![Statistik für Informatiker, SS 2019 [1ex] 2. Ideen aus der ... · ˜2-Tests ˜2-Test fur feste Gewichte¨ Eine Alternative: p-Wert per Simulation Die asymptotische Aussage obigen](https://static.fdocument.org/doc/165x107/5d51039f88c993b8218bb791/statistik-fuer-informatiker-ss-2019-1ex-2-ideen-aus-der-2-tests-2-test.jpg)
Einf¨uhrung in die Wahrscheinlichkeitsrechnung und Statistik · Die deskriptive Statistik arbeitet...
164
Einf¨ uhrung in die Wahrscheinlichkeitsrechnung und Statistik Jan Kallsen und Claudia Kl¨ uppelberg Zentrum Mathematik Technische Universit¨ at M¨ unchen WS 2005/06
-
Upload
nguyenxuyen -
Category
Documents
-
view
221 -
download
0
Transcript of Einf¨uhrung in die Wahrscheinlichkeitsrechnung und Statistik · Die deskriptive Statistik arbeitet...

Einfuhrung in die
Wahrscheinlichkeitsrechnung und Statistik
Jan Kallsen und Claudia Kluppelberg
Zentrum Mathematik
Technische Universitat Munchen
WS 2005/06

Inhaltsverzeichnis
Vorwort
Vorbemerkungen i
Teil 1: Wahrscheinlichkeitsrechnung 1
1 Grundlagen der Wahrscheinlichkeitsrechnung 1
1.1 Das Axiomensystem von Kolmogorov . . . . . . . . . . . . . . . . 1
1.1.1 σ-Algebren . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1.2 Wahrscheinlichkeitsmaße . . . . . . . . . . . . . . . . . . . 5
1.2 Zur Konstruktion von Wahrscheinlichkeitsmaßen . . . . . . . . . . 7
2 Zufallsvariable, Verteilungen und Unabhangigkeit 11
2.1 Zufallsvariable . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.2 Bedingte Wahrscheinlichkeiten und Unabhangigkeit . . . . . . . . 17
2.3 Wahrscheinlichkeitsmaße fur unabhangige Versuchswiederholungen 23
3 Stochastische Standardmodelle 29
3.1 Diskrete Verteilungen . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.1.1 Diskrete Gleichverteilung und Kombinatorik . . . . . . . . 29
3.1.2 Einige wichtige diskrete Verteilungen . . . . . . . . . . . . 34
3.2 Stetige Verteilungen auf R . . . . . . . . . . . . . . . . . . . . . . 39
i

ii
4 Momente und Quantile 45
4.1 Lageparameter . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.2 Streuungsparameter . . . . . . . . . . . . . . . . . . . . . . . . . . 50
4.3 Momente Multivariater Zufallsvariablen . . . . . . . . . . . . . . . 56
4.4 Erzeugende Funktionen . . . . . . . . . . . . . . . . . . . . . . . . 56
5 Grenzwertsatze 61
5.1 Gesetze der großen Zahlen . . . . . . . . . . . . . . . . . . . . . . 61
5.2 Zentraler Grenzwertsatz . . . . . . . . . . . . . . . . . . . . . . . 63
Teil 2: Statistik 69
6 Grundlagen der Statistik 69
6.1 Problemstellungen und Ansatze . . . . . . . . . . . . . . . . . . . 69
6.2 Das statistische Modell . . . . . . . . . . . . . . . . . . . . . . . . 71
7 Parameterschatzung 75
7.1 Definitionen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
7.2 Konstruktion von Schatzern . . . . . . . . . . . . . . . . . . . . . 80
7.2.1 Maximum-Likelihood (ML)-Methode . . . . . . . . . . . . 80
7.2.2 Momentenmethode . . . . . . . . . . . . . . . . . . . . . . 82
7.2.3 Methode der Kleinsten Quadrate . . . . . . . . . . . . . . 83
8 Die multivariate Normalverteilung 85
8.1 Eindimensionale Normalverteilung . . . . . . . . . . . . . . . . . . 85
8.2 Die multivariate Normalverteilung . . . . . . . . . . . . . . . . . . 86
8.3 Abgeleitete Verteilungen . . . . . . . . . . . . . . . . . . . . . . . 89
9 Konfidenzbereiche 95
9.1 Konfidenzintervalle . . . . . . . . . . . . . . . . . . . . . . . . . . 96
9.2 Ein Konstruktionsverfahren fur Konfidenzbereiche . . . . . . . . . 98

iii
10 Tests von Hypothesen 103
10.1 Definitionen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
10.2 Konstruktion von Tests . . . . . . . . . . . . . . . . . . . . . . . . 107
11 Einfuhrung in die linearen Modelle 117
11.1 Einfache lineare Regression . . . . . . . . . . . . . . . . . . . . . . 117
11.2 Allgemeines lineares Modell . . . . . . . . . . . . . . . . . . . . . 120
11.3 Konfidenzintervalle und Hypothesentests . . . . . . . . . . . . . . 126
12 Spezielle Testprobleme 135
12.1 Zweistichproben-Probleme . . . . . . . . . . . . . . . . . . . . . . 135
12.2 χ2-Anpassungstests . . . . . . . . . . . . . . . . . . . . . . . . . . 143
12.3 χ2-Unabhangigkeitstests . . . . . . . . . . . . . . . . . . . . . . . 150

Vorwort
Die Vorlesung “Einfuhrung in die Wahrscheinlichkeitsrechnung und Statistik”
stellt den ersten Teil des viersemestrigen Zyklus mit Wahrscheinlichkeitstheorie
(Stochastik 2), Stochastische Prozesse (Stochastik 3) und Mathematische Stati-
stik (Stochastik 4) an der Technischen Universitat Munchen dar.
Die Vorlesung ist fur Diplom-Mathematiker, Techno-, Finanz- und Wirtschafts-
mathematiker sowie Studierende des Lehramts Mathematik an Gymnasien kon-
zipiert. Sie kann ab dem dritten Semester gehort werden.
In dieser Vorlesung werden hauptsachlich Grundlagen der Stochastik, soweit
sie ohne Maßtheorie vermittelt werden konnen. Da Stochastik ganz ohne Maß-
theorie kaum auskommen kann, werden manche Konzepte benutzt, aber fur Be-
weise und tieferes Verstandnis auf die Vorlesung “Wahrscheinlichkeitstheorie”
(Stochastik 2) verwiesen.
Munchen, Oktober 2005 C. Kluppelberg

Vorbemerkungen
Etwas Historie ...
Stochastik:
Mathematische Lehre des Zufalls = Wahrscheinlichkeitstheorie + Statistik
“stochastikos”: scharfsinnig im Vermuten.
Es ist faszinierend, dass es eine solche Lehre uberhaupt gibt.
Ein dokumentierter Grundstein der Wahrscheinlichkeitsrechnung besteht in ei-
nem Briefwechsel von Pascal und Fermat aus dem Jahr 1654.
Ausgangspunkt war die Frage, wie der Einsatz eines Glucksspieles zwischen zwei
gleichwertigen Partnern bei vorzeitigem Abbruch des Spieles gerecht aufzuteilen
ist. Dabei kamen beide - Fermat und Pascal - unabhangig voneinander bei un-
terschiedlichen Verfahren zu dem gleichen Ergebnis und legten einen Grundstein
fur die Wahrscheinlichkeitsrechnung. Genaueres ist nachzulesen unter
http://www.uni-essen.de/didmath/texte/jahnke/quellen/fermatpascal01.htm
Nach den eher empirischen Untersuchungen und kombinatorischen Uberlegun-
gen, hat David Hilbert eine axiomatische Behandlung der Wahrscheinlichkeits-
rechnung in seinem 6. Problem gefordert. Das ist nachzulesen unter
http://www.mathematik.uni-bielefeld.de/ kersten/hilbert/rede.html
i

ii Vorbemerkungen
Man findet dort folgendes:
Mathematische Probleme
Vortrag, gehalten auf dem internationalen Mathematiker-Kongreß zu Paris 1900
Von David Hilbert
6. Mathematische Behandlung der Axiome der Physik
“Durch die Untersuchungen uber die Grundlagen der Geometrie wird uns die
Aufgabe nahegelegt, nach diesem Vorbilde diejenigen physikalischen Disciplinen
axiomatisch zu behandeln, in denen schon heute die Mathematik eine hervorra-
gende Rolle spielt; dies sind in erster Linie die Wahrscheinlichkeitsrechnung und
die Mechanik.
Was die Axiome der Wahrscheinlichkeitsrechnung (Vgl. Bohlmann, Uber Ver-
sicherungsmathematik 2te Vorlesung aus Klein und Riecke, Uber angewandte
Mathematik und Physik, Leipzig und Berlin 1900) angeht, so scheint es mir
wunschenswert, daß mit der logischen Untersuchung derselben zugleich eine stren-
ge und befriedigende Entwickelung der Methode der mittleren Werte in der ma-
thematischen Physik, speciell in der kinetischen Gastheorie Hand in Hand gehe.”
Kolmogorov hat diese geforderte Axiomatik in seinem Buch dargelegt.
Grundbegriffe der Wahrscheinlichkeitsrechnung
von Andrej N. Kolmogorov publiziert im Jahr 1933 (in Deutsch!).
Damit beginnt diese Vorlesung.

Vorbemerkungen iii
Einige inhaltliche Hinweise
Eine fur die Praxis nicht zu hoch genug einzuschatzende Tatigkeit ist die Mo-
dellbildung, also die Aufgabe, ein reales Problem der Praxis in eine mathema-
tische Form zu ubersetzen. Damit ist, wie auch in den Naturwissenschaften, ei-
ne Idealisierung realer Zufallsexperimente durch ein (mathematisches) Modell
verbunden. Die Wahrscheinlichkeitstheorie zieht Schlussfolgerungen aus einem
gegebenen Modell. Die mathematische Statistik dient dazu, ein zu dem realen
Zufallsexperiment passendes Modell uberhaupt erst auszuwahlen. Dazu benotigt
man jedoch die Methoden der Wahrscheinlichkeitstheorie.
Herkunft des Begriffs “Statistik” aus dem Staatswesen, der Staatskunde.
Die beschreibende (deskriptive) Statistik beschaftigt sich im Gegensatz zur schlies-
senden (beurteilenden, induktiven, inferentiellen) Statistik nur mit der Erhebung
und Darstellung von Daten. Eine Einfuhrung in die deskriptive Statistik wird im
Statistikpraktikum angeboten.
Die deskriptive Statistik arbeitet mit anschaulichen Begriffen wie Population,
Merkmal, (relative) Haufigkeit etc. Die Begriffe und ihre Visualisierung wer-
den im begleitenden SPlus Praktikum vermittelt und geubt. In der axiomatisch
fundierten Wahrscheinlichkeitstheorie werden entsprechende abstrakte Formulie-
rungen verwendet. Die Kenntnis einiger Begriffe der beschreibenden Statistik ist
zwar keine Voraussetzung zum Verstandnis der folgenden Abschnitte, stellt sich
aber erfahrungsgemaß in einem ersten Stochastik-Kurs als hilfreich heraus.

iv Vorbemerkungen
Stochastik im Internet
Auf unserer eigenen Webseite
http://www-m4.ma.tum.de/
gibt es viele interessante Informationen.
Die wichtigste ist fur diese Vorlesung die Seite
http://www-m4.ma.tum.de/courses/index.de.html
wo es einen Link zur Vorlesung gibt.
Ein Mausklick auf “Nutzliche Links” fuhrt zu
http://www-m4.ma.tum.de/recherch/links.html
wo es einige auch schon fur Studierende interessante Seiten anzusehen sind.
Eine weitere nette Seite insbesondere fur neue Interessenten an der Stochastik ist
http://de.wikipedia.org/wiki/Stochastik
Software
Hier gibt es eine eigene Seite unter
http://www-m4.ma.tum.de/software/

Vorbemerkungen v
Literatur
Einfuhrungen in die Wahrscheinlichkeitstheorie gibt es unzahlige in allen Spra-
chen der Welt. Eine Google-Suche “Einfuhrung Wahrscheinlichkeit Statistik”
fuhrt zu 162 000 ”Wahrscheinlichkeit Statistik” fuhrt zu 603 000 ”Probability Sta-
tistics” 26 800 000 ”Introduction Probability Statistics” ergibt 10 900 000
Aufgrund der Tatsache, dass stochastische Modellierung und Analyse fur die mei-
sten Fachgebiete relevant sind, gibt es sehr viel Literatur, die nicht die fur uns
notwendige mathematische Basis und Prazision aufweisen. Eine Auswahl, die wir
fur Sie getroffen haben, findet man im Literaturverzeichnis am Ende dieses Ein-
leitung, Einige der Bucher sind einzusehen im Semesterapparat, einige findet man
eingeordnet in der Bibliothek; in der Lehrbuchsammlung sind einige dieser Bucher
in grosseren Mengen vorhanden.

vi Vorbemerkungen
Literaturverzeichnis
Chung, K.L. (1979) Elementary Probability Theory with Stochastic Processes,
3rd Edition. Springer, New York.
Chung, K.L. and Aitsahlia, F. (2003) Elementary Probability Theory. Springer.
New York.
Fahrmeir L., Kunstler R., Pigeot I. und Tutz G. (1997) Statistik. Der Weg zur
Datenanalyse. Springer, Berlin.
Feller, W. (1968) An Introduction to Probability Theory and its Applictions, Vol.
I & II. Wiley, Chichester.
Georgii, H.O. (2004) Stochastik, 2. Aufl. De Gruyter, Berlin.
Henze, N. (1997) Stochastik fur Einsteiger. Vieweg, Braunschweig.
Krengel, U. (1988) Einfuhrung in die Wahrscheinlichkeitstheorie und Statistik.
Vieweg, Braunschweig.
Jacod, J. and Protter, P. (2000) Probability Essentials. Springer, Berlin.
Ross, S.M. (1972) Introduction to Probability Models. Academic Press, New
York.
Stirzaker, D. (1994) Elementary Probability. Cambridge University Press, Cam-
bridge.
Williams, D. (1991) Probability with Martingales. Cambridge University Press.
Cambridge.
Williams, D. (2001) Weighing the Odds. Cambridge University Press. Cam-
bridge.

Kapitel 1
Grundlagen der
Wahrscheinlichkeitsrechnung
1.1 Das Axiomensystem von Kolmogorov
1.1.1 σ-Algebren
Definition 1.1 (Ergebnisraum, sample space). Die Menge Ω aller moglichen
Ergebnisse eines Zufallsexperiments nennen wir Ergebnisraum, Grundraum oder
Stichprobenraum. Die Elemente ω ∈ Ω heißen Ergebnisse.
Beispiel 1.2 (Zufallsexperimente).
(1) Bernoulli-Experiment: Einmaliger Munzwurf:
Ω = Kopf, Zahl oder Ω = 0, 1
(2) Einmaliger Wurfelwurf: Ω = 1, 2, 3, 4, 5, 6
(3) n-maliger Wurfelwurf:
Ω = 1, 2, 3, 4, 5, 6n = (ω1, . . . , ωn) : ωi ∈ 1, 2, 3, 4, 5, 6 fur i = 1, . . . , n.Bem: (i) Man wahlt hier zur Modellierung nicht Ω = 1, 2, 3, 4, 5, 6 und
n Ergebnisse ωi ∈ 1, 2, 3, 4, 5, 6, sondern einen ”großen” Grundraum, aus
1

2 1. Grundlagen
dem man nur ein Ergebnis ω = (ω1, . . . , ωn) zieht.
(ii) Wenn man nur an der Anzahl der Einsen, Zweien usw. interessiert ist,
kann man wahlen Ω′ = (k1, . . . , k6) : ki ∈ N mit∑6
i=1 ki = n.
(4) Unendlich viele Munzwurfe:
Ω = 0, 1N = (ωi)i∈N : ωi ∈ 0, 1 fur i ∈ N.Bez. N = 1, 2, . . ., N0 = 0, 1, 2, . . .
(5) Schuss auf eine Scheibe: Ω = z ∈ R2 : ‖z‖ < R.
(6) Kurs einer Aktie, des Dax, eines Wechselkurses im Jahr 2004:
Ω = f(t) : 1.1.2004 ≤ t ≤ 31.12.2004 , f ∈ C(R+) .Mittlerweile liegen sogenannte Hochfrequenzdaten als Finanzdaten vor, die
jeden Handel durch den Handelszeitpunkt und den Preis registrieren. Bei
liquiden Markten fuhrt das zu einer so hochfrequentigen Zeitreihe, dass die
Preise als stetige Funktionen modelliert werden.
Beispiele (4) und (6) zeigen, dass auch Folgen und Funktionen als Ergebnisse
eines Zufallsexperiments auftreten konnen. Ω kann also endlich, abzahlbar oder
sogar uberabzahlbar unendlich sein.
Oft interessiert man sich nicht fur einzelne Ergebnisse, sondern fur Mengen von
Ergebnissen, den Ereignissen.
Beispiel 1.3. (1) Ein Ereignis zu Beispiel 1.2(2) oben: ”Der Wurfelwurf ist
eine gerade Zahl”: A = 2, 4, 6.
(2) Ein Ereignis zu Beispiel 1.2(5) oben: A = ein Treffer landet im Ziel Zmit
Z = ( x = r cos ϕ , y = r sin ϕ ) | 0 ≤ r < 5 ; 0 ≤ ϕ < 2π
(3) Ein Ereignis zu Beispiel 1.2(6) oben:
A = der Dax uberschritt nie den Wert 5 500 .

1.1. Das Axiomensystem von Kolmogorov 3
Den Ereignissen sollen spater Wahrscheinlichkeiten zugeordnet werden.
Problem: Manchmal ist es aus tiefliegenden mathematischen Grunden nicht moglich,
jeder Menge A ⊂ Ω in vernunftiger Weise eine Wahrscheinlichkeit zuzuordnen.
Ausweg: Wir beschranken uns auf eine Teilmenge A ⊂ P(Ω) der denkbaren
Ereignisse, eine sogenannte σ-Algebra.
Vereinbarung: Wir verwenden “⊂” im Sinne von “⊆”.
Definition 1.4 (σ-Algebra, Ereignisraum). Sei Ω 6= ∅. Ein Mengensystem
F ⊂ P(Ω) heißt σ-Algebra auf Ω, falls es folgende Eigenschaften besitzt:
(A1) Ω ∈ F(A2) A ∈ F =⇒ Ac := Ω \ A ∈ F
(A3) falls A1, A2, . . . ∈ F =⇒∞⋃
i=1
Ai ∈ F .
(Ω,F) heißt Ereignisraum, Messraum, messbarer Raum, measurable space.
Bemerkung 1.5. (1) Aus den Axiomen folgt:
(a) ∅ ∈ F (denn ∅ = Ωc)
(b) A1, A2, . . . ∈ F =⇒∞⋂i=1
Ai ∈ F (denn∞⋂i=1
Ai =
( ∞⋃i=1
Aci
)c
)
(c) A1, . . . , An ∈ F =⇒ A1 ∪ A2 ∪ . . . ∪ An ∈ FA1 ∪ A2 ∪ . . . ∪ An =
∞⋃i=1
Ai mit Ai = ∅ fur i > n
(d) A1, . . . , An ∈ F =⇒ A1 ∩ A2 ∩ . . . ∩ An ∈ FA1 ∩ A2 ∩ . . . ∩ An =
∞⋂i=1
Ai mit Ai = Ω fur i > n
(e) A,B ∈ F =⇒ A \ B ∈ F (denn A \ B = A ∩ Bc).
(2) Die Idee ist, dass wir zwar nicht jeder Menge eine Wahrscheinlichkeit zu-
ordnen (sie messen) konnen, dass uns aber abzahlbare Mengenoperationen
nicht aus den in diesem Sinn messbaren Mengen herausfuhren.
Definition 1.6 (Erzeuger einer σ-Algebra). Seien Ω 6= ∅, G ⊂ P(Ω) beliebig.
Dann heißt
σ(G) :=⋂
F ⊂ P(Ω) : F ist σ-Algebra mit G ⊂ F (1.1)
die von G erzeugte σ-Algebra.

4 1. Grundlagen
Bemerkung 1.7. σ(G) ist tatsachlich eine σ-Algebra (nachrechnen!), und zwar
die kleinste σ-Algebra in Ω, die G umfasst.
Beispiel 1.8. (1) ∅, Ω ist die kleinste σ-Algebra in Ω uberhaupt.
(2) Die Potenzmenge P(Ω) ist die großte σ-Algebra in Ω.
Wenn Ω abzahlbar ist, gilt P(Ω) = σ(ω : ω ∈ Ω), d.h. P(Ω) wird von
den einelementigen Mengen erzeugt. (Denn fur A = ω1, ω2 . . . ⊂ Ω gilt
A =∞⋃i=1
ωi.)Wenn Ω eine abzahlbare Menge ist, verwenden wir in aller Regel die Po-
tenzmenge als σ-Algebra.
(3) Fur Ω = Rn verwenden wir in aller Regel die Borel-σ-Algebra
Bn = σ(A ⊂ Ω : A offen)
= σ(A ⊂ Ω : A abgeschlossen)
= σ([a1, b1] × · · · × [an, bn] : ai, bi ∈ Q mit ai < bi fur i = 1, . . . , n).
Fur n = 1 gilt B = B1 = σ((−∞, c] : c ∈ R).(Beweis der Gleichheit entfallt, ist aber nicht schwer.)
Nicht Borel-messbare Mengen existieren, aber sie sind sehr exotisch.
(4) Fur ∅ 6= Ω ⊂ Rn verwenden wir stets die σ-Algebra
BnΩ := A ∩ Ω : A ∈ Bn ,
die Borel-σ-Algebra auf Ω (nachrechnen!)
(5) Seien (Ei, Ei) messbare Raume fur i ∈ N. Sei
Ω :=∞∏
i=1
Ei = (ei)i∈N : ei ∈ Ei fur i ∈ N .
Definiere πj : Ω → Ej, (ei)i∈N 7→ ej, die j-te Projektion und
G := π−1j (A) ⊂ Ω : j ∈ N, A ∈ Ej .

1.1. Das Axiomensystem von Kolmogorov 5
∞⊗i=1
Ei := σ(G) heißt Produkt σ-Algebra auf Ω.
Analog fur endlich viele Mengen: Fur Ω :=n∏
i=1
Ej = E1 × · · · ×En definiere
n⊗i=1
Ei := E1 ⊗ · · ·⊗En wie oben. Auf kartesischen Produkten verwenden wir
stets die Produkt-σ-Algebra.
(Bemerkung ohne Beweis: Fur Rn =n∏
i=1
R1 gilt Bn =n⊗
i=1
B1.)
Definition 1.9 (Verschiedene Ereignisse).
Ω heißt sicheres Ereignis (tritt also immer ein).
∅ heißt unmogliches Ereignis (kann nie eintreten).
Fur ein Ereignis A heißt Ac Komplementarereignis, complementary event.
Ereignisse A, B heißen disjunkt, disjoint oder unvereinbar, falls A ∩ B = ∅.
Fur ω ∈ Ω heißt ω Elementarereignis, singleton.
1.1.2 Wahrscheinlichkeitsmaße
Jetzt sollen den Ereignissen A ∈ F Wahrscheinlichkeiten P (A) zugeordnet wer-
den.
Definition 1.10 (Wahrscheinlichkeitsmaß, Wahrscheinlichkeitsraum). Sei
(Ω,F) ein Ereignisraum.
(1) Eine Abbildung P : F → [0, 1] heißt Wahrscheinlichkeitsmaß, probability
measure auf (Ω,F), falls
(P1) P (Ω) = 1 (Normiertheit)
(P2) Fur A1, A2, . . . ∈ F paarweise disjunkt (d.h. Ai ∩ Aj = ∅ fur i 6= j) gilt
P
( ∞⋃
i=1
Ai
)=
∞∑
i=1
P (Ai) .
(σ-Additivitat).
(2) (Ω,F , P ) heißt Wahrscheinlichkeitsraum. Er ist die Konsequenz des Axio-

6 1. Grundlagen
mensystems von Kolmogorov, gegeben durch Definition von σ-Algebra und Wahr-
scheinlichkeitsmaß.
Bemerkung 1.11. [Interpretation von Wahrscheinlichkeiten]
(1) Frequentistische Deutung: P (A) = Anteil der Versuchswiederholungen, in
denen Ereignis A eintritt, wenn man das Experiment theoretisch/im Geiste un-
endlich oft unter gleichen Bedingungen ablaufen ließe.
(2) Motivation der Axiome von Kolmogorov: Diese gelten fur relative Haufigkei-
ten, zumindest die endliche Additivitat (s.u.).
Ohne σ-Additivitat weniger relevante Folgerungen.
(3) Die konkrete Wahl von P bleibt noch offen. Die Festlegung von P ist eine
Aufgabe der Modellbildung und der Statistik.
Satz 1.12. Sei (Ω,F , P ) ein Wahrscheinlichkeitsraum.
Seien A,B,A1, A2, . . . ∈ F . Dann gelten
(a) P (∅) = 0
(b) endliche Additivitat:
A1, . . . , An paarweise disjunkt ⇒ P (n⋃
i=1
Ai) =n∑
i=1
P (Ai)
(c) P (A ∪ B) = P (A) + P (B) − P (A ∩ B)
(d) Monotonie: A ⊂ B ⇒ P (A) ≤ P (B)
(e) σ-Subadditivitat: P (∞⋃i=1
Ai) ≤∞∑i=1
P (Ai)
(f) σ-Stetigkeit bzw. Stetigkeit von unten/oben:
An ↑ A (d.h. A1 ⊂ A2 ⊂ · · · und A =∞⋃i=1
Ai) ⇒ P (An) → P (A) fur n → ∞
An ↓ A (d.h. A1 ⊃ A2 ⊃ · · · und A =∞⋂i=1
Ai) ⇒ P (An) → P (A) fur n → ∞(g) P (Ac) = 1 − P (A).
Beweis. (a) P (∅) = P (∞⋃i=1
∅) =∞∑i=1
P (∅) ⇒ P (∅) = 0.
(b) σ-Additivitat mit ∅ = An+1 = An+2 = · · ·
(c) P (A) = P (A \ B) + P (A ∩ B) (nach (b))

1.2. Zur Konstruktion von Wahrscheinlichkeitsmaßen 7
P (B) = P (B \ A) + P (A ∩ B) (nach (b))
P (A ∪ B) = P (A \ B) + P (B \ A) + P (A ∩ B) (nach (b))
(d) P (B)(b)= P (A) + P (B \ A) ≥ P (A)
(e)∞⋃i=1
Ai =∞⋃i=1
(Ai \i−1⋃j=1
Aj) (paarweise disjunkt, A0 := ∅)
P (∞⋃i=1
Ai) = P (∞⋃i=1
(Ai \i−1⋃j=1
Aj))P2=
∞∑i=1
P (Ai \i−1⋃j=1
Aj)(d)
≤∞∑i=1
P (Ai).
(g) P (A) + P (Ac)(b)= P (Ω) = 1
(f) P (A) = P (∞⋃i=1
(Ai \ Ai−1))P2=
∞∑i=1
P (Ai \ Ai−1) (A0 := ∅)
= limn→∞
n∑i=1
P (Ai \ Ai−1)(b)= lim
n→∞P (
n⋃i=1
(Ai \ Ai−1)) = limn→∞
P (An).
An ↓ A ⇒ Acn ↑ Ac ⇒ 1 − P (An) = P (Ac
n) → P (Ac) = 1 − P (A). ¤
Satz 1.13. [Eindeutigkeitssatz] Sei G ein ∩-stabiler Erzeuger des Ereignisraums
(Ω,F), (d.h. F = σ(G) und A ∩ B ∈ G fur A,B ∈ G). Fur Wahrscheinlichkeits-
maße P,Q auf (Ω,F) mit P |G = Q|G gilt P ≡ Q.
Beweis. Wahrscheinlichkeitstheorie. ¤
1.2 Zur Konstruktion von Wahrscheinlichkeits-
maßen
Das einfachste Beispiel ist “kein Zufall”, d.h. ein deterministisches Experiment.
Definition 1.14 (Einpunktmaß, Diracmaß). Sei (Ω,F) ein Ereignisraum
und ξ ∈ Ω. Das durch
εξ(A) :=
1 falls ξ ∈ A ,
0 sonst
definierte Wahrscheinlichkeitsmaß εξ auf (Ω,F) heißt Einpunktmaß oder Dirac-
maß in ξ. Manchmal wird es auch mit δξ bezeichnet.

8 1. Grundlagen
Ein weiteres einfaches Beispiel erhalt man fur abzahlbares Ω.
Satz 1.15. Sei Ω 6= ∅ abzahlbar. Zu jeder Funktion ρ : Ω → [0, 1] mit∑ω∈Ω
ρ(ω) =
1 existiert genau ein Wahrscheinlichkeitsmaß P auf (Ω,P(Ω)), so dass
P (A) =∑
ω∈A
ρ(ω) fur A ∈ P(Ω) . (1.2)
Insbesondere gilt P (ω) = ρ(ω) fur ω ∈ Ω. ρ heißt Zahldichte von P .
Beweis. P aus (1.2) ist ein Wahrscheinlichkeitsmaß: P (Ω) = 1 ist klar.
Fur paarweise disjunkte A1, A2, . . . ⊂ Ω gilt
P (∞⋃
i=1
Ai) =∑
ω∈∪∞i=1Ai
ρ(ω) =∞∑
i=1
∑
ω∈Ai
ρ(ω) =∞∑
i=1
P (Ai) .
Wir haben bei der 2. Identitat den Doppelreihensatz benutzt; siehe z.B. Heuser,
Analysis 1, Satz 45.1.
Die Eindeutigkeit ist klar. ¤
Fur den stetigen Fall brauchen wir Anleihen aus der Maßtheorie (Analysis 3 oder
Wahrscheinlichkeitstheorie).
Bemerkung 1.16. (1) f : Rn → R+ heißt (Borel-) messbar, falls
x ∈ Rn : f(x) ≤ c ∈ Bn fur alle c > 0 (gilt z.B. fur alle stetigen Funktionen).
Fur jede solche Funktion f existiert das Lebesgue Integral∫
f(x)dx, das u.a.
folgende Eigenschaften hat:
(a) f Riemann integrierbar ⇒ Lebesgue-∫
f(x)dx = Riemann-∫
f(x)dx
(b) Fur Funktionen f1, f2, . . . wie oben gilt∫ ∞∑
i=1
fi(x)dx =∞∑i=1
∫fi(x)dx.
(2) Fur f : Rn → R+ und A ∈ Bn setze∫
Af(x)dx :=
∫1A(x)f(x)dx. Dabei ist
1A(x) = 1 bzw. 0, falls x ∈ A bzw. x /∈ A ist; 1 heißt Indikatorfunktion.
(3) Die Abbildung λn : Bn → R+ mit λn(A) =∫
1A(x)dx heißt Lebesguemaß
auf Rn. Dies ist der naturliche Volumenbegriff im Rn. Fur Ω ⊂ Rn heißt λnΩ :=
λn|BnΩ
: BnΩ → R+ Lebesguemaß auf Ω.

1.2. Zur Konstruktion von Wahrscheinlichkeitsmaßen 9
Satz 1.17. Sei Ω ⊂ Rn eine Borelmenge (d.h. in Bn). Zu jeder Funktion ρ :
Ω → R+ mit
• x ∈ Ω : ρ(x) ≤ c ∈ BnΩ fur alle c > 0 (Messbarkeit)
•∫Ω
ρ(x)dx = 1
existiert genau ein Wahrscheinlichkeitsmaß auf (Ω,BnΩ) mit
P (A) =
∫
A
ρ(x)dx fur A ∈ BnΩ . (1.3)
ρ heißt (Lebesgue-) Dichte von P .
Beweis. P aus (1.3) ist ein Wahrscheinlichkeitsmaß: P (Ω) = 1 ist klar.
Fur paarweise disjunkte A1, A2, . . . ⊂ Ω gilt
P (∞⋃
i=1
Ai) =
∫1 ∞⋃
i=1Ai
(x)ρ(x)dx =
∫ ∞∑
i=1
1Ai(x)ρ(x)dx =
∞∑
i=1
∫1Ai
(x)ρ(x)dx =∞∑
i=1
P (Ai) .
¤
Beispiel 1.18. (1) Diskrete Gleichverteilung UΩ.
Seien Ω endlich, UΩ das Wahrscheinlichkeitsmaß mit Zahldichte ρ(ω) :=1
|Ω| fur
ω ∈ Ω. Somit ist UΩ(A) =|A||Ω| fur A ∈ P(Ω).
Der Wahrscheinlichkeitsraum (Ω,P(Ω), UΩ) heißt auch Laplace-Raum.
(2) Stetige Gleichverteilung UΩ.
Sei Ω ⊂ Bn mit λn(Ω) ∈ (0,∞). Sei dazu UΩ das Wahrscheinlichkeitsmaß mit
Lebesguedichte ρ(x) :=1
λn(Ω)fur x ∈ Ω. Somit ist UΩ(A) =
λn(A)
λn(Ω)fur A ∈ Bn
Ω.

10 1. Grundlagen

Kapitel 2
Zufallsvariable, Verteilungen und
Unabhangigkeit
2.1 Zufallsvariable
Oft ist man gar nicht an den Ergebnissen ω ∈ Ω selbst interessiert, sondern an de-
ren Merkmalen; z. B. an der “Verteilung” von Große oder Gewicht von Individuen
ω in einer Population Ω. Es zeigt sich, dass die Festlegung interessierender Wahr-
scheinlichkeiten besonders einfach fur bestimmte Abbildungen erfolgen kann.
Definition 2.1 (Zufallsvariable, random variable). Sei (Ω,F) ein Ereig-
nisraum. Eine Abbildung X : Ω → R mit X−1(B) ∈ F fur alle B ∈ B heißt
Zufallsvariable oder messbare Abbildung.
Allgemeiner: Fur einen Ereignisraum (Ω′,F ′) heißt X : Ω → Ω′ mit X−1(A′) ∈ Ffur alle A′ ∈ F ′ Zufallsvariable oder F − F ′-messbare Abbildung von (Ω,F)
nach (Ω′,F ′).
Bemerkung 2.2. (1) Messbare Abbildungen sind die gutartigen, da struk-
turerhaltenden Abbildungen in der Maßtheorie; vgl. stetige Abbildungen in der
Topologie, lineare Abbildungen in der Linearen Algebra usw.
11

12 2. Zufallsvariable, Verteilungen und Unabhangigkeit
(2) Schreibweise:
X ∈ A′ := ω ∈ Ω : X(ω) ∈ A′ = X−1(A′),
X > 5 = ω ∈ Ω : X(ω) > 5 = X−1((5,∞)) usw.
Satz 2.3. (1) Fur F = P(Ω) ist jede Abbildung X : Ω → Ω′ messbar.
(2) Im Fall F ′ = σ(G ′) reicht fur die Messbarkeit von X : Ω → Ω′ zu zeigen,
dass X−1(A′) ∈ F fur alle A′ ∈ G ′ gilt.
(3) Fur die Messbarkeit von X : Ω → R reicht es zu zeigen, dass X ≤ c ∈ Ffur alle c ∈ R gilt.
(4) Fur Ω ⊂ Rn (mit F = BnΩ) ist jede stetige Abbildung X : Ω → R messbar.
Beweis. (1) Klar.
(2) A′ := A′ ⊂ Ω′ : X−1(A′) ∈ F ist eine σ-Algebra mit G ′ ⊂ A′
(nachrechnen!). Also gilt F ′ = σ(G ′) ⊂ A′.
(3) Aussage (2) und Beispiel 1.7.(3).
(4) Fur c ∈ R ist X ≤ c = X−1((−∞, c]) abgeschlossen, also in BnΩ. Die
Aussage folgt dann mit (2). ¤
Beispiel 2.4. Ω = 0, 1n : n Munzwurfe 0∧=“Kopf”,1
∧=“Zahl”, die Zufallsva-
riable X : Ω → Ω′ := 0, 1, . . . , n, ω = (ω1, . . . , ωn) 7→n∑
i=1
ωi misst die Anzahl
der “Zahl”-Wurfe.
Satz 2.5. Seien (Ω,F , P ) ein Wahrscheinlichkeitsraum, (Ω′,F ′) ein Ereignis-
raum und X : Ω → Ω′ eine Zufallsvariable. Dann ist
P ′ : F ′ → [0, 1], A′ 7→ P (X−1(A′)) = P (X ∈ A′)
ein Wahrscheinlichkeitsmaß auf (Ω′,F ′).
Beweis. Wegen X−1(A′) ∈ F ist P ′ definiert. Weiter gilt P ′(Ω′) = P (Ω) = 1. Fur
paarweise disjunkte A′1, A
′2, . . . ∈ F ′ sind X−1(A′
1), X−1(A′
2), . . . ∈ F paarweise

2.1. Zufallsvariable 13
disjunkt, also
P ′(∞⋃
i=1
A′i) = P (
∞⋃
i=1
X−1(A′i)) = P (
∞⋃
i=1
Ai) =∞∑
i=1
P (X−1(A′i)) =
∞∑
i=1
P ′(A′i) . ¤
Definition 2.6 (Verteilung). (1) P ′ aus Satz 2.5 heißt Verteilung (distribu-
tion) von X oder Bildmaß von P unter X.
Schreibweise: PX = P X−1 = X(P ) = L(X; P ) = L(X).
(2) Zufallsvariable X,Y heißen identisch verteilt, falls PX ≡ PY .
Die Verteilung reeller Zufallsvariablen kann durch die Verteilungsfunktion be-
schrieben werden.
Definition 2.7 (Verteilungsfunktion). (1) Sei X : (Ω,F , P ) → (R,B) eine
(reelle) Zufallsvariable. Die Abbildung FX : R → [0, 1] mit FX(x) := P (X ≤ x)
fur x ∈ R heißt Verteilungsfunktion von X.
(2) Fur ein Wahrscheinlichkeitsmaß P auf (R,B) heißt FP : R → [0, 1] mit
FP (x) := P ((−∞, x]) Verteilungsfunktion von P .
Bemerkung 2.8. FX ≡ FPXfur X : (Ω,F , P ) → (R,B).
Satz 2.9. Sei F die Verteilungsfunktion einer Zufallsvariablen X oder einer Ver-
teilung P . Dann gilt
(1) F ist monoton wachsend,
(2) F ist rechtsseitig stetig,
(3) limx→∞ F (x) = 1, limx→−∞ F (x) = 0.
Beweis. (1) folgt nach Satz 1.12(d),
(2) folgt nach Satz 1.12(f),
(3) Fur xnn→∞−→ ∞ gilt: F (xn) = P ((−∞, xn])
Satz 1.12(f)−→ P ((−∞,∞)) = 1;
analog fur xnn→−∞−→ ∞. ¤
Bemerkung 2.10. (1) Jede Funktion F : R → [0, 1] mit Eigenschaften (1)-(3)
aus Satz 2.9 ist Verteilungsfunktion einer Zufallsvariable bzw. eines Wahrschein-
lichkeitsmaßes auf (R,B) (Beweis folgt in Wahrscheinlichkeitstheorie).

14 2. Zufallsvariable, Verteilungen und Unabhangigkeit
(2) Die Verteilungsfunktion von X (bzw. P ) legt die Verteilung PX (bzw P )
schon eindeutig fest (wegen Satz 1.13).
(3) Sei X : (Ω,F , P ) → (R,B) eine Zufallsvariable. Falls
FX(c) =
∫ c
−∞f(x)dx , c ∈ R ,
fur eine messbare Funktion f : R → R+ gilt, dann besitzt PX die Dichte f . Dies
gilt insbesondere, wenn FX stetig differenzierbar ist. Dann ist F ′X = f .
Definition 2.11 (Verteilungsfunktion). Sei X : (Ω,F , P ) → (Rn,Bn) eine
Zufallsvariable. Die Abbildung FX : Rn → [0, 1] mit
FX(x1, . . . , xn) = P (X1 ≤ x1, . . . , Xn ≤ xn) , x1, . . . , xn ∈ R ,
heißt Verteilungsfunktion von X = (X1, . . . , Xn).
Bemerkung 2.12. (1) Fur n = 1 gilt fur a < b
P (a < X ≤ b) = P (X ≤ b) − P (X ≤ a) = FX(b) − FX(a) .
Fur n = 2 gilt fur a1 < b1 und a2 < b2
P (a1 < X1 ≤ b1, a2 < X2 ≤ b2)
= P (X1 ≤ b1, X2 ≤ b2) − P (X1 ≤ b1, X2 ≤ a2) − P (X1 ≤ a1, X2 ≤ b2)
+P (X1 ≤ a1, X2 ≤ a2)
= FX(b1, b2) − FX(b1, a2) − FX(a1, b2) + FX(a1, a2) .
(2) FX legt die Verteilung PX eindeutig fest (vgl. Bem. 2.10(2)).
(3) Sei X : (Ω,F , P ) → (Rn,Bn) eine Zufallsvariable.
Falls fur alle (c1, . . . , cn) ∈ Rn
FX(c1, . . . , cn) =
∫
(−∞,c1]×···×(−∞,cn]
f(x)dx =
∫ c1
−∞. . .
∫ cn
−∞f(x1, . . . , xn)dxn . . . dx1
fur eine messbare Funktion f : Rn → R+ gilt, dann besitzt PX die Dichte
f . Dies gilt insbesondere, wenn FX n-fach stetig differenzierbar ist. Dann ist
f = D12···nFX =∂nFX
∂c1 · · · ∂cn
(vgl. Bem. 2.10(3)).

