
Regular and Context-Free Grammars - Computer Sciencerlc/Courses/Theory/ClassNotes/... ·...
70
Regular and Context-Free Grammars Foundations of Computer Science Theory
Transcript of Regular and Context-Free Grammars - Computer Sciencerlc/Courses/Theory/ClassNotes/... ·...

Regular and Context-Free Grammars
Foundations of Computer Science Theory

Grammars Define Languages
• A grammar is a set of rules that are stated in terms of two alphabets: • terminal alphabet, Σ, that contains the symbols that
make up the strings in L(G), and • nonterminal alphabet, the elements of which will
function as working symbols that will be used while the grammar is operating • These symbols will disappear by the time the grammar
finishes its job and generates a string
• A grammar has a unique start symbol, often called S

Rewrite Systems and Grammars
• A rewrite system (or production system or rule-based system) is: – a list of rules, and – an algorithm for applying them
• Each rule has a left-hand side and a right-hand side
• Example rules: S → aSb aS → ε aSb → bSabSa

Simple Rewrite
simple-rewrite(R: rewrite system, w: initial string) : 1. Set working-string to w 2. Until told by R to halt do:
• Match the left-hand-side of some rule against some part of the working-string
• Replace the matched part of the working-string with the right-hand-side of the rule that was matched
3. Return the working-string

Simple Rewrite Example
• If the re-write rules are: S → aSb, S → bSa, S → ε, then a derivation of working string w = aaabbb is: S ⇒ aSb ⇒ aaSbb ⇒ aaaSbbb ⇒ aaabbb This derivation uses the first rule three times, and then the third rule to derive aaabbb.

Rewrite System Formalism
• A rewrite system formalism specifies: – The form of the rules
• Variables may be used: aSa → aa • Regular expressions may be used: ab*ab*a → aaa
– How do I know which rule to apply? • Any rule that matches may be tried, or • Rules have to tried in the order given, where the first
one that matches is the one that is applied – When should I stop applying rules?
• See next slide

When To Stop
The derivation process ends when one of the following things happens:
1. The working string no longer contains any non-terminal symbols (including, as a special case, when the working string is ε)
Example: S ⇒ aSb ⇒ aaSbb ⇒ aabb
2. There are non-terminal symbols in the working string but none of them appears on the left-hand side of any rule in the grammar. In this case, we have a blocked or non-terminated derivation but no generated string.
Example: Rules: S → aSb, S → bTa, and S → ε Derivations: S ⇒ aSb ⇒ abTab ⇒ [blocked]

When To Stop
It is possible that neither (1) nor (2) is achieved. Example: If G contains only the rules S → Ba and B → bB, with
S the start symbol, then all derivations will proceed as:
S ⇒ Ba ⇒ bBa ⇒ bbBa ⇒ bbbBa ⇒ bbbbBa ⇒ ...
This grammar generates the language ∅

Generating Many Strings
• A rule might match in more than one way • If S → aTTb, T → bTa, and T → ε, then a
derivation would begin as S ⇒ aTTb ⇒ • Notice there are four choices at the next step:
1. S ⇒ aTTb ⇒ abTaTb ⇒ 2. S ⇒ aTTb ⇒ aTb ⇒ 3. S ⇒ aTTb ⇒ aTbTab ⇒ 4. S ⇒ aTTb ⇒ aTb ⇒

Regular Grammars
• A regular grammar G is a 4-tuple (V, Σ, R, S) where: – V is the rule alphabet which contains non-terminals – Σ is the set of terminals – R is a finite set of rules of the form:
X → Y – S is the start symbol (a non-terminal)

Regular Grammars
• In a right-linear regular grammar, all rules must have a left hand side that is a single non-terminal, and a right hand side that is either zero or more terminals, or zero or more terminals followed by a single non-terminal – Legal right-linear regular grammar: S → ε, S → a,
S → abb, S → T, S → aT, S → abaT – Not legal right-linear regular grammar: S → aSa, aSa → T, S → TA

Regular Grammars
• A grammar is said to be right-linear if all productions are of the form S → x or S → xT, where x is any string of zero or more terminals
• A grammar is said to be left-linear if all productions are of the form S → x or S → Tx, where x is any string of zero or more terminals
• A regular grammar is one that is either right-linear or left-linear

Regular Grammars
• The grammar G1 = ({S}, {a,b}, R1, S} with R1 as: S → abS | a is right-linear • Using G1 we can derive the string ababa using
the sequence: S ⇒ abS ⇒ ababS ⇒ ababa • From this derivation, we can see that L(G1) is
the language denoted by the regular expression (ab)*a

Regular Grammars
• The grammar G2 = ({S, A, B}, {a,b}, R2, S} with R2 as:
S → Aab A → Aab | B B → a is left-linear • L(G2) is the language denoted by the regular
expression L(aab(ab)*)

Non-Regular Grammars
• A linear grammar is a grammar in which at most one variable can occur on the right side of any production, without restriction on the position of this variable
• A regular grammar is always linear, but not all linear grammars are regular

Non-Regular Grammars
The grammar G = ({S, A, B}, {a,b}, R, S} with R: S → A A → aB | ε B → Ab is not regular. Although every production is either right-linear or left-linear, the grammar itself is neither right-linear nor left-linear, and therefore it is not regular (but it is linear).

L = {w ∈ {a, b}* : |w| is even} ((aa) ∪ (ab) ∪ (ba) ∪ (bb))*
S → aT | ε S → bT | ε T → aS T → bS
Regular Grammars and DFAs
The job of the non-terminal S is to generate an even length string. It does this either by generating the empty string or by generating a single character and then creating T. The job of T is to generate an odd length string. It does this by generating a single character and then creating S.

