
Splash: User-friendly Programming Interface for Parallelizing Stochastic Learning Algorithms
57
Splash A User-friendly Programming Interface for Parallelizing Stochastic Algorithms Yuchen Zhang and Michael Jordan AMP Lab, UC Berkeley AMP Lab Splash April 2015 1/1
-
Upload
turi-inc -
Category
Technology
-
view
382 -
download
2
Transcript of Splash: User-friendly Programming Interface for Parallelizing Stochastic Learning Algorithms

Splash
A User-friendly Programming Interface forParallelizing Stochastic Algorithms
Yuchen Zhang and Michael Jordan
AMP Lab, UC Berkeley
AMP Lab Splash April 2015 1 / 1

Batch Algorithms vs. Stochastic Algorithms
Consider minimizing a loss function L(w) := 1n
∑ni=1 `i (w).
Gradient Descent: iteratively update
wt+1 = wt − ηt∇L(wt).
Pros: Easy to parallelize (via Spark).Cons: May need hundreds of iterations to converge.
running time (seconds)
0 50 100 150 200 250
loss
funct
ion
0.55
0.6
0.65
0.7Gradient Descent - 64 threads
AMP Lab Splash April 2015 2 / 1

Batch Algorithms vs. Stochastic Algorithms
Consider minimizing a loss function L(w) := 1n
∑ni=1 `i (w).
Gradient Descent: iteratively update
wt+1 = wt − ηt∇L(wt).
Pros: Easy to parallelize (via Spark).Cons: May need hundreds of iterations to converge.
running time (seconds)
0 50 100 150 200 250
loss
funct
ion
0.55
0.6
0.65
0.7Gradient Descent - 64 threads
AMP Lab Splash April 2015 2 / 1
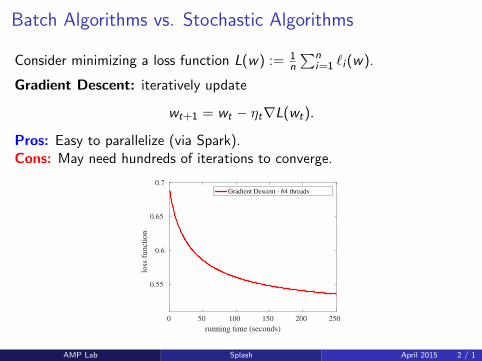
Batch Algorithms vs. Stochastic Algorithms
Consider minimizing a loss function L(w) := 1n
∑ni=1 `i (w).
Gradient Descent: iteratively update
wt+1 = wt − ηt∇L(wt).
Pros: Easy to parallelize (via Spark).Cons: May need hundreds of iterations to converge.
running time (seconds)
0 50 100 150 200 250
loss
funct
ion
0.55
0.6
0.65
0.7Gradient Descent - 64 threads
AMP Lab Splash April 2015 2 / 1

Batch Algorithm v.s. Stochastic Algorithm
Consider minimizing a loss function L(w) := 1n
∑ni=1 `i (w).
Stochastic Gradient Descent (SGD): randomly draw `t , then
wt+1 = wt − ηt∇`t(wt).
Pros: Much faster convergence.Cons: Sequential algorithm, non-trivial to parallelize.
running time (seconds)
0 50 100 150 200 250
loss
funct
ion
0.55
0.6
0.65
0.7Gradient Descent - 64 threads
Stochastic Gradient Descent
AMP Lab Splash April 2015 3 / 1
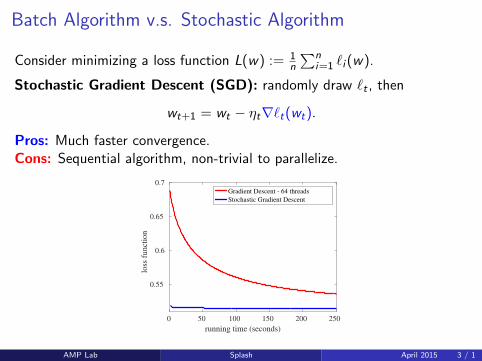
Batch Algorithm v.s. Stochastic Algorithm
Consider minimizing a loss function L(w) := 1n
∑ni=1 `i (w).
Stochastic Gradient Descent (SGD): randomly draw `t , then
wt+1 = wt − ηt∇`t(wt).
Pros: Much faster convergence.Cons: Sequential algorithm, non-trivial to parallelize.
running time (seconds)
0 50 100 150 200 250
loss
funct
ion
0.55
0.6
0.65
0.7Gradient Descent - 64 threads
Stochastic Gradient Descent
AMP Lab Splash April 2015 3 / 1