2.1. Zufallsvariable 15
Definition 2.13 (Randverteilungen, Marginalverteilungen, marginal dis-
tributions). Sei X : (Ω,F , P ) → (Rn,Bn) eine Zufallsvariable. Die Verteilungen
der Komponenten Xi, i = 1, . . . , n, heißen (eindimensionale) Randverteilungen
von X.
Satz 2.14. Sei X : (Ω,F , P ) → (Rn,Bn) eine Zufallsvariable. Dann gelten:
(a) FXi(c) = FX(∞, . . . ,∞, c,∞ . . . ,∞) := limu→∞ FX(u, . . . , u, c, u . . . , u)
fur c ∈ R und i = 1, . . . , n.
(b) Falls X eine Dichte besitzt, hat Xi eine Dichte fi : R → R+ mit
fi(x) =
∫ ∞
−∞· · ·
∫ ∞
−∞f(x1, . . . , xi−1, x, xi+1, . . . , xn)dx1 · · · dxi−1dxi+1 · · · dxn .
Beweis. (a) Wir benutzen die Stetigkeit von unten:
FXi(c) = P (Xi ≤ c)
= limu→∞
P (X1 ≤ u, . . . , Xi−1 ≤ u,Xi ≤ c,Xi+1 ≤ u, . . . , Xn ≤ u)
= limu→∞
FX(u, . . . , u, c, u, . . . , u) .
(b) Nach (a) gilt fur c ∈ R
FXi(c) = lim
u→∞FX(u, . . . , u, c, u, . . . , u)
= limu→∞
∫
(−∞,u]×···×(−∞,u]×(−∞,c]×(−∞,u]×···×(−∞,u]
f(x)dx
=
∫
(−∞,∞]×···×(−∞,∞]×(−∞,c]×(−∞,∞]×···×(−∞,∞]
f(x)dx (monotone Konvergenz)
=
∫ c
−∞
∫ ∞
−∞· · ·
∫ ∞
−∞f(x1, . . . , , xn)dx1 . . . dxi−1dxi+1 · · · dxn
︸ ︷︷ ︸fi(xi)
dxi (Fubini)
=:
∫ c
−∞fi(xi)dxi .
¤
Oft hat mit X auch ϕ(X) eine Dichte fur ϕ : Rn → Rn.
Satz 2.15 (Transformationssatz fur Dichten).
Sei X : (Ω,F , P ) → (Rn,Bn) eine Zufallsvariable mit Dichte f . Ferner seien

16 2. Zufallsvariable, Verteilungen und Unabhangigkeit
ϕ : Rn → Rn messbar mit ϕ(x) = (ϕ1(x), . . . , ϕn(x)) fur x ∈ Rn. Die Mengen
U1, . . . , Um ⊂ Rn seien offen und paarweise disjunkt, so dass ϕj := ϕ|Uj: Uj →
ϕ(Uj) bijektiv, in beide Richtungen stetig differenzierbar mit f = 0 außerhalb von
U1∪. . .∪Um ist. Es seien ϕj(x) = (ϕ1j(x), . . . , ϕn
j (x)) fur x ∈ Uj und j = 1, . . . ,m.
Dann hat die Zufallsvariable ϕ(X) : (Ω,F , P ) → (Rn,Bn) die Dichte g mit
g(y) =m∑
j=1
1ϕj(Uj)(y)f(ϕ−1j (y))|Jj(ϕ
−1j (y))|−1 , y ∈ Rn ,
wobei fur j = 1, . . . ,m,
Jj(x) =
∣∣∣∣∣∣∣∣∣∣∣
∂ϕ1j(x)
∂x1
· · · ∂ϕnj
∂x1...
...
∂ϕ1j(x)
∂xn
· · · ∂ϕnj
∂xn
∣∣∣∣∣∣∣∣∣∣∣
, x ∈ Rn .
die Jacobi-Determinante von ϕj ist.
Beweis. In Analysis 2. ¤
Beispiel 2.16. Seien X : (Ω,F , P ) → (Rn,Bn) eine Zufallsvariable mit Dichte
f , A ∈ Rn×n eine Matrix mit det(A) 6= 0, a∈ Rn, ϕ : Rn → Rn, x 7→ Ax + a.
Dann hat ϕ(X) die Dichte g : Rn → R+ mit g(y) =1
|det(A)|f(A−1(y − a)).
Im Fall n = 1 gilt ϕ(x) = bx + a fur a ∈ R, b ∈ R \ 0; dann hat ϕ(X) also die
Dichte g(y) =1
|b|f(y − a
b), y ∈ R.
Bemerkung 2.17. Seien X : (Ω,F , P ) → (R,B) eine Zufallsvariable mit Ver-
teilungsfunktion FX und ϕ : R → R eine streng monoton wachsende, stetige
Funktion. Dann gilt
FϕX(c) = P (ϕ X ≤ c) = P (X ≤ ϕ−1(c)) = FX(ϕ−1(c)) , c ∈ ϕ(R) .
Bsp. X gleichverteilt auf [0, 1], d.h. PX = U[0,1], G streng monoton wachsende,
stetige Verteilungsfunktion eines Wahrscheinlichkeitsmaßes Q auf (R,B). Dann
ist FG−1(X)(c) = FX(G(c)) = G(c), also ist PG−1(X) ≡ Q. Auf diesem Zusammen-
hang beruht die Simulation von Zufallszahlen.

2.2. Bedingte Wahrscheinlichkeiten und Unabhangigkeit 17
2.2 Bedingte Wahrscheinlichkeiten und Unabhangig-
keit
Motivation: Sei (x1, . . . , xn) eine Stichprobe der Zufallsvariablen X : Ω → M .
Fur A ⊂ M ist die relative Haufigkeit
r(A) =Anzahl der xi ∈ A in (x1, . . . , xn)
n.
Fur festes B ⊂ M entfernen wir nun alle Beobachtungen aus der Stichprobe, die
nicht in B liegen; das ergibt eine neue kleinere Stichprobe (x1, . . . , xk) mit k ≤ n.
In dieser neuen Stichprobe ist die relative Haufigkeit von A ⊂ M
rB(A) =Anzahl der xi ∈ A in (x1, . . . , xk)
k=
n r(A ∩ B)
n r(B)=
r(A ∩ B)
r(B).
Falls keine “Beziehung” zwischen A und B besteht, wird man erwarten, dass der
Anteil von A in der verminderten Stichprobe dem in der ursprunglichen Stich-
probe ahnelt: rB(A) ≈ r(A).
Bsp. (x1, . . . , xn) sei eine Stichprobe von TU-Studenten; das Ereignis A bedeute
“Student ist weiblich”, Ereignis B bedeute “Student ist im November geboren”.
Definition 2.18 (Bedingte Wahrscheinlichkeit). Seien (Ω,F , P ) ein Wahr-
scheinlichkeitsraum und B ∈ F mit P (B) > 0. Fur A ∈ F heißt
P (A | B) := PB(A) :=P (A ∩ B)
P (B)
bedingte Wahrscheinlichkeit von A gegeben B.
Satz 2.19. Seien (Ω,F , P ) ein Wahrscheinlichkeitsraum und B ∈ F mit P (B) >
0. Dann ist PB : F → [0, 1] ein Wahrscheinlichkeitsmaß mit PB(B) = 1.
Beweis. Nachrechnen! ¤
Beispiel 2.20. [Zweimaliger Wurfelwurf]
Seien Ω = 1, . . . , 62 und P = UΩ die Gleichverteilung.

18 2. Zufallsvariable, Verteilungen und Unabhangigkeit
A = 2. Wurf ist eine 6 = 1, . . . , 6 × 6 und P (A) =|A||Ω| =
1
6.
B = Augensumme ist 11 = (5, 6), (6, 5) und P (B) =|B||Ω| =
1
18.
Weiter gilt A ∩ B = (5, 6) und P (A ∩ B) =|A ∩ B||Ω| =
1
36.
Damit gilt P (A | B) =P (A ∩ B)
P (B)=
1
2. ¤
Im Folgenden sei (Ω,F , P ) ein Wahrscheinlichkeitsraum.
Satz 2.21 (Multiplikationsformel). Seien A1, . . . , An ∈ F mit P (A1 ∩ . . . ∩An) > 0. Dann gilt
P (A1 ∩ . . . ∩ An) = P (A1)P (A2 | A1) · · ·P (An | A1 ∩ . . . ∩ An−1) .
Beweis. Vollstandige Induktion: n = 1 ist klar.
P (A1 ∩ . . . ∩ An) =P (An ∩ (A1 ∩ . . . ∩ An−1))
P (A1 ∩ . . . ∩ An−1)P (A1 ∩ . . . ∩ An−1)
I.V.= P (An | A1 ∩ . . . ∩ An−1)P (A1)P (A2 | A1) · · ·P (An−1 | A1 ∩ . . . ∩ An−2) .
¤
Satz 2.22 (Satz von der totalen Wahrscheinlichkeit). Sei Ω =⋃i∈I
Bi eine
(hochstens) abzahlbare Zerlegung von Ω in paarweise disjunkte Mengen Bi ∈ F .
Dann gilt fur alle A ∈ F
P (A) =∑
i∈I:P (Bi)>0)P (A | Bi)P (Bi) .
Beweis. A =⋃i∈I
(A ∩ Bi) ist paarweise disjunkte Zerlegung von A. Also gilt
P (A) =∑
i∈I
P (A ∩ Bi) =∑
i∈I:P (Bi)>0)P (A ∩ Bi) =
∑
i∈I:P (Bi)>0)P (A | Bi)P (Bi) .
¤
Satz 2.23 (Formel von Bayes). Sei (Bi)i∈I eine Zerlegung von Ω wie in
Satz 2.22. Fur alle A ∈ F mit P (A) > 0 und alle j ∈ I mit P (Bj) > 0 gilt
P (Bj | A) =P (A | Bj)P (Bj)∑
i∈I:P (Bi)>0) P (A | Bi)P (Bi).

2.2. Bedingte Wahrscheinlichkeiten und Unabhangigkeit 19
Beweis.
P (Bj | A) =P (A ∩ Bj)
P (A)Satz 2.22
=P (A | Bj)P (Bj)∑
i∈I:P (Bi)>0) P (A | Bi)P (Bi). ¤
Anwendung: Falls man nur die “umgekehrten” Wahrscheinlichkeiten kennt.
Beispiel 2.24. Eine Krankheit trete mit Haufigkeit1
145auf.
Ereignis B : “Sie haben K” ⇒ P (B) =1
145.
Test zur Untersuchung auf K: Ereignis A : “Test ist positiv”.
Der Test sei relativ gut: P (A | B) = 0.96; P (Ac | Bc) = 0.94.
Dann gilt aber
P (B | A)Satz 2.23
=P (A | B)P (B)
P (A | B)P (B) + P (A | Bc)P (Bc)=
0.96 · 1/145
0.96 · 1/145 + 0.06 · 144/145=
1
10.
Nur mit Wahrscheinlichkeit1
10sind Sie bei positivem Testergebnis wirklich krank.
Bemerkung 2.25. Falls reellwertige Zufallsvariable X,Y nur abzahlbar viele
Werte annehmen, gilt
P (X = x | Y = y) =P (X = x, Y = y)
P (Y = y)falls P (Y = y) > 0 ,
P (X = x) =∑
y:P (Y =y)>0P (X = x | Y = y)P (Y = y) ,
P (Y = y | X = x) =P (X = x | Y = y)P (Y = y)
P (X = x)
=P (X = x | Y = y)P (Y = y)∑
y:P (Y =y)>0 P (X = x | Y = y)P (Y = y),
falls P (X = x), P (Y = y) > 0. ¤
Dies motiviert die folgende Definition.
Definition 2.26 (Bedingte Dichte). Seien X,Y reellwertige Zufallsvariable
mit gemeinsamer Dichte fX,Y : R2 → R+ (d.h. fX,Y ist Dichte von (X,Y ) : Ω →R2) und Randdichten fX , fY : R → R+ (d.h. fX ist Dichte von X und fY ist
Dichte von Y ). Fur y ∈ R mit fY (y) > 0 heißt
fX|Y =y : R → R+ mit fX|Y =y(x) := fX|Y (x | y) :=fX,Y (x, y)
fY (y)

20 2. Zufallsvariable, Verteilungen und Unabhangigkeit
bedingte Dichte von X gegeben Y = y.
Anschaulich ist fX|Y =y die Dichte des Wahrscheinlichkeitsmaßes B 7→ P (X ∈ B |Y = y). Dies ist jedoch nicht definiert, da P (Y = y) = 0! Trotzdem stimmt die
Intuition und kann auch (in Wahrscheinlichkeitstheorie) exakt gemacht werden.
Satz 2.27. Seien X,Y wie in Definition 2.26. Dann gelten
(1) fX|Y =y ist Dichte eines Wahrscheinlichkeitsmaßes auf (R,B) (im Sinne von
Satz 1.17).
(2) fX(x) =∫
fX|Y =y(x)fY (y)dy , x, y ∈ R.
(3) fY |X=x(y) =fX|Y =y(x)fY (y)
fX(x)=
fX|Y =y(x)fY (y)∫fX|Y =z(x)fY (z)dz
falls fX(x) > 0.
(Bayessche Formel fur Dichten).
Beweis. (1) Messbarkeit wird in der Wahrscheinlichkeitstheorie bewiesen.
∫fX|Y =y(x)dx =
1
fY (y)
∫fX,Y (x, y)dx
Satz 2.14(b)=
1
fY (y)fY (y) = 1.
(2) Benutze fX|Y =y(x)fY (y) = fX,Y (x, y) und Satz 2.14(b).
(3) 1. Gleichung: Definition; 2. Gleichung: (2). ¤
Definition 2.28 (Stochastische Unabhangigkeit, zwei Ereignisse). Zwei
Ereignisse A,B ∈ F heißen (stochastisch) unabhangig, falls
P (A ∩ B) = P (A)P (B) .
Bemerkung 2.29. (1) Im Fall P (B) > 0 ist dies aquivalent zu P (A | B) =
P (A); vgl. dazu die Motivation zu Beginn von Abschnitt 2.2 und Definition 2.18.
(2) A und Ω (bzw. A und ∅) sind stets unabhangig.
(3) Unabhangigkeit hat nicht unbedingt mit Kausalbeziehungen zu tun:
Bsp. 1. Man kann eine stochastische Abhangigkeit zwischen der Zahl der Storche
und der Zahl der Geburten messen. Das konnte auf eine Kausalbeziehung hin-
deuten, obwohl beide nur von einer dritten Grosse abhangen. Das Beispiel macht

2.2. Bedingte Wahrscheinlichkeiten und Unabhangigkeit 21
die Gefahr der Fehlinterpretation in der Statistik deutlich.
Bsp. 2. Umgekehrt kann trotz einer statistischen Kausalbeziehung Unabhangig-
keit vorliegen. Zweifacher Wurfelwurf: Ω = 1, . . . , 62, P = UΩ.
A = 2. Wurf ist eine 6 = 1, . . . , 6 × 6, P (A) =1
6.
B = Augensumme ist 7 = (1, 6), . . . , (6, 1), P (B) =1
6.
A∩B = (1, 6), P (A∩B) =1
36= P (A)P (B) ⇒ A,B sind unabhangig. ¤
Definition 2.30 (Stochastische Unabhangigkeit, Familie von Ereignis-
sen). Sei I 6= ∅ eine Indexmenge, Ai ∈ F fur alle i ∈ I. Die Familie (Ai)i∈I
heißt unabhangig, falls fur jede endliche Teilmenge ∅ 6= J ⊂ I gilt:
P (⋂
i∈J
Ai) =∏
i∈J
P (Ai) .
Bemerkung 2.31. Falls fur (Ai)i∈I nur gilt P (Ai∩Aj) = P (Ai)P (Aj), heißt die
Familie paarweise unabhangig. Das ist i.a. schwacher als Unabhangigkeit.
Bsp. Zweifacher Munzwurf: Ω = 0, 12, P = UΩ.
A = 1. Wurf ist “0” = 0 × 0, 1, P (A) =1
2.
B = 2. Wurf ist “0” = 0, 1 × 0, P (B) =1
2.
C = Beide Wurfe sind gleich = (0, 0), (1, 1), P (C) =1
2.
A ∩ B = B ∩ C = A ∩ C = A ∩ B ∩ C = (0, 0) hat Wahrscheinlichkeit1
4.
Somit gilt paarweise Unabhangigkeit, aber
P (A ∩ B ∩ C) =1
46= 1
2
1
2
1
2= P (A)P (B)P (C) ,
also A,B,C nicht unabhangig. ¤
Als nachstes definieren wir die Unabhangigkeit von Zufallsvariablen.
Definition 2.32 (Unabhangige Zufallsvariable). Seien I 6= ∅ eine Index-
menge, Xi : (Ω,F) → (Ωi,Fi) Zufallsvariable fur alle i ∈ I. Die Familie (Xi)i∈I
heißt unabhangig, falls fur jede endliche Teilmenge ∅ 6= J ⊂ I und alle Bi ∈ Fi,

22 2. Zufallsvariable, Verteilungen und Unabhangigkeit
i ∈ J , gilt:
P( ⋂
i∈J
Xi ∈ Bi)
=∏
i∈J
P (Xi ∈ Bi) (2.1)
(d.h. fur alle Bi ∈ Fi, i ∈ I, ist die Familie (Xi ∈ Bi)i∈I unabhangig).
Satz 2.33. In Definition 2.32 sei Gi ein ∩-stabiler Erzeuger von Fi fur alle
i ∈ I. Dann genugt es, in Definition 2.32, die Eigenschaft (2.1) fur alle Bi ∈ Gi
nachzuweisen.
Beweis. Wahrscheinlichkeitstheorie. ¤
Korollar 2.34. Sei (Ai)i∈I eine unabhangige Familie von Ereignissen. Seien Ci ∈Ai, A
ci fur alle i ∈ I. Dann ist auch (Ci)i∈I unabhangig.
Beweis. Betrachte Xi := 1Ai: Ω → 0, 1. Es ist G := 1 ∩-stabiler Erzeuger
von P(0, 1). Wegen Xi ∈ 1 = 1Ai= 1 = Ai ist die Familie (Xi ∈
1)i∈I unabhangig. Nach Satz 2.33 ist (Xi)i∈I unabhangig. Damit ist nach
Definition 2.32 (Xi ∈ Bi)i∈I unabhangig fur beliebige Bi ∈ P(0, 1). Fur
Bi :=
1 falls Ci = Ai ,
0 falls Ci = Aci
gilt Xi ∈ Bi = Ci. ¤
Satz 2.35. Seien Xi : (Ω,F) → (Ωi,P(Ωi)), i = 1, . . . , n, Zufallsvariable mit
abzahlbaren Ωi. X1, . . . , Xn sind genau dann unabhangig, wenn
P (X1 = ω1, . . . , Xn = ωn) =n∏
i=1
P (Xi = ωi) fur alle ω1 ∈ Ω1, . . . , ωn ∈ Ωn .
Beweis. “ ⇒′′ Setze Bi = ωi.“ ⇐′′ Seien J , (Bi)i∈J wie in Definition 2.32. O.B.d.A. sei J = 1, . . . , n (sonst
wahle Bi = Ωi fur i /∈ J).
P (n⋂
i=1
Xi ∈ Bi) σ−Add.=
∑
ω1∈B1,...,ωn∈Bn
P (X1 = ω1, . . . , Xn = ωn)
=∑
ω1∈B1,...,ωn∈Bn
n∏
i=1
P (Xi = ωi) =n∏
i=1
(∑
ωi∈Bi
P (Xi = ωi)
)σ−Add.
=n∏
i=1
P (Xi ∈ Bi) .

2.3. Wahrscheinlichkeitsmaße fur unabhangige Versuchswiederholungen 23
¤
Satz 2.36. Seien X1, . . . , Xn reelle Zufallsvariable. Sie sind genau dann un-
abhangig, wenn
P (X1 ≤ c1, . . . , Xn ≤ cn) =n∏
i=1
P (Xi ≤ ci) , c1, . . . , cn ∈ R . (2.2)
Beweis. “ ⇒′′: Klar mit Bi := (−∞, ci].
“ ⇐′′: Sei J ⊂ 1, . . . , n. Dann gilt
P (⋂
i∈J
Xi ≤ ci) =∏
i∈J
P (Xi ≤ ci) ;
denn z.B. gilt fur J = 1, . . . , n − 1 mit der Stetigkeit von unten:
P (⋂
i∈J
Xi ≤ ci) = limu→∞
P (X1 ≤ c1, . . . , Xn−1 ≤ cn−1, Xn ≤ u)
(2.2)= lim
u→∞
n−1∏
i=1
P (Xi ≤ ci)P (Xn ≤ u) =n−1∏
i=1
P (Xi ≤ ci) .
Da (−∞, c] : c ∈ R ein ∩-stabiler Erzeuger von B ist (s. Bsp. 1.8(3)), folgt die
Behauptung nach Satz 2.33. ¤
Bemerkung 2.37. Wenn eine Familie (Xi)i∈I von Zufallsvariablen unabhangig
ist, dann ist das auch (fi(Xi))i∈I , wenn die fi messbare Funktionen sind. Ferner
sind auch Kombinationen der Zufallsvariablen unabhangig; z.B. gilt
X1, . . . , X5 unabhangig ⇒ X1 + X2, X3
√X4X5 unabhangig
(Beweis in der Wahrscheinlichkeitstheorie).
2.3 Wahrscheinlichkeitsmaße fur unabhangige Ver-
suchswiederholungen
Sei (Ω,F , P ) als Wahrscheinlichkeitsraum das Modell fur ein Zufallsexperiment.
Wenn das zugehorige Experiment n-mal wiederholt wird, passt dazu der Grund-
raum Ωn = Ω × · · · × Ω (vgl. Bsp. 1.2(3)) mit dazu passender σ-Algebra F⊗n =

24 2. Zufallsvariable, Verteilungen und Unabhangigkeit
F ⊗ . . . ⊗ F (vgl. Bsp. 1.8(5)). Die j-te Projektion πj : Ωn → Ω, gegeben durch
(ω1, . . . , ωn) 7→ ωj steht fur das j-te Einzelexperiment.
Frage: Welches Wahrscheinlichkeitsmaß Q auf (Ωn,F⊗n) passt zu dem Mehr-
fachexperiment?
Wir wollen: Das Einzelexperiment πj hat Verteilung P , Einzelexperimente sind
unabhangig.
Antwort: Das Produktmaß P⊗n = P ⊗ · · · ⊗ P .
Satz 2.38. Sei I 6= ∅ eine (hochstens) abzahlbare Indexmenge. Seien (Ωi,Fi, Pi)
fur i ∈ I Wahrscheinlichkeitsraume und Ω =∏i∈I
Ωi, F =⊗i∈I
Fi. Dann existiert
genau ein Wahrscheinlichkeitsmaß P auf (Ω,F) so, dass die Projektionen πi :
Ω → Ωi die Verteilung Pi haben und dass die Familie (πi)i∈I unabhangig ist.
Beweis. Wahrscheinlichkeitstheorie. ¤
Definition 2.39. Das in Satz 2.38 definierte Maß P heißt das Produktmaß der
Pi und man schreibt P =⊗i∈I
Pi.
Bemerkung 2.40. (1) P ist das Produktmaß auf (Ω,F) = (n∏
i=1
Ωi,n⊗
i=1
Fi) genau
dann, wenn
P (A1 × · · · × An) =n∏
i=1
Pi(Ai) fur alle A1 ∈ F1, . . . , An ∈ Fn .
Beweis: “ ⇒′′ π1, . . . , πn sind unabhangig. Daraus folgt
P (A1 × · · · × An) = P (π1 ∈ A1, . . . , πn ∈ An) =n∏
i=1
P (πi ∈ Ai) =n∏
i=1
Pi(Ai) ,
die Umkehrung beweist man analog. ¤
(2) Seien Xi : (Ω,F , P ) → (Γi,Gi) fur i = 1, . . . , n Zufallsvariable und
X = (X1, . . . , Xn) : (Ω,F , P ) → (n∏
i=1
Γi,n⊗
i=1
Gi). Dann gilt
X1, . . . , Xn sind unabhangig ⇔ PX =n⊗
i=1
PXi

2.3. Wahrscheinlichkeitsmaße fur unabhangige Versuchswiederholungen 25
(die gemeinsame Verteilung ist das Produkt der Randverteilungen).
Beweis: Linke Seite ⇔
P (n⋂
i=1
Xi ∈ Bi) =n∏
i=1
P (Xi ∈ Bi) fur Bi ∈ Gi , i = 1 . . . , n
⇔ PX(B1 × · · · × Bn) =n∏
i=1
PXi(Bi) fur Bi ∈ Gi , i = 1 . . . , n
⇔ rechte Seite. ¤
Beispiel 2.41. (1) Fur i = 1, . . . , n seien (Ωi,P(Ωi), Pi) endliche Wahrschein-
lichkeitsraume mit Pi = UΩi(die diskrete Gleichverteilung aus Bsp. 1.18(1)). Fur
P =n⊗
i=1
Pi auf (Ω,P(Ω)) = (Ω1 × · · · × Ωn,P(Ω1) ⊗ · · · ⊗ P(Ωn)) gilt
P ((ω1, . . . , ωn)) =n∏
i=1
Pi(ωi) =n∏
i=1
1
|Ωi|=
1∏ni=1 |Ωi|
=1
|Ω| ,
also ist P = UΩ die diskrete Gleichverteilung auf Ω.
(2) n-maliger Wurf einer p-Munze mit p ∈ [0, 1].
Ω1 = · · · = Ωn = 0, 1, Pi(1) = p = 1 − Pi(0) fur i = 1, . . . , n.
Dann ist (Ω,F , P ) = (n∏
i=1
Ωi,n⊗
i=1
P(0, 1),n⊗
i=1
Pi) = (0, 1n,P(0, 1n), P ) mit
P ((ω1, . . . , ωn)) = pAnzahl der Einsen(1−p)Anzahl derNullen = p∑n
i=1 ωi(1−p)n−∑ni=1 ωi .
P heißt n-dimensionale Bernoulli Verteilung. ¤
Der folgende Satz ist ein Analogon zu Satz 2.35.
Satz 2.42. Seien X1, . . . , Xn : (Ω,F) → (R,B) Zufallsvariable mit Dichten
f1, . . . , fn : R → R+ und sei X = (X1, . . . , Xn) : (Ω,F) → (Rn,Bn).
X1, . . . , Xn sind unabhangig ⇔ f : Rn → R+ mit f(x1, . . . , xn) = f1(x) · · · fn(xn)
ist Dichte von X.

26 2. Zufallsvariable, Verteilungen und Unabhangigkeit
Beweis. fi ist Dichte zur Verteilung PXi. Damit folgt
n⊗
i=1
PXi(A1 × · · · × An) =
n∏
i=1
PXi(Ai) =
n∏
i=1
∫
Ai
fi(xi)dxi
=
∫
A1
· · ·∫
An
n∏
i=1
fi(xi)dx1 · · · dxn =
∫
A1
· · ·∫
An
f(x1, . . . , xn)dx1 · · · dxn
=
∫
A1×···×An
f(x)dx (Fubini).
Nach dem Eindeutigkeitssatz 1.13 ist f Dichte von⊗n
i=1 PXi. Zusammen mit
Bemerkung 2.40(2) folgt die Behauptung. ¤
Eine wichtige Operation ist das Addieren von unabhangigen Zufallsvariablen.
Definition 2.43 (Faltung von Zufallsvariablen). Seien X,Y unabhangige,
reelle Zufallsvariable und S = X + Y . PS heißt Faltung von PX und PY .
Schreibweise: PS = PX ∗ PY .
Satz 2.44. Seien X,Y unabhangige reellwertige Zufallsvariable.
(1) Seien X,Y Z-wertig, ρX , ρY : Z → [0, 1] Zahldichten von PX , PY . Dann ist
ρS : Z → [0, 1] mit
ρS(k) =∑
l∈Z
ρX(l)ρY (k − l)
Zahldichte von PS.
Schreibweise: ρS = ρX ∗ ρY (Faltung von ρX und ρY ).
(2) Seien fX , fY Dichten von X,Y . Dann ist fS : R → R+ mit
fS(u) =
∫ ∞
−∞fX(x)fY (u − x)dx
Dichte von S.
Schreibweise: fS = fX ∗ fY (Faltung von fX und fY ).
Beweis. (1) ρS(k) = PX+Y (k) = P (X + Y = k) =∑l∈Z
P (X = l, Y = k − l)unabh.
=∑l∈Z
P (X = l)P (Y = k − l) =∑l∈Z
ρX(l)ρY (k − l).

2.3. Wahrscheinlichkeitsmaße fur unabhangige Versuchswiederholungen 27
(2) f : R2 → R+ mit f(x, y) = fX(x)fY (y) ist gemeinsame Dichte von (X,Y ).
Sei ϕ : R2 → R2,
(x
y
)7→
(x
x + y
)= A
(x
y
)mit A =
(1 0
1 1
); damit ist A−1 =
(1 0
−1 1
).
Nach Beispiel 2.16 hat (X,X + Y )⊤ die Dichte g : R2 → R+ mit
g(u, v) = f(u, v − u) = fX(u)fY (v − u). Nach Satz 2.14(b) hat X + Y die Dichte
fS : R → R+ mit fS(v) =∫ ∞−∞ fX(u)fY (v − u)du. ¤
Eine weitere wichtige Operation ist das Ordnen von Stichproben.
Satz 2.45. Seien X1, . . . , Xn unabhangige, identisch verteilte, reellwertige Zu-
fallsvariable mit Verteilungsfunktion F . Seien X(1), . . . , X(n) die nach ihrer Große
geordneten X1, . . . , Xn (die Ordnungsstatistiken), also X(1) ≤ · · · ≤ X(n) mit
X(1) = minX1, . . . , Xn, . . . , X(n) = maxX1, . . . , Xn. Dann gilt fur k = 1, . . . , n:
(1) FX(k)(c) =
n∑j=k
(nj
)(F (c))j(1 − F (c))n−j , c ∈ R , ist die Verteilungsfunktion
der k-ten Ordnungsstatistik X(k).
(2) Falls F stetig differenzierbar ist mit Ableitung F ′ = f , hat X(k) eine Dichte
gk : R → R+, gegeben durch
gk(x) =n!
(k − 1)!(n − k)!(F (x))k−1(1 − F (x))n−kf(x) , x ∈ R .
Außerdem hat (X(1), . . . , X(n)) eine Dichte g : Rn → R+, gegeben durch
g(x1, . . . , xn) =
n!n∏
i=1
f(xi) falls x1 ≤ x2 ≤ · · · ≤ xn ,
0 sonst.

28 2. Zufallsvariable, Verteilungen und Unabhangigkeit
Beweis. (1) Fur c ∈ R definiere Bn =∑n
i=1 1Xi≤c. Dann gilt
FX(k)(c) = P (X(k) ≤ c) = P (Bn ≥ k) =
n∑
j=k
P (Bn = j)
=n∑
j=k
∑
T⊂1,...,n:|T |=j(P (Xi ≤ c))j(P (Xi > c))n−j
=n∑
j=k
∑
T
(F (c))j(1 − F (c))n−j .
Die Behauptung folgt, da∑
T genau(
nj
)Summanden besitzt.
(2) Man rechnet leicht nach, dass FX(k)(c) =
∫ c
−∞ gk(x)dx fur c ∈ R gilt.
Fur die mehrdimensionale Dichte beachte, dass (X(1), . . . , X(n)) = ϕ(X1, . . . , Xn)
mit ϕ : Rn → Rn. Fur π ∈ Sn := Permutationen von 1, . . . , n definiert man
Uπ := (y1, . . . , yn) ∈ Rn : yπ(1)) < · · · < yπ(n),
dann sind die Uπ offen und paarweise disjunkt. Ferner sei
R := Rn \ (⋃
π∈Sn
Uπ) = (y1, . . . , yn) ∈ Rn : ∃i, j mit yi = yj.Dann gilt λn(R) = 0, also o.B.d.A. ist f(X1,...,Xn) = 0 auf R (Beweis in Wahr-
scheinlichkeitstheorie).
Fur ϕπ := ϕ|Uπ: Uπ → ϕ(Uπ) = (x1, . . . , xn) ∈ Rn : x1 < · · · < xn gilt
ϕπ(x) = Aπx, wobei Aπ = (eπ(1), . . . , eπ(n))⊤ mit dem i-ten Einheitsvektor
ei := (0, . . . , 0, 1, 0, . . . , 0) (mit 1 an i-ter Komponente). Dann ist det(Aπ) = 1.
Nach Satz 2.42 gilt f(X1,...,Xn)(x1, . . . , xn) =n∏
i=1
f(xi), also
f(ϕ−1π (y1, . . . , yn)) = f(yϕ−1(1), . . . , yϕ−1(n)) =
n∏
i=1
f(yϕ−1(i)) =n∏
i=1
f(yi) .
Nach dem Transformationssatz 2.15 hat (X(1), . . . , X(n)) die Dichte
g(y) =∑
π∈Sn
1(y1,...,yn)∈Rn : y1<···<yn(y)n∏
i=1
f(yi) .
= n!n∏
i=1
f(yi)1(y1,...,yn)∈Rn : y1<···<yn(y) .
Beachte : Fur k = 1, . . . , n folgt durch Differenzieren von FX(k)die Form von gk
wie in der Aussage. ¤

Kapitel 3
Stochastische Standardmodelle
Frage: wie entscheidet man sich fur ein konkretes Wahrscheinlichkeitsmaß P
(Modell) ?
– theoretische Uberlegungen (z.B. alle Ausgange gleichwahrscheinlich)
– empirische/statistische Untersuchungen
– eine Kombination von Beidem.
3.1 Diskrete Verteilungen
3.1.1 Diskrete Gleichverteilung und Kombinatorik
Zur Erinnerung: Sei |Ω| < ∞; UΩ : P(Ω) → [0, 1], A 7→ |A||Ω| heißt (diskrete)
Gleichverteilung auf Ω; (Ω,P(Ω), UΩ) heißt Laplace-Raum.
Idee: Es liegt z.B. aus physikalischen Grunden nahe anzunehmen, dass alle Er-
gebnisse gleichwahrscheinlich sind.
Konsequenz: Zur Berechnung von Laplace-Wahrscheinlichkeitkeiten mussen Ele-
mente von Mengen abgezahlt werden.
29

30 3. Stochastische Standardmodelle
Lemma 3.1 (Grundelemente der Kombinatorik). Seien A,B endliche Men-
gen.
(1) (a) Falls eine Bijektion f : A → B existiert, gilt |A| = |B|.(b) Im Fall A ∩ B = ∅ gilt |A ∪ B| = |A| + |B|.(c) Im Fall A ⊂ B gilt |B \ A| = |B| − |A|.
(2) Machtigkeit des kartesischen Produkts:
A × B = |A| · |B|,und allgemeiner: |A1 × · · · × An| =
n∏i=1
|Ai|, insbesondere |An| = |A|n.
(3) Anzahl von Funktionen:
(a) beliebige Funktion:
Fur Abb(A,B) := f : A → B = BA gilt |BA| = |B||A|.
(b) Injektive Funktionen: |f ∈ Abb(A,B) : f injektiv| =|B|!
(|B| − |A|)! .Spezialfall bijektive Funktionen. Falls |A| = |B|:|f ∈ Abb(A,B) : f bijektiv| = |A|!.
(4) Teilmengen:
(a) k-elementige Teilmengen: |C ⊂ A : |C| = k| =
(|A|k
)fur k ≤ |A|,
wobei
(n
k
):=
n(n − 1) · · · (n − k + 1)
k!=
n!
(n − k)!k!fur k, n ∈ N, k ≤ n
der Binomialkoeffizient ist.
(b) Aufteilen auf Teilmengen gegebener Große.
Seien n1, . . . , nr ∈ N mit n1 + · · · + nr = n := |A|. Definiere
M = (A1, . . . , Ar) : A1, . . . , Ar ⊂ A paarweise disjunkt, |Ai| = ni fur i = 1, . . . , r
Dann gilt
|M | =n!
n1! · · ·nr!(Multinomialkoeffizient)
(c) Alle Teilmengen: |P(Ω)| = 2|A|.

3.1. Diskrete Verteilungen 31
Beweis. (Exemplarische Begrundungen):
(3a) Sei A = a1, . . . , an. Identifiziere die Funktion f : A → B mit einem
Tupel (f(a1, . . . f(an)) = (x1, . . . , xn) ∈ B × · · · × B = Bn, also
|f : A → B| (1a)= |Bn| (2)
= |B|n = |B||A|.
(3b) Seien A = a1, . . . , ak, B = b1, . . . , bn.Identifiziere die injektive Funktion f : A → B mit einem Tupel (x1, . . . , xn) ∈ Bn:
x1 ∈ 1, . . . , n : Rangplatz von f(a1) in b1, . . . , bn,x2 ∈ 1, . . . , n − 1 : Rangplatz von f(a2) in b1, . . . , bn \ f(a1),...
xk ∈ 1, . . . , n−k+1 : Rangplatz von f(ak) in b1, . . . , bn\f(a1), . . . , f(ak−1)Nach (1a) folgt
|f ∈ Abb(A,B) : f injektiv| (1a)= |1, . . . , n × 1, . . . , n − 1 × · · · × 1, . . . , n − k + 1|
(2a)= n(n − 1) · · · (n − k + 1) =
n!
(n − k)!.
(4b) Seien A = a1, . . . , an. Identifiziere die Bijektion f : A → A mit einem
Tupel α, π1, . . . , πr ∈ M × Sn1 × · · · × Snrvia
(f(a1), . . . , f(an1)︸ ︷︷ ︸A1
, f(an1+1), . . . , f(an1+n2)︸ ︷︷ ︸A2
, . . . , f(an1+···+nr−1+1), . . . , f(an)︸ ︷︷ ︸Ar
) .
Eine Permutation von A entspricht einer Aufteilung von A in r Mengen wie
abgebildet, zusammen mit einer Festlegung der Reihenfolge in den r einzelnen
Teilmengen. Also:
n!(3b)= |f ∈ Abb(A,A) : f bijektiv| (1a)
= |M × Sn1 × · · · × Snr|
(2)= |M | · |Sn1 | · · · |Snr
| (3b)= |M | · n1! · · ·nr! ,
d.h. |M | =n!
n1! · · ·nr!.
(4a) Identifiziere eine k-elementige Teilmenge C von A mit einer Aufteilung von
A in zwei Mengen A1, A2 mit |A1| = k,|A2| = |A| − k (via A1 := C,A2 := A \C).
Somit gilt: |C ⊂ A : |C| = k| (1a,4b)=
|A|!k!(|A| − k)!
.

