Modelling Missing Data - The University of...
24
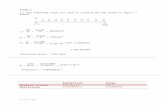
Modelling Missing Data Complete-data model: ◦ independent and identically distributed (iid) draws Y 1 ,...,Y n ◦ from multivariate distribution P θ , Y i =(Y i1 ,...,Y ip ) T ∼ P θ . ◦ Data matrix: Y =(Y 1 ,...,Y n ) T =(Y ij ) i=1,...,n;j =1,...,p 1 2 . . . n Y i1 Y i2 ··· ··· Y ip Units Inference: estimate θ ◦ likelihood approach maximize likelihood function ◦ Bayesian approach consider posterior distribution Likelihood function of the complete data: f Y (y |θ)= n i=1 f Y i (y i |θ) where f Y i (·|θ) is the density of P θ Maximum Likelihood with Missing Data, Mar 30, 2004 -1-
Transcript of Modelling Missing Data - The University of...

Modelling Missing Data
Complete-data model:
◦ independent and identically distributed (iid) draws Y1, . . . , Yn
◦ from multivariate distribution Pθ,
Yi = (Yi1, . . . , Yip)T ∼ Pθ.
◦ Data matrix:
Y = (Y1, . . . , Yn)T = (Yij)i=1,...,n;j=1,...,p
1
2...
n
Yi1 Yi2 · · ·
· · ·
Yip
Units
Inference: estimate θ
◦ likelihood approach maximize likelihood function
◦ Bayesian approach consider posterior distribution
Likelihood function of the complete data:
fY (y|θ) =n∏
i=1fYi
(yi|θ)
where fYi(·|θ) is the density of Pθ
Maximum Likelihood with Missing Data, Mar 30, 2004 - 1 -

Modelling Missing Data
Problem: Some data Yij may be missing
Example: Cholesterol levels of heart-attack patients
Data:
◦ Serum-cholesterol levels for n = 28 patients treated for heart attacks.
◦ Cholesterol levels were measured for all patients 2 and 4 days after the
attack.
◦ For 19 of the 28 patients, an additional measurement was taken 14 days
after the attack.
◦ See also Schafer, sections 5.3.6 and 5.4.3.
Id Y1 Y2 Y3 Id Y1 Y2 Y3
1 270 218 156 15 294 240 264
2 236 234 — 16 282 294 —
3 210 214 242 17 234 220 264
4 142 116 — 18 224 200 —
5 280 200 — 19 276 220 188
6 272 276 256 20 282 186 182
7 160 146 142 21 360 352 294
8 220 182 216 22 310 202 214
9 226 238 248 23 280 218 —
10 242 288 — 24 278 248 198
11 186 190 168 25 288 278 —
12 266 236 236 26 288 248 256
13 206 244 — 27 244 270 280
14 318 258 200 28 236 242 204
Maximum Likelihood with Missing Data, Mar 30, 2004 - 2 -

Modelling Missing Data
Idea: describe missingness of Yij by indicator variable Rij
Rij =
{1 Yij has been observed
0 Yij is missing
Multivariate dataset with missing values:
Yi1 Yi2 · · · Yip Ri1 Ri2 · · · Rip
Units 1, . . . , n1 1 1 1
. . . , n2 0 1 1
. . . , n3 1 0 1
. . . , n4 1 1 0
. . . , n5 0 0 1
. . . , n6 0 1 0
. . . , n7 0 1 0
. . . , n8 0 0 0
Observed-data model:
◦ The observed information consists of
� observed values yij
� the values rij indicating which values are missing
◦ A statistical model for the observations should make use of all available
information
Notation:
Y = (Yobs, Ymis)
where
◦ Yobs are the observed variables
◦ Ymis are the missing variables
Maximum Likelihood with Missing Data, Mar 30, 2004 - 3 -

Missing Data Mechanism
Statistical model for missing data:
P(R = r|Y = y) = fR|Y (r|y, ξ)
with parameters ξ ∈ Ξ.
Definition Missing completely at random (MCAR)
The observations are missing completely at random if
P(R = r|Y = y) = P(R = r)
or equivalently
fR|Y (r|y, ξ) = fR(r, ξ),
that is, R and Y are independent.
Definition Missing at random (MAR)
The observations are missing at random if
P(R = r|Y = y) = P(R = r|Yobs)
or equivalently
fR|Y (r|y, ξ) = fR|Yobs(r|yobs, ξ),
that is, knowledge about Ymis does not provide any additional infor-
mation about R if Yobs is already known (R and Ymis are conditionally
independent given Yobs).
Definition Not missing at random (NMAR)
Observations are not missing at random if the above assumption for
MAR is not fulfilled.
Maximum Likelihood with Missing Data, Mar 30, 2004 - 4 -

