
REGRESSÃO LINEAR SIMPLES - fenix.tecnico.ulisboa.pt · padrão funcional de comportamento. Se os...
13
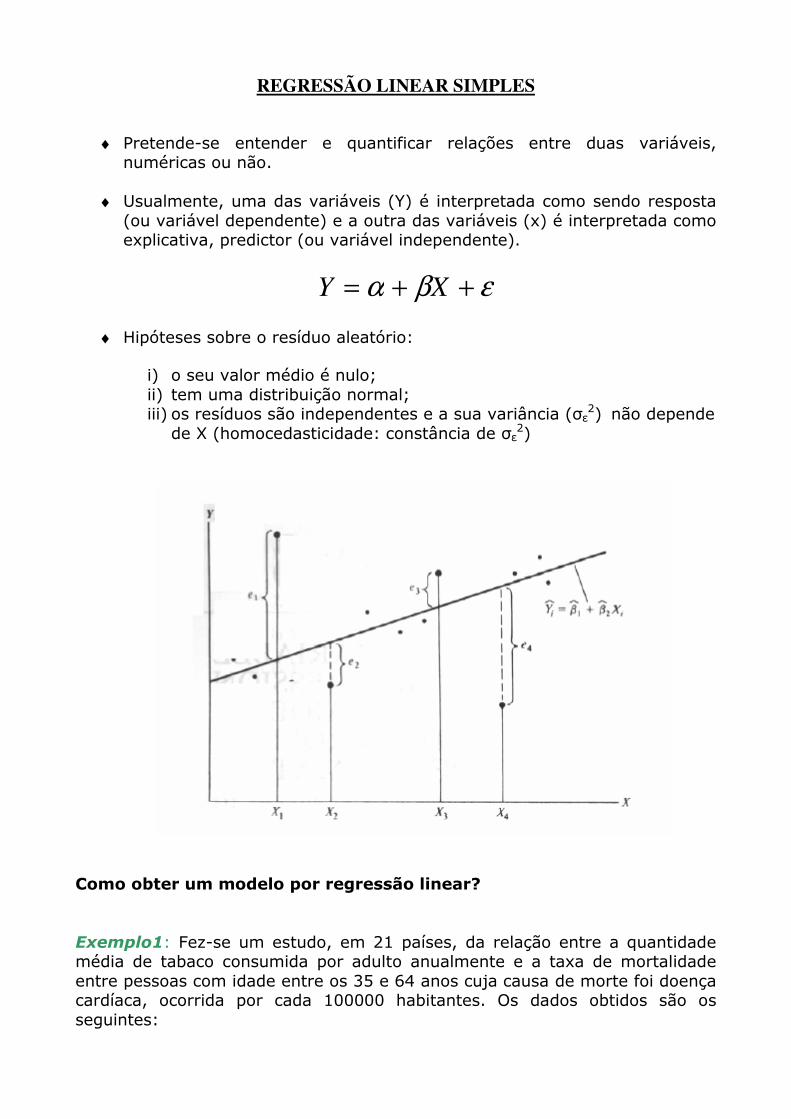
REGRESSÃO LINEAR SIMPLES ♦ Pretende-se entender e quantificar relações entre duas variáveis, numéricas ou não. ♦ Usualmente, uma das variáveis (Y) é interpretada como sendo resposta (ou variável dependente) e a outra das variáveis (x) é interpretada como explicativa, predictor (ou variável independente). ε β α + + = X Y ♦ Hipóteses sobre o resíduo aleatório: i) o seu valor médio é nulo; ii) tem uma distribuição normal; iii) os resíduos são independentes e a sua variância (σ ε 2 ) não depende de X (homocedasticidade: constância de σ ε 2 ) Como obter um modelo por regressão linear? Exemplo1: Fez-se um estudo, em 21 países, da relação entre a quantidade média de tabaco consumida por adulto anualmente e a taxa de mortalidade entre pessoas com idade entre os 35 e 64 anos cuja causa de morte foi doença cardíaca, ocorrida por cada 100000 habitantes. Os dados obtidos são os seguintes:
Transcript of REGRESSÃO LINEAR SIMPLES - fenix.tecnico.ulisboa.pt · padrão funcional de comportamento. Se os...
REGRESSÃO LINEAR SIMPLES
♦ Pretende-se entender e quantificar relações entre duas variáveis, numéricas ou não.
♦ Usualmente, uma das variáveis (Y) é interpretada como sendo resposta
(ou variável dependente) e a outra das variáveis (x) é interpretada como explicativa, predictor (ou variável independente).
εβα ++= XY
♦ Hipóteses sobre o resíduo aleatório:
i) o seu valor médio é nulo; ii) tem uma distribuição normal; iii) os resíduos são independentes e a sua variância (σε2) não depende
de X (homocedasticidade: constância de σε2)
Como obter um modelo por regressão linear?
