
Tema 4.2: FUNCIONES DISCRIMINANTES … Desarrollo del algoritmo SV de forma lineal sobre los nuevos...
33
1 Tema 4.2: FUNCIONES DISCRIMINANTES LINEALES y SV Some Figures in these slides were taken from Pattern Classification (2nd ed) by R. O. Duda, P. E. Hart and D. G. Stork, John Wiley & Sons, 2000 with the permission of the authors Febrero-Mayo 2007
Transcript of Tema 4.2: FUNCIONES DISCRIMINANTES … Desarrollo del algoritmo SV de forma lineal sobre los nuevos...

1
Tema 4.2: FUNCIONES DISCRIMINANTES LINEALES y SV
Some Figures in these slides were taken from Pattern Classification (2nd ed) by R. O. Duda, P. E. Hart and D. G.
Stork, John Wiley & Sons, 2000with the permission of the authors
Febrero-Mayo 2007

2
INDICE
1 INTRODUCCIÓN2 FUNCIONES DISCRIMINANTES LINEALES Y SUPERFICIES DE
DECISIÓN3 CASO SEPARABLE DE 2 CATEGORÍAS4 ALGORITMO DE GRADIENTE DESCENDENTE
– Función Perceptron– Procedimientos De Mínimo Error Cuadrático
5 SV: Support Vector Classifier– Caso Lineal– Funciones de Kernel– SV Non Linear Classifier
6 CONCLUSIONES

3
1 INTRODUCCIÓNSe asume:• No se conocen las f.d.p.• Se deciden las funciones discriminates salvo parámetros:
– Funciones lineales respecto al vector de características (como lqd: MAP con distribuciones gaussianas y matrices de covarianza iguales)
– No lineales: Funciones lineales respecto a conjunto de funcionesque a su vez dependen del vector de características de forma no lineal
– La función discriminante se diseña como resultado de minimizar una función criterio.
• Propiedades de interés:– Eficiencia computacional– Convergencia rápida con procedimientos de gradiente
descendente, (al utilizar la base de datos de entrenamiento paraestimar los parámetros de dichas funciones).

4
2 FUNCIONES DISCRIMINANTES LINEALES Y SUPERFICIES DE DECISIÓN
Definición de función lineal.
• Vector de características• Vector de pesos• Offset
• Parámetros a ajustar
• C clases: C funciones discriminantes
0( ) Tg w= +x w x
wx
0w
0( )1..
Ti i ig w
i c−= +
=
x w x
0w⎛ ⎞⎜ ⎟⎝ ⎠
w
5
2 FUNCIONES DISCRIMINANTES LINEALES Y SUPERFICIES DE DECISIÓN
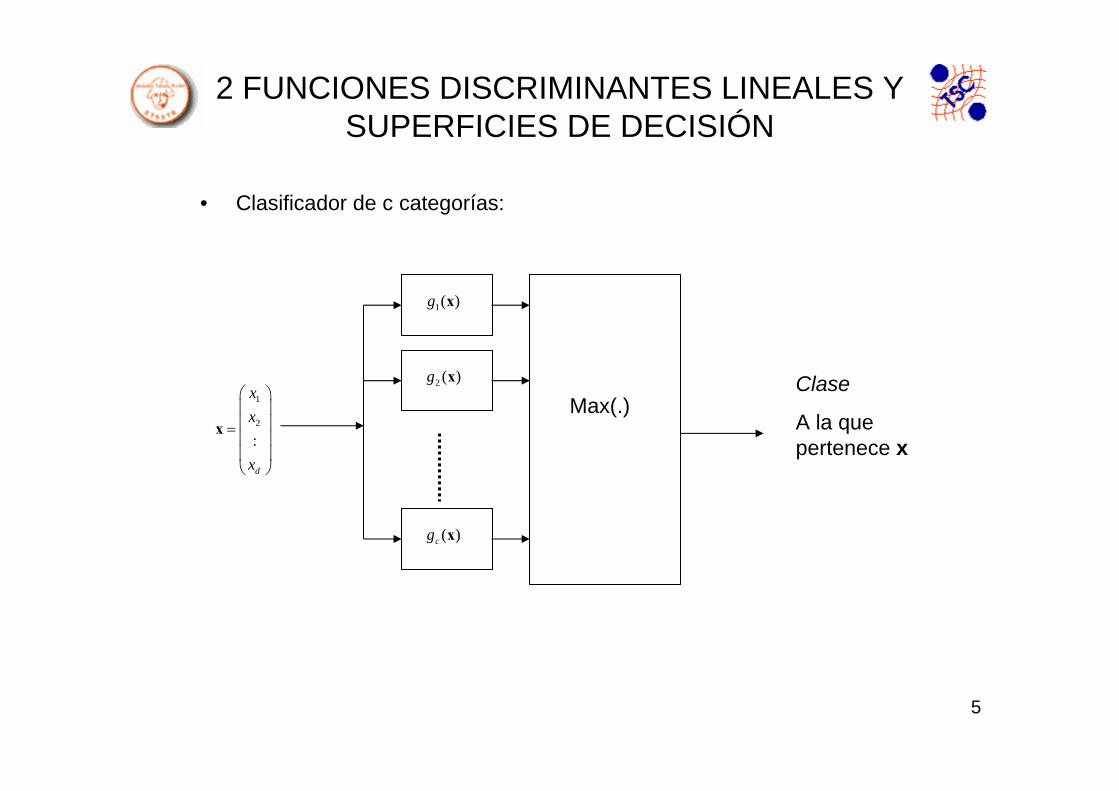
1( )g x
1
2
:
d
xx
x
⎛ ⎞⎜ ⎟⎜ ⎟=⎜ ⎟⎜ ⎟⎝ ⎠
x
2 ( )g x
( )cg x
Max(.)Clase
A la que pertenece x
• Clasificador de c categorías:
6
2 FUNCIONES DISCRIMINANTES LINEALES Y SUPERFICIES DE DECISIÓN
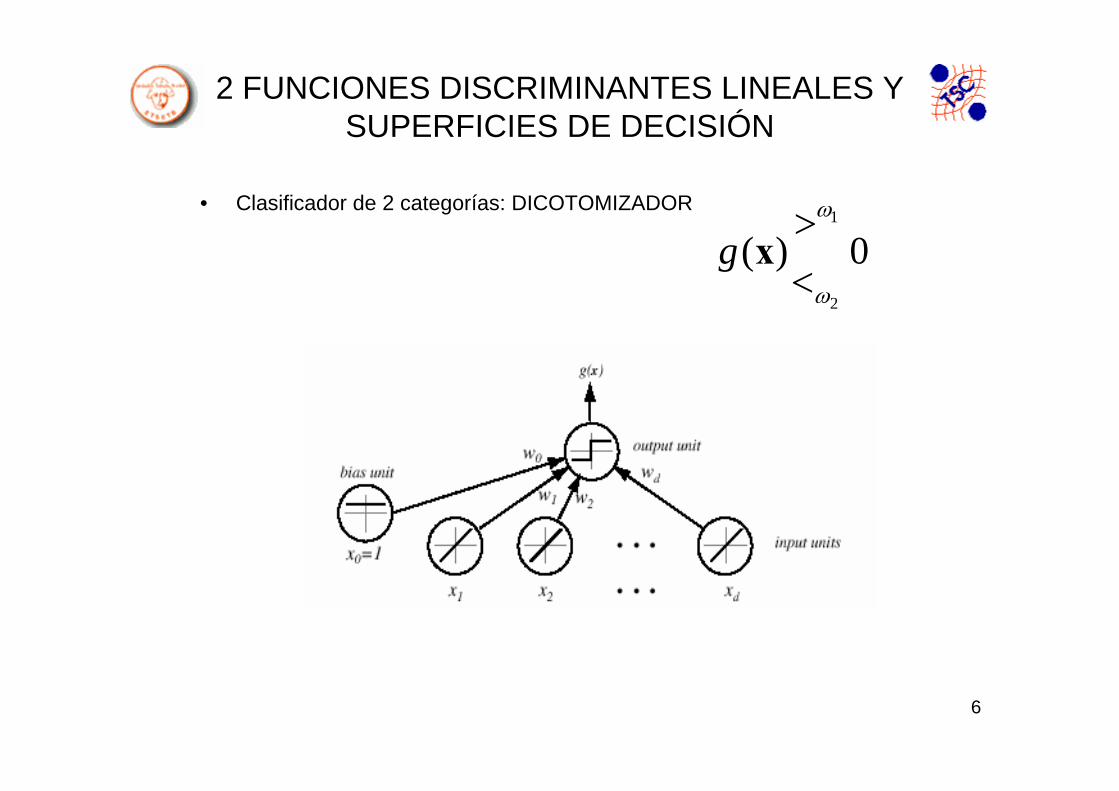
• Clasificador de 2 categorías: DICOTOMIZADOR1
2
( ) 0gω
ω
><
x

