

Improving scalability in ILP incremental systems Marenglen Biba, Teresa Maria Altomare Basile,...
21
Improving scalability in ILP incremental systems Marenglen Biba, Teresa Maria Altomare Basile, Stefano Ferilli, Floriana Esposito
-
date post
18-Dec-2015 -
Category
Documents
-
view
218 -
download
0
Transcript of Improving scalability in ILP incremental systems Marenglen Biba, Teresa Maria Altomare Basile,...

Improving scalabilityin ILP incremental systems
Marenglen Biba, Teresa Maria Altomare Basile, Stefano Ferilli, Floriana Esposito

Inductive Logic Programming: Why do that? Can learn sets of rules “if-then” that contain variables called First-Order Horn clauses. Ancestor(x,y) ← Parent(x,y) Ancestor(x,y) ← Parent(x,z) Λ Ancestor(z,y)
thus Complex structural descriptions can be learned such as:
Molecular 2D and 3D structure Document structure as a set of logic components Protein fold description
andAny other set of descriptions that need to model complex relations among objects

ILP: Formal setting (Muggleton 1994) Given: set of examples E = E+ ∪ E−
Background knowledge B Learn: a logic theory T such as
T B |─ ∪ E+ CompletenessT B ∪ ∪ E− Consistency
Under the conditions:B E+ Necessity
B T ∪ ∪ E− Strong ConsistencyB T ∪ Weak Consistency
B T |─∪ E+ Sufficiency Neither Sufficiency nor Strong Consistency are required for systems
that deal with noise. How to check Completeness and Consistency: Theorem prover
E
E
E
E
E
E

Example: Describing protein folds
fold(’Four-helical up-and-down bundle’,P) :- helix(P,H1),
length(H1,hi),
position(P,H1,Pos),interval(1<Pos<3),
adjacent(P,H1,H2),helix(P,H2).
The protein P has fold class “Four-helical up-and-down bundle” if it contains a long helix H1 at a secondary structure position between 1 and 3, and H1 is followed by a second helix H2.
A positive and a negative example of the
protein fold “4-helical-up-and-down-bundle”.
3-D arrangement of secondary structure unitsshown for -helices (cylinders) and -sheets (arrows).

Learning logic programs: proving theorems T, B, and E are each logic programs. A logic program is a set of definite clauses each having the form: h ← b1,..,bn
where h is an atom and b1,..,bn are atoms. E+ and E− consist of ground clauses.
Procedure Tuning (E: example; T: theory; B: background knowledge; M: historical memory);
If E is a positive example AND ¬ covers(T,E) then
Generalize(T,E,B,M−)
else
if E is a negative example AND covers(T,E) then
Specialize(T,E,B,M+)
end if
end if
M := M U E. What we need is nothing more than a Prolog interpreter as theorem prover

Learning logic programs: doing it incrementally How to learn? Batch or Incremental?
Batch: Learning starts always from an empty theory and the refinement of the theory continues until all the examples are explained. Whenever a problematic example appears, everything starts again from the beginning without using the previously generated theory. Since everything must be learned again the computational effort is relevant.
Incremental: Why learn from scratch? What if we use the theory learned till now and try to refine it? We could save computational resources learning in an incremental fashion.
INTHELEX (INcremental THEory Learner from EXamples) is an ILP system that adopts incremental refinement of the theories.
INTHELEX adopts multistrategic learning, can start from scratch, learns simultanously various concepts. It’s a close loop learning system.

ILP applications: What has successfully been done Relational Data Mining and Knowledge Discovery for:
Drug Design/Toxicology,
SAR (Structure Activity Relationship),
Protein Structure Prediction,
Functional Genomics,
Systems Biology Learning rules for early diagnosis of rheumatic diseases Learning qualitative models of dynamic systems Applications in finite mesh design. Applications in Natural Language Processing Document Classification and Understanding

ILP future applications: one of the challenges Computational complexity remains a major challenge for
practical applications of ILP, for example:In Systems Biology the scientific knowledge discovery is made possible by the potentiality of ILP, but millions of records that contain 3-D molecule descriptions must be elaborated leading therefore to extremely expensive computional processes.
The huge space of hypotheses to search makes this tasks NP-Hard and thus the need for scalable ILP system that are able to process in reasonable limits of time great quantities of data.

