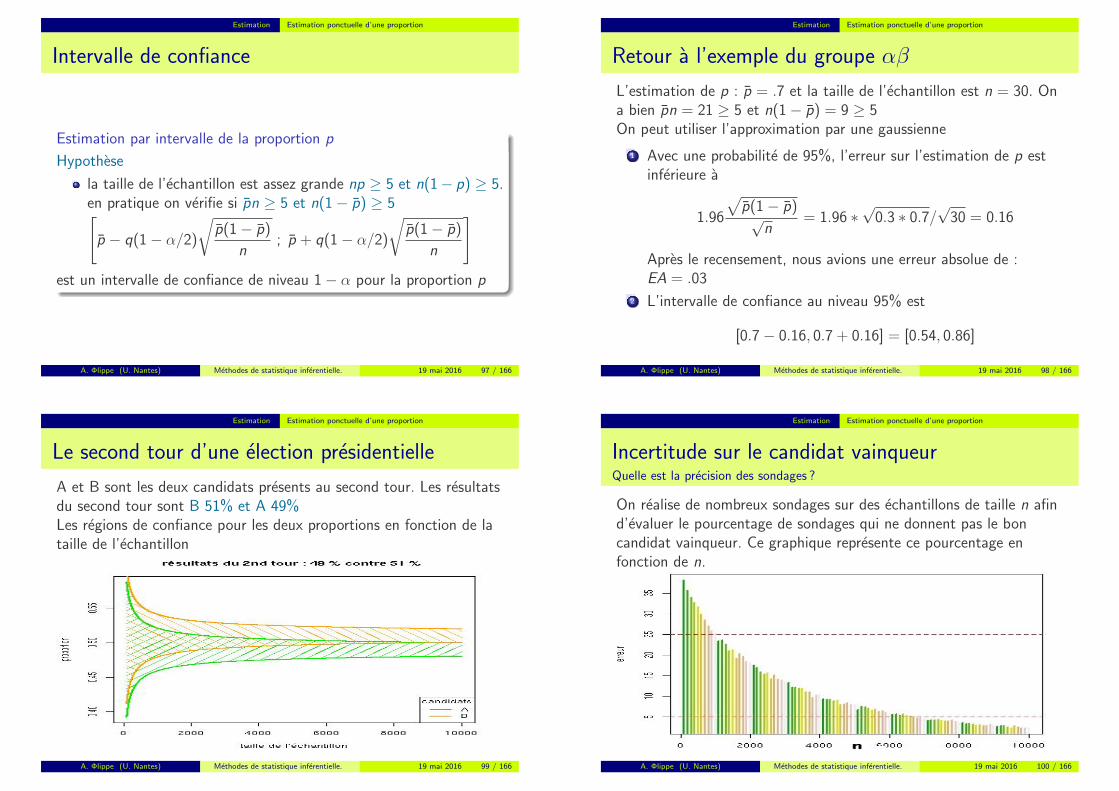
Estimation Estimation ponctuelle d’une proportion
Intervalle de confiance
Estimation par intervalle de la proportion p
Hypothese
la taille de l’echantillon est assez grande np ≥ 5 et n(1− p) ≥ 5.en pratique on verifie si pn ≥ 5 et n(1− p) ≥ 5[
p − q(1− α/2)
√p(1− p)
n; p + q(1− α/2)
√p(1− p)
n
]est un intervalle de confiance de niveau 1− α pour la proportion p
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 97 / 166
Estimation Estimation ponctuelle d’une proportion
Retour a l’exemple du groupe αβ
L’estimation de p : p = .7 et la taille de l’echantillon est n = 30. Ona bien pn = 21 ≥ 5 et n(1− p) = 9 ≥ 5On peut utiliser l’approximation par une gaussienne
1 Avec une probabilite de 95%, l’erreur sur l’estimation de p estinferieure a
1.96
√p(1− p)√
n= 1.96 ∗
√0.3 ∗ 0.7/
√30 = 0.16
Apres le recensement, nous avions une erreur absolue de :EA = .03
2 L’intervalle de confiance au niveau 95% est
[0.7− 0.16, 0.7 + 0.16] = [0.54, 0.86]
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 98 / 166
Estimation Estimation ponctuelle d’une proportion
Le second tour d’une election presidentielle
A et B sont les deux candidats presents au second tour. Les resultatsdu second tour sont B 51% et A 49%Les regions de confiance pour les deux proportions en fonction de lataille de l’echantillon
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 99 / 166
Estimation Estimation ponctuelle d’une proportion
Incertitude sur le candidat vainqueurQuelle est la precision des sondages ?
On realise de nombreux sondages sur des echantillons de taille n afind’evaluer le pourcentage de sondages qui ne donnent pas le boncandidat vainqueur. Ce graphique represente ce pourcentage enfonction de n.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 100 / 166
Estimation Estimation ponctuelle d’une proportion
un autre resultat : 52,5% contre 47.5%
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 101 / 166
Estimation Conclusion
3 EstimationExemple introductifEchantillonnageEstimation ponctuelle d’une moyenneTheoreme central limiteErreur d’estimation : Conclusions probabilistesEstimation par intervalle de la moyenneEstimation ponctuelle d’une varianceEstimation ponctuelle d’une proportionConclusion
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 102 / 166
Estimation Conclusion
La bonne demarche
La demarche statistique pour estimer une caracteristique/unparametre de la population (moyenne, variance, proportion, etc.) estla suivante
1 On constitue un echantillon de taille n
2 On recolte les observations x1, . . . , xn3 On calcule l’estimateur du parametre d’interet.4 Avant d’evaluer la qualite de l’estimateur, on doit repondre aux
questions suivantes :1 Dispose-t-on d’un grand echantillon ?2 La population est-elle gaussienne ?
5 On fixe un niveau de confiance 1− α6 On calcule l’erreur d’estimation et/ou un intervalle de confiance
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 103 / 166
Tests
Plan de la section
4 TestsDefinitions et exemplesTest sur la moyenneComparaison de deux echantillonsTest du χ2
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 104 / 166

Tests Definitions et exemples
4 TestsDefinitions et exemplesTest sur la moyenneComparaison de deux echantillonsTest du χ2
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 105 / 166
Tests Definitions et exemples
Un test statistique
Dans la premiere partie du cours un echantillon est utilise pourestimer les parametres d’une caracteristique de la population, parexemple
une moyenne
une variance
une proportion
Nous poursuivons l’inference statistique par la description des testsstatistiques.
Un test statistique est utilise pour determiner si uneassertion sur une caracteristique de la population doit etrerejetee.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 106 / 166
Tests Definitions et exemples
Le controle de qualite.
