
P vrijednost - Početna_granice_pouzdanosti.pdf · P vrijednost Standardna pogrješka Interval...
45
P vrijednost Standardna pogrješka Interval pouzdanosti Klinički zavod za kemiju, Odjel za molekularnu dijagnostiku Klinička bolnica “Sestre milosrdnice”, Zagreb Ana-Maria Šimundić
Transcript of P vrijednost - Početna_granice_pouzdanosti.pdf · P vrijednost Standardna pogrješka Interval...

P vrijednost
Standardna pogrješka
Interval pouzdanosti
Klinički zavod za kemiju, Odjel za molekularnu dijagnostiku
Klinička bolnica “Sestre milosrdnice”, Zagreb
Ana-Maria Šimundić

Standardna pogrješka
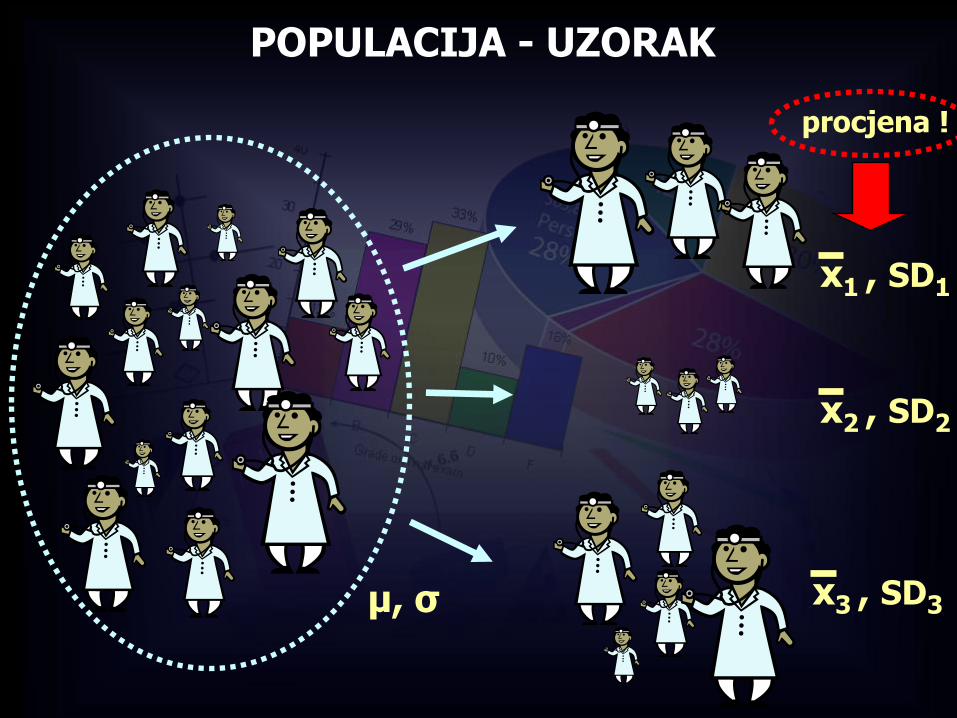
