
SVMs Reprised Reading: Bishop, Sec 4.1.1, 6.0, 6.1, 7.0, 7.1.
39
SVMs Reprised Reading: Bishop, Sec 4.1.1, 6.0, 6.1, 7.0, 7.1
-
date post
21-Dec-2015 -
Category
Documents
-
view
224 -
download
0
Transcript of SVMs Reprised Reading: Bishop, Sec 4.1.1, 6.0, 6.1, 7.0, 7.1.

SVMs ReprisedReading: Bishop, Sec 4.1.1, 6.0, 6.1, 7.0, 7.1

Administrivia
•HW1 back today
•μ=18.7 (of 25)
•σ=5.4

I’ve slept since then...•Last time:
•LSE example
•Regression to linear discriminants
•Binary discriminants to multi-class
• Intro to nonlinearly separable data and nonlinear projections
•Today:
•Geometry of hyperplanes
•The maximum margin method
•The SVM optimization problem
•Quadratic programming (briefly)

Tides of history•Last time
•Linear classification (briefly)
•Multi-classes from sets of hyperplanes
•SVMs: nonlinear data projections
•Today
•Vector geometry
•The SVM objective function
•Linear programming (briefly)
•Slack variables
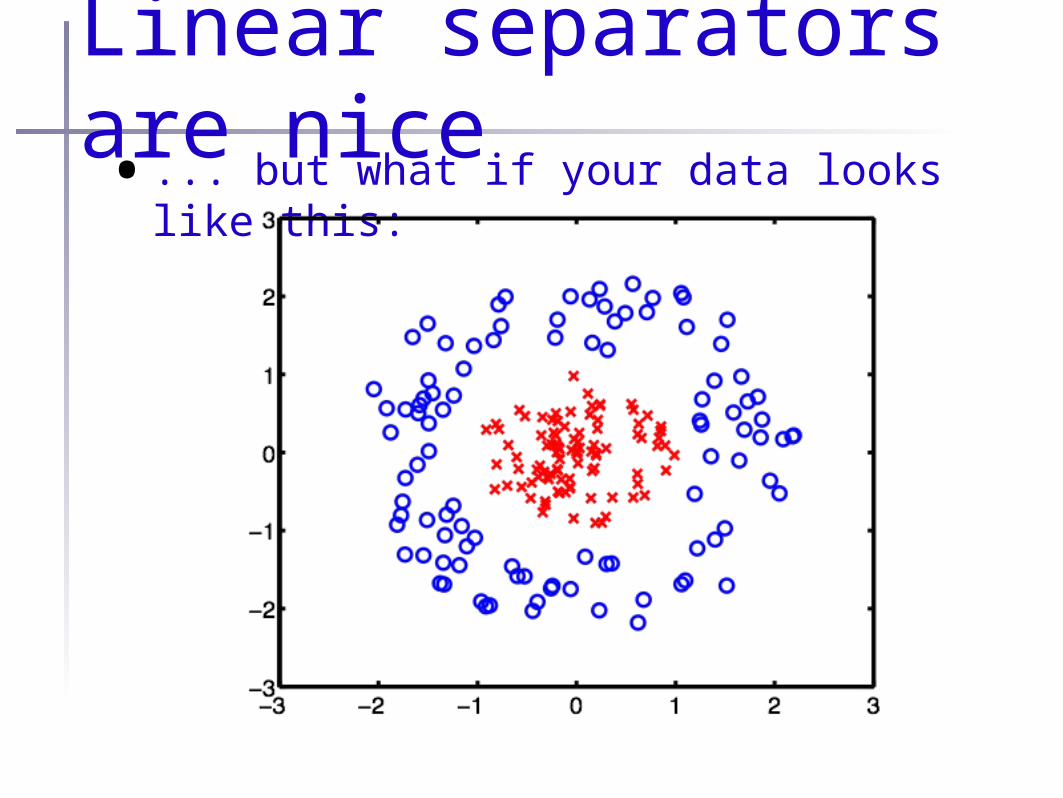
Linear separators are nice• ... but what if your data looks like this:

