Test: max y , h w T Ψ ( x , y , h )
1
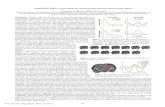
Test: max y,h w T Ψ(x,y,h) Modeling Latent Variable Uncertainty for Loss-based Learning M. Pawan Kumar Ben Packer Daphne Koller http://cvc.centrale-ponts.fr Aim: Accurate parameter estimation from weakly supervised datasets atent Variable Models Results y http://dags.stanford.edu x : input y : output latent variables (LV) y = “Deer” x h Objective x y h lues known during training lues unknown during training • Predict the image class y • Predict the object location h Object Detection Latent SVM Linear prediction rule with parameter w Train: min w Σ i Δ(y i ,y i (w),h i (w)) Train: max θ Σ i Σ h i log (P θ (y i ,h i |x i )) Test: max y,h θ T Ψ(x,y,h) The EM Algorithm P θ (y,h|x) = exp(θ T Ψ(x,y,h)) Z Models uncertainty in LV oes not model accuracy of LV prediction es not employ a user-defined loss function ys a user-defined loss function (with restricted form) oes not model uncertainty in LV Overview h i P θ (h i |y i ,x i ) P w (y i ,h i |x i ) (y i ,h i ) (y i (w),h i (w)) Two distributions for two tasks Models uncertainty in LV Models predicted output and LV Optimization Block coordinate descent over (w,θ) Minimize Rao’s Dissimilarity Coefficient P θ (h i |y i ,x i ) P w (y i ,h i |x i ) min θ,w Σ i Σ h Δ(y i ,h,y i (w),h i (w))P θ (h|y i ,x i ) -βΣ h,h’ Δ(y i ,h,y i ,h’)P θ (h|y i ,x i )P θ (h’|y i ,x i ) Encourages prediction with correct output and high probability LV Fix delta distribution; Optimize conditional distribution Case I: Delta distribution predicts correct output, y = y(w) Case II: Delta distribution predicts incorrect output, y ≠ y(w) Fix conditional distribution; Optimize delta distribution Increase the probability of the predicted LV h(w) Increase the diversity of the conditional distribution Predict correct output and high probability LV h i (w) h i (w) (y i ,h i (w)) (y i ,h i (w)) Property 1 If loss function is independent of h, we recover latent SVM Property 2 If P θ is modeled as delta, we recover iterative latent SVM Code available at http://cvc.centrale-ponts.fr/personnel/pawan , the two learned distributions should match exactly ed representational power prevents exact match Difference-of-convex upper bound of expected loss Efficient concave-convex procedure similar to latent SVM Fold 1 Fold 2 Fold 3 Fold 4 Fold 5 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Average 0/1 Test Loss LSVM Our Fold 1 Fold 2 Fold 3 Fold 4 Fold 5 0 0.1 0.2 0.3 0.4 0.5 0.6 Average Overlap Test Loss LSVM Our Fold 1 Fold 2 Fold 3 Fold 4 Fold 5 0 0.2 0.4 0.6 0.8 1 1.2 Average 0/1 Test Loss LSVM Our Fold 1 Fold 2 Fold 3 Fold 4 Fold 5 0.62 0.64 0.66 0.68 0.7 0.72 0.74 Average Overlap Test Loss LSVM Our Object Detection Action Detection Statistically Significant Not Statistically Signific Statistically Significant Statistically Significant HOG Features No object scale variation Latent Space = All possible pixel positions Poselet Features Large object scale variation Latent Space = Top k person detections Known ground-truth LV values at test joint feature vector Δ: loss function; measures risk
description
h. y. x. Modeling Latent Variable Uncertainty for Loss-based Learning. M. Pawan Kumar Ben Packer Daphne Koller. http:// cvc.centrale-ponts.fr. http:// dags.stanford.edu. Aim: Accurate parameter estimation f rom weakly supervised datasets. Results. - PowerPoint PPT Presentation
Transcript of Test: max y , h w T Ψ ( x , y , h )

Test: maxy,h wTΨ(x,y,h)
