![Queries on TreesAutomata, logic, and XML [Nev02b, Nev02a] Automata for XML – a survey [Sch07] Effective Characterizations of Tree Logics [Boj08a] Treewalking automata [Boj08b] Books](https://static.fdocument.org/doc/165x107/5fde4ddcef0206202f21ac29/queries-on-trees-automata-logic-and-xml-nev02b-nev02a-automata-for-xml-a.jpg)
Mercury: Supporting Scalable Multi-Attribute Range Queries A. Bharambe, M. Agrawal, S. Seshan In...
24
Mercury: Supporting Mercury: Supporting Scalable Multi- Scalable Multi- Attribute Range Attribute Range Queries Queries A. Bharambe, M. Agrawal, S. Seshan A. Bharambe, M. Agrawal, S. Seshan In Proceedings of the SIGCOMM’04, USA In Proceedings of the SIGCOMM’04, USA Παρουσίαση: Παρουσίαση: Τζιοβάρα Βίκυ Τζιοβάρα Βίκυ Τσώτσος Θοδωρής Τσώτσος Θοδωρής Χριστοδουλίδου Μαρία Χριστοδουλίδου Μαρία
-
date post
21-Dec-2015 -
Category
Documents
-
view
214 -
download
0
Transcript of Mercury: Supporting Scalable Multi-Attribute Range Queries A. Bharambe, M. Agrawal, S. Seshan In...

Mercury: Supporting Mercury: Supporting Scalable Multi-Scalable Multi-Attribute Range Attribute Range
QueriesQueriesA. Bharambe, M. Agrawal, S. SeshanA. Bharambe, M. Agrawal, S. Seshan
In Proceedings of the SIGCOMM’04, USAIn Proceedings of the SIGCOMM’04, USA
Παρουσίαση:Παρουσίαση:Τζιοβάρα ΒίκυΤζιοβάρα Βίκυ
Τσώτσος ΘοδωρήςΤσώτσος ΘοδωρήςΧριστοδουλίδου ΜαρίαΧριστοδουλίδου Μαρία

2
Introduction (1/2)Introduction (1/2)
Mercury is a scalable protocol for Mercury is a scalable protocol for supportingsupporting multi-attribute range-based searchesmulti-attribute range-based searches explicit load balancingexplicit load balancing
Achieve its goals of logarithmic-hop Achieve its goals of logarithmic-hop routing and near-uniform load routing and near-uniform load balancingbalancing

3
Introduction (2/2)Introduction (2/2)
Main components of Mercury’s designMain components of Mercury’s design1.1. Handles multi-attribute queries by creating a Handles multi-attribute queries by creating a
routing hub for each attribute in the application routing hub for each attribute in the application schemaschema
Routing hub: a logical connection of nodes in the systemRouting hub: a logical connection of nodes in the system Queries are passed to exactly one of the hubs associated Queries are passed to exactly one of the hubs associated
with its queried attributeswith its queried attributes A new data item is sent to all associated hubsA new data item is sent to all associated hubs
2.2. Each routing hub is organized into a circular Each routing hub is organized into a circular overlay of nodesoverlay of nodes
Data is placed contiguously on this ring, i.e. each node is Data is placed contiguously on this ring, i.e. each node is responsible for a range of values for the particular responsible for a range of values for the particular attributeattribute

4
Using existing DHTs for Using existing DHTs for range queriesrange queries
Can we implement range queries using Can we implement range queries using insert and lookup abstractions provided by insert and lookup abstractions provided by DHTs???DHTs???
DHTs designs use randomizing hash functions for DHTs designs use randomizing hash functions for inserting and looking up keys in the hash tableinserting and looking up keys in the hash table
Thus, the hash of a range is not correlated to the hash Thus, the hash of a range is not correlated to the hash of the values within a range.of the values within a range.
One way to correlate ranges and values is:One way to correlate ranges and values is: Partition the value space into buckets. A bucket forms Partition the value space into buckets. A bucket forms
the lookup key for the hash table.the lookup key for the hash table. Then a range query can be satisfied by performing Then a range query can be satisfied by performing
lookups on the corresponding buckets.lookups on the corresponding buckets. Drawbacks!!!!!!!Drawbacks!!!!!!!
1.1. Perform the partitioning of space Perform the partitioning of space a prioria priori which is difficult, which is difficult, i.e. partitioning of file namesi.e. partitioning of file names
2.2. Query performance depends on the way partitioning Query performance depends on the way partitioning performed.performed.
3.3. The implementation is complicatedThe implementation is complicated