7
2 FUNCIONES DISCRIMINANTES LINEALES Y SUPERFICIES DE DECISIÓN
INTERPRETACIONES GEOMÉTRICAS:• Las superficies de decisión son hiperplanos.• El vector w es ortogonal al hiperplano que separa las zonas de
decisión, y por tanto a través de él se determina la orientación de la superficie.
• El bias w0 fija la superficie en un punto determinado.• La función g(x) da una medida de distancia del vector x al hiperplano:
• Hiperplano Hs:
• Proyección de x sobre Hs: xp
• Distancia de x a Hs:
p r= + wwx x
s( , H )r d= ± x
sH ( ) 0g∈ ⇒ =x x
( )2
0 0
0
s
( )
( ) 0
( , H )
T Tp
T Tp p
g w r w
w r g r r
d
= + = + + =
+ + = + = + =
±
ww
www w
x w x w x
w x w x w
x w

8
2 FUNCIONES DISCRIMINANTES LINEALES Y SUPERFICIES DE DECISIÓN
p r= + wwx x
s( , H )r d= x
2x
1x
sH
px

9
2 FUNCIONES DISCRIMINANTES LINEALES Y SUPERFICIES DE DECISIÓN
• Medida de distancia del vector x al hiperplano:
px x r= + ww
s( ) ( ,H )g d=x x w
10
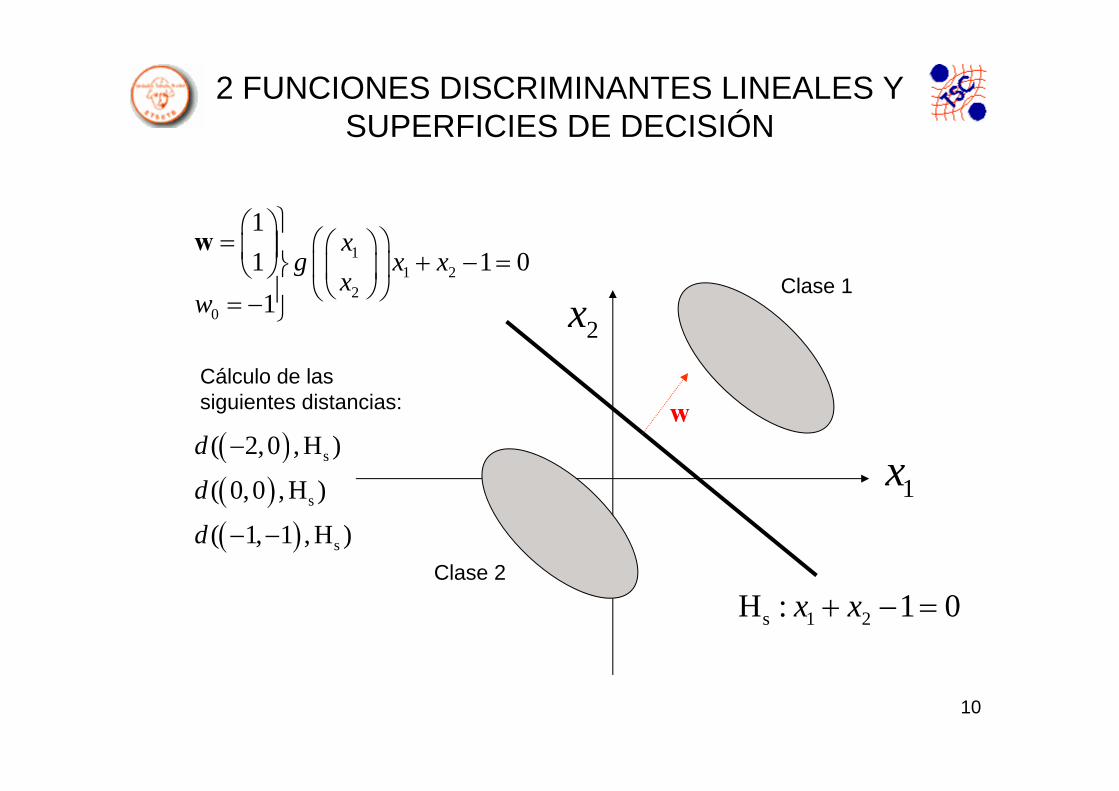
2 FUNCIONES DISCRIMINANTES LINEALES Y SUPERFICIES DE DECISIÓN
2x
1x
Clase 1
Clase 2
s 1 2H : 1 0x x+ − =
11 2
20
11 1 01
xg x x
xw
⎫⎛ ⎞= ⎛ ⎞⎛ ⎞⎪⎜ ⎟ + − =⎜ ⎟⎬⎝ ⎠ ⎜ ⎟
⎝ ⎠⎝ ⎠⎪= − ⎭
w
Cálculo de las siguientes distancias:
( )( )( )
s
s
s
( 2,0 , H )
( 0,0 , H )
( 1, 1 , H )
d
d
d
−
− −
w
11
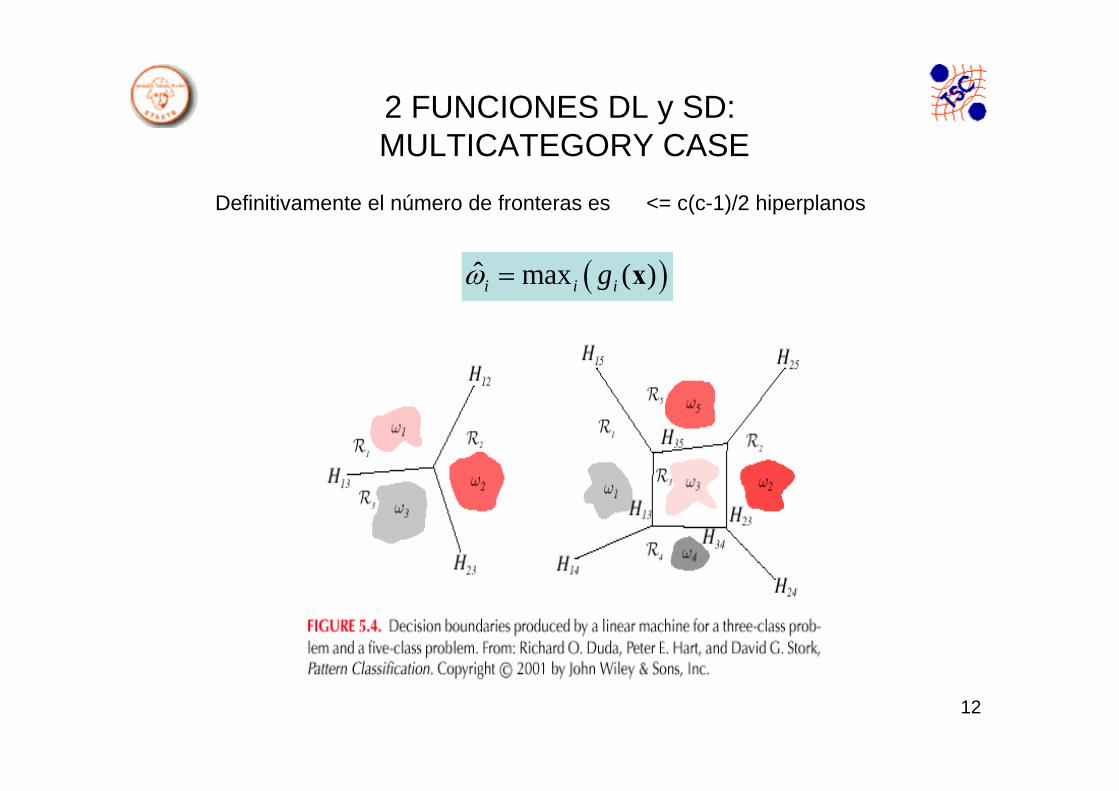
2 FUNCIONES DL y SD:MULTICATEGORY CASE
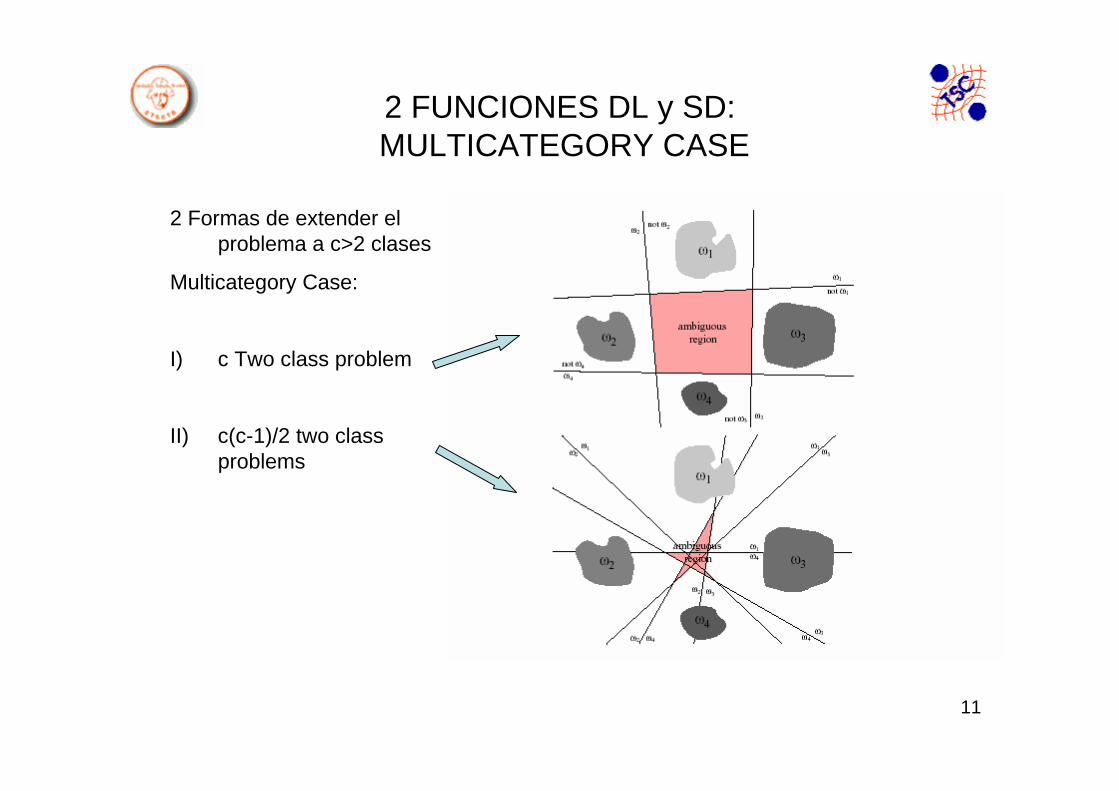
2 Formas de extender el problema a c>2 clases
Multicategory Case:
I) c Two class problem
II) c(c-1)/2 two classproblems
12
2 FUNCIONES DL y SD:MULTICATEGORY CASE
( )ˆ max ( )i i igω = x
Definitivamente el número de fronteras es <= c(c-1)/2 hiperplanos

