
ELEMENTI DI CALCOLO DELLE PROBABILITA’ proprietà Dato Ω lo spazio di tutti gli eventi e A,B ⊆...
55
ELEMENTI DI CALCOLO DELLE PROBABILITA’ Premessa importante : il comportamento della popolazione rispetto una variabile casuale X viene descritto attraverso una funzione parametrica di probabilità p X (x | θ) dove θ è l’insieme dei parametri che caratterizza la popolazione. In questo contesto, i dati osservati o raccolti rappresentano possibili realizzazioni della variabile casuale avvenute attraverso esperimenti casuali. Data la legge p X (x | θ), possiamo calcolare la probabilità/densità di probabilità per ogni realizzazione X = x o insieme di realizzazioni X 1 = x 1 ,...,X n = x n . Statistica, CLEA – p. 1/55
Transcript of ELEMENTI DI CALCOLO DELLE PROBABILITA’ proprietà Dato Ω lo spazio di tutti gli eventi e A,B ⊆...

ELEMENTI DI CALCOLO
DELLE PROBABILITA’Premessa importante: il comportamento della popolazione rispetto una variabile casuale
X viene descritto attraverso una funzione parametrica di probabilità pX(x | θ) dove θ è
l’insieme dei parametri che caratterizza la popolazione. In questo contesto, i dati
osservati o raccolti rappresentano possibili realizzazioni della variabile casuale avvenute
attraverso esperimenti casuali. Data la legge pX(x | θ), possiamo calcolare la
probabilità/densità di probabilità per ogni realizzazione X = x o insieme di realizzazioni
X1 = x1, . . . , Xn = xn.
Statistica, CLEA – p. 1/55

Esperimento casuale
L’esperimento casuale è un esperimento il cui risultato non si può determinare con
certezza. Ad esempio:
risultato del lancio di una moneta
colore di una pallina estratta da un’urna contente palline di vario colore
numeri estratti per il gioco del lotto
Ciò che si può fare è calcolare la probabilità di ogni relizzazione dell’esperimento. Si
necessita:
spazio di tutti i possibili eventi Ω
variabile aleatoria X
distribuzione di probabilità pX(x | θ)
Statistica, CLEA – p. 2/55

Spazio degli eventi Ω
Definiamo con Ω, l’insieme di tutti i possibili eventi elementari ω che si possono
realizzare da un esperimento casuale. Consideriamo gli esperimenti
k lanci consecutivi di una moneta
k estrazioni da un’urna contenente palline bianche e nere
Spazio degli eventi Ω
k = 1 k = 2 k = 3
T TT TTT
C TC TTC
CT TCT
CC CTT
TCC
CCT
CTC
CCC
Spazio degli eventi Ω
k = 1 k = 2 k = 3
B BB BBB
N BN BBN
NB BNB
NN NBB
BNN
NNB
NBN
NNN
Statistica, CLEA – p. 3/55

Insiemi di eventi
Consideriamo 3 lanci consecutivi di una moneta. L’insieme degli eventi elemenatari ω:
Ω = TTT, TTC, TCT, CTT, TCC,CCT,CTC,CCC
Altri eventi
almeno una volta testa: A = TTT, TTC, TCT, CTT, TCC,CCT,CTCdue volte croce: B = TCC,CCT,CTCal massimo una volta testa: C = TCC,CCT,CTC,CCCtre volte croce, coincide con un evento elementare: ω = CCC
Statistica, CLEA – p. 4/55

Operazione fra insiemi di eventi
Consideriamo 2 eventi in Ω = TTT, TTC, TCT, CTT, TCC,CCT,CTC,CCC:
A = TCC,CCT,CTC, B = TTT, TCC,CTC,CCC
UNIONE di eventi A ∪ B: insieme di eventi in A o in B
A ∪B = TCC,CCT,CTC, TTT, CCC
INTERSEZIONI di eventi A ∩B: insieme di eventi in A e in B
A ∩B = TCC,CTC
NEGAZIONE di eventi A: insieme di eventi che non sono in A
Ω \A = TTT, TTC, TCT, CTT, CCC
Statistica, CLEA – p. 5/55

Alcune proprietà
Dato Ω lo spazio di tutti gli eventi e A,B ⊆ Ω, con A,B 6= ∅A ∪B non è mai un insieme vuoto ∅A ∩B può essere un insieme vuoto, allora A e B sono due eventi incompatibili,
non si possono verificare contemporaneamente
dati k eventi H1, . . . , Hk fra loro incompatibili, Hi ∩Hj = ∅, i, j = 1, . . . , k, sono
anche esaustivi se
Ω = H1 ∪H2 ∪ · · · ∪Hk
A = ∅, se e solo se A ≡ Ω
A è un evento impossibile se non può mai verificarsi, quindi A * Ω
A è un evento certo se si verifica sempre, ad esempio: A ≡ Ω
dato A, l’evento complementare è l’evento negato A = Ω \ A
Statistica, CLEA – p. 6/55

Eventi condizionati
Condizionare significa ridurre lo spazio Ω poiché si è verificato l’evento B ⊆ Ω, per cui
B diventa un evento certo
B = Ω \B è un evento impossibile
Consideriamo nello spazio Ω = TTT, TTC, TCT, CTT, TCC,CCT,CTC,CCCA = TTT, TTC, TCT, CTT: almeno due volte testa
C = TTC, TCT, CTT, TCC,CCT,CTC,CCC: almeno 1 volta croce
D = CCT,CCC: i primi due lanci croce
Supponiamo di conoscere l’esito del primo lancio che è T : evento certo B= testa al
primo lancio e evento impossibile B= non testa al primo lancio. Lo spazio degli eventi
possibili diventa
Ω | B = TTT, TTC, TCT, TCC
da cui gli eventi condiziontati sono relativi non a Ω, ma a Ω | BA | B = TTT, TTC, TCTC | B = TTC, TCT, TCCD | B = ∅ è un evento impossibile perché D e B sono incompatibili
Statistica, CLEA – p. 7/55

Probabilità: approccio classico
Approccio classico:
se tutti i casi sono equiprobabili, la probabilità di ogni evento A è il rapporto
P (A) =numero dei casi favorevoli all’evento
numero di tutti i casi possibili
Esempi di esperimenti casuali con risultati equiprobabili:
lancio di un dado
P (1) = P (2) = P (3) = P (4) = P (5) = P (6) = 1/6
lancio di una moneta non truccata
P (T ) = P (C) = 1/2 = 0.5
estrazione di un numero da 1 a 90
P (1) = P (2) = · · · = P (90) = 1/90
Statistica, CLEA – p. 8/55

Esempio
Consideriamo lo spazio Ω = TTT, TTC, TCT, CTT, TCC,CCT,CTC,CCCA = TTT, TTC, TCT, CTT: due volte testa
P (A) = 4/8 = 0.5
C = TTC, TCT, CTT, TCC,CCT,CTC,CCC: almeno 1 volta croce
P (C) = 7/8 = 0.875
D = CCT,CCC: i primi due lanci croce
P (D) = 2/8 = 0.25
Statistica, CLEA – p. 9/55

Probabilità condizionata
Supponiamo di conoscere l’esito del primo lancio che è T . Lo spazio degli eventi
possibili diventa
Ω | B = TTT, TTC, TCT, TCC
A | B = TTT, TTC, TCT
P (A | B) = 3/4 = 0.75
C | B = TTC, TCT, TCC
P (C | B) = 3/4 = 0.75
D | B = ∅P (D | B) = 0
Statistica, CLEA – p. 10/55

Assiomi e proprietà
La probabilità è una funzione definita sullo spazio degli eventi Ω che associa ad ogni
evento A ⊆ Ω un numero reale P (A)
0 ≤ P (A) ≤ 1
la prob. di un evento certo è 1: P (Ω) = 1
la prob. di un evento impossibile è 0, ma viceversa non è vero
P (A ∪B) = P (A) + P (B)− P (A ∩B)
P (A ∪B) = P (A) + P (B) se A ∩B = ∅P (A) = 1− P (A)
P (A ∩B) = P (A | B)P (B) = P (B | A)P (A), da cui
P (A | B) = P (A ∩B)/P (B)
P (A ∩B) = P (A)P (B) se e solo se A e B sono indipendenti, da cui
P (A | B) = P (A) e P (B | A) = P (B)
Statistica, CLEA – p. 11/55

Indipendenza
Due eventi A e B sono indipendenti, A⊥⊥ B se e solo se
P (A ∩B) = P (A)P (B)
Questo vuol dire che il verificarsi di B non influisce sulla probabilità di A e viceversa
P (A | B) =P (A ∩B)
P (B)=
P (A)P (B)
P (B)= P (A)
P (B | A) =P (A ∩B)
P (A)=
P (A)P (B)
P (A)= P (B)
N.B. Se due eventi A e B con probabilità positive sono incompatibili, sicuramente
non sono indipendenti, poiché se A e B sono incompatibili, A | B = ∅, quindi
P (A | B) = 0 6= P (A).
Analogamente, se due eventi sono indipendenti sono necessariamente compatibili.
Statistica, CLEA – p. 12/55

Teorema delle probabilità totali
Siano E1, . . . , Ek k eventi esaustivi ed incompatibili
Ω = E1 ∪ · · · ∪ Ek
Ej ∩ Ei = ∅, i, j = 1, . . . , k
Dato un qualunque evento B ⊆ Ω
P (B) = P (B ∩ E1) + · · ·+ P (B ∩ Ek)
P (B) = P (B | E1)P (E1) + · · ·+ P (B | Ek)P (Ek)
Esempio. Ci sono k urne E1, . . . , Ek contenenti palline bianche e nere. La probabilità di
estrarre una pallina bianca considerando che la scelta delle urne è equiprobabile
P (Ei) =1
k, P (B | Ei) =
numero palline bianche in Ei
numero palline in Ei
P (B) =numero palline bianche in E1
numero palline in E1
1
k+ · · ·+ numero palline bianche in Ek
numero palline in Ek
1
k
Statistica, CLEA – p. 13/55