Exemplo1: Fez-se um estudo, em 21 países, da relação entre a quantidade média de tabaco consumida por adulto anualmente e a taxa de mortalidade entre pessoas com idade entre os 35 e 64 anos cuja causa de morte foi doença cardíaca, ocorrida por cada 100000 habitantes. Os dados obtidos são os seguintes:
STATISTICA:
ii) Criar um novo documento no Statistica;
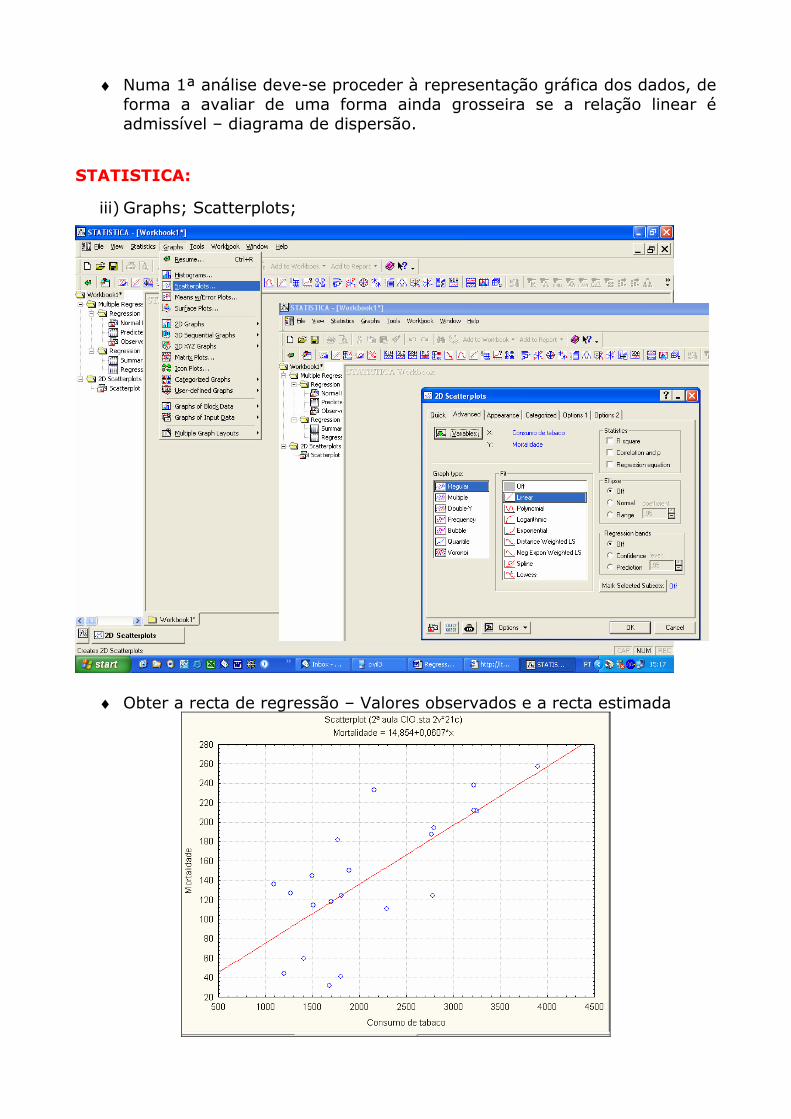
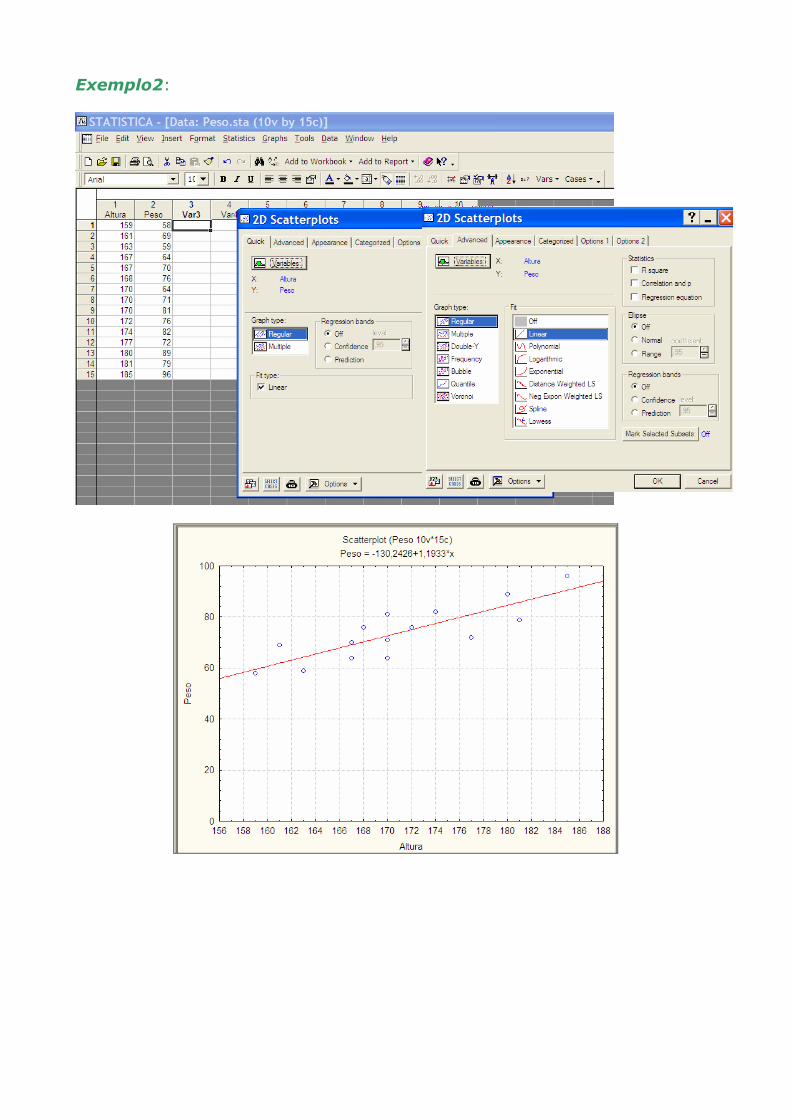
♦ Numa 1ª análise deve-se proceder à representação gráfica dos dados, de forma a avaliar de uma forma ainda grosseira se a relação linear é admissível – diagrama de dispersão.
