
Material Science By: Juan Carlos Uribe. ΔT = 1,000,000 °C / s.

Introduction Array API Runtime Code Generation Preliminary Results Conclusions
A Composable Array Function Interface forHeterogeneous Computing in Java
Juan Jose Fumeroλ Michel Steuwerπ Christophe Dubachλ
λUniversity of Edinburgh, UK
πUniversity of Münster, Germany
ARRAY’14 , 13.06.2014
1

Introduction Array API Runtime Code Generation Preliminary Results Conclusions
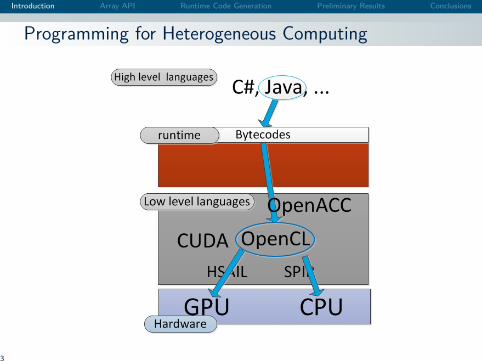
Programming for Heterogeneous Computing
2
Introduction Array API Runtime Code Generation Preliminary Results Conclusions
Programming for Heterogeneous Computing
3
Introduction Array API Runtime Code Generation Preliminary Results Conclusions
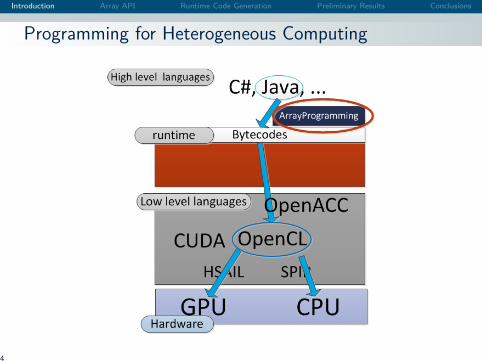
Programming for Heterogeneous Computing
4

Introduction Array API Runtime Code Generation Preliminary Results Conclusions
Previous Work
Embedded DSL in High Level Languages:PyCUDA, PyOpenCL,...JOCL, JavaCL, JCuda, ...
Stream programming:IBM Liquid Metal: new operators for tasks and data parallelismSumatra: Stream API based on JDK 8 for GPU arrayprogramming
5

Introduction Array API Runtime Code Generation Preliminary Results Conclusions
API DescriptionArray Programming Interface
Function<T,R>
ArrayFunction<T,R>
Map<I,T,R> Reduce<I,T,R> Zip<I,T,R>
6

Introduction Array API Runtime Code Generation Preliminary Results Conclusions
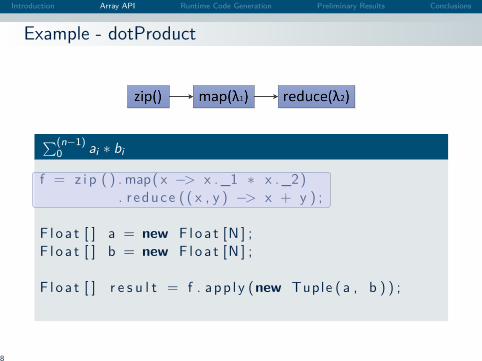
Example - dotProduct
∑(n−1)0 ai ∗ bi
f = z i p ( ) . map( x −> x . _1 ∗ x . _2). r educe ( ( x , y ) −> x + y ) ;
F l o a t [ ] a = new F l o a t [N ] ;F l o a t [ ] b = new F l o a t [N ] ;
F l o a t [ ] r e s u l t = f . app l y (new Tuple ( a , b ) ) ;
7
Introduction Array API Runtime Code Generation Preliminary Results Conclusions
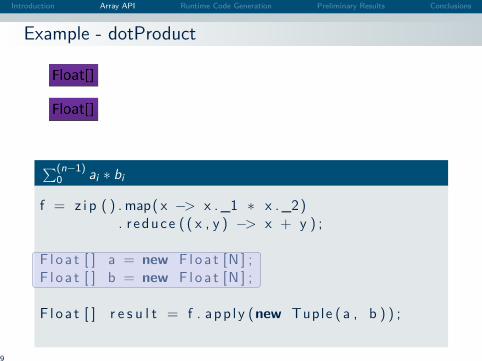
Example - dotProduct
∑(n−1)0 ai ∗ bi
f = z i p ( ) . map( x −> x . _1 ∗ x . _2). r educe ( ( x , y ) −> x + y ) ;
F l o a t [ ] a = new F l o a t [N ] ;F l o a t [ ] b = new F l o a t [N ] ;
F l o a t [ ] r e s u l t = f . app l y (new Tuple ( a , b ) ) ;
8
Introduction Array API Runtime Code Generation Preliminary Results Conclusions
Example - dotProduct
∑(n−1)0 ai ∗ bi
f = z i p ( ) . map( x −> x . _1 ∗ x . _2). r educe ( ( x , y ) −> x + y ) ;
F l o a t [ ] a = new F l o a t [N ] ;F l o a t [ ] b = new F l o a t [N ] ;
F l o a t [ ] r e s u l t = f . app l y (new Tuple ( a , b ) ) ;
9

