
Three New Algorithms for Regular Language Enumeration Erkki Makinen University of Tempere Tempere,...
45
Three New Algorithms for Regular Language Enumeration Erkki Makinen University of Tempere Tempere, Finland Margareta Ackerman University of Waterloo Waterloo, ON
-
Upload
arlene-johnson -
Category
Documents
-
view
249 -
download
0
Transcript of Three New Algorithms for Regular Language Enumeration Erkki Makinen University of Tempere Tempere,...

Three New Algorithms for Regular Language Enumeration
Erkki MakinenUniversity of Tempere Tempere, Finland
Margareta AckermanUniversity of Waterloo
Waterloo, ON
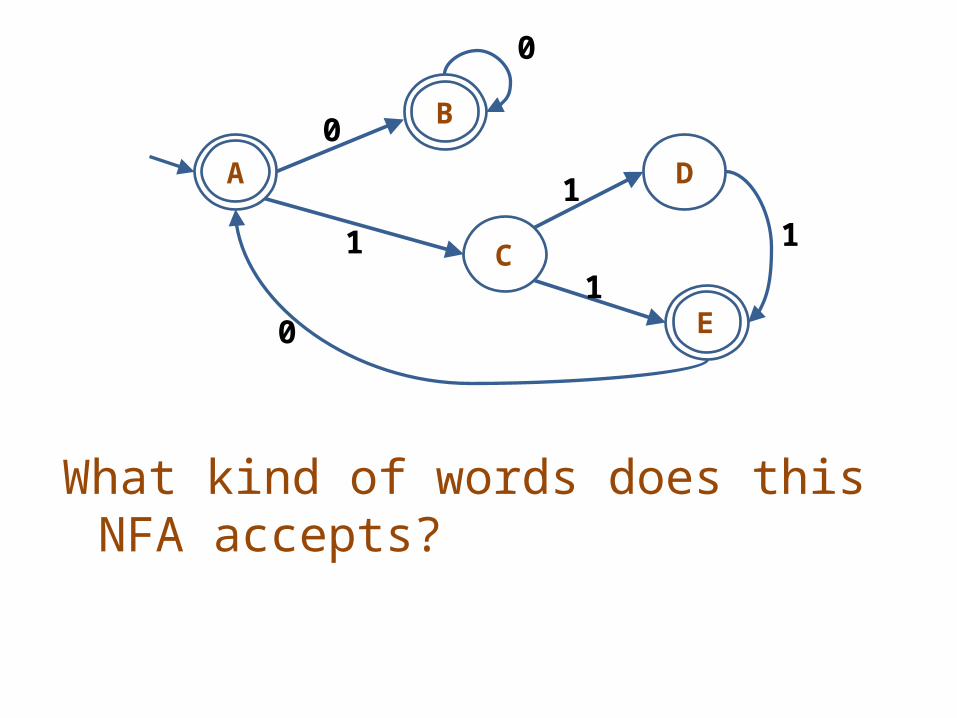
What kind of words does this NFA accepts?
0
1
1
10
1
0
A
B
C
D
E
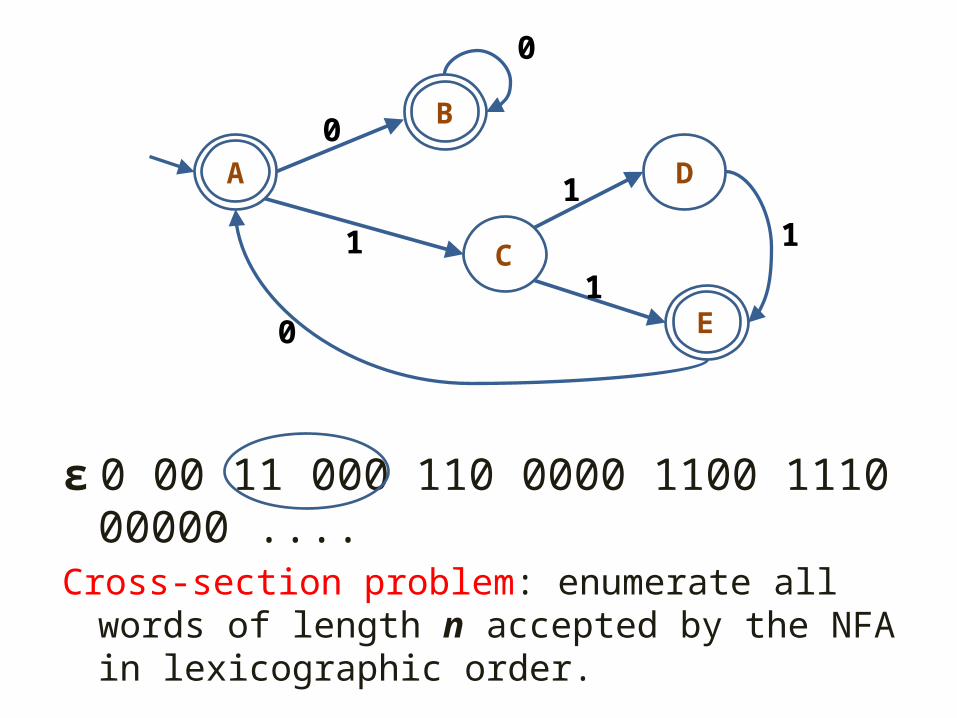
ε 0 00 11 000 110 0000 1100 1110 00000 ....Cross-section problem: enumerate all words of length n accepted by the NFA in lexicographic order.
0
1
1
10
1
0
A
B
C
D
E
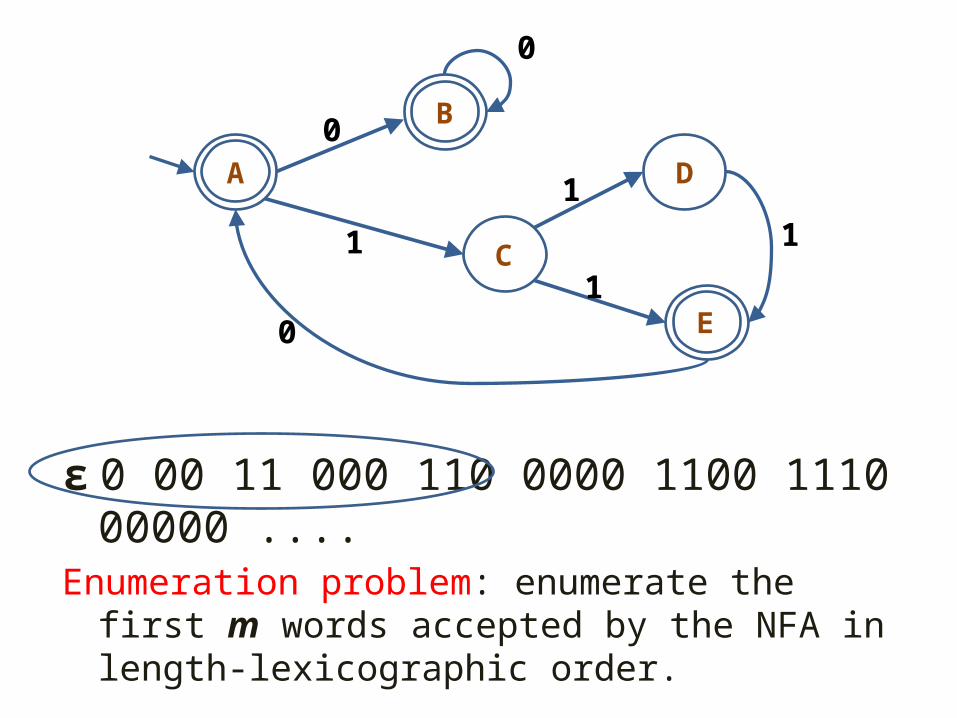
ε 0 00 11 000 110 0000 1100 1110 00000 ....Enumeration problem: enumerate the first m words accepted by the NFA in length-lexicographic order.
0
1
1
10
1
0
A
B
C
D
E
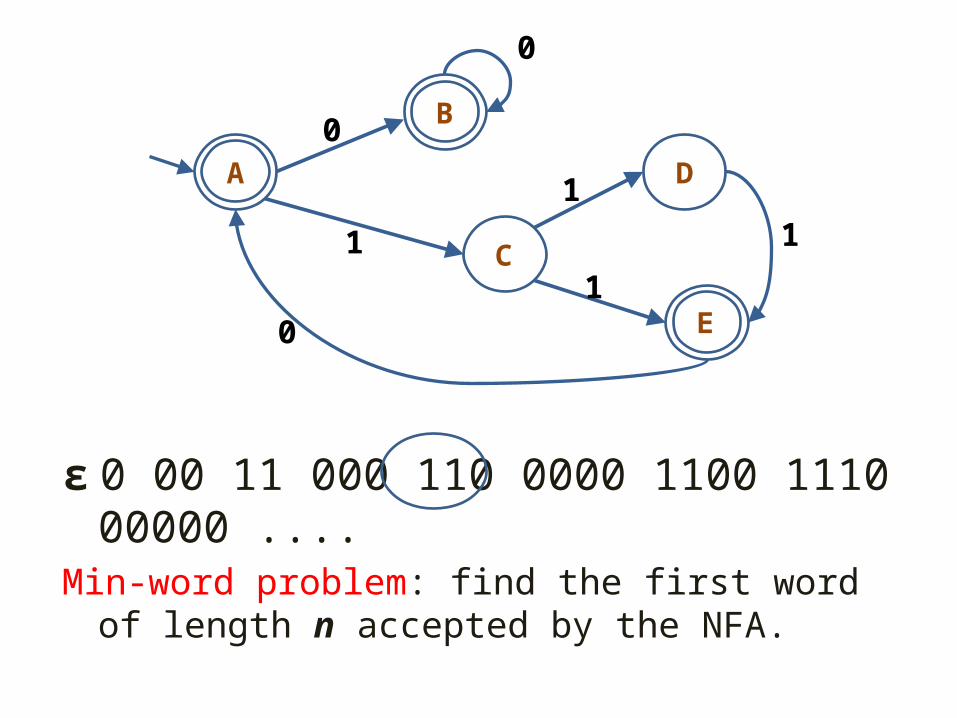
ε 0 00 11 000 110 0000 1100 1110 00000 ....Min-word problem: find the first word of length n accepted by the NFA.
0
1
1
10
1
0
A
B
C
D
E

