
Cost Based Satisficing Search Considered Harmful William Cushing J. Benton Subbarao Kambhampati.
29
Cost Based Satisficing Search Considered Harmful William Cushing J. Benton Subbarao Kambhampati
-
Upload
lilian-leonard -
Category
Documents
-
view
215 -
download
0
Transcript of Cost Based Satisficing Search Considered Harmful William Cushing J. Benton Subbarao Kambhampati.

Cost Based Satisficing Search Considered
Harmful
William CushingJ. Benton
Subbarao Kambhampati
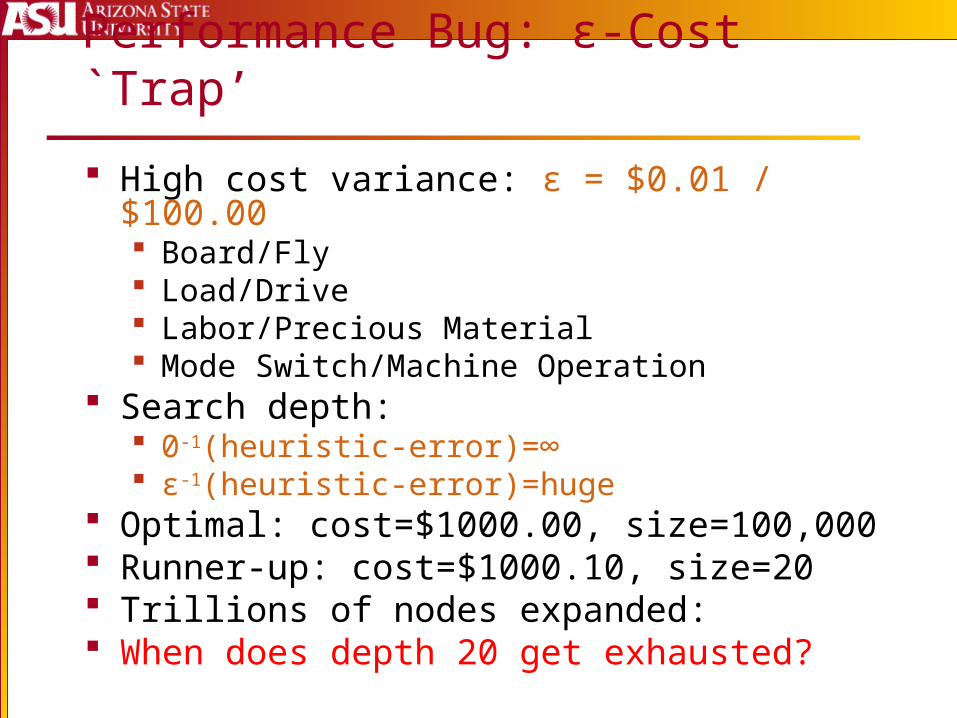
Performance Bug: ε-Cost `Trap’
High cost variance: ε = $0.01 / $100.00 Board/Fly Load/Drive Labor/Precious Material Mode Switch/Machine Operation
Search depth: 0-1(heuristic-error)=∞ ε-1(heuristic-error)=huge
Optimal: cost=$1000.00, size=100,000 Runner-up: cost=$1000.10, size=20 Trillions of nodes expanded: When does depth 20 get exhausted?

