
Goodness of Fit test med Nspire 05 dec 2011 - science-gym.dk · teoretisk model). Denne...
29
χ 2 -test Chokoladeprojektet, 2011 side 1 af 29 sider χ 2 – test Indhold Formål med noten ......................................................................................................................................... 2 Goodness of fit metoden (GOF) ........................................................................................................................ 2 1) Eksempel 1 – er stikprøven repræsentativ for køn? (1 frihedsgrad)..................................................... 2 2) χ 2 -fordelingerne (fordelingsfunktionernes egenskaber) ....................................................................... 6 3) χ 2 - testen ............................................................................................................................................... 8 4) Eksempel 2 - er partierne gået tilbage? (3 frihedsgrader) ................................................................... 9 5) Øvelse 1 – Er befolkningen i Hillerød repræsentativ for hele Danmark? ............................................ 11 6) Øvelse 2 – er karakterfordelingen i 2. ☺ den samme som på landsplan? .......................................... 12 7) Goodness of fit med en hurtigere metode .......................................................................................... 13 8) Goodness of Fit test – oversigt ............................................................................................................ 19 9) Hypotesetestning................................................................................................................................. 20 χ 2 -test for uafhængighed mellem to inddelingskriterier ................................................................................ 22 10) METODE 1: Den teoretiske løsningsmetode ................................................................................... 22 11) METODE 2: den hurtige løsningsmetode ........................................................................................ 25 12) Projekt ............................................................................................................................................. 27 Appendix – Nspire kommandoer til χ 2 -test ............................................................................................. 29
Transcript of Goodness of Fit test med Nspire 05 dec 2011 - science-gym.dk · teoretisk model). Denne...

χ 2-test Chokoladeprojektet, 2011
side 1 af 29 sider
χ2 – test
Indhold Formål med noten ......................................................................................................................................... 2
Goodness of fit metoden (GOF) ........................................................................................................................ 2
1) Eksempel 1 – er stikprøven repræsentativ for køn? (1 frihedsgrad) ..................................................... 2
2) χ2-fordelingerne (fordelingsfunktionernes egenskaber) ....................................................................... 6
3) χ2 - testen ............................................................................................................................................... 8
4) Eksempel 2 - er partierne gået tilbage? (3 frihedsgrader) ................................................................... 9
5) Øvelse 1 – Er befolkningen i Hillerød repræsentativ for hele Danmark? ............................................ 11
6) Øvelse 2 – er karakterfordelingen i 2. ☺ den samme som på landsplan? .......................................... 12
7) Goodness of fit med en hurtigere metode .......................................................................................... 13
8) Goodness of Fit test – oversigt ............................................................................................................ 19
9) Hypotesetestning................................................................................................................................. 20
χ2-test for uafhængighed mellem to inddelingskriterier ................................................................................ 22
10) METODE 1: Den teoretiske løsningsmetode ................................................................................... 22
11) METODE 2: den hurtige løsningsmetode ........................................................................................ 25
12) Projekt ............................................................................................................................................. 27
Appendix – Nspire kommandoer til χ2-test ............................................................................................. 29
χ 2-test Chokoladeprojektet, 2011
side 2 af 29 sider
Formål med noten
I forbindelse med skriftlig eksamen skal du kunne bruge χ2-test (læses: ”ki i anden test”) på to
måder. Dels skal du kunne undersøge om en forelagt fordeling (de observerede data) følger en i
forvejen kendt fordeling (de forventede værdier, kendt fra en større statistisk undersøgelse eller en
teoretisk model). Denne undersøgelse kaldes ”goodness of fit test” og er det første disse noter
handler om. Dels skal du kunne afgøre om nogle observationer er uafhængige. Det kan du læse om i
den sidste del af disse noter. For at kunne forstå noterne skal du inden have sat dig ind i begreberne
uafhængighed i sandsynlighedsregning, og du skal kende til kontinuerte fordelinger.
Noterne til Goodness of Fit er lavet på baggrund af et notesæt af Jakob Bøje Pedersen ,
Frederiksborg Gymnasium og HF. Noterne er resultatet af et arbejde på DASG kurset ”IT i
matematik”, oktober 2011, og er udarbejdet af Mikkel Nielsen, Falkonergården, Bente Quorning,
Karen Gøtzsche-Larsen, Ishak Gürleyik og Eva Danielsen Nærum Gymnasium. Til kapitlet om χ2-
fordelinger hører en fil med opgaver i Nspire.
Goodness of fit metoden (GOF)
1) Eksempel 1 – er stikprøven repræsentativ for køn? (1 frihedsgrad)
Vi starter med et eksempel. De forskellige begreber uddybes teoretisk efterfølgende.
Fordelingen af kvinder og mænd i befolkningen antages at være henholdsvis 51% og 49%. Denne
fordeling skal også kunne findes i en stikprøve, hvis undersøgelsen skal kunne betegnes som
repræsentativ med hensyn til køn. Antag at vi i forbindelse med en statistiskundersøgelse har en
stikprøve på 186 personer. Vi vil så undersøge om de 186 personer fordeler sig over køn på samme
måde som populationen (den danske befolkning).
Nulhypotese (H0): Vi antager at stikprøven på 186 er repræsentativ for befolkningen. Dvs. at den
afvigelse fra befolkningens kønsfordeling, som vi har i stikprøven er så lille, at det kan forklares ud
fra tilfældig variation.
Signifikansniveau: Vi vælger et signifikansniveau på 5%. Dvs., at vi vil forkaste hypotesen, hvis
vores beregning viser, at en så usandsynlig stikprøve højest vil optræde i 5% af tilfældene. Dvs.
hvis sandsynligheden for at vores stikprøve forekommer, er under 5% på betingelse af vores
nulhypotese, så betragter vi det som så usandsynlig en stikprøve, at vi vil forkaste hypotesen.
Vores stikprøve har vist følgende observationer:
Køn Kvinder Mænd Sum
Observerede antal 107 79 186
χ 2-test Chokoladeprojektet, 2011
side 3 af 29 sider
Ud fra hele befolkningens kønsfordeling vil vi forvente:
Køn Kvinder Mænd Sum
Forventede antal 186·0.51 = 94.9 186·0.49=91.1 186
Vi beregner χ2 teststørrelsen:
22
2 22
( )
(107 94.9) (79 91.1)1.55 1.62 3.17
94.9 91.1
antal antaltest
antal
test
obs forv
forvχ
χ
−=
− −= + = + =
∑
Jo større afvigelsen er mellem de observerede og de forventede værdier, jo større er χ2
teststørrelsen. Vi vil gerne vide hvor (u-)sandsynlig vores χ2 teststørrelse er.
Frihedsgrader: For at kunne vurdere denne sandsynlighed skal vi kende antallet af frihedsgrader.
Da vi kender observationssættets størrelse (vi stopper stikprøven, når vi har 186 personer), kan vi
beregne antallet af kvinder, hvis vi kender antallet af mænd (eller omvendt). Man siger derfor
statistisk, at der er én frihedsgrad. Hvis vi kalder antallet af kriterier for k (mand hhv. kvinde) kan
vi beregne antallet af frihedsgrader som 1 2 1 1f k= − = − = .
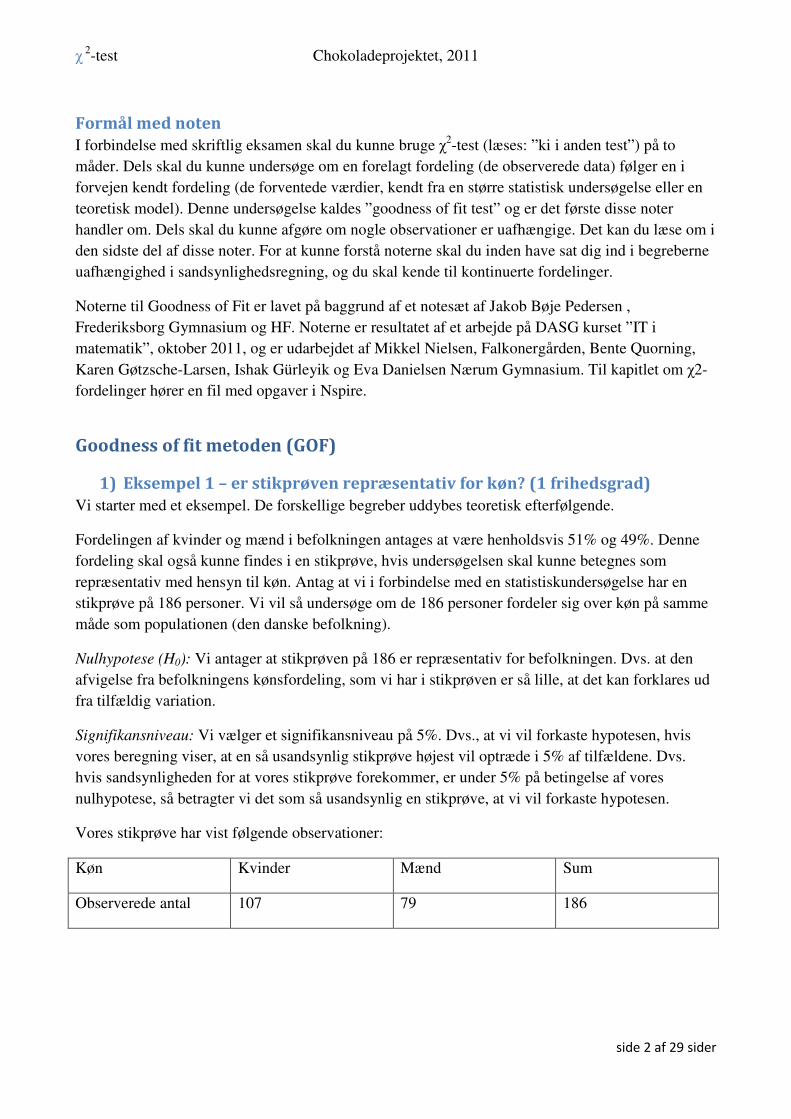
Vi skal nu vurdere teststørrelsen. Statistikere har vist, at χ2 teststørrelsen med stor tilnærmelse
følger en såkaldt χ2 –fordeling med 1 frihedsgrad (se næste kapitel). Fordelingen er vist grafisk
nedenfor.