Applications
• Correctness testing, provides evidence that an NFA generates the expected language.
• An enumeration algorithm can be used to verify whether two NFAs accept the same language (Conway, 1971).
• A cross-section algorithm can be used to determine whether every word accepted by a given NFA is a power - a string of the from wn for n>1, |w|>0. (Anderson, Rampersad, Santean, and Shallit, 2007)
• A cross-section algorithm can be used to solve the “k-subset of an n-set” problem: Enumerate all k-subset of a set in alphabetical order. (Ackerman & Shallit, 2007)

Objectives
Find algorithms for the three problems that are• Asymptotically efficient in
– Size of the NFA (s states and d transitions)– Output size (t)– The length of the words in the cross-section (n)
• Efficient in practice

Previous Work• A cross-section algorithm, where finding each consecutive word is
super-exponential in the size of the cross-section (Domosi, 1998).• A cross-section algorithm that is exponential in n (length of words
in the cross-section) is found in the Grail computation package.– “Breast-First-Search” approach– Trace all paths of length n in the NFA, storing the paths that end at a final state.
– O(dσn+1), where d is the number of transitions in the NFA and σ is the alphabet size.

Previous Polynomial Algorithms: Makinen, 1997
• Dynamic programming solution– Min-word O(dn2) – Cross-section O(dn2+dt)– Enumeration O(d(e+t))
e: the number of empty cross-section encountered d: the number of transitions in the NFAn: the length of words in the cross-sectiont: the number of characters in the output
Quadratic in n

Previous Polynomial Algorithms: Ackerman and Shallit, 2007
• Linear in the length of words in the cross-section– Min-word: O(s2.376n)– Cross-section: O(s2.376n+dt)– Enumeration: O(s2.376c+dt)
c: the number of cross-section encounteredd: the number of transitions in the NFAn: the length of words in the cross-sectiont: the number of characters in the output
Linear in n

Previous Polynomial Algorithms: Ackerman and Shallit, 2007
• The algorithm uses “smart breadth first search,” following only those paths that lead to a final state.
• Main idea: compute a look-ahead matrix, used to determine whether there is a path of length i starting at state s and ending at a final state.
• In practice, Makinen’s algorithm (slightly modified) is usually more efficient, except on some boundary cases.