Regular Grammars and Regular Languages
• Theorem: The class of languages that can be defined with regular grammars is exactly the regular languages
• Proof: By two constructions (see the next slide)

Regular grammar → NFA: 1. Create the NFA with a separate state for each non-terminal 2. The start state is the state corresponding to S 3. If there are any rules in R of the form X → w, for some w ∈ Σ, create a new
state labeled # and add a transition from X to # labeled w 5. For each rule of the form X → wY, add a transition from X to Y labeled w 6. For each rule of the form X → ε, mark state X as accepting 7. Mark state # as accepting NFA → Regular grammar: This proof is effectively the reverse of the
above construction.
Regular Grammars and Regular Languages
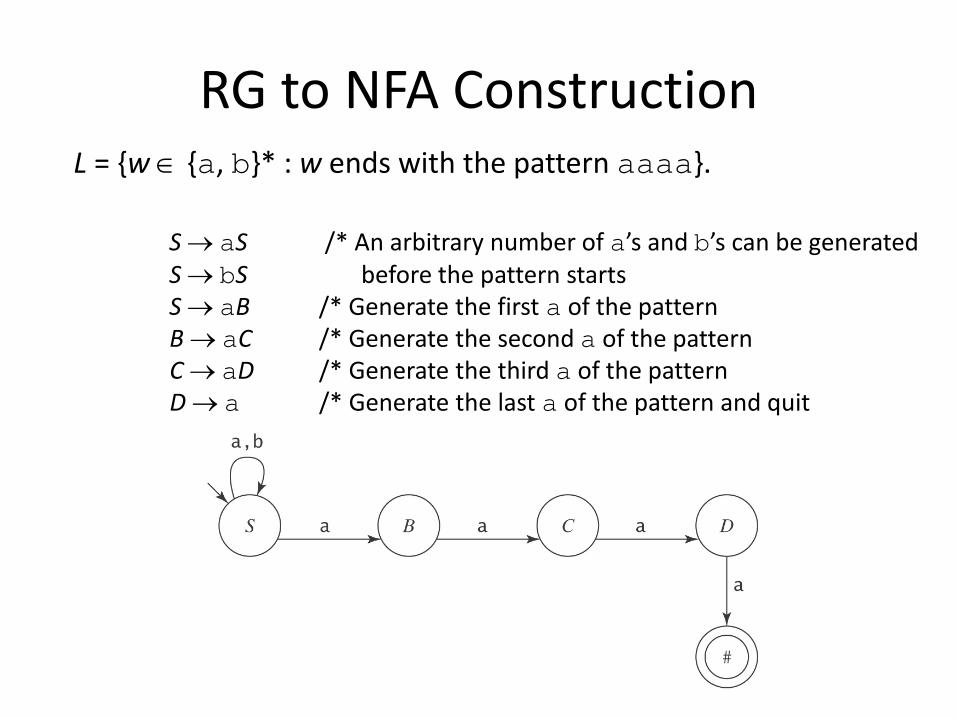
RG to NFA Construction L = {w ∈ {a, b}* : w ends with the pattern aaaa}. S → aS /* An arbitrary number of a’s and b’s can be generated S → bS before the pattern starts S → aB /* Generate the first a of the pattern B → aC /* Generate the second a of the pattern C → aD /* Generate the third a of the pattern D → a /* Generate the last a of the pattern and quit
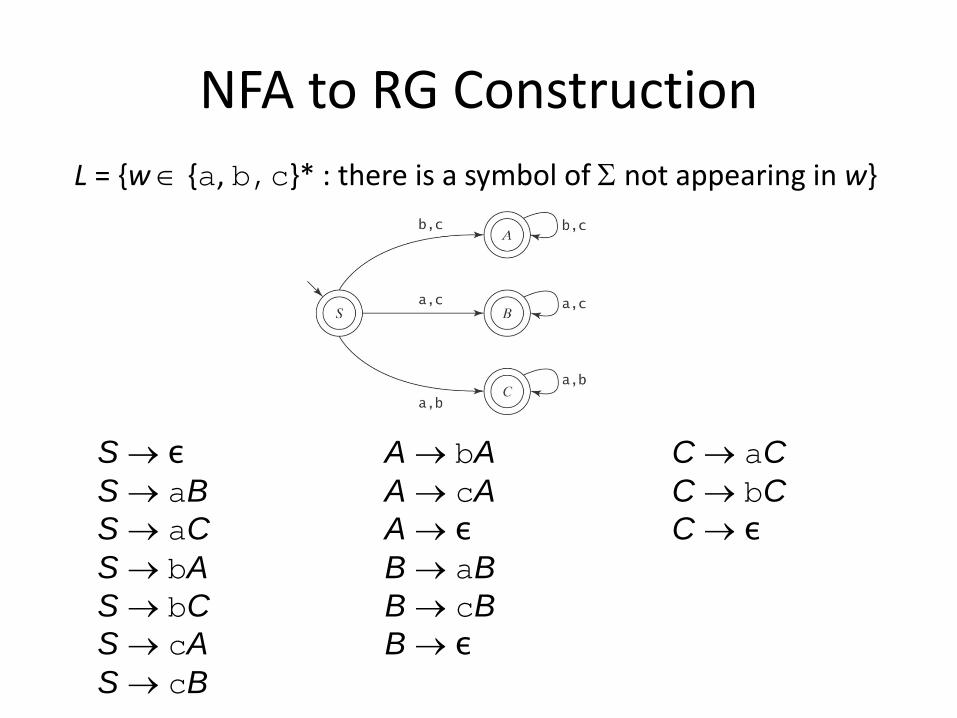
S → ε A → bA C → aC S → aB A → cA C → bC S → aC A → ε C → ε S → bA B → aB S → bC B → cB S → cA B → ε S → cB
NFA to RG Construction L = {w ∈ {a, b,c}* : there is a symbol of Σ not appearing in w}

Satisfying Multiple Criteria Let L = {w ∈ {a,b}* : w contains an odd number of a’s and w ends in a} We can write a regular grammar G that defines L. G will contain three non-terminals, each with a unique function (corresponding to the states of a simple NFA that accepts L). In any partially derived string, if the remaining non-terminal is:
• S, then the number of a’s so far is even. We don’t have to worry about whether the string ends in a since, to derive a string in L, it will be necessary to generate at least one more a anyway
• T, then the number of a’s so far is odd and the derived string ends in a • X, then the number of a’s so far is odd and the derived string does not
end in a

