







γλώσσες
Σελίδες
Νομικός


Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 93
7. ΣΥΣΤΗΜΑΤΑ ΕΞΟΡΥΞΗΣ ΔΕΔΟΜΕΝΩΝ
ΠΡΟΣΟΧΗ:
Κάθε φορά που θα φθάνετε στο σημείο αυτό πριν από τη δημιουργία κάθε
μοντέλου, το σύστημα δίνει αυτόματα δυο αριθμήσεις: (1) στο τέλος του πεδίου
Structure name και (2) στο τέλος του πεδίου Model name.
Επειδή στις αριθμήσεις αυτές δεν λαμβάνεται υπ’ όψιν ότι μπορεί να δουλεύουν
πολλοί χρήστες ταυτόχρονα, για να μην λαμβάνετε συνέχεια μηνύματα λαθών, θα
πρέπει κάθε φορά να φροντίσετε να δίνετε εσείς την επόμενη αρίθμηση. Επομένως
κάθε ομάδα θα φροντίσει να δίνει τη δική της μοναδική αρίθμηση κάθε φορά.
Π.χ. η ομάδα 01 θα αλλάζει τον αριθμό στο τέλος και των δυο πεδίων σε 011
(την πρώτη φορά), 012 (τη δεύτερη φορά), 013 (την τρίτη φορά) κ.ο.κ., φθάνει κάθε
φορά να δίνεται ένας νέος μοναδικός αριθμός.
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 94
Η δυνατότητα λειτουργίας εξόρυξης δεδομένων (Data Mining) αποτελεί μέρος
των δυνατοτήτων του SQL Server 2005. Για ευκολότερη λειτουργία όμως από το
χρήστη υπάρχει η δυνατότητα εγκατάστασης μιας πρόσθετης εφαρμογής στο Excel
2007 η οποία συνεργάζεται με τον SQL Server 2005 με τη λογική πελάτη /
εξυπηρετητή (client / server) όπου πελάτης είναι το Excel και εξυπηρετητής ο SQL
Server.
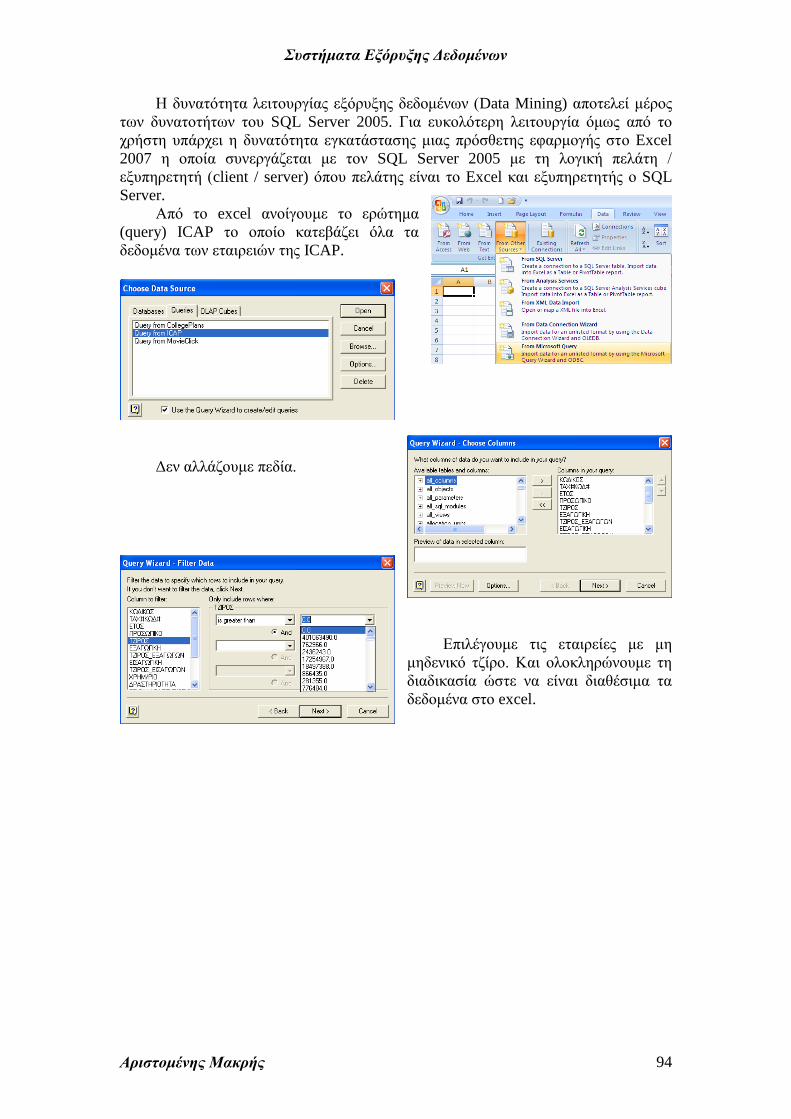
Από το excel ανοίγουμε το ερώτημα
(query) ICAP το οποίο κατεβάζει όλα τα
δεδομένα των εταιρειών της ICAP.
Δεν αλλάζουμε πεδία.
Επιλέγουμε τις εταιρείες με μη
μηδενικό τζίρο. Και ολοκληρώνουμε τη
διαδικασία ώστε να είναι διαθέσιμα τα
δεδομένα στο excel.
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 95
7.1 ΟΜΑΔΟΠΟΙΗΣΗ (CLUSTERING)
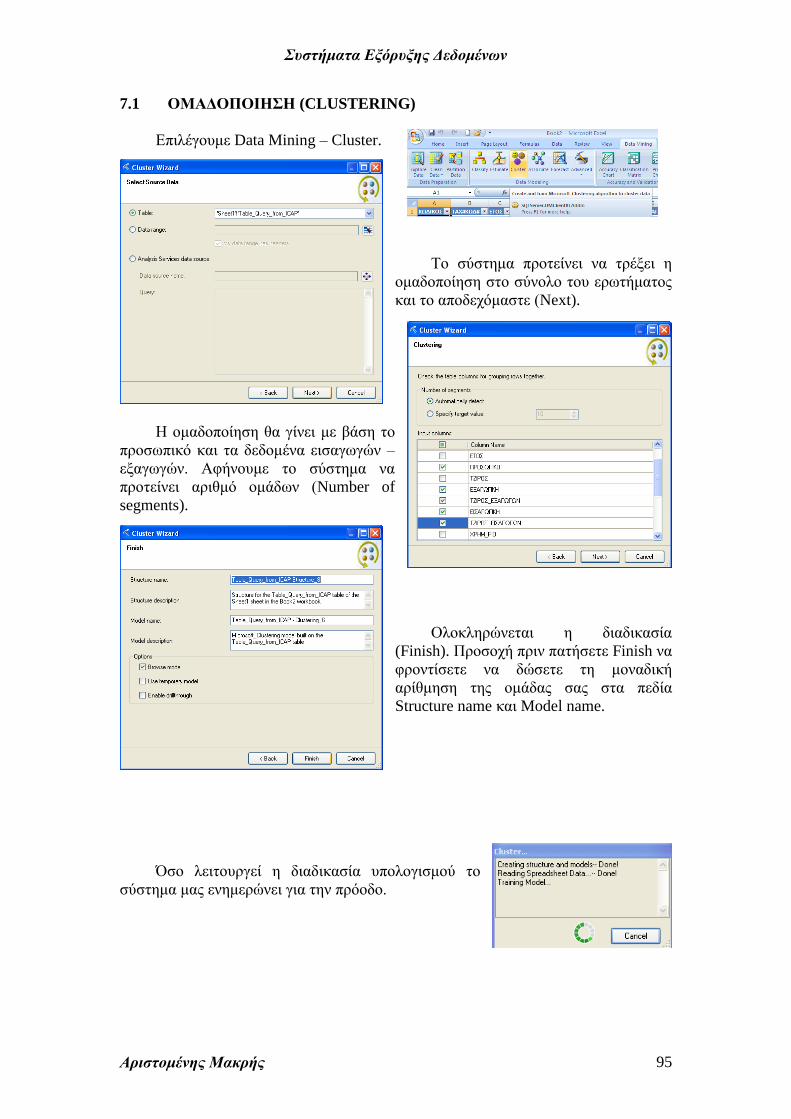
Επιλέγουμε Data Mining – Cluster.
Το σύστημα προτείνει να τρέξει η
ομαδοποίηση στο σύνολο του ερωτήματος
και το αποδεχόμαστε (Next).
Η ομαδοποίηση θα γίνει με βάση το
προσωπικό και τα δεδομένα εισαγωγών –
εξαγωγών. Αφήνουμε το σύστημα να
προτείνει αριθμό ομάδων (Number of
segments).
Ολοκληρώνεται η διαδικασία
(Finish). Προσοχή πριν πατήσετε Finish να
φροντίσετε να δώσετε τη μοναδική
αρίθμηση της ομάδας σας στα πεδία
Structure name και Model name.
Όσο λειτουργεί η διαδικασία υπολογισμού το
σύστημα μας ενημερώνει για την πρόοδο.
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 96
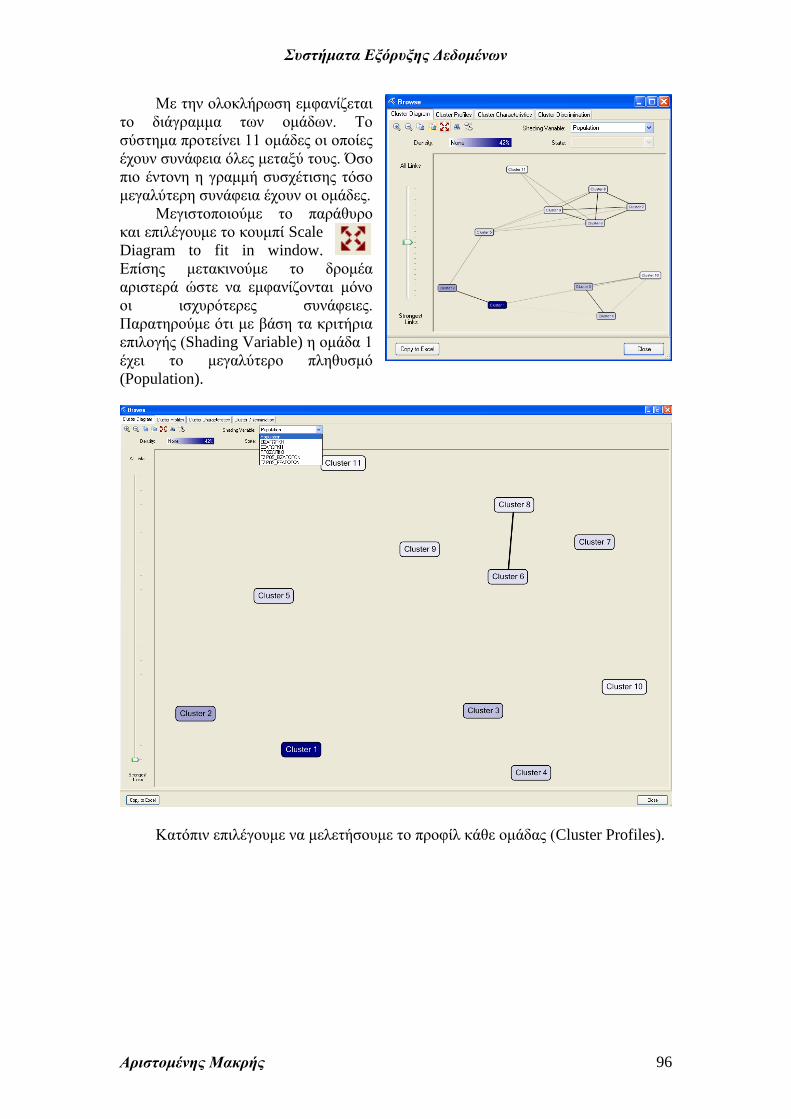
Με την ολοκλήρωση εμφανίζεται
το διάγραμμα των ομάδων. Το
σύστημα προτείνει 11 ομάδες οι οποίες
έχουν συνάφεια όλες μεταξύ τους. Όσο
πιο έντονη η γραμμή συσχέτισης τόσο
μεγαλύτερη συνάφεια έχουν οι ομάδες.
Μεγιστοποιούμε το παράθυρο
και επιλέγουμε το κουμπί Scale
Diagram to fit in window.
Επίσης μετακινούμε το δρομέα
αριστερά ώστε να εμφανίζονται μόνο
οι ισχυρότερες συνάφειες.
Παρατηρούμε ότι με βάση τα κριτήρια
επιλογής (Shading Variable) η ομάδα 1
έχει το μεγαλύτερο πληθυσμό
(Population).
Κατόπιν επιλέγουμε να μελετήσουμε το προφίλ κάθε ομάδας (Cluster Profiles).
