
ΗΜΥ 408 ΨΗΦΙΑΚΟΣ ΣΧΕΔΙΑΣΜΟΣ ΜΕ FPGAs Χειμερινό ... ·...
30
ΗΜΥ 408 ΨΗΦΙΑΚΟΣ ΣΧΕΔΙΑΣΜΟΣ ΜΕ FPGAs Χειμερινό Εξάμηνο 2018 ΔΙΑΛΕΞΗ 8: FPGAs for the Masses ΧΑΡΗΣ ΘΕΟΧΑΡΙΔΗΣ Αναπληρωτής Καθηγητής, ΗΜΜΥ ([email protected]) Slides adopted from: Dr. Christoforos Kachris and Prof. Dimitrios Soudris (ICCS/NTUA, Greece), and Profs. Walid Najjar (UC Riverside, USA) and Paolo Ienne (EPFL, SWITZERLAND)
Transcript of ΗΜΥ 408 ΨΗΦΙΑΚΟΣ ΣΧΕΔΙΑΣΜΟΣ ΜΕ FPGAs Χειμερινό ... ·...

ΗΜΥ 408 ΨΗΦΙΑΚΟΣ ΣΧΕΔΙΑΣΜΟΣ ΜΕ FPGAs
Χειμερινό Εξάμηνο 2018 ΔΙΑΛΕΞΗ 8: FPGAs for the Masses
ΧΑΡΗΣ ΘΕΟΧΑΡΙΔΗΣ Αναπληρωτής Καθηγητής, ΗΜΜΥ
Slides adopted from: Dr. Christoforos Kachris and Prof. Dimitrios Soudris (ICCS/NTUA, Greece), and Profs. Walid Najjar (UC Riverside, USA) and Paolo Ienne (EPFL, SWITZERLAND)

ΗΜΥ408 Δ8 FPGAs for the Masses.2 ©Theocharides, ECE, 2018
Accelerators in data centers
By 2020, Intel predicts a third of cloud providers will use FPGAs, analysts noted in a keynote at their annual data center event…
ΗΜΥ408 Δ8 FPGAs for the Masses.3 ©Theocharides, ECE, 2018
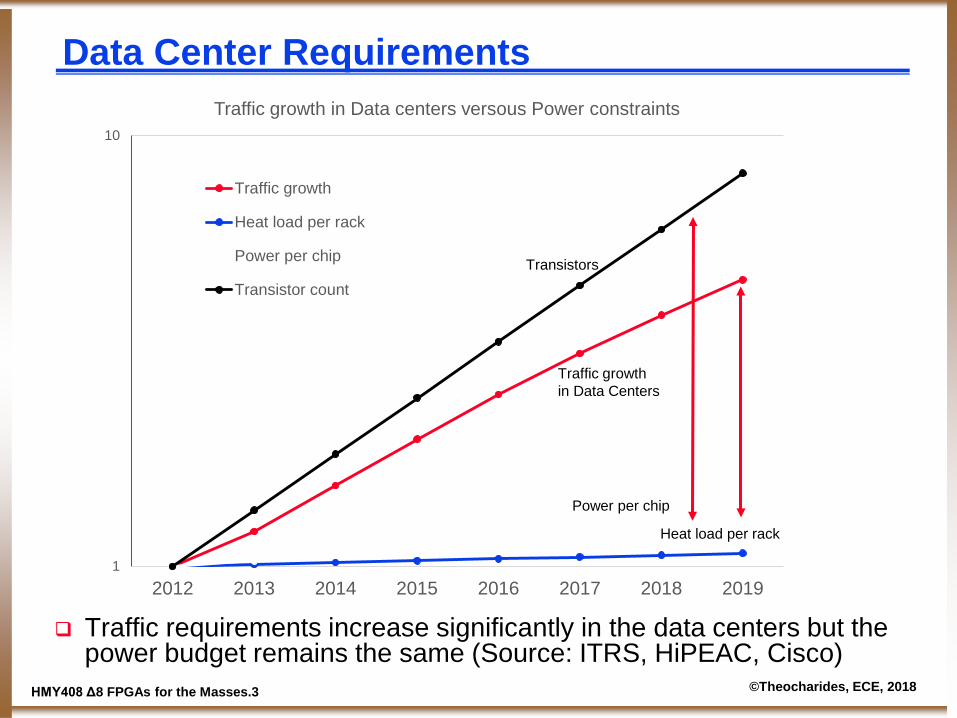
Data Center Requirements
Traffic requirements increase significantly in the data centers but the power budget remains the same (Source: ITRS, HiPEAC, Cisco)
1
10
2012 2013 2014 2015 2016 2017 2018 2019
Traffic growth in Data centers versous Power constraints
Traffic growth
Heat load per rack
Power per chip
Transistor countTransistors
Traffic growth in Data Centers
Power per chip
Heat load per rack
ΗΜΥ408 Δ8 FPGAs for the Masses.4 ©Theocharides, ECE, 2018
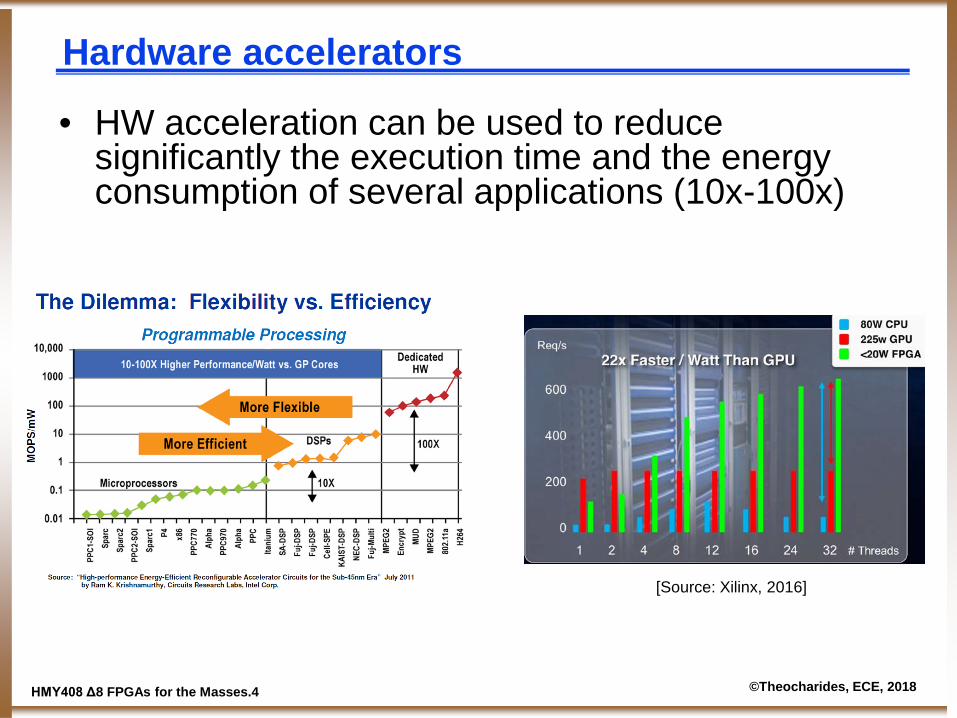
Hardware accelerators
• HW acceleration can be used to reduce significantly the execution time and the energy consumption of several applications (10x-100x)
[Source: Xilinx, 2016]

ΗΜΥ408 Δ8 FPGAs for the Masses.5 ©Theocharides, ECE, 2018
Google application Specific Accelerators deployed in DC
Google Has Built A Custom Chip For Machine Learning
The result is called a Tensor Processing Unit (TPU), a custom ASIC we built specifically for machine learning — and tailored for TensorFlow.