Teorema di Bayes
Consideriamo un modo alternativo di calcolare la probabilità condizionata
P (A | B) =P (B ∩A)
P (B)=
P (B | A)P (A)
P (B | A)P (A) + P (B | A)P (A)
dove il denominatore si può calcolare col teorema delle probabilità totali
Interpretazione: supponiamo che l’evento B sia l’EFFETTO che può essere causato da
tanti eventi E1, . . . , Ek che sono CAUSE esaustive e disgiunte
P (CAUSAi | EFFETTO) =P (EFFETTO | CAUSAi)P (CAUSAi)
P (EFFETTO)
P (Ei | B) =P (B | Ei)P (Ei)
P (B)=
P (B | Ei)P (Ei)
P (B | E1)P (E1) + · · ·+ P (B | Ek)P (Ek)
P (Ei): probabilità a priori della CAUSA (scegliere l’urna Ei)
P (Ei | B): probabilità a posteriori della CAUSA Ei dato l’EFFETTO B (estratta
pallina bianca)
Statistica, CLEA – p. 14/55
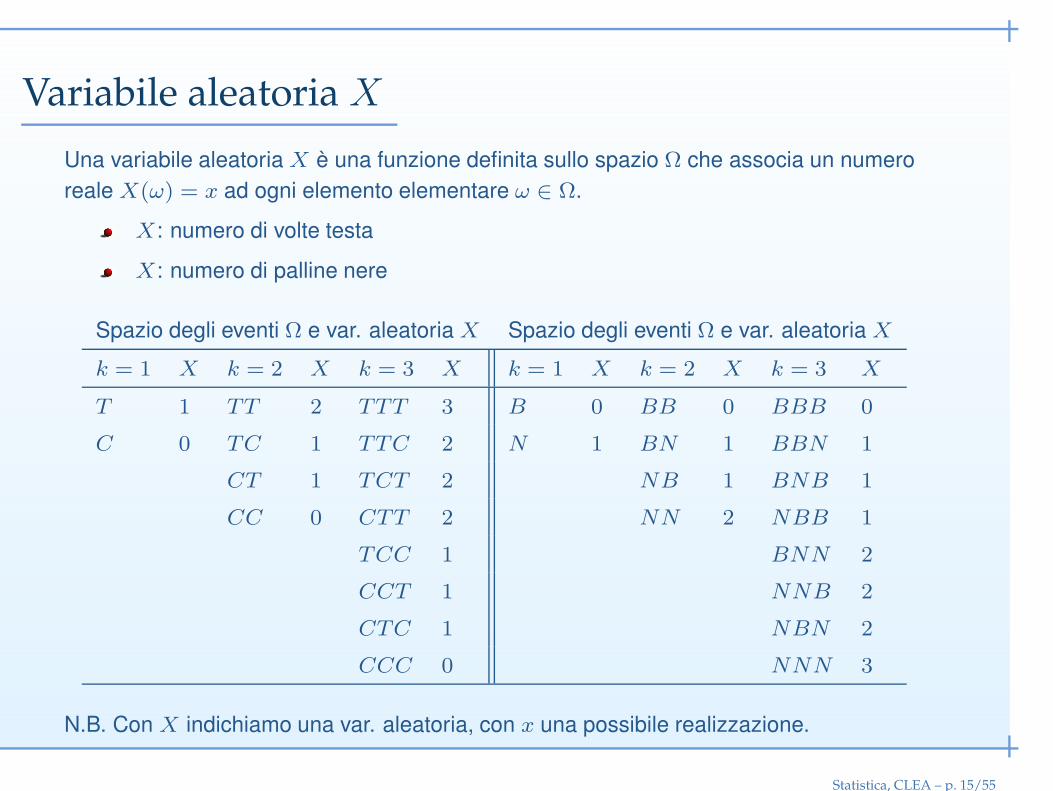
Variabile aleatoria X
Una variabile aleatoria X è una funzione definita sullo spazio Ω che associa un numero
reale X(ω) = x ad ogni elemento elementare ω ∈ Ω.
X: numero di volte testa
X: numero di palline nere
Spazio degli eventi Ω e var. aleatoria X Spazio degli eventi Ω e var. aleatoria X
k = 1 X k = 2 X k = 3 X k = 1 X k = 2 X k = 3 X
T 1 TT 2 TTT 3 B 0 BB 0 BBB 0
C 0 TC 1 TTC 2 N 1 BN 1 BBN 1
CT 1 TCT 2 NB 1 BNB 1
CC 0 CTT 2 NN 2 NBB 1
TCC 1 BNN 2
CCT 1 NNB 2
CTC 1 NBN 2
CCC 0 NNN 3
N.B. Con X indichiamo una var. aleatoria, con x una possibile realizzazione.
Statistica, CLEA – p. 15/55

Variabile aleatoria discreta
Una variabile aleatoria X descrive il comportamento di un fenomeno a
prescindere della realizzazione del singolo esperimento casuale
dopo la realizzazione dell’esperimento casuale, la variabile aleatoria assume un
valore certo X = x
la variabile aleatoria è DISCRETA se X assume un’infinità numerabile di valori
numero di volte testa in 3 lanci de una moneta
numero di palline bianche estratte da un’urna
numero di prodotti difettosi al giorno
numero di auto al casello ogni giorno etc...
Statistica, CLEA – p. 16/55
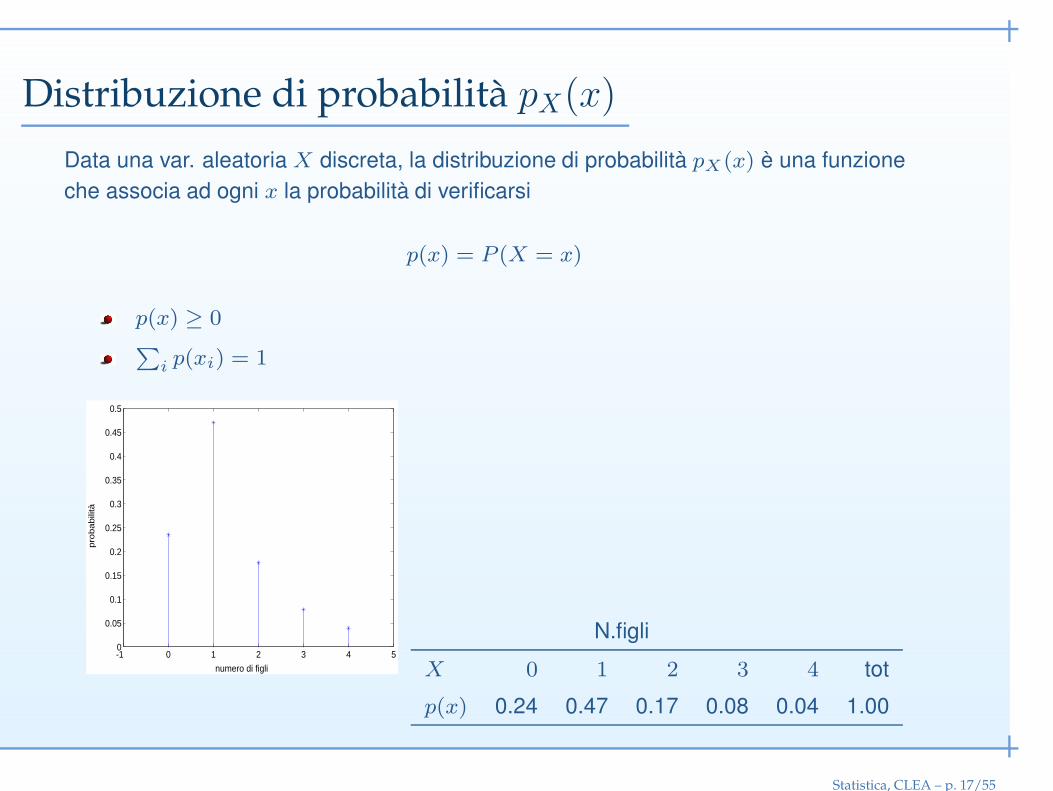
Distribuzione di probabilità pX(x)
Data una var. aleatoria X discreta, la distribuzione di probabilità pX(x) è una funzione
che associa ad ogni x la probabilità di verificarsi
p(x) = P (X = x)
p(x) ≥ 0∑
i p(xi) = 1
-1 0 1 2 3 4 50
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
numero di figli
pro
ba
bili
tà
N.figli
X 0 1 2 3 4 tot
p(x) 0.24 0.47 0.17 0.08 0.04 1.00
Statistica, CLEA – p. 17/55
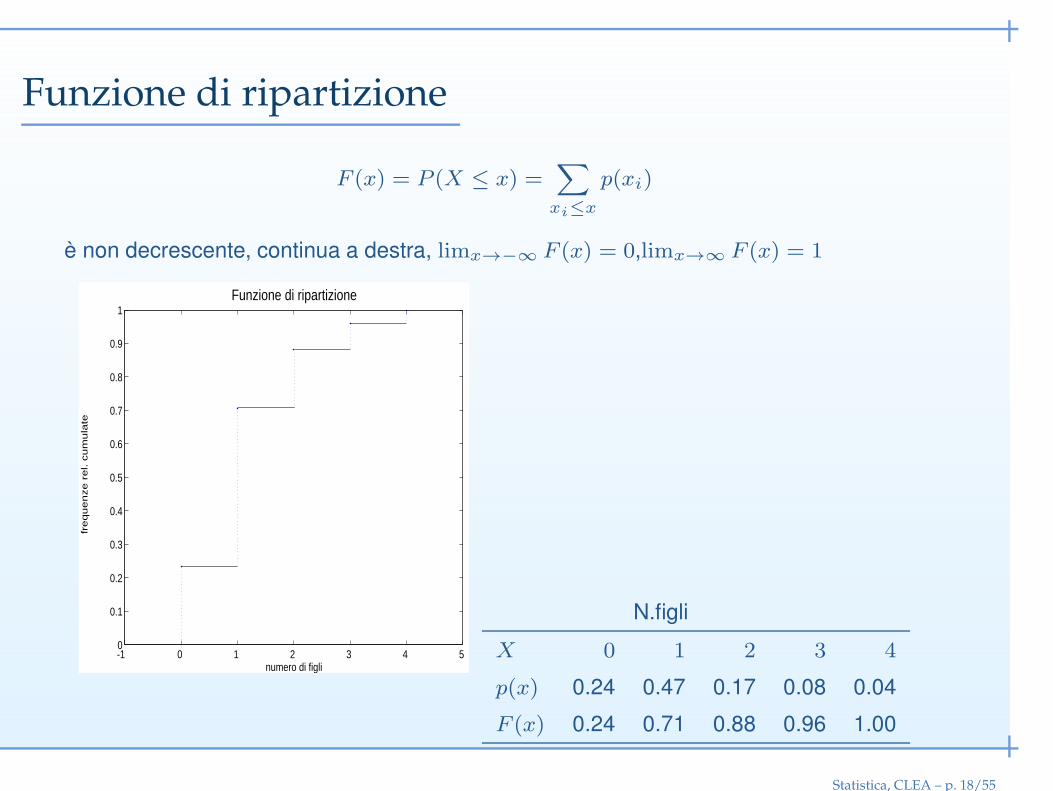
Funzione di ripartizione
F (x) = P (X ≤ x) =∑
xi≤x
p(xi)
è non decrescente, continua a destra, limx→−∞ F (x) = 0,limx→∞ F (x) = 1
-1 0 1 2 3 4 5 0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Funzione di ripartizione
numero di figli
frequenze r
el. c
um
ula
te
N.figli
X 0 1 2 3 4
p(x) 0.24 0.47 0.17 0.08 0.04
F (x) 0.24 0.71 0.88 0.96 1.00
Statistica, CLEA – p. 18/55

Valore atteso e varianza
Il valore atteso di una variabile casuale X discreta è
E(X) = µX =∑
i
xip(xi)
E(X) = µX = 0× 0.24 + 1× 0.47 + 2× 0.17 + 3× 0.08 + 4× 0.04 = 1.21
La varianza di una variabile casuale X discreta è
V(X) = E(X − µX)2 =∑
i
(xi − µX)2p(xi)
V(X) = 1.46×0.24+0.04×0.47+0.62×0.17+3.20×0.08+7.78×0.04 = 1.04
N.figli
X 0 1 2 3 4
p(x) 0.24 0.47 0.17 0.08 0.04
(xi − µX)2 1.46 0.04 0.62 3.20 7.78
Statistica, CLEA – p. 19/55