Introduction Array API Runtime Code Generation Preliminary Results Conclusions
Example - dotProduct
∑(n−1)0 ai ∗ bi
f = z i p ( ) . map( x −> x . _1 ∗ x . _2). r educe ( ( x , y ) −> x + y ) ;
F l o a t [ ] a = new F l o a t [N ] ;F l o a t [ ] b = new F l o a t [N ] ;
F l o a t [ ] r e s u l t = f . app l y (new Tuple ( a , b ) ) ;
10
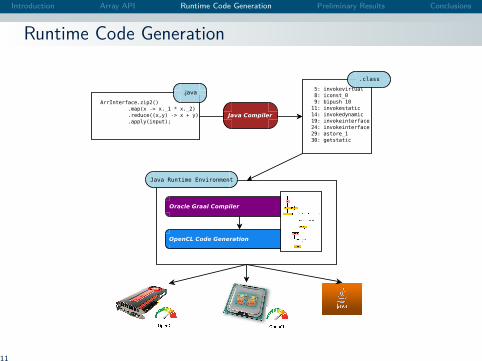
Introduction Array API Runtime Code Generation Preliminary Results Conclusions
Runtime Code Generation
11
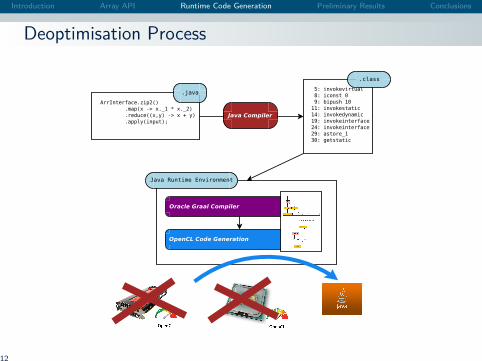
Introduction Array API Runtime Code Generation Preliminary Results Conclusions
Deoptimisation Process
12

Introduction Array API Runtime Code Generation Preliminary Results Conclusions
Vision in the FutureOpportunities for Specialisation
13