Satisfying Multiple Criteria Since only T captures the situation in which the number of a’s so far is odd and the derived string ends in a, T is the only non-terminal that can generate ε. G contains the following rules:
S → bS /* Initial b’s don’t matter S → aT /* After this, the number of a’s is odd and the generated string ends in a T → ε /* Since the number of a’s is odd, and the string ends in a, it’s OK to quit T → aS /* After this, the number of a’s will be even again T → bX /* After this, the number of a’s is still odd, but the the generated string no longer ends in a X → aS /* After this, the number of a’s will be even X → bX /* After this, the number of a’s is still odd, and the generated string does not end in a

Satisfying Multiple Criteria To see how this grammar works, we will derive (generate) the string baaba, using it: S → bS |aT T → ε | aS | bX X → aS | bX
S ⇒ bS /* Start with an even number of (zero) a’s ⇒ baT /* Now an odd number of a’s and ends in a. The process could quit now, since the derived string, ba, is in L ⇒ baaS /* Back to having an even number of a’s ⇒ baabS /* Still an even number of a’s ⇒ baabaT /* Now an odd number of a’s and ends in a ⇒ baaba /* The process can quit now by applying the rule T → ε

Context-Free Grammars
• A context-free grammar (CFG) is a grammar in which each rule must have: – a left-hand side that is a single non-terminal, and – a right-hand side
– The following are not allowable CFG rules:
S → ε S → aSb S → bT T → T S → aSbbTT
ST → aSb a → aSb ε → a

Context-Free Grammars
• Regular grammars always produce strings one character at a time, moving left to right, but context-free grammars allow us to describe string generation more flexibly: – Example 1 (regular language): L = ab*a
S →aBa, B → bB | ε (note: not a regular grammar) – Example 2 (context-free language): L = {anb*an, n ≥ 0}
S → aSa | B, B → ε | bB – Key distinction: Example 1 is not self-embedding

Context-Free Grammars
• With a CFG, there are no restrictions on the form of the right-hand-sides
S → abDeFGab
• But CFGs require a single non-terminal on the left-hand-side
S → abDeF (this is OK)
ASB → abDeF (this is not OK)

Context-Free Grammars
• Formal definition of a CFG: A context-free grammar G is a 4-tuple, (V, Σ, R, S), where: – V is the rule alphabet, which contains non-
terminals and terminals – Σ (the set of terminals) is a subset of V – R (the set of rules) is a finite subset of (V - Σ) × V* – S (the start symbol) is an element of V - Σ
• Example: ({S, a, b}, {a, b}, {S → aSb, S → ε}, S)

Context-Free Languages
• A language that is defined by some CFG is called a context-free language
• All regular languages are context-free, but there are context-free languages that are not regular
• Not all languages are context-free • Intuitively: context-free languages can keep
track of the counts for two variables, not three

Languages and Machines

Let Bal = {w ∈ { (,) }* : the parentheses are balanced}. We showed earlier that Bal is not regular. But it is context-free because it can be generated by the grammar G = ( { S,(,) }, { (,) }, R, S) where R = S → ε S → SS S → (S) Two example derivations:
1. S ⇒ (S) ⇒ () 2. S ⇒ (S) ⇒ (SS) ⇒ ((S)S) ⇒ (()S) ⇒ (()(S)) ⇒ (()())
Therefore, S ⇒* () and S ⇒* (()())
Balanced Parentheses is Context-Free

AnBn is Context-Free
Let AnBn = {anbn : n ≥ 0}. We showed earlier that AnBn is not regular. But it is context-free because it can be generated by the grammar G = ({S, a, b}, {a, b}, R, S) where R = S → ε S → aSb A sample derivation in G: S ⇒ aSb ⇒ aaSbb ⇒ aaaSbbb ⇒ aaaabbbb Therefore, S ⇒* aaaabbbb

Recursive Grammar Rules
• A rule is recursive iff X → w1Yw2, where: Y ⇒* w3Xw4 for some w1, w2, w3, and w4 in V* • A grammar is recursive if and only if it contains
at least one recursive rule • Examples of recursive rules:
S → (S) S → aSb S → aS {S → aT, T → aW, W → aS, W → a}

Self-Embedding Grammar Rules
• A rule in a grammar G is self-embedding iff X → w1Yw2, where Y ⇒* w3Xw4 and both w1w3 and w4w2 are in Σ+ • A grammar is self-embedding if and only if it
contains at least one self-embedding rule • Examples: S → aSa is self-embedding S → aT , T → Sa is self-embedding S → aS is not self-embedding

Even-Length Palindromes
Palindromes that have an even number of characters is not regular, but can be described by a CFG: Let PalEven = {wwR : w ∈ {a, b}*} and G = {{S, a, b}, {a, b}, R, S}, where R =
S → aSa S → bSb S → ε

Equal Number of a’s and b’s
The language where every string has an equal number of a’s and b’s is not regular, but can be described by a CFG: Let L = {w ∈ {a, b}*: #a(w) = #b(w)} and G = {{S, a, b}, {a, b}, R, S}, where R =
S → aSb S → bSa S → SS S → ε

Unequal Number of a’s and b’s
L = {anbm : n ≠ m}, G = (V, Σ, R, S), where V = {a, b, S, A, B}, Σ = {a, b}, and R =
S → A /* more a’s than b’s S → B /* more b’s than a’s A → a /* at least one extra a generated A → aA A → aAb B → b /* at least one extra b generated B → Bb B → aBb

Arithmetic Expressions
Arithmetic expressions are not regular, but they can be described by a CFG: G = (V, Σ, R, S), where V = {+, *, (, ), id, E}, Σ = {+, *, (, ), id}, S = E, and R =
E → E + E E → E ∗ E E → (E) E → id

