
Teaching Material for CSC 789 (Multiparadigmatic programming)matt/tenure/vol7/vol7.pdf · Teaching...
258
Teaching Material for CSC 789 (Multiparadigmatic programming) The content of this package is the material handed out in my CS789 graduate course “Multiparadigmatic Programming. Contents “Scheme Lecture Notes” A set of lecture notes on the Scheme programming language. “Implementing a Simple Substitution Evaluator for a Scheme like λ-calculus Language in Scheme” A small tutorial on how to implement a substitution evaluator for a functional language. “Code for the Substitution Evaluator” “A Simple Scheme Evaluator Using Environments” A small tutorial on how to implement an evaluator for a functional language that uses environment. “Code for the Environment Evaluator” “The Santa Claus Problem in Occam” The assignment text as well as the solution. “A Relational Database in Scheme” A larger Scheme based project where the student must write a relational database system. “Code for the Relational Database System” The solution for the database system.
Transcript of Teaching Material for CSC 789 (Multiparadigmatic programming)matt/tenure/vol7/vol7.pdf · Teaching...
Teaching Material for CSC 789 (Multiparadigmatic programming)
The content of this package is the material handed out in my CS789 graduate course “Multiparadigmatic Programming.
Contents “Scheme Lecture Notes”
A set of lecture notes on the Scheme programming language. “Implementing a Simple Substitution Evaluator for a Scheme like λ-calculus Language in Scheme” A small tutorial on how to implement a substitution evaluator for a functional language. “Code for the Substitution Evaluator” “A Simple Scheme Evaluator Using Environments”
A small tutorial on how to implement an evaluator for a functional language that uses environment.
“Code for the Environment Evaluator” “The Santa Claus Problem in Occam” The assignment text as well as the solution. “A Relational Database in Scheme”
A larger Scheme based project where the student must write a relational database system.
“Code for the Relational Database System” The solution for the database system.

Page 1 of 141
CSC 789
Multiparadigmatic Programming
Scheme Lecture Notes
© 2007 Matt Pedersen
School of Computer Science University of Nevada, Las Vegas

Page 2 of 141
1. Introduction Scheme: More functional in nature rather than imperative (step-by-step) like C or object oriented like Java and C++. Functional: f(x) = (2+x)*69 Why Scheme?
• Supports a number of computation paradigms. • Strong connection to mathematics
o Code is similar to a function in mathematics that solves the problem
• Simple, few syntax rules permitting us to write powerful program right from the beginning.
Definition: A program is an embodiment or implementation of an algorithm for processing/execution by a computer. But what exactly is a computer? We will use the following simple model. A computer is a general purpose device that reads input from an input device (e.g. keyboard, mouse, etc.) and produces output (in some form: screen etc.) according to a set of instructions in a program. In our simple model a computer has:
• Memory (a device for storing data and program instructions) • A Central Processing Unit (CPU) that actually performs the
program instructions on the data. We will think of the computer as the following box:

Page 3 of 141
Input Output Program instructions are stored in memory as data. This idea originated with many researchers, but credit is give to John von Neumann, thus modern computer are called “von Neumann machines”.
• Program is stored in memory as data. • CPU fetches its commands from memory. • CPU executes instructions. • Results are stored in memory for output or further
processing. So a program maps input to the desired output. You might conclude the following:
“Programming is easy – just list all possible inputs and their corresponding outputs”
Is this correct? No. It would take too long to program in this manner: f: 1 0, f: 23, f:38, … to program f(x) = x*x-1 Instead in the computer f(x) is represented by a procedure that computes it for any value.
MEMORY
C P U

Page 4 of 141
It is also too hard to solve some problems for which we are trying to find output for any input, e.g. weather forecasting. Instead we use general problem solving techniques to
1. Break the problem into manageable steps. 2. Write instructions (for the computer) to perform each step.
Example: Suppose you want to compute the area of a trapezoid.
Algorithm: 1. Take length of side1. 2. Add length of side 2. 3. Divide result by 2. 4. Multiply by height.
Or we can represent our algorithm by a mathematical function: A = (s1+s2)/2 *h How do we program this algorithm on out computers in the lab? Programming languages Every family of CPU understands their own machine language.
• Low level language – have to concentrate on every small detail such as loading data etc.
• Far from English or mathematical description of the algorithm.
• Rewrite for every new CPU/computer. • Very little programming is done directly in machine code.
h
S1
S2

Page 5 of 141
Alternatively we typically program in a high-level programming language:
• Abstracts out the low-level detail of the controlling machine.
• Closer to mathematical, business or English notation. In order to be executed by the computer, programs written in a high-level language must be translated into machine language by either a compiler or an interpreter. This means that the same program can be used on different machines. Every language has precise rules defining the
• Syntax – the language’s grammar, i.e. what we can write in the language.
• Semantics – the exact meaning of what we write. In order for a computer to correctly evaluate a program it must properly follow syntax and semantic rules. Scheme is a high-level language modeled on mathematical notation (variant of LISP) Pieces of a program are treated as functions, and look like formula. 1.2 Scheme Basics In math we might write something line min(3,6) to compute the smaller value of 3 and 6. That is, the name of the function followed by a list of arguments in parentheses. In Scheme we represent this by a form (short for formula) in the following way: (min 3 6) Form min: is the name of the function

Page 6 of 141
3 & 6: arguments passed to function min. Arguments are separated by spaces, not commas. Scheme is an interpreter (not a compiler), i.e., it evaluates forms as you type then in and print out their value (result). Example of Scheme forms
Math Scheme min(3,4) >(min 3 4) 3
‘>’ is the prompt displayed by Scheme to tell you that it is ready to receive forms. In the book values are in bold, on the board I will circle them. It is important to understand the difference between a form and its value. 3 * 5 >(* 3 5) 15 * is a function just like min, except tradition dictates using an infix notation (3 * 5). In Scheme we treat it no differently from min. In Scheme we write all forms in prefix form – operator followed by arguments between a set of parentheses. (<op> arg_1 arg_2 … arg_n) where
• <op> is a primitive operation or a primitive. o + * / - sqrt sin cos log are all built into Scheme. o See appendix B.6 (P 672)
(/ 6 2)

Page 7 of 141
3 (sqrt 9) 3 (- 10 8) 2
In each application Scheme evaluates each function applied to its arguments and prints the value of the form. Arguments can be other forms. Eg. returning to the area of a trapezoid problem. Let us assume that s1=12, s2=8 and h=4. We can create the following form (from inside out) (* (/ (+ 12 8) 2) 4) We use to mean “evaluates to”. In order to evaluate the values of the form, we must evaluate the value of the arguments of the * primitive.
(* (/ (+ 12 8) 2) 4) (* (/ 20 2) 4) (* 10 4) 40
Each replacement is a substitution. A few examples more:

Page 8 of 141
Example 1.
A robot travels from (2,1) to (4,2) and on to (6,2). What is the distance traveled?
(+ (sqrt (+ (* 2 2) (* 1 1))) 2) A B Example 2. What is Jim’s CS 124 % average: 90% 97% 100% 68%? (/ (+ (+ (+ 90 97) 100) 68) 4) Let us now look at some other examples: Type the following at the evaluator:
(+ 2 3 <CR>
Scheme waits – nothing happens until the closing ) completes the form. Then Scheme evaluates the form.
matt Error: variable matt is not bound (2) Error: Attempt to apply non-procedure 2
In Scheme ( ) have one purpose: delimits a form in which a function or primitive is applied to a number of arguments. This means you cannot add parentheses arbitrarily.
B A (6,2) (4,2)
(2,1)

Page 9 of 141
86 86
86 is a numeral (a form) – Scheme reads a numeral and interprets it as a number in base 10. Thus numerals are also forms. Let us revise our definition of a form. Definition: (recursive definition) A form is
• A numeral (e.g. 73 1.287 or –0.92) • An application (an operation applied to other forms) i.e.
(<op> form_1 form_2 … form_n) Example: (+ 2 3) 2 and 3 are numeral forms. How does Scheme know how to evaluate forms? For us to be able to program we need to know how Scheme interprets and evaluates the forms we write, i.e. we need to understand the semantic of the Scheme programming language. We are working with the Substitution Model of Evaluation:
1. It has a set of simple rules for evaluating forms that tell us exactly what programs do.
2. We start with a simple set of rules and replace them with a more rigorous set later.
(These rules might seem like overkill for the forms we have seen so far, but they will help you really understand how Scheme works.)

Page 10 of 141
The Rules of Evaluation (Version 1)
• The Number Rule: A numeral’s value is a number, interpreted in base 10.
• The Primitive Rule: Calculate the result (value of the primitive operation) by applying the primitive operation (e.g. + or -) to the supplied values of the arguments)
o A Primitive Rule always finishes off an Application Rule. o Primitive operations are supplied by Scheme.
• The Application Rule: An application is evaluated by o First evaluate all its arguments (using more application
rules or number rules) o Apply Primitive Rule to the partially evaluated from. This is a recursive evaluation procedure! How does it stop? By application of the primitive rule.
Examples: Notation: “ “ indicates the form currently being evaluated.
“22” Number Rule 22 “(+ 3 6)” Application Rule
(+ “3” 6) Number Rule (+ 3 “6”) Number Rule (“+” 3 6) Primitive Rule
9
“(- (* 4 5) 3)” Application Rule (- “(* 4 5)” 3) Application Rule
(- (* “4” 5) 3) Number (- (* 4 “5”) 3) Number (- (“*” 4 5) 3) Primitive
(- 20 “3”) Number Rule (“-“ 20 3) Primitive

Page 11 of 141
17 We need to make two more points:
1. Argument evaluation order: doesn’t matter for the result, but we assume left to right.
2. As a by-product of the rules, in nested forms, inner-most forms are evaluated first.
1.3 Procedures and Definitions We need more that what we learned last time to write useful programs. In particular, we need to be able to write out own primitives. In this section we will learn how to create our own primitives. We call them procedures. We will also learn about the special form define that allows us to name numbers and procedures. Recall our Trapezoidal example: We wrote the following form:
(* (/ (+ 12 8) 2) 4) If we were in the Trapezoid Area computing business we would soon get tired of creating a new form with new values for every new trapezoid.
4
12
8

Page 12 of 141
We don’t want to write a new form for each trapezoid. In math we avoid this problem by creating a generic function (that can be applied to any problem size). In math: A(s1,s2,h) = (s1+s2)/2*h For a particular problem we replace the parameters in the formula with a problem’s actual arguments.
A(12,8,4) 40 The value is computed by applying the formula to the actual arguments. We can do the same thing in Scheme using a Lambda form. A better name for the form might have been “procedure”, but the name arose from McCarthy’s use of Church’s lambda calculus for Lisp, and the name stuck. For example, a lambda form for out trapezoidal area problem is
(lambda (s1 s2 s3) (* s1 s2) 2) h)) Formal parameters Body If you were to type this at the Scheme prompt, it would print #<procedure> Scheme is telling you that the value of a lambda form is a procedure. (That can be evaluated with different actual parameters/arguments) The general syntax for of a lambda form is:
(lambda (<parameter-list>) <body>)

Page 13 of 141
where
• <parameter-list> is a sequence of names (formal parameters) • <body> is any Scheme form, in which the parameters act as
placeholders for actual arguments. The form to be evaluated when the procedure is applied.
Note
1. 0 or more parameters (with 0 parameters: () ) 2. Body can be any form. It does not have to reference
parameters. 3. Names can be anything that isn’t a keyword or a numeral.
a. Use meaningful names. The lambda form is saying:
“Make a procedure with the following parameter list that compute a value according to the body when given a list of actual parameters”
The parameters in the body act like variables in a mathematical function and can be replaced with specific arguments. We apply a lambda form to specific arguments just like a primitive: For example, if we have the lambda form (λ (a b) (+ (* a a) (* b b))) we can apply it to 2 actual parameters, say 2 and 4 in the following way: ( ((λ (a b) (+ (* a a) (* b b))) 2 4) Formal parameters Actual parameters We will talk more about formal evaluation rules for lambda-forms, but for now to evaluate the application a lambda-form the rule is:

Page 14 of 141
1. Evaluate each of its elements. 2. Replace the formal parameters in the body of the lambda-
form with the evaluated actual parameters. Match actual parameters to formal parameters in a strict left to right fashion. The number of formal parameters must match the number of actual parameters.
3. Evaluate the body. 4. For nested lambda-forms, evaluate the inner-most lambda-
form first. Example:
( (λ (a b) (/ a b)) (+ 17 3)
( (λ (x) (+ 3 x)) 3)) The underlined forms are the arguments to the first lambda-form. To evaluate the entire form we must:
1. Evaluate (+ 17 3) 20 2. Evaluate ( (λ (x) (+ 3 x)) 3) 6 3. Then evaluate (/ 20 6) 20/6
Consider the form
( (λ (r) (* (* r r) 3.14)) 6) Is this not a lot of writing? Could we not have written (* (* 6 6) 3.14) to get the same value? We will name procedure (we really mean lambda-forms, as the value of a lambda-form is indeed a procedure) and then reference the name of a procedure to apply it.

Page 15 of 141
For example:
(define carea (λ (r) (* (* r r) 3.14))) This binds the name carea to the lambda-form. We can now use it in the following way:
(caera 2) 12.56
We will use define to name things. Take a look at the following forms, what are they? (* 3.14159 (- (* 10 10) (* 5 5))) The area of a doughnut (inner radius 5, outer radius 10) What about (* (- 1.0 0.40) ( 0.95 1.10)) The price of 2 chocolate bars after 40% discount. How do we know the intent of the programmer? To be able to create readable code, Scheme allows you to associate a name with a value using a define form. Example: (define pi 3.14259) (define inner-rad 5) (define outer-rad 10) (* pi (- (* outer-rad outer-rad) (* inner-rad inner-rad)))

Page 16 of 141
(define discount 0.40) (define Mars 0.95)
(define Aero 1.10) (* (- 1.0 discount) (+ Mars Aero)))
In general the syntax of the define form is: (define <name> <form>) Where <name> is any sequence of characters not reserved as keywords by Scheme. Example: ++, pi, mars1 are all valid names, but min, lambda, ((( and 32 are not valid names. <form> - the value of the form is bound to the name. Note, that a defined name is a form.
(define a (+ 10 3)) a 13
Also note that define did not return a value. Define is a special form.
• Define forms do not return a value o Their purpose is to associate a name with a value o They are used for their side-effects not the value they
return. • Define and lambda are used in special forms.
o Forms in which not all arguments are evaluated (the body of the lambda-form is not evaluated until it is applied to a set of actual parameters)
It is ok to redefine a name:

Page 17 of 141
(define a 10) a 10 (define a 11) a 11
But if you have other programming experience resist the temptation to do the following:
(define count 1) (define count (+ count a))
Only use define to bind a value to a name once and for all. Now that we have seen how to use the define-forms, let us review why we want to bind names to values. Why do we want to bind a value to a name with define?
• Makes forms more readable and understandable. • Easier to change a value
o For example if we use pi all over our program and we want to change its accuracy we just have to change it in one place.
• What is we make a mistake in typing the 6th or 7th digit of pi a couple of times? Such errors are hard to find.
• Saves re-computation of often used values. Note that Scheme does not have a specific concept of “program” – you can put forms together in any way you want and enter the whole collection into Scheme or save them in a file. Let us now suppose that we have written a complex program consisting of lots of defines and other forms. How does Scheme keep track of all the names?

Page 18 of 141
Scheme keeps track of all names with an environment. The Scheme Environment The environment is a set of names and corresponding values for the current Scheme session (if you kill Scheme you wipe out the current environment) Forms are evaluated inside an environment, and may contain names that are in the environment.
• Think of names as buckets in which we store values (not forms)
• The environment is a collection of these buckets. • When Scheme starts up it has some pre-defined names. • As scheme evaluates define-forms, buckets are added to the
environment with the value of its form. • When Scheme is evaluating a form and encounters a name, it
looks up the name in the environment; it replaces the name with the values found in the bucket.
Example:
(define a 4) (define b 5) (define c (+ a b))
The environment looks like this:
Name Value a b c
4 5 9

Page 19 of 141
If you re-define something in the environment, it will replace the value in the bucket. Be careful:
(define + 3) (+ 5 6) Error: Attempt to apply non-procedure 3.
Defining Procedures Example:
(define sum-triple (lambda (x y z) (+ (+ x y ) z)))
The lambda-form evaluates to a procedure – this value is stored in the bucket in the environment. We “call” or “invoke” a procedure just like we would a primitive:
(sum-triple 3 2 6) 11
Scheme replaces the name (sum-triple) with the procedure (value of the lambda-form) and evaluates in the normal fashion. So why name procedures?
3 #<procedure +>
+

Page 20 of 141
• Procedures can be used repeatedly (with different arguments) by referencing its name.
o There is no need to write out the lambda form several times.
• Reduces errors. o Suppose you want to change a part of one computation,
you only need to change it in one spot. • Makes programs understandable.
o When you are writing a procedure you are engaging in abstraction.
o Once it has been created and tested you don’t need to know the implementation, it becomes a new “primitive” for Scheme, and you can use it as a building block to construct more complicated programs and procedures.
o All you need to know is a procedures interface The interface defines what the parameters are and
what the result the procedure computes. Example: Compute the surface area of a rectangular box.
1. Compute the surface area of each side. a. We do not need a special form for each side, create a
generic one.
(define rect (lambda (a b) (* a b)))
2. Sum the areas of all 6 sides.
Length
Width
Height

Page 21 of 141
We can use rect in the procedure to compute the final area.
(define surface (lambda (width height length) (+ (* 2 (rect width height)) (* 2 (rect width length))
(* 2 (rect height length)))))
(surface 1 2 2) 16
We can call rect a helper-procedure. A helper-procedure is a procedure that does a task on behalf of another procedure. We introduced the first version of the rules last time. Since then we have introduced 3 important aspects of Scheme:
1. Define-forms 2. Lambda-forms 3. Environments
We need to revise the rules to reflect these additions. 1.4 The Rules of Evaluation (Version 2)
• Initialization Rule: The environment initially contains only the built-in primitives.
• Number Rule: A numerals value is a number interpreted in base 10.
• Name Rule: A name is evaluated by substituting the value bound to it in the environment
o It does not matter if it is user defined or the name of a primitive procedure.
o If the name does not exist in the environment when the form is evaluated an error is produced.

Page 22 of 141
• Lambda Rule: The value of a lambda-form is a procedure with parameters and body as in the form.
• Application Rule: An application is evaluated by evaluating each of its elements (using Name, Lambda, Number or even another Application rule) and then use
o The Primitive rule if the operator is a primitive. o The Procedure rule if the operator is a procedure.
Note that we always finish an Application rule with either the Primitive or the Procedure rule.
• Primitive Rule: Invoke the built-in primitive procedure with the given arguments.
• Procedure Rule: A procedure application is evaluated in 2 steps:
o In the body of the procedure, replace each of the formal parameters by its corresponding actual argument.
o Replace the entire procedure by the body. • Definition Rule: The 2nd argument is evaluated. The 1st is not
evaluated and must be a name. The name and the value are added to the environment.
We will talk about the If, And and Or rule later. Examples:
“(define foo 12)” Definition (define foo “12”) Number
(define foo 12) Add foo to Env.
“(+ foo 6)” Application (“+” foo 6) Name (#<proc +> “foo” 6) Name (#<proc +> 12 “6”) Name (#<proc +> 12 6) Primitive
18

Page 23 of 141
“(define rect Definition
(lambda (a b) (* a b)))” (define rect Lambda “(lambda (a b) (* a b))”) (define rect #<proc rect>) Add rect to Env.
Let us now apply rect to two arguments.
“(rect 8 12)” Application (“rect” 8 12) Name (#<proc rect> “8” 12) Number (#<proc rect> 8 “12”) Number (#<proc rect> 8 12) Procedure “(* 8 12)” Application (“*” 8 12) Name (#<proc *> 8 12) Primitive 96
Note that every Application rule causes 2 things to happen
1. Evaluation of elements. 2. Use of Primitive or Procedure rule.
Using the rules can be tedious, but it is very important to understand them in order to understand how Scheme evaluates forms (i.e. the semantics of Scheme). 1.6 Notes on Procedure Design & Programming Recall out rectangular box surface area problem that we solved at the beginning of today’s class. We solved it by breaking the problem into smaller steps and solved it by writing 2 procedures. surface: Main procedure Client (or user) only needs to know its interface.

Page 24 of 141
rect: Called 3 times by surface. Helper procedure. A helper procedure is a procedure that performs a task on behalf of another procedure. The approach we took to the solution of the surface area problem, is a simple example of a general problem solving technique called decomposition. The process of breaking a large problem into smaller, more manageable portions (sub problems) that can be understood on their own. Each sub problem may be broken into smaller portions in turn (creating many levels of decomposition). Smaller independent problems can be solved much easier than a complex problem at once. Each sub problem can be implemented by a different procedure, i.e., one main procedure and a number of helpers. Some of the benefits of decomposition are:
• Easier to implement smaller portions of a problem independently.
• Independent procedures tested more easily o In a big program this is a lifesaver. o As you create each procedure you can test it – bottom
up approach or top down. • Main procedure (and other procedures) is simpler to read,
write and test. • More efficient (sometime) – intermediate values can be
computed once and passed as parameters.

Page 25 of 141
When you create a procedure to solve a portion of the problem you engage in abstraction, i.e. suppress (or hide) irrelevant detail of an implementation. Once you have created the procedure and tested I, you don’t have to know the details of its implementation. You can use it as a building block for solving the current problem, or if you design it generally enough, use it to solve a different problem altogether. All you need to know is the interface, which defines what the parameters are, any assumptions and what the result of the procedure is. Good programmers often collect frequently used procedure into a library. (A collection of procedure solving frequently encountered problems that can be used as building blocks in other programs). For example: Scheme has add1 and sub1 built in. Another example: We could use out rect procedure to solve another problem: “Compute the cost of painting a room (ceiling and walls) with 2 identical windows. Assume one gallon of paint covers 15 square meters and cost 33$” First we should name these constants to improve readability of our code.
(define coverage 15) (define paint-cost 33) Now we are ready to write our main procedure to determine the cost: (define room-cost (lambda (rl rw rh ww wh) (* (/ (room-area rl rw rh ww wh) coverage) paint-cost)))

Page 26 of 141
Note we have written room-cost only with the specification of the interface. The area of a room without doors and windows is: 2*l*h + 2*w*h + l*w = 2*h*(l+w)+l*w (define room-area (lambda (rl rw rh ww wh) (- (+ (* 2 (* rh (+ rl rw))) (* rl rw)) (* 2 (rect wh ww))))) 1.5 Boolean values, Conditions and Decisions So far we have seen how to write procedure that follow a fixed sequence of steps reaching a numerical value (result). Independent of the input the same steps are always executed. Most programs need to make decisions by asking true/false questions. Example: if your income is < $6,000 you pay no income tax, otherwise you pay 0.29*(income-$6,000) We want to create a procedure that asks the “income question” and returns the appropriate amount of tax. We don’t want the user to make the decision to decide whether to call the procedure. (define base 6000) (define tax-rate 0.29) (define income-tax (lambda (income) (if (< income base) 0 (* tax-rate (- income base)))))

Page 27 of 141
(income-tax 4000) 0 (income-tax 6000) 0 (income-tax 6002) 0.58
The if-form is a special form with the following general syntax: (if <condition> <then-form> <else-form>) So far we have seen 2 data types: numbers and procedure. The condition is any form that yields a boolean value. There are two boolean values: true (#t) and false (#f). Because the if-form is a special form it does not necessarily evaluate all its arguments. Evaluation: If the condition’s value is #t then evaluate the <then-form> and return the value of it, else (if condition is false (#f)) evaluate the <else-form> and return that value. Also note:
• If is a keyword and is not evaluated. • Only one of the two forms (<the-form> and <else-form>) is
evaluated depending on the value of <condition>. • The <then-form> and the <else-form> can be any form.
(if #t 4 5) 4 (if #f (/ 69 0) (income-tax 2.32)) 0 (if (+ 3 2) 5 6) 5
Note that the last form here does not produce an error, only #f is considered to be false, anything else is considered to be true.

Page 28 of 141
Typically conditions are not simply #t or #f. Why? Then you have ‘hard-wired” the result of the decision, and you will always execute the same form, and that renders the if statement obsolete. So how do we construct conditions? Conditions A predicate is any procedure that takes a number of arguments and yields a Boolean value. Primitive predicates include: < <= = => > Other predicates are: zero? number? boolean? procedure? odd? even? (By convention all predicates whose name are words end in?)
(< 6 5) #f (<= 6 6) #t (if (procedure? +) 5 #f) (if #t 5 #f) 5
Example: Write a procedure for x/y, that returns #f if y is 0, the value otherwise. (define my-div (lambda (a b) (if (= b 0) #f (/ a b))))

Page 29 of 141
(my-div 2 0) #f (my-div 9 7) 9/7
Sometimes we need to combine these elementary conditions. For example: How would you implement the decision:
If it is not raining and temp>0 then
take car else
take train? To combine Boolean values (or predicates) use the and, or and not operators. In Scheme you can construct forms with these operators as you would expect: (and <cond1> <cond2>) If both conditions are true then return #t else return #f. Example:
(and (> 6 5) (= 6 5)) #f
(or <cond1> <cond2>) If either or both conditions are true then return #t else return #f. Example:
(or (<= 3 3.1) (even? 17)) #t
(not <cond>)

Page 30 of 141
If <cond> is #t return #f, else if <cond> is #f return #t. Example:
(not (procedure? 69)) #t
Consider another example:
(and (> a 0) (> (/ 20 a) 6)) Is this form valid? Yes. Does it ever give an error? No, not as long as a is defined in the environment. If the first condition is #f then the second condition is never evaluated, because both and and or are special forms, and may not evaluate all their conditions. The each evaluate enough conditions to determine the answer. And: Keep evaluating conditions while they are #t. If a #f is found stop evaluating and return #f. It only takes one #f to make the and-form false. Or: Keep evaluating conditions while they are #f. If a #t is found stop evaluating and return #t. It only takes one #t to make the or-form true. We can write our own predicates as well. Example: “Write a predicate (procedure) that determines is a person’s age is less and 5 or greater than 95”. (define xtrm-age (lambda (age) (if (and (>= age 5) (<= age 95)) #f #t)))

Page 31 of 141
The body could have been written this way as well: (if (not (and (>= age 5) (<= age 95))
#t #f)))
This could be exchanged for one single or: (if (or (< age 5) (> age 95)) #t #f)) This procedure is sill overly complex: The value of the condition matches the value returned: Never write a form like (if <cond> #t #f) instead use <cond> (if <cond> #f #t) instead use (not <cond>) So we can change our predicate to look like this: (define xtrm-age (lambda (age) (or (< age 5) (> age 95))))
Example: Modify the income tax example so that people with an “extreme-age” and income < $10.000 pay no tax and actually get a rebate of $500. (define base 6000) (define xtrm-base 10000) (define tax-rate 0.29) (define rebate –500)

Page 32 of 141
(define income-tax (lambda (income age) (if (< income base) 0 (if (and (xtrm-age age) (< income xtrm-income)) rebate (* tax-rate (- income base)))))) What is wrong with this solution? Only extreme age people with income greater than or equal to 6,000$ get a rebate. (define income-tax (lambda (income age) (if (and (xtrm-age age) (< income xtrm-base) rebate (if (< income base) 0 (* tax-rate (- income base))))))
2. Recursion. We have already seen most of the basic features needed to build Scheme programs. Scheme is a procedure centric language. We have seen hot to create procedures that
1. Execute a sequence of computations 2. Can choose between computations 3. Can call sub procedures (helpers)
But our programs are not fully exploiting the power of computers. They can execute millions of instructions pr second, but we don’t want to write programs with millions of lines of code.

Page 33 of 141
Instead we want do design programs to repeat a small subset of instructions with different data values. Other languages use keywords like FOR, WHILE, DO, REPEAT to control repetition. In Scheme we don’t use any special keywords, in fact, we don’t need any new features. To repeatedly execute a step we make a procedure call it self. Definition: Recursion is when a procedure call itself in order to repeat its application with a “simpler” argument. The Rules for the substitution Model of Evaluation are important for a clear understanding of form evaluation, but a procedure application using the rules is very clumsy. We need a more compact model for procedure application in order to understand recursion. 2.1 The Droid Model. In this model each procedure call creates a new droid (or worker) to evaluate the application with the given arguments. Once created the droid performs the application by executing the following steps:
1. Make a table of name/value pairs for the incoming parameters.
2. Evaluate the body using the Rules, argument table and environment.
3. Return the computed value to who ever called the droid. Let us apply this new model of application to a small problem. Example: (define foo

Page 34 of 141
(lambda (x) (- (bar (add1 x)) 5)))) (define bar (lambda (y) (* y 2))) Let us evaluate (foo 3) To perform the application we create a droid. It is common to use a graphical representation of each droid: When the foo droid evaluates its body it calls add1. We do not usually show the new droid in this case; it returns immediately. In order to evaluate the body of the foo function, the first droid spawns a second droid to evaluate the call to bar. Note that a droid remembers who asked it to do the job (called it), so
1. An arrow points to the caller (i.e. where the result is returned to)
2. Each droid does the work for only one procedure call.
x : 3
foo
y : 4
bar
User
8 3

Page 35 of 141
When one procedure calls another procedure you can think of the first procedure as hiring a worker to do the work for them. But
1. Only one droid is working at a time (All other droids are dormant, waiting for results to be returned to them so they can carry on with their computation).
2. A droids life ends when it returns a value to the caller. The droid model really only replaces the use of the application rule. We must still use the rules for names, number and special forms such as if, or, and, lambda etc. Now let us return to the original problem. 2.2 Iteration and Recursion Real programs need to repeat things, let us start by looking at an example: Example: Factorial By definition we have 0! = 1 n! = n * (n-1) * (n-2) * … * 2 *1 But note that we can define n! in terms of itself: n! = n * (n-1)! which is the product of n and a smaller more simple factorial problem. Let us try to implement this in Scheme: (define fact

Page 36 of 141
(lambda (n) (* n (fact (- n 1))))) Let us consider using it to computer 3!.
(fact 3) (* 3 (fact 2)) (* 3 (* 2 (fact 1))) (* 3 (* 2 (* 1 (fact 0)))) (* 3 (* 2 (* 1 (* 0 (fact –1))))) …
What is wrong?
1. If the computation completes all factorials will be zero! 2. The recursive call never terminates.
We must explicitly control termination, remember the recursive definition of factorial: 0! = 1 n! = n * (n-1)! We simply forgot to include the case where 0! = 1 and not 0 * (-1)! So we need to test to see if n has the value 0 and if it does return the value 1 instead of calling the procedure recursively: (define fact (lambda (n) (if (= n 0) 1 (* n (fact (- n 1)))))) Now let us try to evaluate this using the droid model that we just discussed:
(fact 3)

Page 37 of 141
Remember each call to fact creates a new droid: Remember that each droid has its own copy of the procedure. Substituting its formal arguments for its actual parameters do not affect other droids applying the same procedure. Each droid uses its own arguments, and each droid calls another droid (except when n=0) and waits for the result to be returned, and then does one multiplication and returns the result to its caller. This procedure clearly illustrates the general characteristics of recursion:
• Recursion works by reducing the problem one step at a time, to make it a simpler problem.
• The recursion stops when the problem is simple enough to directly solve it.
Example: Let us apply out knowledge to another problem. Given an integer n and a number y, compute yn. How can we reduce this problem to a simpler one? Recursive definition: yn = y * yn-1 what simple problem can we solve directly? y0 = 1
n : 0
fact
n : 2
fact
n : 1
fact
n : 3
fact
2 1 1 6

Page 38 of 141
Let us create a Scheme procedure for this: (define power (lambda (y n) (if (= n 0) 1 (* y (power y (sub1 n)))))) Let us consider the application
(power 2 4) Remember each call to power creates its own droid with its own copy of the procedure. Scheme cannot draw droids up on the screen, so to help you understand recursive procedures you can “trace” procedure calls. To trace a procedure call, do the following:
(trace <procedure name>) To stop tracing:
(untrace <procedure name>) Example:
(trace fact) (fact 10)
y : 2 n : 4
power
4 2 1 8 y : 2 n : 3
power
y : 2 n : 2
power
y : 2 n : 1
power
y : 2 n : 0
power
16

Page 39 of 141
(fact 10) | (fact 9) | | (fact 8) | | | (fact 7) | | | | (fact 6) | | | | | (fact 5) | | | | | | (fact 4) | | | | | | | (fact 3) | | | | | | | | (fact 2) | | | | | | | | | (fact 1) | | | | | | | | | | (fact 0) | | | | | | | | | | 1 | | | | | | | | | 1 | | | | | | | | 2 | | | | | | | 6 | | | | | | 24 | | | | | 120 | | | | 720 | | | 5040 | | 40320 | 362880 3628800
Both factorial and power illustrate key concepts for the design of recursive procedures: In both cases an if-form divides the procedure’s computations into 2 possible cases:

Page 40 of 141
1. Base case: The result in this case is known or can be computers without calling the procedure again (e.g. 0! or y0=1).
2. Recursive case: This step applies the procedure again to a “simpler” problem (i.e. an argument closer to the base case than the original parameter(s)). (For example, (sub1 n) brings the argument closer to 0, the base case).
The key point is that the recursion step must bring you closer to the base case, because the base case terminates the recursion. Let us for a moment look into the two cases above: Base case: The base case consists of two components:
1. Base case test (BCT): The if-statement that determines that the base case has been reached.
2. Base case value (BCV): The value or simple computation that is returned if the base case test is true, i.e. that the base case has been reached.
Recursive case: The recursive case can often be divided into the following points:
1. Parameter reduction: In order to terminate the recursion the parameters passed to the recursive procedure call must me simpler, i.e. represent a smaller problem; the parameter reduction is the action taken to change the value of the parameters before they are passed on.
2. Recursive call: The call its self with the reduced parameters.
3. Local computation: The procedure often calculates part of the solution it self. For example, for factorial the local computation is just the value of ‘n’, and for the power function the local computation is simply ‘y’
4. Combine function: Since the procedure calls itself recursively and also computes part of the result itself it is necessary to combine these two results to form the final result. In both the power and factorial the function used to combine the local computation and the recursive call is the multiplication function (*).

Page 41 of 141
Question: What does
(fact –3) return ?? The answer is undefined mathematically, but what will our procedure return? In this case, the recursion step gets us farther away from the base case, and that leads to infinite recursion: (fact –3)
(* -3 (fact –4)) (* -3 (* -4 (fact –5))) …
It will eventually slow down the machine and it will run out of resources and crash. There are only finite resources on a machine. This brings up another important point: Why does infinite recursion have to stop or crash? Why can’t it keep going? While waiting for each recursive procedure call to finish, Scheme must store information needed for each dormant droid:
• The values of the parameters. • Who to return the value to. • What the result of the partial evaluation is. • What to do when it gets the result back from the recursive
call. Suppose each call to factorial or power uses a constant amount of space (memory of the computer), let us say K units. How much space is used to evaluate (fact n)?

Page 42 of 141
We are interested in analyzing the space requirements of the generic problem, i.e. derive an expression in terms of the size of the input. The space costs are:
• K units pr recursive call (K units for each droid) • We take n steps to complete (fact n)
So the total amount of space needed to complete the computation is Kn units. But we don’t know what this constant K is. For comparison purposes we use the Big-Oh notation that ignores constants. Thus we get the space complexity of factorial to be O(n). We will come back to the notation of complexity for space and time later. Complexity analysis is a way of measuring the costs of a computation as a function of the size of the input. Some algorithms will be more attractive than others because of their lower time or space complexity. Let us practice our skills with one more example: Example: Sum the first n odd numbers. Note that the nth odd number is 2n-1. 1st odd number is 2(1)-1 = 1 2nd odd number is 2(2)-1 = 3 etc The first step in our solution process is to determine the base case test and base case value and recursion step.
• Base case:

Page 43 of 141
o Base case test: The recursion terminates when the result can be determined without calling recursively. In this case that is when we try to compute the sum of the 1 first odd numbers. (i.e. when n = 1)
o Base case value: The sum of the first 1 odd number is just 1.
• Recursive case: o Parameter reduction: We are going to call recursively
to compute the sum of the n-1 first odd numbers, so the reduction of the parameter is n-1.
o Local computation: We need to compute the value of the nth odd number locally and later on add it to the result of the recursive call (which is the sum of the (n-1)th odd numbers. Thus the local computation is merely 2*n-1.
o Combine function: Since we are computing the sum of the first n odd numbers the combine function must necessarily be +.
The recursive step thus look like this: (sum-odd n) = (2*n-1) + (sum-odd n-1)
Translating this into Scheme gets us: (define sum-odd (lambda (n) (if (= n 1) 1 (+ (sub1 (* 2 n)) (sum-odd (sub1 n))))))
let us practice on a more complicated example.
Example: Create a procedure (add-odd) that adds up the digits at odd positions in the decimal representation of a positive number (assuming that we count from right to left, i.e. beginning with the least significant digit)

Page 44 of 141
(add-odd 1543) = 5 + 3 = 8 (add-odd 369) = 3 + 9 = 12
The first step in our solution is to determine the base case and the recursive case:
Base case: The base case must terminate the recursion. In this case we should be able to determine the result without further computation.
(add-odd n) = n if n < 10 as n only has one digit.
For a general positive integer the recursive step must get us closer to the base case:
Recursion step: This step is not obvious, so let us think a little. A generic n looks like n = ….d5 d4 d3 d2 d1 The way to do it is thus:
1. Get digit d1 and add it to the sum 2. Throw away d1 and d2 and call recursively
Thus the number we call with (the reduced parameter) is ….d5 d4 d3. How do we get digit d1 in Scheme? Use the remainder function. (remainder n 10) local computation For example:
(remainder 29 3) 2 (remainder 13 10)

Page 45 of 141
3 (remainder 0 10) 0
But how do we get rid of the last two digits? Use the quotient function. (quotient n 100) parameter reduction For example:
(quotient 1536 100) 15
Now we should be able to write the recursive procedure, keeping in mind that the combine function is +. (define add-odd (lambda (n) (if (< n 10) n (+ (remainder n 10) (add-odd (quotient n 100)))))) Example:
(add-odd 284628162)
(add-odd 284628162) | (add-odd 2846281) | | (add-odd 28462) | | | (add-odd 284) | | | | (add-odd 4) | | | | 2 | | | 6 | | 8 | 9 11

Page 46 of 141
2.3 The cost of computation So far we have been writing Scheme routines without much regards to the efficiency of the underlying algorithm. We cannot ignore algorithm efficiency. No matter how fast a computer is some algorithms will take too long time. Example: Weather forecasting.
• Predictions are needed in real time. • We could discretize the world:
o Gird too large Bad predictions. o Grid too small Slow and requires a lot of memory.
• There are many different algorithms o Bad algorithm Simulation may never complete in
your lifetime o Takes up too much memory
In order to evaluate algorithms we want
• A method for comparing the efficiency of 2 algorithms that compute exactly the same result.
• This comparison method should be independent of the particular computer or language used.
A measure for a program’s efficiency is its algorithmic complexity. Most commonly we are interested in an algorithms time (execution time) and space (memory consumption) complexity. 2.3.1 Space complexity and tail recursion Even though we can purchase more memory, it does have limits and is a scarce resource. Earlier we considered the time and space complexity of the power procedures:

Page 47 of 141
• We saw each recursive call requires Scheme to store information while the dormant droids wait for a result.
• If n is large significant levels of memory can be used for computing a factorial or power.
How can we reduce memory usage? Recall our original power procedure: (define power1 (lambda (x n) (if (= n 0) 1 (* x (power1 x (- n 1))))))
• Each procedure call creates a droid. • Each droid waits around for its recursive call to return. • It then does its multiplication and passes the result to the
droid that called it. • Thus each droid contributes one multiplication to the power,
but the first droids created do their bit last. How can we reduce the memory requirements of (power x n)?
• Reduce the number of steps (We will see how to do this later; this also saves time)
• Do something to prevent workers from hanging around. The way that we accomplish this is
o Get each droid to do its multiplication before the recursion step.
o Then the droid would be finished and wouldn’t have to wait around using up space.
o (power x n) would simply tell (power x n-1) who to return the value to, and then disappear.
In terms of computer science terminology, to avoid having droids hanging around:

Page 48 of 141
Convert power1 into a tail recursive procedure – in a tail recursive procedure the recursive call is the very last thing the procedure does. Let us create a tail recursive version of power and we will then discuss it: (define power2 (lambda (x n) (pow-helper2 x n 1))) (define pow-helper2 (lambda (x n acc) (if (= n 0) acc (pow-helper2 x (- n 1) (* x acc))))) Note:
• The interface to power1 and power2 is identical, but pow-helper2 does the work for power2.
• Notice the important difference between the recursion steps. o Pow-helper2 makes its contribution to the product
before making the recursive call. • n is still counting the number of times to multiply by, but now
pow-helper2 has a third parameter: acc – an accumulator. • The accumulator holds the growing result.
o Think of it like a bucket into which we accumulate the product.
o Before calling (pow-helper2 x (- n 1) (* x acc)) it accumulates another x in the bucket by performing the multiplication.
• When n=0 the accumulator (acc) holds the result o Thus the answer can be given back directly o No previous workers need to wait.
A trace of power2 makes it clear that it uses less memory

Page 49 of 141
(power2 2 10)
(pow-helper2 2 10 1) (pow-helper2 2 9 2) (pow-helper2 2 8 4) (pow-helper2 2 7 8) (pow-helper2 2 6 16) (pow-helper2 2 5 32) (pow-helper2 2 4 64) (pow-helper2 2 3 128) (pow-helper2 2 2 256) (pow-helper2 2 1 512) (pow-helper2 2 0 1024)
1024 The lack of indentation indicates
1. No more worker is done when pow-helper2 returns. As a result 2. A new droid is not created for each recursive call
a. There are two ways to think about happens to droids at each tail recursive call:
i. The current droid spawns a new droid and then dies after telling the new droid who to return the value to.
ii. The current droid can compute the next call to pow-helper2 itself because it doesn’t have any more work to do.
Thus, independent of the size of n, only one droid is needed to evaluate pow-helper2. In contrast, (power1 x n) always needs n droids at one point of the evaluation. If n=1000 this is a very big saving. Looking at the recursive calls to pow-helper2 it is important to notice the following: Invariance property

Page 50 of 141
Let x and m be the arguments to power2 For every call to pow-helper2 we have
xn * acc = xm Invariant First call: m=n and acc=1 Invariant holds. At each call n goes down by one but acc goes up by a factor of x: x n acc 2 10 1 2 9 2 2 8 4 .. .. .. 2 0 1024 Once n=0 we have the result: x0 * acc = xm This invariance is the key to tail recursive, and is how you prove that the procedure calculates the right result. At each recursive step we still have all the necessary information to compute the final result. Thus there is nothing for the previous droids to “remember”. (This is not true of power1) In summary The key points about tail recursion are:
• Recursive call is the last step performed. • It reduces the required memory. • Needs an accumulator to hold the partial result. • More complicated to implement.

Page 51 of 141
• Don’t worry about tail recursion the first time you write the procedure.
• Many but not all procedure can be written using tail recursion.
In general time is often a more critical resource than space. In any area of computer science some of the most difficult problems are trying to solve problems that take too much time. You can buy more memory, but you cannot buy more time. 2.3.2 Time Complexity Let us reconsider the power example. We want to compute y = xn (assume that n is an integer >= 0). We constructed the following Scheme procedure (define power1 (lambda (x n) (if (= n 0) 1 (* x (power1 x (- n 1)))))) The power2 procedure was tail recursive and used less memory but had the same time complexity. Let us construct another power procedure based on a different algorithm, but one that always produces the same result. Recall that xn = xn/2 * xn/2 if n>0 and even xn = x * (x(n-1)/2)2 if n>0 and odd xn = 1 if n = 0 The last one is the base case, and the two top ones are the recursive cases. Using this recursive formula we can define a new power procedure:

Page 52 of 141
(define power3 (lambda (x n) (if (= n 0) 1 (if (even? n) (square (power3 x (/ n 2))) (* x (square (power3 x (/ (sub1 n) 2)))))))) (define square (lambda (x) (* x x))) power1 and power3 always give the same result. The important difference between the 2 algorithms is their time complexity (power1 and power2 take about the same time) Initially we can measure the amount of work each algorithm is carrying out by counting the number of recursive calls each makes. In this respect, which is the best algorithm? Trace power1 and power3 computing 28
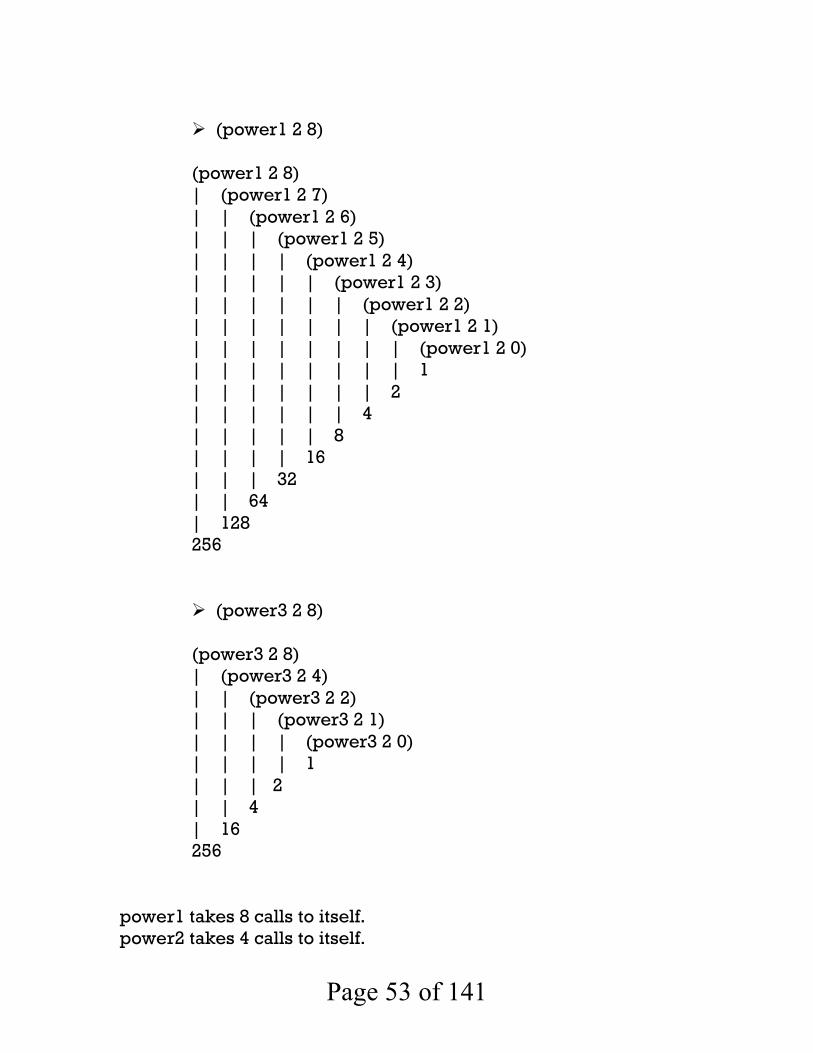
Page 53 of 141
(power1 2 8) (power1 2 8) | (power1 2 7) | | (power1 2 6) | | | (power1 2 5) | | | | (power1 2 4) | | | | | (power1 2 3) | | | | | | (power1 2 2) | | | | | | | (power1 2 1) | | | | | | | | (power1 2 0) | | | | | | | | 1 | | | | | | | 2 | | | | | | 4 | | | | | 8 | | | | 16 | | | 32 | | 64 | 128 256
(power3 2 8) (power3 2 8) | (power3 2 4) | | (power3 2 2) | | | (power3 2 1) | | | | (power3 2 0) | | | | 1 | | | 2 | | 4 | 16 256
power1 takes 8 calls to itself. power2 takes 4 calls to itself.