Google has been running TPUs inside the data centers for more than a year, and have found them to deliver an order of magnitude better-optimized performance per watt for machine learning.
This is roughly equivalent to fast-forwarding technology about seven years into the future (three generations of Moore’s Law).

ΗΜΥ408 Δ8 FPGAs for the Masses.6 ©Theocharides, ECE, 2018
A survey on HW accelerator for Cloud computing
HW accelerators Search engine and Page ranking Spark Memcached Databases
FPGAs in the cloud framework
FPL 2016, Christoforos Kachris,
6
ΗΜΥ408 Δ8 FPGAs for the Masses.7 ©Theocharides, ECE, 2018
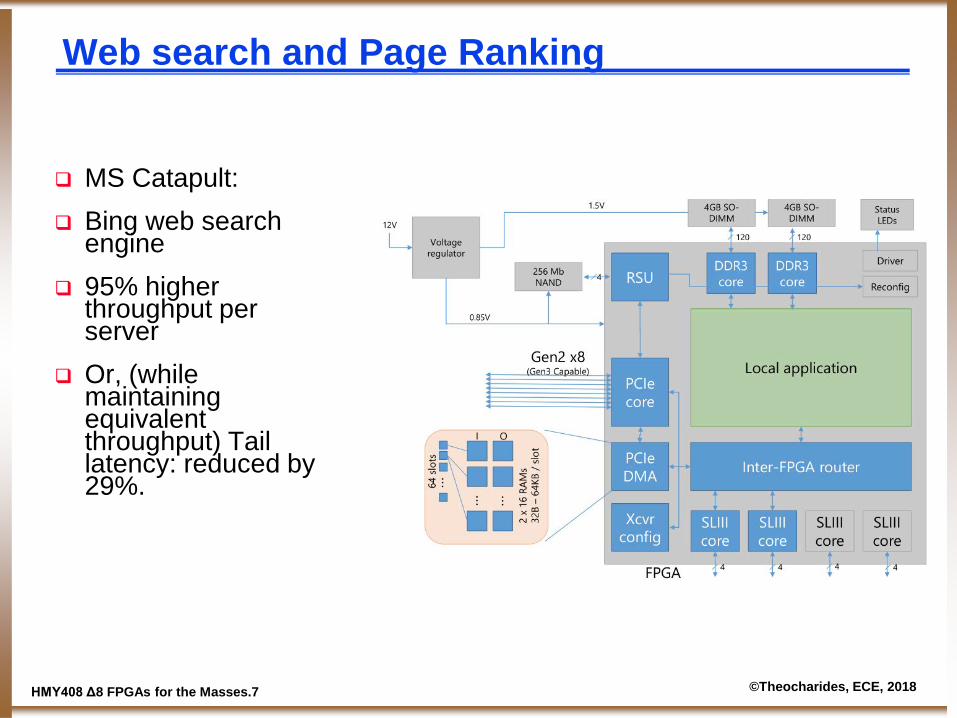
Web search and Page Ranking
MS Catapult: Bing web search
engine 95% higher
throughput per server
Or, (while maintaining equivalent throughput) Tail latency: reduced by 29%.