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 97
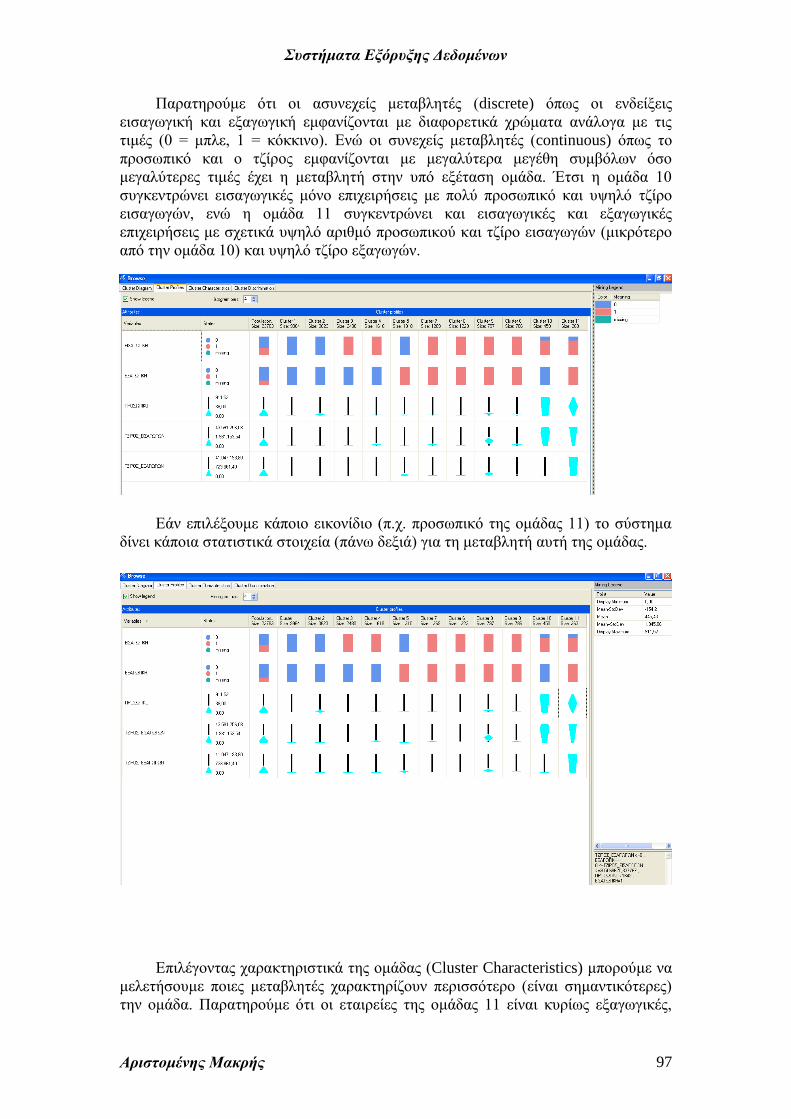
Παρατηρούμε ότι οι ασυνεχείς μεταβλητές (discrete) όπως οι ενδείξεις
εισαγωγική και εξαγωγική εμφανίζονται με διαφορετικά χρώματα ανάλογα με τις
τιμές (0 = μπλε, 1 = κόκκινο). Ενώ οι συνεχείς μεταβλητές (continuous) όπως το
προσωπικό και ο τζίρος εμφανίζονται με μεγαλύτερα μεγέθη συμβόλων όσο
μεγαλύτερες τιμές έχει η μεταβλητή στην υπό εξέταση ομάδα. Έτσι η ομάδα 10
συγκεντρώνει εισαγωγικές μόνο επιχειρήσεις με πολύ προσωπικό και υψηλό τζίρο
εισαγωγών, ενώ η ομάδα 11 συγκεντρώνει και εισαγωγικές και εξαγωγικές
επιχειρήσεις με σχετικά υψηλό αριθμό προσωπικού και τζίρο εισαγωγών (μικρότερο
από την ομάδα 10) και υψηλό τζίρο εξαγωγών.
Εάν επιλέξουμε κάποιο εικονίδιο (π.χ. προσωπικό της ομάδας 11) το σύστημα
δίνει κάποια στατιστικά στοιχεία (πάνω δεξιά) για τη μεταβλητή αυτή της ομάδας.
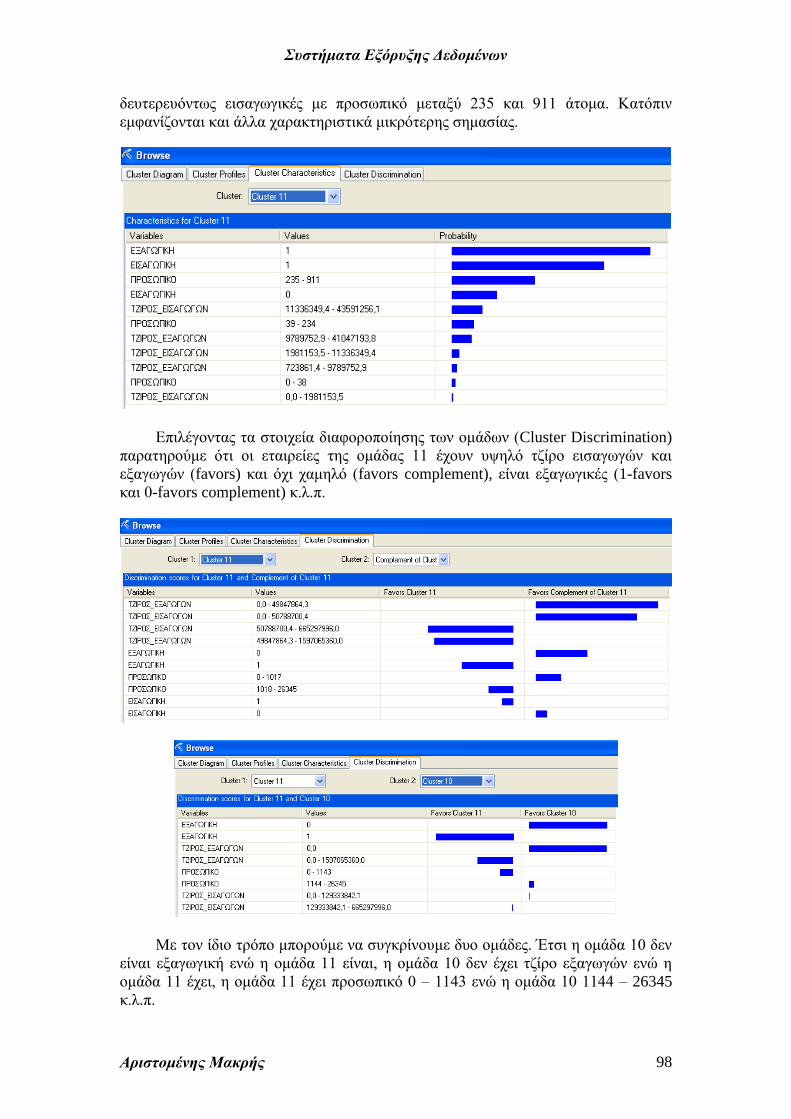
Επιλέγοντας χαρακτηριστικά της ομάδας (Cluster Characteristics) μπορούμε να
μελετήσουμε ποιες μεταβλητές χαρακτηρίζουν περισσότερο (είναι σημαντικότερες)
την ομάδα. Παρατηρούμε ότι οι εταιρείες της ομάδας 11 είναι κυρίως εξαγωγικές,
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 98
δευτερευόντως εισαγωγικές με προσωπικό μεταξύ 235 και 911 άτομα. Κατόπιν
εμφανίζονται και άλλα χαρακτηριστικά μικρότερης σημασίας.
Επιλέγοντας τα στοιχεία διαφοροποίησης των ομάδων (Cluster Discrimination)
παρατηρούμε ότι οι εταιρείες της ομάδας 11 έχουν υψηλό τζίρο εισαγωγών και
εξαγωγών (favors) και όχι χαμηλό (favors complement), είναι εξαγωγικές (1-favors
και 0-favors complement) κ.λ.π.
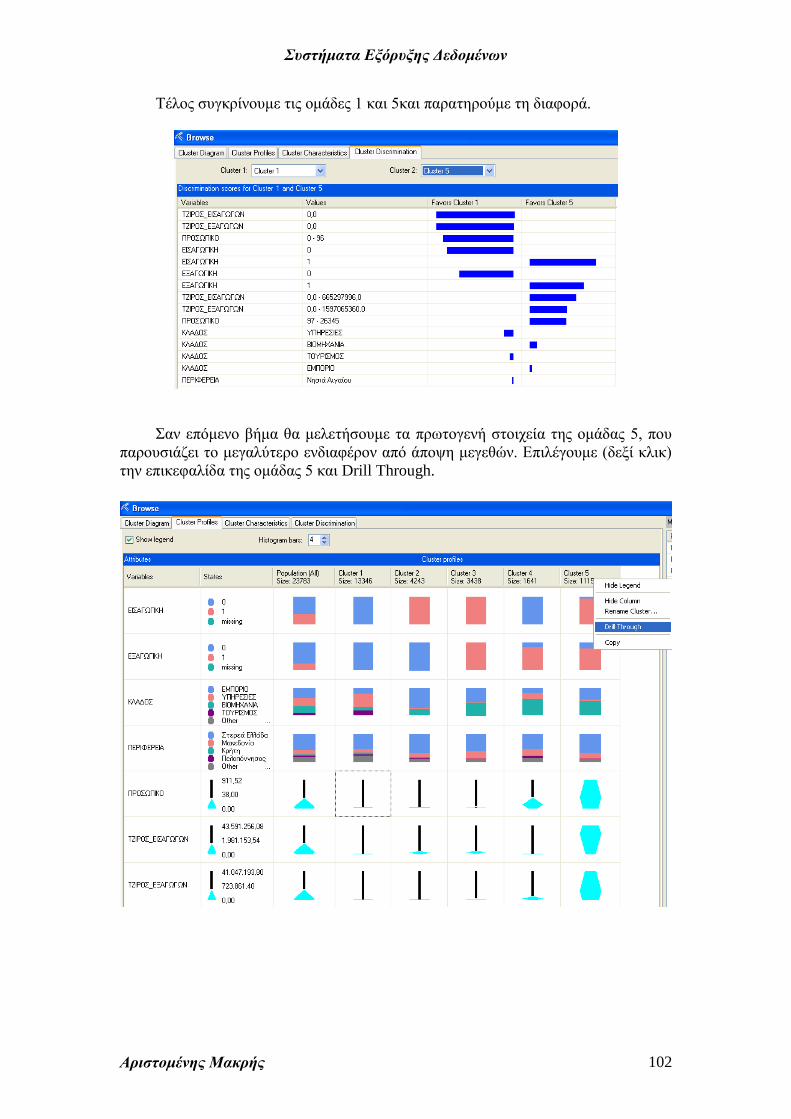
Με τον ίδιο τρόπο μπορούμε να συγκρίνουμε δυο ομάδες. Έτσι η ομάδα 10 δεν
είναι εξαγωγική ενώ η ομάδα 11 είναι, η ομάδα 10 δεν έχει τζίρο εξαγωγών ενώ η
ομάδα 11 έχει, η ομάδα 11 έχει προσωπικό 0 – 1143 ενώ η ομάδα 10 1144 – 26345
κ.λ.π.
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 99
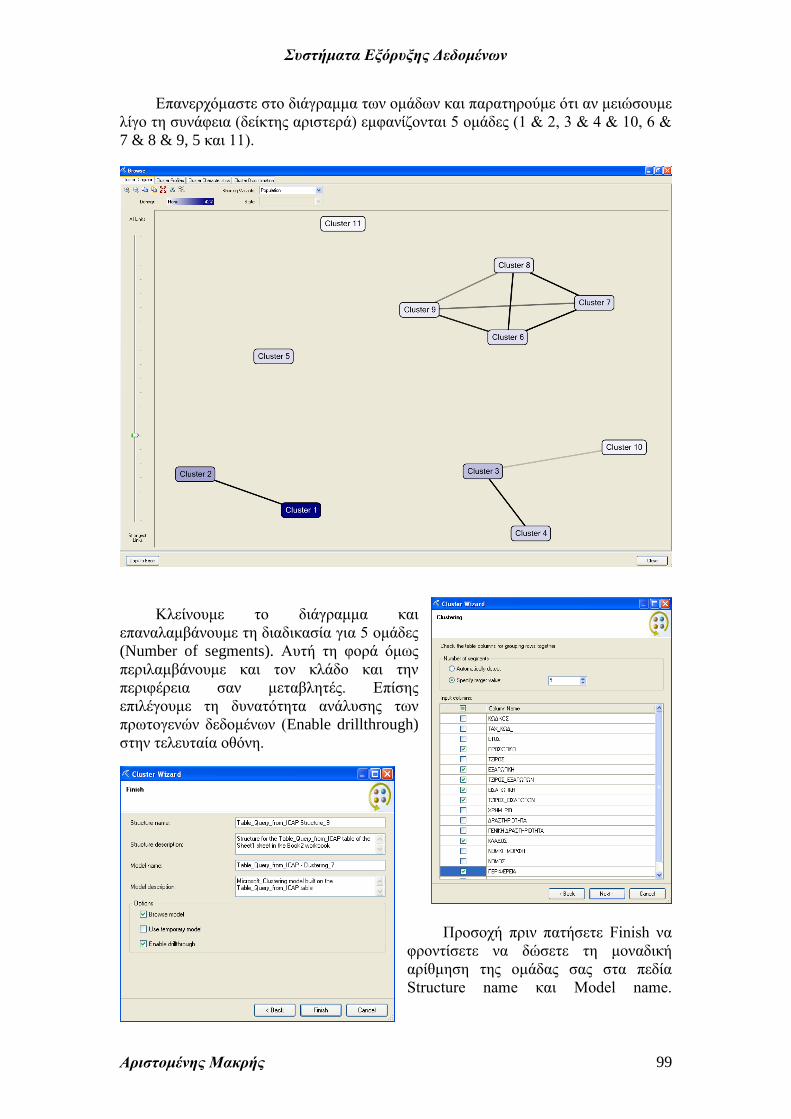
Επανερχόμαστε στο διάγραμμα των ομάδων και παρατηρούμε ότι αν μειώσουμε
λίγο τη συνάφεια (δείκτης αριστερά) εμφανίζονται 5 ομάδες (1 & 2, 3 & 4 & 10, 6 &
7 & 8 & 9, 5 και 11).
Κλείνουμε το διάγραμμα και
επαναλαμβάνουμε τη διαδικασία για 5 ομάδες
(Number of segments). Αυτή τη φορά όμως
περιλαμβάνουμε και τον κλάδο και την
περιφέρεια σαν μεταβλητές. Επίσης
επιλέγουμε τη δυνατότητα ανάλυσης των
πρωτογενών δεδομένων (Enable drillthrough)
στην τελευταία οθόνη.