Dans une des entreprises du groupe αβ, on procede a l’assemblage de10 composants electroniques sur une plate-forme.La qualite de soudure sur la plate-forme ne satisfait pas les criteres dequalite etablis pour ce produit.
l’avis de l’ingenieur
Un ingenieur a emis l’hypothese que le probleme serait du a desdefauts de placage sur les plates-formes.
Question
La proportion de plates-formes defectueuses dans les stocks del’entreprise est-elle superieure a celle annoncee par le fournisseur ?
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 107 / 166
Tests Definitions et exemples
Principe general
Etape 1 On commence par formuler une premiere hypothese sur unecaracteristique de la population.Cette hypothese, notee H0, est appelee l’hypothese nulle.
Etape 2 On definit ensuite une seconde hypothese qui contreditl’hypothese nulle H0. Cette hypothese, notee Ha, est appeleel’hypothese alternative.
Etape 3 On utilise les donnees issues d’un echantillon pour tester lesdeux hypotheses en competition H0 et Ha.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 108 / 166
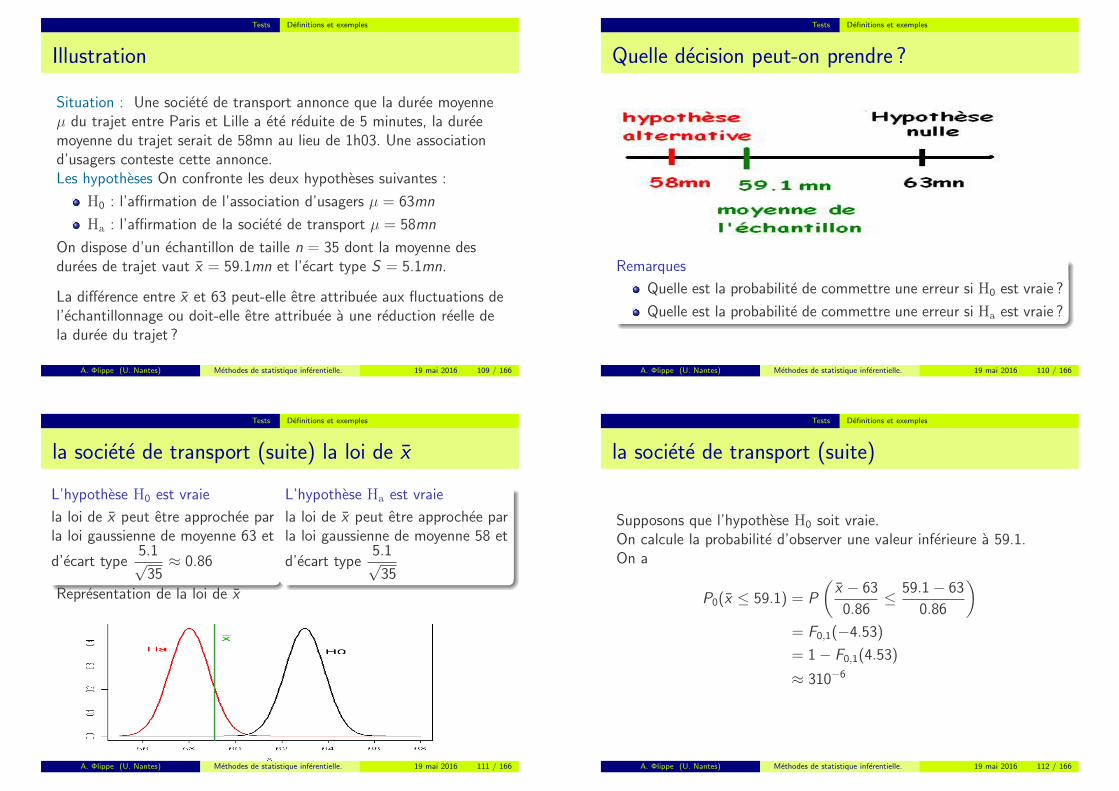
Tests Definitions et exemples
Illustration
Situation : Une societe de transport annonce que la duree moyenneµ du trajet entre Paris et Lille a ete reduite de 5 minutes, la dureemoyenne du trajet serait de 58mn au lieu de 1h03. Une associationd’usagers conteste cette annonce.Les hypotheses On confronte les deux hypotheses suivantes :
H0 : l’affirmation de l’association d’usagers µ = 63mn
Ha : l’affirmation de la societe de transport µ = 58mn
On dispose d’un echantillon de taille n = 35 dont la moyenne desdurees de trajet vaut x = 59.1mn et l’ecart type S = 5.1mn.
La difference entre x et 63 peut-elle etre attribuee aux fluctuations del’echantillonnage ou doit-elle etre attribuee a une reduction reelle dela duree du trajet ?
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 109 / 166
Tests Definitions et exemples
Quelle decision peut-on prendre ?
Remarques
Quelle est la probabilite de commettre une erreur si H0 est vraie ?
Quelle est la probabilite de commettre une erreur si Ha est vraie ?
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 110 / 166
Tests Definitions et exemples
la societe de transport (suite) la loi de x
L’hypothese H0 est vraie
la loi de x peut etre approchee parla loi gaussienne de moyenne 63 et
d’ecart type5.1√
35≈ 0.86
L’hypothese Ha est vraie
la loi de x peut etre approchee parla loi gaussienne de moyenne 58 et
d’ecart type5.1√
35
Representation de la loi de x
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 111 / 166
Tests Definitions et exemples
la societe de transport (suite)
Supposons que l’hypothese H0 soit vraie.On calcule la probabilite d’observer une valeur inferieure a 59.1.On a
P0(x ≤ 59.1) = P
(x − 63
0.86≤ 59.1− 63
0.86
)= F0,1(−4.53)
= 1− F0,1(4.53)
≈ 310−6
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 112 / 166

Tests Definitions et exemples
la societe de transport (suite)
Comment choisir la limite c ?