Contributions
Present 3 algorithms for each of theenumeration problems, including:• O(dn) algorithm for min-word • O(dn+dt) algorithm for cross-section• Algorithms with improved practical performance for each of the enumeration problems

Contributions: Detailed• We present three sets of algorithms
1. AMSorted: - An efficient min-word algorithm, based on Makinen’s original algorithm.- A cross-section and enumeration algorithms based on this min-word algorithm.
2. AMBoolean:- A more efficient min-word algorithm, based on minWordAMSorted.- A cross-section and enumeration algorithms based on this min-word algorithm.
3. Intersection-based:- An elegant min-word algorithm. - A cross-section algorithm based on this min-word algorithm.

Key ideas behind our first two algorithms
- Makinen’s algorithm uses simple dynamic programming, which is efficient in practice on most NFAs.
- The algorithm by Ackerman & Shallit uses “smart breadth first search,” following only those paths that lead to a final state.
- We build on these ideas to yield algorithms that are more efficient both asymptotically and in practice.
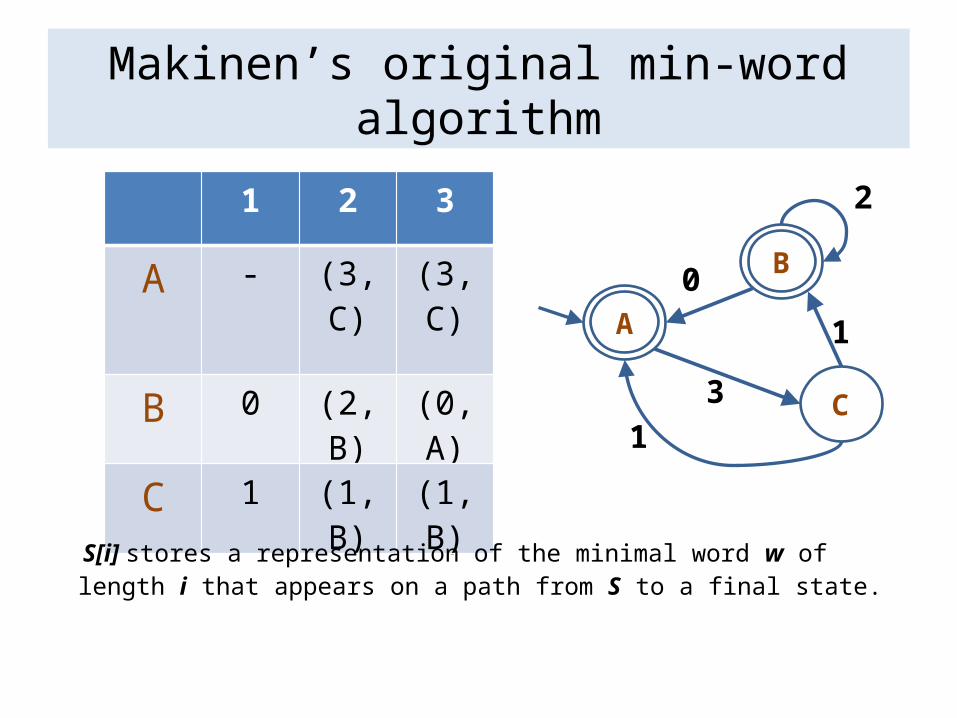
Makinen’s original min-word algorithm
0
3
1
2
A
B
C
1 2 3
A - (3,C) (3,C)
B 0 (2,B) (0,A)
C 1 (1,B) (1,B)
S[i] stores a representation of the minimal word w of length i that appears on a path from S to a final state.
1
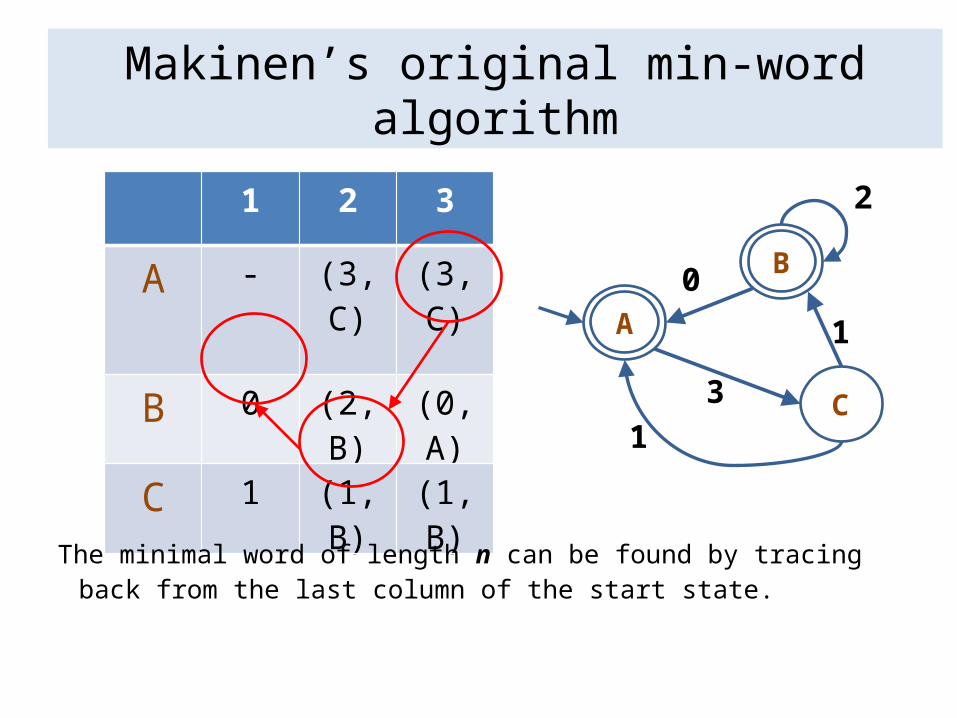
Makinen’s original min-word algorithm
0
3
1
2
A
B
C
1 2 3
A - (3,C) (3,C)
B 0 (2,B) (0,A)
C 1 (1,B) (1,B)
The minimal word of length n can be found by tracing back from the last column of the start state.
1
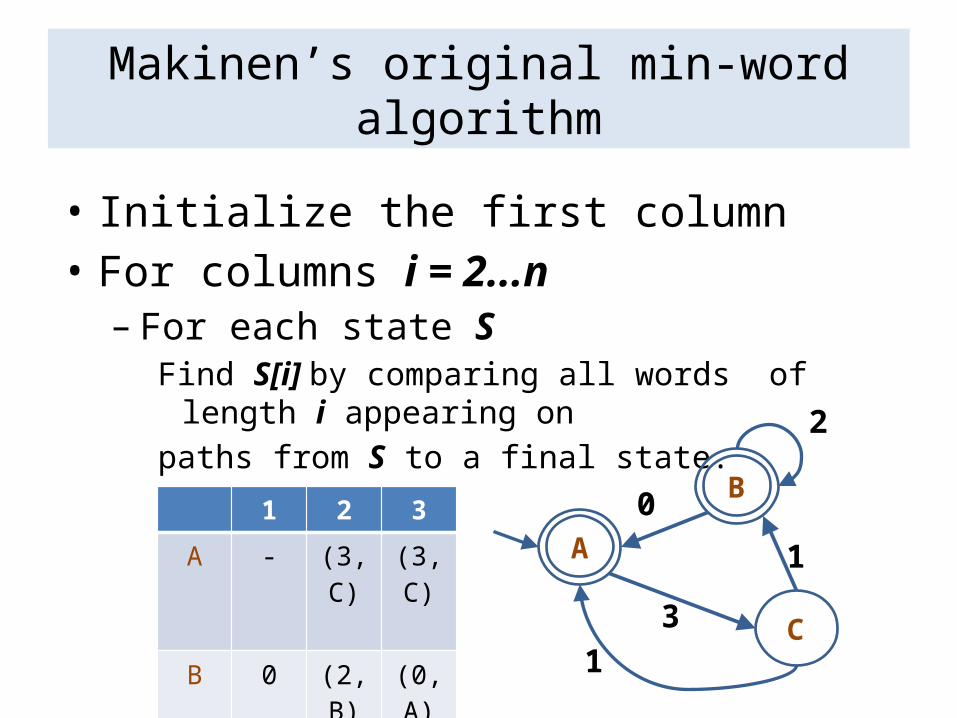
Makinen’s original min-word algorithm
• Initialize the first column• For columns i = 2...n
– For each state SFind S[i] by comparing all words of length i appearing onpaths from S to a final state.
1 2 3
A - (3,C) (3,C)
B 0 (2,B) (0,A)C 1 (1,B) (1,B)
0
3
1
2
A
B
C1
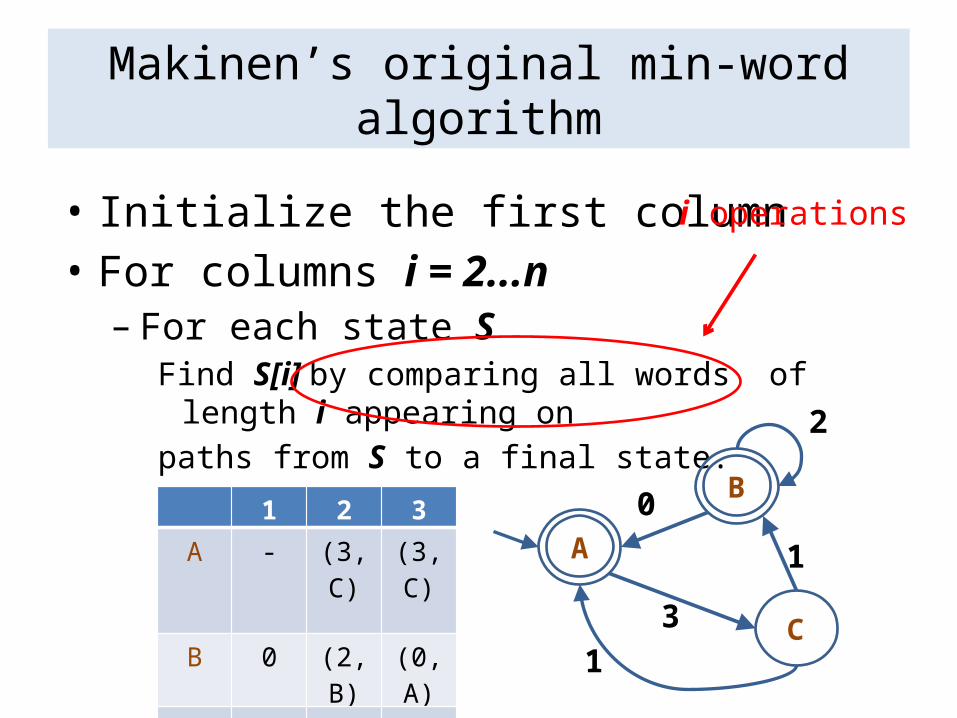
Makinen’s original min-word algorithm
• Initialize the first column• For columns i = 2...n
– For each state SFind S[i] by comparing all words of length i appearing onpaths from S to a final state.
i operations
1 2 3
A - (3,C) (3,C)
B 0 (2,B) (0,A)
C 1 (1,B) (1,B)
0
3
1
2
A
B
C1