Outline
Inevitability of e-cost Traps Cycle Trap Branching Trap Travel Domain
If Cost is Bad, then what? Surrogate Search Simple First: Size Then: Cost-Sensitive Size-Based
Search
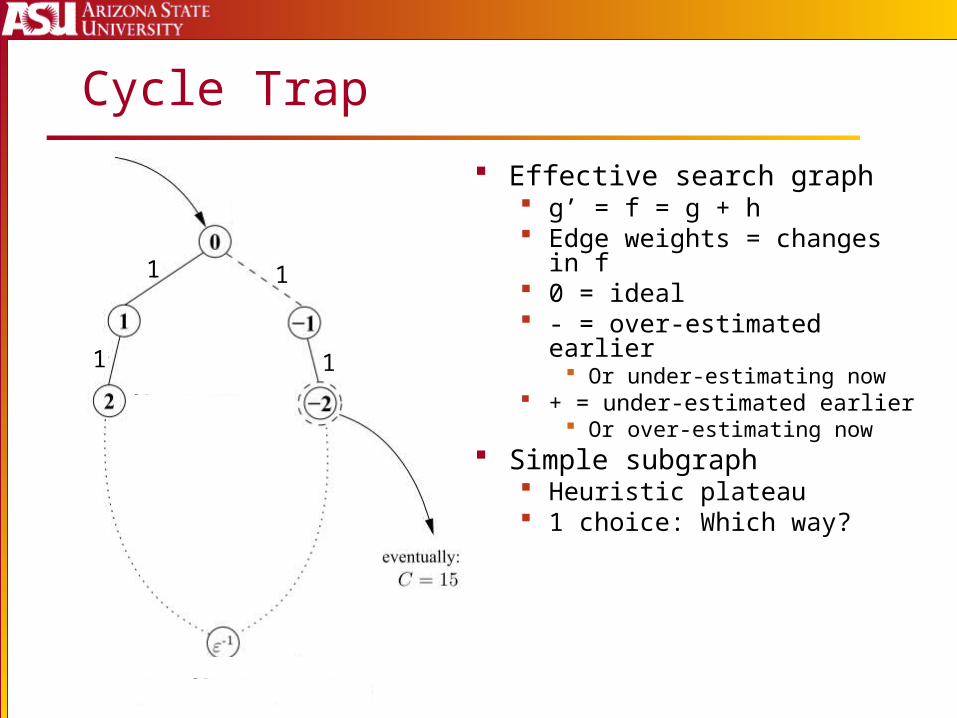
Cycle Trap
Effective search graph g’ = f = g + h Edge weights = changes in
f 0 = ideal - = over-estimated earlier
Or under-estimating now + = under-estimated earlier
Or over-estimating now Simple subgraph
Heuristic plateau 1 choice: Which way?
1
1 1
1
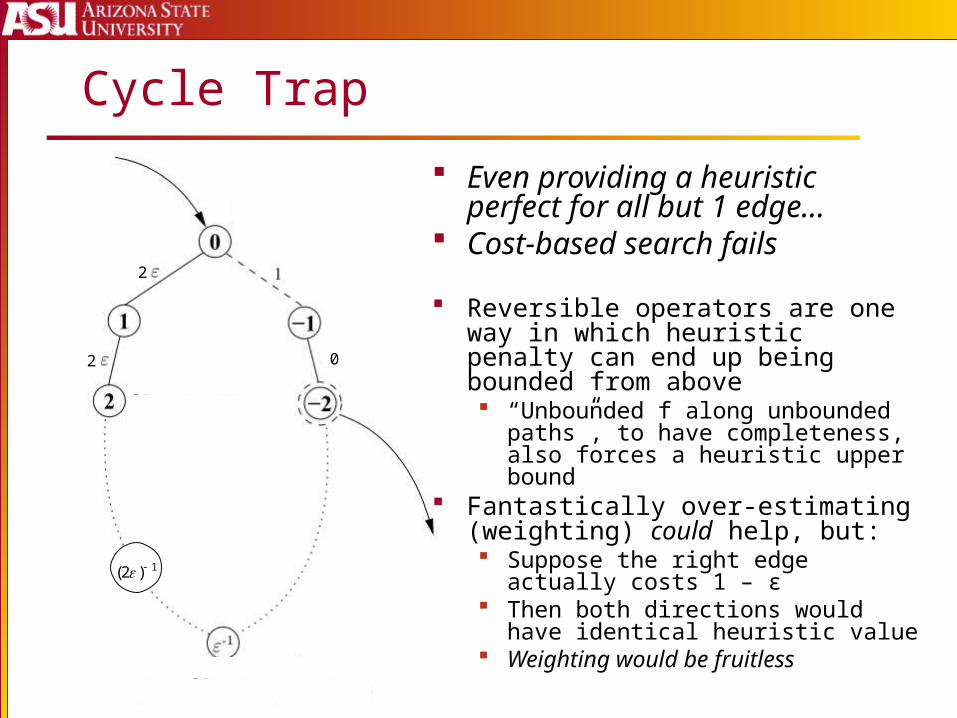
Cycle Trap
2
2 0
1)2(
Even providing a heuristic perfect for all but 1 edge…
Cost-based search fails