On fixe α = 5%, la probabilite de commettre une erreur quand H0 estvraie, autrement dit α est la probabilite que x < c quand H0 est vraie.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 113 / 166
Tests Definitions et exemples
la societe de transport (suite)
Autrement dit on cherche la valeur c telle que1 la loi de x peut etre approchee par la loi gaussienne de moyenne
63 et d’ecart type5.1√
352 P0(x < c) = 0.05
P0(x < c) = P
(x − 63
0.86<
c − 63
0.86
)= F0,1
(c − 63
0.86
)= 0.05
d’ou
F0,1
(−c − 63
0.86
)= 0.95
et
−c − 63
0.86= 1.64 ⇒ c = 61.58
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 114 / 166
Tests Definitions et exemples
la societe de transport (fin)
La decisionOn a observe x = 59.1. Comme x < c = 61.58, on decide de rejeterl’hypothese nulle (on accepte la reduction de la duree du trajet) pourle test de seuil α = 5%.Un autre type d’erreurOn calcule la probabilite de decider H0 alors que Ha est vraieLa loi de x peut etre approchee par la loi gaussienne de moyenne 58
et d’ecart type5.1√
35
P1(x > 61.58) = P
(x − 58
0.86>
61.58− 58
0.86
)= 1− F0,1
(61.58− 58
0.86
)= 10−5
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 115 / 166
Tests Test sur la moyenne
4 TestsDefinitions et exemplesTest sur la moyenneComparaison de deux echantillonsTest du χ2
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 116 / 166

Tests Test sur la moyenne
Decision et erreur
On teste les hypotheses H0 contre Ha
Etat de la populationH0 est vraie Ha est vraie
DecisionAccepter H0 Decision correcte Erreur de 2nde espece
Rejeter H0 Erreur de 1ere espece Decision correcte
Notations :
α est la probabilite de commettre une erreur de premiere espece
β est la probabilite de commettre une erreur de seconde espece
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 117 / 166
Tests Test sur la moyenne
La demarche
1 On fixe la probabilite d’erreur de premiere espece α c’est le risque de rejeter H0 (accepter Ha) alors que H0 estvraie.
2 On construit une region R0 telle quesi x ∈ Ro alors on rejette l’hypothese nulle H0 (on accepte Ha)la probabilite de x ∈ Ro est egale a α quand H0 est vraie
Definition
On dit que la decision est prise au niveau α
Remarque
La probabilite d’erreur de seconde espece β n’est pas fixee par lestatisticien qui met en œuvre le test.Pour de nombreux tests, il n’est pas possible de calculer la valeur deβ.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 118 / 166
Tests Test sur la moyenne
Les decisions
La decision est prise a partir d’un echantillon de taille n.On calcule la moyenne de l’echantillon x .
Si x ∈ Ro alors on decide de rejeter H0 (d’accepter Ha).
Le risque de commettre une erreur est inferieur ou egala α.
Si x 6∈ Ro alors on decide d’accepter H0.
Remarque
Lorsque β est inconnu, on utilise plutot l’expression ”on ne peut pasrejeter H0” plutot que ”on accepte H0”.Utiliser cette expression permet de differer tout jugement et touteaction.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 119 / 166
Tests Test sur la moyenne
Tester les hypotheses de recherche
Situation : Les voitures de type XYZ consomment en moyenne, 9litres d’essence tous les 100 kilometres. Des chercheurs ont developpeun nouveau moteur pour ce modele.
Hypotheses : Les chercheurs veulent prouver que le nouveau moteurest plus economique.On note µ la consommation moyenne en litres pour 100 kilometres.L’hypothese de recherche est µ < 9Les hypotheses appropriees sont
H0 : µ = 9 et Ha : µ < 9
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 120 / 166

Tests Test sur la moyenne
Construction du test sur la consommation
On mesure la consommation sur un echantillon de 100 voituresequipees du nouveau moteur. On calcule la moyenne x
Si x ≤ Calors on accepte Ha
sinon on accepte H0
Comment fixer la limite C ?1 On fixe l’erreur de premiere espece α = 0.052 On cherche la valeur de C telle que si H0 est vraie [µ = 9], on a
P(accepter Ha) = P(x < C ) = 0.05
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 121 / 166
Tests Test sur la moyenne
On dispose d’un grand echantillon n = 100 > 30 et σ = 1 est connu.
Si H0 est vraie alors la loi de Z =x − 9
1/√
100peut etre approchee par
une loi gaussienne standard
8.6 8.8 9.0 9.2 9.4
01
23
4
x
5%
Decision Ha Decision Ho
loi de sous Hox
On cherche C telle que
P(x < C ) = P(Z ≤ C − 9
1/√
100)
= 0.05
Dans la table, on litC − 9
1/√
100= −1.64 donc C = 8.83
Si x < 8.83 alors on rejette l’hypothese nulle (on accepte l’hypothesealternative) au niveau 5%
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 122 / 166
Tests Test sur la moyenne
Sur l’echantillon constitue par les ingenieurs, la moyenne desconsommations est egale a x = 8.5.
Les resultats de l’echantillon indiquent que l’on rejette H0 etdonc que l’on accepte Ha au niveau 5%
Les ingenieurs ont le support statistique necessaire pour affirmerque le nouveau moteur est plus economique.La production pourra alors commencer.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 123 / 166
Tests Test sur la moyenne
Tester la validite d’une assertion
Situation : Un producteur de tiges filetees pretend que la longueurmoyenne µ des tiges est d’un metre.Un echantillon de tiges est constitue et leur longueur est mesureepour tester l’affirmation du fabricant.