ΗΜΥ408 Δ8 FPGAs for the Masses.8 ©Theocharides, ECE, 2018
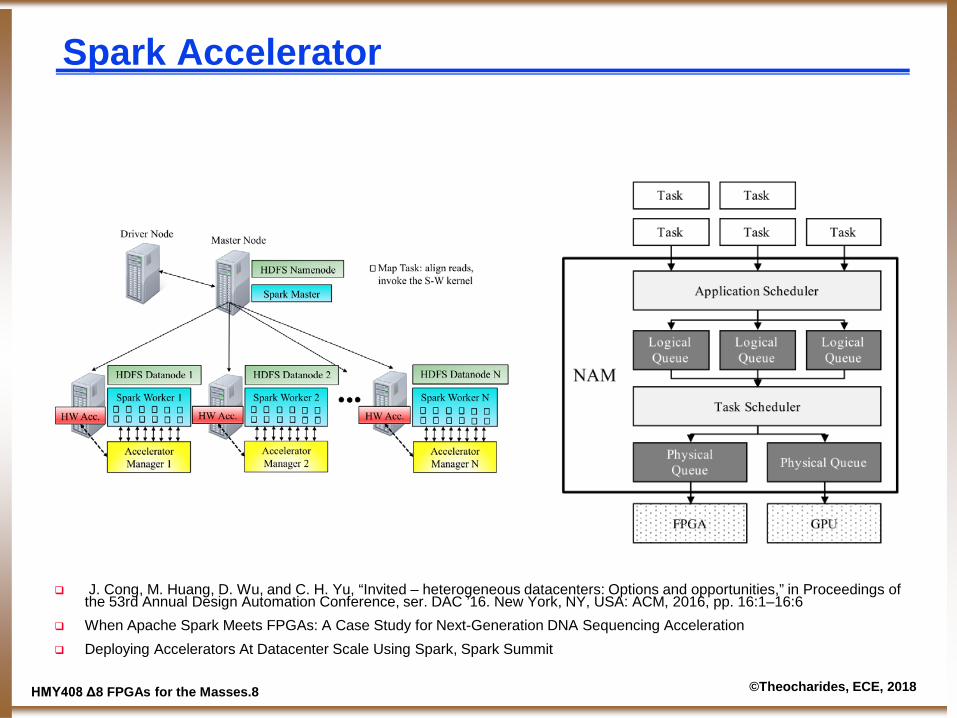
Spark Accelerator
J. Cong, M. Huang, D. Wu, and C. H. Yu, “Invited – heterogeneous datacenters: Options and opportunities,” in Proceedings of the 53rd Annual Design Automation Conference, ser. DAC ’16. New York, NY, USA: ACM, 2016, pp. 16:1–16:6
When Apache Spark Meets FPGAs: A Case Study for Next-Generation DNA Sequencing Acceleration Deploying Accelerators At Datacenter Scale Using Spark, Spark Summit
ΗΜΥ408 Δ8 FPGAs for the Masses.9 ©Theocharides, ECE, 2018
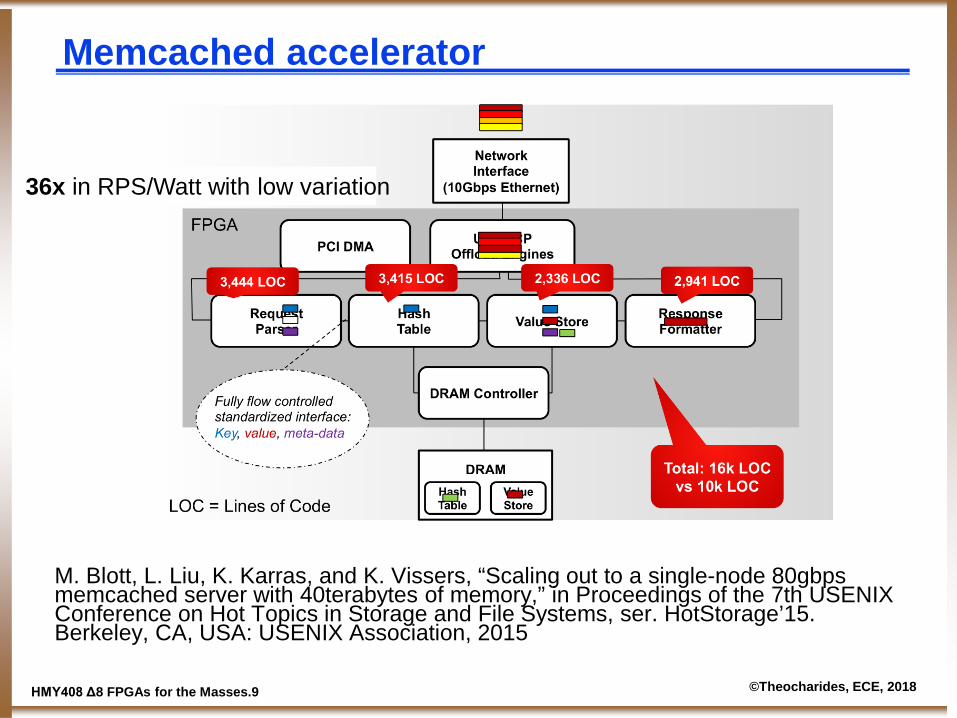
Memcached accelerator
M. Blott, L. Liu, K. Karras, and K. Vissers, “Scaling out to a single-node 80gbps memcached server with 40terabytes of memory,” in Proceedings of the 7th USENIX Conference on Hot Topics in Storage and File Systems, ser. HotStorage’15. Berkeley, CA, USA: USENIX Association, 2015
36x in RPS/Watt with low variation
ΗΜΥ408 Δ8 FPGAs for the Masses.10 ©Theocharides, ECE, 2018
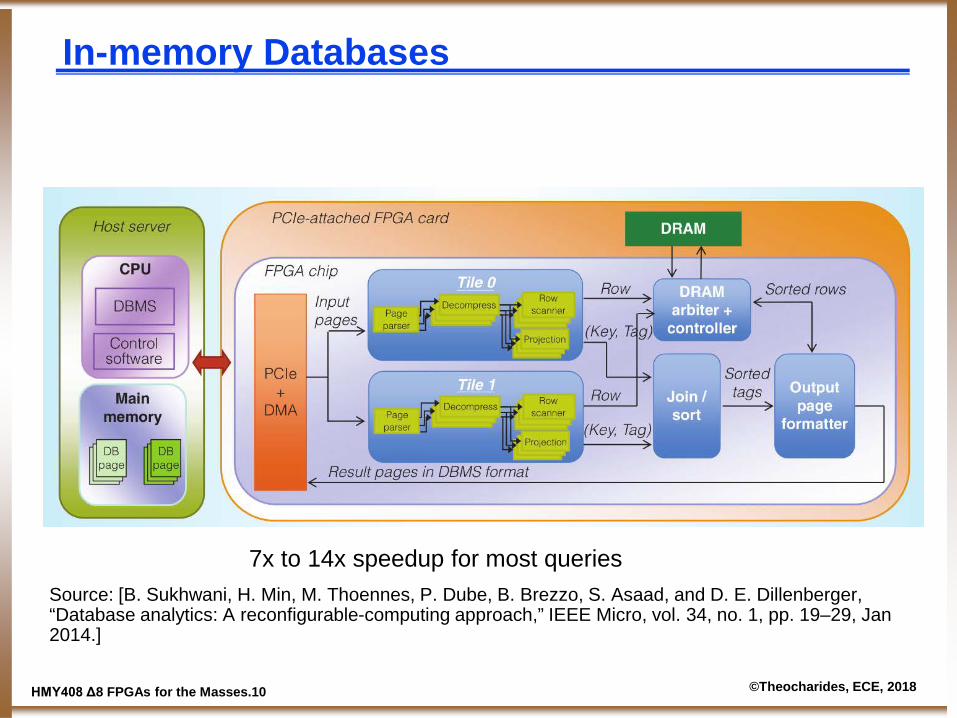
In-memory Databases
Source: [B. Sukhwani, H. Min, M. Thoennes, P. Dube, B. Brezzo, S. Asaad, and D. E. Dillenberger, “Database analytics: A reconfigurable-computing approach,” IEEE Micro, vol. 34, no. 1, pp. 19–29, Jan 2014.]