Page 54 of 141
So according to the metric power3 is faster, but you might say “power3 is doing more work at each step” What happens when we raise 2 to a larger power: (power1 2 100) 100 steps (power3 2 100) 7 steps (100,50,25,12,6,3,1,0) How about (power1 2 1000000) 1000000 steps (gave up waiting) (power3 2 1000000) 20 steps (a screen full of digits) But power1 and power3 both work towards reducing n to 0 for their base cases, but
• power1 reduces n by 1 each step, • power3 reduces n by a factor of 2 each step.
If you double n, power1 will need 2 times as many steps where as power3 only needs one more step. We are interested in finding a function which when supplied with a value of n returns the “time complexity”.
• power1 requires n steps • but how about power3? How many times must n be halved in
order to reach 0? • Another way of asking the same question is to ask how many
times 1 must be doubled in order to be >=n. • power3 requires log2 n steps.
(remember if log2 n = k then 2k = n – k is the power which to raise 2 to in order to get n) Now let us return to the observation that power1 requires fewer computations at each step

Page 55 of 141
Let us assume that power1 uses p units of time and let us be generous and assume that power3 uses 2p units of time pr step. Problem power1 power3 x2 3p 2*2p x4 5p 3*2p
x8 9p 4*2p
x20 21p 5*2p
x1000000 (106-1)p 20*2p 250000 times faster if n is large power3 is faster. So you can see, when the value of n is sufficiently large the cost of each step becomes unimportant. The number of procedure calls dominates the cost of each step. The time complexity of the algorithm is measured in the number of steps or iterations it performs as a function of one or more of its input arguments. A mathematical notation called the Big-O notation allows us to avoid cluttering our algorithm comparison with the cost of each step (which may vary between steps) or with small costs for start-up, etc. It allows us to compare classes of algorithms. The Big-O notation An algorithms complexity is reported as O(f(n)) (f(n) is a function that depends on the input arguments) when there exist constants K and n0 such that Algorithm running time <= K*f(n) for n >= n0
Thus:

Page 56 of 141
• power1 has time complexity O(n). o Linear time – o Double n doubles the time o K*n where K is big enough to account for each step’s
cost. • power3 has time complexity O(log n)
o Logarithmic time o Double n and time goes up by 1. o (Note: K*log2 n = K’*loga n (a any base)
because: loga n / loga b = logb n) Note: since we consider the asymptotic behavior of algorithms with the big-O notation, a logarithmic algorithm is only faster than a linear algorithm for sufficiently large n. For smaller n, we usually don’t care since they are both very fast. In general counting the number of recursive calls (or multiplications or arithmetic operations) often give a messy formula. Example: Suppose a procedure with parameter n makes 3n3 + 10n2 + 2n – 6 recursive calls What is the time complexity? If n = 100: n3 = 1000000 and n2 = 10000. Thus n3 is the dominating term. In fact, for large n we have: 3n3 + 10n2 + 2n – 6 <= 3n3 + 10n3 + 2n3 <= 15n3 but in the big-O notation we ignore the constant, so we get O(n3). Suppose procedure B always takes 2 times as long as procedure A, and suppose A has complexity O(n). What is the time complexity of B? O(n) also.

Page 57 of 141
This last example emphasizes an important characteristic of the big-O notation:
• The Big-O notation doesn’t say anything about an algorithm’s absolute running time.
• Instead, it says how quickly the running time grows as n changes (when n is large)
For example, suppose that Algorithm C takes constant time. In big-O notation we say that the complexity is O(1). Every time it runs it uses a constant amount of time independent of the value of the arguments. If we look at O(1) then we have that the time is <= K*1 for some constant K. However, we don’t know what the value of K is, it could be one second or one year. Thus in practice, we are often interested in the constant that is thrown away by the big-O notation, especially when comparing algorithms in the same complexity class. In computer science an important distinction is made between
• Polynomial time algorithms: O(nk) for some constant k. and • Exponential time algorithms: O(kn) for some constant k.
When n doubles the cost squares for the exponential time algorithm. In general a practical algorithm has polynomial time complexity. A last note, note that tail recursive procedure have space complexity O(1), and non tail recursive procedures OFTEN have a space complexity that is the same as the time complexity (but not always)
Page 58 of 141
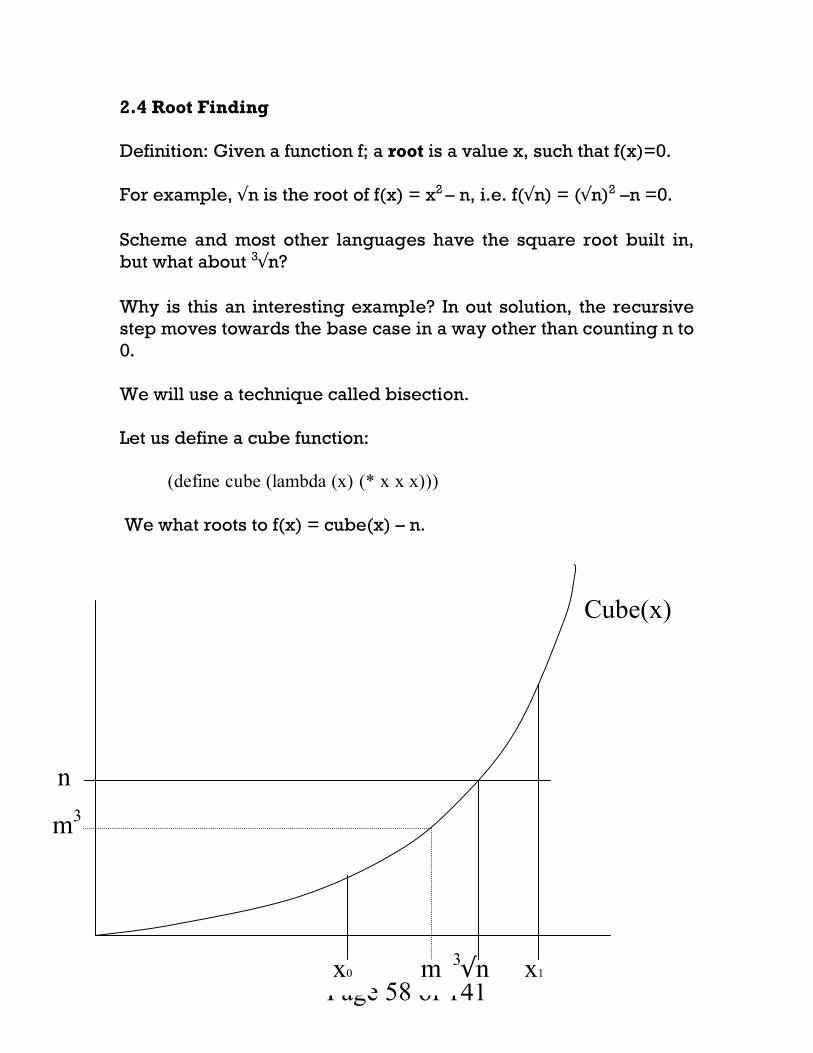
2.4 Root Finding Definition: Given a function f; a root is a value x, such that f(x)=0. For example, √n is the root of f(x) = x2 – n, i.e. f(√n) = (√n)2 –n =0. Scheme and most other languages have the square root built in, but what about 3√n? Why is this an interesting example? In out solution, the recursive step moves towards the base case in a way other than counting n to 0. We will use a technique called bisection. Let us define a cube function: (define cube (lambda (x) (* x x x))) We what roots to f(x) = cube(x) – n.
m3
n
m 3√n x1 x0
Cube(x)

Page 59 of 141
1. Suppose we know that x0 and x1 surround 3√n: x0 <= 3√n <= x1.
2. 3√n is somewhere in between, so let us guess the middle: m = (x0 + x1)/2
3. If m3 is too large or too small it tells us what sub region we must look in:
o If m3 < n then look in the range m to x1. (set x0 = m) o Else look in the range x0 to m. (set x1 = m)
4. Continue searching recursively in the new range (which is half as big as the previous one).
5. Continue until the newest region is small enough or until x0 = x1. The recursive step is now to make the search region smaller.
Here is the first stab at a solution: (define cuberoot-helper (lambda (n x0 x1 m) (if (= x0 x1) m (if (> (cube m) n) (cuberoot-helper n x0 m (/ (+ x0 m) 2.0)) (cuberoot-helper n m x1 (/ (+ x0 m) 2.0)))))) We use 2.0 to obtain a real number instead of a fraction. There are a few problem with our function:
1. The test (= x0 x1) a. You may take the recursive step forever and never
reach the base case. Why? i. All real numbers are represented by a floating
point internally in the computer. ii. Floats have limited precision
1. Only a finite number of bits to store the mantissa.

Page 60 of 141
iii. All “real” computation lead to round-offs. 1. You cannot represent a result exact, so it is
rounded off to a result that is as close as possible.
iv. How can that lead to trouble: x0 = 2.1 and x1 = 2.2. Now suppose we only have 2 decimal digits. Then m = (2.1 + 2.2) / 2 = 2.15 which is rounded off to 2.2
b. Solution: Stop the recursion when x0 and x1 are “close
enough”:
(define epsilon 0.0001) and put the new test in the program: (<= (- x1 x0) epsilon)
2. How do we find x0 and x1 initially? a. Solution: Assume that n >= 1 (this kind of assumption
should be in comments inside the function). Set x0 = 1 and x1 = n.
(define cuberoot (lambda(n) (cuberoot-helper n 1 n (/ (+ 1 n) 2.0))))
Note:
1. since the midpoint cannot before than 0.5*epsilon away from the solution we could change the test to
(< (- x1 x0) (* 2 epsilon))
2. Relative accuracy, not absolute is needed. 3. We need a fix for
o n < 0 o 0 <= n < 1

Page 61 of 141
3. Building Programs. Because it is more natural to continue with out root finding example now, we will cover the material in chapter 3 in a different order than the book.
• Section 3.3 – Procedures as arguments and returned values. • Section 3.1 – Text processing. • Section 3.2 – I/O and Graphics.
3.1 Procedure as arguments and return values. In the last section of the notes for chapter 2 we started talking about root finding. We wrote a special procedure for finding the root of f(x) = x3 for a given n How can we adapt this routine for finding the root of an arbitrary function? Thus this section’s motivating example will be Example: General Root Finding. Find the root of a given function f(x), e.g. f(x) = x2 + 3x + 9 f(x) = (x/6) – log(x) f(x) = x3 - n To reduce the complexity of the problem let us assume that f(x0) and f(x1) are of opposite sign; this implies that the root can be found in the interval [x0; x1]. So we want to create a procedure find-root that
• Finds a root of an arbitrary function

Page 62 of 141
• Takes the following parameters o x0 and x1. o The function that we want to find the root of as well.
Can this be done? Sure. A function can be passed as any other value, remember that the value of a lambda form is a procedure, and such a value can be passed around as an argument and applied using the application brackets ( ) as usual. Example: Suppose we want to find the cube root of 27 like we did in the previous example, but now we want to use out new find-root procedure. (find-root (lambda (x) (- (* x x x) 27)) 1 27) f(x) = x3 – 27 Range Before creating find-root itself, let us learn more about passing procedures as arguments. We have seen lots of procedures that accept number and Boolean values as arguments, and we will soon get to characters and strings. To evaluate a procedure application, say (proc f1 f2 f3), where f1 f2 and f3 are forms we do the following:
1. Evaluate each of the elements (Lambda forms evaluate to a procedure – which also is a value.)
2. Substitute the actual parameters with the formal parameters in the body of the function.
3. Evaluate the body. The result of the procedure is also of the well-known types such as numbers, Booleans, chars, strings etc. Example: The following example is rather silly, but illustrate the point well: (define apply-to-n

Page 63 of 141
(lambda (proc n) (proc n))) apply-to-n applies the 1st arguments (which must be a procedure value) to the second argument (which then must be compatible with the argument that the procedure takes in.
(apply-to-n sqrt 16)
To evaluate this application we can use the substitution model of evaluation (Application rule):
1. Evaluate each of the 3 arguments (2 times name rule and one number rule)
(#<procedure apply-to-n> #<procedure sqrt> 16)
2. Replace arguments into the body of the function of apply-to-n
and replace the entire application with the body.
(#<procedure sqrt> 16)
3. Evaluate the body (Primitive rule)
4 As another example try this one:
(apply-to-n (lambda (y) (+ y 3)) 4) 7
or
(define cube (lambda (x) (* x x x))) (apply-to-n cube 3) 27

Page 64 of 141
What we are dealing with here is a very simple idea: pass a procedure value and use this value in the body of other procedures.
(apply-to-n (lambda (x y) (+ x y)) 4) Error: not enough arguments (apply-to-n (lambda (x y) (+ x y)) 4 7) Error: Too many arguments.
apply-to-n has been designed to accept ONE procedure and ONE argument to pass to that procedure. This means that the procedure passed in can only accept one argument. So a redefinition of apply-to-n is necessary. With this knowledge let us go back to our motivating example. Example: (find-root f x0 x1) which finds a root of an arbitrary function f. Recall our assumptions
1. f(x0) and f(x1) have opposite signs. 2. The root is in the interval [x0; x1].
The basic form of find-root will look just like cube-root. (define epsilon 0.00001) ; Define an error tolerance (define find-root (lambda (f x0 x1) (find-root-helper f x0 x1 (/ (+ x0 x1) 2)))) (define find-root-helper (lambda (func x0 x1 mid) (if (or (<= (- x1 x0) epsilon) (= (f m) 0.0))

Page 65 of 141
m (if (< (* (f x0) (f m)) 0.0) (find-root-helper f x0 m (/ (+ x0 m) 2.0)) (find-root-helper f m x1 (/ (+ x0 m) 2.0)) )))) Let us try to understand this algorithm now. We have changed the test for determining which sub region we want a little bit. We cannot simply test if f(m) is greater or smaller than 0:
We want to make sure we choose the sub region that contains the root. So we choose the sub region in which f changes signs (this means that it passes the x-axis, i.e. the root is in the region). (< (* (f x0) (f m)) 0.0) This test can break down if f(m) = 0.0, which is unlikely, but it could happen, so we add a special termination case: (or ( . . . ) (= (f m) 0.0)) So as long as we can bracket the root with x0 and x1 we can find a root of an arbitrary function.
m x1
x0
f(m) > 0 but we want left sub region.
m
x1
x0
f(m) > 0 but we want right sub region.

Page 66 of 141
(define foo (lambda (x) (+ (* 3 x) 2))) (find-root foo –2 2) -0.666666679
What about the cube root of 27?
(find-root (lambda (x) (- (* x x x) 27)) 1.0 27.0) 2.999999
This last example points out new problems (it seems like it will never end!)
• To compute 3√n with find-root we must write a new lambda-form for each n (representing f(x) = x3 – n)
• But for each value of n we already know how the procedure looks.
• What we need is a procedure that can make procedures for x3 – n for a given n and then return is as a procedure value, sort of a ‘factory-function’ that makes procedure values for us.
Before solving the problem let us do a few examples: Example: (define add-n (lambda (n) (lambda (x) (+ x n)))
(add-n 5)
We can use the substitution model once again (Good thing you learned it so well ;-) ) 1. Evaluate every argument (Application rule, Name rule,
Number rule)

Page 67 of 141
(#<procedure add-n> 5) 2. Substitute in the arguments and replace the body (using
the procedure rule).
(lambda(n) (+ x 5)) 3. Which evaluates to a procedure (using the lambda rule)
#<procedure> ( (add-n 5) 6) 11 (define add-10 (add-n 10)) (add-10 69) 79
Now back to our motivating example. (define make-cube
(lambda (n) (lambda (x) (- (* x x x) n)) ))
(find-root (make-cube 27) 1 27) 2.99999…
We could also redefine cube-root in terms of find-root (define cube-root (lambda (n) (find-root (make-cube n) 1 n))) With our current repertory of Scheme features and programming techniques, we are able to write quite sophisticated programs that manipulate procedure, Boolean values, and numbers.

Page 68 of 141
Sophisticated as they may be, we need to be able to represent and manipulate other types of data. For examples: Represent names of students and addresses etc. This next section introduces two text data types
• Characters • Strings
3.2 Text Processing We will not be able to go into all technical details of this, so you are responsible for reading chapter 3.1 on your own! When you press a key on the keyboard it sends the code to the CPU for that particular character. There is a different code for each character. Our machines use ASCII (American Standard Code for Information Interchange), which provides a different code for each character; Characters include
• Letters (upper and lower case) • Digits (0 to 9) • Punctuation (+ * . ! # $ etc) • Special characters (newline, back space, bell, etc.)
In Scheme we need a special way to represent characters, so that it is not confused with a single letter name in the environment. Consider (char? a) char? is a special predicate that determines if the value of its argument is a character.

Page 69 of 141
Remember that a is looked up in the environment, so char? checks to see if a’s VALUE is a char, not is the character ‘a’ is a char. In Scheme a value of the data type character is written as #\character Example: #\a or #\A (two different chars) Some characters do not have a printable representation, so we use a mnemonic representation: #\space #\newline etc It is important to remember that number and character are not the same. 9 is not the same as #\9
(+ 9 3) 12 (+ #\9 3) Error: #\9 is not a number
We have already talked about the predicate char?, but there are a number of built-in primitives for character manipulation.
• To check for character equality (char=? #\a #\A) #f
• If you want to test for equality without regards to case:
(char-ci=? #\a #\A) ; Case Insensitive #t

Page 70 of 141
• If you want to convert a character to a lover-case (char-downcase #\T) #\t (char-upcase #\t) #\T
• Finally, there are conversion procedures that accept a character and returns its ASCII code.
(char->integer #\c) 99 (integer->char (add1 (char->integer #\s))) #\t
We often need to be able to work with groups of characters as in Lab 6. Scheme has a string data type for this purpose. As for characters, Scheme provides a wide range of primitives for strings
• A type checking primitive
(string? #\5) #f So strings are not that same as characters. (string? “foo”) #t Strings are surrounded by “ “ (string? “”) #t
“” is the empty string.

Page 71 of 141
• We can find out the length of a string (string-length “foofoo”) 6
Example: Count the number of times char c appears in a string. In order to solve this problem we need to understand how Scheme treats a string. In Scheme a string is a collection of chars. Whale is w h a l e
0 1 2 3 4 positions.
The boxes are numbered from 0 to length-1. (string-ref <string> <pos>) return the character at position <pos> in string <string>
(define cnt-str (lambda (c str) (cnt-help c str (string-length str) 0)))
(define cnt-help (lambda (c str len pos) (if (= pos len) 0 (if (char=? c (string-ref str pos)) (+ 1 (cnt-help c str len (add1 pos))) (cnt-help c str len (add1 pos))))))
Another example: Replace all occurrences of character c1 by character c2 in a string. To do this we need three other string primitives: (string <char>) that turns a character into a string.
(string #\a)

Page 72 of 141
“a” and (string-append <string1> <string2>) that glues 2 strings together.
(string-append “Hello” “ World”) “Hello world”
and (substring <string> <from-pos> <count>) returns a string <count> characters long, starting from position <from-pos> in string <string>
(substring “Hello World” 4 3) “o W”
Here is the code, note that we adapt a different approach, we don’t use the position counter anymore, we ‘slice’ a character of the string argument each time we call.
(define replace-char (lambda str c1 c2) (if (string=? “”) “” (if (char=? (string-ref str 0) c1) (string-append (string c2) (replace-char (substring str 1 (string-length str)) c1 c2)) (string-append (string (string-ref str 0)) (replace-char (substring str 1 (string-length str)) c1 c2)) ))))

Page 73 of 141
The trace look like this:
(replace-char “aluaaer” #\a #\b) (replace-char “aluaaer” #\a #\b) | (replace-char “luaaer” #\a #\b) | | (replace-char “uaaer” #\a #\b) | | | (replace-char “aaer” #\a #\b) | | | | (replace-char “aer” #\a #\b) | | | | | (replace-char “er” #\a #\b) | | | | | | (replace-char “r” #\a #\b) | | | | | | | (replace-char “” #\a #\b) | | | | | | | “” | | | | | | “r” | | | | | “er” | | | | “ber” | | | “bberr” | | “ubberr” | “lubber” “blubber”
3.3 Program Organization We are now in a position to write substantial programs. As our programs become more complex, they will consist of many, many procedures participating in complex interactions. As a result, as programs grow larger you will find it difficult to organize them, read them, write them and assure they are free of bugs. We have already talked about several techniques to help create good code.
• Procedural abstraction – hide away the details of a computation in helper procedures. o All procedures can see and access a helper, even
though only one procedure should really need to use it.

Page 74 of 141
• Define forms – bind values or the result of a computation to a name. o But once again, any piece of the program can access
the name bound to the value, when really one procedure or group of procedures should be able to access it
o If you are writing large programs you might by a mistake unknowingly bind a previously used name to value, and that could introduce a horrible bug.
Alternatively in this section we will talk about better techniques for information hiding. We will introduce a new scheme form that allows us to create procedure that hide variables inside them, and program units with locally known procedures. 3.3.1 Let and variable scope Let us look at a specific example. Example: Read into Scheme a file that contain the procedure income-tax, it uses (define taxrate 0.27) Then read in the gst-rebate program, which happens to contain (define taxrate 0.07) What happens now when we call (income-tax … ) Procedure income-tax references taxrate, but which value will taxrate be bound to?

Page 75 of 141
In the global environment only one taxrate exist – the last one to be defined. How do we solve this problem? We can solve this if we can somehow bind taxrate to the appropriate value and make it local (accessible only to) the appropriate procedures. The special form let provides a mechanism for creating local variables. (a name bound to a value stored in a special environment)
(let ((a 3) (add +)) (add a 5)) 8 a is bound to the value 3, and add is bound to the + procedure and they are only known inside the body of the let which is “(add a 5)”. Once the body of the let is evaluated the bindings are forgotten.
a Error: variable a not bound. add Error: variable add not bound.
A very important point is that introducing a variable name with a let-form will not interfere with code outside the form. Example:
(define b 10) (let ((b 6)) (+ b 2)) 8 b 10
1. b exists in the global environment.

Page 76 of 141
2. The let creates a new b and binds it to the value 6 a. It is local to the body of the let b. The b in the global environment is not effected; nor the
definition of any other b for that matter. Let us consider the general let-form (let ((<name_1> <form_1>) (<name_2> <form_2>) … (<name_n> <form_n>)) <body>) where
• <name_i> is any variable name. • <form_i> is an scheme form that is evaluated and bound to
<name_i>. • <body> is any Scheme form except define.
You can think of a let form as saying: “Let name_1 have the value of form_1 let name_2 have the value of form_2
… let name_n have the value of form_n, then evaluate the body then discard the local bindings.” The region of a program in which a variable’s name is known is it’s scope. A variables scope is the region of the program in which it is known.

Page 77 of 141
The notion of scope is not new to us. We have seen scooping in procedures.
• A procedure call binds parameters to a value, the procedure body is evaluated, then the bindings of the parameters are forgotten.
• The parameter / value bindings are only known in the body of the procedure.
Tin let forms the notion of scoping is similar. The scope of a name/value binding in a let form is it’s body (i.e. the body of the let form) We have said that the body of an let form can be any other Scheme form. The body can be any form, including a lambda-form or another let form, just not a define form. Let us look at some more complicated examples that demonstrate these possibilities. (define incometax (lambda (income) (let ((basictac (* 0.17 income)) (surtaxrate 0.07)) (let ((surtax (lambda (value) (if (>= income 28784) (* value surtaxrate) 0)))) (+ basictax (surtax income))))) Note:
• One let is embedded in the other let. o The inner let is nested in the outer let.
Consequently the inner let is in the scope of basictax.

Page 78 of 141
It is also in the scope of the parameter income because the nested let forms are embedded in the outher lambda form.
• The value bound to surtax is a procedure which is then called from the body of the nested let.
• basictax, surtax and surtaxrate are not known outside the procedure incometax.
Some of you may be wondering why we need nested let forms in this example? Question: Why didn’t we list surtax and its procedure binding in the first lef? Answer: basictax and surtaxrate are known only in the body of its let. So if we combined the nested let forms, the surtax procedure would not be in the let form’s body, and thus couldn’t reference basictax or surtaxrate. Let us look at this problem more closely with a simpler example. Example:
(let ((a 2) (let ((b (* 3 a))) (+ a b) ))
8 This is ok, but now let us combine the let forms into one.
(let ((a 2) (b (* 3 a)) (+ a b))
Error: variable a unbound We understand that this error results because the scope of the binding of ‘a’ is the let’s body. This does NOT include the rest of the binding list.

Page 79 of 141
We have always been careful to introduce new rules when we introduce new syntax, but a let form has no new rule, it is just syntactic sugar for a procedure application! Scheme reads let and translates it into a procedure application. Example: The previous example can be written as a procedure application in the following way:
( (lambda (a b) (+ a b)) 2 (* 3 a)) Which clearly shows that ‘a’ is not bound. So the scoping rules for let-forms were already defined for us and we didn’t know it. Everything comes as a consequence of the property of the application-rule. More formally: (let ((n_1 f_1) (n_2 f_2) … (n_n f_n)) body) is equivalent to the following procedure application ( (lambda (n_1 n_2 … n_n) body) f_1 f_2 … f_n) Let us review. We now have 3 ways to bind values to variable names:
1. We have 3 ways a. Define b. Let forms c. Procedure calls
2. What is the scope of each binding? a. Define:

Page 80 of 141
i. Global scope, the binding goes in to the global environment.
ii. It holds everywhere. iii. Lasts as long as the Scheme session.
b. Procedure-call or let-form: i. The body, i.e. the binding is only known in the
body during its evaluation, after that the bindings are removed
ii. Each procedure call or let-form has its own local environment.
What if we used the same name to identify several different values? How does Scheme identify the correct value of a variable given its name? Given a variable name Scheme uses static scoping rules to identify its value during evaluation. This means you can determine the bound value by simply inspecting the text of the program. It is static, so it never changes. To find the binding of a variable name do the following:
1. Find the closest enclosing let or lambda-form in the program text
a. If the name occurs in the binding list (let) or in the parameter list (procedure call) then the name is bound to the value by that let or that procedure call.
b. If not, then proceed to the next closest enclosing let or lambda and so on.
2. If the name is not found in any enclosing let or lambda check the global environment.
3. If name is not in the global environment report an error. Let us apply these scoping rules in some examples.

Page 81 of 141
Example:
(define n 17) ( (lambda (n) (* n 6)) (- n 12)) 30
Example:
(define b 1) (define n 3) ( (lambda (a b) (let ((a n) (c (* a b))) (+ a b c))) 1 4)
11 Note: always start with the inner most forms first. Example:
(define confusing (lambda (p a) ( (lambda (a) (* a 9)) (p a 1))))
(confusing + 3) • The parameter p is bound to + in the procedure call, then
in the body occurrences of p are replaced by the primitive +.
• The old procedure rule in the substitution model said we should replace each occurrence of a parameter in the body by the argument? But what about a?
• Which ‘a’s should be replaced by 3?

Page 82 of 141
o Of course we should never replace names that are in the parameter list or the binding list, so
o Only replace names not bound by a closer enclosing lambda or let form.
This creates a new procedure rule: Only substitute in arguments for ‘free’ variables in the body. With this in mind let us evaluate the above:
(confusing + 3) ( (lambda (p a) ((lambda (a) (* a 9)) (p a 1))) + 3)
First replace free variables by arguments
( (lambda (a) (* a 9)) (+ 3 1))
( (lambda (a) (* a 9)) 4) (* 4 9)
36
To avoid much of this confusion in the first place we should use different parameter names in the two lambda forms:
(define clear
(lambda (p a) ( (lambda (b) (* b 9)) (p a 1)))
But of course the 2 procedures both compute the same result. Let us now return to think about the nested scope created by nested let-forms. We know
• Every let or lambda form creates a new scope

Page 83 of 141
• We saw in out income tax example that the scope created by a let did not include its binding list, only its body.
So for example we had to use nested lets for (let ((a 2)) (let ((b (* 3 a))) (+ a b))) Nested let forms are so common that Scheme has an abbreviation for them called let*. So an equivalent form is (let* ((a 2) (b (* 3 a))) (+ a b)) let* is certainly easier to read and is simply a convenience, but is not necessary, so to summarize: The scope of a binding defined in a let*-form is the remainder of its binding list and the let*’s body. In general: (let* ((n_1 f_1) (n_2 f_2) … (n_n f_n)) <body>) expands to (let ((n_1 f_1)) (let ((n_2 f_2)) … (let ((n_n f_n)) <body>))) …)) Example:

Page 84 of 141
Where should let* be used? Remember the motivation for introducing lets; information hiding. Now let us rework our income tax example (define incometax2 (lambda (income) (let* ((base 28784) (taxrate 0.27) (basictax (* income taxrate)) (surtax (if (> income base) (* 0.07 income) 0))) (+ basictax surtax)))) We have now seen how to hide information; variables and procedures. Let us now turn to one more example, let us revisit power2, the tail recursive version of the power function, and let us try to embed the tail-recursive helper to power2 inside its body. (define power2 (lambda (x n) (let ((ph (lambda (x n acc) (if ( = n 0) acc (ph x (- n 1) (* x acc)))))) (ph x n 1)))
(power2 2 4) Error: variable ph not bound.
Why? Because the ph in the lambda form being bound to ph is not in ph’s scope, and it doesn’t help using let*. To see this we translate into procedure applications:
( (lambda (ph) (ph x n 1) ) (lambda (x n acc) (if ……. (ph x (- n 1) (* x acc)))) )
The ph in the procedure passed in is not bound.

Page 85 of 141
To properly embed recursive helper ph in power2, we must use a special variant of let.
We must use letrec (“let recursive”) instead of let.
Thus power2 becomes:
(define power2
(lambda (x n) (letrec ((ph (lambda (x n acc) (if ( = n 0) acc (ph x (- n 1) (* x acc)))))) (ph x n 1))) Can this procedure be simplified further?
• x is the same value in the scope of the letrec and the lambda form
• It never changes during recursive calls (this is not the case with n and acc)
So we can remove x from the parameter list of ph. At first glance it seems that letrec and let* are the same, they are not! Do not carelessly substitute letrec for let*, they are not the same.
• let* is shorthand for nested let forms. • letrec works in a different manner that we will return to.
Example: (letrec ((taxrate1 0.17)
(taxrate2 (* taxrate1 1.5)) (* 10000 taxrate2))

Page 86 of 141
letrec makes not guarantee of order in which name/value pairs are evaluated, we might get taxrate1 is unbound. For sequential left to right evaluation use let*, but don’t forget to use nested lets if that is more understandable. 3.3.3. Abstract data types Recall procedural abstraction:
• Permits us to write procedures at a high level and delegate lower level implementation details to helper procedures.
• Someone using the procedure only knows the interface to the main procedure, and what it does, but knows nothing about the implementation.
We want abstraction techniques for data that are analogous to procedural abstraction. So far we have written procedures that accept as many arguments as we like, but only return one number, string, Boolean char or procedure. In many cases we would like to treat a structured collection of data as a single unit, i.e. we want to create a new data type from which smaller pieces of data can be extracted and manipulated. A value of this new data type can be passed as an argument or returned from a procedure. Example: Map locations. Suppose the location of an entity on a map is defined by its x and y coordinates. Suppose we are writing procedures that manipulate locations.
• What is the distance between 2 locations? • Which is the most western location?

Page 87 of 141
In these situations we
• Want to logically treat a location as a single object, with 2 components.
• We want to pass locations to procedures and have them returned.
• We want to be able to retrieve each component, but we don’t care how they are stored.
This is the process of Data Abstraction: Specifies the interface to a data type by describing a set of procedures that build the data structure of a value and provide access to its elements. The product of the data abstraction process is an Abstract Data Type, e.g. the location we talked about. A programmer defined data type whose interface specifies the values and operations of the data type, but not the underlying implementation. Let us consider another example. Example: We want to design an ADT for a students record. The ADT interface will permit manipulation of a student record as a single value/object. Two classes of procedures are central to the definition of an ADT: Constructors A constructor is a procedure (mk-record) that create a new student record with

Page 88 of 141
• Name • Student number • Year • Course number
The manner in which these components are combined into a value of the data type, student, is hidden in the implementation of this constructor Constructors hide the storage details of ADT student. With the student ADT defined, other procedures can be designed to accept arguments or return values of this new data type
(student-avg stud) returns the student’s average. (scale stud)
returns a value with all marks scaled by 5%.
But how will it return a single object that actually consists of several components? What does the object look like? Let’s look at a simpler example and think about how to actually implement the constructors and accessors for it. Example: We know that for cs124 a grade cannot consist of a single mark. For example, you must pass both lab and exam portion of the course. Given “grade” we want to be able to check if this is true by retrieving the individual components.

Page 89 of 141
In order to write procedures using this ADT, we will also need to access the individual components of an instance of the ADT student. Accessors: Accessors are procedures for accessing the individual components of a student value. For example:
(student-number stud) (student-grade stud course-number) (student-name stud)
Each of these procedures could be passed a students value, and return the appropriate component of the ADT. Accessors hide the implementation of student ADT, but if we have accessors and the constructor, we don’t need to know how it is implemented. Many other types of procedures could be associated with the ADT: Predicates: Just like char? or number?, it checks a value’s data type. For example (student? stud) which returns true if the value stud is of type student. Let us keep the example simple: “Design an ADT called ‘grade’ that consists of two components:
• Exam Grade • Lab Grade”
To create values of the type grade we need a constructor:

Page 90 of 141
(mk-grade e l)
which returns a new “grade” with exam and lab marks e and l. So a grade will be an entity that can be manipulated as a single unit. But we need to access its individual components. Accessors:
• (exam gr)
returns the exam mark for gr.
• (lab gr)
returns the lab mark for gr. Now all we have done so far is to design an interface to out ADT “grade”. Without knowing the implementation details we can use these routines.
(define sue (mk-grade 90 83)) (exam sue) 90
Or we could compute Sue’s average:
(/ (+ (exam sue) (lab sue)) 2.0)
With this interface to the ADT grade we could also define procedures that accept and return grade values. But before we get too abstract, let us think about how to implement the constructor and the accessors.

Page 91 of 141
Constructor implementation: We want to combine 2 numbers in a way that allows us to extract both components Valid marks range is 0 to 100, so we can shift the exam mark over by multiplying it by 1000: eee * 1000 => eee000 + lll = eeelll (define mk-grade (lambda (examgr labgr) (+ (* examgr 1000) labgr)))
(define matt (mk-grade 100 90)) (matt) 100090 (define bill (mk-grade 33 4)) bill 330004
We also need to implement the 2 accessors so that we can retrieve either of the components marks Accessor implementation: (define exam (lambda (gr) (quotient gr 1000))) (define lab (lambda (gr) (remainder gr 1000))) Now let us use them:

Page 92 of 141
(exam matt) 100 (lab bill) 3
We have also said that there is often a predicate associated with the ADT to check if a value is of that type. Predicate: (define valid-grade? (lambda (gr) (let ((e (exam gr)) (l (lab gr))) (and (>= e 0) (<= e 100) (>= l 0) (<= 1 100)) ))) Note: In this case the predicate doesn’t use the implementation of the data type; if exam and lab return sensible values it all works. Let us use this predicate in another procedure that computes a students average: (define average (lambda gr) (if (not (valid-grade? gr)) (begin (display “Bad grade”) 0) (/ (+ (exam gr) (lab gr)) 2.0))))
(average matt) 95 (average 1000000) “Bad grade” 0

Page 93 of 141
Let us suppose that to pass cs124 you must get more than 50% on both the lab and the exam portion and have an average over 60%. (define pass? (lambda (gr) (and (> (exam gr) 50) (> (lab gr) 50) (> (average gr) 60)))) We can use this predicate in a procedure that returns a student’s letter grade: (define letter-grade (lambda (gr) (let ((avg (average gr))) (if (not (pass? gr)) “F” (if (>= avg 80) “A” (if (>= avg 68) “B” “C”)))))) Now we can write procedures that return a value of the data type “grade” as well. This will be the first time we have returned an object containing more than one component, or is it? What about strings? If the exam mark is 20% higher than the lab mark then increase lab grade by 10 of exam mark to a max of 5. (define lab-scale (lambda (gr) (let ((e (exam gr)) (l (lab gr))) (if (> (- e l) 20) (mk-grade e (+ l (min (* 0.1 e) 5))) gr))))

Page 94 of 141
(define bill (mk-grade 40 4)) bill 40004 (pass? (lab-scale bill)) #f
Exercise: Rewrite the implementation of grade ADT, without changing the interface, to use a string to hold the 2 values. (define mk-grade (lambda (examgr labgr) (append-string (int->string examgr 3) (int->string labgr 3)))) You must implement int->string.
(int-> string 100 3) “100” (int->string 80 3) “080”
The parameter 3 determines the number of characters in the output string. (define exam (lambda (gr) (string->int (substring gr 0 3)))) (define lab (lambda (gr) (string->int (substring gr 3 6))))
Implementation of int->string and string->int (define int->string (lambda (int n)

Page 95 of 141
(if (= n 0) “” (string-append
(int->string (quotient int 10) (- n 1)) (string (dig->char (remainder int 10)))))))
(define string->int (lambda (str) (if (string=? str “”) 0 (+ (char->dig (string-ref str
(- (string-length str) 1))) (* 10 (string->int (substring str – (- (string-length str) 1)))))))) (define dig->char (lambda (d) (integer->char (+ d (char->integer #\0))))) (define char->dig (lambda (ch) (- (char->integer ch) (char->integer #\0)))) We have now re-implemented the constructor and the accessors of the grade ADT, but the interface is unchanged. Thus all the other procedures using “grade” are unaffected by the change. Now consider this problem: What is components of ADT aren’t numeric? Then the quotient/remainder trick fails. String trick might be hard if we don’t know what the lengths are of the different components. Even if they are numeric, negative values and values bigger than 999 would fail. How do we combine string of varying length?

Page 96 of 141
What if we want to combine string with number and Booleans and chars?
4.4 Reduction, Filtering and Mapping Each of these types of processing is an abstraction, an idea, a way of thinking of a particular type of list processing. The types are: Reduction: We have already looked at several examples of reduction. A reduction takes a list and ‘reduces’ it to one element or result. Examples: Total: adds elements of a list. Avg: computes average element value in a list. Do we always have to return a number? No, contains? could be a predicate to determine if an Element exists in a list. Another type of list processing is called Filtering: This type of procedure
• Accepts a list and returns a new list composed of elements in the original list satisfying some predicate.
• Unlike reduction filtering is a many-to-some operation, i.e., the list is not reduced to only one element.

Page 97 of 141
Examples:
• Filter a list of cities, to return a list of cities with population > 200000.
• Return a list of grades with marks in the range 60 to 80.
The third kind of list processing is Mapping: Mapping creates a new list by transforming each element of the original list with the same operation (procedure) It is called mapping because each element is “mapped” to an element in a new list. Mapping is a many-to-many operation. Examples: Produce a list of scaled grades by adding 20 marks to each
grade in the original list. Let us go into depth with these 3 techniques.
Reduction: A simple example is adding all elements in a list: (define sum (lambda (lst) (if (null? lst) 0 (+ (car lst) (sum (cdr lst)))))) Let us take a closer look at sum. We note the following:

Page 98 of 141
• The base case value, i.e. 0 is ‘neutral’ to the combine operation +, i.e., you can add 0 to anything without changing the value.
• If we exchanged 0 with 1 and + with * we would have a procedure that had the same structure but computed a different result.
• Assuming that the list looks like (1 2 3 4) then we can write the reduction as follows (using + and 0):
(sum ‘(1 2 3 4)) = (+ 1 (sum ‘(2 3 4)
= (+ 1 (+ 2 (sum ‘(3 4)))) = (+ 1 (+ 2 (+ 3 (sum ‘(4))))) = (+ 1 (+ 2 (+ 3 (+ 4 (sum ‘()))))) = (+ 1 (+ 2 (+ 3 (+ 4 0)))) • We see that the + operation is always applied to 0 arguments,
and that the base case value is the ‘last’ value in the inner most application.
These observations allow us to write a general reduction routine that takes in a list of elements, a neutral value and a binary operation: (define reduce (lambda (proc neutral lst) (if (null? lst) neutral (proc (car lst) (reduce proc neutral (cdr lst)))))) It is worth noting that Scheme has another reduction operator built in: apply. Examples:
(apply + ‘(1 2 3 4)) 10 (reduce + 0 ‘(1 2 3 4)) 10

Page 99 of 141
Filtering: The point of filtering is to take an old list and produce a new list with potentially fewer elements. How do we do this? Example: (marks-gt lst m) This should return a list of all exam marks > m
(define cs124 ‘(78 30 60 85 49 92)) (marks-gt cs124 75) (78 85 92)
This filter must create a new list and leave the old one intact:
cs124 (78 30 60 85 49 92)
So we want to look at each element, if its value is > m then cons it into a new list: (define marks-gt (lambda (lst m) (if (null? lst) ‘() (if (> (car lst) m) (cons (car lst) (marks-gt (cdr lst) m)) (marks-gt (cdr lst) m))))) Let us make sure this procedure meets our requirements.
(marks-gt ‘(35 20 40) 30) (cons 35 (marks-gt ‘(20 40) 30))

Page 100 of 141
(cons 35 (marks-gt ‘(40) 30)) (cons 35 (cons 40 (marks-gt ‘() 30))) (cons 35 (cons 40 ‘())) (cons 35 (40)) (cons 35 40)
Note that we are building a new list with new pairs as we go along. What if we wanted to create a new filter that puts grades below a particular value in the new list? We could write a new procedure using only a slight modification of the previous one. But filtering often follows this same general predicate test pattern. Let us create a general filter that accepts a predicate and a list. The procedure will look very similar to make-gt, except the predicate is abstracted out of the procedure and passed in as a parameter. (define filter (lambda (test lst) (if (null? lst) ‘() (if (test (car lst)) (cons (car lst) (filter test (cdr lst))) (filter test (cdr lst)))))) This general filter can be used to perform many filtering tasks. Examples: Return a list of cs124 marks <= 60
(filter (lambda (x) (<= x 60)) cs124) (30 60 49)

Page 101 of 141
Suppose we want to create a procedure that duplicates a list of unstructured elements, let’s make a procedure using filter. Is this filtering? Yes, the predicate is true for every element. (define copy-lst (lambda (lst) (filter (lambda (x) #t) lst))) We cannot simply pass in the #t value to filter. It is not a procedure and could not be applied to (car lst)
(define a ‘(30 40 50)) (define b (copy-lst a))
Note that a and b are physically different lists. That is, the take us different pieces of memory, they just happen to have the same values. Now let us take a closer look at mapping.
Mapping: The goal of mapping is to take an old list, and create a new list whose elements are created by applying an operation to the old list’s elements. How do we do that?
• Transform each element of the old list using the same procedure/operation.
• Cons all the transformed elements into a new list. Example: Scheme’s primitive subst:

Page 102 of 141
(subst old new lst) Substitutes each occurrence of old by new in lst.
(subst 1 ‘one ‘(1 2 by 4)) (one 2 by 4)
Let us create a map of out own. Example: (per->gpa lst) Takes a list of % grades and creates a new list with the equivalent gpa marks. (define per->gpa (lambda (lst) (if (null? lst) ‘() (cons (* (/ (car lst) 100.0) 4.0) (per-gpa (cdr lst))))))
(define english ‘(0 25 50 75)) (per-gpa english) (0.0 1.0 2.0 3.0)
Note:
• We get a new list. • The new list has the same length as the old one. • There is a one-to-one correspondence between elements in
the 2 lists. Most mapping procedures acting on a data structures top level will follow the same pattern as per->gpa.

Page 103 of 141
Just as we did for reduction and filtering we can write a general mapping procedure that accept the procedure to be applied to each element as an argument. Let us create a general mapping procedure that accepts a procedure (to apply to each element) and a list of arguments. (define map% (lambda (proc lst) (if (null? lst) ‘() (cons (proc (car lst)) (map% proc (cdr lst))))))
(map% sub1 ‘(0 3 2)) (-1 2 1)
We have created our own general map procedure, but Scheme has a similar primitive called map, with a compatible interface. Examples:
(map (lambda (str) (string-append “hi “ str)) ‘(“bob” “sue”)))
(“hi bob” “hi sue”) But let us suppose you decide to be tricky and use map to “display” the elements of a list
(map display ‘(a b c)) What will this form do? It will traverse the list and display each element, so you expect it to display abc but it displays

Page 104 of 141
bca Why ? Scheme makes no guarantee of the order in which map applies the procedure to each element. This of course doesn’t mean that the list will be screwed up. It’s order will correspond to the original list’s order. The moral is: Do not pass procedures with effects. We are not finished yet though! What does map return? A list. What does display return? #<void>, so we get (#<void> #<void> #<void>) a list of 3 #<void> because that is the return value we get from applying display to the 3 elements. #<void> is a special value that means no value. If we do not wish to get a list of values back we should not use map, but for-each.
(for-each display ‘(1 2 3)) (1 2 3)
for-each returns nothing, and it evaluates in order left to right. Also note that Schemes version of map is variadic:
(map + ‘(1 2 3) ‘(5 6 7)) (6 8 10)
That is, you can pass as many lists in as you wish, just as long as you make sure that the procedure you pass in takes as many arguments as you pass in lists.