Makinen’s original min-word algorithm
• Initialize the first column• For columns i = 2...n
– For each state SFind S[i] by comparing all words of length i appearing onpaths from S to a final state.
i operations
Theorem: Makinen’s original min-word algorithm is O(dn2).
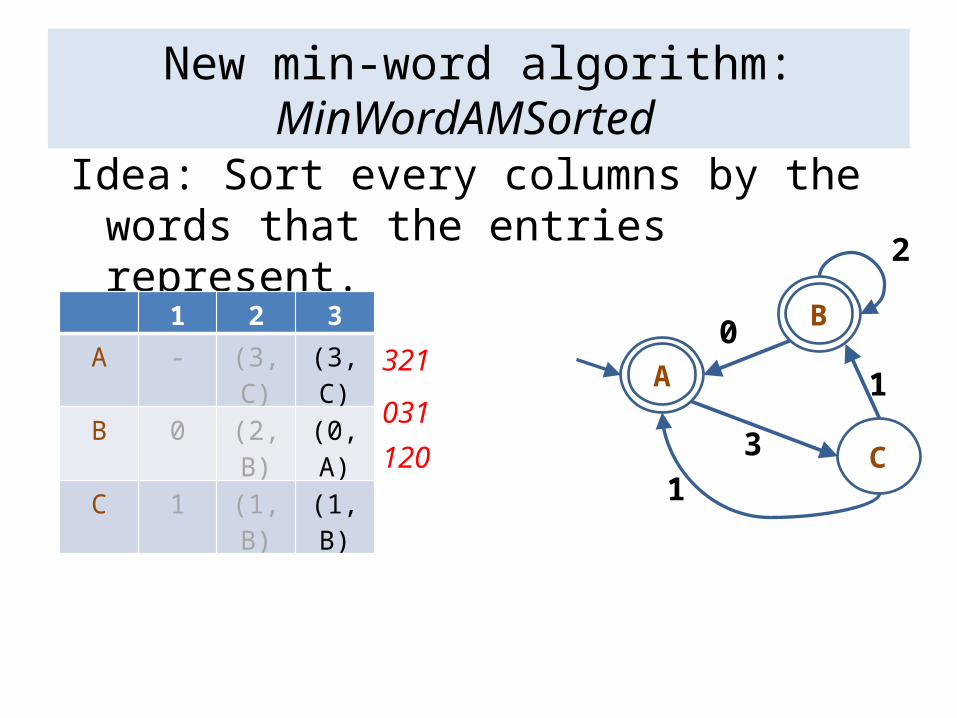
New min-word algorithm: MinWordAMSorted
Idea: Sort every columns by the words that the entries represent.
0
3
1
2
A
B
C1
1 2 3
A - (3,C) (3,C)
B 0 (2,B) (0,A)
C 1 (1,B) (1,B)
321
031
120