Varianza e deviazione standard
La varianza si può calcolare anche
V(X) = E(X2)− µ2x =
∑
i
x2i p(xi)− µ2
X
V(X) = 0× 0.24 + 1× 0.47 + 4× 0.17 + 9× 0.08 + 16× 0.04− 1.212 = 1.04
la deviazione standard è
SD(X) =√
V(X) =√1.04 = 1.01
N.figli
X 0 1 2 3 4
p(x) 0.24 0.47 0.17 0.08 0.04
x2i 0 1 4 9 16
Statistica, CLEA – p. 20/55

Indipendenza fra var. casuali
Date 2 variabili casuali X e Y rispettivamente con legge di probabilità pX(x) e pY (x), la
distribuzione della variabile congiunta (X,Y ) è
pXY (x, y) = pX(x)× pY (y) ⇐⇒ X ⊥⊥ Y
Esempio. Consideriamo il lancio di una moneta per cui P (1) = 0.2 e P (0) = 0.8 dove 1
indica il successo T e 0 l’insuccesso C. Consideriamo le variabili
X= risultato del primo lancio
Y = risultato del secondo lancio
Dato che i due lanci sono indipendenti, possiamo calcolare pXY (x, y)
pXY (X = 1, Y = 0) = pX(1)× pY (0) = 0.2× 0.8
pXY (X = 0, Y = 1) = pX(0)× pY (1) = 0.8× 0.2
pXY (X = 1, Y = 1) = pX(1)× pY (0) = 0.2× 0.2
pXY (X = 0, Y = 0) = pX(1)× pY (0) = 0.8× 0.8
Statistica, CLEA – p. 21/55

Combinazioni lineari di var. casuali
Date n variabili casuali Xi ognuna distribuita con una legge di probabilità pXi(xi) con
un certo valore atteso E(Xi) e una certa varianza V(Xi), consideriamo la variabile
casuale Y ottenuta come combinazione lineare
Y =n∑
i=1
aiXi + bi, dove ai, bi sono costanti
Se le Xi sono tutte indipendenti fra loro
E(Y ) =n∑
i=1
aiE(Xi) + bi, V(Y ) =n∑
i=1
a2iV(Xi)
Esempio. Siano due variabili casuali indipendenti X e Z con E(X) = 8, V(X) = 0.5 e
con E(Z) = 0.4, V(Z) = 0.01. Consideriamo
Y = 3X − 4Z + 5
E(Y ) = 3× 8− 4× 0.4 + 5, V(Y ) = 9× 0.5 + 16× 0.01
Statistica, CLEA – p. 22/55

Alcune variabiabili casuali discrete
X ∼ U(a, b) Uniforme, a ≤ x ≤ b
X ∼ Be(π) Bernoulli, x = 0, 1
X ∼ Bin(n, π), Binomiale, 0 ≤ x ≤ n
X ∼ Po(λ), Poisson, x ≥ 0
N.B. I valori a, b, n, π e λ sono i parametri che caratterizzano la distribuzione di
probabilità che descrive il comportamento della variabile casuale X nella popolazione.
Statistica, CLEA – p. 23/55

Distribuione discreta Uniforme
La variabile casuale discreta X assume un numero finito di valori x1, . . . , xK ed assume
probabilità costante per ogni xi
p(xi) =1
K, F (x) =
num. di xi ≤ x
K, i = 1 . . . ,K
Esempio: X = lancio di un dado 1, 2, 3, 4, 5, 6 ha una distribuzione uniforme discreta
0 1 2 3 4 5 6 7-1
-0.5
0
0.5
1
1.5Distribuzione uniforme discreta
X
pro
ba
bili
tà
0 1 2 3 4 5 6 70
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Distribuzione uniforme discreta
X
Funz. ripart
izio
ne
Statistica, CLEA – p. 24/55

Distribuzione di Bernoulli (1)
La variabile casuale discreta X ∼ Be(x | π), dove π è la probabilità di successo,
assume due valori
x = 1: successo
x = 0: insuccesso
p(x) = πx(1− π)1−x, 0 ≤ π ≤ 1
x = 1, p(x) = π, prob. successo
x = 0, p(x) = 1− π, prob. insuccesso
E(X) = µx = 1× π + 0× (1− π) = π
V(X) = E(X2)− µ2X = 1× π + 0× (1− π)− π2 = π(1− π)
Esempio: consideriamo una moneta truccata per cui la probabilità di successo (T ) è
π = 0.7
P (X = 1) = 0.71 × 0.31−1 = 0.7
P (X = 0) = 0.70 × 0.31−0 = 0.3
Statistica, CLEA – p. 25/55
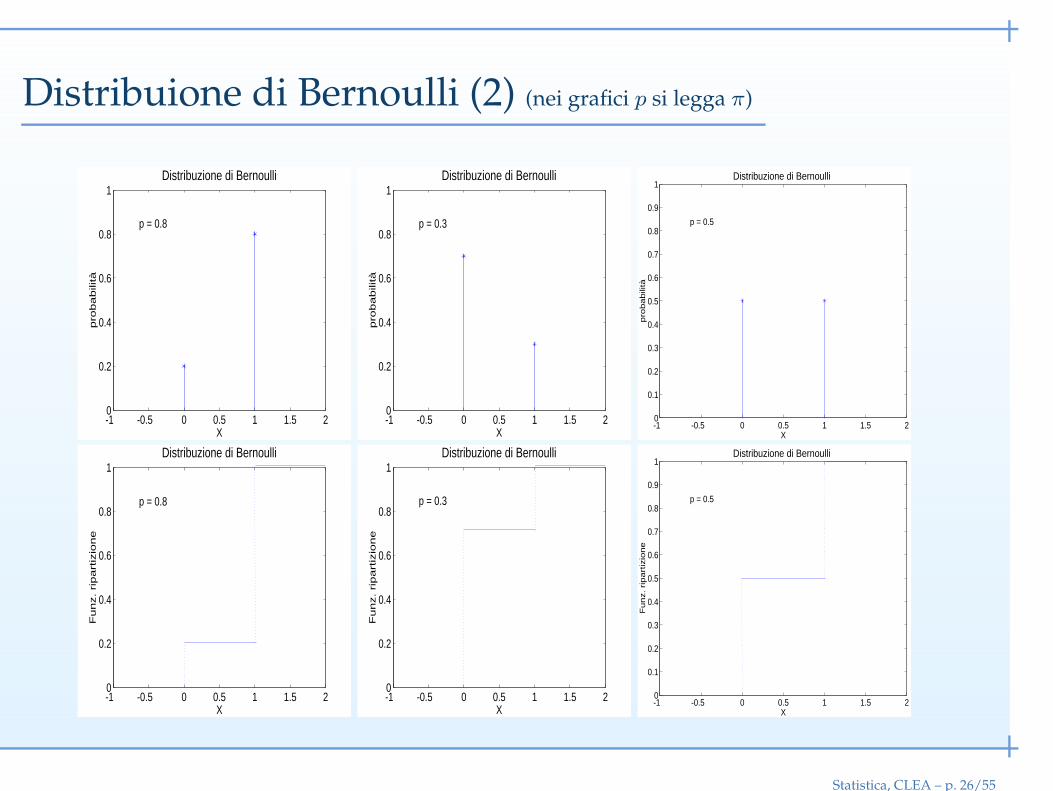
Distribuione di Bernoulli (2) (nei grafici p si legga π)
-1 -0.5 0 0.5 1 1.5 20
0.2
0.4
0.6
0.8
1Distribuzione di Bernoulli
X
pro
babilità
p = 0.8
-1 -0.5 0 0.5 1 1.5 20
0.2
0.4
0.6
0.8
1Distribuzione di Bernoulli
X
pro
babilità
p = 0.3
-1 -0.5 0 0.5 1 1.5 20
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Distribuzione di Bernoulli
X
pro
ba
bili
tà
p = 0.5
-1 -0.5 0 0.5 1 1.5 20
0.2
0.4
0.6
0.8
1Distribuzione di Bernoulli
X
Funz. ripart
izio
ne
p = 0.8
-1 -0.5 0 0.5 1 1.5 20
0.2
0.4
0.6
0.8
1Distribuzione di Bernoulli
X
Funz. ripart
izio
ne
p = 0.3
-1 -0.5 0 0.5 1 1.5 20
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Distribuzione di Bernoulli
X
Fu
nz.
rip
art
izio
ne
p = 0.5
Statistica, CLEA – p. 26/55

Distribuzione Binomiale (1)
La variabile casuale discreta X ∼ Bin(x | n, π), dove π è la probabilità di successo e n
è la dimensione del campione assume valori 0 ≤ x ≤ n
p(x) =(n
x
)
πx(1− π)n−x, 0 ≤ π ≤ 1
dove x indica il numero di successi in n prove indipendenti.
E(X) = µx = nπ, V(X) = nπ(1− π)
Esempio: consideriamo un’urna contenente 10 palline bianche e 15 palline nere. Il
successo è l’estrazione di pallina bianca (B) la cui probabilità è π = 10/25 = 0.4. La
probabilità di ottenere x = 3 successi in n = 5 prove è
P (X = 3) =(5
3
)
0.43 × 0.65−3 =5!
3!2!0.43 × 0.62 = 0.23
P (X = 0) =(5
0
)
0.40 × 0.65 = 0.08, P (X = 5) =(5
5
)
0.45 × 0.60 = 0.01
Statistica, CLEA – p. 27/55

Distribuione Binomiale (2) (nei grafici p si legga π)
-1 0 1 2 3 4 5 60
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45Distribuzione binomiale
X
pro
ba
bili
tà
p = 0.2
-1 0 1 2 3 4 5 60
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4Distribuzione binomiale
X
pro
ba
bili
tà
p = 0.7
-1 0 1 2 3 4 5 60
0.05
0.1
0.15
0.2
0.25
0.3
0.35Distribuzione binomiale
X
pro
ba
bili
tà
p = 0.5
Prob. di più di 3 successi:
P (X > 3) = P (X = 4) + P (X = 5)
Prob, di al massimo 2 successi:
P (X ≤ 2) = P (X = 0) + P (X = 1) + P (X = 2)
Prob. di almeno 1 successo:
P (X ≥ 1) = P (X = 1) + P (X = 2) + P (X = 3) + P (X = 4) + P (X = 5) =
1− P (X = 0)
Statistica, CLEA – p. 28/55

Binomiale come somma di Bernoulli (1)
La variabile casuale X Binomiale può essere vista come somma di n variabili Y
Bernoulli indipendenti e identicamente distribuite (con lo stesso parametro p)
X =n∑
i=1
Yi
Per l’indipendenza
E(X) =n∑
i=1
E(Yi) =n∑
i=1
π = nπ, V(X) =n∑
i=1
V(Yi) =n∑
i=1
π(1− π) = nπ(1− π)
Per ogni var. Yi Bernoulli si può calcolare la prob. di successo P (Yi = T ) in un singolo
lancio di una moneta secondo una prob. di successo π. La var. X binomiale calcola la
prob. di x volte testa (successi) in n lanci indipendenti ognuno dei quali ha la stessa
prob. di successo π.
Statistica, CLEA – p. 29/55