13
3 CASO SEPARABLE DE 2 CATEGORÍAS
ˆ 1d d= +
• Caso de dos categorías:
• Augmented Feature Vector: Vector de características aumentado a dimensión+1
• Función lineal
• Regla de Decisión:
• Estrategia para simplificar el algoritmo de búsqueda de la solución.
– Ejemplo :
1 2,ω ω
ˆ
1d⎛ ⎞
= ∈⎜ ⎟⎝ ⎠
xy
1
2
0Tω
ω
><
a y
( ) Tg =y a y
0w⎛ ⎞
= ⎜ ⎟⎝ ⎠
Wa
1
2
0
0 0
Tk
T Tk k k k
ω
ω
⇒ >
⇒ < ⇒ = − ⇒ >
a y
a y y y a yˆ1, 2d d= =
14
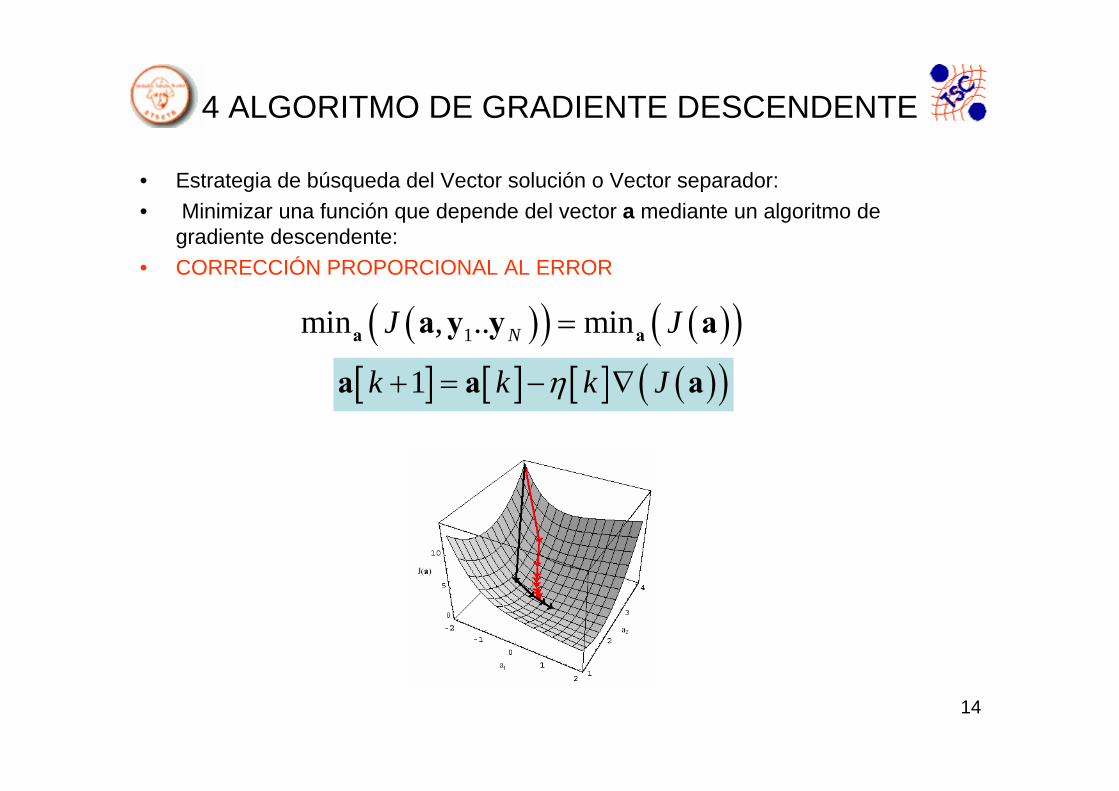
4 ALGORITMO DE GRADIENTE DESCENDENTE
• Estrategia de búsqueda del Vector solución o Vector separador:• Minimizar una función que depende del vector a mediante un algoritmo de
gradiente descendente: • CORRECCIÓN PROPORCIONAL AL ERROR
( )( ) ( )( )1min , .. minNJ J=a aa y y a
[ ] [ ] [ ] ( )( )1k k k Jη+ = − ∇a a a

15
4.1 ALG. de GRAD. : FUNCIÓN PERCEPTRON
• Funciones a Minimizar: FUNCIÓN PERCEPTRON.– Adecuada para casos Separables– E: Conjunto de vectores mal clasificados por a). – Batch Algorithm:
• SIMPLIFICACIÓN: Fixed increment (η constant) single sample perceptron
( ) ( ) ( )
[ ] [ ] [ ] ( )1
Tp pJ J
k k kη∈Ε ∈Ε
∈Ε
= − ⇒ ∇ = −
+ = +
∑ ∑
∑y y
y
a a y y
a a y
[ ] [ ] [ ] [ ][ ] [ ]
1k k k
kk k
⎧ + ∈Ε⎪+ = ⎨ ∉Ε⎪⎩
a y ya
a y

