
Lecture 17 - Murray State Universitycsclab.murraystate.edu/.../301/lectures/lecture_17.pdfThe...
55
Lecture 17: Language Recognition Finite State Automata Deterministic and Non-Deterministic Finite Automata Regular Expressions Push-Down Automata Turing Machines
Transcript of Lecture 17 - Murray State Universitycsclab.murraystate.edu/.../301/lectures/lecture_17.pdfThe...

Lecture 17:
Language Recognition
Finite State Automata
Deterministic and Non-Deterministic Finite Automata
Regular Expressions
Push-Down Automata
Turing Machines

When attempting to deal with theoretical issues concerning digital computers, we need a
simplified definition of what a computer does. Such a description is called a computational
model.
The first computational model we will consider is called a finite automaton or finite state
machine. A finite automaton is depicted below as a state control with a read head that scans
an input string. At the end of the string the state control will indicate whether or not the
scanned string is accepted or rejected as a member of the set of strings recognized by the finite
automaton.
Modeling Computation

The sequence of state transitions shown above is formally defined as
computation in the following manner:
Let M = (Q,Σ,δ,q0,F) be a finite automaton and w = w1w2...wn be a string overthe alphabet Σ. Then M accepts the string w if a sequence of states r0,r1,...,rn
exists in Q with the following three conditions:
1. r0=q0,
2. δ(r,wi+1) = ri+1 for i = 0, ... , n-1, and
3. rn is an element F.
Formal Definition of Computation
These three conditions state that
(1) the inital state must be the start state,
(2) the sequence of state transitions must be valid transitions for thefinite state machine M and
(3) the final state of M after processing w must be an accept state.

(1) Q is a finite set called the states.
(2) S is a finite set called the alphabet.
(3) d:Q x S -> Q is the transition function
(4) q0 is an element of Q called the start state,
and
(5) F is a subset of Q called the set of accept
states.
Formally, a finite Automaton (FA) is defined as a 5-tuple (Q,S, d, q0, F) where,
Finite Automaton
The set of states Q is just a set of labels, q0..q3. The alphabet S is the set of symbols that can be
understood by the FA. In this case the alphabet consists of the two symbols 0 and 1. This means
that the FA will be able to read (scan the symbols in) strings comprised only of 0's and 1's.

The transition function is represented by the arrows in the state transition diagram. This is a
discrete function that maps every possible combination of a state with a symbol from the
alphabet to another state, as shown in the table below:
State Transition Function
Note that there is a transition out of each state for each
symbol, so we have 4x2=8 transitions.
The start state, q0 is the initial state of the FA. The set F
is the set of accept states. In our example F = {q1, q3}.
This means that the binary string being scanned is
recognized or accepted by the FA if the final state (after
scanning the binary string) is one of the accept states.
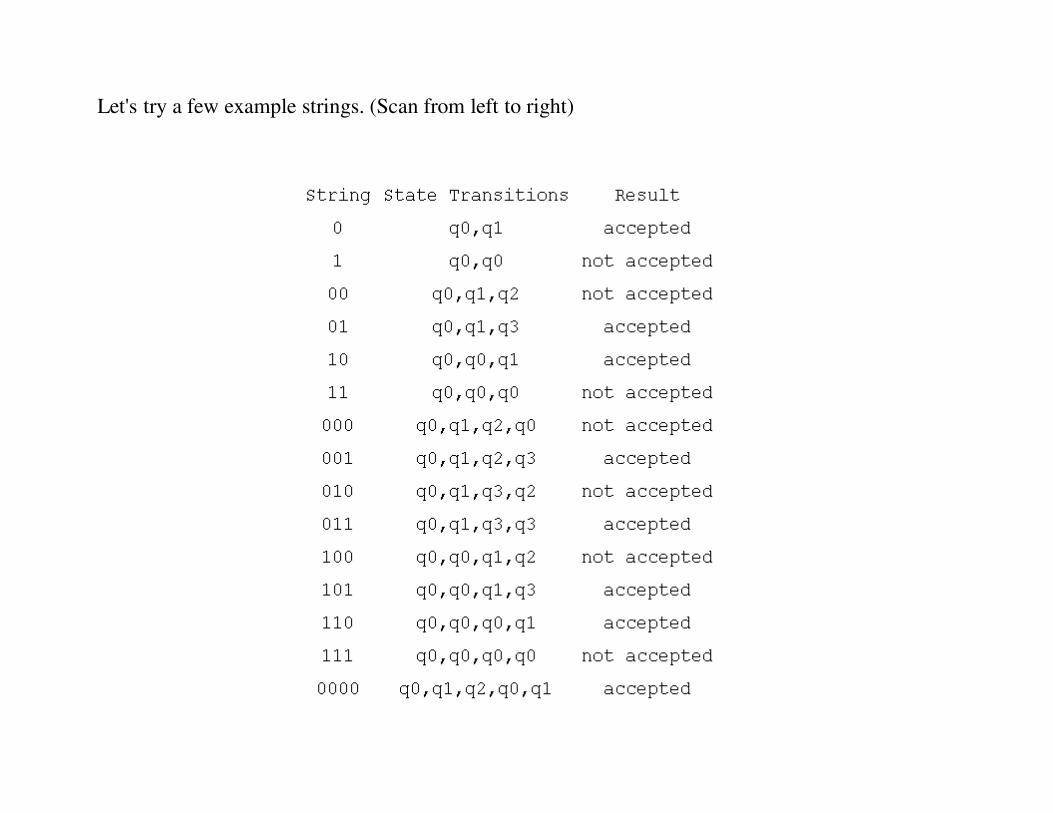
Let's try a few example strings. (Scan from left to right)

The set of all strings A accepted by a finite state machine M is called the language of
M. We say that M accepts or recognizes A.
Sybollically we write,
A={ω|M accepts ω}
We say that A is a regular language if it is recognized by a finite automaton.
Regular Language

Regular Operations
The operations of union, concatenation and Kleene-closure (also called star) are called
regular operations on regular languages.
Union: A U B = {x|x is an element of A or x is an element of B}
Concatenation: AoB = {xy|x is an element of A and y is an element of B}
Kleene-closure: A* = {x1x2...xk|k>= 0 and each xi is an element of A}

