
Making Computerized Adaptive Testing Diagnostic Tools for Schools Hua-Hua Chang University of...
55
Making Computerized Adaptive Testing Diagnostic Tools for Schools Hua-Hua Chang University of Illinois at Urbana- Champaign October 17, 2010
-
Upload
candace-dennis -
Category
Documents
-
view
220 -
download
0
Transcript of Making Computerized Adaptive Testing Diagnostic Tools for Schools Hua-Hua Chang University of...

Making Computerized Adaptive Testing Diagnostic Tools for Schools
Hua-Hua ChangUniversity of Illinois at Urbana-Champaign
October 17, 2010

What is Adaptive Testing?
• Originally called tailored tests (Lord, 1970)– Examinee are measured most effectively if items are
neither too difficult nor too easy.• Θ: latent trait. Heuristically,
– if the answer is correct, the next item should be more difficult;
– If the answer is incorrect, the next item should be easier.• How adaptive test works?
– An item pool, known item properties (such as difficulty level, discrimination level,..
– Algorithm, computer, and network– The core is the item selection algorithm– Need mathematicians help to design algorithm
2

Sequential Design &Robbins-Monro Process (1955)
1 2 3
1 2 3
1 2 3
1
Responses: , , ,.......
Design points: , , ,.......
Constants: , , ,........
(a point of interest)n
n n nn
x x x
b b b
b m
b b x
Numerous Refinements:
Engineering (Goodwin, Ramadge and Caines, 1981; Kumar, 1985) Biomedical science (Finney, 1978)Education (Lord, 1970)
1 ( )n n n nb b x m 3