POPULACIJA - UZORAK
x1 , SD1
μ, σ
procjena !
x2 , SD2
x3 , SD3
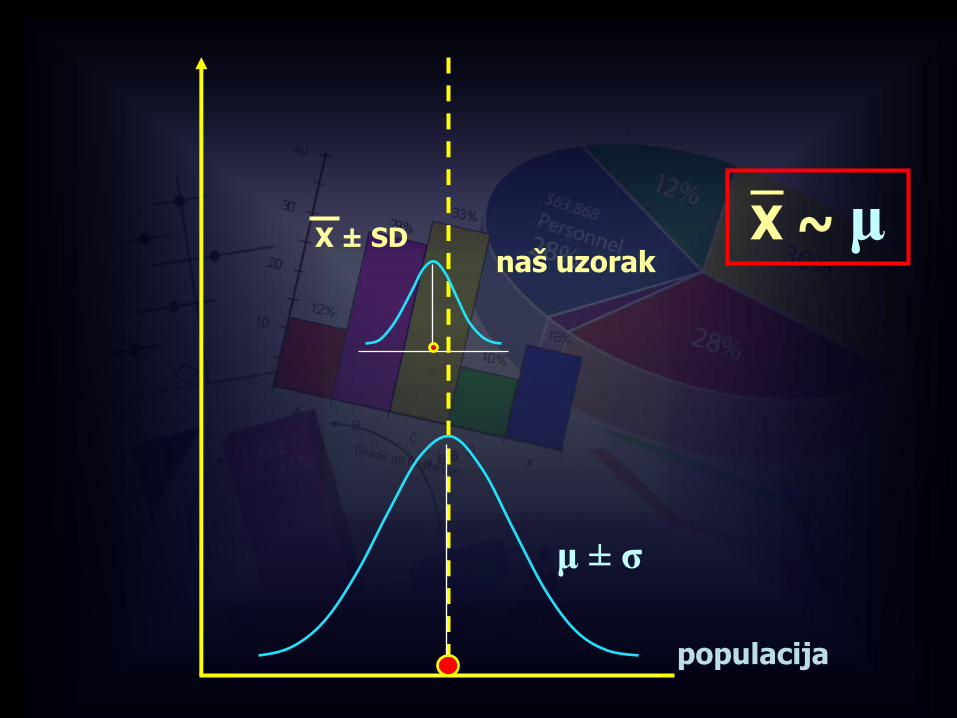
X ± SD
populacija
naš uzorak
μ ± σ
X ~ μ
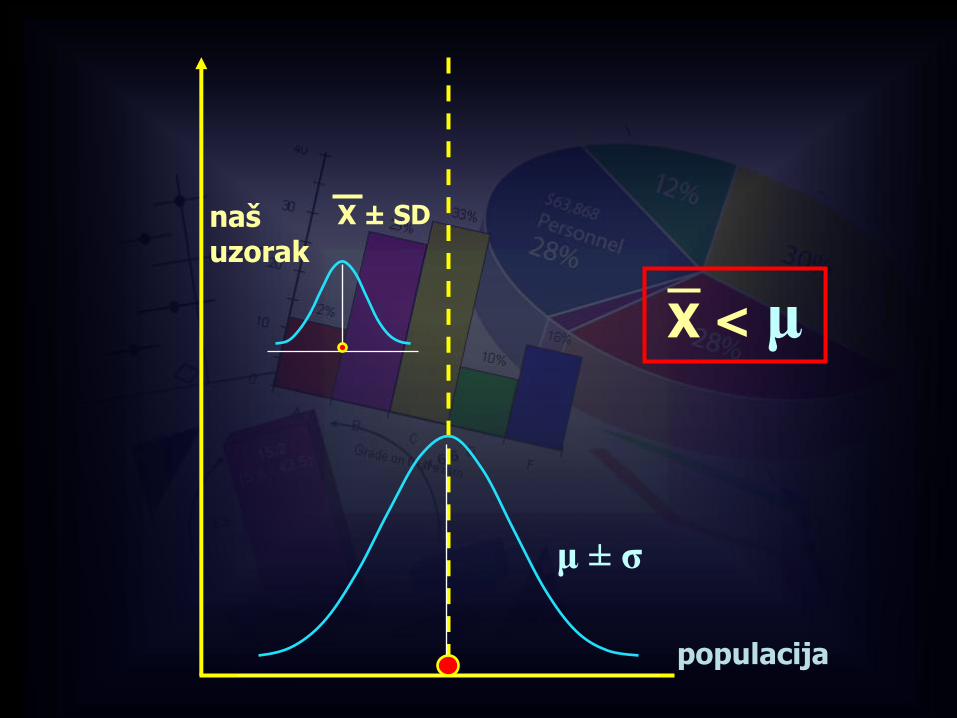
X ± SD
populacija
naš uzorak
μ ± σ
X < μ
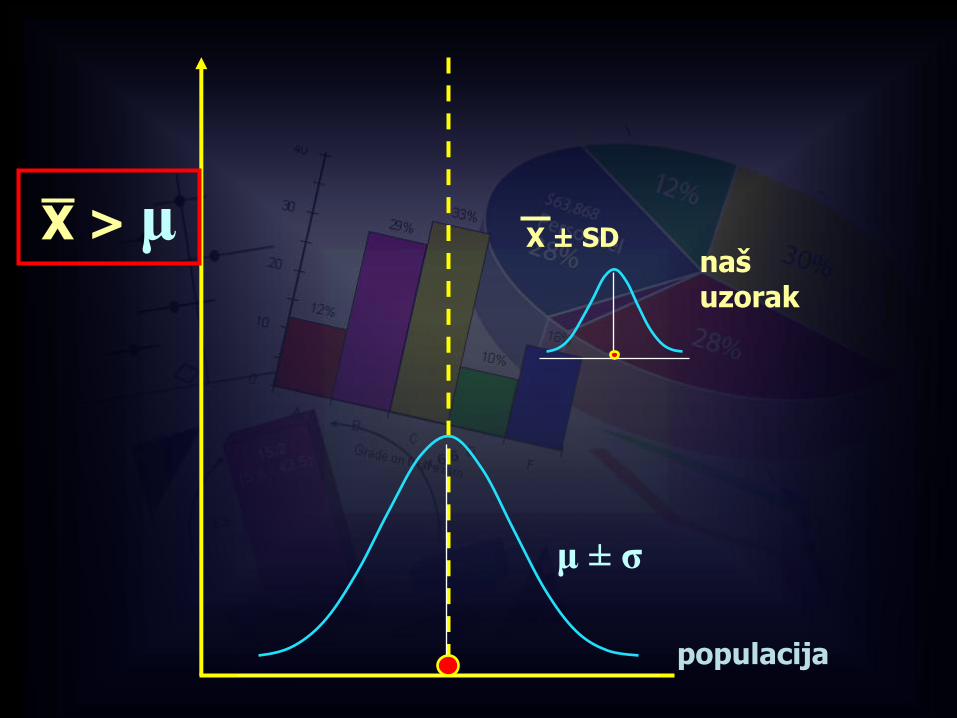
X ± SD
populacija
naš uzorak
μ ± σ
X > μ
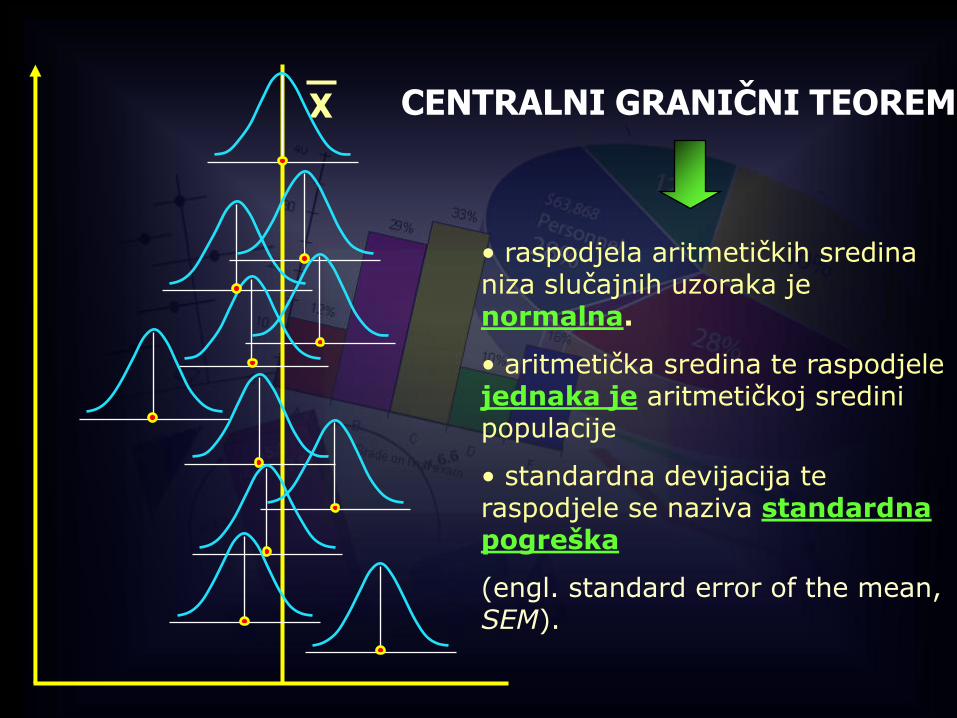
X CENTRALNI GRANIČNI TEOREM
• raspodjela aritmetičkih sredina niza slučajnih uzoraka jenormalna.
• aritmetička sredina te raspodjele jednaka je aritmetičkoj sredini populacije
• standardna devijacija te raspodjele se naziva standardna pogreška
(engl. standard error of the mean, SEM).