7x to 14x speedup for most queries

ΗΜΥ408 Δ8 FPGAs for the Masses.11 ©Theocharides, ECE, 2018
Where is the Parallelism?
Multiple tiles process DB pages in parallel Concurrently evaluate multiple records from a page within a tile
- Concurrently evaluate multiple predicates against different columns within a row
ΗΜΥ408 Δ8 FPGAs for the Masses.12 ©Theocharides, ECE, 2018
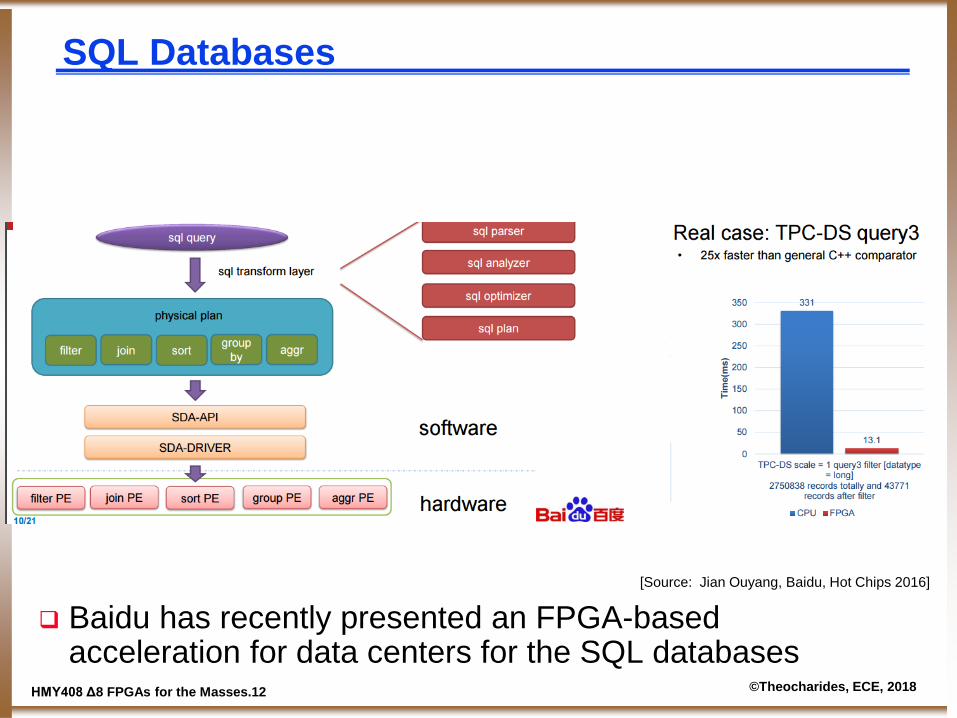
SQL Databases
Baidu has recently presented an FPGA-based acceleration for data centers for the SQL databases
[Source: Jian Ouyang, Baidu, Hot Chips 2016]

ΗΜΥ408 Δ8 FPGAs for the Masses.13 ©Theocharides, ECE, 2018
A survey on HW accelerator for Cloud computing
HW accelerators Search engine and Page ranking MapReduce Spark Memcached Databases
FPGAs in the cloud framework
ΗΜΥ408 Δ8 FPGAs for the Masses.14 ©Theocharides, ECE, 2018
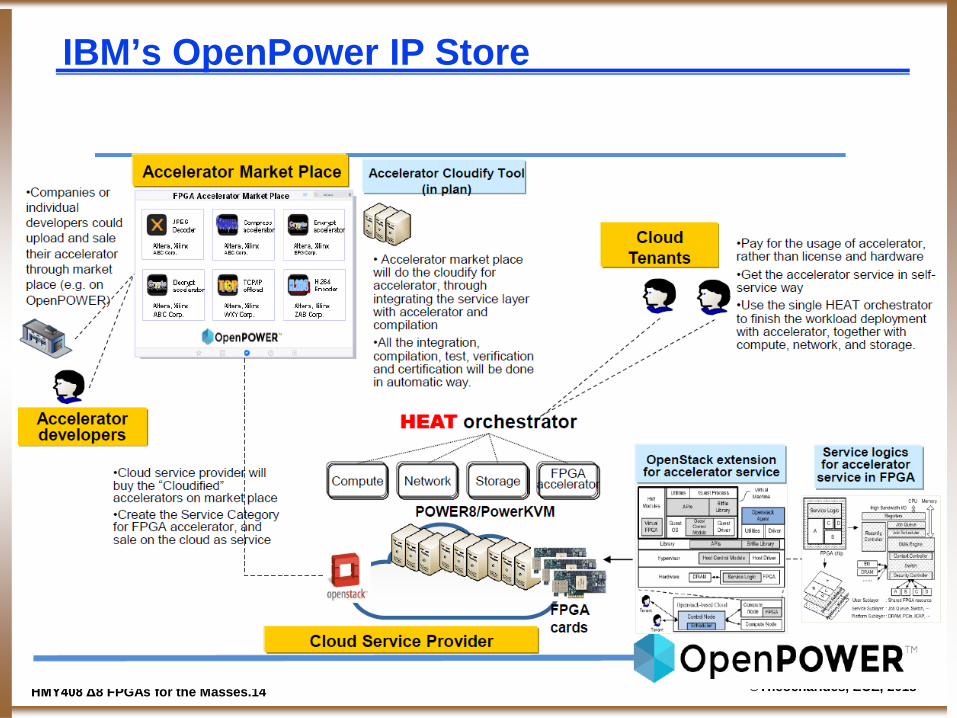
IBM’s OpenPower IP Store
ΗΜΥ408 Δ8 FPGAs for the Masses.15 ©Theocharides, ECE, 2018
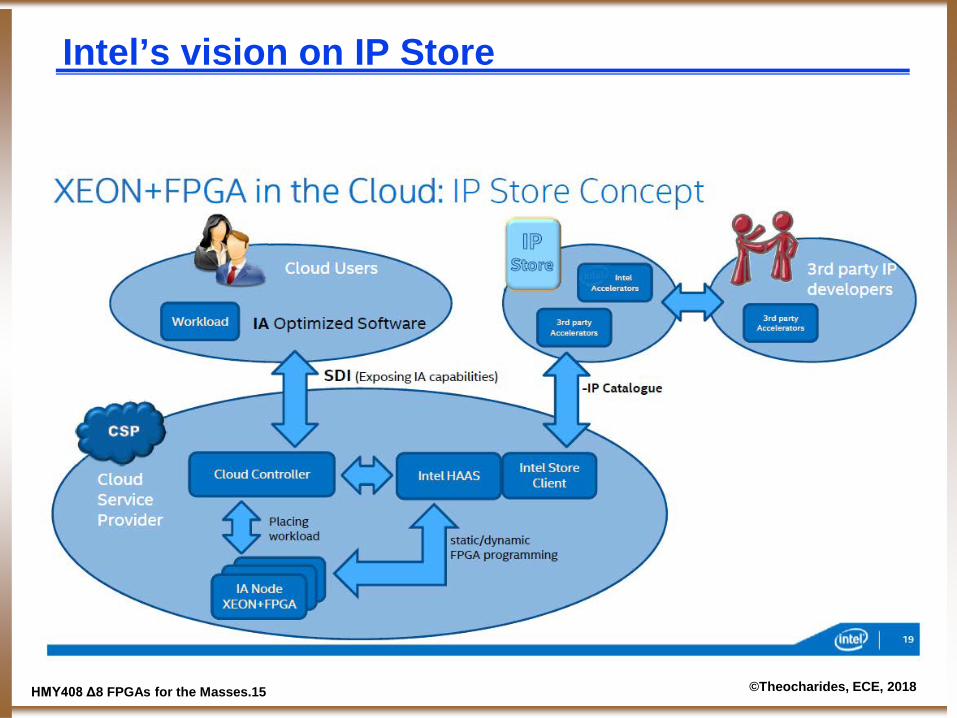
Intel’s vision on IP Store
ΗΜΥ408 Δ8 FPGAs for the Masses.16 ©Theocharides, ECE, 2018