4
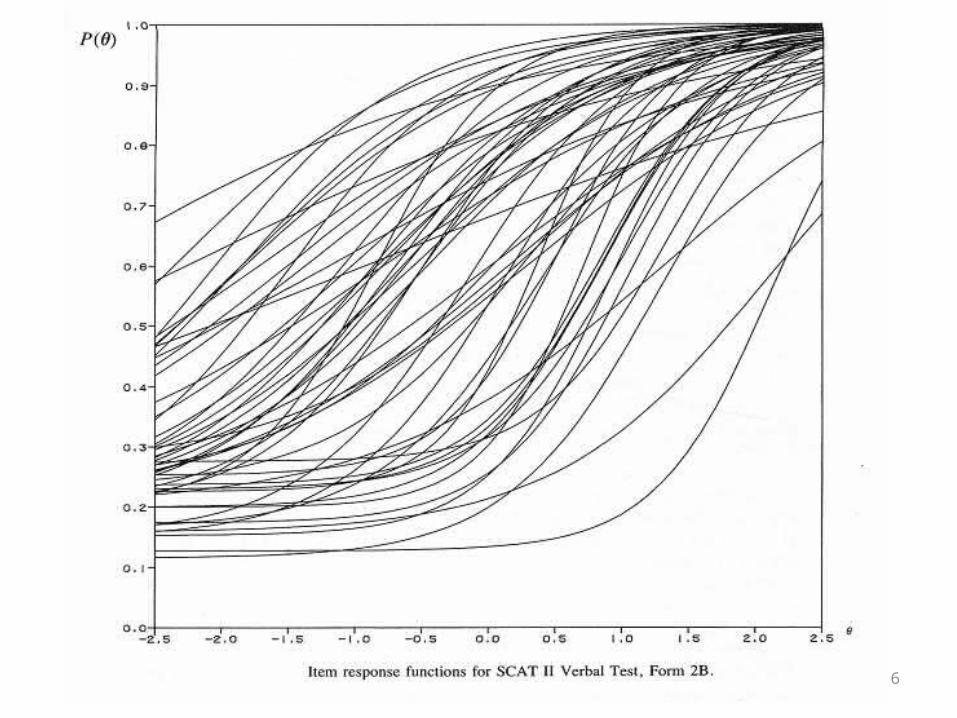
The Maximum Information Criterion (MIC)
• Lord’s (1980) MIC method, the most commonly used method.
• MIC would select items with high discrimination
• There have been many other methods
0
1
: true latent trait
ˆ : MLE after n items were administered
( ) : Item information function
( ) ( ) : Test Information
n
i
n
ii
I
I I
5
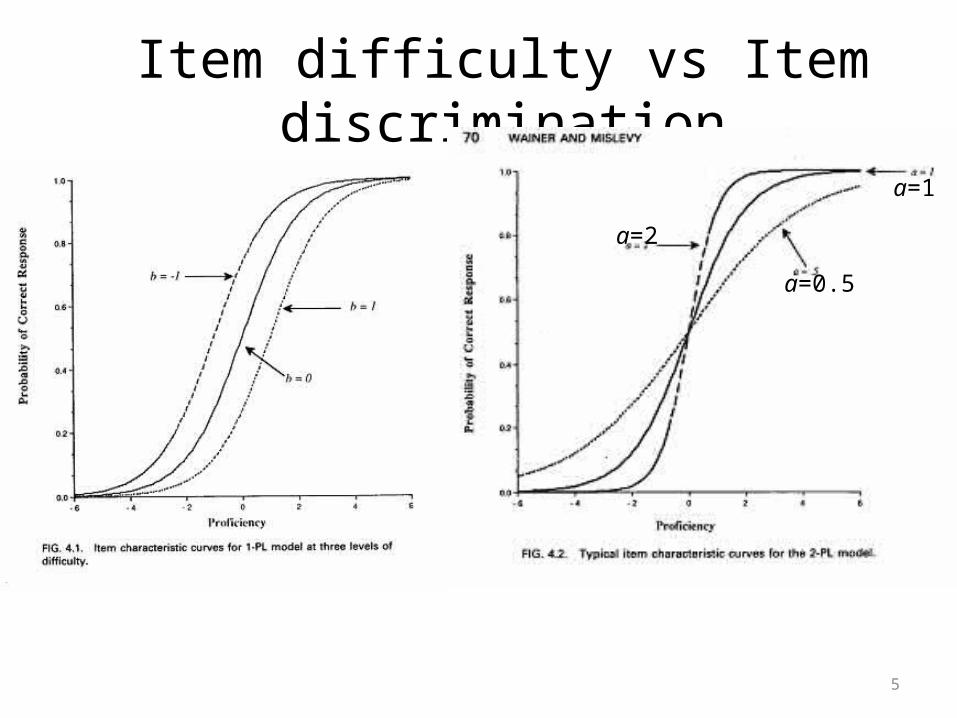
Item difficulty vs Item discrimination
a=2
a=0.5
a=1
6
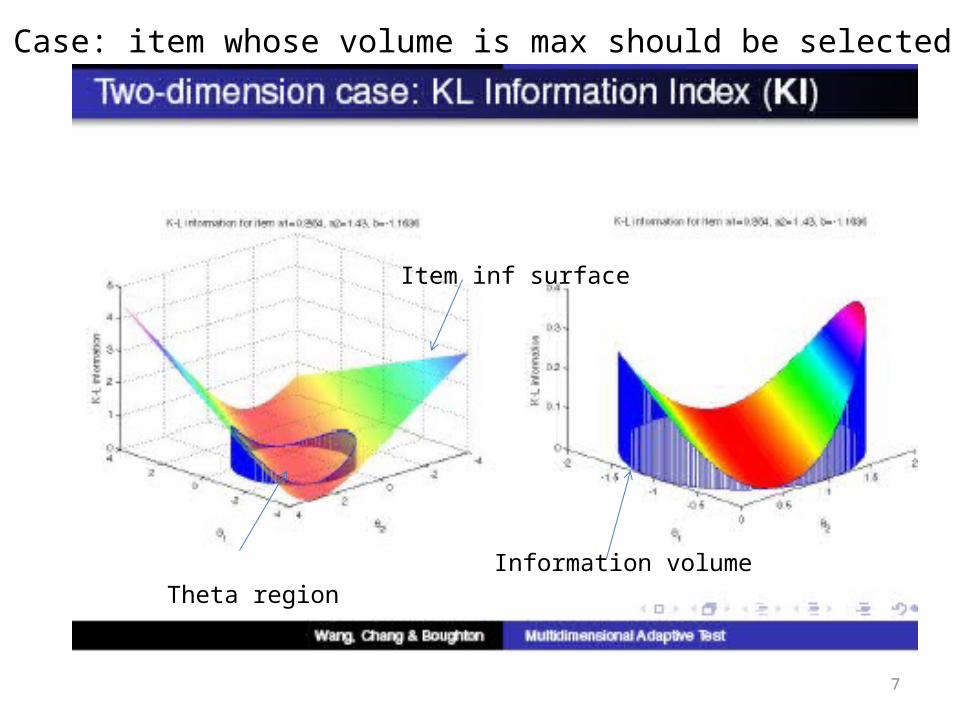
Item inf surface
Theta regionInformation volume
In 2D Case: item whose volume is max should be selected
7

From Theoretical Development to Large Scale Operation
• Issues to be addressed:• Should CAT only use the best items?
– It is common only 50% items are used• Is CAT more secure than paper/pencil test?
– How to improve CAT test security?• How to control non-statistical constraints?• How to get diagnostic information?• How to make CAT affordable to many schools?
8

Two NSF Grants and loads of Papers• Constraint-weighted design
– Cheng, Chang, & Yi (2006), Cheng & Chang, (2008), Cheng, Chang Douglas, & Guo (2009), etc.
• Establish theoretical foundation– Chang & Ying (2009)
• Test Security– Chang & Zhang (2001), Zhang & Chang (2010)
• Cognitive diagnostic CAT– McGlohen & Chang (2008)
• Multi-dimensional CAT– Wang & Chang (in press), Wang & Chang (accepted for publication)
• Large scale k-12 Applications in China– Liu, Yu, Wang, Ding & Chang (2010) 9