Page 105 of 141
To finish off this section let us do an example in which the elements are not flat, unstructured data. List elements might have structure too, they might be a member of an ADT or a list themselves. Example: Couples. I wish to construct a list of couples; each couple will have a man and a woman’s name and the number of years they have been together. Constructor: (define mk-cpl (lambda (yr m w) (cons yr (cons m w)))) Let us make a list of couples to work with. (define lcp (list (mk-cpl 2 ‘Fred ‘Wilma) (mk-cpl 3 ‘Ricky ‘Lucy) (mk-cpl 6 ‘Homer ‘Marge) (mk-cpl 0.5 ‘Romeo ‘Jill))) This structure look like this:
w m yr
L R 3 wJ R 0.5

Page 106 of 141
Suppose we want to pass in a list of couple to a procedure that returns a list of the men; this is an example of mapping. (define men (lambda (lst) (if (null? lst) ‘() (cons (cadr (car lst)) (men (cdr lst))))))
(men lcp) (Fred Ricky Homer Romeo)
Of course, instead of designing this list processing procedure from scratch, we could have used the map primitive: (define men (lambda (lst) (map (lambda (x) (cadr x)) lst))) or simply cadr instead of the lambda form. Now suppose that we want to pass a list of couples to a filter that returns a new list of couples that have been married for more than 2 years. (define together (lambda (lst m) (filter (lambda (x) (> (car x) m)) lst)))
(together lcp 2) ((3 Ricky . Lucy) (6 Homer . Marge))
Sometimes we want to apply both mapping and filtering to a list.
W F 2 M H 6

Page 107 of 141
Problem: Return a list of men who have been married for more than m years.
(men (together lcp 2)) (Ricky Homer)
This approach has the advantage that it is convenient to use existing list processing procedure, but the dis-advantage is that if the lists are long it takes a long time to traverse them 2 times. We could have written it from scratch: (define stable-men (lambda (lst m) (if (null? lst) ‘() (if (> (caar lcp) m) (cons (cadr (car lst)) (stable-men (cdr lst) m)) (stable-men (cdr lst) m)))))
(stable-men 4 lcp) (Homer)
4.5 Equality To test for equality of number we use (= n 0) For strings we use (string=? str “ab”) and for symbols we use (symbol-equal? ‘a ‘b)

Page 108 of 141
But what about comparing two data structures? For example, what if we want to check 2 lists of other pair structures for equality? Are we going to need to have a different procedures for each form of data structure? No. Scheme provides a predicate called equal?, which returns #t if the 2 objects or values have the same structure and the same values. Examples:
(equal? 2 (+ 1 3)) #f (equal? (> 5 2) (<= 6 6)) #t (equal? (list (list #\b) (+ 4 1)) ‘((#\b) 5)) #t (equal? (list ‘a ‘b) (cons ‘a ‘b)) #f (equal (list ‘a (list ‘(5 . 6) (> 5 4)) 7) ‘(a ((5 . 6) #f) 7)) #f To understand how one procedure can check the equality of an arbitrary structure we will try to write our own. We will assume an arbitrary structure, but we assume that all non-list or non-pair values are numbers. Equal will be yet another example of deep list processing. (define equal?% (lambda (a b) (if (and (number? a) (number? b)) (= a b)
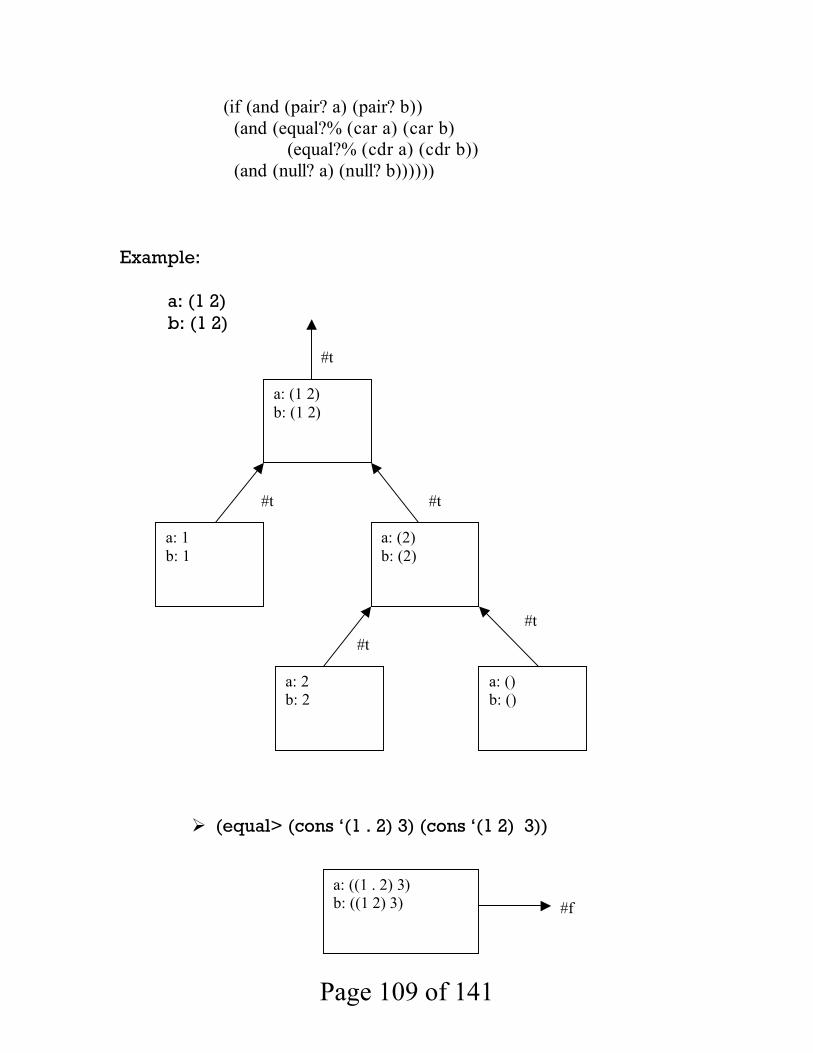
Page 109 of 141
(if (and (pair? a) (pair? b)) (and (equal?% (car a) (car b) (equal?% (cdr a) (cdr b)) (and (null? a) (null? b))))))
Example: a: (1 2) b: (1 2)
(equal> (cons ‘(1 . 2) 3) (cons ‘(1 2) 3))
a: (1 2) b: (1 2)
a: 1 b: 1
a: (2) b: (2)
a: 2 b: 2
a: () b: ()
#t
#t
#t
#t #t
a: ((1 . 2) 3) b: ((1 2) 3)
#f

Page 110 of 141
4.6 Append revisited Several days ago we briefly discussed the append primitive for appending 2 or more lists. (append list1 list2)
(append ‘(1 2 4) ‘(b c)) (1 2 4 b c) (append l ‘(1 2 3)) Error: 1 is not a list. (append ‘(1 2 3) 4) (1 2 3 . 4)
What is going on here? 4 is not a list!
Let us write our own version of append to explain it.
(define append% (lambda (l1 l2 ) (if (null? l1) l2 (cons (car l1) (append% (cdr l1) l2))))
a: (1 . 2) b: (1 2)
a: 1 b: (1)
#f
#f

Page 111 of 141
Let us expand a simple call to append% to see how it works.
(append% ‘(1 2 3) ‘(4 5)) (cons 1 (append% ‘(2 3) ‘(4 5))) (cons 1 (cons 2 (append% ‘(3) ‘(4 5)))) (cons 1 (cons 2 (cons 3 (append% ‘() ‘(4 5))))) (cons 1 (cons 2 (cons 3 (4 5)))) (cons 1 (cons 2 (3 4 5))) (cons 1 (2 3 4 5)) (1 2 3 4 5)
Sow why doesn’t (append ‘(1 2 3) 4) give an error? Append never checks to see if 4 is a list, it just cons the last element of l1 with it, and we can cons any two elements we like. Append% uses cons to copy l1 but not l2!
(define l1 ‘(a b)) (define l2 ‘(c d)) (define both (append l1 l2))
a b
d c
b a both:
l2:
l1:

Page 112 of 141
5. Mutation and state In the last chapter I asked you to investigate the list processing primitive subst on your own. Recall (subst old new list) For example:
(define cs124 ‘(79 86 79 72)) Suppose we don’t want to leave any marks 1% an A.
(subst 79 80 cs124) (80 86 80 72)
For every element equal to 79 replace it by 80 in a new list. The returned list, is a new one, cs124 is still intact. Subst might look something like the following: (define subst (lambda (new old lst) (if (null? lst) ‘() (if (equal? old (car lst)) (cons new (subst old new (cdr lst))) (cons (car lst) (subst old new (cdr lst))))))) The cons are creating the new pair of the new list.

Page 113 of 141
This works well for many tasks, but what if you want to change cs124? We could just define a new list:
(define cs124 (subst 79 80 cs124)) This is often counter intuitive. For example:
• The battery in my Honda recently died. • I bought a new battery • I did not build up a new cars out of copies of my car’s
parts, put in the new battery, and then throw the old one away.
For the list of marks, in real list I sit down and change the individual marks in the list, I don’t construct a new list. I Scheme we mutate the state of individual elements is cs124, and leave the rest unchanged. Until this chapter we have been using a functional (or applicative) programming style. We have defined a bunch of procedures and applied them to pieces of data or objects. Remember when Scheme evaluates (proc agr_1 arg_2 … arg_n) the values of the arguments do not change. We can think of the value returned as a new object created using the old ones, but the old ones remain unchanged. In contrast, with an imperative language such like C, Fortran or Pascal everything is done by mutation (or effect). You
• Define variables. • Change their values

Page 114 of 141
• Use their values. We would like some mechanism for mutating (changing) the objects in out Scheme programs as well. What we will be talking about in this chapter is a simple for of Object Oriented Programming. 5.1 Mutating Data Structures So how do we change the value of individual elements of the list without changing the entire value of the list, i.e., without making new pairs? In Scheme Pairs are a mutable (changeable) data type. Scheme provides two mutators (procedures for changing the content of a pair)
• (set-car! pair form)
Mutates the car of a pair to be the value of the form
• (set-cdr! pair form)
Mutates the cdr to have the value of the form. Both set-car! and set-cdr! are effects. That is, they have effects rather than return a value. Example:
(define x (cons 1 2))
We think of this as looking like this:

Page 115 of 141
(set-car! x 7)
returns nothing
x (7 . 2) the car has changed. (set-cdr! x (list 3 4))
returns nothing
So
x (7 3 4)
so how about
(define z x) (set-car! (cdr z) 6)
z (7 6 4) x (7 6 4) (eqv? x z) returns true if atomic values are the same and
if structures are equivalent. #t
1 2
x
7
x
1 1

Page 116 of 141
The motivating example for mutation was to be able to change individual makes in a grades list without making new pairs.
(define cs124 (list 79 86 79 72)) We are able to access individual elements of this list with list-ref
(list-ref cs124 2) 79
We would like to construct the mutators counterpart to list-ref, list-set!. Scheme doesn’t supply such a primitive, but we can easily write it ourselves: (define list-set! (lambda (lst pos val) (set-car! (list-tail lst pos) val))) Note, list-tail does not construct a new list, it simply applies “pos” cdrs and returns the resulting list.
(list-set! cs124 2 90) Out new mutators has an effect, but returns no value.
cs124 (79 86 90 72)
You can radically alter the structure of a data structure using our mutators.

Page 117 of 141
5.2 Structural Mutation. First a word of warning: Treat structural mutation cautiously. Careless use of set-car! and set-cdr! can leave a data structure in a tangled mess.
(define a (list (cons ‘a ‘b) 3 #f))
This creates the data structure shown by the following box-and-arrow diagram.
(set-cdr! (car a) (cddr a)) (car a) (a #f)
Which is a 2 element list and not a pair!! a ((a #f) 3 #f) Same bit of storage accessed twice.
If we wee to mutate the car of this pair, both occurrences of #f would change.
3 #f
a b
a

Page 118 of 141
In a proper list, that car contains an element and the cdr of each pair contains a pointer to the rest of the list. Changing the cdr of a pair changes the list’s structure.
(define y (list ‘a ‘b ‘c )) (set-cdr! (cddr y) y) y
We have changed the cdr of the last pair to point to y, and we have now created a circular list. Applying a normal list processing routine to y results in an infinite loop. Cycles are often needed in data structures, but they need special processing. Cycles need special processing procedures that e.g. count the number of elements in a cycle, you cannot cdr down to null for the base. Procedures that perform structural mutation are often very useful. Example: destructive list processing: (append! lst1 lst2) Instead of copying lst1 and creating new pairs mutate cdr of it’s last pair to point to lst2. (define append! (lambda (lst1 lst2) (if (null? lst1) lst2 (begin (if (null? (cdr lst1))
a b c
y

Page 119 of 141
(set-cdr lst1 lst2) (append! (cdr lst1) lst2)) lst1)))
(define a ‘(1 2)) (define b ‘(3 4)) (append! a b) (1 2 3 4) a (1 2 3 4) b (3 4)
What would happen if a is null?
(define c ‘()) (append! c b) (3 4)
Everything looks ok until you check c.
c ‘()
When c is null no mutation takes place, cause there is no pair to mutate. How do we fix this? We could mutate the variable c’s binding. We will shortly se how to directly mutate a variable, but a better way to do it is to make a “box” which can be mutated.

Page 120 of 141
5.3 Boxes Stings are also mutable, but the remaining “atomic” data types are not, they are immutable. Rather than always working with collections we want to model, over time, the state of an object with a single element. Scheme provides us with another mutable data type: Boxes. A box is a container for storing a single value of any type. The Primitive Data Structure Box. You can make a box using the constructor: (make-box initial-value) Creates and returns a box containing the initial value. You can access the value stored in a box using the accessors: (box-ref box) Returns the current value in the box. You can test if an object is a box using the predicate: (box? anything) The whole point of introducing boxes was the fact that they are mutable: (box-set! box new-value) Changes the value contained in the box to new-value. The box itself is unchanged, but what is stored inside it does. Examples:

Page 121 of 141
(define b (make-box 6)) b #&6 It is important not to confuse the value of b with the value of what it contains. (box? b) #t (box? (box-ref b)) #f
Now let us mutate the value in the box
(box-set! b (+ (box-ref b) 2)) (box-ref b) 8
Of course, we can mutate the box’s value to a value of a different data type:
(box-set! b ‘(3 4)) (box-ref b) (3 4)
What if we wanted to mutate the list that is contained in the box? Mutate the car of the 2nd pair to 7. We would have to use set-car! on a box-ref!.
(set-car! (cdr (box-ref b)) 7) b #&(3 7) (define c (make-box ‘()) (box-set! c (append! (box-ref c) b)) c (3 4)

Page 122 of 141
So we have successfully mutated c’s content to be the value returned by append!. Let us do another example of structural mutation. Delete the nth element for a list. If we try to delete the first element we run into the same problem as for append. So assume n>0. (define delete-nth (lambda (lst n) (if (null? (or lst (cdr lst)) (display “list too long!”) (if (= n 1) (set-cdr lst (cddr lst)) (delete-nth (cdr lst) (- n 1))))))
(define a (list 1 2 3 4)) (delete-nth a 2) a (1 2 4)
5.4 Another look at Equality. We already have the predicate equals?
• It can compare many kinds of values including pairs and lists. • It compares 2 objects (or values) to see if they have the same
structure and the same value.
(define x (cons 1 2)) (define y (cons 1 2)) (equals? x y) #t (set-car! x 5) (equals? x y) #f

Page 123 of 141
Scheme also provides a predicate for testing equivalence; the predicate eqv?
• It also returns #t if 2 atomic values are equal, but • Behaves differently on composite values (or structures)
(strings, boxes, pairs, etc)
(define a (list ‘x ‘y)) (define b (list ‘x ‘y)) (equals? a b) #t (eqv? a b) #f
We find that a and b are not equivalent, they have the same structure and values, but they do not take up the same storage location. 2 structure are only equivalent when they take up the same place in memory.
This is not the case for a and b.
(define c b) (eqv? c b) #t
b and c point to the same pair. So why do we want to use eqv? Because we want to be able to id cases like this one; if we mutate b we also mutate c.
(set-car! b 3) b
a x y
b x y
c

Page 124 of 141
(3 y) c (3 y)
Note: checking eqv? is easier than equals?
• Checking equal? requires a recursive navigation of both structures.
• Checking eqv? just requires to check that the arrows point to the same place, and that can be done in constant time.
5.5 Mutating Variables In our previous structural mutation examples we ran into trouble if we needed to change a variables binding. In the append example we got around this problem by storing lists in a box. Using a lot of boxes clutters the code with box-ref and box-set! calls. Alternatively, the special form set! mutates the value of a variable:
(set! name form) Where name is a name bound in the environment and for is any scheme form. The value of name in the environment is changed to the value of form. Note that set! is not mutating the value bound to the variable, but it is mutating the variable binding! Set! changes the value bound to name, but doesn’t mutate the previous value bound to it.
(define t 10) (define s t) (set! t 15) s 10

Page 125 of 141
t 15
Set! is a special form, it does not use the name rule and simply replaces t by 15 in the environment. S is unaffected. Really, all set does over boxes is provides clearer code. Like boxes you only want to use them to model state. Let us suppose we are modeling the balance of a bank account over time.
(define bal 100) We can mutate this variable to reflect the change of the balance over time.
(set! bal (+ bal 300)) bal 400
As an example, let’s write a procedure for updating the balance after a withdraw. You might be tempted to write something like the following: (define wd! (lambda (bal w) (if (>= bal w) (begin (set! bal (-bal w)) bal) (display “Insufficient funds!”))))
(wd! bal 150) 250
Everything looks good so far.

Page 126 of 141
bal 400
What went wrong? Remember that the VALUE of bal is passed, and in the local environment of the procedure there exist a parameter named bal, which is the one that will be changed (remember the scoping rules) How do we fix this? Remove the bal as a parameter. Let us look at another example:
(define x (cons ‘a ‘b)) (define y x) (eqv? x y) #t (set! x (cons 1 2)) x (1 . 2) y (a . b)
When we mutated x we created a new pair (using cons) and made x point to it – y still points to what it was pointing to before.
(define a ‘1st) (define b ‘2nd ) (set! a b) (set! b a) (cons a b) (2nd . 2nd)
Both symbols are the same, the first set! wipes out the value originally bound to a. To swap these two values we must use a temporary variable.
(define a ‘1st)

Page 127 of 141
(define b ‘2nd) (let ((tmp a))
(set! a b) (set! b temp))
(cons a b) (2nd . 1st)
As a last example let us consider 3 different examples. > (define a 7) > (define a 7) > (define b (cons 7 8)) > (define change-a! > (define change-a! > (define chg-pair! (lambda () (lambda (a) (lambda (b) (set! a (+ a 1)) (set! a (+ a 1)) (set-car! b 10) a)) a)) b)) > a > a > b 7 7 (7 . 8) > (change-a!) > (change-a! a) > (chg-pair! b) 8 8 (10 . 8) > a > a > b 8 7 (10 . 8) Strange huh? The environment model will help us understand this more clearly. 5.6 The Environment Model. The previous 3 puzzles can be confusing. It is certain that the substitution model cannot help us clearly understand this puzzle. Instead we introduce the Environment Model. There are actually a number of reasons we need this new model.
1. It clearly explains the scope of variables; until now we have been using an informal set of rules to explain static (or lexical) scoping.
2. It explains mutation (especially within procedures). 3. It allows procedures to have state that changes over time
(Scheme allows this using local variables that persist and that can change value whenever the procedure is used. This is crucial for OOP.
Let us look at the environment starting with The Global Environment.

Page 128 of 141
• Whenever we have talked about the global environment
we have drawn the environment as 2 columns, one with names and one for values. Such a picture is called a frame.
• In the environment model all bindings are gathered into frames.
• The global environment consists of 2 frames; the primitive frame and the user frame.
• When Scheme starts up it creates the primitive frame, it contains all the bindings for Scheme’s primitives.
• In the environment model forms are always evaluated in some frame
• The user frame is the frame that the interaction window runs in.
Let us draw the Global environment with the 2 frames: Initially there are no bindings in the User frame. The static link tell you which environment to look in next if you are looking for a name and you cannot find it in your own frame. If you ever get to the primitive frame and you still cannot find the name your are looking for, an error occurs because the name is not bound.
Primitive
+ sqrt . . .
#<plus> #<sqrt> . . .
Name Value Static link
User
x b c
17 42
Name Value Static link
1 2

Page 129 of 141
Define forma do not return a value, but they have an effect on the global environment.
(define x 17) (define b 42) (define c ‘(1 . 2))
Recall that procedures are values too!
(define sub2 (lambda (x) (- x 2)) Now that we have some of the basics of the environment model we can start evaluating procedures.
(sub2 7)
User
x b c sub2
17 42
Name Value Static link Prim.
1 2
x
Points to procedure “bubble”
Point to the frame in which the procedure value was created using the lambda rule.
Right hand side of the bubble contains a list of the parameters and body if space permits it.

Page 130 of 141
If we think of the substitution model it says that we substitute 7 for x in the body of sub2 and then evaluate. This is not a completely satisfactory method of modeling procedure application. Since we learned about scope we have been talking about bindings, so the Environment Model changes the procedure rule:
• Bind parameter x to 7 in a new frame that is constructed for the evaluation of the body of sub 2.
In general the new procedure rule is: Procedure Rule (E.M. version) To evaluate a procedure application (proc a1 … an) we perform 2 steps.
1. Create a new frame, where a. The names in the frame are the parameters names
(formal parameters) b. The values of these parameters are the actual
parameters – values passed in to the procedure by the caller.
c. The parent frame is the parent of the procedure being applied.
2. Evaluate the body of the procedure in this new frame The remaining question is: Where is x bound to 7? In which frame? When a procedure is evaluated a new frame is created to hold the parameter bindings. Let us look more closely at the parts of a frame:
1. A set of names 2. A set of values bound to the names
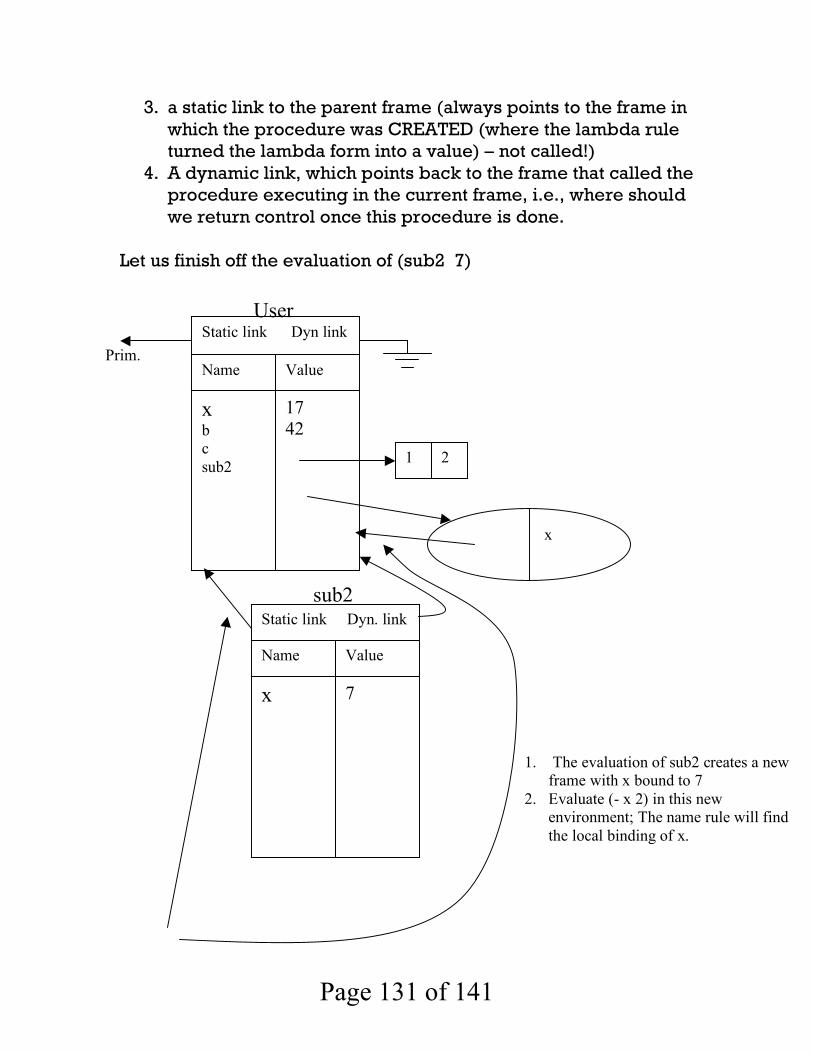
Page 131 of 141
3. a static link to the parent frame (always points to the frame in which the procedure was CREATED (where the lambda rule turned the lambda form into a value) – not called!)
4. A dynamic link, which points back to the frame that called the procedure executing in the current frame, i.e., where should we return control once this procedure is done.
Let us finish off the evaluation of (sub2 7)
User
x b c sub2
17 42
Name Value
Static link Dyn link Prim.
1 2
x
sub2
x
7
Name Value
Static link Dyn. link
1. The evaluation of sub2 creates a new frame with x bound to 7
2. Evaluate (- x 2) in this new environment; The name rule will find the local binding of x.

Page 132 of 141
ALWAYS point to the same frame…. Now let us consider a more complicated example:
(define a 2) (define b 4) (define foo
(lambda (x) ( (lambda (b) (+ b x)) (+ a b))))
(foo 3)
1. First we evaluate the three defines in the user environment 2. Then to apply foo to 3, we use the new procedure rule that
creates a new frame in which foo evaluates. 3. The parent of foo is the user environment. 4. Evaluate the body in this new frame
a. a and b are not found in local environment, so look at the parents environment.
b. (+ a b) 6 which will be the argument to the anonymous lambda form.
c. Evaluating the lambda form creates a procedure 5. To apply the anonymous procedure we create a new
environment. a. B is found in the local frame, x is found in foo’s frame b. (+ b x) 9
Let us draw a snap shot of the environments just before the (+ b x) form is evaluated.
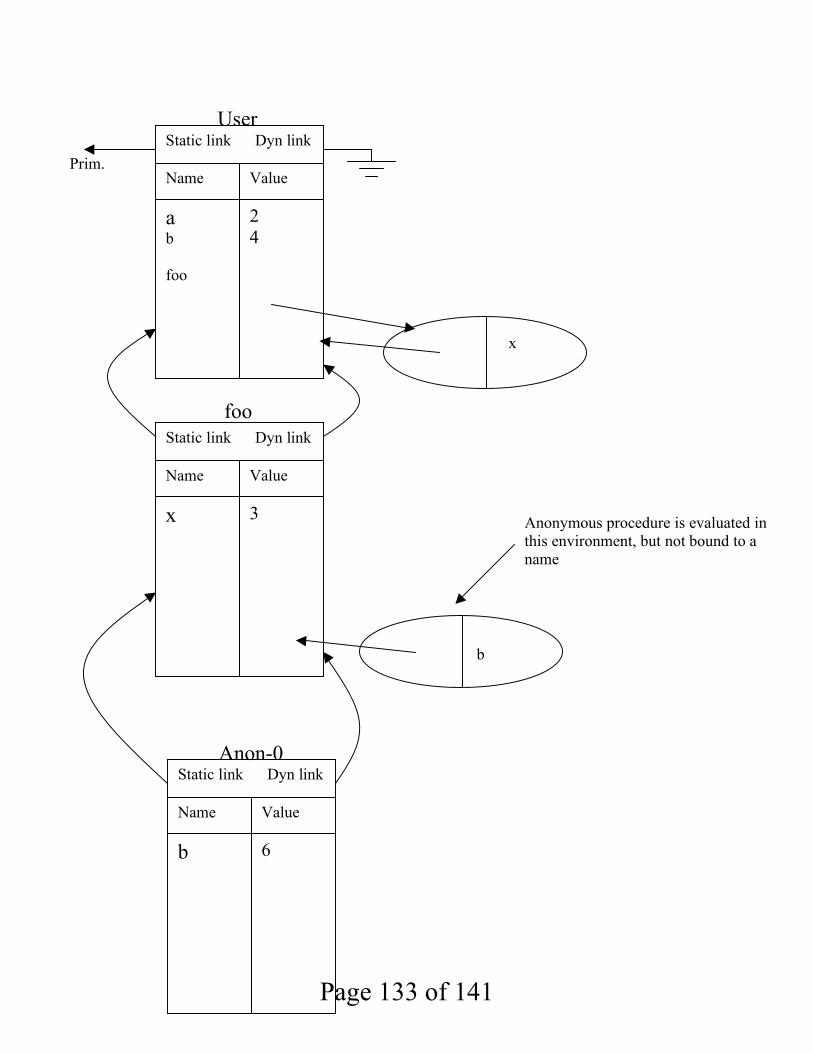
Page 133 of 141
Anonymous procedure is evaluated in this environment, but not bound to a name
User
a b foo
2 4
Name Value
Static link Dyn link Prim.
x
x
3
Name Value
Static link Dyn link
foo
b
b
6
Name Value
Static link Dyn link
Anon-0

Page 134 of 141
This model explains lexical scoping clearly – find the closest name in the chain of frames pointed to by the current frame’s link. This is very important for nested procedures and lets. When (+ a b) is evaluated the bindings for a and b are found in the global environment, consequently we call them global variables. This example clearly shows the advantages of the environment model for explaining lexical scope; the same goes for mutation too – identification of the value being mutated is made easy by the new name rule. But a key feature of the environment model is that procedure can now have local state. This is the most important reason for always carefully defining the link to the parent of each procedure object. Procedures with local state The key to procedures with local state, is to maintain state between calls. The best way to understand local state is to look at an example. Example:
(define addup (let ((acc 0)) (lambda (x) (set! acc (+ acc x)) acc)))
We describe this pattern as let-over-lambda, when a procedure returns a procedure, we call it lambda-over-lambda.
(addup 5) 5 (addup 5)

Page 135 of 141
10 (addup 3) 13 acc Error: variable acc not bound.
To understand this we need to translate this into the equivalent lambda-call.
(define addup ( (lambda (acc) (lambda (x) (set! acc (+ acc x))) 0))
Now we can evaluate this in the Environment Model.
1. Apply lambda rule to outer lambda form 2. Apply the procedure to arg 0 using new procedure rule.
a. Create new frame b. Evaluate body – a lambda form using the lambda
rule. 3. Bind addup to procedure in global environment.
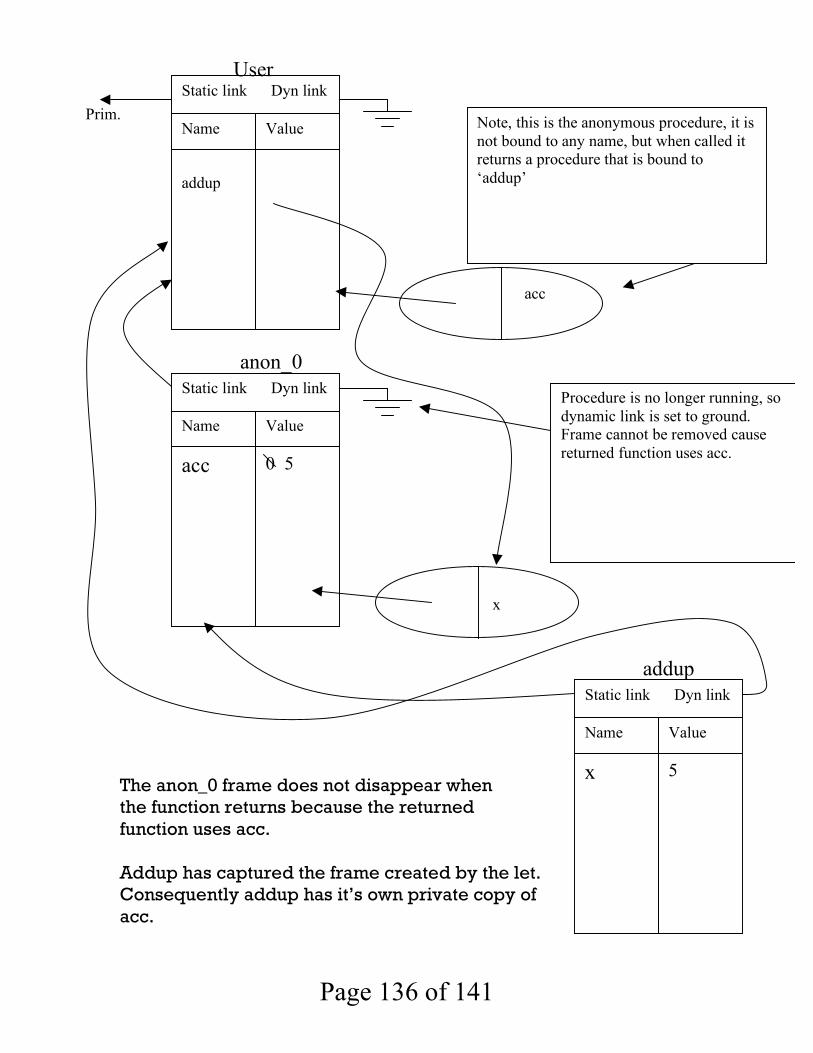
Page 136 of 141
The anon_0 frame does not disappear when the function returns because the returned function uses acc. Addup has captured the frame created by the let. Consequently addup has it’s own private copy of acc.
User
addup
Name Value
Static link Dyn link Prim.
acc
acc
0 5
Name Value
Static link Dyn link
anon_0
x
Note, this is the anonymous procedure, it is not bound to any name, but when called it returns a procedure that is bound to ‘addup’
Procedure is no longer running, so dynamic link is set to ground. Frame cannot be removed cause returned function uses acc.
x
5
Name Value
Static link Dyn link
addup

Page 137 of 141
The figure above shows not only the left over frame, but also the frame that addup creates when it is run.
(addup 5)
4. Apply procedure rule a. Create a new frame with binding x = 5. b. Since addup was ‘conceived’ in the anon frame the
static link MUST point to the anon frame. 5. Evaluate the body of addup
a. Find acc one frame back b. Chance the value from 0 to 5.
6. Return the return value and remove the addup frame (the anon frame stays as long as addup is bound in the global environment.
(addup 6) 11
(define acc 207) (addup 8) 19
The definition of acc is in the global environment, since all addup frames point to the anon frame, which also contains an acc variable, the global one will never be accessed.

Page 138 of 141
The addup example illustrates the general pattern of let-over-lambda.
1. let creates an environment, with bindings in which the lambda is evaluated.
2. This new local environment is the parent of the resulting procedure.
3. When the procedure is evaluated it looks for names in a. Procedures own local frame that was created when the
procedure was applied (and is removed when the procedure stops running)
b. The local environment captured by the let. c. The global environment.
Of course lambda-over-lambda is very similar to let-over-lambda. Lambda-over-lambda shares the same pattern of frames as let-over-lambda Example: (define mk-adder (lambda (n) (lambda (x) (+ x n))) mk-adder is called a factory procedure because it “produces” other procedures when it is called. When mk-adder is called it returns a procedure that captures the frames that mk-adder was evaluated in
(define add5 (mk-adder 5)) Here mk-adder returns a procedure that takes in one parameter and adds 5 to it. The returned procedures parent frame is the frame with the binding of n to 5 (i.e. the frame that mk-adder was evaluated in).

Page 139 of 141
(add5 10) 15 (define add10 (mk-adder 10))
mk-adder creates a new frame for this new evaluation with n bound to 10, this frame is captured by the returned function that is bound to add10.
(add10 25) 35
The creation of add10 has no effect on the local state of add5, they capture different frames.
(add5 16) 21
Example: To get a better understanding of the Environment Model let us look at a small example that we presented last time.
(define b (cons 7 8)) (define chg-pair!
(lambda (b) (set-car! b 10) b))
b (7 . 8) (chg-pair! b) (10 . 8) b (10 . 8)
So let us explain that using a snapshot of the environments.
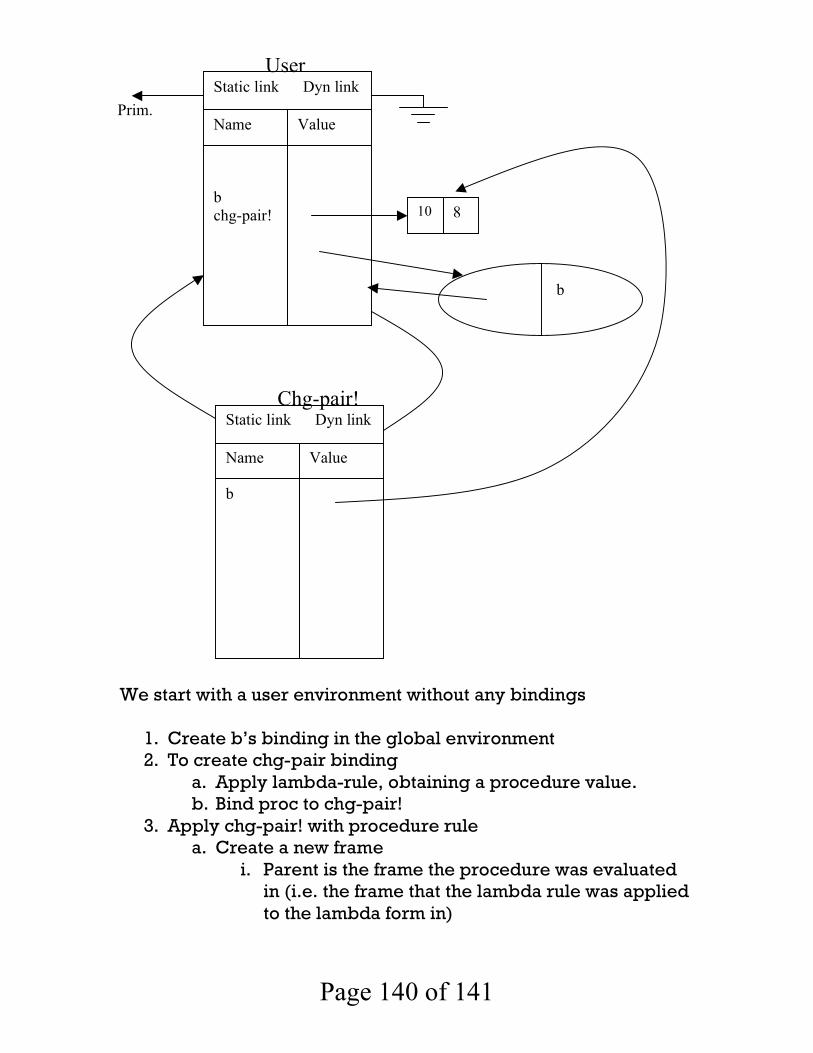
Page 140 of 141
We start with a user environment without any bindings
1. Create b’s binding in the global environment 2. To create chg-pair binding
a. Apply lambda-rule, obtaining a procedure value. b. Bind proc to chg-pair!
3. Apply chg-pair! with procedure rule a. Create a new frame
i. Parent is the frame the procedure was evaluated in (i.e. the frame that the lambda rule was applied to the lambda form in)
Chg-pair!
b
Name Value
Static link Dyn link
User
b chg-pair!
Name Value
Static link Dyn link Prim.
10 8
b

Page 141 of 141
ii. Parameter b is bound to the pair in the global environment
iii. A copy of the arrow is passed in. b. Evaluate the body, find the local b, change the car of
the pair, and then return a copy of the arrow! Note that the global b still points to the same pair after the function call.

1
Implementing a simple substitution evaluator for a Scheme like λ-calculus
language in Scheme
© Matt Pedersen ([email protected]), University of Nevada, Las Vegas, 2007
Preliminaries Before we start writing code we have to agree on what we are implementing. This document will guide you through how to implement a simple Scheme evaluator for a subset of scheme (roughly equivalent to the λ-calculus [Kle35]) and according to The Rules of Evaluation Version 2 from lecture [Ped07]. Let us first try to understand the background, that is, let us introduce the λ-calculus.
The λ-calculus The lambda-calculus was first introduced in 1935 by Church and Kleene, and forms the basis for a number of functional programming languages such as ML, Lisp and Scheme. The basic rules are pretty simple, and can be summarized as follows: A lambda-expression is defined inductively as one of the following
1 V, a variable, where V is any identifier (The precise set of identifiers is arbitrary, but must be finite).
2 (λ V. E), an abstraction, where V is any identifier and E is any lambda expression. An abstraction corresponds to an anonymous function.
3 (E E’), an application, where E and E’ are any lambda expressions. An application corresponds to calling a function E with arguments E’.
We need to consider a few more issues, such as substitution, but we will return to those in a later section. As you can see from the 3 rules above, the ability to declare a function abstraction and to apply it, as well as the ability to reference variables is all that is needed. That does not sound like much, but this is actually a Turing-complete language!

2
The Scheme Rules of Evaluation Version 2 Let us briefly review the rules of evaluation as they are stated in version 2 from lecture:
• [Initialization Rule]: The environment initially contains only the built-in primitives.
• [Number Rule]: A numerals value is a number interpreted in base 10. • [Name Rule]: A name is evaluated by substituting the value bound to it in the
environment. o It does not matter if it is user defined or a name of a primitive procedure. o If the name does not exist in the environment when the form is evaluated,
an error is produced. • [Lambda Rule]: The value of a lambda-form is a procedure with parameters and
a body. • [Application Rule]: An application is evaluated by evaluating each of its
elements (Using the Rules) and then use o The Primitive rule if the operator is a primitive. o The Procedure rule if the operator is a procedure.
• [Primitive Rule]: Invoke the built-in primitive with the given arguments • [Procedure Rule]: A procedure application is evaluated in 2 steps:
o In the body of the procedure, replace each of the formal parameters by its corresponding actual arguments.
o Replace the entire procedure by the body. • [Definition Rule]: The 2nd argument is evaluated. The 1st is not evaluated and
must be a name. The name/value pair is added to the environment. As an aside, it is worth noting that the Initialization and the Definition rules are really not necessary; if we do not have definitions, then we do not need an environment, and definitions are not technically necessary; at least not in order to preserve Turing completeness. The Number and Primitive rules can be discarded on the same account. One might say that a calculus that does not have numbers is not much fun, but in pure lambda-calculus, number can be represented as higher-order functions, something which a little hairy and we shell not bother with that at this moment. You might say that if we remove the environment, then how can the Name rule exist? It is clear that the name rule corresponds to the first rule of the lambda-calculus definitions. We shall see how substitution can also solve this problem later. Furthermore, the Lambda Rule corresponds to the second point in the definition of the lambda-calculus, and the Application (and the Procedure) Rules correspond to the third part of the definition. With that in mind we can now start coding the evaluator.

3
The Scheme Evaluator To make things a little clearer in steps to come I have decided to place all primitives in a ‘primitive environment’ and only use the global environment for user-defined bindings. The task ahead can be defined as follows:
“Write a Scheme function called evaluate, which takes in a form and evaluates it using the global environment according to the Rules of Evaluation Version 2.”
Thus the start of the evaluate function must look like this: (define evaluate (lambda (form ) ... We have not discussed what a form is in our evaluator, but since all Scheme forms are either a variable or a value, or something with ( ) around, then a natural choice is to define a form in our evaluator as
• A symbol representing a variable or a value • A list representing either a lambda-form, an application or a define form.
Note how this definition is very close to the definition of a lambda expression given earlier . We will return to the list part of the above definition a little later.
The environment The first step is to decide how to represent the environment. Recall that the environment is a collection of bindings of values to names, so it can be viewed as a list of pairs whose first element is the name and second element is the value bound to that name. In Scheme the primitive cons (which takes two arguments) constructs a pair:
(cons 1 2) (1 . 2)
The first element of a pair can be accessed using the Scheme primitive car, and the second by the primitive cdr. A note of caution: If x is a pair then (cdr x) is an element. If x is a list then (cdr x) is the list with the first element removed:
(car (cons 1 2)) 1 (cdr (cons 1 2)) 2

4
(car (list 1 2)) 1 (cdr (list 1 2)) (2)
We can thus represent the global environment as a list of pairs (We start with the empty environment): (define env ’()) And we can define the Initialization Rule as follows: (define init-rule (lambda () (set! env ’()))) That is, we use the set! primitive to redefine the global variable env. The primitive environment is defined in the same way (though here we do not need any initialization rule as it always stays the same):
(define prim (list (cons ’+ +) (cons ’- -) (cons ’/ /) (cons ’* *) (cons ’= =) (cons ’> >) (cons ’< <))) In the list of primitives above I have included just a few of the existing ones, but note the content of the various pairs: the fist element (the car) is a symbol representing the operator (it is quoted thus a symbol), but the second element of the pair is not quoted, so it gets evaluated by the cons function before the pair is created. Let us try typing one of the pairs into the Scheme evaluator:
(cons ’+ +) (+ . #<primitive:+>)
And now consider this:
((cdr (cons '+ +)) 4 5) 9
The second element is actually a primitive procedure that can applied by providing arguments and placing application brackets around it. At this point it is worth considering the following problem though: We know that we can apply the actual primitive to one or

5
more arguments by placing application brackets around the primitive and the argument(s); but what do we do if we have a list of arguments and a primitive, say we wish to apply the primitive function + to 4 and 5 but 4 and 5 appear in a list as (4 5)? Let us try:
(+ (4 5)) procedure application: expected procedure,
given: 4; arguments were: 5 (+ ’(4 5))
+: expects argument of type <number>; given (4 5) That the first one fails is not a surprise! (4 5) is an application of 4 to 5! That does not make any sense! But what about the second one? + takes 1 or more arguments (actually, (+) is actually a legal form in Scheme, it gives the element that is neutral to the operator, i.e., the value 0 for + and 1 for * and so on). The arguments must be something that evaluates to numbers, but ’(4 5) is not a number, it is a list! The solution is the Scheme function apply. Apply takes a function and a list and applies the function to the elements in the list in the following way: (apply f ’(e1 e2 e3 ... en)) := f(...(f(f(e1 e2) e3)...) en) Or in scheme notation: (f (... f((f e1 e2) e3) ...) en) So we get:
(apply + ’( 1 2 3 4)) 10
Now that we have this little trick in place let us move on to the next rules.
The Number Rule The Number rule is easy! The Scheme evaluator will do all the work for us; In reality the Number rule can be implemented simply as the identity function: (define number-rule (lambda (number) number)) We simply return the argument! The scheme evaluator (because it is call by value!) will have already turned the textual representation of any number into an actual value by the time the body of the Number rule is executed.

