FTK SIMULATION G. Volpi. Fast Tracker Processor Reminder The FTK processor will provide full...
17
FTK SIMULATION G. Volpi
-
Upload
hillary-howard -
Category
Documents
-
view
219 -
download
0
Transcript of FTK SIMULATION G. Volpi. Fast Tracker Processor Reminder The FTK processor will provide full...

FTK SIMULATIONG. Volpi

G. Volpi - FTK Simulation 2
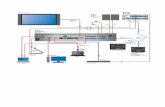
Fast Tracker Processor Reminder• The FTK processor will provide full
tracking for each Lvl1 accept (100 kHz)• Expected latency <100 µs• Reconstruct all tracks with pT>1 GeV, |η|
<2.5, |d0|<2 mm from the BL• Data are obtained receiving raw data
send from the Pixel and strip detectors read-out drivers• FTK works in parallel with the existing
ATLAS DAQ infrastructure• Highly parallel system organized in 64
η-ϕ towers• Internal data transmission uses high speed
serial links
HPC working groupo meeting
• 2 9U VME boards/tower• 4 tracking engines each• 8192 AM Chips• ~2000 FPGAS

G. Volpi - FTK Simulation 3
FTK Main Algorithms
SS
FTK has a custom clustering algorithm, running on FPGAs
The data are geometrically distributed to the processing units and compared to existing
track patterns.
Pattern matching limited to 8 layers: 3 pixels + 5 SCTs.Hits compared at reduced resolution.
Full hits precision restored in good roads.Fits reduced to scalar products.
ij jiji qxCp Good 8-layer tracks are extrapolated to additional layers, improving the fit
HPC working groupo meeting

G. Volpi - FTK Simulation 4
Fast Tracker Emulation Goals• The FTK emulation represents the logic of all the different parts to support:• Development and design of the architecture• Evaluate the physics performance at the trigger level• System monitoring during the system installation and operations
• FTK emulation results need to be combined with HW development data and ATLAS High Level Trigger simulation• Combining the FTK results with data with firmware and boards development allows precise
prediction of the system workflow• Feeding the FTK emulation output in the HLT framework allows to characterize the use of
FTK tracks and design trigger algorithm• Need to combine different goals• HW design require extremely accurate reproduction of the workflow in the different boards,
limited data samples are adequate for the task• Physics performance requires realistic representation and million of simulated events to
evaluate rejection of background events
HPC working groupo meeting

G. Volpi - FTK Simulation 5
FTK Emulation Workflow• The emulation reproduces the entire FTK pipeline• Raw hits can be read from MC or real data• FTK clustering algorithm applied
• Cluster are distributed to the correspondent tower• Clusters compared with a bank of coarse resolution trajectories
(patterns)• All possible track candidates in any found roads are fitted• Linear approximation used to simplify the calculation
• The code has the form of a set of C++ classes• The code can be compiled as standalone static or shared library• Depending by ROOT (I/O and math libraries), BOOST and DCAP (OPT)
• The code can be assembled in an Athena plugin, defining Algorithms and Tools to control the main components• The Athena code is equivalent to the strandalone
HPC working groupo meeting

G. Volpi - FTK Simulation 6
FTK Full Emulation Reminder• The FTK full emulation has been initially developed using the code of an existing
standalone code, describing the functionality of the main components• Most detailed available representation of the hardware• Not an exact replica of the boards’ firmware but very close• Differences are expected to be reduced, or removed, where this is possible and feasible
• Implementing algorithms designed for custom HW is resource intensive using standard computing resources• The whole AM system will have ~25 TB/s for data I/O, able to make about 4E17 32 bit
comparisons per second, a single large FPGA can make up to 1 TFlop/s• Hard to reach similar numbers, for these very specific tasks, on regular CPU based systems
• The full simulation used for a very broad range of studies: • HW dataflow, required to predict the impact of HW decisions• Generation of test vectors and HW control, used for VS and planned board tests• FTK tracks and trigger selection performance, allows to evaluate the quality of the output
and the possibility to build trigger selection algorithm based on those
HPC working groupo meeting

G. Volpi - FTK Simulation 7
FTK Full Emulation Resources• Large use of resource in memory and disk to load the values that will be
loaded in the AM and the FPGAs used for the tracks fitting• 10^9 patterns, 9 integers: 36 byte in memory, ~35 GB in memory• 10^6 1st stage fit constants, 11*12 floats, 500 MB in memory• 1.6*10^6 2nd stage fit constants, 16*17 floats, 1.7 GB in memory• Other auxiliary configuration data will be within 100 MB• Disk usage is about 50% less, due to compression,
• The requirements don’t allow to run in the a single jobs• Defined a general strategy to split the simulation in small orthogonal parts and then
merge the result• Current splitting follows the subdivision in 64 towers with the possibility of further
segmentations (currently 4 partition in each towers, a.k.a 4 sub-regions)• The jobs can be executed sequentially or using more CPU in parallel (independent
processes)
HPC working groupo meeting