When there is exactly one transition from each state for each alphabet symbol a finiteautomaton is said to be deterministic. When there can be zero transitions or more thanone transition from some states for certain alphabet symbols, then the finite automatonis said to be nondeterministic.
Nondeterministic Finite Automata (NFA) are essential to the development of theoreticalcomputer science because they greatly simplify several important proofs. Everydeterministic finite automata (DFA) is automatically an NFA since NFAs are a moregeneral form of DFAs.
A nondeterministic finite automation is a 5-tuple (Q,Σ,δ,q0,F), where,
(1) Q is a finite set of states
(2) Σ is a finite alphabet
(3) δ: QxΣε -> P(Q) is the transition function
(4) q0 is an element of Q (the start state)
(5) F is a subset of Q (the set of accept states).
Nondeterminism
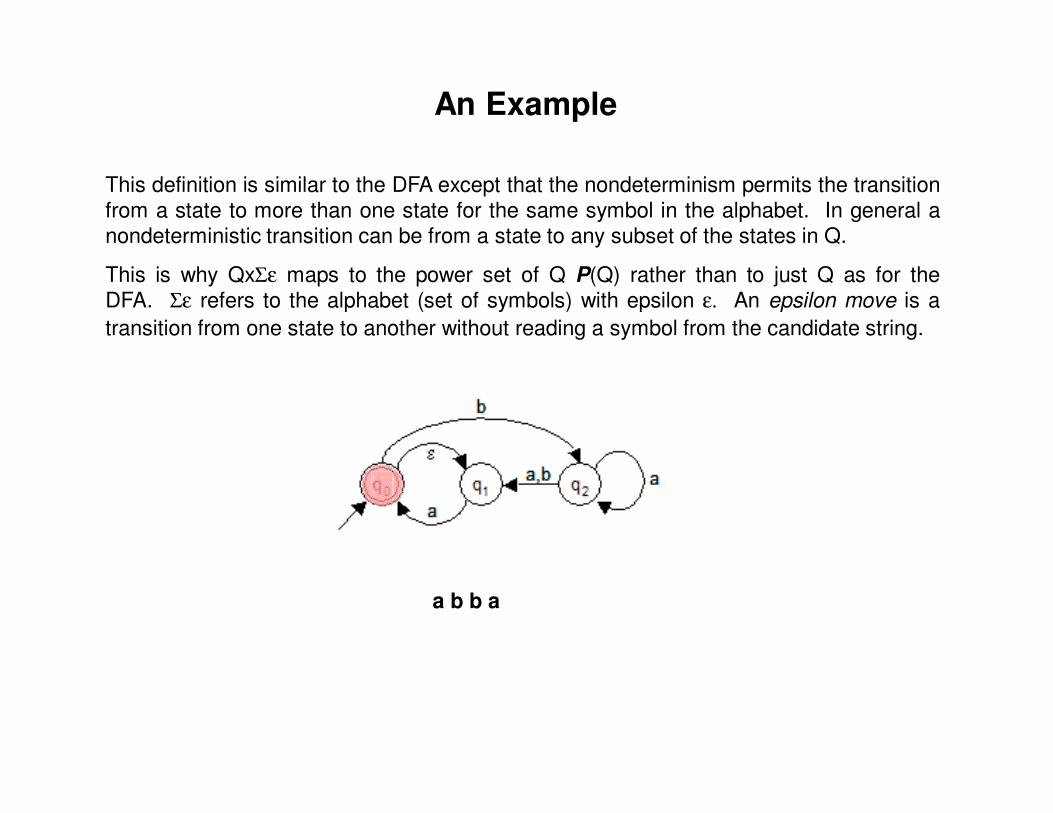
This definition is similar to the DFA except that the nondeterminism permits the transitionfrom a state to more than one state for the same symbol in the alphabet. In general anondeterministic transition can be from a state to any subset of the states in Q.
This is why QxΣε maps to the power set of Q P(Q) rather than to just Q as for theDFA. Σε refers to the alphabet (set of symbols) with epsilon ε. An epsilon move is a
transition from one state to another without reading a symbol from the candidate string.
a b b a
An Example
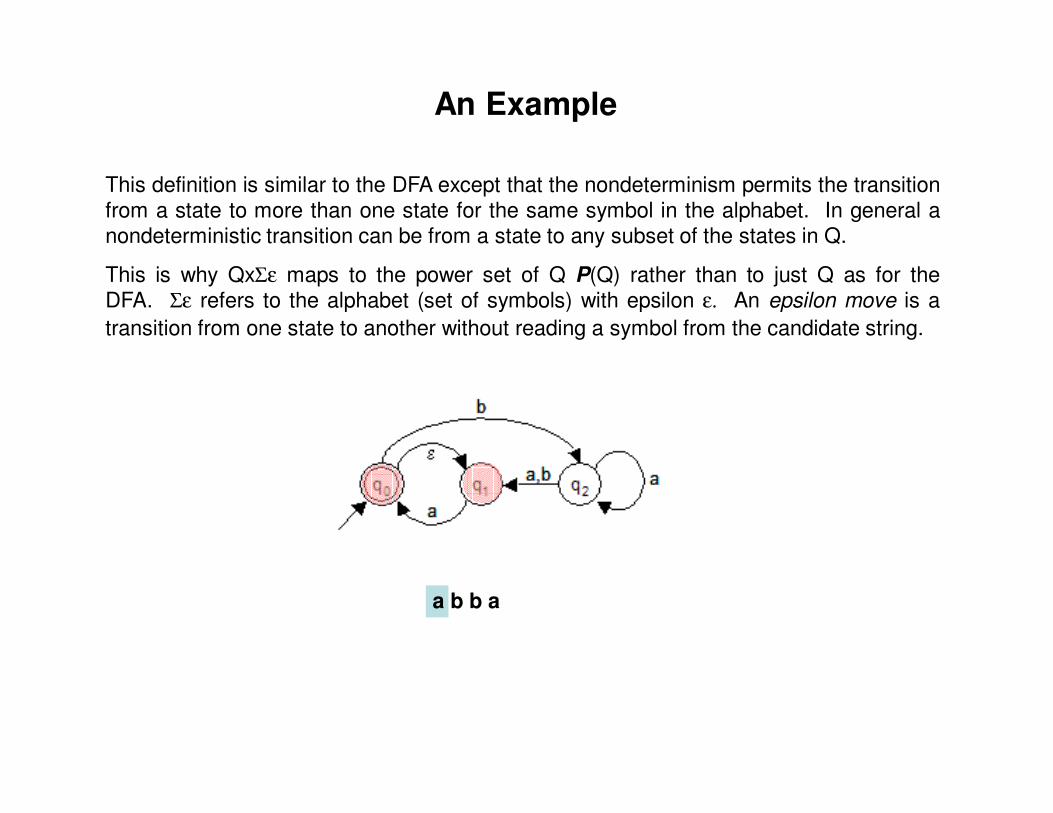
This definition is similar to the DFA except that the nondeterminism permits the transitionfrom a state to more than one state for the same symbol in the alphabet. In general anondeterministic transition can be from a state to any subset of the states in Q.
This is why QxΣε maps to the power set of Q P(Q) rather than to just Q as for theDFA. Σε refers to the alphabet (set of symbols) with epsilon ε. An epsilon move is a
transition from one state to another without reading a symbol from the candidate string.
a b b a
An Example

This definition is similar to the DFA except that the nondeterminism permits the transitionfrom a state to more than one state for the same symbol in the alphabet. In general anondeterministic transition can be from a state to any subset of the states in Q.
This is why QxΣε maps to the power set of Q P(Q) rather than to just Q as for theDFA. Σε refers to the alphabet (set of symbols) with epsilon ε. An epsilon move is a
transition from one state to another without reading a symbol from the candidate string.
a b b a
An Example

This definition is similar to the DFA except that the nondeterminism permits the transitionfrom a state to more than one state for the same symbol in the alphabet. In general anondeterministic transition can be from a state to any subset of the states in Q.
This is why QxΣε maps to the power set of Q P(Q) rather than to just Q as for theDFA. Σε refers to the alphabet (set of symbols) with epsilon ε. An epsilon move is a
transition from one state to another without reading a symbol from the candidate string.
a b b a
An Example

This definition is similar to the DFA except that the nondeterminism permits the transitionfrom a state to more than one state for the same symbol in the alphabet. In general anondeterministic transition can be from a state to any subset of the states in Q.
This is why QxΣε maps to the power set of Q P(Q) rather than to just Q as for theDFA. Σε refers to the alphabet (set of symbols) with epsilon ε. An epsilon move is a
transition from one state to another without reading a symbol from the candidate string.
a b b a
An Example

This definition is similar to the DFA except that the nondeterminism permits the transitionfrom a state to more than one state for the same symbol in the alphabet. In general anondeterministic transition can be from a state to any subset of the states in Q.
This is why QxΣε maps to the power set of Q P(Q) rather than to just Q as for theDFA. Σε refers to the alphabet (set of symbols) with epsilon ε. An epsilon move is a
transition from one state to another without reading a symbol from the candidate string.
a b b a
An Example

This definition is similar to the DFA except that the nondeterminism permits the transitionfrom a state to more than one state for the same symbol in the alphabet. In general anondeterministic transition can be from a state to any subset of the states in Q.
This is why QxΣε maps to the power set of Q P(Q) rather than to just Q as for theDFA. Σε refers to the alphabet (set of symbols) with epsilon ε. An epsilon move is a
transition from one state to another without reading a symbol from the candidate string.
a b b a
An Example

In terms of computational power, the DFA and the NFA are equivalent. This means thatfor every NFA there is a DFA that recognizes the same language. Since every DFA is anNFA the reverse is trivially true. Rather than reviewing the proof we will use the proofidea The methods in this to generate an equivalent DFA for an NFA as shown in the
following example: Given the NFA of the previous examle, we will construct a DFA that
recognizes the same language.
1. We will build a DFA with a set of states QD whose members correspond to themembers of P(Q). Since the NFA has states Q={q0,q1,q2} the DFA will have states
corresponding to { φ, {q0}, {q1}, {q2}, {q0,q1}, {q0,q2}, {q1,q2}, {q0,q1,q2}} and represented by
QD={qφ, q0, q1, q2, q01,q02, q12, q012}.
Equivalence of NFA's and DFA's

2. The start state for the DFA is the state representing the subset of states in the NFA thatincludes the start state and all the states reachable from the start state on an epsilonmove. In this case the start state is q01. The accept states in the DFA are all the statesderived from one or more of the accept states of the NFA. Recall that, in a DFA there is atransition from each state for each symbol in the alphabet Σ. Since states in an NFA mayhave no transitions for some symbols, we need a trap state in our DFA to dump the dead-end transitions (i.e. those that do not exist in the NFA). This trap state is not an accept state
and it has a transition to itself on every symbol.