16
4.1 ALG. de GRAD. : FUNCIÓN PERCEPTRON
SIMPLIFICACIÓN: Fixed increment (η constant) single sample perceptron
17
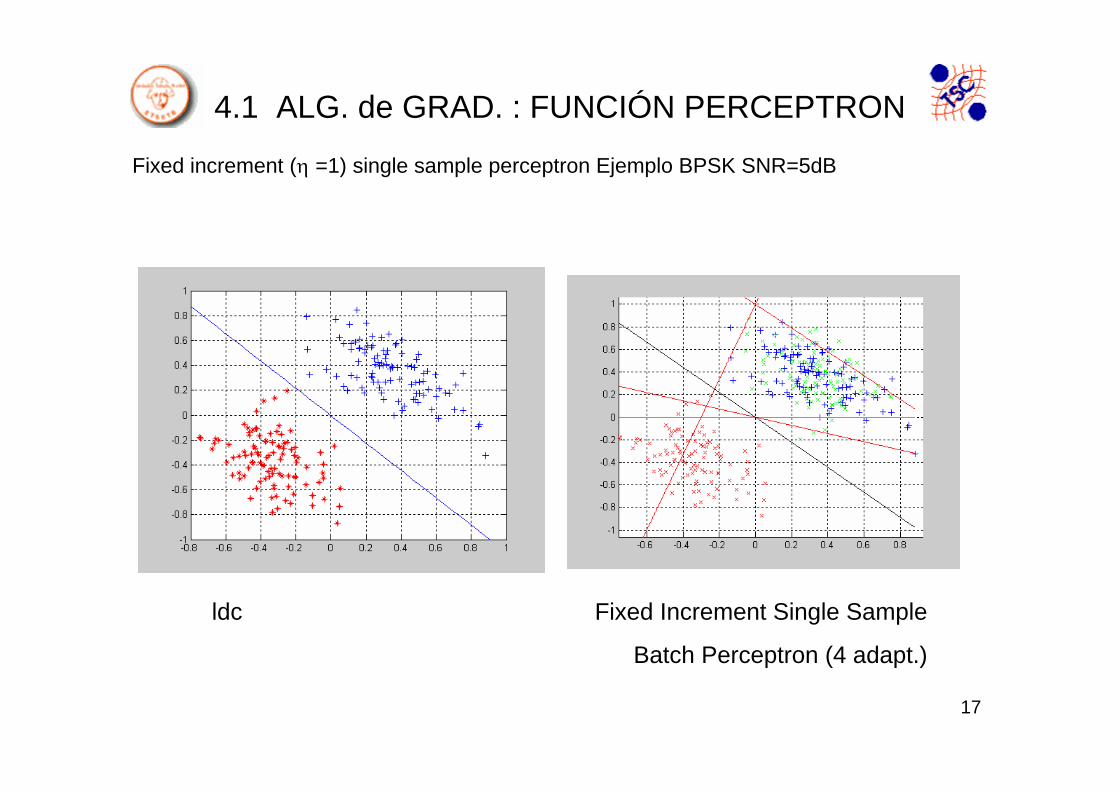
4.1 ALG. de GRAD. : FUNCIÓN PERCEPTRON
Fixed increment (η =1) single sample perceptron Ejemplo BPSK SNR=5dB
ldc Fixed Increment Single Sample
Batch Perceptron (4 adapt.)
18
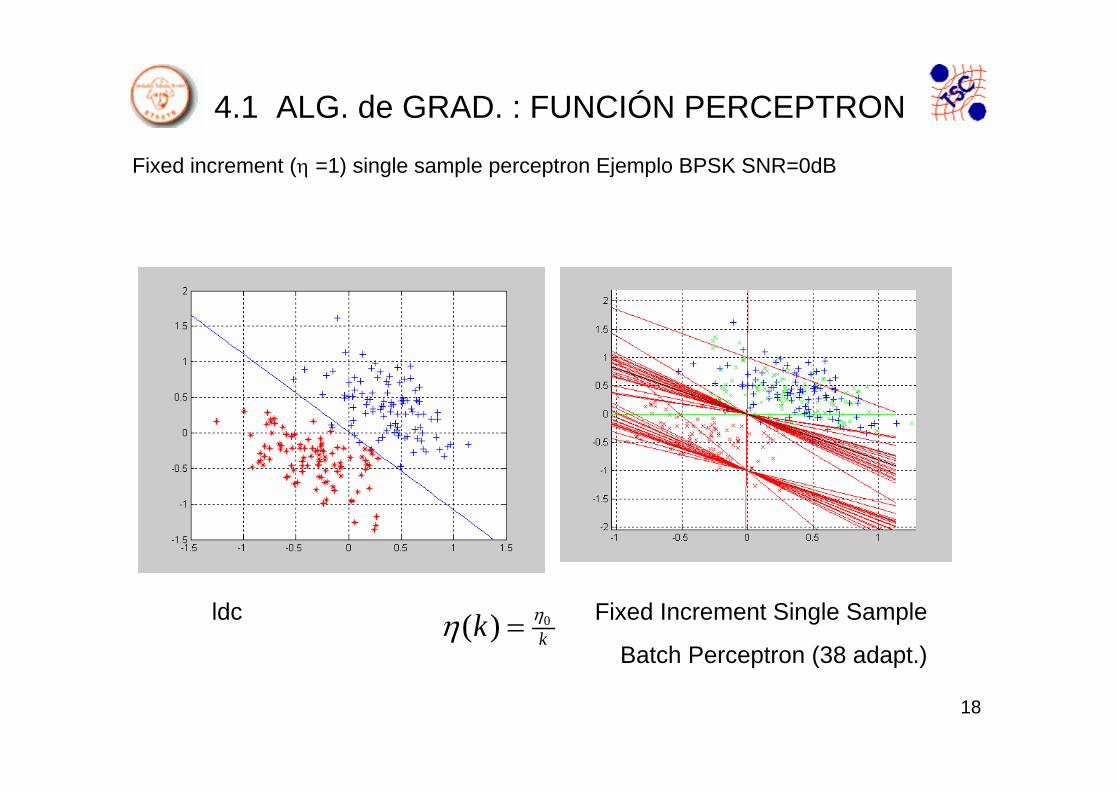
4.1 ALG. de GRAD. : FUNCIÓN PERCEPTRON
Fixed increment (η =1) single sample perceptron Ejemplo BPSK SNR=0dB
ldc Fixed Increment Single Sample
Batch Perceptron (38 adapt.)0( ) kk ηη =

19
Fixed increment (η =0.5) single sample perceptron Ejemplo BPSK SNR=0dB (56 Iteraciones)
4.1 ALG. de GRAD. : FUNCIÓN PERCEPTRON

20
• FUNCIÓN PERCEPTRON: FIXED INCREMENT PARA C CLASES.(c(c-1)/2 funciones)
• Fixed increment rule (Casos Separables)
( ) ( ) ( ); 1.. 0 with T Ti i j ii c t t t D= ⇒ − > ∈a a y a y y
( )1( )
tt
⎛ ⎞= ⎜ ⎟
⎝ ⎠y
x
( ) ( ) ( )[ ] [ ] ( )[ ] [ ] ( )
if and
1
1
T Ti i j
i i
j j
t D t t
t t t
t t t
∈ < ⇒
+ = +
+ = −
y a y a y
a a y
a a y
4.1 ALG. de GRAD. : FUNCIÓN PERCEPTRON