Missing Completely at Random (MCAR)
Example: Bernoulli selection
◦ Complete data: Y1, . . . , Yn
◦ Response indicator: R1, . . . , Rn
◦ Missingness mechanism: Each unit is observed with probability ξ
fR(r|ξ) =n∏
i=1ξri(1− ξ)1−ri
Example: Simple random sample (SRS)
◦ Suppose that only m observations are available, n−m values are miss-
ing.
◦ Responding units are simple random sample of all units:
fR(r|ξ) =
{(nm
)−1if∑n
i=1 ri = m
0 otherwise
◦ Note that ξ = m is a parameter of the distribution of R
Maximum Likelihood with Missing Data, Mar 30, 2004 - 5 -

Missing at Random (MAR)
Example: Hypertension trials
Data: Serial measurements of blood pressure during long-term trials
of drugs which reduce blood pressure
Problem: Patients are withdrawn during the course of the study because
of inadequate blood pressure control.
Example: from: Murray and Findlay (1988), Correcting for the bias caused by drop-
outs in hypertension trials, Statistics in Medicine 7, 941-946.
◦ International double-blind randomized study with 429 patients
◦ 218 receive β-blocker metoprolol
◦ 211 receive serotonergic S2-receptor blocking agent ketanserin
◦ Treatment phase lasted 12 weeks
◦ Scheduled clinic visits for weeks 0, 2, 4, 8, and 12
◦ Patients with diastolic blood pressure exceeding 110 mmHg in week 4
or week 8 “jump” to an open follow-up phase.
◦ Missing data pattern for the two groups:
Metoprolol group
0 2 4 8 12 Number of patients
1 1 1 1 1 1621 1 1 1 0 14 (11 jumps)1 1 1 0 1 21 1 1 0 0 30 (28 jumps)1 1 0 1 1 11 1 0 0 0 21 0 1 1 1 21 0 1 0 1 11 0 1 0 0 11 0 0 1 1 11 0 0 0 1 11 0 0 0 0 1
Ketanserin group
0 2 4 8 12 Number of patients
1 1 1 1 1 1361 1 1 1 0 19 (18 jumps)1 1 1 0 1 11 1 1 0 0 41 (37 jumps)1 1 0 1 1 21 1 0 0 0 41 0 1 1 1 21 0 1 1 0 11 0 1 0 1 11 0 1 0 0 11 0 0 1 1 21 0 0 1 0 11 0 0 0 0 1
◦ “Jumps” (majority of missing observations) lead to missing data which
are missing at random
Maximum Likelihood with Missing Data, Mar 30, 2004 - 6 -

Missing at Random (MAR)
Mean diastolic blood pressure based
a. on all available data at each time point
b. on patients with complete data
c. on all available data, assuming missing data to be missing at random
Weeks on Treatment
Mea
n D
BP
(mm
Hg)
0 4 8 1290
95
100
105
110
KetanserinMetoprolol
(a)
Weeks on Treatment
Mea
n D
BP
(mm
Hg)
0 4 8 1290
95
100
105
110
KetanserinMetoprolol
(b)
Weeks on Treatment
Mea
n D
BP
(mm
Hg)
0 4 8 1290
95
100
105
110
KetanserinMetoprolol
(c)
Maximum Likelihood with Missing Data, Mar 30, 2004 - 7 -

Missing at Random (MAR)
Examples for data missing at random:
◦ Double sampling: sample survey:
� observe variables Yi1, . . . , Yik for all individuals i = 1, . . . , n
� observe variables Yi,k+1, . . . , Yip only for subsample
◦ Sampling with nonresponse followup: sample survey with nonresponses
� intensive followup effort for all units not feasible
� take random sample of all nonresponding units
◦ Randomized experiment with unequal numbers of cases per treatment
group:
� suppose original design was balanced
� missingness mechanism is deterministic, thus data are MAR
◦ Matrix sampling for questionnaire or test items
� divide test or questionnaire into sections
� groups of sections are administered to subjects in a randomized
fashion
Maximum Likelihood with Missing Data, Mar 30, 2004 - 8 -

