Redes Neuronales Multicapa - eva.fing.edu.uy · PDF fileBackpropagation-Consideraciones...
35
Redes Neuronales Multicapa Introducción al Reconocimiento de Patrones IIE - FING - UdelaR 2015
-
Upload
duongkhanh -
Category
Documents
-
view
219 -
download
0
Transcript of Redes Neuronales Multicapa - eva.fing.edu.uy · PDF fileBackpropagation-Consideraciones...

Redes Neuronales Multicapa
Introducción al Reconocimiento de PatronesIIE - FING - UdelaR
2015
Outline

Redes neuronales multicapa (MLNN)
Las funciones discriminantes lineales puras tienen limitaciones:las fronteras de decisión son hiperplanos.Con funciones no lineales φ se pueden obtener fronteras dedecisión complejas: mayor poder de expresión.¿Cómo determinar o aprender las no linealidades φ para lograrbajos errores de clasificación?
Idea de MLNN: aprender las no-linealidades al mismotiempo que los discriminantes lineales.
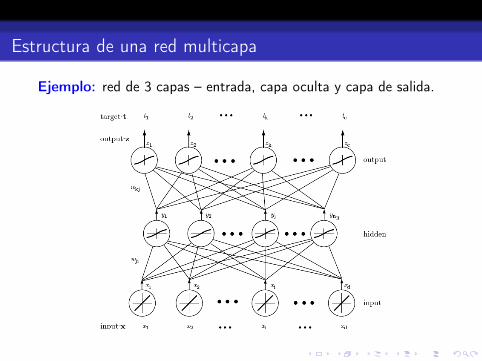
Estructura de una red multicapa
Ejemplo: red de 3 capas – entrada, capa oculta y capa de salida.

Redes de 3 capas
Cada unidad de la capa oculta:
netj =
d∑i=1
wjixi + wj0 =
d∑i=0
wjixi = wtjx
yj = f(netj), e.g. f : función signo o sigmoide.
Unidades de la capa de salida: idem pero tomando las salidas dela capa oculta como entradas:
netk =
nH∑j=1
wkjyj + wk0 = wtky
zk = f(netk), f : en general (no necesariamente) igual a las de la capa oculta.
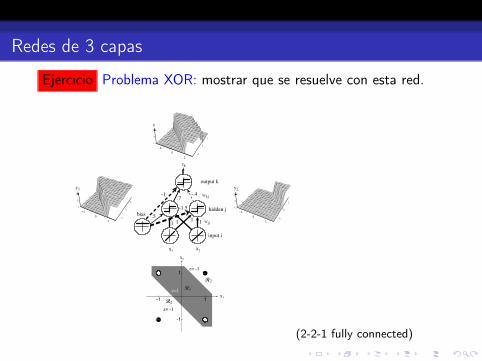
Redes de 3 capas
Ejercicio Problema XOR: mostrar que se resuelve con esta red.
6.2. FEEDFORWARD OPERATION AND CLASSIFICATION 7
biashidden j
output k
input i
111 1
.5
-1.5
.7-.4-1
x1 x2
x1
x2
z=1
z= -1
z= -1
-1
0
1-1
0
1
-1
0
1
-1
0
1
-1
0
1-1
0
1
-1
0
1
-1
0
1
-1
0
1-1
0
1
-1
0
1
-1
0
1
R2
R2
R1
y1 y2
z
zk
wkj
wji
Figure 6.1: The two-bit parity or exclusive-OR problem can be solved by a three-layernetwork. At the bottom is the two-dimensional feature space x1 ! x2, and the fourpatterns to be classified. The three-layer network is shown in the middle. The inputunits are linear and merely distribute their (feature) values through multiplicativeweights to the hidden units. The hidden and output units here are linear thresholdunits, each of which forms the linear sum of its inputs times their associated weight,and emits a +1 if this sum is greater than or equal to 0, and !1 otherwise, as shownby the graphs. Positive (“excitatory”) weights are denoted by solid lines, negative(“inhibitory”) weights by dashed lines; the weight magnitude is indicated by therelative thickness, and is labeled. The single output unit sums the weighted signalsfrom the hidden units (and bias) and emits a +1 if that sum is greater than or equalto 0 and a -1 otherwise. Within each unit we show a graph of its input-output ortransfer function — f(net) vs. net. This function is linear for the input units, aconstant for the bias, and a step or sign function elsewhere. We say that this networkhas a 2-2-1 fully connected topology, describing the number of units (other than thebias) in successive layers.
(2-2-1 fully connected)

Feedforward (clasificación)
La forma general de las salidas de una red de tres capas es:
gk(x) = zk = f
nH∑j=1
wkjf
(d∑
i=1
wjixi + wj0
)+ wk0
Interesa saber la capacidad expresiva de esta formulación: ¿Sepuede aproximar cualquier función?