21
• Función Objetivo:
• Matriz de vectores
• Vector de margen b
• Gradiente:
( ) [ ]( ) ( ) ( )2 2
1
NTT
s ii
J i b=
= − = =∑a a y Ya -b Ya -b Ya -b
[ ] [ ]
[ ] [ ][ ] [ ]
[ ] [ ]
[ ]
[ ][ ]
[ ]
1
1 1 1 11 1
2 2 1 1
1 2 2 1 2
1 1 : 1 1: : : : :1 :1
1 1 1 : 1 1: : : : :1 :
Td
Td
Td
Td
x x
x N x N N
x x N
x N x N N N
⎛ ⎞⎛ ⎞⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟⎛ ⎞ ⎜ ⎟⎜ ⎟= = =⎜ ⎟− − − − − ⎜ ⎟+⎜ ⎟⎝ ⎠⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟
⎜ ⎟ ⎜ ⎟− − − +⎝ ⎠ ⎝ ⎠
y
yXY
X y
y
Ya -b 0
4.2 ALG. de GRA: MÍNIMO ERROR CUADRÁTICO(A aplicar en casos no separables)
( )
( ) ( ) ( ) 1 #2 0
T T T T T Ts
T T T Ts
J
J−
= − +
∇ = = ⇒ = =
a a Y Ya -b Ya a Y b bb
a Y Ya -Y b a Y Y Y b Y b
22
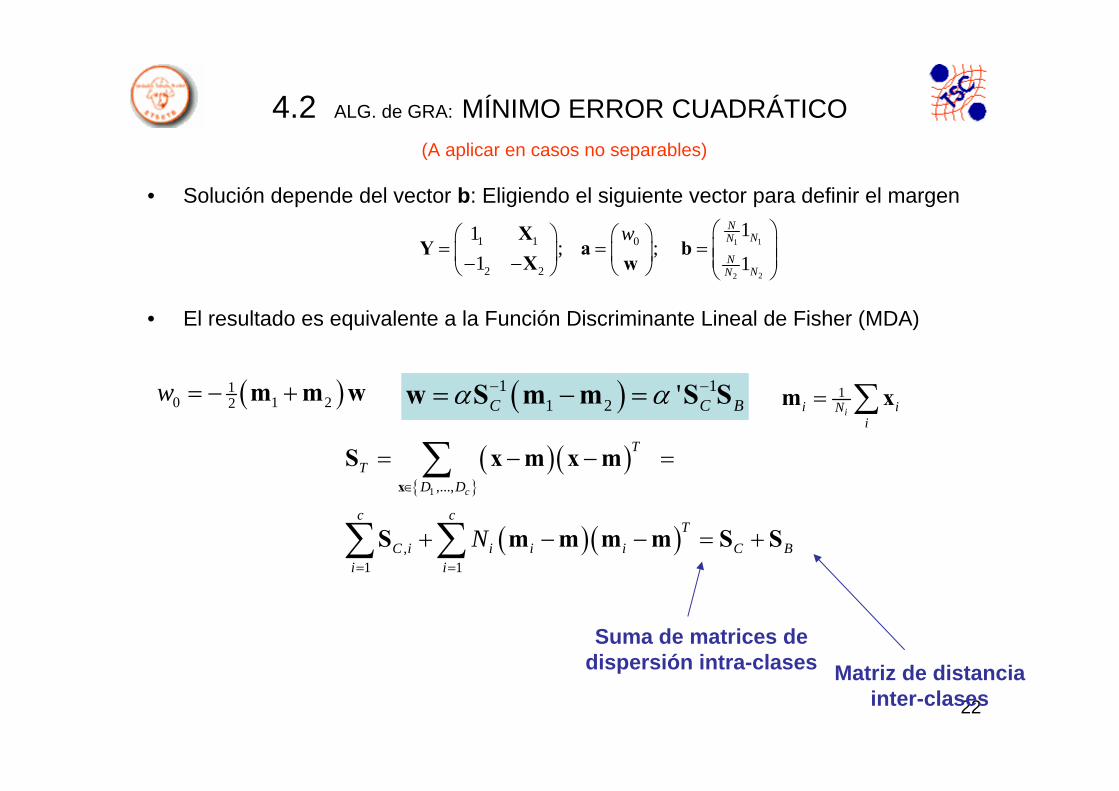
4.2 ALG. de GRA: MÍNIMO ERROR CUADRÁTICO(A aplicar en casos no separables)
• Solución depende del vector b: Eligiendo el siguiente vector para definir el margen
• El resultado es equivalente a la Función Discriminante Lineal de Fisher (MDA)
11
22
1 1 0
2 2
11; ;
1 1
NNN
NNN
w ⎛ ⎞⎛ ⎞ ⎛ ⎞= = = ⎜ ⎟⎜ ⎟ ⎜ ⎟ ⎜ ⎟− − ⎝ ⎠⎝ ⎠ ⎝ ⎠
XY a b
X w
( )1 11 2 'C C Bα α− −= − =w S m m S S( )1
0 1 22w = − +m m w 1ii iN
i= ∑m x
( )( ){ }
( )( )
1 ,...,
,1 1
c
TT
D D
c cT
C i i i i C Bi i
N
∈
= =
= − − =
+ − − = +
∑
∑ ∑x
S x m x m
S m m m m S S
Matriz de distancia inter-clases
Suma de matrices de dispersión intra-clases

23
4.2 ALG. de GRA: MÍNIMO ERROR CUADRÁTICO(A aplicar en casos no separables)
• Solución depende del vector b: Eligiendo el siguiente vector para definir el margen
• El resultado es equivalente a la solución MAP (lqd)
1 1 0
2 2
1; ; 1
1 N
w⎛ ⎞ ⎛ ⎞= = =⎜ ⎟ ⎜ ⎟− − ⎝ ⎠⎝ ⎠
XY a b
X w

24
4.2 ALG. de GRA: MÍNIMO ERROR CUADRÁTICO(A aplicar en casos no separables)
Aplicando el Algoritmo LMS:
• Función a minimizar
• Estimación del gradiente
• Ecuación de adaptación
( ) [ ]( ) [ ]( )2 2
1 1
N NT
s ii i
J i b e i= =
= − =∑ ∑a a y
[ ] [ ] [ ] [ ][ ] [ ] [ ] [ ]( ) [ ]
,1 s
Tk
k k k J k
k k b k k k
η
η
+ = − ∇ =
+ −
wa a
a a y y
[ ] [ ]( ) [ ] [ ] [ ], 2 2Ts kJ k k b k e k k∇ = − =w a y y y