ILP scalability issue: what has been done Subsampling methods focus on a smaller set of examples for
processing very large datasets (Srinivasan 99) .
Local coverage test within a learning from interpretations setting where independence assumptions among examples are reasonable and coverage of each example can be tested without considering the entire background knowledge. (De Raedt 99)
Ad-hoc theta-subsumption techniques to speed-up the coverage test have been also investigated (Di Mauro 2003)
However the NP-Hard nature of problems with a huge space of hypotheses to search motivates for further efforts in implementing scalable ILP system that are able to process very large datasets.
How “large” large datasets are? Do we need scalability? Immagine millions of 3-D sequences of proteins folds to be learned…

ILP systems: their drawbacks Almost all the ILP systems are internal memory systems in that they imply
Prolog interpreters for proving theorems using a main memory. Unfortunately these interpreters are not efficient in that they load all the examples in main memory and whenever the theory must be refined, they try to prove goals scanning the entire main module where thousands of examples may be present.
Prolog interpreters do not maintain any information useful during the theorem proving process. What does it mean? It means no clause knows what examples it covers and whenever it is refined an overall check of the entire memory must be done.
What if every clause knows what examples to check when a cover test should be done?
Prolog interpreters do not maintain any information useful for understanding better the learning process and maybe try other directions in the search of hypotheses.
What if we maintain the various versions of the clauses with relative statistics and use these whenever the search process must be redirected?

Improving scalability: First Step Basic idea: Eliminate main memory handling of terms. Instead of loading them in
main memory, use an external storage that can provide fast access and can eliminate the sequential nature of the Prolog module.
Make it faster, what to choose? Integrate commercial RDBMS or implement a tailored solution for external terms handling?
BerkeleyDB is an Open Source project under the supervision of Sleepycat. It is a database library that provides a powerfull API for data management. It is an “embedded” data engine, in that the libraries are executed in the space of addresses of the hosting application, so no communication between processes is required as an external RDBMS would do (MySql or SQL Server).
The API are available in various languages C, C++, Java, Python, Prolog etc. The underlying structures are hash structures, btrees, record-number-based
storage and queues. Portable: 16,32,64-bit machines, Windows, Unix, Linux and any other OS. The
abstraction layer is about 2500 lines of C code, thus any OS is possible. No query language, only function-calls for data retrieval thus no parsing of queries. Indexing, Page cache management, Transactions and logging, Locking and
Concurrent Access Methods are provided Adopted by HP, SUN, Google, Motorola, Amazon.com for their embedded
systems. (The library is only 300KB but can handle 256 Terabytes of data)

Improving scalability: First step The interface we exploit uses the Concurrent Access Methods product of Berkeley
DB. This means that multiple processes can open the same database, but transactions and disaster recovery are not supported. The environment and the database files are ordinary Berkeley DB entities that use a custom hash function.
We developed a tailored embedded solution using the Sicstus Prolog interface to the Berkeley DB toolset for supporting persistent storage of Prolog terms. The idea is to obtain a behavior similar to the built-in Prolog predicates such as assert/1, retract/1 and clause/2.
DB-Specification: speclist = [spec1, . . . , specM]
spec = functor(argspec1, . . . , argspecN)
argspec = + | -
where functor is a Prolog atom. A spec F(argspec1, . . . ,argspecN) is applicable to any ground term with principal functor F/N.

Improving scalability: First step The functors and the indexing specifications of the terms to be stored have to
be given when the database is created. The indexing is specified when the database is created. It is possible to index
on other parts of the term than just the functor and first argument. Changes affect the database immediately. The database can store variables (Other DBMSs do not).
Example: Storing and fetching examples in Prolog db-spec: examples(+,-,-,-,-). Indexed on the argument signed with “+”
db_create(examples(+,-,-,-,-), MyDb)
db_store(MyDb,examples(KeyExample,Concect,Head,Body,Constraints,Symbolic,Numeric)
db_fetch(MyDb,examples(KeyExample,_,_,_,_,_);
db_iterator(MyDb, examples(KeyExample,_,_,_,_,_);
db_iterator_next(My_Db); db_open(My_Db); db_close(My_Db)
All these operators call C language API functions of Berkeley DB

Improving scalability: Second step Basic idea: having eliminated main memory of Prolog we can link clauses to
examples. Implement a relational schema that keeps links between clauses and examples
they cover. What is this useful for? When a clause is specialized only the examples previously
covered by the clause should be checked. Thus picking up all the examples and all the coverage tests that in a Prolog fashion correspond to proving all these goals, are replaced by an external fast check of only the examples related to the clause.
When a clause is generalized it is useless to check all the past positive examples. The positive examples previously covered will continue to be covered since the clause has been generalized. Through our schema only negative examples of the same concept (clauses and examples indexed also on their concept) are checked saving unnecessary checks that Prolog interpreter would do by checking again the entire main memory.
The expensive cover test is done only the first time an example enters the database. Sucessively it is sufficient to check a hash table with the keys of the clauses and examples.