Προσοχή πριν πατήσετε Finish να
φροντίσετε να δώσετε τη μοναδική
αρίθμηση της ομάδας σας στα πεδία
Structure name και Model name.
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 100
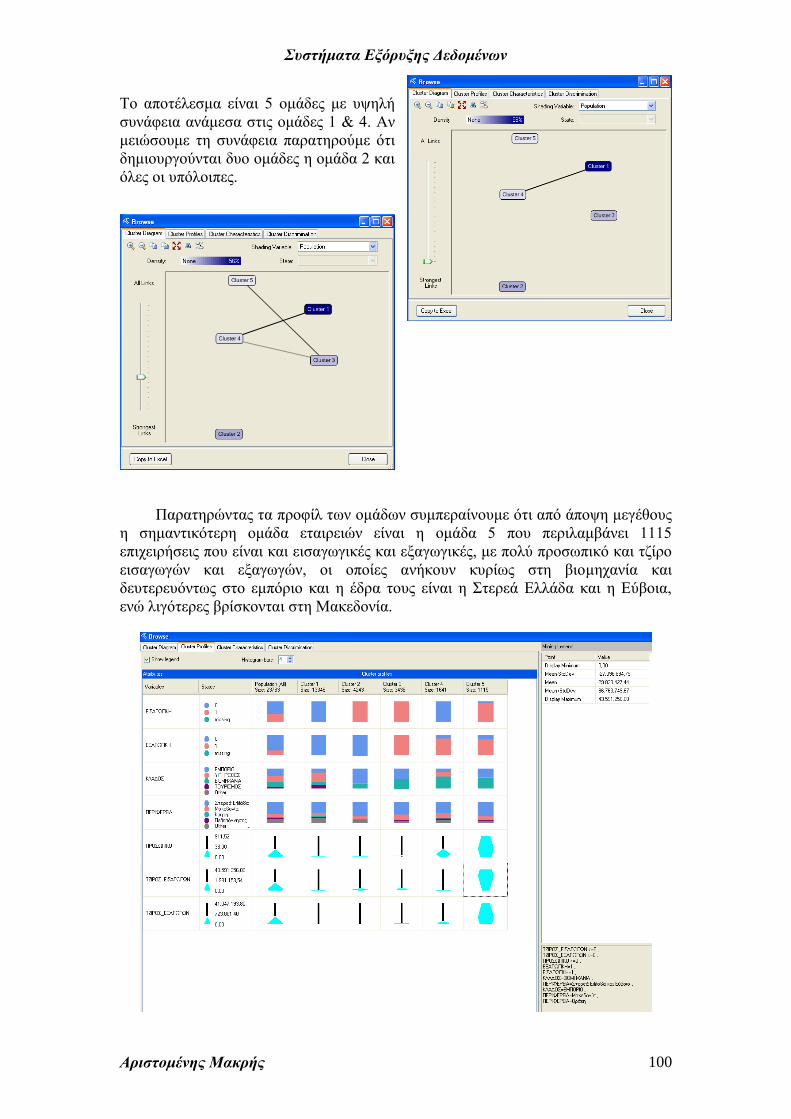
Το αποτέλεσμα είναι 5 ομάδες με υψηλή
συνάφεια ανάμεσα στις ομάδες 1 & 4. Αν
μειώσουμε τη συνάφεια παρατηρούμε ότι
δημιουργούνται δυο ομάδες η ομάδα 2 και
όλες οι υπόλοιπες.
Παρατηρώντας τα προφίλ των ομάδων συμπεραίνουμε ότι από άποψη μεγέθους
η σημαντικότερη ομάδα εταιρειών είναι η ομάδα 5 που περιλαμβάνει 1115
επιχειρήσεις που είναι και εισαγωγικές και εξαγωγικές, με πολύ προσωπικό και τζίρο
εισαγωγών και εξαγωγών, οι οποίες ανήκουν κυρίως στη βιομηχανία και
δευτερευόντως στο εμπόριο και η έδρα τους είναι η Στερεά Ελλάδα και η Εύβοια,
ενώ λιγότερες βρίσκονται στη Μακεδονία.
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 101
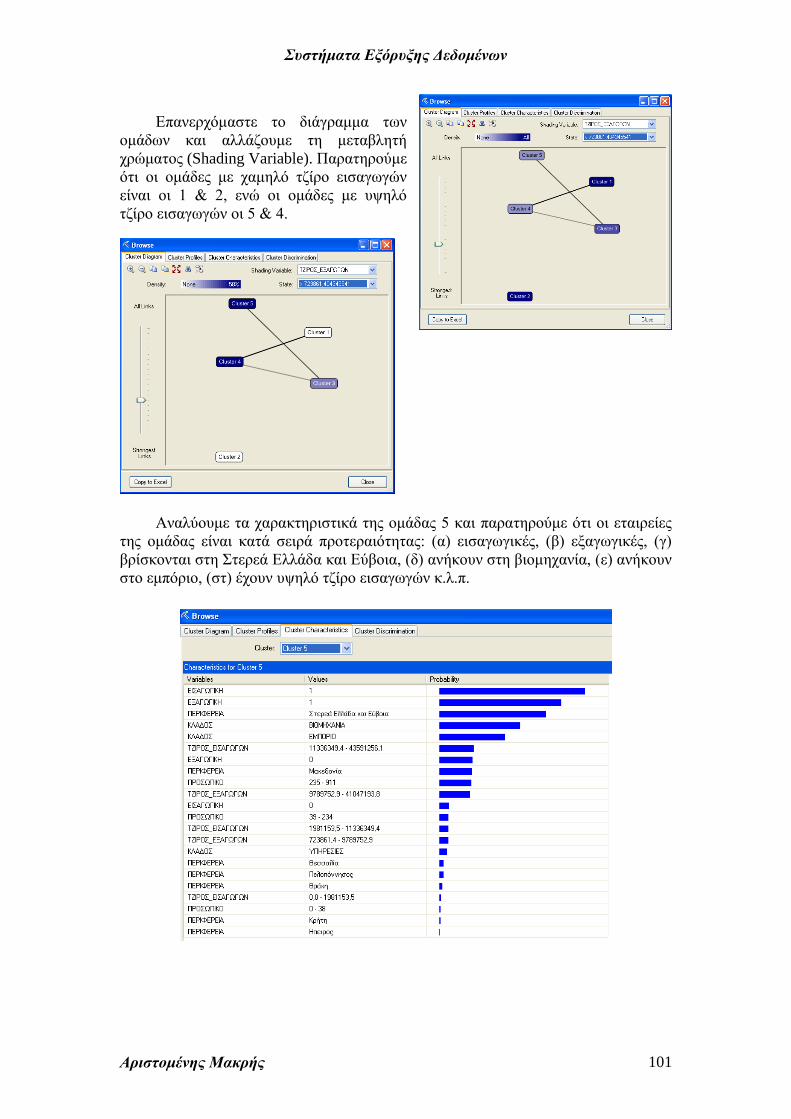
Επανερχόμαστε το διάγραμμα των
ομάδων και αλλάζουμε τη μεταβλητή
χρώματος (Shading Variable). Παρατηρούμε
ότι οι ομάδες με χαμηλό τζίρο εισαγωγών
είναι οι 1 & 2, ενώ οι ομάδες με υψηλό
τζίρο εισαγωγών οι 5 & 4.
Αναλύουμε τα χαρακτηριστικά της ομάδας 5 και παρατηρούμε ότι οι εταιρείες
της ομάδας είναι κατά σειρά προτεραιότητας: (α) εισαγωγικές, (β) εξαγωγικές, (γ)
βρίσκονται στη Στερεά Ελλάδα και Εύβοια, (δ) ανήκουν στη βιομηχανία, (ε) ανήκουν
στο εμπόριο, (στ) έχουν υψηλό τζίρο εισαγωγών κ.λ.π.
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 102
Τέλος συγκρίνουμε τις ομάδες 1 και 5και παρατηρούμε τη διαφορά.
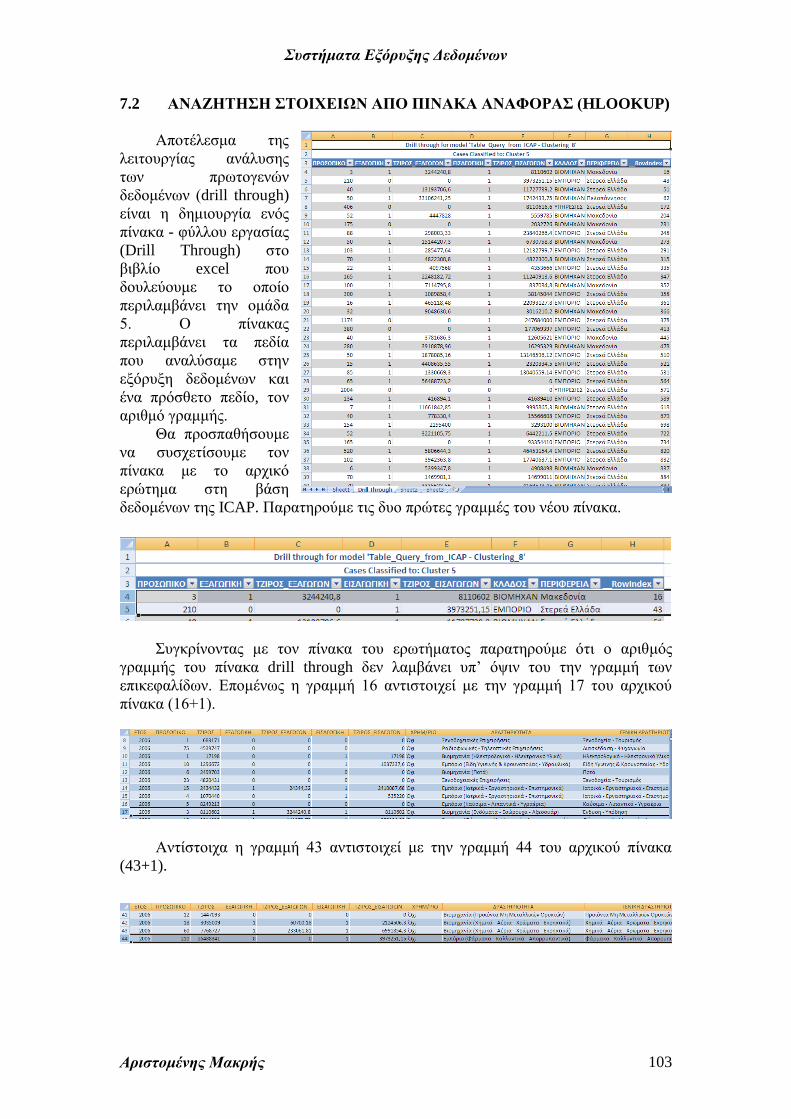
Σαν επόμενο βήμα θα μελετήσουμε τα πρωτογενή στοιχεία της ομάδας 5, που
παρουσιάζει το μεγαλύτερο ενδιαφέρον από άποψη μεγεθών. Επιλέγουμε (δεξί κλικ)
την επικεφαλίδα της ομάδας 5 και Drill Through.
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 103
7.2 ΑΝΑΖΗΤΗΣΗ ΣΤΟΙΧΕΙΩΝ ΑΠΟ ΠΙΝΑΚΑ ΑΝΑΦΟΡΑΣ (HLOOKUP)
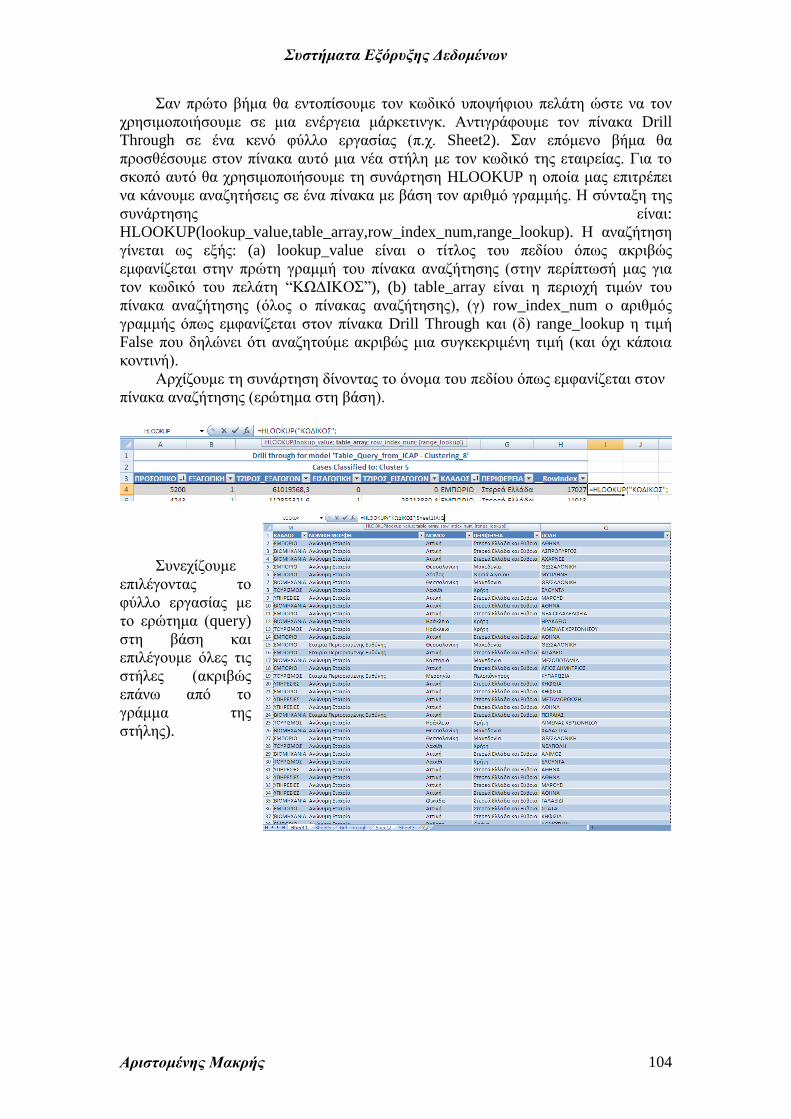
Αποτέλεσμα της
λειτουργίας ανάλυσης
των πρωτογενών
δεδομένων (drill through)
είναι η δημιουργία ενός
πίνακα - φύλλου εργασίας
(Drill Through) στο
βιβλίο excel που
δουλεύουμε το οποίο
περιλαμβάνει την ομάδα
5. Ο πίνακας
περιλαμβάνει τα πεδία
που αναλύσαμε στην
εξόρυξη δεδομένων και
ένα πρόσθετο πεδίο, τον
αριθμό γραμμής.