32 3. Stochastische Standardmodelle
(4c) Fur n ∈ N gilt:
2n = (1 + 1)n =n∑
k=0
(n
k
)1k1n−k =
n∑
k=0
(n
k
),
also
|P(A)| = ||A|⋃
k=0
C ⊂ A : |C| = k| (1b)=
|A|∑
k=0
|C ⊂ A : |C| = k| =
|A|∑
k=0
(|A|k
)= 2|A| .
¤
Korollar 3.2 (Multinomialsatz).
(x1 + · · · + xr)n =
∑
n1,...,nr≥0 :n1+···+nr=n
n!
n1! · · ·nr!xn1
1 · · ·xnrr , x1, . . . , xr ∈ R, r ∈ N .
Beweis.(
r∑
i=1
)n
=∑
(A1,...,Ar) : Zerlegung
von1,...,n
r∏
i=1
x|Ai|i
=∑
n1,...,nr≥0 :n1+···+nr=n
∑
(A1,...,Ar) : Zerlegungvon1,...,nmit|Ai|=ni
r∏
i=1
xni
i
=∑
n1,...,nr≥0 :n1+···+nr=n
n!
n1! · · ·nr!
r∏
i=1
xni
i .
¤
Beispiel 3.3. [Urnenmodelle]
(1) Anordnung der Lange n aus N Elementen mit Wiederholungen:
Ω = (ω1, . . . , ωn) : ωi ∈ 1, . . . , N fur i = 1, . . . , N = 1, . . . , Nn , |Ω| (L.3.1(2))= Nn .
Bsp.: , n-maliges Wurfeln mit N -seitigem Wurfel; Ziehen mit Zurucklegen.
(2) Anordnung der Lange n aus N Elementen ohne Wiederholungen:
Ω = (ω1, . . . , ωn) : ωi 6= ωj fur i 6= j , |Ω| (L.3.1(3b))=
N !
(N − n)!.

3.1. Diskrete Verteilungen 33
Bsp.: Ziehen ohne Zurucklegen; Ziehung der Lottozahlen (vor dem Sortieren).
(3) Kombinationen der Lange n aus N Elementen ohne Wiederholungen:
Ω = (ω1, . . . , ωn) ∈ 1, . . . , Nn : ω1 < ω2 < · · · < ωn .
Die Elemente von Ω entsprechen n-elementigen Teilmengen von 1, . . . , N, also
|Ω| (L.3.1(b),(4a))=
(Nn
).
Bsp.: Ziehen ohne Zurucklegen, ohne Beachtung der Reihenfolge; Zie-
hung der Lottozahlen.
(4) Kombinationen der Lange n aus N Elementen mit Wiederholungen:
Ω = (ω1, . . . , ωn) ∈ 1, . . . , Nn : ω1 ≤ ω2 ≤ · · · ≤ ωn .
Jedes Element von Ω kann via (ω1, . . . , ωn) 7→ (ω1, ω2 + 1, . . . , ωn + n − 1) in
eineindeutiger Weise mit einem Element von
Ω := (ω1, . . . , ωn) ∈ 1, . . . , N + n − 1n : ω1 < ω2 < · · · < ωn
identifiziert werden; also |Ω| (L.3.1(1a),(4a))= |Ω| (L.3.1(3),(4a))
=(
N+n−1n
).
Bsp.: Ziehen mit Zurucklegen ohne Beachtung der Reihenfolge, aber
Achtung: Die Elemente von Ω sind bei realen Zufallsexperimenten (z.B. Wurf
mit n Wurfeln) in aller Regel nicht gleich wahrscheinlich
⇒ die diskrete Gleichverteilung ist unangemessen.
Beispiel 3.4. [Wurfeln mit 3 Wurfeln]
Ω = 1, . . . , 63, P = UΩ die diskrete Gleichverteilung,
A = Gesamtaugenzahl ist 11 = (ω1, ω2, ω3) ∈ Ω : ω1 + ω2 + ω3 = 11 ,
B = Gesamtaugenzahl ist 12 = (ω1, ω2, ω3) ∈ Ω : ω1 + ω2 + ω3 = 12 .
Einzelnes Abzahlen ergibt |A| = 27, |B| = 25, also
P (A) =|A||Ω| =
27
216= 0.125 , P (A) =
|A||Ω| =
25
216= 0.116 .
34 3. Stochastische Standardmodelle
Im Modell aus Beispiel 3.3(4) hatten beide Ereignisse die gleiche Wahrscheinlich-
keitkeit; denn
11 lasst sich darstellen als 146, 155, 236, 245, 335, 344
12 lasst sich darstellen als 156, 246, 255, 336, 345, 444.
Aufpassen bei Verwendung der Gleichverteilungsannahme!
3.1.2 Einige wichtige diskrete Verteilungen
Definition 3.5 (Binomialverteilung, Bn,p). Seien n ∈ N, Ω = 0, 1, . . . , n(oder Ω = N0), p ∈ [0, 1]. Die Binomialverteilung Bn,p auf (Ω,P(Ω)) ist definiert
durch die Zahldichte
ρ(k) = Bn,p(k) :=
(n
k
)pk(1 − p)n−k , k = 0, 1, . . . , n bzw. N0. (3.1)
0
0.1
0.2
0.3
0 2 4 6 8 10
k
ρ(k) =(
nk
)pk(1 − p)n−k ; p = 0.2 , n = 10
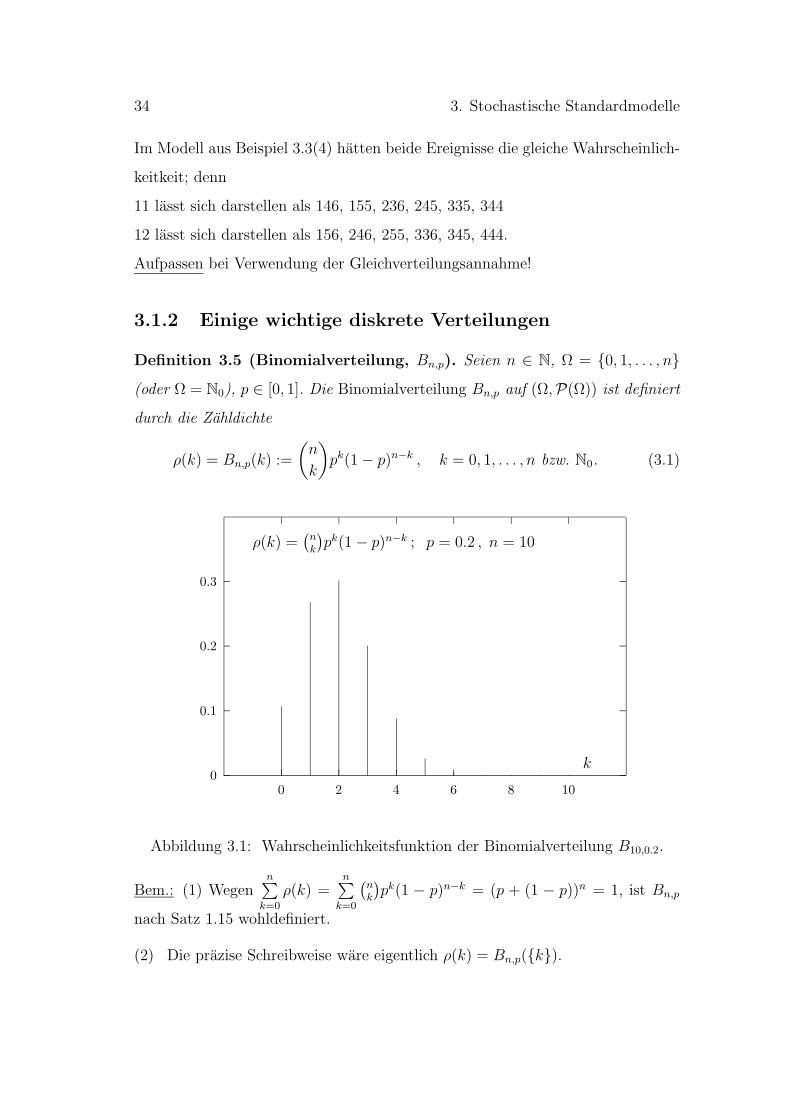
Abbildung 3.1: Wahrscheinlichkeitsfunktion der Binomialverteilung B10,0.2.
Bem.: (1) Wegenn∑
k=0
ρ(k) =n∑
k=0
(nk
)pk(1 − p)n−k = (p + (1 − p))n = 1, ist Bn,p
nach Satz 1.15 wohldefiniert.
(2) Die prazise Schreibweise ware eigentlich ρ(k) = Bn,p(k).

3.1. Diskrete Verteilungen 35
Bsp.: [Urnenmodell: n-maliges Ziehen mit Zurucklegen fur N = 2, vgl. Bsp. 3.3(1);
n-maliger Wurf einer p-Munze, vgl. Bsp. 2.41]
(Ω,F , P ) = (0, 1n,P(Ω), P ) mit P ((ω1, . . . , ωn)) = p∑n
i=1 ωi(1 − p)n−∑ni=1 ωi .
Definiere eine Zufallsvariable X : Ω → 0, . . . , n mit (ω1, . . . , ωn) 7→ ∑ni=1 ωi
Anzahl der gezogenen schwarzen Kugeln, Anzahl der geworfenen Einsen.
Fur k = 0, . . . , n und Ak = (ω1, . . . , ωn) ∈ Ω :∑n
i=1 ωi = k gilt:
Jedes Element lasst sich eineindeutig mit einer k-elementigen Teilmenge von
1, . . . , n identifizieren, also |Ak|L.3.1(a1,4a)
=(
nk
). Somit ist (wir schreiben wieder
PX(k) statt PX(k) und P (ω1, . . . , ωn) statt P ((ω1, . . . , ωn)))
PX(k) = P (X = k) = P (Ak) =∑
(ω1,...,ωk)∈Ak
P (ω1, . . . , ωn)
=∑
(ω1,...,ωk)∈Ak
pk(1 − p)n−k =
(n
k
)pk(1 − p)n−k , k = 0, . . . , n ,
also ist X binomialverteilt mit Zahldichte Bn,p. ¤
Definition 3.6. [Multinomialverteilung, Mn,r,p1,...,pr] Seien n, r ∈ N,
Ω = (n1, . . . , nr) : n1, . . . , nr ∈ N0 und n1 + · · · + nr = n, p1, . . . , pr ∈ [0, 1]
mitr∑
i=1
pi = 1. Die Multinomialverteilung Mn,r,p1,...,prauf (Ω,P(Ω)) ist definiert
durch die Zahldichte
ρ(n1, . . . , nr) = Mn,r,p1,...,pr(n1, . . . , nr) =
n!
n1! · · ·nr!pn1
1 · · · pnrr . (3.2)
Bem.: Nach dem Multinomialsatz, Korollar 3.2, ist Mn,r,p1,...,prnach Satz 1.15
wohldefiniert.
Bsp.: [n-maliges Wurfeln]
(Ω,F , P ) = (1, . . . , 6n,P(Ω), UΩ). Definiere eine Zufallsvariable
X : Ω → (n1, . . . , n6) : n1, . . . , n6 ∈ N mit n1 + · · · + n6 = n mit
(ω1, . . . , ωn) 7→ (|i ∈ 1, . . . , n : ωi = 1|, . . . , |i ∈ 1, . . . , n : ωi = 6|)
= (Anzahl der Einsen, . . . , Anzahl der Sechsen).

36 3. Stochastische Standardmodelle
Analog zum Bsp.in Definition 3.5 (mit Lemma 3.1(4b) anstelle von (4a) folgt
|X = (n1, . . . , nr)| =n!
n1! · · ·nr!und
PX(n1, . . . , nr) = P (X = (n1, . . . , nr)) =|X = (n1, . . . , nr)|
|Ω| =n!
n1! · · ·nr!(1
6)n1 · · · (1
6)nr ,
also ist X multinomialverteilt mit Zahldichte Mn,6, 16,..., 1
6.
Allgemeiner: Mn,r,p1,...,pr, falls der Wurfel r Seiten hat mit Wahrscheinlichkeit pi
fur Seite i. ¤
Definition 3.7 (Hypergeometrische Verteilung, Hn,s,w). Seien n ∈ N,
Ω = 0, 1, . . . , n (oder N0), s, w ∈ N mit s + w ≥ n. Die hypergoemetrische
Verteilung Hn,s,w auf (Ω,P(Ω)) ist definiert durch die Zahldichte
ρ(k) = Hn,s,w(k) =
(sk
)(w
n−k
)(
s+wn
) , k ∈ 0, . . . , n bzw. N0 .
Bsp.: [Urnenmodell: Ziehen ohne Zurucklegen, vgl. Bsp. 3.3(3)]
Von N = s + w Kugeln seien s schwarz und w weiß; n ≤ N Kugeln werden
gezogen.
Ω = (ω1, . . . , ωn) ∈ 1, . . . , Nn : ω1 < · · · < ωn, F = P(Ω), P = UΩ .
Definiere eine Zufallsvariable X : Ω → 0, . . . , n mit
(ω, . . . , ωn) 7→ |i ∈ 1, . . . , n : ωi ≤ s| (Anzahl der gezogenen schwarzen
Kugeln).
Fur k = 0, . . . , n gilt X = k = A × B mit
A = (ω1, . . . , ωk) ∈ 1, . . . , sk : ω1 < · · · < ωk, |A| =(
sk
)
B = (ωk+1, . . . , ωn) ∈ s + 1, . . . , s + wn−k : ωk+1 < · · · < ωn, |B| =(
wn−k
).
Also ist PX(k) = P (X = k) =|A × B|
|Ω| =
(sk
)(w
n−k
)(
Nn
) , d.h. X ist hypergeometrisch
verteilt.
Bem.: Insbesondere ist die hypergeometrische Verteilung ein Wahrscheinlich-
keitsmaß.
Bsp.: [Ziehung der Lottozahlen “6 aus 49”]
N = s+w = 49 Kugeln, s = 6 schwarze (die angekreuzten Zahlen), n = 6 werden

3.1. Diskrete Verteilungen 37
gezogen:
P (5 richtige) = H6,6,43(5) =
(65
)(431
)(496
) ≈ 0, 18 · 10−4 .
¤
Definition 3.8 (Poisson-Verteilung). Sei λ ∈ (0,∞). Die Poisson Verteilung
Poiλ auf (N,P(N)) ist definiert durch die Zahldichte
ρ(k) = Poiλ(k) = e−λ λk
k!, k ∈ N0 .
0
0.05
0.1
0.15
0.2
0 2 4 6 8 10 12 14 16
k
Poiλ(k) = e−λ λk
k!; λ = 5
Abbildung 3.2: Wahrscheinlichkeitsfunktion der Poisson-Verteilung Poi5.
Bem.: Wegen∞∑
k=0
e−λ λk
k!= e−λeλ = 1 ist Poiλ nach Satz 1.15 wohldefiniert.
Bsp.: [Anrufe in einem Callcenter]
Gesucht ist ein Modell (plausible Wahrscheinlichkeitsverteilung) fur die Anzahl
der Anrufe, die innerhalb einer Stunde in einem Callcenter eingehen, wenn im
Mittel 20 Anrufe pro Stunde eingehen. Dies entspricht intuitiv einem Munzwur-
fexperiment: jede Sekunde wird eine Munze geworfen, die mit Wahrscheinlich-
keitkeit p =20
3600Kopf zeigt. Dies legt eine B3600,20/3600-Verteilung nahe. Mit

38 3. Stochastische Standardmodelle
Millisekunden statt Sekunden erhielte man eine B3 600 000,20/3 600 000-Verteilung. In
beiden Einheiten gilt n p = 20. Im Limes ergibt sich eine Poi20 Verteilung nach
folgendem Satz. ¤
Satz 3.9 (Gesetz der kleinen Zahlen). Seien λ ∈ (0,∞), (pn)n∈N eine Folge
in [0, 1] mit npnn→∞→ λ. Dann gilt
Bn,pn(k)
n→∞→ Poiλ(k) , k ∈ N0 .
Beweis. Fur λn := npn gilt
Bn,pn(k) =
n(n − 1) · · · (n − k + 1)
k!
(λn
n
)k (1 − λn
n
)n−k
=n(n − 1) · · · (n − k + 1)
nk
λkn
k!
(1 − λn
n
)n (1 − λn
n
)−k
= 1︸︷︷︸↓1
·(
1 − 1
n
)
︸ ︷︷ ︸↓1
· · ·(
1 − k − 1
n
)
︸ ︷︷ ︸↓1
1
(1 − λn
n)k
︸ ︷︷ ︸↓1
λkn
k!
(1 − λn
n
)n
n→∞→ λk
k!e−λ , (da λn → λ, Analysis 1) .
¤
Definition 3.10 (Negative Binomial-, geometrische Verteilung, Br,p).
Die negative Binomialverteilung oder Pascal Verteilung Br,p auf (N0,P(N)) ist
definiert durch die Zahldichte
Br,p(k) =
(k + r − 1
k
)pr(1 − p)k , k ∈ N0 .
Fur r = 1 heißt Gp := B1,p geometrische Verteilung.
Bsp.: [∞-maliger Munzwurf, vgl. Bsp. 2.41]
(Ω,F , P ) = (∞∏
n=1
0, 1,∞⊗
n=1
P(0, 1),∞⊗
n=1
Pi) mit Pi(1) = p = 1 − Pi(0).
Definiere eine Zufallsvariable X : Ω → N0 mit ω 7→ infk ∈ N0 :r+k∑i=1
ωi = r(Zeitpunkt, zu dem in r + k Wurfen zum r-ten Mal “Kopf” auftritt).

3.2. Stetige Verteilungen 39
Somit ist
P (X = k) = P (r-ter Erfolg beim r + k-ten Versuch )
= P (k Misserfolge vor dem r-ten Erfolg)
= P (ω ∈ Ω : ωk+r = 1,k+r−1∑
i=1
ωi = r − 1)
=∑
A⊂1,...,k+r−1|A|=k
P (ω ∈ Ω : ωi = 0 fur i ∈ A , ωi = 1 fur i ∈ 1, . . . , k + r \ A)
=∑
A⊂1,...,k+r−1|A|=k
pr(1 − p)k =
(k + r − 1
k
)pr(1 − p)k =
(−r
k
)pr(−(1 − p))k .
Also ist die Wartezeit aufs r-te Mal “Kopf” Pascal verteilt.
Bem.: Insbesondere ist die Pascal Verteilung eine Wahrscheinlichkeitsvertei-
lung. ¤
3.2 Stetige Verteilungen auf R
Definition 3.11 (Gleichverteilung, U(a,b)). Seien a, b ∈ R, a < b.
Die Gleichverteilung U(a,b) auf ((a, b),B(a,b)) ist definiert durch die Dichte
u(x) =1
b − a, x ∈ (a, b) .
6
1
b − a
a bx
u(x)
Abbildung 3.3: Dichte der Gleichverteilung auf (a, b).
40 3. Stochastische Standardmodelle
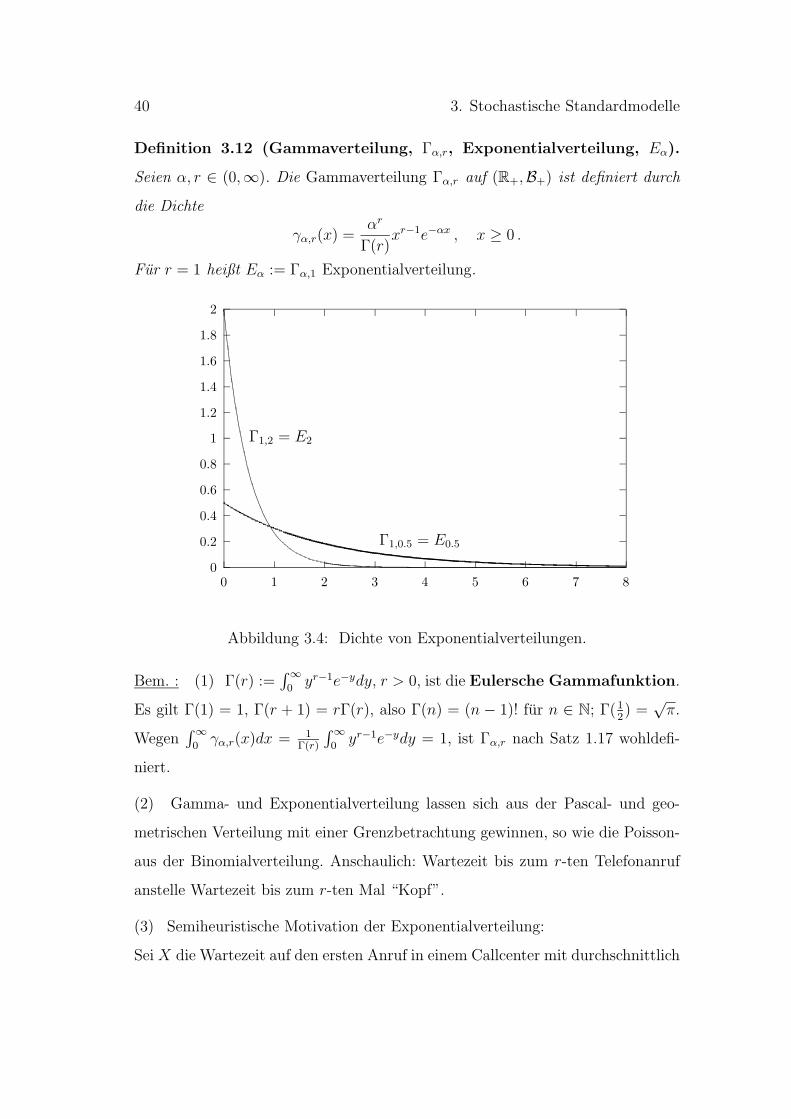
Definition 3.12 (Gammaverteilung, Γα,r, Exponentialverteilung, Eα).
Seien α, r ∈ (0,∞). Die Gammaverteilung Γα,r auf (R+,B+) ist definiert durch
die Dichte
γα,r(x) =αr
Γ(r)xr−1e−αx , x ≥ 0 .
Fur r = 1 heißt Eα := Γα,1 Exponentialverteilung.
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
0 1 2 3 4 5 6 7 8
Γ1,2 = E2
Γ1,0.5 = E0.5
Abbildung 3.4: Dichte von Exponentialverteilungen.
Bem. : (1) Γ(r) :=∫ ∞0
yr−1e−ydy, r > 0, ist die Eulersche Gammafunktion.
Es gilt Γ(1) = 1, Γ(r + 1) = rΓ(r), also Γ(n) = (n − 1)! fur n ∈ N; Γ(12) =
√π.
Wegen∫ ∞
0γα,r(x)dx = 1
Γ(r)
∫ ∞0
yr−1e−ydy = 1, ist Γα,r nach Satz 1.17 wohldefi-
niert.
(2) Gamma- und Exponentialverteilung lassen sich aus der Pascal- und geo-
metrischen Verteilung mit einer Grenzbetrachtung gewinnen, so wie die Poisson-
aus der Binomialverteilung. Anschaulich: Wartezeit bis zum r-ten Telefonanruf
anstelle Wartezeit bis zum r-ten Mal “Kopf”.
(3) Semiheuristische Motivation der Exponentialverteilung:
Sei X die Wartezeit auf den ersten Anruf in einem Callcenter mit durchschnittlich
3.2. Stetige Verteilungen 41
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
0 2 4 6 8 10 12 14
Γ3,0.5
Γ0.5,0.5
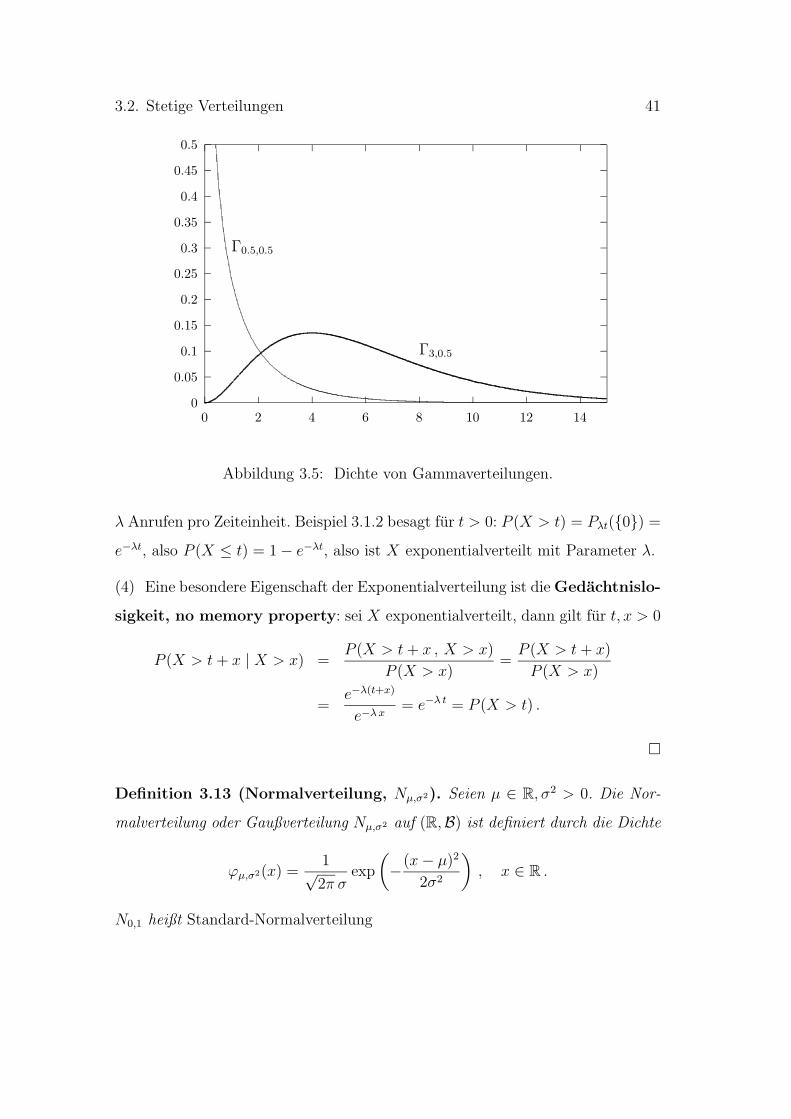
Abbildung 3.5: Dichte von Gammaverteilungen.
λ Anrufen pro Zeiteinheit. Beispiel 3.1.2 besagt fur t > 0: P (X > t) = Pλt(0) =
e−λt, also P (X ≤ t) = 1 − e−λt, also ist X exponentialverteilt mit Parameter λ.
(4) Eine besondere Eigenschaft der Exponentialverteilung ist die Gedachtnislo-
sigkeit, no memory property: sei X exponentialverteilt, dann gilt fur t, x > 0
P (X > t + x | X > x) =P (X > t + x , X > x)
P (X > x)=
P (X > t + x)
P (X > x)
=e−λ(t+x)
e−λ x= e−λ t = P (X > t) .
¤
Definition 3.13 (Normalverteilung, Nµ,σ2). Seien µ ∈ R, σ2 > 0. Die Nor-
malverteilung oder Gaußverteilung Nµ,σ2 auf (R,B) ist definiert durch die Dichte
ϕµ,σ2(x) =1√2π σ
exp
(−(x − µ)2
2σ2
), x ∈ R .
N0,1 heißt Standard-Normalverteilung

42 3. Stochastische Standardmodelle
0.1/σ
0.2/σ
0.3/σ
0.4/σ
µ − 3σ µ − 2σ µ − σ µ µ + σ µ + 2σ µ + 3σ
Gaußsche Glockenkurve
Abbildung 3.6: Dichte der Nµ,σ2-Verteilung.
Bemerkung 3.14. (1) Es gilt (mit der Substitutionsregel aus der Analysis:
x2 + y2 = r2)(∫
R
e−x2
2 dx
)2
=
∫
R
∫
R
e−x2+y2
2 dy dx
=
∫ 2π
0
∫ ∞
0
re−r2
2 dr dϕ =[−2πe−
r2
2
]∞r=0
= 2π .
Setzt man y = x−µσ
, so folgt damit
∫
R
ϕµ,σ2(x)dx =1√2π
∫
R
e−y2
2 dy = 1 ,
also ist Nµ,σ2 wohldefiniert nach Satz 1.17.
(2) Wegen des Zentralen Grenzwertsatzes (Satz 5.12) sind Summen vie-
ler unabhangiger Zufallsvariablen oft approximativ normalverteilt. Daher ist die
Normalverteilung die wichtigste Verteilung uberhaupt.

3.2. Stetige Verteilungen 43
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
-4 -3 -2 -1 0 1 2 3 4
Abbildung 3.7: Verteilungsfunktion Φ der Standardnormalverteilung N0,1.
Bemerkung 3.15. Literaturhinweise:
(1) Johnson, N.L. and Kotz, S. (1970) Distributions in Statistics. Continuous
Univariate Distributions, Vol. I & II. Wiley, New York.
(2) Johnson, N.L. and Kotz, S. (1970) Distributions in Statistics. Continuous
Multivariate Distributions. Wiley, New York.
(3) Johnson, N.L., Kotz, S. and Kemp, A.W. (1992) Univariate Discrete Dis-
tributions, 2nd edition. Wiley, New York.
(4) Gradshteyn, I.S. and Ryshik, I.M. (1080) Table of Integrals, Series, and
Products. Academic Press, New York.

44 3. Stochastische Standardmodelle

Kapitel 4
Momente und Quantile
4.1 Lageparameter
Der Erwartungswert von Zufallsvariable entspricht dem arithmetischen Mittel
von Stichproben.
Definition 4.1 (Erwartungswert). Sei X eine diskrete Zufallsvariable (d.h.
X(Ω) ⊂ R ist abzahlbar).
(1) Man schreibt X ∈ L1, falls∑
x∈X(Ω)
|x|P (X = x) < ∞.
(2) Falls X ∈ L1, heißt E(X) =∑
x∈X(Ω)
xP (X = x) Erwartungswert von X.
Bemerkung 4.2. (1) E(X) hangt nur von der Verteilung PX , nicht von der
Abbildung X : Ω → R selbst ab.
(2) Fur nichtnegative diskrete Zufallsvariable kann E(X) immer definiert werden
(ggf. als ∞), auch wenn X ∈ L1 nicht gilt.
(3) Fur A ∈ F gilt E(1A) = 0 · P (1A = 0) + 1 · P (1A = 1) = P (A).
45

46 4. Momente und Quantile
Beispiel 4.3. [Einfacher Wurfelwurf]
(Ω,F , P ) = (1, . . . , 6,P(Ω), UΩ), X : Ω → R mit ω 7→ ω.
E(X) =6∑
i=1
iP (X = i) =1
6
6∑
i=1
i = 3.5 .
Satz 4.4 (Transformationssatz). Sei Ω abzahlbar, X : Ω → R eine Zufallsva-
riable.
(1) X ∈ L1 ⇐⇒ ∑ω∈Ω
|X(ω)|P (ω) < ∞.
(2) Im Fall X ∈ L1 ist E(X) =∑ω∈Ω
X(ω)P (ω).
Beweis. (1)∑ω∈Ω
|X(ω)|P (ω) =∑
x∈X(Ω)
|x| ∑ω∈X=x
P (ω) =∑
x∈X(Ω)
|x|P (X = x).
(2) ebenso ohne Betrage. ¤
Satz 4.5 (Rechenregeln). Seien X,Y,X1, X2, . . . : Ω → R diskrete Zufallsva-
riable in L1 und c ∈ R. Dann gelten
(1) Monotonie: X ≤ Y ⇒ E(X) ≤ E(Y ).
(2) Linearitat: X + Y ∈ L1 und E(X + Y ) = E(X) + E(Y );
cX ∈ L1 und E(cX) = cE(X) (insbesondere gilt E(c) = c).
(3) Monotone Konvergenz: 0 ≤ Xn ↑ X fur n → ∞⇒ E(Xn) ↑ E(X) fur n → ∞.
(4) Produktregel bei Unabhangigkeit: XY unabhangig
⇒ X,Y ∈ L1 und E(XY ) = E(X)E(Y ).
Beweis. (1) E(X) =∑
x∈X(Ω)
xP (X = x) =∑
x∈X(Ω)y∈Y (Ω)
xP (X = x, Y = y)︸ ︷︷ ︸=0 falls x>y
≤ ∑x∈X(Ω)y∈Y (Ω)
yP (X = x, Y = y) = . . . = E(Y ).
(2)∑
y∈cX(Ω)
|y|P (cX = y)y=cx=
∑x∈X(Ω)
|cx|P (cX = cx)
= |c| ∑x∈X(Ω)
|x|P (X = x) < ∞ fur c 6= 0.

4.1. Erwartungswert und Varianz 47
Ebenso: E(cX) = cE(X).
∑
z∈(X+Y )(Ω)
|z|P (X + Y = z) =∑
z∈(X+Y )(Ω)x∈X(Ω)
|z|P (X = x, Y = z − x)
=∑
z∈(X+Y )(Ω)x∈X(Ω)
|x + y| P (X = x, Y = y)︸ ︷︷ ︸6=0 nur fur y=z−x∈Y (Ω)
=∑
y∈Y (Ω)x∈X(Ω)
|x + y|P (X = x, Y = y)
≤∑
x∈X(Ω)
|x|P (X = x) +∑
y∈Y (Ω)
|y|P (Y = y) < ∞ .
Ebenso E(X + Y ) = E(X) + E(Y ).
(3) In Analysis oder Wahrscheinlichkeitstheorie.
(4)
∑
z∈XY (Ω)
|z|P (XY = z) =∑
z∈XY (Ω)0 6=x∈X(Ω)
|z|P (X = x, Y =z
x)
y=z/x=
∑
y∈Y (Ω)0 6=x∈X(Ω)
|xy|P (X = x, Y = y)
=∑
y∈Y (Ω)0 6=x∈X(Ω)
|xy|P (X = x)P (Y = y)
=∑
y∈Y (Ω)
|y|P (Y = y)∑
x∈X(Ω)
|x|P (X = x) .
Ebenso E(XY ) = E(X)E(Y ). ¤
Beispiel 4.6. [Binomialverteilung] Sei X Bn,p-verteilt (vgl. Def. 3.5).
E(X) =n∑
k=0
k
(n
k
)pk(1−p)n−k =
n∑
k=1
np
(n − 1
k − 1
)pk−1(1−p)n−k = np
n−1∑
k=0
Bn−1,p(k)
︸ ︷︷ ︸=1
= np .
Frage: Wie definiert man E(X) fur allgemeine Zufallsvariable (stetige oder
diskrete reelle)?
Definition 4.7 (Erwartungswert von beliebigen reellen Zufallsvariable).
Sei X eine reelle Zufallsvariable.

48 4. Momente und Quantile
(1) Im Falle X ≥ 0 definiert E(X) = limn→∞
E(Xn) fur eine Folge diskreter
Zufallsvariablen X1, X2 . . . mit Xn ↑ X.
(2) Fur beliebiges X schreibe X ∈ L1, falls E(|X|) < ∞.
(3) Im Fall X ∈ L1 definiere E(X) = E(X+) − E(X−), wobei x+ = max(x, 0)
und x− = max(−x, 0) Positiv- und Negativteil von x ∈ R sind.
Bemerkung 4.8. (1) E(X) ist wohldefiniert (vgl. Wahrscheinlichkeitstheorie).
Man schreibt auch E(X) =∫
XdP (Integral nach dem W’maß P )
(2) Bem. 4.2 und Satz 4.5 gelten weiterhin.
Satz 4.9. Sei X eine Rn-wertige Zufallsvariable mit Dichte ρ und f : Rn → R
sei messbar. Dann gilt
f X ∈ L1 ⇐⇒∫
Rn
|f(x)|ρ(x)dx < ∞ .
In diesem Fall gilt
E(f X) =
∫
Rn
f(x)ρ(x)dx .
Beweis. Wahrscheinlichkeitstheorie. ¤
Bemerkung 4.10. Insbesondere ist E(X) =∫
Rxρ(x)dx, falls X die Dichte ρ
besitzt.
Beispiel 4.11. Sei X U(a,b)-verteilt (vgl. Bsp. 1.18(b)) mit a < b.
E(X) =
∫x1(a,b)(x)
1
λ((a, b))dx =
∫ b
a
x1
b − adx =
1
2
b2 − a2
b − a=
a + b
2.
E(X) ist ein Lageparameter von X. Man kennt noch weitere Lageparameter.
Definition 4.12 (Quantilfunktion). Sei F : R → [0, 1] die Verteilungsfunktion
einer Zufallsvariable X oder einer Verteilung Q auf (R,B). Dann heißt
F← : (0, 1) → R mit p 7→ infx ∈ R : F (x) ≥ p verallgemeinerte Inverse oder
Quantilfunktion von F oder Q.

4.1. Erwartungswert und Varianz 49
Bemerkung 4.13. (1) F← ist linksseitig stetig.
(2) F← = F−1|(0,1), falls F streng monoton steigend und stetig ist.
(3) F←(p) ≤ t ⇐⇒ p ≤ F (t) fur alle t ∈ R, p ∈ (0, 1).
Definition 4.14 (Median, α-Quantil). Sei F die Verteilungsfunktion einer
Zufallsvariablen X oder einer Verteilung Q auf (R,B).
(1) Jede Zahl m ∈ [F←(12), F←(1
2+)] heißt Median von X bzw. Q, wobei
F←(p+) := limq↓p F←(q) ist.
(2) Fur α ∈ (0, 1) heißt jede Zahl q ∈ [F←(α), F←(α+)] α-Quantil von X bzw.
Q.
Bemerkung 4.15. (1) q ist α-Quantil von X ⇐⇒P (X ≤ q) ≥ α und P (X ≥ q) ≥ 1 − α.
(2) 12-Quantile sind Mediane, 1
4- und 3
4-Quantile heißen untere bzw. obere Quar-
tile.
(3) Das Intervall zwischen 14- und 3
4-Quantil nennt man Interquartilsabstand
(inter quartile range).
Beispiel 4.16. [Median der Exponentialverteilung] Sei X exponentialverteilt mit
Parameter λ > 0 (Bsp. Lebensdauer eines radioaktiven Teilchens).
E(X) =
∫ ∞
0
xλe−λxdx =[−xe−λx
]∞x=0
+
∫ ∞
0
e−λxdx = 0 −[
1
λe−λx
]∞
x=0
=1
λ,
FX(u) = P (X ≤ u) =
∫ u
0
λe−λxdx = 1 − e−λu , also F←(p) = −1
λlog(1 − p) ,
also ist der eindeutige Median von X: m = − 1λ
log(12) = 1
λlog 2 (Halbwertzeit).
Definition 4.17 (Modus). Sei X eine Zufallsvariable deren Verteilung die
Zahldichte oder Lebesguedichte f hat. Falls f ein globales Maximum bei x0 ∈ R
hat, heißt sie unimodal und x0 heißt Modus oder Modalwert von X.

50 4. Momente und Quantile
4.2 Streuungsparameter
Definition 4.18 (p-tes Moment). Sei X Zufallsvariable, p ∈ [1,∞). Man
schreibt X ∈ Lp, falls |X|p ∈ L1 (d.h. falls E(|X|p) < ∞). Fur X ∈ Lp heißt
E(Xp) p-tes Moment von X.
Bemerkung 4.19. Fur 1 ≤ p ≤ q gilt Lq ⊂ Lp, denn |X|p ≤ 1 + |X|q.
Definition 4.20. Seien X,Y ∈ L2.
(1) Var(X) := E((X − E(X))2) heißt Varianz von X, σX =√
Var(X) heißt
Standardabweichung oder Streuung von X.
(2) Kov(X,Y ) := E((X − E(X))(Y − E(Y ))) heißt Kovarianz von X und Y .
(3) Im Falle σX , σY 6= 0 heißt ρX,Y =Kov(X,Y )
σXσY
Korrelationskoeffizient von X
und Y .
(4) X,Y heißen unkorreliert, falls Kov(X,Y ) = 0 ist.
Bemerkung 4.21. (1) Kov(X,Y ) ist definiert, denn fur alle X,Y ∈ L2 gilt
E(|(X−E(X))(Y −E(Y ))|) ≤ E(|XY |)+E(|E(X)Y |)+E(|XE(Y )|)+E(|E(X)E(Y )|)
≤ E(|XY |) + 3E(|X|)E(|Y |) ≤ E(X2 + Y 2) + 3E(|X|)E(|Y |) < ∞ (4.1)
(2) Var(X), σX hangen nur von PX ab (vgl. Bem. 4.2).
Satz 4.22 (Rechenregeln). Seien X,Y,X1, . . . , Xn ∈ L2, a, b, c, d ∈ R.
(1) Var(X) = E(X2) − (E(X))2
(2) Kov(X,Y ) = E(XY ) − E(X)E(Y )
(3) aX +b, cY +d ∈ L2 und Kov(aX +b, cY +d) = ac Kov(X,Y ), insbesondere
Var(aX + b) = a2Var(X).
(4) (E(XY ))2 ≤ E(X2)E(Y 2) (Ungleichung von Cauchy-Schwarz),
insbesondere (Kov(X,Y ))2 ≤ Var(X)Var(Y ).