Backus-Naur Form (BNF)
• Backus-Naur Form (BNF) is a notation for writing practical context-free grammars
• BNF allows a non-terminal symbol to be any sequence of characters surrounded by angle brackets
Examples of non-terminals: <program> <variable>

<block> ::= {<stmt-list>} | {} <stmt-list> ::= <stmt> | <stmt-list> <stmt> <stmt> ::= <block> | while (<cond>) <stmt> | if (<cond>) <stmt> | do <stmt> while (<cond>); | <assignment-stmt>; | return | return <expression> | <method-invocation>;
BNF for a Java Block of Code
Example of a legal Java block (assuming appropriate declarations): { while (x < 12) { myClass.myMethod(x); x = x + 2; } }

Designing Context-Free Grammars
• To create a CFG, recall that we usually need to generate related regions together, as in AnBn
• To do this: 1. Generate regions that have a fixed order by
concatenating two (or more) rules together A → BC 2. Generate from the outside in A → aAb

Designing Context-Free Grammars
• For example, to get a grammar for the language {0n1n : n ≥ 0} ∪ {1n0n : n ≥ 0}, first construct the grammar S1 → 0S11|ε for the first language, and then S2 → 1S20|ε for the second language
• Then add rule S → S1|S2 to give the grammar: S → S1|S2 S1 → 0S11 | ε S2 → 1S20 | ε

Concatenating Independent Languages
• Let L = {anbncm : n, m ≥ 0} • The cm portion of any string in L is completely