STATISTICA:
iii) Graphs; Scatterplots;
♦ Obter a recta de regressão – Valores observados e a recta estimada
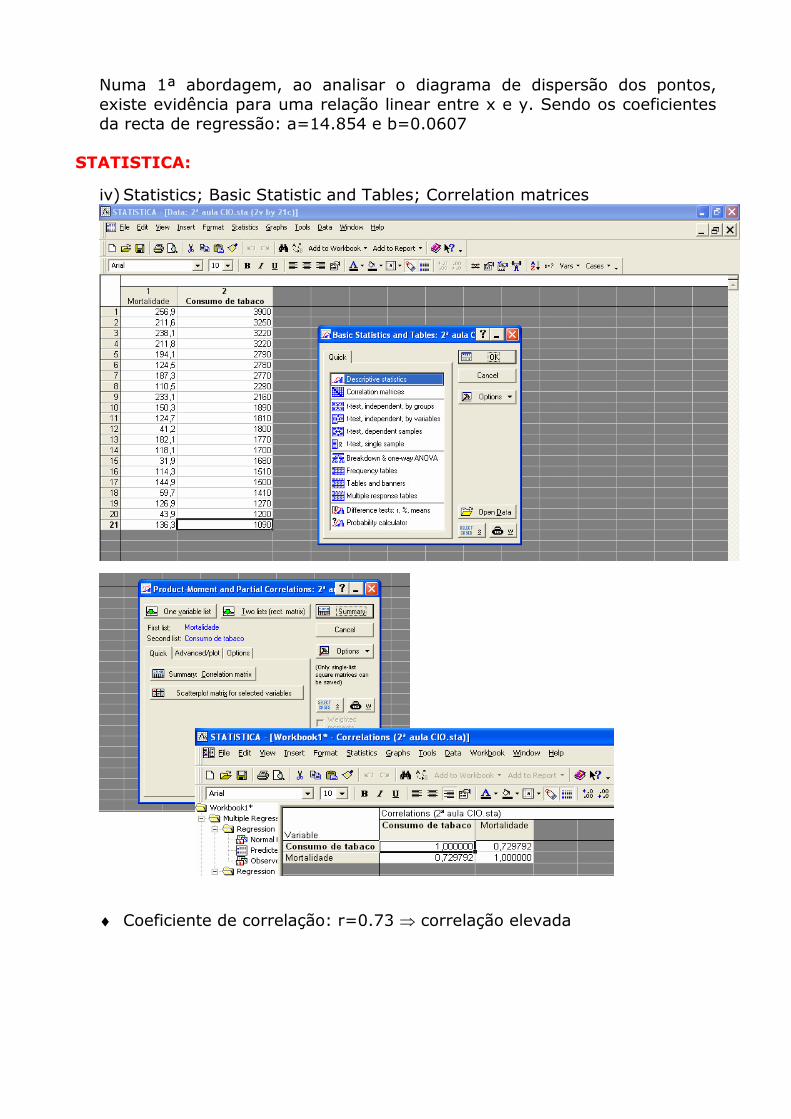
Numa 1ª abordagem, ao analisar o diagrama de dispersão dos pontos, existe evidência para uma relação linear entre x e y. Sendo os coeficientes da recta de regressão: a=14.854 e b=0.0607
STATISTICA:
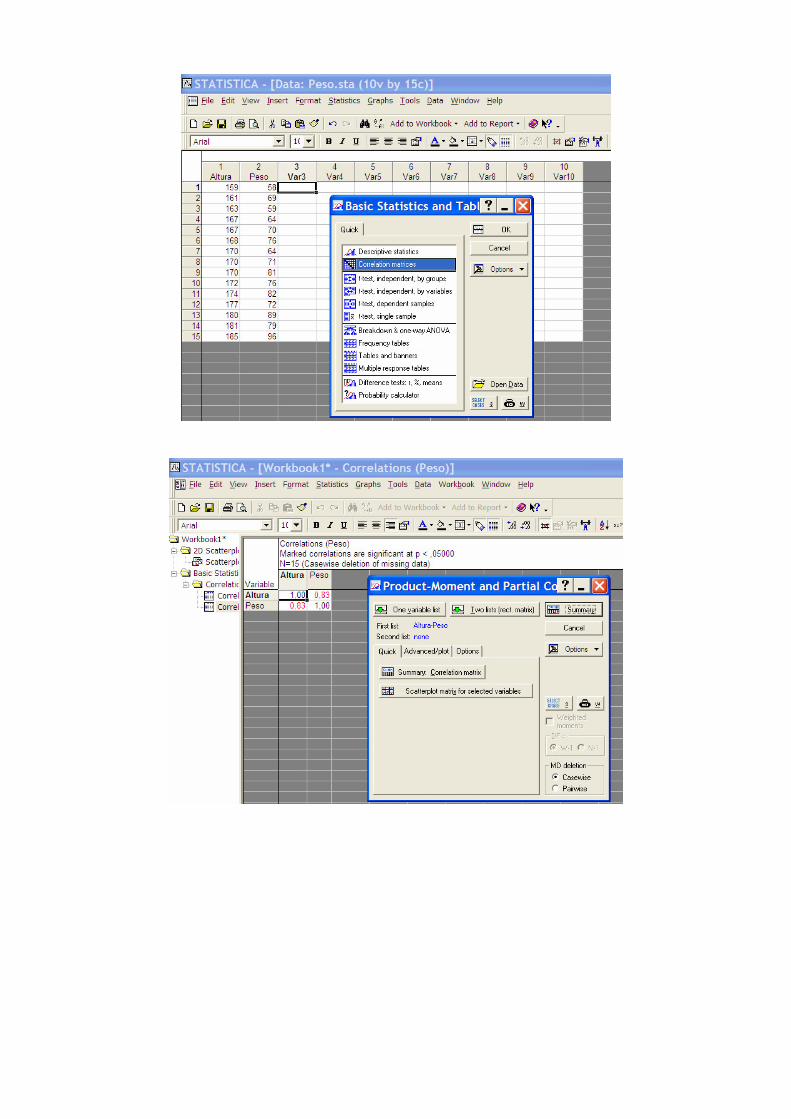
iv) Statistics; Basic Statistic and Tables; Correlation matrices