Vi er interesseret i at udregne testtallet som er arealet under grafen fra 3.17 til ∞. Vi kan slå dette
areal op med en kommando i Nspire:
P(χ2-teststørelse > 3.17) =0.075
χ 2-test Chokoladeprojektet, 2011
side 4 af 29 sider
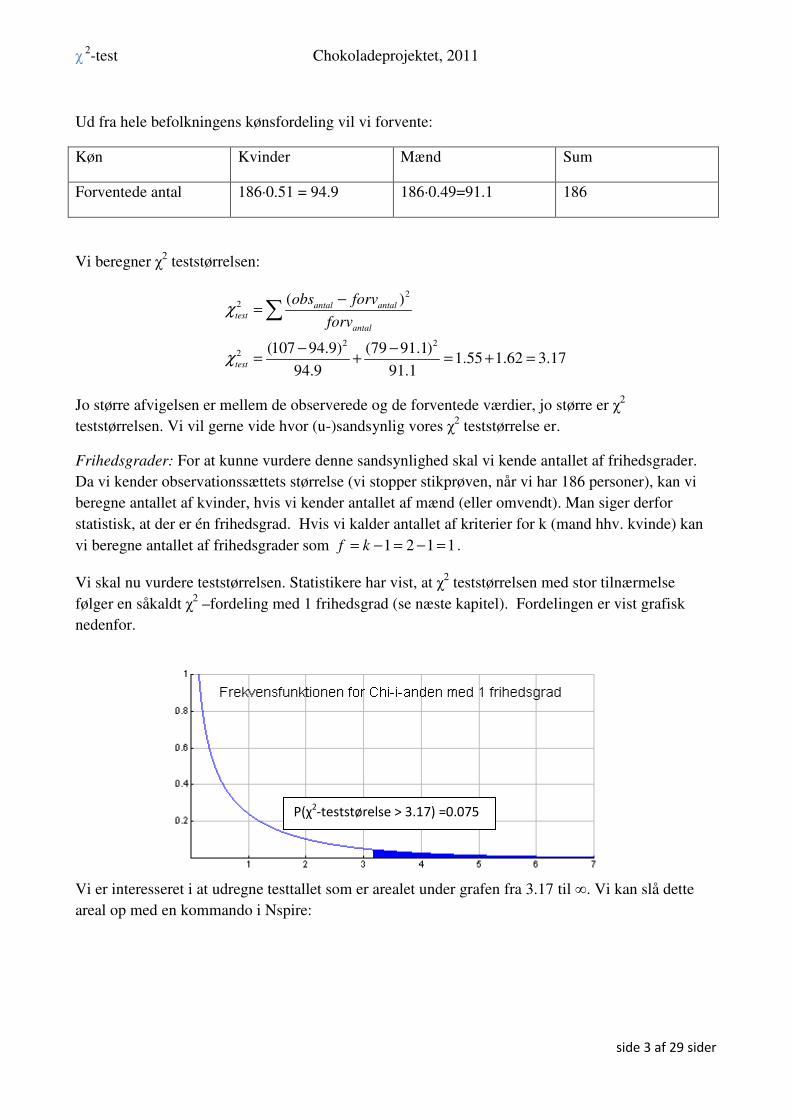
Ovenfor er vist en af de måder, man kan finde den kumulerede χ2 –
fordeling. Efter klikket på ”8: χ2 Cdf” får man følgende menu:
Her vil vi gerne indtaste vores χ2-testværdi, 3.17, som nedre grænse og
uendelig som øvre grænse. Det letteste er i den øvre grænse at indtaste
et stort tal og dernæst i kommando-linjen rette det store tal til uendelig
ved hjælp af symbol-palletten:
”Cdf” står for Cumulated Density Function (kumuleret tæthedsfunktion).
Resultatet 0.075 kaldes p-værdien eller test-sandsynligheden og viser, at der er 7.5% sandsynlighed
for at få en χ2-testværdi på 3.17 eller derover ved en tilfældig stikprøve med en frihedsgrad på 1.
Da p-værdien er større end signifikansniveauet accepteres hypotesen, stikprøven er altså
repræsentativ med hensyn til køn. Bemærk at p-værdien (7,5 %) er tæt på signifikansniveau 5%
dvs. resultatet af testen er usikkert og bør undersøges nærmere (stikprøven bør være større end 186).
Populært sagt, er p-værdien et udtryk for nulhypotesens troværdighed – og med en troværdighed på
7.5 % kan vi ikke afvise nulhypotesen.
Hvis vi havde skullet forkaste nulhypotesen, så kunne vi se på de enkelte bidrag til χ2-testværdien,
der så at sige viser, ”hvem den skyldige er”, ud fra hvilket bidrag, der er størst. Her er de to bidrag
på hhv. 1.55 og 1.62 næsten lige store, så man kan ikke ”skyde skylden” på den ene part mere end
den anden.
χ 2-test Chokoladeprojektet, 2011
side 5 af 29 sider
Hvor stor en χ2-testværdi kunne vi have accepteret? Det kan vi undersøge ved at spørge, ved
hvilken x-værdi er arealet under grafen fra x til ∞ 5%? Vi skal bruge en
kommando i samme menu-kæde som før, bare et trin under sidste
kommando:
Eller man indtaster kommandoen direkte som invchi2(0.95,1). Uanset om man taster eller henter fra
menuen får vi: . Der står 0.95 og ikke 0.05 fordi Nspire finder den x-
værdi, hvor arealet under grafen fra 0 til x er den indtastede værdi. (Fra kontinuerte fordelinger
husker vi, at det samlede areal er 1.)
Resultatet viser, at der er 5% sandsynlighed for at få en χ2-testværdi på 3.84 eller højere.
Hvis Nspire ikke havde haft den inverse kommando indbygget kunne man have løst problemet med
nsolve: .
χ2Cdf kan indtastes som chi2cdf(…).
χ 2-test Chokoladeprojektet, 2011
side 6 af 29 sider
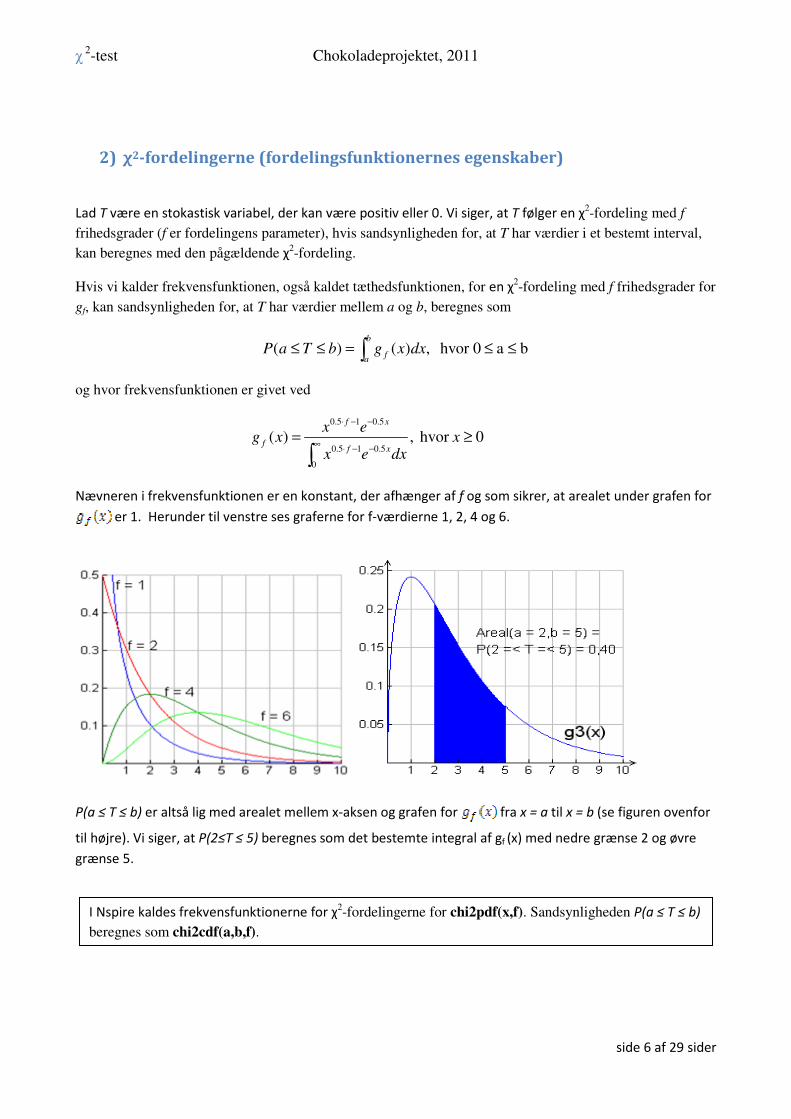
2) χ2-fordelingerne (fordelingsfunktionernes egenskaber)
Lad T være en stokastisk variabel, der kan være positiv eller 0. Vi siger, at T følger en χ2-fordeling med f
frihedsgrader (f er fordelingens parameter), hvis sandsynligheden for, at T har værdier i et bestemt interval,
kan beregnes med den pågældende χ2-fordeling.