4.2. Streuungsparameter 51
(5)n∑
i=1
Xi ∈ L2 und Var(n∑
i=1
Xi) =n∑
i=1
Var(Xi) +n∑
i,j=1i6=j
Kov(Xi, Xj).
Falls X1, . . . , Xn paarweise unkorreliert sind, gilt
Var(n∑
i=1
Xi) =n∑
i=1
Var(Xi) Gleichung von Bienayme .
(6) X,Y unabhangig ⇒ X,Y unkorreliert.
Beweis. (1) folgt aus (2).
(2) Kov(X,Y ) = E((X − E(X))(Y − E(Y )))
= E(XY ) − E(X)E(Y ) − E(X)E(Y ) + E(X)E(Y ) = E(XY ) − E(X)E(Y ).
(3) E((aX + b)2) = a2E(X2) + 2abE(X) + b2 < ∞.
Kov(aX + b, cY + d) = E(a(X − E(X))c(Y − E(Y ))) = ac Kov(X,Y ).
(4) 1. Fall: E(X2) = 0.
Dann gilt P (|X| > ε) = 0 fur alle ε > 0; denn ε21|X|>ε ≤ |X|2
⇒ ε2P (|X| > ε) = E(ε21|X|>ε) ≤ E(|X|2) = 0,
also gilt P (X 6= 0) = 0 (Stetigkeit von oben), also E(XY ) = 0.
2. Fall: E(X2) 6= 0.
Fur beliebiges λ ∈ R gilt 0 ≤ E((λX − Y )2) = λ2E(X2) − 2λE(XY ) + E(Y 2).
Fur λ =E(XY )
E(X2)folgt 0 ≤ (E(XY ))2
E(X2)− 2
(E(XY ))2
E(X2)+ E(Y 2),
also (E(XY ))2 ≤ E(X2)E(Y 2).
(5) o.B.d.A. ist E(Xi) = 0 (wegen (3)).
Var(n∑
i=1
Xi) = E((n∑
i=1
Xi)2) = E(
n∑
i,j=1
XiXj) =n∑
i,j=1
E(XiXj) =n∑
i,j=1
Kov(Xi , Xj);
das beendet den Beweis, da Var(Xi) = Kov(Xi , Xi).
(6) Satz 4.5(4). ¤
52 4. Momente und Quantile
Beispiel 4.23. [Binomialverteilung] Sei X Bn,p-verteilt, vgl. Bsp. 4.6.
E(X2) =n∑
k=0
k2
(n
k
)pk(1 − p)n−k
= np
n∑
k=1
k
(n − 1
k − 1
)pk−1(1 − p)n−k
= npn−1∑
k=0
(k + 1)
(n − 1
k
)pk(1 − p)n−k−1
= np
n−1∑
k=0
k
(n − 1
k
)pk(1 − p)n−k−1
︸ ︷︷ ︸Bsp.4.6
= (n−1)p
+np
n−1∑
k=0
(n − 1
k
)pk(1 − p)n−k−1
= np((n − 1)p + 1) ,
also Var(X) = E(X2) − (E(X))2 Bsp.4.6= (np)2 − np2 + np − (np)2 = np(1 − p).
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0 2 4 6 8 10 12
LNµ,σ2
µ = 1 , σ = 0.5
Abbildung 4.1: Dichte der Lognormalverteilung LNµ,σ2 .
Satz 4.24. Seien X,Y ∈ L2 mit σX , σY 6= 0.
(1) ρXY ∈ [−1, 1],
(2) ρXY = ±1 ⇔ Es existieren a ∈ R, b ∈ (0,∞) mit P (Y = a ± bX) = 1.

4.2. Streuungsparameter 53
Verteilung Zahldichte Erwartungswert Varianz
Uniform auf 1, . . . , n ρ(i) =1
n, i = 1, . . . , n
n + 1
2
(n − 1)(n + 1)
12
Bernoulli B1,p ρ(1) = p = 1 − ρ(0) p p(1 − p)
0 < p < 1
Binomial B(n, p) ρ(i) =(
ni
)pi(1 − p)n−i, np np(1 − p)
0 < p < 1, n ∈ N i = 0, 1, ..., n
Hypergeometrisch Hn,s,w ρ(i) =
(si
)(w
n−i
)(
s+wn
) ns
s + w
nsw (s + w − n)
(s + w)2(s + w − 1)
n ∈ N, s, w ∈ N, s + w ≥ n i ∈ 0, . . . , n bzw. N0
Poisson ρ(i) = e−λ λi
i!, i ∈ N0 λ λ
Poiλ, λ > 0
Pascal Br,p ρ(i) =(
k+r−1k
)pr(1 − p)k r
p− r
r(1 − p)
p2
0 < p < 1, r ∈ N i ∈ N0
Geometrisch ρ(i) = p(1 − p)i, i ∈ N01 − p
p
1 − p
p2
Gp, 0 < p < 1
Tabelle 4.1: Wichtige diskrete Verteilungen. Zur Berechnung von Erwartungswert und
Varianz kann man auch Satz 4.32 benutzen.
Beweis. (1) Satz 4.22(4).
(2) “⇐” Kov(X,Y ) = Kov(X, a ± bX)Satz4.22(2)
= ±b Kov(X,X) = ±bVar(X).
“⇒” Fur X = X − E(X), Y = Y − E(Y ) gilt (E(XY ))2 = E(X2)E(Y 2).
Wie in der Rechnung im Beweis von Satz 4.22(4) gilt also
0 = E((λX − Y )2) fur λ =E(XY )
E(X2)= ρXY
σY
σX
, also P (λX − Y 6= 0) = 0 (vgl.
Beweis von Satz 4.22(4), Fall 1). Wegen P (λX− Y 6= 0) = P (Y 6= λX−λE(X)+
E(Y )) folgt die Behauptung. ¤

54 4. Momente und Quantile
Verteilung Lebesguedichte Erwartungswert Varianz
Normal Nµ,σ2 f(x) =1√2π σ
exp(− (x − µ)2
2σ2
)µ σ2
µ ∈ R, σ2 > 0
Uniform f(x) =1
(b − a)1(a,b)(x)
a + b
2
(b − a)2
12
U(a, b), a < b
Exponential f(x) = λ e−λx 1(0,∞)(x)1
λ
1
λ2
Eλ, λ > 0
Gamma f(x) =αr
Γ(r)xr−1 e−αx 1(0,∞)(x)
r
α
r
α2
Γα,r, r, α > 0
Cauchy f(x) =a
π(a2 + x2)existiert nicht existiert nicht
Ca, a > 0
Pareto f(x) =α
c
( c
x
)α+1
1(c,∞)(x)α c
α − 1
α c2
(α − 1)2(α − 2)
Pα, α, c > 0 falls α > 1 falls α > 2
Lognormal LNµ,σ2 f(x) =1√
2π σxexp
(− (ln x − µ)2
2σ2) eµ+σ2/2 e2 µ+σ2
(eσ2 − 1
)
µ ∈ R, σ2 > 0 1(0,∞)(x)
Tabelle 4.2: Wichtige stetige Verteilungen.
Bemerkung 4.25. Achtung: X,Y sind unkorreliert 6⇒ X,Y unabhangig.
Sei z.B. X Zufallsvariable mit symmetrischer Dichte f (d.h. f(x) = f(−x)) und
definiere Y = X2. Dann gilt
−E(X) = E(−X) =
∫ ∞
−∞−xf(x)dx
y:=−x=
∫ ∞
−∞yf(−y)dy =
∫ ∞
−∞yf(y)dy = E(X) ,
also E(X) = 0. Analog E(X3) = 0. Folglich gilt
Kov(X,Y ) = E(X3) − E(X)E(X2) = 0 ⇒ X,Y unkorreliert, aber ,
P (|X| > 1) = P (|X| > 1, Y > 1) 6= P (|X| > 1)P (Y > 1) = (P (|X| > 1))2 ,
falls P (|X| > 1) ∈ (0, 1). Folglich sind X,Y nicht notwendigerweise unabhangig.

4.2. Streuungsparameter 55
Definition 4.26 (Variationskoeffizient, Schiefe, Kurtosis).
Fur eine Zufallsvariable X ∈ L2 mit E(X) > 0 heißt
CV :=
√Var(X)
E(X)Variationskoeffizient (coefficient of variation).
Fur eine Zufallsvariable X ∈ L4 mit Var(X) 6= 0 heißen
γ3 :=E [(X − E(X))3]
(Var(X))3/2Schiefe (skewness)
δ4 :=E [(X − E(X))4]
(Var(X))2− 3 Kurtosis, Wolbung
Beispiel 4.27. [Momente der Normalverteilung]
Sei X Nµ,σ2-verteilt.
E(X) =
∫ ∞
−∞x
1√2πσ2
exp
(−(x − µ)2
2σ2
)dx
y=x−µ=
∫ ∞
−∞y
1√2πσ2
exp
(− y2
2σ2
)dy
︸ ︷︷ ︸0 da ungerade
+µ
∫ ∞
−∞
1√2πσ2
exp
(− y2
2σ2
)dy
︸ ︷︷ ︸1
= µ
αp := E((X − µ)p) =
∫ ∞
−∞yp 1√
2πσ2exp
(− y2
2σ2
)dy p-tes zentriertes Moment
Falls p ungerade ist, ist der Integrand ungerade, also αp = 0.
Fur p > 1 gerade folgt mit partieller Integration
αp =
∫ ∞
−∞yp−1y
1√2πσ2
exp
(− y2
2σ2
)dy
=1√
2πσ2
([−yp−1σ2 exp
(− y2
2σ2
)]∞
y=−∞+
∫ ∞
−∞(p − 1)yp−2σ2 exp
(− y2
2σ2
)dy
)
= σ2(p − 1)1√
2πσ2
∫ ∞
−∞yp−2 exp
(− y2
2σ2
)dy = σ2(p − 1)αp−2 .
Also gilt αp = σp(p − 1)(p − 3) · · · 3 · 1 fur p gerade (denn α0 = 1).
Insbesondere folgt Var(X) = σ2 und δ4 =3σ4
(σ2)2− 3 = 0.

56 4. Momente und Quantile
4.3 Momente Multivariater Zufallsvariablen
Definition 4.28 (Erwartungswertvektor, Kovarianzmatrix).
Sei X = (X1, . . . , Xn) eine Rn-wertige Zufallsvariable.
(1) Falls X1, . . . , Xn ∈ L1, heißt E(X) = (E(X1), . . . , E(Xn)) ∈ Rn Erwar-
tungswert(vektor) von X.
(2) Falls X1, . . . , Xn ∈ L2, ist die Kovarianzmatrix Kov(X) ∈ Rn×n definiert
durch Kov(X)ij := Kov(Xi, Xj) fur alle 1 ≤ i, j ≤ n.
Satz 4.29. Sei X eine Rn-wertige Zufallsvariable, A ∈ Rm×n, b ∈ Rm.
(1) Falls X1, . . . , Xn ∈ L1, ist E(AX + b) = AE(X) + b.
(2) Falls X1, . . . , Xn ∈ L2, ist Kov(AX + b) = A Kov(X)A⊤.
(3) Falls X1, . . . , Xn ∈ L2, ist Kov(X) symmetrisch und positiv semidefinit.
Beweis. (1) Folgt aus Satz 4.5(2).
(2) Kov(AX + b)ij = Kov(∑n
k=1 AikXk + bi,∑n
l=1 AjlXl + bj)
=∑n
k,l=1 AikAjlKov(Xk, Xl) = (A Kov(X)A⊤)ij.
(3) a⊤Kov(X)a(2)= Kov(a⊤X) = Var(a⊤X) ≥ 0 fur a ∈ Rn
⇒ positiv semidefinit. ¤
4.4 Erzeugende Funktionen
Fur konkrete Berechnungen sind erzeugende Funktionen sehr nutzlich.
Definition 4.30 (Erzeugende Funktion). Sei P ein Wahrscheinlichkeitsmaß
auf (N0,P(N0)) mit Zahldichte ρ. Die Funktion ϕρ : [0, 1] → R, mit
ϕρ(s) =∞∑
k=0
ρ(k)sk
heißt erzeugende Funktion (wahrscheinlichkeitserzeugende Funktion, generating
function) von P .

4.4. Erzeugende Funktionen 57
Bemerkung 4.31. (1) Wegen∑∞
k=0 ρ(k) = 1 ist ϕρ endlich und auf [0, 1)
unendlich oft differenzierbar.
(2) Wenn X eine N0-wertige Zufallsvariable ist, nennt man auch ϕρ = ϕX
erzeugende Funktion von X und es gilt
ϕX(s) =∞∑
k=0
P (X = k)sk = E(sX) , s ∈ [0, 1] .
Verteilung Zahldichte Erzeugende Funktion
Uniform auf 1, . . . , n ρ(i) =1
nϕ(s) =
1
n(s + s2 + · · · + sn)
Bernoulli B1,p ρ(1) = p = 1 − ρ(0) ps + (1 − p)
0 < p < 1
Binomial Bn,p ρ(i) =(
ni
)pi(1 − p)n−i, ϕ(s) =
n∑k=0
(nk
)pk(1 − p)n−ksk
0 < p < 1, n ∈ N i = 0, 1, ..., n = (ps + (1 − p))n
Poisson Poiλ ρ(i) = e−λ λi
i!, i ∈ N0 ϕ(s) =
∞∑k=0
e−λ λk
k!sk
λ > 0 = e−λ(1−s)
Geometrisch Gp ρ(i) = p(1 − p)i, i ∈ N0p
1 − (1 − p)s
0 < p < 1
Pascal Br,p ρ(i) =(
i+r−1i
)pr(1 − p)i, i ∈ N0 ρ(s) =
∞∑k=0
(−rk
)pr(−(1 − p))ksk
0 < p < 1, r ∈ N i ∈ R0 =
(p
1 − (1 − p)s
)r
Tabelle 4.3: Erzeugende Funktionen wichtiger diskreter Verteilungen.
Satz 4.32. (1) Sei P eine Verteilung auf N0 mit Zahldichte ρ. Dann gilt
ρ(k) =1
k!ϕ(k)(0) fur k ∈ N0, insbesondere ist P durch ϕ eindeutig bestimmt.
(2) Sei X eine N0-wertige Zufallsvariable. Dann gilt
(a) X ∈ L1 ⇔ ϕ′X(1−) = lims↑1 ϕ′
X(s) existiert.
In diesem Fall ist E(X) = ϕ′X(1−) = ϕ′
X(1).

58 4. Momente und Quantile
(b) X ∈ L2 ⇔ ϕ′′X(1−) = lims↑1 ϕ′′
X(s) existiert.
In diesem Fall ist Var(X) = ϕ′′X(1) − (ϕ′
X(1))2 + ϕ′X(1).
Beweis. (1) Analysis, z.B. Heuser, Analysis I, 64.2.
(2) (a)
lims↑1
∞∑
k=0
ρ(k)k−1∑
j=0
sj
︸ ︷︷ ︸= (Monotonie)
= lims↑1
∞∑
k=0
ρ(k)1 − sk
1 − s= lim
s↑1
ϕX(1) − ϕX(s)
1 − s= ϕ′
X(1) (ggf. ∞)
sups<1
supn∈N
n∑
k=0
ρ(k)k−1∑
j=0
sj = supn∈N
n∑
k=0
ρ(k)k =∞∑
k=1
ρ(k)k
= lims↑1
∞∑
k=1
ρ(k)ksk−1 = lims↑1
ϕ′X(s)
(b) Analog zu (a) folgt
lims↑1
ϕ′X(1) − ϕ′
X(s)
1 − s=
∞∑
k=0
ρ(k)k(k − 1) (ggf. ∞) .
Insbesondere gilt fur X ∈ L2: ϕ′′X(1) = E(X2−X) = Var(X)+(E(X))2−E(X).
¤
Beispiel 4.33. [Poisson Verteilung]
X sei Poiλ-verteilt fur λ > 0. Dann gilt
E(X) =d
dse−λ(1−s)
∣∣s=1
= λ ,
Var(X) =d2
ds2e−λ(1−s)
∣∣s=1
− λ2 + λ = λ .
Satz 4.34. Seien X,Y unabhangige N0-wertige Zufallsvariable. Dann gilt
ϕX+Y (s) = ϕX(s)ϕY (s) , s ∈ [0, 1] .
Beweis. ϕX+Y (s) = E(sX+Y ) = E(sXsY )Bem.2.37
= E(sX)E(sY ) = ϕX(s)ϕY (s). ¤

4.4. Erzeugende Funktionen 59
Beispiel 4.35. Man kann Satz 4.34 auch umformulieren.
Seien P1, P2 Wahrscheinlichkeitsmaße auf N0, dann gilt ϕP1∗P2 = ϕP1ϕP2 .
Damit erhalt man sofort aus Tabelle 4.3:
(1) Bm,p ∗ Bn,p = Bm+n,p.
(2) Poiλ1 ∗ Poiλ2 = Poiλ1+λ2 .
(3) Br,p ∗ Bs,p = Br+s,p.
Bemerkung 4.36. Ausblick: Bei allgemeinen Zufallsvariablen verwendet man
statt der erzeugenden Funktion die eng verwandte momenterzeugende Funk-
tion oder Laplace Transformierte, definiert durch s 7→ E(esX). Unter Umstanden
ist es praktischer, die Fourier Transformierte, charakteristische Funktion,
definiert durch s 7→ E(eisX) zu verwenden (Wahrscheinlichkeitstheorie). Diese
haben ahnliche Eigenschaften wie die erzeugende Funktion:
• Sie charakterisieren die Verteilung.
• Durch Ableiten (in 0) erhalt man die Momente.
• Unabhangige Summen (Faltung) fuhren zum Produkt der Transformierten.

60 4. Momente und Quantile

Kapitel 5
Grenzwertsatze
5.1 Gesetze der großen Zahlen
Die Gesetze der großen Zahlen besagen, dass bei haufiger unabhangiger Ver-
suchswiederholung das arithmetische Mittel der Daten gegen den Erwartungswert
der Verteilung konvergiert (bzw. die relative Haufigkeit gegen die entsprechende
Wahrscheinlichkeit).
Frage: Konvergenz in welchem Sinne?
Definition 5.1 (Stochastische Konvergenz, fast sichere Konvergenz).
Seien X,X1, X2, . . . : (Ω,F , P ) → (R,B) Zufallsvariable.
(1) (Xn)n∈N konvergiert stochastisch oder in Wahrscheinlichkeit gegen X, falls
limn→∞
P (|Xn − X| ≤ ε) = 1 ∀ε > 0 .
Schreibweise: XnP→ X.
(2) (Xn)n∈N konvergiert P -fast sicher gegen X, falls
P ( limn→∞
Xn = X) = 1 .
Schreibweise: Xn → X P -f.s. oder limn→∞ Xn = X P -f.s..
61

62 5. Grenzwertsatze
Bemerkung 5.2. Es gilt: Xn → X P -f.s. ⇒ XnP→ X.
Der Beweis folgt in der Wahrscheinlichkeitstheorie.
In dieser Vorlesung betrachten wir nur stochastische Konvergenz.
Satz 5.3 (Markov-Ungleichung). Sei X eine Zufallsvariable und f : R+ → R+
monoton wachsend mit f(x) > 0 fur x > 0. Dann gilt
P (|X| ≥ ε) ≤ E(f(|X|))f(ε)
∀ε > 0 .
Beweis. E(f(|X|)) ist definiert, da f(|X|) ≥ 0. Es ist f(ε)1|X|≥ε ≤ f(|X|),also gilt
f(ε)P (|X| ≥ ε)Bem.4.2(3)
= E(f(ε)1|X|≥ε)Monotonie
≤ E(f(|X|)) .
¤
Korollar 5.4 (Tschebyschov-Ungleichung). Fur X ∈ L2 und ε > 0 gilt
P (|X − E(X)| > ε) ≤ Var(X)
ε2.
Beweis. Satz 5.3 fur X ′ := X − E(X) und f(x) = x2. ¤
Bemerkung 5.5. Fur den Namen des russischen Mathematikers Cebysev sind
viele Transliterationen gebrauchlich. Bei Schreibweisen wie Tschebyscheff sollte
man bedenken, dass im russischen Original das letzte ’e’ wie ein ’o’ gesprochen
wird.
Satz 5.6 (Schwaches Gesetz der großen Zahlen). Seien X,X1, X2, . . . un-
abhangige, identisch verteile Zufallsvariable in L2. Dann gilt
1
n
n∑
i=1
XiP→ E(X) , n → ∞ .
Beweis. Fur Yn := 1n
∑ni=1 Xi gilt E(Yn)
Linearitat= 1
n
∑ni=1 E(Xi) = E(X) und
Var(Yn)Unabh.
= 1n2
∑ni=1 Var(Xi) = 1
nVar(X). Nach Korollar 5.4 gilt
P (| 1n
n∑
i=1
Xi − E(X)| > ε) = P (|Yn − E(Yn)| > ε) ≤ Var(X)
nε2→ 0 n → ∞ .
¤

5.2. Zentraler Grenzwertsatz 63
Tschebyschov N(µ, σ2)
t P (|X − µ| < tσ) ≥ 1 − 1/t2 P (|X − µ| < tσ) = 2Φ(t) − 1
1 0 0.6826
2 0.7500 0.9546
3 0.8889 0.9974
4 0.9375 1 − 6 · 10−5
5 0.9600 1 − 7 · 10−7
Tabelle 5.1: Schranken mittels Tschebyschov-Ungleichung im Vergleich zum ex-
akten Wert fur eine normalverteilte Zufallsvariable.
Bemerkung 5.7. (1) Statt ”unabhangig” reicht ”paarweise unkorreliert” in
Satz 5.6 (mit demselben Beweis).
(2) Satz 5.6 gilt sogar mit fast sicherer Konvergenz und heißt dann
starkes Gesetz der großen Zahlen (Wahrscheinlichkeitstheorie).
(3) Konkrete Abschatzungen erhalt man z.B. mit der Ungleichung von Tsche-
byschow; sie sind jedoch meist sehr grob; vgl. Tabelle 5.1.
5.2 Zentraler Grenzwertsatz
Seien X,X1, X2, . . . unabhangige, identisch verteilte Zufallsvariable in L2 und
Sn =∑n
i=1 Xi fur n ∈ N.
Frage: Wie ist Sn fur große n verteilt?
Konvergieren die Verteilungen irgendwie fur n → ∞?
Beachte: E(Sn) =∑n
i=1 E(Xi) = nE(X) und Var(Sn) =∑n
i=1 Var(Xi) =
nVar(X).
Konsequenz: Man muss zunachst standardisieren.
Definiere die standardisierte Summenvariable
S∗n =
Sn − E(Sn)√Var(Sn)
, n ∈ N . (5.1)

64 5. Grenzwertsatze
Bemerkung 5.8. (1) Wegen der Linearitat des Erwartungswertes und mit
Satz 4.22(3) gilt
E(S∗n) =
1√Var(Sn)
(E(Sn)−E(Sn)) = 0 und Var(S∗n) =
1
(√
Var(Sn))2Var(Sn) = 1 .
(2) Fur unabhangige, identisch verteilte Zufallsvariable X,X1, X2, . . . gilt
S∗n =
Sn − nE(X)√nVar(X)
.
Insbesondere gilt fur B1,p-verteilte Zufallsvariable
S∗n =
Sn − np√np(1 − p)
.
In diesem Fall ist Sn nach dem Beispiel in Definition 3.5 Bn,p-verteilt; vgl. auch
Bsp. 4.35(1), sowie Beispiele 4.6 und 4.23.
Satz 5.9 (Lokale Approximation der Binomialverteilung).
Seien p ∈ (0, 1), q = 1 − p and c > 0. Dann gilt
limn→∞
max
∣∣∣∣Bn,p(k)
ϕnp,npq(k)− 1
∣∣∣∣ :
∣∣∣∣k − np√
npq
∣∣∣∣ ≤ c
= 0 ,
mit Normalverteilungsdichten ϕµ,σ wie in Definition 3.13.
Beweis. Hilfsmittel aus der Analysis: n! ∼√
2πn nne−n fur n → ∞ (Formel von
Stirling); siehe z.B. Heuser, Analysis I, Kap. 96.
(Das Symbol ∼ bedeutet, dass der Quotient gegen 1 konvergiert.)
Definiere xn(k) =k − np√
npq. Sei (kn)n∈N beliebige Folge in N mit
∣∣∣∣kn − np√
npq
∣∣∣∣ ≤ c.
Dann gilt
∣∣∣∣kn
n− np
∣∣∣∣ → 0, |n − kn
n− (1− p)| → 0, also kn → ∞ und n− kn → ∞
fur n → ∞. Somit gilt
Bn,p(kn) =n!
kn!(n − kn)!pknqn−kn
Stirling∼ 1√2π
√n
kn(n − kn)
(np
kn
)kn(
nq
n − kn
)n−kn
, n → ∞ .
Es ist
kn
np= 1 +
xn(kn)√n
√q
pund
n − kn
nq= 1 − xn(kn)√
n
√p
q, (5.2)

5.2. Zentraler Grenzwertsatz 65
also gilt
kn(n − kn)
n= npq
(1 +
xn(kn)√n
√q
p
)(1 − xn(kn)√
n
√p
q
)∼ npq , n → ∞ .
Ferner gilt
log
((kn
np
)kn(
n − kn
nq
)n−kn
)= kn log
(kn
np
)+ (n − kn) log
(n − kn
nq
)
(5.2)= np
(1 +
xn(kn)√n
√q
p
)log
(1 +
xn(kn)√n
√q
p
)
+nq
(1 − xn(kn)√
n
√p
q
)log
(1 − xn(kn)√
n
√p
q
)
Taylor= np
(1 +
xn(kn)√n
√q
p
)(xn(kn)√
n
√q
p− (xn(kn))2
2n
q
p+ O(n−3/2)
)
+nq
(1 − xn(kn)√
n
√p
q
)(−xn(kn)√
n
√p
q− (xn(kn))2
2n
p
q+ O(n−3/2)
)
ausmult.= np
(xn(kn)√
n
√q
p+
(xn(kn))2
2n
q
p+ O(n−3/2)
)
+nq
(−xn(kn)√
n
√p
q+ +
(xn(kn))2
2n
p
q+ O(n−3/2)
)
=(xn(kn))2
2+ O(n−1/2) ,
wobei O(np) eine Folge derart ist, dassO(np)
npeine beschrankte Folge ist.
Zusammen folgt
Bn,p(kn) ∼ 1√2π
1√npq
exp
(−(xn(kn))2
2
)= ϕnp,npq(kn) .
Wahle nun kn so, dass das Maximum in Satz 5.9 bei kn angenommen wird. Damit
folgt die Behauptung. ¤
Das folgende Korollar ist ein zentraler Grenzwertsatz fur Bernoulli Folgen.
Korollar 5.10 (Satz von de Moivre-Laplace). Sei (Xn)n∈N eine Folge un-
abhangiger, identisch verteilter Zufallsvariable mit P (X1 = 1) = p = 1−P (X1 =
0) fur ein p ∈ (0, 1). Fur n ∈ N seien S∗n die zugehorigen standardisierten Sum-
men wie in (5.1). Dann gilt fur alle a, b ∈ [−∞,∞] mit a ≤ b:
limn→∞
P (a ≤ S∗n ≤ b) = Φ(b) − Φ(a) ,

66 5. Grenzwertsatze
wobei Φ die Verteilungsfunktion von N0,1 ist: Φ(x) =1√2π
∫ x
−∞e−
u2
2 du, x ∈ R.
Beweis. Fall 1: Sei −∞ < a < b < ∞. Seien c := max|a|, |b| und ε > 0. Nach
Satz 5.9 existiert ein N ∈ N, so dass fur alle n ≥ N gilt
max
∣∣∣∣ϕnp,npq(k)
Bn,p(k)− 1
∣∣∣∣ : |xn(k)| ≤ c
< ε ,
also gilt∣∣∣∣∣∣P (a ≤ S∗
n ≤ b) −∑
k∈N:a≤xn(k)≤b
ϕ0,1(xn(k))√npq
∣∣∣∣∣∣
=
∣∣∣∣∣∣
∑
k∈N:a≤xn(k)≤bBn,p(k) −
∑
k∈N:a≤xn(k)≤bϕnp,npq(k)
∣∣∣∣∣∣
≤∑
k∈N:a≤xn(k)≤bBn,p(k)
∣∣∣∣1 − ϕnp,npq(k)
Bn,p(k)
∣∣∣∣ ≤ ε .
Ferner gilt
∣∣∣∣∣∣
∫ b
a
ϕ0,1(x)dx −∑
k∈N:a≤xn(k)≤b
ϕ0,1(xn(k))√npq
∣∣∣∣∣∣→ 0 , n → ∞ ,
da die Summe die Riemann-Approximation des Integrals ist (beachte: xn(k+1)−xn(k) = 1/
√npq). Die Behauptung folgt nun aus der Dreiecksungleichung.
Fall 2: Sei a = −∞ (b = ∞ folgt analog).
Sei ε > 0. Nach Satz 2.9(3) gibt es ein c >
√3
ε, so dass Φ(−c) <
3
ε. Nach Fall 1
existiert ein N ∈ N, so dass fur alle n ≥ N gilt |P (−c < S∗n ≤ b) − (Φ(b) − Φ(−c))| <
ε3. Damit gilt
|P (−∞ < S∗n ≤ b) − (Φ(b) − Φ(−∞))|
≤ |P (−∞ < S∗n ≤ b) − P (−c < S∗
n ≤ b) + P (−c < S∗n ≤ b) − Φ(b) + Φ(−c) − Φ(−c)|
≤ P (|S∗n| > c)︸ ︷︷ ︸
Tchebychov≤
Var(S∗n)
c2≤
ε
3
+ε
3+
ε
3≤ ε .
¤

5.2. Zentraler Grenzwertsatz 67
Bemerkung 5.11. (1) Seien X1, X2, . . . wie in Korollar 5.10. Fur ganzzahlige
k, l ist offenbar
P (k ≤ Sn ≤ l) = P (k − 1
2≤ Sn ≤ l +
1
2) .
Die Approximation in Korollar 5.10 ist besser, wenn man mit
a =k − 1
2− np
√npq
und b =l + 1
2− np
√npq
anstelle von a =k − np√
npqund b =
l − np√npq
arbeitet.
(2) Faustregel: Approximation ist in Ordnung fur npq ≥ 9. Fur n groß und p
klein ist der Grenzwertsatz von Poisson aus Satz 3.9 die bessere Alternative.
Eine außerst wichtige und weitreichende Tatsache ist, dass Korollar 5.10 sogar fur
weitgehend beliebige Verteilungen gilt, der Beweis folgt in der Wahrscheinlichkeit
stheorie.
Satz 5.12 (Zentraler Grenzwertsatz). Sei (Xn)n∈N eine Folge von unabhangigen,
identisch verteilten Zufallsvariablen in L2 mit Var(X1) > 0. Seien S∗n die zu-
gehorigen standardisierten Summen aus (5.1). Dann gilt fur alle a, b ∈ [−∞,∞]
mit a ≤ b:
limn→∞
P (a ≤ S∗n ≤ b) = Φ(b) − Φ(a) .
Das fuhrt zu einem neuen Konvergenzbegriff.
Definition 5.13 (Verteilungskonvergenz, schwache Konvergenz).
Seien X,X1, X2, . . . Zufallsvariable mit Verteilungsfunktionen FX , F1, F2, . . .. Man
sagt (Xn)n∈N konvergiert in Verteilung gegen X oder (PXn)n∈N konvergiert schwach
gegen PX , falls
limn→∞
Fn(c) = FX(c) fur alle c ∈ R, in denen FX stetig ist.
Schreibweise: Xnd→ X, Xn
L→ X fur n → ∞.

68 5. Grenzwertsatze
Bemerkung 5.14. (1) In Korollar 5.10 und Satz 5.12, aber auch in Satz 3.9 wird
also Verteilungs- bzw. schwache Konvergenz gezeigt.
(2) Verteilungskonvergenz hangt nur von der Folge der Verteilungen (PXn)n∈N ab.
Die Zufallsvariablen selbst brauchen in keiner Beziehung zueinander zu stehen.
(3) Der ZGWS kann unter weit allgemeineren Voraussetzungen bewiesen werden;
das wird in der Wahrscheinlichkeitstheorie geschehen.
Abbildung 5.1: Approximation der Binomialverteilung durch die Normalvertei-
lung
Abbildung 5.2: Approximation der Binomialverteilung durch die Poissonvertei-
lung

Kapitel 6
Grundlagen der Statistik
6.1 Problemstellungen und Ansatze
Frage: Wie kann man in einer zufalligen Situation aus einzelnen Beobachtungen
Schlussfolgerungen ziehen uber die Art und die Eigenschaften eines Zufallsme-
chanismus.
Beispiel 6.1. [Qualitatskontrolle] Ein Apfelsinen-Importeur erhalt eine Liefe-
rung von N = 10 000 Apfelsinen. Er mochte wissen, wieviele davon faul sind. Da-
zu macht er folgendes Zufallsexperiment. Er nimmt eine Stichprobe von n = 50
Apfelsinen. Von diesen ist eine zufallige Anzahl x faul.
Frage: Welche Ruckschlusse kann man auf die wahre Anzahl w der faulen Oran-
gen ziehen?
Antwort: (1) Naive Schatzung: Man rechnet einfach hoch und setzt an: x/n ≈w/N , d.h. die nachste ganze Zahl zu W (x) := Nx/n Orangen sind faul. In der
Statistik heißt W (x) Schatzfunktion oder Schatzer.
Beachte, dass man bei verschiedenen Stichproben verschiedene Schatzungen erhalt.
(2) Schatzen mit Fehlerangabe: Anstatt eines festen Wertes W (x) gibt man ein
von x abhangiges Intervall C(x) an. Da mit x auch C(x) zufallsbehaftet ist, wahlt
69

70 6. Grundlagen
man C(x) so, dass
Pw(x : w ∈ C(x)) ≈ 1
fur das wahre w und das richtige Wahrscheinlichkeitsmaß Pw. Da der Importeur
die Apfelsinen ohne Zurucklegen zieht, entspricht das Experiment dem Urnenmo-
dell, wo man n Kugeln aus einer Urne mit w weißen und N − w = s schwarzen
Kugeln zieht. Die Anzahl der faulen Apfelsinen in der Stichprobe ist also hyper-
geometrisch verteilt. Das richtige Pw ist also Pw = Hn,w,N−w, der wahre Wert w
ist allerdings unbekannt. Die Eigenschaften von C(x) durfen folglich nicht von w
abhangen. Man fordert also
Hn,w,N−w(x : w ∈ C(x)) ≥ 1 − α
fur alle w ∈ 0, . . . , N und ein (kleines) α > 0. Das Intervall C(x) heißt ein
Konfidenzintervall fur w.
(3) Entscheidungsfindung: Der Importeur hat einen Vertrag, der besagt, dass der
vereinbarte Preis nur gezahlt werden muss, wenn weniger als 5% der Apfelsinen
faul sind. Aufgrund der Stichprobe muss entschieden werden, ob die Qualitat
stimmt und er zahlen muss. Er muss entscheiden zwischen
der “Hypothese” H0 : w ∈ 0, . . . , 500der “Alternativhypothese” H1 : w ∈ 501, . . . , 10 000.
Dazu braucht er ein Entscheidungsverfahren, etwa der Art
x ≤ c ⇒ Entscheidung fur die Hypothese,
x > c ⇒ Entscheidung fur die Alternativhypothese.
Eine solche Entscheidungsregel heißt Test.

6.2. Das statistische Modell 71
6.2 Das statistische Modell
In der Wahrscheinlichkeitsrechnung zieht man Schlussfolgerungen aus einem
gegebenen Modell (Ω,F , P ).
In der Statistik bestimmt man fur ein realistisches Experiment mit Hilfe einer
Stichprobe X1, . . . , Xn das Modell (Ω,F , P ).
Insgesamt stellt die Statistik die Regeln auf und entwickelt Verfahren fur die Er-
hebung, Beschreibung, Analyse und Interpretation von numerischen Daten. Die
Erhebung und Beschreibung wird in der Deskriptiven Statistik vorgenommen
(vgl. Statistikpraktikum), Analyse und Interpretation sind Gegenstand der In-
duktiven Statistik.
Mit der Planung der Untersuchung, der Festlegung eines Stichprobenverfahrens,
der Datenerfassung, - kodierung und -verarbeitung sind Mathematiker eher we-
niger befasst. Unsere Aufgabe beginnt meist danach. Dann dient die deskriptive
Statistik der grafischen Aufbereitung und dem komprimieren der in den Daten
erhaltenen Information. Sie ist außerdem eine unverzichtbare Hilfe bei der Fin-
dung eines adaquaten statistischen Modells. Beschrieben und dargestellt werden
Merkmale oder Variable, die Auspragungen oder Werte haben. Dabei un-
terscheidet man Variable, die beeinflusst werden: Zielgroßen, Response (Variable),
abhangige Variable, endogene Großen; sowie Variable, die beeinflussen: Einfluss-
großen, unabhangige Variable, Kovariable, exogene Großen. Man unterscheidet
Merkmale auch nach ihren Skalentype: metrisch (Zahlenwerte), ordinal (in Rang-
folge geordnet), nominal (keine Struktur).
Beispiel 6.2. (1) Bewertung der 40 großten US Mutual Funds (Investment-
fonds).
Merkmale:
LOAD = Spesenanteil mit Auspragungen

72 6. Grundlagen
LOAD =
1 Spesen ≥ 4.5%
2 Spesen ≤ 4.5%
3 keine
EXPRAT = expense ratio = Kostenverahltnis = Kosten pro durchschnittlichem
Vermogenswert
TYPE = Art des Funds
TYPE =
1 orientiertanKapitalwerterhohung
2 wachstumsorientiert
3 wachstumsorientiert, kleinereFirmen
4 einkommens − undwachstumsorientiert
5 dividendenorientiert
5YRRET = 5-jahrige Rendite
1YRRET = 1-jahrige Rendite
ASSET = Vermogenswert des Fonds zum 30.6.2000
Fragen:
• Wie haben sich die Renditen durchschnittlich entwickelt?
• Gibt es Unterschiede bzgl. der Renditen fur die verschiedenen Fondarten?
• Welche Fonds haben die niedrigsten Expense Ratios?
• Wie volatil sind die einzelnen Fonds?
• Wie bewertet man die Fonds?
(2) Schadstoffemissionen von 46 Motoren gleichen Typs.
HC = Kohlenwasserstoff
NOX = Stickoxide
CO = Kohlenmonoxid
Fragen:
• Welche Schadstoffe werden durchschnittlich ausgestoßen?

6.2. Das statistische Modell 73
• Welche Schadstoffe werden maximal ausgestoßen?
• Welche Zusammenhange bestehen zwischen den einzelnen Schadstoffen?
• Welcher Motor ist der schadstoffarmste?
Definition 6.3 (Statistisches Modell). (1) Ein statistisches Modell ist ein
Tripel (X ,F , (Pθ)θ∈Θ) mit einem Grundraum X (Stichprobenraum), einer σ-
Algebra F auf X und einer Familie (Pθ)θ∈Θ von Wahrscheinlichkeitsmaßen auf
(X ,F).
(2) Ein statistisches Modell M = (X ,F , (Pθ)θ∈Θ) heißt parametrisch, wenn
Θ ⊂ Rd ist fur ein d ∈ N, insbesondere heißt M einparametrig fur d = 1. (3) Das
Modell M heißt diskret, falls X abzahlbar ist mit F = P(X ). Dann hat jedes Pθ
eine Zahldichte ρθ : X → [0, 1] mit x 7→ Pθ(x). Das Modell M heißt stetig, falls
X ⊂ Rn eine Borel-Menge ist, F = BnX gilt und jedes Pθ eine Lebesgue-Dichte
ρθ : X → R+ besitzt.
Idee: (X ,F) entspricht mehr oder weniger dem Messraum (Ω,F) aus Teil 1 der
Vorlesung. Das wirkliche Wahrscheinlichkeitsmaß Pθ ist noch unbekannt. Auf-
grund physikalischer Uberlegungen kann man manchmal eine Familie (Pθ)θ∈Θ
angeben. Diese Auswahl ist wichtiger Teil einer mehr oder weniger komplexen
Modellbildung und kann schon hochgradig nichttrivial sein.
Vorstellung: Der Stichprobenraum X wird durch die Stichprobe X1, . . . , Xn er-
zeugt. Anstatt an eine Familie von Wahrscheinlichkeitsmaßen (Pθ)θ∈Θ kann man
auch an eine Familie von Verteilungsfunktionen (Fθ)θ∈Θ denken.
Zur n-fachen unabhangigen Versuchswiederholung gehort wie in Teil 1 ein Pro-
duktraum.
Definition 6.4 (Produktmodell). Seien (E, E , (Qθ)θ∈Θ) ein statistisches Mo-
dell und n ∈ N. Dann heißt (X ,F , (Pθ)θ∈Θ) := (En, E⊗n, (Q⊗nθ )θ∈Θ) das zugehori-
ge n-fache Produktmodell. Die Projektionen Xi : X → E mit (x1, . . . , xn) 7→ xi
stehen fur den Ausgang von Teilexperiment i.