3. Now we will define the DFA transitions for each of the NFA transitions.
Transitions from q0 - Starting with state q0 we observe that there is no transistion in the NFAfrom q0 reading the symbol a, therefore we will include a transition from state q0 in the DFAto state qφ. There is a transistion from q0 to q2 in the NFA so we simply replicate this
transition for the DFA. For convenience we show the NFA on the right below.
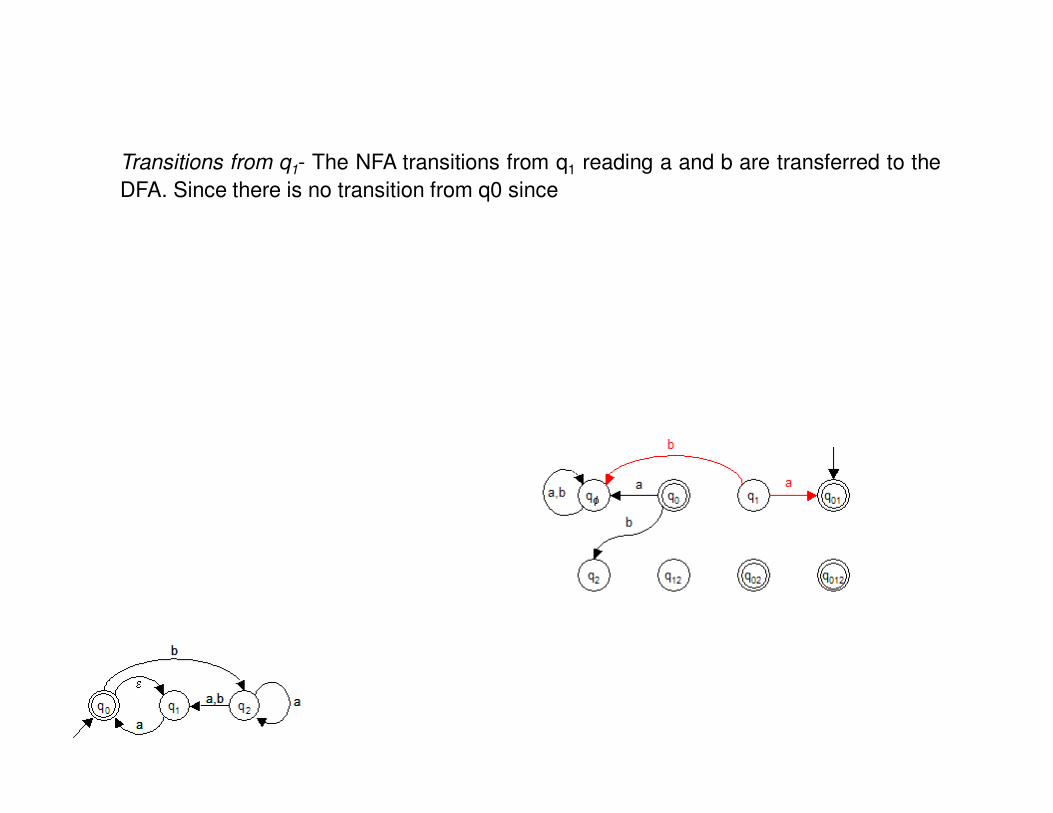
Transitions from q1- The NFA transitions from q1 reading a and b are transferred to the
DFA. Since there is no transition from q0 since
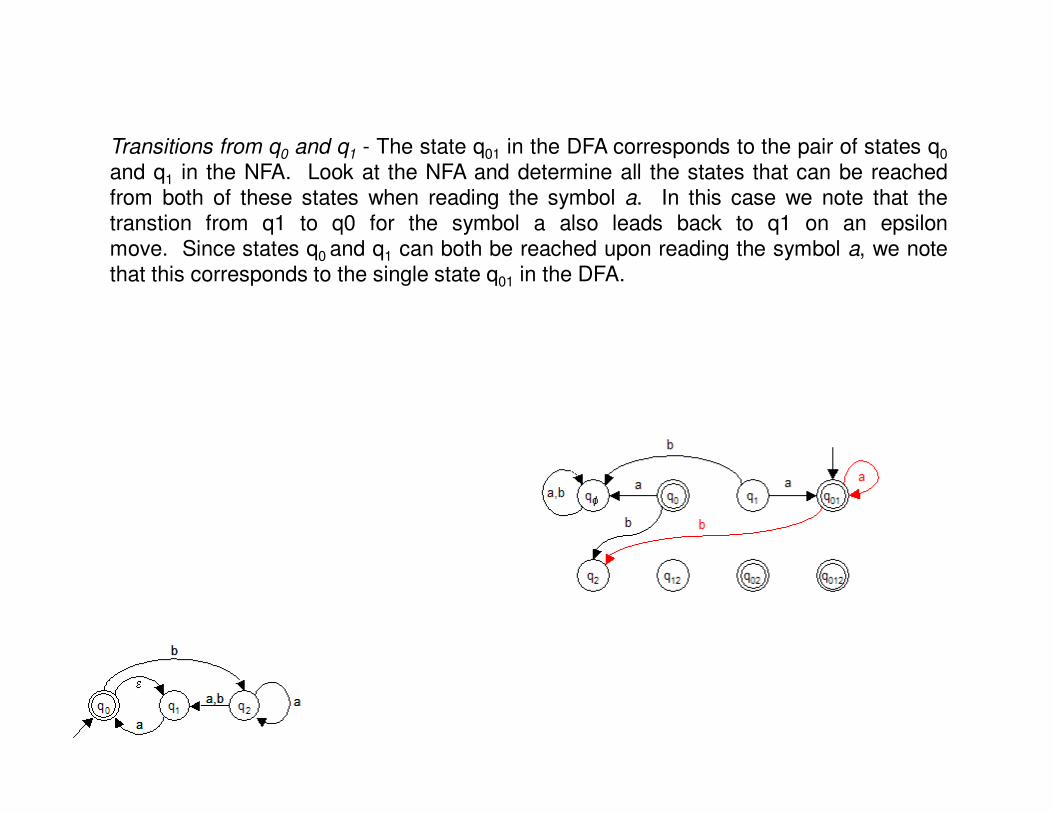
Transitions from q0 and q1 - The state q01 in the DFA corresponds to the pair of states q0
and q1 in the NFA. Look at the NFA and determine all the states that can be reachedfrom both of these states when reading the symbol a. In this case we note that thetranstion from q1 to q0 for the symbol a also leads back to q1 on an epsilonmove. Since states q0 and q1 can both be reached upon reading the symbol a, we notethat this corresponds to the single state q01 in the DFA.
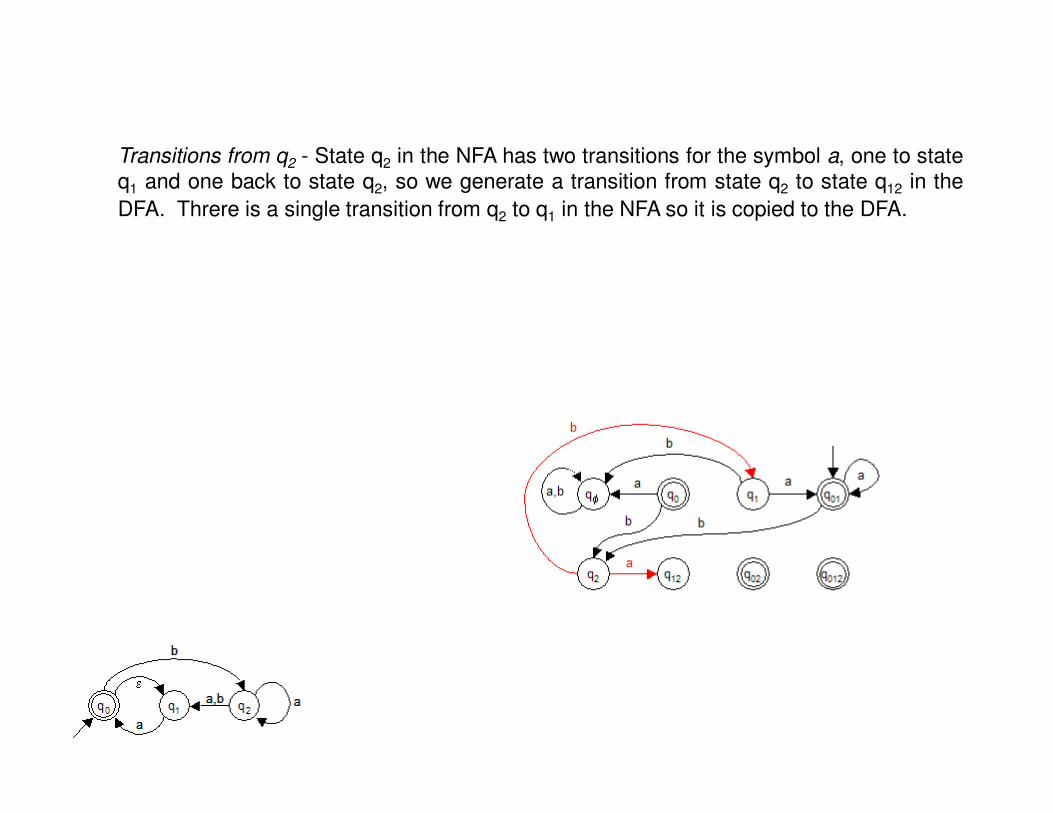
Transitions from q2 - State q2 in the NFA has two transitions for the symbol a, one to stateq1 and one back to state q2, so we generate a transition from state q2 to state q12 in the
DFA. Threre is a single transition from q2 to q1 in the NFA so it is copied to the DFA.