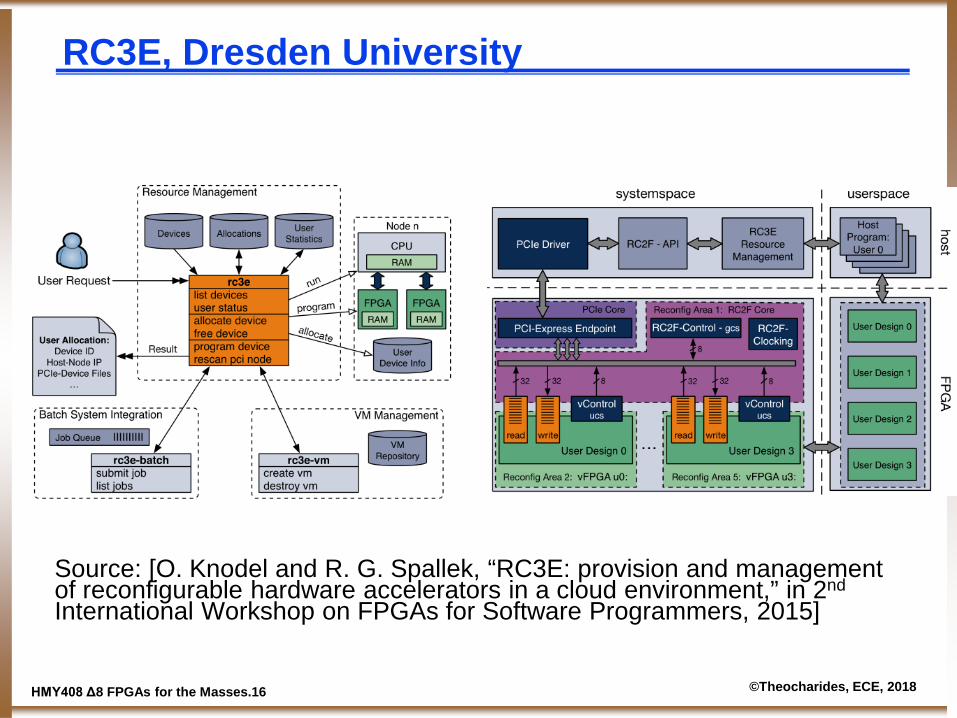
RC3E, Dresden University
Source: [O. Knodel and R. G. Spallek, “RC3E: provision and management of reconfigurable hardware accelerators in a cloud environment,” in 2nd International Workshop on FPGAs for Software Programmers, 2015]
ΗΜΥ408 Δ8 FPGAs for the Masses.17 ©Theocharides, ECE, 2018
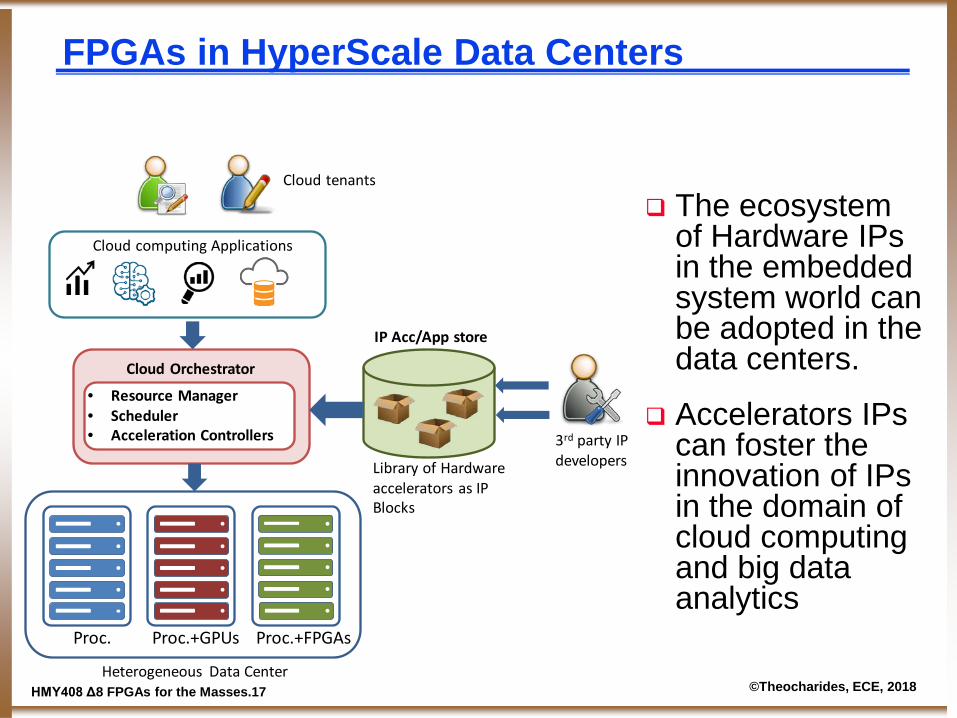
FPGAs in HyperScale Data Centers
Cloud computing Applications
Cloud Orchestrator
3rd party IP developersLibrary of Hardware
accelerators as IP Blocks
• Resource Manager• Scheduler• Acceleration Controllers
Heterogeneous Data Center
Proc. Proc.+GPUs Proc.+FPGAs
IP Acc/App store
Cloud tenants
The ecosystem of Hardware IPs in the embedded system world can be adopted in the data centers.
Accelerators IPs can foster the innovation of IPs in the domain of cloud computing and big data analytics

ΗΜΥ408 Δ8 FPGAs for the Masses.18 ©Theocharides, ECE, 2018
Scaling Reverse Time Migration Performance Through Reconfigurable Dataflow Engines
Haohan Fu1, Lin Gan1, Robert G Clapp2, Huabin Ruan1, Oliver Pell3, Oskar Mencer3, Michael Flynn2,