Nonlinear data projection•Suppose you have a
“projection function”:
•Original feature space
•“Projected” space
•Usually
•Do learning w/ linear model in
•Ex:
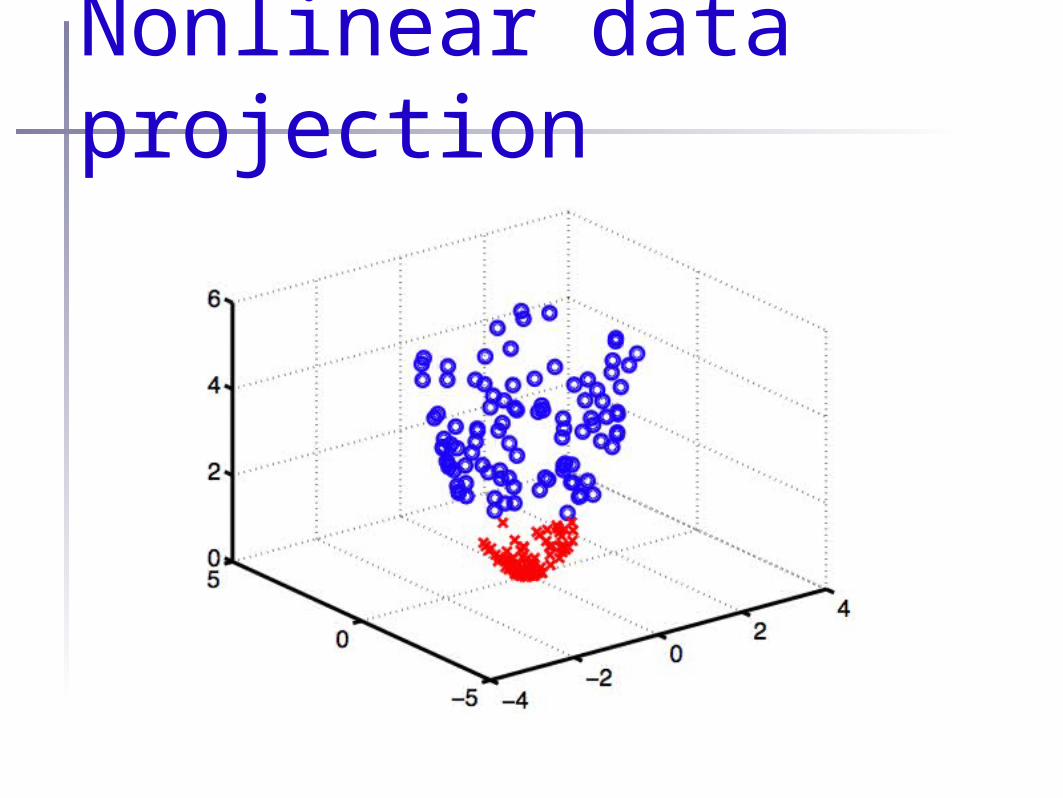
Nonlinear data projection

Nonlinear data projection
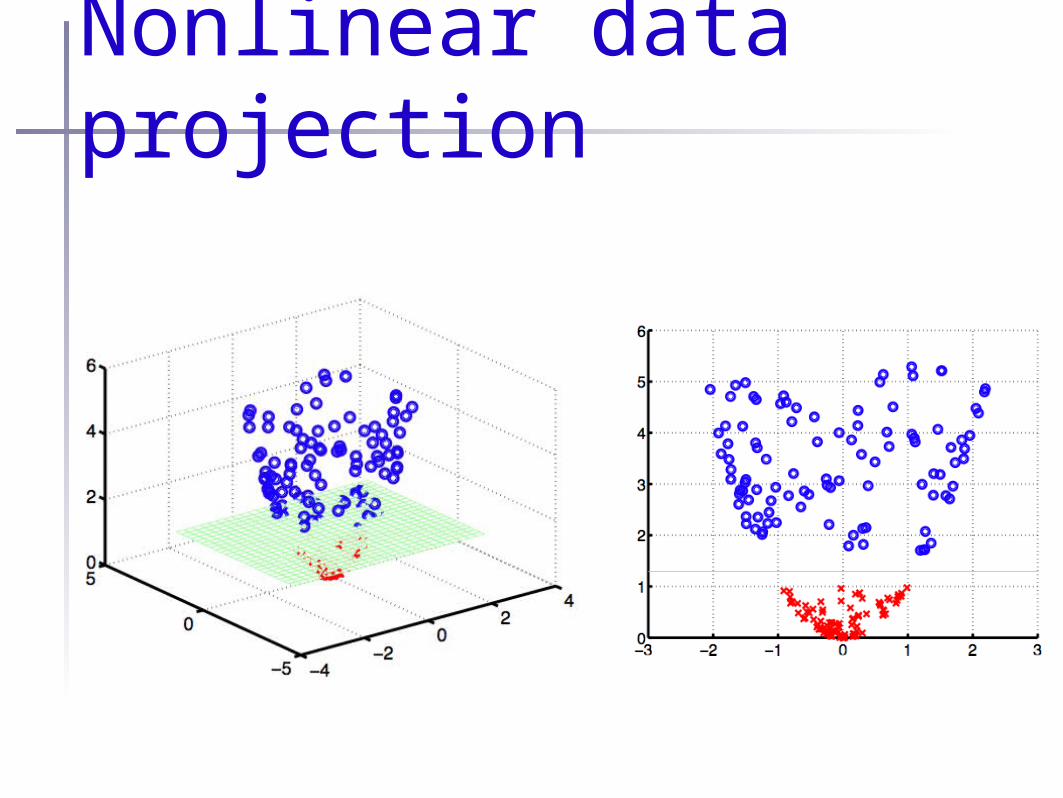
Nonlinear data projection