Hypotheses : On accorde le benefice du doute au producteur et sonassertion correspond a H0.On formule les hypotheses
H0 : µ = 1 et Ha : µ 6= 1
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 124 / 166
Tests Test sur la moyenne
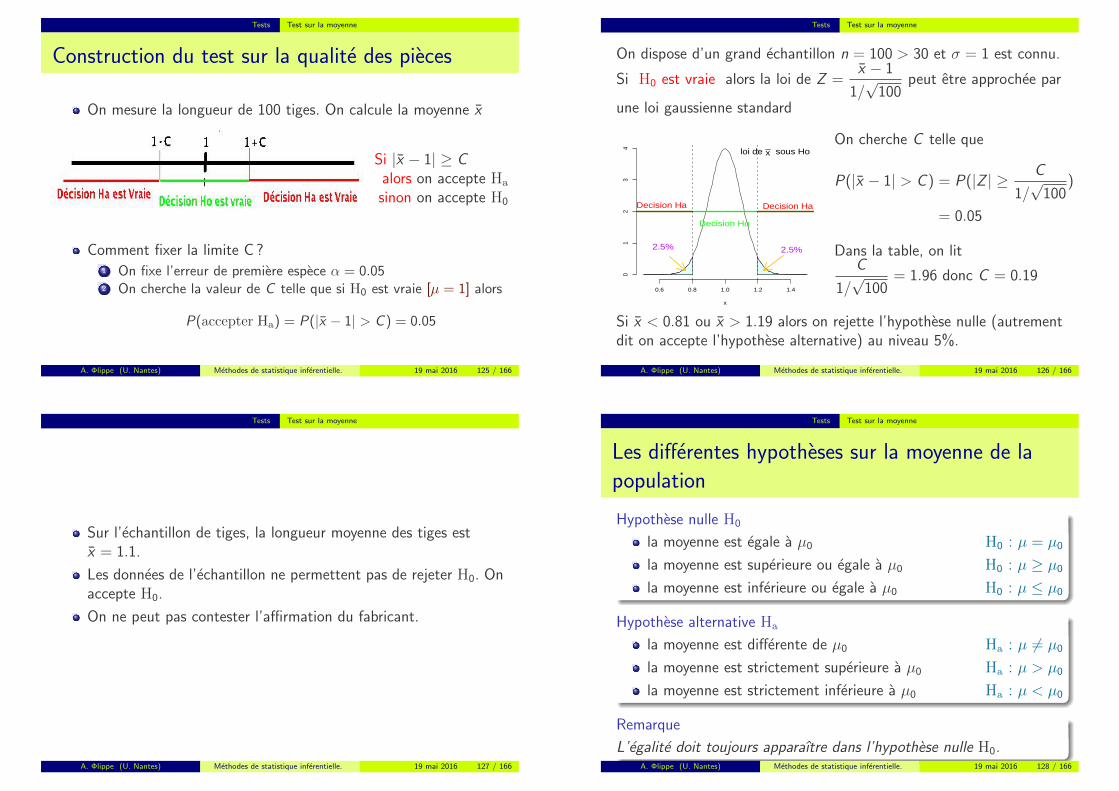
Construction du test sur la qualite des pieces
On mesure la longueur de 100 tiges. On calcule la moyenne x
Si |x − 1| ≥ Calors on accepte Ha
sinon on accepte H0
Comment fixer la limite C ?1 On fixe l’erreur de premiere espece α = 0.052 On cherche la valeur de C telle que si H0 est vraie [µ = 1] alors
P(accepter Ha) = P(|x − 1| > C ) = 0.05
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 125 / 166
Tests Test sur la moyenne
On dispose d’un grand echantillon n = 100 > 30 et σ = 1 est connu.
Si H0 est vraie alors la loi de Z =x − 1
1/√
100peut etre approchee par
une loi gaussienne standard
0.6 0.8 1.0 1.2 1.4
01
23
4
x
2.5% 2.5%
Decision Ha Decision Ha
Decision Ho
loi de sous HoxOn cherche C telle que
P(|x − 1| > C ) = P(|Z | ≥ C
1/√
100)
= 0.05
Dans la table, on litC
1/√
100= 1.96 donc C = 0.19
Si x < 0.81 ou x > 1.19 alors on rejette l’hypothese nulle (autrementdit on accepte l’hypothese alternative) au niveau 5%.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 126 / 166
Tests Test sur la moyenne
Sur l’echantillon de tiges, la longueur moyenne des tiges estx = 1.1.
Les donnees de l’echantillon ne permettent pas de rejeter H0. Onaccepte H0.
On ne peut pas contester l’affirmation du fabricant.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 127 / 166
Tests Test sur la moyenne
Les differentes hypotheses sur la moyenne de la
population
Hypothese nulle H0
la moyenne est egale a µ0 H0 : µ = µ0
la moyenne est superieure ou egale a µ0 H0 : µ ≥ µ0
la moyenne est inferieure ou egale a µ0 H0 : µ ≤ µ0
Hypothese alternative Ha
la moyenne est differente de µ0 Ha : µ 6= µ0
la moyenne est strictement superieure a µ0 Ha : µ > µ0
la moyenne est strictement inferieure a µ0 Ha : µ < µ0
Remarque
L’egalite doit toujours apparaıtre dans l’hypothese nulle H0.A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 128 / 166

Tests Test sur la moyenne
Test sur la moyenne : n grand, σ connu
Hypothese Hypothese Ha est accepteenulle H0 alternative Ha H0 est rejeteeµ = µ0 µ > µ0
µ ≤ µ0 x > µ0 + q(1− α)σ√n
µ = µ0 µ < µ0
µ ≥ µ0 x < µ0 − q(1− α)σ√n
µ = µ0 µ 6= µ0 x > µ0 + q(1− α/2)σ√n
ou bien
x < µ0 − q(1− α/2)σ√n
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 129 / 166
Tests Test sur la moyenne
Test sur la moyenne : n grand, σ inconnu
Hypothese Hypothese Ha est accepteenulle H0 alternative Ha H0 est rejeteeµ = µ0 µ > µ0
µ ≤ µ0 x > µ0 + q(1− α)S√
nµ = µ0 µ < µ0
µ ≥ µ0 x < µ0 − q(1− α)S√
n
µ = µ0 µ 6= µ0 x > µ0 + q(1− α/2)S√
nou bien
x < µ0 − q(1− α/2)S√
n
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 130 / 166
Tests Test sur la moyenne
Test sur la moyenne : cas gaussien, σ connu
Hypothese Hypothese Ha est accepteenulle H0 alternative Ha H0 est rejeteeµ = µ0 µ > µ0
µ ≤ µ0 x > µ0 + q(1− α)σ√n
µ = µ0 µ < µ0
µ ≥ µ0 x < µ0 − q(1− α)σ√n
µ = µ0 µ 6= µ0 x > µ0 + q(1− α/2)σ√n
ou bien
x < µ0 − q(1− α/2)σ√n
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 131 / 166
Tests Test sur la moyenne
Test sur la moyenne : cas gaussien, σ inconnu
Hypothese Hypothese Ha est accepteenulle H0 alternative Ha H0 est rejeteeµ = µ0 µ > µ0
µ ≤ µ0 x > µ0 + t(n − 1, 1− α)Sc√
nµ = µ0 µ < µ0
µ ≥ µ0 x < µ0 − t(n − 1, 1− α)Sc√
n
µ = µ0 µ 6= µ0 x > µ0 + t(n − 1, 1− α/2)Sc√
nou bien
x < µ0 − t(n − 1, 1− α/2)Sc√
n
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 132 / 166

Tests Comparaison de deux echantillons
4 TestsDefinitions et exemplesTest sur la moyenneComparaison de deux echantillonsTest du χ2
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 133 / 166
Tests Comparaison de deux echantillons
Tests de comparaison
Probleme On veut tester si deux echantillons ont la meme moyenne.Deux situations
1 les deux echantillons sont independants
Exemple
On veut comparer les salaires moyens des techniciens de deuxentreprises.