Reversible operators are one way in which heuristic penalty can end up being bounded from above “Unbounded f along unbounded
paths”, to have completeness, also forces a heuristic upper bound
Fantastically over-estimating (weighting) could help, but: Suppose the right edge actually
costs 1 – ε Then both directions would have
identical heuristic value Weighting would be fruitless
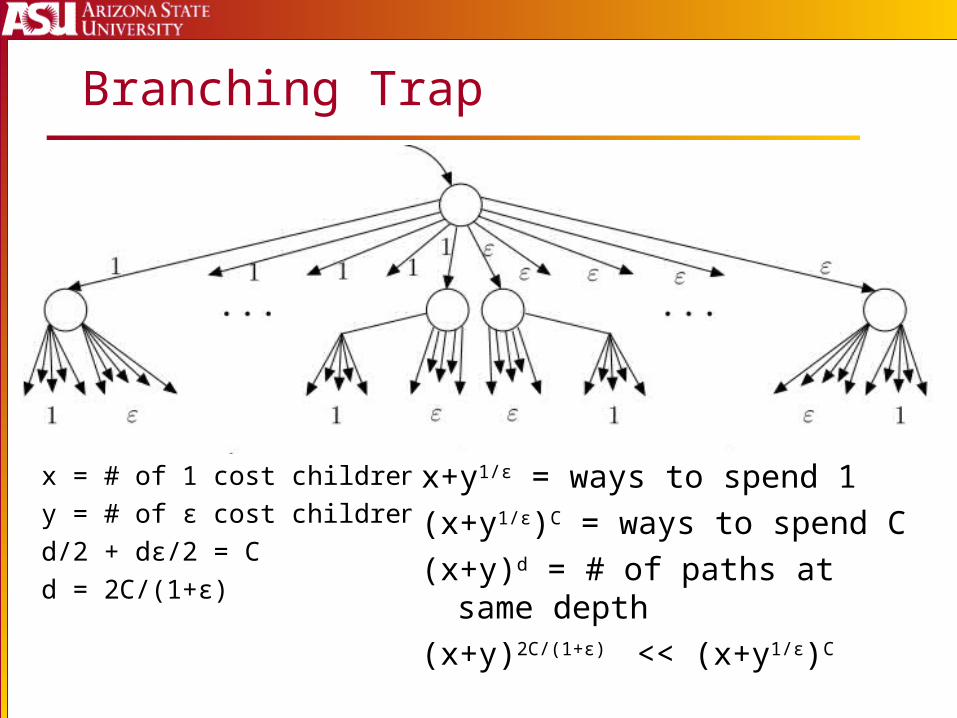
x = # of 1 cost childreny = # of ε cost childrend/2 + dε/2 = Cd = 2C/(1+ε)
Branching Trap
x+y1/ε = ways to spend 1(x+y1/ε)C = ways to spend C(x+y)d = # of paths at same
depth(x+y)2C/(1+ε) << (x+y1/ε)C
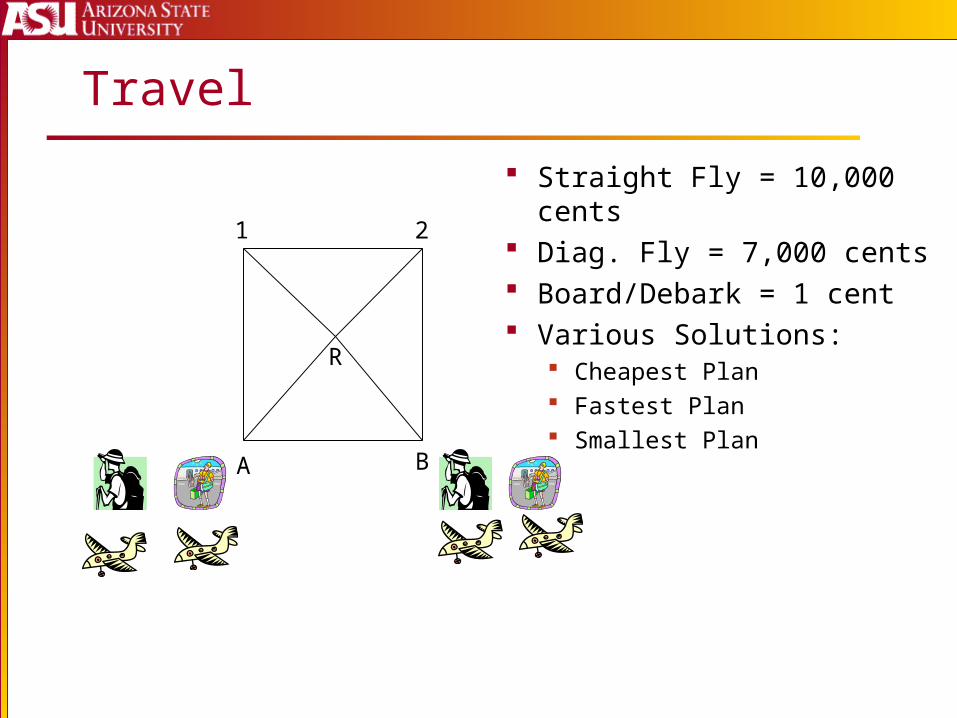