Binomiale come somma di Bernoulli (2)
Esempio. Dati n = 3 lanci indipendenti di una moneta in cui la probabilità di successo
(T ) è π = 0.3, calcolare la probabilità di una volta testa, P (X = 1), X ∼ Bin(x | n, π).
Ad esempio calcoliamo la prob. di questo risultato, che, data l’indipendenza delle prove,
P (T ∩ C ∩ C) = P (T )× P (C)× P (C) = 0.3× 0.7× 0.7 = 0.31 × 0.72
Quanti sono i possibili risultati per cui si ha un solo successo?
(n
x
)
=(3
1
)
= 3 : (TCC), (CTC), (CCT ).
Da cui, se X è Binomaile con n = 3 e π = 0.3,
P (X = 1) =(3
1
)
0.3× 0.72.
Statistica, CLEA – p. 30/55

Variabile aleatoria continua
Una variabile aleatoria X è CONTINUA se X assume un’infinità non numerabile di valori
altezza
peso
distanza
tempo di percorrenza etc...
Alcuni aspetti delle variabili continue:
Se ogni possibile realizzaione della X è equiprobabile, allora P (X = x) = 0, per
ogni x ∈ R.
La funzione di probabilità non si può usare, come nel caso discreto per
descrivere il comportamento di una var. casuale continua.
Con la funzione di ripartizione possiamo calcolare la prob. di un intervallo
F (x) = P (X ≤ x)
Per descrivere la X si utilizza la funzione di densità fX(x) = ddx
F (x)
Statistica, CLEA – p. 31/55

La funzione di densità fX(x)
Data una variabile aleatoria continua X, la funzione di densità
f(x) =d
dxF (x)
è una curva per ogni valore x attribuisce la densità di probabilità 6= probabilità. La
probabilità è l’area al di sotto della curva
P (a ≤ X ≤ b) =
∫ b
afX(x)dx = F (b)− F (a)
Proprietà:
f(x) ≥ 0, per ogni x ∈ R, ma non necessariamente f(x) ≤ 1∫+∞
−∞fX(x)dx = 1
Statistica, CLEA – p. 32/55
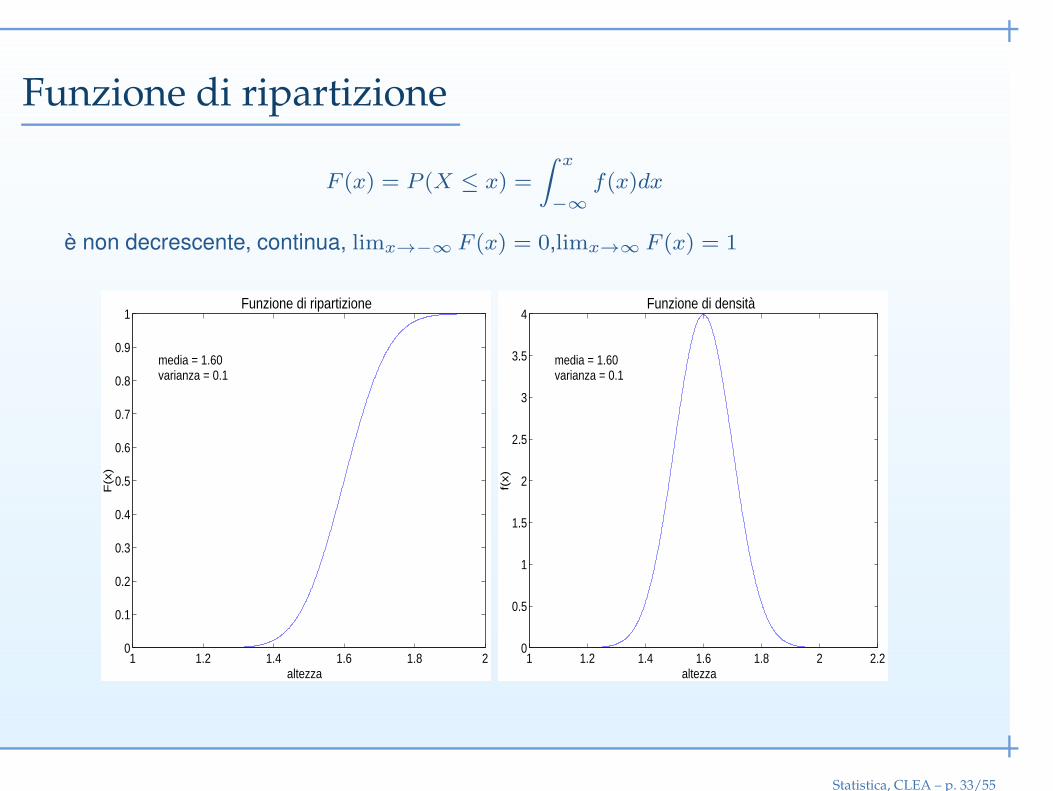
Funzione di ripartizione
F (x) = P (X ≤ x) =
∫ x
−∞
f(x)dx
è non decrescente, continua, limx→−∞ F (x) = 0,limx→∞ F (x) = 1
1 1.2 1.4 1.6 1.8 20
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Funzione di ripartizione
altezza
F(x
)
media = 1.60varianza = 0.1
1 1.2 1.4 1.6 1.8 2 2.20
0.5
1
1.5
2
2.5
3
3.5
4Funzione di densità
altezza
f(x)
media = 1.60varianza = 0.1
Statistica, CLEA – p. 33/55

Valore atteso e varianza
Il valore atteso di una variabile casuale X continua è
E(X) = µX =
∫ +∞
−∞
xf(x)dx
La varianza di una variabile casuale X continua è
V(X) = E(X − µX)2 =
∫ +∞
−∞
(x− µX)2f(x)dx
oppure
V(X) = E(X2)− µ2x =
∫ +∞
−∞
x2f(x)dx− µ2X
la deviazione standard è
SD(X) =√
V(X)
Statistica, CLEA – p. 34/55
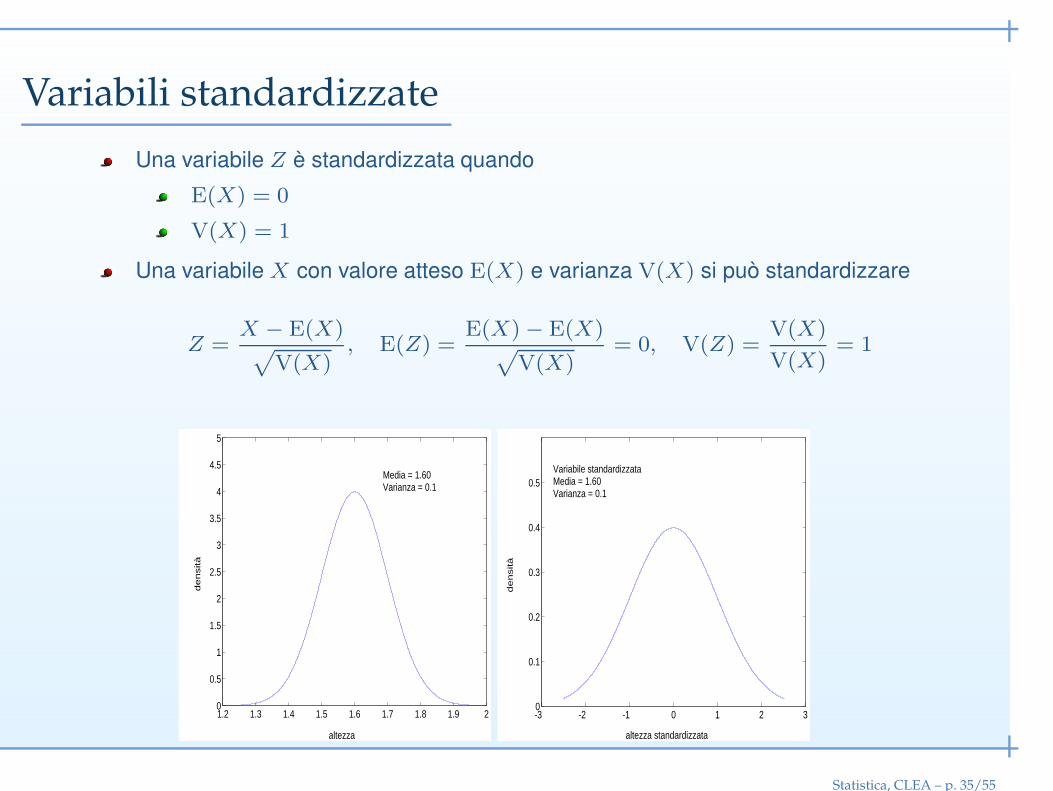
Variabili standardizzate
Una variabile Z è standardizzata quando
E(X) = 0
V(X) = 1
Una variabile X con valore atteso E(X) e varianza V(X) si può standardizzare
Z =X − E(X)√
V(X), E(Z) =
E(X)− E(X)√
V(X)= 0, V(Z) =
V(X)
V(X)= 1
1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 20
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
altezza
de
nsità
Media = 1.60Varianza = 0.1
-3 -2 -1 0 1 2 30
0.1
0.2
0.3
0.4
0.5
altezza standardizzata
de
nsità
Variabile standardizzataMedia = 1.60Varianza = 0.1
Statistica, CLEA – p. 35/55

Indipendenza e combinazioni lineari
Date 2 variabili casuali X e Y rispettivamente con funzione di densità fX(x) e
fY (x), la distribuzione della variabile congiunta (X,Y ) è
fXY (x, y) = fX(x)× fY (y) ⇐⇒ X ⊥⊥ Y
Date n variabili casuali Xi ognuna con funzione di densità fXi(xi) con un certo
valore atteso E(Xi) e una certa varianza V(Xi), consideriamo la variabile
casuale Y ottenuta come combinazione lineare
Y =n∑
i=1
aiXi + bi, dove ai, bi sono costanti
Se le Xi sono tutte indipendenti fra loro
E(Y ) =
n∑
i=1
aiE(Xi) + bi, V(Y ) =
n∑
i=1
a2iV(Xi)
Statistica, CLEA – p. 36/55

Alcune variabili aleatorie continue
X ∼ N(µ, σ2) Normale, −∞ < x < +∞X ∼ t(r) t-Student, −∞ < x < +∞X ∼ χ2(r) chi-quadrato, x ≥ 0
X ∼ F (r1, r2) Fisher x ≥ 0
N.B. I valori µ, σ2, r, r1 e r2 sono i parametri che caratterizzano la distribuzione di
probabilità che descrive il comportamento della variabile casuale X nella popolazione.
Statistica, CLEA – p. 37/55