Not Missing at Random (NMAR)
Example: Medical treatment of blood pressure
n individuals are treated for high blood pressure
◦ Observations: binary responses
Yij = blood pressure of ith individual on jth day
◦ Missing observations: (not every individual shows up every day)
Rij =
{1 ith individual appears for measurement on jth day
0 otherwise
◦ Statistical model for Y and R:
Yijiid∼ N (µi, σ
2)
Rijiid∼ Bin
(1, 1− exp(Yij)
1 + exp(Yij)
) that is, individuals with high blood pressure are less likely to turn
up for a measurement
Maximum Likelihood with Missing Data, Mar 30, 2004 - 9 -

Not Missing at Random (NMAR)
Example: Randomly censored data
◦ Objective: Analysis of data (e.g. survival times)
T1, . . . , Tniid∼ f(·|θ)
◦ Survivor function S(t): Probability of surviving beyond time t
S(t) = P(T1 > t)
◦ Censoring times associated with Ti’s:
C1, . . . , Cniid∼ g(·|ξ)
(e.g. due to loss to follow up, drop out, or termination of the study)
◦ Observations: (Y1, R1), . . . , (Yn, Rn) where
Yi = min(Ti, Ci)
and
Ri =
{1 if Ti ≤ Ci
0 otherwise
Maximum Likelihood with Missing Data, Mar 30, 2004 - 10 -

Observed-Data Likelihood
Likelihood of complete observations (Yobs, R)
Ln(θ, ξ|Yobs, R) = fYobs,R(Yobs, R|θ, ξ)
=
∫fY,R(Yobs, ymis, R|θ, ξ) dymis
=
∫fR|Y (R|Yobs, ymis|ξ)fY (Yobs, ymis|θ) dymis
If the missing observations are missing at random (MAR), the first factor
does not depend on ymis and thus is not affected by integration over ymis:
Ln(θ, ξ|Yobs, R) =
∫fR|Y (R|Yobs|ξ)fY (Yobs, ymis|θ) dymis
= fR|Y (R|Yobs|ξ)∫
fY (Yobs, ymis|θ) dymis
= fR|Y (R|Yobs|ξ)fYobs(Yobs|θ)
= fR|Y (R|Yobs|ξ)Ln(θ|Yobs)
If the parameters ξ do not depend on θ, we get
θ̂ = argmaxθ∈Θ
Ln(θ, ξ|Yobs, R) ⇔ θ̂ = argmaxθ∈Θ
Ln(θ|Yobs),
that is, we can obtain the maximum likelihood estimator by minimizing
Ln(θ|Yobs) with respect to θ.
Definition Observed-data likelihood
The likelihood function
Ln(θ|Yobs) = fYobs(Yobs|θ)
is called the likelihood ignoring the missing-data mechanism or short
observed-data likelihood.
Maximum Likelihood with Missing Data, Mar 30, 2004 - 11 -

Ignorability
Definition
A missing-data mechanism is ignorable for likelihood inference if
◦ observations are missing at random (MAR) and
◦ the parameters ξ (missingness-mechanism) and θ θ (data model)
are distinct, in the sense that the joint parameter space of (θ, ξ) is
the product of the parameter spaces Ξ and Θ.
Example: Non-distinct parameters
Suppose that
◦ Yiiid∼ Bin(1, θ)
◦ Riiid∼ Bin(1, θ)
◦ Yobs = (Y1, . . . , Ym)T (after reordering)
The joint likelihood of Yobs and R is
Ln(θ|Yobs, R) =n∏
i=1θri(1− θ)1−ri
m∏i=1
θyi(1− θ)1−yi
= θm+Y (1− θ)n−Y
This is the likelihood of a Bernoulli experiment with n + m observations.
Consequently
θ̂ML =m + Y
m + n.
Ignoring the missing-data mechanism: The observed-data likelihood is
Ln(θ|Yobs) =m∏
i=1θyi(1− θ)1−yi
which leads to the ML estimator
θ̂ML =Y
m.
Maximum Likelihood with Missing Data, Mar 30, 2004 - 12 -