Travel
A B
1 2
R
Straight Fly = 10,000 cents Diag. Fly = 7,000 cents Board/Debark = 1 cent Various Solutions:
Cheapest Plan Fastest Plan Smallest Plan
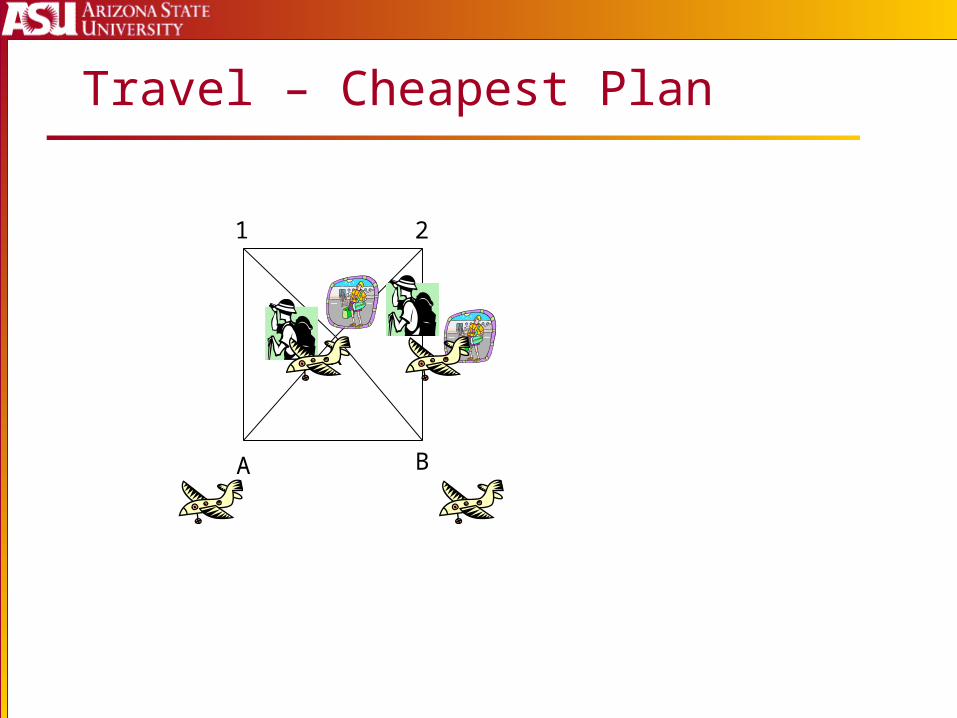
Travel – Cheapest Plan
A B
1 2
R
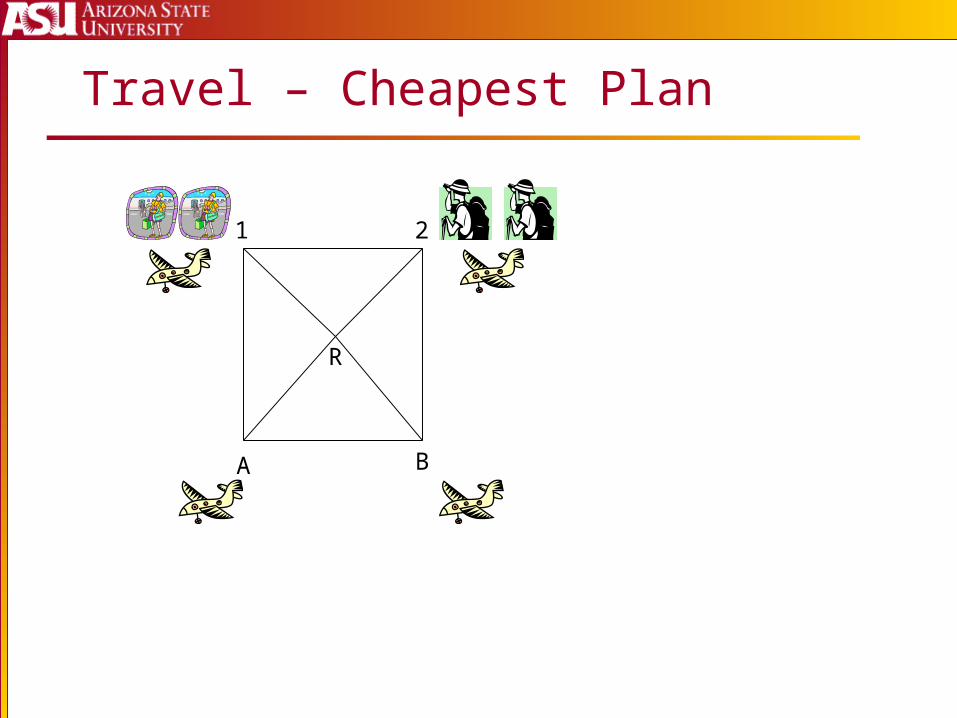
Travel – Cheapest Plan
A B
1 2
R
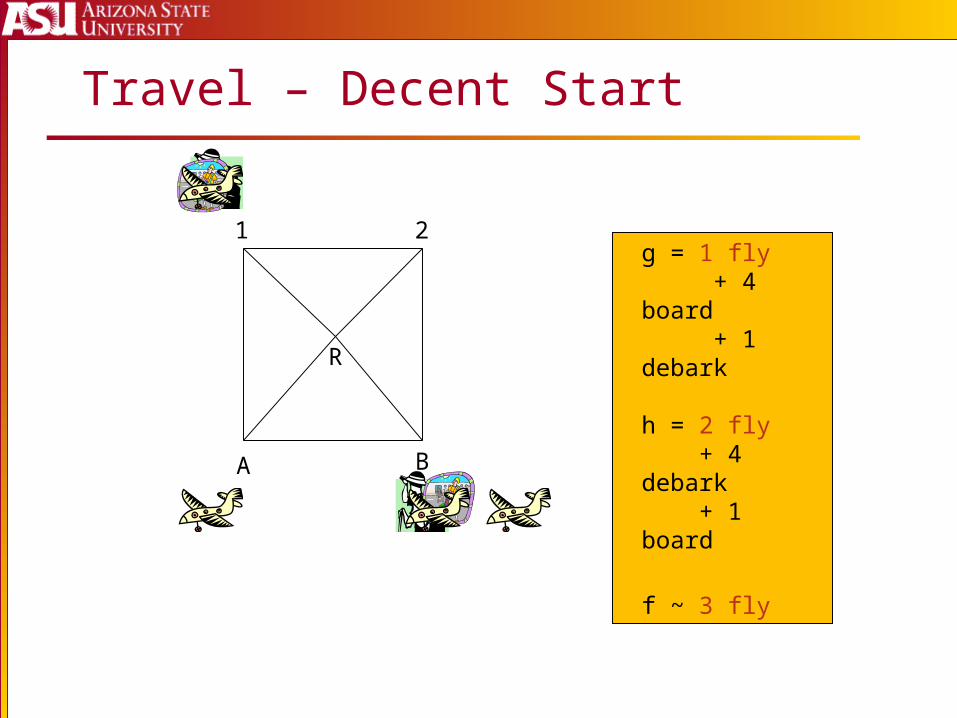
Travel – Decent Start
A B
1 2
R
g = 1 fly + 4 board + 1 debark
h = 2 fly + 4 debark + 1 board
f ~ 3 fly
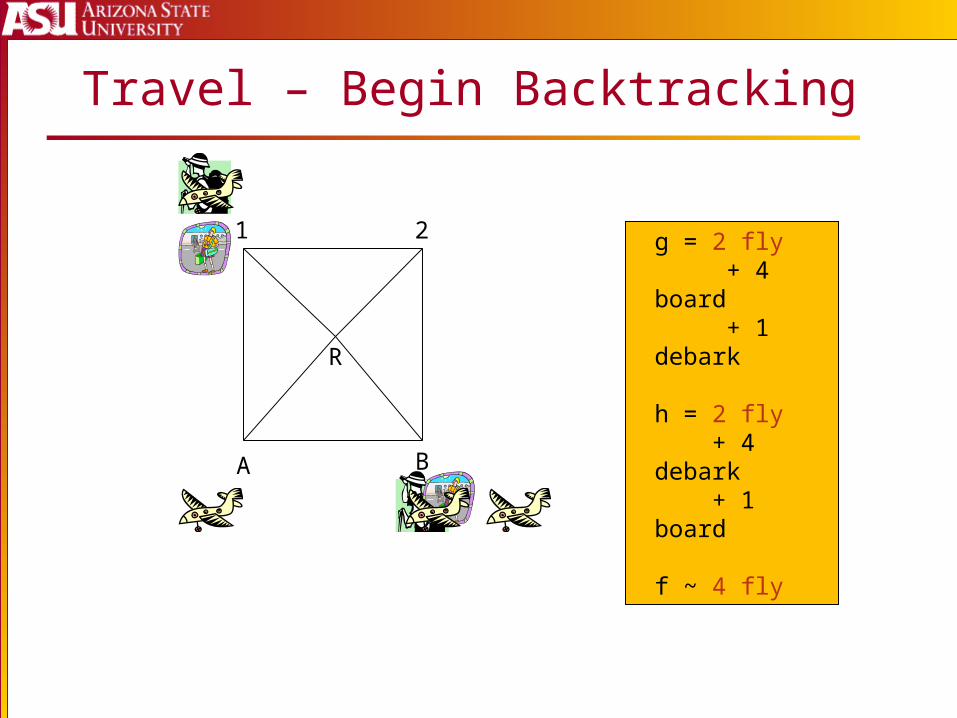
Travel – Begin Backtracking
A B
1 2
R
g = 2 fly + 4 board + 1 debark
h = 2 fly + 4 debark + 1 board
f ~ 4 fly