Hvis vi kalder frekvensfunktionen, også kaldet tæthedsfunktionen, for en χ2-fordeling med f frihedsgrader for
gf, kan sandsynligheden for, at T har værdier mellem a og b, beregnes som
( ) ( ) , hvor 0 a bb
fa
P a T b g x dx≤ ≤ = ≤ ≤∫
og hvor frekvensfunktionen er givet ved
0.5 1 0.5
0.5 1 0.5
0
( ) , hvor 0f x
ff x
x eg x x
x e dx
⋅ − −
∞⋅ − −
= ≥
∫
Nævneren i frekvensfunktionen er en konstant, der afhænger af f og som sikrer, at arealet under grafen for
er 1. Herunder til venstre ses graferne for f-værdierne 1, 2, 4 og 6.
P(a ≤ T ≤ b) er altså lig med arealet mellem x-aksen og grafen for fra x = a til x = b (se figuren ovenfor
til højre). Vi siger, at P(2≤T ≤ 5) beregnes som det bestemte integral af gf (x) med nedre grænse 2 og øvre
grænse 5.
I Nspire kaldes frekvensfunktionerne for χ2-fordelingerne for chi2pdf(x,f). Sandsynligheden P(a ≤ T ≤ b)
beregnes som chi2cdf(a,b,f).

χ 2-test Chokoladeprojektet, 2011
side 7 af 29 sider
Nspire opgave 1
I opgaven er frekvensfunktionerne g(x,f) defineret og grafen for f = 1 er indtegnet nederst til venstre.
Brug g(x,f) til at indtegne graferne for f = 2 og 3 i grafvinduet til venstre. I højre grafvindue indtegner
du de tilsvarene grafer tegnet vha. chi2pdf(x,f). Sammenlign graferne – er der forskelle? Blev de tegnet
lige hurtigt?
Nspire opgave 3
I denne opgave skal du prøve at beregne sandsynligheder både
a) ved beregning med invchi2(areal, f),
b) med arealet under grafen
c) ved at løse en ligning.
Nspire opgave 5
I denne opgave skal du undersøge frekvensfunktionernes maksimum og middelværdi
Nspire opgave 2
Åbn opgave 2 i Nspire-filen. Løs opgaven, der handler om arealet under graferne for
frekvensfunktionerne.
Nspire opgave 4 (ekstra)
Om fordelingsfunktioner
Nspire opgave 6
Man kan her let skifte mellem de forskellige frekvensfunktioner. Prøv selv
I de følgende opgaver skal I bruge Nspire-filen: chi2grafer.tns. Opgaverne ligger som forskellige
”opgaver” (faner i filen). I hver opgave skal I sikre jer at I får alle delspørgsmål med. (Se scroll-baren)
I har nu observeret, at P(0 ≤ T < ∞) = 1, da arealet under hele grafen er 1. Dette svarer til, at summen af
alle sandsynlighederne er 1 i en fordeling med et endeligt antal udfald.
Frekvensfunktionerne har en række egenskaber, som du skal undersøge i den næste opgave.
χ 2-test Chokoladeprojektet, 2011
side 8 af 29 sider
3) χ2 - testen
Hypotesen ”om at to fordelinger er ens” er rimelig, hvis de forventede værdier {forvantal,1,
forvantal,2,...} er tæt på de observerede værdier {obsantal,1, obsantal,2,…}. Derfor ser man på forskellen
mellem disse værdier i χ2-testen. Forskellen kvadreres 2( )antal antal
obs forv− så bidragene altid er
positive, uanset om obsantal,i er større eller mindre end forvantal,i. Dette udtryk for forskellen mellem
obsantal,i og forvantal,i ses i forhold til den forventede værdi forvantal,i. Således giver det god mening at
se på teststørrelsen:
22 ( )
antal antaltest
antal
obs forv
forvχ
−=∑ .
2
testχ er tilnærmelsesvist χ2-fordelt med f = (k – 1) frihedsgrader (når vi kender det observerede antal
for k – 1 kriterier og det totale antal, kender vi det observerede antal for alle k kriterier).
Tilnærmelsen er rimelig, hvis
n ≥ 60 og forvantal,min ≥ 5.
Her er n det samlede antal observationer, og forvantal,min er den laveste forventede værdi for et
bestemt kriterium.
Når man i det konkrete eksempel har beregnet værdien af teststørrelsen 2
testχ , skal man så forkaste
eller acceptere hypotesen. En stor værdi af 2
testχ vil føre til forkastelse af hypotesen, mens en lille
værdi af 2
testχ vil føre til accept af hypotesen. Om 2
testχ er lille eller stor afgøres ved hjælp af p-
værdien, som sammenlignes med et signifikansniveau på (typisk) 5%. Hvis vi antager at hypotesen
er sand, er p-værdien sandsynligheden for at få en værdi, der passer mindst lige så dårligt med
hypotesen som χ2-teststørrelsen. Det vil sige p-værdien er sandsynligheden for at få en χ2-
teststørrelse, der er større end 2
testχ .
p-værdi = P(χ2-teststørrelse ≥ 2
testχ ) , hvor χ2-teststørrelse er χ2-fordelt med (k – 1) frihedsgrader
Hvis p-værdien er over 5% accepteres hypotesen og hvis p-værdien er under 5% forkastes
hypotesen. (Med mindre man har
valgt et andet signifikans-niveau).
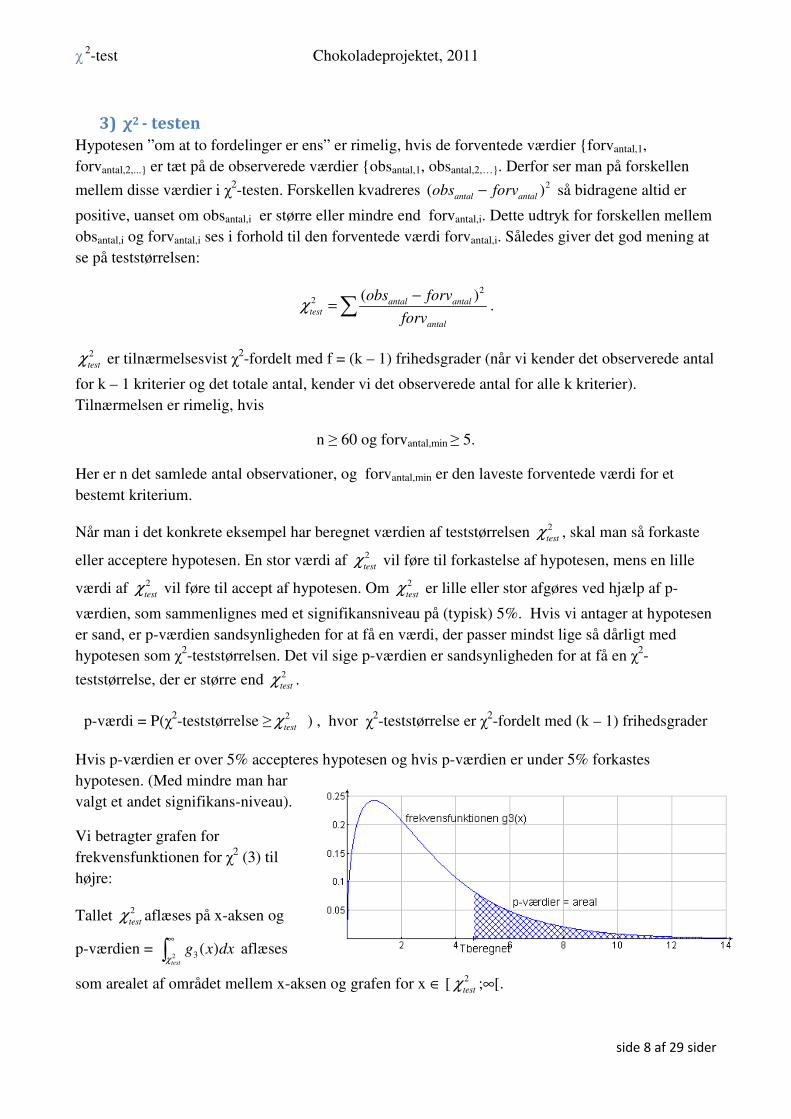
Vi betragter grafen for
frekvensfunktionen for χ2 (3) til
højre:
Tallet 2
testχ aflæses på x-aksen og
p-værdien = 2 3 ( )test
g x dxχ
∞
∫ aflæses
som arealet af området mellem x-aksen og grafen for x ∈ [ 2
testχ ;∞[.

χ 2-test Chokoladeprojektet, 2011
side 9 af 29 sider
Her er g3 som tidligere nævnt givet ved:
0.5 3 1 0.5
30.5 3 1 0.5
0
( ) , hvor 0x
x
x eg x x
x e dx
⋅ − −
∞⋅ − −
= ≥
∫
Hvis vi lader 2
testχ (nedre grænse) vokse ser vi at p-værdien (arealet) bliver mindre.
Vi har at
- hvis 2
testχ er stor er p-værdien lille.
- hvis 2
testχ er lille er p-værdien stor.