Common projections•Degree-k polynomials:
•Fourier expansions:
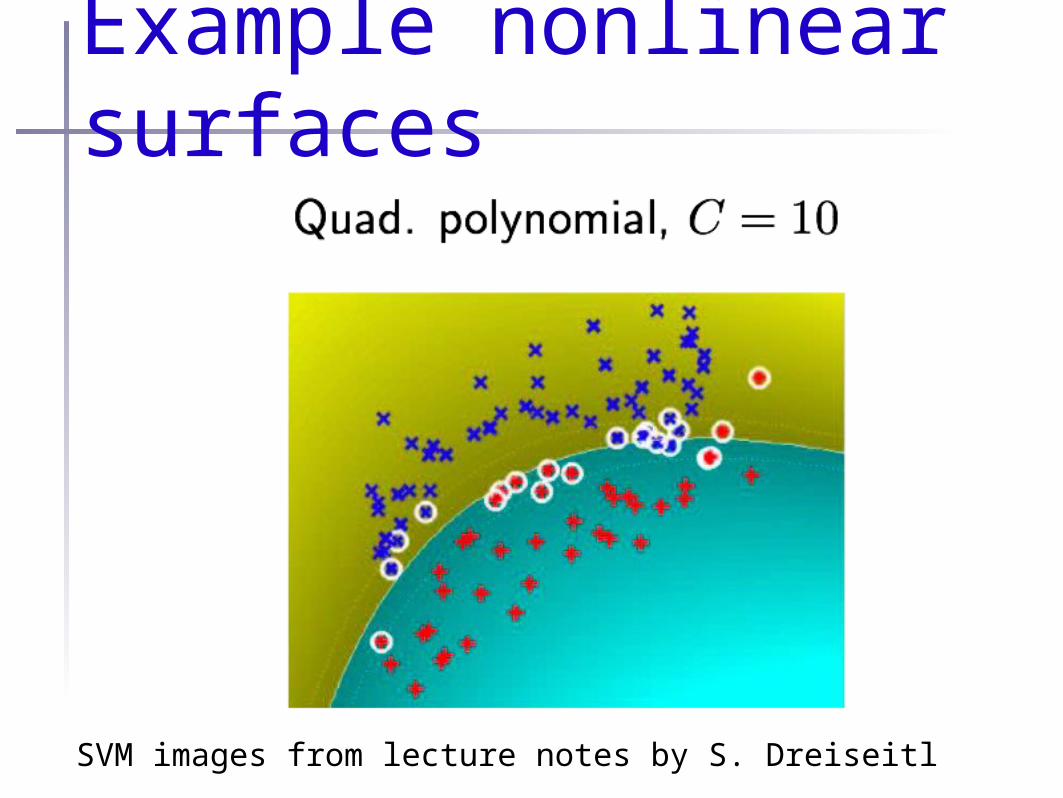
Example nonlinear surfaces
SVM images from lecture notes by S. Dreiseitl

Example nonlinear surfaces
SVM images from lecture notes by S. Dreiseitl

Example nonlinear surfaces
SVM images from lecture notes by S. Dreiseitl

Example nonlinear surfaces
SVM images from lecture notes by S. Dreiseitl

The catch...•How many dimensions does have?
•For degree-k polynomial expansions:
•E.g., for k=4, d=256 (16x16 images),
•Yike!
•For “radial basis functions”,