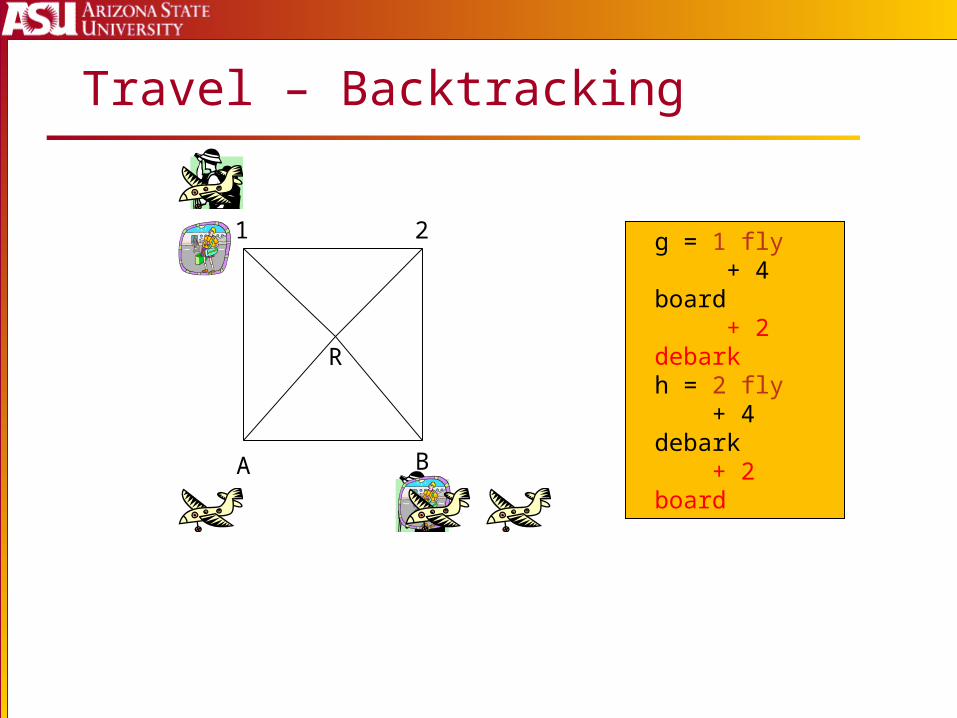
Travel – Backtracking
A B
1 2
R
g = 1 fly + 4 board + 2 debarkh = 2 fly + 4 debark + 2 board
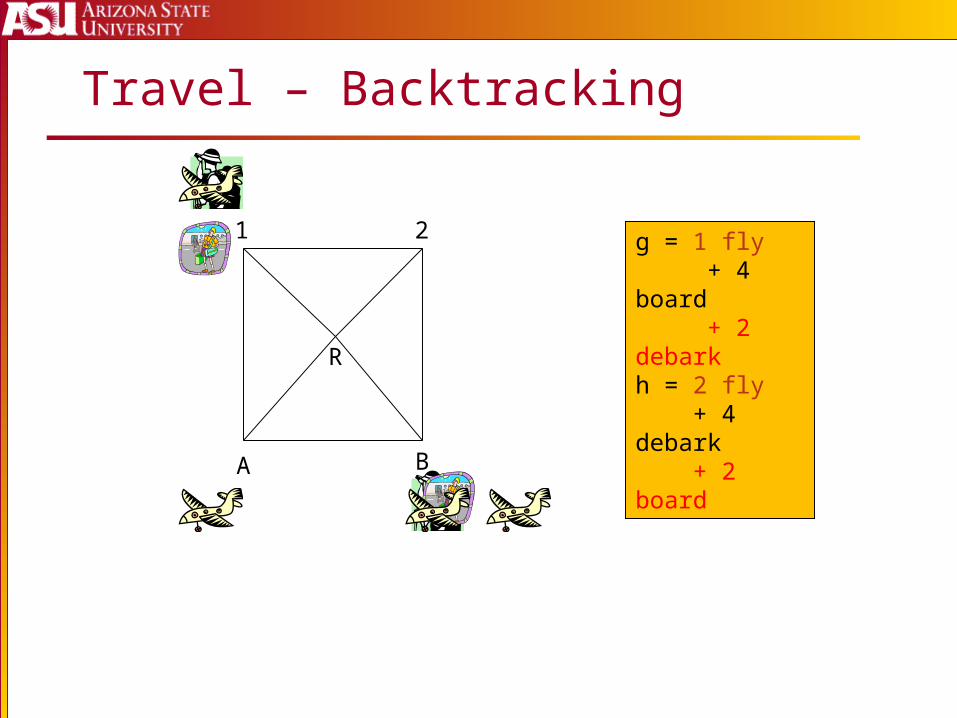
Travel – Backtracking
A B
1 2
R
g = 1 fly + 4 board + 2 debarkh = 2 fly + 4 debark + 2 board
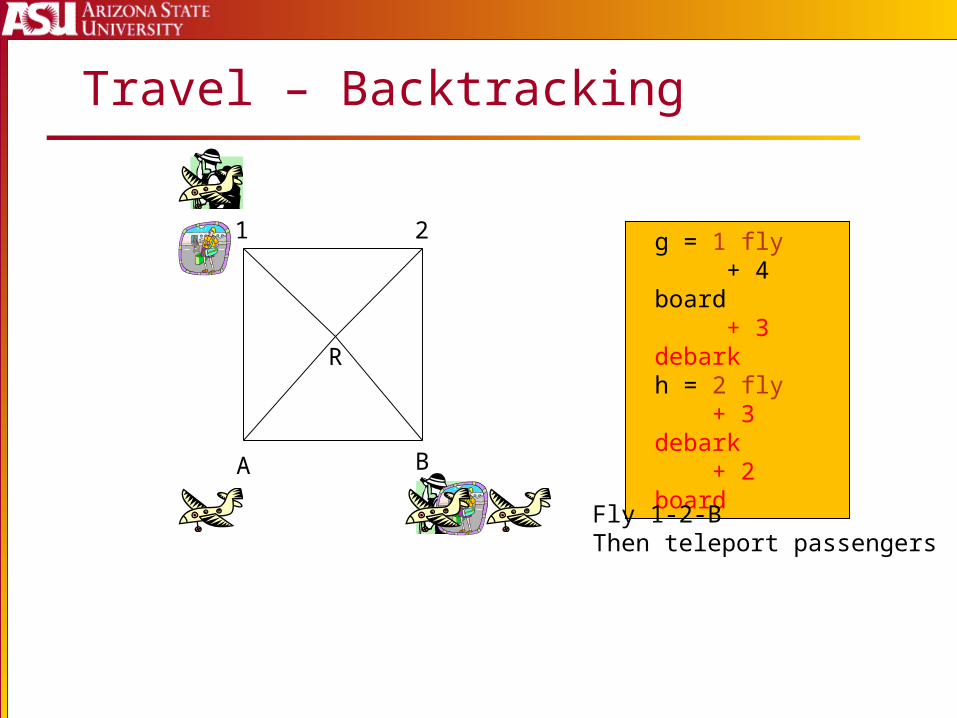
Travel – Backtracking
A B
1 2
R
g = 1 fly + 4 board + 3 debarkh = 2 fly + 3 debark + 2 board
Fly 1-2-B Then teleport passengers
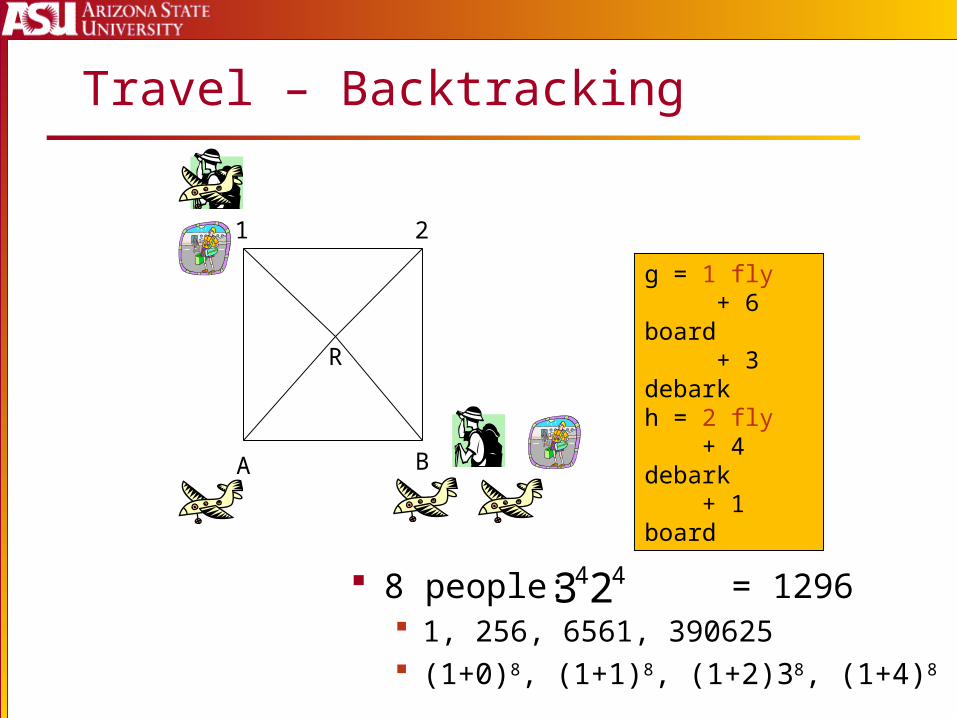
Travel – Backtracking
A B
1 2
R
g = 1 fly + 6 board + 3 debarkh = 2 fly + 4 debark + 1 board
8 people: = 1296 1, 256, 6561, 390625 (1+0)8, (1+1)8, (1+2)38, (1+4)8
4423