O ČEMU OVISI TOČNOST
PROCJENE ARITMETIČKE
SREDINE POPULACIJE?
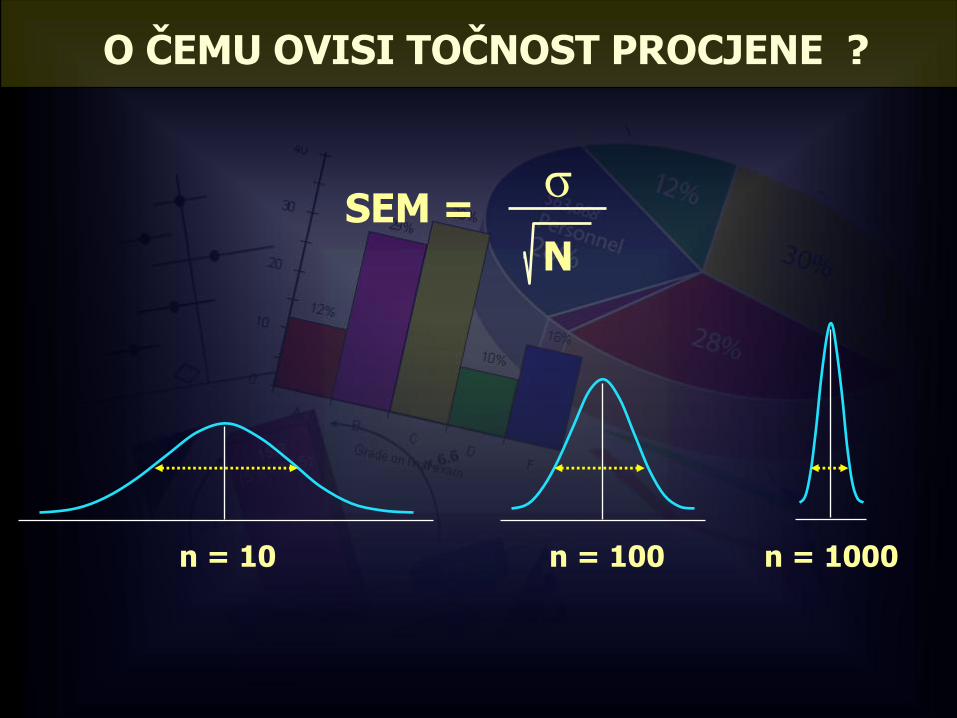
O ČEMU OVISI TOČNOST PROCJENE ?
n = 10 n = 100 n = 1000
SEM =σ
N

PAZITI !!!
SD SEM
mjera varijabilnostiuzorka
je mjera preciznostiprocjene aritmetičke
sredine
ne opisuje uzorak
nego

Interval pouzdanostiConfidence interval (CI)

Interval pouzdanosti za bilo koju statističku mjeru predstavlja raspon mogućih vrijednosti
unutar kojega se s izvjesnom vjerojatnosti nalazi ta statistička mjera populacije.
Što je interval pouzdanosti?
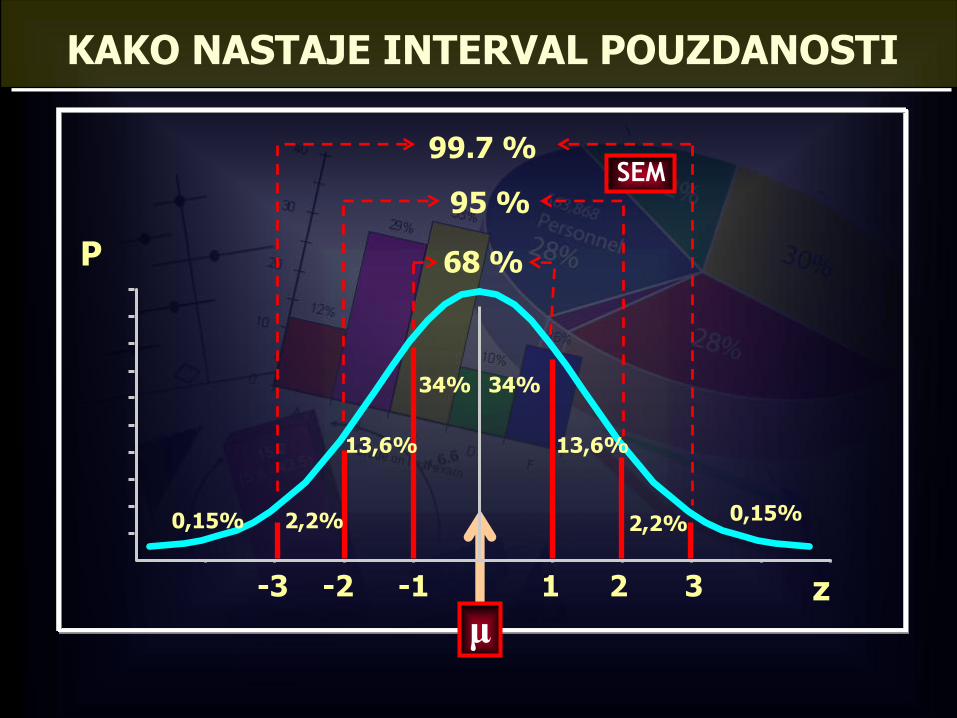
KAKO NASTAJE INTERVAL POUZDANOSTI
z
P
-1-2-3 321
68 %
95 %
99.7 %
34%34%
13,6%13,6%
2,2%2,2% 0,15%0,15%
μ
SEM
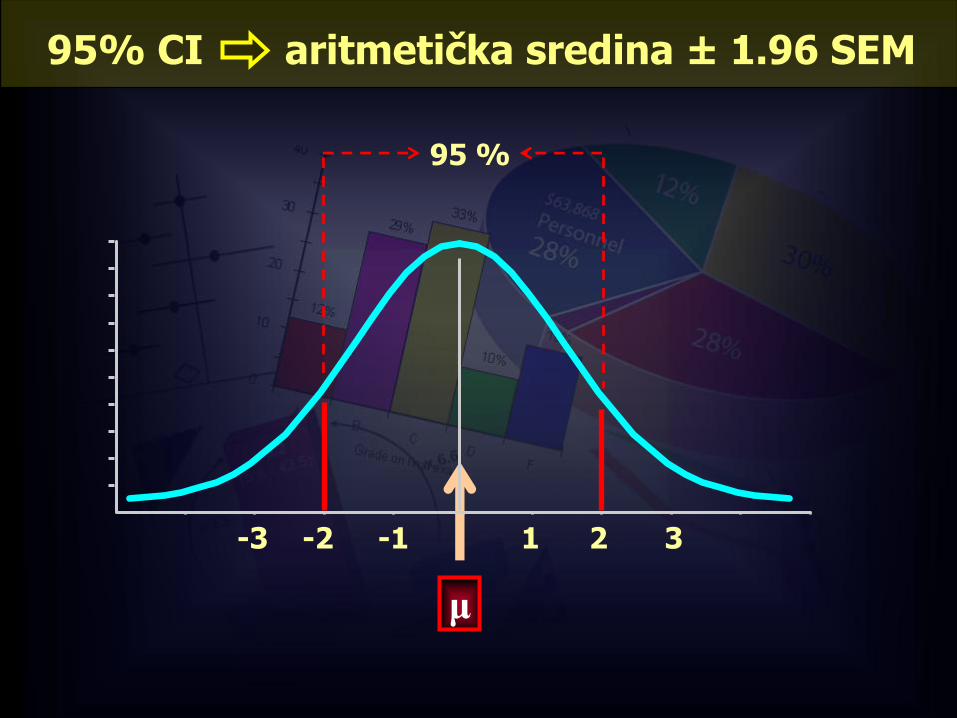
95% CI aritmetička sredina ± 1.96 SEM
-1-2-3 321
95 %
μ