5
Mercury Routing – Data Mercury Routing – Data ModelModel
Data item: A list of typed attribute-value Data item: A list of typed attribute-value pairs, e.g. each field is a tuple of the form pairs, e.g. each field is a tuple of the form (type, attribute, value)(type, attribute, value)
Type: int, char, float and string.Type: int, char, float and string. Query: A conjunction of predicates which Query: A conjunction of predicates which
are tuples of the form (type, attribute, are tuples of the form (type, attribute, operator, value)operator, value)
Operators: <, >, Operators: <, >, ≤, ≥, =.≤, ≥, =. String operators: prefix (“*n”), postfix (“j*”)String operators: prefix (“*n”), postfix (“j*”)
A disjunction is implemented by multiple A disjunction is implemented by multiple distinct queriesdistinct queries

6
Example of data item and Example of data item and a query a query

7
Routing Overview (1/4)Routing Overview (1/4)
The nodes are partitioned into groups The nodes are partitioned into groups called attribute hubscalled attribute hubs! A physical node can be part of multiple A physical node can be part of multiple
logical hubslogical hubs Each hub is responsible for a specific Each hub is responsible for a specific
attribute in the overall schemaattribute in the overall schema! This mechanism does not scale very well as This mechanism does not scale very well as
the number of attributes increases and is the number of attributes increases and is suitable only for applications with suitable only for applications with moderate-sized schemas.moderate-sized schemas.

8
Routing Overview (2/4)Routing Overview (2/4)
NotationNotation AA: set of attributes in the overall schema: set of attributes in the overall schema AAQQ: : set of attributes in a query set of attributes in a query QQ AADD: : set of attributes in a data-record set of attributes in a data-record DD ππαα: : value/range of an attribute value/range of an attribute αα in a data-in a data-
record/query.record/query. HHaa: : hub for attribute hub for attribute αα rraa: : a contiguous range of attribute valuesa contiguous range of attribute values

9
Routing Overview (3/4)Routing Overview (3/4)
A node responsible for a range A node responsible for a range rra a
resolves all queries resolves all queries QQ for which for which ππαα(Q)(Q)∩∩rraa ≠≠ {}{} stores all data-records stores all data-records D D for which for which ππαα(D) r(D) raa
! Ranges are assigned to nodes during the join Ranges are assigned to nodes during the join processprocess
A A query query QQ is passed to is passed to exactly one hubexactly one hub HHaa where where αα is any attribute from the set is any attribute from the set of query attributesof query attributes
Within the chosen hub, the query is Within the chosen hub, the query is delivered and processed at all nodes delivered and processed at all nodes that could have matching valuesthat could have matching values

10
Routing Overview (4/4)Routing Overview (4/4)
In order to guarantee that queries locate all the In order to guarantee that queries locate all the relevant data-records:relevant data-records: A A data-record,data-record, when inserted, is sent to all when inserted, is sent to all HHbb where b where b
AADD
Within each hub, the data-record is routed to the node Within each hub, the data-record is routed to the node responsible for the record’s value for the hub’s responsible for the record’s value for the hub’s attributeattribute
Alternative method: send a data-record to a single Alternative method: send a data-record to a single hub in hub in AAD D and queries to all hubs in and queries to all hubs in AAQQ
Queries may be extremely non-selective in some Queries may be extremely non-selective in some attribute, thereby resort to flooding a particular hub. attribute, thereby resort to flooding a particular hub. Thus the network overhead is larger compared to the Thus the network overhead is larger compared to the previous approach. previous approach.

11
ReplicationReplication
It is not necessary to replicate entire It is not necessary to replicate entire data records across hubs.data records across hubs.
A node within one of the hubs can A node within one of the hubs can hold the data record while the other hold the data record while the other hubs can hold a hubs can hold a pointerpointer to the node to the node Reduction of storage requirements Reduction of storage requirements One additional hop for query resolutionOne additional hop for query resolution