Transitions from q1 and q2 - We observe that from states q1 and q2 every state in the NFAcan be reached on transitions for the symbol a. We represent this set of transitions inthe DFA with an a-transition from q12 to q012. There is only one transition for the symbol
b from states q1 and q2 in the NFA, which we copy to the DFA.
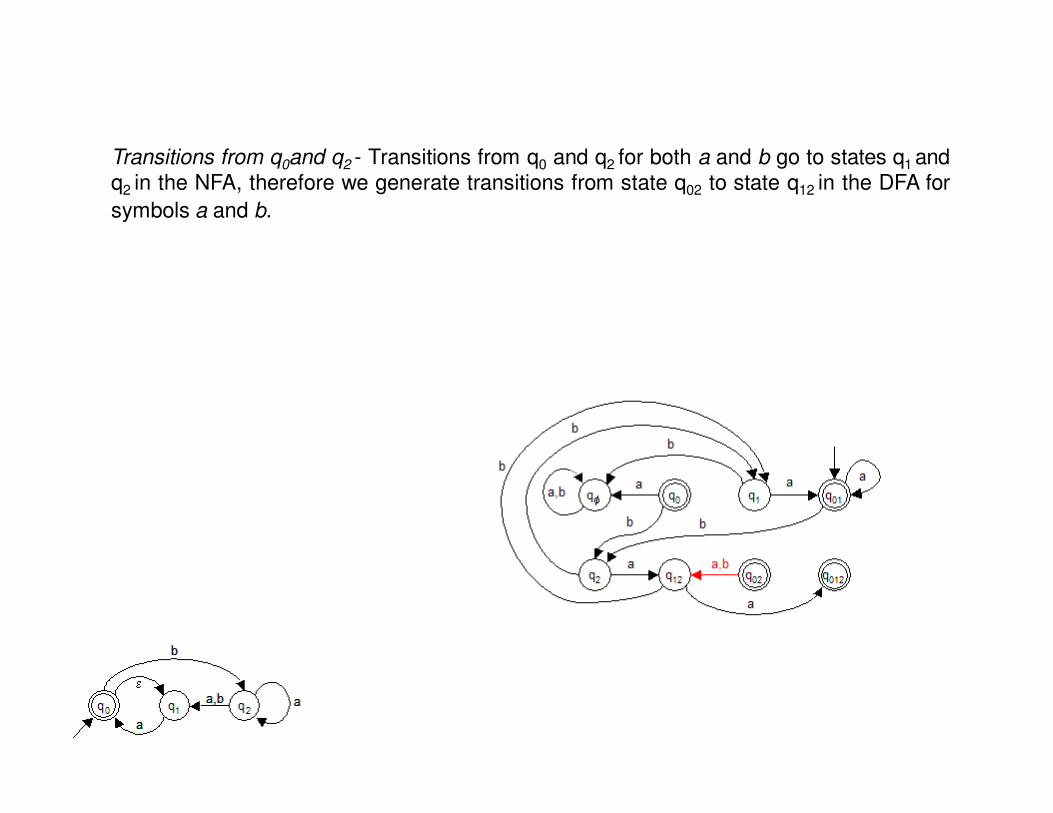
Transitions from q0and q2 - Transitions from q0 and q2 for both a and b go to states q1 andq2 in the NFA, therefore we generate transitions from state q02 to state q12 in the DFA for
symbols a and b.
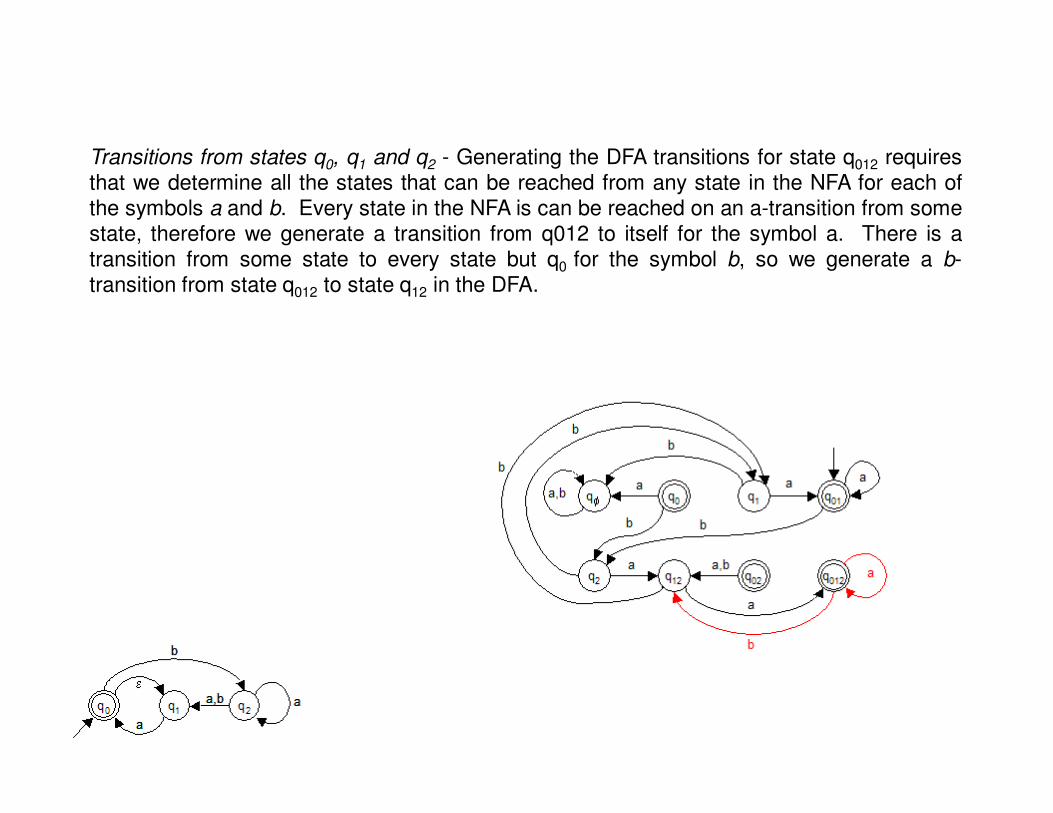
Transitions from states q0, q1 and q2 - Generating the DFA transitions for state q012 requiresthat we determine all the states that can be reached from any state in the NFA for each ofthe symbols a and b. Every state in the NFA is can be reached on an a-transition from somestate, therefore we generate a transition from q012 to itself for the symbol a. There is atransition from some state to every state but q0 for the symbol b, so we generate a b-transition from state q012 to state q12 in the DFA.
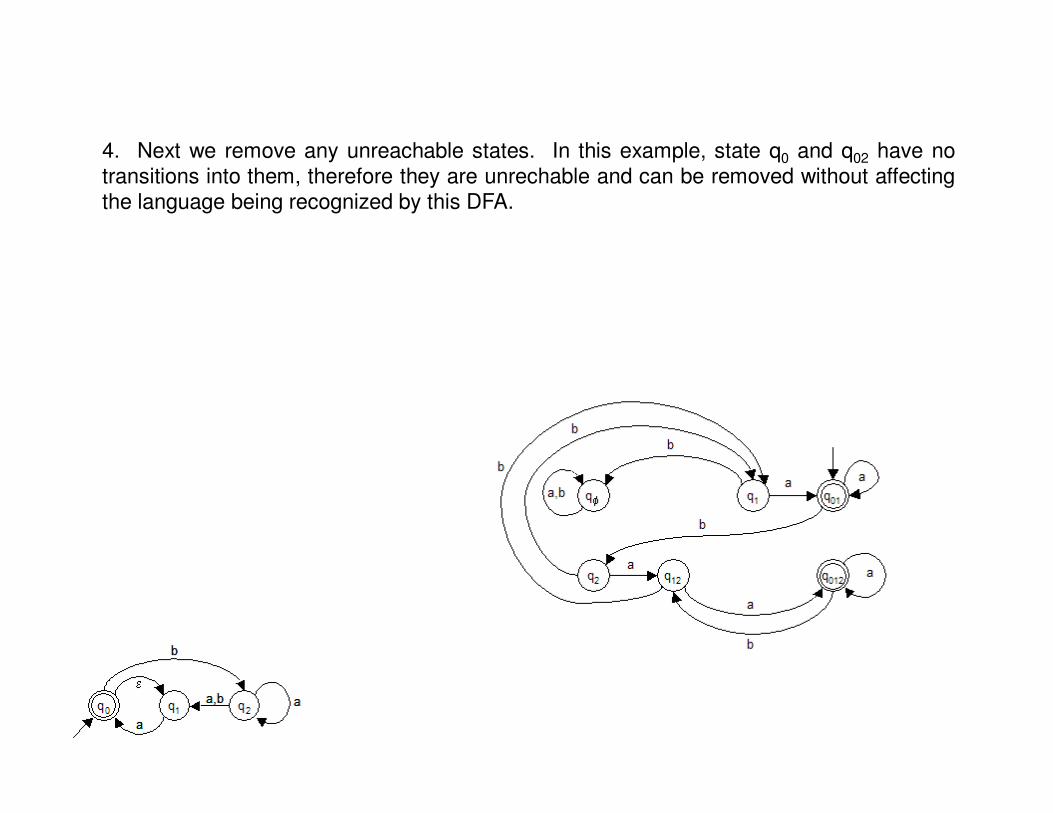
4. Next we remove any unreachable states. In this example, state q0 and q02 have notransitions into them, therefore they are unrechable and can be removed without affectingthe language being recognized by this DFA.
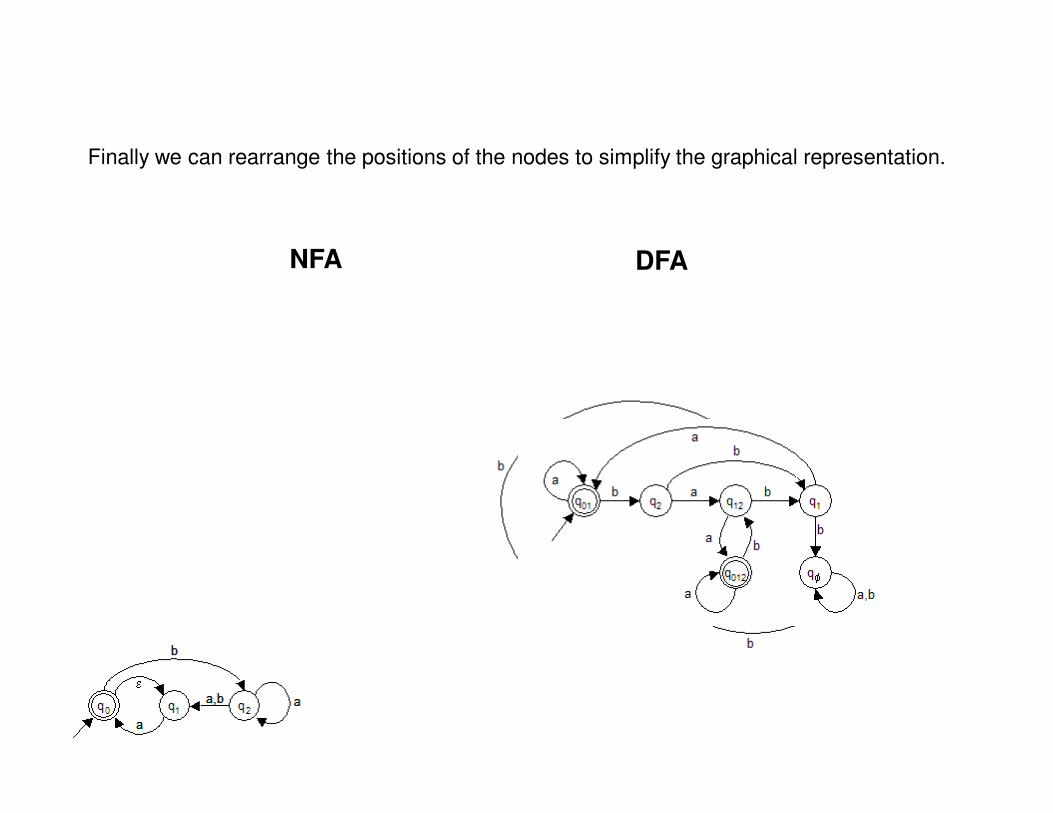
Finally we can rearrange the positions of the nodes to simplify the graphical representation.
NFA DFA