Poder de expresión
Teorema de Kolmogorov: Para toda función g : [0, 1]n → Rcontinua (n ≥ 2), existen funciones Ξj y ψij tales que
g(x) =
2n+1∑j=1
Ξj
(d∑
i=1
ψij(xi)
).
Asegura viabilidad teórica, pero de poco utilidad práctica:
En general las Ξj y ψij son complejas y muy irregulares.
El teorema no nos dice mucho sobre como elegirlas oaprenderlas de los datos, ni como elegir n.
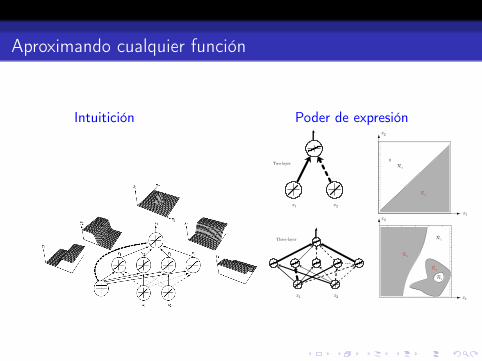
Aproximando cualquier función
Intuitición Poder de expresión
10 CHAPTER 6. MULTILAYER NEURAL NETWORKS
While we can be confident that a complete set of functions, such as all polynomi-als, can represent any function it is nevertheless a fact that a single functional formalso su!ces, so long as each component has appropriate variable parameters. In theabsence of information suggesting otherwise, we generally use a single functional formfor the transfer functions.
While these latter constructions show that any desired function can be imple-mented by a three-layer network, they are not particularly practical because for mostproblems we know ahead of time neither the number of hidden units required, northe proper weight values. Even if there were a constructive proof, it would be of littleuse in pattern recognition since we do not know the desired function anyway — itis related to the training patterns in a very complicated way. All in all, then, theseresults on the expressive power of networks give us confidence we are on the righttrack, but shed little practical light on the problems of designing and training neuralnetworks — their main benefit for pattern recognition (Fig. 6.3).
Two"layer
Three"layer
x1 x2
x1
x2
...
x1 x2
fl
R1
R2
R1
R2
R2
R1
x2
x1
Figure 6.3: Whereas a two-layer network classifier can only implement a linear decisionboundary, given an adequate number of hidden units, three-, four- and higher-layernetworks can implement arbitrary decision boundaries. The decision regions need notbe convex, nor simply connected.
6.3 Backpropagation algorithm
We have just seen that any function from input to output can be implemented as athree-layer neural network. We now turn to the crucial problem of setting the weightsbased on training patterns and desired output.

Backpropagation - Aprendizaje
t: salida objetivo; z: salida de la red.Función de error a minimizar:
J(w) =1
2
c∑k=1
(tk − zk)2 =1
2‖t− z‖2
La minimización se hace evaluando patrones conocidos(feedforward), y corrigiendo los pesos en base a la diferenciacon lo esperado (aprendizaje).

Backpropagation - Aprendizaje
Hay que corregir los pesos para disminuir el error.
Haciendo el descenso por el gradiente, la corrección es:
∆w = −η ∂J∂w
, ∆wpq = −η ∂J
∂wpq
w(m+ 1) = w(m) + ∆w(m)

Backpropagation - Aprendizaje
Pesos de la capa oculta a la capa de salida:
∂J
∂wkj=
∂J
∂netk
∂netk∂wkj
= −δk∂netk∂wkj
donde δk = − ∂J∂netk
es la sensibilidad del nodo k.
∂netk∂wkj
= yj ,
δk = − ∂J
∂netk= − ∂J
∂zk
∂zk∂netk
= (tk − zk)f ′(netk)
⇒ ∆wkj = ηδkyj = η(tk − zk)f ′(netk)yj