4) Eksempel 2 - er partierne gået tilbage? (3 frihedsgrader)
Vi ser på en situation, hvor der kun er 4 politiske partier at stemme på, og hvor de 4 partier ved
sidste valg fik stemmeprocenterne:
AA:27%, BB:16%, CC:39% og DD:18%.
Ved en rundspørge blandt 1000 tilfældigt valgte vælgere fås hyppighederne:
AA:260, BB:170, CC:430 og DD:140.
Vi vil teste om procentfordelingen har ændret sig.
Nul-hypotesen, H0: procentfordelingen har ikke ændret sig.
Signifikansniveau = 5%
Observationer i stikprøven:
Partier AA BB CC DD sum
Observerede antal 260 170 430 140 1000
Forventede Observationer
Partier AA BB CC DD sum
Forventede
antal
0.27·1000 = 270 160 390 180 1000
Bidrag til χ2
teststørrelsen: (260-270)2/270 = 0.37 0.63 4.10 8.89 13.99
Bemærk at forvantal,min er større end 5.
Antallet af frihedsgrader: f = k-1 = 4 – 1 = 3.
χ 2-test Chokoladeprojektet, 2011
side 10 af 29 sider
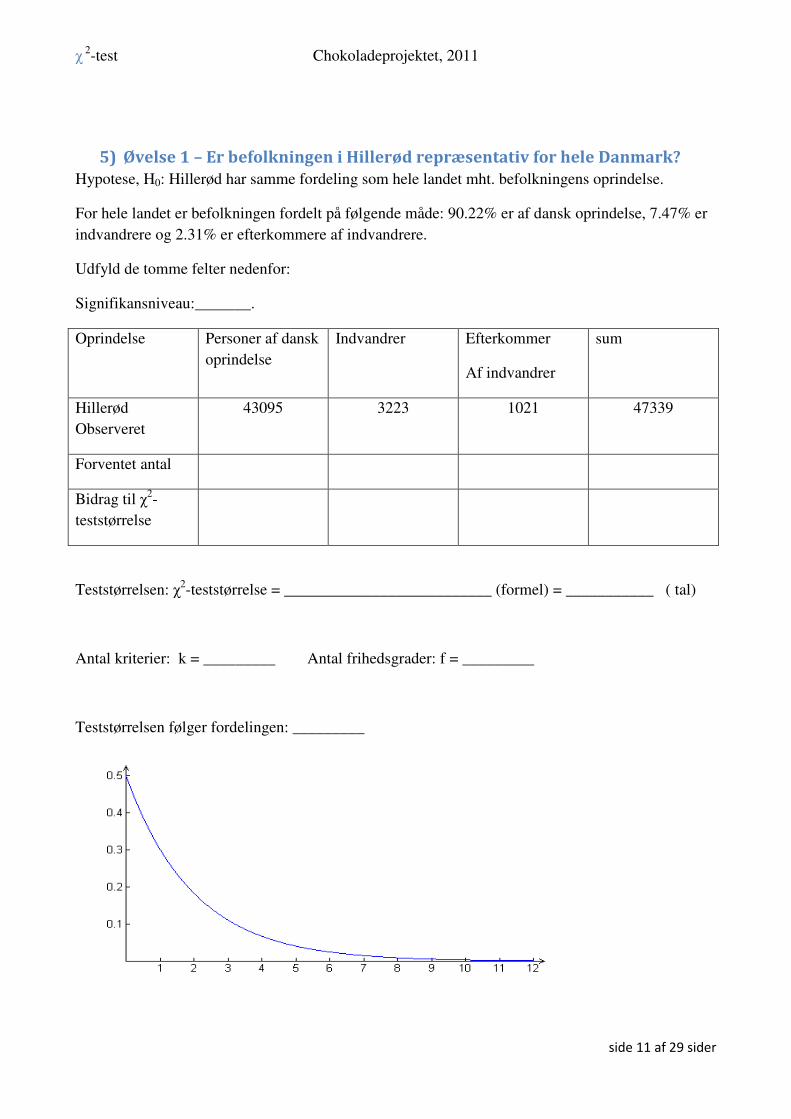
χ2 teststørrelsen:
22 ( )
0.37 0.63 4.10 8.89 13.99antal antaltest
antal
obs forv
forvχ
−= = + + + =∑
Fordelingen: Lad 2
testχ være værdien for χ2 teststørrelsen i en ny stikprøve med 1000 personer dvs.
vi forventer at fordelingen af 2
testχ er en χ2(3)-fordeling, altså en χ2 fordeling med 3 frihedsgrader
Observationssættets p-værdi: 2
313.99
( 13.99) ( ) 0.0029 0.29%test
p P g x dxχ∞
= ≥ = = =∫
I Nspire ser beregningen således ud:
Da p-værdien er mindre end signifikansniveauet forkastes hypotesen, dvs. det er rimeligt at antage,
at procentfordelingen har ændret sig. Vi ser, at det specielt er ændringerne for partierne CC og DD,
der førte til forkastelse af hypotesen. Der er blevet væsentligt flere, der stemmer på DD, og
væsentligt færre der stemmer på CC.
χ 2-test Chokoladeprojektet, 2011
side 11 af 29 sider
5) Øvelse 1 – Er befolkningen i Hillerød repræsentativ for hele Danmark?
Hypotese, H0: Hillerød har samme fordeling som hele landet mht. befolkningens oprindelse.
For hele landet er befolkningen fordelt på følgende måde: 90.22% er af dansk oprindelse, 7.47% er
indvandrere og 2.31% er efterkommere af indvandrere.
Udfyld de tomme felter nedenfor:
Signifikansniveau:_______.
Oprindelse Personer af dansk
oprindelse
Indvandrer Efterkommer
Af indvandrer
sum
Hillerød
Observeret
43095 3223 1021 47339
Forventet antal
Bidrag til χ2-
teststørrelse
Teststørrelsen: χ2-teststørrelse = __________________________ (formel) = ___________ ( tal)
Antal kriterier: k = _________ Antal frihedsgrader: f = _________
Teststørrelsen følger fordelingen: _________

χ 2-test Chokoladeprojektet, 2011
side 12 af 29 sider
p-værdien = P(_____≥______) = ( )g x dx∫�
�
= =______________
p-værdien betyder at____________________________________________________________
Konklusion = __________________________________________________________________
_____________________________________________________________________________
_____________________________________________________________________________
6) Øvelse 2 – er karakterfordelingen i 2. ☺☺☺☺ den samme som på landsplan?
En gymnasieklasse (2.☺) har opnået følgende beståede standpunktskarakterer i foråret 2011:
karakter 2 4 7 10 12 sum
Antal i 2. ☺ 32 69 145 114 18
Fordeling
på
landsplan
10%
25%
30%
25%
10%
100%
Forventede
antal
Bidrag til
χ2-
teststørrelse
Undersøg om 2.☺’s karakterer har samme fordeling som fordelingen på landsplan ved at lave en
Goodness of Fit test.

χ 2-test Chokoladeprojektet, 2011
side 13 af 29 sider
7) Goodness of fit med en hurtigere metode
I det følgende gennemregner vi eksempel 2 fra side 9 igen – dog kan vi komme frem til p-værdien
noget hurtigere ved at benytte os af de indbyggede test for Goodness of fit.
Vi havde følgende situation: 4 partier havde ved sidste valg opnået stemmeprocenterne:
AA:27%, BB:16%, CC:39% og DD:18%.
Ved en rundspørge blandt 1000 tilfældigt valgte vælgere fås hyppighederne
AA:260, BB:170, CC:430 og DD:140.
Vi vil teste om procentfordelingen har ændret sig.
Nul-hypotesen: procentfordelingen har ikke ændret sig.