6
So far it has not been too complicated, so let us turn to the Name rule.
The Name Rule The Name rule will be a little more complicated because I decided to have two environments: one with user defined bindings and one with primitives. It will not complicate matter too much though. Recall that both the primitive environment and the global user environment is a list of pairs. We could write a function that takes in an environment (a list of pairs) and a symbol (the name we are looking for) and recursively traverses the list of pairs, but scheme has a built in function called assv, which can be utilized in the following way:
(assv ’+ (list (cons ’+ +) (cons ’- -))) (+ . #<primitive:+>) (assv ’a ’((b 5) (c 7))) #f
assv takes in a symbol x and a list of pairs, and if a pair (x . y) exist it returns (x . y). If no such pair exists it returns #f. If we search the global environment first and in case we do not find anything there we can search the primitive environment, then the code looks like this:
(define name-rule (lambda (name) (let ((pair (assv name env))) (if pair (cdr pair) (let ((pair (assv name prim))) (if pair (cdr pair) (error (format "reference to undefined identifier: ~a" name))))))))
First we search the user environment; if nothing is found there we search the primitive environment; if still nothing is found we produce an error and terminate. Note, since the global environment is really global, we do not need to take a parameter representing the environment; if we do, we might run into problems later when writing the function for define. This is not the most elegant way of doing it, but it will work for now; later we will look at the right way of doing it (it work just fine when we are not implementing a language that supports commands like set! and captured frames!).

7
The Primitive Rule Before we continue with the Primitive Rule, it is vital that we understand what data we are working with! Let us consider the Scheme form (+ 4 5). How do we represent that textually in our evaluator? The easiest ways is a list with 3 elements: the symbol + , the number 4 and the number 5 (In Scheme any number quoted becomes just the number) This can be illustrated by the use of the equal? predicate:
(equal? '(+ 4 5) (list '+ '4 '5)) #t
So in our evaluator + will be looked up in the primitive environment and turned into the Scheme primitive #<primitive:+> and the list of arguments (which could be more complex forms than just integers) will be evaluated, and we end up with a list of values. Now we need to apply the primitive to the list of values. This is where the use of the apply function is handy, if the function to evaluate the Primitive rule takes in a primitive and a list of evaluated forms (i.e., a list of values) then we can apply that primitive to the list of arguments by using the apply function:
(define primitive-rule (lambda (primitive arguments) (apply primitive arguments)))
For example. If primitive is #<primitive:+> and arguments is (4 5), then we have: (apply #<primitive:+> (4 5)) = (#<primitive:+> 4 5) which is exactly what we wanted! (Note, you cannot type the first part of the line above into the Scheme evaluator, I just wrote it to illustrate a point!)
The Application Rule The Application rule is simple; it consists of two major parts:
1 Evaluate all the arguments of the form. 2 Use either the Primitive Rule or the Procedure Rule to evaluate the form.
We have already described the Primitive Rule; recall it takes in a Scheme primitive (obtained from a look up in the primitive environment) and a Scheme list of (evaluated) values. How do we evaluate all the arguments of the form? Since we are writing (or at least have started) the evaluate function we can call that function of every element of the list of the application and then decide if we should pass it to the function that handles the Primitive

8
Rule (primitive-rule) or the one that handles the Procedure Rule (which we have not written yet!). Let us consider the Scheme list (+ (+ 4 5) 6). Before the Application Rule decides to pass the job on to the Primitive Rule, it must evaluate the arguments of the application, In this case there are 3 arguments: +, (+ 4 5), and 6. If we pass each of these three parameters (which technically are forms themselves) to the evaluate function then we should get 3 values back, one for each, and if we then collect them back into a list of length 3 (just like the original list for the application) we should get (#<primitive:+> 9 6), which we can then pass on to the primitive-rule function for further evaluation. In the implementation we pass the primitive (car evaluated-args) and the arguments (cdr evaluated-args) in two separate parameters, but the idea is the same. In other words, we wish to evaluate the call (evaluate ...) for each of the members of the application form. Again, we could write a recursive function that takes in the application form, calls evaluate on each element by taking out the first element (using the car function) and cons’ing that together with the result of a recursive call on the tail of the list (using the cdr function). Again Scheme already has a primitive (a very powerful one that is) called map, which can do all the dirty work for us. map is a function that takes a function and a list of elements and applies the function to all the elements of the list and returns a new list with return values of this operation:
(map add1 ’(1 2 3)) (2 3 4)
Or if you wish to use one of your own functions:
(map (lambda (x) (* x 3)) ’(1 2 3)) (3 6 9)
We can formally define map like this: (map f ’(e1 e2 e3 ... en)) := ((f e1) (f e2) ... (f en)) In reality, map can do much more, but in the spirit of Terry Pratchett’s Discworld, we call the above explanation ‘lies to children’; it is enough information for now; it work as it is, so don’t ask! Enough to say that the following Scheme form is valid as well:
(map (lambda (x y) (+ x y)) ’(1 2 3) (4 5 6)) (5 7 9)
It could be simplified to (map + ’(1 2 3) ’(4 5 6)).

9
This means that we can use the map function to evaluate all elements in a list and return the resulting values in a new list as follows (we assume that lst is a list representing the entire application): (map evaluate lst) For completeness, an implementation of map could look like this (one that takes in one function and one list (so not as fancy as the built-in one)): (define map (lambda (f lst) (if (null? lst) ’() (cons (f (car lst)) (map f (cdr lst)))))) Now we know how to evaluate the arguments, all we need to do now is determine if the first element in the application is a primitive or user defined procedure. This is easily done by looking for the textual representation (i.e., before evaluating the elements of the application) in the primitive environment. We simply use assv to search the primitive environment. If the first element is a lambda form or a named procedure (from the user environment, the lookup in the primitive environment will fail and we know that we should use the Procedure rule,; if it succeeds we can pass the application to the Primitive Rule for further evaluation. Thus the Application rule can be implemented as follows:
(define application-rule (lambda (lst) (let ((primitive? (is-primitive? (car lst))) (evaluated-args (map evaluate lst))) (if primitive? (primitive-rule (car evaluated-args)
(cdr evaluated-args)) (procedure-rule (car evaluated-args)
(cdr evaluated-args)))))) To improve readability we can implement the is-primitive? predicate in the following way:
(define is-primitive? (lambda (e) (assv e prim)))
Recall that assv will return #f if nothing is found (i.e., there is no pair in the list prim that has e as the first element).

10
The next step should be the Procedure Rule, but since this is by far the most complicated rule, we shall put that off for just a little while. Let us instead turn to the Define Rule, which is a lot simpler.
The Define Rule The Define rule says to evaluate the 2nd form (well, really, it is the 3rd because the word define is really the 1st) and bind it to the name given in the 1st form (which then is really the 2nd!) of the define form. The evaluation of the 2nd (which is really the 3rd) form is as simple as calling the evaluate function with this form:
(define define-rule (lambda (name form) (let ((value (evaluate form)) (pair (assv name env))) (if pair (set-cdr! pair value) (set! env (cons (cons name value) env))))))
At first sight, the rule looks a little more complex then described above! We need to determine if the name is already bound in the environment. If it is then we simply change the second element of the pair returned from assv (the lookup in the environment). If there is no existing binding we set the environment to what it was before with the new name/value pair added to the front of the list representing the global environment. If you are not familiar with set!, set-car! and set-cdr!, then see the discussion at the end of this write up. We now have everything we need except the main procedure (evaluate) and an implementation of the Procedure Rule, so let us look at the Procedure Rule.
Procedure Rule Before we implement the procedure-rule function we need to understand the rule in detail. The way it is written in The Rules Version 2 is not entirely correct! It could work as stated under one condition: no two procedures (bound in the global environment) or anonymous lambda forms share any parameter names! Let us consider this small example: ((lambda (x) (+ ((lambda (x) (* x 2)) (+ x 4)) 5)) 1)

11
What is the value of such a form? Let us blindly use the procedure rule as stated in Version 2 of the Rules of Evaluation. The first part says to replace each of the formal parameters with its corresponding actual ones. This can be done by a substitution of the name of the formal parameter in the list representing the body of the function being applied with the value of the actual parameter. In the example above if we perform a substitution of x by the value 1, and look at the body, we get: (+ ((lambda (x) (* 1 2)) (+ 1 4)) 5) which if typed into the Scheme evaluator gives us the value 7. This is clearly wrong. If we type the original form into the evaluator we get the value 15, which is the correct value. The problem is of course the ‘mindless’ substitution of x by 1. This substitution should only happen for a certain number of the x’s found in the body, namely the ones that are ‘free’ (we will get to this definition shortly). If you look at it and think about it you would probably arrive at the conclusion that only the underlined x’s in the following should be substituted by the value 1:
((lambda (x) (+ ((lambda (x) (* x 2)) (+ x 4)) 5)) 1) So only the last x should be substituted because the inner x is bound by the formal parameter in the inner most anonymous lambda form. Let us look at the formal definition of a free variable in a lambda expression.
Free and Bound Variables Each variable in a lambda expression is either free or bound. For example the x in (x y) is free, while the x in (lambda (x) (x y)) is bound. A bound variable has a specific lambda with which it is associated, while a free variable does not. The free variables of a lambda expression are defined inductively as follows (we define this for the lambda calculus first):
1 In an expression of the form V, where V is a variable, this V is the single free occurrence.
2 In an expression of the form (λ V. E), the free occurrences are the free occurrences in E except for V. In this case the occurrence of V in E are said to be bound by the λ before V.
3 In an expression of the form (E E’), the free occurrences are the free occurrences in E and in E’
In general all formal parameters of a lambda form ‘binds’ any occurrences of that parameter in the body, making it not free (i.e., bound). We can now define formally the correct rules for substitution.

12
Substitution Substitution, written E[V := E’], corresponds to the replacement of a variable V by expression E’ every place it is free within E. The precise definition must be careful in order to avoid accidental variable substitution. For example, it is not correct for (λ x.y)[y := x] to result in (λ x.x), because the substituted x was supposed to be free but ended up being bound. The correct substitution in this case is (λ z.x). The precise rules are defined inductively as follows:
1. V[V := E] == E 2. W[V := E] == W, if W and V are different. 3. (E1 E2)[V := E] == (E1[v := E] E2[v := E]). 4. (λ W. E’)[V := E] == (λ W. E’[V := E]), if V and W are different
and W is not free in E. 5. (λ W. E’)[V := E] == (λ W’. E’[W := W’])[V := E], if V and
W are the same (i.e., not different) and if W’ is not free in E. We did not include a rule for arbitrarily substituting the formal parameters, and the rules above are only defined for lambda expressions with one parameter, but multi parameter expressions follow trivially. Note that rule 5 solves the problem of accidental variable substitution. Rule 1 and 2 explain how to substitute simple named variables, rule 3 is for applications and rules 4 and 5 are for lambda forms. Also note that substitutions only happen for free variables! We can now rewrite the Procedure Rule as follows: Old version:
• [Procedure Rule]: A procedure application is evaluated in 2 steps: o In the body of the procedure, replace each of the formal parameters by its
corresponding actual arguments. o Replace the entire procedure by the body
New version:
• [Procedure Rule]: A procedure application is evaluated in 2 steps: o In the body of the procedure, replace each of the free formal parameters
by its corresponding actual arguments. o Replace the entire procedure by the body
Note the slight difference; the word free has been added to the new version. You might think that there is no difference because the formal parameters in the body are bound by the enclosing lambda form; yes, you are right, but we are not making the substitution in

13
the entire lambda form, only in the body, where the formal parameter list cannot be seen! A small but very important difference. So if we are considering an application like this: (E E’) where E is a lambda form and E’ is a set of actual parameters, we can expand as follows: ((lambda (p1 p2 ... pn) E’’) f1 f2 ... fn) We now evaluate the forms f1, f2,..., fn, to produce the values of the actual parameters v1,v2,...,vn, and then perform the substitution E’’[p1 := v1, p2 := v2,..., pn := vn] and then evaluate this new form! We could implement the above rules in great detail and compute sets of free and bound variables, but there is a simpler (!) way, which we shall utilize. Let us first write the procedure-rule, and make use of a few helper functions:
(define procedure-rule (lambda (lambda-form args) (evaluate (subst lambda-form args))))
Looks pretty simple! The one line in the body simply calls the evaluate function recursively with the result of the call to the helper function subst called with the lambda form and the list of evaluated arguments. subst returns the body of the lambda form after performing the substitution. The subst helper will do the work of substituting all free occurrences in the body of the lambda form according to a list of pairs where each formal parameter is bound to the corresponding actual parameter value. Since all procedure calls are call-by-value we never substitute any variable names by other variable names, only by values, which makes life a lot easier when it comes to getting the substitution correct. Before we look at the implementation of subst, let us implement another helper function that is often handy to have, namely the filter function. The filter function takes a predicate function (a function that takes in one argument and returns either #t or #f) and a list of elements that are compatible with the function passed to filter. Example:

14
(filter odd? '(1 2 3 4 5 6 7 8 9)) (1 3 5 7 9)
Where the odd? function could be defined as follows: (define odd? (lambda (x) (= (remainder x 2) 1))) Where (remainder x y) returns the remainder of the integer division x/y. The code for the filter function looks like this:
(define filter (lambda (predicate? lst) (if (null? lst) ’() (if (predicate? (car lst)) (cons (car lst)
(filter predicate? (cdr lst))) (filter predicate? (cdr lst))))))
which is a typical structure for a list processing function. We can now write the subst function, which will call another helper with the body of the lambda form as well as a list of pairs that link the formal parameter of the procedure call to the actual ones. We can create this list by using the map function again. Consider this example:
(map (lambda (x y) (cons x y)) '(x y z) '(1 2 3)) ((x . 1) (y . 2) (z . 3))
If actual-parameters is a list of actual parameters, and formal-parameters a list of formals (which can be obtained as the second element of the lambda form) we can create a list of pairs and call the helper like this:
(define subst (lambda (lambda-form actual-parameters) (let* ((formal-parameters (cadr lambda-form)) ((assoc-args (map (lambda (x y) (cons x y)) formal-parameters
actual-parameters))) (substitute (caddr lambda-form) assoc-args))))

15
Note the use of let* rather than let, this is necessary because the value of formal-parameters is used in the second binding in the let* form. So now we pass the problem on to the substitute function, but at least we are getting there. The substitute function will implement the lambda calculus substitution rules (more or less) , so we need to consider the different cases described above. Let us consider the substitute functions first few lines (recall that it will take in a form and a list of pairs representing the variable bindings of the actual parameters to the formal ones): (define substitute (lambda (form bindings) We now consider the 3 different types of forms that we can have:
1. A value or a variable V. 2. An applications (E E’). 3. A lambda form (λ E. E’).
We are going to use a little trick to deal with variables and values; we shall return to that shortly. The easiest of the three cases is probably the application. Recall that an application is represented as a Scheme list, and according to the substitution rules above we simply perform a substitution in all of the elements in this list. Such a list can contain both variables, values or more complex forms (which are represented as lists, and can be dealt with by a recursive call to substitute). If an element is not a list, we check to see if it has a binding in the binding list, and if it does we substitute the variable name by the corresponding value. The easiest way to do this for each element of a list if of course to use the map function:
(map (lambda (element) (if (list? element) (substitute element bindings) (let ((pair (assv element bindings))) (if pair (cdr pair)
element)))) lst) The above action is what we wish to perform if form is a list and not a lambda form. What if the form is not a list, that is, a variable or a value. The easiest way to deal with this case is to place the variable or value in a list and call recursively and then extract the value out of the returned list using the car function; then the last part of the code above will take care of it, so we get:

16
(car (substitute (list form) bindings)) All we have left to do is to deal with the substitution for lambda forms, and then tie it all together. Remember, the first time the substitute function is called, it will be with a binding list and a body of a procedure, so if this body is a lambda form we only want to substitute the free variables in the this lambda form, or in other words, if this lambda form has any formal parameters in common with the enclosing lambda form, then we want to assure that these do not get substituted incorrectly. We assure this by making a recursive call on the body of the lambda form (which formed the body that we are considering in the first place) but with any binding to a formal that also occurs in the inner lambda form removed. Once we get the result back we can reconstruct the lambda form and return it:
(list 'lambda (cadr form) (substitute (caddr form) (remove-binding bindings (cadr form))))
The entire substitute procedure thus looks like this: (define substitute (lambda (form bindings) (if (list? form) (if (eq? (car form) 'lambda)
(list 'lambda (cadr form) (substitute (caddr form) (remove-binding bindings (cadr form)))) (map (lambda (element)
(if (list? element) (substitute element bindings) (let ((pair (assv element bindings))) (if pair (cdr pair)
element)))) lst)) (car (substitute (list form) bindings)))))
Now we just need to consider the remove-binding procedure. All it needs to do is return the original binding list with any binding whose name is equal to any of the names in the formal parameter list removed:
(define remove-binding (lambda (assoc-lst name-lst)

17
(for-each (lambda (name) (set! assoc-lst (filter (lambda (pair)
(not (eq? (car pair) name))) assoc-lst))) name-lst)
assoc-lst))
We use the for-each function, which behaves just like map, except it does not return anything. For each element in the list of names that we wish to remove from the binding list we perform the (set! ...) line, which updates the binding list with the result of the call to filter. In other words, each call to filter will either return the original binding list, or the original binding list with one pair removed, namely the pair(name . ???) if it exists in the list. We do this filtering for each name, and update the binding list each time using set!, once we are done we return the new binding list. With everything in place we can now write the evaluate function.
The Main Evaluate Function A Scheme form is either of the form V, where V is a name or a number, or of the form (...) which is a list. We consider these two different formats as the first part of the evaluate function.
(define evaluate (lambda (form) (if (list? form) ;; case statement here ;; if statement here )))
Let us deal with the if statement first: Either the form is a number (in which case we call the number-rule function) or it is a name (in which case we call the name-rule function) (if (number? form) (number-rule form) (name-rule form)) The case statement looks like this:
(case (car form) ((define) (define-rule (cadr form) (caddr form)))) ((lambda) form)

18
((if) (if-rule (cadr form) (caddr form) (cadddr form)))
(else (application-rule form))) Note that in our evaluator we really do not do anything to evaluate a lambda form (unless it is being applied!), that is why we do not have a lambda-rule like in The Rules of Evaluation. Note, I put an If Rule in, we will describe this rule shortly. Lastly, we can write a loop to constantly read and evaluate input from the user:
(define loop (lambda () (display "> ") (let ((command (read))) (if (eq? command 'stop) #t (begin (let ((result (evaluate command))) (if (not (void? result)) (display (format "Result: ~a" result))) (loop)))))))
This concludes this little exercise in writing an evaluator. Keep in mind that there is no syntax checking, which of course means that the evaluator will crash if you do not feed it syntactically correct programs. You can restart it with the command (loop).

19
Additional Rules
If Rule A programming language is not much fun if we cannot make choices. So for completeness we add an if statement (just like the if statement in Scheme). The If Rule is simple: Syntax: (if form1 form2 form3) [If Rule] Evaluate form1, if it does not evaluate to #f then evaluate form2 else evaluate form3.
(define if-rule (lambda (test-form true-form false-form) (if (evaluate test-form) (evaluate true-form) (evaluate false-form))))
A small curiosity about the If Rule is that only one of either the true-form or the false-form is evaluate. This can be seen in Scheme by the following:
(define a 1) (define b 1) (if #f (set! a 2) (set! b 2)) a 1 b 2
This means that an if form is not evaluated as a regular application. We call an if form a special form because not all elements are evaluated. The define form is also special as the name part is not evaluated (i.e., not attempted looked up in the environment before it is bound!)

20
Global vs local environments Consider the following Scheme forms:
(define x 1) (define f (lambda (x)
(lambda (y) (set! x (+ x y)) x)))
(define g (f 0)) x 1 (g 10) 10 (g 0) 10 x 1
We first define a global variable x (bound in the global user environment) and assign it the value 1. Next we define a function f, which takes in a parameter x and returns a procedure that accepts one parameter y, adds y to x and returns x. We then define g to be the function returns from a call to f with the value 0 for the parameter x. When we make the call (g 10) the return value is 10 and not 11! Why is that? The x used by g is not the x in the global environment, but the value of the parameter passed to f when g was bound. Thus this parameter x must live somewhere else than the global environment. In our version of the Scheme interpreter (the one we just wrote) we cannot emulate the above! We do not have set! in our implementation (set! is not a part of the λ-calculus). As a matter of fact, if we wish to support functions like set! (which alters an existing variable binding, then we cannot implement the evaluator with call-by-value substitution). We would need to consider the frames that get generated using the droid model presented in lecture. A frame is really an activation record, which holds all the bindings for the formal parameters, and sometimes these frames are not removed when the function call with which they were associated terminate. If a function returns another function that accesses some of the formal parameters like in the above example, the frame is ‘captured’ and kept around. For our evaluator to support such craziness we could need to associate with each binding in the global environment of a function an environment, namely the environment in which it was ‘born’. Most function would be born in the global environment if they are straight forward (define <name> (lambda (…) <body))) function. However, if a function is bound and placed in the global environment (like g is above), but the function is ‘born’ in a different frame (in the case above the function bound to g is born in the frame associated with f), then we must associate this frame with the function. This gives us

21
what is commonly referred to as a static-link. A static link is used for scope-resolution, that is, it tells us where to look for variables when we need them; we first look in the frame in which the function was born, then in its parent’s frame etc. This mimics the well known scoping mechanism known as static scoping found in many languages like C and Java. A substitution based language like the one we just implemented does not have the notion of scoping apart from the global environment and the parameters in a lambda form. This can get pretty hairy, so we will not consider the finer details of this problem, but if we wish to extend our evaluator to support set! like functions, we need to do the following:
1. Associate with each binding of a function the frame it was born in. 2. When applying a function to arguments, and when encountering a name, look
for the name in the associated environment, if nothing is found, look in the environment of the closest enclosing lambda form. Keep doing this until the global user environment is reached, and if the name is not defined in this chain of environments, then the name is not bound.
3. Drop the substitution method for the Procedure Rule. Instead, the Procedure Rule creates a new environment, fills it with bindings and then evaluates the body.
4. Change the Name Rule to work in accordance with 2. For completeness it should be noted that set-car! and set-cdr! works just like set! just operates on pairs and sets the car or the cdr. Furthermore, it should be clear that since a function like set! alters state, it breaks the substitution model as there are no variables kept when substituting the free variables in the body (except for the free variables that are not bound by the binding list of formals to actuals) One last small curiosity arises when we do add an extra parameter representing the environment to all our evaluation functions. In particular consider the problem we get if we change the evaluate function to take in a form as well as an environment: In the Application Rule we map the evaluate function onto the list of forms like this (map evaluate lst), but now we need to add an extra parameter to the evaluate function, namely the environment (let us call it env). Let us experiment with map:
(map evaluate lst) map: arity mismatch for procedure evaluate: expects 2 arguments, given 1
or
(map evaluate lst env) map: all lists must have same size; arguments were: #<procedure:evaluate> (4 5 6) ()

22
The last error message is a little confusing; it just happens that env is in fact a list, but even if env had the right length, it would all be wrong because subsequent uses of env would assume it to be a list of pairs, not just a pair! This can take some time for you to understand, but it is well worth spending a little time on; as I said, map is a very powerful and useful function to know and understand. The correct way of doing it is as follows: (map (lambda (form) (evaluate form env)) lst) By wrapping an anonymous lambda form around the call to evaluate, we get a function that takes one parameter (which map will supply from the list lst), and calls evaluate with 2 parameters: the element supplied by map, and the environment.
Tracing In the discussion of the implementation I did not mention anything about tracing the evaluator. It is an interesting ability to have, but it would have cluttered the description of the implementation, so I left it out. However, in my implementation I have added tracing. Tracing can be turned on and off with the commands (trace on) and (trace off). If you turn trace on you will get information about what the evaluator is currently evaluating. Here is an example showing a trace of the factorial function: > (define fact (lambda (n) (if (= n 0) 1 (* n (fact (- n 1)))))) evaluating '(define fact (lambda (n) (if (= n 0) 1 (* n (fact (- n 1))))))' [Define Rule] evaluating '(lambda (n) (if (= n 0) 1 (* n (fact (- n 1)))))' => #<procedure> > (fact 3) Result: 6 > (trace on) > (fact 3) evaluating '(fact 3)' [Application Rule] | evaluating 'fact' => (lambda (n) (if (= n 0) 1 (* n (fact (- n 1))))) [Name Rule] | evaluating '3' => 3 [Number Rule] | [Procedure Rule] | Substituting in '(if (= n 0) 1 (* n (fact (- n 1))))' with bindings: ((n . 3)) | | Substituting in '(= n 0)' with bindings: ((n . 3)) | | => '(= 3 0)' | | Substituting in '(* n (fact (- n 1)))' with bindings: ((n . 3)) | | | Substituting in '(fact (- n 1))' with bindings: ((n . 3)) | | | | Substituting in '(- n 1)' with bindings: ((n . 3)) | | | | => '(- 3 1)' | | | => '(fact (- 3 1))' | | => '(* 3 (fact (- 3 1)))' | => '(if (= 3 0) 1 (* 3 (fact (- 3 1))))' | evaluating '(if (= 3 0) 1 (* 3 (fact (- 3 1))))' [If Rule] | evaluating '(= 3 0)' [Application Rule] | | evaluating '=' => #<primitive:=> [Name Rule] | | evaluating '3' => 3 [Number Rule] | | evaluating '0' => 0 [Number Rule] | => #f [Primitive Rule] | evaluating '(* 3 (fact (- 3 1)))' [Application Rule] | | evaluating '*' => #<primitive:*> [Name Rule] | | evaluating '3' => 3 [Number Rule]

23
| | evaluating '(fact (- 3 1))' [Application Rule] | | | evaluating 'fact' => (lambda (n) (if (= n 0) 1 (* n (fact (- n 1))))) [Name Rule] | | | evaluating '(- 3 1)' [Application Rule] | | | | evaluating '-' => #<primitive:-> [Name Rule] | | | | evaluating '3' => 3 [Number Rule] | | | | evaluating '1' => 1 [Number Rule] | | | => 2 [Primitive Rule] | | [Procedure Rule] | | Substituting in '(if (= n 0) 1 (* n (fact (- n 1))))' with bindings: ((n . 2)) | | | Substituting in '(= n 0)' with bindings: ((n . 2)) | | | => '(= 2 0)' | | | Substituting in '(* n (fact (- n 1)))' with bindings: ((n . 2)) | | | | Substituting in '(fact (- n 1))' with bindings: ((n . 2)) | | | | | Substituting in '(- n 1)' with bindings: ((n . 2)) | | | | | => '(- 2 1)' | | | | => '(fact (- 2 1))' | | | => '(* 2 (fact (- 2 1)))' | | => '(if (= 2 0) 1 (* 2 (fact (- 2 1))))' | | evaluating '(if (= 2 0) 1 (* 2 (fact (- 2 1))))' [If Rule] | | evaluating '(= 2 0)' [Application Rule] | | | evaluating '=' => #<primitive:=> [Name Rule] | | | evaluating '2' => 2 [Number Rule] | | | evaluating '0' => 0 [Number Rule] | | => #f [Primitive Rule] | | evaluating '(* 2 (fact (- 2 1)))' [Application Rule] | | | evaluating '*' => #<primitive:*> [Name Rule] | | | evaluating '2' => 2 [Number Rule] | | | evaluating '(fact (- 2 1))' [Application Rule] | | | | evaluating 'fact' => (lambda (n) (if (= n 0) 1 (* n (fact (- n 1))))) [Name Rule] | | | | evaluating '(- 2 1)' [Application Rule] | | | | | evaluating '-' => #<primitive:-> [Name Rule] | | | | | evaluating '2' => 2 [Number Rule] | | | | | evaluating '1' => 1 [Number Rule] | | | | => 1 [Primitive Rule] | | | | [Procedure Rule] | | | | Substituting in '(if (= n 0) 1 (* n (fact (- n 1))))' with bindings: ((n . 1)) | | | | | Substituting in '(= n 0)' with bindings: ((n . 1)) | | | | | => '(= 1 0)' | | | | | Substituting in '(* n (fact (- n 1)))' with bindings: ((n . 1)) | | | | | | Substituting in '(fact (- n 1))' with bindings: ((n . 1)) | | | | | | | Substituting in '(- n 1)' with bindings: ((n . 1)) | | | | | | | => '(- 1 1)' | | | | | | => '(fact (- 1 1))' | | | | | => '(* 1 (fact (- 1 1)))' | | | | => '(if (= 1 0) 1 (* 1 (fact (- 1 1))))' | | | | evaluating '(if (= 1 0) 1 (* 1 (fact (- 1 1))))' [If Rule] | | | | evaluating '(= 1 0)' [Application Rule] | | | | | evaluating '=' => #<primitive:=> [Name Rule] | | | | | evaluating '1' => 1 [Number Rule] | | | | | evaluating '0' => 0 [Number Rule] | | | | => #f [Primitive Rule] | | | | evaluating '(* 1 (fact (- 1 1)))' [Application Rule] | | | | | evaluating '*' => #<primitive:*> [Name Rule] | | | | | evaluating '1' => 1 [Number Rule] | | | | | evaluating '(fact (- 1 1))' [Application Rule] | | | | | | evaluating 'fact' => (lambda (n) (if (= n 0) 1 (* n (fact (- n 1))))) [Name Rule] | | | | | | evaluating '(- 1 1)' [Application Rule] | | | | | | | evaluating '-' => #<primitive:-> [Name Rule] | | | | | | | evaluating '1' => 1 [Number Rule] | | | | | | | evaluating '1' => 1 [Number Rule] | | | | | | => 0 [Primitive Rule] | | | | | [Procedure Rule] | | | | | Substituting in '(if (= n 0) 1 (* n (fact (- n 1))))' with bindings: ((n . 0)) | | | | | | Substituting in '(= n 0)' with bindings: ((n . 0)) | | | | | | => '(= 0 0)' | | | | | | Substituting in '(* n (fact (- n 1)))' with bindings: ((n . 0)) | | | | | | | Substituting in '(fact (- n 1))' with bindings: ((n . 0)) | | | | | | | | Substituting in '(- n 1)' with bindings: ((n . 0)) | | | | | | | | => '(- 0 1)' | | | | | | | => '(fact (- 0 1))' | | | | | | => '(* 0 (fact (- 0 1)))' | | | | | => '(if (= 0 0) 1 (* 0 (fact (- 0 1))))' | | | | | evaluating '(if (= 0 0) 1 (* 0 (fact (- 0 1))))' [If Rule] | | | | | evaluating '(= 0 0)' [Application Rule] | | | | | | evaluating '=' => #<primitive:=> [Name Rule] | | | | | | evaluating '0' => 0 [Number Rule] | | | | | | evaluating '0' => 0 [Number Rule] | | | | | => #t [Primitive Rule] | | | | | evaluating '1' => 1 [Number Rule] | | | | => 1 [Primitive Rule] | | => 2 [Primitive Rule]

24
| => 6 [Primitive Rule] Result: 6
Syntax Checking As mentioned earlier, the evaluator that we implemented does not have any syntax checking. This means that the evaluator will crash if you type in a syntactically illegal form. I have added a crude syntax checker to my version of the evaluator. The syntax checker catches the most frequently made errors. It is still fairly easy to break it.
My Evaluator You can download and play with my version, and improve it if you like. It can be obtained from the course website (www.cs.unlv.edu/~matt) under teaching/CS789.
References [Kle35] Kleene, Stephen, A theory of positive integers in formal logic, American Journal of Mathematics, 57 (1935), pp. 153–173 and 219–244 [Ped07] Pedersen, Matt, Lecture Notes for CS789 Fall 2007, 2007

(re
qu
ire
(lib
"tr
ace"
))
;;;
Allo
w t
raci
ng
to
be
tu
rne
d o
n a
nd
off
(define
tra
cin
g
#f
);;
; D
efin
e a
str
ing
to
ho
ld t
he
err
or
me
ssa
ge
s cr
ea
ted
du
rin
g s
ynta
x ch
eck
ing
(define
err
or−
msg
"")
;;;
; U
sed
fo
r fa
ncy
err
or
me
ssa
ge
s(define
typ
e "
");
;;;
;;;
De
fine
a li
st o
f p
rim
itive
s;;
;(define
prim
(lis
t (c
on
s ’+
+)
(
con
s ’−
−)
(
con
s ’/
/)
(co
ns
’* *
)
(co
ns
’= =
)
(co
ns
’> >
)
(co
ns
’< <
)))
;;;
is−
prim
itive
?;;
; −
−−
−−
−−
−−
−−
−−
;;;
De
term
ine
s if
e is
a p
rim
itive
by
loo
kin
g it
up
in t
he
prim
itive
en
viro
nm
en
t ’p
rim
’;;
;(define
is−
prim
itive
?
(lambda
(e
)
(a
ssv
e p
rim
)))
;;;
De
fine
th
e g
lob
al e
nvi
ron
me
nt
(define
en
v (lis
t (c
on
s ’a
42
) (
con
s ’fa
ct ’(
lambda
(n
) (
if
(=
n 0
) 1
(*
n (
fac
t (−
n 1
))))
))))
;;;
;;;
De
fine
ind
en
tatio
n a
nd
ou
tpu
t ro
utin
es
for
the
ou
tpu
t fo
r ;;
; th
e e
valu
ato
r;;
;(define
se
t−e
rro
r−m
sg
(lambda
(m
sg)
(set!
err
or−
msg
msg
)
#
f))
(define
ind
en
t 0
)
(define
ou
tpu
t
(lambda
(st
r in
de
nt?
ne
wlin
e?
)
(
if
tra
cin
g
(
begin
(
if
ind
en
t?
(do
−in
de
nt)
)
(d
isp
lay
str)
(
if
ne
wlin
e?
(n
ew
line
))))
)) (define
do
−in
de
nt
(
lambda
()
(letrec
((m
yin
de
nt
(lambda
(n
)
(
if
(>
n 0
)
(
begin
(d
isp
lay
"| "
)
(m
yin
de
nt
(− n
2))
))))
)
(myi
nd
en
t in
de
nt)
)))
(define
ma
ke−
sub
st−
ou
tpu
t
(lambda
(ls
t)
(
if
(n
ull?
lst)
"";
(if
(n
ull?
(cd
r ls
t))
(fo
rma
t "
~a ::
= ~
a" (
caa
r ls
t) (
cda
r ls
t))
Apr
24,
09
15:1
6P
age
1/8
Sch
emeE
valu
ato
rSu
bst
.scm
(str
ing
−a
pp
en
d (
ma
ke−
sub
st−
ou
tpu
t (lis
t (c
ar
lst)
)) "
, "
(ma
ke−
sub
st−
ou
tpu
t (c
dr
lst)
))))
))
;;;
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
=;;
; =
==
==
RU
LE
IM
PL
EM
EN
TA
TIO
N =
==
==
;;;
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
=
;;;
Initi
aliz
atio
n R
ule
(in
it−ru
le)
;;;
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−;;
; C
lea
rs t
he
glo
ba
l en
viro
nm
en
t. I
f yo
u w
an
t th
e g
lob
al e
nvi
ron
me
nt
to h
old
an
y va
lue
s a
t st
art
−u
p;;
; yo
u c
an
pla
ces
the
m h
ere
;−
);;
;(define
init−
rule
(
lambda
()
(set!
en
v (lis
t (c
on
s ’fa
ct ’(
lambda
(n
) (
begin
(if
(=
n 0
) 1
(*
n (
fact
(−
n
1))
))))
))))
)
;;;
La
mb
da
Ru
le (
lam
bd
a−
rule
);;
; −
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
;;;
As
dis
cuss
ed
a la
mb
da
fo
rm h
as
an
IM
PL
ICIT
be
gin
in it
s b
od
y, s
o w
hy
;;;
no
t ju
st p
ut
an
EX
PL
ICIT
on
e in
th
ere
an
d le
t th
e B
eg
in R
ule
ta
ke
;;;
care
of
bu
sin
ess
.;;
;;;
; E
x. (
lam
bd
a (
x) x
) =
> (
lam
bd
a (
x) (
be
gin
x))
;;;
(define
lam
bd
a−
rule
(
lambda
(la
mb
da
−fo
rm)
(let
((l (
list
’lambda
(ca
dr
lam
bd
a−
form
) (c
on
s ’
begin
(cd
dr
lam
bd
a−
form
))))
)
(o
utp
ut
(fo
rma
t "
=>
~a
[Lam
bda
Rul
e]"
l)
#t
#
t)
l)))
;;;
;;;
Nu
mb
er
Ru
le (
nu
mb
er−
rule
);;
; −
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
;;;
Th
is r
ule
is o
bso
lete
; it
is b
ein
g r
ep
lace
d b
y th
e L
itera
l Ru
le;
this
allo
ws
us
;;;
to u
se s
trin
gs
an
d b
oo
lea
n li
tera
ls t
oo
. T
ho
ug
h w
e d
o n
ot
ha
ve a
wa
y to
co
mp
are
;;;
an
yth
ing
by
nu
mb
ers
un
less
we
imp
lem
en
t st
rin
g−
eq
ua
l?,
an
d a
nd
or.
;;;
(define
nu
mb
er−
rule
(
lambda
(n
um
be
r)
(
begin
(ou
tpu
t (f
orm
at
"=
> ~
a [N
umbe
r R
ule]
" n
um
be
r)
#f
#
t)
nu
mb
er)
))
;;;
;;;
Lite
ral R
ule
(lit
era
l−ru
le)
;;;
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−;;
; S
ee
th
e d
esc
rip
tion
fo
r th
e N
um
be
r R
ule
;;;
(define
lite
ral−
rule
(
lambda
(lit
era
l)
(
begin
(o
utp
ut
(fo
rma
t "
=>
~a
[Lite
ral R
ule]
" lit
era
l)
#f
#
t)
lit
era
l)))
;;;
;;;
Na
me
Ru
le (
na
me
−ru
le)
;;;
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−;;
; A
cce
pts
a n
am
e a
nd
re
turn
s th
e v
alu
e f
rom
th
e e
nvi
ron
me
nt.
;;;
(define
na
me
−ru
le
(lambda
(n
am
e)
(let
((p
air (
ass
v n
am
e e
nv)
))
(if
pa
ir
Apr
24,
09
15:1
6P
age
2/8
Sch
emeE
valu
ato
rSu
bst
.scm
Prin
ted
by
Frid
ay A
pril
24, 2
009
1/4
Sch
emeE
valu
ator
Sub
st.s
cm

(
begin
(ou
tpu
t (f
orm
at
"=
> ~
a [N
ame
Rul
e]"
(cd
r p
air))
#
f
#t
)
(c
dr
pa
ir))
(
let
((p
air (
ass
v n
am
e p
rim
)))
(if
pa
ir
(
begin
(o
utp
ut
(fo
rma
t "
=>
~a
[Nam
e R
ule]
" (c
dr
pa
ir))
#
f
#t
)
(cd
r p
air))
(begin
(d
isp
lay
(fo
rma
t "
refe
renc
e to
und
efin
ed id
entif
ier:
~a"
na
me
))
(ne
wlin
e)
(lo
op
))))
))))
;;;
;;
; P
rim
itive
Ru
le (
prim
itive
−ru
le)
;;;
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−;;
; A
cce
pts
a p
rim
itive
an
d a
list
of
arg
um
en
ts,
an
d a
pp
lies
the
prim
itive
;;;
to t
he
list
of
arg
um
en
ts u
sin
g a
pp
ly.
No
te,
an
d a
nd
or
(wh
ich
we
ha
ve n
ot
;;;
imp
lem
en
ted
ca
nn
ot
be
prim
itive
s a
s S
che
me
do
es
no
t a
llow
th
e u
se o
f ;;
; a
nd
an
d o
r w
ith a
pp
ly ;
−(
;;;
(define
prim
itive
−ru
le
(lambda
(p
rim
itive
arg
um
en
ts)
(let
((r
esu
lt (a
pp
ly p
rim
itive
arg
um
en
ts))
)
(ou
tpu
t (f
orm
at
"=
> ~
a [P
rim
itive
Rul
e]"
resu
lt)
#t
#
t)
re
sult)
))
;;;
;;;
Ap
plic
atio
n R
ule
(a
pp
lica
tion
−ru
le)
;;;
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−;;
; E
valu
ate
s th
e a
rgu
me
nts
an
d c
alls
eith
er
the
prim
itive
ru
le o
r th
e;;
; p
roce
du
re r
ule
. ;;
;(define
ap
plic
atio
n−
rule
(
lambda
(ls
t)
(
let
((p
rim
itive
? (
is−
prim
itive
? (
car
lst)
))
(eva
lua
ted
−a
rgs
(ma
p e
valu
ate
lst)
))
(set!
ind
en
t (−
ind
en
t 2
))
(if
prim
itive
?
(prim
itive
−ru
le (
car
eva
lua
ted
−a
rgs)
(cd
r e
valu
ate
d−
arg
s))
(p
roce
du
re−
rule
(ca
r e
valu
ate
d−
arg
s) (
cdr
eva
lua
ted
−a
rgs)
))))
)
;;;
;;;
Pro
ced
ure
Ru
le (
pro
ced
ure
−ru
le)
;;;
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−;;
; T
he
pro
ced
ure
ru
le c
alls
su
bst
to
pe
rfo
rm t
he
ne
ed
ed
su
bst
itutio
ns
;;;
acc
ord
ing
to
th
e n
ew
pro
ced
ure
ru
le g
ive
n in
th
e h
an
do
ut,
an
d t
he
;;;
calls
eva
lua
te o
n t
he
re
sulti
ng
fo
rm.
;;;
(define
pro
ced
ure
−ru
le
(lambda
(la
mb
da
−fo
rm a
rgs)
(set!
ind
en
t (+
ind
en
t 1
))
(o
utp
ut
(fo
rma
t "
[Pro
cedu
re R
ule]
")
#t
#
t)
(let
((r
esu
lt (e
valu
ate
(su
bst
lam
bd
a−
form
arg
s)))
)
(set!
ind
en
t (−
ind
en
t 1
))
resu
lt)))
;;;
;;;
De
fine
Ru
le (
de
fine
−ru
le)
;;;
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−;;
; E
valu
ate
s th
e a
rgu
me
nt
an
d b
ind
s th
e v
alu
e o
f th
e a
rgu
me
nt
to t
he
na
me
;;;
in t
he
glo
ba
l en
viro
nm
en
t. N
ote
, if
the
na
me
is a
lre
ad
y th
ere
it is
;;
; si
mp
ly u
pd
ate
d u
sin
g s
et−
cdr!
;;;
(define
de
fine
−ru
le
(lambda
(n
am
e f
orm
)
(o
utp
ut
(fo
rma
t "
[Def
ine
Rul
e]")
#
f
#t
)
(
let
((v
alu
e (
eva
lua
te f
orm
))
Apr
24,
09
15:1
6P
age
3/8
Sch
emeE
valu
ato
rSu
bst
.scm
(p
air (
ass
v n
am
e e
nv)
))
(if
pa
ir
(se
t−cd
r! p
air v
alu
e)
(
set!
en
v (c
on
s (c
on
s n
am
e v
alu
e)
en
v)))
)))
;;;
;;;
If R
ule
(if−
rule
);;
; −
−−
−−
−−
−−
−−
−−
−−
−−
;;;
Eva
lua
tes
the
bo
ole
an
exp
ress
ion
an
d b
ase
d o
n t
he
va
lue
eva
lua
tes
;;;
eith
er
the
tru
e−
form
or
the
fa
lse
−fo
rm.
An
if f
orm
is r
ea
lly a
;;
; sp
eci
al k
ind
of
form
ca
lled
a ’s
pe
cia
l fo
rm’ b
eca
use
th
e w
ord
;;;
’if’ i
s n
ot
eva
lua
ted
. T
he
sa
me
is t
rue
fo
r a
de
fine
fo
rm,
the
;;;
keyw
ord
’de
fine
’ is
no
t e
valu
ate
d.
;;;;
(define
if−
rule
(
lambda
(te
st−
form
tru
e−
form
fa
lse
−fo
rm)
(ou
tpu
t (f
orm
at
"[I
f R
ule]
")
#f
#
t)
(if
(e
valu
ate
te
st−
form
)
(e
valu
ate
tru
e−
form
)
(e
valu
ate
fa
lse
−fo
rm))
))
;;;
;;;
Be
gin
Ru
le (
be
gin
−ru
le)
;;;
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−;;
; A
ll a
rgu
me
nts
are
eva
lua
ted
in o
rde
r, a
nd
th
e v
alu
e o
f th
e;;
; la
st e
valu
ate
d f
orm
is r
etu
rne
d.
A b
eg
in f
orm
is s
pe
cia
l to
o,
;;;
the
ke
ywo
rd ’b
eg
in’ i
s n
ot
eva
lua
ted
.(define
be
gin
−ru
le
(lambda
(cm
d−
list)
(ou
tpu
t (f
orm
at
"[B
egin
Rul
e]")
#
f
#t
)
(c
ar
(re
vers
e (
ma
p e
valu
ate
cm
d−
list)
))))
;;;
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
=;;
; =
==
==
= E
ND
OF
RU
LE
IM
PL
EM
EN
TA
TIO
N =
==
==
;;;
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
=
;;;
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
;;;
==
==
= T
HE
MA
IN E
VA
LU
AT
OR
FU
NC
TIO
NS
==
==
=;;
; =
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
=
;;;
;;;
Th
e m
ain
eva
lua
tor
(eva
lua
te)
;;;
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−;;
; (define
eva
lua
te
(lambda
(cm
d)
; fu
nct
ion
ap
plic
atio
n,
prim
itive
ap
plic
atio
n o
r fu
nct
ion
de
finiti
on
?
(o
utp
ut
(fo
rma
t "
eval
uatin
g ’~
a’ "
cm
d)
#t
#
f)
(if
(lis
t? c
md
)
;;;
can
be
on
e o
f: d
efin
e,
lam
bd
a,
if, b
eg
in,
or
an
ap
plic
atio
n
(
case
(ca
r cm
d)
((
define
) (d
efin
e−
rule
(ca
dr
cmd
) (c
ad
dr
cmd
)))
((
lambda
) (begin
(o
utp
ut
(fo
rma
t "
=>
#<
proc
edur
e>")
#
f
#t
)
(la
mb
da
−ru
le c
md
)))
((
if
) (if−
rule
(ca
dr
cmd
) (c
ad
dr
cmd
) (c
ad
dd
r cm
d))
)
((begin
) (
be
gin
−ru
le (
cdr
cmd
)))
(e
lse
(begin
;;;
If n
ot
on
e o
f d
efin
e,
lam
bd
a,
if, o
r b
eg
in
the
n a
pp
lica
tion
(
set!
ind
en
t (+
ind
en
t 2
))
(ou
tpu
t (f
orm
at
"[A
pplic
atio
n R
ule]
")
#f
#
t)
(a
pp
lica
tion
−ru
le c
md
))))
(if
(or
(b
oo
lea
n?
cm
d)
(str
ing
? c
md
) (n
um
be
r? c
md
))
(lite
ral−
rule
cm
d)
;;
; If
th
e c
om
ma
nd
is a
bo
ole
an
, a
nu
mb
er
or
a
strin
g
(n
am
e−
rule
cm
d))
)))
;;
; e
lse
it m
ust
be
a n
am
e
;;;
;;;
Th
e m
ain
re
ad
−e
valu
ate
−p
rin
t lo
op
(lo
op
)
Apr
24,
09
15:1
6P
age
4/8
Sch
emeE
valu
ato
rSu
bst
.scm
Prin
ted
by
Frid
ay A
pril
24, 2
009
2/4
Sch
emeE
valu
ator
Sub
st.s
cm