Xiaomeng Huang1, and Guangwen Yang1
1Tsinghua University 2Stanford University 3Maxeler Technologies
A Real Example!
ΗΜΥ408 Δ8 FPGAs for the Masses.19 ©Theocharides, ECE, 2018
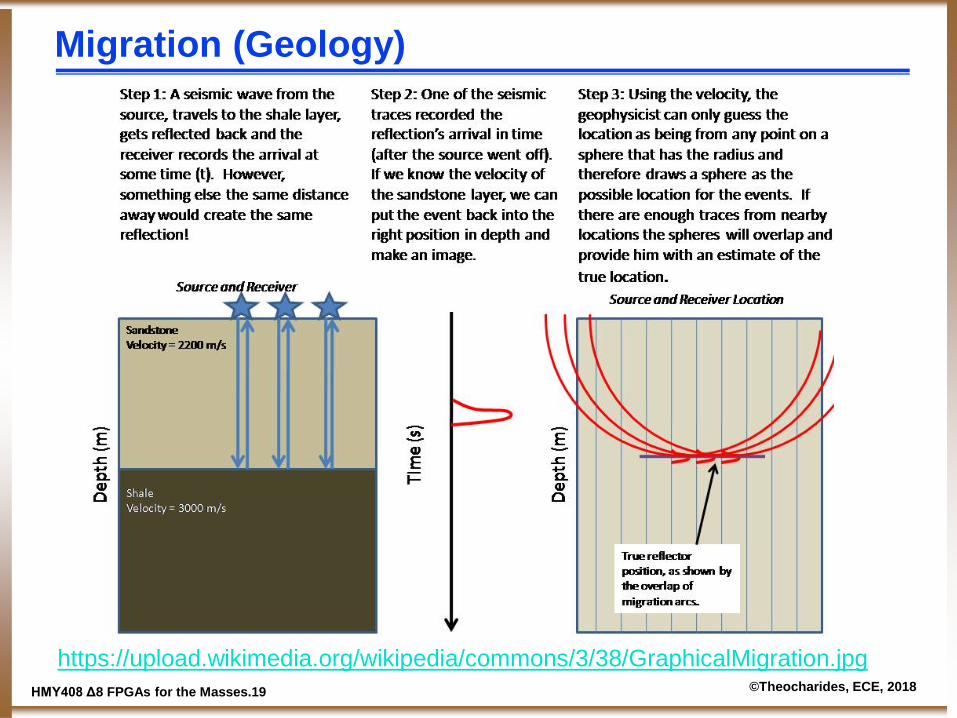
Migration (Geology)
https://upload.wikimedia.org/wikipedia/commons/3/38/GraphicalMigration.jpg

ΗΜΥ408 Δ8 FPGAs for the Masses.20 ©Theocharides, ECE, 2018
Reverse Time Migration (RTM) Imaging algorithm
Used for oil and gas exploration
Computationally demanding

ΗΜΥ408 Δ8 FPGAs for the Masses.21 ©Theocharides, ECE, 2018
RTM Pseudocode
Iterate over time-steps, and 3D grids
Iterations over shots (sources) are independent and easy to parallelize
Iterate over time-steps, and 3D grids
Propagate source wave fields from time 0 to nt - 1
Propagate receiver wave fields from time nt - 1 to 0
Cross-correlate the source and receiver wave field at the same time step to accumulate the result
Add the recorded source signal to the corresponding location
Add the recorded receiver signal to the corresponding location
Boundary conditions
Boundary conditions