Introduction Array API Runtime Code Generation Preliminary Results Conclusions
SetupWorkstation with AMD SDK OCL Driver
Black-Scholes problemComparison with:
Java Sequential: primitivesdata typesJava Objects: using Floatand TuplesArray Function: our APIJava threadsOpenCL GPU
14
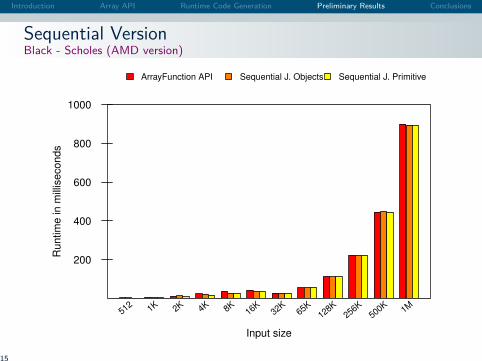
Introduction Array API Runtime Code Generation Preliminary Results Conclusions
Sequential VersionBlack - Scholes (AMD version)
200
400
600
800
1000
512 1K 2K 4K 8K16K
32K65K
128K256K
500K 1M
Runtim
e in m
illis
econds
Input size
ArrayFunction API Sequential J. Objects Sequential J. Primitive
15
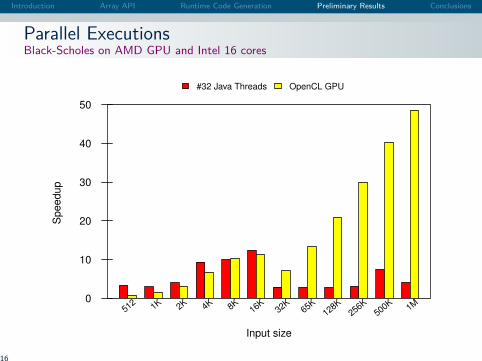
Introduction Array API Runtime Code Generation Preliminary Results Conclusions
Parallel ExecutionsBlack-Scholes on AMD GPU and Intel 16 cores
0
10
20
30
40
50
512 1K 2K 4K 8K16K
32K65K
128K256K
500K 1M
Speedup
Input size
#32 Java Threads OpenCL GPU
16
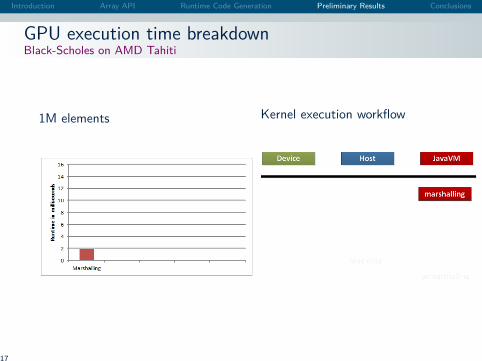
Introduction Array API Runtime Code Generation Preliminary Results Conclusions
GPU execution time breakdownBlack-Scholes on AMD Tahiti
1M elements Kernel execution workflow
17
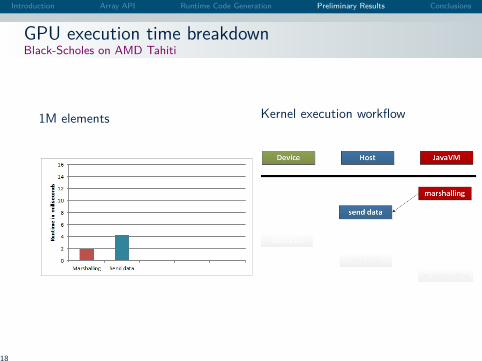
Introduction Array API Runtime Code Generation Preliminary Results Conclusions
GPU execution time breakdownBlack-Scholes on AMD Tahiti
1M elements Kernel execution workflow
18
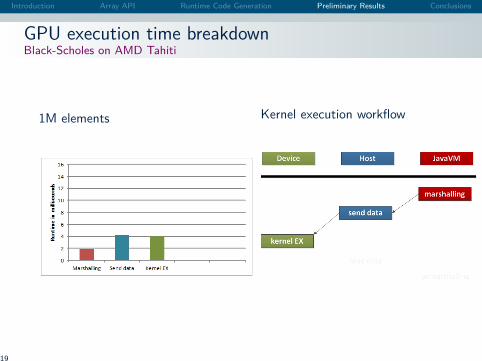
Introduction Array API Runtime Code Generation Preliminary Results Conclusions
GPU execution time breakdownBlack-Scholes on AMD Tahiti
1M elements Kernel execution workflow
19
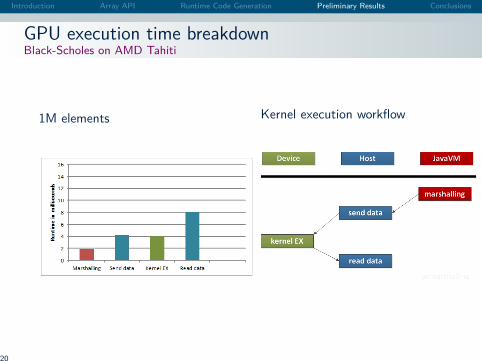
Introduction Array API Runtime Code Generation Preliminary Results Conclusions
GPU execution time breakdownBlack-Scholes on AMD Tahiti
1M elements Kernel execution workflow
20
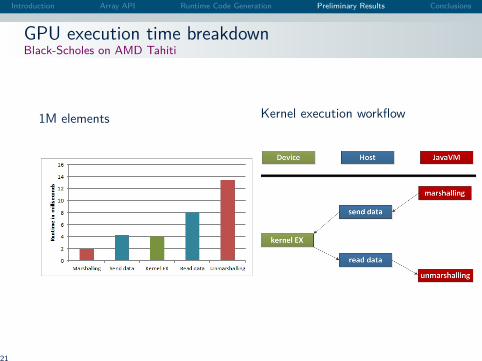
Introduction Array API Runtime Code Generation Preliminary Results Conclusions
GPU execution time breakdownBlack-Scholes on AMD Tahiti
1M elements Kernel execution workflow
21

Introduction Array API Runtime Code Generation Preliminary Results Conclusions
.zip(Conclusions).map(Future)
PresentJava Array Programming API: very high level approach ofusing parallel patterns in heterogeneous systemsWe have presented an early prototype of Map/Reduce byusing Graal JDK8 and OpenCL
FutureRuntime scheduling (Where is the best place to run the code?)Code generation for multiple devicesSpecialised code generation at runtime can improveperformance and portability
22

Introduction Array API Runtime Code Generation Preliminary Results Conclusions
.zip(Conclusions).map(Future)
PresentJava Array Programming API: very high level approach ofusing parallel patterns in heterogeneous systemsWe have presented an early prototype of Map/Reduce byusing Graal JDK8 and OpenCL
FutureRuntime scheduling (Where is the best place to run the code?)Code generation for multiple devicesSpecialised code generation at runtime can improveperformance and portability
22

Introduction Array API Runtime Code Generation Preliminary Results Conclusions
Thanks so much for your attention
This work was supported by agrant from:
Juan José [email protected]
23


