;;;
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
;;;
1.
Re
ad
a f
orm
;;;
2.
Syn
tax−
che
ck a
nd
eva
lua
te;;
; 3
. P
rin
t th
e r
esu
lt a
nd
re
curs
e;;
;(define
loo
p
(lambda
()
(dis
pla
y "
> "
)
(
let
((c
om
ma
nd
(re
ad
)))
(
if
(e
q?
co
mm
an
d ’s
top
)
#
t
(if
(and
(lis
t? c
om
ma
nd
) (>
(le
ng
th c
om
ma
nd
) 0
) (e
q?
(ca
r co
mm
an
d)
’tra
ce))
(
begin
;;;
switc
he
s tr
aci
ng
on
an
d o
ff
(
set!
tra
cin
g (
eq
? (
cad
r co
mm
an
d)
’on
))
(
loo
p))
(
begin
(if
(n
ot
(syn
tax−
che
ck c
om
ma
nd
))
;;;
che
ck t
he
syn
tax
(or
at
lea
st t
ry!)
(begin
(
dis
pla
y (f
orm
at
"~a
: ~a"
typ
e e
rro
r−m
sg))
(
ne
wlin
e)
(
loo
p))
(let
((r
esu
lt (e
valu
ate
co
mm
an
d))
) ;;
; e
very
thin
g w
as
go
od
, n
ow
eva
lua
te
(if
(n
ot
(vo
id?
re
sult)
)
(if
(st
rin
g?
re
sult)
(
dis
pla
y (f
orm
at
"R
esul
t: \"
~a\"
" re
sult)
) ;;
; st
rin
g lo
ok
be
tte
r w
ith "
" a
rou
nd
(
dis
pla
y (f
orm
at
"R
esul
t: ~a
" re
sult)
)))
(
ne
wlin
e)
(
set!
ind
en
t 0
)
(lo
op
))))
))))
)
;;;
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
=;;
; =
==
==
EN
D O
F T
HE
MA
IN E
VA
LU
AT
OR
FU
NC
TIO
NS
==
==
=;;
; =
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
;;;
==
==
==
==
==
==
==
==
==
==
==
==
==
==
;;;
==
==
= H
EL
PE
R F
UN
CT
ION
S =
==
==
;;;
==
==
==
==
==
==
==
==
==
==
==
==
==
==
;;;
;;;
filte
r;;
; −
−−
−−
−;;
; A
cce
pts
a p
red
ica
te a
nd
a li
st a
nd
re
turn
s a
ll th
e e
lem
en
ts in
th
e
;;;
list
tha
t sa
tisfie
s th
e p
red
ica
te.
;;;
(define
filt
er
(
lambda
(p
red
ica
te?
lst)
(if
(n
ull?
lst)
’()
(if
(p
red
ica
te?
(ca
r ls
t))
(co
ns
(ca
r ls
t) (
filte
r p
red
ica
te?
(cd
r ls
t)))
(filt
er
pre
dic
ate
? (
cdr
lst)
))))
)
;;;
;;;
fold
;;;
−−
−−
;;;
fold
is a
ve
rsio
n o
f a
pp
ly t
ha
t a
llow
s yo
u t
o s
pe
cify
th
e n
eu
tra
l ele
me
nt.
;;;
Exa
mp
le:(
fold
r f
(a b
c d
) e
) =
f(f
(f(f
(e d
) c)
b)
a)
;;;
Th
is is
_re
ally
_ ’f
old
l’ fo
r fo
ld−
left
be
cau
se t
he
ne
utr
al e
lem
en
t a
nd
;;;
the
’re
curs
ion
’ is
left
ass
oci
ativ
e;;
;(define
fo
ld
(lambda
(f
lst
e)
(if
(n
ull?
lst)
e
(f
(fo
ld f
(cd
r ls
t) e
) (c
ar
lst)
))))
Apr
24,
09
15:1
6P
age
5/8
Sch
emeE
valu
ato
rSu
bst
.scm
;;;
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
=;;
; =
==
==
SU
BS
TIT
UT
ION
RE
AL
TE
D P
RO
CE
DU
RE
S =
==
==
;;;
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
=
;;;
;;;
sub
st;;
; −
−−
−−
;;;
Cre
ate
s th
e s
ub
stitu
tion
list
ba
sed
on
th
e f
orm
al p
ara
me
ters
an
d;;
; th
e e
valu
ate
d a
ctu
al p
ara
mte
rs.
;;;
Th
e a
ctu
al s
ub
stitu
tion
is d
on
e b
y th
e h
elp
er
sub
stitu
te.
;;;
(define
su
bst
(
lambda
(la
mb
da
−fo
rm a
ctu
al−
pa
ram
ete
rs)
(let*
((f
orm
al−
pa
ram
ete
rs (
cad
r la
mb
da
−fo
rm))
(a
sso
c−a
rgs
(ma
p c
on
s fo
rma
l−p
ara
me
ters
act
ua
l−p
ara
me
ters
)))
(s
ub
stitu
te (
cad
dr
lam
bd
a−
form
) a
sso
c−a
rgs)
)))
;;;
;;;
sub
stitu
te;;
; −
−−
−−
−−
−−
−;;
; T
his
is w
he
re t
he
act
ua
l su
bst
itutio
n t
ake
s p
lace
.;;
; fo
rms
in li
sts
(re
pre
sen
ting
if,
be
gin
, la
mb
da
etc
) a
re s
ub
stitu
ted
;;;
recu
rsiv
ely
, b
ut
for
lam
bd
a f
orm
s a
ny
ass
oci
atio
ns
in t
he
su
bst
itutio
n;;
; lis
t th
at
ha
ve n
am
es
in c
om
mo
n w
ith t
he
fo
rma
l pa
ram
ters
of
the
lam
bd
a;;
; fo
rm a
re r
em
ove
d.
Th
is in
sure
s th
at
the
ne
w p
roce
du
re r
ule
is o
be
yed
,;;
; th
at
is,
on
ly t
he
fre
e v
aria
ble
s in
th
e b
od
y o
f th
e la
mb
da
fo
rm a
re
;;;
sub
stitu
ted
. R
eca
ll th
at
the
pa
ram
ete
r lis
t b
ind
s th
e f
orm
al p
ara
me
ter
;;;
na
me
s in
th
e b
od
y!;;
;(define
su
bst
itute
(lambda
(fo
rm a
sso
c−ls
t)
(o
utp
ut
(fo
rma
t "
Subs
titut
ing
in ’
~a’
with
bin
ding
s: [
~a]"
fo
rm (
ma
ke−
sub
st−
ou
tpu
t a
sso
c−ls
t))
#t
#
t)
(set!
ind
en
t (+
ind
en
t 2
))
(
let
((r
esu
lt
(if
(lis
t? f
orm
) ;;
; if
form
is a
list
(if
(e
q?
(ca
r fo
rm)
’lambda
) ;;
is t
he
lst
a la
mb
da
fo
rm
(lis
t ’
lambda
(ca
dr
form
) (s
ub
stitu
te (
cad
dr
form
) (r
em
ove
−b
in
din
g a
sso
c−ls
t (c
ad
r fo
rm))
))
;; y
es
;; c
rea
te a
ne
w la
mb
da
fo
rm w
ith t
he
sa
me
fo
rma
l pa
ram
ete
r li
st,
;; a
nd
a b
od
y su
bje
ct t
o s
ub
stitu
tion
, b
ut
wh
ere
an
y fo
rma
l pa
ram
ete
rs f
rom
th
is
;;
lam
bd
a f
orm
ha
ve b
ee
n R
EM
OV
ED
fro
m t
he
bin
din
g li
st.
(
ma
p (
lambda
(e
lem
en
t)
;;
no
, so
su
bst
itute
in t
he
en
tire
lis
t
(su
bst
itute
ele
me
nt
ass
oc−
lst)
) fo
rm))
(
let
((p
air (
ass
v fo
rm a
sso
c−ls
t)))
;;
els
e lo
ok
in t
he
ass
oc
tab
le
(if
pa
ir
;; w
as
the
va
ria
ble
na
me
th
ere
?
(
cdr
pa
ir)
;;
ye
s, t
he
n r
etu
rn t
he
su
bst
itute
d v
al
ue
fo
rm))
)))
;;
els
e p
ut
the
ele
me
nt
in a
list
an
d c
all
recu
rsiv
ely
,
;; a
nd
ta
ke t
he
ca
r e
lem
en
t o
ut
an
d r
etu
rn it
.
(set!
ind
en
t (−
ind
en
t 2
))
(ou
tpu
t (f
orm
at
"=
> ’
~a’"
re
sult)
#
t
#t
)
resu
lt)))
;;;
;;;
rem
ove
−b
ind
ing
;;;
−−
−−
−−
−−
−−
−−
−−
;;;
He
lpe
r p
roce
du
re t
ha
t re
mo
ves
bin
din
g e
lem
en
ts f
rom
th
e b
ind
ing
list
;;;
ba
sed
on
a li
st o
f fo
rma
l pa
ram
ete
r n
am
es.
;;;
(define
re
mo
ve−
bin
din
g
(lambda
(a
sso
c−ls
t n
am
e−
lst)
(ou
tpu
t (f
orm
at
"R
emov
ing
bind
ings
for
~a
in ~
a" n
am
e−
lst
ass
oc−
lst)
#
t)
Apr
24,
09
15:1
6P
age
6/8
Sch
emeE
valu
ato
rSu
bst
.scm
Prin
ted
by
Frid
ay A
pril
24, 2
009
3/4
Sch
emeE
valu
ator
Sub
st.s
cm

(ne
wlin
e)
(fo
r−e
ach
(lambda
(n
am
e)
(set!
ass
oc−
lst
(filt
er
(lambda
(p
air)
(n
ot
(eq
? (
car
pa
ir)
na
me
)))
ass
oc−
lst
)))
na
me
−ls
t)
a
sso
c−ls
t))
;;;
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
;;;
==
==
= E
ND
OF
SU
BS
TIT
UT
ION
RE
AL
TE
D P
RO
CE
DU
RE
S =
==
==
;;;
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
;;;
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
;;;
==
==
= S
YN
TA
X C
HE
CK
ING
PR
OC
ED
UR
ES
==
==
=;;
; =
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
=
(define
is−
form
?
(lambda
(e
xp)
(syn
tax−
che
ck e
xp))
)
(define
is−
pa
ram
−lis
t?
(lambda
(ls
t)
(f
old
(lambda
(x
y) (
and
x y
)) (
ma
p is
−n
am
e?
lst)
#
t))
) ;;
; T
his
is h
ow
yo
u
’ap
ply
’ with
an
d a
nd
or
;−)
(define
is−
na
me
?
(lambda
(fo
rm)
(if
(and
(sy
mb
ol?
fo
rm)
(no
t (n
um
be
r? f
orm
)))
#t
(se
t−e
rro
r−m
sg (
form
at
"N
ot a
n id
entif
ier
’~a’
." f
orm
))))
)
(define
is−
lam
bd
a?
(
lambda
(fo
rm)
(set!
typ
e "
lam
bda"
)
(
if
(n
ot
(= (
len
gth
fo
rm)
3))
(se
t−e
rro
r−m
sg (
form
at
"ba
d sy
ntax
in: ~
a" f
orm
))
(
if
(n
ot
(is−
pa
ram
−lis
t? (
cad
r fo
rm))
)
#
f
(
if
(n
ot
(is−
form
? (
cad
dr
form
)))
(se
t−e
rro
r−m
ess
ag
e (
form
at
"ba
d sy
ntax
(no
t a f
orm
) in
: ~a"
(ca
dd
r fo
rm))
)
#
t))
)))
(define
is−
be
gin
?
(lambda
(fo
rm)
(set!
typ
e "
begi
n")
(fo
ld (
lambda
(x
y) (
and
x y
)) (
ma
p is
−fo
rm?
(cd
r fo
rm))
#
t))
)
(define
is−
de
fine
?
(lambda
(fo
rm)
(set!
typ
e "
defi
ne")
(if
(n
ot
(= (
len
gth
fo
rm)
3))
(se
t−e
rro
r−m
sg (
form
at
"ba
d sy
ntax
(m
ultip
le e
xpre
ssio
n af
ter
iden
tifie
r in
: ~a"
fo
rm))
(if
(n
ot
(is−
na
me
? (
cad
r fo
rm))
)
(s
et−
err
or−
msg
(fo
rma
t "
bad
synt
ax in
: ~a"
(ca
dr
form
)))
(if
(n
ot
(is−
form
? (
cad
dr
form
)))
(se
t−e
rro
r−m
sg (
form
at
"ba
d sy
ntax
(no
t a f
orm
) in
: ~a"
(ca
dd
r fo
rm))
)
#
t))
)))
(define
is−
if?
(lambda
(fo
rm)
(set!
typ
e "
if")
(if
(n
ot
(= (
len
gth
fo
rm)
4))
(se
t−e
rro
r−m
sg (
form
at
"ba
d sy
ntax
in: ~
a" f
orm
))
(
if
(n
ot
(is−
form
? (
cad
r fo
rm))
)
(
set−
err
or−
msg
(fo
rma
t "
bad
synt
ax (
not a
for
m)
in: ~
a" (
cad
r fo
rm))
)
(
if
(n
ot
(is−
form
? (
cad
dr
form
)))
(se
t−e
rro
r−m
sg (
form
at
"ba
d sy
ntax
(no
t a f
orm
) in
: ~a"
(ca
dd
r fo
rm))
)
(
if
(n
ot
(is−
form
? (
cad
dd
r fo
rm))
)
(
set−
err
or−
msg
(fo
rma
t "
bad
synt
ax (
not a
for
m)
in: ~
a" (
cad
dr
form
)))
Apr
24,
09
15:1
6P
age
7/8
Sch
emeE
valu
ato
rSu
bst
.scm
#
t))
))))
(define
is−
ap
plic
atio
n?
(
lambda
(fo
rm)
(fo
ld (
lambda
(x
y) (
and
x y
)) (
ma
p is
−fo
rm?
fo
rm)
#t
)))
(define
syn
tax−
che
ck
(lambda
(fo
rm)
(if
(lis
t? f
orm
)
(
if
(=
(le
ng
th f
orm
) 0
)
(
begin
(
set!
typ
e "
appl
icat
ion"
)
(se
t−e
rro
r−m
sg (
form
at
"ba
d sy
ntax
in: ~
a" f
orm
)))
(case
(ca
r fo
rm)
((
define
) (is−
de
fine
? f
orm
))
((lambda
) (is−
lam
bd
a?
fo
rm))
((
if
)
(is−
if?
f
orm
))
((begin
) (
is−
be
gin
?
form
))
(els
e
(
is−
ap
plic
atio
n?
fo
rm))
))
(
or
(n
um
be
r? f
orm
) ;;
nu
mb
ers
(sym
bo
l? f
orm
) ;;
na
me
s
(s
trin
g?
fo
rm))
)))
;;;
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
;;;
==
==
= E
ND
OF
SY
NT
AX
CH
EC
KIN
G R
UL
ES
==
==
=;;
; =
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
=
(in
it−ru
le)
;;;
initi
aliz
e(lo
op
)
;;;
GO
!
Apr
24,
09
15:1
6P
age
8/8
Sch
emeE
valu
ato
rSu
bst
.scm
Prin
ted
by
Frid
ay A
pril
24, 2
009
4/4
Sch
emeE
valu
ator
Sub
st.s
cm

A Simple Scheme Evaluator Using Environments
© Matt Pedersen, University of Nevada, Las Vegas, 2007
Introduction This document is a follow up on the simple substitution evaluator presented earlier. The reason for this document (and a new version of the evaluator that uses environments) arose from the fact that there seemed to be certain inconsistencies between the substitution evaluator, and the droid model. The rules of evaluation were presented as the way to evaluate Scheme forms, but alongside the droid model was used as well. Consider a Scheme form like this: > (define f (lambda (x) (lambda (y) (+ x y)))) > (define g (f 10)) > (g 3) 13 > (g 5) 15 Using the droid model it was clear that the value for x ‘remained’ somewhere to be used for any subsequent calls to g. This in itself did not necessarily pose a problem as the above sequence of steps would work fine in the substitution evaluator. Namely by having g be the form (lambda (y) (+ 10 y)). But now what happens if we change the inner most lambda form slightly: > (define f (lambda (x) (lambda (y) (set! x (+ x y)) x))) > (define g (f 0)) > (g 5) 5 > (g 6) 11 We see that the value of x changes as g is called. We have introduced the notion of state change by the use of the set! function. Now this sequence of forms would not work in the substitution evaluator. The reason is of course that x no longer exists in g. x has been replaced by the value passed to f. There is no longer a binding between x and the value. If such a binding does not exist then we cannot change the value. So if we wish to be able to change values using set! we need to introduce environments (in other languages

these are referred to as activation record). Each evaluation of a form must take place with respect to an environment. In the substitution evaluator we only had the global and the primitive environments. Now we need to introduce a new environment with each application of the procedure rule! Like in imperative languages when a procedure is called, an activation record which maps formal parameters to their actual values, so must the environments associated with the application of a Scheme function to a set of values. Let us start by defining what an environment is and some functions to operate on them.
Environment Related Functions First we need to provide some functions that can handle the creating of environments and the searching for names in the chain of linked environments. Firstly, consider make-new-environment: (define make-new-environment (lambda (bindings old-env) (cons bindings old-env)))) which takes in a list of bindings (pairs) and the old environment, and returns a new environment with the binding list and the old environment as the parent. To look for a name in an environment, we search backwards through the chain of linked environments until we reach the primitive environment. If we do not find the name in any of the visited frames we can return #f. Else we return the pair (name . value). Note, if we just returned the value, then if we were looking for a Boolean variable with the value #f we would not be able to determine if we did not find the variable of it just happened to have the value #f. (define lookup-in-environment (lambda (name env) (if (eq? env 'null) #f (let ((pair (assv name (car env)))) (if pair pair (lookup-in-environment name (cdr env))))))) Note the use of the symbol null as the end marker for the chain of symbol tables. With this in place we can now consider the new Rules of Evaluation.

The Rules of Evaluation---The Environment Way. The following is a recap of the original rules of evaluation with the new procedure rule that we developed added:
• [Initialization Rule]: The environment initially contains only the built-in primitives.
• [Number Rule]: A numerals value is a number interpreted in base 10. • [Name Rule]: A name is evaluated by substituting the value bound to it in the
environment. o It does not matter if it is user defined or a name of a primitive procedure. o If the name does not exist in the environment when the form is evaluated,
an error is produced. • [Lambda Rule]: The value of a lambda-form is a procedure with parameters and
a body. • [Application Rule]: An application is evaluated by evaluating each of its
elements (Using the Rules) and then use o The Primitive rule if the operator is a primitive. o The Procedure rule if the operator is a procedure.
• [Primitive Rule]: Invoke the built-in primitive with the given arguments • [Procedure Rule]: A procedure application is evaluated in 2 steps:
o In the body of the procedure, replace each of the free formal parameters by its corresponding actual arguments.
o Replace the entire procedure by the body. • [Definition Rule]: The 2nd argument is evaluated. The 1st is not evaluated and
must be a name. The name/value pair is added to the environment. The Initialization rule will not change; we start with an empty global environment, which has a parent that points to the primitive environment, which does not have a parent. (parent is set to the symbol null). The Number Rule has been replaced by a Literal Rule, this way we can use Booleans and strings as well. The Name rule basically still works the same way, we just need to be a little more specific: [Name Rule]: A name is evaluated by substituting the value bounds to it in the environment:
• It does not matter if it is user defined or a name of a primitive procedure. • The search for the name starts in the environment associated with the function
currently being evaluated (i.e., the closest enclosing lambda form, using static scoping rules!), if the name is not found here, the search continues in the environment of the parent etc, until the primitive environment is reached.
• If the name does not exist in any of the environments visited, and error is produced.
The Lambda Rule has not changed either, except that when the Lambda Rule is applied to a textual lambda form, the lambda form must record which environment this evaluation (application of the Lambda Rule) took place, for this is the environment that the lambda

form’s environment (when evaluated) must have as a parent. We return to the technical details about how to record this later. The Application and the Primitive Rules are left unchanged, but the Procedure rule must be changed as follows: [Procedure Rule]: A procedure application is evaluated in 2 steps:
• Create a new environment (initially blank), which has the current environment as its parent.
• Fill the environment with the bindings of the formal parameters to their corresponding actual parameters.
• Evaluate the body of the procedure using this newly created environment. The Definition Rule does not change either, and the extra rules, such as If Rule and Begin rule do not change either.
Implementing the New Rules of Evaluation We can now proceed to implementing the new evaluation functions, but first of all let us consider the header for the new version of the evaluate function: (define evaluate (lambda (form env) ... If you compare to the old version you will realize that we are not taking an environment as the second parameter. This is the environment where all applications of the Name Rule must start the search.
The Initialization Rule The Initialization Rule is virtually unchanged. The biggest change is the fact that we link the global environment to the primitive (this makes the implementation of the Name Rule must cleaner): (define init-rule (lambda () (set! global-env (cons '() prim))))

The Literal Rule The Literal Rule is the replacement for the Number rule; though the code is exactly the same, the name is more appropriate. (define literal-rule (lambda (literal) literal))
The Lambda Rule The Lambda Rule is the first rule where a major change has happened. In the substitution version of the evaluator, the Lambda Rule was simply the identity function; nothing was done to the lambda-form. In this new version we need to record the environment in which the Lambda Rule was applied and keep it with the lambda for all time. When the lambda-form is evaluated it must run in a new environment which has, as its parent, this recorded environment. If you think about it and draw some pictures, you will realize that this preserves the static scoping rules. Also note, if a function could not return another function there would be no need for this trick, as no environments could be captured by returning functions. The code looks like this: (define lambda-rule (lambda (lambda-form env) (list 'lambda (cadr lambda-form) (cons 'begin (cddr lambda-form)) env))) We now represent an evaluated lambda form as a 4-tuple, with the 4th entry being the environment in which this lambda-form was evaluated, and thus turned into a procedure. (Note, we still place an explicit being in the body of the lambda-form, as we did in the old version).

The Name Rule Implementing the new Name Rule is simple; we just need to use the helper function for looking through the chain of environments that we already defined: (define name-rule (lambda (name env) (let ((pair (lookup-in-environment name env #t))) (if pair (cdr pair) (begin (display (format "reference to undefined identifier: ~a" name)) (newline) (loop))))))
The Primitive Rule The Primitive Rule has not changed at all, but for good measure, here is the original code: (define primitive-rule (lambda (primitive arguments) (apply primitive arguments)))
The Application Rule The only change to the Application Rule is the new 2nd parameter, the environment, in which the evaluation should take place: (define application-rule (lambda (lst env) (let ((primitive? (is-primitive? (car lst))) (evaluated-args (map (lambda (form)
(evaluate form env)) lst)))
(if primitive? (primitive-rule (car evaluated-args) (cdr evaluated-args)) (procedure-rule (car evaluated-args) (cdr evaluated-args))))))

The Procedure Rule Let us briefly consider the old version of the Procedure Rule: (define procedure-rule (lambda (lambda-form args) (evaluate (subst lambda-form args)))) which by textual standards was pretty small. Though, remember how much work was done in the helper procedures of subst, substitute, and remove-bindings. The new Procedure Rule must set up a new environment with all the bindings of the formal parameters to the actual parameters and with its parent environment being that one that is passed in to the Procedure Rule. We can create the binding list by using map in the following way: (map cons (cadr lambda-form) args) Where (cadr lambda-form) is the formal parameter list, and args is a list of equal length with the actual parameters (already evaluated). We can then use make-environment to create the new environment passing it the binding list and the environment associated with the lambda-form: (define procedure-rule (lambda (lambda-form args) (let* ((env (cadddr lambda-form)) (new-env (make-environment (map cons (cadr lambda-form) args) env))) (evaluate (caddr lambda-form) new-env)))) Note the simplicity of this code, the only helper we call could have been replaced by a one-liner, and no other helpers are needed. We have completely removed the need for any substitution.

The Define Rule The Define Rule seems pretty easy at first, just add en environment and off you go. However, we must be a little careful with the use of state mutation. Recall that the last three lines of the old Define Rule looked like this: (if pair (set-cdr! pair value) (set! global-env (cons (cons name value) global-env))) First of we note that if the pair is found we update the cdr of the binding pair; that should be fine and not cause any problems, so we can retain that code. Now consider what happens if we have the following scheme code: (define f (lambda (x) (lambda (y) (+ x y a)))) (define g (f 3)) (define a 3) Naturally this code should work, but it does not. The problem is as follows: The binding list after evaluating the first define is (f . (lambda (y) (+ x y a))), which is represented as a pair, f in the car, the lambda form in the cdr. The global-env variable point to this pair, which means that when the lambda form is evaluated by the Lambda Rule, it will record the global environment as its parent frame. What actually happens is that a copy of the ‘arrow’ in the value column of the environment is created, and the associated environment is empty (which is incorrect, it should contain f itself!). To further complicate things, when we evaluate f, a new environment is created, which has a parent environment, which should contain f, but it does not. After the 3rd define, if we look at the global environment it does indeed contain 3 definitions: f, g and a; but when evaluating g we fail to look up a; this is because we probably forgot that when copying something that is a list, we only copy the arrow, which means that adding things to the front of the environment is NOT a good idea; this will not update all other references to the global environment as these would all point to the same first element of the list. To solve this problem we simply add things to the end of the environment, and thus we get: (define define-rule (lambda (name form env) (let ((value (evaluate form env)) (pair (lookup-in-environment name global-env))) (if pair (set-cdr! pair value) (set-car! global-env (append (car global-env) (list (cons name value)) ))))))

set-car! is used because an environment is now a pair!
The If Rule The only change to the If Rule is the addition of the environment as a parameter: (define if-rule (lambda (test-form true-form false-form env) (if (evaluate test-form env) (evaluate true-form env) (evaluate false-form env))))
The Begin Rule The same goes for the Begin Rule (define begin-rule (lambda (cmd-list env) (car (reverse (map (lambda (form)
(evaluate form env)) cmd-list)))))
The Main Evaluator Function The main evaluate function has not changed much either; most calls have an extra environment parameter. (define evaluate (lambda (cmd env) (if (list? cmd) (case (car cmd) ((define) (define-rule (cadr cmd)
(caddr cmd) global-env)) ((lambda) (lambda-rule cmd env)) ((if) (if-rule (cadr cmd) (caddr cmd)
(cadddr cmd) env)) ((begin) (begin-rule (cdr cmd) env)) (else (application-rule cmd env))) (if (or (boolean? cmd) (string? cmd) (number? cmd)) (literal-rule cmd) (name-rule cmd env)))))

These are the changes needed to turn the evaluator into an environment based evaluator rather than a substitution based evaluator.
Adding more Functionality Now that we have done all the hard work let us try to make the language that we interpret a little more exciting. We start by adding the let and let* special forms to the evaluator.
Let/Let* Rule We can now easily add a let form to our evaluator. Remember the identity (let ((n1 f1) (n2 f2) ... (nk fk)) body) is equivalent to ((lambda (n1 n2 ... nk) body) f1 f2 ... fk) We do have to be a little careful. First let us consider a let form without binding elements list this example: (let () 1 2 3 4) There is no need to rewrite that to ((lambda () 1 2 3 4)) which then get evaluated to ((lambda () (begin 1 2 3 4)), we might as well just evaluate (begin 1 2 3 4) right away. For let forms with elements in the binding list we will rewrite according to the above formula. It is a little tricky to avoid getting an extra set (or two or more) brackets around the body, so we must be careful when we do the actual coding. If we map the car function on to the list of binding elements we get the list of formal parameters for the new lambda form, and if we map the cadr function on to the same list we get the list of forms that will serve as the argument to the newly created anonymous lambda form.

(define let-rule (lambda (let-form env) (output (format "[Let Rule]") #f #t) (let ((binding-list (cadr let-form))) (if (null? Binding-list) (evaluate (cons 'begin (cddr let-form)) env) ;;; (let () b) => (begin b) (evaluate (cons (append (list 'lambda ;;; ((� (map car binding-list)) ;;; (n1 n2 ... nk) (cddr let-form)) ;;; b (map cadr binding-list)) ;;; ) f1 f2 ... fk) env))))) What about a let* rule? That is not a problem either if we recall the let* rewriting rule: (let* () body) := (begin body) (let* ((n1 v1) ... (nk vk)) body) := ((lambda (n1) (let* ((n2 v2) ... (nk vk)) body) ) v1) We can then easily write up the let*-rule like this: (define let*-rule (lambda (let*-form env) (if (null? (cadr let*-form)) (evaluate (cons 'begin (cddr let*-form)) env) (evaluate (let*-helper let*-form) env)))) Of course we now need to specify the helper; again this is a little more complicated as we have to be careful about not wrapping the body of the last rewrite in an extra set of brackets, so let us introduce another let* identity to the list of the two we had above: (let* ((n v)) body) := (let ((n v)) body) Note that in the code we manage to avoid the extra bracket by using append. We wish to use this rule in the helper if there is only one element in the binding list; this can be checked checking if the length of the binding list is equal to 1. If this is the case

we use the new rewriting rule introduced above. If the binding list does not have length 1 we rewrite as specified originally in the second of the first two rewriting rules above. The entire helper thus looks like this: (define let*-helper (lambda (let*-form) (let ((binding-list (cadr let*-form))) (if (= 1 (length binding-list)) (append (list 'let binding-list)
(cddr let*-form)) (list 'let (list (car binding-list)) (let*-helper (append (list 'let* (cdr binding-list)) (cddr let*-form)))))))) Now consider this example: > (let ((f (lambda (x) (if (= x 0) 1 (* x (f (- x 1))))))) (f 4)) evaluating '(let ((f (lambda (x) (if (= x 0) 1 (* x (f (- x 1))))))) (f 4))' in (() -> parent) [Let Rule] evaluating '((lambda (f) (f 4)) (lambda (x) (if (= x 0) 1 (* x (f (- x 1))))))' in (() -> parent) [Application Rule] | evaluating '(lambda (f) (f 4))' in (() -> parent) => #<procedure> | => (� (f) (begin (f 4))) [Lambda Rule] | evaluating '(lambda (x) (if (= x 0) 1 (* x (f (- x 1)))))' in (() -> parent) => #<procedure> | => (� (x) (begin (if (= x 0) 1 (* x (f (- x 1)))))) [Lambda Rule] | [Procedure Rule] | evaluating '(begin (f 4))' in (((f := (� (x) ...))) -> parent) [Begin Rule] | | evaluating '(f 4)' in (((f := (� (x) ...))) -> parent) [Application Rule] | | | evaluating 'f' in (((f := (� (x) ...))) -> parent) | | | | Looking for 'f' in (((f := (� (x) ...))) -> parent) | | | => (� (x) (begin (if (= x 0) 1 (* x (f (- x 1)))))) [Name Rule] | | | evaluating '4' in (((f := (� (x) ...))) -> parent) => 4 [Literal Rule] | | [Procedure Rule] | | evaluating '(begin (if (= x 0) 1 (* x (f (- x 1)))))' in (((x := 4)) -> parent) [Begin Rule] | | | evaluating '(if (= x 0) 1 (* x (f (- x 1))))' in (((x := 4)) -> parent) [If Rule] | | | evaluating '(= x 0)' in (((x := 4)) -> parent) [Application Rule] | | | | evaluating '=' in (((x := 4)) -> parent) | | | | | Looking for '=' in (((x := 4)) -> parent) | | | | | Looking for '=' in (() -> parent) | | | | | Looking for '=' in (((+ := #<primitive:+>) ... ) -> parent) | | | | => #<primitive:=> [Name Rule] | | | | evaluating 'x' in (((x := 4)) -> parent) | | | | | Looking for 'x' in (((x := 4)) -> parent) | | | | => 4 [Name Rule] | | | | evaluating '0' in (((x := 4)) -> parent) => 0 [Literal Rule] | | | => #f [Primitive Rule] | | | evaluating '(* x (f (- x 1)))' in (((x := 4)) -> parent) [Application Rule] | | | | evaluating '*' in (((x := 4)) -> parent)

| | | | | Looking for '*' in (((x := 4)) -> parent) | | | | | Looking for '*' in (() -> parent) | | | | | Looking for '*' in (((+ := #<primitive ...) -> parent) | | | | => #<primitive:*> [Name Rule] | | | | evaluating 'x' in (((x := 4)) -> parent) | | | | | Looking for 'x' in (((x := 4)) -> parent) | | | | => 4 [Name Rule] | | | | evaluating '(f (- x 1))' in (((x := 4)) -> parent) [Application Rule] | | | | | evaluating 'f' in (((x := 4)) -> parent) | | | | | | Looking for 'f' in (((x := 4)) -> parent) | | | | | | Looking for 'f' in (() -> parent) | | | | | | Looking for 'f' in (((+ := #<primitive:+>) ...) -> parent) reference to undefined identifier: f
Assignment Can you explain what went wrong? Or in other words, can you explain why there is a need for a letrec version of the let/let* keyword? Try to rewrite the let as a lambda, and draw the environment diagrams for the application. When drawing the anonymous lambda functions they will not have anything pointing to them immediately (one will never), but they both should point to the environment in which they were evaluated (i.e., in the environment in which the lambda rule was applied). Keep in mind that letrec should allow the binding of recursive functions, but apart from that it works just like a let*. That is, if you are not binding any recursive functions, the letrec can be replaced by a let*.
Changing state Now that we have gone through all this trouble to introduce state, we should implement the set! operator. Let us start by writing a function that traverses through a list of environments looking for a name and if it is found it updates it: (define set-in-environment (lambda (name env value) (if (eq? env 'null) #f (let ((pair (assv name (car env)))) (if pair (begin (set-cdr! pair value) #t) (set-in-environment name (cdr env) value))))))

If we ever hit the parent of the primitive environment (the null symbol) we return #f, else we look in the current environment using assv, if we find what we are looking for then set the cdr of that pair (i.e., the value) to the new value and return #t; else look in the parent environment (that is the recursive call). Now all we have to do in the set! rule is evaluate the value by a recursive call to evaluate, and then call the above helper; if it returns #t everything went well, if it returns #f the name was not found, and we can produce an error: (define set!-rule (lambda (set!-form env) (let ((name (cadr set!-form)) (value (evaluate (caddr set!-form) env))) (if (set-in-environment name env value) (void) (begin (display (format "set!: cannot set undefined identifier: ~a" name)) (newline) (loop)))))) We now just add the new rules to the main evaluator: ((let) (let-rule cmd env)) ((let*) (let*-rule cmd env)) ((letrec) (letrec-rule cmd env)) ((set!) (set!-rule cmd env))
Conclusion We have succeeded in implementing an environment based evaluator that allows state change, and we have implemented a few new forms. You can download the entire evaluator from my website at http://www.cs.unlv.edu/~matt under teaching → CSC789.

(re
qu
ire
(lib
"tr
ace"
))
;;;
Allo
w t
raci
ng
to
be
tu
rne
d o
n a
nd
off
(define
tra
cin
g
#f
);;
; D
efin
e a
str
ing
to
ho
ld t
he
err
or
me
ssa
ge
s cr
ea
ted
du
rin
g s
ynta
x ch
eck
ing
(define
err
or−
msg
"")
;;;
; U
sed
fo
r fa
ncy
err
or
me
ssa
ge
s(define
typ
e "
");
(define
se
t−e
rro
r−m
ess
ag
e
(lambda
(m
ess
ag
e)
(set!
err
or−
msg
me
ssa
ge
)))
;;;
;;;
En
viro
nm
en
t re
late
d f
un
ctio
n;;
;(define
ma
ke−
ne
w−
en
viro
nm
en
t
(lambda
(b
ind
ing
s o
ld−
en
v)
(c
on
s b
ind
ing
s o
ld−
en
v)))
(define
loo
kup
−in
−e
nvi
ron
me
nt
(
lambda
(n
am
e e
nv
tra
ce?
)
(
if
(e
q?
en
v ’n
ull)
#f
(begin
(
if
tra
ce?
(o
utp
ut
(fo
rma
t "
Loo
king
for
’~a
’ in
~a"
na
me
(p
rett
y−e
nvi
ron
me
nt
en
v))
#t
#
t))
(
let
((p
air (
ass
v n
am
e (
car
en
v)))
)
(
if
pa
ir
p
air
(lo
oku
p−
in−
en
viro
nm
en
t n
am
e (
cdr
en
v) t
race
?))
))))
)
(define
se
t−in
−e
nvi
ron
me
nt
(
lambda
(n
am
e e
nv
valu
e t
race
?)
(if
(e
q?
en
v ’n
ull)
#f
(begin
(
if
tra
ce?
(o
utp
ut
(fo
rma
t "
Loo
king
for
’~a
’ in
~a"
na
me
(p
rett
y−e
nvi
ron
me
nt
en
v))
#t
#
t))
(
let
((p
air (
ass
v n
am
e (
car
en
v)))
)
(
if
pa
ir
(
begin
(s
et−
cdr!
pa
ir v
alu
e)
(o
utp
ut
(fo
rma
t "
Setti
ng ~
a to
~a!
" n
am
e v
alu
e)
#t
#
t)
#
t)
(se
t−in
−e
nvi
ron
me
nt
na
me
(cd
r e
nv)
va
lue
tra
ce?
))))
)))
(define
pre
tty−
en
viro
nm
en
t
(lambda
(e
nv)
(lis
t (m
ap
(lambda
(n
v)
(lis
t n
’:=
v))
(m
ap
ca
r (c
ar
en
v))
(
ma
p (
lambda
(x)
(if
(lis
t? x
)
(lis
t ’λ
(ca
dr
x) ’.
..)
x)
)
(m
ap
cd
r (c
ar
en
v)))
)
’−>
’p
are
nt)
))
;;;
;;;
De
fine
a li
st o
f p
rim
itive
s;;
;(define
prim
(co
ns
(lis
t (c
on
s ’+
+)
(co
ns
’− −
)
Apr
24,
09
15:1
6P
age
1/11
Sch
emeE
valu
ato
rEn
v.sc
m
(
con
s ’/
/)
(
con
s ’*
*)
(co
ns
’= =
)
(
con
s ’>
>)
(co
ns
’< <
)) ’n
ull)
)
;;;
is−
prim
itive
?;;
; −
−−
−−
−−
−−
−−
−−
;;;
De
term
ine
s if
e is
a p
rim
itive
by
loo
kin
g it
up
in t
he
prim
itive
en
viro
nm
en
t ’p
rim
’;;
;(define
is−
prim
itive
?
(lambda
(e
)
(a
ssv
e (
car
prim
))))
;;;
De
fine
th
e g
lob
al e
nvi
ron
me
nt
(define
glo
ba
l−e
nv
(co
ns
’()
prim
))
;;;
;;;
De
fine
ind
en
tatio
n a
nd
ou
tpu
t ro
utin
es
for
the
ou
tpu
t fo
r ;;
; th
e e
valu
ato
r;;
;(define
se
t−e
rro
r−m
sg
(lambda
(m
sg)
(set!
err
or−
msg
msg
)
#
f))
(define
ind
en
t 0
)
(define
ou
tpu
t
(lambda
(st
r in
de
nt?
ne
wlin
e?
)
(
if
tra
cin
g
(
begin
(
if
ind
en
t?
(do
−in
de
nt)
)
(d
isp
lay
str)
(
if
ne
wlin
e?
(n
ew
line
))))
)) (define
do
−in
de
nt
(
lambda
()
(letrec
((m
yin
de
nt
(lambda
(n
)
(
if
(>
n 0
)
(
begin
(d
isp
lay
"| "
)
(m
yin
de
nt
(− n
2))
))))
)
(myi
nd
en
t in
de
nt)
)))
;;;
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
=;;
; =
==
==
RU
LE
IM
PL
EM
EN
TA
TIO
N =
==
==
;;;
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
=
;;;
Initi
aliz
atio
n R
ule
(in
it−ru
le)
;;;
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−;;
; C
lea
rs t
he
glo
ba
l en
viro
nm
en
t. I
f yo
u w
an
t th
e g
lob
al e
nvi
ron
me
nt
to h
old
an
y va
lue
s a
t st
art
−u
p;;
; yo
u c
an
pla
ces
the
m h
ere
;−
);;
;
;;;
old
init−
rule
;;;(
de
fine
init−
rule
;;;
(la
mb
da
()
;;;
(
set!
en
v (lis
t (c
on
s ’fa
ct ’(
lam
bd
a (
n)
(be
gin
(if
(= n
0)
1 (
* n
(fa
ct
(− n
1))
))))
))))
)
;;;
ne
w in
it−ru
le;;
; ;;
; A
n e
nvi
ron
me
nt
is a
pa
ir (
e,n
), e
is t
he
en
viro
nm
en
t b
ind
ing
s, a
nd
n is
th
e
pa
ren
t e
nvi
ron
me
nt.
Apr
24,
09
15:1
6P
age
2/11
Sch
emeE
valu
ato
rEn
v.sc
m
Prin
ted
by
Frid
ay A
pril
24, 2
009
1/6
Sch
emeE
valu
ator
Env
.scm