Θα προσπαθήσουμε
να συσχετίσουμε τον
πίνακα με το αρχικό
ερώτημα στη βάση
δεδομένων της ICAP. Παρατηρούμε τις δυο πρώτες γραμμές του νέου πίνακα.
Συγκρίνοντας με τον πίνακα του ερωτήματος παρατηρούμε ότι ο αριθμός
γραμμής του πίνακα drill through δεν λαμβάνει υπ’ όψιν του την γραμμή των
επικεφαλίδων. Επομένως η γραμμή 16 αντιστοιχεί με την γραμμή 17 του αρχικού
πίνακα (16+1).
Αντίστοιχα η γραμμή 43 αντιστοιχεί με την γραμμή 44 του αρχικού πίνακα
(43+1).
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 104
Σαν πρώτο βήμα θα εντοπίσουμε τον κωδικό υποψήφιου πελάτη ώστε να τον
χρησιμοποιήσουμε σε μια ενέργεια μάρκετινγκ. Αντιγράφουμε τον πίνακα Drill
Through σε ένα κενό φύλλο εργασίας (π.χ. Sheet2). Σαν επόμενο βήμα θα
προσθέσουμε στον πίνακα αυτό μια νέα στήλη με τον κωδικό της εταιρείας. Για το
σκοπό αυτό θα χρησιμοποιήσουμε τη συνάρτηση HLOOKUP η οποία μας επιτρέπει
να κάνουμε αναζητήσεις σε ένα πίνακα με βάση τον αριθμό γραμμής. Η σύνταξη της
συνάρτησης είναι:
HLOOKUP(lookup_value,table_array,row_index_num,range_lookup). Η αναζήτηση
γίνεται ως εξής: (a) lookup_value είναι ο τίτλος του πεδίου όπως ακριβώς
εμφανίζεται στην πρώτη γραμμή του πίνακα αναζήτησης (στην περίπτωσή μας για
τον κωδικό του πελάτη “ΚΩΔΙΚΟΣ”), (b) table_array είναι η περιοχή τιμών του
πίνακα αναζήτησης (όλος ο πίνακας αναζήτησης), (γ) row_index_num ο αριθμός
γραμμής όπως εμφανίζεται στον πίνακα Drill Through και (δ) range_lookup η τιμή
False που δηλώνει ότι αναζητούμε ακριβώς μια συγκεκριμένη τιμή (και όχι κάποια
κοντινή).
Αρχίζουμε τη συνάρτηση δίνοντας το όνομα του πεδίου όπως εμφανίζεται στον
πίνακα αναζήτησης (ερώτημα στη βάση).
Συνεχίζουμε
επιλέγοντας το
φύλλο εργασίας με
το ερώτημα (query)
στη βάση και
επιλέγουμε όλες τις
στήλες (ακριβώς
επάνω από το
γράμμα της
στήλης).

Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 105
Συνεχίζουμε
επιλέγοντας τον αριθμό
γραμμής που αντιστοιχεί
στη συγκεκριμένη γραμμή
(στο παράδειγμα το κελί
H4).
Ολοκληρώνουμε τη
συνάρτηση και πατάμε το
πλήκτρο <Enter>.
Αποτέλεσμα είναι η εμφάνιση του κωδικού του πελάτη στο τέλος κάθε
γραμμής. Μπορούμε κατόπιν να επιλέξουμε κλάδο (π.χ. Βιομηχανία) ή περιφέρεια
(π.χ. Στερεά Ελλάδα και Εύβοια) και να χρησιμοποιήσουμε τους κωδικούς πελατών
που επιλέχθηκαν για τη δημιουργία μιας ενέργειας μάρκετινγκ.
ΕΡΩΤΗΜΑ: Αν είχαμε στη βάση δεδομένων τα στοιχεία των πελατών (επωνυμία,
διεύθυνση κ.ά.) πώς θα μπορούσαμε εύκολα να τα αντλήσουμε ώστε να τα δώσουμε
στους υπευθύνους πωλήσεων;
ΑΠΑΝΤΗΣΗ: Μπορούμε να αντιγράψουμε τη στήλη με τους κωδικούς υποψηφίων
πελατών σε ένα κενό φύλλο εργασίας Excel και κατόπιν να εισάγουμε το φύλλο
εργασίας σαν ένα νέο πίνακα στη βάση της ICAP (με τα εργαλεία Import του SQL
Server). Κατόπιν συσχετίζουμε τον νέο πίνακα με τον πίνακα (ή πίνακες) της ICAP
που περιλαμβάνει τα στοιχεία που θέλουμε και δημιουργούμε ένα νέο ερώτημα
(query) στη βάση με βάση το νέο πίνακα των υποψηφίων πελατών.
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 106
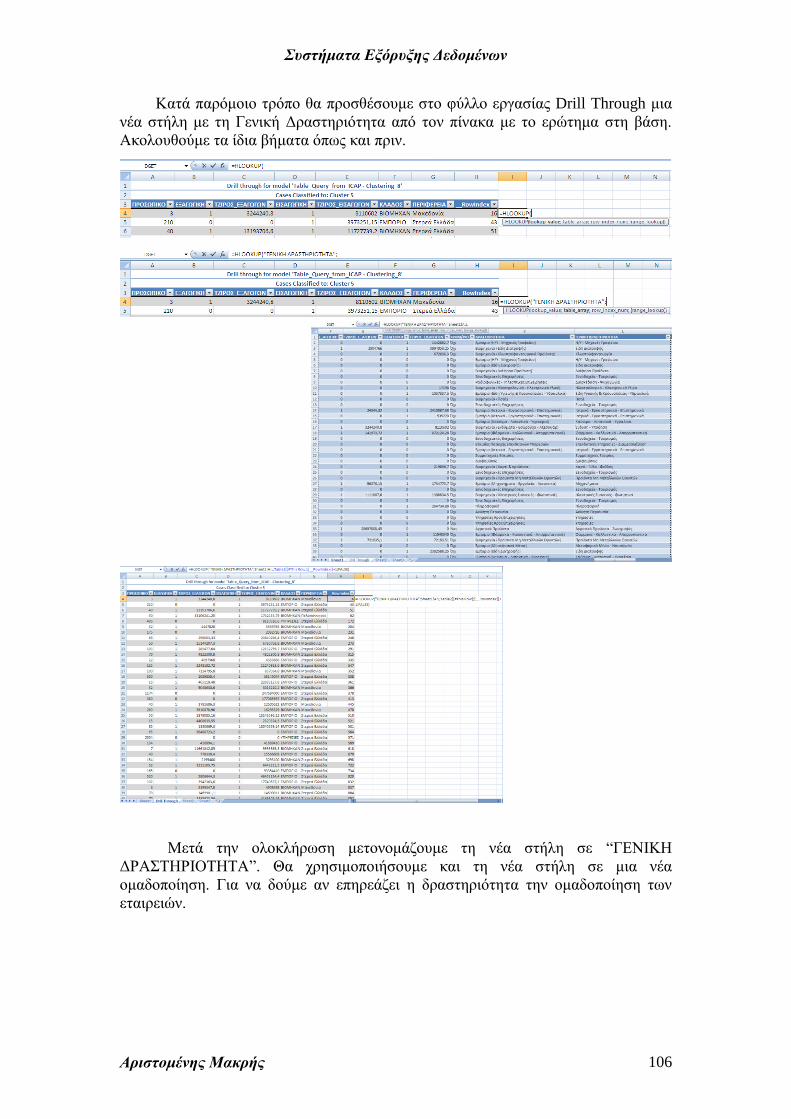
Κατά παρόμοιο τρόπο θα προσθέσουμε στο φύλλο εργασίας Drill Through μια
νέα στήλη με τη Γενική Δραστηριότητα από τον πίνακα με το ερώτημα στη βάση.
Ακολουθούμε τα ίδια βήματα όπως και πριν.
Μετά την ολοκλήρωση μετονομάζουμε τη νέα στήλη σε “ΓΕΝΙΚΗ
ΔΡΑΣΤΗΡΙΟΤΗΤΑ”. Θα χρησιμοποιήσουμε και τη νέα στήλη σε μια νέα
ομαδοποίηση. Για να δούμε αν επηρεάζει η δραστηριότητα την ομαδοποίηση των
εταιρειών.
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 107
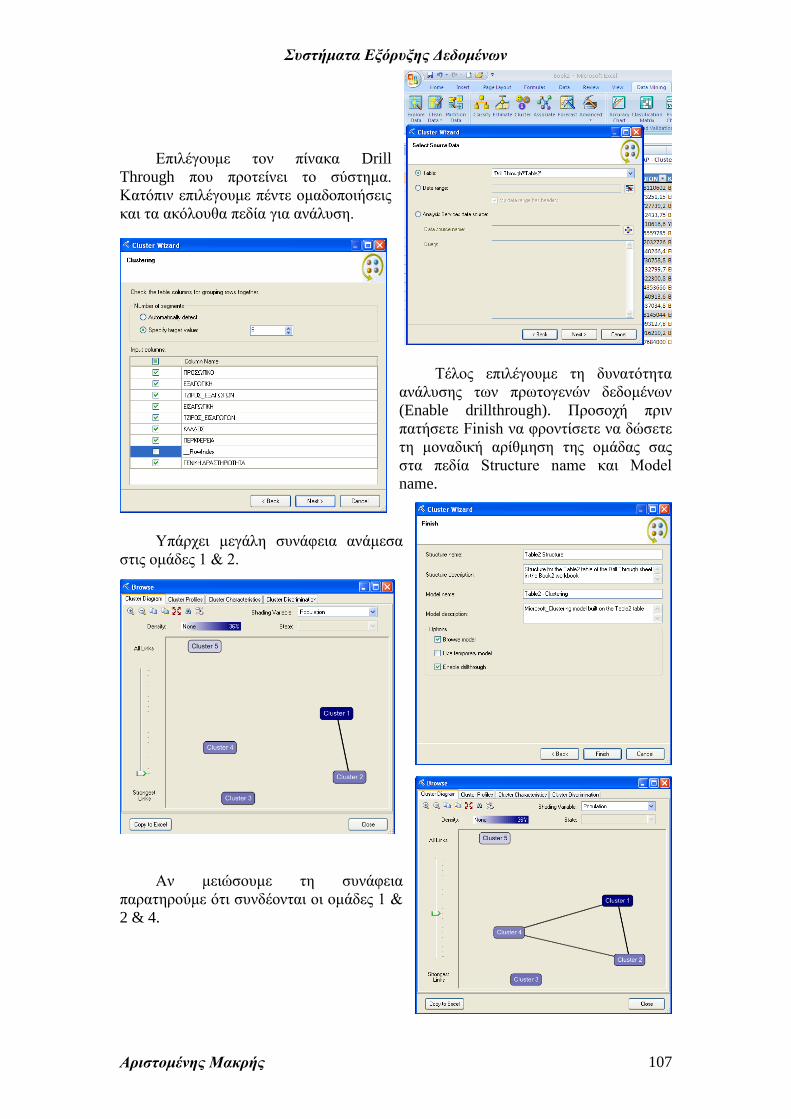
Επιλέγουμε τον πίνακα Drill
Through που προτείνει το σύστημα.
Κατόπιν επιλέγουμε πέντε ομαδοποιήσεις
και τα ακόλουθα πεδία για ανάλυση.
Τέλος επιλέγουμε τη δυνατότητα
ανάλυσης των πρωτογενών δεδομένων
(Enable drillthrough). Προσοχή πριν
πατήσετε Finish να φροντίσετε να δώσετε
τη μοναδική αρίθμηση της ομάδας σας
στα πεδία Structure name και Model
name.
Υπάρχει μεγάλη συνάφεια ανάμεσα
στις ομάδες 1 & 2.
Αν μειώσουμε τη συνάφεια
παρατηρούμε ότι συνδέονται οι ομάδες 1 &
2 & 4.