Distribuzione Normale
La variabile casuale X Normale o Gaussiana ha una forma campanulare ed è
simmetrica. E’ caratterizzata da due parametri
E(X) = µ la media
V(X) = σ2 la varianza
fX(x | µ, σ2) =1√2πσ2
exp[− (x− µ)2
2σ2], −∞ ≤ x ≤ +∞
La probabilità si calcola attraverso l’integrale
P (a ≤ X ≤ b) =
∫ b
afX(x | µ, σ2)dx = F (b)− F (a)
P (X ≤ a) =
∫ a
−∞
fX (x | µ, σ2)dx = F (a), P (X ≥ a) =
∫ +∞
afX(x | µ, σ2)dx = 1−F (a)
N.B. Si dimostra che∫
fX(x | µ, σ2)dx = 1, ma questi integrali non si possono calcolare
in forma analitica, ma numerica (uso delle tavole).
Statistica, CLEA – p. 38/55
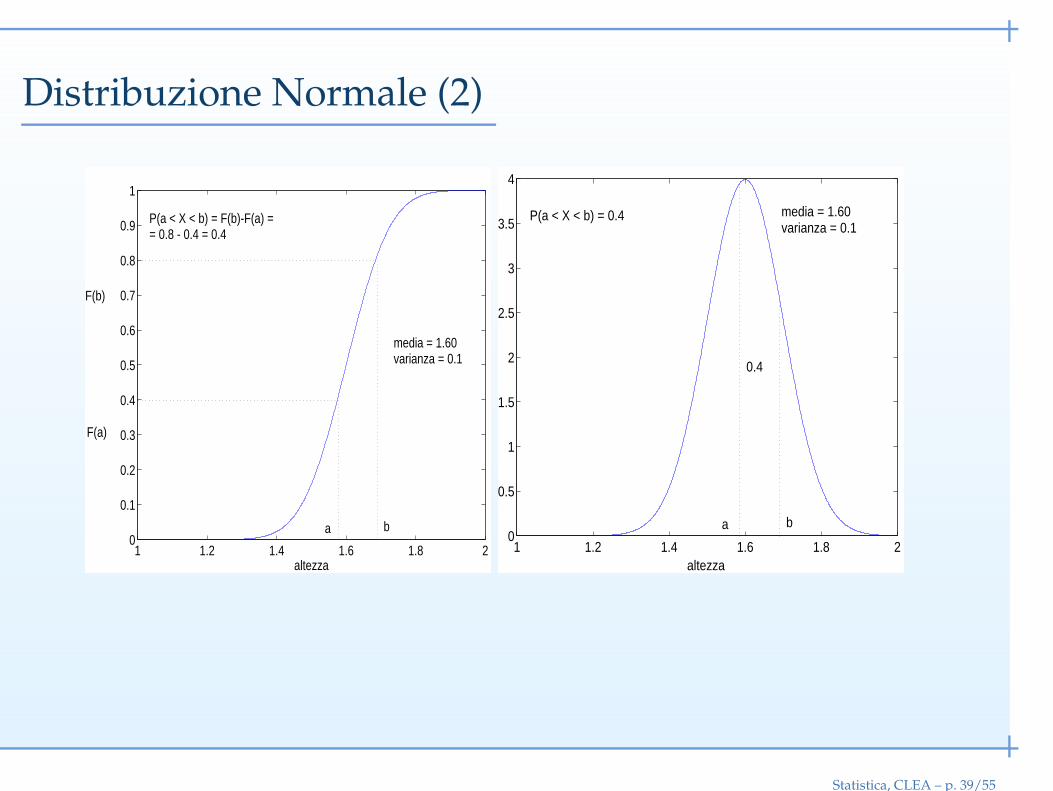
Distribuzione Normale (2)
1 1.2 1.4 1.6 1.8 20
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Funzione di ripartizione
altezza
media = 1.60varianza = 0.1
a b
F(b)
F(a)
P(a < X < b) = F(b)-F(a) == 0.8 - 0.4 = 0.4
1 1.2 1.4 1.6 1.8 20
0.5
1
1.5
2
2.5
3
3.5
4
altezza
media = 1.60varianza = 0.1
a b
P(a < X < b) = 0.4
0.4
Statistica, CLEA – p. 39/55
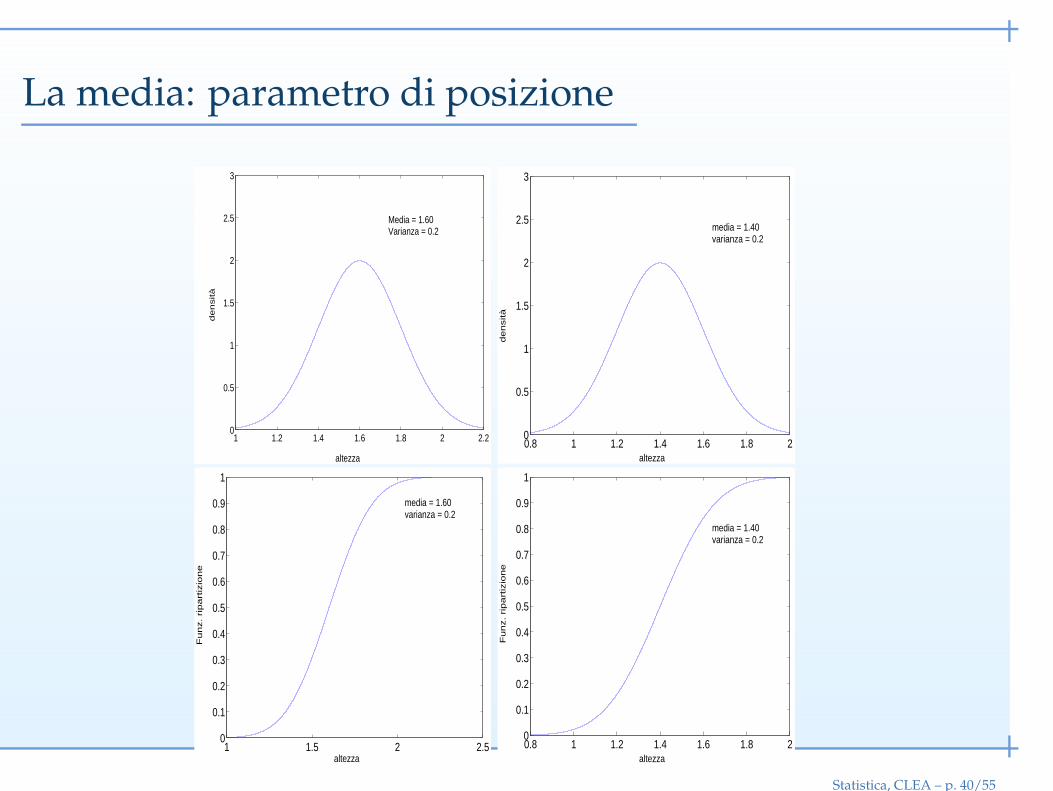
La media: parametro di posizione
1 1.2 1.4 1.6 1.8 2 2.20
0.5
1
1.5
2
2.5
3
altezza
de
nsità
Media = 1.60Varianza = 0.2
0.8 1 1.2 1.4 1.6 1.8 20
0.5
1
1.5
2
2.5
3
media = 1.40varianza = 0.2
altezza
de
nsità
1 1.5 2 2.50
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
media = 1.60varianza = 0.2
altezza
Funz. ripart
izio
ne
0.8 1 1.2 1.4 1.6 1.8 20
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
media = 1.40varianza = 0.2
altezza
Fu
nz.
rip
art
izio
ne
Statistica, CLEA – p. 40/55
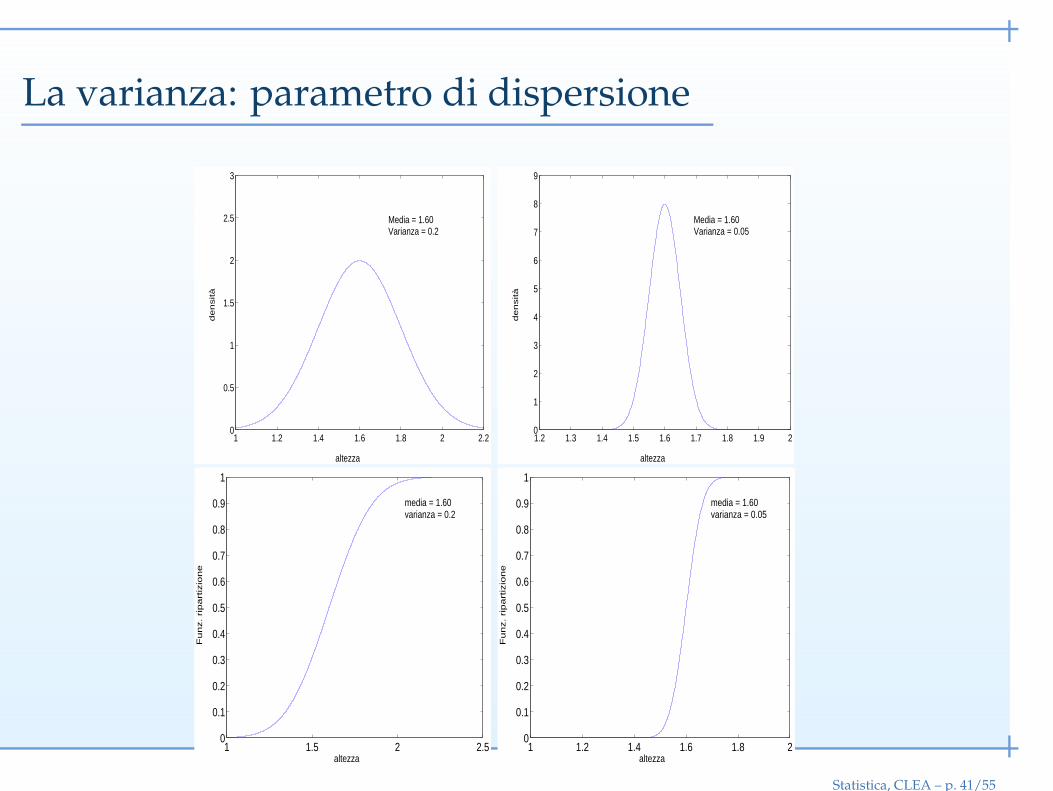
La varianza: parametro di dispersione
1 1.2 1.4 1.6 1.8 2 2.20
0.5
1
1.5
2
2.5
3
altezza
de
nsità
Media = 1.60Varianza = 0.2
1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 20
1
2
3
4
5
6
7
8
9
altezza
de
nsità
Media = 1.60Varianza = 0.05
1 1.5 2 2.50
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
media = 1.60varianza = 0.2
altezza
Funz. ripart
izio
ne
1 1.2 1.4 1.6 1.8 20
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
media = 1.60varianza = 0.05
altezza
Funz. ripart
izio
ne
Statistica, CLEA – p. 41/55