New min-word algorithm: MinWordAMSorted
• We define an order on {S[i] : S a state in N}.• If A[1]=a and B[1]=b, where a<b, then
A[1]<B[1].• For i > 1, A[i] = (a, A’) and B[i] = (b, B’)
– If a<b, then A[i] < B[i].– If a = b, and A’[i-1] < B’[i-1], then A[i] < B[i].
• If A[i] is defined, and B[i] is undefined, then A[i] > B[i].

New min-word algorithm: MinWordAMSorted
• Initialize the first column• For columns i = 2...n
– For each state S• Find S[i] using only column i-1 and the edges leaving S.
– Sort column i
1 2 3
A - (3,C) (3,C)
B 0 (2,B) (0,A)C 1 (1,B) (1,B)
0
3
1
2
A
B
C1

New min-word algorithm: MinWordAMSorted
• Initialize the first column• For columns i = 2...n
– For each state S• Find S[i] using only column i-1 and the edges leaving S.
– Sort column i
d operations
s log s operations
Theorem: The algorithm minWordAMSorted is O((s log s +d) n).
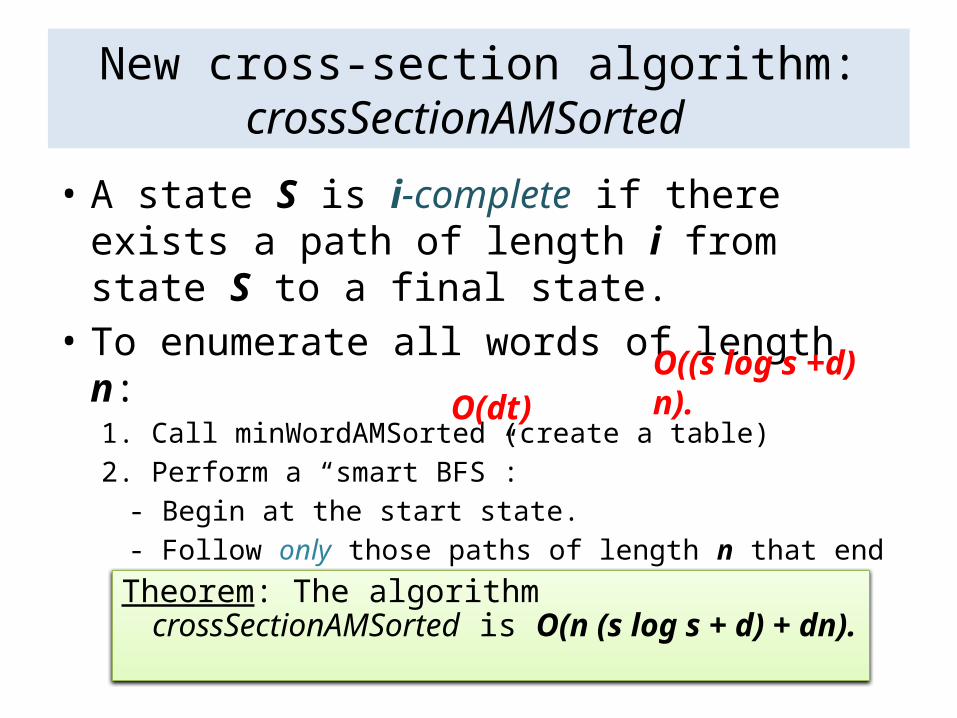
New cross-section algorithm: crossSectionAMSorted
• A state S is i-complete if there exists a path of length i from state S to a final state.
• To enumerate all words of length n:1. Call minWordAMSorted (create a table)2. Perform a “smart BFS”: - Begin at the start state.- Follow only those paths of length n that end at a final state, by using the table to identify i-complete states.
O((s log s +d) n). O(dt)
Theorem: The algorithm crossSectionAMSorted is O(n (s log s + d) + dn).

New enumeration algorithm: enumAMSorted
Run the cross-section algorithm until the required number of words are listed, while reusing the table.
Theorem: The algorithm enumAMSorted is O(c (s log s + d)+ dt).
c: the number of cross-section encounteredd: the number of transitions in the NFAt: the number of characters in the output

What have we got so far? New Algorithms Previous Algorithms
Sorted Makinen Ackerman & Shallit
min-word O((s log s + d)n) O(dn2) O(s2.376n)
cross-section O(n (s log s + d)+dt) O(dn2+dt) O(s2.376n+dt)
enumeration O(c (s log s +d) + dt) O(de + dt) O(s2.376c+dt)
c: the number of cross-section encounterede: the number of empty cross-section encounteredd: the number of transitions in the NFAn: the length of words in the cross-sectiont: the number of characters in the output