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 108
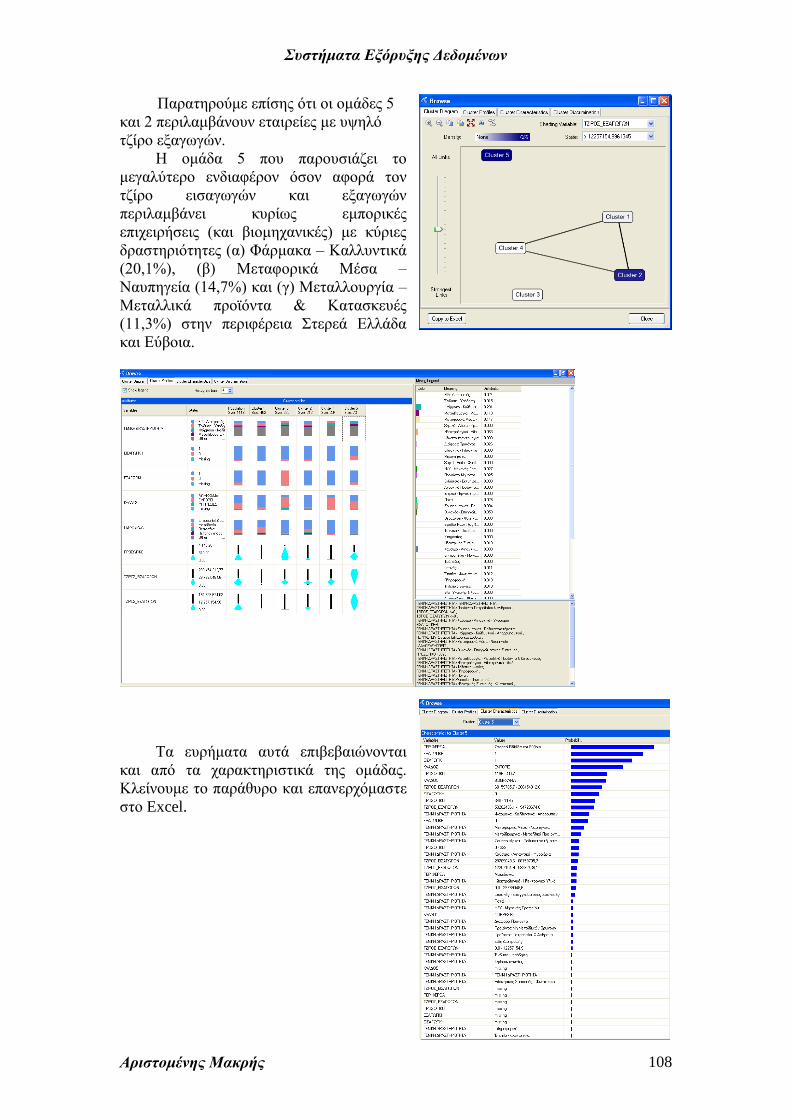
Παρατηρούμε επίσης ότι οι ομάδες 5
και 2 περιλαμβάνουν εταιρείες με υψηλό
τζίρο εξαγωγών.
Η ομάδα 5 που παρουσιάζει το
μεγαλύτερο ενδιαφέρον όσον αφορά τον
τζίρο εισαγωγών και εξαγωγών
περιλαμβάνει κυρίως εμπορικές
επιχειρήσεις (και βιομηχανικές) με κύριες
δραστηριότητες (α) Φάρμακα – Καλλυντικά
(20,1%), (β) Μεταφορικά Μέσα –
Ναυπηγεία (14,7%) και (γ) Μεταλλουργία –
Μεταλλικά προϊόντα & Κατασκευές
(11,3%) στην περιφέρεια Στερεά Ελλάδα
και Εύβοια.
Τα ευρήματα αυτά επιβεβαιώνονται
και από τα χαρακτηριστικά της ομάδας.
Κλείνουμε το παράθυρο και επανερχόμαστε
στο Excel.
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 109
7.3 ΔΕΝΔΡΑ ΑΠΟΦΑΣΕΩΝ (CLASSIFY)
Θα επιβεβαιώσουμε τα
ευρήματα της προηγούμενης
παραγράφου με τη δημιουργία
ενός δένδρου αποφάσεων. Στο
φύλλο εργασίας Drill Through
επιλέγουμε Data Mining –
Classify.
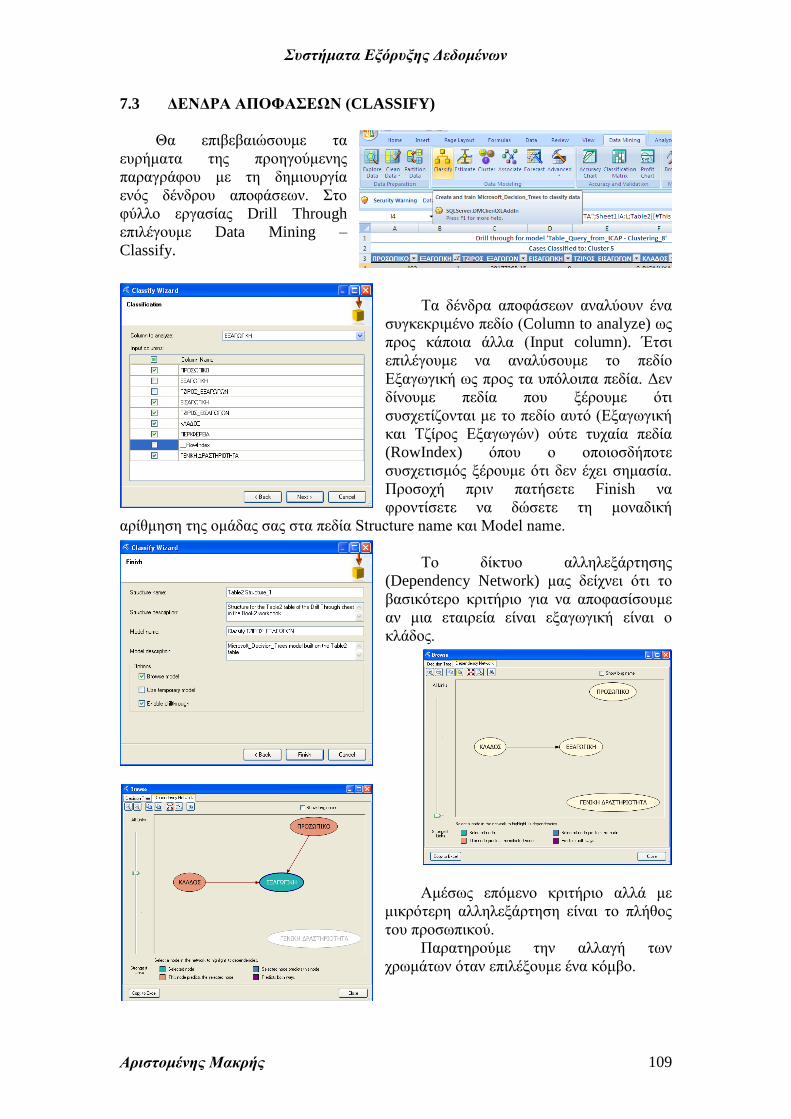
Τα δένδρα αποφάσεων αναλύουν ένα
συγκεκριμένο πεδίο (Column to analyze) ως
προς κάποια άλλα (Input column). Έτσι
επιλέγουμε να αναλύσουμε το πεδίο
Εξαγωγική ως προς τα υπόλοιπα πεδία. Δεν
δίνουμε πεδία που ξέρουμε ότι
συσχετίζονται με το πεδίο αυτό (Εξαγωγική
και Τζίρος Εξαγωγών) ούτε τυχαία πεδία
(RowIndex) όπου ο οποιοσδήποτε
συσχετισμός ξέρουμε ότι δεν έχει σημασία.
Προσοχή πριν πατήσετε Finish να
φροντίσετε να δώσετε τη μοναδική
αρίθμηση της ομάδας σας στα πεδία Structure name και Model name.
Το δίκτυο αλληλεξάρτησης
(Dependency Network) μας δείχνει ότι το
βασικότερο κριτήριο για να αποφασίσουμε
αν μια εταιρεία είναι εξαγωγική είναι ο
κλάδος.
Αμέσως επόμενο κριτήριο αλλά με
μικρότερη αλληλεξάρτηση είναι το πλήθος
του προσωπικού.
Παρατηρούμε την αλλαγή των
χρωμάτων όταν επιλέξουμε ένα κόμβο.
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 110
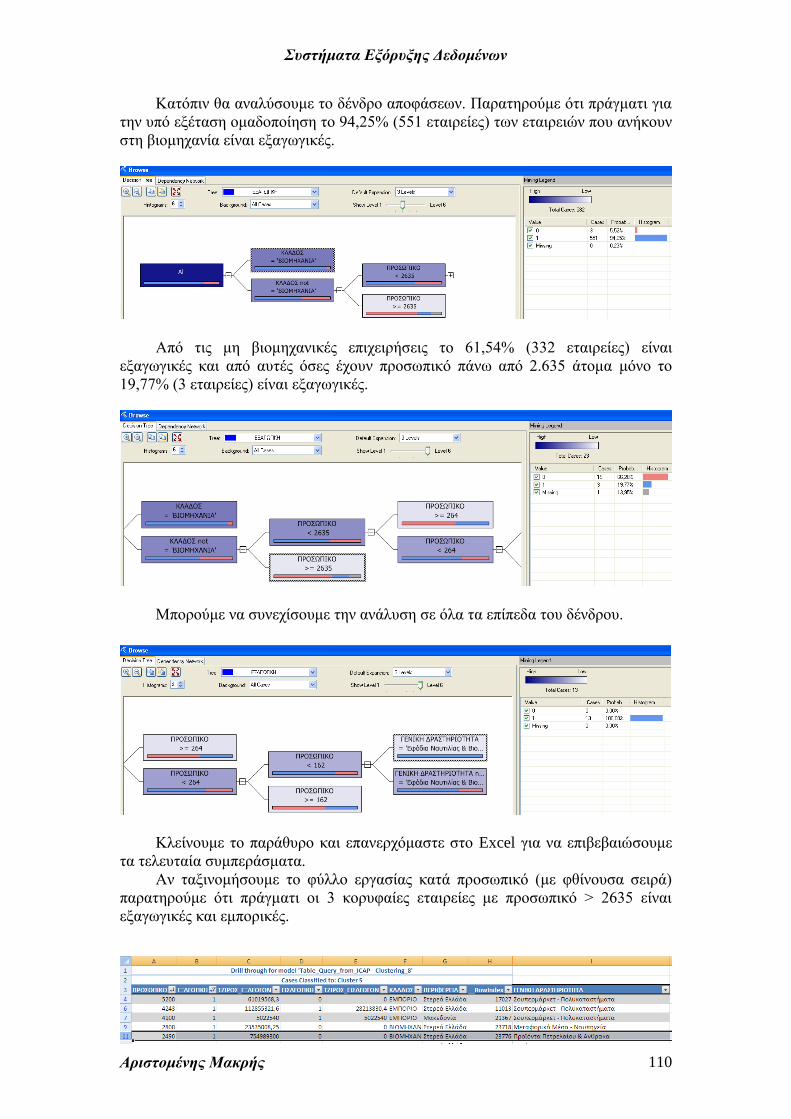
Κατόπιν θα αναλύσουμε το δένδρο αποφάσεων. Παρατηρούμε ότι πράγματι για
την υπό εξέταση ομαδοποίηση το 94,25% (551 εταιρείες) των εταιρειών που ανήκουν
στη βιομηχανία είναι εξαγωγικές.
Από τις μη βιομηχανικές επιχειρήσεις το 61,54% (332 εταιρείες) είναι
εξαγωγικές και από αυτές όσες έχουν προσωπικό πάνω από 2.635 άτομα μόνο το
19,77% (3 εταιρείες) είναι εξαγωγικές.
Μπορούμε να συνεχίσουμε την ανάλυση σε όλα τα επίπεδα του δένδρου.
Κλείνουμε το παράθυρο και επανερχόμαστε στο Excel για να επιβεβαιώσουμε
τα τελευταία συμπεράσματα.
Αν ταξινομήσουμε το φύλλο εργασίας κατά προσωπικό (με φθίνουσα σειρά)
παρατηρούμε ότι πράγματι οι 3 κορυφαίες εταιρείες με προσωπικό > 2635 είναι
εξαγωγικές και εμπορικές.
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 111
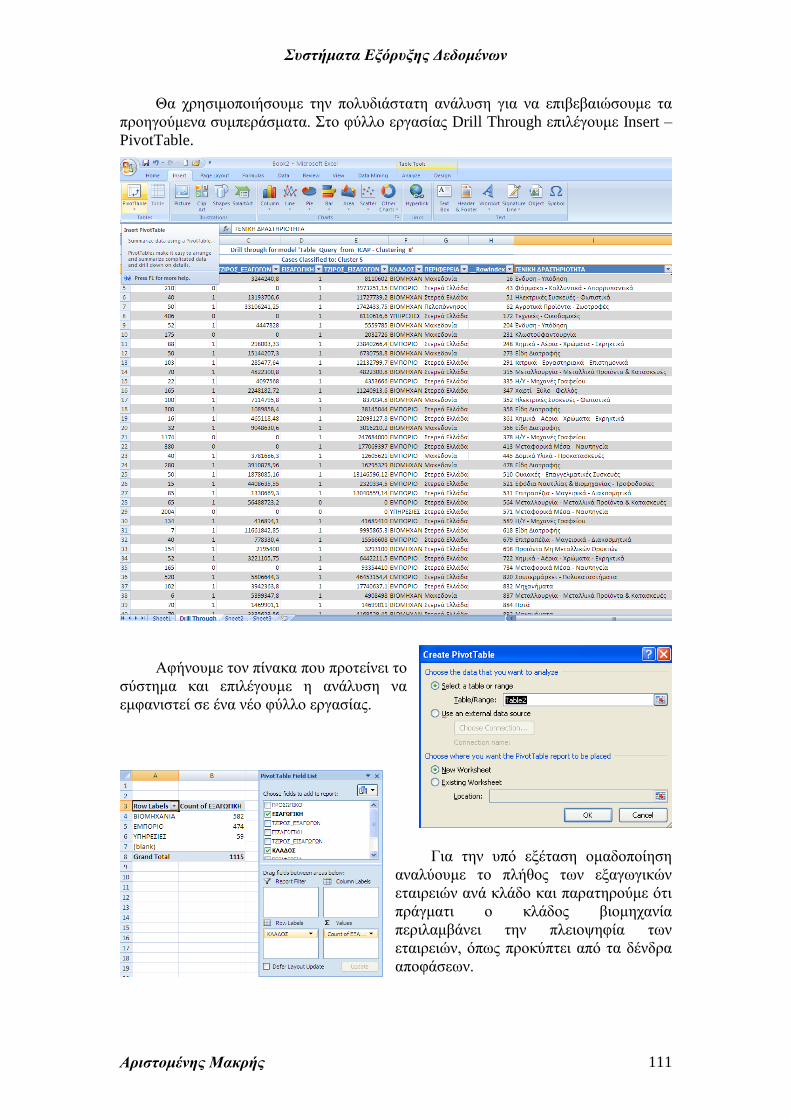
Θα χρησιμοποιήσουμε την πολυδιάστατη ανάλυση για να επιβεβαιώσουμε τα
προηγούμενα συμπεράσματα. Στο φύλλο εργασίας Drill Through επιλέγουμε Insert –
PivotTable.