Combinazioni lineari di Normali
Se X1, . . . , Xn sono var. casuali N(µi, σ2i ) indipendenti, la combinazione lineare
Y =n∑
i=1
aiXi
Y ∼ N(∑
i
aiµi,∑
i
a2iσ2i )
Se X1, . . . , Xn sono i.i.d. N(µ, σ2),
Y ∼ N(nµ, nσ2)
Statistica, CLEA – p. 42/55
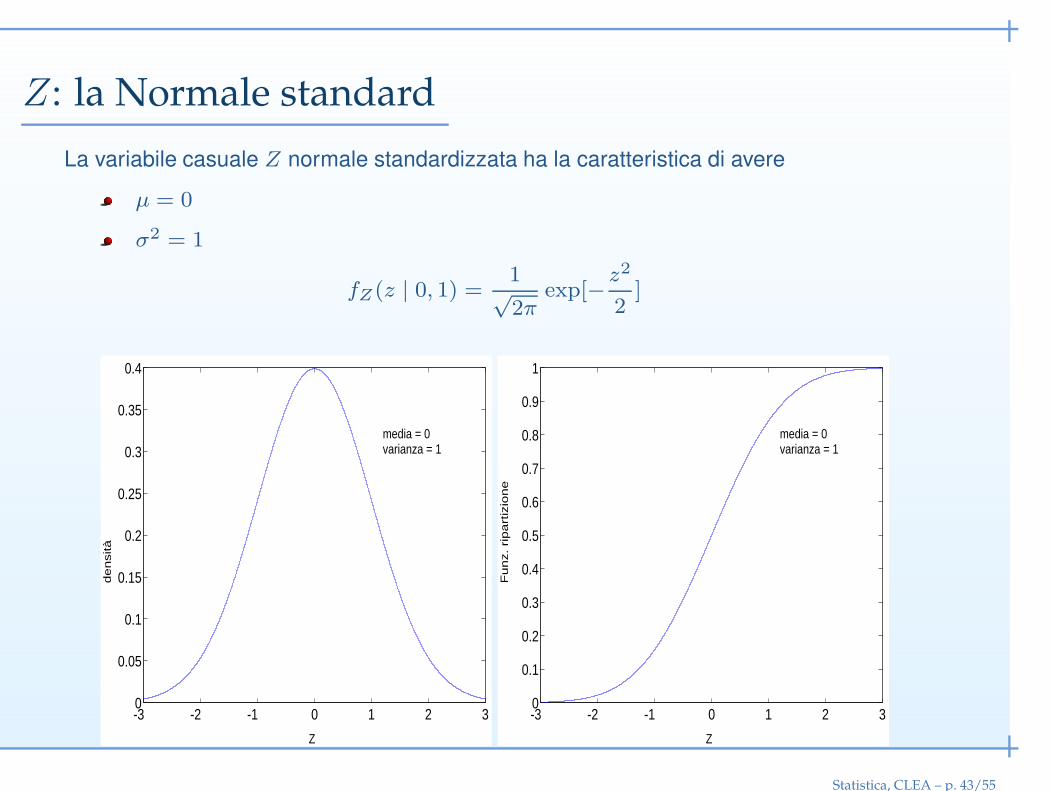
Z: la Normale standard
La variabile casuale Z normale standardizzata ha la caratteristica di avere
µ = 0
σ2 = 1
fZ(z | 0, 1) = 1√2π
exp[− z2
2]
-3 -2 -1 0 1 2 30
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
media = 0varianza = 1
Z
densità
-3 -2 -1 0 1 2 30
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
media = 0varianza = 1
Z
Funz. ripart
izio
ne
Statistica, CLEA – p. 43/55
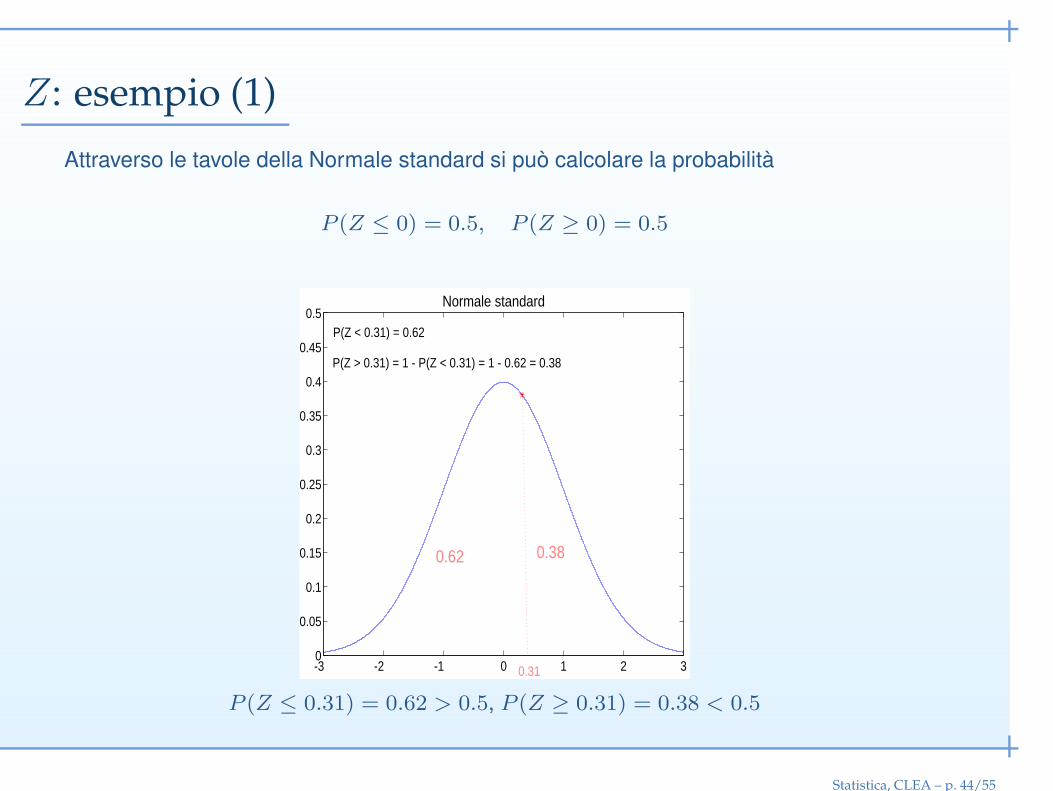
Z: esempio (1)
Attraverso le tavole della Normale standard si può calcolare la probabilità
P (Z ≤ 0) = 0.5, P (Z ≥ 0) = 0.5
-3 -2 -1 0 1 2 30
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5Normale standard
0.31
0.62
P(Z < 0.31) = 0.62
P(Z > 0.31) = 1 - P(Z < 0.31) = 1 - 0.62 = 0.38
0.38
P (Z ≤ 0.31) = 0.62 > 0.5, P (Z ≥ 0.31) = 0.38 < 0.5
Statistica, CLEA – p. 44/55
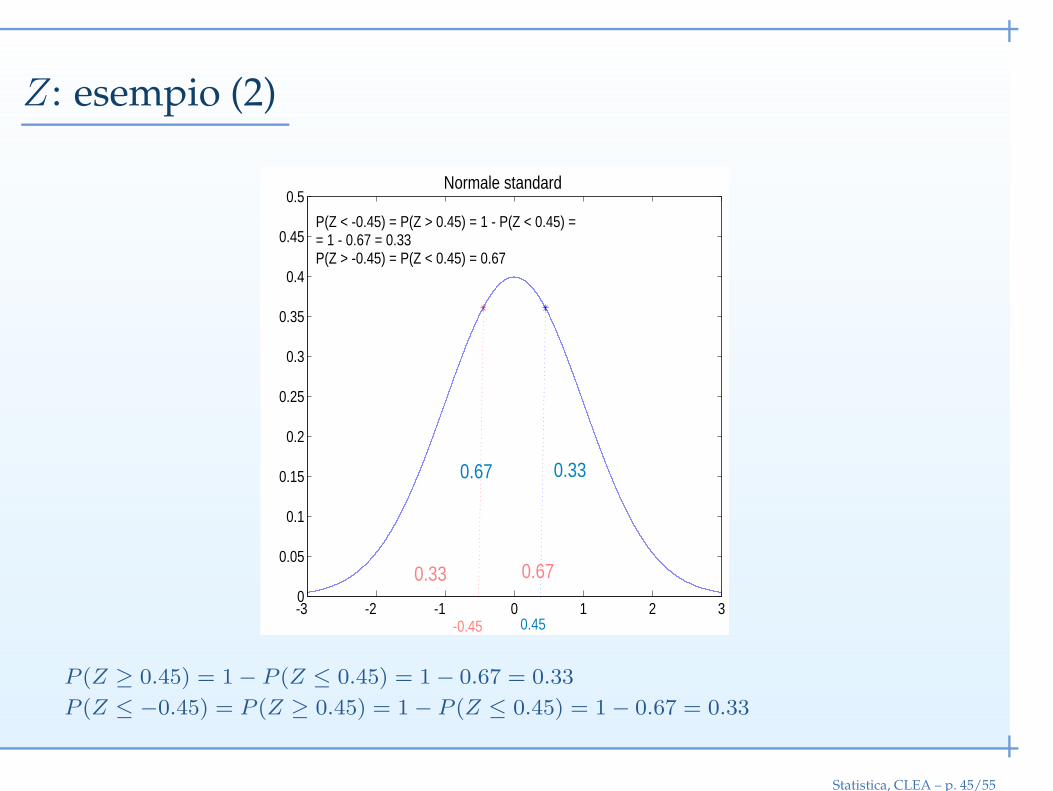
Z: esempio (2)
-3 -2 -1 0 1 2 30
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5Normale standard
-0.45
0.33
P(Z < -0.45) = P(Z > 0.45) = 1 - P(Z < 0.45) == 1 - 0.67 = 0.33P(Z > -0.45) = P(Z < 0.45) = 0.67
0.67
0.45
0.33 0.67
P (Z ≥ 0.45) = 1− P (Z ≤ 0.45) = 1− 0.67 = 0.33
P (Z ≤ −0.45) = P (Z ≥ 0.45) = 1− P (Z ≤ 0.45) = 1− 0.67 = 0.33
Statistica, CLEA – p. 45/55