Improving scalability: Is it all? What if we maintain versions of the theory step after step? At a certain
moment of the search in the hypotheses space, if we would want to backtrack, how can we do it if we don’t know what has happened to the theory (the Prolog case) and how this has evolved in time?
What if we could know which example caused a certain refinement? In a Prolog setting this is not possible. Instead with our solution we can adopt partial memory techniques discriminating the examples on the basis of what kind of modifications they have been able to do to the theory during the learning process.
To understand better the learning process we can maintain statistics about the learning task, such as number of refinements caused by an example, number of refinement of a clause, times of refinement and other precious information that in a Prolog setting are not possible.
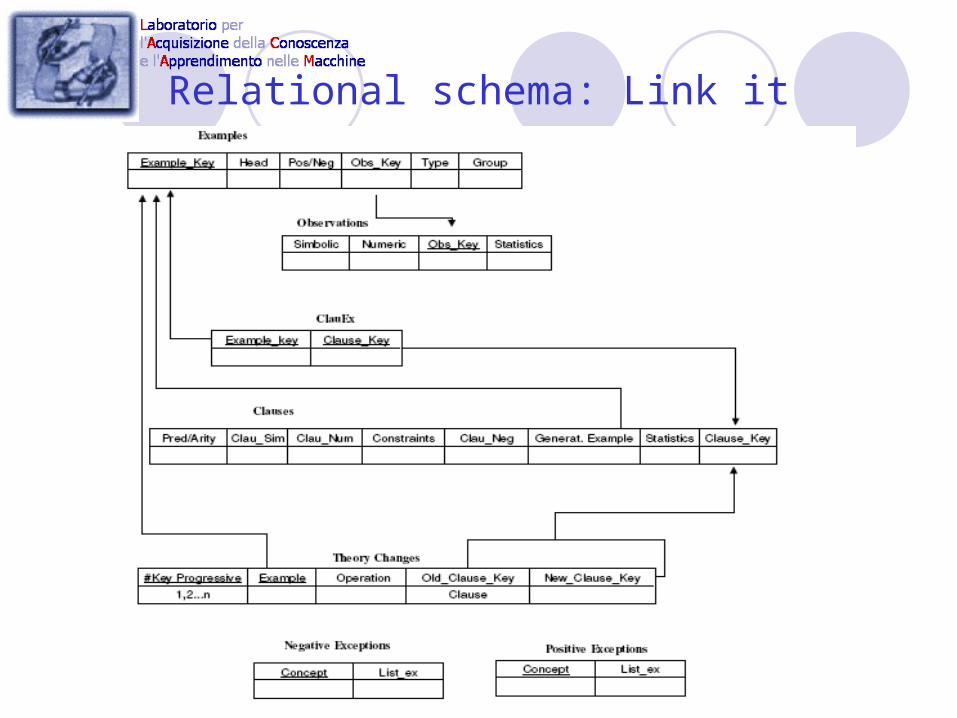
Relational schema: Link it
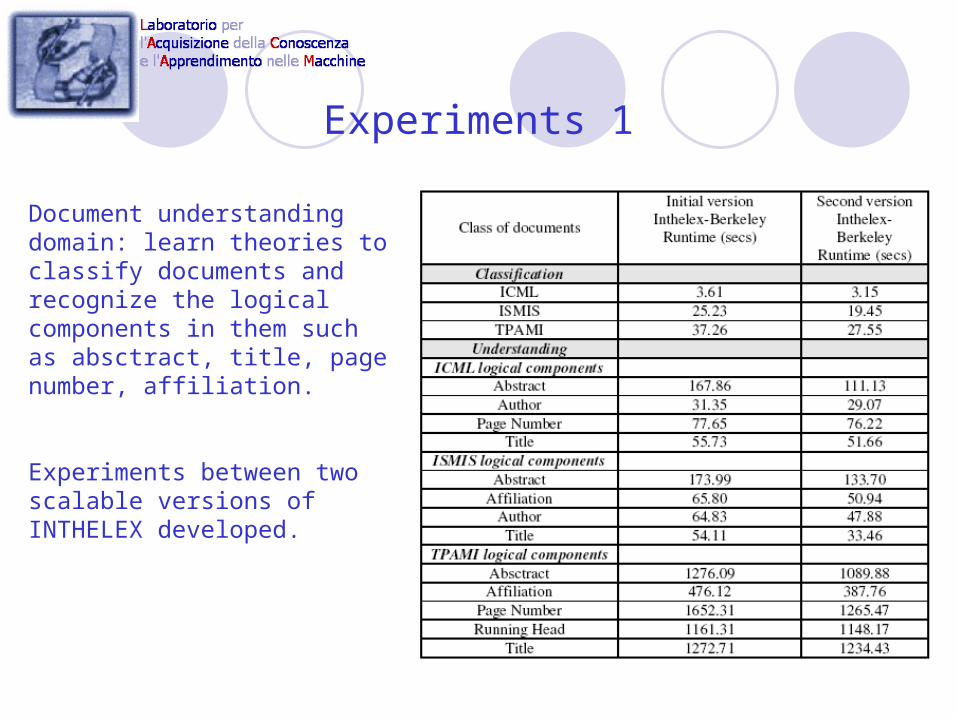
Experiments 1