Ignorability
The first condition (MAR) is typically regarded as the more important
condition:
◦ If MAR does not hold, then the maximum likelihood estimator based
on the observed-data likelihood can be seriously biased.
◦ If the data are MAR but distinctness does not hold, inference based on
the observed-data likelihood Ln(θ|Yobs) is still valid from the frequentist
perspective, but not fully efficient.
Example:
Suppose
◦ Yiiid∼ N (µ, σ2)
◦ Riiid∼ Bin
(1, eµ/(1 + eµ)
) parameter are not distinct
Likelihood
µ
−0.4 −0.2 0.0 0.2 0.4
Ln(µ,1|Yobs)Ln(µ,1|R)Ln(µ,1|R,Yobs)
MLE based on Ln(θ|Yobs)
µ̂obs
Freq
uenc
y
−0.4 −0.2 0.0 0.2 0.40
30
60
90
120
150
180
MLE based on Ln(θ|Yobs,R)
µ̂compl
Freq
uenc
y
−0.4 −0.2 0.0 0.2 0.40
30
60
90
120
150
180
Frequentist interpretation:
◦ Parameter θ0 = (µ0, σ20) is fixed.
◦ If Riiid∼ Bin(1, 1
2) then:
missingness mechanism ignorable
µ̂obs MLE for θ
◦ If µ0 = 0 then Riiid∼ Bin(1, 1
2)
Properties of µ̂obs unchanged.
◦ However, µ̂compl is more efficient.
Maximum Likelihood with Missing Data, Mar 30, 2004 - 13 -

Univariate Data with Missing Observations
Example: Incomplete univariate data
Unit
Y R
1
2...
m
...
n
1
1...
1
0...
0
Suppose that
◦ Y1, . . . , Yn is an iid random sample
◦ only Yobs = (Y1, . . . , Ym)T have been observed
◦ Ymis = (Ym+1, . . . , Yn)T are missing at random
The observed-data likelihood is
Ln(θ|Yobs) =
∫fY (Yobs, ymis|θ) dymis
=
∫· · ·∫
m∏i=1
fYi(Yi|θ)
n∏i=m+1
fYi(yi|θ) dym+1 · · · dyn
=m∏
i=1fYi
(Yi|θ)∫· · ·∫
n∏i=m+1
fYi(yi|θ) dym+1 · · · dyn
=m∏
i=1fYi
(Yi|θ)
Thus the observed-data likelihood is a complete-data likelihood based on
the reduced sample (Y1, . . . , Ym).
Maximum Likelihood with Missing Data, Mar 30, 2004 - 14 -

Multivariate Normal Distribution
Let Y = (Y1, . . . , Yp)T ∼ N (µ, Σ).
Properties
◦ If p = 2
Σ =
(σ2
1 σ12
σ12 σ22
)=
(σ2
1 ρσ1σ2
ρσ1σ2 σ22
)where
ρ =σ12
σ1σ2
is the correlation between Y1 and Y2.
◦ Density of Y
fY (y|µ, Σ) = (2π)−p2 (det(Σ))−
12 exp
(− 1
2(y − µ)TΣ−1(y − µ)),
◦ Linear transformations
AY + b ∼ N (Aµ + b, AΣAT).
◦ Marginal distribution of Y1
Y1 ∼ N (µ1, σ21)
◦ Conditional distribution of Y2 given Y1
Y2|Y1 ∼ N(β0 + β1 Y1, σ
22|1),
with parameters
β0 = µ2 − β1 µ1
β1 =σ12
σ21
σ22|1 = σ2
2 −σ2
12
σ21
Maximum Likelihood with Missing Data, Mar 30, 2004 - 15 -

Bivariate Normal Data
Example: Bivariate data with one variable subject to nonresponse
1
2...
m
...
n
1
1...
1
0...
0
Y1 Y2 R2
Units
Suppose that
Yi = (Yi1, Yi2)T iid∼ N (µ, Σ)
with mean µ = (µ1, µ2)T and covariance matrix
Σ =
(σ2
1 σ12
σ12 σ22
).
The observed-data likelihood is given by
Ln(θ|Yobs) =m∏
i=1fYi
(Yi|µ, Σ)n∏
i=m+1fYi1
(Yi1|µ1, σ21)
=m∏
i=1fYi2|Yi1
(Yi2|Yi1, β0, β1, σ22|1)
n∏i=1
fYi1(Yi1|µ1, σ
21).
Maximum Likelihood with Missing Data, Mar 30, 2004 - 16 -