More Stochastic Algorithms
Convex Optimization
Adaptive SGD (Duchi et al.)
Stochastic Average Gradient Method (Schmidt et al.)
Stochastic Dual Coordinate Ascent (Shalev-Shwartz and Zhang)
Probabilistic Model Inference
Markov chain Monte Carlo (e.g., Gibbs sampling)
Expectation propagation (Minka)
Stochastic variational inference (Hoffman et al.)
SGD variants for
Matrix factorization
Learning neural networks
Learning denoising auto-encoder
How to parallelize these algorithms?
AMP Lab Splash April 2015 4 / 1

More Stochastic Algorithms
Convex Optimization
Adaptive SGD (Duchi et al.)
Stochastic Average Gradient Method (Schmidt et al.)
Stochastic Dual Coordinate Ascent (Shalev-Shwartz and Zhang)
Probabilistic Model Inference
Markov chain Monte Carlo (e.g., Gibbs sampling)
Expectation propagation (Minka)
Stochastic variational inference (Hoffman et al.)
SGD variants for
Matrix factorization
Learning neural networks
Learning denoising auto-encoder
How to parallelize these algorithms?
AMP Lab Splash April 2015 4 / 1

More Stochastic Algorithms
Convex Optimization
Adaptive SGD (Duchi et al.)
Stochastic Average Gradient Method (Schmidt et al.)
Stochastic Dual Coordinate Ascent (Shalev-Shwartz and Zhang)
Probabilistic Model Inference
Markov chain Monte Carlo (e.g., Gibbs sampling)
Expectation propagation (Minka)
Stochastic variational inference (Hoffman et al.)
SGD variants for
Matrix factorization
Learning neural networks
Learning denoising auto-encoder
How to parallelize these algorithms?
AMP Lab Splash April 2015 4 / 1

More Stochastic Algorithms
Convex Optimization
Adaptive SGD (Duchi et al.)
Stochastic Average Gradient Method (Schmidt et al.)
Stochastic Dual Coordinate Ascent (Shalev-Shwartz and Zhang)
Probabilistic Model Inference
Markov chain Monte Carlo (e.g., Gibbs sampling)
Expectation propagation (Minka)
Stochastic variational inference (Hoffman et al.)
SGD variants for
Matrix factorization
Learning neural networks
Learning denoising auto-encoder
How to parallelize these algorithms?
AMP Lab Splash April 2015 4 / 1

Naive Attempt
After processing a subsequence of random samples...Single-thread Algorithm: incremental update w ← w + ∆.
Parallel Algorithm:
Thread 1 (on 1/m of samples): w ← w + ∆1.Thread 2 (on 1/m of samples): w ← w + ∆2.. . .Thread m (on 1/m of samples): w ← w + ∆m.
Aggregate parallel updates w ← w + ∆1 + · · ·+ ∆m.
running time (seconds)
0 20 40 60
loss
fu
nct
ion
0
20
40
60
80
100Single-thread SGD
Parallel SGD - 64 threads
Doesn’t work for SGD!
AMP Lab Splash April 2015 5 / 1

Naive Attempt
After processing a subsequence of random samples...Single-thread Algorithm: incremental update w ← w + ∆.Parallel Algorithm:
Thread 1 (on 1/m of samples): w ← w + ∆1.Thread 2 (on 1/m of samples): w ← w + ∆2.. . .Thread m (on 1/m of samples): w ← w + ∆m.
Aggregate parallel updates w ← w + ∆1 + · · ·+ ∆m.
running time (seconds)
0 20 40 60
loss
fu
nct
ion
0
20
40
60
80
100Single-thread SGD
Parallel SGD - 64 threads
Doesn’t work for SGD!
AMP Lab Splash April 2015 5 / 1