12
Routing within a hubRouting within a hub
Within a hub Within a hub HHaa, routing is done as , routing is done as follows: follows: ffor routingor routing a a data-recorddata-record DD, we route to , we route to
the value the value ππaa(D).(D).
ffor a or a queryquery Q, πQ, πaa(Q)(Q) is a range. Hence, for is a range. Hence, for routing queries, we routerouting queries, we route to the to the fifirst rst value appearing in the range and then value appearing in the range and then use theuse the contiguity of range values to contiguity of range values to spread the query along thespread the query along the circle, as circle, as needed.needed.
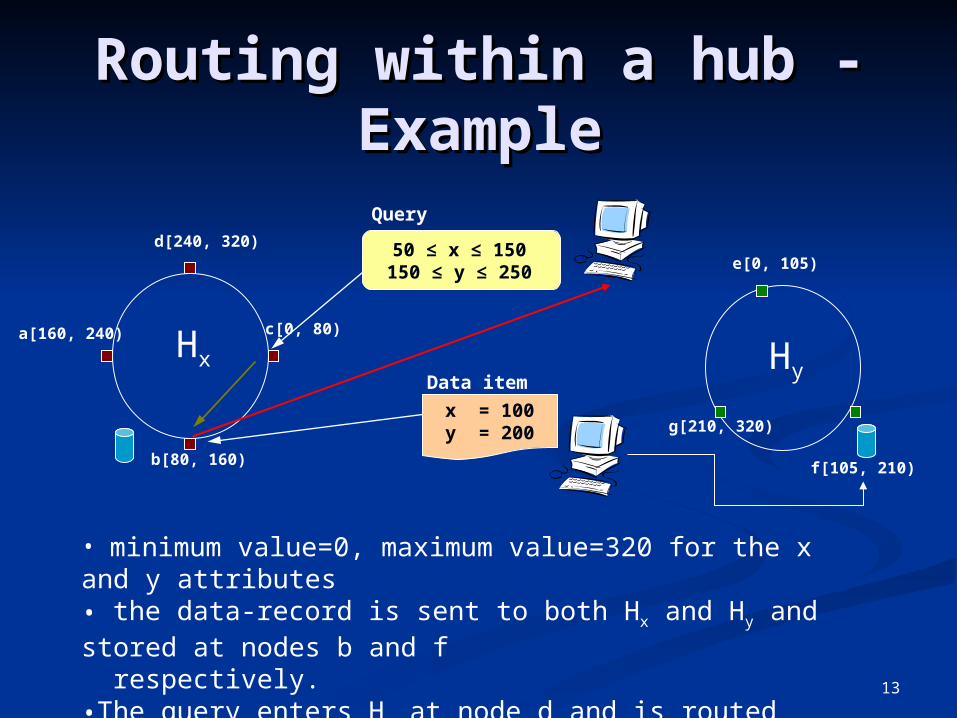
13
c[0, 80)
d[240, 320)
b[80, 160)
a[160, 240)
f[105, 210)
g[210, 320)
e[0, 105)
Hx Hy
50 ≤ x ≤ 150150 ≤ y ≤ 250
Query
x = 100y = 200
Data item
Routing within a hub - Routing within a hub - ExampleExample
• minimum value=0, maximum value=320 for the x and y attributes• the data-record is sent to both Hx and Hy and stored at nodes b and f respectively.•The query enters Hx at node d and is routed and processed at nodes b and c.

14
Additional requirements for Additional requirements for RoutingRouting
Each node must have a link to Each node must have a link to the predecessor and successor nodes the predecessor and successor nodes
within its own hubwithin its own hub each of the other hubs (cross-hub link)each of the other hubs (cross-hub link)
We expect the number of hubs for a We expect the number of hubs for a particular system to remain low particular system to remain low

15
Design RationaleDesign Rationale
The design The design treats the ditreats the difffferent attributes in an erent attributes in an applicationapplication schema schema independentlyindependently, i.e., routing , i.e., routing a data item a data item DD within a within a hub for attribute hub for attribute αα is is accomplished using only accomplished using only ππαα(D).(D).
An An alternate design would be to route using the alternate design would be to route using the values of all attributes present in values of all attributes present in DD Since each node in such a design is responsibleSince each node in such a design is responsible for a for a
value-range of every attribute, a query that containsvalue-range of every attribute, a query that contains a wild-card attribute can get a wild-card attribute can get flflooded to all nodesooded to all nodes
By making the attributes independent,By making the attributes independent, we we restrict such restrict such flflooding to at most one attribute ooding to at most one attribute hub.hub.
Furthermore, it is very likely some attribute of Furthermore, it is very likely some attribute of the query is more selective. Thus routing the the query is more selective. Thus routing the query to that hub, can eliminate flooding.query to that hub, can eliminate flooding.

16
Constructing Efficient Constructing Efficient Routes (1/2)Routes (1/2)
Using only successor and predecessor pointer can Using only successor and predecessor pointer can result in result in θθ(n) routing delays for routing data-records (n) routing delays for routing data-records and queries.and queries.
In order to optimize Mercury’s Routing:In order to optimize Mercury’s Routing: each node stores successor and predecessor links and each node stores successor and predecessor links and
maintains maintains k long-distance linksk long-distance links This results to each node having a routing table of size k+2This results to each node having a routing table of size k+2
The routing algorithm is simple: The routing algorithm is simple: let let neighbor neighbor nnii be in be in chargecharge of the range of the range [l[lii,, r rii),), and and dd denote denotess the clockwise the clockwise distance or value-distance between distance or value-distance between
two nodestwo nodes When a nodeWhen a node is asked to route a value is asked to route a value vv, it chooses the , it chooses the
neighbor neighbor nnii which which minimizes minimizes d(ld(lii,,v).v).