Signifikansniveau = 5%
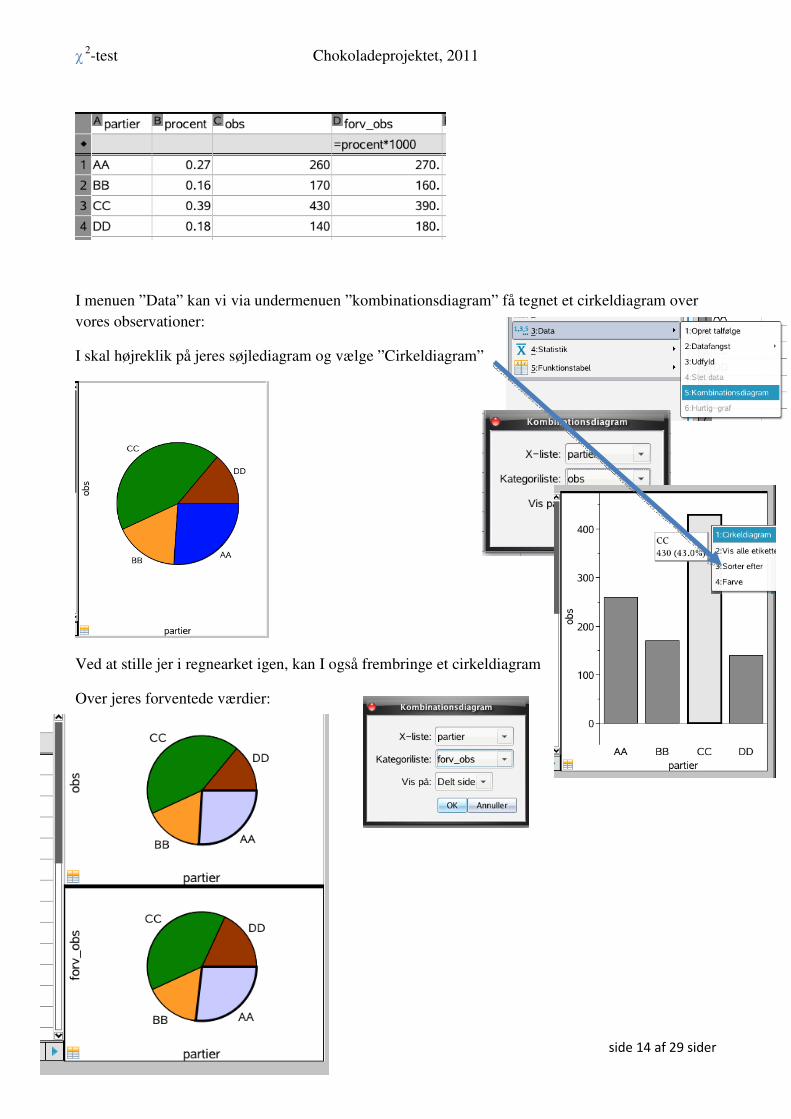
Vi starter med at skrive stikprøvens observationer ind i et regneark – bemærk at man kan skrive
tekst i regnearket ved at bruge anførelsestegn:
Vi kan nu udregne de forventede observationer ved i det grå ”formel felt” at skrive:
= procent*1000
Du skulle nu gerne have følgende oversigt over vores stikprøve:
χ 2-test Chokoladeprojektet, 2011
side 14 af 29 sider
I menuen ”Data” kan vi via undermenuen ”kombinationsdiagram” få tegnet et cirkeldiagram over
vores observationer:
I skal højreklik på jeres søjlediagram og vælge ”Cirkeldiagram”
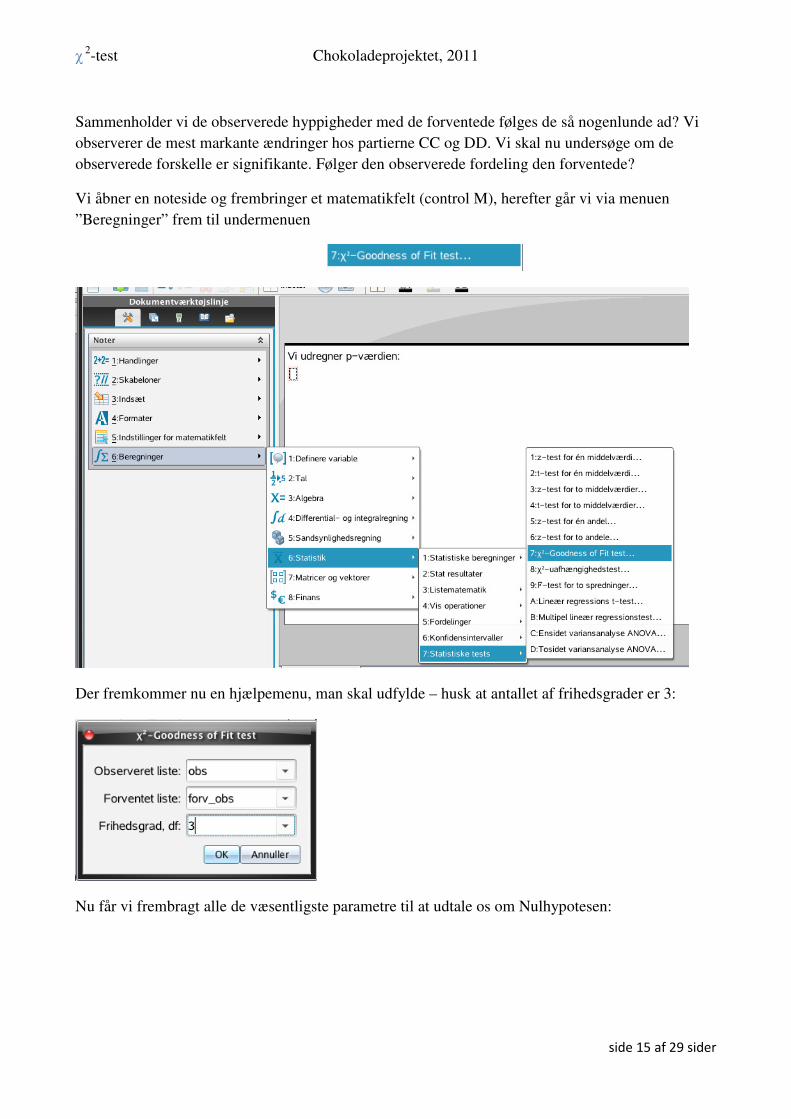
Ved at stille jer i regnearket igen, kan I også frembringe et cirkeldiagram
Over jeres forventede værdier:
χ 2-test Chokoladeprojektet, 2011
side 15 af 29 sider
Sammenholder vi de observerede hyppigheder med de forventede følges de så nogenlunde ad? Vi
observerer de mest markante ændringer hos partierne CC og DD. Vi skal nu undersøge om de
observerede forskelle er signifikante. Følger den observerede fordeling den forventede?
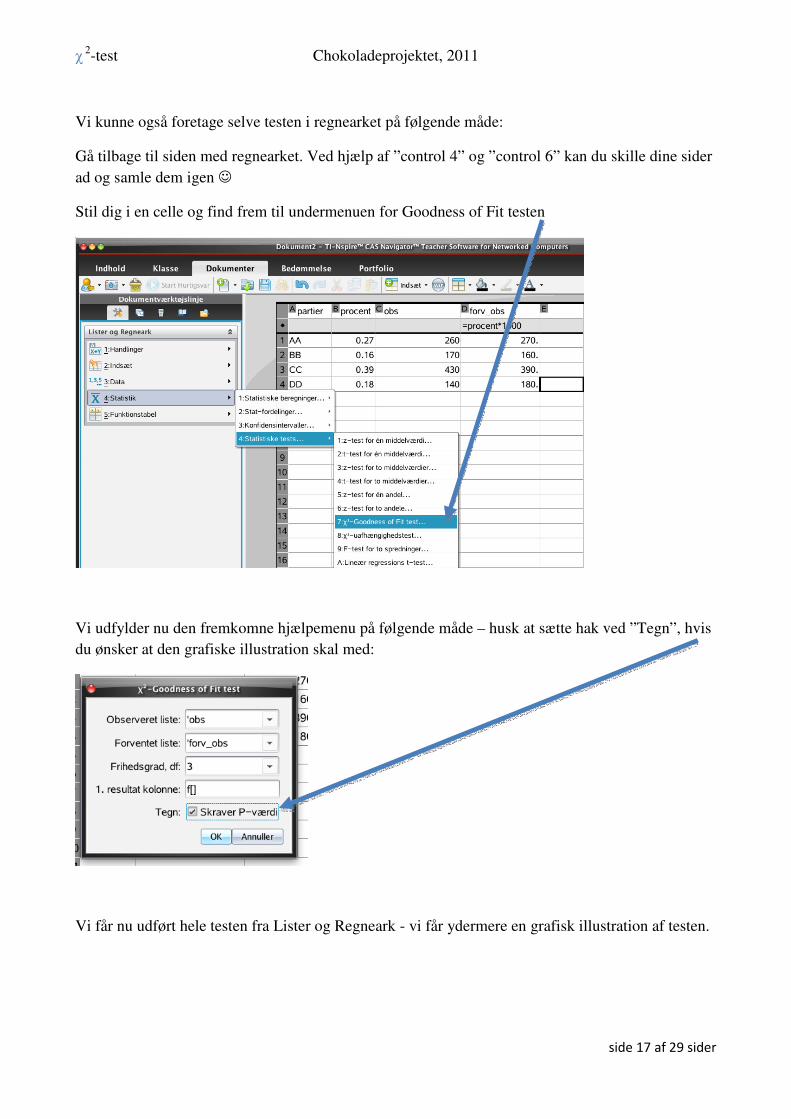
Vi åbner en noteside og frembringer et matematikfelt (control M), herefter går vi via menuen
”Beregninger” frem til undermenuen
Der fremkommer nu en hjælpemenu, man skal udfylde – husk at antallet af frihedsgrader er 3:
Nu får vi frembragt alle de væsentligste parametre til at udtale os om Nulhypotesen:

χ 2-test Chokoladeprojektet, 2011
side 16 af 29 sider
P værdien er på 0.29 % og vi kan da forkaste Nulhypotesen (på 5 %-niveauet). dvs. det er rimeligt
at antage, at procentfordelingen har ændret sig.
Vi kan frembringe de enkelte partiers bidrag til testtallet χ
2 = 13.99 ved at åbne
en mathboks. Derefter vælger vi ”Var” i menubjælken foroven og under ”Var” vælger vi
”Stat.values”:
Vi opnår følgende oversigt:
De enkelte bidrag til χ2 fås frem med kommandoen:
Vi ser at partiet AA bidrager med 0.37, BB bidrager med 0.63, CC bidrager med 4.10 og endelig
bidrager DD med 8.89 til testtallet χ2= 13.99.
Testen bekræfter vores observation fra cirkeldiagrammet - ”synderne” til denne holdningsændring
blandt vælgerne er partierne CC og DD.