Naive Attempt
After processing a subsequence of random samples...Single-thread Algorithm: incremental update w ← w + ∆.Parallel Algorithm:
Thread 1 (on 1/m of samples): w ← w + ∆1.Thread 2 (on 1/m of samples): w ← w + ∆2.. . .Thread m (on 1/m of samples): w ← w + ∆m.
Aggregate parallel updates w ← w + ∆1 + · · ·+ ∆m.
running time (seconds)
0 20 40 60
loss
fu
nct
ion
0
20
40
60
80
100Single-thread SGD
Parallel SGD - 64 threads
Doesn’t work for SGD!
AMP Lab Splash April 2015 5 / 1
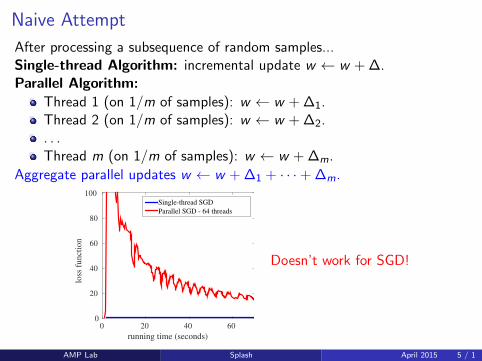
Naive Attempt
After processing a subsequence of random samples...Single-thread Algorithm: incremental update w ← w + ∆.Parallel Algorithm:
Thread 1 (on 1/m of samples): w ← w + ∆1.Thread 2 (on 1/m of samples): w ← w + ∆2.. . .Thread m (on 1/m of samples): w ← w + ∆m.
Aggregate parallel updates w ← w + ∆1 + · · ·+ ∆m.
running time (seconds)
0 20 40 60
loss
fu
nct
ion
0
20
40
60
80
100Single-thread SGD
Parallel SGD - 64 threads
Doesn’t work for SGD!
AMP Lab Splash April 2015 5 / 1

Conflicts in Parallel Updates
Reason for failure: ∆1, . . . ,∆m simultaneously manipulate the samevariable w , causing conflicts in parallel updates.
How to resolve conflicts1 Frequent communication between threads:
Pros: general approach to resolving conflict.Cons: inter-node (asynchronous) communication is expensive!
2 Carefully partition the data to avoid having threads simultaneouslymanipulate the same variable:
Pros: doesn’t need frequent communication.Cons: need problem-specific partitioning schemes; only works for asubset of problems.
AMP Lab Splash April 2015 6 / 1

Conflicts in Parallel Updates
Reason for failure: ∆1, . . . ,∆m simultaneously manipulate the samevariable w , causing conflicts in parallel updates.
How to resolve conflicts
1 Frequent communication between threads:
Pros: general approach to resolving conflict.Cons: inter-node (asynchronous) communication is expensive!
2 Carefully partition the data to avoid having threads simultaneouslymanipulate the same variable:
Pros: doesn’t need frequent communication.Cons: need problem-specific partitioning schemes; only works for asubset of problems.
AMP Lab Splash April 2015 6 / 1

Conflicts in Parallel Updates
Reason for failure: ∆1, . . . ,∆m simultaneously manipulate the samevariable w , causing conflicts in parallel updates.
How to resolve conflicts1 Frequent communication between threads:
Pros: general approach to resolving conflict.Cons: inter-node (asynchronous) communication is expensive!
2 Carefully partition the data to avoid having threads simultaneouslymanipulate the same variable:
Pros: doesn’t need frequent communication.Cons: need problem-specific partitioning schemes; only works for asubset of problems.
AMP Lab Splash April 2015 6 / 1

Conflicts in Parallel Updates
Reason for failure: ∆1, . . . ,∆m simultaneously manipulate the samevariable w , causing conflicts in parallel updates.
How to resolve conflicts1 Frequent communication between threads:
Pros: general approach to resolving conflict.Cons: inter-node (asynchronous) communication is expensive!
2 Carefully partition the data to avoid having threads simultaneouslymanipulate the same variable:
Pros: doesn’t need frequent communication.Cons: need problem-specific partitioning schemes; only works for asubset of problems.
AMP Lab Splash April 2015 6 / 1

Splash: An Omnibus Solution
Splash is
A programming interface for developing stochastic algorithms
An execution engine for running stochastic algorithms on distributedsystems.
Features of Splash include:
Easy Programming: User develop single-thread algorithms viaSplash: no communication protocol, no conflict management, no datapartitioning, no hyper-parameter tuning.
Fast Performance: Splash adopts novel strategy for automaticparallelization with infrequent communication. Communication is nolonger a performance bottleneck.
Integration with Spark: Splash takes an RDD as input and returnsan RDD as output. It works with KeystoneML, MLlib and other dataanalysis tools on Spark.
AMP Lab Splash April 2015 7 / 1