Linear surfaces for cheap•Can’t directly find linear surfaces in
•Have to find a clever “method” for finding them indirectly
• It’ll take (quite) a bit of work to get there...
•Will need different criterion than
•We’ll look for the “maximum margin” classifier
•Surface s.t. class 1 (“true”) data falls as possible on one side; class -1 (“false”) falls as far as possible on the other
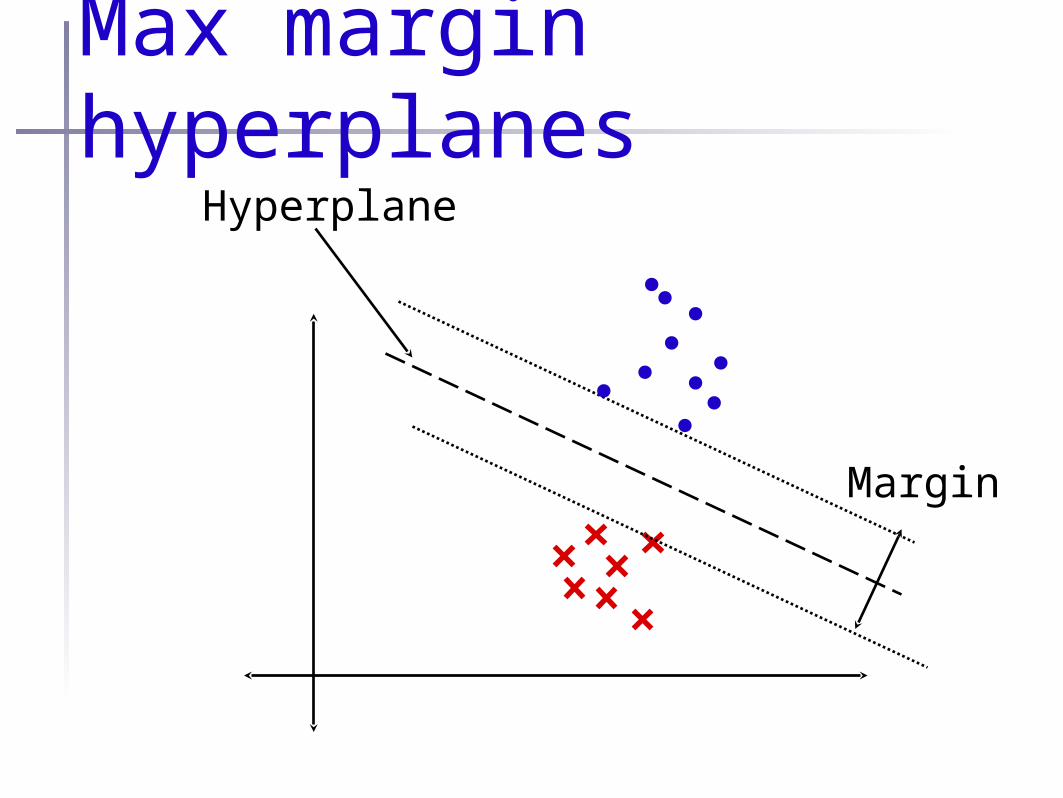
Max margin hyperplanes
Hyperplane
Margin
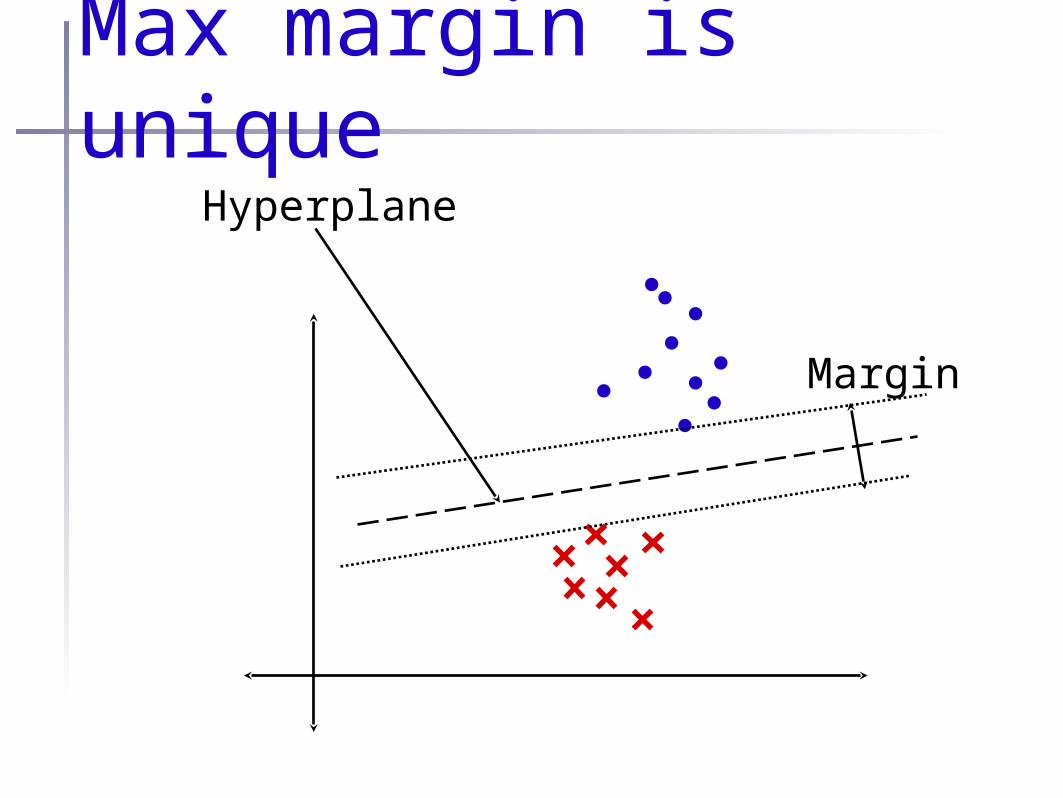
Max margin is uniqueHyperplane
Margin

Exercise•Given a hyperplane defined by a weight vector
•What is the equation for points on the surface of the hyperplane?
•What are the equations for points on the two margins?
•Give an expression for the distance between a point and the hyperplane (and/or either margin)
•What is the role of ?

5 minutes of math...•A dot product (inner product) is a projection of
one vector onto another
•When the projection of x onto w is equal to w0, then x falls exactly onto the w hyperplane
w
Hyperplane
X

5 minutes of math...•BTW, are we sure that hyperplane is
perpendicular to w? Why?