independent of the anbn portion, so we should generate the two portions separately and concatenate them together
• Example: G = ({S, N, M, a, b, c}, {a, b, c}, R, S} where R =
S → NM /* Generate the two independent portions N → aNb /* Generate the anbn portion from outside in N → ε M → cM /* Generate the cm portion M → ε

The Kleene Star of a Language
• L = {anbn : n ≥ 0}* is the same as: • L = {an1 bn1 an2 bn2 ... ank bnk : k ≥ 0 and ∀i (ni ≥ 0)} – Examples of strings in L: ε, abab, aabbabaabb, aabbaaabbbabab • G = ({S, M, a, b}, {a, b}, R, S} where R =
S → MS /* Each M will generate one {anbn : n ≥ 0} region S → ε M → aMb /* Generate one region M → ε
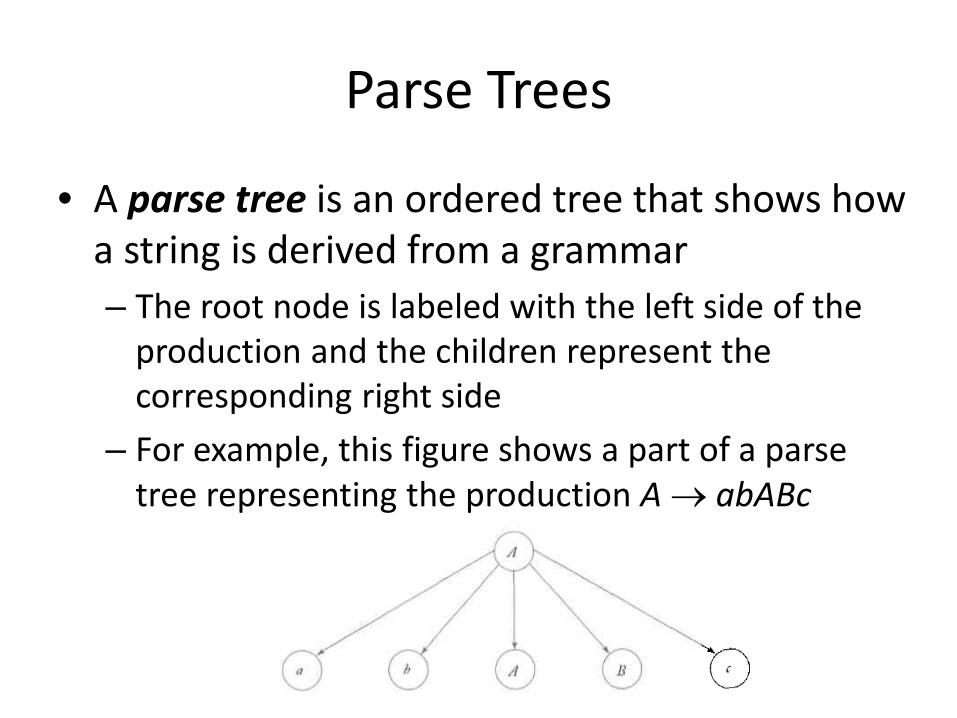
Parse Trees
• A parse tree is an ordered tree that shows how a string is derived from a grammar – The root node is labeled with the left side of the
production and the children represent the corresponding right side
– For example, this figure shows a part of a parse tree representing the production A → abABc
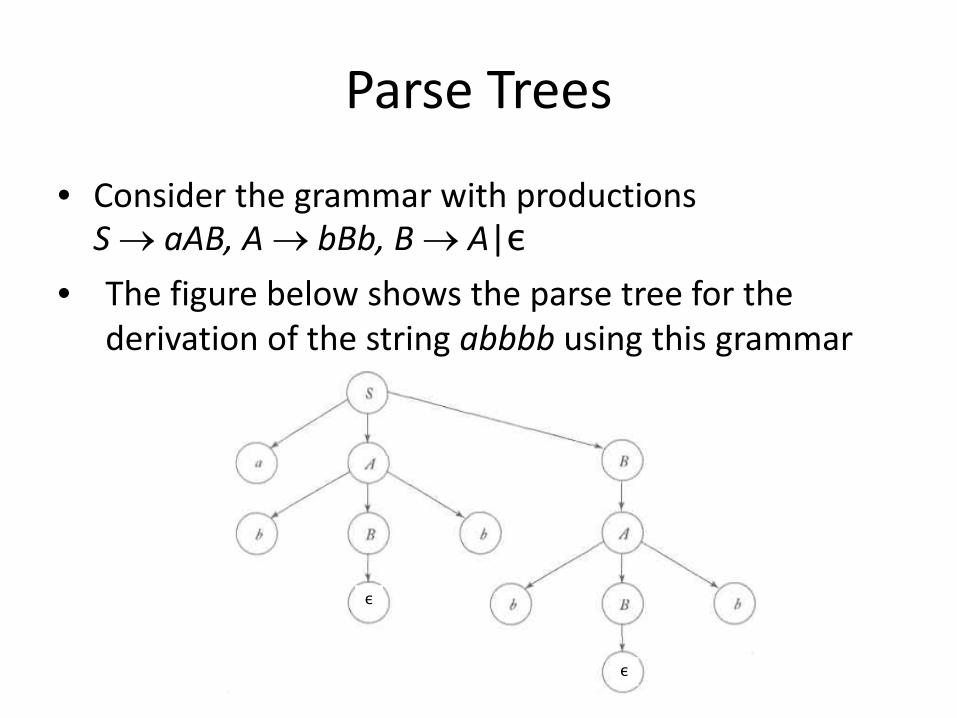
Parse Trees
• Consider the grammar with productions S → aAB, A → bBb, B → A|ε
• The figure below shows the parse tree for the derivation of the string abbbb using this grammar
ε
ε
Parse Trees
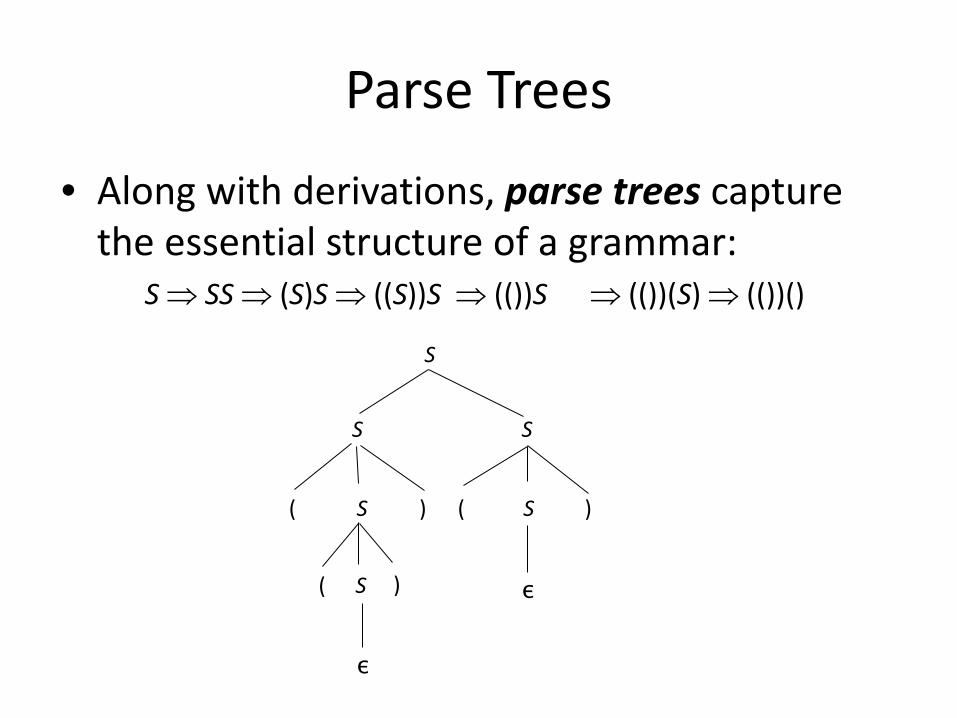
• Along with derivations, parse trees capture the essential structure of a grammar:
S ⇒ SS ⇒ (S)S ⇒ ((S))S ⇒ (())S ⇒ (())(S) ⇒ (())()
S S
( ) S S ) (
(
ε
) ε S
S