Up to now we have defined regular languages using finite automata and we have shownthat DFAs and NFAs are equivalent. Sometimes using a state transition diagram todescribe a regular language is inconvenient. Regular expressions are algebraic formsfor defining regular languages, that use regular operations on the symbols of the regularlanguage to indicate the member strings of the lanugage. For example, the regular
expression,
(0+1)0*
describes the regular language over the alphabet {0,1} consisting of all binay stringsstarting with a 0 or a 1 and followed by zero or more 0's. The regular operations includea choice or union operator (+ or ), concatenation (implied by sequence of symbols orshown as a fixed number of repetitions n e.g. xynz), and star or Kleene closure (*) which
means zero or more repetitions of a substring.
.
Regular Expressions

We wish to show that the regular expressions are equivalent to NFAs and DFAs in theability to describe regular languages (i.e. they all have the same computational power todescribe the class of languages called regular).
The first step in this goal is to show that the class of regular languages are closed underthe regular operations of union, concatenation and star. The formal proofs are covered inthe textbook. Here will look at graphical representations of the proof ideas. Werepresent generic NFAs as collections of three types of states,.
Regular Expressions are Equivalent to NFA's
and we will use epsion moves to combine generic NFAs to construct new NFAsdemonstrating closure for each of the regular operations.
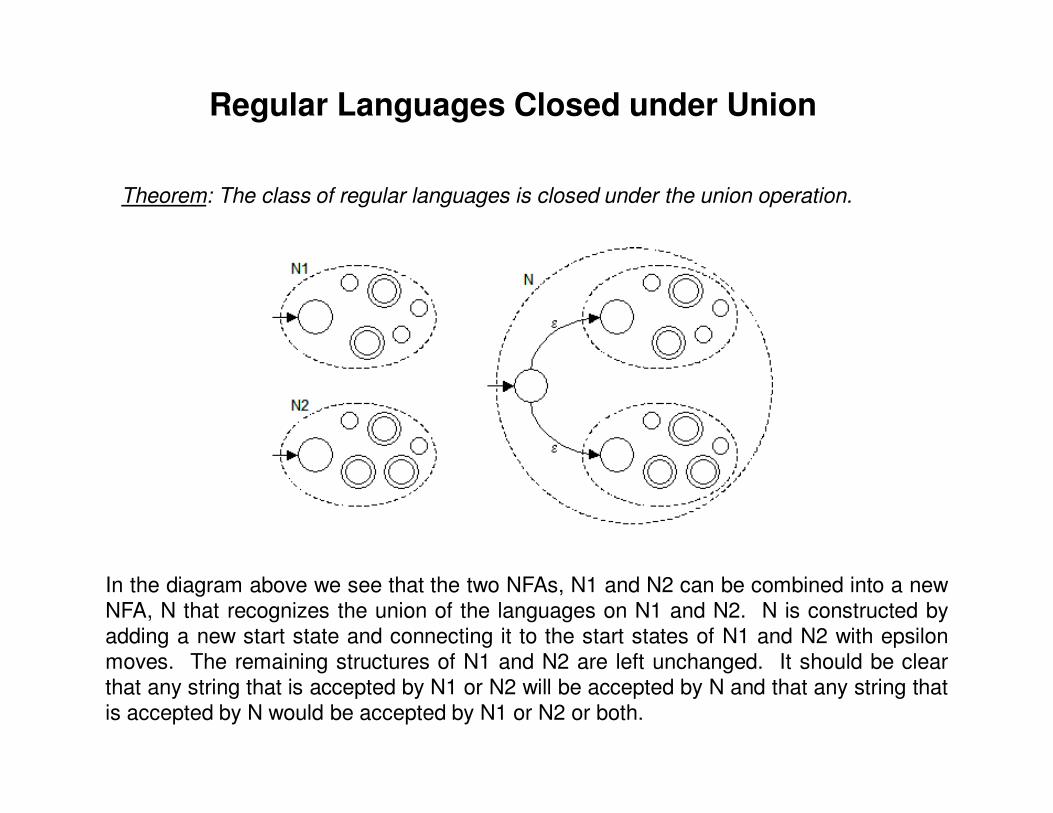
Theorem: The class of regular languages is closed under the union operation.
Regular Languages Closed under Union
In the diagram above we see that the two NFAs, N1 and N2 can be combined into a newNFA, N that recognizes the union of the languages on N1 and N2. N is constructed byadding a new start state and connecting it to the start states of N1 and N2 with epsilonmoves. The remaining structures of N1 and N2 are left unchanged. It should be clearthat any string that is accepted by N1 or N2 will be accepted by N and that any string thatis accepted by N would be accepted by N1 or N2 or both.