CAT & Transformative Research
• National Science Board (2007)unanimously approved a motion to enhance support of transformative research at the NSF.– All proposals received after Jan 5, 2008, will be
reviewed against the criterion.• revolutionizing entire disciplines; • creating entirely new fields; or • disrupting accepted theories and perspectives
• Many CAT researches are transformative!
10

New Developments• Measuring Patient-Reported Outcomes
– Conventional measures of disease such as lab results do not fully capture information about chronic diseases and how treatments affect patients.
– CAT can be used to assess patients subjective experiences such as symptom severity, social well-being, and perceived level of health.
• K-12 Applications– Large State testing– Teaching/learning, within School application– Diagnostic purpose– Web-based learning
11

12
Challenges in NCLB Testing
• Many items are too difficult to students– 70% math items may be too difficult
• The influence of this kind of test taking experience on low-achieving students is not well-understood (e.g., Roderick & Engle, 2001, Ryan & Ryan, 2005; Ryan, Ryan, Arbuthnot, & Samuels, 2007).
• Test security of NCLB• The # of security violations in P&P based NCLB testing in on the
rise. • Documented cases of such incidents have been uncovered in
numerous states including New York, Texas, California, Illinois, and Massachusetts. (Jacob & Levitt, 2003, and Texas Education Agency, 2007).

13
CAT Has Glowing Future in the K-12 Context.
• Why not use benchmark testing?– Adaptive Testing can do better.
• Quellmalz & Pellegrino (2009): – more than 27 states currently have operational or
pilot versions of online tests, including Oregon, North Carolina, Utah, Idaho, Kansas, Wyoming, and Maryland.
– The landscape of educational assessment is changing rapidly with the growth of computer-administered tests.

1. MAKING CAT DIAGNOSTIC TOOL2. DELIVER THE TOOL TO SCHOOLS
Objectives:
14

How to get diagnostic information?
• Post-hoc approach (non-adaptive)– perform CD after students completed CAT
• Adaptive approach– Select the next item which provides the max info
about the student’s strength and weakness– Need a model, item selection algorithm– Psychometric theory– Simulation study– Field test
15

16
Cognitive Diagnosis
Provide examinees with more information than just a single score.
• How? By considering the different attributes measured by the test.
• An attribute is a “task, subtask, cognitive process, or skill” assessed by the test, such as addition or reading comprehension.

17
Traditional Testing: Cognitive Diagnosis:
1 2[ , ,..., ]K
A single score A set of scores:One for each attribute.
(K is the total # of attributes.)
What should be reported to examinees?

18
Feedback from an exam can be more individualized to a student’s specific
strengths and weaknesses.
75
75
Julia R.
Halle B.
]0000111[ˆ
]0101100[ˆ
Why is this beneficial?

19
The Item-Attribute Relationship
Which items measure which attributes is represented by the Q-matrix:
i1 i2 i3 i4
A1
A2
A3
0 1 0 1
1 0 0 1
1 0 1 0

20
Cognitive Diagnostic Models
• Many models have been proposed• DINA model• Fusion model (Stout’s group)
( 1| )ij iP X vector
Itemperson

21
The DINA Model
(Macready & Dayton, 1977, 1989; Junker & Sijstma, 2001)
(1 )
1
Deterministic Input; Noisy "And" Gate
( 1| ) (1 )
( 0 | 1) -- "slip" parameter
( 1| 0) --
ij ij
jk
ij ij j j
Kq
ij ikk
j ij ij
j ij ij
P X s g
where
s P X
g P X
"guess" parameter
Student iItem j

How to adaptively select items?• No direct analogy to “match theta with b-parameter”
– Regular CAT, b-parameter with
• Now is a vector, called latent class
22
: # of attributes
: pt in the latent space (2 )
ˆ : estimated
( | ) : IRF
Kc
i i
K
P X x