♦ Coeficiente de correlação: r=0.73 ⇒ correlação elevada
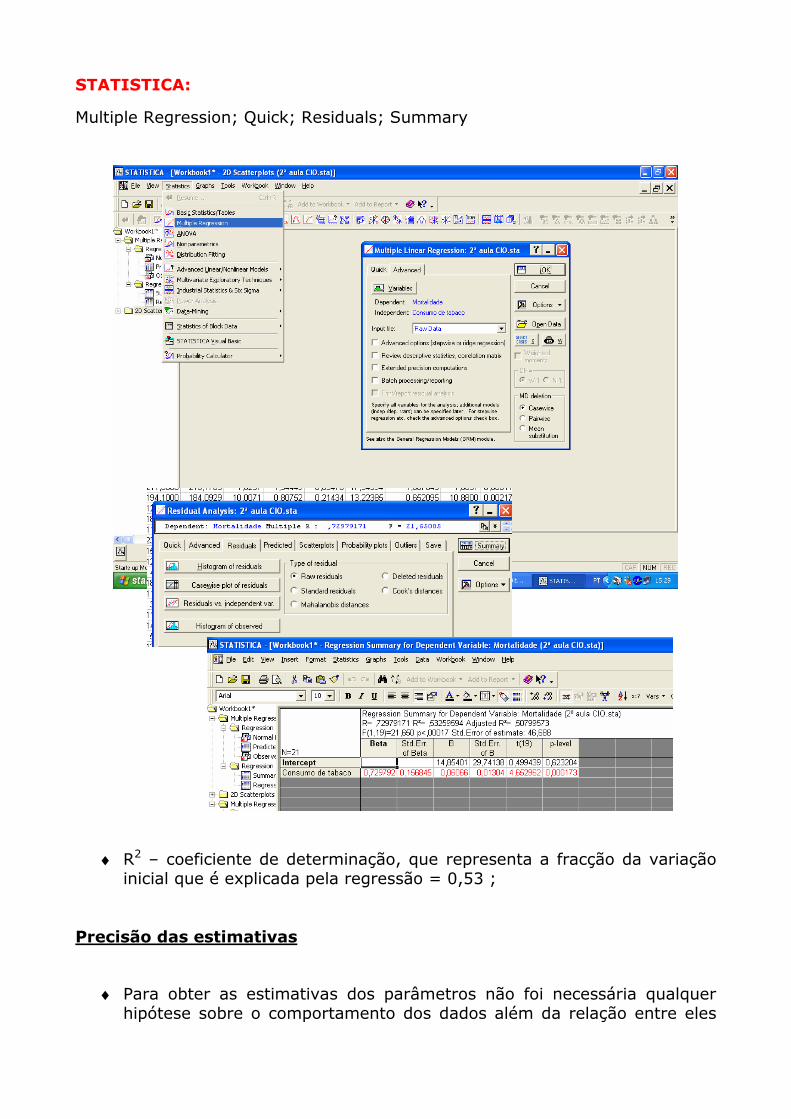
STATISTICA:
Multiple Regression; Quick; Residuals; Summary
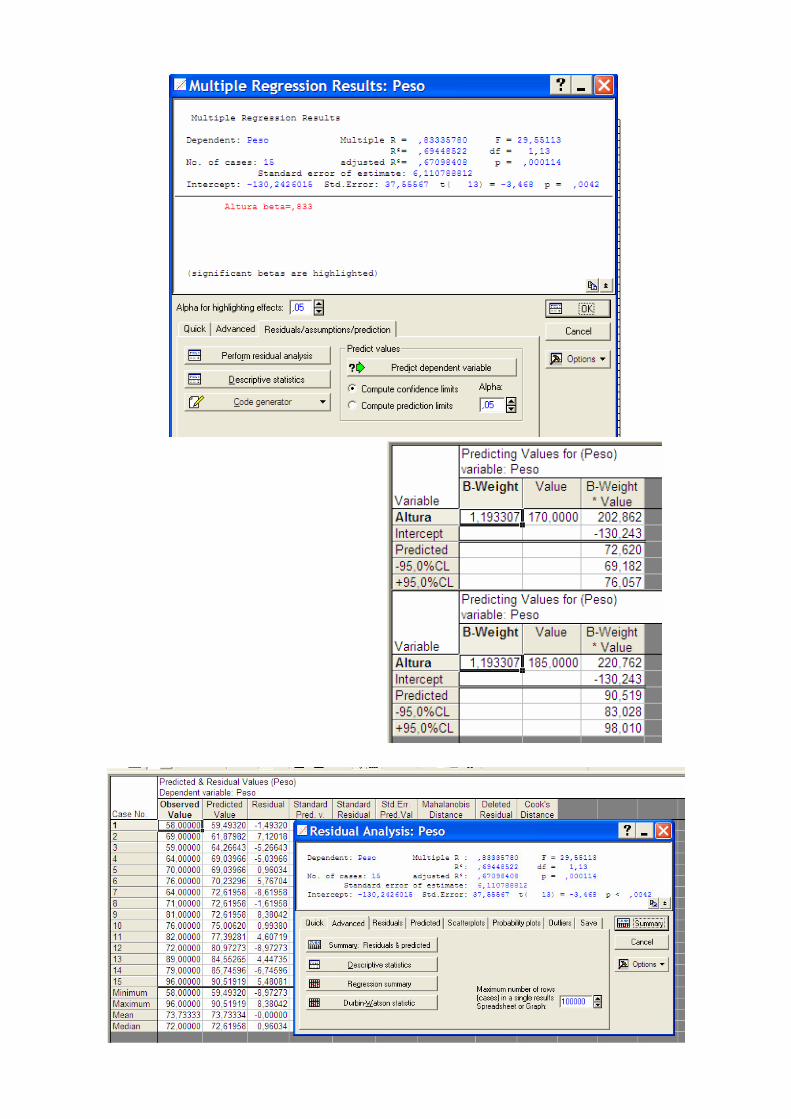
♦ R2 – coeficiente de determinação, que representa a fracção da variação inicial que é explicada pela regressão = 0,53 ;
Precisão das estimativas
♦ Para obter as estimativas dos parâmetros não foi necessária qualquer
hipótese sobre o comportamento dos dados além da relação entre eles