Document understanding domain: learn theories to classify documents and recognize the logical components in them such as absctract, title, page number, affiliation.
Experiments between two scalable versions of INTHELEX developed.
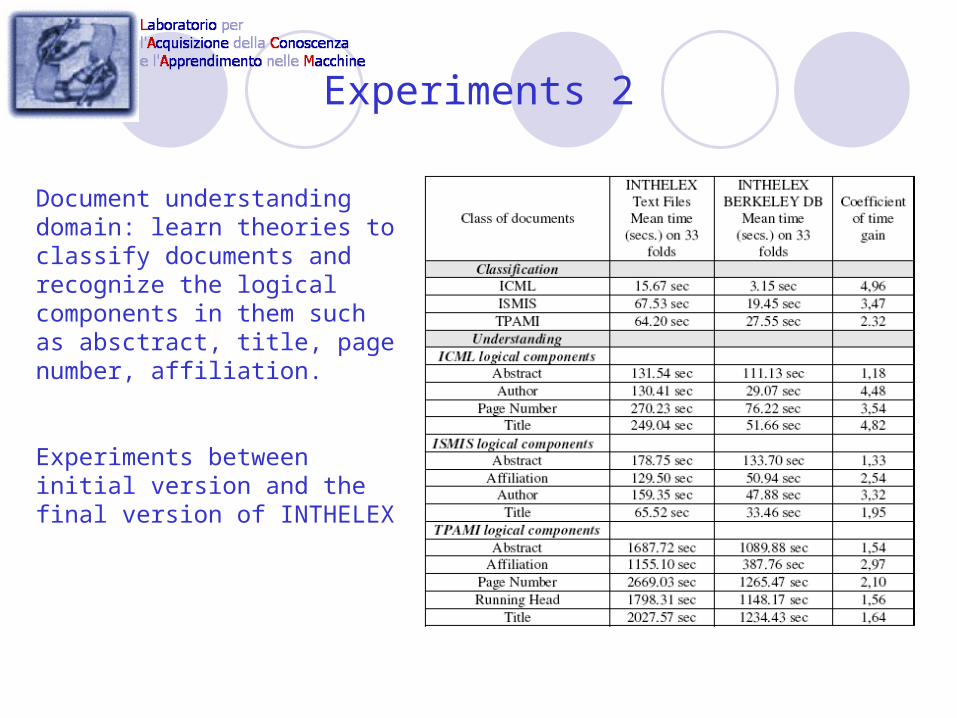
Experiments 2
Document understanding domain: learn theories to classify documents and recognize the logical components in them such as absctract, title, page number, affiliation.
Experiments between initial version and the final version of INTHELEX

Results interpretation
External storage of terms and fast-access through function-call techniques resulted in important savings in times of elaboration.
Linking clauses and examples improved significanlty the learning process in terms of efficiency.

Future work
Investigate the use of the information preserved in the database such as the versions of the theory for backtracking strategies.
Investigate the statistics about the examples for implementing partial memory learning methods.