Primjer:
Pretpostavke:
• slučajnim ste izborom uzeli 30 studenata 1. godine i odredili prosječnu visinu (170 cm).
• SD = 15 cm
Procijenite s 95%-tnom pouzdanosti kolika je prosječna visina studenata 1. godine u Zagrebu.
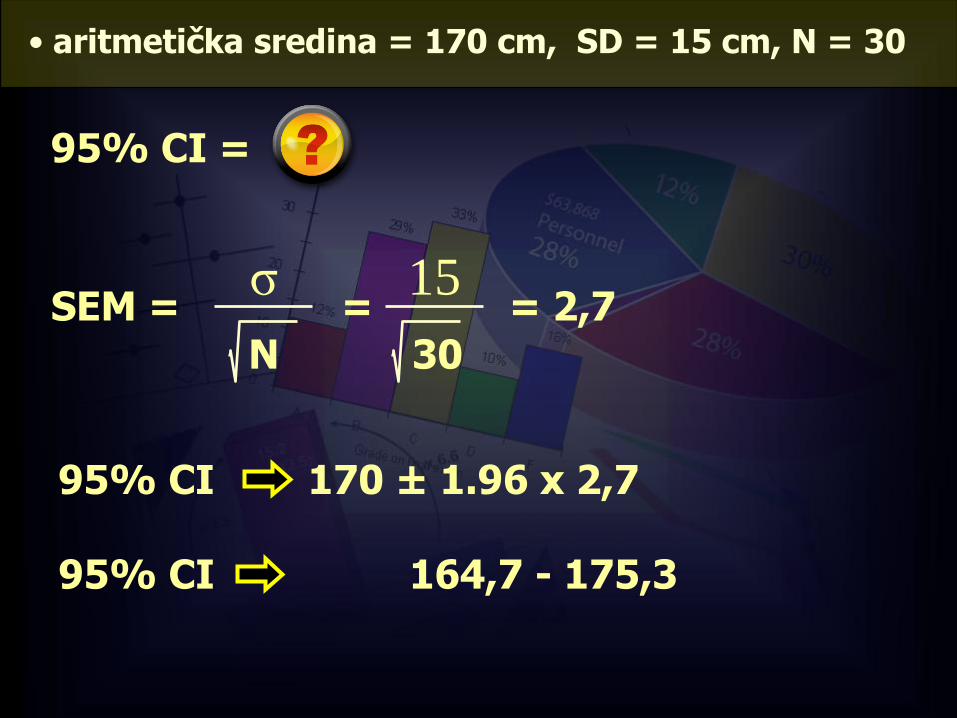
SEM =σ
N=
15
30
• aritmetička sredina = 170 cm, SD = 15 cm, N = 30
95% CI =
= 2,7
95% CI 170 ± 1.96 x 2,7
95% CI 164,7 - 175,3
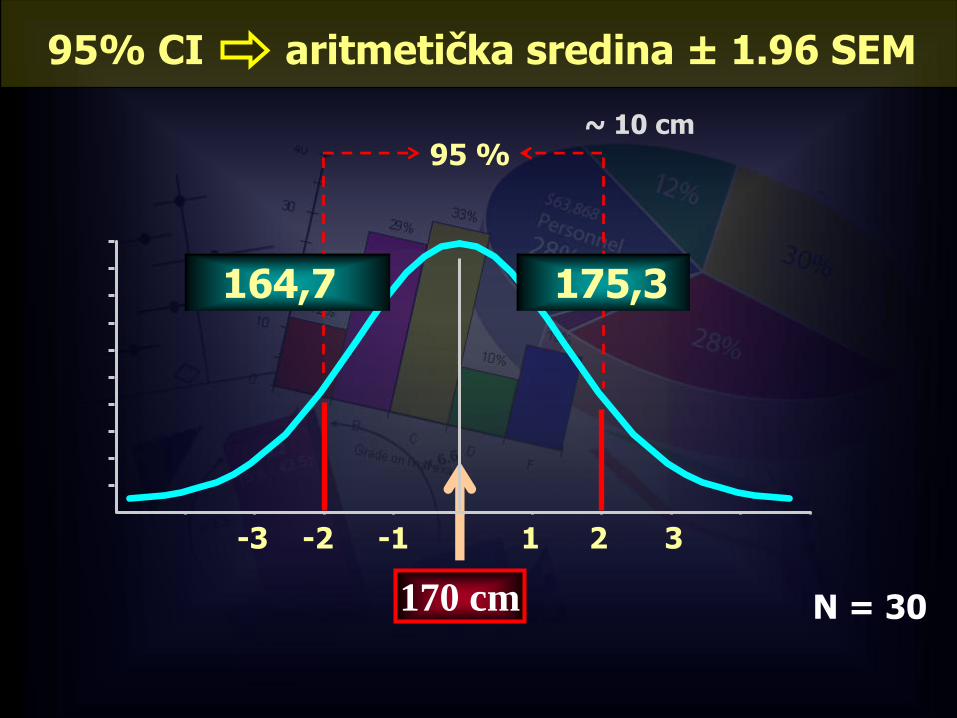
95% CI aritmetička sredina ± 1.96 SEM
-1-2-3 321
95 %
170 cm
175,3164,7
~ 10 cm
N = 30