Backpropagation - Aprendizaje
Pesos de la capa de entrada a la capa oculta:
∂J
∂wji=∂J
∂yj
∂yj∂netj
∂netj∂wji
=∂J
∂yjf ′(netj)xi
∂J
∂yj=
∂
∂yj
(1
2
c∑k=1
(tk − zk)2
)= −
c∑k=1
(tk − zk)∂zk∂yj
= −c∑
k=1
(tk − zk)∂zk∂netk
∂netk∂yj
= −c∑
k=1
(tk − zk)f′(netk)wjk = −
c∑k=1
wkjδk
Sensibilidad, nodo de capa oculta: δj = f ′(netj)∑c
k=1wkjδk.
⇒ ∆wji = ηxiδj = ηxif′(netj)
c∑k=1
wkjδk

Backpropagation - Aprendizaje Capa Oculta
δk = (tk − zk)f ′(netk), δj = f ′(netj)c∑
k=1
wkjδk

Backpropagation - Aprendizaje
La regla se puede generalizar para los casos:
Los nodos de entrada están conectados directamente a los dela salida.Más de una capa ocultaSe usan distintas f en distintas capasCada nodo tiene una f distintaCada nodo tiene un paso de aprendizaje diferente

Backpropagation - Protocolos de Aprendizaje
Tres esquemas básicos de aprendizaje:
Estocástico: se elige un subconjunto aleatorio de los patronesBatch: se usan todos los patronesEn línea: uno a uno a medida que aparecen

Esquema Estocástico

Esquema Batch Backpropagation
Se considera todos los patrones y se actualiza con una suma delaporte de todos, es decir tomando como error:
n∑p=1
Jp

Backpropagation - Curvas de Aprendizaje
Se busca un mínimo de J que se puede ver como unasuperficie de error.Si tiene muchos mínimos locales, puede quedarse en uno.Si es muy suave el descenso es muy lento.En dimensiones grandes es muy probable obtener mínimoslocales. En la práctica se suele llegar a un mínimo local, moverlos pesos de ese punto y volver a iterar.
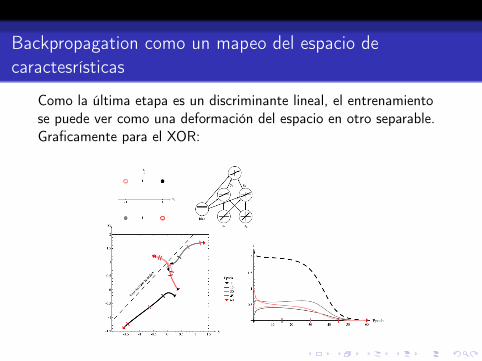
Backpropagation como un mapeo del espacio decaractesrísticas
Como la última etapa es un discriminante lineal, el entrenamientose puede ver como una deformación del espacio en otro separable.Graficamente para el XOR:

Backpropagation - Interpretación de los pesos aprendidos
Los pesos en uno de los nodos de la capa oculta representan losvalores que dan máxima respuesta de ese nodo. Se puede explicarla solución como haber encontrado los pesos que corresponden a unfiltro matcheado.

Backpropagation - Bayes, probabilidad
Se puede probar que en el límite con infinitos datos, la redentrenada aproxima en mínimos cuadrados las probabilidades aposteriori:
gk(x,w) ≈ P (wk|x)
¡Pero asumiendo que hay suficientes nodos en la capa oculta!

Backpropagation - Bayes, probabilidad
La salida de la red se puede interpretar como una probabilidad:Tomando:
f(netk) ∝ enetk
y normalizando para que sean probabilidades:
zk =enetk∑c
m=1 enetm