χ 2-test Chokoladeprojektet, 2011
side 17 af 29 sider
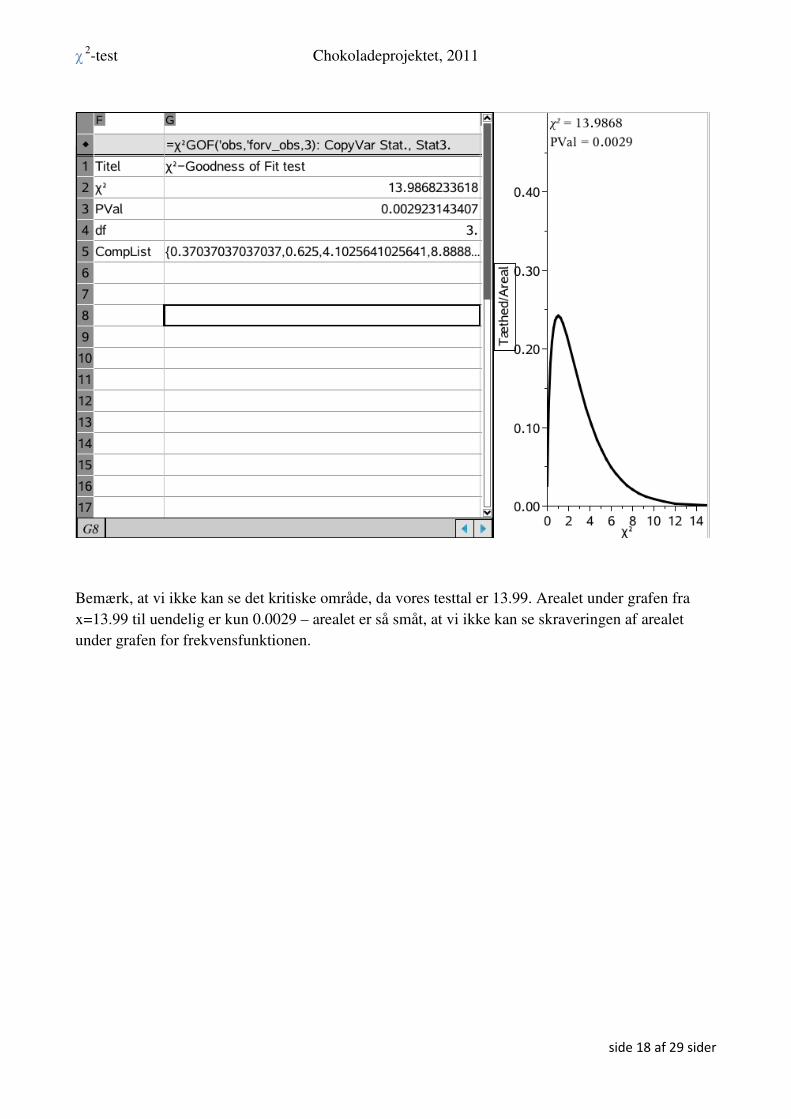
Vi kunne også foretage selve testen i regnearket på følgende måde:
Gå tilbage til siden med regnearket. Ved hjælp af ”control 4” og ”control 6” kan du skille dine sider
ad og samle dem igen ☺
Stil dig i en celle og find frem til undermenuen for Goodness of Fit testen
Vi udfylder nu den fremkomne hjælpemenu på følgende måde – husk at sætte hak ved ”Tegn”, hvis
du ønsker at den grafiske illustration skal med:
Vi får nu udført hele testen fra Lister og Regneark - vi får ydermere en grafisk illustration af testen.
χ 2-test Chokoladeprojektet, 2011
side 18 af 29 sider
Bemærk, at vi ikke kan se det kritiske område, da vores testtal er 13.99. Arealet under grafen fra
x=13.99 til uendelig er kun 0.0029 – arealet er så småt, at vi ikke kan se skraveringen af arealet
under grafen for frekvensfunktionen.
χ 2-test Chokoladeprojektet, 2011
side 19 af 29 sider
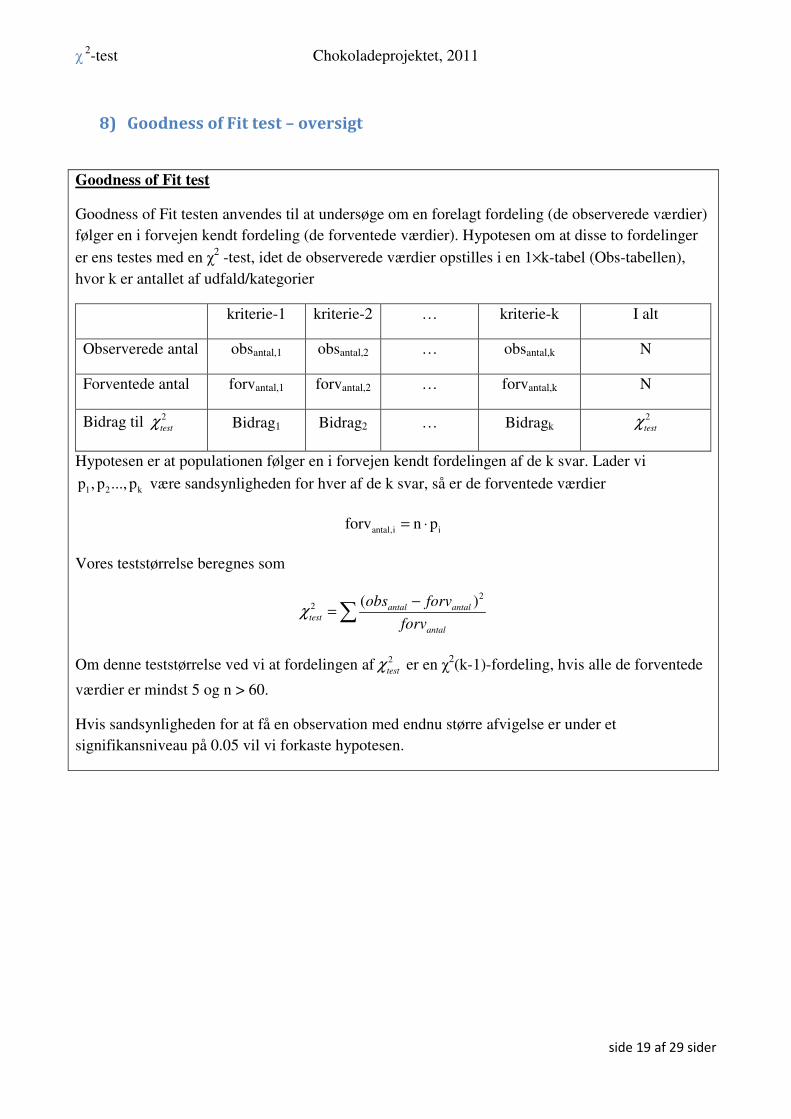
8) Goodness of Fit test – oversigt
Goodness of Fit test
Goodness of Fit testen anvendes til at undersøge om en forelagt fordeling (de observerede værdier)
følger en i forvejen kendt fordeling (de forventede værdier). Hypotesen om at disse to fordelinger
er ens testes med en χ2 -test, idet de observerede værdier opstilles i en 1×k-tabel (Obs-tabellen),
hvor k er antallet af udfald/kategorier
kriterie-1 kriterie-2 … kriterie-k I alt
Observerede antal obsantal,1 obsantal,2 … obsantal,k N
Forventede antal forvantal,1 forvantal,2 … forvantal,k N
Bidrag til 2
testχ Bidrag1 Bidrag2 … Bidragk
2
testχ
Hypotesen er at populationen følger en i forvejen kendt fordelingen af de k svar. Lader vi
1 2 kp , p ..., p være sandsynligheden for hver af de k svar, så er de forventede værdier
antal,i iforv n p= ⋅
Vores teststørrelse beregnes som
22 ( )
antal antaltest
antal
obs forv
forvχ
−=∑
Om denne teststørrelse ved vi at fordelingen af 2
testχ er en χ2(k-1)-fordeling, hvis alle de forventede
værdier er mindst 5 og n > 60.
Hvis sandsynligheden for at få en observation med endnu større afvigelse er under et
signifikansniveau på 0.05 vil vi forkaste hypotesen.

χ 2-test Chokoladeprojektet, 2011
side 20 af 29 sider
9) Hypotesetestning
Når vi ønsker at teste en hypotese, udfører vi et stokastisk eksperiment. Ud fra det vi observerer (de
observerede værdier/observationssættet), vil vi vurdere, om hypotesen kan forkastes eller
accepteres. På dette grundlag kan vi ikke afgøre om en hypotese er sand eller falsk, derfor skal man
være påpasselig med sit ordvalg.
Får vi en observation, der passer dårligt med hypotesen, er det ikke sikkert, at den er falsk. Derfor
bruger man formuleringen: "hypotesen forkastes" og med det mener vi, at det er rimeligt, at
hypotesen er falsk.
Får vi en observation, der passer godt med hypotesen, er det ikke sikkert, at den er sand. Derfor
bruger man formuleringen: "hypotesen accepteres" og med det mener vi, at det er rimeligt, at
hypotesen er sand.
Til en statistisk test hører en teststørrelse T, det vil sige en stokastisk variabel der beskriver
observationssættet. I testene i dette notat er teststørrelse T altid χ2 –fordelt. Teststørrelse T skal
rangordne alle mulige observationssæt efter, hvor godt de passer til hypotesen.
Ved hjælp af teststørrelse beregnes p-værdien, som er sandsynligheden for, at vi i et nyt
eksperiment får et observationssæt, der passer mindst lige så dårligt med hypotesen, som det
observationssæt, som vi har observeret p-værdien beregnes under antagelse af at hypotesen er sand.
Bogstavet p står for det engelske ord "probability", der betyder sandsynlighed.
I χ2 –testen vil vi kalde den beregnede værdi af teststørrelsen for Tberegnet. De observationssæt, der
passer mindst lige så dårligt med hypotesen som vores observationssæt, har T-værdier, der er
mindst lige så store som Tberegnet. Det vil sige, at p-værdien = P(T ≥ Tberegnet), hvor T er χ2 –fordelt.