2 les echantillons sont apparies
Exemple
Pour tester l’efficacite d’un medicament, on compare le taux decholesterol avant et apres le traitement sur un groupe de malades.Les echantillons ne sont pas independants car les mesures sonteffectuees sur les memes individus.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 134 / 166
Tests Comparaison de deux echantillons
Echantillons independants
Un grand magasin implante deux boutiques
l’une est situee dans le centre ville
l’autre dans un centre commercial en banlieue
Le directeur des ventes remarque que les produits qui se vendent biendans un des magasins ne se vendent pas forcement bien dans lesecond. Il attribue cette variation des ventes au fait que l’age moyendes clients est different entre les deux magasins.
boutique taille age moyen ecart typede l’echantillon
pop. 1 centre ville n1 = 36 x1 = 40 ans S1 = 9 anspop. 2 banlieue n2 = 49 x2 = 35 ans S2 = 10 ans
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 135 / 166
Tests Comparaison de deux echantillons
Plus generalement
On suppose que les deux populations sont independantes
Population 1moyenne µ1
ecart type σ1
Population 2moyenne µ2
ecart type σ2
La questionLes deux moyennes sont-elles egales ? µ1 = µ2?
On teste µ1 = µ2 contre µ1 6= µ2
Les observations : on dispose de deux echantillons independants.
echantillon 1extrait de la population 1
taille n1 moyenne x1,ecart type S1
echantillon 2extrait de la population 2
taille n2, moyenne x2,ecart type S2
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 136 / 166

Tests Comparaison de deux echantillons
La procedure de test
Le test H0 : µ1 = µ2 contre Ha : µ1 6= µ2
Hypotheses : on dispose de deux grands echantillons n1 > 30 etn2 > 30. Les deux echantillons sont independants. On supposeque σ1 et σ2 sont connusOn pose
Z =x1 − x2√σ2
1
n1+
σ22
n2
Si |Z | > q(1− α/2)alors
on rejette l’hypothese nulle H0 (donc on accepte Ha) auniveau α .
sinon
on accepte H0
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 137 / 166
Tests Comparaison de deux echantillons
Modification de la procedure de testlorsque les variances sont inconnues
Le test H0 : µ1 = µ2 contre Ha : µ1 6= µ2
Hypotheses : on dispose de deux grands echantillons n1 > 30 etn2 > 30. Les deux echantillons sont independants.On pose
Z =x1 − x2√S2
1
n1+
S22
n2
Si |Z | > q(1− α/2)alors
on rejette l’hypothese nulle H0 (donc on accepte Ha) auniveau α.
sinon
on accepte H0
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 138 / 166
Tests Comparaison de deux echantillons
Retour a l’exemple des deux boutiques
On calcule Z
Z =x1 − x2√S2
1
n1+
S22
n2
=40− 35√
92
36+ 102
49
= 2.41
On fixe l’erreur de premiere espece : α = 5%.On a
q(1− α/2) = q(0.975) = 1.96
On compare |Z | et q(0.975)
|Z | = 2.41 > 1.96 donc on accepte l’hypothese alternative
Ha : l’age moyen des deux populations est different
au niveau 5%
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 139 / 166
Tests Comparaison de deux echantillons
Echantillons apparies
On dispose de deux methodes pour realiser une tache sur une chaınede production. On veut comparer les temps d’execution de ces deuxmethodesOn selectionne un echantillon de n = 40 ouvriers qui vont executercette tache d’abord par la methode 1 puis par la methode 2. .Pour chaque personne, on recolte deux temps d’execution. Voici unextrait des donnees recoltees :
i 1 2 3 4 5 6 7 8 9 · · ·xi 6.50 5.00 3.80 5.70 4.80 6.10 5.70 5.00 4.00 · · ·yi 4.50 6.50 5.70 7.20 4.20 5.60 5.30 5.10 6.90 · · ·
Etc
Remarque
On teste les deux methodes sur le meme groupe de la populationpour diminuer les effets de l’echantillonnage.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 140 / 166

Tests Comparaison de deux echantillons
Plus generalement
Methode 1moyenne µ1
ecart type σ1
Methode 2moyenne µ2
ecart type σ2
On constitue un seul echantillon d’individus
L’echantillon 1 est constituedes resultats obtenus par la
methode 1taille n moyenne x1,
ecart type S1
L’echantillon 2 est constituedes resultats obtenus par la
methode 2taille n, moyenne x2,
ecart type S2
Definition
On dit que les echantillons sont apparies quand deux methodes sonttestees sur les memes individus
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 141 / 166
Tests Comparaison de deux echantillons
Construction du test
On note
x1, . . . , xn l’echantillon obtenu pour la methode 1
y1, . . . , yn l’echantillon obtenu pour la methode 2
On calcule les differences
d1 = x1 − y1, . . . , dn = xn − yn
puis
la moyenne des differences : d =1
n
∑ni=1 di
la variance : S2d = 1
n
n∑i=1
(di − d)2
l’ecart type Sd =
√√√√ 1n
n∑i=1
(di − d)2
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 142 / 166
Tests Comparaison de deux echantillons
Procedure de test
Le test H0 : µ1 = µ2 contre Ha : µ1 6= µ2
Hypotheses : on suppose que les echantillons sont apparies etn > 30
On pose
Z =d√S2d
n
Si |Z | > q(1− α/2)alors
on rejette l’hypothese nulle et donc on accepte Ha auniveau α
sinonon accepte H0
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 143 / 166
Tests Comparaison de deux echantillons
Exemple (suite)
Sur l’echantillon de taille 40, on calcule
d = −0.64
Sd = 1.413
puis Z = −2.89.On compare |Z | avec le quantile q(1− α/2) = q(0.975) = 1.96Comme |Z | > 1.96, on rejette l’hypothese H0 au niveau 5%.Autrement dit, on accepte l’hypothese Ha :
les deux methodes n’ont pas le meme temps d’execution
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 144 / 166

Tests Test du χ2
4 TestsDefinitions et exemplesTest sur la moyenneComparaison de deux echantillonsTest du χ2
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 145 / 166
Tests Test du χ2
Test d’independance sur des tables de contingence
On teste l’independance entre deux variables.
Exemple
On dispose de trois types de biere : blanche / blonde / brune. Legroupe marketing se demande si les preferences des consommateurssont differentes entre les hommes et les femmesLes donnees :
blanche blonde brunehomme 20 40 20femme 30 30 10
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 146 / 166
Tests Test du χ2
Definition d’une table de contingence
On considere deux variables X et Y qui prennent un nombre fini devaleurs
X prend les valeurs A1, . . . ,Ap
Y prend les valeurs B1, . . . ,Bq
A partir d’un echantillon de taille n, on construit la table decontingenceX\Y B1 B2 · · · Bq
A1 e(1,1) e(1,2) . . . e(1,q)A2 e(2,1) e(2,2) . . . e(2,q)...
......
. . ....