Backpropagation - Consejos y Mejoras
La función de transferencia: f(.) debe ser:
No linealQue sature (acotada)Continua y derivable (para poder hacer descenso por elgradiente)monotonía
Polinomios: hacen inestables la solución.
Se suele usar la sigmoide.
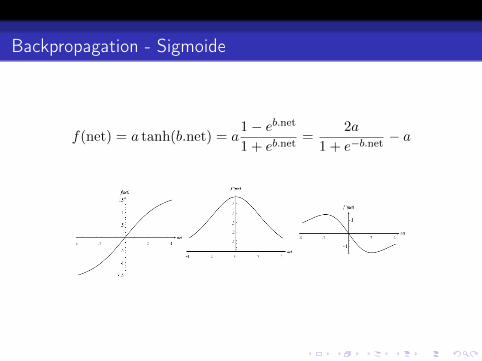
Backpropagation - Sigmoide
f(net) = a tanh(b.net) = a1− eb.net1 + eb.net
=2a
1 + e−b.net− a

Backpropagation - Consideraciones
Normalizar la entrada: es conveniente modificar la entradapara que las caracterísiticas tengan igual media y varianza.Entrenar con ruido: puede ser útil entrenar agregando ruido dehasta 10% en la entrada para evitar sobre-entrenamiento.Transformar los datos de entrada: si se conocetransformaciones que describan la variabilidad de los datos:por ej en OCR: rotación, escala,negrita... entonces se puedehacer crecer el conjunto de entrenamiento aplicando estastransformaciones.

Backpropagation - Tamaño de la capa oculta
Relacionada con la complejidad de la superficie de decisión.En general funciona bien la regla empírica:
Tantos nodos para que haya n/10 parámetros por determinar.

Backpropagation - Inicialización de los pesos
Se quiere aprender las clases a la misma velocidad:Elección de pesos dist uniforme:
−w < w < w
con w de forma que la salida de los nodos ocultos esté en un rangono saturado, −1 < neti < 1, si no es dificil que esos nodos seajusten en el aprendizaje.Ejemplo, d entradas:
w =1√d
Lo mismo se aplica a los pesos de la capa final:inicializar con
−1/√nH < wkj < 1/
√nH

Backpropagation - Velocidad de aprendizaje
Se considera el óptimo como el que lleva al mínimo local en unaaproximación cuadrática:
∂2J
∂w2∆w =
∂J
∂w
Oteniendo:
ηopt =
(∂2J
∂w2
)−1
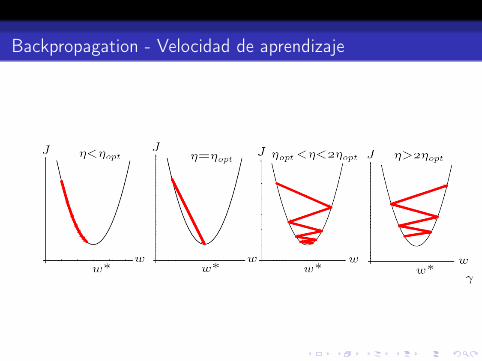
Backpropagation - Velocidad de aprendizaje

Backpropagation - Momento o inercia
Para evitar estancarse en mesetas:
w(m+ 1) = w(m) + ∆w(m) + α∆w(m− 1)
en general con α cercano a 1.

Backpropagation - Paso variable
Weight Decay:
wnew = wold(1− ε), 0 < ε < 1.
Se puede probar que es equivalente a tomar un nuevo J :
Jef (w) = J(w) +2ε
ηwtw
Tiene el efecto de regularizar la frontera ( Porqué? ).
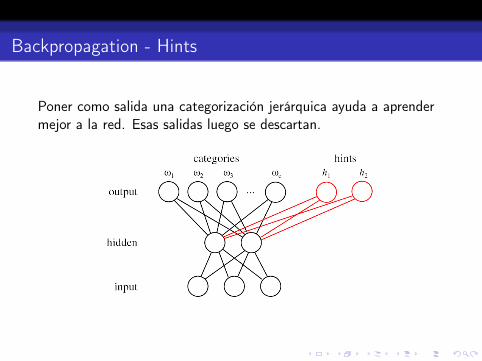
Backpropagation - Hints
Poner como salida una categorización jerárquica ayuda a aprendermejor a la red. Esas salidas luego se descartan.

Backpropagation - Métodos de segundo orden
Se puede usar técnicas más elaboradas para llegar al mínimo:
Hessiana (aproximación de segundo orden)Quickprop (aproximación rápida de segundo orden)Gradiente conjugado (mantiene la dirección de descenso)

Otros tipos de redes
Las funciones no lineales son RBF.TDNN (Time Delay) (con memoria).Recursivas.