Primjer:
Pretpostavke:
• slučajnim ste izborom uzeli 300 studenata 1. godine i odredili prosječnu visinu (170 cm).
• SD = 15 cm
Procijenite s 95%-tnom pouzdanosti kolika je prosječna visina studenata 1. godine u Zagrebu.
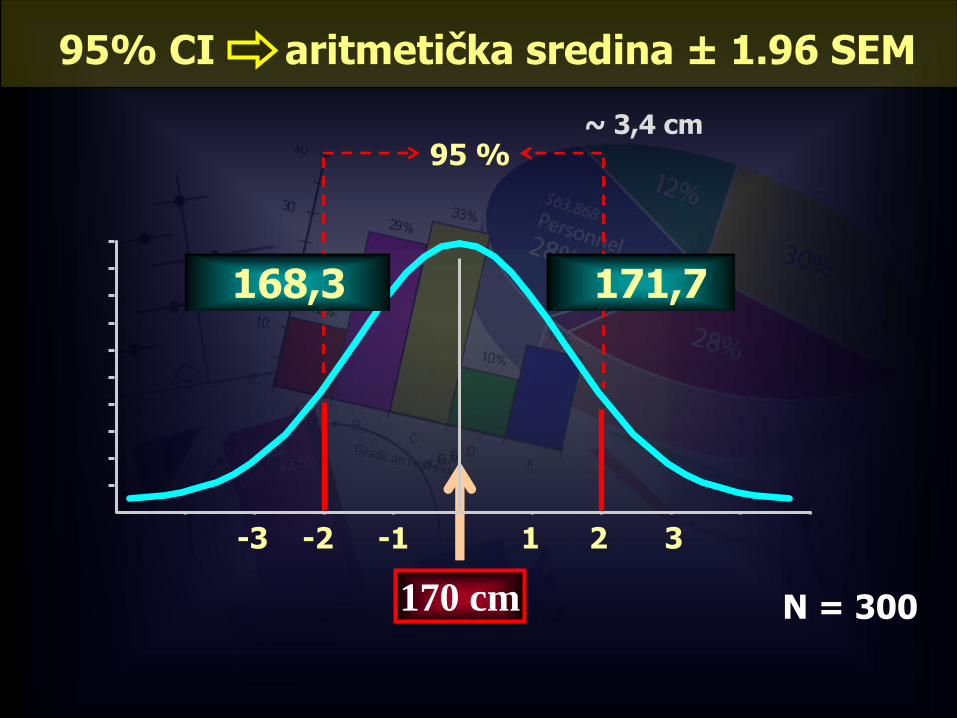
95% CI aritmetička sredina ± 1.96 SEM
-1-2-3 321
95 %
170 cm
171,7168,3
~ 3,4 cm
N = 300
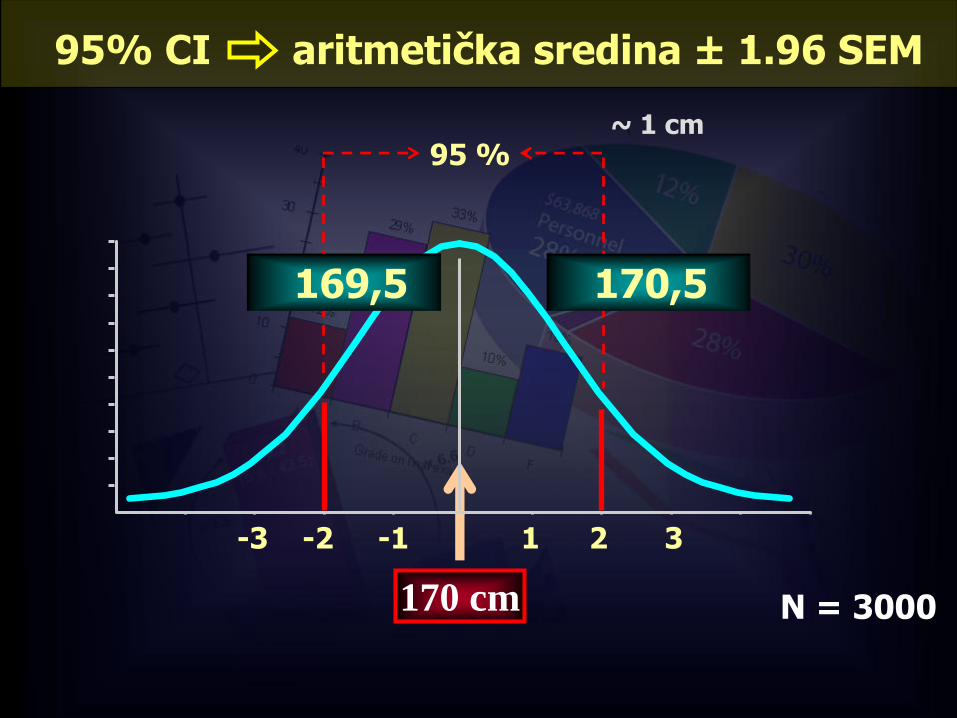
95% CI aritmetička sredina ± 1.96 SEM
-1-2-3 321
95 %
170 cm
170,5169,5
~ 1 cm
N = 3000