Endelig skal vi ud fra p-værdien vurdere, om hypotesen skal forkastes eller accepteres. Der findes
intet logisk matematisk grundlag, der entydigt fortæller os, hvornår vi skal forkaste eller acceptere
en hypotese. Det er et af de steder i statistikken, hvor det bliver lidt løst/subjektivt.
Hvis p-værdien er lille, er observationen ekstrem i forhold til hypotesen, dvs. hypotesen kan
forkastes.
Hvis p-værdien derimod er stor, er observationen ikke ekstrem i forhold til hypotesen, dvs.
hypotesen accepteres.
Grænsen mellem en lille (hypotesen forkastes) og en stor (hypotesen accepteres) p-værdi kaldes for
signifikansniveauet. Signifikant betyder "betydelig" eller "ikke ubetydelig" underforstået grænsen
mellem en ubetydelig effekt og en betydelig effekt. Signifikansniveauet bør fastlægges før
observationen fra det stokastiske eksperiment kendes. Vi siger, at vi tester hypotesen på et 5%
signifikansniveau og mener, at hvis p-værdien er under 5%, vil vi forkastes hypotesen, dvs. der er
en signifikant effekt (en betydelig effekt).

χ 2-test Chokoladeprojektet, 2011
side 21 af 29 sider
Man anvender ofte et signifikansniveau på 5% (eller 1%), men der er ikke nogen logisk grund til
denne værdi, den er nærmest blevet en tradition. Man kan sige, at jo større signifikansniveauet
bliver, jo nemmere er det at få forkastet hypotesen (og det er ofte, det der er interessant), men
hermed bliver det også nemmere at forkaste en sand hypotese, hvilket man kalder fejl af type 1.
Fejl af type 2 er når en falsk hypotese accepteres.
For at få styr på begreben kan vi betragte en tabel over på den ene side hypotesens sandhedsværdi
og på den anden side resultatet af testen:
Hypotesen sand falsk
Accepterer ☺ fejl af type 2
Forkaster fejl af type 1 ☺
I vores retssystem kan vi arbejde med fejl af type 1 og type 2. Hypotesen er, at en mand er uskyldig.
Fejl af type 1, er når manden dømmes, men er uskyldig (den sande hypotese forkastes). Fejl af type
2 er, når manden frifindes og er skyldig (den falske hypotese accepteres). I retssystemet er det altid
anklageren, der har bevisbyrden, og dette er for at mindske risikoen for at dømme en uskyldig (fejl
af type 1).
Hvis en kvinde tager en graviditetstest er hypotesen, at hun ikke er gravid. Fejl af type 1 opstår, hvis
prøven er positiv, når hun ikke er gravid og fejl af type 2 opstår, hvis prøven er negativ, når hun er
gravid.

χ 2-test Chokoladeprojektet, 2011
side 22 af 29 sider
χχχχ2-test for uafhængighed mellem to inddelingskriterier
- Tosidet test eller χ22way
En anden måde at bruge χ2-test er ved undersøgelser af uafhængighed. Vi kan f.eks. spørge om
farveblindhed afhænger af køn. Vi vil så spørge en stor gruppe mennesker om deres køn og om de
er farveblinde. Hvis andelen af farveblinde kvinder er lige så stor som andelen af farveblinde mænd
afhænger farveblindhed ikke af køn. I praksis vil de to andele sjældent være præcis lige store
(selvom der var tale om uafhængige hændelser), fordi de statistiske tilfældigheder i stikprøven
påvirker resultatet. Derfor har vi igen brug for en måde at teste, hvorvidt variationerne er store nok
til at vi afviser vores nulhypotese (at farveblindhed ikke afhænger af køn).
I det følgende vil vi demonstrere, hvordan man laver en χ2-test for uafhængighed i Nspire.Vi vil
tage udgangspunkt i den følgende opgave:
Vi vil gennemgå to løsningsmetoder.
1) Den første metode baseres og forklares ud fra teorien om χ2-test.
2) Den anden metode er en hurtig it-baseret løsningsmetode
Resultaterne i de to metoder sammenlignes og analyseres.
10) METODE 1: Den teoretiske løsningsmetode
Hypoteser og signifikansniveau:
Vi begynde med at opstille en tabel i ”Lister og regneark” af de observerede data ud fra de
informationer vi får i opgavebeskrivelsen.
Observerede data:
En forretningskæde vil undersøge, om farven på indpakningen af nye slik påvirker salget.
Butikken sælger derfor i en periode poser med samme slags slik, alle med 250 g/pose og til samme pris.
Der bliver i alt sendt 600 poser slik ud i butikkerne, hvoraf 520 bliver solgt. Af de solgte poser er 375 gule,
og der er 55 gule poser tilbage. De øvrige poser er blå.
Undersøg, om der er grundlag for at påstå, at farven påvirker salget af slik.

χ 2-test Chokoladeprojektet, 2011
side 23 af 29 sider
Bemærk, at vi, udover de givne data med solgte og usolgte poser, tilføjer en række og en kolonne
med summering af tallene.
De to inddelingskriterier er hhv. farven på poserne og salg af slik.
Vi opstiller en nulhypotese, som vi vil undersøge:
H0: Der er uafhængighed mellem farven på poser og salg af slik.
Dvs. vi antager, at farverne ikke har indflydelse på salget, og at variationer i salget mellem gule og
blå poser kun skyldes tilfældigheder.
Før vi går i gang med at teste vores nulhypotese, vælger vi at fastsætte signifikansniveauet til 5%.
Vi antager, at teststørrelsen følger en χ2-fordeling med 1 frihedsgrad. Frihedsgraden beregnes som
(antal rækker – 1 ).(antal kolonner -1). Vi ser her bort fra summeringslisterne. Her er frihedsgraden
(2-1)·(2-1) = 1.
Beregning af χχχχ2-teststørrelsen:
For at beregne χ2-teststørrelsen, skal vi først beregne de forventede værdier under antagelse af, at
der er uafhængighed.
Beregningseksempel:
Hvis salget ikke afhænger af farven forventer vi ifølge definitionen for uafhængighed, at
det forventede antal solgte gule poser summen af gule poser=
samlet antal solgte poser samlet antal poser
Derfor får vi:
summen af gule poserdet forventede antal solgte gule poser = (samlet antal solgte poser)
samlet antal poseri
430det forventede antal solgte gule poser = 520
600i
Beregning af forventede observationer:
χ 2-test Chokoladeprojektet, 2011
side 24 af 29 sider
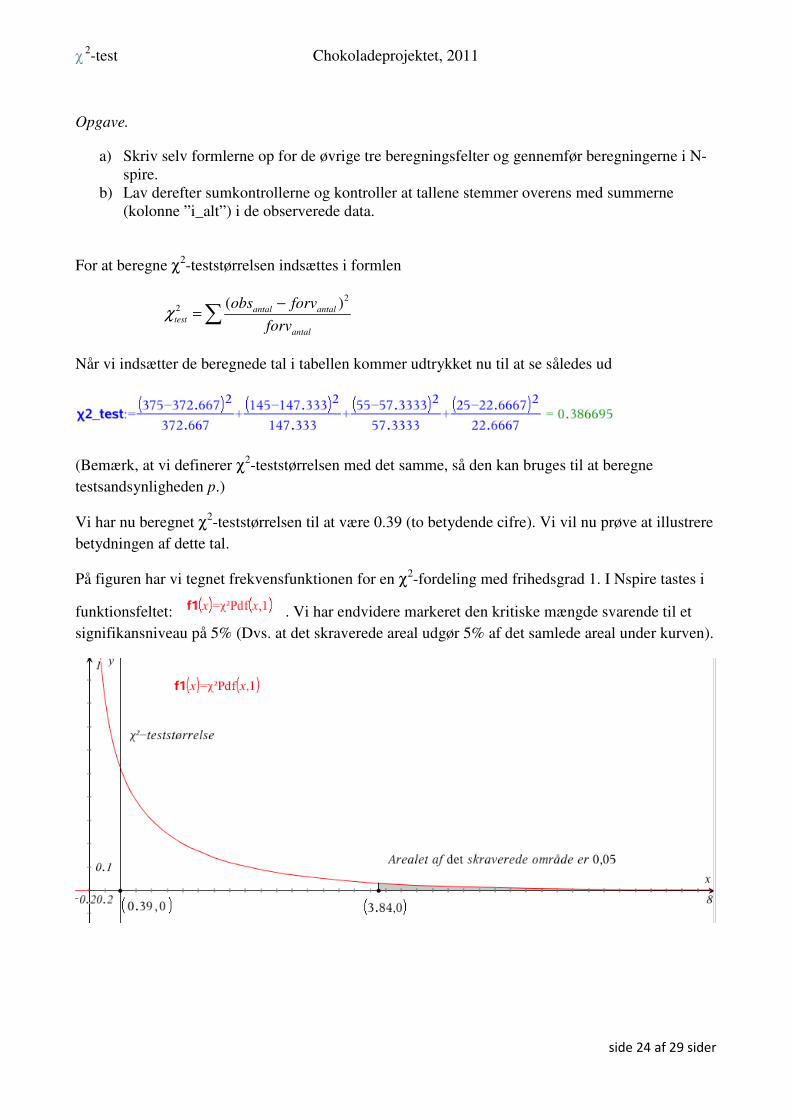
Opgave.
a) Skriv selv formlerne op for de øvrige tre beregningsfelter og gennemfør beregningerne i N-spire.
b) Lav derefter sumkontrollerne og kontroller at tallene stemmer overens med summerne (kolonne ”i_alt”) i de observerede data.