Parse Trees and Structure
• With regular languages, we care about recognizing patterns
• With context-free languages, we care about recognizing structure – Structure allows strings to have meaning

Parse Trees and Structure
• Recall that a derivation captures structure by showing the path that was taken through the grammar to construct a string
• For example, given this set of production rules, S → ε, S → SS, S → (S), there are several possible ways to derive (())(): S ⇒ SS ⇒ (S)S ⇒ ((S))S ⇒ (())S ⇒ (())(S) ⇒ (())() S ⇒ SS ⇒ (S)S ⇒ ((S))S ⇒ ((S))(S) ⇒ (())(S) ⇒ (())()
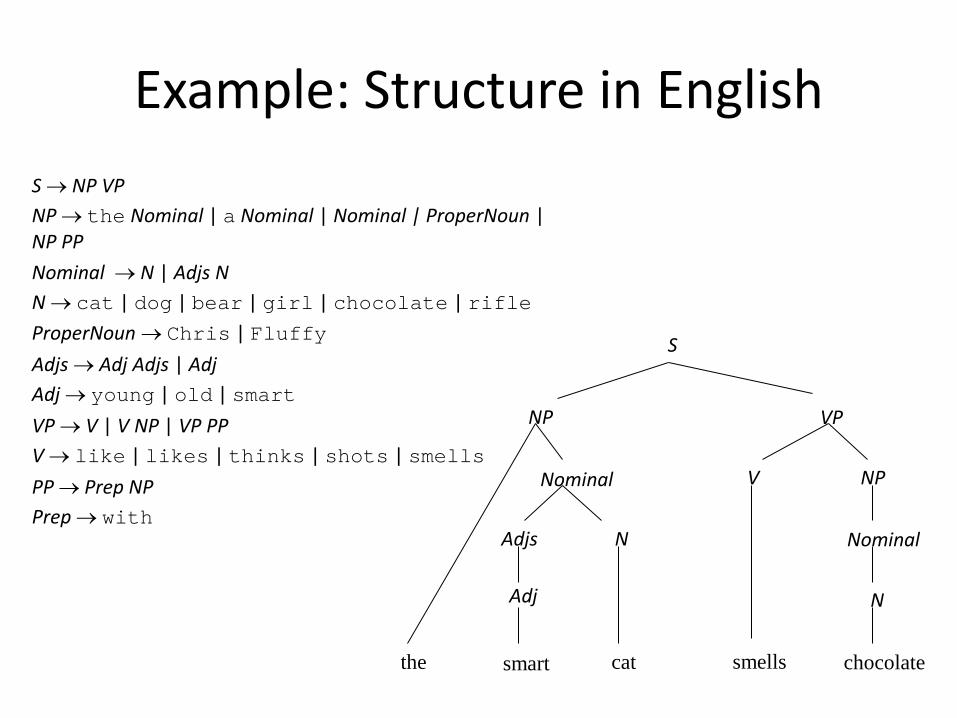
Example: Structure in English
S
NP VP
V NP
N
Nominal
Nominal Adjs
Adj N
the chocolate smells cat smart
S → NP VP NP → the Nominal | a Nominal | Nominal | ProperNoun | NP PP Nominal → N | Adjs N N → cat | dog | bear | girl | chocolate | rifle ProperNoun → Chris | Fluffy Adjs → Adj Adjs | Adj Adj → young | old | smart VP → V | V NP | VP PP V → like | likes | thinks | shots | smells PP → Prep NP Prep → with
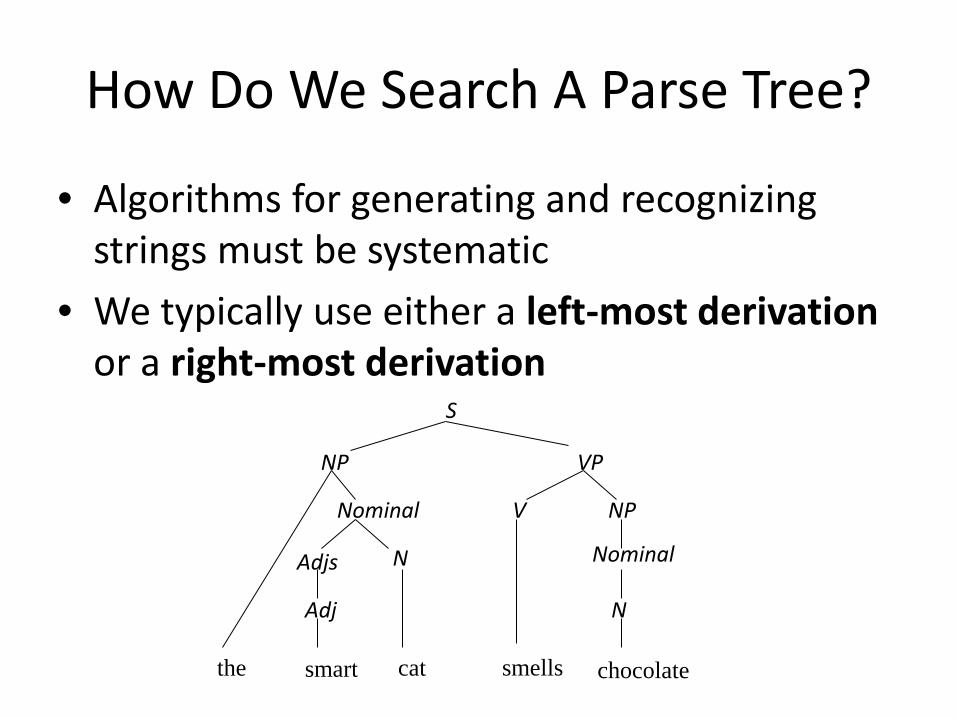
How Do We Search A Parse Tree?
• Algorithms for generating and recognizing strings must be systematic
• We typically use either a left-most derivation or a right-most derivation S
NP VP
V NP
N
Nominal
Nominal Adjs
Adj N
the chocolate smells cat smart
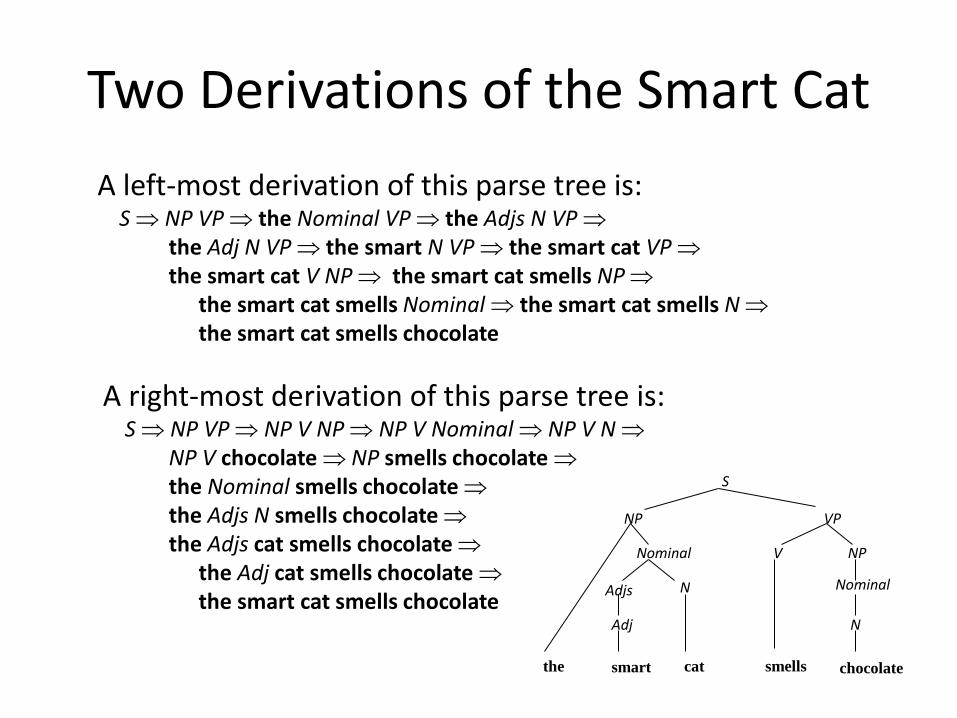
Two Derivations of the Smart Cat A left-most derivation of this parse tree is: S ⇒ NP VP ⇒ the Nominal VP ⇒ the Adjs N VP ⇒ the Adj N VP ⇒ the smart N VP ⇒ the smart cat VP ⇒ the smart cat V NP ⇒ the smart cat smells NP ⇒ the smart cat smells Nominal ⇒ the smart cat smells N ⇒ the smart cat smells chocolate
A right-most derivation of this parse tree is: S ⇒ NP VP ⇒ NP V NP ⇒ NP V Nominal ⇒ NP V N ⇒ NP V chocolate ⇒ NP smells chocolate ⇒ the Nominal smells chocolate ⇒ the Adjs N smells chocolate ⇒ the Adjs cat smells chocolate ⇒ the Adj cat smells chocolate ⇒ the smart cat smells chocolate
S
NP VP
V NP
N
Nominal
Nominal Adjs
Adj N
the chocolate smells cat smart