• The KL information Approach (Xu, Chang, & Douglass, 2004)
• Let’s assume
• The likelihood test is the most powerful test• Intuitively the j-th item selected should make
large
0 1ˆ: , : iH H
ˆ( | )log
( | )j j
j j j
P X x
P X x
23
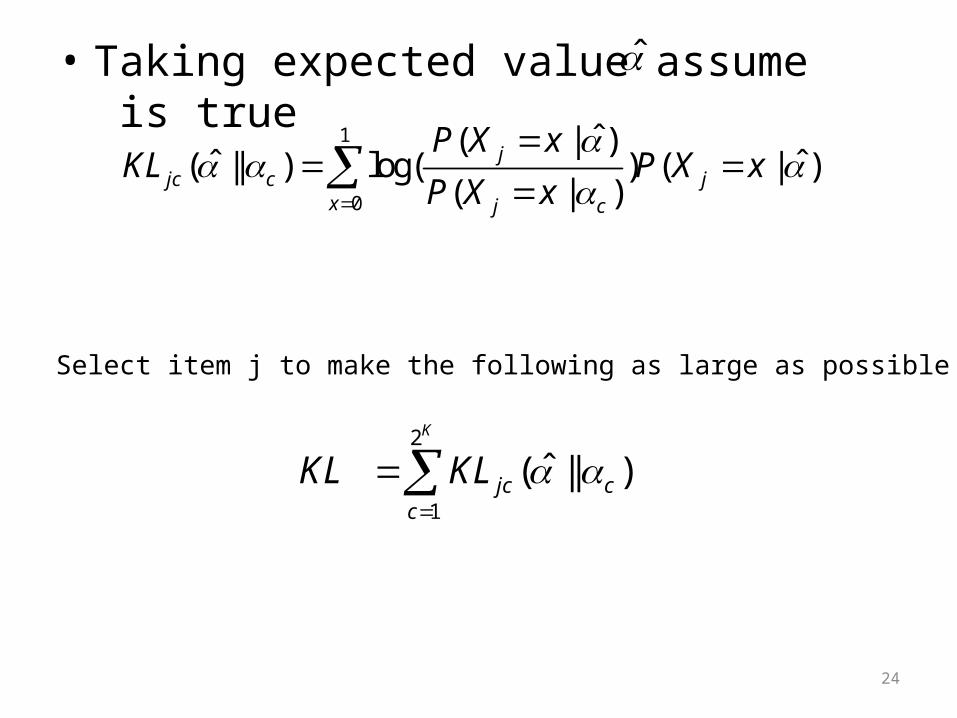
• Taking expected value assume is true ̂
2
1
ˆ( || )K
jc cc
KL KL
1
0
ˆ( | )ˆ ˆ( || ) log( ) ( | )
( | )j
jc c jx j c
P X xKL P X x
P X x
Select item j to make the following as large as possible
24
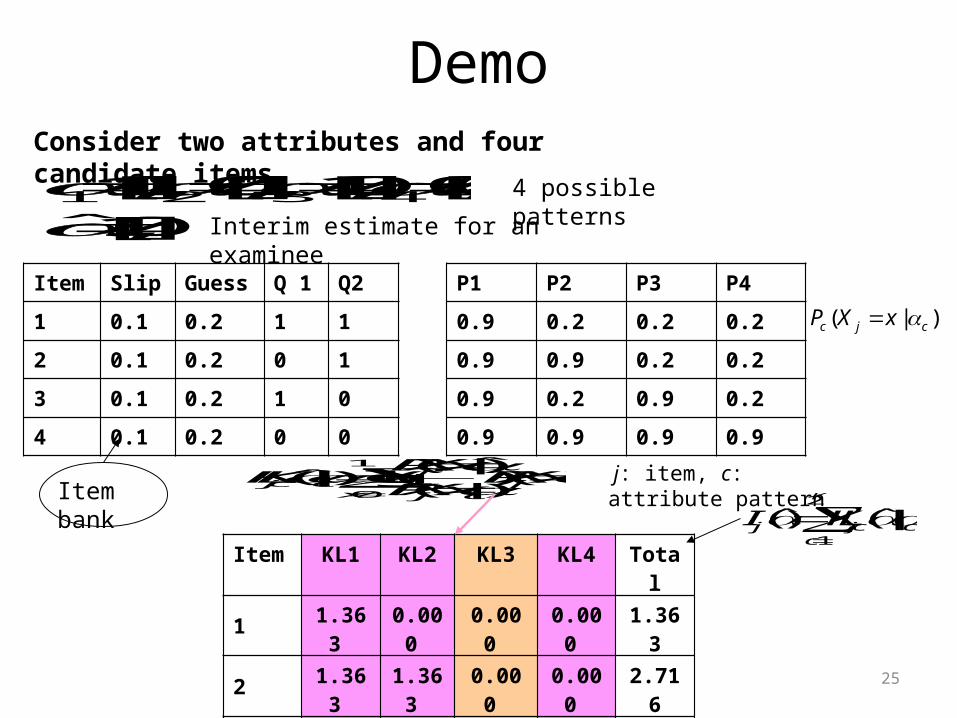
25
Demo
Item Slip Guess Q 1 Q2
1 0.1 0.2 1 1
2 0.1 0.2 0 1
3 0.1 0.2 1 0
4 0.1 0.2 0 0
P1 P2 P3 P4
0.9 0.2 0.2 0.2
0.9 0.9 0.2 0.2
0.9 0.2 0.9 0.2
0.9 0.9 0.9 0.9
( | )c j cP X x
Consider two attributes and four candidate items
1 2 3 4[1,1], [0,1], [1,0], [0,0]
ˆ [1,0]
4 possible patterns
Interim estimate for an examinee
Item bank
Item KL1 KL2 KL3 KL4 Total
1 1.363 0.000 0.000 0.000 1.363
2 1.363 1.363 0.000 0.000 2.716
3 0.000 1.146 0.000 1.146 2.292
4 0.000 0.000 0.000 0.000 0.000
1
0
ˆ( | )ˆ ˆ( || ) log( ) ( | )
( | )j
jc c jx j c