New min-word algorithm: minWordAMBoolean
Idea: instead of using a table to find the minimal word, construct a table whose only purpose is to determine i-complete states.
Can be done using a similar algorithm to minWordAMSorted, but more efficiently, since there is no need to sort.
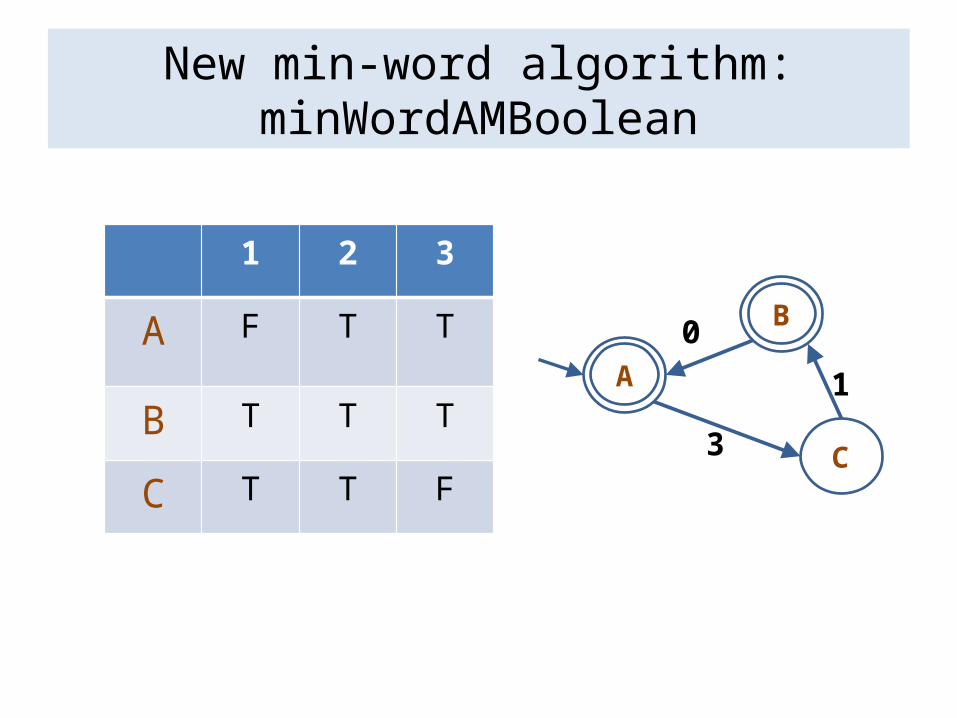
New min-word algorithm: minWordAMBoolean
0
3
1A
B
C
1 2 3
A F T T
B T T T
C T T F

New min-word algorithm: minWordAMBoolean
• Fill in the first column• For i=2 ... n
– For every state S• Determine whether S is i-complete using only the transitions leaving S and column i-1
• Starting at the start state, follow minimal transitions to paths that can complete a word of length n (using the table).
1 2 3
A F T T
B T T TC T T F
0
3
1A
B
C
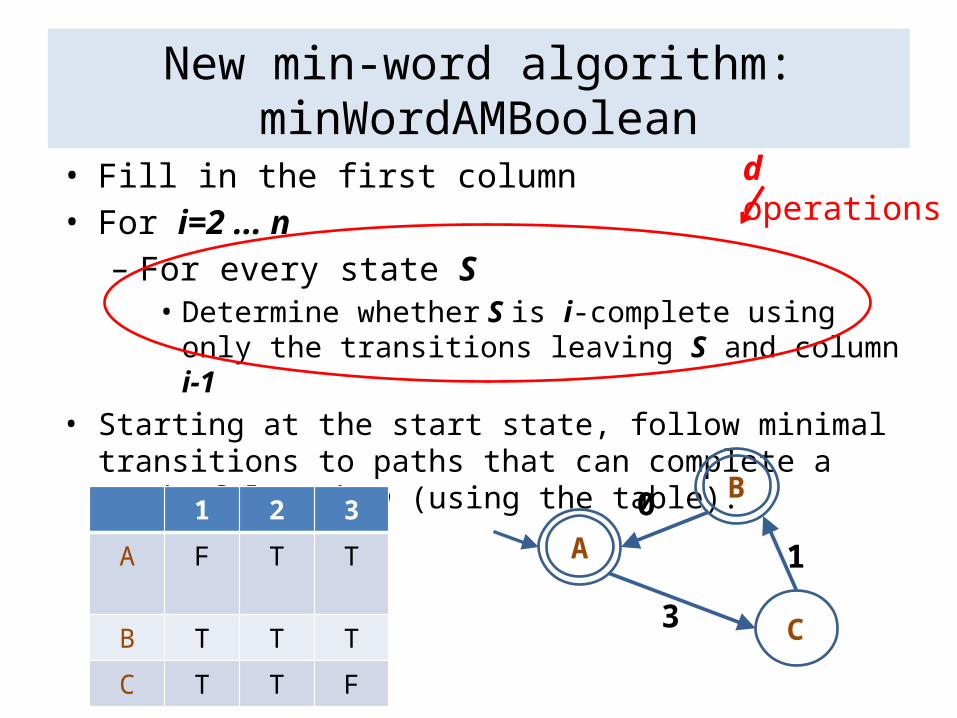
New min-word algorithm: minWordAMBoolean
• Fill in the first column• For i=2 ... n
– For every state S• Determine whether S is i-complete using only the transitions leaving S and column i-1
• Starting at the start state, follow minimal transitions to paths that can complete a word of length n (using the table).
1 2 3
A F T T
B T T TC T T F
0
3
1A
B
C
d operations

New min-word algorithm: minWordAMBoolean
• Fill in the first column• For i=2 ... n
– For every state S• Determine whether S is i-complete using only the transitions leaving S and column i-1
• Starting at the start state, follow minimal transitions to paths that can complete a word of length n (using the table).
d operations
Theorem: The algorithm minWordAMBoolean is O(dn).
New cross-section algorithm: crossSectionAMBoolean
• Extend to a cross-section algorithm using the same approach as the Sorted algorithm.
• To enumerate all words of length n:– Call minWordAMBoolean (create a table)– Perform a “smart BFS”: - Begin at the start state.- Follow only those paths of length n that end at a final state, by using the table to identify i-complete states.
O(dn). O(dt)
Theorem: The algorithm crossSectionAMBoolean is O(dn+dt).