5 minutes of math...•BTW, are we sure that hyperplane is
perpendicular to w? Why?
•Consider any two vectors, x1 and x2, falling exactly on the hyperplane, then:
is perpendicular to any vector in the hyperplane
is some vector in the hyperplane
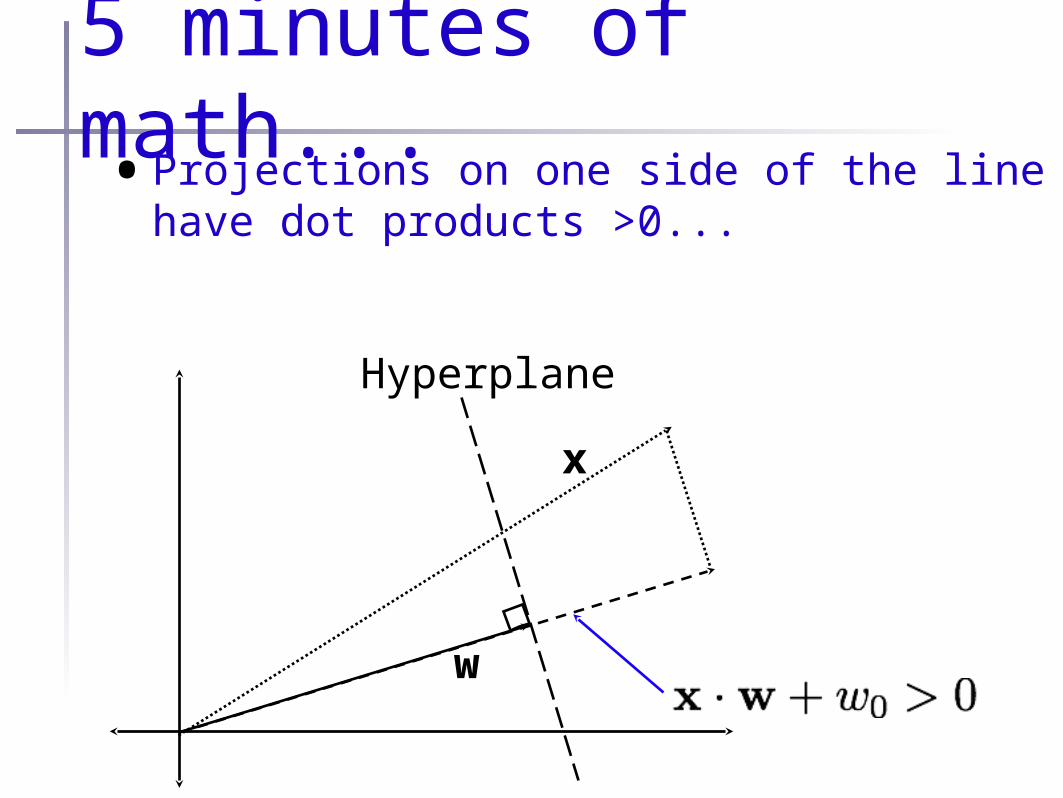
5 minutes of math...•Projections on one side of the line have
dot products >0...
w
Hyperplane
x
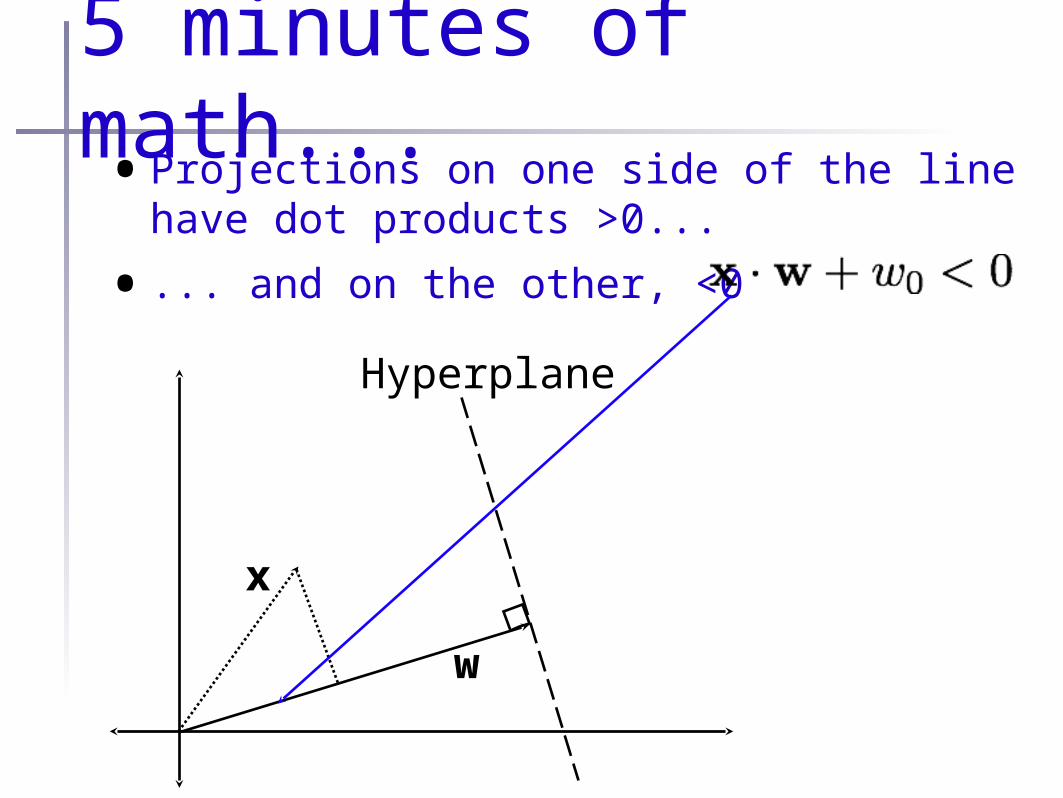