P X xKL P X x
P X x
j: item, c: attribute pattern2
1
ˆ ˆ( ) ( || )K
j jc cc
I KL
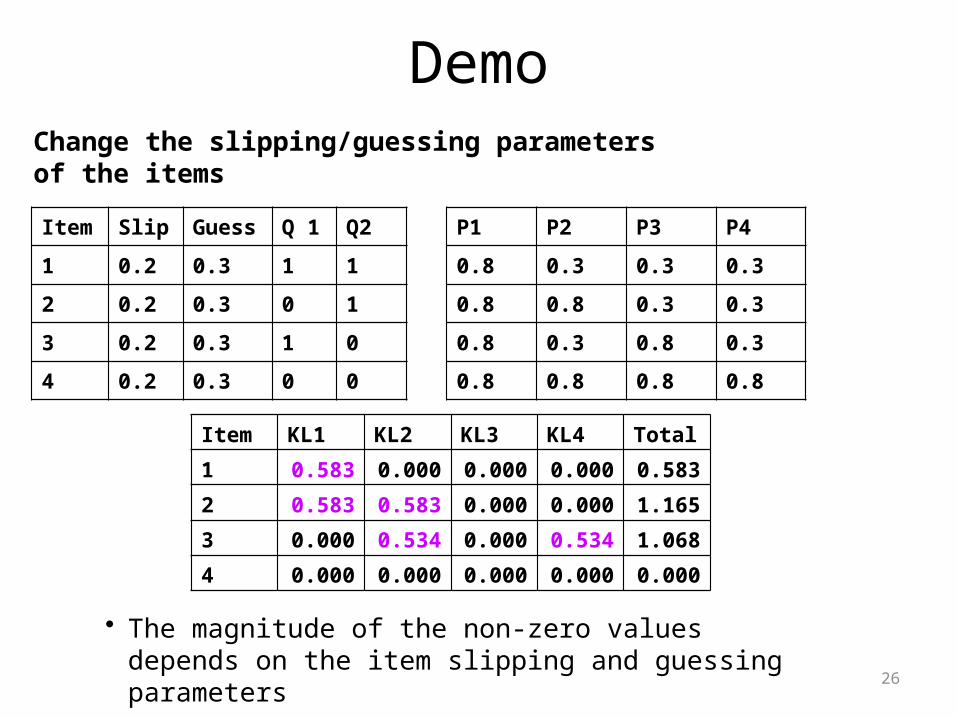
26
Demo
Item Slip Guess Q 1 Q2
1 0.2 0.3 1 1
2 0.2 0.3 0 1
3 0.2 0.3 1 0
4 0.2 0.3 0 0
P1 P2 P3 P4
0.8 0.3 0.3 0.3
0.8 0.8 0.3 0.3
0.8 0.3 0.8 0.3
0.8 0.8 0.8 0.8
Change the slipping/guessing parameters of the items
Item KL1 KL2 KL3 KL4 Total
1 0.583 0.000 0.000 0.000 0.583
2 0.583 0.583 0.000 0.000 1.165
3 0.000 0.534 0.000 0.534 1.068
4 0.000 0.000 0.000 0.000 0.000
• The magnitude of the non-zero values depends on the item slipping and guessing parameters
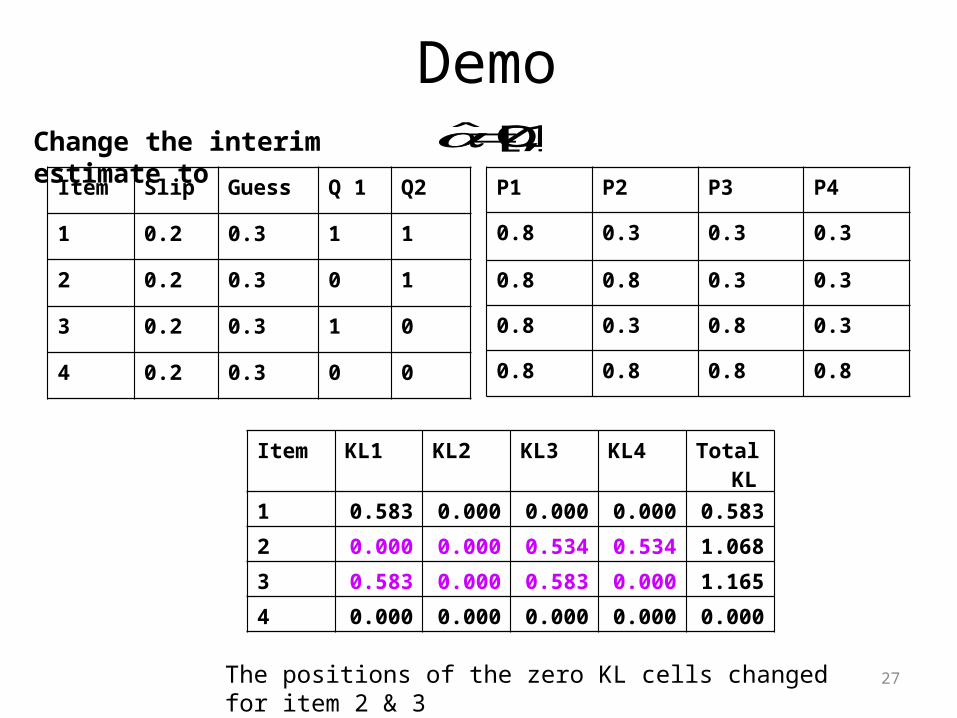
27
Demo
Item Slip Guess Q 1 Q2
1 0.2 0.3 1 1
2 0.2 0.3 0 1
3 0.2 0.3 1 0
4 0.2 0.3 0 0
P1 P2 P3 P4
0.8 0.3 0.3 0.3
0.8 0.8 0.3 0.3
0.8 0.3 0.8 0.3
0.8 0.8 0.8 0.8
Change the interim estimate to ˆ [0,1]
Item KL1 KL2 KL3 KL4 Total KL
1 0.583 0.000 0.000 0.000 0.583
2 0.000 0.000 0.534 0.534 1.068
3 0.583 0.000 0.583 0.000 1.165
4 0.000 0.000 0.000 0.000 0.000
The positions of the zero KL cells changed for item 2 & 3