Αφήνουμε τον πίνακα που προτείνει το
σύστημα και επιλέγουμε η ανάλυση να
εμφανιστεί σε ένα νέο φύλλο εργασίας.
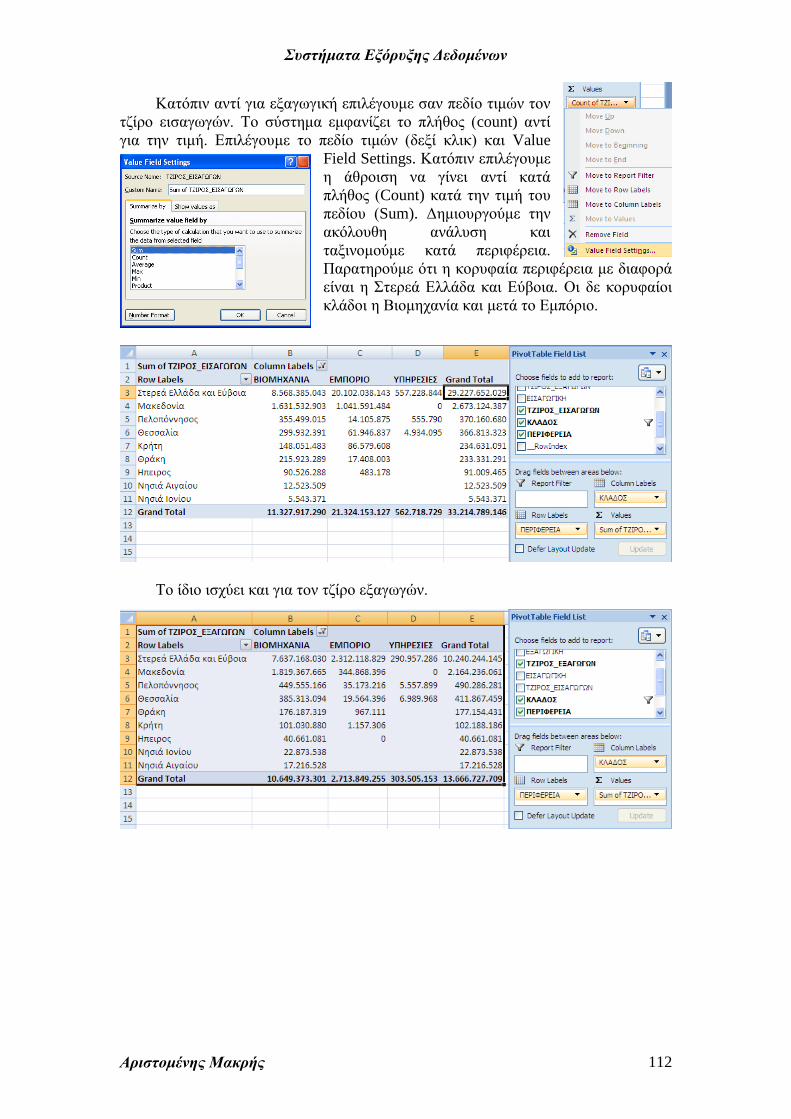
Για την υπό εξέταση ομαδοποίηση
αναλύουμε το πλήθος των εξαγωγικών
εταιρειών ανά κλάδο και παρατηρούμε ότι
πράγματι ο κλάδος βιομηχανία
περιλαμβάνει την πλειοψηφία των
εταιρειών, όπως προκύπτει από τα δένδρα
αποφάσεων.
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 112
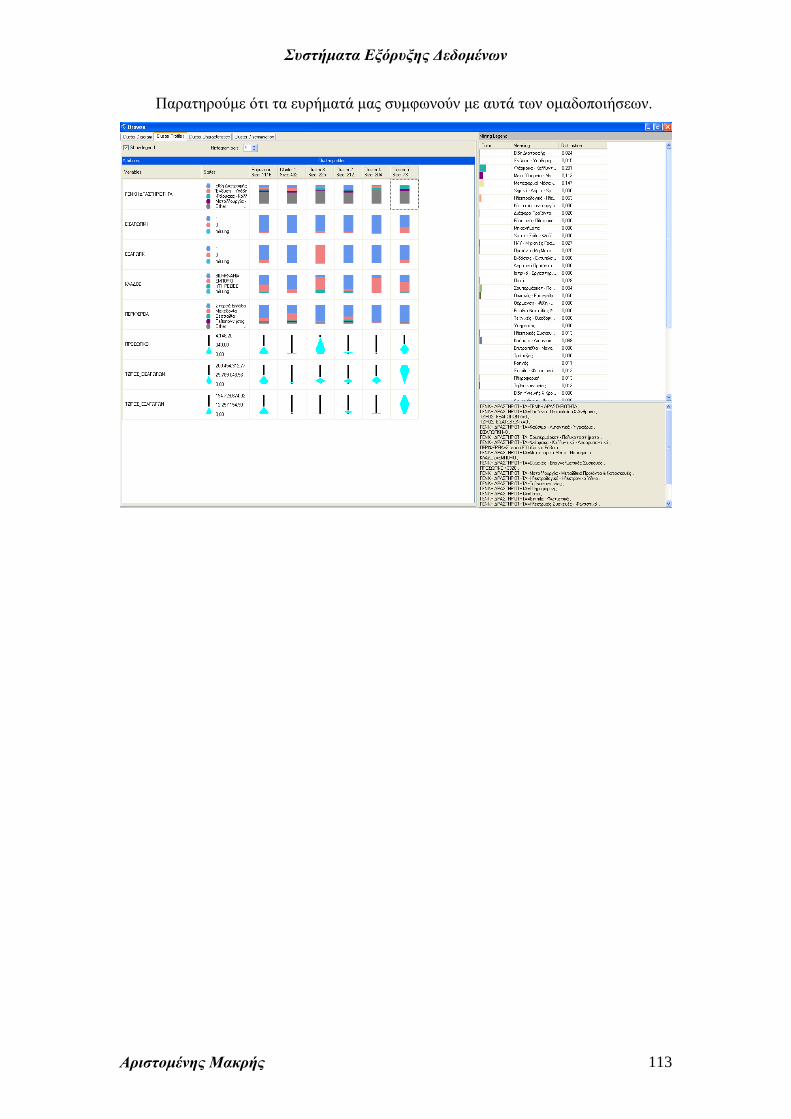
Κατόπιν αντί για εξαγωγική επιλέγουμε σαν πεδίο τιμών τον
τζίρο εισαγωγών. Το σύστημα εμφανίζει το πλήθος (count) αντί
για την τιμή. Επιλέγουμε το πεδίο τιμών (δεξί κλικ) και Value
Field Settings. Κατόπιν επιλέγουμε
η άθροιση να γίνει αντί κατά
πλήθος (Count) κατά την τιμή του
πεδίου (Sum). Δημιουργούμε την
ακόλουθη ανάλυση και
ταξινομούμε κατά περιφέρεια.
Παρατηρούμε ότι η κορυφαία περιφέρεια με διαφορά
είναι η Στερεά Ελλάδα και Εύβοια. Οι δε κορυφαίοι
κλάδοι η Βιομηχανία και μετά το Εμπόριο.
Το ίδιο ισχύει και για τον τζίρο εξαγωγών.
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 113
Παρατηρούμε ότι τα ευρήματά μας συμφωνούν με αυτά των ομαδοποιήσεων.
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 114
7.4 ΑΝΑΛΥΣΗ ΚΑΛΑΘΙΟΥ (ASSOCIATE)
Για τη συγκεκριμένη ανάλυση θα χρησιμοποιήσουμε μια νέα βάση δεδομένων .
Ανοίγουμε το πρόγραμμα SQL Server Management Studio και παρατηρούμε το
διάγραμμα της βάσης MovieClick. Η συγκεκριμένη βάση αποτελείται από ένα
κεντρικό πίνακα με στοιχεία πελατών και διάφορους περιφερειακούς όπως ταινίες,
ηθοποιοί κ.λ.π. Για τις ανάγκες του παραδείγματος θα χρησιμοποιήσουμε τους
πίνακες Customers και Movies. Κλείνουμε το πρόγραμμα.
Στο Excel σε ένα κενό βιβλίο
εργασίας ανοίγουμε και εκτελούμε το
ερώτημα MovieClick.
Το αποτέλεσμα είναι η δημιουργία του πίνακα που ακολουθεί.
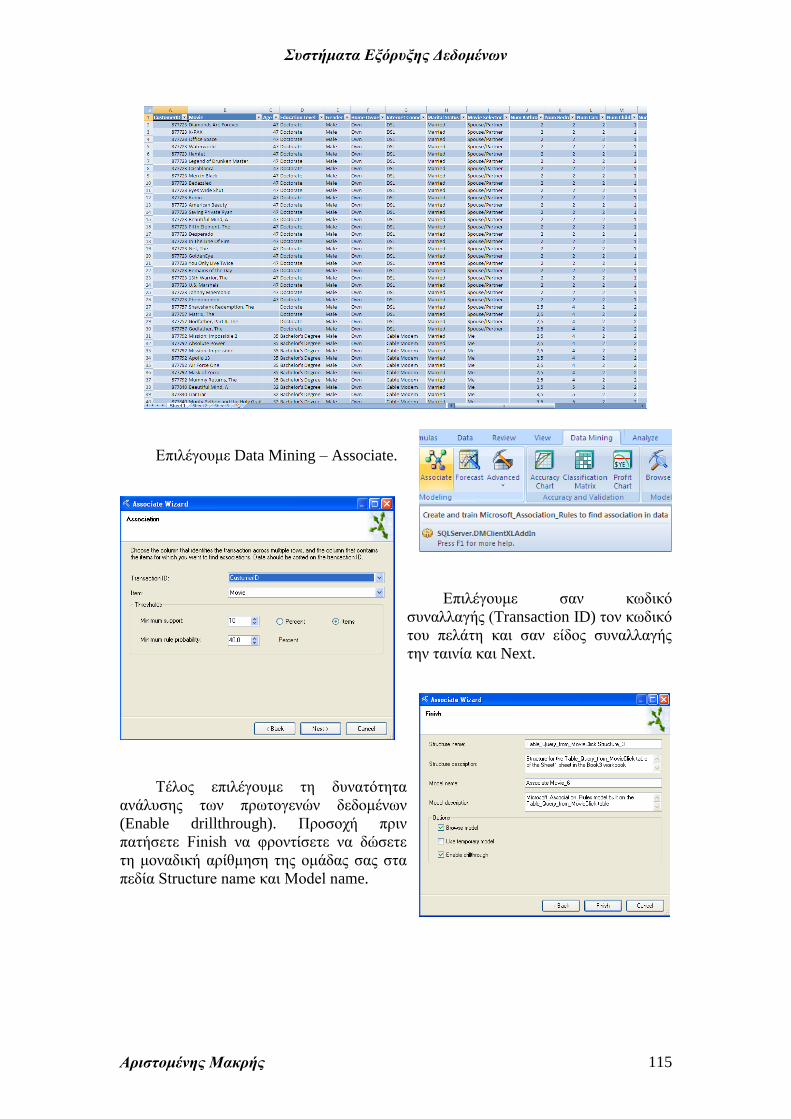
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 115
Επιλέγουμε Data Mining – Associate.
Επιλέγουμε σαν κωδικό
συναλλαγής (Transaction ID) τον κωδικό
του πελάτη και σαν είδος συναλλαγής
την ταινία και Next.
Τέλος επιλέγουμε τη δυνατότητα
ανάλυσης των πρωτογενών δεδομένων
(Enable drillthrough). Προσοχή πριν
πατήσετε Finish να φροντίσετε να δώσετε
τη μοναδική αρίθμηση της ομάδας σας στα
πεδία Structure name και Model name.
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 116
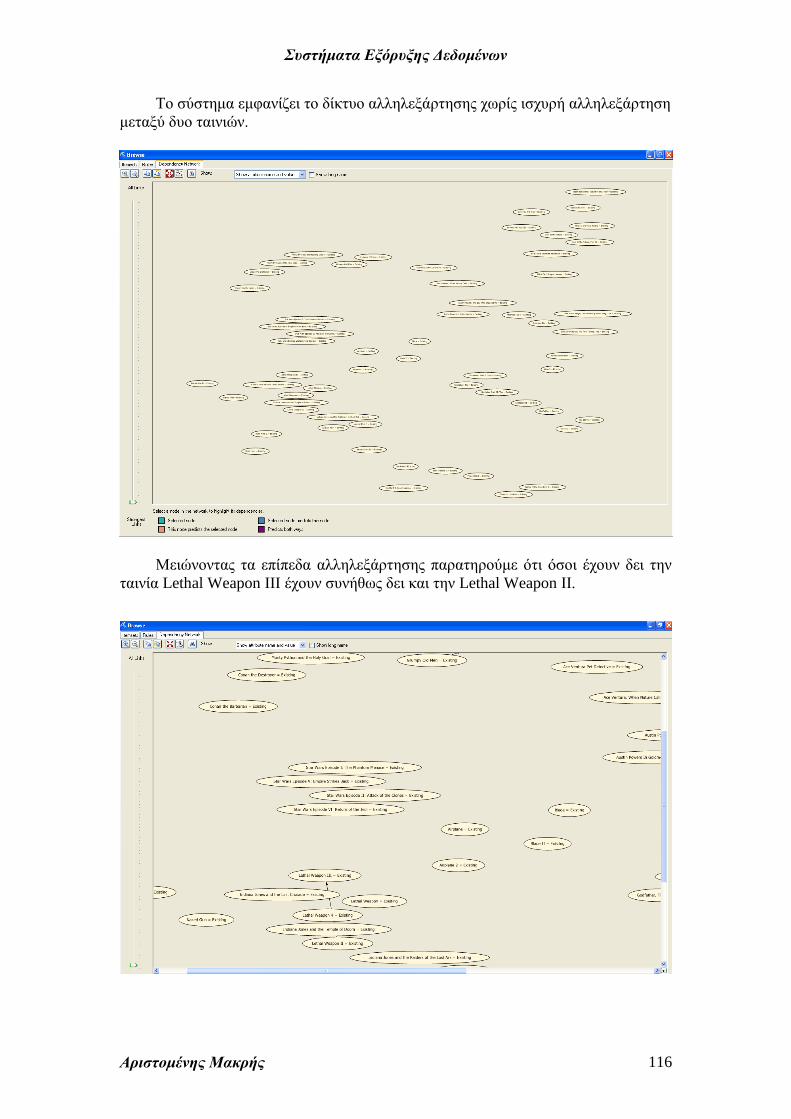
Το σύστημα εμφανίζει το δίκτυο αλληλεξάρτησης χωρίς ισχυρή αλληλεξάρτηση
μεταξύ δυο ταινιών.