Splash: An Omnibus Solution
Splash is
A programming interface for developing stochastic algorithms
An execution engine for running stochastic algorithms on distributedsystems.
Features of Splash include:
Easy Programming: User develop single-thread algorithms viaSplash: no communication protocol, no conflict management, no datapartitioning, no hyper-parameter tuning.
Fast Performance: Splash adopts novel strategy for automaticparallelization with infrequent communication. Communication is nolonger a performance bottleneck.
Integration with Spark: Splash takes an RDD as input and returnsan RDD as output. It works with KeystoneML, MLlib and other dataanalysis tools on Spark.
AMP Lab Splash April 2015 7 / 1

Splash: An Omnibus Solution
Splash is
A programming interface for developing stochastic algorithms
An execution engine for running stochastic algorithms on distributedsystems.
Features of Splash include:
Easy Programming: User develop single-thread algorithms viaSplash: no communication protocol, no conflict management, no datapartitioning, no hyper-parameter tuning.
Fast Performance: Splash adopts novel strategy for automaticparallelization with infrequent communication. Communication is nolonger a performance bottleneck.
Integration with Spark: Splash takes an RDD as input and returnsan RDD as output. It works with KeystoneML, MLlib and other dataanalysis tools on Spark.
AMP Lab Splash April 2015 7 / 1

Splash: An Omnibus Solution
Splash is
A programming interface for developing stochastic algorithms
An execution engine for running stochastic algorithms on distributedsystems.
Features of Splash include:
Easy Programming: User develop single-thread algorithms viaSplash: no communication protocol, no conflict management, no datapartitioning, no hyper-parameter tuning.
Fast Performance: Splash adopts novel strategy for automaticparallelization with infrequent communication. Communication is nolonger a performance bottleneck.
Integration with Spark: Splash takes an RDD as input and returnsan RDD as output. It works with KeystoneML, MLlib and other dataanalysis tools on Spark.
AMP Lab Splash April 2015 7 / 1

Programming Interface
AMP Lab Splash April 2015 8 / 1

Programming with Splash
Splash users implement the following function:
def process(sample: Any, weight: Int, var: VariableSet){/*implement stochastic algorithm*/
}
where
sample — a random sample from the dataset.
weight — the sample is conceptually duplicated weight times.
var — set of all shared variables.
AMP Lab Splash April 2015 9 / 1

Example: SGD for Linear Regression
Goal: find w∗ = arg minw1n
∑ni=1(wxi − yi )
2.
SGD update: randomly draw (xi , yi ), then w ← w − η∇w (wxi − yi )2.
Splash implementation:
def process(sample: Any, weight: Int, var: VariableSet){val stepsize = var.get(“eta”) * weightval gradient = sample.x * (var.get(“w”) * sample.x - sample.y)var.add(“w”, - stepsize * gradient)
}
Supported operations: get, add, multiply, delayedAdd.
AMP Lab Splash April 2015 10 / 1

Example: SGD for Linear Regression
Goal: find w∗ = arg minw1n
∑ni=1(wxi − yi )
2.
SGD update: randomly draw (xi , yi ), then w ← w − η∇w (wxi − yi )2.
Splash implementation:
def process(sample: Any, weight: Int, var: VariableSet){val stepsize = var.get(“eta”) * weightval gradient = sample.x * (var.get(“w”) * sample.x - sample.y)var.add(“w”, - stepsize * gradient)
}
Supported operations: get, add, multiply, delayedAdd.
AMP Lab Splash April 2015 10 / 1

Example: SGD for Linear Regression
Goal: find w∗ = arg minw1n
∑ni=1(wxi − yi )
2.
SGD update: randomly draw (xi , yi ), then w ← w − η∇w (wxi − yi )2.
Splash implementation:
def process(sample: Any, weight: Int, var: VariableSet){val stepsize = var.get(“eta”) * weightval gradient = sample.x * (var.get(“w”) * sample.x - sample.y)var.add(“w”, - stepsize * gradient)
}
Supported operations: get, add, multiply, delayedAdd.
AMP Lab Splash April 2015 10 / 1