ΗΜΥ408 Δ8 FPGAs for the Masses.22 ©Theocharides, ECE, 2018
RTM Computational Challenges Cross-correlate source and receiver signals
Source/receiver wave signals are computed in different directions in time
The size of a source wave field for one time-step can be 0.5 to 4 GB
Checkpointing: store source wave field and certain time steps and recompute the remaining steps when needed
Memory access pattern Neighboring points may be distant in the memory space High cache miss rate (when the domain is large)
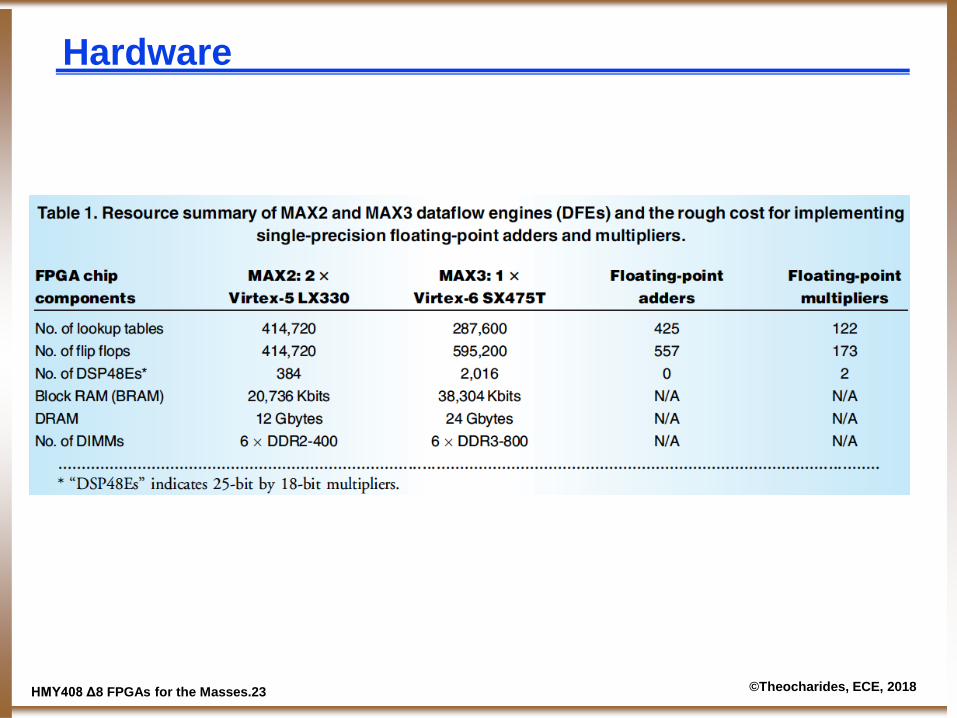
ΗΜΥ408 Δ8 FPGAs for the Masses.23 ©Theocharides, ECE, 2018
Hardware

ΗΜΥ408 Δ8 FPGAs for the Masses.24 ©Theocharides, ECE, 2018
General Architecture

ΗΜΥ408 Δ8 FPGAs for the Masses.25 ©Theocharides, ECE, 2018
Performance Tuning
Optimization strategies Algorithmic requirements Hardware resource limits
Balance resource utilization so that none becomes a bottleneck LUTs DSP Blocks block RAMs I/O bandwidth
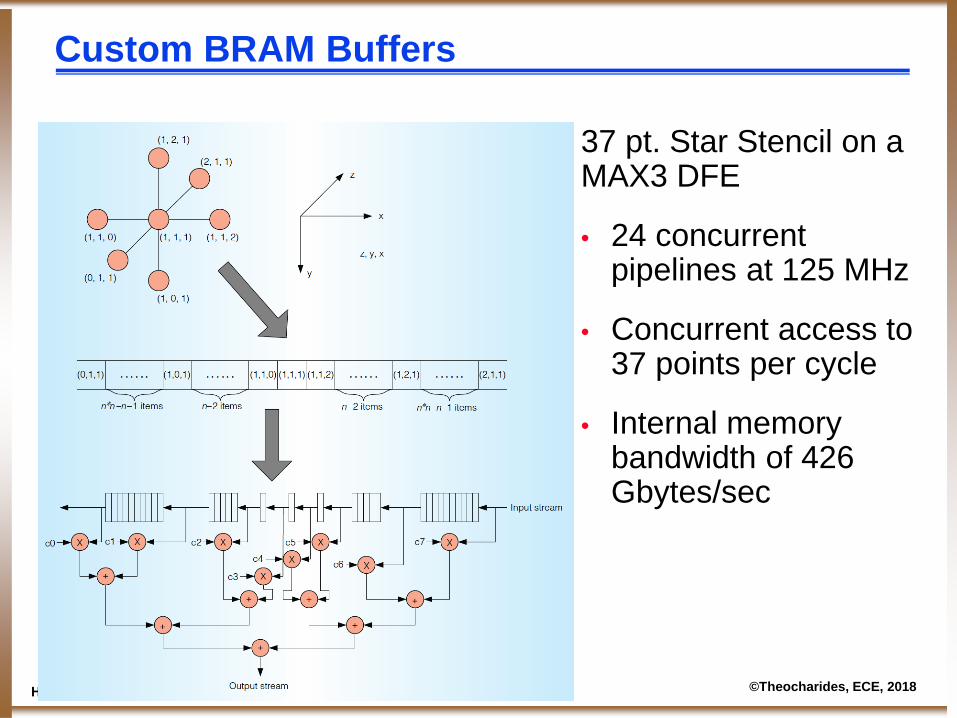
ΗΜΥ408 Δ8 FPGAs for the Masses.26 ©Theocharides, ECE, 2018
Custom BRAM Buffers
37 pt. Star Stencil on a MAX3 DFE