• To explain the last table in the previous slide– “0” means this item provides no information to discriminate the interim
estimate with another possible attribute pattern. – The magnitude of the non-zero values depends on the item slipping
and guessing parameters– Which cell is zero depends on the q-vector and the examinee’s interim
estimate. If for a particular item (e.g., item 4 in this demo), q-vector contains all zeros, all cells will be zero.
28

29
Estimation
11 12 1 11 12 1
21 22 2 21 22 2
1 2 1 2
, ,...., ( , ,..., )
, ,...., ( , ,..., )
:
, ,...., ( , ,..., )
n K
n K
N N Nn N N NK
x x x
x x x
x x x
1 1 2 2( , ), ( , )..., ( , )n ns g s g s g
Response data Students’ latent class
Item parameters

30
New Tests vs. Existing Tests
• Existing Exams– Analyze the responses from an existing large-scale
assessment from a Cognitive Diagnosis framework.– Examine the results across various methods of
constructing a Q-matrix.• New Exams
– Identify Attributes and Content validity structure– Writing items according to cognitive specifications– Pre-testing– Q-matrix validation

31
Application 1: existing dataset– A simple random sample of 2000 examinees who took the
• Grade 3 TAAS from Spring 2002 • Grade 11 TEKS from Spring 2003
– The Math & Reading portion of each test was analyzed by using the Fusion Model
– Item selection methods• Kullback-Libler (KL) • Shannon Entropy (SHE), and etc.
– Reference, e.g.,• McGlohen & Chang (2008)• Download from
http://www.psych.illinois.edu/people/showprofile.php?id=539• Or, google Hua-Hua Chang

32
Taxes 3rd grade reading assessment 6 attributes (Application 1)
The student will determine the meaning of words in a variety of written texts.
The student will identify supporting ideas in a variety of written texts.
The student will summarize a variety of written texts.
The student will perceive relationships and recognize outcomes in a variety of written texts.
The student will analyze information in a variety of written texts in order to make inferences and generalizations.
The student will recognize points of view, propaganda, and/or statements of fact and opinion in a variety of written texts.

HOW TO HELP SCHOOLS TO OWN AND OPERATE CD-CAT?
Why CD-CAT?
33

Building CAT-Driven Assessment and Diagnosis to Improve Student Learning
Chang & Ryan (IES Proposal)
• Develop the technical foundations for a CAT system to meet NCLB accountability and to inform teaching and learning.
• In alignment with race to the top (RTTT) priorities, the proposed CAT will include – individualized diagnostic information to provide teachers,
schools, and states with more-precise information about student achievement levels along with valuable formative feedback to inform instructional planning.
34

HOW TO ADDRESS ISSUES SUCH AS SCHOOLS HAVE NO MONEY TO BUY AND OPERATE CD-CAT?
Address issues reviewers raised
35

New Technologies--- Schools can use existing PCs or MACs
• Client/Server Architecture (CS)– CAT software has to be installed on each client computer
( large workload)– only applicable to Local Area Network (LAN)
• Browser/Server Architecture (BS)– database is still on the server– nearly all the tasks concerning development, maintenance and
upgrade, are carried out on the server. – based on the Wide Area Network (WAN)
• Advantages of BS– Low maintenance, no network programming
36
Hardware and Network Design
Item Bank
37

APPLICATION 2: THE CHINA PROJECT
Develop a CD-CAT system to show its applicability to improve teaching and learning
38