Get Operations
Get the value of the variable (Double or Array[Double]).
get(key) returns var[key]
getArray(key) returns varArray[key]
getArrayElement(key, index) returns varArray[key][index]
getArrayElements(key, indices) returns varArray[key][indices]
Array-based operations are more efficient than element-wise operations,because the key-value retrieval is executed only once when accessing anarray.
AMP Lab Splash April 2015 11 / 1

Add Operations
Add a quantity δ to the variable.
add(key, delta): var[key] += delta
addArray(key, deltaArray): varArray[key] += deltaArray
addArrayElement(key, index, delta): varArray[key][index] += delta
addArrayElements(key, indices, deltaArrayElements):varArray[key][indices] += deltaArrayElements
AMP Lab Splash April 2015 12 / 1

Multiply Operations
Multiply the variable v by a quantity γ.
multiply(key, gamma): var[key] *= gamma
multiplyArray(key, gamma): varArray[key] *= gamma
We have optimized the implementation so that the time complexity ofmultiplyArray is O(1), independent of the array dimension.
Example: SGD with sparse features and `2-norm regularization.
w ← (1− λ) ∗ w (multiply operation) (1)
w ← w − η∇f (w) (addArrayElements operation) (2)
Time complexity of (1) = O(1); Time complexity of (2) = nnz(∇f (w)).
AMP Lab Splash April 2015 13 / 1

Multiply Operations
Multiply the variable v by a quantity γ.
multiply(key, gamma): var[key] *= gamma
multiplyArray(key, gamma): varArray[key] *= gamma
We have optimized the implementation so that the time complexity ofmultiplyArray is O(1), independent of the array dimension.
Example: SGD with sparse features and `2-norm regularization.
w ← (1− λ) ∗ w (multiply operation) (1)
w ← w − η∇f (w) (addArrayElements operation) (2)
Time complexity of (1) = O(1); Time complexity of (2) = nnz(∇f (w)).
AMP Lab Splash April 2015 13 / 1

Delayed Add Operations
Add a quantity δ to the variable v . The operation is not executed until thenext time the same sample is processed by the system.
delayedAdd(key, delta): var[key] += delta
delayedAddArray(key, deltaArray): varArray[key] += deltaArray
delayedAddArrayElement(key, index, delta):varArray[key][index] += delta
Example: Collapsed Gibbs Sampling for LDA – update the count nwkwhen topic k is assigned to word w .
nwk ← nwk + weight (add operation) (3)
nwk ← nwk − weight (delayed add operation) (4)
(3) executed instantly; (4) will be executed at the next time before a newtopic is sampled for the same word.
AMP Lab Splash April 2015 14 / 1

Delayed Add Operations
Add a quantity δ to the variable v . The operation is not executed until thenext time the same sample is processed by the system.
delayedAdd(key, delta): var[key] += delta
delayedAddArray(key, deltaArray): varArray[key] += deltaArray
delayedAddArrayElement(key, index, delta):varArray[key][index] += delta
Example: Collapsed Gibbs Sampling for LDA – update the count nwkwhen topic k is assigned to word w .
nwk ← nwk + weight (add operation) (3)
nwk ← nwk − weight (delayed add operation) (4)
(3) executed instantly; (4) will be executed at the next time before a newtopic is sampled for the same word.
AMP Lab Splash April 2015 14 / 1

Running a Stochastic Algorithm
Three simple steps:
1 Convert RDD dataset to a Parametrized RDD:
val paramRdd = new ParametrizedRDD(rdd)
2 Set a function that implements the algorithm:
paramRdd.setProcessFunction(process)
3 Start running:
paramRdd.run()
AMP Lab Splash April 2015 15 / 1

Running a Stochastic Algorithm
Three simple steps:
1 Convert RDD dataset to a Parametrized RDD:
val paramRdd = new ParametrizedRDD(rdd)
2 Set a function that implements the algorithm:
paramRdd.setProcessFunction(process)
3 Start running:
paramRdd.run()
AMP Lab Splash April 2015 15 / 1

Running a Stochastic Algorithm
Three simple steps:
1 Convert RDD dataset to a Parametrized RDD:
val paramRdd = new ParametrizedRDD(rdd)
2 Set a function that implements the algorithm:
paramRdd.setProcessFunction(process)
3 Start running:
paramRdd.run()
AMP Lab Splash April 2015 15 / 1