Theorem: The class of regular languages is closed under the concatenation operation.
Regular Languages Closed under Concatenation
In this construction we wish to show that N accepts any string that is the contatenation of amember string from N2 to the end of a member string from N1. N is created by connecting allthe accept states in N1 to the start state of N2 with epsilon moves. We then convert all theaccept states of N1 to non-accept states (there will be no accept states in the portion of N thatwas N1.) Note that this works whether or not the start states of N1 and N2 are acceptstates. For example, if N1 accepts the empty string but N2 does not, then N should not acceptthe empty string. On the other hand if both N1 and N2 accept the empty string then there will bean epsion move from the start state of N1 to the start state of N2 (which will still be an acceptstate).

Theorem: The class of regular languages is closed under the star operation.
Regular Languages Closed under Star OperationKleene Closure
Converting an NFA, N1 into N1* can be accomplished by connecting all the accept states to theoriginal start state through epsilon moves. Since N1* must accept the empty string we will add anew start state which is also an accept state and connect it to the original start state of N1through an epsion move. You may wonder why we don't just make the original start state intoan accept state. The reason this does not work is that the NFA, N1 could have a path oftransitions back to the start state for some string of symbols that is not a memberstring. Converting the start state of N1 into an accept state would result in these strings beingaccepted.

Generating Regular Expressions
Create a regular expression for the set of binary strings that contain at least twoconsecutive 0's.
any sequence of 0's and 1's including nothing
followed by
two consecutive 0's
followed by
any sequence of 0's and 1's including nothing
(0 + 1)* 00 (0 + 1)*

another Example
Create a regular expression to generation all binary strings that do not contain twoconsecutive 0's.
01
011011
011101110
01010110101001111011110111101111
(1 + 01)* (0 + λ)
01 01 1 01 1 1 01 01 1 1 01 1 01 1 1 1 1 01 0

Regular Expressions are not Unique
L = { all strings with at least two consecutive 0 }
)0(*)011(1 λ++=r
)0(*1)0(**)011*1(2 λλ +++=r
LrLrL == )()( 211r 2r
and
are equivalentregular expr.
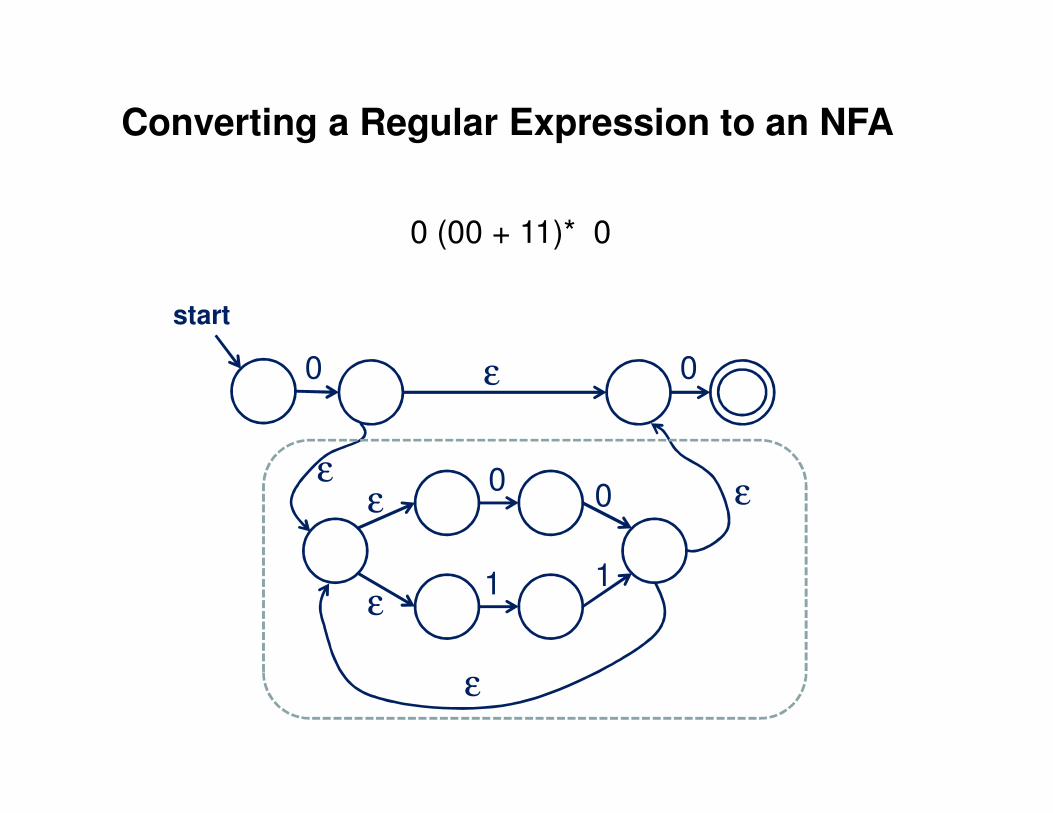
Converting a Regular Expression to an NFA
0 (00 + 11)* 0
start
0 0ε
0
1
ε
ε
ε0
1
ε
ε

Pushdown Automata
We will learn that some context-free grammars are not regular. The reason for this is that
context-free grammars can be recursive. We can modify finite automata to be able to account
for this recursive structure and to recognize context-free languages. The missing feature in
finite automata is an accessible and arbitrarily large memory capacity. We include a stack
memory component to an NFA to obtain the pushdown automata.

A pushdown automata (PDA) reads symbols from the input string and pushes symbols to, and
pops symbols from, a stack memory. The symbol set for the input string is not necessarily the
same as the symbol set for the stack memory. Formally we define a pushdown automata as a
6-tuple (Q,Σ,Γ,δ,q0,F) where
1. Q is the set of states,
2. Σ is the input symbol set,
3. Γ is the stack symbol set,
4. δ:Q x Σε x Γε-> P(Q x Γε) is the transition function,
5. q0 is an element of Q (the start state),
6. F is a subset of Q (the set of accept states).
The symbol ε as a subscript on the input symbol set and the stack symbol set in the definition ofthe transition function means that the PDA can move (transition) without reading an input
symbol or a stack symbol.
Formal Definition of Pushdown Automata

Example: Recall that the language {0n1n | n>= 0 } is not regular so there is no NFA that can
recognize it. As an example of the increased computational power of pushdown automata we
will describe a PDA that recognizes this non-regular language.
Q = { q1, q2, q3, q4},
Σ = { 0,1}
Γ = {0,$},
qstart = q1,
F = {q1,q4},
δ is defined in the table below:
Pushdown Automata is more Computationally Powerful
than Regular Expressions

Also, we can display the PDA graphically as,
The left side of each transition label represents the current input symbol, the right side shows
the stack symbol being popped off the top off the stack followed by the stack symbol to be
pushed onto the stack. Input symbols are read in a left-to-right direction. The ε symbolindicates either an epsilon move (i.e. transition without reading input symbol or a stack
symbol) or that the PDA should not write to the stack for the current transition.
Graphical Representation of the PDA