Travel Calculations
4 planes located in 5 cities 54 = 625 plane assignments
4k passengers, located in 9 places 94k passenger assignments globally
Cheap subspace Product over each city (1 + city-local planes) (city-local passengers)
e.g., (1+2)4(1+1)4 = 1296 Stop exploring
Large evaluation Exhaustion of possibilities
Cost-based search exhausts cheap subspaces Eventually Assuming an upper bound on the heuristic

Outline
Inevitability of e-cost Traps Cycle Trap Branching Trap Travel Domain
If Cost is Bad, then what? Surrogate Search Simple First: Size Then: Cost-Sensitive Size-Based
Search

Surrogate Search
Replace ill-behaved Objective with a well-behaved Evaluation Tradeoff: Trap Defense versus Quality Focus
Evaluation Function: “Go no further” Force ε ~ 1
Make g and f grow fast enough: in o(size) Normalize costs for hybrid methods
Heuristic: “Go this way” Calculate h in the same units as g
Retain true Objective branch-and-bound duplicates elimination + re-expansion
Re-expansion of duplicates should be done carefully Can wait till future iterations, cache heuristics, use path-max, …

Size-based Search
Replace ill-behaved Objective with a well-behaved Evaluation Pure Size
Evaluation Function: “Go no further” Force ε = 1
Heuristic: “Go this way” Replace cost metric with size metric in relaxed
problem
Retain true Objective, for pruning Resolve heuristic with real objective branch-and-bound: gcost+hcost >= best-known-cost duplicates: new.gcost >= old.gcost Re-expand better cost paths discovered