Execution Engine
AMP Lab Splash April 2015 16 / 1

How does Splash work?
In each iteration, the execution engine does:
1 Propose candidate degrees of parallelism m1, . . . ,mk such that∑ki mi = m := (# of cores). For each i ∈ [k], collect mi cores and
do:1 Each core gets a sub-sequence of samples (by default 1
m of the fulldata). They process the samples sequentially using the processfunction. Every sample is weighted by mi .
2 Combine the updates of all mi cores to get the global update. Thereare different strategies for combining different types of updates. Foradd operations, the updates are averaged.
2 If k > 1, select the best mi via a parallel cross-validation procedure.
3 Broadcast the update to all machines to apply this update. Thenproceed to the next iteration.
AMP Lab Splash April 2015 17 / 1

How does Splash work?
In each iteration, the execution engine does:
1 Propose candidate degrees of parallelism m1, . . . ,mk such that∑ki mi = m := (# of cores). For each i ∈ [k], collect mi cores and
do:1 Each core gets a sub-sequence of samples (by default 1
m of the fulldata). They process the samples sequentially using the processfunction. Every sample is weighted by mi .
2 Combine the updates of all mi cores to get the global update. Thereare different strategies for combining different types of updates. Foradd operations, the updates are averaged.
2 If k > 1, select the best mi via a parallel cross-validation procedure.
3 Broadcast the update to all machines to apply this update. Thenproceed to the next iteration.
AMP Lab Splash April 2015 17 / 1

How does Splash work?
In each iteration, the execution engine does:
1 Propose candidate degrees of parallelism m1, . . . ,mk such that∑ki mi = m := (# of cores). For each i ∈ [k], collect mi cores and
do:1 Each core gets a sub-sequence of samples (by default 1
m of the fulldata). They process the samples sequentially using the processfunction. Every sample is weighted by mi .
2 Combine the updates of all mi cores to get the global update. Thereare different strategies for combining different types of updates. Foradd operations, the updates are averaged.
2 If k > 1, select the best mi via a parallel cross-validation procedure.
3 Broadcast the update to all machines to apply this update. Thenproceed to the next iteration.
AMP Lab Splash April 2015 17 / 1

Why Reweighting?
Recall that each thread processes a subsequence of samples.
Without reweighting, the averaged updates make little progresscomparing to the full sequential update, because the subsequence isshorter than the full sequence.
With reweighting, the weighted subsequence approximates thedistribution of the full sequence, so that local updates are nearlyunbiased estimates of the full update.
Averaging reduces the variance of local updates.
Theorem
With m cores, this strategy achieves m times speedup over thesingle-thread SGD if the objective function is smooth and strongly convex.The communication can be arbitrarily infrequent.
AMP Lab Splash April 2015 18 / 1

Why Reweighting?
Recall that each thread processes a subsequence of samples.
Without reweighting, the averaged updates make little progresscomparing to the full sequential update, because the subsequence isshorter than the full sequence.
With reweighting, the weighted subsequence approximates thedistribution of the full sequence, so that local updates are nearlyunbiased estimates of the full update.
Averaging reduces the variance of local updates.
Theorem
With m cores, this strategy achieves m times speedup over thesingle-thread SGD if the objective function is smooth and strongly convex.The communication can be arbitrarily infrequent.
AMP Lab Splash April 2015 18 / 1

Why Reweighting?
Recall that each thread processes a subsequence of samples.
Without reweighting, the averaged updates make little progresscomparing to the full sequential update, because the subsequence isshorter than the full sequence.
With reweighting, the weighted subsequence approximates thedistribution of the full sequence, so that local updates are nearlyunbiased estimates of the full update.
Averaging reduces the variance of local updates.
Theorem
With m cores, this strategy achieves m times speedup over thesingle-thread SGD if the objective function is smooth and strongly convex.The communication can be arbitrarily infrequent.
AMP Lab Splash April 2015 18 / 1