Ap e(p,1) e(p,2) . . . e(p,q)
ou e(i , j) est egal aunombre d’individus dansl’echantillon qui possedentles modalites Ai ,Bj
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 147 / 166
Tests Test du χ2
Procedure de test
On teste H0 : X et Y sont independantes contre Ha : X et Y ne sontpas independantes.On note
pour i = 1 . . . p : `i le total de la ligne i
pour j = 1 . . . q : cj le total de la colonne j
X\Y B1 B2 · · · Bq
A1 e(1,1) e(1,2) . . . e(1,q) `1
A2 e(2,1) e(2,2) . . . e(2,q) `2...
......
. . ....
...Ap e(p,1) e(p,2) . . . e(p,q) `p
c1 c2 . . . cq n
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 148 / 166

Tests Test du χ2
On calcule
Q =
p∑i=1
q∑j=1
(e(i , j)− `icj
n
)2
`icjn
.
Si Q > k((p − 1)(q − 1), 1− α)alors
on rejette l’hypothese nulle H0 (on accepte l’hypothesealternative Ha) au niveau α. Les variables X et Y ne sontpas independantes
sinon
on accepte l’hypothese nulle H0, les variables sontindependantes.
[k((p − 1)(q − 1), 1− α) est le quantile d’ordre 1− α de la loi du χ2 a
(p − 1)(q − 1) degres de liberte.]
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 149 / 166
Tests Test du χ2
Retour a l’exemple
blanche blonde brunehomme 20 40 20 80femme 30 30 10 70
50 70 30 150 = n
On calcule Q = 6.13.
On compare Q avec k((2− 1)(3− 1), 0.95) = 5.99
Conclusion Q = 6.13 > 5.99 donc on rejette l’independance.Il existe un lien entre la preference en matiere de biere et le sexedu consommateur.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 150 / 166
Regression
Plan de la section
5 RegressionIntroductionLa correlationEstimationComplement sur la correlation
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 151 / 166
Regression Introduction
5 RegressionIntroductionLa correlationEstimationComplement sur la correlation
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 152 / 166

Regression Introduction
La regression
On mesure deux variables continues (X ,Y ) sur n individus.Les Observations : on observe donc n couples de points
(x1, y1), . . . , (xn, yn)
Probleme : Existe-t-il une liaison entre ces deux variables ?
Exemple (Une maison de vente par correspondance )
Existe-t-il un lien entre le poids du courrier recu par une entreprisechaque matin et le nombre de commandes traitees pendant la journee.
Probleme
Tester l’existence d’une liaison entre ces deux variables
Estimer la liaison, si elle existe.
Utiliser cette liaison pour prevoir
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 153 / 166
Regression Introduction
Lien lineaire entre la proportion d’etudiants dans la
clientele d’un restaurant et les ventes de Pizza
Prop. Etud. Ventesen % en milliers euros
1 2 582 6 1053 8 884 8 1185 12 1176 16 1377 20 1578 20 1699 22 149
10 26 202
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 154 / 166
Regression La correlation
5 RegressionIntroductionLa correlationEstimationComplement sur la correlation
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 155 / 166
Regression La correlation
Definition du coefficient de correlation
Soit n couples (x1, y1), . . . , (xn, yn). La correlation entre les variablesX et Y est egale a
r =
1n
n∑i=1
(xi − x)(yi − y)
SxSy
oux represente la moyenne et Sx l’ecart type de l’echantillonx1, . . . , xny represente la moyenne et Sy l’ecart type de l’echantillony1, . . . , yn
1 r est un nombre entre −1 et 1.2 |r | = 1 tous les points sont alignes3 Une valeur de r proche de zero indique que les variables ne sont
pas lineairement lieesA. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 156 / 166
Regression La correlation
Illustration
●●
●●●
●
●●
●
●
●
●●
●
●●●
●
●●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●●
●●
●
●●
●●●
●
●
●
●
●
●●
●
●
●
●●
●
●●
●
●
●●
●
●
●
●●●
●
●
●
●
●●
●
●●
●●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●●
●
●
●
●●
●
●
●
●
●
●
●●
●●
●
●●●
●
●
●
●●●
●●
●●
●
●
●●●
●
●
●
●●
●
●●
●
●
●
●
●●
●●●
●
●●
●
●
●
●
●●
●
●
●
●
●●
●●
●
●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●●
●●
●●
●
●●
●
●
●●●
●
●●
●
●
●
●
●
●●●
●
●
●●
●
●
●●●
●
●
●
●
●
●●
●
●
●●
●●●
●
●
●
●
●
●●
●●
●●
●
●
●●
●
●
●●
●●
●●
●●●
●
●
●
●●
●
●
●
●●●
●
●
●
●
●●
●
●
●●
●●●
●
●●
●
●●●
●●
●
●
●
●
●●
●●
●●●●
●
●
●
●●
●
●
●
●
●●
●●
●
●
●
●●●
●●
●
●
●
●
●●
●●●
●
●
●
●
●●●
●
●
●●
●
●●
●
●
●●
●
●
●●
●●
●●
●
●●
●
●●
●
●
●
●●●
●●●
●
●
●
●●
●●
●●
●●●
●
●
●
●●
●
●
●
●●
●●
●●
●
●●
●●●
●●
●
●
●
●
●●●
●●
●●
●
●
●●
●
●
●●
●
●●●
●
●
●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
−3 −1 1 2 3
−3−1
13
x
y
r = −1
●● ●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●
●●
●
●●
●●
●
●●
●●
●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●●
●
●●
●
●●●●●
●●
●●
●
●●
●
●●
●
●●
●●
●●
●
● ●●
●
●●
●●
●●
●●●
●
●
●
●●
●
●●
●
●
●
●●●
●
●
●
●
●
●
●●
●●
●
●
●●●
●
●
●
●
●
●
●● ●
●
●
●
●
●● ●
●
●
●●
●
●
●●
●●
●
●
●●
●
●●●
●
●●
●
●
●
●●●
●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●●
●●
●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●● ●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●● ●
●
●
●
●●●
●
●
●
●●
●
●●●● ●
●
●
●●
●●●
●
●
●
●
●●
●●
●
●●●
●
●●
●●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●●●
●
●
●
●
●
●●
●
●●●
●
●
●
●
●●
●
●●
●
●●
●
●
●
●●
●●
●
●●
●●
●
●
●
●