Μειώνοντας τα επίπεδα αλληλεξάρτησης παρατηρούμε ότι όσοι έχουν δει την
ταινία Lethal Weapon III έχουν συνήθως δει και την Lethal Weapon ΙΙ.

Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 117
Μειώνοντας
ακόμη τα επίπεδα
αλληλεξάρτησης
παρατηρούμε ότι
όσοι έχουν δει την
ταινία Lethal
Weapon III έχουν
συνήθως δει και την
Lethal Weapon ΙΙ
και την Lethal
Weapon 4.
Παράλληλα
εμφανίζονται και άλλες
αλληλεξαρτήσεις.
Κατόπιν επιλέγουμε τις ταινίες (Itemsets), ταξινομούμε ως προς το πλήθος των
προβολών και παρατηρούμε τις ταινίες με τη μεγαλύτερη συχνότητα.
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 118
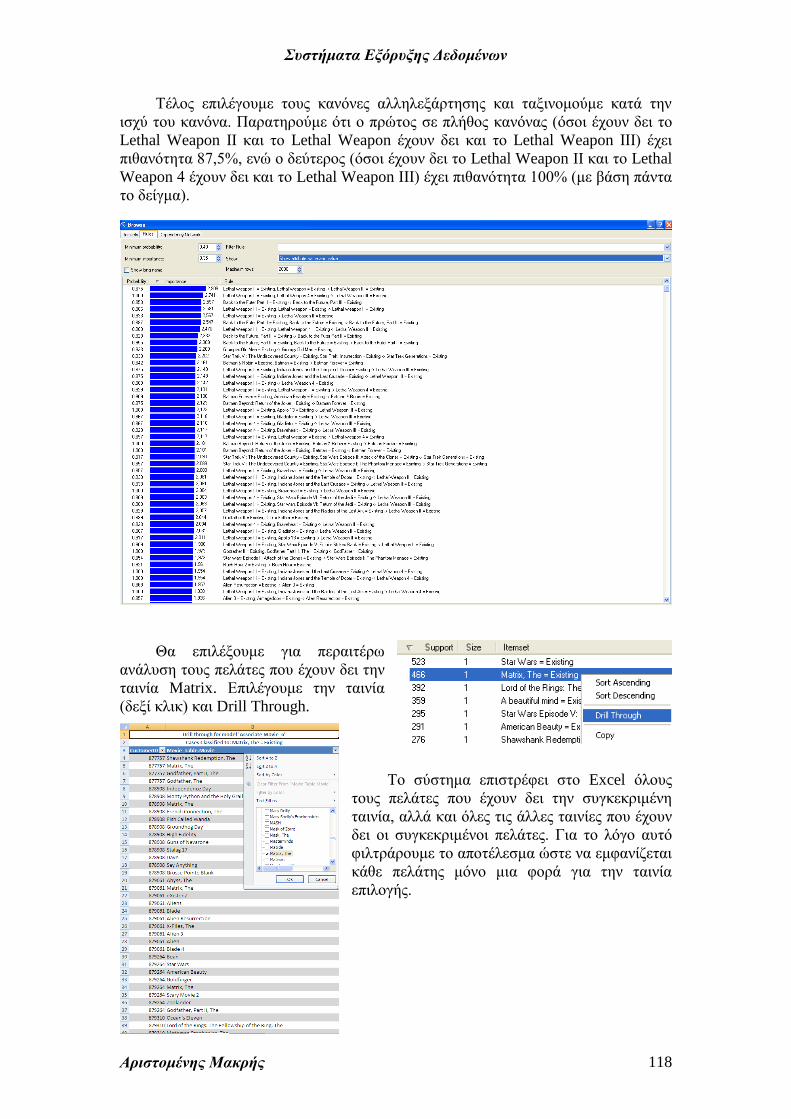
Τέλος επιλέγουμε τους κανόνες αλληλεξάρτησης και ταξινομούμε κατά την
ισχύ του κανόνα. Παρατηρούμε ότι ο πρώτος σε πλήθος κανόνας (όσοι έχουν δει το
Lethal Weapon II και το Lethal Weapon έχουν δει και το Lethal Weapon ΙΙΙ) έχει
πιθανότητα 87,5%, ενώ ο δεύτερος (όσοι έχουν δει το Lethal Weapon II και το Lethal
Weapon 4 έχουν δει και το Lethal Weapon ΙΙΙ) έχει πιθανότητα 100% (με βάση πάντα
το δείγμα).
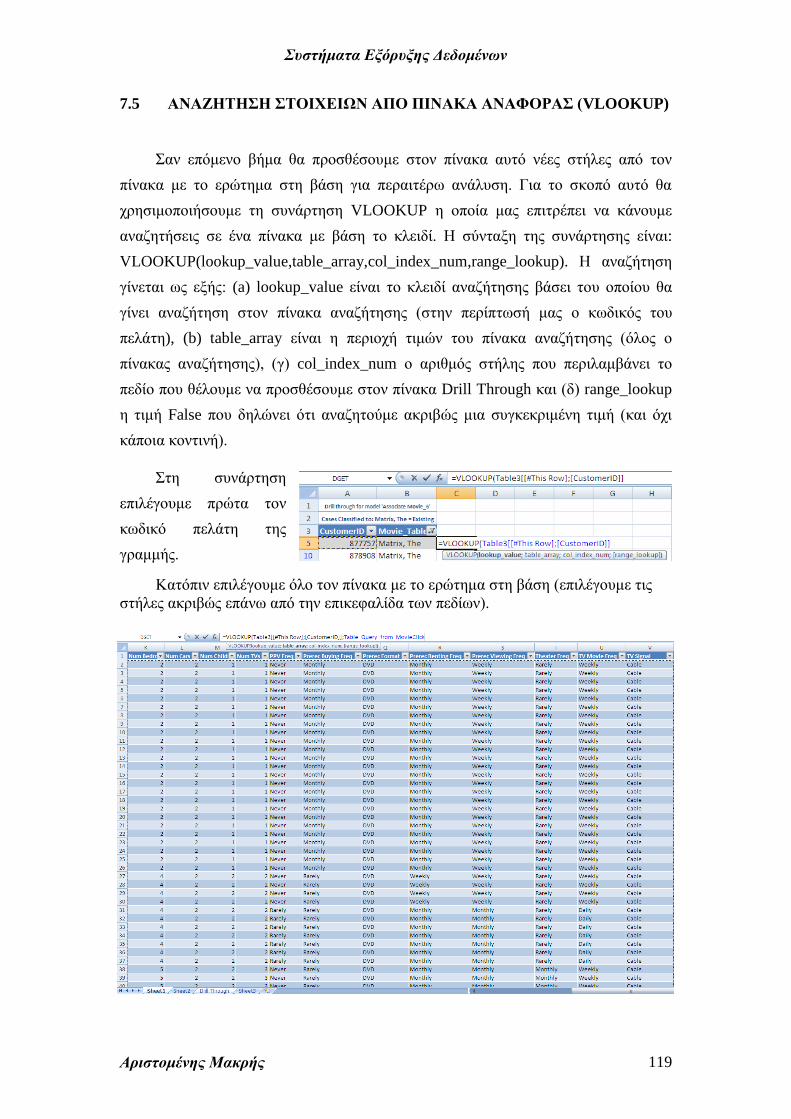
Θα επιλέξουμε για περαιτέρω
ανάλυση τους πελάτες που έχουν δει την
ταινία Matrix. Επιλέγουμε την ταινία
(δεξί κλικ) και Drill Through.
Το σύστημα επιστρέφει στο Excel όλους
τους πελάτες που έχουν δει την συγκεκριμένη
ταινία, αλλά και όλες τις άλλες ταινίες που έχουν
δει οι συγκεκριμένοι πελάτες. Για το λόγο αυτό
φιλτράρουμε το αποτέλεσμα ώστε να εμφανίζεται
κάθε πελάτης μόνο μια φορά για την ταινία
επιλογής.
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 119
7.5 ΑΝΑΖΗΤΗΣΗ ΣΤΟΙΧΕΙΩΝ ΑΠΟ ΠΙΝΑΚΑ ΑΝΑΦΟΡΑΣ (VLOOKUP)
Σαν επόμενο βήμα θα προσθέσουμε στον πίνακα αυτό νέες στήλες από τον
πίνακα με το ερώτημα στη βάση για περαιτέρω ανάλυση. Για το σκοπό αυτό θα
χρησιμοποιήσουμε τη συνάρτηση VLOOKUP η οποία μας επιτρέπει να κάνουμε
αναζητήσεις σε ένα πίνακα με βάση το κλειδί. Η σύνταξη της συνάρτησης είναι:
VLOOKUP(lookup_value,table_array,col_index_num,range_lookup). Η αναζήτηση
γίνεται ως εξής: (a) lookup_value είναι το κλειδί αναζήτησης βάσει του οποίου θα
γίνει αναζήτηση στον πίνακα αναζήτησης (στην περίπτωσή μας ο κωδικός του
πελάτη), (b) table_array είναι η περιοχή τιμών του πίνακα αναζήτησης (όλος ο
πίνακας αναζήτησης), (γ) col_index_num ο αριθμός στήλης που περιλαμβάνει το
πεδίο που θέλουμε να προσθέσουμε στον πίνακα Drill Through και (δ) range_lookup
η τιμή False που δηλώνει ότι αναζητούμε ακριβώς μια συγκεκριμένη τιμή (και όχι
κάποια κοντινή).
Στη συνάρτηση
επιλέγουμε πρώτα τον
κωδικό πελάτη της
γραμμής.
Κατόπιν επιλέγουμε όλο τον πίνακα με το ερώτημα στη βάση (επιλέγουμε τις
στήλες ακριβώς επάνω από την επικεφαλίδα των πεδίων).
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 120
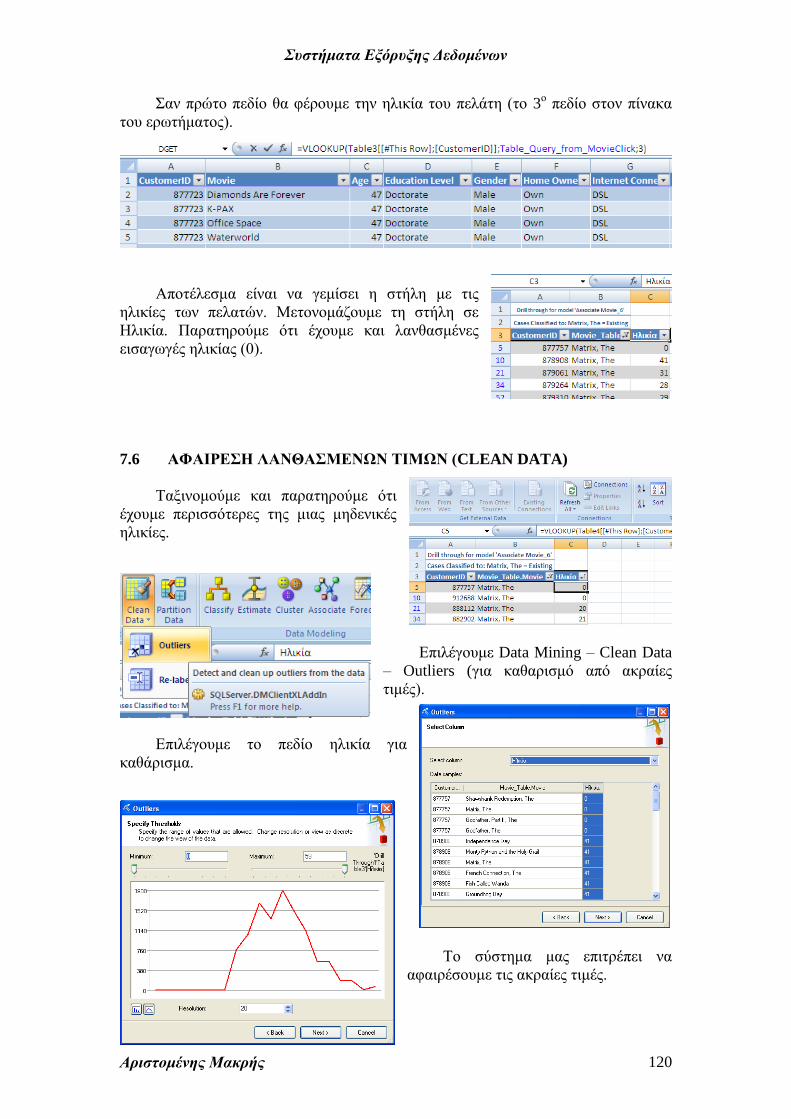
Σαν πρώτο πεδίο θα φέρουμε την ηλικία του πελάτη (το 3ο πεδίο στον πίνακα
του ερωτήματος).