Why Reweighting?
Recall that each thread processes a subsequence of samples.
Without reweighting, the averaged updates make little progresscomparing to the full sequential update, because the subsequence isshorter than the full sequence.
With reweighting, the weighted subsequence approximates thedistribution of the full sequence, so that local updates are nearlyunbiased estimates of the full update.
Averaging reduces the variance of local updates.
Theorem
With m cores, this strategy achieves m times speedup over thesingle-thread SGD if the objective function is smooth and strongly convex.The communication can be arbitrarily infrequent.
AMP Lab Splash April 2015 18 / 1
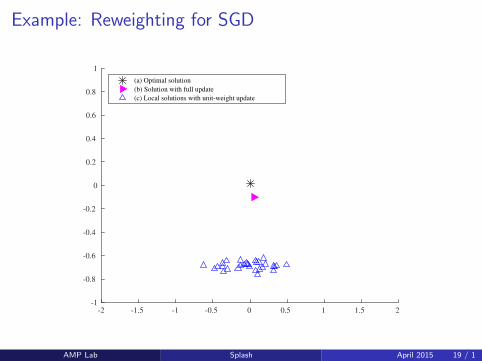
Example: Reweighting for SGD
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
(a) Optimal solution
(b) Solution with full update
(c) Local solutions with unit-weight update
AMP Lab Splash April 2015 19 / 1
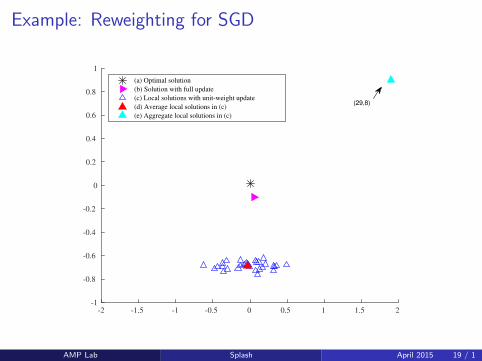
Example: Reweighting for SGD
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
(a) Optimal solution
(b) Solution with full update
(c) Local solutions with unit-weight update
(d) Average local solutions in (c)
(e) Aggregate local solutions in (c)
(29,8)
AMP Lab Splash April 2015 19 / 1
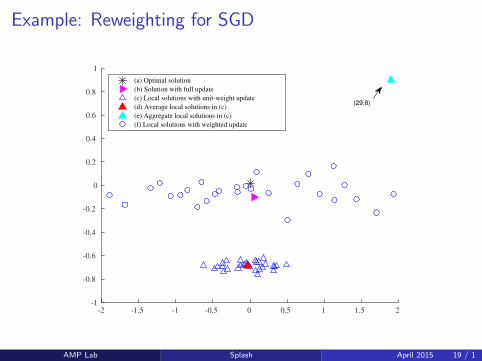
Example: Reweighting for SGD
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
(a) Optimal solution
(b) Solution with full update
(c) Local solutions with unit-weight update
(d) Average local solutions in (c)
(e) Aggregate local solutions in (c)
(f) Local solutions with weighted update
(29,8)
AMP Lab Splash April 2015 19 / 1

Example: Reweighting for SGD
-2 -1.5 -1 -0.5 0 0.5 1 1.5 2-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
(a) Optimal solution
(b) Solution with full update
(c) Local solutions with unit-weight update
(d) Average local solutions in (c)
(e) Aggregate local solutions in (c)
(f) Local solutions with weighted update
(g) Average local solutions in (f)
(29,8)
AMP Lab Splash April 2015 19 / 1