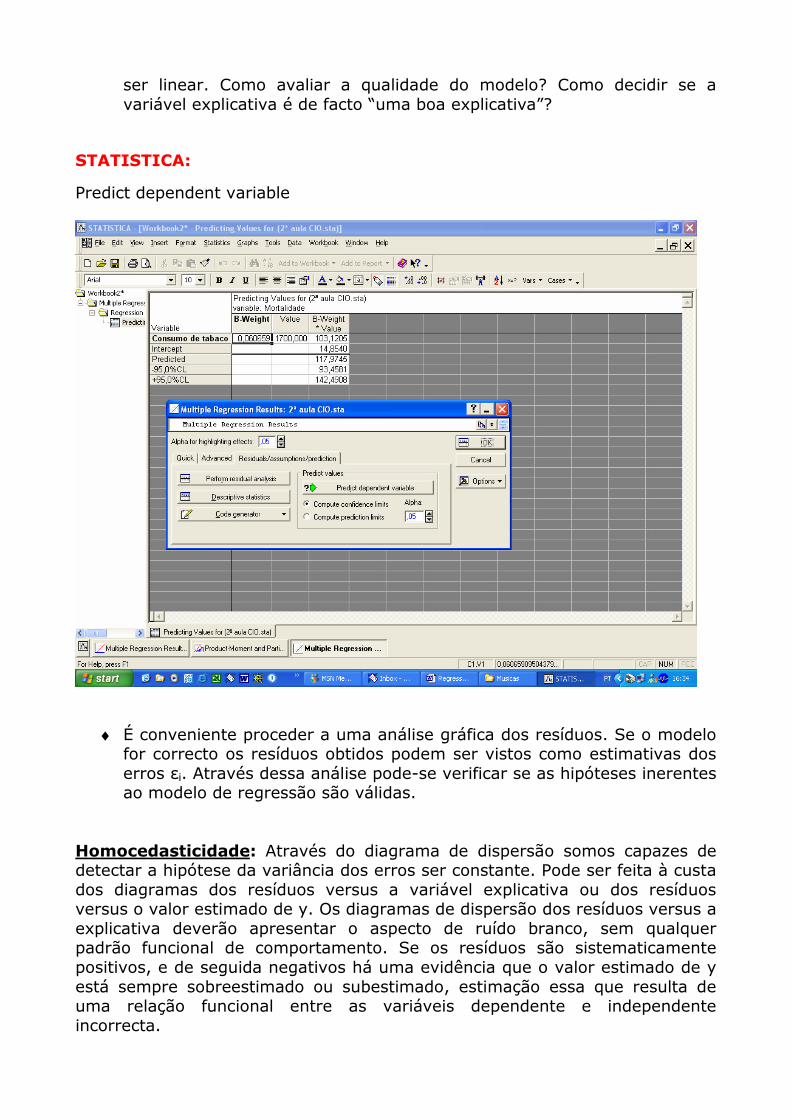
ser linear. Como avaliar a qualidade do modelo? Como decidir se a variável explicativa é de facto “uma boa explicativa”?
STATISTICA:
Predict dependent variable
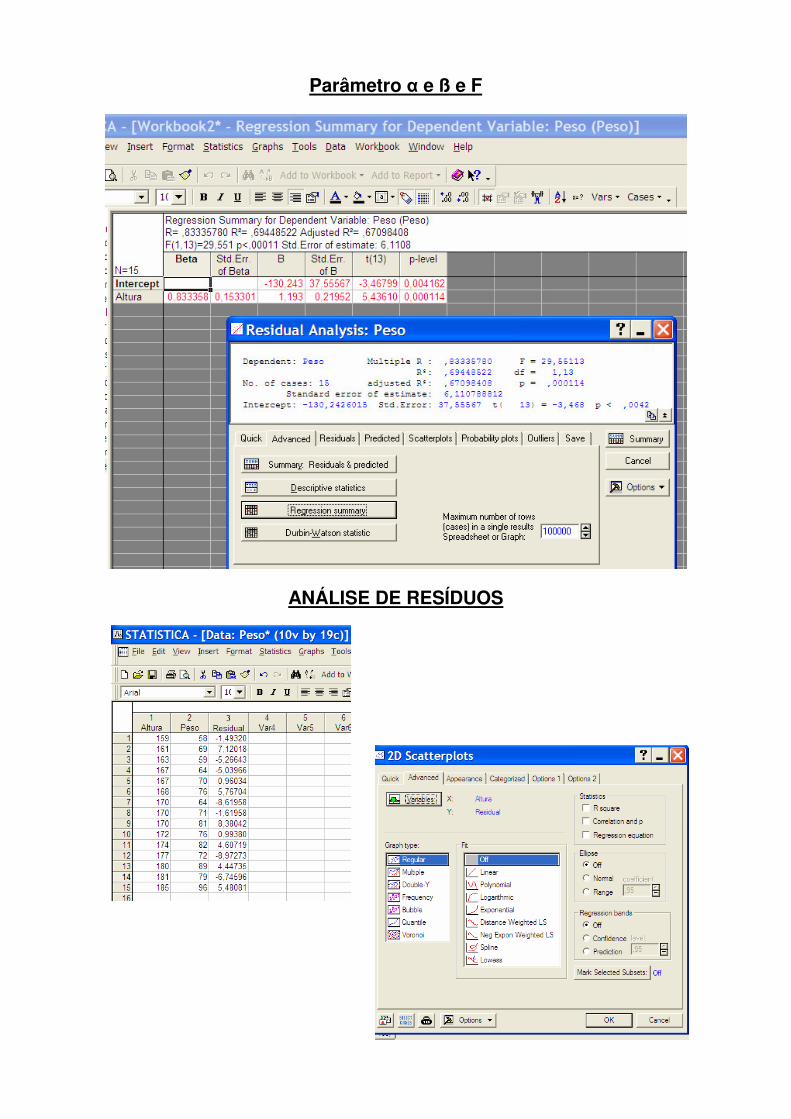
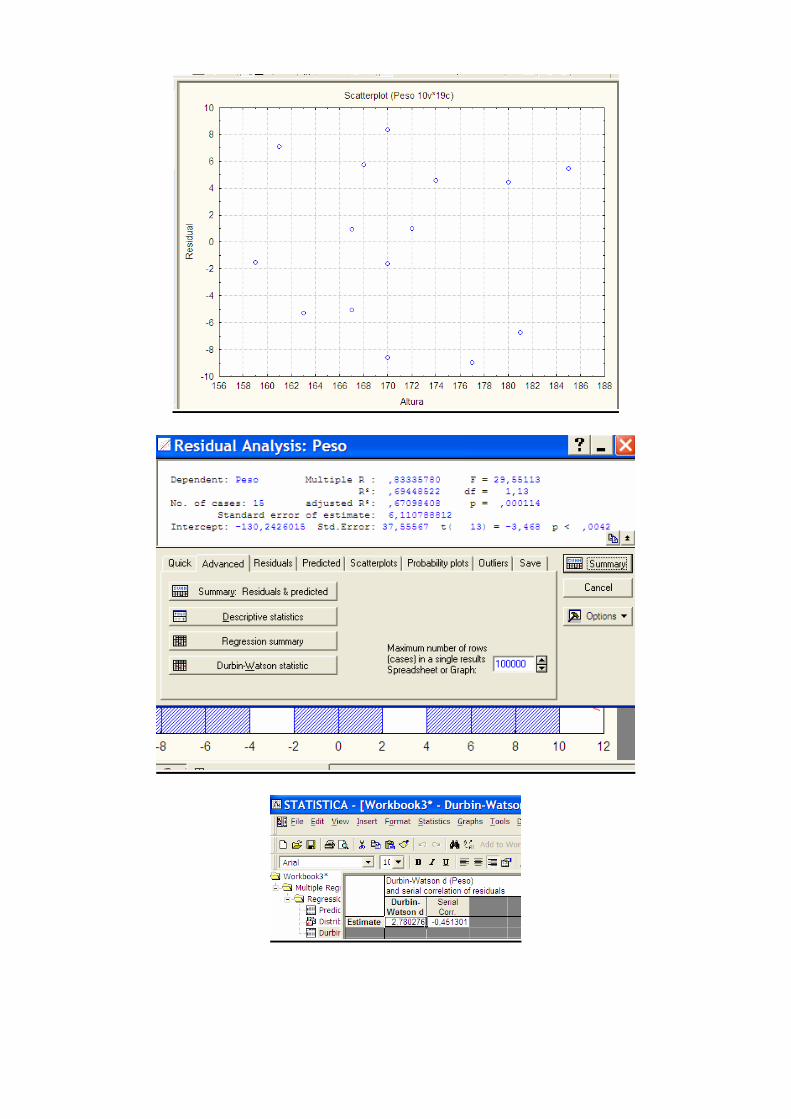
♦ É conveniente proceder a uma análise gráfica dos resíduos. Se o modelo for correcto os resíduos obtidos podem ser vistos como estimativas dos erros εi. Através dessa análise