5 minutes of math...•Projections on one side of the line have
dot products >0...
• ... and on the other, <0
w
Hyperplane
x
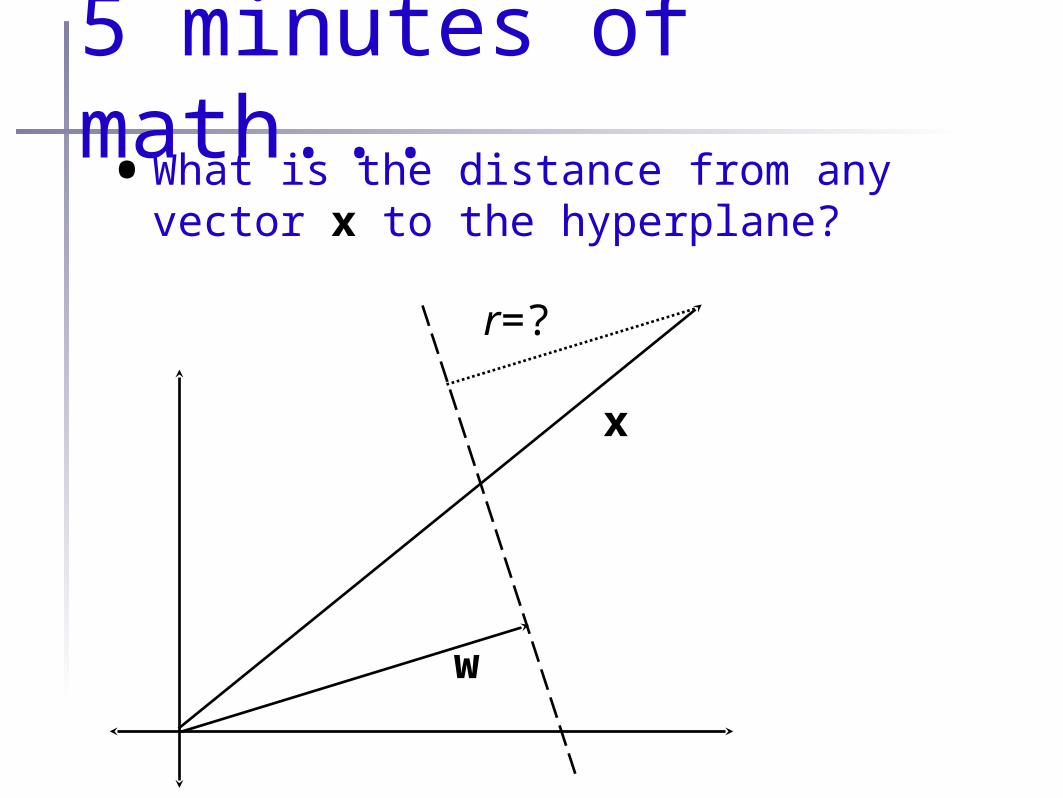
5 minutes of math...•What is the distance from any vector x to
the hyperplane?
w
x
r=?
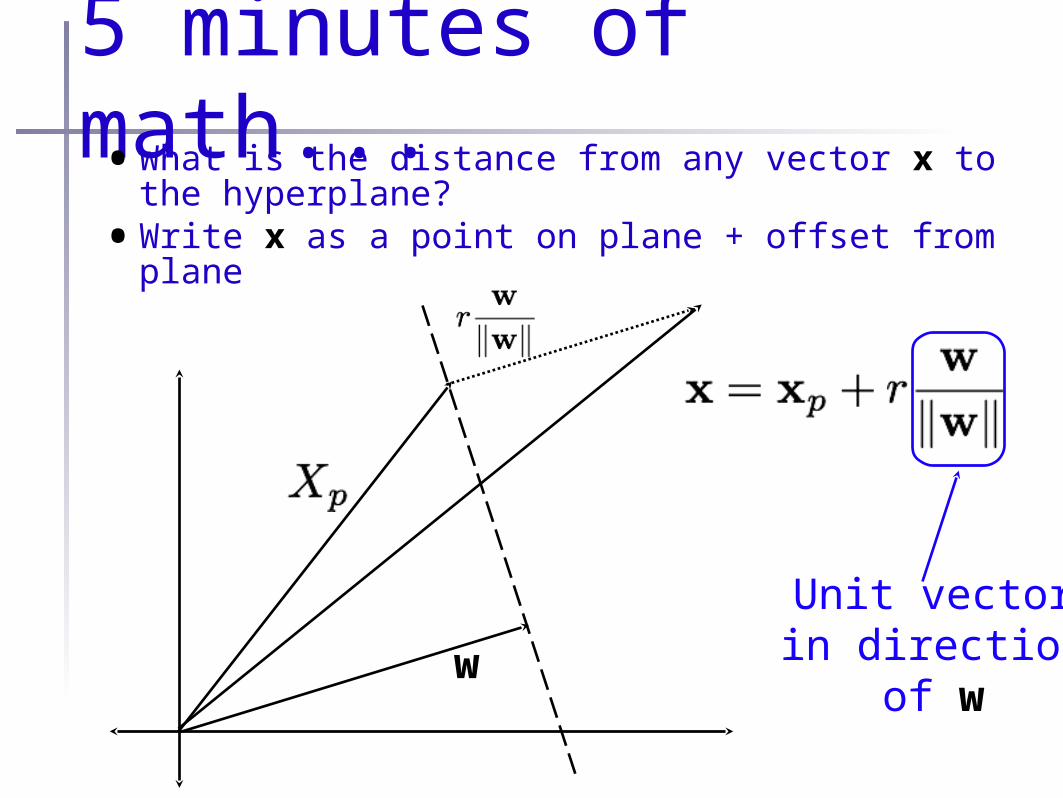
5 minutes of math...•What is the distance from any vector x to the
hyperplane?•Write x as a point on plane + offset from plane
w
Unit vectorin direction
of w