Bivariate Normal Data
Example: Bivariate data with one variable subject to nonresponse
Data: Yi = (Yi1, Yi2)T iid∼ N (µ, Σ)
◦ Parameter: µ1 = µ2 = 0, σ21 = σ2
2 = 1, ρ
◦ Yi1 completely observed
◦ Yi2 has missing values
Missing data mechanism: Proportion of missing data 1− p = 20%
◦ Missing completely at random (MCAR):
Ri2iid∼ Bin(1, p)
◦ Missing at random (MAR):
Ri2 = 0 if Yi1 > zp
◦ Not missing at random (NMAR):
Ri2 = 0 if Yi2 > zp
Simulation study:
◦ 1000 repetitions for ρ = 0, 0.5, 0.9
◦ Simulated means (standard variations) for µ̂CC and µ̂ML
MCAR MAR NMAR
µ̂CC µ̂ML µ̂CC µ̂ML µ̂CC µ̂ML
ρ = 0 0.00046 0.00048 -0.00095 -0.00143 -0.34585 -0.34587
(0.10762) (0.10797) (0.10876) (0.12250) (0.08760) (0.08776)
ρ = 0.5 0.00557 0.00534 -0.17073 0.00459 -0.34919 -0.29226
(0.11294) (0.11229) (0.10585) (0.11850) (0.08406) (0.08171)
ρ = 0.9 -0.00218 -0.00208 -0.31229 -0.00130 -0.34964 -0.10023
(0.11012) (0.10093) (0.09034) (0.10361) (0.08460) (0.08877)
Maximum Likelihood with Missing Data, Mar 30, 2004 - 17 -

Bivariate Normal Data
Missing Values in Y2 (MCAR)
Y1
Y2
−3 −2 −1 0 1 2 3−3
−2
−1
0
1
2
3
observedmissing
Missing Values in Y2 (MAR)
Y1
Y2
−3 −2 −1 0 1 2 3−3
−2
−1
0
1
2
3
observedmissing
Missing Values in Y2 (NMAR)
Y1
Y2
−3 −2 −1 0 1 2 3−3
−2
−1
0
1
2
3
observedmissing
Maximum Likelihood with Missing Data, Mar 30, 2004 - 18 -

Bivariate Normal Data
Complete−case (MCAR)
µ̂CC
Freq
uenc
y
−0.8 −0.4 0.0 0.40
50
100
150
200
250 ρ = 0
Complete−case (MAR)
µ̂CC
Freq
uenc
y
−0.8 −0.4 0.0 0.40
50
100
150
200
250 ρ = 0
Complete−case (NMAR)
µ̂CC
Freq
uenc
y
−0.8 −0.4 0.0 0.40
50
100
150
200
250 ρ = 0
MLE (MCAR)
µ̂ML
Freq
uenc
y
−0.8 −0.4 0.0 0.40
50
100
150
200
250 ρ = 0
MLE (MAR)
µ̂ML
Freq
uenc
y
−0.8 −0.4 0.0 0.40
50
100
150
200
250 ρ = 0
MLE (NMAR)
µ̂ML
Freq
uenc
y
−0.8 −0.4 0.0 0.40
50
100
150
200
250 ρ = 0
Maximum Likelihood with Missing Data, Mar 30, 2004 - 19 -

Bivariate Normal Data
Complete−case (MCAR)
µ̂CC
Freq
uenc
y
−0.8 −0.4 0.0 0.40
50
100
150
200
250 ρ = 0.5
Complete−case (MAR)
µ̂CC
Freq
uenc
y
−0.8 −0.4 0.0 0.40
50
100
150
200
250 ρ = 0.5
Complete−case (NMAR)
µ̂CC
Freq
uenc
y
−0.8 −0.4 0.0 0.40
50
100
150
200
250 ρ = 0.5
MLE (MCAR)
µ̂ML
Freq
uenc
y
−0.8 −0.4 0.0 0.40
50
100
150
200
250 ρ = 0.5
MLE (MAR)
µ̂ML
Freq
uenc
y
−0.8 −0.4 0.0 0.40
50
100
150
200
250 ρ = 0.5
MLE (NMAR)
µ̂ML
Freq
uenc
y
−0.8 −0.4 0.0 0.40
50
100
150
200
250 ρ = 0.5
Maximum Likelihood with Missing Data, Mar 30, 2004 - 20 -