Distribuzione t-Student
La variabile casuale X ∼ t(r) ha una forma campanulare ed è simmetrica rispetto allo 0.
Rispetto alla Normale standard ha le code più pesanti. E’ caratterizzata dal parametro r:
gradi di libertà
fX(x | r) = Γ[(r + 1)/2]√πrΓ(r/2)
, −∞ ≤ x ≤ +∞, r ∈ N+
La probabilità si calcola attraverso l’integrale
P (a ≤ X ≤ b) =
∫ b
afX(x | r)dx = F (b)− F (a)
N.B. Si dimostra che∫
fX(x | r)dx = 1, ma questi integrali non si possono calcolare in
forma analitica, ma numerica (uso delle tavole).
E(X) = 0, V(X) =r
r − 2
Statistica, CLEA – p. 46/55
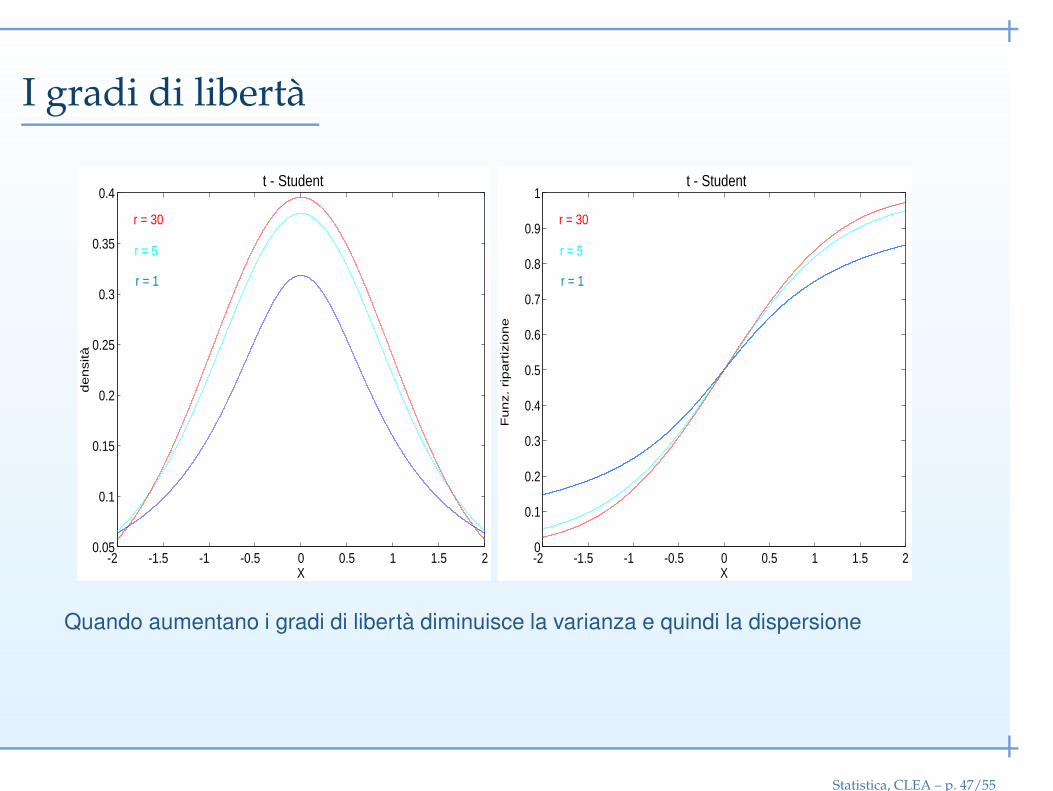
I gradi di libertà
-2 -1.5 -1 -0.5 0 0.5 1 1.5 20.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4t - Student
X
de
nsità
r = 1
r = 5
r = 30
-2 -1.5 -1 -0.5 0 0.5 1 1.5 20
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1t - Student
X
Fu
nz.
rip
art
izio
ne
r = 1
r = 5
r = 30
Quando aumentano i gradi di libertà diminuisce la varianza e quindi la dispersione
Statistica, CLEA – p. 47/55
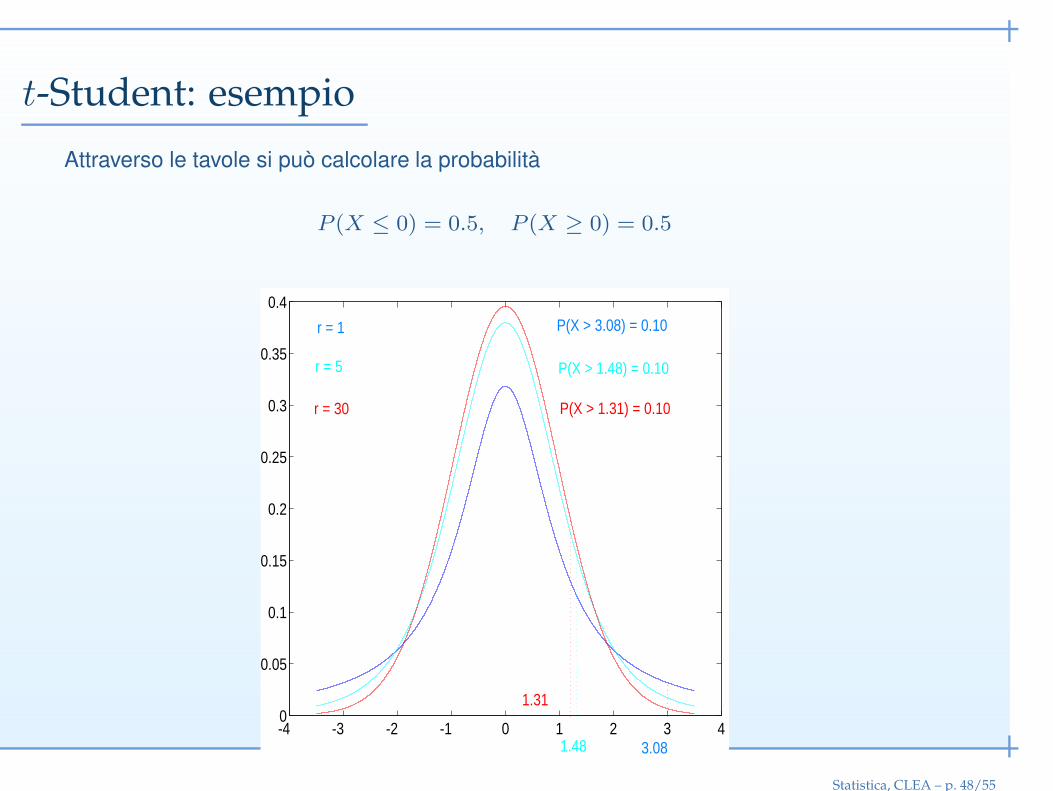
t-Student: esempio
Attraverso le tavole si può calcolare la probabilità
P (X ≤ 0) = 0.5, P (X ≥ 0) = 0.5
-4 -3 -2 -1 0 1 2 3 40
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
r = 1
r = 30
r = 5
1.31
P(X > 1.31) = 0.10
1.48
P(X > 1.48) = 0.10
3.08
P(X > 3.08) = 0.10
Statistica, CLEA – p. 48/55
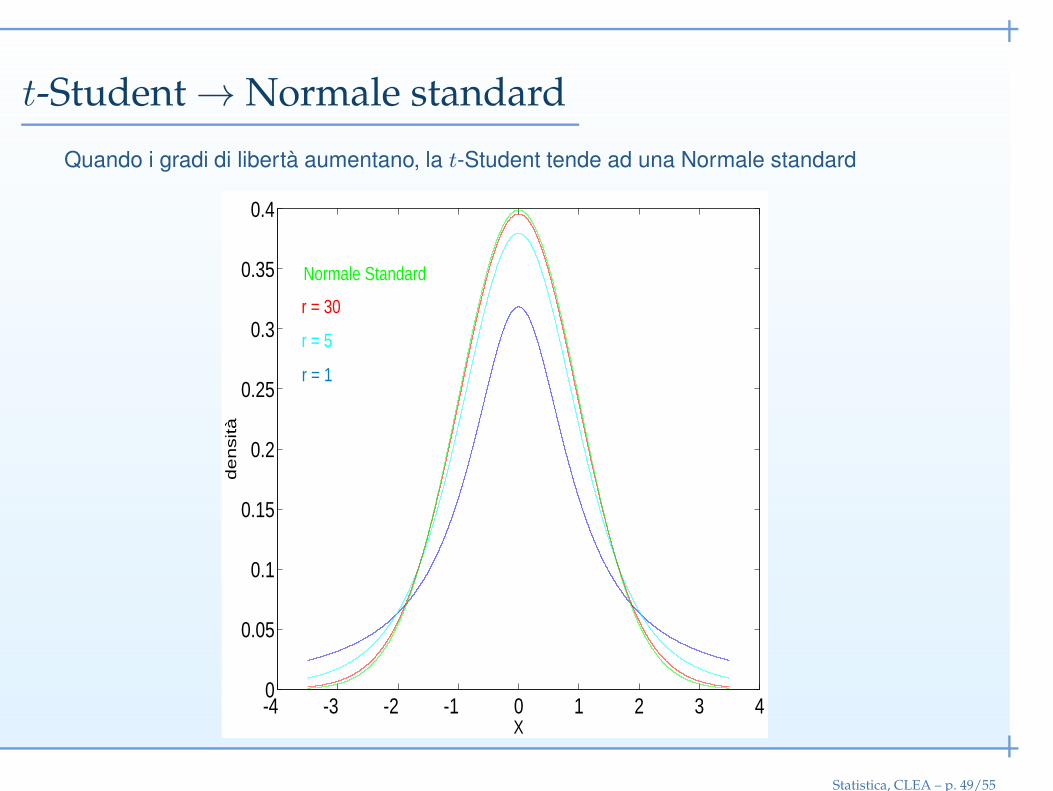
t-Student → Normale standard
Quando i gradi di libertà aumentano, la t-Student tende ad una Normale standard
-4 -3 -2 -1 0 1 2 3 40
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
X
de
nsità
r = 1
r = 5
r = 30
Normale Standard
Statistica, CLEA – p. 49/55