74 6. Grundlagen
Bemerkung 6.5. (1) X1, . . . , Xn sind unter jedem Pθ unabhangig und identisch
verteilt (mit Verteilung Qθ).
(2) Wenn (E, E , (Qθ)θ∈Θ) diskret bzw. stetig ist, dann auch das n-fache Pro-
duktmodell (vgl. Satz 2.35 bzw. Satz 2.42).
Beispiel 6.6. [Fortsetzung von Beispiel 2.41] n-facher Munzwurf mit unbekann-
tem Erfolgsparameter θ.
Einzelexperiment: (E, E , (Qθ)θ∈Θ) := (0, 1,P(0, 1), (B1,θ)θ∈(0,1)).
Statistisches Modell (n-faches Produktmodell):
(X ,F , (Pθ)θ∈Θ) := (0, 1n,P(0, 1n), (B⊗n1,θ )θ∈Θ).

Kapitel 7
Parameterschatzung
7.1 Definitionen
Ziel: Angabe eines “vernunftigen” Schatzwertes fur den unbekannten Parame-
ter(vektor) θ oder einer Funktion τ(θ). Seien X1, . . . , Xn Zufallsvariable. Aus
einer Realisierung x1, . . . , xn von X1, . . . , Xn soll τ(θ) geschatzt werden.
Definition 7.1 (Statistik, Schatzer, Schatzfunktion, estimator). Seien
(X ,F , (Pθ)θ∈Θ) ein statistisches Modell und (Σ,S) ein Messraum.
(1) Eine Statistik ist eine messbare Abbildung S : X → Σ.
(2) Sei τ : Θ → Σ eine Abbildung, die jedem θ ∈ Θ eine Kenngroße τ(θ) ∈ Σ
zuordnet. (Z.B. kann τ(θ) = θ1 die Projektionsabbildung auf die 1. Koordinate
des Parametervektors θ sein.) Eine Statistik T : X → Σ heißt dann Schatzer
(estimator) fur τ .
Beispiel 7.2. [n-facher Munzwurf, Fortsetzung von Beispiel 6.6]
Sei τ : Θ → R mit τ(θ) = θ. Wahle z.B.
T := T (X1, . . . , Xn) :=1
n
n∑
i=1
Xi
als Schatzer fur τ(θ) = θ.
75

76 7. Parameterschatzung
Wunschenswerte Eigenschaften von Schatzern
Definition 7.3 (erwartungstreu, unverzerrt; unbiased).
Seien (X ,F , (Pθ)θ∈Θ) ein statistisches Modell und τ : Θ → R eine Kenn-
große. Ein Schatzer T : Rn → Rm von τ heißt erwartungstreu oder unverzerrt
(unbiased), falls
Eθ(T ) = Eθ
(T (X1, . . . , Xn)
)= τ(θ) ∀θ ∈ Θ .
Dabei ist Eθ(T ) =∫
TdPθ, also der Erwartungswert von T bzgl. des Wahrschein-
lichkeitsmaßes Pθ.
Die Differenz Bθ(T ) := Eθ(T )− τ(θ) heißt Verzerrung, Bias oder systemati-
scher Fehler des Schatzers T .
Beispiel 7.4. [Fortsetzung von Beispiel 7.2]
Eθ(T ) =1
n
n∑
i=1
Eθ(Xi) =1
nnθ = θ = τ(θ)
⇒ T ist erwartungstreu (unbiased).
Satz 7.5. Sei (X ,F , (Pθ)θ∈Θ) = (Rn,Bn, (Q⊗nθ )θ∈Θ) ein n-faches Produktmodell
derart, dass fur alle θ ∈ Θ der Erwartungswert m(θ) := Eθ(X1) und die Varianz
v(θ) = Varθ(X1) existieren und endlich sind. Dann ist das Stichprobenmittel
T = T (X1, . . . , Xn) = X :=1
n
n∑
i=1
Xi
ein erwartungstreuer Schatzer fur µ. Ferner ist die Stichprobenvarianz
T (X1, . . . , Xn) = S2 :=1
n − 1
n∑
i=1
(Xi − X
)2
ein erwartungstreuer Schatzer fur v.

7.1. Definitionen 77
Beweis. Sei θ ∈ Θ.
Eθ(X) =1
n
n∑
i=1
Eθ(Xi) =1
nnEθ(X1) = m(θ) ,
Eθ(S2) =
1
n − 1
n∑
i=1
Eθ((Xi − X)2)Eθ(Xi−X)=0
=1
n − 1
n∑
i=1
Varθ(Xi − X)
=1
n − 1
n∑
i=1
Varθ
(Xi −
1
n
n∑
j=1
Xj
)=
1
n − 1
n∑
i=1
Varθ
(n − 1
nXi −
1
n
∑
j 6=i
Xj
)
unabh.=
1
n − 1
n∑
i=1
(Varθ
(n − 1
nXi
)+
1
n2
∑
j 6=i
Varθ(Xj)
)
=1
n − 1
n∑
i=1
((n − 1
n
)2
Varθ(Xi) +n − 1
n2Varθ(Xi)
)
=1
n − 1n
((n − 1
n
)2
+n − 1
n2
)v(θ) = v(θ) .
¤
Wegen Satz 7.5 nennt man X den empirischen Mittelwert und S2 die empi-
rische Varianz.
Es gibt allerdings noch viele weitere erwartungstreue Schatzer, z.B. ist auch
T := X1 erwartungstreu fur m(θ). Interessant sind in diesem Zusammenhang
dann weitere Qualitatskriterien fur Schatzer.
Definition 7.6 (mittlerer quadratischer Fehler, mean squared error,
MSE). Seien (X ,F , (Pθ)θ∈Θ) ein statistisches Modell und τ : Θ → R eine Kenn-
große. Sei ferner T : X → R ein Schatzer fur τ(θ).
MSEθ(T ) := Eθ[(T − τ(θ))2] = Varθ(T ) + (Bθ(T ))2
heißt mittlerer quadratischer Fehler von T .
Definition 7.7 (varianzminimierend, gleichmaßig bester, uniform mi-
nimum variance unbiased, UMVU). Sei T erwartungstreuer Schatzer von
τ . T heißt varianzminimierender, gleichmaßig bester, uniform minimum variance
unbiased, UMVU Schatzer, falls fur alle erwartungstreuen Schatzer S von τ gilt
Varθ(T ) ≤ Varθ(S) ∀θ ∈ Θ .

78 7. Parameterschatzung
Beispiel 7.8. [UMVU-Schatzer]
Sei (X ,F , (Pθ)θ∈Θ) = (Rn,Bn, (Q⊗nθ )θ∈Θ) n-faches Produktmodell und τ : Θ → R
eine Kenngroße.
(1) Binomialverteilung B1,θ, θ ∈ Θ = (0, 1): X ist UMVU-Schatzer fur θ.
(2) Poissonverteilung Poiλ, λ ∈ Θ = (0,∞): X ist UMVU fur λ.
(3) Normalverteilung Nµ,σ2 , θ = (µ, σ2) ∈ Θ = R × (0,∞):
X ist UMVU fur µ, S2 ist UMVU fur σ2.
(4) Exponentialverteilung Eλ, λ ∈ Θ = (0,∞): X ist UMVU fur 1/λ.
(5) Gleichverteilung in [0, b] U[0,b], b ∈ Θ = (0,∞): b =n + 1
nmax1≤i≤n
Xi ist
UMVU fur b.
Der Beweis folgt in der Mathematischen Statistik.
Bemerkung 7.9. Achtung:
• Es gibt nicht immer gleichmassig beste Schatzer.
• Es lasst sich nicht immer klaren, ob es einen gibt.
• Es kann vorkommen, dass ein nicht erwartungstreuer Schatzer einen gleichmassig
kleineren mittleren quadratischen Fehler aufweist als jeder erwartungstreue Schatzer.
• Das Stichprobenmittel ist nicht immer UMVU fur den Erwartungswert; vgl.
Beispiel 7.8(5) mit m(b) = b/2.
Ein weiteres Gutekriterium fur Schatzer betrifft sein Verhalten fur wachsenden
Stichprobenumfang.
Definition 7.10 (Konsistenz). Sei Mn das n-fache Produktmodell von (E, E , (Qθ)θ∈Θ)
fur n ∈ N. Seien τ : Θ → R eine Kenngroße und Tn : En → R ein Schatzer fur
τ . Die Schatzfolge (Tn)n∈N fur τ(θ) heißt konsistent (consistent) , falls
limn→∞
Q⊗nθ (|Tn − τ(θ)| ≤ ε) = 1 ∀ ε > 0 ,∀ θ ∈ Θ ,
d.h. wenn Tn fur alle θ ∈ Θ stochastisch gegen τ(θ) konvergiert.

7.1. Definitionen 79
Bemerkung 7.11. Stochastische Konvergenz wird hier in etwas verallgemeiner-
tem Sinn aufgefasst, da das Wahrscheinlichkeitsmaß von n abhangt.
Wenn man in Definition 7.10 stattdessen den unendlichen Produktraum (EN, E⊗N, (Q⊗N
θ )θ∈Θ)
und die nur von den ersten n Beobachtungen abhangigen Schatzer Tn := Tn(X1, . . . , Xn)
betrachtet, kann man doch auf einem von n unabhangigen Raum arbeiten.
Lemma 7.12. Seien (Xn)n∈N und (Yn)n∈N Folgen von Zufallsvariable. Dann gel-
ten:
(a) XnP→ 0 ⇒ X2
nP→ 0.
(b) XnP→ 0, Yn
P→ 0 ⇒ Xn + YnP→ 0.
(c) XnP→ X, an → a ∈ R ⇒ an Xn
P→ a X.
Beweis. Sei ε > 0.
(a) P (|X2n| ≤ ε) = P (|Xn| ≤
√ε) → 1 fur n → ∞.
(b) P (|Xn + Yn| > ε) ≤ P (|Xn| > ε/2) + P (|Yn| > ε/2) → 0 fur n → ∞.
(c) Fur δ > 0 und n ∈ N hinreichend groß gilt
P (|anXn − aX| > ε) ≤ P (|anXn − anX| > ε/2) + P (|anX − aX| > ε/2)
= P(|Xn − X| >
ε
2a
a
an
)+ P
(|an − a| |X| >
ε
2
)
≤ P(|Xn − X| >
ε
2a(1 − δ)
)+ P
(|X| >
ε
2|an − a|)
Beide Summanden konvergieren gegen 0 fur n → ∞. ¤
Satz 7.13. In der Situation von Satz 7.5 ist (Xn)n∈N konsistent fur m und
(S2n)n∈N konsistent fur v.
Beweis. (i) Nach dem schwachen Gesetz der großen Zahlen (Satz 5.6) ist (Xn)n∈N
konsistent.
(ii) Sei θ ∈ Θ. Fur S2n := 1
n
∑ni=1(Xi − m(θ))2 fur n ∈ N, gilt nach Satz 5.6 (der
auch fur Zufallsvariable in L1 gultig bleibt) : S2n
P→ v(θ) fur n → ∞. Ferner gilt
nach Satz 5.6 und Lemma 7.12(a): (Xn −m(θ))2 → 0 fur n → ∞. Schließlich ist
S2n − (Xn − m(θ))2 =
1
n
n∑
i=1
(Xi − Xn)2 =n − 1
nS2
n.

80 7. Parameterschatzung
Um die erste Identitat zu beweisen betrachte
S2n − 1
n
n∑
i=1
(Xi − Xn)2 =1
n
n∑
i=1
((Xi − m(θ))2 − (Xi − Xn)2
)
(X2
n − 2m(θ)Xn + m(θ)2) = (Xn − m)2 .
Nach Lemma 7.12(b,c) folgt n−1n
S2n − v(θ) = S2
n − (Xn −m(θ))2 − v(θ)P→ 0, also
auch
S2n − v(θ) =
n
n − 1
(n − 1
nS2
n − v(θ))
+1
n − 1v(θ)
P→ 0 .
¤
7.2 Konstruktion von Schatzern
7.2.1 Maximum-Likelihood (ML)-Methode
Die wohl am haufigsten angewandte Technik zur Konstruktion von Schatzfunktionen
ist die Maximum-Likelihood-Methode.
Definition 7.14 (Maximum-Likelihood-Methode, ML-Schatzung). Sei
(X ,F , (Pθ)θ∈Θ) ein diskretes oder stetiges statistisches Modell (mit Zahl- oder
Lebesgue-Dichte ρθ).
(1) Die Funktion ρ : X × Θ → R+ mit ρ(x, θ) := ρθ(x) heißt Likelihood-
Funktion. Die Abbildung ρx : Θ → R+ mit θ 7→ ρ(x, θ) heißt Likelihood-
Funktion zur Stichprobe x ∈ X .
(2) Ein Schatzer T : X → Θ fur θ heißt Maximum-Likelihood-Schatzung, ML-
Schatzung, maximum likelihood estimation, MLE, falls gilt
ρ(x, T (x)) = maxθ∈Θ
ρ(x, θ) ∀ x ∈ X ,
d.h. ρx wird bei T (x) maximal.
Bemerkung 7.15. (1) Die Idee ist, dass Zufallsexperimente mit großer Wahr-
scheinlichkeitkeit Ergebnisse x mit großer Wahrscheinlichkeitsdichte ρ(x) hervor-
bringen. Man glaubt daher eher an ein θ, unter dem die Stichprobe x1, . . . , xn eine

7.1. Definitionen 81
große Wahrscheinlichkeitsdichte ρθ(x1, . . . , xn) besitzt. Das bedeutet nicht, dass
θ große Wahrscheinlichkeit besitzt; denn auf Θ ist kein Wahrscheinlichkeitsmaß
gegeben. Solche Ideen verfolgt man in der Bayesschen Statistik.
(2) ML-Schatzer sind in der Regel konsistent und oft auch nach anderen Gute-
kriterien sehr gut.
(3) Statt ρx maximiert man in der Regel log ρx, da sich damit leichter rechnen
lasst.
(4) Wenn T ML-Schatzer fur θ ist, heißt τ(T ) ML-Schatzer fur eine Kenngroße
τ(θ).
Beispiel 7.16. [ML-Schatzer fur Erwartungswert und Varianz einer Normalver-
teilung]
Sei (X ,F , (Pθ)θ∈Θ) = (Rn,Bn, (N⊗nµ,σ2)(µ,σ2)∈R×(0,∞)) n-faches Produktmodell mit
θ = (µ, σ2) ∈ R × (0,∞). Dann ist die gemeinsame Lebesgue-Dichte einer Reali-
sierung x = (x1, . . . , xn) gegeben durch
ρx(θ) = ρ(x, θ) =n∏
i=1
1√2πσ2
exp
(−(xi − µ)2
2σ2
)
=1
(2πσ2)n/2exp
(−
n∑
i=1
(xi − µ)2
2σ2
), x ∈ Rn ,
also
lx(µ, σ2) := log ρx(µ, σ2) = −n
2log(2πσ2) − 1
2σ2
n∑
i=1
(xi − µ)2 .
Ableiten ergibt
D1lx(µ, σ2) =1
σ2
n∑
i=1
(xi − µ)
D2lx(µ, σ2) = −n
2
1
σ2+
1
2σ4
n∑
i=1
(xi − µ)2 .
Die Ableitungen werden 0 fur
µ :=1
n
n∑
i=1
xi und σ2 :=1
n
n∑
i=1
(xi − µ)2 .

82 7. Parameterschatzung
Untersuchungen der Hesse-Matrix und Grenzbetrachtungen ergeben:
Bei (µ, σ2) liegt ein globales Maximum. Somit ist
T =
(1
n
n∑
i=1
Xi ,1
n
n∑
i=1
(Xi − X)2
)=
(X ,
n − 1
nS2
)
der ML-Schatzer fur (µ, σ2).
Man beachte, dass T2 = n−1n
S2 nicht erwartungstreu fur σ2 ist.
Beispiel 7.17. [Warten auf die U-Bahn mit unbekanntem Takt θ bei zufalliger
Ankunftzeit]
Sei (X ,F , (Pθ)θ∈Θ) = (Rn,Bn, (U⊗nθ )θ∈(0,∞)) n-faches Produktmodell mit
ρx(θ) = ρ(x, θ) =n∏
i=1
1
θ1[0,θ](x) =
1
θn1max(x1,...,xn)≤θ .
Dies wird maximal fur θ = max(x1, . . . , xn).
Somit ist T := max(X1, . . . , Xn) ML-Schatzer fur θ.
T ist nicht erwartungstreu, denn es gilt stets max(X1, . . . , Xn) ≤ θ.
Der Schatzer n+1n
T ist hingegen sogar UMVU, vgl. Beispiel 7.8(5).
7.2.2 Momentenmethode
Idee: Schatze einen Parameter(vektor) so, dass die empirischen Momente mit
den theoretischen Momenten ubereinstimmen (moment estimators, estimators by
moment matching).
Definition 7.18. Seien (X ,F , (Pθ)θ∈Θ) = (Rn,Bn, (Q⊗nθ )θ∈Θ) ein n-faches Pro-
duktmodell mit θ ∈ Rd. Es existiere das d-te absolute Moment Eθ(|X1|d) fur
alle θ ∈ Θ. Definiere mk(θ) := Eθ(Xk1 ) fur k = 1, . . . , d. Ein Schatzer T =
T (X1, . . . , Xn) heißt Momentenschatzer fur θ, falls
1
n
n∑
i=1
Xki = mk(T ) , k = 1, . . . , d .
Bemerkung 7.19. Unter gewissen Voraussetzungen sind Momentenschatzer kon-
sistent.

7.1. Definitionen 83
Beispiel 7.20. [Erganzung zu Beispiel 7.16]
Seien m1(θ) = µ und m2(θ) = σ2 + µ2. Wahle T = (T1, T2) so, dass
1
n
n∑
i=1
Xi = m1(T1, T2) = T1 ,
1
n
n∑
i=1
X2i = m2(T1, T2) = T 2
1 + T2 ,
also T1 = X, T2 =1
n
∑ni=1 X2
i − X2
=1
n
∑ni=1(Xi − X)2 =
n − 1
nS2. Somit ist
T = (X,n − 1
nS2) auch ein Momentenschatzer fur θ = (µ, σ2).
Man beachte, dass das auch fur jede andere Verteilungsfamilie mit Erwartungs-
wert µ und Varianz σ2 gilt.
7.2.3 Methode der Kleinsten Quadrate
Idee: Schatze einen Parameter(vektor) so, dass die quadratische Abweichung der
Daten von der Kenngroße τ(θ) minimal wird.
Definition 7.21 (Kleinste-Quadrate-Schatzer).
Seien (X ,F , (Pθ)θ∈Θ) = (Rn,Bn, (Q⊗nθ )θ∈Θ) ein n-faches Produktmodell und
τ : Θ → R eine Kenngroße. Ein Schatzer T : X → R heißt Kleinste-Quadrate-
Schatzer (KQ-Schatzer, least squares estimator, LSE) fur τ(θ), falls giltn∑
i=1
(xi − T (x1, . . . , xn))2 = minθ∈Θ
n∑
i=1
(xi − τ(θ))2 ∀ (x1, . . . , xn) ∈ X . (7.1)
Beispiel 7.22. [X als KQ-Schatzer]
Wie im Beweisteil (ii) von Satz 7.13 folgt fur einen Schatzer m von m(θ) = Eθ(X1)
1
n
n∑
i=1
(xi − m)2 =1
n
n∑
i=1
(xi − x)2 + (x − m)2 ≥ 1
n
n∑
i=1
(xi − x)2 .
Diese Formel heißt Verschiebungsformel.
Somit ist X := 1n
∑ni=1 Xi ein KQ-Schatzer fur m.

84 7. Parameterschatzung

Kapitel 8
Die multivariate
Normalverteilung
8.1 Eindimensionale Normalverteilung
Die Lebesgue-Dichte der Normal- oder Gauß-Verteilung Nµ,σ2 :
ϕµ,σ2(z) =1√2π σ
exp(− (z − µ)2
2σ2
), z ∈ R . (8.1)
N0,1 heißt Standardnormalverteilung.
Bemerkung 8.1. Wichtige Eigenschaften
(1) Sei U N0,1-verteilt =⇒ X := µ + σ U ist Nµ,σ2-verteilt.
Durch die Standardisierung
U :=X − µ
σ
kann eine Nµ,σ2-verteilte Zufallsvariable X in eine N0,1-verteilte Zufallsvariable
U transformiert werden.
(2) Fur die Standardnormalverteilungsfunktion
Φ(z) = P (U ≤ z) =1√2π
∫ z
−∞e−t2/2 dt , z ∈ R ,
85

86 8. Die multivariate Normalverteilung
gibt es ausgezeichnete numerische Approximationen. Wegen der Symmetrie der
Dichte ϕ (auch Gaußschen Glockenkurve genannt), gilt
Φ(−z) = 1 − Φ(z) , z ∈ R .
(3) Da Φ streng monoton steigend und stetig ist, ist fur α ∈ (0, 1) das α-Quantil
der Standardnormalverteilung gegeben durch zα := Φ−1(α) und es gilt wegen der
Symmetrie z1−α = −zα.
Aus diesem Grund werden Standardnormalverteilungsquantile nur fur α ∈ [12, 1)
bzw. zα ≥ 0 tabelliert.
(4) Vgl. Beispiel bsp4.27: E(X) = µ, Var(X) = σ2. Fur die Momente gilt
allgemein E((X − µ)k) = 0 fur alle ungeraden k ∈ N und E((X − µ)k) = σk(k −1)(k − 3) · · · 3 · 1 fur alle geraden k ∈ N.
(5) Schatzung der unbekannten Parameter µ und σ2:
Seien X1, . . . , Xn eine Stichprobe unabhangiger Nµ,σ2-verteilter Zufallsvariablen.
Dann sind
µ = X =1
n
n∑
i=1
Xi und σ2 = S2 =1
n − 1
n∑
i=1
(Xi − X)2 (8.2)
erwartungstreue, konsistente und UMVU Schatzer fur die unbekannten Parame-
ter µ und σ2. Außerdem sind µ undn − 1
nS2 die ML-Schatzer und die Momen-
tenschatzer fur µ und σ2.
8.2 Die multivariate Normalverteilung
Satz 8.2. Seien X1, . . . , Xn unabhangige N0,1-verteilte Zufallsvariable, B ∈ Rn×n
regular, µ ∈ Rn. Fur X := (X1, . . . , Xn)⊤ hat Y := BX + µ die Lebesgue-Dichte
ϕµ,Σ(y) =1√
(2π)n|detΣ|exp
(− 1
2(y − µ)⊤Σ−1(y − µ)
), y ∈ Rn , (8.3)
wobei Σ := BB⊤. Ferner gilt E(Y ) = µ, Kov(Y ) = Σ.
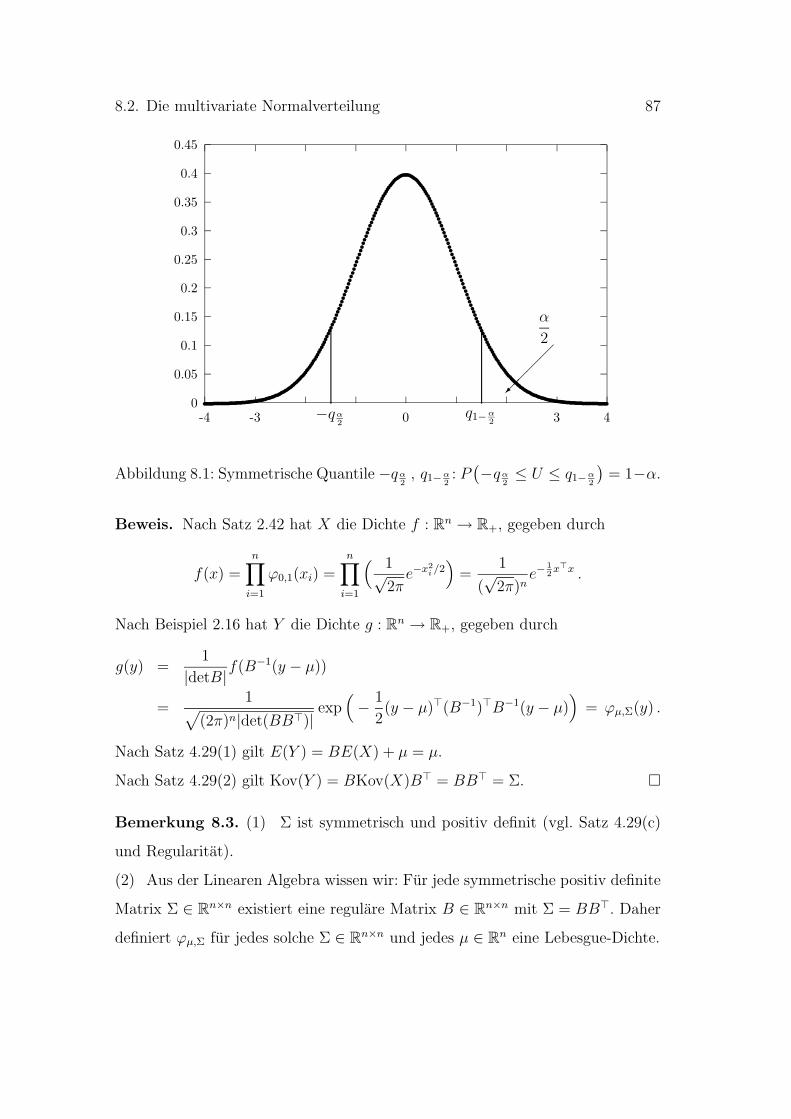
8.2. Die multivariate Normalverteilung 87
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
-4 -3 0 3 4
¡¡
¡¡ª
α
2
q1−α2
−qα2
•••••••••••••••••••••••••••••••••••••••••••••••••••••
•••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••
Abbildung 8.1: Symmetrische Quantile −qα2, q1−α
2: P
(−qα
2≤ U ≤ q1−α
2
)= 1−α.
Beweis. Nach Satz 2.42 hat X die Dichte f : Rn → R+, gegeben durch
f(x) =n∏
i=1
ϕ0,1(xi) =n∏
i=1
( 1√2π
e−x2i /2
)=
1
(√
2π)ne−
12x⊤x .
Nach Beispiel 2.16 hat Y die Dichte g : Rn → R+, gegeben durch
g(y) =1
|detB|f(B−1(y − µ))
=1√
(2π)n|det(BB⊤)|exp
(− 1
2(y − µ)⊤(B−1)⊤B−1(y − µ)
)= ϕµ,Σ(y) .
Nach Satz 4.29(1) gilt E(Y ) = BE(X) + µ = µ.
Nach Satz 4.29(2) gilt Kov(Y ) = BKov(X)B⊤ = BB⊤ = Σ. ¤
Bemerkung 8.3. (1) Σ ist symmetrisch und positiv definit (vgl. Satz 4.29(c)
und Regularitat).
(2) Aus der Linearen Algebra wissen wir: Fur jede symmetrische positiv definite
Matrix Σ ∈ Rn×n existiert eine regulare Matrix B ∈ Rn×n mit Σ = BB⊤. Daher
definiert ϕµ,Σ fur jedes solche Σ ∈ Rn×n und jedes µ ∈ Rn eine Lebesgue-Dichte.

88 8. Die multivariate Normalverteilung
Definition 8.4 (Multivariate Normalverteilung). Seien µ ∈ Rn und Σ ∈Rn×n symmetrisch und positiv definit. Das Wahrscheinlichkeitsmaß Nµ,Σ auf (Rn,Bn)
mit Lebesgue-Dichte ϕµ,Σ aus Satz 8.2 heißt (nicht-singulare oder nicht-degenerierte)
multivariate Normalverteilung oder Gauß-Verteilung mit Erwartungsvektor µ und
Kovarianzmatrix Σ.
N0,1nheißt multivariate Standardnormalverteilung (1n bezeichnet die Einheits-
matrix im Rn×n).
Bemerkung 8.5. Allgemeiner heißt die Verteilung von Y = BX + µ in Satz 8.2
Nµ,Σ-Verteilung, auch wenn B nicht regular ist. Dann existiert allerdings keine
Dichte mehr. Die Verteilung hangt wie oben nur von µ, Σ ab (ohne Beweis).
Satz 8.6. Sei Y Nµ,Σ-verteilt mit µ ∈ Rn und Σ ∈ Rn×n symmetrisch und positiv
semidefinit. Seien außerdem a ∈ Rk und A ∈ Rk×n. Dann ist Z := AY + a
NAµ+a,AΣA⊤-verteilt.
Beweis. Nur fur k = n: Sei O.B.d.A. Y = BX + µ, wobei X = (X1, . . . , Xn)⊤
ein Vektor mit unabhangigen N0,1-verteilten Komponenten ist und Σ = BB⊤.
Dann ist Z = AY + a = ABX + (Aµ + a) nach Bemerkung 8.5 NAµ+a,ABB⊤A⊤-
verteilt. ¤
Korollar 8.7. Seien Y1, . . . , Yn unabhangige Zufallsvariable, wobei Yi Nµi,σ2i-
verteilt ist fur i = 1, . . . , n. Dann ist Y1 + · · · + Yn N∑ni=1 µi,
∑ni=1 σ2
i-verteilt.
Insbesondere ist Nµ1,σ21∗ Nµ2,σ2
2= Nµ1+µ2,σ2
1+σ22.
Beweis. Wahle in Satz 8.6 µ = (µ1, . . . , µn)⊤ und Σ =
σ21 · · · 0...
. . ....
0 · · · σ2n
,
sowie a = 0 und A = (1, 1, . . . , 1). ¤
Korollar 8.8. Sei X eine N0,1n-verteilte Zufallsvariable in Rn und B ∈ Rn×n
orthogonal (d.h. B−1 = B⊤). Dann ist auch BX standardnormalverteilt.
Beweis. Satz 8.6 mit Σ = BB⊤ = BB−1 = 1n. ¤

8.2. Abgeleitete Verteilungen 89
Lemma 8.9. Seien µ ∈ Rn und Σ ∈ Rn×n positiv semidefinit. Y = (Y1, . . . , Yn)⊤
ist genau dann Nµ,Σ-verteilt, wenn t⊤Y (∈ R) Nt⊤µ,t⊤Σt-verteilt ist fur alle t ∈ Rn.
Beweis. “⇒” Sei Y Nµ,Σ-verteilt. Folglich gilt nach Definition 8.4 (in Kombi-
nation mit Bemerkung 8.5), dass Y = BX + µ fur ein B ∈ Rn×m, BB⊤ = Σ,
rang(B) = rang(Σ) = m ≤ n und X = (X1, . . . , Xm), wobei X1, . . . , Xm un-
abhangig N0,1 verteilt sind. Mit Satz 8.6 folgt, t⊤Y ist Nt⊤µ,t⊤Σt verteilt.
“⇐” Sei t⊤Y Nt⊤µ,t⊤Σt verteilt ∀t ∈ Rn. Fur Σ positiv semidefinit existiert (siehe
Lineare Algebra) eine Matrix B ∈ Rn×m mit BB⊤ = Σ, rang(B) = rang(Σ) =
m ≤ n. Sei X := (X1, . . . , Xm)⊤ mit unabhangigen und N0,1-verteilten Kompo-
nenten X1, . . . , Xm. Dann gilt t⊤(BX + µ) ist Nt⊤µ,t⊤Σt verteilt ∀t ∈ Rd. Nach
dem Satz von Cramer-Wold (Beweis folgt in der Wahrscheinlichkeitstheorie) ist
die Verteilung eines Zufallsvektors Y eindeutig bestimmt durch die Verteilung
aller seiner Linearkombinationen t⊤Y , t ∈ Rn. Somit haben Y und BX + µ
dieselbe Verteilung. ¤
Bemerkung 8.10. Literaturhinweis:
Tong, Y.L. (1990) The Multivariate Normal Distribution. Springer, New York.
8.3 Abgeleitete Verteilungen
Satz 8.11. Sei X eine N0,1-verteilte Zufallsvariable. Dann ist X2 Γ 12, 12-verteilt.
Beweis. Wende Satz 2.15 an mit f(x) = 1√2π
e−x2/2, x ∈ R, U1 = (0,∞), U2 =
(−∞, 0) und ϕ(x) = x2 =⇒ X2 hat Lebesgue-Dichte g : R → R+ mit
g(y) =(1(0,∞)(y)
1√2π
e−12(√
y)2 1
|2√y|)× 2
= 1(0,∞)(y)1√2π
e−y/2y−1/2 = γ 12, 12(y) .
¤

90 8. Die multivariate Normalverteilung
Satz 8.12. Seien X,Y unabhangige Γα,r bzw. Γα,s-verteilte Zufallsvariable fur
α, r, s > 0. Dann sind X + Y undX
X + Yunabhangige Zufallsvariable mit Ver-
teilungen Γα,r+s bzw. Br,s, wobei βr,s die Lebesgue-Dichte der Beta-Verteilung
ist, gegeben durch
βr,s(z) =Γ(r + s)
Γ(r)Γ(s)zr−1(1 − z)s−11(0,1)(z) .
Beweis. Wende Satz 2.42 an: (X,Y ) hat Lebesgue-Dichte f : R2 → R+ mit
f(x, y) = γα,r(x)γα,s(y). Wende nun Satz 2.15 and mit ϕ : R2 → R2 mit (x, y) 7→(x + y,
x
x + y
), U1 = (0,∞) × (0,∞). Dann ist ϕ−1(u, v) = (uv, u(1 − v)). Fur
die Lebesgue-Dichte g : R2 → R+ von(X + Y,
X
X + Y
)ergibt sich
g(u, v) = γα,r+s(u)βr,s(v) .
Insbesondere gilt
∫βr,s(v)dv =
∫βr,s(v)
∫γα,r+s(u)du
︸ ︷︷ ︸=1
dvFubini=
∫g(u, v)d(u, v) = 1 ,
also ist βr,s eine Dichte.
Nach Satz 2.42 ist g die Lebesgue-Dichte eines Paares (U, V ), wobei U und V
unabhangig und Γα,r+s- und Br,s-verteilt sind. ¤
Ausintegrieren der β-verteilten Große fuhrt zur Marginaldichte von X + Y .
Korollar 8.13. Fur α, r, s > 0 gilt Γα,r ∗ Γα,s = Γα,r+s.
Definition 8.14 (χ2-Verteilung). Fur n ∈ N heißt χ2n := Γ 1
2, n2
χ2-Verteilung
mit n Freiheitsgraden oder χ2n-Verteilung. Sie hat die Lebesgue-Dichte
χ2n(x) =
xn2−1
Γ(n2)2
n2
e−x/21(0,∞)(x) .
Satz 8.15. Seien X1, . . . , Xn unabhangige, standardnormalverteilte Zufallsvaria-
ble. Dann istn∑
i=1
X2i χ2
n-verteilt.