17
Constructing Efficient Constructing Efficient Routes (2/2)Routes (2/2)
Let Let mmaa and and MMaa be the minimum and be the minimum and maximum maximum values for attribute values for attribute aa, respectively., respectively.
A node selects its A node selects its kk links by using a harmonic links by using a harmonic probability distribution function probability distribution function
It can be proven that the expected number of It can be proven that the expected number of routing hops for routing to any value within a routing hops for routing to any value within a hub is O((1/k)*loghub is O((1/k)*log22n), under the assumption that n), under the assumption that node ranges are uniformnode ranges are uniform

18
Node Join and LeaveNode Join and Leave
Each node in Mercury needs to construct andmaintain the following set of links:
a) successor and predecessor links within the attribute hub,
b) k long-distance links for efficient intra-hub routing and
c) one cross-hub link per hub for connecting to other hubs.

19
Node Join (1/2)Node Join (1/2)
1.1. A node needs information about at least one A node needs information about at least one node already in the systemnode already in the system
2.2. The incoming node queries an existing node The incoming node queries an existing node and obtains and obtains state about the hubsstate about the hubs along with along with a list of representatives for each hub in the a list of representatives for each hub in the systemsystem
3.3. Then, it randomly chooses a hub to join and Then, it randomly chooses a hub to join and contactscontacts a member a member mm of that hub of that hub
4.4. The incoming node installs itselfThe incoming node installs itself as a as a predecessor of predecessor of mm, takes charge of half of , takes charge of half of mm's 's range ofrange of values and becomes a part of the values and becomes a part of the hubhub

20
Node Join (2/2)Node Join (2/2)
5.5. TheThe new node copies the routing state of new node copies the routing state of itsits successor m, including its long-successor m, including its long-distance links as well as linksdistance links as well as links to nodes in to nodes in other hubsother hubs
6.6. ItIt initiates two maintenance initiates two maintenance processes: processes:
FiFirstly, it sets up its own long-distancerstly, it sets up its own long-distance links links by routing to newly sampled values by routing to newly sampled values generated fromgenerated from the harmonic distribution the harmonic distribution
Secondly, itSecondly, it starts random-walks on each of starts random-walks on each of the other hubs to obtain newthe other hubs to obtain new cross-hub cross-hub neighbors distinct from his successor'sneighbors distinct from his successor's

21
Node Departure (1/3)Node Departure (1/3) When nodes depart, the When nodes depart, the
successor/predecessorsuccessor/predecessor links, the long-links, the long-distance links and the inter-hub linksdistance links and the inter-hub links within Mercury must be repairedwithin Mercury must be repaired
SSuccessor/predecessoruccessor/predecessor linkslinks’’ repair: repair: 1.1. within a hub, each node maintains a short within a hub, each node maintains a short
listlist of contiguous nodes further clockwise on of contiguous nodes further clockwise on the ring than itsthe ring than its immediate successorimmediate successor
2.2. When a node's successor departs, thatWhen a node's successor departs, that node node is responsible for is responsible for fifinding the next node along nding the next node along the ringthe ring and creating a new successor linkand creating a new successor link

22
Node Departure (2/3)Node Departure (2/3)
A node's departure will break the A node's departure will break the long-distance links oflong-distance links of a set of nodes a set of nodes in the hubin the hub
LLongong distancedistance linkslinks repair: repair: nodes periodically reconstruct theirnodes periodically reconstruct their
long-distance links using recent long-distance links using recent estimates of estimates of the number of the number of nodenodess..
Such repair is initiated only when the Such repair is initiated only when the number of nodes innumber of nodes in the system changes the system changes dramaticallydramatically

23
Node Departure (3/3)Node Departure (3/3)
BBroken cross-hub linkroken cross-hub link repair: repair: A A node considersnode considers the following three choices:the following three choices:
1.1. it uses a backup cross-hubit uses a backup cross-hub link for that hub to link for that hub to generate a new cross-hub neighbor (usinggenerate a new cross-hub neighbor (using a a random walk within the desired hub), or random walk within the desired hub), or
2.2. if such aif such a backup is not available, it queries its backup is not available, it queries its successor and predecessorsuccessor and predecessor for their links to the for their links to the desired hub, ordesired hub, or
3.3. in the worst case,in the worst case, the node contacts the match-the node contacts the match-making (or bootstrap server) to query the address making (or bootstrap server) to query the address of a node participating in the desiredof a node participating in the desired hub.hub.

24
Τέλος!!!


