● ●
●
●
●
●
●●
●
●
●●●
●
●●●
●
●●●
●
●
●
●●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●
● ●
−3 −1 1 3
−3−1
13
x
y
r = −0.95
●
● ●
●
●
●●
●●●
●
●●●
●
●● ●●
●
●●
●
●
●
●●
●
● ●
●
●●●●
●●●
●
●
● ●●
●
●●●
●
●
●
● ●
●
●
●●
● ●●
●
●
●●
●
●
●
●
●●
●●
●●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●●
●
●●●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●
● ●●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●●●●
●●
●●
●
●
●
●●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●●● ●
●●
●●
●
●
●●
●
●●●
●
●
●●
●●
●
●
●●
●
●
●
● ●
●
●
●
●
●● ● ●
● ●●
●
●
●●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●● ●
●●
●
●
●●
●
●
●
●
●
●
●●
●●
●
●
●
●
● ●●
●
●
●
●
●
●●
● ●
●
●●
●●●
●●
●●
●
●●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●● ●
●
● ●
●
●●●●
●
●
●
●
●●
●●●
● ●●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
● ●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
● ●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●●
●
●
●
●
●●●
●
●●
●●
●
●
● ●
●
●
● ●●
●●
●●● ●
●
●
●
●
● ●
●
●
●
●●
●
●
●●
●
●●● ●●
●●
●●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●●
−3 −1 1 2 3
−3−1
13
x
y
r = −0.75
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●●●●
●●
●
●
●
●
●
●
●●●
●
●
● ●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●●●
●●
●●
●
●
●
●●
●●●●
●●
●●
●
●●
●
●
●
●
●
●
●● ●
●
●●
●
●● ●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●●●
●
●●
●
●
●
●
●
●
●
●
● ●●
●
●
●
●
●●
●
●
●● ●
●●
●
●● ●
●
●●
●
●●
●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●● ●●
●
●
●
●
●
●●●
●●
●
●● ●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●
●
●
●●●
●
●●
●
●
●
●●
●
●
●●
●
●●
●
●
●
●●
●
●●●
●
●●
●
●
●
●● ●
●●●
●
●
●●●
● ●
●
● ●
●
●●
●
●●
●●●
●●
●
●●
●
●● ●
●●
●● ●
●
●●
●
●
●
●●
●
●●●
●
●
●●
●● ●
●
●
●
●● ●
●
●
●
●
●
●●●
●
●
●
●●
●
●●
●●●
●●
●●
●
●●
●
●●
● ●●
●
●
●
●
●
●●
●
●●
●
●
●
●●●
●● ●
●
●
●
●●
●
●
●
●
●
●
●●
●
●●●
●● ●
●
●●●
●
●
● ●
●●
●
● ●
●
●●
●
●
●
●
●
● ●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●●
● ●●
−3 −1 1 3
−3−1
13
x
y
r = −0.25
●●●
● ●●
●
●
● ●● ●●
●●
●
●●
●
●
●
●
●
●
●
●●
● ●●
● ●
●
●
●
●
●
●
●●
●●●
●● ●
●
●●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●
● ●
●●
●
●
●
●
●
●
●
●
●
●
● ● ●
●
●
●
●●
● ●
●●
●
●
● ●
●
●
● ●
●
●
●
●
●
● ●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
● ●●
●
●● ●
●●
●
●● ●
●
●
●●
●
●
●
●●
●
●●
●●
●
●
●
●
●●
●●
●
●●
●
●
●
●
● ●●
●
●
●
●
● ●●
●
●
●
●●
●
●●
●●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●●
●
●
●
●
●
●●
●●
●
●
●●●
●
●
●●
●
● ●●
●●
●
●
●
●
●●
●
● ●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
● ●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●●
●●
●
●
●
●
● ●
●●●
●
●
●
●
●●
●●
●●
●
●
●
●
●
●
● ●
●
●
●●
●
● ●●●
●●
●●●
● ●
●
●●●
●●●
●●
●
●
● ●
●
●
●
●
●
● ●
●●
●
●
●●●
●
●
●●
●
●● ●
●
●
●
●
● ●
●
●
●
●●●
●
●
●●
●
●●
●
●●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●●
● ●●●●
●
●
●
●
●
●
●
●
●●
●
●
●●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●● ●●
●
●
●
●
●●
●
●●
●
● ●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●●
●
−3 −1 1 2 3
−3−1
13
x
y
r = 0
●
●
●
●
●●
●
●
●●
●●
●●
●●●
●
● ●●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●●
●● ●
●●
●
●●
●●● ●
●●
●
●
●
●
●
●●
●
●●
●
●●
●●
●
●
●●
● ●
●
●●
●
●
●
●
●
● ●●
●
●
●
●
●● ●
●
●
●
●●
●
● ●
●●
●●
●●●
●
●●
●●
●●
●
●
●
●●
● ●●
● ●●●●
●
●
●
●●
●●
●
●● ●
●
●
●●
●
●●
●
●
●
● ●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●●
●
●
● ●
●
●
●
● ●●
●
●
● ●●●
●
●
●
●
●
●
●
●●●
●●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●●
●
●
●
●
●●●
●
●
●
●
●
●●
●
●● ●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●● ●
●●
●●
●
●
●
●
●
●●●
●
●
●●
●
●●
●
●
●
●
●
●●
●●
●●
●●
●●
●
●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
● ●●
●
●●
●
●
●●●
●●
●
●
●● ● ●
● ●●●
●
●●
●
●
●
●
● ●●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●
●
●
−3 −1 1 2 3
−3−1
13
x
y
r = 0.25
●
●
●
●
●
●
●●
●●
●
●
●●● ●
●
●●
●
●
● ●
●
●
●
●●●
●
●
●
●●●
●
●●
●
●
●
●
●
●●
●
●●
●●●
●
●
●●
●●●
●
● ●
●●
●
●
●
●
●
●●
●
●●●
●
●
● ●●
●
●● ●
●
●
●
●● ●
●●
●
●
●●
●●
●
●●
●
●● ●
●● ●
●
●●
●●●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●● ●
●
●
●
●
●
●
●●●
●
●
●
● ●
●●
●
●
● ●
●
●
●
●●
●●●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●
●● ●
●
●●
●
●
●●
●
●
●
●● ●
●
● ●
●
●
●
●●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●●
● ●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
● ● ●●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●● ●
●
●
●
●
●
●
●
●
●
●
●
● ●●●●
●●
●
●
●
●
●●
●●
●
●
●●
●
●
●●●
●●
● ●
●
●●
●● ●
●
●
●
●
●
●●
●●● ●●●
●
●●
●
●
●
●●
●
●
●●●
●
● ●
●●●
●
●
●
●
●
●●
●●
●
●● ●
●●●
●●
●● ●
●●
●
●●
●
●
●
●
●●
●
●
●
●
●
● ●
●
●●●●
●
●●
●●
● ●
●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●●
●●●
●●●●
●
●
●
●
−3 −1 1 2 3
−3−1
13
x
y
r = 0.75
●●
●
●
●
●
●●
●
●
●●●
●
●
●●
●
● ●●●
●●
●
●● ●
●
●
●
●
●●
●
●
●●
●●
●●
●
●
●
●
●
●●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●●●
● ●●●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●●●●
●
●
●
●
●
●●
●
●
● ●●
●
●
●
●
●
●
●●
●
●
●
●●
● ●
●
●
●
●●●
●
●
●
●
●●●●
●
●
●
●
●
●
●●
● ●
●●
●
●
●
●
●●
●
●
●
●
●●●
●
●●
●
●●
●
●●
●
●
●
●
●●
●
●
●
●●
● ●