Derivations of Strings
• Consider the grammar with the productions: 1. S → aAB 2. A → bBb 3. B → A | ε
• The left-most derivation of the string abbbb is: S ⇒ aAB ⇒ abBbB ⇒ abAbB ⇒ abbBbbB ⇒ abbbbB ⇒ abbbb
• The right-most derivation of abbbb is: S ⇒ aAB ⇒ aA ⇒ abBb ⇒ abAb ⇒ abbBbb ⇒ abbbb
1 2 3 2 3 3
1 3 2 3 2 3

Derivations of Strings
• Recall the balanced-parentheses grammar: S → SS | (S) | ()
• Left-most derivation of (())(): S ⇒ SS ⇒ (S)S ⇒ (())S ⇒ (())()
• Right-most derivation of (())(): S ⇒ SS ⇒ S() ⇒ (S)() ⇒ (())()
• Neither right-most nor left-most derivation of ()()(): S ⇒ SS ⇒ SSS ⇒ S()S ⇒ ()()S ⇒ ()()()
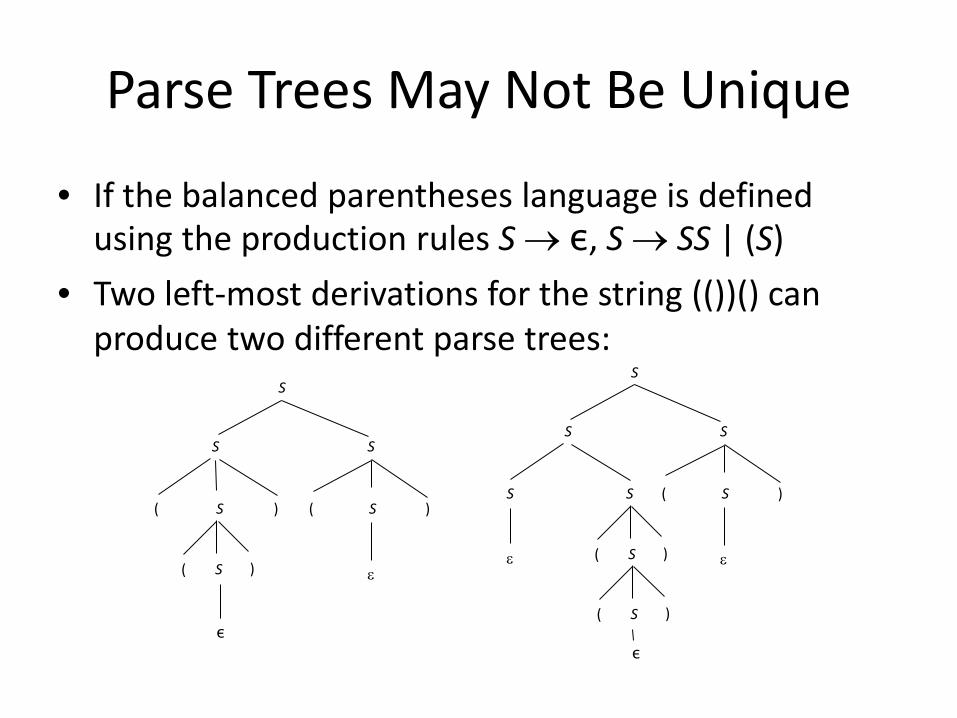
Parse Trees May Not Be Unique
• If the balanced parentheses language is defined using the production rules S → ε, S → SS | (S)
• Two left-most derivations for the string (())() can produce two different parse trees:
S S
( ) S S ) (
(
ε
) ε S
S
ε
S S
S S S ) (
(
ε
) ε S
S
( ) S

The Problem of Ambiguity
• Sometimes a grammar can generate the same string in more than one way – Such a string will have several different parse
trees, and thus will have several different meanings
• If a grammar can generate some string in more than one way, we say that the grammar is ambiguous