Application 2:Level II English Proficiency Test
• Pretest and Calibration of Item bank – Pretest
• 38,662 students from 78 schools, 12 counties participated
– Analyzing pretest data1. Estimated the parameters of DINA model2. Estimated the parameters of 3PLM model3. Calibrate attributes of item again4. If it fits well then stop, otherwise revise q-matrix and got 3
– Assembling the item bank with item parameters and specifications.
39

40
Distribution of the students in pretest
Red: Field Test Sampling Area
Yellow and red: Current Implementation
40

41
Linking Design
Anchor itemsGroup1 Group2 Group3 Group4
Test1Test2Test3Test4Test5Test6Test7Test8Test9Test10Test11Test12Anchor Test
The locations of the anchor items in each booklet are the same (as they appear in anchor test).
Eg, this block has 10 anchor items,
41

42

Item Writing
• About 40 Excellent Teachers in Beijing• Process
1. Psychometric Training2. Identify Attributes3. Writing Items4. Constructing Q-matrix5. Pre-testing and check FITTING6. Revise Q-matrix until fitting is ok; go to 5 if not7. stop
43

Item Selection Strategy
– Shannon Entropy (SHE) procedure was applied to select
next items
• SHE (Tatsuoka, 2002, Xu, Chang, & Douglas, 2004, McGlohen &
Chang, 2008)
– Dual Information (McGlohen & Chang, 2004 and 2008)
Cheng and Chang, 2007)
44

• Parameters Estimation – The knowledge state of examinee is estimated
sequentially.– The Maximum posterior estimation (MAPE)
method was used in the system.
– The ability is estimated at the end of the test.
( )
0,1, ,2 1ˆ arg max ( ( | ))
K ic
mi cP u
1( ) 0
0 1( )
2 1 2 11( )
0 00 0 1
( ) (1 ( ))( ; )
( | )
( ; ) ( ) (1 ( ))
ij ij
iK Ki
ij ij
i
mu u
m c j c j cc c jm
c mu um
c c c j c j cc c j
g P Pg L u
P u
g L u g P P
45

Monte Carlo simulation Studies
• Item selection rule – Content constraints (same test structure as Pretest)
• Listening Dialog (item1-item10), the next items is selected within remaining Listening Dialog items in the item bank.
• Short Talks (item11-item12), two items for a piece of speech is selected within the short-talk items in the item bank.
• Grammar and Vocabulary (item17-item32), the next items is selected within remaining Grammar and Vocabulary items in the item bank.
• Reading Comprehension (item33-item40), the next items is selected within
remaining Reading Comprehension items in the item bank.
• Item selection strategy – the item was selected according to Shannon entropy procedure
46

Classification Accuracy & Evaluation Criteria
• Evaluation criteria– Rate of pattern match (RPM)
– Rate of marginal match (RMM)
– average test information
The number of examinees of pattern matchRPM=
M
ijThe sum of all h
MKRMM
47

Field Test
• SHE with content constraints
• The adaptive test was web-based, consisting of 36 items and lasting for 40 minutes.
• Number of Participants: 584
– 5th and 6th grade, from 8 schools in Beijing, China
48

Validity Study
• Evaluating the consistency of– CD-CAT system results with an existing English
achievement test• a group of students took two exams
– CD-CAT system results with Teachers’ evaluation outcomes.
49
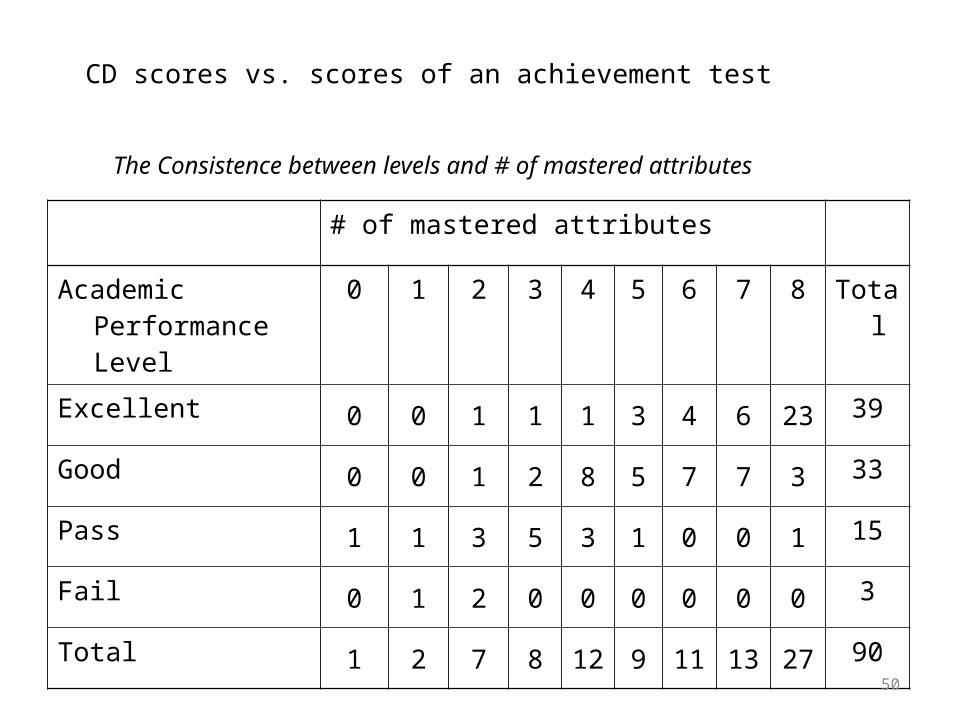
# of mastered attributes
Academic Performance Level
0 1 2 3 4 5 6 7 8 Total
Excellent 0 0 1 1 1 3 4 6 23 39
Good 0 0 1 2 8 5 7 7 3 33
Pass 1 1 3 5 3 1 0 0 1 15
Fail 0 1 2 0 0 0 0 0 0 3
Total 1 2 7 8 12 9 11 13 27 90
The Consistence between levels and # of mastered attributes
CD scores vs. scores of an achievement test
50