25
4.2 ALG. de GRA: MÍNIMO ERROR CUADRÁTICO(A aplicar en casos no separables)

26
5 SV: Support Vector ClassifierCon datos lineales, el SVC es muy similar al algoritmo que minimiza la función de
mínimo error cuadrático medio. :• Se elige la solución que maximiza el margen de separación entre la frontera y los
datos.• El margen se define como el ancho del “tubo” que no contiene muestras y se
halla alrededor de la frontera de decisión.• El nombre del algoritmo (Support Vector) se debe a que en la solución final hay
muy pocas muestras multiplicadas por un factor (multiplicador de Lagrange para el caso no lineal) diferente de cero. Estas muestras corresponden a las más próximas a la frontera.
Referencias SV:
Pattern Recognition and Machine Learning, Christopher M. BishopSpringer(2006). TEMAS 6y7
F. Pérez-Cruz and O. Bousquet, (2004). “Kernel methods and their potential use in signal processing”. IEEE SignalProcessing Magazine, 21(3):57 - 65, May.

27
5.1 SVC: Caso lineal
Función a diseñar:
Condiciones a cumplir
Restricciones:
Se utilizan multiplicadores de Lagrange:
0( ) Tg w= +x w x0 1
0 2
1; if ; 1
1; if ; 1
Tk k k
Tk k k
w D c
w D c
⎧ + ≥ ∈ =⎪⎨
+ ≤ − ∈ = −⎪⎩
w x x
w x x
( )0 1Tk kc w+ ≥w x
( )( )2102
1
1 ; 0N
Tk k k k
k
L c wα α=
= − + − ≥∑w w x

28
5.1 SVC: Caso lineal
En forma Matricial (1):
Gradiente respecto a los parámetros de lla función:
Sustituyendo las expresiones anteriores en (1) se obtiene la forma dual que es la quese debe optimizar (minimizar) respecto a los multiplicadores de Lagrange y con la
restricción (2)
102
1
1 1 1
;
: ; :
N
c c kk
c
N N N
L w
c
c
α
α
α
=
= − + −
⎛ ⎞⎛ ⎞⎜ ⎟⎜ ⎟= = ⎜ ⎟⎜ ⎟
⎜ ⎟ ⎜ ⎟⎝ ⎠ ⎝ ⎠
∑T T T T
T
T
T
w w α Φ w α 1
xα Φ
x
0(2)
0
0 c c
w c
L
L
∇ = − = ⇒ =
∇ = =
T T T Tw
T
w α Φ w α Φ
α 1
1
:
N
α
α
⎛ ⎞⎜ ⎟= ⎜ ⎟⎜ ⎟⎝ ⎠
α12 c cL = −T T Tα 1 α Φ Φα
29
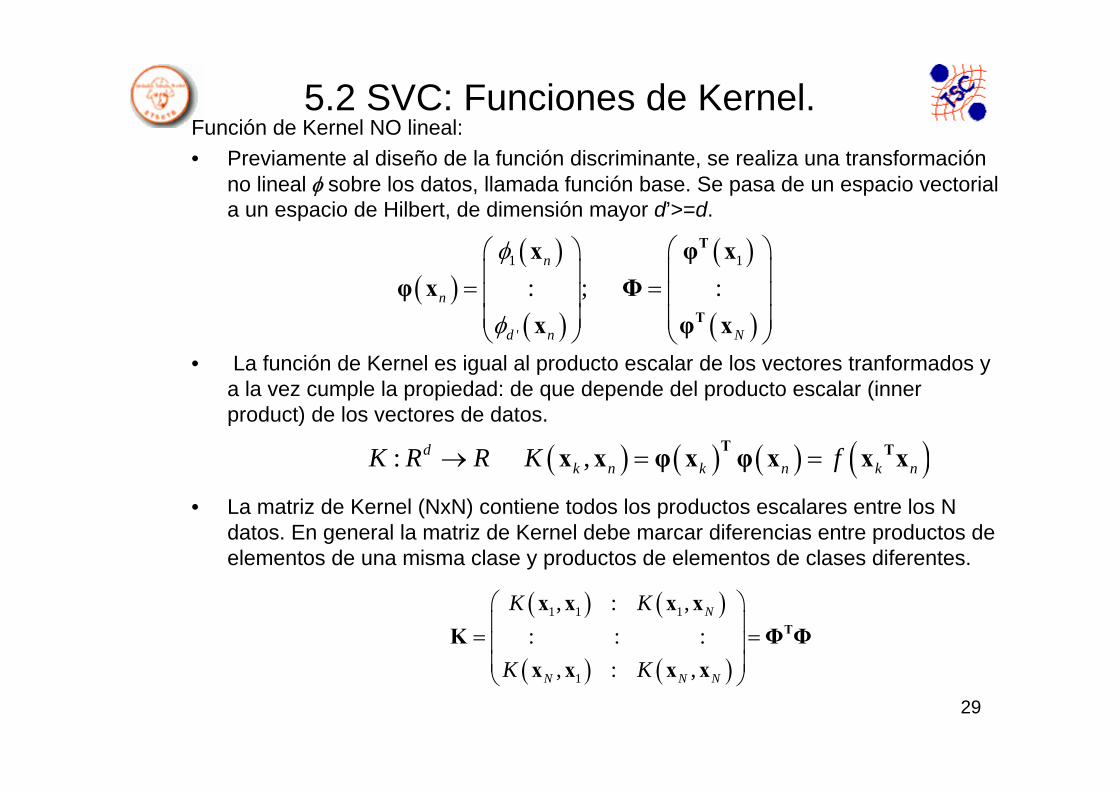
5.2 SVC: Funciones de Kernel.Función de Kernel NO lineal:• Previamente al diseño de la función discriminante, se realiza una transformación
no lineal φ sobre los datos, llamada función base. Se pasa de un espacio vectorial a un espacio de Hilbert, de dimensión mayor d’>=d.
• La función de Kernel es igual al producto escalar de los vectores tranformados y a la vez cumple la propiedad: de que depende del producto escalar (innerproduct) de los vectores de datos.
• La matriz de Kernel (NxN) contiene todos los productos escalares entre los N datos. En general la matriz de Kernel debe marcar diferencias entre productos de elementos de una misma clase y productos de elementos de clases diferentes.
( )( )
( )
( )
( )
1 1
'
: ; :n
n
d n N
φ
φ
⎛ ⎞⎛ ⎞⎜ ⎟⎜ ⎟= = ⎜ ⎟⎜ ⎟
⎜ ⎟ ⎜ ⎟⎝ ⎠ ⎝ ⎠
T
T
x φ xφ x Φ
x φ x
( ) ( ) ( ) ( ): ,dk n k n k nK R R K f→ = =T Tx x φ x φ x x x
( ) ( )
( ) ( )
1 1 1
1
, : ,: : :
, : ,
N
N N N
K K
K K
⎛ ⎞⎜ ⎟= =⎜ ⎟⎜ ⎟⎝ ⎠
T
x x x xK Φ Φ
x x x x
30