●●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●●●●
●
●●
●● ●●
●
●
●
●
●
●
●
●
●
●●
●●
●●●
●
●●
●
●●
●
●●●
●
●
●
●●
●●●
●
●
●
●
●
●
●●●●
●
●
●●
●●
●
●
●●
●
●●● ●●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●●
●● ●●
●
●
●●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●●●
●
●●
●●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●●
●
●●
●
● ●●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●●
●●
●
●
●●●●●
●
●●
●●●
●●
●
●
●
●●
●
●
●
●●
●●●
●●●
●
●
●
●
●
●●
●●●
●●
●
●
●●
●●
●
●●
●
●
●
●
●
●●
●●● ●●●
●
●
●●
●●
●
●●●
●●
●
●●
●
●
●
●
●
●
●
●
−3 −1 1 3
−3−1
13
x
y
r = 0.95
●
●
●●●
●
●
●
●
●●●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●●
●●
●●
●
●
●
●
●●
●
●●
●●●
●●
●
●
●
●
●
●
●
●●
●
●●●
●
●●●●
●●
●
●
●
●
●●
●
●●
●
●
●
●●
●
●●
●●
●
●
●●
●
●
●
●
●
●●
●●
●
●●
●
●●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●●
●
●
●
●●
●
●●
●
●●●
●●
●●●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●●●
●
●
●
●●●
●
●●●
●
●●
●
●●●
●
●●●
●●
●●
●
●
●●●
●
●
●
●●
●
●
●
●
●●
●
●●
●
●
●●
●
●
●
●●
●
●●
●●
●
●
●●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●●
●●●
●
●
●●
●
●
●●
●●●●
●
●
●●
●
●
●
●●
●
●
●●
●
●
●
●●
●●
●●●
●
●●
●●
●
●
●
●
●
●●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●●●
●●
●
●●
●●
●
●
●●
●●
●
●
●
●
●
●
●
●●
●
●●
●●
●●
●
●
●
●
●●
●
●●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●●
●●●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●●
●
●●
●●
●
●
●●
●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●●
●
●
●
●
●
●
●●
●●
●
●
●
●
−3 −1 1 2 3
−3−1
13
x
y
r = 1
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 157 / 166
Regression La correlation
En pratique
1 On calcule le coefficient de correlation r1 Si r est proche de zero les deux variables ne sont pas liees2 si |r | est proche de 1, les variables sont lies.
On cherche a determiner si la nature du lien est lineaire oud’une autre nature.
2 Un outil graphique. On represente le nuage de points (xi , yi)pour i = 1, . . . , n
Si les points semblent dessiner une droite, alors le lien lineaireest confirme.On peut alors chercher la droite qui est la plus proche despoints du nuage.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 158 / 166
Regression Estimation
5 RegressionIntroductionLa correlationEstimationComplement sur la correlation
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 159 / 166
Regression Estimation
Modele lineaire et methode des moindres carres
Estimation du lien lineaire entre X et Y c’est a dire Y = aX + b + ε.
1 ε est une variable aleatoire appelee terme d’erreur
2 y = ax + b est la droite de regression
On utilise les donnees (x1, y1), . . . , (xn, yn) pour estimer lescoefficients de la droite (a, b).
On calcule la somme des carresdes erreurs e1, . . . , en
En(a, b) =n∑
i=1
(ei)2
On cherche les coefficients a et bqui minimisent En(a, b)
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 160 / 166
Regression Estimation
Calcul de la droite de regression
La pente est egale a
a =
1n
n∑i=1
(xi − x)(yi − y)
S2x
ou
x represente la moyenne et S2x la variance de l’echantillon
x1, . . . , xny represente la moyenne de l’echantillon y1, . . . , yn
L’ordonnee a l’origine est egale a
b = y − ax
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 161 / 166
Regression Estimation
Suite de l’exemple sur les ventes de pizzas
La correlation entre les deux variables vaut 0.95. l’ajustement lineaireest satisfaisant
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 162 / 166
Regression Estimation
Prevoir
S’il existe un lien lineaire entre X et Y , on peut prevoir la valeur prisepar Y connaissant la valeur de X
Calcul de la prevision Si on connaıt la valeur de X , X = x0, onprevoit la valeur de la variable Y en prenant ax0 + b.
Exemple
Un restaurateur sait que sa clientele est composee de 10 %d’etudiantsIl peut prevoir ses ventes de pizzas en prenanta × 10 + b = 5× 10 + 60 = 110 milliers d’euros
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 163 / 166
Regression Complement sur la correlation
5 RegressionIntroductionLa correlationEstimationComplement sur la correlation
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 164 / 166
Regression Complement sur la correlation
Le bon usage du coefficient de correlation
On dispose de 4 nuages de points
Dans les 4 cas, on ax = 9 ; y = 7.50,S2x = 10 ; S2
y = 3.75et r = 0.816.
donnees A donnees B donnees C donnees Dx y x y x y x y
10 8.04 10 9.14 10 7.46 8 6.588 6.95 8 8.14 8 6.77 8 5.76
13 7.58 13 8.74 13 12.74 8 7.719 8.81 9 8.77 9 7.11 8 8.84
11 8.33 11 9.26 11 7.81 8 8.4714 9.96 14 8.10 14 8.84 8 7.046 7.24 6 6.13 6 6.08 8 5.254 4.26 4 3.10 4 5.39 19 12.50
12 10.84 12 9.13 12 8.15 8 5.567 4.82 7 7.26 7 6.42 8 7.915 5.68 5 4.74 5 5.73 8 6.89
On obtient donc la meme droite y = 0.5x + 3 pour les 4 nuages depoints.
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 165 / 166
Regression Complement sur la correlation
Les nuages de points associes aux donnees
5 10 15
46
810
12
x
y
5 10 15
46
810
12
x
y
5 10 15
46
810
12
x
y
5 10 15
46
810
12
x
y
nuages de points −− ajustements lineaires
A. Φlippe (U. Nantes) Methodes de statistique inferentielle. 19 mai 2016 166 / 166
Top Related