• 24 concurrent pipelines at 125 MHz
• Concurrent access to 37 points per cycle
• Internal memory bandwidth of 426 Gbytes/sec
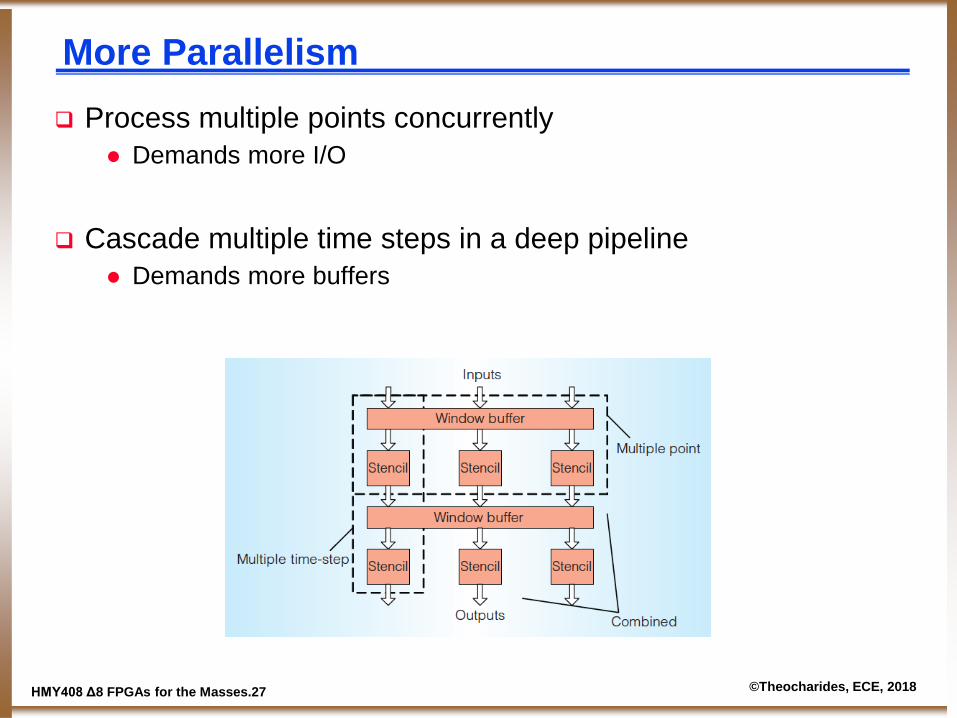
ΗΜΥ408 Δ8 FPGAs for the Masses.27 ©Theocharides, ECE, 2018
More Parallelism Process multiple points concurrently
Demands more I/O
Cascade multiple time steps in a deep pipeline Demands more buffers

ΗΜΥ408 Δ8 FPGAs for the Masses.28 ©Theocharides, ECE, 2018
Number Representation
32-bit floating-point was default
Convert many variables to 24-bit fixed-point Smaller pipelines => MORE pipelines
Floating-point - 16,943 LUTs - 23,735 flip-flops - 24 DSP48Es
Fixed-point - 3,385 LUTs - 3,718 flip-flops - 12 DSP48Es
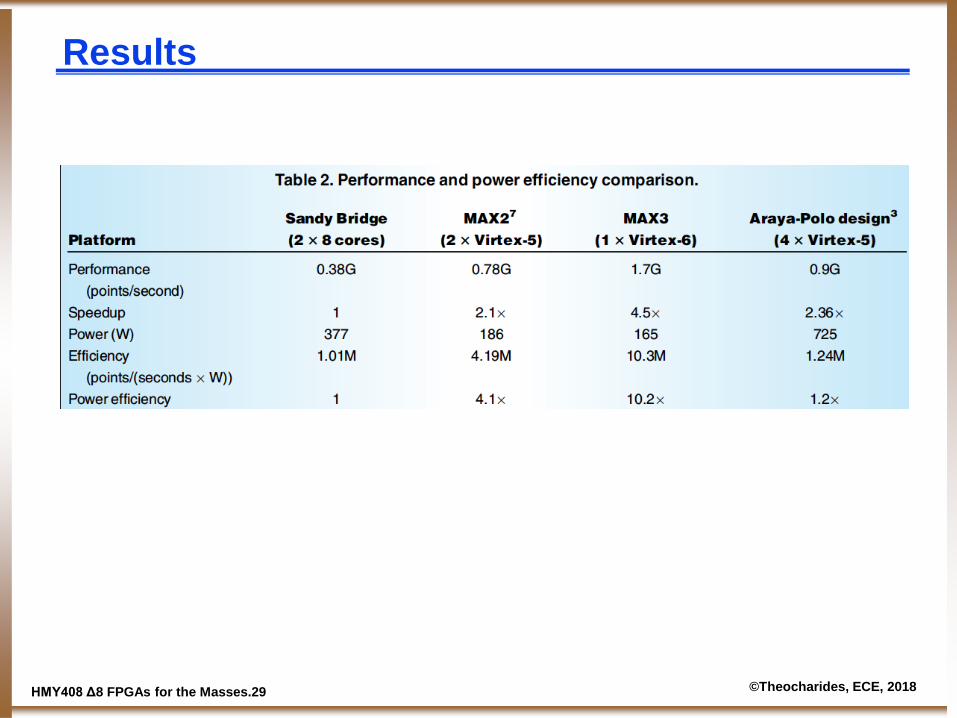
ΗΜΥ408 Δ8 FPGAs for the Masses.29 ©Theocharides, ECE, 2018
Results

ΗΜΥ408 Δ8 FPGAs for the Masses.30 ©Theocharides, ECE, 2018
Roadmap Paradigm shift (From Homogeneous Data Centers to
Heterogeneous Data Centers)
3rd party Hardware IP developers contribute to a common market place for Hardware Accelerators in the same way as Embedded systems


