pode-se verificar se as hipóteses inerentes ao modelo de regressão são válidas.
Homocedasticidade: Através do diagrama de dispersão somos capazes de detectar a hipótese da variância dos erros ser constante. Pode ser feita à custa dos diagramas dos resíduos versus a variável explicativa ou dos resíduos versus o valor estimado de y. Os diagramas de dispersão dos resíduos versus a explicativa deverão apresentar o aspecto de ruído branco, sem qualquer padrão funcional de comportamento. Se os resíduos são sistematicamente positivos, e de seguida negativos há uma evidência que o valor estimado de y está sempre sobreestimado ou subestimado, estimação essa que resulta de uma relação funcional entre as variáveis dependente e independente incorrecta.
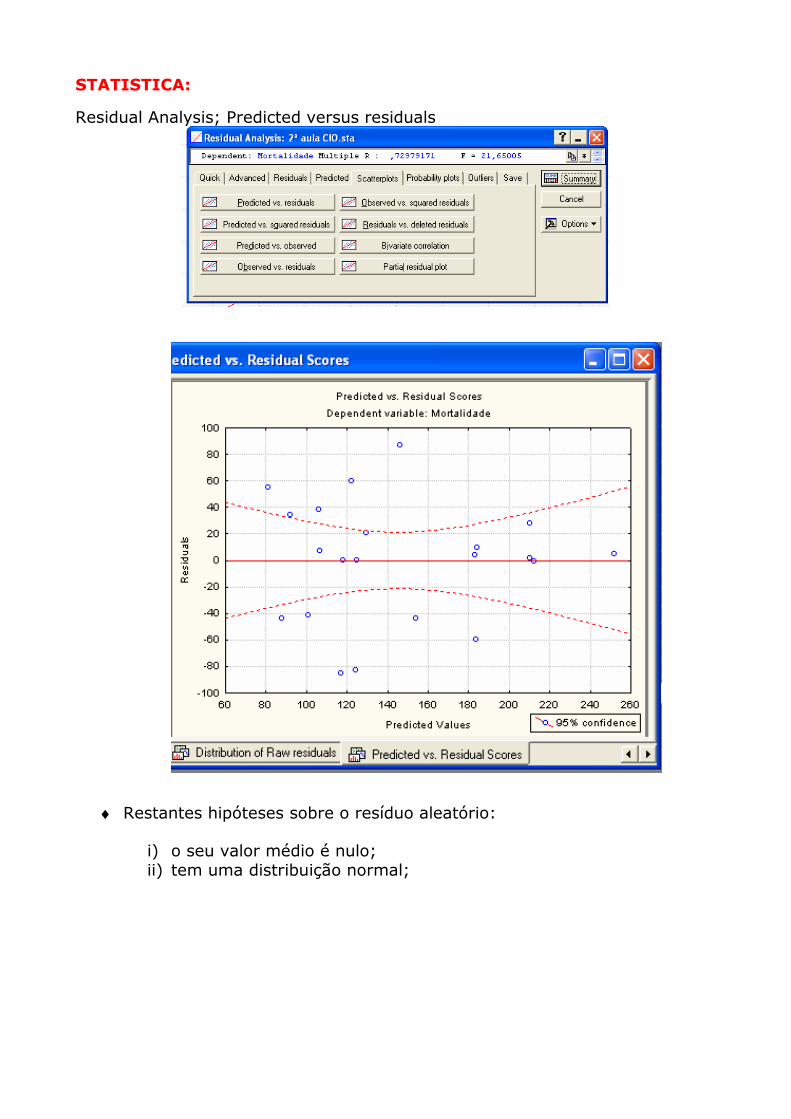
STATISTICA:
Residual Analysis; Predicted versus residuals
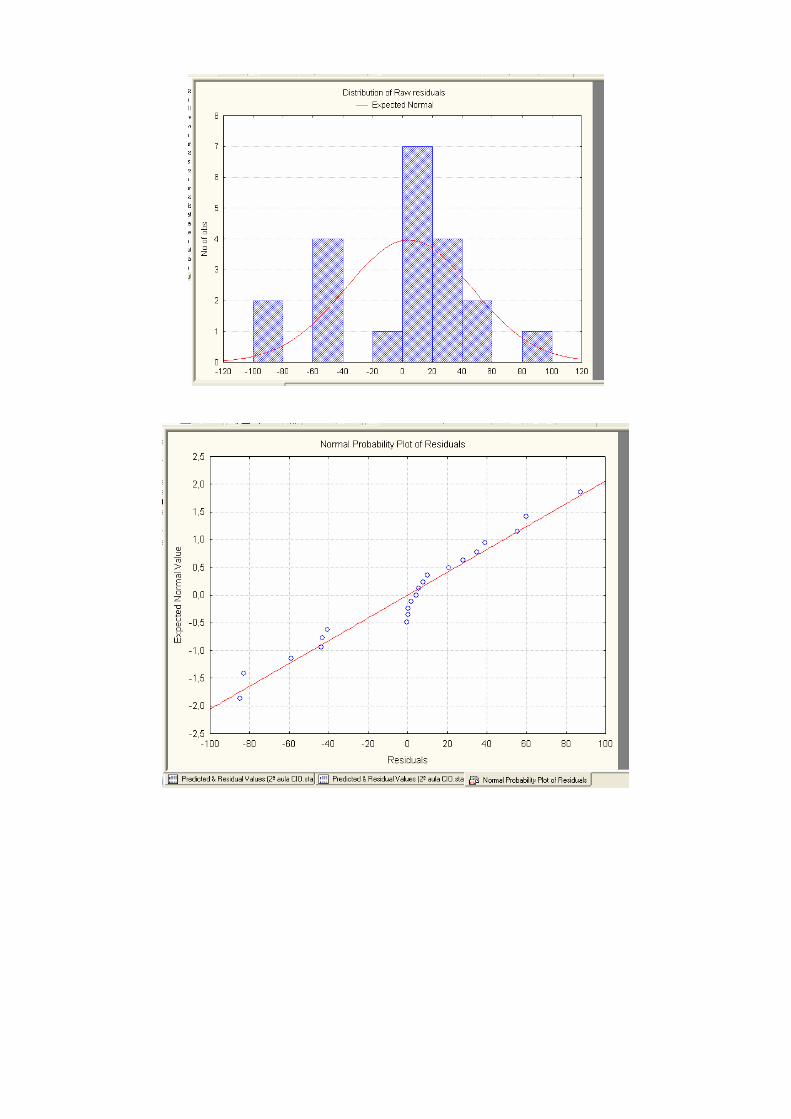
♦ Restantes hipóteses sobre o resíduo aleatório:
i) o seu valor médio é nulo; ii) tem uma distribuição normal;
Exemplo2:
Parâmetro α e ß e F
ANÁLISE DE RESÍDUOS






![Notas sobre o conceito de logos e a origem da Metafísica · semântica do termo logos [λόγος] presentes na cultura popular grega para em seguida comparar com o destino dado](https://static.fdocument.org/doc/165x107/5ba459f809d3f2a9218d40cc/notas-sobre-o-conceito-de-logos-e-a-origem-da-metafisica-semantica-do-termo.jpg)