5 minutes of math...•Now:

5 minutes of math...•Theorem: The distance, r, from any point x to the
hyperplane defined by w and is given by:
•Lemma: The distance from the origin to the hyperplane is given by:
•Also: r>0 for points on one side of the hyperplane; r<0 for points on the other

Back to SVMs & margins•The margins are parallel to hyperplane,
so are defined by same w, plus constant offsets
w
bb
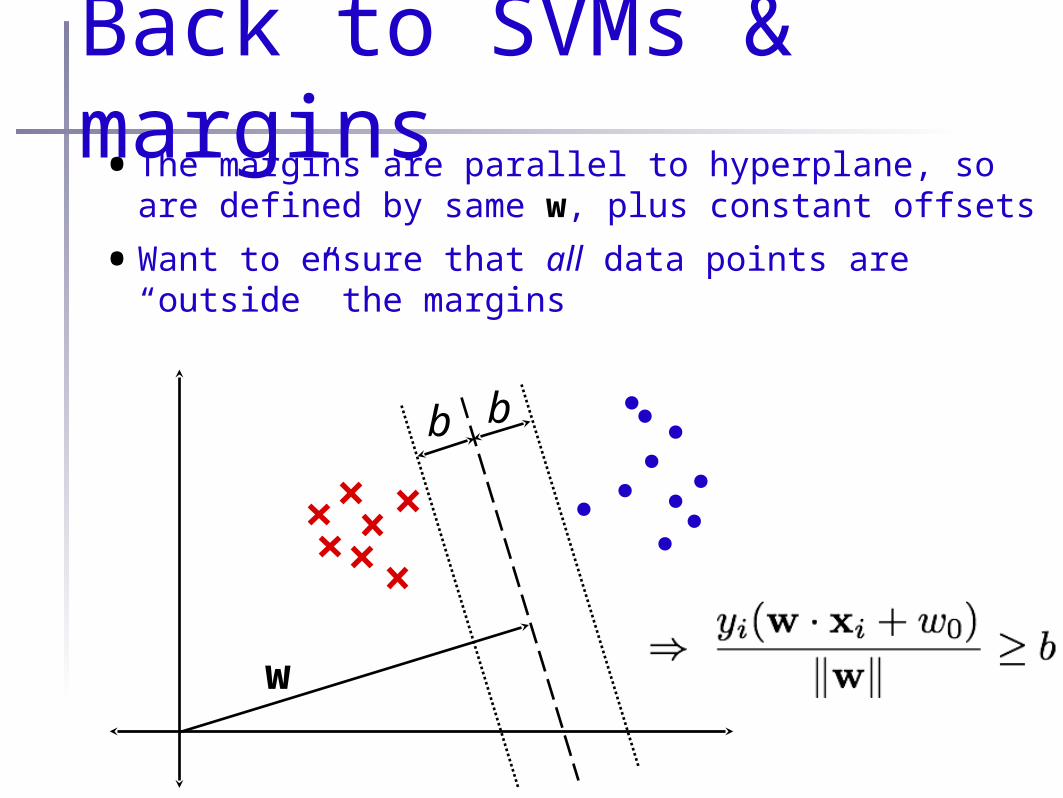
Back to SVMs & margins•The margins are parallel to hyperplane, so
are defined by same w, plus constant offsets
•Want to ensure that all data points are “outside” the margins
w
bb

Maximizing the margin•So now we have a learning criterion
function:
•Pick w to maximize b s.t. all points still satisfy
•Note: w.l.o.g. can rescale w arbitrarily (why?)