G. Volpi - FTK Simulation 8
Pattern Matching with AM chip• The AM chip is a special CAM
chip• The AM identify the presence of
stored patterns in the incoming data• Input data arrives through
independent busses• Patterns with enough matching data
are selected• Threshold can be reprogrammed • DC feature (next slide) allow different
match precision
• The chips are installed in boards able to send data to all the chips in parallel• At every clock incoming data can be
compared with all the patterns
AM COMPUTING POWEREach pattern can be seen as 4 32 bits comparators, operating at 100 MHz.50 106 MIP/chip 4 1011 MIP in the whole AM system
AM CONSUMPTION:~ 2.5 W for 128 kpatterns
HPC working groupo meeting

G. Volpi - FTK Simulation 9
AM Emulation Structure and Workflow
• The AM emulation completely reproduce the matching criteria of the real chip• Workflow differences are required to
improve the algorithm performance and allow tests• Pattern bank scan uses a large indexing
structure to optimize the access time• The DC is implemented as filter for the
roads• The pattern bank indexing structure
has a large memory footprint• Indexing structure is large, almost as the
pattern bank• Necessary because has an enormous gain in
CPU w.r.t. linear scans or other approaches
L7…
L1L0 HITSS0: HIT, HIT, HITSS1: HIT…SSk: HIT, HIT
Clusters
L7
…
L1L0 IDSS0: PATT_ID, PATT_IDSS1: PATT_ID…SSm: PATT_ID, PATT_ID
L0 ... L7 F C
I O
T N
S
T
Patt 0 int ... int
... ... ... ...
Patt n int ... int
PATTERN BANK
L0 ... L7 # HIT
ID 0 1 bit ... 1 bit int
... ... ... ... ...
ID n 1 bit ... 1 bit int
PATTERN MATCH STATUS
Road 0Road 1
…Road N
Bank Indexes
Hit List Memory
Track Fitter
HPC working groupo meeting

G. Volpi - FTK Simulation 10
Track fitting in FTK• After the pattern matching stage the list of
possible roads is passed to the track fitting• Each road can contain 1 or more clusters per layer
• Only 1 layer without hits is allowed, 2 in special cases (dead modules)
• All the combinations composed by 1 hit per layer are candidate tracks and a fit is attempted• Helix parameters and chi-square calculation approximated by
scalar products• The constants used in the products learn the ATLAS ID
geometry and weight common resolution effects• Mean cluster size and resolution, multiple scattering and energy
loss
• The fit is equivalente to a (11,11)*11 matrix-vector product
• A second track fitting step done extending good tracks• Additional hits found extrapolating the tracks, resuing
the same linear approximation• The 2nd stage is equivalent to a(14,14)*14 multiplication
SS
ij jiji qxCp
HPC working groupo meeting

G. Volpi - FTK Simulation 11
Emulating a massively parallel tracking processor• The use of common ATLAS resources has
strict resource request• Single threaded/process jobs• 2 GB/core of real memory• Preferred maximum execution time of several
hours for few 100s of events• Single job uses few GB configuration data
• Natural in FTK to distribute the computation in independent jobs• FTK configuration is naturally divided in towers,
with further internal segmentation possible• Each event is processed many time, using a
different partition of the configuration• Final data require merging stages, typically organized in
2 steps.
• Single jobs can be sequentially executed on a single node or multiple nodes• Usually distributed in parallel to different Grid
nodes
FTK
Trac
ks
Tower 1
T1 J1T1 J2T1 J3T1 J4
Tower 2
T2 J1T2 J2T2 J3T2 J4
....
....
....
....
....
Tower 63
T63 J1T63 J2T63 J3T63 J4
Tower 64
T64 J1T64 J2T64 J3T64 J4
Each tower is segmented to reduce the resource footprint and allow a more parallel use of the resources.
Memory requirement of the single reduced to 1 GB, not dominated by the pattern bank content.
Input data can already organized in towers reducing the time to retrieve the data.
HPC working groupo meeting