Distribuzione chi-quadrato
La variabile casuale X ∼ χ2(r)
mostra un’asimmetria positiva. E’ caratterizzata dal
parametro r: gradi di libertà
fX (x | r) = 1
2r/2Γ(r/2)xr/2−1e−x/2, x ≥ 0, r ∈ N+
La probabilità si calcola attraverso l’integrale
P (a ≤ X ≤ b) =
∫ b
afX(x | r)dx = F (b)− F (a)
N.B. Si dimostra che∫
fX(x | r)dx = 1, ma questi integrali non si possono calcolare in
forma analitica, ma numerica (uso delle tavole).
E(X) = r, V(X) = 2r
Statistica, CLEA – p. 50/55
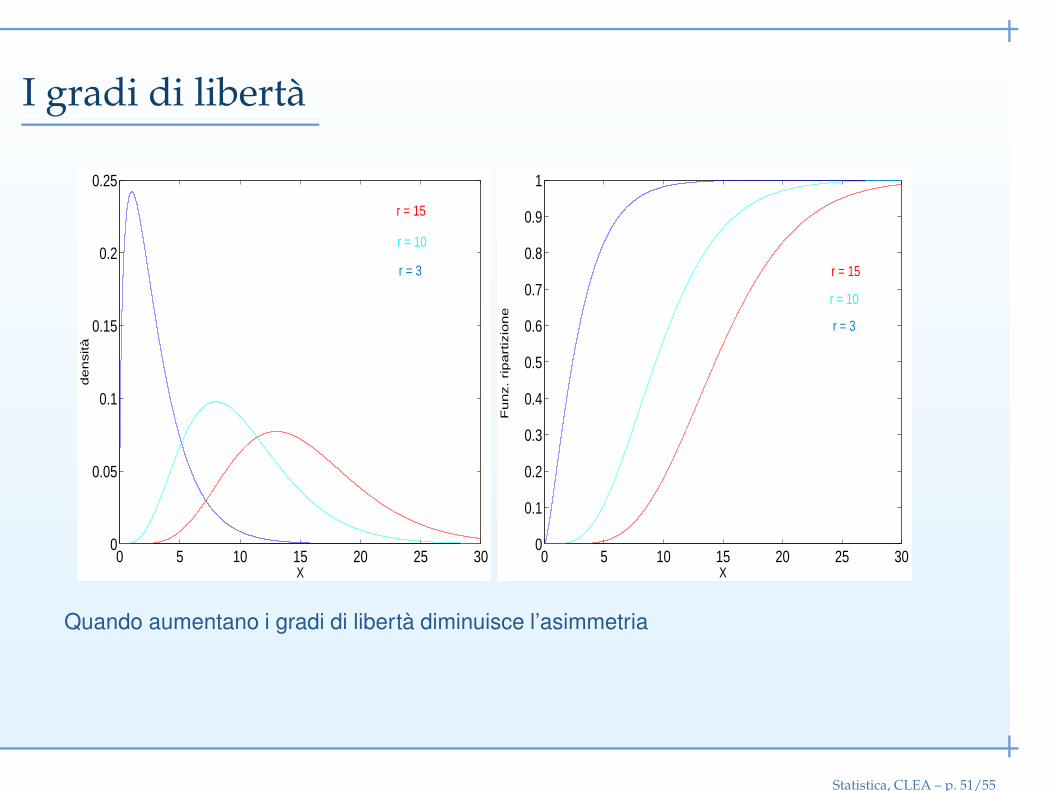
I gradi di libertà
0 5 10 15 20 25 300
0.05
0.1
0.15
0.2
0.25
X
densità
r = 3
r = 10
r = 15
0 5 10 15 20 25 300
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
X
Funz. ripart
izio
ne
r = 3
r = 10
r = 15
Quando aumentano i gradi di libertà diminuisce l’asimmetria
Statistica, CLEA – p. 51/55
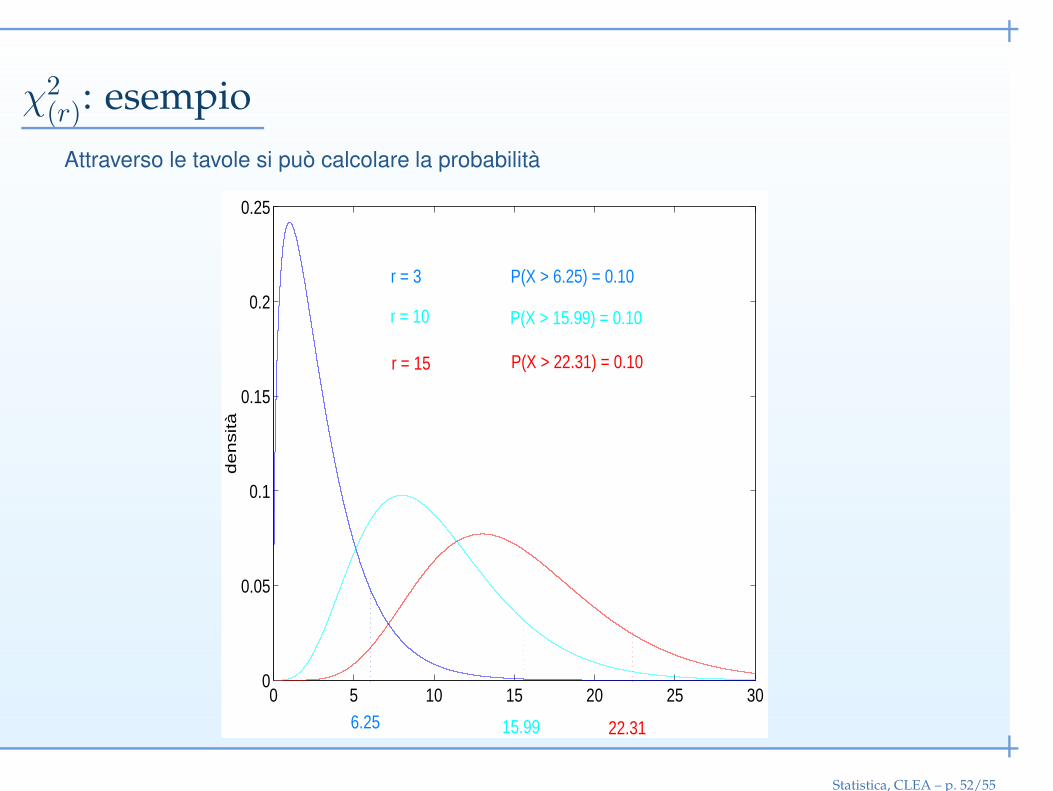
χ2(r): esempio
Attraverso le tavole si può calcolare la probabilità
0 5 10 15 20 25 300
0.05
0.1
0.15
0.2
0.25densità
r = 3
r = 10
r = 15
P(X > 6.25) = 0.10
P(X > 15.99) = 0.10
P(X > 22.31) = 0.10
22.31 15.99 6.25
Statistica, CLEA – p. 52/55

Teorema del limite centrale
Se X1, . . . , Xn sono i.i.d.
E(Xi) = µ, V(Xi) = σ2
allora la loro somma Y =∑n
i=1 Xi,
Y ≈ N(nµ, nσ2)
L’approssimazione è tanto migliore quanto maggiore è n. Inoltre, la bontà
dell’approssimazione dipende molto dalla forma della distribuzione di partenza.
Esempio. Consideriamo n variabili χ2(1)
: X1, . . . , Xn, con E(Xi) = 1 e V(Xi) = 2
Y =n∑
i=1
Xi
Per le proprietà della distribuzione χ2, Y ∼ χ2(n)
. Per il teorema del limite centrale,
quando n è molto grande
Y ≈ N(n, 2n)
Statistica, CLEA – p. 53/55
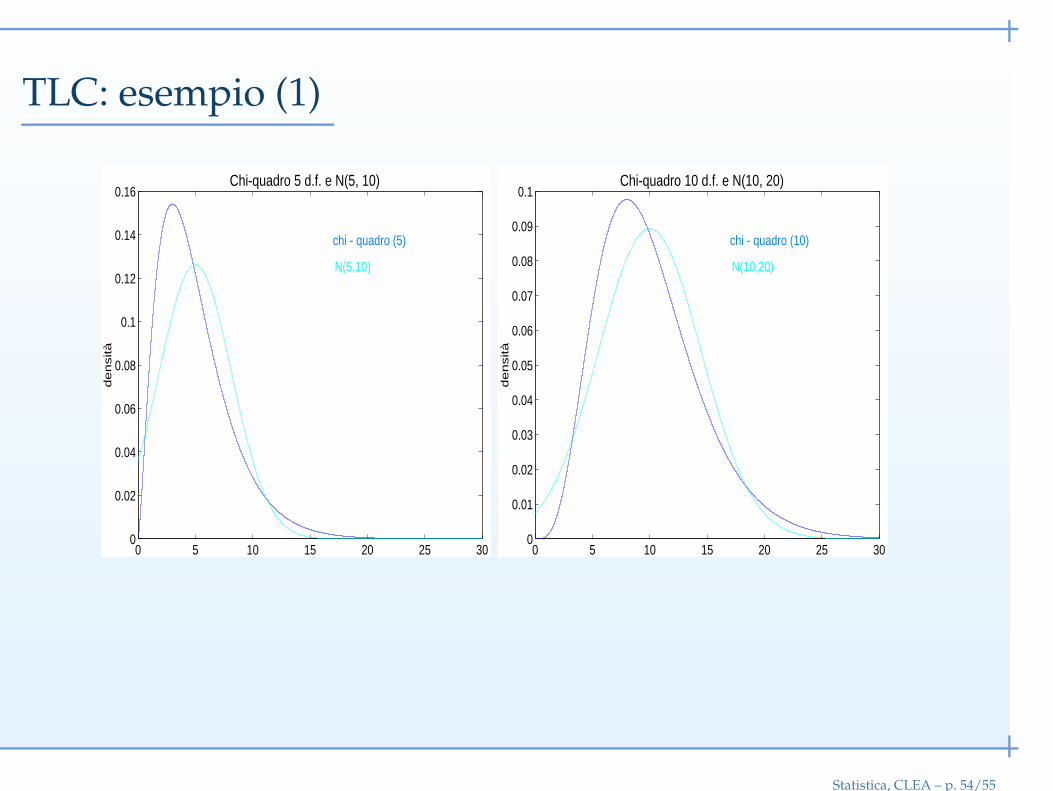
TLC: esempio (1)
0 5 10 15 20 25 300
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16Chi-quadro 5 d.f. e N(5, 10)
densità
chi - quadro (5)
N(5,10)
0 5 10 15 20 25 300
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
0.09
0.1Chi-quadro 10 d.f. e N(10, 20)
densità
chi - quadro (10)
N(10,20)
Statistica, CLEA – p. 54/55
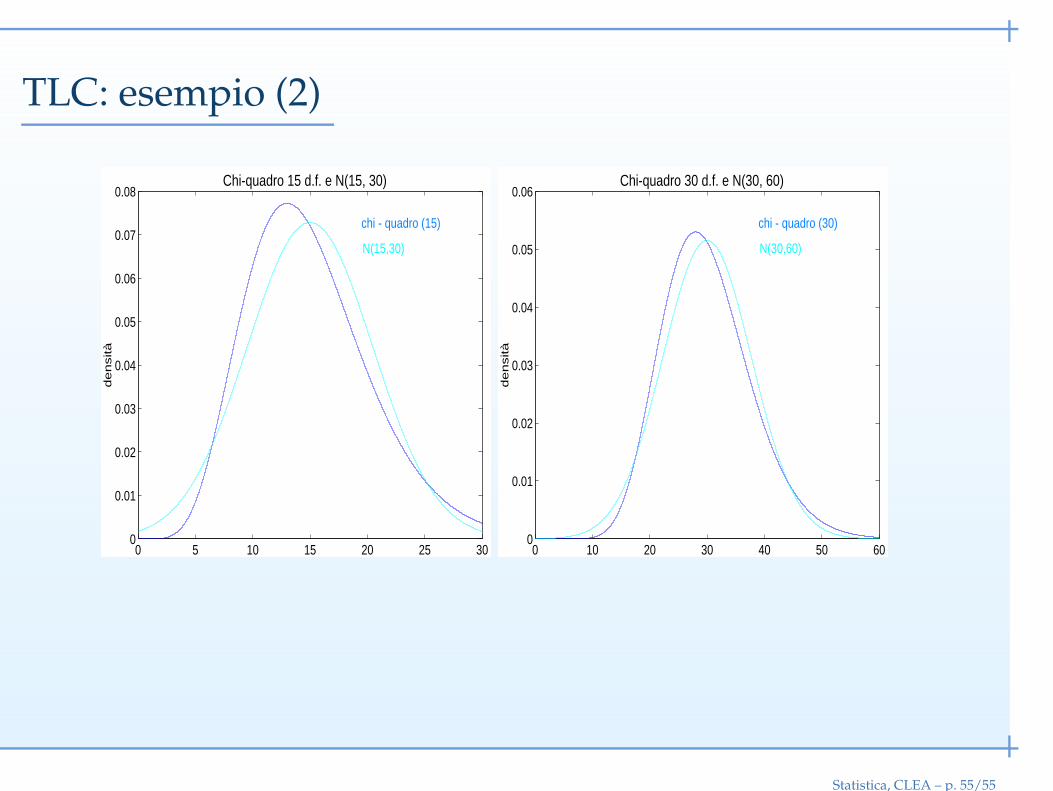
TLC: esempio (2)
0 5 10 15 20 25 300
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08Chi-quadro 15 d.f. e N(15, 30)
densità
chi - quadro (15)
N(15,30)
0 10 20 30 40 50 600
0.01
0.02
0.03
0.04
0.05
0.06Chi-quadro 30 d.f. e N(30, 60)
densità
chi - quadro (30)
N(30,60)
Statistica, CLEA – p. 55/55






![LABORATÓRIO DE SISTEMAS MECATRÔNICOS E ROBÓTICA ] - LAB.pdf · Resistores - 1,0 Ω - 100k Ω 1,2 Ω - 120k Ω 1,5 Ω - 150k Ω 1,8 Ω- 180k Ω 2,2 Ω– 220k Ω 2,7 Ω– 270k](https://static.fdocument.org/doc/165x107/5c245c1a09d3f224508c4b48/laboratorio-de-sistemas-mecatronicos-e-robotica-labpdf-resistores-.jpg)