Primjer:
Pretpostavke:
• slučajnim ste izborom uzeli 30 studenata 1. godine i odredili prosječnu visinu (170 cm).
• SD = 1,5 cm
Procijenite s 95%-tnom pouzdanosti kolika je prosječna visina studenata 1. godine u Zagrebu.
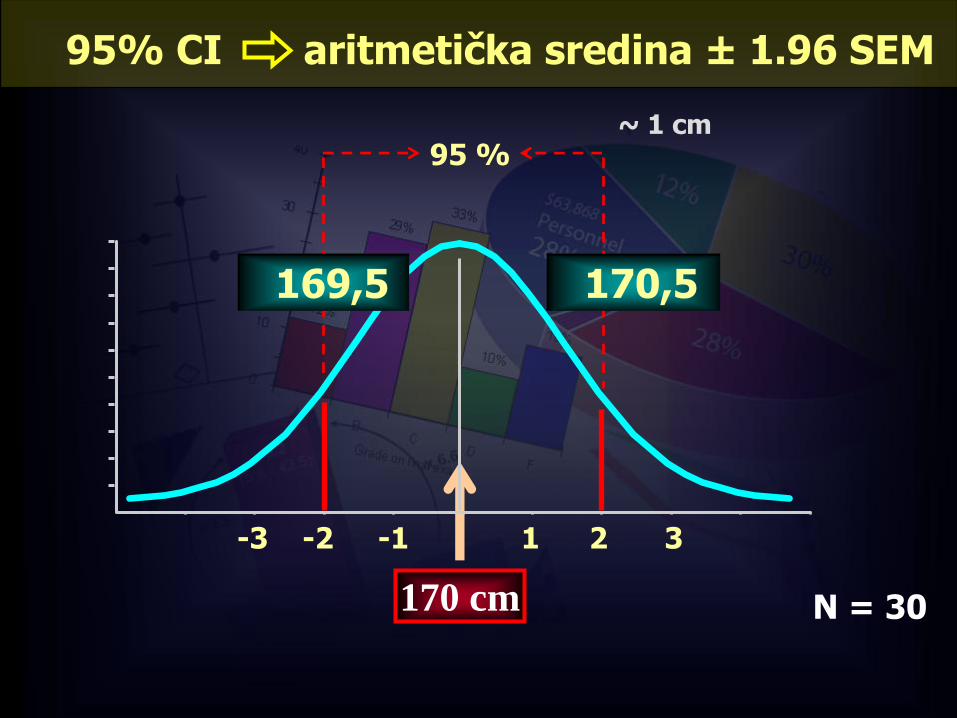
95% CI aritmetička sredina ± 1.96 SEM
-1-2-3 321
95 %
170 cm
170,5169,5
~ 1 cm
N = 30
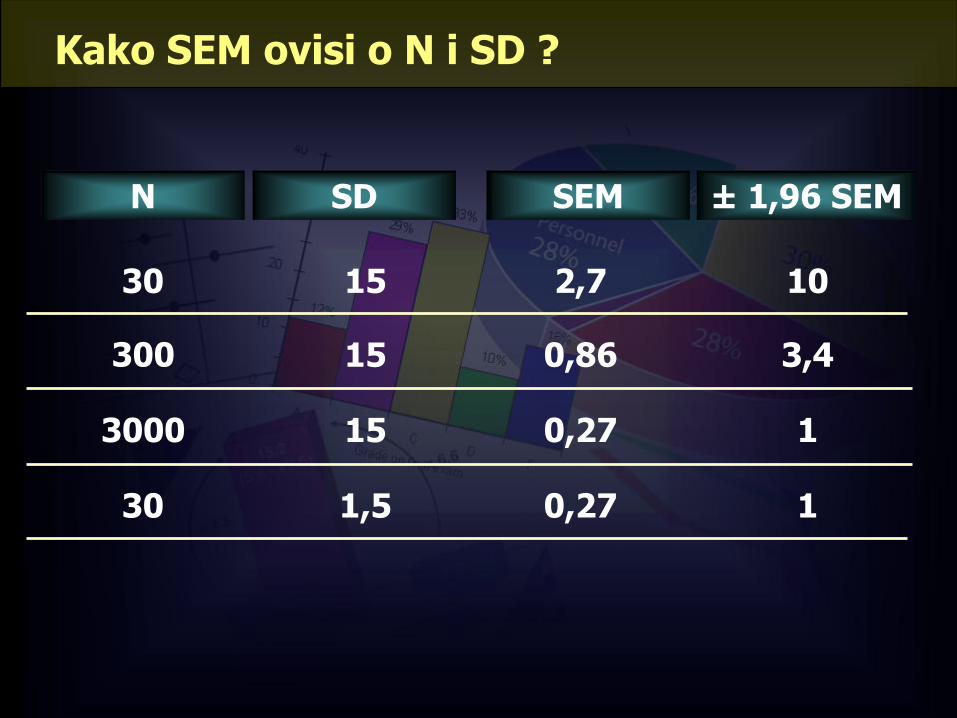
SD SEM
30 15 2,7
15 0,86
15 0,27
300
3000
N ± 1,96 SEM
10
3,4
1
30 1,5 0,27 1
Kako SEM ovisi o N i SD ?