Let's examine the operation of this PDA a little more closely. First of all, since the start state is an
accept state, an empty input string is accepted. Since there is an epsilon move out of state q1, we
also transition to state q2. On this transition a $ symbol is pushed onto the stack when the PDA
transitions to state q2.
Each 0 symbol read from the input string when the PDA is in state q2 causes a 0 to be pushed onto
the stack. When a 1 is read from the input string in state q2 one of the zero's (if stack not empty) is
popped off the stack and the PDA transitions to state q3 without pushing anything back onto the
stack. For each 1 read from the input while in state q3, a 0 is popped off the stack. As soon as the
special symbol $ reaches the top of the stack the PDA executes an epsilon move to state q4.
If the end of the string has been reached at this time it will be accepted (PDA in an accept state). If
another input symbol is read when the PDA is in states q3 and q4 there is no valid transition and all
control paths are terminated.
Operation of the PDA
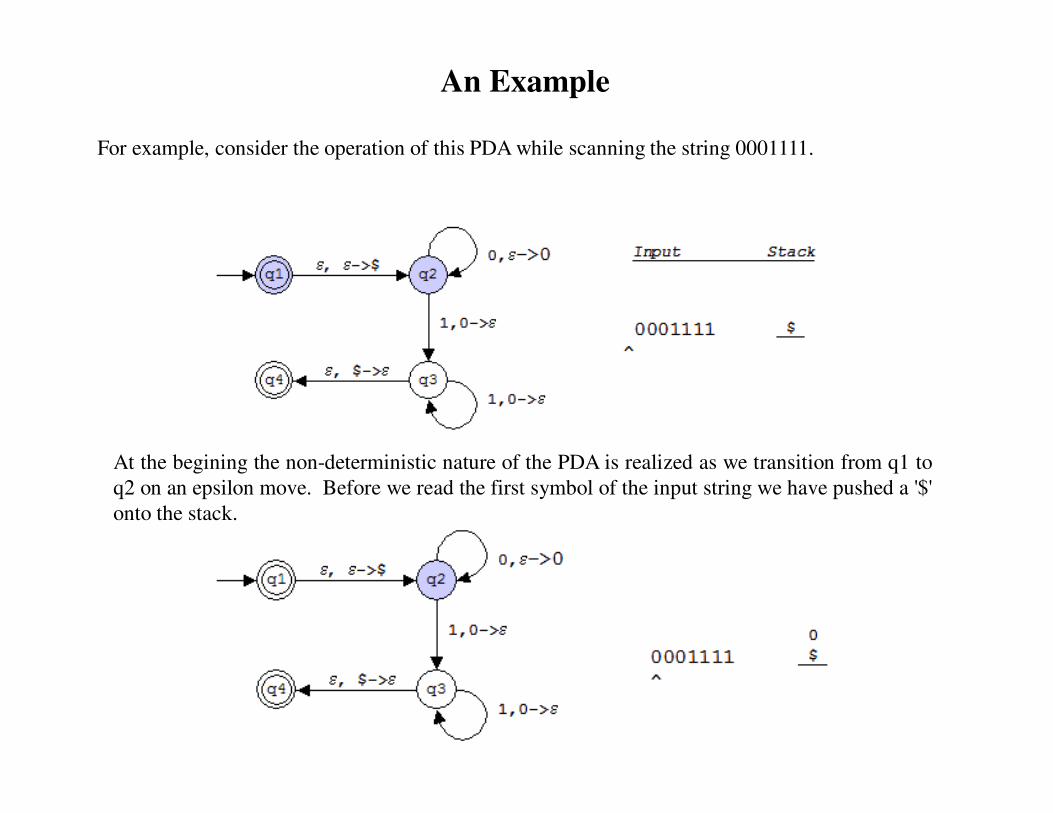
For example, consider the operation of this PDA while scanning the string 0001111.
At the begining the non-deterministic nature of the PDA is realized as we transition from q1 to
q2 on an epsilon move. Before we read the first symbol of the input string we have pushed a '$'
onto the stack.
An Example
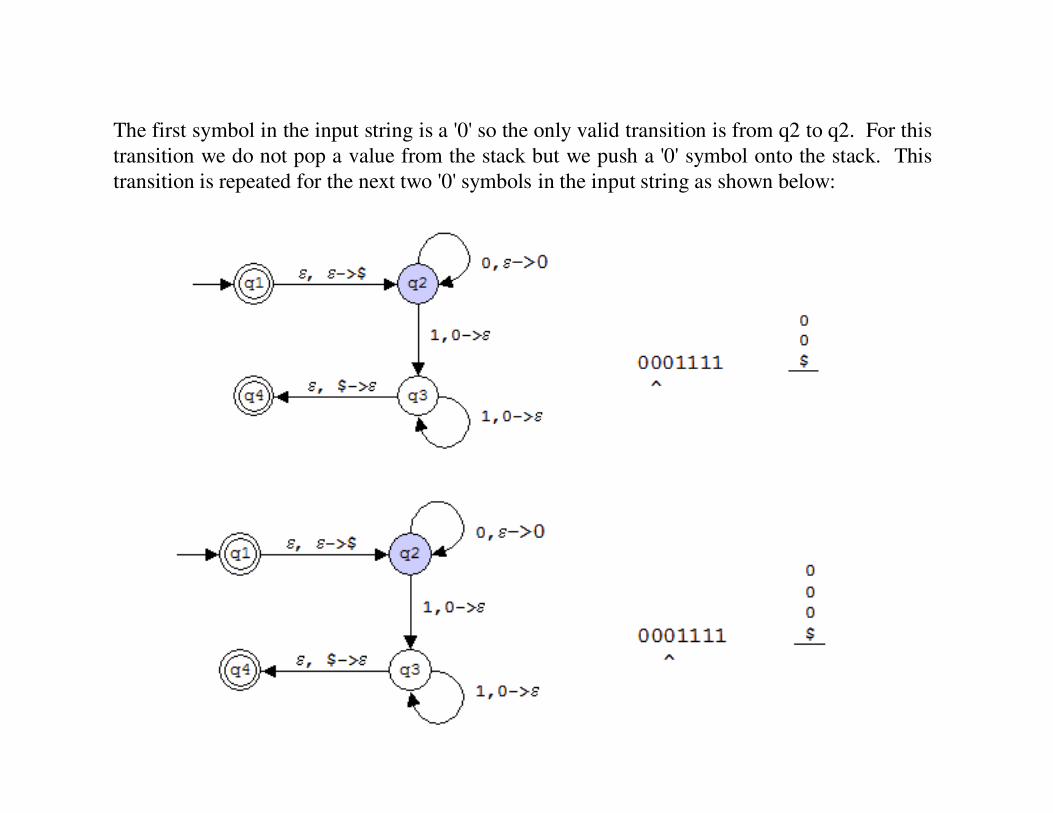
The first symbol in the input string is a '0' so the only valid transition is from q2 to q2. For this
transition we do not pop a value from the stack but we push a '0' symbol onto the stack. This
transition is repeated for the next two '0' symbols in the input string as shown below:

The next input symbol being read is a '1'. For this symbol the only valid transition is from q2
to q3. For this transition we pop a symbol '0' off the stack but we do not push a symbol onto
the stack. Note that there is no epsilon move from q3 to q4 at this point since we are not seeing
a '$' symbol at the top of the stack.
For the next two input symbols (both of them '1's) we stay in state q3 and pop a '0' off the stack.
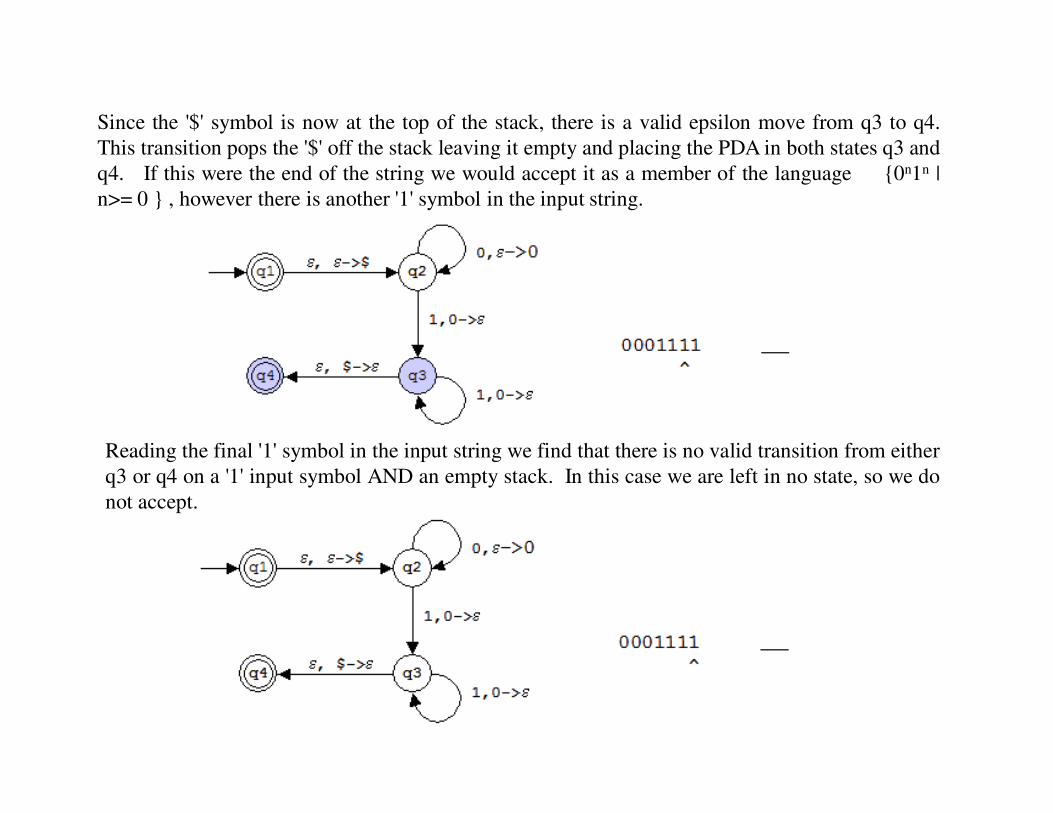
Since the '$' symbol is now at the top of the stack, there is a valid epsilon move from q3 to q4.
This transition pops the '$' off the stack leaving it empty and placing the PDA in both states q3 and
q4. If this were the end of the string we would accept it as a member of the language {0n1n |
n>= 0 } , however there is another '1' symbol in the input string.
Reading the final '1' symbol in the input string we find that there is no valid transition from either
q3 or q4 on a '1' input symbol AND an empty stack. In this case we are left in no state, so we do
not accept.