CD-CAT Results vs. Teachers' Assessment
• Comparison of a CD scores with teachers’ assessment– Participants from three classes:
• 91 6-grade students and 3 teachers were recruited to evaluate the diagnostic reports. one rural school and two urban schools.
– Measurement• Students’ diagnostic reports were presented to three teachers, they
were asked to evaluate the accuracy of this report.
51
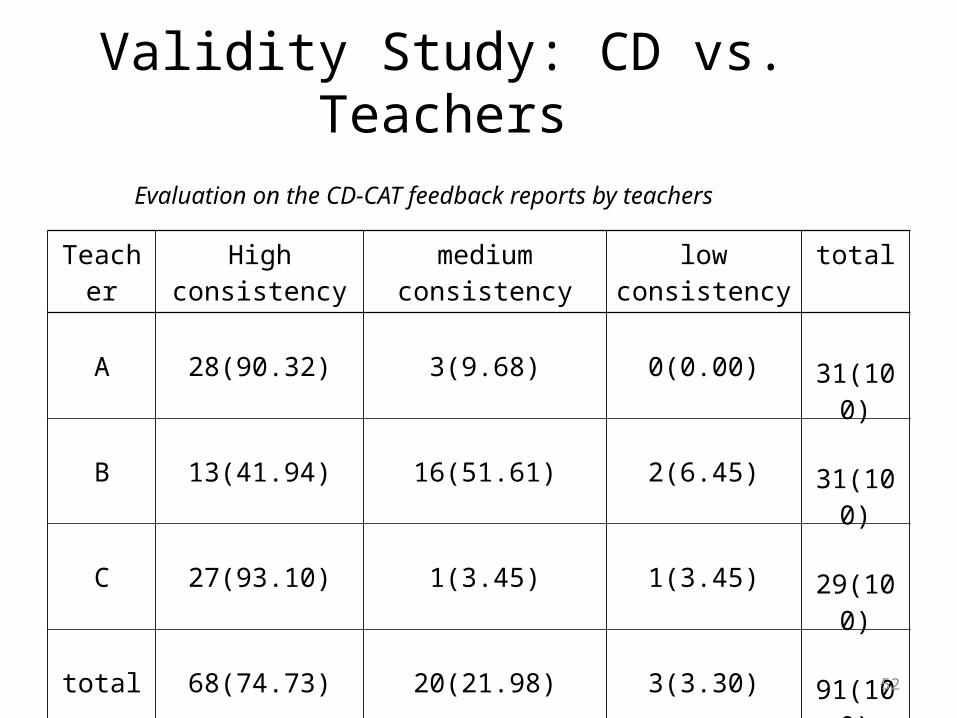
Validity Study: CD vs. Teachers
Evaluation on the CD-CAT feedback reports by teachers
Teacher High consistency medium consistency low consistency total
A 28(90.32) 3(9.68) 0(0.00) 31(100)
B 13(41.94) 16(51.61) 2(6.45) 31(100)
C 27(93.10) 1(3.45) 1(3.45) 29(100)
total 68(74.73) 20(21.98) 3(3.30) 91(100)
52

Discussions• Large scale field tests will take place in Shanghai
and Dalian in the near future.• CD-CAT can be implemented effectively and
economically. • Though the DINA model was used, the results can
be generalized to many other IRT and Cognitive Diagnostic Models!
• The method for on-line calibrating of pre-test items has been developed. In the future, paper/pencil based pretesting is not needed.
53

Conclusion
• CAT is revolutionarily changing the way we address challenges in assessment and learning.
• In June 2010 the IES proposal was revised and resubmitted.
• Any good example of LARGE-SCALE CD-CAT?– http://cp.guoshi.com/
54

Thank you!
55


