razina pouzdanosti broj s kojim množimo SEM
90 %
95 %
99 %
99,9 %
1,65
1,96
2,58
3,291
OSTALI INTERVALI POUZDANOSTI
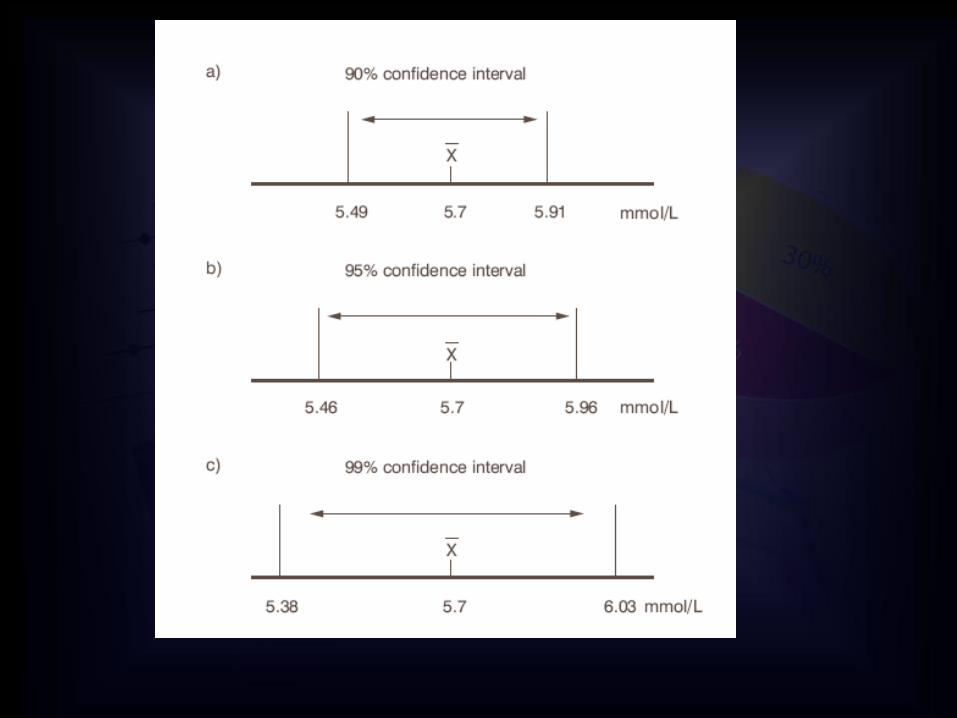
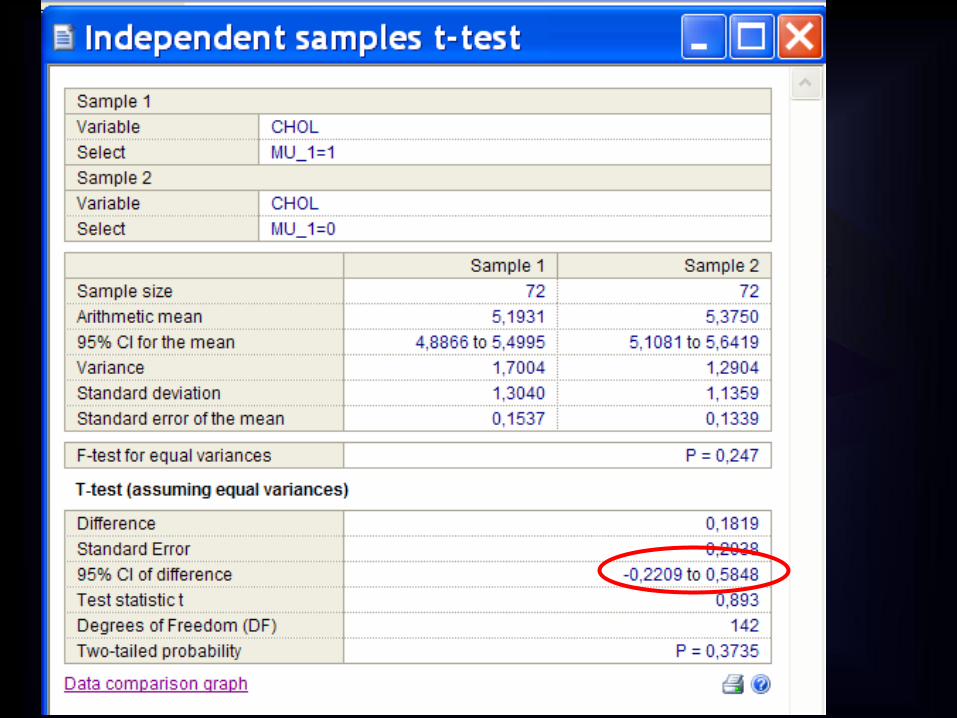
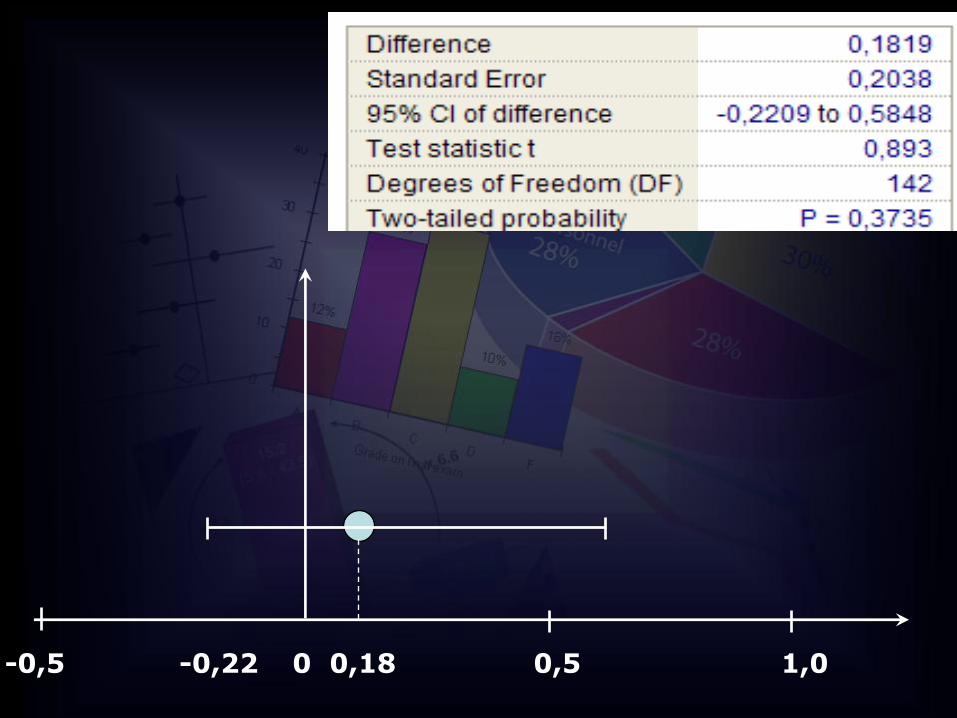
0 0,5 1,00,18-0,22-0,5
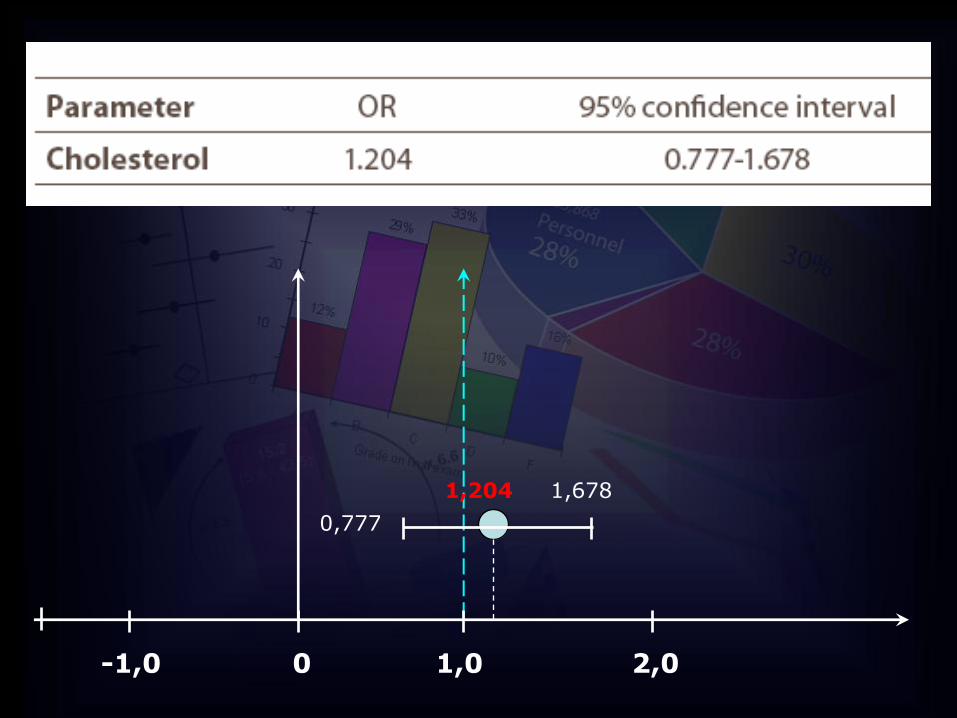
0 1,0 2,0-1,0
0,777
1,6781,204
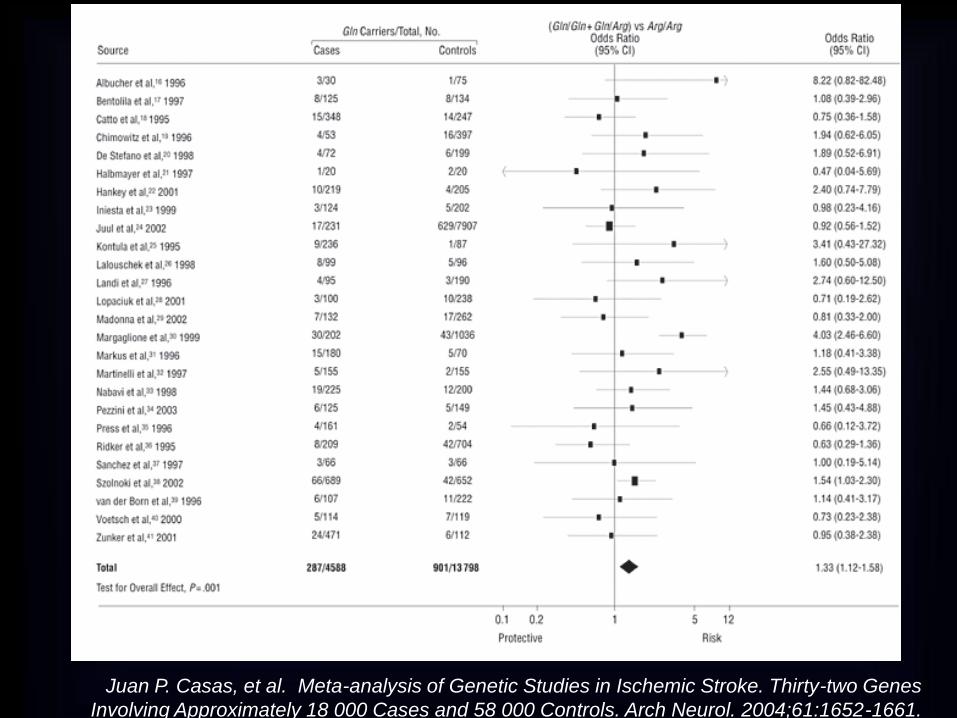
Juan P. Casas, et al. Meta-analysis of Genetic Studies in Ischemic Stroke. Thirty-two Genes
Involving Approximately 18 000 Cases and 58 000 Controls. Arch Neurol. 2004;61:1652-1661.