Bivariate Normal Data
Complete−case (MCAR)
µ̂CC
Freq
uenc
y
−0.8 −0.4 0.0 0.40
50
100
150
200
250 ρ = 0.9
Complete−case (MAR)
µ̂CC
Freq
uenc
y
−0.8 −0.4 0.0 0.40
50
100
150
200
250 ρ = 0.9
Complete−case (NMAR)
µ̂CC
Freq
uenc
y
−0.8 −0.4 0.0 0.40
50
100
150
200
250 ρ = 0.9
MLE (MCAR)
µ̂ML
Freq
uenc
y
−0.8 −0.4 0.0 0.40
50
100
150
200
250 ρ = 0.9
MLE (MAR)
µ̂ML
Freq
uenc
y
−0.8 −0.4 0.0 0.40
50
100
150
200
250 ρ = 0.9
MLE (NMAR)
µ̂ML
Freq
uenc
y
−0.8 −0.4 0.0 0.40
50
100
150
200
250 ρ = 0.9
Maximum Likelihood with Missing Data, Mar 30, 2004 - 21 -

Bivariate Normal Data
Example: Bivariate data with both variables subject to nonresponse
1...
l
l + 1...
m
m + 1...
n
1...
1
0...
0
1...
1
1...
1
1...
1
0...
0
Y1 Y2 R1 R2
Units
Data: Yi = (Yi1, Yi2)T iid∼ N (µ, Σ)
◦ Both variables subject to nonresponse
The observed-data likelihood is given by
Ln(θ|Yobs) =l∏
i=1fYi
(Yi|µ, Σ)m∏
i=l+1fYi1
(Yi1|µ1, σ21)
n∏i=m+1
fYi2(Yi2|µ2, σ
22)
In this case, no appropriate parametrization which leads to a factorization
into likelihoods with distinct parameters can be found.
Maximum Likelihood with Missing Data, Mar 30, 2004 - 22 -

Censored Variables
Example: Randomly censored data
◦ Objective: Analysis of data
Y1, . . . , Yniid∼ N (µ, σ2)
◦ Fixed censoring at c:
Ri =
{1 Yi ≤ c
0 otherwise
The likelihood of the complete observations is
Ln(θ|Yobs, R) =m∏
i=1fYi
(Yi|µ, σ2)n∏
i=m+1
∫ ∞
c
fYi(yi|µ, σ2) dyi
=m∏
i=1fYi
(Yi|µ, σ2)n∏
i=m+1SYi
(c)
=m∏
i=1
1
σϕ
(Yi − µ
σ
)n∏
i=m+1
[1− Φ
(c− µ
σ
)]where
SYi(y) = 1− Φ
(y − µ
σ
)is the survivor function of Yi.
Notation:
◦ ϕ(y) is the density of the standard normal distribution,
ϕ(y) =1√2π
exp(− 1
2y2).
◦ Φ(y) is the corresponding cumulative distribution function (CDF),
Φ(y) =
∫ y
−∞ϕ(z) dz.
Maximum Likelihood with Missing Data, Mar 30, 2004 - 23 -

Censored Variables
Example: Randomly censored data
Derivation of the likelihood:
We have for the missing data mechanism
P(Ri = ri|Y ) = P(Ri = ri|Yi) = 1(−∞,c](Yi)ri(1− 1(−∞,c](Yi))
1−ri
Hence the likelihood of the complete data (including R) is
Ln(θ|Y,R) =n∏
i=1fYi
(Yi|θ)n∏
i=11(−∞,c](Yi)
Ri(1− 1(−∞,c](Yi))1−Ri
Since Ri = 1 and thus 1(−∞,c](Yi)Ri = 1 for uncensored observations Yi, we
have
Ln(θ|Yobs, R)
=
∫m∏
i=1fYi
(Yi|θ)n∏
i=m+1fYi
(yi|θ)1(−∞,c](yi)Ri1(c,∞)(yi)
1−Ri dym+1 · · · dyn
=m∏
i=1fYi
(Yi|θ)∫
n∏i=m+1
fYi(yi|θ)1(c,∞)(Yi) dym+1 · · · dyn
=m∏
i=1fYi
(Yi|θ)∫ ∞
c
n∏i=m+1
fYi(yi|θ) dym+1 · · · dyn
Maximum Likelihood with Missing Data, Mar 30, 2004 - 24 -