;;;
the
glo
ba
l en
viro
nm
en
t d
oe
s n
ot
ha
ve a
pa
ren
t e
nvi
ron
me
nt.
;;;
(define
init−
rule
(
lambda
()
(set!
glo
ba
l−e
nv
(co
ns
’()
prim
))))
;;;
La
mb
da
Ru
le (
lam
bd
a−
rule
);;
; −
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
;;;
As
dis
cuss
ed
a la
mb
da
fo
rm h
as
an
IM
PL
ICIT
be
gin
in it
s b
od
y, s
o w
hy
;;;
no
t ju
st p
ut
an
EX
PL
ICIT
on
e in
th
ere
an
d le
t th
e B
eg
in R
ule
ta
ke
;;;
care
of
bu
sin
ess
.;;
;;;
; E
x. (
lam
bd
a (
x) x
) =
> (
lam
bd
a (
x) (
be
gin
x))
;;;
;;;
==
==
==
==
==
> o
ld L
am
bd
a R
ule
;;;(
de
fine
lam
bd
a−
rule
;;;
(la
mb
da
(la
mb
da
−fo
rm)
;;;
(
let
((l (
list
’lam
bd
a (
cad
r la
mb
da
−fo
rm)
(co
ns
’be
gin
(cd
dr
lam
bd
a−
form
)))
));;
;
(
ou
tpu
t (f
orm
at
"=>
~a
[L
am
bd
a R
ule
]" l)
#t
#t)
;;;
l)))
;;;
==
==
==
==
==
> n
ew
La
mb
da
Ru
le;;
;;;
; A
lam
bd
a (
fun
ctio
n a
bst
ract
ion
) m
ust
no
w c
arr
y w
ith it
an
en
viro
nm
en
t; t
he
en
viro
nm
en
t;;
; b
elo
ng
ing
to
a la
mb
da
fo
rm is
th
e e
nvi
ron
me
nt
wh
ich
we
re t
he
’pre
sen
t’ o
ne
wh
en
th
e
;;;
lam
bd
a r
ule
wa
s ca
lled
. T
he
lam
bd
a−
rule
mu
st t
hu
s ta
ke in
an
en
viro
nm
en
t a
s w
ell.
;;;
We
will
re
pre
sen
t a
lam
bd
a a
s a
pa
ir (
l,e),
wh
ere
l is
th
e a
ctu
al l
am
bd
a f
or
m,
an
d;;
; e
is t
he
ass
oci
ate
d e
nvi
ron
me
nt,
i.e
., t
he
en
viro
nm
en
t to
wh
ich
th
e s
tatic
lin
k;;
; o
f a
ny
fra
me
eva
lua
ting
th
is la
mb
da
fo
rm m
ust
po
int.
(define
lam
bd
a−
rule
(
lambda
(la
mb
da
−fo
rm e
nv)
(let
((l (
list
’lambda
(ca
dr
lam
bd
a−
form
) (c
on
s ’
begin
(cd
dr
lam
bd
a−
form
)) e
nv)
))
(ou
tpu
t (f
orm
at
"=
> ~
a [L
ambd
a R
ule]
" (lis
t ’λ
(ca
dr
l) (
cad
dr
l)))
#
t
#t
)
l)))
;;;
;;;
Nu
mb
er
Ru
le (
nu
mb
er−
rule
);;
; −
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
;;;
Th
is r
ule
is o
bso
lete
; it
is b
ein
g r
ep
lace
d b
y th
e L
itera
l Ru
le;
this
allo
ws
us
;;;
to u
se s
trin
gs
an
d b
oo
lea
n li
tera
ls t
oo
. T
ho
ug
h w
e d
o n
ot
ha
ve a
wa
y to
co
mp
are
;;;
an
yth
ing
by
nu
mb
ers
un
less
we
imp
lem
en
t st
rin
g−
eq
ua
l?,
an
d a
nd
or.
;;;
(define
nu
mb
er−
rule
(
lambda
(n
um
be
r)
(
begin
(ou
tpu
t (f
orm
at
"=
> ~
a [N
umbe
r R
ule]
" n
um
be
r)
#f
#
t)
nu
mb
er)
))
;;;
;;;
Lite
ral R
ule
(lit
era
l−ru
le)
;;;
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−;;
; S
ee
th
e d
esc
rip
tion
fo
r th
e N
um
be
r R
ule
;;;
(define
lite
ral−
rule
(
lambda
(lit
era
l)
(
begin
(o
utp
ut
(fo
rma
t "
=>
~a
[Lite
ral R
ule]
" lit
era
l)
#f
#
t)
Apr
24,
09
15:1
6P
age
3/11
Sch
emeE
valu
ato
rEn
v.sc
m
lite
ral)))
;;;
;;;
Na
me
Ru
le (
na
me
−ru
le)
;;;
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−;;
; A
cce
pts
a n
am
e a
nd
re
turn
s th
e v
alu
e f
rom
th
e e
nvi
ron
me
nt.
;;;
;;;
==
==
==
==
==
> o
ld N
am
e R
ule
;;;
;;;(
de
fine
na
me
−ru
le;;
; (
lam
bd
a (
na
me
);;
;
(le
t ((
pa
ir (
ass
v n
am
e e
nv)
));;
;
(
if p
air
;;;
(b
eg
in;;
;
(o
utp
ut
(fo
rma
t "=
> ~
a [
Na
me
Ru
le]"
(cd
r p
air))
#f
#t)
;;;
(
cdr
pa
ir))
;;;
(le
t ((
pa
ir (
ass
v n
am
e p
rim
)))
;;;
(
if p
air
;;;
(
be
gin
;;;
(o
utp
ut
(fo
rma
t "=
> ~
a [
Na
me
Ru
le]"
(cd
r p
air))
#f
#t)
;;;
(cd
r p
air))
;;;
(
be
gin
;;;
(d
isp
lay
(fo
rma
t "r
efe
ren
ce t
o u
nd
efin
ed
ide
ntif
ier:
~a
" n
am
e))
;;;
(n
ew
line
);;
;
(
loo
p))
))))
))
;;;
==
==
==
==
==
> n
ew
Na
me
Ru
le;;
;;;
; A
ca
ll to
th
e n
am
e r
ule
mu
st n
ow
incl
ud
e a
n e
nvi
ron
me
nt,
an
d in
ste
ad
of
do
ing
an
ass
v ca
ll o
n;;
; th
e g
lob
al e
nvi
ron
me
nt,
we
use
loo
kup
−in
−e
nvi
ron
me
nt
to lo
ok
thro
ug
h t
he
ch
ain
of
en
viro
nm
en
ts.
(define
na
me
−ru
le
(lambda
(n
am
e e
nv)
(if
tra
cin
g
(n
ew
line
))
(
set!
ind
en
t (+
ind
en
t 2
))
(
let
((p
air (
loo
kup
−in
−e
nvi
ron
me
nt
na
me
en
v #
t))
)
(set!
ind
en
t (−
ind
en
t 2
))
(if
pa
ir
(begin
(ou
tpu
t (f
orm
at
"=
> ~
a [N
ame
Rul
e]"
(if
(and
(lis
t? (
cdr
pa
ir))
(e
q?
’l
ambda
(ca
dr
pa
ir))
)
(lis
t ’λ
(ca
dd
r p
air)
(ca
dd
dr
pa
ir))
(cd
r p
air))
) #
t
#t
)
(c
dr
pa
ir))
(
begin
(dis
pla
y (f
orm
at
"re
fere
nce
to u
ndef
ined
iden
tifie
r: ~
a" n
am
e))
(ne
wlin
e)
(lo
op
))))
))
;;;
;;
; P
rim
itive
Ru
le (
prim
itive
−ru
le)
;;;
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−;;
; A
cce
pts
a p
rim
itive
an
d a
list
of
arg
um
en
ts,
an
d a
pp
lies
the
prim
itive
;;;
to t
he
list
of
arg
um
en
ts u
sin
g a
pp
ly.
No
te,
an
d a
nd
or
(wh
ich
we
ha
ve n
ot
;;;
imp
lem
en
ted
ca
nn
ot
be
prim
itive
s a
s S
che
me
do
es
no
t a
llow
th
e u
se o
f ;;
; a
nd
an
d o
r w
ith a
pp
ly ;
−(
;;;
(define
prim
itive
−ru
le
(lambda
(p
rim
itive
arg
um
en
ts)
(let
((r
esu
lt (a
pp
ly p
rim
itive
arg
um
en
ts))
)
(ou
tpu
t (f
orm
at
"=
> ~
a [P
rim
itive
Rul
e]"
resu
lt)
#t
#
t)
re
sult)
))
Apr
24,
09
15:1
6P
age
4/11
Sch
emeE
valu
ato
rEn
v.sc
m
Prin
ted
by
Frid
ay A
pril
24, 2
009
2/6
Sch
emeE
valu
ator
Env
.scm

;;;
;;;
Ap
plic
atio
n R
ule
(a
pp
lica
tion
−ru
le)
;;;
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−;;
; E
valu
ate
s th
e a
rgu
me
nts
an
d c
alls
eith
er
the
prim
itive
ru
le o
r th
e;;
; p
roce
du
re r
ule
. W
e d
o n
ot
ne
ed
an
en
viro
nm
en
t h
ere
as
the
lam
bd
a−
form
;;;
carr
ies
with
it it
s o
wn
en
viro
nm
en
t.;;
;
;;;
==
==
==
==
> o
ld A
pp
lica
tion
Ru
le;;
;(d
efin
e a
pp
lica
tion
−ru
le;;
; (
lam
bd
a (
lst)
;;;
(
let
((p
rim
itive
? (
is−
prim
itive
? (
car
lst)
));;
;
(
eva
lua
ted
−a
rgs
(ma
p e
valu
ate
lst)
));;
;
(
set!
ind
en
t (−
ind
en
t 2
));;
;
(
if p
rim
itive
?;;
;
(
prim
itive
−ru
le (
car
eva
lua
ted
−a
rgs)
(cd
r e
valu
ate
d−
arg
s))
;;;
(p
roce
du
re−
rule
(ca
r e
valu
ate
d−
arg
s) (
cdr
eva
lua
ted
−a
rgs)
))))
)
;;;
==
==
==
==
==
> n
ew
Ap
plic
atio
n R
ule
;;;
We
ha
ve r
ecu
rsiv
e c
alls
to
eva
lua
te h
ere
, so
we
ne
ed
to
brin
g a
lon
g t
he
en
viro
nm
en
t(define
ap
plic
atio
n−
rule
(
lambda
(ls
t e
nv)
(let
((p
rim
itive
? (
is−
prim
itive
? (
car
lst)
))
(eva
lua
ted
−a
rgs
(ma
p (
lambda
(fo
rm)
(eva
lua
te f
orm
en
v))
lst)
))
(set!
ind
en
t (−
ind
en
t 2
))
(if
prim
itive
?
(prim
itive
−ru
le (
car
eva
lua
ted
−a
rgs)
(cd
r e
valu
ate
d−
arg
s))
(p
roce
du
re−
rule
(ca
r e
valu
ate
d−
arg
s) (
cdr
eva
lua
ted
−a
rgs)
))))
)
;;;
Pro
ced
ure
Ru
le (
pro
ced
ure
−ru
le)
;;;
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−;;
; T
he
pro
ced
ure
ru
le c
alls
su
bst
to
pe
rfo
rm t
he
ne
ed
ed
su
bst
itutio
ns
;;;
acc
ord
ing
to
th
e n
ew
pro
ced
ure
ru
le g
ive
n in
th
e h
an
do
ut,
an
d t
he
;;;
calls
eva
lua
te o
n t
he
re
sulti
ng
fo
rm.
;;;
;;;
==
==
==
==
==
> o
ld P
roce
du
re R
ule
;;;(
de
fine
pro
ced
ure
−ru
le;;
; (
lam
bd
a (
lam
bd
a−
form
arg
s);;
;
(se
t! in
de
nt
(+ in
de
nt
1))
;;;
(
ou
tpu
t (f
orm
at
"[P
roce
du
re R
ule
]")
#t
#t)
;;;
(
let
((re
sult
(eva
lua
te (
sub
st la
mb
da
−fo
rm a
rgs)
)))
;;;
(se
t! in
de
nt
(− in
de
nt
1))
;;;
re
sult)
))
;;;
==
==
==
==
==
> n
ew
Pro
ced
ure
Ru
le;;
;;;
; In
ste
ad
of
sub
stitu
ting
we
no
w s
imp
ly c
all
eva
lua
te w
ith t
he
en
viro
nm
en
t in
;;
; w
hic
h w
e w
ish
to
eva
lua
te t
he
ap
plic
atio
n o
f th
e p
roce
du
re.
Th
is e
nvi
ron
me
nt
;;;
if a
ne
w e
nvi
ron
me
nt
wh
ere
th
e a
ctu
al p
ara
me
ters
are
bo
un
d t
o t
he
fo
rma
l on
es, ;;
; a
nd
th
e p
are
nt
en
viro
nm
en
t is
th
e o
ne
pa
sse
d in
(define
pro
ced
ure
−ru
le
(lambda
(la
mb
da
−fo
rm a
rgs)
(set!
ind
en
t (+
ind
en
t 1
))
(o
utp
ut
(fo
rma
t "
[Pro
cedu
re R
ule]
")
#t
#
t)
(let*
((e
nv
(ca
dd
dr
lam
bd
a−
form
))
(
ne
w−
en
v (m
ake
−n
ew
−e
nvi
ron
me
nt
(ma
p c
on
s (c
ad
r la
mb
da
−fo
rm)
arg
s) e
nv
))
(
resu
lt (e
valu
ate
(ca
dd
r la
mb
da
−fo
rm)
ne
w−
en
v)))
(
set!
ind
en
t (−
ind
en
t 1
))
resu
lt)))
;;;
;;;
De
fine
Ru
le (
de
fine
−ru
le)
;;;
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−;;
; E
valu
ate
s th
e a
rgu
me
nt
an
d b
ind
s th
e v
alu
e o
f th
e a
rgu
me
nt
to t
he
na
me
Apr
24,
09
15:1
6P
age
5/11
Sch
emeE
valu
ato
rEn
v.sc
m;;
; in
th
e g
lob
al e
nvi
ron
me
nt.
No
te,
if th
e n
am
e is
alre
ad
y th
ere
it is
;;
; si
mp
ly u
pd
ate
d u
sin
g s
et−
cdr!
;;;
;;;
No
te,
no
thin
g s
top
s th
is e
valu
ato
r fr
om
ha
vin
g d
efin
e f
orm
s th
at
are
;;;
no
t a
t th
e t
op
leve
l....
. ju
st d
on
’t d
o t
ha
t!
;;;
==
==
==
==
==
> o
ld D
efin
e R
ule
;;;(
de
fine
de
fine
−ru
le;;
; (
lam
bd
a (
na
me
fo
rm)
;;;
(
ou
tpu
t (f
orm
at
"[D
efin
e R
ule
]")
#f
#t)
;;;
(
let
((va
lue
(e
valu
ate
fo
rm))
;;;
(p
air (
ass
v n
am
e g
lob
al−
en
v)))
;;;
(if
pa
ir;;
;
(
set−
cdr!
pa
ir v
alu
e)
;;;
(se
t! g
lob
al−
en
v (c
on
s (c
on
s n
am
e v
alu
e)
glo
ba
l−e
nv)
))))
) ;;
; =
==
==
==
==
> n
ew
De
fine
Ru
le(define
de
fine
−ru
le
(lambda
(n
am
e f
orm
en
v)
(o
utp
ut
(fo
rma
t "
[Def
ine
Rul
e]")
#
f
#t
)
(
let
((v
alu
e (
eva
lua
te f
orm
en
v))
(p
air (
loo
kup
−in
−e
nvi
ron
me
nt
na
me
glo
ba
l−e
nv
#f
)))
(
if
pa
ir
(se
t−cd
r! p
air v
alu
e)
(s
et−
car!
glo
ba
l−e
nv
(ap
pe
nd
(ca
r g
lob
al−
en
v) (
list
(co
ns
na
me
va
lue
))))
))))
;;;
;;;
If R
ule
(if−
rule
);;
; −
−−
−−
−−
−−
−−
−−
−−
−−
;;;
Eva
lua
tes
the
bo
ole
an
exp
ress
ion
an
d b
ase
d o
n t
he
va
lue
eva
lua
tes
;;;
eith
er
the
tru
e−
form
or
the
fa
lse
−fo
rm.
An
if f
orm
is r
ea
lly a
;;
; sp
eci
al k
ind
of
form
ca
lled
a ’s
pe
cia
l fo
rm’ b
eca
use
th
e w
ord
;;;
’if’ i
s n
ot
eva
lua
ted
. T
he
sa
me
is t
rue
fo
r a
de
fine
fo
rm,
the
;;;
keyw
ord
’de
fine
’ is
no
t e
valu
ate
d.
;;;
;;;
==
==
==
==
=>
old
If
Ru
le;;
;(d
efin
e if
−ru
le;;
; (
lam
bd
a (
test
−fo
rm t
rue
−fo
rm f
als
e−
form
);;
;
(o
utp
ut
(fo
rma
t "[
If R
ule
]")
#f
#t)
;;;
(
if (e
valu
ate
te
st−
form
);;
;
(e
valu
ate
tru
e−
form
);;
;
(e
valu
ate
fa
lse
−fo
rm))
))
;;;
==
==
==
==
=>
ne
w I
f R
ule
;;;
We
ne
ed
an
en
viro
nm
en
t h
ere
to
o!
(define
if−
rule
(
lambda
(te
st−
form
tru
e−
form
fa
lse
−fo
rm e
nv)
(ou
tpu
t (f
orm
at
"[I
f R
ule]
")
#f
#
t)
(if
(e
valu
ate
te
st−
form
en
v)
(e
valu
ate
tru
e−
form
en
v)
(e
valu
ate
fa
lse
−fo
rm e
nv)
)))
;;;
;;;
Be
gin
Ru
le (
be
gin
−ru
le)
;;;
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−;;
; A
ll a
rgu
me
nts
are
eva
lua
ted
in o
rde
r, a
nd
th
e v
alu
e o
f th
e;;
; la
st e
valu
ate
d f
orm
is r
etu
rne
d.
A b
eg
in f
orm
is s
pe
cia
l to
o,
;;;
the
ke
ywo
rd ’b
eg
in’ i
s n
ot
eva
lua
ted
.
;;;
==
==
==
==
=>
old
Be
gin
Ru
le;;
;(d
efin
e b
eg
in−
rule
;;;
(la
mb
da
(cm
d−
list)
;;;
(
ou
tpu
t (f
orm
at
"[B
eg
in R
ule
]")
#f
#t)
;;;
(
car
(re
vers
e (
ma
p e
valu
ate
cm
d−
list)
))))
Apr
24,
09
15:1
6P
age
6/11
Sch
emeE
valu
ato
rEn
v.sc
m
Prin
ted
by
Frid
ay A
pril
24, 2
009
3/6
Sch
emeE
valu
ator
Env
.scm

;;;
==
==
==
==
==
> n
ew
Be
gin
Ru
le;;
; W
e n
ee
d a
n e
nvi
ron
me
nt
he
re t
oo
.(define
be
gin
−ru
le
(lambda
(cm
d−
list
en
v)
(o
utp
ut
(fo
rma
t "
[Beg
in R
ule]
")
#f
#
t)
(set!
ind
en
t (+
ind
en
t 2
))
(
let
((r
esu
lt (c
ar
(re
vers
e (
ma
p (
lambda
(fo
rm)
(eva
lua
te f
orm
en
v))
cmd
−lis
t)))
))
(set!
ind
en
t (−
ind
en
t 2
))
resu
lt)))
;;;
Le
t R
ule
(le
t−ru
le)
;;;
−−
−−
−−
−−
−−
−−
−−
−−
−−
−;;
;;;
; R
ew
rite
(le
t ((
n1
v1
) ..
. (n
k vk
) b
od
y);;
; to
;;;
((la
mb
da
(n
1 .
.. n
k) b
od
y) v
1 .
.. v
k)(define
let−
rule
(
lambda
(le
t−fo
rm e
nv)
;;;
(le
t ((
n1
f1
) ..
. (n
k fk
) b
)
(o
utp
ut
(fo
rma
t "
[Let
Rul
e]")
#
f
#t
)
(
let
((b
ind
ing
−lis
t (c
ad
r le
t−fo
rm))
)
(if
(n
ull?
bin
din
g−
list)
(e
valu
ate
(co
ns
’begin
(cd
dr
let−
form
)) e
nv)
;;
; (le
t ()
b)
=>
(b
eg
in b
)
(e
valu
ate
(co
ns
(ap
pe
nd
(lis
t ’
lambda
;;
; ((
λ
(m
ap
ca
r b
ind
ing
−lis
t))
;;;
(n
1 n
2 .
.. n
k)
(c
dd
r le
t−fo
rm))
;;
;
b
(ma
p c
ad
r b
ind
ing
−lis
t))
en
v)))
))
;;;
) f
1 f
2 .
.. f
k)
(define
ll ’(
let
((f
#
f))
(set!
f (
lambda
(x)
(if
(=
x 0
) 1
(*
x (f
(−
x 1
))))
)) (
f 4
)))
;;;
;;;
Le
t* R
ule
(le
t*−
rule
);;
; −
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
;;;
Re
write
(le
t* (
(n1
v1
) ..
. (n
k vk
)) b
od
y) a
cco
rdin
g t
o t
his
:;;
;;;
; (le
t* (
) b
od
y) :
= b
od
y;;
;;;
(le
t* (
(n v
)) b
od
y) :
= (
let
((n
v )
) b
od
y);;
;;;
; (le
t* (
(n1
v1
) ..
. (n
k vk
)) b
od
y) :
= (
let
((n
1 v
1))
;;;
(
let*
((n
2 v
2)
...
(nk
vk))
;;;
bo
dy)
);;
;;;
; a
nd
th
en
eva
lua
te t
he
ne
w n
est
ed
lam
bd
a−
form
s/a
pp
lica
tion
s
(define
let*
−h
elp
er
(
lambda
(le
t*−
form
)
(
let
((b
ind
ing
−lis
t (c
ad
r le
t*−
form
)))
(
if
(=
1 (
len
gth
bin
din
g−
list)
)
(ap
pe
nd
(lis
t ’
let
bin
din
g−
list)
(cd
dr
let*
−fo
rm))
(lis
t ’
let
(lis
t (c
ar
bin
din
g−
list)
)
(le
t*−
he
lpe
r (a
pp
en
d (
list
’let*
(cd
r b
ind
ing
−lis
t))
(cd
dr
let*
−fo
rm))
))))
))
(define
let*
−ru
le
(lambda
(le
t*−
form
en
v)
(o
utp
ut
(fo
rma
t "
[Let
* R
ule]
")
#f
#
t)
(if
(n
ull?
(ca
dr
let*
−fo
rm))
(eva
lua
te (
con
s ’
begin
(cd
dr
let*
−fo
rm))
en
v)
(e
valu
ate
(le
t*−
he
lpe
r le
t*−
form
) e
nv)
)))
;;;
;;;
Le
tre
c R
ule
(le
tre
c−ru
le)
Apr
24,
09
15:1
6P
age
7/11
Sch
emeE
valu
ato
rEn
v.sc
m;;
;;;
; (le
tre
c ()
b)
=>
(b
eg
in b
);;
;;;
; (le
tre
c ((
n1
b1
)) b
) =
=>
(le
t ((
n1
#f)
) (s
et!
n1
b1
) (b
eg
in b
));;
;;;
; (le
tre
c ((
n1
b1
)...
(n
k b
k))
b)
=>
;;;
(le
t ((
n1
#f)
);;
;
(se
t! n
1 b
1)
;;;
(le
tre
c ((
n2
b2
) ..
. (n
k b
k))
;;;
b))
(define
letr
ec−
rule
(
lambda
(le
tre
c−fo
rm e
nv)
(ou
tpu
t (f
orm
at
"[L
etre
c R
ule]
")
#f
#
t)
;;
yo
ur
cod
e h
ere
!
)) ;;
;;;
; S
et!
−R
ule
(se
t!−
rule
);;
;;;
; ca
lls t
he
he
lpe
r se
t−in
−e
nvi
ron
me
nt,
wh
ich
is a
sim
ple
mo
difi
catio
n o
f th
e
;;;
de
ep
se
arc
h f
un
ctio
n t
ha
t in
ste
ad
of
retu
rnin
g a
pa
ir s
ets
th
e c
dr
of
it to
;;;
the
ne
w v
alu
e.
;;;
(define
se
t!−
rule
(
lambda
(se
t!−
form
en
v tr
ace
?)
(ou
tpu
t (f
orm
at
"[S
et!
Rul
e]")
#
f
#t
)
(
set!
ind
en
t (+
ind
en
t 2
))
(
let
((n
am
e
(ca
dr
set!
−fo
rm))
(v
alu
e (
eva
lua
te (
cad
dr
set!
−fo
rm)
en
v)))
(
set!
ind
en
t (−
ind
en
t 2
))
(if
(se
t−in
−e
nvi
ron
me
nt
na
me
en
v va
lue
tra
ce?
)
(vo
id)
(
begin
(dis
pla
y (f
orm
at
"se
t!: c
anno
t set
und
efin
ed id
entif
ier:
~a"
na
me
))
(n
ew
line
)
(lo
op
))))
))
;;
; =
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
;;;
==
==
==
EN
D O
F R
UL
E I
MP
LE
ME
NT
AT
ION
==
==
=;;
; =
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
;;;
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
;;;
==
==
= T
HE
MA
IN E
VA
LU
AT
OR
FU
NC
TIO
NS
==
==
=;;
; =
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
=;;
; W
e n
ee
d t
o c
arr
y a
n e
nvi
ron
me
nt
aro
un
d w
he
n w
e e
valu
ate
.(define
eva
lua
te
(lambda
(cm
d e
nv)
; fu
nct
ion
ap
plic
atio
n,
prim
itive
ap
plic
atio
n o
r fu
nct
ion
de
finiti
on
?
(o
utp
ut
(fo
rma
t "
eval
uatin
g ’~
a’ in
~a
" cm
d (
pre
tty−
en
viro
nm
en
t e
nv)
) #
t
#f
)
(
if
(lis
t? c
md
)
;;;
can
be
on
e o
f: d
efin
e,
lam
bd
a,
if, b
eg
in,
or
an
ap
plic
atio
n
(
case
(ca
r cm
d)
((
define
) (d
efin
e−
rule
(ca
dr
cmd
) (c
ad
dr
cmd
) g
lob
al−
en
v))
((
lambda
) (begin
(o
utp
ut
(fo
rma
t "
=>
#<
proc
edur
e>")
#
f
#t
)
(la
mb
da
−ru
le c
md
en
v)))
((
if
)
(if−
rule
(ca
dr
cmd
) (c
ad
dr
cmd
) (c
ad
dd
r cm
d)
en
v))
((
begin
) (
be
gin
−ru
le (
cdr
cmd
) e
nv)
)
((let
)
(le
t−ru
le c
md
en
v))
((
let*
)
(le
t*−
rule
cm
d e
nv)
)
((letrec
) (
letr
ec−
rule
cm
d e
nv)
)
((set!
)
(se
t!−
rule
cm
d e
nv
#t
))
(els
e (
begin
;;;
If n
ot
on
e o
f d
efin
e,
lam
bd
a,
if, b
eg
in,
le/le
t*,
or
set!
th
en
ap
plic
atio
n
(set!
ind
en
t (+
ind
en
t 2
))
Apr
24,
09
15:1
6P
age
8/11
Sch
emeE
valu
ato
rEn
v.sc
m
Prin
ted
by
Frid
ay A
pril
24, 2
009
4/6
Sch
emeE
valu
ator
Env
.scm

(o
utp
ut
(fo
rma
t "
[App
licat
ion
Rul
e]")
#
f
#t
)
(ap
plic
atio
n−
rule
cm
d e
nv)
)))
(if
(or
(b
oo
lea
n?
cm
d)
(str
ing
? c
md
) (n
um
be
r? c
md
))
(lite
ral−
rule
cm
d)
;;
; If
th
e c
om
ma
nd
is a
bo
ole
an
, a
nu
mb
er
or
a
strin
g
(n
am
e−
rule
cm
d e
nv)
))))
;;
; e
lse
it m
ust
be
a n
am
e
;;;
;;;
Th
e m
ain
re
ad
−e
valu
ate
−p
rin
t lo
op
(lo
op
);;
; −
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−−
−;;
; 1
. R
ea
d a
fo
rm;;
; 2
. S
ynta
x−ch
eck
an
d e
valu
ate
;;;
3.
Prin
t th
e r
esu
lt a
nd
re
curs
e;;
;;;
; =
==
==
==
==
=>
ne
w lo
op
− a
dd
ed
th
e g
lob
al e
nvi
ron
me
nt
to t
he
ca
ll to
eva
lua
te.
(define
loo
p
(lambda
()
(set!
ind
en
t 0
)
(d
isp
lay
">
")
(let
((c
om
ma
nd
(re
ad
)))
(
if
(e
q?
co
mm
an
d ’s
top
)
#
t
(if
(and
(lis
t? c
om
ma
nd
) (>
(le
ng
th c
om
ma
nd
) 0
) (e
q?
(ca
r co
mm
an
d)
’tra
ce))
(
begin
;;;
switc
he
s tr
aci
ng
on
an
d o
ff
(
set!
tra
cin
g (
eq
? (
cad
r co
mm
an
d)
’on
))
(
loo
p))
(
begin
(if
(n
ot
(syn
tax−
che
ck c
om
ma
nd
))
;;;
che
ck t
he
syn
tax
(or
at
lea
st t
ry!)
(begin
(
dis
pla
y (f
orm
at
"~a
: ~a"
typ
e e
rro
r−m
sg))
(
ne
wlin
e)
(
loo
p))
(let
((r
esu
lt (e
valu
ate
co
mm
an
d g
lob
al−
en
v)))
;;
; e
very
thin
g w
as
go
od
, n
ow
eva
lua
te
(if
(n
ot
(vo
id?
re
sult)
)
(if
(st
rin
g?
re
sult)
(
dis
pla
y (f
orm
at
"R
esul
t: \"
~a\"
" re
sult)
) ;;
; st
rin
g lo
ok
be
tte
r w
ith "
" a
rou
nd
(
dis
pla
y (f
orm
at
"R
esul
t: ~a
" re
sult)
)))
(
ne
wlin
e)
(
set!
ind
en
t 0
)
(lo
op
))))
))))
)
;;;
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
=;;
; =
==
==
EN
D O
F T
HE
MA
IN E
VA
LU
AT
OR
FU
NC
TIO
NS
==
==
=;;
; =
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
;;;
==
==
==
==
==
==
==
==
==
==
==
==
==
==
;;;
==
==
= H
EL
PE
R F
UN
CT
ION
S =
==
==
;;;
==
==
==
==
==
==
==
==
==
==
==
==
==
==
;;;
;;;
fold
;;;
−−
−−
;;;
fold
is a
ve
rsio
n o
f a
pp
ly t
ha
t a
llow
s yo
u t
o s
pe
cify
th
e n
eu
tra
l ele
me
nt.
;;;
Exa
mp
le:(
fold
r f
(a b
c d
) e
) =
f(f
(f(f
(e d
) c)
b)
a)
;;;
Th
is is
_re
ally
_ ’f
old
l’ fo
r fo
ld−
left
be
cau
se t
he
ne
utr
al e
lem
en
t a
nd
;;;
the
’re
curs
ion
’ is
left
ass
oci
ativ
e;;
;(define
fo
ld
(lambda
(f
lst
e)
(if
(n
ull?
lst)
e
(f
(fo
ld f
(cd
r ls
t) e
) (c
ar
lst)
))))
;;;
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
Apr
24,
09
15:1
6P
age
9/11
Sch
emeE
valu
ato
rEn
v.sc
m;;
; =
==
==
SY
NT
AX
CH
EC
KIN
G P
RO
CE
DU
RE
S =
==
==
;;;
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
==
(define
is−
form
?
(lambda
(e
xp)
(syn
tax−
che
ck e
xp))
)
(define
is−
pa
ram
−lis
t?
(lambda
(ls
t)
(f
old
(lambda
(x
y) (
and
x y
)) (
ma
p is
−n
am
e?
lst)
#
t))
) ;;
; T
his
is h
ow
yo
u
’ap
ply
’ with
an
d a
nd
or
;−)
(define
is−
na
me
?
(lambda
(fo
rm)
(if
(and
(sy
mb
ol?
fo
rm)
(no
t (n
um
be
r? f
orm
)))
#t
(se
t−e
rro
r−m
sg (
form
at
"N
ot a
n id
entif
ier
’~a’
." f
orm
))))
)
(define
is−
lam
bd
a?
(
lambda
(fo
rm)
(set!
typ
e "
lam
bda"
)
(
if
(n
ot
(= (
len
gth
fo
rm)
3))
(se
t−e
rro
r−m
sg (
form
at
"ba
d sy
ntax
in: ~
a" f
orm
))
(
if
(n
ot
(is−
pa
ram
−lis
t? (
cad
r fo
rm))
)
#
f
(
if
(n
ot
(is−
form
? (
cad
dr
form
)))
(se
t−e
rro
r−m
ess
ag
e (
form
at
"ba
d sy
ntax
(no
t a f
orm
) in
: ~a"
(ca
dd
r fo
rm))
)
#
t))
)))
(define
is−
be
gin
?
(lambda
(fo
rm)
(set!
typ
e "
begi
n")
(fo
ld (
lambda
(x
y) (
and
x y
)) (
ma
p is
−fo
rm?
(cd
r fo
rm))
#
t))
)
(define
is−
de
fine
?
(lambda
(fo
rm)
(set!
typ
e "
defi
ne")
(if
(n
ot
(= (
len
gth
fo
rm)
3))
(se
t−e
rro
r−m
sg (
form
at
"ba
d sy
ntax
(m
ultip
le e
xpre
ssio
n af
ter
iden
tifie
r in
: ~a"
fo
rm))
(if
(n
ot
(is−
na
me
? (
cad
r fo
rm))
)
(s
et−
err
or−
msg
(fo
rma
t "
bad
synt
ax in
: ~a"
(ca
dr
form
)))
(if
(n
ot
(is−
form
? (
cad
dr
form
)))
(se
t−e
rro
r−m
sg (
form
at
"ba
d sy
ntax
(no
t a f
orm
) in
: ~a"
(ca
dd
r fo
rm))
)
#
t))
)))
(define
is−
if?
(lambda
(fo
rm)
(set!
typ
e "
if")
(if
(n
ot
(= (
len
gth
fo
rm)
4))
(se
t−e
rro
r−m
sg (
form
at
"ba
d sy
ntax
in: ~
a" f
orm
))
(
if
(n
ot
(is−
form
? (
cad
r fo
rm))
)
(
set−
err
or−
msg
(fo
rma
t "
bad
synt
ax (
not a
for
m)
in: ~
a" (
cad
r fo
rm))
)
(
if
(n
ot
(is−
form
? (
cad
dr
form
)))
(se
t−e
rro
r−m
sg (
form
at
"ba
d sy
ntax
(no
t a f
orm
) in
: ~a"
(ca
dd
r fo
rm))
)
(
if
(n
ot
(is−
form
? (
cad
dd
r fo
rm))
)
(
set−
err
or−
msg
(fo
rma
t "
bad
synt
ax (
not a
for
m)
in: ~
a" (
cad
dr
form
)))
#t
))))
))
(define
is−
ap
plic
atio
n?
(
lambda
(fo
rm)
(fo
ld (
lambda
(x
y) (
and
x y
)) (
ma
p is
−fo
rm?
fo
rm)
#t
)))
(define
is−
bin
din
g−
list?
(
lambda
(fo
rm ls
t)
(
if
(n
ot
(lis
t? ls
t))
(se
t−e
rro
r−m
sg (
form
at
"ba
d sy
ntax
in: ~
a" f
orm
))
(
if
(n
ull?
lst)
#t
Apr
24,
09
15:1
6P
age
10/1
1S
chem
eEva
luat
orE
nv.
scm
Prin
ted
by
Frid
ay A
pril
24, 2
009
5/6
Sch
emeE
valu
ator
Env
.scm

(let
((b
e (
car
lst)
))
(if
(n
ot
(sym
bo
l? (
car
be
)))
(s
et−
err
or−
msg
(fo
rma
t "
bad
synt
ax (
not a
n id
entif
ier)
in ~
a" (
car
be
)))
(
and
(is
−fo
rm?
(ca
dr
be
)) (
is−
bin
din
g−
list?
fo
rm (
cdr
lst)
))))
))))
(define
is−
let?
(
lambda
(fo
rm)
(if
(n
ot
(lis
t? f
orm
))
(s
et−
err
or−
me
ssa
ge
(fo
rma
t "
bad
synt
ax in
: ~a"
fo
rm))
(begin
(
set!
typ
e (
car
form
))
(if
(<
(le
ng
th f
orm
) 3
)
(se
t−e
rro
r−m
ess
ag
e (
form
at
"ba
d sy
ntax
in: ~
a" f
orm
))
(and
(is
−b
ind
ing
−lis
t? f
orm
(ca
dr
form
))
(is
−fo
rm?
(co
ns
’begin
(cd
dr
form
))))
))))
)
(define
is−
let*
?
(lambda
(fo
rm)
(is−
let?
fo
rm))
)
(define
is−
letr
ec?
(
lambda
(fo
rm)
(is−
let?
fo
rm))
)
(define
syn
tax−
che
ck
(lambda
(fo
rm)
(if
(lis
t? f
orm
)
(
if
(=
(le
ng
th f
orm
) 0
)
(
begin
(
set!
typ
e "
appl
icat
ion"
)
(se
t−e
rro
r−m
sg (
form
at
"ba
d sy
ntax
in: ~
a" f
orm
)))
(case
(ca
r fo
rm)
((
define
) (is−
de
fine
? f
orm
))
((lambda
) (is−
lam
bd
a?
fo
rm))
((
if
)
(is−
if?
f
orm
))
((begin
) (
is−
be
gin
?
form
))
((let
)
(is
−le
t?
fo
rm))
((
letrec
) (is−
letr
ec?
fo
rm))
((
let*
)
(is−
let*
?
fo
rm))
(e
lse
(is
−a
pp
lica
tion
? f
orm
))))
(or
(n
um
be
r? f
orm
) ;; numbers
(sym
bo
l? f
orm
) ;; names
(str
ing
? f
orm
) ;;
(bo
ole
an
? f
orm
))))
)
;;; ========================================
;;; ===== END OF SYNTAX CHECKING RULES =====
;;; ========================================
(in
it−ru
le)
;;; initialize
(lo
op
)
;;; GO!
Apr
24,
09
15:1
6P
age
11/1
1S
chem
eEva
luat
orE
nv.
scm
Prin
ted
by
Frid
ay A
pril
24, 2
009
6/6
Sch
emeE
valu
ator
Env
.scm

The Santa Claus Problem
In occam
CSC 789
Multiparadigmatic Programming
(c) Matt Pedersen, 2007
1

1 The Santa Clause Problem
The Santa Clause problem was originally described by John Trono as an exercisein concurrency.
“Santa Claus sleeps in his shop at the North Pole, and can onlybe wakened by either all nine reindeer being back from their yearlong vacation on the beaches of some tropical island in the SouthPacific, or by some elves who are having some difficulties making thetoys. One elf’s problem is never serious enough to wake up Santa(otherwise, he may never get any sleep), so, the elves visit Santain a group of three. When three elves are having their problemssolved, any other elves wishing to visit Santa must wait for thoseelves to return. If Santa wakes up to find three elves waiting athis shop’s door, along with the last reindeer having come back fromthe tropics, Santa has decided that the elves can wait until afterChristmas, because it is more important to get his sleigh ready assoon as possible. (It is assumed that the reindeer don’t want toleave the tropics, and therefore they stay there until the last possiblemoment. They might not even come back, but since Santa is footingthe bill for their year in paradise . . . This could also explain thequickness in their delivering of presents, since the reindeer can’t waitto get back to where it is warm.) The penalty for the last reindeer toarrive is that it must get Santa while the others wait in a warminghut before being harnessed to the sleigh.”
In the paper in which Trono posed the problem, he also proposed a solutionusing locks and mutexes; a typical approach to concurrency control. However,Ben-Ari et al. showed that Trono’s original solution did not function correctly,and proposed a corrected version.
All though this problem seems simple at first, and perhaps to have no tiesto real life concurrent programming problems, we believe it serves as a perfectexercise in concurrency. If we think of the output of the program as controlsignals to external devices, for example, control systems in nuclear power plantsor airplanes, then all of a sudden certain restrictions might need to be enforcedon this output. The simplest example might be the ordering of the outputmessages (i.e., the order in which the signals are sent to the external devices ifwe were modeling a power plant or an airplane). We might need to enforce aLamport happen-before relation between some or all of the outputs.
As a result of such restrictions, the more output that must be ordered, themore complex the implementation gets, and the reasoning about correctnessbecomes much harder.
2

2 The Assignment
The goal of this exercise is to implement the Santa Clause Problem in occamand try to reason about your implementation informally.
I have written some of the code so you do not have to start from scratch.The main issues that you have to deal with in this assignment are, apart
from not deadlocking the code, to make sure that the reporting is done in thecorrect order. We shall look at what the right order is in the following sections.
Firstly, let us start by determining the processes that we need in the system.
3 The Processes
The obvious processes that must be present in the system are of course
• The Santa process.
• 10 Reindeer processes.
• 9 Elf processes.
In addition we need a display process whose job it is to collect all theoutput from the various processes and print it to the screen. I have writtenthis process for you; it is called display and is located in the display.occ filewhich is included at the top of the handout code (santa.occ).
All processes who wish to report any action must have the writing end of ashared reporting channel. The display process holds the reading end, and allit ever does is execute a read-and-print loop.
The protocol to which the messages sent to the display process must adhereis defined in the protocol.occ file, which is also included at the top of thehandout code.
The definition for the report channel in the handout code looks like this:
SHARED ! CHAN MESSAGE report:
and the MESSAGE protocol extends REINDEER.MSG, ELF.MSG, and SANTA.MSG.Reindeer send REINDEER.MSGmessages, elves send ELF.MSG messages, and Santasends SANTA.MSG messages. As an example, if an elf wants to send a messageto the display process that it is working, it could look like this:
CLAIM report!
report ! working; id
Since report is shared at the writing end, it must be claimed before it can beaccessed. Note that the value being sent is the ’working’ kind, which must befollowed by an INT, in this case the id of the elf.
3

3.1 Synchronization
There are a number of different kinds of synchronization that we need to considerfor this problem. The two first ones are as follows:
• All reindeer must return from vacation before notifying Santa. Thismeans that all 10 reindeer must synchronize before Santa can be notifiedthat they are back from vacation. Since all reindeer processes must par-ticipate in this synchronization we can use a full barrier synchronization.A process can synchronize on a barrier (on which it is already enrolled)like this:
SYNC barrier.name
After this synchronization among the reindeer, they can proceed to intro-duce themselves to Santa, who will then harness them one at a time, takethem out delivering toys for a while, then return and unharness them oneat a time and let them go back on vacation.
• A total of exactly 3 elves must have queued up outside Santa’s door beforethey attract Santa’s attention. However, since we have 9 elves, but onlyneed 3 we cannot use a full barrier synchronization, so we need to createour own partial barrier. We actually need 2 slightly different versions ofthe partial barrier: One which 3 elves can synchronize on, and one whichthe same 3 elves can synchronize with Santa on. Here is the code for the2 different partial barriers:
PROC p.barrier.knock (VAL INT n, CHAN BOOL a?, b?, knock!)
WHILE TRUE
SEQ
SEQ i = 0 FOR n -- accept n processes
BOOL any:
a ? any
knock ! TRUE -- knock on Santa’s door
SEQ i = 0 FOR n
BOOL any:
b ? any -- accept the same n processes
:
PROC p.barrier (VAL INT n, CHAN BOOL a?, b?)
WHILE TRUE
SEQ
SEQ i = 0 FOR n -- accept n processes
BOOL any:
a ? any
SEQ i = 0 FOR n -- accept n processes
4

BOOL any:
b ? any
:
If a process wishes to synchronize on either of these barriers, it mustexecute the following code:
CLAIM a!
a ! TRUE
CLAIM b!
b ! TRUE
where a! and b! are the writing ends of either the channels associatedwith p.barrier or p.barrier.knock. Since this operation must be doneoften, we have wrapped it in procedure called sync, which can be calledlike this:
sync (elves.a!, elves.b!)
Naturally we need one p.barrier and one p.barrier.knock process run-ning as well as the Santa, the 10 reindeer and the 9 elves.
Having described the barrier processes let us turn to the internal workingsof the 3 major processes.
4 The Reindeer Process
A reindeer starts out by reporting that it is on holiday. After a random amountof time it returns to the North Pole. We can use a timer to wait for a randomtime in the following way:
wait, my.seed := random (HOLIDAY.TIME, my.seed)
tim ? t
tim ? AFTER t PLUS wait
After returning from holiday a deer reports itself ready, and then waits for allthe other deer to return from holiday. Once that has happened it sends it idto Santa, and waits for Santa to harness everyone (This can be done with afull barrier in which Santa is also enrolled!). Once everyone is ready the deerreports that it is delivering toys, and again waits for Santa and the other deerto finish delivering (Again that is a full barrier synch with Santa and the otherdeer). Then each deer can report that they are done and send their id to Santato be unharnessed before going back on holiday.
The skeleton code for a reindeer looks like this:
5

PROC reindeer (VAL INT id, -- unique id
VAL INT seed, -- seed for the random
number generator
BARRIER just.reindeer, -- barrier for the 10
deer
BARRIER Santa.reindeer, -- barrier for the 10
deer and Santa
SHARED CHAN INT to.Santa!, -- channel to Santa
SHARED CHAN REINDEER.MSG report! -- reporting channel)
INITIAL INT my.seed IS seed:
TIMER tim:
INT t, wait:
SEQ
-- warm up the random number generator
SEQ i = 0 FOR 1000
wait, my.seed := random (HOLIDAY.TIME, my.seed)
WHILE TRUE
-- the deer code goes here
:
5 The Elf Process
An elf starts out by reporting that it is working, which it does for a randomamount of time. When an elf wants to consult with Santa, it reports that itis ready to do so, and tries to synchronize on the partial barrier executed byp.barrier.knock by calling the sync(...) procedure. If he makes it throughthe barrier it is because 2 other elves were ready as well and a ’knock’ to Santahas been accepted by Santa. The elf then sends his id to Santa and synchro-nizes with Santa and the other 2 elves though the p.barrier process. Oncethat has happened an elf can now report that he is consulting, which goes on foras long as Santa wants. This is again modeled by a synchronization with Santaand the other 2 elves using the sync(...) procedure. Once done consulting,an elf can report that he is done, and send his id to Santa as a good-bye greeting.
The code skeleton for an elf looks like this:
PROC elf (VAL INT id, seed,
SHARED CHAN BOOL elves.a!, elves.b!, -- for synchronizing 3 elves.
SHARED CHAN BOOL Santa.elves.a!, Santa.elves.b!, -- 3 elves
& Santa
SHARED CHAN INT to.Santa!, SHARED CHAN ELF.MSG report!)
INITIAL INT my.seed IS seed:
TIMER tim:
INT t, wait:
6

SEQ
-- warm up random number generator
SEQ i = 0 FOR 1000
wait, my.seed := random (WORKING.TIME, my.seed)
WHILE TRUE
-- elf code here
:
6 The Santa Process
Santa Claus start out sleeping; the only thing that can wake his is either all 10reindeer back from holiday or 3 elves that need to consult about toy making.The reindeer have priority over the elves.
If all 10 reindeer are back from holiday they will each send Santa their id, so if heever received one reindeer id he knows he will receive another 9. When receivingthe first reindeer id, Santa reports that the deer are ready, and for each reindeerid he also reports that he is harnessing it. Once everyone has been harnessed(i.e., once Santa has passed the full barrier that he enrolls on with the deer),he can take them out to deliver presents, so he reports mush, mush ;-). Thisdelivering of presents takes a random amount of time, after which he says woah
and returns to the Pole; he then unharnesses each deer as they send him their id.
If 3 elves are ready to consult, a knock on the door will happen from thep.barrier.knock process; once this knock has happened Santa reports theelves ready, and in turn receives the id of the 3 waiting elves and greets them.He then synchronizes with the 3 elves before reporting that he is consulting.This takes a random amount of time, after which Santa reports that he is done
consulting, and he synchronizes with the elves yet again and then as he receivestheir id tells them goodbye. Once either of these actions are done he can goback to sleep.
The skeleton code for the Santa process looks like this:
PROC Santa (VAL INT seed,
CHAN BOOL knock?, CHAN INT from.reindeer?, from.elf?,
BARRIER Santa.reindeer,
SHARED CHAN BOOL Santa.elves.a!, Santa.elves.b!,
SHARED CHAN SANTA.MSG report!)
INITIAL INT my.seed IS seed:
TIMER tim:
INT t, wait:
7