G. Volpi - FTK Simulation 12
FTK emulation flow reminderFTK emulation has very specific needs and consequently doesn’t run as single digitization algorithm, as it should.To complete the emulation 3 sequential steps are used:1. Input preparation:
RDONTUP_FTKIP2. Emulation:
NTUP_FTKIPNTUP_FTKTMP
3. Final merger and trigger emulation: NTUP_FTKTMPNTUP_FT/DESD_FTK
All the steps are controlled by Athena algorithms.The Scheme is supported by prodsys.
HPC working groupo meeting
RDO/RAW
NTUP_FTKTMPDESD_FTK
TrigFTKMergeReco_tf.py
Reco
TrigFTKSM4_tf.py
NTUP_FTKIP
01
23
64
All the intermediate files use custom data types: ntuples containing special objects

G. Volpi - FTK Simulation 13
Possible FTK emulation evolutionWith the RDO representation ready we have to change the ProdSys steps.RDO w/ FTK information an be produced merging intermediate FTK data with the original RDO.Trigger emulation will happen using RDOs, for trigger tests will not require production as now.The changes required in the transform are under development.Which RDO do we want/have to keep? RDO? RDO_FTK? Both?
HPC working groupo meeting
RDO
NTUP_FTKTMP
ESD
Reco
TrigFTKSM4
NTUP_FTKIP
TrigFTKMergeReco
RDO_FTK
0 1
2
3
Reco
4
64

G. Volpi - FTK Simulation 14
Performance of the emulation• The FTK emulation performance is under
constants scrutiny• Performance evaluated using virtual machines based
on Scientific Linux 6• VM score ~1800 SpecInt• Results obtained summing the results of all the
independent jobs and steps for few hundred of events• CPU change according the FTK conditions
• Full pattern bank, 1024 MP• Commissioning bank, 256 MP
• Foreseen for the period after the installation
• Execution time change according the expected LHC condition• Increasing LHC luminosity will bring more overlapping
collisions per bunch crossing (pileup collisions, PU)• Total execution time <50 sec/evt for the small
FTK configuration• To remain in the ATLAS resources 2-3 sec/evt is
required
Road finding time dominated by the AM emulation, ~66% of the time.
The AM emulation time largely depends from the bank size.
Dependence with the pileup is about linear, showing the efficiency of the match scheme.
HPC working groupo meeting

G. Volpi - FTK Simulation 15
Possible benefits and limitations using HPC resources
• FTK emulation can still run outside Athena• Athena is wrapper of a generic library, standalone version still maintained and
functioning• The only remaining dependency is ROOT, can be tricky to remove
• The FTK algorithms naturally scale to a multi-core/node architecture• The pattern matching and the track fitting are designed to be performed in independent
boards• It is possible distribute the workflow in parallel processes or threads• The code build around classes that describe single “engines”, each engine instance is
thread-safe:• Pattern matching of multiple banks can be performed independently in multiple threads
• Algorithms designed from FPGAs can be implemented on accelerators• The “track fitting” is reduced to scalar products, GPU can well suite the problem• AM pattern matching can be trickier, but improvements on accelerators are possible
HPC working groupo meeting

G. Volpi - FTK Simulation 16
Conclusions• The FTK emulation is an important component of the FTK project• Support the HW design, the connection with HLT and the physics performance
• The amount of resources is extremely demanding• Algorithm designed for a massive set of custom electronic boards poorly map to CPU• The memory constraints require to complicate the workflow to complete the emulation• CPU usage remain high, with a negative impact the amount of simulated events
• The use of additional resource can be beneficial for the project and ATLAS• The code design may allow to adapt to distributed architecture• Current solution to run the emulation is to allow to work on sub-events• Porting on GPU can be “easy” for some algorithm, less direct for others
• The manpower to port the emulation can be very limited on the FTK side• Most of the effort currently focusing on the
HPC working groupo meeting

G. Volpi - FTK Simulation 17
Don’t care features• The LSB bit in AM match lines can use
up to 6 ternary bits• Each bit allow 0, 1 and X (don’t care)
• K. Pagiamtzis and A. Sheikholeslami, Solid-State Circuits, IEEE Journal of, vol. 41, no. 3, 2006
• The DC bits allow to reduce the match precision where required
• The use of DC solves the problem in balancing the match precision• Low resolution patterns allow smaller
pattern bank size (less chips, less cost), but the probability of random coincidences grows
• High resolution fakes increase the filtering power at the price of larger banks
• DC allows to merge similar pattern in favored configurations (less patterns) maintaining high-resolution and rejection power where convenient
Pattern in AM chip w/o the DC
Pattern in AM chip w/ the DC
DC set
3 low-resolution patterns
7 high-resolution patterns
Empty areas are a source of fakes
HPC working groupo meeting