Experiments
AMP Lab Splash April 2015 20 / 1

Experimental Setup
System: Amazon EC2 cluster with 8 workers. Each worker has 8Intel Xeon E5-2665 cores and 30 GBs of memory and was connectedto a commodity 1GB network
Algorithms: SGD for logistic regression; Gibbs Sampling andStochastic Variational Inference for topic modelling; BayesianPersonalized Ranking for recommendation system.
Datasets: Covtype, RCV1 and MNIST 8M for logistic regression;NIPS, Enron and NYTimes for topic modelling; Netflix forrecommendation system.
AMP Lab Splash April 2015 21 / 1
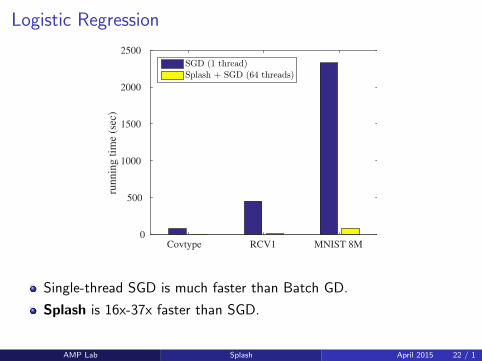
Logistic Regression
Covtype RCV1 MNIST 8M
run
nin
g t
ime
(sec
)
0
500
1000
1500
2000
2500
SGD (1 thread)Splash + SGD (64 threads)
Single-thread SGD is much faster than Batch GD.
Splash is 16x-37x faster than SGD.
AMP Lab Splash April 2015 22 / 1
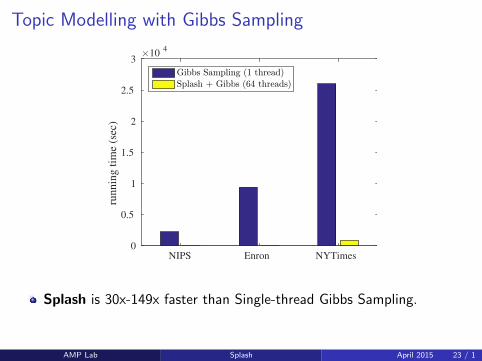
Topic Modelling with Gibbs Sampling
NIPS Enron NYTimes
runnin
g t
ime
(sec
)
×104
0
0.5
1
1.5
2
2.5
3
Gibbs Sampling (1 thread)Splash + Gibbs (64 threads)
Splash is 30x-149x faster than Single-thread Gibbs Sampling.
AMP Lab Splash April 2015 23 / 1
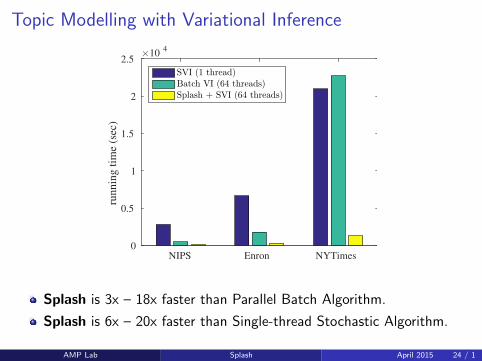
Topic Modelling with Variational Inference
NIPS Enron NYTimes
runnin
g t
ime
(sec
)
×104
0
0.5
1
1.5
2
2.5
SVI (1 thread)Batch VI (64 threads)Splash + SVI (64 threads)
Splash is 3x – 18x faster than Parallel Batch Algorithm.
Splash is 6x – 20x faster than Single-thread Stochastic Algorithm.
AMP Lab Splash April 2015 24 / 1
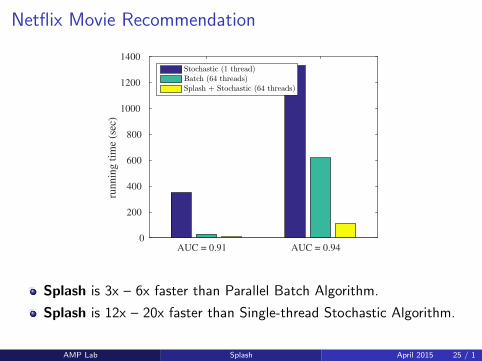
Netflix Movie Recommendation
AUC = 0.91 AUC = 0.94
runnin
g t
ime
(sec
)
0
200
400
600
800
1000
1200
1400
Stochastic (1 thread)Batch (64 threads)Splash + Stochastic (64 threads)
Splash is 3x – 6x faster than Parallel Batch Algorithm.
Splash is 12x – 20x faster than Single-thread Stochastic Algorithm.
AMP Lab Splash April 2015 25 / 1

Machine Learning Package
AMP Lab Splash April 2015 26 / 1

Preimplement Machine Learning Algorithms on Splash
Integrated with other tools in the Spark ecosystem. Ease of use withone line of code.
Parallel AdaGrad SGD: faster than MLlib on large dataset.
(MNIST 8M dataset, 64 cores, 10-class logistic regression)
Parallel Gibbs Sampling for LDA.
Will implement more algorithms in the future...
AMP Lab Splash April 2015 27 / 1

Summary
Splash is a general-purpose programming interface for developingstochastic algorithms.
Splash is also an execution engine for automatic parallelizingstochastic algorithms.
Reweighting is the key to retaining communication efficiency and thusfast performance.
We observe good empirical performance and we have theoreticalguarantees for SGD.
Splash is online at http://zhangyuc.github.io/splash/.
AMP Lab Splash April 2015 28 / 1


