New enumeration algorithm: enumAMBoolean
Run the cross-section algorithm until the required number of words are listed, while reusing the table.
Theorem: The algorithm enumAMBoolean is O(de+ dn).
e: the number of empty cross-section encounteredd: the number of transitions in the NFAn: the length of words in the cross-sectiont: the number of characters in the output
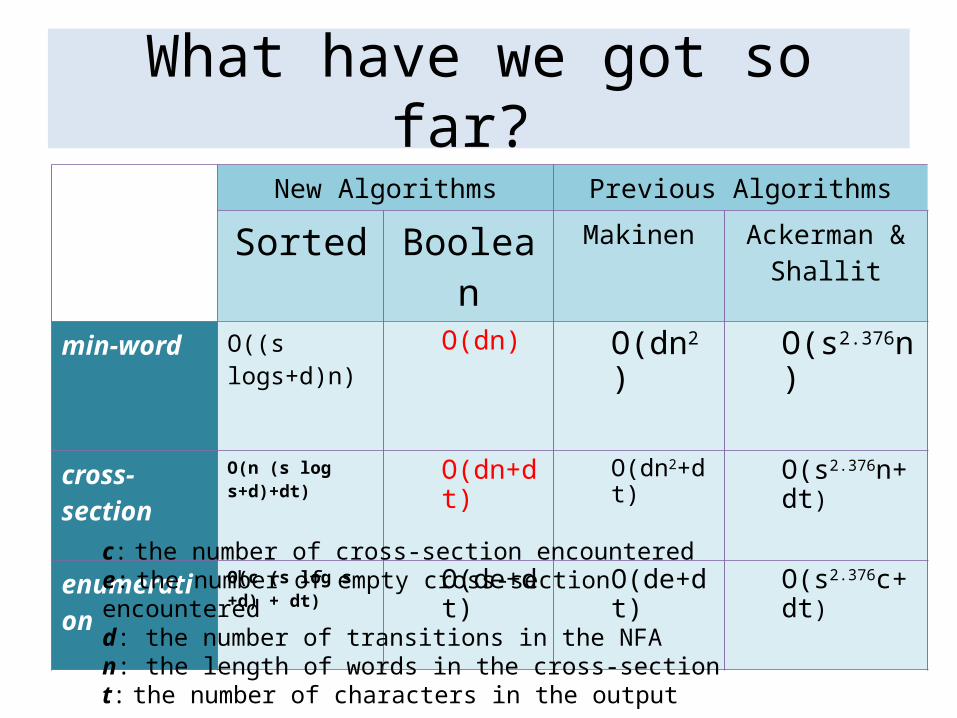
What have we got so far? New Algorithms Previous Algorithms
Sorted Boolean Makinen Ackerman & Shallit
min-word O((s logs+d)n) O(dn) O(dn2) O(s2.376n)
cross-section O(n (s log s+d)+dt) O(dn+dt) O(dn2+dt) O(s2.376n+dt)
enumeration O(c (s log s +d) + dt) O(de+dt) O(de+dt) O(s2.376c+dt)
c: the number of cross-section encounterede: the number of empty cross-section encounteredd: the number of transitions in the NFAn: the length of words in the cross-sectiont: the number of characters in the output

• We present surprisingly elegant min-word and cross-section algorithms that have the asymptotic efficiency of the Boolean-based algorithms.
• However, these algorithms are not as efficient in practice as the Boolean-based and Sorted-based algorithms.
Intersection-Based Algorithms

Let N be the input NFA, and A be the NFA that accepts the language of all words of length n.
1. Let C = N x A2. Remove all states of C that cannot be
reached from the final states of C using reversed transitions.
3. Starting at the start state, follow the minimal n consecutive transitions to a final state.
New min-word algorithm: minWordIntersection
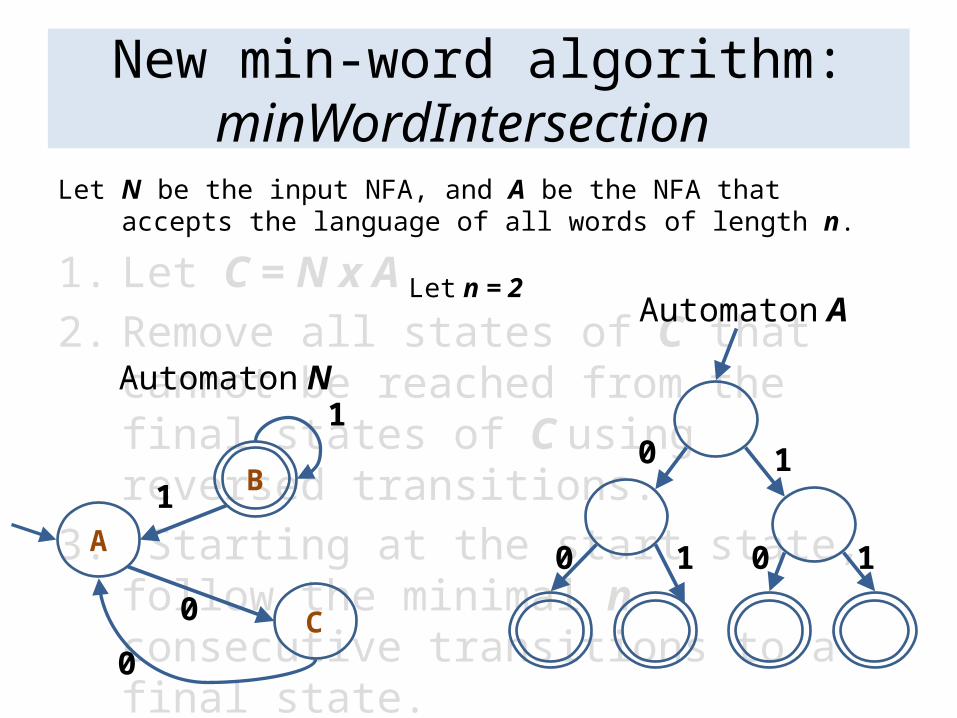
Let N be the input NFA, and A be the NFA that accepts the language of all words of length n.
1. Let C = N x A2. Remove all states of C that cannot be
reached from the final states of C using reversed transitions.
3. Starting at the start state, follow the minimal n consecutive transitions to a final state.
New min-word algorithm: minWordIntersection
1
0
1
A
B
C
Automaton N
Let n = 2
0
0 0
1
1 1
Automaton A
0
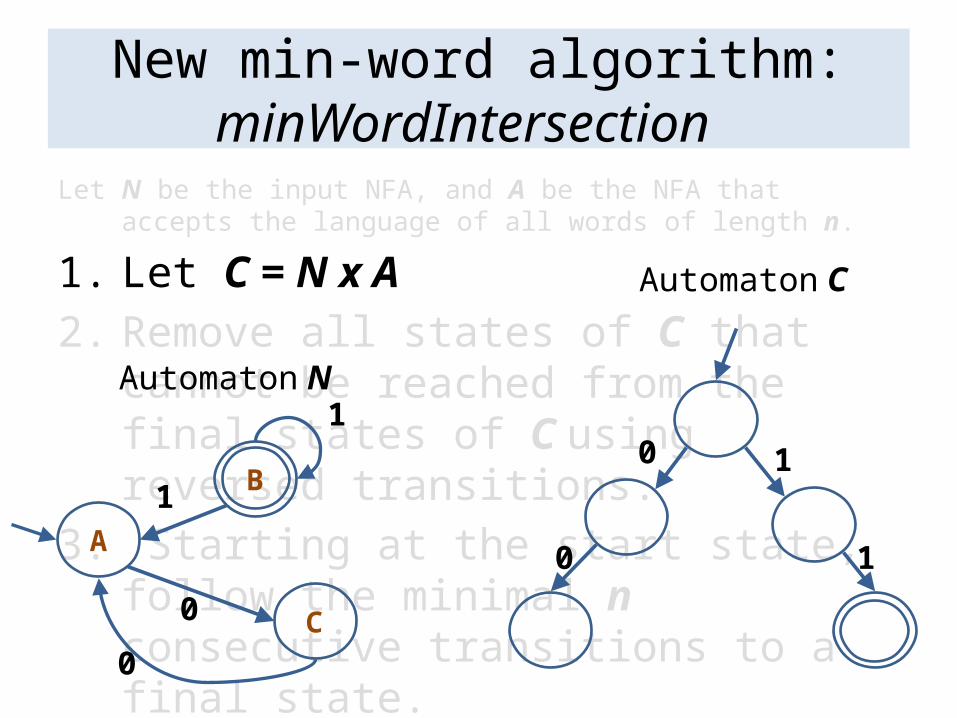
Let N be the input NFA, and A be the NFA that accepts the language of all words of length n.
1. Let C = N x A2. Remove all states of C that cannot be
reached from the final states of C using reversed transitions.
3. Starting at the start state, follow the minimal n consecutive transitions to a final state.
New min-word algorithm: minWordIntersection
Automaton N
0
0
1
1
Automaton C
1
0
1
A
B
C0