Modeling Latent Variable Uncertainty for Loss-based LearningM. Pawan Kumar Ben Packer Daphne Kollerhttp://cvc.centrale-ponts.fr
Aim: Accurate parameter estimationfrom weakly supervised datasets
Latent Variable Models
Results
y
http://dags.stanford.edu
x : input y : output
h : latent variables (LV)
y = “Deer”xh
Objective
x
y
hValues known during training
Values unknown during training
• Predict the image class y • Predict the object location h
Object Detection
Latent SVM Linear prediction rule with parameter w
Train: minw Σi Δ(yi,yi(w),hi(w))
Train: maxθ Σi Σhi log (Pθ(yi,hi|xi))Test: maxy,h θTΨ(x,y,h)
The EM Algorithm Pθ(y,h|x) = exp(θTΨ(x,y,h))Z
✔ Models uncertainty in LV ✖ Does not model accuracy of LV prediction ✖ Does not employ a user-defined loss function
✔ Employs a user-defined loss function (with restricted form) ✖ Does not model uncertainty in LV
Overview
hi
Pθ(hi|yi,xi)
Pw(yi,hi|xi)(yi,hi)
(yi(w),hi(w))
Two distributions for two tasksModels uncertainty
in LV
Models predictedoutput and LV
Optimization Block coordinate descent over (w,θ)
Minimize Rao’s Dissimilarity Coefficient
Pθ(hi|yi,xi) Pw(yi,hi|xi)
minθ,wΣi Σh Δ(yi,h,yi(w),hi(w))Pθ(h|yi,xi)
-βΣh,h’ Δ(yi,h,yi,h’)Pθ(h|yi,xi)Pθ(h’|yi,xi)
Encourages predictionwith correct output and
high probability LV
Fix delta distribution; Optimize conditional distributionCase I: Delta distribution predicts correct output, y = y(w)
Case II: Delta distribution predicts incorrect output, y ≠ y(w)
Fix conditional distribution; Optimize delta distribution
Increase the probability of the predicted LV h(w)
Increase the diversity of the conditional distribution
Predict correct output and high probability LV
hi(w)hi(w)
(yi,hi(w))(yi,hi(w))
Property 1If loss function is independent of h, we recover latent SVM
Property 2If Pθ is modeled as delta, we recover iterative latent SVM
Code available at http://cvc.centrale-ponts.fr/personnel/pawan
Ideally, the two learned distributions should match exactlyLimited representational power prevents exact match
Difference-of-convex upper bound of expected lossEfficient concave-convex procedure similar to latent SVM
Fold 1 Fold 2 Fold 3 Fold 4 Fold 50
0.10.20.30.40.50.60.70.80.9
Average 0/1 Test Loss
LSVMOur
Fold 1 Fold 2 Fold 3 Fold 4 Fold 50
0.1
0.2
0.3
0.4
0.5
0.6Average Overlap Test Loss
LSVMOur
Fold 1 Fold 2 Fold 3 Fold 4 Fold 50
0.2
0.4
0.6
0.8
1
1.2Average 0/1 Test Loss
LSVMOur
Fold 1 Fold 2 Fold 3 Fold 4 Fold 50.62
0.64
0.66
0.68
0.7
0.72
0.74Average Overlap Test Loss
LSVMOur
Object Detection
ActionDetection
Statistically Significant Not Statistically Significant
Statistically Significant Statistically Significant
HOG Features
No objectscale variation
Latent Space =All possiblepixel positions
Poselet Features
Large objectscale variation
Latent Space =Top k persondetections
Known ground-truth LV values at test time
Ψ: joint feature vector Δ: loss function; measures risk
![,%4#-6-.,*3,/ *52&, &*%*5-4!47&.5 ......S h n o ]h ak ` e Y Vfg q f g a & c Y a ED Y < < 8 k lY m ]j g h g ag X f lao c q j VY j p]o Y h W [ ]ao m Tlg q f lao h j g l]j Y aW l` l]o](https://static.fdocument.org/doc/165x107/60c2536b1bc19b3ca51feae1/4-6-3-52-5-4475-s-h-n-o-h-ak-e-y-vfg-q.jpg)









![Heavy Quark Physics and CP Violation (II) · 3. Existence of multiplets (states with same energies) Some consequences of symmetries 0[,] bab a ba b a H G HG GH gg H ψ ψψ ψ ψψ](https://static.fdocument.org/doc/165x107/6122e024fa8ad8651115522e/heavy-quark-physics-and-cp-violation-ii-3-existence-of-multiplets-states-with.jpg)