SEQ
-- warm up the random number generator
SEQ i = 0 FOR 1000
wait, my.seed := random (DELIVERY.TIME, my.seed)
WHILE TRUE
-- Santa code
:
7 The System
The following illustration shows the wiring of the entire system. The thick linesrepresent full barriers.
knock
Santa p.barrier
p.barrier.knock
.... ....Reindeer Reindeer Elf 1 Elf 91 10
santa.reindeer
just.reindeer
reindeer.santaelves.b
elves.a
santa.elves.asanta.elves.b
The following code makes up the main process of the Santa Claus Problem:
PROC Santa.claus.problem (CHAN BYTE screen!)
TIMER tim:
INT seed:
SEQ
tim ? seed
seed := (seed >> 2) + 42
BARRIER just.reindeer, Santa.reindeer:
SHARED ! CHAN BOOL elves.a, elves.b:
CHAN BOOL knock:
SHARED ! CHAN BOOL Santa.elves.a, Santa.elves.b:
SHARED ! CHAN INT reindeer.Santa, elf.Santa:
8

SHARED ! CHAN MESSAGE report:
PAR
-- start all your processes here
:
Apart from passing in the full barriers as arguments, processes must be enrolledin the barrier when they are started. This can be done in two different ways.The first way is a PAR ENROLL barrier.namewhich is like a regular PAR, exceptany process within that par is enrolled on the barrier named barrier.name.The second way is to use a PAR ... FOR ... ENROLL barrier1, barrier2,
... , barriern. The PAR ENROLL can also take any number of barriers.
8 Questions
1. Implement the missing pieces of the code and get it running.
2. Can your code execute in a way such that Santa reports “Ho-ho-ho ...some elves are here!” before all three elves have reported “Need to consultSanta”?
3. Can you argue that your code can never execute in a way such that an elfnever reports “Working” or a reindeer never reports “On holiday” untilSanta has reported either “Goodbye elf” (in the elf case) or “Un-harnessingreindeer” (in the reindeer case)?
4. What part of the code assures that the reindeer report “all toys delivered... want a holiday” before Santa reports “un-harnessing reindeer”?
9 Notes
The handout code can be found on the website along with a file containingsome sample output from my solution. The next page shows an example of thisoutput.
9

SANTA OUTPUT ELF OUTPUT REINDEER OUTPUT
------------------------------------------------------------------------------------------------------
Elf 0: working, :)
Elf 1: working, :)
Elf 2: working, :)
Elf 3: working, :)
Elf 4: working, :)
Elf 5: working, :)
Elf 6: working, :)
Elf 7: working, :)
Elf 8: working, :)
Elf 9: working, :)
Reindeer 0: on holiday ... wish you were here, :)
Reindeer 1: on holiday ... wish you were here, :)
Reindeer 2: on holiday ... wish you were here, :)
Reindeer 3: on holiday ... wish you were here, :)
Reindeer 4: on holiday ... wish you were here, :)
Reindeer 5: on holiday ... wish you were here, :)
Reindeer 6: on holiday ... wish you were here, :)
Reindeer 7: on holiday ... wish you were here, :)
Reindeer 8: on holiday ... wish you were here, :)
Elf 3: need to consult santa, :(
Elf 9: need to consult santa, :(
Reindeer 7: back from holiday ... ready for work, :(
Reindeer 2: back from holiday ... ready for work, :(
Elf 4: need to consult santa, :(
Santa: Ho-ho-ho ... some elves are here!
Santa: hello elf 3 ...
Santa: hello elf 9 ...
Santa: hello elf 4 ...
Elf: 3: about these toys ... ???
Elf: 9: about these toys ... ???
Elf: 4: about these toys ... ???
Santa: consulting with elves ...
Reindeer 8: back from holiday ... ready for work, :(
Reindeer 3: back from holiday ... ready for work, :(
Reindeer 4: back from holiday ... ready for work, :(
OK, all done - thanks!
Elf 3: OK ... we’ll build it, bye ... :(
Elf 9: OK ... we’ll build it, bye ... :(
Elf 4: OK ... we’ll build it, bye ... :(
Santa: goodbye elf 3 ...
Elf 3: working, :)
Santa: goodbye elf 9 ...
Elf 9: working, :)
Santa: goodbye elf 4 ...
10

10 display.occ
PROC display(CHAN MESSAGE in?, CHAN BYTE screen!)
WHILE TRUE
INT id:
in ? CASE
holiday; id
SEQ
out.string ("*t*t*t*t*t*tReindeer ", 0, screen!)
out.int (id, 0, screen!)
out.string (": on holiday ... wish you were here, :)*c*n", 0, screen!)
deer.ready; id
SEQ
out.string ("*t*t*t*t*t*tReindeer ", 0, screen!)
out.int (id, 0, screen!)
out.string (": back from holiday ... ready for work, :(*c*n", 0, screen!)
deliver; id
SEQ
out.string ("*t*t*t*t*t*tReindeer ", 0, screen!)
out.int (id, 0, screen!)
out.string (": delivering toys ... la-di-da-di-da-di-da, :)*c*n", 0, screen!)
deer.done; id
SEQ
out.string ("*t*t*t*t*t*tReindeer: ", 0, screen!)
out.int (id, 0, screen!)
out.string (": all toys delivered ... want a holiday, :(*c*n", 0, screen!)
working; id
SEQ
out.string ("*t*t*tElf ", 0, screen!)
out.int (id, 0, screen!)
out.string (": working, :)*c*n", 0, screen!)
elf.ready; id
SEQ
out.string ("*t*t*tElf ", 0, screen!)
out.int (id, 0, screen!)
out.string (": need to consult santa, :(*c*n", 0, screen!)
consult; id
SEQ
out.string ("*t*t*tElf: ", 0, screen!)
out.int (id, 0, screen!)
out.string (": about these toys ... ???*c*n", 0, screen!)
elf.done; id
SEQ
out.string ("*t*t*tElf ", 0, screen!)
out.int (id, 0, screen!)
out.string (": OK ... we*’ll build it, bye ... :(*c*n", 0, screen!)
11

reindeer.ready
out.string ("Santa: Ho-ho-ho ... the reindeer are back!*c*n", 0, screen!)
harness; id
SEQ
out.string ("Santa: harnessing reindeer ", 0, screen!)
out.int (id, 0, screen!)
out.string (" ... *c*n", 0, screen!)
mush.mush
out.string ("Santa: mush mush ...*c*n", 0, screen!)
woah
out.string ("Santa: woah ... we*’re back home!*c*n", 0, screen!)
unharness; id
SEQ
out.string ("Santa: un-harnessing reindeer ", 0, screen!)
out.int (id, 0, screen!)
out.string (" ... *c*n", 0, screen!)
elves.ready
out.string ("Santa: Ho-ho-ho ... some elves are here!*c*n", 0, screen!)
greet; id
SEQ
out.string ("Santa: hello elf ", 0, screen!)
out.int (id, 0, screen!)
out.string (" ... *c*n", 0, screen!)
consulting
out.string ("Santa: consulting with elves ...*c*n", 0, screen!)
santa.done
out.string ("OK, all done - thanks!*c*n", 0, screen!)
goodbye; id
SEQ
out.string ("Santa: goodbye elf ", 0, screen!)
out.int (id, 0, screen!)
out.string (" ... *c*n", 0, screen!)
:
12

11 protocol.occ
PROTOCOL REINDEER.MSG
CASE
holiday; INT
deer.ready; INT
deliver; INT
deer.done; INT
:
PROTOCOL ELF.MSG
CASE
working; INT
elf.ready; INT
consult; INT
elf.done; INT
:
PROTOCOL SANTA.MSG
CASE
reindeer.ready
harness; INT
mush.mush
woah
unharness; INT
elves.ready
greet; INT
consulting
santa.done
goodbye; INT
:
PROTOCOL MESSAGE EXTENDS REINDEER.MSG, ELF.MSG, SANTA.MSG:
13

−−
go
od
ve
rsio
n:
sta
tic n
etw
ork
, a
ssym
etr
ic (
rein
de
er
use
re
al b
arr
iers
)
#IN
CL
UD
E "
pro
toco
l.occ
"#
US
E "
cou
rse
.lib
"#
INC
LU
DE
"d
isp
lay.
occ
"
VA
L I
NT
N.R
EIN
DE
ER
IS
9:
VA
L I
NT
G.R
EIN
DE
ER
IS
N.R
EIN
DE
ER
:
VA
L I
NT
N.E
LV
ES
IS
10
:V
AL
IN
T G
.EL
VE
S I
S 3
:
VA
L I
NT
HO
LID
AY
.TIM
E I
S 1
0:
VA
L I
NT
WO
RK
ING
.TIM
E I
S 2
0:
VA
L I
NT
DE
LIV
ER
Y.T
IME
IS
10
:V
AL
IN
T C
ON
SU
LT
AT
ION
.TIM
E I
S 2
0:
PR
OC
p.b
arr
ier.
kno
ck (
VA
L I
NT
n,
CH
AN
BO
OL
a?
, b
?,
kno
ck!)
W
HIL
E T
RU
E
S
EQ
S
EQ
i =
0 F
OR
n
B
OO
L a
ny:
a ?
an
y
kno
ck !
TR
UE
S
EQ
i =
0 F
OR
n
B
OO
L a
ny:
b ?
an
y: P
RO
C p
.ba
rrie
r (V
AL
IN
T n
, C
HA
N B
OO
L a
?,
b?
)
WH
ILE
TR
UE
SE
Q
SE
Q i
= 0
FO
R n
BO
OL
an
y:
a
? a
ny
S
EQ
i =
0 F
OR
n
B
OO
L a
ny:
b ?
an
y: P
RO
C s
ync
(SH
AR
ED
CH
AN
BO
OL
a!,
b!)
S
EQ
CL
AIM
a!
a
! T
RU
E
C
LA
IM b
!
b !
TR
UE
: PR
OC
re
ind
ee
r (V
AL
IN
T id
, se
ed
, B
AR
RIE
R ju
st.r
ein
de
er,
sa
nta
.re
ind
ee
r,
SH
AR
ED
CH
AN
IN
T t
o.s
an
ta!,
SH
AR
ED
CH
AN
RE
IND
EE
R.M
SG
re
po
rt!)
IN
ITIA
L I
NT
my.
see
d I
S s
ee
d:
T
IME
R t
im:
IN
T t
, w
ait:
S
EQ
SE
Q i
= 0
FO
R 1
00
0
wa
it, m
y.se
ed
:=
ra
nd
om
(H
OL
IDA
Y.T
IME
, m
y.se
ed
)
W
HIL
E T
RU
E
SE
Q
C
LA
IM r
ep
ort
!
rep
ort
! h
olid
ay;
id
w
ait,
my.
see
d :
= r
an
do
m (
HO
LID
AY
.TIM
E,
my.
see
d)
tim ?
t
tim
? A
FT
ER
t P
LU
S w
ait
CL
AIM
re
po
rt!
re
po
rt !
de
er.
rea
dy;
id
S
YN
C ju
st.r
ein
de
er
−−
wa
it fo
r th
e o
the
rs r
ein
de
er
CL
AIM
to
.sa
nta
!
to.s
an
ta !
id
−
− s
en
d y
ou
r id
to
sa
nta
Apr
24,
09
15:2
0P
age
1/4
san
ta2.
occ
SY
NC
sa
nta
.re
ind
ee
r
−
− w
ait
for
the
oth
ers
an
d t
he
n d
eliv
er
pre
sen
ts
C
LA
IM r
ep
ort
!
rep
ort
! d
eliv
er;
id
S
YN
C s
an
ta.r
ein
de
er
−−
wa
it fo
r th
e o
the
rs a
nd
th
en
re
turn
fro
m d
eli
verin
g p
rese
nts
CL
AIM
re
po
rt!
re
po
rt !
de
er.
do
ne
; id
CL
AIM
to
.sa
nta
!
to.s
an
ta !
id
−−
ask
to
be
un
−h
arn
ess
ed
: PR
OC
elf
(VA
L I
NT
id,
see
d,
S
HA
RE
D C
HA
N B
OO
L e
lve
s.a
!, e
lve
s.b
!, s
an
ta.e
lve
s.a
!, s
an
ta.e
lve
s.b
!,
SH
AR
ED
CH
AN
IN
T t
o.s
an
ta!,
SH
AR
ED
CH
AN
EL
F.M
SG
re
po
rt!)
IN
ITIA
L I
NT
my.
see
d I
S s
ee
d:
T
IME
R t
im:
IN
T t
, w
ait:
S
EQ
SE
Q i
= 0
FO
R 1
00
0
wa
it, m
y.se
ed
:=
ra
nd
om
(W
OR
KIN
G.T
IME
, m
y.se
ed
)
W
HIL
E T
RU
E
SE
Q
C
LA
IM r
ep
ort
!
rep
ort
! w
ork
ing
; id
wa
it, m
y.se
ed
:=
ra
nd
om
(W
OR
KIN
G.T
IME
, m
y.se
ed
)
tim
? t
tim ?
AF
TE
R t
PL
US
wa
it
C
LA
IM r
ep
ort
!
rep
ort
! e
lf.re
ad
y; id
syn
c (e
lve
s.a
!, e
lve
s.b
!) −
− s
ynch
ron
ize
3 e
lve
s
C
LA
IM t
o.s
an
ta!
to
.sa
nta
! id
−
− le
t sa
nta
kn
ow
ho
w t
he
y a
re
sy
nc
(sa
nta
.elv
es.
a!,
sa
nta
.elv
es.
b!)
−−
syn
chro
niz
e w
ith s
an
ta
C
LA
IM r
ep
ort
!
rep
ort
! c
on
sult;
id
sy
nc
(sa
nta
.elv
es.
a!,
sa
nta
.elv
es.
b!)
−−
syn
chro
niz
e w
ith s
an
ta
C
LA
IM r
ep
ort
!
rep
ort
! e
lf.d
on
e;
id
C
LA
IM t
o.s
an
ta!
to
.sa
nta
! id
−−
lea
vin
g: P
RO
C s
an
ta (
VA
L I
NT
se
ed
,
C
HA
N B
OO
L k
no
ck?
, C
HA
N I
NT
fro
m.r
ein
de
er?
, fr
om
.elf?
, B
AR
RIE
R s
an
ta.
rein
de
er,
SH
AR
ED
CH
AN
BO
OL
sa
nta
.elv
es.
a!,
sa
nta
.elv
es.
b!,
SH
AR
ED
CH
AN
SA
NT
A.M
SG
re
po
rt!)
IN
ITIA
L I
NT
my.
see
d I
S s
ee
d:
T
IME
R t
im:
IN
T t
, w
ait:
S
EQ
SE
Q i
= 0
FO
R 1
00
0
wa
it, m
y.se
ed
:=
ra
nd
om
(D
EL
IVE
RY
.TIM
E,
my.
see
d)
WH
ILE
TR
UE
P
RI
AL
T
IN
T id
:
fr
om
.re
ind
ee
r ?
id
SE
Q
C
LA
IM r
ep
ort
!
SE
Q
re
po
rt !
re
ind
ee
r.re
ad
y
re
po
rt !
ha
rne
ss;
id
S
EQ
i =
0 F
OR
G.R
EIN
DE
ER
− 1
S
EQ
fro
m.r
ein
de
er
? id
CL
AIM
re
po
rt!
re
po
rt !
ha
rne
ss;
id
S
YN
C s
an
ta.r
ein
de
er
−−
wa
it fo
r th
e o
the
rs
C
LA
IM r
ep
ort
!
Apr
24,
09
15:2
0P
age
2/4
san
ta2.
occ
Prin
ted
by
Frid
ay A
pril
24, 2
009
1/4
sant
a2.o
cc

re
po
rt !
mu
sh.m
ush
wa
it, m
y.se
ed
:=
ra
nd
om
(D
EL
IVE
RY
.TIM
E,
my.
see
d)
tim ?
t
tim
? A
FT
ER
t P
LU
S w
ait
CL
AIM
re
po
rt!
re
po
rt !
wo
ah
SY
NC
sa
nta
.re
ind
ee
r
−
− w
ait
for
the
oth
ers
SE
Q i
= 0
FO
R G
.RE
IND
EE
R
fro
m.r
ein
de
er
??
id
C
LA
IM r
ep
ort
!
rep
ort
! u
nh
arn
ess
; id
BO
OL
an
y:
kn
ock
? a
ny
IN
T id
:
SE
Q
C
LA
IM r
ep
ort
!
rep
ort
! e
lve
s.re
ad
y
S
EQ
i =
0 F
OR
G.E
LV
ES
S
EQ
fro
m.e
lf ?
id
C
LA
IM r
ep
ort
!
rep
ort
! g
ree
t; id
syn
c (s
an
ta.e
lve
s.a
!, s
an
ta.e
lve
s.b
!)
C
LA
IM r
ep
ort
!
rep
ort
! c
on
sulti
ng
wa
it, m
y.se
ed
:=
ra
nd
om
(C
ON
SU
LT
AT
ION
.TIM
E,
my.
see
d)
tim ?
t
tim
? A
FT
ER
t P
LU
S w
ait
CL
AIM
re
po
rt!
re
po
rt !
sa
nta
.do
ne
syn
c (s
an
ta.e
lve
s.a
!, s
an
ta.e
lve
s.b
!)
S
EQ
i =
0 F
OR
G.E
LV
ES
fr
om
.elf
??
id
C
LA
IM r
ep
ort
!
rep
ort
! g
oo
db
ye;
id: P
RO
C s
an
ta.2
(C
HA
N B
YT
E s
cre
en
!)
T
IME
R t
im:
IN
T s
ee
d:
S
EQ
tim ?
se
ed
see
d :
=
(se
ed
>>
2)
+ 4
2
B
AR
RIE
R ju
st.r
ein
de
er,
sa
nta
.re
ind
ee
r:
SH
AR
ED
! C
HA
N B
OO
L e
lve
s.a
, e
lve
s.b
:
C
HA
N B
OO
L k
no
ck:
SH
AR
ED
! C
HA
N B
OO
L s
an
ta.e
lve
s.a
, sa
nta
.elv
es.
b:
SH
AR
ED
! C
HA
N I
NT
re
ind
ee
r.sa
nta
, e
lf.sa
nta
:
SH
AR
ED
! C
HA
N M
ES
SA
GE
re
po
rt:
PA
R
p
.ba
rrie
r.kn
ock
(G
.EL
VE
S,
elv
es.
a?
, e
lve
s.b
?,
kno
ck!)
p.b
arr
ier
(G.E
LV
ES
+ 1
, sa
nta
.elv
es.
a?
, sa
nta
.elv
es.
b?
)
P
AR
i =
0 F
OR
N.E
LV
ES
elf
(i,
N.R
EIN
DE
ER
+ (
see
d +
i),
elv
es.
a!,
elv
es.
b!,
sa
nta
.elv
es.
a!,
sa
nta
.elv
es.
b!,
elf.
san
ta!,
re
po
rt!)
dis
pla
y (r
ep
ort
?,
scre
en
!)
Apr
24,
09
15:2
0P
age
3/4
san
ta2.
occ
P
AR
EN
RO
LL
sa
nta
.re
ind
ee
r
PA
R i
= 0
FO
R N
.RE
IND
EE
R E
NR
OL
L ju
st.r
ein
de
er,
sa
nta
.re
ind
ee
r
rein
de
er
(i,
see
d +
i, ju
st.r
ein
de
er,
sa
nta
.re
ind
ee
r,
re
ind
ee
r.sa
nta
!, r
ep
ort
!)
san
ta (
see
d +
(N
.RE
IND
EE
R +
N.E
LV
ES
), k
no
ck?
,
re
ind
ee
r.sa
nta
?,
elf.
san
ta?
, sa
nta
.re
ind
ee
r,
sa
nta
.elv
es.
a!,
sa
nta
.elv
es.
b!,
re
po
rt!)
:
Apr
24,
09
15:2
0P
age
4/4
san
ta2.
occ
Prin
ted
by
Frid
ay A
pril
24, 2
009
2/4
sant
a2.o
cc

PR
OC
dis
pla
y(C
HA
N M
ES
SA
GE
in?
, C
HA
N B
YT
E s
cre
en
!)
WH
ILE
TR
UE
INT
id:
in ?
CA
SE
h
olid
ay;
id
S
EQ
o
ut.
strin
g (
"*t*
t*t*
t*t*
tRe
ind
ee
r ",
0,
scre
en
!)
ou
t.in
t (id
, 0
, sc
ree
n!)
o
ut.
strin
g (
": o
n h
olid
ay
...
wis
h y
ou
we
re h
ere
, :)
*c*n
", 0
, sc
ree
n!)
d
ee
r.re
ad
y; id
SE
Q
ou
t.st
rin
g (
"*t*
t*t*
t*t*
tRe
ind
ee
r ",
0,
scre
en
!)
ou
t.in
t (id
, 0
, sc
ree
n!)
o
ut.
strin
g (
": b
ack
fro
m h
olid
ay
...
rea
dy
for
wo
rk,
:(*c
*n",
0,
scre
en
!)
de
live
r; id
SE
Q
ou
t.st
rin
g (
"*t*
t*t*
t*t*
tRe
ind
ee
r ",
0,
scre
en
!)
ou
t.in
t (id
, 0
, sc
ree
n!)
o
ut.
strin
g (
": d
eliv
erin
g t
oys
...
la−
di−
da
−d
i−d
a−
di−
da
, :)
*c*n
", 0
, s
cre
en
!)
de
er.
do
ne
; id
SE
Q
ou
t.st
rin
g (
"*t*
t*t*
t*t*
tRe
ind
ee
r: "
, 0
, sc
ree
n!)
o
ut.
int
(id
, 0
, sc
ree
n!)
o
ut.
strin
g (
": a
ll to
ys d
eliv
ere
d .
.. w
an
t a
ho
lida
y, :
(*c*
n",
0,
scre
en
!)
wo
rkin
g;
id
S
EQ
o
ut.
strin
g (
"*t*
t*tE
lf ",
0,
scre
en
!)
ou
t.in
t (id
, 0
, sc
ree
n!)
o
ut.
strin
g (
": w
ork
ing
, :)
*c*n
", 0
, sc
ree
n!)
e
lf.re
ad
y; id
SE
Q
ou
t.st
rin
g (
"*t*
t*tE
lf ",
0,
scre
en
!)
ou
t.in
t (id
, 0
, sc
ree
n!)
o
ut.
strin
g (
": n
ee
d t
o c
on
sult
san
ta,
:(*c
*n",
0,
scre
en
!)
con
sult;
id
S
EQ
o
ut.
strin
g (
"*t*
t*tE
lf: "
, 0
, sc
ree
n!)
o
ut.
int
(id
, 0
, sc
ree
n!)
o
ut.
strin
g (
": a
bo
ut
the
se t
oys
...
??
?*c
*n",
0,
scre
en
!)
elf.
do
ne
; id
SE
Q
ou
t.st
rin
g (
"*t*
t*tE
lf ",
0,
scre
en
!)
ou
t.in
t (id
, 0
, sc
ree
n!)
o
ut.
strin
g (
": O
K .
.. w
e*’
ll b
uild
it,
bye
...
:(*
c*n
", 0
, sc
ree
n!)
re
ind
ee
r.re
ad
y
o
ut.
strin
g (
"Sa
nta
: H
o−
ho
−h
o .
.. t
he
re
ind
ee
r a
re b
ack
!*c*
n",
0,
scre
en
!)
ha
rne
ss;
id
S
EQ
o
ut.
strin
g (
"Sa
nta
: h
arn
ess
ing
re
ind
ee
r ",
0,
scre
en
!)
ou
t.in
t (id
, 0
, sc
ree
n!)
o
ut.
strin
g (
" ..
. *c
*n",
0,
scre
en
!)
mu
sh.m
ush
ou
t.st
rin
g (
"Sa
nta
: m
ush
mu
sh .
..*c
*n",
0,
scre
en
!)
wo
ah
ou
t.st
rin
g (
"Sa
nta
: w
oa
h .
.. w
e*’
re b
ack
ho
me
!*c*
n",
0,
scre
en
!)
un
ha
rne
ss;
id
S
EQ
o
ut.
strin
g (
"Sa
nta
: u
n−
ha
rne
ssin
g r
ein
de
er
", 0
, sc
ree
n!)
o
ut.
int
(id
, 0
, sc
ree
n!)
o
ut.
strin
g (
" ..
. *c
*n",
0,
scre
en
!)
elv
es.
rea
dy
ou
t.st
rin
g (
"Sa
nta
: H
o−
ho
−h
o .
.. s
om
e e
lve
s a
re h
ere
!*c*
n",
0,
scre
en
!)
gre
et;
id
S
EQ
o
ut.
strin
g (
"Sa
nta
: h
ello
elf
", 0
, sc
ree
n!)
Apr
24,
09
15:2
0P
age
1/2
dis
pla
y.o
cc
ou
t.in
t (id
, 0
, sc
ree
n!)
o
ut.
strin
g (
" ..
. *c
*n",
0,
scre
en
!)
con
sulti
ng
ou
t.st
rin
g (
"Sa
nta
: co
nsu
ltin
g w
ith e
lve
s ..
.*c*
n",
0,
scre
en
!)
san
ta.d
on
e
o
ut.
strin
g (
"OK
, a
ll d
on
e −
th
an
ks!*
c*n
", 0
, sc
ree
n!)
g
oo
db
ye;
id
S
EQ
o
ut.
strin
g (
"Sa
nta
: g
oo
db
ye e
lf ",
0,
scre
en
!)
ou
t.in
t (id
, 0
, sc
ree
n!)
o
ut.
strin
g (
" ..
. *c
*n",
0,
scre
en
!):
Apr
24,
09
15:2
0P
age
2/2
dis
pla
y.o
cc
Prin
ted
by
Frid
ay A
pril
24, 2
009
3/4
disp
lay.
occ
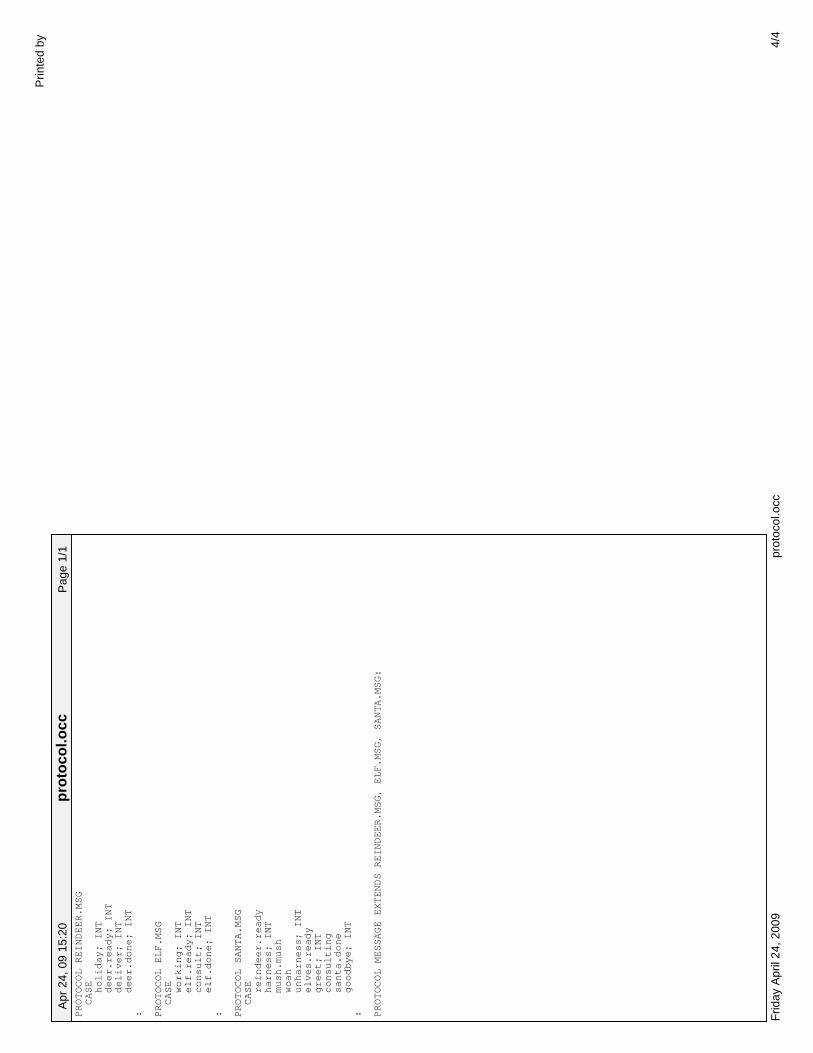
PROTOCOL REINDEER.MSG
CASE
holiday; INT
deer.ready; INT
deliver; INT
deer.done; INT
: PROTOCOL ELF.MSG
CASE
working; INT
elf.ready; INT
consult; INT
elf.done; INT
: PROTOCOL SANTA.MSG
CASE
reindeer.ready
harness; INT
mush.mush
woah
unharness; INT
elves.ready
greet; INT
consulting
santa.done
goodbye; INT
: PROTOCOL MESSAGE EXTENDS REINDEER.MSG, ELF.MSG, SANTA.MSG:
Apr
24,
09
15:2
0P
age
1/1
pro
toco
l.occ
Prin
ted
by
Frid
ay A
pril
24, 2
009
4/4
prot
ocol
.occ


CS789Relational Database
in Scheme
School of Computer ScienceUniversity of Nevada, Las Vegas
(c) 2007, Matt Pedersen
1

1 Introduction
This assignment deals with something called relational databases. You willlearn about relations, and you will work with a relational database system thatI have created for you. The purpose of the assignment is for you to becomefamiliar with relational databases, learn to write expressions for them, and inthe end extend the query language that the database system uses. This assign-ment contains two different kinds of exercises: regular exercises which you mustcomplete and hand in for marks, and special exercises that you should do tobecome familiar with the database and the query language.
Please take the extra 1-2 hours it might take to make your assignment answerlook nice - it took me well over 40 hours to prepare this assignment, to writethe database and to make it all look nice, I am sure you appreciate that thematerial I present you with is easy to read, nice to look at etc., just as muchas I value looking at a well written assignment—especially since I have to readand correct them.
2 Preliminaries
A database consists of a number of relations. Figure 1 shows an example ofa relation containing address information. A relation consists of 2 parts:
1. A Schema (the first row in the relation in Fig. 1).
2. A number of tuples (the last 3 rows in the relation in Fig. 1)
Name : string Address : string Phone : symbolMatt Helmcken Street 604-688-0654Alex Alma Street 604-228-2121Yvonne Hornby Street 604-123-1234
Figure 1: Example of a simple relation with 3 columns and 3 tuples.
The schema of a relation names the columns and gives them types (a name/typepair is called an attribute). In Fig. 1 we have 3 columns, so the schema contains3 entries. Name of type string, Address of type string and Phone of type symbol.If the following we often refer to the name part of an attribute as a ’field’). (Notethat even though strings are normally encased in ” ”, I have omitted them in theabove relation, so it is actually impossible to tell whether the name is a stringor a symbol, but the address must be a string as symbols cannot contain spaces).
The relation in Fig. 1 contains 3 tuples, which are illustrated in Fig. 2.
2

("Matt" "Helmcken Street" 604-688-0654)("Alex" "Alma Street" 604-228-2121)("Yvonne" "Hornby Street" 604-123-1234)
Figure 2: The 3 tuples of the sample relation.
If we want to insert more tuples into the relation they must have exactly 3entries; the first and second must be of type string and the third must be oftype symbol.I have written a little database system which you can download from the coursewebsite. The file is called cs789-database.scm. You also need to downloadthe file called relations.scm, which contains some example relations. Whenyou load the file and evaluate it the system should start up automatically. Ifyou break the execution or it crashes (which it might do if you forgot bracketsin the commands!) then you can restart it by typing (run).
3 Getting Started
When you start the system you should see something similar to Fig 3.
Welcome to DrScheme, version 103p1.Language: Graphical Full Scheme (MrEd).Please wait....Starting up the CS-789 Database/Database:4>
Figure 3: Starting up the CS-789 Database.
When the database starts it has a number of predefined relations defined. Thenumber 4 following the /Database: prompt shows the number of relations inthe database at any given time. Any command to the database system takesthe form of a list. The most simple commands are (quit) and (list). The(quit) command of course quits the database system and returns to the regu-lar Scheme command prompt, while the (list) command will list the relationscurrently defined in the database. This is illustrated in Fig. 4.
As you can see from Fig. 4, the result of executing the (list) command is initself a relation. The schema of the relation returned by the (list) commandhas 2 attributes: name : symbol and size : number. As we expected it has 4tuples, one representing each relation in the database. The size attribute rep-resents the number of tuples in the relation, and the name represents the namethat the relation has in the database.
3
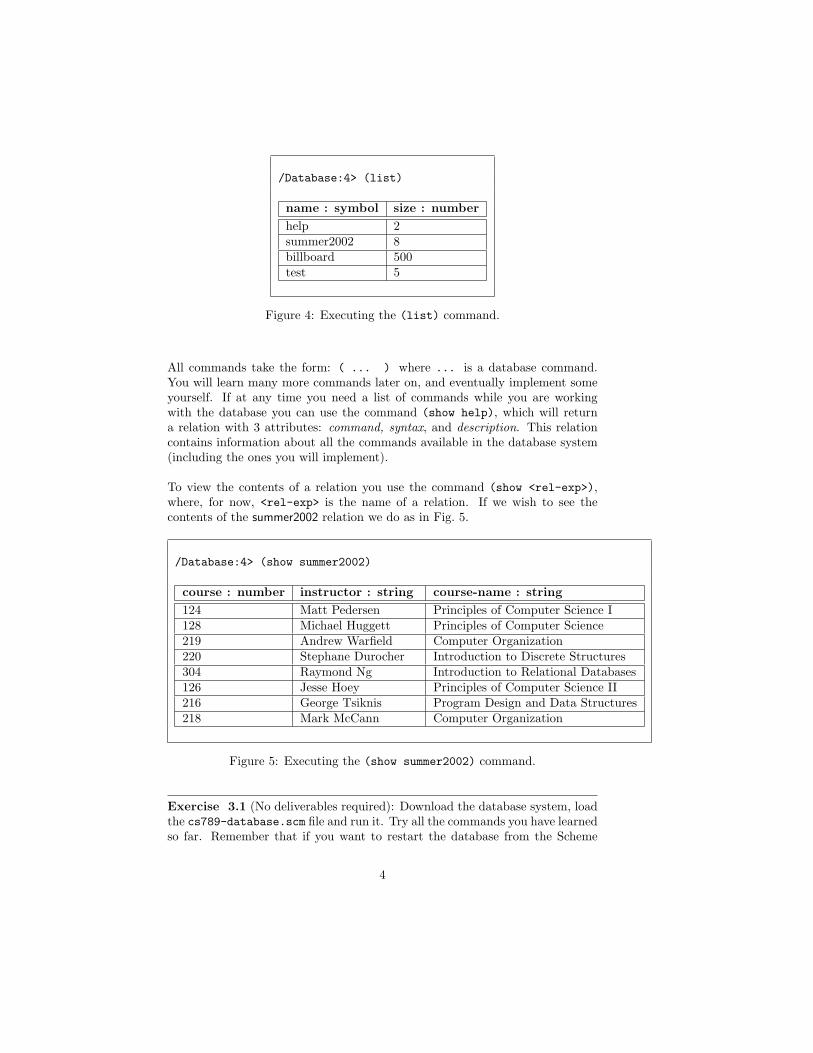
/Database:4> (list)
name : symbol size : numberhelp 2summer2002 8billboard 500test 5
Figure 4: Executing the (list) command.
All commands take the form: ( ... ) where ... is a database command.You will learn many more commands later on, and eventually implement someyourself. If at any time you need a list of commands while you are workingwith the database you can use the command (show help), which will returna relation with 3 attributes: command, syntax, and description. This relationcontains information about all the commands available in the database system(including the ones you will implement).
To view the contents of a relation you use the command (show <rel-exp>),where, for now, <rel-exp> is the name of a relation. If we wish to see thecontents of the summer2002 relation we do as in Fig. 5.
/Database:4> (show summer2002)
course : number instructor : string course-name : string124 Matt Pedersen Principles of Computer Science I128 Michael Huggett Principles of Computer Science219 Andrew Warfield Computer Organization220 Stephane Durocher Introduction to Discrete Structures304 Raymond Ng Introduction to Relational Databases126 Jesse Hoey Principles of Computer Science II216 George Tsiknis Program Design and Data Structures218 Mark McCann Computer Organization
Figure 5: Executing the (show summer2002) command.
Exercise 3.1 (No deliverables required): Download the database system, loadthe cs789-database.scm file and run it. Try all the commands you have learnedso far. Remember that if you want to restart the database from the Scheme
4

prompt you can do so by typing (run).
3.1 Recap
In this section we have introduced the 2 simple commands: (quit), and (list).In addition we have introduced the (show <rel-exp>) command to inspect thecontents of a relation.
4 Creating Relations and Inserting Tuples
A database is not much fun if you cannot create relations yourself. In thissection you will learn to create schemas and how to turn them into relations.We will also look at inserting tuples into relations. The result of executing the(list) command was itself a relation; almost everything in our database is arelation. What about the schema of a relation? As you might have guessed,even a schema is a relation. Using the (schema <rel-expr>) you can obtainthe schema of a relation as a relation. Fig. 6 illustrates this.
/Database:4> (schema summer2002)
name : symbol type : symbolcourse numberlecturer stringcourse-name string
Figure 6: Executing the (schema summer2002) command.
As you can see from Fig. 6, the schema of a relation is itself a relation with 2attributes: name of type symbol and type of type symbol.
Exercise 4.1: Explain why the expression (schema (schema R)), where R isany relation, always computes and returns the same relation no matter whichrelation you choose for R.
Now that you have an understanding of what a schema is, we need to be able tocreate schemas ourselves; thus being able to eventually create relations. Sincethe schema of a ’schema relation’ always looks the same (see Fig. 6 and Ex-ercise 4.1) we have a simple command (make-schema) that creates an empty’schema relation’ with the 2 well known schema attributes.
5

/Database:4> (make-schema)
name : symbol type : symbol
Figure 7: Executing the (make-schema) command.
Figure 7 shows the result of executing the (make-schema) command. Weneed to name this relation (we refer to such a relation as a ’schema relation’)so we can insert tuples into it, thus defining the schema for the relation weare going to create. What we want to do is to add this new ’schema relation’to the database and give it a name. To do this we use the (let <name> be<rel-expr>) command. <name> is the name we wish to give the relation in thedatabase, and <rel-expr> a relation or a command/expression that returns arelation. (make-schema) happens to be such a command, it returns a ’schema-relation’. Supposed we wish to name this new ’schema-relation’ my-schema, wedo as illustrated in Fig. 8. We can use the (list) command to verify thatmy-schema has been added to the database, and we can use (show my-schema)verify the contents (so far the relations should not contain any tuples).
/Database:4> (let my-schema be (make-schema))
name : symbol type : symbol
Figure 8: Creating a new ’schema-relation’ and naming it in the database.
Note that all the commands in the database language always return their results,and they are printed out, and also note that the (let ...) in the database isequivalent to (define ...) in Scheme.
Exercise 4.2 (No deliverables): Verify, using (show ...), that my-schema hasbeen added successfully to the database and list the contents to ensure that ithas the right schema and no tuples.
We now have the ability to add relations (so far only ’schema-relations’) to thedatabase, but we still need to be able to add tuples to a relation. If we wish toadd a tuple T to a relation R, we must make sure that the tuple is compatiblewith the relation, that is, that the tuple matches the schema. The type of eachelement in the tuple must match the corresponding type of the attribute in theschema. More formally, assume T = {e1 e2 . . . en}, where T is a tuple with
6

n elements. Assume that the type of ei is ti. Schema(R) = (a1 a2 . . . am),Schema(R) is the schema of relation R, and ai is an attribute consisting of aname ni and a type si.
In order to be able to insert T into R the following constraints must be met:
1. n = m (the tuple must have as many elements as the relation is ’wide’).
2. ti = si,∀1 ≤ i ≤ n (The types must match).
If these constraints are met the tuples can be successfully inserted into the re-lation. The command to insert tuples into a relation is (insert <tup> into<rel-expr>), where <tup> is a tuple that is compatible with the relation re-turned by <rel-expr>. Figure 9 shows how to insert a tuple into the my-schema’schema-relation’ we created earlier.
/Database:4> (insert (name string) into my-schema)
name : symbol type : symbolname string
Figure 9: Inserting a tuple into a relation.
In Fig. 9 we insert a tuple (name string) which eventually will become an at-tribute name : string in the relations we are about to create.
Exercise 4.3: We wish to eventually create an address database, so finishthe schema by adding more tuples (attributes in the final relation): add an ad-dress of type string, a phone-number of type symbol and an age of type number.
Now you should have a relation called my-schema with 4 tuples in. We can nowuse this schema to create a relation, namely our own little directory. From nowon we will refer to all commands as expressions, this makes more sense becausethey all return relations. In order to create a relation from a ’schema relation’we use the (make-relation <rel-expr>) expression. Figure 10 shows how thisworks.Note that (make-relation <rel-expr>) only accepts a relational expressionthat returns a relation, that is, that has a schema which contains two attributes:the first name : symbol and the second type : symbol. If you try to create a re-lation by passing something that is not a ’schema-relation’ you will get an error.
Exercise 4.3: Explain why it it is impossible to create a relation based on a
7

/Database:4> (make-relation my-schema)
name : string address : string phone-number : symbol age : number
Figure 10: Creating a relation based on a ’schema relation’.
non-’schema-relation’.
Exercise 4.4: We wish to eventually create an address database called directory.Add a new relation with the schema represented by the my-schema relation tothe database.
4.1 Recap
In this section we have introduced the (schema <rel-expr>) expression toretrieve the schema of a relation. We also saw how to create new schemasusing the (make-schema) expression. Tuples can be inserted into relations usingthe (insert <tup> into <rel-expr>) expression, and new relations can becreated based on schema-relations using (make-relations <rel-expr>).
5 The Internals of the CS789 Database Program
In this section we will study the implementation of the database program thatwe have only worked with so far.
5.1 Data Representation
A relation is stored as a list with 4 elements:
1. A list of attribute names (list of symbols) called the schema (technicallythe entire schema contains both names and types).
2. A list of attribute types (list of symbols) called the type-list.
3. A list of the tuples in the relation (list of lists).
4. An internal name, typically the name of the function that created therelation, e.g., make schema .
Figure 11 shows the internal representation for the my-schema relation afterinserting all 4 tuples, and for the directory relation immediately after creation.We call this representation the Relation Abstract Data Type, or Relation ADTfor short.
8

((name type)(symbol symbol)((name string)(address string)(phone-number symbol)(age number))_make_schema_)
((name address phone-number age)(string string symbol number)()_make_relation_)
my-schema directory
Figure 11: The my-schema and the directory relation (internal representation).
Exercise 5.1: Show the internal representation of the directory relation afterinserting the following two tuples: (”Matt Pedersen” ”Helmcken Street” 604-112-2334 35) and (”Yvonne Coady” ”Hornby Street” 604-998-8776 40).
5.2 Evaluating Relational Expressions
The main idea behind the evaluation part of the database system is as follows.Remember that each command is written as a list, so each pair of parentheses( ... ) represents a command. The evaluation works in a number of steps:
1. Read in an expression.
2. Type check the expression.
3. Evaluate all sub expressions that themselves could be an expression of theform ( ... ) by calling recursively on the evaluate function (repeatingthis step on the new expression).
4. Evaluate the expression with the values obtained in the previous step andreturn the resulting relation.
You will need to familiarize yourself with the run and with the evaluate func-tion.
I have written a (type) checker that will check your commands before tryingto evaluate them, thus (hopefully) prohibiting the system from crashing if youtype malformed expressions and non existing attribute names or relation names.
The type checking algorithm works in much the same way as the evaluatingfunction, the only difference is that it does not perform any computation on thetuples, but only on the schemas; that way we can catch anything that might
9

cause an error before we try to evaluate the expression.
Study the name-check function and convince yourself that it works.
Exercise 5.2: Show using a recursion-droid like model how name-check iscalled recursively when checking the following expression, and indicate whichcases are taken in the case statement inside the name-check function:
(make-relation (insert (phone symbol) into(insert (address string) into(insert (name string) into (make-schema)))))
Exercise 5.3: Consider the following two set of expressions (the first one has2 the second has 1):
1.)
(let myrel be (make-relation(insert (name string) into (make-schema))))
(insert ("matt") into myrel)
2.)
(let myrel be (insert ("matt") into(make-relation (insert (name string) into (make-schema))))
In the database system all expressions are checked before they are evaluated(by calling name-check) to avoid any errors during the evaluation, this is calledstatic type checking. Static type checking checks everything without actuallylooking at the tuples, that is, without actually evaluating the expression) bysimply considering the schemas of the relations computed by the expressions.
1. Explain why the first set of expressions numbered 1.) can be staticallytype checked.
2. Explain why the second set of expressions numbered 2.) cannot be stat-ically type checked.
3. Explain why (schema (make-relation (schema R))), where R is anyrelation, can be statically type checked.
Note, that in the main loop of the run function, the variable relations containsa list of all the relations that have been defined by the (let ... ) command.
10