Cost-sensitive Size-Based Heuristic
Replace ill-behaved Objective with a well-behaved Evaluation
Evaluation Function: “Go no further” Heuristic: “Go this way”
Estimate cheapest/best, but, calculate size sum/max/… propagation of real objective for
heuristic make minimization choices with respect to real objective
Last minute change: Recalculate value of minimization choices by surrogate
Retain true Objective, for pruning Calculate relaxed solution’s cost, also
Faster than totally resolving heuristic
branch-and-bound: gcost+hcost >= best-known-cost If heuristic is inadmissible, force it to be admissible eventually

Results – LAMA
LAMA Greedy best-first: bad plans (iterative) WA*: no plan, time out
LAMA-size Greedy best-first: same bad plans (iterative) WA*: direct plans, time out
Better cost! … but no rendezvous
Expected Result:Only one kind of objectCosts not widely varying
Portfolio approach possible
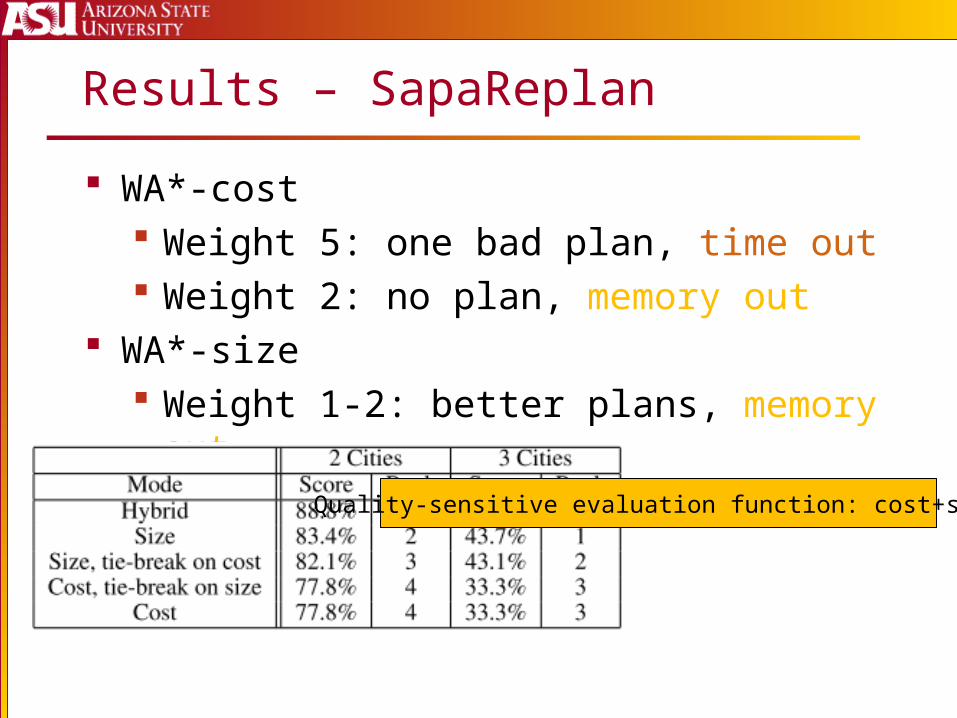
Results – SapaReplan
WA*-cost Weight 5: one bad plan, time out Weight 2: no plan, memory out
WA*-size Weight 1-2: better plans, memory out
Quality-sensitive evaluation function: cost+size

Conclusion
ε-cost traps are inevitable Typical: Large variation in cost Large cheap subspaces Upper-bounded heuristics Large plateaus in objective
Cost-based systematic approaches are susceptible Even with all kinds of search
enhancements: LAMA Because search depth is
“unbounded” by cost-based evaluation function
ε-1(h-error) ~ 0-1(h-error) That is, search depth is bounded
only by duplicate checking
Force good behavior: Evaluation ≠ Objective Force ε~1 Quality Focus versus Trap
Defense Simplest surrogate:
Size-based Search Force ε=1 Performs surprisingly well Despite total lack of Quality
Focus Easy variation:
Cost-sensitive Size-based Heuristic
Still force ε=1 Recalculate heuristic by
surrogate Performs yet better