Kumar M, Agarwal SK, Goel SK. Lung cancer risk in north Indian population: role of
genetic polymorphisms and smoking. Mol Cell Biochem. 2009;322(1-2):73-9.
Lung cancer (LC) is the leading cause of cancer-related mortality in developing as well as developed countries. Life style choices, particularly tobacco smoking, have been implicated as the main cause in the development of the LC. Despite the fact that majority cases of the LC occur among smokers, only 1-15% of smokers develop LC. In the present study, we have explored the role of genetic polymorphism, smoking habit and their association to LC in a cohort of north Indian population. The polymorphic genes explored were CYP1A1, GSTM1, GSTP1 and GSTT1 using techniques of Polymerase chain reaction (PCR), Restriction Fragment Length Polymorphism (RFLP), Real Time PCR (RT PCR), and gene sequencing. Genetic polymorphism was analysed in 253 normal participants (control) and 93 LC patients originating from Lucknow, India. Data were compared using odds ratio and Fisher Exact Test.
Results:We found that smoking increases the susceptibility to LC threefold (OR = 2.9; 95% CI: 0.9-2.8). The most significant risk for LC (OR = 3.2; 95% CI: 0.7-3.8) was found in the association of the homozygous variant of CYP1A1 gene at A2455G base change at Exon 7 (Val/Val) genotype. There was a marginally significant association between LC and GSTT1 null genotype (OR = 1.3; 95% CI: 1.0-1.7) while no significant risk
association was found between GSTP1 polymorphism and LC.
The present study demonstrates that the presence of null genotype of GSTM1/GSTT1 taken together with CYP1A1 (Val/Val) genotype increases the susceptibility to LC eightfold in comparison to CYP1A1 (Ile/Ile) and GSTM1/ GSTT1 genotype.

Što je P vrijednost?

nulta hipoteza: nema razlike
Kako tumačimo P?
P vrijednost – vjerojatnost da opažena razlika
postoji uz pretpostavku da je nulta hipoteza točna
nema razlike
mi vidimo razliku
(P<0,010)
1% vjerojatnosti da je opažena
razlika slučajna

POGRJEŠNO tumačenje P vrijednosti
H0 točna H1 točna
prihvaćamo H0 ispravna odlukapogrješka 2. vrste
(β)
odbacujemo H0
pogrješka 1. vrste ()
ispravna odluka
statističko zaključivanje

Primjer:
cilj: ustanoviti razlikuju li se prosječne visine studenata 1. godine studija u Zagrebu i Splitu
nema razlike
snaga?
mala je vjerojatnost da je opažena razlika slučajna

Što je snaga (power) statističkog testa ?
vjerojatnost da ćemo neki učinak (razlika
ili povezanost) prepoznati kao statistički
značajan, ukoliko on stvarno postoji

O čemu ovisi snaga statističkog testa ?
snaga
veličina uzorka
varijabilnost
veličina učinka
razina značajnosti (P)

snaga (uobičajeno 70-80%)razina značajnosti (0.05)varijabilnost (SD)najmanja (klinički) važna razlika
Razlika u koncentraciji kolesterola između bolesnika i kontrola?

POGRJEŠAN prikaz P vrijednosti
Visina studenata u Splitu i Zagrebu se statistički značajno razlikovala (P<0,05).
Visina studenata u Splitu i Zagrebu se statistički značajno razlikovala (P<0,000).
Visina studenata u Splitu i Zagrebu se statistički značajno razlikovala (P=0,000001).
Visina studenata u Splitu i Zagrebu se statistički značajno razlikovala (P=NS).
? ispravno

ispravno = P<0,001
POGRJEŠAN prikaz P vrijednosti
Visina studenata u Splitu i Zagrebu se statistički značajno razlikovala (P<0,05).
Visina studenata u Splitu i Zagrebu se statistički značajno razlikovala (P<0,000).
Visina studenata u Splitu i Zagrebu se statistički značajno razlikovala (P=0,000001).
Visina studenata u Splitu i Zagrebu se statistički značajno razlikovala (P=NS).

Smislenost rezultata !
osim statističke značajnosti razlike moraju biti i smislene, odnosno klinički značajne.
Primjer:
Izmjerili smo koncentracije glukoze studenata 1. godine studija u Zagrebu i Splitu.
Zagreb (N=10 000)
Split (N=10 000)
5,1 ± 0,11 mmol/L
5,2 ± 0,18 mmol/L
P<0.001

Izmjerili smo prosječnu koncentraciju glukoze natašte u mladića i djevojaka na 1. godini studija.
mladići (N=7)
djevojke (N=6)
6,4 mmol/L
4,6 mmol/LP<0.085
Primjer:

ako je uzorak veliki
ako je uzorak mali

VIŠESTRUKO TESTIRANJE
Ako testiramo niz hipoteza, u konačnici ćemo negdje pronaći statistički značajnu razliku.
Je li ona stvarna?Ili slučajna?
Ako izvedemo 20 testova na istom nizu podataka možemo očekivati barem
jednu pogrješku tipa 1 (α).
ako je = 0.05







![Άσκηση 1η –Μέρος Α - NTUA...Άσκηση1η–Μέρος Α int array[100]; int *p, N; p = &array[8]; while (*p != 0){if (*p < 100) *p = *p % N; else *p = *p / N; p++;}](https://static.fdocument.org/doc/165x107/61213bb539ee736c47746d04/ff-1-aoe-ff1aoe-int-array100.jpg)

![k‑p‑t‑c {‑µ³ F‑ ‑g‑p ‑]‑p¶](https://static.fdocument.org/doc/165x107/61718417c41ca10cb91c5710/kptc-.jpg)