8.2. Abgeleitete Verteilungen 91
0
0.02
0.04
0.06
0.08
0.1
0.12
0 5 10 χ28;0.9 20 25 30
Dichte der χ28-Verteilung
mit n = 8 Freiheitsgraden
α
Abbildung 8.2: Lebesgue-Dichte der χ2-Verteilung mit 8 Freiheitsgraden.
Beweis. Induktion nach n:
n = 1: Satz 8.11.
n 7→ n + 1: Satz 8.11 und Korollar 8.13. ¤
Bemerkung 8.16. Fur die Momente der χ2n-Verteilung erhalt man
E(χ2n) = n
Var(χ2n) = 2n
Modus(χ2n) = n − 2 , n ≥ 2 , Modus(χ2
1) existiert nicht .
Definition 8.17 (F -Verteilung). Seien m,n ∈ N. Die F -Verteilung (Fisher-
Verteilung) mit m und n Freiheitsgraden oder Fm,n-Verteilung wird durch ihre
Lebesgue-Dichte definiert:
fm,n(x) =Γ(m+n
2)
Γ(m2)Γ(n
2)mm/2nn/2 x
m2−1
(mx + n)m+n
2
1(0,∞)(x) .
Satz 8.18. Seien X1, . . . , Xm, Y1, . . . , Yn unabhangige, standardnormalverteilte
Zufallsvariable. Dann ist1m
∑mi=1 X2
i1n
∑nj=1 Y 2
j

92 8. Die multivariate Normalverteilung
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0 0.5 1 1.5 2 2.5 3 3.5
F4,8
F4,2
F4,∞
Abbildung 8.3: Lebesgue-Dichten der Verteilungen F4,2, F4,8 und F4,∞.
Fm,n-verteilt. Insbesondere ist fm,n eine Lebesgue-Dichte.
Beweis. Nach Satz 8.15 sind X :=∑m
i=1 X2i und Y :=
∑nj=1 Y 2
j unabhangig
und Γ 12, m
2- bzw. Γ 1
2, n2-verteilt (vgl. auch Bemerkung 2.37). Nach Satz 8.12 ist
Z :=X
X + Yβm
2, n2-verteilt. Es ist
X/m
Y/n=
n
m
Z
1 − Z. Wende Satz 2.15 an mit
ϕ(z) :=n
m
z
1 − z, U1 = (0,∞). Dann gilt ϕ−1(x) =
mx
mx + n. Es folgt, dass
X/m
Y/ndie Lebesgue-Dichte fm,n besitzt. Insbesondere ist fm,n eine Lebesgue-Dichte. ¤
Bemerkung 8.19. Fur die Momente der Fm,n-Verteilung erhalt man
E(Fm,n) =n
n − 2fur n > 2.
Var(Fm,n) =2n2(m + n − 2)
m(n − 2)2(n − 4)fur n > 4.
Modus(Fm,n) =n (m − 2)
m (n + 2)fur n > 1 und m > 2 .
Definition 8.20 (Student-t-Verteilung). Fur n ∈ N ist die Student-t-Verteilung
mit n Freiheitsgraden oder tn-Verteilung auf (R,B) definiert durch die Dichte
τn(x) =Γ(
n+12
)
Γ(
n2
)√nπ
(1 +
x2
n
)−n+12
, x ∈ R . (8.4)

8.2. Abgeleitete Verteilungen 93
Satz 8.21. Seien X,Y1, . . . , Yn unabhangige N0,1-verteilte Zufallsvariable. Dann
ist
Tn :=X√
1n
∑nj=1 Y 2
j
tn-verteilt.
Beweis. Nach Satz 8.18 ist T 2n F1,n-verteilt. Benutze Satz 2.15 mit ϕ(x) =
√x:
|Tn| =√
T 2n hat die Lebesgue-Dichte y 7→ f1,n(y2)2y1(0,∞)(y). Da Tn symmetrisch
ist (PTn= P−Tn
) hat Tn somit die Lebesgue-Dichte y 7→ f1,n(y2)|y|. ¤
Satz 8.22 (Student). Seien X1, . . . , Xn unabhangig Nµ,σ2-verteilt mit µ ∈ R,
σ2 ∈ (0,∞). Dann gelten:
(1) Stichprobenmittel X und Stichprobenvarianz S2 sind unabhangig.
(2) X ist Nµ,σ2/n-verteilt.
(3)n − 1
σ2S2 ist χ2
n−1-verteilt.
(4) T :=X − µ√
S2/nist tn−1-verteilt.
Beweis. (1) Sei A ∈ Rn×n eine orthogonale Matrix der Form
A =
1√n
1√n
. . . . . .1√n
Rest nach dem Schmidt′schen
Orthogonalisierungsverfahren erganzt
Fur Y := AX gilt∑n
i=1 Y 2i =
∑ni=1 X2
i , da A orthogonal, also normerhaltend ist.
Nach Satz 8.6 ist Y NA(µ,...,µ)⊤,A(σ21n)A⊤-verteilt, also N(µ√
n,0,...,0)⊤,σ21n-verteilt.
Diese Dichte hat Produktgestalt (vgl. ϕµ,Σ in Satz 8.2). Also sind Y1, . . . , Yn
unabhangig mit Y1 Nµ√
n,σ2-verteilt und Y2, . . . , Yn N0,σ2-verteilt. Ferner gilt
X =1√n
n∑
i=1
1√n
Xi =1√n
Y1 ,
(n − 1)S2 =n∑
i=1
(Xi − X)2 vgl. Bsp.7.20=
n∑
i=1
X2i − nX
2=
n∑
i=1
Y 2i − Y 2
1 =n∑
i=2
Y 2i .
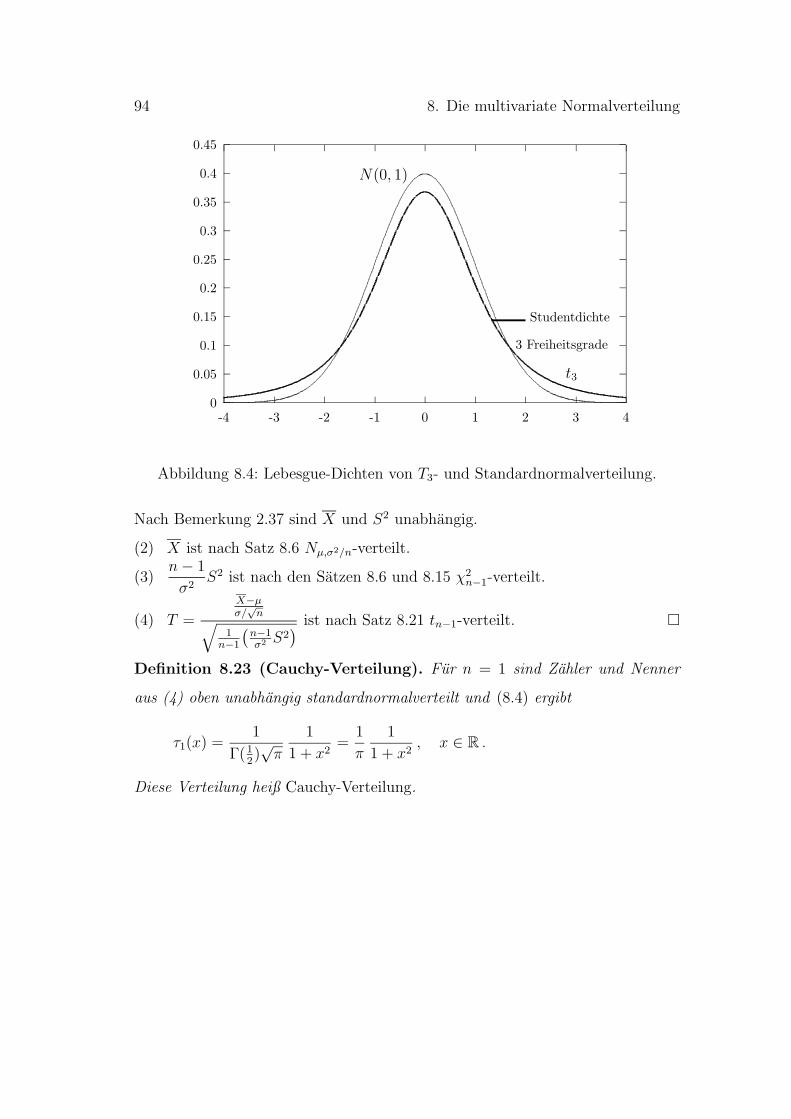
94 8. Die multivariate Normalverteilung
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
-4 -3 -2 -1 0 1 2 3 4
N(0, 1)
Studentdichte
3 Freiheitsgrade
t3
Abbildung 8.4: Lebesgue-Dichten von T3- und Standardnormalverteilung.
Nach Bemerkung 2.37 sind X und S2 unabhangig.
(2) X ist nach Satz 8.6 Nµ,σ2/n-verteilt.
(3)n − 1
σ2S2 ist nach den Satzen 8.6 und 8.15 χ2
n−1-verteilt.
(4) T =
X−µσ/
√n√
1n−1
(n−1σ2 S2
) ist nach Satz 8.21 tn−1-verteilt. ¤
Definition 8.23 (Cauchy-Verteilung). Fur n = 1 sind Zahler und Nenner
aus (4) oben unabhangig standardnormalverteilt und (8.4) ergibt
τ1(x) =1
Γ(12)√
π
1
1 + x2=
1
π
1
1 + x2, x ∈ R .
Diese Verteilung heiß Cauchy-Verteilung.

Kapitel 9
Konfidenzbereiche
Schatzer liefern in aller Regel nicht genau den “wahren”Wert des Parameters θ
oder der Kenngroße τ(θ), sondern weichen mehr oder weniger stark davon ab.
Ausweg: Anstatt eines Punktschatzers wie in Kapitel 7, wahlt man ein gan-
zes Intervall, in welchem man den wahren Wert mit hoher Wahrscheinlichkeit
vermutet.
Definition 9.1 (Bereichsschatzer, Konfidenzbereich, Konfidenzintervall).
Seien (X ,F , (Pθ)θ∈Θ) ein statistisches Modell, τ : Θ → Σ eine Kenngroße und
α ∈ (0, 1). Eine Abbildung C : X → P(Σ) heißt Bereichsschatzer fur τ zum
Irrtumsniveau α (oder Sicherheitsniveau 1 − α), falls
infθ∈Θ
Pθ(x ∈ X : τ(θ) ∈ C(x)) ≥ 1 − α . (9.1)
Fur x ∈ X heißt C(x) Konfidenz- oder Vertrauensbereich fur τ .
Im Falle Σ = R ist C(x) ein Intervall, genannt Konfidenzintervall.
Bemerkung 9.2. (1) Dies bedeutet anschaulich, dass der wahre Parameter
hochstens mit Wahrscheinlichkeit α nicht im Konfidenzbereich liegt.
Achtung: Zufallsbehaftet ist hier die Menge C(x) (da von x abhangig), nicht
aber der Parameter θ oder die Kenngroße τ(θ).
(2) Ziel: Wahle C(x) zu gegebenem α moglichst klein (und nicht etwa C(x) = Σ
95

96 9. Konfidenzbereiche
fur alle x), da die Aussage dann informativer wird.
(3) Mogliches Vorgehen in diskreten oder stetigen Modellen mit Dichten (ρθ)θ∈Θ:
Wahle als Konfidenzbereich ein Intervall um den ML-Schatzer herum.
9.1 Konfidenzintervalle
Beispiel 9.3. [Konfidenzintervall fur den Erwartungswert einer Normalvertei-
lung]
Fur σ2 > 0 bekannt sei (X ,F , (Pθ)θ∈Θ) = (Rn,Bn, (N⊗nµ,σ2)µ∈R) das n-fache Pro-
duktmodell. Zu schatzen sei θ = µ (d.h. τ(θ) = θ). Sei α ∈ (0, 1) gegeben.
Fur die Realisierungen x = (x1, . . . , xn) der normalverteilten Stichprobe X =
(X1, . . . , Xn) mit bekannter Varianz σ2 > 0 macht man folgenden Ansatz:
C(x) = (x − ε, x + ε) symmetrisches Intervall um den ML-Schatzer).
Wahle ε moglichst klein:
Pθ(x ∈ X : θ ∈ C(x)) = N⊗nµ,σ2(|x − µ| < ε)
= N⊗nµ,σ2
( ∣∣∣∣x − µ
σ/√
n
∣∣∣∣ <ε√
n
σ2
)= Nµ,σ2/n
(− ε
√n
σ<
x − µ
σ/√
n<
ε√
n
σ
)
= Φ(ε
√n
σ
)− Φ
(− ε
√n
σ
)= 2Φ
(ε√
n
σ
)− 1 .
Dies ist ≥ 1 − α, falls ε ≥ σ√n
Φ−1(1 − α
2
). Somit ist
C(x) =(x − σ√
nΦ−1
(1 − α
2
), x +
σ√n
Φ−1(1 − α
2
))
ein solches Konfidenzintervall.
Beispiel 9.4. [Konfidenzintervall fur den Erwartungswert einer Normalvertei-
lung bei unbekannter Varianz]
Nach wie vor schatzen wir τ(θ) = τ(µ, σ2) = µ. Sei α ∈ (0, 1) gegeben. Ansatz
fur ein Konfidenzintervall zum Irrtumsniveau α:
C(x) = (x −√
s2ε, x +√
s2ε) ,

9.1 Konfidenzintervalle 97
also analog zu Beispiel 9.3, wobei das unbekannte σ2 durch den Schatzer S2 fur
die Realisierung x = (x1, . . . , xn) ersetzt wird. Wahle ε moglichst klein und vgl.
Satz 8.22(4):
Pµ,σ2(x ∈ X : µ ∈ C(x)) = N⊗nµ,σ2(|x − µ| <
√s2ε)
= N⊗nµ,σ2
(| x − µ√
s2/n| < ε
√n)
= tn−1((−ε√
n, ε√
n))
Symmetrie= 2Ftn−1(ε
√n) − 1 ,
wenn Ftn−1 die Verteilungsfunktion von tn−1 ist.
Dies ist ≥ 1 − α, falls ε ≥ 1√n
F−1tn−1
(1 − α
2
). Somit ist
C(x) =(x −
√s2
√n
F−1tn−1
(1 − α
2
), x +
√s2
√n
F−1tn−1
(1 − α
2
))
ein solches Konfidenzintervall.
Bemerkung 9.5. Die Langen beider Konfidenzintervalle in den Beispielen 9.3
und 9.4 sind proportional zu 1/√
n: fur doppelte Genauigkeit benotigt man vier-
faches n.
Beispiel 9.6. [Qualitatskontrolle]
Produktion von Schrauben mittlerer Lange µ (Maschineneinstellung) und Varianz
σ2 (Maschinenkonstante). Schatzung von µ durch Vermessen von 100 Schrauben.
1. Methode: σ2 = 15.42 mm2 bekannt.
n = 100, α = 0.05, x = 115 mm.
Man erhaltσ√n
Φ−1(1 − α
2
)≈ 2.6, also C = (112.4, 117.6).
2. Methode: s2 = 15.42 mm2 geschatzt.
Man erhalt
√s2
√n
F−1tn−1
(1 − α
2
)≈ 2.65, also C = (112.35, 117.65).

98 9. Konfidenzbereiche
9.2 Ein Konstruktionsverfahren fur Konfidenz-
bereiche
Sei (X ,F , (Pθ)θ∈Θ) ein diskretes/stetiges statistisches Modell mit Dichten (ρθ)θ∈Θ.
Zu schatzen sei τ(θ) = θ. Identifiziere Bereichschatzer C : X → P(Θ) fur θ mit
Mengen
C := (x, θ) ∈ X × Θ : θ ∈ C(x) .
Sei ferner Cθ := x ∈ X : (x, θ) ∈ C. Die Bedingung fur einen Konfidenzbereich
ist: Pθ(Cθ) ≥ 1 − α fur alle θ ∈ Θ.
Idee: Wahle Cθ moglichst klein, indem die Punkte x mit maximaler Dichte
ρθ(x) aufgenommen werden (≈ minimale “Breite” der Menge C), d.h. wahle
Cθ = x ∈ X : ρθ(x) ≥ cθ mit maximalem cθ, so dass Pθ(Cθ) ≥ 1 − α. Dann ist
C(x) = θ ∈ Θ : x ∈ Cθ
Konfidenzbereich zum Irrtumsniveau α.
Beispiel 9.7. [Fortsetzung von Beispiel 9.3]
Es ist (θ = µ, σ2 bekannt):
ρµ(x) =1
(2πσ2)n/2exp
(− 1
2σ2
n∑
i=1
(xi − µ)2)
, x ∈ Rn ,
also
ρµ ≥ cµ ⇐⇒ −n
2log(2πσ2) − 1
2σ2
n∑
i=1
(xi − µ)2 ≥ log cµ
⇐⇒n∑
i=1
(xi − µ
σ
)2 ≤ −2 log cµ − n log(2πσ2) =: c′ ,
wobei die Summe nach Satz 8.15 χ2n-verteilt ist unter Pθ. Somit gilt
Pθ(ρµ(x) ≥ cθ) = χ2n((−∞, c′]) = 1 − α .

9.2 Konstruktion von Konfidenzbereichen 99
Wahle also c′ := χ2n,1−α, das (1 − α)-Quantil von χ2
n. Also gilt µ ∈ C(x) genau
dann, wenn
χ2n,1−α ≥
n∑
i=1
(xi − µ
σ
)2
=1
σ2
(n∑
i=1
(xi − x)2 + n(x − µ)2
)=
n − 1
σ2s2 +
n
σ2(x − µ)2 ,
also ist
C(x) =
(x −
√σ2
nχ2
n,1−α − n − 1
ns2 , x +
√σ2
nχ2
n,1−α − n − 1
ns2
)
ein solches Konfidenzintervall. Dabei wird das Intervall als leer interpretiert, wenn
die Wurzel imaginar wird.
Beispiel 9.8. [Konfidenzintervall im Binomialmodell]
Gegeben sei eine Stichprobe unabhangiger Bernoulli-verteilter Zufallsvariable d.h.
Pθ(1) = θ und Pθ(0) = 1 − θ mit θ unbekannt. Fur dieses Experiment ist der
Stichprobenraum X = 0, . . . , n, der Parameterraum Θ = (0, 1) und die Vertei-
lung ist Pθ = Bn,θ, gegeben durch die Zahldichte der Binomialverteilung.
1. Methode (Anwendung der Ungleichung von Tschebyschov)
Der beste Schatzer fur θ ist die relative Haufigkeit T (X) = X/n. Darauf basiert
der Ansatz
C(x) =(x
n− ε,
x
n+ ε
),
wobei ε > 0 moglichst klein sein soll und geeignet bestimmt werden muss. Be-
dingung (9.1) wird zu
Bn,θ
(x ∈ X : |x
n− θ| ≥ ε
)≤ α .
Die Wahrscheinlichkeiten auf der linken Seite besitzen nach der Ungleichung von
Tschebyschov die obere Schranke
Var(Bn,θ)
n2ε2=
nθ(1 − θ)
n2ε2.

100 9. Konfidenzbereiche
Da wir θ nicht kennen, benutzen wir θ(1− θ) ≤ 1/4 und schatzen die rechte Sei-
te durch ihr Maximum 1/(4nε2) ab. Bedingung (9.1) ist also sicher dann erfullt
(θ(1−θ) ≤ 1/4), wenn 1/(4nε2) ≤ α, also ε ≥ 1/√
4nα. Zum Beispiel erhalt man
fur n = 1000 und α = 0.025 den Wert ε = 1/√
100 = 0.1.
Vorteil der Methode: Einfach zu rechnen, bietet sichere Abschatzung.
Nachteil der Methode: Ungleichung ist nicht angepasst an die Binomialvertei-
lung, daher viel zu grob. Das errechnete ε ist viel zu groß.
2. Methode (Anwendung der Normalapproximation)
Fur den gleichen Ansatz wie oben verwenden wir den Zentralen Grenzwertsatz
von de Moivre-Laplace.
Bn,θ
(x ∈ X : |x
n− θ| < ε
)= Bn,θ
(| x − nθ√
nθ(1 − θ)| < ε
√n
θ(1 − θ)
)
≈ Φ(ε
√n
θ(1 − θ)
)− Φ
(− ε
√n
θ(1 − θ)
)
= 2Φ(ε
√n
θ(1 − θ)
)− 1 .
Fur n = 1000 und α = 0.025, wenn man noch man eine Sicherheitsmarge von 0.02
fur den Approximationsfehler einfuhrt, ist Bedingung (9.1) sicher dann erfullt,
wenn
2Φ(ε
√n
θ(1 − θ)
)− 1 ≥ 0.975 + 0.02 ,
also
ε
√n
θ(1 − θ)≥ Φ−1(0.9975) = 2.82 .
Benutzen wir nun wieder θ(1− θ) ≤ 1/4, erhalt man die hinreichende Bedingung
ε ≥ 2.82/√
4000 ≈ 0.0446.
3. Methode (Verwendung der Binomial- und Beta-Quantile)
Wir werden die folgenden Eigenschaften der Binomialverteilung verwenden:
(a) Fur jedes 0 < θ < 1 ist die Funktion x 7→ Bn,θ(x) streng monoton steigend
fur x < [(n + 1)θ] und streng monoton fallend fur x > [(n + 1)θ], also maximal
fur x = [(n + 1)θ].

9.2 Konstruktion von Konfidenzbereichen 101
(b) Fur jedes x 6= 0 ist die Funktion θ 7→ Bn,θ(x, . . . , n) auf [0, 1] stetig und
streng monoton wachsend. Genauer gilt fur x ∈ 0, 1, . . . , n∑
k=x
n
(n
k
)θx(1−θ)n−x = Bn,θ(x, . . . , n) = βx,n−x+1([0, θ]) =
∫ θ
0
zx−1(1−z)n−x−1 dz .
[Der Beweis von (a) ist trivial. Teil (b) kann mit analytischen Methoden sehr
einfach bewiesen werden, es gibt aber auch einen netten probabilistischen Beweis
(siehe Georgii, Lemma 8.8).
Wir verwenden das Konstruktionsverfahren vom Beginn des Abschnitts.
Aufgabe: Fur jedes θ ∈ (0, 1) finde Cθ so dass Bn,θ(Cθ) ≥ 1 − α.
Nach Eigenschaft (a) sollte Cθ ein geeignetes “Mittelstuck” von X = 0, . . . , nsein. Wahle also Cθ := x−(θ), . . . , x+(θ) mit
x−(θ) = maxx ∈ X : Bn,θ(0, . . . , x − 1) ≤ α/2
x+(θ) = minx ∈ X : Bn,θ(x + 1, . . . , n) ≤ α/2
Sei x der Beobachtungswert, dann finden wir C(x) als Losung von x ∈ Cθ. Nach
(b) oben gilt fur x 6= 0
x ≤ x+(θ) ⇔ βx,n−x+1([0, θ]) = Bn,θ(x, . . . , n) > α/2
⇔ θ > p−(x) ,
wobei p−(x) das α/2-Quantil von βx,n−x+1 ist. Setzt man p−(0) = 0, gilt
x ≤ x+(θ) ⇔ θ > p−(x) auch fur x = 0. Genauso erhalt man
x ≥ x−(θ) ⇔ θ < p+(x) ,
wobei p+(x) das 1−α/2-Quantil von βx,n−x+1 = 1− p−(n−x) ist mit p+(n) = 1.
Also ist
C(x) =(p−(x) , p+(x)
)
ein Konfidenzintervall fur θ zum Irrtumsniveau α.

102 9. Konfidenzbereiche

Kapitel 10
Tests von Hypothesen
10.1 Definitionen
In der Praxis laufen statistische Probleme haufig auf eine Ja-Nein-Entscheidung
hinaus, die davon abhangt, ob eine Hypothese uber einen unbekannten Sach-
verhalt wahr ist oder nicht: Patienten behandeln oder nicht, neue Methoden
einfuhren oder nicht, eine neue wissenschaftliche Theorie glauben oder nicht. Ob
die Hypothese stimmt, kann oft nur indirekt aus Daten erschlossen werden, die
bei einem Zufallsexperiment gewonnen werden.
Beispiel 10.1. Es wird ein neues Verfahren angeboten, das angeblich das Ge-
schlechterverhaltnis bei Rindergeburten beeinflusst: mehr (wertvollere) Kuhkalber
als Stierkalber.
Frage: Soll der Landwirt/Viehzuchter das Verfahren kaufen oder nicht?
Als Entscheidungsgrundlage dienen Ergebnisse von (aus Zeitgrunden nicht zu
vielen) Geburten.
Mathematischer Rahmen:
Definition 10.2 (Testproblem). Sei (X ,F , (Pθ)θ∈Θ) ein statistisches Modell.
Ein Testproblem besteht aus einer disjunkten Zerlegung Θ = Θ0 ∪ Θ1 in eine
103

104 10. Tests von Hypothesen
(Null-)Hypothese Θ0 und eine Alternativ- oder Gegenhypothese Θ1. Ein
Test von
H0 : θ ∈ Θ0 gegen H1 : θ ∈ Θ1
ist eine Statistik D : X → 0, 1. Die Menge K := x ∈ X : D(x) = 1 heißt
Ablehnungsbereich oder kritischer Bereich des Tests.
Bemerkung 10.3. (1) Interpretation: Die Hypothese ist der erwartete Aus-
gang des Experiments, der Normalfall; die Alternative ist die Abweichung von
der Norm, die man ggf. entdecken mochte.
D(x) = 1 bedeutet, dass man sich aufgrund der Daten x fur die Alternative ent-
scheidet.
(2) Zwei Arten von Fehler sind moglich:
Fehler 1. Art: falschliches Ablehnen der Hypothese: D(x) = 1, obwohl θ ∈ Θ0;
Fehler 2. Art: falschliches Akzeptieren der Hypothese: D(x) = 0, obwohl θ ∈ Θ1.
Ziel: Wahrscheinlichkeit fur diese Fehler klein halten.
(3) Schatztheorie: Bestimmung von θ ∈ Θ.
Testtheorie: (nur) Entscheidung, ob θ ∈ Θ0 oder θ ∈ Θ1.
Beispiel 10.4. [Fortsetzung von Beispiel 10.1]
Es liegen Beobachtungen von n = 20 Geburten vor, davon waren x Kuhkalber.
Als statistisches Modell wahlen wir das Binomialmodell
(X ,F , (Pθ)θ∈Θ) = (0, . . . , n,P(0, . . . , n), (Bn,θ)θ∈Θ) mit Θ = [12, 1].
Hypothese: H0 : θ = θ0 =1
2“kein Effekt”
Alternative: H1 : θ ∈ Θ1 =(
12, 1
)“es wirkt”.
Definition 10.5 (Fortsetzung von Definition 10.2).
(1) Der maximale Fehler 1. Art, d.h. supθ∈Θ0Pθ(K) heißt (Signifikanz-)Niveau
von D.
D heißt Test zum (Signifikanz-)Niveau α, falls supθ∈Θ0Pθ(K) ≤ α.
(2) Die Funktion βD : Θ → [0, 1] mit βD(θ) := Pθ(K) (= Eθ(D) heißt Gute-

10.1 Definitionen 105
funktion des Tests.
Fur θ ∈ Θ1 heißt βD(θ) Macht, Starke, Scharfe von D bei θ.
Bemerkung 10.6. Fur θ ∈ Θ0 ist βD(θ) die Wahrscheinlichkeit eines Fehlers 1.
Art; fur θ ∈ Θ1 ist 1 − βD(θ) die Wahrscheinlichkeit eines Fehlers 2. Art
Problem: In der Regel bewirkt eine Verringerung der Wahrscheinlichkeit des
Fehlers 1. Art eine Erhohung der Fehlerwahrscheinlichkeit 2. Art und umgekehrt:
gleichzeitige Minimierung beider Fehler ist nicht moglich.
Ausweg: Asymmetrische Behandlung der Fehler: Man wahlt ein Niveau α ∈(0, 1) (haufig α = 0.05) und sucht unter allen Tests zum Niveau α (d.h. mit
Fehlerwahrscheinlichkeit 1. Art ≤ α) einen Test mit maximaler Macht βD(θ) fur
alle θ ∈ Θ1 (d.h. mit moglichst geringer Fehlerwahrscheinlichkeit 2. Art).
Definition 10.7 (Fortsetzung der Definitionen 10.2 und 10.5).
(1) Ein Test D von Θ0 gegen Θ1 heißt gleichmaßig bester Test zum Niveau
α, falls er ein Test zum Niveau α ist und βD(θ) ≥ βD′(θ), θ ∈ Θ1, fur alle anderen
Tests D′ zum Niveau α.
(2) Ein Test D heißt unverfalscht zum Niveau α, falls
βD(θ0) ≤ α ≤ βD(θ1) ∀θ0 ∈ Θ0 , θ1 ∈ Θ1 ,
d.h. Entscheidung fur die Alternative ist wahrscheinlicher, wenn sie wahr ist als
wenn sie falsch ist.
Bemerkung 10.8. (1) Zuordnung von Hypothese und Alternativhypothese
hangt von Anwendung/Interessen/Folgen ab. Ein Fehler 1. Art ist ein “peinlicher
Irrtum”.
(2) Asymmetrische Sprechweise:
“D(x) = 1′′ : Man lehnt die Hypothese ab und entscheidet sich fur die Alterna-
tive.
“D(x) = 0′′ : Man lehnt die Hypothese nicht ab. Das bedeutet nicht unbedingt,
dass man die Alternative fur falsch halt, sondern moglicherweise nur, dass die

106 10. Tests von Hypothesen
Daten nicht ausreichen, um die Hypothese zu verwerfen.
(3) Achtung: “Test D hat Niveau α = 0.05” bedeutet nicht, dass
– im Falle D(x) = 1 die Alternative mit Wahrscheinlichkeit 0.95 wahr ist oder
– im Falle D(x) = 0 die Hypothese mit Wahrscheinlichkeit 0.95 wahr ist.
Hypothese und Alternative sind nicht zufallig.
(4) Gleichmaßig beste Tests mussen nicht existieren. Manchmal existieren im-
merhin gleichmaßig beste unverfalschte Tests. Aber auch diese mussen nicht exi-
stieren; und selbst wenn, sind sie nicht immer bestimmbar.
Beispiel 10.9. [Fortsetzung von Beispiel 10.1, 10.4]
Wahle z.B. als Niveau α = 0.05 (neues Verfahren mit hochstens 5% Irrtumswahr-
scheinlichkeit kaufen).
Idee: Wahle D(x) = 1(c,∞)(x), d.h. K = c+1, c+2, . . . , n fur ein c ∈ 0, . . . , n.Fehler 1. Art: P 1
2(K) = B20, 1
2(c + 1, c + 2, . . . , n) =
20∑k=c+1
(20k
)(12
)20
.
Dies ist 0.0207 fur c = 14 und 0.0577 fur c = 13.
Das Niveau wird also eingehalten fur c ≥ 14.
Macht bei θ ∈ Θ1:
Pθ(K) = B20,θ(c + 1, . . . , n) =20∑
k=c+1
(20
k
)θk(1 − θ)20−k .
Diese wird mit wachsendem c kleiner.
Ergebnis: Wahle also c = 14; Kauf des Verfahrens bei mehr als 14 Kuhkalbern.
Angenommen, θ = 0.7 ist schon wirtschaftlich interessant. Macht bei θ = 0.7:
P0.7(K) = 0.417, d.h. mit Wahrscheinlichkeit 1 − 0.417 = 0.583 wird ein solches
Verfahren verkannt. Das ist unbefriedigend (Fehler 2. Art).
Moglicher Ausweg: grosseres n zur Erhohung der Trennscharfe.

10.2 Konstruktion von Tests 107
10.2 Konstruktion von Tests
Wir beginnen mit einem sehr einfachen Fall: Θ0 und Θ1 sind einelementig, dann
spricht man von einfachen Hypothesen.
Sei (X ,F , (Pθ)θ∈Θ) ein diskretes oder stetiges statistisches Modell mit den zu-
gehorigen Dichten (ρθ)θ∈Θ. Seien Θ = θ0, θ1, Θ0 = θ0 und Θ1 = θ1.Idee: Wahrscheinlichkeit der Beobachtung x unter θ1 groß und unter θ0 klein
⇒ Entscheidung fur Θ1.
Wahrscheinlichkeit der Beobachtung x unter θ1 klein und unter θ0 groß
⇒ Entscheidung fur Θ0.
Definition 10.10 (Likelihood-Quotienten-Test).
(1) Die Funktion R : X → [0,∞] definiert durch
R(x) =
ρθ1(x)
ρθ0(x)falls ρθ0(x) > 0
∞ sonst
heißt Likelihood-Quotient (LQ).
(2) Ein Likelihood-Quotienten-Test (LQ-Test) fur θ0 gegen θ1 ist ein Test D
der Form
D(x) =
1 falls R(x) > c ,
0 falls R(x) < c ,
fur ein c ≥ 0.
Solche Tests sind tatsachlich optimal.
Satz 10.11 (Neyman-Pearson-Lemma). Im obigen Rahmen ist jeder Likelihood-
Quotienten-Test D ein bester Test zu seinem Signifikanzniveau α.
Beweis. (Nur fur Lebesgue-Dichten, fur Zahldichten geht es analog.)
Sei D′ ein weiterer Test zum Niveau α. Sei x ∈ X .
Fur ρθ1(x) − cρθ0(x) > 0 ist D(x) = 1,
fur ρθ1(x) − cρθ0(x) < 0 ist D(x) = 0,

108 10. Tests von Hypothesen
µ1 µ0
αFehler 1. Art
H0H1
µ1 µ0
Fehler 2. Art
H1 H0
Abbildung 10.1: Fehler 1. und 2. Art.

10.2 Konstruktion von Tests 109
also ist (D(x) − D′(x))(ρθ1(x) − cρθ0(x)) ≥ 0, also ist
∫(D(x) − D′(x))(ρθ1(x) − cρθ0(x))dx ≥ 0 .
Somit gilt
Eθ1(D) − Eθ1(D′) =
∫D(x)ρθ1(x)dx −
∫D′(x)ρθ1(x)dx
≥ c
(∫D(x)ρθ0(x)dx −
∫D′(x)ρθ0(x)dx
)
= c(Eθ0(D) − Eθ0(D
′)).
Wegen der Stetigkeit von ρ0 wird das Niveau exakt erreicht, und mit Eθ0(D) =
α = Eθ0(D′) folgt Eθ1(D) ≥ Eθ1(D
′). ¤
Dieser einfache Fall kommt in der Praxis kaum vor. Dort entscheidet man ubli-
cherweise bgzl. zusammengesetzter (mehrelementiger) Hypothesen.
Sei (X ,F , (Pθ)θ∈Θ) ein diskretes oder stetiges statistisches Modell mit zugehori-
gen Dichten (ρθ)θ∈Θ. Sei Θ = Θ0 ∪ Θ1 eine disjunkte Zerlegung.
Definition 10.12 (Likelihood-Quotienten-Test, allgemeiner Fall).
(1) Die Funktion R : X → [0,∞] definiert durch
R(x) =
supθ∈Θ1ρθ(x)
supθ∈Θ0ρθ(x)
falls supθ∈Θ1ρθ0(x) > 0
∞ sonst
heißt Likelihood-Quotient (LQ).
(2) Ein Likelihood-Quotienten-Test (LQ-Test) fur Θ0 gegen Θ1 ist ein Test D
der Form
D(x) =
1 falls R(x) > c ,
0 falls R(x) < c ,
fur ein c ≥ 0.
Bemerkung 10.13. (1) Solche Tests haben nicht immer, aber oft zumindest
gewisse Optimalitatseigenschaften (vgl. ML-Schatzer).

110 10. Tests von Hypothesen
(2) Wenn T0 : X → Θ0 ein ML-Schatzer von θ bzgl. Θ0 und
T1 : X → Θ1 ein ML-Schatzer von θ bzgl. Θ1 sind, dann gilt
R(x) =ρT1(x)(x)
ρT0(x)(x)fur x ∈ X mit Nenner 6= 0 .
Beispiel 10.14. [Fortsetzung von Beispiel 10.1,10.9]
Frage: Welche Gestalt haben Likelihood-Quotienten-Tests in diesem Beispiel ?
Es ist ρθ(x) =(
nx
)θx(1 − θ)n−x fur x = 0, . . . , n, also
d
dθρθ(x) =
(n
x
)θx−1(1 − θ)n−x−1
︸ ︷︷ ︸>0
(x(1 − θ) − (n − x)θ)︸ ︷︷ ︸=x−nθ
> 0 falls θ < xn
,
< 0 falls θ > xn
.
Somit ist supθ∈( 12,1] ρθ(x) = ρmax 1
2, xn(x), also
R(x) =ρmax 1
2, xn(x)
ρ 12(x)
=
(n
x
)(x
n
)x(1 − x
n)n−x
(n
x
)(1
2
)n=
(2kk(1 − k)1−k
)nfalls k :=
x
n>
1
2,
1 falls k :=x
n≤ 1
2,
Es gilt fur k >1
2,
d
dklog(kk(1 − k)1−k) =
d
dk(k log k + (1 − k) log(1 − k)) = log
( k
1 − k
)> 0 .
Folglich ist x 7→ R(x) monoton wachsend, also sind Likelihood-Quotienten-Tests
von der Form
D(x) =
1 falls x > c ,
0 falls x < c ,
fur ein c ∈ 0, . . . , n, wie in Beispiel 10.9 angesetzt.
Beispiel 10.15. [Einseitiger Test fur den Erwartungswert der Normalverteilung
bei bekannter Varianz, einseitiger Gauß-Test]
Sei (X ,F , (Pθ)θ∈Θ) = (Rn,Bn, (N⊗nµ,σ2)µ∈R) das n-fache Produktmodell mit σ2 > 0

10.2 Konstruktion von Tests 111
gegeben. Unser Testproblem lautet fur ein µ0 ∈ R.
Teste
H0 : Θ0 = (−∞, µ0] gegen H1 : Θ1 = (µ0,∞) .
Frage: Welche Gestalt haben die LQ-Tests?
Es gilt mit der Verschiebungsformel (Beispiel 7.20) und dem arithmetischen Mit-
tel x
ρµ(x) = (2πσ2)−n/2 exp(− 1
2σ2
n∑
i=1
(xi − µ)2)
= (2πσ2)−n/2 exp(− 1
2σ2
( n∑
i=1
(xi − x)2 + n(x − µ)2))
.
Daher ist supµ∈Θ0ρµ(x) = ρminx,µ0(x) und supµ∈Θ1
ρµ(x) = ρmaxx,µ0(x). Damit
ist der LQ
R(x) =ρmaxx,µ0(x)
ρminx,µ0(x)=
exp(− 1
2σ2n(x − µ0)
2)
falls x ≤ µ0 ,
exp( 1
2σ2n(x − µ0)
2)
falls x > µ0 .
Da x 7→ R(x) eine streng monoton wachsende Funktion von x ist, sind LQ-Tests
von der Form
D(x) =
1 falls x > c ,
0 falls x < c ,
fur ein c ∈ R.
Frage: Was ist das Signifikanzniveau α von D ?
Nach Satz 8.22(2) ist X unter Pµ Nµ,σ2/n-verteilt, also gilt
α := supθ∈Θ0
Pθ(D = 1) = supµ≤µ0
Nµ,σ2/n((c,∞)) = supµ≤µ0
N0,1
(( c − µ
σ/√
n,∞
))
= supµ≤µ0
1 − Φ( c − µ
σ/√
n
)= 1 − Φ
(c − µ0
σ/√
n
).
Zu gegebenem Niveau α wahle alsoc − µ0
σ/√
n= Φ−1(1 − α), um das Niveau voll
auszuschopfen. Man erhalt den Test
D(x) =
1 falls x > µ0 +
√σ2
nΦ−1(1 − α) ,
0 sonst .

112 10. Tests von Hypothesen
Die Gutefunktion ist
βD(µ) = Pµ
(x − µ
σ/√
n> Φ−1(1 − α) +
µ0 − µ
σ/√
n
)= 1−Φ
(Φ−1(1 − α) +
µ0 − µ
σ/√
n
).
Bemerkung 10.16. Der einseitige Gauß-Test in Beispiel 10.15 ist gleichmaßig
bester Test zu seinem Niveau (ohne Beweis).
Beispiel 10.17. [Zweiseitiger Test fur den Erwartungswert der Normalverteilung
bei bekannter Varianz, zweiseitiger Gauß-Test]
Sei (X ,F , (Pθ)θ∈Θ) = (Rn,Bn, (N⊗nµ,σ2)µ∈R) das n-fache Produktmodell mit σ2 > 0
gegeben, wie in Beispiel 10.15. Unser Testproblem lautet fur ein µ0 ∈ R: Teste
H0 : Θ0 = µ0 gegen H1 : Θ1 = R \ µ0 .
Frage: Welche Gestalt haben die LQ-Tests?
Analog zu Beispiel 10.15 folgt supθ∈Θ0ρθ(x) = ρµ0(x) und supθ∈Θ1
ρθ(x) = ρx(x),
also
R(x) =ρx(x)
ρµ0(x)= exp
(1
2σ2n(x − µ0)
2
).
Da x 7→ R(x) eine streng monoton wachsende Funktion von |x − µ0| ist, sind
LQ-Tests von der Form
D(x) =
1 falls |x − µ0| > c ,
0 falls |x − µ0| < c ,
fur ein c ∈ R.
Frage: Was ist das Signifikanzniveau α von D ?
α := supθ∈Θ0
Pθ(D = 1) = Nµ0,σ2/n((µ0 − c, µ0 + c)∁) = N0,1
(( −c
σ/√
n,
c
σ/√
n
)c)
= 1 −(
Φ( c
σ/√
n
)− Φ
( −c
σ/√
n
))= 2
(1 − Φ
( c
σ/√
n
)).
Zu gegebenem Niveau α wahle alsoc
σ/√
n= Φ−1
(1 − α
2
), d.h. den Test
D(x) =
1 falls |x − µ0| >
√σ2
nΦ−1
(1 − α
2
),
0 sonst .