5.3 Extending the Evaluator
When you are going to extend the evaluator you do not need to extend thetype checking part of the evaluator. Type checking can be a little complicatedat times, so I have already added all the functionality that you need. You willconcentrate on 2 tasks every time you add a new function to the database querylanguage:
1. Adding a new case in the evaluate function that calls a function to dothe evaluation of the new expression.
2. Writing the function that performs the calculation itself.
We will briefly explain how to implement a simple function and add it to thelanguage now.
Suppose we wish to implement a function (count <rel-expr>) that returns arelation with a schema with just one attribute: count : number, and just onetuple: a number which represents the number of tuples in <rel-expr>.
If you look closely at the other functions already implemented you will seethat they take in the relations they work on plus whatever extra information isneeded. One important thing to remember is that <rel-expr> can it self be anexpression, so before calling the function that calculates the count function weneed to evaluate <rel-expr>. This is done by a recursive call to evaluate:
((COUNT)(count (evaluate (cadr expr) relations)))
We now have to write the count function. All it has to do is return a relationwith one tuple. Let us assume that we were using the database language tocreate this relation. We would probably proceed using the commands listed inFig. 12.
/Database:3> (let count-schema be (make-schema))/Database:4> (insert (count number) into count-schema)/Database:4> (let count-rel be (make-relation count-schema))/Database:5> (insert (???) into count-rel)
Figure 12: The equivalent expressions for (count <rel-expr>) in the querylanguage.
The first step is to create the schema for the resulting relation. Next, we insertthe one attribute that the result relation will have. Then we use the schema
11

relation to create the final relation. The only problem is which number do weinsert? the ??? marks the number that the tuple holds, this number should bethe number of tuples in the relation in which we are interested.
Now that you have a good idea of how you would have written it in the querylanguage (note that you cannot complete Fig. 12 because you do not have away of counting the number of tuples of a relation that is indeed exactly what(count <rel-expr>) will be doing) you can implement it and add it to thelanguage. The implementation could look like this:
(define count(lambda (rel)(let* ((count-schema (make-schema))
(v1 (insert count-schema ’(count number)))(count-rel (make-relation count-schema))(size (length (get-tuples rel))))
(insert count-rel (list size))count-rel)))
A different solution would be to build the relation by hand and simply returnit. We know how it will look so it is not difficult:
(define count(lambda (rel)(list ’(count)
’(number)(list (list (length (get-tuples rel))))’_count_)))
Exercise 5.4: Implement the (count <rel-expr>) function, and show that itworks.
Exercise 5.5: Implement a function (union of <rel-expr1> and <rel-expr2>)that computes the union of two relations. Do not worry about tuples that occurmore than once, that is ok for now. The union is only legal if the schema of<rel-expr1> is the same as <rel-exp2>. However, that is a type checking issue,and I have already dealt with that, so all you need to do it implement a unionfunction that computes the union of the two expressions.
Exercise 5.6: Show that your new (union ...) function works. Create 2relations with the same schema and use union to a new relation with all thetuples in.
12

5.4 Recap
In section 4 we have looked closer at the implementation of the database lan-guage evaluator. You implemented the (count <rel-expr>) expression andthe (union of <rel-expr> and <rel-expr>) yourself.
6 More Database Expressions
In this section we will introduce two of the most useful functions in any databaselanguage: select and project. select is used when you want to select (!)a number of tuples from a relation. The syntax of select is (select from<rel-expr> where <attribute-name> <op> <value>), where <rel-expr> asusual denotes an expression that returns a relation, <attribute-name> is thename of one of an attribute in the <rel-expr> relation, <op> is one of =, !=,<, >, <=, or >=, and finally, <value> is a constant value of the same type asthe type of the attribute specified by <attribute-name>. Figure 13 shows anexample that selects all the courses from the summer2002 relation that has acourse number smaller than 200.
/Database:4> (select from summer2002 where course < 200)
course : number instructor : string course-name : string124 Matt Pedersen Principles of Computer Science I128 Michael Huggett Principles of Computer Science126 Jesse Hoey Principles of Computer Science II
Figure 13: Executing the (select from summer2002 where course < 200)command.
Exercise 6.1: Construct a query expression that returns a relation with all thecourses that have course numbers smaller than 200 or bigger than 300.
select can be used to select tuples from a relation, that is, it picks entirerows from the relation, exactly those that satisfy some predicate. We wouldalso like to be able to select a number of attributes (a number of columns)in our output. For example, it would be nice if we could easily create a re-lation that contains all the tuples in summer2002 but only the course and theinstructor columns (no one ever knows the name of the courses anyway!). Todo that we need a new function. This function is called project. We will im-plement project together, that is, I will provide some of it and you will finish it.First of all, let us consider the syntax of project: (project <rel-expr> over<attribute-name1> ... <attribute-namen>), where <rel-expr> is what it
13

normally is, and <attribute-namei> is the name of a column (an attribute),the resulting relation contains all the same tuples as the relation <rel-expr>but only the columns specified by the attribute names. Figure 14 shows anexample of project.
/Database:4> (project summer2002 over course instructor)
course : number instructor : string124 Matt Pedersen128 Michael Huggett219 Andrew Warfield220 Stephane Durocher304 Raymond Ng126 Jesse Hoey216 George Tsiknis218 Mark McCann
Figure 14: Executing the (project summer2002 over course instructor)command.
Exercise 6.2: We are now going to implement the project command, butbefore we do that we need to look at how to easily select the value of a tuplethat belongs to a certain column. The following algorithm can be used. Assumethat we have a relation rel which has the following internal representation:
((name address phone-number gender age)(string string symbol symbol number)( ... <all the tuples go here> ...)_insert_)
We would like to make a function that when applied to every single tuple returnsthe value in a given column specified by the attribute name of that column, e.g.,say we want to make a function that when applied to a tuple returns the phone-number. Let us write a function that can create such a function (this is agood example of a factory function: a function that returns another function).Assuming that we are trying to create a function that can extract the phone-number out of a tuple, here is the way we do it:
1. Search for the phone-number attribute in the schema, and remember itsindex (for the example this index is 2).
14

2. Return a function, that when applied to a tuple returns the element atposition 2 (i.e., the 3rd element). This can be done using list-ref. Thefunction returned looks like this:
(lambda (tup)(list-ref tup index))
Here is the make-accessor function that does exactly that
(define make-accessor(lambda (rel name)(letrec ((mk-acc(lambda (name-list index)(if (null? name-list)#f(if (equal? (car name-list) name)(lambda (tup) (list-ref tup index))(mk-acc (cdr name-list) (add1 index)))))))
(mk-acc (get-name-list rel) 0))))
If we create such an accessor for every attribute-name in the project commandand put them in a list, we can apply these accessors to each tuple and obtainthe relation we wish. Note that we can also use this list of accessors to createthe schema and type-list of the result, in exactly the same way we do with thetuples. (hint: use map, sometimes twice!)
(define project(lambda (rel names);;; remove any attributes that were repeated(let* ((unique-names (remove-doubles names))
;;; create the list of accessors(accessors (map (lambda (x)
(make-accessor rel x))unique-names))
;;; extract the schema, type-list and tuples;;; from the relation.(tuples (get-tuples rel))(name-list (get-name-list rel))(type-list (get-type-list rel)))
;;; return a new relation with the wanted columns(list
;;; code that computes the new name-list;;; code that computes the new type-list;;; code that computes the new list of tuples
’_project_))))
15

Finish the implementation of project. You just need to write the 3 pieces ofcode that compute the new name-list, type-list and list of tuples.
Exercise 6.3: Use your implementation of project to compute a relation thatcontains the instructor names of all the courses that have course numbers be-tween 200 and 299.
Exercise 6.4 (No deliverables) Study the implementation of select and tryto understand how it works (You will need to change the implementation ina coming exercise). In particular, study the compare function and understandhow the textual representation (as a symbol) of the operator maps to a functionthat can compare the correct types (remember, e.g., < can only be used onnumbers, not strings!).
Exercise 6.5: Implement a function (minimum <rel-expr>) that returns arelation with the same schema as <rel-expr> and with just one tuple: theminimum value for each column. (Hint: You probably need to call (compare’< ... )). Implement a function (maximum <rel-expr>) that works just like(minimum ...) it just computes the largest element in each column. Figure 15shows the result of applying minimum and maximum to summer2002. Note thatthe tuple that the result relation contains might not be in the original relationas the minimum/maximum is computed for each column and the assembledinto one tuple. (Hint: assume that we are working our way through a list oftuples, and also assume that mins = (m0 m1 ... mn) represent the minimumelements we have seen so far. Let tup be the next tuple in the tuple list, whatdoes (map (lambda (t m) (if (compare ’< t m) t m) tup mins) do?
Exercise 6.6: Write an expression that returns a relation containing the nameof the minimum and maximum instructor for all courses with course numberless than 300.
16

/Database:4> (minimum summer2002)
course : number instructor : string course-name : string124 Andrew Warfield Computer Organization
/Database:4> (maximum summer2002)
course : number instructor : string course-name : string304 Stephane Durocher Program Design and Data Structures
Figure 15: Executing the (minimum summer2002) and the (maximumsummer2002) commands.
Exercise 6.7: Recall the syntax of the (select ...) expression:
(select from <rel-expr> where <name> <op> <value>)
We would like to replace <value> by $.<name>, that is, we would like to ex-change the constant value on the right hand side of the operator with a way ofaccessing the value of another element in the tuple. For example:
The filter operation of the select looks like this:
(filter (lambda (tup) (compare op (accessor tup) value))(get-tuples rel))
That is, all the tuples where (compare op (accessor tup) value) evaluatesto true will be included in the end result. We want to change this filter expres-sion into something general where <value> is replaced by a function that takesin tup as well, and if we indeed have a <value> simply returns this value, elseit takes the value of the element in the tuple that corresponds to the name in$.<name>.
So we will rewrite the select function to look like this:
(define select(lambda (rel name op value)(let ((accessor (make-accessor rel name))
(value-accessor << ...............>> ))(mk-relation
(get-name-list rel)
17

(get-type-list rel)(filter (lambda (tup)
(compare op (accessor tup) (value-accessor tup)))(get-tuples rel))
’_select_))))
where << ...............>> is some code that the returns either
• a function that just returns value if value is not of the form $.<name> or
• of value is a symbol $.<name>, that is, has $ as the first character whenturned into a string, use extract-field to get <name> and use make-accessorto make an accessor that can extract the correct value from a tuple, andreturn a function that when applied to a tuple returns the value obtainedby applying the accessor created by the call to make-accessor.
Write the missing piece of code.
The next command we will introduce is the join command. The syntax is asfollows:(join <rel-expr> with <rel-expr>). The result of joining two rela-tions is a new relation whose attributes are a combination of all the attributes inboth relations. Any attributes that exist in both relations (common attributes)will only be added once. (Note, names and types must match for 2 attributesto be common). The tuples in the new relation are formed by combining allpairs of tuples from the 2 relations where the 2 tuples share the same valueson the common attributes. The join expression can return an empty relation ifthere are no two tuples with the same value on the common attributes. If the 2relations do not have any common attributes the result relation will contain anycombination between tuples in the first and the second relation (this is reallyjust the cross product of the two relations).
Figure 16 shows an example of using join where the two relations have commonattributes: addresses and numbers have the attribute Name : string in common.If you inspect both addresses and numbers you will see that they each containtuples that are not in the result returned from join, namely because the namesare not in both relations - thus they will be left out: The name ”Paul Kry” isnot in addresses and the names ”Dima Brodsky” and ”Andy Warfield” are notin sf numbers.
Let us now create 2 new relations - one with just the name column of the ad-dresses relation and one with just the address column of the relation addresses.Figure 17 shows what happens when we join these 2 new relations. Since theydo not have any common attributes join will produce the cross product of thetwo relations, that is, all tuples in R1 will be combines with all tuples in R2, soif R1 has n tuples and R2 has m, the result relation will have n ∗ m tuples.
18

/Database:4> (join addresses with numbers)
Name : string Address : string Phone: symbolMatt Pedersen Helmcken Street 604-688-5456Alex Brodsky West 2nd Avenue 604-283-1635Yvonne Coady Hornby Street 604-682-5432
Figure 16: The result of executing the (join ...) command on two relationswith common attributes.
19

/Database:4> (let r1 be (project addresses over name))
Name : stringMatt PedersenAlex BrodskyYvonne CoadyPaul Kry
/Database:4> (let r2 be (project addresses over address))
Address : stringHelmcken StreetWest 2nd AvenueHornby StreetWest 1st Avenue
/Database:4> (join r1 with r2)
Name : string Address : stringMatt Pedersen Helmcken StreetMatt Pedersen West 2nd AvenueMatt Pedersen Hornby StreetMatt Pedersen West 1st AvenueAlex Brodsky Helmcken StreetAlex Brodsky West 2nd AvenueAlex Brodsky Hornby StreetAlex Brodsky West 1st AvenueYvonne Coady Helmcken StreetYvonne Coady West 2nd AvenueYvonne Coady Hornby StreetYvonne Coady West 1st AvenuePaul Kry Helmcken StreetPaul Kry West 2nd AvenuePaul Kry Hornby StreetPaul Kry West 1st Avenue
Figure 17: The result of executing the (join ...) command with two relationsthat do not have any common attributes.
Exercise 6.8: I have implemented the part of the join command that deals
20

with 2 relations that have common attributes. You must implement the codethat computes the cross product of 2 relations without any common attributes.Complete the code for the the join command.
The second to last expression you need to know is the rename expression. Thesyntax is (rename <att-name> in <rel-expr> to <att-name>). The expres-sion renames an existing column in a relation to have a new name. Figure 18shows an example of using the rename expression. The rename expression can
/Database:4> (show addresses)
Name : string Address : stringMatt Pedersen Helmcken StreetAlex Brodsky West 2nd AvenueYvonne Coady Hornby StreetPaul Kry West 1st Avenue
/Database:4> (rename address in addresses to where-do-they-live)
Name : string Where-do-they-live: stringMatt Pedersen Helmcken StreetAlex Brodsky West 2nd AvenueYvonne Coady Hornby StreetPaul Kry West 1st Avenue
Figure 18: An example of renaming a column using the (rename ...) expres-sion.
be extremely helpful if you need to join two relations that have a column incommon but no shared attribute because the columns are not named the same.Using the rename expression you can rename one of them and thus avoid com-puting a big cross product and having to use select to pick out the ones wherethe two columns have the same value.
Example:
Assume that we have two relations R1 and R2 where
Schema(R1) = (name : string address : string)Schema(R2) = (nombre : string numero-de-telefono : symbol)
So R1 has a column with a name and one with an address, and R2 has a namecolumn, but it happens to be in Spanish - nombre, and a (yet again spanish)
21

telephone number column. We know that the name and the nombre columnsboth contain names, so if we want to join these together without renaming firstwe will get a big cross product. Assuming that R1 has n tuples and R2 hasm tuples, the result of joining R1 with R2 will have n ∗ m tuples, if we wantthe tuples where name = nombre (to get a tuple per person with his/her name,address and phone number) we would do something like:
(select from (join R1 with R2) where name = $.nombre)
We would compute a lot of useless tuples - all the ones where name is not equalto nombre (which would probably be most of them).
Let us now rename the nombre column to name and then join R1 and R2:
(join R1 with (rename nombre in R2 to name))
This would not compute any tuples that we do not get in the final relation.
Finally, in order to improve the output, it might be seful if we could sort arelation according to a column. We wish to implement a sort command withthe following syntax:
(sort <rel-expr> by <attr-name>)
Exercise 6.9: Implement the sort command. Implement quick-sort (useset! when appending to the various lists in quick-sort). Use make-accessorand compare ’< ... to construct the correct accessors to extract the wantedcolumn from a tuple, and to compare such values according to their type.
6.1 Recap
In section 6 you have learned how to select tuples from a relation using the(select from <rel-expr> where <attr-name> <op> <value / $.attr-name>),you have also learned how to project a relation over a number of column usingthe (project <rel-expr> over <attr-name1> ... <attr-namen>) expres-sion. You implemented a (minimum <rel-expr>) and a (maximum <rel-expr>)expression yourself and we did (join <rel-expr> with <rel-expr>) together,and finally you implemented sort <rel-expr> by <attribute-name>) to sorta relation based on one column.
22

7 The Planets and their Moons
You will find 2 relations in the relation list that has to do with planets andmoons in our solar system: planets and moons. In this section you will use youreverything you have learned to compute interesting relations on this material.
Exercise 7.1: Compute a relation that has the following schema:
(planet-name : string name : string distance : number)
and contains one tuple matching the schema above. This one tuple should rep-resent the moon in our solar system that is closest to its planet.
Exercise 7.2: Write an expression that returns a relation with the name andthe days-to-rotate for all planets that have one or more moons that are closerthan 25000 miles to the planet.
Exercise 7.3: Write an expression that returns a relations with one columncontaining the names of the planets that has moons that were discovered by”Voyager 2”.
Exercise 7.4: Write an expression that returns a relation with 2 columns: thefirst contains moon names, the second planet names. We wish to computer arelation where a tuple (moon planet) is present in the relation is the diameter ofthe moon is bigger than the diameter of the planet, that is, computer a relationof all the moons that have a diameter bigger than a (any) planet and list whichplanet it is bigger than. (Hint, a cross product might be useful followed by aselect) - the final relation has 9 tuples in it.
Exercise 7.5: (Hard) Create a query with the following schema:
Planet − name : string P lanet − Diameter : number
that lists all planets which have at least one moon that has a diameter (moondiameter) greater than the smallest planet’s diameter. The relation must besorted by the Planet-Diameter. (The correct result has just 4 tuples).
We can (fairly easily) create a relation that contains the name of the moons(along with their planets) much like the previous exercise if we wish, that is, aquery that results in the following relation:
23

Planet:string Name:string Diameter:numberNeptune Triton 2700.0Jupiter Europa 3138.0Earth Moon 3476.0Jupiter Io 3630.0Jupiter Callisto 4800.0Saturn Titan 5150.0Jupiter Ganymede 5262.0
but creating the following relation is a different story:
Planet:string Number-of-moons:numberNeptune 1Jupiter 4Earth 1Saturn 1
That is, a relation where for each planet that has a moon that is larger thanthe smallest planet, the number of such moons is listed in the Number-of-moonscolumn.
Exercise 7.5: Explain why you cannot write a query for your database that re-turns the above relation; and give a description of the extension to the databasesystem that is needed in order to compute such a relation.
24

A Grammar
db expr ::= “(” Expr “)”| rel name;
Expr ::= “list”| “quite”| “show” db expr| “schema” db expr| “make-schema”| “let” name “be” db expr| “insert” tuple “into” db expr| “make-relation” db expr| “count” db expr| “union” “of” db expr “and” db expr| “select” “from” db expr “where” name op value| “project” db expr “over” att list| “minimum” db expr| “maximum” db expr| “join” db expr “with” db expr| “rename” name “in” db expr “to” name| “sort” db expr “by” name;
tuple ::= “(” value list “)”;
value list ::= value| value list value;
att list ::= name| name att list;
op ::= “=” | “!=” | “<” | “>” | “<=” | “>=”;
value ::= number value | string value | symbol value;
25

(display "Please wait....Starting up the Database ")(newline)
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; General functions ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(define reduce (lambda (f n lst) (if (null? lst) n (f (car lst) (reduce f n (cdr lst))))))
(define myfilter (lambda (f lst) (if (null? lst) '() (if (f (car lst)) (cons (car lst) (myfilter f (cdr lst))) (myfilter f (cdr lst))))))
(define myerror (lambda (s) (display s) (newline) 'ERROR))
(define cddddr (lambda (x) (cdr (cdr (cdr (cdr x))))))
(define caddddr (lambda (x) (car (cddddr x))))(define cadddddr (lambda (x) (cadr (cddddr x))))(define caddddddr (lambda (x) (caddr (cddddr x))))(define ignore (lambda (x) (void)))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; Relation accessors ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(define get-name-list car)(define get-type-list cadr)(define get-tuples caddr)(define get-name cadddr)
(define mk-relation (lambda (names types tuples relation-name) (list names types tuples relation-name)))

(define type->symbol (lambda (t) (if (equal? t string?) 'string (if (equal? t number?) 'number 'symbol))))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; Schema manipulation ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; Creates a new schema relation.;;;;;; -> Relation;;;(define make-schema (lambda () (mk-relation '(name type) '(symbol symbol) '() '_schema_)))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; Checks whether a relation is a schema;;;;;; Relation -> boolean;;;(define is-schema? (lambda (sc) (equal? sc (list (cons 'name 'symbol) (cons 'type 'symbol)))))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; compare-schema;;;;;; Relation -> Relation -> Boolean;;(define compare-schema (lambda (rel1 rel2) (let ((n1 (get-name-list rel1)) (n2 (get-name-list rel2)) (s1 (get-type-list rel1)) (s2 (get-type-list rel2))) (if (= (length s1) (length s2)) ;; if the schemas are the same size (let ((_and (lambda (x y) (and x y))))

;; compare if they have the same names and the same types. (and (reduce _and #t (map (lambda (t1 t2) (equal? t1 t2)) s1 s2)) (reduce _and #t (map (lambda (t1 t2) (equal? t1 t2)) n1 n2)))) #f))))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; Type checking and compare functions ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; List of functions for checking that data members have the right type;;; (define type-checker-list (list (cons 'number number?) (cons 'string string?) (cons 'symbol symbol?)))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; List of functions for comparing data members, for each operator;;; a function for strings, numbers and symbols are provided;;;(define compare-list (list (cons '< (list (cons 'string string-ci<?) (cons 'number <) (cons 'symbol (lambda (x y) (string-ci<? (symbol->string x) (symbol->string y)))))) (cons '> (list (cons 'string string-ci>?) (cons 'number >) (cons 'symbol (lambda (x y) (string-ci>? (symbol->string x) (symbol->string y)))))) (cons '= (list (cons 'string string-ci=?) (cons 'number =) (cons 'symbol equal?))) (cons '!= (list (cons 'string (lambda (x y) (not (string-ci=? x y)))) (cons 'number (lambda (x y) (not (= x y)))) (cons 'symbol (lambda (x y)

(not (equal? x y)))))) (cons '>= (list (cons 'string string-ci>=?) (cons 'number >=) (cons 'symbol (lambda (x y) (string-ci>=? (symbol->string x) (symbol->string y)))))) (cons '<= (list (cons 'string string-ci<=?) (cons 'number <=) (cons 'symbol (lambda (x y) (string-ci<=? (symbol->string x) (symbol->string y))))))))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; Returns the type of a value, either 'string, 'symbol or 'number;;;;;; value -> type;;;
(define type-of (lambda (val) (if (string? val) 'string (if (number? val) 'number (if (symbol? val) 'symbol #f)))))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; compares the values x and y using the operator f. f is looked up;;; in the compare list and then used to compare x and y depending on the;;; type of x and y.;;;;;; value -> value -> Boolean;;;(define compare (lambda (f x y) (let ((comp-f (cdr (assv (type-of x) (cdr (assv f compare-list)))))) (comp-f x y))))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;

;;; Returns a function that when applied to a tuple returns the ;;; value stored in the column represented by the attribute name field.;;;;;; Relation -> name -> (lambda (tup) (list-ref tup n));;;(define make-accessor (lambda (rel field) (letrec ((mk-acc (lambda (schema field n) (if (null? schema) #f (if (equal? (car schema) field) (lambda (tup) (list-ref tup n)) (mk-acc (cdr schema) field (add1 n))))))) (mk-acc (get-name-list rel) field 0)))) ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; Type checking ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; All type checking can be done statically, so there is no need for myerror ;;; checking in the individual functions.;;;;;; Note to students: You do not need to understand the type checking in ;;; great detail. However you should be familiar with the idea.
(define getfield (lambda (S field) (if (null? S) #f (if (equal? field (caar S)) (car S) (getfield (cdr S) field)))))
(define match (lambda (pos x) (lambda (y) (if (equal? x (list-ref y pos)) #t (begin (myerror (format "Expected '~a' - found '~a'." x (list-ref y pos))) #f)))))
(define check-length (lambda (cmd)

(if (equal? (car cmd) 'project) (if (< (length cmd) 4) (myerror (format ("Syntax error: 'project' command malformed."))) #t) (let ((keywords (assv (car cmd) function-list))) (if (not keywords) (myerror (format "Command '~a' not found." (car cmd))) (if (= (length cmd) (cadr keywords)) #t (myerror (format "Syntax error: '~a' command malformed." (car cmd)))))))))
;;; 'name-of-function (list <?> (match <pos> 'symbol-to-match) ...))
(define function-list (list (cons 'let (list 4 (match 0 'let) (match 2 'be))) (cons 'quit (list 1 (match 0 'quit))) (cons 'list (list 1 (match 0 'list))) (cons 'show (list 2 (match 0 'show))) (cons 'insert (list 4 (match 0 'insert) (match 2 'into))) (cons 'unique (list 2 (match 0 'unique))) (cons 'union (list 5 (match 0 'union) (match 1 'of) (match 3 'and))) (cons 'make-schema (list 1 (match 0 'make-schema))) (cons 'select (list 7 (match 0 'select) (match 1 'from) (match 3 'where))) (cons 'count (list 2 (match 0 'count))) (cons 'rename (list 6 (match 0 'rename) (match 2 'in) (match 4 'to))) (cons 'maximum (list 2 (match 0 'maximum))) (cons 'minimum (list 2 (match 0 'minimum))) (cons 'join (list 4 (match 0 'join) (match 2 'with))) (cons 'schema (list 2 (match 0 'schema))) (cons 'make-relation (list 2 (match 0 'make-relation))) (cons 'project (list 0 (match 0 'project) (match 2 'over))) (cons 'sort (list 4 (match 0 'sort) (match 2 'by))))) (define check-cmd (lambda (cmd) ;; look the command name up in the function-list. check contains a list ;; of predicates that when mapped onto the cmd will determine if the ;; correct key words were used for the given command. (let ((check (assv (car cmd) function-list))) (if (not check)

;; if it was not found it was an illegal command (myerror (format "Syntax myerror. Command '~a' not found." (car cmd))) ;; if it was found map the predicates and reduce to either #t or #f (if (not (reduce (lambda (x y) (and x y)) #t (map (lambda (f) (f cmd)) (cddr check)))) 'ERROR #t)))))
(define check-operator (lambda (op) (if (member op '(< > <= >= = !=)) #t #f))) (define name-check (lambda (cmd relations ) (if (list? cmd) (if (or (equal? 'ERROR (check-length cmd)) (equal? 'ERROR (check-cmd cmd))) 'ERROR (begin ;(display cmd) ;(display (car cmd)) ;(display (if (equal? (car cmd) 'quit) #t #f)) ;(case (car cmd) ; ((quit) (display "quitting"))) (case (car cmd) ((quit) #t) ((list) (list (cons 'name 'symbol) (cons 'size 'number))) ((make-relation) (let ((S (name-check (cadr cmd) relations))) (if (equal? S 'ERROR) 'ERROR (if (not (is-schema? S)) (myerror (format "Relation is not a schema relation.~a" S)) #t)))) ;; we simply do not know the schema for this operation ((schema) (if (equal? (name-check (cadr cmd) relations) 'ERROR) 'ERROR (list (cons 'name 'symbol) (cons 'type 'symbol))))

((show) (name-check (cadr cmd) relations)) ((let) (let ((S (name-check (cadddr cmd) relations))) (if (equal? S 'ERROR) 'ERROR (if (not (symbol? (cadr cmd))) (myerror (format "'~a' is not a valid name." (cadr cmd))) S)))) ((insert) (if (not (list? (cadr cmd))) (myerror (format "Insert expected tuple but found '~a'." (cadr cmd))) (let* ((tup-type (map type-of (cadr cmd))) (S (name-check (cadddr cmd) relations))) (if (and (not (equal? S 'ERROR)) (not (equal? S #t))) (let ((rel-type (map cdr S)));;; (display (format "(cadr cmd):~a *** tup-type:~a *** rel-type:~a S:~a " (cadr cmd) tup-type rel-type S)) (if (not (= (length tup-type) (length rel-type))) (myerror "Tuple does not match the schema of the relation.") (if (reduce (lambda (x y) (and x y)) #t (map (lambda (x y z) (if (equal? x y) #t (begin (myerror (format "Value '~a' is of type '~a', something of type '~a' was expected." z x y)) #f))) tup-type rel-type (cadr cmd))) S 'ERROR))) 'ERROR)))) ((unique) (name-check (cadr cmd) relations)) ((union) (let ((S1 (name-check (caddr cmd) relations)) (S2 (name-check (caddddr cmd) relations))) (if (and (not (equal? S1 'ERROR)) (not (equal? S2 'ERROR)) (equal? S1 S2)) S1 (myerror (format "Schemas do not match.")))))

((make-schema) (list (cons 'name 'symbol) (cons 'type 'symbol))) ((select) (let ((S (name-check (caddr cmd) relations)) (field (caddddr cmd)) (operator (cadddddr cmd)) (value (caddddddr cmd)))
;; myerror before we got here (if (equal? S 'ERROR) 'ERROR (let ((sf (getfield S field)))
;; is the field in the schema? (if (not sf) (myerror (format "Field '~a' not found in relation." field))
;; does the type of the value match the field type? (let ((value-type (if (not (symbol? value)) ;;; value is not a symbol so it cannot be $.field (type-of value) (if (char=? (string-ref (symbol->string value) 0) #\$) ;; we have a $.field (let ((fi (getfield S (extract-field value)))) (if fi (cdr fi) (myerror (format "Field '~a' not found in relation." (extract-field value))))) (type-of value))))) (if (equal? value-type 'ERROR) 'ERROR (if (not (equal? value-type (cdr sf))) (myerror (format "'~a' should be of type '~a'." (caddddddr cmd) (cdr sf))) ;; check that the operator exists (if (not (check-operator (cadddddr cmd))) (myerror (format "Operator '~a' does not exist." operator))

S))))))))) ((count) (list (cons 'count 'number))) ((rename) (let ((S (name-check (cadddr cmd) relations)) (f1 (cadr cmd)) (f2 (cadddddr cmd))) (if (equal? S 'ERROR) 'ERROR (let ((fs1 (getfield S f1)) (fs2 (getfield S f2)))
;; renaming back to what it was. that is ok! (if (equal? f1 f2) S
;; is f1 in the schema - it must be! (if (not fs1) (myerror (format "field '~a' not found in relation." f1))
;; is f2 in the schema - it must not be! (if fs2 (myerror "field '~a' already in relation." f2) (map (lambda (x) (if (equal? f1 (car x)) (cons f2 (cdr x)) x)) S)))))))) ((maximum) (name-check (cadr cmd) relations)) ((minimum) (name-check (cadr cmd) relations)) ((join) (let ((S1 (name-check (cadr cmd) relations)) (S2 (name-check (cadddr cmd) relations))) (if (or (equal? S1 'ERROR) (equal? S2 'ERROR)) 'ERROR (let ((S2-S1 (myfilter (lambda (x) (not (getfield S1 (car x)))) S2))) (append S1 S2-S1))))) ((project) (let* ((S (name-check (cadr cmd) relations)) (project-list (cdddr cmd)) (unique-project-list (letrec ((remove (lambda (lst) (if (null? lst) '() (cons (car lst) (remove (myfilter (lambda (x) (not (equal? (car lst) x))) (cdr lst)))))))) (remove project-list))))

(if (equal? S 'ERROR) 'ERROR (if (not (reduce (lambda (x y) (and x y)) #t (map (lambda (x) (if (not (getfield S x)) (begin (myerror (format "Field '~a' not in relation." x)) #f) #t)) unique-project-list))) 'ERROR (map (lambda (x) (getfield S x)) unique-project-list))))) ((sort) (let ((S (name-check (cadr cmd) relations))) (if (equal? S 'ERROR) 'ERROR (let*((field (cadddr cmd)) (f (getfield S (cadddr cmd)))) (if (not f) (myerror (format "Field '~a' not in relation." (cadddr cmd))) #t))))) (else (myerror "Unknown command."))))) (if (not (symbol? cmd)) (myerror (format "'~a' is not a valid relation name." cmd)) (let ((R (get-relation cmd relations))) (if (not R) (myerror (format "Relation '~a' not found" cmd)) (map (lambda (x y) (cons x y)) (get-name-list R) (get-type-list R)))))))) ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; get-relations returns a relation from the database.;;;;;; Name -> Database -> Relation;;;(define get-relation (lambda (rel-name relations) (let ((rel (assv rel-name (cdr relations)))) (if rel (cadr rel) #f))))

;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; Relational functions ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; (MAKE-RELATIOn <rel-expr>);;; ;;; Creates a new empty relation based on a schema relation;;;;;; Relation -> Relation;;(define make-relation (lambda (schema) (let* ((schema-type-list (map cadr (get-tuples schema))) (column-names (map car (get-tuples schema)))) (mk-relation column-names schema-type-list '() '_make_relation_)))) ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; (UNIQUE <rel-expr>);;;;;; Removes extra copies of tuples that exist more than once in the ;;; relation;;;;;; Relation -> Relation
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; ;;; Removes doubles in a list ;;; ;;; list -> list ;;;(define remove-doubles (lambda (lst) (if (null? lst) '() (cons (car lst) (remove-doubles (myfilter (lambda (x) (not (equal? (car lst) x))) (cdr lst)))))))
(define unique (lambda (rel)

(mk-relation (get-name-list rel) (get-type-list rel) (remove-doubles (get-tuples rel)) '_unique_))) ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; (INSERT <tup> INTO <rel-expr>);;;;;; Inserts a tuple into a relation;;;;;; Relation -> Tuple -> Relation;;; (define insert (lambda (rel tup) (set-car! (cddr rel) (append (caddr rel) (list tup))) rel))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; (SELECT FROM <rel-expr> WHERE <name> <op> <value>);;;;;;;;;;;; Relation -> name -> op -> value -> Relation;;;
(define extract-field (lambda ($expr) (let ((s (symbol->string $expr))) (string->symbol (substring s 2 (string-length s))))))
(define select (lambda (rel field op value) (let ((accessor (make-accessor rel field)) (value-accessor (if (not (symbol? value)) ;;; value is not a symbol so it cannot be $.field (lambda (x) value) (if (char=? (string-ref (symbol->string value) 0) #\$) ;; we have a $.field (let ((ac (make-accessor rel (extract-field value)))) (lambda (tup) (ac tup))) (lambda (x) value))))) (mk-relation (get-name-list rel) (get-type-list rel)

(myfilter (lambda (tup) (compare op (accessor tup) (value-accessor tup))) (get-tuples rel)) '_select_))))
(define select-original (lambda (rel field op value) (let ((accessor (make-accessor rel field))) (mk-relation (get-name-list rel) (get-type-list rel) (myfilter (lambda (tup) (compare op (accessor tup) value)) (get-tuples rel)) '_select_))))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; (JOIN <rel-expr> with <rel-expr>);;;;;; Joins 2 relations together. If they have any matching colums the;;; tuples in the result relation must have the same values on all;;; the attributes they share. If no attributes are shared the ;;; cross produce is computed;;;;;; Relation -> Relation -> Relation;;;
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; ;;; Returns a list of the common attributes
(define common-fields (lambda (lst1 lst2) (myfilter (lambda (field) (reduce (lambda (x y) (or x y)) #f (map (lambda (field2) (equal? field field2)) lst2))) lst1)))
(define non-common-fields (lambda (lst1 lst2) (myfilter (lambda (field) (not (reduce (lambda (x y) (or x y)) #f (map (lambda (field2) (equal? field field2)) lst2)))) lst1)))
(define apply-accessor-list

(lambda (accessor-list tup) (map (lambda (accessor) (accessor tup)) accessor-list)))
(define join (lambda (rel1 rel2) (let* ((namelist1 (get-name-list rel1)) (namelist2 (get-name-list rel2)) (com-fields (common-fields namelist1 namelist2)) (fields-in-rel2-not-in-rel1 (non-common-fields namelist2 namelist1)) (com-accessors-rel1 (map (lambda (x) (make-accessor rel1 x)) com-fields)) (com-accessors-rel2 (map (lambda (x) (make-accessor rel2 x)) com-fields)) (fields-in-rel2-not-in-rel1-accessors (map (lambda (x) (make-accessor rel2 x)) fields-in-rel2-not-in-rel1))) (if (null? com-fields) ;;; ;;; no common fields - just compute cross product. ;;; (let ((tuples (map (lambda (tup) (map (lambda (x) (append tup x)) (get-tuples rel2))) (get-tuples rel1)))) (list (append namelist1 namelist2) (append (get-type-list rel1) (get-type-list rel2)) (reduce append '() tuples) '_join_)) ;;; ;;; Some common fields - compute the join relation ;;; ;;; remove all empty lists of tuples (non existing tuples) (let ((tuples ;;; make one big list of tuples (reduce append '() ;;; for each tuple 'tup1' in relation1 do the following: (map (lambda (tup1) ;;; get the values of the common fields from tup1 (let ((comm-fields-rel1 (apply-accessor-list com-accessors-rel1 tup1))) ;;; for all the tuples in relation2 that has the same values on the common ;;; fields as tup1 get the fields not found in relation1 and glue them to ;;; the end of tup1, thus making ONE tuple in the final result.

(map (lambda (tup) (append tup1 (apply-accessor-list fields-in-rel2-not-in-rel1-accessors tup))) ;;; myfilter out all the tuples in relation2 that have the same values on the common ;;; fields as tup1 does. (myfilter (lambda (tup2) (equal? comm-fields-rel1 (apply-accessor-list com-accessors-rel2 tup2))) ;;; myfilter over tuples in realtion2 (get-tuples rel2) )))) ;;; map over tuples in relation1 (get-tuples rel1))))) (list (append namelist1 fields-in-rel2-not-in-rel1) (append (get-type-list rel1) (apply-accessor-list fields-in-rel2-not-in-rel1-accessors (get-type-list rel2))) (myfilter (lambda (x) (not (null? x))) tuples) '_join_)))))) (define schema (lambda (rel) (list '(name type) '(symbol symbol) (map (lambda (x y) (list x y)) (get-name-list rel) (get-type-list rel)) '_schema_)))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; (PROJECT <rel-expr> over <attribute name1> ....);;;;;; Projects an entire relation over a list of attributes;;;;;; Relation -> Relation;;;(define project (lambda (rel names) ;;; remove any attributes that were repeated (let* ((unique-names (remove-doubles names)) ;;; create the list of accessors (accessors (map (lambda (x) (make-accessor rel x)) unique-names)) ;;; extract the schema, type-list and tuples

;;; from the relation. (tuples (get-tuples rel)) (name-list (get-name-list rel)) (type-list (get-type-list rel))) ;;; return a new relation with the wanted columns (list (map (lambda (x) (x name-list)) accessors) (map (lambda (x) (x type-list)) accessors) (map (lambda (tup) (map (lambda (x) (x tup)) accessors)) tuples) '_project_))))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; (RENAME <attribute name> in <rel-expr> to <attribute name>);;;;;; renames one attribute name in a relation.;;;;;; name -> Relation -> name -> Relation
(define rename (lambda (rel field new-field) (list (map (lambda (x) (if (equal? x field) new-field x)) (get-name-list rel)) (get-type-list rel) (get-tuples rel) '_rename_)))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; (LIST);;;;;; list-relations - lists the relations in the current database;;;;;; Database -> void;;;(define list-relations (lambda (dbs) (list '(name size) '(symbol number) (map (lambda (r) (list (car r) (length (get-tuples (cadr r))))) (cdr dbs)) '_list_)))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;

;;; (COUNT <rel-expr>);;;;;; Counts the number of tuples in a relation and returns it as a relation;;;;;; Relation -> Relation;;;(define count (lambda (rel) (let* ((c-schema (make-schema)) (v1 (insert c-schema '(count number))) (c-rel (make-relation c-schema)) (size (length (get-tuples rel)))) (insert c-rel (list size)) c-rel)))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; (MINIMUM <rel-expr>);;;;;; Computes the minimum value of each column and returns a relation with;;; one tuple containing these minimum values.;;;;;; Relation -> Relation;;;(define minimum (lambda (rel) (let ((m (list (get-name-list rel) (get-type-list rel) '() '_minimum_))) (if (null? (get-tuples rel)) m (begin (let ((min (car (get-tuples rel)))) (for-each (lambda (tup) (set! min (map (lambda (x y) (if (compare '< x y) x y)) min tup))) (get-tuples rel)) (insert m min) m))))))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; (MAXIMUM <rel-expr>);;;;;; Computes the maximum value of each column and returns a relation with;;; one tuple containing these maximum values.;;;;;; Relation -> Relation;;;

(define maximum (lambda (rel) (let ((m (list (car rel) (cadr rel) '() '_maximum_))) (if (null? (get-tuples rel)) m (begin (let ((max (car (get-tuples rel)))) (for-each (lambda (tup) (set! max (map (lambda (x y) (if (compare '> x y) x y)) max tup))) (get-tuples rel)) (insert m max) m))))))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; (LET <name> be <rel-expr>);;;;;; defines a new relation with name <name> in the database;;;;;; Relation -> Relation;;;(define define-rel (lambda (relations rel name) (let ((rel2 (get-relation name relations))) (if rel2 ;; if the relation exists overwrite it (begin (set-car! rel2 (car rel)) (set-cdr! rel2 (cdr rel))) ;; if not - add it to the end of the relations list (set-cdr! relations (cons (list name rel) (cdr relations)))) rel)))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; (SHOW <rel-expr>);;;;;; pretty prints a relation;;;;;; Relation ->Relation;;;
(define get-max-lengths (lambda (db) (if (null? (car db)) '() (cons (apply max (map string-length (map car db)))

(get-max-lengths (map cdr db))))))
(define make-blanks (lambda (n s) (if (= n 0) "" (string-append s (make-blanks (- n 1) s)))))
(define print-line (lambda (line fm s) (if (null? line) (begin (display (if (string=? s "-") "+" "|")) (newline)) (begin (display (format "~a~a~a~a~a" (if (string=? s "-") "+" "|") s (car line) (make-blanks (- (car fm) (string-length (car line))) s) s)) (print-line (cdr line) (cdr fm) s)))))
(define to-string (lambda (val) (if (string? val) val (if (symbol? val) (symbol->string val) (if (number? val) (number->string val) "<ERROR>"))))) (define show (lambda (rela) (let* ((rel (unique rela)) (string-schema (map (lambda (f t) (string-append f ":" t)) (map symbol->string (get-name-list rel)) (map symbol->string (get-type-list rel)))) (string-rel (cons string-schema (map (lambda (tup) (map (lambda (val) (to-string val)) tup)) (get-tuples rel)))) (max-len (get-max-lengths string-rel)) (empty-str-lst (map (lambda (x) "") (get-name-list rel)))) (display "Generated by: ") (display (get-name rela)) (newline) (print-line empty-str-lst max-len "-") (print-line string-schema max-len " ") (print-line empty-str-lst max-len "-") (for-each (lambda (x) (print-line x max-len " ")) (cdr string-rel))

(print-line empty-str-lst max-len "-") rel)))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; (UNION of <rel-expr> and <rel-expr>);;;;;; Computes the union of 2 relations;;;;;; Relation -> Relation -> Relation;;;(define union (lambda (rel1 rel2) (list (get-name-list rel1) (get-type-list rel1) (append (get-tuples rel1) (get-tuples rel2)) '_union_)))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; (SORT <rel-expr> by <name>);;;;;; Sorts the relation by the specified name;;;;;; Relation -> Name -> Relation;;;
(define quick-sort (lambda (tuples accessor) (if (<= (length tuples) 1) tuples (let ((less '()) (equal '()) (great '()) (t (accessor (list-ref tuples (round (/ (length tuples) 2)))))) (for-each (lambda (tup) (if (compare '< t (accessor tup)) (set! great (cons tup great)) (if (compare '> t (accessor tup)) (set! less (cons tup less)) (set! equal (cons tup equal))))) tuples) (append (quick-sort less accessor) equal (quick-sort great accessor))))))
(define sort (lambda (rel name)

(let* ((accessor (make-accessor rel name))) (list (get-name-list rel) (get-type-list rel) (quick-sort (get-tuples rel) accessor) '_sort_))))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; EVALUATION ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(define evaluate (lambda (expr relations) (if (not (list? expr)) ;;; expr is just a name of a relation - look it up and return it. (get-relation expr relations) (case (car expr) ((union) ;; (union of <relation-expr> and <relation-expr>) (union (evaluate (caddr expr) relations) (evaluate (caddddr expr) relations))) ((unique) ;; (unique <relation-expr>) (unique (evaluate (cadr expr) relations))) ((make-scheme) (make-schema)) ((make-relation) ;; (make-relation <relation-expr>) (make-relation (evaluate (cadr expr) relations))) ((select) ;; (select from <realtion-expr> where <field> <op> <value>) (select (evaluate (caddr expr) relations) (caddddr expr) (caddr (cdddr expr)) (cadddr (cdddr expr)))) ((project) ;; (project <relation-expr> over <field> ... <field>) (project (evaluate (cadr expr) relations) (cdddr expr))) ((rename) ;; (rename <field> in <relation-expr> to <field-name>) (rename (evaluate (cadddr expr) relations) (cadr expr) (cadr (cddddr expr)))) ((count) ;; (count <relation-expr>) (count (evaluate (cadr expr) relations))) ((minimum) ; (minimum <relation-expr>) (minimum (evaluate (cadr expr) relations))) ((maximum) ; (maximum <relation-expr>) (maximum (evaluate (cadr expr) relations))) ((join) ; (join <relation-expr> with <relation-expr>) (join (evaluate (cadr expr) relations) (evaluate (cadddr expr) relations))) ((insert) ; (insert <tup> into <relation-expr>) (insert (evaluate (cadddr expr) relations) (cadr expr))) ((list) ;; (list) (list-relations relations)) ((show) ;; (show <relation-expr>)

(evaluate (cadr expr) relations)) ((let) ;; (let name be <relation-expr>) (define-rel relations (evaluate (cadddr expr) relations) (cadr expr))) ((schema) ;; (schema <rel-expr>) (schema (evaluate (cadr expr) relations))) ((sort) ;; (sort <rel-expr> by <name>) (sort (evaluate (cadr expr) relations) (cadddr expr))) ((foreach) ;; (foreach <rel-name> in <rel-expr> <rel-expr>) (fforeach (cadr expr) (evaluate (cadddr expr) relations) (caddddr expr)) (else '())) )))) (define fforeach (lambda (tuple-name rel expr) rel)) (define run (lambda () (let ((relations (list '_relations_ (cons 'help (list help)) (cons 'numbers (list rel2)) (cons 'summer2002 (list summer2002)) (cons 'billboard (list billboard)) (cons 'planets (list planets)) (cons 'moons (list moons)) (cons 'addresses (list rel)) ))) (letrec ((query (lambda () (display (format "/Database:~a> " (sub1 (length relations)))) (let ((cmd (read))) (let ((res (name-check cmd relations))) (if (equal? res 'ERROR) (query) (if (not (list? cmd)) (query) (if (equal? cmd '(quit)) (void) (begin (show (evaluate cmd relations)) (query)))))))))) (query)))))

(load "relations.scm")(run)



