31
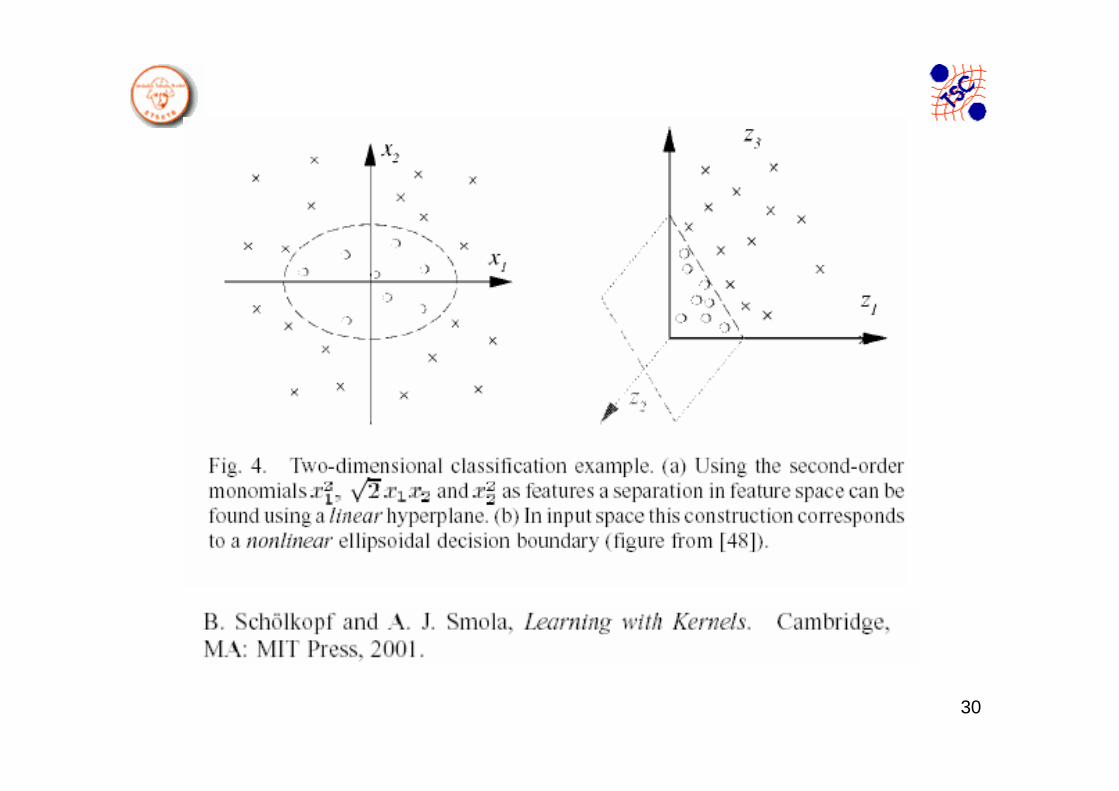
5.2 SVC: Funciones de Kernel.Ejemplos:• Transformación no lineal φ sobre los datos Gaussiana: Función base polinomio de
segundo grado
• Kernel Gaussiano (Función base radial ya que solo depende de la distanciaeucídea).
( ) [ ][ ]
[ ]( )[ ] [ ][ ]( )
( ) ( ) ( ) ( )
2
2
2
11
2 1 22
,k
n
nn n n
n
n
k n k n n
xx
x xx
x d
K
⎛ ⎞⎜ ⎟⎛ ⎞⎛ ⎞ ⎜ ⎟= = ⇒⎜ ⎟⎜ ⎟⎜ ⎟ ⎜ ⎟⎝ ⎠⎝ ⎠ ⎜ ⎟⎝ ⎠
= =T T
φ x φ
x x φ x φ x x x
( ) ( ) ( ) ( )2
21, expk n k n k nKσ
= = − −Tx x φ x φ x x x
La mayor dificultad al aplicar SVC no lineal, consiste en hallar la función de Kernel decuada que trasnsforme los datos a un nuevo espacio en el que sisean separables linealmente. El tipo de función depende de la aplicación.

32
5.3 SVC: Non Linear Classifier
El clasificador SV no lineal se diseña en dos etapas:1.- Transformación no lineal sobre los datos2.- Desarrollo del algoritmo SV de forma lineal sobre los nuevos vectores de datos
transformados.
Función a diseñar:
Función a minimizar (1):
Operando de forma análoga que con el método lineal:
( ) 0( ) Tg w= +x w φ x
102
1
;N
c c kk
L w α=
= − + − ∑T T T Tw w α Φ w α 1
1 12 2c c c cL = − = −T T T T Tα 1 α Φ Φα α 1 α Kα 0 c =Tα 1

33
6 CONCLUSIONES
BÚSQUEDA DE DISCRIMINANTE LINEAL• INTERPRETACIONES GEOMÉTRICAS: El discriminante lineal mide la
distancia de los vectores al hiperplano separador• C=2 categorías separables: Algoritmo de Gradiente descendente mediante
la función perceptron, Generalizable a más categorías.• C=2 categorías NO separables: Algoritmo de MMSE – LMS,Generalizable a
más categorías• C>2 Categorías: Se plantea el problema como c(c-1)/2 problemas de dos
clases.
SV Classifier:• NO Lineal: Es útil especialmente en casos no separables linealmente.• Dificultad: Hallar la función de Kernel adecuada











![davidbuiles.files.wordpress.com · Web viewSea la función f(x) continua en el intervalo [a,b], donde a y b son números reales y sea S el área bajo la curva de dicha función, como](https://static.fdocument.org/doc/165x107/5b0e2ebe7f8b9a3a0d8b54bf/viewsea-la-funcin-fx-continua-en-el-intervalo-ab-donde-a-y-b-son-nmeros-reales.jpg)