10.2 Konstruktion von Tests 113
In praktischen Anwendungen ist die Varianz in der Regel unbekannt.
Beispiel 10.18. [Einseitiger Test fur den Erwartungswert der Normalverteilung
bei unbekannter Varianz, einseitiger t-Test]
Sei (X ,F , (Pθ)θ∈Θ) = (Rn,Bn, (N⊗nµ,σ2)(µ,σ2)∈R×(0,∞)) das n-fache Produktmodell;
vgl. die Beispiele 10.15, 10.17. Unser Testproblem lautet fur ein µ0 ∈ R.
Teste
H0 : Θ0 = (−∞, µ0] × (0,∞) gegen H1 : Θ1 = (µ0,∞) × (0,∞) .
Frage: Welche Gestalt haben die LQ-Tests?
Es ist log ρθ(x) = −n
2log(2πσ2) − 1
2σ2
n∑i=1
(xi − µ)2, also
d
dσ2log ρθ(x) = −n
2
1
σ2+
1
2σ4
n∑
i=1
(xi − µ)2 .
Dies ist > 0 fur σ2 < vµ :=1
n
n∑i=1
(xi − µ)2 und < 0 fur σ2 > vµ.
Somit ist
supθ∈Θ0
ρθ(x) = supµ≤µ0,σ2>0
ρµ,σ2(x) = supµ≤µ0
ρµ,vµ(x) ,
und analog supθ∈Θ1ρθ(x) = supµ≥µ0
ρµ,vµ(x). Also gilt
R(x) =supµ≥µ0
ρ(µ,vµ)(x)
supµ≤µ0ρ(µ,vµ)(x)
=
supµ≥µ0(2πvµ)−n/2 exp
(− 1
2vµ
nvµ
)
supµ≤µ0(2πvµ)−n/2 exp
(− 1
2vµ
nvµ
) =supµ≥µ0
v−n/2µ
supµ≤µ0v−n/2µ
.
vµ =1
n
n∑
i=1
(xi − µ)2 =1
n
n∑
i=1
(xi − x)2
︸ ︷︷ ︸=:σ2
+ (x − µ)2
︸ ︷︷ ︸wachsend in |x−µ|
folgt
R(x) =
(σ2
vµ0
)n/2
falls x < µ0 ,(vµ0
σ2
)n/2
falls x ≥ µ0 .
Ferner istvµ0
σ2= 1 +
(x − µ0)2
σ2= 1 +
τ 2µ0
n − 1

114 10. Tests von Hypothesen
mit τµ0 :=(x − µ0)
√n√
1n−1
∑ni=1(xi − x)2
. Somit ist R eine streng monoton wachsende
Funktion in τµ0 . Ein LQ Test hat also die Form
D(x) =
1 falls τµ0 > c ,
0 falls τµ0 < c ,
fur ein c ∈ R.
Frage: Was ist das Signifikanzniveau α von D ?
Unter Pθ ist τµ :=(x − µ)
√n√
1n−1
∑ni=1(xi − x)2
nach Satz 8.22(4) tn−1-verteilt (un-
abhangig von θ). Wegen
τµ0 = τµ − (µ0 − µ)√
n√1
n−1
∑ni=1(xi − x)2
ist Pθ(D = 1) maximal fur µ = µ0, also
α := supθ∈Θ0
Pθ(D = 1) = tn−1((c,∞)) = 1 − tn−1((−∞, c]) .
Zu gegebenem Niveau α wahle also c = tn−1,1−α, wobei tn−1,1−α das (1 − α)-
Quantil der tn−1-Verteilung ist; d.h. wahle den Test
D(x) =
1 falls τµ0 > tn−1,1−α ,
0 sonst .
Beispiel 10.19. [Zweiseitiger Test fur den Erwartungswert der Normalverteilung
bei unbekannter Varianz, zweiseitiger t-Test]
Sei (X ,F , (Pθ)θ∈Θ) = (Rn,Bn, (N⊗nµ,σ2)(µ,σ2)∈R×(0,∞)) das n-fache Produktmodell
wie in Beispiel 10.18. Unser Testproblem lautet fur ein µ0 ∈ R: Teste
H0 : Θ0 = µ0 × (0,∞) gegen H1 : Θ1 = R \ µ0 × (0,∞) .
Frage: Welche Gestalt haben die LQ-Tests?
Analog zu Beispiel 10.18 folgt supθ∈Θ0ρθ(x) = ρ(µ0,vµ0 )(x) und supθ∈Θ1
ρθ(x) =
ρ(x,σ2)(x), also ist
R(x) =(vµ0
σ2
)n/2
=
(1 +
τ 2µ0
n − 1
)n/2

10.2 Konstruktion von Tests 115
eine streng monoton wachsende Funktion von |τµ0 |. Analog zu Beispiel 10.17 und
10.18 erhalt man den LQ-Test zum Niveau α
D(x) =
1 falls |τµ0 | > tn−1,1−α2,
0 sonst .
Sprechweise: Man sagt, der unbekannte Parameter µ sei signifikant von µ0 ver-
schieden, falls die Hypothese H0 fur α = 0.05 abgelehnt wird; µ heißt hochsigni-
fikant von µ0 verschieden, falls die H0 fur α = 0.01 abgelehnt wird.
Bemerkung 10.20. Die ein- bzw. zweiseitigen t-Tests in Beispiel 10.18, 10.19
sind gleichmaßig beste unverfalschte Tests zum Niveau α, aber nicht gleichmaßig
beste Tests (ohne Beweis).
Bemerkung 10.21. In den bisherigen Beispielen wurden Familien von Tests mit
kritischem Bereich Kα fur α ∈ (0, 1) bestimmt, wobei Kα ⊂ Kα′ fur α ≤ α′; etwa
Kα = T ≥ t1−α fur eine feste Statistik T : X → R. Fur x ∈ X definiert man
den p-Wert als p(x) := infα ∈ (0, 1) : x ∈ Kα, d.h. das kleinste Niveau α
derart, dass die Hypothese bei Beobachtung von x durch den zu α gehorigen Test
der Testfamilie abgelehnt wird.
Bemerkung 10.22. [Zu sauberem und unsauberen Vorgehen!]
(1) man sollte in der folgenden Reihenfolge arbeiten:
(a) Wahl des statistischen Modells;
(b) Wahl von Hypothese und Gegenhypothese;
(c) Wahl des Niveaus;
(d) Wahl des Tests;
(e) Erhebung der Daten;
(f) Entscheidung.
(2) In der Medizinstatistik geht man noch weiter:
(a) Kontrollgruppe: Es wird mit ununterscheidbarem Medikament ohne Wirk-
stoff verglichen, um Placebo-Effekte auszuschließen.

116 10. Tests von Hypothesen
(b) Doppel-Blind: Weder Arzt noch Patient wissen, ob Medikament oder Place-
bo angewandt wird.
(c) Randomisieren: Die Zuordnung Placebo/Wirkstoff erfolg zufallig.
(3) Mogliche Fehler:
(a) Hypothese an gleichen Daten bilden und testen.
(b) Niveau dem Ergebnis anpassen: p-Werte genau interpretieren (s.u.).
(c) Mehrere Tests nacheinander, solange bis Ablehnung erfolgt.
u.v.a.m.
(4) p-Werte:
(a) Sie sind datenabhangig und besitzen keine Fehlerrateninterpretation wie α.
(b) In Statistikprogrammen werden haufig die p-Werte ausgegeben. Man ist an
kleinsten p-Werten interessiert.
(c) Ein großer p-Wert sagt nichts uber die Wahrscheinlichkeit des Fehlers 2. Art
aus.

Kapitel 11
Einfuhrung in die linearen
Modelle
11.1 Einfache lineare Regression
Beispiel 11.1. [Preise und Abnahmemengen bei Tierfutter]
Verschiedene Geschafte in Bayern bieten Tierfutter zu unterschiedlichen Preisen
an. In der folgenden Tabelle sind die Abnahmemengen Y (zufallig) den Preisen
x (deterministisch) gegenubergestellt.
xi 3.5 2.4 1.8 3.2 2.4 3.5 3.0 3.5 4.0 1.8 2.9 3.5 2.4 2.9 3.3
yi 23.2 38.5 42.0 32.1 41.2 25.8 41.0 33.9 22.7 43.3 34.8 33.1 42.6 32.7 24.0
xi 2.6 2.6 1.6 3.0 1.5 3.0 2.4 3.9 2.3 2.1 2.7 2.6 4.0 2.9 1.1
yi 31.5 34.2 47.9 34.4 49.2 34.4 36.6 28.5 40.6 42.1 37.1 33.0 21.8 37.4 52.1
Tabelle 11.1: Preise x und Abnahmemengen Y .
Modell der einfachen linearen Regression: Lineare Abhangigkeit + Messfehler
Yi := γ0 + γ1xi + σξi , i = 1, . . . , n , (11.1)
mit γ0, γ1 ∈ R, σ ∈ (0,∞) und ξ1, . . . , ξn unabhangige, identisch verteilte Zufalls-
variable mit E(ξi) = 0, Var(ξi) = 1.
117
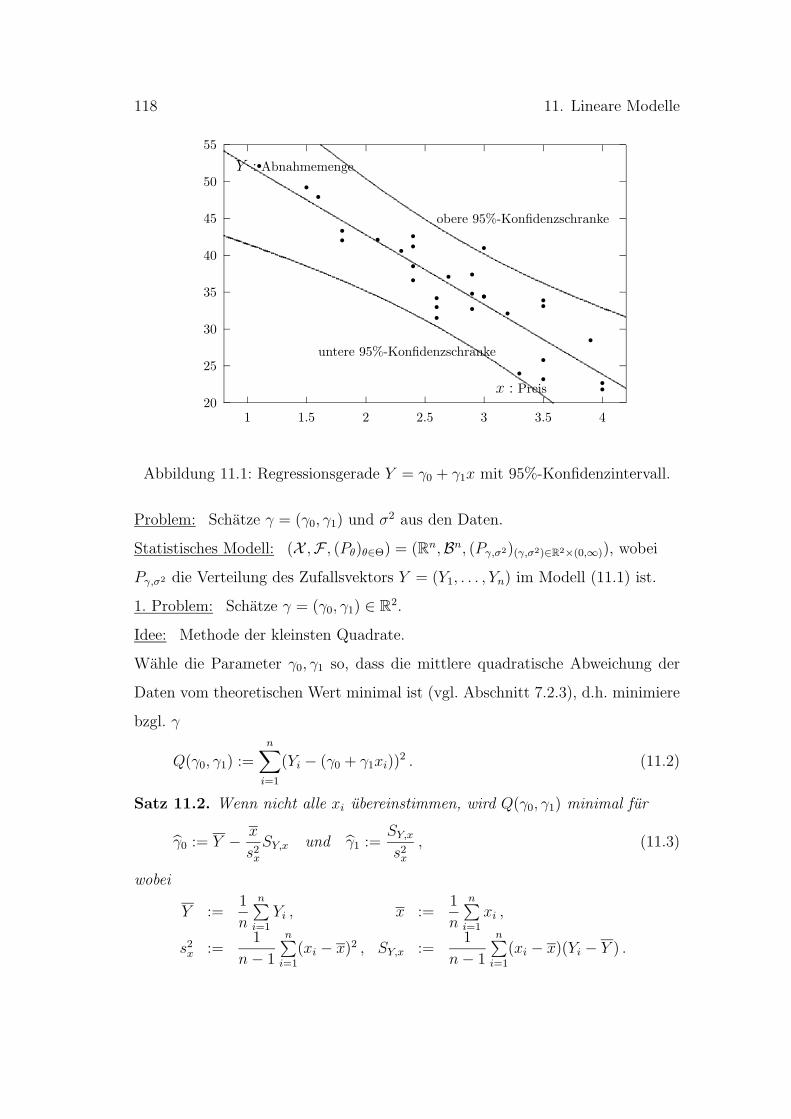
118 11. Lineare Modelle
20
25
30
35
40
45
50
55
1 1.5 2 2.5 3 3.5 4
x : Preis
Y : Abnahmemenge
obere 95%-Konfidenzschranke
untere 95%-Konfidenzschranke
r
r
r
r
r
r
r
r
r
r
r
r
r
r
r
r
r
r
r
r
r
r
r
r
r
r
r
r
r
r
Abbildung 11.1: Regressionsgerade Y = γ0 + γ1x mit 95%-Konfidenzintervall.
Problem: Schatze γ = (γ0, γ1) und σ2 aus den Daten.
Statistisches Modell: (X ,F , (Pθ)θ∈Θ) = (Rn,Bn, (Pγ,σ2)(γ,σ2)∈R2×(0,∞)), wobei
Pγ,σ2 die Verteilung des Zufallsvektors Y = (Y1, . . . , Yn) im Modell (11.1) ist.
1. Problem: Schatze γ = (γ0, γ1) ∈ R2.
Idee: Methode der kleinsten Quadrate.
Wahle die Parameter γ0, γ1 so, dass die mittlere quadratische Abweichung der
Daten vom theoretischen Wert minimal ist (vgl. Abschnitt 7.2.3), d.h. minimiere
bzgl. γ
Q(γ0, γ1) :=n∑
i=1
(Yi − (γ0 + γ1xi))2 . (11.2)
Satz 11.2. Wenn nicht alle xi ubereinstimmen, wird Q(γ0, γ1) minimal fur
γ0 := Y − x
s2x
SY,x und γ1 :=SY,x
s2x
, (11.3)
wobei
Y :=1
n
n∑i=1
Yi , x :=1
n
n∑i=1
xi ,
s2x :=
1
n − 1
n∑i=1
(xi − x)2 , SY,x :=1
n − 1
n∑i=1
(xi − x)(Yi − Y ) .

11.1 Einfache lineare Regression 119
Beweis. Q : R2 → R ist stetig differenzierbar mit
D1Q(γ0, γ1) = −2n∑
i=1
(Yi − γ0 − γ1xi) = −2n(Y − γ0 − γ1x)
D2Q(γ0, γ1) = −2n∑
i=1
(Yi − γ0 − γ1xi)xi = −2
(n∑
i=1
xiYi − γ0nx − γ1
n∑
i=1
x2i
).
Diese beiden Ableitungen werden genau dann 0, wenn γ0 = Y − γ1x und
0 =n∑
i=1
xiYi − nY x − γ1(n∑
i=1
x2i − x2) =
n∑
i=1
(xi − x)(Yi − Y ) − γ1
n∑
i=1
(xi − x)2 ,
also wenn γ0 = γ0 und γ1 = γ1.
Die Hessematrix
H(γ0, γ1) =
D11Q(γ0, γ1) D12Q(γ0, γ1)
D21Q(γ0, γ1) D22Q(γ0, γ1)
= 2n
1 x
x1
n
n∑i=1
x2i
ist positiv definit, denn
det H(γ0, γ1) = 2n( 1
n
n∑
i=1
x2i − x2
)= 2
n∑
i=1
(xi − x)2 > 0 . ¤
Satz 11.3. Die kleinste-Quadrate-Schatzer (KQ-Schatzer) γ0, γ1 sind erwartungs-
treu fur γ0, γ1.
Beweis. Fur θ = (γ, σ2) gilt Eθ(Yi) = γ0 + γ1xi. Folglich gilt
Eθ(SY,x) =1
n − 1
n∑
i=1
(xi − x)(Eθ(Yi) −
1
n
n∑
i=1
Eθ(Yi))
=1
n − 1
n∑
i=1
(xi − x)(γ0 + γ1xi −
1
n
n∑
i=1
(γ0 + γ1xi))
=1
n − 1
n∑
i=1
(xi − x)γ1(xi − x)
= γ1s2x .
Daraus folgt mit (11.3)
Eθ(γ1) =Eθ(SY,x)
s2x
=γ1s
2x
s2x
= γ1

120 11. Lineare Modelle
und
Eθ(γ0) =1
n
n∑
i=1
Eθ(Yi) −x
s2x
Eθ(SY,x) =1
n
n∑
i=1
(γ0 + γ1xi) − xγ1 = γ0 . ¤
Bemerkung 11.4. (1) Die obigen Resultate gelten auch, wenn die xi nicht
deterministisch, sondern ihrerseits Zufallsvariable sind.
(2) Achtung vor Fehlinterpretationen: Der scheinbare Kausalzusammenhang kann
durch eine dritte, unbeobachtete Quelle ausgelost sein.
(3) Bezeichnung: Die xi heißen Ausgangsvariable, unabhangige Variable
oder Regressorvariable;
die Yi heißen Zielvariable oder abhangige Variable;
die ξi heißen Fehler oder Storgrossen;
γ = (γ0, γ1) heißen Verschiebungsparameter;
die Gerade x 7→ γ0 + γ1x heißt Regressionsgerade oder Ausgleichsgerade,
σ2 heißt Skalenparameter.
11.2 Allgemeines lineares Modell
Das Modell in Abschnitt 11.1 ist ein Spezialfall des linearen Modells:
Y = Xγ + σξ . (11.4)
Dabei seien s, n ∈ N mit s < n,
ξ = (ξ1, . . . , ξn)⊤ sei ein Vektor von unabhangigen, identisch verteilten Zufallsva-
riablen mit beliebiger, aber fester Verteilung, so dass E(ξi) = 0, Var(ξi) = 1;
X ∈ Rn×s mit Rang(X) = s sei eine bekannte Matrix, die Designmatrix;
γ = (γ1, . . . , γs)⊤ ∈ Rs ist ein unbekannter Verschiebungsparameter und
σ2 ∈ (0,∞) ist ein unbekannter Skalenparameter,
Y = (Y1, . . . , Yn) ist ein Zufallsvektor, der Beobachtungsvektor.

11.2 Allgemeines lineares Modell 121
Statistisches Modell: (X ,F , (Pθ)θ∈Θ) = (Rn,Bn, (Pγ,σ2)(γ,σ2)∈Rs×(0,∞)), wobei
Pγ,σ2 die Verteilung des Zufallsvektors Y = (Y1, . . . , Yn) in Modell (11.4) ist.
Problem: Schatze γ und σ2.
Idee: Methode der kleinsten Quadrate:
minimiere γ 7→ |Y − Xγ|2 . (11.5)
Das ist gerade die Orthogonalprojektion von Y auf L(X) := Xγ : γ ∈ Rs, d.h.
(11.5) wird minimal fur
γ = ΠL(X)(Y )
wobei ΠL : Rn → L fur einen Unterraum L ⊂ Rn die Orthogonalprojektion auf
L ist.
Zur Erinnerung aus der linearen Algebra: ΠL ist Orthogonalprojektion auf L
⇔ fur alle y ∈ Rn gilt ΠL(y) ∈ L und y − ΠL(y) ∈ L⊥ ( ∗ )
⇔ fur alle y ∈ Rn gilt ΠL(y) ∈ L und |y − ΠL(y)| = minu∈L |y − u|.(nach (∗) ist ΠL eindeutig).
Satz 11.5. X⊤X ist invertierbar und ΠL(X) = X(X⊤X)−1X⊤.
Beweis. (a) Annahme: Es existiert c ∈ Rs \ 0 mit X⊤Xc = 0
=⇒ |Xc|2 = c⊤X⊤Xc = 0 =⇒ Xc = 0 =⇒ Rang(X) 6= s. W!
Also ist Kern(X⊤X) = 0, d.h. X⊤X ist invertierbar.
(b) Fur y ∈ Rn ist X (X⊤X)−1X⊤y︸ ︷︷ ︸∈Rs
∈ L(X) und fur z ∈ Rs gilt
(Xz)⊤(y−X(X⊤X)−1X⊤y) = z⊤(X⊤y − X⊤X(X⊤X)−1X⊤y
)= z⊤
(X⊤y − X⊤y
)= 0
d.h. y − X(X⊤X)−1X⊤y ∈ L(X)⊥.
Nach (∗) ist dann ΠL(X)(y) = X(X⊤X)−1X⊤y := Xγ. ¤
Idee zur Schatzung von σ2:
Es ist σ2 = Var(σξi), wobei ξ1, . . . , ξn unabhangig, identisch verteilt sind mit

122 11. Lineare Modelle
Erwartungswert 0. Ein naheliegender Schatzer ist:
1
n
n∑
i=1
(σξi)2 =
1
n
n∑
i=1
((Y − Xγ)i)2 =
1
n|Y − Xγ|2 .
Problem: γ ist unbekannt.
Ausweg: Ersetze γ durch γ.
Neues Problem:1
n|Y − Xγ|2 ist nicht erwartungstreu fur σ2
(vgl. Stichprobenvarianz in Satz 7.5).
Aber: V ∗ :=1
n − s|Y − Xγ|2 ist erwartungstreu (s.u.).
Satz 11.6. (1) γ := (X⊤X)−1X⊤Y ist erwartungstreuer Schatzer fur γ.
(2) (Satz von Gauß-Markov) Sei τ : Rs → R definiert durch γ 7→ c⊤γ fur
ein c ∈ Rs eine lineare Kenngrosse. Dann ist T := c⊤γ ein erwartungstreuer
Schatzer fur τ . Unter allen linearen erwartungstreuen Schatzern fur τ (d.h.
Schatzern der Form b⊤Y fur ein b ∈ Rn) hat T minimale Varianz (glm. in
θ). (Bester linearer unverfalschter Schatzer, best linear unbiased estimator,
BLUE).
(3) Die Stichprobenvarianz
V ∗ :=1
n − s|Y −Xγ|2 =
1
n − s|Y −ΠL(X)(Y )|2 =
1
n − s
(|Y |2 − |ΠL(X)(Y )|2
)
ist erwartungstreuer Schatzer fur σ2.
Beweis. Sei θ = (γ, σ2) ∈ Θ.
(1) Wegen der Linearitat des Erwartungswertes gilt
Eθ(γ) = (X⊤X)−1X⊤Eθ(Y ) = (X⊤X)−1X⊤Xγ = γ .
(2) Fur a = X (X⊤X)−1c︸ ︷︷ ︸∈Rs
∈ L(X) gilt
T = c⊤γ = c⊤(X⊤X)−1X⊤Y = (X(X⊤X)−1c)⊤Y = a⊤Y . (11.6)

11.2 Allgemeines lineares Modell 123
Ferner ist Eθ(T ) = c⊤Eθ(γ) = c⊤γ (nach Teil (1)). Also ist T erwartungstreu.
Sei S : X → R ein weiterer linearer erwartungstreuer Schatzer fur τ , d.h. S = b⊤Y
fur ein b ∈ Rn und Eθ(b⊤Y ) = τ(γ) = c⊤γ. Daraus folgt
b⊤Xγ = b⊤Eθ(Y ) = Eθ(b⊤Y ) = τ(γ) = Eθ(T )
(11.6)= a⊤Eθ(Y ) = a⊤Xγ ,
d.h. b⊤u = a⊤u fur alle u ∈ L(X).
⇒ b − a ∈ L(X)⊥ ⇒ a = ΠL(X)(b), insbesondere gilt mit dem Satz von
Pythagoras |b|2 = |a|2 + |b − a|2 ≥ |a|2.Also gilt
Varθ(S) − Varθ(T ) = Eθ
(( b⊤Y − b⊤Xγ︸ ︷︷ ︸=b⊤(Y −Xγ)=b⊤σξ
)2 − (a⊤Y − a⊤Xγ︸ ︷︷ ︸=a⊤σξ
)2)
= σ2E(b⊤ξξ⊤b − a⊤ξξ⊤a)
= σ2(b⊤E(ξξ⊤)b − a⊤E(ξξ⊤)a)
= σ2(|b|2 − |a|2) ≥ 0 ,
wobei wir benutzt haben, dass E(ξξ⊤) = E(1n) (mit 1n Einheitsmatrix).
Also hat T minimale Varianz.
(3) Aus Xγ = X(X⊤X)−1X⊤Y = ΠL(X)(Y ) folgt die 2. Gleichheit.
Mit Pythagoras und (∗) folgt |Y |2 = |ΠL(X)(Y )|2 + |Y − ΠL(X)(Y )|2 und damit
die 3. Gleichheit.
Sei u1, . . . , un eine Orthonormalbasis von Rn mit L(X) = span(u1, . . . , us). Sei
O = (u1, . . . , un) ∈ Rn×n die Matrix mit Spalten u1, . . . , un. Dann ist O orthogo-
nale Matrix, die den linearen Raum H := x ∈ Rn : xs+1 = · · · = xn = 0auf L(X) abbildet. Die Orthogonalprojektion auf H wird beschrieben durch
Es :=
1 . . . 0 0 . . . 0
. . .
0 . . . 1 . . . 0
0 . . . 0 . . . 0
. . .
0 0
. Somit gilt ΠL(X) = OEsO⊤ = OEsO
−1.

124 11. Lineare Modelle
(Erlauterung: Denn die Orthogonalprojektion von y ∈ Rn auf L(X) ist cha-
rakterisiert durch
OEs O⊤y︸︷︷︸∈H
= y fur y ∈ L(X) und OEs O⊤y︸︷︷︸∈H⊥
= 0 fur y ∈ L(X)⊥ . ¤
)
Weiter gilt
(n − s)V ∗ = |Y − ΠL(X)(Y )|2Def= |Xγ + σξ − ΠL(X)(Xγ + σξ)|2(∗)= σ2|ξ − ΠL(X)(ξ)|2
= σ2|O⊤(ξ − ΠL(X)(ξ))|2 (O⊤ ist als orthog. Transf. normerhaltend)
= σ2|O⊤ξ − O⊤OEsO⊤ξ|2 setze η := O⊤ξ
= σ2|η − Esη|2 = σ2
n∑
i=s+1
η2i . (11.7)
Es ist mit E(ξkξl) = 1 falls k = l und 0 sonst:
E(η2i ) = E((
n∑
k=1
Oikξk)2) =
n∑
k,l=1
OikOilE(ξkξl) =n∑
k=1
O2ik = 1 .
Daraus folgt, dass (n − s)E(V ∗) = σ2(n − s), also ist V ∗ erwartungstreu. ¤
Beispiel 11.7. [Einfache lineare Regression, vgl. Abschnitt 11.1]
s = 2, X =
1 · · · 1
x1 · · · xn
⊤
, γ =
γ0
γ1
.
Dann ist
X⊤X =
nn∑
i=1
xi
n∑i=1
xi
n∑i=1
x2i
det(X⊤X) = n
n∑
i=1
x2i−
( n∑
i=1
xi
)2
= n2
(1
n
n∑
i=1
x2i − x2
)= n2
(1
n
n∑
i=1
(xi − x)2
)= n(n−1)s2
x .
Also gilt
(X⊤X)−1 =1
det(X⊤X)
n∑i=1
x2i −
n∑i=1
xi
−n∑
i=1
xi n
=
1
(n − 1)s2x
1n
n∑i=1
x2i −x
−x 1

11.2 Allgemeines lineares Modell 125
Folglich gilt mitn∑
i=1
xiYi − nxY =n∑
i=1
(xi − x)(Yi − Y ) = (n − 1)SY,x
γ = (X⊤X)−1X⊤Y = (X⊤X)−1
n∑i=1
Yi
n∑i=1
xiYi
=1
(n − 1)s2x
Yn∑
i=1
x2i − x
n∑i=1
xiYi
−nxY +n∑
i=1
xiYi
=1
(n − 1)s2x
Y((n − 1)s2
x + x2)− x
∑ni=1 xiYi
(n − 1)SY,x
=
γ0
γ1
Ferner gilt
V ∗ =1
n − 2|Y − Xγ|2 =
1
n − 2
∣∣∣Y − γ0
1...
1
− γ1
x1
...
xn
∣∣∣2
=1
n − 2
n∑
i=1
(Yi − γ0 − γ1xi)2 .
Beispiel 11.8. [Polynomiale Regression]
Statt der bisherigen linearen Abhangigkeit kann auch eine polynomiale Abhangig-
keit modelliert werden
Yi = γ0 + γ1xi + γ2x2i + · · · + γdx
di + σξi , i = 1, . . . , n .
Das ist ein Spezialfall des allgemeinen linearen Modells mit s = d + 1, γ =
(γ0, . . . , γd)⊤ und
X =
1 x1 x21 · · · xd
1
......
......
...
1 xn x2n · · · xd
n
.
Beispiel 11.9. [Mehrfache lineare Regression]
Lineare Abhangigkeit von mehreren Einflussgroßen:
Yi = γ0 + γ1xi,1 + · · · + γdxi,d + σξi , i = 1, . . . , n .

126 11. Lineare Modelle
Das ist ein Spezialfall des allgemeinen linearen Modells mit s = d + 1, γ =
(γ0, . . . , γd)⊤,
X =
1 x1,1 · · · x1,d
......
......
1 xn,1 · · · xn,d
.
11.3 Konfidenzintervalle und Hypothesentests
Man muss Verteilungsannahmen machen; ublicherweise setzt man folgendes Mo-
dell voraus.
Modell: Y = Xγ + σξ wie in Abschnitt 11.2 mit N0,1-verteilten Storgrossen ξi.
Statistisches Modell: (X ,F , (Pθ)θ∈Θ) = (Rn,Bn, (NXγ,σ21n)(γ,σ2)∈Rs×(0,∞)).
Dieses Modell heißt normalverteiltes lineares Modell oder lineares Gauß-
modell.
Satz 11.10. Im linearen Gaußmodell gilt fur (γ, σ2) ∈ Rs × (0,∞):
(1) γ ist Nγ,σ2(X⊤X)−1-verteilt.
(2)n − s
σ2V ∗ ist χ2
n−s-verteilt.
(3)|X(γ − γ)|2
σ2=
|ΠL(X)(Y ) − Eγ,σ2(Y )|2σ2
ist χ2s-verteilt und unabhangig von
V ∗. Ausserdem ist|X(γ − γ)|2
sV ∗ Fs,n−s-verteilt.
(4) Sei H ⊂ L(X) ein Unterraum mit r := dim(H) < s und Xγ ∈ H. Dann
ist|ΠL(X)(Y ) − ΠH(Y )|2
σ2χ2
s−r-verteilt und unabhangig von V ∗. Ausserdem
ist
FH,L :=n − s
s − r
|ΠL(X)(Y ) − ΠH(Y )|2|Y − ΠL(X)(Y )|2 =
|Xγ − ΠH(Y )|2(s − r)V ∗
Fs−r,n−s-verteilt.
Beweis. (1) Nach Satz 8.6 ist γ normalverteilt mit Eγ,σ2(γ) = γ. Die Kovarianz

11.3 Konfidenzintervalle und Tests 127
ergibt sich nach Satz 8.6 als
Kovγ,σ2(γ) = (X⊤X)−1X⊤ Kov(Y )︸ ︷︷ ︸=σ21n
X((X⊤X)−1)⊤ = σ2((X⊤X)−1)⊤ = σ2(X⊤X)−1 .
(2)-(4) Sei u1, . . . , un eine Orthonormalbasis von Rn mit
span(u1, . . . , ur) = H und span(u1, . . . , us) = L(X) .
Sei O := (u1, . . . , un) die Matrix mit den Spaltenvektoren u1, . . . , un. Nach Satz 8.2
ist der Vektor ξ := (ξ1, . . . , ξn)⊤ N0,1n-verteilt. Da O orthogonal ist, ist nach Ko-
rollar 8.8 der Vektor η := O⊤ξ ebenfalls N0,1n-verteilt, d.h. η1, . . . , ηn sind un-
abhangig und N0,1 verteilte Zufallsvariable. Nach dem Beweis von Satz 11.6 istn − s
σ2V ∗ =
n∑i=s+1
η2i , und somit nach Satz 8.15 χ2
n−s-verteilt. Damit folgt (2).
Wie im Beweis von Satz 11.6 steht, gilt ΠH(ξ) = OErη mit Diagonalmatrix
Er, die Einsen auf den ersten r Diagonalplatzen hat und sonst Nullen enthalt.
Analog gilt ΠL(X)(ξ) = OEsη mit Es analog definiert. Damit gilt wie in (11.7)
|ΠL(X)(ξ) − ΠH(ξ)|2 = σ2s∑
r+1
η2i ist χ2
s−r-verteilt, und ist nach (11.7) unabhangig
von V ∗. Nach Satz 8.17 ist FH,L Fs−r,n−s-verteilt. Damit folgt (4).
Fur H = 0 und r = 0 folgt, dass
|ΠL(X)(ξ)|2 =1
σ2|ΠL(X)(Y ) − Xγ|2 =
1
σ2|Xγ − Xγ|2
χ2s-verteilt und unabhangig von V ∗ ist. Ausserdem ist
|X(γ − γ)|2sV ∗ =
1s
∑si=1 η2
i1
n−s
∑ni=s+1 η2
i
(11.8)
Fs,n−s-verteilt. Damit folgt (3). ¤
Dieses Resultat fuhrt zu Konfidenzbereichen und zu Hypothesentests.
Satz 11.11 (Konfidenzbereiche im linearen Gaußmodell). Sei α ∈ (0, 1)
ein Irrtumsniveau.
(1) C(y) := γ ∈ Rs : |Xγ − γ(y)|2 < sFs,n−s;1−αV ∗(y)ist ein Konfidenzbereich fur γ zum Niveau α, wobei Fs,n−s;1−α das (1 − α)-
Quantil der Fs,n−s-Verteilung ist.

128 11. Lineare Modelle
(2) Sei τ : γ → c⊤γ mit c ∈ Rs eine lineare Kenngrosse. Dann ist
C(y) :=(c⊤γ(y) − δ
√V ∗(y) , c⊤γ(y) + δ
√V ∗(y)
),
ein Konfidenzintervall fur τ(γ) zum Niveau α, wobei δ := tn−s;1−α/2
√c⊤(X⊤X)−1c
und tn−s;1−α/2 das (1 − α/2)-Quantil der tn−s-Verteilung ist.
(3) C(y) :=
(n − s
q+
V ∗(y) ,n − s
q−V ∗(y)
),
ist ein Konfidenzintervall fur σ2 zum Niveau α, wobei q− = χ2n−s;α/2 und
q+ = χ2n−s;1−α/2 Quantile der χ2
n−s-Verteilung sind.
Beweis. Sei (γ, σ2) ∈ Rs × (0,∞) gegeben.
(1) Pγ,σ2(y ∈ X : γ ∈ C(y)) = Pγ,σ2
( |Xγ − γ|2sV ∗ < Fs,n−s;1−α
)
Satz 11.10(3)= Fs,n−s((−∞, Fs,n−s;1−α)) = 1 − α.
(2) Sei Z := c⊤γ. Nach Satz 11.10(1) und Satz 8.6 ist Z Nc⊤γ,σ2c⊤(X⊤X)−1c-verteilt
unter Pγ,σ2 . Folglich ist
Z∗ :=Z − c⊤γ√
σ2c⊤(X⊤X)−1c
standardnormal verteilt. Ausserdem istn − s
σ2V ∗ nach Satz 11.10(2) χ2
n−s-verteilt.
Sei O ∈ Rn×n eine orthogonale Matrix wie in den Beweisen der Satze 11.6
und 11.10. Im Beweis von Satz 11.6 haben wir gezeigt, dass
n − s
σ2V ∗ =
n∑
i=s+1
η2i .
Ausserdem ist mit γ − γ = (X⊤X)−1X⊤X(γ − γ)
Z∗ :=c⊤(γ − γ)√
σ2c⊤(X⊤X)−1c=
c⊤(X⊤X)−1X√σ2c⊤(X⊤X⊤)−1c
(Xγ − Xγ) ,
wobei nach (11.8) (Xγ − Xγ) = (η1, . . . , ηs, 0, . . . , 0) ist. Folglich sind Z∗ undn − s
σ2V ∗ unabhangig. Nach Satz 8.21 folgt T :=
Z∗√
V ∗/σ2ist tn−s-verteilt. Somit

11.3 Konfidenzintervalle und Tests 129
gilt
Pγ,σ2(y ∈ X : c⊤γ ∈ C(y)) = Pγ,σ2
(c⊤γ − δ
√V ∗ < c⊤γ < c⊤γ + δ
√V ∗
)
= Pγ,σ2
(−tn−s;1−α/2 < −T < tn−s;1−α/2
)
= Pγ,σ2
(tn−s;α/2 < −T < tn−s;1−α/2
)
= tn−s((−∞, tn−s;1−α/2)) − tn−s((−∞, tn−s;α/2))
= 1 − α
2− α
2= 1 − α .
(3) Nach Satz 11.10(2) ist (n − s)V ∗/σ2 χ2n−s-verteilt, also gilt
Pγ,σ2(y ∈ X : σ2 ∈ C(y)) = Pγ,σ2
(n − s
q+
V ∗ < σ2 <n − s
q−V ∗
)
= Pγ,σ2
(q− <
n − s
σ2V ∗ < q+
)= χ2
n−s((−∞, χ2n−s;1−α/2)) − χ2
n−s((−∞, χ2n−s;α/2))
= 1 − α
2− α
2= 1 − α .
¤
Satz 11.12 (Hypothesentests im linearen Gaußmodell). Sei α ∈ (0, 1) ein
Irrtumsniveau. Wir benutzen die Bezeichnungen wie in den Satzen 11.10-11.11.
(1) t-Test der Hypothese c⊤γ = m0:
Seien c ∈ Rs, m0 ∈ R.
Hypothese: Θ0 := (γ, σ2) ∈ Θ : c⊤γ = m0 Alternative: Θ1 := Θ \ Θ0.
Dann ist
D :=
1 falls |c⊤γ − m0| > tn−s;1−α/2
√c⊤(X⊤X)−1cV ∗ ,
0 sonst ,
ein Test zum Niveau α fur Θ0 gegen Θ1.
(2) F -Test der Hypothese Xγ ∈ H:
Sei H ⊂ L(X) ein Unterraum mit r := dim(H) < s.
Hypothese: Θ0 := (γ, σ2) ∈ Θ : Aγ ∈ H Alternative: Θ1 := Θ \ Θ0.

130 11. Lineare Modelle
Dann ist
D :=
1 falls FH,L > Fs−r,n−s;1−α ,
0 sonst ,
ein Test zum Niveau α fur Θ0 gegen Θ1.
(3) χ2-Test fur die Varianz:
Sei σ20 ∈ (0,∞).
Hypothese: Θ0 := (γ, σ2) ∈ Θ : σ2 ≤ σ20 Alternative: Θ1 := Θ \ Θ0.
Dann ist
D :=
1 falls (n − s)V ∗ > σ20χ
2n−s;1−α ,
0 sonst ,
ein Test zum Niveau α fur Θ0 gegen Θ1.
Beweis. (1) Sei (γ, σ2) ∈ Θ0, d.h. c⊤γ = m0. Dann gilt (mit der Stetigkeit der
F -Verteilung)
Pγ,σ2(D = 1) = 1 − Pγ,σ2(D = 0)
= 1 − Pγ,σ2
(−δ
√V ∗ ≤ c⊤γ − c⊤γ ≤ δ
√V ∗
)
= 1 − Pγ,σ2
(−δ
√V ∗ < c⊤γ − c⊤γ ≤ δ
√V ∗
)
Satz 11.11(2)= 1 − (1 − α) = α .
(2) Sei (γ, σ2) ∈ Θ0, d.h. Xγ ∈ H. Dann gilt
Pγ,σ2(D = 1) = 1 − Pγ,σ2(D = 0)
= 1 − Pγ,σ2 (FH,L ≤ Fs−r,n−s;1−α)
Satz 11.10(1)= 1 − Fs−r,n−s((−∞, Fs−r,n−s;1−α])
= 1 − (1 − α) = α .

11.3 Konfidenzintervalle und Tests 131
(3) Sei (γ, σ2) ∈ Θ0, d.h. σ2 ≤ σ20. Dann gilt (mit σ2
0/σ2 ≥ 1)
Pγ,σ2(D = 1) = 1 − Pγ,σ2(D = 0)
= 1 − Pγ,σ2
(n − s
σ2V ∗ ≤ σ2
0
σ2χ2
n−s;1−α
)
≤ 1 − Pγ,σ2
(n − s
σ2V ∗ ≤ χ2
n−s;1−α
)
Satz 11.10(2)= 1 − χ2
n−s((−∞, χ2n−s;1−α]) = α .
¤
Bemerkung 11.13. Tests fur einseitige Hypothesen in (1) und rechtsseitige/zweiseitige
Hypothesen in (3) konstruiert man analog.
Beispiel 11.14. [Einfache lineare Regression; vgl. Abschnitt 11.1 und Beispiel 11.7]
1. Problem: Konfidenzintervall zum Niveau α fur γ0.
Wahle τ(γ) = c⊤γ = γ0 mit c⊤ = (1, 0) in Satz 11.11(b). Dann gilt (vgl. Rechun-
gen in Beispiel 11.7)
δ := tn−s;1−α/2
√c⊤(X⊤X)−1c = tn−2;1−α/2
√√√√ 1
(n − 1)s2x
1
n
n∑
i=1
x2i
= tn−2;1−α/2
√ ∑ni=1 x2
i
n∑n
i=1(xi − x)2.
Damit ist
C(y) =
(γ0(y) − tn−2;1−α/2
√ ∑ni=1 x2
i
n∑n
i=1(xi − x)2V ∗(y) , γ0(y) + tn−2;1−α/2
√ ∑ni=1 x2
i
n∑n
i=1(xi − x)2V ∗(y)
)
ein solches Konfidenzintervall fur γ0.
2. Problem: Konfidenzintervall zum Niveau α fur γ1.
Wahle τ(γ) = c⊤γ = γ1 mit c⊤ = (0, 1) in Satz 11.11(b). Dann gilt
δ := tn−s;1−α/2
√c⊤(X⊤X)−1c = tn−2;1−α/2
√1
(n − 1)s2x
= tn−2;1−α/2
√1∑n
i=1(xi − x)2.
Damit ist
C(y) =
(γ1(y) − tn−2;1−α/2
√V ∗
∑ni=1(xi − x)2
, γ1(y) + tn−2;1−α/2
√V ∗
∑ni=1(xi − x)2
)

132 11. Lineare Modelle
ein solches Konfidenzintervall fur γ1.
3. Problem: Konfidenzintervall zum Niveau α fur die Gerade u 7→ γ0 + γ1u.
Wahle τ(γ) = c⊤γ = γ0 + γ1u mit c⊤ = (1, u) in Satz 11.11(b). Dann gilt
δ := tn−s;1−α/2
√c⊤(X⊤X)−1c
= tn−2;1−α/2
√√√√ 1
(n − 1)s2x
( 1
n
n∑
i=1
x2i − 2ux + u2
)
= tn−2;1−α/2
√1
(n − 1)s2x
(n − 1
ns2
x + x2 − 2ux + u2)
= tn−2;1−α/2
√1
n+
(x − u)2
(n − 1)s2x
, .
Damit ist (s.Bild 11.1)
C(y) =
(γ0 + γ1u − tn−2;1−α/2
√1
n
(x − u)2
(n − 1)s2x
V ∗ , γ0 + γ1u + tn−2;1−α/2
√1
n
(x − u)2
(n − 1)s2x
V ∗
)
ein solches Konfidenzintervall fur τ(γ).
4. Problem: Liegt eine lineare Abhangigkeit von X und Y tatsachlich vor?
Teste die Hypothese Θ0 := (γ, σ2) ∈ Θ : γ1 = 0 gegen die Alternative Θ1 :=
Θ \ Θ0 zum Niveau α ∈ (0, 1).
1. Test. Wahle
H := Xγ ∈ Rn : γ⊤ = (γ0, 0) fur ein γ0 ∈ R = (1, . . . , 1)⊤γ0 ∈ Rn : γ0 ∈ R
Dann ist Θ0 = (γ, σ2) ∈ Θ : Xγ ∈ H. Wahle τ(γ) = c⊤γ = m0 = 0
fur γ = (γ0, 0) und c⊤ = (0, 1) in Satz 11.12(1). Dann gilt√
c⊤(X⊤X)−1c =
1/√∑n
i=1(xi − x)2. Damit ist
D :=
1 falls |γ1| > tn−2;1−α/2
√V ∗
∑ni=1(xi − x)2
0 sonst ,
ein Test zum Niveau α fur Θ0 gegen Θ1.