Why is Ambiguity a Problem?
• A grammar is ambiguous if and only if there is at least one string in L(G) for which G produces more than one parse tree
• For most applications of context-free grammars, this is a problem because we want structure (and hence, meaning) to be unique
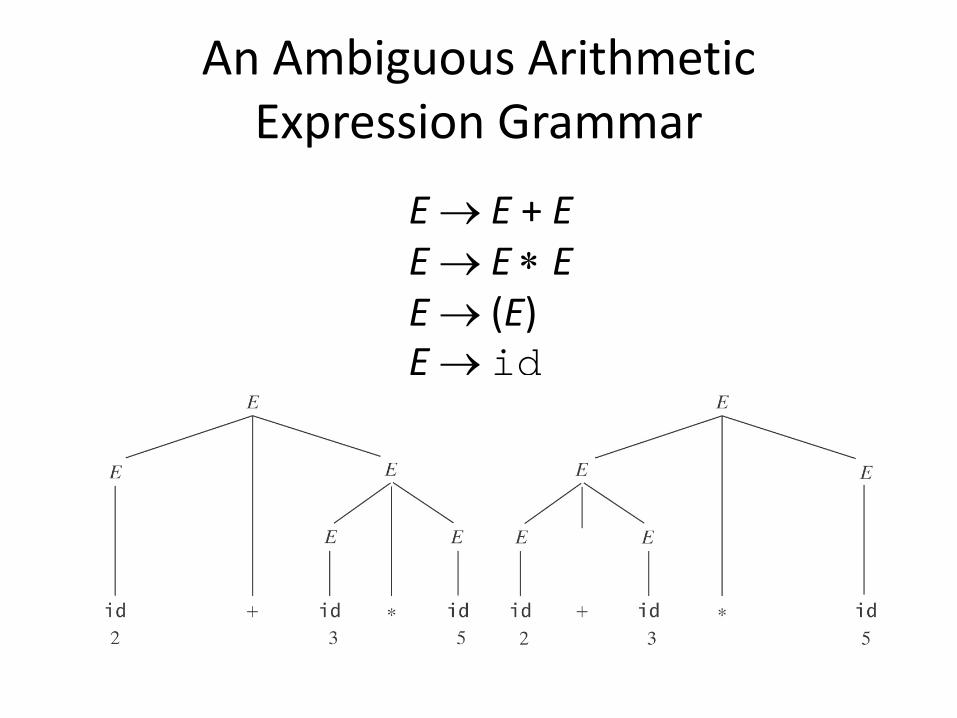
E → E + E E → E ∗ E E → (E) E → id
An Ambiguous Arithmetic Expression Grammar

Decidability of CFGs
• Both of the following problems are undecidable: • Given a context-free grammar G, is G ambiguous? • Given a context-free language L, is L inherently
ambiguous?

Testing Membership
• We would like to be able to efficiently test a string for membership in a CFL
• We could look at all possible derivations of the string, but it is not always obvious how long each derivation might be – It could be exponential in the length of the string
• If we “transform” the grammar to a specific form, then we can test a string for membership in at most the cube of the length of the string

Chomsky Normal Form
• A CFG is said to be in Chomsky normal form if every production is of one of these two forms: 1. A → BC (right side is two non-terminals) 2. A → a (right side is a single terminal) – The grammar S → BC|a is in Chomsky normal
form – The grammar S → AS|AAS, A → SA|aa is not in
Chomsky normal form

Chomsky Normal Form
• We can convert any CFG into Chomsky normal form • The conversion has several stages, wherein rules that violate
the conditions are replaced with equivalent ones that are satisfactory. Steps:
1. Add a new start variable, S0, and the rule S0 → S, where S was the original start variable
2. Remove all є-rules of the form A → є, where A is not the start variable; for each occurrence of an A on the right-hand side of a rule, add a new rule with that occurrence deleted
3. Remove all unit rules of the form A → B 4. Convert the remaining rules into the proper form

Chomsky Normal Form
• Step 2: Remove є-rules • Consider the productions S → ASA | aB | a A → B | S | ε • After removing the ε-rule for A, the new rules
become: S → ASA | aB | a | SA | AS | S A → B | S

Chomsky Normal Form
• Step 4: Convert to proper form • Consider the production A → BcDe • Create new variables Ac and Ae with
productions Ac→ c and Ae→ e – At most one variable is created for each terminal,
and it is used everywhere it is needed • For example, replace A → BcDe with 3 rules:
A → BAcDAe, Ac→ c , and Ae→ e

Chomsky Normal Form
• Step 4 continued: Break right-hand sides having more than 2 variables into a “chain of productions” – For example: A → BCDE is replaced by A → BF,
F → CG, and G → DE – Note: F and G must be new (used nowhere else)
• So A → BAcDAe is replaced with A → BF, F → AcG, and G → DAe

Example of Conversion to CNF
Convert the following grammar to Chomsky normal form: S → ASA | aB A → B | S B → b | ε
1. Result after applying the first step to make a new start variable: S0 → S S → ASA | aB A → B | S B → b | ε

Example of Conversion to CNF 2. Result after removing є-rule B → є:
S0 → S S0 → S S → ASA | aB S → ASA | aB | a A → B | S A → B | S | ε B → b | ε B → b
3. Result after removing є-rule A → є: S0 → S S → ASA | aB | a | SA | AS | S A → B | S B → b
Becomes →

Example of Conversion to CNF 4. Result after removing unit-rule S → S:
S0 → S S0 → S S → ASA | aB | a | SA | AS | S S → ASA | aB | a | SA | AS A → B | S A → B | S B → b B → b
5. Result after removing unit-rule S0 → S: S0 → ASA | aB | a | SA | AS S → ASA | aB | a | SA | AS A → B | S B → b
Becomes →

Example of Conversion to CNF 6. Result after removing unit-rule A → B:
S0 → ASA | aB | a | SA | AS S0 → ASA | aB | a | SA | AS S → ASA | aB | a | SA | AS S → ASA | aB | a | SA | AS A → B | S A → b | S B → b B → b
7. Result after removing unit-rule A → S: S0 → ASA | aB | a | SA | AS S → ASA | aB | a | SA | AS A → b | ASA | aB | a | SA | AS B → b
Becomes →

Example of Conversion to CNF
8. Convert the remaining rules into the proper form by adding additional variables and rules as necessary: S0 → ASA | aB | a | SA | AS S0 → AA1 | UB | a | SA | AS S → ASA | aB | a | SA | AS S → AA1 | UB | a | SA | AS A → b | ASA | aB | a | SA | AS A → b | AA1 | UB | a | SA | AS B → b B → b A1 → SA U → a
Becomes →








![arXiv:2006.15439v1 [math.NT] 27 Jun 2020 · We write the prime factorization of G nas G n= Y p p p(G n) (1.2) where p(G n) = ord p(G(n)). Since G n is an integer, p(G n) 0 for all](https://static.fdocument.org/doc/165x107/5f3385174ef0945b3871855e/arxiv200615439v1-mathnt-27-jun-2020-we-write-the-prime-factorization-of-g-nas.jpg)