Maximizing the margin•So now we have a learning criterion function:
•Pick w to maximize b s.t. all points still satisfy
•Note: w.l.o.g. can rescale w arbitrarily (why?)
•So can formulate full problem as:
Minimize:
Subject to:
•But how do you do that? And how does this help?

Quadratic programming•Problems of the form
Minimize:Subject to:
•are called “quadratic programming” problems•There are off-the-shelf methods to solve them•Actually solving this is way, way beyond the
scope of this class•Consider it a black box• If a solution exists, it will be found & be unique•Expensive, but not intractably so
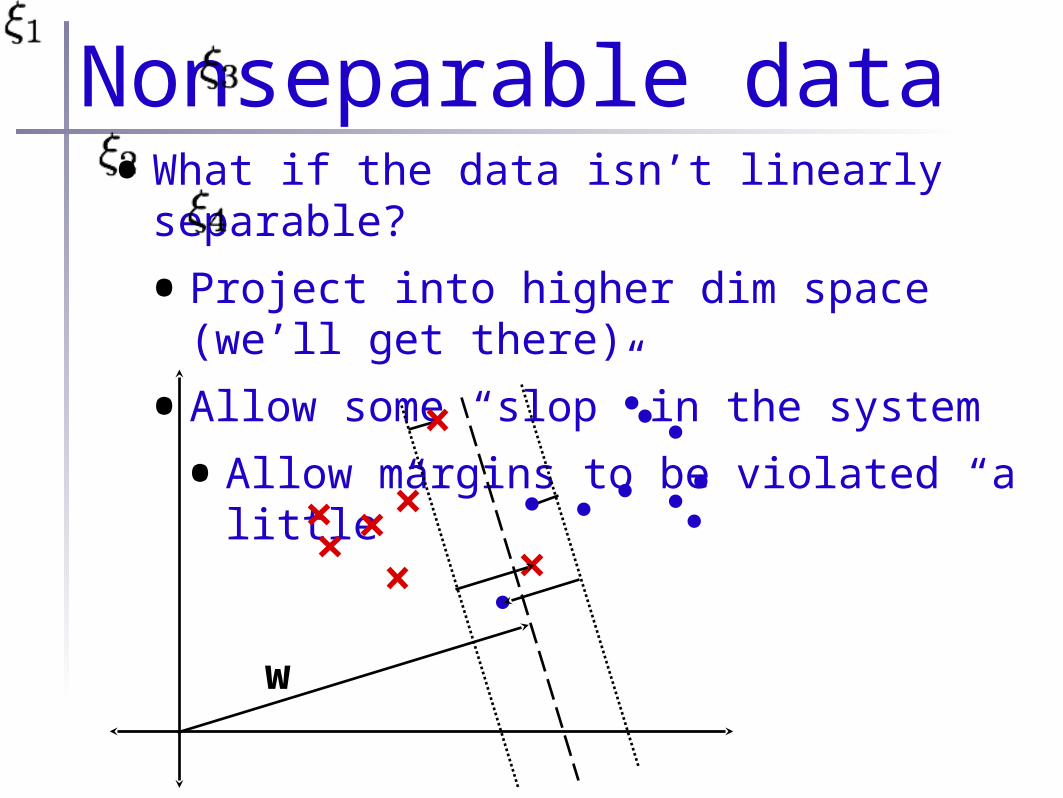
Nonseparable data•What if the data isn’t linearly separable?
•Project into higher dim space (we’ll get there)
•Allow some “slop” in the system
•Allow margins to be violated “a little”
w

The new “slackful” QP•The are “slack variables”
•Allow margins to be violated a little
•Still want to minimize margin violations, so add them to QP instance:
Minimize:
Subject to:

You promised nonlinearity!•Where did the nonlinear transform
go in all this?
•Another clever trick
•With a little algebra (& help from Lagrange multipliers), can rewrite our QP in the form:
Maximize:
Subject to:

Kernel functions•So??? It’s still the same linear system
•Note, though, that appears in the system only as a dot product:

Kernel functions•So??? It’s still the same linear system
•Note, though, that appears in the system only as a dot product:
•Can replace with :
•The inner product
is called a “kernel function”

Why are kernel fns cool?•The cool trick is that many useful
projections can be written as kernel functions in closed form
• I.e., can work with K() rather than
• If you know K(xi,xj) for every (i,j) pair,
then you can construct the maximum margin hyperplane between the projected data without ever explicitly doing the projection!


