Conclusion (Polemic)
Lessons best learnt and then forgotten: goto is how computers work efficiently A* is how search works efficiently
Both are indispensible Both are best-possible
In just the right context Both are fragile
If the context changes
Go enthusiasts: joseki

If size doesn’t work…
Speed Everything Up Reduce All Memory Consumption Improve anytime approach: Iterated, Portfolio, Multi-
Queue Guess (search over) upper bounds Decrease weights Delay duplicate detection Delay re-expansion Delay heuristic computation Exploit external memory Use symbolic methods Learn better heuristics: from search, from inference Precompute/Memoize anything slow: the heuristic Impose hierarchy (state/task abstraction) Accept knowledge (LTL) Use more hardware: (multi-)core/processor/computer,
GPU

Related Work: The Best Approach?
The Best Surrogate? The Best Approach Over All?
Improve Exploitation (Dynamic) Heuristic Weighting (Pohl, Thayer+Ruml) Real-time A* (Korf) Beam search (Zhou) Quality-sensitive probing/lookahead (Benton et al, PROBE)
Improve Exploration Path-max, A** (Dechter+Pearl) Multi-queue approaches (Thayer+Ruml, Richter+Westphal, Helmert) Iterated search (Richter+Westphal) Portfolio methods (Rintanen, Streeter) Breadth-first search [as a serious contender] (Edelkamp)
Directly Address Heuristic Error h_cea, h_ff, h_lama, h_vhpop, h_lpg, h_crikey, h_sapa, … Pattern Databases (Culbertson+Schaeffer, Edelkamp) Limited Discrepancy Search (Ginsberg) Negative Result: “How Good is Almost Perfect?” (Helmert+Röger)
`See’ the Structure (remove the traps) Factored Planning (Brafman+Domshalak) Direct Symmetry Reductions (Korf, Long+Fox) Symbolic Methods, Indirect Symmetry Reduction (Edelkamp)

Related Fields Reinforcement Learning: Exploration/Exploitation Markov Decision Processes: Off-policy/On-policy
Reward Shaping, Potential Field Methods (Path-search) Prioritized Value Iteration
Decision Theory: Heuristic Errors “Decision-Theoretic Search” (?) k-armed Bandit Problems (UCB)
Game-tree Search: Traps, Huge Spaces Without traps, game-tree pathology (Pearl) Upper Confidence Bounds on Trees (UCT) Quiescent Search Proof-number search (Allis?)
Machine Learning: Really Huge Spaces Surrogate Loss Functions Continuous/Differentiable relaxations of 0/1
Probabilistic Reasoning: Extreme Values are Dangerous that 0/1 is bad is well known but also ε is numerically unstable

What isn’t closely related?
Typical Puzzles: Rubik’s Cube, Sliding Tiles, … Prove Optimality/Small Problems Tightly Bounded Memory: IDDFS, IDA*, SMA* Unbounded Memory, but:
Delayed/Relaxed Duplicate Detection (Zhou, Korf) External Memory (Edelkamp, Korf)
More than one problem: D*, D*-Lite, Lifelong Planning A* (Koenig) Case-based planning Learned heuristics
State-space isn’t a blackbox: Bidirectional/Perimeter Search Randomly expanding trees for continuous path planning in low dimensions Waypoint/abstraction methods Any-angle path planning (Koenig)
State-space is far from a blackbox: Explanation Based Learning Theorem Proving (Clause/Constraint Learning) Forward Checking (Unit Propagation)
Planning isn’t (only) State-space search (Kambhampati) Engineering:
Subroutine speedup via Precomputation/Memoization Python vs C Priority Queue implementation (bucket heaps!)

Quotes
“… if in some problem instance we were to allow B to skip even one node that is expanded by A, one could immediately present an infinite set of instances when B grossly outperforms A. (This is normally done by appending to the node skipped a variety of trees with negligible costs and very low h.)” Rina Dechter, Judea Pearl
“I strongly advise that you do not make road movement free (zero-cost). This confuses pathfinding algorithms such as A*, …” Amit Patel
“Then we could choose an somewhat larger than the one defined by (3). The algorithm would no longer be admissible, but it might be more desirable, from a heuristic point of view, than any admissible algorithm.” Peter Hart, Nils Nilsson, Bertram Raphael
Roughly: `… inordinate amount of time selecting among equally meritorious options’ – Ira Pohl
h






![Bisphenol A in “BPA O free” baby feeding bottlesjrms.mui.ac.ir/files/journals/1/articles/8754/public/... · 2013-02-26 · harmful properties[1,2] As antioxidant ingredient, BPA](https://static.fdocument.org/doc/165x107/5ebbf304cf89a0794f45be8b/bisphenol-a-in-aoebpa-o-freea-baby-feeding-2013-02-26-harmful-properties12.jpg)






![ReviewArticle - "A harmful truth is better than a useful lie" · ReviewArticle ... this gene locus and/or its VNTR alleles and PCOS [32–36]. Above all, ... in PCOS is an outcome](https://static.fdocument.org/doc/165x107/5ac6b59d7f8b9af91c8e5783/reviewarticle-a-harmful-truth-is-better-than-a-useful-lie-this-gene-locus.jpg)