11.3 Konfidenzintervalle und Tests 133
2. Test. Wahle
H := Xγ ∈ Rn : γ⊤ = (γ0, 0) fur ein γ0 ∈ R = (1, . . . , 1)⊤γ0 ∈ Rn : γ0 ∈ R
Dann ist Θ0 = (γ, σ2) ∈ Θ : Xγ ∈ H. Benutze Satz 11.12(b) mit B :=
(1, . . . , 1)⊤ ∈ Rn×1 anstelle von X. Dann gilt ΠH(Y ) = B(B⊤B︸ ︷︷ ︸=n
)−1 B⊤Y︸ ︷︷ ︸=
∑ni=1 Yi
=
(Y , . . . , Y )⊤. Damit folgt
FH,L =|Xγ − ΠH(Y )|2
(s − r)V ∗ =|(γ0 + γ1x1 − Y , . . . , γ0 + γ1xn − Y )|2
V ∗
=1
V ∗
n∑
i=1
(γ0 + γ1xi − Y )2
=1
V ∗
n∑
i=1
(−xγ1 + γ1xi)2 = γ2
1
1
V ∗
n∑
i=1
(xi − x)2 . (11.9)
Damit ist
D :=
1 falls γ21 > F1,n−2;1−α
V ∗∑n
i=1(xi − x)2
0 sonst ,
ein Test zum Niveau α fur Θ0 gegen Θ1.
Bemerkung 11.15. Es gilt die folgende Zerlegung der Quadratsummen (als Maß
der Variabilitat).
n∑
i=1
(Yi − Y )2
︸ ︷︷ ︸=:Stotal
=n∑
i=1
(Yi − (γ0 + γ1xi))2
︸ ︷︷ ︸=:SResiduen
+n∑
i=1
((γ0 + γ1xi) − Y )2
︸ ︷︷ ︸=:SRegression
.
Definition 11.16 (Bestimmtheitsmaß).
Die Statistik
R2 :=SRegression
Stotal
= 1 − SResiduen
Stotal
heißt Bestimmtheitsmaß.
Interpretation: Offensichtlich gilt 0 ≤ R2 ≤ 1.
R2 groß : ein großer Teil der Variabilitat der Daten wird durch die Regression
erklart.

134 11. Lineare Modelle
Fur die Statistik FH,L in (11.9) in obigem 3. Testproblem, Test 2 gilt
FH,L =1
V ∗
n∑
i=1
(γ0 + γ1xi − Y )2
=SRegression
(n − 2)|Y − ΠL(X)(Y )|2 =1
n − 2
SRegression
SResiduen
=1
n − 2
SRegression
Stotal − SResiduen
=1
n − 2
(Stotal
SRegression
− 1
)−1
=1
n − 2
(1
R2− 1
)−1
Wegen FH,L > c ⇔ R2 >1
1 + ((n − 2)c)−1hat der obige Test 2 die Form
D :=
1 falls R2 >1
1 + ((n − 2)F1,n−2;1−α)−1,
0 sonst .
Ein großes R2 spricht auch im Sinne dieses Tests fur das Vorliegen einer linearen
Abhangigkeit von x und Y .

Kapitel 12
Spezielle Testprobleme
12.1 Zweistichproben-Probleme
Beispiel 12.1. [Zweistichproben-t-Test]
Frage: Ist Dungemittel B besser als Dungemittel A?
X1, . . . , Xk seien die Ertrage/ha mit Dungemittel A auf k Versuchsfeldern,
Y1, . . . , Yl seien die Ertrage/ha mit Dungemittel B auf l Versuchsfeldern.
Modell: X1, . . . , Xk, Y1, . . . , Yl unabhangig, Xi sind Nµ,σ2-verteilt, Yj sind Nµ′,σ2-
verteilt.
Frage: Ist µ′ > µ ?
Statistisches Modell: (X ,F , (Pθ)θ∈Θ) =(Rk+l,Bk+l, (N⊗k
µ,σ2⊗N⊗lµ′,σ2)(µ,µ′,σ2)∈R2×(0,∞)
).
Hypothese: Θ0 = (µ, µ′, σ2) ∈ R2 × (0,∞) : µ ≤ µ′,Alternative: Θ1 = (µ, µ′, σ2) ∈ R2 × (0,∞) : µ > µ′.LQ-Test: Es gilt
log ρθ(x, y) = −k + l
2log(2πσ2) − 1
2σ2
(k∑
i=1
(xi − µ)2 +l∑
j=1
(yj − µ′)2
),
also
d
d(σ2)log ρθ(x, y) = −k + l
2
1
σ2+
1
2(σ2)2
(k∑
i=1
(xi − µ)2 +l∑
j=1
(yj − µ′)2
).
135

136 12. Spezielle Testprobleme
Dies ist > 0 fur σ2 < vµ,µ′ := 1k+l
(∑ki=1(xi − µ)2 +
∑lj=1(yj − µ′)2
),
und < 0 fur σ2 > vµ,µ′ . Setzt man x = 1k
∑ki=1 xi und y = 1
l
∑li=1 yi, gilt auch
log ρθ(x, y) = −k + l
2log(2πσ2)− 1
2σ2
(k∑
i=1
(xi − x)2 +l∑
j=1
(yj − y)2 + k(x − µ)2 + l(y − µ′)2
).
Dies wird maximal in (µ, µ′) fur µ = x und µ′ = y.
Unter der Nebenbedingung µ′ ≤ µ und im Fall y > x wird es maximal fur µ′ = µ,
namlich bei µ′ = µ = kx+lyk+l
=: µ0.
(Hinweis: Minimiere µ 7→ k(x − µ)2 + l(y − µ)2; die Ableitung ist
µ 7→ 2(−kx − ly + (k + l)µ).)
Analog wird (µ, µ′) 7→ log ρθ(x, y) unter der Nebenbedingung µ′ ≥ µ und im Fall
y < x maximal fur µ′ = µ = µ0.
Es folgt
supθ∈Θ0
ρθ(x, y) = supµ≤µ′,σ2>0
ρµ,µ′,σ2(x, y) =
supσ2>0 ρx,y,σ2(x, y) falls x ≤ y ,
supσ2>0 ρµ0,µ0,σ2(x, y) falls x > y ,
=
ρx,y,vx,y(x, y) falls x ≤ y ,
ρµ0,µ0,vµ0,µ0(x, y) falls x > y .
Analog erhalt man
supθ∈Θ1
ρθ(x, y) =
ρµ0,µ0,vµ0,µ0(x, y) falls x ≤ y ,
ρx,y,vx,y(x, y) falls x > y .
Damit folgt
R(x, y) =supθ∈Θ1
ρθ(x, y)
supθ∈Θ0ρθ(x, y)
=
(vx,y
vµ0,µ0
)(k+l)/2
falls x ≤ y ,(
vµ0,µ0
vx,y
)(k+l)/2
falls x > y .

12.1 Zweistichproben-Probleme 137
Es ist fur x > y
vµ0,µ0
vx,y
=
1
k + l
(k∑
i=1
(xi − x)2 +l∑
j=1
(yj − y)2 + k(x − µ0)2 + l(y − µ0)
2
)
vx,y
= 1 +k((k + l)x − kx − ly)2 + l((k + l)y − kx − ly)2
vx,y(k + l)3
= 1 +kl
(k + l)2
(x − y)2
vx,y
.
Somit ist R((x1, . . . , xk, y1, . . . , yl)) eine streng monoton fallende Funktion in
T :=
√kl
k + l
x − y√V ∗
mit
x =1
k
k∑
i=1
xi , y =1
l
l∑
j=1
yi und V ∗ :=1
k + l − 2
(k∑
i=1
(xi − x)2 +l∑
j=1
(yi − y)2
).
Ein LQ-Test hat also die Form (fur ein c ∈ R)
D(x, y) =
1 falls T > c ,
0 sonst .
Frage: Wie bestimmt man c fur ein vorgegebenes Niveau α?
Ahnlich wie in Satz 8.22(4) folgt:
Tµ,µ′ :=
√kl
k + l
(X − µ) − (Y − µ′)√V ∗
ist unter Pµ,µ′,σ2 tk+l−2-verteilt.
Wegen
T = Tµ,µ′ +
√kl
k + l
µ − µ′√
V ∗︸ ︷︷ ︸
<0 auf Θ0
ist Pθ(D = 1) = Pθ(T < c) maximal fur µ = µ′, also
α = supθ∈Θ0
Pθ(D = 1) = tk+l−2((−∞, c]) .
Zu gegenem Niveau α wahlt man also c = tk+l−2;α (das α-Quantil der tk+l−2-
Verteilung).
Aber:
• Ist die Normalverteilungsannahme wirklich gerechtfertigt?

138 12. Spezielle Testprobleme
• Ist die Varianz in beiden Fallen (Dunger A/B) wirklich gleich gross?
Der Fall mit unbekannter, moglicherweise verschiedener Varianz ist schwierig
(Behrens-Fisher-Problem).
Beispiel 12.2. [F -Test auf gleiche Varianz im Zweistichproben-Problem]
Modell: X1, . . . , Xk, Y1, . . . , Yl unabhangig,
die Xi sind Nµx,σ2x-verteilt und die Yj sind Nµy ,σ2
y-verteilt.
Frage: Ist σ2x = σ2
y ?
Statistisches Modell:
(X ,F , (Pθ)θ∈Θ) =(Rk+l,Bk+l, (N⊗k
µx,σ2x⊗ N⊗l
µy ,σ2y)(µx,µy ,σ2
x,σ2y)∈R2×(0,∞)2
).
Hypothese: Θ0 = (µx, µy, σ2x, σ
2y) ∈ R2 × (0,∞)2 : σ2
x = σ2y,
Alternative: Θ1 = (µx, µy, σ2x, σ
2y) ∈ R2 × (0,∞)2 : σ2
x 6= σ2y.
Frage: Wie konstruiert man einen Test?
Idee: Wir versuchen, eine aussagekraftige Statistik zu finden, deren Verteilung
nicht vom unbekannten Parameter θ abhangt;
vgl.X − µ
σ/√
nin Beispiel 9.3,
X − µ√s2/n
in Beispiel 9.4, X − µ in Beispiel 10.15,10.17,
τµ in Beispiel 10.18,10.19, Tµ,µ′ in Beispiel 12.1.
Nach Satz 8.22(3) sind (unter Pθ)k − 1
σ2x
S2x χ2
k−1-verteilt undl − 1
σ2y
S2y χ2
l−1-verteilt,
wobei S2x, S
2y die Stichprobenvarianzen von X1, . . . , Xk bzw. Y1, . . . , Yl sind. Diese
sind unabhangig, da alle Zufallsvariablen unabhangig sind. Damit ist (unter Pθ)S2
x/σ2x
S2y/σ
2y
Fk−1,l−1-verteilt (vgl. Satz 8.18). Folglich ist fur θ ∈ Θ0, also fur σ2x = σ2
y
die Zufallsvariable S2x/S
2y (unter Pθ) Fk−1,l−1-verteilt.
Idee: Verwirf die Hypothese, falls S2x/S
2y sehr gross oder sehr klein ist.
Sei ein Niveau α vorgegeben und Fk−1,l−1;α/2 und Fk−1,l−1;1−α/2 das α/2- bzw.

12.1 Zweistichproben-Probleme 139
1 − α/2-Quantil der Fk−1,l−1-Verteilung. Dann ist
D(x, y) =
0 falls Fk−1,l−1;α/2 ≤S2
x
S2y
≤ Fk−1,l−1;1−α/2 ,
1 sonst .
ein Test fur Θ0 gegen Θ1.
Beispiel 12.3. [Verbundene Stichproben]
Was tut man in Beispiel 12.1 im Fall verbundener Stichproben, wenn man etwa
misst:
Xi Blutdruck von Patient i mit Medikament A fur i = 1, . . . , n,
Yi Blutdruck von Patient i mit Medikament B fur i = 1, . . . , n.
Beachte: Xi, Yi sind nicht unabhangig, da gleicher Patient.
Ausweg: Betrachte Zi := Xi − Yi fur i = 1, . . . , n.
Modellannahme: Z1, . . . , Zn sind unabhangig Nµ,σ2-verteilt (mit unbekannten µ, σ2).
Frage: Ist Medikament B besser als A, d.h. µ > 0?
Verwende den einseitigen t-Test aus Beispiel 10.18.
Beispiel 12.4. [Zweistichproben-Problem ohne Verteilungsannahme]
Was macht man in Beispiel 12.1, wenn man nicht an die Normalverteilung glaubt,
man aber auch kein anderes Modell zugrundelegen kann/will?
Seien wie oben
X1, . . . , Xk die Ertrage/ha mit Dunger A,
Y1, . . . , Yl die Ertrage/ha mit Dunger B.
Modellannahme: X1, . . . , Xk, Y1, . . . , Yl sind unabhangig,
Xi nach QX-verteilt fur i = 1, . . . , k und Yj nach QY -verteilt fur j = 1, . . . , l.
Weiter seien QX und QY stetige Verteilungen (d.h. einelementige Mengen haben
Wahrscheinlichkeit 0) mit
P (Xi > c) = QX((c,∞)) ≤ QY ((c,∞)) = P (Yj > c) , c ∈ R .
Man schreibt dafur auch QX ≤ QY und spricht von stochastischer Dominanz

140 12. Spezielle Testprobleme
von Y uber X. In unserem Beispiel bedeutet das, dass Dunger B mindestens
ebensogut ist wie A.
Frage: Ist Dunger B besser als A, d.h. gilt QX < QY
⇔ (QX ≤ QY und QX 6= QY ).
Statistisches Modell: (X ,F , (Pθ)θ∈Θ) = (Rk+l,Bk+l, (Q⊗kX ⊗ Q⊗l
Y )(QX ,QY )∈Θ) mit
Θ = (QX , QY ) : QX , QY stetige Verteilungen mit QX ≤ QY
(nichtparametrisches Modell).
Hypothese: Θ0 = (QX , QY ) ∈ Θ : QX = QY Alternative: Θ1 = (QX , QY ) ∈ Θ : QX < QY .
Bezeichnung: Zu x = (x1, . . . , xk, xk+1, . . . , xk+l) ∈ X = Rk+l
setze Xi(x) = xi fur i = 1, . . . , k und Yj(x) = xk+j fur j = 1, . . . , l.
Idee: Lehne die Hypothese ab, falls die Y1, . . . , Yl “eher großer” als die X1, . . . , Xk
sind.
Frage: Was heißt “eher großer”?
Definition 12.5 (Rang, Rangstatistik). Zu (x1, . . . , xn) ∈ Rn definiere die
Rangstatistik (r1, . . . , rn) durch ri := |j ∈ 1, . . . , n : xj ≤ xi|.
Sei (R1, . . . , Rk+l) die Rangstatistik zu (X1, . . . , Xk, Y1, . . . , Yl),
WX := R1 + · · · + Rk die Rangsumme von X1, . . . , Xk und
WY := Rk+1 + · · · + Rk+l die Rangsumme von Y1, . . . , Yl.
Dann gilt (gleiche Range kommen nicht vor, da Verteilungen stetig sind)
WX + WY =k+l∑
i=1
Ri =k+l∑
i=1
i =1
2(k + l)(k + l + 1) .
Idee: Lehne die Hypothese ab, falls WX klein ist.
Lemma 12.6. Es gilt
WX = U +1
2k(k + 1) f.s.
mit U =k∑
i=1
l∑j=1
1Xi>Yj, der sogenannten U-Statistik.

12.1 Zweistichproben-Probleme 141
Beweis. Seien o.B.d.A. X1 < X2 < · · · < Xk (da WX , U invariant unter Permu-
tation von X1, . . . , Xk sind und wegen der Stetigkeit von QX alle Xi f.s. verschie-
den sind). Also gilt R1 < R2 < · · · < Rk, also Ri = i+ |j ∈ 1, . . . , l : Xi > Yj|fur i = 1, . . . , k, also
WX =k∑
i=1
i +k∑
i=1
l∑
j=1
1Xi>Yj =1
2k(k + 1) + U . ¤
Wahle also einen Test der Form
D(x, y) =
1 falls U < c (⇔ W < c + 12k(k + 1)) ,
0 sonst ,
fur ein c ∈ 1, . . . , kl. Dieser Test heißt Mann-Whitney-U-Test oder Wilcoxon-
Zweistichproben-Rangsummentest.
Frage: Welches Signifikanzniveau hat der Test:
Satz 12.7 (Verteilung von U auf Θ0). Fur θ ∈ Θ0 (d.h. wenn QX = QY ) gilt
Pθ(U = m) =N(m; k, l)(
k+lk
) , m = 0, 1, . . . , kl ,
wobei
N(m; k, l) = |(m1, . . . ,mk) ∈ 0, . . . , lk : m1 ≤ m2 ≤ · · · ≤ mk undk∑
i=1
mi = m| ,
unabhangig von θ = (QX , QY ).
Beweis. (1) Beh: Pθ((R1, . . . , Rk+l) = π−1) =1
(k + l)!fur jede Permutation
π ∈ Sk+l.
Bew.: Sei π ∈ Sk+l. Fur A1, . . . Ak+l ∈ B gilt
P πθ (A1 × · · · × Ak+l) = Pθ(π(X1) ∈ A1, . . . , π(Yl) ∈ Ak+l)
= Pθ(X1 ∈ Aπ−1(1), . . . , Yl ∈ Aπ−1(k+l))
=k+l∏
i=1
QX(Aπ−1(i)) =k+l∏
i=1
QX(Ai) .

142 12. Spezielle Testprobleme
Somit gilt
Pθ((R1, . . . , Rk+l) = π−1) = Pθ(π(X1, . . . , Yl) ist aufsteigend sortiert)
= P πθ ((x1, . . . , xk+l) ∈ Rk+l : x1 < x2 < · · · < xk+l)
= Pθ((x1, . . . , xk+l) ∈ Rk+l : x1 < x2 < · · · < xk+l) .
unabhangig von π. Mit Wahrscheinlichkeit 1 ist (R1, . . . , Rk+l) ∈ Sk+l (da Xi 6=Xj f.s. fur i 6= j), ferner ist |Sk+l| = (k + l)!, also gilt
1 =∑
π∈Sk+l
Pθ((R1, . . . , Rk+l) = π−1) = (k + l)!Pθ((R1, . . . , Rk+l) = π−1) .
(2) Sei R := A ⊂ 1, . . . , k+ l : |A| = k. Nach Lemma 3.1(4) gilt |R| =(
k+lk
).
(R1, . . . , Rk+l) ist mit gleicher Wahrscheinlichkeit beliebige Permutation von (1, . . . , k + l)
⇒ R1, . . . , Rk ist mit gleicher Wahrscheinlichkeit beliebige k-elementige Teil-
menge von 1, . . . , k + l, d.h. fur alle A ∈ R gilt
Pθ(R1, . . . , Rk ∈ A) =1
|R| =1(
k+lk
) .
Es ist
U =k∑
i=1
|j ∈ 1, . . . , l : Xi > Yj| =k∑
i=1
|j ∈ k + 1, . . . , k + l : Ri > Rj| .
Schreibe R1, . . . , Rk =: A = r1, . . . , rk mit r1 < r2 < · · · < rk;
ferner Ac = rk+1, . . . , rk+l. Dann gilt
U =k∑
i=1
|s ∈ Ac : ri > s| =k∑
i=1
(ri − i) .
Somit ist
Pθ(U = m) =∑
(r1,...,rk)∈1,...,k+lk
mit r1<···<rkund∑k
i=1(ri−i)=m
Pθ(R1, . . . , Rk = r1, . . . , rk)
=∑
(m1,...,mk)∈0,...,lk
mit m1<···<mkund∑k
i=1mi=m
1(k+lk
) .
¤

12.2 χ2-Anpassungstests 143
Das Signifikanzniveau Pθ(U < c) =c−1∑m=0
Pθ(U = m) lasst sich aus Tabellenwerten
ablesen.
Bemerkung 12.8. (1) Fur k, l → ∞ gilt unter der Nullhypothese (d.h. fur
QX = QY )
U − kl/2√kl(kl+1)
12
d→ N0,1 .
Daraus erhalt man auch asymptotische Werte fur das Signifikanzniveau fur große
k, l.
(2) Achtung: Ist das Modell der stochastischen Dominanz gerechtfertigt?
12.2 χ2-Anpassungstests
Frage: Sind die Daten tatsachlich nach einem gegebenen Wahrscheinlichkeitsmaß
verteilt?
Beispiel 12.9. [Mendels Erbsen]
Versuchsergebnisse zur Vererbungslehre (1865).
Beobachtet wurden zwei Merkmale: Form und Farbe mit Auspragungen rund (A)
und kantig (a), bzw. gelb (B) und grun (b). Die Faktoren A und B sind dominant:
AA, Aa, aA rund
aa kantig
BB, Bb, bB gelb
bb grun
Nachkommen von Pflanzen AaBb sollten im Verhaltnis
9 : 3 : 3 : 1
rund, gelb rund, grun kantig, gelb kantig, grun
auftreten.
Versuchsergebnisse (insgesamt 556 Erbsen):

144 12. Spezielle Testprobleme
gelb grun
rund 315 108
kantig 101 32
Frage: Ist die Kontingenztabelle konsistent mit der Theorie?
Allgemeiner Rahmen: n unabhangige Einzelexperimente mit Werten in E :=
1, . . . , s.Unbekannt: Verteilung des Einzelexperiments, d.h. dessen Zahldichte θ : E →(0, 1) (nur Zahldichten mit Werten 6= 0, 1).
Identifiziere θ mit dem zugehorigen Wahrscheinlichkeitsmaß auf E . Definiere
Θ := Menge aller dieser Zahldichten = θ : E → (0, 1) :s∑
i=1
θ(i) = 1 .
Statistisches Modell: (X ,F , (Pθ)θ∈Θ) = (En,P(En), (θ⊗n)θ∈Θ).
Sei ρ ∈ Θ gegeben (die theoretisch angenommene Verteilung).
Frage: Ist θ = ρ?
Hypothese: Θ0 = ρ, Alternative: Θ1 = Θ \ ρ.Kann man einen LQ-Test konstruieren?
Seien x = (x1, . . . , xn) die beobachteten Stichprobenwerte. Definiere h(i) : X →N definiert durch x 7→ |k ∈ 1, . . . , n : xk = i fur i = 1, . . . , s (absolute
Haufigkeiten) und L : X → [0, 1]s sei definiert durch L :=(h(1)
n, . . . ,
h(s)
n
), das
Histogramm oder die empirische Verteilung (vgl. S-Plus Praktikum). Es gilt
θ⊗n(x) =n∏
i=1
θ(xi) =s∏
i=1
θ(i)h(i) .

12.2 χ2-Anpassungstests 145
Damit ist der LQ
R(x) =supθ∈Θ1
∏si=1 θ(i)h(i)
∏si=1 ρ(i)h(i)
= supθ∈Θ
s∏
i=1
(θ(i)
ρ(i)
)h(i)
(da Θ1 dicht in Θ)
= maxθ∈Θ
s∏
i=1
(θ(i)
ρ(i)
)h(i)
(da Limes am Rand = 0)
= exp
(maxθ∈Θ
s∑
i=1
h(i) log(θ(i)
ρ(i)
))
(da exp monoton) .
Suche also (lokale=globale) Maximalstelle von
(θ(1), . . . , θ(s)) 7→s∑
i=1
h(i) log(θ(i)
ρ(i)
)unter der NB
s∑
i=1
θ(i) = 1 . (12.1)
Wir verwenden die Lagrangesche Multiplikatorenregel (z.B. Heuser, Analysis II,
Satz 174.1):
Der Gradient der zu maximierenden Funktion an der Maximalstelle θ ist ein
Vielfaches des Gradienten der Nebenbedingung, d.h. es existiert λ ∈ R mit
grad
(s∑
i=1
h(i) log(θ(i)
ρ(i)
))
= λ grad
(s∑
i=1
θ(i)
).
Daraus folgt, dass (h(1)
θ(1), . . . ,
h(s)
θ(s)
)= λ(1, . . . , 1) ,
also
n =s∑
i=1
h(i) = λs∑
i=1
θ(i) = λ , (12.2)
d.h. θ(i) =h(i)
nfur i = 1, . . . , s, also θ = L fur die Maximalstelle θ. Somit ist
R(x) = exp
n
s∑
i=1
L(i) log(L(i)
ρ(i)
)
︸ ︷︷ ︸=:H(L,ρ)
=: exp (nH(L, ρ)) . (12.3)
H(L, ρ) heißt relative Entropie von L bgzl. ρ.

146 12. Spezielle Testprobleme
Somit sind LQ-Tests von der Form
D(x) =
1 falls nH(L, ρ) > c ,
0 falls nH(L, ρ) < c ,
fur ein c ∈ R.
Frage: Wie bestimmt man c fur ein vorgegebenes Niveau α?
Unter Θ0 ist nL = (h(1), . . . , h(s)) multinomial, also Mn,s,ρ(1),...,ρ(s)-verteilt (De-
finition 3.6. Fur diese Verteilung sind Quantile schwierig zu bestimmen. Man
macht deshalb fur grosse n eine Grenzwertbetrachtung (vgl. Beispiel Binomial-
verteilung).
Satz 12.10. Mit den Bezeichnungen wie oben setzen wir Ln := L und hn := h,
um die Abhangigkeit vom Stichprobenumfang klar zu machen. Definiere
Dn,ρ :=s∑
i=1
(hn(i) − nρ(i))2
nρ(i)= n
s∑
i=1
ρ(i)
(Ln(i)
ρ(i)− 1
)2
= n
s∑
i=1
L2n(i)
ρ(i)− n .
Dann gilt
nH(Ln, ρ) − 1
2Dn,ρ
Pρ→ 0 , n → ∞ .
Bemerkung 12.11. Strenggenommen muss hier wieder auf einem gemeinsamen
Raum (unendlichen Produktraum) gearbeitet werden; vgl. Bemerkung 7.11.
Beweis von Satz 12.10. Mit (12.2) gilt
H(Ln, ρ) =s∑
i=1
ρ(i) −s∑
i=1
Ln(i) + H(Ln, ρ)
=s∑
i=1
ρ(i)
(1 − Ln(i)
ρ(i)+
Ln(i)
ρ(i)log
(Ln(i)
ρ(i)
))
=s∑
i=1
ρ(i)ψ(1 + a(i)) ,
mit ψ(u) := 1−u+u log u und a(i) :=Ln(i)
ρ(i)−1. Es gilt ψ′(u) = log u, ψ′′(u) =
1
u,
also erhalt man als Taylor-Approximation 2. Ordnung um u = 1:
ψ(u) =(u − 1)2
2+ O((u − 1)3) .

12.2 χ2-Anpassungstests 147
Damit gilt
nH(Ln, ρ) = ns∑
i=1
ρ(i)
(a2(i)
2+ O(a3(i))
)=
1
2Dn,ρ + nO(a3(i)) . (12.4)
Fur c > 0 gilt auf Dn,ρ ≤ c: n∑s
i=1 ρ(i)a2(i) =1
2Dn,ρ ≤ c, also a2(i) ≤ 2c
nρ(i),
also nO(a3(i)) = nO(n−3/2) = O(n−1/2) → 0 fur n → ∞.
Sei ε > 0 gegeben. Fur hinreichend grosse n gilt also
An := |nH(Ln, ρ) − 1
2Dn,ρ| > ε ⊂ Dn,ρ > c .
Ferner ist (da hn(i) binomial Bn,ρ(i)-verteilt),
E(Dn,ρ) =s∑
i=1
1
nρ(i)E
((hn(i) − nρ(i))2
) Tabelle 4.1=
s∑
i=1
1
nρ(i)nρ(i)(1−ρ(i)) = s−1 .
Nach Satz 5.3 gilt mit f(x) = x, dass P (Dn,ρ > c) ≤ s−1c
.
Sei δ > 0. Fur c :=s − 1
δgilt dann P (An) ≤ s−1
c= δ fur hinreichend grosse n,
d.h. stochastische Konvergenz. ¤
Wahle also alternativ Dn,ρ als Teststatistik in (12.5).
Definition 12.12 (χ2-Anpassungstest). Ein Test der Form
D(x) =
1 falls Dn,ρ > c ,
0 falls Dn,ρ < c ,
fur ein c ∈ R heisst χ2-Anpassungstest fur Θ0 gegen Θ1.
Frage: Wie bestimmt man c fur ein vorgegebens Niveau α?
Wir machen wieder eine Grenzbetrachung fur grosse n wie in Satz 12.10.
Satz 12.13. Mit den Bezeichnungen wie oben konvergiert Dn,ρ unter Pρ in Ver-
teilung gegen eine χ2s−1-verteilte Zufallsvariable, d.h. fur alle c > 0 gilt
limn→∞
Pρ(Dn,ρ ≤ c) = χ2s−1([0, c]) .

148 12. Spezielle Testprobleme
Beweis. Nur fur s = 2: dann gilt hn(2) = n−hn(1) und ρ(2) = 1− ρ(1), so dass
Dn,ρ =(hn(1) − nρ(1))2
nρ(1)+
(hn(2) − nρ(2))2
nρ(2)
= (hn(1) − nρ(1))2
(1
nρ(1)+
1
nρ(2)
)
= (hn(1) − nρ(1))2 1
nρ(1)ρ(2)
=
(hn(1) − nρ(1)√
nρ(1)ρ(2)
)2
.
Unter Pθ ist hn(1) Bn,ρ(1)-verteilt. Dann gilt nach dem Zentralen Grenzwertsatz,
Korollar 5.10 fur alle c > 0,
Pθ
(−√
c ≤ hn(1) − nρ(1)√nρ(1)ρ(2)
≤ √c
)→ N0,1([−
√c,√
c]) , n → ∞ .
Damit folgt fur alle c > 0 unter Beachtung, dass fur N0,1-verteiltes X gilt, dass
X2 χ21-verteilt ist:
Pθ(Dn,ρ ≤ c) → N0,1([−√
c,√
c]) = χ21([0, c]) , n → ∞ . ¤
Bemerkung 12.14. (1) Wegen der Satze 12.13 und 12.10 ist auch 2nH(Ln, ρ) =
2 log(R) in (12.3) fur grosse n approximativ χ2s−1-verteilt (ohne Beweis).
(2) Zu vorgegebenem Irrtumsniveau α wahle man also den Test
D(x) =
1 falls Dn,ρ > χ2s−1;1−α ,
0 sonst,
der das Niveau ungefahr einhalt.
Beispiel 12.15. [Mendels Erbsen, Fortsetzung von Beispiel 12.1]
Hier n = 556, s = 4, E = 1, 2, 3, 4, wobei 1 = (rund,gelb), 2 = (rund,grun), 3
= (kantig,gelb), 4 = (kantig,grun).
Θ = θ : E → (0, 1) :∑4
i=1 θ(i) = 1.Statistisches Modell: (X ,F , (Pθ)θ∈Θ) = (En,P(En), (θ⊗n)θ∈Θ).
Theoretisch: ρ gegeben durch (ρ(1), ρ(2), ρ(3), ρ(4)) = ( 916
, 316
, 316
, 116
).

12.2 χ2-Anpassungstests 149
Beobachtet wurden: (h(1), h(2), h(3), h(4)) = (315, 108, 101, 32), also
Dn,ρ =16
556
(3152
9+
1082
3+
1012
3+ 322
)− 556 = 0.470 .
Approximativer Test zum Niveau α = 0.1:
D(x) =
1 falls Dn,ρ > χ2s−1;0.9 = 6.3 ,
0 sonst,
Wegen 0.470 < 6.3 wir die Nullhypothese zum Irrtumsniveau 0.1 nicht verworfen.
Bemerkung 12.16. (1) Das Niveau stimmt nur approximativ. Als Faustregel
zu Satz 12.13 gilt: Die Approximation ist “gut”, falls n ≥ 5/ mini=1,...,s ρ(i).
(2) χ2-Anpassungstest bei stetigen Verteilungen, z.B. bei Normalverteilung: Bil-
de Klassen (vgl. S-Plus Praktikum) unter Beachtung der Faustregel aus Teil (1).

150 12. Spezielle Testprobleme
12.3 χ2-Unabhangigkeitstests
Frage: Sind zwei Merkmale eines Datensatzes stochastisch unabhangig?
Beispiel 12.17. Folgende bivariate Daten stammen aus einer Umfrage von n =
2004 Befragten zum Umweltbewusstsein und Bildungsstand. Auf die Frage nach
der Beeintrachtigung durch Umweltschadstoffe stehen als mogliche Antworten zur
Verfugung: uberhaupt nicht, etwas, ziemlich, sehr
Die Frage nach dem Bildungsstand lasst Antworten zu:
1 = “ungelernt”, . . ., 5= “Hochschulabschluss”.
Folgende Kontingenztabelle ist das Ergebnis:
Schulbildung
Beeintrachtigung 1 2 3 4 5 Σ
uberhaupt nicht 212 434 169 79 45 939
etwas 85 245 146 93 69 638
ziemlich 38 85 74 56 48 301
sehr 20 35 30 21 20 126
Σ 355 799 419 249 182 2004
Allgemeiner Rahmen: n unabhangige Einzelbeobachtungen mit Werten in E =
A × B, mit A = 1, . . . , a, B = 1, . . . , b. Dabei ist die Verteilung des Einzel-
experiments unbekannt, d.h. die Zahldichte θ : E → (0, 1) ist nicht bekannt.
Θ := Menge der positiven Zahldichten = θ : E → (0, 1) :∑
(i,j)∈Eθ(i, j) = 1
Statistisches Modell: (X ,F , (Pθ)θ∈Θ) = (En,P(En), (θ⊗n)θ∈Θ).
Fur θ ∈ Θ setze θA : A → (0, 1) definiert durch θA(i) =∑
j∈B θ(i, j)
und θB : B → (0, 1) definiert durch θB(j) =∑
i∈A θ(i, j), die Randverteilungen
von θ auf A bzw. B.
Frage: Sind die 1. und 2. Koordinate der Beobachtungen unabhangig?
⇔ θ = θA ⊗ θB.

12.2 χ2-Unabhangigkeitstests 151
Hypothese:
Θ0 := Menge aller Zahldichten von Produktgestalt = α⊗β ∈ Θ : α ∈ ΘA, β ∈ ΘB
mit ΘA := α : A → (0, 1) :∑
i∈A α(i) = 1und ΘB := β : B → (0, 1) :
∑j∈b β(j) = 1, Zahldichten auf A bwz. B.
Alternative: Θ1 := Θ \ Θ0.
Kann man einen LQ-Test konstruieren?
Definiere h(i, j) : X → N durch
x = (x1, . . . , xn) 7→ |k ∈ 1, . . . , n : xk = (i, j)|fur (i, j) ∈ E (absolute Haufigkeiten, Kontingenztabelle) und
L : X → [0, 1]E durch L :=
(h(i, j)
n
)
(i,j)∈E, die Matrix der relativen Haufigkeiten.
Bezeichnung:
hA(i) :=∑j∈B
h(i, j), hB(j) :=∑i∈A
h(i, j), LA(i) :=hA(i)
n, LB(j) :=
hB(j)
n.
Es gilt θ⊗n(x1, . . . , xn) =n∏
i=1
θ(xi) =∏
(i,j)∈Eθ(i, j)h(i,j).
Damit ergibt sich der LQ (beachte, dass Θ1 ⊂ Θ dicht und der Limes am Rand
0 ist)
R(x) =supθ∈Θ1
∏(i,j)∈E θ(i, j)h(i,j)
supθ∈Θ0
∏(i,j)∈E θ(i, j)h(i,j)
=maxθ∈Θ
∏(i,j)∈E θ(i, j)h(i,j)
maxα⊗β∈Θ0
∏(i,j)∈E α(i)h(i,j)
∏(i,j)∈E β(j)h(i,j)
Man beachte, dass gilt
∏
(i,j)∈Eβ(j)h(i,j) =
∏
j∈B
β(j)∑
i∈A h(i,j) =∏
j∈B
β(j)hB(j) .
Damit folgt
R(x) =maxθ∈Θ
∏(i,j)∈E θ(i, j)h(i,j)
maxα∈ΘA
∏i∈A β(i)hA(i) maxβ∈ΘB
∏j∈B β(j)hB(j)
.
Suche also (lokale=globale) Maximalstelle von
θ 7→ ∏(i,j)∈E θ(i, j)h(i,j) = exp
(∑(i,j)∈E h(i, j) log(θ(i, j))
)

152 12. Spezielle Testprobleme
unter der Nebenbedingung∑
i,j∈E θ(i, j) = 1.
Analog wie in Abschnitt 12.2 folgt, dass das Maximum bei L angenommen wird.
Entsprechend wird das Maximum im Nenner bei LA bzw. LB angenommen. Damit
folgt
R(x) =
∏(i,j)∈E L(i, j)h(i,j)
∏i∈A LA(i)hA(i)
∏j∈B LB(j)hB(j)
s.o.=
∏(i,j)∈E L(i, j)h(i,j)
∏(i,j)∈E(L
A(i)LB(j))h(i,j)
=∏
(i,j)∈E
(L(i, j)
LA(i)LB(j)
)nL(i,j)
= exp(n
∑
(i,j)∈EL(i, j) log
( L(i, j)
LA(i)LB(j)
)
︸ ︷︷ ︸=H(L,LA⊗LB)relative Entropie
)
= exp(nH(L,LA ⊗ LB)
).
Somit sind die LQ-Tests von der Form
D(x) =
1 falls nH(L,LA ⊗ LB) > c ,
0 falls nH(L,LA ⊗ LB) < c ,
fur ein c ∈ R.
Frage: Wie bestimmt man c fur ein vorgegebens Niveau α?
Das ist noch schwieriger als in Abschnitt 12.2, da Θ0 mehrelementig.
Wir machen wieder eine Grenzbetrachung fur grosse n wie in Satz 12.10.
Definiere
Dn := n∑
(i,j)∈ELA(i)LB(j)
(L(i, j)
LA(i)LB(j)− 1
)2
= n∑
(i,j)∈E
(L2(i, j)
LA(i)LB(j)− 1
)
=∑
(i,j)∈E
(h(i, j) − hA(i)hB(j)/n)2
hA(i)hB(j)/n.

12.2 χ2-Unabhangigkeitstests 153
Ein Test der Form
D(x) =
1 falls Dn > c ,
0 falls Dn < c ,(12.5)
fur ein c ∈ R heisst χ2-Unabhangigkeitstest.
Analog zu Satz 12.13 gilt (ohne Beweis):
Fur jedes ρ = α ⊗ β ∈ Θ0 konvergiert Dn (unter Pρ) fur n → ∞ in Verteilung
gegen eine χ2a−1)(b−1)-Verteilung, d.h.
limn→∞
Pα⊗β(Dn ≤ c) = χ2(a−1)(b−1)([0, c])
fur alle c > 0.
Zu vorgegebenem Irrtumsniveau α wahle man also c = χ2(a−1)(b−1);1−α, damit der
Test D das Niveau α ungefahr einhalt.
Beispiel 12.18. [Fortsetzung zu Beispiel 12.17]
Zu α = 0.01 gehort c = χ2(a−1)(b−1);1−α = χ2
12;0.99 ≈ 26.22. Man berechnet
D2004 = · · · ≈ 125.01. Damit wird die Nullhypothese (stochastische Unabhangig-
keit von Umweltbewusstsein und Schulbildung) zum Irrtumsniveau 1% abgelehnt.


