Let N be the input NFA, and A be the NFA that accepts the language of all words of length n.
1. Let C = N x A2. Remove all states of C that cannot be
reached from the final states of C using reversed transitions.
3. Starting at the start state, follow the minimal n consecutive transitions to a final state.
New min-word algorithm: minWordIntersection
1
1

Let N be the input NFA, and A be the NFA that accepts the language of all words of length n.
1. Let C = N x A2. Remove all states of C that cannot be
reached from the final states of C using reverse transitions.
3. Starting at the start state, follow the minimal n consecutive transitions to a final state.
New min-word algorithm: minWordIntersection
1
1
Thus the minimal word of length 2 accepted by N is “11”

1. Let C = N x A2. Remove all states of C that cannot be
reached from the final states of C using reverse transitions.
3. Starting at the start state, Follow the minimal n consecutive transitions to final.
Asymptotic running time of minWordIntersection
Each step is proportional to size of C, which is O(nd).
Theorem: The algorithm minWordIntersection is O(dn).
Concatenate n copies of N.

• To enumerate all words of length n, perform BFS on C = N x A, and remove all states not reachable from final state removed (using reverse transitions).
• Since all paths of length n starting at the start state lead to a final state, there is no need to check for i-completness.
New cross-section algorithm: crossSectionIntersection
Theorem: The algorithm crossSectionIntersection is O(dn+dt).

• We compared Makinen’s, Ackerman-Shallit, AMSorted, and AMBoolean, and Intersection-based algorithms.
• Tested the algorithms on a variety of NFAs: dense, sparse, few and many final states, different alphabet size, worst case for Makinen’s algorithm, ect…
• Here are the best performing algorithms:– Min-word: AMSorted– Cross-section: AMBoolean– Enumeration: AMBoolean
Practical Performance
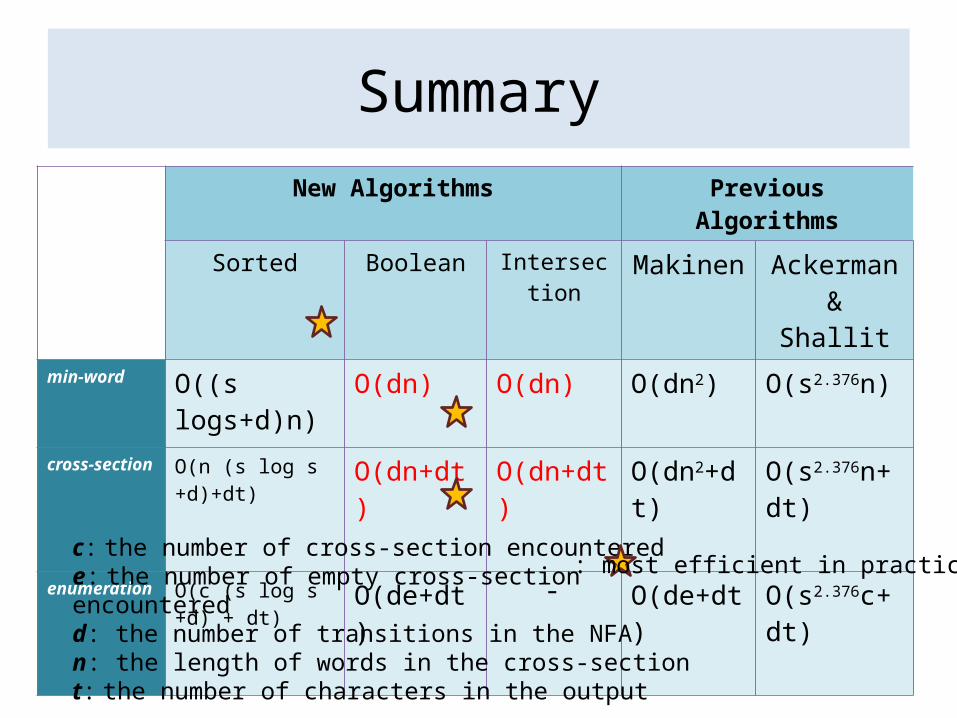
SummaryNew Algorithms Previous Algorithms
Sorted Boolean Intersection Makinen Ackerman & Shallit
min-word O((s logs+d)n) O(dn) O(dn) O(dn2) O(s2.376n)
cross-section O(n (s log s +d)+dt) O(dn+dt) O(dn+dt) O(dn2+dt) O(s2.376n+dt)
enumeration O(c (s log s +d) + dt)
O(de+dt) - O(de+dt) O(s2.376c+dt)
c: the number of cross-section encounterede: the number of empty cross-section encounteredd: the number of transitions in the NFAn: the length of words in the cross-sectiont: the number of characters in the output
: most efficient in practice

• Extending the intersection-based cross-section algorithm to an enumeration algorithm.
• Lower bounds.• Can better results be obtained using a different order?
• Restricting attention to a smaller family of NFAs.
Open problems


