For at beregne χ2-teststørrelsen indsættes i formlen
2
2 ( )antal antal
test
antal
obs forv
forvχ
−=∑
Når vi indsætter de beregnede tal i tabellen kommer udtrykket nu til at se således ud
(Bemærk, at vi definerer χ2-teststørrelsen med det samme, så den kan bruges til at beregne
testsandsynligheden p.)
Vi har nu beregnet χ2-teststørrelsen til at være 0.39 (to betydende cifre). Vi vil nu prøve at illustrere
betydningen af dette tal.
På figuren har vi tegnet frekvensfunktionen for en χ2-fordeling med frihedsgrad 1. I Nspire tastes i
funktionsfeltet: . Vi har endvidere markeret den kritiske mængde svarende til et
signifikansniveau på 5% (Dvs. at det skraverede areal udgør 5% af det samlede areal under kurven).

χ 2-test Chokoladeprojektet, 2011
side 25 af 29 sider
Hvis vores teststørrelse havde ligget i det skraverede område, altså været større end 3.84, så skulle
vi have forkastet vores nulhypotese H0.
Men vores teststørrelse er kun 0.39, så vi kan ikke på det foreliggende grundlag forkaste hypotesen.
Altså må vi formode, at salget af slik er uafhængig af farven på slikposerne.
Grænsetilfældet svarende til et signifikansniveau på 5% kan beregnes i N-spire ved hjælp af den
inverse funktion til χ2-fordelingen. For at lave beregningen skal man først angive acceptmængden
(1 – den kritiske mængde, her 1 – 0.05 = 0.95) dernæst antallet af frihedsgrader.
Beregning af testsandsynligheden
For at færdiggøre vores undersøgelse, vil vi nu beregne den til teststørrelsen hørende
testsandsynlighed p.
Beregningen foretages i N-spire med fordelingsfunktion for χ2-fordelingen (den kumulerede).
(Hvis man ikke har defineret sin teststørrelse, så kan man naturligvis bare indsætte den beregnede
talværdi i stedet for.)
Grafisk svarer testsandsynligheden p til arealet under kurven for frekvensfunktionen til højre for
teststørrelsen. p-værdien repræsenterer dermed nulhypotesens troværdighed. Den er her beregnet til
53.4 % og dvs., at den ligger langt over et signifikansniveau på 5 %.
Dette understøtter derfor det tidligere udsagn om at sliksalget må formodes at være uafhængigt af
farven på poserne.
11) METODE 2: den hurtige løsningsmetode
Datamaterialet i vores opgave om slik er tosidet, da der i opgaven er to inddelingskriterier (farver
og salg). I praksis betyder det, at tosidet data kan opskrives i en tabel med mindst to rækker og to
kolonner.
Til beregning af χ2-teststørrelse og –testsandsynlighed, kan man anvende den beregningsfunktion i
N-spire, som hedder χ2 2-vejstest.
Først skal de givne data defineres som en matrix i Notefeltet.

χ 2-test Chokoladeprojektet, 2011
side 26 af 29 sider
Herefter anvendes en χ2 2-vejstest til beregning
For at få vist resultaterne af beregningerne skrives stat.results i en Math Box.
I resultatboksen kan man nu aflæse χ2-teststørrelsen som 0.39 og χ2 testsandsynligheden p til
53.4%. Man kan ved hjælp af kommandoen stat.CompMatrix få de enkelte bidrag til testtallet frem.
Så kan man lettere få et overblik over de ”skyldige” i vores undersøgelse.
Herefter skal man naturligvis huske at skrive en konklusion i forhold til nulhypotesen.
Da vores χ2-teststørrelse kun er 0.39, kan vi ikke på det foreliggende grundlag forkaste hypotesen.
Altså må vi formode at salget af slik er uafhængig af farven på slikposerne.
p-værdien, der repræsenterer nulhypotesens troværdighed, er her beregnet til 53.4% og dvs. at den
ligger langt over et signifikansniveau på 5%.
Dette understøtter derfor det tidligere udsagn om at sliksalget må formodes at være uafhængig af
farven på poserne.
Når man sammenligner de to metoder, ser man til sin store glæde, at der er overensstemmelse
mellem de beregnede resultater ☺

χ 2-test Chokoladeprojektet, 2011
side 27 af 29 sider
12) Projekt
Gruppestørrelser: 3 mands grupper.
Elevtid: 5 timer
Materialebrug: Hver gruppe medbringer selv: 2 poser Haribos vingummibamser og to små eller en
stor pose M&M’s, de små kulørte chokoladeknapper.
Produktkrav: Der ønskes en besvarelse af nedenstående opgaver.
CASE:
Den lille chokoladefabrik Sukkertop fra Chokoland, ikke
så fjernt fra Kokosland tæt på Ækvator, har haft stor
succes i deres eget land og har ønsker om at ekspandere på
det globale marked.
De har hørt om et firma kaldet Haribo, i det skønne land Danmark, der laver
verdens lækreste, blødeste og mest velsmagende vingummibamser – dem kunne
Sukkertop godt tænke sig at fusionere med. Du bliver ansat som
kvalitetskonsulent og skal gå Haribo i sømmene.
Du får tre opgaver:
1. Firmaet Sukkertop har ikke rigtig forstået, hvordan man kan teste om en givet observation følger en given forventet fordeling. Du skal med egne ord forklare, hvad en Goodness of fit test går ud på – du skal undervejs forklare de begreber du anvender i din redegørelse. (Forklaringerne må gerne flettes sammen med nedenstående opgaver)
2. I en pose af Haribos vingummibamser er der bamser i fem forskellige farver.
På Haribos hjemmeside kan man læse at en pose indeholder:
1/6 hvide guldbamser 1/6 orange guldbamser 1/3 røde guldbamser 1/6 grønne guldbamser 1/6 gule guldbamser

χ 2-test Chokoladeprojektet, 2011
side 28 af 29 sider
Linket til Haribo er http://kortlink.dk/haribo/9pvc. Under menuen spørgsmål og svar vælger I
”Kan man købe guldbamser der er sorteret i de enkelte farver?”
Undersøg om farvefordelingen er rigtig vha. en χ2-test på jeres indkøbte poser.
3. Firmaet Sukkertop er meget urolig for konkurrenten, der fremstiller de populære M&M’s. Firmaet håber på, at kunne fange M&M producenten i at lyve, når de påstår, at de seks forskellige farver forekommer med lige stor hyppighed.
Undersøg om der er lige mange M&M’s i hver farve vha. et χ2-test.
4. Uafhængighedstesten. Sukkertoppen vil i forbindelse med deres markedsførelse gerne vide, om der er forskel på piger
og drenges forhold til chokolade.
Indsaml statistisk materiale ved en spørgeskemaundersøgelse og undersøg derved, om piger er
mere glade for chokolade end drenge.
I kan tage udgangspunkt i nedenstående tabel.
Hvor mange gange spiser du chokolade om ugen?
Køn 0 1 2 3 4 5 6 7 8 9 ≥ 10
Dreng
Pige
I skal være opmærksomme på, at I højst sandsynligt skal omgruppere jeres tabel, for at have mindst
5 forventede observationer i hvert kriterium (jf. teorien).
χ 2-test Chokoladeprojektet, 2011
side 29 af 29 sider
Appendix – Nspire kommandoer til χ2-test
Nspire kommando Indtastes som: Betyder Eksempel
på side
χ²Pdf(x,f) chi2pdf(x,f) χ² tæthedsfunktion i punktet x, for
frihedsgraden, f
6, 24
χ²Cdf(n,ø,f) chi2Cdf(n,ø,f) Arealet under χ²-tæthedsfunktionen fra den
nedre grænse n til den øvre grænse, ø for
frihedsgraden, f
4-6, 10, 25
invχ²(a,f) invChi2(a, f) Finder den x værdi, som svarer til at arealet
under χ²-tæthedsfunktionen fra 0 til x er a for
frihedsgraden, f
5, 25
χ²GOF (obs_liste,
forv_liste, f)
Chi2GOF(obs,
forv, f)
Sammenligner en observeret liste med en
forventet liste for frihedsgraden f. Gemmer
resulatet i stat.results
15-18
Stat.values Stat.values Viser χ²-testtallet, p-værdien, frihedsgraderne
og de enkelte bidrag til χ²-testtallet. (Først
aktiv efter at testen er udført)
16
Stat.results Stat.results Viser χ²-testtallet, p-værdien og
frihedsgraderne. (Først aktiv efter at testen er
udført)
23
Stat1.Complist Stat1.Complist Viser de enkelte bidrag til χ²-testtallet. (Først
aktiv efter at testen er udført)
23
χ²2way(Observeret
matrix)
Chi22way(M) Udfører en chi i anden uafhængighedstest på
en observeret matrix
26
Eksempler og noter der kan hjælpe til at huske og forstå:
Cdf står for cumulated density function
Pdf står for probability density function
svarer til og finder 5% konfindensniveau for en frihedsgrad på 1
viser at 36.6% af arealet ligger over x-værdien 3.17 for en χ²-tæthedsfunktionen
med frihedsgrad 3.
Viser, at hvis testværdien er χ²-fordelt
med frihedsgrad 4, er det mere end 7
gange så sandsynligt at få en testværdi tæt på 2, som at få en testværdi tæt på 9.


