Αποτέλεσμα είναι να γεμίσει η στήλη με τις
ηλικίες των πελατών. Μετονομάζουμε τη στήλη σε
Ηλικία. Παρατηρούμε ότι έχουμε και λανθασμένες
εισαγωγές ηλικίας (0).
7.6 ΑΦΑΙΡΕΣΗ ΛΑΝΘΑΣΜΕΝΩΝ ΤΙΜΩΝ (CLEAN DATA)
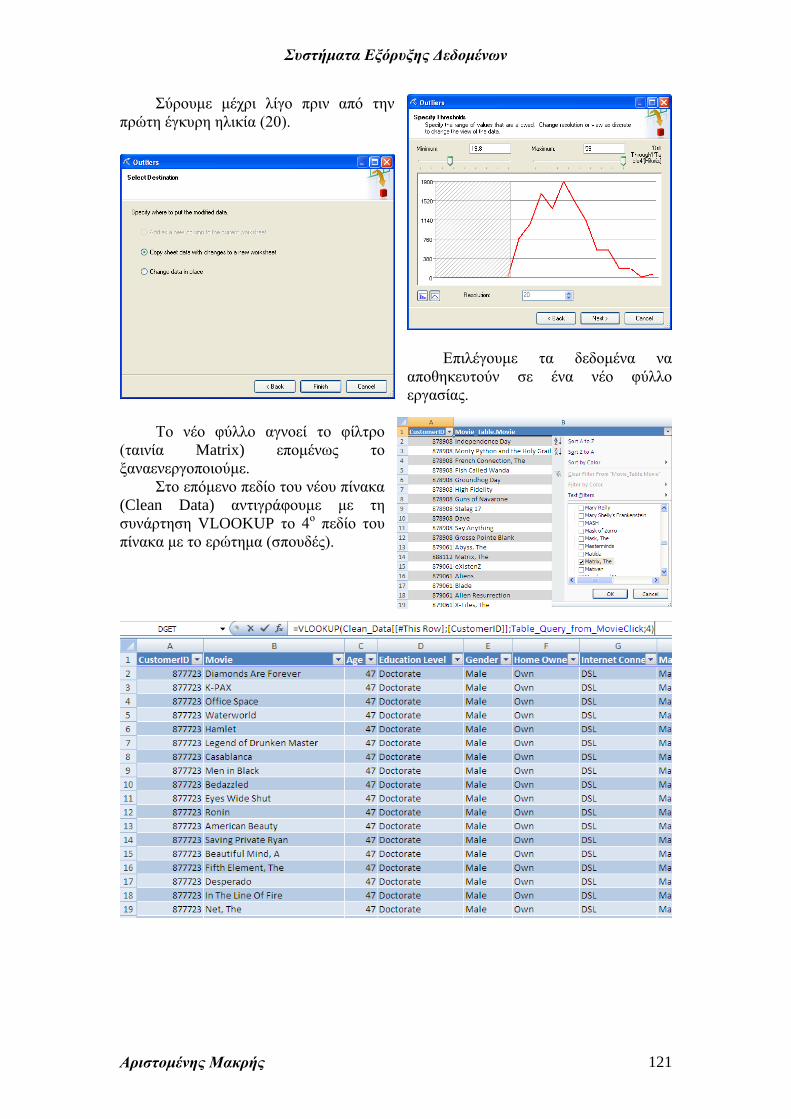
Ταξινομούμε και παρατηρούμε ότι
έχουμε περισσότερες της μιας μηδενικές
ηλικίες.
Επιλέγουμε Data Mining – Clean Data
– Outliers (για καθαρισμό από ακραίες
τιμές).
Επιλέγουμε το πεδίο ηλικία για
καθάρισμα.
Το σύστημα μας επιτρέπει να
αφαιρέσουμε τις ακραίες τιμές.
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 121
Σύρουμε μέχρι λίγο πριν από την
πρώτη έγκυρη ηλικία (20).
Επιλέγουμε τα δεδομένα να
αποθηκευτούν σε ένα νέο φύλλο
εργασίας.
Το νέο φύλλο αγνοεί το φίλτρο
(ταινία Matrix) επομένως το
ξαναενεργοποιούμε.
Στο επόμενο πεδίο του νέου πίνακα
(Clean Data) αντιγράφουμε με τη
συνάρτηση VLOOKUP το 4ο πεδίο του
πίνακα με το ερώτημα (σπουδές).

Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 122
Μετονομάζουμε το πεδίο σε
Σπουδές.
Κατόπιν θα αντιγράψουμε τη
συνάρτηση από το πεδίο Σπουδές στο
αμέσως επόμενο κενό. Κατά την
αντιγραφή αλλάζει το πεδίο κλειδί
(lookup_value). Διαγράφουμε και μόλις
αρχίζουμε να πληκτρολογούμε C το
σύστημα μας προτείνει CustomerID. Το
επιλέγουμε.
Τέλος επιλέγουμε το 5ο πεδίο του πίνακα.
Στο νέο πεδίο εμφανίζεται το
φύλλο του πελάτη. Μετονομάζουμε το
πεδίο σε φύλλο.
Ακριβώς με την ίδια διαδικασία
προσθέτουμε τα πεδία Internet (7),
Οικογένεια (8), Αυτοκίνητα (12), Παιδιά
(13), Τηλεοράσεις (14) και Κεραία (22).
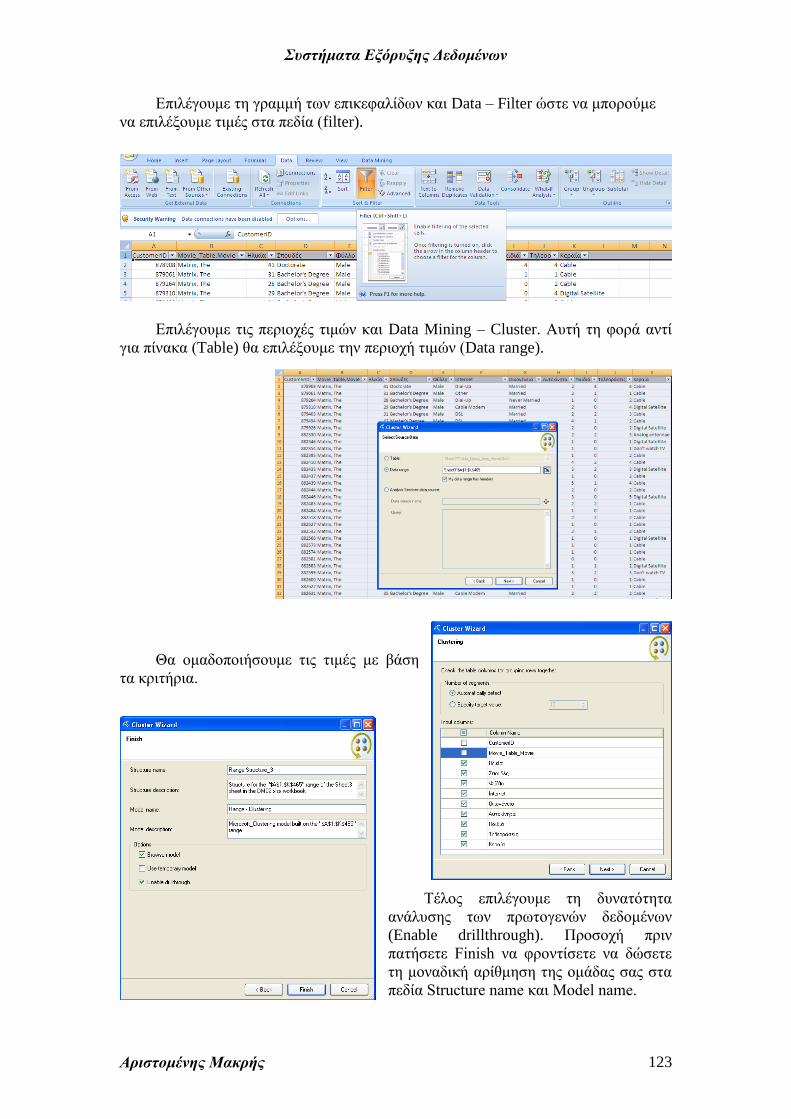
Αντιγράφουμε την περιοχή τιμών του φύλλου εργασίας σε ένα κενό (π.χ.
Sheet3) για να αποφύγουμε επαναλήψεις δεδομένων υποψηφίων πελατών (λόγω του
ότι το φίλτρο θα αγνοηθεί κατά τις περαιτέρω επεξεργασίες) και ταξινομούμε κατά
κωδικό πελάτη.
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 123
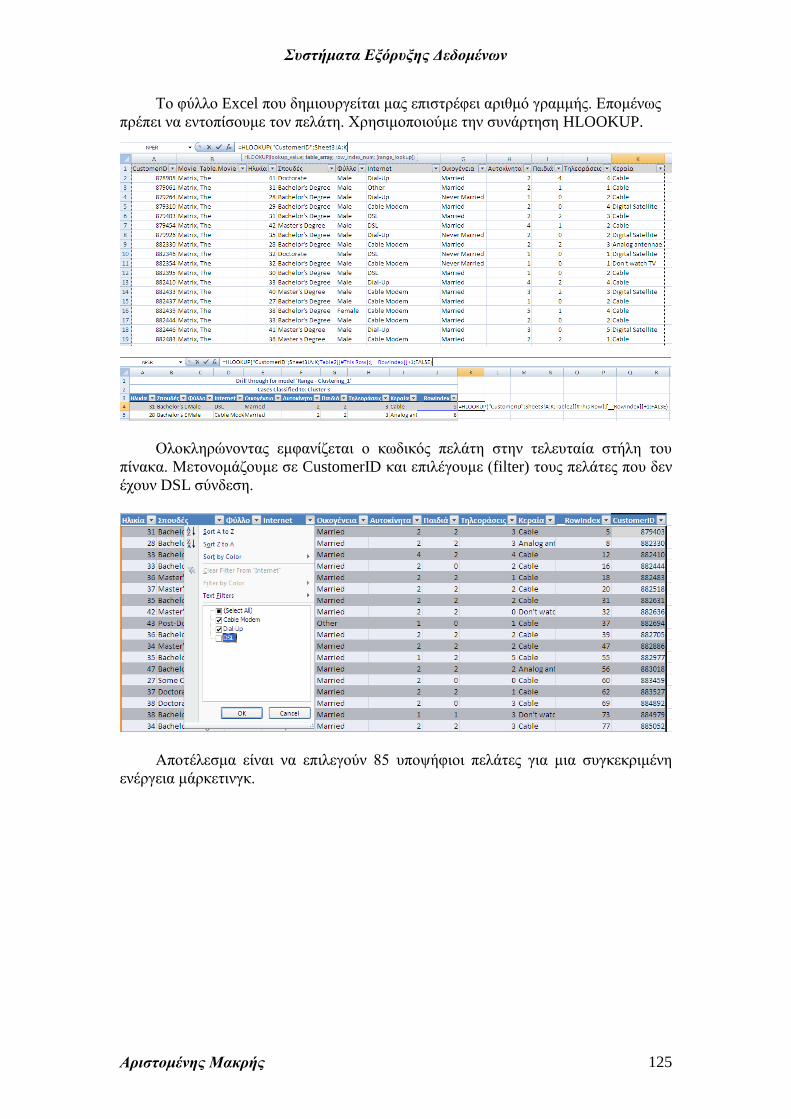
Επιλέγουμε τη γραμμή των επικεφαλίδων και Data – Filter ώστε να μπορούμε
να επιλέξουμε τιμές στα πεδία (filter).
Επιλέγουμε τις περιοχές τιμών και Data Mining – Cluster. Αυτή τη φορά αντί
για πίνακα (Table) θα επιλέξουμε την περιοχή τιμών (Data range).
Θα ομαδοποιήσουμε τις τιμές με βάση
τα κριτήρια.
Τέλος επιλέγουμε τη δυνατότητα
ανάλυσης των πρωτογενών δεδομένων
(Enable drillthrough). Προσοχή πριν
πατήσετε Finish να φροντίσετε να δώσετε
τη μοναδική αρίθμηση της ομάδας σας στα
πεδία Structure name και Model name.

Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 124
Το σύστημα προτείνει έξη
ομαδοποιήσεις. Μας ενδιαφέρει να
επιλέξουμε μια ομάδα με προοπτικές
να πουλήσουμε λύσεις DSL. Οι ομάδες
που ενδείκνυνται (άνδρες με λίγες DSL
συνδέσεις) είναι οι ομάδες 3 και 5. Η
ομάδα 5 είναι μικρής ηλικίας
ανύπαντροι και η ομάδα 3
μεγαλύτερης ηλικίας παντρεμένοι.
Επιλέγουμε να αρχίσουμε τις ενέργειες
μάρκετινγκ από την ομάδα 3. Επιλέγουμε
την ομάδα (δεξί κλικ) και Drill Through.
Συστήματα Εξόρυξης Δεδομένων
Αριστομένης Μακρής 125
Το φύλλο Excel που δημιουργείται μας επιστρέφει αριθμό γραμμής. Επομένως
πρέπει να εντοπίσουμε τον πελάτη. Χρησιμοποιούμε την συνάρτηση HLOOKUP.
Ολοκληρώνοντας εμφανίζεται ο κωδικός πελάτη στην τελευταία στήλη του
πίνακα. Μετονομάζουμε σε CustomerID και επιλέγουμε (filter) τους πελάτες που δεν
έχουν DSL σύνδεση.
Αποτέλεσμα είναι να επιλεγούν 85 υποψήφιοι πελάτες για μια συγκεκριμένη
ενέργεια μάρκετινγκ.
Top Related