Theorem: A language is context free if and only if some pushdown automaton recognizes it. This
theorem is typical of the if and only if theorems in that it requires a proof in two directions.
Lemma: If a language is context free, then some pushdown automaton recognizes it.
We will assume that A is a CFL. By definition A must have a corresponding CFG, G, that
generates it. We need a procedure (an algorithm) for converting any CFG, G into an equivalent
PDA, P. We can define such an algorithm:
1. Place the marker symbol $ and the start variable on the stack of the PDA P.
2. Repeat the following steps forever:
a. If the top of stack is a variable symbol A, nondeterministically select one of the rules for A
and substitute A by the string on the right-hand side of the rule.
b. If the top of stack is a terminal symbol a, read the next symbol from the input and
compare it to a. If they match then repeat. If they do not match, reject on this branch of the
nondeterminism.
c. If the top of stack is the symbol $, enter the accept state. Doing so accepts the input if it
has all been read.
Theorem: Context-Free <=> Pushdown Automaton

Lemma: If a pushdown automaton recognizes some language, then it is context free.
Given a PDA, P we need to design a CFG, G that will generate all the strings accepted by P
where P=(Q,Σ,Γ,δ,q0,{qaccept}). The variables of G are {Apq|p,q are in Q}. the start variable is
Aqo,qaccept. The rules of Γ are:
1. For each p,q,r,s in Q, t in Γ, and a,b in Σε, if δ(p,a,ε) contains (r,t) and δ(s,b,t) contains
(q,ε) put the rule Apq-> aArsb in G.
2. For each p,q,r in Q put the rule Apq -> AprArq in G.
3. Finally, for each p in Q put the rule App->ε in G.
We can prove that this construction works by demonstratring that Apq generates x if and only if
(iff) x can bring P from p with empty stack to q with empty stack.
Once again this proof is broken down into two separate cases corresponding to the two if..then
conditions implied by the iff. Both of these proofs are by induction and can be found in a number
of textbooks. We will assume that the proof is valid and, instead, spend our time using it to
generate CFG's from PDA's and vice versa.

Designing Context-Free Grammars
The design and construction of CFG's is a bit more involved than the creation of finite
automata. We can use the following techniques to make this process simpler.
Technique 1: Many CFG's can be constructed through the union of simpler CFG's. If your
goal CFG can be broken down into a number of simpler CFG's you can combine them by
creating a new rule S -> S1 | S2 | . . . | Sk, where the Si are the start variables for each of the
simpler CFG's and S is the start variable for the goal CFG.
Example: Create the grammar for the language L= { 0n1n or 1n0n | n>=0}.
S1 -> 0S11| ε is the grammar for { 0n1n | n>=0}.
S2 -> 1S20| ε is the grammar for { 1n0n | n>=0}. so
S -> S1|S2
S1 -> 0S11| ε
S2 -> 1S20| ε is the grammar for L.

Technique 2: When constructing a CFG for a language that is regular, you can first create a DFA
for the language. You can convert any DFA into an equivalent CFG in the following way:
1. Make a variable Ri for each state qi of the DFA.
2. Add the rule Ri -> aRj to the CFG for each transition δ(qi,a) = qj in the DFA.
3. Add the rule Ri -> ε if qi is an accept state of the DFA.
4. Make R0 the start variable of the grammar, where q0 is the start state of the DFA.
Example: Create a grammar to recognize the language
over {0,1} of all strings containing the substring 1101.
First we create the DFA as shown below: Now, using these rules, we build the CFG:
R0-> 0R0 | 1R1
R1-> 0R0 | 1R2
R2-> 0R3 | 1R2
R3-> 0R0 | 1R4
R4-> 0R4 | 1R4 | ε

Technique 3: Some context-free languages are defined by the matching or comparing arbitrarily
long substrings. In such cases the substrings are said to be linked.
Consider the example of palindromes, P={ w | wRaw is in P and a is in Σε), where wR is thereverse substring of w. The substrings w and wR are linked.
In such situations we can construct a CFG using a rule of the form R -> uRv, which
simultaneously generates the linked substrings on either side of the variable R.
Example: Create a CFG over {0,1} for the language {0n1n | n>=0} R0 -> 0R1 | ε.

Technique 4: In more practical CFG's such as grammars for computer languages or arithmetic
expressions, the stirngs can contain recursively occurring structures. When generating such
grammars you may place symbols that resolve to these recursive structures into the rules at the
locations at which the recursive structures can appear.
Example: Create a CFG that generates arithmetic expressions with the terminals a,b and c and the
operations of addition (+) and multiplication (x).
<EXPR> -> <EXPR> + <TERM> | <TERM>
<TERM> -> <TERM> x <FACTOR> | <FACTOR>
<FACTOR> -> ( <EXPR> ) | a | b | c
The parse trees above show how the grammar generates valid arithmetic expressions. The tree on
the right includes a recursive component in which a <FACTOR> can generate another expression
inside parentheses.

Theorem: The Pumping Lemma for Context-Free Languages.
If A is a context-free language, then there is a number p (the pumping length) where, if s is any
string in A of length at least p, then s may be divided into five pieces s = uvxyz satisfying the
conditions:
1. For each i >= 0, uvixyiz is an element of A, 2. |vy| > 0, and
3. |vxy| <= p.

Example: Use the pumping lemma for context-free languages to show that the languageB={anbncn | n >= 0} is not context free.
Just as with the pumping lemma for regular expressions we will use proof by contradiction to showthat our example language is not context-free. First assume that B is a context-free language, thenlet p be the pumping length for B. This p must exist by the pumping lemma. Now we select a strings = apbpcp. Possible examples of s include
abc
aabbcc
aaabbbccc
aaaabbbbcccc
We note that s is a member of B and that |s|>=p, as required by the pumping lemma. Now if weassume that s is context-free then we will be able to divide it into five sections s = uvxyz whereeither v or y is nonempty (condition 2). We can now consider one of two possibilities for thesubstrings v and y.
Case 1: The substrings v and y each contain all of the same symbols. Whether v and y both containthe same symbols or different symbols at most there will be two of the three symbols in v andy. Therefore, pumping v and y will result in an unequal number of the symbols a, b and/or c.
Case 2: One of the two substrings v and y (or both) contain more than one type of symbol. In this case pumping v and/or y creates symbols in the wrong order.
One of these two cases must occur and since each results in a contradiction, so B is not context free.

Some Philosophical Questions
Are natural languages context-free?
Are context-free grammars useful for describing/understanding the grammar of a natural
language?
Not too long ago, the answer to the first question was clearly no, however, more recent studies
have brought these earlier conclusions into question. In 1957, Noam Chomsky demonstrated
that context-free grammars were inadequate to represent the grammar of natural languages
(called transformational grammars). He showed that a context free grammar could represent
only the 'base component' of natural language and that any natural language would need the
addition of transformations.
However, in 1982, Gazdar showed that a context free grammar could, in fact, encompass all
the transformations suggested by Chomsky. Since that time it remains an open question if all
natural languages can be represented by context free grammars or if CFG's are the best way to
represent them even if it is possible. Pullum provides a good overview of the history of this
development in formal linguistics.

References
1. Lecture 28. Push-Down Storage Automata and Context-Free Grammars - Ling 409 Lecture
Notes, Partee, Lecture 28, Dec 8, 2003
2. Pullum, Geoffrey K. 1991. The Great Eskimo Snow Vocabulary Hoax and Other Irreverent
Essays on the Study of Language. Chicago: The University of Chicago Press. book review.


















